1. Introducción
El PDF de este documento está disponible |AQUÍ||.
Los ejemplos de este documento están disponibles |AQUÍ|.
1.1. Contenido
En este documento nos proponemos estudiar diferentes configuraciones de explotación de una base de datos. Consideremos la siguiente arquitectura por capas:
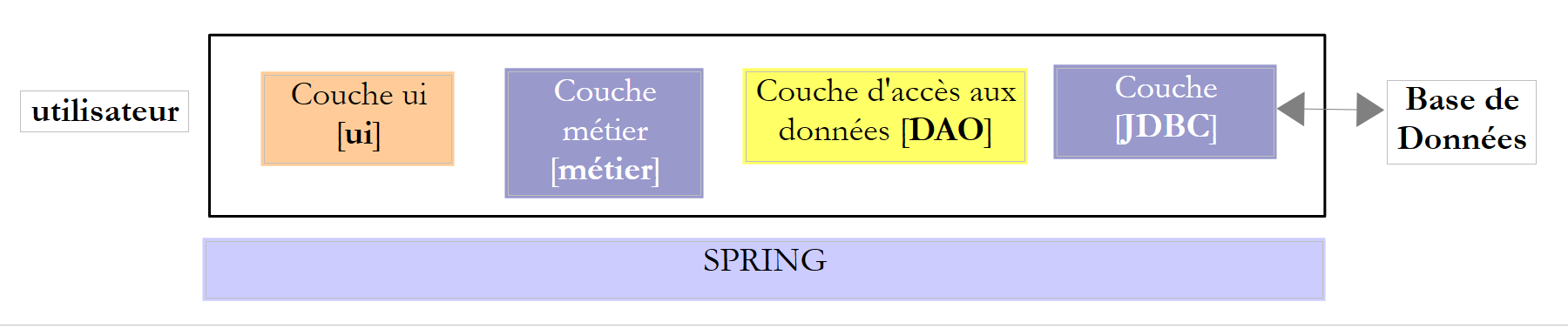 |
El flujo de ejecución va de izquierda a derecha:
- es una de las clases de la capa [ui] (Use Interface) la que se ejecuta en primer lugar. Esta instanciará las capas [metier] y [dao]. Si la capa [ui] es una interfaz gráfica, a continuación espera las acciones del usuario. Una acción de este puede provocar la ejecución de métodos en todas las capas de la arquitectura hasta la base de datos. El resultado de estas ejecuciones se muestra al usuario de una forma u otra;
La función de las diferentes capas podría ser la siguiente:
- la capa [JDBC] (Java DataBase Connectivity) es una interfaz de acceso universal a las bases de datos. Siempre presenta la misma interfaz a la capa [DAO]. Si se cambia de SGBD, basta con cambiar el controlador JDBC. La capa [DAO] no cambia si se han respetado una serie de reglas. Sin embargo, es difícil garantizar una portabilidad del 100 % entre SGBD, ya que estos suelen contener una parte importante de SQL propietario que es difícil ignorar, ya que a menudo aporta mejoras de rendimiento. En cuanto se utiliza SQL propietario, la portabilidad entre SGBD ya no es posible. Por otra parte, los SGBD suelen tener políticas diferentes de generación automática de claves primarias, así como palabras reservadas que no son las mismas en todos los casos. En este documento, se ha logrado, no obstante, portar la arquitectura JDBC estudiada a seis SGBD diferentes, aceptando que haya un proyecto de configuración para cada uno de ellos;
- la capa [DAO] expone una interfaz de acceso a los datos de la base de datos concreta utilizada (que debe diferenciarse de la interfaz JDBC, que expone métodos válidos para cualquier SGBD);
- la capa [métier] implementa las reglas de gestión o las reglas de negocio de la aplicación.
- tiene como datos de entrada los procedentes de la base de datos a través de la capa [dao] y/o los del usuario que le transmite la capa [ui];
- genera datos que puede guardar en la base de datos a través de la capa [dao] y/o devolver a la capa [ui] que la ha consultado, para su visualización por parte del usuario;
- la capa [ui] es la capa que ejecuta las acciones del usuario y le devuelve los resultados de las mismas;
En el ejemplo anterior, la capa [DAO] envía solicitudes SQL a la capa [JDBC] para su ejecución en la capa SGBD. Desde hace algunos años (2006), esta arquitectura puede evolucionar de la siguiente manera:
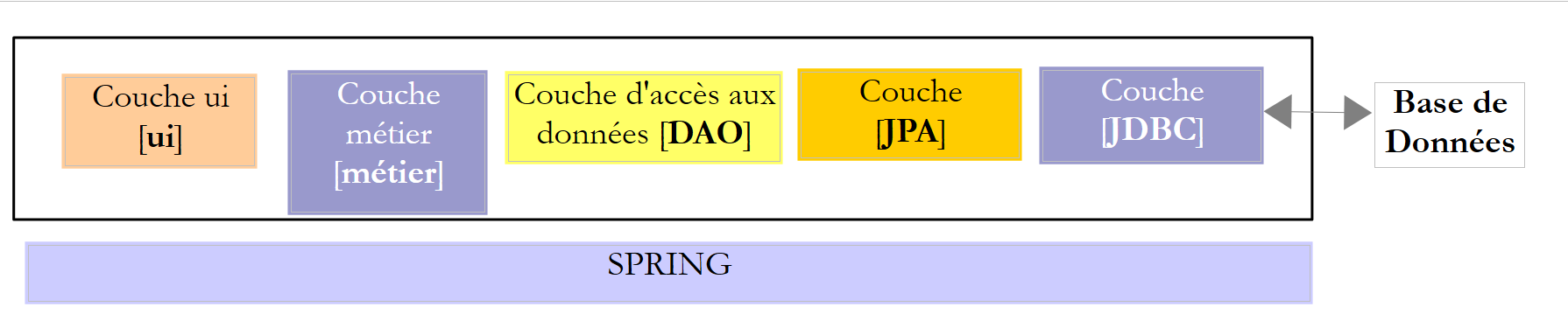 |
Ahora es la capa JPA (Java Persistence API) la que envía solicitudes SQL a la capa JDBC y recibe los resultados. La capa [JPA] presenta a la capa [DAO] operaciones para persistir, modificar, eliminar y obtener objetos. La capa [DAO] ya no envía órdenes SQL. Este enfoque es más portátil, ya que las implementaciones JPA gestionan las diferencias con respecto a SGBD, pero es más lento que la tecnología JDBC. Realizaremos pruebas de rendimiento para demostrarlo. La tecnología JPA formaliza el trabajo realizado por el marco Hibernate [http://hibernate.org/] hace años.
