2. Las entidades JPA
2.1. Ejemplo 1: representación como objeto de una única tabla
2.1.1. La tabla [personne]
Consideremos una base de datos con una única tabla [personne] cuya función es almacenar cierta información sobre personas:
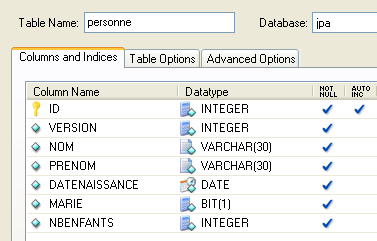 |
clave primaria de la tabla | |
versión de la fila en la tabla. Cada vez que se modifica el registro, se incrementa su número de versión. | |
nombre de la persona | |
su nombre | |
su fecha de nacimiento | |
número entero 0 (soltero) o 1 (casado) | |
Número de hijos de la persona |
2.1.2. La entidad [Personne]
Nos situamos en el siguiente entorno de ejecución:
 |
La capa JPA [5] debe servir de puente entre el mundo relacional de la base de datos [7] y el mundo de objetos [4] manipulado por los programas Java [3]. Este puente se establece mediante configuración y hay dos formas de hacerlo:
- mediante archivos XML. Esta era prácticamente la única forma de hacerlo hasta la llegada de JDK 1.5
- con anotaciones Java a partir de la versión 1.5 de JDK
En este documento, utilizaremos casi exclusivamente el segundo método.
El objeto [Personne] que representa la tabla [personne] presentada anteriormente podría ser el siguiente:
...
@SuppressWarnings("unused")
@Entity
@Table(name="Personne")
public class Personne implements Serializable{
@Id
@Column(name = "ID", nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name = "VERSION", nullable = false)
@Version
private int version;
@Column(name = "NOM", length = 30, nullable = false, unique = true)
private String nom;
@Column(name = "PRENOM", length = 30, nullable = false)
private String prenom;
@Column(name = "DATENAISSANCE", nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(name = "MARIE", nullable = false)
private boolean marie;
@Column(name = "NBENFANTS", nullable = false)
private int nbenfants;
// constructores
public Personne() {
}
public Personne(String nom, String prenom, Date datenaissance, boolean marie,
int nbenfants) {
setNom(nom);
setPrenom(prenom);
setDatenaissance(datenaissance);
setMarie(marie);
setNbenfants(nbenfants);
}
// toString
public String toString() {
...
}
// getters y setters
...
}
La configuración se realiza mediante anotaciones Java @Annotation. Las anotaciones Java son interpretadas bien por el compilador, bien por herramientas especializadas en el momento de la ejecución. A excepción de la anotación de la línea 3, destinada al compilador, todas las demás anotaciones están destinadas a la implementación JPA utilizada, ya sea Hibernate o Toplink. Por lo tanto, se interpretarán en el momento de la ejecución. A falta de herramientas capaces de interpretarlas, estas anotaciones se ignoran. Así, la clase [Personne] anterior podría utilizarse en un contexto ajeno a JPA.
Hay que distinguir dos casos de uso de las anotaciones JPA en una clase C asociada a una tabla T:
- la tabla T ya existe: en ese caso, las anotaciones JPA deben reproducir lo existente (nombre y definición de las columnas, restricciones de integridad, claves externas, claves primarias, etc.)
- la tabla T no existe y se va a crear a partir de las anotaciones que se encuentren en la clase C.
El caso 2 es el más fácil de gestionar. Mediante las anotaciones JPA, indicamos la estructura de la tabla T que deseamos. El caso 1 suele ser más complejo. Es posible que la tabla T se haya creado hace mucho tiempo, al margen de cualquier contexto JPA. Por lo tanto, su estructura puede no estar bien adaptada al puente relacional/objeto de JPA. Para simplificar, nos centraremos en el caso 2, en el que la tabla T asociada a la clase C se creará según las anotaciones JPA de la clase C.
Comentemos las anotaciones JPA de la clase [Personne]:
- línea 4: la anotación @Entity es la primera anotación imprescindible. Se coloca antes de la línea que declara la clase e indica que la clase en cuestión debe ser gestionada por la capa de persistencia JPA. En ausencia de esta anotación, se ignorarían todas las demás anotaciones JPA.
- línea 5: la anotación @Table designa la tabla de la base de datos que representa la clase. Su argumento principal es name, que designa el nombre de la tabla. Si no se incluye este argumento, la tabla llevará el nombre de la clase, en este caso [Personne]. Por lo tanto, en nuestro ejemplo, la anotación @Table es superflua.
- línea 8: la anotación @Id sirve para designar el campo de la clase que representa la clave primaria de la tabla. Esta anotación es obligatoria. Aquí indica que el campo id de la línea 11 representa la clave primaria de la tabla.
- línea 9: la anotación @Column sirve para establecer el vínculo entre un campo de la clase y la columna de la tabla que dicho campo representa. El atributo name indica el nombre de la columna en la tabla. Si no se incluye este atributo, la columna recibe el mismo nombre que el campo. Por lo tanto, en nuestro ejemplo, el argumento name no era obligatorio. El argumento nullable=false indica que la columna asociada al campo no puede tener el valor NULL y que, por lo tanto, el campo debe tener necesariamente un valor.
- línea 10: la anotación @GeneratedValue indica cómo se genera la clave primaria cuando la genera automáticamente el SGBD. Este será el caso en todos nuestros ejemplos. No es obligatorio. Así, nuestra persona podría tener un número de estudiante que sirviera como clave primaria y que no fuera generado por el SGBD, sino fijado por la aplicación. En ese caso, la anotación @GeneratedValue no estaría presente. El argumento strategy indica cómo se genera la clave primaria cuando la genera el SGBD. No todos los SGBD utilizan la misma técnica para generar los valores de la clave primaria. Por ejemplo:
utiliza un generador de valores que se invoca antes de cada inserción | |
El campo de clave primaria se define con el tipo Identity. El resultado es similar al del generador de valores de Firebird, salvo que el valor de la clave solo se conoce tras la inserción de la fila. | |
utiliza un objeto denominado SEQUENCE que, una vez más, desempeña la función de generador de valores |
La capa JPA debe generar órdenes SQL diferentes en función de los SGBD para crear el generador de valores. Mediante la configuración, se le indica el tipo de SGBD que debe gestionar. De este modo, puede saber cuál es la estrategia habitual de generación de valores de clave primaria de ese SGBD. El argumento strategy = GenerationType.AUTO indica a la capa JPA que debe utilizar esta estrategia habitual. Esta técnica ha funcionado en todos los ejemplos de este documento para los siete SGBD utilizados.
- línea 14: la anotación @Version designa el campo que se utiliza para gestionar los accesos concurrentes a una misma línea de la tabla.
Para comprender este problema de accesos concurrentes a una misma fila de la tabla [personne], supongamos que una aplicación web permite actualizar los datos de una persona y analicemos el siguiente caso:
En el momento T1, un usuario U1 accede para modificar un registro de persona P. En ese momento, el número de hijos es 0. Cambia este número a 1, pero antes de que valide su modificación, un usuario U2 accede para modificar el mismo perfil P. Dado que U1 aún no ha validado su modificación, U2 ve en su pantalla que el número de hijos es 0. U2 cambia el nombre de la persona P a mayúsculas. A continuación, U1 y U2 validan sus modificaciones en ese orden. La modificación de U2 será la que prevalezca: en la base de datos, el nombre pasará a estar en mayúsculas y el número de hijos se mantendrá en cero, aunque U1 crea haberlo cambiado a 1.
El concepto de «versión de persona» nos ayuda a resolver este problema. Volvamos al mismo caso práctico:
En el momento T1, un usuario U1 accede para modificar una persona P. En ese momento, el número de hijos es 0 y la versión es V1. Cambia el número de hijos a 1, pero antes de que valide su modificación, un usuario U2 accede para modificar la misma persona P. Dado que U1 aún no ha validado su modificación, U2 ve que el número de hijos es 0 y que la versión es V1. U2 cambia el nombre de la persona P a mayúsculas. A continuación, U1 y U2 validan sus modificaciones en ese orden. Antes de validar una modificación, se comprueba que quien modifica a una persona P tenga la misma versión que la persona P registrada actualmente. Este será el caso del usuario U1. Por lo tanto, su modificación se acepta y se cambia la versión de la persona modificada de V1 a V2 para indicar que la persona ha sufrido un cambio. Al validar la modificación de U2, se observará que U2 contiene una versión V1 de la persona P, mientras que actualmente la versión de esta es V2. Entonces podremos indicar al usuario U2 que alguien le ha adelantado y que debe partir de la nueva versión de la persona P. Lo hará, recuperará una persona P de la versión V2 que ahora tiene un hijo, escribirá el nombre en mayúsculas y validará. Su modificación se aceptará si la persona P registrada sigue teniendo la versión V2. Al final, se tendrán en cuenta las modificaciones realizadas por U1 y U2, mientras que en el caso de uso sin versión, una de las modificaciones se perdía.
La capa [dao] de la aplicación cliente puede gestionar por sí misma la versión de la clase [Personne]. Cada vez que se produzca una modificación de un objeto P, la versión de dicho objeto se incrementará en 1 en la tabla. La anotación @Version permite transferir esta gestión a la capa JPA. El campo en cuestión no tiene por qué llamarse version, como en el ejemplo. Puede tener cualquier nombre.
Los campos correspondientes a las anotaciones @Id y @Version están presentes por motivos de persistencia. No serían necesarios si la clase [Personne] no tuviera que ser persistente. Por lo tanto, se observa que un objeto no tiene la misma representación dependiendo de si necesita o no ser persistente.
- Línea 17: de nuevo la anotación @Column para proporcionar información sobre la columna de la tabla [personne] asociada al campo nom de la clase Personne. Aquí encontramos dos nuevos argumentos:
- unique=true indica que el nombre de una persona debe ser único. Esto se traducirá en la base de datos en la adición de una restricción de unicidad en la columna NOM de la tabla [personne].
- length=30 establece en 30 el número de caracteres de la columna NOM. Esto significa que el tipo de esta columna será VARCHAR(30).
- línea 24: la anotación @Temporal sirve para indicar qué tipo SQL se debe asignar a una columna o campo de tipo fecha/hora. El tipo TemporalType.DATE designa una fecha sin hora asociada. Los demás tipos posibles son TemporalType.TIME para codificar una hora y TemporalType.TIMESTAMP para codificar una fecha con hora.
Comentemos ahora el resto del código de la clase [Personne]:
- línea 6: la clase implementa la interfaz Serializable. La sérialisation de un objeto consiste en transformarlo en una secuencia de bits. La désérialisation es la operación inversa. La serialización y deserialización se utilizan, en particular, en aplicaciones cliente-servidor en las que se intercambian objetos a través de la red. Las aplicaciones cliente o servidor desconocen esta operación, que se realiza de forma transparente mediante los JVM. Sin embargo, para que sea posible, es necesario que las clases de los objetos intercambiados estén «etiquetadas» con la palabra clave Serializable.
- Línea 37: un constructor de la clase. Cabe señalar que los campos id y version no forman parte de los parámetros. De hecho, estos dos campos son gestionados por la capa JPA y no por la aplicación.
- líneas 51 y siguientes: los métodos get y set de cada uno de los campos de la clase. Cabe señalar que las anotaciones JPA pueden colocarse en los métodos get de los campos en lugar de en los propios campos. La ubicación de las anotaciones indica el modo que debe utilizar JPA para acceder a los campos:
- si las anotaciones se colocan a nivel de campo, JPA accederá directamente a los campos para leerlos o escribirlos
- si las anotaciones se colocan a nivel de get, JPA accederá a los campos a través de los métodos get/set para leerlos o escribirlos
Es la posición de la anotación @Id la que determina la posición de las anotaciones JPA de una clase. Si se coloca a nivel de campo, indica un acceso directo a los campos, y si se coloca a nivel de get, indica un acceso a los campos a través de los métodos get y set. Las demás anotaciones deben colocarse entonces de la misma forma que la anotación @Id.
2.1.3. El proyecto Eclipse de las pruebas
Vamos a realizar nuestros primeros experimentos con la entidad [Personne] mencionada anteriormente. Los llevaremos a cabo con la siguiente arquitectura:
 |
- en [7]: la base de datos que se generará a partir de las anotaciones de la entidad [Personne], así como de configuraciones adicionales realizadas en un archivo denominado [persistence.xml]
- en [5, 6]: una capa JPA implementada por Hibernate
- en [4]: la entidad [Personne]
- en [3]: un programa de prueba de tipo consola
Realizaremos varios experimentos:
- generar el esquema de BD a partir de un script Ant y de la herramienta Hibernate Tools
- generar la BD e inicializarla con algunos datos
- utilizar la tabla BD y realizar las cuatro operaciones básicas en la tabla [personne] (inserción, actualización, eliminación y consulta)
Las herramientas necesarias son las siguientes:
- Eclipse y sus complementos, descritos en el apartado 5.2.
- el proyecto [hibernate-personnes-entites], que se encuentra en la carpeta <ejemplos>/hibernate/direct/personas-entidades
- los distintos SGBD descritos en los anexos (apartado 5 y siguientes).
El proyecto de Eclipse es el siguiente:
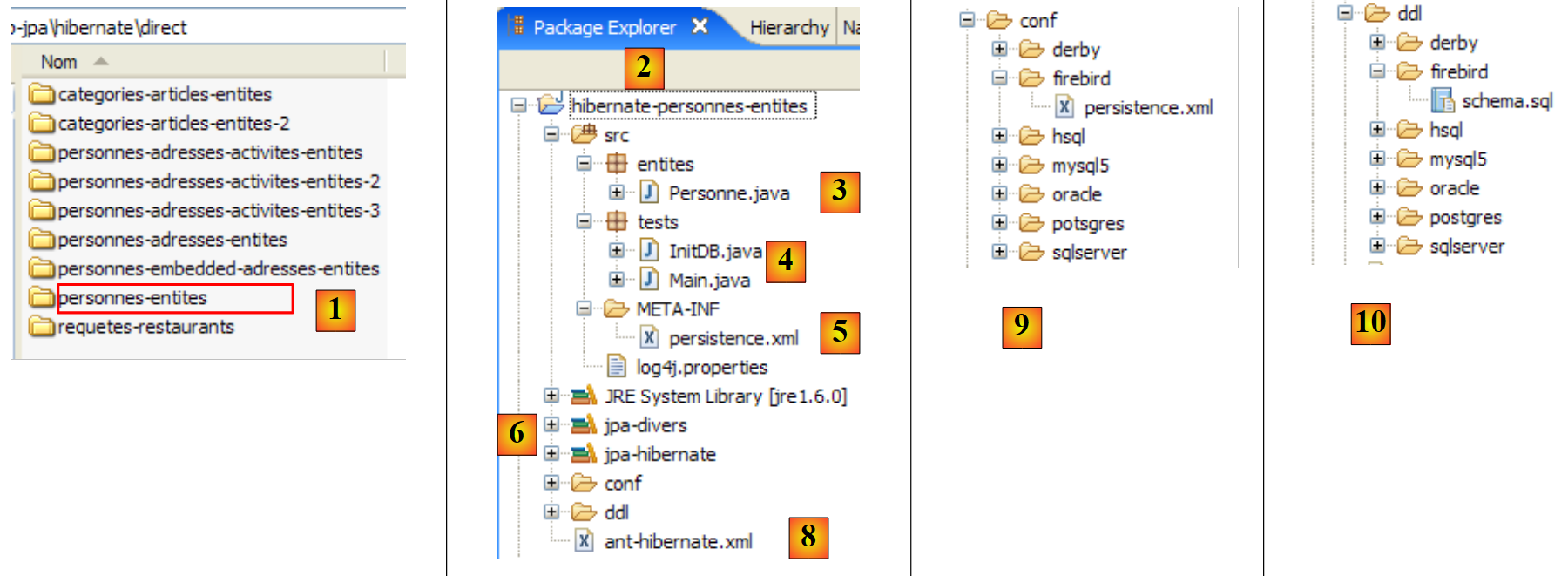 |
- en [1]: la carpeta del proyecto de Eclipse
- en [2]: el proyecto importado a Eclipse (Archivo / Importar)
- en [3]: la entidad [Personne] objeto de las pruebas
- en [4]: los programas de prueba
- en [5]: [persistence.xml] es el archivo de configuración de la capa JPA
- en [6]: las bibliotecas utilizadas. Se han descrito en el apartado 1.5.
- en [8]: un script Ant que se utilizará para generar la tabla asociada a la entidad [Personne]
- en [9]: los archivos [persistence.xml] para cada uno de los SGBD utilizados
- en [10]: los esquemas de la base de datos generada para cada uno de los SGBD utilizados
Vamos a describir estos elementos uno por uno.
2.1.4. La entidad [Personne] (2)
Introducimos una ligera modificación en la descripción realizada anteriormente de la entidad [Personne], así como información adicional:
package entites;
...
@SuppressWarnings({ "unused", "serial" })
@Entity
@Table(name="jpa01_personne")
public class Personne implements Serializable{
@Id
@Column(name = "ID", nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name = "VERSION", nullable = false)
@Version
private int version;
@Column(name = "NOM", length = 30, nullable = false, unique = true)
private String nom;
@Column(name = "PRENOM", length = 30, nullable = false)
private String prenom;
@Column(name = "DATENAISSANCE", nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(name = "MARIE", nullable = false)
private boolean marie;
@Column(name = "NBENFANTS", nullable = false)
private int nbenfants;
// constructores
public Personne() {
}
public Personne(String nom, String prenom, Date datenaissance, boolean marie,
int nbenfants) {
....
}
// toString
public String toString() {
return String.format("[%d,%d,%s,%s,%s,%s,%d]", getId(), getVersion(),
getNom(), getPrenom(), new SimpleDateFormat("dd/MM/yyyy")
.format(getDatenaissance()), isMarie(), getNbenfants());
}
// métodos getter y setter
...
}
- línea 7: asignamos el nombre [jpa01_personne] a la tabla asociada a la entidad [Personne]. En el documento se crearán varias tablas en un esquema denominado jpa. Al final de este tutorial, el esquema jpa contendrá numerosas tablas. Para que el lector pueda orientarse, las tablas relacionadas entre sí tendrán el mismo prefijo: jpaxx_.
- Línea 45: un método [toString] para mostrar un objeto [Personne] en la consola.
2.1.5. Configuración de la capa de acceso a datos
En el proyecto de Eclipse anterior, la configuración de la capa JPA se realiza mediante el archivo [META-INF/persistence.xml]:
 |
En el momento de la ejecución, se busca el archivo [META-INF/persistence.xml] en el directorio classpath de la aplicación. En nuestro proyecto de Eclipse, todo el contenido de la carpeta [/src] [1] se copia en una carpeta [/bin] [2]. Esta última forma parte del classpath del proyecto. Por este motivo, se encontrará [META-INF/persistence.xml] cuando se configure la capa JPA.
Por defecto, Eclipse no coloca los códigos fuente en la carpeta [/src] del proyecto, sino directamente en la propia carpeta. Todos nuestros proyectos de Eclipse se configurarán para que los códigos fuente se encuentren en [/src] y las clases compiladas en [/bin], tal y como se muestra en el apartado 5.2.1.
Veamos la configuración de la capa JPA realizada en el archivo [persistence.xml] de nuestro proyecto:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- proveedor -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- clases persistentes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- registros SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- conexión JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
<property name="hibernate.connection.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- Creación automática del esquema -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialecto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!-- propiedades DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
Para comprender esta configuración, debemos repasar la arquitectura de acceso a los datos de nuestra aplicación:
 |
- El archivo [persistence.xml] configurará las capas [4, 5, 6]
- [4]: implementación de Hibernate de JPA
- [5]: Hibernate accede a la base de datos a través de un grupo de conexiones. Un grupo de conexiones es una reserva de conexiones abiertas con el SGBD. Un SGBD es utilizado por múltiples usuarios, aunque, por motivos de rendimiento, no puede superar un número límite N de conexiones abiertas simultáneamente. Un código bien escrito abre una conexión con el SGBD durante el menor tiempo posible: envía órdenes al SQL y cierra la conexión. Lo hará de forma repetida, cada vez que necesite trabajar con la base de datos. El coste de abrir y cerrar una conexión no es insignificante, y ahí es donde entra en juego el grupo de conexiones. Este, al iniciarse la aplicación, abrirá N1 conexiones con el SGBD. Es a este al que la aplicación solicitará una conexión abierta cuando la necesite. Dicha conexión se devolverá al grupo tan pronto como la aplicación ya no la necesite, preferiblemente lo antes posible. La conexión no se cierra y permanece disponible para el siguiente usuario. Por lo tanto, un grupo de conexiones es un sistema para compartir conexiones abiertas.
- [6]: el controlador JDBC del SGBD utilizado
Ahora veamos cómo el archivo [persistence.xml] configura las capas [4, 5, 6] anteriores:
- línea 2: la etiqueta raíz del archivo XML es <persistence>.
- línea 3: <persistence-unit> sirve para definir una unidad de persistencia. Puede haber varias unidades de persistencia. Cada una de ellas tiene un nombre (atributo name) y un tipo de transacción (atributo transaction-type). La aplicación tendrá acceso a la unidad de persistencia a través de su nombre, en este caso jpa. El tipo de transacción RESOURCE_LOCAL indica que la propia aplicación gestiona las transacciones con el SGBD. Este será el caso aquí. Cuando la aplicación se ejecuta en un contenedor EJB3, puede utilizar el servicio de transacciones de este. En este caso, se establecerá transaction-type=JTA (Java Transaction API). JTA es el valor por defecto cuando no se especifica el atributo transaction-type.
- Línea 5: la etiqueta <provider> sirve para definir una clase que implemente la interfaz [javax.persistence.spi.PersistenceProvider], interfaz que permite a la aplicación inicializar la capa de persistencia. Dado que se utiliza una implementación de JPA / Hibernate, la clase utilizada aquí es una clase de Hibernate.
- línea 6: la etiqueta <properties> introduce propiedades específicas del provider concreto elegido. Así, dependiendo de si se ha elegido Hibernate, Toplink, Kodo, etc., tendremos propiedades diferentes. Las que siguen son específicas de Hibernate.
- línea 8: solicita a Hibernate que explore el classpath del proyecto para encontrar las clases que tengan la anotación @Entity con el fin de gestionarlas. Las clases @Entity también pueden declararse mediante las etiquetas <class>nom_de_la_classe</class>, directamente bajo la etiqueta <persistence-unit>. Esto es lo que haremos con el provider JPA / Toplink.
- Las líneas 10-12, que aquí aparecen comentadas, configuran los registros de consola de Hibernate:
- línea 10: para mostrar o no los comandos SQL emitidos por Hibernate en el SGBD. Esto resulta muy útil durante la fase de aprendizaje. Debido al puente relacional/objeto, la aplicación trabaja con objetos persistentes a los que aplica operaciones de tipo [persist, merge, remove]. Resulta muy interesante saber cuáles son los comandos SQL que se emiten realmente en estas operaciones. Al estudiarlas, poco a poco se va adivinando cuáles son las órdenes SQL que Hibernate generará al realizar tal operación sobre los objetos persistentes, y el puente relacional/objeto empieza a cobrar sentido en la mente.
- línea 11: las órdenes SQL que se muestran en la consola se pueden formatear de forma clara para facilitar su lectura
- línea 12: además, los comandos SQL que se muestren irán acompañados de comentarios
- Las líneas 15-19 definen la capa JDBC (capa [6] en la arquitectura):
- línea 15: la clase del controlador JDBC del SGBD, en este caso MySQL5
- línea 16: la URL de la base de datos utilizada
- líneas 17 y 18: el usuario de la conexión y su contraseña
- Aquí utilizamos elementos explicados en los anexos del apartado 5.5. Se invita al lector a consultar esta sección sobre MySQL5.
- línea 22: Hibernate necesita conocer el SGBD con el que está trabajando. De hecho, todos los SGBD tienen extensiones SQL propias, una forma específica de gestionar la generación automática de los valores de una clave primaria, ... lo que hace que Hibernate necesite conocer el SGBD con el que está trabajando para enviarle las órdenes SQL que este entenderá. [MySQL5InnoDBDialect] hace referencia al SGBD MySQL5 con tablas de tipo InnoDB que admiten transacciones.
- Las líneas 24-28 configuran el grupo de conexiones c3p0 (capa [5] en la arquitectura):
- líneas 24 y 25: el número mínimo (por defecto, 3) y máximo de conexiones (por defecto, 15) en el grupo. El número inicial de conexiones por defecto es 3.
- línea 26: tiempo máximo, en milisegundos, de espera de una solicitud de conexión por parte del cliente. Transcurrido este tiempo, c3p0 le devolverá una excepción.
- línea 27: para acceder a BD, Hibernate utiliza órdenes SQL preparadas (PreparedStatement) que c3p0 puede almacenar en caché. Esto significa que, si la aplicación solicita por segunda vez una orden SQL preparada que ya se encuentra en la caché, no será necesario volver a prepararla (la preparación de una orden SQL tiene un coste) y se utilizará la que está en la caché. Aquí se indica el número máximo de órdenes SQL preparadas que puede contener la caché, para todas las conexiones en conjunto (una orden SQL preparada pertenece a una conexión).
- línea 28: frecuencia de comprobación, en milisegundos, de la validez de las conexiones. Una conexión del grupo puede dejar de ser válida por diversas razones (el controlador JDBC invalida la conexión porque dura demasiado, el controlador JDBC presenta «errores», etc.).
- línea 20: aquí se solicita que, al inicializar la unidad de persistencia, se genere la base de datos de los objetos @Entity. Hibernate dispone ahora de todas las herramientas para emitir las órdenes SQL de generación de las tablas de la base de datos:
- la configuración de los objetos @Entity le permite saber qué tablas debe generar
- las líneas 15-18 y 24-28 le permiten establecer una conexión con el SGBD
- la línea 22 le permite saber qué dialecto SQL debe utilizar para generar las tablas
De este modo, el archivo [persistence.xml] utilizado aquí recrea una base de datos nueva cada vez que se ejecuta la aplicación. Las tablas se recrean (create table) tras haber sido eliminadas (drop table) si ya existían. Cabe señalar que, evidentemente, esto no debe hacerse con una base de datos en producción...
Las pruebas han demostrado que la fase «drop / create» de las tablas podía fallar. Esto ocurría, en particular, cuando, en una misma prueba, se pasaba de una capa JPA/Hibernate a una capa JPA/Toplink o viceversa. A partir de los mismos objetos @Entity, las dos implementaciones no generan exactamente las mismas tablas, generadores, secuencias, etc., y en ocasiones ha ocurrido que la fase de eliminación y creación ha fallado y nos hemos visto obligados a eliminar las tablas manualmente. La sección «Anexos», a partir del párrafo 5, describe las aplicaciones que se pueden utilizar para realizar este trabajo manualmente. Cabe señalar que la implementación JPA/Hibernate ha demostrado ser la más eficaz en esta fase de creación inicial del contenido de la base de datos: los fallos han sido muy escasos.
Las herramientas utilizadas por la capa JPA / Hibernate se encuentran en la biblioteca [jpa-hibernate], presentada en el apartado 1.5, página 8. Los controladores JDBC necesarios para acceder a los SGBD se encuentran en la biblioteca [jpa-divers]. Estas dos bibliotecas se han incluido en el classpath del proyecto que aquí se estudia. A continuación recordamos su contenido:
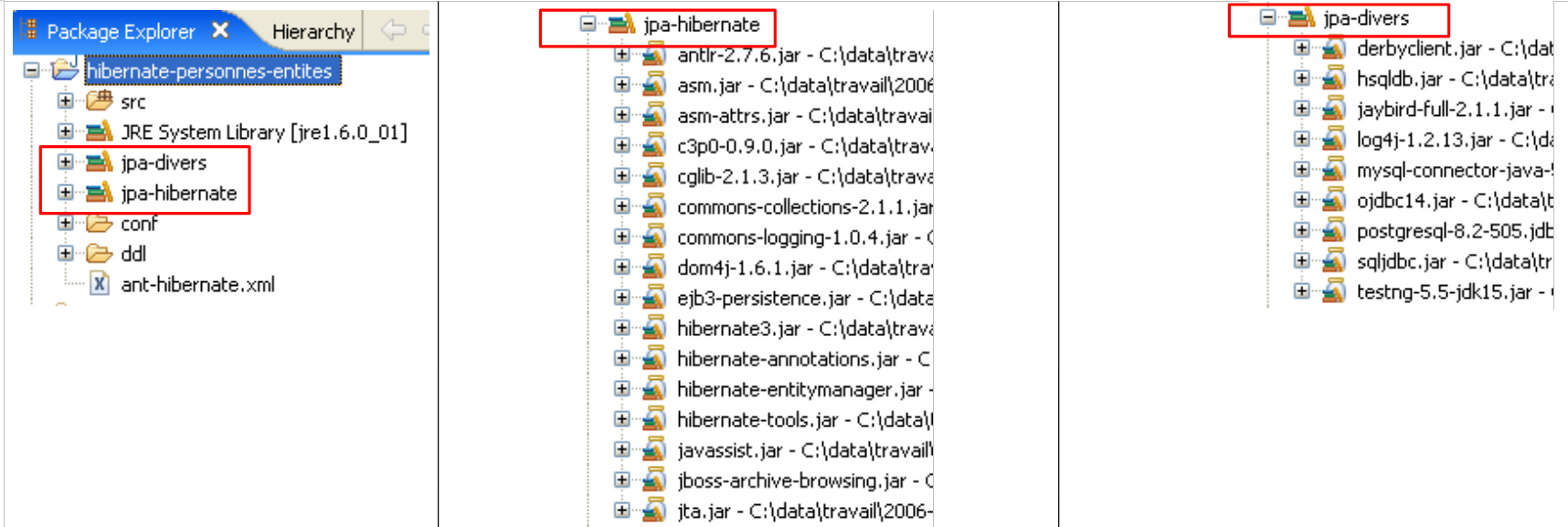 |
2.1.6. Generación de la base de datos con un script de Ant
Como acabamos de ver, Hibernate proporciona herramientas para generar la base de datos de imagen de los objetos @Entity de la aplicación. Hibernate puede:
- generar el archivo de texto con las órdenes SQL que crean la base de datos. En ese caso, solo se utiliza el dialecto de [persistence.xml].
- crear las tablas que representan los objetos @Entity en la base de datos de destino definida en [persistence.xml]. En este caso, se utiliza la totalidad del archivo [persistence.xml].
Vamos a presentar un script de Ant capaz de generar el esquema de la base de datos, es decir, las tablas de los objetos @Entity. Este script no es mío: se basa en un script similar de [ref1]. Ant (Another Neat Tool) es una herramienta de ejecución por lotes de tareas en Java. Los scripts Ant no son fáciles de entender para un principiante. Solo utilizaremos uno, el que vamos a comentar a continuación:
 |
- en [1]: la estructura de directorios de los ejemplos de este tutorial.
- en [2]: la carpeta [personnes-entites] del proyecto de Eclipse que estamos analizando actualmente
- en [3]: la carpeta <lib> que contiene las cinco bibliotecas JAR definidas en el apartado 1.5.
- en [4]: el archivo [hibernate-tools.jar] necesario para una de las tareas del script [ant-hibernate.xml] que vamos a estudiar.
 |
- en [5]: el proyecto de Eclipse y el script [ant-hibernate.xml]
- en [6]: la carpeta [src] del proyecto
El script [ant-hibernate.xml] [5] utilizará los archivos JAR de la carpeta <lib> [3], en concreto el archivo [hibernate-tools.jar] [4] de la carpeta [lib/hibernate]. Hemos reproducido la estructura de carpetas para que el lector vea que, para encontrar la carpeta [lib] partiendo de la carpeta [personnes-entites] [2] del script [ant-hibernate.xml], hay que seguir la ruta: ../../../lib.
Analicemos el script [ant-hibernate.xml]:
<project name="jpa-hibernate" default="compile" basedir=".">
<!-- nombre del proyecto y versión -->
<property name="proj.name" value="jpa-hibernate" />
<property name="proj.shortname" value="jpa-hibernate" />
<property name="version" value="1.0" />
<!-- Propiedades globales -->
<property name="src.java.dir" value="src" />
<property name="lib.dir" value="../../../lib" />
<property name="build.dir" value="bin" />
<!-- La ruta de clases del proyecto -->
<path id="project.classpath">
<fileset dir="${lib.dir}">
<include name="**/*.jar" />
</fileset>
</path>
<!-- Los archivos de configuración que deben estar en la ruta de clases-->
<patternset id="conf">
<include name="**/*.xml" />
<include name="**/*.properties" />
</patternset>
<!-- Limpieza del proyecto -->
<target name="clean" description="Nettoyer le projet">
<delete dir="${build.dir}" />
<mkdir dir="${build.dir}" />
</target>
<!-- Compilación del proyecto -->
<target name="compile" depends="clean">
<javac srcdir="${src.java.dir}" destdir="${build.dir}" classpathref="project.classpath" />
</target>
<!-- Copiar los archivos de configuración en la ruta de clases -->
<target name="copyconf">
<mkdir dir="${build.dir}" />
<copy todir="${build.dir}">
<fileset dir="${src.java.dir}">
<patternset refid="conf" />
</fileset>
</copy>
</target>
<!-- Herramientas de Hibernate -->
<taskdef name="hibernatetool" classname="org.hibernate.tool.ant.HibernateToolTask" classpathref="project.classpath" />
<!-- Generar el archivo DDL de la base de datos -->
<target name="DDL" depends="compile, copyconf" description="Génération DDL base">
<hibernatetool destdir="${basedir}">
<classpath path="${build.dir}" />
<!-- Utilizar META-INF/persistence.xml -->
<jpaconfiguration />
<!-- exportar -->
<hbm2ddl drop="true" create="true" export="false" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
</hibernatetool>
</target>
<!-- Generar la base -->
<target name="BD" depends="compile, copyconf" description="Génération BD">
<hibernatetool destdir="${basedir}">
<classpath path="${build.dir}" />
<!-- Utilizar META-INF/persistence.xml -->
<jpaconfiguration />
<!-- exportar -->
<hbm2ddl drop="true" create="true" export="true" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
</hibernatetool>
</target>
</project>
- línea 1: el proyecto [ant] se llama «jpa-hibernate». Reúne un conjunto de tareas, una de las cuales es la tarea por defecto: en este caso, la tarea denominada «compile». Se invoca un script ant para ejecutar una tarea T. Si esta no se especifica, se ejecuta la tarea por defecto. basedir="." indica que, para todas las rutas relativas que se encuentren en el script, el punto de partida es la carpeta en la que se encuentra el script ant, en este caso la carpeta <ejemplos>/hibernate/direct/personas-entidades.
- Líneas 3-11: definen variables de script con la etiqueta <property name="nomVariable" value="valeurVariable"/>. La variable puede utilizarse posteriormente en el script con la notación ${nomVariable}. Los nombres pueden ser cualesquiera. Centrémonos en las variables definidas en las líneas 9-11:
- línea 9: define una variable llamada «src.java.dir» (el nombre es libre) que, en el resto del script, designará la carpeta que contiene los códigos fuente de Java. Su valor es «src», una ruta relativa a la carpeta designada por el atributo basedir (línea 1). Se trata, por tanto, de la ruta «./src», donde «.» designa aquí la carpeta <ejemplos>/hibernate/direct/personas-entidades. Es precisamente en la carpeta <personas-entidades>/src donde se encuentran los códigos fuente Java (véase [6] más arriba).
- línea 10: define una variable denominada «lib.dir» que, en el resto del script, designará la carpeta que contiene los archivos JAR que necesitan las tareas Java del script. Su valor ../../../lib hace referencia a la carpeta <ejemplos>/lib (véase [3] más arriba).
- línea 11: define una variable denominada «build.dir» que, en el resto del script, designará la carpeta donde deben generarse los archivos .class resultantes de la compilación de los fuentes .java. Su valor «bin» designa la carpeta <personas-entidades>/bin. Ya hemos explicado que, en el proyecto de Eclipse analizado, la carpeta <bin> era aquella en la que se generaban los archivos .class. Ant hará lo mismo.
- líneas 14-18: la etiqueta <path> sirve para definir elementos del archivo classpath que deberán utilizar las tareas ant. En este caso, la ruta «project.classpath» (el nombre es libre) agrupa todos los archivos .jar del árbol de directorios <ejemplos>/lib.
- Líneas 21-24: la etiqueta <patternset> sirve para designar un conjunto de archivos mediante patrones de nombres. En este caso, el patternset denominado «conf» designa todos los archivos con la extensión .xml o .properties. Este patternset servirá para designar los archivos .xml y .properties de la carpeta <src> (persistence.xml, log4j.properties) (véase [6]), que son archivos de configuración de la aplicación. Al ejecutar determinadas tareas, estos archivos deben copiarse en la carpeta <bin> para que se incluyan en el classpath del proyecto. Para designarlos, se utilizará entonces el patternset conf.
- Líneas 27-30: la etiqueta <target> designa una tarea del script. Es la primera que encontramos. Todo lo anterior corresponde a la configuración del entorno de ejecución del script ant. La tarea se llama «clean». Se ejecuta en dos pasos: se elimina la carpeta <bin> (línea 28) para volver a crearla a continuación (línea 29).
- líneas 33-35: la tarea «compile», que es la tarea por defecto del script (línea 1). Depende (atributo «depends») de la tarea «clean». Esto significa que, antes de ejecutar la tarea «compile», ant debe ejecutar la tarea «clean», c.a.d, para limpiar la carpeta <bin>. El objetivo de la tarea «compile» es, en este caso, compilar los fuentes Java de la carpeta <src>.
- línea 34: llamada al compilador de Java con tres parámetros:
- srcdir: la carpeta que contiene los códigos fuente Java, en este caso la carpeta <src>
- destdir: la carpeta donde deben guardarse los archivos .class generados, en este caso la carpeta <bin>
- classpathref: la ruta de clases que se utilizará para la compilación; en este caso, todos los archivos jar del árbol de directorios de la carpeta <lib>
- (continuación)
- líneas 38-45: la tarea «copyconf», cuyo objetivo es copiar en la carpeta <bin> todos los archivos .xml y .properties de la carpeta <src>.
- línea 48: definición de una tarea mediante la etiqueta <taskdef>. Este tipo de tarea está pensada para ser reutilizada en otras partes del script. Se trata de una facilidad de programación. Dado que la tarea se utiliza en varios puntos del script, se define una sola vez con la etiqueta <taskdef> y luego se reutiliza mediante su nombre, cuando sea necesario.
- La tarea se llama hibernatetool (atributo name).
- Su clase se define mediante el atributo classname. En este caso, la clase indicada se encuentra en el archivo [hibernate-tools.jar] del que ya hemos hablado.
- El atributo classpathref indica a ant dónde buscar la clase anterior
- (continuación)
- Las líneas 51-60 se refieren a la tarea que nos interesa aquí: la generación del esquema de la base de datos de imagen de los objetos @Entity de nuestro proyecto Eclipse.
- Línea 51: la tarea se llama DDL (como Data Definition Language, el SQL asociado a la creación de objetos de una base de datos). Depende de las tareas «compile» y «copyconf», en ese orden. Por lo tanto, la tarea DDL provocará, en este orden, la ejecución de las tareas «clean», «compile» y «copyconf». Cuando se inicia la tarea DDL, la carpeta <bin> contiene los archivos .class de los fuentes .java, en particular de los objetos @Entity, así como el archivo [META-INF/persistence.xml] que configura la capa JPA / Hibernate.
- Líneas 53-59: se invoca la tarea [hibernatetool] definida en la línea 48. Se le pasan numerosos parámetros, además de los ya definidos en la línea 48:
- línea 53: la carpeta de salida de los resultados generados por la tarea será la carpeta actual.
- línea 54: el directorio <bin> será el directorio de la tarea classpath
- línea 56: indica a la tarea [hibernatetool] cómo puede conocer su entorno de ejecución: la etiqueta <jpaconfiguration/> le indica que se encuentra en un entorno JPA y que, por lo tanto, debe utilizar el archivo [META-INF/persistence.xml] que encontrará aquí, en su classpath.
- La línea 58 establece las condiciones para la generación de la base de datos: drop=true indica que deben emitirse las órdenes SQL «drop table» antes de crear las tablas; create=true indica que debe crearse el archivo de texto con las órdenes SQL para la creación de la base de datos; outputfilename indica el nombre de dicho archivo SQL —en este caso, schema.sql— en la carpeta <ddl> del proyecto de Eclipse; export=false indica que los comandos SQL generados no deben ejecutarse en una conexión con SGBD. Este punto es importante: implica que, para ejecutar la tarea, no es necesario iniciar el SGBD de destino. delimiter establece el carácter que separa dos órdenes SQL en el esquema generado, mientras que format=true solicita que se aplique un formato básico al texto generado.
- Las líneas 51-60 se refieren a la tarea que nos interesa aquí: la generación del esquema de la base de datos de imagen de los objetos @Entity de nuestro proyecto Eclipse.
- (continuación)
- Las líneas 63-72 definen la tarea denominada BD. Es idéntica a la tarea anterior DDL, salvo que en esta ocasión genera la base de datos (export="true" en la línea 70). La tarea abre una conexión con la tarea SGBD utilizando la información encontrada en [persistence.xml], para ejecutar en ella el esquema SQL y generar la base de datos. Por lo tanto, para ejecutar la tarea BD, es necesario que se haya iniciado la tarea SGBD.
2.1.7. Ejecución de la tarea ant DDL
Para ejecutar el script [ant-hibernate.xml], primero debemos realizar algunas configuraciones en Eclipse.
 |
- en [1]: seleccionar [External Tools]
- en [2]: crear una nueva configuración ant
 |
- en [3]: asignar un nombre a la configuración ant
- en [5]: seleccionar el script ant mediante el botón [4]
- en [6]: aplicar los cambios
- en [7]: se ha creado la configuración ant DDL
 |
 |
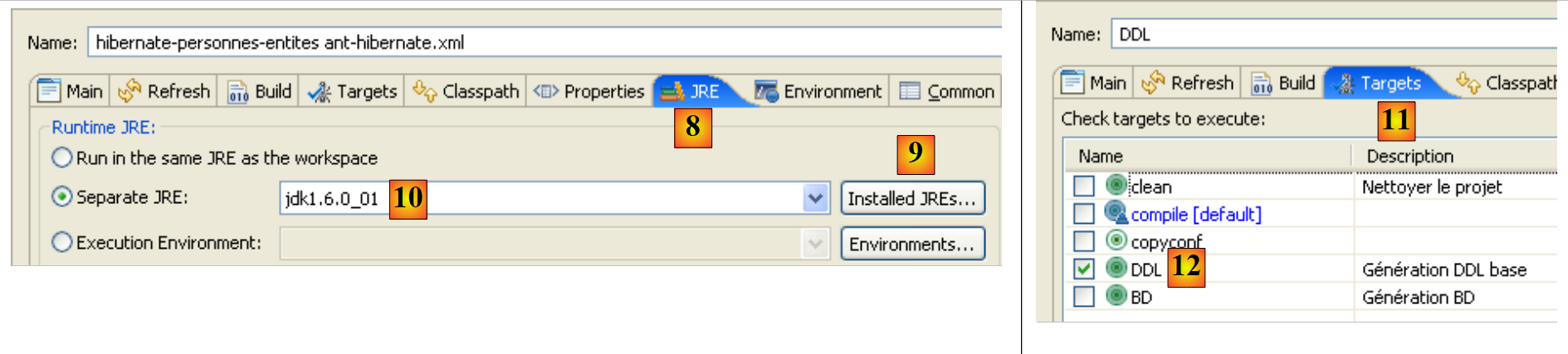
- en [8]: en la pestaña JRE, se define el JRE que se va a utilizar. El campo [10] suele aparecer ya rellenado con el JRE que utiliza Eclipse. Por lo tanto, normalmente no hay que hacer nada en este panel. Sin embargo, me he encontrado con un caso en el que el script ant no conseguía encontrar el compilador <javac>. Este no se encuentra en un JRE (Java Runtime Environment), sino en un JDK (Java Development Kit). La herramienta ant de Eclipse encuentra este compilador a través de la variable de entorno JAVA_HOME (Inicio / Panel de control / Rendimiento y mantenimiento / Sistema / pestaña Avanzado / botón Variables de entorno) [A]. Si esta variable no se ha definido, se puede permitir que ant encuentre el compilador <javac> introduciendo en [10], no un JRE, sino un JDK. Este se encuentra en la misma carpeta que JRE y [B]. Utilizaremos el botón [9] para declarar el JDK entre los JRE disponibles [C], con el fin de poder seleccionarlo posteriormente en [10].
- en [12]: en la pestaña [Targets], se selecciona la tarea DDL. De este modo, la configuración ant, a la que hemos denominado DDL [7], corresponderá a la ejecución de la tarea denominada DDL [12], la cual, como sabemos, genera el esquema DDL de la base de datos de imágenes de los objetos @Entity de la aplicación.
 |
- en [13]: se valida la configuración
- en [14]: se ejecuta
En la vista [console] se obtienen los registros de la ejecución de la tarea ant DDL:
Buildfile: C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\ant-hibernate.xml
clean:
[delete] Deleting directory C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
[mkdir] Created dir: C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
compile:
[javac] Compiling 3 source files to C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
copyconf:
[copy] Copying 2 files to C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
DDL:
[hibernatetool] Executing Hibernate Tool with a JPA Configuration
[hibernatetool] 1. task: hbm2ddl (Generates database schema)
[hibernatetool] drop table if exists jpa01_personne;
[hibernatetool] create table jpa01_personne (
[hibernatetool] ID integer not null auto_increment,
[hibernatetool] VERSION integer not null,
[hibernatetool] NOM varchar(30) not null unique,
[hibernatetool] PRENOM varchar(30) not null,
[hibernatetool] DATENAISSANCE date not null,
[hibernatetool] MARIE bit not null,
[hibernatetool] NBENFANTS integer not null,
[hibernatetool] primary key (ID)
[hibernatetool] ) ENGINE=InnoDB;
BUILD SUCCESSFUL
Total time: 5 seconds
- Recordemos que la tarea DDL se denomina [hibernatetool] (línea 10) y que depende de las tareas clean (línea 2), compile (línea 5) y copyconf (línea 7).
