5. Anexos
A continuación describimos la instalación y el uso básico de las herramientas utilizadas en el documento «Persistencia en Java 5: guía práctica». La información que se ofrece a continuación es la disponible en mayo de 2007. Quedará obsoleta en breve. Cuando esto ocurra, se invitará al lector a seguir pasos similares, aunque no idénticos. Las instalaciones se han realizado en un equipo con Windows XP Professional.
5.1. Java
Utilizaremos la última versión de Java disponible en Sun [http://www.sun.com]. Las descargas están disponibles en la URL [http://java.sun.com/javase/downloads/index.jsp]:


Inicie la instalación de JDK desde el archivo descargado. Por defecto, Java se instala en [C:\Program Files\Java]:
5.2. Eclipse
5.2.1. Instalación básica
Eclipse es un IDE disponible en la URL [http://www.eclipse.org/] y se puede descargar desde la URL [http://www.eclipse.org/downloads/]. A continuación descargamos Eclipse 3.2.2:
![]()
Una vez descargado el archivo zip, lo descomprimimos en una carpeta del disco:
A partir de ahora, llamaremos <eclipse> a la carpeta de instalación de Eclipse, que en el ejemplo anterior es [C:\devjava\eclipse 3.2.2\eclipse]. [eclipse.exe] es el ejecutable y [eclipse.ini], su archivo de configuración. Veamos el contenido de este último:
Estos argumentos se utilizan al iniciar Eclipse de la siguiente manera:
Se obtiene el mismo resultado que con el archivo .ini, creando un acceso directo que ejecute Eclipse con estos mismos argumentos. Veamos en qué consisten:
- -vmargs: indica que los argumentos que le siguen están destinados a la máquina virtual Java que ejecutará Eclipse. Eclipse es una aplicación Java.
- -Xms40m: ?
- -Xmx256m: establece el tamaño de memoria en MB asignado a la máquina virtual Java (JVM) que ejecuta Eclipse. Por defecto, este tamaño es de 256 MB, tal y como se muestra aquí. Si el equipo lo permite, es preferible 512 MB.
Estos argumentos se pasan a JVM, que ejecutará Eclipse. JVM está representado por un archivo [java.exe] o [javaw.exe]. ¿Cómo se localiza este archivo? De hecho, se busca de diferentes maneras:
- en el archivo PATH del OS
- en la carpeta <JAVA_HOME>/jre/bin, donde JAVA_HOME es una variable del sistema que define la carpeta raíz de un JDK.
- a una ubicación pasada como argumento a Eclipse en el formato -vm <ruta>\javaw.exe
Esta última solución es preferible, ya que las otras dos están sujetas a los imprevistos de futuras instalaciones de aplicaciones que pueden cambiar tanto el PATH del OS como la variable JAVA_HOME.
Por lo tanto, creamos el siguiente acceso directo:
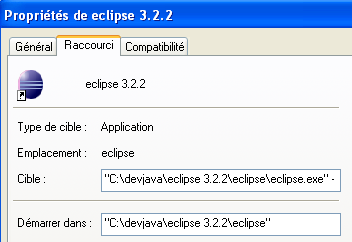
<eclipse>\eclipse.exe" -vm "C:\Archivos de programa\Java\jre1.6.0_01\bin\javaw.exe" -vmargs -Xms40m -Xmx512m | |
carpeta <eclipse> de instalación de Eclipse |
Una vez hecho esto, iniciamos Eclipse mediante este acceso directo. Aparece un primer cuadro de diálogo:
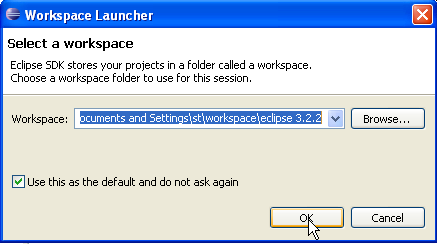
Un [workspace] es un espacio de trabajo. Aceptemos los valores predeterminados propuestos. Por defecto, los proyectos de Eclipse se crearán en la carpeta <workspace> especificada en este cuadro de diálogo. Existe la posibilidad de evitar este comportamiento. Es lo que haremos sistemáticamente. Por lo tanto, la respuesta que se dé a este cuadro de diálogo no es importante.
Una vez superado este paso, se muestra el entorno de desarrollo de Eclipse:
Cerramos la vista [Welcome] tal y como se ha sugerido anteriormente:
Antes de crear un proyecto Java, vamos a configurar Eclipse para indicar que se utilice JDK para compilar los proyectos Java. Para ello, seleccionamos la opción [Window / Preferences / Java / Installed JREs ]:
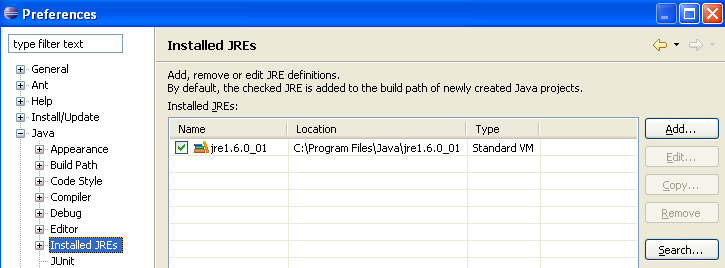
Normalmente, el JRE (Java Runtime Environment) que se ha utilizado para iniciar el propio Eclipse debe aparecer en la lista de JRE. Normalmente, este será el único. Es posible añadir JRE mediante el botón [Add]. Para ello, hay que indicar la ruta raíz del JRE. Por su parte, el botón [Search] iniciará una búsqueda de JREs en el disco. Es una buena forma de saber en qué punto nos encontramos con los JREs que instalamos y luego nos olvidamos de desinstalar al pasar a una versión más reciente. En la imagen anterior, el JRE marcado es el que se utilizará para compilar y ejecutar los proyectos Java. Es el que se instaló en el apartado 5.1 y que también se utilizó para iniciar Eclipse. Al hacer doble clic sobre él, se accede a sus propiedades:
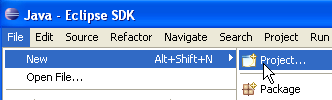
Ahora, creemos un proyecto Java [File / New / Project]:
 | 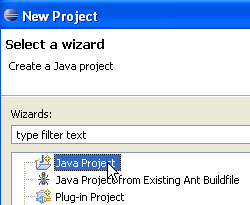 |
Selecciona [Java Project] y, a continuación, [Next] ->
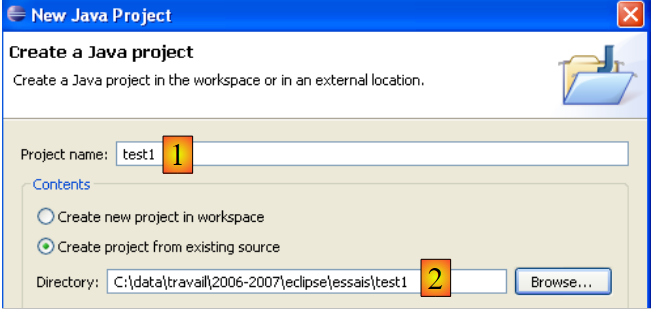
En [2], indicamos una carpeta vacía en la que se instalará el proyecto Java. En [1], le damos un nombre al proyecto. No es necesario que el nombre del proyecto coincida con el de la carpeta, como podría sugerir el ejemplo anterior. Una vez hecho esto, utilizamos el botón [Next] para pasar a la siguiente página del asistente de creación:
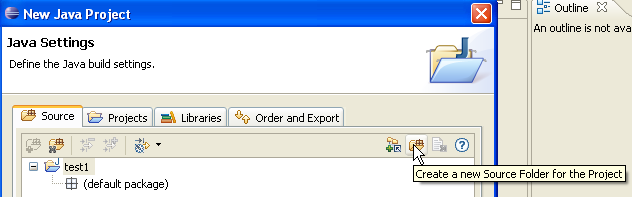
En la imagen anterior, creamos una carpeta especial dentro del proyecto para almacenar los archivos fuente (.java):
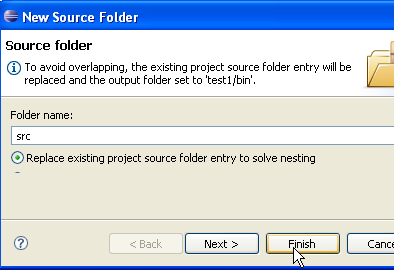
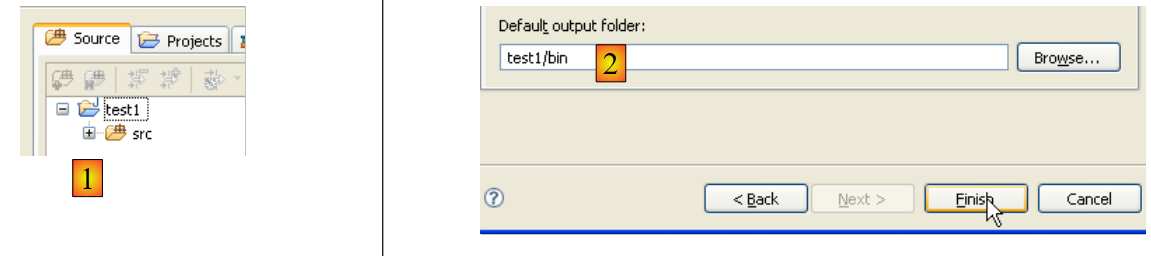 |
- En [1], vemos la carpeta [src], en la que se guardarán los archivos fuente .java
- En [2], vemos la carpeta [bin], en la que se guardarán los archivos compilados .class
Terminamos el asistente con [Finish]. De este modo, obtenemos un esqueleto de proyecto Java:
Hacemos clic con el botón derecho del ratón sobre el proyecto [test1] para crear una clase Java:
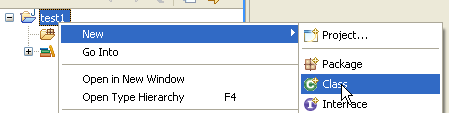
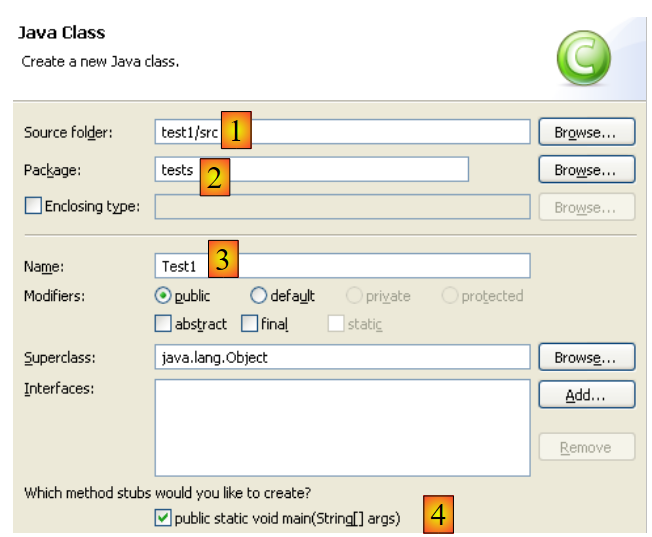 |
- en [1], la carpeta donde se creará la clase. Eclipse propone por defecto la carpeta del proyecto actual.
- en [2], el paquete en el que se colocará la clase
- en [3], el nombre de la clase
- en [4], solicitamos que se genere el método estático [main]
Confirmamos el asistente mediante [Finish]. A continuación, el proyecto se amplía con una clase:
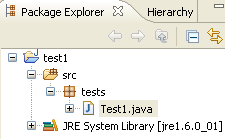
Eclipse ha generado el esqueleto de la clase. Se puede acceder a él haciendo doble clic en [Test1.java], como se muestra arriba:
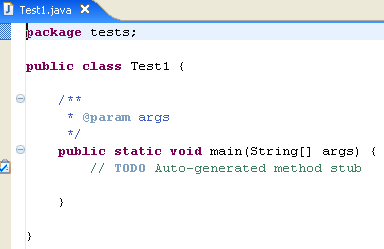
Modificamos el código anterior de la siguiente manera:
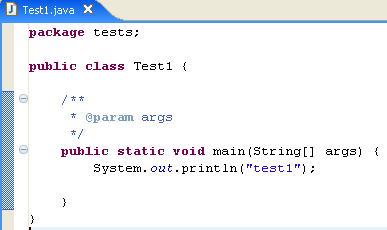
Ejecutamos el programa [Test1.java]: [clic droit sur Test1.java -> Run As -> Java Application]
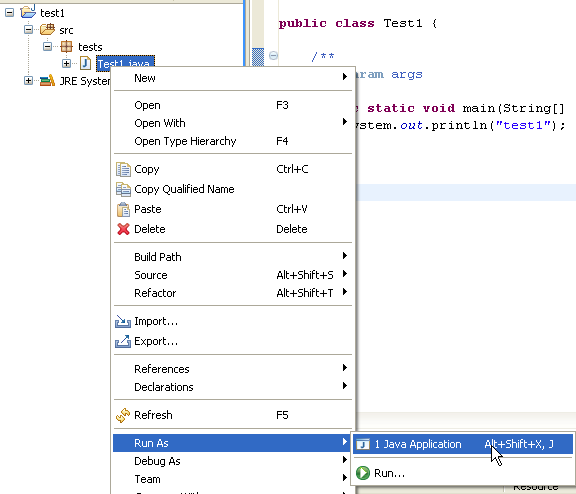
El resultado de la ejecución se muestra en la ventana [Console]:
La ventana [Console] debería aparecer por defecto. Si no fuera así, se puede solicitar su visualización mediante [Window/Show View/Console]:
5.2.2. Elección del compilador
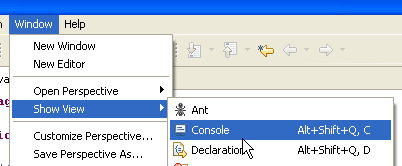
Eclipse permite generar código compatible con Java 1.4, Java 1.5 y Java 1.6. Por defecto, está configurado para generar código compatible con Java 1.4. El API JPA requiere código Java 1.5. Cambiamos el tipo de código generado por [Window / Preferences / Java / Compiler]:
 |
- a [1]: selección de la opción [Java / Compiler]
- a [2]: selección de la compatibilidad con Java 5.0
5.2.3. Instalación de los complementos de Callisto
La versión básica instalada anteriormente permite crear aplicaciones Java de consola, pero no aplicaciones Java de tipo web o Swing; de lo contrario, hay que hacerlo todo uno mismo. Vamos a instalar varios complementos:
Procedamos de la siguiente manera [Help/Software Udates/Find and Install]:
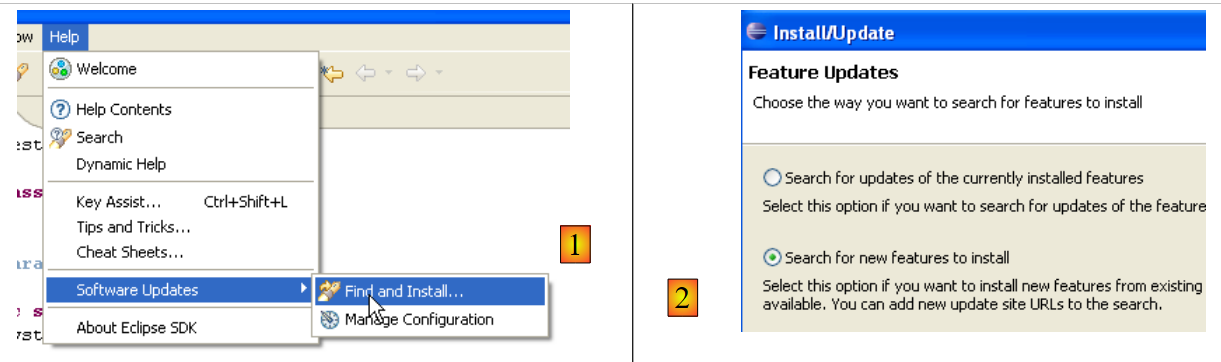 |
- En [2], indicamos que queremos instalar nuevos complementos
 |
- en [3], se indican los sitios que hay que explorar para encontrar los complementos
- En [4], se marcan los complementos deseados
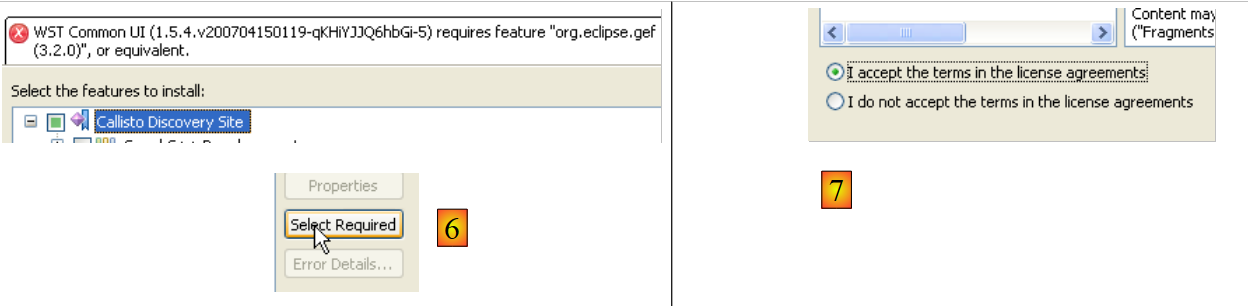 |
- En [5], Eclipse indica que se ha seleccionado un complemento que depende de otros complementos que no se han seleccionado
- en [6], se utiliza el botón [Select Required] para seleccionar automáticamente los complementos que faltan
- en [7], se aceptan las condiciones de las licencias de estos distintos complementos
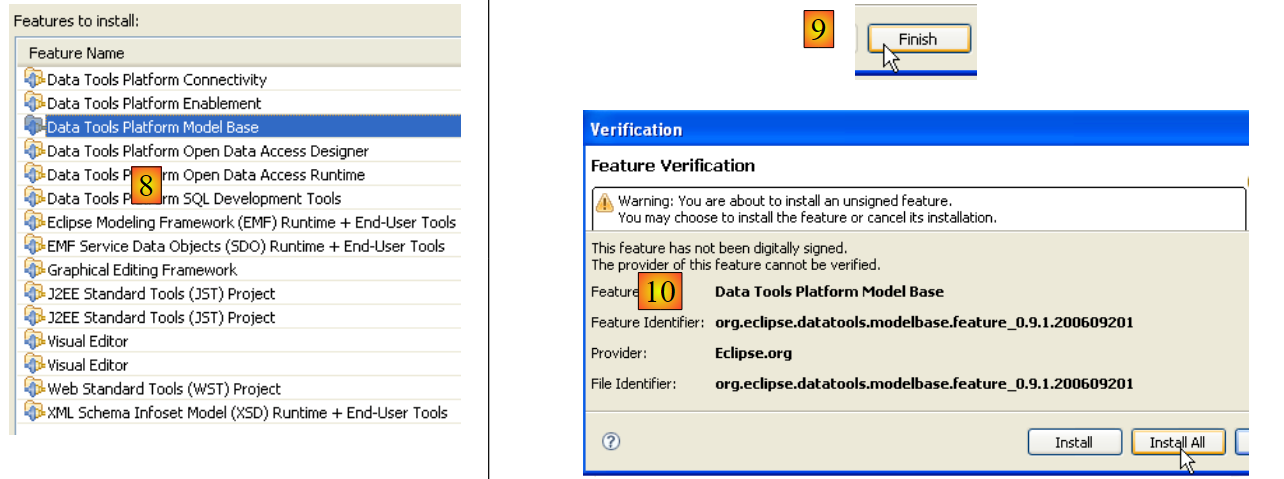 |
- En [8], aparece la lista de todos los complementos que se van a instalar
- en [9], se inicia la descarga de estos complementos
- en [10], una vez descargados, se instalan todos sin comprobar su firma
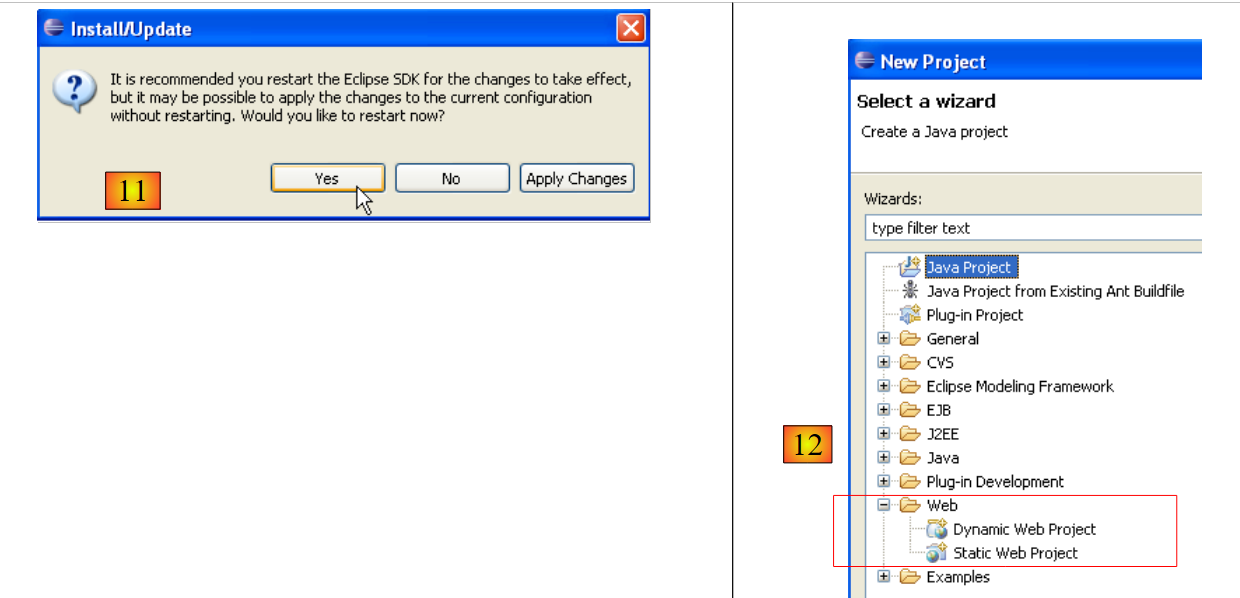 |
- en [11], al finalizar la instalación de los complementos, se deja que Eclipse se reinicie
- en [12], si se ejecuta [File/New/Project], se comprueba que ahora se pueden crear aplicaciones web, lo que inicialmente no era posible.
5.2.4. Instalación del complemento [TestNG]
TestNG (Test Next Generation) es una herramienta de pruebas unitarias similar en su concepto a JUnit. Sin embargo, aporta mejoras que hacen que aquí la prefiramos a JUnit. Procedemos como anteriormente: [Help/Software Udates/Find and Install]:
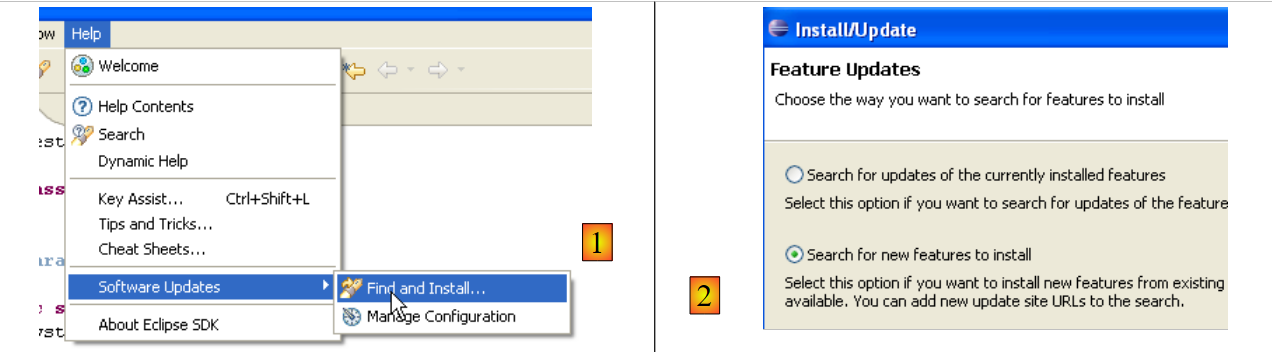 |
- En [2], se indica que se quieren instalar nuevos complementos
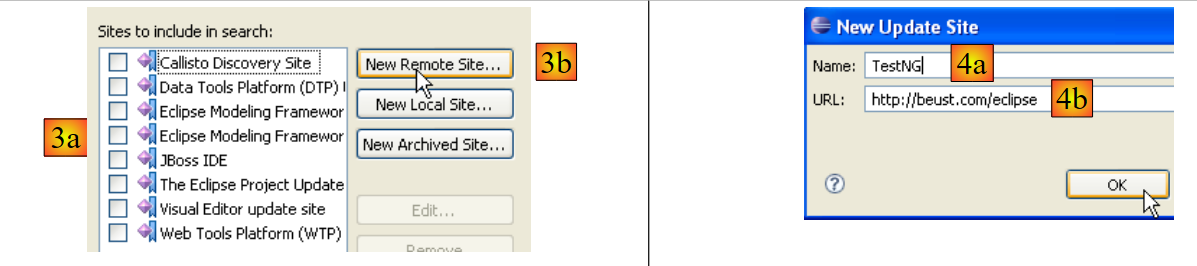 |
- En [3a], no aparece el sitio de descarga de [TestNG]. Lo añadimos con [3b]
- en [4b]: la página del plugin es [http://beust.com/eclipse]. En [4a], se introduce lo que se desee.
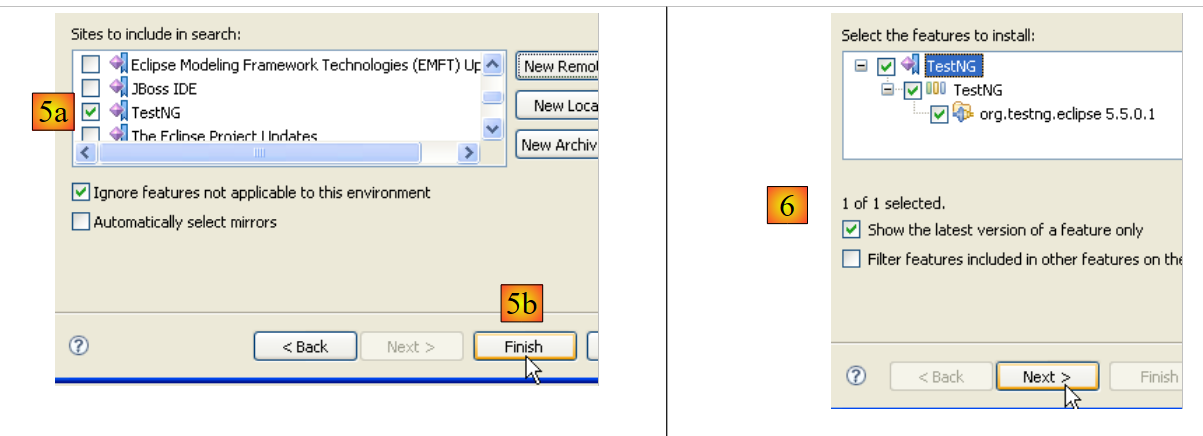 |
- En [5a], se selecciona el plugin [TestNG] para la actualización. En [5b], se inicia la actualización.
- En [6], se ha establecido la conexión con la página web del complemento. Se nos muestran todos los complementos disponibles en la página web. En este caso, solo hay uno, que seleccionamos antes de pasar al siguiente paso.
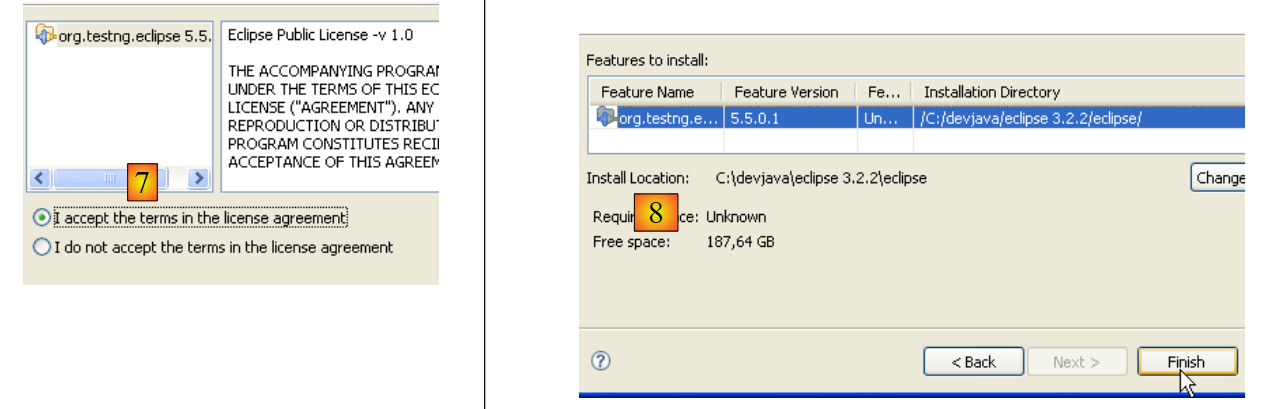 |
- En [7], aceptamos las condiciones de las licencias del complemento
- en [8], aparece la lista de todos los complementos que se van a instalar; aquí hay uno. Iniciamos la descarga. A continuación, todo transcurre tal y como se ha descrito anteriormente para los complementos de Callisto.
Una vez reiniciado Eclipse, se puede comprobar la presencia del nuevo complemento solicitando, por ejemplo, ver las vistas disponibles [Window / show View / Other]:
 |
Como vemos arriba, existe una vista [TestNG] que antes no existía.
5.2.5. Instalación del complemento [Hibernate Tools]
Hibernate es un proveedor JPA y el complemento [Hibernate Tools] para Eclipse resulta útil a la hora de desarrollar aplicaciones JPA. En mayo de 2007, solo su última versión (3.2.0beta9) permite trabajar con Hibernate/JPA y no está disponible a través del mecanismo que acabamos de describir. Solo lo están las versiones anteriores. Por lo tanto, procederemos de otra manera.
El complemento está disponible en la página web de Hibernate Tools: http://tools.hibernate.org/.
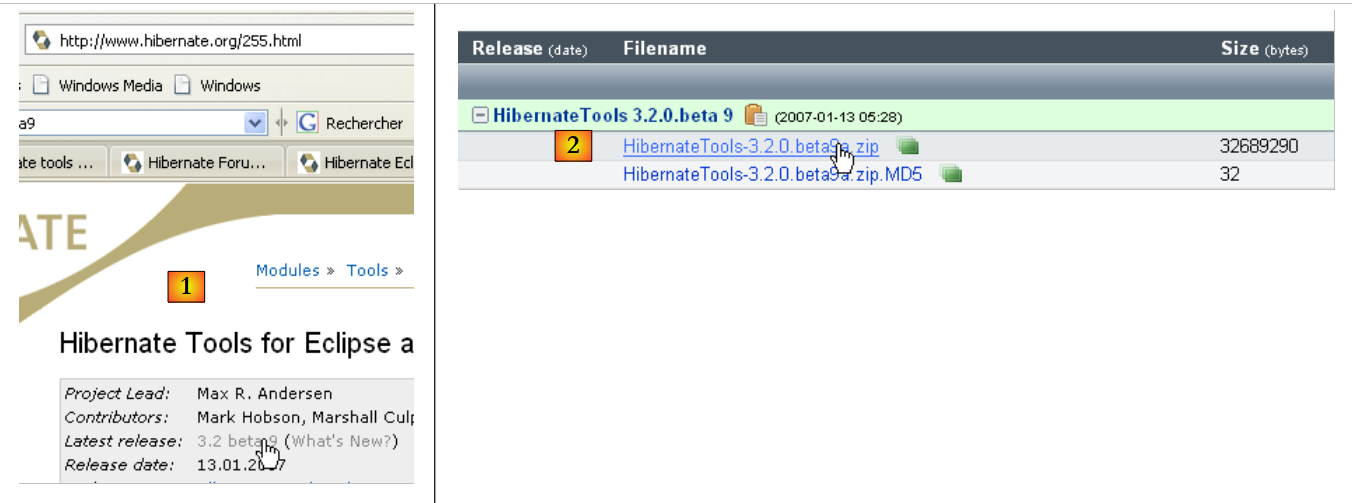 |
- en [1], seleccionamos la última versión de Hibernate Tools
- en [2], la descargamos
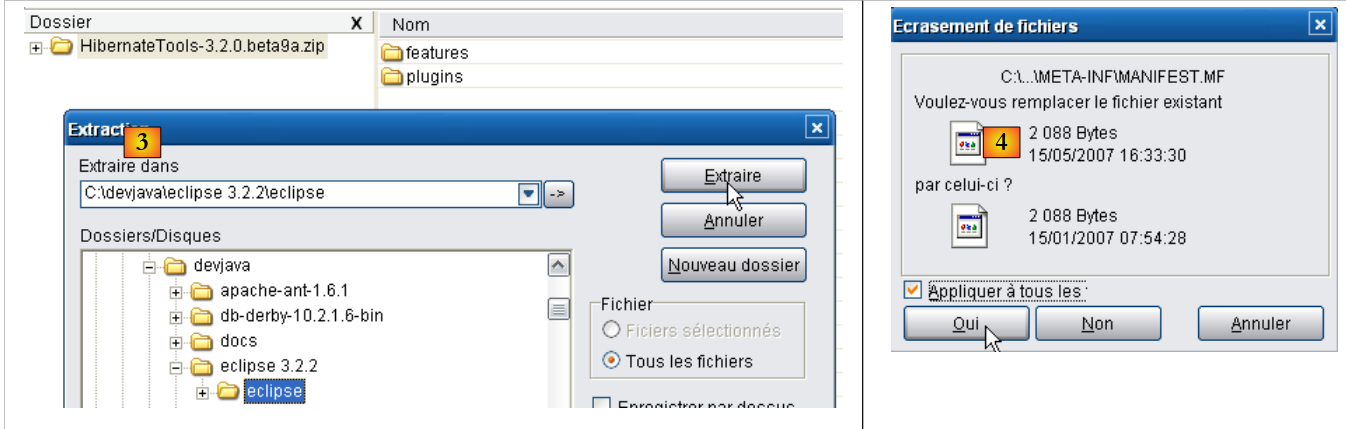 |
- en [3], con un programa de descompresión, descomprimimos en la carpeta <eclipse> el archivo zip descargado (es preferible que Eclipse no esté activo)
- en [4], se acepta que algunos archivos se sobrescriban durante la operación
Reiniciamos Eclipse:
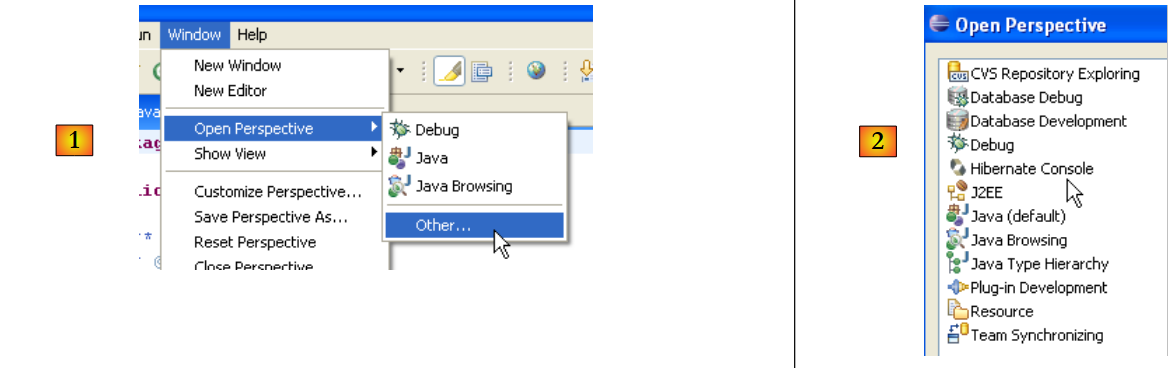 |
- En [1]: se abre una perspectiva
- en [2]: ahora existe una perspectiva [Hibernate Console]
No seguiremos adelante con el complemento [Hibernate Tools] (Cancel en [2]). Su modo de uso se explica en los ejemplos del tutorial.
A veces, Eclipse no detecta la presencia de nuevos complementos. Se le puede obligar a volver a escanear todos sus complementos con la opción -clean. De este modo, el ejecutable del acceso directo de Eclipse se modificaría de la siguiente manera:
"<eclipse>\eclipse.exe" -clean -vm "C:\Program Files\Java\jre1.6.0_01\bin\javaw.exe" -vmargs -Xms40m -Xmx512m
Una vez que Eclipse haya detectado los nuevos complementos, se eliminará la opción -clean anterior.
5.2.6. Instalación del complemento [SQL Explorer]
Ahora vamos a instalar un complemento que nos permitirá explorar el contenido de una base de datos directamente desde Eclipse. Los complementos disponibles para Eclipse se pueden encontrar en la página web [http://eclipse-plugins.2y.net/eclipse/plugins.jsp]:
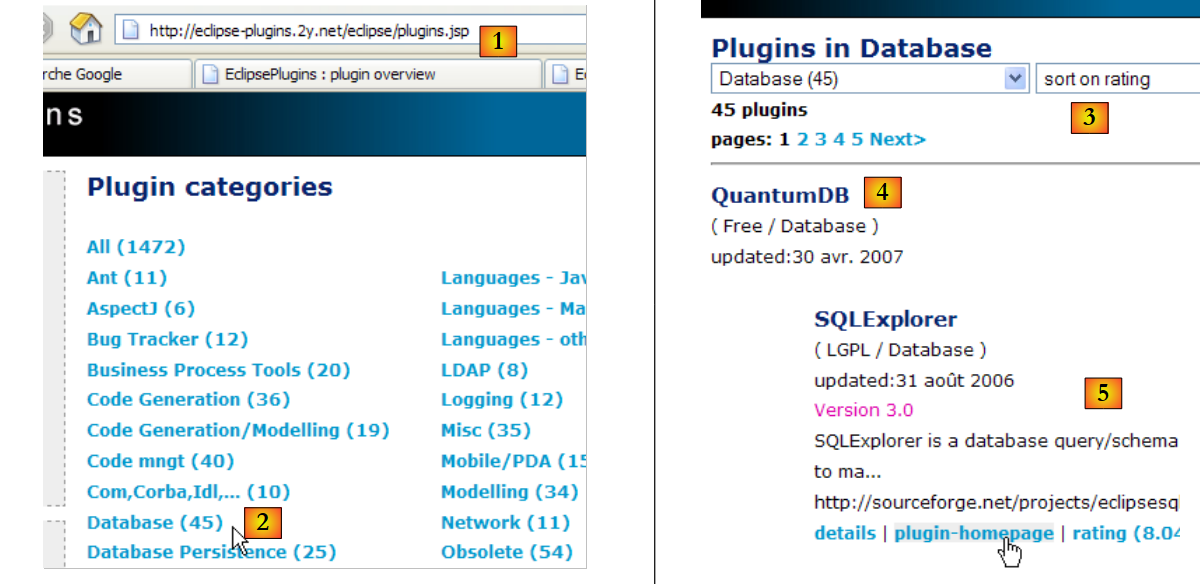 |
- en [1]: el sitio web de los complementos de Eclipse
- en [2]: selecciona la categoría [Database]
- en [3]: en la categoría [Database], elegir la visualización por clasificación (poco fiable, dado el escaso número de personas que votan)
- en [4]: QuantumDB ocupa la primera posición
- en [5]: elegimos SQLExplorer, más antiguo, peor valorado (3.º) pero muy bueno de todos modos. Vamos a la página web del plugin [plugin-homepage]
 |
- en [6] y [7]: procedemos a descargar el plugin.
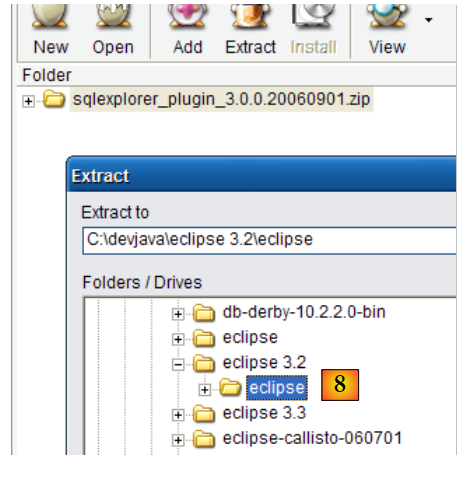 |
- en [8]: descomprimimos el archivo zip del complemento en la carpeta de Eclipse.
Para comprobarlo, reinicia Eclipse, si es necesario con la opción -clean:
 |
- en [1]: abre una nueva perspectiva
- en [2]: se ve que hay una perspectiva [SQL Explorer] disponible. Volveremos sobre ella más adelante.
5.3. El contenedor de servlets Tomcat 5.5
5.3.1. Instalación
Para ejecutar servlets, necesitamos un contenedor de servlets. Aquí presentamos uno de ellos, Tomcat 5.5, disponible en la URL http://tomcat.apache.org/. A continuación indicamos los pasos (mayo de 2007) para instalarlo. Si ya hay instalada una versión anterior de Tomcat, es preferible desinstalarla antes.

