2. Un exemple d'introduction
Mes premiers contacts avec RxJava se sont faits au travers de cours et de tutoriels trouvés sur internet. Outre que la théorie utilisait des concepts auxquels je n'étais pas habitué et que j'avais du mal à comprendre, je ne voyais surtout pas à quoi ça pouvait servir dans la vraie vie. Nous allons donc commencer par présenter un exemple (simple j'espère) où l'utilisation de RxJava amène une réelle simplification de l'écriture du code et à partir de là, nous essaierons de cerner les éléments importants de cette bibliothèque.
La bibliothèque RxJava s'appuie sur le concept suivant : un flux d'éléments de type T Observable<T> est observé par un ou plusieurs souscripteurs (abonnés, observateurs, consommateurs) Subscriber<T>. La bibliothèque RxJava permet que le flux Observable<T> s'exécute dans un thread T1 et son observateur Subscriber<T> dans un thread T2 sans que le développeur n'ait à se soucier de gérer le cycle de vie de ces threads et de problèmes naturellement difficiles, tels que le partage de données entre threads et la synchronisation de ceux-ci pour exécuter une tâche globale. Elle facilite donc la programmation asynchrone.
Un flux Observable<T> produit des éléments de type T, observables au fur et à mesure qu'ils sont produits. Si l'observateur et l'observable (désigne le type Observable<T> par abus de langage) se trouvent dans le même thread, alors l'observable ne peut produire l'élément (i+1) que lorsque l'observateur a consommé l'élément i. Il y a peu de cas où cette architecture présente un intérêt. Si l'observateur et l'observable ne se trouvent pas dans le même thread, alors l'observable et son observateur ont des comportements autonomes : l'observable produit à son rythme et l'observateur consomme à son rythme. C'est là que réside l'intérêt de la bibliothèque. Nous avons toujours parlé jusqu'ici d'un observateur. En réalité, un observable peut avoir un nombre quelconque d'observateurs.
2.1. L'architecture de l'application exemple
L'application exemple a l'architecture suivante :
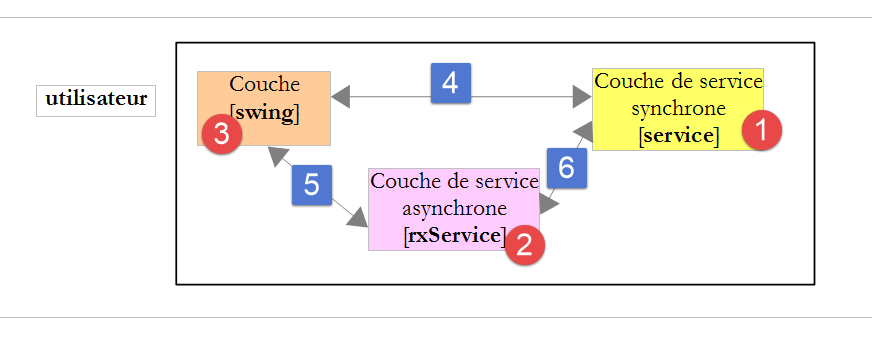
- en [1], une couche de service délivre des listes de nombres aléatoires. Cette couche est exécutée dans le même thread que la méthode [swing] qui l'utilise. Elle délivre alors ses nombres de façon synchrone ;
- en [2], une mince couche d'adaptation implémentée avec RxJava permet de présenter à la couche [swing] une implémentation asynchrone du même service : celui-ci peut être exécuté dans un thread différent de celui de la méthode [swing] qui l'utilise ;
- l'appel [4] est synchrone alors que l'appel [5-6] est lui asynchrone ;
Ce que nous voulons montrer ici, c'est que la bibliothèque Rx permet de transformer aisément une interface synchrone en interface asynchrone. Pourquoi est-ce utile ? Les événements d'une interface Swing sont traités dans un thread appelé communément event loop. Les événements sont mis en attente dans une file et traités les uns après les autres. L'événement Ei+1 ne peut être traité que lorsque l'événement précédent Ei a été complètement traité. Il est donc important que la gestion d'un événement soit la plus courte possible pour que l'interface graphique reste réactive. Parfois, la gestion d'un événement peut prendre beaucoup de temps. C'est le cas, si cette gestion implique des accès réseau. Si on ne veut pas figer l'interface graphique d'une façon inacceptable pour l'utilisateur, il faut alors que ces accès réseau se fassent dans des threads séparés de l'event loop pour libérer celui-ci. On entre alors dans le domaine de la programmation concurrente (plusieurs threads s'exécutent en parallèle) considérée à juste titre difficile. La bibliothèque Rx amène une solution simple et élégante à ce problème.
Pour simuler des traitements longs, le service de l'exemple délivre ses nombres aléatoires après un certain délai d'attente afin que l'on puisse voir le comportement de l'interface graphique.
