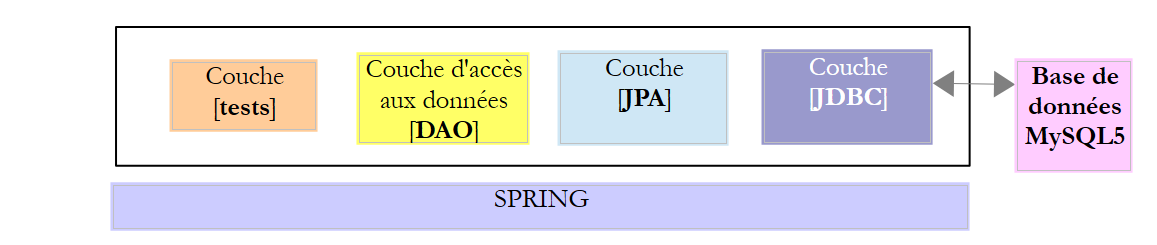
4. Introducción a Spring JDBC
En este capítulo, estudiaremos la siguiente arquitectura:
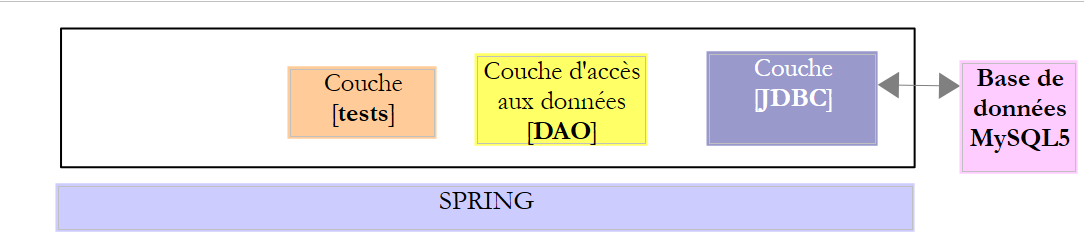 |
Se trata, por tanto, de la misma arquitectura que antes. Vamos a introducir dos modificaciones:
- la base de datos tendrá dos tablas vinculadas por una relación de clave externa;
- la capa [DAO] se implementará con la biblioteca [Spring JDBC], que facilita la gestión de API y JDBC;
4.1. Configuración del entorno de trabajo
Con STS, importe el proyecto [spring-jdbc-04] que se encuentra en la carpeta [<exemples>/spring-database-generic/spring-jdbc]
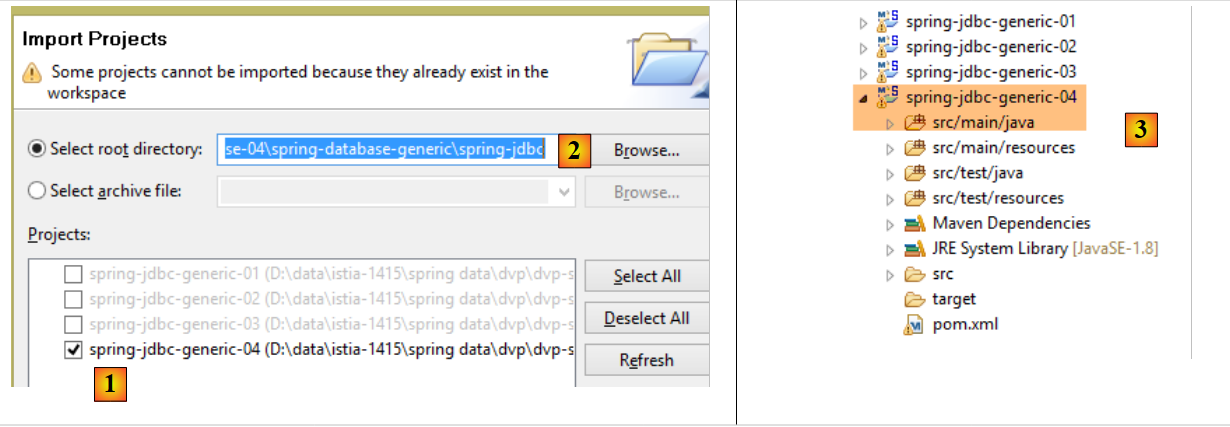 |
Además, debemos crear una nueva base de datos MySQL con el cliente [MyManager] (véase el apartado 3.1):
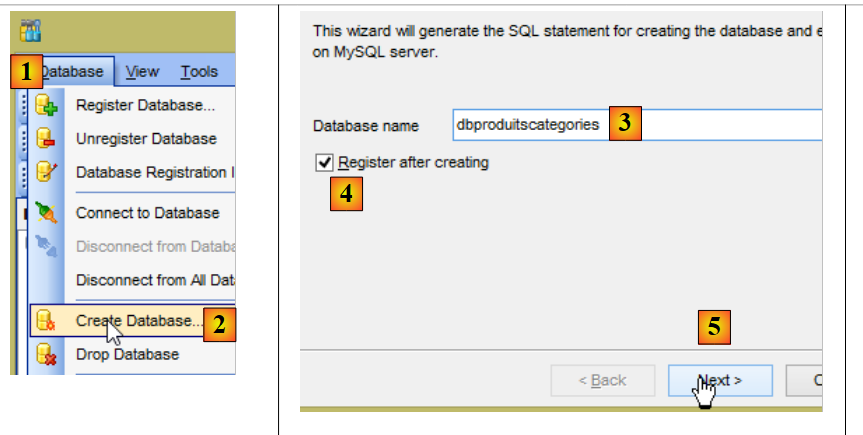 |
- en [3], los ejemplos siguientes se basan en una base MySQL denominada [dbproduitscategories];
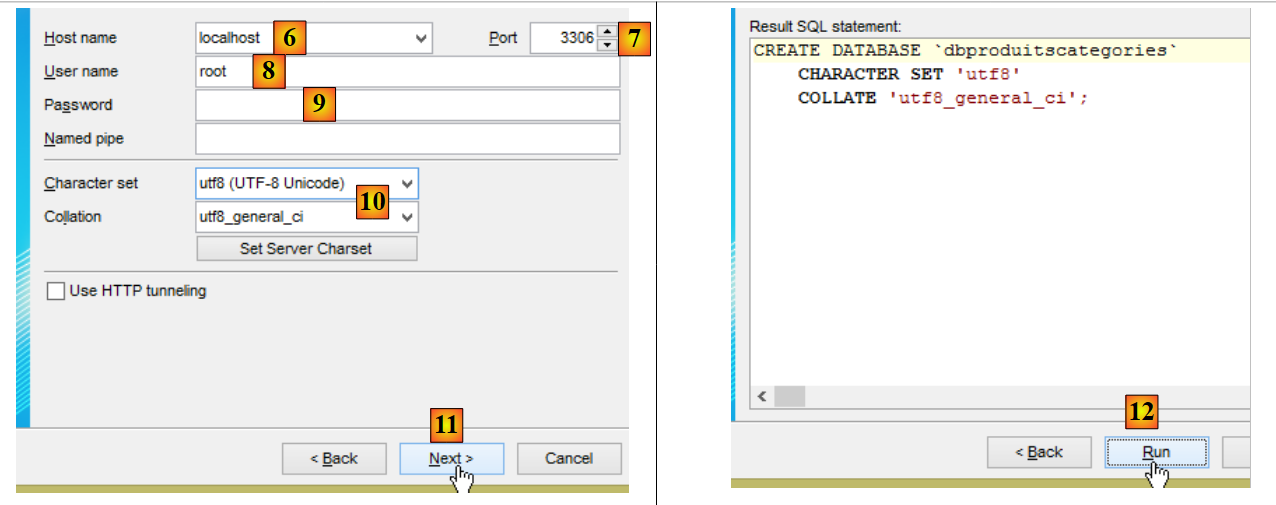 |
- en [9], introduzca la contraseña del usuario root (en este documento, dicha contraseña es «root»);
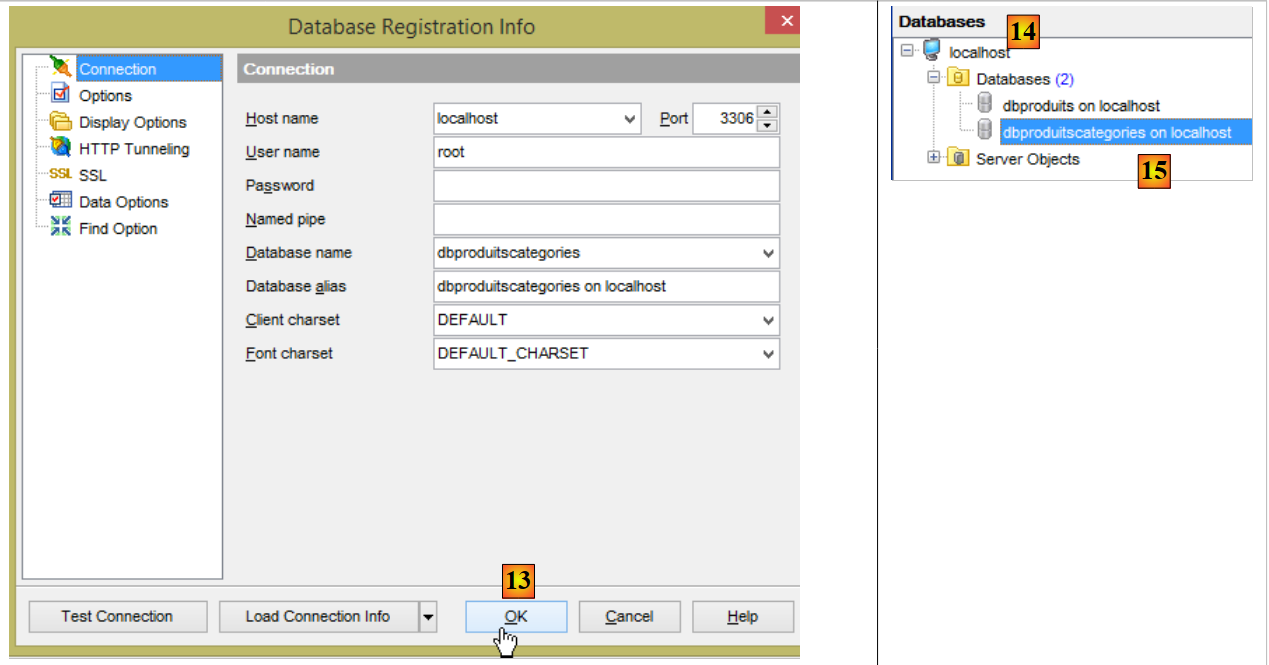 |
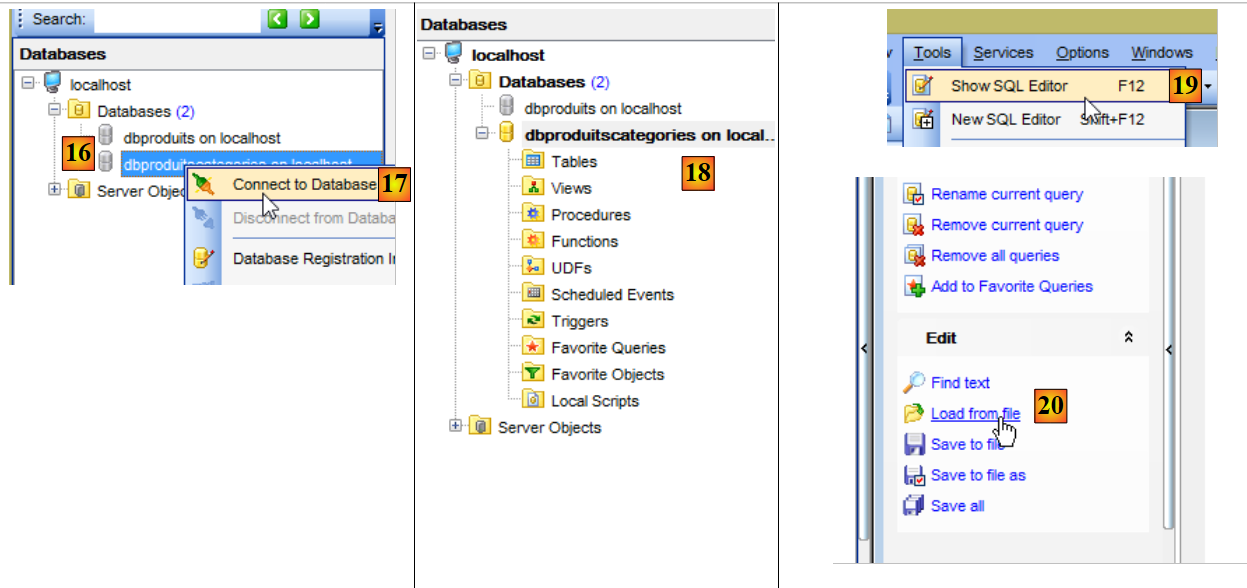 |
- en [18], la base de datos [dbproduitscategories] se ha creado vacía. Se crean tablas y se rellena con un script SQL [19-20] ;
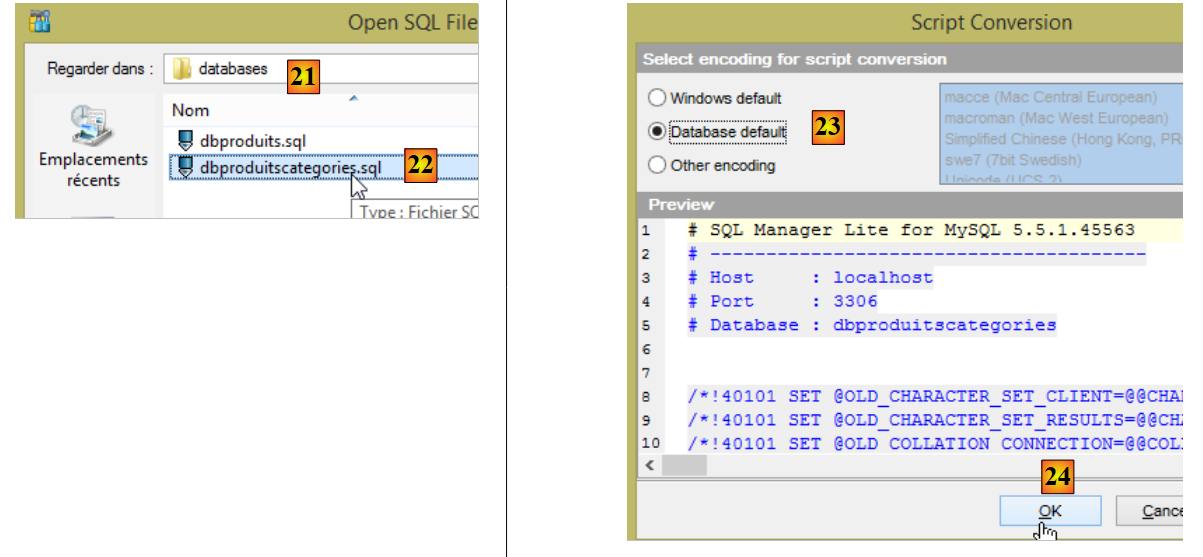 |
- en [21], vaya a la carpeta [<exemples>/spring-database-config/mysql/databases];
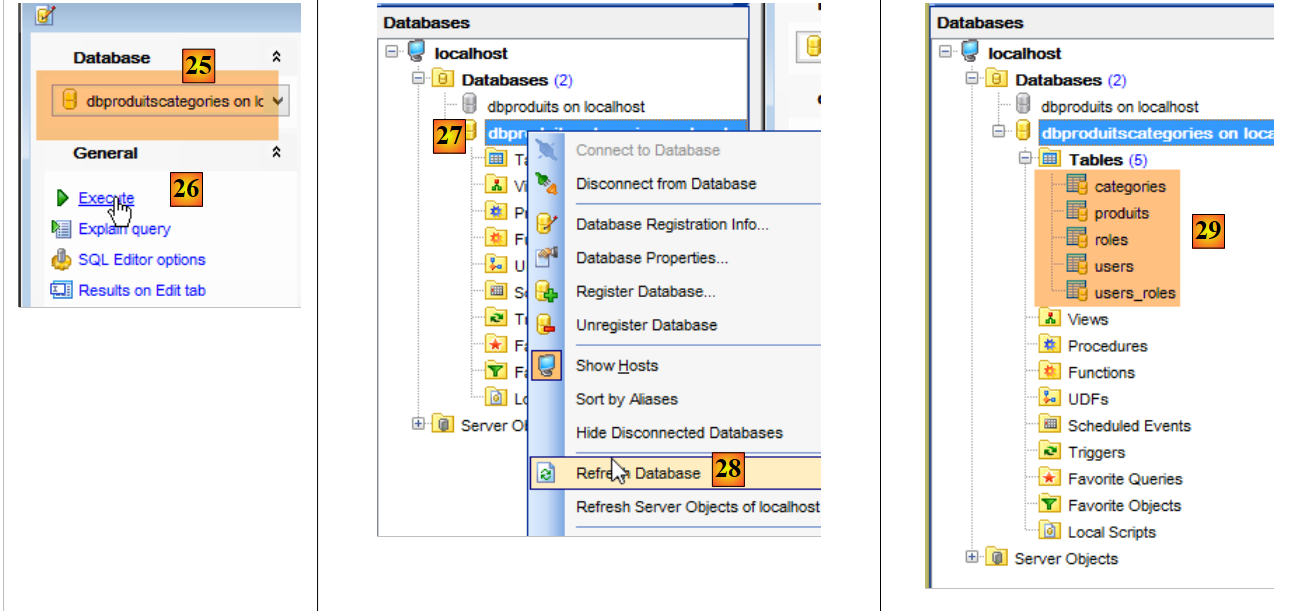 |
- en [25], asegúrese de que se encuentra en la base [dbproduitscategories] y no en la base [dbproduits];
- En [29], el script SQL ha creado cinco tablas. Las tablas [ROLES, USERS, USERS_ROLES] solo se utilizarán cuando se aborde la seguridad del servicio web creado para exponer la base de datos [dbproduitscategories] en la web;
4.2. La base de datos [dbproduitscategories]
La base de datos [dbproduitscategories] es una extensión de la base [dbproduits] estudiada anteriormente. Mientras que en la tabla [PRODUITS] el producto tenía una categoría identificada por un número que no tenía ningún significado concreto, aquí ese número será una clave externa en la tabla [CATEGORIES].