Estudiaremos dos capas [DAO] con una de las dos arquitecturas siguientes:
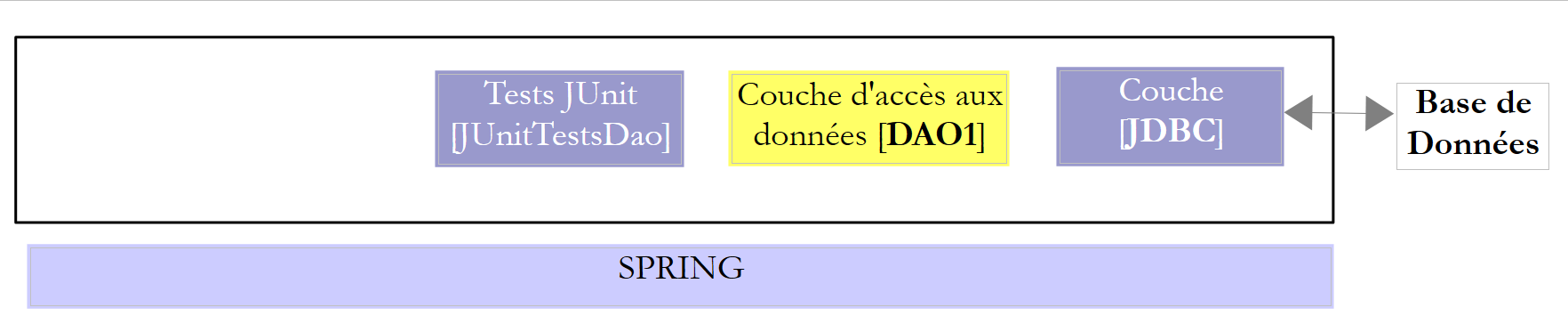 |
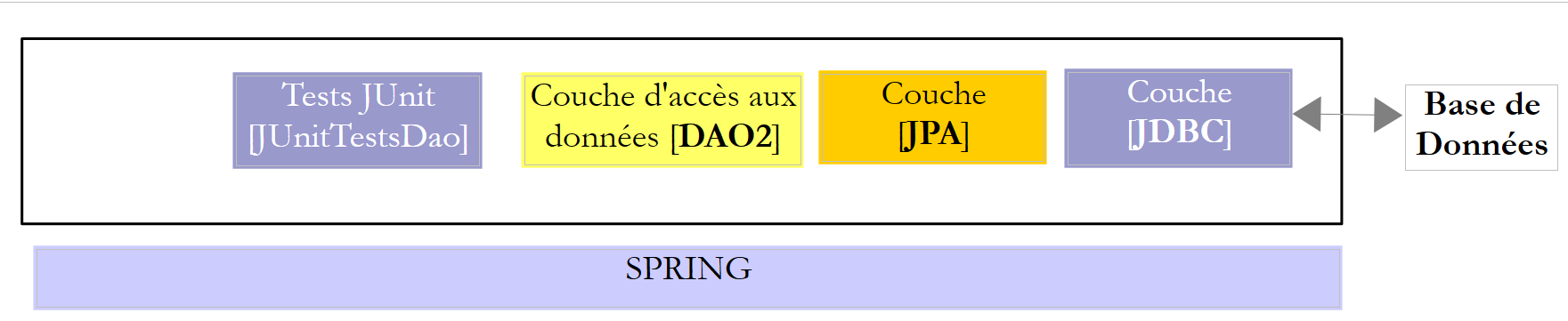 |
Se exigirá a las capas [DAO1] y [DAO2] que implementen la misma interfaz [IDAO]. Además, la prueba [JUnitTestsDao] será la misma para ambas configuraciones y nos permitirá comparar el rendimiento. La capa [DAO1] se implementará con Spring JDBC y la capa [DAO2] con Spring JPA;
Una vez hecho esto, expondremos la interfaz [IDAO] en la web de la siguiente manera:
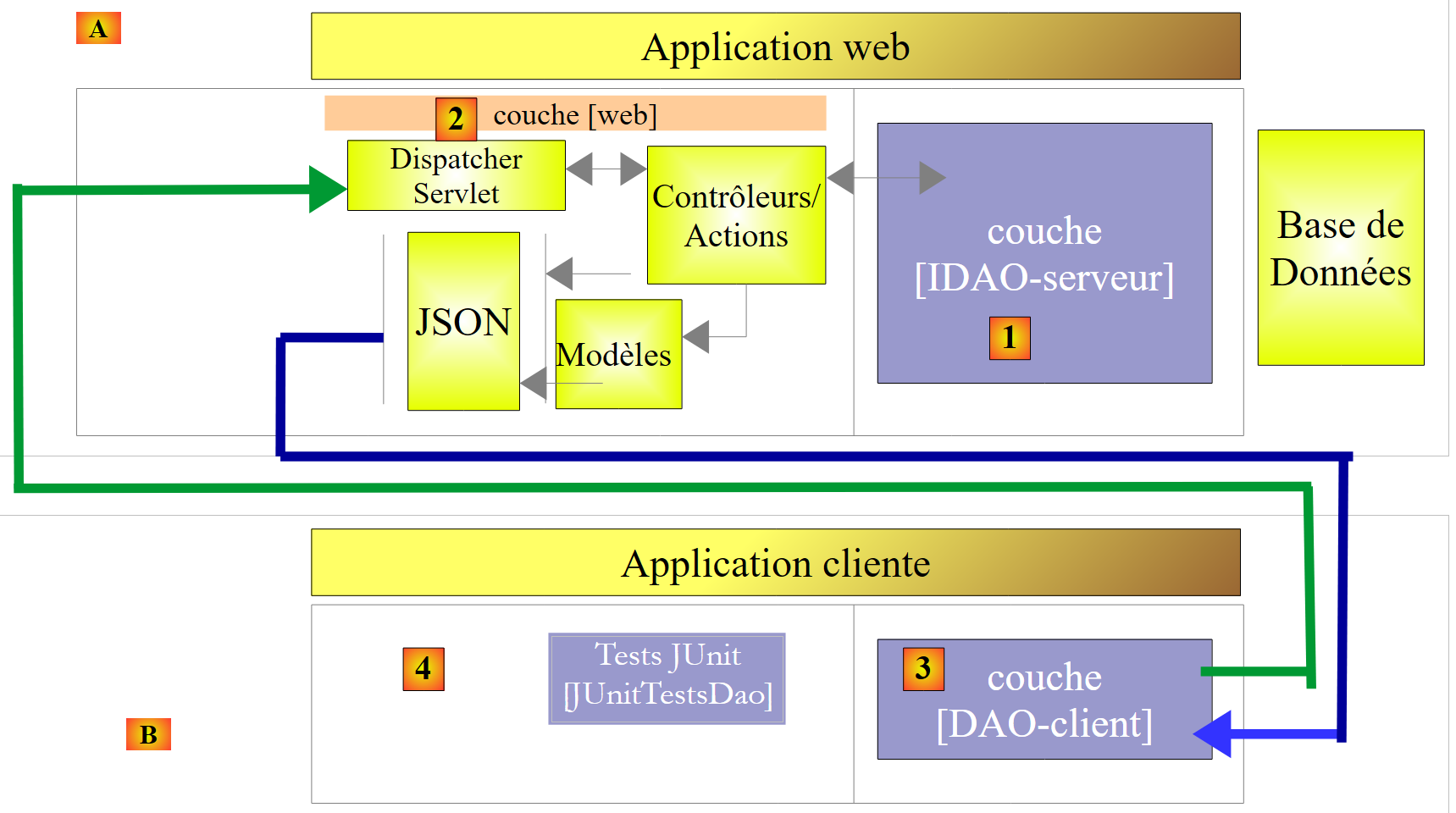 |
- en [1], la capa [IDAO] se expone en la web a través de una capa web [2] implementada por Spring MVC. Es precisamente la interfaz [IDAO] la que se expone y construiremos dos versiones del servicio web dependiendo de si esta interfaz se implementa con una arquitectura [DAO-JDBC] o [DAO-JPA-JDBC];
- en [B], un cliente remoto utiliza los URL expuestos por el servicio web y que dan acceso a los métodos de la capa [IDAO-serveur]. Nos aseguraremos de que la capa [DAO-Client] [3] implemente la interfaz [IDAO-serveur] [1]. Esto nos permitirá utilizar la misma prueba [JUnitTestsDao] ya utilizada dos veces [4];
- en [3], la capa [DAO-client] se implementará con Spring RestTemplate;
Una vez hecho esto, protegeremos el acceso al servicio web:
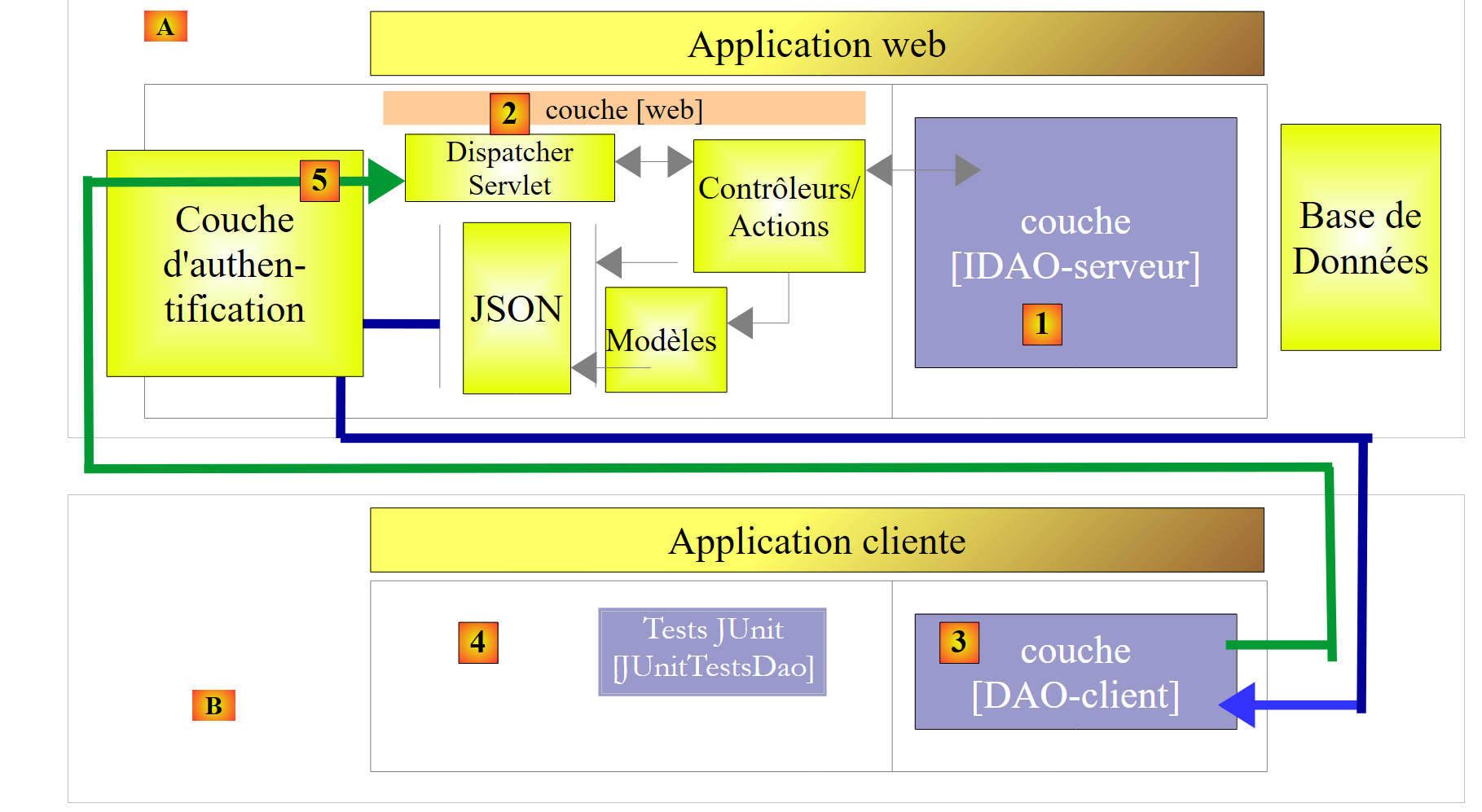 |
- en [5], la solicitud HTTP del cliente pasa por una capa de autenticación implementada con Spring Security;