2.2. L'exécutable
L'exécutable de l'application exemple se trouve dans le dossier [dvp/executables] des exemples :
 |  |
Il y a diverses façons d'exécuter l'archive [swing-01] selon la configuration du poste utilisé pour l'exécuter. On pourra par exemple suivre le processus [1-3]. On obtient alors l'interface graphique suivante :
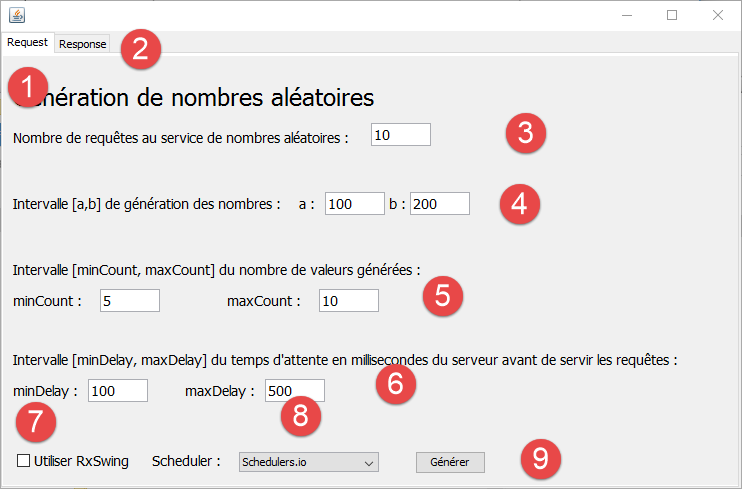 |
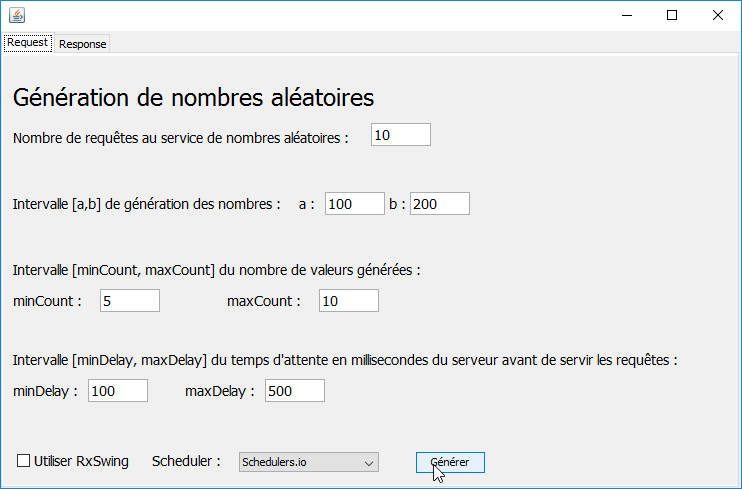
- l'interface présente deux onglets [1-2], l'un [Request] pour la requête au service de génération des nombres aléatoires, l'autre [Response] pour l'affichage des nombres reçus ;
- en [3], on indique combien de requêtes on veut faire au service ;
- en [4], on indique l'intervalle [a,b] de génération des nombres souhaités ;
- en [5], le nombre de valeurs renvoyées par le service sera un nombre aléatoire dans l'intervalle [minCount, maxCount] fixé par l'utilisateur ;
- en [6], avant de renvoyer sa réponse, le service attendra delay millisecondes où delay est un nombre aléatoire dans l'intervalle [minDelay, maxDelay] fixé par l'utilisateur ;
- par défaut, la couche [swing] s'adressera à l'interface synchrone du service. Pour s'adresser à la couche asynchrone, l'utilisateur cochera [7]. Dans ce cas, le service de génération s'exécutera dans des threads séparés de l'event loop de l'interface graphique. La bibliothèque Rx dispose de diverses stratégies de génération de ces threads. L'utilisateur pourra choisir sa stratégie en [8] ;
- la génération des nombres se fait avec le bouton [9] ;
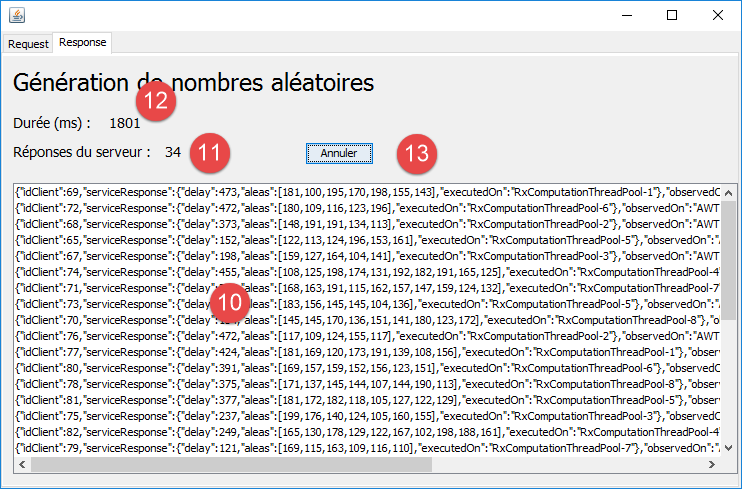 |
- en [10], affichage des résultats. Nous allons expliquer la structure de ceux-ci ;
- en [11], le nombre de résultats obtenus ;
- en [12], la durée d'exécution en millisecondes ;
- en [13], l'utilisateur a la possibilité d'annuler l'exécution ;
Chaque résultat a la forme suivante :
{"idClient":0,"serviceResponse":{"delay":412,"aleas":[146,115,128,174,159,112,162,127],"executedOn":"RxComputationThreadPool-6"},"observedOn":"AWT-EventQueue-0","requestAt":"02:42:47:708","responseAt":"02:42:52:931"}
- [idClient] : le n° de la requête. On rappelle que plusieurs requêtes sont faites au service de génération ;
- [delay] : le temps d'attente en millisecondes que le service a observé avant d'envoyer son résultat ;
- [aleas] : les nombres aléatoires renvoyés par le service ;
- [executedOn] : le nom du thread dans lequel le service s'est exécuté ;
- [observedOn] : le nom du thread qui a affiché le résultat. Avec une interface Swing, cela ne peut être que le thread de l'event loop, ici [AWT-EventQueue-0] ;
- [requestAt] : l'heure de la requête sous la forme [heures:minutes:secondes:millisecondes] ;
- [responseAt] : l'heure de réception des résultats sous la même forme ;
Nous allons maintenant présenter les portions de code utiles pour la compréhension de l'exemple.
2.3. L'interface synchrone
La couche de service [1] présente l'interface suivante :
public interface IService {
// nombres aléatoires dans [a,b]
// n nombres sont générés avec n aléatoire dans l'intervalle [minCount, maxCount]
// les nombres sont générés après une attente de delay millisecondes,
// où [delay] est un nombre aléatoire dans l'intervalle [minDelay, maxDelay]
public ServiceResponse getAleas(int a, int b, int minCount, int maxCount, int minDelay, int maxDelay);
}
La réponse [ServiceResponse] est la suivante :
public class ServiceResponse {
// délai d'attente du service
private int delay;
// nombres aléatoires
private List<Integer> aleas;
// thread d'exécution
private String executedOn;
// constructeurs
public ServiceResponse(int delay, List<Integer> aleas) {
executedOn = Thread.currentThread().getName();
this.delay = delay;
this.aleas = aleas;
}
// getters et setters
...
}
La réponse a trois éléments :
- ligne 6 : les nombres aléatoires générés ;
- ligne 4 : le délai d'attente observé par le service avant de rendre son résultat ;
- ligne 8 : le thread d'exécution du service ;
2.4. L'appel synchrone
Nous détaillons maintenant l'appel synchrone [4] que fait la couche [swing] au service [1] :
private void doGenerateWithService() {
// début attente
beginWaiting();
try {
for (int i = 0; i < nbRequests; i++) {
UiResponse uiResponse = new UiResponse();
uiResponse.setIdClient(i);
uiResponse.setServiceResponse(service.getAleas(a, b, minCount, maxCount, minDelay, maxDelay));
uiResponse.setResponseAt();
model.add(0, jsonMapper.writeValueAsString(uiResponse));
jLabelNbReponses.setText(String.valueOf(Integer.parseInt(jLabelNbReponses.getText()) + 1));
}
} catch (JsonProcessingException | RuntimeException e) {
System.out.println(e);
}
// fin attente
endWaiting();
}
- lignes 5-12 : la boucle d'exécution des [nbRequests] requêtes demandées par l'utilisateur ;
- ligne 8 : [service] est l'implémentation de l'interface synchrone [IService] présentée au paragraphe 2.3 ;
- ligne 10, [model] est le modèle affiché par le composant JList de l'onglet [Response]. Les éléments de ce modèle sont les chaînes jSON d'éléments de type [UiResponse] suivant :
public class UiResponse {
// id du client
private int idClient;
// réponse du service
private ServiceResponse serviceResponse;
// nom du thread d'observation
private String observedOn;
// heure de la requête
private String requestAt;
// heure de la réponse
private String responseAt;
// constructeurs
public UiResponse() {
observedOn = Thread.currentThread().getName();
requestAt = getTimeStamp();
}
// méthodes privées
private String getTimeStamp() {
return new SimpleDateFormat("hh:mm:ss:SSS").format(Calendar.getInstance().getTime());
}
// getters et setters
...
