2. Noções básicas de programação web
O objetivo principal deste capítulo é dar a conhecer os grandes princípios da programação Web, que são independentes da tecnologia específica utilizada para os implementar. Apresenta numerosos exemplos que se recomenda testar, a fim de «assimilar» gradualmente a filosofia do desenvolvimento Web. O leitor que já possua estes conhecimentos pode passar diretamente para o capítulo 3.
Os componentes de uma aplicação Web são os seguintes:
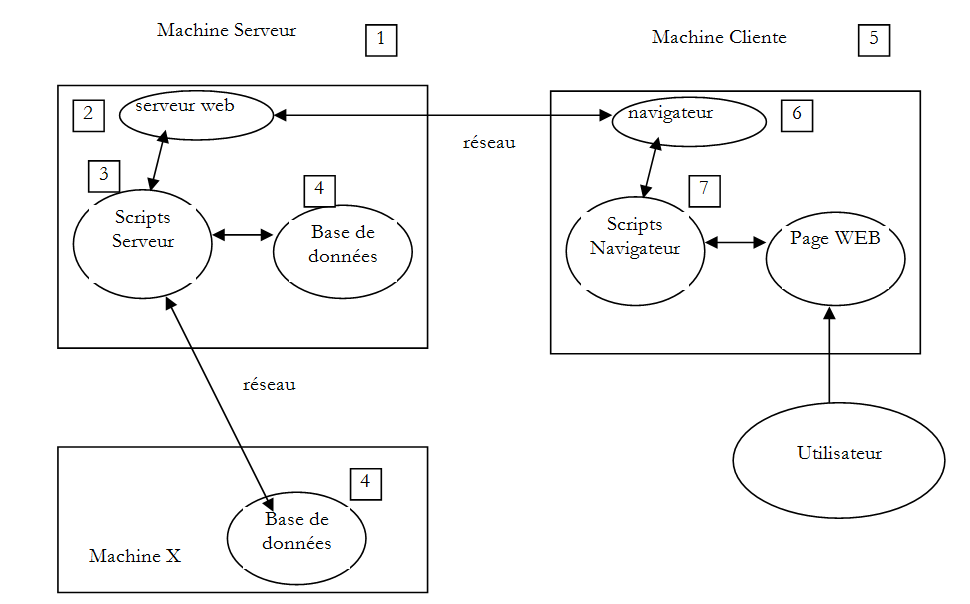
Número | Função | Exemplos comuns |
1 | OS Servidor | Unix, Linux, Windows |
2 | Servidor Web | Apache (Unix, Linux, Windows) IIS (Windows + plataforma .NET) Node.js (Unix, Linux, Windows) |
3 | Códigos executados no lado do servidor. Podem ser executados por módulos do servidor ou por programas externos ao servidor (CGI). | JAVASCRIPT (Node.js) PHP (Apache, IIS) JAVA (Tomcat, Websphere, JBoss, Weblogic, ...) C#, VB.NET (IIS) |
4 | Base de dados — Esta pode estar na mesma máquina que o programa que a utiliza ou noutra máquina através da Internet. | Oracle (Linux, Windows) MySQL (Linux, Windows) Postgres (Linux, Windows) SQL Server (Windows) |
5 | OS Cliente | Unix, Linux, Windows |
6 | Navegador da Web | Chrome, Internet Explorer, Firefox, Opera, Safari, ... |
7 | Scripts executados no lado do cliente, no navegador. Estes scripts não têm qualquer acesso aos discos do computador do cliente. | JavaScript (qualquer navegador) |
2.1. A troca de dados numa aplicação Web com formulário
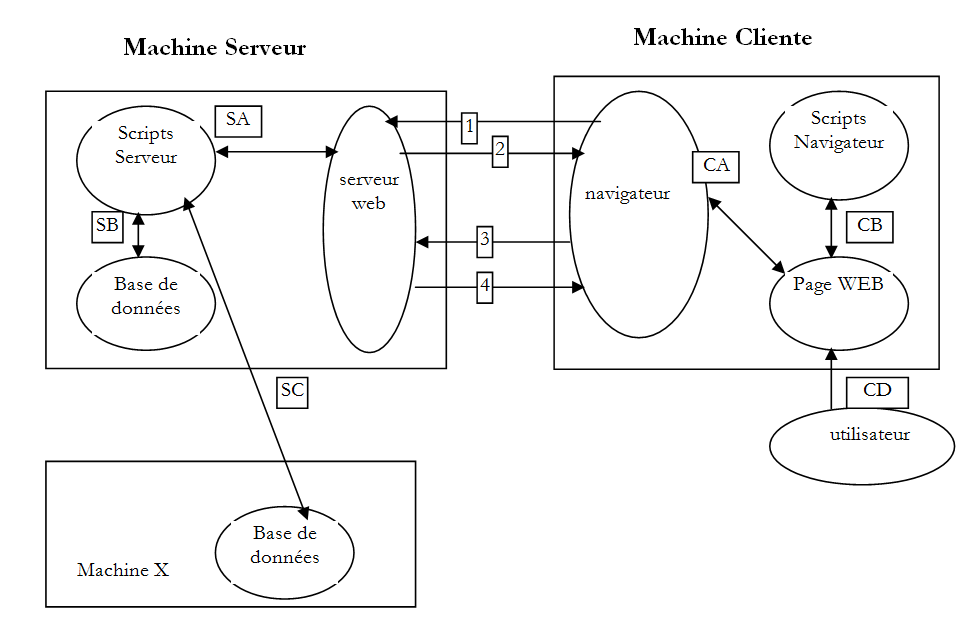
Número | Função |
1 | O navegador solicita um URL pela primeira vez: (http://machine/url). Não é passado nenhum parâmetro. |
2 | O servidor Web envia-lhe a página Web correspondente a este URL. Esta pode ser estática ou gerada dinamicamente por um script do servidor (SA), que pode ter utilizado o conteúdo de bases de dados (SB, SC). Neste caso, o script detetará que o URL foi solicitado sem a passagem de parâmetros e gerará a página Web inicial. O navegador recebe a página e exibe-a (CA). Os scripts do lado do navegador (CB) puderam alterar a página inicial enviada pelo servidor. Posteriormente, através de interações entre o utilizador (CD) e os scripts (CB), a página Web será alterada. Em particular, os formulários serão preenchidos. |
3 | O utilizador valida os dados do formulário, que devem então ser enviados para o servidor Web. O navegador volta a solicitar a página inicial URL ou outra, consoante o caso, e transmite simultaneamente ao servidor os valores do formulário. Para tal, pode utilizar dois métodos denominados GET e POST. Ao receber o pedido do cliente, o servidor executa o script (SA) associado ao URL solicitado, script esse que irá detetar os parâmetros e processá-los. |
4 | O servidor fornece a página Web gerada programaticamente (SA, SB, SC). Esta etapa é idêntica à etapa 2 anterior. As trocas de dados realizam-se agora de acordo com as etapas 2 e 3. |
2.2. Páginas Web estáticas, Páginas Web dinâmicas
Uma página estática é representada por um ficheiro HTML. Uma página dinâmica é uma página HTML gerada «em tempo real» pelo servidor Web.
2.2.1. Página estática HTML (Linguagem de marcação HyperText)
Vamos criar um primeiro projeto Spring MVC [1-2]:
 |
- no [1-2], criamos um novo projeto baseado no Spring Boot [http://projects.spring.io/spring-boot/];
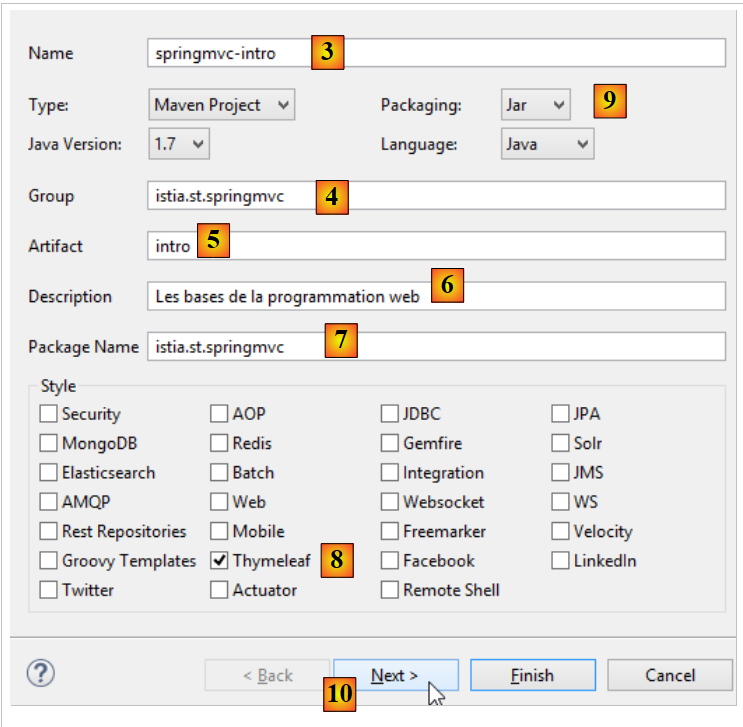 |
- as informações [3-7] destinam-se à configuração Maven do projeto;
- em [3], o nome do projeto Maven;
- em [4], o grupo Maven no qual será colocado o resultado da compilação do projeto;
- em [5], o nome atribuído ao produto da compilação;
- em [6], uma descrição do projeto;
- em [7], o pacote no qual será colocada a classe executável do projeto;
- em [8], a natureza do projeto. Trata-se de um projeto web com vistas Thymeleaf. Vemos aqui todas as dependências Maven prontas a utilizar oferecidas pelo projeto Spring Boot;
- em [9], indica-se que o produto resultante da compilação Maven será empacotado num arquivo jar e não num war. O projeto irá, então, utilizar um servidor Tomcat incorporado que se encontrará nas suas dependências;
- em [10], avançamos para a próxima etapa do assistente;
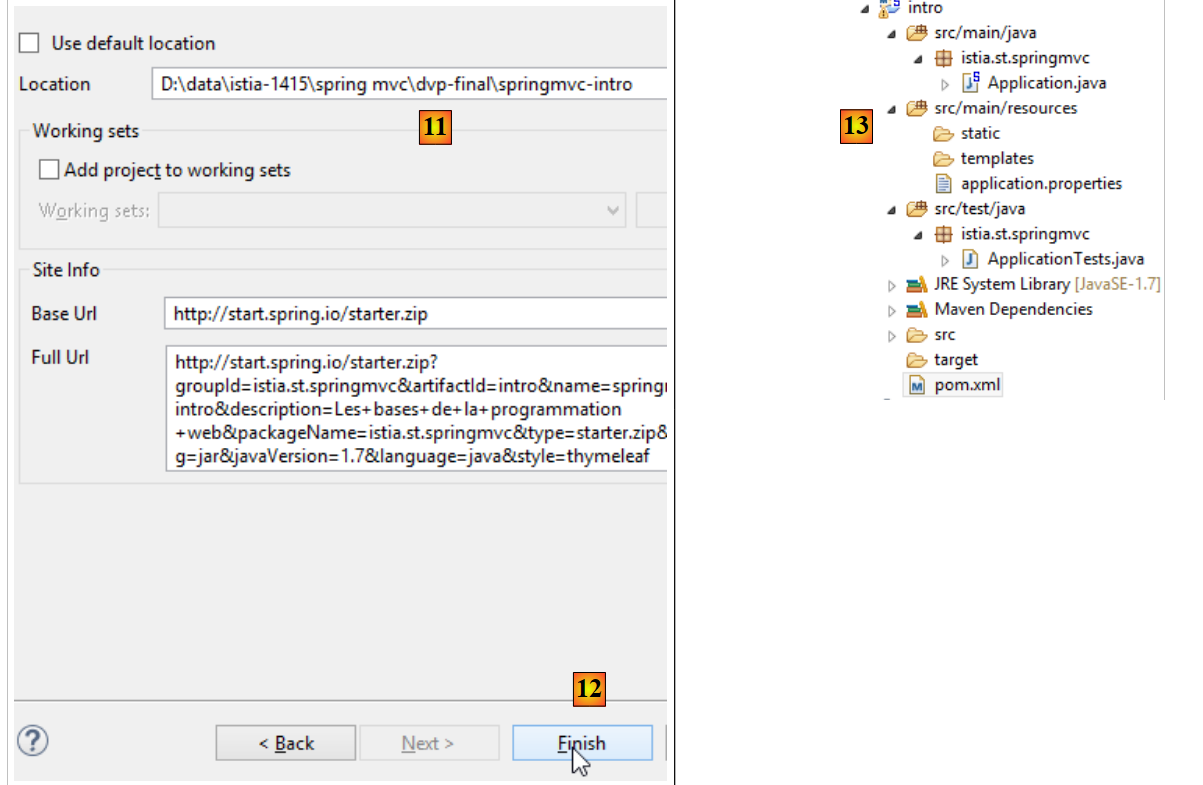 |
- em [11], indica-se a pasta do projeto;
- em [12], conclui-se o assistente;
- em [13], o projeto gerado.
