3. Introduction à l'API JDBC
3.1. Mise en place de l'environnement de travail
Nous allons travailler avec une base de données MySQL5.
Vous devez avoir :
- installé un JDK (Java Development Kit) (paragraphe 23.1) ;
- installé le gestionnaire de dépendances Maven ( paragraphe 23.2) ;
- installé l'IDE Spring Tool Suite (STS) ( paragraphe 23.3) ;
- installé le SGBD MySQL5 ( paragraphe 23.4) et son client EMS MyManager ( paragraphe 23.5) ;
- téléchargé les codes du document [http://tahe.developpez.com/java/spring-database];
On suppose dans la suite que l'administrateur de MySQL5 est root avec le mot de passe root. Lancez le SGBD MySQL5 et son client [MyManager]. A l'aide de [MyManager], nous créons la base [dbproduits] [1-34] :
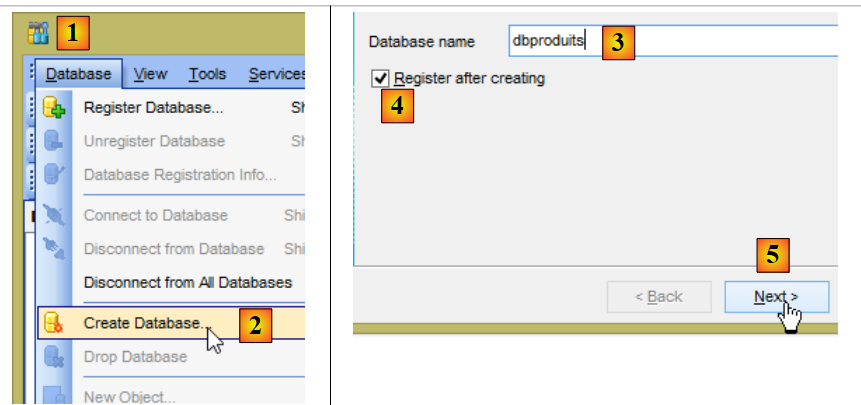 |
- en [3], la base doit s'appeler [dbproduits] ;
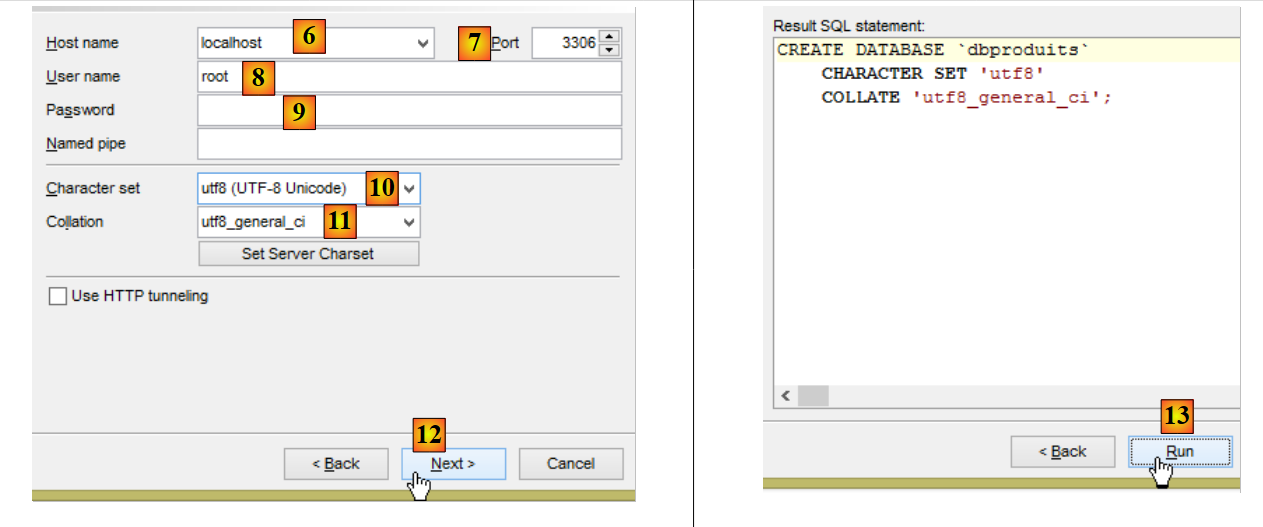 |
- en [8-9], root avec le mot de passe root (ce que ne montre pas la copie d'écran ci-dessus) ;
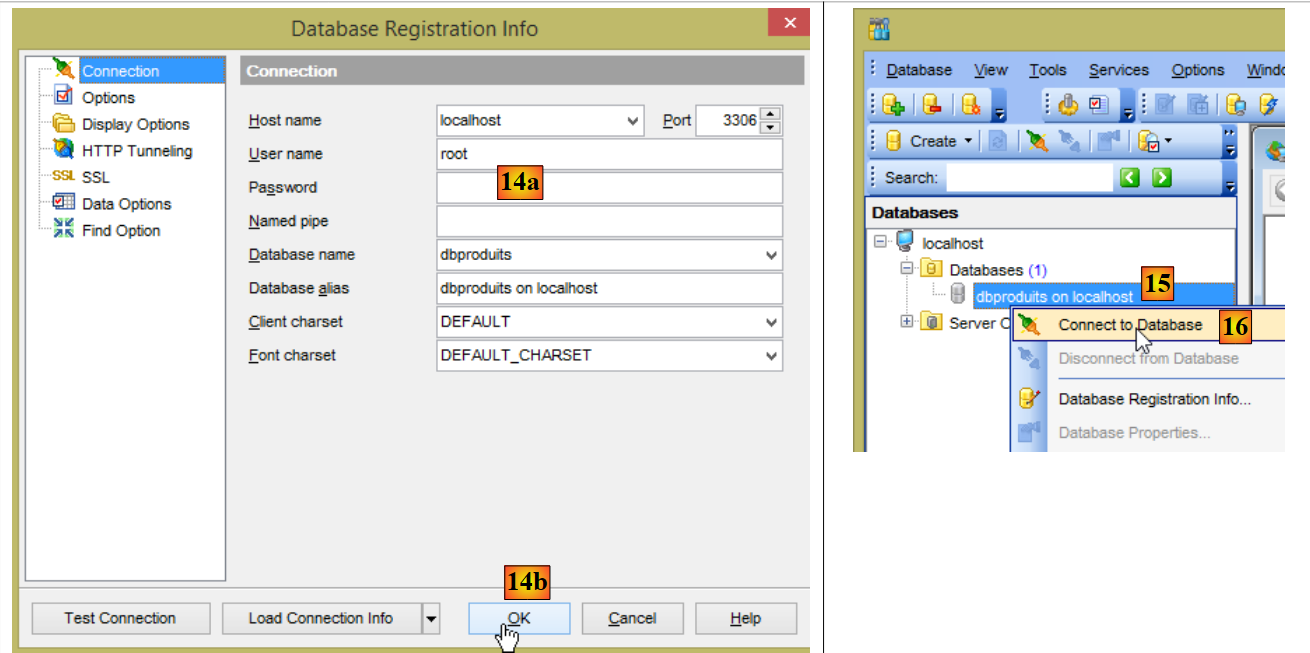 |
- en [14a], le mot de passe est root de nouveau (ce que ne montre pas la copie d'écran) ;
- en [15], la base [dbproduits] a été créée ;
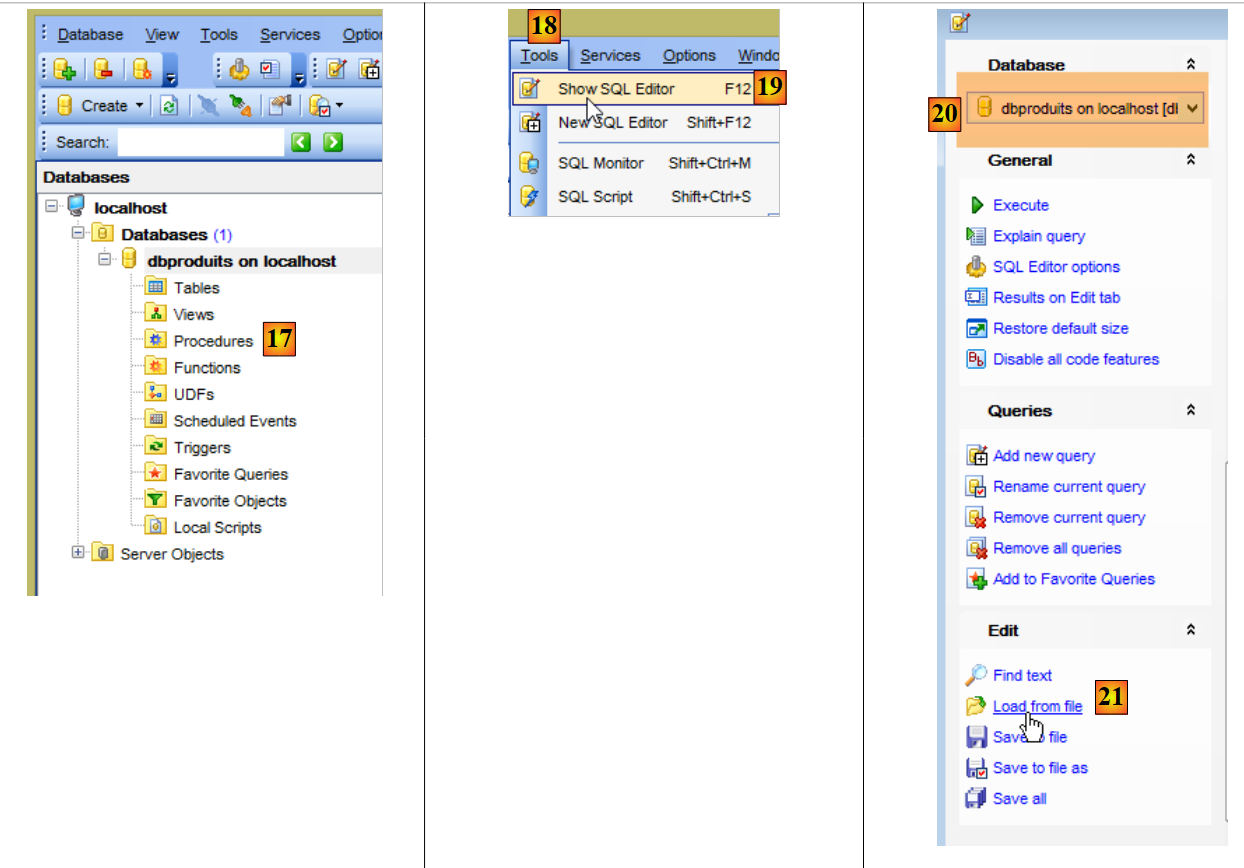 |
- en [20], faire attention à la base sélectionnée. Ce doit être la base [dbproduits] ;
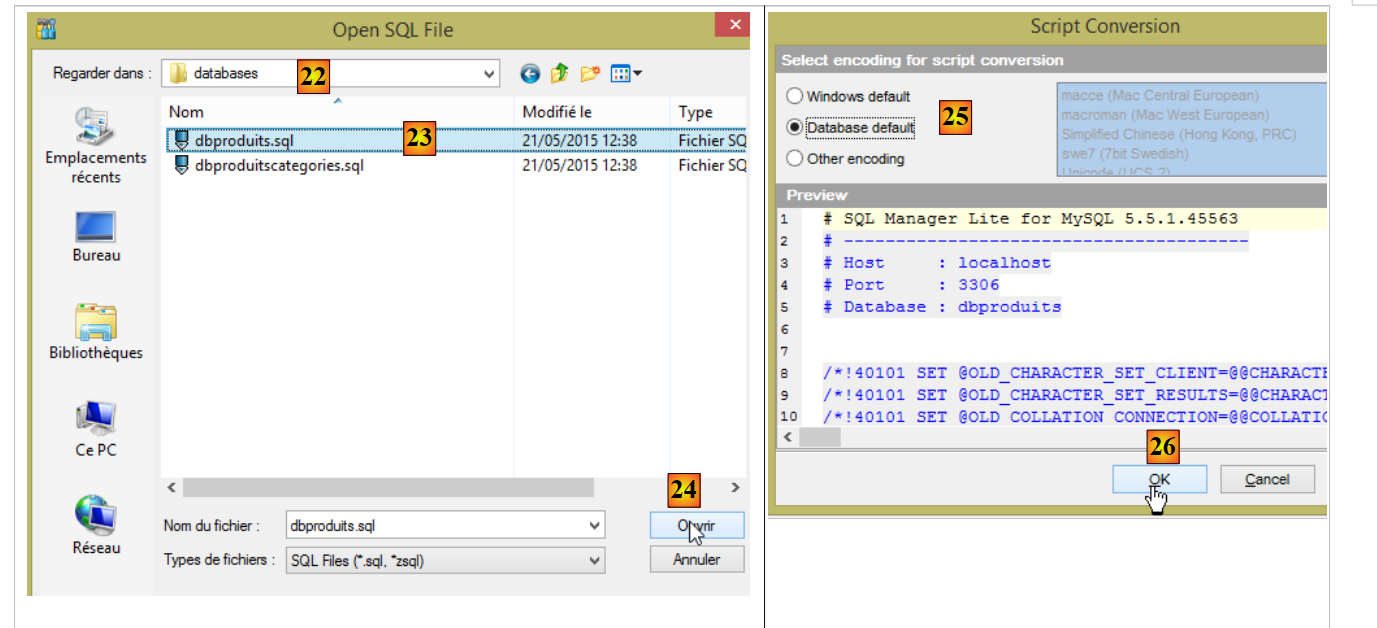 |
- en [22], le dossier est <exemples>/spring-database-config/mysql/databases où <exemples> est le dossier des exemples téléchargés ;
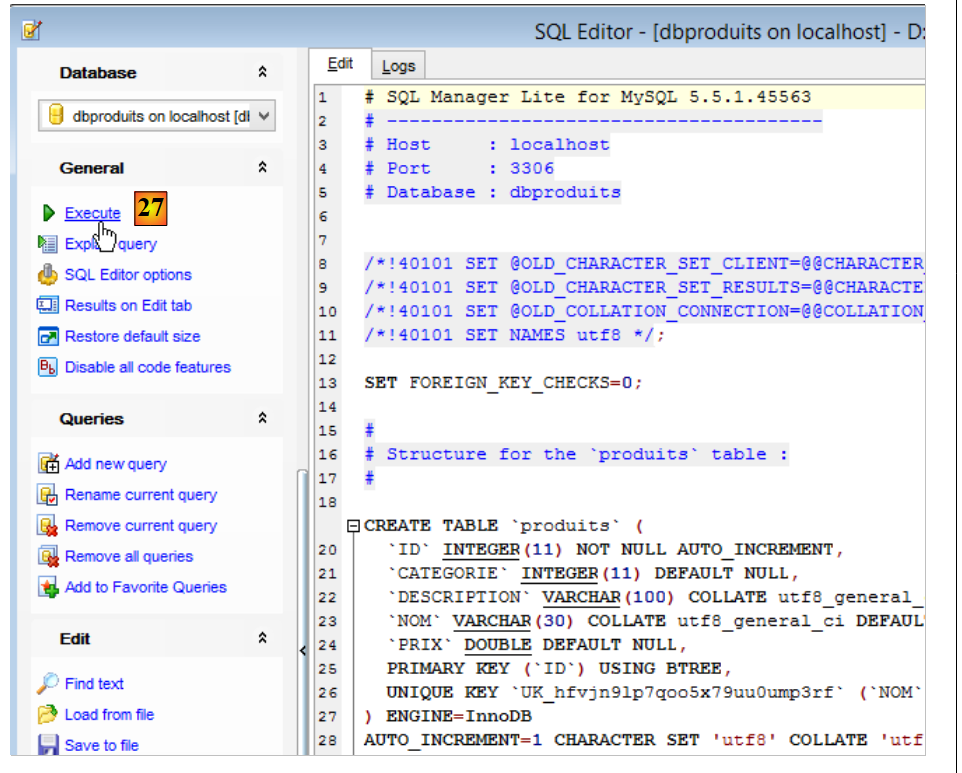
- en [23], sélectionnez le script SQL [dbproduits.sql]. Il va générer la table [PRODUITS] dans la base [dbproduits] ;
 |
 |
- en [30], la table [produits] a été créée ;
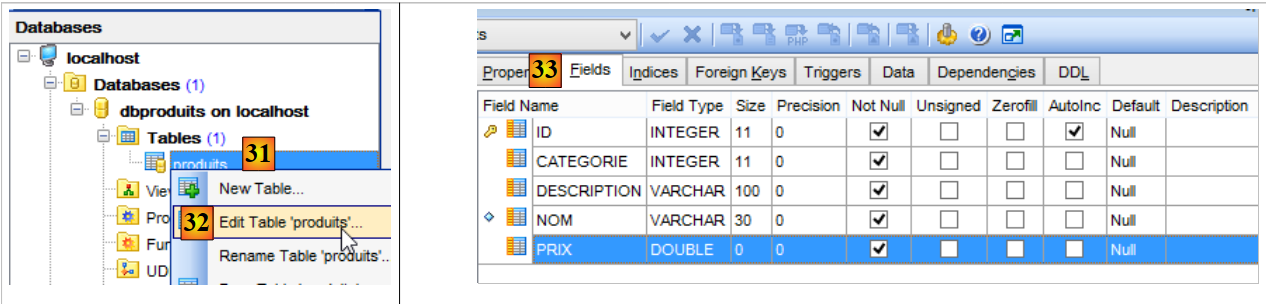 |
- en [33], les colonnes de la table [produits] ;
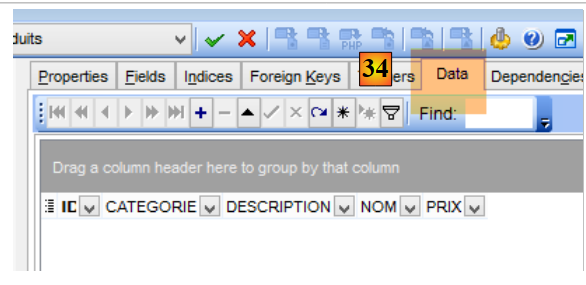 |
- en [34], elle est initialement vide ;
Maintenant avec STS, importez les projets suivants (suivez la démarche utilisée pour les projets du dossier <exemples>/spring-core) :
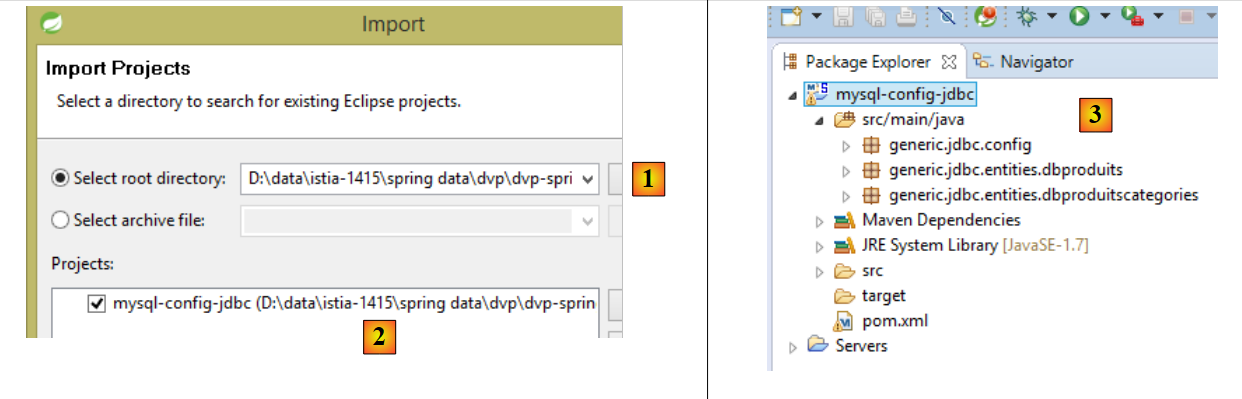 |
- en [2], le projet [mysql-config-jdbc] sera trouvé dans le dossier [<exemples>/spring-database-config/mysql/eclipse/mysql-config-jdbc] [1] ;
Ce projet configure la couche JDBC de l'architecture ci-dessous :
 |
Puis importez de nouveau, les trois projets suivants :
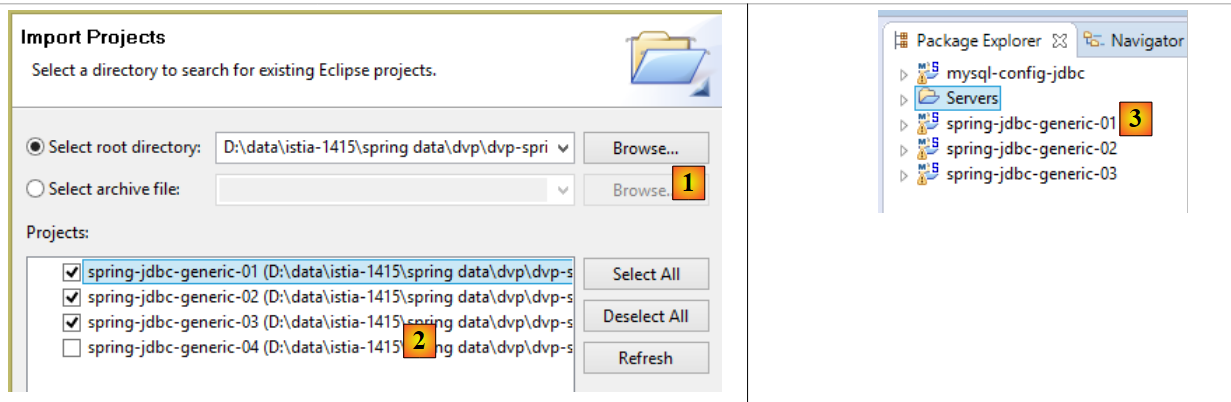 |
- en [2], les projets seront trouvés dans le dossier [<exemples>/spring-database-config/spring-jdbc] [1] ;
Ces trois projets sont des projets Maven qui utilisent le projet Maven [mysql-config-jdbc]. Ce dernier projet génère l'artifact Maven suivant (cf pom.xml) :
<groupId>dvp.spring.database</groupId>
<artifactId>generic-config-jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
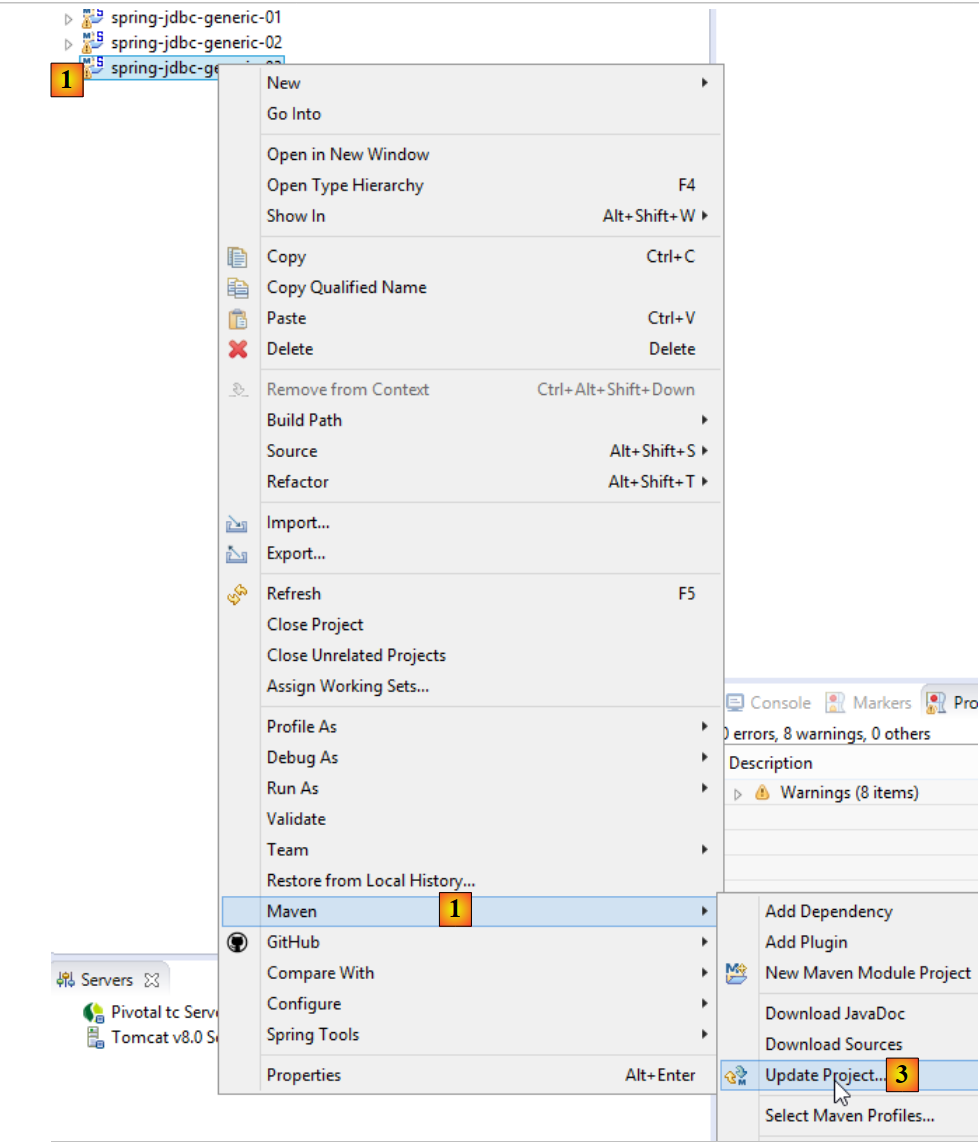
Le même artifact sera généré par le projet [oracle-config-jdbc, db2-config-jdbc, ...]. Pour vous assurer que les projets [spring-generic-jdbc-*] chargés actuellement dans STS utilisent bien le projet [mysql-config-jdbc] :
- assurez-vous qu'un autre projet [sgbd-config-jdbc] n'est pas chargé en même temps. Cela pourrait provoquer des erreurs difficilement compréhensibles ;
- mettez à jour la configuration Maven des projets chargés de la façon suivante :
 |
 |
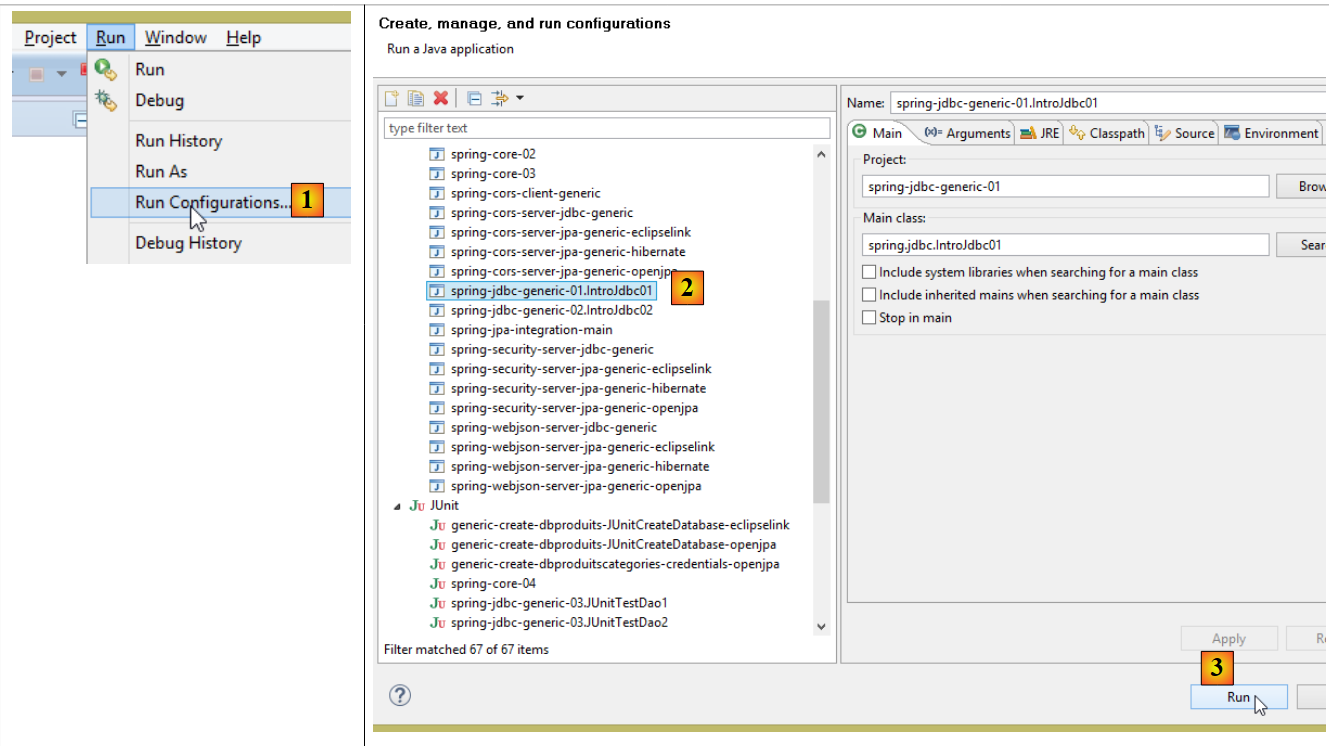
Pour vérifier votre configuration, exécutez la configuration d'exécution [spring-jdbc-generic-01.IntroJdbc01] [1-3] :
 |
Vous devez obtenir les résultats console suivants :
Dans les exemples qui suivent, le lecteur pourra :
- soit travailler directement avec les projets chargés précédemment ;
- soit construire lui-même les projets ;
3.2. Les étapes d'exploitation d'une base de données
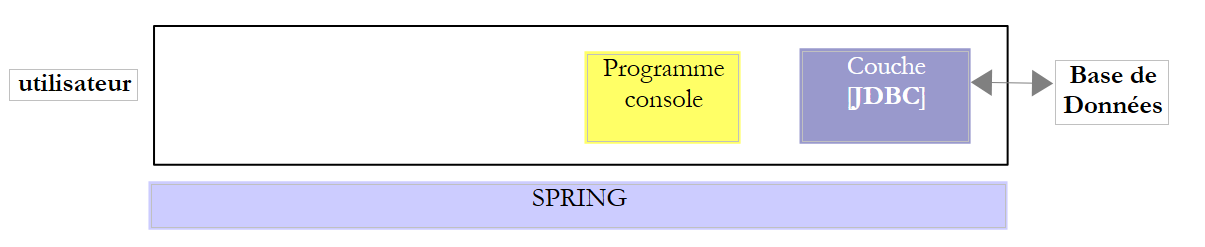 |
Dans l'architecture ci-dessus, l'exploitation d'une base de données par le programme console comporte les étapes suivantes :
- chargement du pilote JDBC de la base de données ;
- ouverture d'une connexion avec la base ;
- émission d'un ordre SQL sur la base et traitement des résultats de l'ordre SQL ;
- fermeture de la connexion ;
L'étape 1 ne se fait qu'une fois. Les étapes 2-4 se font de façon répétée. On notera qu'on ne laisse pas une connexion ouverte. On la ferme dès qu'on en n'a plus besoin.
3.2.1. étape 1 - chargement en mémoire du pilote JDBC
Le code
// chargement du pilote JDBC
try {
Class.forName(nom de la classe du pilote JDBC);
} catch (ClassNotFoundException e1) {
// traiter l'exception
}
L'opération de la ligne 3 a pour but de charger en mémoire le pilote JDBC de la base de données. Cette opération n'a besoin d'être faite qu'une fois. La répéter ne cause cependant pas d'erreur. La classe du pilote JDBC est cherchée dans le Classpath du projet. Il faut donc que dans le projet Eclipse, le [jar] contenant la classe du pilote JDBC ait été inclus dans le Classpath du projet.
