11. Revisión del sitio HTML generado
Ahora vamos a examinar el resultado HTML de este documento ODT / DOCX. Ya hemos visto que el conversor respeta la tabla de contenidos.
11.1. La barra superior del sitio
Echemos un vistazo a la barra superior del sitio:
 |
- En [1], el nombre del sitio definido en [config.py];
- En [2], el icono que permite cambiar al modo oscuro o claro;
- En [3], el icono que es un enlace al repositorio de GitHub donde se exportará el sitio HTML. También definido en [config.py];
- En [4], el icono que permite ocultar o mostrar el índice;
11.2. El pie de página del sitio
Veamos ahora el pie de página:
 |
Este es el pie de página definido en el archivo [config.py].
11.3. La página de inicio
La página de título del documento ODT/DOCX era la siguiente:
 |
Esta página de título del documento ODT/DOCX se convierte en la página de inicio del sitio HTML:
 |
El conversor Gemini 3 / ChatGPT incluye en la página de inicio todo lo anterior, es decir, en el documento ODT / DOCX, el primer título de nivel 1, con el estilo «Título 1». Si incluye imágenes como las anteriores, las mostrará. Por lo tanto, puede imaginar que le da una portada a su sitio web como si fuera un libro real. En [1], se trata del título principal del documento. Su visualización se controla mediante las siguientes líneas del archivo de configuración [config.py]:
# -------------------------------------------------------------------------
# Detección del título del documento
# -------------------------------------------------------------------------
"document_title": {
# Estilos ODT que se deben considerar como el título principal del documento (H1 global)
"style_names": [
"P1"
],
# CSS aplicado a este título en el Markdown generado
"css": "font-size: 28px; font-weight: bold; margin-bottom: 1em; line-height: 1.2; color: #2c3e50;"
},
- líneas [6-8]: la lista de estilos disponibles para el título de tu documento. Cuando miro este documento, el estilo de LibreOffice de mi título es «Título principal». Pero el conversor Gemini no lo encontraba. Generó registros de los estilos que encontraba y mostró [P1]. Este es un gran problema con LibreOffice: los nombres que se muestran de los estilos no se corresponden con los nombres internos que utiliza el programa. Solo están ahí para adaptarse al idioma del usuario;
- línea 10: una vez detectado el título principal, puedes configurar su apariencia. Yo quería una fuente de tamaño 28 (font-size: 28px;) y negrita (font-weight: bold);
Con las imágenes y el estilo del título, puedes crear una página de inicio atractiva.
Es posible que el título principal de tu documento no tenga ninguno de los estilos definidos en las líneas [6-8]. Para encontrar el estilo de tu título principal, utiliza la siguiente línea del archivo [config.py]
Con el valor [true], el estilo de los párrafos que preceden al primer título de nivel 1, es decir, los párrafos de la página de inicio, se mostrará al ejecutar el conversor Gemini / ChatGPT. Así, para un documento distinto a este, obtuve los siguientes registros:
[DEBUG PRE-H1] Style='Standard (WW)' (Clean='standard (ww)') | Texto='...'
[DEBUG PRE-H1] Estilo='P1' (Limpio='p1') | Texto='...'
[DEBUG PRE-H1] Style='P1' (Clean='p1') | Texto='...'
[DEBUG PRE-H1] Style='P1' (Clean='p1') | Texto='...'
[DEBUG PRE-H1] Estilo='P3' (Limpieza='p3') | Texto='...'
[DEBUG PRE-H1] Estilo='P1' (Limpio='p1') | Texto='...'
[DEBUG PRE-H1] Estilo='P1' (Limpio='p1') | Texto='...'
[DEBUG PRE-H1] Estilo='P1' (Limpio='p1') | Texto='...'
[DEBUG PRE-H1] Estilo='P1' (Limpio='p1') | Texto='...'
[DEBUG PRE-H1] Estilo='P4' (Limpio='p4') | Texto='Introducción al lenguaje PHP7 a través de ejemplos...'
>>> TÍTULO DEL DOCUMENTO DETECTADO: Introducción al lenguaje PHP7 a través de ejemplos
[DEBUG PRE-H1] Estilo='Estándar (WW)' (Limpio='estándar (ww)') | Texto='...'
[DEBUG PRE-H1] Estilo='Estándar (WW)' (Limpio='estándar (ww)') | Texto='...'
[DEBUG PRE-H1] Estilo='Estándar (WW)' (Limpio='estándar (ww)') | Texto='...'
[DEBUG PRE-H1] Estilo='Estándar (WW)' (Limpio='estándar (ww)') | Texto='...'
[DEBUG PRE-H1] Estilo='Estándar (WW)' (Limpieza='estándar (ww)') | Texto='...'
[DEBUG PRE-H1] Estilo='Estándar (WW)' (Limpieza='estándar (ww)') | Texto='...'
[DEBUG PRE-H1] Estilo='P5' (Limpieza='p5') | Texto='Serge Tahé, julio de 2019...'
[DEBUG PRE-H1] Estilo='P5' (Limpio='p5') | Texto='...'
[DEBUG PRE-H1] Estilo='P6' (Limpio='p6') | Texto='...'
[DEBUG PRE-H1] Estilo='Encabezado 1' (Clean='encabezado 1') | Texto='Introducción al lenguaje PHP 7...'
- línea 10, el título del documento tiene el estilo «P4»;
En el archivo [config.py], he añadido las siguientes líneas:
"document_title": {
"style_names": [
"P4"
],
"css": "font-size: 28px; font-weight: bold; margin-bottom: 1em; line-height: 1.2; color: #2c3e50;"
},
- línea 3, el estilo que buscaba;
Por este motivo, el depurador muestra las líneas:
[DEBUG PRE-H1] Style='P4' (Clean='p4') | Texto='Introducción al lenguaje PHP7 a través de ejemplos...'
>>> TÍTULO DEL DOCUMENTO DETECTADO: Introducción al lenguaje PHP7 a través de ejemplos
Ha encontrado el estilo «P4» y muestra que se ha encontrado el título del documento. Una vez encontrado, puedes establecer la clave [debug] en [false] en [config.py]:
Veamos ahora la conversión del capítulo [Ejemplos], que agrupa los ejemplos que el conversor Gemini / ChatGPT sabe gestionar:
11.4. Listas con viñetas
Documento ODT / DOCX:
 |
Arriba, el texto [Listas con viñetas] aparece resaltado porque es una referencia asociada a un enlace.
Documento HTML:
 |
Se observa que, mientras que el documento ODT / DOCX utiliza diferentes viñetas, el documento HTML solo utiliza un tipo de viñeta.
11.5. Listas numeradas
Documento ODT / DOCX:
 |
Documento HTML:
 |
11.5.1. Listas mixtas 1
Documento ODT / DOCX
 |
Documento HTML
 |
En este caso también, a veces hay diferencias entre los tipos de viñetas utilizados.
