1. Introducción
1.1. Objetivos
El PDF del documento está disponible |AQUÍ|.
Los ejemplos del documento están disponibles |AQUÍ|.
El objetivo de este documento es descubrir los conceptos principales de la persistencia de datos con API JPA (Java Persistence API). Tras leer este documento y probar los ejemplos, el lector debería haber adquirido los fundamentos necesarios para poder valerse por sí mismo.
La API JPA es reciente. Solo está disponible a partir de la versión 1.5 de JDK. La capa JPA tiene su lugar en una arquitectura multicapa. Consideremos una arquitectura de este tipo bastante extendida, la de tres capas:
 |
- la capa [1], denominada aquí [ui] (interfaz de usuario), es la capa que interactúa con el usuario a través de una interfaz gráfica Swing, una interfaz de consola o una interfaz web. Su función es proporcionar los datos procedentes del usuario a la capa [2] o bien presentar al usuario los datos proporcionados por la capa [2].
- La capa [2], denominada aquí [metier], es la capa que aplica las reglas denominadas «de negocio», c.a.d. La lógica específica de la aplicación, sin preocuparse por el origen de los datos que se le proporcionan ni por el destino de los resultados que genera.
- La capa [3], denominada aquí [dao] (Data Access Object), es la capa que proporciona a la capa [2] datos pregrabados (archivos, bases de datos, ...) y que almacena algunos de los resultados proporcionados por la capa [2].
- La capa [JDBC] es la capa estándar utilizada en Java para acceder a bases de datos. Es lo que habitualmente se denomina el controlador JDBC de SGBD.
Se han realizado múltiples esfuerzos para facilitar a los desarrolladores la escritura de estas diferentes capas. Entre ellos, JPA tiene como objetivo facilitar la programación de la capa [dao], la que gestiona los datos denominados «persistentes», de ahí el nombre de API (Java Persistence API). Una solución que ha cobrado importancia en los últimos años en este ámbito es la de Hibernate:
 |
La capa [Hibernate] se sitúa entre la capa [dao], escrita por el desarrollador, y la capa [Jdbc]. Hibernate es un ORM (mapeo objeto-relacional), una herramienta que sirve de puente entre el mundo relacional de las bases de datos y el de los objetos manipulados por Java. El desarrollador de la capa [dao] ya no ve la capa [Jdbc] ni las tablas de la base de datos cuyo contenido desea explotar. Solo ve la imagen objeto de la base de datos, imagen objeto proporcionada por la capa [Hibernate]. El puente entre las tablas de la base de datos y los objetos manipulados por la capa [dao] se establece principalmente de dos maneras:
- mediante archivos de configuración de tipo XML
- mediante anotaciones Java en el código, técnica disponible únicamente a partir de la versión 1.5 de JDK
La capa [Hibernate] es una capa de abstracción que pretende ser lo más transparente posible. El objetivo ideal es que el desarrollador de la capa [dao] pueda ignorar por completo que está trabajando con una base de datos. Esto es posible si no es él quien escribe la configuración que sirve de puente entre el mundo relacional y el mundo de objetos. La configuración de este puente es bastante delicada y requiere cierta práctica.
La capa [4] de los objetos, que es un reflejo de la BD, se denomina «contexto de persistencia». Una capa [dao] basada en Hibernate realiza acciones de persistencia (CRUD: crear, leer, actualizar, eliminar) sobre los objetos del contexto de persistencia, acciones que Hibernate traduce en órdenes SQL. Para las operaciones de consulta a la base de datos (el SQL Select), Hibernate proporciona al desarrollador un lenguaje HQL (Hibernate Query Language) para consultar el contexto de persistencia [4] y no la propia base de datos BD.
Hibernate es popular, pero complejo de dominar. La curva de aprendizaje, que a menudo se presenta como fácil, es en realidad bastante pronunciada. En cuanto se tiene una base de datos con tablas que presentan relaciones uno a varios o varios a varios, la configuración del puente relacional/objetos no está al alcance del primer principiante que se le presente. Los errores de configuración pueden dar lugar a aplicaciones con un rendimiento deficiente.
