1. Introduction
1.1. Objectives
The PDF of the document is available |HERE|.
The examples in the document are available |HERE|.
The aim here is to explore the main concepts of data persistence using API JPA (Java Persistence Api). After reading this document and testing the examples, the reader should have acquired the necessary foundation to then stand on their own two feet.
API JPA is a recent addition. It has only been available since JDK 1.5. The JPA layer has its place in a multi-tier architecture. Let’s consider a fairly common architecture of this type: the three-layer architecture:
 |
- the [1] layer, referred to here as [ui] (User Interface), is the layer that interacts with the user via a Swing GUI, a console interface, or a web interface. Its role is to provide data from the user to the [2] layer or to present data provided by the [2] layer to the user.
- The [2] layer, referred to here as [metier], is the layer that applies the so-called business rules, c.a.d. the application-specific logic, without concerning itself with where the data it is given comes from, or where the results it produces go.
- The [3] layer, referred to here as [dao] (Data Access Object), is the layer that provides the [2] layer with pre-stored data (files, databases, ...) and which saves some of the results provided by the [2] layer.
- The [JDBC] layer is the standard layer used in Java to access databases. This is commonly referred to as the SGBD JDBC driver.
Numerous efforts have been made to make it easier for developers to write these various layers. Among these, JPA aims to simplify the development of the [dao] layer, which manages so-called persistent data, hence the name API (Java Persistence Api). One solution that has gained traction in recent years in this field is Hibernate:
 |
The [Hibernate] layer sits between the [dao] layer written by the developer and the [Jdbc] layer. Hibernate is an ORM (Object-Relational Mapping) tool that bridges the gap between the relational world of databases and the world of objects manipulated by Java. The developer of the [dao] layer no longer sees the [Jdbc] layer or the database tables whose content they wish to utilize. They see only the object representation of the database, provided by the [Hibernate] layer. The bridge between the database tables and the objects manipulated by the [dao] layer is established primarily in two ways:
- via XML-type configuration files
- via Java annotations in the code, a technique available only since JDK 1.5
The [Hibernate] layer is an abstraction layer designed to be as transparent as possible. The ideal scenario is for the [dao] layer developer to be completely unaware that they are working with a database. This is feasible if they are not the one writing the configuration that bridges the relational and object-oriented worlds. Configuring this bridge is quite delicate and requires some experience.
The [4] object layer, a mirror of BD, is called the "persistence context." A [dao] layer based on Hibernate performs persistence operations (CRUD: create, read, update, delete) on the objects in the persistence context; these operations are translated by Hibernate into SQL commands. For database query operations (the SQL Select), Hibernate provides developers with a language (Hibernate Query Language) to query the persistence context, not the database itself.
Hibernate is popular but complex to master. The learning curve, often presented as easy, is actually quite steep. As soon as you have a database with tables featuring one-to-many or many-to-many relationships, configuring the relational-to-object bridge is not within the reach of the average beginner. Configuration errors can then lead to poor-performing applications.
In the commercial world, there was a product equivalent to Hibernate called Toplink:
 |
Given the success of the ORM products, Sun, the creator of Java, decided to standardize a ORM layer via a specification called JPA, which appeared alongside Java 5. The JPA specification was implemented by both Toplink and Hibernate. Toplink, which was a commercial product, has since become an open-source product. With JPA, the previous architecture becomes the following:
 |
The [dao] layer now interacts with the JPA specification, a set of interfaces. The developer has gained in terms of standardization. Previously, if he changed his ORM layer, he also had to change his [dao] layer, which had been written to interact with a specific ORM. Now, they will write a [dao] layer that will communicate with a JPA layer. Regardless of the product that implements it, the interface of the JPA layer presented to the [dao] layer remains the same.
This document will present examples of JPA in various domains:
- First, we will focus on the relational/object bridge that the ORM layer constructs. This will be created using Java 5 annotations for databases containing table relationships of the type:
- one-to-one
- one-to-many
- many-to-many
To illustrate this area, we will create the following test architectures:
 |
Our test programs will be console applications that directly query the JPA layer. In doing so, we will explore the main methods of the JPA layer. We will be working in a so-called "Java SE" (Standard Edition) environment. JPA runs in both a Java SE and Java EE5 (Enterprise Edition) environment.
