5. Relações entre tabelas
5.1. Chaves estrangeiras
Uma base de dados relacional é um conjunto de tabelas ligadas entre si por relações. Vejamos um exemplo inspirado na tabela [BIBLIO] anterior, cuja estrutura era a seguinte:
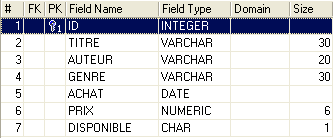
Um exemplo de conteúdo era o seguinte:
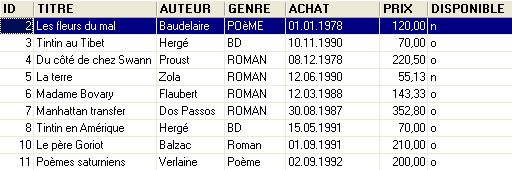
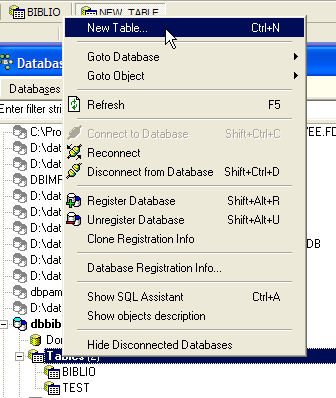
Podemos querer obter informações sobre os diferentes autores destas obras, por exemplo, os seus nom e prénom, a sua data de nascimento, o seu nationalité. Vamos criar uma tabela com esses dados. Clicamos com o botão direito do rato em [DBBIBLIO / Tables] e selecionamos a opção [New Table]:
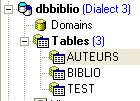
Vamos agora criar a seguinte tabela [AUTEURS]:
 | 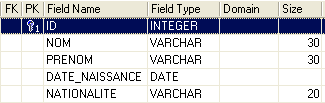 |
chave primária da tabela — serve para identificar uma linha de forma única | |
nome do autor | |
nome próprio do autor, caso exista | |
data de nascimento | |
país de origem |
O conteúdo da tabela [AUTEURS] poderia ser o seguinte:
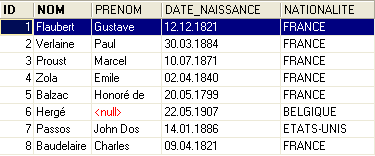
Voltemos à tabela [BIBLIO] e ao seu conteúdo:
Na rubrica [AUTEUR] da tabela, deixa de ser necessário indicar o nome do autor. É preferível indicar o número (id) que este possui na tabela [AUTEURS]. Criemos, portanto, uma nova tabela denominada [LIVRES]. Para a criar, vamos utilizar o script [biblio.sql] criado no parágrafo 3.14. Carregamos este script com a ferramenta [Script Executive, Ctrl-F12]:
Alteramos o script de criação da tabela BIBLIO para o adaptar ao da tabela LIVRES:
Apenas comentamos as alterações:
- linha 4: o campo [AUTEUR] da tabela passa a ser um número inteiro. Este número remete para um dos autores da tabela [AUTEURS] criada anteriormente.
- linhas 11-19: os nomes dos autores foram substituídos pelos respetivos números de autor.
- linha 29: o nome da restrição foi alterado. Anteriormente chamava-se [ UNQ1_BIBLIO ]. Passa agora a chamar-se [ UNQ1_LIVRES ]. Este nome pode ser qualquer um. No entanto, é preferível que tenha algum sentido. Neste caso, esse esforço não foi feito. As restrições nos diferentes campos e nas diferentes tabelas de uma base de dados devem ser diferenciadas por nomes distintos. Recorde-se que a restrição da linha 29 exige que um título seja único na tabela.
- linha 36: alteração do nome da restrição sobre a chave primária ID.
Vamos executar este script. Se for bem-sucedido, obtemos a seguinte nova tabela [LIVRES]:
 | 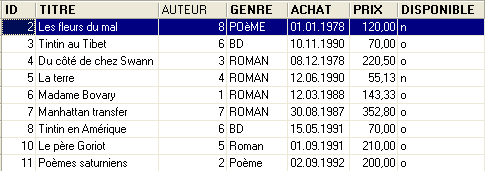 |
Podemos questionar-nos se, afinal, saímos a ganhar com esta alteração. Com efeito, a tabela [LIVRES] apresenta números de autores em vez dos seus nomes. Como existem milhares de autores, a ligação entre um livro e o seu autor parece difícil de estabelecer. Felizmente, a linguagem SQL está aqui para nos ajudar. Permite-nos consultar várias tabelas ao mesmo tempo. A título de exemplo, apresentamos a consulta SQL, que nos permite obter os títulos dos livros da biblioteca, associados às informações dos seus autores. Utilizemos o editor SQL (F12) para emitir o comando SQL seguinte:
SQL> select LIVRES.titre, AUTEURS.nom, AUTEURS.prenom,AUTEURS.date_naissance
FROM LIVRES inner join AUTEURS on LIVRES.AUTEUR=AUTEURS.ID
ORDER BY AUTEURS.nom asc
Ainda é cedo para explicar esta ordem SQL. Voltaremos a este assunto em breve. O resultado desta consulta é o seguinte:
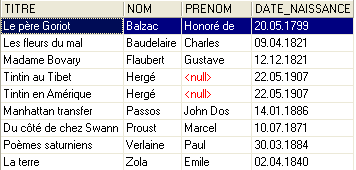
Cada livro foi associado corretamente ao seu autor e às informações que lhe dizem respeito.