- línea 10: la tarea [hibernatetool] utiliza el archivo [persistence.xml] de una configuración JPA
- línea 11: la tarea [hbm2ddl] generará el esquema DDL de la base de datos
- líneas 12-22: el esquema DDL de la base de datos
Recordemos que se le había indicado a la tarea [hbm2ddl] que generara el esquema DDL en una ubicación concreta:
<hbm2ddl drop="true" create="true" export="true" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
- línea 74: el esquema debe generarse en el archivo ddl/schema.sql. Comprobémoslo:
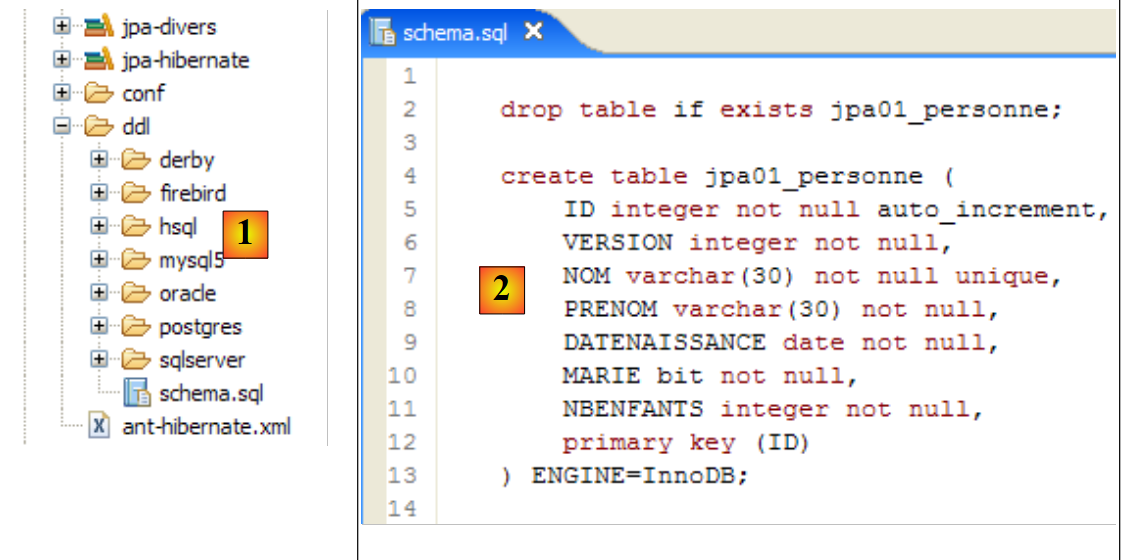 |
- en [1]: el archivo ddl/schema.sql está presente (ejecuta F5 para actualizar el árbol de directorios)
- en [2]: su contenido. Se trata del esquema de una base de datos MySQL5. El archivo de configuración [persistence.xml] de la capa JPA especificaba, en efecto, un SGBD MySQL5 (línea 8 a continuación):
<!-- conexión JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
...
<!-- creación automática del esquema -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- dialecto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!-- propiedades DataSource c3p0 -->
...
Analicemos el puente entre el objeto y la relación que se ha establecido aquí, examinando la configuración del objeto @Entity «Persona» y el esquema DDL generado:
 |
 |
Cabe destacar algunos puntos:
- A1-B1: el nombre de la tabla especificado en A1 es, efectivamente, el mismo que se utiliza en B1. Cabe destacar que drop precede a create en B1.
- A2-B2: muestra el modo de generación de la clave primaria. El modo AUTO especificado en A2 se ha traducido en el atributo autoincrement propio de MySQL5. El modo de generación de la clave primaria suele ser específico de SGBD.
- A3-B3: muestra el tipo SQL, un bit propio de MySQL5, para representar un tipo boolean de Java.
Repitamos esta prueba con otro SGBD:
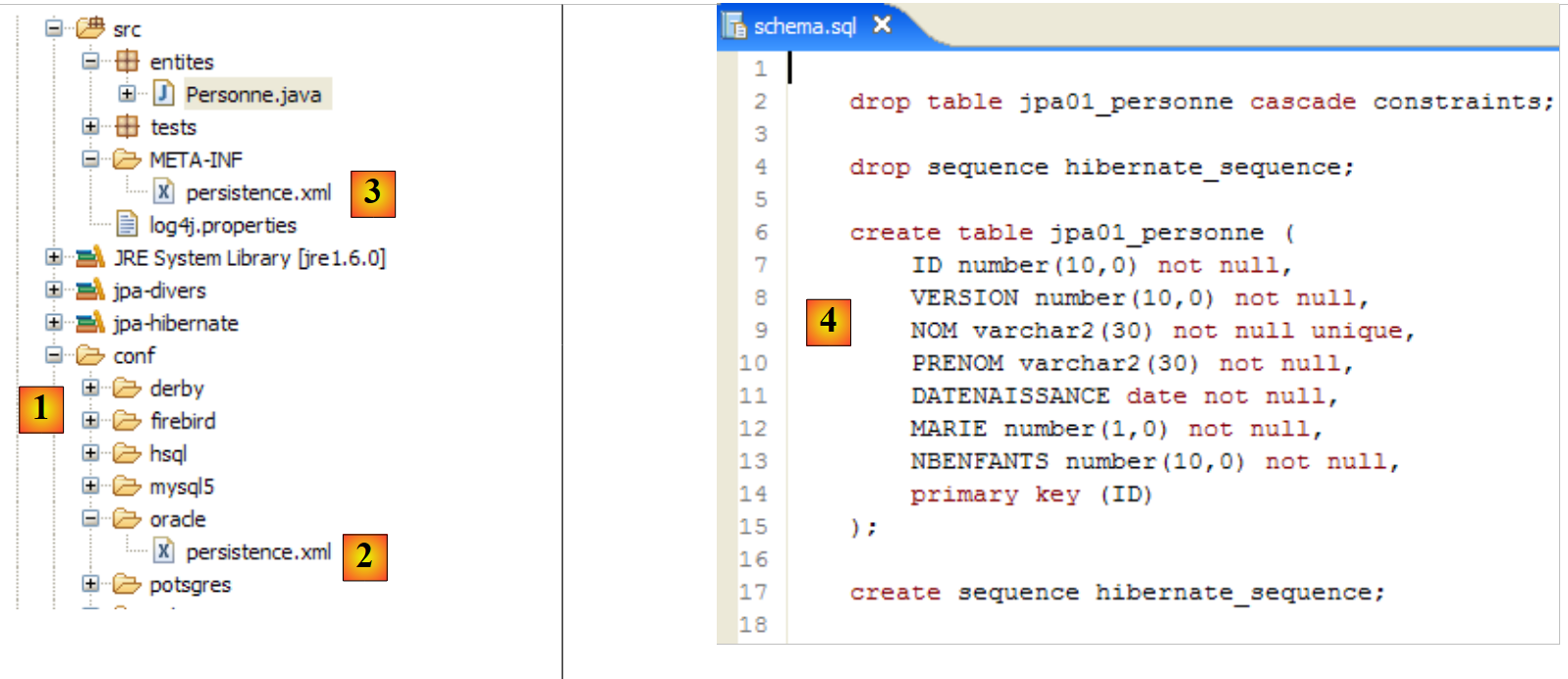 |
- La carpeta [conf] [1] contiene los archivos [persistence.xml] para diversos SGBD. Tomemos como ejemplo el de Oracle, [2], y coloquémoslo en la carpeta [META-INF] [3] en lugar del anterior. Su contenido es el siguiente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- proveedor -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Clases persistentes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- registros SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- conexión JDBC -->
<property name="hibernate.connection.driver_class" value="oracle.jdbc.OracleDriver" />
<property name="hibernate.connection.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- Creación automática del esquema -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialecto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.OracleDialect" />
<!-- propiedades DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
Se recomienda al lector que consulte en los anexos la sección sobre Oracle (apartado 5.7), especialmente para comprender la configuración de JDBC.
Aquí solo es realmente importante la línea 25: se indica a Hibernate que, a partir de ahora, el SGBD es un SGBD de Oracle. La ejecución de la tarea ant DDL da como resultado el [4] anterior. Cabe destacar que el esquema de Oracle es diferente del esquema MySQL5. Esta es una de las ventajas de JPA: el desarrollador no tiene que preocuparse por estos detalles, lo que aumenta considerablemente la portabilidad de sus desarrollos.
2.1.8. Ejecución de la tarea ant BD
Quizá recordemos que la tarea ant, denominada BD, hace lo mismo que la tarea ant DDL, pero además genera la base de datos. Por lo tanto, es necesario que se ejecute la tarea SGBD. Nos centraremos en el caso de SGBD y MySQL5, e invitamos al lector a copiar el archivo [conf/mysql5/persistence.xml] en la carpeta [src/META-INF]. Para comprobar el funcionamiento de la tarea, vamos a utilizar el complemento SQL Explorer (véase el apartado 5.2.6) para comprobar el estado del archivo jpa BD antes y después de la ejecución de la tarea ant BD.
En primer lugar, debemos crear una nueva configuración ant para ejecutar la tarea BD. Se recomienda al lector que siga los pasos descritos para la configuración anterior DDL en el apartado 2.1.7. La nueva configuración ant se llamará BD:
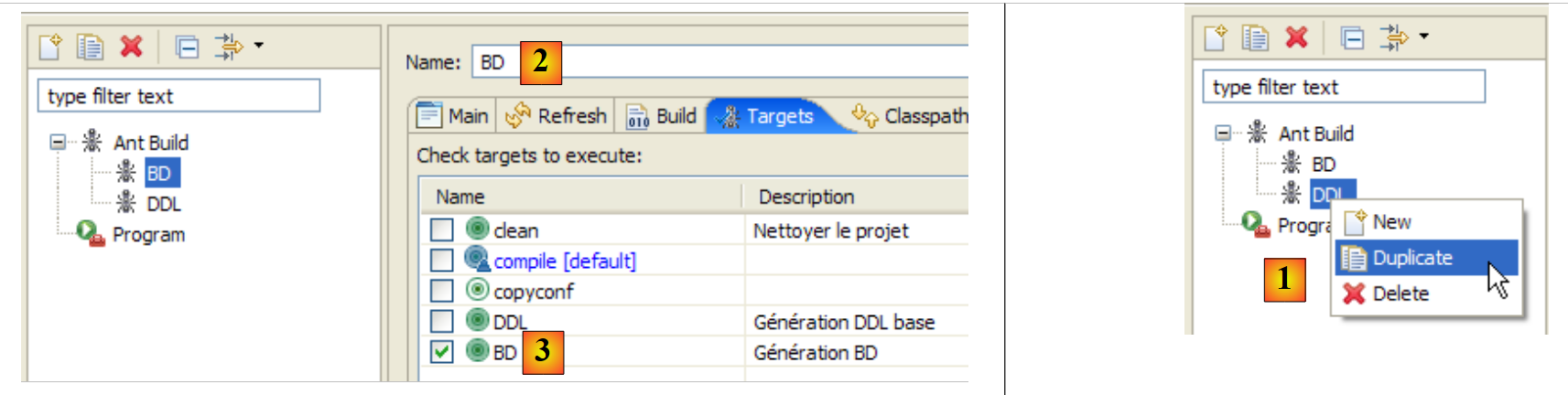 |
- en [1]: se duplica la configuración anterior denominada DDL
- en [2]: la nueva configuración se denomina BD. Esta ejecuta la tarea ant BD [3], que genera físicamente la base de datos.
- Una vez hecho esto, ejecute SGBD y MySQL5 (apartado 5.5).
Ahora utilizamos el complemento SQL Explorer para explorar las bases de datos gestionadas por el SGBD. El lector debe familiarizarse previamente con este complemento si es necesario (véase el apartado 5.2.6).
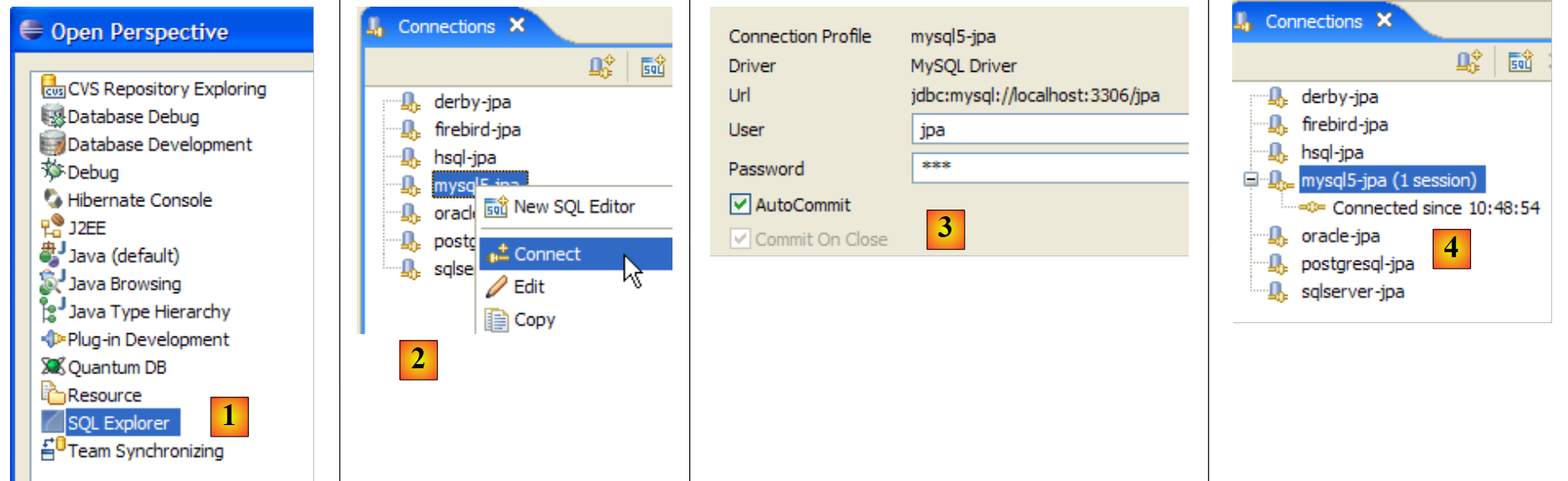 |
- [1]: se abre la perspectiva SQL Explorer [Window / Open Perspective / Other]
- [2]: si es necesario, se crea una conexión [mysql5-jpa] (véase el apartado 5.5.5, página 252) y se abre
- [3]: se inicia sesión con jpa / jpa
- [4]: estamos conectados a MySQL5.
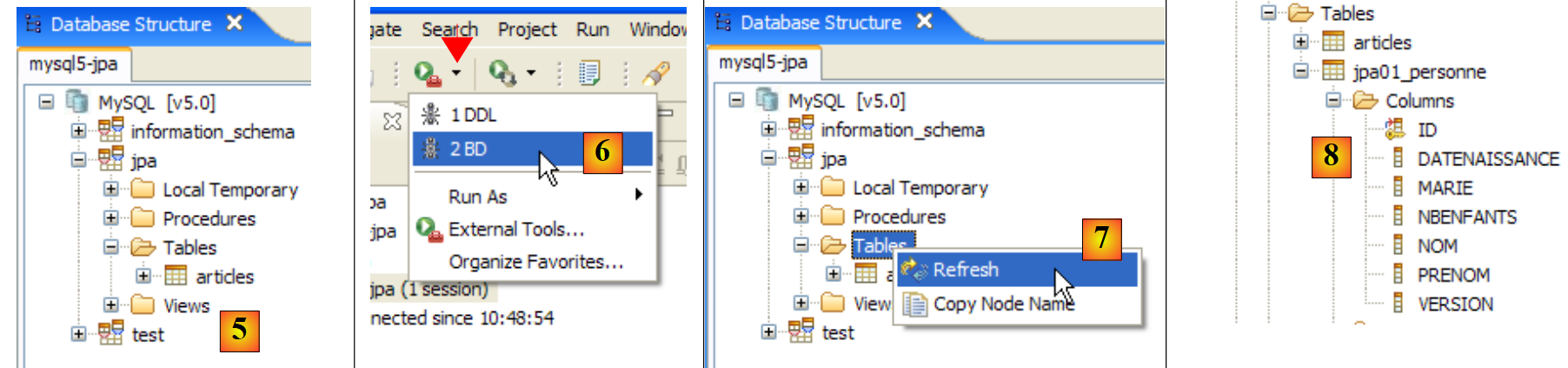 |
- en [5]: la tabla BD jpa solo tiene una tabla: [articles]
- en [6]: se inicia la ejecución de la tarea ant BD. Como nos encontramos en la perspectiva [SQL Explorer], no vemos la vista [Console], que nos muestra los registros de la tarea. Podemos mostrar esta vista [Window / Show View / ...] o volver a la perspectiva Java [Window / Open Perspective / ...].
- En [7]: una vez finalizada la tarea Ant BD, volver, si es necesario, a la perspectiva [SQL Explorer] y actualizar el árbol de la JPA BD.
- En [8]: se puede ver la tabla [jpa01_personne] que se ha creado.
Se invita al lector a volver a generar BD con otros SGBD. El procedimiento a seguir es el siguiente:
- copiar el archivo [conf/<sgbd>/persistence.xml] en la carpeta [src/META-INF], donde <sgbd> es el SGBD probado
- ejecutar <sgbd> siguiendo las instrucciones que figuran en los anexos relativas a este
- en el explorador SQL, crear una conexión con <sgbd>. Esto también se explica en los anexos para cada uno de los SGBD
- Repetir las pruebas anteriores
Llegados a este punto, hemos adquirido una serie de conocimientos:
- entendemos mejor el concepto de puente objeto-relacional. En este caso, lo ha implementado Hibernate. Más adelante utilizaremos Toplink.
- Sabemos que este puente objeto-relacional se configura en dos lugares:
- en los objetos @Entity, donde se indican las relaciones entre los campos de los objetos y las columnas de las tablas de la BD
- en [META-INF/persistence.xml], donde se proporciona a la implementación JPA información sobre los dos elementos del puente objeto-relacional: los objetos @Entity (objeto) y la base de datos (relacional).
- Hemos creado dos tareas Ant, denominadas DDL y BD, que nos permiten crear la base de datos a partir de la configuración anterior, incluso antes de escribir código Java.
Ahora que la capa JPA de nuestra aplicación está correctamente configurada, podemos empezar a explorar API y JPA con código Java.
2.1.9. El contexto de persistencia de una aplicación
Aclaremos un poco el entorno de ejecución de un cliente JPA:
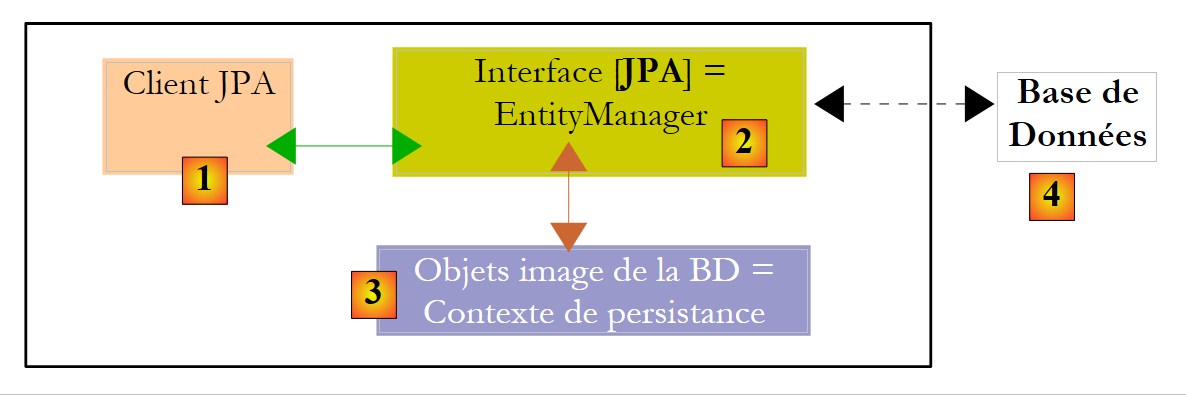 |
Sabemos que la capa JPA [2] crea un puente entre objetos [3] y relaciones [4]. Se denomina «contexto de persistencia» al conjunto de objetos gestionados por la capa JPA en el marco de este puente objeto/relacional. Para acceder a los datos del contexto de persistencia, un cliente JPA [1] debe pasar por la capa JPA [2]:
- puede crear un objeto y solicitar a la capa JPA que lo haga persistente. El objeto pasa entonces a formar parte del contexto de persistencia.
- puede solicitar a la capa [JPA] una referencia a un objeto persistente existente.
- Puede modificar un objeto persistente obtenido de la capa JPA.
- Puede solicitar a la capa JPA que elimine un objeto del contexto de persistencia.
La capa JPA presenta al cliente una interfaz denominada [EntityManager] que, como su nombre indica, permite gestionar los objetos @Entity del contexto de persistencia. A continuación, presentamos los principales métodos de esta interfaz:
coloca entity en el contexto de persistencia | |
elimina entity del contexto de persistencia | |
fusiona un objeto entity del cliente no gestionado por el contexto de persistencia con el objeto entity del contexto de persistencia que tiene la misma clave primaria. El resultado obtenido es el objeto entity del contexto de persistencia. | |
introduce en el contexto de persistencia un objeto buscado en la base a través de su clave primaria. El tipo T del objeto permite que la capa JPA sepa qué tabla consultar. El objeto persistente así creado se devuelve al cliente. | |
crea un objeto Query a partir de una consulta JPQL (Java Persistence Query Language). Una consulta JPQL es análoga a una consulta SQL, salvo que se consultan objetos en lugar de tablas. | |
método similar al anterior, salvo que queryText es, una orden SQL y no JPQL. | |
Método idéntico al de createQuery, salvo que la orden JPQL queryText se ha se ha externalizado a un archivo de configuración y se le ha asignado un nombre. Este nombre es el parámetro del método. |
Un objeto EntityManager tiene un ciclo de vida que no es necesariamente el de la aplicación. Tiene un inicio y un final. Así, un cliente JPA puede trabajar sucesivamente con diferentes objetos EntityManager. El contexto de persistencia asociado a un EntityManager tiene el mismo ciclo de vida que este. Son inseparables el uno del otro. Cuando se cierra un objeto EntityManager, su contexto de persistencia se sincroniza, si es necesario, con la base de datos y, a continuación, deja de existir. Es necesario crear un nuevo EntityManager para disponer de nuevo de un contexto de persistencia.
El cliente JPA puede crear un EntityManager y, por lo tanto, un contexto de persistencia con la siguiente instrucción:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
- javax.persistence.Persistence es una clase estática que permite obtener una fábrica (factory) de objetos EntityManager. Esta fábrica está vinculada a una unidad de persistencia concreta. Recordemos que el archivo de configuración [META-INF/persistence.xml] permite definir unidades de persistencia y que estas tienen un nombre:
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
En el ejemplo anterior, la unidad de persistencia se denomina jpa. Con ella viene toda una configuración propia, en particular la unidad SGBD con la que trabaja. La instrucción [Persistence.createEntityManagerFactory("jpa")] crea una fábrica de objetos de tipo EntityManagerFactory capaz de proporcionar objetos EntityManager destinados a gestionar contextos de persistencia vinculados a la unidad de persistencia denominada jpa. La obtención de un objeto EntityManager y, por lo tanto, de un contexto de persistencia, se realiza a partir del objeto EntityManagerFactory de la siguiente manera:
Los siguientes métodos de la interfaz [EntityManager] permiten gestionar el ciclo de vida del contexto de persistencia:
Se cierra el contexto de persistencia. Fuerza la sincronización del contexto de persistencia con la base de datos:
| |
El contexto de persistencia se vacía de todos sus objetos, pero no se cierra. | |
el contexto de persistencia se sincroniza con la base de datos tal y como se describe para close() |
El cliente JPA puede forzar la sincronización del contexto de persistencia con la base de datos mediante el método [EntityManager].flush anterior. La sincronización puede ser explícita o implícita. En el primer caso, es el cliente quien debe realizar las operaciones flush cuando desee llevar a cabo sincronizaciones; de lo contrario, estas se realizan en determinados momentos que especificaremos a continuación. El modo de sincronización se gestiona mediante los siguientes métodos de la interfaz [EntityManager]:
Hay dos valores posibles para flushmode: FlushModeType.AUTO (por defecto): la sincronización se lleva a cabo antes de cada consulta SELECT realizada en la base de datos. FlushModeType.COMMIT: la sincronización solo se lleva a cabo al finalizar las transacciones en la base de datos. | |
indica el modo de sincronización actual |
Resumamos. En el modo FlushModeType.AUTO, que es el modo por defecto, el contexto de persistencia se sincronizará con la base de datos en los siguientes momentos:
- antes de cada operación SELECT en la base de datos
- al finalizar una transacción en la base de datos
- tras una operación flush o close en el contexto de persistencia
En el modo FlushModeType.COMMIT, ocurre lo mismo, salvo que la operación 1 no tiene lugar. El modo normal de interacción con la capa JPA es un modo transaccional. El cliente realiza diversas operaciones en el contexto de persistencia, dentro de una transacción. En este caso, los momentos de sincronización del contexto de persistencia con la base de datos son los casos 1 y 2 anteriores en el modo AUTO, y únicamente el caso 2 en el modo COMMIT.
Terminemos con el API de la interfaz Query, interfaz que permite emitir órdenes JPQL en el contexto de persistencia o bien órdenes SQL directamente en la base de datos para recuperar datos de ella. La interfaz Query es la siguiente:
 |
Tendremos que utilizar los métodos del 1 al 4 anteriores:
- 1 - El método getResultList ejecuta un SELECT que devuelve varios objetos. Estos se obtendrán en un objeto List. Este objeto es una interfaz. Dicha interfaz ofrece un objeto Iterator que permite recorrer los elementos de la lista L de la siguiente forma:
Iterator iterator = L.iterator();
while (iterator.hasNext()) {
// procesar el objeto iterator.next() que representa el elemento actual de la lista
...
}
La lista L también se puede utilizar con un for:
for (Object o : L) {
// utilizar el objeto o
}
- 2 - El método getSingleResult ejecuta una orden JPQL / SQL / SELECT que devuelve un único objeto.
- 3 - El método executeUpdate ejecuta una orden SQL de actualización o eliminación y devuelve el número de filas afectadas por la operación.
- 4 - El método setParameter(String, Object) permite asignar un valor a un parámetro con nombre de una orden JPQL configurada
- 5 - El método setParameter(int, Object) no designa el parámetro por su nombre, sino por su posición en la orden JPQL.
2.1.10. Un primer cliente JPA
Volvamos a la perspectiva Java del proyecto:
 |
Ahora ya sabemos prácticamente todo sobre este proyecto, salvo el contenido de la carpeta [src/tests], que vamos a examinar a continuación. La carpeta contiene dos programas de prueba de la capa JPA:
- [InitDB.java] es un programa que inserta unas cuantas líneas en la tabla [jpa01_personne] de la base de datos. Su código nos proporcionará los primeros elementos de la capa JPA.
- [Main.java] es un programa que realiza las operaciones CRUD en la tabla [jpa01_personne]. El análisis de su código nos permitirá abordar los conceptos fundamentales del contexto de persistencia y del ciclo de vida de los objetos de dicho contexto.
2.1.10.1. El código
El código del programa [InitDB.java] es el siguiente:
package tests;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
import javax.persistence.Persistence;
import entites.Personne;
public class InitDB {
// constantes
private final static String TABLE_NAME = "jpa01_personne";
public static void main(String[] args) throws ParseException {
// Unidad de persistencia
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
// Recuperar un EntityManagerFactory a partir de la unidad de persistencia
EntityManager em = emf.createEntityManager();
// Inicio de transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// Eliminar los elementos de la tabla de personas
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
// crear dos personas
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// persistencia de personas
em.persist(p1);
em.persist(p2);
// visualización de personas
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// fin de la transacción
tx.commit();
// fin de EntityManager
em.close();
// fin de EntityManagerFactory
emf.close();
// registro
System.out.println("terminé ...");
}
}
Este código debe interpretarse a la luz de lo explicado en el apartado 2.1.9.
- línea 19: se solicita un objeto EntityManagerFactory emf para la unidad de persistencia jpa (definida en persistence.xml). Esta operación normalmente solo se realiza una vez durante el ciclo de vida de una aplicación.
- línea 21: se solicita un objeto EntityManager «em» para gestionar un contexto de persistencia.
- línea 23: se solicita un objeto Transaction para gestionar una transacción. Cabe recordar aquí que las operaciones sobre el contexto de persistencia se realizan dentro de una transacción. Veremos que esto no es obligatorio, pero que, de no hacerlo, pueden surgir problemas. Si la aplicación se ejecuta en un contenedor EJB3, las operaciones sobre el contexto de persistencia siempre se realizan dentro de una transacción.
- línea 24: comienza la transacción
- línea 26: ejecuta una orden «delete» SQL sobre la tabla «jpa01_personne» (nativeQuery). Esto se hace para vaciar la tabla de todo su contenido y así poder ver mejor el resultado de la ejecución de la aplicación [InitDB]
- líneas 28-29: se crean dos objetos Personne, p1 y p2. Se trata de objetos normales y, por el momento, no tienen nada que ver con el contexto de persistencia. En lo que respecta al contexto de persistencia, Hibernate afirma que estos objetos se encuentran en un estado transitorio (transient), para diferenciarlos de los objetos persistentes (persistent), que son gestionados por el contexto de persistencia. Hablaremos más bien de objetos no persistentes (expresión no utilizada en francés) para indicar que aún no son gestionados por el contexto de persistencia, y de objetos persistentes para aquellos que sí lo son. Encontraremos una tercera categoría de objetos, los objetos desvinculados (detached), que son objetos que anteriormente eran persistentes pero cuyo contexto de persistencia se ha cerrado. El cliente puede mantener referencias a dichos objetos, lo que explica que no se destruyan necesariamente al cerrarse el contexto de persistencia. Se dice entonces que se encuentran en estado «desvinculado». La operación [EntityManager].merge permite volver a vincularlos a un contexto de persistencia de nueva creación.
- líneas 31-32: las personas p1 y p2 se integran en el contexto de persistencia mediante la operación [EntityManager].persist. De este modo, pasan a ser objetos persistentes.
- líneas 35-37: se ejecuta una orden JPQL «select p from Personne p order by p.nom asc». Personne no es la tabla (que se llama jpa01_personne), sino el objeto @Entity asociado a la tabla. Aquí tenemos una consulta JPQL (Java Persistence Query Language) en el contexto de persistencia y no una orden SQL en la base de datos. Dicho esto, aparte del objeto Personne, que ha sustituido a la tabla jpa01_personne, las sintaxis son idénticas. Un bucle for recorre la lista (de personas) resultante de la consulta select para mostrar cada elemento en la consola. Lo que se pretende comprobar aquí es que los elementos introducidos en el contexto de persistencia en las líneas 31-32 se encuentran efectivamente en la tabla. De forma transparente, se llevará a cabo una sincronización del contexto de persistencia con la base de datos. De hecho, se emitirá una consulta select y ya se ha indicado que este es uno de los casos en los que se realiza una sincronización. Por lo tanto, es en ese momento cuando, en segundo plano, JPA / Hibernate emitirá las dos órdenes SQL y insert, que insertarán a las dos personas en la tabla jpa01_personne. La operación persist no lo había hecho. Esta operación integra objetos en el contexto de persistencia sin que ello tenga ninguna consecuencia en la base de datos. Las acciones reales se llevan a cabo durante las sincronizaciones, en este caso justo antes de la operación select en la base de datos.
- Línea 39: se finaliza la transacción iniciada en la línea 24. Se va a producir de nuevo una sincronización. Aquí no ocurrirá nada, ya que el contexto de persistencia no ha cambiado desde la última sincronización.
- línea 41: se cierra el contexto de persistencia.
- línea 43: se cierra la fábrica de EntityManager.
2.1.10.2. a ejecución del código
- ejecutar el SGBD MySQL5
- Colocar conf/mysql5/persistence.xml en META-INF/persistence.xml si es necesario
- ejecutar la aplicación [InitDB]
Se obtienen los siguientes resultados:
 |
- en [1]: la salida de la consola en la perspectiva Java. Se obtiene lo esperado.
- en [2]: se comprueba el contenido de la tabla [jpa01_personne] con la perspectiva SQL Explorer, tal y como se ha explicado en el apartado 2.1.8. Cabe destacar dos puntos:
- la clave primaria ID se ha generado automáticamente
- lo mismo ocurre con el número de versión. Se observa que la primera versión tiene el número 0..
Aquí tenemos los primeros elementos de la cultura JPA. Hemos conseguido insertar datos en una tabla. Vamos a partir de estos conocimientos para escribir la segunda prueba, pero antes hablemos de los registros.
2.1.11. Implementar los registros de Hibernate
Es posible conocer las órdenes SQL emitidas a la base de datos por la capa JPA / Hibernate. Es interesante conocerlos para comprobar si la capa JPA es tan eficaz como un desarrollador que hubiera escrito él mismo las órdenes SQL.
Con JPA / Hibernate, los registros SQL se pueden consultar en el archivo [persistence.xml]:
<!-- Clases persistentes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- registros SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- conexión JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
- líneas 4-6: los registros SQL no estaban activados por el momento. Ahora se activan eliminando la etiqueta de comentario de las líneas 3 y 7.
Volvemos a ejecutar la aplicación [InitDB]. Los mensajes de la consola pasan a ser los siguientes:
- líneas 2-4: la orden SQL delete derivada de la instrucción:
// eliminar elementos de la tabla de personas
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
- líneas 5-18: las órdenes SQL insert derivadas de las instrucciones:
// Persistencia de personas
em.persist(p1);
em.persist(p2);
- líneas 21-32: la orden «select» SQL derivada de la instrucción:
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList())
Si se realizan salidas intermedias a la consola, se observará que la escritura de los registros SQL de una instrucción I del código Java se produce cuando se ejecuta dicha instrucción I. Esto no significa que la orden SQL mostrada se ejecute en la base de datos en ese momento. De hecho, se almacena en caché para su ejecución durante la próxima sincronización del contexto de persistencia con la base de datos.
Se pueden obtener otros registros a través del archivo [src/log4j.properties]:
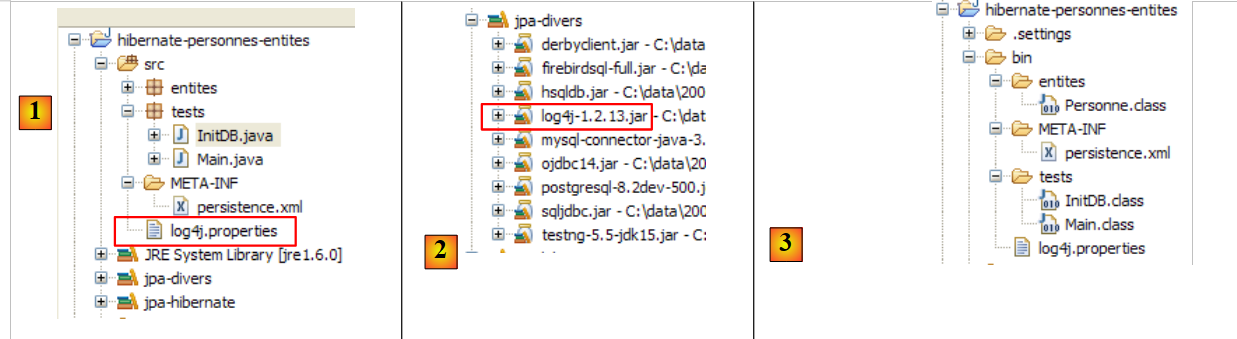 |
- en [1], el archivo [log4j.properties] es procesado por el archivo [log4j-1.2.13.jar] [2] de la herramienta denominada LOG4j (Logs for Java), disponible en la URL [http://logging.apache.org/log4j/docs/index.html]. Al estar ubicado en la carpeta [src] del proyecto Eclipse, sabemos que [log4j.properties] se copiará automáticamente en la carpeta [bin] del proyecto [3]. Una vez hecho esto, ahora se encuentra en el archivo classpath del proyecto y es allí donde el archivo [2] lo recuperará.
El archivo [log4j.properties] nos permite controlar determinados registros de Hibernate. En ejecuciones anteriores, su contenido era el siguiente:
# Dirigir los mensajes de registro a stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
# Opción de registro raíz
log4j.rootLogger=ERROR, stdout
# Opciones de registro de Hibernate (INFO solo muestra mensajes de inicio)
#log4j.logger.org.hibernate=INFO
# Registrar los argumentos en tiempo de ejecución de los parámetros de enlace de JDBC
#log4j.logger.org.hibernate.type=DEBUG
No voy a comentar mucho esta configuración, ya que nunca me he tomado la molestia de informarme en profundidad sobre LOG4j.
- Las líneas 1-8 aparecen en todos los archivos log4j.properties con los que me he encontrado
- Las líneas 10-14 están presentes en los archivos log4j.properties de los ejemplos de Hibernate.
- Línea 11: controla los registros generales de Hibernate. Al estar la línea comentada, estos registros están desactivados aquí. Puede haber varios niveles de registros: INFO (información general sobre lo que hace Hibernate), WARN (Hibernate nos avisa de un posible problema), DEBUG (registros detallados). El nivel INFO es el menos detallado, mientras que el modo DEBUG es el más detallado. Al activar la línea 11 se puede saber qué hace Hibernate, especialmente al iniciar la aplicación. A menudo resulta interesante.
- La línea 12, si está activa, permite conocer los argumentos que se utilizan realmente al ejecutar las consultas SQL configuradas.
Empecemos por descomentar la línea 14
# Registro de los argumentos de tiempo de ejecución de los parámetros de enlace de JDBC
log4j.logger.org.hibernate.type=DEBUG
y volvamos a ejecutar [InitDB]. Los nuevos registros generados por esta modificación son los siguientes (vista parcial):
- Las líneas 8-10 son nuevos registros generados por la activación de la línea 14 de [log4j.properties]. Indican los 5 valores asignados a los parámetros formales ? de la consulta parametrizada de las líneas 2-7. Así, vemos que la columna VERSION recibirá el valor 0 (línea 8).
Ahora activemos la línea 11 de [log4j.properties]:
# Opciones de registro de Hibernate (INFO solo muestra mensajes de inicio)
log4j.logger.org.hibernate=INFO
y volvamos a ejecutar [InitDB]:
La lectura de estos registros aporta mucha información interesante:
- línea 7: Hibernate indica el nombre de una clase @Entity que ha encontrado
- línea 8: indica que la clase [Personne] se va a vincular a la tabla [jpa01_personne]
- línea 9: indica el grupo de conexiones C3P0 que se va a utilizar, el nombre del controlador JDBC y la URL de la base de datos que se va a gestionar
- línea 10: proporciona otras características de la conexión JDBC: propietario, tipo de commit, etc.
- línea 14: el dialecto utilizado para comunicarse con SGBD
- línea 15: el tipo de transacción utilizado. JDBCTransactionFactory indica que la propia aplicación gestiona sus transacciones. No se ejecuta en un contenedor EJB3 que proporcionaría su propio servicio de transacciones.
- Las siguientes líneas se refieren a opciones de configuración de Hibernate con las que no nos hemos encontrado. Se invita al lector interesado a consultar la documentación de Hibernate.
- Línea 37: las órdenes SQL se mostrarán en la consola. Esto se solicitó en [persistence.xml]:
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.format_sql" value="true" />
<property name="use_sql_comments" value="true" />
- líneas 43-45: el esquema de la base de datos se exporta a los archivos SGBD y c.a.d. A continuación, la base de datos se vacía y se vuelve a crear. Este mecanismo se debe a la configuración realizada en [persistence.xml] (línea 4 más abajo):
...
<property name="hibernate.connection.password" value="jpa" />
<!-- Creación automática del esquema -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialecto -->
...
Cuando una aplicación «se cuelga» con una excepción de Hibernate que no se entiende, lo primero que hay que hacer es activar los registros de Hibernate en modo DEBUG en [log4j.properties] para tener una visión más clara:
# Opción de registrador raíz
log4j.rootLogger=ERROR, stdout
# Opciones de registro de Hibernate (INFO solo muestra mensajes de inicio)
log4j.logger.org.hibernate=DEBUG
En el resto de este documento, los registros están desactivados por defecto para que la visualización en la consola sea más legible.
2.1.12. Descubre el lenguaje JPQL / HQL con la consola de Hibernate
Nota: Esta sección requiere el complemento Hibernate Tools (apartado 5.2.5).
En el código de la aplicación [InitDB], hemos utilizado una consulta JPQL. JPQL (Java Persistence Query Language) es un lenguaje para realizar consultas al contexto de persistencia. La consulta detectada era la siguiente:
Seleccionaba todos los elementos de la tabla asociada a la @Entity [Personne] y los devolvía en orden ascendente por nombre. En la consulta anterior, p.nom es el campo «nombre» de una instancia p de la clase [Personne]. Por lo tanto, una consulta JPQL opera sobre los objetos @Entity del contexto de persistencia y no directamente sobre las tablas de la base de datos. La capa JPA traducirá esta consulta JPQL a una consulta SQL adecuada para el SGBD con el que trabaja. Así, en el caso de una implementación JPA / Hibernate vinculada a un SGBD MySQL5, la consulta anterior JPQL se traduce en la siguiente consulta SQL:
select
personne0_.ID as ID0_,
personne0_.VERSION as VERSION0_,
personne0_.NOM as NOM0_,
personne0_.PRENOM as PRENOM0_,
personne0_.DATENAISSANCE as DATENAIS5_0_,
personne0_.MARIE as MARIE0_,
personne0_.NBENFANTS as NBENFANTS0_
from
jpa01_personne personne0_
order by
personne0_.NOM asc
La capa JPA ha utilizado la configuración del objeto @Entity [Personne] para generar el pedido SQL correcto. En este caso se ha implementado el puente objeto-relacional.
El complemento [Hibernate Tools] (apartado 5.2.5) ofrece una herramienta denominada «Consola de Hibernate» que permite
- emitir órdenes JPQL o del superconjunto HQL (Hibernate Query Language) en el contexto de persistencia
- obtener los resultados
- conocer el equivalente SQL que se ha ejecutado en la base de datos
La consola de Hibernate es una herramienta de gran valor para aprender el lenguaje JPQL y familiarizarse con el puente JPQL / SQL. Se sabe que JPA se ha inspirado en gran medida en herramientas ORM como Hibernate o Toplink. JPQL es muy similar al lenguaje HQL de Hibernate, pero no incluye todas sus funcionalidades. En la consola de Hibernate se pueden introducir comandos HQL que se ejecutarán normalmente en la consola, pero que no forman parte del lenguaje JPQL y que, por lo tanto, no se podrían utilizar en un cliente JPA. Cuando sea así, lo indicaremos.
Creemos una consola de Hibernate para nuestro proyecto actual de Eclipse:
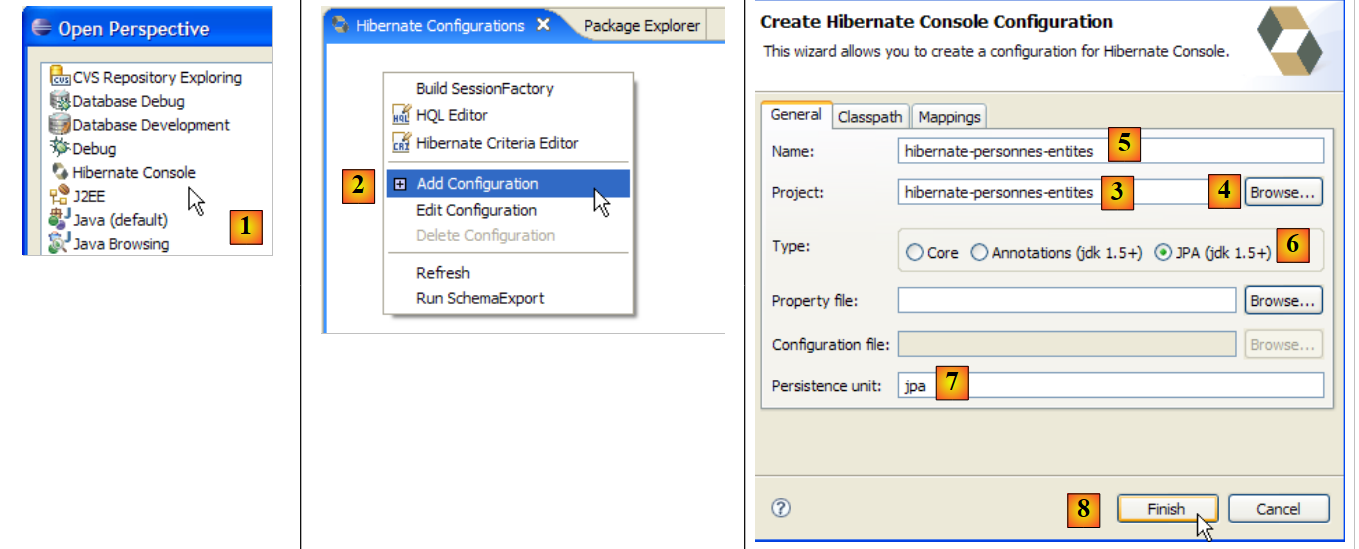 |
- [1]: pasamos a una perspectiva [Hibernate Console] (Ventana / Abrir perspectiva / Otra)
- [2]: creamos una nueva configuración en la ventana [Hibernate Configuration]
- mediante el botón [4], seleccionamos el proyecto Java para el que se crea la configuración de Hibernate. Su nombre aparece en [3].