}
- ligne 6 : la réponse du service de génération de nombres ;
- ligne 4 : le n° de la requête à laquelle il est répondu ;
- ligne 8 : le thread d'affichage de cette réponse. On l'a dit, ce sera toujours le thread de l'event loop ;
- lignes 10 et 12 : l'heure de la requête et celle de la réponse ;
2.5. Tests des appels synchrones
Nous exécutons la configuration suivante :
 |
Nous obtenons les résultats suivants dans l'onglet [Response] :
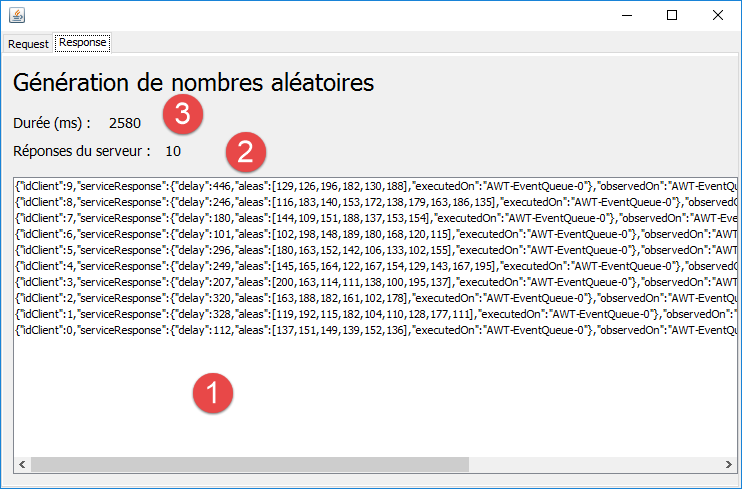 |
- en [1-2], on a bien obtenu 10 réponses telle qu'il avait été demandé. Elles ont été insérées en première position dans leur ordre d'arrivée. On voit qu'elles ont été obtenues dans l'ordre des requêtes ;
- elles ont toutes été exécutées et affichées dans le thread de l'event loop [AWT-EventQueue-0]. Les requêtes ont donc été exécutées les unes après les autres dans ce thread. Il n'y a pas eu de requêtes simultanées ;
- ce qui n'est pas visible ici, c'est que pendant l'exécution, l'interface graphique est gelée. Il n'y a par exemple pas moyen d'accéder à l'onglet [Response] pour voir les réponses arriver ou interrompre l'exécution avec le bouton [Annuler]. Même si ce bouton avait été présent sur l'onglet [Request], il aurait été inutilisable. En effet, il y aurait alors deux événements :
- le clic sur le bouton [Générer] ;
- le clic sur le bouton [Annuler] ;
Le clic sur le bouton [Annuler] n'est géré qu'après la fin de l'opération enclenchée par le clic sur le bouton [Générer]. Nous venons de voir, que celle-ci occupait le thread de l'event loop pendant toute la durée de l'exécution, empêchant par là la gestion du clic sur le bouton [Annuler]. C'est typiquement le genre de situations où Rx peut apporter une nette amélioration ;
2.6. L'interface asynchrone et son implémentation
Nous nous intéressons maintenant à l'interface de la couche [2] ainsi qu'à son implémentation avec Rx. Celle-ci ne sera pas immédiatement intelligible. On veut simplement faire ressortir la simplicité du code de cette implémentation.
L'interface asynchrone est la suivante :
public interface IRxService {
// nombres aléatoires dans [a,b]
// n nombres sont générés avec n aléatoire dans l'intervalle [minCount, maxCount]
// les nombres sont générés après une attente de delay millisecondes,
// où [delay] est un nombre aléatoire dans l'intervalle [minDelay, maxDelay]
public Observable<UiResponse> getAleas(int a, int b, int minCount, int maxCount, int minDelay, int maxDelay, UiResponse uiResponse);
}
Les différences avec l'interface synchrone présentée au paragraphe 2.3 sont les suivantes :
- la classe [UiResponse] présentée au paragraphe 2.3 fait désormais partie des paramètres de la méthode [getAleas] (ligne 6). La raison en est que, parce que les requêtes s'exécutent désormais en parallèle et que le service attend un temps aléatoire avant de rendre son résultat, les réponses ne vont pas nous revenir dans l'ordre des requêtes. On passe donc l'objet [UiResponse] qui contient entre autres informations le n° de la requête :
// id du client (requête)
private int idClient;
// réponse du service
private ServiceResponse serviceResponse;
// nom du thread d'observation
private String observedOn;
// heure de la requête
private String requestAt;
// heure de la réponse
private String responseAt;
- le type de la réponse du service asynchrone est un type [Observable<UiResponse>]. Le type [Observable<>] est fourni par la bibliothèque Rx. Le résultat de type [Observable<UiResponse>] indique que la méthode [getAleas] fournit un flux de valeurs de type [UiResponse], valeurs qui sont poussées (pushed) une à une vers leur observateur ;
Regardons maintenant, l'implémentation de cette interface :
public class RxService implements IRxService {
// service
private IService service;
// constructeur
public RxService(IService service) {
this.service = service;
}
@Override
public Observable<UiResponse> getAleas(int a, int b, int minCount, int maxCount, int minDelay, int maxDelay, UiResponse uiResponse) {
return Observable.create(subscriber -> {
try {
uiResponse.setServiceResponse(service.getAleas(a, b, minCount, maxCount, minDelay, maxDelay));
subscriber.onNext(uiResponse);
} catch (Exception e) {
subscriber.onError(e);
} finally {
subscriber.onCompleted();
}
});
}
}
- lignes 7-9 : on fournit au constructeur une référence sur l'interface synchrone [IService]. C'est elle qui fera le travail de génération des nombres aléatoires ;
- l'observable rendu par la méthode [getAleas] est construit par la méthode statique [Observable.create]. C'est cette méthode qui permet de construire une implémentation asynchrone à partir d'une implémentation synchrone ;
- ligne 13 : le paramètre de la méthode statique [Observable.create] est ici une fonction lambda qui reçoit pour paramètre un type [Subscriber], là encore un type Rx. Un [Subscriber] est un objet qui s'abonne à un flux d'observables, ç-à-d un flux de données délivrées de façon asynchrone. On utilise ici trois méthodes de cet abonné :
- [Subscriber.onNext] pour lui transmettre une donnée (ligne 16) ;
- [Subscriber.onError] pour lui transmettre une exception (ligne 18) ;
- [Subscriber.onCompleted] pour indiquer à l'abonné que le flux de données est terminé (ligne 20) ;
Il peut y avoir plusieurs abonnés à un même observable. Ici, nous n'aurons qu'un abonné qui s'abonne à un flux d'une unique donnée, celle produite aux lignes 15-16. La donnée est produite par l'implémentation synchrone du service (ligne 15) et rendue à l'abonné (ligne 16).