Vamos analisar o ficheiro [pom.xml] gerado:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>istia.st.springmvc</groupId>
<artifactId>intro</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>springmvc-intro</name>
<description>Les bases de la programmation web</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.1.9.RELEASE</version>
<relativePath /> <!-- pesquisa do pai no repositório -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<start-class>istia.st.springmvc.Application</start-class>
<java.version>1.7</java.version>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
Este ficheiro contém todas as informações fornecidas no assistente. Nas linhas 26 a 30, encontramos uma dependência que não conhecíamos. Esta permite a integração dos testes unitários JUnit com o Spring.
Comecemos por criar uma página estática HTML neste projeto. Por predefinição, deve ser colocada na pasta [src / main / resources / static]:
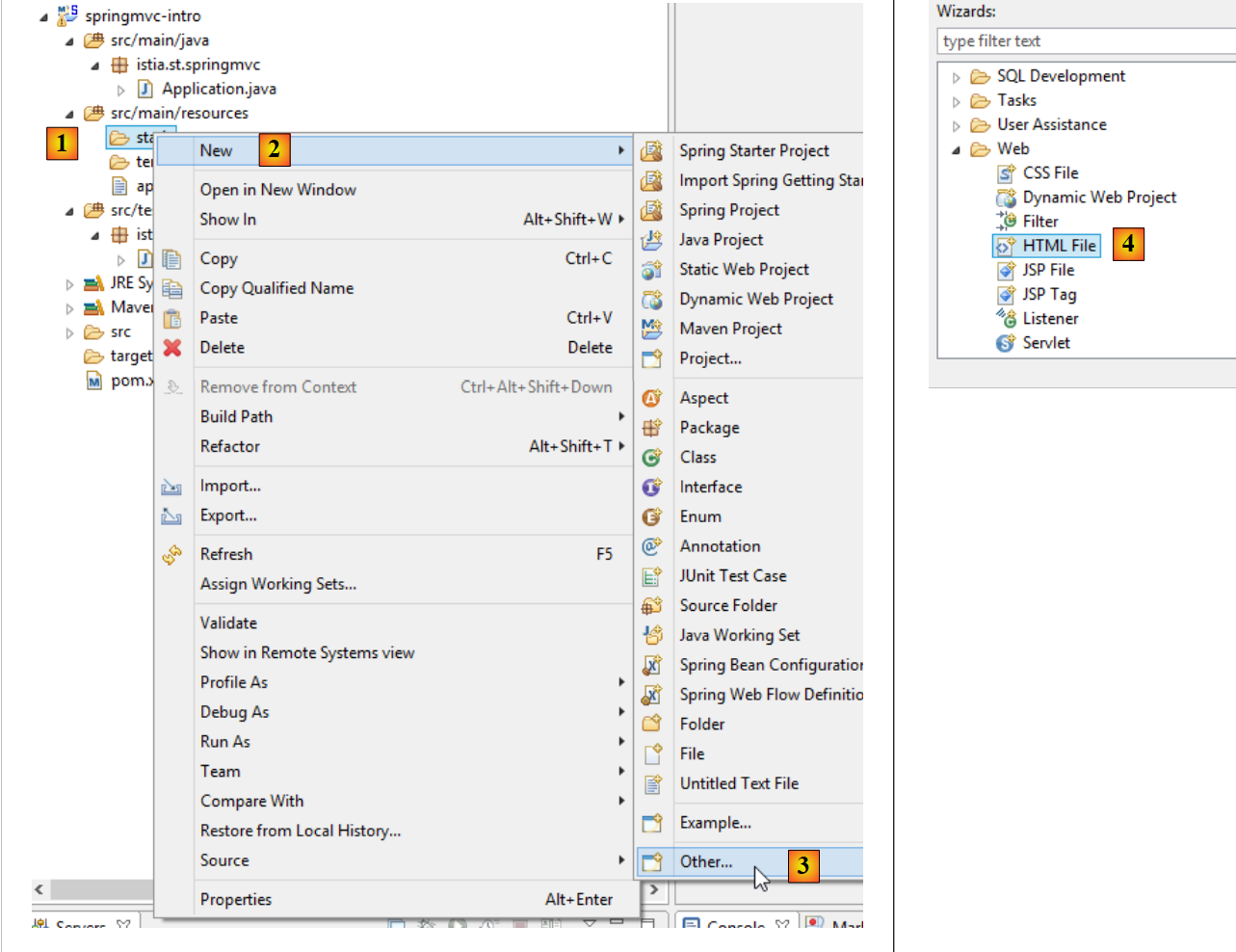 |
- em [1-4], criamos um ficheiro HTML na pasta [static];
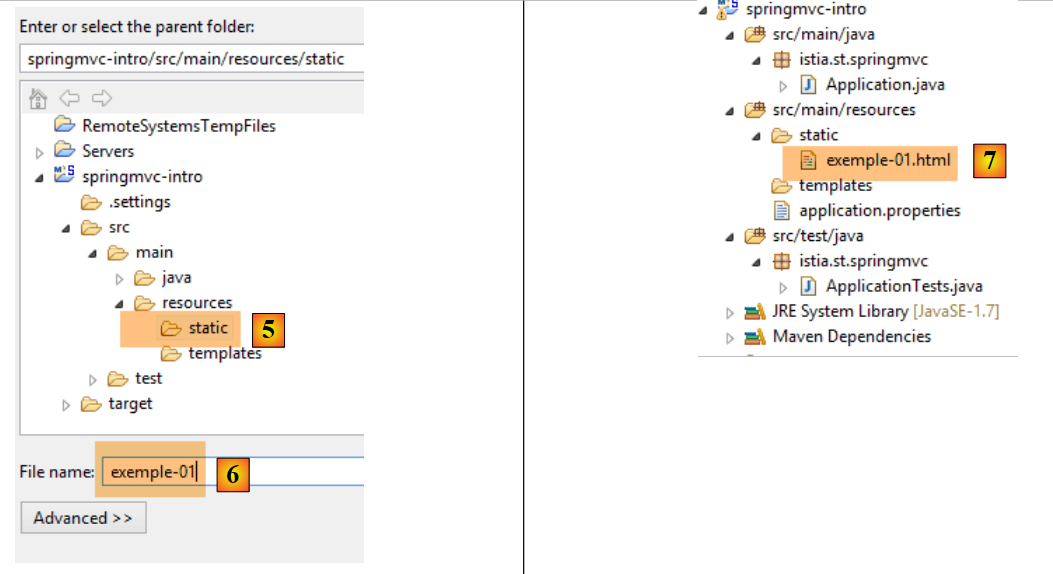 |
- em [6], atribuir um nome à página;
- em [7], a página foi adicionada.
O conteúdo da página criada é o seguinte:
<!DOCTYPE html>
<html>
<head>
<meta charset="ISO-8859-1">
<title>Insert title here</title>
</head>
<body>
</body>
</html>
- linhas 2-10: o código é delimitado pela baliza raiz <html>;
- linhas 3-6: a baliza <head> delimita o que se denomina cabeçalho da página;
- linhas 7-9: a baliza <body> delimita o que se denomina o corpo da página.
Vamos alterar este código da seguinte forma:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>essai 1 : une page statique</title>
</head>
<body>
<h1>Une page statique...</h1>
</body>
</html>
- linha 5: define o título da página – será exibido como título da janela do navegador que apresenta a página;
- linha 8: um texto em letras grandes (<h1>).
Vamos executar a aplicação [1-3]:
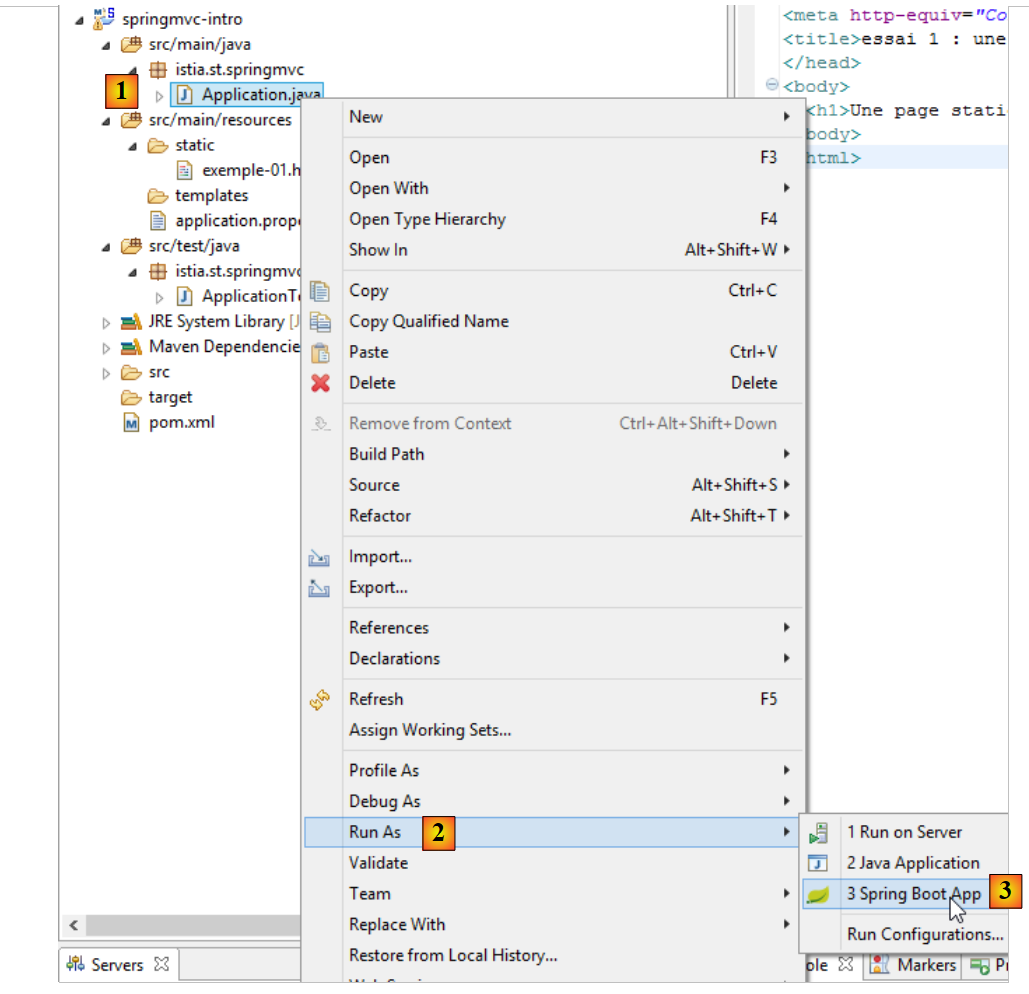 |
depois, num navegador, acedamos à página URL [http://localhost:8080/exemple-01.html]:
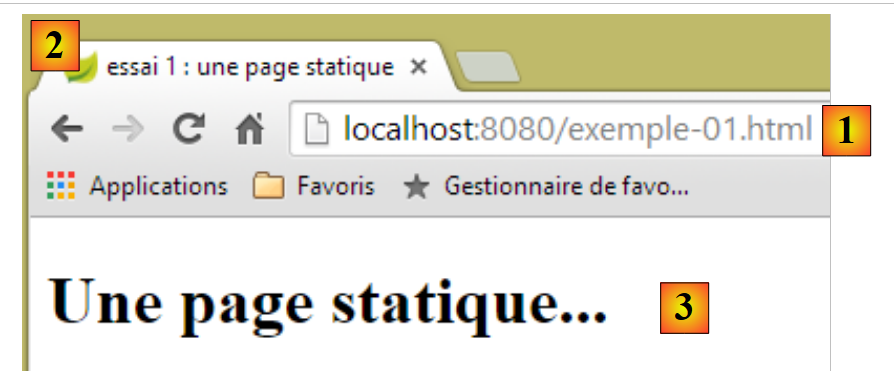 |
- no [1], o URL da página visualizada;
- em [2], o título da janela – fornecido pela baliza <title> da página;
- em [3], o corpo da página – foi fornecido pela baliza <h1>.
