6. XML e JAVA
In questo capitolo introduciamo l’utilizzo dei documenti XML con Java. Lo faremo nel contesto dell’applicazione fiscale esaminata nel capitolo precedente.
6.1. File XML e fogli di stile XSL
Consideriamo il seguente file XML simulations.xml, che potrebbe rappresentare il risultato di simulazioni di calcolo delle imposte:
<?xml version="1.0" encoding="ISO-8859-1"?>
<simulations>
<simulation marie="oui" enfants="2" salaire="200000" impot="22504"/>
<simulation marie="non" enfants="2" salaire="200000" impot="33388"/>
</simulations>
Se lo si visualizza con IE 6, si ottiene il seguente risultato:
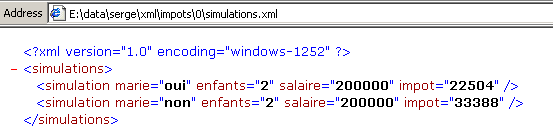
IE6 riconosce che si tratta di un file XML (grazie al suffisso .xml del file) e lo impagina a modo suo. Con Netscape si ottiene una pagina vuota. Tuttavia, se si osserva il codice sorgente (View/Source), si nota che è presente il file originale XML:
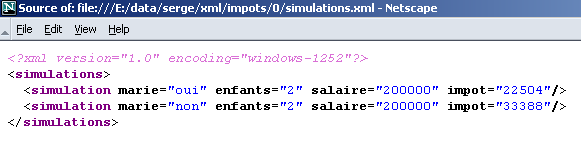
Perché Netscape non visualizza nulla? Perché ha bisogno di un foglio di stile che gli indichi come trasformare il file XML nel file HTML, che potrà quindi visualizzare. Si dà il caso che IE 6 disponga di un foglio di stile predefinito, mentre il file XML non ne propone alcuno, come nel caso in questione.
Esiste un linguaggio chiamato XSL (eXtended StyleSheet Language) che permette di descrivere le trasformazioni da effettuare per convertire un file XML in un file di testo qualsiasi. XSL consente l’uso di numerose istruzioni e assomiglia molto ai linguaggi di programmazione. Non lo descriveremo in dettaglio qui, poiché ci vorrebbero diverse decine di pagine. Ci limiteremo semplicemente a descrivere due esempi di fogli di stile XSL. Il primo è quello che trasformerà il file XML simulations.xml in codice HTML. Modifichiamo quest’ultimo in modo che indichi il foglio di stile che i browser potranno utilizzare per trasformarlo nel documento HTML, documento che potranno visualizzare:
<?xml version="1.0" encoding="ISO-8859-1" ?>
<?xml-stylesheet type="text/xsl" href="simulations.xsl"?>
<simulations>
<simulation marie="oui" enfants="2" salaire="200000" impot="22504"/>
<simulation marie="non" enfants="2" salaire="200000" impot="33388"/>
</simulations>
L'ordine XML
indica il file simulations.xsl come foglio di stile (xml-stylesheet) di tipo text/xsl c.a.d. un file di testo contenente codice XSL. Questo foglio di stile verrà utilizzato dai browser per trasformare il testo XML in un documento HTML. Ecco il risultato ottenuto con Netscape 7 quando si carica il file XML simulations.xml:

Quando si esamina il codice sorgente del documento (Visualizza/Sorgente), si ritrova il documento XML iniziale e non il documento HTML visualizzato:
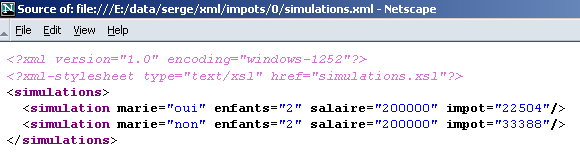
Netscape ha utilizzato il foglio di stile simulations.xsl per trasformare il documento XML sopra riportato nel documento HTML visualizzabile. È ora il momento di esaminare il contenuto di questo foglio di stile:
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" indent="yes"/>
<xsl:template match="/">
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impôts</h3>
<hr/>
<table border="1">
<th>marié</th><th>enfants</th><th>salaire</th><th>impôt</th>
<xsl:apply-templates select="/simulations/simulation"/>
</table>
</center>
</body>
</html>
</xsl:template>
<xsl:template match="simulation">
<tr>
<td><xsl:value-of select="@marie"/></td>
<td><xsl:value-of select="@enfants"/></td>
<td><xsl:value-of select="@salaire"/></td>
<td><xsl:value-of select="@impot"/></td>
</tr>
</xsl:template>
</xsl:stylesheet>
- Un foglio di stile XSL è un file XML e ne segue quindi le regole. Deve essere, tra le altre cose, "ben formato", ovvero ogni tag aperto deve essere chiuso.