11.5.2. Listas mixtas 2
Documento ODT / DOCX
 |
Documento HTML
 |
11.6. Los bloques de código enriquecido
Los bloques de código enriquecido se representan de forma idéntica en HTML (excepto el color de fondo). A continuación se muestran tres ejemplos:
11.6.1. Ejemplo 1
Documento ODT / DOCX
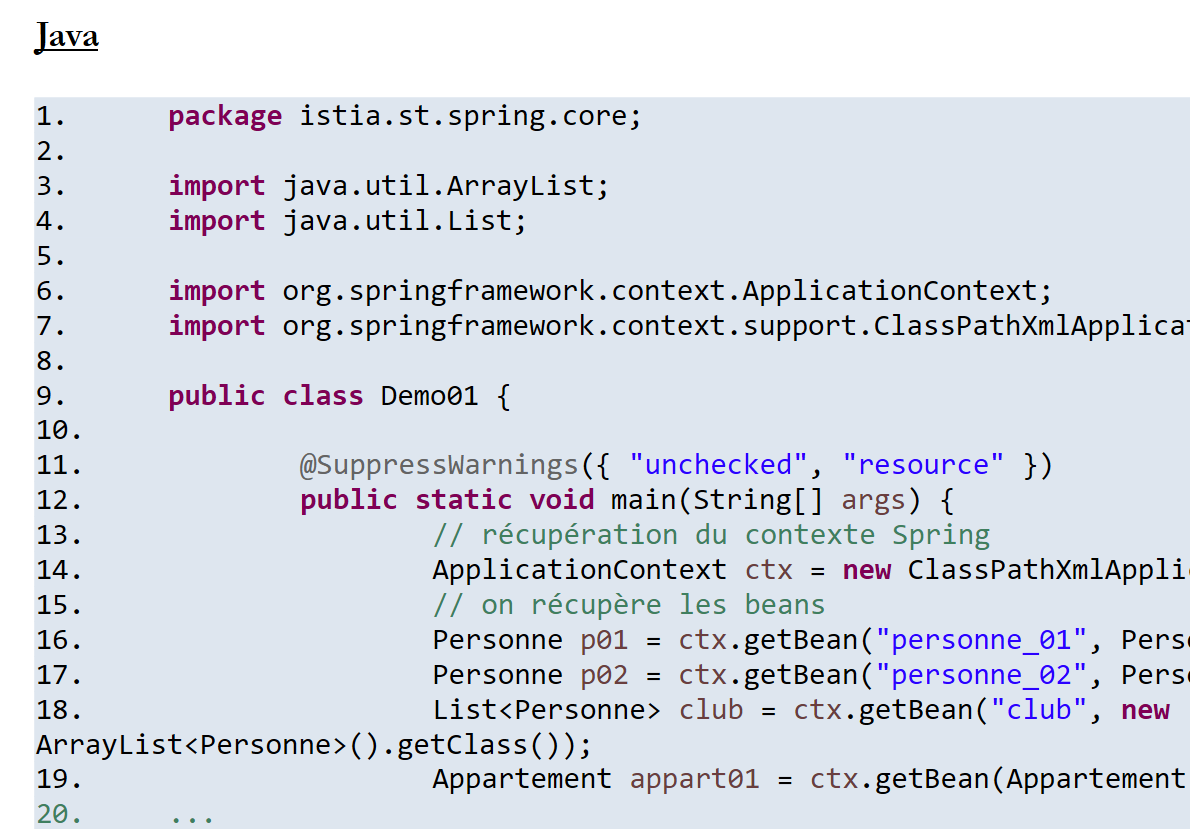 |
Representación HTML
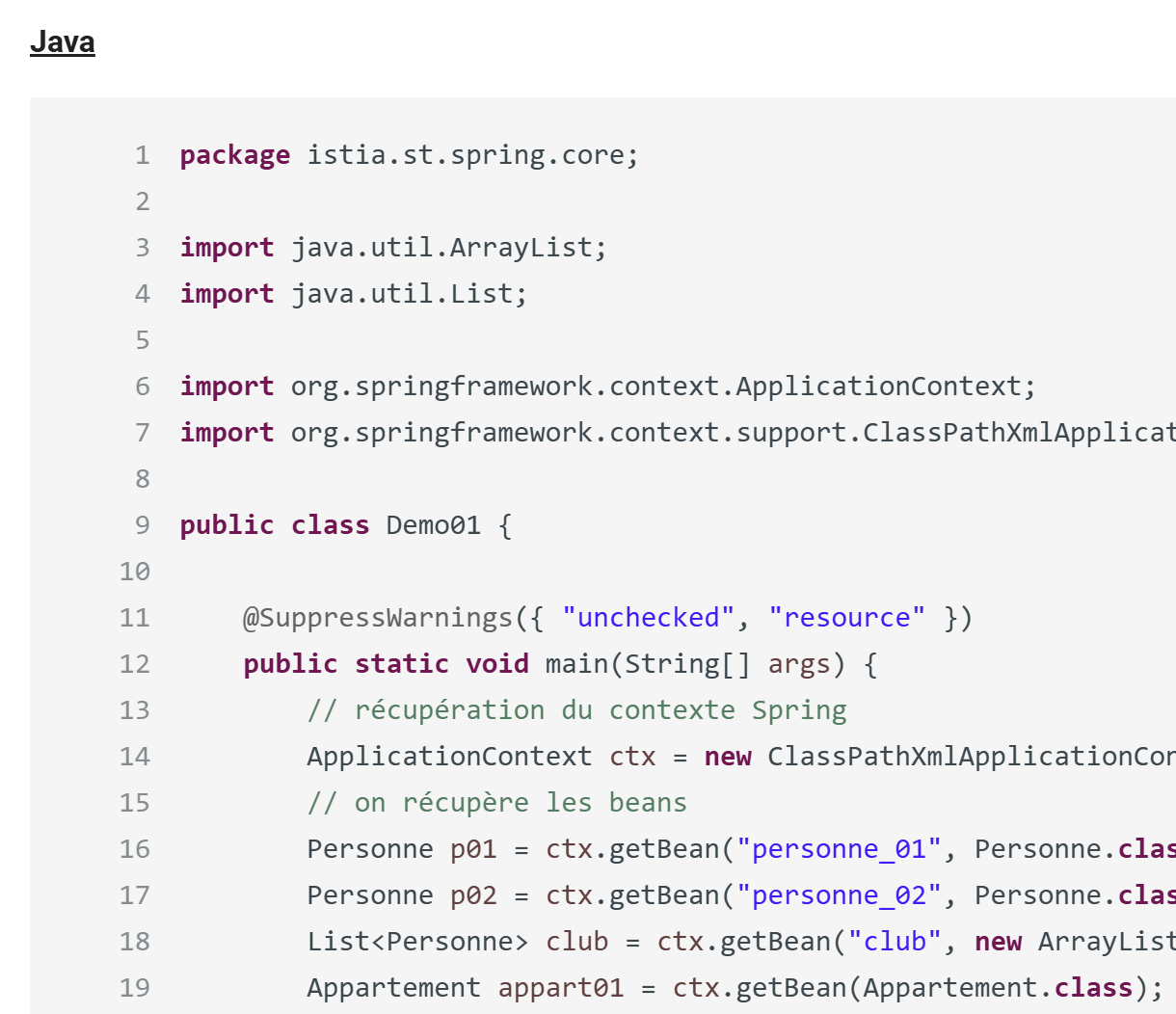 |
11.6.2. Ejemplo 2
Documento ODT / DOCX:
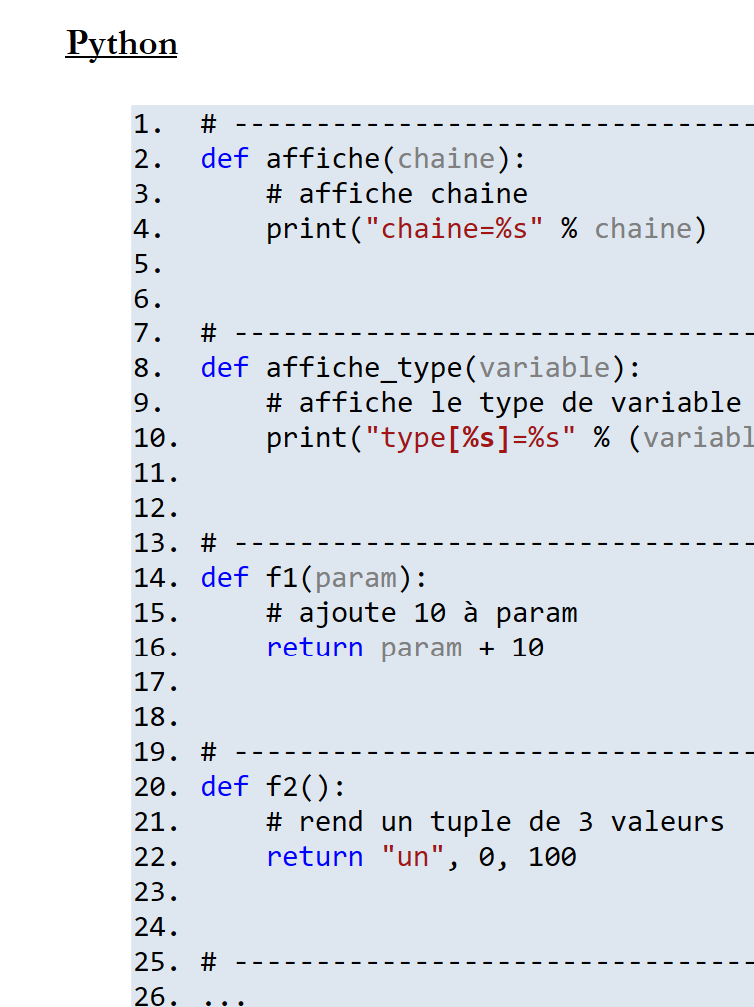 |
Resultado HTML
 |
11.6.3. Ejemplo 3
Documento ODT / DOCX
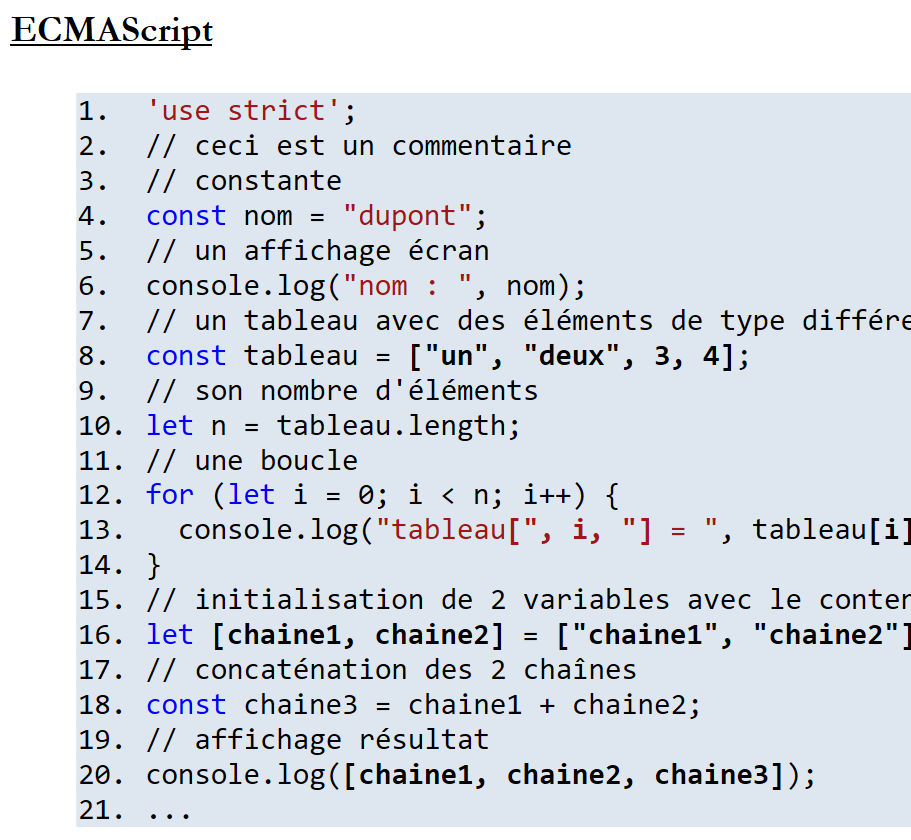 |
Resultado HTML
 |
11.7. Los bloques de código sin formato (texto sin formato)