- Once we have mastered both the configuration of the relational/object bridge and the use of the methods in the JPA layer, we will return to a more traditional multi-layer architecture:
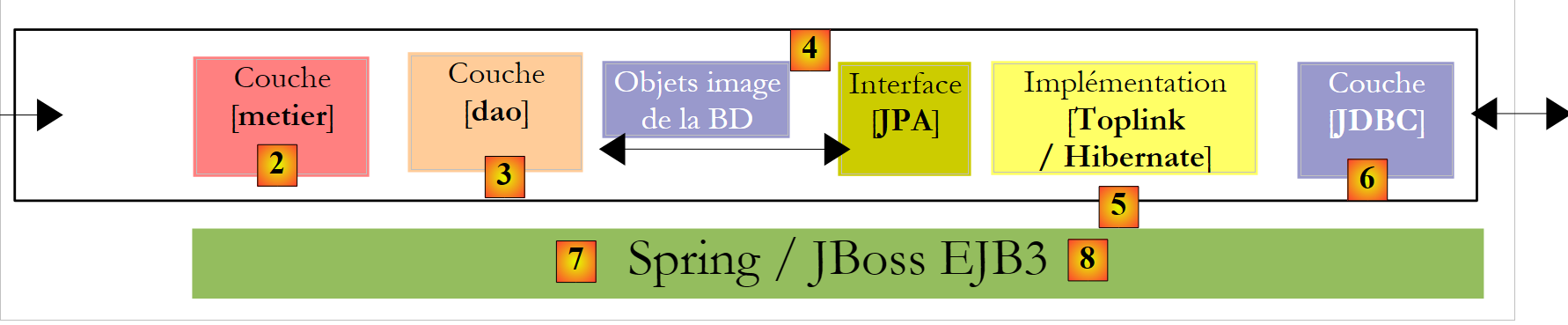 |
The [JPA] layer will be accessed via a two-tier architecture consisting of [metier] and [dao]. The Spring framework [7], followed by the EJB3 container from JBoss, will be used to link these layers together.
As mentioned earlier, JPA is available in the SE and EE5 environments. The Java environment EE5 provides numerous services related to accessing persistent data, including connection pools, transaction managers, and more. It may be beneficial for a developer to take advantage of these services. The Java environment EE5 is not yet widely used (May 2007). It is currently available on the Sun Application Server 9.x (Glassfish). An application server is essentially a web application server. If you build a standalone Swing-based graphical application, you cannot use the EE environment and the services it provides. This is a problem. We are beginning to see "stand-alone" EE and c.a.d environments. that can be used outside of an application server. This is the case with JBos and EJB3, which we will use in this document.
In a EE5 environment, the layers are implemented by objects called EJB (Enterprise Java Beans). In previous versions of EE, EJB (EJB 2.x) were considered difficult to implement, test, and sometimes underperformed. We distinguish between EJB2.x "entity" and EJB2.x "session". In short, a EJB2.x "entity" represents a database table row, and a EJB2.x "session" is an object used to implement the [metier], [dao] of a multi-layer architecture. One of the main criticisms of layers implemented with EJB is that they can only be used within EJB containers, a service provided by the EE environment. This makes unit testing problematic. Thus, in the diagram above, unit tests for the [metier] and [dao] layers built with EJB would require setting up an application server, a rather cumbersome operation that does not really encourage developers to test frequently.
The Spring framework was created in response to the complexity of EJB2. Spring provides, within a SE environment, a significant number of the services typically provided by EE environments. Thus, in the "Data Persistence" section that concerns us here, Spring provides the connection pools and transaction managers that applications require. The emergence of Spring has fostered a culture of unit testing, which has suddenly become much easier to implement. Spring allows the implementation of application layers using standard Java objects (POJO, Plain Old/Ordinary Java Object), enabling their reuse in a different context. Finally, it integrates numerous third-party tools fairly transparently, notably persistence tools such as Hibernate, iBatis, ...
Java EE5 was designed to address the shortcomings of the previous EE specification. EJB 2.x has become EJB3. These are POJOs instances tagged with annotations that make them special objects when they are within a EJB3 container. Within this container, the EJB3 will be able to benefit from the container’s services (connection pool, transaction manager, etc.). Outside the EJB3 container, the EJB3 becomes a normal Java object. Its EJB annotations are ignored.
Above, we have depicted Spring and JBoss EJB3 as a possible infrastructure (framework) for our multi-layer architecture. It is this infrastructure that will provide the services we need: a connection pool and a transaction manager.