3.2.2. étape 2 - ouverture d'une connexion
Une fois le pilote JDBC en place, on lui demande d'ouvrir une connexion avec la BD :
Le code
package spring.jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class IntroJdbc01 {
...
Connection connexion = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
// ouverture connexion
connexion = DriverManager.getConnection(url, user, passwd);
...
} catch (SQLException e1) {
// on traite l'exception
...
} finally {
// fermer la connexion
if (connexion != null) {
try {
connexion.close();
} catch (SQLException e2) {
// traiter l'exception
...
}
}
}
- lignes 3-7 : les classes d'implémentation de l'interface JDBC sont toutes dans le package [java.sql]. Par ailleurs, en cas d'erreur elles lancent toutes une exception de type [SQLException] (ligne 19, 27). Cette exception dérive de la classe [Exception] et est une exception dite contrôlée : on est obligé de mettre un try / catch pour la gérer ou de façon alternative de ne pas la gérer et d'indiquer que la méthode laisse sortir l'exception en complétant la signature de la méthode par [throws SQLException] ;
- ligne 17, [DriverManager.getConnection] est une méthode statique qui attend trois paramètres :
- [url] : l'URL de la base de données. C'est une chaîne de caractères dépendante de la BD utilisée. Pour MySQL, elle est de la forme [jdbc:mysql://localhost:3306/nom_de_la_bd];
- [user] : le propriétaire de la connexion ;
- [passwd] : son mot de passe ;
- lignes 24-30 : la connexion doit être fermée dans la clause [finally] afin qu'elle soit fermée qu'il y ait exception ou non.
3.2.3. étape 3 - émission d'ordres SQL [SELECT]
Une fois obtenue une connexion, on peut émettre des ordres SQL. La façon de gérer des ordres de lecture [SELECT] diffère de celle utilisée pour les opérations de mise à jour [UPDATE, INSERT, DELETE]. Nous commençons par les ordres SQL [SELECT] :
Le code
Connection connexion = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
// ouverture connexion
connexion = DriverManager.getConnection(url, user, passwd);
// début transaction
connexion.setAutoCommit(false);
// en mode lecture seule
connexion.setReadOnly(true);
// on lit la table [PRODUITS]
ps = connexion.prepareStatement("SELECT ID, NOM, CATEGORIE, PRIX, DESCRIPTION FROM PRODUITS");
rs = ps.executeQuery();
System.out.println("Liste des produits : ");
while (rs.next()) {
System.out.println(new Produit(rs.getInt(1), rs.getString(2), rs.getInt(3), rs.getDouble(4), rs.getString(5)));
}
// commit transaction
connexion.commit();
} catch (SQLException e1) {
// on traite l'exception
doCatchException(connexion,e1);
} finally {
// on traite le finally
doFinally(rs, ps, connexion);
}
private void doFinally(ResultSet rs, PreparedStatement ps, Connection connexion) {
....
}
- lignes 8, 10 : ouverture d'une transaction (ligne 8) en mode lecture seule (ligne 10). Une transaction est une séquence d'ordes SQL qui soit tous réussissent soit tous échouent. Ainsi dans une transaction comportant N ordres SQL, si l'ordre I+1 échoue, alors les I précédents seront annulés. Pour une opération de lecture, une transaction n'est pas nécessaire. Néanmoins créer une transaction en lecture seule peut permettre à certains SGBD de faire certaines optimisations ;
- ligne 12 : utilisation d'un [PreparedStatement]. Un [PreparedStatement] a normalement des paramètres notés par le caractère ?. Ici il n'en a pas. Un [PreparedStatement] est un ordre préparé par le SGBD. Cette préparation a un coût et elle n'est faite qu'une fois. Ensuite cet ordre préparé est exécuté par le SGBD avec différents paramètres effectifs qui vont venir remplacer les paramètres formels ?. A noter qu'il est préférable de nommer les colonnes désirées plutôt que d'utiliser la notation * pour obtenir toutes les colonnes. En précisant le nom des colonnes on peut ensuite obtenir leurs valeurs à partir de leur position dans la requête SELECT ;
- ligne 13 : exécution du [PreparedStatement]. On récupère un objet de type [ResultSet] ;
Un objet de type [ResultSet] représente une table, c’est à dire un ensemble de lignes et de colonnes. A un moment donné, on n’a accès qu’à une ligne de la table appelée ligne courante. Lors de la création initiale du [ResultSet], il n'y a pas de ligne courante. Il faut faire une opération [ResultSet.next()] pour l'obtenir. La signature de la méthode next est la suivante :
Cette méthode tente de passer à la ligne suivante du [ResultSet] et rend true si elle réussit, false sinon. En cas de réussite, la ligne suivante devient la nouvelle ligne courante. La ligne précédente est perdue et on ne pourra revenir en arrière pour la récupérer.
