5. فئات .NET شائعة الاستخدام
نقدم هنا بعض الفئات من منصة .NET التي يتم استخدامها بشكل متكرر. قبل ذلك، نوضح كيفية الحصول على معلومات حول مئات الفئات المتاحة. هذه المساعدة ضرورية للمطورين في C# حتى المتمرسين منهم. يمكن أن يحدد مستوى جودة المساعدة (سهولة الوصول، التنظيم المفهوم، ملاءمة المعلومات، ...) نجاح أو فشل بيئة التطوير.
5.1. البحث عن المساعدة بشأن فئات .NET
نقدم هنا بعض الإرشادات للعثور على المساعدة باستخدام Visual Studio.NET
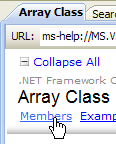
5.1.1. Help/Contents
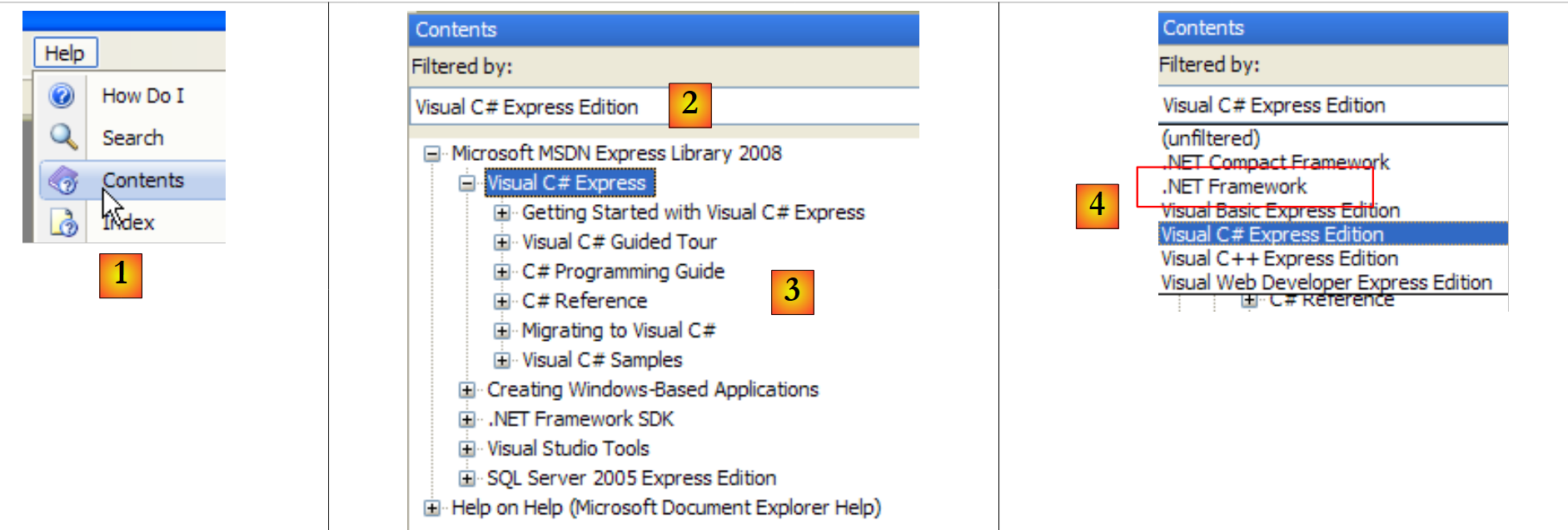 |
- في [1]، اختر الخيار Help/Contents من القائمة.
- في [2]، اختر الخيار Visual C# Express Edition
- في [3]، شجرة المساعدة حول C#
- في [4]، هناك خيار آخر مفيد وهو .NET Framework الذي يتيح الوصول إلى جميع فئات إطار العمل .NET.
دعونا نلقي نظرة على عناوين فصول المساعدة في C#:
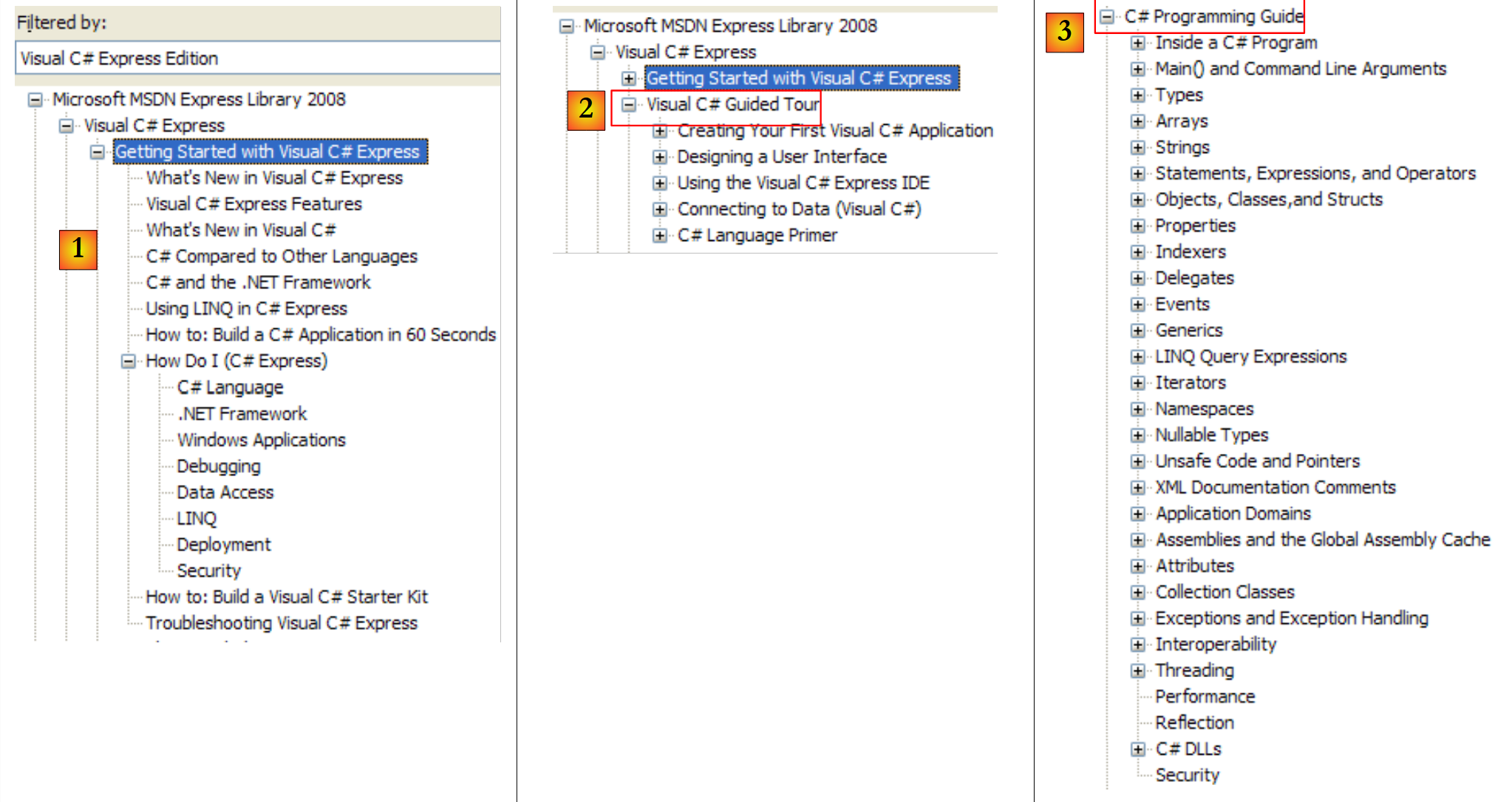 |
- [1]: نظرة عامة على C#
- [2]: سلسلة من الأمثلة حول بعض نقاط C#
- [3]: دورة تدريبية في C# - يمكن أن تحل محل هذا المستند بشكل مفيد...
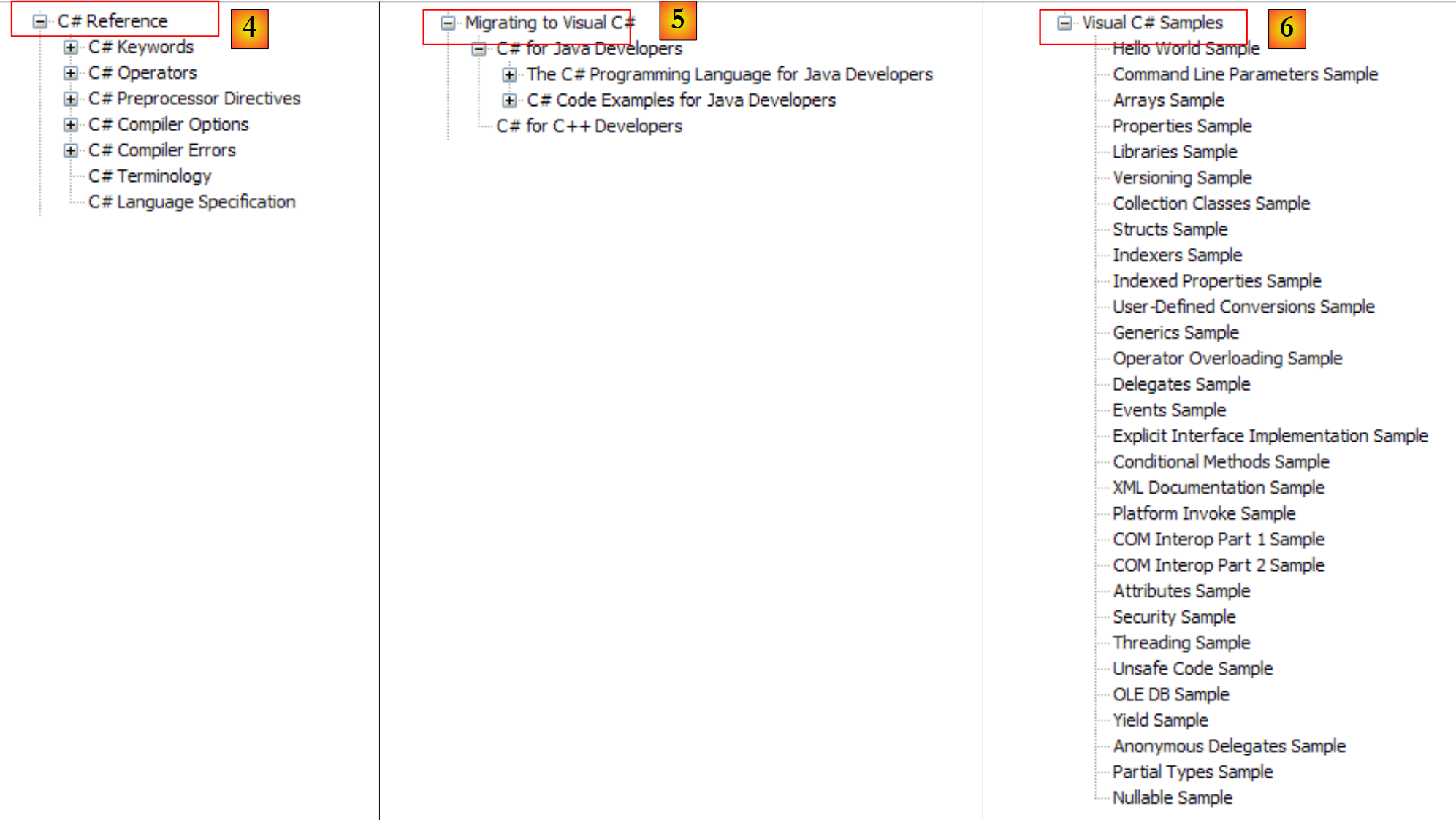 |
- [4]: للتعمق في تفاصيل لغة C#
- [5]: مفيد لمطوري C++ أو Java. يساعد على تجنب بعض الأخطاء.
- [6]: عندما تبحث عن أمثلة، يمكنك البدء من هنا.
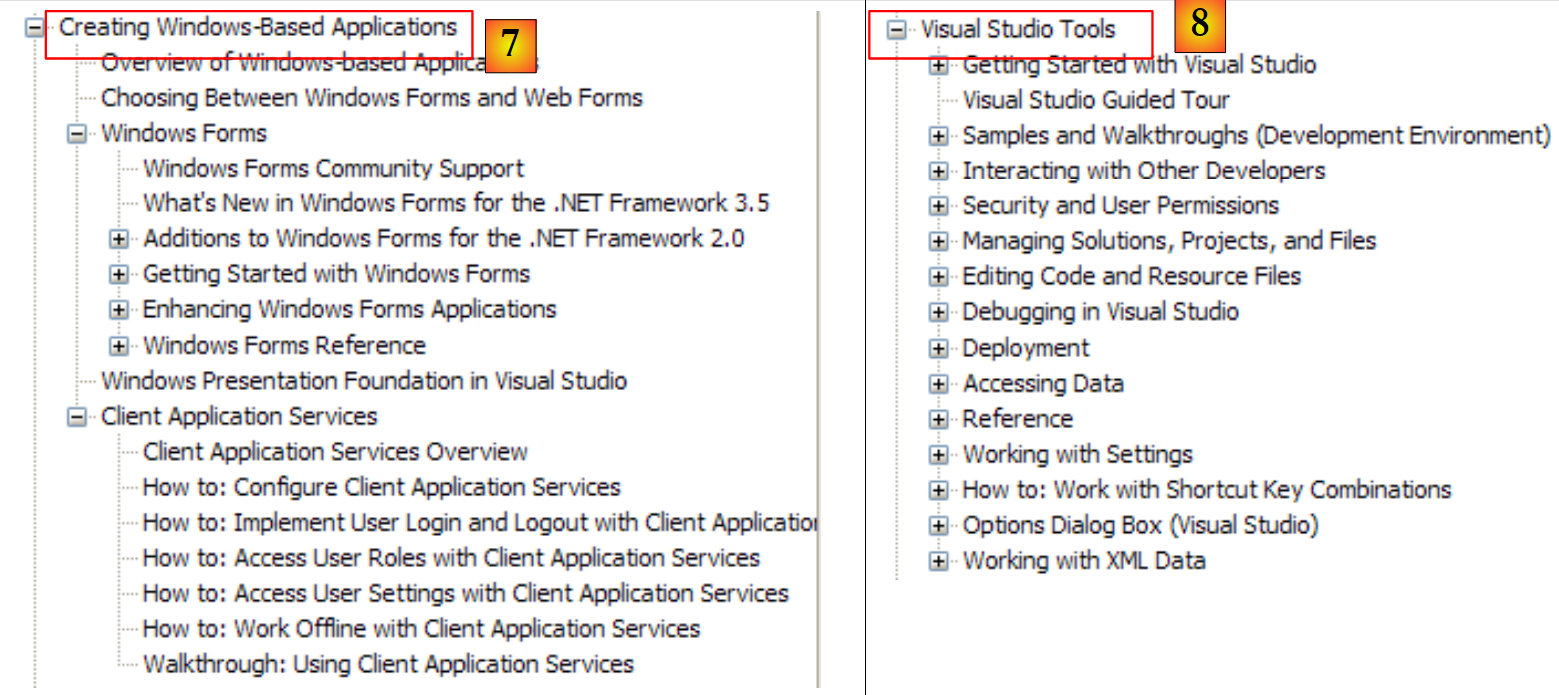 |
- [7]: ما تحتاج إلى معرفته لإنشاء واجهات رسومية
- [8]: لاستخدام IDE Visual Studio Express بشكل أفضل
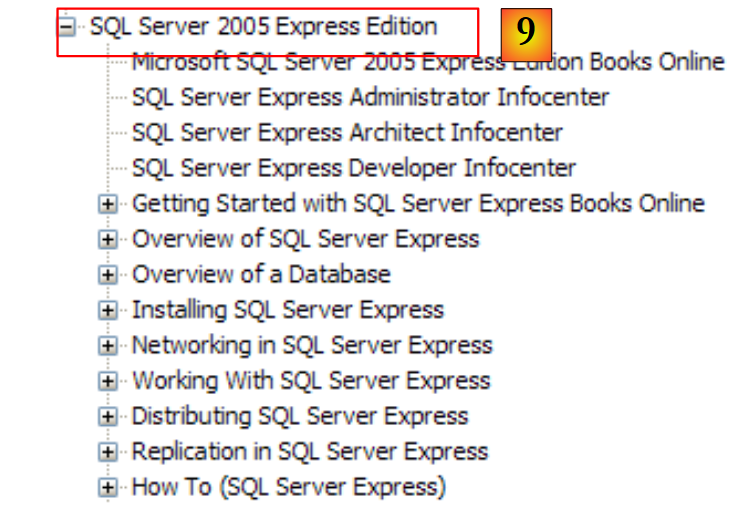 |
- [9]: SQL Server Express 2005 هو برنامج عالي الجودة يتم توزيعه مجانًا. سنستخدمه في هذه الدورة.
