2. JPA entities
2.1. Example 1 - Object representation of a single table
2.1.1. The [person] table
Consider a database with a single [person] table whose purpose is to store some information about individuals:
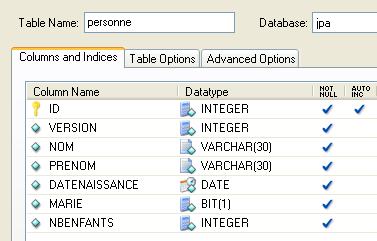 |
primary key of the table | |
version of the row in the table. Every time the person is modified, their version number is incremented. | |
person's last name | |
first name | |
her date of birth | |
integer 0 (unmarried) or 1 (married) | |
number of children |
2.1.2. The [Person] entity
We are in the following runtime environment:
 |
The JPA layer [5] must bridge the relational world of the database [7] and the object world [4] manipulated by Java programs [3]. This bridge is established through configuration, and there are two ways to do this:
- using XML files. This was virtually the only way to do it until the advent of JDK 1.5
- using Java annotations since JDK 1.5
In this document, we will use almost exclusively the second method.
The [Person] object representing the [person] table presented earlier could be as follows:
...
@SuppressWarnings("unused")
@Entity
@Table(name="Personne")
public class Personne implements Serializable{
@Id
@Column(name = "ID", nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name = "VERSION", nullable = false)
@Version
private int version;
@Column(name = "NOM", length = 30, nullable = false, unique = true)
private String nom;
@Column(name = "PRENOM", length = 30, nullable = false)
private String prenom;
@Column(name = "DATENAISSANCE", nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(name = "MARIE", nullable = false)
private boolean marie;
@Column(name = "NBENFANTS", nullable = false)
private int nbenfants;
// manufacturers
public Personne() {
}
public Personne(String nom, String prenom, Date datenaissance, boolean marie,
int nbenfants) {
setNom(nom);
setPrenom(prenom);
setDatenaissance(datenaissance);
setMarie(marie);
setNbenfants(nbenfants);
}
// toString
public String toString() {
...
}
// getters and setters
...
}
Configuration is performed using Java annotations (@Annotation). Java annotations are either processed by the compiler or by specialized tools at runtime. Apart from the annotation on line 3 intended for the compiler, all annotations here are intended for the JPA implementation being used, Hibernate or Toplink. They will therefore be processed at runtime. In the absence of tools capable of interpreting them, these annotations are ignored. Thus, the [Person] class above could be used in a non-JPA context.
There are two distinct cases for using JPA annotations in a class C associated with a table T:
- the table T already exists: the JPA annotations must then replicate the existing structure (column names and definitions, integrity constraints, foreign keys, primary keys, etc.)
- Table T does not exist and will be created based on the annotations found in class C.
Case 2 is the easiest to handle. Using JPA annotations, we specify the structure of the table T we want. Case 1 is often more complex. Table T may have been created a long time ago outside of any JPA context. Its structure may therefore be ill-suited to JPA’s relational-to-object bridge. To simplify matters, we’ll focus on Case 2, where the table T associated with class C will be created based on the JPA annotations in class C.
Let’s examine the JPA annotations of the [Person] class:
- line 4: the @Entity annotation is the first essential annotation. It is placed before the line declaring the class and indicates that the class in question must be managed by the JPA persistence layer. Without this annotation, all other JPA annotations would be ignored.
- line 5: the @Table annotation designates the database table that the class represents. Its main argument is name, which specifies the table’s name. Without this argument, the table will be named after the class, in this case [Person]. In our example, the @Table annotation is therefore unnecessary.
- Line 8: The @Id annotation is used to designate the field in the class that represents the table’s primary key. This annotation is mandatory. Here, it indicates that the id field on line 11 represents the table’s primary key.
- Line 9: The @Column annotation is used to link a field in the class to the table column that the field represents. The name attribute specifies the name of the column in the table. If this attribute is omitted, the column takes the same name as the field. In our example, the name argument was therefore not required. The nullable=false argument indicates that the column associated with the field cannot have the value NULL and that the field must therefore have a value.
- Line 10: The @GeneratedValue annotation specifies how the primary key is generated when it is automatically generated by the DBMS. This will be the case in all our examples. It is not mandatory. Thus, our Person could have a student ID that serves as the primary key and is not generated by the DBMS but set by the application. In this case, the @GeneratedValue annotation would be omitted. The strategy argument specifies how the primary key is generated when generated by the DBMS. Not all DBMSs use the same technique for generating primary key values. For example:
uses a value generator called before each insertion | |
the primary key field is defined as having the Identity type. The result is similar to Firebird’s value generator, except that the key value is not known until after the row is inserted. | |
uses an object called SEQUENCE, which again acts as a value generator |
The JPA layer must generate different SQL statements depending on the DBMS in order to create the value generator. We specify the type of DBMS it needs to handle through configuration. As a result, it can determine the standard strategy for generating primary key values for that DBMS. The argument strategy = GenerationType.*****AUTO* tells the JPA layer to use this standard strategy. This technique has worked in all the examples in this document for the seven DBMSs used.
- Line 14: The @Version annotation designates the field used to manage concurrent access to the same row in the table.
To understand this issue of concurrent access to the same row in the [person] table, let’s assume a web application allows a person’s information to be updated and consider the following scenario:
At time T1, user U1 begins editing a person P. At this moment, the number of children is 0. He changes this number to 1, but before he submits his changes, user U2 begins editing the same person P. Since U1 has not yet submitted his changes, U2 sees the number of children as 0 on his screen. U2 changes the name of person P to uppercase. Then U1 and U2 save their changes in that order. U2’s change will take precedence: in the database, the name will be in uppercase and the number of children will remain at zero, even though U1 believes they changed it to 1.
The concept of a person’s version helps us solve this problem. Let’s revisit the same use case:
At time T1, a user U1 begins editing a person P. At this point, the number of children is 0 and the version is V1. They change the number of children to 1, but before they commit their change, a user U2 begins editing the same person P. Since U1 has not yet committed their change, U2 sees the number of children as 0 and the version as V1. U2 changes the name of person P to uppercase. Then U1 and U2 commit their changes in that order. Before committing a change, we verify that the user modifying person P holds the same version as the currently saved version of person P. This will be the case for user U1. Their change is therefore accepted, and we then change the version of the modified person from V1 to V2 to indicate that the person has undergone a change. When validating U2’s modification, we will notice that U2 has version V1 of person P, whereas the current version is V2. We can then inform user U2 that someone else acted before them and that they must start with the new version of person P. They will do so, retrieve a version V2 of person P who now has a child, capitalize the name, and validate. Their modification will be accepted if the registered person P is still version V2. Ultimately, the modifications made by U1 and U2 will be taken into account, whereas in the use case without versions, one of the modifications would have been lost.
The [DAO] layer of the client application can manage the version of the [Person] class itself. Every time an object P is modified, the version of that object will be incremented by 1 in the table. The @Version annotation allows this management to be transferred to the JPA layer. The field in question does not need to be named version as in the example. It can have any name.
The fields corresponding to the @Id and @Version annotations are present for persistence purposes. They would not be needed if the [Person] class did not need to be persisted. We can see, therefore, that an object is represented differently depending on whether or not it needs to be persisted.
- Line 17: Once again, the @Column annotation provides information about the column in the [person] table associated with the name field of the Person class. Here we find two new arguments:
- unique=true indicates that a person’s name must be unique. This will result in the addition of a uniqueness constraint on the NAME column of the [person] table in the database.
- length=30 sets the number of characters in the NAME column to 30. This means that the type of this column will be VARCHAR(30).
- Line 24: The @Temporal annotation is used to specify the SQL type for a date/time column or field. The TemporalType.DATE type denotes a date without an associated time. The other possible types are TemporalType.TIME for encoding a time and TemporalType.TIMESTAMP for encoding a date and time.
Let’s now comment on the rest of the code in the [Person] class:
- Line 6: The class implements the Serializable interface. Serializing an object involves converting it into a sequence of bits. Deserialization is the reverse operation. Serialization/deserialization is particularly used in client/server applications where objects are exchanged over the network. Client or server applications are unaware of this operation, which is performed transparently by the JVMs. For this to be possible, however, the classes of the exchanged objects must be "tagged" with the Serializable keyword.
- Line 37: a constructor for the class. Note that the id and version fields are not included among the parameters. This is because these two fields are managed by the JPA layer and not by the application.
- Lines 51 and beyond: the get and set methods for each of the class’s fields. Note that JPA annotations can be placed on the fields’ get methods instead of on the fields themselves. The placement of the annotations indicates the mode JPA should use to access the fields:
- if the annotations are placed at the field level, JPA will access the fields directly to read or write them
- if the annotations are placed at the get level, JPA will access the fields via the get/set methods to read or write them
The position of the @Id annotation determines the placement of JPA annotations in a class. When placed at the field level, it indicates direct access to the fields; when placed at the get level, it indicates access to the fields via the get and set methods. The other annotations must then be placed in the same way as the @Id annotation.
2.1.3. The Eclipse Test Project
We will conduct our first experiments with the previous [Person] entity. We will carry them out using the following architecture:
 |
- in [7]: the database that will be generated based on the annotations of the [Person] entity, as well as additional configurations specified in a file named [persistence.xml]
- in [5, 6]: a JPA layer implemented by Hibernate
- in [4]: the [Person] entity
- in [3]: a console-based test program
We will conduct various experiments:
- generate the database schema using an Ant script and the Hibernate Tools
- generate the database and initialize it with some data
- interact with the database and perform the four basic operations on the [person] table (insert, update, delete, query)
The necessary tools are as follows:
- Eclipse and its plugins described in Section 5.2.
- the [hibernate-personnes-entites] project, which can be found in the <examples>/hibernate/direct/personnes-entites folder
- the various DBMSs described in the appendices (Section 5 and beyond).
The Eclipse project is as follows:
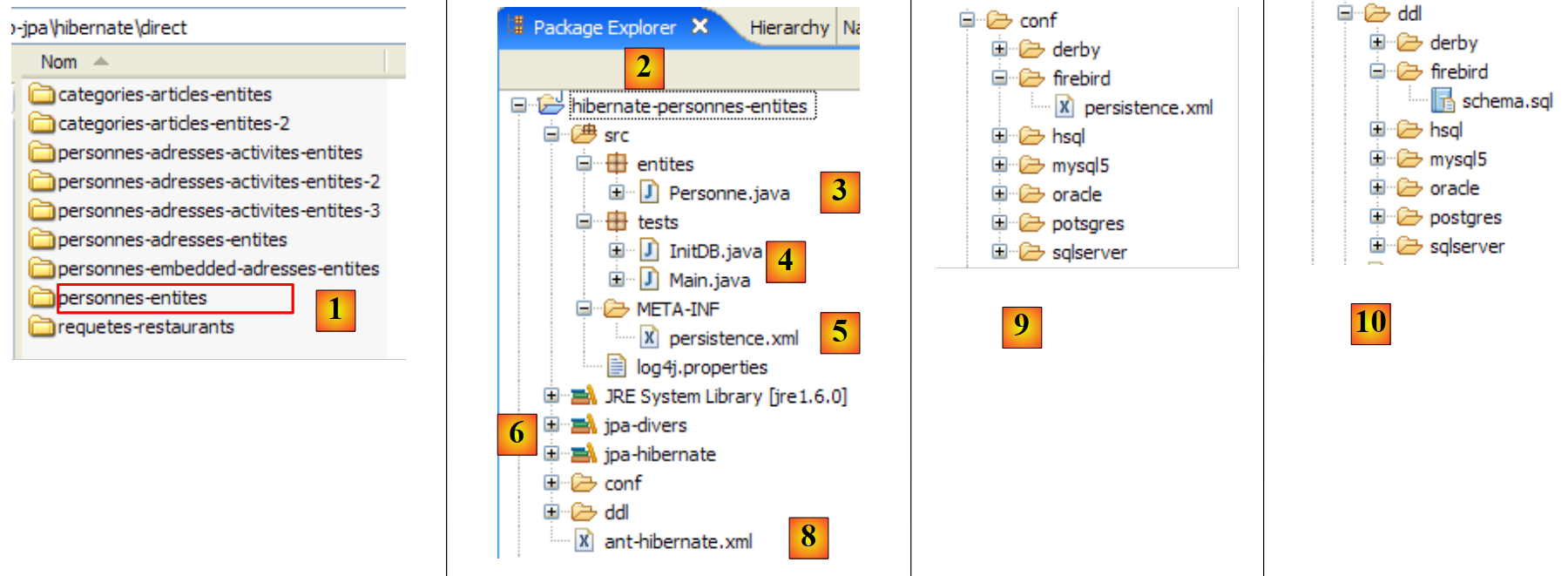 |
- in [1]: the Eclipse project folder
- in [2]: the project imported into Eclipse (File / Import)
- in [3]: the [Person] entity being tested
- in [4]: the test programs
- in [5]: [persistence.xml] is the configuration file for the JPA layer
- in [6]: the libraries used. They were described in section 1.5.
- in [8]: an Ant script that will be used to generate the table associated with the [Person] entity
- in [9]: the [persistence.xml] files for each of the DBMSs used
- in [10]: the schemas of the generated database for each of the DBMSs used
We will describe these elements one by one.
2.1.4. The [Person] entity (2)
We are making a slight modification to the previous description of the [Person] entity, as well as adding some additional information:
package entites;
...
@SuppressWarnings({ "unused", "serial" })
@Entity
@Table(name="jpa01_personne")
public class Personne implements Serializable{
@Id
@Column(name = "ID", nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name = "VERSION", nullable = false)
@Version
private int version;
@Column(name = "NOM", length = 30, nullable = false, unique = true)
private String nom;
@Column(name = "PRENOM", length = 30, nullable = false)
private String prenom;
@Column(name = "DATENAISSANCE", nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(name = "MARIE", nullable = false)
private boolean marie;
@Column(name = "NBENFANTS", nullable = false)
private int nbenfants;
// manufacturers
public Personne() {
}
public Personne(String nom, String prenom, Date datenaissance, boolean marie,
int nbenfants) {
....
}
// toString
public String toString() {
return String.format("[%d,%d,%s,%s,%s,%s,%d]", getId(), getVersion(),
getNom(), getPrenom(), new SimpleDateFormat("dd/MM/yyyy")
.format(getDatenaissance()), isMarie(), getNbenfants());
}
// getters and setters
...
}
- line 7: we name the table associated with the [Person] entity [jpa01_personne]. In this document, various tables will be created in a schema always named jpa. By the end of this tutorial, the jpa schema will contain many tables. To help the reader keep track, tables that are related to each other will have the same prefix jpaxx_.
- line 45: a [toString] method to display a [Person] object on the console.
2.1.5. Configuring the Data Access Layer
In the Eclipse project above, the JPA layer is configured via the [META-INF/persistence.xml] file:
 |
At runtime, the [META-INF/persistence.xml] file is searched for in the application’s classpath. In our Eclipse project, everything in the [/src] folder [1] is copied to a [/bin] folder [2]. This folder is part of the project’s classpath. This is why [META-INF/persistence.xml] will be found when the JPA layer configures itself.
By default, Eclipse does not place source code in the project’s [/src] folder but directly under the project folder itself. All our Eclipse projects will be configured so that the sources are in [/src] and the compiled classes in [/bin], as shown in Section 5.2.1.
Let’s examine the JPA layer configuration in our project’s [persistence.xml] file:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Persistent classes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
<property name="hibernate.connection.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- automatic schematic creation -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!-- properties DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
To understand this configuration, we need to revisit the data access architecture of our application:
 |
- the [persistence.xml] file configures layers [4, 5, 6]
- [4]: Hibernate implementation of JPA
- [5]: Hibernate accesses the database via a connection pool. A connection pool is a pool of open connections to the DBMS. A DBMS is accessed by multiple users, yet for performance reasons, it cannot exceed a limit N of open connections simultaneously. Well-written code opens a connection to the DBMS for the minimum amount of time: it executes SQL commands and closes the connection. It will do this repeatedly, every time it needs to work with the database. The cost of opening and closing a connection is not negligible, and this is where the connection pool comes in. When the application starts, the connection pool opens N1 connections to the DBMS. The application requests an open connection from the pool whenever it needs one. The connection is returned to the pool as soon as the application no longer needs it, preferably as quickly as possible. The connection is not closed and remains available for the next user. A connection pool is therefore a system for sharing open connections.
- [6]: the JDBC driver for the DBMS being used
Now let’s see how the [persistence.xml] file configures the layers [4, 5, 6] above:
- line 2: the root tag of the XML file is <persistence>.
- line 3: <persistence-unit> is used to define a persistence unit. There can be multiple persistence units. Each one has a name (name attribute) and a transaction type (transaction-type attribute). The application will access the persistence unit via its name, in this case jpa. The transaction type RESOURCE_LOCAL indicates that the application manages transactions with the DBMS itself. This will be the case here. When the application runs in an EJB3 container, it can use the container’s transaction service. In that case, we would set transaction-type=JTA (Java Transaction API). JTA is the default value when the transaction-type attribute is omitted.
- Line 5: The <provider> tag is used to define a class that implements the [javax.persistence.spi.PersistenceProvider] interface, which allows the application to initialize the persistence layer. Because we are using a JPA/Hibernate implementation, the class used here is a Hibernate class.
- Line 6: The <properties> tag introduces properties specific to the chosen provider. Thus, depending on whether you have chosen Hibernate, TopLink, Kodo, etc., you will have different properties. The following are specific to Hibernate.
- Line 8: Instructs Hibernate to scan the project’s classpath to find classes annotated with @Entity so it can manage them. @Entity classes can also be declared using <class>class_name</class> tags, directly under the <persistence-unit> tag. This is what we will do with the JPA/Toplink provider.
- Lines 10–12, which are commented out here, configure Hibernate’s console logs:
- Line 10: to enable or disable the display of SQL statements issued by Hibernate to the DBMS. This is very useful during the learning phase. Due to the relational/object bridge, the application works on persistent objects to which it applies operations such as [persist, merge, remove]. It is very helpful to know which SQL statements are actually issued for these operations. By studying them, you gradually learn to anticipate the SQL statements Hibernate will generate when performing such operations on persistent objects, and the relational/object bridge begins to take shape in your mind.
- Line 11: The SQL statements displayed on the console can be formatted neatly to make them easier to read
- Line 12: The displayed SQL statements will also be annotated
- Lines 15–19 define the JDBC layer (layer [6] in the architecture):
- line 15: the JDBC driver class for the DBMS, here MySQL5
- line 16: the URL of the database being used
- Lines 17, 18: the connection username and password
- Here we use elements explained in the appendices in section 5.5. The reader is encouraged to read this section on MySQL5.
- line 22: Hibernate needs to know which DBMS it is working with. This is because all DBMSs have proprietary SQL extensions, such as their own way of handling the automatic generation of primary key values, ... which means that Hibernate needs to know the DBMS it is working with in order to send it SQL commands that the DBMS will understand. [MySQL5InnoDBDialect] refers to the MySQL5 DBMS with InnoDB tables that support transactions.
- Lines 24–28 configure the c3p0 connection pool (layer [5] in the architecture):
- Lines 24, 25: the minimum (default 3) and maximum number of connections (default 15) in the pool. The default initial number of connections is 3.
- Line 26: maximum wait time in milliseconds for a connection request from the client. After this timeout, c3p0 will throw an exception.
- line 27: to access the database, Hibernate uses prepared SQL statements (PreparedStatement) that c3p0 can cache. This means that if the application requests a prepared SQL statement that is already in the cache a second time, it will not need to be prepared (preparing an SQL statement incurs a cost) and the one in the cache will be used. Here, we specify the maximum number of prepared SQL statements the cache can hold, across all connections (a prepared SQL statement belongs to a single connection).
- Line 28: Connection validity check interval in milliseconds. A connection in the pool can become invalid for various reasons (the JDBC driver invalidates the connection because it has been idle too long, the JDBC driver has bugs, etc.).
- Line 20: Here, we specify that when the persistence layer is initialized, the database schema for @Entity objects should be generated. Hibernate now has all the tools to generate the SQL statements for creating the database tables:
- the configuration of the @Entity objects allows it to know which tables to generate
- Lines 15–18 and 24–28 allow it to establish a connection with the DBMS
- line 22 tells it which SQL dialect to use to generate the tables
Thus, the [persistence.xml] file used here recreates a new database with each new execution of the application. The tables are recreated (create table) after being dropped (drop table) if they existed. Note that this is obviously not something to do with a production database...
Tests have shown that the drop/create phase for tables can fail. This was particularly the case when, for the same test, we switched from a JPA/Hibernate layer to a JPA/Toplink layer or vice versa. Starting from the same @Entity objects, the two implementations do not generate exactly the same tables, generators, sequences, etc., and it has sometimes happened that the drop/create phase failed, requiring the tables to be deleted manually. The "Appendices" section, starting from paragraph 5, describes the tools available for performing this task manually. It should be noted that the JPA/Hibernate implementation proved to be the most efficient during this initial phase of database content creation: crashes were rare.
The tools used by the JPA/Hibernate layer are in the [jpa-hibernate] library, presented in section 1.5, page 8. The JDBC drivers required to access the DBMS are in the [jpa-divers] library. These two libraries have been added to the classpath of the project studied here. Their contents are summarized below:
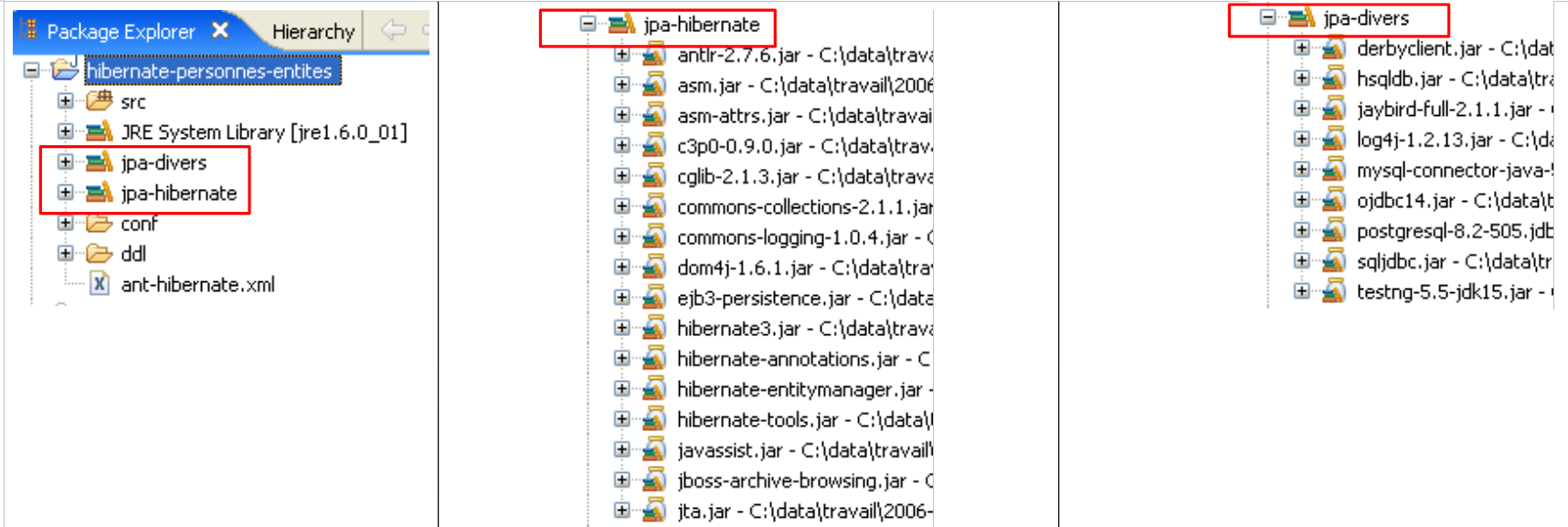 |
2.1.6. Generating the database with an Ant script
As we have just seen, Hibernate provides tools to generate the database schema for the application’s @Entity objects. Hibernate can:
- generate the text file containing the SQL statements that create the database. Only the dialect specified in [persistence.xml] is used in this case.
- create the tables representing the @Entity objects in the target database defined in [persistence.xml]. In this case, the entire [persistence.xml] file is used.
We will present an Ant script capable of generating the database schema for @Entity objects. This script is not my own: it is based on a similar script from [ref1]. Ant (Another Neat Tool) is a Java batch task tool. Ant scripts are not easy for beginners to understand. We will use only one, the one we are now commenting on:
 |
- in [1]: the directory structure of the examples in this tutorial.
- in [2]: the [people-entities] folder of the Eclipse project currently being studied
- in [3]: the <lib> folder containing the five JAR libraries defined in section 1.5.
- in [4]: the [hibernate-tools.jar] archive required for one of the tasks in the [ant-hibernate.xml] script that we will examine.
 |
- in [5]: the Eclipse project and the [ant-hibernate.xml] script
- in [6]: the [src] folder of the project
The [ant-hibernate.xml] script [5] will use the JAR files in the <lib> folder [3], specifically the [hibernate-tools.jar] file [4] in the [lib/hibernate] folder. We have reproduced the directory tree so that the reader can see that to find the [lib] folder from the [people-entities] folder [2] in the [ant-hibernate.xml] script, you must follow the path: ../../../lib.
Let’s examine the [ant-hibernate.xml] script:
<project name="jpa-hibernate" default="compile" basedir=".">
<!-- nom du projet et version -->
<property name="proj.name" value="jpa-hibernate" />
<property name="proj.shortname" value="jpa-hibernate" />
<property name="version" value="1.0" />
<!-- Propriété globales -->
<property name="src.java.dir" value="src" />
<property name="lib.dir" value="../../../lib" />
<property name="build.dir" value="bin" />
<!-- le Classpath du projet -->
<path id="project.classpath">
<fileset dir="${lib.dir}">
<include name="**/*.jar" />
</fileset>
</path>
<!-- les fichiers de configuration qui doivent être dans le classpath-->
<patternset id="conf">
<include name="**/*.xml" />
<include name="**/*.properties" />
</patternset>
<!-- Nettoyage projet -->
<target name="clean" description="Nettoyer le projet">
<delete dir="${build.dir}" />
<mkdir dir="${build.dir}" />
</target>
<!-- Compilation projet -->
<target name="compile" depends="clean">
<javac srcdir="${src.java.dir}" destdir="${build.dir}" classpathref="project.classpath" />
</target>
<!-- Copier les fichiers de configuration dans le classpath -->
<target name="copyconf">
<mkdir dir="${build.dir}" />
<copy todir="${build.dir}">
<fileset dir="${src.java.dir}">
<patternset refid="conf" />
</fileset>
</copy>
</target>
<!-- Hibernate Tools -->
<taskdef name="hibernatetool" classname="org.hibernate.tool.ant.HibernateToolTask" classpathref="project.classpath" />
<!-- Générer la DDL de la base -->
<target name="DDL" depends="compile, copyconf" description="Génération DDL base">
<hibernatetool destdir="${basedir}">
<classpath path="${build.dir}" />
<!-- Utiliser META-INF/persistence.xml -->
<jpaconfiguration />
<!-- export -->
<hbm2ddl drop="true" create="true" export="false" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
</hibernatetool>
</target>
<!-- Générer la base -->
<target name="BD" depends="compile, copyconf" description="Génération BD">
<hibernatetool destdir="${basedir}">
<classpath path="${build.dir}" />
<!-- Utiliser META-INF/persistence.xml -->
<jpaconfiguration />
<!-- export -->
<hbm2ddl drop="true" create="true" export="true" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
</hibernatetool>
</target>
</project>
- Line 1: The [ant] project is named "jpa-hibernate". It consists of a set of tasks, one of which is the default task: in this case, the task named "compile". An Ant script is called to execute a task T. If no task is specified, the default task is executed. basedir="." indicates that for all relative paths found in the script, the starting point is the folder containing the Ant script, in this case the <examples>/hibernate/direct/people-entities folder.
- Lines 3–11: define script variables using the tag <property name="variableName" value="variableValue"/>. The variable can then be used in the script with the notation ${variableName}. The names can be anything. Let’s take a closer look at the variables defined on lines 9–11:
- Line 9: defines a variable named "src.java.dir" (the name is arbitrary) which, later in the script, will refer to the folder containing the Java source code. Its value is "src", a path relative to the folder designated by the basedir attribute (line 1). This is therefore the path "./src", where . here refers to the folder <examples>/hibernate/direct/people-entities. The Java source code is indeed located in the <people-entities>/src folder (see [6] above).
- Line 10: defines a variable named "lib.dir" which, later in the script, will refer to the folder containing the JAR files required by the script’s Java tasks. Its value ../../../lib refers to the <examples>/lib folder (see [3] above).
- Line 11: defines a variable named "build.dir" which, later in the script, will refer to the folder where the .class files generated from compiling the .java sources must be placed. Its value "bin" refers to the <personnes-entites>/bin folder. We have already explained that in the Eclipse project we studied, the <bin> folder was where the .class files were generated. Ant will do the same.
- Lines 14–18: The <path> tag is used to define elements of the classpath that the Ant tasks will use. Here, the path "project.classpath" (the name is arbitrary) includes all the .jar files in the <examples>/lib directory tree.
- Lines 21–24: The <patternset> tag is used to designate a set of files using naming patterns. Here, the patternset named conf refers to all files with the .xml or .properties extension. This patternset will be used to refer to the .xml and .properties files in the <src> folder (persistence.xml, log4j.properties) (see [6]), which are application configuration files. When certain tasks are executed, these files must be copied to the <bin> folder so that they are in the project’s classpath. We will then use the conf patternset to reference them.
- Lines 27–30: The <target> tag denotes a task in the script. This is the first one we encounter. Everything that preceded this pertains to the configuration of the Ant script’s execution environment. The task is called clean. It runs in two steps: the <bin> folder is deleted (line 28) and then recreated (line 29).
- Lines 33–35: The compile task, which is the script’s default task (line 1). It depends (depends attribute) on the clean task. This means that before executing the compile task, Ant must execute the clean task, i.e., clean the <bin> folder. The purpose of the compile task here is to compile the Java source files in the <src> folder.
- Line 34: Call to the Java compiler with three parameters:
- srcdir: the folder containing the Java source files, here the <src> folder
- destdir: the folder where the generated .class files should be stored, here the <bin> folder
- classpathref: the classpath to use for compilation, here all the JAR files in the <lib> directory tree
- (continued)
- lines 38–45: the copyconf task, whose purpose is to copy all .xml and .properties files from the <src> directory into the <bin> directory.
- line 48: definition of a task using the <taskdef> tag. Such a task is intended to be reused elsewhere in the script. This is a coding convenience. Because the task is used in various places in the script, it is defined once with the <taskdef> tag and then reused via its name when needed.
- The task is called hibernatetool (name attribute).
- Its class is defined by the classname attribute. Here, the specified class will be found in the [hibernate-tools.jar] archive we mentioned earlier.
- The classpathref attribute tells Ant where to look for the preceding class
- (continued)
- Lines 51–60 pertain to the task of interest here: generating the database schema for the @Entity objects in our Eclipse project.
- Line 51: The task is called DDL (short for Data Definition Language, the SQL used to create database objects). It depends on the compile and copyconf tasks, in that order. The DDL task will therefore trigger, in order, the execution of the clean, compile, and copyconf tasks. When the DDL task starts, the <bin> folder contains the .class files generated from the .java sources, notably the @Entity objects, as well as the [META-INF/persistence.xml] file that configures the JPA/Hibernate layer.
- Lines 53–59: The [hibernatetool] task defined on line 48 is called. It is passed numerous parameters, in addition to those already defined on line 48:
- Line 53: The output directory for the results produced by the task will be the current directory.
- Line 54: The task’s classpath will be the <bin> folder.
- Line 56: tells the [hibernatetool] task how to determine its runtime environment: the <jpaconfiguration/> tag indicates that it is in a JPA environment and that it must therefore use the [META-INF/persistence.xml] file, which it will find here in its classpath.
- Line 58 sets the conditions for generating the database: drop=true indicates that SQL drop table statements must be issued before the tables are created; create=true indicates that the text file containing the SQL statements for creating the database must be created; outputfilename specifies the name of this SQL file—here schema.sql in the <ddl> folder of the Eclipse project; export=false indicates that the generated SQL statements must not be executed in a connection to the DBMS. This point is important: it means that the target DBMS does not need to be running to execute the task. delimiter sets the character that separates two SQL statements in the generated schema, and format=true requests that basic formatting be applied to the generated text.
- Lines 51–60 pertain to the task of interest here: generating the database schema for the @Entity objects in our Eclipse project.
- (continued)
- Lines 63–72 define the task named BD. It is identical to the previous DDL task, except that this time it generates the database (export="true" on line 70). The task opens a connection to the DBMS using the information found in [persistence.xml], to execute the SQL schema and generate the database. To run the BD task, the DBMS must therefore be running.
2.1.7. Running the ant DDL task
To run the [ant-hibernate.xml] script, we first need to make a few configurations within Eclipse.
 |
- in [1]: select [External Tools]
- in [2]: create a new Ant configuration
 |
- in [3]: name the Ant configuration
- In [5]: Specify the Ant script using the [4] button
- Step [6]: Apply the changes
- in [7]: the DDL Ant configuration has been created
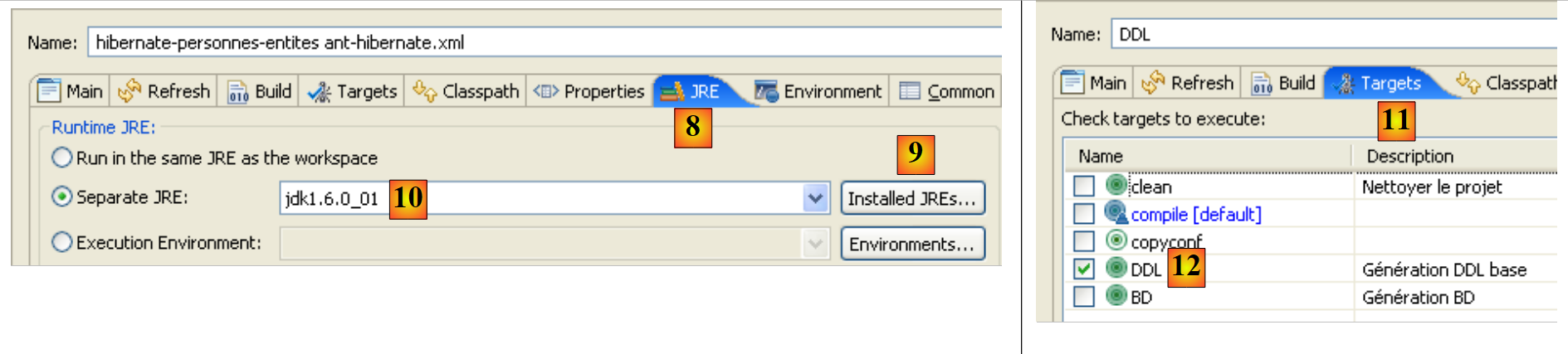 |
 |
- in [8]: in the JRE tab, define the JRE to use. Field [10] is normally pre-filled with the JRE used by Eclipse. Therefore, there is usually nothing to do in this panel. However, I encountered a case where the Ant script could not find the <javac> compiler. This compiler is not located in a JRE (Java Runtime Environment) but in a JDK (Java Development Kit). Eclipse’s Ant tool locates this compiler via the JAVA_HOME environment variable (Start / Control Panel / Performance and Maintenance / System / Advanced tab / Environment Variables button) [A]. If this variable has not been defined, you can allow Ant to find the <javac> compiler by specifying a JDK instead of a JRE in [10]. The JDK is available in the same folder as the JRE [B]. Use button [9] to register the JDK among the available JREs [C] so that you can then select it in [10].
- In [12]: In the [Targets] tab, select the DDL task. Thus, the Ant configuration we named DDL [7] will correspond to the execution of the task named DDL [12], which, as we know, generates the DDL schema for the database representing the application’s @Entity objects.
 |
- in [13]: validate the configuration
- In [14]: Run it
In the [Console] view, you will see logs from the execution of the DDL Ant task:
Buildfile: C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\ant-hibernate.xml
clean:
[delete] Deleting directory C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
[mkdir] Created dir: C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
compile:
[javac] Compiling 3 source files to C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
copyconf:
[copy] Copying 2 files to C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
DDL:
[hibernatetool] Executing Hibernate Tool with a JPA Configuration
[hibernatetool] 1. task: hbm2ddl (Generates database schema)
[hibernatetool] drop table if exists jpa01_personne;
[hibernatetool] create table jpa01_personne (
[hibernatetool] ID integer not null auto_increment,
[hibernatetool] VERSION integer not null,
[hibernatetool] NOM varchar(30) not null unique,
[hibernatetool] PRENOM varchar(30) not null,
[hibernatetool] DATENAISSANCE date not null,
[hibernatetool] MARIE bit not null,
[hibernatetool] NBENFANTS integer not null,
[hibernatetool] primary key (ID)
[hibernatetool] ) ENGINE=InnoDB;
BUILD SUCCESSFUL
Total time: 5 seconds
- Recall that the DDL task is named [hibernatetool] (line 10) and depends on the tasks clean (line 2), compile (line 5), and copyconf (line 7).
- Line 10: The [hibernatetool] task uses the [persistence.xml] file from a JPA configuration
- line 11: the [hbm2ddl] task will generate the database DDL schema
- Lines 12–22: the database DDL schema
Recall that we instructed the [hbm2ddl] task to generate the DDL schema in a specific location:
<hbm2ddl drop="true" create="true" export="true" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
- line 74: the schema must be generated in the file ddl/schema.sql. Let’s check:
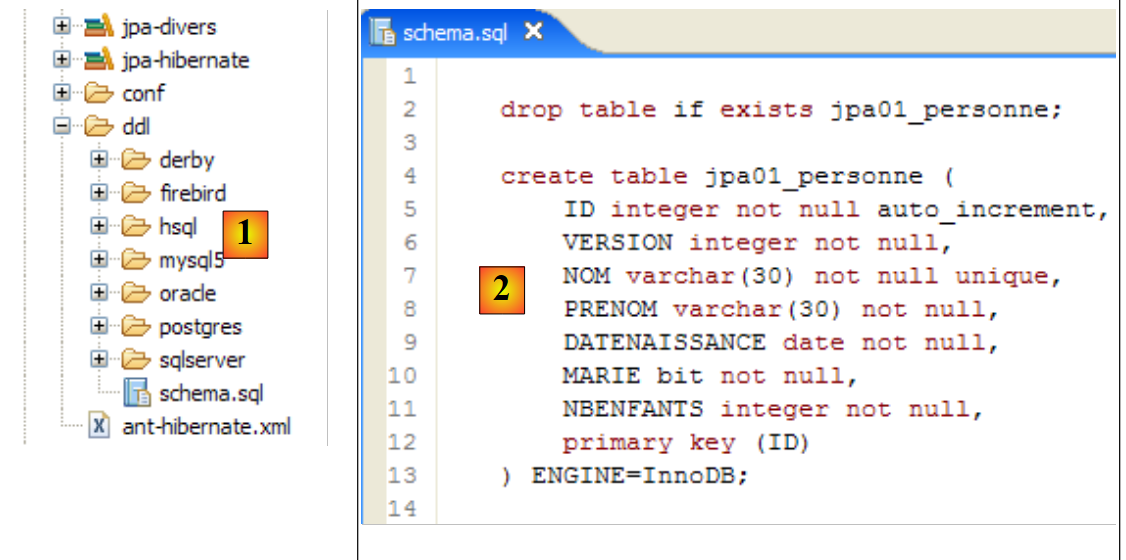 |
- in [1]: the ddl/schema.sql file is indeed present (press F5 to refresh the directory tree)
- in [2]: its contents. This is the schema for a MySQL5 database. The [persistence.xml] configuration file for the JPA layer did indeed specify a MySQL5 DBMS (line 8 below):
<!-- connexion JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
...
