5. Le type Stream<T> de Java 8
5.1. Exemple-01 - la classe Stream
Les opérations sur les flux Observable ont de nombreux points communs avec les flux Stream. Une différence est qu'un élément d'un flux Stream ne peut être traité avant que le flux Stream tout entier ne soit obtenu, alors qu'un élément d'un flux Observable peut être traité (observé) dès qu'il est obtenu sans attendre l'obtention de l'intégralité du flux Observable. Une autre différence est, qu'une fois le Stream obtenu, on exploite ses valeurs en les tirant (pull) une à une du Stream. Pour l'observable, c'est différent. Dès que celui-ci émet une valeur, celle-ci est poussée (pushed) à son abonné.
Plusieurs classes implémentent la notion de Stream. Nous présentons ici la classe Stream<T> :
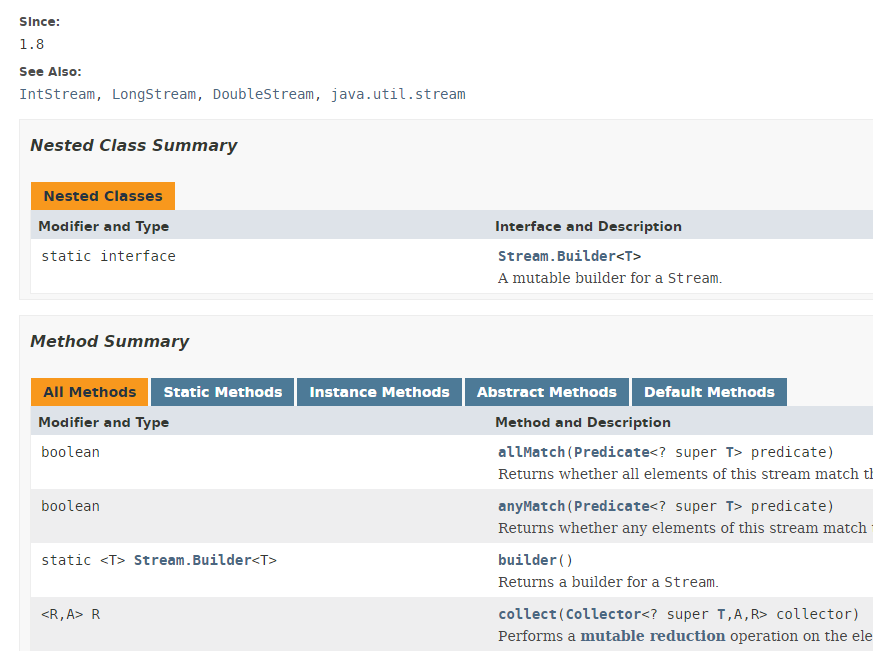
La classe Stream est riche de 39 méthodes. Nous allons en présenter quelques unes. Considérons le code suivant :
 |
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple01 {
public static void main(String[] args) {
// liste de personnes
List<Personne> personnes = Personnes.get();
// affichage 1
personnes.stream().forEach(p -> {
System.out.println(p);
});
System.out.println("----------------");
// affichage 2
personnes.stream().forEach(System.out::println);
}
}
- ligne 11 : on instancie une liste de personnes ;
- ligne 13 : à partir de cette liste, on crée un Stream. Toutes les collections peuvent être ainsi transformées en flux Stream. Cela permet de bénéficier de toutes les méthodes de cette classe qui permet de traiter les éléments de la collection de façon plus concise qu'avec des boucles. Cela permet de bénéficier également du parallélisme du traiement des éléments lorsque celui-ci est possible ;
- ligne 13 : la méthode [Stream.forEach] a la signature suivante :
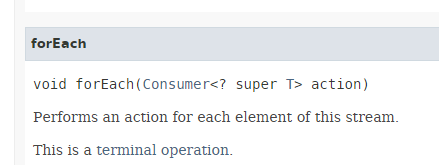 |
On voit que le paramètre de la méthode est l'interface fonctionnelle [Consumer<T>] présentée au paragraphe 4.4 une interface dont l'unique méthode exploite le type T et ne rend rien.
- dans le code :
personnes.stream().forEach(p -> {
System.out.println(p);
});
- [personnes.stream()] produit un flux d'éléments de type [Personne] qui alimente la méthode [forEach]. Le paramètre p est de type [Personne] et la fonction lambda fournie affiche cette personne ;
Le code précédent peut être simplifié de la façon suivante (ligne 18) :
personnes.stream().forEach(System.out::println);
Plutôt que passer en paramètre la valeur d'une fonction lambda, nous passons la référence d'une méthode existante, ici la méthode println de la classe System.out. Il faut bien sûr que cette méthode ait la bonne signature, ici la signature de la méthode [Consumer.accept] : void accept(T t). Comme il a été dit précédemment, le paramètre de la méthode [accept] sera un type [Personne] ;
Nous obtenons les résultats suivants :
Lorsqu'un flux Stream a été exploité, il n'est plus exploitable. Il faut le reconstruire si on souhaite l'exploiter de nouveau. Ceci est montré par le code suivant [Exemple01b] :
package dvp.java8.streams;
import java.util.stream.Stream;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple01b {
public static void main(String[] args) {
// flux de personnes
Stream<Personne> personnes = Personnes.get().stream();
// affichage 1
personnes.forEach(p -> {
System.out.println(p);
});
System.out.println("----------------");
// affichage 2
personnes.forEach(System.out::println);
}
}
- ligne 11 : pour optimiser le code, on décide de construire le Stream une unique fois. Les résultats obtenus sont alors les suivants :
{"nom":"jean","age":20,"poids":70.0,"sexe":"HOMME"}
{"nom":"marie","age":10,"poids":30.0,"sexe":"FEMME"}
{"nom":"camille","age":30,"poids":55.0,"sexe":"FEMME"}
----------------
Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.sourceStageSpliterator(Unknown Source)
at java.util.stream.ReferencePipeline$Head.forEach(Unknown Source)
at dvp.java8.streams.Exemple02b.main(Exemple02b.java:18)
A chaque fois qu'on veut exploiter un Stream, il faut le construire même s'il a été construit précédemment.
5.2. Exemple-02 - traitement en parallèle des éléments d'un Stream
 |
Considérons le code suivant :
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple02 {
public static void main(String[] args) {
// liste de personnes
List<Personne> personnes = Personnes.get();
// affichage 1
personnes.stream().forEach(Exemple02::affiche);
System.out.println("-----------------");
// affichage 2
personnes.stream().parallel().forEach(Exemple02::affiche);
}
public static void affiche(Personne p) {
System.out.printf("Personne %s sur thread %s%n", p, Thread.currentThread().getName());
}
}
- lignes 19-21 : la méthode [affiche] écrit sur la console, la chaîne jSON d'une personne ainsi que le nom du thread d'exécution dans lequel se fait l'affichage ;
- ligne 13 : affiche une liste de personnes. On notera que le paramètre de la méthode [forEach] est la référence de la méthode statique précédente ;
- ligne 16 : on fait la même chose, mais avec la méthode [parallel] on demande à ce que le traitement des éléments du stream soient faits en parallèle sur plusieurs threads. Tout traitement ne peut se faire en parallèle. Ici, il faut supposer que l'ordre d'affichage n'a pas d'importance car dans un traitement parallèle, on n'est pas assuré de l'ordre d'exécution des threads. On remarquera par ailleurs une syntaxe qui va devenir omniprésente aussi bien pour les Stream que les Observable :
- (suite)
- flux produit des éléments e1 qui alimentent la méthode m1 ;
- flux.m1 est à son tour un flux d'éléments e2 qui alimentent la méthode m2 ;
- flux.m1.m2 est un flux d'éléments e3 qui alimentent la méthode m3 ;
Le type des éléments e1, e2, e3 peut changer au fil des traitements subits par le flux initial.
