9. Génération des bases de données à partir des entités JPA
Il est possible de créer les tables d'une base de données à partir des entités JPA. C'est ce que nous montrons maintenant. L'intérêt est de vérifier que la base de données générée à partir des entités JPA est bien celle qu'on veut.
9.1. Mise en place de l'environnement de travail
Nous allons travailler tout d'abord avec une implémentation JPA EclipseLink [1].
 |
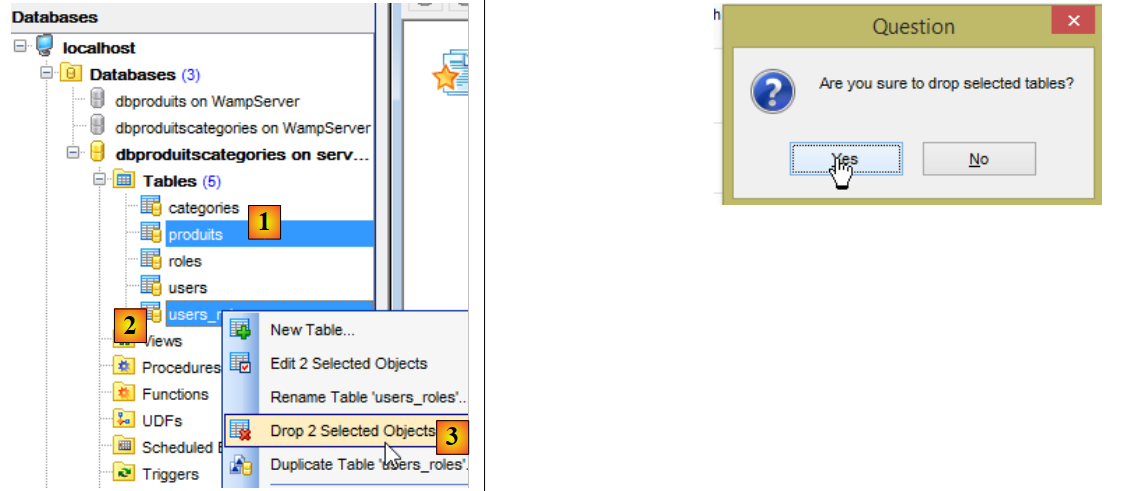
Puis nous supprimons les tables de la base MySQL [dbproduitscategories] avec le client [MyManager] (cf paragraphe 23.5). Nous commençons par supprimer les tables qui contiennent les clés étrangères [1-3] :
 |
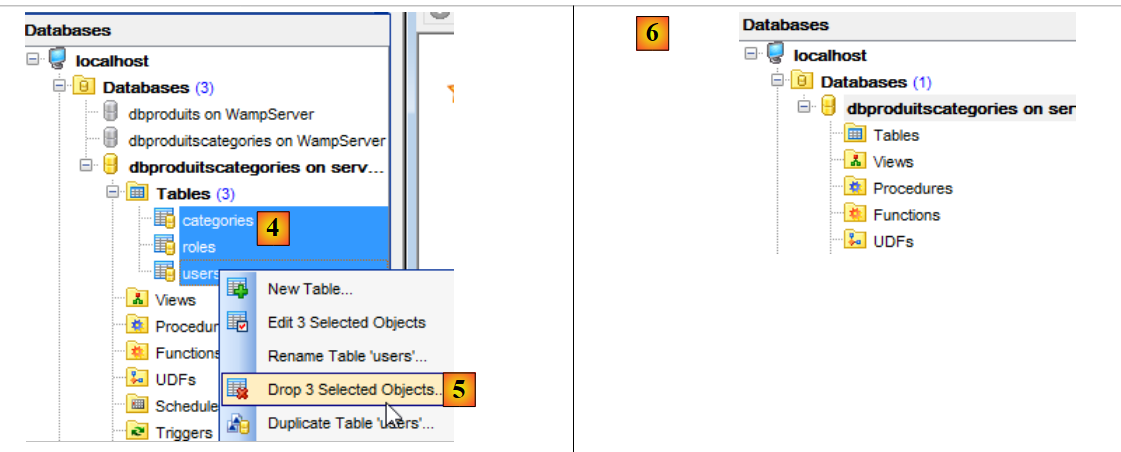
Puis nous recommençons avec les trois tables restantes [4-6] :
 |
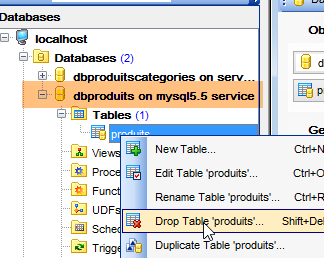
Nous faisons de même avec la table [dbproduits] utilisée par les projets [spring-jdbc-01 à 03] :
 | 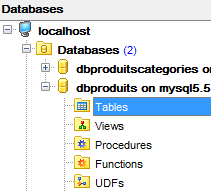 |
Par ailleurs, il faut importer les deux projets de génération des deux bases de données :
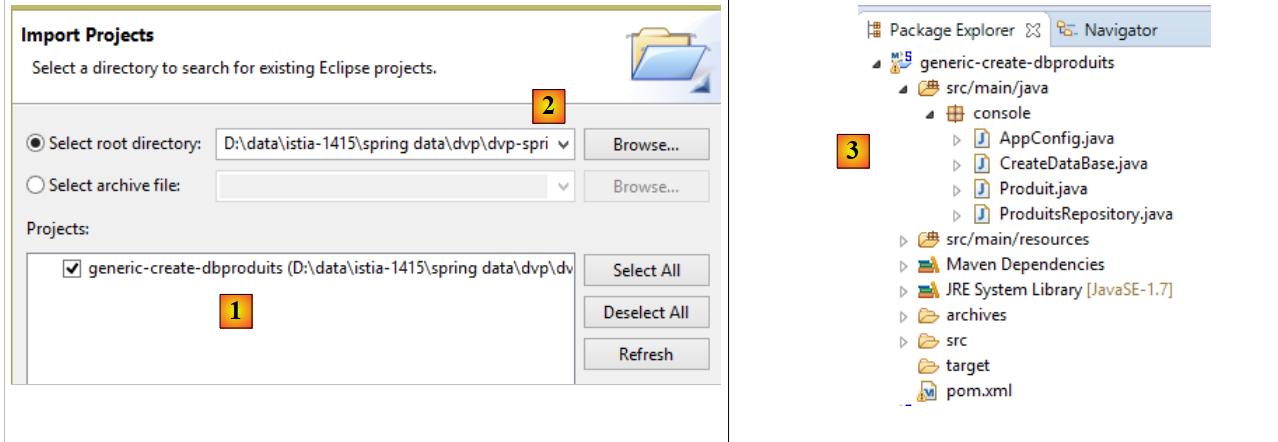 |
- en [1], on importe le projet [generic-create-dbproduits] qu'on trouvera en [<exemples>/spring-database-generic/spring-jpa] [2] ;
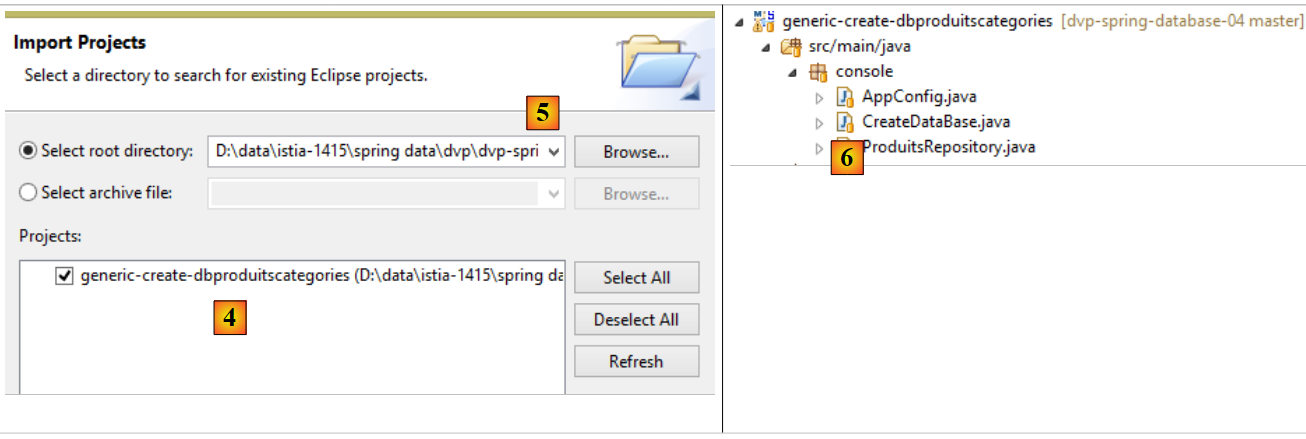 |
- en [4], on importe le projet [generic-create-dbproduitscategories] qu'on trouvera en [<exemples>/spring-database-generic/spring-jpa] [5] ;
Note : faire Alt-F5 et régénérer tous les projets Maven ;
9.2. Génération de la base [dbproduitscategories]
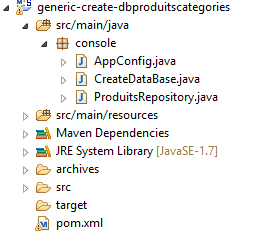 |
9.2.1. Configuration Maven
Le fichier [pom.xml] du projet est le suivant :
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-create-dbproduitscategories</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>generic-create-dbproduitscategories</name>
<description>création de la bases de données [dbproduitscategories] à l'aide des annotations JPA</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<!-- spring-jpa-generic -->
<dependency>
<groupId>dvp.spring.database</groupId>
<artifactId>spring-jpa-generic</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<!-- Weaver Spring -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-instrument</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<start-class>spring.data.console.Main</start-class>