<!-- création automatique du schéma -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialecte -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!-- propriétés DataSource c3p0 -->
...
Let’s examine the object-relational mapping implemented here by looking at the configuration of the @Entity Person object and the generated DDL schema:
 |
 |
A few points are worth noting:
- A1-B1: The table name specified in A1 is indeed the one used in B1. Note the `DROP` statement preceding the `CREATE` in B1.
- A2-B2: show how the primary key is generated. The AUTO mode specified in A2 resulted in the autoincrement attribute specific to MySQL5. The primary key generation mode is most often specific to the DBMS.
- A3-B3: show the SQL bit type specific to MySQL 5 used to represent a Java boolean type.
Let’s repeat this test with another DBMS:
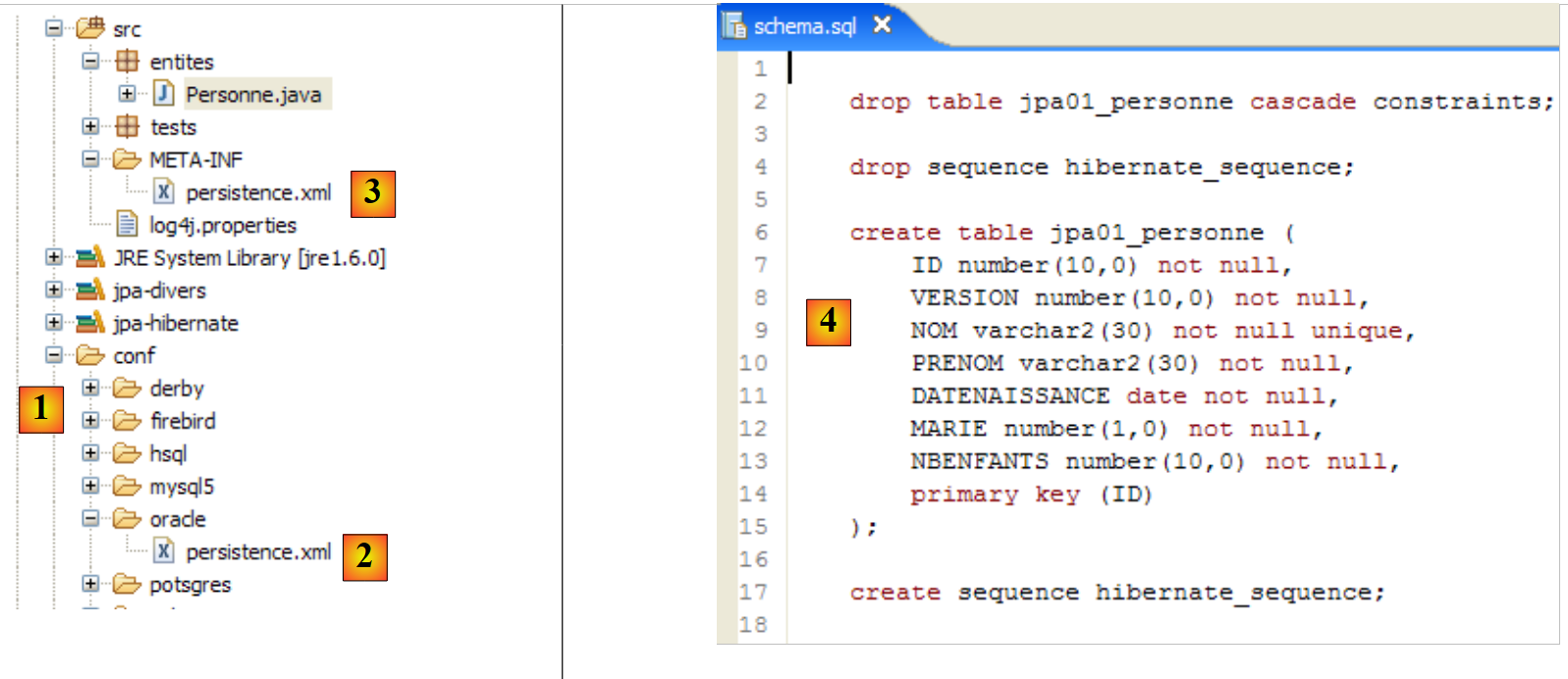 |
- the [conf] folder [1] contains [persistence.xml] files for various DBMSs. Take the Oracle one [2], for example, and place it in the [META-INF] folder [3] in place of the previous one. Its contents are as follows:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Persistent classes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="oracle.jdbc.OracleDriver" />
<property name="hibernate.connection.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- automatic schematic creation -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.OracleDialect" />
<!-- properties DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
Readers are encouraged to consult the appendix, specifically the section on Oracle (Section 5.7), particularly to understand the JDBC configuration.
Only line 25 is truly important here: we are telling Hibernate that the DBMS is now an Oracle DBMS. Executing the ant DDL task yields the result [4] shown above. Note that the Oracle schema differs from the MySQL5 schema. This is a key strength of JPA: the developer does not need to worry about these details, which significantly increases the portability of their applications.
2.1.8. Executing the " " Ant task
You may recall that the Ant task named BD does the same thing as the *DDL* task but also generates the database. The DBMS must therefore be running. We will use the MySQL5 DBMS and invite the reader to copy the file [conf/mysql5/persistence.xml] into the [src/META-INF] folder. To verify that the task is working, we will use the SQL Explorer plugin (see Section 5.2.6) to check the status of the JPA database before and after running the ant BD task.
First, we need to create a new Ant configuration to run the BD task. The reader is invited to follow the procedure outlined for the DDL Ant configuration in section 2.1.7. The new Ant configuration will be named BD:
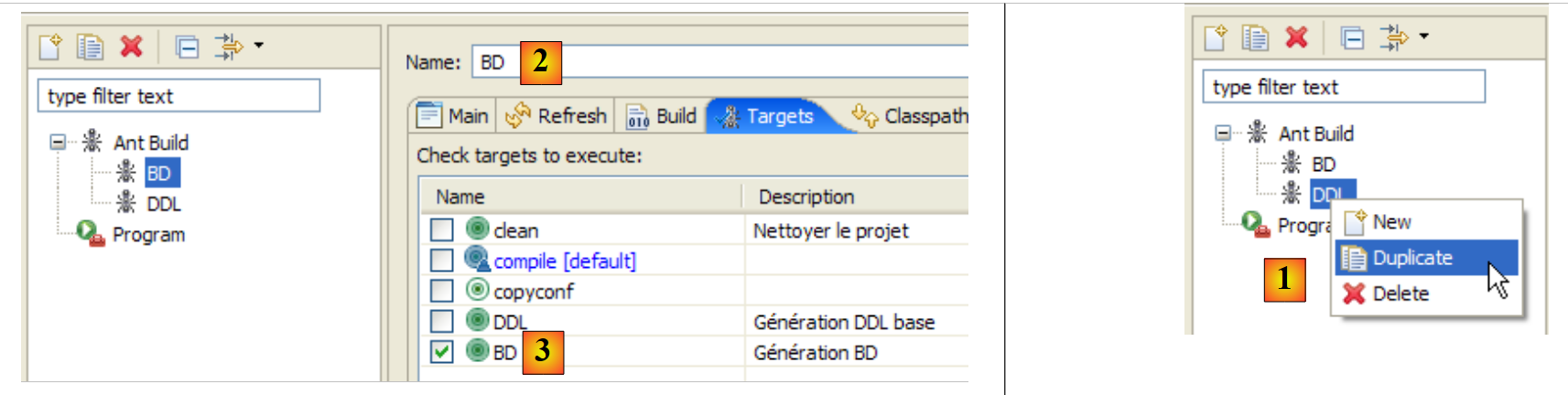 |
- in [1]: we duplicate the previous configuration named DDL
- in [2]: name the new configuration BD. It executes the ant BD task [3], which physically generates the database.
- Once this is done, launch the MySQL5 DBMS (Section 5.5).
We now use the SQL Explorer plugin to explore the databases managed by the DBMS. The reader should familiarize themselves with this plugin beforehand if necessary (see section 5.2.6).
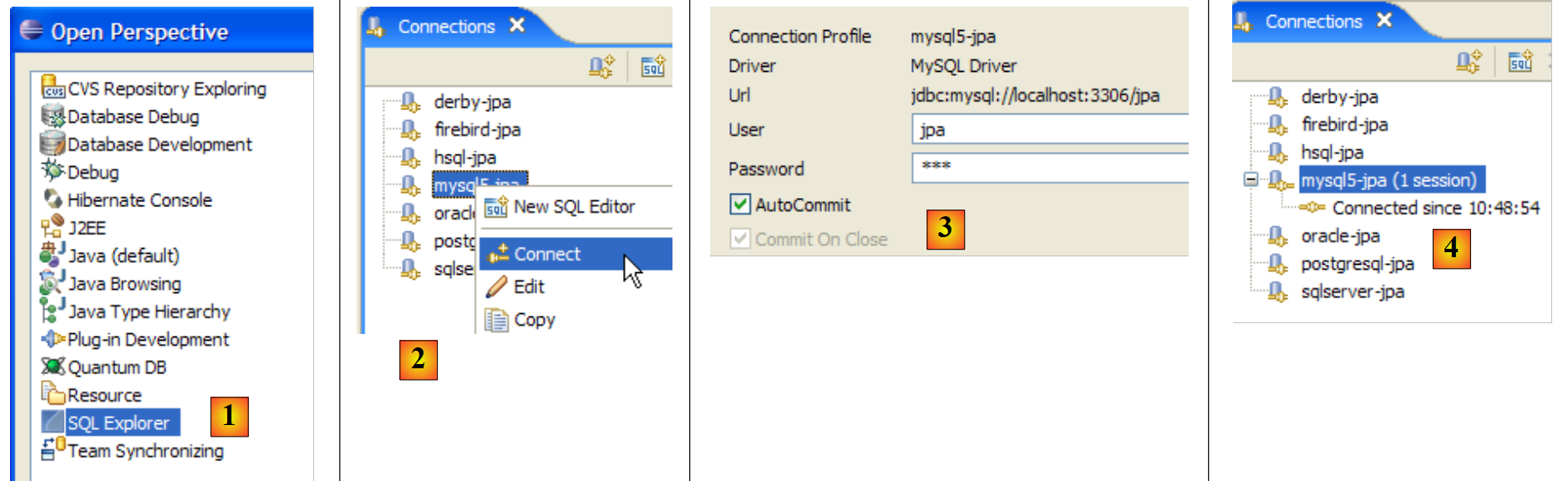 |
- [1]: Open the SQL Explorer perspective [Window / Open Perspective / Other]
- [2]: If necessary, create a connection [mysql5-jpa] (see section 5.5.5, page 252) and open it
- [3]: Log in as jpa / jpa
- [4]: You are now connected to MySQL5.
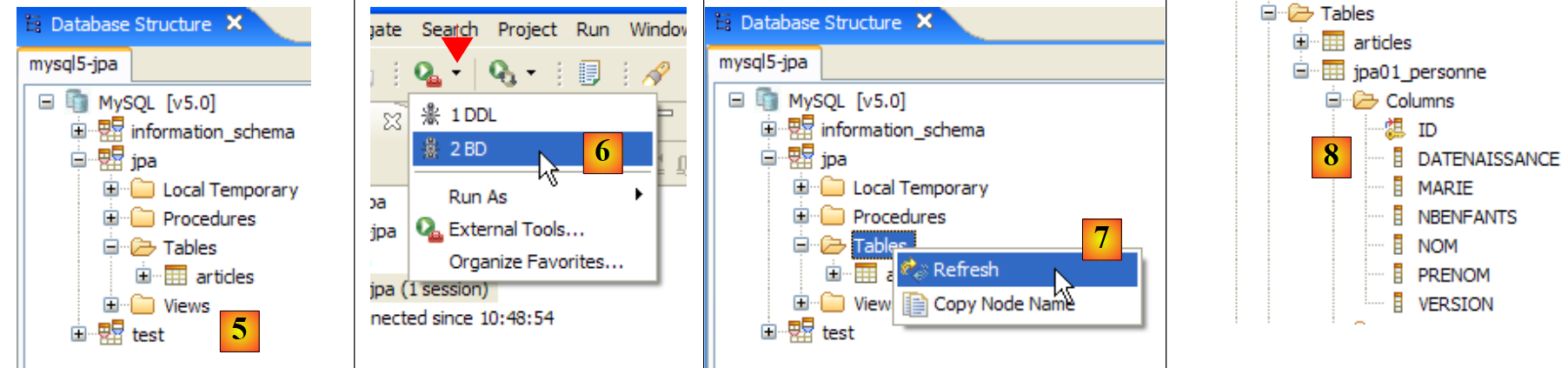 |
- In [5]: The jpa database has only one table: [articles]
- in [6]: Run the Ant DB task. Because you are in the [SQL Explorer] perspective, you cannot see the [Console] view, which displays the task logs. You can display this view [Window / Show View / ...] or return to the Java perspective [Window / Open Perspective / ...].
- in [7]: once the DB task is complete, return to the [SQL Explorer] perspective if necessary and refresh the JPA database tree.
- In [8]: You can see the [jpa01_personne] table that was created.
Readers are encouraged to repeat this database generation process with other DBMSs. The procedure is as follows:
- Copy the file [conf/<dbms>/persistence.xml] to the [src/META-INF] folder, where <dbms> is the DBMS being tested
- launch <dbms> by following the instructions in the appendix for that DBMS
- in the SQL Explorer view, create a connection to <dbms>. This is also explained in the appendices for each DBMS
- Repeat the previous tests
At this point, we have gained a number of insights:
- We have a better understanding of the object-relational bridge concept. Here, it was implemented using Hibernate. We will use TopLink later.
- We know that this object-relational bridge is configured in two places:
- in the @Entity objects, where we specify the relationships between object fields and database table columns
- in [META-INF/persistence.xml], where we provide the JPA implementation with information about the two components of the object-relational bridge: the @Entity objects (object) and the database (relational).
- We have created two Ant tasks, named DDL and DB, that allow us to create the database based on the previous configuration, even before writing any Java code.
Now that the JPA layer of our application is properly configured, we can begin exploring the JPA API with Java code.
2.1.9. s an application's persistence context
Let’s take a closer look at the runtime environment of a JPA client:
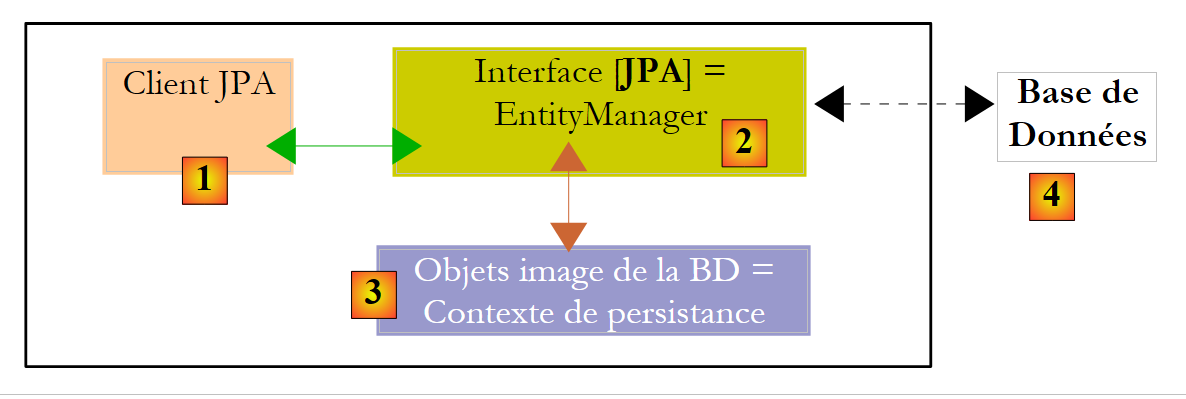 |
We know that the JPA layer [2] creates a bridge between objects [3] and relational data [4]. The "persistence context" refers to the set of objects managed by the JPA layer within this object-relational bridge. To access data in the persistence context, a JPA client [1] must go through the JPA layer [2]:
- it can create an object and ask the JPA layer to make it persistent. The object then becomes part of the persistence context.
- it can request a reference to an existing persistent object from the [JPA] layer.
- it can modify a persistent object obtained from the JPA layer.
- it can ask the JPA layer to remove an object from the persistence context.
The JPA layer provides the client with an interface called [EntityManager] which, as its name suggests, allows for the management of @Entity objects in the persistence context. Below are the main methods of this interface:
Adds the entity to the persistence context | |
removes entity from the persistence context | |
merges an entity object from the client that is not managed by the persistence context with the entity object in the persistence context that has the same primary key. The result returned is the entity object from the persistence context. | |
places an object retrieved from the database via its primary key. The type T of the object allows the JPA layer to know which table to query. The persistent object thus created is returned to the client. | |
creates a Query object from a JPQL query (Java Persistence Query Language). A JPQL query is analogous to an SQL query, except that it queries objects rather than tables. | |
A method similar to the previous one, except that queryText is an SQL statement rather than a JPQL query. | |
A method identical to createQuery, except that the JPQL query queryText has been externalized into a configuration file and associated with a name. This name is the method’s parameter. |
An EntityManager object has a lifecycle that is not necessarily the same as that of the application. It has a beginning and an end. Thus, a JPA client can work successively with different EntityManager objects. The persistence context associated with an EntityManager has the same lifecycle as the EntityManager itself. They are inseparable from one another. When an EntityManager object is closed, its persistence context is synchronized with the database if necessary, and then ceases to exist. A new EntityManager must be created to obtain a new persistence context.
The JPA client can create an EntityManager and thus a persistence context with the following statement:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
- javax.persistence.Persistence is a static class used to obtain a factory for EntityManager objects. This factory is associated with a specific persistence unit. Recall that the configuration file [META-INF/persistence.xml] is used to define persistence units, each of which has a name:
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
In the example above, the persistence unit is named jpa. It comes with its own specific configuration, including the database management system (DBMS) it works with. The statement [Persistence.createEntityManagerFactory("jpa")] creates an EntityManagerFactory capable of providing EntityManager objects designed to manage persistence contexts associated with the persistence unit named jpa. An EntityManager object—and thus a persistence context—is obtained from the EntityManagerFactory object as follows:
The following methods of the [EntityManager] interface allow you to manage the lifecycle of the persistence context:
The persistence context is closed. Forces synchronization of the persistence context with the database:
| |
The persistence context is cleared of all its objects but not closed. | |
The persistence context is synchronized with the database as described for close() |
The JPA client can force synchronization of the persistence context with the database using the [EntityManager].flush method. Synchronization can be explicit or implicit. In the first case, it is up to the client to perform flush operations when it wants to synchronize; otherwise, synchronization occurs at specific times that we will specify. The synchronization mode is managed by the following methods of the [EntityManager] interface:
There are two possible values for flushMode: FlushModeType.AUTO (default): synchronization occurs before each SELECT query made on the database. FlushModeType.COMMIT: synchronization occurs only at the end of database transactions. | |
returns the current synchronization mode |
Let’s summarize. In FlushModeType.AUTO mode, which is the default, the persistence context will be synchronized with the database at the following times:
- before each SELECT operation on the database
- at the end of a transaction on the database
- following a flush or close operation on the persistence context
In FlushModeType.COMMIT mode, the same applies except for operation 1, which does not occur. The normal mode of interaction with the JPA layer is transactional mode. The client performs various operations on the persistence context within a transaction. In this case, the synchronization points between the persistence context and the database are cases 1 and 2 above in AUTO mode, and case 2 only in COMMIT mode.
Let’s conclude with the Query interface API, which allows you to issue JPQL commands on the persistence context or SQL commands directly on the database to retrieve data. The Query interface is as follows:
 |
We will use methods 1 through 4 above:
- 1 - The getResultList method executes a SELECT query that returns multiple objects. These are returned in a List object. This object is an interface. It provides an Iterator object that allows you to iterate through the elements of the list L as follows:
Iterator iterator = L.iterator();
while (iterator.hasNext()) {
// exploiter l'objet iterator.next() qui représente l'élément courant de la liste
...
}
The list L can also be iterated over using a for loop:
for (Object o : L) {
// exploiter objet o
}
- 2 - The getSingleResult method executes a JPQL/SQL SELECT statement that returns a single object.
- 3 - The `executeUpdate` method executes an SQL UPDATE or DELETE statement and returns the number of rows affected by the operation.
- 4 - The setParameter(String, Object) method allows you to assign a value to a named parameter in a parameterized JPQL query.
- 5 - The setParameter(int, Object) method sets the parameter, but the parameter is identified not by its name but by its position in the JPQL query.
2.1.10. A First JPA Client
Let’s return to the Java perspective of the project:
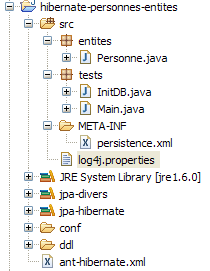 |
We now know almost everything about this project except for the contents of the [src/tests] folder, which we will examine next. The folder contains two test programs for the JPA layer:
- [InitDB.java] is a program that inserts a few rows into the [jpa01_personne] table in the database. Its code will introduce us to the first elements of the JPA layer.
- [Main.java] is a program that performs CRUD operations on the [jpa01_personne] table. Studying its code will allow us to explore the fundamental concepts of the persistence context and the lifecycle of objects within that context.
2.1.10.1. The code
The code for the [InitDB.java] program is as follows:
package tests;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
import javax.persistence.Persistence;
import entites.Personne;
public class InitDB {
// constant
private final static String TABLE_NAME = "jpa01_personne";
public static void main(String[] args) throws ParseException {
// Persistence unit
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
// retrieve a EntityManagerFactory from the persistence unit
EntityManager em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// delete items from the people table
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
// create two people
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// persistence of people
em.persist(p1);
em.persist(p2);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
// log
System.out.println("terminé ...");
}
}
This code should be read in light of what was explained in section 2.1.9.
- Line 19: An EntityManagerFactory (emf) object is requested for the JPA persistence unit (defined in persistence.xml). This operation is normally performed only once during the lifetime of an application.
- line 21: an EntityManager (em) object is requested to manage a persistence context.
- line 23: a Transaction object is requested to manage a transaction. Note that operations on the persistence context must be performed within a transaction. We will see that this is not strictly required, but failing to do so can lead to problems. If the application runs in an EJB3 container, operations on the persistence context are always performed within a transaction.
- Line 24: The transaction begins
- line 26: executes a delete SQL statement on the "jpa01_personne" table (nativeQuery). We do this to clear the table of all content and thus better see the result of the application's execution [InitDB]
- Lines 28–29: Two Person objects, p1 and p2, are created. These are ordinary objects and, for now, have nothing to do with the persistence context. In relation to the persistence context, Hibernate refers to these objects as being in a transient state, as opposed to persistent objects, which are managed by the persistence context. We will instead refer to non-persistent objects (a non-standard term) to indicate that they are not yet managed by the persistence context, and to persistent objects for those that are managed by it. We will encounter a third category of objects: detached objects, which are objects that were previously persistent but whose persistence context has been closed. The client may hold references to such objects, which explains why they are not necessarily destroyed when the persistence context is closed. They are then said to be in a detached state. The [EntityManager].merge operation allows them to be reattached to a newly created persistence context.
- Lines 31–32: The entities p1 and p2 are added to the persistence context via the [EntityManager].persist operation. They then become persistent objects.
- Lines 35–37: A JPQL query “select p from Person p order by p.name asc” is executed. Person is not the table (which is named jpa01_person) but the @Entity object associated with the table. Here we have a JPQL (Java Persistence Query Language) query on the persistence context, not an SQL query on the database. That said, apart from the Person object that has replaced the jpa01_personne table, the syntaxes are identical. A for loop iterates through the list (of people) resulting from the select to display each element on the console. Here, we are verifying that the elements placed in the persistence context in lines 31–32 are indeed present in the table. Transparent synchronization of the persistence context with the database will occur. In fact, a SELECT query will be issued, and we noted that this is one of the cases where synchronization occurs. It is therefore at this moment that, in the background, JPA/Hibernate will issue the two SQL INSERT statements that will insert the two people into the jpa01_personne table. The `persist` operation did not do this. This operation adds objects to the persistence context without affecting the database. The actual work happens during synchronization, here just before the `SELECT` query on the database.
- Line 39: We end the transaction started on line 24. A synchronization will take place again. Nothing will happen here since the persistence context has not changed since the last synchronization.
- Line 41: We close the persistence context.
- Line 43: We close the EntityManager factory.
2.1.10.2. The : executing the code
- Start the MySQL5 DBMS
- Place conf/mysql5/persistence.xml in META-INF/persistence.xml if necessary
- Run the [InitDB] application
The following results are obtained:
 |
- in [1]: the console output in the Java perspective. The expected results are obtained.
- in [2]: we verify the contents of the [jpa01_personne] table using the SQL Explorer view, as explained in section 2.1.8. Two points are worth noting:
- the primary key ID was generated automatically
- the same applies to the version number. We see that the first version has the number 0..
Here we have the first elements of the JPA framework. We have successfully inserted data into a table. We will build on this foundation to write the second test, but first let’s discuss logs.
2.1.11. Implementing Hibernate logs
It is possible to view the SQL statements sent to the database by the JPA/Hibernate layer. It is useful to examine these to see if the JPA layer is as efficient as a developer who had written the SQL statements themselves.
With JPA/Hibernate, SQL logging can be configured in the [persistence.xml] file:
<!-- Classes persistantes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connexion JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
- Lines 4–6: SQL logs were not enabled at this point. We enable them now by removing the comment tags from lines 3 and 7.
We rerun the [InitDB] application. The console output then becomes as follows:
- Lines 2-4: The SQL DELETE statement resulting from the command:
// supprimer les éléments de la table des personnes
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
- lines 5-18: the SQL insert statements from the instructions:
// persistance des personnes
em.persist(p1);
em.persist(p2);
- lines 21-32: the SQL SELECT statement resulting from the instruction:
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList())
If we perform intermediate console prints, we will see that the SQL logs for a statement I in the Java code are written when statement I is executed. This does not mean that the displayed SQL statement is executed on the database at that moment. It is actually cached for execution during the next synchronization of the persistence context with the database.
Additional logs can be obtained via the [src/log4j.properties] file:
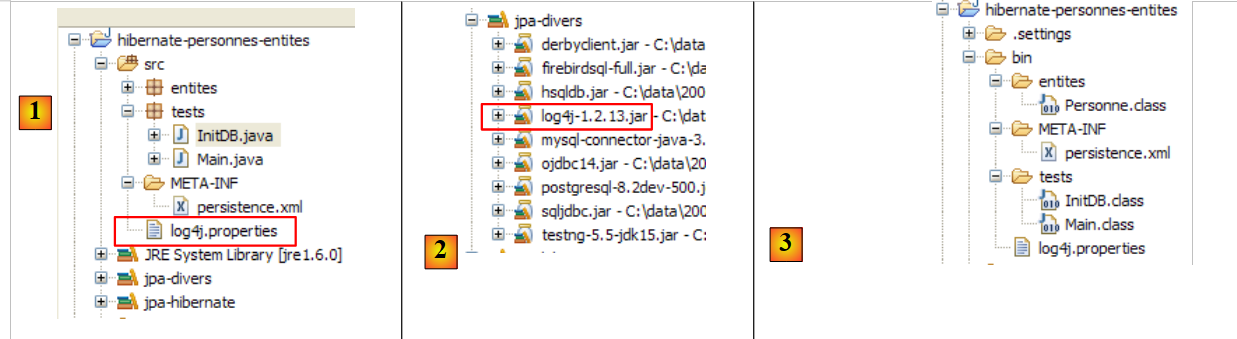 |
- In [1], the [log4j.properties] file is used by the [log4j-1.2.13.jar] [2] archive from the tool called LOG4j (Logs for Java), available at the URL [http://logging.apache.org/log4j/docs/index.html]. Placed in the [src] folder of the Eclipse project, we know that [log4j.properties] will be automatically copied to the [bin] folder of the project [3]. Once this is done, it is now in the project’s classpath, and that is where the [2] archive will retrieve it.
The [log4j.properties] file allows us to control certain Hibernate logs. In previous runs, its contents were as follows:
# Direct log messages to stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
# Root logger option
log4j.rootLogger=ERROR, stdout
# Hibernate logging options (INFO only shows startup messages)
#log4j.logger.org.hibernate=INFO
# Log JDBC bind parameter runtime arguments
#log4j.logger.org.hibernate.type=DEBUG
I won’t comment much on this configuration since I’ve never taken the time to seriously learn about LOG4j.
- Lines 1–8 are found in all log4j.properties files I have encountered
- Lines 10–14 are present in the log4j.properties files of the Hibernate examples.
- Line 11: controls Hibernate’s general logs. Since the line is commented out, these logs are disabled here. There are several log levels: INFO (general information about what Hibernate is doing), WARN (Hibernate warns us of a potential problem), DEBUG (detailed logs). The INFO level is the least verbose, while DEBUG mode is the most verbose. Enabling line 11 allows you to see what Hibernate is doing, particularly when the application starts up. This is often useful.
- Line 12, if enabled, allows you to see the actual arguments used when executing parameterized SQL queries.
Let’s start by uncommenting line 14
# Log JDBC bind parameter runtime arguments
log4j.logger.org.hibernate.type=DEBUG
and rerun [InitDB]. The new logs generated by this change are as follows (partial view):
- Lines 8–10 are new logs generated by enabling line 14 of [log4j.properties]. They indicate the 5 values assigned to the formal parameters ? of the parameterized query in lines 2–7. Thus, we see that the VERSION column will receive the value 0 (line 8).
Now let’s enable line 11 of [log4j.properties]:
and rerun [InitDB]:
Reading these logs provides a lot of interesting information:
- line 7: Hibernate indicates the name of an @Entity class it has found
- line 8: indicates that the [Person] class will be mapped to the [jpa01_person] table
- line 9: indicates the C3P0 connection pool that will be used, the name of the JDBC driver, and the URL of the database to be managed
- line 10: provides additional details about the JDBC connection: owner, commit type, etc.
- line 14: the dialect used to communicate with the DBMS
- line 15: the type of transaction used. JDBCTransactionFactory indicates that the application manages its own transactions. It does not run in an EJB3 container that would provide its own transaction service.
- The following lines relate to Hibernate configuration options that we have not encountered. Interested readers are encouraged to consult the Hibernate documentation.
- Line 37: SQL statements will be displayed on the console. This was requested in [persistence.xml]:
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.format_sql" value="true" />
<property name="use_sql_comments" value="true" />
- Lines 43–45: The database schema is exported to the DBMS, i.e., the database is emptied and then recreated. This mechanism stems from the configuration in [persistence.xml] (line 4 below):
...
<property name="hibernate.connection.password" value="jpa" />
<!-- création automatique du schéma -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialecte -->
...
When an application "crashes" with a Hibernate exception that you don't understand, start by enabling Hibernate logs in DEBUG mode in [log4j.properties] to get a clearer picture:
# Root logger option
log4j.rootLogger=ERROR, stdout
# Hibernate logging options (INFO only shows startup messages)
log4j.logger.org.hibernate=DEBUG
In the rest of this document, logging is disabled by default to ensure a more readable console output.
2.1.12. Exploring the JPQL/HQL language with the Hibernate console
Note: This section requires the Hibernate Tools plugin (section 5.2.5).
In the code for the [InitDB] application, we used a JPQL query. JPQL (Java Persistence Query Language) is a language for querying the persistence context. The query used was as follows:
It selected all records from the table associated with the @Entity [Person] and returned them in ascending order by name. In the query above, p.name is the name field of an instance p of the [Person] class. A JPQL query therefore operates on the @Entity objects in the persistence context and not directly on the database tables. The JPA layer translates this JPQL query into an SQL query appropriate for the DBMS it is working with. Thus, in the case of a JPA/Hibernate implementation connected to a MySQL5 DBMS, the previous JPQL query is translated into the following SQL query:
select
personne0_.ID as ID0_,
personne0_.VERSION as VERSION0_,
personne0_.NOM as NOM0_,
personne0_.PRENOM as PRENOM0_,
personne0_.DATENAISSANCE as DATENAIS5_0_,
personne0_.MARIE as MARIE0_,
personne0_.NBENFANTS as NBENFANTS0_
from
jpa01_personne personne0_
order by
personne0_.NOM asc
The JPA layer used the configuration of the @Entity object [Person] to generate the correct SQL query. This is an example of the object-relational mapping being implemented here.
The [Hibernate Tools] plugin (Section 5.2.5) offers a tool called "Hibernate Console" that allows
- you to issue JPQL or HQL (Hibernate Query Language) queries on the persistence context
- to retrieve the results
- to see the SQL equivalent that was executed on the database
The Hibernate Console is an invaluable tool for learning the JPQL language and becoming familiar with the JPQL/SQL bridge. It is well known that JPA drew heavily on ORM tools such as Hibernate or TopLink. JPQL is very similar to Hibernate’s HQL but does not include all of its features. In the Hibernate console, you can issue HQL commands that will execute normally in the console but are not part of the JPQL language and therefore cannot be used in a JPA client. When this is the case, we will point it out.
Let’s create a Hibernate console for our current Eclipse project:
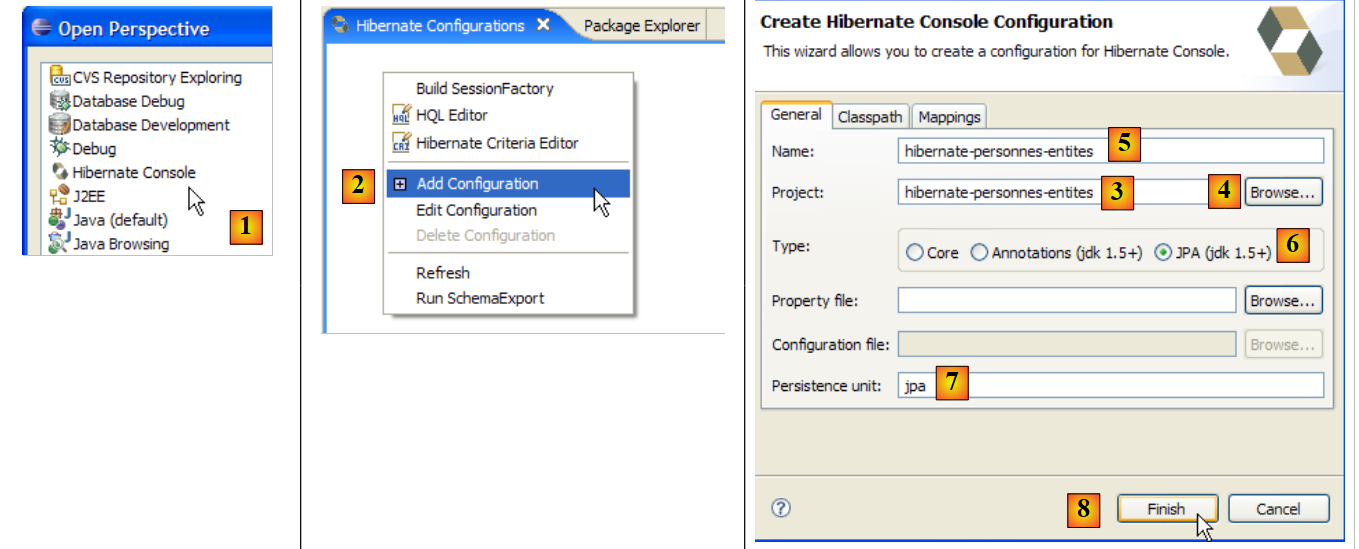 |
- [1]: Switch to the [Hibernate Console] perspective (Window / Open Perspective / Other)
- [2]: We create a new configuration in the [Hibernate Configuration] window
- using the [4] button, we select the Java project for which the Hibernate configuration is being created. Its name appears in [3].
- In [5], we enter the name we want for this configuration. Here, we’ve used [3].
- In [6], we specify that we are using a JPA configuration so that the tool knows it must use the [META-INF/persistence.xml] file
- In [7], we specify that in this [META-INF/persistence.xml] file, the persistence unit named jpa should be used.
- In [8], we validate the configuration.
Next, the DBMS must be started. Here, we are using MySQL 5.
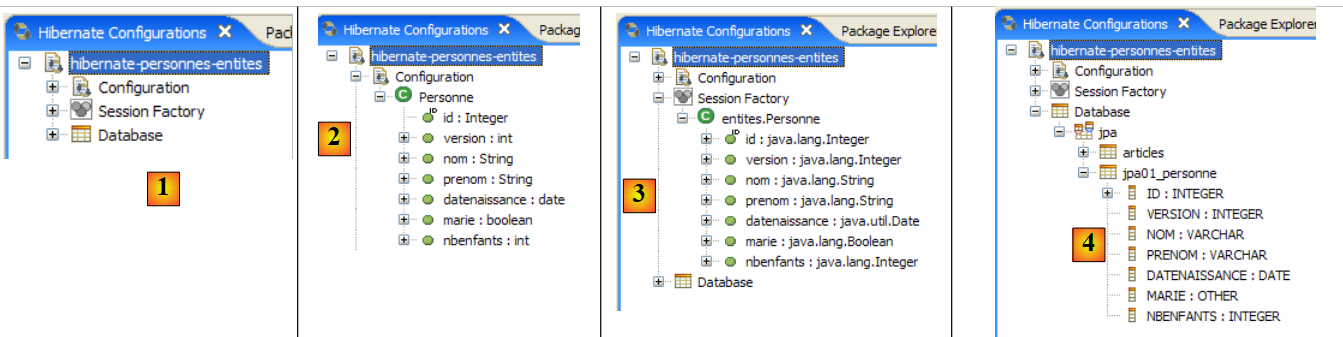 |
- In [1]: The created configuration displays a three-branch tree
- In [2]: The [Configuration] branch lists the objects the console used to configure itself: here, the @Entity Person.
- In [3]: The Session Factory is a Hibernate concept similar to JPA’s EntityManager. It bridges the object-relational gap using the objects in the [Configuration] branch. In [3], the objects of the persistence context are shown; here, again, the @Entity Person.