En el ámbito comercial, existía un producto equivalente a Hibernate llamado Toplink:
 |
Ante el éxito de los productos ORM, Sun, el creador de Java, decidió estandarizar una capa ORM mediante una especificación denominada JPA, que apareció al mismo tiempo que Java 5. La especificación JPA ha sido implementada por los dos productos Toplink e Hibernate. Toplink, que era un producto comercial, se ha convertido desde entonces en un producto libre. Con JPA, la arquitectura anterior queda así:
 |
La capa [dao] interactúa ahora con la especificación JPA, un conjunto de interfaces. El desarrollador ha ganado en estandarización. Antes, si modificaba su capa ORM, también tenía que modificar su capa [dao], que se había escrito para interactuar con un ORM específico. Ahora, escribirá una capa [dao] que se comunicará con una capa JPA. Independientemente del producto que la implemente, la interfaz de la capa JPA que se presenta a la capa [dao] sigue siendo la misma.
Este documento presentará ejemplos de JPA en diversos ámbitos:
- en primer lugar, nos centraremos en el puente relacional/objeto que construye la capa ORM. Este se creará mediante anotaciones de Java 5 para bases de datos en las que existan relaciones entre tablas de tipo:
- uno a uno
- uno a varios
- varios a varios
Para ilustrar este ámbito, crearemos las siguientes arquitecturas de prueba:
 |
Nuestros programas de pruebas serán aplicaciones de consola que consultarán directamente la capa JPA. En esta ocasión, descubriremos los principales métodos de la capa JPA. Nos encontraremos en un entorno denominado «Java SE» (Standard Edition). JPA funciona tanto en un entorno Java SE como en uno Java EE5 (Enterprise Edition).
- Cuando dominemos tanto la configuración del puente relacional/objeto como el uso de los métodos de la capa JPA, volveremos a una arquitectura multicapa más clásica:
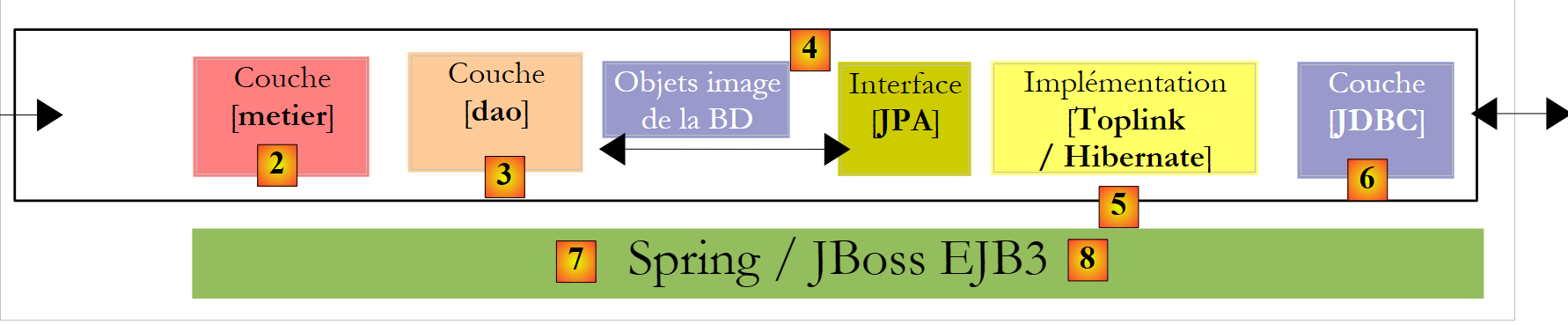 |
Se accederá a la capa [JPA] a través de una arquitectura de dos capas: [metier] y [dao]. Se utilizarán el framework Spring [7] y, a continuación, el contenedor EJB3 de JBoss para vincular estas capas entre sí.
Como hemos mencionado anteriormente, JPA está disponible en los entornos SE y EE5. El entorno Java EE5 ofrece numerosos servicios en el ámbito del acceso a datos persistentes, en particular grupos de conexiones, gestores de transacciones, etc. Puede resultar interesante para un desarrollador aprovechar estos servicios. El entorno Java EE5 aún no está muy extendido (mayo de 2007). Actualmente se encuentra en el servidor de aplicaciones Sun Application Server 9.x (Glassfish). Un servidor de aplicaciones es, esencialmente, un servidor de aplicaciones web. Si se crea una aplicación gráfica independiente de tipo Swing, no se puede disponer del entorno EE ni de los servicios que ofrece. Esto supone un problema. Empiezan a aparecer entornos «autónomos» EE, c.a.d. que pueden utilizarse fuera de un servidor de aplicaciones. Es el caso de JBos y EJB3, que vamos a utilizar en este documento.