La tabla [PRODUITS] es la siguiente:
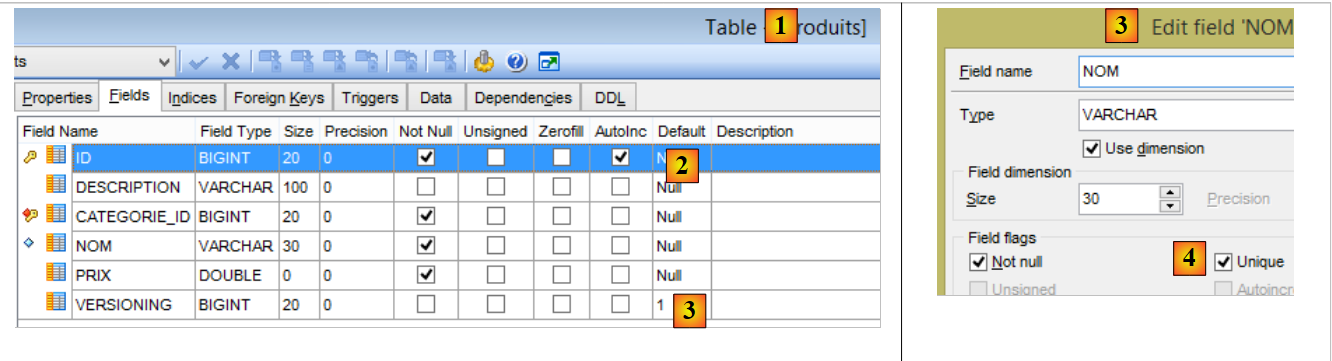 |
- [ID]: la clave primaria autoincrementada de la tabla [2];
- [NOM]: el nombre único del producto [4];
- [PRIX]: el precio del producto;
- [DESCRIPTION]: la descripción del producto;
- [VERSIONING] es el n.º de version del producto. Su version inicial es 1 [3]. Cada vez que se modifique el producto, su n.º version se incrementará mediante el código que gestiona la tabla;
- [CATEGORIE_ID]: la clave externa de la tabla [CATEGORIES] para designar la categoría a la que pertenece el producto;
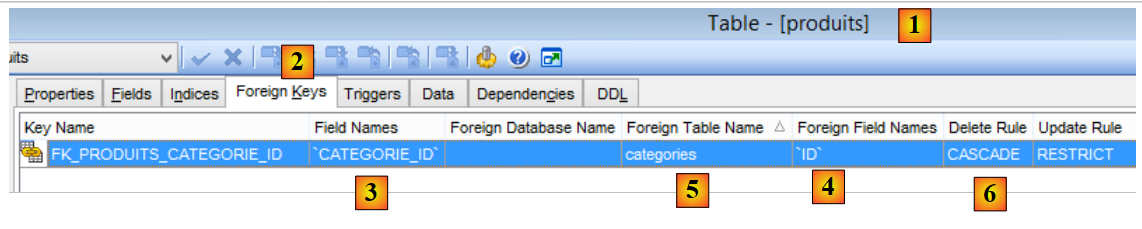 |
- en [1-3], la clave externa [CATEGORIE_ID] de la tabla [PRODUITS]. Se dirige a la columna [ID] de la tabla [CATEGORIES] [4-5];
- cuando se elimina una categoría, también se eliminan todos los productos vinculados a ella [6]. Es importante señalar este punto, ya que se utiliza en la construcción de la capa [DAO] que explota la base [dbproduitscategories];
La tabla [CATEGORIES] de categorías es la siguiente:
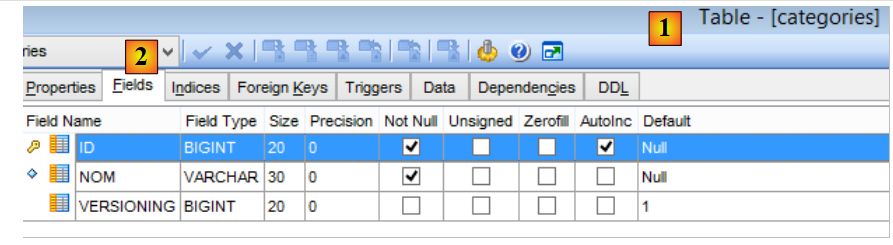 |
- [ID]: clave primaria autoincrementada;
- [VERSIONING]: n.º de version de la categoría;
- [NOM]: nombre único de la categoría;
4.3. El proyecto Eclipse
 |
El proyecto [spring-jdbc-04] implementa la siguiente arquitectura:
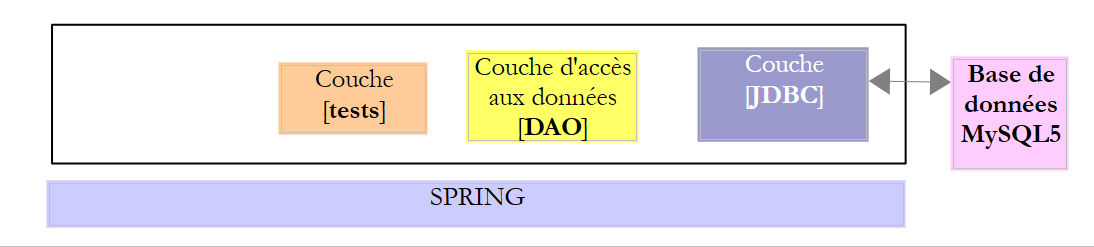 |
El proyecto [spring-jdbc-04] es un proyecto Maven configurado por el siguiente archivo [pom.xml]:
 |
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dvp.spring.database</groupId>
<artifactId>spring-jdbc-generic-04</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>spring-jdbc-generic-04</name>
<description>Demo project for Spring JdbcTemplate</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
<relativePath /> <!-- búsqueda de padre en el repositorio -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!-- configuración JDBC del SGBD -->
<dependency>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-config-jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<!-- Spring JdbcTemplate -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
</plugin>
</plugins>
</build>
</project>
- líneas 28-32: el proyecto se basa en el proyecto [mysql-config-jdbc], que configura la capa JDBC;
- líneas 34-37: el artefacto [spring-boot-starter-jdbc] incluye las bibliotecas de Spring JDBC;
En definitiva, las dependencias son las siguientes:
 |
4.4. Configuración de Spring
 |
La clase [AppConfig] que configura el proyecto Spring es la siguiente:
package spring.jdbc.config;
import generic.jdbc.config.ConfigJdbc;
import org.apache.tomcat.jdbc.pool.DataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.jdbc.core.namedparam.NamedParameterJdbcTemplate;
import org.springframework.jdbc.core.simple.SimpleJdbcInsert;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@Configuration
@ComponentScan(basePackages = { "spring.jdbc.dao" })
@EnableTransactionManagement
@Import({ generic.jdbc.config.ConfigJdbc.class })
public class AppConfig {
// fuente de datos
@Bean
public DataSource dataSource() {
// fuente de datos TomcatJdbc
DataSource dataSource = new DataSource();
// configuración de acceso JDBC
dataSource.setDriverClassName(ConfigJdbc.DRIVER_CLASSNAME);
dataSource.setUsername(ConfigJdbc.USER_DBPRODUITSCATEGORIES);
dataSource.setPassword(ConfigJdbc.PASSWD_DBPRODUITSCATEGORIES);
dataSource.setUrl(ConfigJdbc.URL_DBPRODUITSCATEGORIES);
// conexiones abiertas inicialmente
dataSource.setInitialSize(5);
// resultado
return dataSource;
}
// Gestor de transacciones
@Bean
public PlatformTransactionManager transactionManager(DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
// JdbcTemplate
@Bean
public NamedParameterJdbcTemplate namedParameterJdbcTemplate(DataSource dataSource) {
return new NamedParameterJdbcTemplate(dataSource);
}
// Inserción de producto
@Bean
public SimpleJdbcInsert simpleJdbcInsertProduit(DataSource dataSource) {
return new SimpleJdbcInsert(dataSource).withTableName(ConfigJdbc.TAB_PRODUITS).usingGeneratedKeyColumns(
ConfigJdbc.TAB_PRODUITS_ID);
}
// Inserción de categoría
@Bean
public SimpleJdbcInsert simpleJdbcInsertCategorie(DataSource dataSource) {
return new SimpleJdbcInsert(dataSource).withTableName(ConfigJdbc.TAB_CATEGORIES).usingGeneratedKeyColumns(
ConfigJdbc.TAB_CATEGORIES_ID);
}
}
- línea 16: la clase es una clase de configuración de Spring;
- línea 17: se analizará el paquete [spring.jdbc.dao] para buscar otros componentes Spring distintos de los presentes en la clase [AppConfig]. En él se encontrará el componente que implementa la capa [DAO];
- línea 18: no gestionaremos las transacciones nosotros mismos, sino que dejaremos que se encargue de ellas Spring JDBC. Lo único que habrá que hacer será anotar los métodos que deben ejecutarse en una transacción con la anotación Spring [@Transactional]. La línea 18 garantiza que esta anotación se gestionará y no se ignorará. La gestión de las transacciones corre a cargo de una de las dependencias del proyecto Spring JDBC importado por el archivo [pom.xml];
- línea 19: se importan los beans ya definidos en la clase [generic.jdbc.config.ConfigJdbc] del proyecto [mysql-config-jdbc];
- líneas 23-36: la fuente de datos [tomcat-jdbc] introducida en el ejemplo [spring-jdbc-02];
- líneas 40-42: el gestor de transacciones vinculado a la fuente de datos definida anteriormente. El bean debe llamarse obligatoriamente [transactionManager], ya que es este nombre el que utiliza la anotación [@EnableTransactionManagement]. El gestor [DataSourceTransactionManager] es proporcionado por la biblioteca Spring JDBC (línea 12);
- líneas 45-48: el bean [namedParameterJdbcTemplate] sobre el que se basará la implementación de la capa [DAO]. Este bean es proporcionado por la biblioteca Spring JDBC (línea 10). Este bean también está vinculado a la fuente de datos definida anteriormente (línea 47);
- líneas 51-55: el bean [simpleJdbcInsertProduit] (nombre libre) se utilizará para insertar un producto en la tabla [PRODUITS] y recuperar la clave primaria generada. Los distintos parámetros utilizados son los siguientes:
- [dataSource]: la fuente de datos [tomcat-jdbc] de las líneas 24-36;
- [ConfigJdbc.TAB_PRODUITS]: la tabla [PRODUITS];
- [ConfigJdbc.TAB_CATEGORIES_ID]: la columna de clave primaria de la tabla [PRODUITS]. Recordamos que, para PostgreSQL, el nombre de esta columna deberá estar en minúsculas;
- líneas 58-62: el bean [simpleJdbcInsertCategorie] se utilizará para insertar una categoría en la tabla [CATEGORIES] y recuperar la clave primaria generada;
4.5. Las excepciones del proyecto
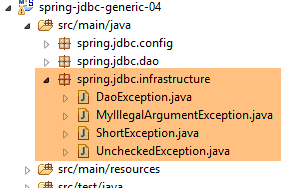 |
Ya hemos visto las clases [UncheckedException, DaoException, ShortException] en el proyecto [spring-jdbc-03]. Añadimos una nueva:
package spring.jdbc.infrastructure;
public class MyIllegalArgumentException extends UncheckedException {
private static final long serialVersionUID = 1L;
// fabricantes
public MyIllegalArgumentException() {
super();
}
public MyIllegalArgumentException(int code, Throwable e, String className) {
super(code, e, className);
}
}
- La clase [MyIllegalArgumentException] deriva de la clase [UncheckedException] y, por lo tanto, es una clase no controlada. Se utilizará para señalar una llamada con argumentos incorrectos a un método de la capa [DAO]. No se ha llamado [IllegalArgumentException] porque esta excepción ya existe en JDK y esto provocaba en ocasiones que el compilador generara un [import] incorrecto;
4.6. Las entidades del proyecto
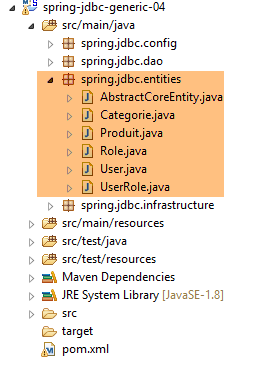 |
Las clases del paquete [spring.jdbc.entities] son las representaciones de las filas de las tablas de la base de datos [dbproduitscategories]. Por el momento, ignoraremos las representaciones de las tablas [USERS, ROLES, USERS_ROLE].
Todas las entidades heredan de la clase principal [AbstractCoreEntity]:
package spring.jdbc.entities;
public abstract class AbstractCoreEntity {
// propiedades
protected Long id;
protected Long version;
// constructores
public AbstractCoreEntity() {
}
public AbstractCoreEntity(Long id, Long version) {
this.id = id;
this.version = version;
}
public AbstractCoreEntity(AbstractCoreEntity entity) {
this.id = entity.id;
this.version = entity.version;
}
public void setAbstractCoreEntity(AbstractCoreEntity entity) {
this.id = entity.id;
this.version = entity.version;
}
// ------------------------------------------------------------
// redefinición de [equals] y [hashcode]
@Override
public int hashCode() {
return (id != null ? id.hashCode() : 0);
}
@Override
public boolean equals(Object entity) {
if (!(entity instanceof AbstractCoreEntity)) {
return false;
}
String class1 = this.getClass().getName();
String class2 = entity.getClass().getName();
if (!class2.equals(class1)) {
return false;
}
AbstractCoreEntity other = (AbstractCoreEntity) entity;
return id != null && other.id != null && id.equals(other.id);
}
// getters y setters
...
}
- línea 5: el campo [id] se asociará a la columna [ID], clave primaria de las tablas;
- línea 6: el campo [version] se asociará a la columna [VERSIONING] de las tablas;
- líneas 8-26: diferentes constructores y métodos para crear o inicializar un objeto [AbstractCoreEntity];
- líneas 35-47: el método [equals] establece que dos objetos [AbstractCoreEntity] son iguales si tienen el mismo campo [id]. Hay que recordar aquí que los objetos [AbstractCoreEntity] serán imágenes de filas de tablas donde [id] es la clave primaria y donde, por lo tanto, no puede haber dos filas con el mismo [id];
- líneas 30-33: una propuesta de [hashCode];
La clase [Produit] será la imagen de una fila de la tabla [PRODUITS]:
package spring.jdbc.entities;
import com.fasterxml.jackson.annotation.JsonFilter;
@JsonFilter("jsonFilterProduit")
public class Produit extends AbstractCoreEntity {
// propiedades
private String nom;
private Long idCategorie;
private double prix;
private String description;
private Categorie categorie;
// constructores
public Produit() {
}
public Produit(Long id, Long version, String nom, Long idCategorie, double prix, String description,
Categorie categorie) {
super(id, version);
this.nom = nom;
this.idCategorie = idCategorie;
this.prix = prix;
this.description = description;
this.categorie = categorie;
}
// firma
public String toString() {
return String.format("[id=%s, version=%s, nom=%s, prix=10.2f, desc=%s, idCategorie=%s]", id, version, nom, prix,
description, idCategorie);
}
// getters y setters
...
}
- línea 6: la clase [Produit] extiende la clase [AbstractCoreEntity];
- líneas 8-12: los campos [id, version, nom, idCategorie, prix, description] son las imágenes de las columnas [ID, VERSIONING, NOM, CATEGORIE_ID, PRIX, DESCRIPTION] de la tabla [PRODUITS];
- línea 12: el objeto de tipo [Categorie] con clave primaria [idCategorie]. Este campo se rellenará o no según el caso. Cuando se rellena, se hablará de producto version largo [LongProduit]; en caso contrario, de producto version corto [ShortProduit];
- línea 5: un filtro jSON. Recordamos que el proyecto [mysql-config-jdbc] incluye una biblioteca jSON. La necesidad del filtro se debe a que el campo [categorie] puede estar rellenado o no. En este caso, la representación jSON del producto difiere. Para gestionar estos dos casos, se configurará el filtro [jsonFilterProduit] de la línea 5. Un filtro jSON permite especificar, de forma dinámica, los campos que deben excluirse de la representación jSON. Cuando se detecte que el campo [categorie] no se ha rellenado, se excluirá de la representación jSON del producto;
La clase [Categorie] es la imagen de una línea de la tabla [CATEGORIES]:
package spring.jdbc.entities;
import java.util.ArrayList;
import java.util.List;
import com.fasterxml.jackson.annotation.JsonFilter;
@JsonFilter("jsonFilterCategorie")
public class Categorie extends AbstractCoreEntity {
// propiedades
private String nom;
public List<Produit> produits;
// constructores
public Categorie() {
}
public Categorie(Long id, Long version, String nom, List<Produit> produits) {
super(id, version);
this.nom = nom;
this.produits = produits;
}
// firma
public String toString() {
return String.format("[id=%s, version=%s, nom=%s]", id, version, nom);
}
// métodos
public void addProduit(Produit produit) {
// añadir un producto
if (produits == null) {
produits = new ArrayList<Produit>();
}
if (produit != null) {
// se añade el producto
produits.add(produit);
// se establece su categoría
produit.setCategorie(this);
produit.setIdCategorie(this.id);
}
}
// getters y setters
...