Para descargar el producto, siga el enlace [Tomcat 5.x] que aparece más arriba:

Se puede descargar el archivo .exe destinado a la plataforma Windows. Una vez descargado, se inicia la instalación de Tomcat haciendo doble clic sobre él:
Acepta las condiciones de la licencia ->
Hacer [next] ->
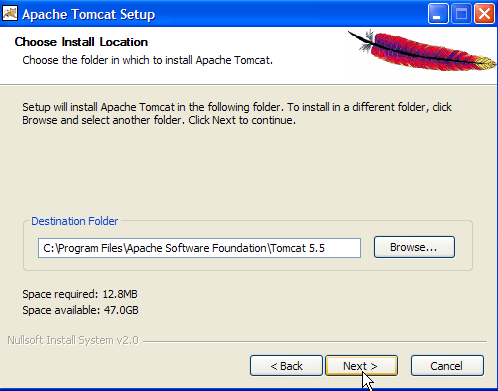
Aceptar la carpeta de instalación propuesta o cambiarla con [Browse] ->
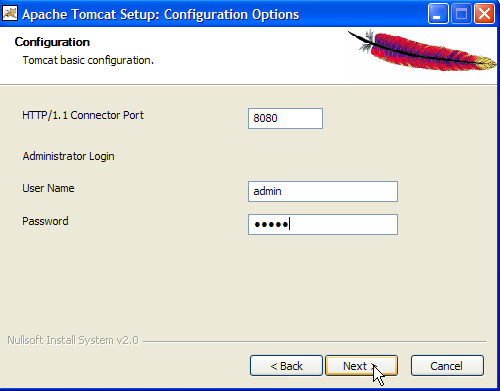
Establecer el nombre de usuario y la contraseña del administrador del servidor Tomcat. Aquí se ha introducido [admin / admin] ->
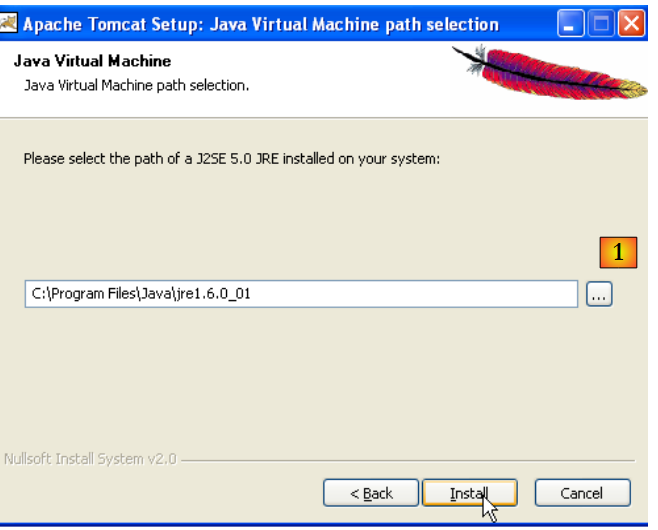 |
Tomcat 5.x necesita un JRE 1.5. Normalmente debería encontrar el que está instalado en tu equipo. Arriba, la ruta indicada es la del JRE 1.6 descargado en el apartado 5.1. Si no se encuentra ningún JRE, especifica su directorio raíz utilizando el botón [1]. Una vez hecho esto, utiliza el botón [Install] para instalar Tomcat 5.x ->
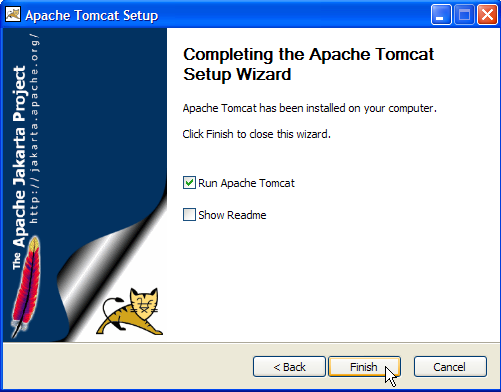
El botón [Finish] finaliza la instalación. La presencia de Tomcat se indica mediante un icono situado a la derecha en la barra de tareas de Windows:
Al hacer clic con el botón derecho del ratón sobre este icono, se accede a los comandos de inicio y parada del servidor:
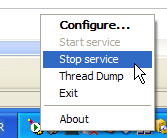
Utilizamos la opción [Stop service] para detener ahora el servidor web:
Obsérvese el cambio de estado del icono. Este se puede eliminar de la barra de tareas:
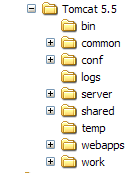
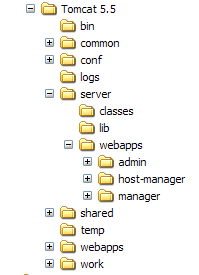
La instalación de Tomcat se ha realizado en la carpeta elegida por el usuario, a la que a partir de ahora llamaremos <tomcat>. La estructura de esta carpeta para la versión Tomcat 5.5.23 descargada es la siguiente:
La instalación de Tomcat ha añadido varios accesos directos al menú [Démarrer]. Utilizamos el enlace [Monitor] que aparece a continuación para iniciar la herramienta de parada/inicio de Tomcat:
A continuación, vemos el icono que se ha mostrado anteriormente:
El monitor de Tomcat se puede activar haciendo doble clic en este icono:
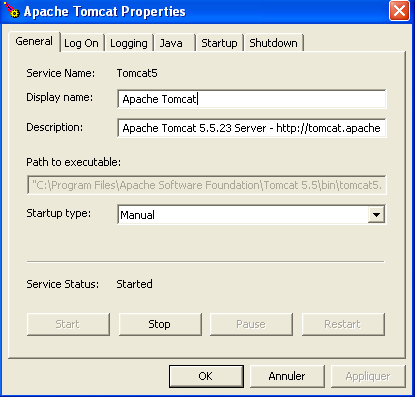
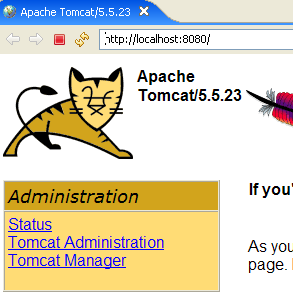
Los botones [Start - Stop - Pause] - Restart nos permiten iniciar, detener y reiniciar el servidor. Iniciamos el servidor mediante [Start] y, a continuación, desde un navegador, accedemos a la URL http://localhost:8080. Deberíamos obtener una página similar a la siguiente:
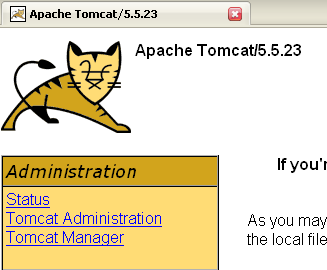
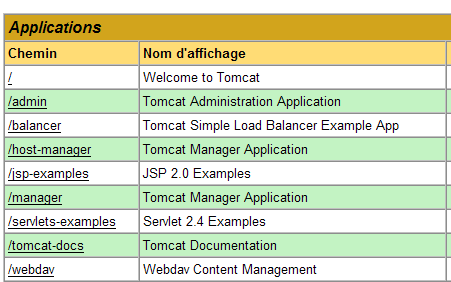
Podemos seguir los enlaces que aparecen a continuación para comprobar que Tomcat se ha instalado correctamente:

Todos los enlaces de la página [http://localhost:8080] son de interés y se invita al lector a explorarlos. Tendremos ocasión de volver sobre los enlaces que permiten gestionar las aplicaciones web desplegadas en el servidor:

5.3.2. Despliegue de una aplicación web en el servidor Tomcat
5.3.3. Despliegue
Una aplicación web debe cumplir ciertas reglas para poder implementarse en un contenedor de servlets. Supongamos que <webapp> es la carpeta de una aplicación web. Una aplicación web se compone de:
en la carpeta <webapp>\WEB-INF\classes | |
en la carpeta <webapp>\WEB-INF\lib | |
en la carpeta <webapp> o en sus subcarpetas |
La aplicación web se configura mediante un archivo XML: <webapp>\WEB-INF\web.xml. Este archivo no es necesario en casos sencillos, especialmente cuando la aplicación web solo contiene archivos estáticos. Creemos el siguiente archivo HTML:
<html>
<head>
<title>Application exemple</title>
</head>
<body>
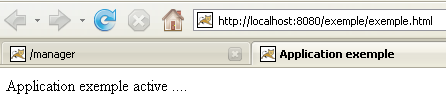
Application exemple active ....
</body>
</html>
y guardémoslo en una carpeta:
Si cargamos este archivo en un navegador, obtenemos la siguiente página:

El código URL que muestra el navegador indica que la página no ha sido servida por un servidor web, sino que el navegador la ha cargado directamente. Ahora queremos que esté disponible a través del servidor web Tomcat.
Volvamos a la estructura de directorios de <tomcat>:
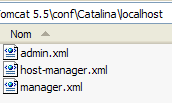
La configuración de las aplicaciones web desplegadas en el servidor Tomcat se realiza mediante los archivos XML ubicados en la carpeta [<tomcat>\conf\Catalina\localhost]:
 |  |
Estos archivos XML se pueden crear manualmente, ya que su estructura es sencilla. En lugar de seguir este procedimiento, utilizaremos las herramientas web que nos ofrece Tomcat.
5.3.4. Administración de Tomcat
En su página de inicio http://localhost:8080, el servidor nos ofrece enlaces para administrarlo:

El enlace [Tomcat Administration] nos permite configurar los recursos que Tomcat pone a disposición de las aplicaciones web desplegadas en él, por ejemplo, un grupo de conexiones a una base de datos. Sigamos el enlace:

La página que aparece nos indica que la administración de Tomcat 5.x requiere un paquete específico denominado «admin». Volvamos al sitio web de Tomcat [http://tomcat.apache.org/download-55.cgi]:
Descarguemos el archivo zip denominado [Administration Web Application] y descomprimámoslo. Su contenido es el siguiente:
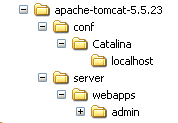
La carpeta [admin] debe copiarse en [<tomcat>\server\webapps], donde <tomcat> es la carpeta en la que se ha instalado Tomcat 5.x:
La carpeta [localhost] contiene un archivo [admin.xml] que debe copiarse en [<tomcat>\conf\Catalina\localhost]:
Detengamos y reiniciemos Tomcat si estaba activo. A continuación, con un navegador, volvamos a acceder a la página de inicio del servidor web:

Sigamos el enlace [Tomcat Administration]. Aparece una página de inicio de sesión (para que se cargue, puede que haya que «actualizar» la página):
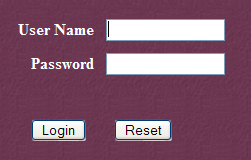 | 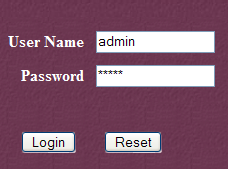 |
Aquí hay que volver a introducir los datos que proporcionamos durante la instalación de Tomcat. En nuestro caso, introducimos el nombre de usuario y la contraseña «admin / admin». El botón [Login] nos lleva a la siguiente página:
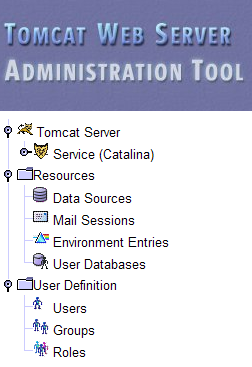
Esta página permite al administrador de Tomcat definir
- fuentes de datos (Data Sources),
- la información necesaria para el envío de correo (Mail Sessions),
- los datos de entorno accesibles para todas las aplicaciones (Environment Entries),
- gestionar los usuarios y administradores de Tomcat (Users),
- gestionar grupos de usuarios (Groups),
- definir roles (= lo que un usuario puede o no puede hacer),
- definir las características de las aplicaciones web desplegadas por el servidor (Service Catalina)
Sigamos el enlace [Roles] anterior:
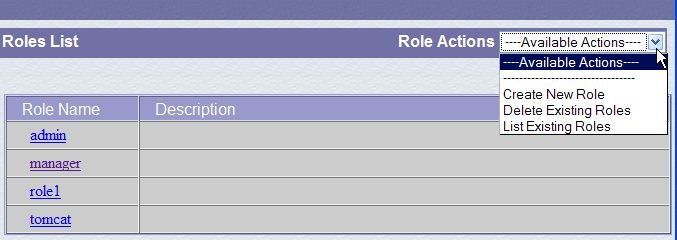
Un rol permite definir lo que un usuario o un grupo de usuarios puede o no puede hacer. A cada rol se le asignan determinados derechos. Cada usuario está asociado a uno o varios roles y dispone de los derechos de los mismos. El rol [manager] que se muestra a continuación otorga el derecho a gestionar las aplicaciones web desplegadas en Tomcat (despliegue, inicio, parada, descarga). Vamos a crear un usuario [manager] al que asociaremos el rol [manager] para que pueda gestionar las aplicaciones de Tomcat. Para ello, seguimos el enlace [Users] de la página de administración:
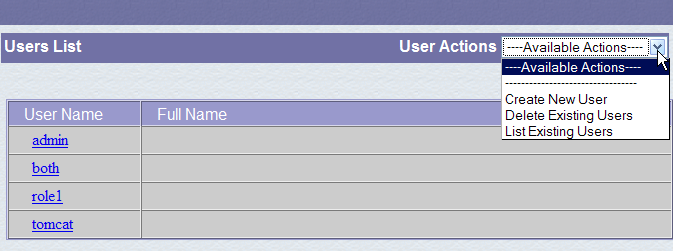
Vemos que ya existen varios usuarios. Utilizamos la opción [Create New User] para crear un nuevo usuario:
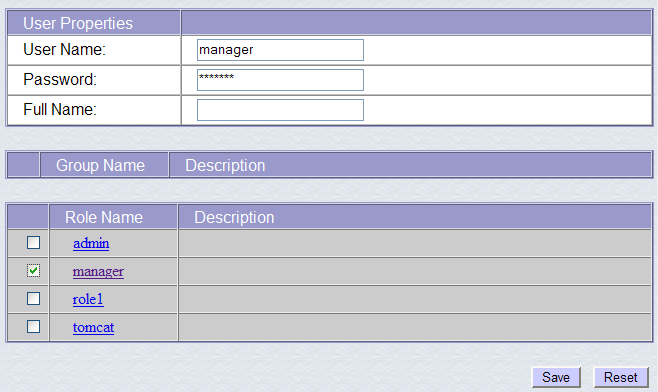
Le asignamos al usuario «manager» la contraseña «manager» y le asignamos el rol «manager». Utilizamos el botón [Save] para validar esta incorporación. El nuevo usuario aparece en la lista de usuarios:
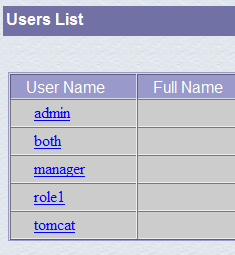
Este nuevo usuario se añadirá al archivo [<tomcat>\conf\tomcat-users.xml]:
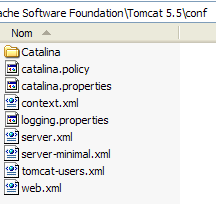
cuyo contenido es el siguiente:
<?xml version='1.0' encoding='utf-8'?>
<tomcat-users>
<role rolename="tomcat"/>
<role rolename="role1"/>
<role rolename="manager"/>
<role rolename="admin"/>
<user username="tomcat" password="tomcat" roles="tomcat"/>
<user username="role1" password="tomcat" roles="role1"/>
<user username="both" password="tomcat" roles="tomcat,role1"/>
<user username="manager" password="manager" fullName="" roles="manager"/>
<user username="admin" password="admin" roles="admin,manager"/>
</tomcat-users>
- línea 10: el usuario [manager] que se ha creado
Otra forma de añadir usuarios es modificar directamente este archivo. Este es el procedimiento que hay que seguir, sobre todo, si por casualidad se ha olvidado la contraseña del administrador «admin» o del «manager».
5.3.5. Gestión de las aplicaciones web implementadas
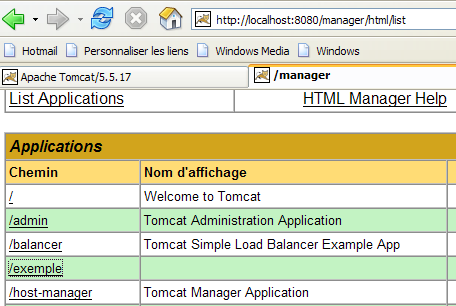
Volvamos ahora a la página de inicio [http://localhost:8080] y sigamos el enlace [Tomcat Manager]:

A continuación, aparece una página de autenticación. Iniciamos sesión como «manager / manager», c.a.d, el usuario con el rol [manager] que acabamos de crear. De hecho, solo un usuario con este rol puede utilizar este enlace. En la línea 11 de [tomcat-users.xml], vemos que el usuario [admin] también tiene el rol [manager]. Por lo tanto, también podríamos utilizar la autenticación [admin / admin].
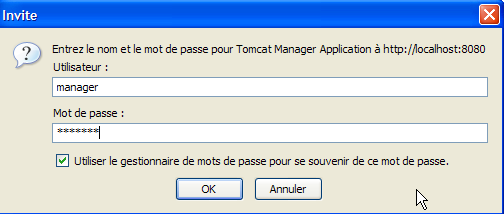
Aparece una página con la lista de aplicaciones actualmente desplegadas en Tomcat:
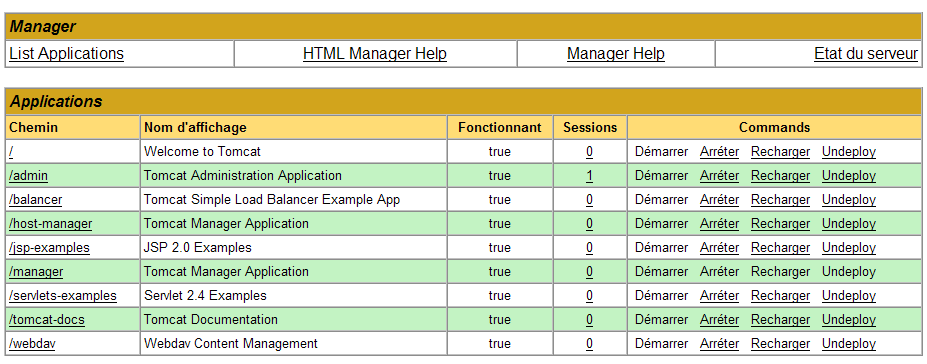
Podemos añadir una nueva aplicación mediante los formularios que se encuentran al final de la página:
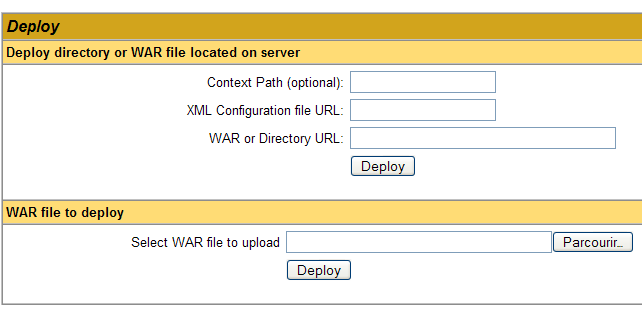
En este caso, queremos implementar en Tomcat la aplicación de ejemplo que hemos creado anteriormente. Lo hacemos de la siguiente manera:
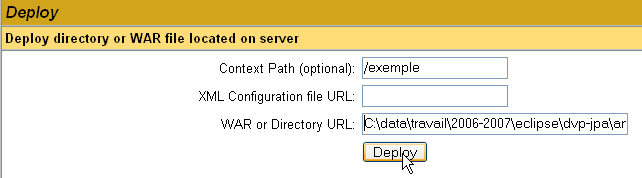
/ejemplo | el nombre utilizado para designar la aplicación web que se va a implementar | |
C:\data\trabajo\2006-2007\eclipse\dvp-jpa\anexos\tomcat\ejemplo | la carpeta de la aplicación web |
Para obtener el archivo [C:\data\travail\2006-2007\eclipse\dvp-jpa\annexes\tomcat\exemple\exemple.html], le pediremos a Tomcat el URL y el [http://localhost:8080/exemple/exemple.html]. El contexto sirve para asignar un nombre a la raíz del árbol de la aplicación web desplegada. Utilizamos el botón [Deploy] para llevar a cabo el despliegue de la aplicación. Si todo va bien, obtendremos la siguiente página de respuesta:

y la nueva aplicación aparece en la lista de aplicaciones desplegadas:
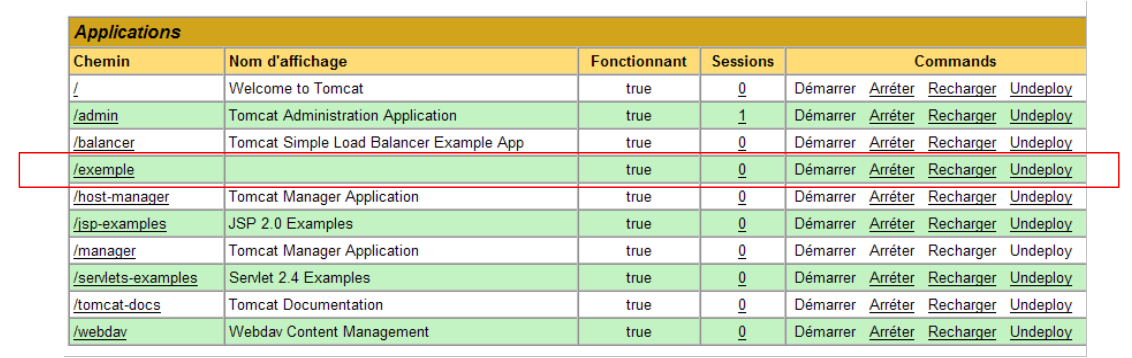 |
Comentemos la línea del contexto /ejemplo anterior:
enlace a http://localhost:8080/exemple | |
permite iniciar la aplicación | |
permite cerrar la aplicación | |
permite recargar la aplicación. Esto es necesario, por ejemplo, cuando se han añadido, modificado o eliminado determinadas clases de la aplicación. | |
Eliminación del contexto [/exemple]. La aplicación desaparece de la lista de aplicaciones disponibles. |
Ahora que nuestra aplicación /ejemplo está implementada, podemos realizar algunas pruebas. Accedemos a la página [exemple.html] a través de la URL [http://localhost:8080/exemple/vues/exemple.html]:
Otra forma de implementar una aplicación web en el servidor Tomcat es introducir la información que hemos proporcionado a través de la interfaz web en un archivo [contexte].xml ubicado en la carpeta [<tomcat>\conf\Catalina\localhost], donde [contexte] es el nombre de la aplicación web.
Volvamos a la interfaz de administración de Tomcat:

Eliminemos la aplicación [/exemple] junto con su enlace [Undeploy]:
La aplicación [/exemple] ya no forma parte de la lista de aplicaciones activas. Ahora definamos el siguiente archivo [exemple.xml]:
El archivo XML consta de una única etiqueta <Context> cuyo atributo docBase define la carpeta que contiene la aplicación web que se va a implementar. Coloquemos este archivo en <tomcat>\conf\Catalina\localhost:
Detengamos y reiniciemos Tomcat si es necesario y, a continuación, veamos la lista de aplicaciones activas con el administrador de Tomcat:
La aplicación [/exemple] aparece correctamente. Accedamos, con un navegador, a la URL:
[http://localhost:8080/exemple/exemple.html]:
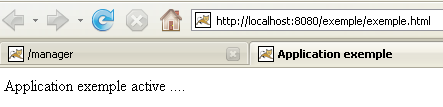
Una aplicación web desplegada de este modo puede eliminarse de la lista de aplicaciones desplegadas, del mismo modo que antes, mediante el enlace [Undeploy]:
En este caso, el archivo [exemple.xml] se elimina automáticamente de la carpeta [<tomcat>\conf\Catalina\localhost].
Por último, para desplegar una aplicación web en Tomcat, también se puede definir su contexto en el archivo [<tomcat>\conf\server.xml]. No profundizaremos en este punto aquí.
5.3.6. Aplicación web con página de inicio
Cuando solicitamos la URL [http://localhost:8080/exemple/], obtenemos la siguiente respuesta:
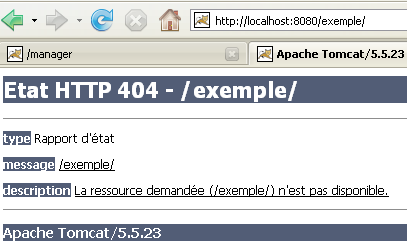
Con algunas versiones anteriores de Tomcat, habríamos obtenido el contenido de la carpeta física de la aplicación [/exemple].
Podemos hacer que, cuando se solicite el contexto, se muestre una página denominada «página de inicio». Para ello, creamos un archivo [web.xml] que colocamos en la carpeta <ejemplo>\WEB-INF, donde <ejemplo> es la carpeta física de la aplicación web [/exemple]. Este archivo es el siguiente:
- líneas 2-5: la etiqueta raíz <web-app> con los atributos obtenidos al copiar y pegar del archivo [web.xml] de la aplicación [/admin] de Tomcat (<tomcat>/server/webapps/admin/WEB-INF/web.xml).
- línea 7: el nombre de visualización de la aplicación web. Se trata de un nombre libre que tiene menos restricciones que el nombre de contexto de la aplicación. Se pueden incluir espacios, por ejemplo, lo cual no es posible con el nombre de contexto. Este nombre lo muestra, por ejemplo, el administrador de Tomcat:

- línea 8: descripción de la aplicación web. Este texto se puede obtener posteriormente mediante programación.
- líneas 9-11: la lista de archivos de bienvenida. La etiqueta <welcome-file-list> sirve para definir la lista de vistas que se mostrarán cuando un cliente solicite el contexto de la aplicación. Puede haber varias vistas. Se muestra al cliente la primera que se encuentre. En este caso solo tenemos una: [/exemple.html]. Así, cuando un cliente solicite la URL [/exemple], lo que se le proporcionará en realidad será la URL [/exemple/exemple.html].
Guardemos este archivo [web.xml] en <ejemplo>\WEB-INF:
Si Tomcat sigue activo, es posible forzar que recargue la aplicación web [/exemple] con el enlace [Recharger]:

Durante esta operación de «recarga», Tomcat vuelve a leer el archivo [web.xml] contenido en [<exemple>\WEB-INF], si existe. Este será el caso aquí. Si Tomcat se hubiera detenido, reinícialo.
Con un navegador, solicitemos el archivo URL y [http://localhost:8080/exemple/]:
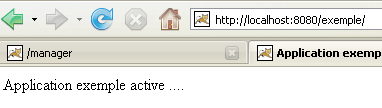
El mecanismo de los archivos de bienvenida ha funcionado.
5.3.7. Integración de Tomcat en Eclipse
Ahora vamos a integrar Tomcat en Eclipse. Esta integración permite:
- iniciar y detener Tomcat desde Eclipse
- desarrollar aplicaciones web en Java y ejecutarlas en Tomcat. La integración entre Eclipse y Tomcat permite depurar la ejecución de la aplicación, incluida la ejecución de las clases Java (servlets) ejecutadas por Tomcat.
Iniciemos Eclipse y, a continuación, veamos la vista [Servers]:
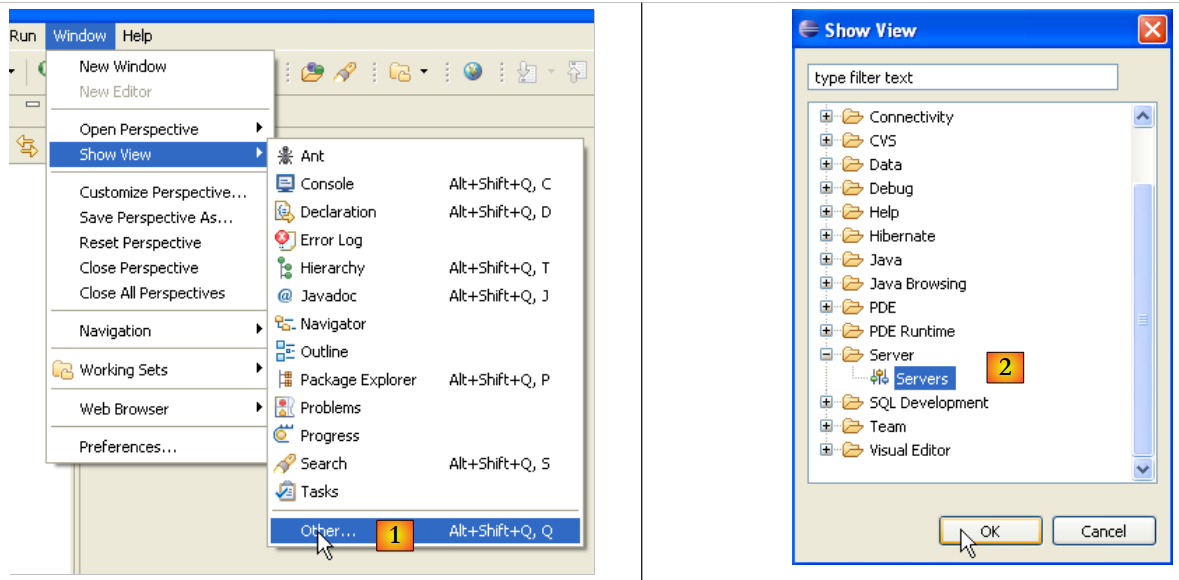 |
- en [1]: Window/Show View/Other
- en [2]: selecciona la vista [Servers] y haz [OK]
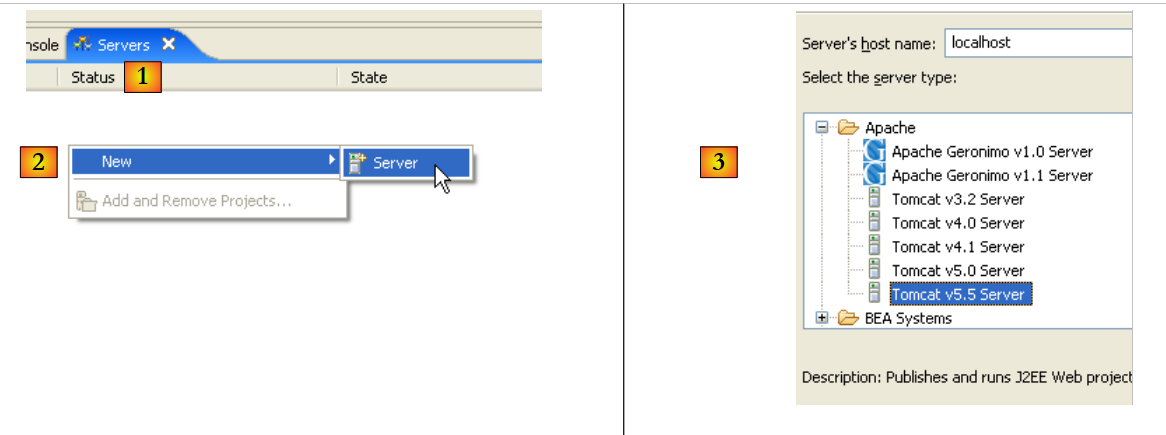 |
- en [1], aparece una nueva vista [Servers]
- en [2], hacemos clic con el botón derecho del ratón sobre la vista y solicitamos crear un nuevo servidor [New/Server]
- en [3], se selecciona el servidor [Tomcat 5.5] y, a continuación, se crea [Next]
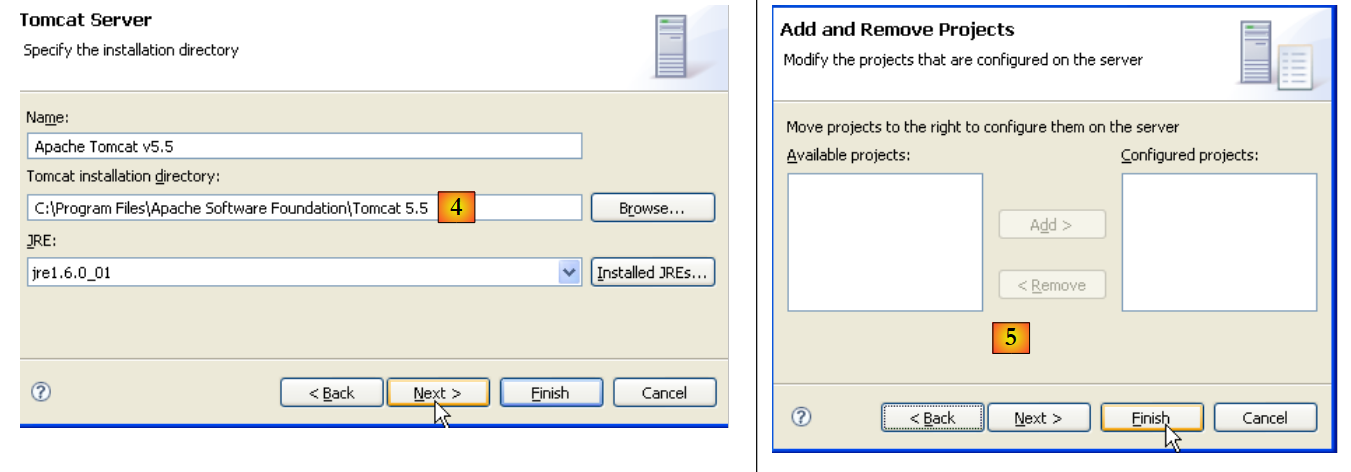 |
- en [4], se indica la carpeta de instalación de Tomcat 5.5
- en [5], se indica que, por el momento, no hay proyectos de Eclipse/Tomcat. Se ejecuta [Finish]
La incorporación del servidor se materializa con la adición de una carpeta en el explorador de proyectos de Eclipse [6] y la aparición de un servidor en la vista [servers] [7]:
 |
En la vista [Servers] aparecen todos los servidores declarados; en este caso, únicamente el servidor Tomcat 5.5 que acabamos de registrar. Al hacer clic con el botón derecho del ratón sobre él, se accede a los comandos que permiten iniciar, detener y reiniciar el servidor:
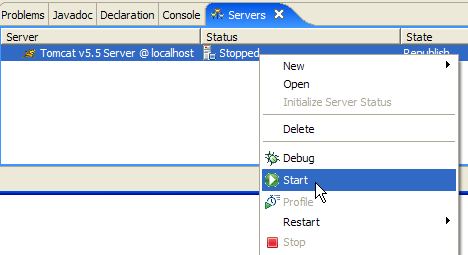
En el ejemplo anterior, iniciamos el servidor. Al iniciarse, se registran varios mensajes de log en la vista [Console]:
Entender estos registros requiere cierta práctica. Por el momento, no nos detendremos en ellos. Sin embargo, es importante comprobar que no indiquen errores al cargar los contextos. De hecho, al iniciarse, el servidor Tomcat/Eclipse intentará cargar el contexto de las aplicaciones que gestiona. Cargar el contexto de una aplicación implica procesar su archivo [web.xml] y cargar una o varias clases que lo inicializan. En este proceso pueden producirse varios tipos de errores:
- el archivo [web.xml] tiene errores sintácticos. Este es el error más frecuente. Se recomienda utilizar una herramienta capaz de verificar la validez de un documento XML durante su creación.
- No se han encontrado algunas de las clases que se deben cargar. Se buscan en [WEB-INF/classes] y [WEB-INF/lib]. Por lo general, hay que comprobar la presencia de las clases necesarias y la ortografía de las declaradas en el archivo [web.xml].
El servidor iniciado desde Eclipse no tiene la misma configuración que el instalado en el apartado 5.3. Para asegurarnos de ello, solicitemos la URL [http://localhost:8080] con un navegador:
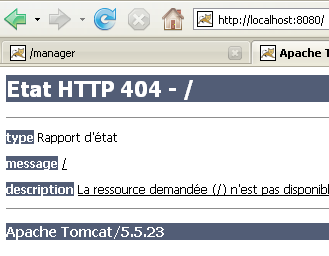
Esta respuesta no indica que el servidor no funcione, sino que el recurso / que se le solicita no está disponible. Con el servidor Tomcat integrado en Eclipse, estos recursos serán proyectos web. Lo veremos más adelante. Por ahora, detengamos Tomcat:
El modo de funcionamiento anterior se puede modificar. Volvamos a la vista [Servers] y hagamos doble clic en el servidor Tomcat para acceder a sus propiedades:
 | 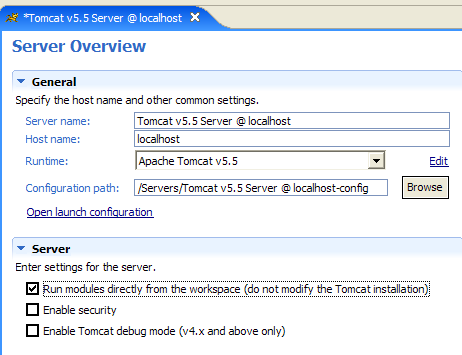 |
La casilla de selección [1] es la responsable del funcionamiento anterior. Cuando está marcada, las aplicaciones web desarrolladas en Eclipse no se declaran en los archivos de configuración del servidor Tomcat asociado, sino en archivos de configuración independientes. Al hacerlo, no se dispone de las aplicaciones definidas por defecto en el servidor Tomcat: [admin] y [manager], que son dos aplicaciones útiles. Por lo tanto, vamos a desmarcar [1] y reiniciar Tomcat:
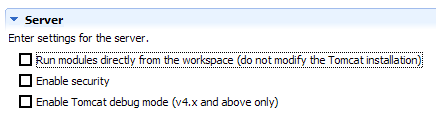 |  |
Una vez hecho esto, accedamos a la URL [http://localhost:8080] con un navegador:
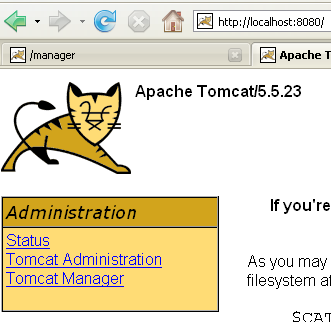
Observamos el funcionamiento descrito en el apartado 5.3.4.
En nuestros ejemplos anteriores hemos utilizado un navegador externo a Eclipse. También se puede utilizar un navegador interno de Eclipse:
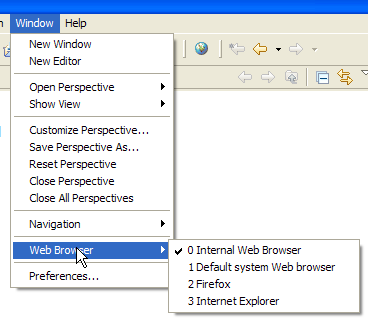
En la imagen anterior, seleccionamos el navegador interno. Para iniciarlo desde Eclipse, se puede utilizar el siguiente icono:
El navegador que se iniciará realmente será el seleccionado mediante la opción [Window -> Web Browser]. En este caso, se abre el navegador interno:

Si es necesario, iniciemos Tomcat desde Eclipse y solicitemos en [1] la URL [http://localhost:8080]:
Sigamos el enlace [Tomcat Manager]:
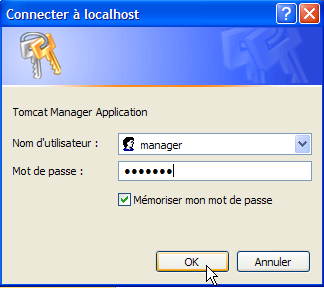
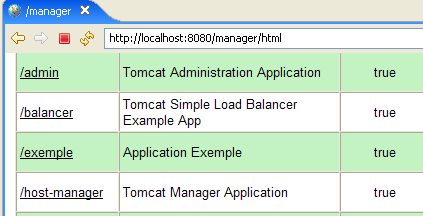
Se solicita el par [login / mot de passe] necesario para acceder a la aplicación [manager]. Según la configuración de Tomcat que hemos realizado anteriormente, podemos introducir [admin / admin] o [manager / manager]. A continuación, se muestra la lista de aplicaciones desplegadas:
5.4. SGBD Firebird
5.4.1. SGBD Firebird
El SGBD Firebird está disponible en la URL [http://www.firebirdsql.org/]:
 |
- en [1]: se utiliza la opción [Download.Firebird Relational Database]
- en [2]: se indica la versión deseada de Firebird
- en [3]: se descarga el archivo binario de instalación
Una vez descargado el archivo [3], se hace doble clic en él para instalar Firebird SGBD. SGBD se instala en una carpeta cuyo contenido es similar al siguiente:
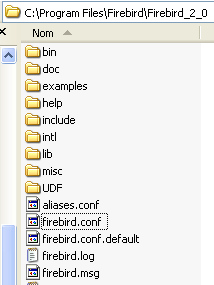
Los archivos binarios se encuentran en la carpeta [bin]:
permite iniciar/detener el SGBD | |
cliente de línea que permite gestionar bases de datos |
Cabe señalar que, por defecto, el administrador de SGBD se llama [SYSDBA] y su contraseña es [masterkey]. Se han instalado menús en [Démarrer]:
La opción [Firebird Guardian] permite iniciar o detener el SGBD. Tras el inicio, el icono del SGBD permanece en la barra de tareas de Windows:
 |
Para crear y gestionar bases de datos Firebird con el cliente de línea de comandos [isql.exe], es necesario consultar la documentación incluida con el producto, a la que se puede acceder a través de los accesos directos de Firebird en [Démarrer/Programmes/Firebird 2.0].
Una forma rápida de trabajar con Firebird y aprender el lenguaje SQL es utilizar un cliente gráfico. Un ejemplo de este tipo de cliente es IB-Expert, que se describe en el siguiente apartado.
5.4.2. Trabajar con Firebird SGBD con IB- Expert
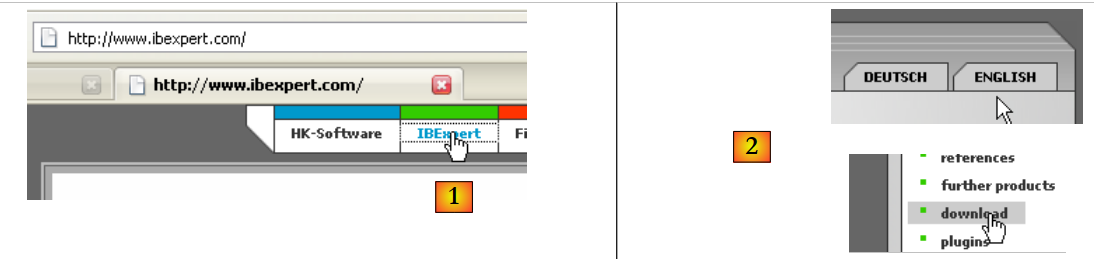
La página web principal de IB-Expert es [http://www.ibexpert.com/].
 |
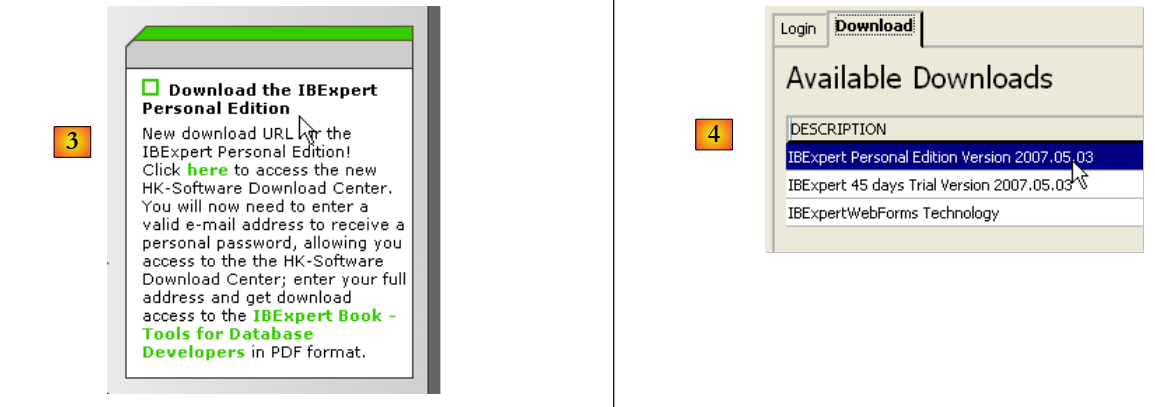 |
- en [1], se selecciona IBExpert
- En [2], se selecciona la descarga tras haber elegido, si se desea, el idioma que se prefiera
- en [3], se selecciona la versión denominada «personal», ya que es gratuita. No obstante, es necesario registrarse en la página web.
- En [4], se descarga IBExpert
IBExpert se instala en una carpeta similar a la siguiente:
El ejecutable es [ibexpert.exe]. Normalmente hay un acceso directo disponible en el menú [Démarrer]:

Una vez ejecutado, IBExpert muestra la siguiente ventana:
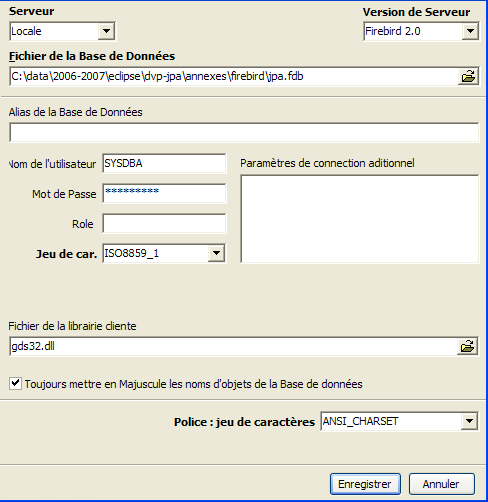
Utilicemos la opción [Database/Create Database] « » para crear una base de datos:
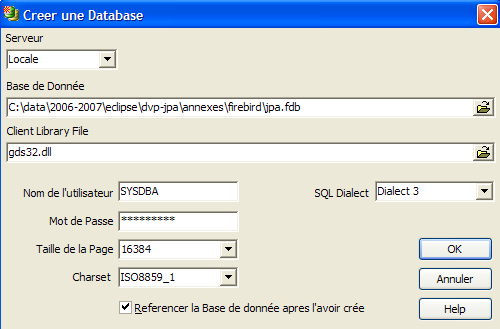
puede ser [local] o [remote]. En este caso, nuestro servidor está en la misma máquina que [IBExpert]. Elegimos , por tanto, [local] | |
utilizar el botón del tipo [dossier] del menú desplegable para seleccionar el archivo de la base de datos. Firebird coloca toda la base de datos en un único archivo. Esa es una de sus ventajas. La base de datos se transfiere de un equipo a otro simplemente copiando el archivo. El sufijo [.fdb] se añade automáticamente. | |
SYSDBA es el administrador por defecto de las distribuciones actuales de Firebird | |
masterkey es la contraseña del administrador SYSDBA de las distribuciones actuales de Firebird | |
el dialecto SQL que se debe utilizar | |
Si la casilla está marcada, IBExpert mostrará un enlace a la base de datos creada una vez que se haya creado esta |
Si al hacer clic en el botón de creación [OK] aparece el siguiente aviso:
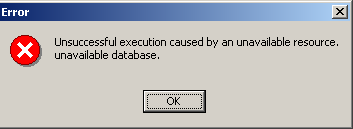
es que no has iniciado Firebird. Inícialo. Aparecerá una nueva ventana:
Familia de caracteres que se debe utilizar. Se recomienda seleccionar en la lista desplegable la familia [ISO-8859-1], que permite utilizar caracteres latinos acentuados. |
[IBExpert] es capaz de gestionar diferentes SGBD derivados de Interbase. Seleccione la versión de Firebird que tenga instalada. |
Una vez que [Register] haya validado esta nueva ventana, obtendremos el resultado [1] en la ventana [Database Explorer]. Esta ventana puede cerrarse accidentalmente. Para volver a obtenerla, ejecute [2]:
 |
Para acceder a la base de datos creada, basta con hacer doble clic en su enlace. IBExpert muestra entonces un árbol de navegación que permite acceder a las propiedades de la base de datos:
5.4.3. Creación de una tabla de datos
Creemos una tabla. Hacemos clic con el botón derecho del ratón en [Tables] (véase la ventana anterior) y seleccionamos la opción [New Table]. Aparece la ventana de definición de las propiedades de la tabla:
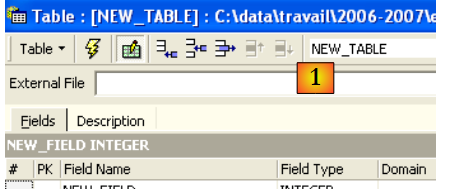 |
Empecemos por asignar el nombre [ARTICLES] a la tabla utilizando el campo de entrada [1]:
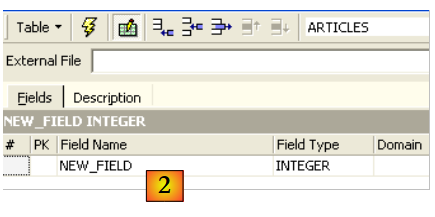
Utilicemos el campo de entrada [2] para definir una clave primaria [ID]:
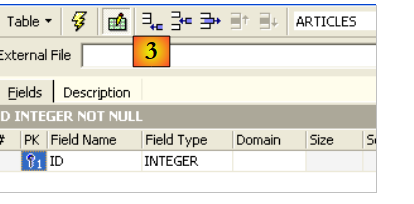
Para convertir un campo en clave primaria, hay que hacer doble clic en el campo [PK] (Primary Key) del campo. Añadamos campos con el botón situado encima de [3]:
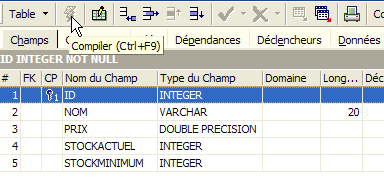
Mientras no hayamos «compilado» nuestra definición, la tabla no se creará. Utilicemos el botón [Compile] situado arriba para finalizar la definición de la tabla. IBExpert prepara las consultas SQL para la generación de la tabla y solicita confirmación:
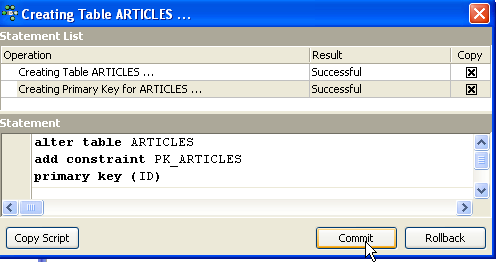
Curiosamente, IBExpert muestra las consultas SQL que ha ejecutado. Esto permite familiarizarse tanto con el lenguaje SQL como con el dialecto SQL, que podría ser propio de la empresa. El botón [Commit] permite validar la transacción en curso, mientras que [Rollback] la cancela. Aquí la aceptamos mediante [Commit]. Una vez hecho esto, IBExpert añade la tabla creada al árbol de nuestra base de datos:
Al hacer doble clic en la tabla, se accede a sus propiedades:
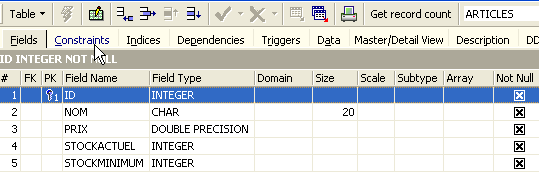
El panel [Constraints] nos permite añadir nuevas restricciones de integridad a la tabla. Abrámoslo:
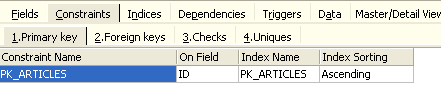
Aquí encontramos la restricción de clave primaria que hemos creado. Podemos añadir otras restricciones:
- claves externas [Foreign Keys]
- restricciones de integridad de campos [Checks]
- restricciones de unicidad de campos [Uniques]
Tenga en cuenta que:
- los campos [ID, PRIX, STOCKACTUEL, STOKMINIMUM] deben ser >0
- el campo [NOM] debe ser distinto de vacío y único
Abramos el panel [Checks] y hagamos clic con el botón derecho en su área de definición de restricciones para añadir una nueva restricción:
Definamos las restricciones deseadas:
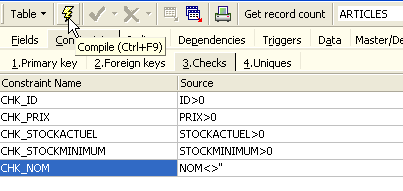
Cabe señalar que la restricción [NOM<>''] utiliza dos apóstrofos y no comillas. Compilemos estas restricciones con el botón [Compile] que aparece arriba:
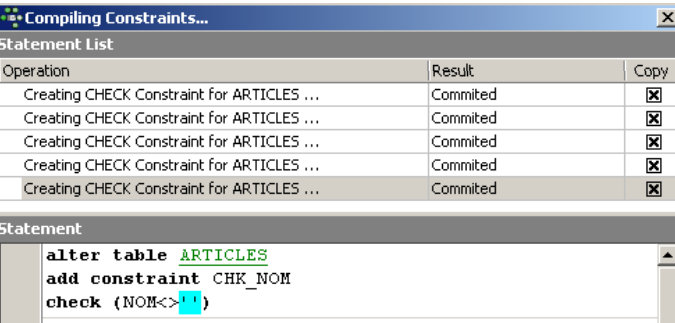
Una vez más, IBExpert demuestra su carácter didáctico al indicar las consultas SQL que ha ejecutado. Pasemos ahora al panel [Constraints/Uniques] para indicar que el nombre debe ser único. Esto significa que no puede haber dos nombres iguales en la tabla.
Definamos la restricción:
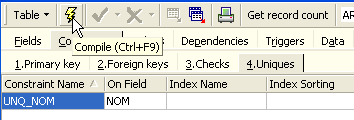
A continuación, compilémosla. Una vez hecho esto, abramos el panel [DDL] (Lenguaje de Definición de Datos) de la tabla [ARTICLES]:

Este panel proporciona el código SQL para generar la tabla con todas sus restricciones. Podemos guardar este código en un script para volver a ejecutarlo más adelante:
SET SQL DIALECT 3;
SET NAMES ISO8859_1;
CREATE TABLE ARTICLES (
ID INTEGER NOT NULL,
NOM VARCHAR(20) NOT NULL,
PRIX DOUBLE PRECISION NOT NULL,
STOCKACTUEL INTEGER NOT NULL,
STOCKMINIMUM INTEGER NOT NULL
);
ALTER TABLE ARTICLES ADD CONSTRAINT CHK_ID check (ID>0);
ALTER TABLE ARTICLES ADD CONSTRAINT CHK_PRIX check (PRIX>0);
ALTER TABLE ARTICLES ADD CONSTRAINT CHK_STOCKACTUEL check (STOCKACTUEL>0);
ALTER TABLE ARTICLES ADD CONSTRAINT CHK_STOCKMINIMUM check (STOCKMINIMUM>0);
ALTER TABLE ARTICLES ADD CONSTRAINT CHK_NOM check (NOM<>'');
ALTER TABLE ARTICLES ADD CONSTRAINT UNQ_NOM UNIQUE (NOM);
ALTER TABLE ARTICLES ADD CONSTRAINT PK_ARTICLES PRIMARY KEY (ID);
5.4.4. Inserción de datos en una tabla
Ahora es el momento de introducir datos en la tabla [ARTICLES]. Para ello, utilizaremos su panel [Data]:
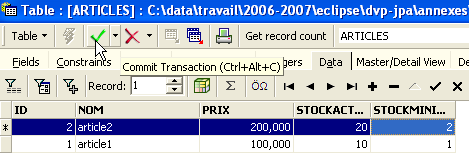
Los datos se introducen haciendo doble clic en los campos de entrada de cada fila de la tabla. Se añade una nueva línea con el botón [+] y se elimina una línea con el botón [-]. Estas operaciones se realizan en una transacción que se valida mediante el botón [Commit Transaction] (véase más arriba). Sin esta validación, los datos se perderán.
5.4.5. El editor SQL de [IB-Expert]
El lenguaje SQL (Structured Query Language) permite al usuario:
- crear tablas especificando el tipo de datos que van a almacenar y las restricciones que deben cumplir dichos datos
- insertar datos en ellas
- modificar algunos de ellos
- eliminar otros
- explotar su contenido para obtener información
- ...
IBExpert permite al usuario realizar las operaciones del 1 al 4 de forma gráfica. Acabamos de verlo. Cuando la base de datos contiene numerosas tablas, cada una con cientos de filas, se necesita información que resulta difícil de obtener visualmente. Supongamos, por ejemplo, que una tienda virtual en Internet tiene miles de compradores al mes. Todas las compras se registran en una base de datos. Al cabo de seis meses, se descubre que un producto «X» presenta defectos. Se desea ponerse en contacto con todas las personas que lo han comprado para que devuelvan el producto y se les ofrezca un cambio gratuito. ¿Cómo encontrar las direcciones de estos compradores?
- Se pueden consultar visualmente todas las tablas y buscar a esos compradores. Esto llevará unas horas.
- Se puede ejecutar una orden SQL que proporcionará la lista de estas personas en unos segundos
El lenguaje SQL resulta útil siempre que
- la cantidad de datos en las tablas es considerable
- cuando hay muchas tablas relacionadas entre sí
- la información que se desea obtener esté repartida en varias tablas
- ...
A continuación, presentamos el editor SQL de IBExpert. Se puede acceder a él a través de la opción [Tools/SQL Editor] o [F12]:
De este modo, se accede a un editor de consultas avanzado, SQL, con el que se pueden realizar consultas. Escribamos una consulta:
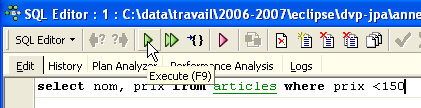
Ejecutamos la consulta SQL con el botón [Execute] situado arriba. Obtenemos el siguiente resultado:
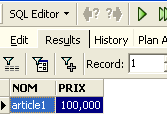
Arriba, la pestaña [Results] muestra la tabla de resultados de la orden SQL [Select]. Para emitir una nueva orden SQL, basta con volver a la pestaña [Edit]. Allí se encuentra la orden SQL, que ya se ha ejecutado.

Hay varios botones de la barra de herramientas que resultan útiles:
- el botón [New Query] permite pasar a una nueva consulta SQL:

A continuación, aparece una página de edición en blanco:
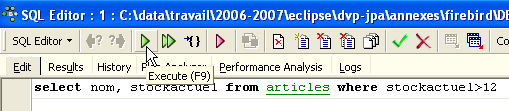
A continuación, se puede introducir una nueva orden SQL:
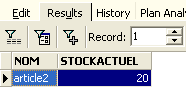
y ejecutarla:
Volvamos a la pestaña [Edit]. Las diferentes órdenes SQL emitidas quedan almacenadas en [IBExpert]. El botón [Previous Query] permite volver a una orden SQL emitida anteriormente:

De este modo, se vuelve a la consulta anterior:
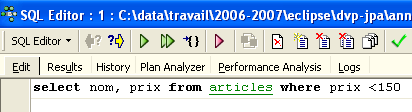
El botón [Next Query] permite, por su parte, pasar a la orden siguiente, SQL:
A continuación, encontramos la orden SQL, que es la siguiente en la lista de órdenes SQL guardadas:
El botón [Delete Query] permite eliminar una orden SQL de la lista de órdenes memorizadas:
El botón [Clear Current Query] permite borrar el contenido del editor correspondiente a la orden SQL que se muestra:
El botón [Commit] permite validar definitivamente los cambios realizados en la base de datos:

El botón [RollBack] permite deshacer los cambios realizados en la base de datos desde la última ejecución de [Commit]. Si no se ha ejecutado ningún [Commit] desde la última conexión a la base de datos, se desharán los cambios realizados desde dicha conexión.
Veamos un ejemplo. Insertemos una nueva fila en la tabla:

Se ejecuta el comando SQL, pero no se muestra nada. No sabemos si la inserción se ha realizado. Para averiguarlo, ejecutemos el comando SQL tras el comando [New Query]:
Se obtiene el siguiente resultado con [Execute]:
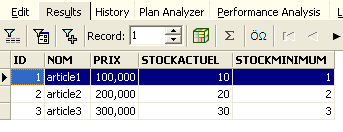
Por lo tanto, la fila se ha insertado correctamente. Ahora examinemos el contenido de la tabla de otra forma. Hagamos doble clic en la tabla [ARTICLES] en el explorador de bases de datos:
Se obtiene la siguiente tabla:
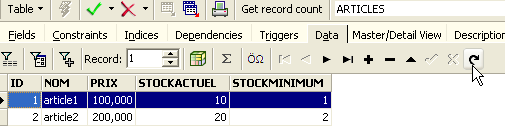
El botón con la flecha de arriba permite actualizar la tabla. Tras la actualización, la tabla anterior no cambia. Da la impresión de que la nueva línea no se ha insertado. Volvamos al editor SQL (F12) y, a continuación, validemos la orden SQL emitida con el botón [Commit]:
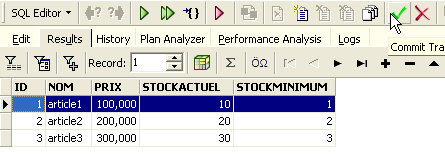
Una vez hecho esto, volvamos a la tabla [ARTICLES]. Podemos observar que no ha cambiado nada, ni siquiera al utilizar el botón [Refresh]:
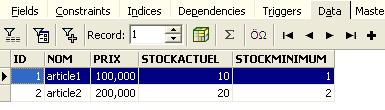
A continuación, abramos la pestaña [Fields] y volvamos a la pestaña [Data]. Esta vez, la línea insertada aparece correctamente:
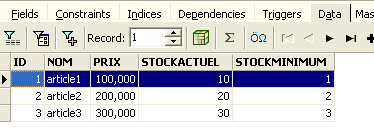
Cuando comienza la ejecución de las distintas órdenes SQL, el editor abre lo que se denomina una transacción en la base de datos. Las modificaciones realizadas por estas órdenes SQL del editor SQL solo serán visibles mientras permanezcamos en el mismo editor SQL (se pueden abrir varios). Es como si el editor SQL no trabajara en la base de datos real, sino en una copia propia. En realidad, no es exactamente así como ocurre, pero esta imagen puede ayudarnos a comprender el concepto de transacción. Todos los cambios realizados en la copia durante una transacción solo serán visibles en la base de datos real una vez que hayan sido validados mediante un [Commit Transaction]. La transacción actual finaliza entonces y comienza una nueva.
Las modificaciones realizadas durante una transacción pueden anularse mediante una operación denominada [Rollback]. Hagamos el siguiente experimento. Iniciemos una nueva transacción (basta con ejecutar [Commit] en la transacción actual) con la orden SQL siguiente:
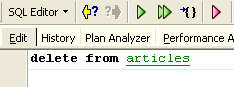
Ejecutemos esta orden, que elimina todas las líneas de la tabla [ARTICLES], y a continuación ejecutemos [New Query], la nueva orden SQL:
Obtenemos el siguiente resultado:
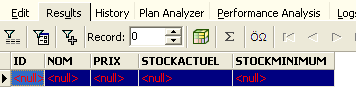
Se han eliminado todas las filas. Recordemos que esto se ha realizado en una copia de la tabla [ARTICLES]. Para comprobarlo, hagamos doble clic en la tabla [ARTICLES] que aparece a continuación:
y veamos la pestaña [Data]:
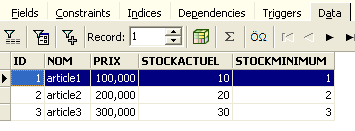
Incluso si utilizamos el botón [Refresh] o pasamos a la pestaña [Fields] para volver después a la pestaña [Data], el contenido anterior no cambia. Esto ya se ha explicado. Nos encontramos en otra transacción que trabaja con su propia copia. Ahora volvamos al editor SQL (F12) y utilicemos el botón [RollBack] para deshacer las eliminaciones de líneas que se han realizado:

Se nos solicita confirmación:
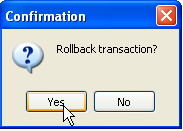
Confirmemos. El editor SQL confirma que se han deshecho los cambios:
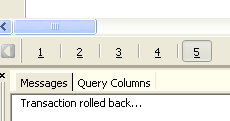
Volvamos a ejecutar la consulta SQL anterior para comprobarlo. Vemos que las líneas que se habían eliminado vuelven a aparecer:
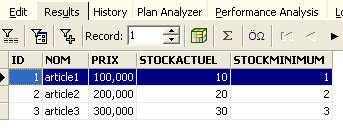
La operación [Rollback] ha devuelto la copia en la que está trabajando el editor SQL al estado en el que se encontraba al inicio de la transacción.
5.4.6. Exportación de una base de datos Firebird a un script SQL
Cuando se trabaja con varios SGBD, como ocurre en el tutorial «Persistencia en Java 5: práctica», resulta interesante poder exportar una base de datos desde un SGBD 1 a un script SQL para, a continuación, importar este último a un SGBD 2. Esto evita una serie de operaciones manuales. Sin embargo, esto no siempre es posible, ya que los archivos SGBD suelen tener extensiones SQL propias.
Veamos cómo exportar la base de datos [dbarticles] anterior a un script SQL:
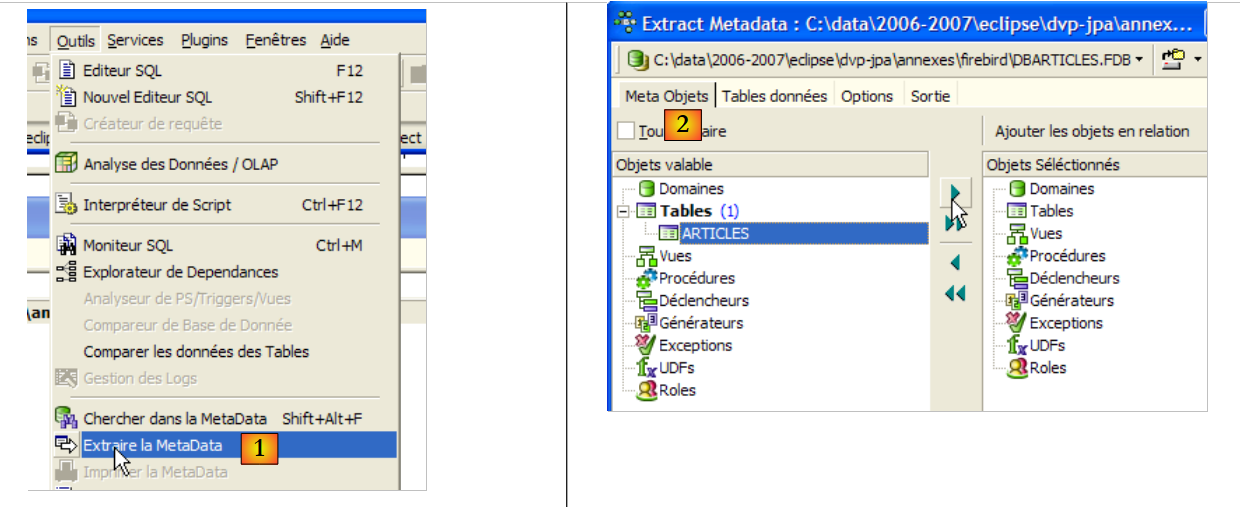 |
- a [1]: Herramientas / Extraer el MetaData, para extraer los metadatos
- en [2]: pestaña «Metaobjetos»
- en [3]: seleccionar la tabla [Articles] de la que se desea extraer la estructura (metadatos)
- en [4]: para desplazar hacia la derecha el objeto seleccionado a la izquierda
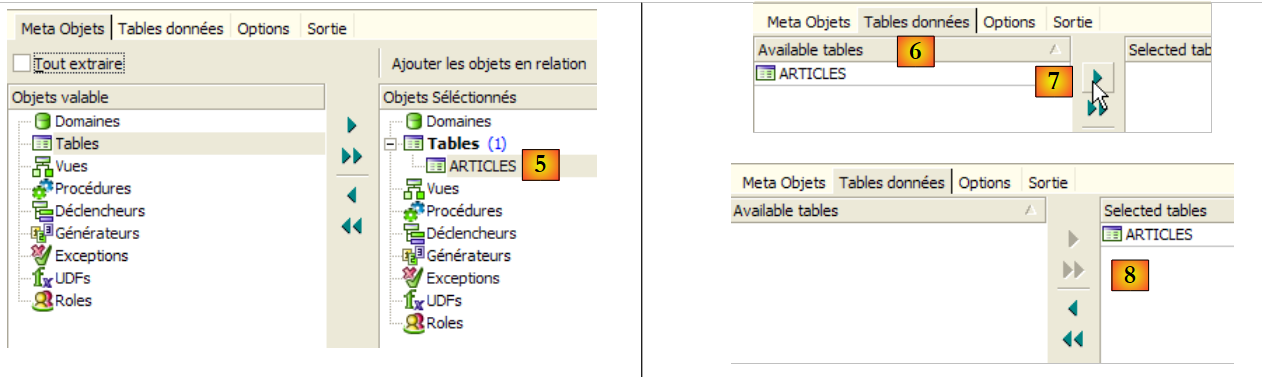 |
- en [5]: la tabla [ARTICLES] formará parte de los metadatos extraídos
- en [6]: la pestaña [Table de données] sirve para seleccionar las tablas cuyo contenido se desea extraer (en el paso anterior, lo que se exportaba era la estructura de la tabla)
- en [7]: para desplazar hacia la derecha el objeto seleccionado a la izquierda
- en [8]: el resultado obtenido
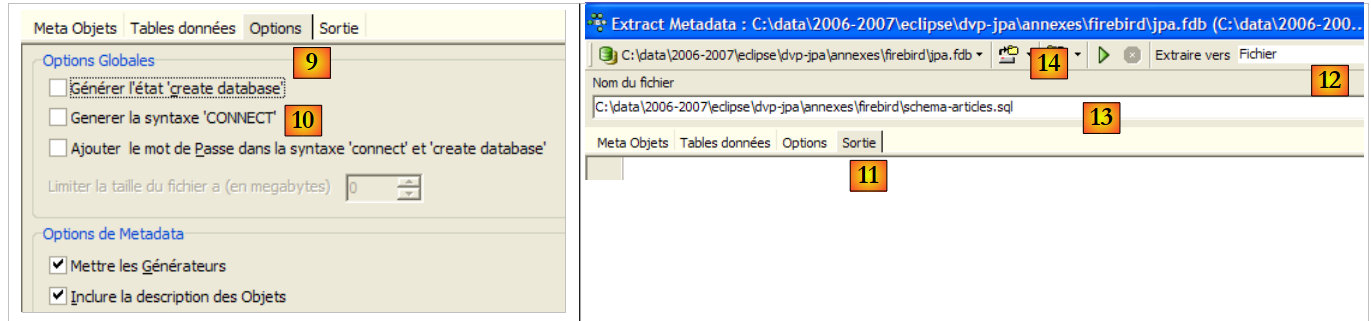 |
- en [9]: la pestaña [Options] permite configurar determinados parámetros de la extracción
- en [10]: desmarcamos las opciones relacionadas con la generación de órdenes SQL que permiten conectarse a la base de datos. Son propias de Firebird y, por lo tanto, no nos interesan.
- en [11]: la pestaña [Sortie] permite especificar dónde se generará el script SQL
- en [12]: se especifica que el script debe generarse en un archivo
- en [13]: se especifica la ubicación de dicho archivo
- en [14]: se inicia la generación del script SQL
El script generado, sin comentarios, es el siguiente:
Nota: las líneas 1 y 2 son específicas de Firebird. Deben eliminarse del script generado para obtener un SQL genérico.
5.4.7. Controlador JDBC de Firebird
Un programa Java accede a los datos de una base de datos a través de un controlador JDBC específico para el SGBD utilizado:
 |
En una arquitectura multicapa como la anterior, el controlador JDBC [1] es utilizado por la capa [dao] (objeto de acceso a datos) para acceder a los datos de una base de datos.
El controlador JDBC de Firebird está disponible en la URL desde la que se descargó Firebird:
 |
 |
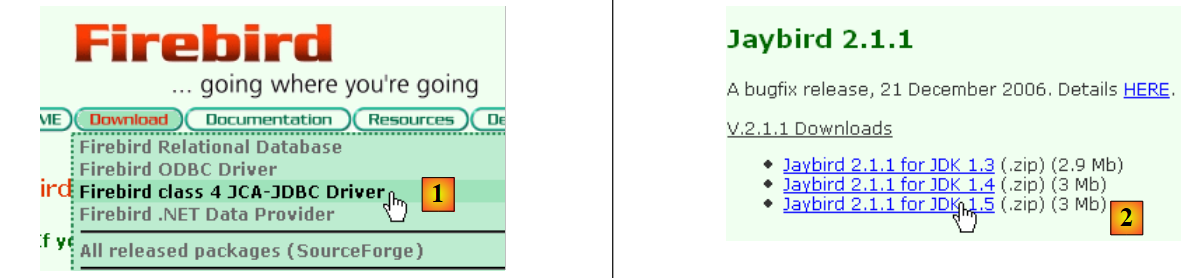
- en [1]: se opta por descargar el controlador JDBC
- en [2]: se elige un controlador JDBC compatible con JDK 1.5
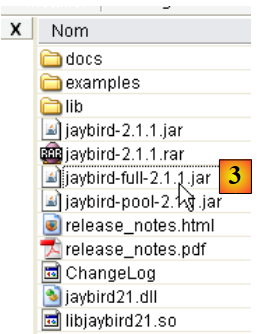
- en [3]: el archivo que contiene el controlador JDBC es [jaybird-full-2.1.1.jar]. Descomprimiremos este archivo. Se utilizará para todos los ejemplos de JPA con Firebird.
Lo colocamos en una carpeta a la que a partir de ahora llamaremos <jdbc>:
Para comprobar este controlador JDBC, utilizaremos Eclipse y el complemento SQL Explorer (apartado 5.2.6). Comenzamos declarando el controlador JDBC de Firebird:
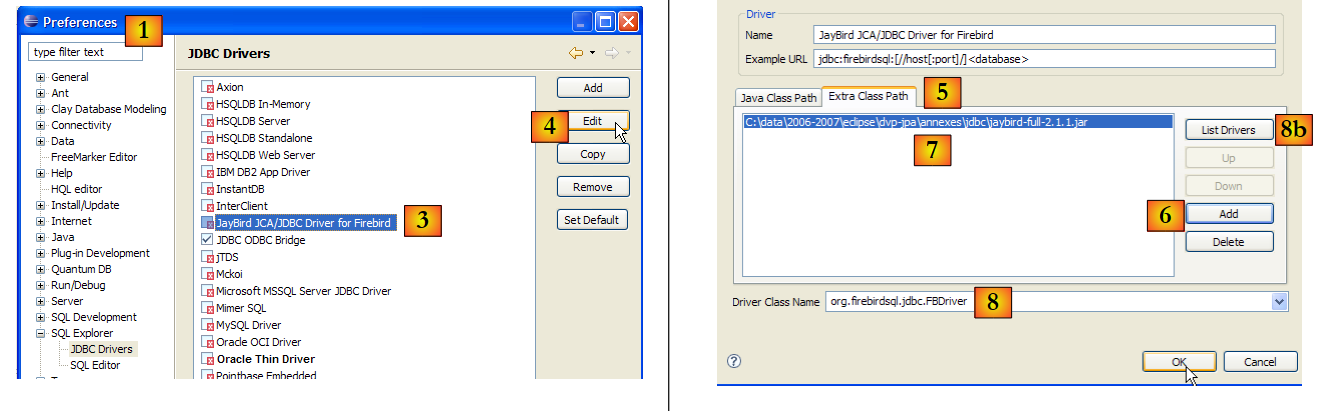 |
- en [1]: ve a Ventana / Preferencias
- en [2]: selecciona la opción «SQL Explorer / JDBC Drivers»
- en [3]: selecciona el controlador JDBC para Firebird
- en [4]: pasar a la fase de configuración
- en [5]: ve a la pestaña [Extra Class Path]
- con [6], seleccionar el archivo del controlador JDBC. Una vez hecho esto, este aparecerá en [7]. Aquí se seleccionará el controlador colocado previamente en la carpeta <jdbc>
- en [8]: el nombre de la clase Java del controlador JDBC. Se puede obtener mediante el botón [8b].
- Pulsamos [OK] para validar la configuración
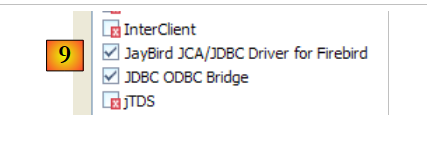 |
- en [9]: el controlador JDBC de Firebird ya está configurado. Ya podemos empezar a utilizarlo.
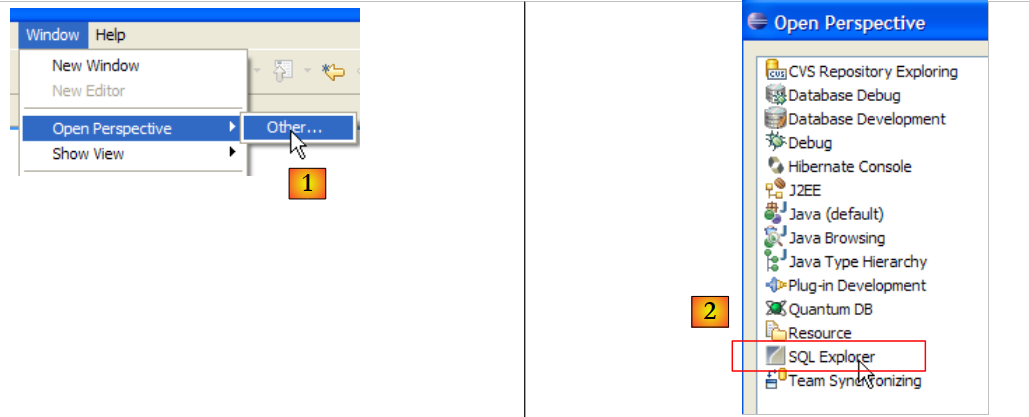 |
- a [1]: abre una nueva perspectiva
- en [2]: seleccionar la perspectiva [SQL Explorer]
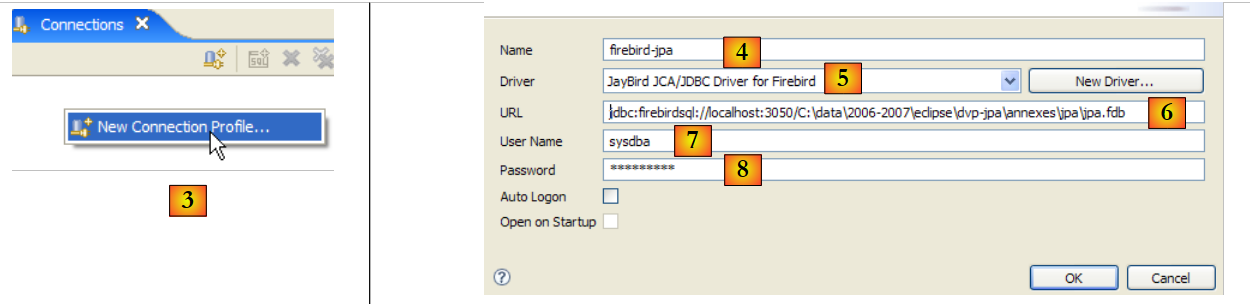 |
- en [3]: crear una nueva conexión
- en [4]: asignarle un nombre
- en [5]: seleccionar el controlador de Firebird JDBC en la lista desplegable
- en [6]: especificar la URL de la base de datos a la que queremos conectarnos, en este caso: [jdbc:firebirdsql:localhost/3050:C:\data\2006-2007\eclipse\dvp-jpa\annexes\jpa\jpa.fdb]. [jpa.fdb] es la base de datos creada anteriormente con IBExpert.
- en [7]: el nombre de usuario de la conexión, en este caso [sysdba], el administrador de Firebird
- en [8]: su contraseña [masterkey]
- Se valida la configuración de la conexión mediante [OK]
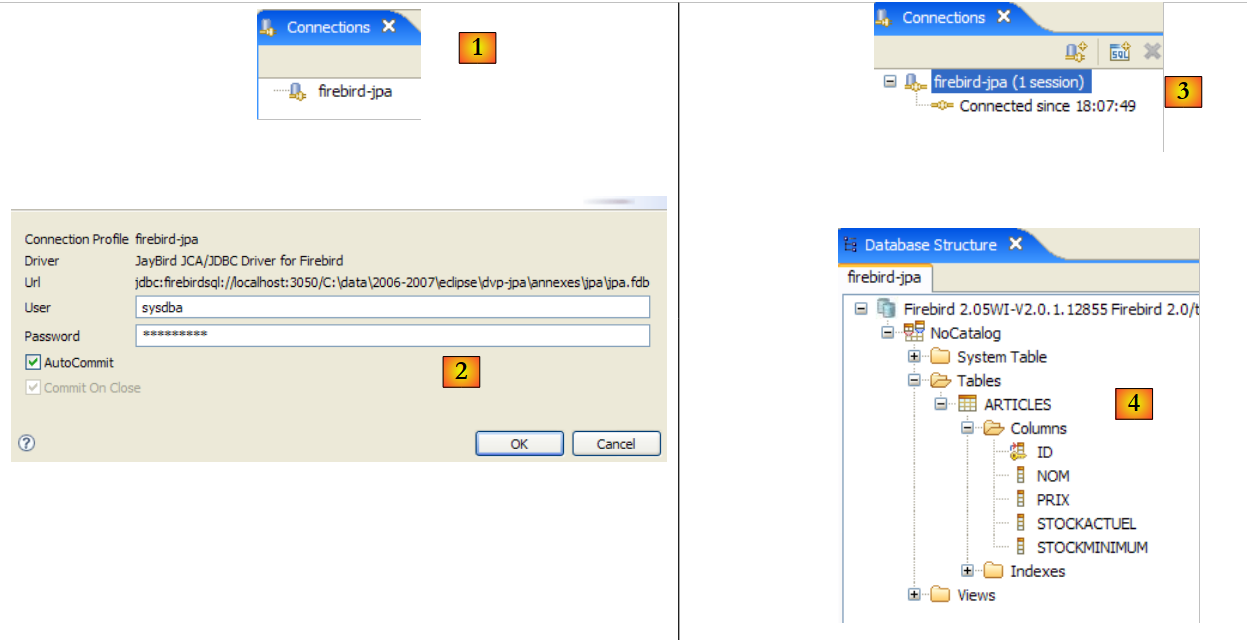 |
- en [1]: se hace doble clic en el nombre de la conexión que se desea abrir
- En [2]: se inicia sesión (sysdba, masterkey)
- en [3]: la conexión está abierta
- en [4]: se muestra la estructura de la base de datos. Se ve la tabla [ARTICLES]. Se selecciona.
 |
- en [5]: en la ventana [Database Detail], se muestran los detalles del objeto seleccionado en [4], en este caso la tabla [ARTICLES]
- en [6]: la pestaña [Columns] muestra la estructura de la tabla
- en [7]: la pestaña [Preview] muestra la estructura de la tabla
Se pueden realizar consultas SQL en la ventana [SQL Editor]:
 |
- en [1]: selecciona una conexión abierta
- en [2]: introducir la orden SQL que se va a ejecutar
- en [3]: ejecutarla
- en [4]: resumen de la orden ejecutada
- en [5]: su resultado
5.5. El SGBD e a MySQL5
5.5.1. Instalación
El SGBD MySQL5 está disponible en la URL [http://dev.mysql.com/downloads/]:
 |
- en [1]: elige la versión que desees
- en [2]: elige una versión de Windows
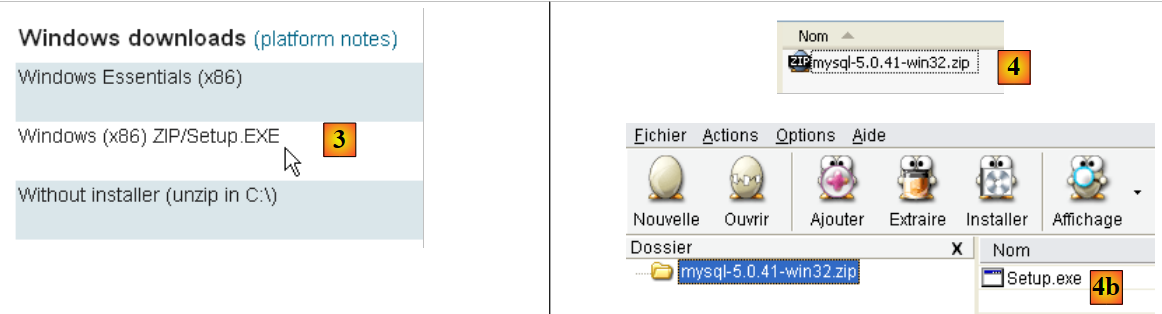 |
- en [3]: elige la versión de Windows que desees
- en [4]: el archivo ZIP descargado contiene un ejecutable [Setup.exe] [4b] que hay que extraer y ejecutar para instalar MySQL5
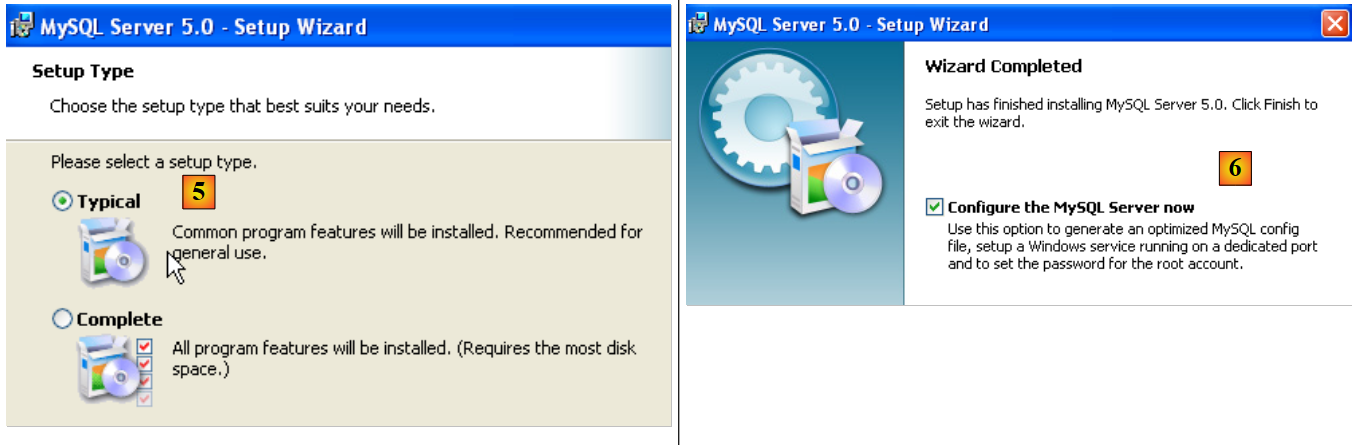 |
- en [5]: elige una instalación típica
- en [6]: una vez finalizada la instalación, se puede configurar el servidor MySQL5
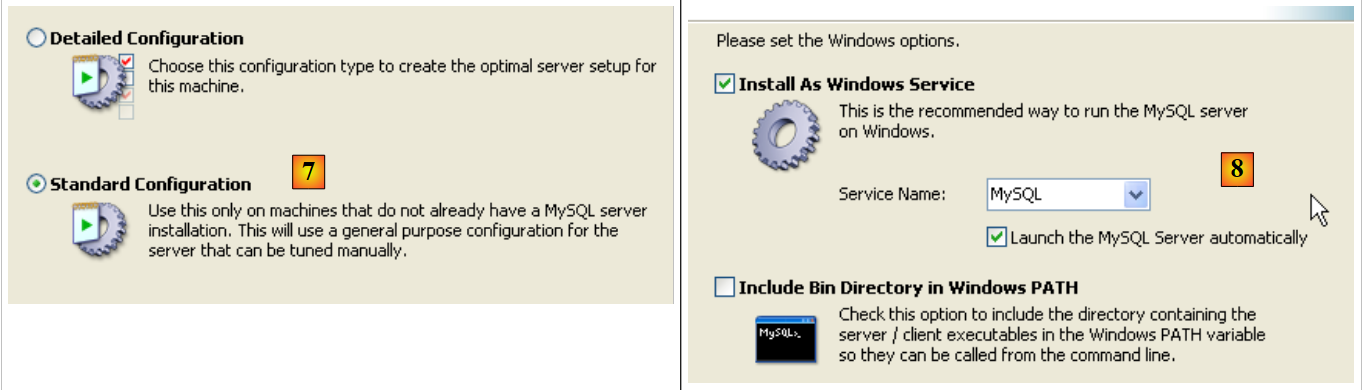 |
- en [7]: elegir una configuración estándar, la que plantee menos preguntas
- en [8]: el servidor MySQL5 será un servicio de Windows
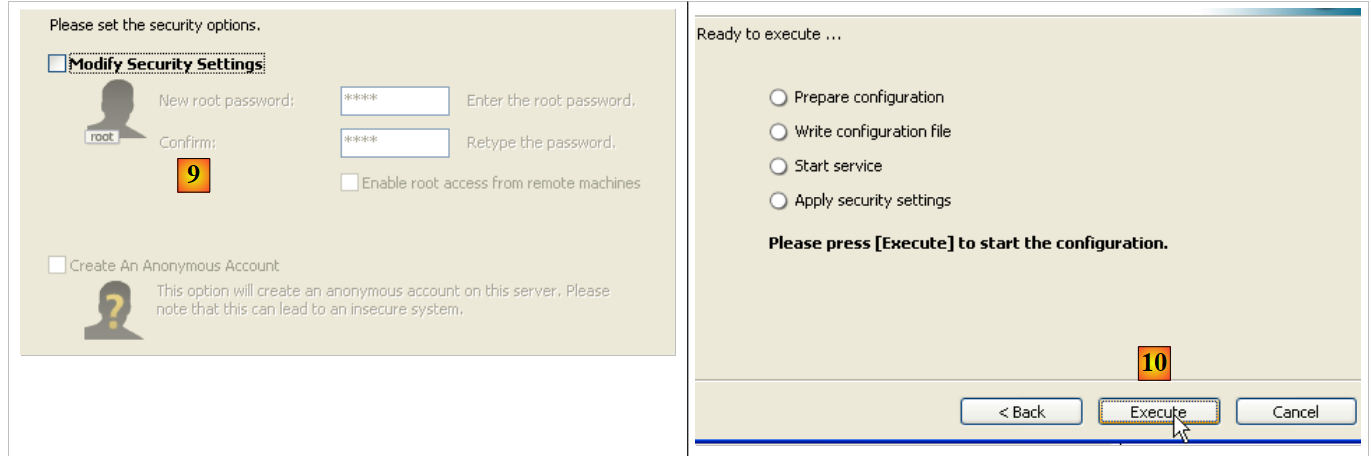 |
- en [9]: por defecto, el administrador del servidor es «root» sin contraseña. Se puede mantener esta configuración o asignar una nueva contraseña a «root». Si la instalación de MySQL5 se realiza tras la desinstalación de una versión anterior, esta operación puede fallar. Hay pocas formas de revertirla.
- En [10]: se solicita la configuración del servidor
La instalación de MySQL5 crea una carpeta en [Démarrer / Programmes ]:

Se puede utilizar [MySQL Server Instance Config Wizard] para reconfigurar el servidor:
 |
 |
 |
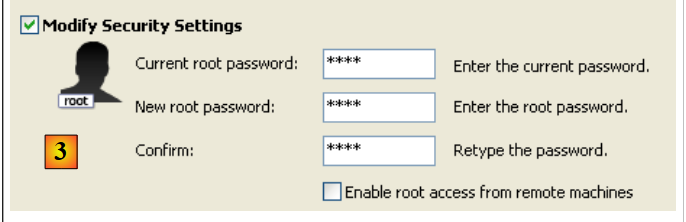
- en [3]: cambiamos la contraseña de root (en este caso, root/root)
5.5.2. Iniciar/Detener MySQL5
El servidor MySQL5 se ha instalado como un servicio de Windows de inicio automático, c.a.d se inicia nada más arrancar Windows. Este modo de funcionamiento resulta poco práctico. Vamos a cambiarlo:
[Démarrer / Panneau de configuration / Performances et maintenance / Outils d'administration / Services ]:
 |
- en [1]: hacemos doble clic en [Services]
- en [2]: vemos que hay un servicio llamado [MySQL], que está iniciado ([3]) y que su inicio es automático ([4]).
Para modificar este comportamiento, hacemos doble clic en el servicio [MySQL]:
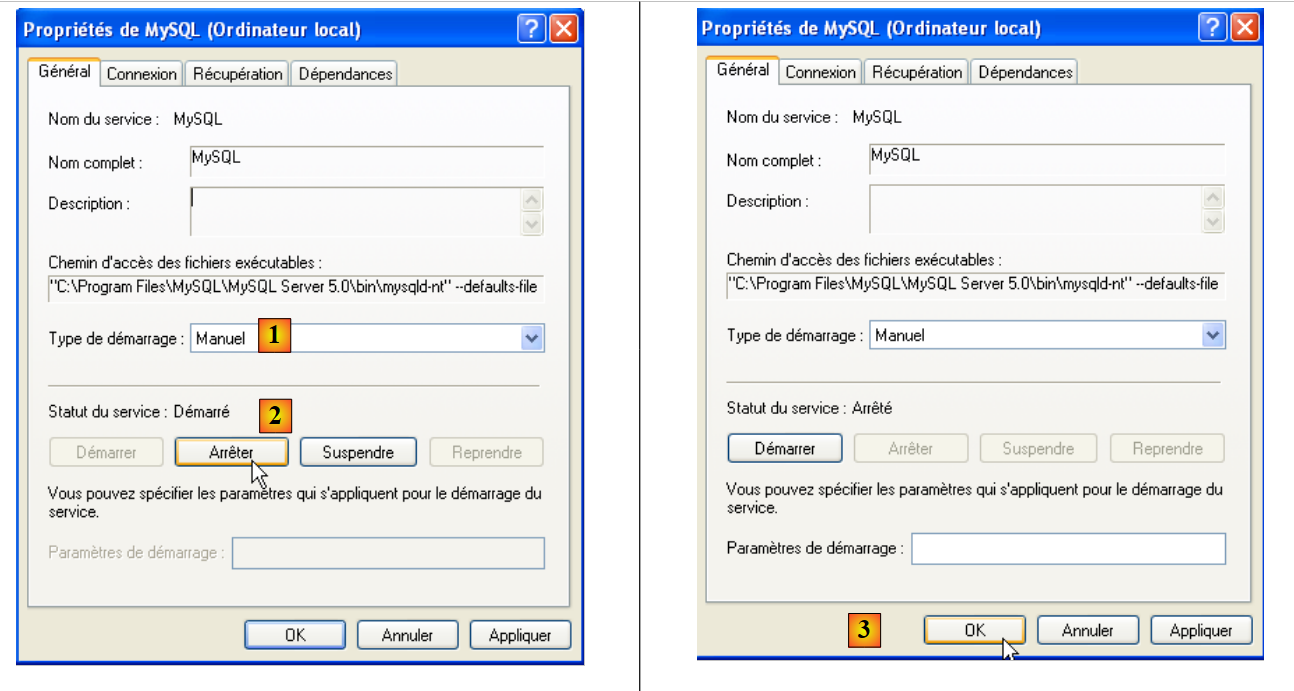 |
- en [1]: configuramos el servicio para que se inicie manualmente
- en [2]: lo detenemos
- en [3]: confirmamos la nueva configuración del servicio
Para iniciar y detener manualmente el servicio MySQL, se pueden crear dos accesos directos:
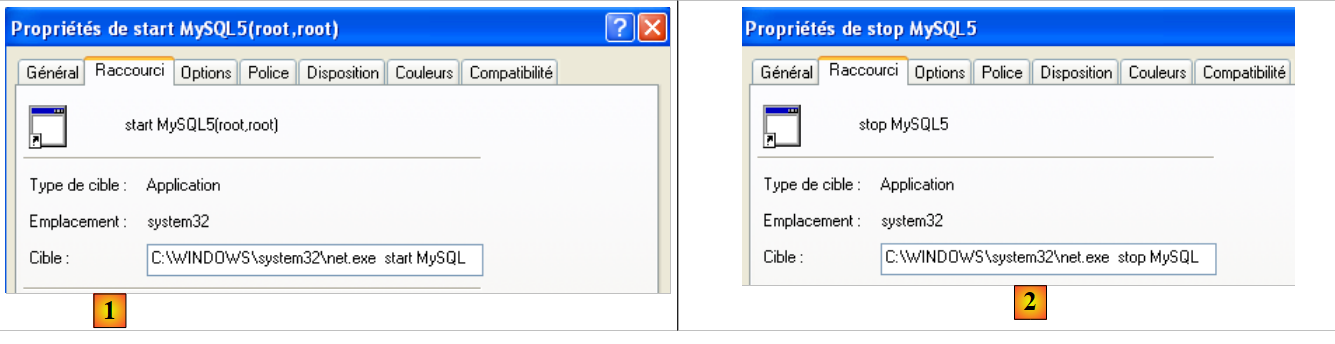 |
- en [1]: el acceso directo para iniciar MySQL5
- en [2]: el acceso directo para detenerlo
5.5.3. Clientes de administración de MySQL
En la página web de MySQL se pueden encontrar clientes de administración de SGBD:
 |
- en [1]: elige [MySQL GUI Tools], que reúne varios clientes gráficos que permiten tanto administrar el SGBD como utilizarlo
- en [2]: elegir la versión de Windows adecuada
 |
- en [3]: se obtiene un archivo .msi que hay que ejecutar
- en [4]: una vez realizada la instalación, aparecerán nuevos accesos directos en la carpeta [Menu Démarrer / Programmes / mySQL].
Ejecutemos MySQL (a través de los accesos directos que has creado) y, a continuación, ejecutemos [MySQL Administrator] desde el menú anterior:
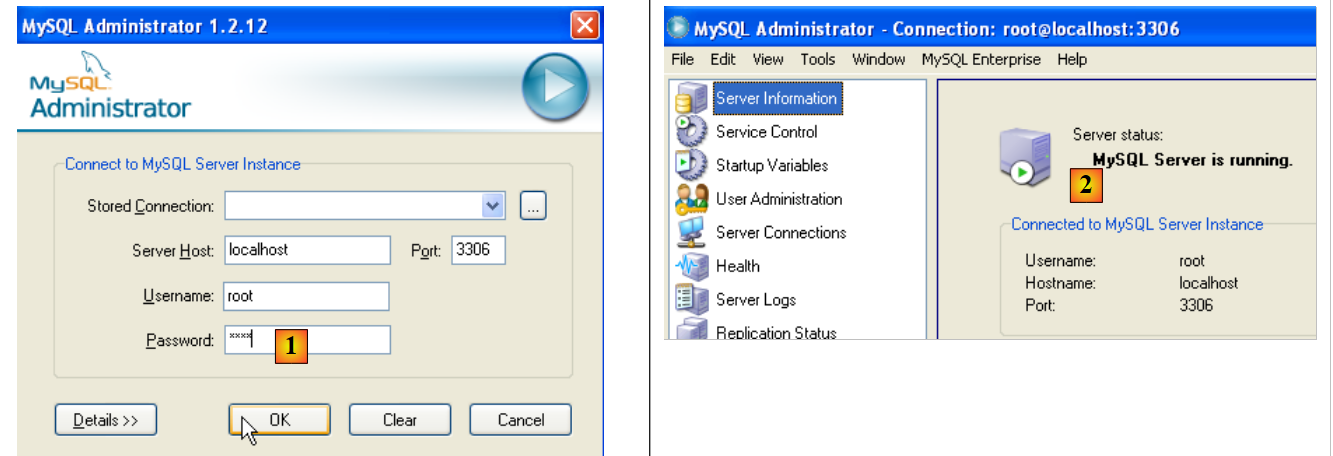 |
- en [1]: introduce la contraseña del usuario root (en este caso, «root»)
- en [2]: ya estamos conectados y vemos que MySQL está activo
5.5.4. Creación de un usuario «jpa» y una base de datos «jpa»
El tutorial utiliza MySQL5 con una base de datos llamada jpa y un usuario con el mismo nombre. Ahora los vamos a crear. Primero, el usuario:
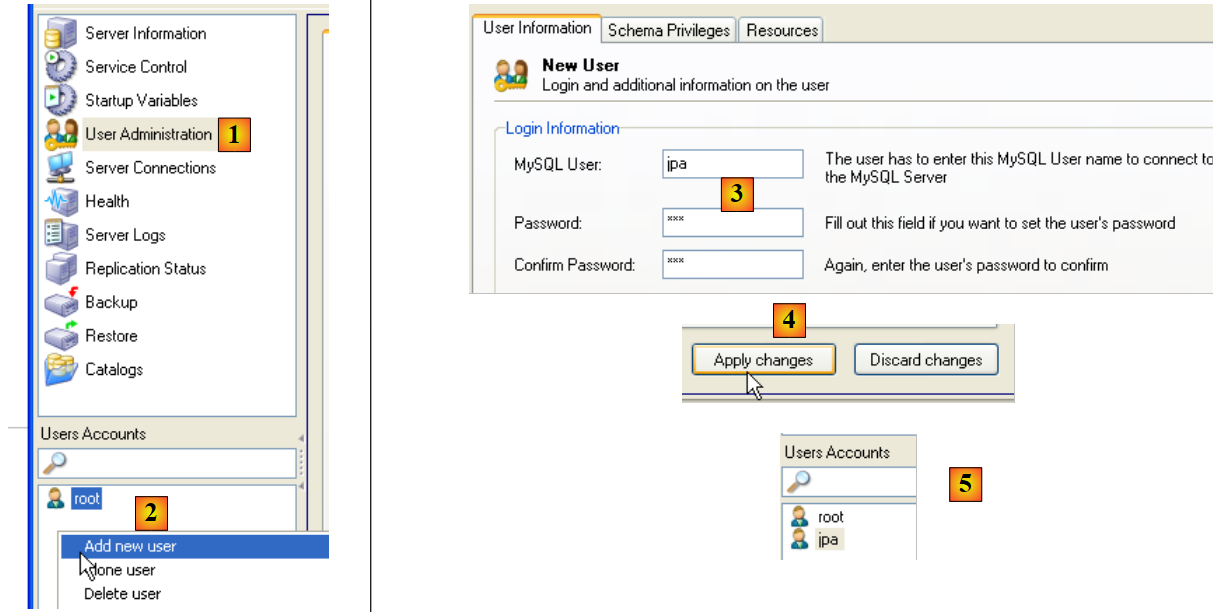 |
- en [1]: seleccionamos [User Administration]
- en [2]: hacemos clic con el botón derecho en la parte de [User accounts] para crear un nuevo usuario
- en [3]: el usuario se llama jpa y su contraseña es jpa
- en [4]: se confirma la creación
- en [5]: el usuario [jpa] aparece en la ventana [User Accounts]
Ahora, la base de datos:
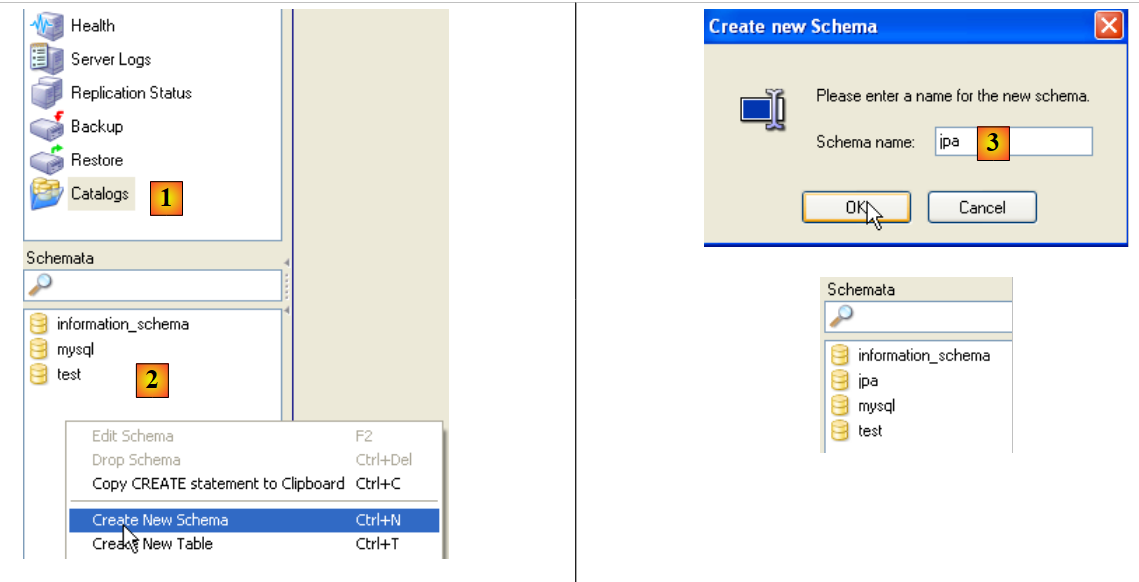 |
- en [1]: selección de la opción [Catalogs]
- en [2]: clic con el botón derecho del ratón en la ventana [Schemata] para crear un nuevo esquema (que designa una base de datos)
- en [3]: se le da nombre al nuevo esquema
- en [4]: aparece en la ventana [Schemata]
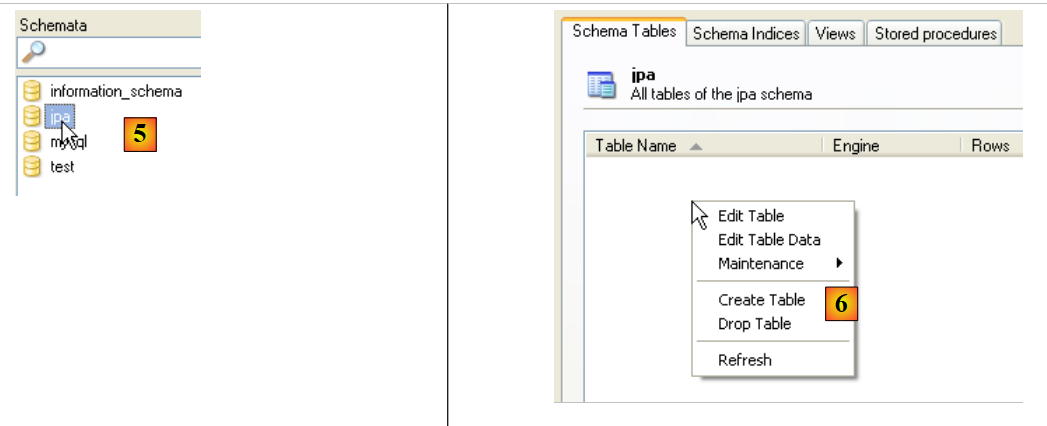 |
- en [5]: se selecciona el esquema [jpa]
- en [6]: aparecen los objetos del esquema [jpa], en particular las tablas. Todavía no hay ninguna. Con un clic con el botón derecho se podrían crear. Dejamos que el lector lo haga.
Volvamos al usuario [jpa] para concederle todos los derechos sobre el esquema [jpa]:
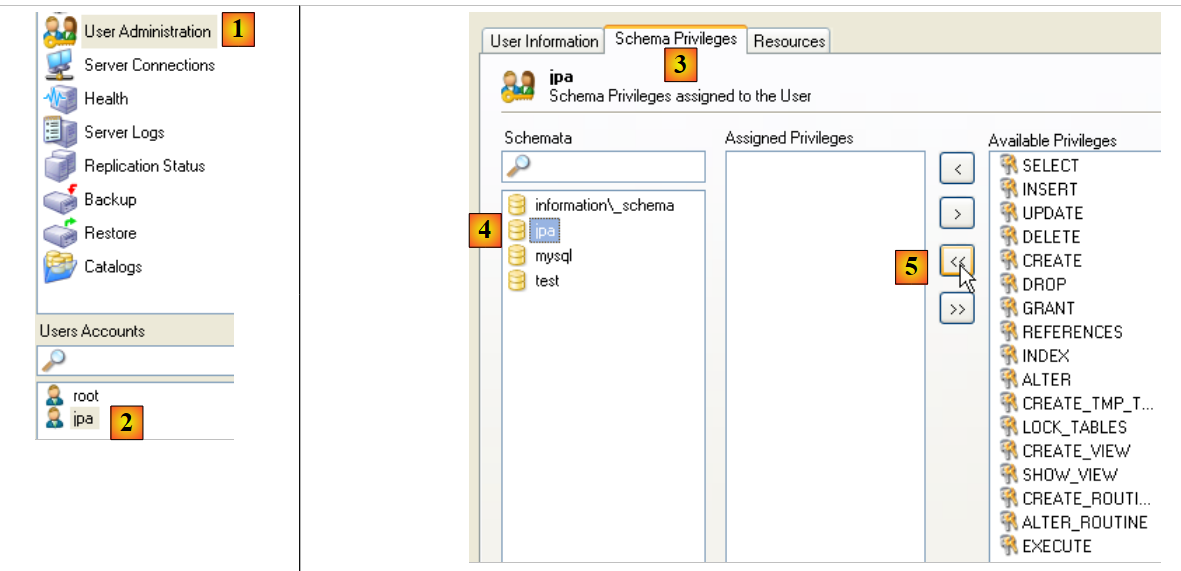 |
- en [1] y, a continuación, en [2]: seleccionamos el usuario [jpa]
- en [3]: se selecciona la pestaña [Schema Privileges]
- en [4]: se selecciona el esquema [jpa]
- en [5]: vamos a otorgar al usuario [jpa] todos los privilegios sobre el esquema [jpa]
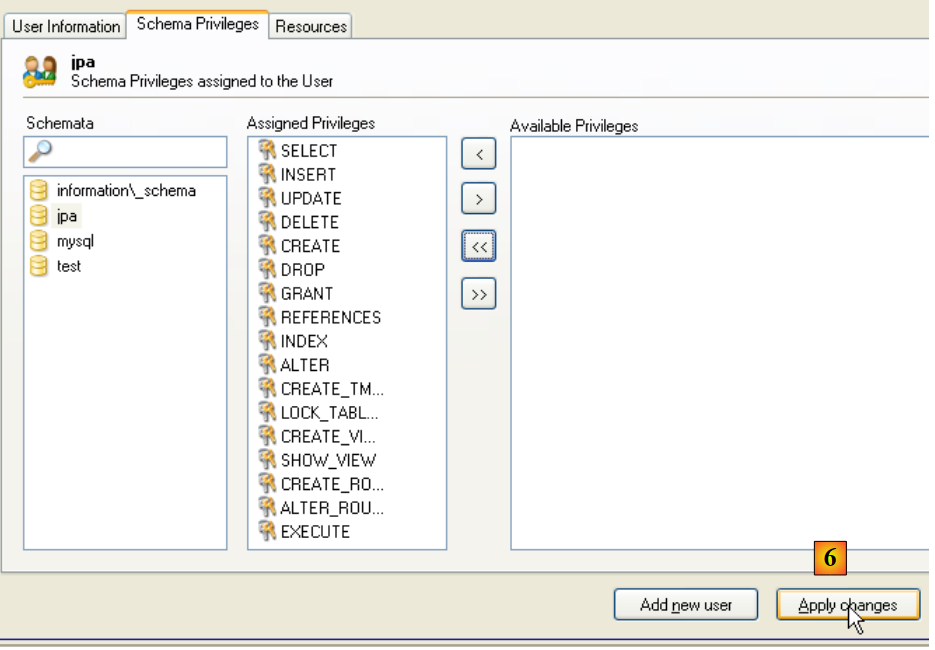 |
- a [6]: se validan los cambios realizados
Para comprobar que el usuario [jpa] puede trabajar con el esquema [jpa], cerramos la sesión del administrador MySQL. Lo reiniciamos y, esta vez, iniciamos sesión con el nombre [jpa/jpa]:
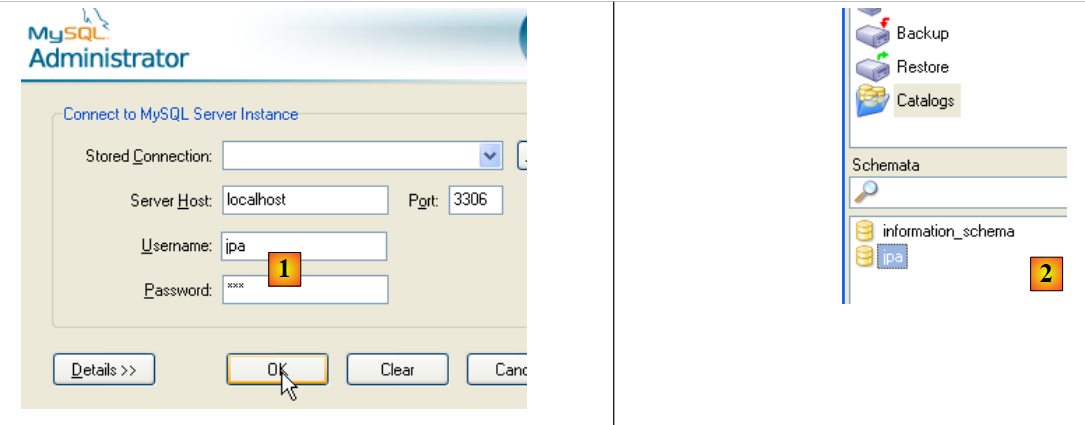 |
- en [1]: nos identificamos (jpa/jpa)
- en [2]: la conexión se ha realizado correctamente y, en [Schemata], vemos los esquemas sobre los que tenemos derechos. Vemos el esquema [jpa].
Ahora vamos a crear la misma tabla [ARTICLES] que con el Firebird SGBD utilizando el script SQL [schema-articles.sql] generado en el apartado 5.4.6.
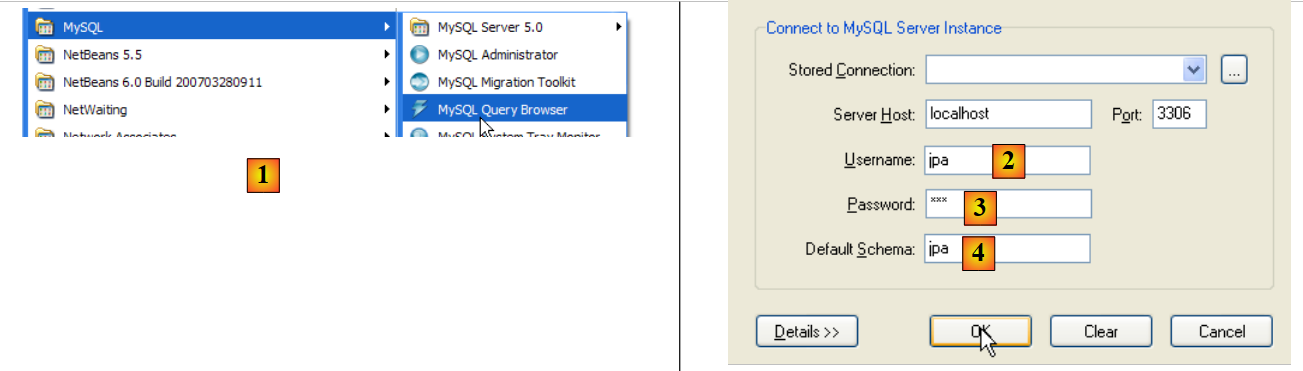 |
- a [1]: utilice la aplicación [MySQL Query Browser]
- en [2], [3], [4]: iniciar sesión (jpa / jpa / jpa)
 |
- en [5]: abrir un script SQL para ejecutarlo
- en [6]: se refiere al script [schema-articles.sql] creado en el apartado 5.4.6.
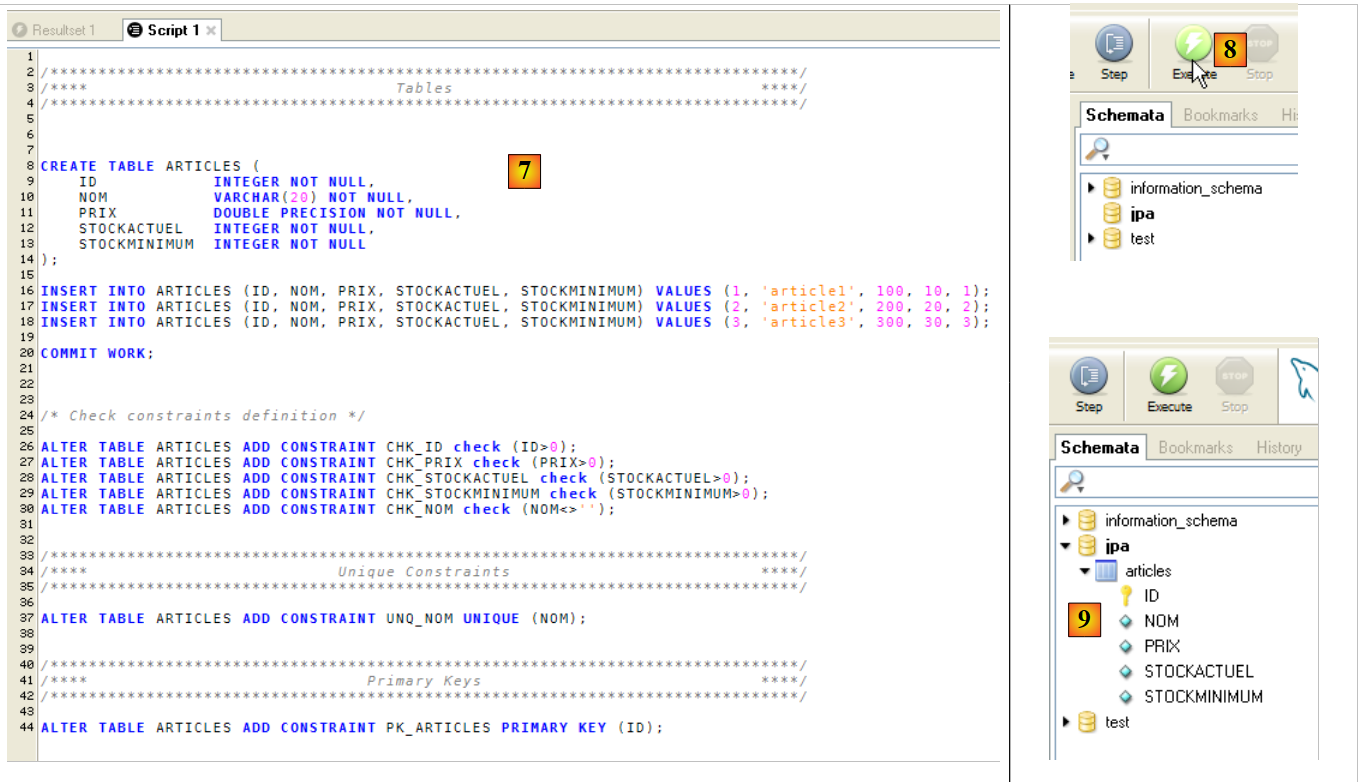 |
- en [7]: el script cargado
- en [8]: se ejecuta
- en [9]: se ha creado la tabla [ARTICLES]
5.5.5. Controlador JDBC de MySQL5
El controlador JDBC de MySQL se puede descargar en el mismo lugar que el SGBD:
 |
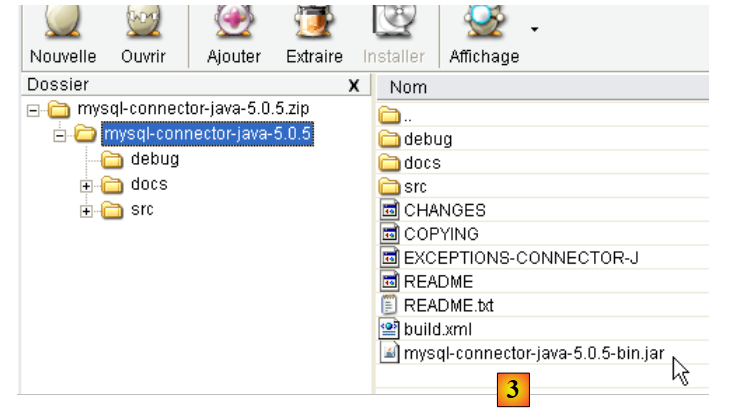 |
- en [1]: elige el controlador JDBC adecuado
- en [2]: elige la versión para Windows adecuada
- en [3]: en el archivo zip descargado, el archivo Java que contiene el controlador JDBC es [mysql-connector-java-5.0.5-bin.jar]. Lo extraeremos para utilizarlo en los ejemplos del tutorial JPA.
Lo colocamos igual que el anterior (apartado 5.4.7) en la carpeta <jdbc>:
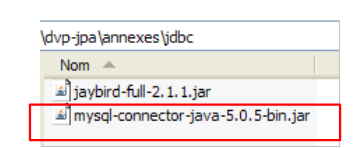 |
Para probar este controlador JDBC, utilizaremos Eclipse y el complemento SQL Explorer. Se recomienda al lector que siga los pasos explicados en el apartado 5.4.7. A continuación, mostramos algunas capturas de pantalla significativas:
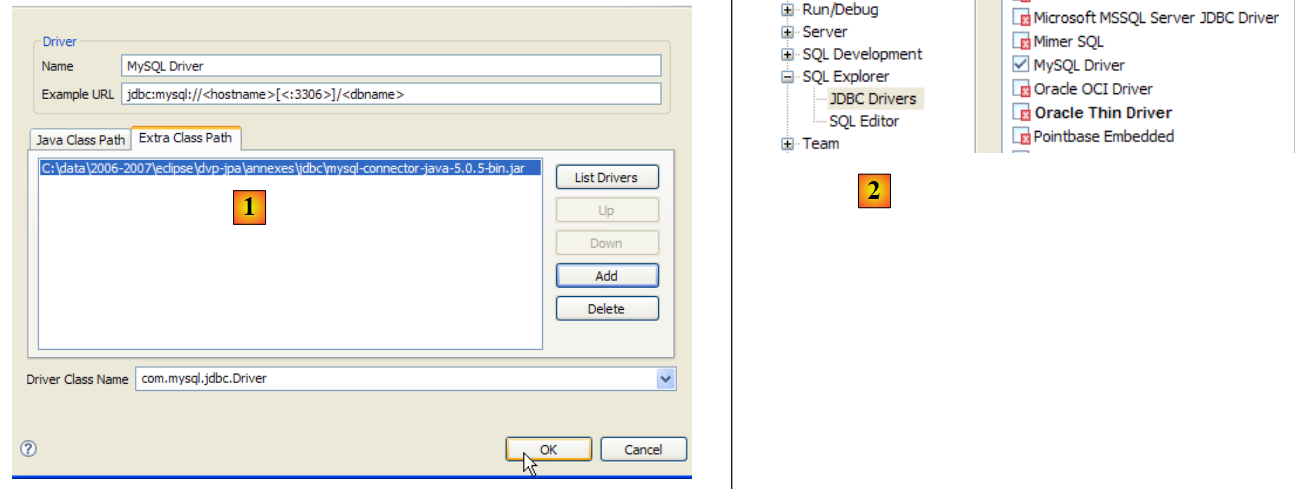 |
- en [1]: se ha cambiado el nombre del archivo del controlador JDBC de MySQL5
- en [2]: el controlador JDBC de MySQL5 está disponible
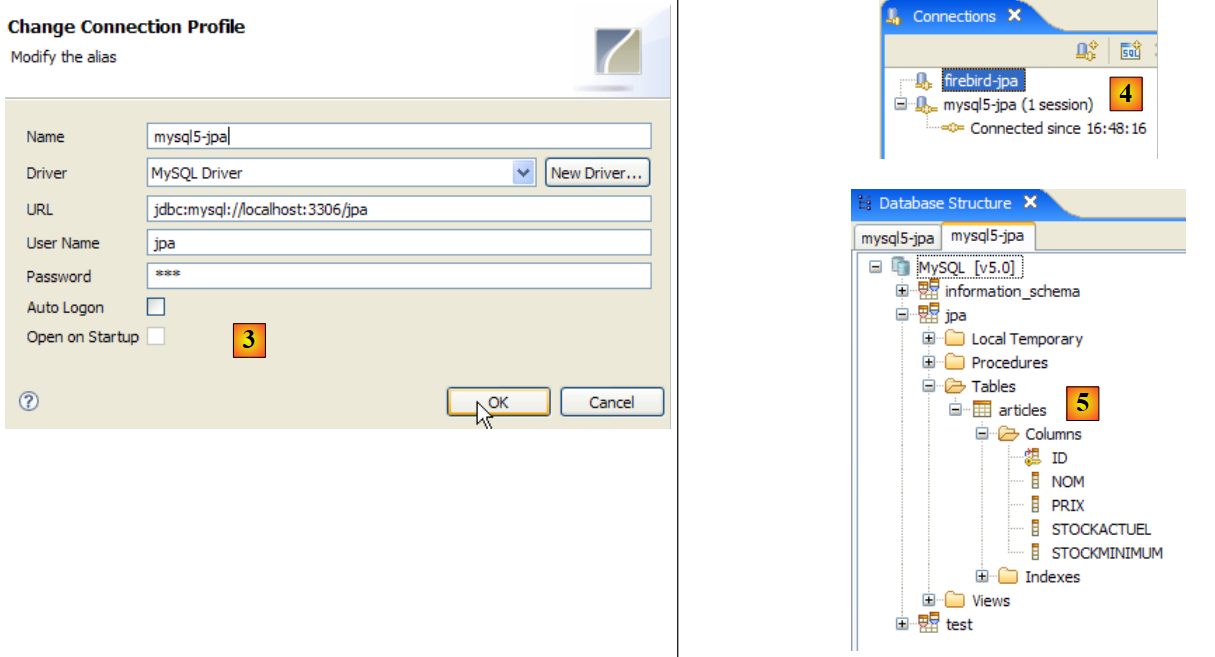 |
- a [3]: definición de la conexión (usuario, contraseña)=(jpa, jpa)
- en [4]: la conexión está activa
- en [5]: base de datos conectada
5.6. El SGBD e a PostgreSQL
5.6.1. Instalación
El SGBD PostgreSQL está disponible en la URL [http://www.postgresql.org/download/]:
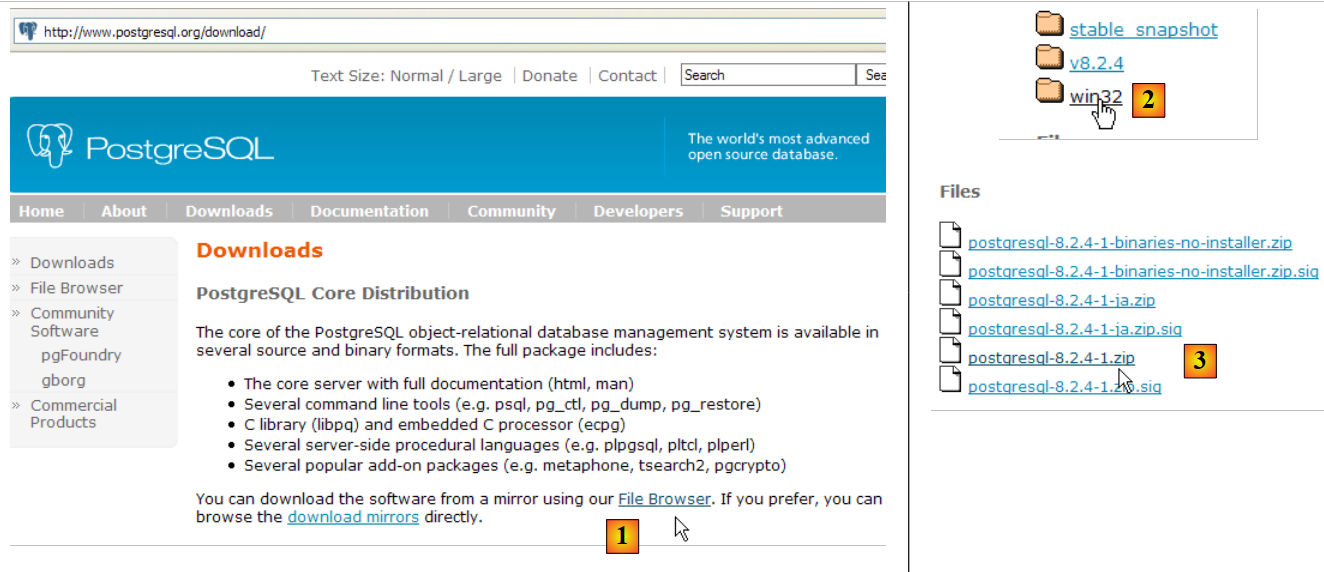 |
- en [1]: los sitios de descarga de PostgreSQL
- en [2]: elegir una versión para Windows
- en [3]: elegir una versión con instalador
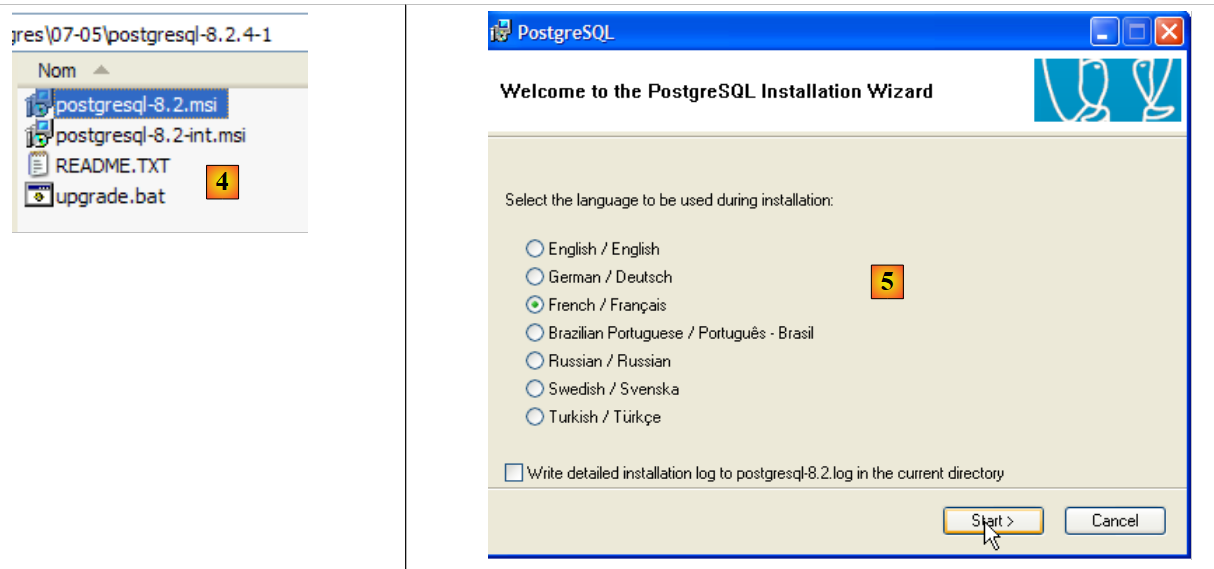 |
- en [4]: el contenido del archivo zip descargado. Haz doble clic en el archivo [postgresql-8.2.msi]
- en [5]: la primera página del asistente de instalación
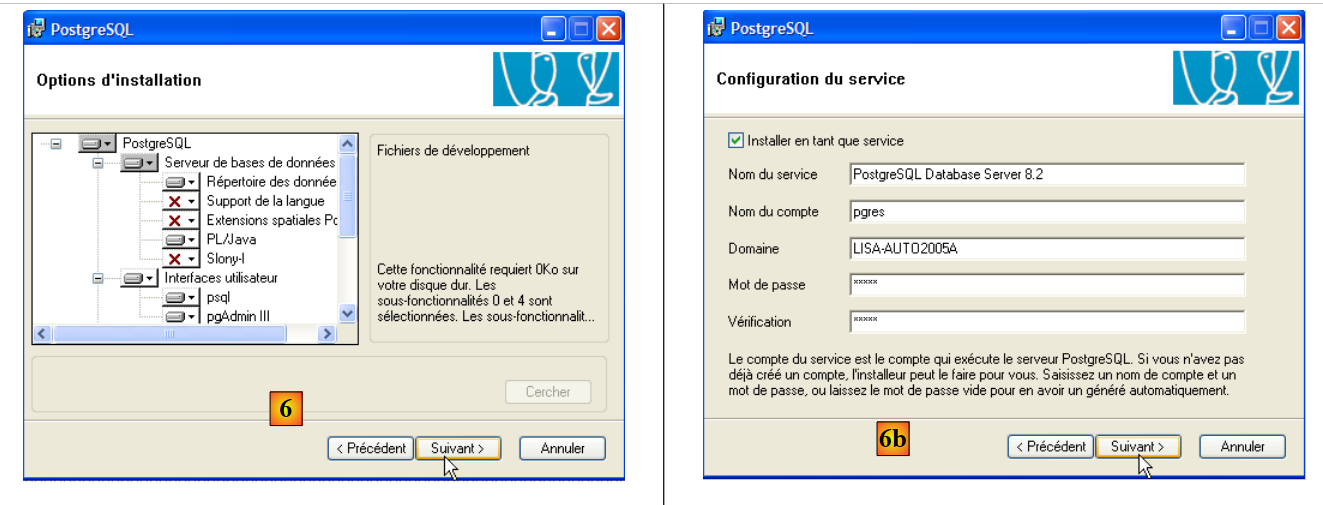 |
- en [6]: elige una instalación típica aceptando los valores predeterminados
- en [6b]: creación de la cuenta de Windows que iniciará el servicio PostgreSQL; en este caso, la cuenta «pgres» con la contraseña «pgres».
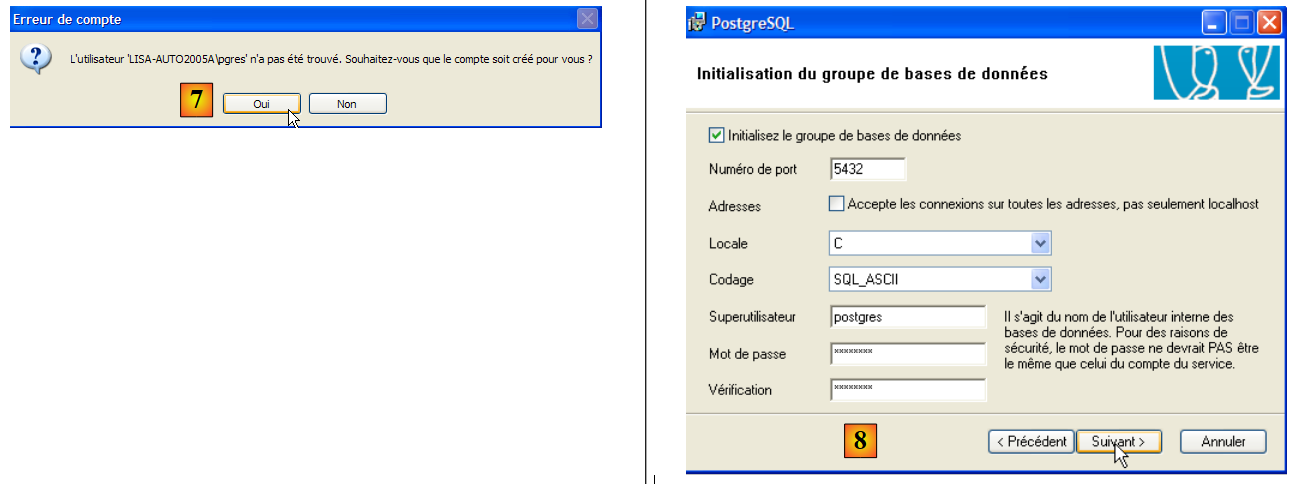 |
- en [7]: dejar que PostgreSQL cree la cuenta [pgres] si aún no existe
- en [8]: definir la cuenta de administrador de SGBD, en este caso «postgres» con la contraseña «postgres»
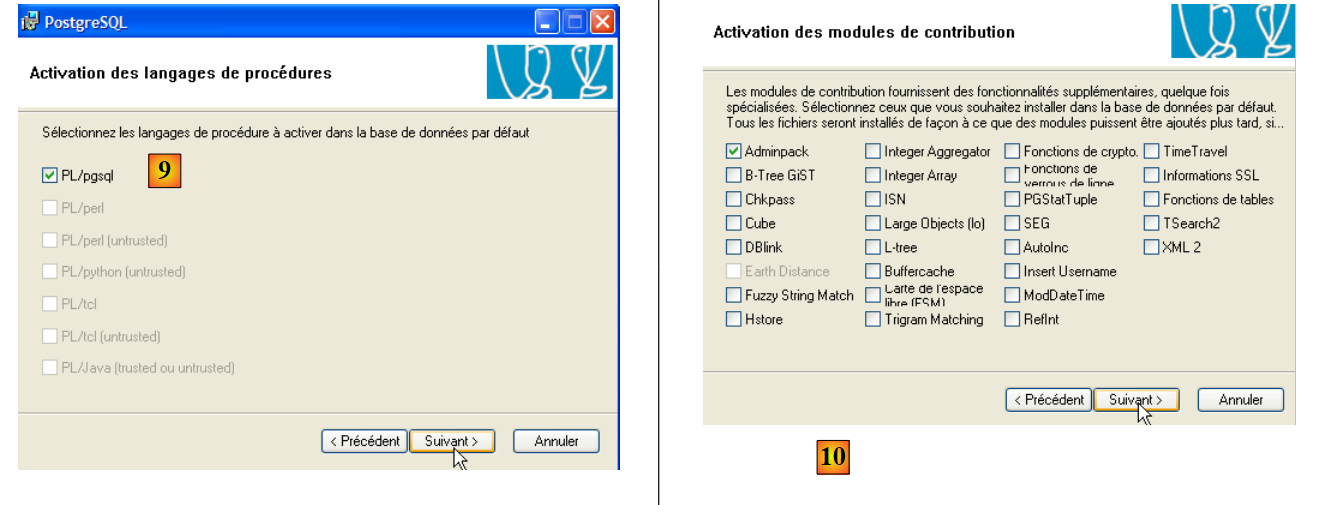 |
- en [9] y [10]: acepta los valores por defecto hasta el final del asistente. Se instalará PostgreSQL.
La instalación de PostgreSQL crea una carpeta en [Démarrer / Programmes ]:
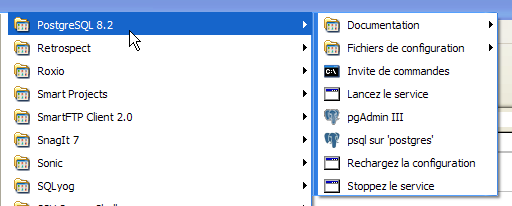
5.6.2. Iniciar/Detener PostgreSQL
El servidor PostgreSQL se ha instalado como un servicio de Windows de inicio automático; c.a.d se inicia nada más arrancar Windows. Este modo de funcionamiento resulta poco práctico. Vamos a cambiarlo:
[Démarrer / Panneau de configuration / Performances et maintenance / Outils d'administration / Services ]:
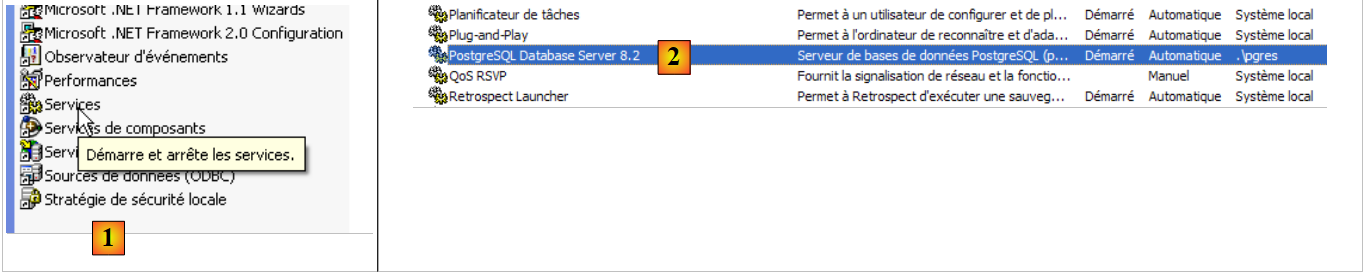 |
- en [1]: hacemos doble clic en [Services]
- en [2]: vemos que hay un servicio llamado [PostgreSQL], que está en marcha ([3]) y que su inicio es automático ([4]).
Para modificar este comportamiento, hacemos doble clic en el servicio [PostgreSQL]:
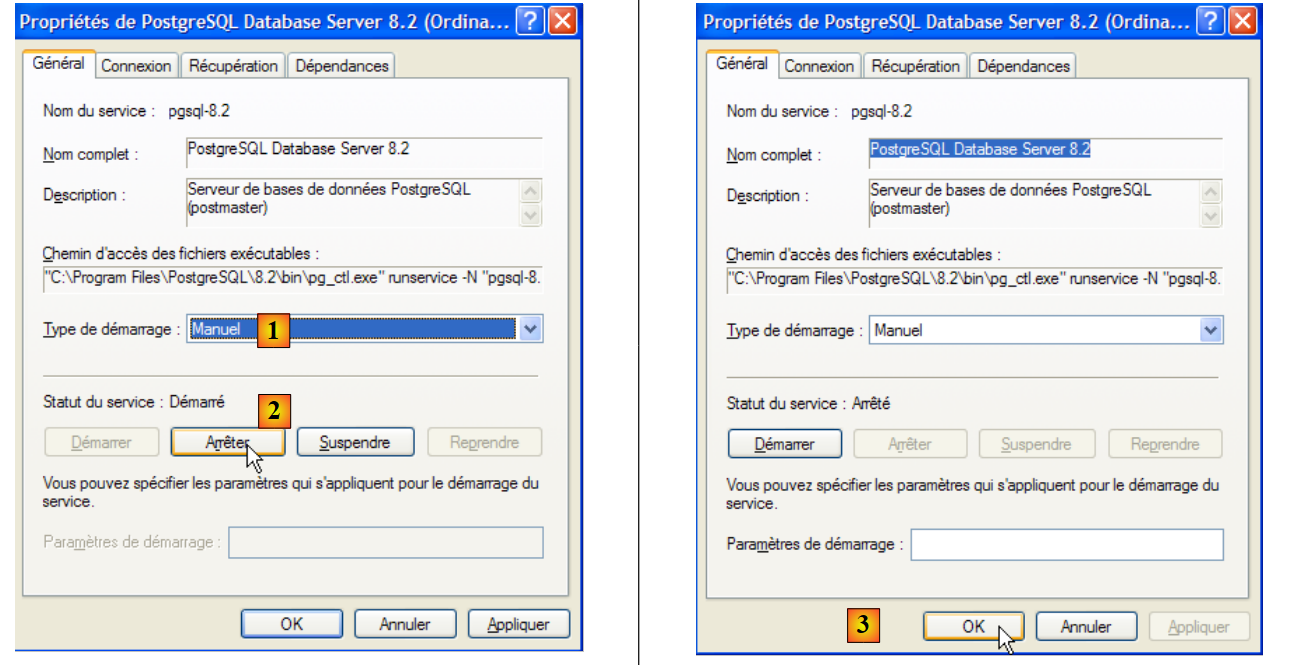 |
- en [1]: configuramos el servicio para que se inicie manualmente
- en [2]: lo detenemos
- en [3]: confirmamos la nueva configuración del servicio
Para iniciar y detener manualmente el servicio PostgreSQL, se pueden utilizar los accesos directos de la carpeta [PostgreSQL]:
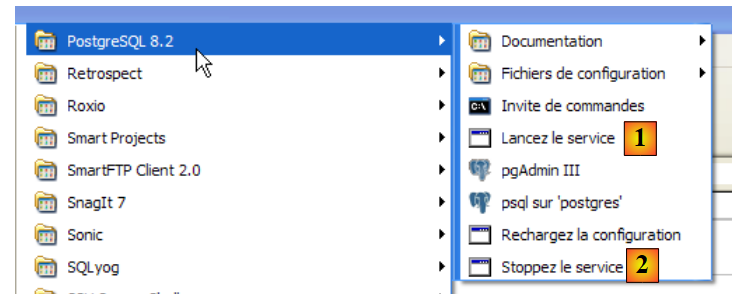 |
- en [1]: el acceso directo para iniciar PostgreSQL
- en [2]: el acceso directo para detenerlo
5.6.3. Administrar PostgreSQL
En la captura de pantalla anterior, la aplicación [pgAdmin III] (3) permite administrar SGBD y PostgreSQL. Iniciemos SGBD y, a continuación, [pgAdmin III] a través del menú anterior:
 |
- en [1]: haz doble clic en el servidor PostgreSQL para conectarte a él
- en [2,3]: iniciar sesión como administrador de SGBD, en este caso (postgres / postgres)
