18. Estudo de caso: Struts 2 / Tiles / Spring / Hibernate / MySQL
Vamos concluir a nossa aprendizagem do Struts com um estudo de caso. Para ser realista, o exemplo em análise será significativamente mais complexo do que os analisados anteriormente. Para os principiantes, é sem dúvida preferível aprofundar os conceitos básicos do Struts 2 com aplicações pessoais antes de abordar este estudo de caso.
A aplicação irá utilizar uma arquitetura em camadas:
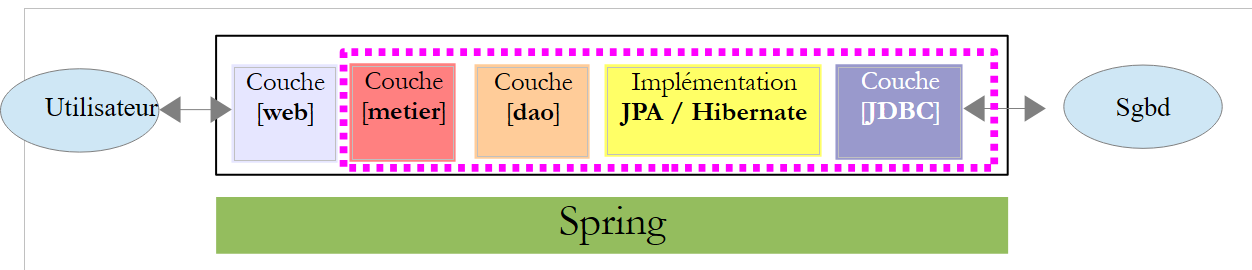 |
O conjunto de camadas [metier], [dao], [jpa/hibernate] será-nos fornecido sob a forma de um arquivo jar, cujas funcionalidades iremos detalhar. A integração das camadas será assegurada pelo Spring. A camada [web] será implementada pelo Struts 2.
 |
18.1. O problema
Propõe-se a criação de uma aplicação web que permita elaborar a folha de pagamento das amas empregadas pela «Maison de la petite enfance» de um município.

Este estudo de caso é apresentado no documento:
Introdução ao Java EE 5, disponível em URL [http://tahe.developpez.com/java/javaee]
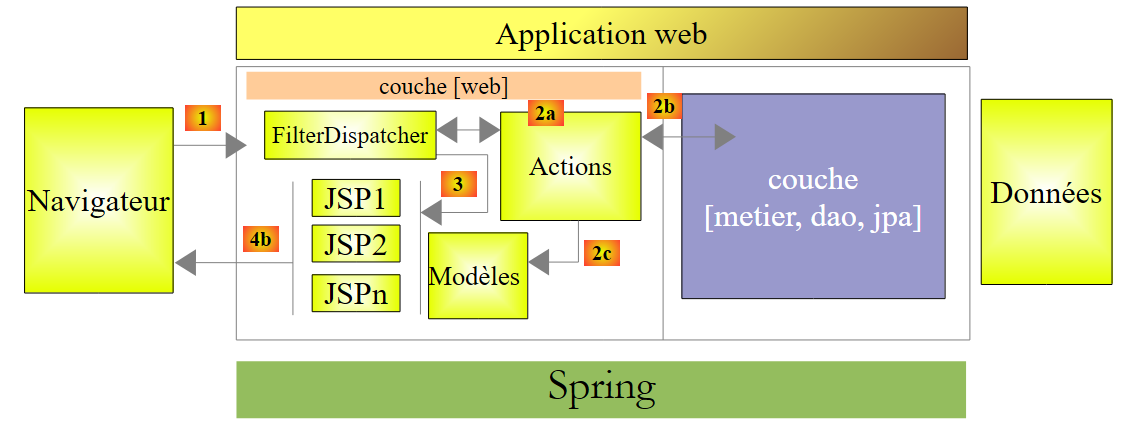
Neste documento, o estudo de caso é implementado com a seguinte arquitetura multicamadas:
 |
A camada [web] é implementada utilizando o framework JSF (Java Server Faces). Vamos adotar esta mesma arquitetura ao implementar a camada [web] com o Struts 2. Para demonstrar a vantagem das arquiteturas em camadas, vamos utilizar o ficheiro jar das camadas [metier, dao, jpa] da versão JSF e ligá-lo a uma camada [web / struts2]:
 |
Apresentaremos os seguintes elementos das camadas [metier, dao, jpa]:
- a camada [web] comunica com a interface da camada [métier]. Apresentaremos essa interface.