Même si tout cela reste probablement obscur, on ne peut qu'être frappé par l'extrême concision de cette implémentation asynchrone du service.
2.7. L'appel asynchrone
Nous détaillons maintenant l'appel synchrone [5] que fait la couche [swing] au service [2] :
private void doGenerateWithRxService() {
// début attente
beginWaiting();
// on demande les nombres aléatoires
Observable<UiResponse> observables = Observable.empty();
for (int i = 0; i < nbRequests; i++) {
UiResponse uiResponse = new UiResponse();
uiResponse.setIdClient(i);
// scheduler
int schedulerIndex = jComboBoxSchedulers.getSelectedIndex();
switch (schedulerIndex) {
case 0:
observables = observables.mergeWith(rxService.getAleas(a, b, minCount, maxCount, minDelay, maxDelay, uiResponse).subscribeOn(Schedulers.io()));
break;
...
}
}
...
}
- lignes 6-10 : exécution des [nbRequests] requêtes demandées par l'utilisateur ;
- lignes 7-8 : préparation de l'objet [UiResponse] dont a besoin la méthode [getAleas] du service asynchrone (ligne 13). Il s'agit principalement d'enregistrer le n° [idClient] de la requête ;
- ligne 13 : la méthode [getAleas] du service asynchrone est appelée. Elle rend un objet [Observable<UiResponse>]. Cet appel n'invoque pas encore le service synchrone. Revenons au code de [getAleas] asynchrone :
@Override
public Observable<UiResponse> getAleas(int a, int b, int minCount, int maxCount, int minDelay, int maxDelay, UiResponse uiResponse) {
return Observable.create(subscriber -> {
try {
uiResponse.setServiceResponse(service.getAleas(a, b, minCount, maxCount, minDelay, maxDelay));
subscriber.onNext(uiResponse);
} catch (Exception e) {
subscriber.onError(e);
} finally {
subscriber.onCompleted();
}
});
}
Le code les lignes 4-11 qui va appeler le service synchrone n'est exécuté que lorsqu'un abonné se déclare. Tant qu'il n'y a pas d'abonnés, ce code est inexécuté.
Revenons au code de la méthode [doGenerateWithRxService] :
- ligne 5 : on crée un observable vide (rien n'est observé) ;
- ligne 13 : on crée un observable dont le flux sera la fusion des [nbRequests] flux asynchrones associés aux [nbRequests] requêtes. Cela est obtenu avec la méthode [Observable.mergeWith] qui permet de fusionner deux flux asynchrones. Dans la terminologie Rx, [mergeWith] est appelé un opérateur de flux. Ces opérateurs ont la particularité que le résultat de l'opération est la plupart du temps de nouveau un [Observable]. Au final, après la ligne 17, la variable [observables] désigne un unique flux constitué par les [nbRequests] réponses asynchrones faites par le service asynchrone ;
- ligne 13 : l'opération de fusion aurait pu s'écrire :
observables = observables.mergeWith(rxService.getAleas(a, b, minCount, maxCount, minDelay, maxDelay, uiResponse));
mais nous avons écrit :
observables = observables.mergeWith(rxService.getAleas(a, b, minCount, maxCount, minDelay, maxDelay, uiResponse).subscribeOn(Schedulers.io()));
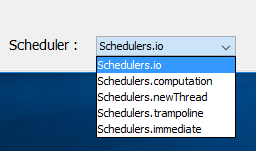
Nous avons utilisé ici l'opérateur [subscribeOn] sur l'observable [rxService.getAleas]. Comme souvent le résultat est de nouveau un observable. L'opérateur [subscribeOn] permet de préciser que l'observable doit être exécuté dans un thread fourni par un [Scheduler]. Il existe plusieurs [Scheduler] possibles adaptés à différentes situations. Dans l'interface graphique, nous en avons proposé plusieurs pour voir les effets des uns et des autres :
 |
Cela donne le code suivant :
private void doGenerateWithRxService() {
// début attente
beginWaiting();
// on demande les nombres aléatoires
Observable<UiResponse> observables = Observable.empty();
for (int i = 0; i < nbRequests; i++) {
UiResponse uiResponse = new UiResponse();
uiResponse.setIdClient(i);
// scheduler
int schedulerIndex = jComboBoxSchedulers.getSelectedIndex();
switch (schedulerIndex) {
case 0:
observables = observables.mergeWith(rxService.getAleas(a, b, minCount, maxCount, minDelay, maxDelay, uiResponse).subscribeOn(Schedulers.io()));
break;
case 1:
observables = observables.mergeWith(rxService.getAleas(a, b, minCount, maxCount, minDelay, maxDelay, uiResponse).subscribeOn(Schedulers.computation()));
break;
case 2:
observables = observables.mergeWith(rxService.getAleas(a, b, minCount, maxCount, minDelay, maxDelay, uiResponse).subscribeOn(Schedulers.newThread()));
break;
case 3:
observables = observables.mergeWith(rxService.getAleas(a, b, minCount, maxCount, minDelay, maxDelay, uiResponse).subscribeOn(Schedulers.trampoline()));
break;
case 4:
observables = observables.mergeWith(rxService.getAleas(a, b, minCount, maxCount, minDelay, maxDelay, uiResponse).subscribeOn(Schedulers.immediate()));
break;
}
}
...