- Il file inizia con due comandi XML che possono essere mantenuti in qualsiasi foglio di stile XSL:
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
L'attributo encoding="ISO-8859-1" consente di utilizzare i caratteri accentati nel foglio di stile.
- Il tag <xsl:output method="html" indent="yes"/> indica all'interprete XSL che si desidera generare un HTML "indentato".
- Il tag <xsl:template match="elemento"> serve a definire l'elemento del documento XML a cui si applicheranno le istruzioni contenute tra <xsl:template ...> e </xsl:template>.
Nell'esempio sopra riportato, l'elemento "/" indica la radice del documento. Ciò significa che non appena verrà individuato l'inizio del documento XML, verranno eseguiti i comandi XSL situati tra i due tag.
- Tutto ciò che non è un tag XSL viene inserito così com'è nel flusso di output. I tag XSL vengono invece eseguiti. Alcuni di essi producono un risultato che viene inserito nel flusso di output. Esaminiamo il seguente esempio:
<xsl:template match="/">
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impôts</h3>
<hr/>
<table border="1">
<th>marié</th><th>enfants</th><th>salaire</th><th>impôt</th>
<xsl:apply-templates select="/simulations/simulation"/>
</table>
</center>
</body>
</html>
</xsl:template>
Ricordiamo che il documento XML analizzato è il seguente:
<?xml version="1.0" encoding="ISO-8859-1"?>
<simulations>
<simulation marie="oui" enfants="2" salaire="200000" impot="22504"/>
<simulation marie="non" enfants="2" salaire="200000" impot="33388"/>
</simulations>
Fin dall'inizio del documento XML analizzato (match="/"), l'interprete XSL produrrà in uscita il testo
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impôts</h3>
<hr>
<table border="1">
<th>marié</th><th>enfants</th><th>salaire</th><th>impôt</th>
Si noti che nel testo iniziale era presente <hr/> e non <hr>. Nel testo iniziale non era possibile scrivere <hr>, che, pur essendo un tag HTML valido, è un tag XML non valido. Ora, qui abbiamo a che fare con un testo XML che deve essere «ben formato», c.a.d il che significa che ogni tag deve essere chiuso. Si scrive quindi <hr/> e, poiché si è scritto <xsl:output text="html ...">, l’interprete XSL trasformerà il testo <hr/> in <hr>. A seguito di questo testo, seguirà il testo prodotto dal comando XSL:
Vedremo in seguito di quale testo si tratta. Infine, l’interprete aggiungerà il testo:
Il comando <xsl:apply-templates select="/simulations/simulation"/> richiede l'esecuzione del "template" (modello) dell'elemento /simulations/simulation. Verrà eseguito ogni volta che l’interprete XSL incontrerà nel testo analizzato XML un tag <simulation>..</simulations> o <simulation/> all’interno di un tag <simulations>..</simulations>. All'individuazione del tag <simulation>, l'interprete eseguirà le istruzioni del modello seguente:
<xsl:template match="simulation">
<tr>
<td><xsl:value-of select="@marie"/></td>
<td><xsl:value-of select="@enfants"/></td>
<td><xsl:value-of select="@salaire"/></td>
<td><xsl:value-of select="@impot"/></td>
</tr>
</xsl:template>
Consideriamo le seguenti righe XML:
La riga <simulation ..> corrisponde al modello dell'istruzione XSL <xsl:apply-templates select="/simulations/simulation>". L'interprete XSL cercherà quindi di applicarvi le istruzioni che corrispondono a questo modello. Troverà il modello <xsl:template match="simulation"> e lo eseguirà. Ricordiamo che ciò che non è un comando XSL viene ripreso tal quale dall’interprete XSL, mentre i comandi XSL vengono sostituiti dal risultato della loro esecuzione. L’istruzione XSL <xsl:value-of select="@champ"/> viene quindi sostituita dal valore dell’attributo "champ" del nodo analizzato (in questo caso un nodo <simulation>). L'analisi della riga precedente XML produrrà in uscita il seguente risultato:
XSL | output |
<tr><td> | <tr><td> |
<xsl:value-of select="@marie"/> | sì |
</td><td> | </td><td> |
<xsl:value-of select="@enfants"/> | 2 |
</td><td> | </td><td> |
<xsl:value-of select="@salaire"/> | 200000 |
</td><td> | </td><td> |
<xsl:value-of select="@imposta"/> | 22504 |
</td></tr> | </td></tr> |
In totale, la riga XML
verrà trasformata nella riga HTML:
Tutte queste spiegazioni sono un po’ rudimentali, ma ora dovrebbe risultare chiaro al lettore che il testo XML seguente:
<?xml version="1.0" encoding="ISO-8859-1"?>
<?xml-stylesheet type="text/xsl" href="simulations.xsl"?>
<simulations>
<simulation marie="oui" enfants="2" salaire="200000" impot="22504"/>
<simulation marie="non" enfants="2" salaire="200000" impot="33388"/>
</simulations>
accompagnato dal seguente foglio di stile XSL simulations.xsl:
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" indent="yes"/>
<xsl:template match="/">
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impôts</h3>
<hr/>
<table border="1">
<th>marié</th><th>enfants</th><th>salaire</th><th>impôt</th>
<xsl:apply-templates select="/simulations/simulation"/>
</table>
</center>
</body>
</html>
</xsl:template>
<xsl:template match="simulation">
<tr>
<td><xsl:value-of select="@marie"/></td>
<td><xsl:value-of select="@enfants"/></td>
<td><xsl:value-of select="@salaire"/></td>
<td><xsl:value-of select="@impot"/></td>
</tr>
</xsl:template>
</xsl:stylesheet>
genera il seguente testo HTML:
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impots</h3>
<hr>
<table border="1">
<th>marié</th><th>enfants</th><th>salaire</th><th>impôt</th>
<tr>
<td>oui</td><td>2</td><td>200000</td><td>22504</td>
</tr>
<tr>
<td>non</td><td>2</td><td>200000</td><td>33388</td>
</tr>
</table>
</center>
</body>
</html>
Il file XML simulations.xml, accompagnato dal foglio di stile simulations.xsl, visualizzato con un browser recente (in questo caso Netscape 7), viene quindi visualizzato come segue:
6.2. Applicazione fiscale: versione 6
6.2.1. I file XML e i fogli di stile XSL dell’applicazione fiscale
Torniamo all’applicazione web per le imposte e modifichiamola in modo che la risposta inviata ai clienti sia in formato XML anziché HTML. Questa risposta XML sarà accompagnata da un foglio di stile XSL affinché i browser possano visualizzarla. Nel paragrafo precedente abbiamo presentato:
- il file simulations.xml, che è il prototipo di una risposta XML contenente simulazioni di calcolo delle imposte
- il file simulations.xsl, che costituirà il foglio di stile XSL che accompagnerà questa risposta XML
Dobbiamo prevedere anche il caso di una risposta contenente errori. Il prototipo della risposta XML in questo caso sarà il seguente file erreurs.xml:
<?xml version="1.0" encoding="windows-1252"?>
<?xml-stylesheet type="text/xsl" href="erreurs.xsl"?>
<erreurs>
<erreur>erreur 1</erreur>
<erreur>erreur 2</erreur>
</erreurs>
Il foglio di stile erreurs.xsl che consente di visualizzare questo documento XML in un browser sarà il seguente:
<?xml version="1.0" encoding="windows-1252"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" indent="yes"/>
<xsl:template match="/">
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impôts</h3>
</center>
<hr/>
Les erreurs suivantes se sont produites :
<ul>
<xsl:apply-templates select="/erreurs/erreur"/>
</ul>
</body>
</html>
</xsl:template>
<xsl:template match="erreur">
<li><xsl:value-of select="."/></li>
</xsl:template>
</xsl:stylesheet>
Questo foglio di stile introduce un comando XSL non ancora incontrato: <xsl:value-of select="."/>. Questo comando produce in uscita il valore del nodo analizzato, in questo caso un nodo <erreur>texte</erreur>. Il valore di questo nodo è il testo compreso tra i due tag di apertura e chiusura, in questo caso texte.