تعد مساعدة C# جزءًا فقط مما يحتاجه المطور. الجزء الآخر هو المساعدة المتعلقة بمئات الفئات في إطار عمل .NET التي ستسهل عمله.
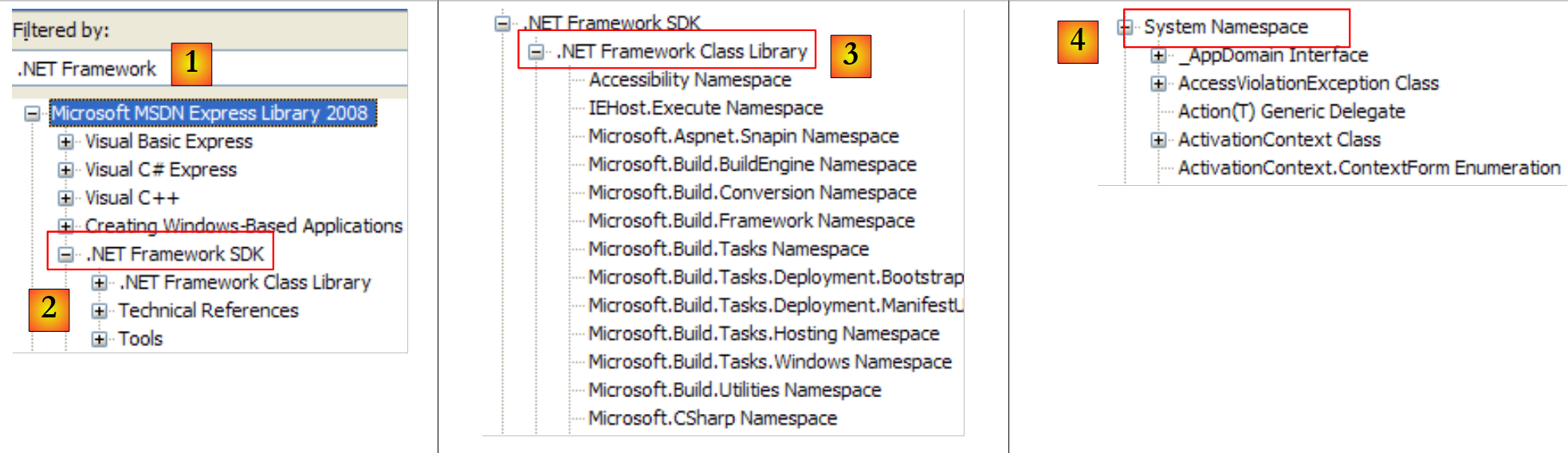 |
- [1]: نختار المساعدة الخاصة بإطار العمل .NET
- [2]: توجد المساعدة في الفرع .NET Framework SDK
- [3]: الفرع .NET Framework Class Library يعرض جميع الفئات .NET وفقًا لمساحة الأسماء التي تنتمي إليها
- [4]: مساحة الأسماء System التي تم استخدامها بشكل متكرر في أمثلة الفصول السابقة
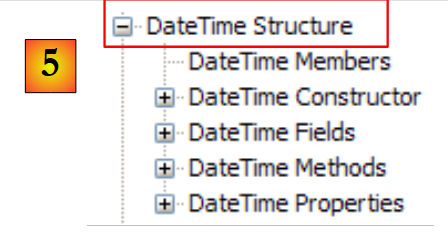 |
- [5]: في مساحة الاسم System، مثال، هنا البنية DateTime
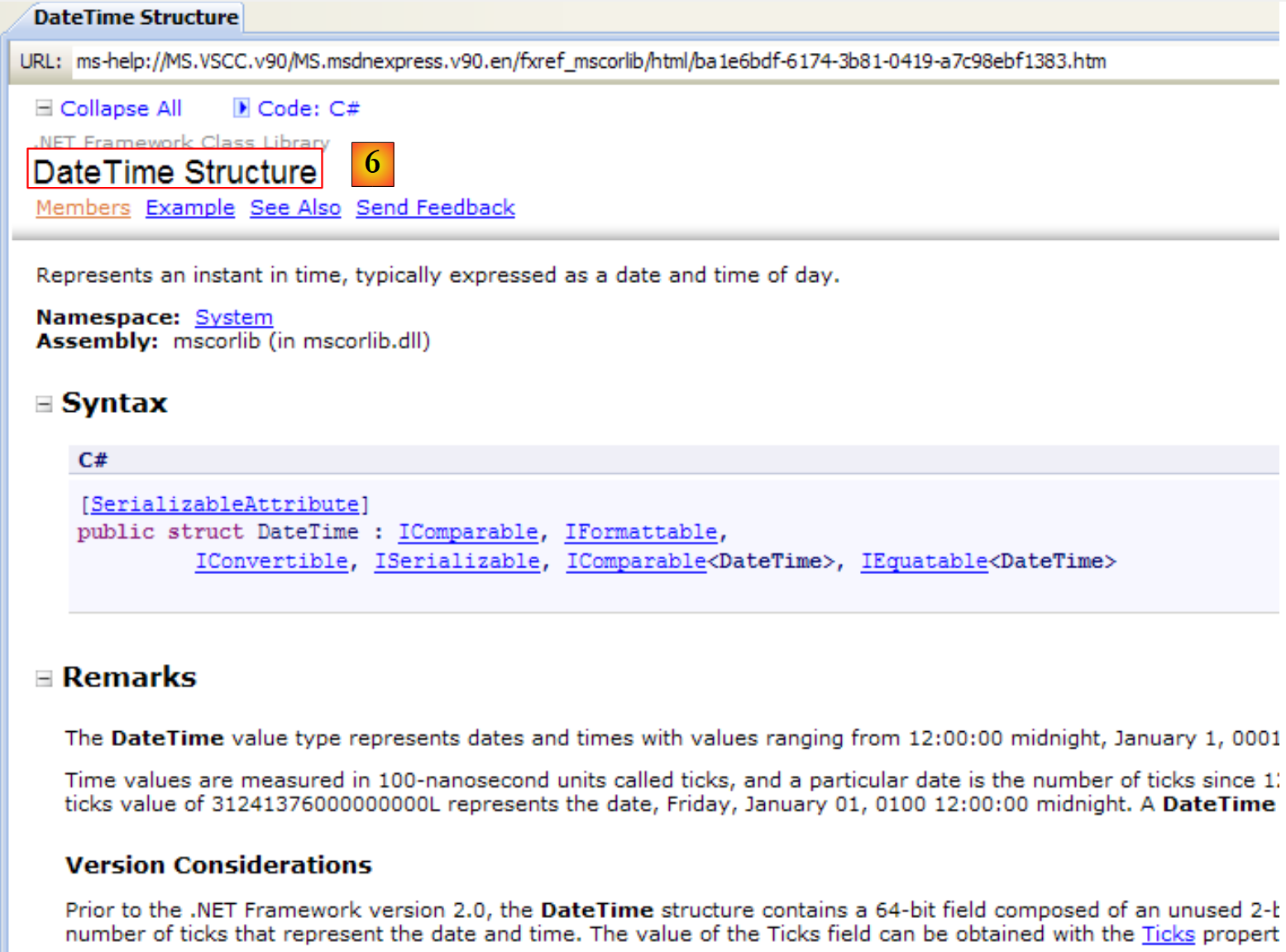 |
- [6]: المساعدة حول البنية DateTime
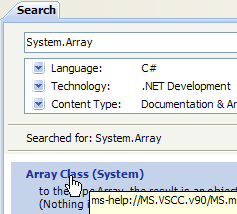
5.1.2. Help/Index/Search
المساعدة التي يقدمها MSDN هائلة وقد لا تعرف أين تبحث. يمكنك عندئذ استخدام فهرس المساعدة:
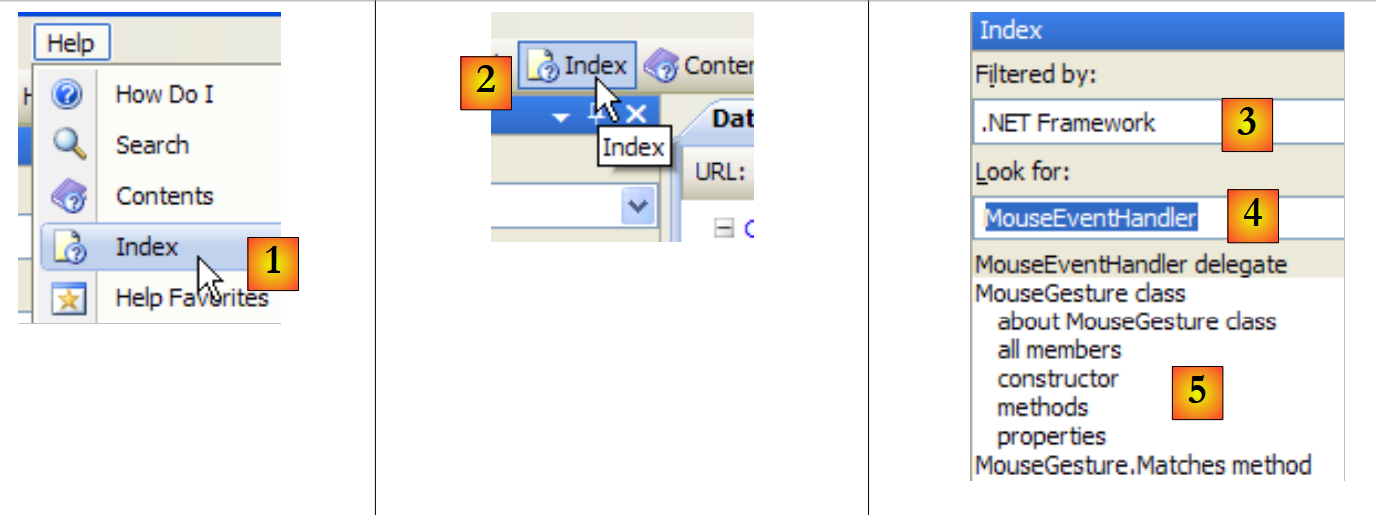 |
- في [1]، استخدم الخيار [Help/Index] إذا لم تكن نافذة المساعدة مفتوحة بالفعل، وإلا استخدم [2] في نافذة مساعدة موجودة.
- إلى [3]، حدد المجال الذي يجب إجراء البحث فيه
- في [4]، حدد ما تبحث عنه، هنا فصل دراسي
- في [5]، الإجابة
هناك طريقة أخرى للبحث عن المساعدة وهي استخدام وظيفة البحث في قسم المساعدة:
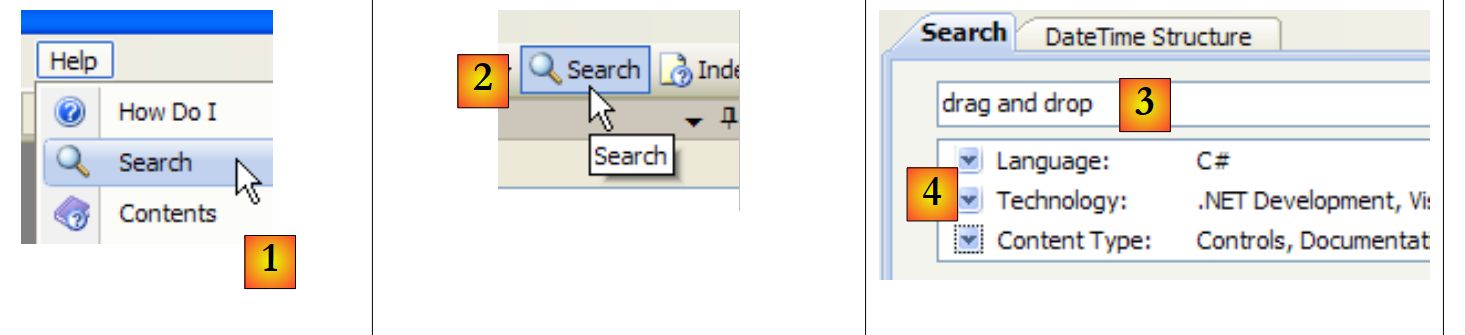 |
- في [1]، استخدم الخيار [Help/Search] إذا لم تكن نافذة المساعدة مفتوحة بالفعل، وإلا استخدم [2] في نافذة مساعدة موجودة.