L'exécution de ce code donne le résultat suivant :
On voit que l'exécution parallèle (lignes 5-7) s'est faite sur trois threads différents et n'a pas respecté l'ordre des éléments qui est celui des lignes 1-3. Dans ce document, nous insisterons peu sur le traitement en parallèle des éléments d'un Stream, parce qu'il faut alors parler des conditions qui rendent possible ce traitement. On découvre alors que peu de traitements peuvent être réalisés en parallèle. L'un de ceux qui se prête naturellement au parallélisme est la somme des éléments numériques d'un flux que nous présentons maintenant.
5.3. Exemple-03 - traitement en parallèle des éléments d'un Stream
 |
Considérons le code suivant (Exemple03a) :
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class Exemple03a {
public static void main(String[] args) {
final long limite = 10_000_000L;
// nombre de processeurs
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// liste de nombres
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// somme des nombres - méthode séquentielle
début = new Date().getTime();
long somme = nombres.stream().reduce(0L, (s, i) -> s + i);
System.out.printf("somme séquentielle : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- ligne 22, nous utilisons la méthode [reduce] dont la signature est la suivante :
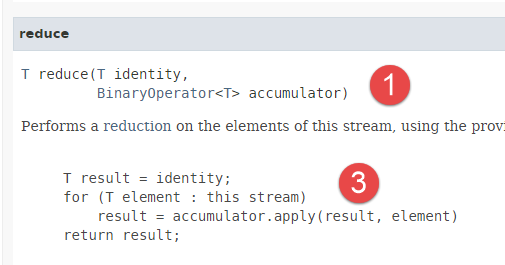 |  |
- la méthode [reduce] travaille avec des éléments de type T ;
- la méhode [reduce] applique le même traitement à tous les éléments d'un flux : la valeur initiale d'un accumulateur est fourni en 1er paramètre. Une méthode instanciant l'interface fonctionnelle [BinaryOperator] [2] est fournie comme second paramètre : à partir de chaque élément et de l'accumulateur, cette méthode fournit une nouvelle valeur de l'accumulateur. La valeur finale de celui-ci est la valeur rendue par la méthode [reduce]. Le code [3] explicite ce mécanisme. La méthode [apply] est la méthode de l'interface fonctionnelle [BinaryOperator] [2] ;
Revenons au code exemple :
- ligne 12 : on affiche le nombre de coeurs vus par la JVM ;
- lignes 15-18 : on crée une liste de 10 millions de nombres ;
- ligne 22 : la somme de ces nombres est calculée séquentiellement avec un seul thread ;
On obtient les résultats suivants :
Maintenant, remplaçons la ligne 22 du code par la suivante (Exemple03b) :
long somme = nombres.stream().parallel().reduce(0L, (s, i) -> s + i);
On demande à ce que les éléments du Stream soient traités en parallèle à l'aide de plusieurs threads. Ceci est possible parce que l'ordre de sommation des nombres n'a pas d'importance. On peut donc affecter n1 nombres à un thread T1, n2 nombres à un thread T2, ... et au final sommer les sommes fournies par ces différents threads. On obtient alors les résultats suivants :
Il n'y a donc quasiment pas de gains de performance. Dans les exemples qui vont suivre ce sera souvent le cas. La gestion des threads est elle-même coûteuse en temps. Il faut que l'opération effectuée par chaque coeur soit suffisamment complexe pour que le gain en performance apparaisse. C'est ce que montre l'exemple suivant (Exemple03c) :
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.function.BinaryOperator;
public class Exemple03c {
public static void main(String[] args) {
final long limite = 10_000L;
// nombre de processeurs
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// liste de nombres
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// somme des nombres - méthode séquentielle
début = new Date().getTime();
BinaryOperator<Long> bo = (s, i) -> {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
}
return s + i;
};
long somme = nombres.stream().reduce(0L, bo);
System.out.printf("somme séquentielle : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- ligne 30 : on utilise de nouveau la méthode [reduce] à qui on fournit comme paramètre, la référence de la méthode des lignes 23-29 ;
- ligne 28 : la méthode [bo] fournit la somme de ses deux paramètres ;
- lignes 24-27 : artificiellement, on fait attendre le thread 1 milliseconde pour simuler un travail intensif ;
On obtient alors les résultats suivants :
Maintenant, si on remplace la ligne 30 par la suivante :
long somme = nombres.stream().parallel().reduce(0L, bo);
on obtient les résultats suivants :
On voit nettement le gain de performance amené par l'exécution en parallèle du calcul de la somme. Pour le traitement de 8 nombres :
- le thread séquentiel attend 8 fois 1 milliseconde, donc 8 ms ;
- les 8 threads parallèles attendent en même temps chacun 1 milliseconde (vue de l'esprit pour simplifier), donc au total 1 milliseconde pour les 8 nombres ;
On peut donc s'attendre à ce que l'exécution parallèle aille 8 fois plus vite que l'exécution séquentielle. C'est à peu près le cas ici.
5.4. Exemple-04 - filtrer un Stream
 |
Considérons le code suivant :
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple04 {
public static void main(String[] args) {
// liste de personnes
List<Personne> personnes = Personnes.get();
// affichages
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(p -> {
System.out.println(p);
});
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(p -> {
System.out.println(p);
});
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(System.out::println);
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(System.out::println);
}
}
- ligne 14 : la méthode [Stream.filter] a la signature suivante :
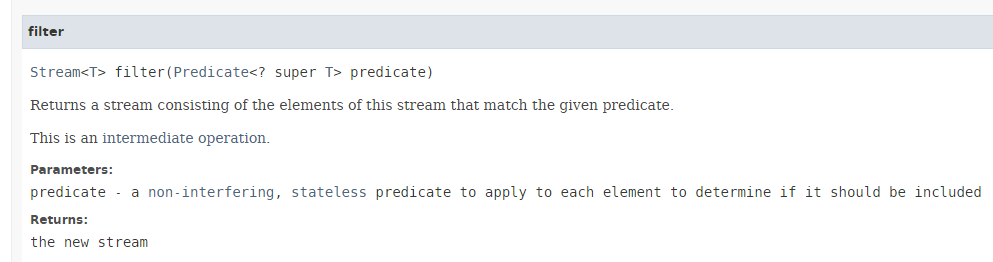 |
- la méthode [filter] attend comme paramètre une instance de l'interface fonctionnelle [Predicate] présentée au paragraphe 4.2 et dont la méthode unique à implémenter est la suivante : boolean test(T t) ;
- la méthode [filter] rend les éléments du Stream vérifiant le Predicate. Elle sert à donc à filtrer le Stream ;
Considérons le code suivant :
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple04 {
public static void main(String[] args) {
// liste de personnes
List<Personne> personnes = Personnes.get();
// affichages
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(p -> {
System.out.println(p);
});
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(p -> {
System.out.println(p);
});
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(System.out::println);
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(System.out::println);
}
}
- lignes 14-16 : affichent les personnes ayant un âge <28 ;
- ligne 18-20 : affichent les personnes ayant un poids <50 ;
- ligne 22 : fait la même chose que les lignes 14-16 mais de façon plus concise ;
- ligne 24 : fait la même chose que les lignes 18-20 mais de façon plus concise ;
Les résultats de l'exécution sont les suivants :
5.5. Exemple-05 - créer un Stream<T2> à partir d'un Stream<T1>
 |
Considérons le code suivant :
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple05 {
public static void main(String[] args) {
// liste de personnes
List<Personne> personnes = Personnes.get();
// affichages
System.out.println("Personne --> String ----------------------");
personnes.stream().map(p -> p.getNom()).forEach(System.out::println);
System.out.println("Personne --> Integer ----------------------");
personnes.stream().map(p -> p.getAge()).forEach(System.out::println);
}
}
- ligne 13, la méthode [Stream.map] a la signature suivante :
 |
Le paramètre de la méthode [Stream.map] est une instance de l'interface fonctionnelle [Function] présentée au paragraphe 4.3 et dont l'unique méthode à implémenter est : R apply(T t). On voit qu'à partir d'un type T la fonction [apply] produit un type R. La méthode [Stream.map] va donc produire un flux Stream de type R à partir d'un flux de type T (flux de type T signifie ici, par un abus de langage que nous conserverons, flux d'éléments de type T).