Una vez hecho esto, evolucionaremos la arquitectura anterior hacia la siguiente:
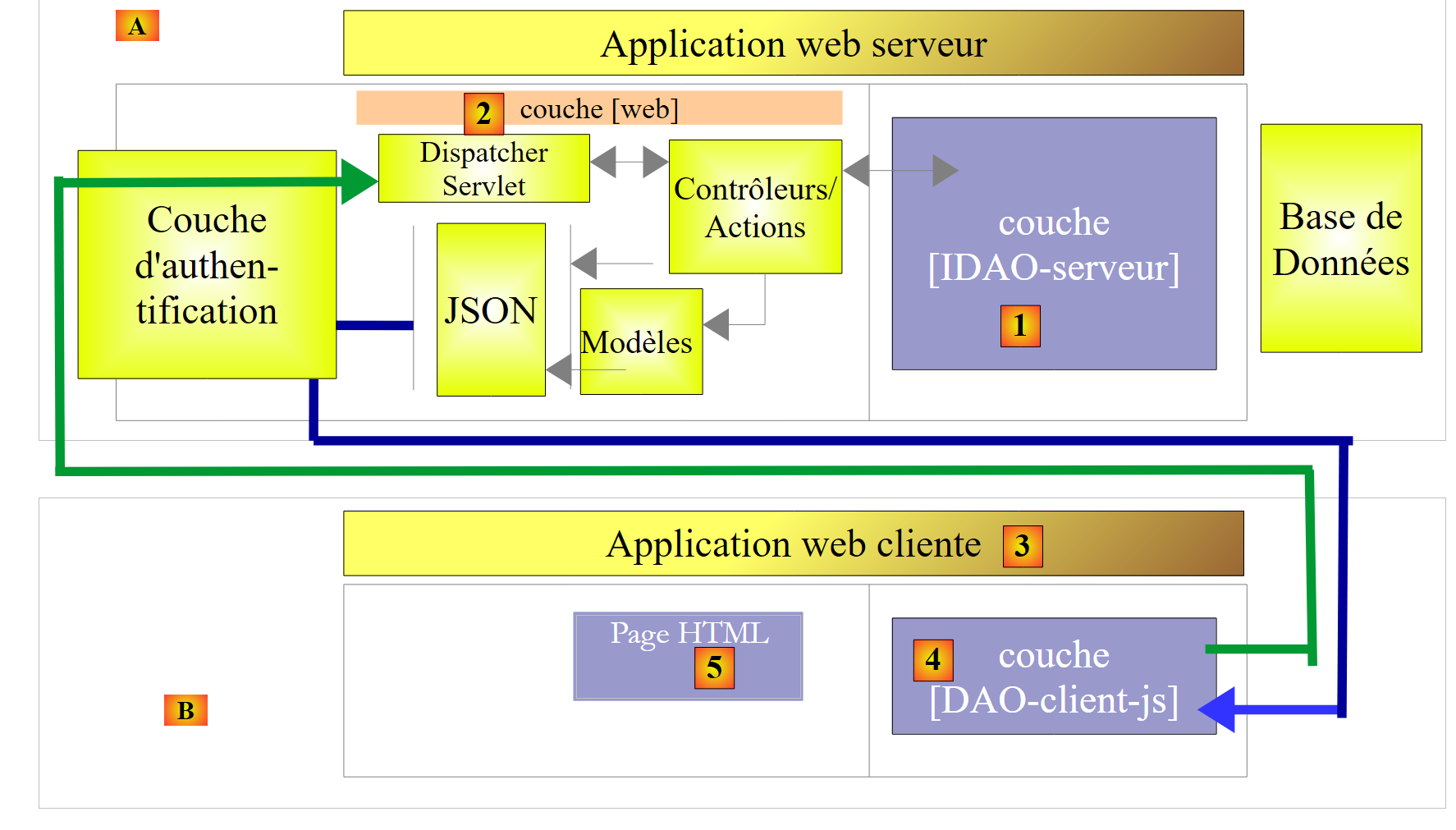 |
- en [3], la aplicación cliente es en sí misma una aplicación web. Esta presentará un formulario [5] que permitirá consultar los URL del servicio web seguro. Los accesos HTTP al servicio web seguro se realizarán a través de una capa [DAO-client-js] implementada en Javascript. Esta arquitectura implementa lo que se denomina solicitudes entre dominios:
- el servicio web [2] presenta URL de la forma [http://machine1:port1/];
- La aplicación web cliente [3] se descarga desde una URL [http://machine2:port2/]. Si [http://machine2:port2/] no es idéntico a [http://machine1:port1/] (misma máquina, mismo puerto), el navegador cliente bloqueará las llamadas HTTP de la capa [DAO-client-js]. Para solucionar este problema, el servicio web debe permitir las solicitudes entre dominios. Veremos cómo;
Los proyectos presentados se han probado con los seis SGBD siguientes:
- MySQL 5 Community Edition;
- SQL Server 2014 Express;
- PostgreSQL 9.4;
- Oracle Express 11g versión 2;
- IBM DB2 Express-C 10.5;
- Firebird 2.5.4;
Para cada uno de estos SGBD, se han desarrollado cuatro capas [DAO] diferentes:
- una capa implementada con Spring JDBC;
- una capa implementada con Spring JPA y el proveedor JPA Hibernate;
- una capa implementada con Spring JPA y el proveedor JPA EclipseLink;
- una capa implementada con Spring JPA y el proveedor JPA OpenJPA;
