10. Oracle Express 11g release 2
Ahora abordamos la migración a Oracle Express 11g release 2 de lo que se ha hecho con MySQL5.
 |
10.1. Configuración del entorno de trabajo
10.1.1. Entorno Eclipse
Trabajaremos con el siguiente entorno Eclipse:
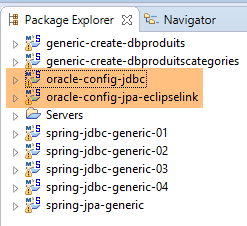 |
Los proyectos de Oracle mencionados anteriormente se encuentran en la carpeta [<exemples>/spring-database-config\oracle\eclipse].
Nota: ejecute [Alt-F5] para regenerar todos los proyectos Maven.
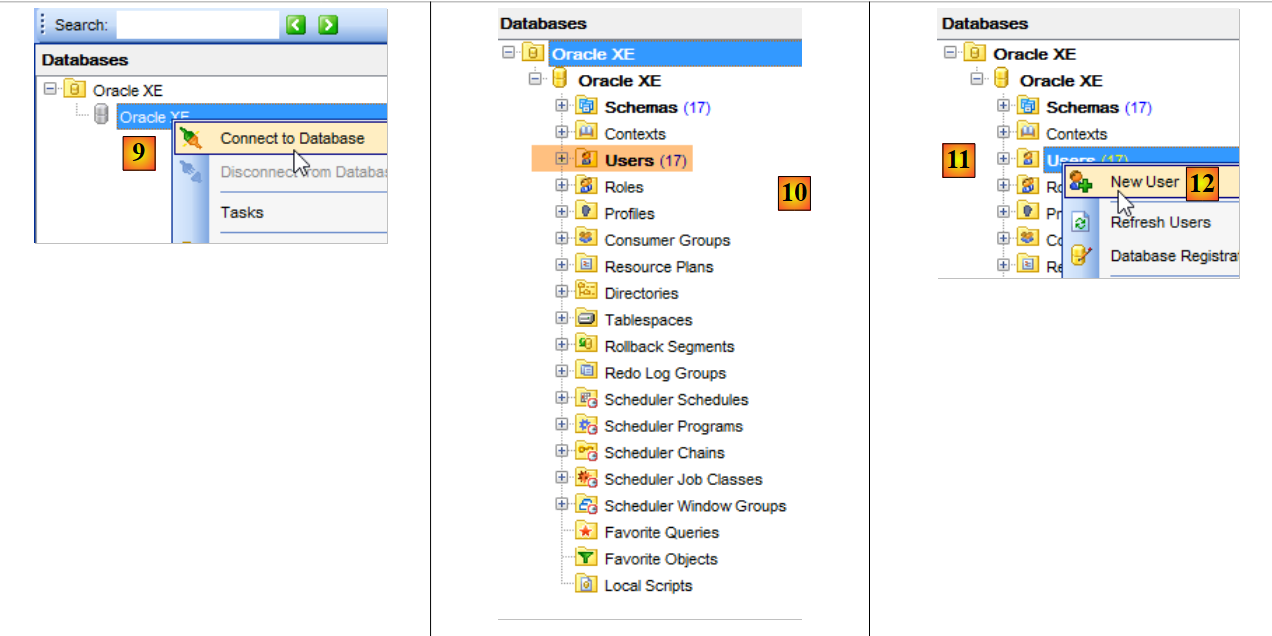
Inicie Oracle Express y su cliente [OraManager] (véase el apartado 23.6). Vamos a generar:
- la base de datos [dbproduits] con el proyecto [generic-create-dbproduits];
- la base de datos [dbproduitscategories] con el proyecto [generic-create-dbproduitscategories];
10.1.2. Creación de usuarios
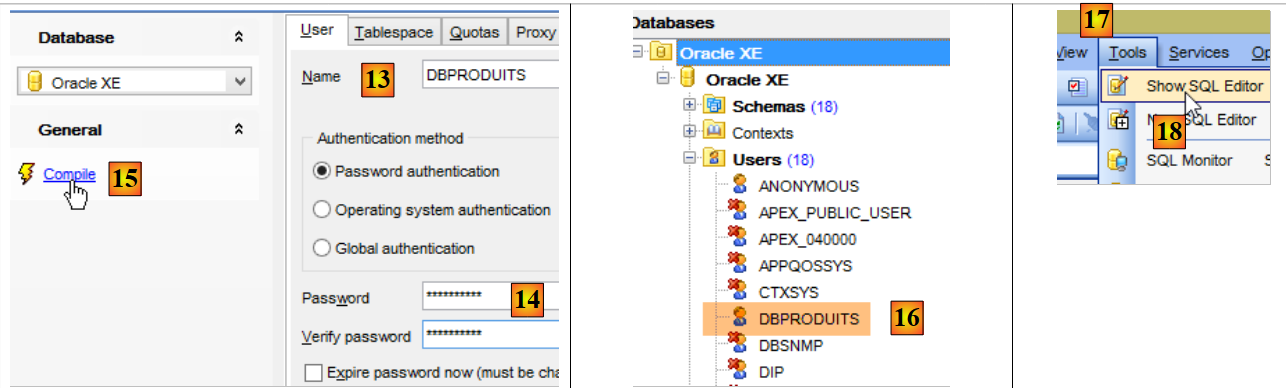
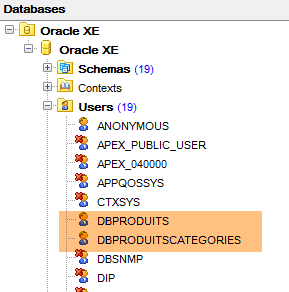
Ahora todo se realiza en [OraManager]. Se debe iniciar el proceso Oracle SGBD. Se utilizan las credenciales system / system para el administrador del sistema (debe haberse configurado previamente). Vamos a crear dos usuarios:
- [DBPRODUITS / dbproduits], que será el propietario de la base de datos [dbproduits];