<java.version>1.7</java.version>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
</plugin>
</plugins>
</build>
</project>
- lignes 22-26 : la dépendance sur le projet [spring-jpa-generic] étudié au paragraphe 6.4 ;
- lignes 28-32 : la dépendance sur un weaver qui sera utilisé pour enrichir les entités JPA des implémentations EclipseLink et OpenJpa. Sa dépendance n'est pas nécessaire dans le fichier [pom.xml] mais son jar sera l'agent Java utilisé. Mettre la dépendance dans le fichier [pom.xml] nous assure que le jar sera bien disponible ;
Au final, les dépendances sont les suivantes :
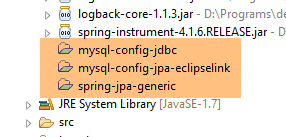 |
9.2.2. Configuration Spring
 |
La classe [AppConfig] configure le projet Spring :
package console;
import generic.jpa.config.ConfigJpa;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
@Configuration
@Import({ ConfigJpa.class })
@EnableJpaRepositories(basePackages = { "console" })
public class AppConfig {
}
- ligne 10 : la classe récupère les beans de la classe [ConfigJpa]. On rappelle que cette cette classe travaille avec les entités JPA de la base de données [dbproduitscategories] (cf paragraphe 6.3) ;
- ligne 11 : on déclare que le package [console] doit être scanné pour y trouver des instances [CrudRepository] ;
Dans la classe [ConfigJpa], on trouve le bean suivant (varie selon l'implémentation JPA utilisée) :
// le provider JPA
@Bean
public JpaVendorAdapter jpaVendorAdapter() {
// Note : les entités JPA et la configuration d'Eclipselink sont dans le fichier META-INF/persistence.xml
EclipseLinkJpaVendorAdapter eclipseLinkJpaVendorAdapter = new EclipseLinkJpaVendorAdapter();
eclipseLinkJpaVendorAdapter.setShowSql(false);
eclipseLinkJpaVendorAdapter.setDatabase(Database.MYSQL);
eclipseLinkJpaVendorAdapter.setGenerateDdl(true);
return eclipseLinkJpaVendorAdapter;
}
C'est la ligne 8 qui est importante ici. Elle est présente dans toutes les implémentations JPA utilisées. Elle dit que si les tables associées aux entités JPA n'existent pas, elles doivent être créées. Nous allons nous appuyer sur cette propriété pour générer les tables.