Vejamos o código [4-5], recebido pelo navegador:
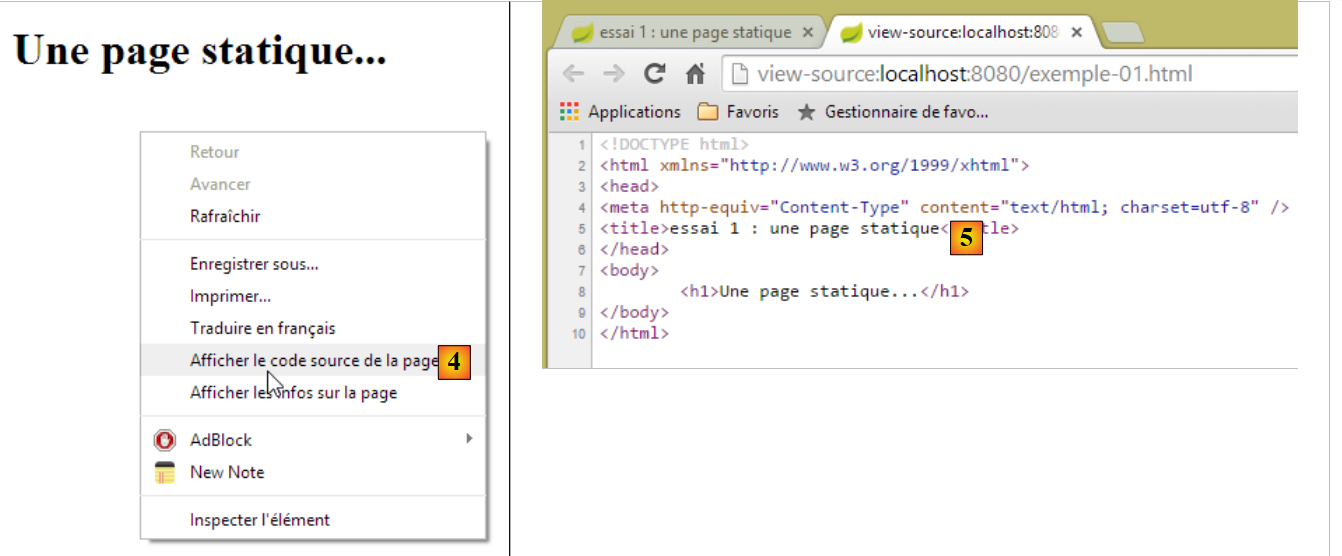 |
- em [5], o navegador recebeu a página HTML que tínhamos criado. Interpretou-a e transformou-a numa apresentação gráfica.
2.2.2. Uma página Thymeleaf dinâmica
Vamos agora criar uma página Thymeleaf. Trata-se de uma página HTML clássica com tags enriquecidas com atributos [Thymeleaf] e [http://www.thymeleaf.org/]. Seguimos um procedimento semelhante ao da criação da página HTML, mas, desta vez, é na pasta [templates] que devemos colocar a nova página HTML:
 |
A página [exemple-02.html] terá o seguinte aspeto:
<!DOCTYPE HTML>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>spring mvc intro</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
</head>
<body>
<p th:text="'Il est ' + ${heure}">Voici l'heure</p>
</body>
</html>
- linha 8: a baliza <p> é uma baliza HTML que introduz um parágrafo na página apresentada. [th:text] é um atributo [Thymeleaf] que tem duas funções diferentes, dependendo de [Thymeleaf] estar ou não em funcionamento:
- se o [Thymeleaf] não interpretar a página HTML, o atributo [th:text] será ignorado, uma vez que é desconhecido no HTML. O texto apresentado será, então, [Voici l'heure],
- se o [Thymeleaf] interpretar a página HTML, o atributo [th:text] será avaliado e o seu valor substituirá o texto [Voici l'heure]. O seu valor será do tipo [Il est 17:11:06];
Vamos ver isto em ação. Duplicamos a página [templates / exemple-02.html] na pasta [static]. As páginas HTML colocadas nesta pasta não são interpretadas por [Thymeleaf]:
 |  |  |
Executamos a aplicação como já fizemos várias vezes e, em seguida, acedemos através de um navegador aos ficheiros URL e [http://localhost:8080/exemple-02.html]:
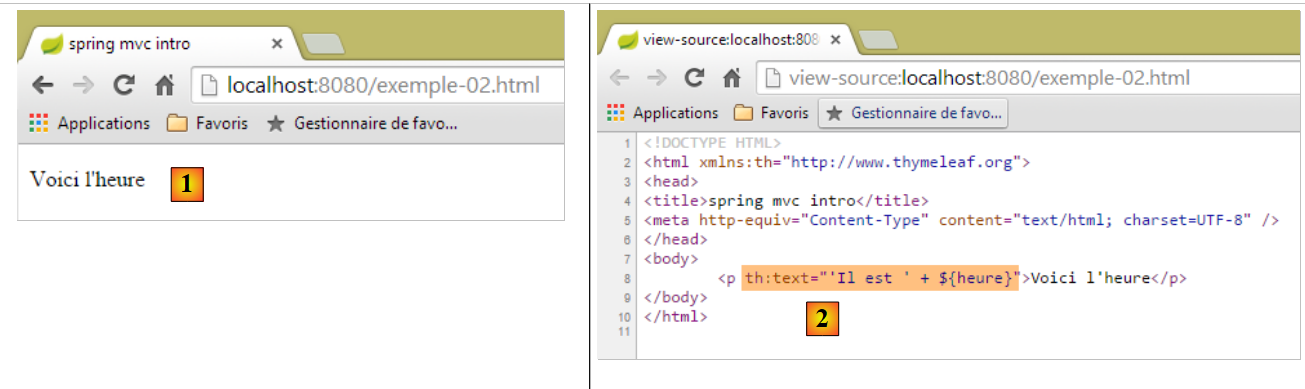 |
Verificamos em [1] que o atributo [th:text] não foi interpretado, mas também não provocou qualquer erro. O código-fonte da página recebida em [2] mostra que o navegador recebeu corretamente a página completa.
Voltemos à página [exemple-02.html] da pasta [templates]:
 |
As páginas HTML colocadas na pasta [templates] são interpretadas por [Thymeleaf]. Voltemos ao código da página:
<!DOCTYPE HTML>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>spring mvc intro</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
</head>
<body>
<p th:text="'Il est ' + ${heure}">Voici l'heure</p>
</body>
</html>
- linha 7: o [Thymeleaf] irá interpretar o atributo [th:text] e substituirá o [Voici l'heure] pelo valor da expressão:
Esta expressão utiliza a variável [${heure}], em que [heure] pertence ao modelo da vista [exemple-02.html]. Por isso, temos de criar esse modelo. Para tal, vamos seguir o exemplo analisado no parágrafo 1.6. Alteramos o projeto da seguinte forma:
 |
Em [1], adicionamos o seguinte controlador:
package istia.st.springmvc;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.RequestMapping;
@Controller
public class MyController {
@RequestMapping("/")
public String heure(Model model) {
// formato da hora
SimpleDateFormat formater = new SimpleDateFormat("HH:MM:ss");
// hora atual
String heure = formater.format(new Date());
// inserimos a hora no modelo da vista
model.addAttribute("heure", heure);
// exibir a vista [exemple-02.html]
return "exemple-02";
}
}
- linhas 13-14: o método [heure] processa o URL e o [/];
- linha 14: o [Model model] é um modelo vazio. A ação [heure] deve inserir nele os atributos que pretende ver no modelo. Sabe-se que a vista [exemple-02.html] espera um atributo denominado [heure];
- linhas 19-22: concretizam o que acabámos de explicar. A vista [exemple-02.html] será apresentada (linha 22) com, no seu modelo, um atributo denominado [heure] (linha 20);
- linha 16: cria-se um formatador de data. O formato [HH:MM:ss] utilizado é um formato [heures:minutes:secondes] em que as horas se situam no intervalo [0-24];
- linha 18: com este formatador, formata-se a data de hoje;
- linha 20: a hora obtida é associada a um atributo denominado [heure];
Lançamos a aplicação e solicitamos o URL [/]:
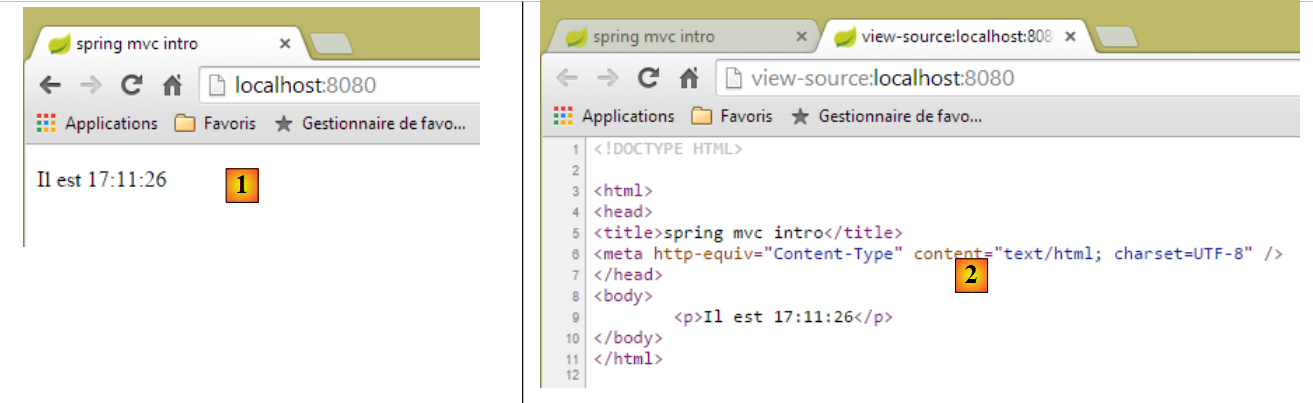 |
- em [1] a página obtida e em [2] o seu conteúdo HTML. É possível constatar que o texto inicial [Voici l'heure] desapareceu completamente;
Se agora atualizarmos a página [1] (F5), obtemos uma apresentação diferente (nova hora), enquanto que o URL não se altera. É este o aspeto dinâmico da página: o seu conteúdo pode alterar-se ao longo do tempo.
Do exposto, fica claro que as páginas dinâmicas e estáticas têm uma natureza fundamentalmente diferente.
2.2.3. Configuração da aplicação Spring Boot
Voltemos à arquitetura do projeto Eclipse:
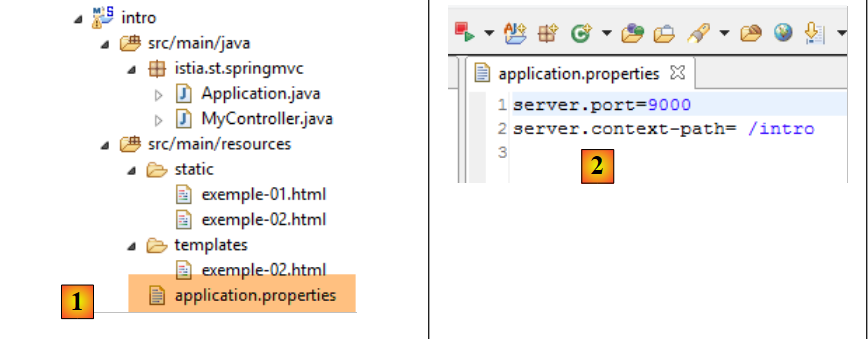 |
O ficheiro [application.properties] permite configurar a aplicação Spring Boot. Por enquanto, este ficheiro está vazio. Podemos utilizá-lo para configurar a aplicação de várias formas, descritas nos ficheiros URL e [http://docs.spring.io/spring-boot/docs/current/reference/html/common-application-properties.html]. Vamos utilizar o ficheiro [application.properties] de acordo com o [2]:
- linha 1: define a porta de serviço da aplicação web;
- linha 2: define o contexto da aplicação web;
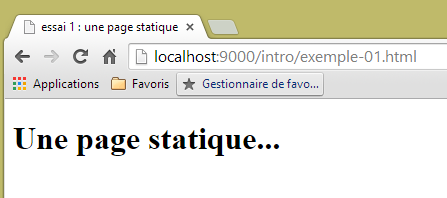
Com esta configuração, a página estática [exemple-01.html] será obtida com o URL e o [http://localhost:9000/intro/exemple-01.html]:
 |
2.3. Scripts do lado do navegador
Uma página HTML pode conter scripts que serão executados pelo navegador. A principal linguagem de script do lado do navegador é, atualmente (janeiro de 2015), o JavaScript. Foram criadas centenas de bibliotecas com esta linguagem para facilitar o trabalho do programador.
Vamos criar uma nova página [exemple-03.html] na pasta [static] do projeto existente:
 |
Vamos editar o ficheiro [exemple-03.html] com o seguinte conteúdo:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>exemple Javascript</title>
<script type="text/javascript">
function réagir() {
alert("Vous avez cliqué sur le bouton !");
}
</script>
</head>
<body>
<input type="button" value="Cliquez-moi" onclick="réagir()" />
</body>
</html>
- linha 13: define um botão (atributo type) com o texto «Clique aqui» (atributo value). Ao clicar nele, a função JavaScript [réagir] é executada (atributo onclick);
- linhas 6-10: um script JavaScript;
- linhas 7-9: a função [réagir];
- linha 8: exibe uma caixa de diálogo com a mensagem [Vous avez cliqué sur le bouton].
Vamos visualizar a página num navegador:
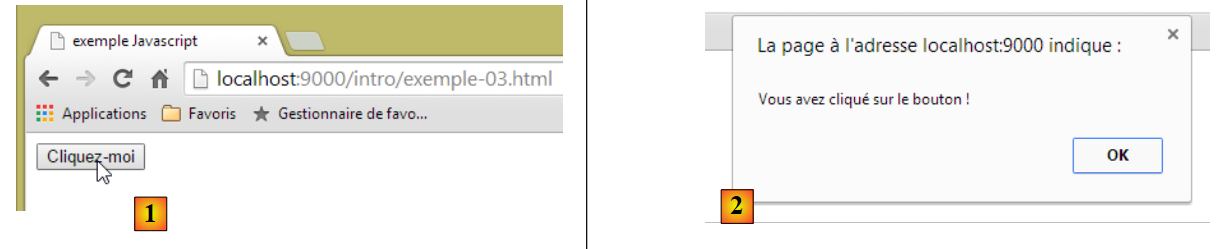 |
- em [1], a página apresentada;
- em [2], a caixa de diálogo que aparece quando se clica no botão.