En un entorno EE5, las capas se implementan mediante objetos denominados EJB (Enterprise Java Bean). En versiones anteriores de EE, los EJB (EJB y 2.x) tenían fama de ser difíciles de implementar y de probar, y en ocasiones ofrecían un rendimiento deficiente. Se distingue entre los EJB2.x «entity» y los EJB2.x «session». En resumen, un EJB2.x «entity» es la representación de una fila de una tabla de base de datos y un EJB2.x «session» es un objeto utilizado para implementar las capas [metier], [dao] de una arquitectura multicapa. Una de las principales críticas que se hacen a las capas implementadas con EJB es que solo se pueden utilizar dentro de contenedores EJB, un servicio proporcionado por el entorno EE. Esto complica las pruebas unitarias. Así, en el esquema anterior, las pruebas unitarias de las capas [metier] y [dao], construidas con EJB, requerirían la puesta en marcha de un servidor de aplicaciones, una operación bastante engorrosa que no anima precisamente al desarrollador a realizar pruebas con frecuencia.
El marco Spring surgió como respuesta a la complejidad de los EJB2. Spring proporciona, en un entorno SE, un número considerable de los servicios que suelen ofrecer los entornos EE. Así, en el ámbito de la «persistencia de datos», que es el que nos interesa aquí, Spring proporciona los grupos de conexiones y los gestores de transacciones que necesitan las aplicaciones. La aparición de Spring ha fomentado la cultura de las pruebas unitarias, que de repente se han vuelto mucho más fáciles de implementar. Spring permite implementar las capas de una aplicación mediante objetos Java clásicos (POJO, Plain Old/Ordinary Java Object), lo que permite su reutilización en otro contexto. Por último, integra numerosas herramientas de terceros de forma bastante transparente, en particular herramientas de persistencia como Hibernate, iBatis, etc.
Java EE5 se diseñó para subsanar las deficiencias de la especificación anterior EE. Los EJB y 2.x se han convertido en los EJB3. Estos son POJOs etiquetados con anotaciones que los convierten en objetos especiales cuando se encuentran dentro de un contenedor EJB3. Dentro de este, el EJB3 podrá beneficiarse de los servicios del contenedor (pool de conexiones, gestor de transacciones, etc.). Fuera del contenedor EJB3, el EJB3 se convierte en un objeto Java normal. Sus anotaciones EJB se ignoran.
En lo anterior, hemos representado Spring y JBoss EJB3 como una posible infraestructura (framework) de nuestra arquitectura multicapa. Es esta infraestructura la que proporcionará los servicios que necesitamos: un grupo de conexiones y un gestor de transacciones.
- Con Spring, las capas se implementarán mediante POJOs. Estos tendrán acceso a los servicios de Spring (grupo de conexiones, gestor de transacciones) mediante la inyección de dependencias en dichos POJOs: al crearlos, Spring les inyecta referencias a los servicios que van a necesitar.
- JBoss EJB3 es un contenedor EJB que puede funcionar fuera de un servidor de aplicaciones. Su principio de funcionamiento (para el desarrollador) es análogo al descrito para Spring. Encontraremos pocas diferencias.
- Terminaremos el documento con un ejemplo de aplicación web de tres capas, básico pero representativo:
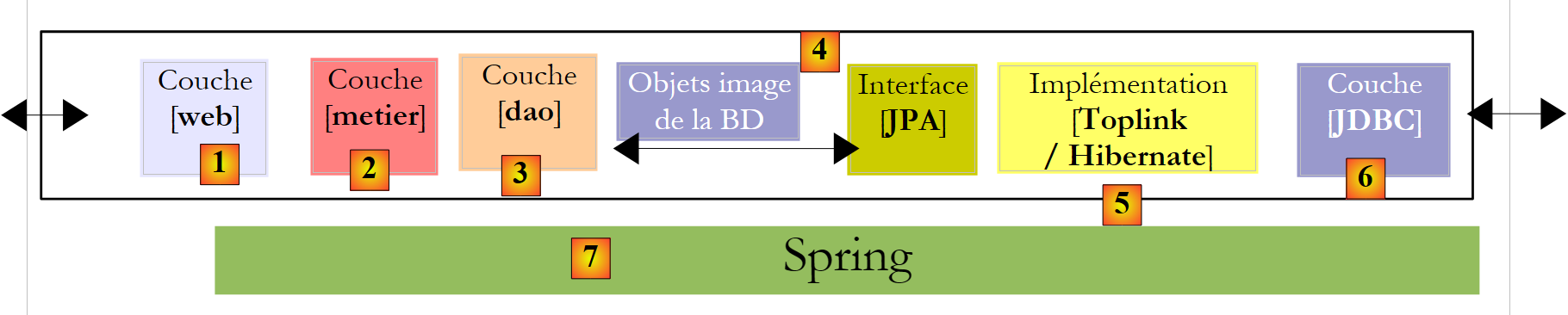 |
1.2. Referencias
[ref1]: Java Persistence with Hibernate, de Christian Bauer y Gavin King, editorial Manning.