- in [4]: the database accessed via the configuration found in [persistence.xml]. The [jpa01_personne] table is found there.
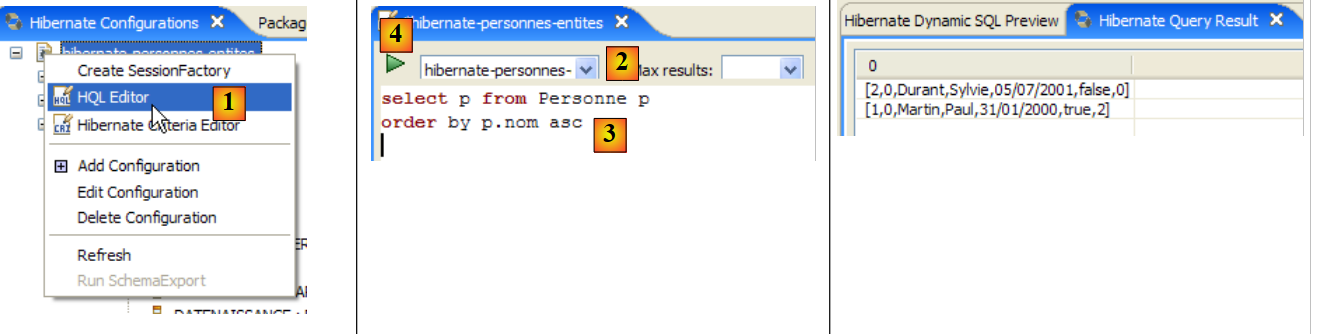 |
- In [1], we create an HQL editor
- in the HQL editor,
- in [2], we select the Hibernate configuration to use if there are multiple
- in [3], we type the JPQL command we want to execute
- in [4], execute it
- In [5], you get the query results in the [Hibernate Query Result] window. You may encounter two issues here:
- You get nothing (no rows). The Hibernate console used the contents of [persistence.xml] to establish a connection with the DBMS. However, this configuration has a property that instructs the database to be emptied:
<property name="hibernate.hbm2ddl.auto" value="create" />
You must therefore rerun the [InitDB] application before re-executing the JPQL command above.
- (continued)
- The [Hibernate Query Result] window is not displayed. You can open it via [Window / Show View / ...]
The [Hibernate Dynamic SQL preview] window ([1] below) allows you to see the SQL query that will be executed to run the JPQL command you are currently writing. As soon as the JPQL command syntax is correct, the corresponding SQL command appears in this window:
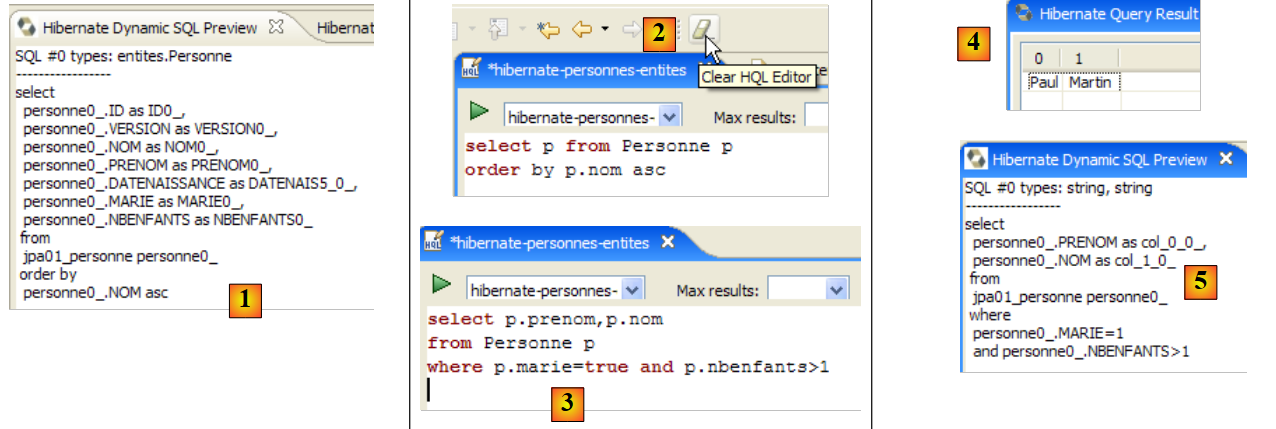 |
- In [2], you can clear the previous HQL command
- At [3], you execute a new one
- at [4], the result
- in [5], the SQL command that was executed on the database
The HQL editor provides assistance for writing HQL commands:
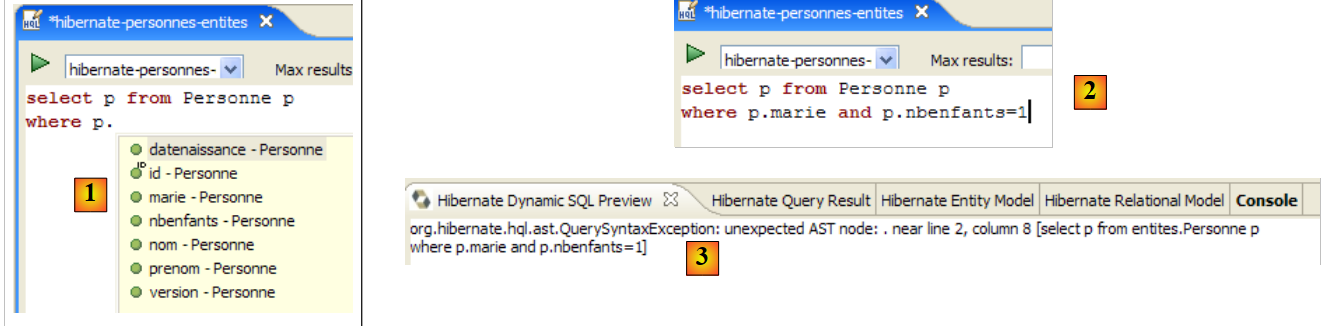 |
- in [1]: once the editor knows that p is a Person object, it can suggest p’s fields as you type.
- in [2]: an incorrect HQL query. You must write where p.marie=true.
- in [3]: the error is reported in the [SQL Preview] window
We invite the reader to issue other HQL/JPQL commands on the database.
2.1.13. A second JPA client
Let’s return to the Java perspective of the project:
|
- [InitDB.java] is a program that inserted a few rows into the [jpa01_personne] table in the database. Studying its code allowed us to grasp the basics of the JPA API.
- [Main.java] is a program that performs CRUD operations on the [jpa01_personne] table. Examining its code will allow us to revisit the fundamental concepts of the persistence context and the lifecycle of objects within that context.
2.1.13.1. The structure of the code
[Main.java] will run a series of tests, each designed to demonstrate a specific aspect of JPA:
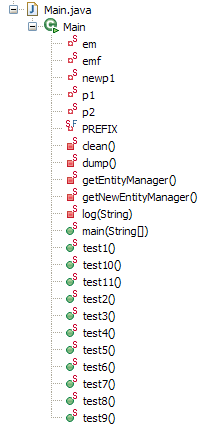 |
The [main] method
- successively calls the methods test1 through test11. We will present the code for each of these methods separately.
- It also uses private utility methods: clean, dump, log, getEntityManager, getNewEntityManager.
We present the main method and the so-called utility methods:
package tests;
...
import entites.Personne;
@SuppressWarnings("unchecked")
public class Main {
// constant
private final static String TABLE_NAME = "jpa01_personne";
// Persistence context
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = null;
// shared objects
private static Personne p1, p2, newp1;
public static void main(String[] args) throws Exception {
// base cleaning
log("clean");clean();
// dump table
dump();
// test1
log("test1");test1();
...
// test11
log("test11");test11();
// fine persistence context
if (em.isOpen())
em.close();
// closure EntityManagerFactory
emf.close();
}
// retrieve the current EntityManager
private static EntityManager getEntityManager() {
if (em == null || !em.isOpen()) {
em = emf.createEntityManager();
}
return em;
}
// pick up a new EntityManager
private static EntityManager getNewEntityManager() {
if (em != null && em.isOpen()) {
em.close();
}
em = emf.createEntityManager();
return em;
}
// table content display
private static void dump() {
// current persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
}
// raz BD
private static void clean() {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// delete elements from the PERSONNES table
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
// end transaction
tx.commit();
}
// logs
private static void log(String message) {
System.out.println("main : ----------- " + message);
}
// object creation
public static void test1() throws ParseException {
...
}
// modify a context object
public static void test2() {
...
}
// request items
public static void test3() {
...
}
// delete an object belonging to the persistence context
public static void test4() {
....
}
// detach, reattach and modify
public static void test5() {
...
}
// delete an object not belonging to the persistence context
public static void test6() {
...
}
// modify an object not belonging to the persistence context
public static void test7() {
...
}
// reattach an object to the persistence context
public static void test8() {
...
}
// a select request causes synchronization
// with the persistence context
public static void test9() {
....
}
// version control (optimistic locking)
public static void test10() {
...
}
// transaction rollback
public static void test11() throws ParseException {
...
}
}
- Line 13: The EntityManagerFactory object (emf) is constructed from the JPA persistence unit defined in [persistence.xml]. It will allow us to create various persistence contexts throughout the application.
- line 14: an EntityManager persistence context that has not yet been initialized
- line 17: three [Person] objects shared by the tests
- Line 21: The jpa01_personne table is cleared and then displayed on line 24 to ensure that we are starting with an empty table.
- Lines 27–31: sequence of tests
- Lines 34–35: Close the persistence context if it was open.
- Line 38: The EntityManagerFactory object emf is closed.
- Lines 42–47: The [getEntityManager] method returns the current EntityManager (or persistence context) or creates a new one if it does not exist (lines 43–44).
- lines 50-56: the [getNewEntityManager] method returns a new persistence context. If one existed previously, it is closed (lines 51-52)
- lines 59-72: the [dump] method displays the contents of the [jpa01_personne] table. This code has already been encountered in [InitDB].
- lines 75-85: the [clean] method empties the [jpa01_personne] table. This code has already been seen in [InitDB].
- Lines 88–90: The [log] method displays the message passed to it as a parameter on the console so that it is noticed.
We can now move on to studying the tests.
2.1.13.2. Test 1
The code for test1 is as follows:
// création d'objets
public static void test1() throws ParseException {
// contexte de persistance
EntityManager em = getEntityManager();
// création personnes
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistance des personnes
em.persist(p1);
em.persist(p2);
// fin transaction
tx.commit();
// on affiche la table
dump();
}
This code has already been seen in [InitDB]: it creates two people and places them in the persistence context.
- line 4: we retrieve the current persistence context
- lines 6-7: create the two people
- lines 9–15: the two people are placed in the persistence context within a transaction
- line 15: because the transaction is committed, the persistence context is synchronized with the database. The two people will be added to the [jpa01_personne] table.
- Line 17: The table is displayed
The console output for this first test is as follows:
main : ----------- test1
[personnes]
[2,0,Durant,Sylvie,05/07/2001,false,0]
[1,0,Martin,Paul,31/01/2000,true,2]
2.1.13.3. Test 2
The code for test2 is as follows:
// modifier un objet du contexte
public static void test2() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on incrémente le nbre d'enfants de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// on modifie son état marital
p1.setMarie(false);
// l'objet p1 est automatiquement sauvegardé (dirty checking)
// lors de la prochaine synchronisation (commit ou select)
// fin transaction
tx.commit();
// on affiche la nouvelle table
dump();
}
- Test 2 aims to modify an object in the persistence context and then display the table contents to see if the modification took place
- Line 4: Retrieve the current persistence context
- Lines 6–7: The operations will be performed within a transaction
- Lines 9, 11: The number of children for person p1 is changed, as is their marital status
- Line 15: End of the transaction, so the persistence context is synchronized with the database
- line 17: display table
The console output for Test 2 is as follows:
- line 4: person p1 before modification
- line 8: person p1 after modification. Note that their version number has changed to 1. This number is incremented by 1 each time the line is updated.
2.1.13.4. Test 3
The code for Test 3 is as follows:
// demander des objets
public static void test3() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on demande la personne p1
Personne p1b = em.find(Personne.class, p1.getId());
// parce que p1 est déjà dans le contexte de persistance, il n'y a pas eu d'accès à la base
// p1b et p1 sont les mêmes références
System.out.format("p1==p1b ? %s%n", p1 == p1b);
// demander un objet qui n'existe pas rend 1 pointeur null
Personne px = em.find(Personne.class, -4);
System.out.format("px==null ? %s%n", px == null);
// fin transaction
tx.commit();
}
- Test 3 focuses on the [EntityManager.find] method, which retrieves an object from the database and places it in the persistence context. We will no longer explain the transaction that occurs in all tests unless it is used in an unusual way.
- Line 9: We ask the persistence context for the person with the same primary key as person p1. There are two cases:
- p1 is already in the persistence context. This is the case here. Therefore, no database access is performed. The find method simply returns a reference to the persisted object.
- p1 is not in the persistence context. In this case, a database query is performed using the provided primary key. The retrieved record is added to the persistence context, and find returns a reference to this new persisted object.
- Line 12: We verify that `find` has returned the reference to the `p1` object already in the context
- Line 14: We request an object that exists neither in the persistence context nor in the database. The find method then returns a null pointer. This is verified on line 15.
The console output for Test 3 is as follows:
2.1.13.5. Test 4
The code for test4 is as follows:
// supprimer un objet appartenant au contexte de persistance
public static void test4() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on supprime l'objet persisté p2
em.remove(p2);
// fin transaction
tx.commit();
// on affiche la nouvelle table
dump();
}
- Test 4 focuses on the [EntityManager.remove] method, which allows you to remove an element from the persistence context and thus from the database.
- line 9: person p2 is removed from the persistence context
- line 11: synchronize the context with the database
- Line 13: Display of the table. Normally, person p2 should no longer be there.
The console output for Test 4 is as follows:
- line 3: person p2 in test1
- lines 12-14: they no longer exist after test4.
2.1.13.6. Test 5
The code for test5 is as follows:
// détacher, réattacher et modifier
public static void test5() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// p1 détaché
Personne oldp1=p1;
// on réattache p1 au nouveau contexte
p1 = em.find(Personne.class, p1.getId());
// vérification
System.out.format("p1==oldp1 ? %s%n", p1 == oldp1);
// fin transaction
tx.commit();
// on incrémente le nbre d'enfants de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// on affiche la nouvelle table
dump();
}
- Test 5 examines the lifecycle of persisted objects across several successive persistence contexts. Until now, we had always used the same persistence context across the various tests.
- Line 4: A new persistence context is requested. The [getNewEntityManager] method closes the previous one and opens a new one. As a result, the objects p1 and p2 held by the application are no longer in a persistent state. They belonged to a context that has been closed. We say they are in a detached state. They do not belong to the new persistence context.
- Lines 6–7: Start of the transaction. Here, it will be used in an unusual way.
- Line 9: We note the address of the now detached object p1.
- Line 11: The persistence context is queried for person p1 (using p1’s primary key). Since the context is new, person p1 is not present in it. A database query will therefore be performed. The retrieved object will be placed in the new context.
- Line 13: We verify that the persistent object p1 in the context is different from the object oldp1, which was the old detached object p1.
- Line 15: The transaction is completed
- Line 17: We modify the new persisted object p1 outside the transaction. What happens in this case? We want to know.
- Line 19: We request that the table be displayed. Note that because of the `SELECT` statement issued by the `dump` method, the persistence context is automatically synchronized with the database.
The console output for Test 5 is as follows:
- line 5: the find method did indeed access the database; otherwise, the two pointers would be equal
- Lines 7 and 3: The number of children of p1 has indeed increased by 1. The modification, made outside a transaction, was therefore taken into account. This actually depends on the DBMS used. In a DBMS, an SQL statement always executes within a transaction. If the JPA client does not start an explicit transaction itself, the DBMS will start an implicit transaction. There are two common cases:
- 1 - Each individual SQL statement is part of a transaction, opened before the statement and closed after. This is known as autocommit mode. Everything therefore behaves as if the JPA client were performing transactions for each SQL statement.
- 2 - The DBMS is not in autocommit mode and starts an implicit transaction on the first SQL statement that the JPA client issues outside of a transaction, leaving it to the client to close it. All SQL statements issued by the JPA client are then part of the implicit transaction. This transaction can end due to various events: the client closes the connection, starts a new transaction, etc.
This situation depends on the DBMS configuration. Therefore, the code is not portable. We will show a transaction-free code example later and see that not all DBMSs behave the same way with this code. We will therefore consider working outside of transactions to be a programming error.
- Line 7: Note that the version number has been updated to 2.
2.1.13.7. Test 6
The code for Test 6 is as follows:
// supprimer un objet n'appartenant pas au contexte de persistance
public static void test6() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on supprime p1 qui n'appartient pas au nouveau contexte
try {
em.remove(p1);
// fin transaction
tx.commit();
} catch (RuntimeException e1) {
System.out.format("Erreur à la suppression de p1 : [%s,%s]%n", e1.getClass().getName(), e1.getMessage());
// on fait un rollback de la transaction
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s,%s]%n", e2.getClass().getName(), e2.getMessage());
}
}
// on affiche la nouvelle table
dump();
}
- Test 6 attempts to delete an object that does not belong to the persistence context.
- line 4: a new persistence context is requested. The old one is therefore closed, and the objects it contained become detached. This is the case for the p1 object from the previous test 5.
- Lines 6–7: Start of the transaction.
- Line 10: The detached object p1 is deleted. We know this will cause an exception, so we have wrapped the operation in a try/catch block.
- Line 12: The commit will not take place.
- lines 16–21: A transaction must end with a commit (all operations in the transaction are validated) or a rollback (all operations in the transaction are rolled back). An exception occurred, so we roll back the transaction. There is nothing to undo since the single operation in the transaction failed, but the rollback terminates the transaction. This is the first time we’ve used the [EntityTransaction].rollback operation. We should have done this from the very first examples. We didn’t do it to keep the code simple. The reader should nevertheless keep in mind that the case of a transaction rollback must always be accounted for in the code.
- Line 24: We display the table. Normally, it shouldn’t have changed.
The console output for Test 6 is as follows:
- line 6: Deleting p1 failed. The exception message explains that an attempt was made to delete a detached object, which is not part of the context. This is not possible.
- Line 8: The person p1 is still there.
2.1.13.8. Test 7
The code for Test 7 is as follows:
// modifier un objet n'appartenant pas au contexte de persistance
public static void test7() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on incrémente le nbre d'enfants de p1 qui n'appartient pas au nouveau contexte
p1.setNbenfants(p1.getNbenfants() + 1);
// fin transaction
tx.commit();
// on affiche la nouvelle table - elle n'a pas du changer
dump();
}
- Test 7 attempts to modify an object that does not belong to the persistence context and observes the impact this has on the database. One might expect that there is none. This is what the test results show.
- Line 4: A new persistence context is requested. We therefore have a new context with no persisted objects in it.
- Lines 6–7: Start of the transaction.
- Line 9: The detached object p1 is modified. This is an operation that does not involve the persistence context em. Therefore, we should not expect an exception or anything of the sort. It is a basic operation on a POJO.
- Line 11: The commit synchronizes the context with the database. This context is empty. Therefore, the database remains unchanged.
- Line 24: The table is displayed. Normally, it should not have changed.
The console output for test 7 is as follows:
- line 7: person p1 has not changed in the database. For the next test, however, we will keep in mind that in memory, the number of children is now 5.
2.1.13.9. Test 8
The code for test8 is as follows:
// réattacher un objet au contexte de persistance
public static void test8() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on réattache l'objet détaché p1 au nouveau contexte
newp1 = em.merge(p1);
// c'est newp1 qui fait désormais partie du contexte, pas p1
// fin transaction
tx.commit();
// on affiche la nouvelle table - le nbre d'enfants de p1 a du changer
dump();
}
- Test 8 reattaches a detached object to the persistence context.
- Line 4: A new persistence context is requested. We therefore have a new context with no persistent objects in it.
- lines 6-7: start of the transaction.
- Line 9: The detached object p1 is reattached to the persistence context. The merge operation can involve several scenarios:
- Case 1: There is a persistent object ps1 in the persistence context with the same primary key as the detached object p1. The contents of p1 are copied into ps1, and merge returns a reference to ps1.
- Case 2: There is no persistent object ps1 in the persistence context with the same primary key as the detached object p1. The database is then queried to determine if the sought-after object exists in the database. If so, this object is brought into the persistence context, becomes the persistent object ps1, and we return to the previous Case 1.
- Case 3: There is no object with the same primary key as the detached object p1, neither in the persistence context nor in the database. A new [Person] object (new) is then created and placed in the persistence context. We then return to Case 1.
- In the end: the detached object p1 remains detached. The merge operation returns a reference (here newp1) to the persistent object ps1 resulting from the merge. The client application must now work with the persistent object ps1 and not with the detached object p1.
- Note the difference between cases 1 and 3 regarding the SQL statement used for the merge: in cases 1 and 2, it is an UPDATE statement, whereas in case 3, it is an INSERT statement.
- Line 12: The commit synchronizes the context with the database. This context is no longer empty. It contains the object newp1. This object will be persisted in the database.
- Line 24: We display the table to verify it.
The console output for Test 8 is as follows:
- The number of children for p1 was 4 in test 6 (line 4), then changed to 5 in test 7 but was not persisted in the database (line 7). After the merge, newp1 was persisted in the database: line 10, we now have 5 children.
- Line 10: The version number of newp1 has been updated to 3.
2.1.13.10. Test 9
The code for Test 9 is as follows:
// a select request causes synchronization
// with the persistence context
public static void test9() {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// increment the number of children of newp1
newp1.setNbenfants(newp1.getNbenfants() + 1);
// people display - the number of children in newp1 must have changed
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
}
- Test 9 demonstrates the context synchronization mechanism that occurs automatically before a SELECT statement.
- line 5: the persistence context is not changed. newp1 is therefore within it.
- Lines 7–8: Start of the transaction.
- Line 10: The number of children of the persistent object newp1 is increased by 1 (5 -> 6).
- Lines 12–15: The table is displayed using a SELECT statement. The context will be synchronized with the database before the SELECT statement is executed.
- Line 17: End of the transaction
To view the synchronization, enable Hibernate log output in DEBUG mode (log4j.properties):
# Root logger option
log4j.rootLogger=ERROR, stdout
# Hibernate logging options (INFO only shows startup messages)
log4j.logger.org.hibernate=DEBUG
The console output for test 9 is as follows:
- Line 1: Test 9 starts
- lines 2–6: the JDBC transaction starts. The DBMS’s autocommit mode is disabled (line 5)
- line 7: display triggered by line 12 of the Java code. The following lines of Java code will trigger a SELECT and thus synchronize the persistence context with the database.
- line 8: the JPQL query we want to execute has already been executed. Hibernate finds it in its "prepared queries" cache.
- Line 9: Hibernate announces that it will flush the persistence context
- Lines 11–12: Hibernate (Hb) detects that the Person#1 entity (with primary key 1) has been modified (dirty).
- Lines 12–13: Hb announces that it is updating this element and increments its version number from 3 to 4.
- Line 15: Context synchronization will result in 0 inserts, 1 update, and 0 deletes
- Lines 17-34: Context synchronization (flush). Note: the version increment (line 19), the prepared SQL update statement (line 21), and the parameter values for the update statement (lines 24-31).
- Line 35: The SELECT statement begins
- line 38: the SQL statement to be executed
- line 40: the SELECT returns only one row
- line 42: Hb discovers that it already has, in its persistence context, the Person#1 entity that the SELECT returned from the database. It therefore does not copy the row obtained from the database into the context, an operation it calls "hydration."
- line 43: he checks whether the objects returned by the SELECT have dependencies (usually foreign keys) that would also need to be loaded (non-lazy collections). Here, there are none.
- Line 44: Display triggered by the Java code
- Line 45: End of the JDBC transaction requested by the Java code
- Line 46: Automatic context synchronization, which occurs during commits, begins.
- Line 48: Hb detects that the context has not changed since the last synchronization.
- Line 50: End of commit.
Once again, Hibernate logs in DEBUG mode prove very useful for understanding exactly what Hibernate is doing.
2.1.13.11. Test 10
The code for test10 is as follows:
// contrôle de version (optimistic locking)
public static void test10() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// incrémenter la version de newp1 directement dans la base (native query)
em.createNativeQuery(String.format("update %s set VERSION=VERSION+1 WHERE ID=%d", TABLE_NAME, newp1.getId())).executeUpdate();
// fin transaction
tx.commit();
// début nouvelle transaction
tx = em.getTransaction();
tx.begin();
// on incrémente le nbre d'enfants de newp1
newp1.setNbenfants(newp1.getNbenfants() + 1);
// fin transaction - elle doit échouer car newp1 n'a plus la bonne version
try {
tx.commit();
} catch (RuntimeException e1) {
System.out.format("Erreur lors de la mise à jour de newp1 [%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(), e1.getCause().getClass().getName(), e1.getCause().getMessage());
// on fait un rollback de la transaction
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s,%s]%n", e2.getClass().getName(), e2.getMessage());
}
}
// on ferme le contexte qui n'est plus à jour
em.close();
// dump de la table - la version de p1 a du changer
dump();
}
- Test 10 demonstrates the mechanism introduced by the version field of the @Entity Person, which is annotated with the JPA @Version annotation. We explained that this annotation causes the value of the column associated with the @Version annotation to be incremented in the database with every update made to the row to which it belongs. This mechanism, also known as optimistic locking, requires that a client wishing to modify an object O in the database have the latest version of that object. If it does not, it means the object has been modified since the client obtained it, and the client must be notified.
- Line 4: We do not change the persistence context. newp1 is therefore inside it.
- Lines 6–7: Start of a transaction.
- Line 9: The version of the newp1 object is incremented by 1 (4 -> 5) directly in the database. nativeQuery-type queries bypass the persistence context and write directly to the database. The result is that the persistent object newp1 and its representation in the database no longer have the same version.
- Line 10: end of the first transaction
- Lines 13–14: Start of a second transaction
- line 16: the number of children of the persistent object newp1 is increased by 1 (6 -> 7).
- line 19: end of the transaction. Synchronization therefore takes place. This will trigger an update of the number of children of newp1 in the database. This will fail because the persistent object newp1 has version 4, whereas in the database the object to be updated has version 5. An exception will be thrown, which justifies the try/catch block in the code.
- Line 21: The exception and its cause are displayed.
- Line 25: Rollback the transaction
- Line 33: Display the table: we should see that the version of newp1 is 5 in the database.
The console output for test 10 is as follows:
- Line 5: The commit does indeed throw an exception. It is of type [javax.persistence.RollbackException]. The associated message is vague. If we look at the cause of this exception (Exception.getCause), we see that we have a Hibernate exception due to the fact that we are trying to modify a row in the database without having the correct version.
- Line 7: We see that the version of newp1 in the database has indeed been set to 5 by the nativeQuery.
2.1.13.12. Test 11
The code for test11 is as follows:
// transaction rollback
public static void test11() throws ParseException {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = null;
try {
tx = em.getTransaction();
tx.begin();
// reattach p1 to the context by fetching it from the base
p1 = em.find(Personne.class, p1.getId());
// increment the number of children in p1
p1.setNbenfants(p1.getNbenfants() + 1);
// display people - the number of children in p1 must have changed
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// creation of 2 persons with identical names, which is forbidden by the DDL
Personne p3 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p4 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
// persistence of people
em.persist(p3);
em.persist(p4);
// end transaction
tx.commit();
} catch (RuntimeException e1) {
// we had a problem
System.out.format("Erreur dans transaction [%s,%s,%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage(), e1.getCause().getCause().getClass().getName(), e1.getCause().getCause()
.getMessage());
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s]%n", e2.getMessage());
}
// we abandon the current context
em.clear();
}
// dump - table must not have changed due to rollback
dump();
}
- Test 11 focuses on the transaction rollback mechanism. A transaction operates on an all-or-nothing basis: the SQL operations it contains are either all successfully executed (commit) or all rolled back if any of them fails (rollback).
- line 4: we continue with the same persistence context. The reader may recall that the context was closed following the crash in the previous test. In this case, [getEntityManager] returns a brand-new, and therefore empty, context.
- Lines 7–27: A single try/catch block to handle any issues that may arise
- Lines 8–9: Start of a transaction that will contain several SQL operations
- Line 11: p1 is retrieved from the database and placed in the context
- Line 13: The number of children of p1 is increased (6 → 7)
- Lines 15–18: We display the database contents, which will force a context synchronization. In the database, the number of children of p1 will change to 7, which the console output should confirm.
- Lines 20–21: Creation of two people, p3 and p4, with the same name. However, the name field of the @Entity Person has the attribute unique=true, which results in a uniqueness constraint on the NAME column of the [jpa01_personne] table.
- Lines 23–24: Persons p3 and p4 are added to the persistence context.
- Line 26: The transaction is committed. This is followed by a second synchronization of the context, the first having occurred during the SELECT statement. JPA will issue two SQL INSERT statements for persons p3 and p4. p3 will be inserted. For p4, the DBMS will throw an exception because p4 has the same name as p3. p4 is therefore not inserted, and the JDBC driver raises an exception to the client.
- Line 27: We handle the exception
- Lines 29–31: We display the exception and its two preceding causes in the exception chain that led us to this point.
- Line 34: We roll back the currently active transaction. This transaction began on line 9 of the Java code. Since then, an update operation was performed to change the number of children for p1, followed by an insert operation for person p3. All of this will be undone by the rollback.
- line 39: the persistence context is cleared
- Line 42: The [jpa01_personne] table is displayed. We must verify that p1 still has 6 children and that neither p3 nor p4 are in the table.
The console output for test 11 is as follows:
main : ----------- test11
[personnes]
[1,6,Martin,Paul,31/01/2000,false,7]
14:50:30,312 ERROR JDBCExceptionReporter:72 - Duplicate entry 'X' for key 2
Erreur dans transaction [javax.persistence.EntityExistsException,org.hibernate.exception.ConstraintViolationException: could not insert: [entites.Personne],org.hibernate.exception.ConstraintViolationException,could not insert: [entites.Personne],java.sql.SQLException,Duplicate entry 'X' for key 2]
[personnes]
[1,5,Martin,Paul,31/01/2000,false,6]
- line 3: the number of children for p1 has changed from 6 to 7 in the database; the version of p1 has been updated to 6.
- Line 4: The exception caught during the transaction commit. If you read carefully, you can see that the cause is a duplicate key X (the name). It is the insertion of p4 that causes this error, since p3, which has already been inserted, also has the name X.
- Line 7: The table after the rollback. p1 has reverted to version 5 and has 6 children again; p3 and p4 were not inserted.
2.1.13.13. Test 12
The code for test12 is as follows:
// we do the same thing again but without the transactions
// we obtain the same result as before with SGBD : FIREBIRD, ORACLE XE, POSTGRES, MYSQL5
// with SQLSERVER we have an empty table. The connection is left in a state that prevents reexecution
// of the program. The server must then be restarted.
// idem with SGBD Derby
// HSQL inserts 1st person - there is no rollback
public static void test12() throws ParseException {
// reconnect p1
p1 = em.find(Personne.class, p1.getId());
// increment the number of children in p1
p1.setNbenfants(p1.getNbenfants() + 1);
// display people - the number of children in p1 must have changed
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// creation of 2 persons with identical names, which is forbidden by the DDL
Personne p3 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p4 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
// persistence of people
em.persist(p3);
em.persist(p4);
// dump, which will sync the em context with the BD
try {
dump();
} catch (RuntimeException e3) {
System.out.format("Erreur dans dump [%s,%s,%s,%s]%n", e3.getClass().getName(), e3.getMessage(), e3.getCause().getClass().getName(), e3
.getCause().getMessage());
}
// we close the current context
em.close();
// dump
dump();
}
- Test 12 repeats the same process as Test 11 but outside a transaction. We want to see what happens in this case.
- Lines 1–6: show the test results with various DBMSs:
- with a number of DBMSs (Firebird, Oracle, MySQL5, Postgres), we get the same result as with test 11. This suggests that these DBMSs initiated a transaction on their own covering all SQL statements received up to the one that caused the error, and that they initiated a rollback themselves.
- With other DBMSs (SQL Server, Apache Derby), the application and/or the DBMS crashes.
- With the HSQLDB DBMS, it appears that the transaction opened by the DBMS is in autocommit mode: the modification of the number of children of p1 and the insertion of p3 are made permanent. Only the insertion of p4 fails.
We therefore have a result that depends on the DBMS, which makes the application non-portable. Note that operations on the persistence context must always be performed within a transaction.
2.1.14. Changing the DBMS
Let’s revisit the test architecture of our current project:
 |
The client application [3] sees only the JPA interface [5]. It sees neither its actual implementation nor the target DBMS. We must therefore be able to change these two elements of the chain without making changes to the client [3]. This is what we will now attempt to demonstrate, starting by changing the DBMS. Until now, we have been using MySQL5. We present six others described in the appendices (section 5), hoping that among them is the reader’s preferred DBMS.
In any case, the modification to be made in the Eclipse project is simple (see below): replace the persistence.xml [1] configuration file for the JPA layer with one of those in the project’s conf [2] folder. The JDBC drivers for these DBMSs are already present in the [jpa-divers] [3] and [4] libraries.
 |
2.1.14.1. Oracle 10g Express
Oracle 10g Express is presented in the Appendices in section 5.7. The Oracle persistence.xml file is as follows:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Persistent classes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="oracle.jdbc.OracleDriver" />
<property name="hibernate.connection.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- automatic schematic creation -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.OracleDialect" />
<!-- properties DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
This configuration is identical to that used for the MySQL5 DBMS, with the following minor differences:
- lines 15–18, which configure the JDBC connection to the database
- line 22: which sets the SQL dialect to use
For the examples to follow, we will only specify the lines that change. For an explanation of the configuration, refer to the appendix dedicated to the DBMS in use. An example of using the JDBC connection is provided there each time, in the context of the [SQL Explorer] plugin. With the information from the appendix, the reader can repeat the process of verifying the result of the [InitDB] application performed in section 2.1.10.2.
We proceed as indicated in the aforementioned section:
- start the Oracle DBMS
- place conf/oracle/persistence.xml in META-INF/persistence.xml
- run the [InitDB] application
The following results appear on the console:
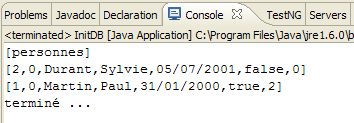 |
From now on, we will no longer show this screenshot, as it remains the same. More interesting is the SQL Explorer view of the JDBC connection to the DBMS. We will follow the procedure explained in section 2.1.8.
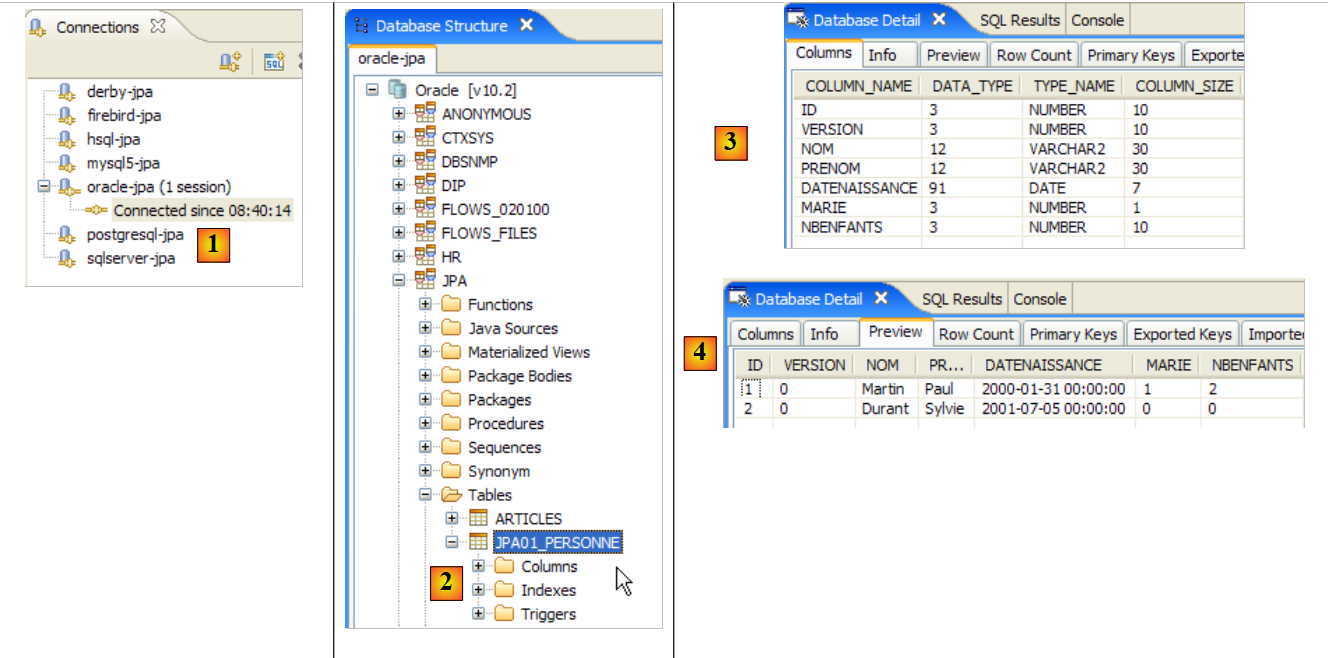 |
- in [1]: the connection to Oracle
- in [2]: the connection tree after running [InitDB]
- in [3]: the structure of the [jpa01_personne] table
- in [4]: its contents.
Once this is done, the reader is invited to run the [Main] application and then shut down the DBMS.
2.1.14.2. PostgreSQL 8.2
PostgreSQL 8.2 is presented in the Appendices in section 5.6. Its persistence.xml file is as follows:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="org.postgresql.Driver" />
<property name="hibernate.connection.url" value="jdbc:postgresql:jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.PostgreSQLDialect" />
...
</persistence-unit>
</persistence>
To run [InitDB]:
- Start the PostgreSQL DBMS
- place conf/postgres/persistence.xml in META-INF/persistence.xml
- run the [InitDB] application
The SQL Explorer view of the JDBC connection to the DBMS is as follows:
 |
- in [1]: the connection to PostgreSQL
- at [2]: the connection tree after running [InitDB]
- at [3]: the structure of the [jpa01_personne] table
- at [4]: its contents.
Once this is done, the reader is invited to run the [Main] application and then shut down the DBMS
2.1.14.3. SQL Server Express 2005
SQL Server Express 2005 is presented in the Appendices in section 5.8, page 270. Its persistence.xml file is as follows:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="com.microsoft.sqlserver.jdbc.SQLServerDriver" />
<property name="hibernate.connection.url" value="jdbc:sqlserver://localhost\\SQLEXPRESS:1433;databaseName=jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.SQLServerDialect" />
...