}
Revenons sur le code des lignes 12-14. Le scheduler [Schedulers.io()] affecte un nouveau thread à chaque observable. Si on suit le code :
- ligne 5 : on a un observable vide ;
- ligne 13, itération 1 : observables est la liste [observable0/thread0] (Observable observable0 exécuté sur thread thread0) ;
- ligne 13, itération 2 : observables est la liste [observable0/thread0, observable1/thread1] ;
- etc...
Au final, après la ligne 28, on a un observable résultat de la fusion de [nbRequests] observables qui s'exécutent sur [nbRequests] threads différents. Tous les schédulers ne fonctionnent pas ainsi comme nous allons le voir lors des tests.
Continuons l'étude du code d'appel du service asynchrone :
private void doGenerateWithRxService() {
// début attente
beginWaiting();
// on demande les nombres aléatoires
Observable<UiResponse> observables = Observable.empty();
for (int i = 0; i < nbRequests; i++) {
...
}
// observateur
observables = observables.observeOn(SwingScheduler.getInstance());
// on exécute ces observables
subscriptions.add(observables.subscribe(uiResponse -> {
updateUi(uiResponse);
} , th -> {
System.out.println(th);
doCancel();
} , this::doCancel));
}
- nous avons vu que lorsqu'on arrive à la ligne 10, on a un unique observable, fusion de [nbRequests] observables pouvant s'exécuter sur [nbRequests] threads différents ou pas, selon le schéduler choisi par l'utilisateur ;
- ligne 10 : l'opérateur [observeOn] permet de préciser sur quel thread on veut récupérer les données provenant de l'observable, ici les [nbRequests] objets de type [UiResponse]. Dans une interface Swing, on n'a pas le choix. Toute mise à jour de l'interface doit se faire dans le thread de l'event loop. Ici, les données de l'observable vont être affichées dans un composant Swing JList. Le thread [SwingScheduler.getInstance()] représente le thread de l'event loop. La classe [SwingScheduler] ne provient pas de la bibliothèque RxJava mais de celle dérivée RxSwing ;
- lorsqu'on arrive ligne 12, le service synchrone n'a toujours pas été appelé car l'observable de la ligne 10 n'a encore pas d'abonné. Les lignes 12-17 lui en donnent un, grâce à l'opérateur [subscribe]. Les paramètres de cet opérateur sont ici trois fonctions lambda :
- la première [uiResponse -> {updateUi(uiResponse);}] admet pour paramètre un des objets [UiResponse] produits par l'observable. Rappelons qu'ici, nous aurons [nbRequests] objets de ce type. La méthode associée, updateUi ici, doit exploiter ce résultat ;
- la deuxième [th -> {System.out.println(th);doCancel();}] admet pour paramètre un type [Throwable], ici une exception qui s'est produite lors de l'exécution de l'observable. La méthode associée doit exploiter cette information. Ici, on l'affiche sur la console (ligne 15) et on annule l'exécution ce qui va avoir pour effet de mettre à jour certains éléments de l'interface graphique ;
- la troisième [this::doCancel] est appelée lorsque l'observable signale qu'il n'a plus de données à transmettre. Ici, l'observable est la réunion de [nbRequests] observables. L'observable résultat indiquera qu'il a fini lorsque tous les observables le composant auront eux-mêmes signalé qu'ils ont fini leur travail. Donc lorsque cette troisième fonction lambda est exécutée, on a reçu toutes les données. La méthode locale [doCancel] met à jour l'interface graphique pour refléter le fait que l'exécution est terminée ;
La variable [subscriptions] est défini de la façon suivante :
// les souscriptions aux observables
protected List<Subscription> subscriptions = new ArrayList<Subscription>();
Le type [Subscription] représente un abonnement, ç-à-d le lien entre un abonné [Subscriber] et ce qu'il observe [Observable]. Nous avons utilisé ici une liste d'abonnements bien que dans cet exemple, il n'y en ait qu'un. La méthode locale [doCancel] exécutée lorsque l'observable signale qu'il n'a plus de données à transmettre est la suivante :
@Override
protected void doCancel() {
// fin attente
endWaiting();
// dans le cas de souscriptions
if (jCheckBoxRxSwing.isSelected() && subscriptions != null) {
subscriptions.forEach(Subscription::unsubscribe);
}
}
- la ligne 7 désabonne tous les abonnés à l'observable ;
De cette explication sommaire, on pourra retenir les points clés suivants :
- le type [Observable] désigne un flux de valeurs, valeurs qui sont poussées une à une vers des abonnés ou observateurs ;
- le type [Subscriber] désigne un abonné du type [Observable] ;
- le type [Subscription] désigne un abonnement, ç-à-d le lien entre un [Subscriber] et un [Observable] ;
- le type [Observable] admet des opérateurs [mergeWith, empty, subscribeOn, observeOn, ...] qui pour la plupart produisent des observables. Ces opérateurs servent à configurer l'observable avant son exécution :
- ce qu'on veut observer ;
- le thread sur lequel l'observable s'exécute ;
- le thread sur lequel l'abonné reçoit les données de l'observable ;
- on distingue deux types d'observables, les [froid / cold] et les [chaud / hot]. Un observable froid est entièrement exécuté à chaque nouvel abonné. Si chaque exécution produit les mêmes données, chaque nouvel abonné reçoit les mêmes données que le précédent. Un observable chaud produit généralement des données de façon continue. Lorsqu'un abonné s'abonne, il reçoit les données émises à partir de l'heure de son abonnement. Il ne reçoit pas les données qui ont pu être émises précédemment. Dans notre exemple, l'observable est froid : il est entièrement réexécuté à chaque nouvel abonné. Qu'est-ce qui est réellement exécuté dans notre exemple ? Pour le savoir, il faut revenir à la définition de l'observable observé :
@Override
public Observable<UiResponse> getAleas(int a, int b, int minCount, int maxCount, int minDelay, int maxDelay, UiResponse uiResponse) {
return Observable.create(subscriber -> {
try {
uiResponse.setServiceResponse(service.getAleas(a, b, minCount, maxCount, minDelay, maxDelay));
subscriber.onNext(uiResponse);
} catch (Exception e) {
subscriber.onError(e);
} finally {
subscriber.onCompleted();
}
});
}
A chaque nouvel abonné, la fonction lambda, paramètre de la méthode [Observable.create] (ligne 3) est réexécutée. Ce sont donc les lignes 4-11 qui sont exécutées pour chaque nouvel abonné [subscriber] ;
2.8. Tests des appels asynchrones
Nous commençons par montrer l'effet des différents schedulers proposés. Nous utilisons pour cela les paramètres suivants :
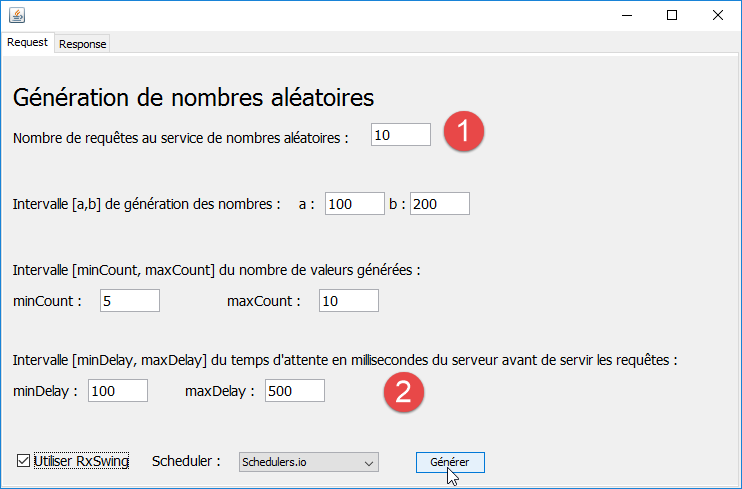 |
Nous mettons en [1-2] des valeurs petites pour que si les requêtes sont exécutées sur un même thread, on n'attende quand même pas trop longtemps.