- En [5], le damos el nombre que queramos a esta configuración. En este caso, hemos utilizado [3].
- En [6], indicamos que utilizamos una configuración JPA para que la herramienta sepa que debe procesar el archivo [META-INF/persistence.xml]
- en [7]: indicamos que, en este archivo [META-INF/persistence.xml], hay que utilizar la unidad de persistencia denominada jpa.
- En [8], validamos la configuración.
A continuación, hay que ejecutar el SGBD. En este caso, se trata del MySQL5.
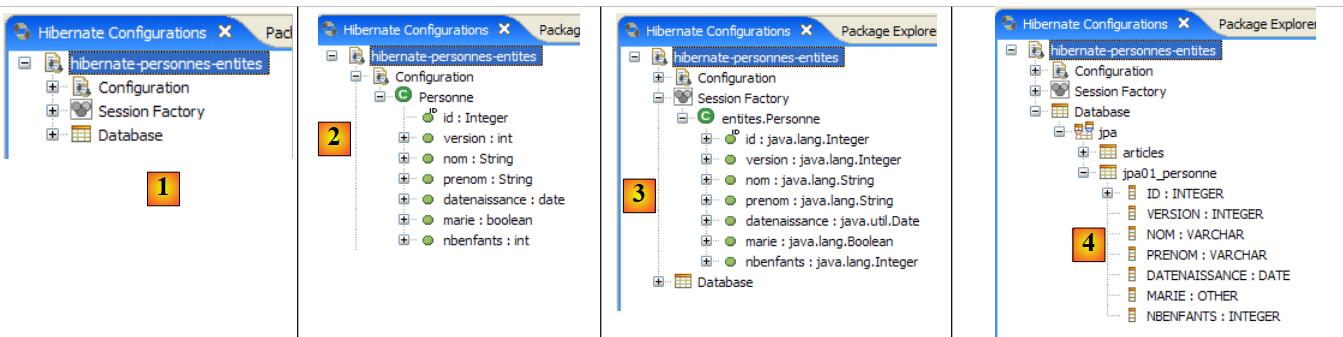 |
- en [1]: la configuración creada presenta un árbol de tres ramas
- en [2]: la rama [Configuration] enumera los objetos que la consola ha utilizado para configurarse: en este caso, la @Entity Personne.
- En [3]: la «Session Factory» es un concepto de Hibernate similar al de EntityManager de JPA. Establece el puente entre objetos y relaciones gracias a los objetos de la rama [Configuration]. En [3] se presentan los objetos del contexto de persistencia, en este caso de nuevo la @Entity Personne.
- En [4]: la base de datos a la que se accede mediante la configuración que se encuentra en [persistence.xml]. En ella se encuentra la tabla [jpa01_personne].
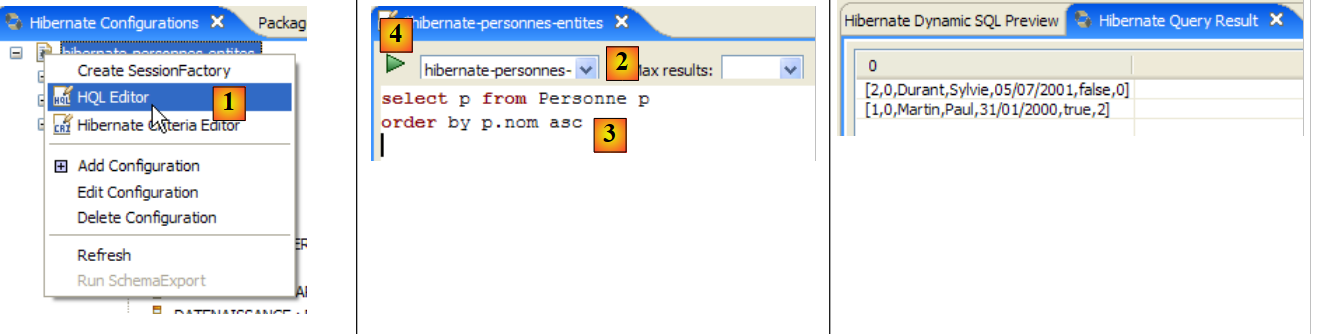 |
- en [1], se crea un editor HQL
- en el editor HQL,
- en [2], se elige la configuración de Hibernate que se va a utilizar si hay varias
- en [3], se escribe el comando JPQL que se desea ejecutar
- en [4], se ejecuta
- en [5], se obtienen los resultados de la consulta en la ventana [Hibernate Query Result]. Aquí pueden surgir dos problemas:
- no se obtiene nada (ninguna línea). La consola de Hibernate ha utilizado el contenido de [persistence.xml] para crear una conexión con SGBD. Sin embargo, esta configuración tiene una propiedad que indica que se vacíe la base de datos:
<property name="hibernate.hbm2ddl.auto" value="create" />
Por lo tanto, hay que volver a ejecutar la aplicación [InitDB] antes de volver a ejecutar el comando JPQL anterior.
- (continuación)
- No tenemos la ventana [Hibernate Query Result]. La solicitamos mediante [Window / Show View / ...]
La ventana [Hibernate Dynamic SQL preview] ([1] a continuación) permite ver la consulta SQL que se va a ejecutar para llevar a cabo el comando JPQL que estamos escribiendo. En cuanto la sintaxis del comando JPQL sea correcta, el comando SQL correspondiente aparecerá en esta ventana:
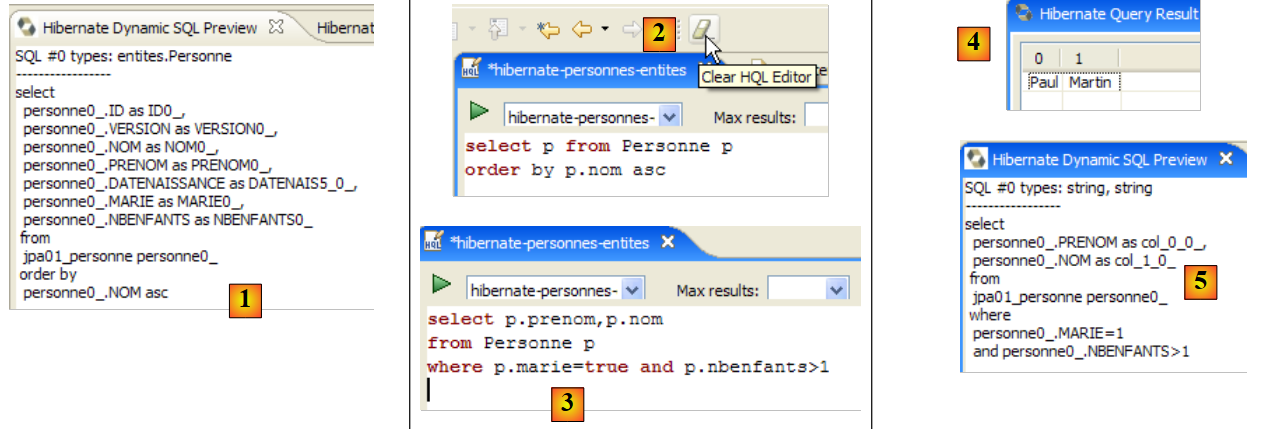 |
- en [2], se borra el comando anterior HQL
- en [3], se ejecuta uno nuevo
- en [4], el resultado
- en [5], el comando SQL que se ha ejecutado en base a
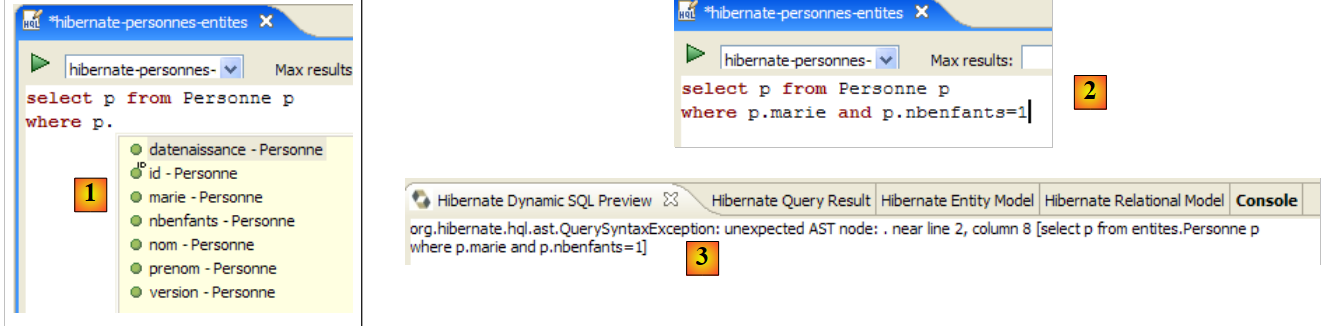
El editor HQL ofrece ayuda para escribir los comandos HQL:
 |
- en [1]: una vez que el editor sabe que p es un objeto Personne, puede sugerirnos los campos de p mientras escribimos.
- en [2]: un comando HQL incorrecto. Hay que escribir «where p.marie=true».
- En [3]: el error se indica en la ventana [SQL Preview]
Invitamos al lector a introducir otros comandos HQL / JPQL en la base.
2.1.13. Un segundo cliente JPA
Volvamos a la perspectiva Java del proyecto:
|
- [InitDB.java] es un programa que insertaba algunas filas en la tabla [jpa01_personne] de la base de datos. El análisis de su código nos ha permitido obtener los primeros elementos de API y JPA.
- [Main.java] es un programa que realiza las operaciones CRUD en la tabla [jpa01_personne]. El análisis de su código nos permitirá repasar los conceptos fundamentales del contexto de persistencia y del ciclo de vida de los objetos de dicho contexto.
2.1.13.1. La estructura del código
[Main.java] encadenará una serie de pruebas, cada una de las cuales tiene como objetivo mostrar una faceta concreta de JPA:
 |
El método [main]
- llama sucesivamente a los métodos test1 a test11. Presentaremos por separado el código de cada uno de estos métodos.
- Además, utiliza métodos auxiliares privados: clean, dump, log, getEntityManager y getNewEntityManager.
A continuación, presentamos el método main y los denominados métodos utilitarios:
package tests;
...
import entites.Personne;
@SuppressWarnings("unchecked")
public class Main {
// Constantes
private final static String TABLE_NAME = "jpa01_personne";
// Contexto de persistencia
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = null;
// Objetos compartidos
private static Personne p1, p2, newp1;
public static void main(String[] args) throws Exception {
// Limpieza de la base de datos
log("clean");clean();
// volcado de tabla
dump();
// prueba1
log("test1");test1();
...
// prueba11
log("test11");test11();
// fin del contexto de persistencia
if (em.isOpen())
em.close();
// cierre de EntityManagerFactory
emf.close();
}
// recuperar el EntityManager actual
private static EntityManager getEntityManager() {
if (em == null || !em.isOpen()) {
em = emf.createEntityManager();
}
return em;
}
// obtener un nuevo EntityManager
private static EntityManager getNewEntityManager() {
if (em != null && em.isOpen()) {
em.close();
}
em = emf.createEntityManager();
return em;
}
// mostrar el contenido de la tabla
private static void dump() {
// contexto de persistencia actual
EntityManager em = getEntityManager();
// inicio de transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// visualización de personas
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// fin de transacción
tx.commit();
}
// borrado BD
private static void clean() {
// contexto de persistencia
EntityManager em = getEntityManager();
// Inicio de transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// eliminar los elementos de la tabla PERSONNES
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
// fin de la transacción
tx.commit();
}
// registros
private static void log(String message) {
System.out.println("main : ----------- " + message);
}
// creación de objetos
public static void test1() throws ParseException {
...
}
// modificar un objeto del contexto
public static void test2() {
...
}
// solicitar objetos
public static void test3() {
...
}
// eliminar un objeto perteneciente al contexto de persistencia
public static void test4() {
....
}
// desvincular, volver a vincular y modificar
public static void test5() {
...
}
// eliminar un objeto que no pertenece al contexto de persistencia
public static void test6() {
...
}
// modificar un objeto que no pertenece al contexto de persistencia
public static void test7() {
...
}
// volver a vincular un objeto al contexto de persistencia
public static void test8() {
...
}
// una consulta SELECT provoca una sincronización
// de la base de datos con el contexto de persistencia
public static void test9() {
....
}
// control de versiones (bloqueo optimista)
public static void test10() {
...
}
// reversión de una transacción
public static void test11() throws ParseException {
...
}
}
- línea 13: el objeto EntityManagerFactory emf construido a partir de la unidad de persistencia jpa definida en [persistence.xml]. Nos permitirá crear, a lo largo de la aplicación, diversos contextos de persistencia.
- línea 14: un contexto de persistencia EntityManager em aún sin inicializar
- línea 17: tres objetos [Personne] compartidos por las pruebas
- línea 21: la tabla jpa01_personne se vacía y, a continuación, se muestra en la línea 24 para asegurarnos de que partimos de una tabla vacía.
- líneas 27-31: secuencia de pruebas
- líneas 34-35: cierre del contexto de persistencia em si estaba abierto.
- línea 38: cierre del objeto EntityManagerFactory emf.
- líneas 42-47: el método [getEntityManager] establece el EntityManager (o contexto de persistencia) como el actual o como uno nuevo si no existe (líneas 43-44).
- líneas 50-56: el método [getNewEntityManager] crea un nuevo contexto de persistencia. Si ya existía uno anteriormente, se cierra (líneas 51-52)
- líneas 59-72: el método [dump] muestra el contenido de la tabla [jpa01_personne]. Este código ya se ha encontrado en [InitDB].
- líneas 75-85: el método [clean] vacía la tabla [jpa01_personne]. Este código ya se ha visto en [InitDB].
- líneas 88-90: el método [log] muestra en la consola el mensaje que se le pasa como parámetro para que se pueda observar.
Ahora podemos pasar al análisis de las pruebas.
2.1.13.2. Prueba 1
El código de la prueba 1 es el siguiente:
// creación de objetos
public static void test1() throws ParseException {
// contexto de persistencia
EntityManager em = getEntityManager();
// creación de personas
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// Inicio de una transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistencia de personas
em.persist(p1);
em.persist(p2);
// fin de transacción
tx.commit();
// se muestra la tabla
dump();
}
Este código ya se ha visto en [InitDB]: crea dos personas y las coloca en el contexto de persistencia.
- línea 4: se solicita el contexto de persistencia actual
- líneas 6-7: se crean las dos personas
- líneas 9-15: las dos personas se colocan en el contexto de persistencia dentro de una transacción.
- línea 15: debido a la confirmación de la transacción, se sincroniza el contexto de persistencia con la base de datos. Las dos personas se añadirán a la tabla [jpa01_personne].
- línea 17: se muestra la tabla
La salida en la consola de esta primera prueba es la siguiente:
main : ----------- test1
[personnes]
[2,0,Durant,Sylvie,05/07/2001,false,0]
[1,0,Martin,Paul,31/01/2000,true,2]
2.1.13.3. Prueba 2
El código de la prueba 2 es el siguiente:
// modificar un objeto del contexto
public static void test2() {
// contexto de persistencia
EntityManager em = getEntityManager();
// Inicio de transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// se incrementa el número de hijos de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// se modifica su estado civil
p1.setMarie(false);
// el objeto p1 se guarda automáticamente (comprobación de cambios)
// en la próxima sincronización (commit o select)
// fin de la transacción
tx.commit();
// se muestra la nueva tabla
dump();
}
- El objetivo de la prueba 2 es modificar un objeto del contexto de persistencia y, a continuación, mostrar el contenido de la tabla para comprobar si se ha producido la modificación
- Línea 4: se recupera el contexto de persistencia actual
- líneas 6-7: las operaciones se realizarán dentro de una transacción
- líneas 9 y 11: se modifica el número de hijos de la persona p1, así como su estado civil
- línea 15: fin de la transacción, por lo que se sincroniza el contexto de persistencia con la base de datos
- línea 17: visualización de la tabla
La salida en consola de la prueba 2 es la siguiente:
- línea 4: la persona p1 antes de la modificación
- línea 8: la persona p1 tras la modificación. Cabe destacar que su número de versión ha pasado a 1. Este se incrementa en 1 con cada actualización de la línea.
2.1.13.4. Prueba 3
El código de la prueba 3 es el siguiente:
// solicitar objetos
public static void test3() {
// contexto de persistencia
EntityManager em = getEntityManager();
// inicio de la transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// se solicita la persona p1
Personne p1b = em.find(Personne.class, p1.getId());
// como p1 ya se encuentra en el contexto de persistencia, no se ha producido ningún acceso a la base de datos
// p1b y p1 son las mismas referencias
System.out.format("p1==p1b ? %s%n", p1 == p1b);
// al solicitar un objeto que no existe, se devuelve un puntero nulo
Personne px = em.find(Personne.class, -4);
System.out.format("px==null ? %s%n", px == null);
// fin de la transacción
tx.commit();
}
- La prueba 3 se centra en el método [EntityManager.find], que permite recuperar un objeto de la base de datos para colocarlo en el contexto de persistencia. A partir de ahora ya no explicaremos la transacción que tiene lugar en todas las pruebas, salvo cuando se utilice de forma inusual.
- Línea 9: se solicita al contexto de persistencia la persona que tiene la misma clave primaria que la persona p1. Hay dos casos:
- p1 ya se encuentra en el contexto de persistencia. Este es el caso aquí. Por lo tanto, no se realiza ningún acceso a la base de datos. El método find se limita a devolver una referencia al objeto persistido.
- p1 no está en el contexto de persistencia. En ese caso, se realiza un acceso a la base de datos mediante la clave primaria proporcionada. La línea recuperada se introduce en el contexto de persistencia y find devuelve la referencia de este nuevo objeto persistido.
- línea 12: se comprueba que find ya ha devuelto la referencia del objeto p1 en el contexto
- línea 14: se solicita un objeto que no existe ni en el contexto de persistencia ni en la base de datos. El método find devuelve entonces el puntero null. Esto se comprueba en la línea 15.
La salida de la consola de la prueba 3 es la siguiente:
2.1.13.5. Prueba 4
El código de la prueba 4 es el siguiente:
// eliminar un objeto que pertenece al contexto de persistencia
public static void test4() {
// contexto de persistencia
EntityManager em = getEntityManager();
// Inicio de transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// se elimina el objeto persistido p2
em.remove(p2);
// fin de transacción
tx.commit();
// se muestra la nueva tabla
dump();
}
- La prueba 4 se centra en el método [EntityManager.remove], que permite eliminar un elemento del contexto de persistencia y, por lo tanto, de la base de datos.
- Línea 9: se elimina a la persona p2 del contexto de persistencia
- línea 11: sincronización del contexto con la base de datos
- línea 13: visualización de la tabla. Normalmente, la persona p2 ya no debería aparecer.
La salida de consola de la prueba 4 es la siguiente:
- línea 3: la persona p2 en test1
- líneas 12-14: ya no existe al finalizar test4.
2.1.13.6. Prueba 5
El código de la prueba 5 es el siguiente:
// desvincular, volver a vincular y modificar
public static void test5() {
// nuevo contexto de persistencia
EntityManager em = getNewEntityManager();
// inicio de la transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// p1 desvinculado
Personne oldp1=p1;
// se vuelve a vincular p1 al nuevo contexto
p1 = em.find(Personne.class, p1.getId());
// verificación
System.out.format("p1==oldp1 ? %s%n", p1 == oldp1);
// fin de la transacción
tx.commit();
// se incrementa el número de hijos de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// se muestra la nueva tabla
dump();
}
- La prueba 5 analiza el ciclo de vida de los objetos persistentes a lo largo de varios contextos de persistencia sucesivos. Hasta ahora, siempre habíamos utilizado el mismo contexto de persistencia en las diferentes pruebas.
- Línea 4: se solicita un nuevo contexto de persistencia. El método [getNewEntityManager] cierra el anterior y abre uno nuevo. Esto tiene como consecuencia que los objetos p1 y p2 que posee la aplicación ya no se encuentran en un estado persistente. Pertenecían a un contexto que se ha cerrado. Se dice que se encuentran en un estado «desvinculado». No pertenecen al nuevo contexto de persistencia.
- Líneas 6-7: inicio de la transacción. En este caso, se va a utilizar de forma inusual.
- línea 9: se anota la dirección del objeto p1, ahora desvinculado.
- línea 11: se solicita al contexto de persistencia la persona p1 (utilizando la clave primaria de p1). Como el contexto es nuevo, la persona p1 no se encuentra en él. Por lo tanto, se realizará un acceso a la base de datos. El objeto recuperado se colocará en el nuevo contexto.
- línea 13: se comprueba que el objeto persistente p1 del contexto es diferente del objeto oldp1, que era el antiguo objeto p1 desvinculado.
- línea 15: la transacción ha finalizado
- línea 17: se modifica, fuera de la transacción, el nuevo objeto persistente p1. ¿Qué ocurre en este caso? Queremos saberlo.
- Línea 19: se solicita la visualización de la tabla. Recordemos que, debido al select emitido por el método dump, se lleva a cabo automáticamente una sincronización del contexto de persistencia con la base de datos.
La salida en consola de la prueba 5 es la siguiente:
- línea 5: el método find sí ha accedido a la base de datos; de lo contrario, los dos punteros serían iguales
- líneas 7 y 3: el número de hijos de p1 ha aumentado efectivamente en 1. Por lo tanto, se ha tenido en cuenta la modificación, realizada fuera de la transacción. De hecho, esto depende del SGBD utilizado. En un SGBD, una orden SQL siempre se ejecuta dentro de una transacción. Si el cliente JPA no inicia por sí mismo una transacción explícita, el SGBD iniciará entonces una transacción implícita. Hay dos casos habituales:
- 1 - Cada orden SQL individual forma parte de una transacción, que se abre antes de la orden y se cierra después. Se dice que estamos en modo autocommit. Por lo tanto, todo ocurre como si el cliente JPA realizara transacciones para cada orden SQL.
- 2 - El SGBD no está en modo autocommit e inicia una transacción implícita con el primer pedido SQL que el cliente JPA emite fuera de una transacción, y deja que sea el cliente quien la cierre. Todas las órdenes SQL emitidas por el cliente JPA pasan a formar parte de la transacción implícita. Esta puede finalizar por diferentes motivos: el cliente cierra la conexión, inicia una nueva transacción, etc.
Nos encontramos ante una situación que depende de la configuración de SGBD. Por lo tanto, se trata de código no portátil. Más adelante mostraremos un código sin transacciones y veremos que no todos los SGBD se comportan de la misma manera con respecto a este código. Por lo tanto, consideraremos que trabajar sin transacciones es un error de programación.
- Línea 7: cabe señalar que el número de versión ha pasado a ser 2.
2.1.13.7. Prueba 6
El código de la prueba 6 es el siguiente:
// eliminar un objeto que no pertenece al contexto de persistencia
public static void test6() {
// nuevo contexto de persistencia
EntityManager em = getNewEntityManager();
// Inicio de la transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// se elimina p1, que no pertenece al nuevo contexto
try {
em.remove(p1);
// fin de la transacción
tx.commit();
} catch (RuntimeException e1) {
System.out.format("Erreur à la suppression de p1 : [%s,%s]%n", e1.getClass().getName(), e1.getMessage());
// se realiza un rollback de la transacción
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s,%s]%n", e2.getClass().getName(), e2.getMessage());
}
}
// se muestra la nueva tabla
dump();
}
- La prueba 6 intenta eliminar un objeto que no pertenece al contexto de persistencia.
- Línea 4: se solicita un nuevo contexto de persistencia. Por lo tanto, el anterior se cierra y los objetos que contenía quedan desvinculados. Este es el caso del objeto p1 de la prueba 5 anterior.
- Líneas 6-7: inicio de la transacción.
- Línea 10: se elimina el objeto desvinculado p1. Sabemos que esto provocará una excepción, por lo que hemos rodeado la operación con un try/catch.
- línea 12: el commit no se llevará a cabo.
- líneas 16-21: una transacción debe finalizar con un commit (todas las operaciones de la transacción se validan) o con un rollback (todas las operaciones de la transacción se anulan). Se ha producido una excepción, por lo que se ejecuta un rollback de la transacción. No hay nada que revertir, ya que la única operación de la transacción ha fallado, pero el rollback pone fin a la transacción. Es la primera vez que utilizamos la operación [EntityTransaction].rollback. Deberíamos haberlo hecho desde los primeros ejemplos. No lo hemos hecho para mantener el código sencillo. No obstante, el lector debe tener presente que el caso del rollback de la transacción siempre debe preverse en el código.
- Línea 24: se muestra la tabla. Normalmente, no debería haber cambiado.
La salida de la consola de la prueba 6 es la siguiente:
- línea 6: la eliminación de p1 ha fallado. El mensaje de la excepción explica que se ha intentado eliminar un objeto desvinculado, por lo que no forma parte del contexto. Esto no es posible.
- Línea 8: la persona p1 sigue ahí.
2.1.13.8. Prueba 7
El código de la prueba 7 es el siguiente:
// Modificar un objeto que no pertenece al contexto de persistencia
public static void test7() {
// nuevo contexto de persistencia
EntityManager em = getNewEntityManager();
// Inicio de la transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// se incrementa el número de hijos de p1 que no pertenecen al nuevo contexto
p1.setNbenfants(p1.getNbenfants() + 1);
// fin de la transacción
tx.commit();
// se muestra la nueva tabla; no debería haber cambiado
dump();
}
- La prueba 7 pretende modificar un objeto que no pertenece al contexto de persistencia y comprobar el impacto que esto tiene en la base de datos. Es de suponer que no tiene ninguno. Eso es lo que muestran los resultados de la prueba.
- Línea 4: se solicita un nuevo contexto de persistencia. Por lo tanto, tenemos un contexto nuevo sin objetos persistidos en su interior.
- Líneas 6-7: inicio de la transacción.
- línea 9: se modifica el objeto desvinculado p1. Se trata de una operación que no implica al contexto de persistencia em. Por lo tanto, no cabe esperar una excepción ni nada por el estilo. Es una operación básica sobre un POJO.
- línea 11: el commit provoca la sincronización del contexto con la base de datos. Este contexto está vacío. Por lo tanto, la base de datos no se modifica.
- línea 24: se muestra la tabla. Normalmente, no debería haber cambiado.
La salida de la consola de la prueba 7 es la siguiente:
- línea 7: la persona p1 no ha cambiado en la base de datos. Para la siguiente prueba, recordaremos, no obstante, que en memoria su número de hijos es ahora de 5.
2.1.13.9. Prueba 8
El código de la prueba 8 es el siguiente:
// Volver a vincular un objeto al contexto de persistencia
public static void test8() {
// nuevo contexto de persistencia
EntityManager em = getNewEntityManager();
// Inicio de la transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// Se vuelve a vincular el objeto desvinculado p1 al nuevo contexto
newp1 = em.merge(p1);
// Ahora es newp1 el que forma parte del contexto, no p1
// fin de la transacción
tx.commit();
// se muestra la nueva tabla; el número de hijos de p1 debe de haber cambiado
dump();
}
- La prueba 8 vuelve a vincular al contexto de persistencia un objeto desvinculado.
- Línea 4: se solicita un nuevo contexto de persistencia. Por lo tanto, tenemos un contexto nuevo sin objetos persistentes en su interior.
- Líneas 6-7: inicio de la transacción.
- Línea 9: se vuelve a vincular al contexto de persistencia el objeto desvinculado p1. La operación «merge» puede implicar varias operaciones:
- Caso 1: en el contexto de persistencia existe un objeto persistente ps1 que tiene la misma clave primaria que el objeto desvinculado p1. El contenido de p1 se copia en ps1 y merge hace referencia a ps1.
- Caso 2: en el contexto de persistencia no existe ningún objeto persistente ps1 que tenga la misma clave primaria que el objeto desvinculado p1. A continuación, se consulta la base de datos para comprobar si el objeto buscado existe en ella. Si es así, dicho objeto se incorpora al contexto de persistencia, se convierte en el objeto persistente ps1 y se vuelve al caso 1 anterior.
- Caso 3: no existe, ni en el contexto de persistencia ni en la base de datos, ningún objeto con la misma clave primaria que el objeto desvinculado p1. A continuación, se crea un nuevo objeto [Personne] (new) y se introduce en el contexto de persistencia. Después, se vuelve al caso 1.
- En definitiva: el objeto desacoplado p1 permanece desacoplado. La operación merge devuelve una referencia (en este caso, newp1) al objeto persistente ps1 derivado de merge. La aplicación cliente debe trabajar ahora con el objeto persistente ps1 y no con el objeto desvinculado p1.
- Cabe señalar una diferencia entre los casos 1 y 3 en cuanto a la orden SQL programada para el merge: en los casos 1 y 2, se trata de la orden UPDATE, mientras que en el caso 3 es una orden INSERT.
- línea 12: el commit provoca la sincronización del contexto con la base de datos. Este contexto ya no está vacío. Contiene el objeto newp1. Este se va a guardar en la base de datos.
- línea 24: se muestra la tabla para comprobarlo.
La salida de la consola de la prueba 8 es la siguiente:
- El número de hijos de p1 era 4 en la prueba 6 (línea 4), luego pasó a ser 5 en la prueba 7, pero no se había guardado en la base de datos (línea 7). Tras el merge, el newp1 se ha guardado en la base de datos: en la línea 10, se observan efectivamente 5 hijos.
- línea 10: el número de versión de newp1 ha pasado a 3.
2.1.13.10. Prueba 9
El código de la prueba 9 es el siguiente:
// una consulta SELECT provoca una sincronización
// de la base de datos con el contexto de persistencia
public static void test9() {
// contexto de persistencia
EntityManager em = getEntityManager();
// Inicio de la transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// se incrementa el número de hijos de newp1
newp1.setNbenfants(newp1.getNbenfants() + 1);
// visualización de personas: el número de hijos de newp1 debe haber cambiado
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// fin de la transacción
tx.commit();
}
- La prueba 9 pretende mostrar el mecanismo de sincronización del contexto que se produce automáticamente antes de un select.
- Línea 5: no se cambia el contexto de persistencia. Por lo tanto, newp1 está dentro.
- Líneas 7-8: inicio de la transacción.
- Línea 10: el número de elementos secundarios del objeto persistente newp1 se incrementa en 1 (5 → 6).
- Líneas 12-15: se muestra la tabla mediante una instrucción SELECT. El contexto se sincronizará con la base de datos antes de la ejecución de select.
- línea 17: fin de la transacción
Para ver la sincronización, activamos la visualización de los registros de Hibernate en modo DEBUG (log4j.properties):
# Opción de registro raíz
log4j.rootLogger=ERROR, stdout
# Opciones de registro de Hibernate (INFO solo muestra mensajes de inicio)
log4j.logger.org.hibernate=DEBUG
La salida de la consola de la prueba 9 es la siguiente:
- línea 1: se inicia la prueba 9
- líneas 2-6: se inicia la transacción JDBC. El modo autocommit de SGBD está desactivado (línea 5)
- línea 7: salida provocada por la línea 12 del código Java. Las siguientes líneas del código Java provocarán un select y, por lo tanto, una sincronización del contexto de persistencia con la base de datos.
- línea 8: la orden JPQL que queremos emitir ya se ha emitido. Hibernate la encuentra en su caché de «consultas preparadas».
- Línea 9: Hibernate anuncia que va a realizar un flush del contexto de persistencia
- líneas 11-12: Hibernate (Hb) detecta que la entidad Persona#1 (con clave primaria 1) ha sido modificada (dirty).
- líneas 12-13: Hb anuncia que actualiza este elemento y cambia su número de versión de 3 a 4.
- línea 15: la sincronización del contexto provocará 0 inserciones, 1 actualización (update) y 0 eliminaciones (delete)
- líneas 17-34: sincronización del contexto (flush). A tener en cuenta: el incremento de la versión (línea 19), la orden SQL update preparada (línea 21), los valores de los parámetros de la orden update (líneas 24-31).
- línea 35: comienza la orden select
- línea 38: la orden SQL que se va a ejecutar
- línea 40: el select solo devuelve una línea
- línea 42: Hb descubre que ya tiene en su contexto de persistencia la entidad Personne#1 que la consulta SELECT ha recuperado de la base de datos. Por lo tanto, no copia la línea obtenida de la base de datos en el contexto, operación que denomina «hidratación».
- línea 43: comprueba si los objetos devueltos por select tienen dependencias (normalmente claves externas) que también habría que cargar (colecciones no perezosas). En este caso, no hay ninguna.
- línea 44: visualización provocada por el código Java
- línea 45: fin de la transacción JDBC solicitada por el código Java
- línea 46: comienza la sincronización automática del contexto que tiene lugar durante el commit.
- línea 48: Hb detecta que el contexto no ha cambiado desde la sincronización anterior.
- línea 50: fin de commit.
Una vez más, los registros de Hibernate en modo DEBUG resultan muy útiles para saber exactamente qué hace Hibernate.
2.1.13.11. Prueba 10
El código de la prueba 10 es el siguiente:
// control de versiones (bloqueo optimista)
public static void test10() {
// Contexto de persistencia
EntityManager em = getEntityManager();
// Inicio de transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// incrementar la versión de newp1 directamente en la base de datos (consulta nativa)
em.createNativeQuery(String.format("update %s set VERSION=VERSION+1 WHERE ID=%d", TABLE_NAME, newp1.getId())).executeUpdate();
// fin de transacción
tx.commit();
// Inicio de una nueva transacción
tx = em.getTransaction();
tx.begin();
// se incrementa el número de hijos de newp1
newp1.setNbenfants(newp1.getNbenfants() + 1);
// fin de la transacción: debe fallar porque «newp1» ya no tiene la versión correcta
try {
tx.commit();
} catch (RuntimeException e1) {
System.out.format("Erreur lors de la mise à jour de newp1 [%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(), e1.getCause().getClass().getName(), e1.getCause().getMessage());
// se realiza un rollback de la transacción
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s,%s]%n", e2.getClass().getName(), e2.getMessage());
}
}
// se cierra el contexto, que ya no está actualizado
em.close();
// volcado de la tabla: la versión de p1 debe de haber cambiado
dump();
}
- La prueba 10 pretende mostrar el mecanismo que aporta el campo version de la @Entity «Persona», que cuenta con el atributo JPA @Version. Ya hemos explicado que esta anotación hace que, en la base de datos, el valor de la columna asociada a la anotación @Version se incremente cada vez que se realice un update en la fila a la que pertenece. Este mecanismo, también denominado bloqueo optimista (optimistic locking), exige que el cliente que desee modificar un objeto O en la base de datos disponga de la última versión del mismo. Si no la tiene, significa que el objeto ha sido modificado desde que lo obtuvo y hay que avisarle de ello.
- línea 4: no se cambia el contexto de persistencia. Por lo tanto, newp1 se encuentra dentro de él.
- Líneas 6-7: inicio de una transacción.
- línea 9: la versión del objeto newp1 se incrementa en 1 (4 → 5) directamente en la base de datos. Las consultas del tipo nativeQuery eluden el contexto de persistencia y acceden directamente a la base de datos. El resultado es que el objeto persistente newp1 y su imagen en la base de datos ya no tienen la misma versión.
- línea 10: fin de la primera transacción
- líneas 13-14: inicio de una segunda transacción
- línea 16: el número de hijos del objeto persistente newp1 aumenta en 1 (6 → 7).
- línea 19: fin de la transacción. Por lo tanto, se produce una sincronización. Esta provocará la actualización del número de hijos de newp1 en la base de datos. Esta actualización fallará porque el objeto persistente newp1 tiene la versión 4, mientras que en la base de datos el objeto que se debe actualizar tiene la versión 5. Se lanzará una excepción, lo que justifica el bloque «try / catch» del código.
- Línea 21: se muestra la excepción y su causa.
- Línea 25: se revierte la transacción
- línea 33: visualización de la tabla: deberíamos ver que la versión de newp1 es la 5 en la base de datos.
La salida de la consola de la prueba 10 es la siguiente:
- línea 5: el commit lanza efectivamente una excepción. Es de tipo [javax.persistence.RollbackException]. El mensaje asociado es impreciso. Si nos fijamos en la causa de esta excepción (Exception.getCause), vemos que se trata de una excepción de Hibernate debida a que se intenta modificar una fila de la base de datos sin tener la versión correcta.
- Línea 7: vemos que la versión de newp1 en la base de datos se ha actualizado correctamente a 5 mediante nativeQuery.
2.1.13.12. Prueba 11
El código de la prueba 11 es el siguiente:
// reversión de una transacción
public static void test11() throws ParseException {
// contexto de persistencia
EntityManager em = getEntityManager();
// inicio de transacción
EntityTransaction tx = null;
try {
tx = em.getTransaction();
tx.begin();
// se vuelve a vincular p1 al contexto recuperándolo de la base de datos
p1 = em.find(Personne.class, p1.getId());
// se incrementa el número de hijos de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// Visualización de personas: el número de hijos de p1 debe haber cambiado
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// creación de dos personas con el mismo nombre, lo cual está prohibido por la DDL
Personne p3 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p4 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
// Persistencia de las personas
em.persist(p3);
em.persist(p4);
// fin de la transacción
tx.commit();
} catch (RuntimeException e1) {
// Ha surgido un problema
System.out.format("Erreur dans transaction [%s,%s,%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage(), e1.getCause().getCause().getClass().getName(), e1.getCause().getCause()
.getMessage());
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s]%n", e2.getMessage());
}
// se abandona el contexto actual
em.clear();
}
// volcado: la tabla no debería haber cambiado debido a la reversión
dump();
}
- La prueba 11 se centra en el mecanismo de la transacción rollback. Una transacción funciona según el principio de «todo o nada»: las operaciones SQL que contiene o bien se ejecutan todas con éxito (commit), o bien se anulan todas en caso de que falle alguna de ellas (rollback).
- línea 4: se continúa con el mismo contexto de persistencia. Quizá el lector recuerde que el contexto se cerró tras el fallo de la prueba anterior. En este caso, [getEntityManager] proporciona un contexto completamente nuevo, es decir, vacío.
- líneas 7-27: un único try/catch para gestionar los problemas que puedan surgir
- líneas 8-9: inicio de una transacción que contendrá varias operaciones SQL
- línea 11: se busca p1 en la base de datos y se introduce en el contexto
- línea 13: se incrementa el número de hijos de p1 (de 6 a 7)
- líneas 15-18: se muestra el contenido de la base de datos, lo que forzará una sincronización del contexto. En la base de datos, el número de hijos de p1 pasará a ser 7, lo que debería confirmarse en la salida de la consola.
- Líneas 20-21: creación de dos personas, p3 y p4, con el mismo nombre. Sin embargo, el campo «nombre» de la @Entity «Persona» tiene el atributo «unique=true», lo que ha dado lugar a una restricción de unicidad en la columna «NOM» de la tabla «[jpa01_personne]».
- Líneas 23-24: las personas p3 y p4 se añaden al contexto de persistencia.
- línea 26: se confirma la transacción. A continuación se produce una segunda sincronización del contexto, tras la primera que tuvo lugar con el select. JPA emitirá dos órdenes SQL y insert para las personas p3 y p4. Se insertará p3. En el caso de p4, SGBD lanzará una excepción, ya que p4 tiene el mismo nombre que p3. Por lo tanto, p4 no se inserta y el controlador JDBC devuelve una excepción al cliente.
- Línea 27: se gestiona la excepción
- Líneas 29-31: se muestra la excepción y sus dos causas anteriores en la cadena de excepciones que nos han llevado hasta aquí.
- Línea 34: se realiza un rollback de la transacción actualmente activa. Esta comenzó en la línea 9 del código Java. Desde entonces, se ha realizado una operación update para modificar el número de hijos de p1 y, a continuación, una operación insert para la persona p3. Todo ello quedará anulado por la reversión.
- línea 39: se vacía el contexto de persistencia
- línea 42: se muestra la tabla [jpa01_personne]. Hay que comprobar que p1 sigue teniendo 6 hijos y que ni p3 ni p4 aparecen en la tabla.
La salida de la consola de la prueba 11 es la siguiente:
main : ----------- test11
[personnes]
[1,6,Martin,Paul,31/01/2000,false,7]
14:50:30,312 ERROR JDBCExceptionReporter:72 - Duplicate entry 'X' for key 2
Erreur dans transaction [javax.persistence.EntityExistsException,org.hibernate.exception.ConstraintViolationException: could not insert: [entites.Personne],org.hibernate.exception.ConstraintViolationException,could not insert: [entites.Personne],java.sql.SQLException,Duplicate entry 'X' for key 2]
[personnes]
[1,5,Martin,Paul,31/01/2000,false,6]
- línea 3: el número de hijos de p1 ha pasado de 6 a 7 en la base de datos; la versión de p1 ha pasado a 6.
- línea 4: la excepción capturada al confirmar la transacción. Si se lee con atención, se ve que la causa es una clave duplicada X (el nombre). Es la inserción de p4 la que provoca este error, ya que p3, ya insertado, también tiene el nombre X.
- línea 7: la tabla tras el rollback. p1 ha recuperado su versión 5 y su número de hijos 6; p3 y p4 no se han insertado.
2.1.13.13. Prueba 12
El código de la prueba 12 es el siguiente:
//: volvemos a hacer lo mismo, pero sin las transacciones
// se obtiene el mismo resultado que antes con los SGBD: FIREBIRD, ORACLE, XE, POSTGRES, MYSQL5
// con SQLSERVER, la tabla queda vacía. La conexión queda en un estado que impide la reejecución
// del programa. En ese caso, hay que reiniciar el servidor.
// lo mismo ocurre con el Derby SGBD
// HSQL inserta la primera persona; no hay rollback
public static void test12() throws ParseException {
// se vuelve a vincular a p1
p1 = em.find(Personne.class, p1.getId());
// se incrementa el número de hijos de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// Visualización de personas: el número de hijos de p1 debe haber cambiado
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// creación de dos personas con el mismo nombre, lo cual está prohibido por la DDL
Personne p3 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p4 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
// Persistencia de las personas
em.persist(p3);
em.persist(p4);
// volcado que provocará la sincronización del contexto em con el BD
try {
dump();
} catch (RuntimeException e3) {
System.out.format("Erreur dans dump [%s,%s,%s,%s]%n", e3.getClass().getName(), e3.getMessage(), e3.getCause().getClass().getName(), e3
.getCause().getMessage());
}
// se cierra el contexto actual
em.close();
// volcado
dump();
}
- La prueba 12 repite lo mismo que la prueba 11, pero fuera de la transacción. Queremos ver qué ocurre en este caso.
- Líneas 1-6: muestran los resultados de las pruebas con diversos SGBD:
- con una serie de SGBD (Firebird, Oracle, MySQL5, Postgres) se obtiene el mismo resultado que con la prueba 11. Lo que sugiere que estos SGBD iniciaron por sí mismos una transacción que abarcaba todas las órdenes SQL recibidas hasta la que provocó el error y que ellos mismos iniciaron un rollback.
- Con otros SGBD (SQL Server, Apache Derby) se produce un fallo de la aplicación y/o del SGBD.
- Con el SGBD y el HSQLDB, parece que la transacción abierta por el SGBD está en modo autocommit: la modificación del número de hijos de p1 y la inserción de p3 se hacen permanentes. Solo falla la inserción de p4.
Por lo tanto, obtenemos un resultado que depende de SGBD, lo que hace que la aplicación no sea portátil. Hay que tener en cuenta que las operaciones en el contexto de persistencia siempre deben realizarse dentro de una transacción.
2.1.14. Cambiar a SGBD
Volvamos a la arquitectura de prueba de nuestro proyecto actual:
 |
La aplicación cliente [3] solo ve la interfaz JPA [5]. No ve ni la implementación real de esta, ni el SGBD de destino. Por lo tanto, debe ser posible modificar estos dos elementos de la cadena sin necesidad de realizar cambios en el cliente [3]. Eso es lo que intentamos comprobar ahora, empezando por cambiar el SGBD. Hasta ahora habíamos utilizado MySQL5. Presentamos otros seis descritos en los anexos (apartado 5), con la esperanza de que entre ellos se encuentre el SGBD preferido por el lector.
En cualquier caso, la modificación que hay que realizar en el proyecto de Eclipse es sencilla (véase más abajo): sustituir el archivo de configuración de la capa persistence.xml [1] por uno de los que se encuentran en la carpeta conf [2] del proyecto. Los controladores JDBC y SGBD ya están presentes en la biblioteca [jpa-divers], [3] y [4].
 |
2.1.14.1. Oracle 10g Express
Oracle 10g Express se presenta en los anexos, en el apartado 5.7. El archivo persistence.xml de Oracle es el siguiente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- proveedor -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Clases persistentes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- registros SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- conexión JDBC -->
<property name="hibernate.connection.driver_class" value="oracle.jdbc.OracleDriver" />
<property name="hibernate.connection.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- Creación automática del esquema -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialecto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.OracleDialect" />
<!-- propiedades DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
Esta configuración es idéntica a la realizada para los archivos SGBD y MySQL5, salvo por los siguientes detalles:
- las líneas 15-18, que configuran la conexión JDBC con la base de datos
- línea 22: que establece el dialecto SQL que se va a utilizar
En los ejemplos siguientes, solo especificaremos las líneas que cambian. Para obtener una explicación de la configuración, consulte el anexo dedicado al SGBD utilizado. En él se ofrece en cada caso un ejemplo de uso de la conexión JDBC, en el contexto del complemento [SQL Explorer]. Con la información del anexo, el lector podrá repetir la operación de verificación del resultado de la aplicación [InitDB] realizada en el apartado 2.1.10.2.