</persistence-unit>
</persistence>
To run [InitDB]:
- Start the SQL Server DBMS
- place conf/sqlserver/persistence.xml in META-INF/persistence.xml
- run the [InitDB] application
The SQL Explorer view of the JDBC connection to the DBMS is as follows:
 |
- in [1]: the connection to SQL Server
- at [2]: the connection tree after running [InitDB]
- at [3]: the structure of the [jpa01_personne] table
- at [4]: its contents.
Once this is done, the reader is invited to run the [Main] application and then shut down the DBMS
2.1.14.4. Firebird 2.0
Firebird 2.0 is presented in the Appendices in section 5.4. Its persistence.xml file is as follows:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="org.firebirdsql.jdbc.FBDriver" />
<property name="hibernate.connection.url" value="jdbc:firebirdsql:localhost/3050:C:\data\2006-2007\eclipse\dvp-jpa\annexes\firebird\jpa.fdb" />
<property name="hibernate.connection.username" value="sysdba" />
<property name="hibernate.connection.password" value="masterkey" />
...
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.FirebirdDialect" />
...
</persistence-unit>
</persistence>
To run [InitDB]:
- Start the Firebird DBMS
- place conf/firebird/persistence.xml in META-INF/persistence.xml
- run the [InitDB] application
The SQL Explorer view of the JDBC connection to the DBMS is as follows:
 |
- in [1]: the connection to Firebird
- at [2]: the connection tree after running [InitDB]
- at [3]: the structure of the [jpa01_personne] table
- at [4]: its contents.
Once this is done, the reader is invited to run the [Main] application and then shut down the DBMS.
2.1.14.5. Apache Derby
Apache Derby is presented in the Appendices in Section 5.10. Its persistence.xml file is as follows:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="org.apache.derby.jdbc.ClientDriver" />
<property name="hibernate.connection.url" value="jdbc:derby://localhost:1527//data/2006-2007/eclipse/dvp-jpa/annexes/derby/jpa;create=true" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialect -->
...
</persistence-unit>
</persistence>
To run [InitDB]:
- start the Apache Derby DBMS
- place conf/derby/persistence.xml in META-INF/persistence.xml
- run the [InitDB] application
The SQL Explorer view of the JDBC connection to the DBMS is as follows:
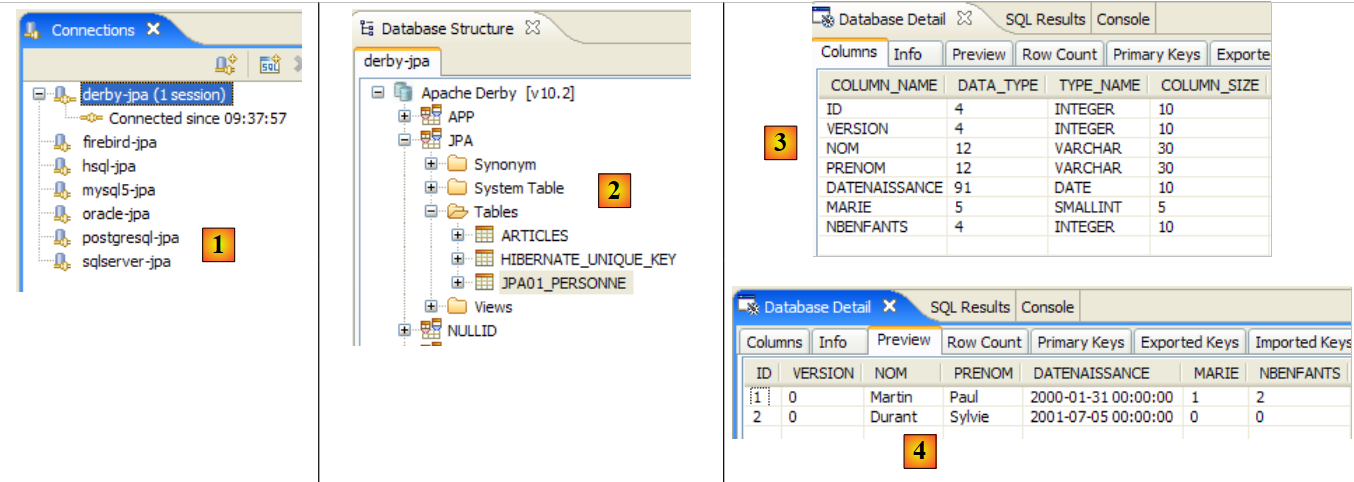 |
- in [1]: the connection to Apache Derby
- at [2]: the connection tree after running [InitDB]. Note the [HIBERNATE_UNIQUE_KEY] table created by JPA/Hibernate to automatically generate successive values for the primary key ID. We have already noted that this mechanism is often proprietary. This is clearly evident here. Thanks to JPA, the developer does not have to delve into these DBMS details.
- in [3]: the structure of the [jpa01_personne] table
- in [4]: its contents.
Once this is done, the reader is invited to run the [Main] application and then shut down the DBMS.
2.1.14.6. HSQLDB
HSQLDB is presented in the Appendices in Section 5.9. Its persistence.xml file is as follows:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="org.hsqldb.jdbcDriver" />
<property name="hibernate.connection.url" value="jdbc:hsqldb:hsql://localhost" />
<property name="hibernate.connection.username" value="sa" />
<!--
<property name="hibernate.connection.password" value="" />
-->
...
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.HSQLDialect" />
...
</properties>
</persistence-unit>
</persistence>
To run [InitDB]:
- start the HSQL DBMS
- Place conf/hsql/persistence.xml in META-INF/persistence.xml
- run the [InitDB] application
The SQL Explorer view of the JDBC connection to the DBMS is as follows:
 |
- in [1]: the connection to HSQL
- at [2]: the connection tree after running [InitDB].
- at [3]: the structure of the [jpa01_personne] table
- at [4]: its contents.
Once this is done, the reader is invited to run the [Main] application and then stop the DBMS.
2.1.15. Changing the JPA implementation
Let’s revisit the test architecture of our current project:
 |
The previous study showed that we were able to change the DBMS [7] without changing anything in the client code [3]. We will now change the JPA implementation [6] and demonstrate once again that this can be done transparently for the client code [3]. We will use a TopLink implementation [http://www.oracle.com/technology/products/ias/toplink/jpa/index.html]:
 |
2.1.15.1. The Eclipse Project
In conjunction with the change in the JPA implementation, we are creating a new Eclipse project so as not to contaminate the existing project. Indeed, the new project uses persistence libraries that may conflict with those of Hibernate:
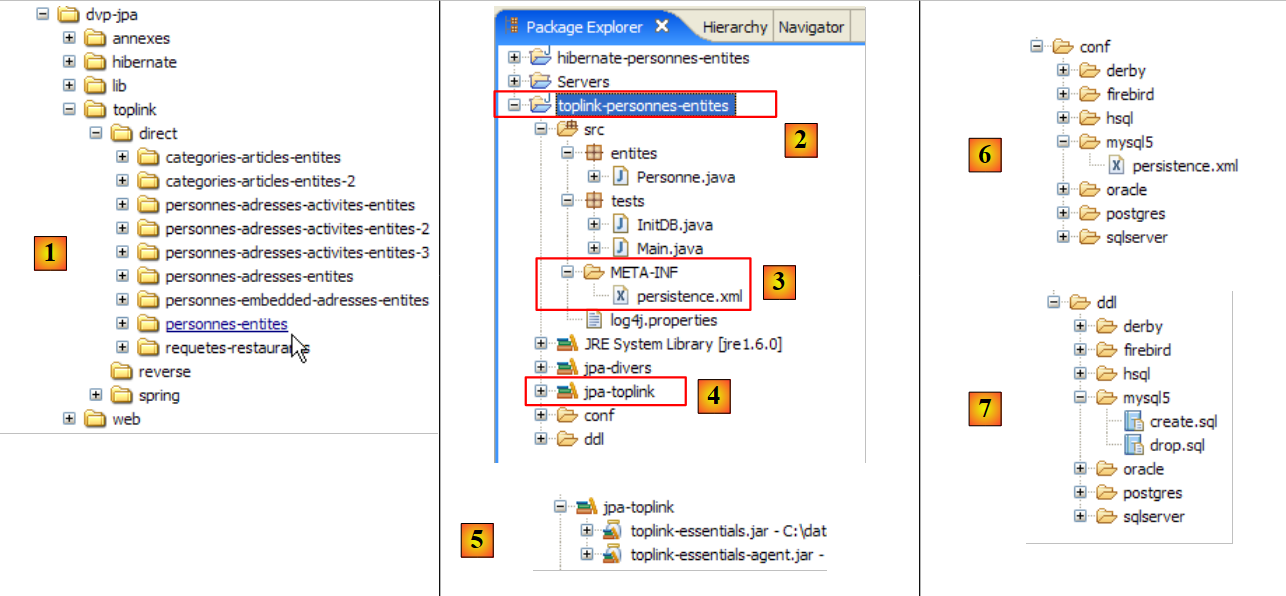 |
- in [1]: the folder [<examples>/toplink/direct/people-entities] contains the Eclipse project. Import it.
- in [2]: the imported [toplink-personnes-entites] project. It is identical (it was copied) to the [hibernate-personne-entites] project, with the exception of two details:
- the [META-INF/persistence.xml] file [3] now configures a JPA/Toplink layer
- the [jpa-hibernate] library has been replaced by the [jpa-toplink] library [4] and [5] (see paragraph 1.5).
- in [6]: the [conf] folder contains a version of the [persistence.xml] file for each DBMS.
- in [7]: the [ddl] folder, which will contain the SQL scripts for generating the database schema.
2.1.15.2. Configuring the JPA / Toplink
We know that the JPA layer is configured by the [META-INF/persistence.xml] file. This file now configures a JPA / Toplink implementation. Its content for a JPA layer interfacing with the MySQL5 DBMS is as follows:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- persistent classes -->
<class>entites.Personne</class>
<!-- persistence unit properties -->
<properties>
<!-- connection JDBC -->
<property name="toplink.jdbc.driver" value="com.mysql.jdbc.Driver" />
<property name="toplink.jdbc.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="toplink.jdbc.user" value="jpa" />
<property name="toplink.jdbc.password" value="jpa" />
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
<!-- SGBD -->
<property name="toplink.target-database" value="MySQL4" />
<!-- application server -->
<property name="toplink.target-server" value="None" />
<!-- generation diagram -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/mysql5" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
<!-- logs -->
<property name="toplink.logging.level" value="OFF" />
</properties>
</persistence-unit>
</persistence>
- Line 3: unchanged
- line 5: the provider is now Toplink. The class named here can be found in the [jpa-toplink] library ([1] below):
 |
- line 7: the <class> tag is used to list all @Entity classes in the project; here, only the Person class. Hibernate had a configuration option that allowed us to avoid listing these classes. It would scan the project’s classpath to find the @Entity classes.
- line 9: the <properties> tag introduces properties specific to the JPA implementation being used, in this case Toplink.
- Lines 11–14: Configuration of the JDBC connection to the MySQL5 DBMS
- Lines 15–18: Configuration of the JDBC connection pool natively managed by Toplink:
- Lines 15, 16: maximum and minimum number of connections in the read connection pool. Default (2,2)
- Lines 17, 18: Maximum and minimum number of connections in the write connection pool. Default (10,2)
- line 20: the target DBMS. The list of supported DBMSs is available in the [oracle.toplink.essentials.platform.database] package (see [2] above). The MySQL5 DBMS is not included in list [2], so we chose MySQL4. TopLink supports slightly fewer DBMSs than Hibernate. Thus, of the seven DBMSs used in our examples, Firebird is not supported. Oracle is also not found in the list. It is actually in another package ([3] above). If, in these two packages, the target DBMS is designated by the <Sgbd>Platform.class class, the tag will be written as:
<property name="toplink.target-database" value="<Sgbd>" />
- Line 22: Sets the application server if the application runs on such a server. Current possible values (None, OC4J_10_1_3, SunAS9). Default (None).
- Lines 24–28: When the JPA layer initializes, it is instructed to clear the database defined by the JDBC connection in lines 11–14. This ensures we start with an empty database.
- Line 24: TopLink is instructed to drop and then create the tables in the database schema
- Line 25: We instruct TopLink to generate the SQL scripts for the drop and create operations. application-location specifies the directory where these scripts will be generated. Default: (current directory).
- Line 26: Name of the SQL script for the create operations. Default: createDDL.jdbc.
- Line 27: Name of the SQL script for the drop operations. Default: dropDDL.jdbc.
- Line 28: schema generation mode (Default: both):
- both: scripts and database
- database: database only
- sql-script: scripts only
- Line 30: TopLink logging is disabled (OFF). The available logging levels are: OFF, SEVERE, WARNING, INFO, CONFIG, FINE, FINER, FINEST. Default: INFO.
See the URL [http://www.oracle.com/technology/products/ias/toplink/JPA/essentials/toplink-jpa-extensions.html] for a comprehensive definition of the <property> tags that can be used with Toplink.
2.1.15.3. Test [InitDB]
There is nothing else to do. We are ready to run the first [InitDB] test:
- Start the DBMS, in this case MySQL5
- run [InitDB]
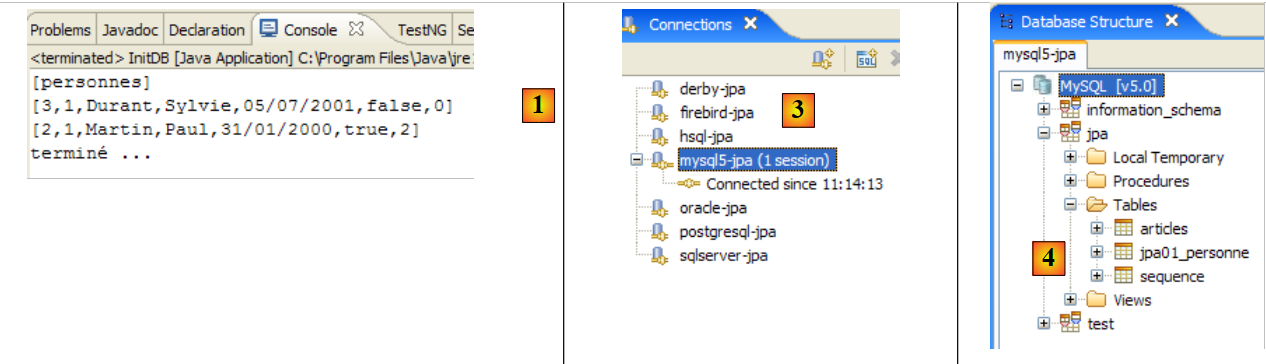 |
- in [1]: the console display. We see the results already obtained with JPA / Hibernate.
- in [3]: open the [SQL Explorer] perspective, then open the [mysql5-jpa] connection
- in [4]: the jpa database tree. We see that running [InitDB] created two tables: [jpa01_personne], which was expected, and the [sequence] table, which was less expected.
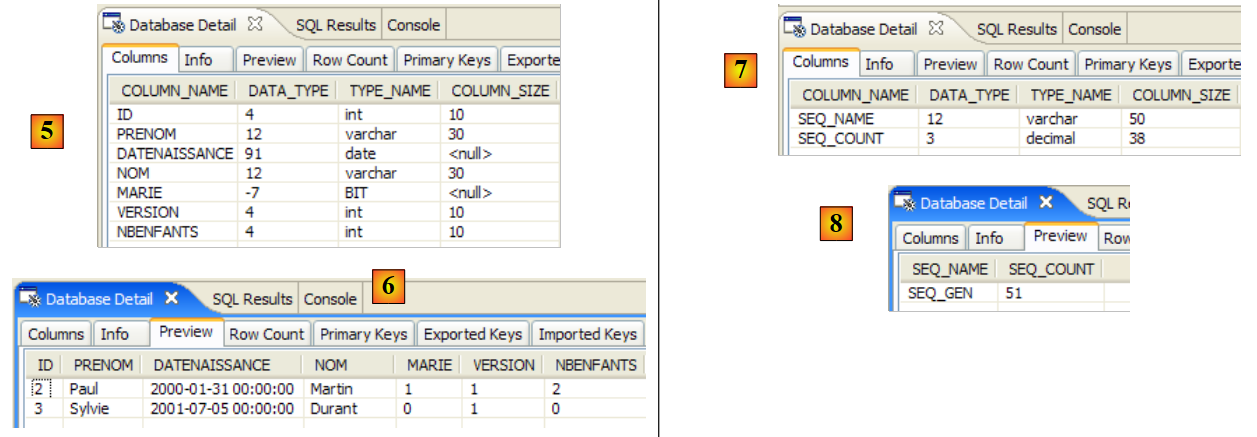 |
- in [5]: the structure of the [jpa01_personne] table and in [6] its contents
- In [7]: the structure of the [sequence] table, and in [8] its contents.
The configuration file [persistence.xml] requested the generation of DDL scripts:
<!-- génération schéma -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/mysql5" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
Let's take a look at what was generated in the [ddl/mysql5] folder:
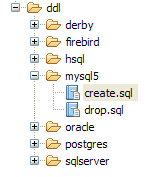 |
create.sql
CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
- Line 1: The DDL for the [jpa01_personne] table. Note that Toplink did not use the autoincrement attribute for the ID primary key. As a result, the ID is not automatically incremented when rows are inserted.
- Line 2: The DDL for the [sequence] table. Its name suggests that Toplink uses this table to generate values for the ID primary key.
- Line 3: Insertion of a single row into [SEQUENCE]
drop.sql
DROP TABLE jpa01_personne
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
- Line 1: Deletion of the [jpa01_personne] table
- Line 2: Deletes a specific row from the [SEQUENCE] table. The table itself is not deleted, nor are any other rows it may contain.
To learn more about the role of the [SEQUENCE] table, enable TopLink logs at the FINE level in [persistence.xml], a level that tracks the SQL statements issued by TopLink:
<!-- logs -->
<property name="toplink.logging.level" value="FINE" />
Run InitDB again. Below is a partial view of the console output:
...
[TopLink Config]: 2007.05.28 12:07:52.796--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--Connected: jdbc:mysql://localhost:3306/jpa
User: jpa@localhost
Database: MySQL Version: 5.0.37-community-nt
Driver: MySQL-AB JDBC Driver Version: mysql-connector-java-3.1.9 ( $Date: 2005/05/19 15:52:23 $, $Revision: 1.1.2.2 $ )
...
[TopLink Fine]: 2007.05.28 12:07:53.093--ServerSession(12910198)--Connection(19255406)--Thread(Thread[main,5,main])--DROP TABLE jpa01_personne
[TopLink Fine]: 2007.05.28 12:07:53.265--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
[TopLink Fine]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Connection(19255406)--Thread(Thread[main,5,main])--CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
[TopLink Warning]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Thread(Thread[main,5,main])--Exception [TOPLINK-4002] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (03/30/2007)): oracle.toplink.essentials.exceptions.DatabaseException
Internal Exception: java.sql.SQLException: Table 'sequence' already exists
Error Code: 1050
Call: CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
Query: DataModifyQuery()
[TopLink Fine]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
[TopLink Fine]: 2007.05.28 12:07:53.609--ServerSession(12910198)--Connection(19255406)--Thread(Thread[main,5,main])--SELECT * FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
[TopLink Fine]: 2007.05.28 12:07:53.609--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
[TopLink Fine]: 2007.05.28 12:07:53.734--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--delete from jpa01_personne
[TopLink Fine]: 2007.05.28 12:07:53.750--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--UPDATE SEQUENCE SET SEQ_COUNT = SEQ_COUNT + ? WHERE SEQ_NAME = ?
bind => [50, SEQ_GEN]
[TopLink Fine]: 2007.05.28 12:07:53.750--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--SELECT SEQ_COUNT FROM SEQUENCE WHERE SEQ_NAME = ?
bind => [SEQ_GEN]
[personnes]
[TopLink Fine]: 2007.05.28 12:07:53.906--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--INSERT INTO jpa01_personne (ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS) VALUES (?, ?, ?, ?, ?, ?, ?)
bind => [3, Sylvie, 2001-07-05, Durant, false, 1, 0]
[TopLink Fine]: 2007.05.28 12:07:53.921--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--INSERT INTO jpa01_personne (ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS) VALUES (?, ?, ?, ?, ?, ?, ?)
bind => [2, Paul, 2000-01-31, Martin, true, 1, 2]
[TopLink Fine]: 2007.05.28 12:07:53.937--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--SELECT ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS FROM jpa01_personne ORDER BY NOM ASC
[3,1,Durant,Sylvie,05/07/2001,false,0]
[2,1,Martin,Paul,31/01/2000,true,2]
[TopLink Config]: 2007.05.28 12:07:54.062--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--disconnect
[TopLink Info]: 2007.05.28 12:07:54.062--ServerSession(12910198)--Thread(Thread[main,5,main])--file:/C:/data/2006-2007/eclipse/dvp-jpa/toplink/direct/personnes-entites/bin/-jpa logout successful
...
terminé ...
- Lines 2-5: a connection to the DBMS with its parameters. In fact, the logs show that Toplink actually creates 3 connections to the DBMS. We need to check if this number is related to one of the configuration values used for the JDBC connection pool:
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
- Line 7: Deletion of the [jpa01_personne] table. This is normal, since the [persistence.xml] file requests the cleanup of the JPA database.
- line 8: creation of the [jpa01_personne] table. Note that the primary key ID does not have the autoincrement attribute.
- line 9: creation of the [SEQUENCE] table, which already exists, having been created during the previous execution.
- Lines 10–13: TopLink reports an error creating the [SEQUENCE] table.
- Lines 15–18: TopLink clears the [SEQUENCE] table. After this cleanup, the [SEQUENCE] table contains one row (SEQ_NAME, SEQ_COUNT) with the values ('SEQ_GEN', 1).
- Line 18: The [jpa01_personne] table is emptied.
- Lines 19–20: Toplink updates the single row where SEQ_NAME = 'SEQ_GEN' in the [SEQUENCE] table, changing the value from ('SEQ_GEN', 1) to ('SEQ_GEN', 51).
- Line 21: TopLink retrieves the value 51 from the row ('SEQ_GEN', 51) in the [SEQUENCE] table.
- Lines 24–27: Toplink inserts the two people 'Martin' and 'Durant' into the [jpa01_personne] table. There is a mystery here: the primary keys of these two rows are assigned the values 2 and 3, without any explanation of how these values were obtained. It is unclear whether the SEQ_COUNT value (51) obtained in line 21 served any purpose. Note that the version value of the rows is 1, whereas Hibernate started at 0.
- Line 28: TopLink performs the SELECT to retrieve all rows from the [jpa01_personne] table
- Lines 29–30: Rows displayed by the Java client
- Lines 31-32: TopLink closes a connection. It will repeat the operation for each of the connections initially opened.
Ultimately, we don’t know exactly what the [SEQUENCE] table is for, but it still seems to play a role in generating the primary key ID values. By setting the log level to the finest level, FINEST, we learn a little more about the role of the [SEQUENCE] table.
<!-- logs -->
<property name="toplink.logging.level" value="FINEST" />
Below, we have included only the logs concerning the insertion of the two people into the table. This is where we see the mechanism for generating the primary key values:
- line 4: we see that the number 51 retrieved from the [SEQUENCE] table on line 2 is used to delimit a range of values for the primary key: [2,51]
- line 5: the first person is assigned the value 2 as the primary key
- line 8: the second person is assigned the value 3 as the primary key
- line 12: shows version management for the first person
- line 17: same for the second person
The [FINEST] log level also shows the boundaries of transactions issued by Toplink. Analyzing these logs reveals what Toplink does and is a great way to understand the object-relational bridge.
Key takeaways from the above:
- Different JPA implementations will generate different database schemas. In this example, Hibernate and Toplink did not generate the same schemas.
- that Toplink’s FINE, FINER, and FINEST log levels should be used whenever you want clarification on exactly what Toplink is doing.
2.1.15.4. Test [Main]
We now run the [Main] test:
 |
- in [1]: all tests pass except test 11 [2]
- in [3]: line 376, the line of code where the exception occurred
The code that throws the exception is as follows:
} catch (RuntimeException e1) {
// on a eu un pb
System.out.format("Erreur dans transaction [%s,%s,%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage(), e1.getCause().getCause().getClass().getName(), e1.getCause().getCause()
.getMessage());
try {
...
- line [3]: the line of the exception. We have a NullPointerException, which suggests that one of the getCause methods on lines 4 and 5 returned a null pointer. An expression such as [e1.getCause().getCause()] assumes that the exception chain has 3 elements [e1.getCause().getCause(), e1.getCause(), e1]. If it has only two, the first expression will cause an exception.
We modify the previous code so that it displays only the last two exceptions in the exception chain:
} catch (RuntimeException e1) {
// on a eu un pb
System.out.format("Erreur dans transaction [%s,%s,%s,%s,]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage());
try {
...
When executed, we get the following result:
...
[personnes]
[2,5,Martin,Paul,31/01/2000,false,6]
main : ----------- test11
[personnes]
Erreur dans transaction [javax.persistence.OptimisticLockException,Exception [TOPLINK-5006] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (03/30/2007))): oracle.toplink.essentials.exceptions.OptimisticLockException
Exception Description: The object [[2,6,Martin,Paul,31/01/2000,false,7]] cannot be updated because it has changed or been deleted since it was last read.
Class> entites.Personne Primary Key> [2],oracle.toplink.essentials.exceptions.OptimisticLockException,
Exception Description: The object [[2,6,Martin,Paul,31/01/2000,false,7]] cannot be updated because it has changed or been deleted since it was last read.
Class> entites.Personne Primary Key> [2],]
[personnes]
[2,5,Martin,Paul,31/01/2000,false,6]
This time, Test 11 passes. The exception logs (lines 6–10) were triggered by the Java code (line 3 of the code above). Recall that Test 11 chained together, within a single transaction, several SQL operations, one of which failed and was expected to cause the transaction to roll back. The states of the [jpa01_personne] table before (line 3) and after the test (line 12) are identical, showing that the rollback occurred.
It is important to note here that the JPA/Hibernate and JPA/Toplink implementations are not 100% interchangeable. In this example, we must modify the JPA client code to avoid a NullPointerException. We will encounter this issue again later, this time in the context of an exception.
2.1.16. Changing the DBMS in the JPA/Toplink implementation
Let’s revisit the test architecture of our current project:
 |
Previously, the DBMS used in [7] was MySQL 5. We’ll demonstrate how to switch DBMSes using Oracle. In any case, the modification required in the Eclipse project is simple (see below): replace the persistence.xml configuration file [1] for the JPA layer with one of those in the project’s conf folder ([2] and [3]).
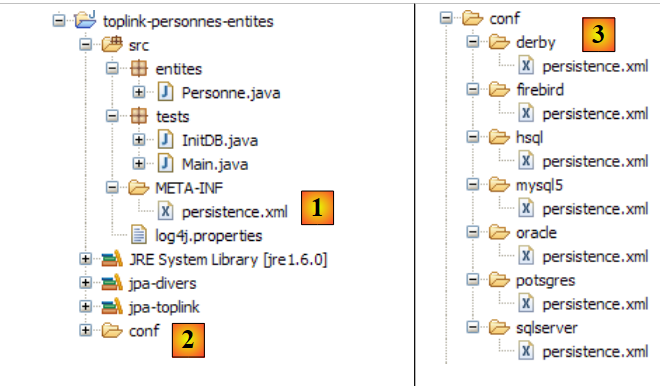 |
2.1.16.1. Oracle 10g Express
Oracle 10g Express is presented in the Appendices in section 5.7. The Oracle persistence.xml file for Toplink is as follows:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- persistent classes -->
<class>entites.Personne</class>
<!-- persistence unit properties -->
<properties>
<!-- connection JDBC -->
<property name="toplink.jdbc.driver" value="oracle.jdbc.OracleDriver" />
<property name="toplink.jdbc.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="toplink.jdbc.user" value="jpa" />
<property name="toplink.jdbc.password" value="jpa" />
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
<!-- SGBD -->
<property name="toplink.target-database" value="Oracle" />
<!-- application server -->
<property name="toplink.target-server" value="None" />
<!-- generation diagram -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/oracle" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
<!-- logs -->
<property name="toplink.logging.level" value="OFF" />
</properties>
</persistence-unit>
</persistence>
This configuration is identical to that used for the MySQL5 DBMS, with the following minor differences:
- lines 11–14, which configure the JDBC connection to the database
- line 20: which specifies the target DBMS
- line 25: which specifies the directory for generating DDL SQL scripts
To run the [InitDB] test:
- start the Oracle DBMS
- Place conf/oracle/persistence.xml in META-INF/persistence.xml
- Run the [InitDB] application
The following results are displayed on the console and in the [SQL Explorer] view:
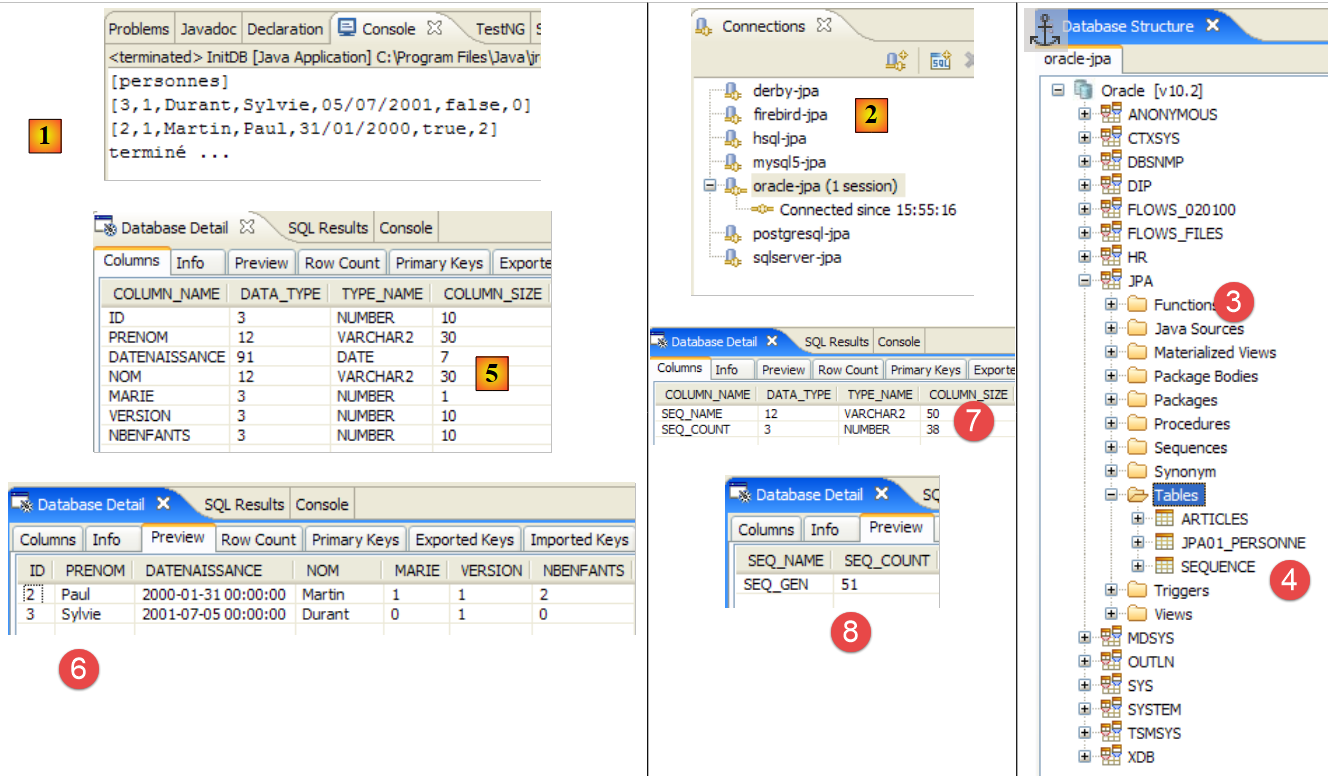 |
- [1]: the console display
- [2]: the [oracle-jpa] connection in SQL Explorer
- [3]: the jpa database
- [4]: InitDB has created two tables: JPA01_PERSONNE and SEQUENCE, as with MySQL5. Sometimes in [4], [BIN*] tables appear. These correspond to deleted tables. To observe this phenomenon, simply re-run [InitDB]. The initialization phase of the JPA layer includes a cleanup of the JPA database during which the [JPA01_PERSONNE] table is deleted:
 |
In [A], a [BIN] table appears. Oracle does not permanently delete a table that has been dropped but places it in a [Recycle Bin]. This Recycle Bin is visible [B] using the SQL Developer tool described in section 5.7.4. In [B], we can purge the [JPA01_PERSONNE] table from the Recycle Bin. This empties the Recycle Bin [C]. If we refresh the tables in SQL Explorer (right-click / Refresh), we see that the BIN table is no longer there [D].
- [5, 6]: the structure and contents of the [JPA01_PERSONNE] table
- [7, 8]: the structure and contents of the [SEQUENCE] table
There you go! The reader is now invited to run the [Main] application on Oracle.
2.1.16.2. Other DBMSs
We will not cover other DBMSs in detail. You simply need to follow the same procedure used for Oracle. Note the following points:
- Regardless of the DBMS, Toplink always uses the same technique to generate the primary key ID values for the [JPA01_PERSONNE] table: it uses the [SEQUENCE] table described above.
- TopLink does not support the Firebird DBMS. There is a generic database setting for such cases:
With this generic database named [Auto], tests with Firebird fail due to SQL syntax errors. Toplink uses the SQL type Number(10) for the primary key ID, which Firebird does not recognize. You must therefore choose a DBMS with the same SQL types as Firebird (for this example). This is the case with Apache Derby:
<!-- connexion JDBC -->
<property name="toplink.jdbc.driver" value="org.firebirdsql.jdbc.FBDriver" />
...
<!-- SGBD -->
<!--
TopLink ne reconnaît pas Firebird pour l'instant (05/07). Derby convient pour remplacer.
-->
<property name="toplink.target-database" value="Derby" />
...
- Toplink cannot generate the original database schema for the HSQLDB DBMS. That is, the directive:
<!-- génération schéma -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
fails for HSQLDB. The cause is a syntax error when creating the table [jpa01_personne]:
[TopLink Fine]: 2007.05.29 09:44:18.515--ServerSession(12910198)--Connection(29775659)--Thread(Thread[main,5,main])--DROP TABLE jpa01_personne
[TopLink Fine]: 2007.05.29 09:44:18.531--ServerSession(12910198)--Connection(29775659)--Thread(Thread[main,5,main])--CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
[TopLink Warning]: 2007.05.29 09:44:18.531--ServerSession(12910198)--Thread(Thread[main,5,main])--Exception [TOPLINK-4002] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (03/30/2007)): oracle.toplink.essentials.exceptions.DatabaseException
Internal Exception: java.sql.SQLException: Unexpected token: UNIQUE in statement [CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE]
Line 4: the syntax LAST_NAME VARCHAR(30) UNIQUE NOT NULL is not accepted by HSQL. Hibernate used the syntax: LAST_NAME VARCHAR(30) NOT NULL, UNIQUE(LAST_NAME).
In general, Hibernate was more effective than Toplink at recognizing the DBMSs used in the tests described in this document.
2.1.17. Conclusion
The study of the @Entity [Person] ends here. From a conceptual standpoint, not much has been done: we have examined the object-relational bridge in its simplest form: an @Entity object <--> a table. However, this examination has allowed us to introduce the tools we will use throughout this document. This will enable us to proceed a bit more quickly from here on in as we examine the other cases of the object-relational bridge:
- to the previous @Entity [Person], we will add an address field modeled by a [Address] class. On the database side, we will look at two possible implementations. The [Person] and [Address] objects give rise to
- a single [Person] table that includes the address
- two tables [person] and [address] linked by a one-to-one foreign key relationship.
- an example of a one-to-many relationship where a [item] table is linked to a [category] table via a foreign key
- an example of a many-to-many relationship where two tables [Person] and [Activity] are linked by a join table [Person_Activity].
2.2. Example 2: One-to-one relationship via an inclusion
2.2.1. The database schema
1  | 2 |
- in [1]: the database (Azurri Clay plugin)
- in [2]: the DDL generated by Hibernate for MySQL5
The table [jpa02_personne] is the [jpa01_personne] table discussed earlier, to which an address has been added (lines 12–18 of the DDL).
2.2.2. The @Entity objects representing the database
A person's address will be represented by the following [Address] class:
package entites;
...
@SuppressWarnings("serial")
@Embeddable
public class Adresse implements Serializable {
// fields
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
// manufacturers
public Adresse() {
}
public Adresse(String adr1, String adr2, String adr3, String codePostal, String ville, String cedex, String pays) {
...
}
// getters and setters
...
// toString
public String toString() {
return String.format("A[%s,%s,%s,%s,%s,%s,%s]", getAdr1(), getAdr2(), getAdr3(), getCodePostal(), getVille(), getCedex(), getPays());
}
}
- The main innovation lies in the @Embeddable annotation on line 5. The [Address] class is not intended to create a table, so it does not have the @Entity annotation. The @Embeddable annotation indicates that the class is intended to be embedded within an @Entity object and thus within the table associated with it. This is why, in the database schema, the [Address] class does not appear as a separate table, but as part of the table associated with the @Entity [Person].
The @Entity [Person] has changed little from its previous version: an address field has simply been added:
package entites;
...
@Entity
@Table(name = "jpa02_hb_personne")
public class Personne implements Serializable{
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
@Embedded
private Adresse adresse;
// manufacturers
public Personne() {
}
...
}
- The change occurs on lines 33–34. The [Person] object now has an address field of type Address. That’s for the POJO. The @Embedded annotation is intended for the object-relational bridge. It indicates that the [Address address] field must be encapsulated in the same table as the [Person] object.
2.2.3. The testing environment
We will perform tests very similar to those studied previously. They will be conducted in the following context:
 |
The implementation used is JPA/Hibernate [6]. The Eclipse test project is as follows:
 |
The Eclipse project [1] differs from the previous one only in its Java code [2]. The environment (libraries – persistence.xml – DBMS – conf and DDL folders – Ant script) is the one already discussed previously, particularly in Section 2.1.5. This will continue to be the case for future Hibernate projects, and, barring exceptions, we will not revisit this environment. Notably, the persistence.xml files that configure the JPA/Hibernate layer for different DBMSs are those already examined and are located in the <conf> folder.
If the reader has any doubts about the procedures to follow, they are encouraged to review those covered in the previous study.
The Eclipse project is available [3] in the examples folder [4]. We will import it.
2.2.4. Generating the Database DDL
Following the instructions in Section 2.1.7, the DDL generated for the MySQL5 DBMS is as follows:
drop table if exists jpa02_hb_personne;
create table jpa02_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
Hibernate correctly recognized that the person's address needed to be included in the table associated with the @Entity Person (lines 11–17).