- إلى [3]، حدد ما تبحث عنه
- في [4]، قم بتصفية مجالات البحث
 |
- في [5]، الإجابة في شكل مواضيع مختلفة حيث تم العثور على النص المطلوب.
5.2. سلاسل الأحرف
5.2.1. الفئة System.String
 |  |  |
الفئة System.String مطابقة لنوع string البسيط. وهي تتميز بالعديد من الخصائص والطرق. وفيما يلي بعض منها:
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
تجدر الإشارة إلى نقطة مهمة: عندما تُرجع إحدى الطرق سلسلة أحرف، فإن هذه السلسلة تختلف عن السلسلة التي طُبقت عليها الطريقة. وبالتالي، فإن S1.Trim() تُرجع سلسلة S2، وتُعد S1 و S2 سلسلتين مختلفتين.
يمكن اعتبار السلسلة C مصفوفة من الأحرف. وبالتالي
- C[i] هو الحرف i في C
- C.Length هو عدد أحرف C
لنأخذ المثال التالي:
using System;
namespace Chap3 {
class Program {
static void Main(string[] args) {
string uneChaine = "l'oiseau vole au-dessus des nuages";
affiche("uneChaine=" + uneChaine);
affiche("uneChaine.Length=" + uneChaine.Length);
affiche("chaine[10]=" + uneChaine[10]);
affiche("uneChaine.IndexOf(\"vole\")=" + uneChaine.IndexOf("vole"));
affiche("uneChaine.IndexOf(\"x\")=" + uneChaine.IndexOf("x"));
affiche("uneChaine.LastIndexOf('a')=" + uneChaine.LastIndexOf('a'));
affiche("uneChaine.LastIndexOf('x')=" + uneChaine.LastIndexOf('x'));
affiche("uneChaine.Substring(4,7)=" + uneChaine.Substring(4, 7));
affiche("uneChaine.ToUpper()=" + uneChaine.ToUpper());
affiche("uneChaine.ToLower()=" + uneChaine.ToLower());
affiche("uneChaine.Replace('a','A')=" + uneChaine.Replace('a', 'A'));
string[] champs = uneChaine.Split(null);
for (int i = 0; i < champs.Length; i++) {
affiche("champs[" + i + "]=[" + champs[i] + "]");
}//for
affiche("Join(\":\",champs)=" + System.String.Join(":", champs));
affiche("(\" abc \").Trim()=[" + " abc ".Trim() + "]");
}//Main
public static void affiche(string msg) {
// عرض الرسالة
Console.WriteLine(msg);
}//يعرض
}//فئة
}//مساحة الاسم
يؤدي التنفيذ إلى النتائج التالية:
لنأخذ مثالاً جديداً:
using System;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// السطر المراد تحليله
string ligne = "un:deux::trois:";
// فواصل الحقول
char[] séparateurs = new char[] { ':' };
// التقسيم
string[] champs = ligne.Split(séparateurs);
for (int i = 0; i < champs.Length; i++) {
Console.WriteLine("Champs[" + i + "]=" + champs[i]);
}
// الانضمام
Console.WriteLine("join=[" + System.String.Join(":", champs) + "]");
}
}
}
ونظر إلى نتائج التنفيذ:
تسمح طريقة Split الخاصة بالفئة String بوضع عناصر سلسلة أحرف في مصفوفة. تعريف طريقة Split المستخدمة هنا هو التالي:
public string[] Split(char[] separator);
جدول الأحرف. تمثل هذه الأحرف العلامات المستخدمة لفصل الحقول في السلسلة. لذا، إذا كانت السلسلة هي "champ1, champ2, champ3""، فيمكن استخدام separator=new char[] {','}. إذا كان الفاصل عبارة عن سلسلة من المسافات، فسنستخدم separator=null. | |
مصفوفة من سلاسل الأحرف حيث يكون كل عنصر في المصفوفة حقلًا في السلسلة. |
طريقة Join هي طريقة ثابتة لفئة String:
public static string Join(string separator, string[] value);
مصفوفة سلاسل أحرف | |
سلسلة أحرف ستُستخدم كفاصل بين الحقول | |
سلسلة أحرف مكونة من ربط عناصر المصفوفة value بفاصل السلسلة separator. |
5.2.2. الفئة System.Text.StringBuilder
 |  |  |
سبق أن ذكرنا أن طرق فئة String التي تنطبق على سلسلة أحرف S1 تُرجع سلسلة أخرى S2. تسمح الفئة System.Text.StringBuilder بمعالجة S1 دون الحاجة إلى إنشاء سلسلة S2. وهذا يحسن الأداء عن طريق تجنب تكاثر السلاسل ذات العمر الافتراضي المحدود للغاية.
تقبل الفئة العديد من المنشئين:
| |
|
يعمل الكائن StringBuilder مع كتل من capacité الأحرف لتخزين السلسلة الأساسية. بشكل افتراضي، تبلغ قيمة capacité 16. يسمح المنشئ الثالث أعلاه بتحديد سعة الكتل. يتم ضبط عدد كتل الأحرف capacité اللازمة لتخزين سلسلة S تلقائيًا بواسطة الفئة StringBuilder. توجد منشئات لتحديد الحد الأقصى لعدد الأحرف في كائن StringBuilder. بشكل افتراضي، تبلغ هذه السعة القصوى 2 147 483 647.
فيما يلي مثال يوضح مفهوم capacité:
using System.Text;
using System;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// str
StringBuilder str = new StringBuilder("test");
Console.WriteLine("taille={0}, capacité={1}", str.Length, str.Capacity);
for (int i = 0; i < 10; i++) {
str.Append("test");
Console.WriteLine("taille={0}, capacité={1}", str.Length, str.Capacity);
}
// str2
StringBuilder str2 = new StringBuilder("test",10);
Console.WriteLine("taille={0}, capacité={1}", str2.Length, str2.Capacity);
for (int i = 0; i < 10; i++) {
str2.Append("test");
Console.WriteLine("taille={0}, capacité={1}", str2.Length, str2.Capacity);
}
}
}
}
- السطر 7: إنشاء كائن StringBuilder بحجم كتلة يبلغ 16 حرفًا
- السطر 8: str.Length هو العدد الحالي لأحرف السلسلة str. str.Capacity هو عدد الأحرف التي يمكن أن تخزنها السلسلة الحالية str قبل إعادة تخصيص كتلة جديدة.
- السطر 10: تسمح str.Append(String S) بضم السلسلة S من النوع String إلى السلسلة str من النوع StringBuilder.
- السطر 14: إنشاء كائن StringBuilder بسعة كتلة تبلغ 10 أحرف
نتيجة التنفيذ:
تُظهر هذه النتائج أن الفئة تتبع خوارزمية خاصة بها لتخصيص كتل جديدة عندما تكون سعتها غير كافية:
- السطران 4-5: زيادة السعة بمقدار 16 حرفًا
- السطران 8-9: زيادة السعة بمقدار 32 حرفًا في حين أن 16 حرفًا كانت كافية.
فيما يلي بعض أساليب الفئة:
| |
| |
| |
| |
|
إليك مثال:
using System.Text;
using System;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// str3
StringBuilder str3 = new StringBuilder("test");
Console.WriteLine(str3.Append("abCD").Insert(2, "xyZT").Remove(0, 2).Replace("xy", "XY"));
}
}
}
وإليكم النتائج:
5.3. الجداول
تستمد الجداول من فئة Array:
 |  | 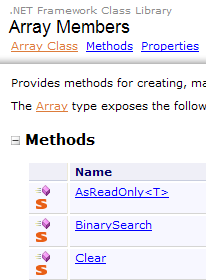 |
تحتوي فئة Array على طرق متنوعة لفرز مصفوفة، والبحث عن عنصر في مصفوفة، وتغيير حجم مصفوفة، ... نقدم بعض خصائص وطرق هذه الفئة. وهي جميعها تقريبًا مُثبَّتة، c.a.d. بحيث توجد في أشكال مختلفة. وترثها كل مصفوفة.
الخصائص
الطرق
يوضح البرنامج التالي استخدام بعض طرق الفئة Array:
using System;
namespace Chap3 {
class Program {
// نوع البحث
enum TypeRecherche { linéaire, dichotomique };
// الطريقة الرئيسية
static void Main(string[] args) {
// قراءة عناصر المصفوفة التي تم إدخالها عبر لوحة المفاتيح
double[] éléments;
Saisie(out éléments);
// عرض المصفوفة غير المرتبة
Affiche("Tableau non trié", éléments);
// البحث الخطي في الجدول غير المرتب
Recherche(éléments, TypeRecherche.linéaire);
// فرز الجدول
Array.Sort(éléments);
// عرض الجدول المرتب
Affiche("Tableau trié", éléments);
// البحث الثنائي في الجدول المرتب
Recherche(éléments, TypeRecherche.dichotomique);
}
// إدخال قيم عناصر المصفوفة
// العناصر: مرجع إلى الجدول الذي تم إنشاؤه بواسطة الطريقة
static void Saisie(out double[] éléments) {
bool terminé = false;
string réponse;
bool erreur;
double élément = 0;
int i = 0;
// في البداية، الجدول غير موجود
éléments = null;
// حلقة إدخال عناصر الجدول
while (!terminé) {
// السؤال
Console.Write("Elément (réel) " + i + " du tableau (rien pour terminer) : ");
// قراءة الإجابة
réponse = Console.ReadLine().Trim();
// نهاية الإدخال إذا كانت السلسلة فارغة
if (réponse.Equals(""))
break;
// التحقق من الإدخال
try {
élément = Double.Parse(réponse);
erreur = false;
} catch {
Console.Error.WriteLine("Saisie incorrecte, recommencez");
erreur = true;
}//محاولة-التعليق
// إذا لم يكن هناك خطأ
if (!erreur) {
// عنصر إضافي في المصفوفة
i += 1;
// تغيير حجم المصفوفة لاستيعاب العنصر الجديد
Array.Resize(ref éléments, i);
// إدراج عنصر جديد
éléments[i - 1] = élément;
}
}//while
}
// طريقة عامة لعرض عناصر المصفوفة
static void Affiche<T>(string texte, T[] éléments) {
Console.WriteLine(texte.PadRight(50, '-'));
foreach (T élément in éléments) {
Console.WriteLine(élément);
}
}
// البحث عن عنصر في الجدول
// العناصر: مصفوفة من الأعداد الحقيقية
// TypeRecherche: ثنائي أو خطي
static void Recherche(double[] éléments, TypeRecherche type) {
// البحث
bool terminé = false;
string réponse = null;
double élément = 0;
bool erreur = false;
int i = 0;
while (!terminé) {
// السؤال
Console.WriteLine("Elément cherché (rien pour arrêter) : ");
// قراءة-التحقق من الإجابة
réponse = Console.ReadLine().Trim();
// انتهى؟
if (réponse.Equals(""))
break;
// التحقق
try {
élément = Double.Parse(réponse);
erreur = false;
} catch {
Console.WriteLine("Erreur, recommencez...");
erreur = true;
}//محاولة-التقاط
// إذا لم يكن هناك خطأ
if (!erreur) {
// نبحث عن العنصر في المصفوفة
if (type == TypeRecherche.dichotomique)
// البحث الثنائي
i = Array.BinarySearch(éléments, élément);
else
// البحث الخطي
i = Array.IndexOf(éléments, élément);
// عرض الإجابة
if (i >= 0)
Console.WriteLine("Trouvé en position " + i);
else
Console.WriteLine("Pas dans le tableau");
}//if
}//while
}
}
}
- الأسطر 27-62: تقوم الطريقة Saisie بإدخال عناصر مصفوفة éléments التي تمت كتابتها على لوحة المفاتيح. وبما أنه لا يمكن تحديد حجم المصفوفة مسبقًا (لا نعرف حجمها النهائي)، فإننا مضطرون إلى تغيير حجمها مع كل عنصر جديد (السطر 57). كان من الممكن استخدام خوارزمية أكثر كفاءة تتمثل في تخصيص مساحة للجدول لكل مجموعة من N عنصر. لكن الجدول ليس مصممًا لتغيير حجمه. ومن الأفضل معالجة هذه الحالة باستخدام قائمة (ArrayList، List<T>).
- السطور 75-113: تسمح الطريقة Recherche بالبحث في المصفوفة éléments عن عنصر تمت كتابته على لوحة المفاتيح. يختلف أسلوب البحث حسب ما إذا كان المصفوفة مرتبة أم لا. بالنسبة للمصفوفة غير المرتبة، يتم إجراء بحث خطي باستخدام الطريقة IndexOf في السطر 106. بالنسبة للمصفوفة المرتبة، يتم إجراء بحث ثنائي باستخدام الطريقة BinarySearch في السطر 103.
- السطر 18: يتم فرز الجدول éléments. نستخدم هنا نسخة معدلة من Sort التي تحتوي على معلمة واحدة فقط: الجدول المراد فرزه. وعندئذ تكون علاقة الترتيب المستخدمة لمقارنة عناصر المصفوفة هي العلاقة الضمنية لهذه العناصر. وهنا، تكون العناصر أرقامًا. ويُستخدم الترتيب الطبيعي للأرقام.