Etudions maintenant, le code de l'exemple :
- ligne 14 : d'une personne p, on ne garde que le nom. On obtient donc un flux de String ;
- ligne 14 : d'une personne p, on ne garde que le nom. On obtient donc un flux de Integer ;
Les résultats obtenus sont les suivants :
5.6. Exemple-06 - autres méthodes de la classe Stream<T>
 |
Nous illustrons certaines des 39 méthodes de la classe Stream avec le code suivant :
package dvp.java8.streams;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import dvp.data.Personne;
import dvp.data.Personnes;
import java.util.Comparator;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.DoubleStream;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class Exemple06 {
// mappeur jSON
static private ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// liste de personnes
List<Personne> personnes = Personnes.get();
// toutes les personnes
affiche("all", personnes);
// la 1ère personne
affiche("findFirst", personnes.stream().findFirst().get());
// n'importe quelle personne
affiche("findAny", personnes.stream().findAny().get());
// les personnes sans la 1ère
affiche("skip 1", personnes.stream().skip(1L).collect(Collectors.toList()));
// les 2 premières personnes
affiche("limit 2", personnes.stream().limit(2L).collect(Collectors.toList()));
// le nombre de personnes
affiche("count", personnes.stream().count());
// la personne la + âgée
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
// la personne la + légère
affiche("poids min", personnes.stream().min(Comparator.comparingDouble(Personne::getPoids)).get());
// la dernière personne par ordre alphabétique des noms
affiche("nom max", personnes.stream().max((p1, p2) -> p1.getNom().compareToIgnoreCase(p2.getNom())).get());
// l'âge total de toutes les personnes
affiche("âge total (reduce)", personnes.stream().map(p -> p.getAge()).reduce(0, (a1, a2) -> a1 + a2));
// les personnes par âge croissant
affiche("personnes par âge croissant",
personnes.stream().sorted(Comparator.comparingInt(Personne::getAge)).collect(Collectors.toList()));
// y-a-t-il des personnes de + de 100 ans ?
affiche("des personnes de + de 100 ans (anyMatch)", personnes.stream().anyMatch(p -> p.getAge() > 100));
// est-ce que toutes les personnes ont au plus 100 ans ?
affiche("des personnes de + de 100 ans (noneMatch)", personnes.stream().noneMatch(p -> p.getAge() > 100));
// est-ce que toutes les personnes ont + de 8 ans
affiche("des personnes de + de 8 ans (allMatch)", personnes.stream().allMatch(p -> p.getAge() > 8));
// on regroupe les personnes par sexe
affiche("personnes regroupées par sexe", personnes.stream().collect(Collectors.groupingBy(p -> p.getSexe())));
// supression des éléments en double d'une liste
affiche("distinct", Stream.of(1, 2, 1).distinct().collect(Collectors.toList()));
// d'un Stream<Stream<T>>, on fait un Stream<T>
affiche("flatMap", Stream.of(1, 2, 3).flatMap(i -> Stream.of(i, i + 10)).collect(Collectors.toList()));
// d'un Stream<Stream<Integer>>, on fait un IntStream dont on calcule la somme
affiche("flatMapToInt", Stream.of(1, 2, 3).flatMapToInt(i -> IntStream.of(i, i + 10)).sum());
// d'un Stream<Stream<Integer>>, on fait un DoubleStream puis un tableau
affiche("flatMapToDouble", Stream.of(1, 2, 3).flatMapToDouble(i -> DoubleStream.of(i, i * 1.2)).toArray());
// max d'un flux d'entiers
affiche("reduce Integer::max", Stream.of(1, 10, 8).reduce(Integer::max).get());
// min d'un flux de Double
affiche("reduce Integer::min", Stream.of(1.5, 10.4, 8.9).reduce(Double::min).get());
// moyenne d'un flux d'entiers
affiche("IntStream average", IntStream.of(1, 10, 8).average().getAsDouble());
// statistiques d'un flux d'entiers
affiche("IntStream summaryStatistics", IntStream.of(1, 10, 8).summaryStatistics());
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- lignes 72,75 : affichent la chaîne jSON du second paramètre de la méthode ;
- ligne 24 : affiche la chaîne jSON de toutes les personnes. On obtient le résultat suivant :
5.6.1. [findFirst]
// la 1ère personne
affiche("findFirst", personnes.stream().findFirst().get());
La méthode [findFirst] rend le 1er élément d'un flux s'il existe. Sa signature est la suivante :
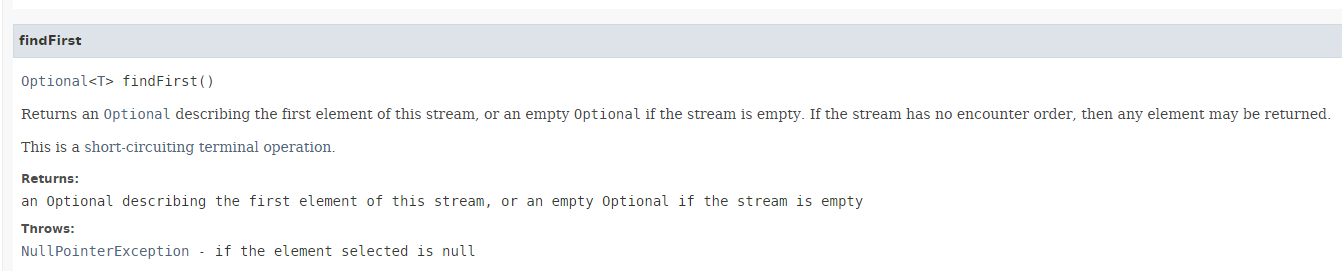 |
Le résultat est de type Optional<T>, un type introduit par Java 8 :
 |
La classe Optional<T> permet de gérer différemment les pointeurs null. Une méthode devant rendre un type T pouvant avoir la valeur null peut décider de rendre un type Optional<T>. La méthode [Optional<T>.isPresent()] permet de savoir si la méthode a rendu une valeur ou non. Le code suivant [Exemple06b] illustre une partie du fonctionnement du Optional<T> :