La table du [ResultSet] a des colonnes nommées labelCol1, labelCol2,... précisées dans la requête [SELECT] exécutée. Avec la requête :
SELECT ID as myId, NOM as myNom, CATEGORIE as myCategorie, PRIX as myPrix, DESCRIPTION as myDescription FROM PRODUITS
- la colonne [ID] ira dans une colonne du [ResultSet] nommée [myId] ;
- la colonne [NOM] ira dans une colonne du [ResultSet] nommée [myNom] ;
- ...
Ci-dessus, les identifiants [myCol] sont appelés des labels de colonne. En l'absence de ces labels, les noms des colonnes du [ResultSet] sont dépendants du SGBD. Lorsque le [SELECT] opère sur une unique table, les labels des colonnes seront par défaut les noms des colonnes demandées par le SELECT. Le problème surgit lorsque le [SELECT] opère sur plusieurs tables et que dans celles-ci on trouve des noms de colonnes identiques comme dans l'exemple suivant :
SELECT PRODUITS.NOM, CATEGORIES.NOM FROM PRODUITS, CATEGORIES WHERE PRODUITS.CATEGORIE_ID=CATEGORIES.ID
en imaginant que la table [PRODUITS] ait une clé étrangère vers la table [CATEGORIES] symbolisée par la relation [Produits].CATEGORIE_ID --> [CATEGORIES].ID, et que les tables [PRODUITS] et [CATEGORIES] aient toutes les deux un champ [NOM]. Dans ce cas, les noms donnés dans le [ResultSet] aux colonnes [PRODUITS.NOM] et [CATEGORIES.NOM] sont dépendants du SGBD. Pour la portabilité entre SGBD, il faut donc utiliser des labels de colonnes ici et on écrira :
SELECT PRODUITS.NOM as p_NOM, CATEGORIES.NOM as c_NOM FROM PRODUITS, CATEGORIES WHERE PRODUITS.CATEGORIE_ID=CATEGORIES.ID
Pour exploiter les différents champs de la ligne courante du [ResultSet], on dispose des méthodes suivantes :
pour obtenir la colonne nommée «labelColi» de la ligne courante et donc la colonne du [SELECT] ayant ce label. Type désigne le type du champ coli. On peut utiliser les méthodes [getType] suivantes : getInt, getLong, getString, getDouble, getFloat, getDate, ... Au lieu d'utiliser le nom de la colonne, on peut utiliser sa position dans la requête [SELECT] exécutée :
où i est l’indice de la colonne désirée (i>=1).
- lignes 15-17 : récupération des valeurs lues dans la BD ;
- ligne 19 : la transaction est validée (on dit également committée). Cela la termine et libère les ressources que le SGBD avait mobilisées pour elle ;
- ligne 25 : les ressources sont libérées dans le [finally]. Celui-ci appelle la méthode [doFinally] suivante :
private void doFinally(ResultSet rs, PreparedStatement ps, Connection connexion) {
// fermeture ResultSet
if (rs != null) {
try {
rs.close();
} catch (SQLException e1) {
}
}
// fermeture [PreparedStatement]
if (ps != null) {
try {
ps.close();
} catch (SQLException e2) {
}
}
if (connexion != null) {
try {
// fermer la connexion
connexion.close();
} catch (SQLException e3) {
// traiter l'exception
}
}
}
- lignes 3-9 : fermeture du [ResultSet] ;
- lignes 11-17 : fermeture du [PreparedStatement] ;
- lignes 18-27 : fermeture de la connexion ;
Les fermetures des lignes 3-17 semblent redondantes dans la mesure on ferme la connexion lignes 18-25. En fait, dans certains cas elles ne le sont pas et il est conseillé de les laisser [http://stackoverflow.com/questions/4507440/must-jdbc-resultsets-and-statements-be-closed-separately-although-the-connection].
- ligne 22 : l'exception est traitée par la méthode [doCatchException] suivante :
private static void doCatchException(Connection connexion, Throwable th) {
// annulation transaction
try {
if (connexion != null) {
connexion.rollback();
}
} catch (SQLException e2) {
// traiter l'exception
}
}
- lignes 4-6 : la transaction est annulée. Cela la termine et le SGBD va pouvoir relâcher les ressources mobilisées pour elle ;
3.2.4. étape 3 - émission d'ordres SQL [INSERT, UPDATE, DELETE]
Les ordres SQL [INSERT, UPDATE, DELETE] sont des opérations de mise à jour : elles modifient la base de données mais ne ramènent aucune ligne. La seule information rendue est le nombre de lignes affectées par l'opération de mise à jour.
Le code
Connection connexion = null;
PreparedStatement ps = null;
try {
// ouverture connexion
connexion = DriverManager.getConnection(url, user, passwd);
// début transaction
connexion.setAutoCommit(false);
// en mode lecture / écriture
connexion.setReadOnly(false);
// on met à jour la table
ps = connexion.prepareStatement("UPDATE PRODUITS SET PRIX=PRIX*1.1 WHERE CATEGORIE=?");
// catégorie 1
ps.setInt(1, 10);
// exécution
int nbLignes=ps.executeUpdate();
// commit transaction
connexion.commit();
} catch (SQLException e1) {
// on traite l'exception
doCatchException(connexion, e1);
} finally {
// on traite le finally
doFinally(null, ps, connexion);
}
}
- ligne 9 : la connexion est utilisée en lecture et écriture ;
- ligne 11 : un [PreparedStatement] avec 1 paramètre (symbolisé par ?). On peut avoir plusieurs paramètres. Ils sont numérotés à partir de 1 ;
- ligne 13 : on affecte sa valeur à l'unique paramètre. Le 1er paramètre de [setType] est la position du paramètre dans le [PreparedStatement] (1, 2, ...) et le second la valeur qui lui est attribuée. On peut utiliser les méthodes [setInt, setLong, setFloat, setDouble, setString, setDate, ...] ;
- ligne 15 : on utilise la méthode [executeUpdate] et non [executeQuery] réservée aux ordres SELECT. La méthode rend le nombre de lignes affectées par l'opération. Peut être 0.
- ligne 17 : la transaction est validée ;
3.2.5. étape 4 - fermeture de la connexion
Une connexion doit être fermée le plus vite possible dans un contexte multi-utilisateurs car un SGBD accepte un nombre limité de connexions ouvertes. Dans les exemples précédents, elle était fermée dans la clause [finally] des opérations SQL afin qu'elle soit fermée qu'il y ait eu exception ou pas.
3.3. Configuration de la couche JDBC du SGBD MySQL5
Nous allons étudier le projet [mysql-config-jdbc] qui configure la couche JDBC ci-dessous :
 |
3.3.1. Le projet Eclipse
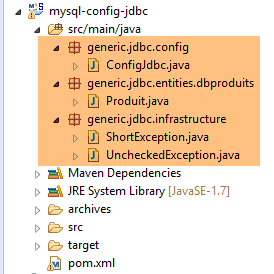 |
3.3.2. Configuration Maven
Le fichier [pom.xml] du projet est le suivant :
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-config-jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>configuration generic jdbc</name>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<!-- dépendances variables ********************************************** -->
<!-- pilote JDBC du SGBD -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- dépendances constantes ********************************************** -->
<!-- Tomcat JDBC -->
<dependency>
<groupId>org.apache.tomcat</groupId>
<artifactId>tomcat-jdbc</artifactId>
</dependency>
<!-- bibliothèque jSON -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<!-- Google Guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>16.0.1</version>
</dependency>
<!-- Spring Boot -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot</artifactId>
</dependency>
<!-- Spring Boot Test -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<!-- logs -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</dependency>
</dependencies>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.7</java.version>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
</plugin>
</plugins>
</build>
</project>
On a regroupé dans cette configuration Maven, un certain nombre d'archives qui sont nécessaires soit au projet [mysql-config-jdbc] soit aux projets qui vont s'appuyer dessus :
- lignes 4-6 : l'artifact Maven généré par le projet. Comme il a déjà été dit, tous les projets du type [*-config-jdbc] génèrent ce même artifact. Il ne faut donc pas que deux projets de type [*-config-jdbc] soient chargés en même temps ;
- lignes 9-13 : le projet Maven parent de celui-ci. Il définit les versions d'un grand nombre d'archives utilisées par l'écosystème Spring. Cela évite de préciser celles-ci dans les projets qui en dérivent ;
- lignes 18-21 : l'archive du pilote JDBC du SGBD MySQL5. C'est la seule archive nécessaire au projet [spring-jdbc-01] ;
- lignes 24-27 : l'artifact [tomcat-jdbc] amène une archive nécessaire aux projets JDBC [spring-jdbc-02 à 04] ;
- lignes 29-36 : amènent les bibliothèques nécessaires à la gestion du jSON. Utilisées dans quasiment tous les projets du document ;
- lignes 38-42 : Google Guava est une bibliothèque de gestion de collections. Utilisée dans quasiment tous les projets du document ;
- lignes 43-52 : les bibliothèques permettant l'écriture de tests intégrant Spring et JUnit. Utilisées dans quasiment tous les projets du document ;
- lignes 54-57 : les bibliothèques de logs. Utilisées dans quasiment tous les projets du document ;
- lignes 67-71 : le plugin permettant d'installer l'artifact du projet [mysql-config-jdbc] dans le dépôt Maven local ;
3.3.3. La classe de configuration [ConfigJdbc]
 |
La classe [ConfigJdbc] est la suivante :
package generic.jdbc.config;
import org.springframework.beans.factory.config.ConfigurableBeanFactory;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Scope;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.ser.impl.SimpleBeanPropertyFilter;
import com.fasterxml.jackson.databind.ser.impl.SimpleFilterProvider;
public class ConfigJdbc {
// paramètres de connexion
public final static String DRIVER_CLASSNAME = "com.mysql.jdbc.Driver";
public final static String URL_DBPRODUITS = "jdbc:mysql://localhost:3306/dbproduits";
public final static String USER_DBPRODUITS = "root";
public final static String PASSWD_DBPRODUITS = "root";
...
// ordres SQL [jdbc-01, jdbc-02]
public final static String V1_INSERT_PRODUITS_WITH_ID = "INSERT INTO PRODUITS(ID, NOM, CATEGORIE, PRIX, DESCRIPTION) VALUES (?, ?, ?, ?, ?)";
public final static String V1_DELETE_PRODUITS = "DELETE FROM PRODUITS";
//public final static String V1_DELETE_PRODUITS = String.format("DELETE FROM %s", TAB_PRODUITS);
public final static String V1_SELECT_PRODUITS = "SELECT ID, NOM, CATEGORIE, PRIX, DESCRIPTION FROM PRODUITS";
public final static String V1_UPDATE_PRODUITS = "UPDATE PRODUITS SET PRIX=PRIX*1.1 WHERE CATEGORIE=?";
public final static String V1_INSERT_PRODUITS_2 = "INSERT INTO PRODUITS(ID, NOM, CATEGORIE, PRIX, DESCRIPTION) VALUES (100,'X',1,1,'x')";
// ordres SQL [jdbc-03]
public final static String V2_INSERT_PRODUITS = "INSERT INTO PRODUITS(NOM, CATEGORIE, PRIX, DESCRIPTION) VALUES (?, ?, ?, ?)";
public final static String V2_DELETE_ALLPRODUITS = "DELETE FROM PRODUITS";
public final static String V2_DELETE_PRODUITS = "DELETE FROM PRODUITS WHERE ID=?";
public final static String V2_SELECT_ALLPRODUITS = "SELECT ID, NOM, CATEGORIE, PRIX, DESCRIPTION FROM PRODUITS";
public final static String V2_SELECT_PRODUIT_BYID = "SELECT NOM, CATEGORIE, PRIX, DESCRIPTION FROM PRODUITS WHERE ID=?";
public final static String V2_SELECT_PRODUIT_BYNAME = "SELECT ID, CATEGORIE, PRIX, DESCRIPTION FROM PRODUITS WHERE NOM=?";
public final static String V2_UPDATE_PRODUITS = "UPDATE PRODUITS SET NOM=?, PRIX=?, CATEGORIE=?, DESCRIPTION=? WHERE ID=?";
...
}
La classe [ConfigJdbc] sert à configurer la couche JDBC des quatre projets [spring-jdbc-01 à 04]. La majeure partie de la configuration concerne le projet [spring-jdbc-04]. Nous présenterons cette partie lorsqu'on étudiera ce projet. On n'a gardé ci-dessus que la configuration des projets [spring-jdbc-01 à 03].
- lignes 14-17 : les paramètres de connexion à la base MySQL5 [dbproduits] ;
- lignes 20-25 : les ordres SQL utilisés dans les projets [spring-jdbc-01 et 02] ;
- lignes 28-34 : les ordres SQL utilisés dans le projet [spring-jdbc-03] ;
Ces ordres SQL exploitent la table [PRODUITS] de la base MySQL5 [dbproduits] dont la structure est la suivante :
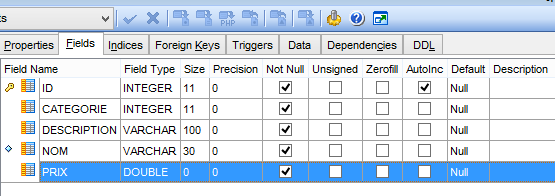 |
- [ID] : clé primaire en mode AUTO_INCREMENT (si on ne donne pas de clé primaire, le SGBD la génère) ;
- [NOM] : nom d'un produit - unique ;
- [CATEGORIE] : n° de sa catégorie ;
- [PRIX] : son prix ;
- [DESCRIPTION] : une description du produit ;
3.3.4. La classe [Produit]
 |
La classe [Produit] est l'image d'une ligne de la table [PRODUITS] :
package generic.jdbc.entities.dbproduits;
public class Produit {
// champs
private int id;
private String nom;
private int categorie;
private double prix;
private String description;
// constructeurs
public Produit() {
}
public Produit(int id, String nom, int categorie, double prix, String description) {
this.id = id;
this.nom = nom;
this.categorie = categorie;
this.prix = prix;
this.description = description;
}
// getters et setters
...
}
Nous aurons besoin ultérieurement de comparer deux produits pour savoir s'ils sont égaux ou non. Nous dirons que deux produits sont égaux si tous leurs champs sont égaux. Pour cela, nous allons redéfinir la méthode [equals] de la classe [Object] dont dérive la classe [Produit] :
// méthode d'égalité
@Override
public boolean equals(Object o) {
// cas simples
if (o == null || o.getClass() != this.getClass()) {
return false;
}
Produit p = (Produit) o;
return this == o
|| (this.id == p.id && this.nom.equals(p.getNom()) && this.categorie == p.categorie
&& Math.abs(this.prix - p.prix) < 1e-6 && this.description.equals(p.description));
}
- ligne 3 : la méthode [equals] reçoit un objet o qu'elle doit comparer à l'objet this ;
- lignes 5-7 : les cas simples où on peut dire tout de suite que les deux objets ne sont pas égaux. [Object].getClass() fournit une instance du type [Class], un type qui représente la classe réelle de l'objet ;
- ligne 8 : l'objet o est converti en produit p ;
- ligne 9 : si les deux références o et p sur un produit sont égales, alors il s'agit physiquement du même produit ;
- ligne 9 : si o et p sont deux références différentes sur deux produits ayant les mêmes champs, on dira qu'ils sont égaux. Parce que le prix est de type [double] et qu'il n'y a pas de représentation exacte des réels en informatique, nous considèrerons que deux prix sont identiques s'ils sont égaux à 10-6 près ;
Par ailleurs, nous redéfinirons la méthode [hasCode] de la classe [Object] :
// hashcode
@Override
public int hashCode() {
return id + 2 * nom.hashCode() + 3 * categorie + 4 * description.hashCode();
}
Les valeurs du hashCode de deux produits doivent être les mêmes si la méthode [equals] a déclaré ces deux produits égaux. Cette valeur du hashCode est utilisée pour répartir des objets dans des ensembles tels que des dictionnaires. Ci-dessus, si deux produits sont identiques, ils auront bien le même hashCode.