نتائج الشاشة هي كما يلي:
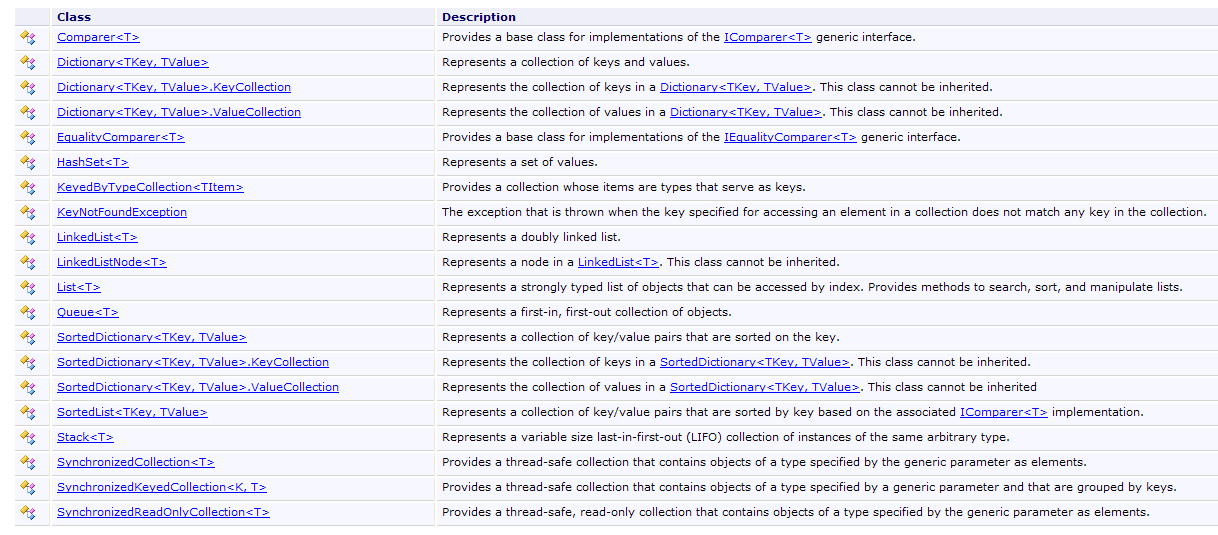
5.4. المجموعات العامة
بالإضافة إلى الجدول، توجد فئات متنوعة لتخزين مجموعات العناصر. توجد إصدارات عامة في مساحة الاسم System.Collections.Generic وإصدارات غير عامة في System.Collections. سنقدم مجموعتين عامتين مستخدمتين بشكل متكرر: القائمة والقاموس.
قائمة المجموعات العامة هي كما يلي:
5.4.1. الفئة العامة List<T>
تسمح الفئة System.Collections.Generic.List<T> بتنفيذ مجموعات من الكائنات من النوع T التي يتغير حجمها أثناء تشغيل البرنامج. يتم التعامل مع كائن من النوع List<T> تقريبًا كصفيف. وبالتالي، يُرمز للعنصر i في قائمة l بـ l[i].
يوجد أيضًا نوع من القوائم غير العامة: ArrayList قادر على تخزين مراجع لأي كائنات. ArrayList مكافئ وظيفيًا لـ List<Object>. يبدو الكائن ArrayList كما يلي:
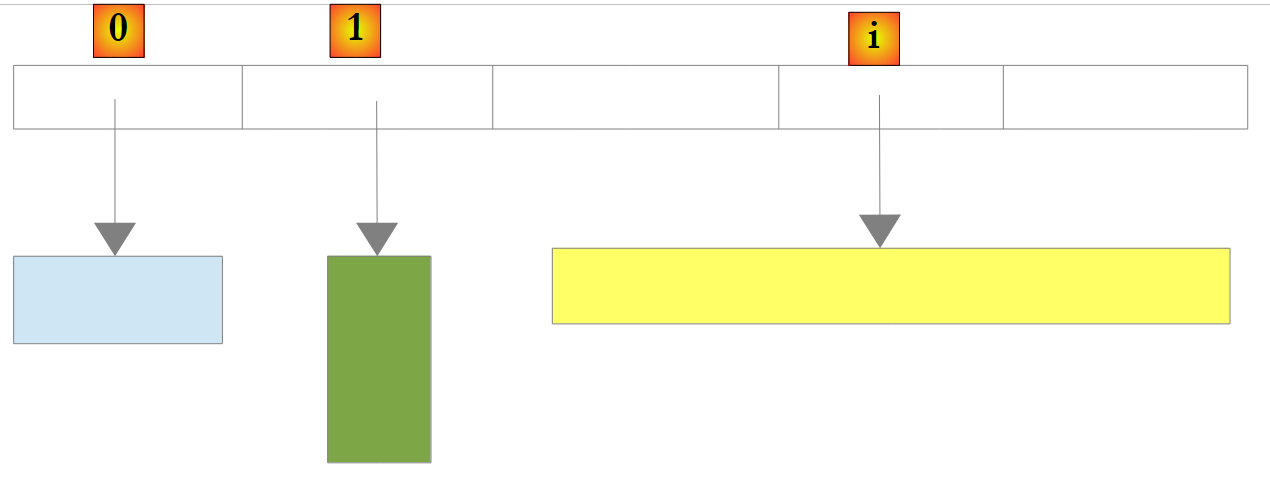 |
فيما سبق، تشير العناصر 0 و 1 و i في القائمة إلى كائنات من أنواع مختلفة. يجب إنشاء الكائن أولاً قبل إضافة مرجع له إلى القائمة ArrayList. على الرغم من أن ArrayList يخزن مراجع الكائنات، إلا أنه من الممكن تخزين الأرقام فيه. ويتم ذلك من خلال آلية تسمى Boxing: يتم تغليف الرقم في كائن O من النوع Object ويتم تخزين مرجع O في القائمة. وهذه آلية شفافة بالنسبة للمطور. وبذلك يمكننا كتابة:
سيؤدي ذلك إلى النتيجة التالية:
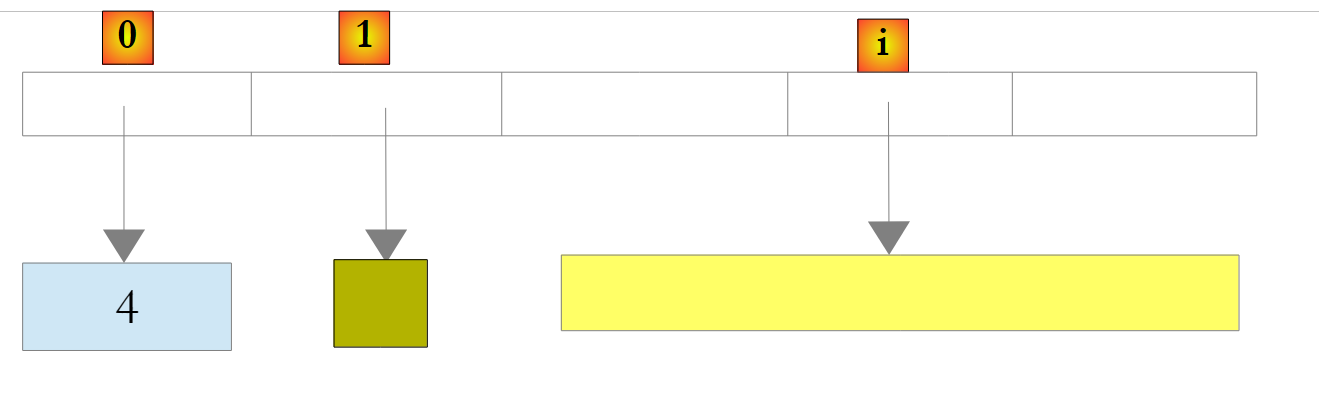 |
في المثال أعلاه، تم تغليف الرقم 4 في كائن O وتم تخزين المرجع O في القائمة. لاستعادته، يمكننا كتابة:
int i = (int)liste[0];
تسمى العملية Object -> int بـ Unboxing. إذا كانت القائمة مكونة بالكامل من أنواع int، فإن إعلانها على أنها List<int> يحسن الأداء. في الواقع، يتم تخزين الأرقام من النوع int في القائمة نفسها وليس في أنواع Object خارج القائمة. لم تعد عمليات Boxing / Unboxing تحدث.
بالنسبة لكائن List<T> أو T الذي يمثل فئة، تقوم القائمة مرة أخرى بتخزين مراجع الكائنات من النوع T:
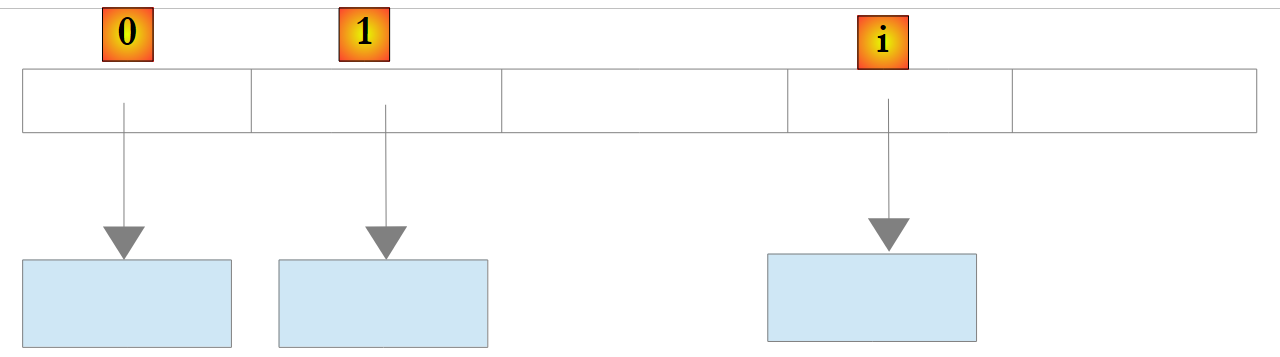 |
فيما يلي بعض خصائص وأساليب القوائم العامة:
الخصائص
الطرق
لنعد إلى المثال الذي تناولناه سابقًا باستخدام كائن من النوع Array ونعالجه الآن باستخدام كائن من النوع List<T>. نظرًا لأن القائمة هي كائن قريب من المصفوفة، فإن الكود لا يتغير كثيرًا. نقدم فقط التعديلات الملحوظة:
using System;
using System.Collections.Generic;
namespace Chap3 {
class Program {
// نوع البحث
enum TypeRecherche { linéaire, dichotomique };
// الطريقة الرئيسية
static void Main(string[] args) {
// قراءة عناصر قائمة تم إدخالها عبر لوحة المفاتيح
List<double> éléments;
Saisie(out éléments);
// عدد العناصر
Console.WriteLine("La liste a {0} éléments et une capacité de {1} éléments", éléments.Count, éléments.Capacity);
// عرض قائمة غير مرتبة
Affiche("Liste non triée", éléments);
// البحث الخطي في القائمة غير المرتبة
Recherche(éléments, TypeRecherche.linéaire);
// فرز القائمة
éléments.Sort();
// عرض القائمة المرتبة
Affiche("Liste triée", éléments);
// البحث الثنائي في القائمة المرتبة
Recherche(éléments, TypeRecherche.dichotomique);
}
// إدخال قيم قائمة العناصر
// العناصر: مرجع إلى القائمة التي تم إنشاؤها بواسطة الطريقة
static void Saisie(out List<double> éléments) {
...
// في البداية، القائمة فارغة
éléments = new List<double>();
// حلقة إدخال عناصر القائمة
while (!terminé) {
...
// إذا لم تكن هناك أخطاء
if (!erreur) {
// عنصر إضافي في القائمة
éléments.Add(élément);
}
}//while
}
// طريقة عامة لعرض عناصر كائن قابل للتعداد
static void Affiche<T>(string texte, IEnumerable<T> éléments) {
Console.WriteLine(texte.PadRight(50, '-'));
foreach (T élément in éléments) {
Console.WriteLine(élément);
}
}
// البحث عن عنصر في القائمة
// العناصر: قائمة من الأعداد الحقيقية
// TypeRecherche: ثنائي أو خطي
static void Recherche(List<double> éléments, TypeRecherche type) {
...
while (!terminé) {
...
// إذا لم يكن هناك خطأ
if (!erreur) {
// نبحث عن العنصر في القائمة
if (type == TypeRecherche.dichotomique)
// بحث ثنائي
i = éléments.BinarySearch(élément);
else
// بحث خطي
i = éléments.IndexOf(élément);
// عرض الإجابة
...
}//if
}//while
}
}
}
- الأسطر 46-51: تقبل الطريقة العامة Affiche<T> معلمتين:
- المعلمة الأولى هي نص يجب كتابته
- المعلمة الثانية هي كائن ينفذ الواجهة العامة IEnumerable<T>:
هيكل foreach( T عنصر في عناصر) في السطر 48، صالح لأي كائن éléments ينفذ واجهة IEnumerable. تنفذ المصفوفات (Array) والقوائم (List<T>) واجهة IEnumerable<T>. لذلك فإن الطريقة Affiche مناسبة لعرض الجداول والقوائم على حد سواء.
نتائج تنفيذ البرنامج هي نفسها كما في المثال الذي يستخدم الفئة Array.
5.4.2. الفئة Dictionary<TKey,TValue>
تسمح الفئة System.Collections.Generic.Dictionary<TKey,TValue> بتنفيذ قاموس. يمكن النظر إلى القاموس على أنه مصفوفة ذات عمودين:
المفتاح | القيمة |
المفتاح 1 | القيمة 1 |
المفتاح 2 | القيمة 2 |
.. | ... |
في الفئة Dictionary<TKey,TValue>، تكون المفاتيح من النوع Tkey، والقيم من النوع TValue. المفاتيح فريدة، c.a.d. بحيث لا يمكن أن يكون هناك مفتاحان متطابقان. قد يبدو هذا القاموس كما يلي إذا كانت الأنواع TKey و TValue تشير إلى فئات:
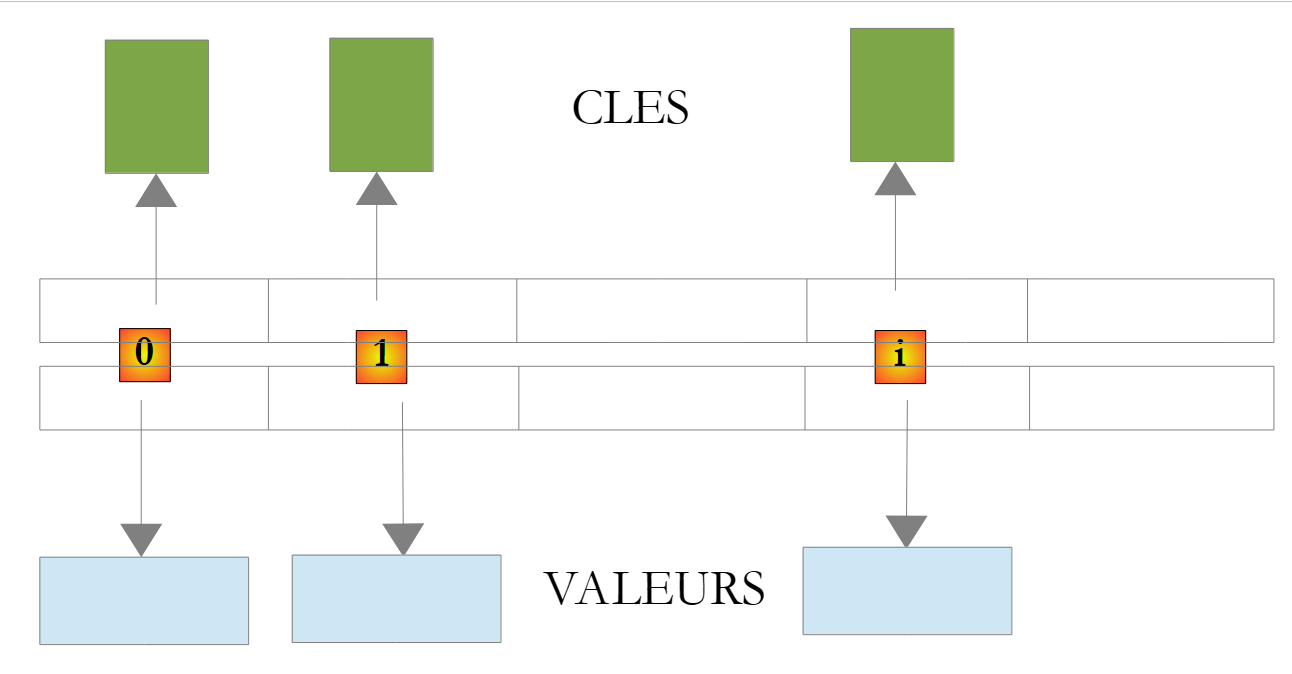 |
يتم الحصول على القيمة المرتبطة بالمفتاح C في القاموس D من خلال الترميز D[C]. هذه القيمة قابلة للقراءة والكتابة. وبالتالي يمكننا كتابة:
إذا لم يكن المفتاح c موجودًا في القاموس D، فإن الترميز D[c] يطلق استثناءً.