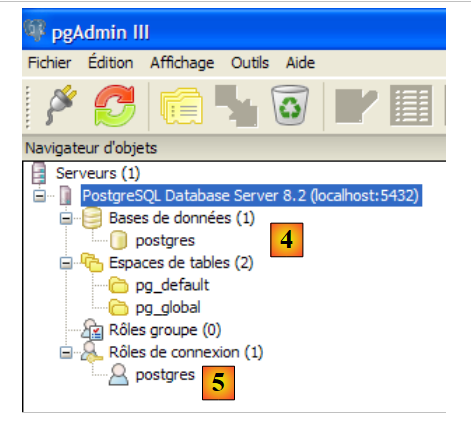 |
- en [4]: la única base de datos existente
- en [5]: el único usuario existente
5.6.4. Creación de un usuario «jpa» y de una base de datos «jpa»
El tutorial utiliza PostgreSQL con una base de datos llamada jpa y un usuario con el mismo nombre. Ahora los vamos a crear. Primero, el usuario:
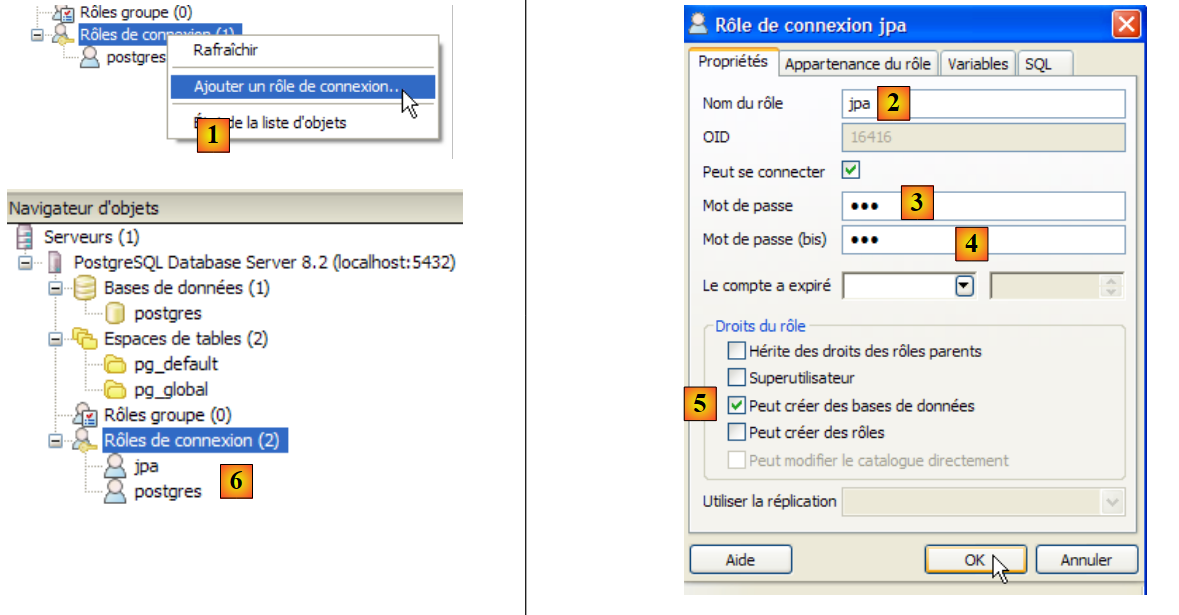 |
- en [1]: creamos un nuevo rol (~usuario)
- en [2]: creación del usuario jpa
- en [3]: su contraseña es jpa
- en [4]: se repite la contraseña
- en [5]: se autoriza al usuario a crear bases de datos
- en [6]: el usuario [jpa] aparece entre los roles de conexión
Ahora, la base de datos:
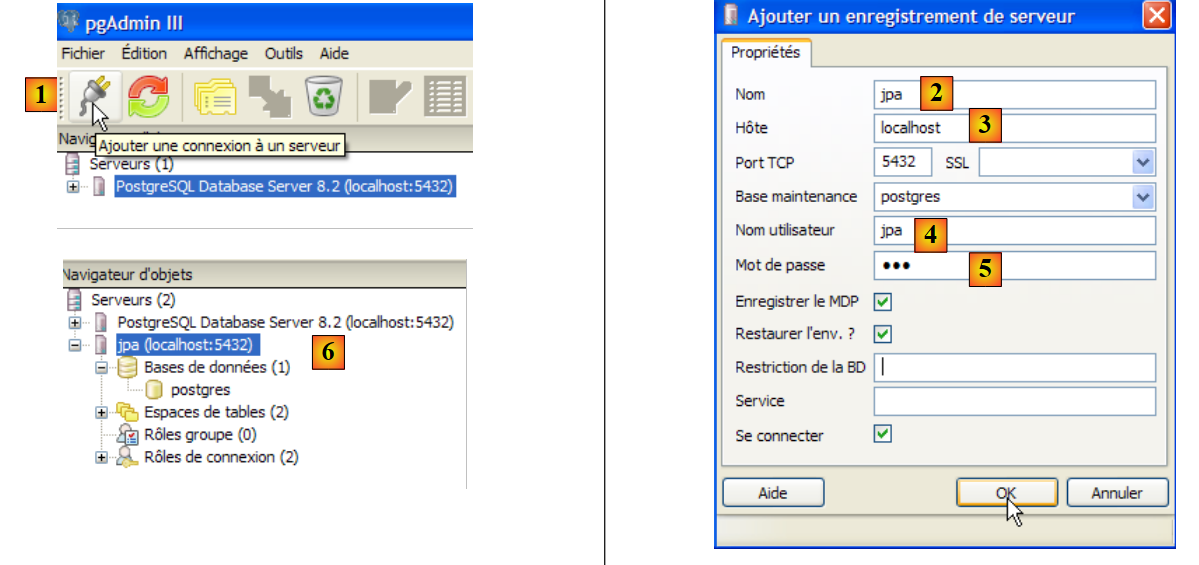 |
- en [1]: se crea una nueva conexión al servidor
- en [2]: se llamará jpa
- en [3]: máquina a la que queremos conectarnos
- en [4]: el usuario que se conecta
- en [5]: su contraseña. Se valida la configuración de la conexión mediante [OK]
- en [6]: se ha creado la nueva conexión. Pertenece al usuario jpa. Este va a crear ahora una nueva base de datos:
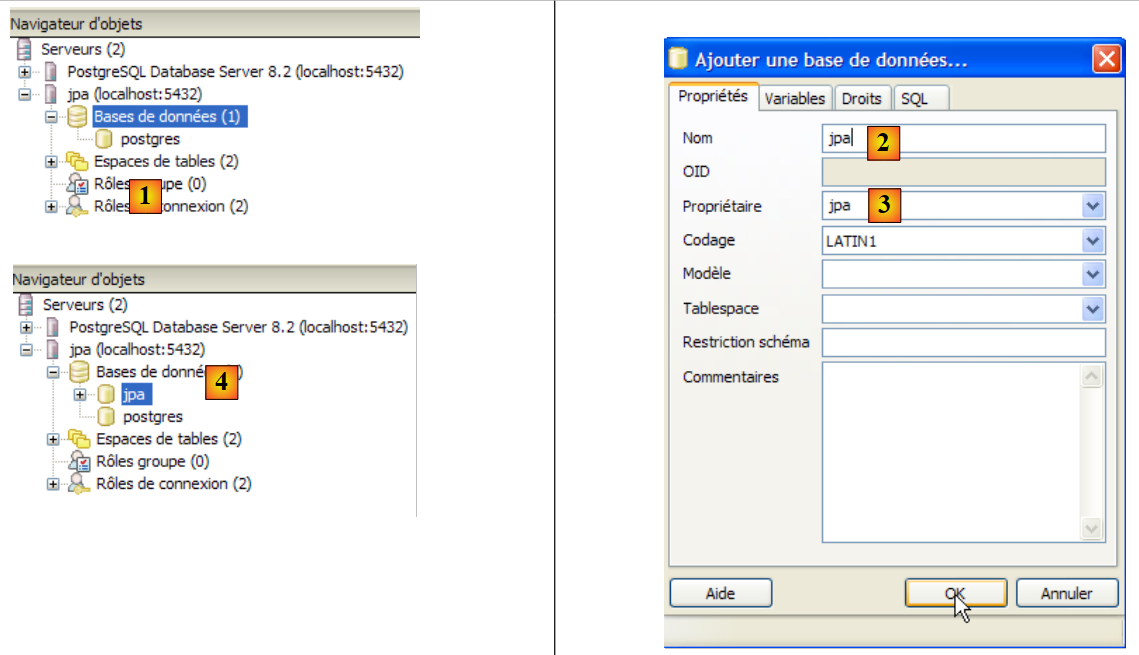 |
- n [1]: se añade una nueva base de datos
- en [2]: su nombre es jpa
- en [3]: su propietario es el usuario jpa creado anteriormente. Se valida mediante [OK]
- en [4]: se ha creado la base de datos «jpa». Con un simple clic sobre ella, nos conectamos a ella y podemos ver su estructura:
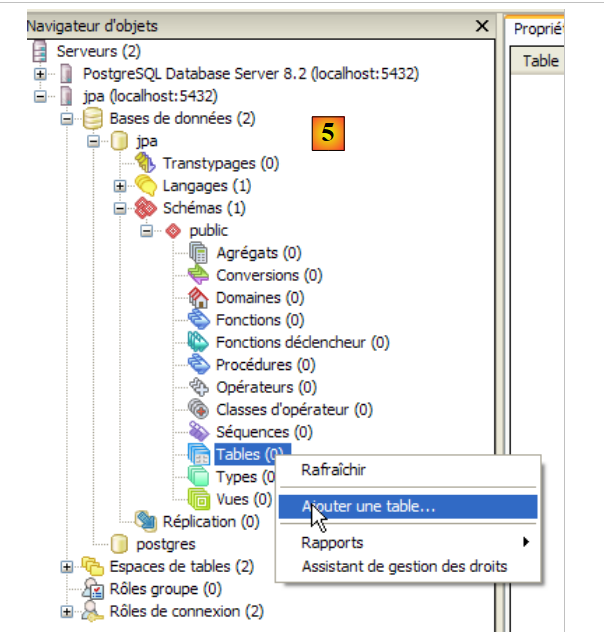 |
- en [5]: aparecen los objetos del esquema [jpa], en particular las tablas. Todavía no hay ninguna. Con un clic con el botón derecho se podrían crear. Dejamos que el lector lo haga.
Ahora vamos a crear la misma tabla [ARTICLES] que con las anteriores SGBD utilizando el script SQL [schema-articles.sql] generado en el apartado 5.4.6.
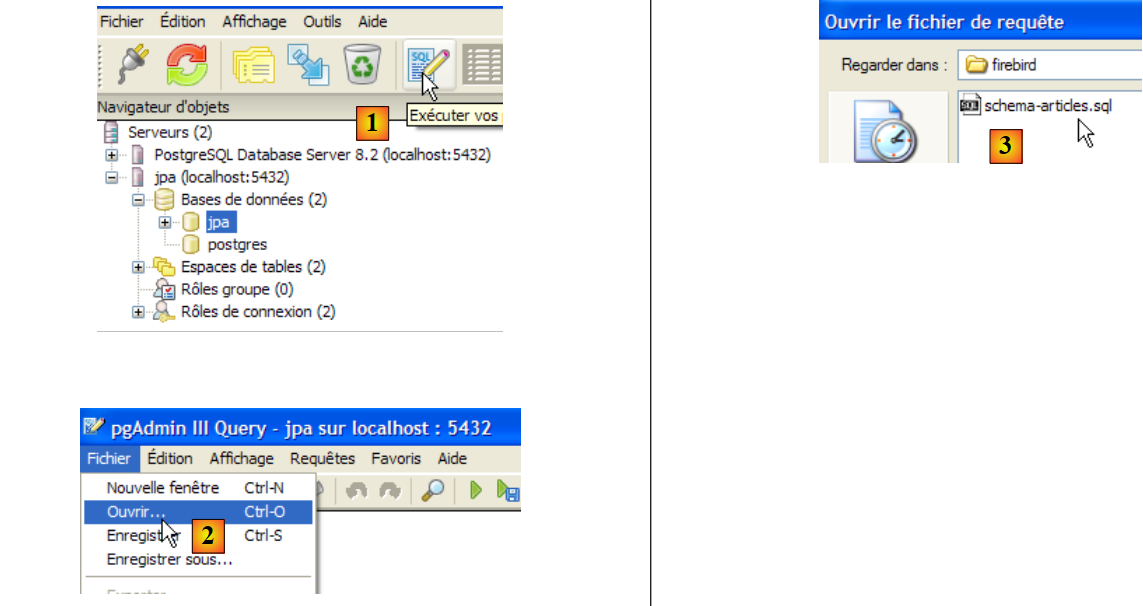 |
- en [1]: abrir el editor SQL
- en [2]: abrir un script SQL
- en [3]: seleccionar el script [schema-articles.sql] creado en el apartado 5.4.6.
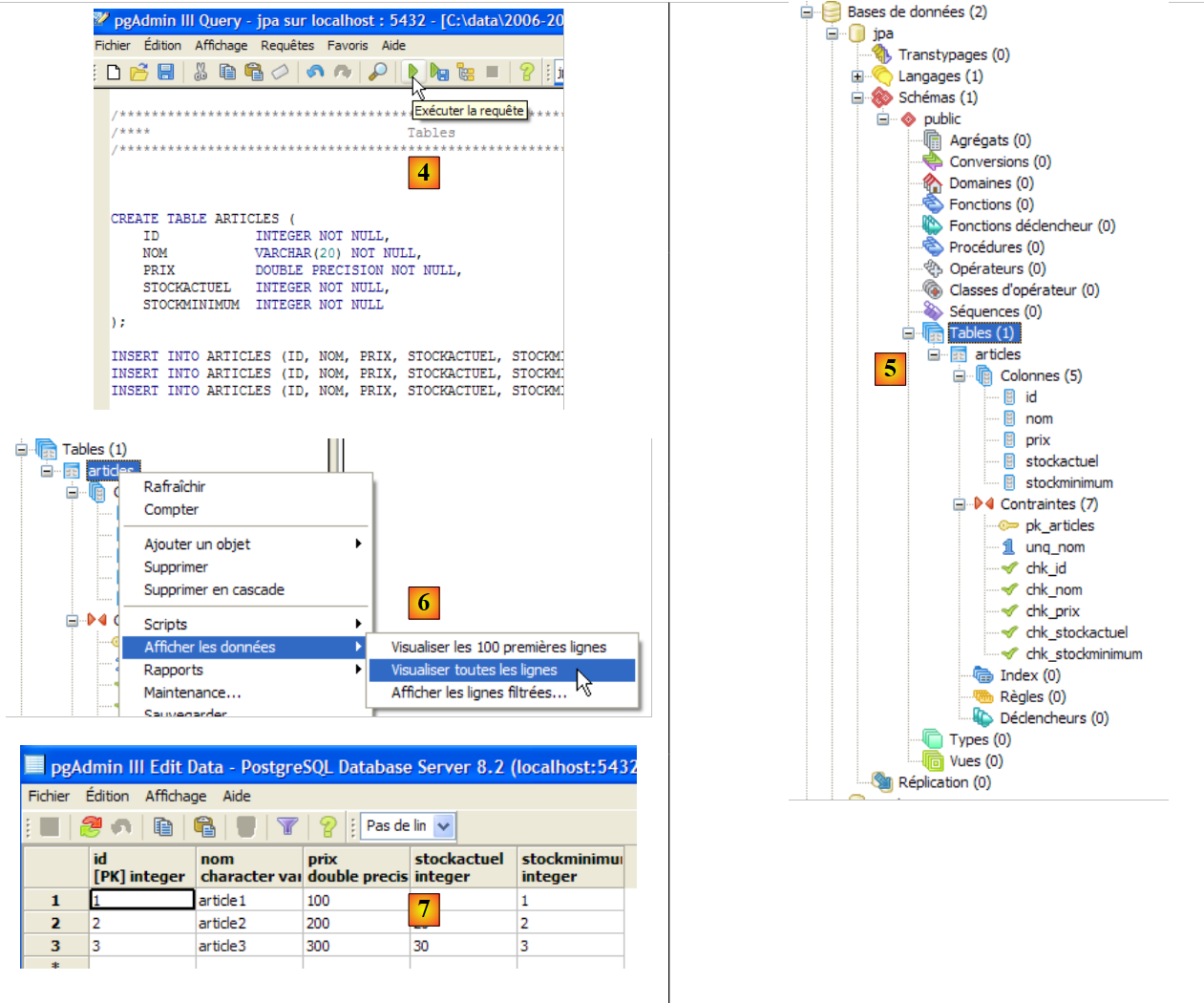 |
- en [4]: el script se ha cargado. Se ejecuta.
- en [5]: se ha creado la tabla [ARTICLES].
- en [6, 7]: su contenido
5.6.5. Controlador JDBC de PostgreSQL
El controlador JDBC de PostgreSQL está disponible en la carpeta [jdbc] de la carpeta de instalación de PostgreSQL:
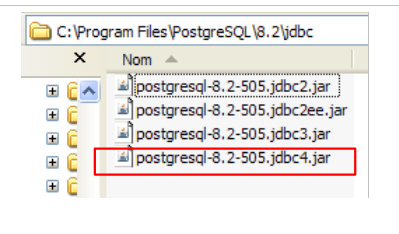 |
Colocamos el archivo Jdbc, al igual que los anteriores (apartado 5.4.7), en la carpeta <jdbc>:
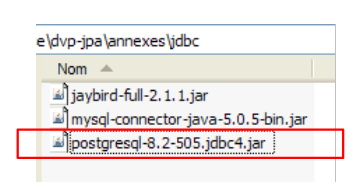 |
Para probar este controlador JDBC, utilizaremos Eclipse y el complemento SQL Explorer. Se recomienda al lector que siga los pasos explicados en el apartado 5.4.7. A continuación se muestran algunas capturas de pantalla significativas:
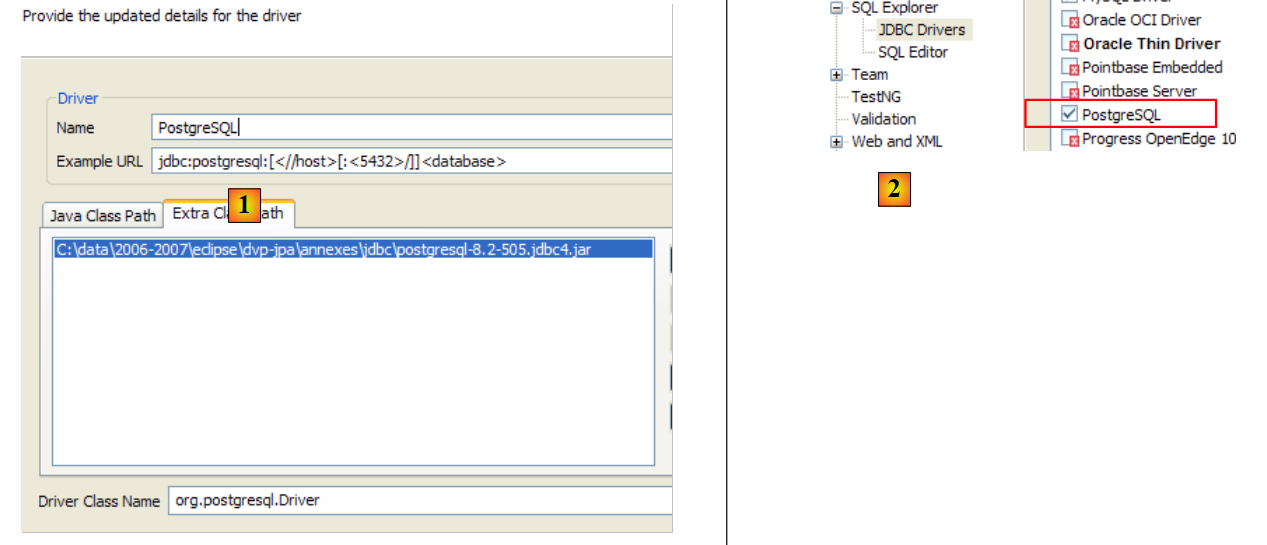 |
- en [1]: se ha cambiado el nombre del archivo del controlador JDBC de PostgreSQL
- en [2]: el controlador JDBC de PostgreSQL está disponible
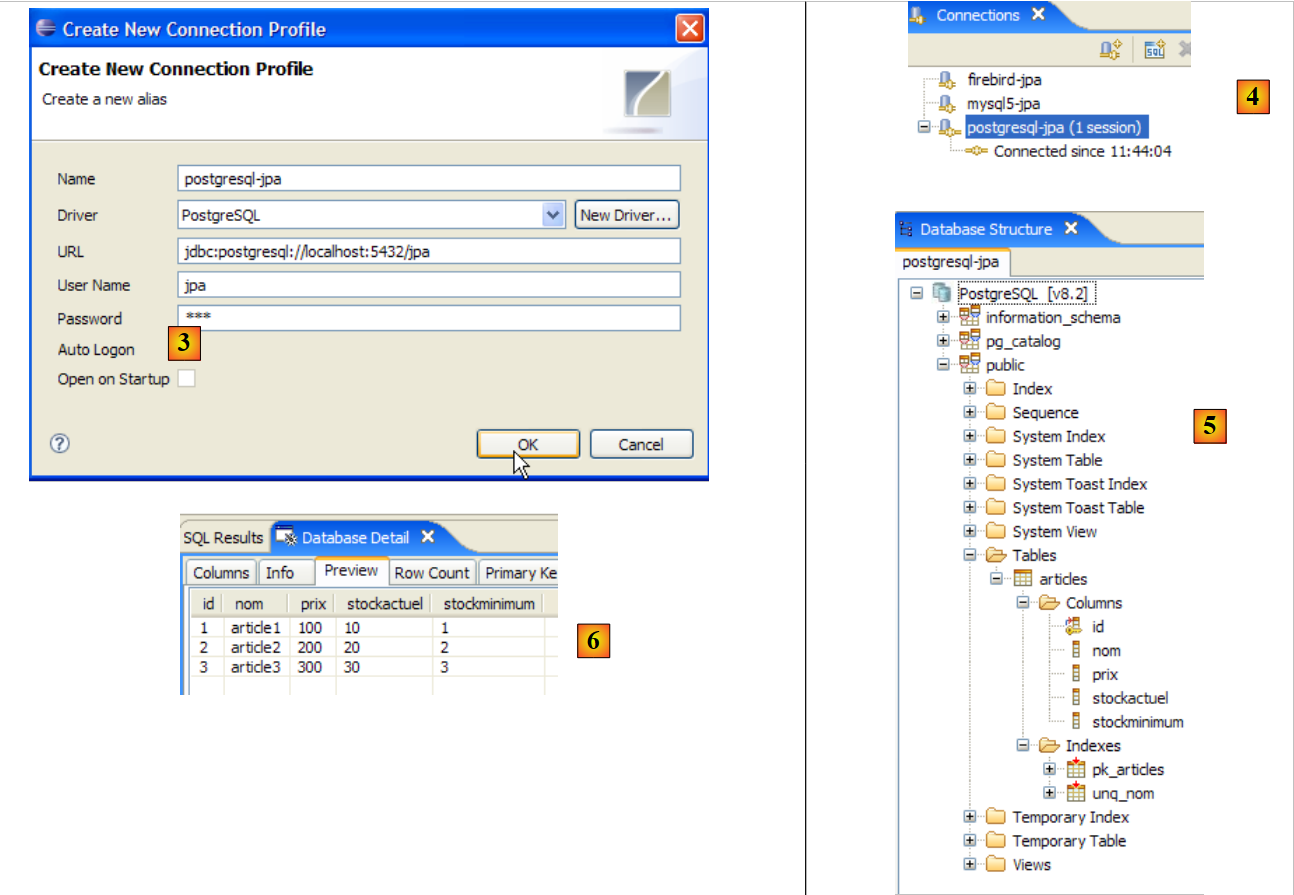 |
- a [3]: definición de la conexión (usuario, contraseña)=(jpa, jpa)
- en [4]: la conexión está activa
- en [5]: base de datos conectada
- en [6]: el contenido de la tabla [ARTICLES]
5.7. El SGBD a Oracle 10g Express
5.7.1. Instalación
El SGBD Oracle 10g Express está disponible en la URL [http://www.oracle.com/technology/software/products/database/xe/index.html]:
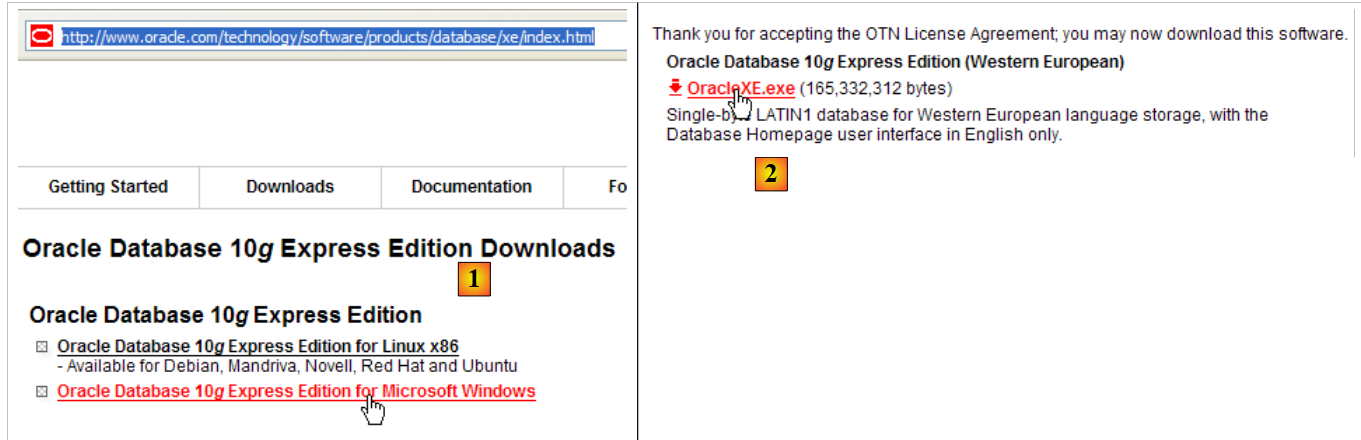 |
- en [1]: la página de descargas de Oracle 10g Express
- en [2]: elige una versión para Windows. Una vez descargado el archivo, ejecútalo:
 |
- en [1]: hacer doble clic en el archivo [OracleXE.exe]
- en [2]: la primera página del asistente de instalación
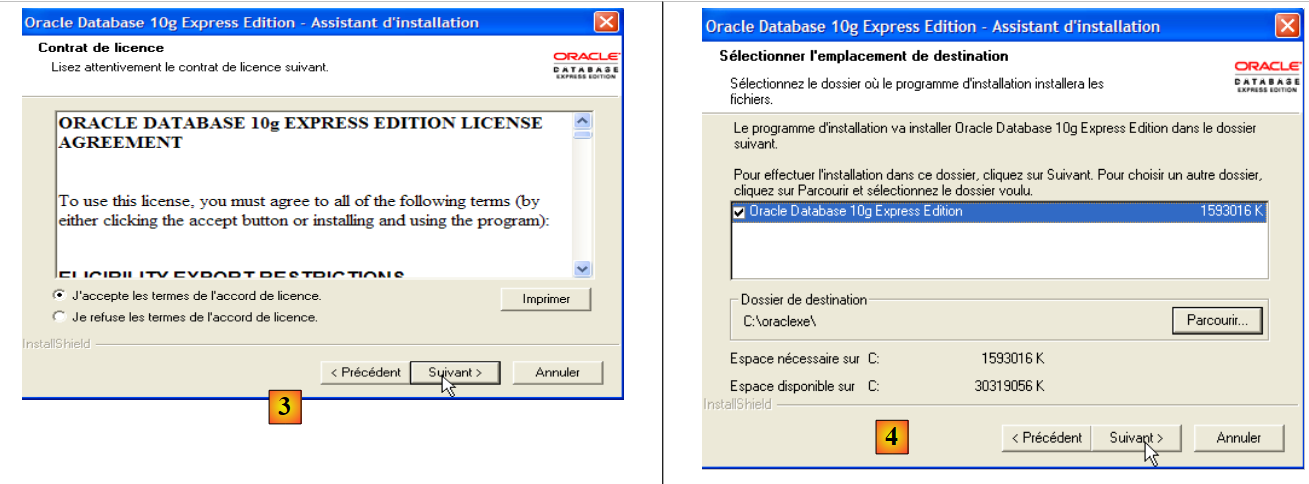 |
- en [3]: acepta la licencia
- en [4]: acepta los valores predeterminados.
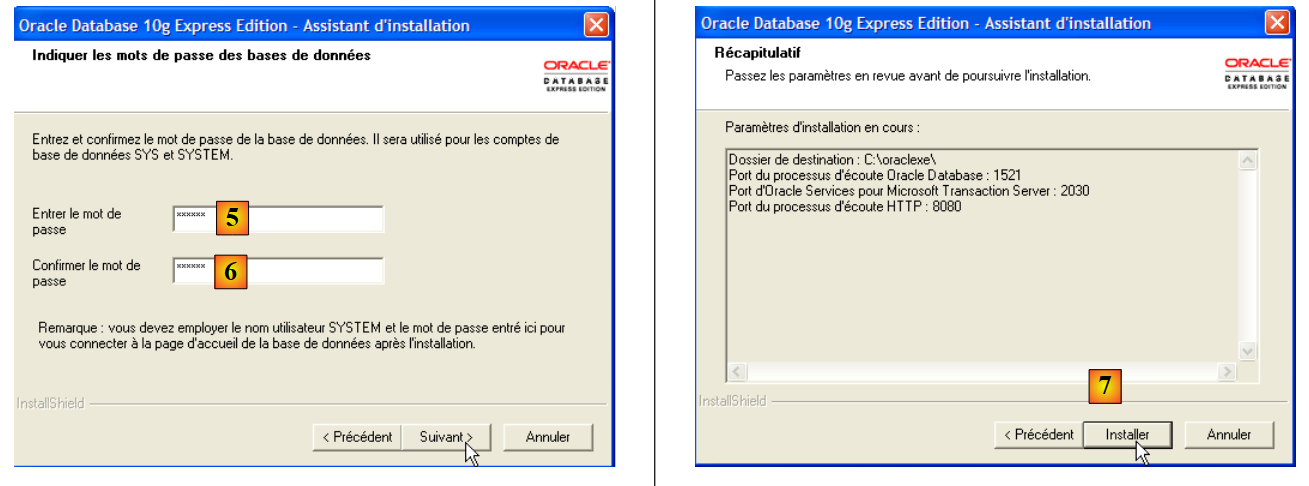 |
- en [5,6]: el usuario SYSTEM tendrá la contraseña «system».
- en [7]: se inicia la instalación
La instalación de Oracle 10g Express crea una carpeta en [Démarrer / Programmes ]:
5.7.2. Iniciar/Detener Oracle 10g
Al igual que en los SGBD anteriores, Oracle 10g se instaló como un servicio de Windows de inicio automático. Modificamos esta configuración:
[Démarrer / Panneau de configuration / Performances et maintenance / Outils d'administration / Services ]:
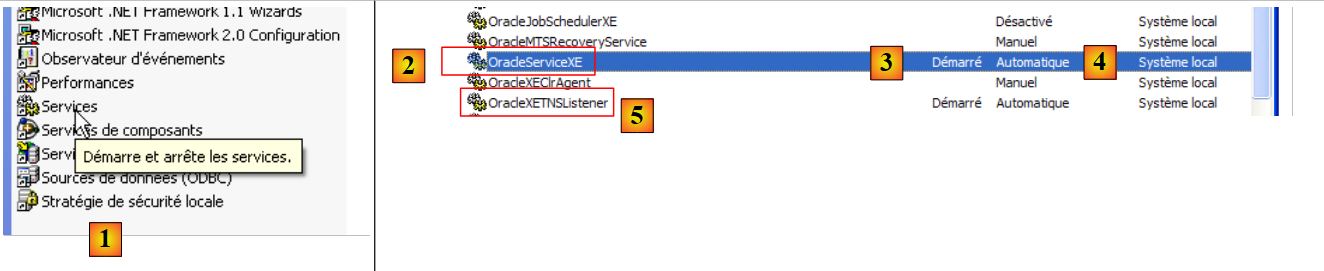 |
- en [1]: hacemos doble clic en [Services]
- en [2]: vemos que hay un servicio llamado [OracleServiceXE], que está en marcha ([3]) y que su inicio es automático ([4]).
- en [5]: otro servicio de Oracle, llamado «Listener», también está activo y se inicia automáticamente.
Para modificar este comportamiento, hacemos doble clic en el servicio [OracleServiceXE]:
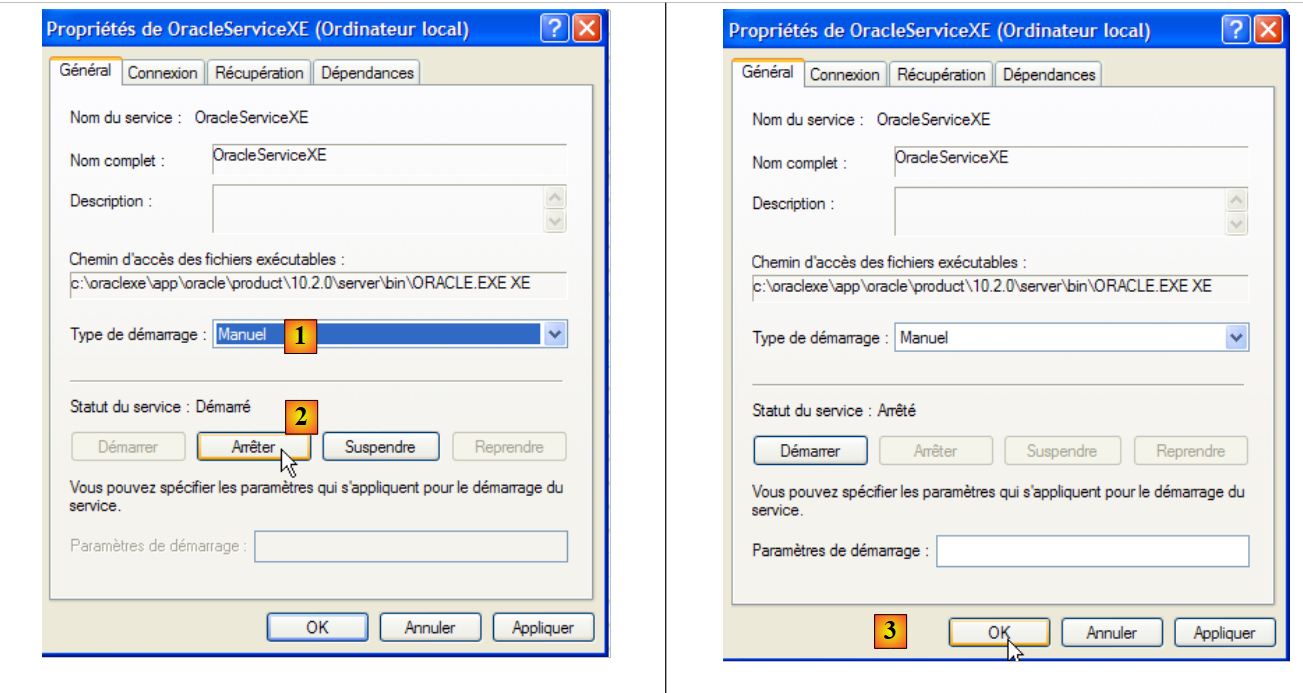 |
- en [1]: configuramos el servicio para que se inicie manualmente
- en [2]: lo detenemos
- en [3]: confirmamos la nueva configuración del servicio
Se procederá de la misma manera con el servicio [OracleXETNSListener] (véase [5] más arriba). Para iniciar y detener manualmente el servicio OracleServiceXE, se pueden utilizar los accesos directos de la carpeta [Oracle]:
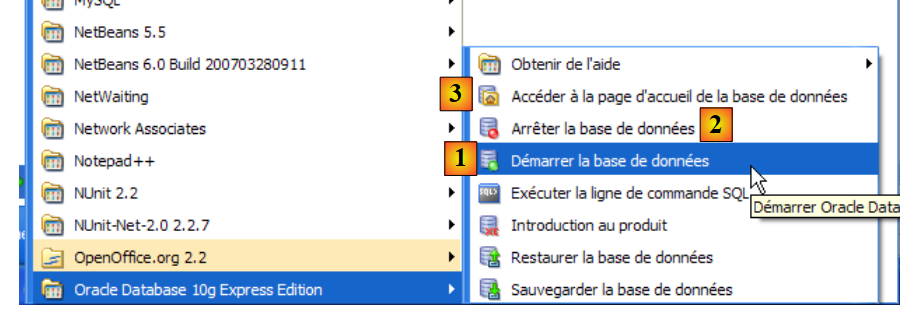 |
- en [1]: para iniciar el SGBD
- en [2]: para detenerlo
- en [3]: para administrarlo (lo que lo inicia si aún no está en marcha)
5.7.3. Creación de un usuario jpa y de una base de datos jpa
En la captura de pantalla anterior, la aplicación [3] permite administrar el SGBD Oracle 10g Express. Iniciemos SGBD [1] y, a continuación, la aplicación de administración [3] a través del menú anterior:
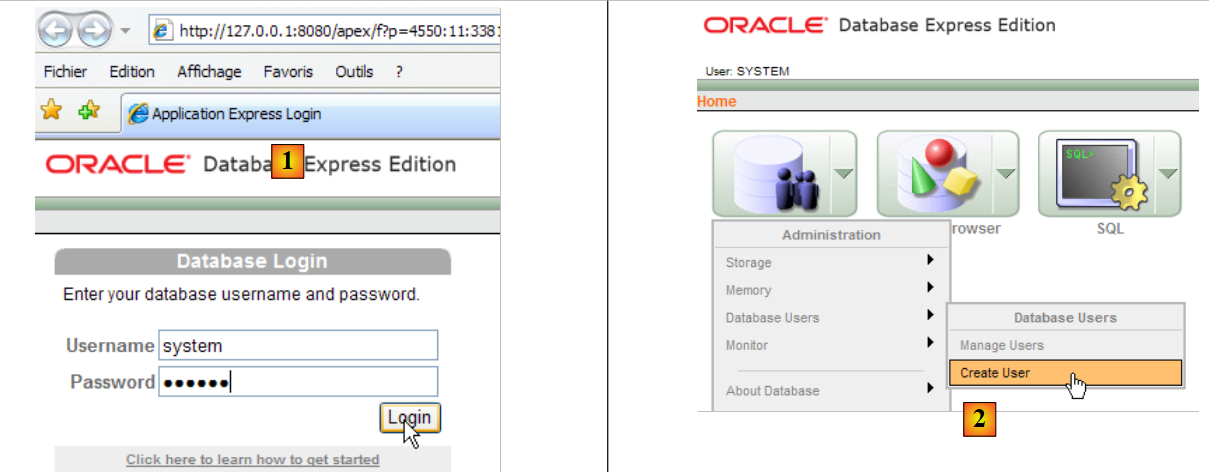 |
- en [1]: iniciar sesión como administrador de SGBD, en este caso (system / system)
- en [2]: se crea un nuevo usuario
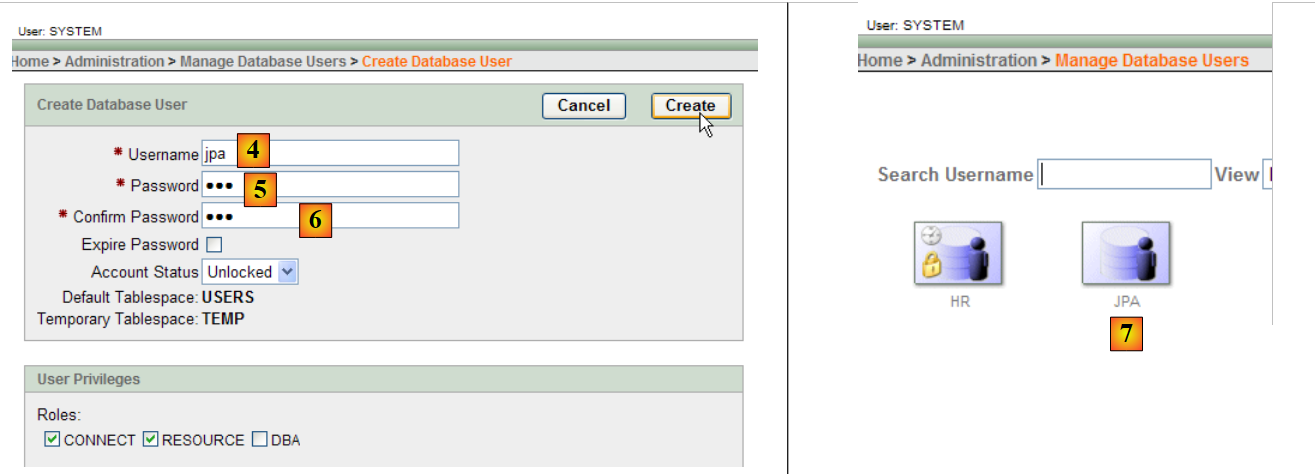 |
- en [4]: nombre de usuario
- en [5, 6]: su contraseña, en este caso «jpa»
- en [7]: se ha creado el usuario «jpa»
En Oracle, un usuario se asocia automáticamente a una base de datos con el mismo nombre. Por lo tanto, la base de datos «jpa» existe al mismo tiempo que el usuario «jpa».
5.7.4. Creación de la tabla [ARTICLES] de la base de datos jpa
OracleXE se ha instalado con un cliente SQL que funciona en modo de línea de comandos. Se puede trabajar con mayor comodidad con el e SQL Developer, también proporcionado por Oracle. Se puede encontrar en la página web:
[http://www.oracle.com/technology/products/database/sql_developer/index.html]
 |
- en [1]: la página de descargas
- en [2]: elegir una versión para Windows sin JRE si ya está instalado (como es el caso aquí), ya que [SQL Developer] es una aplicación Java.
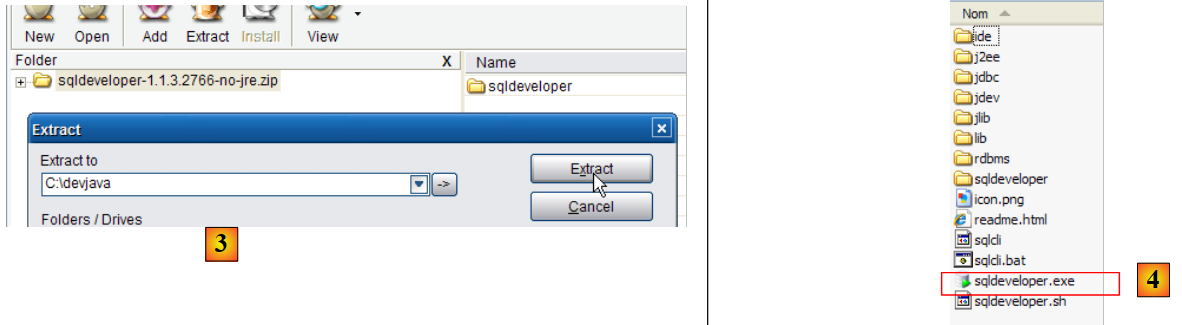 |
- en [3]: descomprimir el archivo ZIP descargado
- en [4]: ejecutar el archivo ejecutable [sqldeveloper.exe]
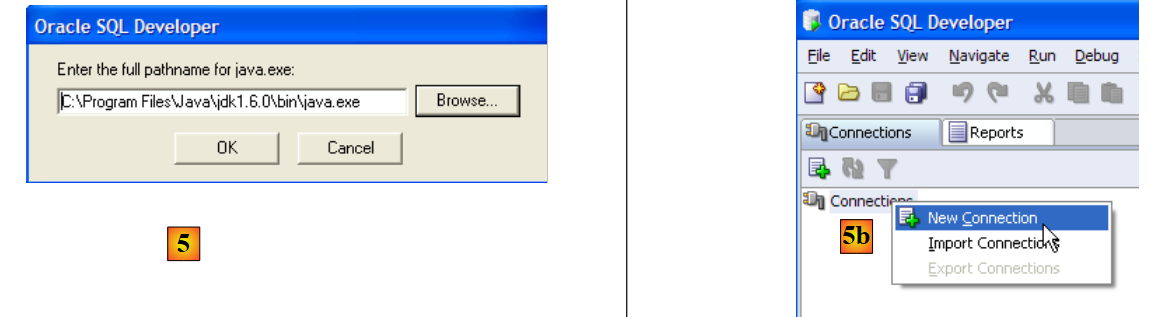 |
- en [5]: al iniciar [SQL Developer] por primera vez, indica la ruta del JRE instalado en el equipo
- en [5b]: crear una nueva conexión
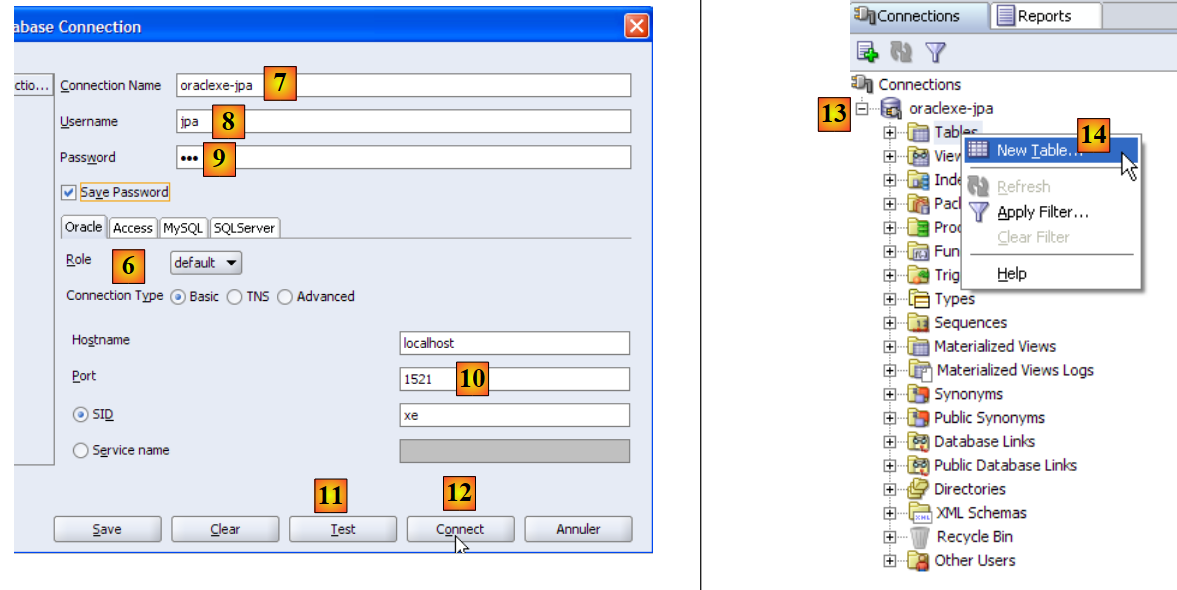 |
- en [6]: SQL Developer permite conectarse a diversos SGBD. Selecciona Oracle.
- en [7]: nombre asignado a la conexión que se está creando
- en [8]: propietario de la conexión
- en [9]: su contraseña (jpa)
- en [10]: mantener los valores por defecto
- en [11]: para probar la conexión (Oracle debe estar en ejecución)
- en [12]: para finalizar la configuración de la conexión
- en [13]: los objetos de la base de datos jpa
- en [14]: se pueden crear tablas. Al igual que en los casos anteriores, vamos a crear la tabla [ARTICLES] a partir del script creado en el apartado 5.4.6.
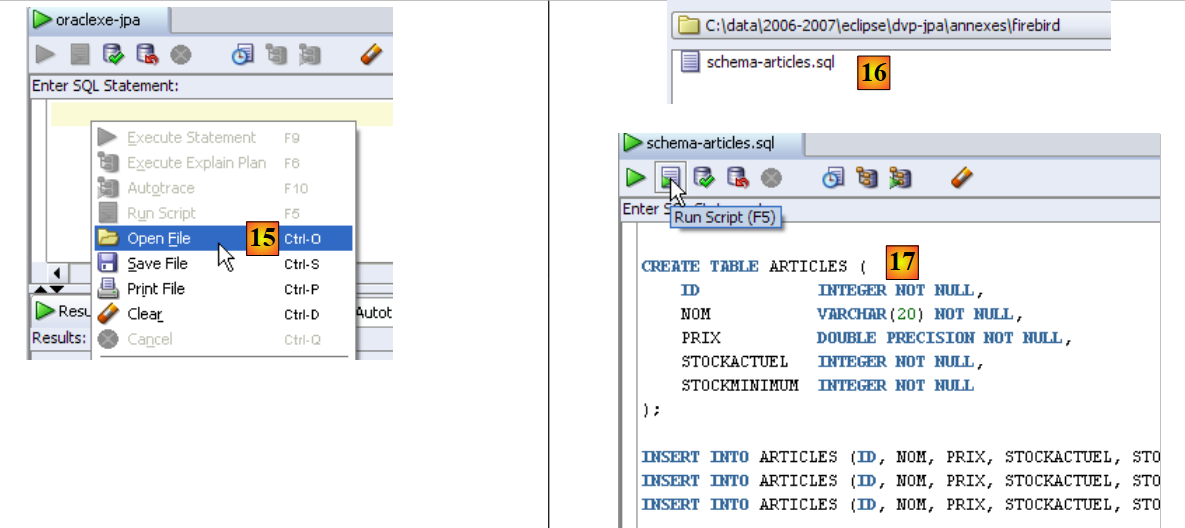 |
- en [15]: se abre un script SQL
- en [16]: se designa el script SQL creado en el apartado 5.4.6.
- en [17]: el script que se va a ejecutar
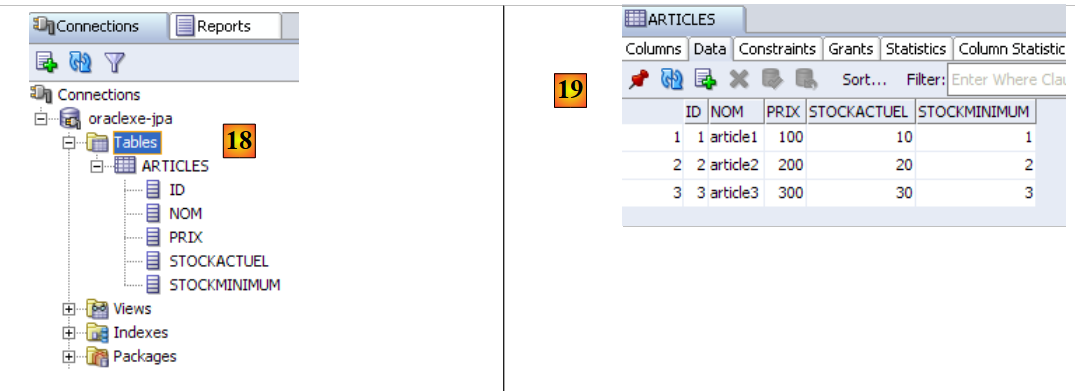 |
- en [18]: el resultado de la ejecución: se ha creado la tabla [ARTICLES]. Haz doble clic sobre ella para acceder a sus propiedades.
- en [19]: el contenido de la tabla.
5.7.5. Controlador JDBC de OracleXE
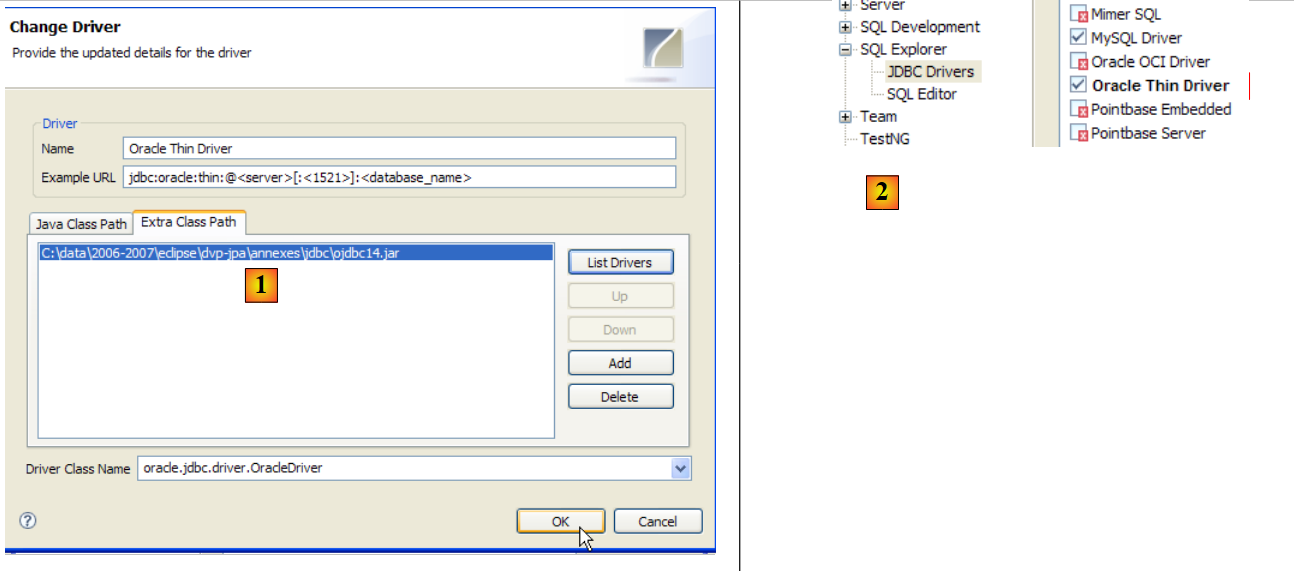
El controlador JDBC de OracleXE está disponible en la carpeta [jdbc/lib] de la carpeta de instalación de OracleXE [1]:
 |
Colocamos el archivo JDBC [ojdbc14.jar], al igual que los anteriores (apartado 5.4.7), en la carpeta <jdbc> [2]:
Para probar este controlador JDBC, utilizaremos Eclipse y el complemento SQL Explorer. Se recomienda al lector que siga los pasos explicados en el apartado 5.4.7. A continuación, mostramos algunas capturas de pantalla significativas:
 |
- en [1]: se ha designado el archivo del controlador JDBC de OracleXE