3.3.5. L'exception [UncheckedException]
 |
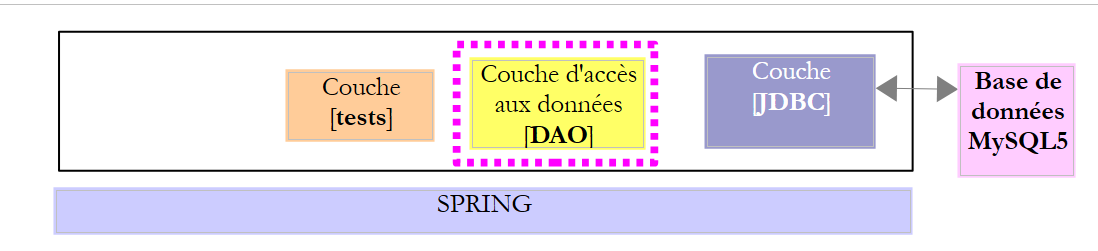
Considérons l'architecture suivante :
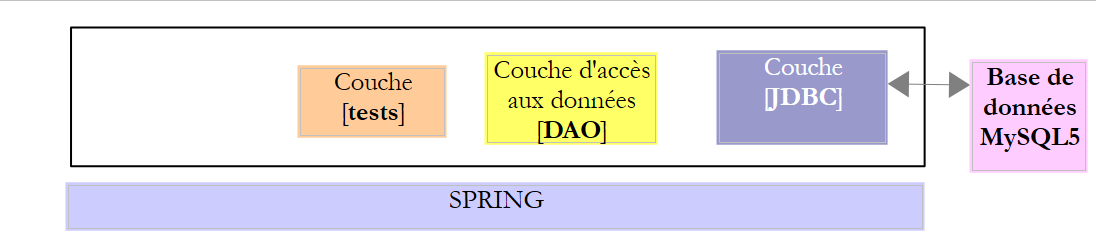 |
- la couche [JDBC] lance des exceptions de type [SQLException]. Cette exception doit remonter les couches jusqu'à atteindre la couche la plus haute, ici la couche de tests ;
La couche [DAO] pourrait se contenter de laisser remonter la [SQLException] jusqu'à la couche de tests. Mais comme cette exception est non contrôlée (dérive directement de [Exception]), cela impliquerait que l'interface [IDao] de la couche [DAO] soit la suivante :
public interface IDao {
// ajouter des produits
public List<Produit> addProduits(List<Produit> produits) throws SQLException;
// liste de tous les produits
public List<Produit> getAllProduits() throws SQLException;
// un produit particulier
public Produit getProduitById(int id) throws SQLException;
public Produit getProduitByName(String name) throws SQLException;
// mise à jour de plusieurs produits
public int updateProduits(List<Produit> produits) throws SQLException;
// suppression de tous les produits
public int deleteAllProduits() throws SQLException;
// suppression de plusieurs produits
public int deleteProduits(int[] ids) throws SQLException;
}
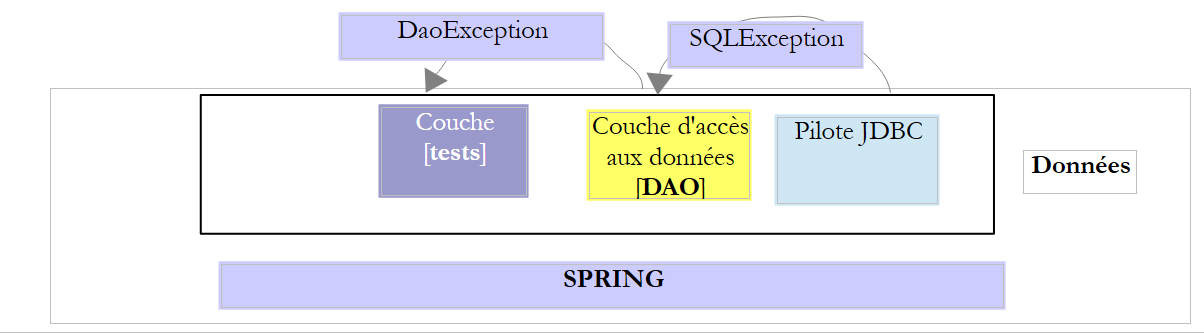
Et ça c'est très ennuyeux car cela nous empêche d'implémenter l'interface [IDao] par une classe qui lancerait une exception différente. Pour contourner cette difficulté, la couche [DAO] va lancer une exception [DaoException] non contrôlée (dérivée de [RuntimeException]), ce qui nous évite la clause [throws] dans la signature des méthodes de l'interface. Du coup, celle-ci pourra être implémentée par toute classe lançant elle aussi une exception non contrôlée qui pourra être différente de l'exception [DaoException]. Notre architecture devient maintenant la suivante :
 |
Pour faciliter la création d'exceptions non contrôlées pour différentes couches d'une application, nous leur créons une classe parent [UncheckedException] :
|
package generic.jdbc.infrastructure;
import java.util.ArrayList;
import java.util.List;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
// classe d'exception générique
// l'exception est non contrôlée
public class UncheckedException extends RuntimeException {
// serial ID généré
private static final long serialVersionUID = -2924871763340170310L;
// propriétés
private int code;
private String trace;
private List<ShortException> exceptions;
// constructeurs
public UncheckedException() {
super();
}
public UncheckedException(int code, Throwable e, String simpleClassName) {
super(e);
// local
this.code = code;
this.exceptions = getErreursForException(e);
// trace
String fileName = String.format("%s.java", simpleClassName);
StackTraceElement[] traces = e.getStackTrace();
boolean trouve = false;
for (int i = 0; !trouve && i < traces.length; i++) {
StackTraceElement trace = traces[i];
if (fileName.equals(trace.getFileName())) {
this.trace = String.format("[%s,%s,%s]", simpleClassName, trace.getMethodName(), trace.getLineNumber());
trouve = true;
}
}
}
@Override
public String getMessage() {
return this.toString();
}
@Override
public void printStackTrace() {
System.out.println(this);
}
// liste des messages d'erreur d'une exception
private List<ShortException> getErreursForException(Throwable th) {
// on récupère les éléments de la pile de l'exception
Throwable cause = th;
List<ShortException> exceptions = new ArrayList<ShortException>();
while (cause != null) {
// on récupère l'exception courante
exceptions.add(new ShortException(cause.getClass().getName(), cause.getMessage()));
// exception suivante
cause = cause.getCause();
}
return exceptions;
}
@Override
public String toString() {
ObjectMapper jsonMapper = new ObjectMapper();
try {
return String.format("[code=%s, trace=%s, exceptions=%s", code, trace, jsonMapper.writeValueAsString(exceptions));
} catch (JsonProcessingException e) {
e.printStackTrace();
return null;
}
}
// getters et setters
...
}
- ligne 12 : la classe dérive de [RuntimeException] et est donc un type d'exception non contrôlée. Elle servira à encapsuler une exception contrôlée (SQLException) dans un type d'exception non contrôlée (UncheckedException) ;
- pour différencier les exceptions de type [UncheckedException] entre-elles, on pourra leur affecter un code qui sera mémorisé par le champ privé de la ligne 18. Un code Java interceptant une exception de type [UncheckedException] aura accès à ce code d'erreur grâce à la méthode [getCode] (lignes 80 et au-delà) ;
- ligne 20 : stocke les messages d'erreurs de la pile de l'exception encapsulée ;
- lignes 23-43 : les différentes façons de construire un objet de type [UncheckedException] ;
- lignes 56-67 : une méthode privée qui permet de construire la liste des erreurs de la ligne 20 à partir d'un objet [Throwable] ou dérivé, en particulier le type [Exception] ;
- lignes 69-78 : la méthode [toString] rend une chaîne de caractères représentant l'exception. Pour afficher la liste des erreurs de la ligne 20, elle utilise une bibliothèque jSON. Celle-ci est présente dans les dépendances Maven du projet :
<!-- bibliothèque jSON -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
- lignes 45-48 : redéfinissent la méthode [getMessage] de la classe parent [RuntimeException]. Celle-ci rend ici, la signature [toString] de la classe ;
- lignes 50-53 : redéfinissent la méthode [printStackTrace] de la classe parent [RuntimeException]. C'est la signature [toString] de la classe qui sera affichée ;
La classe [UncheckedException] enregistre dans le champ de la ligne 20, une liste d'exceptions décrites par le type [ShortException] suivant :
package pam.dao.exceptions;
public class ShortException {
// propriétés
private String className;
private String errorMessage;
// constructeurs
public ShortException() {
}
public ShortException(String className, String errorMessage) {
this.className = className;
this.errorMessage = errorMessage;
}
// getters et setters
...
}
- ligne 6 : le nom de la classe de l'exception qui s'est produite ;
- ligne 7 : le message d'erreur associé ;
Examinons le constructeur suivant de la classe [UncheckedException] :
public UncheckedException(int code, Throwable e, String simpleClassName) {
super(e);
// local
this.code = code;
this.exceptions = getErreursForException(e);
// trace
String fileName = String.format("%s.java", simpleClassName);
StackTraceElement[] traces = e.getStackTrace();
boolean trouve = false;
for (int i = 0; !trouve && i < traces.length; i++) {
StackTraceElement trace = traces[i];
if (fileName.equals(trace.getFileName())) {
this.trace = String.format("[%s,%s,%s]", simpleClassName, trace.getMethodName(), trace.getLineNumber());
trouve = true;
}
}
}
- ligne 1, les paramètres sont les suivants :
- [code] : un code d'erreur ;
- [e] : l'exception qu'on encapsule. [Throwable] est la classe parent de la classe [Exception] et dérive directement de la classe [Object]. C'est la classe parent de toutes les classes C avec lesquelles on peut écrire [throw c;] où c est une instance de C ;
- [simpleClassName] : le nom simple de la classe du code utilisateur où l'exception e a été détectée ;
- ligne 4 : le code d'erreur est enregistré ;
- ligne 5 : la liste de [ShortException] est construite à partir du [Throwable e] passé en paramètre ;
- lignes 7-16 : on examine ce qu'on appelle les traces de l'exception. Une exception initiale se produit à un endroit précis du code puis remonte à la méthode qui a appelé celle où s'est produite l'exception, et ainsi de suite jusqu'à ce qu'un try / catch l'arrête. Dans cette remontée, l'exception initiale laisse des traces mémorisées dans le tableau [e.stackTrace] de l'exception e. Celles-ci sont ici obtenues ligne 8, à partir du [Throwable e] passé en paramètre. Chaque élément de type [StackTraceElement] est un objet ayant parmi ses champs, les suivants :
- [fileName] : le nom du fichier Java où s'est produite l'exception ;
- [lineNumber] : le n° de ligne dans ce fichier, où s'est produite l'exception ;
- [methodName] : la nom de la méthode dans ce fichier, où s'est produite l'exception ;
- les lignes 10-16 recherchent dans le tableau des traces de l'exception passée en paramètre, la première occurrence de la condition [trace.fileName==simpleClassName.java] où [simpleClassName] est le 3ième paramètre du constructeur. L'idée est de mémoriser où s'est produit l'exception dans le code utilisateur. Celui-ci encapsulera une exception de la façon suivante :
- ligne 13 : on crée une chaîne de caractères de type [fileName, methodName, lineNumber] caractérisant l'endroit du code utilisateur où l'exception e a été arrêtée ;
Maintenant, examinons le code qui enregistre la liste des exceptions de la pile d'exception de l'exception [Throwable th] encapsulée par le constructeur précédent :
// liste des messages d'erreur d'une exception
private List<ShortException> getErreursForException(Throwable th) {
// on récupère les éléments de la pile de l'exception
Throwable cause = th;
List<ShortException> exceptions = new ArrayList<ShortException>();
while (cause != null) {
// on récupère l'exception courante
exceptions.add(new ShortException(cause.getClass().getName(), cause.getMessage()));
// exception suivante
cause = cause.getCause();
}
return exceptions;
}
Au cours de sa remontée vers la méthode qui l'a arrêtée par un try / catch, l'exception initiale e a pu être encapsulée dans une exception. C'est alors cette dernière qui effectue sa remontée vers la méthode qui l'arrêtera définitivement. Elle peut donc elle aussi subir une encapsulation. Au final, lorsqu'une méthode décide d'arrêter une exception th et de l'exploiter, elle trouvera l'exception initiale e enfouie au fond d'une pile d'exceptions. Ainsi, ci-dessus, le paramètre [Throwable th] n'est que la partie visible de l'iceberg des exceptions. Son attribut [th.cause] permet de connaître l'exception qu'elle même encapsule. Et ainsi de suite. Lorsqu'une exception e est telle que [e.getCause()==null] c'est que e est l'exception initiale.
- ligne 8 : pour chaque exception de la pile des exceptions de [Throwable th], on mémorise deux informations :
- [getClass().getName()] : le nom complet de l'exception ;
- [getMessage()] : le message d'erreur associé ;
3.4. Exemple-01
3.4.1. L'architecture du projet
 |
Dans cet exemple, un programme console utilise l'interface de la couche [JDBC].
3.4.2. Le projet Eclipse
Nous créons un projet Spring / Maven [spring-jdbc-01] en suivant la démarche du paragraphe 2.5.2.1.
 |
Le projet est un projet Maven défini par le fichier [pom.xml] suivant :
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dvp.spring.database</groupId>
<artifactId>spring-jdbc-generic-01</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>spring-jdbc-generic-01</name>
<description>Demo project for API JDBC</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
<relativePath /> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!-- configuration JDBC du SGBD -->
<dependency>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-config-jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
</plugin>
</plugins>
</build>
</project>
- lignes 28-32 : le projet utilise l'artifact [generic-config-jdbc] du projet [mysql-config-jdbc] que nous venons d'étudier. Le projet [spring-jdbc-01] a donc accès à tous les éléments du projet [mysql-config-jdbc] ;
On peut voir ce dernier point de deux façons en inspectant les dépendances Maven du projet :
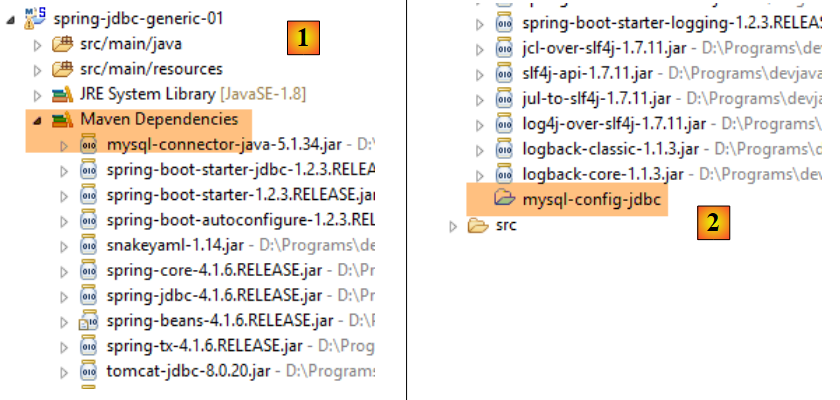 |
- en [2], on voit que le projet [mysql-config-jdbc] est dans les dépendances Maven du projet. Comme ces dernières sont dans le Classpath du projet, cela signifie que le projet [mysql-config-jdbc] est lui aussi dans ce Classpath et que donc ses classes et interfaces sont visibles dans le projet [spring-jdbc-01] ;
Le projet Maven [mysql-config-jdbc] n'a pas besoin d'être présent dans l'onglet [Package Explorer] pour être utilisable par d'autres projets Maven. Il lui suffit d'être présent dans le dépôt local Maven. Contrairement à un IDE comme Netbeans, cette présence n'est pas automatique avec Eclipse. Il faut la forcer :
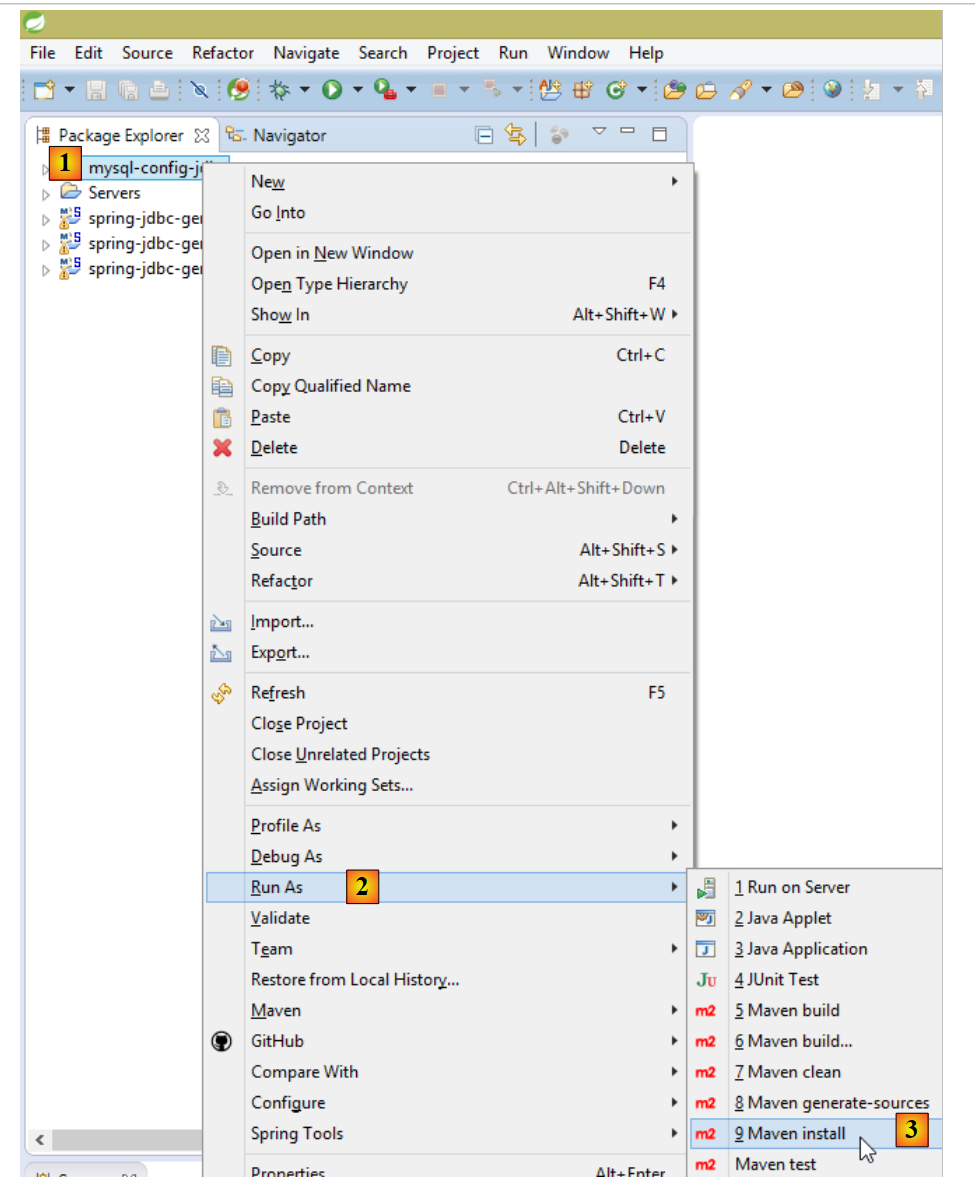 |
Nous avons vu les conditions qui rendent possible cette génération au paragraphe 2.3.5. Lorsqu'elle a été faite, on peut alors retirer le projet [mysql-config-jdbc] de l'onglet [Package Explorer] :
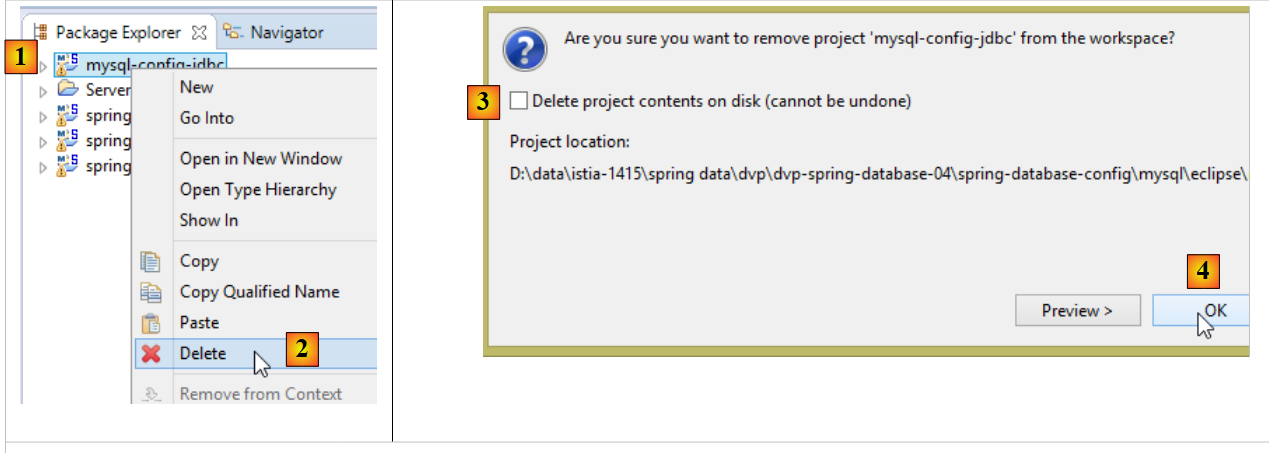 |
- il ne faut pas cocher [3] qui supprime physiquement le projet du disque le rendant alors irrécupérable ;