- [DBPRODUITSCATEGORIES / dbproduitscategories], que será el propietario de la base de datos [dbproduits];
 |
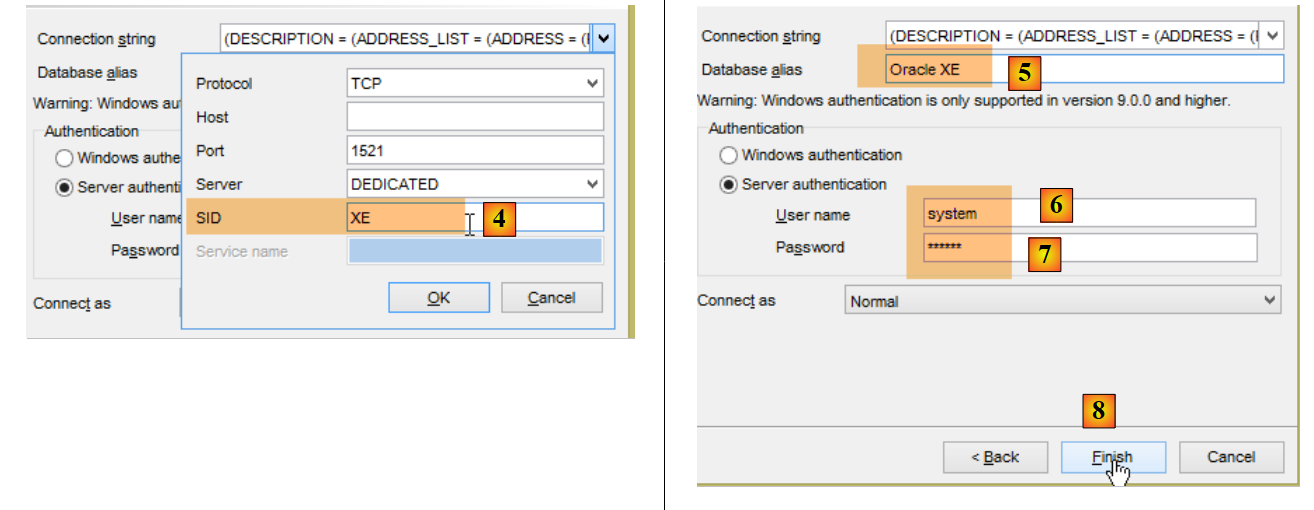 |
- en [6-7], los identificadores son [system / system];
 |
 |
- en [14]: poner dbproduits;
- en [16], se ha creado el usuario, pero no tiene los derechos suficientes para conectarse. Se los vamos a dar mediante un script SQL [17-18];
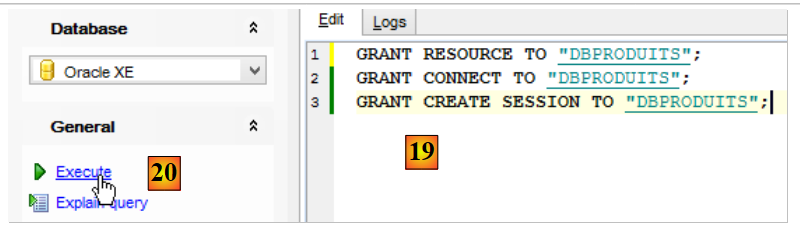 |
- en [19], poner el nombre de usuario en mayúsculas;
Hacemos lo mismo para crear el usuario [DBPRODUITSCATEGORIES / dbproduitscategories]:
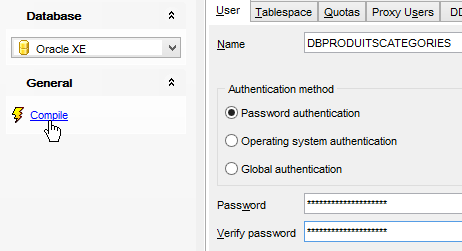 | 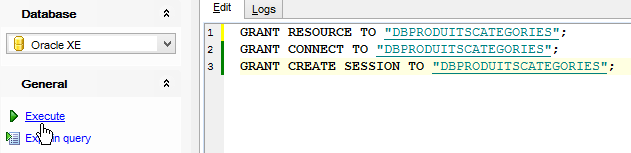 |
 |
10.1.3. Instalación del controlador JDBC de Oracle en el repositorio Maven
El controlador JDBC de Oracle no está disponible en los repositorios centrales de Maven. Debe descargarse desde Oracle [http://www.oracle.com/technetwork/apps-tech/jdbc-112010-090769.html]:
 |
Una vez descargado, hay que instalarlo en el repositorio local de Maven. Esto se hace con el siguiente script:
"%M2_HOME%\bin\mvn.bat" install:install-file -Dfile=ojdbc6.jar -Dpackaging=jar -DgroupId=com.oracle.jdbc -DartifactId=ojdbc6 -Dversion=1.0
donde se sustituirá [%M2_HOME%] por la ruta del directorio de instalación de Maven (véase el apartado 23.2). Una vez hecho esto, el controlador JDBC se puede importar a los proyectos Maven mediante la configuración:
<dependency>
<groupId>com.oracle.jdbc</groupId>
<artifactId>ojdbc6</artifactId>
<version>1.0</version>
</dependency>
10.1.4. Generación de la base de datos [dbproduits]
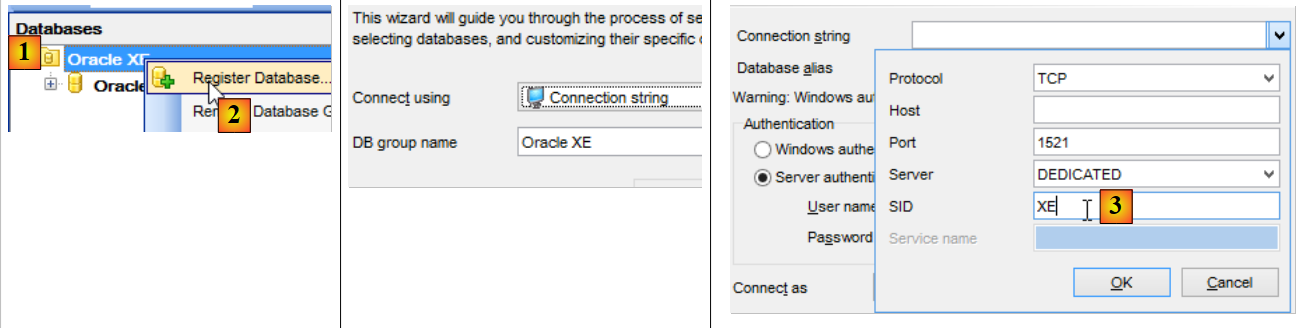
Ahora que tenemos un usuario [DBPRODUITS / dbproduits], vamos a conectarnos a Oracle con estas credenciales:
 |
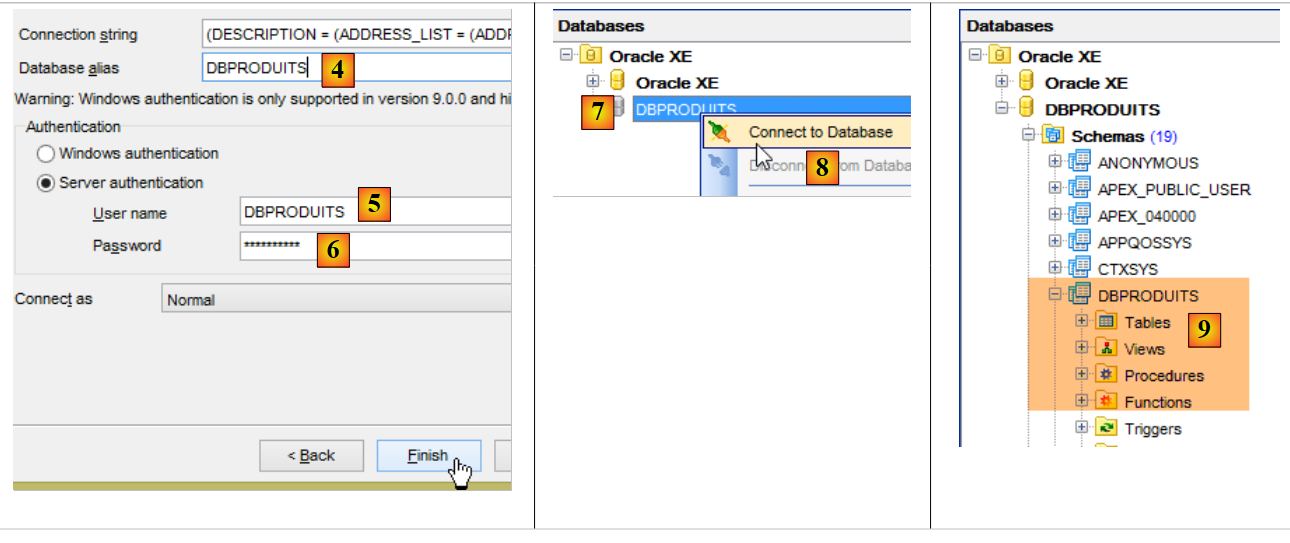 |
- en [6], introducir «dbproduits»;
- en [9], la base de datos [DBPRODUITS] que vamos a utilizar;
En la clase [ConfigJdbc] del proyecto [oracle-config-jdbc], los parámetros de conexión utilizados son los siguientes:
public final static String DRIVER_CLASSNAME = "oracle.jdbc.OracleDriver";
public final static String URL_DBPRODUITS = "jdbc:oracle:thin:@localhost:1521:xe";
public final static String USER_DBPRODUITS = "DBPRODUITS";
public final static String PASSWD_DBPRODUITS = "dbproduits";
public final static String URL_DBPRODUITSCATEGORIES = "jdbc:oracle:thin:@localhost:1521:xe";
public final static String USER_DBPRODUITSCATEGORIES = "DBPRODUITSCATEGORIES";
public final static String PASSWD_DBPRODUITSCATEGORIES = "dbproduitscategories";
Debe adaptarlos a su configuración de Oracle.