}
- línea 9: la clase [Categorie] amplía la clase [AbstractCoreEntity];
- línea 12: los campos [id, version, nom] son las imágenes de las columnas [ID, VERSIONING, NOM] de la tabla [CATEGORIES];
- línea 13: el campo [produits] representa la lista de productos de la categoría. Este campo no siempre está rellenado. Cuando no lo está, se hablará de categoría version corta [ShortCategorie]; en caso contrario, de categoría version larga [LongCategorie];
- líneas 32-44: el método [addProduit] permite añadir un producto a la categoría (línea 39) y establecer en el producto añadido las características de su categoría (idCategorie y categoría);
- línea 8: un filtro jSON. Cuando la biblioteca jSON tenga que serializar/deserializar un objeto [Categorie], habrá que indicarle cómo gestionar el filtro denominado [jsonFilterCategorie];
4.7. La interfaz Idao<T>
 |
 |
La interfaz [IDao] de la capa [DAO] tiene la siguiente firma:
package spring.jdbc.dao;
import java.util.List;
import spring.jdbc.entities.AbstractCoreEntity;
public interface IDao<T extends AbstractCoreEntity> {
// lista de todas las entidades T
public List<T> getAllShortEntities();
public List<T> getAllLongEntities();
// de entidades específicas - version breve
public List<T> getShortEntitiesById(Iterable<Long> ids);
public List<T> getShortEntitiesById(Long... ids);
public List<T> getShortEntitiesByName(Iterable<String> names);
public List<T> getShortEntitiesByName(String... names);
// de entidades específicas - version larga
public List<T> getLongEntitiesById(Iterable<Long> ids);
public List<T> getLongEntitiesById(Long... ids);
public List<T> getLongEntitiesByName(Iterable<String> names);
public List<T> getLongEntitiesByName(String... names);
// actualización de varias entidades
public List<T> saveEntities(Iterable<T> entities);
public List<T> saveEntities(@SuppressWarnings("unchecked") T... entities);
// eliminación de todas las entidades
public void deleteAllEntities();
// eliminación de varias entidades
public void deleteEntitiesById(Iterable<Long> ids);
public void deleteEntitiesById(Long... ids);
public void deleteEntitiesByName(Iterable<String> names);
public void deleteEntitiesByName(String... names);
public void deleteEntitiesByEntity(Iterable<T> entities);
public void deleteEntitiesByEntity(@SuppressWarnings("unchecked") T... entities);
}
- línea 7: aquí tenemos una interfaz [IDao] parametrizada por un tipo T con una condición: este tipo debe extender la clase [AbstractCoreEntity] o implementar la interfaz [AbstractCoreEntity]. La palabra clave [extends] se utiliza en ambos casos. Aquí, T se instanciará bien mediante el tipo [Produit], bien mediante el tipo [Categorie]. De hecho, pronto nos damos cuenta de que realizamos el mismo tipo de operaciones (inserción, modificación, eliminación, selección) sobre los tipos [Produit] y [Categorie]. Por lo tanto, parece lógico agrupar estos métodos en una interfaz genérica;
- según el caso, los términos [LongEntity] y [ShortEntity] designan situaciones diferentes:
- cuando T es el tipo [Produit]:
- [ShortEntity] es el producto sin su campo [Categorie categorie] rellenado;
- [LongEntity] es el producto con el campo [Categorie categorie] rellenado;
- cuando T es el tipo [Categorie]:
- [ShortEntity] es la categoría sin el campo [List<Produit> produits] rellenado;
- [LongEntity] es el producto con su campo [List<Produit> produits] rellenado;
- cuando T es el tipo [Produit]:
Por lo tanto, tenemos una interfaz con 19 métodos. La mayoría de los métodos están duplicados. Tomemos como ejemplo el método [getShortEntitiesById]:
public List<T> getShortEntitiesById(Iterable<Long> ids);
public List<T> getShortEntitiesById(Long... ids);
- líneas 1 y 3: el parámetro es la lista de claves primarias de las entidades de las que queremos la versión corta version. Esta lista se presenta en dos formas diferentes:
- línea 1: una lista que implementa la interfaz [Iterable<Long>]. El tipo [List<Long>] implementa esta interfaz, pero hay muchos otros. Si hubiéramos puesto [List<Long> ids], habría sido suficiente para nuestros ejemplos, pero habríamos obligado al usuario de nuestros ejemplos a realizar conversiones si su parámetro no fuera del tipo exacto esperado;
- línea 3: lamentablemente, el tipo Long[] no implementa la interfaz [Iterable<Long>]. En este caso, utilizaremos el version de la línea 3. El parámetro formal [Long... ids] (3 puntos) puede recibir el valor tanto de una matriz como de una secuencia de ids: getShortEntitiesById(id1, id2, ...);
Es esta misma interfaz IDao<T> la que se implementará mediante la siguiente arquitectura:
 |
donde una capa [JPA] (Java Persistence Api) se intercalará entre la capa [DAO] y el controlador JDBC del SGBD. Esto nos permitirá disponer de una capa de pruebas común a ambas arquitecturas. En ambos casos, la capa [DAO] presentará dos interfaces:
- IDao<Producto> para acceder a la tabla [PRODUITS];
- IDao<Categoría> para acceder a la tabla [CATEGORIES];
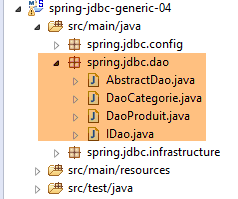
4.8. Implementación de la interfaz IDao<T>
|
- la interfaz IDao<Producto> está implementada por la clase [DaoProduit] ;
- la interfaz IDao<Categoría> está implementada por la clase [DaoCategorie];
Las clases [DaoProduit] y [DaoCategorie] extienden ambas la clase abstracta [AbstractDao] siguiente:
package spring.jdbc.dao;
import java.util.ArrayList;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.transaction.annotation.Transactional;
import spring.jdbc.entities.AbstractCoreEntity;
import spring.jdbc.infrastructure.MyIllegalArgumentException;
import com.google.common.collect.Lists;
public abstract class AbstractDao<T extends AbstractCoreEntity> implements IDao<T> {
// inserciones
@Autowired
@Qualifier("maxPreparedStatementParameters")
protected int maxPreparedStatementParameters;
// local
protected String simpleClassName = getClass().getSimpleName();
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesById(Iterable<Long> ids) {
// validez del argumento
List<T> entities = checkNullOrEmptyArgument(true, ids);
if (entities != null) {
return entities;
}
// obtención por tramos
entities = new ArrayList<T>();
int taille = maxPreparedStatementParameters;
List<Long> listIds = Lists.newArrayList(ids);
int nbIds = listIds.size();
for (int i = 0; i < nbIds; i += taille) {
int limit = Math.min(nbIds, i + taille);
entities.addAll(getShortEntitiesById(listIds.subList(i, limit)));
}
// resultado
return entities;
}
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesById(Long... ids) {
// validez del argumento
List<T> entities = checkNullOrEmptyArgument(true, ids);
if (entities != null) {
return entities;
}
// resultado
return getShortEntitiesById((Iterable<Long>) Lists.newArrayList(ids));
}
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesByName(Iterable<String> names) {
...
}
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesByName(String... names) {
...
}
@Override
@Transactional(readOnly = true)
public List<T> getLongEntitiesById(Iterable<Long> ids) {
...
}
@Override
@Transactional(readOnly = true)
public List<T> getLongEntitiesById(Long... ids) {
...
}
@Override
@Transactional(readOnly = true)
public List<T> getLongEntitiesByName(Iterable<String> names) {
...
}
@Override
@Transactional(readOnly = true)
public List<T> getLongEntitiesByName(String... names) {
...
}
@Override
@Transactional
public List<T> saveEntities(Iterable<T> entities) {
...
}
@Override
@Transactional
public List<T> saveEntities(@SuppressWarnings("unchecked") T... entities) {
...
}
@Override
public void deleteEntitiesById(Iterable<Long> ids) {
...
}
@Override
public void deleteEntitiesById(Long... ids) {
...
}
@Override
public void deleteEntitiesByName(Iterable<String> names) {
...
}
@Override
public void deleteEntitiesByName(String... names) {
...
}
@Override
public void deleteEntitiesByEntity(Iterable<T> entities) {
...
}
@Override
public void deleteEntitiesByEntity(@SuppressWarnings("unchecked") T... entities) {
...
}
protected void deleteEntitiesByEntity(List<T> entities) {
...
}
@Override
@Transactional(readOnly = true)
public abstract List<T> getAllShortEntities();
@Override
@Transactional(readOnly = true)
public abstract List<T> getAllLongEntities();
@Override
public abstract void deleteAllEntities();
// métodos privados ----------------------------------------------
private <T2> List<T> checkNullOrEmptyArgument(boolean checkEmpty, Iterable<T2> elements) {
...
}
@SuppressWarnings("unchecked")
private <T2> List<T> checkNullOrEmptyArgument(boolean checkEmpty, T2... elements) {
...
}
// métodos protegidos ----------------------------------------------
abstract protected List<T> getShortEntitiesById(List<Long> ids);
abstract protected List<T> getShortEntitiesByName(List<String> names);
abstract protected List<T> getLongEntitiesById(List<Long> ids);
abstract protected List<T> getLongEntitiesByName(List<String> names);
abstract protected List<T> saveEntities(List<T> entities);
abstract protected void deleteEntitiesById(List<Long> ids);
abstract protected void deleteEntitiesByName(List<String> names);
}
- línea 15: la clase [AbstractDao] es abstracta (palabra clave abstract). Como tal, no puede instanciarse. Solo puede derivarse. Esta clase tiene varias funciones:
- determinar la naturaleza de la transacción en la que se ejecuta cada método;
- realizar el máximo de tareas comunes a las dos implementaciones de las interfaces [IDao<Produit>] y [IDao<Categorie>]. Se trata principalmente de verificar la validez de los argumentos. No se aceptarán argumentos nulos ni listas vacías;
- unificar el tipo de los parámetros T... params e Iterable<T> params en uno solo: List<T> params;
- delegar el trabajo a las clases hijas tan pronto como este se vuelva específico de una de las dos interfaces;
Gracias a la unificación de los parámetros de los distintos métodos realizada por la clase [AbstractDao], las clases hijas [DaoProduit] y [DaoCategorie] solo tendrán que implementar 10 métodos en lugar de 19:
// métodos implementados por las clases hijas ----------------------------------------------
abstract protected List<T> getShortEntitiesById(List<Long> ids);
abstract protected List<T> getShortEntitiesByName(List<String> names);
abstract protected List<T> getLongEntitiesById(List<Long> ids);
abstract protected List<T> getLongEntitiesByName(List<String> names);
abstract protected List<T> saveEntities(List<T> entities);
abstract protected void deleteEntitiesById(List<Long> ids);
abstract protected void deleteEntitiesByName(List<String> names);
@Override
@Transactional(readOnly = true)
public abstract List<T> getAllShortEntities();
@Override
@Transactional(readOnly = true)
public abstract List<T> getAllLongEntities();
@Override
public abstract void deleteAllEntities();
Veamos algunos métodos de la clase [AbstractDao].
Método [getShortEntitiesById]
Este método tiene como objetivo obtener la version abreviada de las entidades cuyas claves primarias se proporcionan.
// inyecciones
@Autowired
@Qualifier("maxPreparedStatementParameters")
protected int maxPreparedStatementParameters;
// local
protected String simpleClassName = getClass().getSimpleName();
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesById(Iterable<Long> ids) {
...
}
- líneas 2-4: se inyecta el bean [maxPreparedStatementParameters] definido en el archivo de configuración [ConfigJdbc], que configura la capa JDBC de un SGBD concreto:
// número máximo de parámetros de un [PreparedStatement]
public final static int MAX_PREPAREDSTATEMENT_PARAMETERS = 10000;
@Bean(name = "maxPreparedStatementParameters")
public int maxPreparedStatementParameters() {
return MAX_PREPAREDSTATEMENT_PARAMETERS;
}
- líneas 1-7: definen el bean [maxPreparedStatementParameters] que establecerá el número máximo de parámetros que se podrán asignar a un tipo [PreparedStatement]. Esta necesidad no surgió con el SGBD MySQL, que aceptó 10 000 parámetros para un tipo [PreparedStatement]. Durante las pruebas con el servidor SGBD SQL, este lanzó una excepción indicando que el número máximo de parámetros para un tipo [PreparedStatement] era de 2100. Por lo tanto, este número se ha convertido en un parámetro de la configuración de los distintos SGBD. Por lo tanto, debe incluirse en el proyecto de configuración [sgbd-config-jdbc] de cada SGBD;
Volvamos al código del método [getShortEntitiesById]:
// inyecciones
@Autowired
@Qualifier("maxPreparedStatementParameters")
protected int maxPreparedStatementParameters;
// local
protected String simpleClassName = getClass().getSimpleName();
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesById(Iterable<Long> ids) {
...
}
- línea 7: el nombre de la clase. Se utiliza como parámetro de uno de los constructores de la clase de excepción [DaoException];
- línea 10: la anotación [@Transactional(readOnly = true)] indica que el método debe ejecutarse en una transacción de solo lectura. Cabe preguntarse por la utilidad de tal transacción, ya que el método solo realiza lecturas y, por lo tanto, en caso de fallo, no hay nada que anular. Es el autor de la biblioteca [Spring Data] quien lo aconseja y explica por qué. He seguido su consejo;
El cuerpo del método es el siguiente:
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesById(Iterable<Long> ids) {
// validez del argumento
List<T> entities = checkNullOrEmptyArgument(true, ids);
if (entities != null) {
return entities;
}
...
}
- línea 5: la validez del parámetro [ids] se comprueba mediante el siguiente método:
private <T2> List<T> checkNullOrEmptyArgument(boolean checkEmpty, Iterable<T2> elements) {
// elements null ?
if (elements == null) {
throw new MyIllegalArgumentException(222, new NullPointerException("L'argument ne peut être null"), simpleClassName);
}
// elements vide ?
if (!elements.iterator().hasNext()) {
if (checkEmpty) {
throw new MyIllegalArgumentException(223, new RuntimeException("l'argument ne peut être une liste vide"),
simpleClassName);
} else {
return new ArrayList<T>();
}
}
// résultat par défaut
return null;
}
- línea 1: el método [checkNullOrEmptyArgument] es un método genérico parametrizado por el tipo <T2>. T2 es el tipo de los elementos pasados como segundo parámetro del método. Puede ser [Long, String, AbstractCoreEntity];
- línea 1: el método [checkNullOrEmptyArgument] admite dos parámetros:
- [Iterable<T2> elements]: el parámetro que se va a comprobar;
- [checkEmpty]: se establece en verdadero si hay que comprobar que el parámetro anterior es una lista no vacía;
- líneas 4-6: se comprueba que el parámetro [elements] no sea nulo. Si no es así, se lanza una excepción de tipo [MyIllegalArgumentException];
- líneas 8-15: si la lista está vacía y se debía comprobar que no lo estuviera, se lanza una excepción de tipo [MyIllegalArgumentException];
- línea 13: si la lista está vacía y no se debe comprobar que no lo esté, se devuelve una lista vacía de elementos de tipo T. La interfaz [Iterable<T2>] tiene un método [iterator()] que permite iterar sobre los elementos de la lista que implementa la interfaz. Dos métodos de este iterador son útiles:
- [itérateur].hasNext(): devuelve verdadero si la lista aún tiene un elemento por procesar, falso en caso contrario;
- [iterateur].next(): devuelve el elemento actual de la lista y avanza un elemento;
- finalmente,
- si el argumento [T2... elements] es nulo o está vacío, se lanza una excepción de tipo [MyIllegalArgumentException];
- si el argumento [T2... elements] es una lista vacía y era válido, entonces se devuelve una lista vacía de elementos de tipo T;
Existe un método análogo cuando el argumento a comprobar es de tipo [T2... elements]:
@SuppressWarnings("unchecked")
private <T2> List<T> checkNullOrEmptyArgument(boolean checkEmpty, T2... elements) {
...
}
Volvamos al código del método [getShortEntitiesById]:
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesById(Iterable<Long> ids) {
// validez del argumento
List<T> entities = checkNullOrEmptyArgument(true, ids);
// obtención por tramos
entities = new ArrayList<T>();
int taille = maxPreparedStatementParameters;
List<Long> listIds = Lists.newArrayList(ids);
int nbIds = listIds.size();
for (int i = 0; i < nbIds; i += taille) {
int limit = Math.min(nbIds, i + taille);
entities.addAll(getShortEntitiesById(listIds.subList(i, limit)));
}
// resultado
return entities;
}
- línea 7: si llegamos hasta aquí, es porque el argumento [Iterable<Long> ids] es válido;
- líneas 7-14: veremos más adelante que el método [getShortEntitiesById] se implementará mediante un tipo [PreparedStatement] que tendrá como parámetros la lista de claves primarias que se deben buscar. Por ejemplo:
public final static String SELECT_SHORTCATEGORIE_BYID = "SELECT c.ID as c_ID, c.VERSIONING as c_VERSIONING, c.NOM as c_NOM FROM CATEGORIES c WHERE c.ID in (:ids)";
: ids es un parámetro cuyo valor efectivo será un tipo List<Long>. Cada elemento de esta lista será objeto de un parámetro ? en un tipo [PreparedStatement]. Ahora bien, hemos dicho que este tipo admite un número máximo de parámetros, número fijado por el campo [maxPreparedStatementParameters] de la clase;
- línea 7: la lista de entidades T que devolverá el método [getShortEntitiesById]. Esta lista se construirá por fragmentos de elementos [maxPreparedStatementParameters];
- línea 9: a partir del argumento [Iterable<Long> ids], se crea un tipo [List<Long> listIds]. La clase [Lists] es una clase de la biblioteca Google Guava que ofrece numerosos métodos estáticos para manipular colecciones de objetos. La biblioteca Google Guava ha sido importada (pom.xml) por el proyecto Maven [mysql-config-jdbc]:
<!-- Google Guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>16.0.1</version>
</dependency>
- línea 10: el número de entidades T que se deben buscar en la base de datos;
- líneas 11-13: se buscan por grupos de [taille = maxPreparedStatementParameters] elementos;
- línea 12: un cálculo para evitar sobrepasar el final de la lista [listIds];
- línea 13: las entidades T se obtienen mediante la llamada [getShortEntitiesById(listIds.subList(i, limit))]. Este método se define en la clase mediante:
abstract protected List<T> getShortEntitiesById(List<Long> ids);
Por lo tanto, es la clase hija la que buscará las entidades T en la base de datos:
- [DaoProduit] si T es del tipo [Produit];
- [DaoCategorie] si T es del tipo [Categorie];
El interés de este trabajo de la clase padre es doble:
- la firma del método [getShortEntitiesById] en la clase hija es única: su argumento es de tipo [List<Long> ids];
- la clase hija no tiene que ocuparse del problema de los parámetros [maxPreparedStatementParameters] de un [PreparedStatement]. Su clase madre se ha encargado de ello por ella;
- línea 13: las entidades devueltas por la clase hija se acumulan en la lista de entidades que devolverá la clase madre (línea 16);
Ahora, veamos la implementación del otro método [getShortEntitiesById] de la clase:
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesById(Long... ids) {
// validez del argumento
List<T> entities = checkNullOrEmptyArgument(true, ids);
// resultado
return getShortEntitiesById((Iterable<Long>) Lists.newArrayList(ids));
}
- línea 3: la naturaleza del argumento ha cambiado: Long... ids;
- línea 5: se comprueba la validez de este argumento;
- línea 7: se llama al método [getShortEntitiesById] que acabamos de describir. Una vez más, se recurre a la clase [Lists] de la biblioteca [Google Guava]. Tenga en cuenta que es necesario realizar un cast explícito al tipo [Iterable<Long>] para ayudar al compilador a elegir el método correcto, ya que el método [getShortEntitiesById] tiene tres firmas en la clase:
- List<T> getShortEntitiesById(Long... ids);
- List<T> getShortEntitiesById(Iterable<Long> ids);
- List<T> getShortEntitiesById(List<Long> ids), que es abstracta y está implementada por la clase hija;
No comentaremos más la clase abstracta [AbstractDao], clase padre de las clases [DaoProduit] y [DaoCategorie]. Simplemente recordaremos que a veces resulta interesante factorizar comportamientos comunes a varias clases en una clase padre, ya sea abstracta o no. Tras este trabajo, a las clases hijas solo les queda implementar los siguientes métodos:
// métodos implementados por las clases hijas ----------------------------------------------
abstract protected List<T> getShortEntitiesById(List<Long> ids);
abstract protected List<T> getShortEntitiesByName(List<String> names);
abstract protected List<T> getLongEntitiesById(List<Long> ids);
abstract protected List<T> getLongEntitiesByName(List<String> names);
abstract protected List<T> saveEntities(List<T> entities);
abstract protected void deleteEntitiesById(List<Long> ids);
abstract protected void deleteEntitiesByName(List<String> names);
@Override
@Transactional(readOnly = true)
public abstract List<T> getAllShortEntities();
@Override
@Transactional(readOnly = true)
public abstract List<T> getAllLongEntities();
@Override
public abstract void deleteAllEntities();
El código del apartado 4.8 muestra los diferentes tipos de transacción utilizados para cada método. Cabe destacar algunos puntos:
- los métodos que leen la base de datos están anotados con [@Transactional(readOnly = true)];
- los métodos que modifican la base de datos están anotados con [@Transactional];
- los métodos [delete] no están anotados y, por lo tanto, no se ejecutan en una transacción. La idea es que, si falla una eliminación, es probable que el usuario no quiera anular todas las que se han realizado correctamente anteriormente;
4.9. La clase [DaoCategorie]
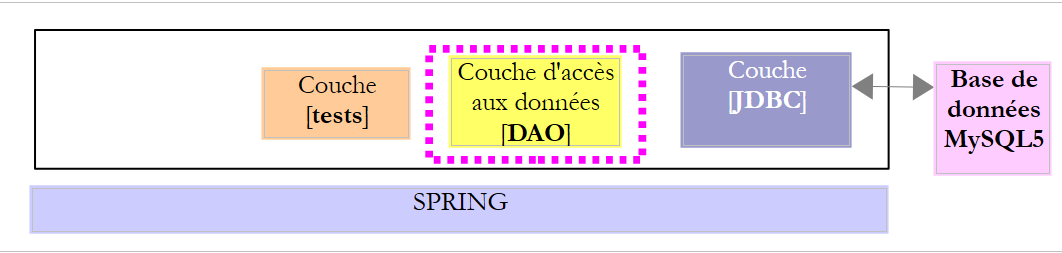 |
|
La clase [DaoCategorie] implementa la interfaz [IDao<Categorie>], que garantiza elacceso a los datos de la tabla [CATEGORIES] de la base de datos MySQL [dbproduitscategories]. Su esqueleto es el siguiente:
package spring.jdbc.dao;
import generic.jdbc.config.ConfigJdbc;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.RowMapper;
import org.springframework.jdbc.core.namedparam.MapSqlParameterSource;
import org.springframework.jdbc.core.namedparam.NamedParameterJdbcTemplate;
import org.springframework.jdbc.core.namedparam.SqlParameterSource;
import org.springframework.jdbc.core.namedparam.SqlParameterSourceUtils;
import org.springframework.jdbc.core.simple.SimpleJdbcInsert;
import org.springframework.stereotype.Component;
import spring.jdbc.entities.Categorie;
import spring.jdbc.entities.Produit;
import spring.jdbc.infrastructure.DaoException;
import com.google.common.collect.Lists;
@Component
public class DaoCategorie extends AbstractDao<Categorie> {
// constantes
// inyecciones
@Autowired
private NamedParameterJdbcTemplate namedParameterJdbcTemplate;
@Autowired
private SimpleJdbcInsert simpleJdbcInsertCategorie;
@Autowired
private IDao<Produit> daoProduit;
@Override
public List<Categorie> getAllShortEntities() {
...