الطرق والخصائص الرئيسية لفئة Dictionary<TKey,TValue> هي التالية:
المنشئات
الخصائص
الطرق
لنأخذ البرنامج التالي كمثال:
using System;
using System.Collections.Generic;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// إنشاء قاموس <string,int>
string[] liste = { "jean:20", "paul:18", "mélanie:10", "violette:15" };
string[] champs = null;
char[] séparateurs = new char[] { ':' };
Dictionary<string,int> dico = new Dictionary<string,int>();
for (int i = 0; i <liste.Length; i++) {
champs = liste[i].Split(séparateurs);
dico[champs[0]]= int.Parse(champs[1]);
}//for
// عدد العناصر في القاموس
Console.WriteLine("Le dictionnaire a " + dico.Count + " éléments");
// قائمة المفاتيح
Affiche("[Liste des clés]",dico.Keys);
// قائمة القيم
Affiche("[Liste des valeurs]", dico.Values);
// قائمة المفاتيح والقيم
Console.WriteLine("[Liste des clés & valeurs]");
foreach (string clé in dico.Keys) {
Console.WriteLine("clé=" + clé + " valeur=" + dico[clé]);
}
// يتم حذف المفتاح "paul"
Console.WriteLine("[Suppression d'une clé]");
dico.Remove("paul");
// قائمة المفاتيح والقيم
Console.WriteLine("[Liste des clés & valeurs]");
foreach (string clé in dico.Keys) {
Console.WriteLine("clé=" + clé + " valeur=" + dico[clé]);
}
// البحث في القاموس
String nomCherché = null;
Console.Write("Nom recherché (rien pour arrêter) : ");
nomCherché = Console.ReadLine().Trim();
int value;
while (!nomCherché.Equals("")) {
dico.TryGetValue(nomCherché, out value);
if (value!=0) {
Console.WriteLine(nomCherché + "," + value);
} else {
Console.WriteLine("Nom " + nomCherché + " inconnu");
}
// البحث التالي
Console.Out.Write("Nom recherché (rien pour arrêter) : ");
nomCherché = Console.ReadLine().Trim();
}//while
}
// طريقة عامة لعرض عناصر نوع قابل للتعداد
static void Affiche<T>(string texte, IEnumerable<T> éléments) {
Console.WriteLine(texte.PadRight(50, '-'));
foreach (T élément in éléments) {
Console.WriteLine(élément);
}
}
}
}
- السطر 8: مصفوفة من string ستُستخدم لتهيئة القاموس <string,int>
- السطر 11: القاموس <string,int>
- الأسطر 12-15: تهيئته من مصفوفة string في السطر 8
- السطر 17: عدد إدخالات القاموس
- السطر 19: مفاتيح القاموس
- السطر 21: قيم القاموس
- السطر 29: حذف إدخال من القاموس
- السطر 41: البحث عن مفتاح في القاموس. إذا لم يكن موجودًا، فستضع الطريقة TryGetValue القيمة 0 في value، لأن value من النوع الرقمي. لا يمكن استخدام هذه التقنية هنا إلا لأننا نعلم أن القيمة 0 غير موجودة في القاموس.
نتائج التنفيذ هي كما يلي:
5.5. الملفات النصية
5.5.1. الفئة StreamReader
تسمح الفئة System.IO.StreamReader بقراءة محتوى ملف نصي. وهي في الواقع قادرة على استغلال تدفقات ليست ملفات. فيما يلي بعض خصائصها وأساليبها:
المنشئات
الخصائص
الأساليب
إليك مثال:
using System;
using System.IO;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// دليل التنفيذ
Console.WriteLine("Répertoire d'exécution : "+Environment.CurrentDirectory);
string ligne = null;
StreamReader fluxInfos = null;
// قراءة محتوى الملف infos.txt
try {
// قراءة 1
Console.WriteLine("Lecture 1----------------");
using (fluxInfos = new StreamReader("infos.txt")) {
ligne = fluxInfos.ReadLine();
while (ligne != null) {
Console.WriteLine(ligne);
ligne = fluxInfos.ReadLine();
}
}
// قراءة 2
Console.WriteLine("Lecture 2----------------");
using (fluxInfos = new StreamReader("infos.txt")) {
Console.WriteLine(fluxInfos.ReadToEnd());
}
} catch (Exception e) {
Console.WriteLine("L'erreur suivante s'est produite : " + e.Message);
}
}
}
}
- السطر 8: يعرض اسم دليل التشغيل
- السطران 12 و27: try / catch لإدارة أي استثناء محتمل.
- السطر 15: البنية using flux=new StreamReader(...) هي وسيلة لتجنب الحاجة إلى إغلاق التدفق بشكل صريح بعد استخدامه. يتم هذا الإغلاق تلقائيًا بمجرد الخروج من نطاق using.
- السطر 15: الملف الذي يتم قراءته يسمى infos.txt. ونظرًا لأنه اسم نسبي، فسيتم البحث عنه في دليل التنفيذ المعروض في السطر 8. وإذا لم يكن موجودًا، فسيتم إطلاق استثناء وإدارته بواسطة try / catch.
- الأسطر 16-20: يتم قراءة الملف سطراً تلو الآخر
- السطر 25: يتم قراءة الملف دفعة واحدة
الملف infos.txt هو التالي:
ويتم وضعه في المجلد التالي من مشروع C#:
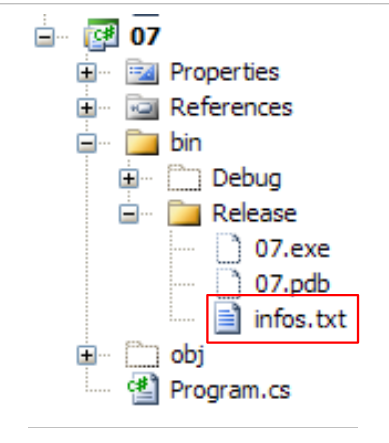 |
سنكتشف أن bin/Release هو مجلد التنفيذ عند تشغيل المشروع بواسطة Ctrl-F5.
يؤدي التنفيذ إلى النتائج التالية:
إذا أدخلنا في السطر 15 اسم الملف xx.txt، فسنحصل على النتائج التالية:
5.5.2. الفئة StreamWriter
تسمح الفئة System.IO.StreamReader بالكتابة في ملف نصي. ومثل الفئة StreamReader، فهي قادرة في الواقع على استغلال تدفقات ليست ملفات. فيما يلي بعض خصائصها وأساليبها:
المنشئات
الخصائص
الطرق
لنأخذ المثال التالي:
using System;
using System.IO;
namespace Chap3 {
class Program2 {
static void Main(string[] args) {
// مجلد التشغيل
Console.WriteLine("Répertoire d'exécution : " + Environment.CurrentDirectory);
string ligne = null; // سطر نصي
StreamWriter fluxInfos = null; // ملف نصي
try {
// إنشاء الملف النصي
using (fluxInfos = new StreamWriter("infos2.txt")) {
Console.WriteLine("Mode AutoFlush : {0}", fluxInfos.AutoFlush);
// قراءة السطر المكتوب على لوحة المفاتيح
Console.Write("ligne (rien pour arrêter) : ");
ligne = Console.ReadLine().Trim();
// حلقة ما دام السطر المدخل غير فارغ
while (ligne != "") {
// كتابة السطر في ملف نصي
fluxInfos.WriteLine(ligne);
// قراءة سطر جديد من لوحة المفاتيح
Console.Write("ligne (rien pour arrêter) : ");
ligne = Console.ReadLine().Trim();
}//while
}
} catch (Exception e) {
Console.WriteLine("L'erreur suivante s'est produite : " + e.Message);
}
}
}
}
- السطر 13: مرة أخرى، نستخدم صيغة using(flux) حتى لا نضطر إلى إغلاق التدفق بشكل صريح بواسطة عملية Close. يتم هذا الإغلاق تلقائيًا عند الخروج من using.
- لماذا نستخدم try / catch، السطران 11 و27؟ في السطر 13، يمكننا تحديد اسم ملف بالصيغة /rep1/rep2/ .../fichier مع مسار /rep1/rep2/... غير موجود، مما يجعل من المستحيل إنشاء fichier. عندها سيتم إطلاق استثناء. هناك حالات استثناء أخرى محتملة (قرص ممتلئ، حقوق غير كافية، ...)
نتائج التنفيذ هي كما يلي:
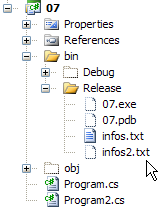
تم إنشاء الملف infos2.txt في المجلد bin/Release للمشروع:
 |  |
5.6. الملفات الثنائية
تُستخدم الفئتان System.IO.BinaryReader و System.IO.BinaryWriter لقراءة وكتابة الملفات الثنائية.
لنأخذ التطبيق التالي كمثال:
// صياغة pg نص ثنائي سجلات
// يتم قراءة ملف نصي (text) وتخزين محتواه في ملف ثنائي (bin
// يحتوي الملف النصي على أسطر بالشكل اسم : عمر سيتم تخزينها في بنية string، int
// (logs) هو ملف نصي للسجلات
يحتوي الملف النصي على المحتوى التالي:
البرنامج هو التالي:
using System;
using System.IO;
// صياغة pg نص ثنائي سجلات
// يتم قراءة ملف نصي (نص) وتخزين محتواه في ملف ثنائي (bin)
// يحتوي الملف النصي على أسطر بالصيغة اسم : عمر سيتم تخزينها في بنية string, int
// (logs) هو ملف نصي للسجلات
namespace Chap3 {
class Program {
static void Main(string[] arguments) {
// يلزم 3 معلمات
if (arguments.Length != 3) {
Console.WriteLine("syntaxe : pg texte binaire log");
Environment.Exit(1);
}//if
// متغيرات
string ligne=null;
string nom=null;
int age=0;
int numLigne = 0;
char[] séparateurs = new char[] { ':' };
string[] champs=null;
StreamReader input = null;
BinaryWriter output = null;
StreamWriter logs = null;
bool erreur = false;
// قراءة ملف نصي - كتابة ملف ثنائي
try {
// فتح ملف نصي للقراءة
input = new StreamReader(arguments[0]);
// فتح الملف الثنائي للكتابة
output = new BinaryWriter(new FileStream(arguments[1], FileMode.Create, FileAccess.Write));
// فتح ملف السجلات للكتابة
logs = new StreamWriter(arguments[2]);
// استخدام الملف النصي
while ((ligne = input.ReadLine()) != null) {
// سطر إضافي
numLigne++;
// سطر فارغ؟
if (ligne.Trim() == "") {
// غير معروف
continue;
}
// سطر اسم: العمر
champs = ligne.Split(séparateurs);
// نحتاج إلى حقلين
if (champs.Length != 2) {
// تسجيل الخطأ
logs.WriteLine("La ligne n° [{0}] du fichier [{1}] a un nombre de champs incorrect", numLigne, arguments[0]);
// السطر التالي
continue;
}//if
// يجب ألا يكون الحقل الأول فارغًا
erreur = false;
nom = champs[0].Trim();
if (nom == "") {
// يتم تسجيل الخطأ
logs.WriteLine("La ligne n° [{0}] du fichier [{1}] a un nom vide", numLigne, arguments[0]);
erreur = true;
}
// يجب أن يكون الحقل الثاني عددًا صحيحًا >=0
if (!int.TryParse(champs[1],out age) || age<0) {
// يتم تسجيل الخطأ
logs.WriteLine("La ligne n° [{0}] du fichier [{1}] a un âge [{2}] incorrect", numLigne, arguments[0], champs[1].Trim());
erreur = true;
}//إذا
// إذا لم تكن هناك أخطاء، يتم كتابة البيانات في الملف الثنائي
if (!erreur) {
output.Write(nom);
output.Write(age);
}
// السطر التالي
}//while
}catch(Exception e){