Ao clicar no botão, não há troca de dados com o servidor. O código JavaScript é executado pelo navegador.
Com as inúmeras bibliotecas JavaScript disponíveis, é agora possível incorporar verdadeiras aplicações no navegador. Assim, tende-se a adotar as seguintes arquiteturas:
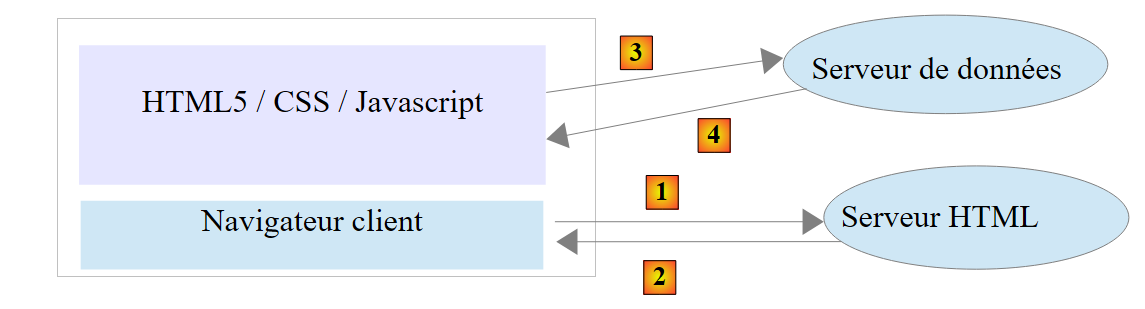 |
- 1-2: o servidor HTML é um servidor de páginas estáticas HTML5 / CSS / JavaScript;
- 3-4: as páginas HTML5 / CSS / Javascript geradas interagem diretamente com o servidor de dados. Este fornece apenas dados sem formatação HTML. É o JavaScript que as insere nas páginas HTML já presentes no navegador.
Nesta arquitetura, o código JavaScript pode tornar-se pesado. Por isso, procura-se estruturá-lo em camadas, tal como se faz com o código do lado do servidor:
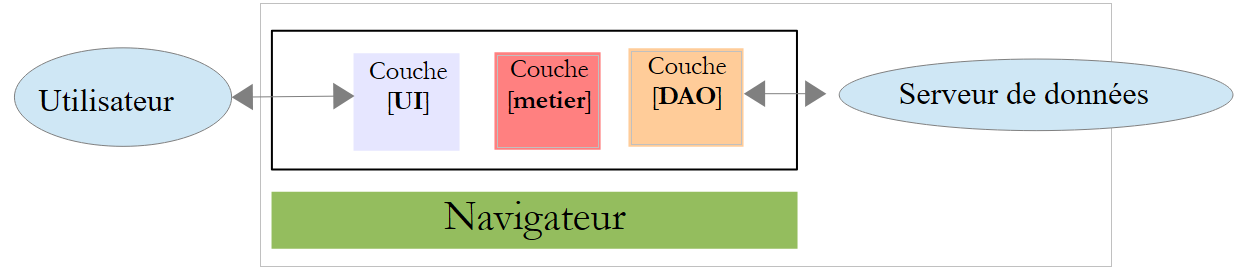 |
- a camada [UI] é a que interage com o utilizador;
- a camada [DAO] interage com o servidor de dados;
- a camada [métier] reúne os procedimentos de negócio que não interagem nem com o utilizador, nem com o servidor de dados. Esta camada pode não existir.
2.4. As interações cliente-servidor
Voltemos ao nosso esquema inicial, que ilustrava os intervenientes de uma aplicação Web:
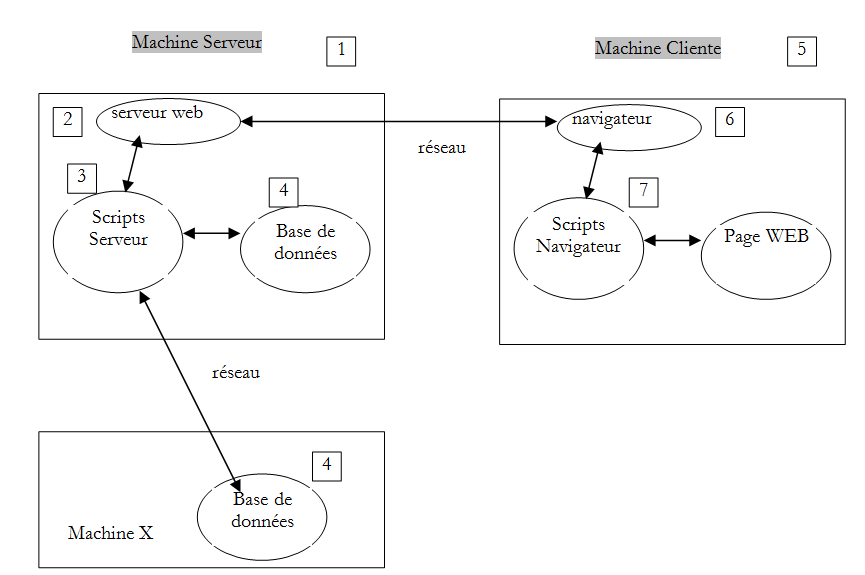
Aqui, estamos interessados nas trocas entre o computador cliente e o computador servidor. Estas ocorrem através de uma rede e é importante recordar a estrutura geral das trocas entre dois computadores remotos.
2.4.1. O modelo OSI
O modelo de rede aberta denominado OSI (Open Systems Interconnection Reference Model), definido pela ISO (Organização Internacional de Normalização), descreve uma rede ideal onde a comunicação entre máquinas pode ser representada por um modelo de sete camadas:
 |
Cada camada recebe serviços da camada inferior e fornece os seus à camada superior. Suponhamos que duas aplicações localizadas em máquinas A e B diferentes pretendem comunicar: fazem-no ao nível da camada Application. Não precisam de conhecer todos os detalhes do funcionamento da rede: cada aplicação entrega a informação que pretende transmitir à camada inferior: a camada Présentation. A aplicação só precisa, portanto, de conhecer as regras de interface com a camada Présentation. Assim que a informação chega à camada Présentation, é encaminhada, de acordo com outras regras, para a camada Session e assim sucessivamente, até que a informação chegue ao suporte físico e seja transmitida fisicamente para a máquina de destino. Aí, será submetida ao processo inverso ao que sofreu na máquina remetente.
Em cada camada, o processo remetente encarregado de enviar a informação transmite-a a um processo recetor na outra máquina, pertencente à mesma camada que ele. Faz-o de acordo com determinadas regras a que se chama protocolo da camada. Temos, portanto, o seguinte esquema de comunicação final:
 |
O papel das diferentes camadas é o seguinte:
Física | Assegura a transmissão de bits num suporte físico. Nesta camada encontram-se equipamentos terminais de processamento de dados (E.T.T.D.), tais como terminais ou computadores, bem como equipamentos de terminação de circuitos de dados (E.T.C.D.), tais como moduladores/demoduladores, multiplexadores e concentradores. Os pontos de interesse a este nível são:
|
Ligação de dados | Oculta as particularidades físicas da camada Física. Deteta e corrige os erros de transmissão. |
Rede | Gere o percurso que as informações enviadas pela rede devem seguir. A isto chama-se routage: determinar o percurso que uma informação deve seguir para chegar ao seu destinatário. |
Transporte | Permite a comunicação entre duas aplicações, enquanto as camadas anteriores apenas permitiam a comunicação entre máquinas. Um serviço prestado por esta camada pode ser o multiplexamento: a camada de transporte pode utilizar uma mesma ligação de rede (de máquina para máquina) para transmitir informações pertencentes a várias aplicações. |
Sessão | Nesta camada, encontramos serviços que permitem a uma aplicação abrir e manter uma sessão de trabalho numa máquina remota. |
Apresentação | Tem como objetivo uniformizar a representação dos dados nas diferentes máquinas. Assim, os dados provenientes de uma máquina A serão «formatos» pela camada Présentation da máquina A, de acordo com um formato padrão, antes de serem enviados pela rede. Ao chegarem à camada Présentation da máquina destinatária B, que as reconhecerá graças ao seu formato padrão, serão reformatadas de outra forma para que a aplicação da máquina B as reconheça. |
Aplicação | Nesta camada, encontram-se as aplicações geralmente mais próximas do utilizador, tais como o correio eletrónico ou a transferência de ficheiros. |
2.4.2. O modelo TCP/IP
O modelo OSI é um modelo ideal. O conjunto de protocolos TCP/IP aproxima-se deste modelo da seguinte forma:
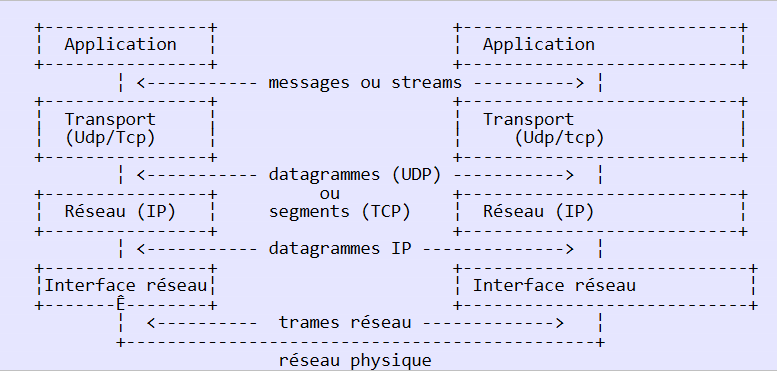 |
- a interface de rede (a placa de rede do computador) assegura as funções das camadas 1 e 2 do modelo OSI
- a camada IP (Protocolo de Internet) desempenha as funções da camada 3 (rede)
- A camada TCP (Protocolo de Controlo de Transferência) ou UDP (Protocolo de Datagrama do Utilizador) assegura as funções da camada 4 (transporte). O protocolo TCP garante que os pacotes de dados trocados entre os computadores cheguem corretamente ao destino. Caso contrário, reenvia os pacotes que se perderam. O protocolo UDP não desempenha essa função, cabendo ao programador de aplicações fazê-lo. É por isso que, na Internet — que não é uma rede 100% fiável —, o protocolo TCP é o mais utilizado. Fala-se, então, de rede TCP-IP.
- A camada de Aplicação abrange as funções dos níveis 5 a 7 do modelo OSI.
As aplicações Web encontram-se na camada Application e baseiam-se, portanto, nos protocolos TCP-IP. As camadas Application das máquinas cliente e servidor trocam mensagens que são confiadas às camadas 1 a 4 do modelo para serem encaminhadas para o destino. Para se compreenderem, as camadas de aplicação de ambas as máquinas têm de «falar» a mesma linguagem ou protocolo. O protocolo das aplicações Web chama-se HTTP (HyperText Transfer Protocol). Trata-se de um protocolo de tipo texto, c.a.d, através do qual as máquinas trocam linhas de texto na rede para se compreenderem. Estas trocas são padronizadas, ou seja, o cliente dispõe de um determinado número de mensagens para indicar exatamente o que pretende ao servidor e este último dispõe igualmente de um determinado número de mensagens para dar a sua resposta ao cliente. Esta troca de mensagens tem a seguinte forma:
Cliente --> Servidor
Quando o cliente faz o seu pedido ao servidor Web, envia
- linhas de texto no formato HTTP para indicar o que pretende;
- uma linha em branco;
- opcionalmente, um documento.
Servidor --> Cliente
Quando o servidor responde ao cliente, envia
- linhas de texto no formato HTTP para indicar o que está a enviar;
- uma linha em branco;
- opcionalmente, um documento.
As trocas têm, portanto, o mesmo formato em ambos os sentidos. Em ambos os casos, pode haver o envio de um documento, embora seja raro um cliente enviar um documento ao servidor. Mas o protocolo HTTP prevê essa possibilidade. É isso que permite, por exemplo, que os assinantes de um fornecedor de acesso descarreguem diversos documentos para o seu site pessoal alojado nesse fornecedor de acesso. Os documentos trocados podem ser quaisquer. Tomemos como exemplo um navegador que solicita uma página Web contendo imagens:
- o navegador liga-se ao servidor Web e solicita a página que pretende. Os recursos solicitados são identificados de forma única por meio de URL (Uniform Resource Locator). O navegador envia apenas cabeçalhos HTTP e nenhum documento.
- O servidor responde-lhe. Em primeiro lugar, envia cabeçalhos HTTP indicando o tipo de resposta que está a enviar. Pode tratar-se de um erro se a página solicitada não existir. Se a página existir, o servidor indicará nos cabeçalhos HTTP da sua resposta que, após estes, irá enviar um documento HTML (HyperText Markup Language). Este documento é uma sequência de linhas de texto no formato HTML. Um texto HTML contém balizas (marcadores) que fornecem ao navegador instruções sobre a forma de apresentar o texto.