9.2.3. Les repository
 |
L'interface [ProduitsRepository] est la suivante :
package console;
import generic.jpa.entities.dbproduitscategories.Produit;
import org.springframework.data.repository.CrudRepository;
public interface ProduitsRepository extends CrudRepository<Produit, Long> {
}
C'est son instanciation qui va provoquer l'instanciation de la couche JPA. En effet, ligne 7, l'interface référence l'entité JPA [Produit], ce qui va forcer l'instanciation de la couche JPA. On aurait pu mettre n'importe quelle interface [CrudRepository] référençant une des entités JPA. On constate en effet que bien que le [repository] ne référence que l'entité JPA [Produit], ce sont bien toutes les tables de toutes les entités JPA qui sont générées.
9.2.4. La classe exécutable
 |
La classe [CreateDatabase] est la suivante :
package console;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class CreateDataBase {
public static void main(String[] args) {
// il suffit d'instancier le contexte Spring pour créer les tables de la base de données [dbproduitscategories]
// il faut également au moins un Spring Data Repository sinon rien ne se passe
System.out.println("Travail en cours...");
new AnnotationConfigApplicationContext(AppConfig.class).close();
System.out.println("Travail terminé...");
}
}
- ligne 11 : on instancie le contexte Spring pour le refermer aussitôt. Dans ce contexte, il y a le bean [ProduitsRepository] qui référence l'entité JPA [Produit]. C'est suffisant pour instancier la couche JPA et donc de générer les tables de la base de données [dbproduitscategories].
9.2.5. Génération des tables avec EclipseLink
Nous sommes dans la configuration suivante :
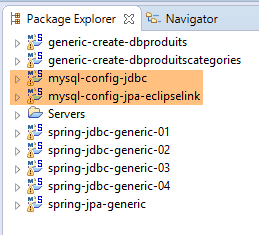 |
- la couche [JDBC] est configurée pour la base de données [dbproduitscategories] de MySQL ;
- la couche [JPA] est implémentée avec EclipseLink ;
- la base de données [dbproduitscategories] n'a pas de tables ;
Note : faire Alt-F5 et régénérer tous les projets Maven ;
On utilise la configuration d'exécution suivante :
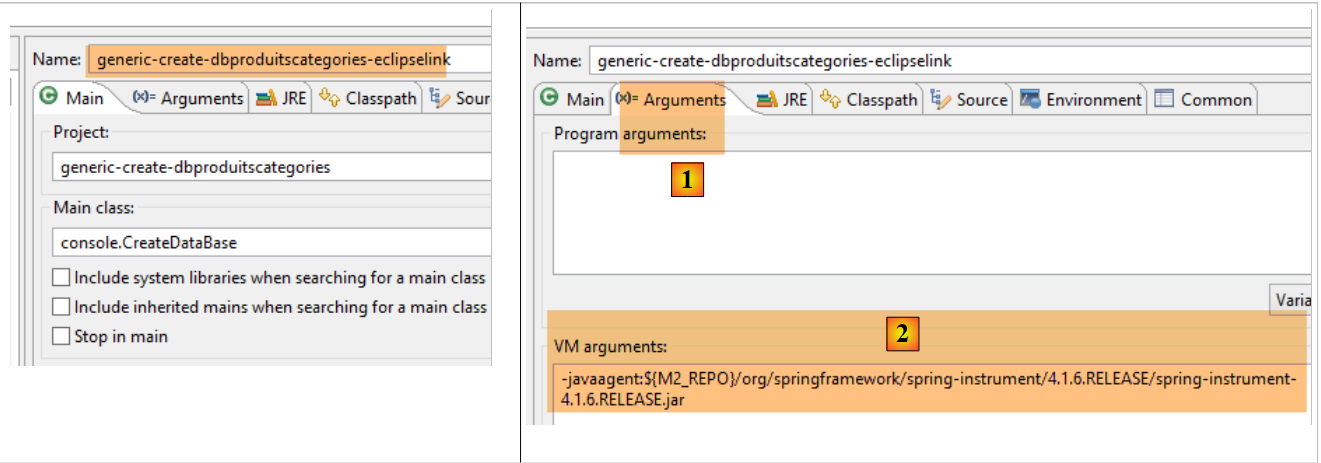 |
- en [1-2], cette configuration d'exécution nécessite un agent Java pour que le test réussisse. Selon les cas, EclipseLink n'a pas toujours besoin de cet agent mais ici l'exécution échoue s'il n'est pas là. Cet agent n'est pas un agent EclipseLink mais un agent Spring. Il est fourni par la dépendance :
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-instrument</artifactId>
<scope>runtime</scope>
</dependency>
inscrite dans le fichier [pom.xml] du projet. L'agent est trouvé dans [<m2-repo>/org/springframework/spring-instrument/4.1.6.RELEASE/spring-instrument-4.1.6.RELEASE.jar] où <m2-repo> est le dépôt local de Maven ;
L'exécution donne le résultat suivant :
 |
En [3], on voit que les tables ont été générées. Maintenant vérifions la DDL (Domain Definition Language) de la base de données :
 | 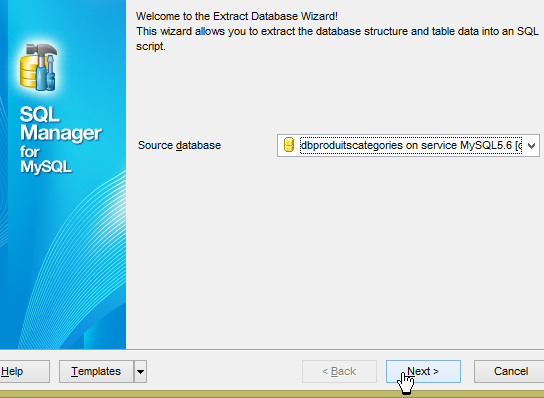 |
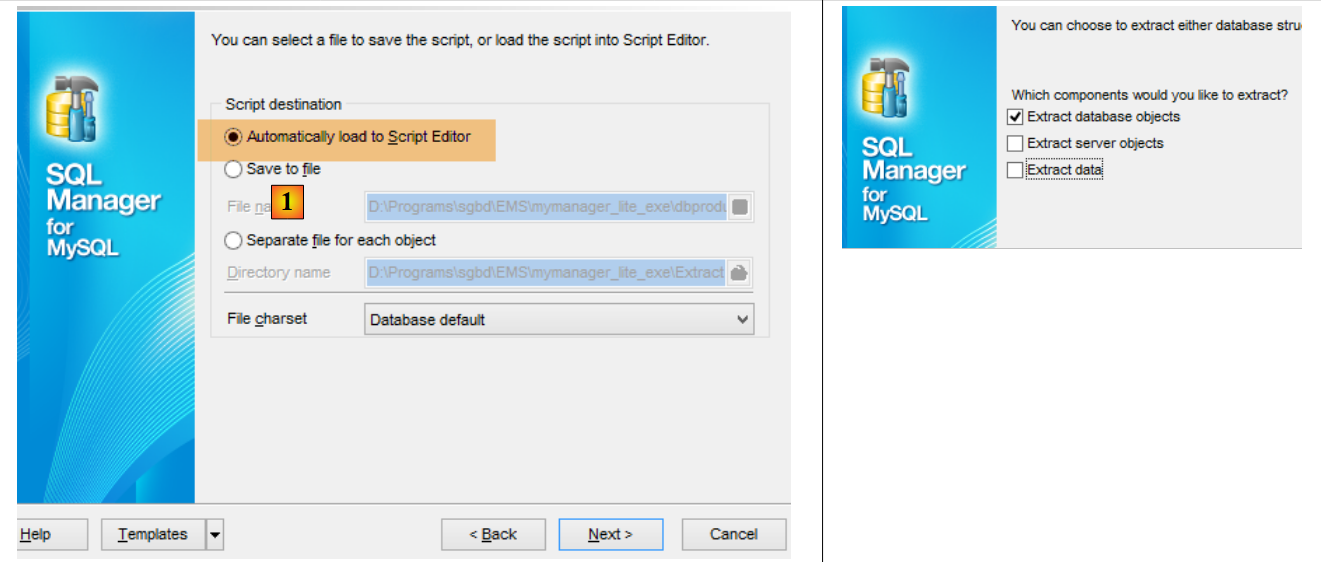 |
Le script SQL de génération des tables peut être également sauvegardé dans un fichier [1].