Console.WriteLine("L'erreur suivante s'est produite : {0}", e.Message);
} finally {
// إغلاق الملفات
if(input!=null) input.Close();
if(output!=null) output.Close();
if(logs!=null) logs.Close();
}
}
}
}
لنركز على العمليات المتعلقة بالفئة BinaryWriter:
- السطر 34: يتم فتح الكائن BinaryWriter بواسطة العملية
output=new BinaryWriter(new FileStream(arguments[1],FileMode.Create,FileAccess.Write));
يجب أن يكون وسيط المنشئ دفقًا (Stream). هنا، هو دفق تم إنشاؤه من ملف (FileStream) الذي نقدم:
- (تابع)
- الاسم
- العملية المطلوب إجراؤها، وهي هنا FileMode.Create لإنشاء الملف
- نوع الوصول، وهو هنا FileAccess.Write للوصول للكتابة إلى الملف
- السطور 70-73: عمليات الكتابة
تحتوي الفئة BinaryWriter على طرق مختلفة Write مفرطة لتحميل أنواع مختلفة من البيانات البسيطة
- السطر 81: عملية إغلاق التدفق
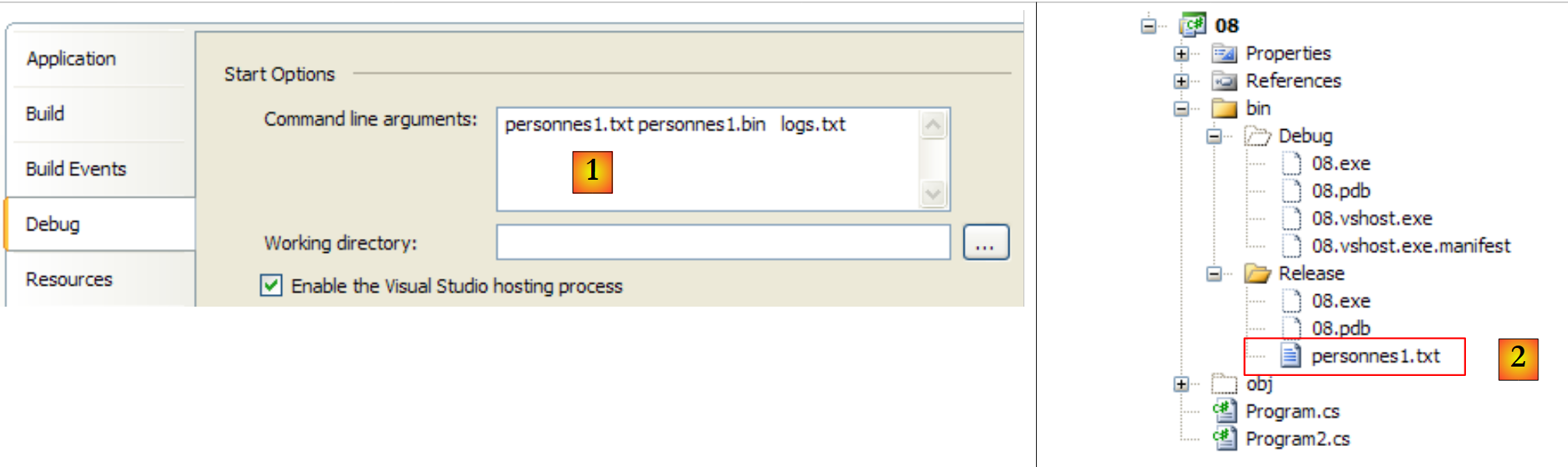
يتم توفير المعلمات الثلاثة للطريقة Main للمشروع (عبر خصائصه) [1] ويتم وضع الملف النصي المطلوب استخدامه في المجلد bin/Release [2]:
 |
مع الملف [personnes1.txt] التالي:
تكون نتائج التنفيذ كما يلي:
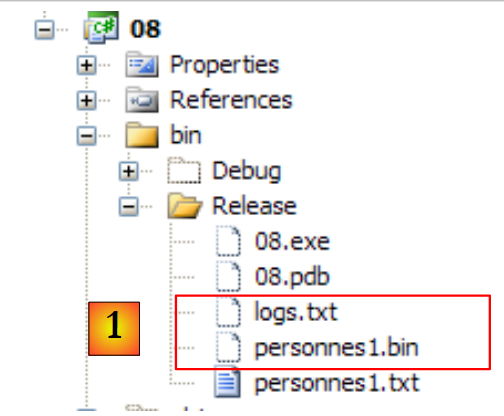 |
- في [1]، تم إنشاء الملف الثنائي [personnes1.bin] بالإضافة إلى ملف السجلات [logs.txt]. يحتوي هذا الملف على المحتوى التالي:
سيتم تزويدنا بمحتوى الملف الثنائي [personnes1.bin] بواسطة البرنامج التالي. يقبل هذا البرنامج أيضًا ثلاث معلمات:
// صياغة pg bin text logs
// قراءة ملف ثنائي bin وتخزين محتواه في ملف نصي (نص)
// الملف الثنائي له بنية string، int
// يحتوي الملف النصي على أسطر بالشكل اسم : عمر
// logs هو ملف نصي للسجلات
لذلك نقوم بالعملية العكسية. نقوم بقراءة ملف ثنائي لإنشاء ملف نصي. إذا كان الملف النصي الناتج مطابقًا للملف الأصلي، فسنعرف أن التحويل من نص إلى ثنائي ثم إلى نص قد تم بنجاح. الرمز هو كما يلي:
using System;
using System.IO;
// الصيغة pg bin text logs
// يتم قراءة ملف ثنائي بن وتخزين محتواه في ملف نصي (نص)
// الملف الثنائي له بنية string, int
// يحتوي الملف النصي على أسطر بالشكل اسم : عمر
// logs هو ملف نصي للسجلات
namespace Chap3 {
class Program2 {
static void Main(string[] arguments) {
// يلزم 3 معلمات
if (arguments.Length != 3) {
Console.WriteLine("syntaxe : pg binaire texte log");
Environment.Exit(1);
}//if
// متغيرات
string nom = null;
int age = 0;
int numPersonne = 1;
BinaryReader input = null;
StreamWriter output = null;
StreamWriter logs = null;
bool fini;
// قراءة ملف ثنائي - كتابة ملف نصي
try {
// فتح الملف الثنائي للقراءة
input = new BinaryReader(new FileStream(arguments[0], FileMode.Open, FileAccess.Read));
// فتح الملف النصي للكتابة
output = new StreamWriter(arguments[1]);
// فتح ملف السجلات للكتابة
logs = new StreamWriter(arguments[2]);
// استخدام الملف الثنائي
fini = false;
while (!fini) {
try {
// قراءة الاسم
nom = input.ReadString().Trim();
// قراءة العمر
age = input.ReadInt32();
// الكتابة في ملف نصي
output.WriteLine(nom + ":" + age);
// الشخص التالي
numPersonne++;
} catch (EndOfStreamException) {
fini = true;
} catch (Exception e) {
logs.WriteLine("L'erreur suivante s'est produite à la lecture de la personne n° {0} : {1}", numPersonne, e.Message);
}
}//while
} catch (Exception e) {
Console.WriteLine("L'erreur suivante s'est produite : {0}", e.Message);
} finally {
// إغلاق الملفات
if (input != null)
input.Close();
if (output != null)
output.Close();
if (logs != null)
logs.Close();
}
}
}
}
لنركز على العمليات المتعلقة بالفئة BinaryReader:
- السطر 30: يتم فتح الكائن BinaryReader بواسطة العملية
input=new BinaryReader(new FileStream(arguments[0],FileMode.Open,FileAccess.Read));
يجب أن يكون وسيط المنشئ دفقًا (Stream). هنا هو دفق تم إنشاؤه من ملف (FileStream) الذي نقدم:
- (تابع)
- الاسم
- العملية المطلوب إجراؤها، وهي هنا FileMode.Open لفتح ملف موجود
- نوع الوصول، هنا FileAccess.Read للوصول للقراءة إلى الملف
- السطران 40 و42: عمليات القراءة
تحتوي الفئة BinaryReader على طرق مختلفة ReadXX لقراءة أنواع مختلفة من البيانات البسيطة
- السطر 60: عملية إغلاق التدفق
إذا تم تنفيذ البرنامجين بالتسلسل لتحويل personnes1.txt إلى personnes1.bin ثم personnes1.bin إلى personnes2.txt2، نحصل على النتائج التالية:
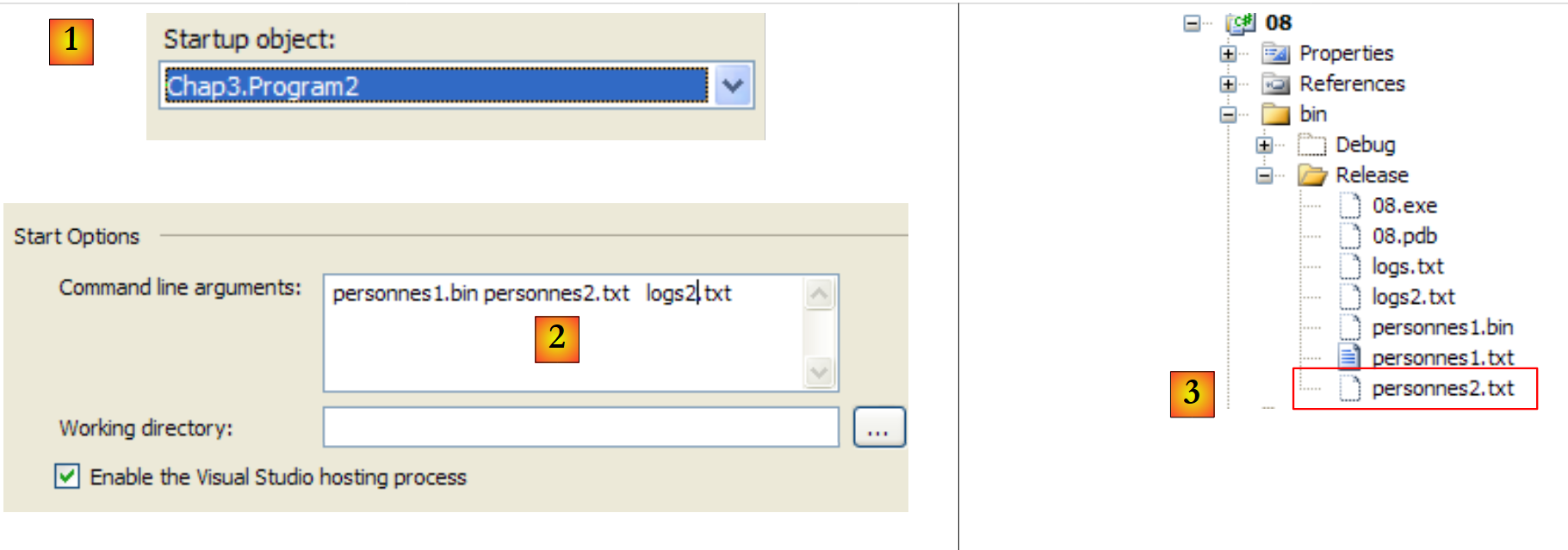 |
- في [1]، تم تكوين المشروع لتنفيذ التطبيق الثاني
- في [2]، الحجج التي تم تمريرها إلى Main
- في [3]، الملفات الناتجة عن تشغيل التطبيق.
محتوى [personnes2.txt] هو كما يلي:
5.7. التعبيرات العادية
تسمح الفئة System.Text.RegularExpressions.Regex باستخدام التعبيرات العادية. تسمح هذه التعبيرات باختبار تنسيق سلسلة أحرف. وبالتالي يمكن التحقق من أن سلسلة تمثل تاريخًا هي بالفعل بتنسيق يي/ش/س. نستخدم لهذا الغرض نموذجًا ونقارن السلسلة بهذا النموذج. وبالتالي في هذا المثال، يجب أن تكون j و m و a أرقامًا. يكون نموذج تنسيق التاريخ الصحيح هو "\d\d/\d\d/\d\d" حيث يشير الرمز \d إلى رقم. الرموز التي يمكن استخدامها في النموذج هي التالية:
الوصف | |
يُشير إلى الحرف التالي على أنه حرف خاص أو حرف عادي. على سبيل المثال، "n" يُشير إلى الحرف "n". "\n" يُشير إلى حرف السطر الجديد. التسلسل "\\" يُشير إلى "\"، بينما "\(" يُشير إلى "(". | |
يمثل بداية الإدخال. | |
يتوافق مع نهاية الإدخال. | |
يتطابق مع الحرف السابق صفر مرة أو عدة مرات. وبالتالي، فإن "zo*" يتطابق مع "z" أو "zoo". | |
يتطابق مع الحرف السابق مرة واحدة أو عدة مرات. وبالتالي، فإن "zo+" يتطابق مع "zoo"، ولكنه لا يتطابق مع "z". | |
يتطابق مع الحرف السابق صفر أو مرة واحدة. على سبيل المثال، "a?ve?" يتطابق مع "ve" في "lever". | |
يتطابق مع أي حرف فردي، باستثناء حرف السطر الجديد. | |
يبحث عن modèle ويحفظ المطابقة. يمكن استخراج السلسلة الفرعية المطابقة من مجموعة Matches التي تم الحصول عليها، باستخدام Item [0]...[n]. للعثور على تطابقات مع أحرف بين قوسين ( )، استخدم "\(" أو "\)". | |
يتطابق مع x أو y. على سبيل المثال، "z|foot" يتطابق مع "z" أو "foot". "(z|f)oo" يتطابق مع "zoo" أو "foo". | |
n هو عدد صحيح غير سالب. يتطابق تمامًا مع n مضروبًا في الحرف. على سبيل المثال، "o{2}" لا يتطابق مع "o" في "Bob"، بل مع أول حرفين "o" في "fooooot". | |
n هو عدد صحيح غير سالب. يتطابق مع ما لا يقل عن n ضعف الحرف. على سبيل المثال، "o{2,}" لا يتطابق مع "o" في "Bob"، بل مع جميع أحرف "o" في "fooooot". "o{1,}" يعادل "o+" و "o{0,}" يعادل "o*". | |
m و n أعداد صحيحة غير سالبة. يتطابق مع ما لا يقل عن n وما لا يزيد عن m مرة من الحرف. على سبيل المثال، "o{1,3}" يتطابق مع الأحرف "o" الثلاثة الأولى في "foooooot" و"o{0,1}" يعادل "o?". | |
مجموعة الأحرف. تتطابق مع أحد الأحرف المحددة. على سبيل المثال، "[abc]" تتطابق مع "a" في "plat". | |
مجموعة أحرف سلبية. تتطابق مع أي حرف غير محدد. على سبيل المثال، "[^abc]" تتطابق مع "p" في "plat". | |
نطاق الأحرف. يطابق أي حرف في السلسلة المحددة. على سبيل المثال، "[a-z]" يطابق أي حرف أبجدي صغير بين "a" و "z". | |
نطاق أحرف سلبي. يطابق أي حرف غير موجود في السلسلة المحددة. على سبيل المثال، "[^m-z]" يطابق أي حرف غير موجود بين "m" و "z". | |
يتطابق مع حد يمثل كلمة، بمعنى آخر، الموضع بين كلمة ومسافة. على سبيل المثال، "er\b" يتطابق مع "er" في "lever"، ولكنه لا يتطابق مع "er" في "verbe". | |
يتوافق مع حد لا يمثل كلمة. "en*t\B" يتوافق مع "ent" في "bien entendu". | |
يتطابق مع حرف يمثل رقمًا. يعادل [0-9]. | |
يتوافق مع حرف لا يمثل رقمًا. يعادل [^0-9]. | |
يُقابل حرف انتقال الصفحة. | |
يتوافق مع حرف سطر جديد. | |
يتوافق مع حرف إرجاع عربة. | |
يُقابل أي مسافة بيضاء، بما في ذلك المسافة، والتبويب، والانتقال إلى صفحة جديدة، وما إلى ذلك. يعادل "[ \f\n\r\t\v]". | |
يتوافق مع أي حرف مسافة غير فارغ. يعادل "[^ \f\n\r\t\v]". | |
يتوافق مع حرف الجدولة. | |
يتوافق مع حرف الجدولة العمودية. | |
يُقابل أي حرف يمثل كلمة ويتضمن شرطة سفلية. يعادل "[A-Za-z0-9_]". | |
يتوافق مع أي حرف لا يمثل كلمة. يعادل "[^A-Za-z0-9_]". | |
يتوافق مع num، حيث num هو عدد صحيح موجب. يشير إلى المطابقات المخزنة. على سبيل المثال، "(.)\1" يتوافق مع حرفين متطابقين متتاليين. | |
تتوافق مع n، حيث n هي قيمة هروب ثمانية. يجب أن تتكون قيم الهروب الثمانية من 1 أو 2 أو 3 أرقام. على سبيل المثال، "\11" و "\011" كلاهما يمثلان حرف الجدولة. "\0011" تعادل "\001" و "1". يجب ألا تتجاوز قيم الهروب الثمانية 256. إذا كان الأمر كذلك، فسيتم أخذ أول رقمين فقط في الاعتبار في التعبير. يسمح باستخدام الرموز ASCII في التعبيرات العادية. | |
يتوافق مع n، حيث n هي قيمة هروب سداسية عشرية. يجب أن تتكون قيم الهروب السداسية العشرية من رقمين. على سبيل المثال، "\x41" تعني "A". "\x041" تعني "\x04" و "1". يسمح باستخدام الرموز ASCII في التعبيرات العادية. |
يمكن أن يتواجد عنصر في نموذج في نسخة واحدة أو أكثر. لنأخذ بعض الأمثلة حول الرمز \d الذي يمثل رقمًا واحدًا:
القالب | المعنى |
\d | رقم واحد |
\d? | رقم واحد أو صفر |
\d* | رقم واحد أو أكثر |
\d+ | رقم واحد أو أكثر |
\d{2} | رقمان |
\d{3,} | 3 أرقام على الأقل |
\d{5,7} | بين 5 و7 أرقام |