[ref1] es el documento en el que se basa lo que sigue. Se trata de un libro exhaustivo de más de 800 páginas sobre el uso de Hibernate en dos contextos diferentes: con o sin JPA. El uso de Hibernate sin JPA sigue siendo, de hecho, una opción válida para los desarrolladores que utilizan JDK 1.4 o versiones anteriores, ya que JPA no apareció hasta la versión 1.5 de JDK.
Tras haber leído más de tres cuartas partes del libro y haber echado un vistazo al resto, me ha parecido que todo lo que contiene este documento resulta útil. El usuario experto en Hibernate debería conocer prácticamente toda la información que se ofrece en sus 800 páginas. Christian Bauer y Gavin King han sido exhaustivos, pero rara vez para describir situaciones con las que nunca nos encontraremos. Vale la pena leerlo todo. El libro está escrito de forma didáctica: se nota una voluntad real de no dejar nada en la oscuridad. El hecho de que se haya escrito para utilizar Hibernate tanto con como sin JPA supone una dificultad para quienes solo están interesados en una u otra de estas tecnologías. Por ejemplo, los autores describen, a través de numerosos ejemplos, el puente relacional/objeto en ambos contextos. Los conceptos utilizados son muy similares, ya que JPA se ha inspirado en gran medida en Hibernate. Sin embargo, presentan algunas diferencias. De tal manera que algo que es cierto para Hibernate puede no serlo para JPA, lo que acaba creando confusión en el lector.
Los autores muestran ejemplos de aplicaciones de tres capas en el contexto de un contenedor EJB3. No mencionan Spring. Veremos con un ejemplo que Spring es, sin embargo, más sencillo de usar y tiene un enfoque más global que el contenedor JBoss EJB3 utilizado en [ref1]. No obstante, «Java Persistence with Hibernate» es un libro excelente que recomiendo por todos los conceptos básicos que enseña sobre los ORM.
Utilizar un ORM resulta complejo para un principiante.
- Hay que comprender ciertos conceptos para configurar el puente relacional/objeto.
- Está el concepto de contexto de persistencia, con sus nociones de objetos en estado «persistente», «desvinculado» o «nuevo»;
- está la mecánica en torno a la persistencia (transacciones, grupos de conexiones), que suelen ser servicios proporcionados por un contenedor
- Hay que realizar ajustes para optimizar el rendimiento (caché de segundo nivel).
- ...
Introduciremos estos conceptos mediante ejemplos. No profundizaremos mucho en la teoría que los rodea. Nuestro objetivo es, simplemente, permitir que el lector comprenda el ejemplo y lo asimile hasta el punto de ser capaz de introducir modificaciones por sí mismo o de aplicarlo en otro contexto.
1.3. Herramientas utilizadas
Los ejemplos de este documento utilizan las siguientes herramientas. Algunas se describen en los anexos (descarga, instalación, configuración, uso). En ese caso, se indica el número de párrafo y la página.
