5. Relaciones entre tablas
5.1. Las claves externas
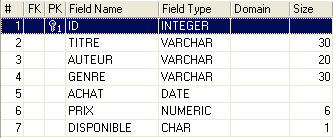
Una base de datos relacional es un conjunto de tablas relacionadas entre sí mediante relaciones. Tomemos un ejemplo inspirado en la tabla [BIBLIO] anterior, cuya estructura era la siguiente:
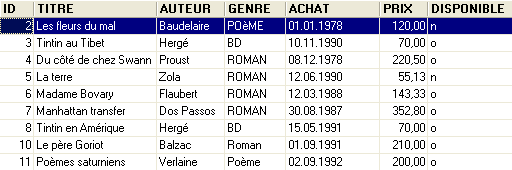
Un ejemplo de contenido era el siguiente:
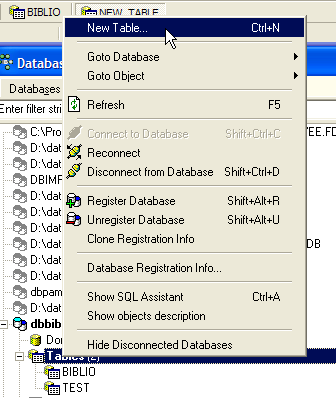
Podríamos querer información sobre los diferentes autores de estas obras, por ejemplo, su nom y prénom, su fecha de nacimiento, su nationalité. Creemos una tabla de este tipo. Hagamos clic con el botón derecho en [DBBIBLIO / Tables] y luego seleccionemos option [New Table]:
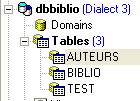
Ahora construyamos la siguiente tabla [AUTEURS]:
 | 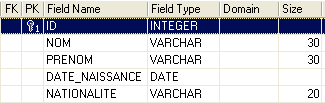 |
clave primaria de la tabla: sirve para identificar una fila de forma única | |
nombre del autor | |
nombre del autor, si lo tiene | |
su fecha de nacimiento | |
su país de origen |
El contenido de la tabla [AUTEURS] podría ser el siguiente:
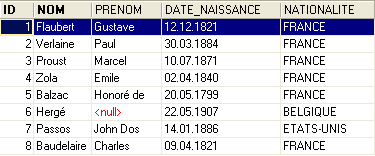
Volvamos a la tabla [BIBLIO] y a su contenido:
En la columna [AUTEUR] de la tabla, ya no es necesario indicar el nombre del autor. Es preferible indicar el número (id) que tiene en la tabla [AUTEURS]. Creemos, pues, una nueva tabla llamada [LIVRES]. Para crearla, utilizaremos el script [biblio.sql] creado en el apartado 3.14. Cargamos este script con la herramienta [Script Executive, Ctrl-F12]:
Modificamos el script de creación de la tabla BIBLIO para adaptarlo al de la tabla LIVRES:
Solo comentamos los cambios:
- línea 4: la columna [AUTEUR] de la tabla pasa a ser un número entero. Este número hace referencia a uno de los autores de la tabla [AUTEURS] creada anteriormente.
- líneas 11-19: los nombres de los autores se han sustituido por sus números de autor.
- línea 29: se ha cambiado el nombre de la restricción. Antes se llamaba [ UNQ1_BIBLIO ]. Ahora se llama [ UNQ1_LIVRES ]. Este nombre puede ser cualquiera. Sin embargo, es preferible que tenga sentido. En este caso no se ha hecho ese esfuerzo. Las restricciones sobre los diferentes campos y las diferentes tablas de una base de datos deben diferenciarse mediante nombres distintos. Recordemos que la restricción de la línea 29 exige que un título sea único en la tabla.
- Línea 36: cambio del nombre de la restricción sobre la clave primaria ID.
Ejecutemos este script. Si se ejecuta correctamente, obtendremos la siguiente tabla nueva [LIVRES]:
 | 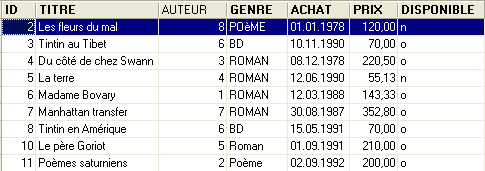 |
Cabe preguntarse si, al final, hemos salido ganando con el cambio. De hecho, la tabla [LIVRES] muestra números de autor en lugar de sus nombres. Como hay miles de autores, parece difícil establecer la relación entre un libro y su autor. Afortunadamente, el lenguaje SQL está ahí para ayudarnos. Nos permite consultar varias tablas al mismo tiempo. A modo de ejemplo, presentamos la consulta SQL, que nos permite obtener los títulos de los libros de la biblioteca, asociados a la información de sus autores. Utilicemos el editor SQL (F12) para emitir la orden SQL siguiente:
SQL> select LIVRES.titre, AUTEURS.nom, AUTEURS.prenom,AUTEURS.date_naissance
FROM LIVRES inner join AUTEURS on LIVRES.AUTEUR=AUTEURS.ID
ORDER BY AUTEURS.nom asc
Es demasiado pronto para explicar esta orden SQL. Volveremos sobre ella próximamente. El resultado de esta consulta es el siguiente:
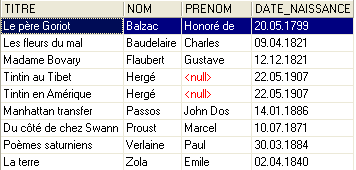
Cada libro se ha asociado correctamente con su autor y con la información relacionada con él.