Los bloques de código sin formato que se encuentran en el documento ODT / DOCX son resaltados sintácticamente por MkDocs según el lenguaje detectado en el bloque de código. Para ayudar al conversor a identificar el lenguaje correcto, se han incluido «cadenas clave» en el archivo [config.py] para cada lenguaje. El conversor cuenta las «cadenas clave» encontradas. A continuación, asocia el bloque de código al lenguaje que tenga más «cadenas clave» encontradas.
Veamos algunos ejemplos.
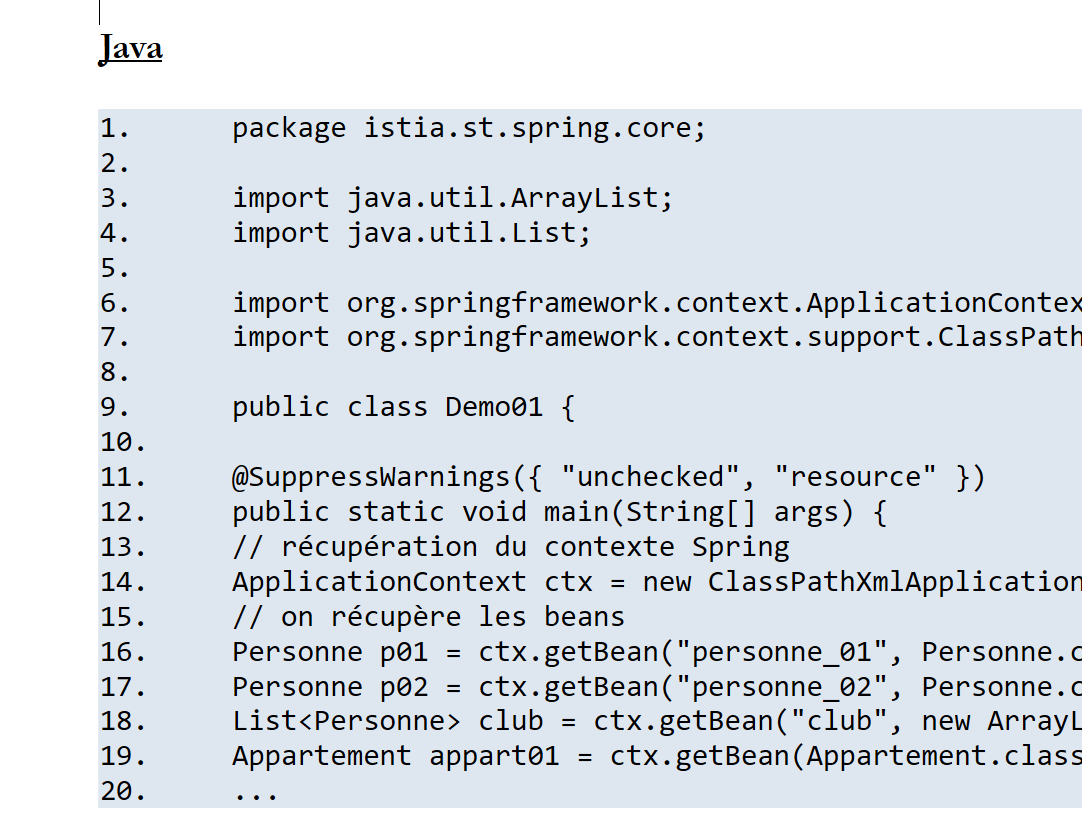
11.7.1. Ejemplo 1
Documento ODT / DOCX (Java)
 |
Resultado HTML
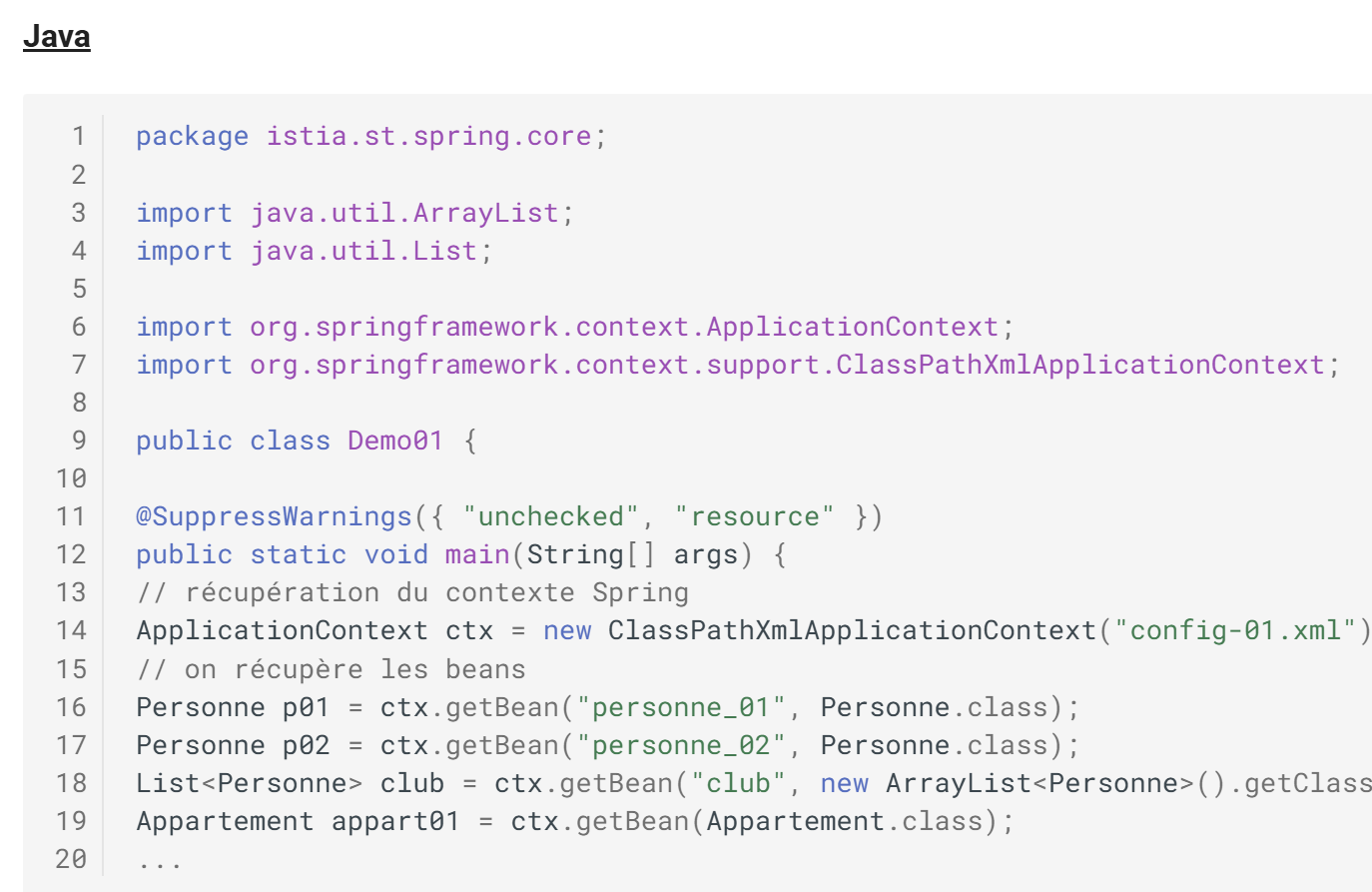 |
En el documento HTML se observa que el código Java se ha resaltado sintácticamente.