Procedemos tal y como se indica en el apartado mencionado anteriormente:
- ejecutar el plugin SGBD de Oracle
- colocar conf/oracle/persistence.xml en META-INF/persistence.xml
- ejecutar la aplicación [InitDB]
Se obtienen los siguientes resultados en la consola:
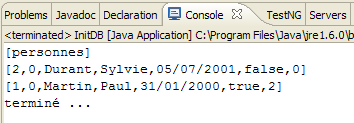 |
A partir de ahora, ya no volveremos a mostrar esta captura de pantalla, ya que siempre es la misma. Más interesante resulta la vista SQL Explorer de la conexión entre JDBC y SGBD. Seguiremos el procedimiento explicado en el apartado 2.1.8.
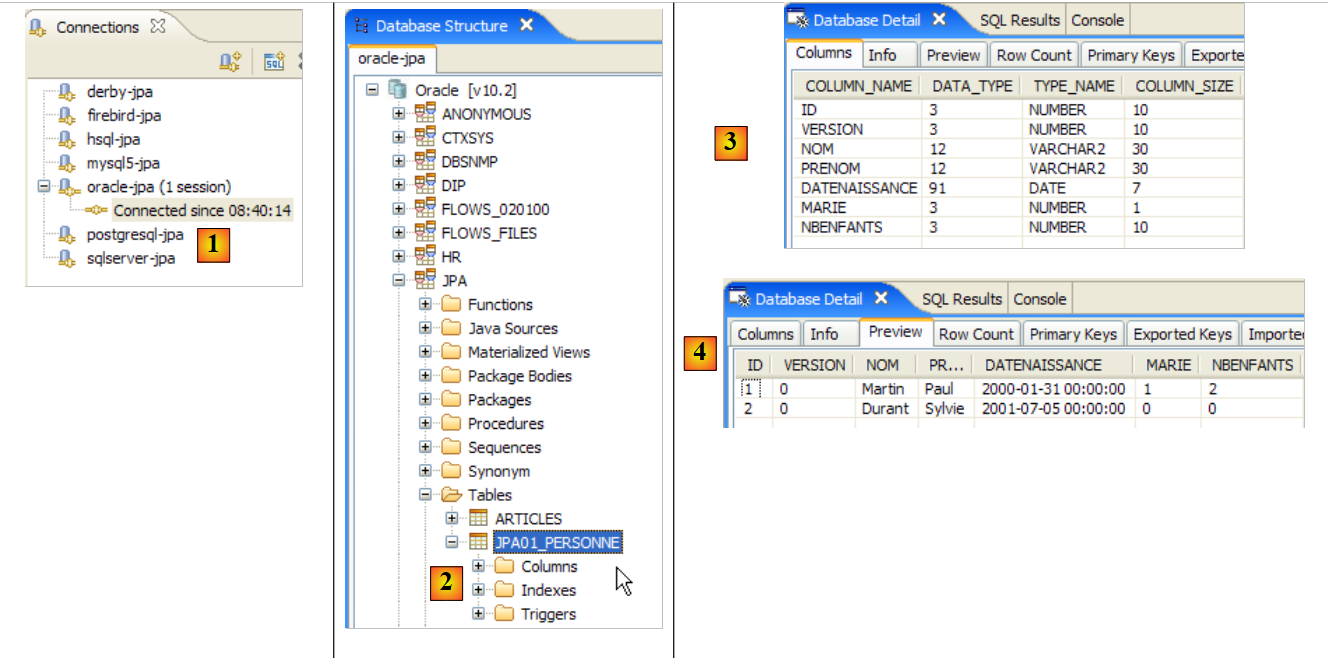 |
- en [1]: la conexión con Oracle
- en [2]: el árbol de la conexión tras la ejecución de [InitDB]
- en [3]: la estructura de la tabla [jpa01_personne]
- en [4]: su contenido.
Una vez hecho esto, se invita al lector a ejecutar la aplicación [Main] y, a continuación, a detener SGBD.
2.1.14.2. PostgreSQL 8.2
PostgreSQL 8.2 se presenta en los anexos, en el apartado 5.6. Su archivo persistence.xml es el siguiente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- conexión JDBC -->
<property name="hibernate.connection.driver_class" value="org.postgresql.Driver" />
<property name="hibernate.connection.url" value="jdbc:postgresql:jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialecto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.PostgreSQLDialect" />
...
</persistence-unit>
</persistence>
Para ejecutar [InitDB]:
- ejecuta el SGBD PostgreSQL
- colocar conf/postgres/persistence.xml en META-INF/persistence.xml
- ejecutar la aplicación [InitDB]
La vista de SQL Explorer de la conexión entre JDBC y SGBD es la siguiente:
 |
- en [1]: la conexión con PostgreSQL
- en [2]: el árbol de la conexión tras la ejecución de [InitDB]
- en [3]: la estructura de la tabla [jpa01_personne]
- en [4]: su contenido.
Una vez hecho esto, se invita al lector a ejecutar la aplicación [Main] y, a continuación, a detener SGBD
2.1.14.3. SQL Server Express 2005
SQL Server Express 2005 se presenta en los anexos, en el apartado 5.8, página 270. Su archivo persistence.xml es el siguiente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- conexión JDBC -->
<property name="hibernate.connection.driver_class" value="com.microsoft.sqlserver.jdbc.SQLServerDriver" />
<property name="hibernate.connection.url" value="jdbc:sqlserver://localhost\\SQLEXPRESS:1433;databaseName=jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialecto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.SQLServerDialect" />
...
</persistence-unit>
</persistence>
Para ejecutar [InitDB]:
- ejecuta el SGBD SQL Server
- colocar conf/sqlserver/persistence.xml en META-INF/persistence.xml
- ejecutar la aplicación [InitDB]
La vista de SQL Explorer de la conexión de JDBC con SGBD es la siguiente:
 |
- en [1]: la conexión con el servidor SQL
- en [2]: el árbol de la conexión tras la ejecución de [InitDB]
- en [3]: la estructura de la tabla [jpa01_personne]
- en [4]: su contenido.
Una vez hecho esto, se invita al lector a ejecutar la aplicación [Main] y, a continuación, a detener SGBD
2.1.14.4. Firebird 2.0
Firebird 2.0 se presenta en los anexos, en el apartado 5.4. Su archivo persistence.xml es el siguiente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- conexión JDBC -->
<property name="hibernate.connection.driver_class" value="org.firebirdsql.jdbc.FBDriver" />
<property name="hibernate.connection.url" value="jdbc:firebirdsql:localhost/3050:C:\data\2006-2007\eclipse\dvp-jpa\annexes\firebird\jpa.fdb" />
<property name="hibernate.connection.username" value="sysdba" />
<property name="hibernate.connection.password" value="masterkey" />
...
<!-- Dialecto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.FirebirdDialect" />
...
</persistence-unit>
</persistence>
Para ejecutar [InitDB]:
- ejecuta el archivo SGBD de Firebird
- colocar conf/firebird/persistence.xml en META-INF/persistence.xml
- ejecutar la aplicación [InitDB]
La vista SQL Explorer de la relación entre JDBC y SGBD es la siguiente:
 |
- en [1]: la conexión con Firebird
- en [2]: el árbol de la conexión tras la ejecución de [InitDB]
- en [3]: la estructura de la tabla [jpa01_personne]
- en [4]: su contenido.
Una vez hecho esto, se invita al lector a ejecutar la aplicación [Main] y, a continuación, a detener SGBD.
2.1.14.5. Apache Derby
Apache Derby se presenta en los anexos, en el apartado 5.10. Su archivo persistence.xml es el siguiente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- conexión JDBC -->
<property name="hibernate.connection.driver_class" value="org.apache.derby.jdbc.ClientDriver" />
<property name="hibernate.connection.url" value="jdbc:derby://localhost:1527//data/2006-2007/eclipse/dvp-jpa/annexes/derby/jpa;create=true" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialecto -->
...
</persistence-unit>
</persistence>
Para ejecutar [InitDB]:
- ejecuta el archivo SGBD de Apache Derby
- colocar conf/derby/persistence.xml en META-INF/persistence.xml
- ejecutar la aplicación [InitDB]
La vista «Explorer» de SQL de la conexión entre JDBC y SGBD es la siguiente:
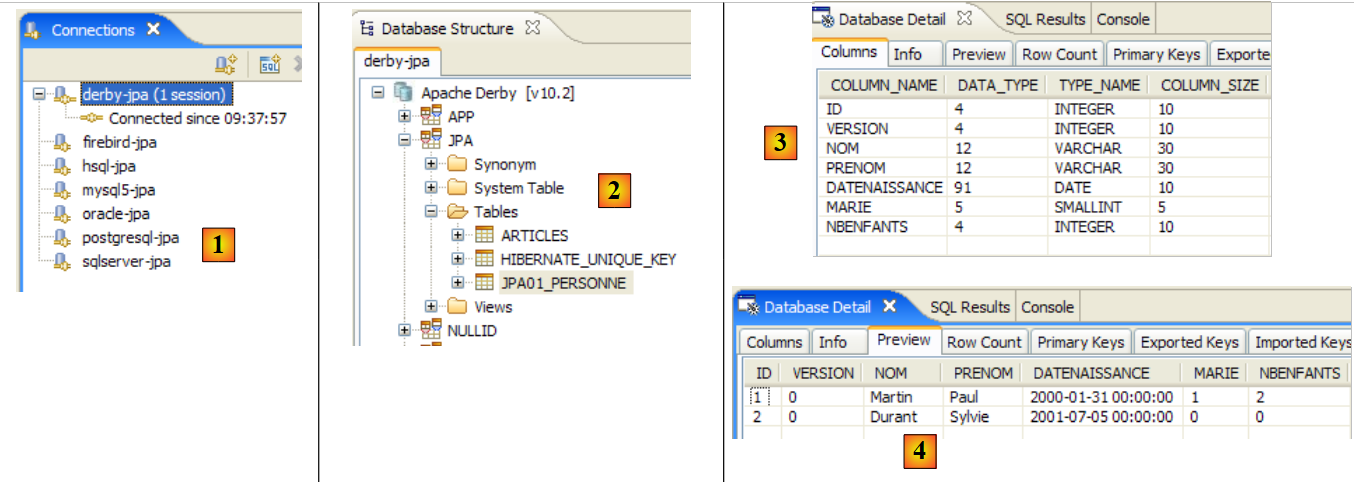 |
- en [1]: la conexión con Apache Derby
- en [2]: el árbol de la conexión tras la ejecución de [InitDB]. Cabe destacar la tabla [HIBERNATE_UNIQUE_KEY], creada por JPA / Hibernate para generar automáticamente los valores sucesivos de la clave primaria ID. Ya hemos señalado que este mecanismo suele ser propio. Aquí se ve claramente. Gracias a JPA, el desarrollador no tiene que entrar en estos detalles de SGBD.
- en [3]: la estructura de la tabla [jpa01_personne]
- en [4]: su contenido.
Una vez hecho esto, se invita al lector a ejecutar la aplicación [Main] y, a continuación, a detener SGBD.
2.1.14.6. HSQLDB
HSQLDB se presenta en los anexos, en el apartado 5.9. Su archivo persistence.xml es el siguiente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- conexión JDBC -->
<property name="hibernate.connection.driver_class" value="org.hsqldb.jdbcDriver" />
<property name="hibernate.connection.url" value="jdbc:hsqldb:hsql://localhost" />
<property name="hibernate.connection.username" value="sa" />
<!--
<property name="hibernate.connection.password" value="" />
-->
...
<!-- Dialecto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.HSQLDialect" />
...
</properties>
</persistence-unit>
</persistence>
Para ejecutar [InitDB]:
- ejecuta el archivo SGBD HSQL
- colocar conf/hsql/persistence.xml en META-INF/persistence.xml
- ejecutar la aplicación [InitDB]
La vista «Explorador» de SQL de la conexión entre JDBC y SGBD es la siguiente:
 |
- en [1]: la conexión con HSQL
- en [2]: el árbol de la conexión tras la ejecución de [InitDB].
- en [3]: la estructura de la tabla [jpa01_personne]
- en [4]: su contenido.
Una vez hecho esto, se invita al lector a ejecutar la aplicación [Main] y, a continuación, a detener SGBD.
2.1.15. Cambiar la implementación JPA
Volvamos a la arquitectura de pruebas de nuestro proyecto actual:
 |
El estudio anterior demostró que pudimos cambiar SGBD por [7] sin modificar el código del cliente [3]. Ahora cambiamos la implementación JPA [6] y demostramos, una vez más, que esto se hace de forma transparente para el código cliente [3]. Tomamos una implementación TopLink y [http://www.oracle.com/technology/products/ias/toplink/jpa/index.html]:
 |
2.1.15.1. El proyecto Eclipse
Con motivo del cambio de implementación JPA, creamos un nuevo proyecto de Eclipse para no alterar el proyecto existente. De hecho, el nuevo proyecto utiliza bibliotecas de persistencia que pueden entrar en conflicto con las de Hibernate:
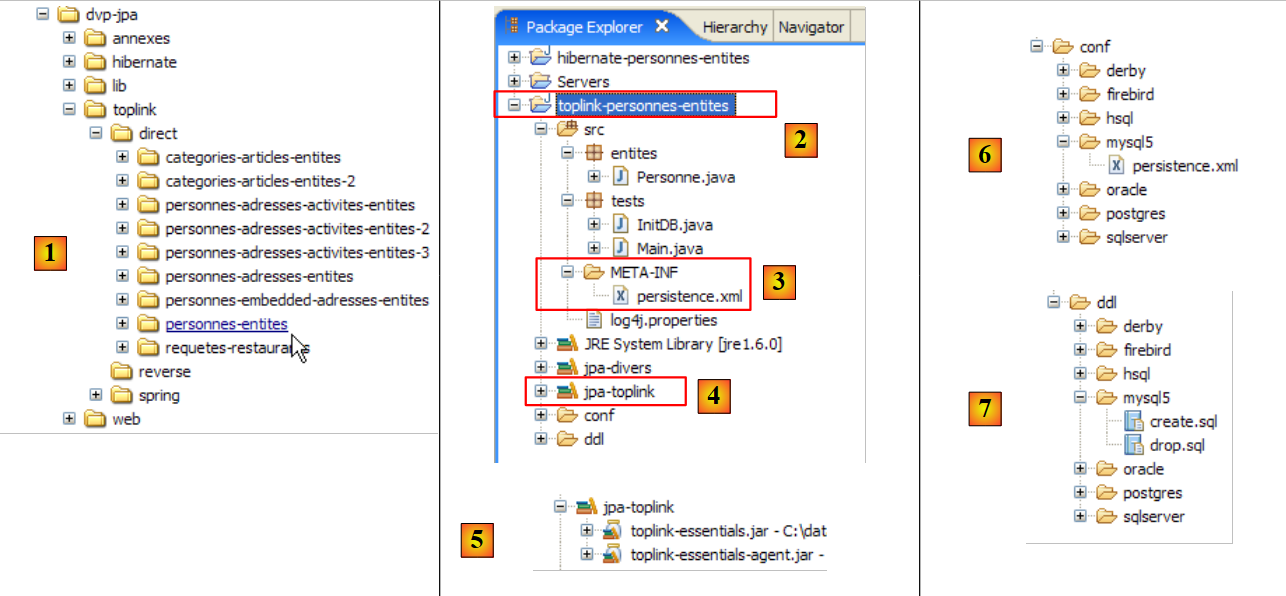 |
- en [1]: la carpeta [<exemples>/toplink/direct/personnes-entites] contiene el proyecto Eclipse. Importe este último.
- en [2]: el proyecto [toplink-personnes-entites] importado. Es idéntico (se ha obtenido mediante copia) al proyecto [hibernate-personne-entites], salvo por dos detalles:
- el archivo [META-INF/persistence.xml] [3] configura ahora una capa JPA / Toplink
- la biblioteca [jpa-hibernate] ha sido sustituida por la biblioteca [jpa-toplink], [4] y [5] (véase el apartado 1.5).
- En [6]: la carpeta [conf] contiene una versión del archivo [persistence.xml] para cada SGBD.
- en [7]: la carpeta [ddl], que contendrá los scripts SQL para la generación del esquema de la base de datos.
2.1.15.2. Configuración de la capa JPA / Toplink
Sabemos que la capa JPA se configura mediante el archivo [META-INF/persistence.xml]. Este, a su vez, configura ahora una implementación JPA / Toplink. Su contenido para una capa JPA interconectada con SGBD y MySQL5 es el siguiente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- proveedor -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- clases persistentes -->
<class>entites.Personne</class>
<!-- propiedades de la unidad de persistencia -->
<properties>
<!-- conexión JDBC -->
<property name="toplink.jdbc.driver" value="com.mysql.jdbc.Driver" />
<property name="toplink.jdbc.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="toplink.jdbc.user" value="jpa" />
<property name="toplink.jdbc.password" value="jpa" />
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
<!-- SGBD -->
<property name="toplink.target-database" value="MySQL4" />
<!-- servidor de aplicaciones -->
<property name="toplink.target-server" value="None" />
<!-- generación de esquemas -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/mysql5" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
<!-- registros -->
<property name="toplink.logging.level" value="OFF" />
</properties>
</persistence-unit>
</persistence>
- línea 3: no ha cambiado
- línea 5: el proveedor es ahora Toplink. La clase que aquí se menciona se encuentra en la biblioteca [jpa-toplink] ([1] más abajo):
 |
- línea 7: la etiqueta <class> sirve para nombrar todas las clases @Entity del proyecto; en este caso, solo la clase Personne. Hibernate tenía una opción de configuración que nos evitaba tener que nombrar estas clases. Exploraba el archivo classpath del proyecto para encontrar las clases @Entity.
- línea 9: la etiqueta <properties>, que introduce propiedades específicas de la implementación JPA utilizada, en este caso Toplink.
- líneas 11-14: configuración de la conexión JDBC con el SGBD MySQL5
- líneas 15-18: configuración del grupo de conexiones JDBC gestionado de forma nativa por Toplink:
- líneas 15 y 16: número máximo y mínimo de conexiones en el grupo de conexiones de lectura. Valor por defecto (2,2)
- líneas 17 y 18: número máximo y mínimo de conexiones en el grupo de conexiones de escritura. Por defecto (10,2)
- línea 20: el SGBD de destino. La lista de SGBD utilizables está disponible en el paquete [oracle.toplink.essentials.platform.database] (véase [2] más arriba). El SGBD MySQL5 no figura en la lista [2], por lo que se ha elegido MySQL4. Toplink es compatible con un número ligeramente inferior de SGBD que Hibernate. Así, de los siete SGBD utilizados en nuestros ejemplos, Firebird no es compatible. Tampoco aparece Oracle en la lista. De hecho, se encuentra en otro paquete ([3], mencionado anteriormente). Si en estos dos paquetes el SGBD de destino se designa mediante la clase <Sgbd>Platform.class, la etiqueta se escribirá así:
<property name="toplink.target-database" value="<Sgbd>" />
- línea 22: establece el servidor de aplicaciones si la aplicación se ejecuta en uno de estos servidores. Valores posibles actuales (None, OC4J_10_1_3, SunAS9). Valor por defecto (None).
- líneas 24-28: cuando se inicialice la capa JPA, se le pedirá que realice una limpieza de la base de datos definida por la conexión JDBC de las líneas 11-14. De este modo, se partirá de una base vacía.
- línea 24: se le pide a Toplink que realice un drop seguido de un create de las tablas del esquema de la base de datos
- línea 25: se le pedirá a Toplink que genere los scripts SQL de las operaciones drop y create. application-location establece la carpeta en la que se generarán estos scripts. Por defecto: (carpeta actual).
- línea 26: nombre del script SQL de las operaciones create.. Por defecto: createDDL.jdbc.
- línea 27: nombre del script SQL de las operaciones drop.. Por defecto: dropDDL.jdbc.
- línea 28: modo de generación del esquema (por defecto: both):
- both: scripts y base de datos
- database: solo base de datos
- sql-script: solo scripts
- línea 30: se desactivan (OFF) los registros de Toplink. Los distintos niveles de registro disponibles son los siguientes: OFF, SEVERE, WARNING, INFO, CONFIG, FINE, FINER, FINEST. Por defecto: INFO.
Consulte la URL [http://www.oracle.com/technology/products/ias/toplink/JPA/essentials/toplink-jpa-extensions.html] para obtener una definición exhaustiva de las etiquetas <property> que se pueden utilizar con Toplink.
2.1.15.3. Prueba [InitDB]
No hay nada más que hacer. Ya estamos listos para ejecutar la primera prueba [InitDB]:
- ejecutar el SGBD, en este caso MySQL5
- ejecutar [InitDB]
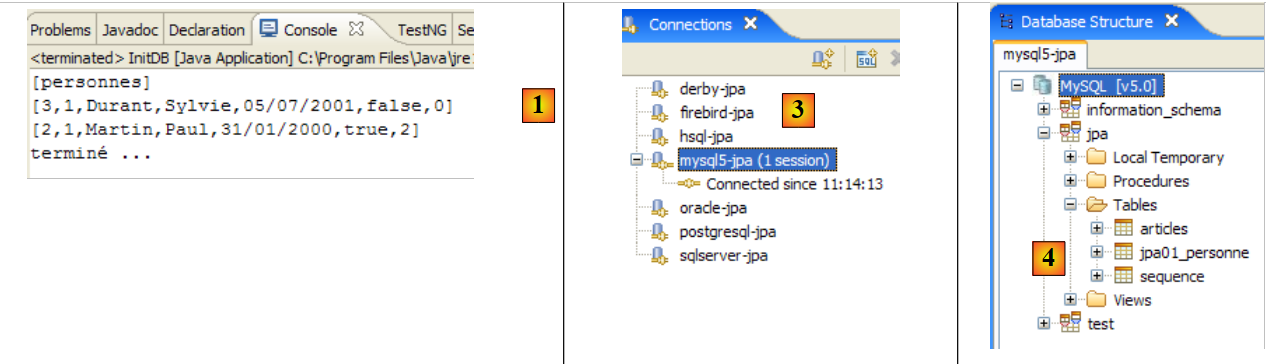 |
- en [1]: la salida de la consola. Encontramos los resultados ya obtenidos con JPA / Hibernate.
- en [3]: se abre la perspectiva [SQL Explorer] y, a continuación, se abre la conexión [mysql5-jpa]
- En [4]: el árbol de la base de datos JPA. Se observa que la ejecución de [InitDB] ha creado dos tablas: [jpa01_personne], que era la esperada, y la tabla [sequence], que no se esperaba.
 |
- en [5]: la estructura de la tabla [jpa01_personne] y en [6] su contenido
- en [7]: la estructura de la tabla [sequence] y en [8] su contenido.
El archivo de configuración [persistence.xml] solicitaba la generación de los scripts de DDL:
<!-- generación de esquema -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/mysql5" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
Veamos qué se ha generado en la carpeta [ddl/mysql5]:
 |
create.sql
CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
- Línea 1: el registro DDL de la tabla [jpa01_personne]. Se observa que Toplink no ha utilizado el atributo «autoincrement» para la clave primaria ID. Esto hace que no se produzca un incremento automático de la misma al insertar filas.
- línea 2: la DDL de la tabla [sequence]. Su nombre parece indicar que Toplink utiliza esta tabla para generar los valores de la clave primaria ID.
- línea 3: inserción de una única línea en [SEQUENCE]
drop.sql
DROP TABLE jpa01_personne
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
- línea 1: eliminación de la tabla [jpa01_personne]
- línea 2: eliminación de una línea concreta de la tabla [SEQUENCE]. Ni la tabla en sí ni las demás líneas que pudiera contener se eliminan.
Para obtener más información sobre la función de la tabla [SEQUENCE], se activan en [persistence.xml] los registros de Toplink en el nivel FINE, un nivel que registra las órdenes SQL emitidas por Toplink:
<!-- registros -->
<property name="toplink.logging.level" value="FINE" />
Se vuelve a ejecutar InitDB. A continuación, solo se ha conservado una vista parcial de la pantalla de la consola:
...
[TopLink Config]: 2007.05.28 12:07:52.796--ServerSession(12910198)--Conexión(30708295)--Hilo(Thread[main,5,main])--Conectado: jdbc:mysql://localhost:3306/jpa
User: jpa@localhost
Database: MySQL Version: 5.0.37-community-nt
Driver: MySQL-AB JDBC Driver Version: mysql-connector-java-3.1.9 ( $Date: 2005/05/19 15:52:23 $, $Revision: 1.1.2.2 $ )
...
[TopLink Fine]: 2007.05.28 12:07:53.093--ServerSession(12910198)--Conexión(19255406)--Hilo(Thread[main,5,main])--DROP TABLE jpa01_personne
[TopLink Fine]: 2007.05.28 12:07:53.265--ServerSession(12910198)--Conexión(30708295)--Hilo(Thread[main,5,main])--CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT(1) por defecto 0 NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
[TopLink Fine]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Conexión(19255406)--Hilo(Thread[main,5,main])--CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
[TopLink Warning]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Hilo(Hilo[main,5,main])--Excepción [TOPLINK-4002] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (30/03/2007))): oracle.toplink.essentials.exceptions.DatabaseException
Internal Exception: java.sql.SQLException: Table 'sequence' already exists
Error Code: 1050
Call: CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
Query: DataModifyQuery()
[TopLink Fine]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Conexión(30708295)--Hilo(Thread[main,5,main])--DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
[TopLink Fine]: 2007.05.28 12:07:53.609--ServerSession(12910198)--Conexión(19255406)--Hilo(Thread[main,5,main])--SELECT * FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
[TopLink Fine]: 2007.05.28 12:07:53.609--ServerSession(12910198)--Conexión(30708295)--Hilo(Thread[main,5,main])--INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) valores («SEQ_GEN», 1)
[TopLink Fine]: 2007.05.28 12:07:53.734--ClientSession(15308417)--Conexión(14069849)--Hilo (Thread[main,5,main])--eliminar de jpa01_personne
[TopLink Fine]: 2007.05.28 12:07:53.750--ClientSession(15308417)--Conexión(14069849)--Hilo(Hilo[main,5,main])--UPDATE SEQUENCE SET SEQ_COUNT = SEQ_COUNT + ? WHERE SEQ_NAME = ?
bind => [50, SEQ_GEN]
[TopLink Fine]: 2007.05.28 12:07:53.750--ClientSession(15308417)--Conexión(14069849)--Hilo(Thread[main,5,main])--SELECT SEQ_COUNT FROM SEQUENCE WHERE SEQ_NAME = ?
bind => [SEQ_GEN]
[personnes]
[TopLink Fine]: 2007.05.28 12:07:53.906--ClientSession(15308417)--Conexión(14069849)--Hilo(Thread[main,5,main])--INSERT INTO jpa01_personne (ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS) VALUES (?, ?, ?, ?, ?, ?, ?)
bind => [3, Sylvie, 2001-07-05, Durant, false, 1, 0]
[TopLink Fine]: 2007.05.28 12:07:53.921--ClientSession(15308417)--Conexión(14069849)--Hilo(Thread[main,5,main])--INSERT INTO jpa01_personne (ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS) VALUES (?, ?, ?, ?, ?, ?, ?)
bind => [2, Paul, 2000-01-31, Martin, true, 1, 2]
[TopLink Fine]: 2007.05.28 12:07:53.937--ClientSession(15308417)--Conexión(14069849)--Hilo(Thread[main,5,main])--SELECT ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS FROM jpa01_personne ORDER BY NOM ASC
[3,1,Durant,Sylvie,05/07/2001,false,0]
[2,1,Martin,Paul,31/01/2000,true,2]
[TopLink Config]: 2007.05.28 12:07:54.062--ServerSession(12910198)--Conexión(30708295)--Hilo(Thread[main,5,main])--desconexión
[TopLink Info]: 2007.05.28 12:07:54.062--ServerSession(12910198)--Hilo(Thread[main,5,main])--archivo:/C:/data/2006-2007/eclipse/dvp-jpa/toplink/direct/personas-entidades/bin/-jpa cierre de sesión correcto
...
terminé ...
- líneas 2-5: una conexión al SGBD con sus parámetros. De hecho, los registros muestran que, en realidad, Toplink crea tres conexiones con el SGBD. Habría que comprobar si este número está relacionado con alguno de los valores de configuración utilizados para el grupo de conexiones JDBC:
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
- línea 7: eliminación de la tabla [jpa01_personne]. Es normal, ya que el archivo [persistence.xml] solicita la limpieza de la base de datos JPA.
- línea 8: creación de la tabla [jpa01_personne]. Se observa que la clave primaria ID no tiene el atributo autoincrement.
- línea 9: creación de la tabla [SEQUENCE], que ya existe, ya que se creó en la ejecución anterior.
- Líneas 10-13: Toplink señala el error al crear la tabla [SEQUENCE].
- Líneas 15-18: Toplink limpia la tabla [SEQUENCE]. Tras esta limpieza, la tabla [SEQUENCE] tiene una fila (SEQ_NAME, SEQ_COUNT) con los valores («SEQ_GEN», 1).
- línea 18: la tabla [jpa01_personne] se vacía.
- líneas 19-20: Toplink pasa la única línea en la que SEQ_NAME = «SEQ_GEN» de la tabla [SEQUENCE], del valor («SEQ_GEN», 1) al valor («SEQ_GEN», 51)
- línea 21: Toplink recupera el valor 51 de la línea («SEQ_GEN», 51) de la tabla [SEQUENCE].
- líneas 24-27: Toplink inserta en la tabla [jpa01_personne] a las dos personas «Martin» y «Durant». Aquí hay un misterio: las claves primarias de estas dos líneas reciben los valores 2 y 3 sin que se sepa cómo se obtuvieron dichos valores. No se sabe si el valor SEQ_COUNT (51) obtenido en la línea 21 ha servido para algo. Cabe señalar que el valor de la versión de las líneas es 1, mientras que Hibernate comenzaba en 0.
- línea 28: Toplink genera el valor SELECT para obtener todas las líneas de la tabla [jpa01_personne]
- Líneas 29-30: líneas mostradas por el cliente Java
- líneas 31-32: Toplink cierra una conexión. Repetirá la operación para cada una de las conexiones abiertas inicialmente.
Al final, no se conoce con exactitud la función de la tabla [SEQUENCE], pero parece que desempeña algún papel en la generación de los valores de la clave primaria ID. Al seleccionar el nivel de registro más detallado, FINEST, se obtiene algo más de información sobre la función de la tabla [SEQUENCE].
<!-- registros -->
<property name="toplink.logging.level" value="FINEST" />
A continuación solo hemos incluido los registros relativos a la inserción de las dos personas en la tabla. Aquí es donde se aprecia el mecanismo de generación de los valores de la clave primaria:
- línea 4: se observa que el número 51 obtenido de la tabla [SEQUENCE] en la línea 2 sirve para delimitar un intervalo de valores para la clave primaria: [2,51]
- línea 5: a la primera persona se le asigna el valor 2 como clave primaria
- línea 8: a la segunda persona se le asigna el valor 3 como clave primaria
- línea 12: muestra la gestión de versiones de la primera persona
- línea 17: lo mismo para la segunda persona
El nivel de registros [FINEST] también muestra los límites de las transacciones emitidas por Toplink. El análisis de estos registros permite ver qué hace Toplink y es una excelente forma de comprender el puente entre objetos y relaciones.
De lo anterior cabe destacar que:
- que diferentes implementaciones de JPA generarán esquemas de bases de datos distintos. En este ejemplo, Hibernate y Toplink no han generado los mismos esquemas.
- que los niveles de registro FINE, FINER y FINEST de Toplink deben utilizarse siempre que se desee obtener aclaraciones sobre lo que hace exactamente Toplink.
2.1.15.4. Prueba [Main]
Ahora ejecutamos la prueba [Main]:
 |
- en [1]: todas las pruebas se superan excepto la prueba 11, [2]
- en [3]: línea 376, la línea de código donde se produjo la excepción
El código que genera la excepción es el siguiente:
} catch (RuntimeException e1) {
// hemos tenido un problema
System.out.format("Erreur dans transaction [%s,%s,%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage(), e1.getCause().getCause().getClass().getName(), e1.getCause().getCause()
.getMessage());
try {
...
- línea [3]: la línea de la excepción. Tenemos un NullPointerException, lo que sugiere que uno de los métodos getCause de las líneas 4 y 5 devolvió un puntero null. Una expresión como [e1.getCause().getCause()] supone que la cadena de excepciones tiene tres elementos [e1.getCause().getCause(), e1.getCause(), e1]. Si solo tiene dos, la primera expresión provocará una excepción.
Modificamos el código anterior para que solo muestre las dos últimas excepciones de la cadena de excepciones:
} catch (RuntimeException e1) {
// hemos tenido un problema
System.out.format("Erreur dans transaction [%s,%s,%s,%s,]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage());
try {
...
Al ejecutarlo, obtenemos el siguiente resultado:
...
[personnes]
[2,5,Martin,Paul,31/01/2000,false,6]
main : ----------- prueba11
[personnes]
Erreur dans transaction [javax.persistence.OptimisticLockException,Exception [TOPLINK-5006] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (03/30/2007))): oracle.toplink.essentials.exceptions.OptimisticLockException
Exception Description: The object [[2,6,Martin,Paul,31/01/2000,false,7]] cannot be updated because it has changed or been deleted since it was last read.
Class> entites.Personne Primary Key> [2],oracle.toplink.essentials.exceptions.OptimisticLockException,
Exception Description: The object [[2,6,Martin,Paul,31/01/2000,false,7]] cannot be updated because it has changed or been deleted since it was last read.
Class> entites.Personne Primary Key> [2],]
[personnes]
[2,5,Martin,Paul,31/01/2000,false,6]
Esta vez, la prueba 11 se supera. Las visualizaciones de la excepción (líneas 6-10) han sido solicitadas por el código Java (línea 3 del código anterior). Recordemos que la prueba 11 encadenaba, en una misma transacción, varias operaciones SQL, una de las cuales fallaba y debía provocar un rollback de la transacción. Los estados de la tabla [jpa01_personne] antes (línea 3) y después de la prueba (línea 12) son idénticos, lo que demuestra que se ha producido la reversión.
Cabe destacar aquí un punto importante: las implementaciones JPA / Hibernate y JPA / Toplink no son 100 % intercambiables. En este ejemplo, debemos modificar el código del cliente JPA para evitar un NullPointerException. Volveremos a encontrarnos con este problema más adelante, de nuevo en el contexto de una excepción.
2.1.16. Cambiar de SGBD a JPA en la implementación de Toplink
Volvamos a la arquitectura de pruebas de nuestro proyecto actual:
 |
Anteriormente, el SGBD utilizado en [7] era MySQL5. A continuación, mostramos con Oracle cómo cambiar a SGBD. En cualquier caso, la modificación que hay que realizar en el proyecto de Eclipse es sencilla (véase más abajo): sustituir el archivo de configuración de la capa persistence.xml [1] por uno de los que se encuentran en la carpeta conf ([2] y [3]) del proyecto.
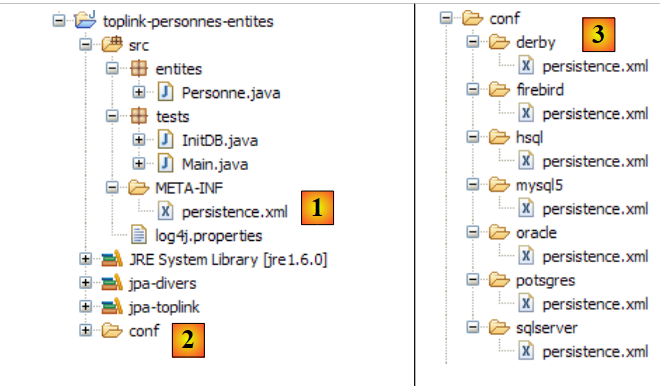 |
2.1.16.1. Oracle 10g Express
Oracle 10g Express se presenta en los anexos, en el apartado 5.7. El archivo persistence.xml de Oracle para Toplink es el siguiente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- proveedor -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- clases persistentes -->
<class>entites.Personne</class>
<!-- propiedades de la unidad de persistencia -->
<properties>
<!-- conexión JDBC -->
<property name="toplink.jdbc.driver" value="oracle.jdbc.OracleDriver" />
<property name="toplink.jdbc.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="toplink.jdbc.user" value="jpa" />
<property name="toplink.jdbc.password" value="jpa" />
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
<!-- SGBD -->
<property name="toplink.target-database" value="Oracle" />
<!-- servidor de aplicaciones -->
<property name="toplink.target-server" value="None" />
<!-- generación de esquemas -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/oracle" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
<!-- registros -->
<property name="toplink.logging.level" value="OFF" />
</properties>
</persistence-unit>
</persistence>
Esta configuración es idéntica a la realizada para los archivos SGBD y MySQL5, salvo por los siguientes detalles:
- las líneas 11-14, que configuran la conexión JDBC con la base de datos
- línea 20: que establece el destino SGBD
- línea 25: que establece la carpeta de generación de scripts SQL de DDL
Para ejecutar la prueba [InitDB]:
- ejecuta el SGBD de Oracle
- colocar conf/oracle/persistence.xml en META-INF/persistence.xml
- ejecutar la aplicación [InitDB]
Se obtienen los siguientes resultados en la consola y en la perspectiva [SQL Explorer]:
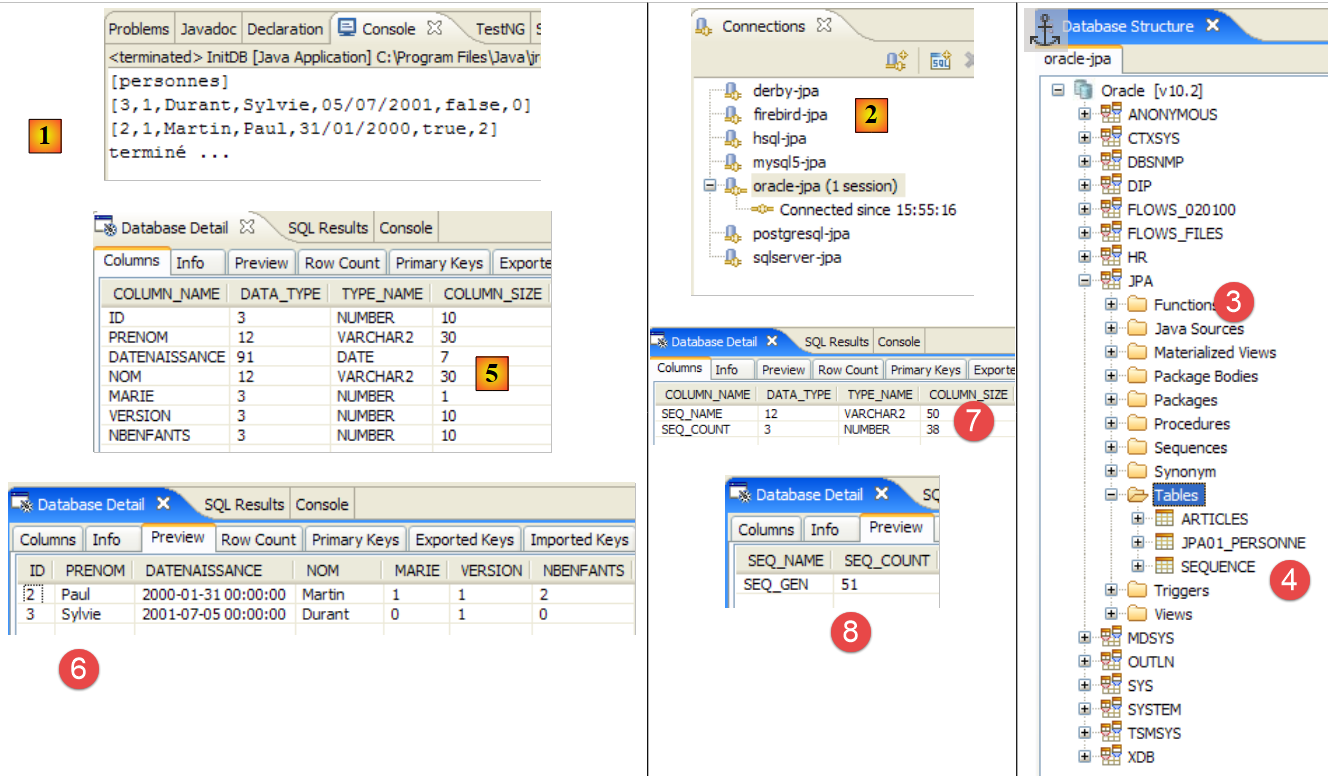 |
- [1]: la visualización de la consola
- [2]: la conexión [oracle-jpa] en SQL Explorer
- [3]: la base de datos jpa
- [4]: InitDB ha creado dos tablas: JPA01_PERSONNE y SEQUENCE, al igual que con MySQL5. A veces, en [4], aparecen tablas [BIN*]. Estas corresponden a tablas eliminadas. Para observar este fenómeno, basta con volver a ejecutar [InitDB]. La fase de inicialización de la capa JPA incluye una limpieza de la base de datos jpa durante la cual se elimina la tabla [JPA01_PERSONNE]:
 |
En [A], aparece una tabla [BIN]. Oracle no elimina definitivamente una tabla que haya sido sometida a un drop, sino que la coloca en una papelera [Recycle Bin]. Esta papelera es visible ([B]) con la herramienta SQL Developer descrita en el apartado 5.7.4. En [B], se puede purgar la tabla [JPA01_PERSONNE] que se encuentra en la papelera. Esto vacía la papelera [C]. Si en SQL Explorer se actualizan las tablas (clic con el botón derecho / Refresh), se observa que la tabla BIN ya no está presente en [D].
- [5, 6]: la estructura y el contenido de la tabla [JPA01_PERSONNE]
- [7, 8]: la estructura y el contenido de la tabla [SEQUENCE]
¡Ya está! Ahora se invita al lector a ejecutar la aplicación [Main] en Oracle.
2.1.16.2. Las demás SGBD
No entraremos en detalles sobre los demás SGBD. Basta con repetir el procedimiento seguido para Oracle. Cabe destacar los siguientes puntos:
- independientemente del SGBD, Toplink siempre utiliza la misma técnica para generar los valores de la clave primaria ID de la tabla [JPA01_PERSONNE]: utiliza la tabla [SEQUENCE] descrita anteriormente.
- Toplink no reconoce el SGBD de Firebird. Existe una base de datos genérica para estos casos:
Con esta base genérica denominada [Auto], las pruebas con Firebird fallan debido a errores de sintaxis en SQL. Toplink utiliza para la clave primaria ID un tipo SQL Number(10) que Firebird no reconoce. Por lo tanto, hay que elegir un SGBD que tenga los mismos tipos SQL que Firebird (en este ejemplo). Este es el caso de Apache Derby:
<!-- conexión JDBC -->
<property name="toplink.jdbc.driver" value="org.firebirdsql.jdbc.FBDriver" />
...
<!-- SGBD -->
<!--
TopLink ne reconnaît pas Firebird pour l'instant (05/07). Derby convient pour remplacer.
-->
<property name="toplink.target-database" value="Derby" />
...
- Toplink no sabe generar el esquema original de la base de datos para el SGBD HSQLDB. Es decir, la directiva:
<!-- generación de esquema -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
falla en el caso de HSQLDB. La causa es un error de sintaxis al crear la tabla [jpa01_personne]:
[TopLink Fine]: 2007.05.29 09:44:18.515--ServerSession(12910198)--Conexión(29775659)--Hilo(Thread[main,5,main])--DROP TABLE jpa01_personne
[TopLink Fine]: 2007.05.29 09:44:18.531--ServerSession(12910198)--Conexión(29775659)--Hilo(Thread[main,5,main])--CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
[TopLink Warning]: 2007.05.29 09:44:18.531--ServerSession(12910198)--Hilo(Hilo[main,5,main])--Excepción [TOPLINK-4002] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (30/03/2007))): oracle.toplink.essentials.exceptions.DatabaseException
Internal Exception: java.sql.SQLException: Unexpected token: UNIQUE in statement [CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE]
Línea 4, la sintaxis NOM VARCHAR(30) UNIQUE NOT NULL no es aceptada por HSQL. Hibernate había utilizado la sintaxis: NOM VARCHAR(30) NOT NULL, UNIQUE(NOM).
En general, Hibernate ha sido más eficaz que Toplink a la hora de reconocer los SGBD con los que se han realizado las pruebas de este documento.
2.1.17. Conclusión
El estudio de la @Entity [Personne] termina aquí. Desde un punto de vista conceptual, se ha hecho relativamente poco: hemos estudiado el puente objeto-relacional en el caso más sencillo: un objeto @Entity <--> una tabla. Sin embargo, su estudio nos ha permitido presentar las herramientas que utilizaremos a lo largo de todo el documento. Esto nos permitirá avanzar un poco más rápido a partir de ahora en el estudio de los demás casos del puente objeto-relacional que vamos a analizar:
- al @Entity [Personne] anterior, vamos a añadir un campo adresse modelado por una clase [Adresse]. En cuanto a la base de datos, veremos dos posibles implementaciones. Los objetos [Personne] y [Adresse] dan lugar a
- una única tabla [personne] que incluye la dirección
- dos tablas, [personne] y [adresse], vinculadas mediante una relación de clave externa de tipo uno a uno.
- un ejemplo de relación uno a varios, en la que una tabla [article] está vinculada a una tabla [categorie] mediante una clave externa
- Un ejemplo de relación «muchos a muchos», en la que las dos tablas [personne] y [activite] están relacionadas mediante una tabla de unión [personne_activite].
2.2. Ejemplo 2: relación uno a uno mediante una inclusión
2.2.1. El esquema de la base de datos
1  | 2 |
- en [1]: la base de datos (complemento Azurri Clay)
- en [2]: la tabla DDL generada por Hibernate para MySQL5
La tabla [jpa02_personne] es la tabla [jpa01_personne] analizada anteriormente, a la que se le ha añadido una dirección (líneas 12-18 de la DDL).
2.2.2. Los objetos @Entity que representan la base de datos
La dirección de una persona vendrá representada por la siguiente clase [Adresse]:
package entites;
...