Resumamos lo que acabamos de hacer:
- tenemos dos tablas que recopilan información de diferente naturaleza:
- la tabla AUTEURS recopila información sobre los autores
- la tabla LIVRES recopila información sobre los libros adquiridos por la biblioteca
- estas tablas están relacionadas entre sí. Un libro tiene necesariamente un autor. Incluso puede tener varios. Este caso no se ha tenido en cuenta aquí. La columna [AUTEUR] de la tabla [LIVRES] hace referencia a una fila de la tabla [AUTEURS]. A esto se le llama una relación.
La relación que vincula la tabla [LIVRES] con la tabla [AUTEURS] es, de hecho, una forma de restricción: una fila de la tabla [LIVRES] siempre debe tener un número de autor que exista en la tabla [AUTEURS]. Si una fila de [LIVRES] tuviera un número de autor que no existiera en la tabla [AUTEURS], nos encontraríamos en una situación anómala en la que no podríamos localizar al autor de un libro.
La tabla SGBD es capaz de verificar que esta restricción se cumple en todo momento. Para ello, vamos a añadir una restricción a la tabla [LIVRES]:
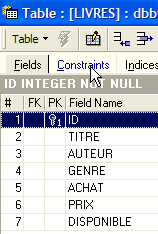 |  | 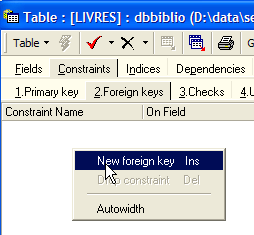 |
El enlace que une la entrada [AUTEUR] de la tabla [LIVRES] con el campo [ID] de la tabla [AUTEURS] se denomina enlace de clave externa. El campo [AUTEUR] de la tabla [LIVRES] se denomina «clave externa» o «foreign key» en el asistente anterior. Definir una clave externa significa que el valor de una columna [c1] de una tabla [T1] debe existir en la columna [c2] de la tabla [T2]. La columna [c1] se denomina «clave externa» de la tabla T1 sobre la columna [c2] de la tabla [T2]. La columna [c2] suele ser la clave primaria de la tabla [T2], pero no es obligatorio.
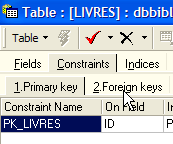
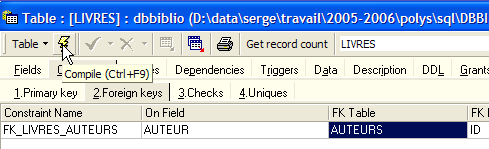
Definimos la clave externa [AUTEUR] de la tabla [LIVRES] sobre el campo [ID] de la tabla [AUTEURS] de la siguiente manera:
 |
- nombre de la restricción: libre
- columna «clave externa», en este caso la columna [AUTEUR] de la tabla [LIVRES]
- tabla a la que hace referencia la clave externa. En este caso, la columna [AUTEUR] de la tabla [LIVRES] debe tener un valor en la columna [ID] de la tabla [AUTEURS]. Por lo tanto, se hace referencia a la tabla [AUTEURS].
- Columna a la que hace referencia la clave externa. En este caso, la columna [ID] de la tabla [AUTEURS].
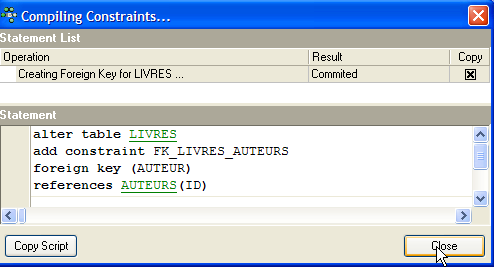
Validamos esta restricción:
Si todo va bien, se acepta:
¿Cuál es la consecuencia de esta nueva restricción de clave externa? Con el editor SQL (F12), intentemos insertar una fila en la tabla LIVRES con un número de autor inexistente:
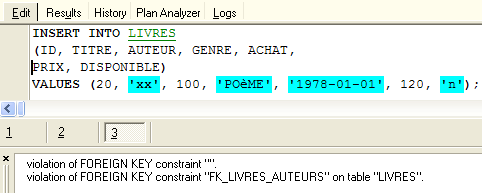
La operación [INSERT] anterior intentó insertar un libro con un número de autor (100) inexistente. La ejecución de la consulta falló. El mensaje de error asociado indica que se ha producido una violación de la restricción de clave externa «FK_LIVRES_AUTEURS». Es la que acabamos de definir.