2.2.5. InitDB
The code for [InitDB] is as follows:
package tests;
...
public class InitDB {
// constant
private final static String TABLE_NAME = "jpa02_hb_personne";
public static void main(String[] args) throws ParseException {
// Persistence context
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// a EntityManager is retrieved from the previous EntityManagerFactory
em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// request
Query sql1;
// delete elements from the PERSONNE table
sql1 = em.createNativeQuery("delete from " + TABLE_NAME);
sql1.executeUpdate();
// creating people
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// address creation
Adresse a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
Adresse a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
// associations person <--> address
p1.setAdresse(a1);
p2.setAdresse(a2);
// persistence of people
em.persist(p1);
em.persist(p2);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
// log
System.out.println("terminé...");
}
}
There is nothing new in this code. Everything has been covered before. Running [InitDB] with MySQL5 yields the following results:
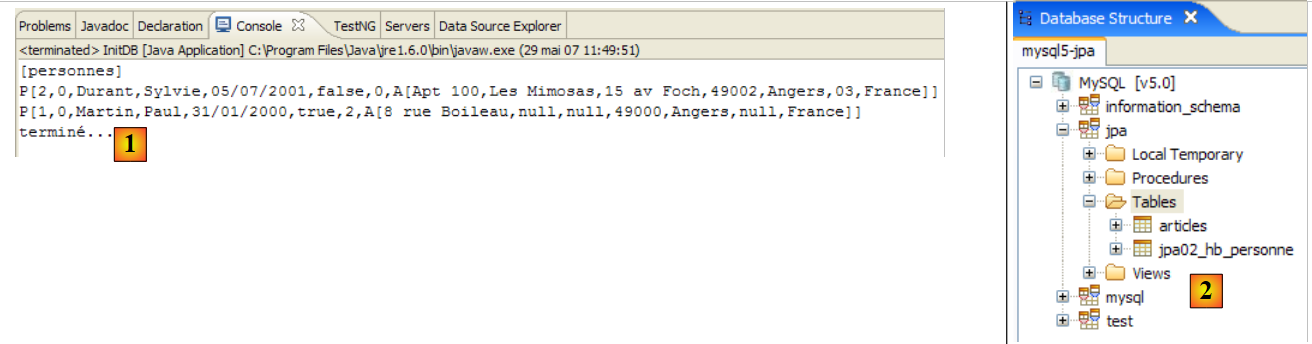 |
 |
- [1]: the console output
- [2]: the [jpa02_hb_personne] table in the SQL Explorer view
- [3] and [4]: its structure and content.
2.2.6. Main
The [Main] class is as follows:
package tests;
...
import entites.Adresse;
import entites.Personne;
@SuppressWarnings( { "unused", "unchecked" })
public class Main {
// constant
private final static String TABLE_NAME = "jpa02_hb_personne";
// Persistence context
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = null;
// shared objects
private static Personne p1, p2, newp1;
private static Adresse a1, a2, a3, a4, newa1, newa4;
public static void main(String[] args) throws Exception {
// we retrieve a EntityManager from the EntityManagerFactory
em = emf.createEntityManager();
// base cleaning
log("clean");clean();
// dump table
dumpPersonne();
// test1
log("test1"); test1();
// test2
log("test2"); test2();
// test3
log("test3"); test3();
// test4
log("test4"); test4();
// test5
log("test5");test5();
// fine persistence context
if (em != null && em.isOpen())
em.close();
// closure EntityManagerFactory
emf.close();
}
// retrieve the current EntityManager
private static EntityManager getEntityManager() {
...
}
// pick up a new EntityManager
private static EntityManager getNewEntityManager() {
...
}
// display table content Person
private static void dumpPersonne() {
...
}
// raz BD
private static void clean() {
...
}
// logs
private static void log(String message) {
...
}
// object creation
public static void test1() throws ParseException {
// persistence context
EntityManager em = getEntityManager();
// creating people
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// address creation
a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
// associations person <--> address
p1.setAdresse(a1);
p2.setAdresse(a2);
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistence of people
em.persist(p1);
em.persist(p2);
// end transaction
tx.commit();
// dump
dumpPersonne();
}
// modify a context object
public static void test2() {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// increment the number of children in p1
p1.setNbenfants(p1.getNbenfants() + 1);
// change your marital status
p1.setMarie(false);
// object p1 is automatically saved (dirty checking)
// at next synchronization (commit or select)
// end transaction
tx.commit();
// the new table is displayed
dumpPersonne();
}
// delete an object belonging to the persistence context
public static void test4() {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// delete attached object p2
em.remove(p2);
// end transaction
tx.commit();
// the new table is displayed
dumpPersonne();
}
// detach, reattach and modify
public static void test5() {
// new persistence context
EntityManager em = getNewEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// reattach p1 to the new context
p1 = em.find(Personne.class, p1.getId());
// end transaction
tx.commit();
// change p1's address
p1.getAdresse().setVille("Paris");
// the new table is displayed
dumpPersonne();
}
}
Again, nothing we haven't seen before. The console output is as follows:
The reader is invited to make the connection between the results and the code.
2.2.7. JPA / Toplink Implementation
We are now using a JPA / Toplink implementation:
 |
The new Eclipse test project is as follows:
 |
The Java code is identical to that of the previous Hibernate project. The environment (libraries – persistence.xml – DBMS – conf and ddl folders – Ant script) is the one already discussed in section 2.1.15.2. This will continue to be the case for future Toplink projects, and, barring exceptions, we will not revisit this environment. In particular, the persistence.xml files that configure the JPA/Toplink layer for different DBMSs are those already discussed and located in the <conf> folder.
If the reader has any doubts about the procedures to follow, they are encouraged to review those covered in the previous study.
The Eclipse project is available [3] in the examples folder [4]. We will import it.
Running [InitDB] with the MySQL5 DBMS yields the following results:
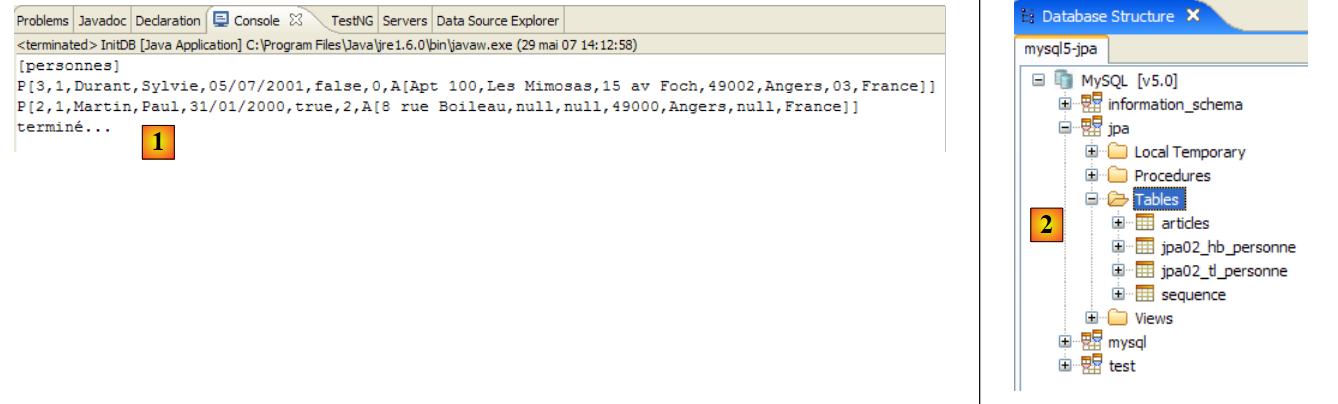 |
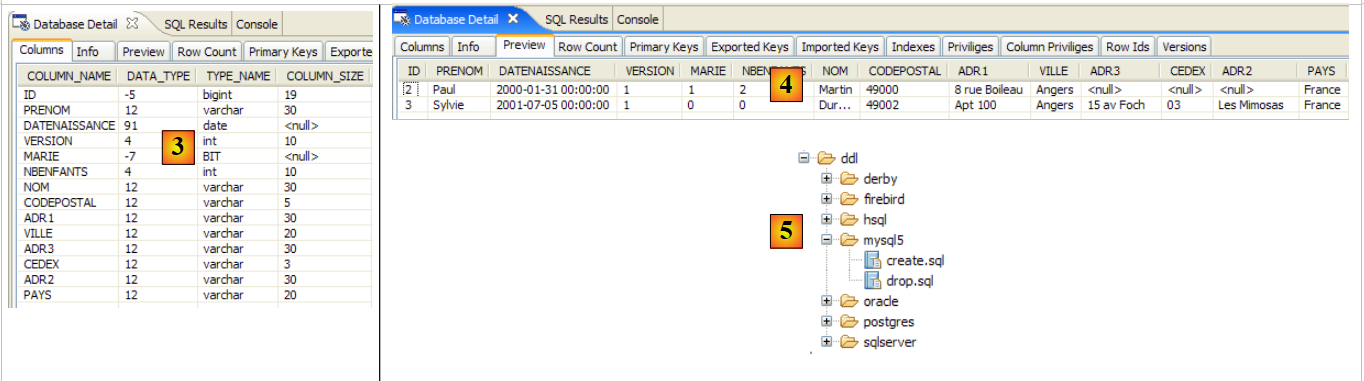 |
- [1]: the console output
- [2]: the tables [jpa02_tl_personne] and [SEQENCE] in the SQL Explorer view
- [3] and [4]: the structure and content of [jpa02_tl_personne].
The SQL scripts generated in ddl/mysql5 [5] are as follows:
create.sql
CREATE TABLE jpa02_tl_personne (ID BIGINT NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, VERSION INTEGER NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NBENFANTS INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, CODEPOSTAL VARCHAR(5) NOT NULL, ADR1 VARCHAR(30) NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR3 VARCHAR(30), CEDEX VARCHAR(3), ADR2 VARCHAR(30), PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
DROP TABLE jpa02_tl_personne
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
2.3. Example 3: One-to-one relationship via a foreign key
2.3.1. : Database schema
1  | 2 |
- in [1]: the database. This time, the person's address is stored in a separate table [adresse]. The [personne] table is linked to this table via a foreign key.
- in [2]: the DDL generated by Hibernate for MySQL5:
- lines 9–20: the [address] table that will be linked to the [Address] class, which has become an @Entity object.
- line 10: the primary key of the [address] table
- line 30: instead of a full address, the [person] table now contains the [address_id] identifier for that address.
- lines 34–38: `person(address_id)` is a foreign key on `address(id)`.
2.3.2. The @Entity objects representing the database
A person with an address is now represented by the following [Person] class:
package entites;
...
@Entity
@Table(name = "jpa03_hb_personne")
public class Personne implements Serializable{
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
...
}
- lines 32–34: the person’s address
- line 32: the @OneToOne annotation denotes a one-to-one relationship: a person has at least one and at most one address. The cascade = CascadeType.ALL attribute means that any operation (persist, merge, remove) on the @Entity [Person] must be cascaded to the @Entity [Address]. From the perspective of the em persistence context, this means the following. If p is a person and has an address:
- an explicit em.persist(p) operation will trigger an implicit em.persist(a) operation
- an explicit em.merge(p) operation will trigger an implicit em.merge(a) operation
- an explicit em.remove(p) operation will trigger an implicit em.remove(a) operation
- line 32: the @OneToOne annotation denotes a one-to-one relationship: a person has at least one and at most one address. The cascade = CascadeType.ALL attribute means that any operation (persist, merge, remove) on the @Entity [Person] must be cascaded to the @Entity [Address]. From the perspective of the em persistence context, this means the following. If p is a person and has an address:
Experience shows that these implicit cascades are not a panacea. Developers eventually forget what they do. Explicit operations in the code may be preferred. There are different types of cascades. The @OneToOne annotation could have been written as follows:
//@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@OneToOne(cascade = {CascadeType.MERGE, CascadeType.PERSIST, CascadeType.REFRESH, CascadeType.REMOVE}, fetch=FetchType.LAZY)
The cascade attribute accepts as its value an array of constants specifying the desired cascade types.
The fetch=FetchType.LAZY attribute instructs Hibernate to load the dependency at the last possible moment. When adding a list of people to the persistence context, you may not necessarily want to include their addresses. For example, you might only want that address for a specific person selected by a user through a web interface. The fetch=FetchType.EAGER attribute, on the other hand, requests that dependencies be loaded immediately.
- (continued)
- line 33: the @JoinColumn annotation defines the foreign key that the @Entity [Person] table has on the @Entity [Address] table. The name attribute defines the name of the column that serves as the foreign key. The unique=true attribute enforces a one-to-one relationship: the same value cannot appear twice in the [address_id] column. The nullable=false attribute enforces that a person must have an address.
A person's address is now represented by the following @Entity [Address]:
package entites;
...
@Entity
@Table(name = "jpa03_hb_adresse")
public class Adresse implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
// manufacturers
public Adresse() {
}
...
}
- line 4: the [Address] class becomes an @Entity object. It will therefore be the subject of a table in the database.
- lines 9–12: Like any @Entity object, [Address] has a primary key. It has been named Id and has the same (standard) annotations as the primary key Id of the @Entity [Person].
- lines 39–40: the one-to-one relationship with the @Entity [Person]. There are several subtleties here:
- First of all, the `person` field is not required. It allows us to use an address to identify the single person associated with that address. If we didn't want this functionality, the `person` field wouldn't exist, and everything would still work.
- The one-to-one relationship linking the two entities [Person] and [Address] has already been configured in the @Entity [Person]:
@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
To prevent the two one-to-one configurations from conflicting with each other, one is considered primary and the other inverse. It is the primary relationship that is managed by the object-relational bridge. The other relationship, known as the inverse relationship, is not managed directly: it is managed indirectly through the primary relationship. In @Entity [Address]:
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
it is the mappedBy attribute that makes the one-to-one relationship above the inverse relationship of the primary one-to-one relationship defined by the address field of @Entity [Person].
2.3.3. The Eclipse / Hibernate 1 project
The JPA implementation used here is Hibernate. The Eclipse test project is as follows:
 |
The project is located [3] in the examples folder [4]. We will import it.
2.3.4. Generating the Database DDL
Following the instructions in Section 2.1.7, the DDL obtained for the MySQL5 DBMS is the one shown at the beginning of this section.
2.3.5. InitDB
The code for [InitDB] is as follows:
package tests;
...
import entites.Adresse;
import entites.Personne;
public class InitDB {
// constant
private final static String TABLE_PERSONNE = "jpa03_hb_personne";
private final static String TABLE_ADRESSE = "jpa03_hb_adresse";
public static void main(String[] args) throws ParseException {
// Persistence context
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// a EntityManager is retrieved from the previous EntityManagerFactory
em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// request
Query sql1;
// delete elements from the PERSONNE table
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE);
sql1.executeUpdate();
// delete elements from the ADRESSE table
sql1 = em.createNativeQuery("delete from " + TABLE_ADRESSE);
sql1.executeUpdate();
// creating people
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// address creation
Adresse a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
Adresse a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
Adresse a3 = new Adresse("x", "x", "x", "x", "x", "x", "x");
Adresse a4 = new Adresse("y", "y", "y", "y", "y", "y", "y");
// associations person <--> address
p1.setAdresse(a1);
a1.setPersonne(p1);
p2.setAdresse(a2);
a2.setPersonne(p2);
// persistence of persons and cascading of their addresses
em.persist(p1);
em.persist(p2);
// and a3 and a4 addresses not linked to persons
em.persist(a3);
em.persist(a4);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// address display
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
// log
System.out.println("terminé...");
}
}
We will only comment on what is new compared to what has already been covered:
- lines 31–32: we create two people
- lines 34–37: we create four addresses
- lines 39-42: we associate the people (p1, p2) with the addresses (a1, a2). The addresses (a3, a4) are orphaned. No person references them. The DDL allows this. While a person must have an address, the reverse is not true.
- lines 44-45: we persist the people (p1, p2). Since we set the cascade attribute to CascadeType.ALL on the one-to-one relationship linking a person to their address, the addresses (a1, a2) of these two people should also be persisted. This is what we want to verify. For the orphaned addresses (a3, a4), we have to do this explicitly (lines 47–48).
- lines 51–53: display of the people table
- Lines 56–57: Display the addresses table
Running [InitDB] with MySQL5 yields the following results:
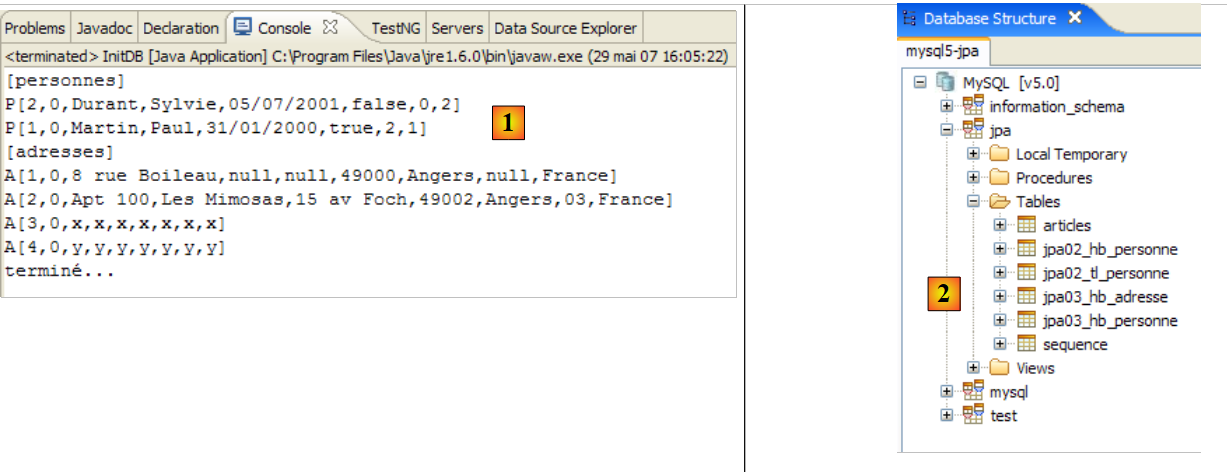 |
 |
- [1]: the console output
- [2]: the [jpa03_hb_*] tables in the SQL Explorer view
- [3]: the people table
- [4]: the addresses table. They are all there. Note also the relationship between the [adresse_id] column in [3] and the [id] column in [4] (foreign key).
2.3.6. Main
The [Main] class runs six tests, which we will review.
2.3.6.1. Test1
This test is as follows:
// création d'objets
public static void test1() throws ParseException {
// contexte de persistance
EntityManager em = getEntityManager();
// création personnes
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// création adresses
a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
a3 = new Adresse("x", "x", "x", "x", "x", "x", "x");
a4 = new Adresse("y", "y", "y", "y", "y", "y", "y");
// associations personne <--> adresse
p1.setAdresse(a1);
a1.setPersonne(p1);
p2.setAdresse(a2);
a2.setPersonne(p2);
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistance des personnes
em.persist(p1);
em.persist(p2);
// et des adresses a3 et a4 non liées à des personnes
em.persist(a3);
em.persist(a4);
// fin transaction
tx.commit();
// on affiche les tables
dumpPersonne();
dumpAdresse();
}
This code is taken from [InitDB]. The result is as follows:
Both tables have been filled.
2.3.6.2. Test2
This test is as follows:
// modifier un objet du contexte
public static void test2() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on incrémente le nbre d'enfants de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// on modifie son état marital
p1.setMarie(false);
// l'objet p1 est automatiquement sauvegardé (dirty checking)
// lors de la prochaine synchronisation (commit ou select)
// fin transaction
tx.commit();
// on affiche la nouvelle table
dumpPersonne();
}
The result is as follows:
- line 4: person p1 saw their number of children increase by 1, and their version change from 0 to 1
2.3.6.3. Test4
This test is as follows:
// supprimer un objet appartenant au contexte de persistance
public static void test4() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on supprime l'objet attaché p2
em.remove(p2);
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpAdresse();
}
- Line 9: We remove person p2. This person has a cascade relationship with address a2. Therefore, address a2 should also be removed.
The result of test 4 is as follows:
- The person p2 appearing in line 3 of test 1 is no longer present in test 4
- The same applies to their address a2, which appears in line 7 of test 1 but is absent from test 4.
2.3.6.4. Test5
This test is as follows:
// détacher, réattacher et modifier
public static void test5() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on réattache p1 au nouveau contexte
p1 = em.find(Personne.class, p1.getId());
// on change l'adresse de p1
p1.getAdresse().setVille("Paris");
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpAdresse();
}
- Line 4: We have a new persistence context, so it is empty.
- line 9: we add the person p1 to it. p1 is fetched from the database because it is not in the context. The elements dependent on p1 (its address) are not fetched from the database because we wrote:
@OneToOne(..., fetch=FetchType.LAZY)
This is the concept of "lazy loading": the dependencies of a persistent object are only loaded into memory when they are needed.
- Line 11: We modify the city field of p1’s address. Because of the getAddress call, and if p1’s address was not already in the persistence context, it will be fetched from the database.
- Line 13: We commit the transaction, which will synchronize the persistence context with the database. The database will detect that the address of person p1 has been modified and will save it.
Running test5 produces the following results:
- Person p1 (line 3 of test4, line 10 of test5) correctly observed their city change from Angers (line 5 of test4) to Paris (line 12 of test5).
2.3.6.5. Test6
This test is as follows:
// delete an Address object
public static void test6() {
EntityTransaction tx = null;
// new persistence context
EntityManager em = getNewEntityManager();
// start of transaction
tx = em.getTransaction();
tx.begin();
// reattach address a3 to new context
a3 = em.find(Adresse.class, a3.getId());
System.out.println(a3);
// we delete it
em.remove(a3);
// end transaction
tx.commit();
// dump table Address
dumpAdresse();
}
- Line 5: We are in a new persistence context, so it is empty.
- Line 10: We place the address a3 into the persistence context
- line 13: we delete it. It was an orphaned address (not linked to a person). Deletion is therefore possible.
The result of the execution is as follows:
- Address a3 from test 5 (line 6) has disappeared from the addresses in test 6 (lines 11-12)
2.3.6.6. Test7
This test is as follows:
// rollback
public static void test7() {
EntityTransaction tx = null;
try {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
tx = em.getTransaction();
tx.begin();
// on réattache l'adresse a1 au nouveau contexte
newa1 = em.find(Adresse.class, a1.getId());
// on réattache l'adresse a4 au nouveau contexte
newa4 = em.find(Adresse.class, a4.getId());
// on essaie de les supprimer - devrait lancer une exception car on ne peut supprimer une adresse liée à une personne, ce qui est le cas de newa1
em.remove(newa4);
em.remove(newa1);
// fin transaction
tx.commit();
} catch (RuntimeException e1) {
// on a eu un pb
System.out.format("Erreur dans transaction [%s%n%s%n%s%n%s]%n", e1.getClass().getName(), e1.getMessage(), e1.getCause(), e1.getCause()
.getCause());
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s]%n", e2.getMessage());
}
// on abandonne le contexte courant
em.clear();
}
// dump - la table Adresse n'a pas du changer à cause du rollback
dumpAdresse();
}
- test7: testing a transaction rollback
- line 6: we are in a new persistence context, so it is empty.
- line 11: we put the address a1 into the persistence context, under the reference newa1
- line 13: we place address a4 in the persistence context, under the reference newa4
- lines 15-16: we delete the two addresses newa1 and newa4. newa1 is the address of person p1 and is therefore referenced by p1 in the database via a foreign key. Deleting newa1 will therefore fail and throw an exception when the persistence context is synchronized upon transaction commit (line 18). The transaction will be rolled back (line 25), and thus both operations in the transaction will be canceled. We should therefore observe that the address newa4, which could have been legally deleted, was not deleted.
The execution yields the following result:
main : ----------- test6
A[3,0,x,x,x,x,x,x,x]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
main : ----------- test7
Erreur dans transaction [javax.persistence.RollbackException
Error while commiting the transaction
org.hibernate.ObjectDeletedException: deleted entity passed to persist: [entites.Adresse#<null>]
null]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
- The addresses table in Test 7 (lines 12–13) is identical to that in Test 6 (lines 4–5). The rollback appears to have occurred. That said, the error message on line 9 is a mystery and warrants further investigation. It seems that the exception that occurred is not the one expected. We need to set Hibernate logs to DEBUG mode in log4j.properties to get a clearer picture:
# Root logger option
log4j.rootLogger=ERROR, stdout
# Hibernate logging options (INFO only shows startup messages)
log4j.logger.org.hibernate=DEBUG
We can then see that when the address a1 was placed in the persistence context, Hibernate also placed the person p1 there, likely due to the one-to-one relationship of the @Entity [Address]:
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
Although "LazyLoading" was requested here, the [Person] dependency is nevertheless loaded immediately. This likely means that the fetch=FetchType.LAZY attribute has no effect here. We then observe that upon committing the transaction, Hibernate has prepared the deletion of addresses a1 and a4 as well as the saving of person p1. And this is where the exception occurs: because person p1 has a cascade on its address, Hibernate also wants to persist address a1 even though it has just been deleted. It is Hibernate that throws the exception, not the JDBC driver. Hence the message on line 9 above. Furthermore, we can see that the rollback on line 25 is never executed because the transaction has become inactive. The test on line 24 therefore prevents the rollback.
We have therefore not achieved the desired goal: to demonstrate a rollback. In fact, no SQL statements were ever issued to the database. Let’s take away a few key points:
- the value of enabling detailed logging to understand what the ORM is doing
- while an ORM can make a developer’s life easier, it can also complicate it by hiding behaviors that the developer needs to know. In this case, the way dependencies of an @Entity are loaded.
2.3.7. Eclipse / Hibernate 2 Project
We copy and paste the Eclipse/Hibernate project to make some minor changes to the configuration of the @Entity objects:
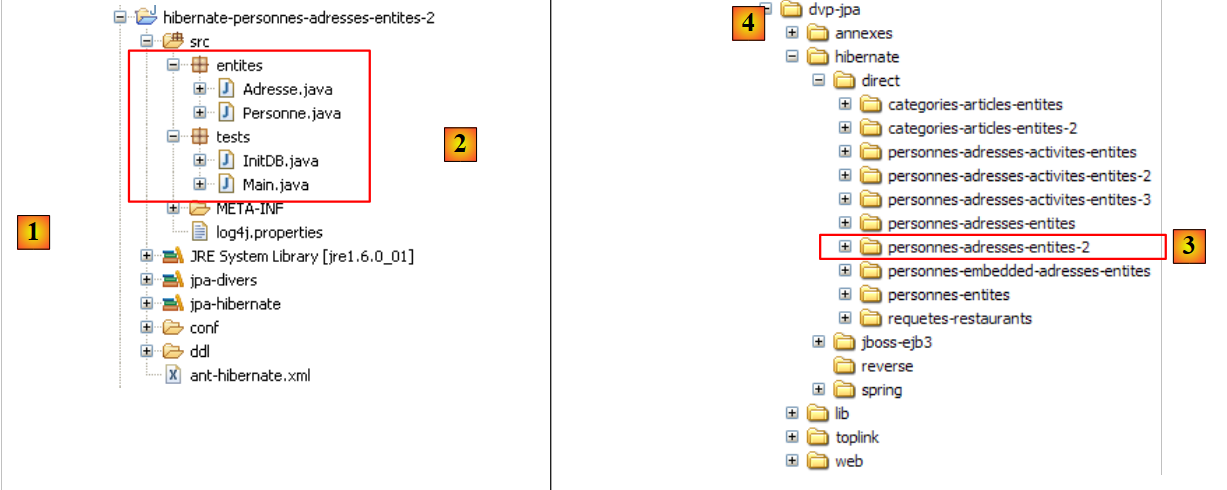 |
The project is located [3] in the examples folder [4]. We will import it.
We modify only the @Entity [Address] so that it no longer has a one-to-one inverse relationship with the @Entity [Person]:
package entites;
...
@Entity
@Table(name = "jpa04_hb_adresse")
public class Adresse implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
...
@Column(length = 20, nullable = false)
private String pays;
// @OneToOne(mappedBy = "address", fetch=FetchType.LAZY)
// private Person person;
// manufacturers
public Adresse() {
}
- lines 25-26: the inverse @OneToOne relationship is removed. It is important to understand that a reverse relationship is never essential. Only the primary relationship is. The reverse relationship can be used for convenience. Here, it provided a simple way to retrieve the owner of an address. A reverse relationship can always be replaced by a JPQL query. This is what we will demonstrate in the following example.
The test programs are identical. The one of interest to us is only Test 7, the one in which we saw the one-to-one inverse relationship in action. We are also adding Test 8 to show how, without the Address -> Person inverse relationship, we can still retrieve the person with a given address.
Test 7 remains unchanged. Running it now yields the following results (logs disabled):
main : ----------- test6
A[3,0,x,x,x,x,x,x,x]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
main : ----------- test7
Erreur dans transaction [javax.persistence.RollbackException
Error while commiting the transaction
org.hibernate.exception.ConstraintViolationException: could not delete: [entites.Adresse#1]
java.sql.SQLException: Cannot delete or update a parent row: a foreign key constraint fails (`jpa/jpa04_hb_personne`, CONSTRAINT `FKEA3F04515FE379D0` FOREIGN KEY (`adresse_id`) REFERENCES `jpa04_hb_adresse` (`id`))]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
- This time, we get the expected exception: the one thrown by the JDBC driver because we tried to delete a row in the [address] table that is referenced by a foreign key from a row in the [person] table. Row [10] clearly explains the cause of the error.
- The rollback did indeed take place: at the end of test 7, the [address] table (rows 12–13) is the same as it was at the end of test 6 (rows 4–5).
What is the difference from Test 7 in the previous Eclipse project? Why do we get a Jdbc exception here that we didn't encounter in the previous test? Because the @Entity [Address] no longer has a one-to-one inverse relationship with the @Entity [Person]; it is managed independently by Hibernate. When the address newa1 was brought into the persistence context, Hibernate did not also place the person p1 with that address into that context. The deletion of addresses newa1 and newa4 therefore took place without any Person entities in the context.
Now, how could we use the address newa1 to find the person p1 with that address? That is a legitimate question. The following Test 8 answers it:
// relation inverse un-à-un
// réalisée par une requête JPQL
public static void test8() {
EntityTransaction tx = null;
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
tx = em.getTransaction();
tx.begin();
// on réattache l'adresse a1 au nouveau contexte
newa1 = em.find(Adresse.class, a1.getId());
// on récupère la personne propriétaire de cette adresse
Personne p1 = (Personne) em.createQuery("select p from Personne p join p.adresse a where a.id=:adresseId").setParameter("adresseId", newa1.getId())
.getSingleResult();
// on les affiche
System.out.println("adresse=" + newa1);
System.out.println("personne=" + p1);
// fin transaction
tx.commit();
}
- line 6: new empty persistence context
- lines 8-9: start transaction
- line 11: the address a1 is brought into the persistence context and referenced by newa1.
- line 13: the person p1 with address newa1 is retrieved via a JPQL query. We know that [Person] and [Address] are linked by a foreign key relationship. In the [Person] class, it is the [address] field that has the @OneToOne annotation, which defines this relationship. The JPQL statement "select p from Person p join p.address a" performs a join between the [Person] and [Address] tables. The equivalent SQL generated in a Hibernate console (see examples in section 2.1.12) is as follows:
The join between the two tables is clearly visible. Each person is now linked to their address. It remains to be specified that we are only interested in the address newa1. The query becomes "select p from Person p join p.address a where a.id=:addressId". Note the use of the aliases p and a. JPQL queries make extensive use of aliases. Thus, the expression "from Person p join p.address a" means that a person is represented by the alias p and their address (p.address) by the alias a. The restriction operation "where a.id=:adresseId" limits the requested rows to only those persons p whose address a has the value :adresseId as its identifier. :adresseId is called a parameter, and the JPQL query is a parameterized JPQL query. At runtime, this parameter must be assigned a value. This is done using the method
that allows you to assign a value to a parameter identified by its name. Note that setParameter returns a Query object, just like the createQuery method. This means you can chain method calls [e.g., createQuery(...).setParameter(...).getSingleResult(...)], since the [setParameter, getSingleResult] methods are methods of the Query interface. The [getSingleResult] method is used for Select queries that return only a single result. This is the case here.
- Lines 16–17: We display the address newa1 and the person p1 associated with that address, for verification.
The result obtained is as follows:
It is correct. We can conclude from this example that the one-to-one inverse relationship from the @entity [Address] to the @entity [Person] was not essential. Experience has shown here that removing it resulted in more predictable code behavior. This is often the case.
2.3.8. Hibernate Console
The previous Test 8 used a JPQL command to perform a join between the Person and Address entities. Although similar to SQL, JPA’s JPQL and Hibernate’s HQL require learning, and the Hibernate console is excellent for this purpose. We already used it in Section 2.1.12 to query a single table. We’ll do it again here to query two tables linked by a foreign key relationship.
Let’s create a Hibernate console for our current Eclipse project:
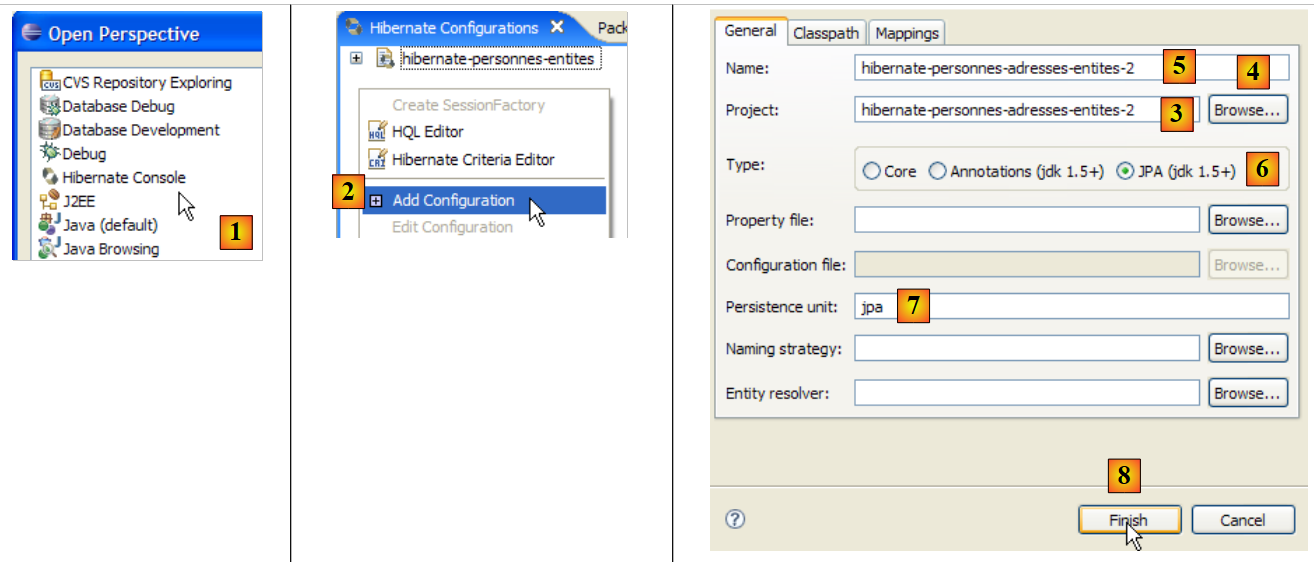 |
- [1]: Switch to the [Hibernate Console] perspective (Window / Open Perspective / Other)
- [2]: We create a new configuration
- using the [4] button, we select the Java project for which the Hibernate configuration is being created. Its name appears in [3].
- In [5], we enter the name we want for this configuration. Here, we have used the name of the Java project.
- In [6], we specify that we are using a JPA configuration so that the tool knows it must use the [META-INF/persistence.xml] file
- In [7], we specify in the [META-INF/persistence.xml] file that the persistence unit named jpa should be used.
- In [8], we validate the configuration.
Next, the DBMS must be started. In this case, it is MySQL 5.
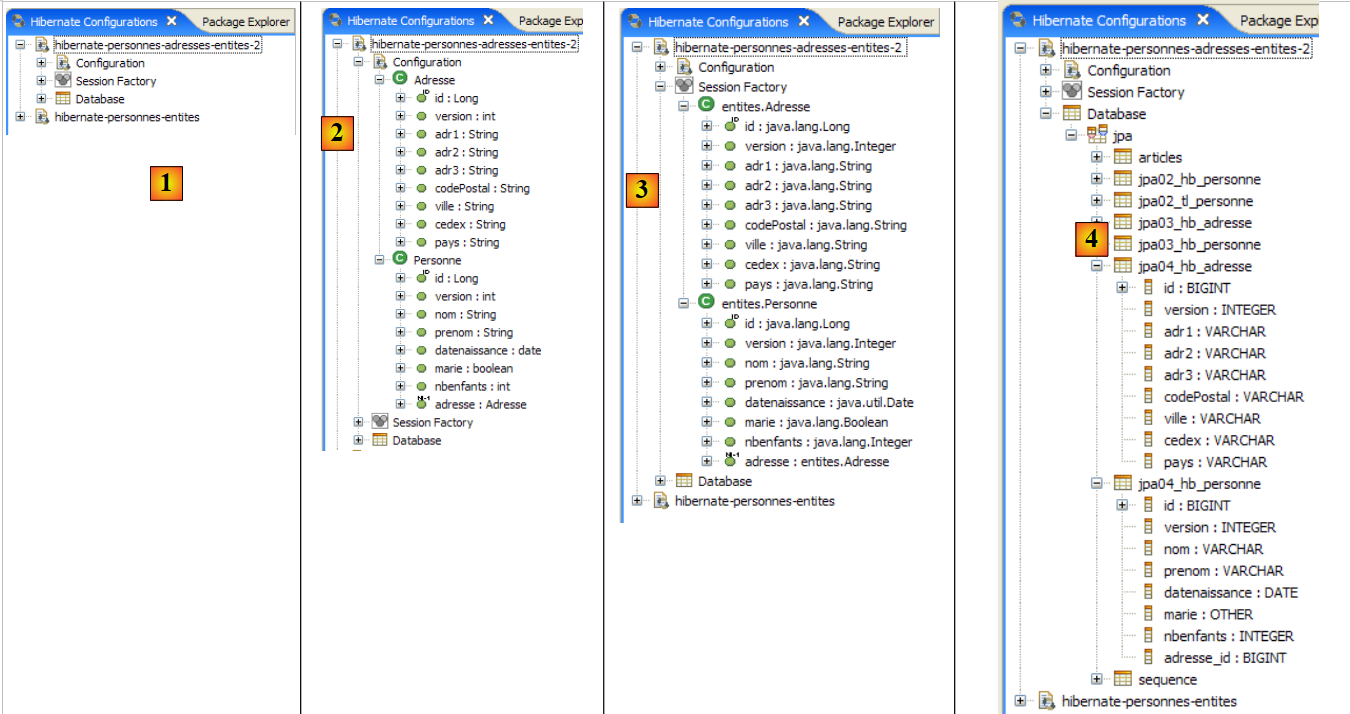 |
- In [1]: The created configuration has a three-branch tree structure
- in [2]: the [Configuration] branch lists the objects the console used to configure itself: here, the @Entity Person and Address.