}
@Override
public List<Categorie> getAllLongEntities() {
...
}
@Override
public void deleteAllEntities() {
...
}
@Override
protected List<Categorie> getShortEntitiesById(List<Long> ids) {
...
}
@Override
protected List<Categorie> getShortEntitiesByName(List<String> names) {
...
}
@Override
protected List<Categorie> getLongEntitiesById(List<Long> ids) {
...
}
@Override
protected List<Categorie> getLongEntitiesByName(List<String> names) {
...
}
@Override
protected List<Categorie> saveEntities(List<Categorie> entities) {
...
}
@Override
protected void deleteEntitiesById(List<Long> ids) {
...
}
@Override
protected void deleteEntitiesByName(List<String> names) {
...
}
...
}
// --------------------- mapeadores
class ShortCategorieMapper implements RowMapper<Categorie> {
....
}
class LongCategorieMapper implements RowMapper<Categorie> {
....
}
- línea 28: la clase [DaoCategorie] es un componente Spring y, como tal, podrá inyectarse en otros componentes Spring;
- línea 29: la clase [DaoCategorie] extiende la clase abstracta [AbstractDao<Categorie>], lo que la convierte en una implementación de la interfaz [IDao<Categorie>];
- líneas 34-37: inyección de beans definidos en la clase [AppConfig] descrita en el apartado 4.4;
- líneas 38-39: inyección de una referencia a la clase [DaoProduit], que implementa la interfaz [IDao<Produit>], la cual gestiona el acceso a los datos de la tabla [PRODUITS];
- líneas 41-89: implementación de la interfaz [IDao<Categorie>];
- líneas 95-101: dos clases internas que implementan la interfaz [RowMapper<T>];
Analicemos los métodos uno por uno.
4.9.1. El método [getAllShortEntities]
El método [getAllShortEntities] devuelve todas las categorías de la tabla [CATEGORIES] en su forma abreviada version:
@Override
public List<Categorie> getAllShortEntities() {
try {
return namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_ALLSHORTCATEGORIES, new ShortCategorieMapper());
} catch (Exception e) {
throw new DaoException(202, e, simpleClassName);
}
}
Todos los métodos se basan en el objeto [namedParameterJdbcTemplate] definido en el archivo de configuración de Spring y proporcionado por la biblioteca Spring JDBC. Sus métodos son numerosos. El utilizado anteriormente es el siguiente:
![]()
- [sql] es la orden SQL que se debe ejecutar;
- [rowMapper] es una instancia de la siguiente interfaz [RowMapper<T>]:

La idea es la siguiente:
- el método [namedParameterJdbcTemplate].query(String sql, RowMapper<T> rowMapper) ejecuta la orden SQL de tipo [Select]. Gestiona las posibles excepciones, así como la apertura y el cierre de la conexión con SGBD. Lo único que no puede hacer esencapsular los elementos del [ResultSet] de los objetos que obtiene en un tipo [Categorie], ya que desconoce la relación que existe entre los campos del tipo [Categorie] y las columnas del [Resultset]. Más adelante veremos que esta relación se crea con la tecnología JPA, lo que automatizará la encapsulación de los elementos de un [ResultSet] en instancias de tipo T. Por ahora, el segundo parámetro del método [query] es una instancia de la interfaz [RowMapper<T>] capaz de realizar esta encapsulación;
Volvamos al código:
@Override
public List<Categorie> getAllShortEntities() {
try {
return namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_ALLSHORTCATEGORIES, new ShortCategorieMapper());
} catch (Exception e) {
throw new DaoException(202, e, simpleClassName);
}
}
El orden SQL [ConfigJdbc.SELECT_ALLSHORTCATEGORIES] es el siguiente:
public final static String SELECT_ALLSHORTCATEGORIES = "SELECT c.ID as c_ID, c.VERSIONING as c_VERSIONING, c.NOM as c_NOM FROM CATEGORIES c";
La consulta solicita las columnas [ID, VERSIONING, NOM] de los elementos de la tabla [CATEGORIES]. Utilizaremos sistemáticamente la sintaxis:
SELECT t1.COL1 as t1_COL1, t1.COL2 as t1_COL2 FROM TABLE1 t1, TABLE2 t2 WHERE ...
Lo importante es la denominación de las columnas obtenidas por el SELECT con el atributo [as nom_colonne]. Es la única forma de garantizar la portabilidad entre SGBD, ya que todos ellos tienen una forma propia de nombrar las columnas obtenidas mediante un SELECT, en el que columnas de tablas diferentes tienen el mismo nombre (ID, NOM o VERSIONING, por ejemplo, en nuestro caso). De este modo, eliminamos esta ambigüedad indicando nosotros mismos el nombre que deben llevar estas columnas.
La clase interna [ShortCategorieMapper] es la siguiente:
class ShortCategorieMapper implements RowMapper<Categorie> {
@Override
public Categorie mapRow(ResultSet rs, int rowNum) throws SQLException {
return new Categorie(rs.getLong("c_ID"), rs.getLong("c_VERSIONING"), rs.getString("c_NOM"), null);
}
}
- línea 1: la clase [ShortCategorieMapper] implementa la interfaz [RowMapper<Categorie>] y, como tal, debe implementar el método [mapRow] de las líneas 4-5, cuya función es encapsular una línea del [ResultSet rs] generado por la orden [SELECT] en un tipo [Categorie];
- línea 5: esta encapsulación ya se ha realizado. Cabe destacar que el nombre utilizado por los métodos [rs.getType(nom)] es el mismo que se utiliza en los atributos [as nom] de las columnas del SELECT;
Así pues, hemos obtenido la lista de categorías en su formato abreviado sin gestionar excepciones ni conexiones. Este es el interés de la biblioteca Spring, que gestiona todo lo que puede factorizarse en la gestión de los elementos de una tabla y deja al desarrollador lo que no puede factorizarse.
4.9.2. El método [getAllLongEntities]
El método [getAllLongEntities] devuelve todas las categorías de la tabla [CATEGORIES] en su versión larga version:
@Override
public List<Categorie> getAllLongEntities() {
try {
return filterCategories(namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_ALLLONGCATEGORIES,
new LongCategorieMapper()));
} catch (Exception e) {
throw new DaoException(223, e, simpleClassName);
}
}
El orden SQL [ConfigJdbc.SELECT_ALLLONGCATEGORIES] es el siguiente:
public final static String SELECT_ALLLONGCATEGORIES = "SELECT p.ID as p_ID, p.VERSIONING as p_VERSION, p.NOM as p_NOM, p.PRIX as p_PRIX, p.DESCRIPTION as p_DESCRIPTION, p.CATEGORIE_ID AS p_CATEGORIE_ID, c.ID as c_ID, c.NOM as c_NOM, c.VERSIONING as c_VERSION FROM PRODUITS p RIGHT JOIN CATEGORIES c ON p.CATEGORIE_ID=c.ID";
Se trata de relacionar las categorías con sus productos. Esto se consigue realizando una unión de la tabla [CATEGORIES] con la tabla [PRODUITS] a través de la clave externa [CATEGORIE_ID] quela tabla [PRODUITS] a la tabla [CATEGORIES]. La sintaxis [FROM PRODUITS p RIGHT JOIN CATEGORIES c ON p.CATEGORIE_ID=c.ID] permite recuperar también las categorías que no tienen productos asociados. En este caso, la consulta SELECT devuelve una categoría y un producto con todas sus columnas a NULL.
La clase [LongCategorieMapper] es la siguiente:
class LongCategorieMapper implements RowMapper<Categorie> {
@Override
public Categorie mapRow(ResultSet rs, int rowNum) throws SQLException {
Categorie categorie = new Categorie(rs.getLong("c_ID"), rs.getLong("c_VERSION"), rs.getString("c_NOM"), null);
List<Produit> produits = new ArrayList<Produit>();
long idProduit = rs.getLong("p_ID");
// caso de la categoría sin productos
if (!rs.wasNull()) {
produits.add(new Produit(idProduit, rs.getLong("p_VERSION"), rs.getString("p_NOM"), rs.getLong("p_CATEGORIE_ID"),
rs.getDouble("p_PRIX"), rs.getString("p_DESCRIPTION"), categorie));
}
categorie.setProduits(produits);
return categorie;
}
}
- línea 4: el método [mapRow] debe devolver un objeto [Categorie] con su campo [produits] rellenado, a partir de una línea del [ResultSet] procedente de la orden SELECT anterior;
Al final, la operación:
[namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_ALLLONGCATEGORIES,new LongCategorieMapper())]
dará como resultado una lista del tipo:
donde cada categoría [ci] tendrá un campo [produits] que será una lista de productos que contiene un único elemento [produitsij]. Sin embargo, necesitamos la siguiente lista:
donde cada categoría [ci] tendrá un campo [produits] que será la lista de productos [produiti1, produiti2, ...]. Esto se consigue pasando la lista de categorías obtenida a un método privado [filterCategories]:
@Override
public List<Categorie> getAllLongEntities() {
try {
return filterCategories(namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_ALLLONGCATEGORIES,
new LongCategorieMapper()));
} catch (Exception e) {
throw new DaoException(223, e, simpleClassName);
}
}
El método [filterCategories] es el siguiente:
private List<Categorie> filterCategories(List<Categorie> categories) {
if (categories.size() == 0) {
return categories;
}
// catégories à rendre
List<Categorie> cats = new ArrayList<Categorie>();
// on parcourt la liste des catégories obtenues
for (Categorie categorie : categories) {
boolean trouve = false;
for (Categorie cat : cats) {
if (categorie.equals(cat)) {
cat.addProduit(categorie.getProduits().get(0));
trouve = true;
break;
}
}
// trouvé ?
if (!trouve) {
cats.add(categorie);
}
}
// résultat
return cats;
}
- línea 1: [List<Categorie> categories] es la lista de categorías que se van a filtrar (o agrupar);
- línea 6: la lista de categorías que se deben devolver al solicitante;
- líneas 8-21: se procesa cada categoría de la lista que se va a filtrar;
- líneas 10-16: se comprueba si la categoría actual [categorie] ya está presente en la lista de categorías [cats] que se va a construir (recordemos que dos categorías se consideran iguales si tienen la misma clave primaria, véase el apartado 4.6);
- líneas 11-14: si ya es así, entonces el producto encapsulado en [categorie] se añade a la lista de productos de [cat];
- líneas 18-20: si la categoría actual [categorie] no está ya presente en la lista de categorías [cats] que se va a construir, entonces se añade a ella con su lista de productos, que contiene un único elemento;
Veamos el caso en el que el comando SQL Select devuelve categorías sin productos asociados. ¿Qué entidad devuelve la clase [LongCategorieMapper]?
class LongCategorieMapper implements RowMapper<Categorie> {
@Override
public Categorie mapRow(ResultSet rs, int rowNum) throws SQLException {
Categorie categorie = new Categorie(rs.getLong("c_ID"), rs.getLong("c_VERSION"), rs.getString("c_NOM"), null);
List<Produit> produits = new ArrayList<Produit>();
long idProduit = rs.getLong("p_ID");
// caso de la categoría sin productos
if (!rs.wasNull()) {
produits.add(new Produit(idProduit, rs.getLong("p_VERSION"), rs.getString("p_NOM"), rs.getLong("p_CATEGORIE_ID"),
rs.getDouble("p_PRIX"), rs.getString("p_DESCRIPTION"), categorie));
}
categorie.setProduits(produits);
return categorie;
}
}
En el caso de que la orden SQL Select haya devuelto una categoría sin productos, las columnas del producto devuelto con la categoría contienen todas el valor SQL NULL. Este caso se trata en las líneas 7-9:
- línea 7: se recupera la clave primaria del producto como un entero long;
- línea 9: se comprueba si el valor leído era SQL NULL (rs.wasNull). Si no es así, se añade el producto a la lista de la línea 6; de lo contrario, no se añade nada y la lista de productos permanece vacía.
Cabe señalar que, en todos los casos, se devuelve una categoría con un campo [produits] que no es nulo.
4.9.3. El método [getShortEntitiesById]
El método [getShortEntitiesById] es análogo al método [getAllShortEntities], salvo que solo devuelve las entidades cuyas claves primarias se especifican en una lista:
@Override
protected List<Categorie> getShortEntitiesById(List<Long> ids) {
try {
return namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_SHORTCATEGORIE_BYID,
Collections.singletonMap("ids", ids), new ShortCategorieMapper());
} catch (Exception e) {
throw new DaoException(203, e, simpleClassName);
}
}
- línea 4, la firma del método [query] utilizado es la siguiente:

El primer parámetro es una orden SQL [Select] configurada. El segundo es un diccionario que asocia cada uno de los parámetros a un valor. El tercero es la instancia de la clase que encapsula una línea del [ResultSet], resultado del [Select], en un objeto de tipo T;
- línea 4: la orden SQL [Select] configurada es la siguiente:
public final static String SELECT_SHORTCATEGORIE_BYID = "SELECT c.ID as c_ID, c.VERSIONING as c_VERSIONING, c.NOM as c_NOM FROM CATEGORIES c WHERE c.ID in (:ids)";
Esta orden extrae de la tabla [CATEGORIES] las categorías cuyas claves primarias se encuentran en la lista: ids.
- línea 5: el segundo parámetro del método [query] es aquí un diccionario que asocia la clave «ids» (primer parámetro) con la lista [ids] pasada en la línea 1 como parámetro al método [getShortEntitiesById]. La clase [Collections] pertenece a la biblioteca [Google Guava] de la que ya hemos hablado. [Collections.singleMap] devuelve un diccionario de un elemento;
- línea 5: la clase encargada de encapsular una línea del [ResultSet], resultado del [Select], en un objeto de tipo [Categorie] es la clase [ShortCategorieMapper], ya estudiada;
Es precisamente aquí donde entra en juego el bean [maxPreparedStatementParameters]. De hecho, el parámetro [:ids] de la orden SQL, que representa una lista de claves primarias, puede contener desde 1 hasta varios miles de parámetros. Existe un límite para este número que depende de cada SGBD. Para MySQL, se han podido pasar 10 000 parámetros sin errores y no se ha probado más allá de ese número. Para SQL Server, el límite oficial es 2100. Para Firebird, 1000 era demasiado. Se redujo a 100. En general, no se ha probado el límite máximo de este número para los diferentes SGBD.