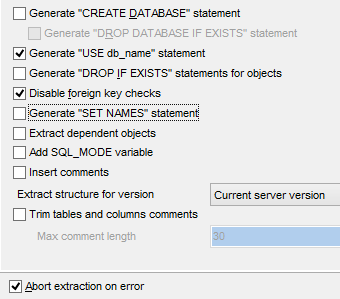 |  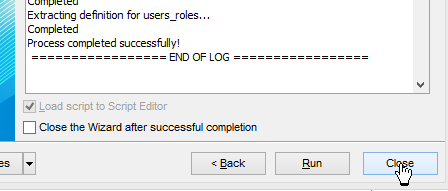 |
Le script SQL généré est le suivant :
SET FOREIGN_KEY_CHECKS=0;
USE `dbproduitscategories`;
CREATE TABLE `categories` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `NOM` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci DEFAULT NULL,
`CATEGORIE_ID` BIGINT(20) NOT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
`CATEGORIE` INTEGER(11) NOT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `NOM` (`NOM`) USING BTREE,
KEY `FK_PRODUITS_CATEGORIE_ID` (`CATEGORIE_ID`) USING BTREE,
CONSTRAINT `FK_PRODUITS_CATEGORIE_ID` FOREIGN KEY (`CATEGORIE_ID`) REFERENCES `categories` (`ID`) ON DELETE CASCADE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `roles` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users_roles` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
Regardons par exemple le script SQL qui génère la table [PRODUITS] (lignes 15-29) :
- ligne 16 : [ID] est clé primaire (ligne 23) avec l'attribut [AUTO_INCREMENT] (ligne 5). Cela correspond aux annotations [@Id, @GeneratedValue(strategy = GenerationType.IDENTITY), @Column(name = ConfigJdbc.TAB_JPA_ID)] du champ [id] de l'entité JPA ;
- ligne 17 : la définition de la colonne [DESCRIPTION] correspond à l'annotation [@Column(name = ConfigJdbc.TAB_PRODUITS_DESCRIPTION, length = 100)] du champ [description] de l'entité JPA ;
- ligne 18 : la colonne [CATEGORIE_ID] est clé étrangère de la table [PRODUITS] sur la colonne [CATEGORIES.ID] (ligne 26). Par ailleurs cette clé étrangère a l'attribut [ON DELETE CASCADE]. Cela correspond aux annotations [@ManyToOne(fetch = FetchType.LAZY), @JoinColumn(name = ConfigJdbc.TAB_PRODUITS_CATEGORIE_ID)] du champ [Produit.categorie] et à l'annotation [@OneToMany(fetch = FetchType.LAZY, mappedBy = "categorie", cascade = { CascadeType.ALL }), @CascadeOnDelete] du champ [Categorie.produits] ;
- ligne 19 : la définition de la colonne [NOM] correspond à l'annotation [@Column(name = ConfigJdbc.TAB_PRODUITS_NOM, unique = true, length = 30, nullable = false)] du champ [Produit.nom] ;
- ligne 20 : la définition de la colonne [PRIX] correspond à l'annotation [@Column(name = ConfigJdbc.TAB_PRODUITS_PRIX, nullable = false)] du champ [Produit.prix] ;
- lignes 24-25 : le script crée trois indices pour chacune des colonnes uniques de la table ;
Les tables générées n'ont pas de valeur par défaut pour le champ VERSIONING des tables alors que le code Java s'attend à ce qu'il y en ait une. Si cette valeur par défaut n'est pas présente, certains tests ne passent pas. On ajoute cet attribut de la façon suivante :
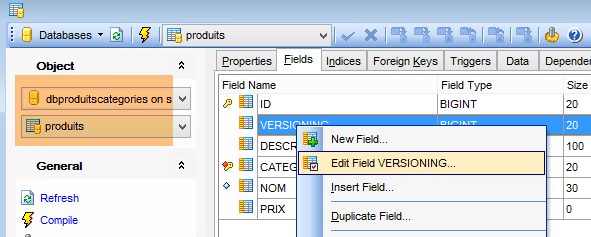 |
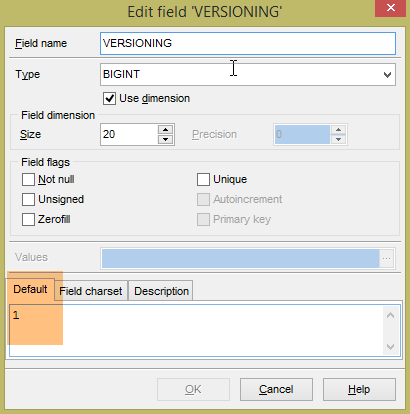 |
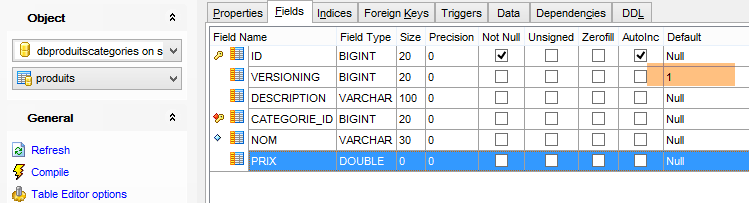 |
On le fait pour les cinq tables qui ont la colonne [VERSIONING]. La valeur par défaut n'a pas d'importance. Il faut simplement qu'elle existe. Ensuite, elle est incrémentée de 1 à chaque modification de la ligne à laquelle elle appartient.