Por lo tanto, lo que se presenta aquí es un conjunto de veinticuatro configuraciones diferentes. Se ha realizado un gran esfuerzo de factorización:
- la mayor parte del código solo se escribe una vez. Se basa en dos proyectos de configuración de Maven:
- uno configura la capa JDBC;
- el otro configura la capa JPA;
 |
 |
El proyecto de configuración Maven de la capa JDBC [1] de un SGBD concreto consta de dos pasos:
- importar el archivo del controlador JDBC;
- definir las credenciales de acceso a la base de datos utilizada y las diferentes órdenes SQL que la capa [DAO1] enviará al controlador JDBC. Aunque SQL está estandarizado, se han encontrado problemas de portabilidad debido principalmente a la presencia en las consultas de nombres de tablas/columnas que resultaron ser palabras clave prohibidas en algunos SGBD (tabla ROLES para DB2, columna PASSWORD para Firebird). Por otra parte, aunque un nombre de columna normalmente no distingue entre mayúsculas y minúsculas, se ha encontrado un problema con PostgreSQL con la columna ID de la clave primaria de las tablas. Quería que se llamara id en minúsculas. Estos son problemas típicos de portabilidad inesperados;
Los tres proyectos Maven de configuración de la capa JPA [2] de un SGBD concreto consisten también en dos puntos:
- importar el archivo de la implementación JPA;