4.9.4. El método [getLongEntitiesById]
El método [getLongEntitiesById] es análogo al método [getShortEntitiesById], salvo que devuelve las versiones largas de las categorías:
@Override
protected List<Categorie> getLongEntitiesById(List<Long> ids) {
try {
return filterCategories(namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_LONGCATEGORIE_BYID,
Collections.singletonMap("ids", ids), new LongCategorieMapper()));
} catch (Exception e) {
throw new DaoException(205, e, simpleClassName);
}
}
Línea 4, la consulta SQL [ConfigJdbc.SELECT_LONGCATEGORIE_BYID] es la siguiente:
public final static String SELECT_LONGCATEGORIE_BYID = "SELECT p.ID as p_ID, p.VERSIONING as p_VERSION, p.NOM as p_NOM, p.PRIX as p_PRIX, p.DESCRIPTION as p_DESCRIPTION, p.CATEGORIE_ID AS p_CATEGORIE_ID, c.ID as c_ID, c.NOM as c_NOM, c.VERSIONING as c_VERSION FROM PRODUITS p RIGHT JOIN CATEGORIES c ON c.ID=p.CATEGORIE_ID WHERE c.ID in (:ids)";
4.9.5. El método [getShortEntitiesByName]
El método [getShortEntitiesByName] es análogo al método [getShortEntitiesById], salvo que las categorías se buscan por sus nombres en lugar de por sus claves primarias:
@Override
protected List<Categorie> getShortEntitiesByName(List<String> names) {
try {
return namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_SHORTCATEGORIE_BYNAME,
Collections.singletonMap("noms", names), new ShortCategorieMapper());
} catch (Exception e) {
throw new DaoException(204, e, simpleClassName);
}
}
Línea 4, el orden SQL [ConfigJdbc.SELECT_SHORTCATEGORIE_BYNAME] es el siguiente:
public final static String SELECT_SHORTCATEGORIE_BYNAME = "SELECT c.ID as c_ID, c.VERSIONING as c_VERSIONING, c.NOM as c_NOM FROM CATEGORIES c WHERE c.NOM in (:noms)";
4.9.6. El método [getLongEntitiesByName]
El método [getLongEntitiesByName] es análogo al método [getShortEntitiesByName], salvo que las categorías se buscan en sus versiones completas:
@Override
protected List<Categorie> getLongEntitiesByName(List<String> names) {
try {
return filterCategories(namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_LONGCATEGORIE_BYNAME,
Collections.singletonMap("noms", names), new LongCategorieMapper()));
} catch (Exception e) {
throw new DaoException(215, e, simpleClassName);
}
}
Línea 4, el orden SQL [ConfigJdbc.SELECT_LONGCATEGORIE_BYNAME] es el siguiente:
public final static String SELECT_LONGCATEGORIE_BYNAME = "SELECT p.ID as p_ID, p.VERSIONING as p_VERSION, p.NOM as p_NOM, p.PRIX as p_PRIX, p.DESCRIPTION as p_DESCRIPTION, p.CATEGORIE_ID AS p_CATEGORIE_ID, c.ID as c_ID, c.NOM as c_NOM, c.VERSIONING as c_VERSION FROM PRODUITS p RIGHT JOIN CATEGORIES c ON c.ID=p.CATEGORIE_ID WHERE c.NOM in(:noms)";
4.9.7. El método [deleteAllEntities]
El método [deleteAllEntities] elimina todas las categorías de la tabla [CATEGORIES]:
@Override
public void deleteAllEntities() {
try {
// se eliminan todas las categorías y, por consiguiente, todos los productos
namedParameterJdbcTemplate.update(ConfigJdbc.DELETE_ALLCATEGORIES, (Map<String, Object>) null);
} catch (Exception e) {
throw new DaoException(208, e, simpleClassName);
}
}
- línea 4: el método [namedParameterJdbcTemplate.update] utilizado tiene la siguiente firma:
![]()
El primer parámetro es una orden SQL configurada para la actualización (INSERT, UPDATE, DELETE). El segundo parámetro es el diccionario que asocia valores a los diferentes parámetros de la orden SQL. El método devuelve el número de líneas actualizadas por la orden SQL.
- línea 4: la orden SQL [ConfigJdbc.DELETE_ALLCATEGORIES] es la siguiente:
public final static String DELETE_ALLCATEGORIES = "DELETE FROM CATEGORIES";
Por lo tanto, no se trata de una orden parametrizada. Por eso, el segundo parámetro del método [update] tiene el valor nulo.
4.9.8. El método [deleteAllEntitiesById]
El método [deleteAllEntitiesById] elimina las categorías de la tabla [CATEGORIES] cuyas claves primarias se pasan:
@Override
protected void deleteEntitiesById(List<Long> ids) {
try {
namedParameterJdbcTemplate.update(ConfigJdbc.DELETE_CATEGORIESBYID, Collections.singletonMap("ids", ids));
} catch (Exception e) {
throw new DaoException(209, e, simpleClassName);
}
}
Línea 4, el orden SQL [ConfigJdbc.DELETE_CATEGORIESBYID] es el siguiente:
public final static String DELETE_CATEGORIESBYID = "DELETE FROM CATEGORIES WHERE ID in (:ids)";
4.9.9. El método [deleteAllEntitiesByName]
El método [deleteAllEntitiesByName] elimina las categorías de la tabla [CATEGORIES] cuyos nombres se le pasan:
@Override
protected void deleteEntitiesByName(List<String> names) {
try {
namedParameterJdbcTemplate.update(ConfigJdbc.DELETE_CATEGORIESBYNAME, Collections.singletonMap("noms", names));
} catch (Exception e) {
throw new DaoException(225, e, simpleClassName);
}
}
Línea 4, el orden SQL [ConfigJdbc.DELETE_CATEGORIESBYNAME] es el siguiente:
public final static String DELETE_CATEGORIESBYNAME = "DELETE FROM CATEGORIES WHERE NOM in (:noms)";
4.9.10. El método [saveEntities]
4.9.10.1. El código
La firma de este método es la siguiente:
@Override
protected List<Categorie> saveEntities(List<Categorie> entities) {
El método recibe como parámetro una lista de categorías. Realiza las siguientes operaciones con ellas:
- si la categoría tiene una clave primaria nula, se realiza una operación SQL INSERT; en caso contrario, se realiza una operación SQL UPDATE;
- esta operación se repite para cada uno de los productos de la categoría;
El método devuelve la lista de categorías persistidas o actualizadas. La lista devuelta es el reflejo exacto de las categorías y productos presentes en las tablas, salvo por las versiones: estas, de hecho, no se modifican en las entidades actualizadas, aunque se hayan incrementado en la base de datos.
Es, con diferencia, el método más complejo. Su código es el siguiente:
@Override
protected List<Categorie> saveEntities(List<Categorie> entities) {
try {
// --------------------------------------------- categorías
List<Categorie> insertCategories = new ArrayList<Categorie>();
List<Categorie> updateCategories = new ArrayList<Categorie>();
// se escanean las categorías
for (Categorie categorie : entities) {
// ¿Insertar o actualizar?
if (categorie.getId() == null) {
insertCategories.add(categorie);
} else {
updateCategories.add(categorie);
}
}
// Inserciones de categorías
if (insertCategories.size() > 0) {
insertCategories(insertCategories);
}
// actualizaciones de categorías
if (updateCategories.size() > 0) {
updateCategories(updateCategories);
}
// --------------------------------------------- productos
// se actualizan los productos de las categorías
List<Produit> allProduits = new ArrayList<Produit>();
for (Categorie categorie : entities) {
List<Produit> produits = categorie.getProduits();
Long idCategorie = categorie.getId();
if (produits != null) {
// se añade a la lista de todos los productos
allProduits.addAll(produits);
// se escanean los productos uno a uno para vincularlos a su categoría
for (Produit produit : produits) {
// se vincula el producto a su categoría
produit.setIdCategorie(idCategorie);
produit.setCategorie(categorie);
}
}
}
// insertar/actualizar productos
daoProduit.saveEntities(allProduits);
// resultado
return entities;
} catch (DaoException e) {
throw e;
} catch (Exception e) {
throw new DaoException(207, e, simpleClassName);
}
}
- líneas 5-23: inserción o actualización de las categorías;
- líneas 26-43: inserción o actualización de productos;
- líneas 35-39: este código vincula cada producto a su categoría. En la fase anterior de inserción de categorías, estas recibieron una clave primaria que hay que introducir en el campo [idCategorie] del producto (línea 37). Por otra parte, las líneas 37-38 permiten corregir las situaciones en las que el autor no ha vinculado correctamente cada producto a su categoría. Para que esta relación sea correcta, hay que utilizar el método [Categorie] .add(Producto p), pero nada impide que un usuario añada un producto directamente a la lista de productos de la categoría sin pasar por este método, con el riesgo de que los campos [idCategorie, categorie] del producto p queden mal rellenados;
- línea 43: se delega en la instancia de la interfaz [IDao<Produit>] la tarea de persistir / actualizar los productos. Recordemos que esta instancia se ha inyectado en la clase [DaoCategorie]:
@Autowired
private IDao<Produit> daoProduit;
4.9.10.2. Inserción de categorías
Las categorías se insertan en la tabla [CATEGORIES] mediante el siguiente método privado [insertCategories]:
private List<Categorie> insertCategories(List<Categorie> categories) {
Map<Long, Categorie> mapCategories=new HashMap<Long,Categorie>();
try {
// catégories à ajouter
for (Categorie categorie : categories) {
Number newId = simpleJdbcInsertCategorie.executeAndReturnKey(getMapForCategorie(categorie));
// on mémorise la clé primaire
mapCategories.put(newId.longValue(), categorie);
}
} catch (Exception e) {
throw new DaoException(201, e, simpleClassName);
}
// tout est OK - on affecte les clés primaires aux catégories persistées
for(Long id : mapCategories.keySet()){
Categorie categorie=mapCategories.get(id);
categorie.setId(id);
}
// résultat
return categories;
}
- línea 6: se utiliza el bean [simpleJdbcInsertCategorie], inyectado en la clase mediante las siguientes líneas:
@Autowired
private SimpleJdbcInsert simpleJdbcInsertCategorie;
Este bean se define en la clase [AppConfig] del proyecto de la siguiente manera:
import org.springframework.jdbc.core.simple.SimpleJdbcInsert;
@Bean
public SimpleJdbcInsert simpleJdbcInsertCategorie(DataSource dataSource) {
return new SimpleJdbcInsert(dataSource).withTableName(ConfigJdbc.TAB_CATEGORIES)
.usingGeneratedKeyColumns(ConfigJdbc.TAB_CATEGORIES_ID)
.usingColumns(ConfigJdbc.TAB_CATEGORIES_NOM);
}
- línea 5, la clase [SimpleJdbcInsert] es una clase de la biblioteca Spring JDBC (línea 1):
- el parámetro del constructor [SimpleJdbcInsert] es la fuente de datos sobre la que se opera;
- la cláusula [withTableName] permite indicar la tabla en la que se desea insertar un elemento, en este caso la tabla [CATEGORIES];
- la cláusula [usingGeneratedKeyColumns] permite especificar la columna de la clave primaria autogenerada, en este caso la columna [ID];
- la cláusula [usingColumns] permite restringir la inserción a determinadas columnas. Aquí se excluye la columna [ID], que es generada automáticamente por SGBD, y la columna [VERSIONING], que tiene un valor por defecto de 1;
Volvamos al código del método [insertCategories]:
private List<Categorie> insertCategories(List<Categorie> categories) {
Map<Long, Categorie> mapCategories=new HashMap<Long,Categorie>();
try {
// catégories à ajouter
for (Categorie categorie : categories) {
Number newId = simpleJdbcInsertCategorie.executeAndReturnKey(getMapForCategorie(categorie));
// on mémorise la clé primaire
mapCategories.put(newId.longValue(), categorie);
}
} catch (Exception e) {
throw new DaoException(201, e, simpleClassName);
}
// tout est OK - on affecte les clés primaires aux catégories persistées
for(Long id : mapCategories.keySet()){
Categorie categorie=mapCategories.get(id);
categorie.setId(id);
}
// résultat
return categories;
}
- línea 6: se utiliza el método [simpleJdbcInsertCategorie.executeAndReturnKey]:
![]()
El método espera como parámetro un diccionario que establece los vínculos entre las columnas de la tabla y los valores que se deben insertar en ellas. Devuelve como resultado la clave primaria en forma de un tipo [Number]. El método [Number.longValue()] permite obtener la clave primaria en forma de un tipo [Long].
El método [getMapForCategorie] es el siguiente método privado:
private Map<String, ?> getMapForCategorie(Categorie categorie) {
Map<String, Object> map = new HashMap<String, Object>();
map.put(ConfigJdbc.TAB_CATEGORIES_NOM, categorie.getNom());
return map;
}
Las claves del diccionario son los nombres de las columnas que deben rellenarse [NOM], y los valores del diccionario son los valores que deben insertarse en dichas columnas.
- Línea 8 [insertCategories]: la clave primaria recuperada se almacena en un diccionario. Esperaremos a estar seguros de que se han insertado todas las entidades antes de asignarles sus claves primarias. De hecho, en caso de excepción, todas las inserciones se anularán y queremos que, en ese caso, las entidades [categories] de la línea 1 también permanezcan sin cambios;
- líneas 14-17: ahora que estamos seguros de que todo ha salido bien, asignamos las claves primarias generadas a las categorías;
- línea 19: devolvemos la lista de categorías con sus claves primarias;
4.9.10.3. Actualización de las categorías
Las categorías se actualizan con el siguiente método privado [updateCategories]:
private void updateCategories(List<Categorie> categories) {
try {
for (Categorie categorie : categories) {
// actualización de la categoría en la base de datos
int nbLignes = namedParameterJdbcTemplate.update(ConfigJdbc.UPDATE_CATEGORIES,
new BeanPropertySqlParameterSource(categorie));
// ¿Se ha realizado correctamente?
Long idCategorie = null;
if (nbLignes == 0) {
// No ha funcionado; se investiga el motivo
// buscando la categoría en la base de datos
idCategorie = categorie.getId();
List<Categorie> categoriesInBd = getShortEntitiesById(idCategorie);
if (categoriesInBd.size() == 0) {
// la categoría no existe
throw new RuntimeException(String.format("Erreur de mise à jour. La catégorie de clé [%s] n'existe pas",
idCategorie));
} else {
// la version no era correcta
throw new RuntimeException(String.format(
"Erreur de mise à jour. La catégorie de clé [%s] n'a pas la bonne version", idCategorie));
}
}
}
} catch (DaoException e) {
throw e;
} catch (Exception e) {
throw new DaoException(206, e, simpleClassName);
}
}
La actualización de una categoría C1 en la base de datos mediante una categoría C2 en memoriaestá permitida a menos que las categorías C1 y C2 tengan el mismo version. Este n.º de version sirve para impedir la actualización simultánea de la entidad por parte de dos usuarios diferentes: dos usuarios, U1 y U2, leen la entidad E con un número de version igual a V1. U1 modifica E y guarda esta modificación en la base de datos: el n.º de version pasa entonces a V1+1. U2 modifica a su vez E y persiste esta modificación en la base: recibirá una excepción porque tiene un version (V1) diferente al de la base (V1+1).
- Líneas 2-29: el try tiene dos catch:
- el primero, en la línea 25, está ahí para dejar pasar la posible excepción de tipo [DaoException] lanzada por el código de la línea 13;
- el segundo, en la línea 27, está ahí para gestionar los demás tipos de excepción;
- línea 3: se escanean todas las categorías que hay que actualizar;
- línea 4: se actualiza la categoría actual con el método [namedParameterJdbcTemplate.update]:
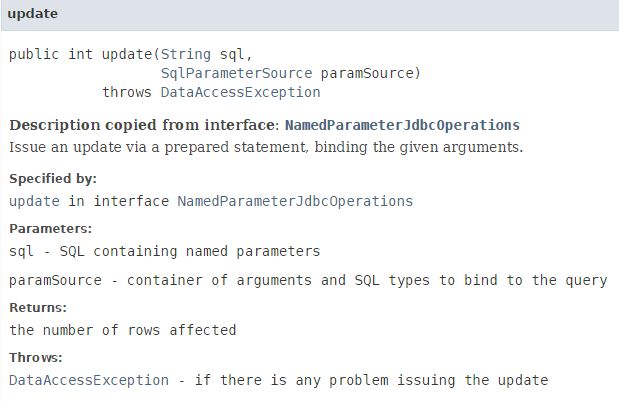
- analicemos la instrucción:
int nbLignes = namedParameterJdbcTemplate.update(ConfigJdbc.UPDATE_CATEGORIES, new BeanPropertySqlParameterSource(categorie));
La orden SQL [ConfigJdbc.UPDATE_CATEGORIES] es la siguiente:
public final static String UPDATE_CATEGORIES = "UPDATE CATEGORIES SET VERSIONING=VERSIONING+1, NOM=:nom WHERE ID=:id AND VERSIONING=:version";
La orden tiene tres parámetros (:id, :version, :nombre) cuyos valores se encuentran en los campos del mismo nombre del objeto [categorie] modificado. Se utiliza esta particularidad pasando como segundo parámetro [new BeanPropertySqlParameterSource(categorie)], que indica «los valores de los parámetros se encuentran en los campos del mismo nombre de este Java bean»;
El resultado de esta operación, cuando se ejecuta con normalidad, es el número de líneas modificadas, es decir, 0 o 1.
Volvamos al código analizado:
private void updateCategories(List<Categorie> categories) {
try {
for (Categorie categorie : categories) {
// actualización de la categoría en la base
int nbLignes = namedParameterJdbcTemplate.update(ConfigJdbc.UPDATE_CATEGORIES,
new BeanPropertySqlParameterSource(categorie));
// ¿Se ha realizado correctamente?
Long idCategorie = null;
if (nbLignes == 0) {
// no ha funcionado; se está investigando el motivo
// buscando la categoría en la base de datos
idCategorie = categorie.getId();
List<Categorie> categoriesInBd = getShortEntitiesById(idCategorie);
if (categoriesInBd.size() == 0) {
// la categoría no existe
throw new RuntimeException(String.format("Erreur de mise à jour. La catégorie de clé [%s] n'existe pas",
idCategorie));
} else {
// la version no era correcta
throw new RuntimeException(String.format(
"Erreur de mise à jour. La catégorie de clé [%s] n'a pas la bonne version", idCategorie));
}
}
}
} catch (DaoException e) {
throw e;
} catch (Exception e) {
throw new DaoException(206, e, simpleClassName);
}
}
- línea 9: se comprueba si la modificación se ha realizado correctamente;
- línea 10: la modificación no se ha realizado correctamente. Como la cláusula [WHERE] implica las columnas [ID] y [VERSIONING], se busca la columna que ha provocado el fallo de [WHERE];
- líneas 12-18: se comprueba que la clave [id] de la categoría se encuentra en la base de datos. Si no es así, se ejecuta una [RuntimeException] con un mensaje de error adecuado;
- líneas 19-22: tratan el caso en el que era la version la que no era correcta;
4.10. La clase [DaoProduit]
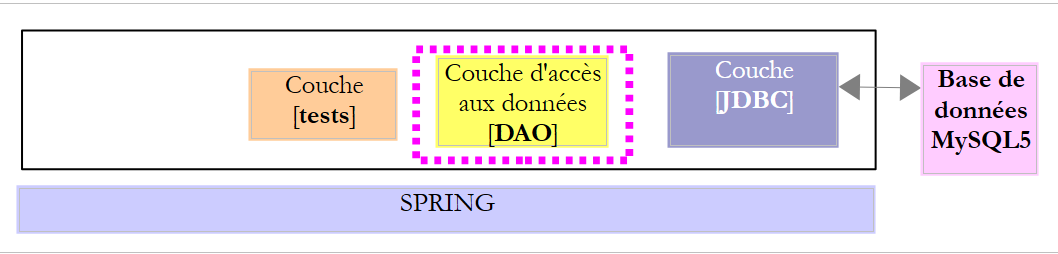 |
|
La clase [DaoProduit] implementa la interfaz [IDao<Produit>], que garantiza elacceso a los datos de la tabla [PRODUITS] de la base de datos MySQL [dbproduitscategories]. Su esqueleto es el siguiente:
package spring.jdbc.dao;
import generic.jdbc.config.ConfigJdbc;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.RowMapper;
import org.springframework.jdbc.core.namedparam.NamedParameterJdbcTemplate;
import org.springframework.jdbc.core.namedparam.SqlParameterSource;
import org.springframework.jdbc.core.simple.SimpleJdbcInsert;
import org.springframework.stereotype.Component;
import spring.jdbc.entities.Categorie;
import spring.jdbc.entities.Produit;
import spring.jdbc.infrastructure.DaoException;
import com.google.common.collect.Lists;
@Component
public class DaoProduit extends AbstractDao<Produit> {
// inyecciones
@Autowired
private NamedParameterJdbcTemplate namedParameterJdbcTemplate;
@Autowired
private SimpleJdbcInsert simpleJdbcInsertProduit;
@Override
public List<Produit> getAllShortEntities() {
...