- O cliente sabe, com base nos cabeçalhos HTTP do servidor, que irá receber um documento HTML. Irá analisar esse documento e poderá perceber que este contém referências a imagens. Estas imagens não se encontram no documento HTML. Por isso, faz um novo pedido ao mesmo servidor Web para solicitar a primeira imagem de que necessita. Este pedido é idêntico ao feito no ponto 1, exceto que o recurso solicitado é diferente. O servidor irá processar esta solicitação, enviando ao seu cliente a imagem solicitada. Desta vez, na sua resposta, os cabeçalhos HTTP indicarão que o documento enviado é uma imagem e não um documento HTML.
- O cliente recebe a imagem enviada. Os passos 3 e 4 serão repetidos até que o cliente (geralmente um navegador) tenha todos os documentos necessários para apresentar a página na íntegra.
2.4.3. O protocolo HTTP
Vamos explorar o protocolo HTTP através de exemplos. O que é que um navegador e um servidor Web trocam entre si?
O serviço Web ou serviço HTTP é um serviço TCP-IP que funciona normalmente na porta 80. Pode funcionar noutra porta. Nesse caso, o navegador cliente seria obrigado a especificar essa porta no URL que solicita. Um URL tem o seguinte formato geral:
protocolo://máquina[:port]/caminho/informações
onde
protocolo | http para o serviço Web. Um navegador também pode funcionar como cliente de serviços ftp, news, telnet, etc. |
máquina | nome da máquina onde o serviço Web está a funcionar |
porta | porta do serviço Web. Se for 80, pode omitir-se o número da porta. Este é o caso mais frequente |
caminho | caminho que designa o recurso solicitado |
informações | informações adicionais fornecidas ao servidor para especificar o pedido do cliente |
O que faz um navegador quando um utilizador solicita o carregamento de um URL?
- abre uma comunicação TCP-IP com a máquina e a porta indicadas na parte «machine[:port]» do URL. Estabelecer uma comunicação TCP-IP significa criar um «canal» de comunicação entre duas máquinas. Uma vez criado esse canal, todas as informações trocadas entre as duas máquinas passarão por ele. A criação deste canal TCP-IP ainda não envolve o protocolo Web HTTP.
- Uma vez criado o canal TCP-IP, o cliente enviará o seu pedido ao servidor Web, enviando-lhe linhas de texto (comandos) no formato HTTP. Enviará ao servidor a parte «caminho/informações» do URL
- o servidor responderá da mesma forma e no mesmo canal
- um dos dois parceiros tomará a decisão de encerrar o canal. Isso depende do protocolo HTTP utilizado. Com o protocolo HTTP 1.0, o servidor encerra a ligação após cada uma das suas respostas. Isto obriga um cliente que precise de efetuar várias solicitações para obter os diferentes documentos que constituem uma página Web a abrir uma nova ligação em cada solicitação, o que acarreta um custo. Com o protocolo HTTP/1.1, o cliente pode indicar ao servidor para manter a ligação aberta até que lhe peça para a encerrar. Assim, pode recuperar todos os documentos de uma página Web com uma única ligação e encerrar ele próprio a ligação assim que o último documento for obtido. O servidor detetará este encerramento e também encerrará a ligação.
Para descobrir as trocas de dados entre um cliente e um servidor Web, vamos utilizar a extensão [Advanced Rest Client] do navegador Chrome que instalámos no parágrafo 9.6. Estaremos na seguinte situação:
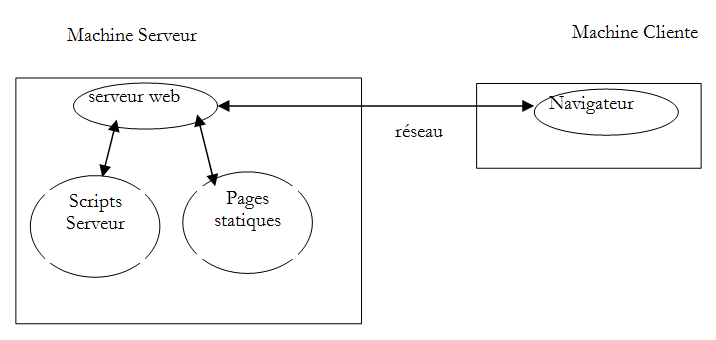
O servidor Web pode ser qualquer um. O nosso objetivo aqui é compreender as interações que irão ocorrer entre o navegador e o servidor Web. Anteriormente, criámos a seguinte página estática HTML:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>essai 1 : une page statique</title>
</head>
<body>
<h1>Une page statique...</h1>
</body>
</html>
que visualizamos num navegador:
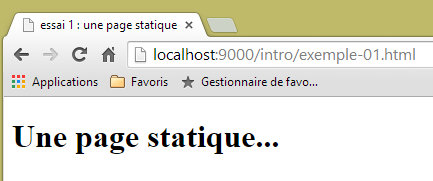 |
Vemos que a página URL solicitada é: [http://localhost:9000/intro/exemple-01.html]. A máquina do serviço Web é, portanto, localhost (=máquina local) e a porta 9000. Utilizemos a aplicação [Advanced Rest Client] para solicitar o mesmo URL:
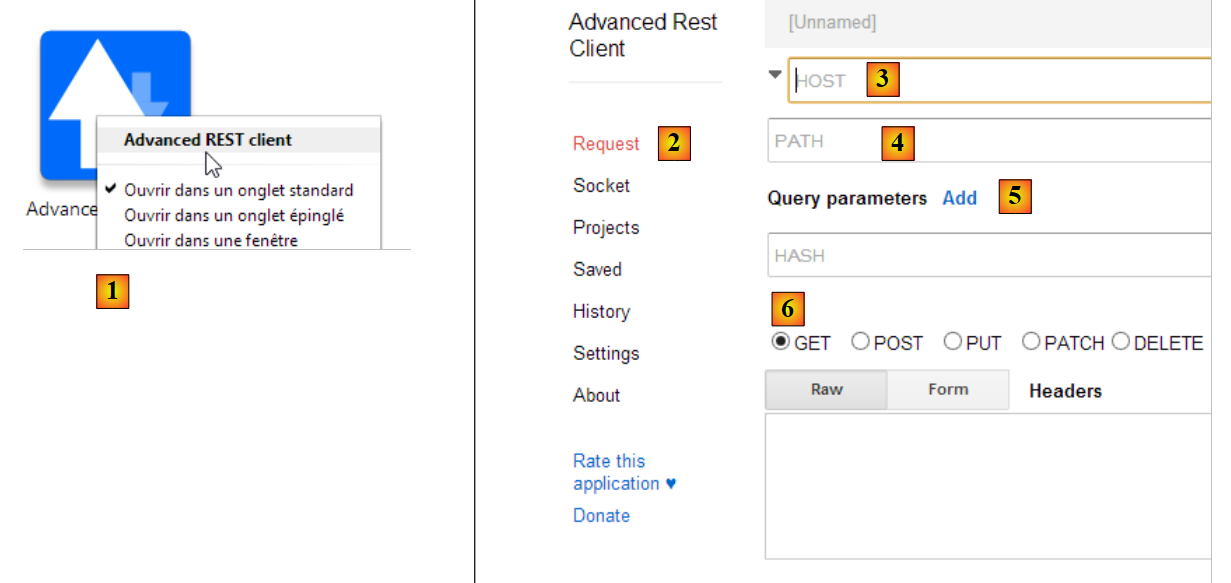 |
- em [1], iniciamos a aplicação (no separador [Applications] de um novo separador do Chrome);
- em [2], seleciona-se a opção [Request];
- em [3], especifica-se o servidor a consultar: http://localhost:9000;
- em [4], especifica-se a URL solicitada: /intro/exemple-01.html;
- em [5], adicionam-se eventuais parâmetros à URL. Neste caso, não há nenhum;
- em [6], especifica-se o comando HTTP utilizado para a consulta, neste caso GET.
Isto resulta na seguinte consulta:
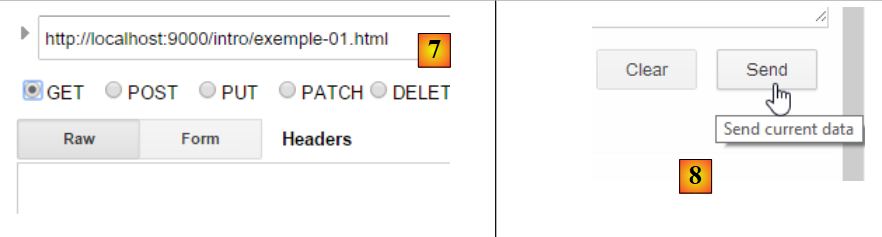 |
A consulta assim preparada, [7], é enviada ao servidor por [8]. A resposta obtida é então a seguinte:
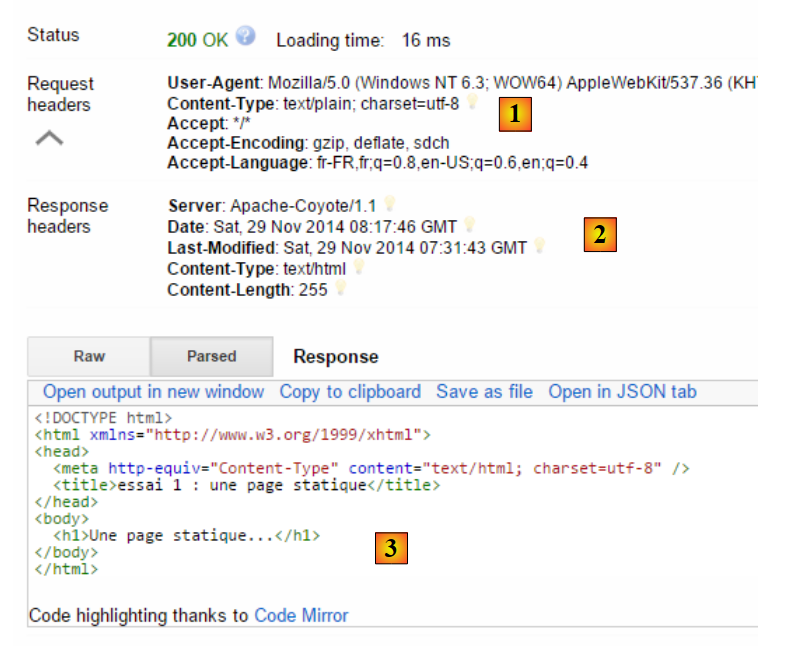 |
Como referimos anteriormente, as trocas cliente-servidor assumem a seguinte forma:
- em [1], vemos os cabeçalhos HTTP enviados pelo navegador na sua solicitação. Não havia nenhum documento para enviar;
- em [2], vemos os cabeçalhos HTTP enviados pelo servidor em resposta. Em [3], vemos o documento que este enviou.
Em [3], reconhece-se a página estática HTML que colocámos no servidor web.
Analisemos o pedido HTTP do navegador:
- a linha 1 não foi apresentada pela aplicação;
- linha 6: o navegador identifica-se com o cabeçalho [User-Agent];
- linha 7: o navegador indica que está a enviar ao servidor um documento de texto (text/plain) no formato UTF-8. Na verdade, neste caso, o navegador não enviou nenhum documento;
- linha 8: o navegador indica que aceita qualquer tipo de documento como resposta;
- linha 9: o navegador especifica os formatos de documento aceites;
- linha 10: o navegador especifica os idiomas que pretende, por ordem de preferência.
O servidor respondeu-lhe enviando os seguintes cabeçalhos HTTP:
- linha 1: não foi apresentada pela aplicação;
- linha 2: o servidor identifica-se, neste caso um servidor Apache-Coyote;
- linha 3: a data da última modificação do documento enviado;
- linha 4: a natureza do documento enviado pelo servidor. Neste caso, um documento HTML;
- linha 5: o tamanho, em bytes, do documento HTML enviado.
- linha 6: data e hora da resposta;
2.4.4. Conclusão
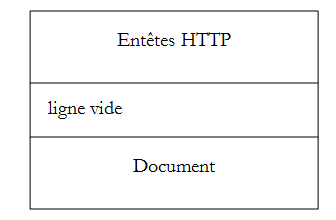
Descobrimos a estrutura do pedido de um cliente Web e a da resposta que lhe é dada pelo servidor Web através de alguns exemplos. O diálogo realiza-se através do protocolo HTTP, um conjunto de comandos em formato de texto trocados entre as duas partes. O pedido do cliente e a resposta do servidor têm a seguinte estrutura:
Os dois comandos habituais para solicitar um recurso são GET e POST. O comando GET não é acompanhado por um documento. O comando POST, por sua vez, é acompanhado por um documento que, na maioria das vezes, é uma cadeia de caracteres que reúne o conjunto de valores introduzidos num formulário. O comando HEAD permite solicitar apenas os cabeçalhos HTTP e não é acompanhado por nenhum documento.