En el proyecto [oracle-config-jpa-eclipselink], la entidad JPA se define de la siguiente manera:
 |
package generic.jpa.entities.dbproduits;
import generic.jdbc.config.ConfigJdbc;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.SequenceGenerator;
import javax.persistence.Table;
@Entity(name="Produit1")
@Table(name = ConfigJdbc.TAB_PRODUITS)
public class Produit {
// campos
@Id
@GeneratedValue(strategy=GenerationType.SEQUENCE,generator="genSeqProduits")
@SequenceGenerator(name="genSeqProduits",sequenceName="PRODUITS_SEQUENCE", allocationSize=5)
@Column(name = ConfigJdbc.TAB_PRODUITS_ID)
private Long id;
@Column(name = ConfigJdbc.TAB_PRODUITS_NOM, unique = true, length = 30, nullable = false)
private String nom;
@Column(name = ConfigJdbc.TAB_PRODUITS_CATEGORIE, nullable = false)
private int categorie;
@Column(name = ConfigJdbc.TAB_PRODUITS_PRIX, nullable = false)
private double prix;
@Column(name = ConfigJdbc.TAB_PRODUITS_DESCRIPTION, length = 100, nullable = false)
private String description;
...
}
- líneas 18-19: la estrategia de generación de la clave primaria de la tabla [PRODUITS] es [strategy=GenerationType.SEQUENCE]. Para MySQL, se había utilizado la estrategia [@GeneratedValue(strategy = GenerationType.IDENTITY)]. Con Oracle Express 11g, esta estrategia no es utilizable;
- línea 18: se indica que la clave primaria se obtendrá mediante un generador de números que a menudo se denomina secuencia;
- línea 19: el generador de secuencias (el atributo name hace referencia al generador de la línea 18) creará una secuencia llamada [PRODUITS_SEQUENCE] en la base [dbproduits]. Dado que se busca la portabilidad entre las implementaciones JPA, es importante nombrar la secuencia. De lo contrario, si no existe la línea 19, las tres implementaciones JPA crearán secuencias que no tendrán el mismo nombre, lo que imposibilitará que JPA2 utilice una base creada por JPA1;