Ceci fait, vérifiez que les configurations d'exécution suivantes passent :
- [spring-jdbc-generic-04.JUnitTestDao] qui teste l'implémentation JDBC ;
- [spring-jpa-generic-JUnitTestDao-hibernate-eclipselink] qui teste les implémentations JPA Hibernate ou Eclipselink (ici ce sera EclipseLink)
Les deux exécutions doivent réussir.
9.2.6. Génération des tables avec Hibernate
Nous créons les tables Hibernate avec l'environnement Eclipse suivant :
 |
La génération des tables est faite par la configuration d'exécution nommée [generic-create-dbproduitscategories-hibernate] sans agent Java ;
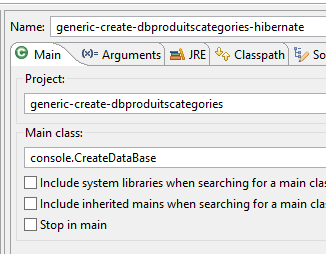 |  |
Le script SQL de la base générée par Hibernate est le suivant :
SET FOREIGN_KEY_CHECKS=0;
USE `dbproduitscategories`;
CREATE TABLE `categories` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `UK_7ajcg7japnxw846ru01damg8s` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci DEFAULT NULL,
`CATEGORIE_ID` BIGINT(20) NOT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `UK_hfvjn9lp7qoo5x79uu0ump3rf` (`NOM`) USING BTREE,
KEY `FK_p3foj9yrqnmi7856n9s8mbpue` (`CATEGORIE_ID`) USING BTREE,
CONSTRAINT `FK_p3foj9yrqnmi7856n9s8mbpue` FOREIGN KEY (`CATEGORIE_ID`) REFERENCES `categories` (`ID`)
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `roles` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users_roles` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
Les tables générées sont les mêmes puisque Hibernate a utilisé lui aussi les annotations JPA. Pour Hibernate, je n'ai pas trouvé l'équivalent de l'annotation EclipseLink [@OnCascadeDelete] qui a généré l'attribut SQL [ON DELTE CASCADE] sur la clé étrangère [PRODUITS.CATEGORIE_ID] (ligne 25). Il faut donc générer cet attribut à la main car il est nécessaire pour les tests :
 |
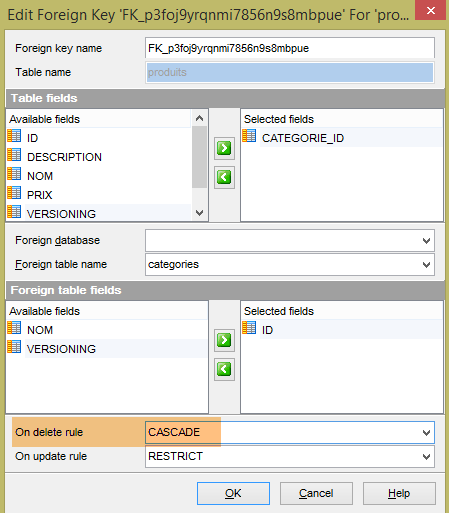 |
 |
Il faut faire de même avec les deux clés étrangères de la table [USERS_ROLES] :
 |
Enfin, comme il a été fait avec l'implémentation EclipseLink, il faut que les colonnes [VERSIONING] des cinq tables aient une valeur par défaut :
|
Ceci fait, vérifiez que les configurations d'exécution suivantes passent :
- [spring-jdbc-generic-04.JUnitTestDao] qui teste l'implémentation JDBC ;
- [spring-jpa-generic-JUnitTestDao-hibernate-eclipselink] qui teste les implémentations JPA Hibernate ou Eclipselink (ici ce sera Hibernate)
Les deux exécutions doivent réussir.
9.2.7. Génération des tables avec OpenJpa
Nous recommençons la procédure précédente avec une implémentation JPA OpenJpa :
 |
Note : faire Alt-F5 et régénérer tous les projets Maven ;
Nous modifions la classe [ConfigJpa] qui configure le projet [mysql-config-jpa-openjpa] de la façon suivante :
package generic.jpa.config;
import generic.jdbc.config.ConfigJdbc;
import java.util.Map;
import javax.persistence.EntityManagerFactory;
import org.apache.tomcat.jdbc.pool.DataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.orm.jpa.JpaTransactionManager;
import org.springframework.orm.jpa.JpaVendorAdapter;
import org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean;
import org.springframework.orm.jpa.vendor.Database;
import org.springframework.orm.jpa.vendor.OpenJpaVendorAdapter;
import org.springframework.transaction.PlatformTransactionManager;
@Configuration
@Import({ ConfigJdbc.class })
public class ConfigJpa {
// le provider JPA
@Bean
public JpaVendorAdapter jpaVendorAdapter() {
OpenJpaVendorAdapter openJpaVendorAdapter = new OpenJpaVendorAdapter();
openJpaVendorAdapter.setShowSql(false);
openJpaVendorAdapter.setDatabase(Database.MYSQL);
openJpaVendorAdapter.setGenerateDdl(true);
return openJpaVendorAdapter;
}
..