package dvp.java8.streams;
import java.util.Optional;
import com.fasterxml.jackson.core.JsonProcessingException;
public class Exemple06b {
public static void main(String[] args) throws JsonProcessingException {
// optional sans valeur
Optional<Integer> o1 = m1();
System.out.println(o1.isPresent());
affiche(o1);
// optional avec valeur
Optional<Integer> o2 = m2();
System.out.println(o2.isPresent());
affiche(o2);
}
private static void affiche(Optional<Integer> o1) {
try {
// on récupère la valeur de l'Optional
// lance 1 exception si pas de valeur
System.out.println(o1.get());
} catch (Throwable th) {
System.out.printf("%s : %s%n", th.getClass().getName(), th.getMessage());
}
}
public static Optional<Integer> m1() {
// pas de valeur
return Optional.empty();
}
public static Optional<Integer> m2() {
// une valeur
return Optional.of(10);
}
}
Les résultats obtenus sont les suivants :
false
java.util.NoSuchElementException : No value present
true
10
Revenons au code d'illustration de la méthode [findFirst] :
// la 1ère personne
affiche("findFirst", personnes.stream().findFirst().get());
- ligne 2 : pour simplifier le code, nous utilisons la méthode [get] sur l'Optional<Personne> produit par la méthode [findFirst]. Un code propre voudrait qu'on appelle la méthode [Optional<Personne>.isPresent()] avant d'appeler la méthode [get] ;
Le résultat obtenu est le suivant :
5.6.2. [findAny]
// n'importe quelle personne
affiche("findAny", personnes.stream().findAny().get());
La méthode [findAny] a la signature suivante :
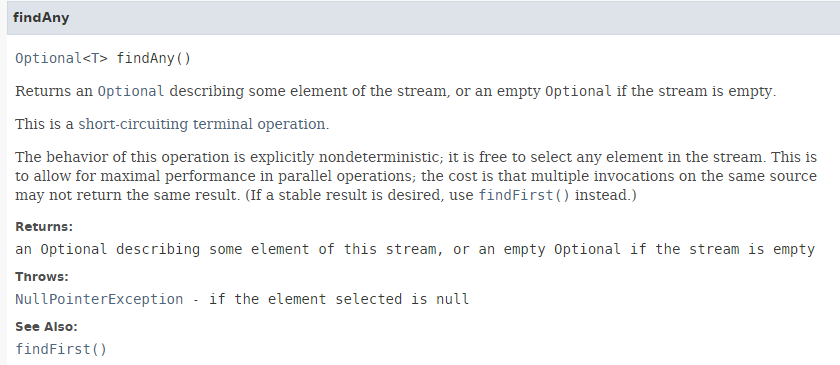 |
La méthode [findAny] peut rendre n'importe quel élément du flux. Lors des tests, on remarque qu'une exécution séquentielle rend le 1er élément du flux alors qu'une exécution parallèle peut effectivement rendre n'importe quel élément. Ceci est montré par le code suivant [Exemple06c] :
package dvp.java8.streams;
import java.util.List;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple06c {
// mappeur jSON
static private ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// liste de personnes
List<Personne> personnes = Personnes.get();
// toutes les personnes
affiche("all", personnes);
// n'importe quelle personne
affiche("findAny parallèle", personnes.stream().parallel().findAny().get());
// n'importe quelle personne
affiche("findAny séquentiel", personnes.stream().findAny().get());
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- ligne 22 : findAny exécuté en parallèle ;
- ligne 24 : findAny exécuté séquentiellement ;
Les résultats obtenus sont les suivants :
- ligne 4 : l'exécution parallèle a rendu l'élément 2 de la liste de personnes. Cela aurait pu être un autre ;
- ligne 6 : l'exécution séquentielle a rendu le premier élément de la liste de personnes ;
L'usage de la méthode [findAny] ne semble avoir de sens que dans le traitement parallèle d'un flux.
5.6.3. [skip]
// les personnes sans la 1ère
affiche("skip 1", personnes.stream().skip(1L).collect(Collectors.toList()));
La méthode [skip] a la signature suivante :
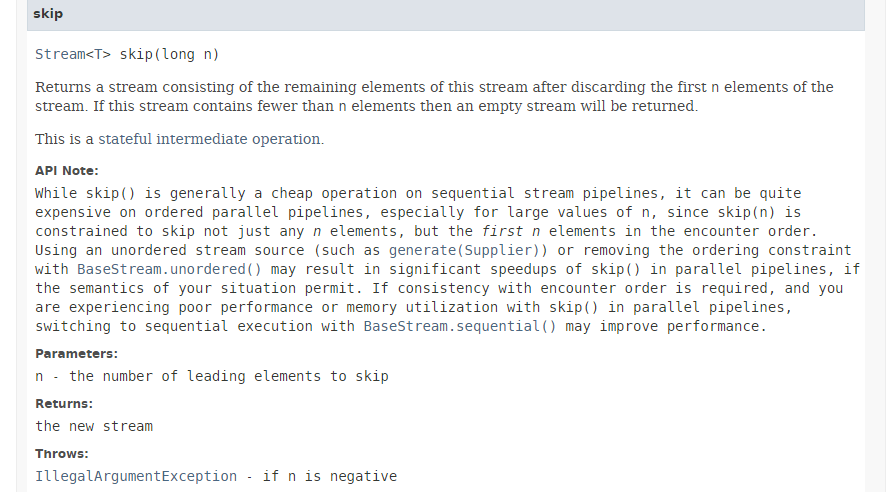 |
La méthode [skip] ignore les n premiers éléments d'un flux. Comme l'indique la documentation ci-dessus, l'exécution de cette méthode en parallèle amène peu de gains de performance et peut même en faire perdre. En effet, pour ignorer les n premiers éléments, les threads sont obligés de se coordonner ce qui annule les performances dûes au parallélisme.
La méthode [skip] rend un flux Stream<Personne> qui est transformé en un type List<Personne> par la méthode [collect] dont la signature est la suivante :
 |
La méthode [collect] admet pour paramètre une instance du type [Collector] dont la signature est complexe. Il existe des implémentations prédéfinies du type [Collector] qui permettent le plus souvent d'éviter de l'implémenter soi-même. Ici l'implémentation utilisée est [Collectors.toList()]. [Collectors] est une classe possédant de nombreuses méthodes statiques implémentant le type [Collector<T,A,R>]. C'est d'abord là qu'il faut chercher lorsqu'on veut transformer un Stream en une collection standard de Java :
 |
Nous utiliserons certaines de ces méthodes par la suite.
L'exécution donne le résultat suivant :
Le 1er élément de la liste (jean) a été omis.
5.6.4. [limit]
// les 2 premières personnes
affiche("limit 2", personnes.stream().limit(2L).collect(Collectors.toList()));
La méthode [limit] a la signature suivante :
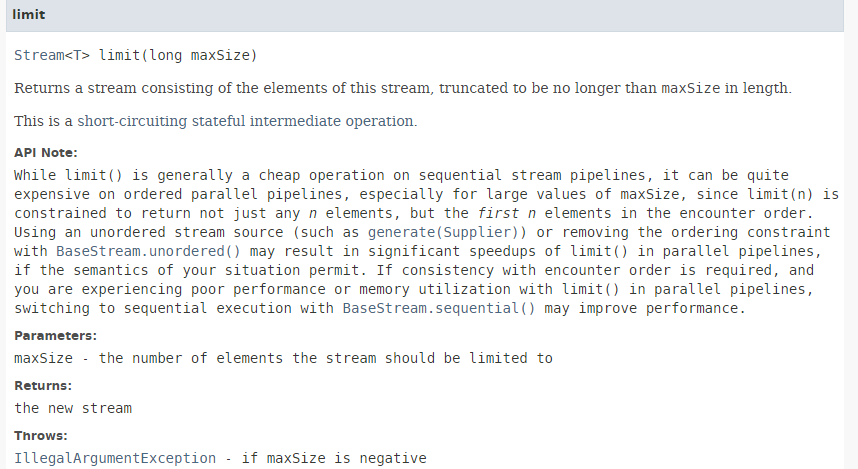 |
La méthode [limit] permet de ne garder que les n premiers éléments d'un flux. Elle n'est pas adaptée à un traitement parallèle.