}
@Override
public List<Produit> getAllLongEntities() {
....
}
@Override
public void deleteAllEntities() {
...
}
@Override
protected List<Produit> getShortEntitiesById(List<Long> ids) {
...
}
@Override
protected List<Produit> getShortEntitiesByName(List<String> names) {
....
}
@Override
protected List<Produit> getLongEntitiesById(List<Long> ids) {
...
}
@Override
protected List<Produit> getLongEntitiesByName(List<String> names) {
try {
return namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_LONGPRODUIT_BYNAME,
Collections.singletonMap("noms", names), new LongProduitMapper());
} catch (Exception e) {
throw new DaoException(112, e, simpleClassName);
}
}
@Override
protected List<Produit> saveEntities(List<Produit> entities) {
...
}
@Override
protected void deleteEntitiesById(List<Long> ids) {
....
}
@Override
protected void deleteEntitiesByName(List<String> names) {
...
}
}
// --------------------- mappers
class ShortProduitMapper implements RowMapper<Produit> {
...
}
class LongProduitMapper implements RowMapper<Produit> {
...
}
El código es muy similar al de la clase [DaoCategorie]. Solo vamos a estudiar algunos métodos.
4.10.1. El método [getShortEntitiesById]
El método [getShortEntitiesById] genera la version abreviada de los productos cuyas claves primarias se le pasan:
@Override
protected List<Produit> getShortEntitiesById(List<Long> ids) {
try {
return namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_SHORTPRODUIT_BYID,
Collections.singletonMap("ids", ids), new ShortProduitMapper());
} catch (Exception e) {
throw new DaoException(109, e, simpleClassName);
}
}
- línea 4: la orden SQL Select [ConfigJdbc.SELECT_SHORTPRODUIT_BYID] es la siguiente:
public final static String SELECT_SHORTPRODUIT_BYID = "SELECT p.ID as p_ID, p.VERSIONING as p_VERSIONING, p.NOM as p_NOM, p.CATEGORIE_ID as p_CATEGORIE_ID, p.PRIX as p_PRIX, p.DESCRIPTION as p_DESCRIPTION FROM PRODUITS p WHERE p.ID in (:ids)";
- línea 4: la clase [ShortProduitMapper] encargada de encapsular [ResultSet] en una lista de productos es la siguiente:
class ShortProduitMapper implements RowMapper<Produit> {
@Override
public Produit mapRow(ResultSet rs, int rowNum) throws SQLException {
return new Produit(rs.getLong("p_ID"), rs.getLong("p_VERSIONING"), rs.getString("p_NOM"),
rs.getLong("p_CATEGORIE_ID"), rs.getDouble("p_PRIX"), rs.getString("p_DESCRIPTION"), null);
}
}
4.10.2. El método [getLongEntitiesByName]
El método [getShortEntitiesById] convierte version en una lista de productos cuyos nombres se pasan como parámetros:
@Override
protected List<Produit> getLongEntitiesByName(List<String> names) {
try {
return namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_LONGPRODUIT_BYNAME,
Collections.singletonMap("noms", names), new LongProduitMapper());
} catch (Exception e) {
throw new DaoException(112, e, simpleClassName);
}
}
- línea 4: la orden SQL Seleccionar [ConfigJdbc.SELECT_LONGPRODUIT_BYNAME] es la siguiente:
public final static String SELECT_LONGPRODUIT_BYID = "SELECT p.ID as p_ID, p.VERSIONING as p_VERSION, p.NOM as p_NOM, p.PRIX as p_PRIX, p.DESCRIPTION as p_DESCRIPTION, p.CATEGORIE_ID AS p_CATEGORIE_ID, c.ID as c_ID, c.NOM as c_NOM, c.VERSIONING as c_VERSION FROM PRODUITS p, CATEGORIES c WHERE p.ID in (:ids) AND p.CATEGORIE_ID=c.ID";
- línea 4: la clase [LongProduitMapper], encargada de encapsular los elementos de [ResultSet] en productos, version larga, es la siguiente:
class LongProduitMapper implements RowMapper<Produit> {
@Override
public Produit mapRow(ResultSet rs, int rowNum) throws SQLException {
return new Produit(rs.getLong("p_ID"), rs.getLong("p_VERSION"), rs.getString("p_NOM"),
rs.getLong("p_CATEGORIE_ID"), rs.getDouble("p_PRIX"), rs.getString("p_DESCRIPTION"), new Categorie(rs.getLong("c_ID"), rs.getLong("c_VERSION"), rs.getString("c_NOM"), null));
}
}
4.10.3. El método [saveEntities]
El método [saveEntities] se utiliza indistintamente para insertar nuevos productos (id==null) o actualizar productos existentes (id!=null):
@Override
protected List<Produit> saveEntities(List<Produit> entities) {
try {
// productos que insertar
List<Produit> insertProduits = new ArrayList<Produit>();
// productos que actualizar
List<Produit> updateproduits = new ArrayList<Produit>();
// se escanea la lista de entidades recibidas
for (Produit produit : entities) {
Long id = produit.getId();
if (id == null) {
insertProduits.add(produit);
} else {
updateproduits.add(produit);
}
}
// adiciones
insertProduits(insertProduits);
// modificaciones
updateProduits(updateproduits);
// resultado
return entities;
} catch (DaoException e) {
throw e;
} catch (Exception e) {
throw new DaoException(103, e, simpleClassName);
}
}
Línea 18, los productos que se van a insertar se insertan mediante el siguiente método privado [insertProduits]:
private List<Produit> insertProduits(List<Produit> produits) {
Map<Long, Produit> mapProduits = new HashMap<Long, Produit>();
try {
// produits à ajouter
for (Produit produit : produits) {
Number newId = simpleJdbcInsertProduit.executeAndReturnKey(getMapForProduit(produit));
// on note la clé primaire
mapProduits.put(newId.longValue(), produit);
}
} catch (Exception e) {
throw new DaoException(201, e, simpleClassName);
}
// tout est OK - on affecte les clés primaires aux produits persistés
for (Long id : mapProduits.keySet()) {
Produit produit = mapProduits.get(id);
produit.setId(id);
}
// résultat
return produits;
}
private Map<String, ?> getMapForProduit(Produit produit) {
Map<String, Object> map = new HashMap<String, Object>();
map.put(ConfigJdbc.TAB_PRODUITS_NOM, produit.getNom());
map.put(ConfigJdbc.TAB_PRODUITS_CATEGORIE_ID, produit.getIdCategorie());
map.put(ConfigJdbc.TAB_PRODUITS_PRIX, produit.getPrix());
map.put(ConfigJdbc.TAB_PRODUITS_DESCRIPTION, produit.getDescription());
return map;
}
Este método es análogo al método [insertCategories] estudiado en el apartado 4.9.10.3.
- Línea 4: se utiliza el bean [simpleJdbcInsertProduit] que se ha inyectado en la clase:
@Autowired
private SimpleJdbcInsert simpleJdbcInsertProduit;
Este bean se ha definido en la clase [AppConfig], que configura el proyecto:
@Bean
public SimpleJdbcInsert simpleJdbcInsertProduit(DataSource dataSource) {
return new SimpleJdbcInsert(dataSource)
.withTableName(ConfigJdbc.TAB_PRODUITS)
.usingGeneratedKeyColumns(ConfigJdbc.TAB_PRODUITS_ID)
.usingColumns(ConfigJdbc.TAB_PRODUITS_NOM, ConfigJdbc.TAB_PRODUITS_PRIX, ConfigJdbc.TAB_PRODUITS_DESCRIPTION,ConfigJdbc.TAB_PRODUITS_CATEGORIE_ID);
}
- líneas 3-6: el bean [simpleJdbcInsertProduit]
- está vinculado a la fuente de datos de la base [dbproduitscategories] (línea 3) y a la tabla [ConfigJdbc.TAB_PRODUITS] de dicha fuente (línea 4);
- la clave primaria de esta tabla se genera en la columna [ConfigJdbc.TAB_PRODUITS_ID] (línea 5);
- solo se asignan valores a las columnas [ConfigJdbc.TAB_PRODUITS_NOM, ConfigJdbc.TAB_PRODUITS_PRIX, ConfigJdbc.TAB_PRODUITS_DESCRIPTION, ConfigJdbc.TAB_PRODUITS_CATEGORIE_ID] (línea 6);
El método [updateProduits] que actualiza los productos (línea 20 de [saveEntities]) es el siguiente:
private void updateProduits(List<Produit> updateProduits) {
try {
// se escanean los productos
for (Produit produit : updateProduits) {
// actualización del producto en la base de datos
int nbLignes = namedParameterJdbcTemplate.update(ConfigJdbc.UPDATE_PRODUITS,
new BeanPropertySqlParameterSource(produit));
// ¿Ha sido un éxito?
Long idProduit = null;
if (nbLignes == 0) {
// no ha funcionado; se investiga el motivo
// se busca el producto en la base de datos
idProduit = produit.getId();
List<Produit> produitsInBd = getShortEntitiesById(idProduit);
if (produitsInBd.size() == 0) {
// el producto no existe
throw new RuntimeException(String.format("Erreur de mise à jour. Le produit de clé [%s] n'existe pas",
idProduit));
} else {
// la version no era correcta
throw new RuntimeException(String.format(
"Erreur de mise à jour. Le produit de clé [%s] n'a pas la bonne version", idProduit));
}
}
}
} catch (DaoException e) {
throw e;
} catch (Exception e) {
throw new DaoException(106, e, simpleClassName);
}
}
Es análogo al que actualiza las categorías (véase el apartado 4.9.10.3). En la línea 23, la orden SQL [ConfigJdbc.UPDATE_PRODUITS] ejecutada para actualizar los productos es la siguiente:
public final static String UPDATE_PRODUITS = "UPDATE PRODUITS SET VERSIONING=VERSIONING+1, NOM=:nom, PRIX=:prix, CATEGORIE_ID=:idCategorie, DESCRIPTION=:description WHERE ID=:id AND VERSIONING=:version";
Los nombres de los parámetros [:id,:version,:nom,:prix,:idCategorie,:description] son también los nombres de los campos de la clase [Produit], lo que permite utilizar la instrucción de las líneas 6-7 para actualizar el producto actual.
4.11. La capa de pruebas
 |
 |
La capa de pruebas se compone de tres clases de prueba:
- [JUnitTestCheckArguments]: las pruebas de esta clase llaman a los diferentes métodos de la capa [DAO] con argumentos no válidos y comprueban que reaccionen correctamente;
- [JUnitTestDao]: las pruebas de esta clase invocan los distintos métodos de la capa [DAO] y comprueban que hacen lo que se espera;
- [JUnitTestPushTheLimits] no tiene por objeto probar la capa [DAO], sino medir su rendimiento;
Esta capa de pruebas desempeña un papel importante en este documento. De hecho, es común a todas las implementaciones de la interfaz [IDao<T>]. Hay seis por SGBD (1 implementación JDBC, 3 implementaciones JPA, 1 implementación Spring MVC, 1 implementación Spring MVC segura), por lo que son 36 para los seis SGBD probados. La capa de pruebas nos permite verificar que todas las implementaciones reaccionan de la misma manera.
4.11.1. La prueba [JUnitTestCheckArguments]
La clase de prueba [JUnitTestCheckArguments] tiene 48 métodos que prueban la reacción de los métodos de la capa [DAO] cuando se invocan con argumentos incorrectos. Su estructura es la siguiente:
package spring.jdbc.tests;
import org.junit.Assert;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.SpringApplicationConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import spring.jdbc.config.AppConfig;
import spring.jdbc.dao.IDao;
import spring.jdbc.entities.Categorie;
import spring.jdbc.entities.Produit;
import spring.jdbc.infrastructure.MyIllegalArgumentException;
import com.google.common.collect.Lists;
@SpringApplicationConfiguration(classes = AppConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class JUnitTestCheckArguments {
// capa [DAO]
@Autowired
private IDao<Produit> daoProduit;
@Autowired
private IDao<Categorie> daoCategorie;
// datos locales
private Iterable<String> names1 = null;
private Iterable<String> names2 = Lists.newArrayList(new String[0]);
private String[] names3 = null;
private String[] names4 = new String[0];
private Iterable<Long> ids1 = null;
private Iterable<Long> ids2 = Lists.newArrayList(new Long[0]);
private Long[] ids3 = null;
private Long[] ids4 = new Long[0];
private Iterable<Categorie> categories1 = null;
private Iterable<Categorie> categories2 = Lists.newArrayList(new Categorie[0]);
private Categorie[] categories3 = null;
private Categorie[] categories4 = new Categorie[0];
private Iterable<Produit> produits1 = null;
private Iterable<Produit> produits2 = Lists.newArrayList(new Produit[0]);
private Produit[] produits3 = null;
private Produit[] produits4 = new Produit[0];
...
}
- línea 19: la prueba JUnit se realizará en integración con el framework Spring;
- línea 18: antes de las pruebas, se instanciarán los beans definidos en la clase [AppConfig] del proyecto;
- líneas 23-26: inyección de una instancia de cada una de las dos interfaces de la capa [DAO];
- líneas 29-44: los parámetros de llamada de los métodos de la capa [DAO] son incorrectos;
- línea 29: un puntero nulo de tipo [Iterable<String>] como lista de nombres;
- línea 30: una lista vacía de tipo [Iterable<String>] como lista de nombres;
- línea 29: un puntero nulo de tipo String[] como matriz de nombres;
- línea 30: una matriz vacía de tipo String[] como matriz de nombres;
- ...
Con el campo [names1], se realiza, por ejemplo, la siguiente prueba:
@Test(expected = MyIllegalArgumentException.class)
public void getShortProduitsByName1() {
daoProduit.getShortEntitiesByName(names1);
}
- línea 1: se indica que la prueba [getShortProduitsByName1] debe encontrar la excepción de tipo [MyIllegalArgumentException]
Con el campo [names2], se realiza, por ejemplo, la siguiente prueba:
@Test(expected = MyIllegalArgumentException.class)
public void getLongCategoriesByName2() {
daoCategorie.getLongEntitiesByName(names2);
}
Con el campo [names3], se realiza, por ejemplo, la prueba siguiente:
@Test(expected = MyIllegalArgumentException.class)
public void getLongCategoriesByName3() {
daoCategorie.getLongEntitiesByName(names3);
}
Con el campo [names4], se realiza, por ejemplo, la siguiente prueba:
@Test(expected = MyIllegalArgumentException.class)
public void getShortProduitsByName4() {
daoProduit.getShortEntitiesByName(names4);
}
De este modo, se realizan 48 pruebas para comprobar todos los casos posibles. Se ejecuta la configuración de ejecución denominada [spring-jdbc-generic-04-JUnitTestCheckArguments] [1]. El resultado obtenido es el siguiente [2]:
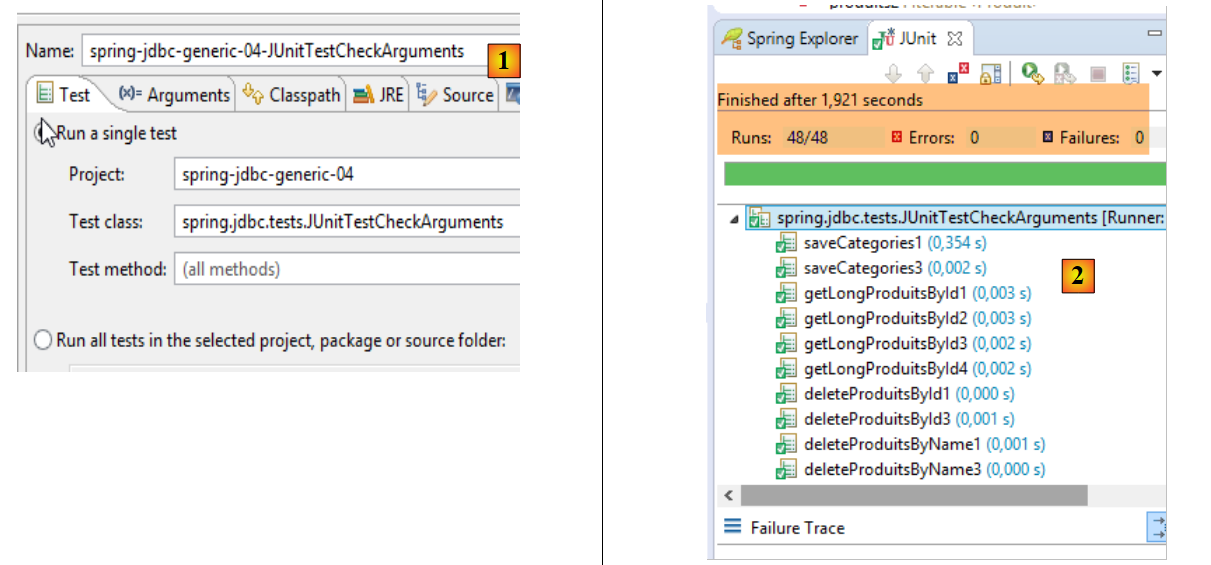 |
4.11.2. La prueba [JUnitTestDao]
La prueba [JUnitTestDao] invoca los métodos de la capa [DAO] con argumentos válidos y comprueba que los métodos realizan lo que se espera de ellos. Hay un total de 74 pruebas que verifican las operaciones de inserción, selección, actualización y eliminación de entidades, categorías o productos. En total, hay más de 1000 líneas de código. Vamos a estudiar solo algunos de estos métodos.