@SuppressWarnings("serial")
@Embeddable
public class Adresse implements Serializable {
// campos
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
// constructores
public Adresse() {
}
public Adresse(String adr1, String adr2, String adr3, String codePostal, String ville, String cedex, String pays) {
...
}
// getters y setters
...
// toString
public String toString() {
return String.format("A[%s,%s,%s,%s,%s,%s,%s]", getAdr1(), getAdr2(), getAdr3(), getCodePostal(), getVille(), getCedex(), getPays());
}
}
- La principal novedad reside en la anotación @Embeddable de la línea 5. La clase [Adresse] no está destinada a dar lugar a una tabla, por lo que no lleva la anotación @Entity. La anotación @Embeddable indica que la clase está destinada a integrarse en un objeto @Entity y, por lo tanto, en la tabla asociada a este. Por eso, en el esquema de la base de datos, la clase [Adresse] no aparece como una tabla independiente, sino como parte de la tabla asociada a la @Entity [Personne].
La @Entity [Personne] presenta pocos cambios con respecto a su versión anterior: simplemente se le añade un campo adresse:
package entites;
...
@Entity
@Table(name = "jpa02_hb_personne")
public class Personne implements Serializable{
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
@Embedded
private Adresse adresse;
// constructores
public Personne() {
}
...
}
- La modificación se produce en las líneas 33-34. El objeto [Personne] tiene ahora un campo adresse de tipo Adresse. Esto es para el POJO. La anotación @Embedded está destinada al puente objeto-relacional. Indica que el campo [Adresse adresse] deberá encapsularse en la misma tabla que el objeto [Personne].
2.2.3. El entorno de pruebas
Vamos a realizar pruebas muy similares a las que hemos visto anteriormente. Se llevarán a cabo en el siguiente contexto:
 |
La implementación utilizada es JPA / Hibernate [6]. El proyecto Eclipse de las pruebas es el siguiente:
 |
El proyecto Eclipse [1] solo se diferencia del anterior en sus códigos Java [2]. El entorno (bibliotecas – persistence.xml – SGBD – carpetas de configuración, DDL – script Ant) es el ya estudiado anteriormente, en concreto en el apartado 2.1.5. Este seguirá siendo el caso para los futuros proyectos de Hibernate y, salvo excepciones, no volveremos a tratar este entorno. En particular, los archivos persistence.xml que configuran la capa JPA/Hibernate para diferentes SGBD son los ya analizados y que se encuentran en la carpeta <conf>.
Si tiene alguna duda sobre los procedimientos a seguir, se invita al lector a consultar los seguidos en el estudio anterior.
El proyecto Eclipse se encuentra en la carpeta de ejemplos. Lo importaremos.
2.2.4. Generación de la DDL de la base de datos
Siguiendo las instrucciones del apartado 2.1.7, el archivo DDL obtenido para el SGBD MySQL5 es el siguiente:
drop table if exists jpa02_hb_personne;
create table jpa02_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
Hibernate ha reconocido correctamente que la dirección de la persona debía integrarse en la tabla asociada a la @Entity Personne (líneas 11-17).
2.2.5. InitDB
El código de [InitDB] es el siguiente:
package tests;
...
public class InitDB {
// constantes
private final static String TABLE_NAME = "jpa02_hb_personne";
public static void main(String[] args) throws ParseException {
// Contexto de persistencia
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// se recupera un EntityManager a partir del EntityManagerFactory anterior
em = emf.createEntityManager();
// Inicio de la transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// solicitud
Query sql1;
// eliminar los elementos de la tabla PERSONNE
sql1 = em.createNativeQuery("delete from " + TABLE_NAME);
sql1.executeUpdate();
// creación de personas
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// creación de direcciones
Adresse a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
Adresse a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
// asociaciones persona <--> dirección
p1.setAdresse(a1);
p2.setAdresse(a2);
// persistencia de personas
em.persist(p1);
em.persist(p2);
// visualización de personas
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// fin de la transacción
tx.commit();
// fin de EntityManager
em.close();
// fin de EntityManagerFactory
emf.close();
// registro
System.out.println("terminé...");
}
}
No hay nada nuevo en este código. Ya se ha visto todo. La ejecución de [InitDB] junto con MySQL5 da los siguientes resultados:
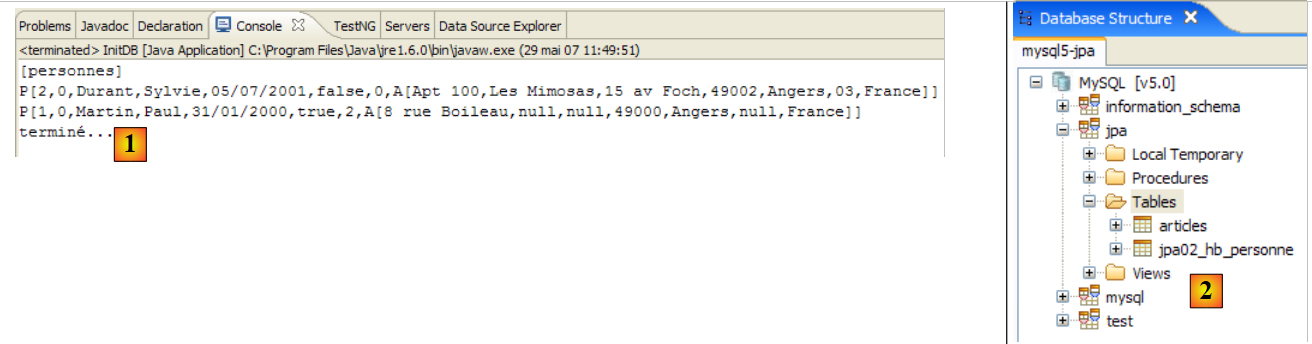 |
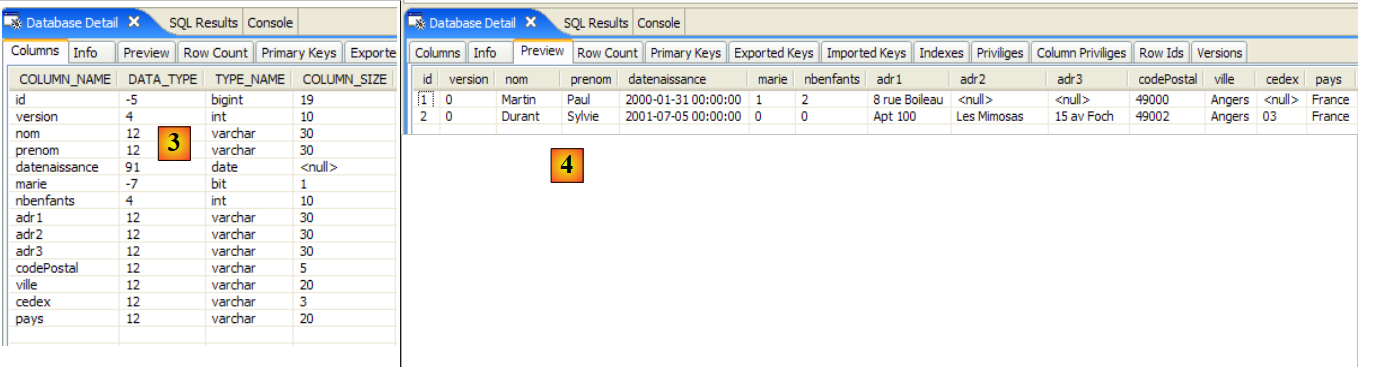 |
- [1]: la salida de la consola
- [2]: la tabla [jpa02_hb_personne] en la perspectiva SQL Explorer
- [3] y [4]: su estructura y contenido.
2.2.6. Inicio
La clase [Main] es la siguiente:
package tests;
...
import entites.Adresse;
import entites.Personne;
@SuppressWarnings( { "unused", "unchecked" })
public class Main {
// constantes
private final static String TABLE_NAME = "jpa02_hb_personne";
// Contexto de persistencia
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = null;
// objetos compartidos
private static Personne p1, p2, newp1;
private static Adresse a1, a2, a3, a4, newa1, newa4;
public static void main(String[] args) throws Exception {
// se recupera un EntityManager a partir del EntityManagerFactory
em = emf.createEntityManager();
// limpieza de la base de datos
log("clean");clean();
// volcado de tabla
dumpPersonne();
// prueba1
log("test1"); test1();
// prueba2
log("test2"); test2();
// prueba3
log("test3"); test3();
// prueba4
log("test4"); test4();
// prueba5
log("test5");test5();
// fin del contexto de persistencia
if (em != null && em.isOpen())
em.close();
// cierre de EntityManagerFactory
emf.close();
}
// recuperar el EntityManager actual
private static EntityManager getEntityManager() {
...
}
// obtener un nuevo EntityManager
private static EntityManager getNewEntityManager() {
...
}
// Visualización del contenido de la tabla «Persona»
private static void dumpPersonne() {
...
}
// borrar BD
private static void clean() {
...
}
// registros
private static void log(String message) {
...
}
// creación de objetos
public static void test1() throws ParseException {
// contexto de persistencia
EntityManager em = getEntityManager();
// creación de personas
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// creación de direcciones
a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
// asociaciones persona <--> dirección
p1.setAdresse(a1);
p2.setAdresse(a2);
// Inicio de transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistencia de personas
em.persist(p1);
em.persist(p2);
// fin de transacción
tx.commit();
// volcado
dumpPersonne();
}
// modificar un objeto del contexto
public static void test2() {
// contexto de persistencia
EntityManager em = getEntityManager();
// Inicio de transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// se incrementa el número de hijos de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// se modifica su estado civil
p1.setMarie(false);
// el objeto p1 se guarda automáticamente (comprobación de cambios)
// durante la próxima sincronización (commit o select)
// fin de la transacción
tx.commit();
// se muestra la nueva tabla
dumpPersonne();
}
// eliminar un objeto perteneciente al contexto de persistencia
public static void test4() {
// contexto de persistencia
EntityManager em = getEntityManager();
// inicio de transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// se elimina el objeto asociado p2
em.remove(p2);
// fin de transacción
tx.commit();
// se muestra la nueva tabla
dumpPersonne();
}
// desvincular, volver a vincular y modificar
public static void test5() {
// nuevo contexto de persistencia
EntityManager em = getNewEntityManager();
// inicio de la transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// Se vuelve a vincular p1 al nuevo contexto
p1 = em.find(Personne.class, p1.getId());
// fin de la transacción
tx.commit();
// se cambia la dirección de p1
p1.getAdresse().setVille("Paris");
// se muestra la nueva tabla
dumpPersonne();
}
}
De nuevo, nada que no se haya visto ya. La salida de la consola es la siguiente:
Se invita al lector a establecer la relación entre los resultados y el código.
2.2.7. Implementación JPA / Toplink
Ahora utilizamos una implementación JPA / Toplink:
 |
El nuevo proyecto Eclipse de las pruebas es el siguiente:
 |
Los códigos Java son idénticos a los del proyecto Hibernate anterior. El entorno (bibliotecas – persistence.xml – SGBD – carpetas de configuración, DDL – script Ant) es el ya analizado en el apartado 2.1.15.2. Este seguirá siendo el caso para los futuros proyectos de Toplink y, salvo excepciones, no volveremos a tratar este entorno. En particular, los archivos persistence.xml que configuran la capa JPA/Toplink para diferentes SGBD son los ya analizados y que se encuentran en la carpeta <conf>.
Si tiene alguna duda sobre los procedimientos a seguir, se invita al lector a consultar los que se siguieron en el estudio anterior.
El proyecto Eclipse [3] se encuentra en la carpeta de ejemplos [4]. Lo importaremos.
La ejecución de [InitDB] junto con SGBD y MySQL5 ofrece los siguientes resultados:
 |
 |
- [1]: la salida de la consola
- [2]: las tablas [jpa02_tl_personne] y [SEQENCE] en la perspectiva SQL Explorer
- [3] y [4]: la estructura y el contenido de [jpa02_tl_personne].
Los scripts SQL generados en ddl/mysql5 [5] son los siguientes:
create.sql
CREATE TABLE jpa02_tl_personne (ID BIGINT NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, VERSION INTEGER NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NBENFANTS INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, CODEPOSTAL VARCHAR(5) NOT NULL, ADR1 VARCHAR(30) NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR3 VARCHAR(30), CEDEX VARCHAR(3), ADR2 VARCHAR(30), PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
DROP TABLE jpa02_tl_personne
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
2.3. Ejemplo 3: relación uno a uno mediante una clave externa
2.3.1. e del esquema de la base de datos
1 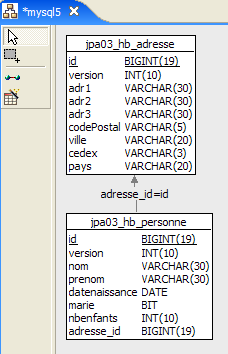 | 2 |
- en [1]: la base de datos. En esta ocasión, la dirección de la persona se almacena en una tabla propia, [adresse]. La tabla [personne] está vinculada a esta tabla mediante una clave foránea.
- en [2]: la tabla DDL generada por Hibernate para MySQL5:
- líneas 9-20: la tabla [adresse], que se vinculará a la clase [Adresse], convertida en un objeto @Entity.
- línea 10: la clave primaria de la tabla [adresse]
- línea 30: en lugar de una dirección completa, ahora se encuentra en la tabla [personne] el identificador [adresse_id] de dicha dirección.
- Líneas 34-38: persona (adresse_id) es una clave externa sobre dirección (id).
2.3.2. Los objetos @Entity que representan la base de datos
Una persona con dirección queda representada ahora por la siguiente clase [Personne]:
package entites;
...
@Entity
@Table(name = "jpa03_hb_personne")
public class Personne implements Serializable{
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
...
}
- líneas 32-34: la dirección de la persona
- línea 32: la anotación @OneToOne indica una relación uno a uno: una persona tiene como mínimo y como máximo una dirección. El atributo cascade = CascadeType.ALL significa que cualquier operación (persist, merge, remove) sobre la @Entity [Personne] debe propagarse en cascada a la @Entity [Adresse]. Desde el punto de vista del contexto de persistencia em, esto significa lo siguiente. Si p es una persona y tiene su dirección:
- una operación explícita em.persist(p) dará lugar a una operación implícita em.persist(a)
- una operación explícita em.merge(p) dará lugar a una operación implícita em.merge(a)
- una operación explícita em.remove(p) dará lugar a una operación implícita em.remove(a)
- línea 32: la anotación @OneToOne indica una relación uno a uno: una persona tiene como mínimo y como máximo una dirección. El atributo cascade = CascadeType.ALL significa que cualquier operación (persist, merge, remove) sobre la @Entity [Personne] debe propagarse en cascada a la @Entity [Adresse]. Desde el punto de vista del contexto de persistencia em, esto significa lo siguiente. Si p es una persona y tiene su dirección:
La experiencia demuestra que estas cascadas implícitas no son la panacea. El desarrollador acaba olvidando lo que hacen. Puede ser preferible utilizar operaciones explícitas en el código. Existen diferentes tipos de cascada. La anotación @OneToOne podría haberse escrito de la siguiente manera:
//@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@OneToOne(cascade = {CascadeType.MERGE, CascadeType.PERSIST, CascadeType.REFRESH, CascadeType.REMOVE}, fetch=FetchType.LAZY)
El atributo cascade admite aquí como valor una matriz de constantes que especifican los tipos de cascadas deseadas.
El atributo fetch=FetchType.LAZY indica a Hibernate que cargue la dependencia en el último momento. Cuando se introduce una lista de personas en el contexto de persistencia, no siempre se desea incluir sus direcciones. Por ejemplo, es posible que solo se quiera esa dirección para una persona concreta elegida por un usuario a través de una interfaz web. El atributo fetch=FetchType.EAGER, por su parte, solicita la carga inmediata de las dependencias.
- (continuación)
- línea 33: la anotación @JoinColumn define la clave foránea que tiene la tabla de la @Entity [Personne] sobre la tabla de la @Entity [Adresse]. El atributo name define el nombre de la columna que sirve como clave externa. El atributo unique=true impone una relación uno a uno: no puede haber dos veces el mismo valor en la columna [adresse_id]. El atributo nullable=false obliga a que cada persona tenga una dirección.
La dirección de una persona queda ahora representada por la siguiente @Entity [Adresse]:
package entites;
...
@Entity
@Table(name = "jpa03_hb_adresse")
public class Adresse implements Serializable {
// campos
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
// constructores
public Adresse() {
}
...
}
- línea 4: la clase [Adresse] se convierte en un objeto @Entity. Por lo tanto, será el objeto de una tabla en la base de datos.
- líneas 9-12: al igual que cualquier objeto @Entity, [Adresse] tiene una clave primaria. Se ha denominado «Id» y presenta las mismas anotaciones (estándar) que la clave primaria Id de la @Entity [Personne].
- Líneas 39-40: la relación uno a uno con la @Entity [Personne]. Aquí hay varias sutilezas:
- en primer lugar, el campo personne no es obligatorio. Nos permite, a partir de una dirección, identificar a la única persona que tiene esa dirección. Si no hubiéramos querido esta comodidad, el campo personne no existiría y todo seguiría funcionando igualmente.
- La relación uno a uno que vincula las dos entidades [Personne] y [Adresse] ya se ha configurado en la @Entity [Personne]:
@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
Para que las dos configuraciones uno a uno no entren en conflicto entre sí, una se considera principale y la otra, inverse. La relación denominada principale es la que gestiona el puente objeto-relacional. La otra relación, denominada inverse, no se gestiona directamente, sino que se gestiona indirectamente a través de la relación principale. En @Entity [Adresse]:
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
es el atributo mappedBy el que establece la relación uno a uno anterior, la relación inverse de la relación uno a uno principale, definida por el campo adresse de @Entity [Personne].
2.3.3. El proyecto Eclipse / Hibernate 1
La implementación JPA utilizada aquí es la de Hibernate. El proyecto Eclipse de las pruebas es el siguiente:
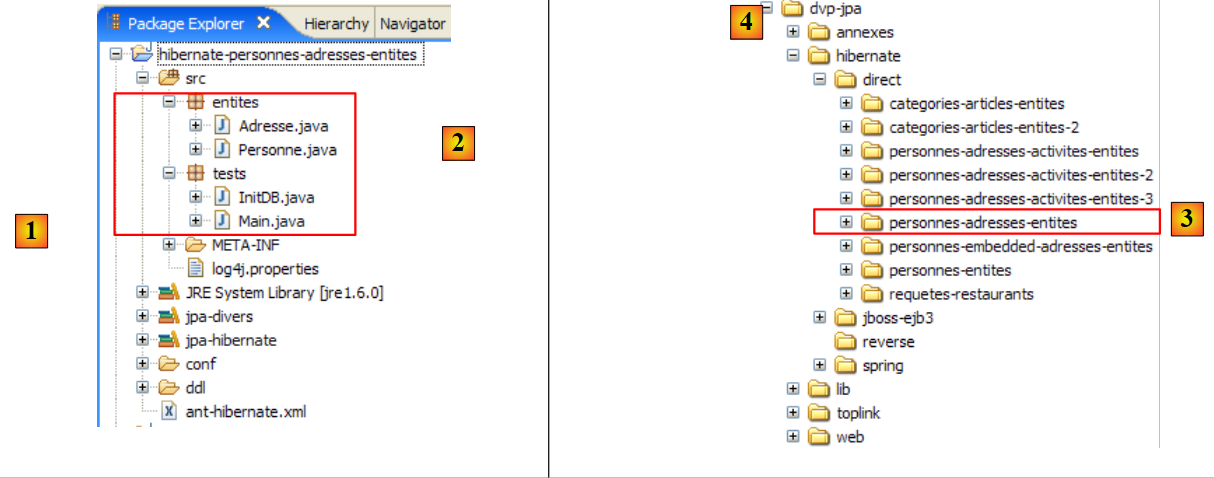 |
El proyecto [3] se encuentra en la carpeta de ejemplos [4]. Lo importaremos.
2.3.4. Generación del archivo DDL de la base de datos
Siguiendo las instrucciones del apartado 2.1.7, el archivo DDL obtenido para el SGBD MySQL5 es el que se muestra al principio de este apartado.
2.3.5. InitDB
El código de [InitDB] es el siguiente:
package tests;
...
import entites.Adresse;
import entites.Personne;
public class InitDB {
// constantes
private final static String TABLE_PERSONNE = "jpa03_hb_personne";
private final static String TABLE_ADRESSE = "jpa03_hb_adresse";
public static void main(String[] args) throws ParseException {
// Contexto de persistencia
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// se recupera un EntityManager a partir del EntityManagerFactory anterior
em = emf.createEntityManager();
// Inicio de la transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// solicitud
Query sql1;
// eliminar los elementos de la tabla PERSONNE
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE);
sql1.executeUpdate();
// eliminar elementos de la tabla ADRESSE
sql1 = em.createNativeQuery("delete from " + TABLE_ADRESSE);
sql1.executeUpdate();
// creación de personas
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// creación de direcciones
Adresse a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
Adresse a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
Adresse a3 = new Adresse("x", "x", "x", "x", "x", "x", "x");
Adresse a4 = new Adresse("y", "y", "y", "y", "y", "y", "y");
// asociaciones persona <--> dirección
p1.setAdresse(a1);
a1.setPersonne(p1);
p2.setAdresse(a2);
a2.setPersonne(p2);
// persistencia de las personas y, en consecuencia, de sus direcciones
em.persist(p1);
em.persist(p2);
// y de las direcciones a3 y a4 no vinculadas a personas
em.persist(a3);
em.persist(a4);
// visualización de personas
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// visualización de direcciones
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
// fin de la transacción
tx.commit();
// fin EntityManager
em.close();
// fin de EntityManagerFactory
emf.close();
// registro
System.out.println("terminé...");
}
}
Solo comentaremos lo que presente un interés nuevo con respecto a lo que ya se ha estudiado:
- líneas 31-32: se crean dos personas
- líneas 34-37: se crean cuatro direcciones
- líneas 39-42: se asocian las personas (p1, p2) a las direcciones (a1, a2). Las direcciones (a3, a4) quedan huérfanas. Ninguna persona las referencia. El código DDL lo permite. Si bien una persona tiene necesariamente una dirección, lo contrario no es cierto.
- líneas 44-45: se persisten las personas (p1, p2). Como hemos establecido un atributo cascade = CascadeType.ALL en la relación uno a uno que vincula a una persona con su dirección, las direcciones (a1, a2) de estas dos personas también deberían someterse a un persist. Esto es lo que queremos comprobar. En el caso de las direcciones huérfanas (a3, a4), nos vemos obligados a hacerlo de forma explícita (líneas 47-48).
- líneas 51-53: visualización de la tabla de personas
- líneas 56-57: visualización de la tabla de direcciones
La ejecución de [InitDB] junto con MySQL5 ofrece los siguientes resultados:
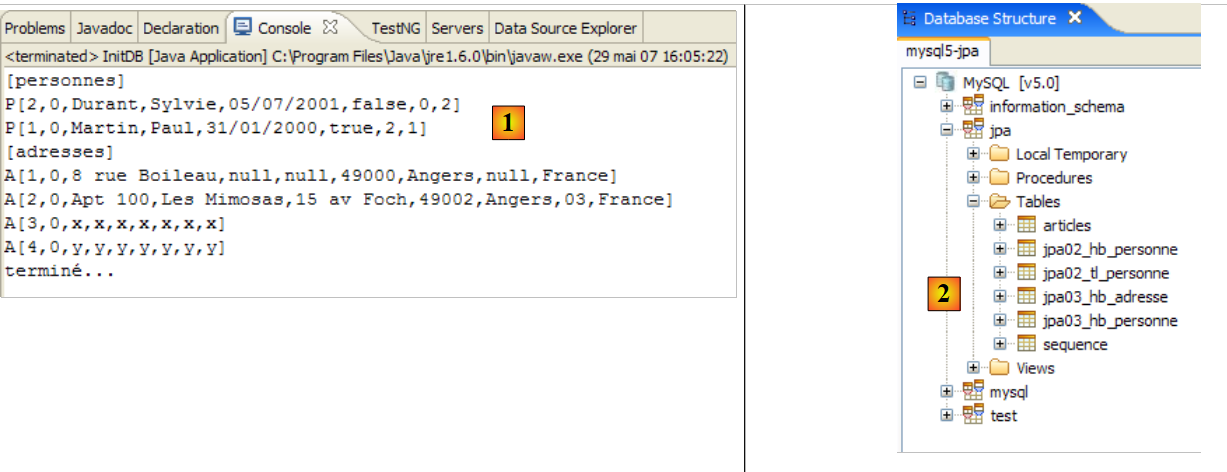 |
 |
- [1]: la salida de la consola
- [2]: las tablas de [jpa03_hb_*] en la perspectiva SQL Explorer
- [3]: la tabla de personas
- [4]: la tabla de direcciones. Están todas ahí. Cabe destacar también la relación que existe entre la columna [adresse_id] de [3] y la columna [id] de [4] (clave externa).
2.3.6. Inicio
La clase [Main] encadena seis pruebas que vamos a repasar.
2.3.6.1. Test1
Esta prueba es la siguiente:
// creación de objetos
public static void test1() throws ParseException {
// contexto de persistencia
EntityManager em = getEntityManager();
// creación de personas
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// creación de direcciones
a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
a3 = new Adresse("x", "x", "x", "x", "x", "x", "x");
a4 = new Adresse("y", "y", "y", "y", "y", "y", "y");
// asociaciones persona <--> dirección
p1.setAdresse(a1);
a1.setPersonne(p1);
p2.setAdresse(a2);
a2.setPersonne(p2);
// Inicio de transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistencia de personas
em.persist(p1);
em.persist(p2);
// y de las direcciones a3 y a4 no vinculadas a personas
em.persist(a3);
em.persist(a4);
// fin de la transacción
tx.commit();
// se muestran las tablas
dumpPersonne();
dumpAdresse();
}
Este código se ha extraído de [InitDB]. Su resultado es el siguiente:
Se han rellenado ambas tablas.
2.3.6.2. Test2
Esta prueba es la siguiente:
// modificar un objeto del contexto
public static void test2() {
// contexto de persistencia
EntityManager em = getEntityManager();
// inicio de transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// se incrementa el número de hijos de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// se modifica su estado civil
p1.setMarie(false);
// el objeto p1 se guarda automáticamente (comprobación de cambios)
// durante la próxima sincronización (commit o select)
// fin de la transacción
tx.commit();
// se muestra la nueva tabla
dumpPersonne();
}
Su resultado es el siguiente:
- línea 4: la persona p1 ha visto cómo su número de hijos aumentaba en 1 y su versión pasaba de 0 a 1
2.3.6.3. Test4
Esta prueba es la siguiente:
// eliminar un objeto perteneciente al contexto de persistencia
public static void test4() {
// contexto de persistencia
EntityManager em = getEntityManager();
// inicio de transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// Se elimina el objeto asociado p2
em.remove(p2);
// fin de transacción
tx.commit();
// se muestran las nuevas tablas
dumpPersonne();
dumpAdresse();
}
- línea 9: se elimina a la persona p2. Esta tiene una relación en cascada con la dirección a2. Por lo tanto, la dirección a2 también debería eliminarse.
El resultado de la prueba 4 es el siguiente:
- la persona p2, que aparece en la línea 3 de la prueba 1, ya no aparece en la prueba 4
- Lo mismo ocurre con su dirección a2, que aparece en la línea 7 de la prueba 1 y no aparece en la prueba 4.
2.3.6.4. Test5
Esta prueba es la siguiente:
// desvincular, volver a vincular y modificar
public static void test5() {
// nuevo contexto de persistencia
EntityManager em = getNewEntityManager();
// inicio de la transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// se vuelve a vincular p1 al nuevo contexto
p1 = em.find(Personne.class, p1.getId());
// se cambia la dirección de p1
p1.getAdresse().setVille("Paris");
// fin de la transacción
tx.commit();
// se muestran las nuevas tablas
dumpPersonne();
dumpAdresse();
}
- Línea 4: tenemos un contexto de persistencia nuevo, por lo que está vacío.
- línea 9: se introduce la persona p1 en él. Se busca p1 en la base de datos porque no está en el contexto. Los elementos que dependen de p1 (su dirección), por su parte, no se recuperan de la base de datos porque se ha escrito:
@OneToOne(..., fetch=FetchType.LAZY)
Este es el concepto de «lazy loading» o «carga diferida»: las dependencias de un objeto persistente solo se cargan en memoria cuando se necesitan.
- Línea 11: se modifica el campo «ciudad» de la dirección de p1. Debido a getAdresse, y si la dirección de p1 aún no se encontrara en el contexto de persistencia, se cargará en él mediante una lectura de la base de datos.
- línea 13: se valida la transacción, lo que provocará la sincronización del contexto de persistencia con la base de datos. Este detectará que se ha modificado la dirección de la persona p1 y la guardará.
La ejecución de test5 ofrece los siguientes resultados:
- la persona p1 (línea 3 de test4, línea 10 de test5) ha visto cómo su ciudad ha pasado de Angers (línea 5 de test4) a París (línea 12 de test5).
2.3.6.5. Test6
Esta prueba es la siguiente:
// eliminar un objeto «Dirección»
public static void test6() {
EntityTransaction tx = null;
// nuevo contexto de persistencia
EntityManager em = getNewEntityManager();
// Inicio de la transacción
tx = em.getTransaction();
tx.begin();
// Se vuelve a vincular la dirección a3 al nuevo contexto
a3 = em.find(Adresse.class, a3.getId());
System.out.println(a3);
// se elimina
em.remove(a3);
// fin de la transacción
tx.commit();
// volcado de la tabla «Dirección»
dumpAdresse();
}
- línea 5: nos encontramos en un contexto de persistencia nuevo, por lo que está vacío.
- línea 10: se introduce la dirección a3 en el contexto de persistencia
- línea 13: se elimina. Era una dirección huérfana (no vinculada a ninguna persona). Por lo tanto, es posible eliminarla.
El resultado de la ejecución es el siguiente:
- la dirección a3 de la prueba 5 (línea 6) ha desaparecido de las direcciones de la prueba 6 (líneas 11-12)
2.3.6.6. Test7
Esta prueba es la siguiente:
// revertir
public static void test7() {
EntityTransaction tx = null;
try {
// nuevo contexto de persistencia
EntityManager em = getNewEntityManager();
// inicio de transacción
tx = em.getTransaction();
tx.begin();
// se vuelve a vincular la dirección a1 al nuevo contexto
newa1 = em.find(Adresse.class, a1.getId());
// se vuelve a vincular la dirección a4 al nuevo contexto
newa4 = em.find(Adresse.class, a4.getId());
// Se intenta eliminarlas; debería lanzarse una excepción, ya que no se puede eliminar una dirección vinculada a una persona, como es el caso de newa1
em.remove(newa4);
em.remove(newa1);
// fin de la transacción
tx.commit();
} catch (RuntimeException e1) {
// ha surgido un problema
System.out.format("Erreur dans transaction [%s%n%s%n%s%n%s]%n", e1.getClass().getName(), e1.getMessage(), e1.getCause(), e1.getCause()
.getCause());
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s]%n", e2.getMessage());
}
// Se abandona el contexto actual
em.clear();
}
// volcado: la tabla «Dirección» no debería haber cambiado debido a la reversión
dumpAdresse();
}
- test7: se comprueba la reversión de una transacción
- línea 6: nos encontramos en un contexto de persistencia nuevo, por lo tanto vacío.
- línea 11: se introduce la dirección a1 en el contexto de persistencia, bajo la referencia newa1
- línea 13: se introduce la dirección a4 en el contexto de persistencia, bajo la referencia newa4
- líneas 15-16: se eliminan las dos direcciones newa1 y newa4. newa1 es la dirección de la persona p1 y, por lo tanto, en la base de datos p1 hace referencia a newa1 mediante una clave externa. Por lo tanto, la eliminación de newa1 fracasará y provocará una excepción durante la sincronización del contexto de persistencia al confirmar la transacción (línea 18). Esta sufrirá un rollback (línea 25) y, por lo tanto, las dos operaciones de la transacción se anularán. Por lo tanto, deberíamos comprobar que la dirección newa4, que podría haberse eliminado legalmente, no lo ha sido.
La ejecución da el siguiente resultado:
main : ----------- test6
A[3,0,x,x,x,x,x,x,x]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
main : ----------- test7
Erreur dans transaction [javax.persistence.RollbackException
Error while commiting the transaction
org.hibernate.ObjectDeletedException: deleted entity passed to persist: [entites.Adresse#<null>]
null]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
- la tabla de direcciones de la prueba 7 (líneas 12-13) es idéntica a la de la prueba 6 (líneas 4-5). Parece que la reversión se ha producido. Dicho esto, el mensaje de error de la línea 9 es un enigma y merece ser investigado. Parece que la excepción que se ha producido no es la esperada. Hay que pasar los registros de Hibernate de log4j.properties al modo DEBUG para verlo con más claridad:
# Opción de registro raíz
log4j.rootLogger=ERROR, stdout
# Opciones de registro de Hibernate (INFO solo muestra mensajes de inicio)
log4j.logger.org.hibernate=DEBUG
Se observa entonces que, cuando la dirección a1 se colocó en el contexto de persistencia, Hibernate también colocó allí a la persona p1, probablemente debido a la relación uno a uno de la @Entity [Adresse]:
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
Aunque aquí se ha solicitado «LazyLoading», la dependencia [Personne] se carga de inmediato. Esto significa probablemente que el atributo fetch=FetchType.LAZY no tiene sentido en este caso. A continuación, se observa que, al confirmar la transacción, Hibernate ha preparado la eliminación de las direcciones «a1» y «a4», pero también el almacenamiento de la persona «p1». Y ahí es donde se produce la excepción: dado que la persona p1 tiene una cascada en su dirección, Hibernate quiere persistir también la dirección a1, a pesar de que acaba de ser eliminada. Es Hibernate quien lanza la excepción y no el controlador JDBC. De ahí el mensaje de la línea 9 anterior. Por otra parte, se puede observar que el rollback de la línea 25 nunca se ejecuta, ya que la transacción ha pasado a estar inactiva. La prueba de la línea 24 impide, por tanto, el rollback.
Por lo tanto, no se ha alcanzado el objetivo deseado: mostrar una reversión. De hecho, no se ha emitido ninguna orden SQL en la base de datos. Cabe destacar algunos puntos:
- La importancia de activar registros detallados para comprender qué hace el ORM
- Si bien un ORM puede facilitarle la vida al desarrollador, también puede complicársela al ocultar comportamientos que el desarrollador necesitaría conocer. En este caso, el modo de carga de las dependencias de una @Entity.
2.3.7. Proyecto Eclipse / Hibernate 2
Copiamos y pegamos el proyecto Eclipse / Hibernate para modificar ligeramente la configuración de los objetos @Entity:
 |
El proyecto se encuentra en [3], dentro de la carpeta de ejemplos [4]. Lo importaremos.
Solo modificamos la @Entity [Adresse] para que ya no tenga una relación inversa uno a uno con la @Entity [Personne]:
package entites;
...
@Entity
@Table(name = "jpa04_hb_adresse")
public class Adresse implements Serializable {
// campos
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
...
@Column(length = 20, nullable = false)
private String pays;
// @OneToOne(mappedBy = «dirección», fetch=FetchType.LAZY)
// private Persona persona;
// constructores
public Adresse() {
}
- líneas 25-26: se elimina la relación inversa @OneToOne. Hay que tener claro que una relación inversa nunca es imprescindible. Solo lo es la relación principal. La relación inversa puede utilizarse por comodidad. En este caso, permitía obtener de forma sencilla el propietario de una dirección. Una relación inversa siempre puede sustituirse por una consulta JPQL. Eso es lo que vamos a mostrar en el siguiente ejemplo.
Los programas de prueba se mantienen tal cual. El que nos interesa es únicamente la prueba 7, aquella en la que vimos la relación inversa uno a uno en acción. Además, añadimos una prueba 8 para mostrar cómo, sin la relación inversa Dirección -> Persona, se puede, no obstante, recuperar la persona que tiene dicha dirección.
La prueba 7 no cambia. Su ejecución ofrece ahora los siguientes resultados (registros desactivados):
main : ----------- prueba6
A[3,0,x,x,x,x,x,x,x]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
main : ----------- prueba7
Erreur dans transaction [javax.persistence.RollbackException
Error while commiting the transaction
org.hibernate.exception.ConstraintViolationException: could not delete: [entites.Adresse#1]
java.sql.SQLException: Cannot delete or update a parent row: a foreign key constraint fails (`jpa/jpa04_hb_personne`, CONSTRAINT `FKEA3F04515FE379D0` FOREIGN KEY (`adresse_id`) REFERENCES `jpa04_hb_adresse` (`id`))]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
- Esta vez sí que se produce la excepción esperada: la lanzada por el controlador JDBC porque se ha intentado eliminar de la tabla [adresse] una fila a la que hace referencia una clave externa de una fila de la tabla [personne]. La línea [10] deja clara la causa del error.
- La reversión se ha llevado a cabo correctamente: al finalizar la prueba 7, la tabla [adresse] (líneas 12-13) es la misma que teníamos al finalizar la prueba 6 (líneas 4-5).
¿Cuál es la diferencia con la prueba 7 del proyecto Eclipse anterior? ¿Por qué se produce aquí una excepción Jdbc que no se había producido en la prueba anterior? Debido a que la @Entity [Adresse] ya no tiene una relación inversa uno a uno con la @Entity [Personne], Hibernate la gestiona de forma aislada. Cuando la dirección newa1 se incorporó al contexto de persistencia, Hibernate no incluyó también en dicho contexto a la persona p1, que tiene esa dirección. Por lo tanto, la eliminación de las direcciones newa1 y newa4 se llevó a cabo sin que hubiera entidades Personne en el contexto.
Ahora bien, ¿cómo se podría deducir, a partir de la dirección newa1, que la persona p1 tiene esa dirección? Es una pregunta legítima. La prueba 8 que sigue responde a ella:
// relación inversa uno a uno
// realizada mediante una consulta JPQL
public static void test8() {
EntityTransaction tx = null;
// nuevo contexto de persistencia
EntityManager em = getNewEntityManager();
// inicio de transacción
tx = em.getTransaction();
tx.begin();
// se vuelve a vincular la dirección a1 al nuevo contexto
newa1 = em.find(Adresse.class, a1.getId());
// se recupera la persona propietaria de esta dirección
Personne p1 = (Personne) em.createQuery("select p from Personne p join p.adresse a where a.id=:adresseId").setParameter("adresseId", newa1.getId())
.getSingleResult();
// se muestran
System.out.println("adresse=" + newa1);
System.out.println("personne=" + p1);
// fin de la transacción
tx.commit();
}
- línea 6: nuevo contexto de persistencia vacío
- líneas 8-9: inicio de la transacción
- línea 11: la dirección a1 se introduce en el contexto de persistencia y se referencia mediante newa1.
- línea 13: se recupera la persona p1, que tiene la dirección newa1, mediante una consulta JPQL. Sabemos que [Personne] y [Adresse] están vinculadas mediante una relación de clave externa. En la clase [Personne], es el campo [adresse], que tiene la anotación @OneToOne, el que materializa esta relación. La instrucción JPQL «select p from Personne p join p.adresse a» realiza una unión entre las tablas [personne] y [adresse]. El equivalente SQL generado en una consola de Hibernate (véanse los ejemplos del apartado 2.1.12) es el siguiente:
Se aprecia claramente la unión de las dos tablas. Ahora cada persona está vinculada a su dirección. Queda por precisar que solo nos interesa la dirección newa1. La consulta queda así: «select p from Personne p join p.adresse a where a.id=:adresseId». Cabe destacar el uso de los alias p y a. Las consultas JPQL utilizan los alias de forma intensiva. Así, la expresión «from Personne p join p.adresse a» hace que una persona quede representada por el alias p y su dirección (p.adresse) por el alias a. La operación de restricción «where a.id=:adresseId» limita las filas solicitadas únicamente a las personas p que tengan el valor:adresseId como identificador de su dirección a. :adresseId se denomina parámetro, y la orden JPQL, una orden parametrizada. En el momento de la ejecución, este parámetro debe recibir un valor. Este es el método
que permite asignar un valor a un parámetro identificado por su nombre. Cabe señalar que setParameter devuelve un objeto Query, al igual que el método createQuery. De este modo, se pueden encadenar las llamadas a los métodos [em.createQuery(...).setParameter(...).getSingleResult(...)], ya que los métodos [setParameter, getSingleResult] forman parte de la interfaz Query. El método [getSingleResult] se utiliza para las consultas Select que solo devuelven un único resultado. Este es el caso aquí.
- Líneas 16-17: se muestra la dirección newa1 y la persona p1 que tiene dicha dirección, a modo de verificación.
El resultado obtenido es el siguiente:
Es correcto. De este ejemplo se desprende que la relación inversa uno a uno de la @entity [Adresse] hacia la @entity [Personne] no era imprescindible. La experiencia ha demostrado aquí que su eliminación daba lugar a un comportamiento más predecible del código. Esto suele ser así.
2.3.8. Consola de Hibernate
En la prueba 8 anterior se utilizó un comando JPQL para realizar una unión entre las entidades Personne y Adresse. Aunque son similares al lenguaje SQL, los lenguajes JPQL, JPA o HQL de Hibernate requieren un proceso de aprendizaje, y la consola de Hibernate es excelente para ello. Ya la hemos utilizado en el apartado 2.1.12 para trabajar con una única tabla. Volvemos a hacerlo aquí para trabajar con dos tablas relacionadas mediante una clave foránea.
Creemos una consola de Hibernate para nuestro proyecto actual de Eclipse:
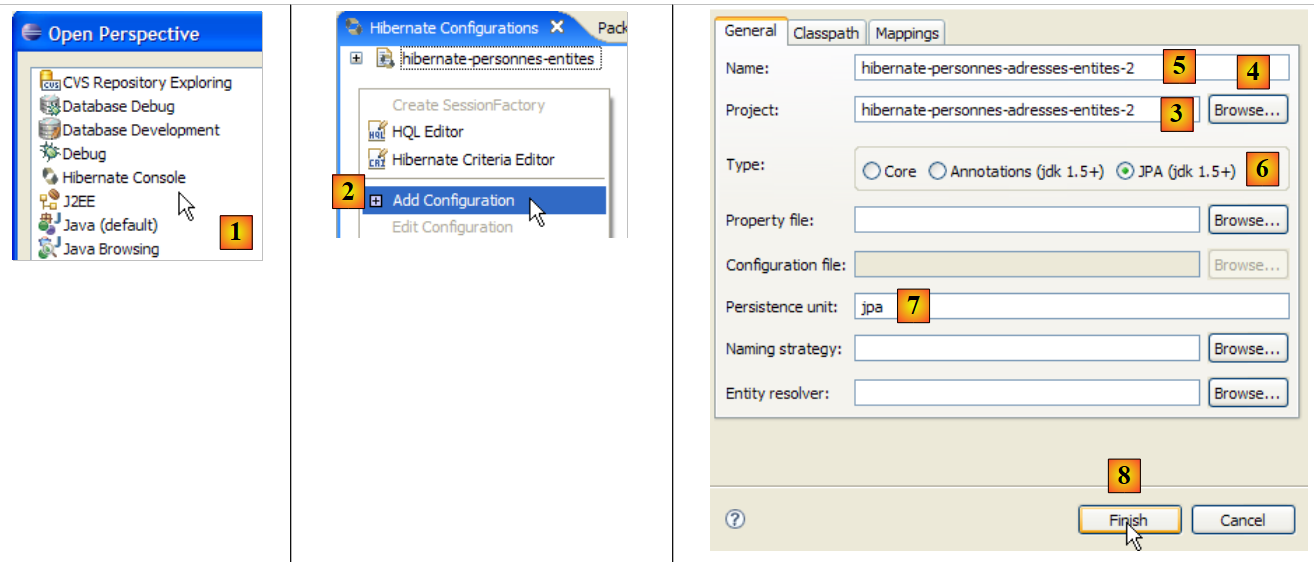 |
- [1]: cambiamos a la perspectiva [Hibernate Console] (Ventana / Abrir perspectiva / Otra)
- [2]: creamos una nueva configuración
- mediante el botón [4]; seleccionamos el proyecto Java para el que se crea la configuración de Hibernate. Su nombre aparece en [3].
- En [5], le damos el nombre que queramos a esta configuración. En este caso, hemos utilizado el nombre del proyecto Java.
- En [6], indicamos que utilizamos una configuración JPA para que la herramienta sepa que debe utilizar el archivo [META-INF/persistence.xml]
- En [7]: indicamos que, en este archivo [META-INF/persistence.xml], hay que utilizar la unidad de persistencia denominada jpa.
- En [8], validamos la configuración.
A continuación, hay que ejecutar el archivo SGBD. En este caso, se trata del archivo MySQL5.