L'exécution donne le résultat suivant :
5.6.5. [count]
// le nombre de personnes
affiche("count", personnes.stream().count());
La méthode [count] a la signature suivante :
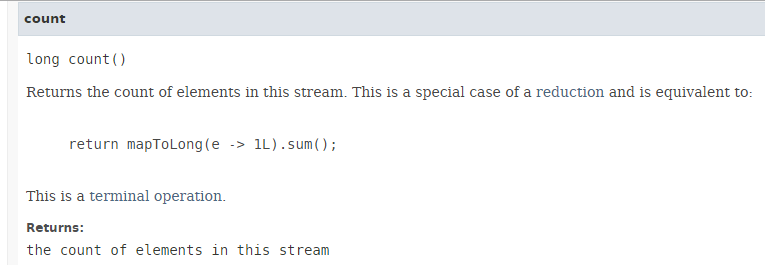 |
La méthode [count] rend le nombre d'éléments d'un Stream. L'exécution en parallèle de la méthode n'amène pas de gain de performance comme le montre le code suivant (Exemple06d1) :
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.stream.Stream;
public class Exemple06d1 {
public static void main(String[] args) {
final long limite = 10_000_000L;
// nombre de processeurs
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// liste de nombres
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// comptage des nombres - méthode séquentielle
Stream<Long> sNombres = nombres.stream();
début = new Date().getTime();
long count = sNombres.count();
System.out.printf("comptage séquentiel : compteur=%s, durée (ms)=%s%n", count, new Date().getTime() - début);
}
}
- lignes 11-22 : on crée un Stream de 10 millions de nombres ;
- lignes 22-24 : le comptage du Stream ;
L'exécution donne le résultat suivant :
Si on remplace la ligne 22 du code par la suivante (Exemple06d2) :
Stream<Long> sNombres = nombres.stream().parallel();
on obtient les résultats suivants :
5.6.6. [max, min]
// la personne la + âgée
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
La méthode [max] a la signature suivante :
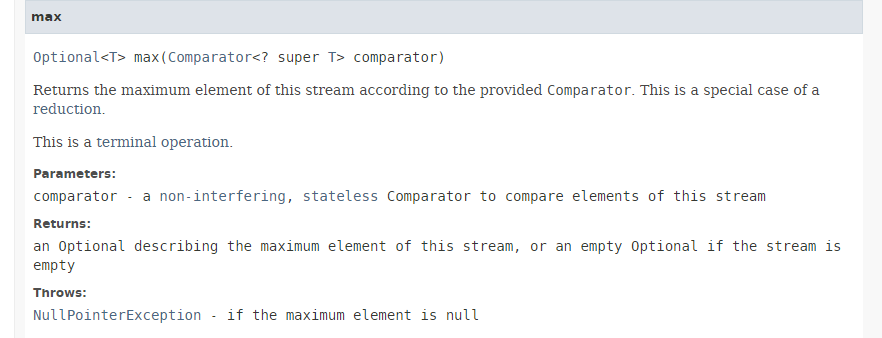 |
La méthode [max] rend la valeur maximale d'un flux en utilisant le comparateur qui lui est passé en paramètre. Comparator est une interface fonctionnelle dont la seule méthode à implémenter a la signature : int compare (T o1, T o2). Cette méthode doit rendre -1 si o1 < o2, 0 si o1.equals(o2), +1 si o1>o2. L'interface fonctionnelle Comparator a de nombreuses méthodes statiques par défaut qui implémentent l'interface Comparator pour les cas les plus courants. Ainsi dans l'instruction :
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
nous utilisons la méthode statique [Comparator.comparingInt] dont la signature est la suivante :
 |
Le type ToIntFunction est une interface fonctionnelle :
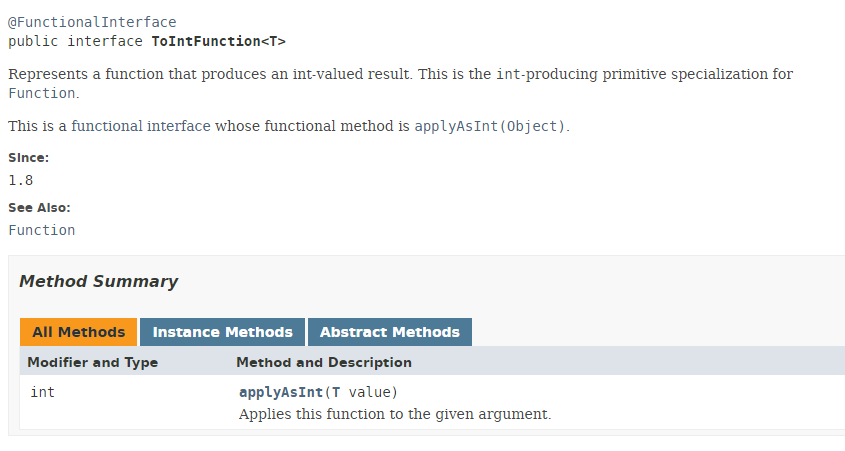 |
La méthode [applyAsInt] de l'interface fonctionnelle ToIntFunction produit un type int à partir d'un type T. Revenons à notre code :
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
Le paramètre effectif de la méthode [Comparator.comparingInt] doit être ici un lambda Personne --> int. Nous passons la référence de la méthode [Personne.getAge] qui a bien cette signature. Au final, on aura la personne ayant l'âge le plus grand. On obtient un type Optional<Personne> dont on extrait la valeur avec la méthode [Optional.get]. On obtient le résultat suivant :
Le calcul du max en parallèle n'amène pas de gains de performance comme le montre l'exemple suivant : (Exemple06e1) :
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Date;
import java.util.List;
import java.util.Random;
import java.util.stream.Stream;
public class Exemple06e1 {
public static void main(String[] args) {
// data
// final long limite = 100L;
// final boolean verbose = true;
final long limite = 10_000_000L;
final boolean verbose = false;
// nombre de processeurs
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// liste de nombres
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextLong());
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// max des nombres - méthode séquentielle
Stream<Long> sNombres = nombres.stream();
Comparator<Long> compLong = (l1, l2) -> {
if (verbose) {
// thread
System.out.printf("[%s]", Thread.currentThread().getName());
}
// comparaison
long v1 = l1.longValue();
long v2 = l2.longValue();
if (v1 < v2) {
return -1;
} else {
if (v1 == v2) {
return 0;
} else {
return +1;
}
}
};
début = new Date().getTime();
// long max = sNombres.max(Comparator.naturalOrder()).get();
long max = sNombres.max(compLong).get();
System.out.printf("%nmax séquentiel : max=%s, durée (ms)=%s%n", max, new Date().getTime() - début);
}
}
- ligne 29 : on a un flux de limite nombres aléatoires de type Long ;
- lignes 30-47 : la variable lambda compLong impémente l'interface Comparator<Long>. Cette interface est normalement implémentée par la méthode [Comparator.naturalOrder()] de la ligne 49. Mais ici, nous voulons afficher le thread d'exécution (lignes 31-33). Aussi implémentons-nous l'interface nous-mêmes ;
- ligne 50 : recherche du max ;
On obtient les résultats suivants :
 |
Si maintenant, on remplace la ligne 27 par la suivante (Exemple06e2) :
Stream<Long> sNombres = nombres.stream().parallel();
on obtient les résultats suivants :
 |
L'exécution parallèle a donc été plus lente. Si on passe à 10 millions de nombres avec verbose=false, on obtient les résultats suivants :
pour l'exécution séquentielle :
pour l'exécution parallèle qui reste donc plus lente.