- a camada [jpa] acede a uma base de dados. Iremos apresentá-la.
- A camada [jpa] transforma as linhas das tabelas da base de dados em entidades JPA manipuladas por todas as camadas da aplicação. Iremos apresentá-las.
- As camadas [metier, dao, jpa] são instanciadas pelo Spring. Apresentaremos o ficheiro de configuração que realiza essa instanciação e integração.
18.2. A base de dados
Iremos utilizar a seguinte base de dados MySQL [dbpam_hibernate]:

- Em [1], a base de dados tem três tabelas:
- [employes]: uma tabela que regista as funcionárias de uma creche
- [cotisations]: uma tabela que regista as taxas de contribuições sociais
- [indemnites]: uma tabela que regista informações que permitem calcular a remuneração das funcionárias
Tabela [employes]
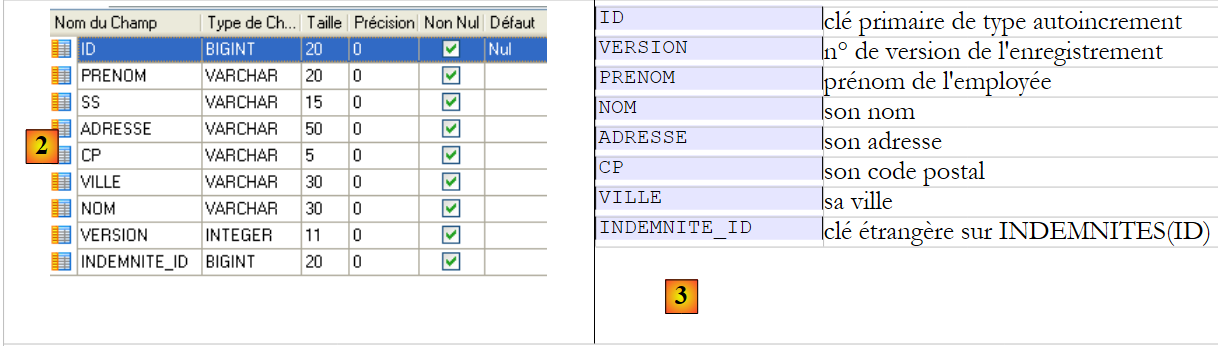 |
- em [2], a tabela dos funcionários e em [3], o significado dos seus campos
O conteúdo da tabela poderia ser o seguinte:
Tabela [cotisations]
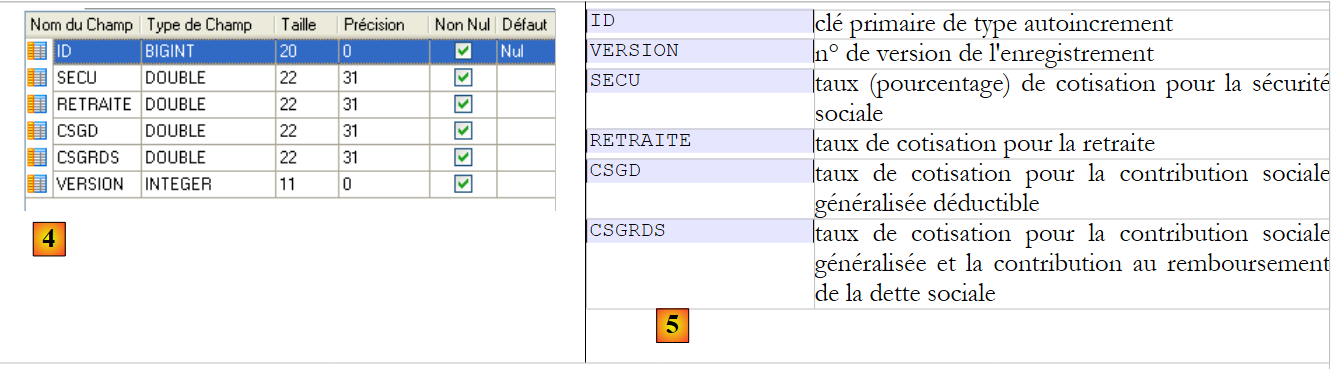 |
- em [4], a tabela das contribuições e em [5], o significado dos seus campos