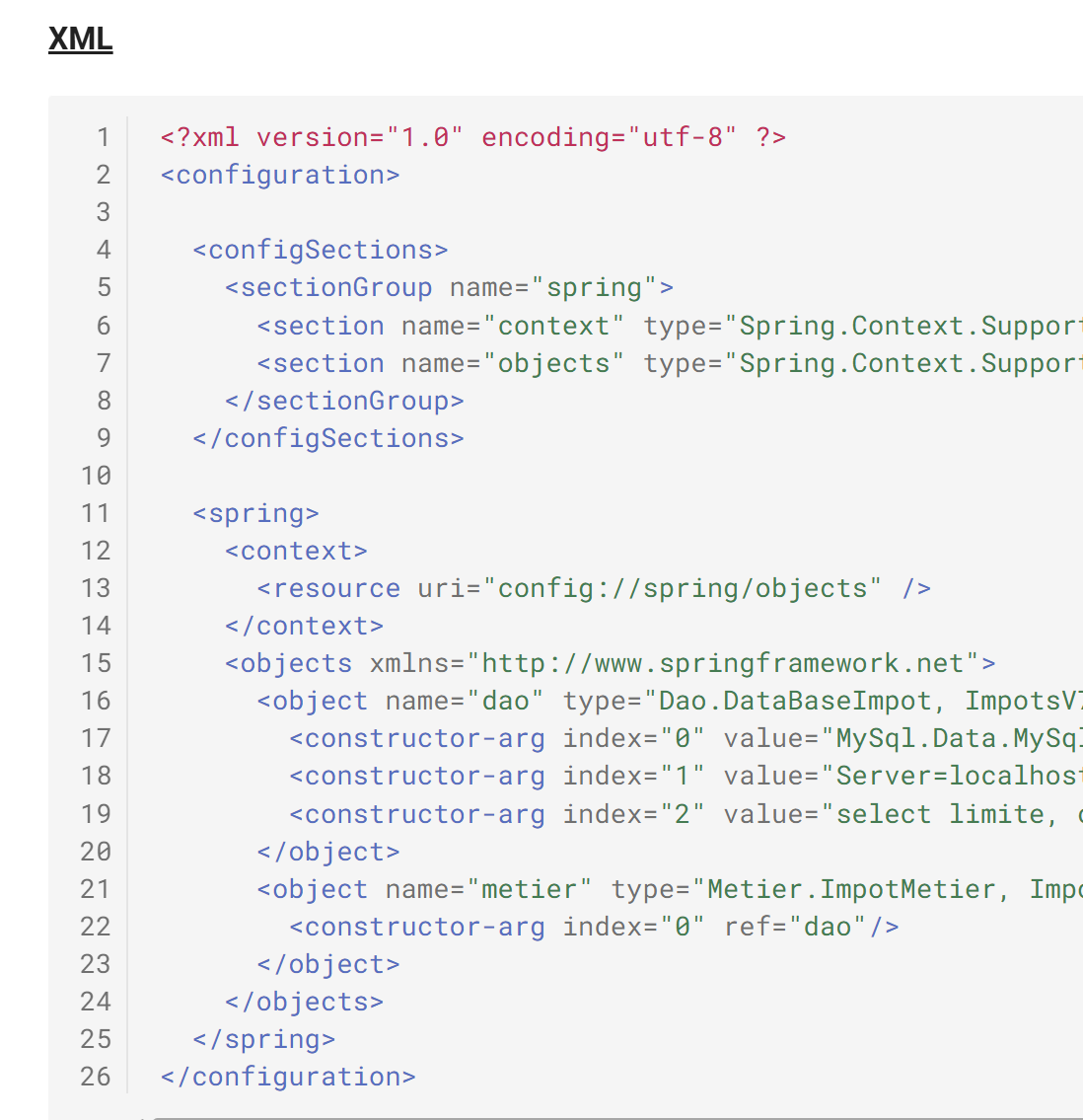
11.7.2. Ejemplo 2
Documento ODT / DOCX (XML)
 |
Resultado HTML
 |
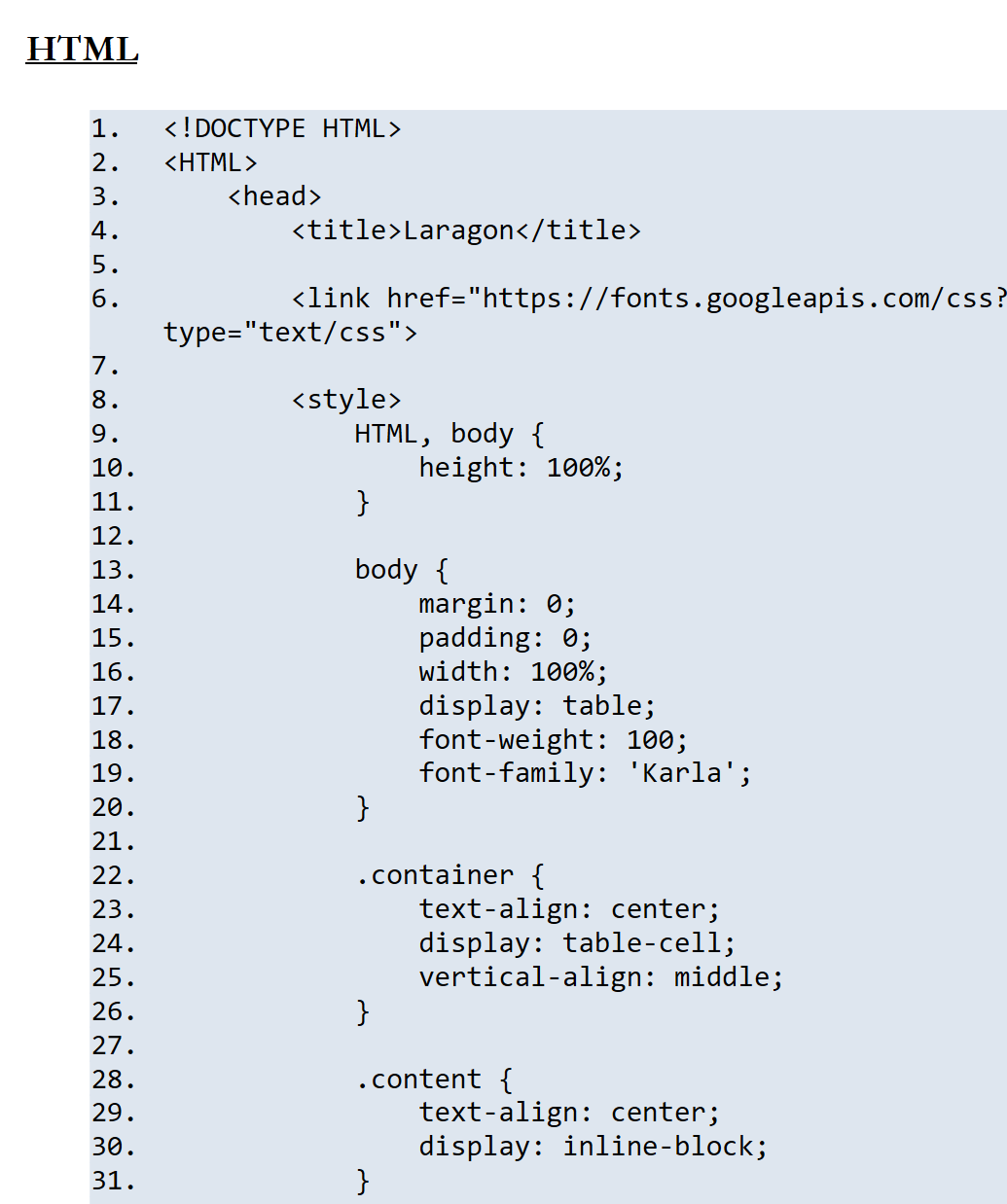
11.7.3. Ejemplo 3
Documento ODT / DOCX (HTML)
 |
Resultado HTML
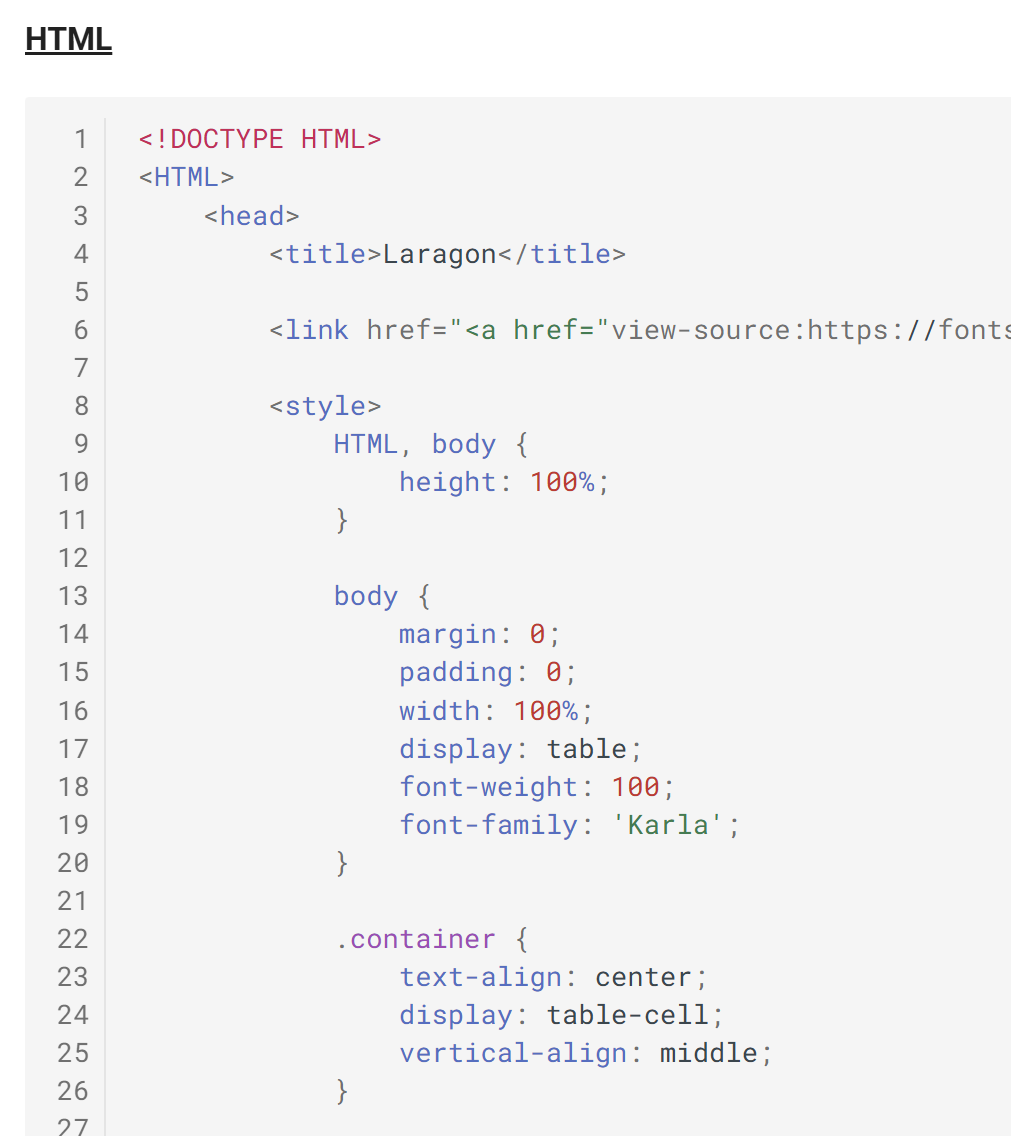 |
11.8. Otros bloques de código
Documento ODT / DOCX