Cette opération relance le calcul des dépendances Maven des projets qui dépendent du projet sorti du [Package Explorer]. Cela change la branche [Maven Dependencies] de ces projets. Par exemple pour le projet [spring-jdbc-01], la branche [Maven Dependencies] devient la suivante :
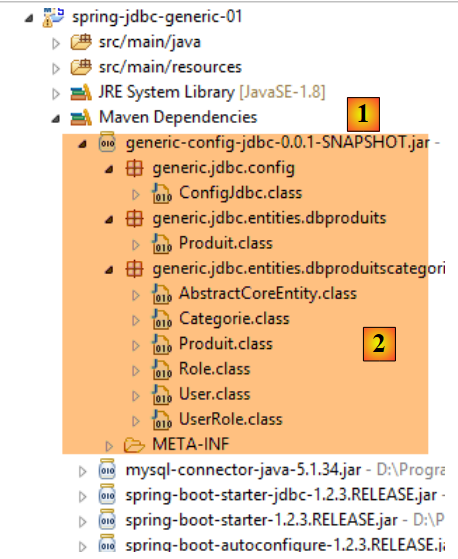 |
Cette fois-ci, la dépendance n'est plus sur un projet mais sur l'artifact Maven de celui-ci, ici l'artifact [generic-config-jdbc] [1]. On voit qu'on a bien accès à toutes les classes et interfaces de cet artifact. Comme il a été dit, cet artifact sera généré par tous les projets [*-config-jdbc]. Pour éviter les erreurs, nous :
- garderons toujours un unique projet [*-config-jdbc] dans l'onglet [Package Explorer] ;
- mettrons à jour la configuration Maven de tous les projets de l'onglet [Package Explorer] (Alt-F5) pour que ceux-ci fassent apparaître dans leurs dépendances Maven, le projet [*-config-jdbc] utilisé ;
3.4.3. Le squelette de la classe principale
 |
Le squelette de la classe principale [IntroJdbc01] est le suivant :
package spring.jdbc;
import generic.jdbc.config.ConfigJdbc;
import generic.jdbc.entities.dbproduits.Produit;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class IntroJdbc01 {
// constantes
final static ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) {
// chargement du pilote JDBC du SGBD
try {
Class.forName(ConfigJdbc.DRIVER_CLASSNAME);
} catch (ClassNotFoundException e1) {
doCatchException("Pilote JDBC introuvable", null, e1);
return;
}
// on vide la table [PRODUITS]
System.out.println(String.format("------------------------------ %s", "Vidage de la table [PRODUITS]"));
delete();
// on la remplit
System.out.println(String.format("------------------------------ %s", "Remplissage de la table [PRODUITS]"));
insert();
// on la lit
System.out.println(String.format("------------------------------ %s", "Affichage de la table [PRODUITS]"));
select();
// mise à jour
System.out.println(String.format("------------------------------ %s", "Mise à jour de la table [PRODUITS]"));
update();
// affichage
System.out.println(String.format("------------------------------ %s", "Affichage de la table [PRODUITS]"));
select();
// on vide la table [PRODUITS]
System.out.println(String.format("------------------------------ %s", "Vidage de la table [PRODUITS]"));
delete();
// on l'affiche
System.out.println(String.format("------------------------------ %s", "Affichage de la table [PRODUITS]"));
select();
// INSERTion de deux éléments identiques
// l'INSERTion doit échouer et aucun des deux éléments n'est inséré à cause de la transaction
System.out.println(String.format("------------------------------ %s",
"Insertion de deux produits de même clé primaire dans la table [PRODUITS]"));
insert2();
// on vérifie
System.out.println(String.format("------------------------------ %s", "Affichage de la table [PRODUITS]"));
select();
// fini
System.out.println(String.format("------------------------------ %s", "Travail terminé"));
}
// liste des produits
private static void select() {
...
}
// affichage jSON d'un objet
private static void affiche(Object object) {
...
}
// suppression produits
public static void delete() {
...
}
// ajout produits
public static void insert() {
...
}
// ajout de 2 produits de mêmes clés primaires
public static void insert2() {
...
}
// mise à jour de certains produits
public static void update() {
...
}
private static void doFinally(ResultSet rs, PreparedStatement ps, Connection connexion) {
// fermeture ResultSet
if (rs != null) {
try {
rs.close();
} catch (SQLException e1) {
}
}
// fermeture [PreparedStatement]
if (ps != null) {
try {
ps.close();
} catch (SQLException e2) {
}
}
if (connexion != null) {
try {
// fermer la connexion
connexion.close();
} catch (SQLException e3) {
// on affiche les msg d'erreur
show("Les erreurs suivantes se sont produites lors de la fermeture de la connexion",
getErreursFromThrowable(e3));
}
}
}
private static void doCatchException(String title, Connection connexion, Throwable th) {
// on affiche les msg d'erreur
show(title, getErreursFromThrowable(th));
// annulation transaction
try {
if (connexion != null) {
connexion.rollback();
}
} catch (SQLException e2) {
// on affiche les msg d'erreur
show("Erreur lors de l'annulation de la transaction", getErreursFromThrowable(e2));
}
}
private static List<String> getErreursFromThrowable(Throwable th) {
// on récupère la liste des msg d'erreur de l'exception
List<String> erreurs = new ArrayList<String>();
while (th != null) {
// message d'erreur du throwable
erreurs.add(th.getMessage());
// on passe à la cause du throwable
th = th.getCause();
}
// résultat
return erreurs;
}
private static void show(String title, List<String> messages) {
// titre
System.out.println(String.format("%s : ", title));
// messages
for (String message : messages) {
System.out.println(String.format("- %s", message));
}
}
}
- lignes 23-29 : chargement du pilote JDBC du SGBD. Ligne 25, on utilise la constante [ConfigJdbc.DRIVER_CLASSNAME] définie dans le projet [mysql-config-jdbc] ;
- lignes 136-147 : la méthode [getErreursFromThrowable] rend la liste des messages d'erreur encapsulés dans un objet de type [Throwable] qui est la classe parent de la classe [Exception]. Une exception peut en contenir une autre qu'on obtient avec la méthode [Throwable].getCause(). On passe ainsi en revue toutes les exceptions encapsulées dans l'objet [Throwable] ;
- lignes 149-156 : la méthode [show(String title, List<String> messages)] affiche les messages précédés du texte [title] ;
- lignes 122-134 : la méthode [doCatchException(String title, Connection connexion, Throwable th))] gère les exceptions rencontrées par les méthodes de la classe. L'exception gérée est représentée par le paramètre [Throwable th]. L'objectif de la méthode est :
- d'annuler la transaction en cours de l'objet [Connection connexion] (lignes 127-129) ;
- d'écrire les messages d'erreur encapsulées dans l'exception [Throwable th] (lignes 124, 132) ;
- lignes 93-120 : la méthode [doFinally(ResultSet rs, PreparedStatement ps, Connection connexion)] gère la branche [finally] des méthodes d'accès au SGBD. Elle a pour objectif de libérer les ressources mobilisées par la connexion ;
3.4.4. Suppression du contenu de la table des produits
La méthode [delete] supprime le contenu de la table :
// suppression produits
public static void delete() {
Connection connexion = null;
PreparedStatement ps = null;
try {
// ouverture connexion
connexion = DriverManager.getConnection(ConfigJdbc.URL_DBPRODUITS , ConfigJdbc.USER_DBPRODUITS, ConfigJdbc.PASSWD_DBPRODUITS);
// début transaction
connexion.setAutoCommit(false);
// en mode lecture / écriture
connexion.setReadOnly(false);
// on vide la table [PRODUITS]
ps = connexion.prepareStatement(ConfigJdbc.V1_DELETE_PRODUITS);
ps.executeUpdate();
// commit transaction
connexion.commit();
} catch (SQLException e1) {
// on traite l'exception
doCatchException("Les erreurs suivantes se sont produites à la suppression du contenu de la table", connexion, e1);
} finally {
// on traite le finally
doFinally(null, ps, connexion);
}
}
La ligne 7 utilise les constantes suivantes de la classe [ConfigJdbc] :
public final static String URL_DBPRODUITS = "jdbc:mysql://localhost:3306/dbproduits";
public final static String USER_DBPRODUITS = "root";
public final static String PASSWD_DBPRODUITS = "";
Ligne 13, l'ordre SQL préparé est le suivant :
public final static String V1_DELETE_PRODUITS = "DELETE FROM PRODUITS";
La méthode [delete] utilise des transactions. Une transaction permet de regrouper des ordres SQL qui doivent être tous réussis ou tous annulés. Il y a quatre opérations à connaître :
- début d'une transaction : [connexion.setAutoCommit(false)] ;
- fin d'une transaction avec succès : [connexion.commit()]. Dans ce cas, toutes les opérations faites sur la BD lors de la transaction sont validées ;
- fin d'une transaction avec échec : [connexion.rollback()]. Dans ce cas, toutes les opérations faites sur la BD lors de la transaction sont annulées ;
Dans nos exemples, à chaque fois que se produit une exception, nous annulons la transaction dans la méthode [doCatchException] :
private static void doCatchException(String title, Connection connexion, Throwable th) {
// on affiche les msg d'erreur
Static.show(title, Static.getErreursFromThrowable(th));
// annulation transaction
try {
if (connexion != null) {
connexion.rollback();
}
} catch (SQLException e2) {
// on affiche les msg d'erreur
Static.show("Erreur lors de l'annulation de la transaction", Static.getErreursFromThrowable(e2));
}
}
3.4.5. Création du contenu de la table des produits
La méthode [insert] crée le contenu de la table :
public static void insert() {
Connection connexion = null;
PreparedStatement ps = null;
try {
// ouverture connexion
connexion = DriverManager.getConnection(ConfigJdbc.URL_DBPRODUITS , ConfigJdbc.USER_DBPRODUITS, ConfigJdbc.PASSWD_DBPRODUITS);
// début transaction
connexion.setAutoCommit(false);
// en mode lecture / écriture
connexion.setReadOnly(false);
// on remplit la table
ps = connexion.prepareStatement(ConfigJdbc.V1_INSERT_PRODUITS_WITH_ID);
for (int i = 0; i < 10; i++) {
// préparation
int n = i + 1;
ps.setInt(1, n);
ps.setString(2, String.format("NOM%s", n));
ps.setInt(3, n / 5 + 1);
ps.setDouble(4, 100 * (1 + (double) i / 100));
ps.setString(5, String.format("DESC%s", n));
// exécution
ps.executeUpdate();
}
// commit transaction
connexion.commit();
} catch (SQLException e1) {
// on traite l'exception
doCatchException("Les erreurs suivantes se sont produites à la création du contenu de la table", connexion, e1);
} finally {
// on traite le finally
doFinally(null, ps, connexion);
}
}
Ligne 12, l'ordre SQL préparé est le suivant :
public final static String V1_INSERT_PRODUITS_WITH_ID = "INSERT INTO PRODUITS(ID, NOM, CATEGORIE, PRIX, DESCRIPTION) VALUES (?, ?, ?, ?, ?)";
3.4.6. Affichage du contenu de la table des produits
La méthode [select] affiche le contenu de la table :
// liste des produits
private static void select() {
Connection connexion = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
// ouverture connexion
connexion = DriverManager.getConnection(ConfigJdbc.URL_DBPRODUITS , ConfigJdbc.USER_DBPRODUITS, ConfigJdbc.PASSWD_DBPRODUITS);
// début transaction
connexion.setAutoCommit(false);
// en mode lecture seule
connexion.setReadOnly(true);
// on lit la table [PRODUITS]
ps = connexion.prepareStatement(ConfigJdbc.V1_SELECT_PRODUITS);
rs = ps.executeQuery();
System.out.println("Liste des produits : ");
while (rs.next()) {
affiche(new Produit(rs.getInt(1), rs.getString(2), rs.getInt(3), rs.getDouble(4), rs.getString(5)));
}
// commit transaction
connexion.commit();
} catch (SQLException e1) {
// on traite l'exception
doCatchException("Les erreurs suivantes se sont produites à la lecture de la table", connexion, e1);
} finally {
// on traite le finally
doFinally(rs, ps, connexion);
}
}
Ligne 14, l'ordre SQL préparé est le suivant :
public final static String V1_SELECT_PRODUITS = "SELECT ID, NOM, CATEGORIE, PRIX, DESCRIPTION FROM PRODUITS";
La méthode [affiche] (ligne 18) est la suivante :
// affichage jSON d'un objet
private static void affiche(Object object) {
try {
System.out.println(jsonMapper.writeValueAsString(object));
} catch (JsonProcessingException e) {
e.printStackTrace();
}
}
Elle affiche la représentation jSON de l'objet passé en paramètre (cf jSON paragraphe 23.12).
3.4.7. Mise à jour du contenu de la table
La méthode [update] met à jour certains produits :
// mise à jour de certains produits
public static void update() {
Connection connexion = null;
PreparedStatement ps = null;
try {
// ouverture connexion
connexion = DriverManager.getConnection(ConfigJdbc.URL_DBPRODUITS , ConfigJdbc.USER_DBPRODUITS, ConfigJdbc.PASSWD_DBPRODUITS);
// début transaction
connexion.setAutoCommit(false);
// en mode lecture / écriture
connexion.setReadOnly(false);
// on met à jour la table
ps = connexion.prepareStatement(ConfigJdbc.V1_UPDATE_PRODUITS);
// catégorie 1
ps.setInt(1, 1);
// exécution
ps.executeUpdate();
// commit transaction
connexion.commit();
} catch (SQLException e1) {
// on traite l'exception
doCatchException("Les erreurs suivantes se sont produites à la mise à jour du contenu de la table", connexion, e1);
} finally {
// on traite le finally
doFinally(null, ps, connexion);
}
}
Ligne 13, l'ordre SQL préparé est le suivant :
public final static String V1_UPDATE_PRODUITS = "UPDATE PRODUITS SET PRIX=PRIX*1.1 WHERE CATEGORIE=?";
3.4.8. Rôle de la transaction
La méthode [insert2] insère deux produits de même clé primaire dans la table, ce qui n'est pas possible. Comme on est dans une transaction, la première insertion va être annulée.