- In [3]: The Session Factory is a Hibernate concept similar to JPA’s EntityManager. It bridges the object-relational gap using objects from the [Configuration] branch. [3] presents the objects of the persistence context, in this case the @Entity Person and Address entities.
- in [4]: the database accessed via the configuration found in [persistence.xml]. Here we find the [jpa04_hb_*] tables generated by our current Eclipse project.
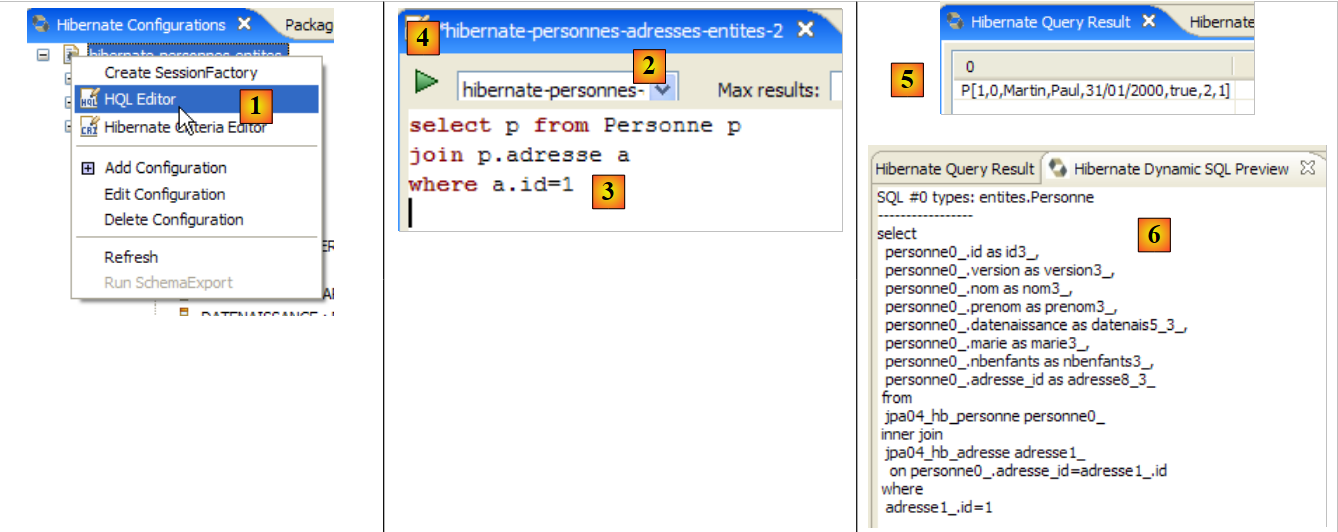 |
- In [1], we create an HQL editor
- in the HQL editor,
- in [2], we select the Hibernate configuration to use if there are multiple (which is the case here)
- in [3], type the JPQL command you want to execute; here, the JPQL command from Test 8
- in [4], we execute it
- In [5], you get the query results in the [Hibernate Query Result] window.
- In [6], the [Hibernate Dynamic SQL preview] window allows you to view the SQL query that was executed.
Another way to get the same result:
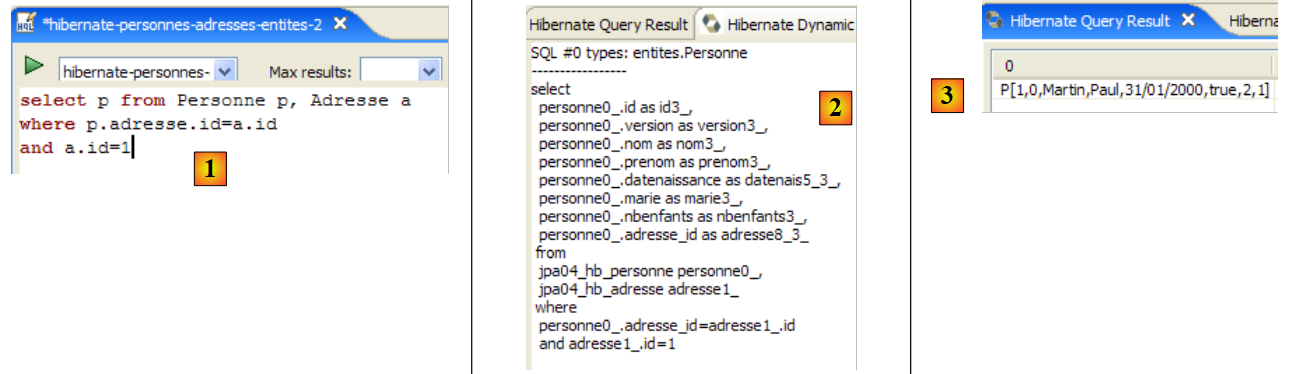 |
- In [1]: the JPQL command performing the join between the Person and Address entities. [ref1] refers to this form as a "theta join".
- in [2]: the SQL equivalent
- In [3]: the result
A third form accepted only by Hibernate (HQL):
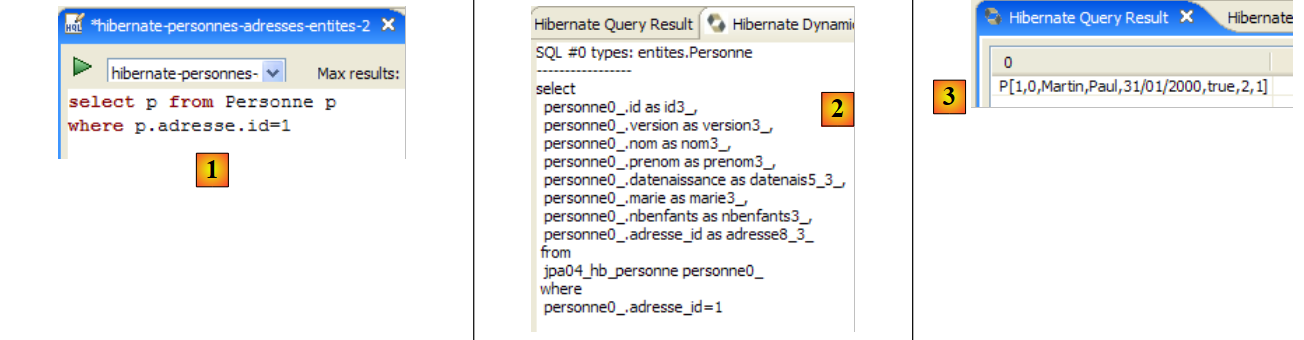 |
- in [1]: the HQL query. JPQL does not accept the notation p.address.id. It only accepts one level of indirection.
- in [2]: the SQL equivalent. Note that it avoids the table join.
- in [3]: the result
Here are some other examples:
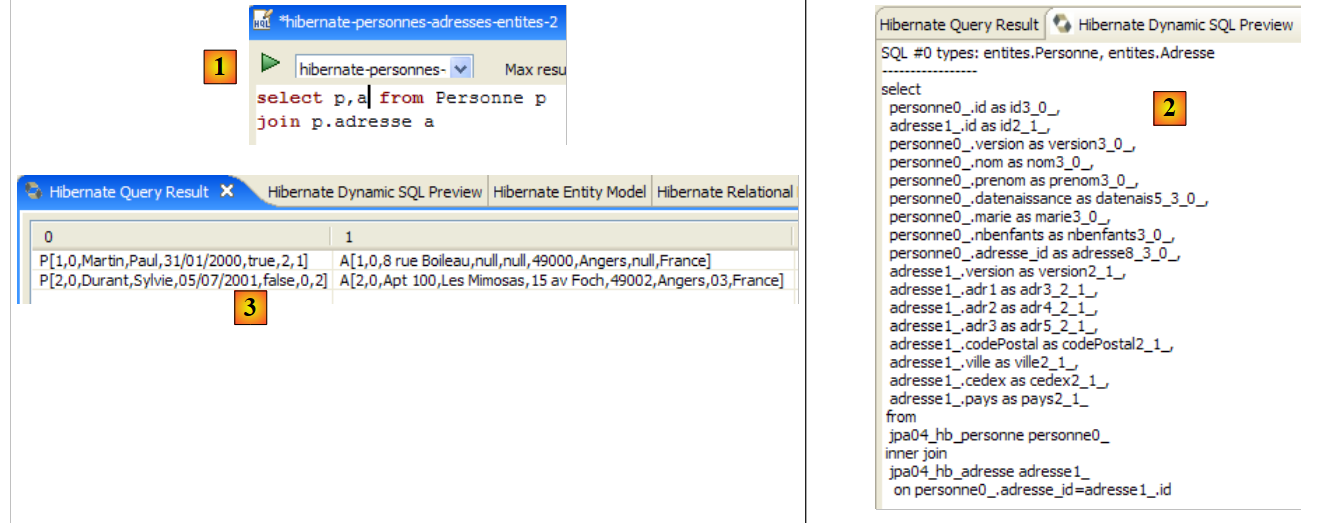 |
- in [1]: the list of people with their addresses
- in [2]: the SQL equivalent.
- in [3]: the result
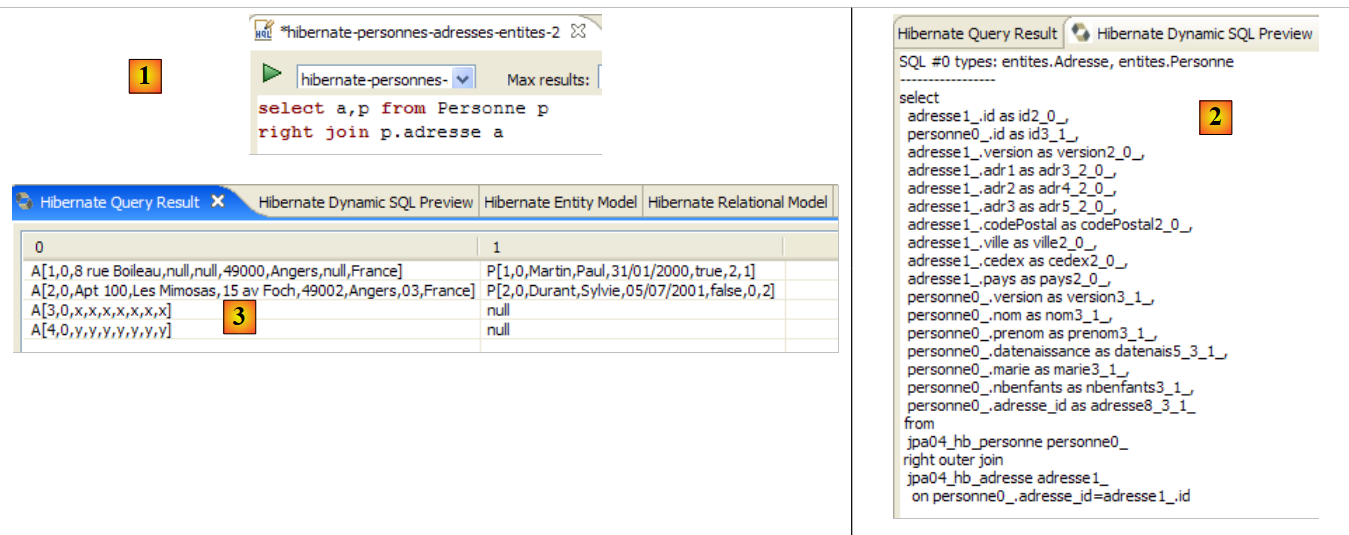 |
- in [1]: the list of addresses with their owner, if there is one, or none otherwise (right outer join: the Address entity, which will provide the rows unrelated to Person, is to the right of the join keyword).
- in [2]: the SQL equivalent.
- in [3]: the result
Note that only the Person entity has a relationship with the Address entity. The reverse is no longer true since we removed the one-to-one inverse relationship called Person in the Address entity. If this inverse relationship existed, we could have written:
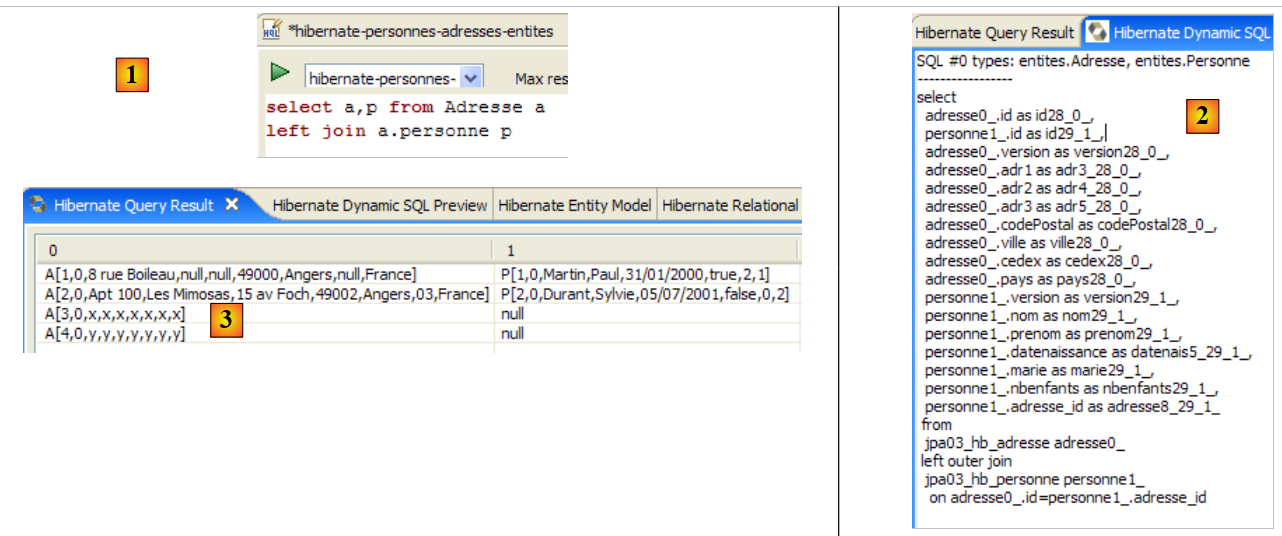 |
- in [1]: the list of addresses with their owner if there is one, or none otherwise (left outer join: the Address entity, which will return rows with no relationship to Person, is on the left side of the join keyword).
- in [2]: the SQL equivalent.
- in [3]: the result
We strongly encourage the reader to practice the JPQL language using the Hibernate console.
2.3.9. JPA / Toplink Implementation
We are now using a JPA / Toplink implementation:
 |
The new Eclipse test project is as follows:
 |
The Java code is identical to that of the previous Hibernate project. The environment (libraries – persistence.xml – DBMS – conf and ddl folders – Ant script) is the one discussed in section 2.1.15.2. The Eclipse project is available [3] in the examples folder [4]. We will import it.
The <persistence.xml> file is modified in one place, specifically the declared entities:
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- classes persistantes -->
<class>entites.Personne</class>
<class>entites.Adresse</class>
<!-- propriétés de l'unité de persistance -->
...
- lines 5 and 6: the two managed entities
Running [InitDB] with the MySQL5 DBMS yields the following results:
 |
In [1], the console output; in [2], the two generated [jpa04_tl] tables; in [3], the generated SQL scripts. Their content is as follows:
create.sql
CREATE TABLE jpa04_tl_personne (ID BIGINT NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, VERSION INTEGER NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NBENFANTS INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa04_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, ADR1 VARCHAR(30) NOT NULL, VILLE VARCHAR(20) NOT NULL, VERSION INTEGER NOT NULL, CEDEX VARCHAR(3), ADR2 VARCHAR(30), PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa04_tl_personne ADD CONSTRAINT FK_jpa04_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa04_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
ALTER TABLE jpa04_tl_personne DROP FOREIGN KEY FK_jpa04_tl_personne_adresse_id
DROP TABLE jpa04_tl_personne
DROP TABLE jpa04_tl_adresse
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
2.4. Example 4: One-to-many relationship
2.4.1. The database schema
1  | 2 |
- in [1], the database, and in [2], its DDL (MySQL5)
An article A(id, version, name) belongs to exactly one category C(id, version, name). A category C can contain 0, 1, or more articles. We have a one-to-many relationship (Category -> Article) and the inverse many-to-one relationship (Article -> Category). This relationship is represented by the foreign key that the [article] table has on the [category] table (lines 24–28 of the DDL).
2.4.2. The @Entity objects representing the database
An article is represented by the following @Entity [Article]:
package entites;
...
@Entity
@Table(name="jpa05_hb_article")
public class Article implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// main relationship Article (many) -> Category (one)
// implemented by a foreign key (categorie_id) in Article
// 1 Article must have 1 Category (nullable=false)
@ManyToOne(fetch=FetchType.LAZY)
@JoinColumn(name = "categorie_id", nullable = false)
private Categorie categorie;
// manufacturers
public Article() {
}
// getters and setters
...
// toString
public String toString() {
return String.format("Article[%d,%d,%s,%d]", id, version, nom, categorie.getId());
}
}
- lines 9-11: primary key of the @Entity
- lines 13-15: its version number
- lines 17-18: name of the article
- lines 20-25: many-to-one relationship linking the @Entity Article to the @Entity Category:
- line 23: the ManyToOne annotation. The Many refers to the @Entity Article in which we are located, and the One refers to the @Entity Category (line 25). A category (One) can have multiple articles (Many).
- line 24: the ManyToOne annotation defines the foreign key column in the [article] table. It will be named (name) categorie_id, and each row must have a value in this column (nullable=false).
- Line 25: The category to which the article belongs. When an article is added to the persistence context, we request that its category not be added immediately (fetch=FetchType.LAZY, line 23). We don’t know if this request makes sense. We’ll see.
A category is represented by the following @Entity [Category]:
package entites;
...
@Entity
@Table(name="jpa05_hb_categorie")
public class Categorie implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// inverse relationship Category (one) -> Article (many) from relationship Article (many) -> Category (one)
// cascade insertion Category -> insertion Articles
// cascade maj Category -> maj Articles
// cascade delete Category -> delete Articles
@OneToMany(mappedBy = "categorie", cascade = { CascadeType.ALL })
private Set<Article> articles = new HashSet<Article>();
// manufacturers
public Categorie() {
}
// getters and setters
...
// toString
public String toString() {
return String.format("Categorie[%d,%d,%s]", id, version, nom);
}
// bidirectional association Category <--> Article
public void addArticle(Article article) {
// the item is added to the collection of items in the category
articles.add(article);
// article changes category
article.setCategorie(this);
}
}
- lines 8-11: the primary key of the @Entity
- lines 12-14: its version
- lines 16-17: the category name
- lines 19-24: the set of items in the category
- Line 23: The @OneToMany annotation denotes a one-to-many relationship. The "One" refers to the @Entity [Category] we are currently in, and the "Many" refers to the [Article] type on line 24: one (One) category has many (Many) articles.
- Line 23: The annotation is the inverse (mappedBy) of the ManyToOne annotation placed on the category field of the @Entity Article: mappedBy=category. The ManyToOne relationship placed on the category field of the @Entity Article is the primary relationship. It is essential. It implements the foreign key relationship that links the @Entity Article to the @Entity Category. The OneToMany relationship placed on the articles field of the @Entity Category is the inverse relationship. It is not essential. It is a convenience for retrieving the articles of a category. Without this convenience, these articles would be retrieved via a JPQL query.
- Line 23: `cascadeType.ALL` specifies that operations (persist, merge, remove) performed on a `@Entity Category` should cascade to its articles.
- Line 24: The articles in a category will be placed in an object of type `Set<Article>`. The `Set` type does not allow duplicates. Thus, the same article cannot be added twice to the `Set<Article>` object. What does “the same article” mean? To indicate that article `a` is the same as article `b`, Java uses the expression `a.equals(b)`. In the Object class, the parent of all classes, a.equals(b) is true if a==b, i.e., if objects a and b have the same memory location. One might want to say that items a and b are the same if they have the same name. In this case, the developer must redefine two methods in the [Item] class:
- equals: which must return true if the two items have the same name
- hashCode: must return an identical integer value for two [Article] objects that the equals method considers equal. Here, the value will therefore be constructed from the article’s name. The value returned by hashCode can be any integer. It is used in various object containers, notably dictionaries (Hashtable).
The OneToMany relationship can use types other than Set to store the Many, such as List objects. We will not cover these cases in this document. The reader can find them in [ref1].
- Line 38: The [addArticle] method allows us to add an article to a category. The method ensures that both ends of the OneToMany relationship linking [Category] to [Article] are updated.
2.4.3. The Eclipse / Hibernate 1 Project
The JPA implementation used here is Hibernate. The Eclipse test project is as follows:
 |
The project is located [3] in the examples folder [4]. We will import it.
2.4.4. Generating the Database DDL
Following the instructions in Section 2.1.7, the DDL generated for the MySQL5 DBMS is the one shown at the beginning of this example, in Section 2.4.1.
2.4.5. InitDB
The code for [InitDB] is as follows:
package tests;
...
public class InitDB {
// constant
private final static String TABLE_ARTICLE = "jpa05_hb_article";
private final static String TABLE_CATEGORIE = "jpa05_hb_categorie";
public static void main(String[] args) {
// Persistence context
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// a EntityManager is retrieved from the previous EntityManagerFactory
em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// request
Query sql1;
// delete elements from the ARTICLE table
sql1 = em.createNativeQuery("delete from " + TABLE_ARTICLE);
sql1.executeUpdate();
// delete elements from the CATEGORIE table
sql1 = em.createNativeQuery("delete from " + TABLE_CATEGORIE);
sql1.executeUpdate();
// create three categories
Categorie categorieA = new Categorie();
categorieA.setNom("A");
Categorie categorieB = new Categorie();
categorieB.setNom("B");
Categorie categorieC = new Categorie();
categorieC.setNom("C");
// create 3 items
Article articleA1 = new Article();
articleA1.setNom("A1");
Article articleA2 = new Article();
articleA2.setNom("A2");
Article articleB1 = new Article();
articleB1.setNom("B1");
// link them to their category
categorieA.addArticle(articleA1);
categorieA.addArticle(articleA2);
categorieB.addArticle(articleB1);
// persist categories and cascade (insert) articles
em.persist(categorieA);
em.persist(categorieB);
em.persist(categorieC);
// category display
System.out.println("[categories]");
for (Object p : em.createQuery("select c from Categorie c order by c.nom asc").getResultList()) {
System.out.println(p);
}
// item display
System.out.println("[articles]");
for (Object p : em.createQuery("select a from Article a order by a.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityMangerFactory
emf.close();
// log
System.out.println("terminé...");
}
}
- lines 22-27: the [article] and [category] tables are emptied. Note that we must start with the table containing the foreign key. If we started with the [category] table, we would delete categories referenced by rows in the [article] table, and the DBMS would reject this.
- lines 29-34: we create three categories A, B, C
- Lines 36–41: We create three articles: A1, A2, and B1 (the letter indicates the category)
- Lines 43–45: The three articles are placed in their respective categories
- Lines 47–49: The three categories are placed in the persistence context. Because of the Category → Article cascade, their associated articles will also be placed there. Thus, all created objects are now in the persistence context.
- Lines 50-59: The persistence context is queried to obtain the list of categories and items. We know that this will trigger a synchronization of the context with the database. It is at this point that the categories and items will be saved to their respective tables.
Running [InitDB] with MySQL5 yields the following results:
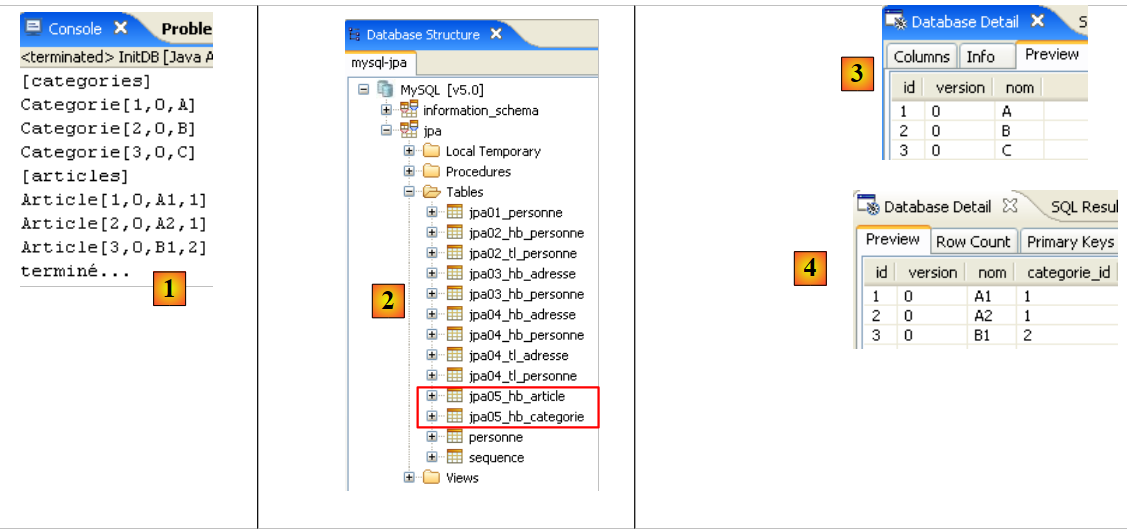 |
- [1]: the console output
- [2]: the [jpa05_hb_*] tables in the SQL Explorer view
- [3]: the categories table
- [4]: the articles table. Note the relationship between [categorie_id] in [4] and [id] in [3] (foreign key).
2.4.6. Main
The [Main] class runs a series of tests that we review, except for tests 1 and 2, which use the code from [InitDB] to initialize the database.
2.4.6.1. Test3
This test is as follows:
// search for a particular item
public static void test3() {
// new persistence context
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// loading category
Categorie categorie = em.find(Categorie.class, categorieA.getId());
// category display and related articles
System.out.format("Articles de la catégorie %s :%n", categorie);
for (Article a : categorie.getArticles()) {
System.out.println(a);
}
// end transaction
tx.commit();
}
- line 4: we have a new persistence context, so it is empty
- lines 6-7: start transaction
- line 9: category A is retrieved from the database into the persistence context
- line 11: we display category A
- lines 12–14: we display the items in category A. This demonstrates the benefit of the OneToMany reverse relationship for the @Entity Category. Its presence saves us from having to make a JPQL query to retrieve the items in category A. To obtain them, we use the get method of the items field.
The results are as follows:
- line 20: category A
- Lines 21-22: the two items in category A
2.4.6.2. Test4
This test is as follows:
// supprimer un article
@SuppressWarnings("unchecked")
public static void test4() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// chargement article A1
Article newarticle1 = em.find(Article.class, articleA1.getId());
// suppression article A1 (aucune catégorie n'est actuellement chargée)
em.remove(newarticle1);
// toplink : l'article doit être enlevé de sa catégorie sinon le test6 plante
// hibernate : ce n'est pas nécessaire
newarticle1.getCategorie().getArticles().remove(newarticle1);
// fin transaction
tx.commit();
// dump des articles
dumpArticles();
}
- Test 4 deletes item A1
- line 5: we start with a new, empty context
- line 10: article A1 is added to the persistence context. It will be referenced there by newarticle1.
- line 12: it is removed from the context
- line 15: categories A, B, and C, and items A1, A2, and B1, if they are no longer persistent, are nevertheless still in memory. They are simply detached from the persistence context. Article A1, which is part of the articles in category A, is removed from it. This will later make it possible to reattach category A to the persistence context. If this is not done, category A will be reattached with a set of articles, one of which has been deleted. This does not seem to bother Hibernate but causes TopLink to crash.
- Line 19: We display all items to verify that A1 is gone.
The results are as follows:
Item A1 has indeed disappeared.
2.4.6.3. Test5
This test is as follows:
// modification d'1 article
public static void test5() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// modification articleA2
articleA2.setNom(articleA2.getNom() + "-");
// articleA2 est remis dans le contexte de persistance
em.merge(articleA2);
// fin transaction
tx.commit();
// dump des articles
dumpArticles();
}
- Test 5 changes the name of item A2
- Line 4: We start with a new, empty context
- line 9: we change the name of the detached item A2, which becomes "A2-".
- line 11: the detached item A2 is reattached to the persistence context. Note that A2 remains a detached object. It is the object em.merge(itemA2) that is now part of the persistence context. This object has not been stored in a variable here, as is customary. It is therefore inaccessible.
- Line 13: Synchronization of the persistence context with the database. Article A2 will be modified in the database, and its version number will change from N to N+1. The detached memory version articleA2 is no longer valid. The same applies to the detached object representing category A, because it contains articleA2 among its articles.
- Line 15: We display all items to verify the name change of item A2
The results are as follows:
The name of item A2 has indeed changed.
2.4.6.4. Test6
This test is as follows:
// modification d'1 catégorie et de ses articles
public static void test6() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// chargement catégorie
categorieA = em.find(Categorie.class, categorieA.getId());
// liste des articles de la catégorie A
for (Article a : categorieA.getArticles()) {
a.setNom(a.getNom() + "-");
}
// modification nom catégorie
categorieA.setNom(categorieA.getNom() + "-");
// fin transaction
tx.commit();
// dump des catégories et des articles
dumpCategories();
dumpArticles();
}
- Test 6 changes the name of category A and all its articles
- line 4: we start with a new, empty context
- line 9: we retrieve category A from the database. We do not merge the detached categoryA object because we know it has a reference to article A2, which has become obsolete. We therefore start from scratch.
- Lines 11–12: We change the name of all articles in category A. Again, we use the inverse OneToMany relationship via the getArticles method.
- Line 15: The category name is also changed
- Line 17: End of the transaction. The context is synchronized with the database. All objects in the context that have been modified will be updated in the database.
- Lines 21–22: The items and categories are displayed for verification
The results are as follows:
Article A2 has changed its name again, as has category A.
2.4.6.5. Test7
This test is as follows:
// category deletion
public static void test7() {
// new persistence context
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistence catégorieB and cascade (merge) associated items
Categorie mergedcategorieB = em.merge(categorieB);
// category deletion and cascading (delete) of associated items
em.remove(mergedcategorieB);
// end transaction
tx.commit();
// dump categories and articles
dumpCategories();
dumpArticles();
}
- Test 7 deletes category B and, consequently, its articles
- line 4: we start with a new, empty context
- line 9: Category B exists in memory as an object detached from the persistence context. We merge it back into the persistence context. As a result, its articles (article B1) will also be merged and thus reintegrated into the persistence context.
- line 11: now that category B is in the context, we can remove it. By cascade, its items will also be removed. This operation is possible because the merge operation in line 9 reintegrated them into the persistence context.
- Line 13: End of the transaction. The context will be synchronized. Objects in the context that have been removed will be deleted from the database.
- Lines 15–16: We display the items and categories for verification
The results are as follows:
Category B and article B1 have indeed disappeared.
2.4.6.6. Test8
This test is as follows:
// requêtes
@SuppressWarnings("unchecked")
public static void test8() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// liste des articles de la catégorie A
List articles = em
.createQuery(
"select a from Categorie c join c.articles a where c.nom like 'A%' order by a.nom asc")
.getResultList();
// affichages articles
System.out.println("Articles de la catégorie A");
for (Object a : articles) {
System.out.println(a);
}
// fin transaction
tx.commit();
}
- Test 7 shows how to retrieve items from a category without using the inverse relationship. This demonstrates that the inverse relationship is not essential.
- line 4: we start with a new, empty context
- line 10: a JPQL query that retrieves all articles in a category whose name starts with A
- Lines 15–17: Displaying the query results.
The results are as follows:
2.4.7. Eclipse / Hibernate Project 2
We copy and paste the Eclipse / Hibernate project to clarify a point regarding the concept of primary relationship / inverse relationship that we established around the @ManyToOne (primary) annotation of the @Entity [Article] and the inverse @OneToMany (inverse) relationship of the @Entity [Category]. We want to show that if this latter relationship is not declared as the inverse of the other, then the schema generated for the database is completely different from the one generated previously.
 |
In [1] is the new Eclipse project. In [2] is the Java code, and in [3] is the Ant script that will generate the database’s SQL schema. The project is located [4] in the examples folder [5]. We will import it.
We modify only the @Entity [Category] so that its @OneToMany relationship with the @Entity [Article] is no longer declared as the inverse of the @ManyToOne relationship that the @Entity [Article] has with the @Entity [Category]:
...
@Entity
@Table(name="jpa05_hb_categorie")
public class Categorie implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// relationship OneToMany not inverse (no mappedby) Category (one) -> Article (many)
// implemented by a Categorie_Article join table, so that, starting from a category
// you can reach the items in this category
@OneToMany(cascade=CascadeType.ALL, fetch=FetchType.LAZY)
private Set<Article> articles = new HashSet<Article>();
// manufacturers
...
- lines 18–22: we still want to retain the ability to find articles in a given category using the @OneToMany relationship on line 21. However, we want to understand the effect of the mappedBy attribute, which turns a relationship into the inverse of a primary relationship defined elsewhere in another @Entity. Here, the mappedBy has been removed.
We run the ant-DLL task (see section 2.1.7) with the MySQL5 DBMS. The resulting schema is as follows:
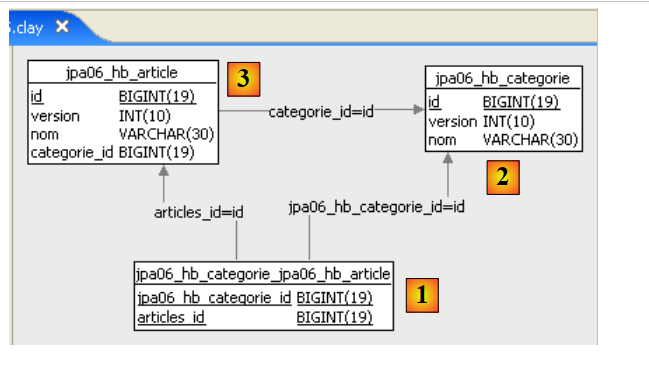 |
Note the following points:
- A new table [categorie_article] [1] has been created. It did not exist previously.
- This is a join table between the tables [categorie] [2] and [article] [3]. If the Article objects a1 and a2 belong to category c1, the join table will contain the following rows:
where c1, a1, and a2 are the primary keys of the corresponding objects.
- The join table [category_article] [1] was created by Hibernate so that, starting from a Category object c, we can retrieve the Article objects a belonging to c. It is the @OneToMany relationship that forced the creation of this table. Because we did not declare it as the inverse of the @ManyToOne primary relationship of the @Entity Article, Hibernate did not know that it could use this primary relationship to retrieve the articles of a category c. It therefore found another way.
- This example helps clarify the concepts of primary and inverse relationships. One (the inverse) uses the properties of the other (the primary).
The SQL schema for this database in MySQL 5 is as follows:
alter table jpa05_hb_categorie_jpa06_hb_article
drop
foreign key FK79D4BA1D26D17756;
alter table jpa05_hb_categorie_jpa06_hb_article
drop
foreign key FK79D4BA1D424C61C9;
alter table jpa06_hb_article
drop
foreign key FK4547168FECCE8750;
drop table if exists jpa05_hb_categorie;
drop table if exists jpa05_hb_categorie_jpa06_hb_article;
drop table if exists jpa06_hb_article;
create table jpa05_hb_categorie (
id bigint not null auto_increment,
version integer not null,
nom varchar(30),
primary key (id)
) ENGINE=InnoDB;
create table jpa05_hb_categorie_jpa06_hb_article (
jpa05_hb_categorie_id bigint not null,
articles_id bigint not null,
primary key (jpa05_hb_categorie_id, articles_id),
unique (articles_id)
) ENGINE=InnoDB;
create table jpa06_hb_article (
id bigint not null auto_increment,
version integer not null,
nom varchar(30),
categorie_id bigint not null,
primary key (id)
) ENGINE=InnoDB;
alter table jpa05_hb_categorie_jpa06_hb_article
add index FK79D4BA1D26D17756 (jpa05_hb_categorie_id),
add constraint FK79D4BA1D26D17756
foreign key (jpa05_hb_categorie_id)
references jpa05_hb_categorie (id);
alter table jpa05_hb_categorie_jpa06_hb_article
add index FK79D4BA1D424C61C9 (articles_id),
add constraint FK79D4BA1D424C61C9
foreign key (articles_id)
references jpa06_hb_article (id);
alter table jpa06_hb_article
add index FK4547168FECCE8750 (categorie_id),
add constraint FK4547168FECCE8750
foreign key (categorie_id)
references jpa05_hb_categorie (id);
- Lines 19–24: creation of the [categorie] table, and lines 33–39: creation of the [article] table. Note that these are identical to those in the previous example.
- Lines 26–31: creation of the join table [categorie_article] due to the presence of the non-inverse @OneToMany relationship of the @Entity Categorie. The rows in this table are of type [c,a], where c is the primary key of a category c and a is the primary key of an item a belonging to category c. The primary key of this join table consists of the two primary keys [c,a] concatenated (line 29).
- lines 41-45: the foreign key constraint from the [categorie_article] table to the [categorie] table
- lines 47–51: the foreign key constraint from the [categorie_article] table to the [article] table
- Lines 53–57: The foreign key constraint from the [article] table to the [categorie] table
The reader is invited to run the [InitDB] and [Main] tests. They yield the same results as before. However, the database schema is redundant, and performance will be degraded compared to the previous version. We should probably explore this issue of inverse/primary relationships further to see if the new configuration also introduces conflicts due to the fact that we have two independent relationships representing the same thing: the many-to-one relationship between the [article] table and the [category] table.
2.4.8. JPA / Toplink Implementation - 1
We are now using a JPA / Toplink implementation:
 |
The Eclipse project with Toplink is a copy of the Eclipse project with Hibernate, version 1:
 |
The Java code is identical to that of the previous Hibernate project—version 1. The environment (libraries – persistence.xml – DBMS – conf and ddl folders – Ant script) is the one discussed in section 2.1.15.2. The Eclipse project is available [3] in the examples folder [4]. We will import it.
The <persistence.xml> file [2] has been modified in one respect, namely the declared entities:
...
<!-- classes persistantes -->
<class>entites.Categorie</class>
<class>entites.Article</class>
...
- Lines 3 and 4: the two managed entities
Running [InitDB] with the MySQL5 DBMS yields the following results:
 |
In [1], the console output; in [2], the two generated [jpa05_tl] tables; in [3], the generated SQL scripts. Their content is as follows:
create.sql
CREATE TABLE jpa05_tl_article (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), categorie_id BIGINT NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa05_tl_categorie (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), PRIMARY KEY (ID))
ALTER TABLE jpa05_tl_article ADD CONSTRAINT FK_jpa05_tl_article_categorie_id FOREIGN KEY (categorie_id) REFERENCES jpa05_tl_categorie (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
ALTER TABLE jpa05_tl_article DROP FOREIGN KEY FK_jpa05_tl_article_categorie_id
DROP TABLE jpa05_tl_article
DROP TABLE jpa05_tl_categorie
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
The execution of [Main] completes without errors.