Un resultado de ejecución con una primera línea que no empieza por 1:
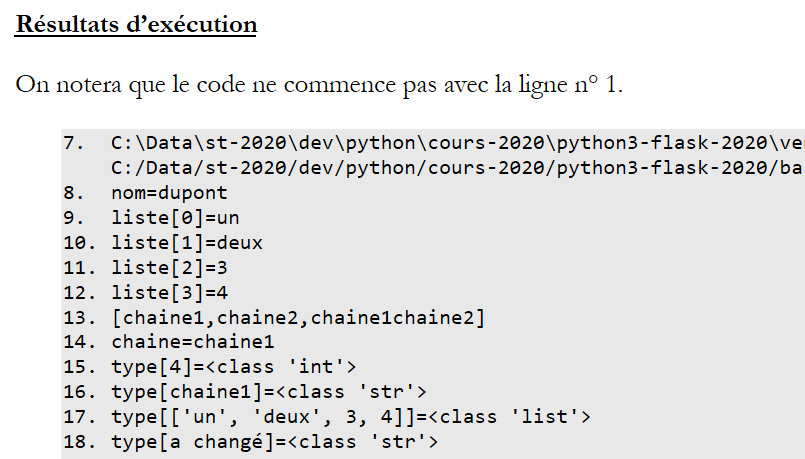 |
Resultado HTML
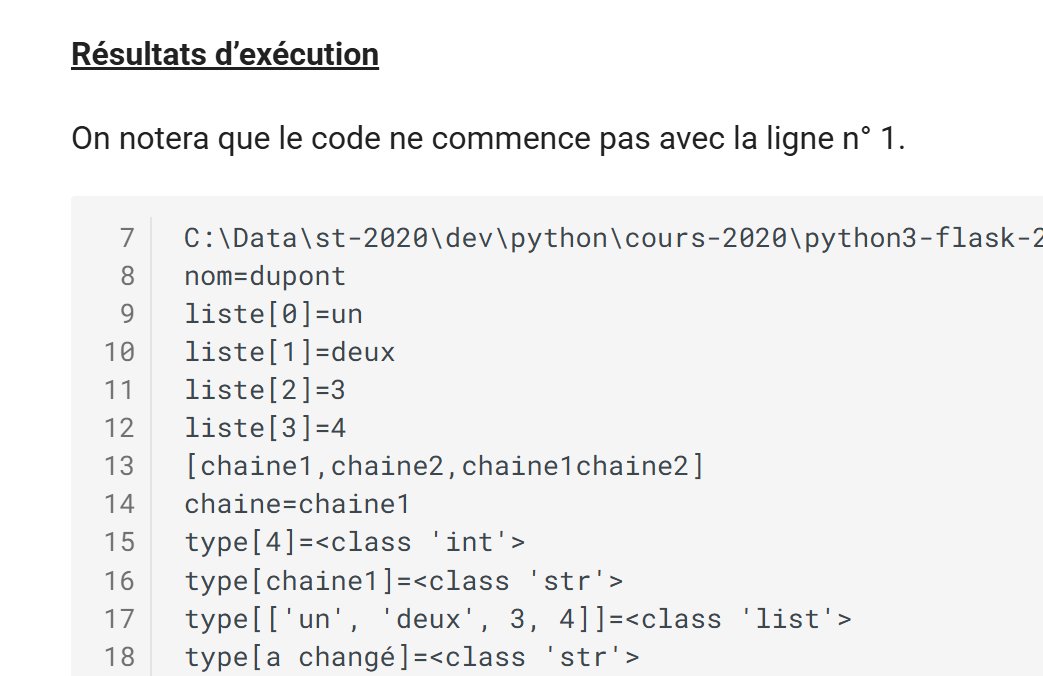 |
Un bloque de código sin numerar en ODT, el resto en HTML:
Documento ODT / DOCX
 |
Resultado HTML
 |
11.9. Los enlaces
Documento ODT / DOCX
 |
Resultado HTML