On utilise la méthode [Stream.min] de façon analogue :
// la personne la + légère
affiche("poids min", personnes.stream().min(Comparator.comparingDouble(Personne::getPoids)).get());
5.6.7. [reduce]
// l'âge total de toutes les personnes
affiche("âge total (reduce)", personnes.stream().map(p -> p.getAge()).reduce(0, (a1, a2) -> a1 + a2));
La méthode [reduce] a été présentée au paragraphe 5.3. La ligne 2 ci-dessus somme les âges de toutes les personnes. Le résultat est le suivant :
5.6.8. [sorted]
// les personnes par âge croissant
affiche("personnes par âge croissant",
personnes.stream().sorted(Comparator.comparingInt(Personne::getAge)).collect(Collectors.toList()));
// les personnes par ordre alphabétique des noms
List<Personne> lPersonnes=personnes.stream().sorted((p1, p2) -> p1.getNom().compareTo(p2.getNom())).collect(Collectors.toList());
affiche("personnes par ordre alphabétique des noms", lPersonnes);
La méthode [sorted] (lignes 3 et 5) a la signature suivante :
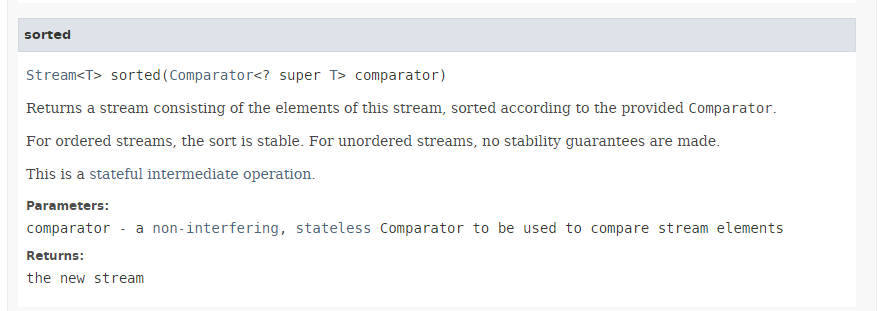 |
La méthode [sorted] admet pour paramètre le type [Comparator] décrit au paragraphe 5.6.6 pour les méthodes min et max. Elle permet de trier un Stream dans l'ordre du comparateur qui lui est passé en paramètre. Nous avons vu que l'interface [Comparator] offrait plusieurs méthodes statiques par défaut implémentant les comparateurs courants, notamment de nombres et de chaînes de caractères. Ici, nous utilisons la méthode [Comparator.comparingInt] qui admet pour paramètre un type ToIntFunction qui est une interface fonctionnelle de méthode [applyAsInt] ayant la signature suivante : int applyAsInt(T t). Ici, le paramètre effectif passé à la méthode [Comparator.comparingInt] ligne 3 est la référence de la méthode [Personne.age] qui donne l'âge de la personne.
L'interface [Comparator] n'offre pas de méthodes statiques pour comparer des chaînes de caractères. Ligne 5, nous construisons nous-mêmes un lambda implémentant l'unique méthode de cette interface : int compare(T t1, T t2)
(p1, p2) -> p1.getNom().compareTo(p2.getNom())
Ce lambda compare les noms des personnes. Les résultats obtenus sont les suivants :
L'exécution en parallèle du tri ne semble pas possible comme le montre le code suivant (Exemple06f1) :
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Date;
import java.util.List;
import java.util.Random;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class Exemple06f1 {
// mappeur jSON
static ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// data
final long limite = 100L;
final boolean verbose = true;
// final long limite = 10_000_000L;
// final boolean verbose = false;
// nombre de processeurs
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// liste de nombres
long début = new Date().getTime();
List<Integer> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextInt(1000));
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// tri des nombres - méthode séquentielle
Stream<Integer> sNombres = nombres.stream();
début = new Date().getTime();
Comparator<Integer> compInt = (i1, i2) -> {
if (verbose) {
// thread
System.out.printf("[%s]", Thread.currentThread().getName());
}
// comparaison
int v1 = i1.intValue();
int v2 = i2.intValue();
if (v1 < v2) {
return +1;
} else {
if (v1 == v2) {
return 0;
} else {
return -1;
}
}
};
if (verbose) {
affiche("nombres", sNombres.sorted(compInt).collect(Collectors.toList()));
}
System.out.printf("tri séquentiel : durée (ms)=%s%n", new Date().getTime() - début);
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- lignes 30-36 : on construit un flux de limite nombres aléatoires ;
- ligne 32, on passe le lambda compInt (lignes 38-55) à la méthode [sorted]. Ce lambda trie les nombres dans l'ordre décroissant et affiche le thread qui l'exécute.
Les résultats obtenus sont les suivants :
 |
Si dans le code précédent, on remplace la ligne 36 par la suivante (Exemple06f2) :
Stream<Integer> sNombres = nombres.stream().parallel();
on obtient les résultats suivants :
 |
On découvre que, de façon étonnante, le tri du flux de nombres s'est fait avec un unique thread. Il n'y a eu aucun parallélisme. Ou alors, il y a quelque chose qui m'échappe ?
5.6.9. [anyMatch, noneMatch, allMatch]
// y-a-t-il des personnes de + de 100 ans ?
affiche("des personnes de + de 100 ans (anyMatch)", personnes.stream().anyMatch(p -> p.getAge() > 100));
// est-ce que toutes les personnes ont au plus 100 ans ?