- configurar la implementación JPA utilizada para el SGBD concreto conectado. De hecho, es la capa JPA la que envía las órdenes SQL a la capa JDBC. Para ser eficaz, debe conocer el SGBD con el fin de enviarle las órdenes SQL que este reconocerá. Estas órdenes podrán utilizar el SQL propietario de este SGBD, así como las características particulares de este último (tipos de datos, secuencias, triggers, procedimientos, generación automática de claves primarias, etc.);
De este modo, contamos con veinticuatro proyectos (4 configuraciones x 6 SGBD) de configuración de Maven en los que se basarán todos los demás proyectos de explotación de la base de datos. En los esquemas anteriores, dado que las capas [DAO1] y [DAO2] ofrecen la misma interfaz, las 24 configuraciones de las dos arquitecturas anteriores se probarán con una única clase de prueba [JUnitTestsDao]. Una vez verificadas estas arquitecturas, ya no hay dificultades:
- el proyecto Maven de publicación de la base de datos en la web se basa en estas dos arquitecturas. Por lo tanto, también hay 24 configuraciones posibles;
- el proyecto Maven de securización del acceso al servicio web se basa en el proyecto anterior y cuenta también con 24 configuraciones posibles;
- por último, el proyecto Maven que permite las solicitudes entre dominios al servicio web seguro se basa en el proyecto anterior y también tiene 24 configuraciones posibles;
El estudio se realiza con SGBD, MySQL5 y la implementación JPA de Hibernate. A continuación, se realiza la adaptación a las implementaciones JPA Eclipselink y OpenJPA. A continuación, se realiza la migración a las demás bases de datos (PostgresQL, Oracle; SQL, Server; DB2, Firebird).