2.4.9. JPA / Toplink Implementation - 2
This Eclipse project was created by cloning the previous one. Since it was built with Hibernate, we remove the mappedBy attribute from the @OneToMany relationship of the @Entity Category.
@Entity
@Table(name = "jpa06_tl_categorie")
public class Categorie implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
private int version;
@Column(length = 30)
private String nom;
// relation OneToMany not inverse (no mappedby) Category (one) ->
// Article (many)
// implemented by a Categorie_Article join table, so that from
// category
// several items can be reached
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private Set<Article> articles = new HashSet<Article>();
The SQL schema generated for MySQL5 is then as follows:
create.sql
CREATE TABLE jpa06_tl_categorie (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), PRIMARY KEY (ID))
CREATE TABLE jpa06_tl_categorie_jpa06_tl_article (Categorie_ID BIGINT NOT NULL, articles_ID BIGINT NOT NULL, PRIMARY KEY (Categorie_ID, articles_ID))
CREATE TABLE jpa06_tl_article (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), categorie_id BIGINT NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa06_tl_categorie_jpa06_tl_article ADD CONSTRAINT FK_jpa06_tl_categorie_jpa06_tl_article_articles_ID FOREIGN KEY (articles_ID) REFERENCES jpa06_tl_article (ID)
ALTER TABLE jpa06_tl_categorie_jpa06_tl_article ADD CONSTRAINT jpa06_tl_categorie_jpa06_tl_article_Categorie_ID FOREIGN KEY (Categorie_ID) REFERENCES jpa06_tl_categorie (ID)
ALTER TABLE jpa06_tl_article ADD CONSTRAINT FK_jpa06_tl_article_categorie_id FOREIGN KEY (categorie_id) REFERENCES jpa06_tl_categorie (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
- Line 2: the join table that implements the previous non-inverted @OneToMany relationship.
The execution of [InitDB] completes without errors, but the execution of [Main] crashes at test 7 with the following logs (FINEST):
- Line 3: the merge on category B
- line 4: the dependent article B1 is placed in the context
- line 5: same for category B itself
- line 6: the remove on category B
- line 7: remove on item B1 (cascading)
- Line 8: The Java code requests a commit of the transaction
- line 9: a transaction starts—so it apparently hadn’t started yet.
- line 10: item B1 is about to be deleted by a DELETE operation on the [item] table. This is where the problem lies. The join table [category_item] has a reference to row B1 in the [item] table. Deleting B1 from [item] will violate a foreign key constraint.
- Lines 13 and beyond: the exception occurs
What can we conclude?
- Once again, we have a portability issue between Hibernate and Toplink: Hibernate passed this test
- TopLink has difficulty handling situations where two relationships are actually inverse to each other, with one not declared as the primary relationship and the other as the inverse. This is acceptable because this scenario actually represents a configuration error. In our example, the [article] table has no relationship with the join table [categorie_article]. It therefore seems natural that during an operation on the [article] table, Toplink does not attempt to work with the [categorie_article] table.
2.5. Example 5: Many-to-many relationship with an explicit join table
2.5.1. The database schema
|
- in [1], the MySQL5 database
We are already familiar with the tables [person] [2] and [address] [3]. They were discussed in Section 2.3.1. We are using the version where the person’s address is stored in a separate table [address] [3]. In the [person] table, the relationship linking a person to their address is implemented via a foreign key constraint.
A person engages in activities. These activities are stored in the [activity] table [4]. A person can engage in multiple activities, and an activity can be engaged in by multiple people. A many-to-many relationship therefore links the [person] and [activity] tables. This relationship is represented by the join table [person_activity] [5].
2.5.2. The @Entity objects representing the database
The tables above will be represented by the following @Entities:
- the @Entity Person will represent the [person] table
- the @Entity Address will represent the [address] table
- the @Entity Activity will represent the [activity] table
- the @Entity PersonneActivite will represent the [personne_activite] table
The relationships between these entities are as follows:
- A one-to-one relationship links the Person entity to the Address entity: a person p has an address a. The Person entity holding the foreign key will be the primary entity, and the Address entity will be the inverse entity.
- A many-to-many relationship connects the Person and Activity entities: a person has multiple activities, and an activity is practiced by multiple people. This relationship could be implemented directly using a @ManyToMany annotation in each of the two entities, with one declared as the inverse of the other. This solution will be explored later. Here, we implement the many-to-many relationship using two one-to-many relationships:
- a one-to-many relationship linking the Person entity to the PersonActivity entity: a single row (One) in the [person] table is referenced by multiple (Many) rows in the [person_activity] table. The [person_activity] table, which holds the foreign key, will have the primary @ManyToOne relationship, and the Person entity will have the inverse @OneToMany relationship.
- a one-to-many relationship linking the Activity entity to the PersonActivity entity: one (One) row in the [activity] table is referenced by many (Many) rows in the [person_activity] table. The [person_activity] table, which holds the foreign key, will have the primary @ManyToOne relationship, and the Activity entity will have the inverse @OneToMany relationship.
The @Entity Person is as follows:
@Entity
@Table(name = "jpa07_hb_personne")
public class Personne implements Serializable {
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
// main relationship Person (one) -> Address (one)
// implemented by the foreign key Person(adresse_id) -> Address
// cascade insert Person -> insert Address
// cascade shift Person -> shift Address
// cascade deletion Person -> deletion Address
// a Person must have 1 Address (nullable=false)
// 1 Address belongs to 1 person only (unique=true)
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
// relation Person (one) -> PersonneActivite (many)
// inverse of existing relationship PersonneActivite (many) -> Personne (one)
// cascade deletion Person -> supression PersonneActivite
@OneToMany(mappedBy = "personne", cascade = { CascadeType.REMOVE })
private Set<PersonneActivite> activites = new HashSet<PersonneActivite>();
// manufacturers
This @Entity is well-known. We will only comment on the relationships it has with other entities:
- lines 30–39: a one-to-one @OneToOne relationship with the @Entity Address, implemented via a foreign key [address_id] (line 38) that the [Person] table will have on the [Address] table.
- Lines 41–45: a one-to-many relationship (@OneToMany) with the @Entity PersonneActivite. A person (One) is referenced by multiple (Many) rows in the join table [personne_activite] represented by the @Entity PersonneActivite. These PersonneActivite objects will be placed in a Set<PersonneActivite> type, where PersonneActivite is a type we will define shortly.
- Line 44: The one-to-many relationship defined here is the inverse of a primary relationship defined on the person field of the @Entity PersonneActivite (mappedBy keyword). We have a Person -> Activity cascade on deletes: deleting a person p will result in the deletion of persistent elements of type PersonneActivite found in the p.activites collection.
The @Entity Address is as follows:
@Entity
@Table(name = "jpa07_hb_adresse")
public class Adresse implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse")
private Personne personne;
- Lines 28-29: the @OneToOne relationship that is the inverse of the @OneToOne address relationship of the @Entity Person (lines 37-38 of Person).
The @Entity Activity is as follows
@Entity
@Table(name = "jpa07_hb_activite")
public class Activite implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
// relation Activite (one) -> PersonneActivite (many)
// inverse of existing relationship PersonneActivite (many) -> Activite (one)
// cascade suppression Activite -> supression PersonneActivite
@OneToMany(mappedBy = "activite", cascade = { CascadeType.REMOVE })
private Set<PersonneActivite> personnes = new HashSet<PersonneActivite>();
- lines 6-9: the primary key of the activity
- lines 11-13: the activity version number
- lines 15-16: the activity name
- lines 18-22: the one-to-many relationship linking the @Entity Activity to the @Entity PersonActivity: one activity (One) is referenced by multiple (Many) rows in the join table [person_activity] represented by the @Entity PersonActivity. These PersonneActivite objects will be placed in a Set<PersonneActivite> type.
- Line 22: The one-to-many relationship defined here is the inverse of a primary relationship defined on the `activity` field in the `@Entity PersonneActivite` (using the `mappedBy` keyword). We have an Activity -> PersonActivity cascade on deletes: deleting an activity from the [activity] table will trigger the deletion of persistent PersonActivity entities found in the a.people collection from the [person_activity] join table.
The @Entity PersonneActivite is as follows:
@Entity
// join table
@Table(name = "jpa07_hb_personne_activite")
public class PersonneActivite {
@Embeddable
public static class Id implements Serializable {
// composite key components
// points to a Person
@Column(name = "PERSONNE_ID")
private Long personneId;
// on an Activity
@Column(name = "ACTIVITE_ID")
private Long activiteId;
// manufacturers
...
// getters and setters
...
// toString
public String toString() {
return String.format("[%d,%d]", getPersonneId(), getActiviteId());
}
}
// fields of the Personne_Activite class
// composite key
@EmbeddedId
private Id id = new Id();
// main relationship PersonneActivite (many) -> Nobody (one)
// implemented by the foreign key: personneId (PersonneActivite (many) -> Personne (one)
// personneId is also part of the composite primary key
// JPA does not need to manage this foreign key (insertable = false, updatable = false), as this is done by the application itself in its constructor
@ManyToOne
@JoinColumn(name = "PERSONNE_ID", insertable = false, updatable = false)
private Personne personne;
// main relationship PersonneActivite -> Activity
// implemented by the foreign key: activiteId (PersonneActivite (many) -> Activite (one)
// activiteId is also part of the composite primary key
// JPA does not need to manage this foreign key (insertable = false, updatable = false), as this is done by the application itself in its constructor
@ManyToOne()
@JoinColumn(name = "ACTIVITE_ID", insertable = false, updatable = false)
private Activite activite;
// manufacturers
public PersonneActivite() {
}
public PersonneActivite(Personne p, Activite a) {
// foreign keys are set by the application
getId().setPersonneId(p.getId());
getId().setActiviteId(a.getId());
// two-way associations
this.setPersonne(p);
this.setActivite(a);
p.getActivites().add(this);
a.getPersonnes().add(this);
}
// getters and setters
...
// toString
public String toString() {
return String.format("[%s,%s,%s]", getId(), getPersonne().getNom(), getActivite().getNom());
}
}
This class is more complex than the previous ones.
- The [person_activity] table has rows of the form [p,a], where p is the primary key of a person and a is the primary key of an activity. Every table must have a primary key, and [person_activity] is no exception. Until now, we had defined primary keys dynamically generated by the DBMS. We could do the same here. We will use another technique, one where the application itself defines the values of a table’s primary key. Here, a row [p1,a1] indicates that a person p1 participates in activity a1. This same row cannot appear a second time in the table. Thus, the pair (p,a) is a good candidate for a primary key. This is called a composite primary key.
- Lines 30–31: the composite primary key. The @EmbeddedId annotation (previously @Id) is analogous to the @Embedded notation applied to a person’s Address field. In that case, it meant that the Address field was an instance of an external class but had to be inserted into the same table as the person. Here, the meaning is the same, except that to indicate we are dealing with the primary key, the annotation becomes @EmbeddedId.
- Line 31: An empty object representing the primary key `id` is created when the `PersonneActivite` object is instantiated. The class representing the primary key is defined on lines 7–26 as a public static class internal to the `PersonneActivite` class. The fact that it is public and static is required by Hibernate. If we replace public static with private, an exception occurs, and the associated error message indicates that Hibernate attempted to execute the statement new PersonneActivite$Id. Therefore, the Id class must be both static and public.
- Line 6: The Id class of the primary key is declared @Embeddable. Recall that the primary key id on line 31 was declared @EmbeddedId. The corresponding class must therefore have the @Embeddable annotation.
- We stated that the primary key of the [person_activity] table consists of the pair (p, a), where p is the primary key of a person and a is the primary key of an activity. We find the two elements (p,a) of the composite key in line 11 (personId) and line 15 (activityId). The columns associated with these two fields are named: PERSON_ID for the person, ACTIVITY_ID for the activity.
- Line 31: The primary key has been defined with its two columns (PERSON_ID, ACTIVITY_ID). There are no other columns in the [person_activity] table. All that remains is to define the relationships between the @Entity PersonneActivite we are currently describing and the other @Entities in the relational schema. These relationships reflect the foreign key constraints that the [personne_activite] table has with the other tables.
- Lines 33–39: define the foreign key from the [person_activity] table to the [person] table
- Line 37: The relationship is of type @ManyToOne: one (One) row in the [person] table is referenced by many (Many) rows in the [person_activity] table.
- Line 38: We name the foreign key column. We use the same name as the one given for the "person" component of the foreign key (line 10). The attributes insertable=false, updatable=false are there to prevent Hibernate from managing the foreign key. This key is, in fact, a component of a primary key calculated by the application, and Hibernate must not intervene.
- Lines 41–47: Define the foreign key from the [person_activity] table to the [activity] table. The explanations are the same as those given previously.
- Lines 54–63: Constructor for a PersonActivity object based on a person p and an activity a. Recall that when constructing a PersonActivity object, the primary key id in line 31 pointed to an empty Id object. Lines 56–57 assign a value to each of the fields (personId, activityId) of the Id object. These values are, respectively, the primary keys of the person p and the activity a passed as parameters to the constructor. The primary key id (line 31) therefore now has a value.
- Line 59: The person field in line 39 is assigned the value p
- Line 60: The activite field in line 47 is assigned the value a
- A [PersonActivity] object is now created and initialized. We update the inverse relationships between the @Entity Person (line 61) and Activity (line 62) with the @Entity PersonActivity that has just been created.
We have completed the description of the database entities. We are in a complex but unfortunately common situation. We will see that there is another possible configuration of the JPA layer that hides part of this complexity: the join table becomes implicit, built and managed by the JPA layer. Here, we have chosen the most complex solution, but one that allows the relational schema to evolve. This allows columns to be added to the join table, which is not possible in the configuration where the join table is not an explicit @Entity. [ref1] recommends the solution we are currently examining. The information that enabled the development of this solution was found in [ref1].
2.5.3. The Eclipse / Hibernate Project
The JPA implementation used here is Hibernate. The Eclipse project for the tests is as follows:
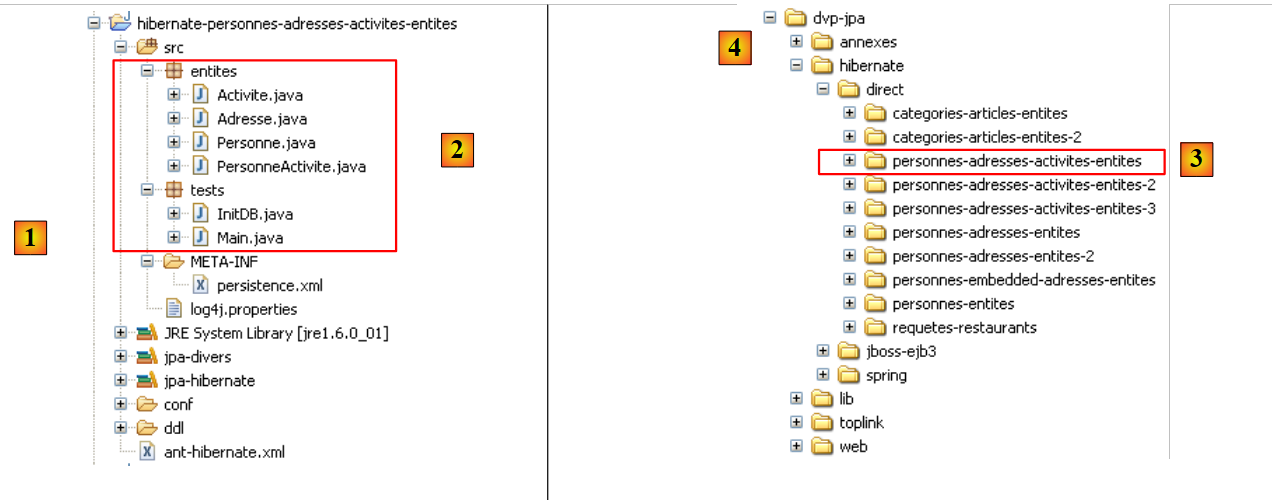
In [1], the Eclipse project; in [2], the Java code. The project is located in [3] within the examples folder [4]. We will import it.
2.5.4. Generating the Database DDL
Following the instructions in section 2.1.7, the DDL generated for the MySQL5 DBMS is as follows:
alter table jpa07_hb_personne
drop
foreign key FKB5C817D45FE379D0;
alter table jpa07_hb_personne_activite
drop
foreign key FKD3E49B06CD852024;
alter table jpa07_hb_personne_activite
drop
foreign key FKD3E49B0668C7A284;
drop table if exists jpa07_hb_activite;
drop table if exists jpa07_hb_adresse;
drop table if exists jpa07_hb_personne;
drop table if exists jpa07_hb_personne_activite;
create table jpa07_hb_activite (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_adresse (
id bigint not null auto_increment,
version integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adresse_id bigint not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_personne_activite (
PERSONNE_ID bigint not null,
ACTIVITE_ID bigint not null,
primary key (PERSONNE_ID, ACTIVITE_ID)
) ENGINE=InnoDB;
alter table jpa07_hb_personne
add index FKB5C817D45FE379D0 (adresse_id),
add constraint FKB5C817D45FE379D0
foreign key (adresse_id)
references jpa07_hb_adresse (id);
alter table jpa07_hb_personne_activite
add index FKD3E49B06CD852024 (ACTIVITE_ID),
add constraint FKD3E49B06CD852024
foreign key (ACTIVITE_ID)
references jpa07_hb_activite (id);
alter table jpa07_hb_personne_activite
add index FKD3E49B0668C7A284 (PERSONNE_ID),
add constraint FKD3E49B0668C7A284
foreign key (PERSONNE_ID)
references jpa07_hb_personne (id);
- lines 21-26: the [activity] table
- lines 28-39: the [address] table
- lines 41-51: the [person] table
- lines 53-57: the join table [person_activity]. Note the composite key (line 56)
- lines 59-63: the foreign key from the [person] table to the [address] table
- lines 65-69: the foreign key from the [person_activity] table to the [activity] table
- lines 71-75: the foreign key from the [person_activity] table to the [person] table
2.5.5. InitDB
The code for [InitDB] is as follows:
package tests;
...
public class InitDB {
// constant
private final static String TABLE_PERSONNE_ACTIVITE = "jpa07_hb_personne_activite";
private final static String TABLE_PERSONNE = "jpa07_hb_personne";
private final static String TABLE_ACTIVITE = "jpa07_hb_activite";
private final static String TABLE_ADRESSE = "jpa07_hb_adresse";
public static void main(String[] args) throws ParseException {
// Persistence context
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// we retrieve a EntityManager from the EntityManagerFactory
// previous
em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// request
Query sql1;
// delete elements from the PERSONNE_ACTIVITE table
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE_ACTIVITE);
sql1.executeUpdate();
// delete elements from the PERSONNE table
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE);
sql1.executeUpdate();
// delete elements from the ACTIVITE table
sql1 = em.createNativeQuery("delete from " + TABLE_ACTIVITE);
sql1.executeUpdate();
// delete elements from the ADRESSE table
sql1 = em.createNativeQuery("delete from " + TABLE_ADRESSE);
sql1.executeUpdate();
// creation activities
Activite act1 = new Activite();
act1.setNom("act1");
Activite act2 = new Activite();
act2.setNom("act2");
Activite act3 = new Activite();
act3.setNom("act3");
// persistence activities
em.persist(act1);
em.persist(act2);
em.persist(act3);
// creating people
Personne p1 = new Personne("p1", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("p2", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
Personne p3 = new Personne("p3", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// address creation
Adresse adr1 = new Adresse("adr1", null, null, "49000", "Angers", null, "France");
Adresse adr2 = new Adresse("adr2", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
Adresse adr3 = new Adresse("adr3", "x", "x", "x", "x", "x", "x");
Adresse adr4 = new Adresse("adr4", "y", "y", "y", "y", "y", "y");
// associations person <--> address
p1.setAdresse(adr1);
adr1.setPersonne(p1);
p2.setAdresse(adr2);
adr2.setPersonne(p2);
p3.setAdresse(adr3);
adr3.setPersonne(p3);
// persistence of persons and therefore of associated addresses
em.persist(p1);
em.persist(p2);
em.persist(p3);
// persistence of a4 address not linked to a person
em.persist(adr4);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// address display
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
System.out.println("[activites]");
for (Object a : em.createQuery("select a from Activite a").getResultList()) {
System.out.println(a);
}
// associations person <-->activity
PersonneActivite p1act1 = new PersonneActivite(p1, act1);
PersonneActivite p1act2 = new PersonneActivite(p1, act2);
PersonneActivite p2act1 = new PersonneActivite(p2, act1);
PersonneActivite p2act3 = new PersonneActivite(p2, act3);
// persistence of person <--> activity associations
em.persist(p1act1);
em.persist(p1act2);
em.persist(p2act1);
em.persist(p2act3);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// address display
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
System.out.println("[activites]");
for (Object a : em.createQuery("select a from Activite a").getResultList()) {
System.out.println(a);
}
System.out.println("[personnes/activites]");
for (Object pa : em.createQuery("select pa from PersonneActivite pa").getResultList()) {
System.out.println(pa);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
// log
System.out.println("terminé...");
}
}
- lines 27-38: the tables [person_activity], [person], [address], and [activity] are emptied. Note that we must start with the tables that have foreign keys.
- lines 40-45: we create three activities: act1, act2, and act3
- lines 47–49: they are placed in the persistence context.
- lines 51-53: three people, p1, p2, and p3, are created.
- Lines 55–58: Four addresses (adr1 through adr4) are created.
- Lines 60–65: The addresses adr1–adr4 are associated with the people p1–p3. There are two operations to perform each time because the Person <-> Address relationship is bidirectional.
- lines 67–69: the persons p1 through p3 are placed in the persistence context. Due to the Person -> Address cascade, this will also be the case for the addresses adr1 through adr3.
- Line 71: The fourth address, adr4, which is not associated with a person, is explicitly placed in the persistence context.
- Lines 73–85: The persistence context is queried to retrieve the lists of entities of type [Person], [Address], and [Activity]. We know that these queries will trigger the synchronization of the context with the database: the created entities will be inserted into the database and assigned their primary keys. It is important to understand this for what follows.
- Lines 87–90: We create four Person <-> Activity associations. Their names indicate which person is linked to which activity. You may recall that the primary key of a PersonActivity entity is a composite key consisting of the primary keys of a Person and an Activity. This operation is possible because the Person and Activity entities obtained their primary keys during a previous synchronization.
- Lines 92–95: These 4 associations are added to the persistence context.
- Lines 87–86: The persistence context is queried to retrieve the lists of entities of type [Person], [Address], [Activity], and [PersonActivity]. We know that these queries will trigger the synchronization of the context with the database: the created PersonActivity entities will be inserted into the database.
Running [InitDB] with MySQL5 produces the following console output:
It may be surprising to see that in lines 15–16, the version numbers for people p1 and p2 are 1, and that the same is true in lines 24–26 for the three activities. Let’s try to understand.
In lines 2–4, the version numbers for persons are 0, and in lines 11–13, the version numbers for activities are 0. These displays occur before the Person <-> Activity relationships are created. Lines 87–90 of the Java code create relationships between persons p1 and p2 and activities act1, act2, and act3. These are created using the @Entity PersonneActivite constructor (see Section 2.5.2). Reading the code for this constructor shows that when a person p is linked to an activity a:
- activity a is added to the set p.activities
- person p is added to the set a.personnes
Thus, when we write new PersonneActivite(p, a)*, the person p and the activity a undergo a modification in memory. When lines 97–113 of [InitDB] are executed, the persistence context is synchronized with the database, and JPA/Hibernate detects that the persistent entities p1, p2, act1, act2, and act3* have been modified. These changes must be made in the database. They are actually written to the join table [person_activity], but JPA/Hibernate still increments the version number of each modified persistent entity.
In the SQL Explorer view, the results are as follows:
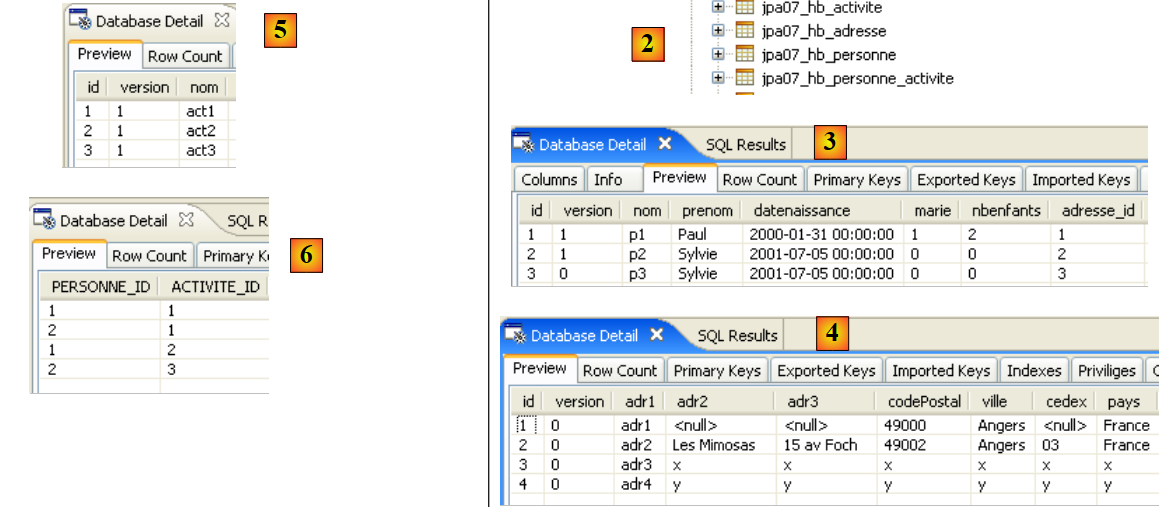 |
- [2]: the [jpa07_hb_*]
- [3]: the people table
- [4]: the addresses table.
- [5]: the activities table
- [6]: the person <-> activity join table
2.5.6. Main
The [Main] class runs a series of tests that we go through, except for test 1, which uses the code from [InitDB] to initialize the database.
2.5.6.1. Test2
This test is as follows:
// suppression Personne p1
public static void test2() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// suppression dépendances sur p1 : pas nécessaire à hibernate mais
// indispensable à toplink
act1.getPersonnes().remove(p1act1);
act2.getPersonnes().remove(p1act2);
// suppression personne p1
em.remove(p1);
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- Line 4: We use the persistence context of test1, where person p1 is an object in the context.
- line 13: deletion of person p1. Because of the attribute:
- cascadeType.ALL on Address, the address associated with person p1 will be deleted
- cascadeType.REMOVE on PersonActivity, the activities of person p1 will be deleted.
- Lines 10–11: We remove the dependencies that other entities have on person p1, who will be deleted on line 13. Activities act1 and act2 are performed by person p1. The links were created by the PersonActivity entity constructor, whose code is as follows:
public PersonneActivite(Personne p, Activite a) {
// les clés étrangères sont fixées par l'application
getId().setPersonneId(p.getId());
getId().setActiviteId(a.getId());
// associations bidirectionnelles
setPersonne(p);
setActivite(a);
p.getActivites().add(this);
a.getPersonnes().add(this);
}
On line 9, activity a receives an additional element of type PersonActivity in its persons collection. This element is of type (p,a) to indicate that person p participates in activity a. In test1 within [Main], two links (p1,act1) and (p1,act2) were created in this way. Lines 10 and 11 of test2 remove these dependencies. Note that Hibernate works without removing these dependencies on person p1, but Toplink does not.
- Lines 17–20: all tables are displayed
The results are as follows:
- Person p1, who is present in test1 (line 3), is no longer present at the end of test2 (lines 22–23)
- The address adr1 of person p1, present in test1 (line 11), is no longer present after test2 (lines 29–31)
- the activities (p1,act1) (line 16) and (p1,act2) (line 18) of person p1, present in test1, are no longer present at the end of test2 (lines 33-34)
2.5.6.2. Test3
This test is as follows:
// suppression activite act1
public static void test3() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// suppression dépendances sur act1 : pas nécessaire à hibernate mais
// indispensable à toplink
p2.getActivites().remove(p2act1);
// suppression activité act1
em.remove(act1);
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- Line 4: We use the persistence context of test2
- line 12: deletion of activity act1. Because of the attribute:
- cascadeType.REMOVE on PersonneActivite, the rows (p, act1) in the [personne_activite] table will be deleted.
- Line 10: Before removing act1 from the persistence context, we remove any dependencies that other entities may have on this persistent object. After deleting person p1 in the previous test, only person p2 performs activity act1.
- Lines 13–16: All tables are displayed
The results are as follows:
- In test2, activity act1 exists (line 6). In test3, it no longer exists (lines 21-22)
- In test2, the link (p2,act1) exists (line 14). In test3, it no longer exists (line 28)
2.5.6.3. Test4
This test is as follows:
// récupération activités d'une personne
public static void test4() {
// contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on récupère la personne p2
p2 = em.find(Personne.class, p2.getId());
System.out.format("1 - Activités de la personne p2 (JPQL) :%n");
// on scanne ses activités
for (Object pa : em.createQuery("select a.nom from Activite a join a.personnes pa where pa.personne.nom='p2'").getResultList()) {
System.out.println(pa);
}
// on passe par la relation inverse de p2
p2 = em.find(Personne.class, p2.getId());
System.out.format("2 - Activités de la personne p2 (relation inverse) :%n");
// on scanne ses activités
for (PersonneActivite pa : p2.getActivites()) {
System.out.println(pa.getActivite().getNom());
}
// fin transaction
tx.commit();
}
- Test 4 displays the activities of person p2.
- line 4: we start with a new, empty context
- lines 12–14: we display the names of the activities performed by person p2 using a JPQL query.
- A join between Activity (a) and PersonActivity (pa) is performed (join a.people)
- In the rows of this join (a, pa), we display the activity name (a.name) for person p2 (pa.person.name='p2').
- Lines 16–21: We do the same as before, but using the OneToMany relationship p2.activites of person p2. The JPQL query will be generated by JPA. Here we see the benefit of the inverse OneToMany relationship: it avoids a JPQL query.
The results are as follows:
2.5.6.4. Test5
This test is as follows:
// récupération personnes faisant une activité donnée
public static void test5() {
// contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
System.out.format("1 - Personnes pratiquant l'activité act3 (JPQL) :%n");
// on demande les activités de p2
for (Object pa : em.createQuery("select p.nom from Personne p join p.activites pa where pa.activite.nom='act3'").getResultList()) {
System.out.println(pa);
}
// on passe par la relation inverse de act3
System.out.format("2 - Personnes pratiquant l'activité act3 (relation inverse) :%n");
act3 = em.find(Activite.class, act3.getId());
for (PersonneActivite pa : act3.getPersonnes()) {
System.out.println(pa.getPersonne().getNom());
}
// fin transaction
tx.commit();
}
- Test 6 displays the people performing activity act3. The approach is similar to that of Test 6. We leave it to the reader to draw the connection between the two code snippets.
The results are as follows:
Tests 4 and 5 were intended to demonstrate once again that a reverse relationship is never essential and can always be replaced by a JPQL query.
2.5.7. JPA / Toplink Implementation
We are now using a JPA / Toplink implementation:
 |
The Eclipse project with Toplink is a copy of the Eclipse project with Hibernate:
 |
The Java code is identical to that of the previous Hibernate project, with a few minor differences that we will discuss. The environment (libraries – persistence.xml – DBMS – conf and ddl folders – Ant script) is the one described in section 2.1.15.2. The Eclipse project is available [3] in the examples folder [4]. We will import it.
The <persistence.xml> file [2] has been modified in one respect: the declared entities:
<!-- classes persistantes -->
<class>entites.Activite</class>
<class>entites.Adresse</class>
<class>entites.Personne</class>
<class>entites.PersonneActivite</class>
- Lines 2–5: the four managed entities
Running [InitDB] with the MySQL5 DBMS yields the following results:
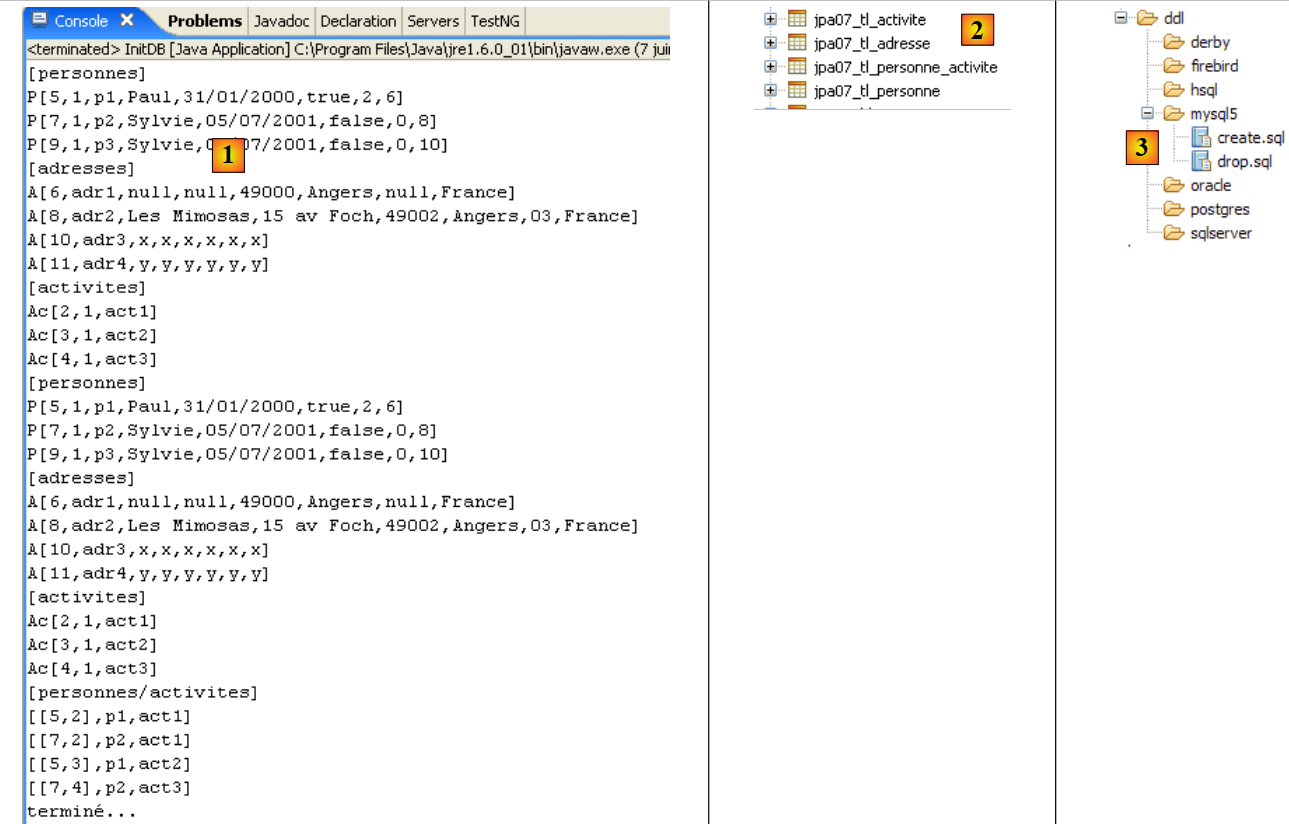 |
In [1], the console output; in [2], the generated [jpa07_tl] tables; in [3], the generated SQL scripts. Their contents are as follows:
create.sql
CREATE TABLE jpa07_tl_activite (ID BIGINT NOT NULL, VERSION INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa07_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, VERSION INTEGER NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR2 VARCHAR(30), CEDEX VARCHAR(3), ADR1 VARCHAR(30) NOT NULL, PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa07_tl_personne_activite (PERSONNE_ID BIGINT NOT NULL, ACTIVITE_ID BIGINT NOT NULL, PRIMARY KEY (PERSONNE_ID, ACTIVITE_ID))
CREATE TABLE jpa07_tl_personne (ID BIGINT NOT NULL, DATENAISSANCE DATE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, NBENFANTS INTEGER NOT NULL, VERSION INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa07_tl_personne_activite ADD CONSTRAINT FK_jpa07_tl_personne_activite_ACTIVITE_ID FOREIGN KEY (ACTIVITE_ID) REFERENCES jpa07_tl_activite (ID)
ALTER TABLE jpa07_tl_personne_activite ADD CONSTRAINT FK_jpa07_tl_personne_activite_PERSONNE_ID FOREIGN KEY (PERSONNE_ID) REFERENCES jpa07_tl_personne (ID)
ALTER TABLE jpa07_tl_personne ADD CONSTRAINT FK_jpa07_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa07_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
The execution of [InitDB] and [Main] completes without errors.
2.6. Example 6: Many-to-many relationship with an implicit join table
We return to Example 4 but now handle it with an implicit join table generated by the JPA layer itself.
2.6.1. The database schema
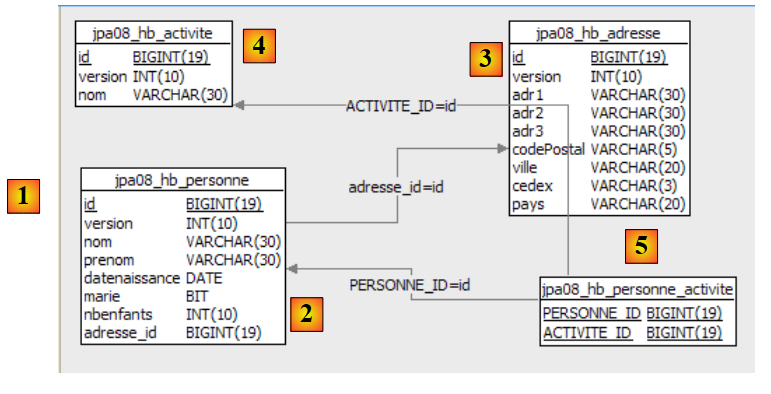 |
- in [1], the MySQL5 database – in [2]: the [person] table – in [3]: the associated [address] table – in [4]: the [activity] table for activities – in [5]: the join table [person_activity] that links people and activities.
2.6.2. The @Entity objects representing the database
The tables above will be represented by the following @Entity annotations:
- The @Entity Person will represent the [person] table
- the @Entity Address will represent the [address] table
- the @Entity Activity will represent the [activity] table
- The [person_activity] table is no longer represented by an @Entity
The relationships between these entities are as follows:
- A one-to-one relationship links the Person entity to the Address entity: a person p has an address a. The Person entity holding the foreign key will be the primary entity, and the Address entity will be the inverse entity.
- A many-to-many relationship connects the Person and Activity entities: a person has multiple activities, and an activity is practiced by multiple people. This relationship will be implemented using a @ManyToMany annotation in each of the two entities, with one declared as the inverse of the other.