- With Spring, the layers will be implemented using POJOs. These will have access to Spring’s services (connection pool, transaction manager) through dependency injection into these POJOs: when constructing them, Spring injects references to the services they will need.
-
JBoss EJB3 is a EJB container capable of running outside an application server. Its operating principle (from the developer’s perspective) is analogous to that described for Spring. We will find few differences.
-
We will conclude this document with an example of a three-tier web application—basic but nonetheless representative:
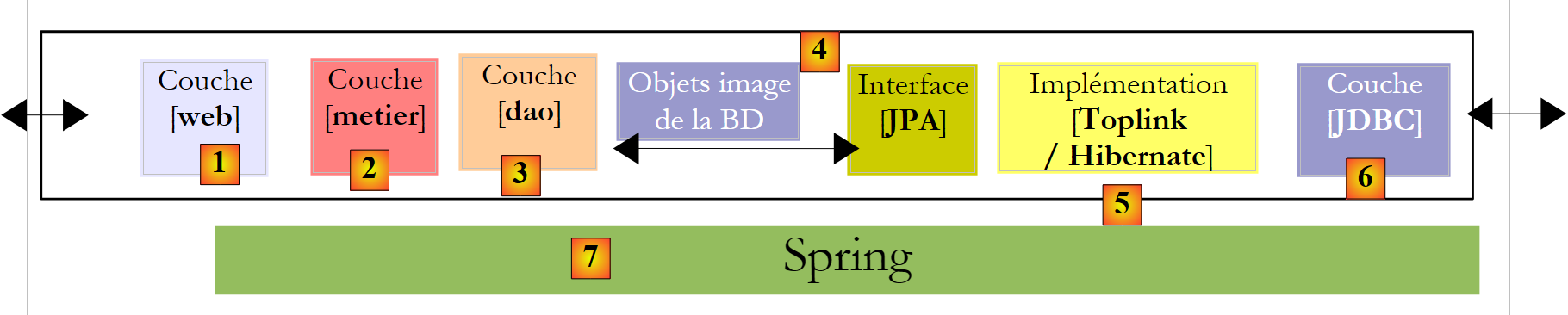 |
1.2. References
[ref1]: Java Persistence with Hibernate, by Christian Bauer and Gavin King, published by Manning.
[ref1] is the document that served as the basis for what follows. It is a comprehensive book of over 800 pages on the use of Hibernate in two different contexts: with or without JPA. The use of Hibernate without JPA is indeed still relevant for developers using JDK 1.4 or lower, as JPA only appeared with JDK 1.5.
Having read more than three-quarters of the book and skimmed the rest, it struck me that everything in this document was useful. The experienced Hibernate user should be familiar with nearly all the information provided in the 800 pages. Christian Bauer and Gavin King have been exhaustive, yet rarely to the point of describing situations one will never encounter. It’s all worth reading. The book is written in an educational style: there is a genuine effort to leave nothing in the dark. The fact that it was written for using Hibernate both with and without JPA poses a challenge for those interested in only one or the other of these technologies. For example, the authors describe, through numerous examples, the relational/object bridge in both contexts. The concepts used are very similar since JPA was heavily inspired by Hibernate. But there are some differences. As a result, something that is true for Hibernate may not be true for JPA, which ultimately creates confusion for the reader.
The authors present examples of three-tier applications in the context of a EJB3 container. They do not mention Spring. We will see from an example that Spring is, however, simpler to use and has a broader scope than the JBoss EJB3 container used in [ref1]. Nevertheless, "Java Persistence with Hibernate" is an excellent book that I recommend for all the fundamentals it teaches about ORM.
Using a ORM is complex for a beginner.
- There are concepts to understand in order to configure the relational/object bridge.
- There is the concept of the persistence context with its notions of objects in a "persisted," "detached," or "new" state
- There are the mechanics surrounding persistence (transactions, connection pools), typically services provided by a container
- There are performance settings to configure (second-level cache)
- ...
We will introduce these concepts using examples. We will not delve deeply into the theory behind them. Our goal is simply, in each case, to enable the reader to understand the example and internalize it to the point where they can make modifications themselves or apply it in a different context.
1.3. Tools Used
The examples in this document use the following tools. Some are described in the appendices (download, installation, configuration, usage). In such cases, we provide the paragraph number and page number.