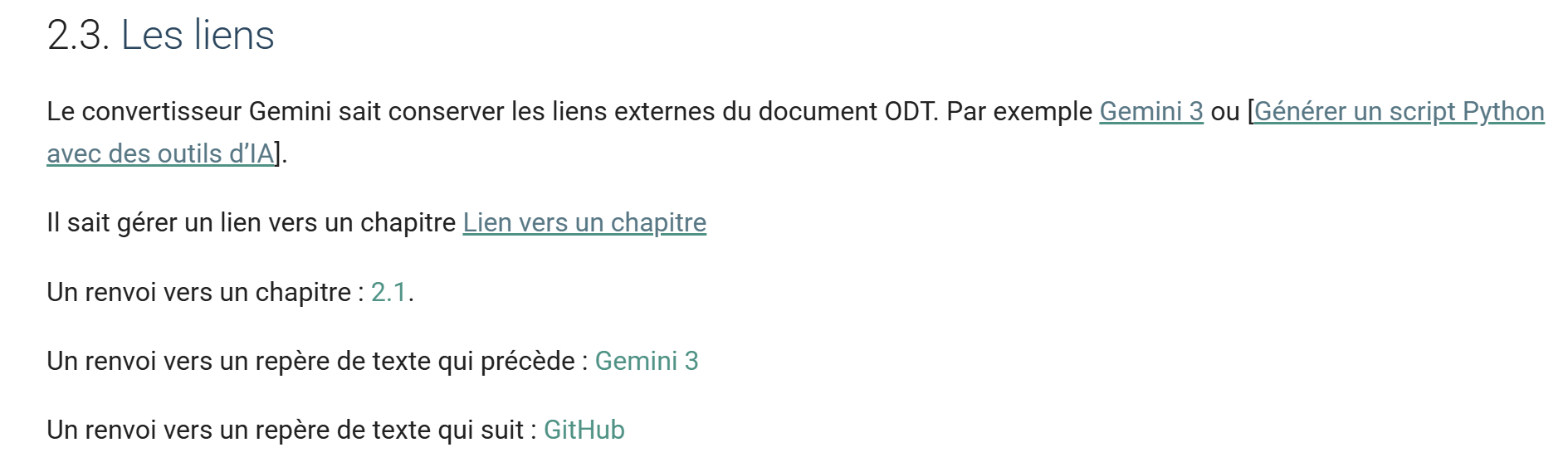 |
11.10. Formato de texto
Documento ODT / DOCX
  |
Representación HTML
 |
11.11. Las imágenes
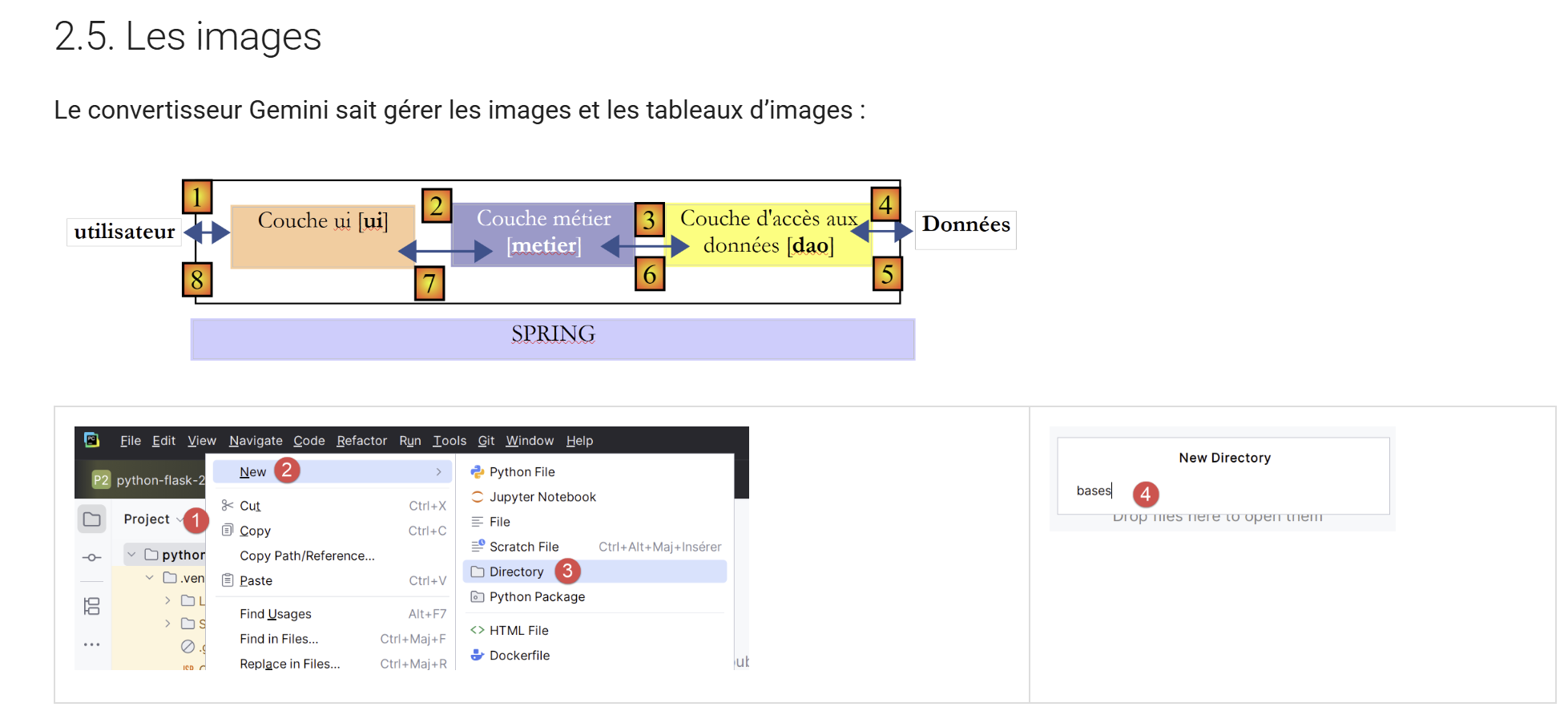 |
Cabe señalar que el conversor Gemini / ChatGPT respeta los cambios de tamaño de las imágenes realizados en el documento ODT / DOCX.