2.8.1. avec le schéduler [Schedulers.io]
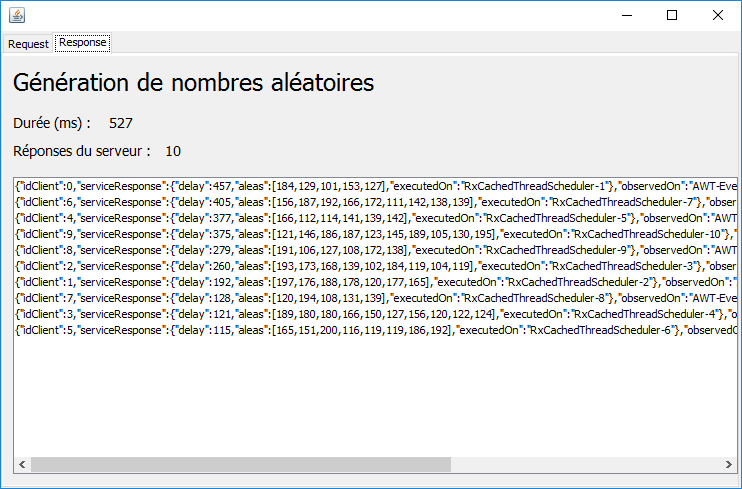 |
On peut remarquer les points suivants :
- on obtient les réponses dans un ordre qui n'est pas celui des requêtes (cf idClient) ;
- chaque requête s'est déroulée dans un thread différent ;
- l'interface graphique n'est cette fois plus figée :
- on peut passer d'un onglet à l'autre ;
- on voit les données arriver ;
- on n'a pas le temps de voir le bouton [Annuler] parce que l'exécution est trop rapide. Nous le mettrons en évidence dans un autre test ;
2.8.2. avec le schéduler [Schedulers.computation]
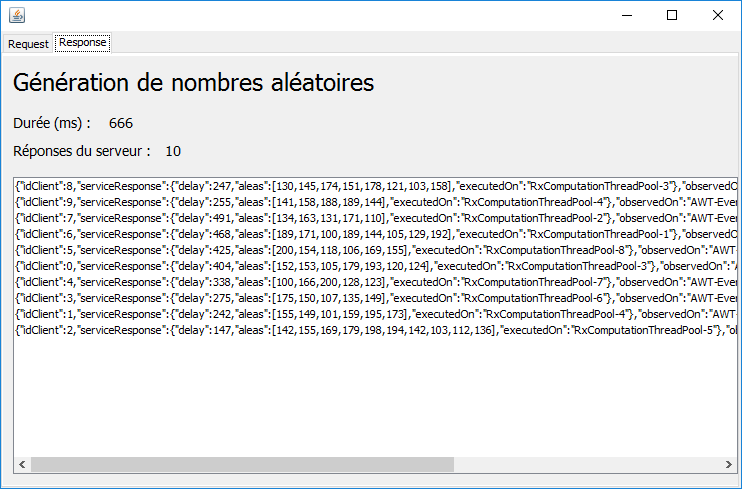 |
On peut remarquer les points suivants :
- on obtient les réponses dans un ordre qui n'est pas celui des requêtes (cf idClient) ;
- les requêtes se sont exécutées dans 8 threads ;
- le thread n° 3 a été utilisé pour les requêtes 8 et 0 ;
- le thread n° 4 a été utilisé pour les requêtes 9 et 1 ;
- les autres requêtes ont chacune eu un thread différent ;
Le schéduler [Schedulers.computation] utilise autant de threads qu'il y a de coeurs sur la machine utilisée. Cette information est obtenue par l'expression [Runtime.getRuntime().availableProcessors()].
2.8.3. avec le schéduler [Schedulers.newThread]
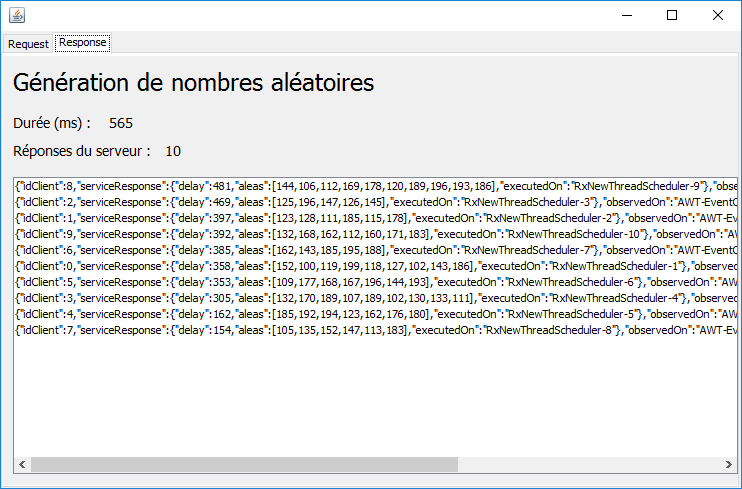 |
On a un fonctionnement analogue à celui du schéduler [Schedulers.io].