- JDK 1.6 (paragraph 5.1)
- the IDE Java development plugin for Eclipse 3.2.2 (section 5.2)
- Eclipse plugin WTP (Web Tools Package) (section 5.2.3)
- Eclipse SQL Explorer plugin (section 5.2.6)
- Eclipse Hibernate Tools plugin (section 5.2.5)
- Eclipse plugin TestNG (section 5.2.4)
- Tomcat 5.5.23 servlet container (section 5.3)
- SGBD Firebird 2.1 (Section 5.4)
- SGBD MySQL5 (Section 5.5)
- SGBD PosgreSQL (Section 5.6)
- SGBD Oracle 10g Express (section 5.7)
- SGBD SQL Server 2005 Express (section 5.8)
- SGBD HSQLDB (Section 5.9)
- SGBD Apache Derby (Section 5.10)
- Spring 2.1 (Section 5.11)
- EJB3 container from JBoss (section 5.12)
1.4. Downloading the example e
On the website for this document, the examples covered can be downloaded as a ZIP file, which, once extracted, creates the following folder:
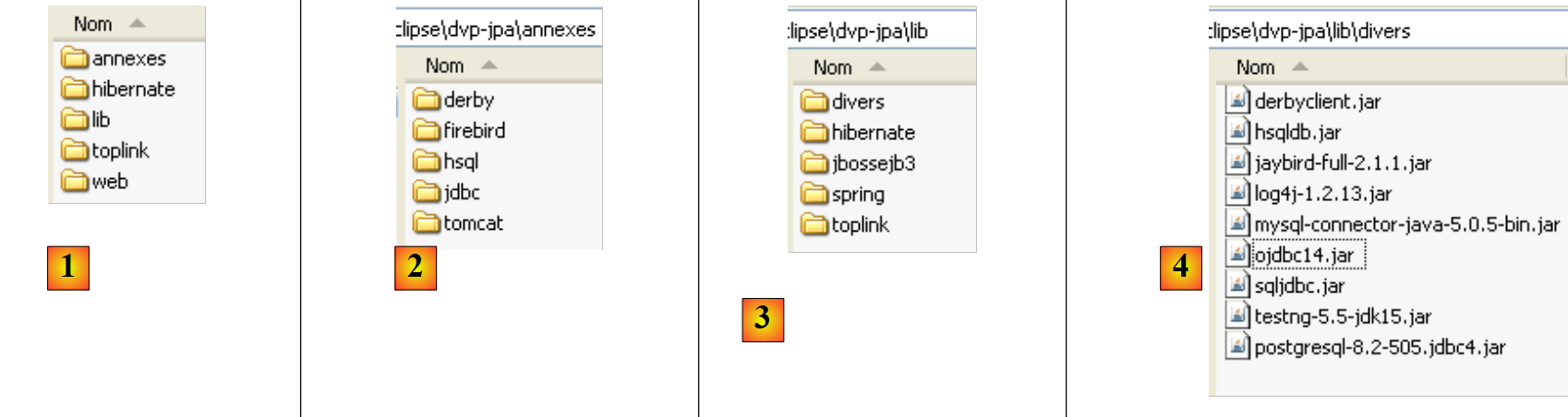 |
- in [1]: the directory structure of the examples
- in [2]: the <annexes> folder contains items presented in section ANNEXES, paragraph 5. In particular, the <jdbc> folder contains the JDBC drivers from SGBD used for the tutorial examples.