- un JDK 1.6 (apartado 5.1)
- el IDE para el entorno de desarrollo Java Eclipse 3.2.2 (apartado 5.2)
- el complemento de Eclipse WTP (Web Tools Package) (apartado 5.2.3)
- Complemento de Eclipse SQL Explorer (apartado 5.2.6)
- Complemento de Eclipse «Hibernate Tools» (apartado 5.2.5)
- Complemento de Eclipse TestNG (apartado 5.2.4)
- contenedor de servlets Tomcat 5.5.23 (apartado 5.3)
- SGBD Firebird 2.1 (apartado 5.4)
- SGBD MySQL5 (apartado 5.5)
- SGBD PosgreSQL (apartado 5.6)
- SGBD Oracle 10g Express (apartado 5.7)
- SGBD SQL Server 2005 Express (apartado 5.8)
- SGBD HSQLDB (apartado 5.9)
- SGBD Apache Derby (apartado 5.10)
- Spring 2.1 (apartado 5.11)
- Contenedor EJB3 de JBoss (apartado 5.12)
1.4. Descarga de los ejemplos de
En la página web de este documento, los ejemplos analizados se pueden descargar en forma de archivo zip que, una vez descomprimido, genera la siguiente carpeta:
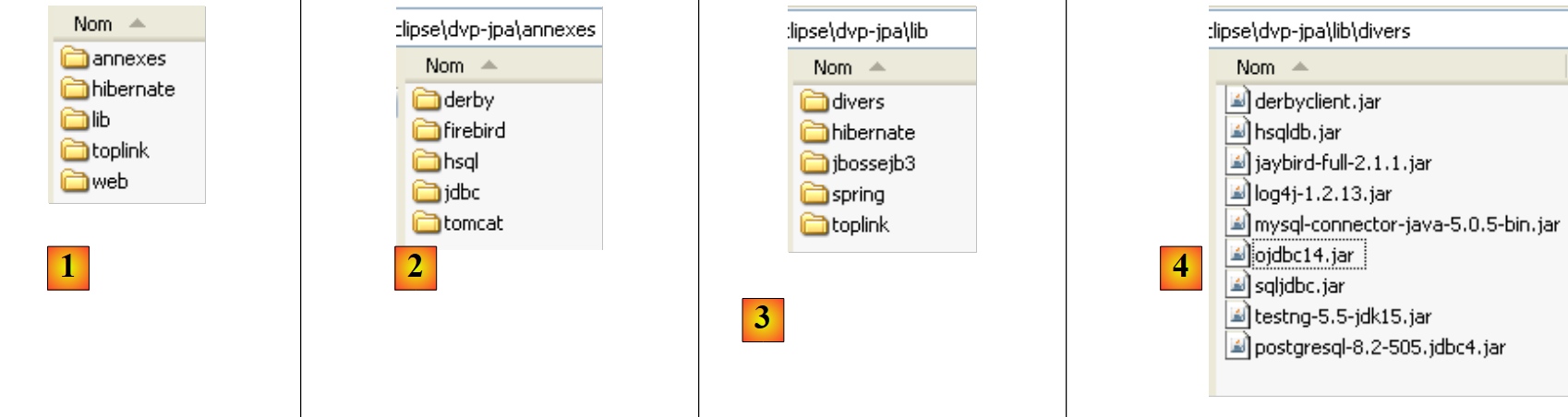 |
- en [1]: la estructura de los ejemplos