O conteúdo da tabela poderia ser o seguinte:
Tabela [indemnites]
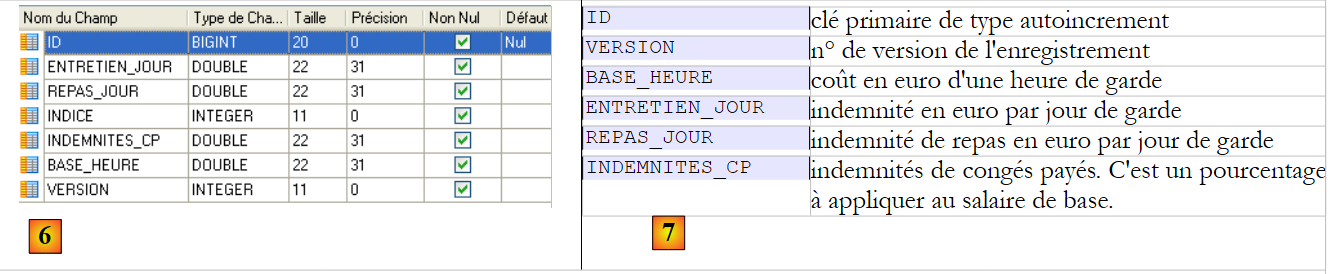 |
- em [6], a tabela de indemnizações e em [7], o significado dos seus campos
O conteúdo da tabela poderia ser o seguinte:
A exportação da estrutura da base de dados para um ficheiro SQL dá o seguinte resultado:
18.3. As entidades JPA
Na seguinte arquitetura
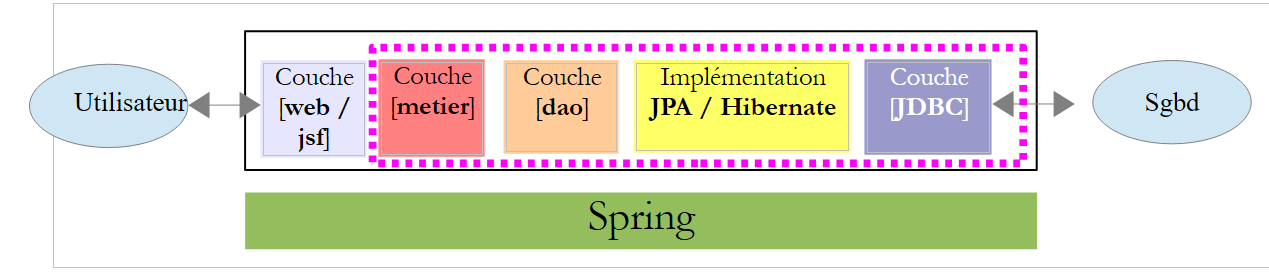 |
A camada [Jpa] funciona como uma ponte entre os objetos manipulados pela camada [dao] e as linhas das tabelas da base de dados manipuladas pelo controlador JDBC. As linhas das tabelas lidas na base de dados são transformadas em objetos denominados entidades JPA. Por outro lado, na gravação, as entidades JPA são transformadas em linhas nas tabelas. Estas entidades são manipuladas por todas as camadas e, em particular, pela camada web. Por isso, é necessário conhecê-las:
A entidade [Employe] representa uma linha da tabela [Employes]
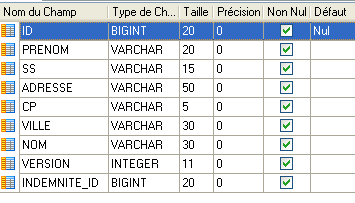 |
|
A entidade [Employe] é a seguinte:
package jpa;
...