Este curso está dirigido a principiantes. Se explica la mayor parte de los conceptos utilizados. No es necesario tener conocimientos de programación de bases de datos ni de programación web. Sin embargo, se requieren conocimientos sólidos del lenguaje SQL, ya que no se explican las consultas SQL utilizadas.
Para comprender los ejemplos, se requieren conocimientos básicos del lenguaje Java, que se pueden encontrar en cualquier curso de introducción a este lenguaje. Los dos primeros capítulos del documento [Introduction au langage Java] son suficientes. Se trata de un documento antiguo (de 1998, revisado en 2002), pero contiene los fundamentos. Para un curso completo, se puede consultar el extenso libro de Jean-Marie Doudoux [http://www.jmdoudoux.fr/java].
Este documento no es en absoluto exhaustivo. Solo pretende ofrecer una metodología y códigos que se puedan reutilizar en contextos similares. El documento se ha redactado de tal manera que se pueda leer sin necesidad de tener un ordenador a mano. Por ello, se incluyen muchas capturas de pantalla.
Aunque no abarca todas las capacidades del lenguaje Java ni todos sus ámbitos de aplicación, este documento puede utilizarse como material de aprendizaje del lenguaje. Si sigue este documento sin saltarse nada, el lector principiante alcanzará un nivel de «Java avanzado» tanto en el uso del lenguaje como en el del framework Spring. A continuación, podrá continuar su formación en Java con las siguientes obras:
- [Introducción a Spring MVC y Thymeleaf a través de ejemplos (2015)], que continúa el aprendizaje del ecosistema Spring presentando su rama de «programación web MVC»;
- [Un ejemplo de cliente/servidor: AngularJS 1.x / Spring 4 (2014)], que presenta una arquitectura web cliente/servidor, en la que el cliente se implementa con el marco [AngularJS] y el servidor con [Spring MVC];
- [Introducción a Java EE con el IDE NetBeans y el servidor de aplicaciones GlassFish (2012)], que abandona el entorno Spring para adoptar una arquitectura web basada en JSF (Java Server Faces) y EJB (Enterprise Java Bean);
- [Introducción a la programación para tabletas Android con Android Studio (2016)], que describe una arquitectura cliente/servidor, donde el cliente es una tableta Android y el servidor un servicio web implementado por Spring MVC;
1.2. Fuentes
Este documento tiene dos fuentes principales:
- [ref1] : [Introducción a Spring MVC y Thymeleaf a través de ejemplos (2015)]. El presente documento retoma, con otra base de datos, el trabajo realizado y presentado en [ref1]. Simplemente, lo saca del contexto de la programación web con Spring MVC. Como consideré que los códigos y la metodología utilizados en [ref1] para exponer una base de datos en la web eran reutilizables, decidí crear un documento aparte;
- [ref2] : [Persistencia en Java 5 a través de la práctica (2007)];
Para profundizar en Spring, se pueden utilizar las siguientes referencias:
- el documento de referencia del marco Spring [http://docs.spring.io/spring/docs/current/spring-framework-reference/pdf/spring-framework-reference.pdf];
- Encontrará numerosos tutoriales de Spring en URL y [http://spring.io/guides];
- el sitio web de [developpez.com] dedicado a Spring [http://spring.developpez.com/];
- el tutorial [http://www.tutorialspoint.com/spring/spring_tutorial.pdf];
El lector que no tenga suficientes conocimientos SQL podrá adquirir los fundamentos con la obra [Introducción al lenguaje SQL con el SGBD Firebird (2006)].