2.8.4. avec les schédulers [Schedulers.trampoline, Schedulers.immediate]
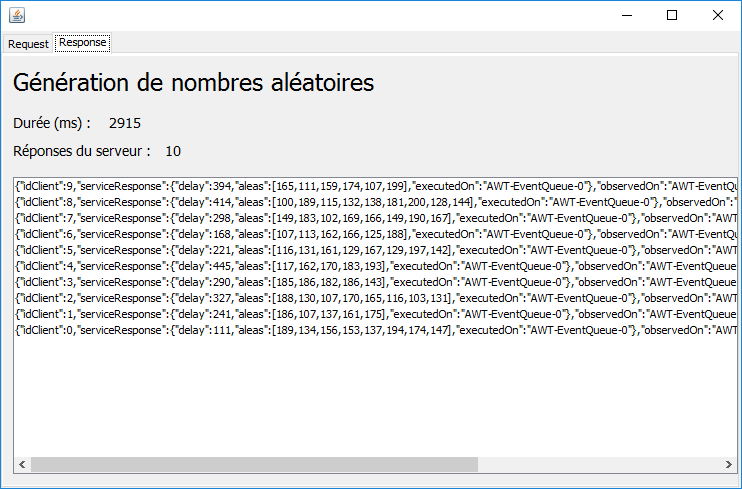 |
On a un fonctionnement synchrone. Toutes les requêtes sont exécutées sur le thread de l'event loop. Il ne faut pas généraliser ce résultat mais dire que simplement sur cet exemple précis les deux schédulers ont fonctionné de façon synchrone.
2.9. Cas limites
Nous allons travailler avec les schédulers qui permettent un fonctionnement asynchrone sur cet exemple. Tout d'abord nous augmentons le nombre de requêtes à 100 avec le schéduler [Schedulers.computation] qui travaille ici avec 8 threads. Nous obtenons le résultat suivant :
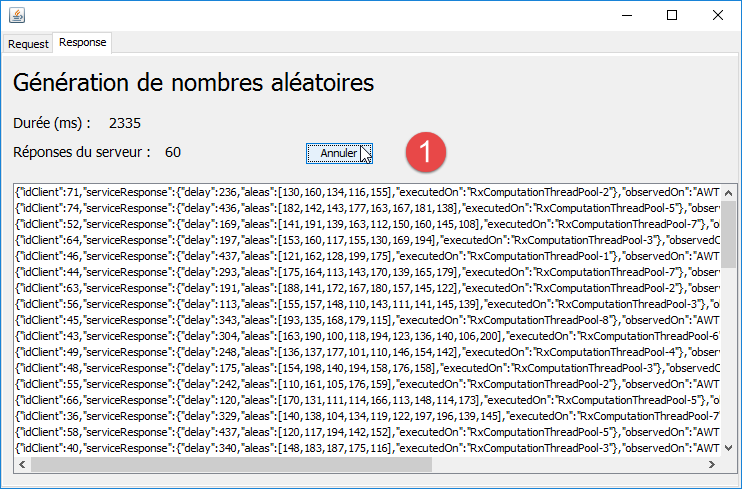 |
- en [1], le bouton [Annuler] est présent et utilisable (fonctionnement asynchrone) ;
Maintenant, laissons l'exécution aller jusqu'au bout :
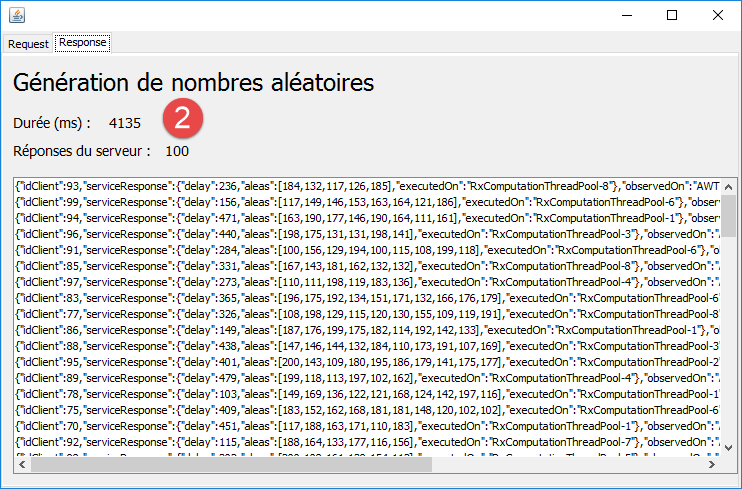 |
On voit en [2] que l'exécution des 100 requêtes a pris environ 4 secondes (sur 8 threads).
Maintenant, faisons ces mêmes 100 requêtes avec le schéduler [Schedulers.newThread] qui exécute chaque requête sur un thread séparé :
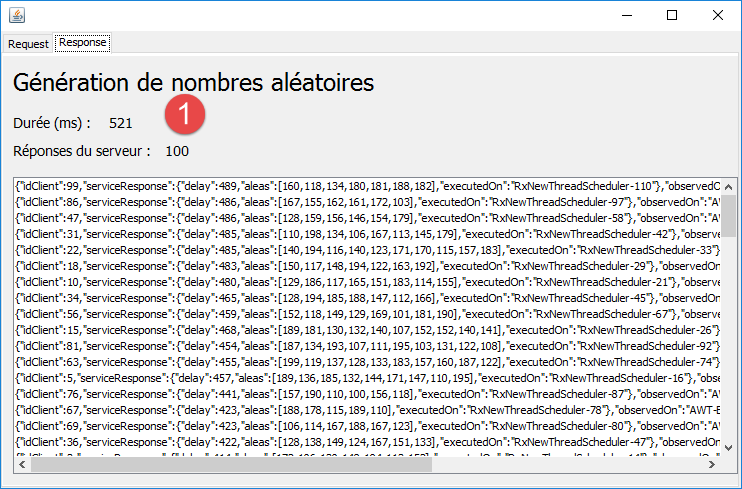 |
En [1], on voit que l'exécution des 100 requêtes (sur 100 threads) a pris une demi-seconde. C'est donc nettement plus rapide qu'avec le schéduler [Schedulers.computation].
Maintenant, faisons 800 requêtes dans les mêmes conditions toujours avec le schéduler [Schedulers.newThread]. On obtient les résultats suivants :
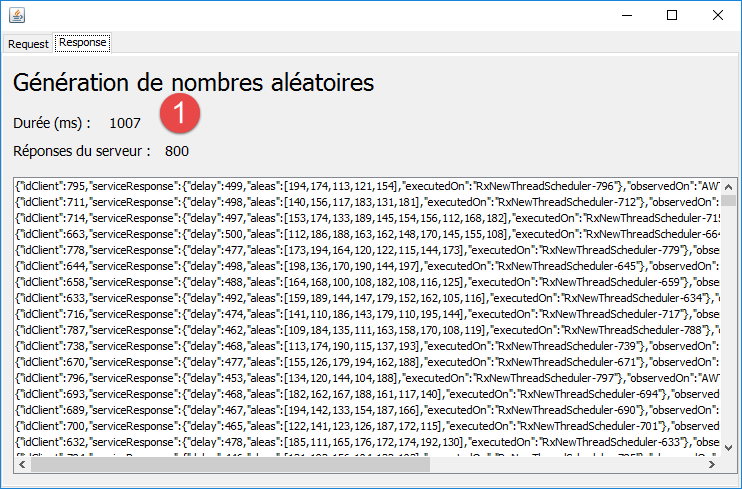 |
Les 800 requêtes sont exécutées en 1 seconde à peu près.