4.11.2.1. Estructura de la prueba
La clase [JUnitTestDao] tiene la estructura siguiente:
package spring.jdbc.tests;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.junit.Assert;
import org.junit.Before;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.SpringApplicationConfiguration;
import org.springframework.context.ApplicationContext;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import spring.jdbc.config.AppConfig;
import spring.jdbc.dao.IDao;
import spring.jdbc.entities.Categorie;
import spring.jdbc.entities.Produit;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.google.common.collect.Lists;
@SpringApplicationConfiguration(classes = AppConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class JUnitTestDao {
// contexto Spring
@Autowired
private ApplicationContext context;
// capa [DAO]
@Autowired
private IDao<Produit> daoProduit;
@Autowired
private IDao<Categorie> daoCategorie;
// constantes
private final int NB_PRODUITS = 5;
private final int NB_CATEGORIES = 2;
// local
// local
private Map<Long, Categorie> mapCategories = new HashMap<Long, Categorie>();
private Map<Long, Produit> mapProduits = new HashMap<Long, Produit>();
@Before
public void clean() {
// se limpia la base de datos antes de cada prueba
log("Vidage de la base de données", 1);
// se vacía la tabla [CATEGORIES] y, en cadena, la tabla [PRODUITS]
daoCategorie.deleteAllEntities();
// se vacían los diccionarios
for (Long id : mapCategories.keySet()) {
mapCategories.remove(id);
}
for (Long id : mapProduits.keySet()) {
mapProduits.remove(id);
}
}
...
}
- líneas 27-28: al igual que en la prueba [JUnitTestCheckArguments], se trata de una prueba integrada con Spring y configurada por la clase [AppConfig] del proyecto;
- líneas 32-33: inyección del contexto de Spring que da acceso a todos sus beans;
- líneas 35-36: inyección de la instancia de la interfaz [IDao<Produit>] probada por la clase;
- líneas 37-38: inyección de la instancia de la interfaz [IDao<Categorie>] probada por la clase;
- líneas 41-42: cuando una prueba necesite datos de la base de datos, se generará una base de datos de [NB_CATEGORIES] categorías, cada una con [NB_PRODUITS] productos. De este modo, tendremos [NB_CATEGORIES] categorías en la tabla [CATEGORIES] y [NB_CATEGORIES] * [NB_PRODUITS] productos en la tabla [PRODUITS];
- líneas 46-47: dos diccionarios donde se almacenarán los productos y las categorías;
- líneas 49-62: el método [clean] se ejecuta antes de cada prueba (línea 49). En la línea 54, se vacía la tabla [CATEGORIES]. Hay que recordar aquí que la tabla [PRODUITS] tiene una clave primaria [CATEGORIE_ID] en la columna ID de la tabla [CATEGORIES] y que esta se define de la siguiente manera;
 |
- (continuación)
- en [1-3], la clave externa [CATEGORIE_ID] de la tabla [PRODUITS]. Apunta a la columna [ID] de la tabla [CATEGORIES] [4-5];
- cuando se elimina una categoría, también se eliminan todos los productos vinculados a ella [6]. Es importante señalar este punto, ya que se utiliza en la construcción de la capa [DAO] que explota la base [dbproduitscategories];
Por lo tanto, cuando se elimina el contenido de la tabla [CATEGORIES], el de la tabla [PRODUITS] también se eliminará.
- líneas 56-58: se vacía el diccionario de categorías;
- líneas 59-61: se hace lo mismo con el de productos;
Cabe destacar que, antes de cada prueba, tenemos tablas vacías en la base de datos y diccionarios vacíos en memoria.
4.11.2.2. El método [verifyClean]
El método [verifyClean] comprueba que, tras el método [clean], las tablas estén vacías:
@Test
public void verifyClean() {
log("verifyClean", 1);
List<Categorie> categories = daoCategorie.getAllShortEntities();
Assert.assertEquals(0, categories.size());
List<Produit> produits = daoProduit.getAllShortEntities();
Assert.assertEquals(0, produits.size());
}
4.11.2.3. El método [fillDataBase]
Este método comprueba que la base de datos se haya rellenado correctamente con datos de prueba:
@Test
public void fillDataBase() throws BeansException, JsonProcessingException {
// remplissage base et dictionnaires
registerCategories(fill(NB_CATEGORIES, NB_PRODUITS));
// affichage
Object[] data = showDataBase();
List<Categorie> categories = (List<Categorie>) data[0];
List<Produit> produits = (List<Produit>) data[1];
// quelques vérifications
Assert.assertEquals(NB_CATEGORIES, categories.size());
Assert.assertEquals(NB_PRODUITS * NB_CATEGORIES, produits.size());
for (Categorie categorie : categories) {
checkShortCategorie(categorie);
}
for (Produit produit : produits) {
checkShortProduit(produit);
}
// les dictionnaires doivent avoir été épuisés
Assert.assertEquals(0, mapCategories.size());
Assert.assertEquals(0, mapProduits.size());
}
Esta prueba utiliza varios métodos privados:
- [fill], línea 4, que rellena la base de datos con datos de prueba;
- [registerCategories], línea 4, que rellena los diccionarios con los datos devueltos por el método [fill]. Estos dos diccionarios representan las entidades persistentes;
- [showDataBase], línea 6, que lee las dos tablas [CATEGORIES] y [PRODUITS] y devuelve lo que ha leído;
- [checkShortCategorie], línea 13, comprueba la categoría leída por [showDataBase]. Comprueba que el código version de esta categoría se corresponde con lo registrado en el diccionario de categorías;
- [checkShortProduit], línea 16, hace lo mismo con los productos;
- cuando se encuentra una entidad en un diccionario, se elimina del diccionario. Las líneas 19-20 comprueban que ambos diccionarios estén vacíos. Si estas dos afirmaciones son válidas, significa que:
- todos los valores leídos por [showDataBase] se han encontrado efectivamente en los diccionarios;
- que estos no contienen otras entidades distintas de las que se han leído;
El método privado [fill] es el siguiente:
private List<Categorie> fill(int nbCategories, int nbProduits) {
// on remplit les tables
List<Categorie> categories = new ArrayList<Categorie>();
for (int i = 0; i < nbCategories; i++) {
Categorie categorie = new Categorie(null, null, String.format("categorie[%d]", i), null);
for (int j = 0; j < nbProduits; j++) {
Produit produit = new Produit(null, null, String.format("produit[%d,%d]", i, j), null,
100 * (1 + (double) (i * 10 + j) / 100), String.format("desc[%d,%d]", i, j), null);
categorie.addProduit(produit);
}
categories.add(categorie);
}
// ajout de la catégorie - par cascade les produits vont eux aussi être
// insérés
categories = daoCategorie.saveEntities(categories);
// résultat
return categories;
}
- líneas 3-12: se construye una lista de [nbCategories] categorías con [nbProduits] productos para cada una;
- línea 15: esta lista de categorías se persiste. Hemos visto que el método [daoCategorie.saveEntities] también persistía los productos de las categorías cuando estas los tenían;
- línea 17: se devuelve la lista de categorías persistida. Las entidades persistidas (categorías y productos) tienen ahora una clave primaria en su campo [id];
El método privado [registerCategories] va a introducir estas entidades en los dos diccionarios:
private void registerCategories(List<Categorie> categories) {
// diccionarios
for (Categorie categorie : categories) {
mapCategories.put(categorie.getId(), categorie);
for (Produit produit : categorie.getProduits()) {
mapProduits.put(produit.getId(), produit);
}
}
}
Cada diccionario tiene como clave de acceso la clave primaria de las entidades.
Una vez hecho esto, la base de datos rellenada anteriormente se leerá y se mostrará mediante el siguiente método privado [showDataBase]:
private Object[] showDataBase() throws BeansException, JsonProcessingException {
// lista de categorías
log("Liste des catégories", 2);
List<Categorie> categories = daoCategorie.getAllShortEntities();
affiche(categories, context.getBean("jsonMapperShortCategorie", ObjectMapper.class));
// lista de productos
log("Liste des produits", 2);
List<Produit> produits = daoProduit.getAllShortEntities();
affiche(produits, context.getBean("jsonMapperShortProduit", ObjectMapper.class));
// resultado
return new Object[] { categories, produits };
}
- líneas 4 y 8: se recuperan las versiones cortas de las categorías y los productos;
- línea 11: se devuelve una matriz que contiene las dos listas de entidades recuperadas;
- líneas 5 y 9: las listas de entidades se muestran mediante el siguiente método privado [affiche]:
// visualización de una lista de elementos de tipo T
private <T> void affiche(List<T> elements, ObjectMapper mapper) throws JsonProcessingException {
for (T element : elements) {
affiche(element, mapper);
}
}
// visualización de un elemento de tipo T
private <T> void affiche(T element, ObjectMapper mapper) throws JsonProcessingException {
System.out.println(mapper.writeValueAsString(element));
}
Las entidades se muestran mediante un mapeador jSON (línea 10). Este mapeador es el segundo parámetro del método [affiche], línea 2. El contexto Spring define cuatro mapeadores jSON en el archivo [ConfigJdbc] de la dependencia Maven [mysql-config-jdbc]:
// filtros jSON -------------------------------------
@Bean
public ObjectMapper jsonMapper() {
return new ObjectMapper();
}
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
ObjectMapper jsonMapperShortCategorie() {
ObjectMapper jsonMapper = jsonMapper();
jsonMapper.setFilters(new SimpleFilterProvider().addFilter("jsonFilterCategorie",
SimpleBeanPropertyFilter.serializeAllExcept("produits")));
return jsonMapper;
}
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
ObjectMapper jsonMapperLongCategorie() {
ObjectMapper jsonMapper = jsonMapper();
jsonMapper.setFilters(new SimpleFilterProvider().addFilter("jsonFilterCategorie",
SimpleBeanPropertyFilter.serializeAllExcept()).addFilter("jsonFilterProduit",
SimpleBeanPropertyFilter.serializeAllExcept("categorie")));
return jsonMapper;
}
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
ObjectMapper jsonMapperShortProduit() {
ObjectMapper jsonMapper = jsonMapper();
jsonMapper.setFilters(new SimpleFilterProvider().addFilter("jsonFilterProduit",
SimpleBeanPropertyFilter.serializeAllExcept("categorie")));
return jsonMapper;
}
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
ObjectMapper jsonMapperLongProduit() {
ObjectMapper jsonMapper = jsonMapper();
jsonMapper.setFilters(new SimpleFilterProvider().addFilter("jsonFilterProduit",
SimpleBeanPropertyFilter.serializeAllExcept()).addFilter("jsonFilterCategorie",
SimpleBeanPropertyFilter.serializeAllExcept("produits")));
return jsonMapper;
}
- estos mapeadores jSON (líneas 7-9, 16-18, 26-28, 35-37) tienen un atributo
[@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)]
que los convierte en beans instanciados cada vez que se realiza una solicitud al contexto de Spring. Esto es nuevo. Todos los beans de Spring vistos hasta ahora eran singletons: se creaba un único ejemplar y era este el que se devolvía cada vez que se solicitaba una referencia al contexto de Spring. ¿Por qué este cambio? De hecho, los cuatro beans [jsonMapperShortCategorie, jsonMapperLongCategorie, jsonMapperShortProduit , jsonMapperLongProduit] configuran el único mapeador jSON (este sí es un singleton) definido en las líneas 2-5. Este debe reconfigurarse en cada llamada a uno de los cuatro beans anteriores y no una sola vez al inicializar el contexto. Si hubiéramos decidido tener cuatro mapeadores jSON diferentes, uno para cada uno de los cuatro beans, entonces estos podrían haber sido singletons. Era perfectamente posible. Habríamos escrito entonces en las líneas 10, 19, 29 y 38:
ObjectMapper jsonMapper = new ObjectMapper();
- los cuatro mapeadores json sirven para configurar los filtros jSON de las entidades [Produit] y [Categorie]. De hecho, se ha escrito (véanse los apartados 4.6 y 4.6) lo siguiente:
@JsonFilter("jsonFilterCategorie")
public class Categorie extends AbstractCoreEntity {
y
@JsonFilter("jsonFilterProduit")
public class Produit extends AbstractCoreEntity {
La representación jSON de la entidad [Categorie] está controlada por el filtro jSON [jsonFilterCategorie] y la de laentidad [produit] por el filtro jSON [jsonFilterProduit]. Los cuatro mapeadores jSON del contexto Spring configuran estos dos filtros de la siguiente manera:
- el mapeador [jsonMapperShortCategorie] configura el filtro jSON [jsonFilterCategorie] para una versión abreviada de la categoría: el campo [produits] no se incluirá en la representación jSON de la categoría;
- el mapeador [jsonMapperLongCategorie] configura el filtro jSON [jsonFilterCategorie] para una version larga de la categoría: el campo [produits] se incluirá en la representación jSON de la categoría;
- el mapeador [jsonMapperShortProduit] configura el filtro jSON [jsonFilterProduit] para una versión corta del producto version: el campo [categorie] no se incluirá en la representación jSON del producto;
- el mapeador [jsonMapperLongProduit] configura el filtro jSON [jsonFilterProduit] para una version larga del producto: el campo [categorie] se incluirá en la representación jSON del producto;
Hemos terminado con el método privado [showDataBase]. Volvamos al código de la prueba [fillDataBase]:
@Test
public void fillDataBase() throws BeansException, JsonProcessingException {
// remplissage base et dictionnaires
registerCategories(fill(NB_CATEGORIES, NB_PRODUITS));
// affichage
Object[] data = showDataBase();
List<Categorie> categories = (List<Categorie>) data[0];
List<Produit> produits = (List<Produit>) data[1];
// quelques vérifications
Assert.assertEquals(NB_CATEGORIES, categories.size());
Assert.assertEquals(NB_PRODUITS * NB_CATEGORIES, produits.size());
for (Categorie categorie : categories) {
checkShortCategorie(categorie);
}
for (Produit produit : produits) {
checkShortProduit(produit);
}
// les dictionnaires doivent avoir été épuisés
Assert.assertEquals(0, mapCategories.size());
Assert.assertEquals(0, mapProduits.size());
}
- líneas 6-8: recuperamos las versiones cortas de los productos y categorías leídos en la base de datos;
- líneas 10-11: primeras comprobaciones;
- líneas 12-14: cada categoría devuelta por el método [showDataBase] se comprueba mediante el siguiente método privado [checkShortCategorie]:
private void checkShortCategorie(Categorie actual) {
Long id = actual.getId();
Categorie expected = mapCategories.get(actual.getId());
mapCategories.remove(id);
Assert.assertEquals(expected.getNom(), actual.getNom());
// no se puede probar el campo [produits] de forma portátil con las implementaciones jPA
}
- línea 1: [Categorie actual] es la categoría leída en la base de datos y debe ser idéntica a la categoría presente en el diccionario [mapCategories];
- línea 2: se recupera la clave primaria de la categoría leída;
- línea 3: se recupera la categoría registrada con esta clave primaria en el diccionario de categorías;
- línea 4: se retira la clave del diccionario para asegurarse de que ninguna otra categoría leída utilice esa misma clave;
- línea 5: se comprueba que ambas categorías tengan el mismo nombre;
La clave version de los productos devueltos por el método [showDataBase] se verifica mediante el siguiente método privado [checkShortProduit]:
private void checkShortProduit(Produit actual) {
Long id = actual.getId();
Produit expected = mapProduits.get(id);
mapProduits.remove(id);
Assert.assertEquals(expected.getNom(), actual.getNom());
Assert.assertEquals(expected.getDescription(), actual.getDescription());
Assert.assertEquals(expected.getPrix(), actual.getPrix(), 1e-6);
Assert.assertEquals(actual.getIdCategorie(), expected.getIdCategorie());
// no se puede probar el campo [categorie] de forma portátil con las implementaciones jPA
}
- línea 1: [Produit actual] es el producto abreviado leído en la base;
- líneas 2-3: se recupera del diccionario de productos persistentes el producto con la misma clave primaria;
- línea 4: se elimina la entrada encontrada en el diccionario;
- líneas 5-8: se comprueba que ambos productos tengan los mismos valores de campo;
4.11.2.4. El método [getLongCategoriesByName3]
Esta prueba es la siguiente:
@Test
public void getLongCategoriesByName3() {
// remplissage base
List<Categorie> categories = fill(NB_CATEGORIES, NB_PRODUITS);
// test
log("getLongCategoriesByName3", 1);
List<Categorie> categories2 = daoCategorie.getLongEntitiesByName("categorie[0]", "categorie[1]");
Assert.assertEquals(2, categories2.size());
registerCategories(Lists.newArrayList(categories.get(0), categories.get(1)));
for (Categorie categorie : categories) {
checkLongCategorie(categorie);
}
Assert.assertEquals(0, mapCategories.size());
}
- línea 4: se rellena la base de datos y se recupera la lista de categorías y productos persistentes;
- línea 7: se prueba el método [daoCategorie.getLongEntitiesByName(Iterable<String> names)] de la capa [DAO]. Se solicita una lista de dos productos designados por sus nombres en sus versiones completas;
- línea 8: se comprueba que la lista devuelta por [daoCategorie.getLongEntitiesByName(Iterable<String> names)] tiene efectivamente dos elementos;
- línea 9: los dos elementos guardados en la línea 4 se añaden al diccionario de categorías;
- líneas 10-12: se comprueba que los dos elementos leídos son efectivamente los que se han guardado;
- línea 13: se comprueba que el diccionario de categorías está vacío, lo que significa tanto que todas las categorías leídas se han encontrado en el diccionario como que este no contiene valores que no se hayan leído;
Línea 11, el método [checkLongCategorie] comprueba la longitud de una categoría:
private void checkLongCategorie(Categorie actual) {
Long id = actual.getId();
Categorie expected = mapCategories.get(actual.getId());
mapCategories.remove(id);
Assert.assertEquals(expected.getNom(), actual.getNom());
Assert.assertNotNull(actual.getProduits());
}
- la línea 6 comprueba que el campo [produits] de la categoría no sea nulo. De hecho, la lectura de una categoría en formato long siempre devuelve esta con un campo [produits] no nulo. Si la categoría no tiene productos, entonces el campo [produits] es una lista vacía pero existente;
4.11.2.5. El método [updateDataBase1]
@Test
public void updateDataBase1() {
// remplissage
fill(NB_CATEGORIES, NB_PRODUITS);
// test
log("Mise à jour du prix des produits de [categorie1]", 1);
Categorie categorie1 = daoCategorie.getLongEntitiesByName("categorie[1]").get(0);
List<Produit> produits = categorie1.getProduits();
Map<Produit, Long> versions = new HashMap<Produit, Long>();
for (Produit produit : produits) {
produit.setPrix(1.1 * produit.getPrix());
versions.put(produit, produit.getVersion());
}
daoProduit.saveEntities(produits);
// relecture
List<Produit> produitsInBd = daoCategorie.getLongEntitiesByName("categorie[1]").get(0)
.getProduits();
Assert.assertEquals(produits.size(), produitsInBd.size());
// vérifications
for (Produit produit2 : produitsInBd) {
Produit produit = findProduitByName(produit2.getNom(), produits);
Assert.assertEquals(produit2.getPrix(), produit.getPrix(), 1e-6);
Assert.assertEquals(produit2.getVersion().longValue(), versions.get(produit) + 1);
}
}
private Produit findProduitByName(String nom, List<Produit> produits) {
for (Produit produit : produits) {
if (produit.getNom().equals(nom)) {
return produit;
}
}
return null;
}
El método [updateDataBase1] aumenta el precio de los productos de la categoría denominada categorie[1] en un 10 % y comprueba dos cosas:
- que el precio base haya cambiado efectivamente;
- que el version del producto actualizado se ha incrementado en 1;
El código realiza lo siguiente:
- línea 4: rellenar la base de datos;
- línea 7: se recupera de la base de datos la categoría denominada «categorie[1]»;
- líneas 8-13: se aumenta en un 10 % el precio de todos sus productos (línea 11). Además, se crea un diccionario que asocia un producto a su version (líneas 9 y 12);
- línea 14: se llama al método [daoProduit.saveEntities]. Este método actualizará los productos;
- línea 16: se recuperan de la base de datos los productos de la categoría denominada «categorie[1]»;
- líneas 20-24: para todos los productos de esta categoría, se comprueba que el precio se ha modificado correctamente (línea 22) y que version se ha incrementado en 1 (línea 23);
4.11.2.6. El método [deleteProduitsByProduit1]
El método [deleteProduitsByProduit1] elimina productos de la tabla [PRODUITS]:
@Test
public void deleteProduitsByProduit1() {
// relleno
fill(NB_CATEGORIES, NB_PRODUITS);
// eliminación
daoProduit.deleteEntitiesByEntity(daoProduit.getShortEntitiesByName("produit[0,0]", "produit[1,1]"));
// verificación
List<Produit> produits = daoProduit.getShortEntitiesByName("produit[0,0]", "produit[1,1]");
Assert.assertEquals(0, produits.size());
}
- línea 6: se eliminan dos productos;
- líneas 8-9: se comprueba que ya no están en la base de datos;
4.11.2.7. El método [getLongProduitsById3]
@Test
public void getLongProduitsById3() {
// remplissage
List<Categorie> categories = fill(NB_CATEGORIES, NB_PRODUITS);
// test
log("getLongProduitsById3", 1);
List<Produit> produits = daoProduit.getLongEntitiesByName("produit[0,3]", "produit[1,4]");
Assert.assertEquals(2, produits.size());
registerProduits(Lists.newArrayList(categories.get(0).getProduits().get(3), categories.get(1).getProduits().get(4)));
produits = daoProduit.getLongEntitiesById(produits.get(0).getId(), produits.get(1).getId());
for (Produit produit : produits) {
checkLongProduit(produit);
}
Assert.assertEquals(0, mapProduits.size());
}
- línea 4: se rellena la base de datos y se recupera la lista de categorías guardadas;
- línea 7: se recupera de la base de datos la tabla version, que contiene dos productos identificados por sus nombres;
- línea 9: los productos [produit[0,3], produit[1,4]] presentes en la lista de categorías de la línea 4 se añaden al diccionario de productos;
- línea 10: estos dos mismos productos se buscan en la base de datos mediante sus claves primarias;
- líneas 11-14: se comprueba que los datos leídos son idénticos a los datos registrados en el diccionario;
El método privado [checkLongProduit] es el siguiente:
private void checkLongProduit(Produit actual) {
Long id = actual.getId();
Produit expected = mapProduits.get(id);
mapProduits.remove(id);
Assert.assertEquals(expected.getNom(), actual.getNom());
Assert.assertEquals(expected.getDescription(), actual.getDescription());
Assert.assertEquals(expected.getPrix(), actual.getPrix(), 1e-6);
Assert.assertNotNull(actual.getCategorie());
}
4.11.2.8. Conclusión
Vamos a dejarlo aquí. Por ahora hay 74 pruebas y se podrían añadir otras, ya que probablemente se me hayan olvidado algunos casos que habría que probar. Aunque no sean exhaustivas, estas pruebas han permitido detectar numerosos errores, en general casos límite que no se habían previsto al escribir inicialmente la capa [DAO]. Una fase de pruebas exhaustivas es indispensable en cualquier proyecto.