The @Entity Person is as follows:
@Entity
@Table(name = "jpa08_hb_personne")
public class Personne implements Serializable {
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
// toplink sqlserver :@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
// main relationship Person (one) -> Address (one)
// implemented by the foreign key Person(adresse_id) -> Address
// cascade insert Person -> insert Address
// cascade shift Person -> shift Address
// cascade deletion Person -> deletion Address
// a Person must have 1 Address (nullable=false)
// 1 Address belongs to 1 person only (unique=true)
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
// relationship Person (many) -> Activity (many) via a personne_activite join table
// personne_activite(PERSONNE_ID) is a foreign key on Person(id)
// personne_activite(ACTIVITE_ID) is a foreign key on Activite(id)
// cascade=CascadeType.PERSIST: persistence of 1 person leads to persistence of their activities
@ManyToMany(cascade={CascadeType.PERSIST})
@JoinTable(name="jpa08_hb_personne_activite",joinColumns = @JoinColumn(name = "PERSONNE_ID"), inverseJoinColumns = @JoinColumn(name = "ACTIVITE_ID"))
private Set<Activite> activites = new HashSet<Activite>();
// manufacturers
public Personne() {
}
We will only comment on the @ManyToMany relationship in lines 46–48, which links the @Entity Person to the @Entity Activity:
- line 48: a person has activities. The activities field will represent these. In the previous version, the type of the elements in the activities set was PersonActivity. Here, it is Activity. We therefore access a person’s activities directly, whereas in the previous version we had to go through the intermediate PersonActivity entity.
- Line 46: The relationship linking the @Entity Person we are examining to the @Entity Activity in the activities set on line 48 is of the many-to-many (ManyToMany) type:
- one person (One) has multiple activities (Many)
- one activity (One) is practiced by several people (Many)
- Ultimately, the @Entity Person and Activity are linked by a ManyToMany relationship. As with the OneToOne relationship, the entities in this relationship are symmetrical. We can freely choose which @Entity will hold the primary relationship and which will hold the inverse relationship. Here, we decide that the @Entity Person will hold the primary relationship.
- As we saw in the previous example, the @ManyToMany relationship requires a join table. Whereas previously we defined this using an @Entity, the join table here is defined using the @JoinTable annotation on line 47.
- The name attribute gives the table a name.
- The join table consists of the foreign keys from the tables it joins. Here, there are two foreign keys: one from the [person] table, the other from the [activity] table. These foreign key columns are defined by the joinColumns and inverseJoinColumns attributes.
- The @JoinColumn annotation on the joinColumns attribute defines the foreign key on the table of the @Entity holding the primary @ManyToMany relationship, here the [person] table. This foreign key column will be named PERSON_ID.
- The @JoinColumn annotation of the inverseJoinColumns attribute defines the foreign key on the table of the @Entity holding the inverse @ManyToMany relationship, in this case the [activity] table. This foreign key column will be named ACTIVITY_ID.
The @Entity Address is as follows:
@Entity
@Table(name = "jpa07_hb_adresse")
public class Adresse implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse")
private Personne personne;
- Lines 28-29: the @OneToOne relationship that is the inverse of the @OneToOne address relationship of the @Entity Person (lines 37-38 of Person).
The @Entity Activity is as follows
@Entity
@Table(name = "jpa08_hb_activite")
public class Activite implements Serializable {
// fields
@Id()
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
// toplink sqlserver : @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
// inverse relationship Activity -> Person
@ManyToMany(mappedBy = "activites")
private Set<Personne> personnes = new HashSet<Personne>();
...
- Lines 20–21: The many-to-many relationship linking the @Entity Activity to the @Entity Person. This relationship has already been defined in the @Entity Person. Here, we simply specify that the relationship is the inverse (mappedBy) of the existing @ManyToMany relationship on the activites field (mappedBy="activites") of the @Entity Person.
- Remember that a reverse relationship is always optional. Here, we use it to retrieve the people participating in the current activity. The Set<Person> people collection will be used to retrieve them. The loading mode for the Person dependencies of the @Entity Activity is not specified. We did not specify it in the previous example either. By default, this mode is fetch=FetchType.LAZY.
We have finished describing the database entities. This was simpler than in the case where the join table [person_activity] is an explicit table. This simpler solution may present drawbacks over time: it does not allow adding columns to the join table. This may, however, prove necessary to meet new requirements, such as adding a column to the [person_activity] table indicating the date the person registered for the activity.
2.6.3. The Eclipse / Hibernate Project
The JPA implementation used here is Hibernate. The Eclipse project for the tests is as follows:
 |
In [1], the Eclipse project; in [2], the Java code. The project is located in [3] within the examples folder [4]. We will import it.
2.6.4. Generating the Database DDL
Following the instructions in section 2.1.7, the DDL generated for the MySQL5 DBMS is as follows:
alter table jpa08_hb_personne
drop
foreign key FKA44B1E555FE379D0;
alter table jpa08_hb_personne_activite
drop
foreign key FK5A6A55A5CD852024;
alter table jpa08_hb_personne_activite
drop
foreign key FK5A6A55A568C7A284;
drop table if exists jpa08_hb_activite;
drop table if exists jpa08_hb_adresse;
drop table if exists jpa08_hb_personne;
drop table if exists jpa08_hb_personne_activite;
create table jpa08_hb_activite (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_adresse (
id bigint not null auto_increment,
version integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adresse_id bigint not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_personne_activite (
PERSONNE_ID bigint not null,
ACTIVITE_ID bigint not null,
primary key (PERSONNE_ID, ACTIVITE_ID)
) ENGINE=InnoDB;
alter table jpa08_hb_personne
add index FKA44B1E555FE379D0 (adresse_id),
add constraint FKA44B1E555FE379D0
foreign key (adresse_id)
references jpa08_hb_adresse (id);
alter table jpa08_hb_personne_activite
add index FK5A6A55A5CD852024 (ACTIVITE_ID),
add constraint FK5A6A55A5CD852024
foreign key (ACTIVITE_ID)
references jpa08_hb_activite (id);
alter table jpa08_hb_personne_activite
add index FK5A6A55A568C7A284 (PERSONNE_ID),
add constraint FK5A6A55A568C7A284
foreign key (PERSONNE_ID)
references jpa08_hb_personne (id);
This DDL is analogous to that obtained with the explicit join table and corresponds to the schema already presented:
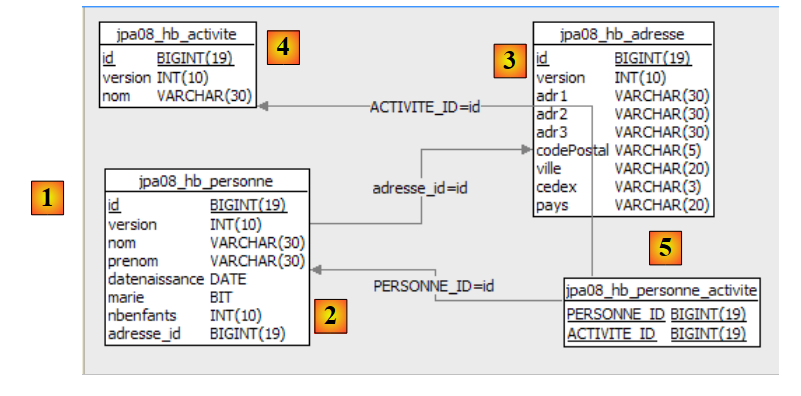 |
2.6.5. InitDB
We will not comment much on the [InitDB] class, which is identical to its previous version and yields the same results. Instead, let’s focus on the following code that displays the Person <-> Activity join:
// people/activities display
System.out.println("[personnes/activites]");
Iterator iterator = em.createQuery("select p.id,a.id from Personne p join p.activites a").getResultList().iterator();
while (iterator.hasNext()) {
Object[] row = (Object[]) iterator.next();
System.out.format("[%d,%d]%n", (Long) row[0], (Long) row[1]);
}
- Line 3: The JPQL query that performs the join. The result of the SELECT statement returns the IDs of the Person and Activity entities linked by the join table. The list returned by the SELECT statement consists of rows containing two Long objects. To iterate over this list, line 3 requests an Iterator object for the list.
- Lines 4–7: Using the Iterator object from the previous line, the list is traversed.
- Line 5: Each element of the list is an array containing a row from the SELECT result
- Line 6: The elements of the current row resulting from the SELECT statement are retrieved by making the appropriate type conversions.
The result of [InitDB] is as follows:
2.6.6. Main
The [Main] class runs a series of tests, some of which we will review.
2.6.6.1. Test3
This test is as follows:
// suppression activite act1
public static void test3() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// suppression activité act1 de p2
p2.getActivites().remove(act1);
// on retire act1 du contexte de persistance
em.remove(act1);
// fin transactions
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- Line 11: Activity act1 is removed from the persistence context
- Line 9: The activity act1 is one of the activities of the only person remaining in the context, person p2. Line 9 removes the activity act1 from person p2’s activities. We do this to maintain the consistency of the persistence context, as we will be using it later.
The results are as follows:
- The activity act1 on line 26 in test2 has disappeared from the activities in test3 (lines 40-41)
- Person p2 had activity act1 in test2 (line 33). At the end of test3, they no longer have it (line 47)
2.6.6.2. Test6
This test is as follows:
// modification des activités d'une personne
public static void test6() {
// contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on récupère la personne p2
p2 = em.find(Personne.class, p2.getId());
// on récupère l'activité act2
act2 = em.find(Activite.class, act2.getId());
// p2 ne pratique plus que l'activité act2
p2.getActivites().clear();
p2.getActivites().add(act2);
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpActivite();
dumpPersonne_Activite();
}
- Line 4: A new, empty persistence context is used
- line 9: person p2 is retrieved from the database into the persistence context
- line 11: activity act2 is fetched from the database into the persistence context
- line 13: person p2’s activities (act3) are fetched from the database into the context (fetchType.LAZY). The [getActivites] call triggers this loading. We remove p2’s activities. This is not an actual removal of activities (remove) but a modification of person p2’s state. They no longer engage in any activities.
- Line 14: Activity act2 is added to person p2. Ultimately, the set of new activities for person p2 is the set {act2}.
- Line 16: End of the transaction. Synchronization will review the objects in the context (p2, act2, act3) and will detect that the state of p2 has changed. The SQL statements reflecting this change in the database will be executed.
- Lines 18–20: All tables are displayed
The results are as follows:
- At the end of test 4, person p2 was performing activity act3 (line 3).
- At the end of test 6 (line 19), person p2 is no longer performing activity act3 (line 3) and is performing activity act2.
2.6.7. JPA / Toplink Implementation
We are now using a JPA / Toplink implementation:
 |
The Eclipse project with Toplink is a copy of the Eclipse project with Hibernate:
 |
The <persistence.xml> file [2] has been modified in one place, specifically regarding the declared entities:
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- classes persistantes -->
<class>entites.Activite</class>
<class>entites.Adresse</class>
<class>entites.Personne</class>
...
- lines 4-6: the managed entities
Running [InitDB] with the MySQL5 DBMS yields the following results:
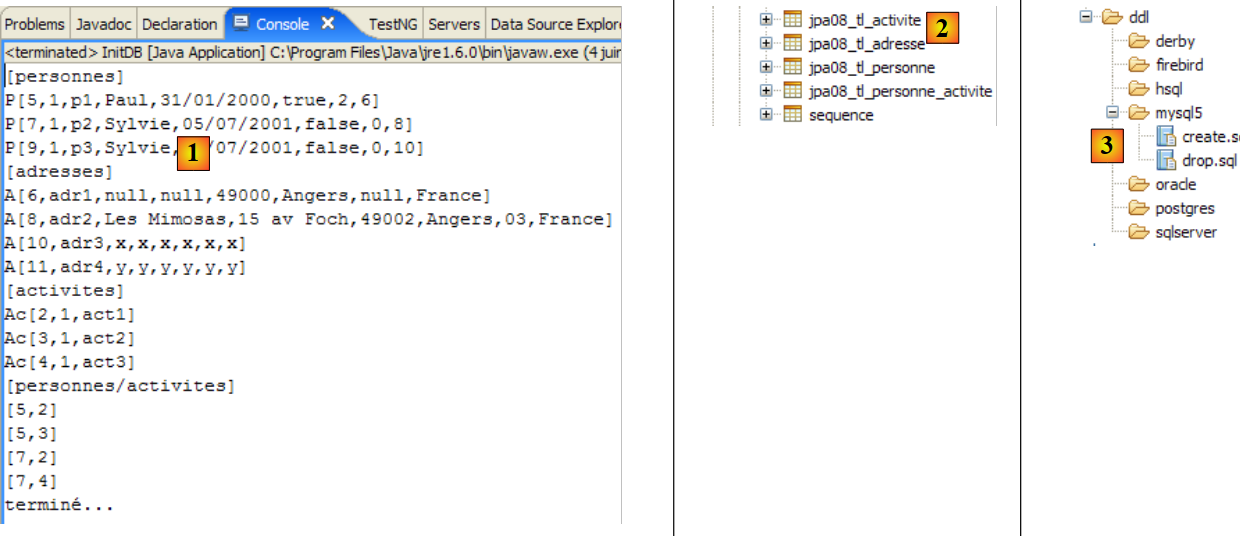 |
In [1], the console output; in [2], the generated [jpa07_tl] tables; in [3], the generated SQL scripts. Their content is as follows:
create.sql
CREATE TABLE jpa08_tl_personne_activite (PERSONNE_ID BIGINT NOT NULL, ACTIVITE_ID BIGINT NOT NULL, PRIMARY KEY (PERSONNE_ID, ACTIVITE_ID))
CREATE TABLE jpa08_tl_activite (ID BIGINT NOT NULL, VERSION INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa08_tl_personne (ID BIGINT NOT NULL, DATENAISSANCE DATE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, NBENFANTS INTEGER NOT NULL, VERSION INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa08_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, VERSION INTEGER NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR2 VARCHAR(30), CEDEX VARCHAR(3), ADR1 VARCHAR(30) NOT NULL, PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa08_tl_personne_activite ADD CONSTRAINT FK_jpa08_tl_personne_activite_ACTIVITE_ID FOREIGN KEY (ACTIVITE_ID) REFERENCES jpa08_tl_activite (ID)
ALTER TABLE jpa08_tl_personne_activite ADD CONSTRAINT FK_jpa08_tl_personne_activite_PERSONNE_ID FOREIGN KEY (PERSONNE_ID) REFERENCES jpa08_tl_personne (ID)
ALTER TABLE jpa08_tl_personne ADD CONSTRAINT FK_jpa08_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa08_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
The execution of [InitDB] and [Main] completes without errors.
2.6.8. The Eclipse / Hibernate 2 Project
We create an Eclipse project based on the previous one by copying it:
 |
In [1], the Eclipse project; in [2], the Java code. The project is located in [3] within the examples folder [4]. We will import it.
We modify the relationship linking Person to Activity as follows:
Person
// relation Personne (many) -> Activite (many) via une table de jointure personne_activite
// personne_activite(PERSONNE_ID) est clé étangère sur Personne(id)
// personne_activite(ACTIVITE_ID) est clé étangère sur Activite(id)
// plus de cascade sur les activités
// @ManyToMany(cascade={CascadeType.PERSIST})
@ManyToMany()
@JoinTable(name = "jpa09_hb_personne_activite", joinColumns = @JoinColumn(name = "PERSONNE_ID"), inverseJoinColumns = @JoinColumn(name = "ACTIVITE_ID"))
private Set<Activite> activites = new HashSet<Activite>();
- Line 6: The primary @ManyToMany relationship no longer has a Person -> Activity persistence cascade (see previous version, line 5)
Activity
// plus de relation inverse avec Personne
// @ManyToMany(mappedBy = "activites")
// private Set<Personne> personnes = new HashSet<Personne>();
- Lines 2-3: The inverse @ManyToMany relationship Activity -> Person has been removed
We aim to demonstrate that the removed attributes (cascade and inverse relationship) are not essential. The first change introduced by this new configuration is found in [InitDB]:
// associations personnes <--> activites
p1.getActivites().add(act1);
p1.getActivites().add(act2);
p2.getActivites().add(act1);
p2.getActivites().add(act3);
// persistance des activites
em.persist(act1);
em.persist(act2);
em.persist(act3);
// persistance des personnes
em.persist(p1);
em.persist(p2);
em.persist(p3);
// et de l'adresse a4 non liée à une personne
em.persist(adr4);
- lines 7–9: we are required to explicitly place activities act1 through act3 in the persistence context. When the Person -> Activity persistence cascade existed, lines 11–13 persisted both persons p1 through p3 and those persons’ activities act1 through act3.
A second change is visible in [Main]:
// récupération personnes faisant une activité donnée
public static void test5() {
// contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
System.out.format("1 - Personnes pratiquant l'activité act3 (JPQL) :%n");
// on demande les activités de p2
for (Object pa : em.createQuery("select p.nom from Personne p join p.activites a where a.nom='act3'").getResultList()) {
System.out.println(pa);
}
// fin transaction
tx.commit();
}
- lines 9-12: the JPQL query retrieving the people participating in activity act3
- In the previous version, the same result was also obtained via the inverse relationship Activity -> Person, which has now been removed:
// we use the inverse relationship of act3
System.out.format("2 - Personnes pratiquant l'activité act3 (relation inverse) :%n");
act3 = em.find(Activite.class, act3.getId());
for (Personne p : act3.getPersonnes()) {
System.out.println(p.getNom());
}
2.6.9. The Eclipse / Toplink 2 Project
We are creating an Eclipse project based on the previous Eclipse / Toplink project by copying it:
 |
In [1], the Eclipse project; in [2], the Java code. The project is located in [3] in the examples folder [4]. We will import it.
The Java code is identical to that of the Hibernate version.
2.7. Example 7: Using Named Queries
We conclude this lengthy overview of JPA entities, which began in paragraph 2, with one final example that demonstrates the use of JPQL queries externalized in a configuration file. This example is taken from the following source:
[ref2]: "Getting Started With JPA in Spring 2.0" by Mark Fisher at the URL
[http://blog.springframework.com/markf/archives/2006/05/30/getting-started-with-jpa-in-spring-20/].
2.7.1. The sample database
The database is as follows:
 |
- in [1]: a list of restaurants with their names and addresses
- in [2]: the table of restaurant addresses, limited to the street number and street name. There is a one-to-one relationship between the restaurant and address tables: a restaurant has one and only one address.
- in [3]: a table of dishes with their names and a true/false flag indicating whether the dish is vegetarian or not
- in [4]: the restaurant/dish join table: a restaurant serves multiple dishes, and the same dish can be served by multiple restaurants. There is a many-to-many relationship between the restaurant and dish tables.
2.7.2. The @Entity objects representing the database
The tables above will be represented by the following @Entities:
- the @Entity Restaurant will represent the [restaurant] table
- the @Entity Address will represent the [address] table
- the @Entity Dish will represent the [dish] table
The relationships between these entities are as follows:
- A one-to-one relationship links the Restaurant entity to the Address entity: a restaurant r has an address a. The Restaurant entity, which holds the foreign key, will be the primary entity. The Address entity will not have a reverse relationship.
- A many-to-many relationship connects the Restaurant and Dish entities: a restaurant serves multiple dishes, and the same dish can be served by multiple restaurants. This relationship will be implemented using a @ManyToMany annotation in the Restaurant entity. The Dish entity will not have a reverse relationship.
The @Entity Restaurant is as follows:
package entites;
...
@Entity
@Table(name = "jpa10_hb_restaurant")
public class Restaurant implements java.io.Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(unique = true, length = 30, nullable = false)
private String nom;
@OneToOne(cascade = CascadeType.ALL)
private Adresse adresse;
@ManyToMany(cascade = { CascadeType.PERSIST, CascadeType.MERGE })
@JoinTable(name = "jpa10_hb_restaurant_plat", inverseJoinColumns = @JoinColumn(name = "plat_id"))
private Set<Plat> plats = new HashSet<Plat>();
// manufacturers
public Restaurant() {
}
public Restaurant(String name, Adresse address, Set<Plat> entrees) {
...
}
// getters and setters
...
// toString
public String toString() {
String signature = "R[" + getNom() + "," + getAdresse();
for (Plat e : getPlats()) {
signature += "," + e;
}
return signature + "]";
}
}
- Line 17: The one-to-one relationship between the Restaurant entity and the Address entity. All persistence operations on a restaurant are cascaded to its address.
- line 20: the relationship linking the @Entity Restaurant to the @Entity Dish in the dishes collection on line 22 is of the many-to-many (ManyToMany) type:
- a restaurant (One) has multiple dishes (Many)
- a dish (One) can be served by multiple restaurants (Many)
- Ultimately, the @Entity Restaurant and @Entity Dish are linked by a ManyToMany relationship. We decide that the @Entity Restaurant will be the primary relationship and that the @Entity Dish will not have a reverse relationship.
- The @ManyToMany relationship requires a join table. This is defined using the @JoinTable annotation on line 47.
- The name attribute gives the table a name.
- The join table consists of the foreign keys from the tables it joins. Here, there are two foreign keys: one from the [restaurant] table and the other from the [dish] table. These foreign key columns are defined by the joinColumns and inverseJoinColumns attributes.
- The joinColumns attribute defines the foreign key on the table of the @Entity holding the primary @ManyToMany relationship, in this case the [restaurant] table. The joinColumns attribute is missing here. JPA has a default value in this case: [table]_[table_primary_key], here [jpa10_hb_restaurant_id].
- The @JoinColumn annotation for the inverseJoinColumns attribute defines the foreign key on the table of the @Entity holding the inverse @ManyToMany relationship, in this case the [dish] table. This foreign key column will be named dish_id.
The @Entity Address is as follows:
package entites;
...
@Entity
@Table(name="jpa10_hb_adresse")
public class Adresse implements java.io.Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(name = "NUMERO_RUE")
private int numeroRue;
@Column(name = "NOM_RUE", length=30, nullable=false)
private String nomRue;
// getters and setters
...
// manufacturers
public Adresse(int streetNumber, String streetName){
...
}
public Adresse(){
}
// toString
public String toString(){
return "A["+getNumeroRue()+","+getNomRue()+"]";
}
}
- The @Entity Address is an entity with no direct relationship to other entities. It can only be persisted through a Restaurant entity.
- An address is defined by a street name (line 16) and a house number (line 13).
The @Entity Dish is as follows
package entites;
...
@Entity
@Table(name="jpa10_hb_plat")
public class Plat implements java.io.Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(unique=true, length=50, nullable=false)
private String nom;
private boolean vegetarien;
// manufacturers
public Plat() {
}
public Plat(String name, boolean vegetarian) {
...
}
// getters and setters
...
// toString
public String toString() {
return "E[" + getNom() + "," + isVegetarien() + "]";
}
}
- The @Entity Dish is an entity with no direct relationship to other entities. It can only be persisted through a Restaurant entity.
- A dish is defined by a name (line 12) and whether it is vegetarian or not (line 14).
2.7.3. The Eclipse / Hibernate Project
The JPA implementation used here is Hibernate. The Eclipse test project is as follows:
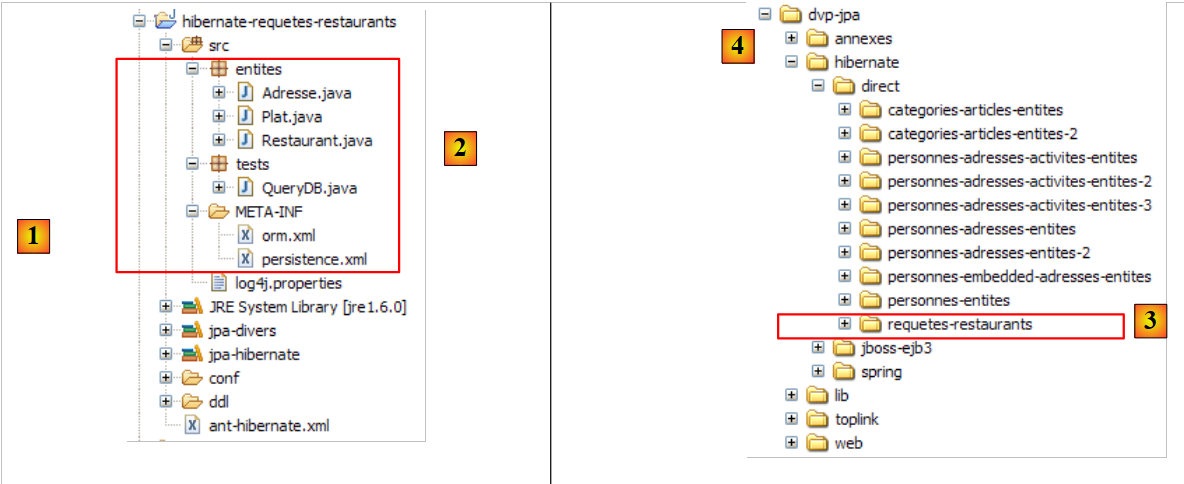 |
In [1], the Eclipse project; in [2], the Java code and the JPA layer configuration. Note the presence of an [orm.xml] file, which we have not encountered before. The project is located in [3] within the examples folder [4]. We will import it.
2.7.4. Generating the Database DDL
Following the instructions in section 2.1.7, the resulting DDL for the MySQL5 DBMS is as follows:
alter table jpa10_hb_restaurant
drop
foreign key FK3E8E4F5D5FE379D0;
alter table jpa10_hb_restaurant_plat
drop
foreign key FK1D2D06D11F0F78A4;
alter table jpa10_hb_restaurant_plat
drop
foreign key FK1D2D06D1AFAC3E44;
drop table if exists jpa10_hb_adresse;
drop table if exists jpa10_hb_plat;
drop table if exists jpa10_hb_restaurant;
drop table if exists jpa10_hb_restaurant_plat;
create table jpa10_hb_adresse (
id bigint not null auto_increment,
NUMERO_RUE integer,
NOM_RUE varchar(30) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_plat (
id bigint not null auto_increment,
nom varchar(50) not null unique,
vegetarien bit not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_restaurant (
id bigint not null auto_increment,
nom varchar(30) not null unique,
adresse_id bigint,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_restaurant_plat (
jpa10_hb_restaurant_id bigint not null,
plat_id bigint not null,
primary key (jpa10_hb_restaurant_id, plat_id)
) ENGINE=InnoDB;
alter table jpa10_hb_restaurant
add index FK3E8E4F5D5FE379D0 (adresse_id),
add constraint FK3E8E4F5D5FE379D0
foreign key (adresse_id)
references jpa10_hb_adresse (id);
alter table jpa10_hb_restaurant_plat
add index FK1D2D06D11F0F78A4 (plat_id),
add constraint FK1D2D06D11F0F78A4
foreign key (plat_id)
references jpa10_hb_plat (id);
alter table jpa10_hb_restaurant_plat
add index FK1D2D06D1AFAC3E44 (jpa10_hb_restaurant_id),
add constraint FK1D2D06D1AFAC3E44
foreign key (jpa10_hb_restaurant_id)
references jpa10_hb_restaurant (id);
- lines 21-26: the [address] table
- lines 28-33: the [dish] table
- lines 35-40: the [restaurant] table
- lines 42-46: the join table [restaurant_dish]. Note the composite key (line 45)
- lines 48-52: the foreign key from the [restaurant] table to the [address] table
- lines 54–58: the foreign key from the [restaurant_dish] table to the [dish] table
- Lines 60–64: the foreign key from the [restaurant_dish] table to the [restaurant] table
This DDL corresponds to the schema already presented:
 |
In the SQL Explorer view, the database appears as follows:
 |
- in [1]: the database’s 4 tables
- at [2]: the addresses
- at [3]: the dishes
- at [4]: the restaurants. [address_id] references the addresses from [2].
- in [5]: the join table [restaurant,dish]. [jpa10_hb_restaurant_id] references the restaurants in [4] and [dish_id] references the dishes in [3]. Thus, [1,1] means that the restaurant "Burger Barn" serves the dish "CheeseBurger".
To retrieve the data above, the [QueryDB] program from the Eclipse project was executed.
2.7.5. JPQL Queries with a Hibernate Console
We create a Hibernate console linked to the previous Eclipse project. We will follow the procedure already outlined twice, notably in section 2.1.12.
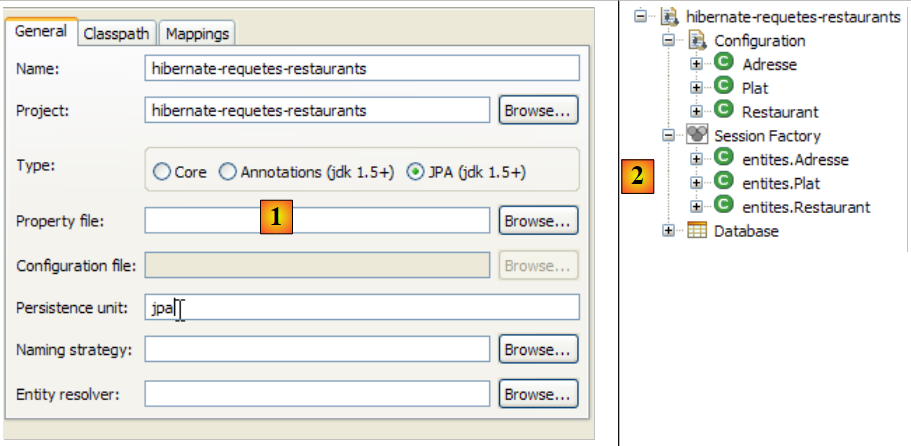 |
- In [1] and [2]: the configuration of the Hibernate console
 |
- in [3]: a JPQL query and in [4] the result.
- in [5]: the equivalent SQL statement
We will now present a series of JPQL queries. The reader is invited to run them and discover the SQL statement generated by Hibernate to execute them.
Get all restaurants with their dishes:
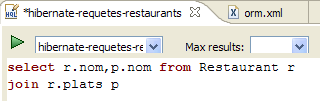 | 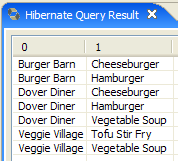 |
Get restaurants serving at least one vegetarian dish:
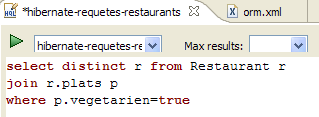 |  |
Get the names of restaurants that serve only vegetarian dishes:
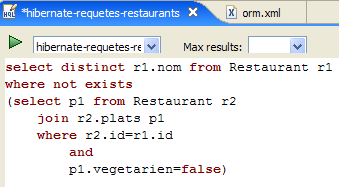 | 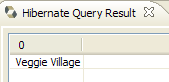 |
Get the restaurants that serve burgers:
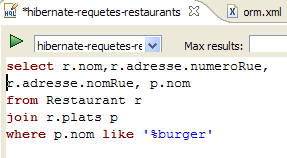 | 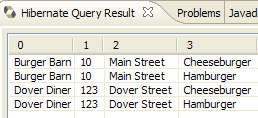 |
2.7.6. QueryDB
We will now look at the [QueryDB] program from the Eclipse project, which:
- populates the database
- and executes a number of JPQL queries on it. These are stored in the [META-INF/orm.xml] file of the Eclipse project:
 |
The [orm.xml] file can be used to configure the JPA layer instead of Java annotations. This provides flexibility in configuring the JPA layer. It can be modified without recompiling the Java code or the [ . JPA configuration is first set up using Java annotations and then using the [orm.xml] file. Therefore, if you want to modify a configuration defined by a Java annotation without recompiling, simply place that configuration in [orm.xml]. It will take precedence.
In our example, the [orm.xml] file is used to store JPQL query texts. Its content is as follows:
<?xml version="1.0" encoding="UTF-8" ?>
<entity-mappings xmlns="http://java.sun.com/xml/ns/persistence/orm" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence/orm http://java.sun.com/xml/ns/persistence/orm_1_0.xsd" version="1.0">
<description>Restaurants</description>
<named-query name="supprimer le contenu de la table restaurant">
<query>delete from Restaurant</query>
</named-query>
<named-query name="supprimer le contenu de la table plat">
<query>delete from Plat</query>
</named-query>
<named-query name="obtenir tous les restaurants">
<query>select r from Restaurant r order by r.nom asc</query>
</named-query>
<named-query name="obtenir toutes les adresses">
<query>select a from Adresse a order by a.nomRue asc</query>
</named-query>
<named-query name="obtenir tous les plats">
<query>select p from Plat p order by p.nom asc</query>
</named-query>
<named-query name="obtenir tous les restaurants avec leurs plats">
<query>select r.nom,p.nom from Restaurant r join r.plats p</query>
</named-query>
<named-query name="obtenir les restaurants ayant au moins un plat vegetarien">
<query>select distinct r from Restaurant r join r.plats p where p.vegetarien=true</query>
</named-query>
<named-query name="obtenir les restaurants avec uniquement des plats vegetariens">
<query>
select distinct r1.nom from Restaurant r1 where not exists (select p1 from Restaurant r2 join r2.plats p1 where r2.id=r1.id and
p1.vegetarien=false)
</query>
</named-query>
<named-query name="obtenir les restaurants d'une certaine rue">
<query>select r from Restaurant r where r.adresse.nomRue=:nomRue</query>
</named-query>
<named-query name="obtenir les restaurants qui servent des burgers">
<query>select r.nom,r.adresse.numeroRue, r.adresse.nomRue, p.nom from Restaurant r join r.plats p where p.nom like '%burger'</query>
</named-query>
<named-query name="obtenir les plats du restaurant untel">
<query>select p.nom from Restaurant r join r.plats p where r.nom=:nomRestaurant</query>
</named-query>
</entity-mappings>
- The root of the [orm.xml] file is <entity-mappings> (line 2).
- Lines 5–7: Named JPQL queries are enclosed in <named-query name="...">text</named-query> tags.
- The tag's name attribute is the name of the query.
- The text content of the tag is the query text.
QueryDB will execute the preceding queries. Its code is as follows:
package tests;
...
public class QueryDB {
// Persistence context
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = emf.createEntityManager();
public static void main(String[] args) {
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// delete [restaurant] table items
em.createNamedQuery("supprimer le contenu de la table restaurant").executeUpdate();
// delete table items [flat]
em.createNamedQuery("supprimer le contenu de la table plat").executeUpdate();
// creation of Address objects
Adresse adr1 = new Adresse(10, "Main Street");
Adresse adr2 = new Adresse(20, "Main Street");
Adresse adr3 = new Adresse(123, "Dover Street");
// creation of Entree objects
Plat ent1 = new Plat("Hamburger", false);
Plat ent2 = new Plat("Cheeseburger", false);
Plat ent3 = new Plat("Tofu Stir Fry", true);
Plat ent4 = new Plat("Vegetable Soup", true);
// creation of Restaurant objects
Restaurant restaurant1 = new Restaurant();
restaurant1.setNom("Burger Barn");
restaurant1.setAdresse(adr1);
restaurant1.getPlats().add(ent1);
restaurant1.getPlats().add(ent2);
Restaurant restaurant2 = new Restaurant();
restaurant2.setNom("Veggie Village");
restaurant2.setAdresse(adr2);
restaurant2.getPlats().add(ent3);
restaurant2.getPlats().add(ent4);
Restaurant restaurant3 = new Restaurant();
restaurant3.setNom("Dover Diner");
restaurant3.setAdresse(adr3);
restaurant3.getPlats().add(ent1);
restaurant3.getPlats().add(ent2);
restaurant3.getPlats().add(ent4);
// persistence of Restaurant objects (and other objects through cascading)
em.persist(restaurant1);
em.persist(restaurant2);
em.persist(restaurant3);
// end transaction
tx.commit();
// dump base
dumpDataBase();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
}
// database content display
@SuppressWarnings("unchecked")
private static void dumpDataBase() {
// test2
log("données de la base");
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// restaurant displays
log("[restaurants]");
for (Object restaurant : em.createNamedQuery("obtenir tous les restaurants").getResultList()) {
System.out.println(restaurant);
}
// address display
log("[adresses]");
for (Object adresse : em.createNamedQuery("obtenir toutes les adresses").getResultList()) {
System.out.println(adresse);
}
// flat displays
log("[plats]");
for (Object plat : em.createNamedQuery("obtenir tous les plats").getResultList()) {
System.out.println(plat);
}
// displays links restaurants <--> dishes
log("[restaurants/plats]");
Iterator record = em.createNamedQuery("obtenir tous les restaurants avec leurs plats").getResultList().iterator();
while (record.hasNext()) {
Object[] currentRecord = (Object[]) record.next();
System.out.format("[%s,%s]%n", currentRecord[0], currentRecord[1]);
}
log("[Liste des restaurants avec au moins un plat végétarien]");
for (Object r : em.createNamedQuery("obtenir les restaurants ayant au moins un plat vegetarien").getResultList()) {
System.out.println(r);
}
// query
log("[Liste des restaurants avec seulement des plats végétariens]");
for (Object r : em.createNamedQuery("obtenir les restaurants avec uniquement des plats vegetariens").getResultList()) {
System.out.println(r);
}
// query
log("[Liste des restaurants dans Dover Street]");
for (Object r : em.createNamedQuery("obtenir les restaurants d'une certaine rue").setParameter("nomRue", "Dover Street").getResultList()) {
System.out.println(r);
}
// query
log("[Liste des restaurants ayant un plat de type burger]");
record = em.createNamedQuery("obtenir les restaurants qui servent des burgers").getResultList().iterator();
while (record.hasNext()) {
Object[] currentRecord = (Object[]) record.next();
System.out.format("[%s,%d,%s,%s]%n", currentRecord[0], currentRecord[1], currentRecord[2], currentRecord[3]);
}
// query
log("[Plats de Veggie Village]");
for (Object r : em.createNamedQuery("obtenir les plats du restaurant untel").setParameter("nomRestaurant", "Veggie Village").getResultList()) {
System.out.println(r);
}
// end transaction
tx.commit();
}
// logs
private static void log(String message) {
System.out.println(" -----------" + message);
}
}
The result of executing [QueryDB] is as follows:
We leave it to the reader to make the connection between the code and the results. To do so, we recommend running the JPQL queries in the Hibernate console and examining the corresponding SQL code.
2.7.7. The Eclipse / Toplink Project
Interested readers will find the previous project implemented with Toplink in the examples available for download with this tutorial:
 |
The Eclipse project with Toplink is a copy of the Eclipse project with Hibernate:
 |
The <persistence.xml> file [2] declares the managed entities:
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- classes persistantes -->
<class>entites.Restaurant</class>
<class>entites.Adresse</class>
<class>entites.Plat</class>
...
- lines 4-6: managed entities
The JPQL queries stored in [orm.xml] are correctly executed by TopLink. To ensure this, in the previous project we took care not to use HQL (Hibernate Query Language) queries, which are in fact a superset of JPQL and whose syntax is not fully supported by JPQL.
2.8. Conclusion
This concludes our overview of JPA entities. It has been a lengthy process, yet some important topics (for the advanced developer) have not been covered. Once again, we recommend reading a reference book such as the one used for this tutorial:
[ref1]: Java Persistence with Hibernate, by Christian Bauer and Gavin King, published by Manning.