11.12. Los caracteres protegidos
Documento ODT / DOCX
 |
Resultado HTML
 |
Documento ODT / DOCX (MarkDown)
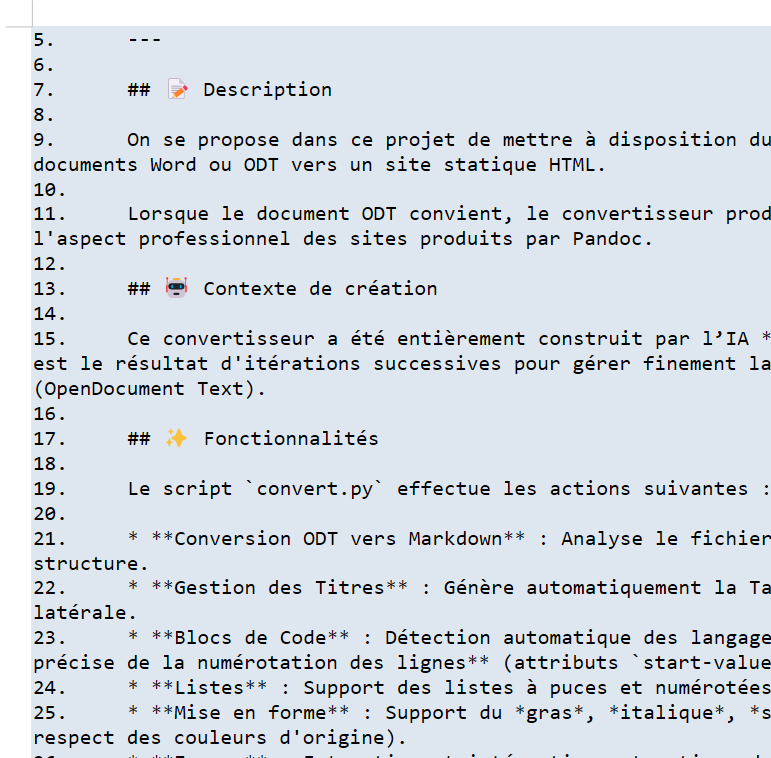 |
Resultado HTML
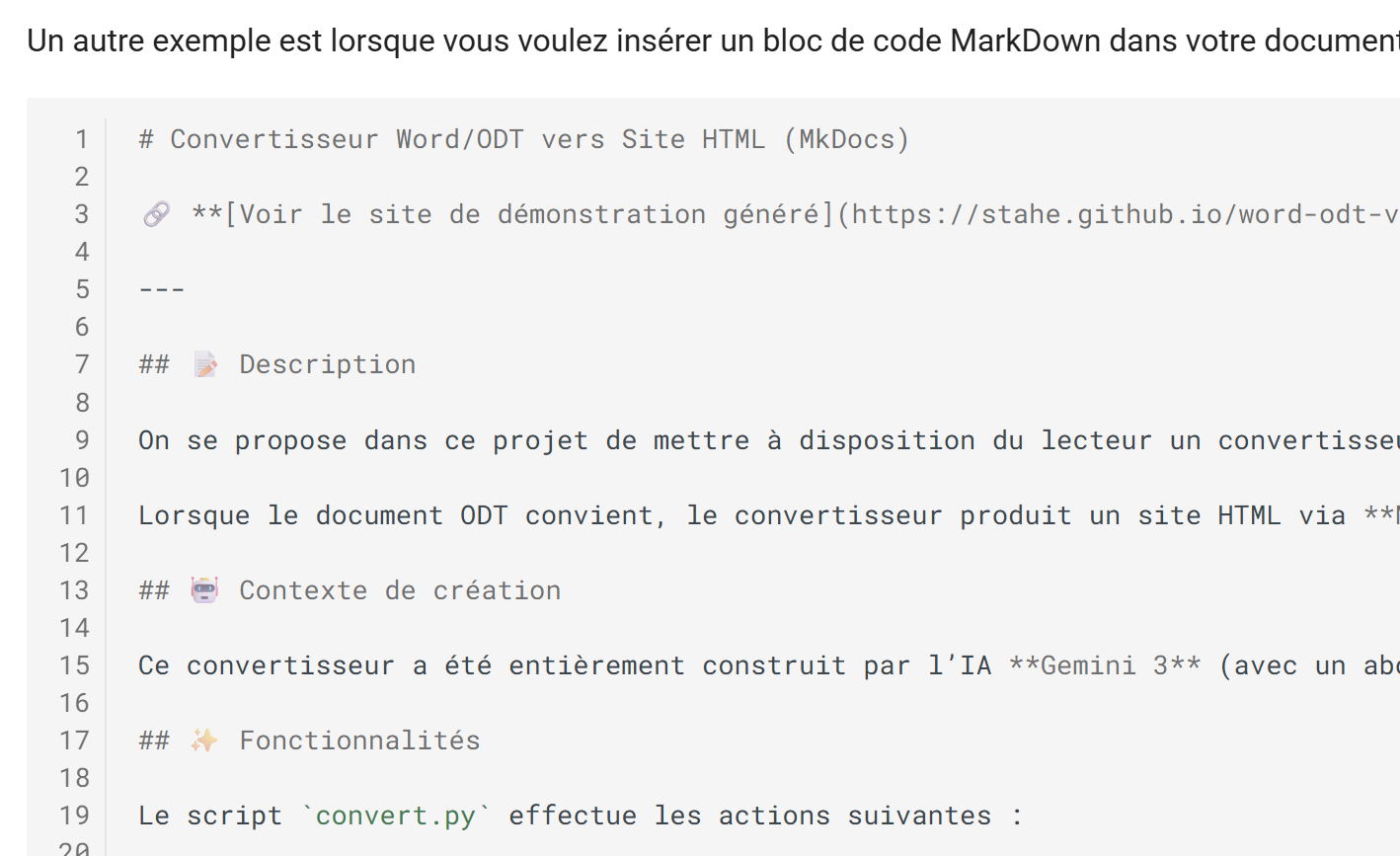 |
- Se ha conservado el código MarkDown;
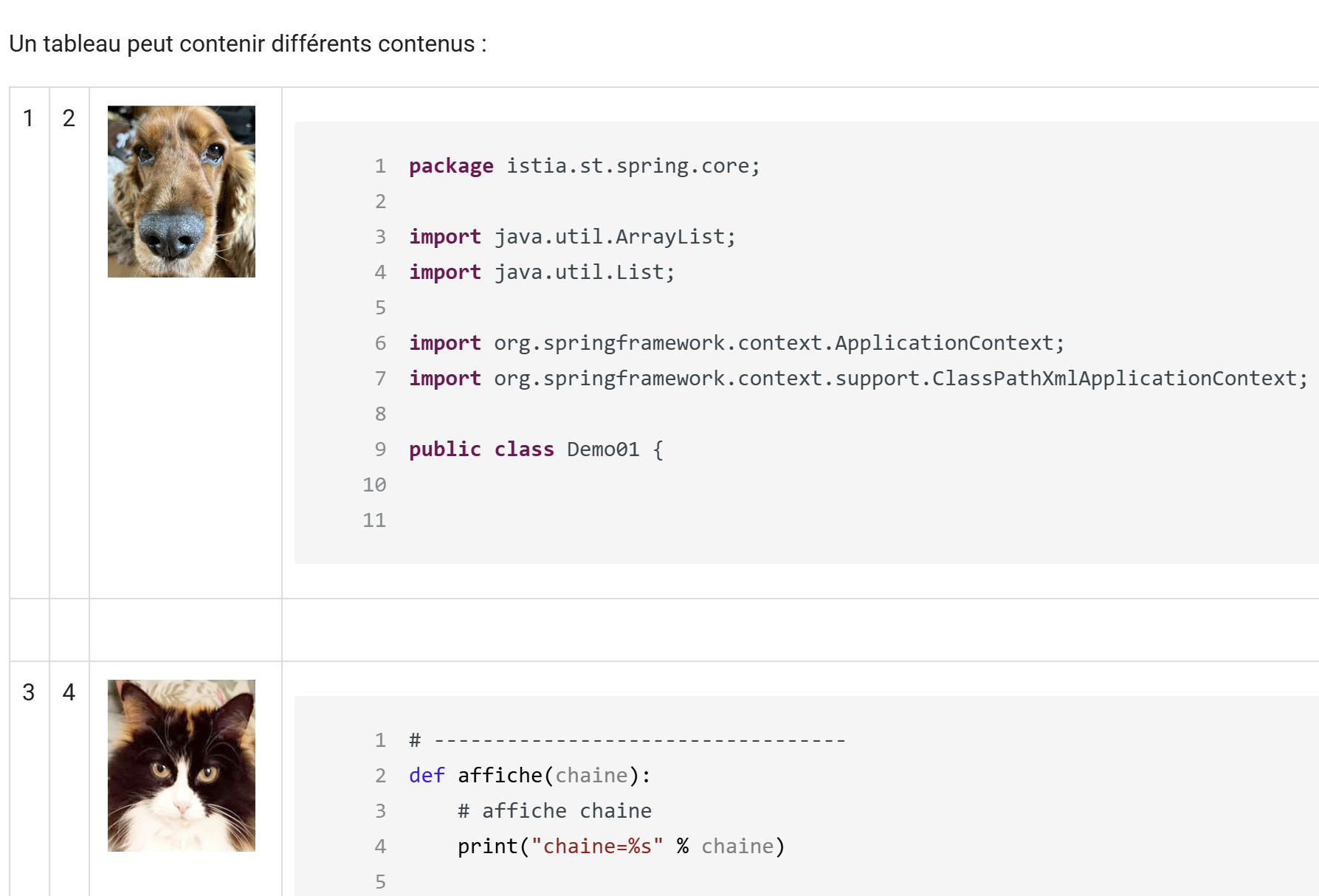
11.13. Las tablas
Documento ODT / DOCX
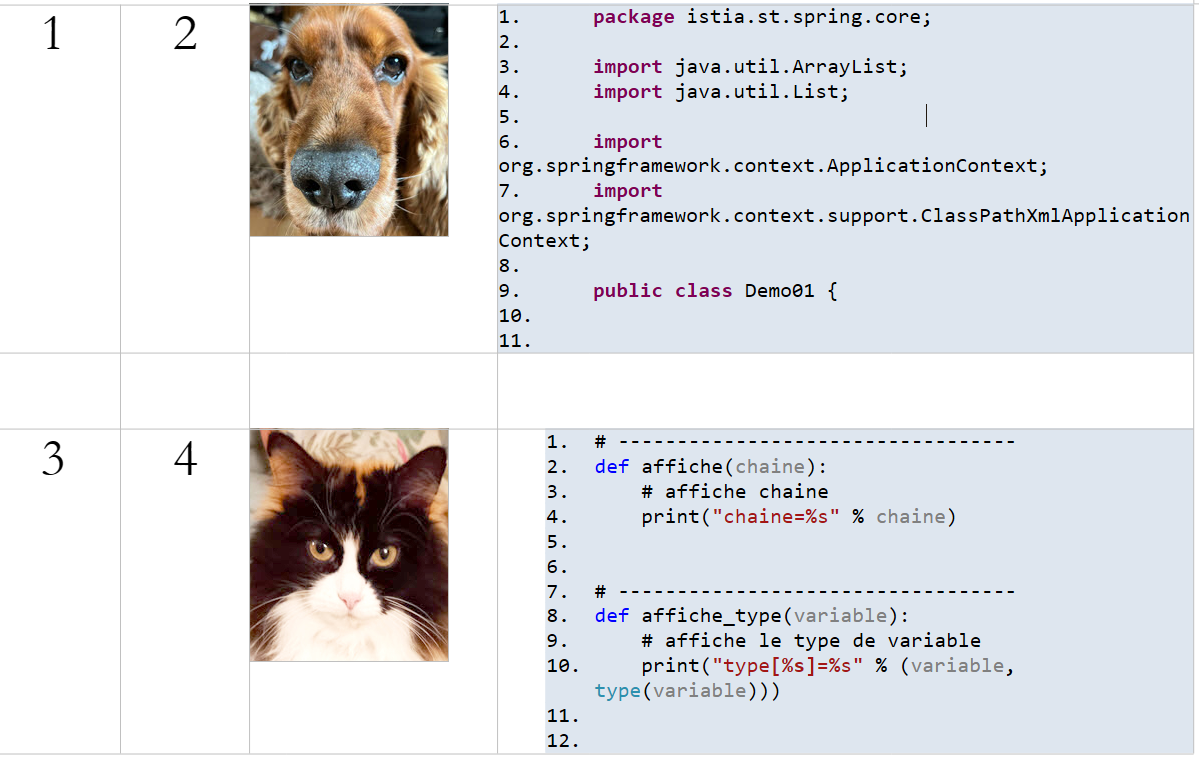 |
Resultado HTML
 |
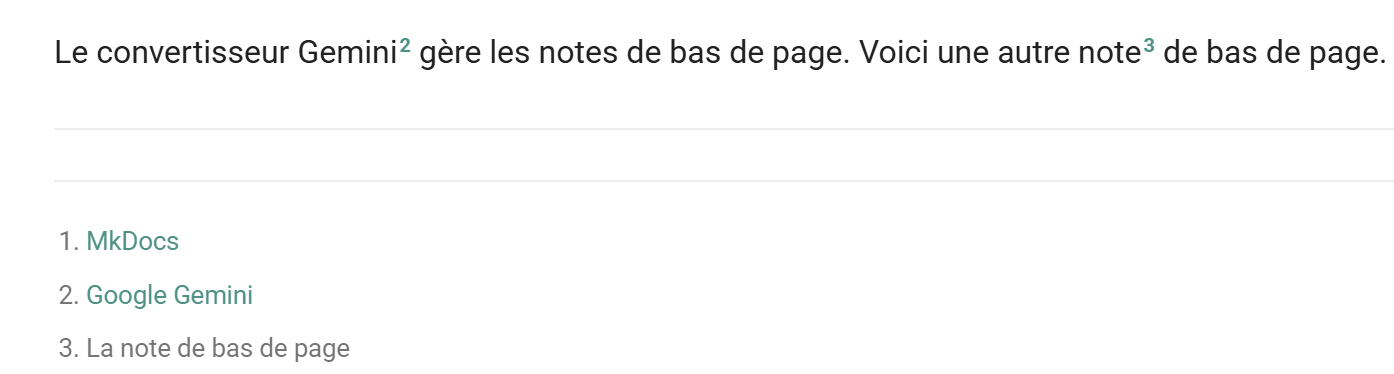
11.14. Notas al pie
 |
11.15. Anomalías conocidas
Se han detectado algunas anomalías, pero pueden corregirse modificando el ODT / DOCX:
- los bloques de código deben ir seguidos de una línea en blanco; de lo contrario, el bloque de código puede mostrarse incorrectamente. El caso detectado es un código seguido inmediatamente de un título sin estar separado de este por una línea en blanco;
- las listas con viñetas no pueden tener borde inferior. Para que lo tengan, hay que añadir una línea en blanco detrás del último elemento de la lista;
- las listas con viñetas deben estar jerarquizadas. Así, una lista de nivel 2 debe incluirse siempre dentro de una lista de nivel 1; de lo contrario, la lista de nivel 2 se muestra como código;