affiche("des personnes de + de 100 ans (noneMatch)", personnes.stream().noneMatch(p -> p.getAge() > 100));
// est-ce que toutes les personnes ont + de 8 ans
affiche("des personnes de + de 8 ans (allMatch)", personnes.stream().allMatch(p -> p.getAge() > 8));
Lignes 2, 4 et 6, les méthodes [anyMatch, noneMatch, allMatch] ont pour paramètre un type Predicate décrit au paragraphe 4.2. Elles opérent donc un filtrage. Elles rendent toutes trois un booléen :
- anyMatch rend true s'il existe au moins un élément du Stream vérifiant le filtre ;
- noneMatch rend true s'il n'existe aucun élément du Stream vérifiant le filtre ;
- allMatch rend true si tous les éléments du Stream vérifient le filtre ;
Les résultats obtenus sont les suivants :
5.6.10. [collect(Collectors.groupingBy)]
// on regroupe les personnes par sexe
affiche("personnes regroupées par sexe", personnes.stream().collect(Collectors.groupingBy(p -> p.getSexe())));
La méthode [collect] a été présentée au paragraphe 5.6.3. Son paramètre est une implémentation de l'interface [Collector]. La classe [Collectors] offre un certain nombre de méthodes statiques implémentant l'interface [Collector]. Nous avons utilisé jusqu'à maintenant la méthode [Collectors.toList()]. Nous utilisons ici la méthode statique [Collectors.groupingBy] qui crée un dictionnaire à partir du Stream. Sa signature est la suivante :
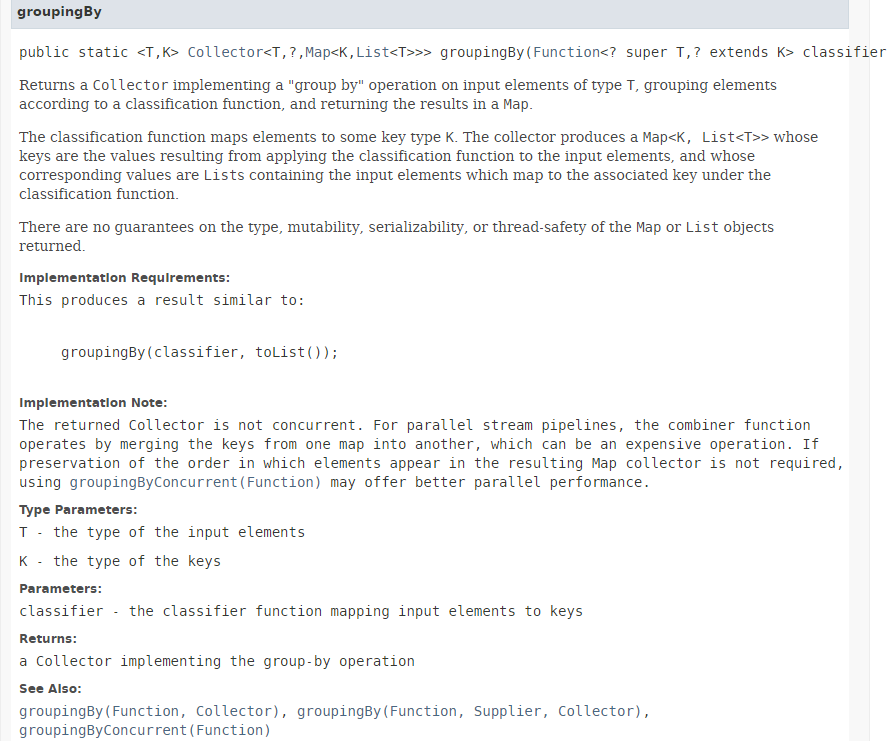 |
La méthode [groupingBy] crée à partir d'un type Stream<T> un type Map<K,List<T>>. La clé K est fournie par le paramètre de la méthode [groupingBy] de type Function<T,K> dont l'unique méthode a la signature : K apply(T t). Si on veut créer un dictionnaire indexé par le sexe des personnes, on doit fournir une fonction générant le sexe à partir d'une personne. Ici, nous passons comme paramètre effectif de la méthode [groupingBy], la référence de la méthode [Personne.getSexe]. Les résultats obtenus sont les suivants :
Ligne 2, on a la chaîne jSON d'un dictionnaire indexé par deux clés : HOMME et FEMME.
Le calcul parallèle n'amène pas de gains de performances comme le montre l'exemple suivant (Exemple06g1) :
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class Exemple06g1 {
// mppeur jSON
static ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// data
final long limite = 100L;
final boolean verbose = true;
// final long limite = 10_000_000L;
// final boolean verbose = false;
// nombre de processeurs
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// liste de nombres
long début = new Date().getTime();
List<Integer> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextInt(1000));
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// regroupement des nombres par centaine - méthode séquentielle
Stream<Integer> sNombres = nombres.stream();
Function<Integer, Integer> groupByCent = n -> {
if (verbose) {
System.out.printf("[%s]", Thread.currentThread().getName());
}
return n / 100;
};
début = new Date().getTime();
// Map<Integer, List<Integer>> lNombres = sNombres.collect(Collectors.groupingBy(nombre -> nombre / 100));
Map<Integer, List<Integer>> lNombres = sNombres.collect(Collectors.groupingBy(groupByCent));
System.out.printf("%nregroupement séquentiel : durée (ms)=%s%n", new Date().getTime() - début);
// résultats
if (verbose) {
affiche("nombres regroupés", lNombres);
}
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- lignes 23-38 : construction d'un flux de limite nombres ;
- ligne 47, les nombres sont regroupés par centaine. On utilise la fonction lambda des lignes 39-44 afin de pouvoir afficher le thread d'exécution ;
Les résultats d'exécution sont les suivants :
 |
Si dans le code, on remplace la ligne 38 par la ligne suivante (Exemple06g2) :
Stream<Integer> sNombres = nombres.stream().parallel();
on obtient les résultats suivants :
 |
On voit que l'exécution parallèle du regroupement a dégradé les performances.
5.6.11. [distinct]
// supression des éléments en double d'une liste
affiche("distinct", Stream.of(1, 2, 1).distinct().collect(Collectors.toList()));
La méthode [distinct] a la signature suivante :
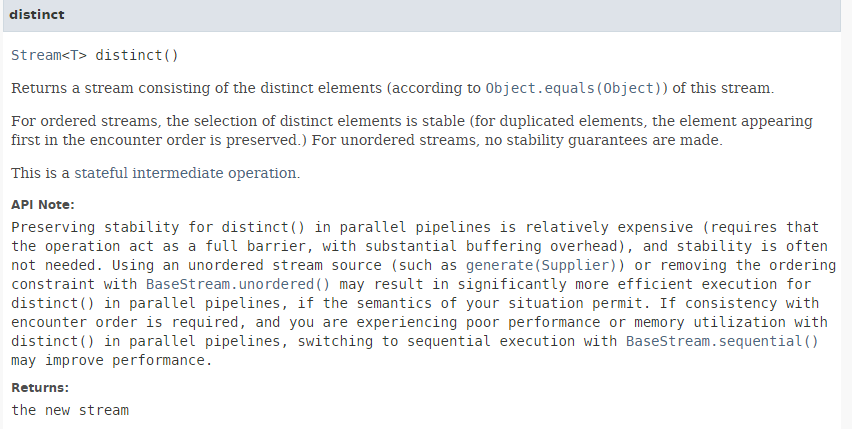 |
Elle permet d'éliminer les doublons d'un flux. La méthode [Stream.of] (ligne 2) a la signature suivante :
 |
Elle permet de créer un Stream à partir de valeurs explicitement fournies. Les résultats de l'exécution sont les suivants :
5.6.12. [flatMap]
// d'un Stream<Stream<T>>, on fait un Stream<T>
affiche("flatMap", Stream.of(1, 2, 3).flatMap(i -> Stream.of(i, i + 10)).collect(Collectors.toList()));
La méthode [flatMap] a la signature suivante :
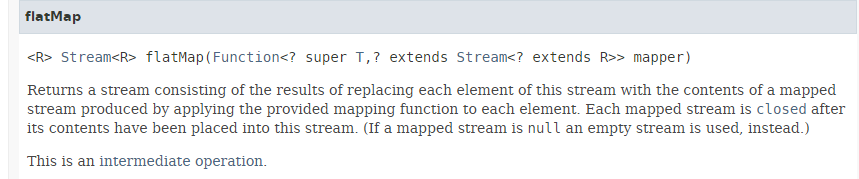  |
La méthode [flatMap] admet pour paramètre une fonction qui :
- admet pour paramètre un élément de type T du Stream ;
- rend pour résultat un flux Stream<R> ;
Si au lieu de la méthode [flatMap], on avait utilisé la méthode [map] décrite au paragraphe 5.5, le résultat serait un type Stream<Stream<R>> où chaque élément de type T du flux initial aurait donné naissance à un élément Stream<R>. La méthode [flatMap] rend elle un type Stream<R>. Elle aplatit (flatten) les différents flux Stream<R> en un unique flux. C'est ce que montrent les résultats de l'exécution du code précédent :
Il existe des variantes spécialisées de [flatMap] :
// d'un Stream<IntStream>, on fait un IntStream dont on calcule la somme
affiche("flatMapToInt", Stream.of(1, 2, 3).flatMapToInt(i -> IntStream.of(i, i + 10)).sum());
La méthode [flatMapToInt] a la signature suivante :
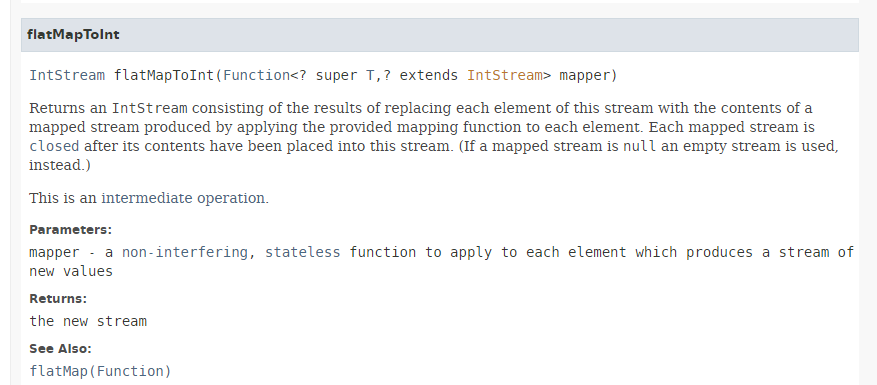 |
La méthode [flatMapToInt] admet pour paramètre une fonction produisant comme résultat un type IntStream suivant :
 |
IntStream est un flux de int. Ce type est préférable au type Stream<Integer> car son traitement évite les boxing / unboxing entre les types Integer et int. Cette interface reprend de nombreuses méthodes du type Stream<T> et en ajoute d'autres dont la méthode [sum] ci-dessus qui somme les éléments du IntStream.