لنتخيل الآن النموذج القادر على وصف التنسيق المتوقع لسلسلة أحرف:
السلسلة المطلوبة | النموذج |
تاريخ بتنسيق يي/ش/س | \d{2}/\d{2}/\d{2} |
ساعة بتنسيق hh:mm:ss | \d{2}:\d{2}:\d{2} |
عدد صحيح غير موقّع | \d+ |
سلسلة من المسافات قد تكون فارغة | \s* |
عدد صحيح غير موقّع يمكن أن يسبقه أو يتبعه مسافات | \s*\d+\s* |
عدد صحيح قد يكون موقّعًا ويسبقه أو يتبعه مسافات | \s*[+|-]?\s*\d+\s* |
عدد حقيقي غير موقّع يمكن أن يسبقه أو يتبعه مسافات | \s*\d+(.\d*)?\s* |
عدد حقيقي يمكن أن يكون موقّعًا ويسبقه أو يتبعه مسافات | \s*[+|]?\s*\d+(.\d*)?\s* |
سلسلة تحتوي على الكلمة juste | \bjuste\b |
يمكن تحديد مكان البحث عن النمط في السلسلة:
النمط | المعنى |
^النمط | يبدأ النموذج السلسلة |
النمط$ | ينهي النموذج السلسلة |
^النمط$ | يبدأ النموذج وينهي السلسلة |
النمط | يتم البحث عن النمط في كل أجزاء السلسلة بدءًا من بدايتها. |
السلسلة المطلوبة | النمط |
سلسلة تنتهي بعلامة تعجب | !$ |
سلسلة تنتهي بنقطة | \.$ |
سلسلة تبدأ بالتسلسل // | ^// |
سلسلة تتكون من كلمة واحدة فقط قد تسبقها أو تليها مسافات | ^\s*\w+\s*$ |
سلسلة تتكون من كلمتين قد تسبقهما أو تتبعهما مسافات | ^\s*\w+\s*\w+\s*$ |
سلسلة تحتوي على الكلمة secret | \bsecret\b |
يمكن "استرداد" المجموعات الفرعية لنموذج ما. وبالتالي، لا يمكننا فقط التحقق من أن سلسلة ما تتطابق مع نموذج معين، بل يمكننا أيضًا استرداد العناصر الموجودة في هذه السلسلة والتي تتطابق مع المجموعات الفرعية للنموذج التي تم وضعها بين قوسين. لذلك، إذا قمنا بتحليل سلسلة تحتوي على تاريخ يوم/شهر/سنة، وأردنا أيضًا استرداد العناصر يوم، شهر، سنة من هذا التاريخ، فسنستخدم النموذج (\d\d)/(\d\d)/(\d\d).
5.7.1. التحقق من أن سلسلة ما تتطابق مع نموذج معين
يتم إنشاء كائن من نوع Regex بالطريقة التالية:
بمجرد إنشاء التعبير العادي النموذجي، يمكن مقارنته بسلاسل الأحرف باستخدام الطريقة IsMatch:
إليك مثال:
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// نمط تعبير عادي
string modèle1 = @"^\s*\d+\s*$";
Regex regex1 = new Regex(modèle1);
// مقارنة نسخة بالنموذج
string exemplaire1 = " 123 ";
if (regex1.IsMatch(exemplaire1)) {
Console.WriteLine("[{0}] correspond au modèle [{1}]", exemplaire1, modèle1);
} else {
Console.WriteLine("[{0}] ne correspond pas au modèle [{1}]", exemplaire1, modèle1);
}//if
string exemplaire2 = " 123a ";
if (regex1.IsMatch(exemplaire2)) {
Console.WriteLine("[{0}] correspond au modèle [{1}]", exemplaire2, modèle1);
} else {
Console.WriteLine("[{0}] ne correspond pas au modèle [{1}]", exemplaire2, modèle1);
}//if
}
}
}
ونتيجة التنفيذ:
5.7.2. البحث عن جميع مرات ظهور نمط ما في سلسلة
تسمح طريقة Matches باسترداد عناصر سلسلة تتطابق مع نموذج:
تحتوي الفئة MatchCollection على خاصية Count وهي عدد عناصر المجموعة. إذا كان résultats كائنًا من نوع MatchCollection، فإن results[i] هو العنصر i في هذه المجموعة وهو من النوع Match. تحتوي الفئة Match على خصائص متنوعة منها ما يلي:
- Value: قيمة الكائن Match,، أي عنصر مطابق للنموذج
- Index: الموضع الذي تم العثور فيه على العنصر في السلسلة التي تم استكشافها
لنلقِ نظرة على المثال التالي:
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program2 {
static void Main(string[] args) {
// عدة تكرارات للنموذج في النسخة
string modèle2 = @"\d+";
Regex regex2 = new Regex(modèle2);
string exemplaire3 = " 123 456 789 ";
MatchCollection résultats = regex2.Matches(exemplaire3);
Console.WriteLine("Modèle=[{0}],exemplaire=[{1}]", modèle2, exemplaire3);
Console.WriteLine("Il y a {0} occurrences du modèle dans l'exemplaire ", résultats.Count);
for (int i = 0; i < résultats.Count; i++) {
Console.WriteLine("[{0}] trouvé en position {1}", résultats[i].Value, résultats[i].Index);
}//for
}
}
}
- السطر 8: النموذج المطلوب هو سلسلة من الأرقام
- السطر 10: السلسلة التي يتم البحث فيها عن هذا النموذج
- السطر 11: يتم استرداد جميع عناصر exemplaire3 للتحقق من النمط modèle2
- الأسطر 14-16: يتم عرضها
نتائج تنفيذ البرنامج هي كما يلي:
5.7.3. استرداد أجزاء من نموذج
يمكن "استرداد" مجموعات فرعية من نموذج. وبالتالي، لا يمكننا فقط التحقق من أن سلسلة ما تتطابق مع نموذج معين، بل يمكننا أيضًا استرداد العناصر الموجودة في هذه السلسلة والتي تتطابق مع المجموعات الفرعية للنموذج التي تم وضعها بين قوسين. لذا، إذا قمنا بتحليل سلسلة تحتوي على تاريخ ي/ش/س، وأردنا أيضًا استرداد العناصر ي، ش، س من هذا التاريخ، فسنستخدم النموذج (\d\d)/(\d\d)/(\d\d).
لننظر إلى المثال التالي:
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program3 {
static void Main(string[] args) {
// التقاط عناصر في النموذج
string modèle3 = @"(\d\d):(\d\d):(\d\d)";
Regex regex3 = new Regex(modèle3);
string exemplaire4 = "Il est 18:05:49";
// التحقق من النموذج
Match résultat = regex3.Match(exemplaire4);
if (résultat.Success) {
// النسخة تتطابق مع النموذج
Console.WriteLine("L'exemplaire [{0}] correspond au modèle [{1}]",exemplaire4,modèle3);
// يتم عرض مجموعات الأقواس
for (int i = 0; i < résultat.Groups.Count; i++) {
Console.WriteLine("groupes[{0}]=[{1}] trouvé en position {2}",i, résultat.Groups[i].Value,résultat.Groups[i].Index);
}//for
} else {
// النسخة لا تتطابق مع النموذج
Console.WriteLine("L'exemplaire[{0}] ne correspond pas au modèle [{1}]", exemplaire4, modèle3);
}
}
}
}
يؤدي تنفيذ هذا البرنامج إلى النتائج التالية:
تكمن الجديد في الأسطر 12-19:
- السطر 12: تتم مقارنة السلسلة exemplaire4 بالنموذج regex3 من خلال الطريقة Match. وتُرجع هذه الطريقة كائن Match الذي تم عرضه سابقًا. نستخدم هنا خاصيتين جديدتين لهذه الفئة:
- Success (السطر 13): تشير إلى ما إذا كان هناك تطابق
- Groups (السطران 17 و18): مجموعة حيث
- Groups[0] إلى جزء السلسلة المطابق للنموذج
- Groups[i] (i>=1) تتطابق مع مجموعة الأقواس رقم i
إذا كان résultat من النوع Match، فإن résultats.Groups يكون من النوع GroupCollection و résultats.Groups[i] من النوع Group. تحتوي الفئة Group على خاصيتين نستخدمهما هنا:
- Value (السطر 18): قيمة الكائن Group الذي يمثل العنصر المطابق لمحتوى قوس
- Index (السطر 18): الموضع الذي تم العثور فيه على العنصر في السلسلة التي تم استكشافها
5.7.4. برنامج للتدريب
قد يمثل العثور على التعبير النمطي الذي يسمح بالتحقق من أن سلسلة ما تتطابق بالفعل مع نموذج معين تحديًا حقيقيًا في بعض الأحيان. يتيح البرنامج التالي التدريب على ذلك. فهو يطلب نموذجًا وسلسلة ويشير إلى ما إذا كانت السلسلة تتطابق مع النموذج أم لا.
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program4 {
static void Main(string[] args) {
// البيانات
string modèle, chaine;
Regex regex = null;
MatchCollection résultats;
// يُطلب من المستخدم النماذج والنسخ التي يجب مقارنتها بهذه
while (true) {
// يُطلب النموذج
Console.Write("Tapez le modèle à tester ou rien pour arrêter :");
modèle = Console.In.ReadLine();
// انتهى؟
if (modèle.Trim() == "")
break;
// يتم إنشاء التعبير العادي
try {
regex = new Regex(modèle);
} catch (Exception ex) {
Console.WriteLine("Erreur : " + ex.Message);
continue;
}
// نطلب من المستخدم النسخ التي سيتم مقارنتها بالنموذج
while (true) {
Console.Write("Tapez la chaîne à comparer au modèle [{0}] ou rien pour arrêter :", modèle);
chaine = Console.ReadLine();
// انتهى؟
if (chaine.Trim() == "")
break;
// إجراء المقارنة
résultats = regex.Matches(chaine);
// نجاح؟
if (résultats.Count == 0) {
Console.WriteLine("Je n'ai pas trouvé de correspondances");
continue;
}//if
// يتم عرض العناصر المطابقة للنموذج
for (int i = 0; i < résultats.Count; i++) {
Console.WriteLine("J'ai trouvé la correspondance [{0}] en position [{1}]", résultats[i].Value, résultats[i].Index);
// العناصر الفرعية
if (résultats[i].Groups.Count != 1) {
for (int j = 1; j < résultats[i].Groups.Count; j++) {
Console.WriteLine("\tsous-élément [{0}] en position [{1}]", résultats[i].Groups[j].Value, résultats[i].Groups[j].Index);
}
}
}
}
}
}
}
}
فيما يلي مثال على التنفيذ:
5.7.5. طريقة Split
لقد سبق أن تعرفنا على هذه الطريقة في الفصل String:
|
تسمح لنا الطريقة Split من الفئة Regex بالتعبير عن الفاصل وفقًا لنموذج:
|
لنفترض على سبيل المثال أن لدينا في ملف نصي أسطر بالشكل حقل1، حقل2، ..، حقلn. الحقول مفصولة بفاصلة ولكن قد تسبقها أو تتبعها مسافات. في هذه الحالة، لا تناسبنا الطريقة Split من الفئة string. أما الطريقة RegEx فهي الحل المناسب. إذا كان ligne هو السطر الذي تمت قراءته، فيمكن الحصول على الحقول بواسطة
كما يوضح المثال التالي:
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program5 {
static void Main(string[] args) {
// سطر
string ligne = "abc , def , ghi";
// نموذج
Regex modèle = new Regex(@"\s*,\s*");
// تفصيل السطر إلى حقول
string[] champs = modèle.Split(ligne);
// العرض
for (int i = 0; i < champs.Length; i++) {
Console.WriteLine("champs[{0}]=[{1}]", i, champs[i]);
}
}
}
}
نتائج التنفيذ:
5.8. تطبيق مثال - V3
نستأنف التطبيق الذي تمت دراسته في الفقرتين 3.6 (الإصدار 1) و 4.10 (الإصدار 2).