1.3. Herramientas utilizadas
Los siguientes ejemplos se han probado en el siguiente entorno:
- ordenador con Windows 8.1 Pro de 64 bits;
- JDK 1.8 (apartado 23.1);
- IDE Spring Tool Suite 3.6.3 (apartado 1);
- navegador Chrome (no se han utilizado otros navegadores);
- extensión de Chrome [Advanced Rest Client] (apartado 1);
- SGBD MySQL 5.6 Community Edition (apartado 23.4);
- SGBD SQL Server 2014 Express (apartado 23.9);
- SGBD PostgreSQL 9.4 (apartado 23.7);
- SGBD Oracle Express 11g versión 2 (apartado 23.6);
- SGBD IBM DB2 Express-C 10.5 (apartado 23.8);
- SGBD Firebird 2.5.4 (apartado 23.10);
- los clients EMS Gestor de sus seis SGBD (apartado 23.5);
Atención al JDK 1.8. Un método del caso práctico utiliza un método del paquete [java.lang] de Java 8.
La mayoría de los ejemplos son proyectos Maven que se pueden abrir indistintamente con IDE Eclipse, IntellijIDEA y Netbeans. A continuación, las capturas de pantalla proceden de IDE Spring Tool Suite, una variante de Eclipse.
1.4. Los ejemplos
Los ejemplos están disponibles en URL [http://tahe.developpez.com/java/spring-database] en forma de archivo zip para descargar.
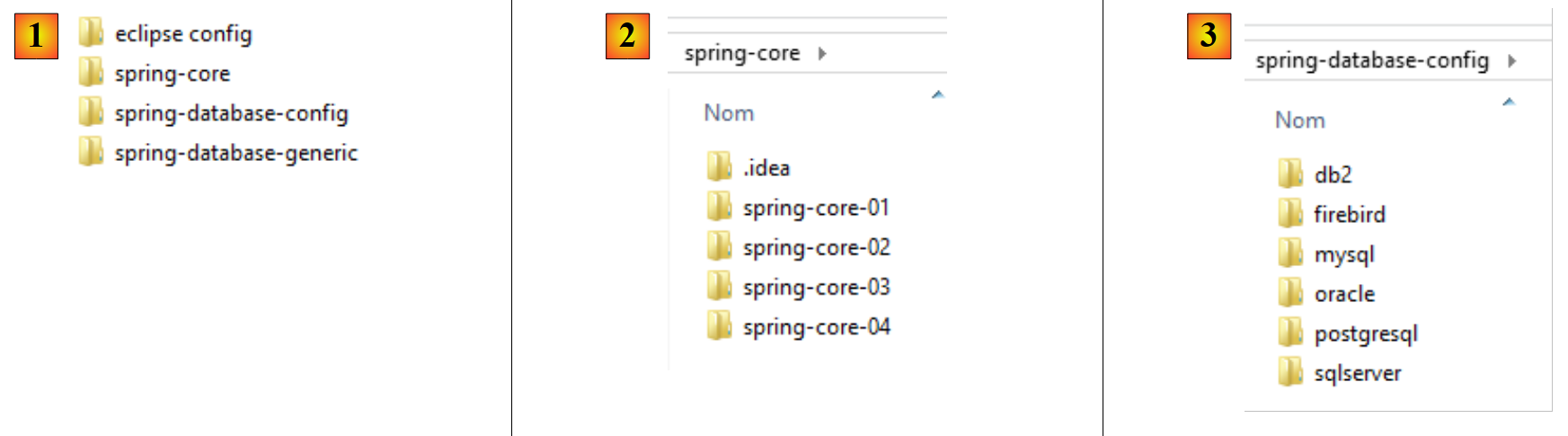 |
- en [1], las carpetas de los ejemplos;
- en [2], la carpeta [spring-core] contiene los proyectos de aprendizaje de Spring;
- en [3], la carpeta [spring-database-config] contiene los proyectos de configuración JDBC y JPA de las seis bases de datos;
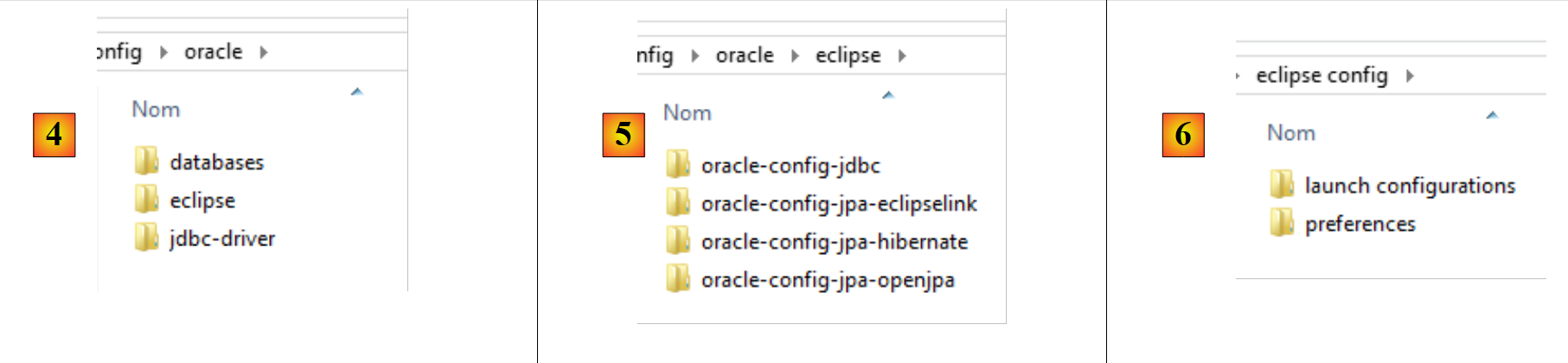 |
- en [4], la configuración de SGBD Oracle. En ella hay tres carpetas:
- [databases] contiene los scripts SQL para la generación de las dos bases de datos utilizadas por el documento;
- [jdbc-driver] contiene el controlador JDBC de Oracle, así como un script para su instalación en el repositorio local de Maven;
- [eclipse] contiene los cuatro proyectos de configuración de Oracle:
- [oracle-config-jdbc] configura la capa de acceso JDBC a SGBD;
- [oracle-config-jpa-hibernate] configura la capa JPA de acceso a SGBD con el proveedor JPA Hibernate;
- [oracle-config-jpa-eclipselink] configura la capa JPA de acceso a SGBD con el proveedor JPA Eclipselink;
- [oracle-config-jpa-openjpa] configura la capa JPA de acceso a SGBD con el proveedor JPA OpenJPA;