@Entity
@Table(name="EMPLOYES")
public class Employe implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
@Column(name="VERSION",nullable=false)
private int version;
@Column(name="SS", nullable=false, unique=true, length=15)
private String SS;
@Column(name="NOM", nullable=false, length=30)
private String nom;
@Column(name="PRENOM", nullable=false, length=20)
private String prenom;
@Column(name="ADRESSE", nullable=false, length=50)
private String adresse;
@Column(name="VILLE", nullable=false, length=30)
private String ville;
@Column(name="CP", nullable=false, length=5)
private String codePostal;
@ManyToOne
@JoinColumn(name="INDEMNITE_ID",nullable=false)
private Indemnite indemnite;
public Employe() {
}
public Employe(String SS, String nom, String prenom, String adresse, String ville, String codePostal, Indemnite indemnite){
setSS(SS);
setNom(nom);
setPrenom(prenom);
setAdresse(adresse);
setVille(ville);
setCodePostal(codePostal);
setIndemnite(indemnite);
}
@Override
public String toString() {
return "jpa.Employe[id=" + getId()
+ ",version="+getVersion()
+",SS="+getSS()
+ ",nom="+getNom()
+ ",prenom="+getPrenom()
+ ",adresse="+getAdresse()
+",ville="+getVille()
+",code postal="+getCodePostal()
+",indice="+getIndemnite().getIndice()
+"]";
}
// getters e setters
...
}
Ignorar-se-ão as anotações @ destinadas à camada [Jpa]. Os diferentes campos da classe refletem as diferentes colunas da tabela [EMPLOYES]. O campo «indemnizações» (linha 29) reflete o facto de a tabela [EMPLOYES] ter uma chave estrangeira na tabela [INDEMNITES]. Ao editar um funcionário, editam-se também as suas indemnizações.
A entidade [Indemnite] é a expressão objeto de uma linha da tabela [INDEMNITES]:
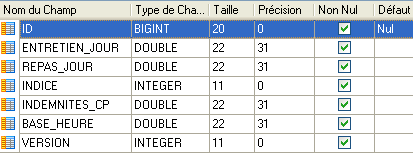 |
|
A entidade [Indemnite] é a seguinte:
package jpa;
...
@Entity
@Table(name="INDEMNITES")
public class Indemnite implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
@Column(name="VERSION",nullable=false)
private int version;
@Column(name="INDICE", nullable=false,unique=true)
private int indice;
@Column(name="BASE_HEURE",nullable=false)
private double baseHeure;
@Column(name="ENTRETIEN_JOUR",nullable=false)
private double entretienJour;
@Column(name="REPAS_JOUR",nullable=false)
private double repasJour;
@Column(name="INDEMNITES_CP",nullable=false)
private double indemnitesCP;
public Indemnite() {
}
public Indemnite(int indice, double baseHeure, double entretienJour, double repasJour, double indemnitesCP){
setIndice(indice);
setBaseHeure(baseHeure);
setEntretienJour(entretienJour);
setRepasJour(repasJour);
setIndemnitesCP(indemnitesCP);
}
@Override
public String toString() {
return "jpa.Indemnite[id=" + getId()
+ ",version="+getVersion()
+",indice="+getIndice()
+",base heure="+getBaseHeure()
+",entretien jour"+getEntretienJour()
+",repas jour="+getRepasJour()
+",indemnités CP="+getIndemnitesCP()
+ "]";
}
// getters e setters
....
}
Os diferentes campos da classe refletem as diferentes colunas da tabela [INDEMNITES].
A entidade [Cotisation] é a expressão que corresponde a uma linha da tabela [COTISATIONS]:
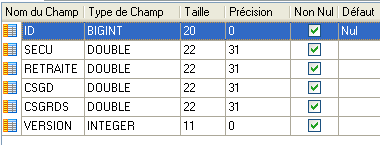 |
|
A entidade [Cotisation] é a seguinte:
package jpa;
...
@Entity
@Table(name="COTISATIONS")
public class Cotisation implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
@Column(name="VERSION",nullable=false)
private int version;
@Column(name="CSGRDS",nullable=false)
private double csgrds;
@Column(name="CSGD",nullable=false)
private double csgd;
@Column(name="SECU",nullable=false)
private double secu;
@Column(name="RETRAITE",nullable=false)
private double retraite;
public Cotisation() {
}
public Cotisation(double csgrds, double csgd, double secu, double retraite){
setCsgrds(csgrds);
setCsgd(csgd);
setSecu(secu);
setRetraite(retraite);
}
@Override
public String toString() {
return "jpa.Cotisation[id=" + getId() + ",version=" + getVersion()+",csgrds="+getCsgrds()+"" +
",csgd="+getCsgd()+",secu="+getSecu()+",retraite="+getRetraite()+"]";
}
// getters e setters
...