- in [3]: the <lib> folder groups the various .jar archives used by the tutorial into 5 folders
- In [4]: the <lib/divers> folder contains the archives: - Jdbc drivers for SGBD - for the unit testing tool [testNG] - the logging tool [log4j]
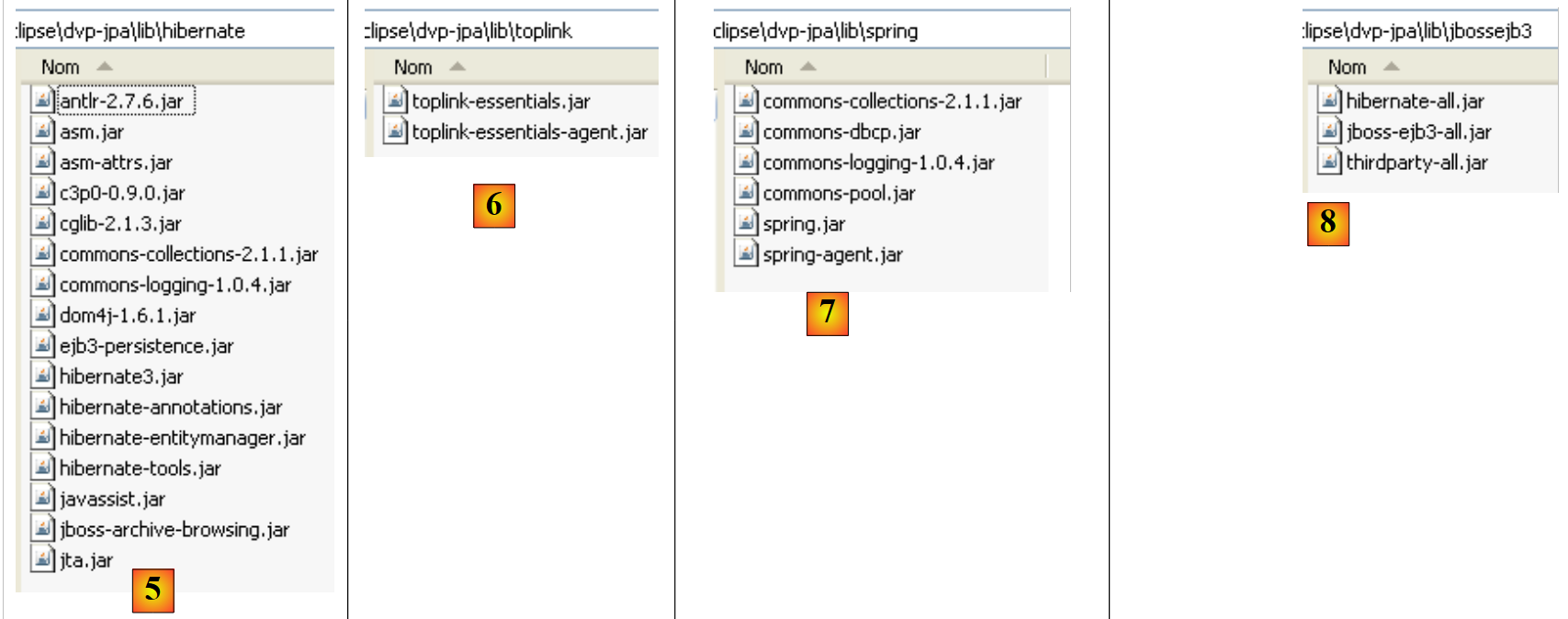 |
- in [5]: the archives for the JPA/Hibernate implementation and third-party tools required by Hibernate
- to [6]: the archives of the JPA/Toplink implementation
- in [7]: the Spring 2.x and third-party tool archives required for Spring
- in [8]: the EJB3 container archives from JBoss
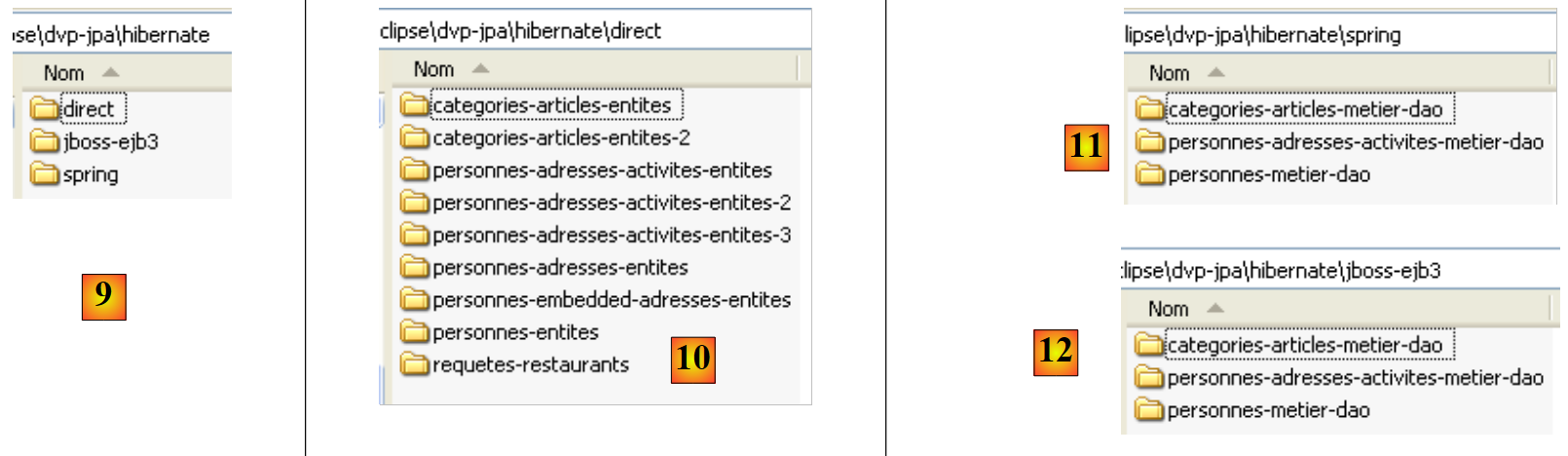 |
- in [9]: the <hibernate> folder contains examples using the JPA/Hibernate persistence layer
- in [10]: the <hibernate/direct> folder contains examples where the JPA layer is used directly with a program of the type [Main].