Em resposta a um pedido de um cliente, o servidor envia uma resposta com a mesma estrutura. O recurso solicitado é transmitido na parte [Document], a menos que o comando do cliente tenha sido HEAD, caso em que apenas os cabeçalhos HTTP são enviados.
2.5. Noções básicas da linguagem HTML
Um navegador da Web pode apresentar vários documentos, sendo o mais comum o documento HTML (HyperText Markup Language). Trata-se de um texto formatado com balizas do tipo <balise>texte</balise>. Assim, o texto <B>important</B> apresentará o texto importante em negrito. Existem balizas isoladas, como a baliza <hr/>, que apresenta uma linha horizontal. Não iremos analisar as balizas que podem ser encontradas num texto HTML. Existem inúmeros programas WYSIWYG que permitem criar uma página Web sem escrever uma única linha de código HTML. Estas ferramentas geram automaticamente o código HTML a partir de um layout criado com o rato e controlos predefinidos. Assim, é possível inserir (com o rato) uma tabela na página e, em seguida, consultar o código HTML gerado pelo software para descobrir as balizas a utilizar para definir uma tabela numa página Web. Não é mais complicado do que isso. Além disso, o conhecimento da linguagem HTML é indispensável, uma vez que as aplicações Web dinâmicas têm de gerar elas próprias o código HTML a enviar aos clientes Web. Este código é gerado por programa e é, naturalmente, necessário saber o que deve ser gerado para que o cliente tenha a página Web que deseja.
Resumindo, não é necessário conhecer toda a linguagem HTML para começar a programar para a Web. No entanto, esse conhecimento é necessário e pode ser adquirido através da utilização de software WYSIWYG para a criação de páginas Web, como o DreamWeaver e dezenas de outros. Outra forma de descobrir as subtilezas da linguagem HTML é navegar na Web e visualizar o código-fonte das páginas que apresentam características interessantes e ainda desconhecidas para si.
2.5.1. Um exemplo
Consideremos o exemplo seguinte, que apresenta alguns elementos que podem ser encontrados num documento Web, tais como:
- uma tabela;
- uma imagem;
- um link.
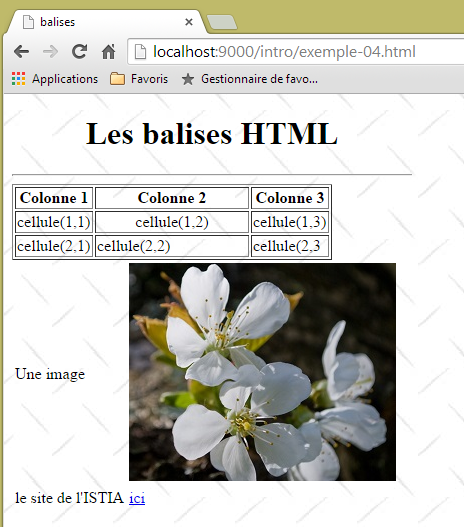 |  |
Um documento HTML tem o seguinte formato geral:
Todo o documento é delimitado pelas balizas <html>...</html>. É composto por duas partes:
- <head>...</head>: esta é a parte não visível do documento. Fornece informações ao navegador que irá apresentar o documento. Nesta parte encontra-se frequentemente a baliza <title>...</title>, que define o texto que será apresentado na barra de título do navegador. Também podem existir outras balizas, nomeadamente as que definem as palavras-chave do documento, palavras-chave posteriormente utilizadas pelos motores de busca. Nesta parte também podem encontrar-se scripts, na maioria das vezes escritos em JavaScript ou VBScript, que serão executados pelo navegador.
- <body atributos>...</body>: esta é a parte que será apresentada pelo navegador. As balizas HTML contidas nesta parte indicam ao navegador a forma visual «desejada» para o documento. Cada navegador interpretará estas balizas à sua maneira. Dois navegadores podem, assim, visualizar de forma diferente um mesmo documento Web. Este é, geralmente, um dos desafios dos web designers.
O código HTML do nosso documento de exemplo é o seguinte:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>balises</title>
</head>
<body style="height: 400px; width: 400px; background-image: url(images/standard.jpg)">
<h1 style="text-align: center">Les balises HTML</h1>
<hr />
<table border="1">
<thead>
<tr>
<th>Colonne 1</th>
<th>Colonne 2</th>
<th>Colonne 3</th>
</tr>
</thead>
<tbody>
<tr>
<td>cellule(1,1)</td>
<td style="width: 150px; text-align: center;">cellule(1,2)</td>
<td>cellule(1,3)</td>
</tr>
<tr>
<td>cellule(2,1)</td>
<td>cellule(2,2)</td>
<td>cellule(2,3</td>
</tr>
</tbody>
</table>
<table>
<tr>
<td>Une image</td>
<td><img border="0" src="images/cerisier.jpg" /></td>
</tr>
<tr>
<td>le site de l'ISTIA</td>
<td><a href="http://istia.univ-angers.fr">ici</a></td>
</tr>
</table>
</body>
</html>
Elemento | etiquetas e exemplos HTML |
título do documento | <title>etiquetas</title> (linha 5) o texto balises aparecerá na barra de título do navegador que exibirá o documento |
barra horizontal | <hr/>: exibe uma linha horizontal (linha 10) |
tabela | <table atributos>....</table>: para definir a tabela (linhas 11, 31) <thead>...</thead>: para definir os cabeçalhos das colunas (linhas 12, 18) <tbody>...</tbody>: para definir o conteúdo da tabela (linhas 19, 30) <tr atributos>...</tr>: para definir uma linha (linhas 20, 24) <td atributos>...</td>: para definir uma célula (linha 21) exemplos: <table border="1">...</table>: o atributo border define a espessura da borda da tabela <td style="width: 150px; text-align: center;">célula(1,2)</td>: define uma célula cujo conteúdo será célula(1,2). Este conteúdo será centrado horizontalmente (text-align: center). A célula terá uma largura de 150 píxeis (width: 150px) |
imagem | <img border="0" src="/images/cerisier.jpg"/> (linha 36): define uma imagem sem borda (border="0") cujo ficheiro de origem é /images/cerisier.jpg no servidor Web (src="images/cerisier.jpg"). Esta ligação encontra-se num documento Web obtido com o URL http://localhost:port/intro/exemple-04.html. Assim, o navegador irá solicitar o URL http://localhost:port/intro/images/cerisier.jpg para obter a imagem aqui referenciada. |
ligação | <a href="http://istia.univ-angers.fr">aqui</a> (linha 40): faz com que o texto ici funcione como um link para o URL http://istia.univ-angers.fr. |
final da página | <body style="height:400px;width:400px;background-image:url(images/standard.jpg)"> (linha 8): indica que a imagem que deve servir de fundo da página se encontra no URL [images/standard.jpg] do servidor Web. No contexto do nosso exemplo, o navegador irá solicitar o ficheiro URL http://localhost:port/intro/images/standard.jpg para obter esta imagem de fundo. Além disso, o corpo do documento será apresentado num retângulo com 400 píxeis de altura e 400 píxeis de largura. |
Neste exemplo simples, verifica-se que, para construir o documento na íntegra, o navegador tem de efetuar três pedidos ao servidor:
- http://localhost:port/intro/exemple-04.html para obter a fonte HTML do documento
- http://localhost:port/intro/images/cerisier.jpg para obter a imagem cerisier.jpg
- http://localhost:port/intro/images/standard.jpg para obter a imagem de fundo standard.jpg
2.5.2. Um formulário HTML
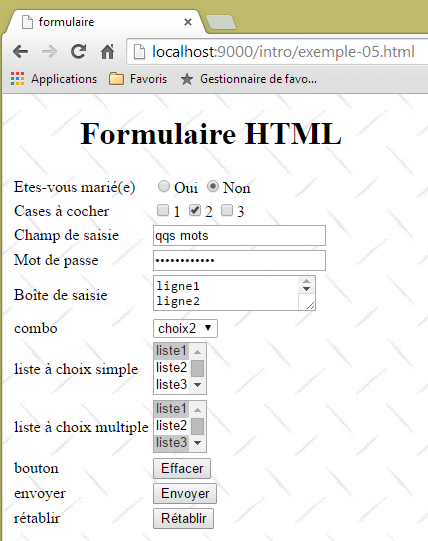
O exemplo seguinte apresenta um formulário:
 |  |
O código HTML que gera esta visualização é o seguinte:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>formulaire</title>
<script type="text/javascript">
function effacer() {
alert("Vous avez cliqué sur le bouton Effacer");
}
</script>
</head>
<body style="height: 400px; width: 400px; background-image: url(images/standard.jpg)">
<h1 style="text-align: center">Formulaire HTML</h1>
<form method="post" action="postFormulaire">
<table>
<tr>
<td>Etes-vous marié(e)</td>
<td>
<input type="radio" value="Oui" name="R1" />Oui
<input type="radio" name="R1" value="non" checked="checked" />Non
</td>
</tr>
<tr>
<td>Cases à cocher</td>
<td>
<input type="checkbox" name="C1" value="un" />1
<input type="checkbox" name="C2" value="deux" checked="checked" />2
<input type="checkbox" name="C3" value="trois" />3
</td>
</tr>
<tr>
<td>Champ de saisie</td>
<td>
<input type="text" name="txtSaisie" size="20" value="qqs mots" />
</td>
</tr>
<tr>
<td>Mot de passe</td>
<td>
<input type="password" name="txtMdp" size="20" value="unMotDePasse" />
</td>
</tr>
<tr>
<td>Boîte de saisie</td>
<td>
<textarea rows="2" name="areaSaisie" cols="20">
ligne1
ligne2
ligne3
</textarea>
</td>
</tr>
<tr>
<td>combo</td>
<td>
<select size="1" name="cmbValeurs">
<option value="1">choix1</option>
<option selected="selected" value="2">choix2</option>
<option value="3">choix3</option>
</select>
</td>
</tr>
<tr>
<td>liste à choix simple</td>
<td>
<select size="3" name="lst1">
<option selected="selected" value="1">liste1</option>
<option value="2">liste2</option>
<option value="3">liste3</option>
<option value="4">liste4</option>
<option value="5">liste5</option>
</select>
</td>
</tr>
<tr>
<td>liste à choix multiple</td>
<td>
<select size="3" name="lst2" multiple="multiple">
<option value="1" selected="selected">liste1</option>
<option value="2">liste2</option>
<option selected="selected" value="3">liste3</option>
<option value="4">liste4</option>
<option value="5">liste5</option>
</select>
</td>
</tr>
<tr>
<td>bouton</td>
<td>
<input type="button" value="Effacer" name="cmdEffacer" onclick="effacer()" />
</td>
</tr>
<tr>
<td>envoyer</td>
<td>
<input type="submit" value="Envoyer" name="cmdRenvoyer" />
</td>
</tr>
<tr>
<td>rétablir</td>
<td>
<input type="reset" value="Rétablir" name="cmdRétablir" />
</td>
</tr>
</table>
<input type="hidden" name="secret" value="uneValeur" />
</form>
</body>
</html>
A correspondência entre o controlo visual e a baliza HTML é a seguinte:
Controlo | etiqueta HTML |
formulário | <form method="post" action="..."> |
campo de introdução | <input type="text" name="txtSaisie" size="20" value="algumas palavras" /> |
campo de introdução oculto | <input type="password" name="txtMdp" size="20" value="unMotDePasse" /> |
campo de introdução de texto com várias linhas | <textarea rows="2" name="areaSaisie" cols="20"> linha1 linha 2 linha 3 </textarea> |
botões de opção | <input type="radio" value="Sim" name="R1" />Sim <input type="radio" name="R1" value="não" checked="checked" />Não |
caixas de seleção | <input type="checkbox" name="C1" value="um" />1 <input type="checkbox" name="C2" value="dois" checked="checked" />2 <input type="checkbox" name="C3" value="três" />3 |
Lista suspensa | <select size="1" name="cmbValeurs"> <option value="1">opção 1</option> <option selected="selected" value="2">opção 2</option> <option value="3">opção 3</option> </select> |
lista de seleção única | <select size="3" name="lst1"> <option selected="selected" value="1">lista1</option> <option value="2">lista2</option> <option value="3">lista3</option> <option value="4">lista4</option> <option value="5">lista5</option> </select> |
lista de seleção múltipla | <select size="3" name="lst2" multiple="multiple"> <option value="1">lista1</option> <option value="2">lista2</option> <option selected="selected" value="3">lista3</option> <option value="4">lista4</option> <option value="5">lista5</option> </select> |
botão do tipo «submit» | <input type="submit" value="Enviar" name="cmdRenvoyer" /> |
botão do tipo «reset» | <input type="reset" value="Restaurar" name="cmdRétablir" /> |
botão do tipo button | <input type="button" value="Apagar" name="cmdEffacer" onclick="effacer()" /> |
Vamos analisar estas diferentes tags:
2.5.2.1. O formulário « »
formulário | |
tag HTML | <form name="..." method="..." action="...">...</form> |