}
Os diferentes campos da classe refletem as diferentes colunas da tabela [INDEMNITES].
18.4. Método de cálculo do salário de uma ama
A aplicação web que vamos criar permitirá calcular o salário de uma funcionária com base em três informações:
- o índice da funcionária
- o número de dias trabalhados
- o número de horas trabalhadas
Eis uma captura de ecrã do cálculo de um salário:
Apresentamos agora o método de cálculo do salário mensal de uma ama. Este não pretende ser o método utilizado na realidade. Tomamos como exemplo o salário da Sra. Marie Jouveinal, que trabalhou 150 horas ao longo de 20 dias durante o mês a pagar.
São tidos em conta os seguintes elementos: | ||
O salário base da assistente é dado pela fórmula seguinte: | ||
Uma determinada quantia de contribuições sociais devem ser deduzidas deste salário de base: | ||
Total das contribuições sociais: | ||
Além disso, a ama tem direito, por cada dia trabalhado, a um subsídio de subsistência, bem como a um subsídio de refeição. A este título, recebe as indemnizações seguintes: | ||
No final, o salário líquido a pagar à ama é o seguinte: |
18.5. A interface da camada [métier]
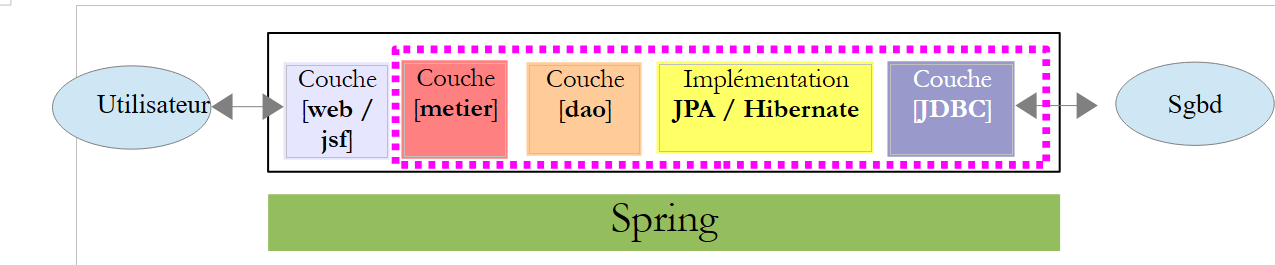
Voltemos à arquitetura da aplicação que estamos a desenvolver:
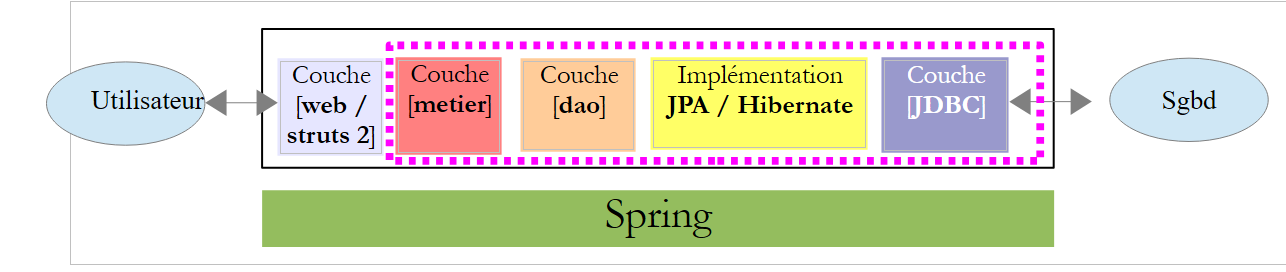 |
A camada [web / struts 2] comunica com a interface da camada [métier]. Esta é a seguinte:
package metier;
import java.util.List;
import jpa.Employe;
public interface IMetier {
// obter a folha de vencimentos
FeuilleSalaire calculerFeuilleSalaire(String SS, double nbHeuresTravaillées, int nbJoursTravaillés );
// lista de funcionários
List<Employe> findAllEmployes();
}
- linha 8: o método que nos permitirá calcular o salário de um funcionário
- linha 10: o método que nos permitirá preencher a lista suspensa dos funcionários
O método calculerFeuillesalaire devolve uma instância da classe [FeuilleSalaire], como se segue:
package metier;
import java.io.Serializable;
import jpa.Cotisation;
import jpa.Employe;
public class FeuilleSalaire implements Serializable {
// campos privados
private Employe employe;
private Cotisation cotisation;
private ElementsSalaire elementsSalaire;
// construtores
public FeuilleSalaire() {
}
public FeuilleSalaire(Employe employe, Cotisation cotisation,
ElementsSalaire elementsSalaire) {
setEmploye(employe);
setCotisation(cotisation);
setElementsSalaire(elementsSalaire);
}
// toString
@Override
public String toString() {
return "[" + employe + "," + cotisation + ","
+ elementsSalaire + "]";
}
// getters e setters
...