Vamos resumir o que acabámos de fazer:
- temos duas tabelas que reúnem informações de natureza diferente:
- a tabela AUTEURS reúne informações sobre os autores
- a tabela LIVRES reúne informações sobre os livros adquiridos pela biblioteca
- estas tabelas estão interligadas. Um livro tem, necessariamente, um autor. Pode até ter vários. Este caso não foi aqui considerado. A coluna [AUTEUR] da tabela [LIVRES] faz referência a uma linha da tabela [AUTEURS]. A isto chama-se uma relação.
A relação que liga a tabela [LIVRES] à tabela [AUTEURS] é, na verdade, uma forma de restrição: uma linha da tabela [LIVRES] deve ter sempre um número de autor que exista na tabela [AUTEURS]. Se uma linha da tabela [LIVRES] tivesse um número de autor que não existisse na tabela [AUTEURS], estaríamos numa situação anómala em que não seria possível identificar o autor de um livro.
A tabela SGBD permite verificar se esta restrição é sempre cumprida. Para tal, vamos adicionar uma restrição à tabela [LIVRES]:
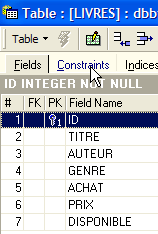 | 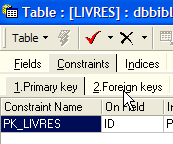 | 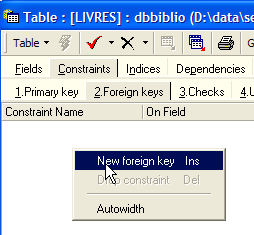 |
A ligação que une a rubrica [AUTEUR] da tabela [LIVRES] ao campo [ID] da tabela [AUTEURS] denomina-se «ligação de chave estrangeira». A coluna [AUTEUR] da tabela [LIVRES] é designada por «chave estrangeira» ou «foreign key» no assistente acima. Definir uma chave estrangeira significa que o valor de uma coluna [c1] de uma tabela [T1] deve existir na coluna [c2] da tabela [T2]. A coluna [c1] é designada como «chave estrangeira» da tabela T1 em relação à coluna [c2] da tabela [T2]. A coluna [c2] é frequentemente a chave primária da tabela [T2], mas isso não é obrigatório.
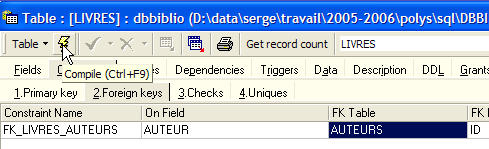
Definimos a chave estrangeira [AUTEUR] da tabela [LIVRES] no campo [ID] da tabela [AUTEURS] da seguinte forma:
 |
- nome da restrição: livre
- coluna «chave estrangeira», neste caso a coluna [AUTEUR] da tabela [LIVRES]
- tabela referenciada pela chave estrangeira. Neste caso, a coluna [AUTEUR] da tabela [LIVRES] deve ter um valor na coluna [ID] da tabela [AUTEURS]. É, portanto, a tabela [AUTEURS] que é referenciada.
- Coluna referenciada pela chave estrangeira. Neste caso, a coluna [ID] da tabela [AUTEURS].
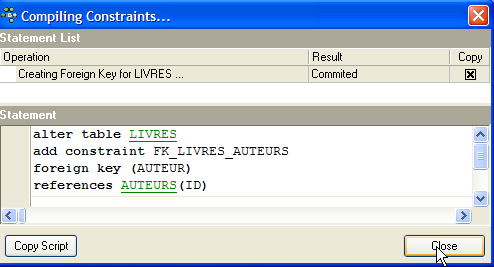
Validamos esta restrição:
Se tudo correr bem, é aceite:
Qual é a consequência desta nova restrição de chave estrangeira? Com o editor SQL (F12), vamos tentar inserir uma linha na tabela LIVRES com um número de autor inexistente:
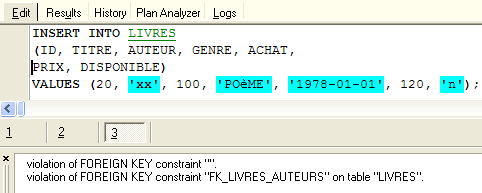
A operação [INSERT] acima tentou inserir um livro com um número de autor (100) inexistente. A execução da consulta falhou. A mensagem de erro associada indica que ocorreu uma violação da restrição de chave estrangeira «FK_LIVRES_AUTEURS». Trata-se da restrição que acabámos de definir.