- en [2]: la carpeta <annexes> contiene los elementos presentados en la sección ANNEXES, apartado 5. En concreto, la carpeta <jdbc> contiene los controladores JDBC de SGBD utilizados para los ejemplos del tutorial.
- en [3]: la carpeta <lib> agrupa en 5 carpetas los distintos archivos .jar utilizados por el tutorial
- En [4]: la carpeta <lib/divers> agrupa los archivos:
- los controladores JDBC de SGBD
- de la herramienta de pruebas unitarias [testNG]
- de la herramienta de registros [log4j]
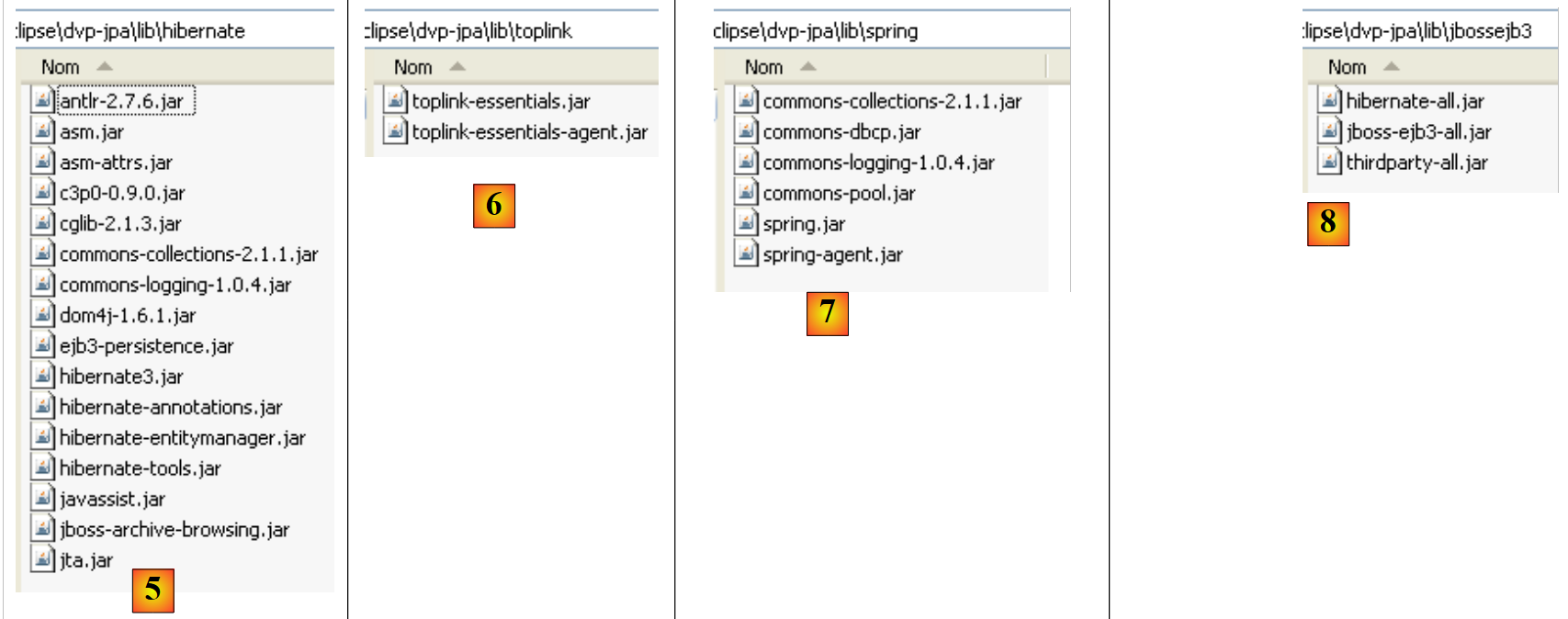 |
- en [5]: los archivos de la implementación JPA/Hibernate y de las herramientas de terceros necesarias para Hibernate
- en [6]: los archivos de la implementación JPA/Toplink
- en [7]: los archivos de Spring 2.x y de las herramientas de terceros necesarias para Spring
- en [8]: los archivos del contenedor EJB3 de JBoss
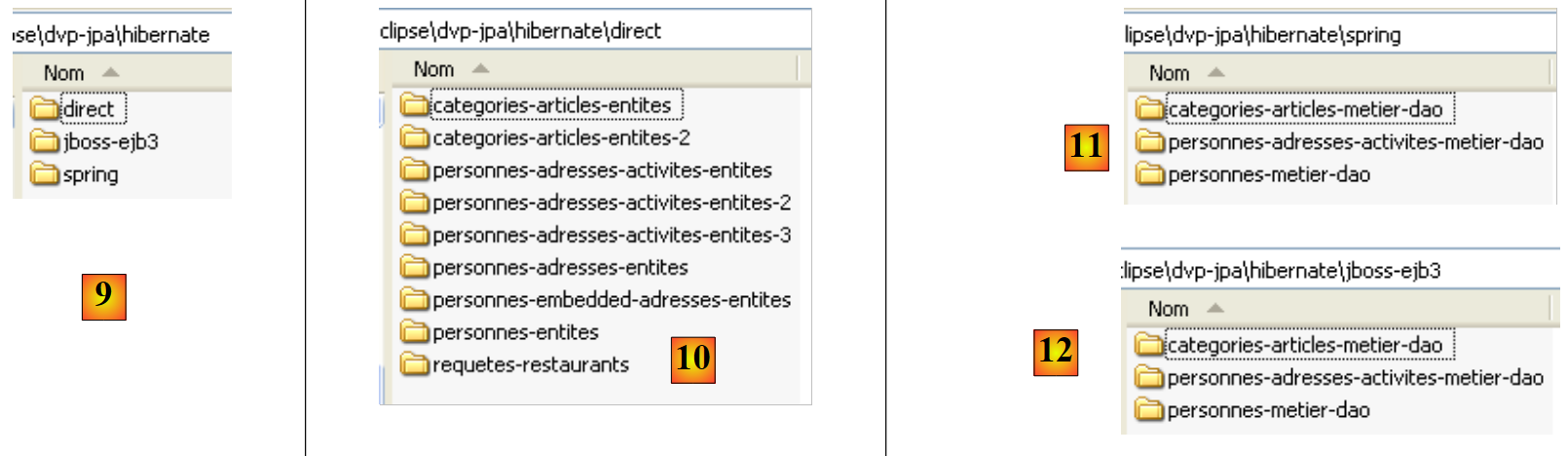 |
- en [9]: la carpeta <hibernate> recoge los ejemplos tratados con la capa de persistencia JPA/Hibernate
- en [10]: la carpeta <hibernate/direct> agrupa los ejemplos en los que la capa JPA se utiliza directamente con un programa de tipo [Main].