Estamos listos para ejecutar la configuración [generic-create-dbproduits-eclipselink]:
 |  |
La ejecución de esta configuración crea dos objetos:
- una tabla [PRODUITS];
- una secuencia denominada [PRODUITS_SEQUENCE]
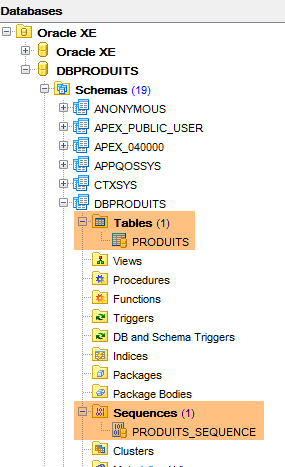 | 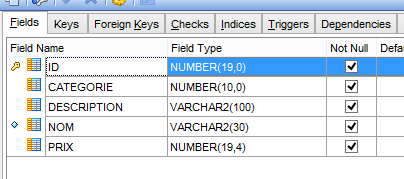 |
La DDL de la tabla [PRODUITS] es la siguiente:
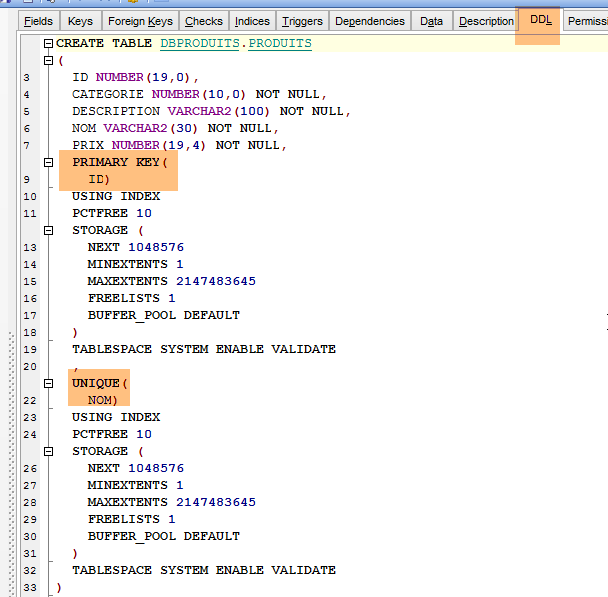 |
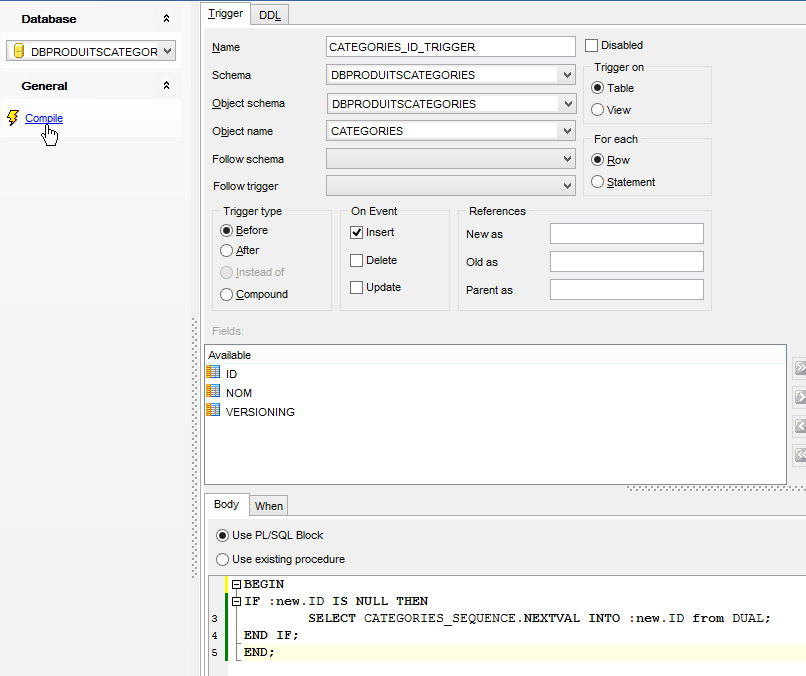
La clave primaria [ID] no se autoincrementa como lo hacía con MySQL. Sin embargo, el proyecto [spring-jdbc-03] supone que SGBD se encarga de generar las claves primarias de la tabla [PRODUITS]. Vamos a crear un trigger. Un trigger es un procedimiento almacenado dentro de SGBD que se ejecuta bajo ciertas condiciones. Vamos a crear un trigger que, con cada nueva inserción, genere la clave primaria del producto insertado a partir de la secuencia [PRODUITS_SEQUENCE] creada por la configuración JPA.
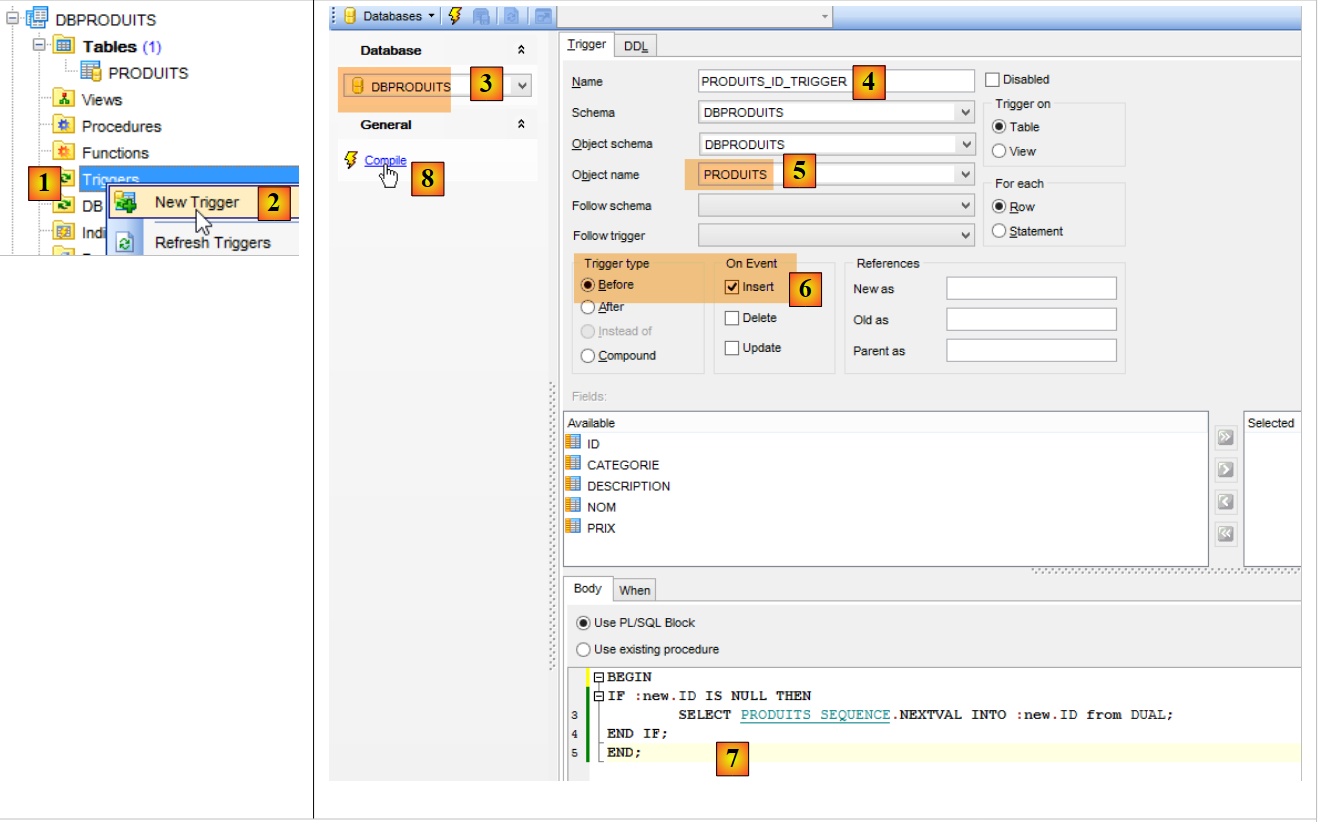 |
- en [6], el trigger [PRODUITS_ID_TRIGGER] [4] se ejecutará antes de cada inserción;
- en [7], un procedimiento almacenado específico de SGBD de Oracle. Indica que el campo [ID] de la línea que se va a insertar debe inicializarse con el siguiente valor del generador denominado [PRODUITS_SEQUENCE];
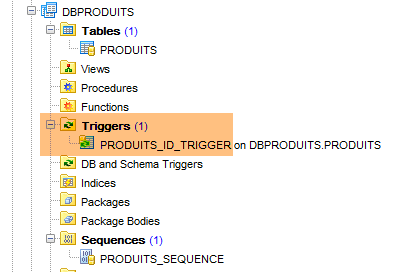 |
La base [dbproduits] ya está lista. Ejecute las siguientes configuraciones:
- [spring-jdbc-generic-01.IntroJdbc01];
- [spring-jdbc-generic-01.IntroJdbc02];
- [spring-jdbc-generic-03.JUnitTestDao1] ;
- [spring-jdbc-generic-03.JUnitTestDao2] ;
Todas deben completarse con éxito.