}
A folha de salário contém as seguintes informações:
- linha 10: informações sobre o funcionário cujo salário está a ser calculado
- linha 11: as diferentes taxas de contribuição
- linha 12: componentes do salário
A classe [ElementsSalaire] é a seguinte:
package metier;
import java.io.Serializable;
public class ElementsSalaire implements Serializable{
// campos privados
private double salaireBase;
private double cotisationsSociales;
private double indemnitesEntretien;
private double indemnitesRepas;
private double salaireNet;
// construtores
public ElementsSalaire() {
}
public ElementsSalaire(double salaireBase, double cotisationsSociales,
double indemnitesEntretien, double indemnitesRepas,
double salaireNet) {
setSalaireBase(salaireBase);
setCotisationsSociales(cotisationsSociales);
setIndemnitesEntretien(indemnitesEntretien);
setIndemnitesRepas(indemnitesRepas);
setSalaireNet(salaireNet);
}
// toString
@Override
public String toString() {
return "[salaire base=" + salaireBase + ",cotisations sociales=" + cotisationsSociales + ",indemnités d'entretien="
+ indemnitesEntretien + ",indemnités de repas=" + indemnitesRepas + ",salaire net="
+ salaireNet + "]";
}
// getters e setters
...
}
- linhas 8-12: os elementos do salário
18.6. O ficheiro de configuração do Spring
A integração das camadas [métier, dao, jpa] é assegurada pelo seguinte ficheiro de configuração do Spring:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.0.xsd">
<!-- camadas de aplicação -->
<!-- domínio de negócio -->
<bean id="metier" class="metier.Metier">
<property name="employeDao" ref="employeDao"/>
<property name="cotisationDao" ref="cotisationDao"/>
</bean>
<!-- DAO -->
<bean id="employeDao" class="dao.EmployeDao" />
<bean id="indemniteDao" class="dao.IndemniteDao" />
<bean id="cotisationDao" class="dao.CotisationDao" />
<!-- configuração JPA -->
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter">
<property name="databasePlatform" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
</bean>
</property>
<property name="loadTimeWeaver">
<bean class="org.springframework.instrument.classloading.InstrumentationLoadTimeWeaver" />
</property>
</bean>
<!-- a fonte de dados DBCP -->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="URL" value="jdbc:mysql://localhost:3306/dbpam_hibernate" />
<property name="username" value="root" />
<property name="password" value="" />
</bean>
<!-- o gestor de transações -->
<tx:annotation-driven transaction-manager="txManager" />
<bean id="txManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactory" />
</bean>
<!-- tradução de exceções -->
<bean class="org.springframework.dao.annotation.PersistenceExceptionTranslationPostProcessor" />
<!-- persistência -->
<bean class="org.springframework.orm.jpa.support.PersistenceAnnotationBeanPostProcessor" />
</beans>
Não tentaremos explicar esta configuração. É necessária para a instanciação e integração das camadas [métier, dao, jpa]. A nossa aplicação web, que se baseará nestas camadas, terá, portanto, de adotar esta configuração. Note-se que as linhas 32-37 configuram as características JDBC da base de dados. O leitor que pretenda mudar de base de dados deve alterar estas linhas.
Para mais informações sobre esta configuração, consulte o documento «Introdução ao Java EE 5», disponível no URL [http://tahe.developpez.com/java/javaee].