A medida que se actualicen las versiones del conversor, algunas de estas anomalías desaparecerán. Las tres anteriores se pueden evitar corrigiendo el documento de origen.
11.16. Otros casos
Si su documento utiliza otras particularidades distintas a las mencionadas anteriormente, es muy probable que el conversor Gemini / ChatGPT no las tenga en cuenta. ¿Qué hacer entonces? Puede enviar su nueva solicitud a una de las IA proporcionándole el conversor actual:
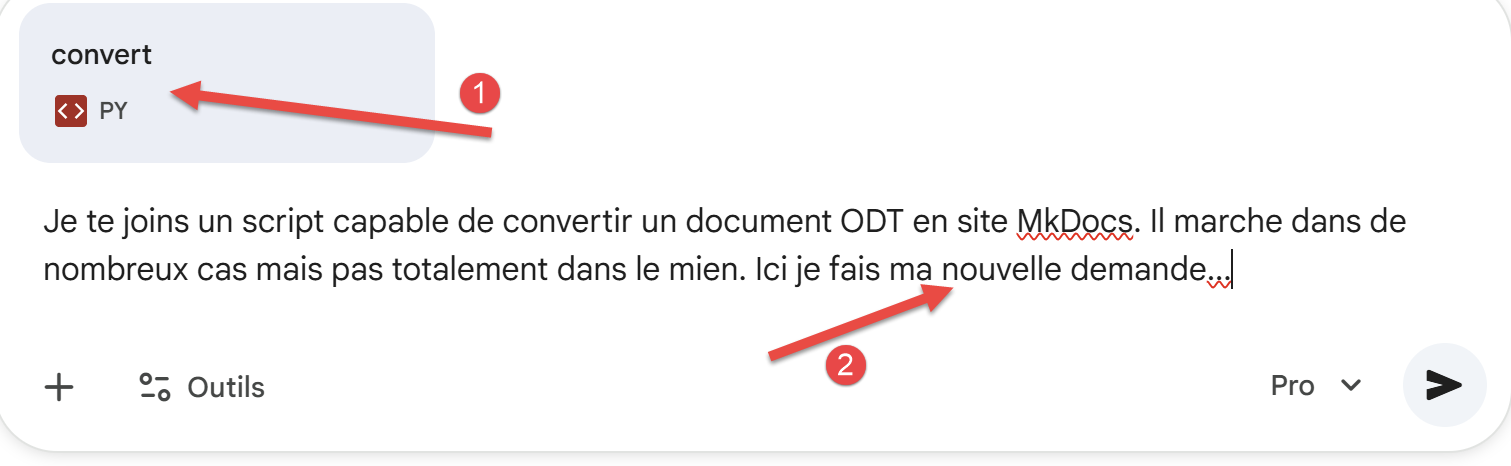 |
- En [1], adjunto el convertidor de este documento;
- En [2], realizo mi nueva solicitud;
Probablemente tendrás que pasar por muchas iteraciones. Cuando una versión sea estable, anota su número para poder volver a dárselo a la IA en caso de regresión. También es recomendable hacer una copia de cada versión estable. Una desventaja importante de ambas IA es que sufren regresiones con bastante facilidad. Basta con pedirle una nueva funcionalidad para que la IA rompa el código que antes funcionaba. De ahí la importancia de anotar el número de versión de las versiones estables para poder volver a ellas. En enero de 2026, me pareció que ChatGPT 5.2 tenía menos tendencia a sufrir regresiones que Gemini 3.