Le code suivant illustre l'usage de la méthode analogue [flatMapToDouble] :
// d'un Stream<DoubleStream>, on fait un DoubleStream puis un tableau
affiche("flatMapToDouble", Stream.of(1, 2, 3).flatMapToDouble(i -> DoubleStream.of(i, i * 1.2)).toArray());
La méthode [DoubleStream.toArray] permet de passer d'un type DoubleStream à un type double[].
Les résultats sont, pour ces deux exemples, les suivants :
L'exemple suivant montre les gains de performance obtenus en passant d'un type Stream<Long> à un type LongStream (Exemple06i1) :
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class Exemple06i1 {
public static void main(String[] args) {
final long limite = 10_000_000L;
// nombre de processeurs
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// liste de nombres
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// somme des nombres - méthode séquentielle
début = new Date().getTime();
long somme = nombres.stream().reduce(0L, (s, i) -> s + i);
System.out.printf("somme séquentielle du Stream<Integer> : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- ligne 22 : calcul de la somme d'un flux de nombres de type Long ;
On obtient les résultats suivants :
Maintenant, remplaçons la ligne 22 par la suivante (Exemple06i2) :
long somme = nombres.stream().mapToLong(n -> n.longValue()).sum();
La méthode Stream<Integer>.mapToLong nous permet d'obtenir un flux de type LongStream d'éléments de type primitif long, que l'on somme ensuite avec la fonction sum. On obtient alors les résultats suivants :
Le gain de performance est net.
5.6.13. méthodes de flux de nombres primitifs
// max d'un flux de int
affiche("IntStream max", IntStream.of(1, 10, 8).max());
// min d'un flux de double
affiche("DoubleStream min", DoubleStream.of(1.5, 10.4, 8.9).min());
// moyenne d'un flux de int
affiche("IntStream average", IntStream.of(1, 10, 8).average().getAsDouble());
// statistiques d'un flux de int
affiche("IntStream summaryStatistics", IntStream.of(1, 10, 8).summaryStatistics());
Les flux de valeurs primitives (int, long, double) offrent des méthodes adaptées à ces types. Le résultat de l'exécution du code précédent est le suivant :
- le résultat de la ligne 2 du code est un type OptionalInt analogue au type Optional<Integer>. La valeur stockée dans cet objet peut être obtenue avec la méthode [getAsInt()]. La présence d'une valeur peut être testée avec la méthode [isPresent()]. La ligne 2 des résultats ne signifie pas que la classe [OptionalInt] a des champs appelés [asInt, present]. Par défaut, la bibliothèque jSON utilise toutes les méthodes publiques getX et isY de l'objet à sérialiser en jSON. Et ici, il y a bien une méthode [getAsInt] et une autre méthode [isPresent] sans que les champs [asInt, present] eux n'existent ;
- le résultat de la ligne 4 du code est un type OptionalDouble analogue au type Optional<Double> ;
- le résultat de la ligne 6 du code est un type OptionalDouble dont on peut obtenir la valeur avec la méthode [getAsDouble()]. La méthode [average] calcule la moyenne du flux de nombres ;
- le résultat de la ligne 8 du code est un type IntSummaryStatistics défini de la façon suivante :
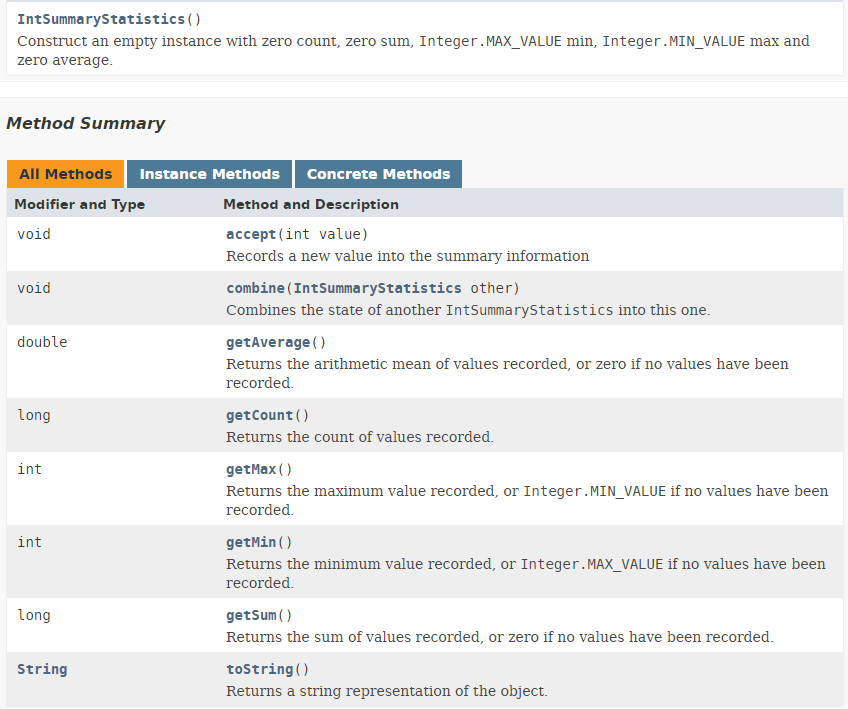 |
On voit que l'objet IntSummaryStatistics obtenu donne différentes informations sur le flux de nombres telles que nombre de valeurs, somme, max, min, moyenne.