- en [11] y [12]: ejemplos en los que la capa JPA se utiliza a través de las capas [metier] y [dao] en una arquitectura multicapa, lo cual constituye el caso de uso habitual. Los servicios (grupo de conexiones, gestor de transacciones) utilizados por las capas [metier] y [dao] son proporcionados bien por Spring [11], bien por JBoss, EJB3 y [12].
 |
- en [13]: la carpeta <toplink> recoge los ejemplos de la carpeta <hibernate> [9], pero en esta ocasión con una capa de persistencia JPA/Toplink en lugar de JPA/Hibernate. NoEn [13] no hay ninguna carpeta <jbossejb3>, ya que no ha sido posible hacer funcionar un ejemplo en el que la capa de persistencia la gestione Toplink y los servicios los gestione el contenedor EJB3 de JBoss.
- En [14]: una carpeta <web> agrupa tres ejemplos de aplicaciones web con una capa de persistencia JPA:
- [15]: un ejemplo con Spring / JPA / Hibernate
- [16]: el mismo ejemplo con Spring / JPA / Toplink
- [17]: el mismo ejemplo con JBoss, EJB3 y JPA / Hibernate. Este ejemplo no funciona, probablemente debido a un problema de configuración aún sin resolver. No obstante, se ha dejado para que el lector pueda analizarlo y, quizá, encontrar una solución a este problema.