- en [2]: el controlador JDBC de OracleXE está disponible
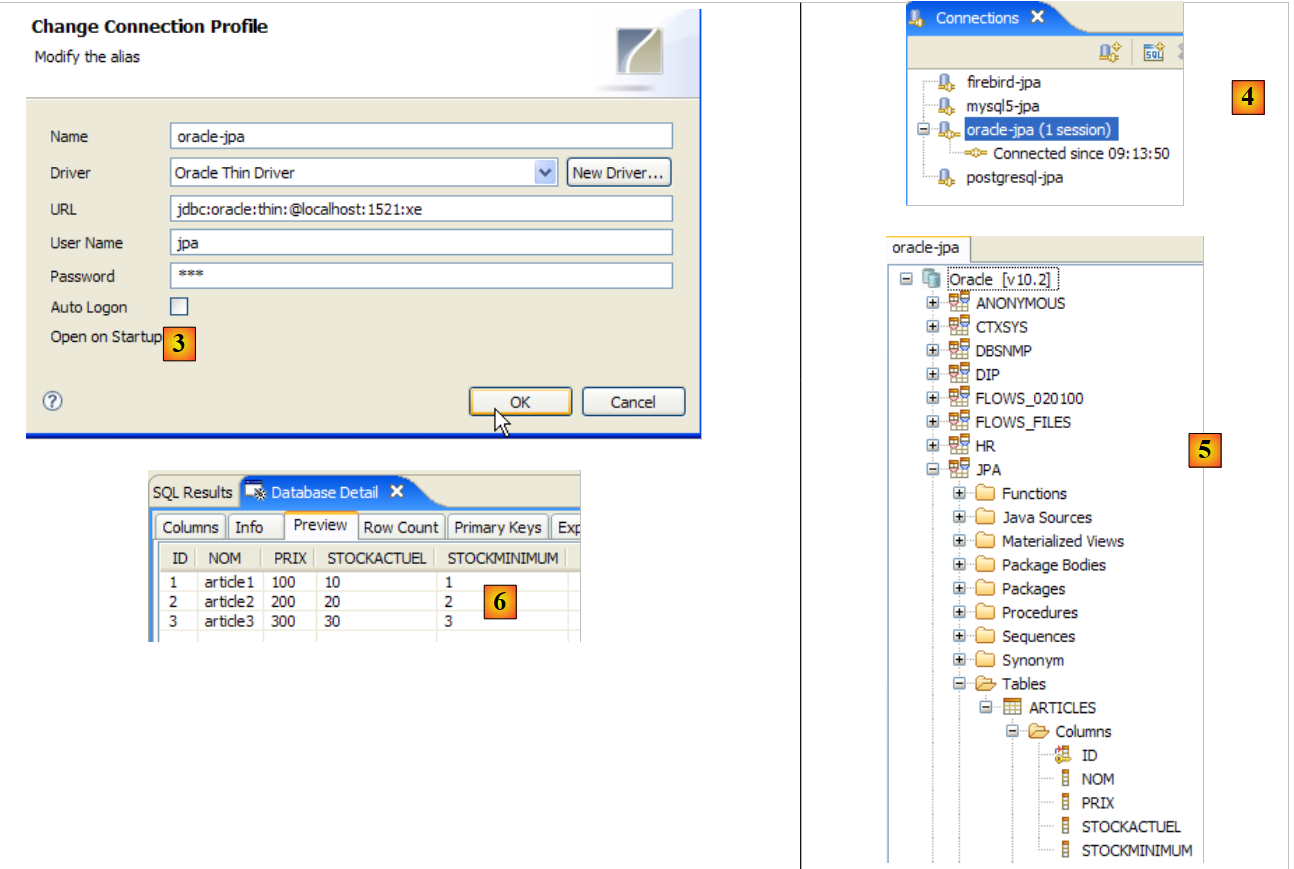 |
- en [3]: definición de la conexión (usuario, contraseña)=(jpa, jpa)
- en [4]: la conexión está activa
- en [5]: base de datos conectada
- en [6]: el contenido de la tabla [ARTICLES]
5.8. El SGBD e al SQL Server Express 2005
5.8.1. Instalación
El SGBD SQL Server Express 2005 está disponible en la URL [http://msdn.microsoft.com/vstudio/express/sql/download/]:
 |
- en [1]: primero descarga e instala la plataforma .NET 2.0
- en [2]: a continuación, instalar y descargar SQL Server Express 2005
- en [3]: a continuación, instalar y descargar SQL Server Management Studio Express, que permite administrar SQL Server
La instalación de SQL Server Express crea una carpeta en [Démarrer / Programmes ]:
 |
- en [1]: la aplicación de configuración de SQL Server. También permite iniciar y detener el servidor
- en [2]: la aplicación de administración del servidor
5.8.2. Iniciar/detener el servidor SQL
Al igual que en los casos anteriores de SGBD, el servidor SQL Express se ha instalado como un servicio de Windows de inicio automático. Modificamos esta configuración:
[Démarrer / Panneau de configuration / Performances et maintenance / Outils d'administration / Services ]:
 |
- en [1]: hacemos doble clic en [Services]
- en [2]: vemos que hay un servicio llamado [SQL Server], que está en marcha ([3]) y que su inicio es automático ([4]).
- en [5]: otro servicio relacionado con SQL Server, denominado «SQL Server Browser», también está activo y se inicia automáticamente.
Para modificar este comportamiento, hacemos doble clic en el servicio [SQL Server]:
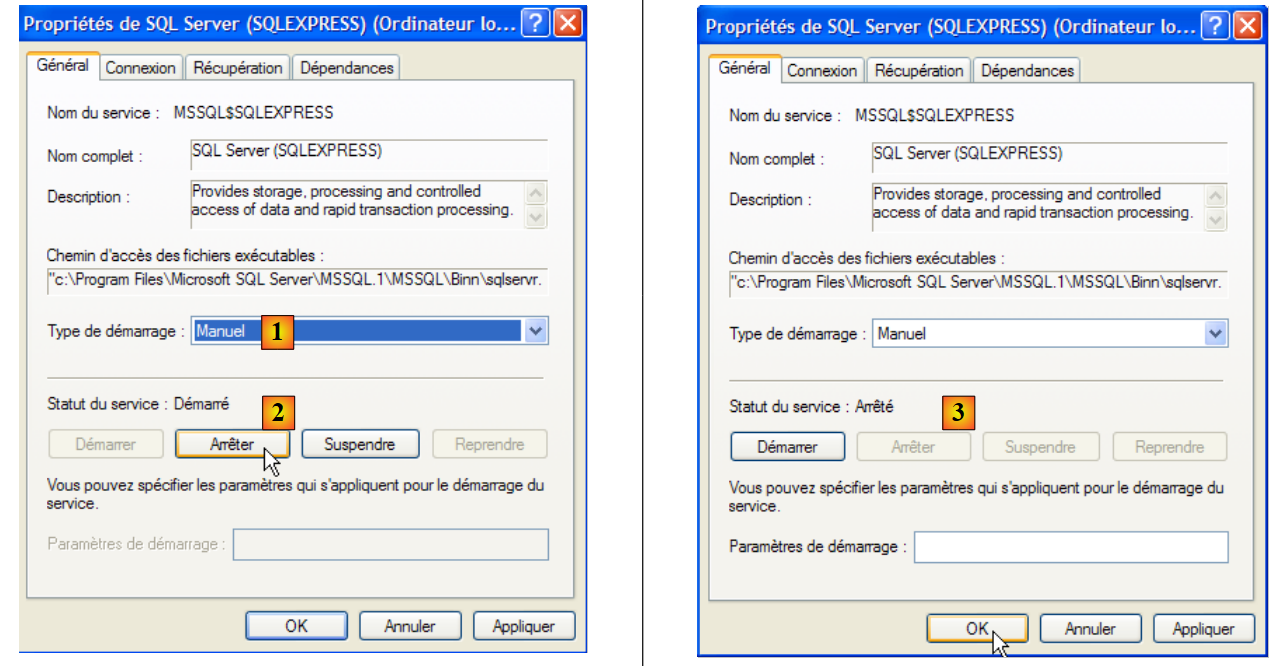 |
- en [1]: configuramos el servicio para que se inicie manualmente
- en [2]: lo detenemos
- en [3]: confirmamos la nueva configuración del servicio
Se procederá de la misma manera con el servicio [SQL Server Browser] (véase [5] más arriba). Para iniciar y detener manualmente el servidor del servicio SQL, se puede utilizar la aplicación [1] de la carpeta [SQL server]:
 |
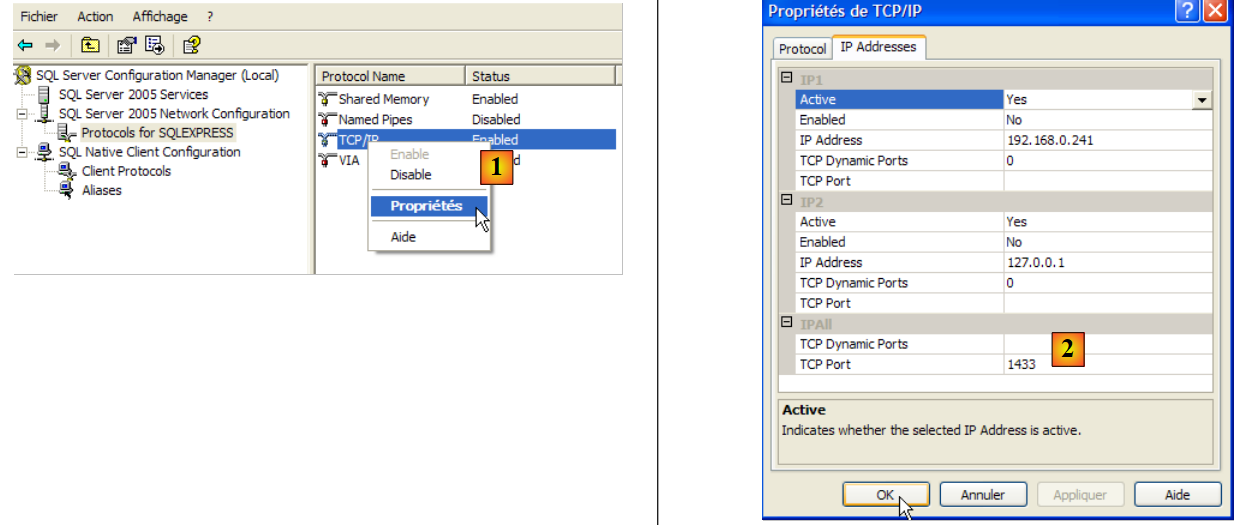 |
- en [1]: asegúrese de que el protocolo TCP/IP esté activo (enabled) y, a continuación, acceda a las propiedades del protocolo.
- en [2]: en la pestaña [IP Addresses], opción [IPAll]:
- el campo [TCP Dynamic ports] se deja vacío
- el puerto de escucha del servidor se establece en 1433 en [TCP Port]
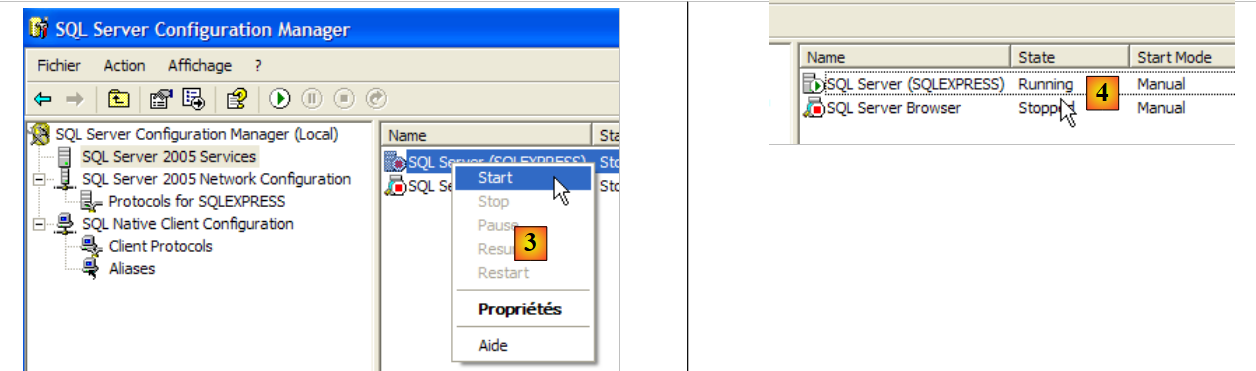 |
- en [3]: al hacer clic con el botón derecho del ratón sobre el servicio [SQL Server] se accede a las opciones de inicio y parada del servidor. Aquí lo iniciamos.
- En [4]: se ha iniciado el servidor SQL
5.8.3. Creación de un usuario jpa y de una base de datos jpa
Iniciemos el SGBD tal y como se ha indicado anteriormente y, a continuación, la aplicación de administración [1] a través del menú que aparece a continuación:
 |
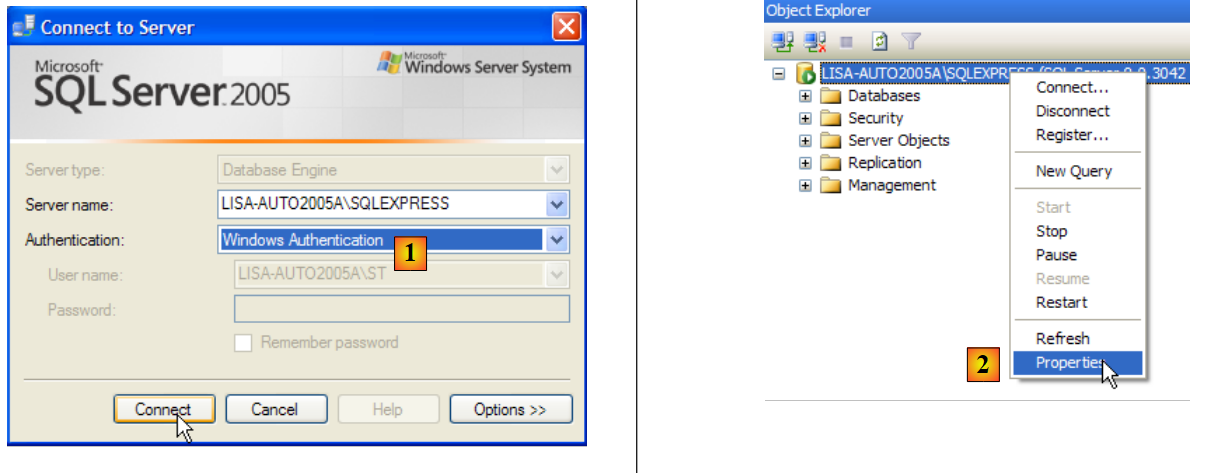 |
- en [1]: nos conectamos al servidor SQL como administrador de Windows
- en [2]: se configuran las propiedades de la conexión
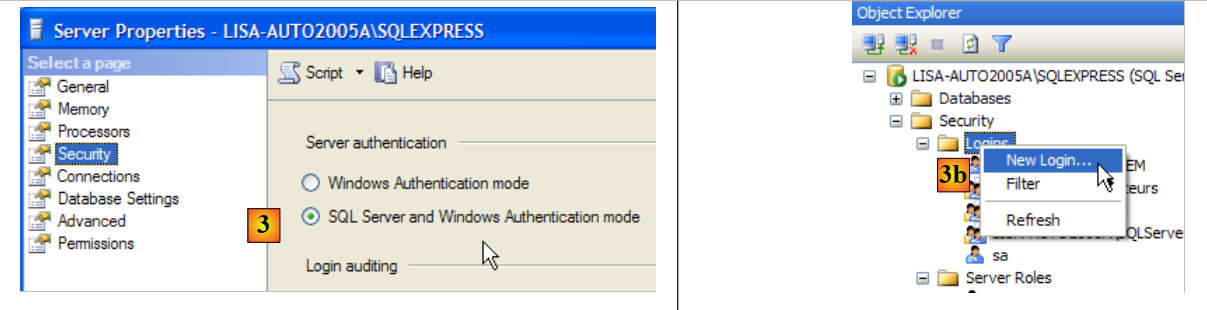 |
- en [3]: se habilita un modo mixto de conexión al servidor: bien con un inicio de sesión de Windows (un usuario de Windows), bien con un inicio de sesión de SQL Server (cuenta definida en SQL Server, independiente de cualquier cuenta de Windows).
- en [3b]: se crea un usuario del servidor SQL
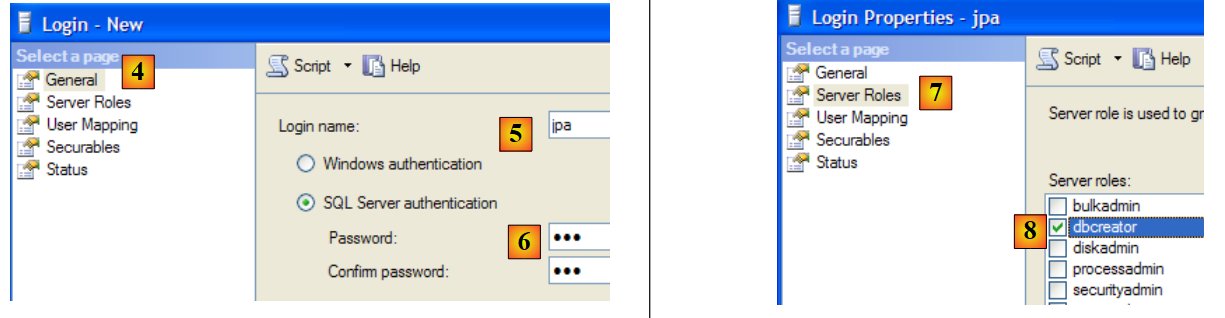 |
- en [4]: opción [General]
- en [5]: el nombre de usuario
- en [6]: la contraseña (jpa aquí)
- en [7]: opción [Server Roles]
- en [8]: el usuario «jpa» tendrá permiso para crear bases de datos
Validamos esta configuración:
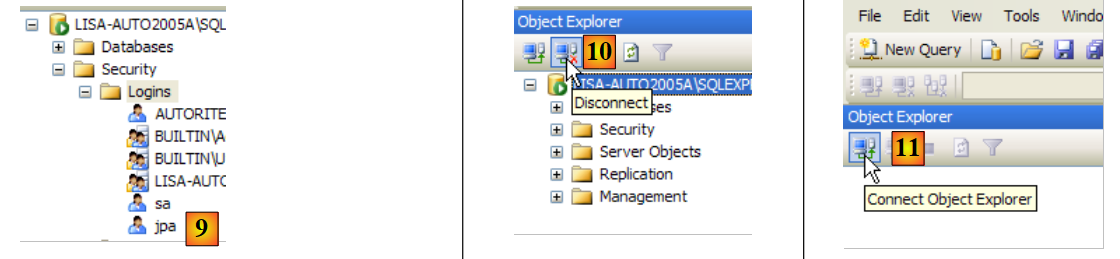 |
- en [9]: se ha creado el usuario «jpa»
- en [10]: nos desconectamos
- en [11]: volvemos a conectarnos
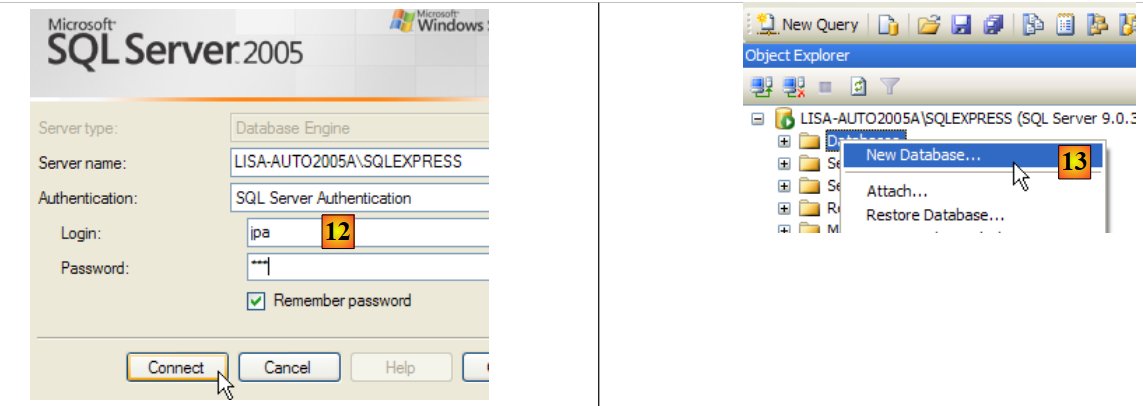 |
- en [12]: se inicia sesión como usuario jpa/jpa
- en [13]: una vez conectado, el usuario jpa crea una base de datos
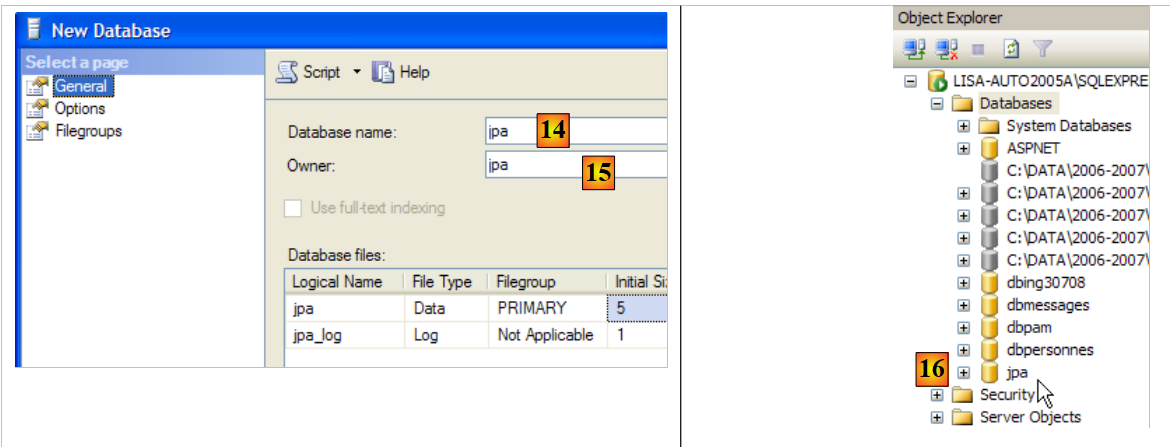 |
- en [14]: la base se llamará jpa
- en [15]: y pertenecerá al usuario jpa
- en [16]: se ha creado la base de datos jpa
5.8.4. Creación de la tabla [ARTICLES] de la base de datos jpa
Al igual que en los ejemplos anteriores, vamos a crear la tabla [ARTICLES] a partir del script creado en el apartado 5.4.6.
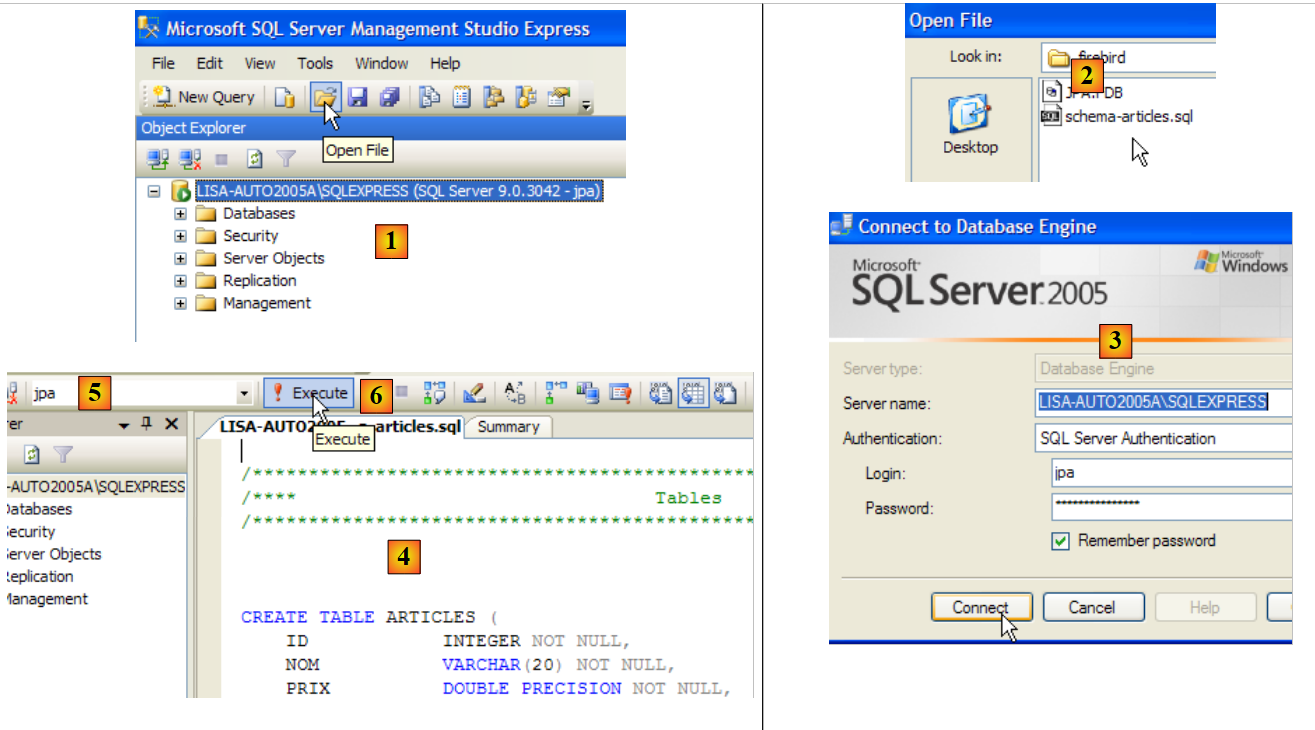 |
- en [1]: se abre un script SQL
- en [2]: se selecciona el script SQL creado en el apartado 5.4.6, página 240.
- en [3]: hay que volver a identificarse (jpa/jpa)
- en [4]: el script que se va a ejecutar
- en [5]: seleccionar la base de datos en la que se ejecutará el script
- en [6]: ejecutarlo
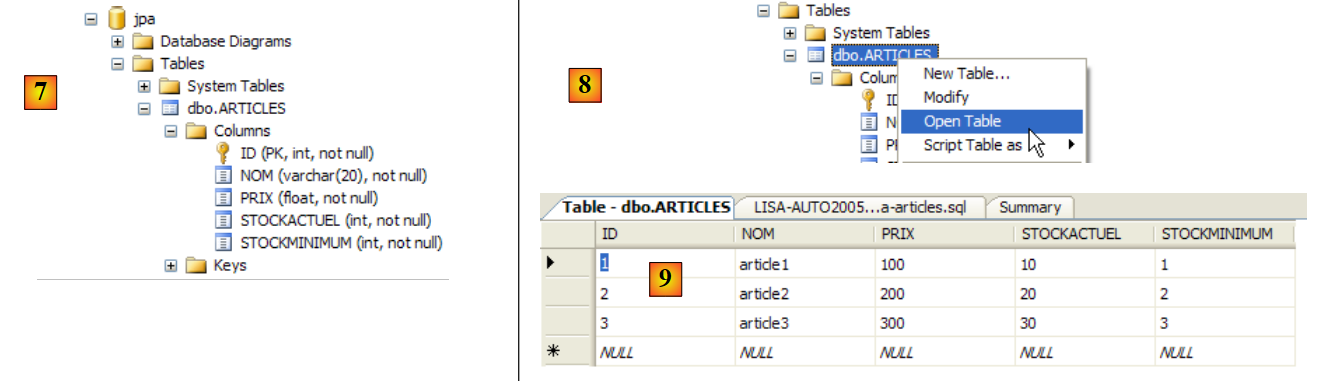 |
- en [7]: el resultado de la ejecución: se ha creado la tabla [ARTICLES].
- en [8]: se solicita ver su contenido
- en [9]: el contenido de la tabla.
5.8.5. Controlador JDBC de SQL Server Express
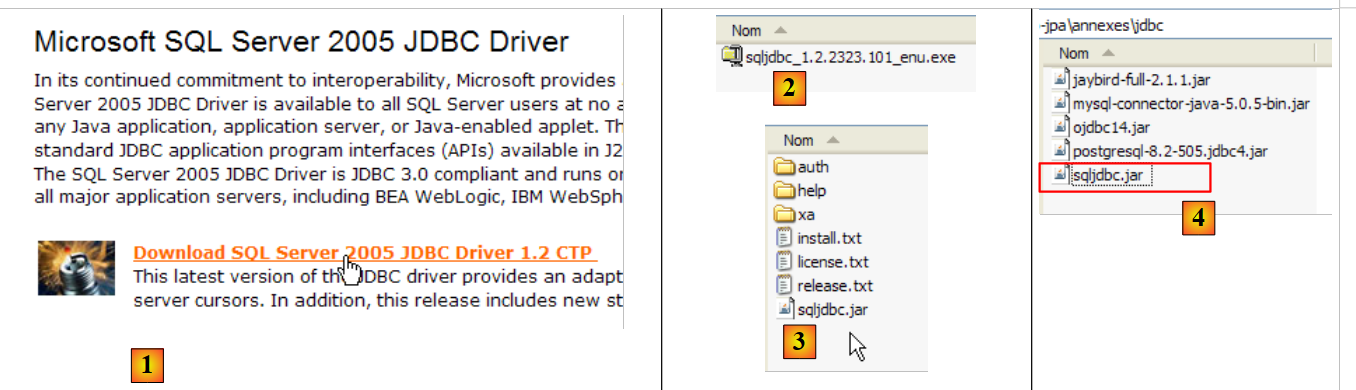 |
- en [1]: una búsqueda en Google con el texto [Microsoft SQL Server 2005 JDBC Driver] nos lleva a la página de descarga del controlador JDBC. Seleccionamos la versión más reciente
- en [2]: el archivo descargado. Hacemos doble clic sobre él. Se lleva a cabo una descompresión y se crea una carpeta en la que encontramos el controlador Jdbc [3]
- con el nombre [4]: colocamos el archivo Jdbc [sqljdbc.jar], al igual que los anteriores (apartado 5.4.7), en la carpeta <jdbc>
Para probar este controlador JDBC, utilizaremos Eclipse y el complemento SQL Explorer. Se recomienda al lector que siga los pasos explicados en el apartado 5.4.7. A continuación, mostramos algunas capturas de pantalla significativas:
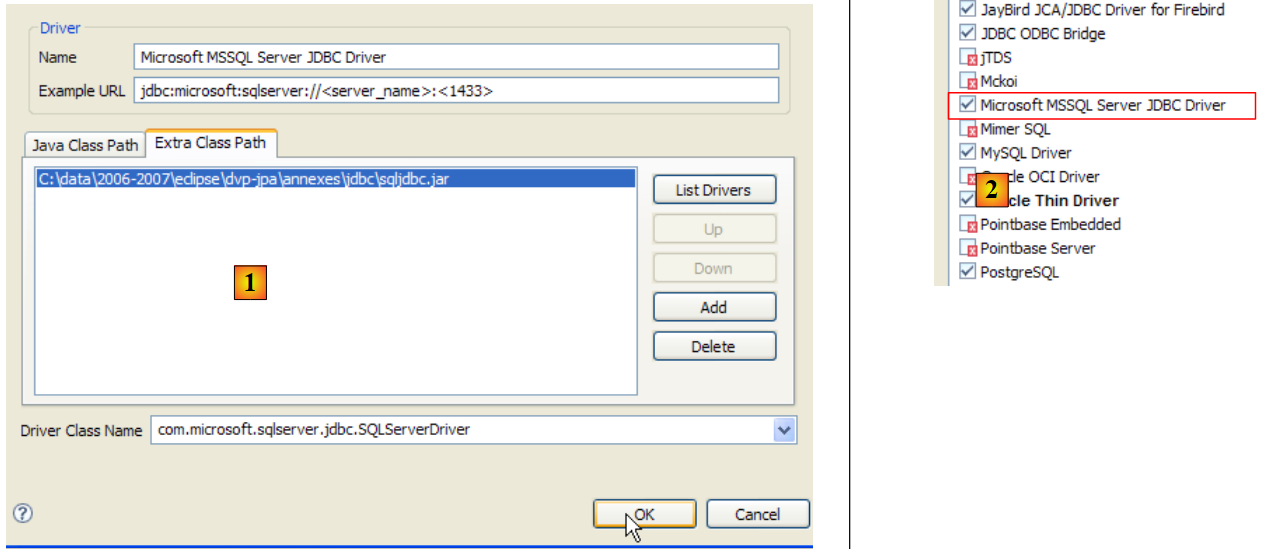 |
- en [1]: se ha designado el archivo del controlador JDBC de SQL Server
- en [2]: el controlador JDBC del servidor SQL está disponible
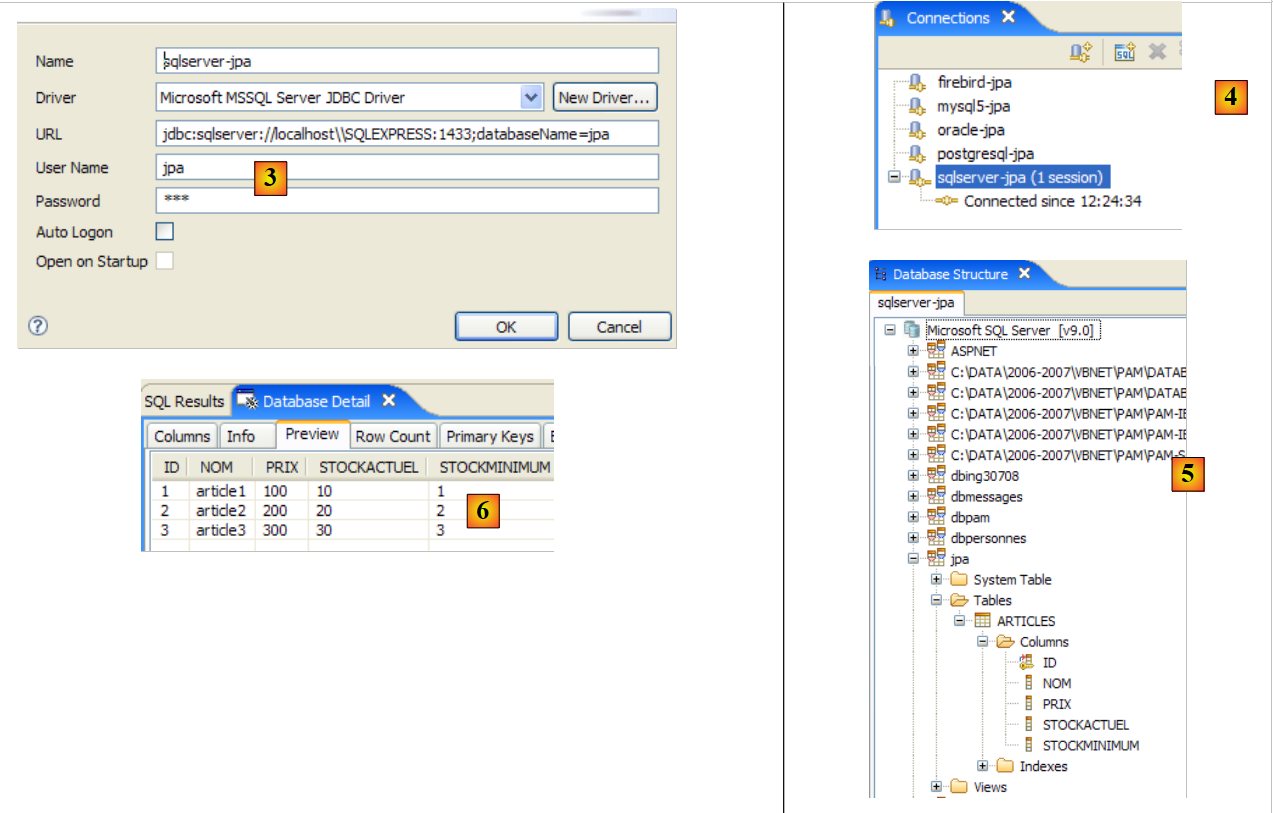 |
- en [3]: definición de la conexión (usuario, contraseña)=(jpa, jpa)
- en [4]: la conexión está activa
- en [5]: base de datos conectada
- en [6]: el contenido de la tabla [ARTICLES]
5.9. El SGBD e al HSQLDB
5.9.1. Instalación
El SGBD HSQLDB está disponible en la URL [http://sourceforge.net/projects/hsqldb]. Se trata de un SGBD escrito en Java, que ocupa muy poca memoria y gestiona bases de datos en memoria, en lugar de en disco. El resultado es una gran rapidez en la ejecución de las consultas. Esa es su principal ventaja. Las bases de datos creadas de este modo en memoria pueden recuperarse cuando se apaga y se reinicia el servidor. De hecho, las órdenes SQL emitidas para crear las bases se almacenan en un archivo de registro para volver a ejecutarlas en el siguiente arranque del servidor. De este modo, se consigue la persistencia de las bases a lo largo del tiempo.
El método tiene sus limitaciones y HSQLDB no es un SGBD destinado a fines comerciales. Su principal interés radica en las pruebas o las aplicaciones de demostración. Por ejemplo, el hecho de que HSQLDB esté escrito en Java permite incluirlo en tareas de Ant (Another Neat Tool), una herramienta Java de automatización de tareas. De este modo, las pruebas diarias del código en desarrollo, automatizadas por Ant, podrán integrar pruebas de bases de datos gestionadas por SGBD y HSQLDB. El servidor se iniciará, se detendrá y se gestionará mediante tareas Java.
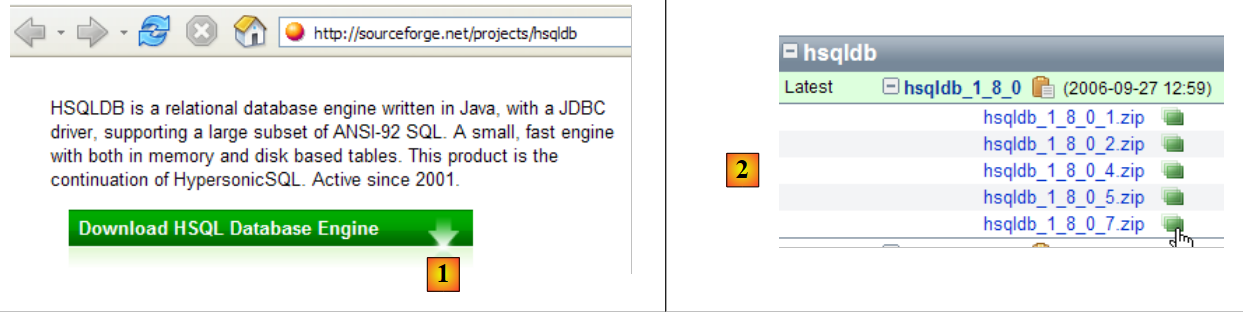 |
- en [1]: la página de descargas
- en [2]: descargar la versión más reciente
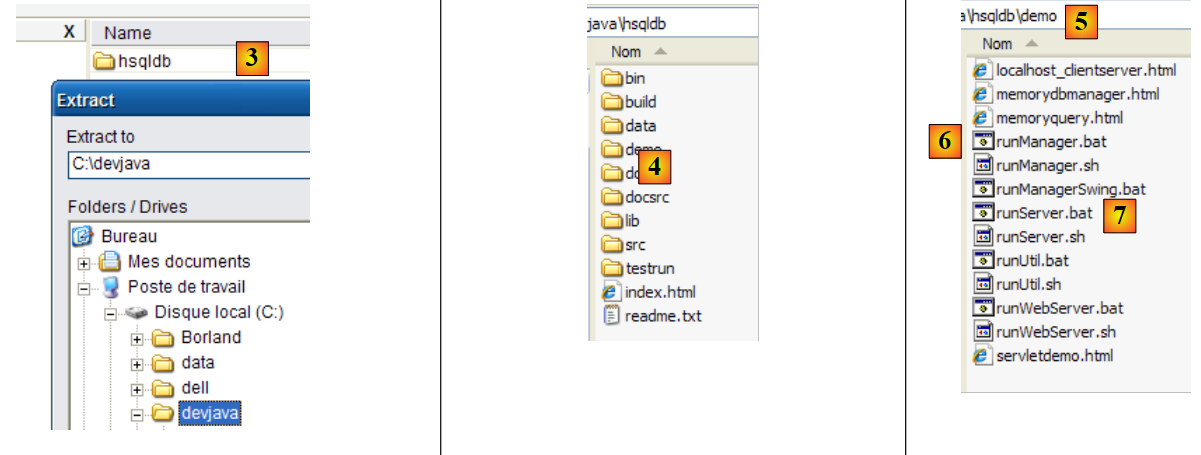 |
- en [3]: descomprimir el archivo zip descargado
- en [4]: la carpeta [hsqldb] resultante de la descompresión
- en [5]: la carpeta [demo], que contiene el script que permite iniciar el servidor [hsql] y [6], y en [7], el que permite iniciar una herramienta básica de administración del servidor.
5.9.2. Iniciar/Detener HSQLDB
Para iniciar el servidor HSQLDB, hay que hacer doble clic en la aplicación [runManager.bat] [6] que aparece arriba:
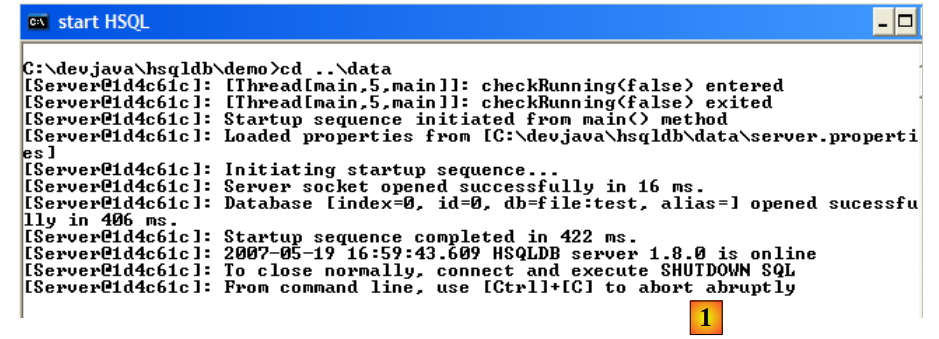 |
- en [1]: se puede ver que, para detener el servidor, basta con pulsar Ctrl+C en la ventana.
5.9.3. La base de datos [test]
La base de datos gestionada por defecto se encuentra en la carpeta [data]:
 |
- en [1]: al iniciarse, el SGBD HSQL ejecuta el script denominado [test.script]
- línea 1: se crea un esquema [public]
- línea 2: se crea un usuario [sa] con una contraseña vacía
- línea 3: se otorgan derechos de administración al usuario [sa]