atributos | name="frmexemple": nome do formulário method="..." : método utilizado pelo navegador para enviar ao servidor Web os valores recolhidos no formulário action="..." : URL para onde serão enviados os valores recolhidos no formulário. Um formulário Web é delimitado pelas balizas <form>...</form>. O formulário pode ter um nome (name="xx"). É o caso de todos os controlos que se podem encontrar num formulário. O objetivo de um formulário é recolher as informações fornecidas pelo utilizador através do teclado/rato e enviá-las para um URL de servidor Web. Qual? Aquele referenciado no atributo action="URL". Se este atributo estiver ausente, as informações serão enviadas para o URL do documento no qual o formulário se encontra. Um cliente Web pode utilizar dois métodos diferentes, denominados POST e GET, para enviar dados para um servidor Web. O atributo method="méthode", com method igual a GET ou POST, da baliza <form> indica ao navegador o método a utilizar para enviar as informações recolhidas no formulário para o URL especificado pelo atributo action="URL". Quando o atributo method não é especificado, o método GET é utilizado por predefinição. |
2.5.2.2. Os campos de introdução de texto
campo de introdução de texto | <input type="text" name="txtSaisie" size="20" value="algumas palavras" /> <input type="password" name="txtMdp" size="20" value="unMotDePasse" /> |
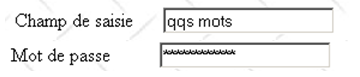 |
tag HTML | <input type="..." name="..." size=".." value=".."/> A tag input existe para vários controlos. É o atributo type que permite diferenciar esses controlos entre si. |
atributos | type="text": especifica que se trata de um campo de introdução de dados type="password": os caracteres presentes no campo de introdução são substituídos por asteriscos (*). Esta é a única diferença em relação ao campo de introdução normal. Este tipo de controlo é adequado para a introdução de palavras-passe. size="20": número de caracteres visíveis no campo — não impede a introdução de mais caracteres name="txtSaisie": nome do controlo value="algumas palavras": texto que será exibido no campo de introdução. |
2.5.2.3. Os campos de introdução de texto com várias linhas
campo de introdução de texto com várias linhas | <textarea rows="2" name="areaSaisie" cols="20"> linha1 linha 2 linha 3 </textarea> |
 |
tag HTML | <textarea ...>texto</textarea> exibe uma área de introdução de texto com várias linhas, com o texto já inserido inicialmente |
atributos | rows="2": número de linhas cols="'20" : número de colunas name="areaSaisie": nome do controlo |
2.5.2.4. Os botões de opção
botões de opção | <input type="radio" value="Sim" name="R1" />Sim <input type="radio" name="R1" value="não" checked="checked" />Não |
etiqueta HTML | <input type="radio" atributo2="valor2" ..../>texto exibe um botão de opção com texto ao lado. |
atributos | name="radio": nome do controlo. Os botões de opção com o mesmo nome formam um grupo de botões mutuamente exclusivos: só é possível selecionar um deles. value="valor": valor atribuído ao botão de opção. Não se deve confundir este valor com o texto apresentado ao lado do botão de opção. Este último destina-se apenas à visualização. checked="checked": se esta palavra-chave estiver presente, o botão de opção está marcado; caso contrário, não está. |
2.5.2.5. As caixas de seleção
caixas de seleção | <input type="checkbox" name="C1" value="um" />1 <input type="checkbox" name="C2" value="dois" checked="checked" />2 <input type="checkbox" name="C3" value="três" />3 |
etiqueta HTML | <input type="checkbox" atributo2="valor2" ....>texto exibe uma caixa de seleção com texto ao lado. |
atributos | name="C1": nome do controlo. As caixas de seleção podem ou não ter o mesmo nome. As caixas com o mesmo nome formam um grupo de caixas associadas. value="valor": valor atribuído à caixa de seleção. Não se deve confundir este valor com o texto exibido ao lado da caixa de seleção. Este último destina-se apenas à exibição. checked= "checked": se esta palavra-chave estiver presente, a caixa de seleção está marcada; caso contrário, não está. |
2.5.2.6. A lista suspensa (combo)
Combo | <select size="1" name="cmbValeurs"> <option value="1">opção1</option> <option selected="selected" value="2">opção 2</option> <option value="3">opção 3</option> </select> |
tag HTML | <select size=".." name=".."> <option [selected="selected"] value=”v”>...</option> ... </select> exibe numa lista os textos contidos entre as balizas <option>...</option> |
atributos | name="cmbValeurs": nome do controlo. size="1": número de elementos da lista visíveis. size="1" transforma a lista no equivalente a uma caixa de seleção. selected="selected": se esta palavra-chave estiver presente para um elemento da lista, este aparece selecionado na lista. No nosso exemplo acima, o elemento da lista choix2 aparece como o elemento selecionado da caixa de seleção quando esta é apresentada pela primeira vez. value=”v”: se o elemento for selecionado pelo utilizador, é este valor, [v], que é enviado para o servidor. Na ausência deste atributo, é o texto apresentado e selecionado que é enviado para o servidor. |
2.5.2.7. Lista de seleção única
lista de seleção única | <select size="3" name="lst1"> <option selected="selected" value="1">lista1</option> <option value="2">lista2</option> <option value="3">lista3</option> <option value="4">lista4</option> <option value="5">lista5</option> </select> |
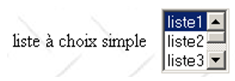 |
tag HTML | <select size=".." name=".."> <option [selected="selected"]>...</option> ... </select> exibe numa lista os textos contidos entre as balizas <option>...</option> |
atributos | os mesmos que para a lista suspensa que apresenta apenas um elemento. Este controlo difere da lista suspensa anterior apenas pelo seu atributo size>1. |
2.5.2.8. Lista de seleção múltipla
lista de seleção única | <select size="3" name="lst2" multiple="multiple"> <option value="1" selected="selected">lista1</option> <option value="2">lista2</option> <option selected="selected" value="3">lista3</option> <option value="4">lista4</option> <option value="5">lista5</option> </select> |
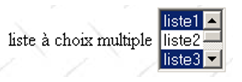 |
tag HTML | <select size=".." name=".." multiple="multiple"> <option [selected="selected"]>...</option> ... </select> exibe numa lista os textos contidos entre as balizas <option>...</option> |
atributos | múltiplo: permite a seleção de vários elementos da lista. No exemplo acima, os elementos liste1 e liste3 estão ambos selecionados. |
2.5.2.9. Botão do tipo «button»
botão do tipo button | <input type="button" value="Apagar" name="cmdEffacer" onclick="effacer()" /> |
tag HTML | <input type="button" value="..." name="..." onclick="effacer()" ..../> |
atributos | type="button": define um controlo de botão. Existem outros dois tipos de botão: os tipos submit e reset. value="Apagar": o texto exibido no botão onclick="função()": permite definir uma função a executar quando o utilizador clica no botão. Esta função faz parte dos scripts definidos no documento Web apresentado. A sintaxe anterior é uma sintaxe javascript. Se os scripts forem escritos em VBScript, deve escrever-se onclick="função" sem os parênteses. A sintaxe torna-se idêntica se for necessário passar parâmetros para a função: onclick="função(val1, val2,...)" No nosso exemplo, um clique no botão Effacer chama a seguinte função JavaScript effacer: <script type="text/javascript"> function apagar() { alert("Clicou no botão Apagar"); } </script> A função effacer apresenta uma mensagem: 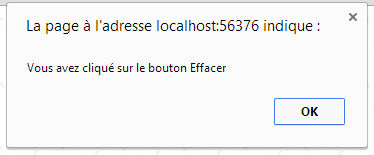 |
2.5.2.10. Botão do tipo «submit»
botão do tipo «submit» | <input type="submit" value="Enviar" name="cmdRenvoyer" /> |
tag HTML | <input type="submit" value="Enviar" name="cmdRenvoyer" /> |
atributos | type="submit": define o botão como um botão para enviar os dados do formulário para o servidor Web. Quando o utilizador clicar neste botão, o navegador enviará os dados do formulário para o URL definido no atributo action da tag <form>, de acordo com o método definido pelo atributo method dessa mesma tag. value="Enviar": o texto exibido no botão |
2.5.2.11. Botão do tipo «reset»
Botão do tipo «reset» | <input type="reset" value="Restaurar" name="cmdRétablir" /> |
etiqueta HTML | <input type="reset" value="Restaurar" name="cmdRétablir"/> |
atributos | type="reset": define o botão como um botão de reinicialização do formulário. Quando o utilizador clicar neste botão, o navegador irá repor o formulário no estado em que o recebeu. value="Restaurar": o texto exibido no botão |
2.5.2.12. Campo oculto
campo oculto | <input type="hidden" name="secret" value="uneValeur" /> |
etiqueta HTML | <input type="hidden" name="..." value="..."/> |
atributos | type="hidden": indica que se trata de um campo oculto. Um campo oculto faz parte do formulário, mas não é apresentado ao utilizador. No entanto, se este solicitasse ao seu navegador a visualização do código-fonte, veria a presença da baliza <input type="hidden" value="..."> e, consequentemente, o valor do campo oculto. value="umValor": valor do campo oculto. Qual é a utilidade do campo oculto? Pode permitir que o servidor Web guarde informações ao longo das solicitações de um cliente. Consideremos uma aplicação de compras na Web. O cliente compra um primeiro artigo art1 na quantidade q1 numa primeira página de um catálogo e, em seguida, passa para uma nova página do catálogo. Para se lembrar de que o cliente comprou q1 artigos art1, o servidor pode colocar estas duas informações num campo oculto do formulário Web da nova página. Nesta nova página, o cliente compra os artigos q2 e art2. Quando os dados deste segundo formulário forem enviados para o servidor (submit), este irá receber não só a informação (q2,art2), mas também (q1,art1), que também fazem parte do formulário como campos ocultos. O servidor Web irá então colocar num novo campo oculto as informações (q1,art1) e (q2,art2) e enviar uma nova página do catálogo. E assim sucessivamente. |
2.5.3. Envio dos valores de um formulário de um cliente Web para um servidor Web
No estudo anterior, referimos que o cliente Web dispõe de dois métodos para enviar a um servidor Web os valores de um formulário que apresentou: os métodos GET e POST. Vejamos, através de um exemplo, a diferença entre os dois métodos.
2.5.3.1. Método GET
Vamos fazer um primeiro teste, em que, no código HTML do documento, a baliza <form> está definida da seguinte forma:
<form method="get" action="doNothing">
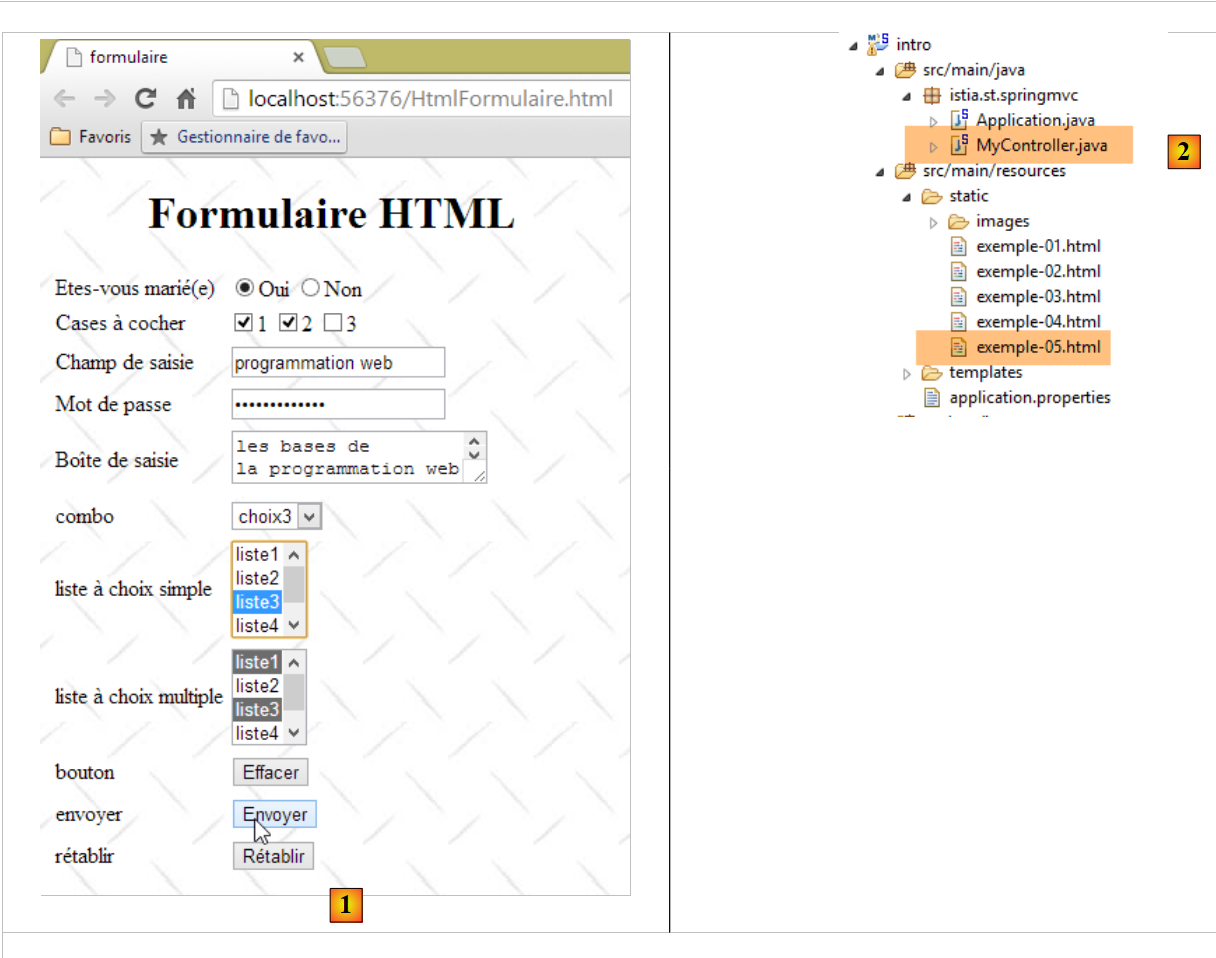 |
Quando o utilizador clicar no botão [1], os valores introduzidos no formulário serão enviados para o controlador Spring [2]. Vimos que os valores do formulário seriam enviados para o URL [doNothing]:
<form method="get" action="doNothing">
A ação [doNothing] está definida no controlador [MyController] [2] da seguinte forma:
// ----------------------- esvaziar um fluxo [Content-Length=0]
@RequestMapping(value = "/doNothing")
@ResponseBody
public void doNothing() {
}
- linha 1: a ação processa o URL [/doNothing], ou seja, na realidade, o [/context/doNothing], em que [context] é o contexto ou nome da aplicação web, neste caso, [/intro];
- linha 3: a anotação [@ResponseBody] indica que o resultado do método anotado deve ser enviado diretamente ao cliente;
- linha 4: o método não devolve nada. Assim, o cliente receberá uma resposta vazia do servidor.