في الإصدار الأخير الذي تمت دراسته، كان حساب الضريبة يتم في الفئة المجردة AbstractImpot:
namespace Chap2 {
abstract class AbstractImpot : IImpot {
// شرائح الضريبة اللازمة لحساب الضريبة
// تأتي من مصدر خارجي
protected TrancheImpot[] tranchesImpot;
// حساب الضريبة
public int calculer(bool marié, int nbEnfants, int salaire) {
// حساب عدد الحصص
decimal nbParts;
if (marié) nbParts = (decimal)nbEnfants / 2 + 2;
else nbParts = (decimal)nbEnfants / 2 + 1;
if (nbEnfants >= 3) nbParts += 0.5M;
// حساب الدخل الخاضع للضريبة و"الناتج العائلي"
decimal revenu = 0.72M * salaire;
decimal QF = revenu / nbParts;
// حساب الضريبة
tranchesImpot[tranchesImpot.Length - 1].Limite = QF + 1;
int i = 0;
while (QF > tranchesImpot[i].Limite) i++;
// إرجاع النتيجة
return (int)(revenu * tranchesImpot[i].CoeffR - nbParts * tranchesImpot[i].CoeffN);
}//الحساب
}//الفئة
}
تستخدم الطريقة calculer في السطر 38 المصفوفة tranchesImpot في السطر 35، وهي مصفوفة لم يتم تهيئتها بواسطة الفئة AbstractImpot. ولهذا السبب فهي مجردة ويجب اشتقاقها لتكون مفيدة. تم إجراء هذا التهيئة بواسطة الفئة المشتقة HardwiredImpot:
using System;
namespace Chap2 {
class HardwiredImpot : AbstractImpot {
// جداول البيانات اللازمة لحساب الضريبة
decimal[] limites = { 4962M, 8382M, 14753M, 23888M, 38868M, 47932M, 0M };
decimal[] coeffR = { 0M, 0.068M, 0.191M, 0.283M, 0.374M, 0.426M, 0.481M };
decimal[] coeffN = { 0M, 291.09M, 1322.92M, 2668.39M, 4846.98M, 6883.66M, 9505.54M };
public HardwiredImpot() {
// إنشاء جدول شرائح الضريبة
tranchesImpot = new TrancheImpot[limites.Length];
// ملء
for (int i = 0; i < tranchesImpot.Length; i++) {
tranchesImpot[i] = new TrancheImpot { Limite = limites[i], CoeffR = coeffR[i], CoeffN = coeffN[i] };
}
}
}// فئة
}// مساحة الاسم
فيما سبق، كانت البيانات اللازمة لحساب الضريبة موضوعة بشكل "ثابت" في كود الفئة. أما النسخة الجديدة من المثال فتضعها في ملف نصي:
4962:0:0
8382:0,068:291,09
14753:0,191:1322,92
23888:0,283:2668,39
38868:0,374:4846,98
47932:0,426:6883,66
0:0,481:9505,54
نظرًا لأن استخدام هذا الملف قد يؤدي إلى حدوث استثناءات، فإننا نقوم بإنشاء فئة خاصة لإدارة هذه الاستثناءات:
using System;
namespace Chap3 {
class FileImpotException : Exception {
// رموز الأخطاء
[Flags]
public enum CodeErreurs { Acces = 1, Ligne = 2, Champ1 = 4, Champ2 = 8, Champ3 = 16 };
// رمز الخطأ
public CodeErreurs Code { get; set; }
// المنشئات
public FileImpotException() {
}
public FileImpotException(string message)
: base(message) {
}
public FileImpotException(string message, Exception e)
: base(message,e) {
}
}
}
- السطر 4: الفئة FileImpotException مشتقة من الفئة Exception. وستُستخدم لتخزين أي خطأ يحدث أثناء معالجة ملف البيانات النصي.
- السطر 7: قائمة تمثل رموز الأخطاء:
- Acces: خطأ في الوصول إلى ملف البيانات النصي
- Ligne: السطر لا يحتوي على الحقول الثلاثة المتوقعة
- Champ1: الحقل رقم 1 خاطئ
- Champ2: الحقل رقم 2 غير صحيح
- Champ3: الحقل رقم 3 غير صحيح
قد تتكرر بعض هذه الأخطاء (Champ1، Champ2، Champ3). لذلك تم توضيح التعداد CodeErreurs بالسمة [Flags] التي تشير إلى أن القيم المختلفة للتعداد يجب أن تكون قوى لعدد 2. سيؤدي أي خطأ في الحقلين 1 و 2 إلى ظهور رمز الخطأ Champ1 | Champ2.
- السطر 10: ستقوم الخاصية التلقائية Code بتخزين رمز الخطأ.
- السطر 15: منشئ يسمح بإنشاء كائن FileImpotException عن طريق تمرير رسالة خطأ كمعلمة له.
- السطر 18: مُنشئ يُسمح بإنشاء كائن FileImpotException عن طريق تمرير رسالة الخطأ والاستثناء الذي تسبب في الخطأ كمعلمات له.
أصبحت الفئة التي تقوم بتهيئة المصفوفة tranchesImpot الخاصة بالفئة AbstractImpot كما يلي:
using System;
using System.Collections.Generic;
using System.IO;
using System.Text.RegularExpressions;
namespace Chap3 {
class FileImpot : AbstractImpot {
public FileImpot(string fileName) {
// البيانات
List<TrancheImpot> listTranchesImpot = new List<TrancheImpot>();
int numLigne = 1;
// استثناء
FileImpotException fe = null;
// قراءة محتوى الملف fileName، سطراً سطراً
Regex pattern = new Regex(@"s*:\s*");
// في البداية لا توجد أخطاء
FileImpotException.CodeErreurs code = 0;
try {
using (StreamReader input = new StreamReader(fileName)) {
while (!input.EndOfStream && code == 0) {
// السطر الحالي
string ligne = input.ReadLine().Trim();
// يتم تجاهل الأسطر الفارغة
if (ligne == "") continue;
// السطر مقسم إلى ثلاثة حقول مفصولة بـ:
string[] champsLigne = pattern.Split(ligne);
// هل لدينا 3 حقول؟
if (champsLigne.Length != 3) {
code = FileImpotException.CodeErreurs.Ligne;
}
// تحويلات الحقول الثلاثة
decimal limite = 0, coeffR = 0, coeffN = 0;
if (code == 0) {
if (!Decimal.TryParse(champsLigne[0], out limite)) code = FileImpotException.CodeErreurs.Champ1;
if (!Decimal.TryParse(champsLigne[1], out coeffR)) code |= FileImpotException.CodeErreurs.Champ2;
if (!Decimal.TryParse(champsLigne[2], out coeffN)) code |= FileImpotException.CodeErreurs.Champ3; ;
}
// خطأ؟
if (code != 0) {
// يتم تسجيل الخطأ
fe = new FileImpotException(String.Format("Ligne n° {0} incorrecte", numLigne)) { Code = code };
} else {
// يتم حفظ الشريحة الضريبية الجديدة
listTranchesImpot.Add(new TrancheImpot() { Limite = limite, CoeffR = coeffR, CoeffN = coeffN });
// السطر التالي
numLigne++;
}
}
}
// ننقل القائمة listImpot إلى الجدول tranchesImpot
if (code == 0) {
// يتم نقل القائمة listImpot إلى الجدول tranchesImpot
tranchesImpot = listTranchesImpot.ToArray();
}
} catch (Exception e) {
// يتم تسجيل الخطأ
fe= new FileImpotException(String.Format("Erreur lors de la lecture du fichier {0}", fileName), e) { Code = FileImpotException.CodeErreurs.Acces };
}
// هل يجب الإبلاغ عن الخطأ؟
if (fe != null) throw fe;
}
}
}
- السطر 7: الفئة FileImpot مشتقة من الفئة AbstractImpot كما كانت الفئة HardwiredImpot في الإصدار 2.
- السطر 9: دور منشئ الفئة FileImpot هو تهيئة الحقل trancheImpot من فئتها الأساسية AbstractImpot. ويقبل كمعلمة اسم الملف النصي الذي يحتوي على البيانات.
- السطر 11: الحقل tranchesImpot للفئة الأساسية AbstractImpot هو مصفوفة يجب ملؤها ببيانات الملف filename الذي تم تمريره كمعلمة. تتم قراءة الملف النصي بشكل متسلسل. لا يمكن معرفة عدد الأسطر إلا بعد قراءة الملف بالكامل. لذلك لا يمكن تحديد حجم المصفوفة tranchesImpot. سيتم تخزين البيانات مؤقتًا في القائمة العامة listTranchesImpot.
يُذكر أن النوع TrancheImpot هو بنية:
namespace Chap3 {
// شريحة ضريبية
struct TrancheImpot {
public decimal Limite { get; set; }
public decimal CoeffR { get; set; }
public decimal CoeffN { get; set; }
}
}
- السطر 14: fe من النوع FileImpotException يستخدم لتغليف أي خطأ محتمل في تشغيل الملف النصي.
- السطر 16: التعبير العادي لفاصل الحقول في سطر champ1:champ2:champ3 من الملف النصي. يتم فصل الحقول بواسطة الحرف: الذي يسبقه ويليه أي عدد من المسافات.
- السطر 18: رمز الخطأ في حالة حدوث خطأ
- السطر 20: معالجة الملف النصي باستخدام StreamReader
- السطر 21: يتم تكرار العملية طالما بقيت هناك سطر واحد ليتم قراءته ولم تحدث أي أخطاء
- السطر 27: يتم تقسيم السطر الذي تمت قراءته إلى حقول باستخدام التعبير العادي في السطر 16
- الأسطر 29-31: يتم التحقق من أن السطر يحتوي بالفعل على ثلاثة حقول - يتم تسجيل أي خطأ محتمل
- الأسطر 33-38: تحويل السلاسل الثلاثة إلى ثلاثة أرقام عشرية - يتم تسجيل الأخطاء المحتملة
- الأسطر 40-43: في حالة وجود خطأ، يتم إنشاء استثناء من النوع FileImpotException.
- الأسطر 44-47: إذا لم يكن هناك خطأ، ننتقل إلى قراءة السطر التالي من الملف النصي بعد حفظ البيانات المستمدة من السطر الحالي.
- الأسطر 52-55: عند الخروج من الفوهة while، يتم نسخ بيانات القائمة العامة listTranchesImpot إلى الجدول tranchesImpot من الفئة الأساسية AbstractImpot. يُذكر أن هذا كان هدف المُصمم.
- الأسطر 56-59: إدارة أي استثناء محتمل. يتم تغليف هذا الاستثناء في كائن من النوع FileImpotException.
- السطر 61: إذا تم تهيئة الاستثناء fe في السطر 18، يتم إطلاقه.
المشروع C# بالكامل هو كما يلي:
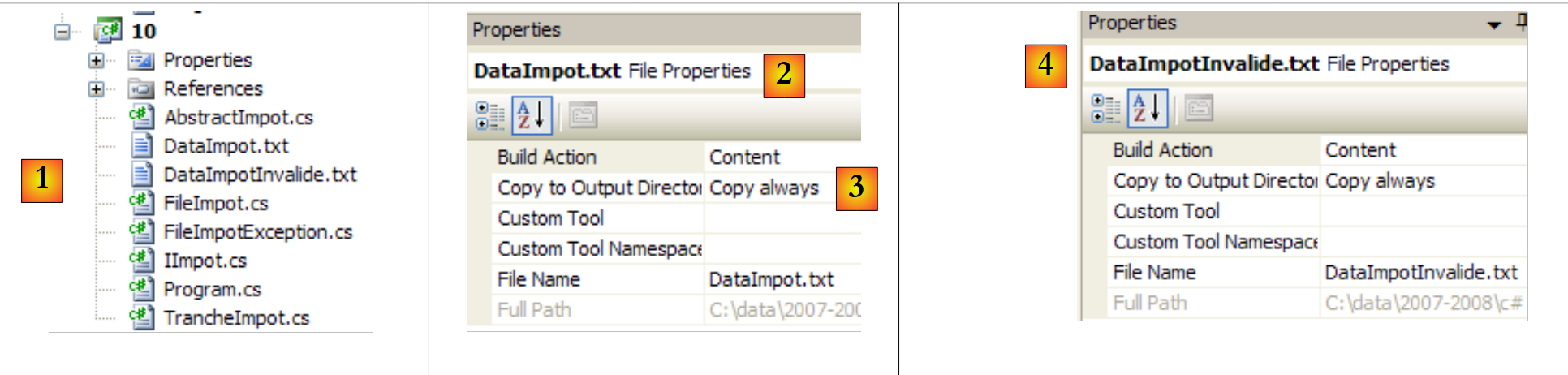 |
- في [1]: المشروع بأكمله
- في [2,3]: خصائص الملف [DataImpot.txt] [2]. يتم تعيين الخاصية [Copy to Output Directory] [3] على always. وهذا يؤدي إلى نسخ الملف [DataImpot.txt] إلى المجلد bin/Release (وضع Release) أو bin/Debug (وضع Debug) عند كل عملية تشغيل. وهنا يتم البحث عنه بواسطة الملف القابل للتنفيذ.
- في [4]: يتم إجراء نفس الشيء مع الملف [DataImpotInvalide.txt].
محتوى [DataImpot.txt] هو التالي:
4962:0:0
8382:0,068:291,09
14753:0,191:1322,92
23888:0,283:2668,39
38868:0,374:4846,98
47932:0,426:6883,66
0:0,481:9505,54
محتوى [DataImpotInvalide.txt] هو كما يلي:
لم يتغير برنامج الاختبار [Program.cs]: فهو نفس البرنامج الوارد في الفقرة 4.10 من الإصدار 2، مع الاختلاف التالي:
using System;
namespace Chap3 {
class Program {
static void Main() {
...
// إنشاء كائن IImpot
IImpot impot = null;
try {
// إنشاء كائن IImpot
impot = new FileImpot("DataImpot.txt");
} catch (FileImpotException e) {
// عرض خطأ
string msg = e.InnerException == null ? null : String.Format(", Exception d'origine : {0}", e.InnerException.Message);
Console.WriteLine("L'erreur suivante s'est produite : [Code={0},Message={1}{2}]", e.Code, e.Message, msg == null ? "" : msg);
// إيقاف البرنامج
Environment.Exit(1);
}
// حلقة لا نهائية
while (true) {
...
}//while
}
}
}
- السطر 8: كائن impot من نوع واجهة IImpot
- السطر 11: إنشاء مثيل للكائن impot باستخدام كائن من النوع FileImpot. قد يؤدي ذلك إلى حدوث استثناء يتم معالجته بواسطة try / catch في الأسطر 9 / 12 / 18.
فيما يلي أمثلة على التنفيذ:
مع الملف [DataImpot.txt]
مع ملف [xx] غير موجود
مع الملف [DataImpotInvalide.txt]