5.2. Operações de junção entre duas tabelas
Ainda na base de dados [DBBIBLIO] (ou noutra base de dados, não importa), vamos criar duas tabelas de teste chamadas TA e TB, definidas da seguinte forma:
Tabela TA
- ID: chave primária da tabela TA - DATA: um dado qualquer | 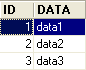 |
Tabela TB
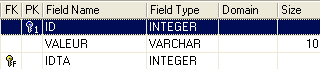 - ID: chave primária da tabela TB - IDTA: chave estrangeira da tabela TB que faz referência à coluna ID da tabela TA. Assim, um valor da coluna IDTA da tabela TA deve existir na coluna ID da tabela TA - VALEUR: qualquer valor | 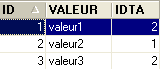 |
No editor SQL (F12), vamos emitir ordens SQL que utilizam simultaneamente as duas tabelas TA e TB.
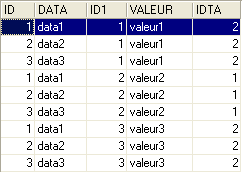
A ordem SQL envolve, a seguir à palavra-chave FROM, as duas tabelas TA e TB. A operação FROM TA, TB irá provocar a criação temporária de uma nova tabela na qual cada linha da tabela TA será associada a cada uma das linhas da tabela TB. Assim, se a tabela TA tiver NA linhas e a tabela TB tiver NB linhas, a tabela resultante terá NA × NB linhas. É isso que mostra a captura de ecrã acima. Além disso, cada linha contém as colunas das duas tabelas. As colunas coli especificadas na ordem [SELECT col1, col2, ... FROM ...] indicam aquelas que devem ser mantidas. Aqui, a palavra-chave * indica que são solicitadas todas as colunas da tabela resultante. Por vezes, diz-se que a tabela resultante da ordem anterior SQL é o produto cartesiano das tabelas TA e TB.
No exemplo acima, cada linha da tabela TA foi associada a cada linha da tabela TB. Em geral, pretende-se associar a uma linha da tabela TA as linhas da tabela TB que têm uma relação com ela. Esta relação assume frequentemente a forma de uma restrição de chave estrangeira. É o que acontece neste caso. A uma linha da tabela TA, podem ser associadas as linhas da tabela TB que satisfazem a relação TB.IDTA=TA.ID. Existem várias formas de solicitar isto:
A ordem SQL é análoga à anterior, mas apresenta duas diferenças:
- as linhas resultantes do produto cartesiano TA x TB são filtradas por uma cláusula WHERE que associa a uma linha da tabela TA, as únicas linhas da tabela TB que satisfazem a relação TB.IDTA=TA.ID
- só são solicitadas determinadas colunas com a sintaxe [T.col], em que T é o nome de uma tabela e col o nome de uma coluna dessa tabela. Esta sintaxe permite eliminar a ambiguidade que poderia surgir se duas tabelas tivessem colunas com o mesmo nome. Quando essa ambiguidade não existe, pode-se utilizar a sintaxe [col] sem especificar a tabela a que essa coluna pertence.
O resultado obtido é o seguinte:
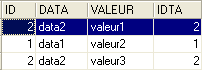
O mesmo resultado pode ser obtido com a seguinte ordem SQL:
Do termo [inner join] deriva o nome «junção interna», atribuído a este tipo de operações entre duas tabelas. Veremos que existe também uma «junção externa». Numa junção interna, a ordem das tabelas na consulta não tem qualquer impacto no resultado: FROM TA inner join TB é equivalente a FROM TB inner join TA.
A instrução anterior SQL inclui na tabela resultante apenas as linhas da tabela TA referenciadas por, pelo menos, uma linha da tabela TB. Assim, a linha de TA [3, data3] não aparece no resultado, pois não é referenciada por uma linha de TB. Pode ser que se pretenda obter todas as linhas da tabela TA, independentemente de estarem ou não referenciadas por uma linha da tabela TB. Nesse caso, utiliza-se uma junção externa entre as duas tabelas:
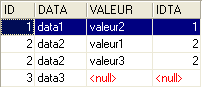
Temos aqui uma junção externa à esquerda («left outer join»). Para compreender o termo «FROM TA left outer join TB», é preciso imaginar uma junção com a tabela TA à esquerda e a tabela TB à direita. Todas as linhas da tabela da esquerda aparecem no resultado de uma junção externa à esquerda, mesmo aquelas para as quais a relação de junção não é verificada. Esta relação de junção não é necessariamente uma restrição de chave estrangeira, embora seja, no entanto, o caso mais comum.
Na seguinte ordem:
é a tabela TB que está à «esquerda» na junção externa. Assim, todas as linhas de TB estarão presentes no resultado:
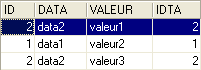
Ao contrário da junção interna, a ordem das tabelas é, portanto, importante. Existem também junções externas direitas:
- FROM TA left outer join TB é equivalente a FROM TB right outer join TA: a tabela TA está à esquerda
- FROM TB com uma junção externa à esquerda com TA é equivalente a FROM TA com uma junção externa à direita com TB: a tabela TB está à esquerda
Agora que já conhecemos os fundamentos da exploração simultânea de várias tabelas, podemos abordar operações de consulta mais complexas nas bases de dados.