Queremos apenas saber como é que o navegador transmite os valores introduzidos ao servidor web. Para tal, vamos utilizar uma ferramenta de depuração disponível no Chrome. Ativa-se premindo CTRL-Shift-I ( maiúscula) [3]:
 |
Como estamos interessados nas trocas de dados entre o navegador e o servidor web, ativamos acima o separador [Network] e, em seguida, clicamos no botão [Envoyer] do formulário. Este é um botão do tipo [submit] dentro de uma baliza [form]. O navegador reage ao clique solicitando o URL [/intro/doNothing] indicado no atributo [action] da baliza [form], com o método GET indicado no atributo [method]. Obtemos então as seguintes informações:
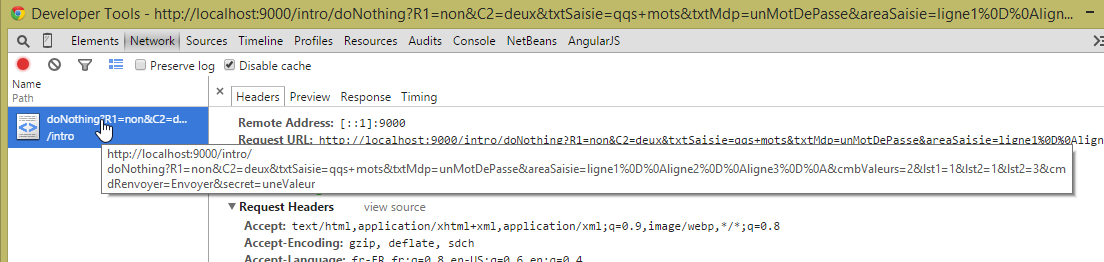 |
A captura de ecrã acima mostra-nos o URL solicitado pelo navegador após clicar no botão [envoyer]. O navegador solicita efetivamente o URL, previsto como [/intro/doNothing], mas acrescenta informações adicionais, que correspondem aos valores introduzidos no formulário. Para obter mais informações, clicamos na ligação acima:
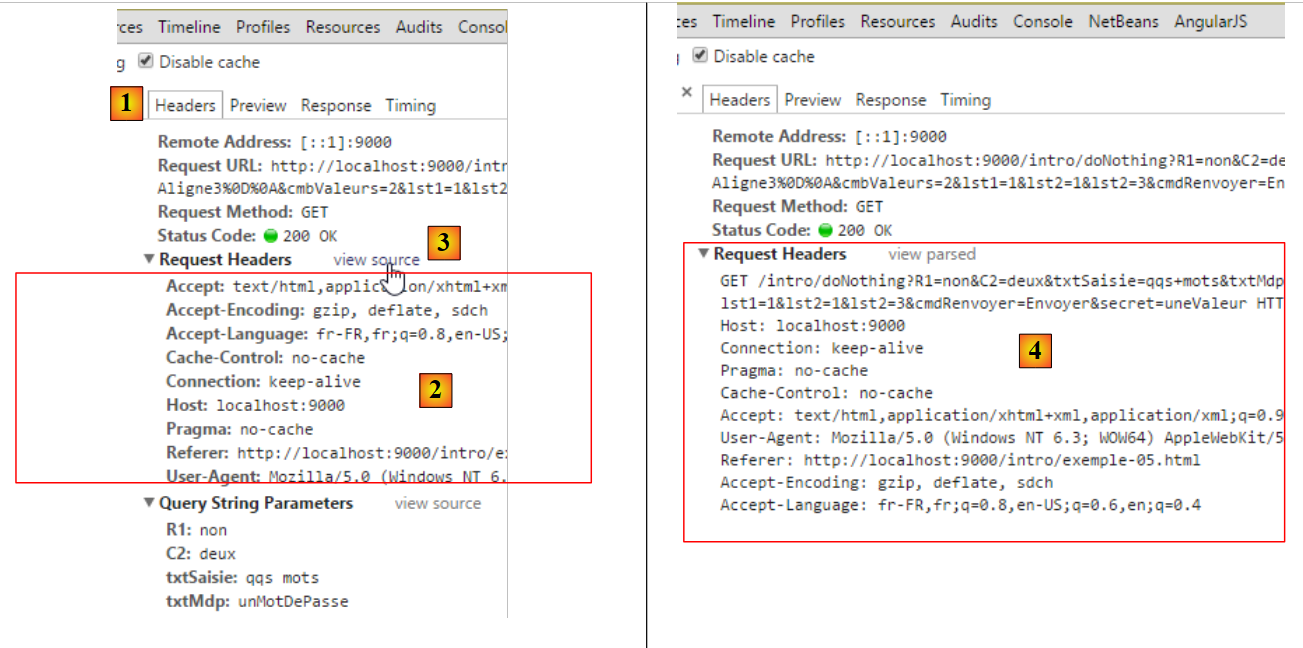 |
Acima de [1, 2], vemos os cabeçalhos HTTP enviados pelo navegador. Estes foram aqui formatados. Para ver o texto bruto destes cabeçalhos, seguimos a ligação [view source] [3, 4]. O texto completo é o seguinte:
Encontramos aqui elementos já vistos anteriormente. Outros surgem pela primeira vez:
Connection: keep-alive | o cliente solicita ao servidor que não encerre a ligação após a sua resposta. Isto permitirá que utilize a mesma ligação para um pedido posterior. A ligação não permanece aberta indefinidamente. O servidor irá encerrá-la após um período demasiado longo de inatividade. |
Referer | o URL que estava a ser apresentado no navegador quando a nova solicitação foi efetuada. |
A novidade é a linha 1 nas informações que se seguem ao URL. Verifica-se que as opções selecionadas no formulário se encontram no URL. Os valores introduzidos pelo utilizador no formulário foram passados para o comando GET URL?param1=valor1¶m2=valor2&... HTTP/1.1, em que os parami são os nomes (atributo name) dos controlos do formulário Web e os valeuri são os valores que lhes estão associados. Apresentamos abaixo uma tabela com três colunas:
- coluna 1: apresenta a definição de um controlo HTML do exemplo;
- coluna 2: apresenta a visualização desse controlo num navegador;
- coluna 3: apresenta o valor enviado ao servidor pelo navegador para o controlo da coluna 1, na forma em que aparece na solicitação GET do exemplo.
controlo HTML | visual | valor(es) devolvido(s) |
<input type="radio" value="Sim" name="R1"/>Sim <input type="radio" name="R1" value="não" checked="checked"/>Não | R1=Sim - o valor do atributo value do botão de opção selecionado pelo utilizador. | |
<input type="checkbox" name="C1" value="um"/>1 <input type="checkbox" name="C2" value="dois" checked="checked"/>2 <input type="checkbox" name="C3" value="três"/>3 | C1=um C2=dois - valores dos atributos value das caixas de seleção marcadas pelo utilizador | |
<input type="text" name="txtSaisie" size="20" value="algumas palavras"/> | txtSaisida=programação+Web - texto digitado pelo utilizador no campo de introdução. Os espaços foram substituídos pelo sinal + | |
<input type="password" name="txtMdp" size="20" value="unMotDePasse"/> | txtMdp=istoé-secreto - texto digitado pelo utilizador no campo de introdução | |
<textarea rows="2" name="areaSaisie" cols="20"> linha1 linha 2 linha 3 </textarea> | areaSaisie=os+fundamentos+da%0D%0A programação+Web - texto digitado pelo utilizador no campo de introdução. %OD%OA é o marcador de fim de linha. Os espaços foram substituídos pelo sinal + | |
<select size="1" name="cmbValeurs"> <option value='1'>opção1</option> <option selected="selected" value='2'>opção2</option> <option value='3'>opção 3</option> </select> | cmbValores=3 - atributo [value] do elemento selecionado pelo utilizador | |
<select size="3" name="lst1"> <option selected="selected" value='1'>lista1</option> <option value='2'>lista2</option> <option value='3'>lista3</option> <option value='4'>lista4</option> <option value='5'>lista5</option> </select> | 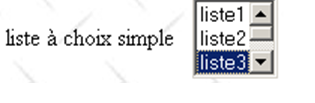 | lst1=3 - atributo [value] do elemento selecionado pelo utilizador |
<select size="3" name="lst2" multiple="multiple"> <option selected="selected" value='1'>lista1</option> <option value='2'>lista2</option> <option selected="selected" value='3'>lista3</option> <option value='4'>lista4</option> <option value='5'>lista5</option> </select> | lst2=1 lst2=3 - atributos [value] dos elementos selecionados pelo utilizador | |
<input type="submit" value="Enviar" name="cmdRenvoyer"/> | cmdRenvoyer=Enviar - nome e atributo value do botão utilizado para enviar os dados do formulário para o servidor | |
<input type="hidden" name="secret" value="uneValeur"/> | secret=umValor - atributo value do campo oculto |
2.5.3.2. Método POST
Alteramos o documento HTML para que o navegador utilize agora o método POST para enviar os valores do formulário para o servidor Web:
<form method="post" action="doNothing">
Preenchemos o formulário tal como para o método GET e enviamos os parâmetros para o servidor através do botão [Envoyer]. Tal como foi feito no parágrafo anterior, na página 62, temos acesso no Chrome aos cabeçalhos HTTP do pedido enviado pelo navegador:
Surgem novidades na solicitação HTTP do cliente:
POST URL HTTP/1.1 | A consulta GET foi substituída por uma consulta POST. Os parâmetros já não estão presentes nesta primeira linha da solicitação. É possível verificar que agora se encontram (linha 15) a seguir à solicitação HTTP, após uma linha em branco. A sua codificação é idêntica à que tinham na solicitação GET. |
Content-Length | número de caracteres «enviados», c.a.d. O número de caracteres que o servidor Web terá de ler após receber os cabeçalhos HTTP para recuperar o documento que o cliente lhe envia. O documento em questão é, neste caso, a lista de valores do formulário. |
Content-type | especifica o tipo de documento que o cliente enviará após os cabeçalhos HTTP. O tipo [application/x-www-form-urlencoded] indica que se trata de um documento que contém valores de formulário. |
Existem dois métodos para transmitir dados a um servidor Web: GET e POST. Será que um método é melhor do que o outro? Vimos que, se os valores de um formulário fossem enviados pelo navegador com o método GET, o navegador exibia no seu campo Adresse o URL solicitado na forma URL?param1=val1¶m2=val2&.... Isto pode ser visto como uma vantagem ou uma desvantagem:
- uma vantagem se se quiser permitir que o utilizador coloque este URL configurado nos seus favoritos;
- uma desvantagem se não se quiser que o utilizador tenha acesso a determinadas informações do formulário, tais como, por exemplo, os campos ocultos.
Posteriormente, utilizaremos quase exclusivamente o método POST nos nossos formulários.
2.6. Conclusion
Este capítulo apresentou vários conceitos básicos do desenvolvimento Web:
- as trocas cliente-servidor através do protocolo HTTP;
- a conceção de um documento utilizando a linguagem HTML;
- a conceção de formulários de introdução de dados.
Pudemos ver, através de um exemplo, como um cliente pode enviar informações para o servidor Web. Não abordámos a forma como o servidor pode
- recuperar essas informações;
- processá-las;
- enviar ao cliente uma resposta dinâmica dependente do resultado do processamento.
Este é o domínio da programação Web, tema que abordaremos no capítulo seguinte com a apresentação da tecnologia Spring MVC.