Al final, se ha creado un usuario con derechos de administración. Este es el usuario que utilizaremos a partir de ahora.
5.9.4. Controlador JDBC de HSQL
El controlador JDBC de SGBD HSQL se encuentra en la carpeta [lib]:
 |
- en [1]: el archivo [hsqldb.jar] contiene el controlador JDBC de SGBD HSQL
- en [2]: colocamos este archivo, al igual que los anteriores (apartado 5.4.7), en la carpeta <jdbc>
Para comprobar este controlador JDBC, utilizaremos Eclipse y el complemento SQL Explorer. Se recomienda al lector que siga los pasos explicados en el apartado 5.4.7. A continuación, mostramos algunas capturas de pantalla significativas:
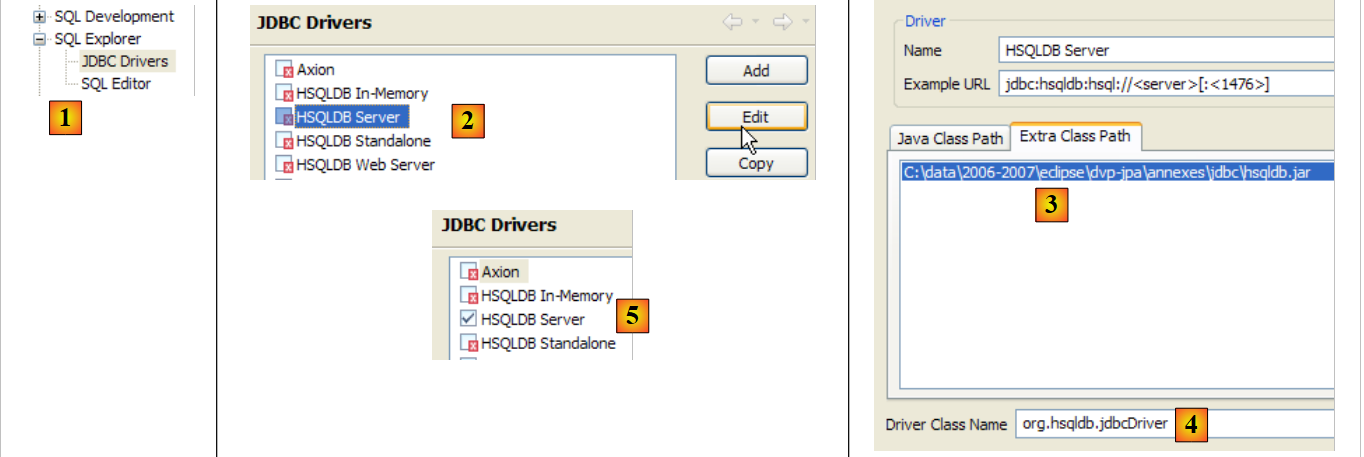 |
- en [1]: [window / preferences / SQL Explorer / JDBC Drivers]
- en [2]: se configura el servidor [HSQLDB]
- en [3]: se indica el archivo [hsqldb.jar] que contiene el controlador JDBC
- en [4]: el nombre de la clase Java del controlador JDBC
- en [5]: el controlador JDBC está configurado
Una vez hecho esto, nos conectamos al servidor HSQL. Antes hay que iniciarlo.
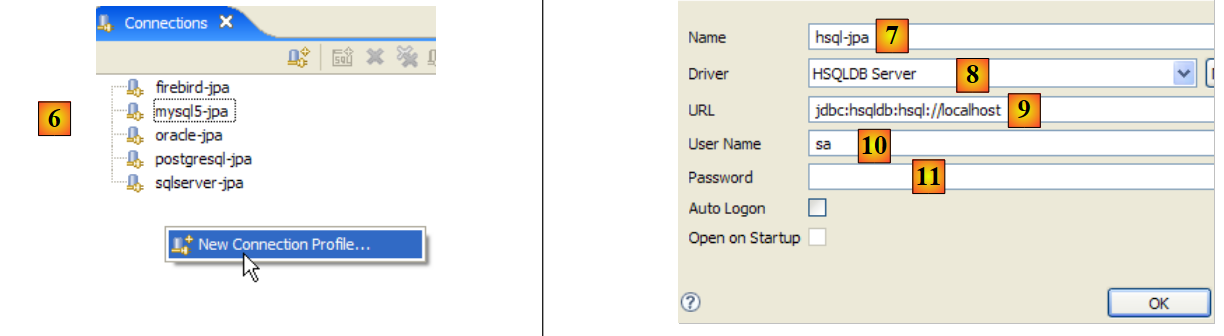 |
- en [6]: se crea una nueva conexión
- en [7]: se le asigna un nombre
- en [8]: queremos conectarnos al servidor HSQLDB
- en [9]: la URL de la base de datos a la que queremos conectarnos. Será la base [test] vista anteriormente.
- en [10]: nos conectamos como usuario [sa]. Ya hemos visto que es administrador de SGBD.
- En [11]: el usuario [sa] no tiene contraseña.
Validamos la configuración de la conexión.
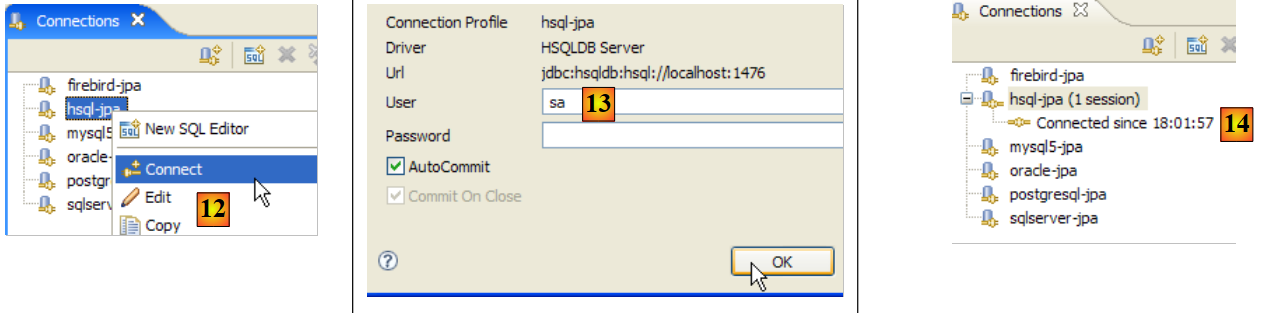 |
- en [12]: nos conectamos
- en [13]: se realiza la identificación
- en [14]: ya estamos conectados
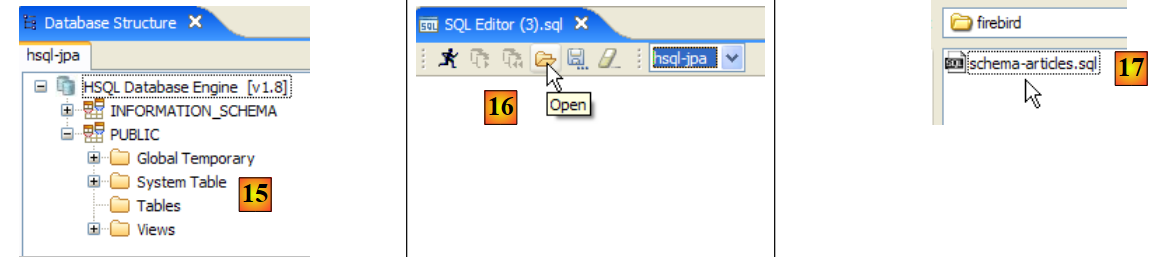 |
- en [15]: el esquema [PUBLIC] aún no tiene ninguna tabla
- en [16]: se va a crear la tabla [ARTICLES] a partir del script [schema-articles.sql] creado en el apartado 5.4.6.
- en [17]: se selecciona el script
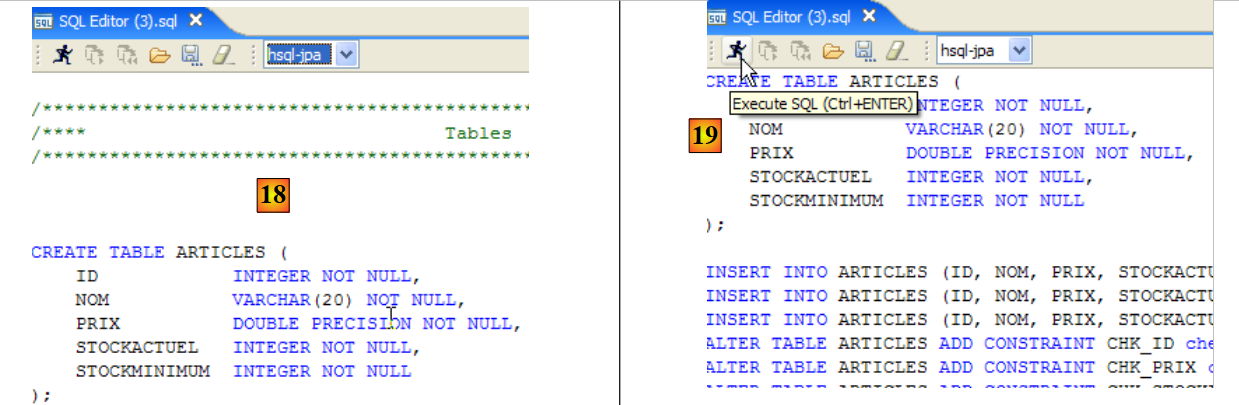 |
- en [18]: el script que se va a ejecutar
- en [19]: se ejecuta tras eliminar todos los comentarios, ya que HSQLB no los admite.
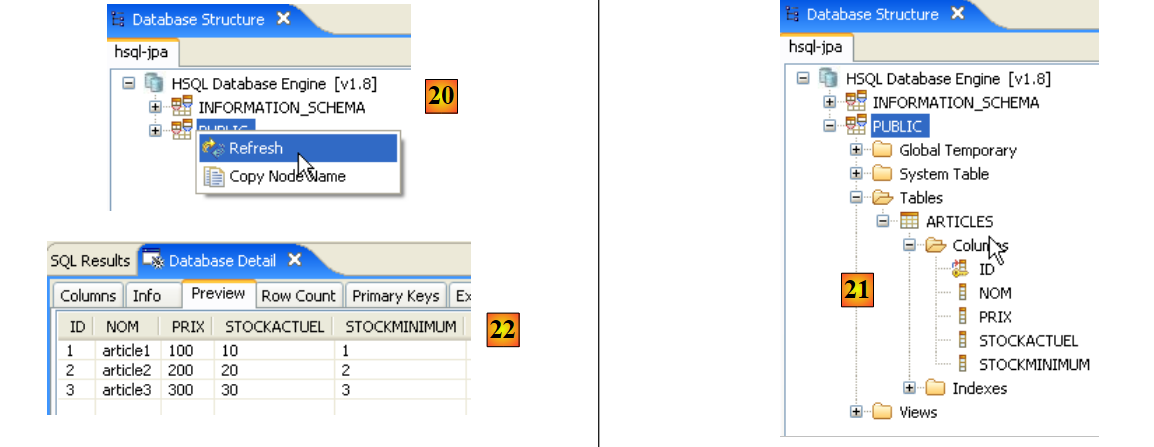 |
- una vez ejecutado el script, se actualiza en [20] la visualización de la base de datos
- en [21]: la tabla [ARTICLES] aparece correctamente
- en [22]: su contenido
Detengamos y reiniciemos el servidor HSQLDB. Una vez hecho esto, examinemos el archivo [test.script]:
Se observa que el archivo SGBD ha almacenado las diferentes órdenes SQL ejecutadas durante la sesión anterior y que las vuelve a ejecutar al iniciar la nueva sesión. Además, se observa (línea 2) que la tabla [ARTICLES] se crea en memoria (MEMORY). En cada sesión, las órdenes SQL emitidas se almacenan en [test.log] para ser copiadas al inicio de la siguiente sesión en [test.script] y reproducidas al inicio de la sesión.
5.10. El SGBD o de Apache Derby
5.10.1. Instalación
El SGBD Apache Derby está disponible en la URL [http://db.apache.org/derby/]. Se trata de un SGBD escrito también en Java y que, asimismo, ocupa muy poca memoria. Presenta ventajas similares a las del HSQLDB. También puede integrarse en aplicaciones Java, c.a.d, formar parte integrante de la aplicación y funcionar en la misma JVM.
 |
- en [1]: la página de descargas
- en [2,3]: descargar la versión más reciente
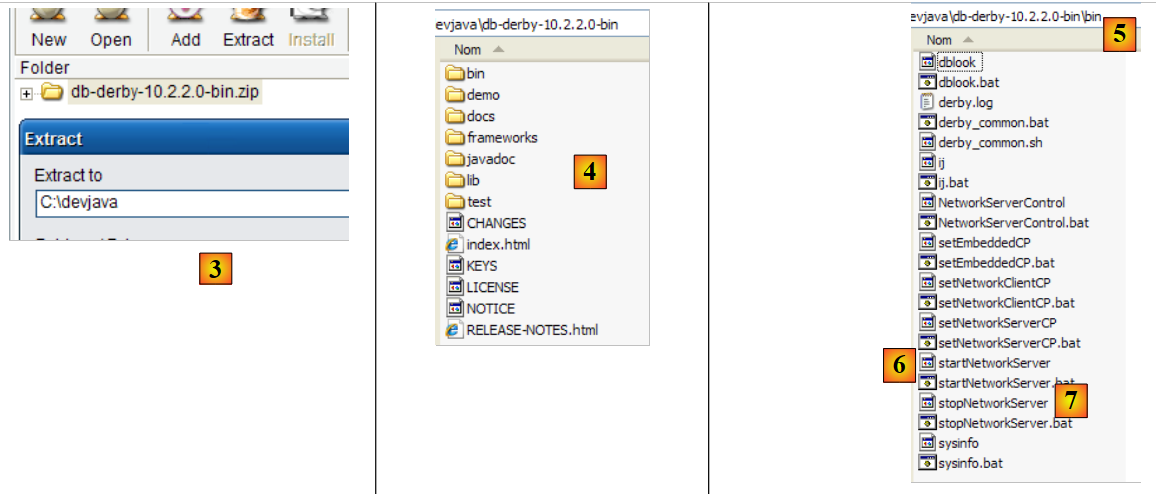 |
- en [3]: descomprimir el archivo zip descargado
- en [4]: la carpeta [db-derby-*-bin] resultante de la descompresión
- en [5]: la carpeta [bin], que contiene el script para iniciar el servidor [db derby] [6] y, en [7], el script para detenerlo.
5.10.2. Iniciar/detener Apache Derby (Db Derby)
Para iniciar el servidor Db Derby, haz doble clic en la aplicación [startNetworkServer] [6] que aparece arriba:
 |
- en [1]: el servidor se ha iniciado. Se detendrá con la aplicación [stopNetworkServer] [7] que aparece arriba.
5.10.3. Controlador JDBC de Db Derby
El controlador JDBC de la base de datos Derby SGBD se encuentra en la carpeta [lib] de la carpeta de instalación:
 |
- en [1]: el archivo [derbyclient.jar] contiene el controlador JDBC de SGBD Db Derby
- en [2]: colocamos este archivo, al igual que los anteriores (apartado 5.4.7), en la carpeta <jdbc>
Para probar este controlador JDBC, utilizaremos Eclipse y el complemento SQL Explorer. Se recomienda al lector que siga los pasos explicados en el apartado 5.4.7. A continuación, mostramos algunas capturas de pantalla significativas:
 |
- en [1]: [window / preferences / SQL Explorer / JDBC Drivers]
- en [2]: el controlador JDBC de Apache Derby no aparece en la lista. Lo añadimos.
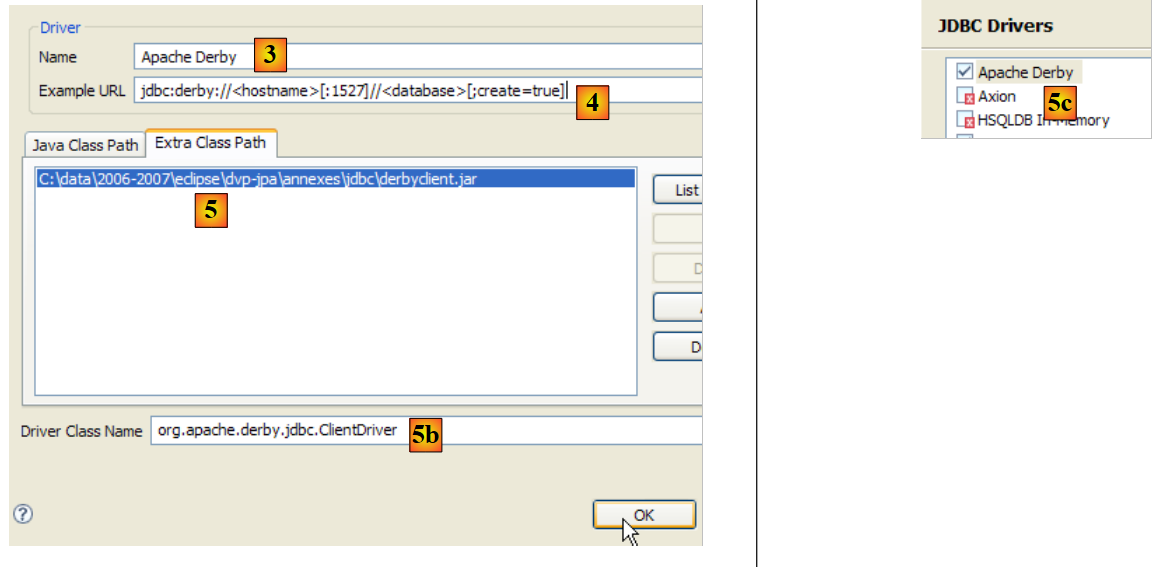 |
- en [3]: se asigna un nombre al nuevo controlador
- en [4]: se especifica el formato de las URL gestionadas por el controlador JDBC
- en [5]: se ha especificado el archivo .jar del controlador JDBC
- en [5b]: el nombre de la clase Java del controlador JDBC
- en [5c]: el controlador JDBC está configurado
Una vez hecho esto, nos conectamos al servidor Apache Derby. Antes hay que iniciarlo.
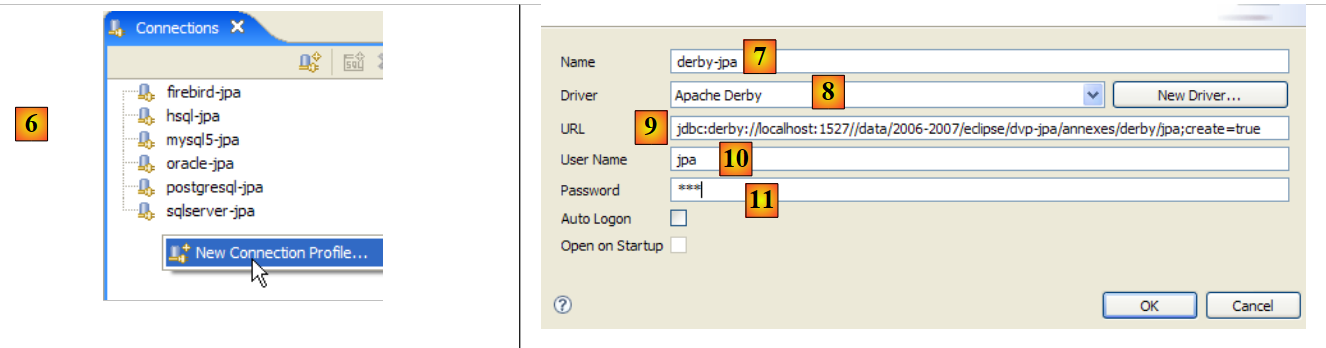 |
- en [6]: se crea una nueva conexión
- en [7]: se le asigna un nombre
- en [8]: queremos conectarnos al servidor Apache Derby
- en [9]: la URL de la base de datos a la que queremos conectarnos. Tras el prefijo estándar [jdbc:derby://localhost:1527], se indicará la ruta de una carpeta del disco que contenga una base de datos Derby. La opción [create=true] permite crear esta carpeta si aún no existe.
- en [10,11]: se establece la conexión como usuario [jpa/jpa]. No he profundizado en el tema, pero parece que se puede introducir lo que se quiera como nombre de usuario y contraseña. Aquí se indica el propietario de la base de datos, si create=true.
Validamos la configuración de la conexión.
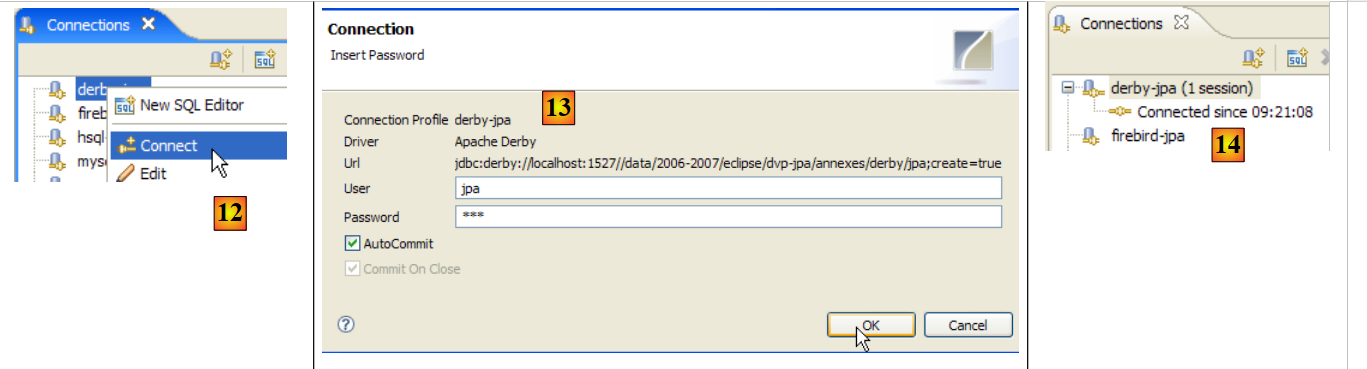 |
- en [12]: iniciamos sesión
- en [13]: se inicia sesión (jpa/jpa)
- en [14]: ya estamos conectados
 |
- en [15]: el esquema [jpa] aún no aparece.
- en [16]: vamos a crear la tabla [ARTICLES] a partir del script [schema-articles.sql] creado en el apartado 5.4.6.
- En [17]: se selecciona el script
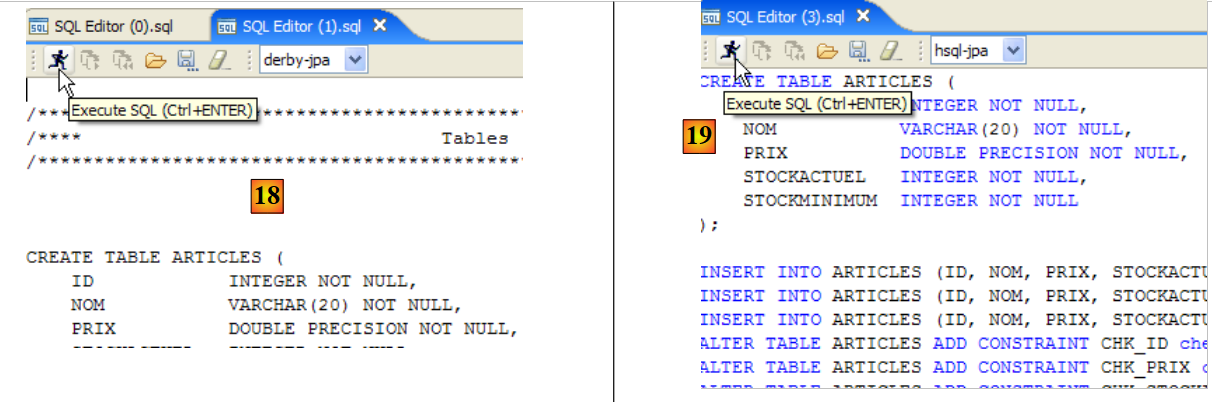 |
- en [18]: el script que se va a ejecutar
- en [19]: se ejecuta tras eliminar todos los comentarios, ya que Apache Derby, al igual que HSQLB, no los acepta.
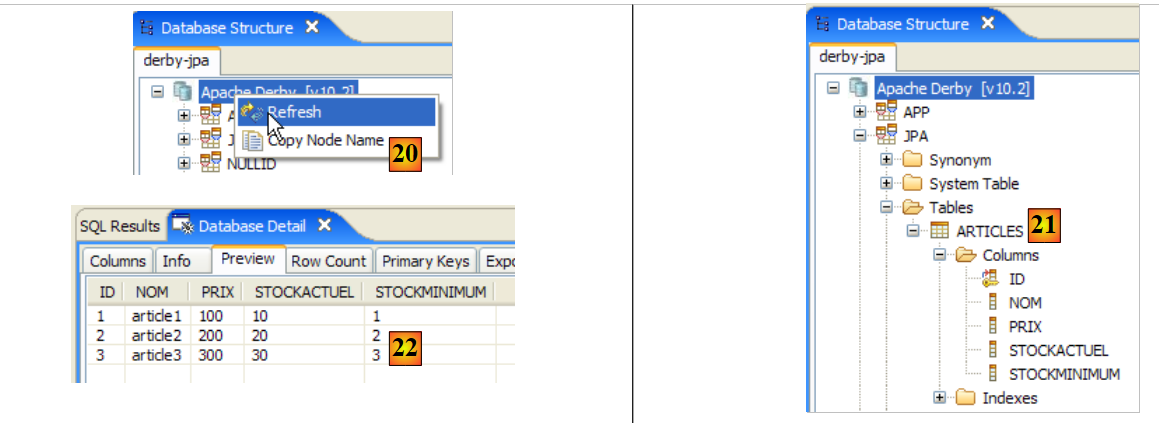 |
- una vez ejecutado el script, se actualiza en [20] la visualización de la base de datos
- en [21]: el esquema [jpa] y la tabla [ARTICLES] están ahí
- en [22]: el contenido de la tabla [ARTICLES]
 |
- en [23]: el contenido de la carpeta [derby\jpa] en la que se ha creado la base de datos.
5.11. El marco de trabajo Spring 2 de
El framework Spring 2 está disponible en la URL [http://www.springframework.org/download]:
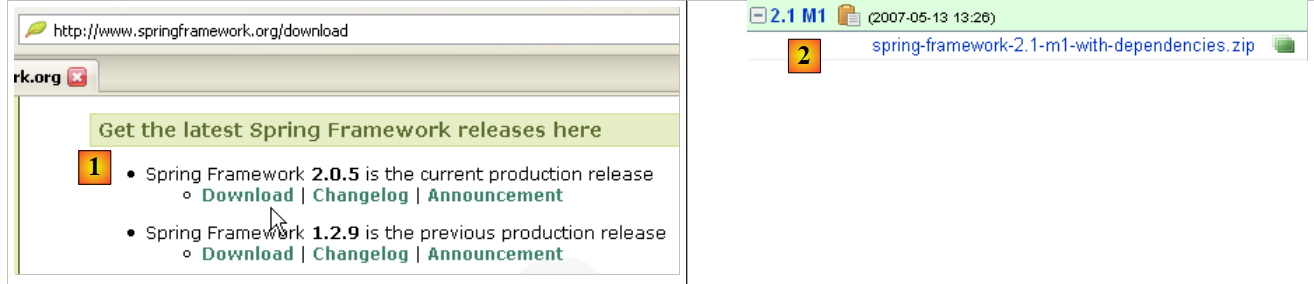 |
- en [1]: se descarga la última versión
- en [2]: se descarga la versión denominada «con dependencias», ya que contiene los archivos .jar de las herramientas de terceros que Spring integra y que se necesitan constantemente.
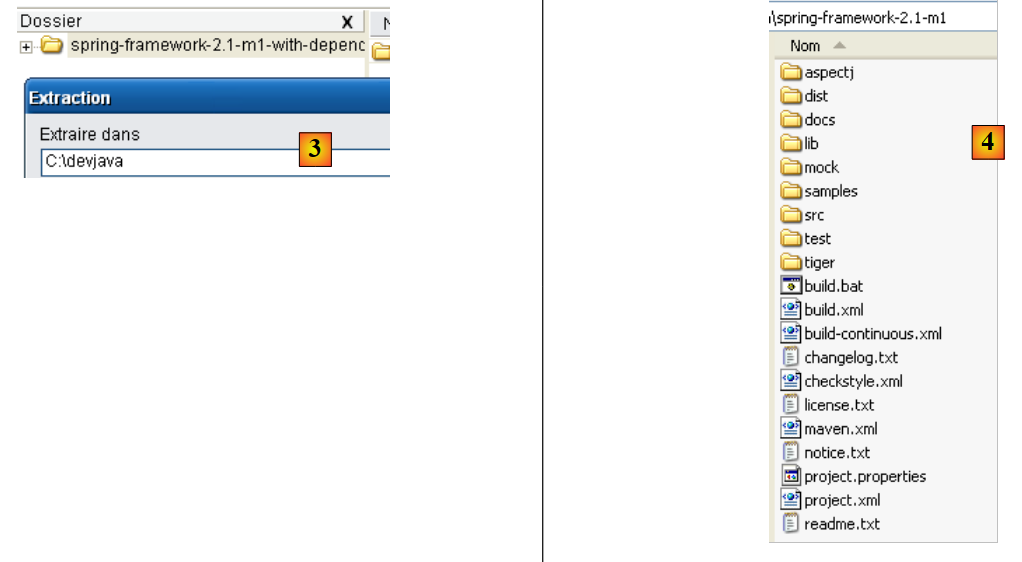 |
- en [3]: descomprimimos el archivo descargado
- en [4]: la carpeta de instalación de Spring 2.1
 |
- en [5]: en la carpeta <dist> se encuentran los archivos de Spring. El archivo [spring.jar] reúne todas las clases del framework Spring. Estas también están disponibles por módulos en la carpeta <modules> en [6]. Si sabemos qué módulos necesitamos, podemos encontrarlos aquí. De este modo, evitamos incluir en la aplicación archivos que no necesita.
 |
- en [7]: la carpeta <lib> contiene los archivos de las herramientas de terceros utilizadas por Spring
- en [8]: algunos archivos del proyecto [jakarta-commons]
Cuando el tutorial utilice archivos de Spring, hay que buscarlos en la carpeta <dist> o en la carpeta <lib> de la carpeta de instalación de Spring.
5.12. El contenedor EJB3 de JBoss
El contenedor EJB3 de JBoss está disponible en la URL [http://labs.jboss.com/jbossejb3/downloads/embeddableEJB3]:
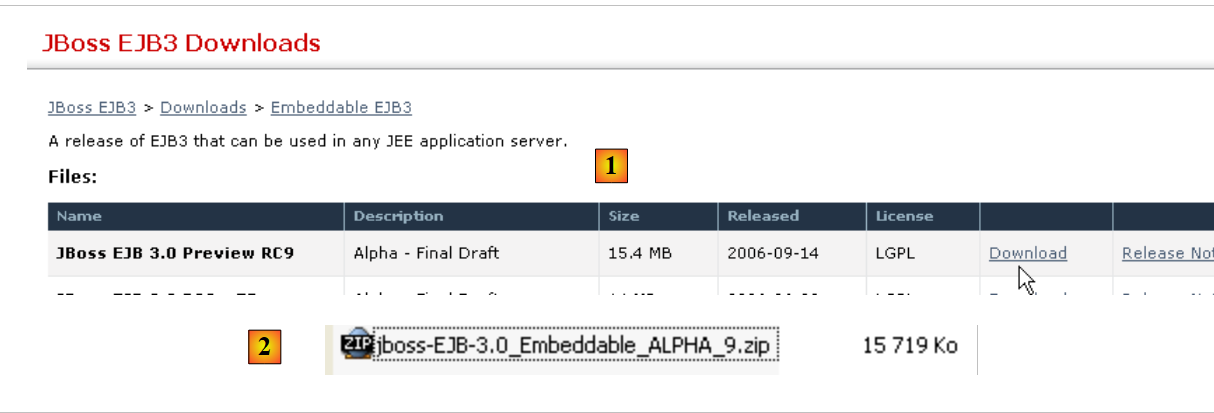 |
- en [1]: se descargan JBoss y EJB3. Cabe destacar la fecha del producto (septiembre de 2006), mientras que la descarga se realiza en mayo de 2007. Cabe preguntarse si este producto sigue en desarrollo.
- en [2]: el archivo descargado
 |
- en [3]: el archivo ZIP descomprimido
- en [4]: los archivos [hibernate-all.jar, jboss-ejb3-all.jar, thirdparty-all.jar] forman el contenedor EJB3 de JBoss. Hay que colocarlos en la ruta de clases de la aplicación que utilice este contenedor.