10.1.5. Generación de la base de datos [dbproduitscategories]
 |
Ahora ejecutamos el proyecto [generic-create-dbproduitscategories], que generará la base [dbproduitscategories]. Antes de eso, en [OraManager], nos conectamos con las credenciales de [DBPRODUITSCATEGORIES / dbproduitscategories] para poder observar los cambios realizados en la base [dbproduitscategories]:
 | 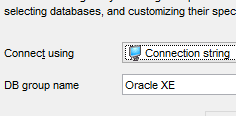 | 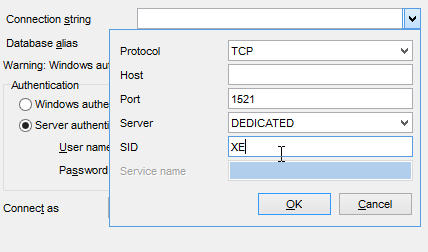 |
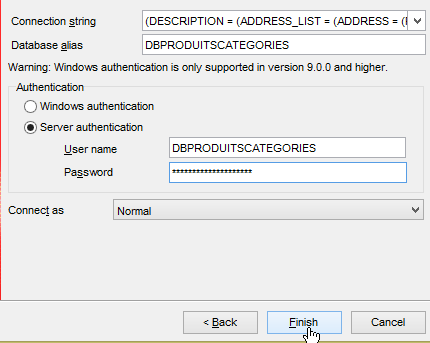 | 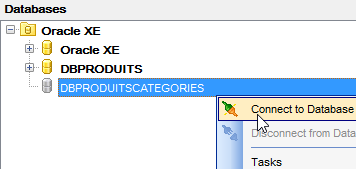 |
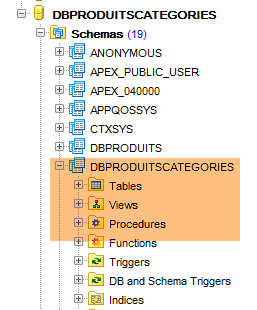 |
Las entidades JPA utilizadas tienen las siguientes estrategias de generación de claves primarias:
[Categorie]
public class Categorie implements AbstractCoreEntity {
@Id
@GeneratedValue(strategy=GenerationType.SEQUENCE,generator="genSeqCategories")
@SequenceGenerator(name="genSeqCategories",sequenceName="CATEGORIES_SEQUENCE", allocationSize=5)
@Column(name = ConfigJdbc.TAB_JPA_ID)
protected Long id;
[Produit]
public class Produit implements AbstractCoreEntity {
// propiedades
@Id
@GeneratedValue(strategy=GenerationType.SEQUENCE,generator="genSeqProduits2")
@SequenceGenerator(name="genSeqProduits2",sequenceName="PRODUITS_SEQUENCE", allocationSize=5)
@Column(name = ConfigJdbc.TAB_JPA_ID)
protected Long id;
[Role]
public class Role implements AbstractCoreEntity {
// propiedades
@Id
@GeneratedValue(strategy=GenerationType.SEQUENCE,generator="genSeqRoles")
@SequenceGenerator(name="genSeqRoles",sequenceName="ROLES_SEQUENCE", allocationSize=5)
@Column(name = ConfigJdbc.TAB_JPA_ID)
protected Long id;
[User]
public class User implements AbstractCoreEntity {
// propiedades
@Id
@GeneratedValue(strategy=GenerationType.SEQUENCE,generator="genSeqUsers")
@SequenceGenerator(name="genSeqUsers",sequenceName="USERS_SEQUENCE", allocationSize=5)
@Column(name = ConfigJdbc.TAB_JPA_ID)
protected Long id;
[UserRole]
public class UserRole implements AbstractCoreEntity {
// propiedades
@Id
@GeneratedValue(strategy=GenerationType.SEQUENCE,generator="genSeqUsersRoles")
@SequenceGenerator(name="genSeqUsersRoles",sequenceName="USERS_ROLES_SEQUENCE", allocationSize=5)
@Column(name = ConfigJdbc.TAB_JPA_ID)
protected Long id;
Al igual que se hizo con la base [dbproduits], se generarán cinco secuencias. Las implementaciones JPA las utilizan para generar las claves primarias. Las implementaciones JPA no utilizan disparadores como hemos hecho anteriormente, sino que consultan las secuencias para obtener la siguiente clave primaria. Nosotros generaremos las claves primarias también con disparadores. Estos son necesarios para el proyecto [spring-jdbc-04].