// EntityManagerFactory
@Bean
public EntityManagerFactory entityManagerFactory(JpaVendorAdapter jpaVendorAdapter, DataSource dataSource) {
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(jpaVendorAdapter);
factory.setPackagesToScan(ENTITIES_PACKAGES);
Map<String, Object> mapJpaProperties = factory.getJpaPropertyMap();
mapJpaProperties.put("openjpa.jdbc.MappingDefaults",
"ForeignKeyDeleteAction=cascade,JoinForeignKeyDeleteAction=restrict");
factory.setDataSource(dataSource);
factory.afterPropertiesSet();
return factory.getObject();
}
}
- lignes 40-41 : on crée une propriété pour OpenJPA qui indique la façon de générer les clés étrangères lors de la génération des tables. Sans cette propriété, les clés étrangères ne sont pas générées. L'attribut [ForeignKeyDeleteAction=cascade] permet de générer l'attribut [ON DELETE CASCADE] sur ces clés étrangères ;
La génération des tables est faite par la configuration d'exécution nommée [generic-create-dbproduitscategories-openjpa] qui a deux agents Java ;
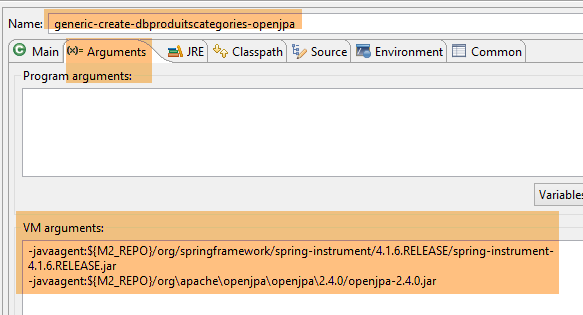
- le premier agent Java est l'agent Spring déjà utilisé avec EclipseLink ;
- le second agent Java est fourni par OpenJpa ;
Le script SQL de la base générée est alors le suivant :
SET FOREIGN_KEY_CHECKS=0;
USE `dbproduitscategories`;
CREATE TABLE `categories` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `U_CTGORIS_NOM` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci DEFAULT NULL,
`CATEGORIE_ID` BIGINT(20) DEFAULT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `U_PRODUTS_NOM` (`NOM`) USING BTREE,
KEY `CATEGORIE_ID` (`CATEGORIE_ID`) USING BTREE,
CONSTRAINT `produits_ibfk_1` FOREIGN KEY (`CATEGORIE_ID`) REFERENCES `categories` (`ID`) ON DELETE CASCADE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `roles` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`NAME` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `U_ROLES_NAME` (`NAME`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`LOGIN` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`NAME` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PASSWORD` VARCHAR(60) COLLATE utf8_general_ci NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `U_USERS_LOGIN` (`LOGIN`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users_roles` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`VERSIONING` BIGINT(20) DEFAULT NULL,
`ROLE_ID` BIGINT(20) NOT NULL,
`USER_ID` BIGINT(20) NOT NULL,
PRIMARY KEY (`ID`) USING BTREE,
KEY `ROLE_ID` (`ROLE_ID`) USING BTREE,
KEY `USER_ID` (`USER_ID`) USING BTREE,
CONSTRAINT `users_roles_ibfk_2` FOREIGN KEY (`USER_ID`) REFERENCES `users` (`ID`) ON DELETE CASCADE,
CONSTRAINT `users_roles_ibfk_1` FOREIGN KEY (`ROLE_ID`) REFERENCES `roles` (`ID`) ON DELETE CASCADE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
C'est le même qu'avec EclipseLink. On procèdera donc aux mêmes corrections sur les tables. Ceci fait, vérifiez que les configurations d'exécution suivantes passent :
- [spring-jdbc-generic-04.JUnitTestDao] qui teste l'implémentation JDBC ;
- [spring-jpa-generic-JUnitTestDao-openjpa] qui teste une implémentation JPA OpenJpa ;
Les deux exécutions doivent réussir.
9.3. Génération de la base [dbproduits]
La base [dbproduits] est utilisée par les projets [spring-jdbc-01 à 03]. On peut également la générer à partir d'une entité JPA.