- in [11] and [12]: examples where the JPA layer is used via the [metier] and [dao] layers in a multi-layer architecture, which is the standard operating scenario. The services (connection pool, transaction manager) used by layers [metier] and [dao] are provided either by Spring [11] or by JBoss EJB3 [12].
 |
- In [13]: the <toplink> folder includes the examples from the <hibernate> folder [9], but this time with a JPA/Toplink persistence layer instead of JPA/Hibernate. Thereis no <jbossejb3> folder in [13] because it was not possible to get an example working where the persistence layer is provided by Toplink and the services are provided by the EJB3 container from JBoss.
- In [14]: a <web> folder contains three examples of web applications with a persistence layer JPA:
- [15]: an example with Spring / JPA / Hibernate
- [16]: the same example with Spring / JPA / Toplink
- [17]: the same example with JBoss EJB3 / JPA / Hibernate. This example does not work, likely due to an unresolved configuration issue. It has nevertheless been included so that the reader can examine it and possibly find a solution to this problem.
The tutorial frequently refers to this directory structure, particularly when testing the examples covered. Readers are encouraged to download these examples and install them. Hereafter, we will refer to the directory structure described above as <examples>.
1.5. Configuring the Eclipse " " projects for the examples
The examples use "user" libraries. These are .jar archives grouped under a single name. When such a library is included in a Java project’s classpath, all the archives it contains are then included in that classpath. Let’s see how to do this in Eclipse:
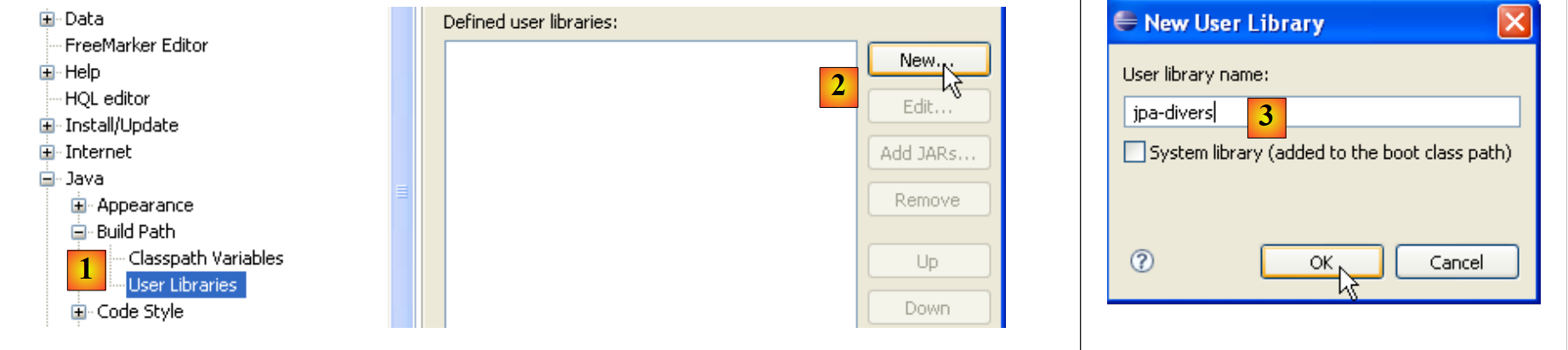 |
- in [1]: [Window / Preferences / Java / Buld Path / User Libraries]
- in [2]: create a new library
- in [3]: give it a name and confirm
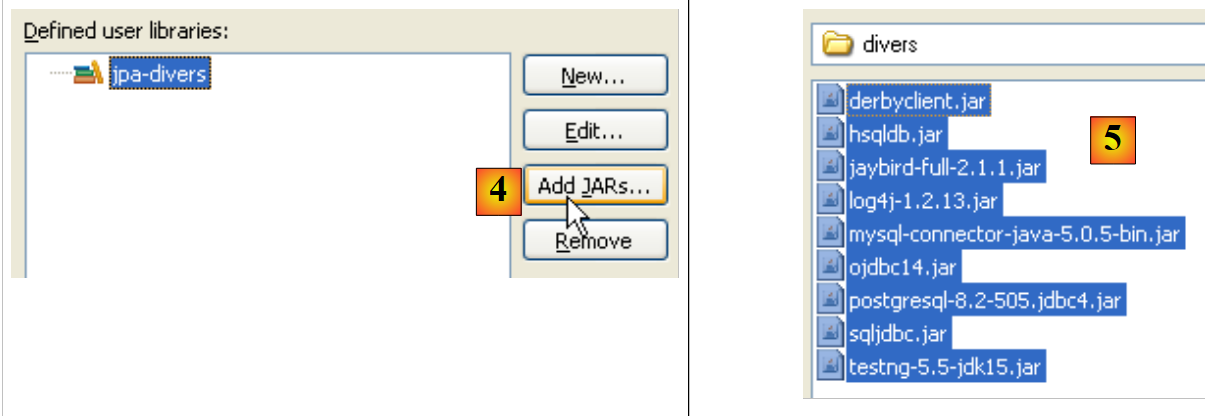 |
- in [4]: select the JARs that will be part of the library [jpa-divers]
- in [5]: select all JARs from the <examples>/lib/misc folder
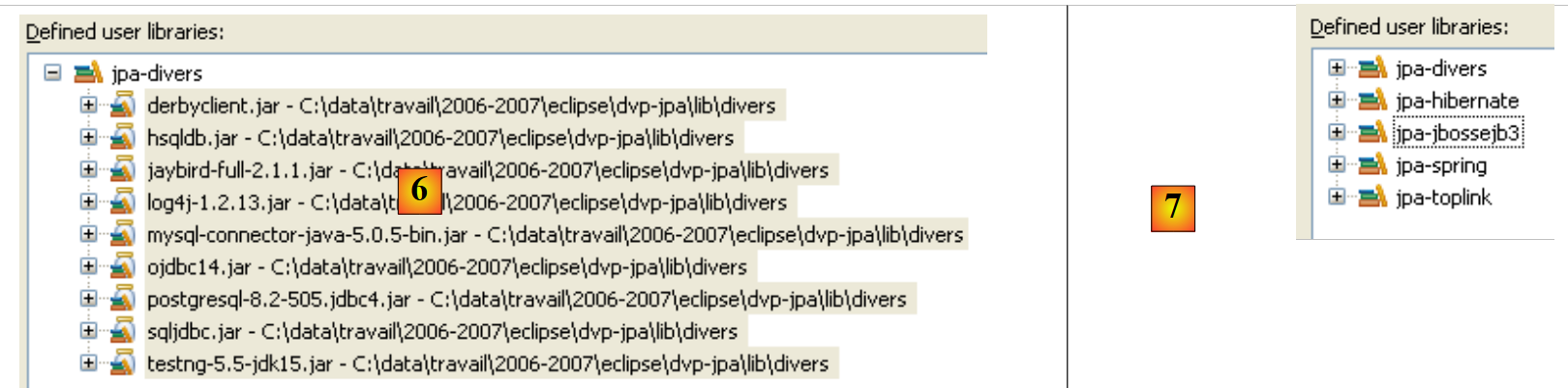 |
- in [6]: the user library [jpa-divers] has been defined
- in [7]: repeat the same process to create 4 more libraries:
Library | Folder containing the library's JARs |
<examples>/lib/hibernate | |
<examples>/lib/toplink | |
<examples>/lib/spring | |
<examples>/lib/jbossejb3 |