Ejecutamos la configuración [generic-create-dbproduitscategories-eclipselink]:
 |  |
y obtenemos el siguiente resultado:
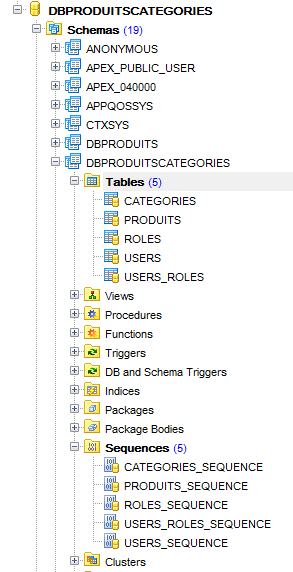 |
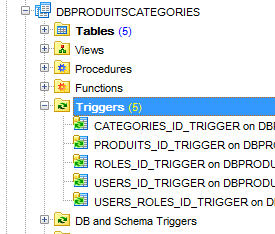
A continuación, generamos cinco triggers para generar las claves primarias de las cinco tablas:
 |
Los disparadores se asocian a las tablas de la siguiente manera:
CATEGORIES | CATEGORIES_ID_TRIGGER | CATEGORIES_SEQUENCE |
PRODUITS | PRODUITS_ID_TRIGGER | PRODUITS_SEQUENCE |
ROLES | ROLES_ID_TRIGGER | ROLES_SEQUENCE |
USERS | USERS_ID_TRIGGER | USERS_SEQUENCE |
USERS_ROLES | USERS_ROLES_ID_TRIGGER | USERS_ROLES_SEQUENCE |
 |
El proyecto [spring-jdbc-04] necesita que la columna [VERSIONING] tenga un valor por defecto en cada una de las tablas:
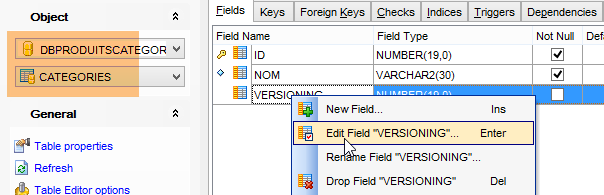 | 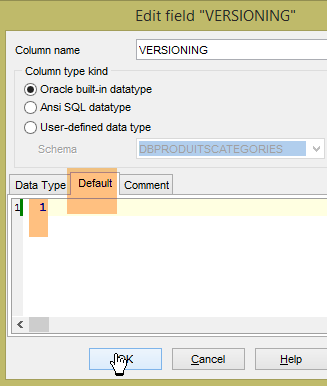 |
Hacemos esto para las cinco tablas.
Ahora, ejecute las configuraciones:
- [spring-jdbc-generic-04.JUnitTestDao] ;
- [spring-jpa-generic-JUnitTestDao-hibernate-eclipselink] ;
Ambas deben completarse con éxito.
10.2. Configuración de la capa JDBC
 |  |
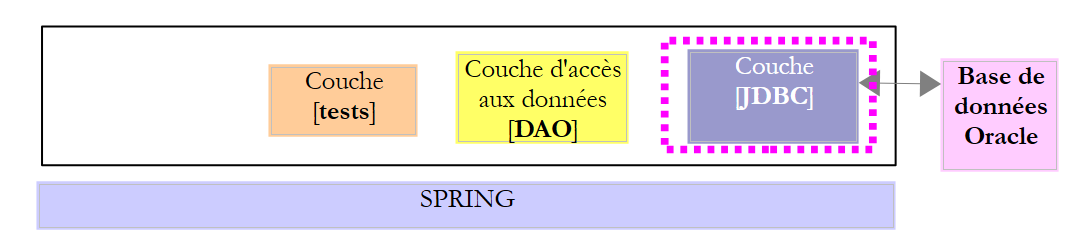
El proyecto [oracle-config-jdbc] configura la capa [JDBC] de la siguiente arquitectura de pruebas:
 |
El proyecto es análogo al proyecto de configuración [mysql-config-jdbc] de la capa JDBC del SGBD MySQL (véase el apartado 3.3). Solo presentamos las modificaciones:
El archivo [pom.xml] importa el controlador JDBC de Oracle:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-config-jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>configuration generic jdbc</name>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<!-- dependencias variables ********************************************** -->
<!-- controlador JDBC del SGBD -->
<dependency>
<groupId>com.oracle.jdbc</groupId>
<artifactId>ojdbc6</artifactId>
<version>1.0</version>
</dependency>
<!-- dependencias constantes ********************************************** -->
....
</dependencies>
...