Il codice erreurs.xml viene trasformato dal foglio di stile erreurs.xsl nel seguente documento HTML:
<html>
<head>
<title>Simulations de calculs d'impots</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impots</h3>
</center>
<hr>
Les erreurs suivantes se sont produites :
<ul>
<li>erreur 1</li>
<li>erreur 2</li>
</ul>
</body>
</html>
Il file erreurs.xml, insieme al relativo foglio di stile, viene visualizzato dal browser nel modo seguente:
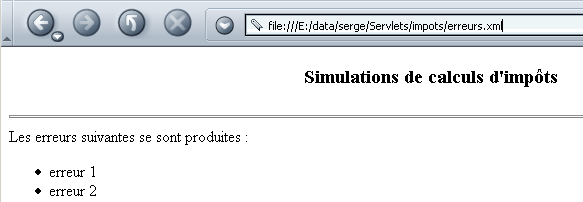
6.2.2. Il servlet xmlsimulations
Creiamo un file index.html che inseriamo nella directory dell'applicazione impots. La pagina visualizzata è la seguente:
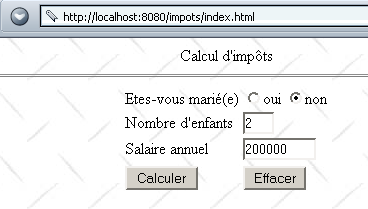
Questo documento HTML è un documento statico. Il suo codice è il seguente:
<html>
<head>
<title>impots</title>
<script language="JavaScript" type="text/javascript">
function effacer(){
// azzeramento del modulo
with(document.frmImpots){
optMarie[0].checked=false;
optMarie[1].checked=true;
txtEnfants.value="";
txtSalaire.value="";
txtImpots.value="";
}//with
}//cancella
function calculer(){
// verifica dei parametri prima dell'invio al server
with(document.frmImpots){
//numero di figli
champs=/^\s*(\d+)\s*$/.exec(txtEnfants.value);
if(champs==null){
// il modello non è stato verificato
alert("Le nombre d'enfants n'a pas été donné ou est incorrect");
nbEnfants.focus();
return;
}//if
//stipendio
champs=/^\s*(\d+)\s*$/.exec(txtSalaire.value);
if(champs==null){
// il modello non è stato verificato
alert("Le salaire n'a pas été donné ou est incorrect");
salaire.focus();
return;
}//se
// Va bene - inviamo
submit();
}//con
}//calcolare
</script>
</head>
<body background="/impots/images/standard.jpg">
<center>
Calcul d'impôts
<hr>
<form name="frmImpots" action="/impots/xmlsimulations" method="POST">
<table>
<tr>
<td>Etes-vous marié(e)</td>
<td>
<input type="radio" name="optMarie" value="oui">oui
<input type="radio" name="optMarie" value="non" checked>non
</td>
</tr>
<tr>
<td>Nombre d'enfants</td>
<td><input type="text" size="3" name="txtEnfants" value=""></td>
</tr>
<tr>
<td>Salaire annuel</td>
<td><input type="text" size="10" name="txtSalaire" value=""></td>
</tr>
<tr></tr>
<tr>
<td><input type="button" value="Calculer" onclick="calculer()"></td>
<td><input type="button" value="Effacer" onclick="effacer()"></td>
</tr>
</table>
</form>
</center>
</body>
</html>
Si noti che i dati del modulo vengono inviati a URL /impots/xmlsimulations. Questa applicazione è un servlet Java configurato come segue nel file web.xml dell'applicazione impots:
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
...........