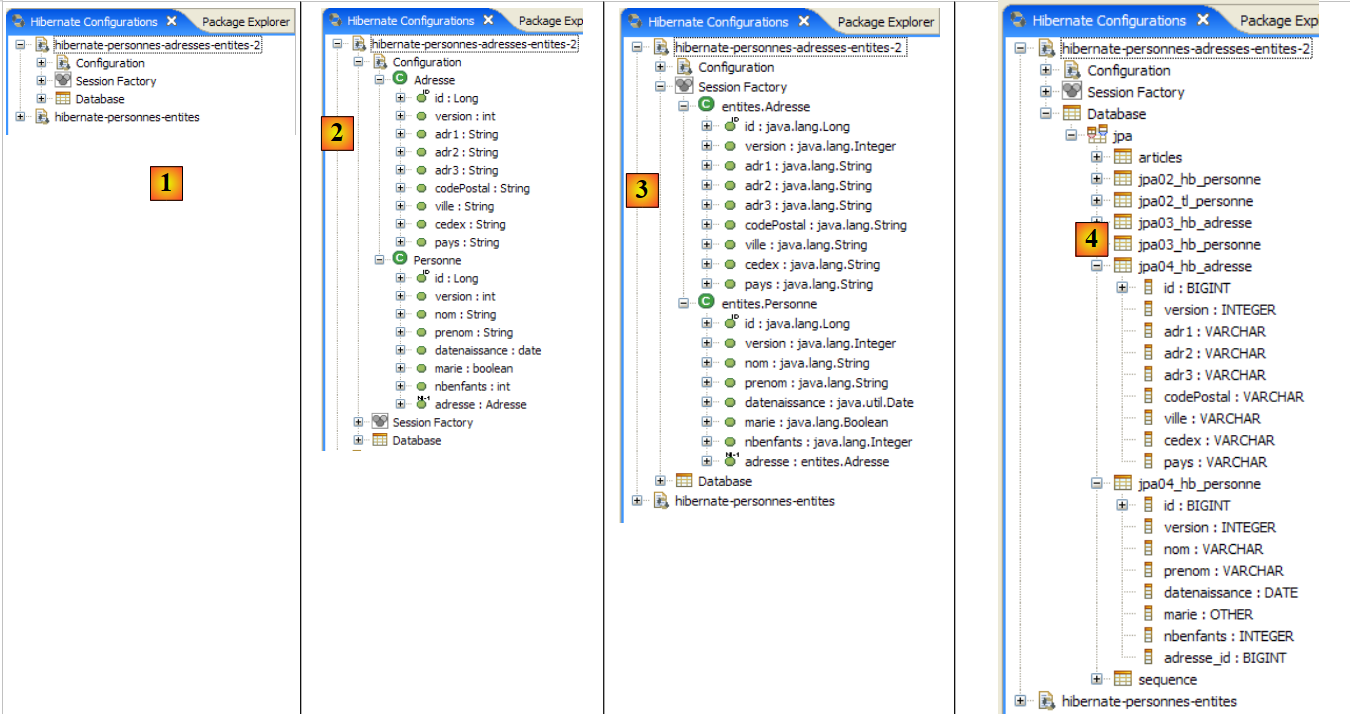 |
- En [1]: la configuración creada presenta un árbol de tres ramas
- en [2]: la rama [Configuration] enumera los objetos que la consola ha utilizado para configurarse: en este caso, las @Entity Personne y Adresse.
- En [3]: la «Session Factory» es un concepto de Hibernate similar al de EntityManager de JPA. Establece el puente entre objetos y relaciones gracias a los objetos de la rama [Configuration]. En [3] se presentan los objetos del contexto de persistencia, en este caso de nuevo las @Entity Personne y Adresse.
- En [4]: la base de datos a la que se accede mediante la configuración que se encuentra en [persistence.xml]. En ella se encuentran las tablas [jpa04_hb_*] generadas por nuestro proyecto actual de Eclipse.
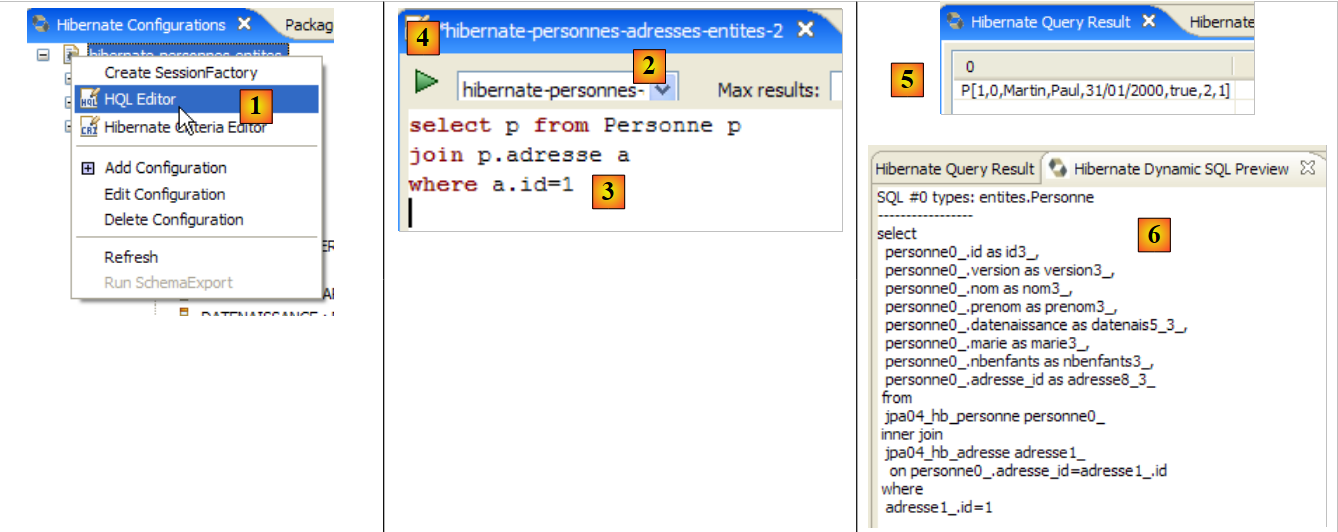 |
- en [1], se crea un editor HQL
- en el editor HQL,
- en [2], se elige la configuración de Hibernate que se va a utilizar si hay varias (como es el caso aquí)
- en [3], se escribe el comando JPQL que se desea ejecutar; en este caso, el comando JPQL de la prueba 8
- En [4], se ejecuta
- en [5], se obtienen los resultados de la consulta en la ventana [Hibernate Query Result].
- En [6], la ventana [Hibernate Dynamic SQL preview] permite ver la consulta SQL que se ha ejecutado.
Otra forma de obtener el mismo resultado:
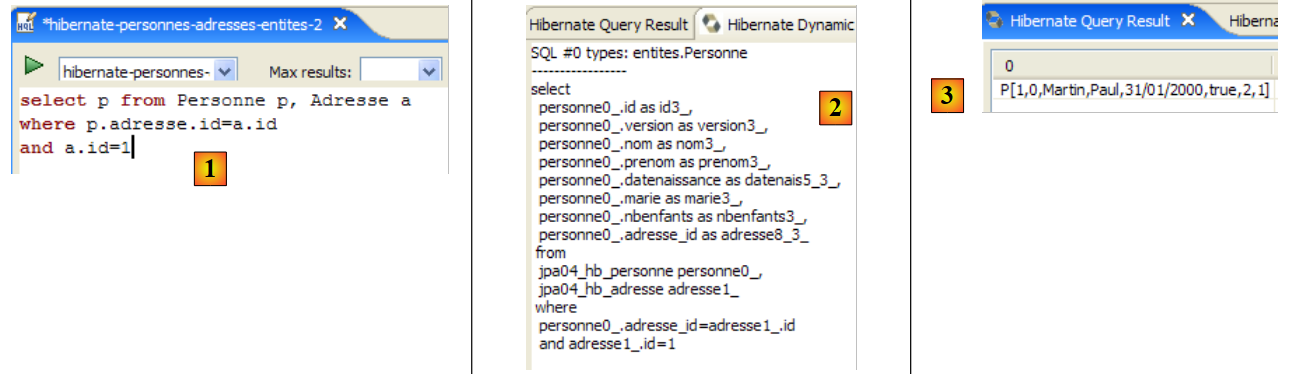 |
- en [1]: el comando JPQL realiza la unión de las entidades Personne y Adresse. [ref1] denomina a esta forma «unión theta».
- en [2]: el equivalente SQL
- en [3]: el resultado
Una tercera forma aceptada únicamente por Hibernate (HQL):
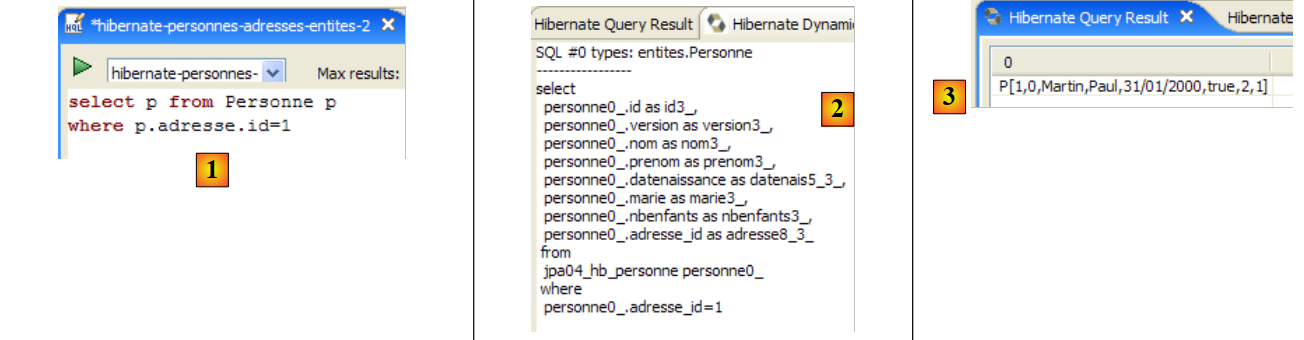 |
- en [1]: el comando HQL. JPQL no admite la notación p.adresse.id. Solo admite un nivel de indirección.
- en [2]: el equivalente SQL. Se observa que evita la unión entre tablas.
- en [3]: el resultado
Aquí tienes otros ejemplos:
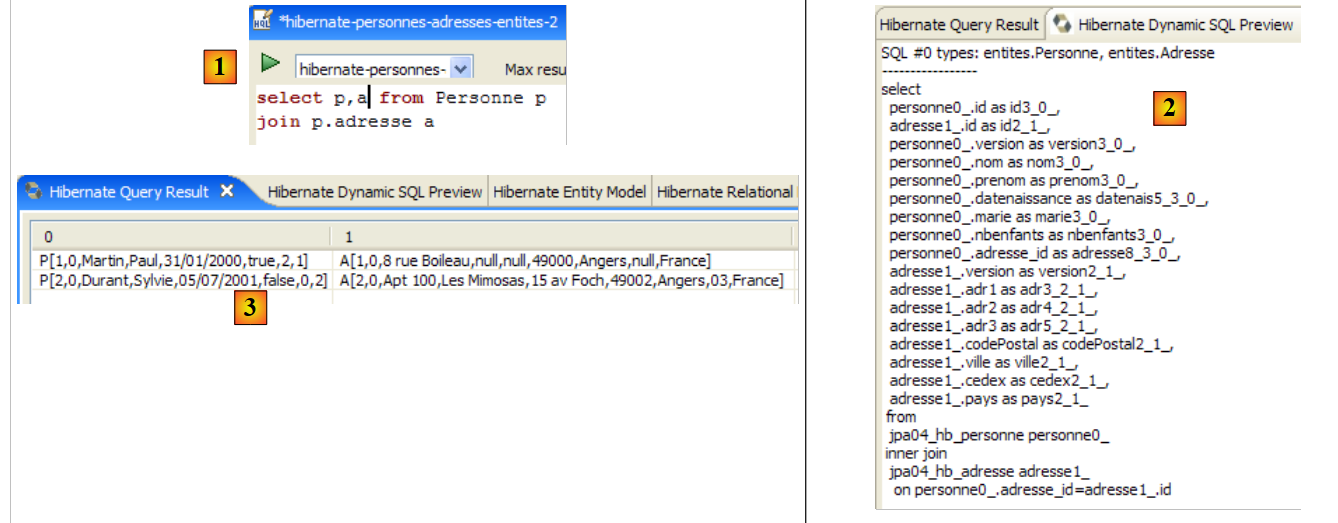 |
- en [1]: la lista de personas con sus direcciones
- en [2]: el equivalente SQL.
- en [3]: el resultado
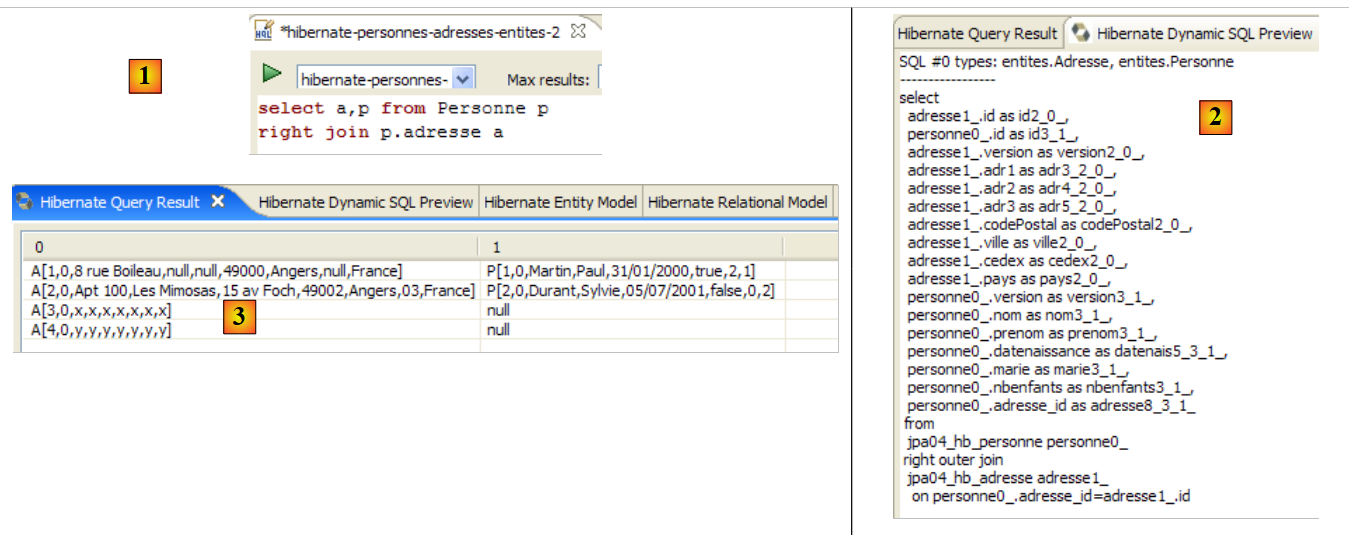 |
- en [1]: la lista de direcciones con su propietario, si lo hay, o ninguno en caso contrario (unión externa derecha: la entidad Adresse, que proporcionará las filas sin relación con Personne, se encuentra a la derecha de la palabra clave join).
- en [2]: el equivalente a SQL.
- en [3]: el resultado
Cabe señalar que solo la entidad Personne mantiene una relación con la entidad Adresse. Lo contrario ya no es cierto desde que se eliminó la relación inversa uno a uno denominada personne en la entidad Adresse. Si esta relación inversa existiera, se habría podido escribir:
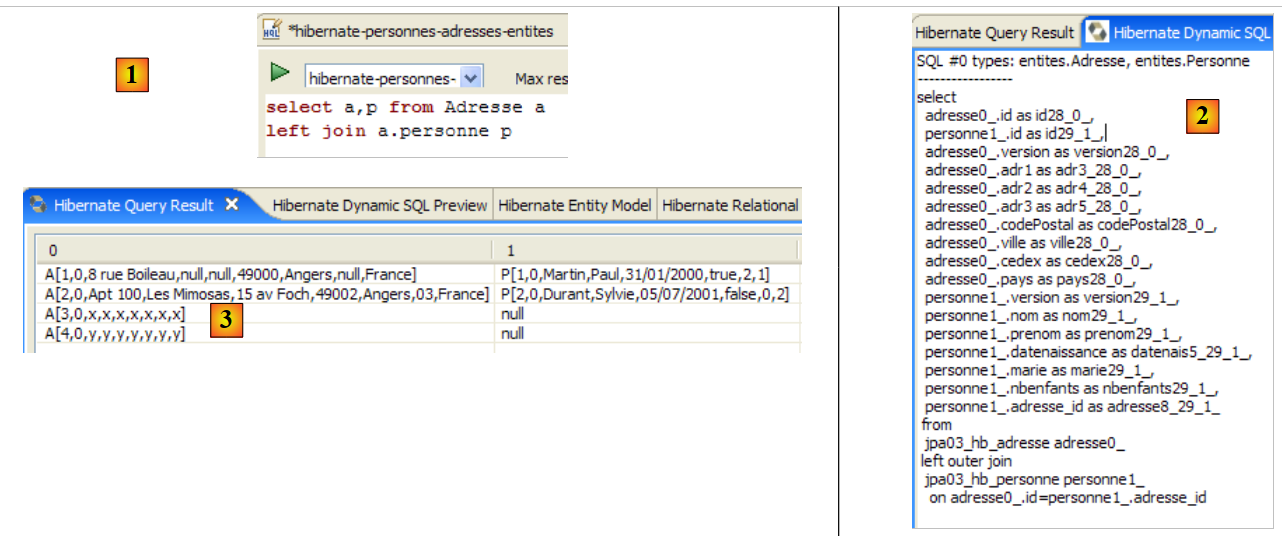 |
- en [1]: la lista de direcciones con su propietario, si lo hay, o ninguna si no lo hay (unión externa izquierda: la entidad Adresse, que proporcionará las filas sin relación con Personne, se encuentra a la izquierda de la palabra clave join).
- en [2]: el equivalente a SQL.
- en [3]: el resultado
Recomendamos encarecidamente al lector que practique con el lenguaje JPQL utilizando la consola de Hibernate.
2.3.9. Implementación JPA / Toplink
Ahora utilizamos una implementación JPA / Toplink:
 |
El nuevo proyecto Eclipse de pruebas es el siguiente:
 |
Los códigos Java son idénticos a los del proyecto Hibernate anterior. El entorno (bibliotecas – persistence.xml – SGBD – carpetas conf, ddl – script ant) es el que se ha estudiado en el apartado 2.1.15.2. El proyecto de Eclipse [3] se encuentra en la carpeta de ejemplos [4]. Lo importaremos.
El archivo <persistence.xml> se modifica en un punto, el de las entidades declaradas:
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- proveedor -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- clases persistentes -->
<class>entites.Personne</class>
<class>entites.Adresse</class>
<!-- propiedades de la unidad de persistencia -->
...
- líneas 5 y 6: las dos entidades gestionadas
La ejecución de [InitDB] junto con SGBD y MySQL5 ofrece los siguientes resultados:
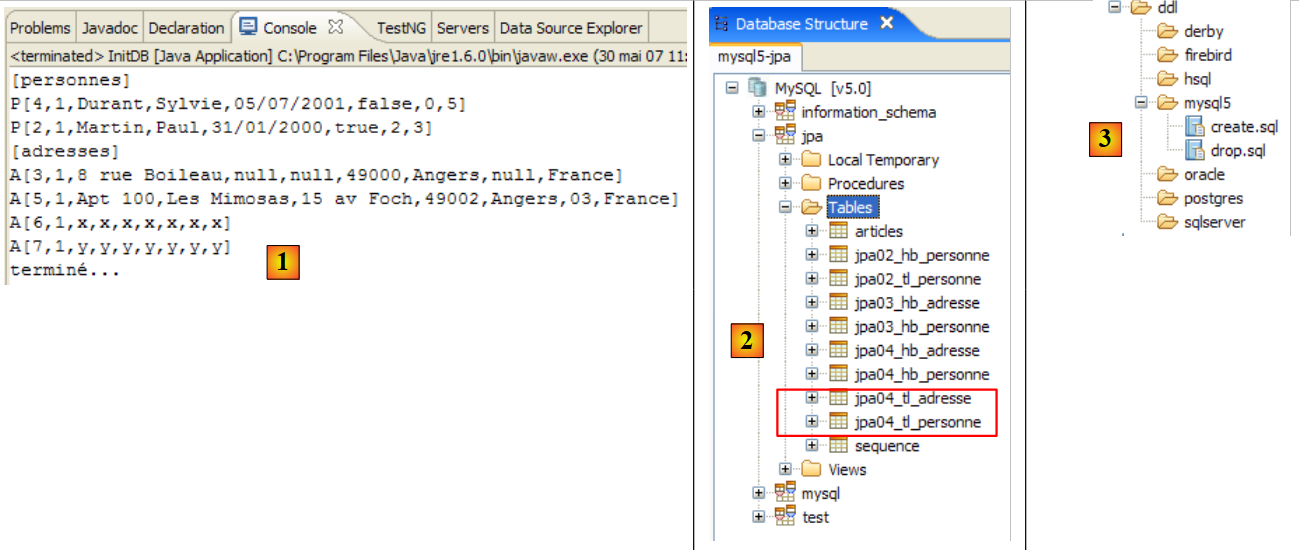 |
En [1], la salida de la consola; en [2], las dos tablas generadas [jpa04_tl]; y en [3], los scripts generados SQL. Su contenido es el siguiente:
create.sql
CREATE TABLE jpa04_tl_personne (ID BIGINT NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, VERSION INTEGER NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NBENFANTS INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa04_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, ADR1 VARCHAR(30) NOT NULL, VILLE VARCHAR(20) NOT NULL, VERSION INTEGER NOT NULL, CEDEX VARCHAR(3), ADR2 VARCHAR(30), PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa04_tl_personne ADD CONSTRAINT FK_jpa04_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa04_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
ALTER TABLE jpa04_tl_personne DROP FOREIGN KEY FK_jpa04_tl_personne_adresse_id
DROP TABLE jpa04_tl_personne
DROP TABLE jpa04_tl_adresse
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
2.4. Ejemplo 4: relación uno a varios
2.4.1. El esquema de la base de datos « »
1  | 2 |
- en [1], la base de datos, y en [2], su DDL (MySQL5)
Un artículo A(id, versión, nombre) pertenece exactamente a una categoría C(id, versión, nombre). Una categoría C puede contener 0, 1 o varios artículos. Se trata de una relación uno a varios (Categoría → Artículo) y de la relación inversa varios a uno (Artículo → Categoría). Esta relación se materializa mediante la clave foránea que posee la tabla [article] sobre la tabla [categorie] (líneas 24-28 de la DDL).
2.4.2. Los objetos @Entity que representan la base de datos
Un artículo se representa mediante la siguiente @Entity [Article]:
package entites;
...
@Entity
@Table(name="jpa05_hb_article")
public class Article implements Serializable {
// campos
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// relación principal Artículo (muchos) -> Categoría (uno)
// implementada mediante una clave foránea (categorie_id) en Artículo
// 1 Artículo tiene necesariamente 1 Categoría (nullable=false)
@ManyToOne(fetch=FetchType.LAZY)
@JoinColumn(name = "categorie_id", nullable = false)
private Categorie categorie;
// constructores
public Article() {
}
// getter y setter
...
// toString
public String toString() {
return String.format("Article[%d,%d,%s,%d]", id, version, nom, categorie.getId());
}
}
- líneas 9-11: clave primaria de la @Entity
- líneas 13-15: su número de versión
- líneas 17-18: nombre del artículo
- líneas 20-25: relación «muchos a uno» que vincula la @Entity Article con la @Entity Categorie:
- línea 23: la anotación ManyToOne. El «Many» hace referencia a la @Entity Article en la que nos encontramos, y el «One» a la @Entity Categorie (línea 25). Una categoría (One) puede tener varios artículos (Many).
- línea 24: la anotación ManyToOne define la columna de clave externa en la tabla [article]. Se llamará (name) categorie_id y cada fila deberá tener un valor en esta columna (nullable=false).
- línea 25: la categoría a la que pertenece el artículo. Cuando un artículo se incluya en el contexto de persistencia, se solicita que su categoría no se incluya allí inmediatamente (fetch=FetchType.LAZY, línea 23). No sabemos si esta solicitud tiene sentido. Ya lo veremos.
Una categoría está representada por la siguiente @Entity [Categorie]:
package entites;
...
@Entity
@Table(name="jpa05_hb_categorie")
public class Categorie implements Serializable {
// campos
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// relación inversa Categoría (uno) -> Artículo (muchos) de la relación Artículo (muchos) -> Categoría (uno)
// inserción en cascada de Categoría -> inserción de Artículos
// cascada de actualización de Categoría -> actualización de Artículos
// eliminación en cascada de Categoría -> eliminación de Artículos
@OneToMany(mappedBy = "categorie", cascade = { CascadeType.ALL })
private Set<Article> articles = new HashSet<Article>();
// constructores
public Categorie() {
}
// getters y setters
...
// toString
public String toString() {
return String.format("Categorie[%d,%d,%s]", id, version, nom);
}
// asociación bidireccional Categoría <--> Artículo
public void addArticle(Article article) {
// el artículo se añade a la colección de artículos de la categoría
articles.add(article);
// El artículo cambia de categoría
article.setCategorie(this);
}
}
- líneas 8-11: la clave primaria de la @Entity
- líneas 12-14: su versión
- líneas 16-17: el nombre de la categoría
- líneas 19-24: el conjunto (set) de artículos de la categoría
- línea 23: la anotación @OneToMany indica una relación uno a varios. El «One» hace referencia a la @Entity [Categorie] en la que nos encontramos, y el «Many» al tipo [Article] de la línea 24: una (One) categoría tiene varios (Many) artículos.
- línea 23: la anotación es la inversa (mappedBy) de la anotación ManyToOne colocada en el campo categorie de la @Entity Article: mappedBy=categoría. La relación ManyToOne, aplicada al campo categorie de la @Entity Article, es la relación principal. Es imprescindible. Esta relación materializa la relación de clave externa que vincula la @Entity Article con la @Entity Categorie. La relación OneToMany, definida sobre el campo articles de la @Entity Categorie, es la relación inversa. No es imprescindible. Es una facilidad para obtener los artículos de una categoría. Sin esta facilidad, dichos artículos se obtendrían mediante una consulta JPQL.
- Línea 23: cascadeType.ALL solicita que las operaciones (persist, merge, remove) realizadas sobre una @Entity Categorie se apliquen en cascada a sus artículos.
- línea 24: los artículos de una categoría se colocarán en un objeto de tipo Set<Article>. El tipo Set no admite duplicados. Por lo tanto, no se puede incluir dos veces el mismo artículo en el objeto Set<Article>. ¿Qué significa «el mismo artículo»? Para indicar que el artículo a es el mismo que el artículo b, Java utiliza la expresión a.equals(b). En la clase Object, clase padre de todas las clases, a.equals(b) es verdadera si a == b, c.a.d. si los objetos a y b tienen la misma ubicación en memoria. Podríamos querer decir que los artículos a y b son los mismos si tienen el mismo nombre. En este caso, el desarrollador debe redefinir dos métodos en la clase [Article]:
- equals: que debe devolver «verdadero» si ambos artículos tienen el mismo nombre
- hashCode: debe devolver un valor entero idéntico para dos objetos [Article] que el método equals considere iguales. En este caso, el valor se construirá a partir del nombre del artículo. El valor devuelto por hashCode puede ser cualquier número entero. Se utiliza en diferentes contenedores de objetos, especialmente en los diccionarios (Hashtable).
La relación OneToMany puede utilizar otros tipos distintos de «Set» para almacenar el «Many», como por ejemplo objetos de tipo «List». No trataremos estos casos en este documento. El lector podrá encontrarlos en [ref1].
- Línea 38: el método [addArticle] nos permite añadir un artículo a una categoría. El método se encarga de actualizar ambos extremos de la relación OneToMany que vincula [Categorie] con [Article].
2.4.3. El proyecto Eclipse / Hibernate 1
La implementación JPA utilizada aquí es la de Hibernate. El proyecto Eclipse de las pruebas es el siguiente:
 |
El proyecto [3] se encuentra en la carpeta de ejemplos [4]. Lo importaremos.
2.4.4. Generación del archivo DDL de la base de datos
Siguiendo las instrucciones del apartado 2.1.7, el archivo DDL obtenido para el SGBD MySQL5 es el que se muestra al principio de este ejemplo, en el apartado 2.4.1.
2.4.5. InitDB
El código de [InitDB] es el siguiente:
package tests;
...
public class InitDB {
// constantes
private final static String TABLE_ARTICLE = "jpa05_hb_article";
private final static String TABLE_CATEGORIE = "jpa05_hb_categorie";
public static void main(String[] args) {
// Contexto de persistencia
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// se recupera un EntityManager a partir del EntityManagerFactory anterior
em = emf.createEntityManager();
// Inicio de la transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// solicitud
Query sql1;
// eliminar los elementos de la tabla ARTICLE
sql1 = em.createNativeQuery("delete from " + TABLE_ARTICLE);
sql1.executeUpdate();
// eliminar los elementos de la tabla CATEGORIE
sql1 = em.createNativeQuery("delete from " + TABLE_CATEGORIE);
sql1.executeUpdate();
// crear tres categorías
Categorie categorieA = new Categorie();
categorieA.setNom("A");
Categorie categorieB = new Categorie();
categorieB.setNom("B");
Categorie categorieC = new Categorie();
categorieC.setNom("C");
// crear 3 artículos
Article articleA1 = new Article();
articleA1.setNom("A1");
Article articleA2 = new Article();
articleA2.setNom("A2");
Article articleB1 = new Article();
articleB1.setNom("B1");
// vincularlos a su categoría
categorieA.addArticle(articleA1);
categorieA.addArticle(articleA2);
categorieB.addArticle(articleB1);
// guardar las categorías y, de forma cascada (inserción), los artículos
em.persist(categorieA);
em.persist(categorieB);
em.persist(categorieC);
// mostrar categorías
System.out.println("[categories]");
for (Object p : em.createQuery("select c from Categorie c order by c.nom asc").getResultList()) {
System.out.println(p);
}
// visualización de artículos
System.out.println("[articles]");
for (Object p : em.createQuery("select a from Article a order by a.nom asc").getResultList()) {
System.out.println(p);
}
// fin de la transacción
tx.commit();
// fin de EntityManager
em.close();
// fin de EntityMangerFactory
emf.close();
// registro
System.out.println("terminé...");
}
}
- líneas 22-27: las tablas [article] y [categorie] se vacían. Cabe señalar que es obligatorio comenzar por la que tiene la clave externa. Si se comenzara por la tabla [categorie], se eliminarían categorías a las que hacen referencia las líneas de la tabla [article], y esto lo rechazaría la tabla SGBD.
- líneas 29-34: se crean tres categorías A, B, C
- líneas 36-41: se crean tres artículos: A1, A2 y B1 (la letra indica la categoría)
- líneas 43-45: los tres artículos se colocan en sus respectivas categorías
- líneas 47-49: las tres categorías se añaden al contexto de persistencia. Debido a la cascada «Categoría → Artículo», sus artículos también se colocarán allí. Por lo tanto, todos los objetos creados se encuentran ahora en el contexto de persistencia.
- líneas 50-59: se realiza una consulta al contexto de persistencia para obtener la lista de categorías y artículos. Sabemos que esto provocará una sincronización del contexto con la base de datos. Es en este momento cuando las categorías y los artículos se guardarán en sus respectivas tablas.
La ejecución de [InitDB] junto con MySQL5 ofrece los siguientes resultados:
 |
- [1]: la salida de la consola
- [2]: las tablas de [jpa05_hb_*] en la perspectiva SQL Explorer
- [3]: la tabla de categorías
- [4]: la tabla de artículos. Cabe destacar la relación entre [categorie_id] en [4] y [id] en [3] (clave externa).
2.4.6. Inicio
La clase [Main] encadena una serie de pruebas que vamos a revisar, excepto las pruebas 1 y 2, que retoman el código de [InitDB] para inicializar la base de datos.
2.4.6.1. Test3
Esta prueba es la siguiente:
// buscar un elemento concreto
public static void test3() {
// nuevo contexto de persistencia
EntityManager em = getNewEntityManager();
// transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// carga de categoría
Categorie categorie = em.find(Categorie.class, categorieA.getId());
// visualización de la categoría y sus artículos asociados
System.out.format("Articles de la catégorie %s :%n", categorie);
for (Article a : categorie.getArticles()) {
System.out.println(a);
}
// fin de la transacción
tx.commit();
}
- línea 4: tenemos un contexto de persistencia nuevo, por lo que está vacío
- líneas 6-7: inicio de la transacción
- línea 9: la categoría A se transfiere desde la base de datos al contexto de persistencia
- línea 11: se muestra la categoría A
- líneas 12-14: se muestran los artículos de la categoría A. Aquí se pone de manifiesto la utilidad de la relación inversa OneToMany, que enlaza con los artículos de la @Entity Categorie. Su presencia nos evita tener que realizar una consulta JPQL para solicitar los artículos de la categoría A. Para obtenerlos, se utiliza el método get del campo articles.
Los resultados son los siguientes:
- línea 20: la categoría A
- líneas 21-22: los dos artículos de la categoría A
2.4.6.2. Test4
Esta prueba es la siguiente:
// eliminar un artículo
@SuppressWarnings("unchecked")
public static void test4() {
// nuevo contexto de persistencia
EntityManager em = getNewEntityManager();
// transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// carga de artículo A1
Article newarticle1 = em.find(Article.class, articleA1.getId());
// eliminación del artículo A1 (actualmente no hay ninguna categoría cargada)
em.remove(newarticle1);
// toplink: el artículo debe eliminarse de su categoría; de lo contrario, la prueba 6 falla
// hibernate: no es necesario
newarticle1.getCategorie().getArticles().remove(newarticle1);
// fin de la transacción
tx.commit();
// volcado de artículos
dumpArticles();
}
- La prueba 4 elimina el artículo A1
- línea 5: se parte de un contexto nuevo y vacío
- línea 10: el artículo A1 se introduce en el contexto de persistencia. Allí se referenciará mediante newarticle1.
- línea 12: se elimina del contexto
- línea 15: las categorías A, B y C y los artículos A1, A2 y B1, aunque ya no sean persistentes, siguen estando en memoria. Simplemente se han desvinculado del contexto de persistencia. El artículo A1, que forma parte de los artículos de la categoría A, se elimina de esta. Esto permitirá posteriormente volver a vincular la categoría A al contexto de persistencia. Si no se hace así, la categoría A se vinculará con un conjunto de artículos de los que uno ha sido eliminado. Esto no parece suponer ningún problema para Hibernate, pero provoca un fallo en Toplink.
- Línea 19: se muestran todos los artículos para comprobar que A1 ha desaparecido.
Los resultados son los siguientes:
El artículo A1 ha desaparecido correctamente.
2.4.6.3. Test5
Esta prueba es la siguiente:
// modificación de 1 artículo
public static void test5() {
// nuevo contexto de persistencia
EntityManager em = getNewEntityManager();
// transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// modificación de articleA2
articleA2.setNom(articleA2.getNom() + "-");
// articleA2 se vuelve a colocar en el contexto de persistencia
em.merge(articleA2);
// fin de la transacción
tx.commit();
// volcado de artículos
dumpArticles();
}
- La prueba 5 cambia el nombre del artículo A2
- línea 4: se parte de un contexto nuevo y vacío
- línea 9: se cambia el nombre del artículo independiente A2, que pasará a ser «A2-».
- línea 11: el artículo desvinculado A2 se vuelve a vincular al contexto de persistencia. Cabe señalar que A2 sigue siendo un objeto desvinculado. El objeto em.merge (articleA2) es el que ahora forma parte del contexto de persistencia. Este objeto no se ha almacenado aquí en una variable, como es habitual. Por lo tanto, no es accesible.
- Línea 13: sincronización del contexto de persistencia con la base de datos. El artículo A2 se va a modificar en la base de datos y su número de versión pasará de N a N+1. La versión en memoria separada articleA2 ya no es válida. Lo mismo ocurre con el objeto separado que representa la categoría A, ya que este contiene articleA2 entre sus artículos.
- línea 15: se muestran todos los artículos para comprobar el cambio de nombre del artículo A2
Los resultados son los siguientes:
El artículo A2 ha cambiado de nombre correctamente.
2.4.6.4. Test6
Esta prueba es la siguiente:
// modificación de una categoría y sus artículos
public static void test6() {
// nuevo contexto de persistencia
EntityManager em = getNewEntityManager();
// transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// carga de categoría
categorieA = em.find(Categorie.class, categorieA.getId());
// lista de artículos de la categoría A
for (Article a : categorieA.getArticles()) {
a.setNom(a.getNom() + "-");
}
// modificación del nombre de la categoría
categorieA.setNom(categorieA.getNom() + "-");
// fin de la transacción
tx.commit();
// volcado de categorías y artículos
dumpCategories();
dumpArticles();
}
- La prueba 6 cambia el nombre de la categoría A y de todos sus artículos
- línea 4: se parte de un contexto nuevo y vacío
- línea 9: se busca la categoría A en la base de datos. No se realiza un merge del objeto independiente categorieA, ya que se sabe que tiene una referencia al artículo A2, que ha quedado obsoleto. Por lo tanto, se vuelve a empezar desde cero.
- líneas 11-12: se cambia el nombre de todos los artículos de la categoría A. De nuevo se utiliza la relación inversa OneToMany mediante el método getArticles.
- línea 15: también se modifica el nombre de la categoría
- línea 17: fin de la transacción. Se realiza una sincronización del contexto con la base de datos. Todos los objetos del contexto que se han modificado se actualizarán en la base de datos.
- Líneas 21-22: se muestran los artículos y las categorías para su verificación
Los resultados son los siguientes:
El artículo A2 ha vuelto a cambiar de nombre, al igual que la categoría A.
2.4.6.5. Test7
Esta prueba es la siguiente:
// eliminación de una categoría
public static void test7() {
// nuevo contexto de persistencia
EntityManager em = getNewEntityManager();
// transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistencia catégorieB y eliminación en cascada (merge) de los artículos asociados
Categorie mergedcategorieB = em.merge(categorieB);
// eliminación de categoría y, en cascada (delete), de los artículos asociados
em.remove(mergedcategorieB);
// fin de la transacción
tx.commit();
// volcado de categorías y artículos
dumpCategories();
dumpArticles();
}
- La prueba 7 elimina la categoría B y, en consecuencia, sus artículos
- línea 4: se parte de un contexto nuevo y vacío
- línea 9: la categoría B existe en memoria como un objeto separado del contexto de persistencia. Se vuelve a integrar (merge) en el contexto de persistencia. En consecuencia, sus artículos (el artículo B1) se someterán a un merge y, por lo tanto, volverán a integrarse en el contexto de persistencia.
- línea 11: ahora que la categoría B se encuentra en el contexto, podemos eliminarla (remove). Por efecto en cadena, sus artículos también se someterán a una operación remove. Esta operación es posible porque la operación merge de la línea 9 los ha reintegrado en el contexto de persistencia.
- línea 13: fin de la transacción. El contexto se va a sincronizar. Los objetos del contexto que hayan sido sometidos a una operación remove se eliminarán de la base de datos.
- Líneas 15-16: se muestran los artículos y las categorías para su verificación
Los resultados son los siguientes:
La categoría B y el artículo B1 han desaparecido correctamente.
2.4.6.6. Test8
Esta prueba es la siguiente:
// consultas
@SuppressWarnings("unchecked")
public static void test8() {
// nuevo contexto de persistencia
EntityManager em = getNewEntityManager();
// transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// lista de artículos de la categoría A
List articles = em
.createQuery(
"select a from Categorie c join c.articles a where c.nom like 'A%' order by a.nom asc")
.getResultList();
// visualizaciones de artículos
System.out.println("Articles de la catégorie A");
for (Object a : articles) {
System.out.println(a);
}
// fin de la transacción
tx.commit();
}
- La prueba 7 muestra cómo recuperar los artículos de una categoría sin pasar por la relación inversa. Esto demuestra que dicha relación no es, por tanto, imprescindible.
- línea 4: se parte de un contexto nuevo y vacío
- línea 10: una consulta JPQL que solicita todos los artículos de una categoría cuyo nombre comience por A
- líneas 15-17: visualización del resultado de la consulta.
Los resultados son los siguientes:
2.4.7. Proyecto Eclipse / Hibernate 2
Copiamos y pegamos el proyecto Eclipse / Hibernate para aclarar un aspecto sobre el concepto de relación principal y relación inversa que hemos creado en torno a la anotación @ManyToOne (principal) de la @Entity [Article] y la relación inversa @OneToMany (inversa) de la @Entity [Categorie]. Queremos demostrar que, si esta última relación no se declara inversa a la otra, el esquema generado para la base de datos es totalmente diferente al generado anteriormente.
 |
En [1], el nuevo proyecto de Eclipse. En [2] está el código Java; en [3], el script ant que generará el esquema SQL de la base de datos. El proyecto se encuentra en [4], dentro de la carpeta de ejemplos [5]. Lo importaremos.
Solo modificaremos la @Entity [Categorie] para que su relación @OneToMany con la @entidad [Article] ya no se declare inversa a la relación @ManyToOne que tiene la @Entity [Article] con la @Entity [Categorie]:
...
@Entity
@Table(name="jpa05_hb_categorie")
public class Categorie implements Serializable {
// campos
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// relación OneToMany no inversa (sin «mappedby») Categoría (uno) -> Artículo (muchos)
// implementada mediante una tabla de unión Categorie_Article para que, a partir de una categoría
// se pueda acceder a los artículos de dicha categoría
@OneToMany(cascade=CascadeType.ALL, fetch=FetchType.LAZY)
private Set<Article> articles = new HashSet<Article>();
// fabricantes
...
- líneas 18-22: queremos seguir conservando la posibilidad de encontrar los artículos de una categoría determinada gracias a la relación @OneToMany de la línea 21. Pero queremos conocer la influencia del atributo mappedBy, que convierte una relación en la inversa de una relación principal definida en otro lugar, en otra @Entity. En este caso, se ha eliminado el mappedBy.
Ejecutamos la tarea ant-DLL (véase el apartado 2.1.7) con SGBD y MySQL5. El esquema obtenido es el siguiente:
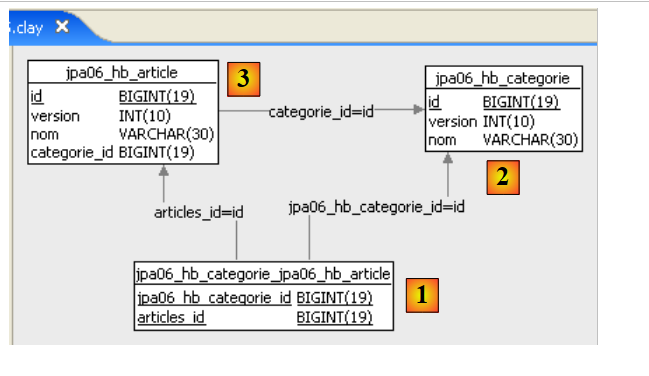 |
Cabe destacar los siguientes puntos:
- se ha creado una nueva tabla [categorie_article] [1]. Antes no existía.
- Se trata de una tabla de unión entre las tablas [categorie], [2] y [article], [3]. Si los objetos Artículo a1 y a2 pertenecen a la categoría c1, en la tabla de unión aparecerán las siguientes filas:
donde c1, a1 y a2 son las claves primarias de los objetos correspondientes.
- La tabla de unión [categorie_article] [1] ha sido creada por Hibernate para que, a partir de un objeto Categorie c, se puedan recuperar los objetos Article a que pertenecen a c. Ha sido la relación @OneToMany la que ha obligado a crear esta tabla. Como no se declaró inversa a la relación principal @ManyToOne de la @Entity Artículo, Hibernate no sabía que podía utilizar esta relación principal para recuperar los artículos de una categoría c. Por lo tanto, lo resolvió de otra manera.
- Con este ejemplo, se comprenden mejor los conceptos de las relaciones principale y inverse. Una (la inversa) utiliza las propiedades de la otra (la principal).
El esquema SQL de esta base de datos para MySQL5 es el siguiente:
alter table jpa05_hb_categorie_jpa06_hb_article
drop
foreign key FK79D4BA1D26D17756;
alter table jpa05_hb_categorie_jpa06_hb_article
drop
foreign key FK79D4BA1D424C61C9;
alter table jpa06_hb_article
drop
foreign key FK4547168FECCE8750;
drop table if exists jpa05_hb_categorie;
drop table if exists jpa05_hb_categorie_jpa06_hb_article;
drop table if exists jpa06_hb_article;
create table jpa05_hb_categorie (
id bigint not null auto_increment,
version integer not null,
nom varchar(30),
primary key (id)
) ENGINE=InnoDB;
create table jpa05_hb_categorie_jpa06_hb_article (
jpa05_hb_categorie_id bigint not null,
articles_id bigint not null,
primary key (jpa05_hb_categorie_id, articles_id),
unique (articles_id)
) ENGINE=InnoDB;
create table jpa06_hb_article (
id bigint not null auto_increment,
version integer not null,
nom varchar(30),
categorie_id bigint not null,
primary key (id)
) ENGINE=InnoDB;
alter table jpa05_hb_categorie_jpa06_hb_article
add index FK79D4BA1D26D17756 (jpa05_hb_categorie_id),
add constraint FK79D4BA1D26D17756
foreign key (jpa05_hb_categorie_id)
references jpa05_hb_categorie (id);
alter table jpa05_hb_categorie_jpa06_hb_article
add index FK79D4BA1D424C61C9 (articles_id),
add constraint FK79D4BA1D424C61C9
foreign key (articles_id)
references jpa06_hb_article (id);
alter table jpa06_hb_article
add index FK4547168FECCE8750 (categorie_id),
add constraint FK4547168FECCE8750
foreign key (categorie_id)
references jpa05_hb_categorie (id);
- líneas 19-24: creación de la tabla [categorie]; y líneas 33-39: creación de la tabla [article]. Cabe señalar que son idénticas a las del ejemplo anterior.
- Líneas 26-31: creación de la tabla de unión [categorie_article] debido a la presencia de la relación no inversa @OneToMany de la @Entity Categorie. Las entradas de esta tabla son de tipo [c,a], donde c es la clave primaria de una categoría c y a la clave primaria deun artículo a perteneciente a la categoría c. La clave primaria de esta tabla de unión está formada por las dos claves primarias [c,a] concatenadas (fila 29).