Lorsqu'on augmente ce nombre (au-delà de 2500 requêtes sur ma machine - exécutées en 1,5 s - ce nombre est bien sûr très dépendant de l'environnement de travail au moment de l'exécution), on finit par avoir l'exception suivante :
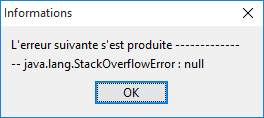 |
On a donc un débordement de pile. Les tests montrent que le fonctionnement du schéduler [Schedulers.newThread] n'est pas déterministe. On peut avoir l'exception précédente, faire de nouveaux essais, revenir ensuite à la configuration ayant provoqué l'exception et ne plus l'avoir.
2.10. Conclusion
Nous avons montré un exemple d'utilisation de la bibliothèque Rx. Résumons ce que nous avons appris :
Nous sommes partis de l'architecture suivante :
- en [4], la couche [swing] faisait des appels synchrones à la couche [service] ;
- en [5], la couche [swing] faisait des appels asynchrones à la couche [rxService] qui appelait à son tour [6] de façon synchrone la couche [service] ;
La première chose que nous avons vue est que la bibliothèque Rx permettait de créer facilement l'interface asynchrone [rxService] à partir de l'interface synchrone [service] (cf paragraphe 2.4). C'est un enseignement important parce que cela veut dire qu'on peut faire aisément évoluer une application synchrone vers une application asynchrone.
Dans la couche [swing], deux méthodes séparées ont été écrites :
- l'une pour faire des appels synchrones au service (cf paragraphe 2.4) ;
- l'autre pour lui faire des appels asynchrones (cf paragraphe 2.7) ;
L'écriture des appels asynchrones s'est révélée nettement plus complexe que celle des appels synchrones. Néanmoins, ceux qui ont fait de la programmation concurrente avec plusieurs threads à synchroniser, trouveront que la solution Rx se révèle plus simple à écrire et évite tous les problèmes de synchronisation et de communication entre threads qui sont des problèmes difficiles. Lors de cette écriture, nous avons distingué les points importants suivants :
- le type [Observable] désigne un flux d'événements (valeurs) qui peuvent être (mais pas forcément) asynchrones et qui peuvent être observés ;
- le type [Subscriber] désigne un abonné à un type [Observable] ;
- le type [Subscription] désigne un abonnement, ç-à-d le lien entre un [Subscriber] et un [Observable] ;
- le type [Observable] admet des opérateurs [mergeWith, empty, subscribeOn, observeOn, ...] qui pour la plupart produisent des observables. Ces opérateurs servent à configurer l'observable avant son exécution :
- ce qu'on veut observer ;
- le thread sur lequel l'observable s'exécute ;
- le thread sur lequel l'abonné reçoit les données de l'observable ;
- on distingue deux types d'observables, les [froid / cold] et les [chaud / hot]. Un observable froid est entièrement exécuté à chaque nouvel abonné. Si chaque exécution produit les mêmes données, chaque nouvel abonné reçoit les mêmes données que le précédent. Un observable chaud produit généralement des données de façon continue. Lorsqu'un abonné s'abonne, il reçoit les données émises à partir de l'heure de son abonnement. Il ne reçoit pas les données qui ont pu être émises précédemment. Dans notre exemple, l'observable est froid : il est entièrement réexécuté à chaque nouvel abonné.
Maintenant que nous avons vu un exemple qui nous a montré l'intérêt de la bibliothèque Rx, nous allons la présenter plus en détail.
La bibliothèque Rx possède de nombreuses méthodes ayant des paramètres génériques dans leur signature. Nous ferons un bref rappel sur ces signatures (paragraphe 3). Les paramètres de ces méthodes sont la plupart du temps des interfaces fonctionnelles (Java 8), ç-à-d des interfaces n'ayant qu'une unique méthode. Les paramètres effectifs doivent être alors des instances de ces interfaces. Avant Java 8, il était d'usage d'implémenter une interface par une classe anonyme. Avec Java 8 et si l'interface est une interface fonctionnelle, alors il est plus concis de l'implémenter avec une fonction lambda. Nous présenterons donc celles-ci (paragraphe 4). Lorsque ceci aura été fait, nous présenterons la classe [Stream] (paragraphe 5) qui permet de traiter des collections Java avec des fonctions lambda. Cette classe est intéressante car la classe [Observable] de RxJava lui emprunte :
- certaines méthodes ;
- la même façon de chaîner les méthodes entre-elles pour traiter un même observable ;
Nous présenterons ensuite les interfaces fonctionnelles spécifiques à la bibliothèque RxJava (paragraphe 6). Nous continuerons avec les principaux éléments de la bibliothèque Rx [Observable, Subscriber, Subscription, opérateurs] (paragraphe 7). La classe [Observable] a plusieurs dizaines d'opérateurs qui sont eux-mêmes surchargés plusieurs fois. Cela crée au départ une grande complexité car ces opérateurs et leurs surcharges ne diffèrent parfois que d'un détail et il est difficile, sans expérience, de savoir quel opérateur utiliser. Nous ne présenterons qu'un nombre limité d'opérateurs et la plupart du temps nous ignorerons leurs surcharges.
Toute la partie précédente sera faite avec la bibliothèque RxJava dans des applications console simples. Une fois la bibliothèque RxJava acquise, nous l'utiliserons dans deux types d'applications graphiques :
- au paragraphe 8 nous reviendrons sur l'application Swing exemple pour la détailler davantage. Nous utiliserons alors la bibliothèque RxSwing ;
- au paragraphe 9 nous créerons une applications Android avec la bibliothèque RxAndroid ;
Lorsque tout ceci sera fait, le lecteur aura les outils pour voler de ses propres ailes. Cela demandera probablement du temps avant qu'il n'arrive à utiliser la bibliothèque Rx de façon intuitive. J'ai trouvé cette bibliothèque particulièrement intéressante. Cependant, je l'ai trouvée complexe à comprendre et le temps d'apprentissage a été long. J'espère que ce document rendra celui-ci plus court pour le lecteur. Il me semble que le jeu en vaut la chandelle.