Para ejecutar la prueba, se puede utilizar la configuración de ejecución importada y denominada [spring-jdbc-generic-04.JUnitTestDao].
 | 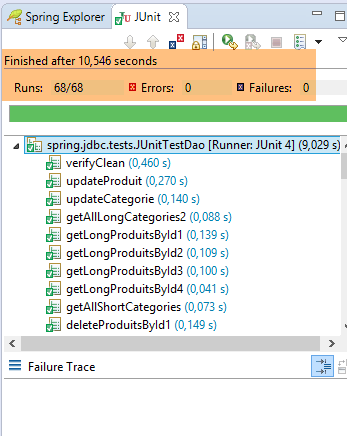 |
4.11.3. La prueba [JUnitTestPushTheLimits]
La prueba [JUnitTestPushTheLimits] es una prueba de rendimiento. Aprovechamos el hecho de que las pruebas JUnit muestran su tiempo de ejecución para medir el rendimiento de la capa [DAO]. A continuación, estos resultados se compararán con los de las implementaciones JPA de la capa [DAO].
4.11.3.1. Esqueleto
El esqueleto de la clase [JUnitTestPushTheLimits] es el siguiente:
package spring.jdbc.tests;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.junit.Assert;
import org.junit.Before;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.SpringApplicationConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import spring.jdbc.config.AppConfig;
import spring.jdbc.dao.IDao;
import spring.jdbc.entities.Categorie;
import spring.jdbc.entities.Produit;
@SpringApplicationConfiguration(classes = AppConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class JUnitTestPushTheLimits {
// capa [DAO]
@Autowired
private IDao<Produit> daoProduit;
@Autowired
private IDao<Categorie> daoCategorie;
// constantes
private final int NB_CATEGORIES = 2500;
private final int NB_PRODUITS = 2;
// local
private Map<Long, Categorie> hCategories;
private Map<Long, Produit> hProduits;
@Before
public void clean() {
// se vacía la tabla [CATEGORIES]
daoCategorie.deleteAllEntities();
// diccionarios
hCategories = new HashMap<Long, Categorie>();
hProduits = new HashMap<Long, Produit>();
}
private List<Categorie> fill(int nbCategories, int nbProduits) {
// se rellenan las tablas
List<Categorie> categories = new ArrayList<Categorie>();
for (int i = 0; i < nbCategories; i++) {
Categorie categorie = new Categorie(null, 0L, String.format("categorie[%d]", i), null);
for (int j = 0; j < nbProduits; j++) {
Produit produit = new Produit(null, 0L, String.format("produit[%d,%d]", i, j), 0L,
100 * (1 + (double) (i * 10 + j) / 100), String.format("desc[%d,%d]", i, j), null);
categorie.addProduit(produit);
}
categories.add(categorie);
}
// se añade la categoría; los productos también se insertarán de forma cascada
categories = daoCategorie.saveEntities(categories);
// diccionarios
for (Categorie categorie : categories) {
hCategories.put(categorie.getId(), categorie);
for (Produit produit : categorie.getProduits()) {
hProduits.put(produit.getId(), produit);
}
}
// resultado
return categories;
}
....
// -------------------- métodos privados
private void checkLongProduit(Produit actual) {
Long id = actual.getId();
Produit expected = hProduits.get(id);
hProduits.remove(id);
Assert.assertEquals(expected.getNom(), actual.getNom());
Assert.assertEquals(expected.getDescription(), actual.getDescription());
Assert.assertEquals(expected.getPrix(), actual.getPrix(), 1e-6);
Assert.assertEquals(expected.getIdCategorie(), actual.getIdCategorie());
Assert.assertNotNull(actual.getCategorie());
}
private void checkShortProduit(Produit actual) {
Long id = actual.getId();
Produit expected = hProduits.get(id);
hProduits.remove(id);
Assert.assertEquals(expected.getNom(), actual.getNom());
Assert.assertEquals(expected.getDescription(), actual.getDescription());
Assert.assertEquals(expected.getPrix(), actual.getPrix(), 1e-6);
Assert.assertEquals(expected.getIdCategorie(), actual.getIdCategorie());
boolean erreur = false;
try {
actual.getCategorie().getNom();
} catch (Exception e) {
erreur = true;
}
Assert.assertTrue(erreur);
}
private void checkShortCategorie(Categorie actual) {
Long id = actual.getId();
Categorie expected = hCategories.get(actual.getId());
hCategories.remove(id);
Assert.assertEquals(expected.getNom(), actual.getNom());
boolean erreur = false;
try {
actual.getProduits().size();
} catch (Exception e) {
erreur = true;
}
Assert.assertTrue(erreur);
}
private void checkLongCategorie(Categorie actual) {
Long id = actual.getId();
Categorie expected = hCategories.get(actual.getId());
hCategories.remove(id);
Assert.assertEquals(expected.getNom(), actual.getNom());
Assert.assertNotNull(actual.getProduits());
}
}
Aquí encontramos el esqueleto de la clase [JUnitTestDao]. Ya hemos visto todos estos métodos. La prueba trabaja con una base de 2500 categorías, cada una con 2 productos (líneas 32-33). Por lo tanto, la tabla [CATEGORIES] tendrá 2500 filas y la tabla [PRODUITS], 5000 filas. Se podrían haber incluido más filas, pero la prueba ya dura casi un minuto. Por lo tanto, se han elegido valores aceptables para el usuario que espera a que finalice la prueba.
Hay 18 pruebas en total. Se ejecutan con la configuración de ejecución [1]. Los tiempos de ejecución se muestran en [2]:
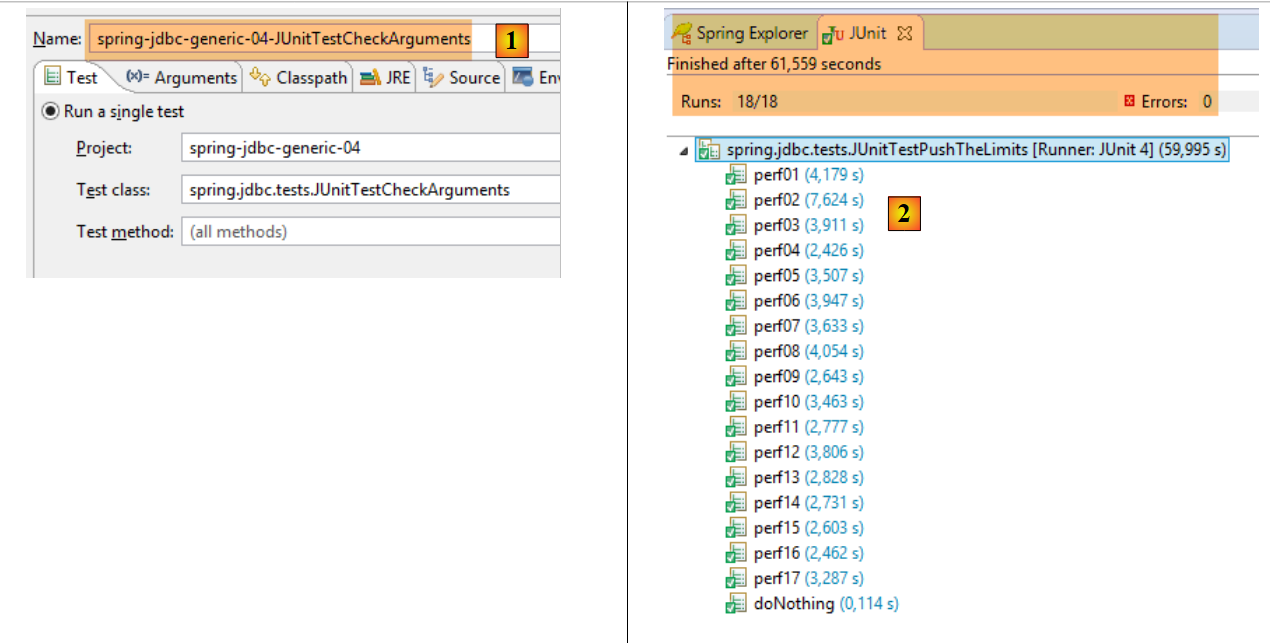 |
4.11.3.2. doNothing [0,114]
El método [doNothing] no hace nada. Permite medir la duración del método [clean], que se ejecuta antes de cada prueba y vacía la base de datos. Como se ve arriba, la duración de esta operación es insignificante en comparación con las demás.
@Test
public void doNothing() {
// limpiar
}
4.11.3.3. perf01 [4,179]
La prueba [perf01] sirve para medir el tiempo de llenado de la base de datos:
@Test
public void perf01() {
// insertar
fill(NB_CATEGORIES, NB_PRODUITS);
}
4.11.3.4. perf02 [7,624]
El método [perf02]:
- llena la base de datos;
- a continuación, modifica el nombre de todas las categorías y el precio de todos los productos.
@Test
public void perf02() {
// update
List<Categorie> categories = fill(NB_CATEGORIES, NB_PRODUITS);
for (Categorie categorie : categories) {
categorie.setNom(categorie.getNom() + "*");
for (Produit produit : categorie.getProduits()) {
produit.setPrix(produit.getPrix() * 1.1);
}
}
// mise à jour
daoCategorie.saveEntities(categories);
}
4.11.3.5. perf03[3,911]
El método [perf03]:
- rellena la base de datos
- y, a continuación, elimina todas las categorías una por una. Los productos también se eliminan debido a la relación de cascada que existe entre la tabla [CATEGORIES] y la tabla [PRODUITS].
Puede sorprender que esta operación dure menos tiempo que la operación [perf01] [4,179 s], que realiza menos acciones.
@Test
public void perf03() {
// eliminar categorías y, en cascada, los productos
daoCategorie.deleteEntitiesByEntity(fill(NB_CATEGORIES, NB_PRODUITS));
}
Si observamos el código del método [daoCategorie.deleteEntitiesByEntity], vemos que se va a ejecutar un [PreparedStatement] con 2500 parámetros (el número de categorías). Ahí es donde interviene el bean [maxPreparedStatementParameters], que dividirá la orden SQL en varios [PreparedStatement] con un número de parámetros que pueda soportar el SGBD concreto utilizado.
4.11.3.6. perf04[2,426]
El método [perf04]:
- rellena la base;
- a continuación, solicita el version completo de todas las categorías;
@Test
public void perf04() {
// select
List<Categorie> categories = fill(NB_CATEGORIES, NB_PRODUITS);
List<Long> ids = new ArrayList<Long>();
for (Categorie categorie : categories) {
ids.add(categorie.getId());
}
daoCategorie.getLongEntitiesById(ids);
}
4.11.3.7. perf05 [3,507]
El método [perf05]:
- rellena la base;
- luego elimina los 5000 productos mediante sus claves primarias (por lo que potencialmente tenemos un [PreparedStatement] con 5000 parámetros);
- comprueba que la tabla de productos quede vacía;
@Test
public void perf05() {
// eliminar productos
List<Categorie> categories = fill(NB_CATEGORIES, NB_PRODUITS);
List<Long> ids = new ArrayList<Long>();
for (Categorie categorie : categories) {
for (Produit p : categorie.getProduits()) {
ids.add(p.getId());
}
}
daoProduit.deleteEntitiesById(ids);
// verificación
List<Produit> produits = daoProduit.getAllShortEntities();
Assert.assertEquals(0, produits.size());
}
4.11.3.8. Resultados
No vamos a seguir presentando las diferentes pruebas. Simplemente indicaremos qué hacen y su duración. Estas duraciones solo son interesantes si se comparan entre sí. De hecho, sus valores dependen del entorno de prueba utilizado (hardware y configuración del software). Pero, si se obtienen en el mismo entorno, se pueden comparar.
Duración total de la prueba: 59,995 segundos
función | ||
rellena la base de datos con 2500 categorías y 5000 productos | ||
rellena y luego modifica la base de datos | ||
rellena la base de datos y luego elimina todas las categorías y sus productos | ||
rellena la base de datos y solicita el código version de todas las categorías | ||
rellena la base de datos y elimina los 5000 productos uno a uno mediante sus claves primarias | ||
rellena la base de datos y elimina los 5000 productos uno a uno mediante sus nombres | ||
rellena la base de datos y elimina los 5000 productos uno a uno por su referencia | ||
rellena la base de datos y solicita la version breve de todos los productos mediante sus nombres | ||
rellena la base de datos y solicita la version larga de todos los productos por sus nombres | ||
rellena la base de datos y solicita la version corta de todos los productos mediante sus claves primarias | ||
rellena la base de datos y solicita la version larga de todos los productos a través de sus claves primarias | ||
rellena la base de datos y, a continuación, elimina todas las categorías (y, por tanto, los productos asociados) una por una mediante sus nombres | ||
rellena la base de datos y luego elimina todas las categorías (y, por tanto, los productos asociados) una por una mediante sus referencias | ||
rellena la base de datos y solicita la lista breve de todas las categorías mediante sus nombres | ||
rellena la base y solicita la version larga de todas las categorías por sus nombres | ||
rellena la base de datos y solicita la version corta de todas las categorías mediante sus claves primarias | ||
rellena la base de datos y solicita la version larga de todas las categorías mediante sus claves primarias |
Estos resultados son a veces sorprendentes:
- fue más rápido obtener la version larga de los productos (perf09) que su version corta (perf08), mientras que la version larga implica una unión entre dos tablas;
- la duración del primer rellenado (perf01) supera claramente a la de todos los demás rellenados que le siguen;
- solicitar la versión corta version de los productos a través de sus nombres (perf08) es más rápido que solicitarla a través de las claves primarias (perf10). Esto parece bastante lógico. Pero para las versiones largas ocurre lo contrario (perf09, perf11);
Por lo tanto, no nos detendremos en estos resultados. Sin embargo, nos serán útiles para comparar esta solución [Spring JDBC] con las soluciones:
- [Spring JDBC] de las otras cinco SGBD;
- [Spring JPA] que vendrán a continuación;