- líneas 41-45: la restricción de clave externa de la tabla [categorie_article] hacia la tabla [categorie]
- líneas 47-51: la restricción de clave externa de la tabla [categorie_article] hacia la tabla [article]
- líneas 53-57: la restricción de clave externa de la tabla [article] a la tabla [categorie]
Se invita al lector a ejecutar las pruebas [InitDB] y [Main]. Estas dan los mismos resultados que antes. Sin embargo, el esquema de la base de datos es redundante y el rendimiento se verá mermado con respecto a la versión anterior. Sin duda, habría que profundizar en esta cuestión de las relaciones inversas y principales para ver si la nueva configuración no genera, además, conflictos debidos al hecho de que hay dos relaciones independientes para representar lo mismo: la relación «muchos a uno» que tiene la tabla [article] con la tabla [categorie].
2.4.8. Implementación JPA / Toplink - 1
Ahora utilizamos una implementación JPA / Toplink:
 |
El proyecto de Eclipse con Toplink es una copia del proyecto de Eclipse con Hibernate, versión 1:
 |
Los códigos Java son idénticos a los del proyecto Hibernate —versión 1— anterior. El entorno (bibliotecas – persistence.xml – SGBD – carpetas conf, ddl – script ant) es el que se ha estudiado en el apartado 2.1.15.2. El proyecto de Eclipse se encuentra en [3], dentro de la carpeta de ejemplos [4]. Lo importaremos.
El archivo <persistence.xml> [2] se modifica en un punto, el de las entidades declaradas:
...
<!-- clases persistentes -->
<class>entites.Categorie</class>
<class>entites.Article</class>
...
- líneas 3 y 4: las dos entidades gestionadas
La ejecución de [InitDB] junto con SGBD y MySQL5 ofrece los siguientes resultados:
 |
En [1], la pantalla de la consola, en [2], las dos tablas [jpa05_tl] generadas, en [3] los scripts SQL generados. Su contenido es el siguiente:
create.sql
CREATE TABLE jpa05_tl_article (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), categorie_id BIGINT NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa05_tl_categorie (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), PRIMARY KEY (ID))
ALTER TABLE jpa05_tl_article ADD CONSTRAINT FK_jpa05_tl_article_categorie_id FOREIGN KEY (categorie_id) REFERENCES jpa05_tl_categorie (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
ALTER TABLE jpa05_tl_article DROP FOREIGN KEY FK_jpa05_tl_article_categorie_id
DROP TABLE jpa05_tl_article
DROP TABLE jpa05_tl_categorie
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
La ejecución de [Main] se realiza sin errores.
2.4.9. Implementación de JPA / Toplink - 2
Este proyecto de Eclipse se ha creado a partir del anterior mediante copia. Como se ha realizado con Hibernate, se elimina el atributo mappedBy de la relación @OneToMany de la @Entity Categorie.
@Entity
@Table(name = "jpa06_tl_categorie")
public class Categorie implements Serializable {
// campos
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
private int version;
@Column(length = 30)
private String nom;
// relación OneToMany no inversa (sin mappedby) Categoría (one) ->
// Artículo (muchos)
// implementada mediante una tabla de unión Categorie_Article para que, a partir
// una categoría
// se pueda acceder a varios artículos
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private Set<Article> articles = new HashSet<Article>();
El esquema SQL generado para MySQL5 es, por tanto, el siguiente:
create.sql
CREATE TABLE jpa06_tl_categorie (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), PRIMARY KEY (ID))
CREATE TABLE jpa06_tl_categorie_jpa06_tl_article (Categorie_ID BIGINT NOT NULL, articles_ID BIGINT NOT NULL, PRIMARY KEY (Categorie_ID, articles_ID))
CREATE TABLE jpa06_tl_article (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), categorie_id BIGINT NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa06_tl_categorie_jpa06_tl_article ADD CONSTRAINT FK_jpa06_tl_categorie_jpa06_tl_article_articles_ID FOREIGN KEY (articles_ID) REFERENCES jpa06_tl_article (ID)
ALTER TABLE jpa06_tl_categorie_jpa06_tl_article ADD CONSTRAINT jpa06_tl_categorie_jpa06_tl_article_Categorie_ID FOREIGN KEY (Categorie_ID) REFERENCES jpa06_tl_categorie (ID)
ALTER TABLE jpa06_tl_article ADD CONSTRAINT FK_jpa06_tl_article_categorie_id FOREIGN KEY (categorie_id) REFERENCES jpa06_tl_categorie (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
- línea 2: la tabla de unión que materializa la relación @OneToMany no inversa anterior.
La ejecución de [InitDB] se realiza sin errores, pero la de [Main] falla en la prueba 7 con los siguientes registros (FINEST):
- línea 3: el merge en la categoría B
- línea 4: el artículo dependiente B1 se incluye en el contexto
- línea 5: lo mismo ocurre con la propia categoría B
- línea 6: el remove en la categoría B
- línea 7: el remove en el artículo B1 (por cascada)
- línea 8: el código Java solicita el commit de la transacción
- línea 9: se inicia una transacción; por lo tanto, al parecer aún no había comenzado.
- línea 10: el artículo B1 va a ser eliminado mediante una operación DELETE en la tabla [article]. Ahí es donde está el problema. La tabla de unión [categorie_article] tiene una referencia a la fila B1 de la tabla [article]. La eliminación de B1 en [article] infringirá una restricción de clave externa.
- líneas 13 y siguientes: se produce la excepción
¿Qué conclusión podemos sacar?
- Una vez más, nos encontramos con un problema de portabilidad entre Hibernate y Toplink: Hibernate había superado esta prueba
- Toplink no gestiona bien el caso en el que, cuando dos relaciones son en realidad inversas entre sí, una de ellas no se declare principal y la otra inversa. Esto se puede aceptar, ya que este caso representa, de hecho, un error de configuración. En nuestro ejemplo, la tabla [article] no tiene ninguna relación con la tabla de unión [categorie_article]. Por lo tanto, parece lógico que, al realizar una operación en la tabla [article], Toplink no intente trabajar con la tabla [categorie_article].
2.5. Ejemplo 5: relación muchos-a-muchos con una tabla de unión explícita
2.5.1. El esquema de la base de datos
|
- en [1], la base de datos MySQL5
Ya conocemos las tablas [personne], [2] y [adresse], [3]. Se han analizado en el apartado 2.3.1. Tomamos la versión en la que la dirección de la persona figura en una tabla propia: [adresse] y [3]. En la tabla [personne], la relación que vincula a una persona con su dirección se materializa mediante una restricción de clave externa.
Una persona realiza actividades. Estas figuran en la tabla [activite] [4]. Una persona puede realizar varias actividades y una actividad puede ser realizada por varias personas. Por lo tanto, una relación muchos-a-muchos vincula las tablas [personne] y [activite]. Esta relación se materializa mediante la tabla de unión [personne_activite] [5].
2.5.2. Los objetos @Entity que representan la base de datos
Las tablas anteriores se representarán mediante las siguientes @Entity:
- la @Entity Personne representará la tabla [personne]
- la @Entity Adresse representará la tabla [adresse]
- la @Entity Activite representará la tabla [activite]
- la @Entity PersonneActivite representará la tabla [personne_activite]
Las relaciones entre estas entidades son las siguientes:
- una relación uno a uno vincula la entidad Personne con la entidad Adresse: una persona p tiene una dirección a. La entidad Personne, que posee la clave externa, tendrá la relación principal, mientras que la entidad Adresse tendrá la relación inversa.
- Una relación «muchos a muchos» vincula las entidades Personne y Activite: una persona tiene varias actividades y una actividad la practican varias personas. Esta relación podría establecerse directamente mediante una anotación @ManyToMany en cada una de las dos entidades, declarando una de ellas como inversa de la otra. Esta solución se analizará más adelante. En este caso, establecemos la relación «muchos a muchos» mediante dos relaciones «uno a muchos»:
- una relación uno-a-varios que vincula la entidad Personne con la entidad PersonneActivite: una fila (One) de la tabla [personne] es referenciada por varias (Many) filas de la tabla [personne_activite]. La tabla [personne_activite], que contiene la clave foránea, tendrá la relación principal @ManyToOne, y la entidad Personne tendrá la relación inversa @OneToMany.
- una relación uno a varios que vincula la entidad Activite con la entidad PersonneActivite: una fila (One) de la tabla [activite] es referenciada por varias (Many) filas de la tabla [personne_activite]. La tabla [personne_activite], que contiene la clave foránea, tendrá la relación principal @ManyToOne, y la entidad Activite tendrá la relación inversa @OneToMany.
La @Entity Personne es la siguiente:
@Entity
@Table(name = "jpa07_hb_personne")
public class Personne implements Serializable {
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
// relación principal Persona (una) -> Dirección (una)
// implementada por la clave externa Persona (adresse_id) -> Dirección
// inserción en cascada de Persona -> inserción de Dirección
// cascada de actualización de Persona -> actualización de Dirección
// eliminación en cascada de Persona -> eliminación de Dirección
// una persona debe tener una dirección (nullable=false)
// una dirección solo pertenece a una persona (única=true)
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
// relación Persona (una) -> PersonneActivite (varias)
// inverso de la relación existente PersonneActivite (muchos) -> Persona (uno)
// eliminación en cascada de «Persona» -> eliminación de PersonneActivite
@OneToMany(mappedBy = "personne", cascade = { CascadeType.REMOVE })
private Set<PersonneActivite> activites = new HashSet<PersonneActivite>();
// constructores
Esta @Entity ya es conocida. Solo comentaremos las relaciones que mantiene con las demás entidades:
- líneas 30-39: una relación uno a uno @OneToOne con la @Entity Adresse, materializada mediante una clave foránea [adresse_id] (línea 38) que tendrá la tabla [personne] sobre la tabla [adresse].
- líneas 41-45: una relación uno a varios @OneToMany con la @Entity PersonneActivite. Una persona (One) es referenciada por varias (Many) filas de la tabla de unión [personne_activite], representada por la @Entity PersonneActivite. Estos objetos PersonneActivite se colocarán en un tipo Set<PersonneActivite>, donde PersonneActivite es un tipo que definiremos más adelante.
- Línea 44: la relación uno-a-varios definida aquí es la relación inversa de una relación principal definida sobre el campo personne de la @Entity PersonneActivite (palabra clave mappedBy). Tenemos una cascada Persona -> Actividad en las eliminaciones: la eliminación de una persona p provocará la eliminación de los elementos persistentes de tipo PersonneActivite que se encuentren en el conjunto p.activites.
La @Entity Adresse es la siguiente:
@Entity
@Table(name = "jpa07_hb_adresse")
public class Adresse implements Serializable {
// campos
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse")
private Personne personne;
- líneas 28-29: la relación @OneToOne, inversa de la relación @OneToOne, apunta a la @Entity Personne (líneas 37-38 de Personne).
La @Entity Activite es la siguiente
@Entity
@Table(name = "jpa07_hb_activite")
public class Activite implements Serializable {
// campos
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
// relación Actividad (uno) -> PersonneActivite (muchos)
// inversión de la relación existente PersonneActivite (muchos) -> Actividad (uno)
// eliminación en cascada de Actividad -> eliminación de PersonneActivite
@OneToMany(mappedBy = "activite", cascade = { CascadeType.REMOVE })
private Set<PersonneActivite> personnes = new HashSet<PersonneActivite>();
- líneas 6-9: la clave primaria de la actividad
- líneas 11-13: el número de versión de la actividad
- líneas 15-16: el nombre de la actividad
- líneas 18-22: la relación uno-a-varios que vincula la @Entity Activite con la @Entity PersonneActivite: una actividad (One) es referenciada por varias (Many) líneas de la tabla de unión [personne_activite], representada por la @Entity PersonneActivite. Estos objetos PersonneActivite se colocarán en un tipo Set<PersonneActivite>.
- línea 22: la relación uno-a-varios definida aquí es la relación inversa de una relación principal definida sobre el campo activite en la @Entity PersonneActivite (palabra clave mappedBy). Existe una cascada «Actividad» → «PersonneActivite» en las eliminaciones: la eliminación de la tabla «[activite]» deuna actividad a provocará la eliminación de la tabla de unión [personne_activite] de los elementos persistentes de tipo PersonneActivite que se encuentren en el conjunto a.personnes.
La @Entity PersonneActivite es la siguiente:
@Entity
// tabla de unión
@Table(name = "jpa07_hb_personne_activite")
public class PersonneActivite {
@Embeddable
public static class Id implements Serializable {
// componentes de la clave compuesta
// apunta a una persona
@Column(name = "PERSONNE_ID")
private Long personneId;
// apunta a una actividad
@Column(name = "ACTIVITE_ID")
private Long activiteId;
// constructores
...
// getters y setters
...
// toString
public String toString() {
return String.format("[%d,%d]", getPersonneId(), getActiviteId());
}
}
// campos de la clase Personne_Activite
// clave compuesta
@EmbeddedId
private Id id = new Id();
// relación principal PersonneActivite (many) -> Persona (one)
// implementada mediante la clave foránea: personneId (PersonneActivite (muchos) -> Persona (uno)
// personneId es, al mismo tiempo, parte de la clave primaria compuesta
// JPA no debe gestionar esta clave externa (insertable = false, updatable = false), ya que esto lo hace la propia aplicación en su constructor
@ManyToOne
@JoinColumn(name = "PERSONNE_ID", insertable = false, updatable = false)
private Personne personne;
// relación principal PersonneActivite -> Actividad
// implementada mediante la clave foránea: activiteId (PersonneActivite (many) → Actividad (one)
// activiteId es, al mismo tiempo, parte de la clave primaria compuesta
// JPA no debe gestionar esta clave externa (insertable = false, updatable = false), ya que esto lo hace la propia aplicación en su constructor
@ManyToOne()
@JoinColumn(name = "ACTIVITE_ID", insertable = false, updatable = false)
private Activite activite;
// constructores
public PersonneActivite() {
}
public PersonneActivite(Personne p, Activite a) {
// las claves externas las establece la aplicación
getId().setPersonneId(p.getId());
getId().setActiviteId(a.getId());
// asociaciones bidireccionales
this.setPersonne(p);
this.setActivite(a);
p.getActivites().add(this);
a.getPersonnes().add(this);
}
// getter y setter
...
// toString
public String toString() {
return String.format("[%s,%s,%s]", getId(), getPersonne().getNom(), getActivite().getNom());
}
}
Esta clase es más compleja que las anteriores.
- La tabla [personne_activite] contiene registros con el formato [p,a], donde p es la clave primaria de una persona y a, la clave primaria de una actividad. Toda tabla debe tener una clave primaria y [personne_activite] no es una excepción a la regla. Hasta ahora, habíamos definido claves primarias generadas dinámicamente por el SGBD. Podríamos hacerlo también aquí. Vamos a utilizar otra técnica, aquella en la que la propia aplicación define los valores de la clave primaria de una tabla. En este caso, una fila [p1,a1] indica que una persona p1 practica la actividad a1. No puede aparecer una segunda vez esta misma fila en la tabla. Por lo tanto, el par (p, a) es un buen candidato para ser clave primaria. A esto se le denomina clave primaria compuesta.
- líneas 30-31: la clave primaria compuesta. La anotación @EmbeddedId (que normalmente era @Id) es análoga a la notación @Embedded aplicada al campo Adresse de una persona. En este último caso, significaba que el campo Adresse formaba parte de una clase externa, pero debía insertarse en la misma tabla que la persona. Aquí el significado es el mismo, salvo que, para indicar que se trata de la clave primaria, la notación pasa a ser @EmbeddedId.
- Línea 31: se crea un objeto vacío que representa la clave primaria id en el momento de la creación del objeto [PersonneActivite]. La clase que representa la clave primaria se define en las líneas 7-26 como una clase pública, estática e interna de la clase [PersonneActivite]. El hecho de que sea pública y estática lo impone Hibernate. Si sustituimos «public static» por «private,», se produce una excepción y, en el mensaje de error asociado, vemos que Hibernate ha intentado ejecutar la instrucción «new PersonneActivite$Id». Por lo tanto, la clase «Id» debe ser tanto estática como pública.
- Línea 6: la clase Id de la clave primaria se declara como @Embeddable. Recordemos que la clave primaria id de la línea 31 se declaró como @EmbeddedId. Por lo tanto, la clase correspondiente debe tener la anotación @Embeddable.
- Hemos dicho que la clave primaria de la tabla [personne_activite] estaba compuesta por el par (p, a), donde p es la clave primaria de una persona y a la clave primaria de una actividad. Los dos elementos (p, a) de la clave compuesta se encuentran en la línea 11 (personneId) y en la línea 15 (activiteId). Las columnas asociadas a estos dos campos se denominan: PERSONNE_ID para la persona y ACTIVITE_ID para la actividad.
- línea 31: se ha definido la clave primaria con sus dos columnas (PERSONNE_ID, ACTIVITE_ID). No hay más columnas en la tabla [personne_activite]. Ahora solo queda definir las relaciones que existen entre la @Entity PersonneActivite que estamos describiendo y las demás @Entity del esquema relacional. Estas relaciones reflejan las restricciones de claves externas que tiene la tabla [personne_activite] con respecto a las demás tablas.
- líneas 33-39: definen la clave foránea que tiene la tabla [personne_activite] sobre la tabla [personne]
- línea 37: la relación es de tipo @ManyToOne: una fila (One) de la tabla [personne] es referenciada por varias (Many) filas de la tabla [personne_activite].
- línea 38: se nombra la columna de clave externa. Se utiliza el mismo nombre que el asignado al componente «persona» de la clave externa (línea 10). Los atributos insertable=false y updatable=false sirven para impedir que Hibernate gestione la clave externa. De hecho, esta es un componente de una clave primaria calculada por la aplicación y Hibernate no debe intervenir.
- líneas 41-47: definen la clave externa que tiene la tabla [personne_activite] sobre la tabla [activite]. Las explicaciones son las mismas que las dadas anteriormente.
- Líneas 54-63: constructor de un objeto PersonneActivite a partir de una persona p y una actividad a. Recordemos que, al crear un objeto PersonneActivite, la clave primaria id de la línea 31 apuntaba a un objeto Id vacío. Las líneas 56-57 asignan un valor a cada uno de los campos (personneId, activiteId) del objeto Id. Estos valores son, respectivamente, las claves primarias de la persona p y de la actividad a, pasadas como parámetros al constructor. Por lo tanto, la clave primaria id (línea 31) tiene ahora un valor.
- línea 59: el campo personne de la línea 39 recibe el valor p
- línea 60: el campo activite de la línea 47 recibe el valor a
- Se crea e inicializa un objeto [PersonneActivite]. Se actualizan las relaciones inversas que tienen las @Entity Personne (línea 61) y Activite (línea 62) con la @Entity PersonneActivite que se acaba de crear.
Hemos terminado la descripción de las entidades de la base de datos. Nos encontramos ante una situación compleja, pero, por desgracia, frecuente. Veremos que existe otra configuración posible de la capa JPA que oculta parte de esta complejidad: la tabla de unión pasa a ser implícita, construida y gestionada por la capa JPA. Hemos elegido aquí la solución más compleja, pero que permite que el esquema relacional evolucione. De este modo, permite añadir columnas a la tabla de unión, algo que no permite la configuración en la que la tabla de unión no es una @Entity explícita. [ref1] recomienda la solución que estamos estudiando. En [ref1] se encontró la información que ha permitido elaborar esta solución.
2.5.3. El proyecto Eclipse / Hibernate
La implementación JPA utilizada aquí es la de Hibernate. El proyecto Eclipse de las pruebas es el siguiente:
En [1] se encuentra el proyecto de Eclipse, y en [2], los códigos Java. El proyecto se encuentra en [3], dentro de la carpeta de ejemplos [4]. Lo importaremos.
2.5.4. Generación del archivo DDL de la base de datos
Siguiendo las instrucciones del apartado 2.1.7, el archivo DDL obtenido para el SGBD MySQL5 es el siguiente:
alter table jpa07_hb_personne
drop
foreign key FKB5C817D45FE379D0;
alter table jpa07_hb_personne_activite
drop
foreign key FKD3E49B06CD852024;
alter table jpa07_hb_personne_activite
drop
foreign key FKD3E49B0668C7A284;
drop table if exists jpa07_hb_activite;
drop table if exists jpa07_hb_adresse;
drop table if exists jpa07_hb_personne;
drop table if exists jpa07_hb_personne_activite;
create table jpa07_hb_activite (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_adresse (
id bigint not null auto_increment,
version integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adresse_id bigint not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_personne_activite (
PERSONNE_ID bigint not null,
ACTIVITE_ID bigint not null,
primary key (PERSONNE_ID, ACTIVITE_ID)
) ENGINE=InnoDB;
alter table jpa07_hb_personne
add index FKB5C817D45FE379D0 (adresse_id),
add constraint FKB5C817D45FE379D0
foreign key (adresse_id)
references jpa07_hb_adresse (id);
alter table jpa07_hb_personne_activite
add index FKD3E49B06CD852024 (ACTIVITE_ID),
add constraint FKD3E49B06CD852024
foreign key (ACTIVITE_ID)
references jpa07_hb_activite (id);
alter table jpa07_hb_personne_activite
add index FKD3E49B0668C7A284 (PERSONNE_ID),
add constraint FKD3E49B0668C7A284
foreign key (PERSONNE_ID)
references jpa07_hb_personne (id);
- líneas 21-26: la tabla [activite]
- líneas 28-39: la tabla [adresse]
- líneas 41-51: la tabla [personne]
- líneas 53-57: la tabla de unión [personne_activite]. Cabe destacar la clave compuesta (línea 56)
- líneas 59-63: la clave externa de la tabla [personne] hacia la tabla [adresse]
- líneas 65-69: la clave externa de la tabla [personne_activite] hacia la tabla [activite]
- líneas 71-75: la clave externa de la tabla [personne_activite] hacia la tabla [personne]
2.5.5. InitDB
El código de [InitDB] es el siguiente:
package tests;
...
public class InitDB {
// constantes
private final static String TABLE_PERSONNE_ACTIVITE = "jpa07_hb_personne_activite";
private final static String TABLE_PERSONNE = "jpa07_hb_personne";
private final static String TABLE_ACTIVITE = "jpa07_hb_activite";
private final static String TABLE_ADRESSE = "jpa07_hb_adresse";
public static void main(String[] args) throws ParseException {
// Contexto de persistencia
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// se recupera un EntityManager a partir del EntityManagerFactory
// anterior
em = emf.createEntityManager();
// inicio de la transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// solicitud
Query sql1;
// eliminar los elementos de la tabla PERSONNE_ACTIVITE
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE_ACTIVITE);
sql1.executeUpdate();
// eliminar elementos de la tabla PERSONNE
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE);
sql1.executeUpdate();
// eliminar los elementos de la tabla ACTIVITE
sql1 = em.createNativeQuery("delete from " + TABLE_ACTIVITE);
sql1.executeUpdate();
// eliminar los elementos de la tabla ADRESSE
sql1 = em.createNativeQuery("delete from " + TABLE_ADRESSE);
sql1.executeUpdate();
// creación de actividades
Activite act1 = new Activite();
act1.setNom("act1");
Activite act2 = new Activite();
act2.setNom("act2");
Activite act3 = new Activite();
act3.setNom("act3");
// persistencia de actividades
em.persist(act1);
em.persist(act2);
em.persist(act3);
// creación de personas
Personne p1 = new Personne("p1", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("p2", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
Personne p3 = new Personne("p3", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// creación de direcciones
Adresse adr1 = new Adresse("adr1", null, null, "49000", "Angers", null, "France");
Adresse adr2 = new Adresse("adr2", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
Adresse adr3 = new Adresse("adr3", "x", "x", "x", "x", "x", "x");
Adresse adr4 = new Adresse("adr4", "y", "y", "y", "y", "y", "y");
// asociaciones persona <--> dirección
p1.setAdresse(adr1);
adr1.setPersonne(p1);
p2.setAdresse(adr2);
adr2.setPersonne(p2);
p3.setAdresse(adr3);
adr3.setPersonne(p3);
// persistencia de las personas y, por tanto, de las direcciones asociadas
em.persist(p1);
em.persist(p2);
em.persist(p3);
// persistencia de la dirección a4 no vinculada a una persona
em.persist(adr4);
// visualización de personas
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// visualización de direcciones
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
System.out.println("[activites]");
for (Object a : em.createQuery("select a from Activite a").getResultList()) {
System.out.println(a);
}
// asociaciones persona <--> actividad
PersonneActivite p1act1 = new PersonneActivite(p1, act1);
PersonneActivite p1act2 = new PersonneActivite(p1, act2);
PersonneActivite p2act1 = new PersonneActivite(p2, act1);
PersonneActivite p2act3 = new PersonneActivite(p2, act3);
// Persistencia de las asociaciones persona <--> actividad
em.persist(p1act1);
em.persist(p1act2);
em.persist(p2act1);
em.persist(p2act3);
// visualización de personas
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// visualización de direcciones
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
System.out.println("[activites]");
for (Object a : em.createQuery("select a from Activite a").getResultList()) {
System.out.println(a);
}
System.out.println("[personnes/activites]");
for (Object pa : em.createQuery("select pa from PersonneActivite pa").getResultList()) {
System.out.println(pa);
}
// fin de la transacción
tx.commit();
// fin de EntityManager
em.close();
// fin de EntityManagerFactory
emf.close();
// registro
System.out.println("terminé...");
}
}
- líneas 27-38: se vacían las tablas [personne_activite], [personne], [adresse] y [activite]. Cabe señalar que es obligatorio comenzar por las tablas que contienen claves externas.
- líneas 40-45: se crean tres actividades: act1, act2 y act3
- líneas 47-49: se colocan en el contexto de persistencia.
- líneas 51-53: se crean tres personas: p1, p2 y p3.
- líneas 55-58: se crean cuatro direcciones, desde adr1 hasta adr4.
- líneas 60-65: las direcciones adri se asocian a las personas pi. En cada caso hay que realizar dos operaciones, ya que la relación Persona <-> Dirección es bidireccional.
- líneas 67-69: los registros p1 a p3 se incluyen en el contexto de persistencia. Debido a la cascada «Persona -> Dirección», esto también se aplicará a las direcciones adr1 a adr3.
- línea 71: la cuarta dirección adr4, que no está asociada a ninguna persona, se incluye explícitamente en el contexto de persistencia.
- Líneas 73-85: se realiza una consulta al contexto de persistencia para obtener la lista de entidades de tipo [Personne], [Adresse] y [Activite]. Sabemos que estas consultas provocarán la sincronización del contexto con la base de datos: las entidades creadas se insertarán en la base de datos y obtendrán su clave primaria. Es importante comprenderlo para lo que viene a continuación.
- Líneas 87-90: se crean cuatro asociaciones Persona <-> Actividad. Su nombre indica qué persona está vinculada a qué actividad. Quizá recordemos que la clave primaria de una entidad PersonneActivite es una clave compuesta formada por la clave primaria de una persona y la de una actividad. Por lo tanto, esta operación es posible precisamente porque las entidades Personne y Activite obtuvieron sus claves primarias durante una sincronización anterior.
- líneas 92-95: estas cuatro asociaciones se colocan en el contexto de persistencia.
- líneas 87-86: se realiza una consulta al contexto de persistencia para obtener la lista de entidades de tipo [Personne], [Adresse], [Activite] y [PersonneActivite]. Sabemos que estas consultas provocarán la sincronización del contexto con la base de datos: las entidades PersonneActivite creadas se insertarán en la base de datos.
Al ejecutar [InitDB] junto con MySQL5, se muestra el siguiente mensaje en la consola:
Puede resultar sorprendente ver que, en las líneas 15-16, las personas p1 y p2 tienen su número de versión en 1 y que ocurre lo mismo, en las líneas 24-26, con las tres actividades. Intentemos entenderlo.
En las líneas 2-4, los números de versión de las personas son 0, y en las líneas 11-13, los números de versión de las actividades son 0. Estas visualizaciones tienen lugar antes de la creación de las relaciones Persona <-> Actividad. En las líneas 87-90 del código Java, se crean relaciones entre las personas p1 y p2 y las actividades act1, act2, act3. Se crean mediante el constructor de la @Entity PersonneActivite (véase el apartado 2.5.2). Al examinar el código de este constructor, se observa que, cuando una persona p está vinculada a una actividad a:
- la actividad a se añade al conjunto p.activites
- la persona p se añade al conjunto a.personnes
Así, cuando se escribe new PersonneActivite(p,a), la persona p y la actividad a sufren una modificación en memoria. En las líneas 97-113 de [InitDB], el contexto de persistencia se sincroniza con la base de datos, JPA / Hibernate detecta que los elementos persistentes p1, p2, act1, act2 y act3 han sido modificados. Estos cambios deben realizarse en la base de datos. De hecho, se registran en la tabla de unión [personne_activite], pero JPA / Hibernate incrementa de todos modos el número de versión de cada uno de los elementos persistentes modificados.
En la vista de SQL Explorer, los resultados son los siguientes:
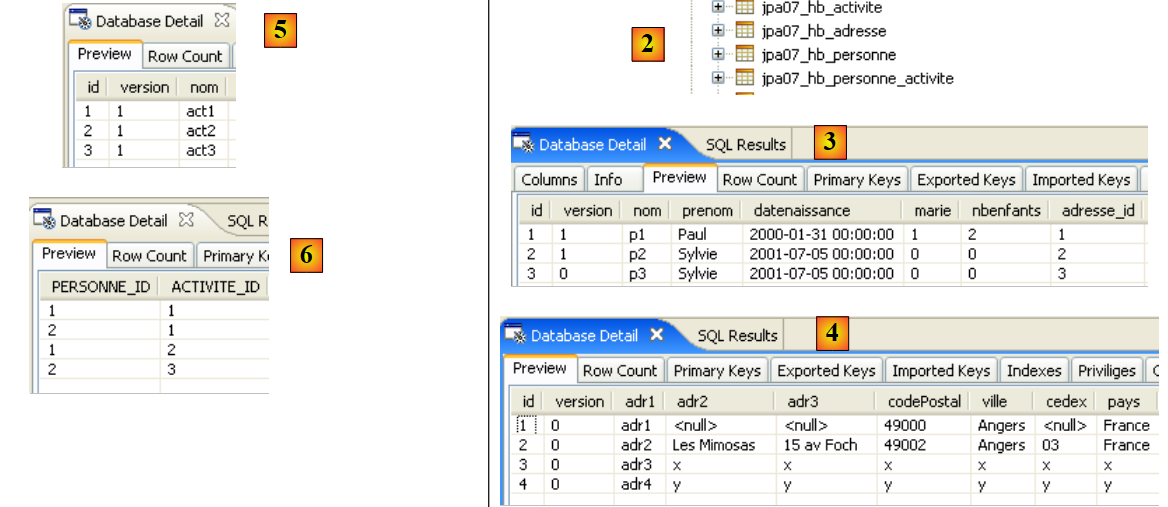 |
- [2]: las tablas [jpa07_hb_*]
- [3]: la tabla de personas
- [4]: la tabla de direcciones.
- [5]: la tabla de actividades
- [6]: la tabla de unión persona <-> actividad
2.5.6. Inicio
La clase [Main] encadena una serie de pruebas que vamos a revisar, excepto la prueba 1, que retoma el código de [InitDB] para inicializar la base de datos.
2.5.6.1. Test2
Esta prueba es la siguiente:
// eliminación de persona p1
public static void test2() {
// contexto de persistencia
EntityManager em = getEntityManager();
// inicio de transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// eliminación de dependencias en p1: no es necesario para Hibernate, pero
// imprescindible para TopLink
act1.getPersonnes().remove(p1act1);
act2.getPersonnes().remove(p1act2);
// eliminación de la persona p1
em.remove(p1);
// fin de la transacción
tx.commit();
// se muestran las nuevas tablas
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- línea 4: se utiliza el contexto de persistencia de test1, donde la persona p1 es un objeto del contexto.
- línea 13: eliminación de la persona p1. Debido al atributo:
- cascadeType.ALL en Adresse, se eliminará la dirección de la persona p1
- cascadeType.REMOVE sobre PersonneActivite: se eliminarán las actividades de la persona p1.
- Líneas 10-11: se eliminan las dependencias que tienen las demás entidades sobre la persona p1, que se va a eliminar en la línea 13. Las actividades act1 y act2 las realiza la persona p1. Los enlaces han sido creados por el generador de la entidad PersonneActivite, cuyo código es el siguiente:
public PersonneActivite(Personne p, Activite a) {
// las claves externas las establece la aplicación
getId().setPersonneId(p.getId());
getId().setActiviteId(a.getId());
// asociaciones bidireccionales
setPersonne(p);
setActivite(a);
p.getActivites().add(this);
a.getPersonnes().add(this);
}
En la línea 9, la actividad a recibe un elemento adicional de tipo PersonneActivite en su conjunto personnes. Este elemento es de tipo (p,a) para indicar que la persona p realiza la actividad a. En test1 de [Main], se han creado así dos enlaces: (p1,act1) y (p1,act2). Las líneas 10 y 11 de test2 eliminan estas dependencias. Cabe señalar que Hibernate funciona sin la eliminación de estas dependencias en el objeto p1, pero Toplink no.
- Líneas 17-20: se muestran todas las tablas
Los resultados son los siguientes:
- el registro p1, presente en test1 (línea 3), ya no lo está al finalizar test2 (líneas 22-23)
- la dirección adr1 de la persona p1, que aparece en test1 (línea 11) ya no lo es tras la ejecución de test2 (líneas 29-31)
- las actividades (p1,act1) (línea 16) y (p1,act2) (línea 18) de la persona p1, presentes en test1, ya no lo son al finalizar test2 (líneas 33-34)
2.5.6.2. Test3
Esta prueba es la siguiente:
// eliminación de la actividad act1
public static void test3() {
// contexto de persistencia
EntityManager em = getEntityManager();
// Inicio de transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// eliminación de dependencias en act1: no es necesario para Hibernate, pero
// imprescindible para TopLink
p2.getActivites().remove(p2act1);
// eliminación de la actividad act1
em.remove(act1);
// fin de la transacción
tx.commit();
// se muestran las nuevas tablas
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- línea 4: se utiliza el contexto de persistencia de test2
- línea 12: eliminación de la actividad act1. Debido al atributo:
- cascadeType.REMOVE sobre PersonneActivite, se eliminarán las líneas (p, act1) de la tabla [personne_activite].
- línea 10: antes de sacar act1 del contexto de persistencia, se eliminan las dependencias que otras entidades puedan tener sobre este objeto persistente. Tras la eliminación de la persona p1 en la prueba anterior, solo la persona p2 realiza la actividad act1.
- Líneas 13-16: se muestran todas las tablas
Los resultados son los siguientes:
- en test2, la actividad act1 existe (línea 6). En test3, ya no existe (líneas 21-22)
- En test2, existe el enlace (p2,act1)) (línea 14). En test3, ya no existe (línea 28)
2.5.6.3. Test4
Esta prueba es la siguiente:
// Recuperación de actividades de una persona
public static void test4() {
// contexto de persistencia
EntityManager em = getNewEntityManager();
// Inicio de la transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// se recupera a la persona p2
p2 = em.find(Personne.class, p2.getId());
System.out.format("1 - Activités de la personne p2 (JPQL) :%n");
// se analizan sus actividades
for (Object pa : em.createQuery("select a.nom from Activite a join a.personnes pa where pa.personne.nom='p2'").getResultList()) {
System.out.println(pa);
}
// se recorre la relación inversa de p2
p2 = em.find(Personne.class, p2.getId());
System.out.format("2 - Activités de la personne p2 (relation inverse) :%n");
// se analizan sus actividades
for (PersonneActivite pa : p2.getActivites()) {
System.out.println(pa.getActivite().getNom());
}
// fin de la transacción
tx.commit();
}
- La prueba 4 muestra las actividades de la persona p2.
- línea 4: se parte de un contexto nuevo y vacío
- líneas 12-14: se muestran los nombres de las actividades que realiza la persona p2 mediante una consulta JPQL.
- Se realiza una unión entre Activite (a) y PersonneActivite (pa) (unir a.personnes)
- en las filas de esta unión (a,pa), se muestra el nombre de la actividad (a.nom) correspondiente a la persona p2 (pa.personne.nom='p2').
- líneas 16-21: se hace lo mismo que anteriormente, pero utilizando la relación OneToMany p2.activites de la persona p2. La consulta JPQL se generará a partir de JPA. Aquí se aprecia la utilidad de la relación inversa OneToMany: evita una consulta JPQL.
Los resultados son los siguientes:
2.5.6.4. Test5
Esta prueba es la siguiente:
// se recuperan las personas que realizan una actividad determinada
public static void test5() {
// contexto de persistencia
EntityManager em = getNewEntityManager();
// inicio de la transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
System.out.format("1 - Personnes pratiquant l'activité act3 (JPQL) :%n");
// se solicitan las actividades de p2
for (Object pa : em.createQuery("select p.nom from Personne p join p.activites pa where pa.activite.nom='act3'").getResultList()) {
System.out.println(pa);
}
// se recurre a la relación inversa de act3
System.out.format("2 - Personnes pratiquant l'activité act3 (relation inverse) :%n");
act3 = em.find(Activite.class, act3.getId());
for (PersonneActivite pa : act3.getPersonnes()) {
System.out.println(pa.getPersonne().getNom());
}
// fin de la transacción
tx.commit();
}
- La prueba 6 muestra a las personas que realizan la actividad act3. El procedimiento es similar al de la prueba 6. Dejamos que sea el lector quien establezca la relación entre ambos códigos.
Los resultados son los siguientes:
Las pruebas 4 y 5 tenían como objetivo demostrar una vez más que una relación inversa nunca es imprescindible y siempre puede sustituirse por una consulta JPQL.
2.5.7. Implementación JPA / Toplink
Ahora utilizamos una implementación JPA / Toplink:
 |
El proyecto de Eclipse con Toplink es una copia del proyecto de Eclipse con Hibernate:
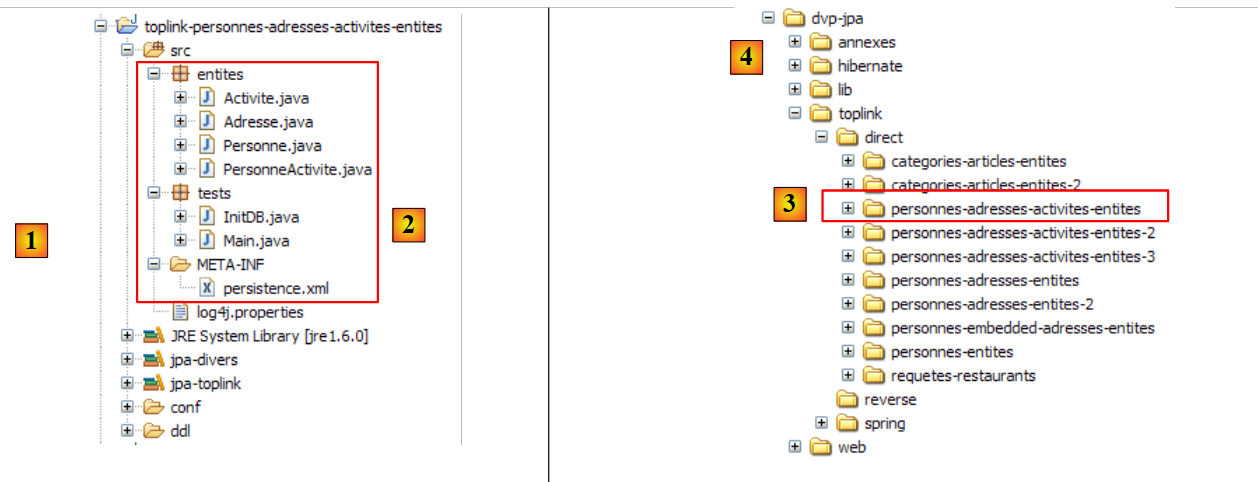 |
Los códigos Java son idénticos a los del proyecto anterior con Hibernate, salvo por algunos detalles que comentaremos a continuación. El entorno (bibliotecas – persistence.xml – SGBD – carpetas conf, ddl – script ant) es el que se ha estudiado en el apartado 2.1.15.2. El proyecto de Eclipse se encuentra en [3], dentro de la carpeta de ejemplos [4]. Lo importaremos.
El archivo <persistence.xml> [2] se modifica en un punto, el de las entidades declaradas:
<!-- clases persistentes -->
<class>entites.Activite</class>
<class>entites.Adresse</class>
<class>entites.Personne</class>
<class>entites.PersonneActivite</class>
- líneas 2-5: las cuatro entidades gestionadas
La ejecución de [InitDB] junto con SGBD y MySQL5 ofrece los siguientes resultados:
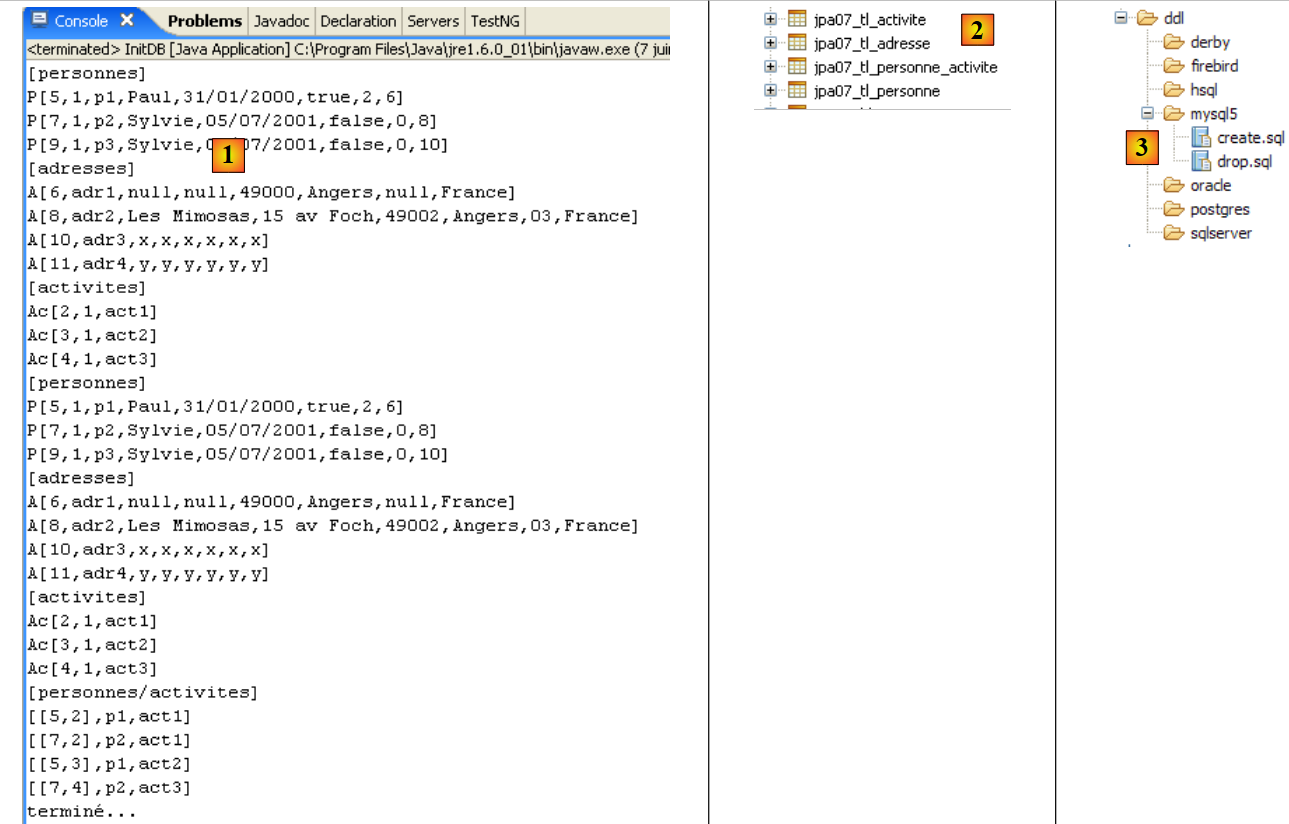 |
En [1], la salida de la consola; en [2], las tablas generadas [jpa07_tl]; y en [3], los scripts generados SQL. Su contenido es el siguiente:
create.sql
CREATE TABLE jpa07_tl_activite (ID BIGINT NOT NULL, VERSION INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa07_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, VERSION INTEGER NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR2 VARCHAR(30), CEDEX VARCHAR(3), ADR1 VARCHAR(30) NOT NULL, PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa07_tl_personne_activite (PERSONNE_ID BIGINT NOT NULL, ACTIVITE_ID BIGINT NOT NULL, PRIMARY KEY (PERSONNE_ID, ACTIVITE_ID))
CREATE TABLE jpa07_tl_personne (ID BIGINT NOT NULL, DATENAISSANCE DATE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, NBENFANTS INTEGER NOT NULL, VERSION INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa07_tl_personne_activite ADD CONSTRAINT FK_jpa07_tl_personne_activite_ACTIVITE_ID FOREIGN KEY (ACTIVITE_ID) REFERENCES jpa07_tl_activite (ID)
ALTER TABLE jpa07_tl_personne_activite ADD CONSTRAINT FK_jpa07_tl_personne_activite_PERSONNE_ID FOREIGN KEY (PERSONNE_ID) REFERENCES jpa07_tl_personne (ID)
ALTER TABLE jpa07_tl_personne ADD CONSTRAINT FK_jpa07_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa07_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
La ejecución de [InitDB] y de [Main] se lleva a cabo sin errores.
2.6. Ejemplo 6: relación muchos a muchos con una tabla de unión implícita
Retomamos el ejemplo 4, pero ahora lo tratamos con una tabla de unión implícita generada por la propia capa JPA.
2.6.1. El esquema de la base de datos
 |
- en [1], la base de datos MySQL5 —en [2]—: la tabla [personne] —en [3]—: la tabla asociada [adresse] – en [4]: la tabla [activite] de actividades – en [5]: la tabla de unión [personne_activite] que vincula a las personas con las actividades.