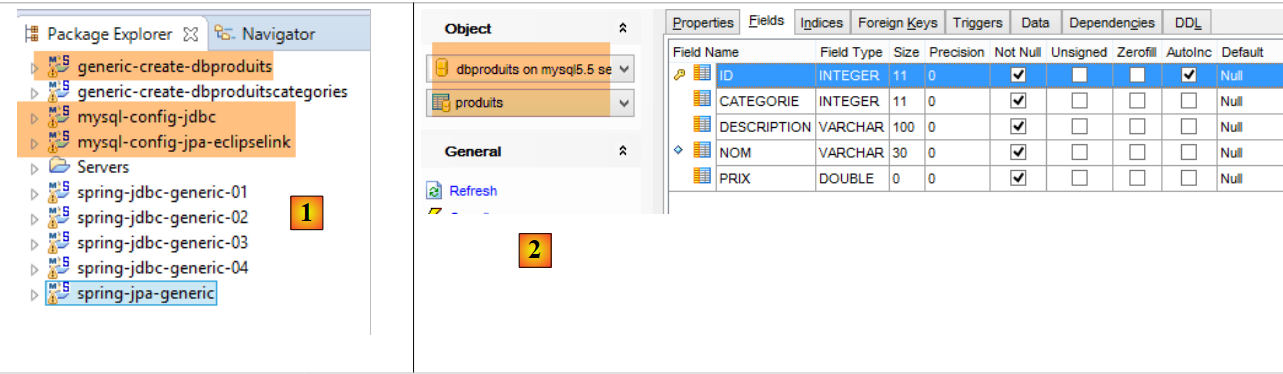 |
- en [1], les projets Eclipse. On sera dans une configuration MySQL / EclipseLink. Le projet de génération de la base [dbproduits] est [generic-create-dbproduits] ;
- en [2], la table [PRODUITS] à générer ;
Note : faire Alt-F5 et régénérer tous les projets Maven ;
9.3.1. Configuration Maven
La configuration Maven du projet [generic-create-dbproduits] est la suivante :
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-create-dbproduits</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>generic-create-dbproduits</name>
<description>création de la bases de données [dbproduits] à l'aide des annotations JPA</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<!-- configuration JPA du SGBD -->
<dependency>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-config-jpa</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
</dependencies>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<start-class>spring.data.console.Main</start-class>
<java.version>1.7</java.version>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
</plugin>
</plugins>
</build>
</project>
Il n'y a qu'une dépendance, lignes 22-26, sur le projet qui configure la couche JPA. Au final, les dépendances sont les suivantes :
 |
9.3.2. La configuration Spring
 |
La classe de configuration Spring est la suivante :
package console;
import generic.jdbc.config.ConfigJdbc;
import generic.jpa.config.ConfigJpa;
import javax.persistence.EntityManagerFactory;
import org.apache.tomcat.jdbc.pool.DataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.orm.jpa.JpaVendorAdapter;
import org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean;
@EnableJpaRepositories(basePackages = { "console" })
@Configuration
@Import({ ConfigJpa.class })
public class AppConfig {
// source de données
@Bean
public DataSource dataSource() {
// source de données TomcatJdbc
DataSource dataSource = new DataSource();
// configuration accès JDBC
dataSource.setDriverClassName(ConfigJdbc.DRIVER_CLASSNAME);
dataSource.setUsername(ConfigJdbc.USER_DBPRODUITS);
dataSource.setPassword(ConfigJdbc.PASSWD_DBPRODUITS);
dataSource.setUrl(ConfigJdbc.URL_DBPRODUITS);
// connexions ouvertes initialement
dataSource.setInitialSize(5);
// résultat
return dataSource;
}
// EntityManagerFactory
@Bean
public EntityManagerFactory entityManagerFactory(JpaVendorAdapter jpaVendorAdapter, DataSource dataSource) {
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(jpaVendorAdapter);
factory.setPersistenceUnitName("generic-jpa-entities-dbproduits");
factory.setDataSource(dataSource);
factory.afterPropertiesSet();
return factory.getObject();
}
}
- ligne 18 : on importe les beans de la classe [ConfigJpa] (paragraphe 7.3) ;
- lignes 22-35 : on redéfinit la source de données [dataSource]. Dans [ConfigJpa] la source de données est la base [dbproduitscategories]. Ici ce sera la base [dbproduits] ;
- ligne 38-46 : on redéfinit le bean [entityManagerFactory] de la classe [ConfigJpa]. Dans cette classe, les entités JPA étaient [Produit, Categorie]. Ici c'est seulement [Produit] et elle n'a pas la même définition que dans le projet qui configure la couche JPA ;
- ligne 42 : pour définir cette nouvelle entité JPA, on référence les entités JPA définies dans le fichier [META-INF/persistence.xml] :
 |
Le fichier [persistence.xml] est le suivant :
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd">
<persistence-unit name="generic-jpa-entities-dbproduits" transaction-type="RESOURCE_LOCAL">
<!-- entités JPA -->
<class>generic.jpa.entities.dbproduits.Produit</class>
<exclude-unlisted-classes>true</exclude-unlisted-classes>
</persistence-unit>
</persistence>
- ligne 6 : l'unique entité JPA ;
- ligne 4 : le nom de l'unité de persistance [generic-jpa-entities-dbproduits] qui est référencée dans le bean [entityManagerFactory] ;
9.3.3. L'entité JPA [Produit]
 |
L'entité JPA est définie dans le projet [mysql-config-jpa-eclipselink] de la façon suivante :
package generic.jpa.entities.dbproduits;
import generic.jdbc.config.ConfigJdbc;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity(name="Produit1")
@Table(name = ConfigJdbc.TAB_PRODUITS)
public class Produit {
// champs
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = ConfigJdbc.TAB_PRODUITS_ID)
private int id;
@Column(name = ConfigJdbc.TAB_PRODUITS_NOM, unique = true, length = 30, nullable = false)
private String nom;
@Column(name = ConfigJdbc.TAB_PRODUITS_CATEGORIE, nullable = false)
private int categorie;
@Column(name = ConfigJdbc.TAB_PRODUITS_PRIX, nullable = false)
private double prix;
@Column(name = ConfigJdbc.TAB_PRODUITS_DESCRIPTION, length = 100, nullable = false)
private String description;
// constructeurs
public Produit() {
}
public Produit(int id, String nom, int categorie, double prix, String description) {
this.id = id;
this.nom = nom;
this.categorie = categorie;
this.prix = prix;
this.description = description;
}
// getters et setters
...
}
C'est une définition JPA devenue maintenant classique. On notera simplement les points suivants :
- ligne 12 : on a donné un nom [Produit1] à l'entité. Par défaut, le nom d'une entité est le nom de la classe, ici [Produit]. Or parce qu'il y a une autre entité JPA [Produit] dans le même projet, une erreur a été signalée avant même toute exécution. On l'a levée de cette façon ;
- ligne 24 : la catégorie est ici un simple numéro ;
- il n'y a pas de relations inter-entités. On a donc une situation très simple ;
9.3.4. La classe exécutable
 |
La classe [CreateDatabase] est la suivante :
package console;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class CreateDataBase {
public static void main(String[] args) {
// il suffit d'instancier le contexte Spring pour créer les tables de la base de données [dbproduits]
// il faut également au moins un Spring Data Repository sinon rien ne se passe
System.out.println("Travail en cours...");
new AnnotationConfigApplicationContext(AppConfig.class).close();
System.out.println("Travail terminé...");
}
}
C'est un code que nous avons déjà rencontré.