// ajout de 2 produits de mêmes clés primaires
public static void insert2() {
Connection connexion = null;
PreparedStatement ps = null;
try {
// ouverture connexion
connexion = DriverManager.getConnection(ConfigJdbc.URL_DBPRODUITS , ConfigJdbc.USER_DBPRODUITS, ConfigJdbc.PASSWD_DBPRODUITS);
// début transaction
connexion.setAutoCommit(false);
// en mode lecture / écriture
connexion.setReadOnly(false);
// on ajoute 1 ligne
ps = connexion.prepareStatement(ConfigJdbc.V1_INSERT_PRODUITS_2);
// exécution
ps.executeUpdate();
// on ajoute la même ligne une 2ème fois donc avec la même clé primaire
// l'INSERTion doit échouer et aucun des deux éléments ne doit être inséré à cause de la transaction
ps.executeUpdate();
// commit transaction
connexion.commit();
} catch (SQLException e1) {
// on traite l'exception
doCatchException("Les erreurs suivantes se sont produites lors de l'ajout de deux produits de même clé primaire",
connexion, e1);
} finally {
// on traite le finally
doFinally(null, ps, connexion);
}
}
Ligne 13, l'ordre SQL préparé est le suivant :
public final static String V1_INSERT_PRODUITS_2 = "INSERT INTO PRODUITS(ID, NOM, CATEGORIE, PRIX, DESCRIPTION) VALUES (100,'X',1,1,'x')";
3.4.9. Résultats
On exécute la configuration d'exécution nommée [spring-jdbc-generic-01.IntroJdbc01] :
 |
On obtient les résultats console suivants :
------------------------------ Vidage de la table [PRODUITS]
------------------------------ Remplissage de la table [PRODUITS]
------------------------------ Affichage de la table [PRODUITS]
Liste des produits :
{"id":1,"nom":"NOM1","categorie":1,"prix":100.0,"description":"DESC1"}
{"id":2,"nom":"NOM2","categorie":1,"prix":101.0,"description":"DESC2"}
{"id":3,"nom":"NOM3","categorie":1,"prix":102.0,"description":"DESC3"}
{"id":4,"nom":"NOM4","categorie":1,"prix":103.0,"description":"DESC4"}
{"id":5,"nom":"NOM5","categorie":2,"prix":104.0,"description":"DESC5"}
{"id":6,"nom":"NOM6","categorie":2,"prix":105.0,"description":"DESC6"}
{"id":7,"nom":"NOM7","categorie":2,"prix":106.0,"description":"DESC7"}
{"id":8,"nom":"NOM8","categorie":2,"prix":107.0,"description":"DESC8"}
{"id":9,"nom":"NOM9","categorie":2,"prix":108.0,"description":"DESC9"}
{"id":10,"nom":"NOM10","categorie":3,"prix":109.0,"description":"DESC10"}
------------------------------ Mise à jour de la table [PRODUITS]
------------------------------ Affichage de la table [PRODUITS]
Liste des produits :
{"id":1,"nom":"NOM1","categorie":1,"prix":110.0,"description":"DESC1"}
{"id":2,"nom":"NOM2","categorie":1,"prix":111.0,"description":"DESC2"}
{"id":3,"nom":"NOM3","categorie":1,"prix":112.0,"description":"DESC3"}
{"id":4,"nom":"NOM4","categorie":1,"prix":113.0,"description":"DESC4"}
{"id":5,"nom":"NOM5","categorie":2,"prix":104.0,"description":"DESC5"}
{"id":6,"nom":"NOM6","categorie":2,"prix":105.0,"description":"DESC6"}
{"id":7,"nom":"NOM7","categorie":2,"prix":106.0,"description":"DESC7"}
{"id":8,"nom":"NOM8","categorie":2,"prix":107.0,"description":"DESC8"}
{"id":9,"nom":"NOM9","categorie":2,"prix":108.0,"description":"DESC9"}
{"id":10,"nom":"NOM10","categorie":3,"prix":109.0,"description":"DESC10"}
------------------------------ Vidage de la table [PRODUITS]
------------------------------ Affichage de la table [PRODUITS]
Liste des produits :
------------------------------ Insertion de deux produits de même clé primaire dans la table [PRODUITS]
Les erreurs suivantes se sont produites lors de l'ajout de deux produits de même clé primaire :
- Duplicate entry '100' for key 'PRIMARY'
------------------------------ Affichage de la table [PRODUITS]
Liste des produits :
------------------------------ Travail terminé
- ligne 30 : avant l'insertion des deux produits de même clé primaire, la table est vide ;
- ligne 35 : après l'insertion des deux produits de même clé primaire, la table est vide. Ceci montre le rôle de la transaction :
- la première insertion réussit. Elle n'a aucune raison d'échouer ;
- la seconde insertion échoue (ligne 32). Du coup, parce que ces deux insertions sont au sein de la même transaction, tous les ordres SQL de celle-ci sont annulés, dont la première insertion.
3.4.10. Conclusion
Ce qui est remarquable dans les codes précédents, c'est la grande place prise par la gestion de l'exception [SQLException]. Toute opération JDBC étant susceptible de la lancer, on a de nombreux try / catch dans le code.
3.5. Exemple-02
Nous allons reprendre l'application précédente en utilisant une source de données de type [javax.sql.DataSource] :

Nous allons utiliser une source de données implémentée par la classe [org.apache.tomcat.jdbc.pool.DataSource]. Cette classe utilise un pool de connexions ç-à-d un ensemble de connexions ouvertes :
- lorsque le pool est instancié, un certain nombre de connexions est ouvert avec la base de données. Ce nombre est configurable ;
- lorsque le code Java ouvre une connexion, celle-ci est fournie par le pool ;
- lorsque le code Java ferme une connexion, celle-ci est rendue au pool ;
Au final, les connexions ne sont ouvertes qu'une fois, ce qui améliore la performance d'accès à la base de données. La source de données sera définie dans une classe de configuration Spring
3.5.1. L'architecture du projet
 |
Dans cet exemple, un programme console utilise l'interface de la couche [JDBC].
3.5.2. Le projet Eclipse
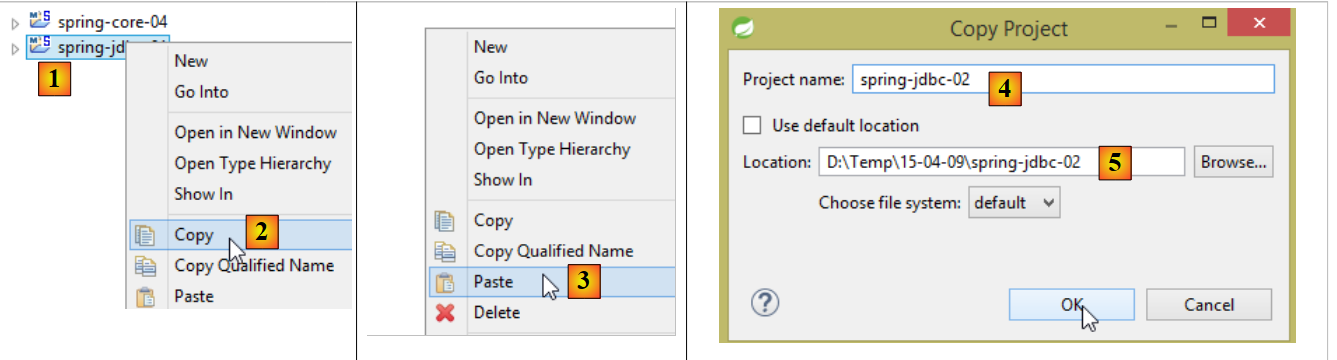
Le nouveau projet Eclipse peut être obtenu par copie du précédent [1-6] :
 |
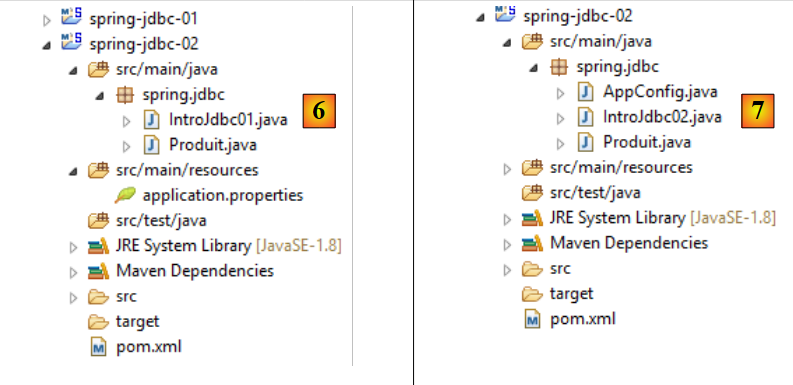 |
On fait ensuite évoluer le projet de [6] en [7] :
3.5.3. Configuration Maven
Le projet [7] est un projet Maven défini par le fichier [pom.xml] suivant :
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dvp.spring.database</groupId>
<artifactId>spring-jdbc-generic-02</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>spring-jdbc-generic-02</name>
<description>Demo project for API JDBC</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
<relativePath /> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!-- configuration JDBC du SGBD -->
<dependency>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-config-jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
</plugin>
</plugins>
</build>
</project>
- lignes 28-33 : la dépendance Maven sur le projet [mysql-config-jdbc] ;
C'est le projet [mysql-config-jdbc] qui amène dans ses dépendances Maven la bibliothèque fournissant une implémentation d'une source de données de type [javax.sql.DataSource] (cf paragraphe 3.3.2) :
<!-- Tomcat JDBC -->
<dependency>
<groupId>org.apache.tomcat</groupId>
<artifactId>tomcat-jdbc</artifactId>
</dependency>
3.5.4. Configuration Spring
 |
La classe de configuration de Spring [AppConfig] est la suivante :
package spring.jdbc;
import generic.jdbc.config.ConfigJdbc;
import org.apache.tomcat.jdbc.pool.DataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
@Configuration
@Import({ generic.jdbc.config.ConfigJdbc.class })
public class AppConfig {
// source de données
@Bean
public DataSource dataSource() {
// source de données TomcatJdbc
DataSource dataSource = new DataSource();
// configuration accès JDBC
dataSource.setDriverClassName(ConfigJdbc.DRIVER_CLASSNAME);
dataSource.setUsername(ConfigJdbc.USER_DBPRODUITS);
dataSource.setPassword(ConfigJdbc.PASSWD_DBPRODUITS);
dataSource.setUrl(ConfigJdbc.URL_DBPRODUITS);
// connexions ouvertes initialement
dataSource.setInitialSize(5);
// résultat
return dataSource;
}
}
- ligne 10 : [AppConfig] est une classe de configuration Spring ;
- ligne 11 : import de la classe de configuration [generic.jdbc.config.ConfigJdbc.class] définie dans le projet [mysql-config-jdbc]. Cela signifie qu'on dispose de tous les beans définis par ce fichier de configuration ;
- lignes 14-27 : le bean Spring définissant la source de données ;
- ligne 17 : création de la source de données encore non configurée ;
- lignes 19-22 : les informations qui permettent à la source de données de se connecter à la base de données ;
- ligne 24 : crée un pool de 5 connexions. On n'en a besoin que d'une ici. Il n'y a jamais plusieurs connexions simultanées ;
3.5.5. La classe principale
La classe principale [IntroJdbc02] est la suivante :
package spring.jdbc;
import generic.jdbc.config.ConfigJdbc;
import generic.jdbc.entities.dbproduits.Produit;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import javax.sql.DataSource;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class IntroJdbc02 {
// mapper jSON
final static ObjectMapper jsonMapper = new ObjectMapper();
// source de données
private static DataSource dataSource;
public static void main(String[] args) {
AnnotationConfigApplicationContext ctx = null;
try {
// récupération du contexte Spring
ctx = new AnnotationConfigApplicationContext(AppConfig.class);
// récupération de la source de données
dataSource = ctx.getBean(DataSource.class);
// on vide la table [PRODUITS]
System.out.println(String.format("------------------------------ %s", "Vidage de la table [PRODUITS]"));
delete();
...
// fini
System.out.println(String.format("------------------------------ %s", "Travail terminé"));
}
// liste des produits
private static void select() {
Connection connexion = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
// ouverture connexion
connexion = dataSource.getConnection();
// début transaction
connexion.setAutoCommit(false);
// en mode lecture seule
connexion.setReadOnly(true);
// on lit la table [PRODUITS]
ps = connexion.prepareStatement(ConfigJdbc.V1_SELECT_PRODUITS);
rs = ps.executeQuery();
System.out.println("Liste des produits : ");
while (rs.next()) {
affiche(new Produit(rs.getInt(1), rs.getString(2), rs.getInt(3), rs.getDouble(4), rs.getString(5)));
}
// commit transaction
connexion.commit();
} catch (SQLException e1) {
// on traite l'exception
doCatchException("Les erreurs suivantes se sont produites à la lecture de la table", connexion, e1);
} finally {
// on traite le finally
doFinally(rs, ps, connexion);
}
}
...
- ligne 25 : la source de données. On notera qu'elle est de type [javax.sql.DataSource] (ligne 13) qui est une interface ;
- ligne 31 : instanciation des objets Spring ;
- ligne 32 : obtention d'une référence sur la source de données. On notera qu'à aucun moment on ne cite la classe réellement utilisée. Ainsi ici, rien ne laisse supposer qu'on utilise une implémentation [TomcatJdbc] ;
- ligne 49 : obtention d'une connexion ouverte. C'est comme cela, que les différentes méthodes de [IntroJdbc02] obtiennent une connexion à la base de données. Le reste du code est identique à celui de la classe [IntroJdbc01] ;
3.5.6. Les tests
On exécute la configuration d'exécution nommée [spring-jdbc-generic-02.IntroJdbc02] :
 |
On obtient les mêmes résultats que précédemment (paragraphe 3.4.9).
3.6. Exemple-03
3.6.1. L'architecture du projet
 |
Dans cet exemple, les méthodes d'accès aux données sont isolées dans une couche [dao]. Elles vont être testées par un test JUnit.
3.6.2. Le projet Eclipse
Le projet Eclipse [spring-jdbc-03] est un projet Spring / Maven construit comme le précédent puis complété de la façon suivante :
 |  |
Les différents packages ont les rôles suivants :
- [spring.jdbc.config] : configuration du projet Spring ;
- [spring.jdbc.dao] : implémentation de la couche [DAO] ;
- [spring.jdbc.infrastructure] : implémente l'exception non contrôlée [DaoException] ;
3.6.3. Configuration Maven
Le projet Maven est configuré par le fichier [pom.xml] suivant :
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dvp.spring.database</groupId>
<artifactId>spring-jdbc-generic-03</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>spring-jdbc-generic-03</name>
<description>Demo project for API JDBC</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
<relativePath /> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!-- configuration JDBC du SGBD -->
<dependency>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-config-jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
</plugin>
</plugins>
</build>
</project>
Il est identique à celui du projet [spring-jdbc-02]. Il utilise notamment la dépendance Maven du projet [mysql-config-jdbc] (lignes 28-32).
3.6.4. Interface de la couche [DAO]
 |
La couche [DAO] présente l'interface [IDao] suivante :
package spring.jdbc.dao;
import java.util.List;
import spring.jdbc.entities.Produit;
public interface IDao {
// ajouter des produits
public List<Produit> addProduits(List<Produit> produits);
// liste de tous les produits
public List<Produit> getAllProduits();
// un produit particulier
public Produit getProduitById(int id);
public Produit getProduitByName(String name);
// mise à jour de plusieurs produits
public int updateProduits(List<Produit> produits);
// suppression de tous les produits
public int deleteAllProduits();
// suppression de plusieurs produits
public int deleteProduits(int[] ids);
}
3.6.5. La classe [DaoException]
La classe [DaoException] se contente d'étendre la classe [UncheckedException] présentée au paragraphe 3.3.5 :
 |
package spring.jdbc.infrastructure;
public class DaoException extends UncheckedException {
private static final long serialVersionUID = 1L;
// constructeurs
public DaoException() {
super();
}
public DaoException(int code, Throwable e, String className) {
super(code, e, className);
}
}
3.6.6. Configuration du projet Spring
 |
La classe [AppConfig] qui configure le projet Spring est identique au fichier de configuration Spring de l'exemple [spring-jdbc-02] à la ligne 11 près :
package spring.jdbc.config;
import generic.jdbc.config.ConfigJdbc;
import org.apache.tomcat.jdbc.pool.DataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@ComponentScan(basePackages = { "spring.jdbc.dao" })
public class AppConfig {
// source de données
@Bean
public DataSource dataSource() {
// source de données TomcatJdbc
DataSource dataSource = new DataSource();
// configuration accès JDBC
dataSource.setDriverClassName(ConfigJdbc.DRIVER_CLASSNAME);
dataSource.setUsername(ConfigJdbc.USER_DBPRODUITS);
dataSource.setPassword(ConfigJdbc.PASSWD_DBPRODUITS);
dataSource.setUrl(ConfigJdbc.URL_DBPRODUITS);
// connexions ouvertes initialement
dataSource.setInitialSize(5);
// résultat
return dataSource;
}
}
- ligne 11 : le package [spring.jdbc.dao] sera scanné pour y trouver d'autres composants Spring que ceux définis dans ce fichier de configuration ;
3.6.7. Implémentation de la couche [DAO]
 |
 |
Rappelons (paragraphe 3.6.4) que la couche [DAO] implémente l'interface [IDao] suivante :
package spring.jdbc.dao;
import generic.jdbc.entities.dbproduits.Produit;
import java.util.List;
public interface IDao {
// ajouter des produits
public List<Produit> addProduits(List<Produit> produits);
// liste de tous les produits
public List<Produit> getAllProduits();
// un produit particulier
public Produit getProduitById(int id);
public Produit getProduitByName(String name);
// mise à jour de plusieurs produits
public int updateProduits(List<Produit> produits);
// suppression de tous les produits
public int deleteAllProduits();
// suppression de plusieurs produits
public int deleteProduits(int[] ids);
}
Les classes [Dao1, Dao2] implémentent toutes deux cette interface. La classe [Dao2] est une variante de la classe [Dao1] qui introduit une nouveauté syntaxique. Nous allons nous concentrer sur la classe [Dao1]. Le squelette de celle-ci est la suivante :
package spring.jdbc.dao;
import generic.jdbc.config.ConfigJdbc;
import generic.jdbc.entities.dbproduits.Produit;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import javax.sql.DataSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import spring.jdbc.infrastructure.DaoException;
@Component("dao1")
public class Dao1 implements IDao {
// nom de la classe
private String simpleClassName = getClass().getSimpleName();
// source de données
@Autowired
protected DataSource dataSource;
// constructeur
public Dao1() {
System.out.println("building Dao1...");
}
// ------------------------------- interface
@Override
public List<Produit> getAllProduits() {
...
}
@Override
public Produit getProduitById(int id) {
...
}
@Override
public Produit getProduitByName(String name) {
...
}
@Override
public List<Produit> addProduits(List<Produit> produits) {
....
}
@Override
public int updateProduits(List<Produit> produits) {
...
}
@Override
public int deleteAllProduits() {
...
}
@Override
public int deleteProduits(int[] ids) {
...
}
// ---------------------------------------- méthodes locales
// gestion finally
protected DaoException doFinally(ResultSet rs, PreparedStatement ps, Connection connexion, int code,
DaoException daoException) {
...
}
// gestion catch
protected DaoException doCatchException(Connection connexion, Throwable th, int code, DaoException daoException) {
...