2.6.2. Los objetos @Entity que representan la base de datos
Las tablas anteriores se representarán mediante las siguientes @Entity:
- la @Entity Personne representará la tabla [personne]
- la @Entity Adresse representará la tabla [adresse]
- la @Entity Activite representará la tabla [activite]
- La tabla [personne_activite] ya no está representada por una @Entity
Las relaciones entre estas entidades son las siguientes:
- una relación uno a uno vincula la entidad Personne con la entidad Adresse: una persona p tiene una dirección a. La entidad Personne, que posee la clave foránea, tendrá la relación principal, mientras que la entidad Adresse tendrá la relación inversa.
- Una relación «muchos a muchos» une las entidades Personne y Activite: una persona tiene varias actividades y una actividad la practican varias personas. Esta relación se materializará mediante una anotación @ManyToMany en cada una de las dos entidades, declarándose una de ellas como inversa de la otra.
La @Entity Personne es la siguiente:
@Entity
@Table(name = "jpa08_hb_personne")
public class Personne implements Serializable {
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
// toplink sqlserver: @GeneratedValue (strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
// relación principal Persona (one) -> Dirección (one)
// implementada mediante la clave foránea Persona (adresse_id) -> Dirección
// inserción en cascada de Persona -> inserción de Dirección
// cascada de actualización de Persona -> actualización de Dirección
// eliminación en cascada de Persona -> eliminación de Dirección
// una persona debe tener una dirección (nullable=false)
// una dirección solo pertenece a una persona (única=true)
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
// relación Persona (many) -> Actividad (many) a través de una tabla de unión personne_activite
// personne_activite(PERSONNE_ID) es una clave foránea en Persona(id)
// personne_activite(ACTIVITE_ID) es una clave foránea en «Actividad» (id)
// cascada=CascadeType.PERSIST: la persistencia de una persona implica la de sus actividades
@ManyToMany(cascade={CascadeType.PERSIST})
@JoinTable(name="jpa08_hb_personne_activite",joinColumns = @JoinColumn(name = "PERSONNE_ID"), inverseJoinColumns = @JoinColumn(name = "ACTIVITE_ID"))
private Set<Activite> activites = new HashSet<Activite>();
// constructores
public Personne() {
}
Solo comentamos la relación @ManyToMany de las líneas 46-48, que vincula la @Entity Personne con la @Entity Activite:
- línea 48: una persona tiene actividades. El campo «activites» las representará. En la versión anterior, el tipo de los elementos del conjunto activites era PersonneActivite. Aquí es Activite. Por lo tanto, se accede directamente a las actividades de una persona, mientras que en la versión anterior había que pasar por la entidad intermedia PersonneActivite.
- línea 46: la relación que vincula la @Entity Personne que estamos analizando con la @Entity Activite del conjunto activites de la línea 48 es de tipo «muchos a muchos» (ManyToMany):
- una persona (One) tiene varias actividades (Many)
- una actividad (One) la realizan varias personas (Many)
- en definitiva, las @Entity Personne y Activite están vinculadas por una relación ManyToMany. Al igual que en la relación OneToOne, existe simetría entre las entidades en esta relación. Se puede elegir libremente qué @Entity tendrá la relación principal y cuál tendrá la relación inversa. En este caso, decidimos que la @Entity Personne tendrá la relación principal.
- Como hemos visto en el ejemplo anterior, la relación @ManyToMany requiere una tabla de unión. Mientras que anteriormente la habíamos definido mediante una @Entity, aquí la tabla de unión se define mediante la anotación @JoinTable de la línea 47.
- El atributo «name» asigna un nombre a la tabla.
- La tabla de unión está formada por las claves externas de las tablas que une. En este caso, hay dos claves externas: una en la tabla [personne] y otra en la tabla [activite]. Estas columnas de clave externa se definen mediante los atributos joinColumns y inverseJoinColumns.
- La anotación @JoinColumn del atributo joinColumns define la clave foránea en la tabla de la @Entity que contiene la relación principal @ManyToMany, en este caso la tabla [personne]. Esta columna de clave externa se llamará PERSONNE_ID.
- La anotación @JoinColumn del atributo inverseJoinColumns define la clave foránea en la tabla de la @Entity que contiene la relación inversa @ManyToMany, en este caso la tabla [activite]. Esta columna de clave externa se llamará ACTIVITE_ID.
La @Entity Adresse es la siguiente:
@Entity
@Table(name = "jpa07_hb_adresse")
public class Adresse implements Serializable {
// campos
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse")
private Personne personne;
- líneas 28-29: la relación @OneToOne, inversa de la relación @OneToOne, que apunta a la @Entity Personne (líneas 37-38 de Personne).
La @Entity Activite es la siguiente
@Entity
@Table(name = "jpa08_hb_activite")
public class Activite implements Serializable {
// campos
@Id()
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
// toplink sqlserver: @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
// relación inversa Actividad -> Persona
@ManyToMany(mappedBy = "activites")
private Set<Personne> personnes = new HashSet<Personne>();
...
- líneas 20-21: la relación muchos-a-muchos que vincula la @Entity Activite con la @Entity Personne. Esta relación ya se ha definido en la @Entity Personne. Por lo tanto, aquí basta con indicar que la relación es inversa (mappedBy) a la relación @ManyToMany existente en el campo «activites» (mappedBy = «activites») de la @entidad Personne.
- Recordemos que una relación inversa siempre es opcional. En este caso, la utilizamos para obtener las personas que realizan la actividad actual. El conjunto Set<Persona> personas nos permitirá obtenerlas. No se especifica el modo de carga de las dependencias Personne de la @Entity Activite. Tampoco lo habíamos especificado en el ejemplo anterior. Por defecto, este modo es fetch=FetchType.LAZY.
Hemos terminado la descripción de las entidades de la base de datos. Ha resultado más sencillo que en el caso en que la tabla de unión [personne_activite] sea una tabla explícita. Esta solución más sencilla puede presentar inconvenientes con el paso del tiempo: no permite añadir columnas a la tabla de unión. Sin embargo, esto puede resultar necesario para satisfacer nuevas necesidades, por ejemplo, añadir a la tabla [personne_activite] una columna que indique la fecha de inscripción de la persona en la actividad.
2.6.3. El proyecto Eclipse / Hibernate
La implementación JPA utilizada aquí es la de Hibernate. El proyecto Eclipse de las pruebas es el siguiente:
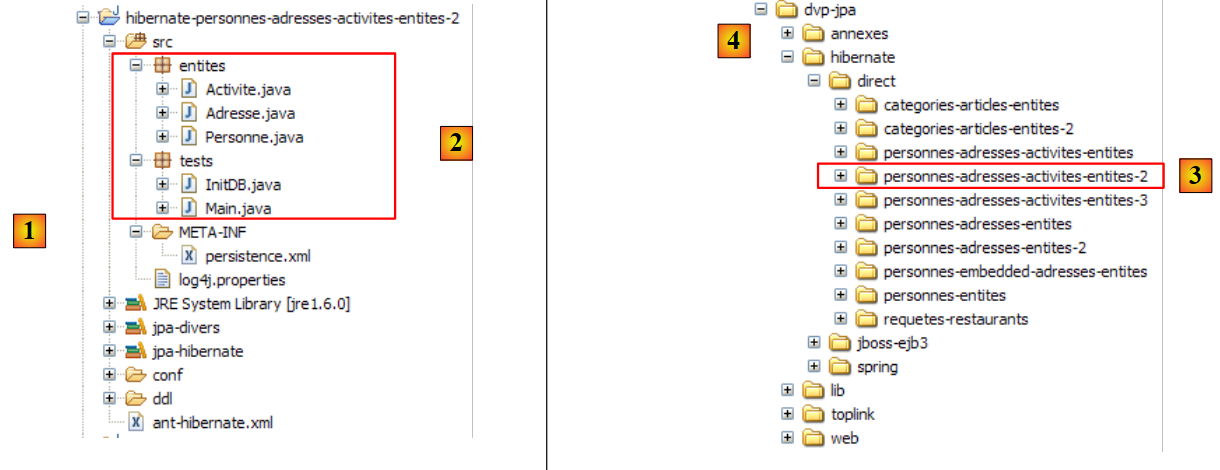 |
En [1], el proyecto Eclipse; en [2], los códigos Java. El proyecto se encuentra en [3], dentro de la carpeta de ejemplos [4]. Lo importaremos.
2.6.4. Generación del archivo DDL de la base de datos
Siguiendo las instrucciones del apartado 2.1.7, el archivo DDL obtenido para el SGBD MySQL5 es el siguiente:
alter table jpa08_hb_personne
drop
foreign key FKA44B1E555FE379D0;
alter table jpa08_hb_personne_activite
drop
foreign key FK5A6A55A5CD852024;
alter table jpa08_hb_personne_activite
drop
foreign key FK5A6A55A568C7A284;
drop table if exists jpa08_hb_activite;
drop table if exists jpa08_hb_adresse;
drop table if exists jpa08_hb_personne;
drop table if exists jpa08_hb_personne_activite;
create table jpa08_hb_activite (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_adresse (
id bigint not null auto_increment,
version integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adresse_id bigint not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_personne_activite (
PERSONNE_ID bigint not null,
ACTIVITE_ID bigint not null,
primary key (PERSONNE_ID, ACTIVITE_ID)
) ENGINE=InnoDB;
alter table jpa08_hb_personne
add index FKA44B1E555FE379D0 (adresse_id),
add constraint FKA44B1E555FE379D0
foreign key (adresse_id)
references jpa08_hb_adresse (id);
alter table jpa08_hb_personne_activite
add index FK5A6A55A5CD852024 (ACTIVITE_ID),
add constraint FK5A6A55A5CD852024
foreign key (ACTIVITE_ID)
references jpa08_hb_activite (id);
alter table jpa08_hb_personne_activite
add index FK5A6A55A568C7A284 (PERSONNE_ID),
add constraint FK5A6A55A568C7A284
foreign key (PERSONNE_ID)
references jpa08_hb_personne (id);
Este código DDL es análogo al obtenido con la tabla de unión explícita y se corresponde con el esquema ya presentado:
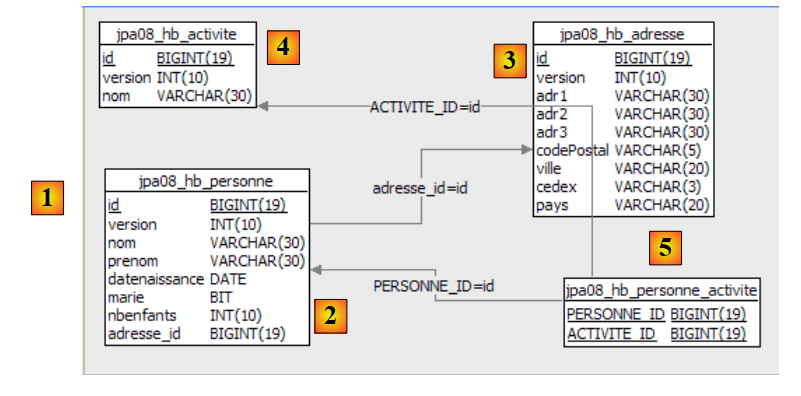 |
2.6.5. InitDB
No nos detendremos mucho en la clase [InitDB], ya que es idéntica a su versión anterior y ofrece los mismos resultados. Simplemente, fijémonos en el siguiente código, que muestra la unión Personne <-> Activite:
// visualización de personas/actividades
System.out.println("[personnes/activites]");
Iterator iterator = em.createQuery("select p.id,a.id from Personne p join p.activites a").getResultList().iterator();
while (iterator.hasNext()) {
Object[] row = (Object[]) iterator.next();
System.out.format("[%d,%d]%n", (Long) row[0], (Long) row[1]);
}
- línea 3: la orden JPQL que realiza la unión. El resultado de select devuelve los identificadores de las entidades Personne y Activite, vinculadas entre sí mediante la tabla de unión. La lista devuelta por select está formada por líneas que contienen dos objetos de tipo Long. Para recorrer esta lista, la línea 3 solicita un objeto Iterator de la lista.
- líneas 4-7: con ayuda del objeto de tipo Iterator anterior, se recorre la lista.
- línea 5: cada elemento de la lista es una matriz que contiene una línea resultante del select
- línea 6: se recuperan los elementos de la línea actual resultante de select realizando los cambios de tipo adecuados.
El resultado de [InitDB] es el siguiente:
2.6.6. Principal
La clase [Main] encadena una serie de pruebas, algunas de las cuales vamos a repasar.
2.6.6.1. Test3
Esta prueba es la siguiente:
// eliminación de la actividad act1
public static void test3() {
// contexto de persistencia
EntityManager em = getEntityManager();
// Inicio de transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// eliminación de la actividad act1 de p2
p2.getActivites().remove(act1);
// se retira act1 del contexto de persistencia
em.remove(act1);
// fin de las transacciones
tx.commit();
// se muestran las nuevas tablas
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- línea 11: la actividad act1 se retira del contexto de persistencia
- línea 9: la actividad act1 forma parte de las actividades de la única persona que queda en el contexto, la persona p2. La línea 9 elimina la actividad act1 de las actividades de la persona p2. Hacemos esto para mantener la coherencia del contexto de persistencia, ya que lo conservamos para más adelante.
Los resultados son los siguientes:
- la actividad act1, que aparece en la línea 26 de test2, ha desaparecido de las actividades de test3 (líneas 40-41)
- La persona p2 tenía en test2 la actividad act1 (línea 33). Al finalizar test3, ya no la tiene (línea 47)
2.6.6.2. Test6
Esta prueba es la siguiente:
// Modificación de las actividades de una persona
public static void test6() {
// contexto de persistencia
EntityManager em = getNewEntityManager();
// Inicio de transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// se recupera la persona p2
p2 = em.find(Personne.class, p2.getId());
// se recupera la actividad act2
act2 = em.find(Activite.class, act2.getId());
// p2 ya solo realiza la actividad act2
p2.getActivites().clear();
p2.getActivites().add(act2);
// fin de la transacción
tx.commit();
// se muestran las nuevas tablas
dumpPersonne();
dumpActivite();
dumpPersonne_Activite();
}
- línea 4: se utiliza un contexto de persistencia nuevo y vacío
- línea 9: la persona p2 se transfiere desde la base de datos al contexto de persistencia
- línea 11: la actividad act2 se transfiere desde la base de datos al contexto de persistencia
- línea 13: las actividades de la persona p2 (act3) se transfieren desde la base de datos al contexto (fetchType.LAZY). Es la llamada [getActivites] la que provoca esta carga. Se eliminan las actividades de p2. No se trata de una eliminación real de actividades (remove), sino de una modificación del estado de la persona p2. Ya no realiza ninguna actividad.
- línea 14: se añade a la persona p2 la actividad act2. Al final, el conjunto de nuevas actividades de la persona p2 es el conjunto {act2}.
- línea 16: fin de la transacción. La sincronización revisará los objetos del contexto (p2, act2, act3) y detectará que el estado de p2 ha cambiado. Se ejecutarán las órdenes SQL que reflejan este cambio en la base de datos.
- Líneas 18-20: se muestran todas las tablas
Los resultados son los siguientes:
- Al finalizar la prueba 4, la persona p2 realizaba la actividad act3 (línea 3).
- Al finalizar la prueba 6 (línea 19), la persona p2 ya no realiza la actividad act3 (línea 3) y realiza la actividad act2.
2.6.7. Implementación JPA / Toplink
Ahora utilizamos una implementación JPA / Toplink:
 |
El proyecto de Eclipse con Toplink es una copia del proyecto de Eclipse con Hibernate:
 |
El archivo <persistence.xml> [2] se ha modificado en un punto, el de las entidades declaradas:
<!-- proveedor -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- clases persistentes -->
<class>entites.Activite</class>
<class>entites.Adresse</class>
<class>entites.Personne</class>
...
- líneas 4-6: las entidades gestionadas
La ejecución de [InitDB] junto con SGBD y MySQL5 ofrece los siguientes resultados:
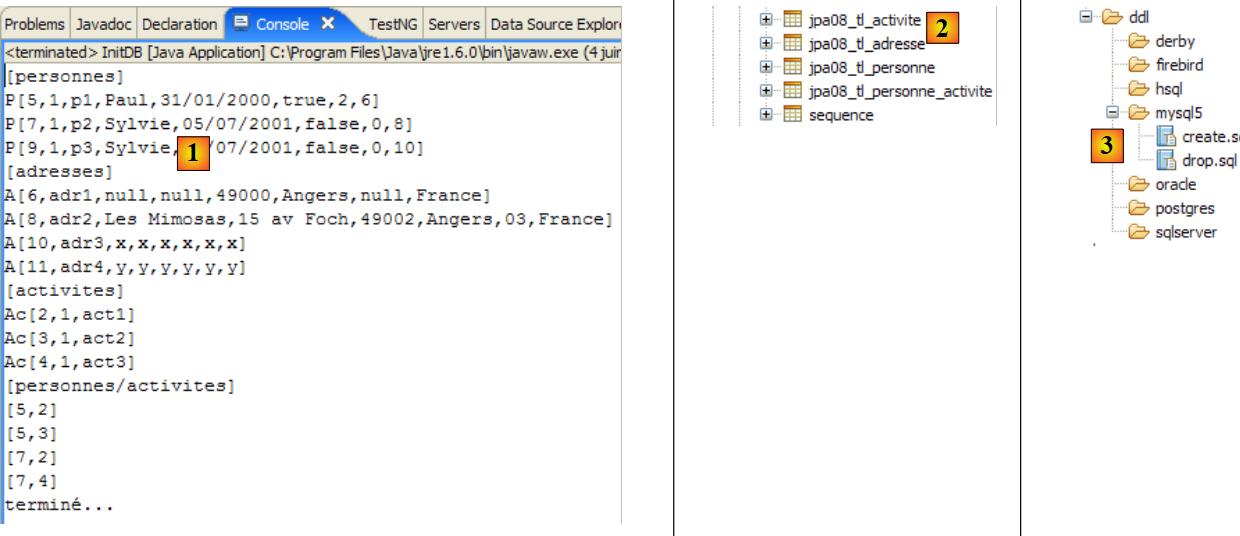 |
En [1], la salida de la consola; en [2], las tablas generadas [jpa07_tl]; y en [3], los scripts generados SQL. Su contenido es el siguiente:
create.sql
CREATE TABLE jpa08_tl_personne_activite (PERSONNE_ID BIGINT NOT NULL, ACTIVITE_ID BIGINT NOT NULL, PRIMARY KEY (PERSONNE_ID, ACTIVITE_ID))
CREATE TABLE jpa08_tl_activite (ID BIGINT NOT NULL, VERSION INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa08_tl_personne (ID BIGINT NOT NULL, DATENAISSANCE DATE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, NBENFANTS INTEGER NOT NULL, VERSION INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa08_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, VERSION INTEGER NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR2 VARCHAR(30), CEDEX VARCHAR(3), ADR1 VARCHAR(30) NOT NULL, PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa08_tl_personne_activite ADD CONSTRAINT FK_jpa08_tl_personne_activite_ACTIVITE_ID FOREIGN KEY (ACTIVITE_ID) REFERENCES jpa08_tl_activite (ID)
ALTER TABLE jpa08_tl_personne_activite ADD CONSTRAINT FK_jpa08_tl_personne_activite_PERSONNE_ID FOREIGN KEY (PERSONNE_ID) REFERENCES jpa08_tl_personne (ID)
ALTER TABLE jpa08_tl_personne ADD CONSTRAINT FK_jpa08_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa08_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
La ejecución de [InitDB] y la de [Main] se realizan sin errores.
2.6.8. El proyecto Eclipse / Hibernate 2
Creamos un proyecto de Eclipse a partir del anterior copiándolo:
 |
En [1], el proyecto Eclipse; en [2], los códigos Java. El proyecto se encuentra en [3], dentro de la carpeta de ejemplos [4]. Lo importaremos.
Modificamos la relación que vincula Personne con Activité de la siguiente manera:
Persona
// relación Persona (many) -> Actividad (many) a través de una tabla de unión personne_activite
// personne_activite(PERSONNE_ID) es una clave foránea en Persona (id)
// personne_activite(ACTIVITE_ID) es una clave foránea en Actividad(id)
// sin cascada en las actividades
// @ManyToMany(cascada={CascadeType.PERSIST})
@ManyToMany()
@JoinTable(name = "jpa09_hb_personne_activite", joinColumns = @JoinColumn(name = "PERSONNE_ID"), inverseJoinColumns = @JoinColumn(name = "ACTIVITE_ID"))
private Set<Activite> activites = new HashSet<Activite>();
- línea 6: la relación principal @ManyToMany ya no tiene una cascada de persistencia Persona -> Actividad (véase la versión anterior, línea 5)
Actividad
// ya no hay relación inversa con «Persona»
// @ManyToMany(mappedBy = "actividades")
// private Set<Persona> personas = new HashSet<Persona>();
- líneas 2-3: se ha eliminado la relación inversa @ManyToMany Actividad -> Persona
Queremos demostrar que los atributos eliminados (cascada y relación inversa) no son imprescindibles. El primer cambio que introduce esta nueva configuración se encuentra en [InitDB]:
// relaciones personas <--> actividades
p1.getActivites().add(act1);
p1.getActivites().add(act2);
p2.getActivites().add(act1);
p2.getActivites().add(act3);
// persistencia de las actividades
em.persist(act1);
em.persist(act2);
em.persist(act3);
// persistencia de las personas
em.persist(p1);
em.persist(p2);
em.persist(p3);
// y de la dirección a4 no vinculada a una persona
em.persist(adr4);
- líneas 7-9: nos vemos obligados a incluir explícitamente las actividades de act1 a act3 en el contexto de persistencia. Cuando existía la cascada de persistencia Persona -> Actividad existía, las líneas 11-13 persistían tanto las personas de p1 a p3 como las actividades de dichas personas de act1 a act3.
Se observa un segundo cambio en [Main]:
// búsqueda de personas que realizan una actividad determinada
public static void test5() {
// contexto de persistencia
EntityManager em = getNewEntityManager();
// Inicio de la transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
System.out.format("1 - Personnes pratiquant l'activité act3 (JPQL) :%n");
// se solicitan las actividades de p2
for (Object pa : em.createQuery("select p.nom from Personne p join p.activites a where a.nom='act3'").getResultList()) {
System.out.println(pa);
}
// fin de la transacción
tx.commit();
}
- líneas 9-12: la consulta JPQL, que obtiene las personas que realizan la actividad act3
- en la versión anterior, el mismo resultado también se había obtenido a través de la relación inversa «Actividad» → «Persona», ahora eliminada:
// se pasa por la relación inversa de act3
System.out.format("2 - Personnes pratiquant l'activité act3 (relation inverse) :%n");
act3 = em.find(Activite.class, act3.getId());
for (Personne p : act3.getPersonnes()) {
System.out.println(p.getNom());
}
2.6.9. El proyecto Eclipse / Toplink 2
Creamos un proyecto Eclipse a partir del anterior proyecto Eclipse / Toplink mediante copia:
 |
En [1], el proyecto Eclipse; en [2], los códigos Java. El proyecto se encuentra en [3], dentro de la carpeta de ejemplos [4]. Lo importaremos.
Los códigos Java son idénticos a los de la versión de Hibernate.
2.7. Ejemplo 7: uso de consultas con nombre
Terminamos esta extensa presentación de las entidades JPA, iniciada en el párrafo 2, con un último ejemplo que muestra el uso de consultas JPQL externalizadas en un archivo de configuración. Este ejemplo tiene su origen en la siguiente fuente:
[ref2]: «Getting started With JPA in Spring 2.0», de Mark Fisher, en la URL
[http://blog.springframework.com/markf/archives/2006/05/30/getting-started-with-jpa-in-spring-20/].
2.7.1. La base de datos de ejemplo
La base de datos es la siguiente:
 |
- en [1]: una lista de restaurantes con su nombre y dirección
- en [2]: la tabla de direcciones de los restaurantes, limitada al número de la calle y al nombre de la calle. Existe una relación uno a uno entre las tablas restaurant y adresse: un restaurante tiene una dirección y solo una.
- en [3]: una tabla de platos con su nombre y un indicador verdadero/falso que indica si el plato es vegetariano o no
- en [4]: la tabla de unión entre restaurantes y platos: un restaurante sirve varios platos y un mismo plato puede ser servido por varios restaurantes. Existe una relación «muchos a muchos» entre las tablas restaurant y plat.
2.7.2. Los objetos @Entity que representan la base de datos
Las tablas anteriores se representarán mediante las siguientes @Entity:
- la @Entity Restaurant representará la tabla [restaurant]
- el @Entity Adresse representará la tabla [adresse]
- la @Entity Plat representará la tabla [plat]
Las relaciones entre estas entidades son las siguientes:
- una relación uno a uno vincula la entidad Restaurant con la entidad Adresse: un restaurante r tiene una dirección a. La entidad Restaurant, que posee la clave foránea, tendrá la relación principal. La entidad Adresse no tendrá relación inversa.
- Una relación «muchos a muchos» une las entidades Restaurant y Plat: un restaurante sirve varios platos y un mismo plato puede ser servido por varios restaurantes. Esta relación se materializará mediante una anotación @ManyToMany en la entidad Restaurant. La entidad Plat no tendrá relación inversa.
La @Entity Restaurant es la siguiente:
package entites;
...
@Entity
@Table(name = "jpa10_hb_restaurant")
public class Restaurant implements java.io.Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(unique = true, length = 30, nullable = false)
private String nom;
@OneToOne(cascade = CascadeType.ALL)
private Adresse adresse;
@ManyToMany(cascade = { CascadeType.PERSIST, CascadeType.MERGE })
@JoinTable(name = "jpa10_hb_restaurant_plat", inverseJoinColumns = @JoinColumn(name = "plat_id"))
private Set<Plat> plats = new HashSet<Plat>();
// constructores
public Restaurant() {
}
public Restaurant(String name, Adresse address, Set<Plat> entrees) {
...
}
// getters y setters
...
// toString
public String toString() {
String signature = "R[" + getNom() + "," + getAdresse();
for (Plat e : getPlats()) {
signature += "," + e;
}
return signature + "]";
}
}
- línea 17: la relación uno a uno que tiene la entidad Restaurant con la entidad Adresse. Todas las operaciones de persistencia sobre un restaurante se propagan a su dirección.
- línea 20: la relación que vincula la @Entity Restaurant con la @Entity Plat del conjunto plats de la línea 22 es de tipo «varios a varios» (ManyToMany):
- un restaurante (One) tiene varios platos (Many)
- un plato (One) puede ser servido por varios restaurantes (Many)
- en definitiva, las @Entity Restaurant y Plat están vinculadas por una relación ManyToMany. Decidimos que la @Entity Restaurant tendrá la relación principal y que la @Entity Plat no tendrá relación inversa.
- La relación @ManyToMany requiere una tabla de unión. Esta se define mediante la anotación @JoinTable de la línea 47.
- El atributo «name» asigna un nombre a la tabla.
- La tabla de unión está formada por las claves externas de las tablas que une. En este caso, hay dos claves externas: una en la tabla [restaurant] y otra en la tabla [plat]. Estas columnas de clave externa se definen mediante los atributos joinColumns y inverseJoinColumns.
- El atributo joinColumns define la clave foránea en la tabla de la @Entity que contiene la relación principal @ManyToMany, en este caso la tabla [restaurant]. El atributo joinColumns no aparece aquí. JPA tiene un valor por defecto en este caso: [table]_[clé_primaire_de_table], en este caso [jpa10_hb_restaurant_id].
- La anotación @JoinColumn del atributo inverseJoinColumns define la clave foránea en la tabla de la @Entity que contiene la relación inversa @ManyToMany, en este caso la tabla [plat]. Esta columna de clave externa se llamará plat_id.
La @Entity Adresse es la siguiente:
package entites;
...
@Entity
@Table(name="jpa10_hb_adresse")
public class Adresse implements java.io.Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(name = "NUMERO_RUE")
private int numeroRue;
@Column(name = "NOM_RUE", length=30, nullable=false)
private String nomRue;
// getters y setters
...
// constructores
public Adresse(int streetNumber, String streetName){
...
}
public Adresse(){
}
// toString
public String toString(){
return "A["+getNumeroRue()+","+getNomRue()+"]";
}
}
- La @Entity «Dirección» es una entidad sin relación directa con las demás entidades. Solo se puede persistir a través de una entidad Restaurant.
- Una dirección se define mediante un nombre de calle (línea 16) y un número de la calle (línea 13).
La @Entity Plat es la siguiente
package entites;
...
@Entity
@Table(name="jpa10_hb_plat")
public class Plat implements java.io.Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(unique=true, length=50, nullable=false)
private String nom;
private boolean vegetarien;
// constructores
public Plat() {
}
public Plat(String name, boolean vegetarian) {
...
}
// getters y setters
...
// toString
public String toString() {
return "E[" + getNom() + "," + isVegetarien() + "]";
}
}
- La @Entity Plat es una entidad sin relación directa con las demás entidades. Solo se puede persistir a través de una entidad Restaurant.
- Un plato se define por un nombre (línea 12) y un tipo (vegetariano o no) (línea 14).
2.7.3. El proyecto Eclipse / Hibernate
La implementación JPA utilizada aquí es la de Hibernate. El proyecto Eclipse de las pruebas es el siguiente:
 |
En [1] se encuentra el proyecto Eclipse; en [2], los códigos Java; y en JPA, la configuración de la capa. Cabe destacar la presencia de un archivo [orm.xml] que aún no hemos visto. El proyecto se encuentra en [3], dentro de la carpeta de ejemplos [4]. Lo importaremos.
2.7.4. Generación del archivo DDL de la base de datos
Siguiendo las instrucciones del apartado 2.1.7, el archivo DDL obtenido para el SGBD y el MySQL5 es el siguiente:
alter table jpa10_hb_restaurant
drop
foreign key FK3E8E4F5D5FE379D0;
alter table jpa10_hb_restaurant_plat
drop
foreign key FK1D2D06D11F0F78A4;
alter table jpa10_hb_restaurant_plat
drop
foreign key FK1D2D06D1AFAC3E44;
drop table if exists jpa10_hb_adresse;
drop table if exists jpa10_hb_plat;
drop table if exists jpa10_hb_restaurant;
drop table if exists jpa10_hb_restaurant_plat;
create table jpa10_hb_adresse (
id bigint not null auto_increment,
NUMERO_RUE integer,
NOM_RUE varchar(30) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_plat (
id bigint not null auto_increment,
nom varchar(50) not null unique,
vegetarien bit not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_restaurant (
id bigint not null auto_increment,
nom varchar(30) not null unique,
adresse_id bigint,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_restaurant_plat (
jpa10_hb_restaurant_id bigint not null,
plat_id bigint not null,
primary key (jpa10_hb_restaurant_id, plat_id)
) ENGINE=InnoDB;
alter table jpa10_hb_restaurant
add index FK3E8E4F5D5FE379D0 (adresse_id),
add constraint FK3E8E4F5D5FE379D0
foreign key (adresse_id)
references jpa10_hb_adresse (id);
alter table jpa10_hb_restaurant_plat
add index FK1D2D06D11F0F78A4 (plat_id),
add constraint FK1D2D06D11F0F78A4
foreign key (plat_id)
references jpa10_hb_plat (id);
alter table jpa10_hb_restaurant_plat
add index FK1D2D06D1AFAC3E44 (jpa10_hb_restaurant_id),
add constraint FK1D2D06D1AFAC3E44
foreign key (jpa10_hb_restaurant_id)
references jpa10_hb_restaurant (id);
- líneas 21-26: la tabla [adresse]
- líneas 28-33: la tabla [plat]
- líneas 35-40: la tabla [restaurant]
- líneas 42-46: la tabla de unión [restaurant_plat]. Cabe destacar la clave compuesta (línea 45)
- líneas 48-52: la clave externa de la tabla [restaurant] hacia la tabla [adresse]
- líneas 54-58: la clave externa de la tabla [restaurant_plat] hacia la tabla [plat]
- líneas 60-64: la clave externa de la tabla [restaurant_plat] hacia la tabla [restaurant]
Esta tabla DDL se corresponde con el esquema ya presentado:
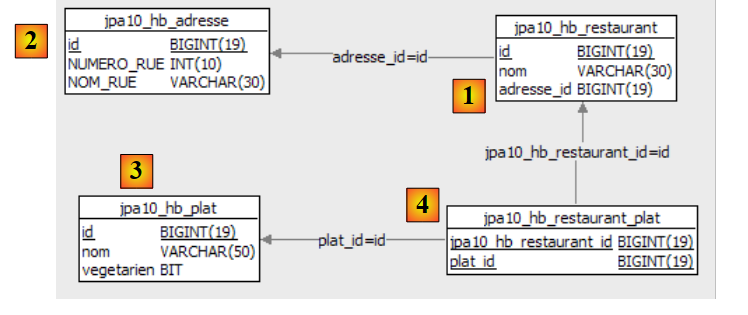 |
En la vista «Explorer» de SQL, la base de datos se presenta de la siguiente manera:
 |
- en [1]: las 4 tablas de la base de datos
- en [2]: las direcciones
- en [3]: los platos
- en [4]: los restaurantes. [adresse_id] hace referencia a las direcciones de [2].
- en [5]: la tabla de unión [restaurant,plat]. [jpa10_hb_restaurant_id] hace referencia a los restaurantes de [4] y [plat_id] a los platos de [3]. Así, [1,1] significa que el restaurante «Burger Barn» sirve el plato «CheeseBurger».
Para obtener los datos anteriores, se ejecutó el programa [QueryDB] del proyecto Eclipse.
2.7.5. Consultas JPQL con una consola de Hibernate
Creamos una consola de Hibernate vinculada al proyecto Eclipse anterior. Seguiremos el procedimiento ya expuesto en dos ocasiones, concretamente en el apartado 2.1.12.
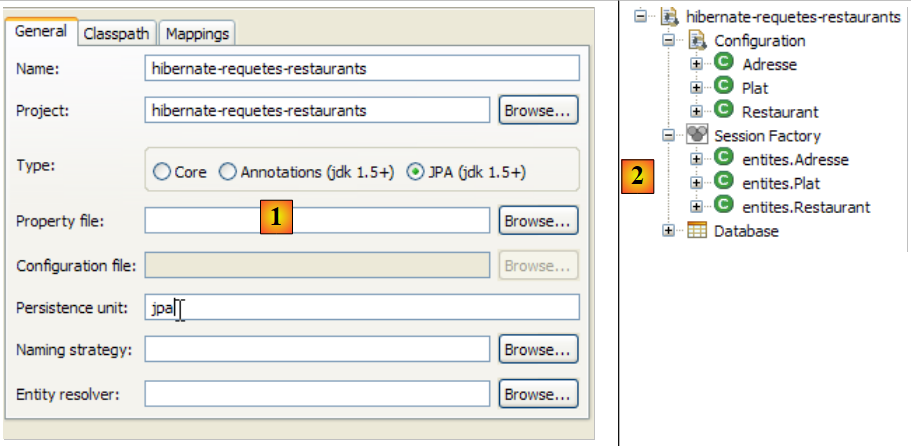 |
- en [1] y [2]: la configuración de la consola de Hibernate
 |
- en [3]: una consulta JPQL y en [4] el resultado.
- en [5]: la orden equivalente SQL
A continuación, presentamos una serie de consultas JPQL. Invitamos al lector a ejecutarlas y a descubrir la orden SQL generada por Hibernate para ejecutarlas.
Obtener todos los restaurantes con sus platos:
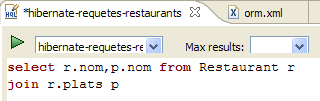 | 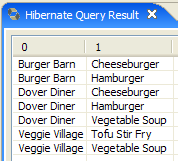 |
Obtener los restaurantes que sirven al menos un plato vegetariano:
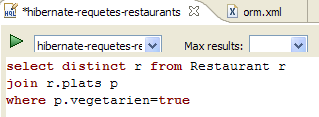 |  |
Obtener los nombres de los restaurantes que solo sirven platos vegetarianos:
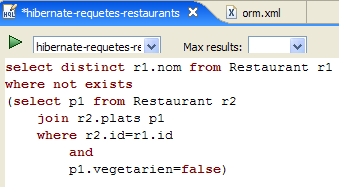 | 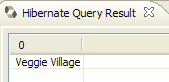 |
Obtener los restaurantes que sirven hamburguesas:
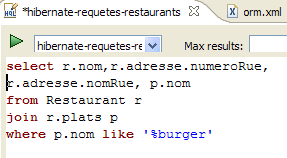 | 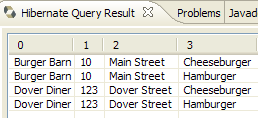 |
2.7.6. QueryDB
Ahora nos centramos en el programa [QueryDB] del proyecto Eclipse, que:
- rellena la base de datos
- y envía una serie de consultas JPQL. Estas se registran en el archivo [META-INF/orm.xml] del proyecto Eclipse:
 |
El archivo [orm.xml] puede utilizarse para configurar la capa JPA en lugar de las anotaciones Java. Esto aporta flexibilidad a la configuración de la capa JPA. Se puede modificar sin necesidad de recompilar el código Java. Se pueden utilizar ambos métodos simultáneamente: anotaciones Java y el archivo [orm.xml]. La configuración JPA se realiza primero con las anotaciones Java y, a continuación, con el archivo [orm.xml]. Por lo tanto, si se desea modificar una configuración realizada mediante una anotación Java sin necesidad de recompilar, basta con incluir dicha configuración en [orm.xml]. Será esta la que prevalezca.
En nuestro ejemplo, el archivo [orm.xml] se utiliza para guardar los textos de las consultas de JPQL. Su contenido es el siguiente:
<?xml version="1.0" encoding="UTF-8" ?>
<entity-mappings xmlns="http://java.sun.com/xml/ns/persistence/orm" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence/orm http://java.sun.com/xml/ns/persistence/orm_1_0.xsd" version="1.0">
<description>Restaurants</description>
<named-query name="supprimer le contenu de la table restaurant">
<query>delete from Restaurant</query>
</named-query>
<named-query name="supprimer le contenu de la table plat">
<query>delete from Plat</query>
</named-query>
<named-query name="obtenir tous les restaurants">
<query>select r from Restaurant r order by r.nom asc</query>
</named-query>
<named-query name="obtenir toutes les adresses">
<query>select a from Adresse a order by a.nomRue asc</query>
</named-query>
<named-query name="obtenir tous les plats">
<query>select p from Plat p order by p.nom asc</query>
</named-query>
<named-query name="obtenir tous les restaurants avec leurs plats">
<query>select r.nom,p.nom from Restaurant r join r.plats p</query>
</named-query>
<named-query name="obtenir les restaurants ayant au moins un plat vegetarien">
<query>select distinct r from Restaurant r join r.plats p where p.vegetarien=true</query>
</named-query>
<named-query name="obtenir les restaurants avec uniquement des plats vegetariens">
<query>
select distinct r1.nom from Restaurant r1 where not exists (select p1 from Restaurant r2 join r2.plats p1 where r2.id=r1.id and
p1.vegetarien=false)
</query>
</named-query>
<named-query name="obtenir les restaurants d'une certaine rue">
<query>select r from Restaurant r where r.adresse.nomRue=:nomRue</query>
</named-query>
<named-query name="obtenir les restaurants qui servent des burgers">
<query>select r.nom,r.adresse.numeroRue, r.adresse.nomRue, p.nom from Restaurant r join r.plats p where p.nom like '%burger'</query>
</named-query>
<named-query name="obtenir les plats du restaurant untel">
<query>select p.nom from Restaurant r join r.plats p where r.nom=:nomRestaurant</query>
</named-query>
</entity-mappings>
- La raíz del archivo [orm.xml] es <entity-mappings> (línea 2).
- líneas 5-7: las consultas JPQL con nombre son objeto de las etiquetas <named-query name= «...»>texto</namedquery>.
- El atributo name de la etiqueta es el nombre de la consulta.
- El contenido texte de la etiqueta es el texto de la consulta.
QueryDB ejecutará las consultas anteriores. Su código es el siguiente:
package tests;
...
public class QueryDB {
// Contexto de persistencia
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = emf.createEntityManager();
public static void main(String[] args) {
// Inicio de transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// eliminar elementos de la tabla [restaurant]
em.createNamedQuery("supprimer le contenu de la table restaurant").executeUpdate();
// Eliminar elementos de la tabla [plat]
em.createNamedQuery("supprimer le contenu de la table plat").executeUpdate();
// creación de objetos Address
Adresse adr1 = new Adresse(10, "Main Street");
Adresse adr2 = new Adresse(20, "Main Street");
Adresse adr3 = new Adresse(123, "Dover Street");
// creación de objetos Entrada
Plat ent1 = new Plat("Hamburger", false);
Plat ent2 = new Plat("Cheeseburger", false);
Plat ent3 = new Plat("Tofu Stir Fry", true);
Plat ent4 = new Plat("Vegetable Soup", true);
// creación de objetos «Restaurante»
Restaurant restaurant1 = new Restaurant();
restaurant1.setNom("Burger Barn");
restaurant1.setAdresse(adr1);
restaurant1.getPlats().add(ent1);
restaurant1.getPlats().add(ent2);
Restaurant restaurant2 = new Restaurant();
restaurant2.setNom("Veggie Village");
restaurant2.setAdresse(adr2);
restaurant2.getPlats().add(ent3);
restaurant2.getPlats().add(ent4);
Restaurant restaurant3 = new Restaurant();
restaurant3.setNom("Dover Diner");
restaurant3.setAdresse(adr3);
restaurant3.getPlats().add(ent1);
restaurant3.getPlats().add(ent2);
restaurant3.getPlats().add(ent4);
// persistencia de los objetos «Restaurante» (y de los demás objetos en cascada)
em.persist(restaurant1);
em.persist(restaurant2);
em.persist(restaurant3);
// fin de la transacción
tx.commit();
// volcado de la base de datos
dumpDataBase();
// fin EntityManager
em.close();
// fin de EntityManagerFactory
emf.close();
}
// visualización del contenido de la base
@SuppressWarnings("unchecked")
private static void dumpDataBase() {
// prueba2
log("données de la base");
// inicio de la transacción
EntityTransaction tx = em.getTransaction();
tx.begin();
// visualización de restaurantes
log("[restaurants]");
for (Object restaurant : em.createNamedQuery("obtenir tous les restaurants").getResultList()) {
System.out.println(restaurant);
}
// visualizaciones de direcciones
log("[adresses]");
for (Object adresse : em.createNamedQuery("obtenir toutes les adresses").getResultList()) {
System.out.println(adresse);
}
// visualizaciones de platos
log("[plats]");
for (Object plat : em.createNamedQuery("obtenir tous les plats").getResultList()) {
System.out.println(plat);
}
// visualizaciones de enlaces entre restaurantes y platos
log("[restaurants/plats]");
Iterator record = em.createNamedQuery("obtenir tous les restaurants avec leurs plats").getResultList().iterator();
while (record.hasNext()) {
Object[] currentRecord = (Object[]) record.next();
System.out.format("[%s,%s]%n", currentRecord[0], currentRecord[1]);
}
log("[Liste des restaurants avec au moins un plat végétarien]");
for (Object r : em.createNamedQuery("obtenir les restaurants ayant au moins un plat vegetarien").getResultList()) {
System.out.println(r);
}
// consulta
log("[Liste des restaurants avec seulement des plats végétariens]");
for (Object r : em.createNamedQuery("obtenir les restaurants avec uniquement des plats vegetariens").getResultList()) {
System.out.println(r);
}
// consulta
log("[Liste des restaurants dans Dover Street]");
for (Object r : em.createNamedQuery("obtenir les restaurants d'une certaine rue").setParameter("nomRue", "Dover Street").getResultList()) {
System.out.println(r);
}
// consulta
log("[Liste des restaurants ayant un plat de type burger]");
record = em.createNamedQuery("obtenir les restaurants qui servent des burgers").getResultList().iterator();
while (record.hasNext()) {
Object[] currentRecord = (Object[]) record.next();
System.out.format("[%s,%d,%s,%s]%n", currentRecord[0], currentRecord[1], currentRecord[2], currentRecord[3]);
}
// consulta
log("[Plats de Veggie Village]");
for (Object r : em.createNamedQuery("obtenir les plats du restaurant untel").setParameter("nomRestaurant", "Veggie Village").getResultList()) {
System.out.println(r);
}
// fin de transacción
tx.commit();
}
// registros
private static void log(String message) {
System.out.println(" -----------" + message);
}
}
El resultado de la ejecución de [QueryDB] es el siguiente:
Dejamos al lector la tarea de establecer la relación entre el código y los resultados. Para ello, le recomendamos que ejecute las consultas JPQL en la consola de Hibernate y examine el código SQL correspondiente.
2.7.7. El proyecto Eclipse / Toplink
El lector interesado encontrará en los ejemplos descargables con este tutorial el proyecto anterior implementado con Toplink:
 |
El proyecto de Eclipse con Toplink es una copia del proyecto de Eclipse con Hibernate:
 |
El archivo <persistence.xml> [2] declara las entidades gestionadas:
<!-- proveedor -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- clases persistentes -->
<class>entites.Restaurant</class>
<class>entites.Adresse</class>
<class>entites.Plat</class>
...
- líneas 4-6: las entidades gestionadas
Las consultas JPQL registradas en [orm.xml] se ejecutan correctamente mediante Toplink. Para ello, en el proyecto anterior se tuvo cuidado de no utilizar consultas HQL (Hibernate Query Language), que es, de hecho, un superconjunto de JPQL y cuya sintaxis, en algunos casos, no es aceptada por JPQL.
2.8. Conclusión
Con esto concluimos nuestro estudio de las entidades JPA. Ha sido un proceso largo y, sin embargo, quedan por abordar aspectos importantes (para el desarrollador avanzado). Una vez más, se recomienda leer un libro de referencia como el que se ha utilizado para este tutorial:
[ref1]: Java Persistence with Hibernate, de Christian Bauer y Gavin King, editorial Manning.