5.2. Operaciones de unión entre dos tablas
Siempre en la base [DBBIBLIO] (o en cualquier otra base, da igual), creemos dos tablas de prueba llamadas TA y TB y definidas de la siguiente manera:
Tabla TA
- ID: clave primaria de la tabla TA - DATA: cualquier dato | 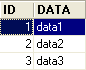 |
Tabla TB
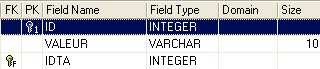 - ID: clave primaria de la tabla TB - IDTA: clave externa de la tabla TB que hace referencia a la columna ID de la tabla TA. Por lo tanto, un valor de la columna IDTA de la tabla TA debe existir en la columna ID de la tabla TA - VALEUR: cualquier dato | 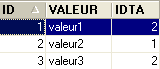 |
En el editor SQL (F12), vamos a emitir órdenes SQL que utilizan simultáneamente las dos tablas TA y TB.
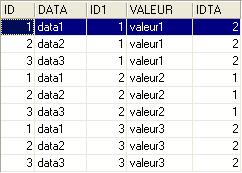
La orden SQL utiliza, tras la palabra clave FROM, las dos tablas TA y TB. La operación FROM TA, TB provocará la creación temporal de una nueva tabla en la que cada fila de la tabla TA se asociará a cada una de las filas de la tabla TB. Así, si la tabla TA tiene NA filas y la tabla TB tiene NB filas, la tabla resultante tendrá NA x NB filas. Esto es lo que muestra la captura de pantalla anterior. Además, cada fila contiene las columnas de ambas tablas. Las columnas coli especificadas en la orden [SELECT col1, col2, ... FROM ...] indican cuáles deben conservarse. Aquí, la palabra clave * indica que se solicitan todas las columnas de la tabla resultante. A veces se dice que la tabla resultante de la orden SQL anterior es el producto cartesiano de las tablas TA y TB.
En el ejemplo anterior, cada fila de la tabla TA se ha asociado a cada fila de la tabla TB. En general, se desea asociar a una fila de TA las filas de TB que tienen una relación con ella. Esta relación suele adoptar la forma de una restricción de clave externa. Este es el caso aquí. A una fila de la tabla TA se le pueden asociar las filas de la tabla TB que cumplen la relación TB.IDTA=TA.ID. Hay varias formas de solicitar esto:
La orden SQL anterior es análoga a la anterior, con dos diferencias:
- las filas resultantes del producto cartesiano TA x TB se filtran mediante una cláusula WHERE que asocia a una fila de la tabla TA, las únicas filas de la tabla TB que verifican la relación TB.IDTA=TA.ID
- solo se solicitan determinadas columnas con la sintaxis [T.col], donde T es el nombre de una tabla y col el nombre de una columna de dicha tabla. Esta sintaxis permite eliminar la ambigüedad que podría surgir si dos tablas tuvieran columnas con el mismo nombre. Cuando no existe esta ambigüedad, se puede utilizar la sintaxis [col] sin especificar la tabla de dicha columna.
El resultado obtenido es el siguiente:
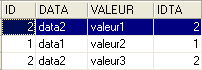
Se puede obtener el mismo resultado con la siguiente orden SQL:
Del término [inner join] proviene el nombre de «unión interna» que se da a este tipo de operaciones entre dos tablas. Veremos que existe una «unión externa». En una unión interna, el orden de las tablas en la consulta no tiene consecuencias en el resultado: FROM TA inner join TB es equivalente a FROM TB inner join TA.
La orden SQL anterior solo incluye en la tabla resultante las filas de la tabla TA a las que hace referencia al menos una fila de la tabla TB. Por lo tanto, la línea de TA [3, data3] no aparece en el resultado, ya que no está referenciada por ninguna línea de TB. Es posible que se deseen todas las filas de TA, independientemente de si están referenciadas o no por una fila de TB. En ese caso, se utiliza una unión externa entre las dos tablas:
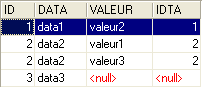
Aquí tenemos una unión externa izquierda («left outer join»). Para entender la expresión «FROM TA left outer join TB», hay que imaginarse una unión con la tabla TA a la izquierda y la tabla TB a la derecha. Todas las filas de la tabla de la izquierda aparecen en el resultado de una unión externa a la izquierda, incluso aquellas para las que no se cumple la relación de unión. Esta relación de unión no es necesariamente una restricción de clave externa, aunque sí es el caso más habitual.
En el siguiente orden:
la tabla TB es la que está a la «izquierda» en la unión externa. Por lo tanto, todas las filas de TB aparecerán en el resultado:
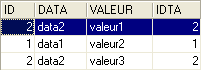
A diferencia de la unión interna, el orden de las tablas sí importa. También existen uniones externas a la derecha:
- FROM TA left outer join TB es equivalente a FROM TB right outer join TA: la tabla TA está a la izquierda
- FROM TB left outer join TA es equivalente a FROM TA right outer join TB: la tabla TB está a la izquierda
Ahora que ya conocemos los fundamentos del uso simultáneo de varias tablas, podemos abordar operaciones de consulta más complejas en las bases de datos.