}
- ligne 20 : la classe [Dao] est un composant Spring nommé [dao1]. Ce nom est facultatif. Lorsqu'il n'est pas présent, le nom utilisé est le nom de la classe avec la 1ère majuscule passée en minuscule ;
- ligne 24 : le nom de la classe. On évite d'écrire en dur [Dao] pour laisser la possibilité de renommer la classe sans avoir à redéfinir ce champ qui reste ainsi toujours valide ;
- lignes 26-27 : injection de la source de données [tomcat-jdbc] définie dans la classe de configuration [AppConfig] ;
- lignes 36-68 : implémentation de l'interface [IDao] ;
- lignes 78-80 : gestion centralisée du catch des différentes méthodes ;
- lignes 72-75 : gestion centralisée du finally des différentes méthodes ;
Le catch des différentes méthodes est géré de la façon suivante :
// gestion catch
protected DaoException doCatchException(Connection connexion, Throwable th, int code) {
// annulation transaction
try {
if (connexion != null) {
connexion.rollback();
}
} catch (SQLException e2) {
e2.printStackTrace();
}
// daoException
return new DaoException(code, th, simpleClassName);
}
- ligne 2 : la méthode est déclarée [protected] ce qui permet aux classes filles de l'utiliser sans qu'elle soit pour autant publique. Elle reçoit les paramètres suivants :
- [Connection connexion] : la connexion avec le SGBD - peut-être null ;
- [Throwable th] : l'exception qui s'est produite et qu'on va encapsuler dans un type [DaoException] ;
- [int code] : un code d'erreur à utiliser si la méthode crée une nouvelle [DaoException] ;
- lignes 4-7 : le rôle premier de cette méthode est d'annuler la transaction liée à la connexion passée en paramètre 1 ;
- lignes 8-10 : si l'annulation de la transaction s'est mal passée, on écrit la trace de l'exception sur la console. On ne peut pas faire grand chose d'autre dans la mesure où on va lancer une exception ligne 12 ;
Le finally des différentes méthodes est géré de la façon suivante :
// gestion finally
protected DaoException doFinally(ResultSet rs, PreparedStatement ps, Connection connexion, int code,
DaoException daoException) {
// fermeture ResultSet
if (rs != null) {
try {
rs.close();
} catch (SQLException e1) {
}
}
// fermeture [PreparedStatement]
if (ps != null) {
try {
ps.close();
} catch (SQLException e2) {
}
}
// fermerture connexion
if (connexion != null) {
try {
connexion.close();
} catch (SQLException e3) {
// on enregistre l'erreur si c'est possible
if (daoException == null) {
daoException = new DaoException(code, e3, simpleClassName);
}
}
}
// résultat
return daoException;
}
- ligne 2 : cette méthode est elle aussi déclarée [protected]. Elle reçoit les paramètres suivants :
- [ResultSet rs] : l'éventuel [ResultSet] si une opération [SELECT] a été exécutée - peut-être null ;
- [PreparedStatement ps] : le [PreparedStatement] qui a été exécuté - peut-être null ;
- [Connection connexion] : la connexion avec le SGBD - peut-être null ;
- [int code] : un code d'erreur à utiliser si la méthode crée une nouvelle [DaoException] ;
- [DaoException daoException] : l'éventuelle [DaoException] si il y a eu une exception avant le finally- peut-être null ;
- lignes 21-30 : l'objectif premier de cette méthode est de fermer la connexion (ligne 23) ;
- lignes 24-29 : si lors de cette fermeture, il y a exception, alors on regarde l'état du paramètre [DaoException daoException] qu'on nous a passé : si [daoException == null] alors on crée une nouvelle [DaoException] avec le code passé en paramètre ;
- ligne 32 : l'ancienne ou la nouvelle [DaoException] est rendue comme résultat ;
Nous n'allons pas présenter toutes les méthodes de la classe [Dao] mais seulement quelques unes. Elles se ressemblent toutes.
3.6.7.1. La méthode [getProduitById]
La méthode [getProduitById]rend le produit dont la clé primaire est égale au paramètre [id] ou null sinon ;
@Override
public Produit getProduitById(int id) {
// ressources de la connexion
Connection connexion = null;
PreparedStatement ps = null;
ResultSet rs = null;
// au départ pas d'exception
DaoException daoException = null;
// le produit recherché
Produit produit = null;
try {
// ouverture connexion
connexion = dataSource.getConnection();
// début transaction
connexion.setAutoCommit(false);
// en mode lecture seule
connexion.setReadOnly(true);
// on lit la table [PRODUITS]
ps = connexion.prepareStatement(ConfigJdbc.V2_SELECT_PRODUIT_BYID);
ps.setInt(1, id);
rs = ps.executeQuery();
if (rs.next()) {
produit = new Produit(id, rs.getString(1), rs.getInt(2), rs.getDouble(3), rs.getString(4));
}
// commit transaction
connexion.commit();
// retour au mode par défaut
connexion.setAutoCommit(true);
} catch (SQLException e1) {
// on traite l'exception
daoException = doCatchException(connexion, e1, 112);
} finally {
// on traite le finally
daoException = doFinally(rs, ps, connexion, 113, daoException);
}
// exception ?
if (daoException != null) {
throw daoException;
}
// résultat
return produit;
}
- ligne 10 : le produit à rendre est mis à null ;
- ligne 19 : l'ordre SQL [ConfigJdbc.V2_SELECT_PRODUIT_BYID] est le suivant :
public final static String V2_SELECT_PRODUIT_BYID = "SELECT NOM, CATEGORIE, PRIX, DESCRIPTION FROM PRODUITS WHERE ID=?";
- lignes 22-24 : si le [ResultSet] a une ligne, on l'utilise pour créer le produit à rendre, sinon le produit à rendre reste à null ;
- ligne 41 : on rend le produit ;
- ligne 8 : l'exception [DaoException] de la méthode est initialisée à null ;
- ligne 31 : la méthode [doCatchException] crée une exception [DaoException] ;
- ligne 34 : le paramètre [daoException] de la méthode [doFinally] est soit null, soit l'exception créée par la méthode [doCatchException]. La méthode [doFinally] :
- laisse ce paramètre en l'état si elle arrive à fermer la connexion ;
- laisse ce paramètre en l'état si elle n'arrive pas à fermer la connexion et qu'il y a déjà eu une [DaoException] auparavant ;
- crée une nouvelle [DaoException] si elle n'arrive pas à fermer la connexion et qu'il y a pas eu de [DaoException] auparavant ;
- lignes 37-39 : si l'exception locale [daoException] ne vaut pas null, alors on la lance sinon on rend le résultat demandé (ligne 41) ;
3.6.7.2. La méthode [deleteProduits]
La méthode [deleteProduits] supprime les produits dont on lui passe les clés primaires en paramètre. Elle rend le nombre de produits supprimés.
@Override
public int deleteProduits(int[] ids) {
// ressources de la connexion
PreparedStatement ps = null;
Connection connexion = null;
// au départ pas d'exception
DaoException daoException = null;
// nombre de produits mis à jour
int nbProduits = 0;
try {
// ouverture connexion
connexion = dataSource.getConnection();
// début transaction
connexion.setAutoCommit(false);
// en mode lecture / écriture
connexion.setReadOnly(false);
// on supprime les produits
ps = connexion.prepareStatement(ConfigJdbc.V2_DELETE_PRODUITS);
for (int id : ids) {
// paramètres
ps.setInt(1, id);
// exécution
nbProduits += ps.executeUpdate();
}
// commit transaction
connexion.commit();
// retour au mode par défaut
connexion.setAutoCommit(true);
} catch (SQLException e1) {
// on traite l'exception
daoException = doCatchException(connexion, e1, 171);
} finally {
// on traite le finally
daoException = doFinally(null, ps, connexion, 172, daoException);
}
// exception ?
if (daoException != null) {
throw daoException;
}
// résultat
return nbProduits;
}
- ligne 18, l'ordre SQL [ConfigJdbc.V2_DELETE_PRODUITS] est le suivant :
public final static String V2_DELETE_PRODUITS = "DELETE FROM PRODUITS WHERE ID=?";
- lignes 18-24 : le code de suppression des produits. On voit que l'ordre SQL est préparé 1 fois (ligne 18) et exécuté n fois (lignes 19-24). C'est l'intérêt de l'objet [PreparedStatement] ;
- ligne 23 : la méthode [PreparedStatement].executeUpdate() rend le nombre de lignes affectées par l'opération de mise à jour ;
- ligne 41 : on rend le nombre de produits mis à jour ;
3.6.7.3. La méthode [updateProduits]
La méthode [updateProduits] met à jour en base les produits qu'on lui passe en paramètres. Elle rend le nombre de produits mis à jour.
@Override
public int updateProduits(List<Produit> produits) {
// ressources de la connexion
PreparedStatement ps = null;
Connection connexion = null;
// au départ pas d'exception
DaoException daoException = null;
// nombre de produits mis à jour
int nbProduits = 0;
try {
// ouverture connexion
connexion = dataSource.getConnection();
// début transaction
connexion.setAutoCommit(false);
// en mode lecture / écriture
connexion.setReadOnly(false);
// on met à jour la table [PRODUITS]
ps = connexion.prepareStatement(ConfigJdbc.V2_UPDATE_PRODUITS);
for (Produit produit : produits) {
// paramètres
ps.setString(1, produit.getNom());
ps.setDouble(2, produit.getPrix());
ps.setInt(3, produit.getCategorie());
ps.setString(4, produit.getDescription());
ps.setInt(5, produit.getId());
// exécution
nbProduits += ps.executeUpdate();
}
// commit transaction
connexion.commit();
// retour au mode par défaut
connexion.setAutoCommit(true);
} catch (SQLException e1) {
// on traite l'exception
daoException = doCatchException(connexion, e1, 131);
} finally {
// on traite le finally
daoException = doFinally(null, ps, connexion, 132, daoException);
}
// exception ?
if (daoException != null) {
throw daoException;
}
// résultat
return nbProduits;
}
- ligne 18 : l'ordre SQL [ConfigJdbc.V2_UPDATE_PRODUITS] est le suivant :
public final static String V2_UPDATE_PRODUITS = "UPDATE PRODUITS SET NOM=?, PRIX=?, CATEGORIE=?, DESCRIPTION=? WHERE ID=?";
- lignes 19-28 : le code de mise à jour des produits ;
3.6.7.4. La méthode [addProduits]
La méthode [addProduits] ajoute en base les produits qu'on lui passe en paramètres. Elle rend ces mêmes produits avec leurs clés primaires (avant la mise en base, les produits n'ont pas de clé primaire).
@Override
public List<Produit> addProduits(List<Produit> produits) {
// ressources de la connexion
PreparedStatement ps = null;
Connection connexion = null;
// au départ pas d'exception
DaoException daoException = null;
try {
// ouverture connexion
connexion = dataSource.getConnection();
// en mode lecture / écriture
connexion.setReadOnly(false);
// début transaction
connexion.setAutoCommit(false);
// on ajoute des éléments à la table [PRODUITS]
String generatedColumns[] = { ConfigJdbc.TAB_PRODUITS_ID };
ps = connexion.prepareStatement(ConfigJdbc.V2_INSERT_PRODUITS, generatedColumns);
for (Produit produit : produits) {
// paramètres
ps.setString(1, produit.getNom());
ps.setLong(2, produit.getCategorie());
ps.setDouble(3, produit.getPrix());
ps.setString(4, produit.getDescription());
// exécution commande
ps.executeUpdate();
// clé primaire générée
ResultSet generatedKeys = ps.getGeneratedKeys();
if (generatedKeys.next()) {
produit.setId(generatedKeys.getInt(1));
} else {
throw new RuntimeException(String.format("Le produit de nom [%s] n'a pas récupéré de clé primaire",
produit.getNom()));
}
}
// commit transaction
connexion.commit();
// retour au mode par défaut
connexion.setAutoCommit(true);
} catch (SQLException | RuntimeException e1) {
// on traite l'exception
daoException = doCatchException(connexion, e1, 151);
} finally {
// on traite le finally
daoException = doFinally(null, ps, connexion, 152, daoException);
}
// exception ?
if (daoException != null) {
throw daoException;
}
// résultat
return produits;
}
- ligne 16, l'ordre SQL [ConfigJdbc.V2_INSERT_PRODUITS] est le suivant :
public final static String V2_INSERT_PRODUITS = "INSERT INTO PRODUITS(NOM, CATEGORIE, PRIX, DESCRIPTION) VALUES (?, ?, ?, ?)";
Ci-dessus, la commande d'insertion d'un produit n'inclut pas la clé primaire [ID]. Comme la clé primaire de la base MySQL a l'attribut [AUTOINCREMENT], le SGBD va alors générer une clé primaire pour chaque insertion. Se pose le problème de récupérer celle-ci. C'est un point important car les opérations sur les produits se font via leurs clés primaires. Il faut donc connaître celles-ci ;
- lignes 17-33 : la boucle d'insertion des produits ;
- ligne 16 : une forme particulière de la méthode [prepareStatement]. Le second paramètre [generatedColumns] est un tableau de noms de colonnes dont on veut récupérer les valeurs après l'insertion. Ligne 16, nous avons indiqué que nous voulions récupérer la valeur de la colonne [id]. On notera ici que bien que le nom des colonnes d'une table soit insensible à la casse (majuscules / minuscules], le SGBD PostgreSQL a voulu que ce nom soit en minuscules. C'est typiquement le genre de problèmes qu'on trouve lors des portages d'un code d'un SGBD à un autre ;
- ligne 24 : insertion dans la base d'une ligne ;
- ligne 26 : on récupère la liste des valeurs des colonnes précisées ligne 16 dans un [ResultSet]. Ici, pour 1 insertion, le [ResultSet] aura 1 ligne et cette ligne aura 1 unique colonne qui contient la clé primaire ;
- ligne 28 : on récupère la clé primaire générée par le SGBD ;
- lignes 29-32 : si on n'obtient pas la clé primaire générée, on lance une [RuntimeException] qui sera encapsulée dans une [DaoException] lignes 38-40 ;
3.6.8. La classe [Dao2]
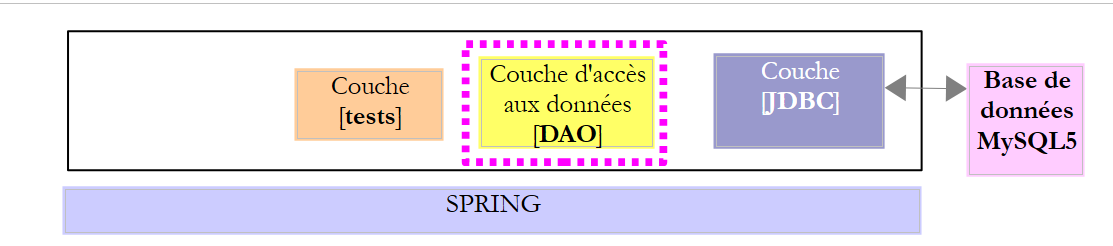 |
 |
La classe [Dao2] est une variante de la classe [Dao1] utilisant une syntaxe appelée try-with-resource(resource) :
- [resource] est une ressource qui implémente l'interface [java.lang.AutoCloseable]. Toutes les ressources qu'on libère avec la méthode [close] en font partie. Cette syntaxe assure que ligne 4, la ressource [resource] sera fermée. Cela évite d'écrire une clause [finally] pour faire ce travail de fermeture ;
Prenons comme exemple, la méthode [getAllProduits] de la classe [Dao2] :
@Override
public List<Produit> getAllProduits() {
// éventuelle exception
DaoException daoException = null;
// liste des produits
List<Produit> produits = new ArrayList<Produit>();
try (Connection connexion = dataSource.getConnection()) {
// début transaction
connexion.setAutoCommit(false);
// en mode lecture seule
connexion.setReadOnly(true);
// on lit la table [PRODUITS]
try (PreparedStatement ps = connexion.prepareStatement(ConfigJdbc.V2_SELECT_ALLPRODUITS)) {
try (ResultSet rs = ps.executeQuery()) {
while (rs.next()) {
produits.add(new Produit(rs.getInt(1), rs.getString(2), rs.getInt(3), rs.getDouble(4), rs.getString(5)));
}
}
// fin transaction
connexion.commit();
// retour au mode par défaut
connexion.setAutoCommit(true);
} catch (SQLException e1) {
// on annule la transaction
daoException = doRollback(connexion, e1, 111);
}
} catch (SQLException e2) {
// on traite l'exception
if (daoException == null) {
daoException = new DaoException(112, e2, simpleClassName);
}
}
// exception ?
if (daoException != null) {
throw daoException;
}
// résultat
return produits;
}
- ligne 7 : try avec la ressource [Connection]. Ligne 27, on est assuré que celle-ci est fermée ;
- ligne 13 : try avec la ressource [PreparedStatement]. Ligne 23, on est assuré que celle-ci est fermée ;
- ligne 14 : try avec la ressource [ResultSet]. Ligne 19, on est assuré que celle-ci est fermée ;
- ligne 25 : la transaction est annulée de la façon suivante :
private DaoException doRollback(Connection connexion, Throwable e1, int code) {
try {
if (connexion != null) {
connexion.rollback();
}
} catch (SQLException e) {
e.printStackTrace();
}
// génération de l'exception
return new DaoException(code, e1, simpleClassName);
}
Au final, on a un code plus simple à lire.