9.3.5. Génération EclipseLink
La table [PRODUITS] est créée avec la configuration d'exécution suivante :
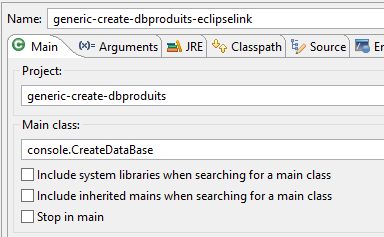 | 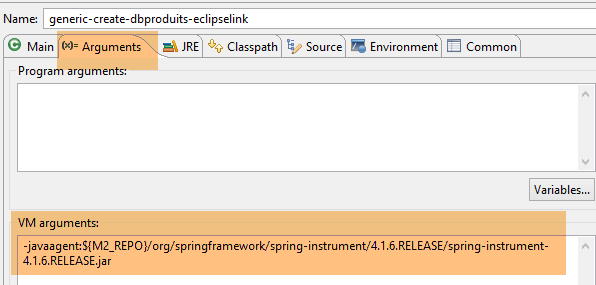 |
Les logs de la console sont les suivants :
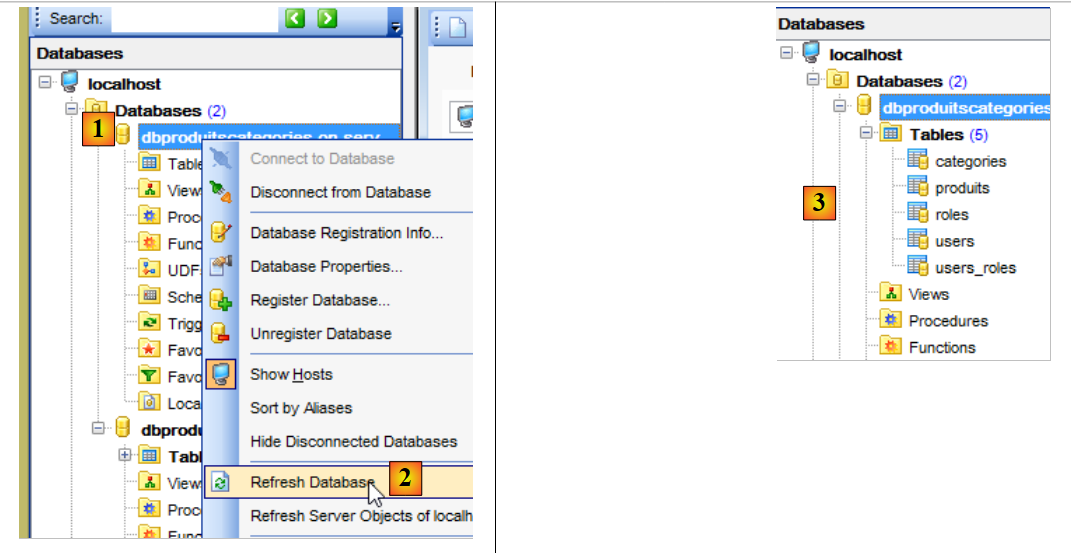
Maintenant, revenons au client [MyManager] et rafraîchissons l'affichage [1-2] :
 |
En [3], on voit qu'une table a été générée. Maintenant vérifions la DDL (Domain Definition Language) de la base de données :
SET FOREIGN_KEY_CHECKS=0;
USE `dbproduits`;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`CATEGORIE` INTEGER(11) NOT NULL,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci NOT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `NOM` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
On obtient bien la table attendue. Pour le vérifier, on exécutera la configuration suivante :
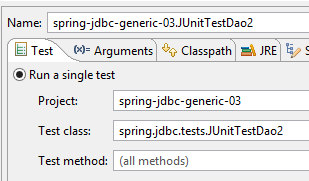 | 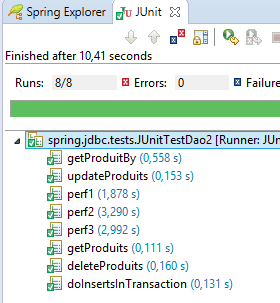 |
Elle doit réussir.
9.3.6. Génération Hibernate
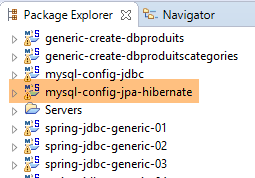 | 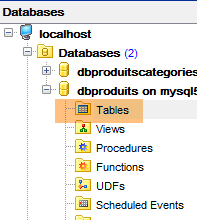 |
Note : faire Alt-F5 et régénérer tous les projets Maven ;
La configuration d'exécution est la suivante :
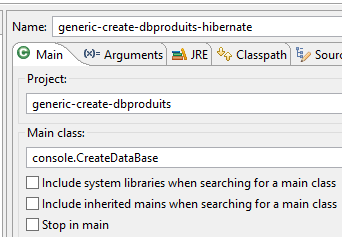 |  |
Le script SQL généré par Hibernate est le suivant :
USE `dbproduits`;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`CATEGORIE` INTEGER(11) NOT NULL,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci NOT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `UK_hfvjn9lp7qoo5x79uu0ump3rf` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
9.3.7. Génération OpenJpa
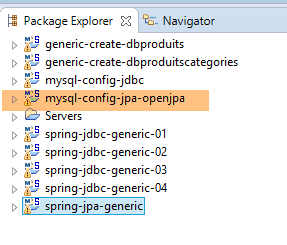 | |
Note : faire Alt-F5 et régénérer tous les projets Maven ;
La configuration d'exécution est la suivante :
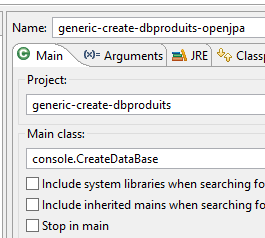 | 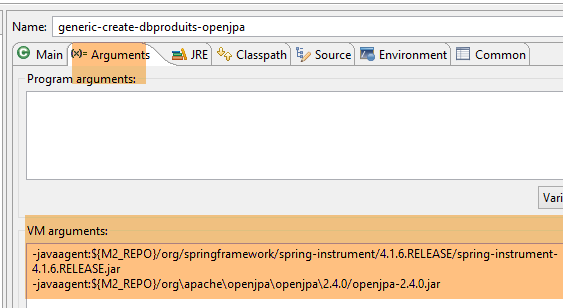 |
Le script SQL généré par OpenJpa est le suivant :
USE `dbproduits`;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`CATEGORIE` INTEGER(11) NOT NULL,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci NOT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `U_PRODUTS_NOM` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;