- en [6], la carpeta [eclipse config / launch configurations] contiene las configuraciones de ejecución que el lector podrá importar a Eclipse para luego adaptarlas a su propio entorno;
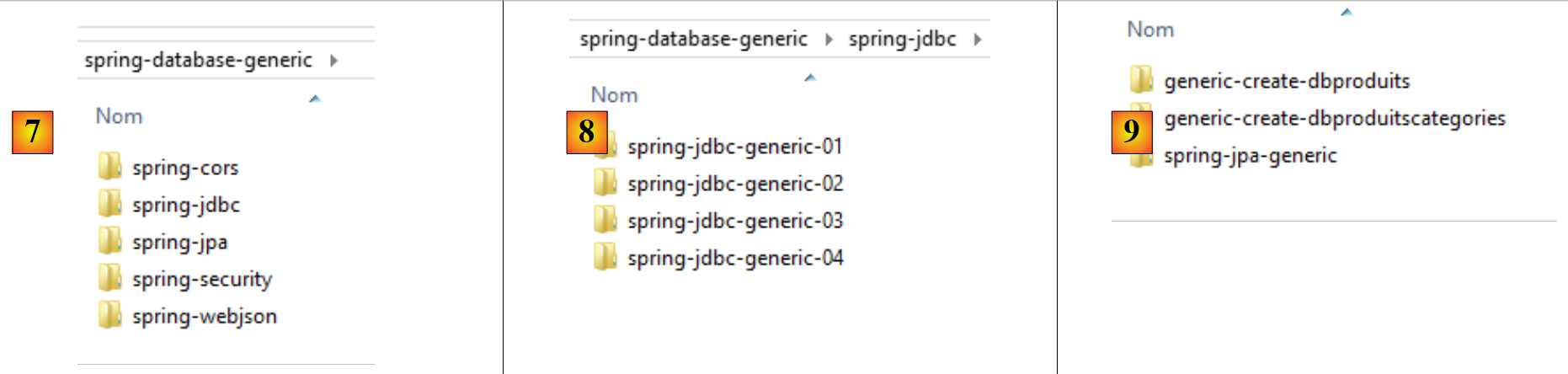 |
- en [7], la carpeta [spring-database-generic] contiene todo el código de acceso a SGBD común a los seis SGBD y a los tres proveedores JPA;
- en [8], [spring-jdbc] contiene cuatro proyectos que presentan API, JDBC y Spring JDBC;
- en [9], [spring-jpa / spring-jpa-generic] es el proyecto que utiliza una capa JPA para acceder a una base de datos. Los proyectos [generic-create-db*] son proyectos JPA que permiten crear las bases de datos utilizadas por la capa JPA;
 |
- en [10], la carpeta [spring-webjson] contiene los proyectos que exponen la base de datos en la web;
- [spring-webjson-server-jdbc-generic] es el servicio web que expone la base de datos a la que se accede con Spring JDBC;
- [spring-webjson-server-jpa-generic] es el servicio web que expone la base de datos a la que se accede mediante Spring JPA;
- [spring-webjson-client-generic] es el único cliente que permite acceder a los dos servicios web anteriores;
- en [11], la carpeta [spring-security] contiene los proyectos que exponen la base de datos en la web con acceso seguro;
- [spring-security-server-jdbc-generic] es el servicio web seguro que expone la base de datos a la que se accede con Spring JDBC;
- [spring-security-server-jpa-generic] es el servicio web seguro que expone la base de datos a la que se accede mediante Spring JPA;
- [spring-security-client-generic] es el único cliente que permite acceder a los dos servicios web seguros anteriores;
- en [12], la carpeta [spring-cors] contiene los proyectos que exponen la base de datos en la web con un acceso seguro que permite accesos entre dominios, como los procedentes del código Javascript de un navegador;
- [spring-cors-server-jdbc-generic] es el servicio web seguro que permite el acceso entre dominios y que expone la base de datos a la que se accede mediante Spring JDBC;
- [spring-cors-server-jpa-generic] es el servicio web seguro que permite el acceso entre dominios y que expone la base de datos a la que se accede con Spring JPA;
- [spring-cors-client-generic] es una aplicación web que permite consultar los dos servicios web anteriores;