3.6.9. Implémentation de la couche de tests
3.6.9.1. Les classes de test
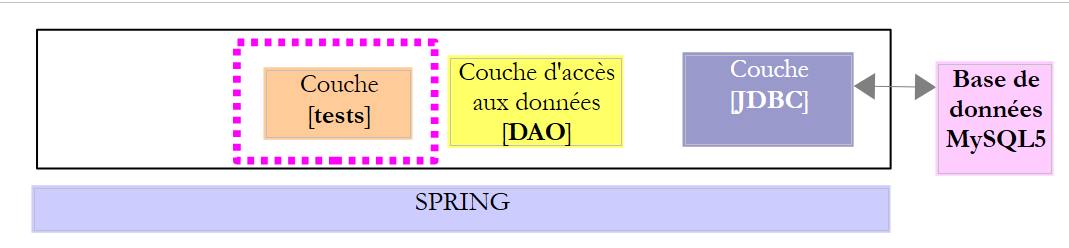 |
 |
- le test [JUnitTestDao1] est un test JUnit de la classe [Dao1] ;
- le test [JUnitTestDao2] est un test JUnit de la classe [Dao2] ;
- [AbstractJUnitTestDao] est la classe parent des deux classes de test précédentes ;
- [MainTestDao1] est une classe console de test de la classe [Dao1] ;
- [MainTestDao2] est une classe console de test de la classe [Dao2] ;
- [AbstractMainTestDao] est la classe parent des deux classes précédentes. Elle reprend le code des classes console [IntroJdbc01, IntroJdbc02] déjà présentées, aussi n'étudierons-nous pas ces classes console ;
Le classe [JUnitTestDao1] est la suivante :
package spring.jdbc.tests;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.test.SpringApplicationConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import spring.jdbc.config.AppConfig;
import spring.jdbc.dao.IDao;
@SpringApplicationConfiguration(classes = AppConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class JUnitTestDao1 extends AbstractJUnitTestDao {
// couche [DAO]
@Autowired
@Qualifier("dao1")
private IDao dao;
@Override
IDao getDao() {
return dao;
}
}
- les annotations des lignes 12-13 ont été présentées au paragraphe 2.5.5. Elles permettent à un test Junit d'avoir un accès simple au contexte Spring et ses beans. Ce contexte est configuré par la classe [AppConfig] (ligne 12) étudiée au paragraphe 2.4.3 ;
- ligne 14 : la classe étend la classe [AbstractJUnitTestDao] que nous allons présenter. C'est dans cette classe que se trouvent les méthodes de test JUnit ;
- lignes 17-19 : le bean nommé [dao1] (ligne 18) est injecté (ligne 17). C'est donc une instance de la classe [Dao1] qui est ici injectée ;
- lignes 21-24 : la méthode [getDao] redéfinit la méthode de même nom dans la classe parent ;
Au final, le but de cette classe est de rendre à la classe parent, une référence sur la couche [DAO] qui doit être testée, ici une instance de [Dao1]. De la même façon la classe [JUnitTestDao2] rend à la classe parent [AbstractJUnitTestDao] une instance de la classe [Dao2].
La classe [AbstractJUnitTestDao] est une classe de tests JUnit :
package spring.jdbc.tests;
import generic.jdbc.entities.dbproduits.Produit;
import java.util.ArrayList;
import java.util.List;
import org.junit.Assert;
import org.junit.Before;
import org.junit.Test;
import org.springframework.beans.BeansException;
import spring.jdbc.dao.IDao;
import spring.jdbc.infrastructure.DaoException;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public abstract class AbstractJUnitTestDao {
// couche [DAO]
abstract IDao getDao();
// mapper jSON
final static ObjectMapper jsonMapper = new ObjectMapper();
@Before
public void clean() {
// on nettoie la base avant chaque test
log("Vidage de la base de données", 1);
getDao().deleteAllProduits();
}
@Test
public void getProduits() throws JsonProcessingException {
...
}
@Test
public void getProduitBy() {
...
}
@Test
public void doInsertsInTransaction() {
...
}
@Test
public void updateProduits() {
...
}
@Test
public void deleteProduits() {
....
}
@Test
public void perf1() {
...
}
@Test
public void perf2() {
...
}
@Test
public void perf3() {
....
}
// -------------- méthodes privées
...
}
- ligne 19, la classe [AbstractJUnitTestDao] est abstraite ;
- ligne 22 : la méthode abstraite [getDao] qui permet d'avoir la référence sur la couche [DAO] à tester. Cette méthode est implémentée par les classes filles ;
- ligne 25 : un mappeur jSON qui va nous permettre d'afficher sur la console la valeur jSON de produits ;
- lignes 27-32 : avant chaque test (ligne 27), la table [PRODUITS] est vidée ;
3.6.9.2. La méthode privée [fill]
La méthode privée [fill] est utilisée pour mettre des produits dans la table [PRODUITS].
private List<Produit> fill(int nbProduits) {
log("Remplissage de la base de données", 1);
// on crée une liste de produits
List<Produit> produits = new ArrayList<Produit>();
for (int i = 0; i < nbProduits; i++) {
int n = i + 1;
// int id, String nom, int categorie, double prix, String description
produits.add(new Produit(0, String.format("NOM%s", n), n / 5 + 1, 100 * (1 + (double) i / 100), String.format(
"DESC%s", n)));
}
// on la persiste en base - on récupère des produits avec leur clé primaire
produits = getDao().addProduits(produits);
// on crée un dictionnaire des produits pour pouvoir les retrouver + facilement
// la clé du dictionnaire est la clé primaire du produit en base
for (Produit produit : produits) {
mapProduits.put(produit.getId(), produit);
}
// on rend les produits
return produits;
}
- ligne 1 : la méthode [fill] insère [nbProduits] dans la table [PRODUITS] supposée vide ;
- lignes 3-10 : création d'une liste de produits de la forme :
new Produit(0, String.format("NOM%s", n), n / 5 + 1, 100 * (1 + (double) i / 100), String.format("DESC%s", n)));
qui utilise le constructeur Produit(int id, String nom, int categorie, double prix, String description). La valeur du premier paramètre [id] (clé primaire de la table [PRODUITS]) n'a pas d'importance puisque la méthode [addProduits] de la ligne 10 ne l'insère pas dans la base et laisse le SGBD générer sa valeur ;
- ligne 12 : la liste des produits est persistée en base. Chacun des produits de cette liste se voit enrichie d'une clé primaire [id] nouvelle. La méthode [addProduits] rend pour résultat son paramètre [produits]. On aurait pu donc ne pas récupérer le résultat ;
- lignes 15-17 : on met les produits dans un dictionnaire :
// dictionnaire des produits
private Map<Integer, Produit> mapProduits = new HashMap<Integer, Produit>();
La clé du dictionnaire est la clé primaire du produit et la valeur associée, le produit lui-même ;
- ligne 19 : on rend la liste des produits ;
3.6.9.3. Le test [getProduits]
Celui-ci est le suivant :
@Test
public void getProduits() throws JsonProcessingException {
// remplissage
fill(10);
// liste des produits
log("Liste des produits", 2);
List<Produit> produits = getDao().getAllProduits();
affiche(produits);
// on vérifie que la liste récupérée et celle persistée sont les mêmes
for (Produit produit : produits) {
Produit found = mapProduits.get(produit.getId());
Assert.assertEquals(found, produit);
mapProduits.remove(found.getId());
}
// tous les produits initiaux doivent avoir disparu du dictionnaire
Assert.assertEquals(0, mapProduits.size());
}
}
- ligne 4 : 10 produits sont mis dans la base ;
- ligne 7 : ceci fait, on demande à voir tous les produits de la base ;
- ligne 8 : on les affiche. Le but est de voir que les produits ont bien été enregistrés et qu'ils ont une clé primaire ;
- lignes 10-13 : on vérifie que les produits retrouvés sont identiques à ceux qu'on a persistés et qu'on peut retrouver dans le dictionnaire [mapProduits] ;
- ligne 11 : on récupère dans le dictionnaire le produit ayant la même clé primaire que celui ramené de la base. Cela montre que les produits persistés ont bien récupéré une clé primaire ;
- ligne 12 : on s'assure que les deux produits sont identiques. On rappelle que la classe [Produit] a défini une méthode [equals] (cf paragraphe 3.3.4) ;
- ligne 13 : on supprime du dictionnaire l'élément trouvé ;
- ligne 16 : on vérifie que le dictionnaire des produits initiaux est bien vide signifiant par là que ces produits initiaux étaient tous présents dans la liste des produits ramenés de la base ;
La méthode [affiche] de la ligne 8, est la méthode privée suivante :
// affichage liste de produits
private <T> void affiche(List<T> elements) throws JsonProcessingException {
for (T element : elements) {
System.out.println(jsonMapper.writeValueAsString(element));
}
}
- ligne 2 : la méthode [affiche] est une méthode générique. Elle est paramétrée par un type T noté syntaxiquement <T>. Si elle était paramétrée par deux types T1 et T2, on écrirait <T1,T2>. La syntaxe d'une méthode m paramétrée par un type T est la suivante :
Dans le code de la méthode m, on va trouver des données de type T. La méthode m d'une instance c d'une classe C peut alors être appelée de la façon suivante :
où T1 est le type effectif qui va remplacer le type formel T de la méthode m. La plupart du temps, le compilateur est capable de déduire le type T1 d'après les arguments de la méthode m. Aussi, l'instruction précédente sera le plus souvent simplifiée en :
Revenons à la méthode [affiche]. Elle affiche une liste d'éléments de type T. Ceci est possible parce que le mappeur jSON utilisé ligne 4 est capable de rendre la représentation jSON de tout type d'objet. Dans cet exemple précis, le seul type T utilisé sera le type [Produit].
La méthode [affiche] aurait pu également être écrite de la façon suivante :
// affichage liste de produits
private void affiche(Object o) throws JsonProcessingException {
System.out.println(jsonMapper.writeValueAsString(o));
}
Le paramètre effectif étant une liste de produits, la ligne 3 aurait écrit la représentation jSON de cette liste. Ce n'est pas la même chose que d'écrire une par une, la représentation de chacun de ses éléments.
L'affichage produit par le test [getProduits] est le suivant :
3.6.9.4. Le test [getProduitBy]
Celui-ci est le suivant :
@Test
public void getProduitBy() {
// remplissage
fill(10);
log("getProduitBy", 1);
Produit produit = getDao().getProduitByName("NOM3");
Produit produit2 = getDao().getProduitById(produit.getId());
Assert.assertNotNull(produit2);
Assert.assertEquals(produit2.getNom(), produit.getNom());
Assert.assertEquals(produit2.getId(), produit.getId());
}
- ligne 6 : la méthode [getProduitByName] de l'interface [IDao] est utilisée pour ramener le produit de nom [NOM3] ;
- ligne 7 : la méthode [getProduitById] de l'interface [IDao] est ensuite utilisée pour ramener le même produit identifié cette fois par sa clé primaire ;
- lignes 8-10 : on vérifie que [produit2] et [produit] ont les mêmes caractéristiques ;
3.6.9.5. Le test [doInsertsInTransaction]
Celui-ci est le suivant :
@Test
public void doInsertsInTransaction() {
log("Ajout de deux produits de même nom", 1);
// on fait l'insertion
List<Produit> inserts = new ArrayList<Produit>();
inserts.add(new Produit(0, "x", 1, 1.0, ""));
inserts.add(new Produit(0, "x", 1, 1.0, ""));
boolean erreur = false;
try {
getDao().addProduits(inserts);
} catch (DaoException daoException) {
erreur = true;
}
// vérifications
Assert.assertTrue(erreur);
List<Produit> produits = getDao().getAllProduits();
Assert.assertEquals(0, produits.size());
}
- lignes 5-7 : on crée une liste de deux produits ayant le même nom [x] ;
- ligne 10 : ces deux produits sont insérés dans la table [PRODUITS] qui est vide (méthode [clean] annotée avec [@Before]). La première insertion va se faire mais pas la deuxième car la table [PRODUITS] a une contrainte d'unicité sur le nom des produits. Il doit donc se produire une exception. Celle-ci est testée ligne 15 ;
- parce que toutes les méthodes de l'interface [IDao] se font à l'intérieur d'une transaction, le fait que la deuxième insertion échoue va faire annuler la totalité de la transaction donc la première insertion. Au final, aucune insertion ne doit se faire dans la table [PRODUITS] ;
- lignes 16-17 : on vérifie ce point en demandant la liste des produits contenus dans la table [PRODUITS] et en vérifiant que cette liste est vide ;
3.6.9.6. Le test [updateProduits]
Celui-ci est le suivant :
@Test
public void updateProduits() {
// remplissage
fill(10);
log("Mise à jour du prix des produits de catégorie 1", 1);
// on récupère les produits
List<Produit> produits = getDao().getAllProduits();
// on met à jour ceux de catégorie 1
List<Produit> updated = new ArrayList<Produit>();
int nbUpdated = 0;
for (Produit produit : produits) {
if (produit.getCategorie() == 1) {
// int id, String nom, int categorie, double prix, String description
updated
.add(new Produit(produit.getId(), produit.getNom(), 1, produit.getPrix() * 1.1, produit.getDescription()));
nbUpdated++;
}
}
int nbProduits = getDao().updateProduits(updated);
// vérifications
// Assert.assertEquals(nbUpdated, nbProduits); -- ne passe pas avec DB2
for (Produit produit : updated) {
Produit produit2 = getDao().getProduitById(produit.getId());
Assert.assertEquals(produit2.getPrix(), produit.getPrix(), 1e-6);
}
}
- ligne 4 : on met 10 produits dans la base ;
- ligne 7 : on les récupère ;
- lignes 9-18 : on augmente de 10% les prix des produits de la catégorie n° 1 ;
- ligne 19 : ces modifications sont inscrites dans la base ;
- lignes 22-25 : on parcourt en mémoire la liste des produits qui a servi à la mise à jour. Pour chacun d'entre-eux, on va chercher en base le produit de même clé primaire et on vérifie que la mise à jour du prix a bien eu lieu ;
- ligne 19 : on récupère le nombre de produits mis à jour par l'opération [updateProduits] ;
- ligne 21 : on vérifie que ce nombre est bien celui attendu. Ce test passe pour tous les SGBD sauf pour le SGBD DB2. On l'a donc mis en commentaires ;
3.6.9.7. Le test [deleteProduits]
Celui-ci est le suivant :
@Test
public void deleteProduits() {
// remplissage
fill(10);
log("deleteProduits", 1);
// liste des produits
List<Produit> produits = getDao().getAllProduits();
// suppression de deux produits
Produit produit0 = produits.get(0);
Produit produit5 = produits.get(5);
int nbDeleted = getDao().deleteProduits(new int[] { produit0.getId(), produit5.getId() });
// vérifications
// Assert.assertEquals(2, nbDeleted); -- ne passe pas avec DB2
Assert.assertNull(getDao().getProduitById(produit0.getId()));
Assert.assertNull(getDao().getProduitById(produit5.getId()));
Assert.assertEquals(produits.size() - 2, getDao().getAllProduits().size());
}
- ligne 4 : on met 10 produits dans la base ;
- lignes 7-11 : on récupère tous les produits dans la base et on supprime de celle-ci les produits récupérés en positions 0 et 5 ;
- lignes 14-16 : on vérifie que les deux produits ne sont plus dans la base et que celle-ci a deux produits de moins ;
- le test de la ligne 13 ne passe pas avec le SGBD DB2. Il passe avec les autres SGBD ;
3.6.9.8. Les tests de performance
On a inclus dans les tests trois méthodes qui n'ont d'autre but que d'évaluer les performances du SGBD :
@Test
public void perf1() {
// remplissage
fill(10000);
}
@Test
public void perf2() {
// remplissage
fill(10000);
// modification
List<Produit> produits = getDao().getAllProduits();
// on met à jour ceux de catégorie 1
List<Produit> updated = new ArrayList<Produit>();
for (Produit produit : produits) {
// int id, String nom, int categorie, double prix, String description
updated.add(new Produit(produit.getId(), produit.getNom(), 1, produit.getPrix() * 1.1, produit.getDescription()));
}
getDao().updateProduits(updated);
}
@Test
public void perf3() {
// remplissage
fill(10000);
// suppression
List<Produit> produits = getDao().getAllProduits();
// clés primaires
int[] keys = new int[produits.size()];
for (int i = 0; i < keys.length; i++) {
keys[i] = produits.get(i).getId();
}
getDao().deleteProduits(keys);
}
- lignes 1-5 : insertion de 10000 produits ;
- lignes 8-20 : insertion de 10000 produits puis modification de ceux-ci via leurs clés primaires ;
- lignes 23-34 : insertion de 10000 produits puis suppression de ceux-ci via leurs clés primaires ;
Pour exécuter les tests [JUnitTestDao1] et [JUnitTestDao2], on pourra utiliser les configurations d'exécution suivantes :
 |  |
Les résultats du test [JUnitTestDao1] sont les suivants :
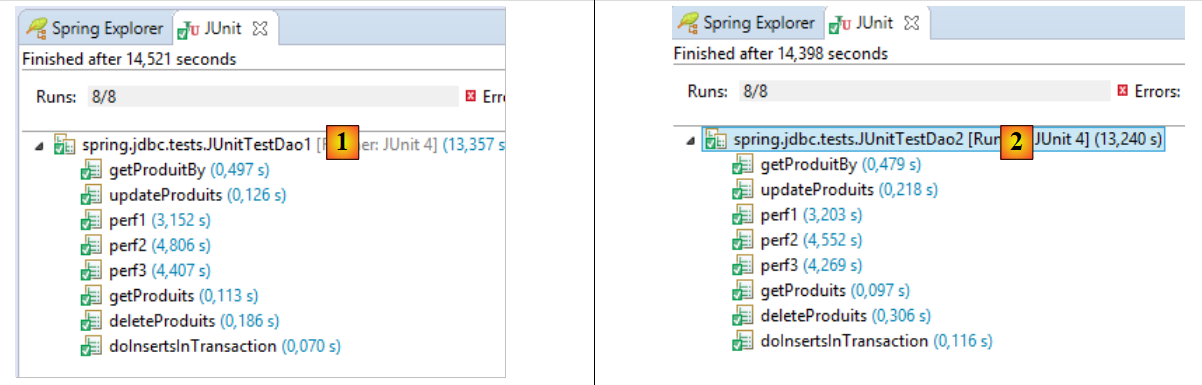 |
En [1] les résultats de [JUnitTestDao1] et en [2] ceux de [JUnitTestDao2]. Il n'y a pas de différences significatives entre-eux. En [1] :
- le test est réussi ;
- l'insertion de 10000 produits dure 3,15 secondes ;
- l'insertion de 10000 produits suivie de leur modification dure 4,80 secondes ;
- l'insertion de 10000 produits suivie de leur suppression dure 4,40 secondes ;
- donc le plus coûteux est l'insertion ;