El tutorial hace referencia a menudo a esta estructura de directorios, especialmente al probar los ejemplos estudiados. Se invita al lector a descargar estos ejemplos e instalarlos. A partir de ahora, denominaremos <ejemplos> a la estructura de directorios de los ejemplos descrita anteriormente.
1.5. Configuración de los proyectos « » de Eclipse de los ejemplos
Los ejemplos utilizan bibliotecas «de usuario». Se trata de archivos .jar agrupados bajo un mismo nombre. Cuando se incluye una biblioteca de este tipo en el classpath de un proyecto Java, todos los archivos que contiene se incluyen en dicha ruta de clases. Veamos cómo hacerlo en Eclipse:
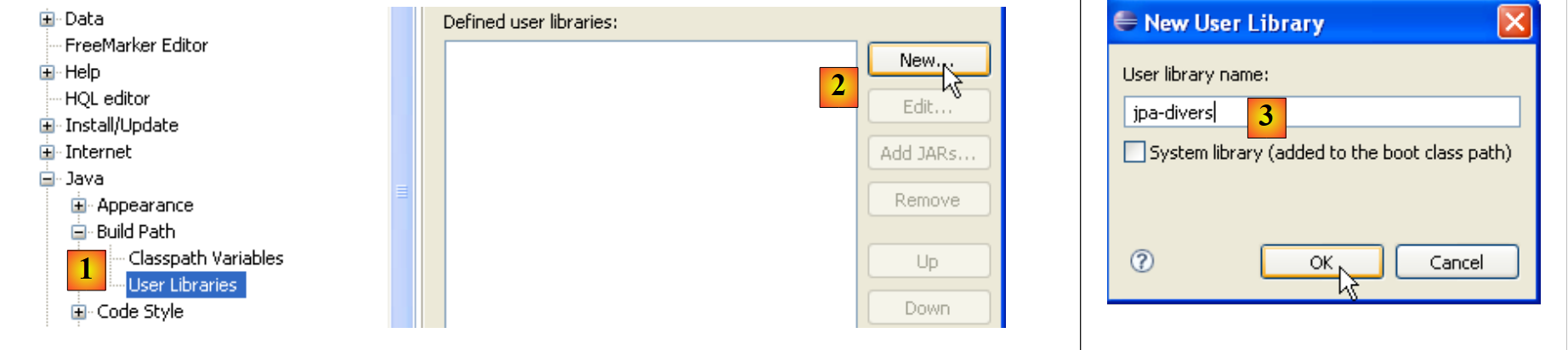 |
- en [1]: [Window / Preferences / Java / Buld Path / User Libraries]
- en [2]: se crea una nueva biblioteca
- en [3]: le damos un nombre y lo validamos
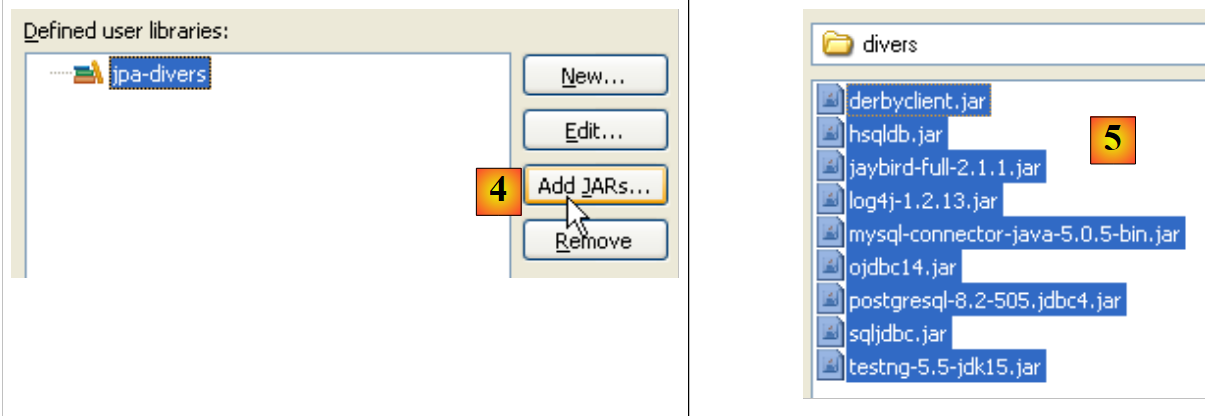 |
- en [4]: seleccionamos los archivos JAR que formarán parte de la biblioteca [jpa-divers]
- en [5]: seleccionamos todos los archivos JAR de la carpeta <ejemplos>/lib/divers
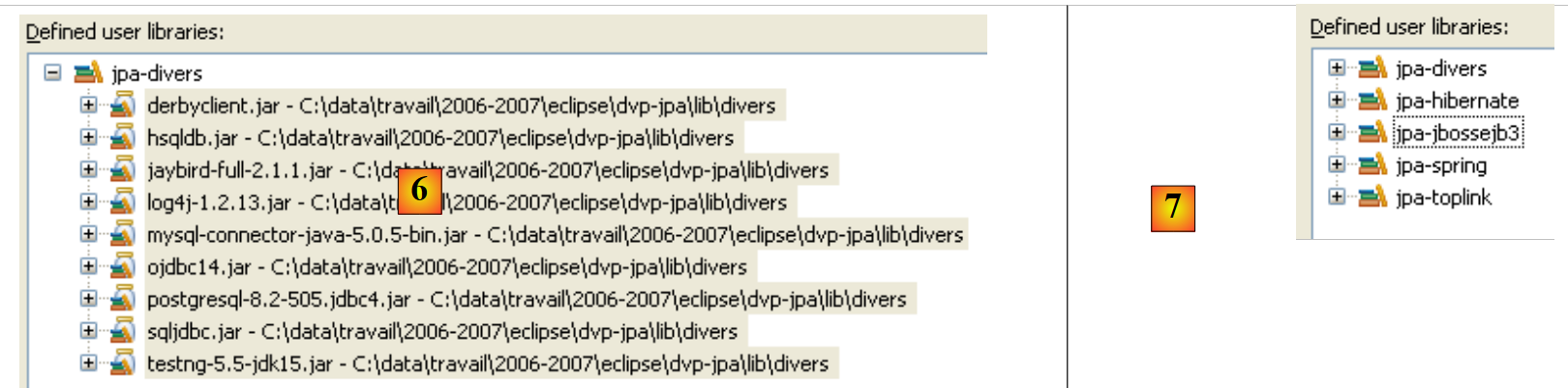 |
- en [6]: se ha definido la biblioteca de usuario [jpa-divers]
- en [7]: se repite el mismo proceso para crear otras 4 bibliotecas:
Biblioteca | Ficha de los libros de la biblioteca |
<ejemplos>/lib/hibernate | |
<ejemplos>/lib/toplink | |
<ejemplos>/lib/spring | |
<ejemplos>/lib/jbossejb3 |