</project>
- líneas 18-22: el controlador JDBC de Oracle sustituye al de MySQL;
La segunda modificación se encuentra en la clase [ConfigJdbc], que define los identificadores de acceso a las bases de datos:
// parámetros de conexión
public final static String DRIVER_CLASSNAME = "oracle.jdbc.OracleDriver";
public final static String URL_DBPRODUITS = "jdbc:oracle:thin:@localhost:1521:xe";
public final static String USER_DBPRODUITS = "DBPRODUITS";
public final static String PASSWD_DBPRODUITS = "dbproduits";
public final static String URL_DBPRODUITSCATEGORIES = "jdbc:oracle:thin:@localhost:1521:xe";
public final static String USER_DBPRODUITSCATEGORIES = "DBPRODUITSCATEGORIES";
public final static String PASSWD_DBPRODUITSCATEGORIES = "dbproduitscategories";
La tercera modificación se refiere al número máximo de parámetros que un puede admitir:
// número máximo de parámetros de un [PreparedStatement]
public final static int MAX_PREPAREDSTATEMENT_PARAMETERS = 1000;
La prueba [JUnitTestPushTheLimits] genera órdenes SQL sobre 5000 productos que generarán [PreparedStatement] con 5000 parámetros. MySQL había soportado este valor, pero Oracle no. Hemos reducido este valor a 1000 y ahora funciona.
10.3. Configuración de la capa JPA EclipseLink
 |  |
Nota: ejecute [Alt-F5] para regenerar todos los proyectos Maven.
El proyecto [oracle-config-jpa-eclipseLink] configura la capa [JPA] de la arquitectura de pruebas:
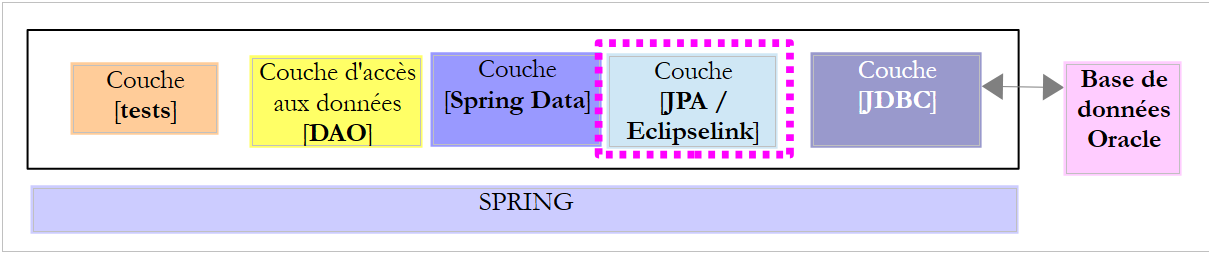 |
El proyecto es análogo al proyecto de configuración [mysql-config-jpa-eclipselink] (véase el apartado 7.3) de la capa JPA Eclipselink del SGBD MySQL. Solo presentamos las modificaciones:
La primera se encuentra en la clase [ConfigJpa], en la definición del bean [jpaVendorAdapter]:
// el proveedor JPA
@Bean
public JpaVendorAdapter jpaVendorAdapter() {
// Nota: las entidades JPA y la configuración de EclipseLink se encuentran en el archivo META-INF/persistence.xml
EclipseLinkJpaVendorAdapter eclipseLinkJpaVendorAdapter = new EclipseLinkJpaVendorAdapter();
eclipseLinkJpaVendorAdapter.setShowSql(false);
eclipseLinkJpaVendorAdapter.setDatabase(Database.ORACLE);
eclipseLinkJpaVendorAdapter.setGenerateDdl(true);
return eclipseLinkJpaVendorAdapter;
}
- línea 7: se indica a la implementación JPA que va a trabajar con una base de datos Oracle. La implementación JPA adoptará entonces tanto los tipos de datos propietarios como el SQL propietario de Oracle.
La segunda modificación se refiere a la estrategia de generación de claves primarias. La nueva estrategia se ha presentado en el apartado 10.1.
10.4. Configuración de la capa JPA de Hibernate
 |  |
Nota: ejecute [Alt-F5] para regenerar todos los proyectos Maven.
El proyecto [oracle-config-jpa-hibernate] es similar al proyecto [mysql-config-jpa-hibernate] (apartado 6.3) y presenta las mismas modificaciones que se aplicaron al pasar del proyecto [mysql-config-jpa-eclipselink] al proyecto [oracle-config-jpa-eclipselink] (apartado 10.3).
Una vez realizadas estas modificaciones, la ejecución de la configuración [spring-jpa-generic-JUnitTestDao-hibernate-eclipselink] debería completarse con éxito.
10.5. Configuración de la capa JPA OpenJpa
 |  |
Nota: ejecute [Alt-F5] para regenerar todos los proyectos Maven.
El proyecto [oracle-config-jpa-openjpa] es análogo al proyecto [mysql-config-jpa-openjpa] (apartado 8.3) con las mismas modificaciones que se aplicaron al portar [mysql-config-jpa-eclipselink] al proyecto [oracle-config-jpa-eclipselink] (apartado 10.3).
Una vez realizadas estas modificaciones, la ejecución de la configuración [spring-jpa-generic-JUnitTestDao-openjpa] debería completarse con éxito.
 |  |