<servlet>
<servlet-name>xmlsimulations</servlet-name>
<servlet-class>xmlsimulations</servlet-class>
<init-param>
<param-name>xslSimulations</param-name>
<param-value>simulations.xsl</param-value>
</init-param>
<init-param>
<param-name>xslErreurs</param-name>
<param-value>erreurs.xsl</param-value>
</init-param>
<init-param>
<param-name>DSNimpots</param-name>
<param-value>mysql-dbimpots</param-value>
</init-param>
<init-param>
<param-name>admimpots</param-name>
<param-value>admimpots</param-value>
</init-param>
<init-param>
<param-name>mdpimpots</param-name>
<param-value>mdpimpots</param-value>
</init-param>
</servlet>
........
<servlet-mapping>
<servlet-name>xmlsimulations</servlet-name>
<url-pattern>/xmlsimulations</url-pattern>
</servlet-mapping>
</web-app>
- La servlet si chiama xmlsimulations e si basa sulla classe xmlsimulations.class.
- Come parametri utilizza i valori DSNimpots, admimpots e mdpimpots, necessari per accedere al database delle imposte. Inoltre, accetta altri due parametri:
- xslSimulations, che è il nome del file di stile che deve accompagnare la risposta XML contenente le simulazioni
- xslErreurs, che è il nome del file di stile che deve accompagnare la risposta XML contenente eventuali errori
- ha un alias xmlsimulations che la rende accessibile tramite URL http://localhost:8080/impots/xmlsimulations.
La struttura del servlet xmlsimulations è simile a quella del servlet simulations già esaminato. La differenza principale sta nel fatto che deve generare XML invece di HTML. Ciò comporterà l’eliminazione dei file JSP utilizzati nelle applicazioni precedenti. Il loro ruolo principale era quello di migliorare la leggibilità del codice HTML generato, evitando che questo fosse sepolto nel codice Java del servlet. Questo ruolo ora non ha più ragione di esistere. Il servlet deve generare due tipi di codice XML:
- quello per le simulazioni
- quello per gli errori
In precedenza abbiamo presentato e analizzato i due tipi di risposta XML da fornire in questi due casi, nonché i fogli di stile che devono accompagnarli. Il codice della servlet è il seguente:
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
import java.util.regex.*;
import java.util.*;
public class xmlsimulations extends HttpServlet{
// variabili di istanza
String msgErreur=null;
String xslSimulations=null;
String xslErreurs=null;
String DSNimpots=null;
String admimpots=null;
String mdpimpots=null;
impotsJDBC impots=null;
//-------- GET
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException{
// si recupera il flusso di scrittura verso il client
PrintWriter out=response.getWriter();
// si specifica il tipo di risposta
response.setContentType("text/xml");
// l'elenco degli errori
ArrayList erreurs=new ArrayList();
// L'inizializzazione è andata a buon fine?
if(msgErreur!=null){
// Operazione completata: si invia la risposta con gli errori al server
erreurs.add(msgErreur);
sendErreurs(out,xslErreurs,erreurs);
// È tutto
return;
}
// si recuperano le simulazioni precedenti della sessione
HttpSession session=request.getSession();
ArrayList simulations=(ArrayList)session.getAttribute("simulations");
if(simulations==null) simulations=new ArrayList();
// si recuperano i parametri della richiesta corrente
String optMarie=request.getParameter("optMarie"); // stato civile
String txtEnfants=request.getParameter("txtEnfants"); // numero di figli
String txtSalaire=request.getParameter("txtSalaire"); // stipendio annuo
// Sono presenti tutti i parametri previsti?
if(optMarie==null || txtEnfants==null || txtSalaire==null){
// mancano dei parametri
// si invia la risposta con gli errori
erreurs.add("Demande incomplète. Il manque des paramètres");
sendErreurs(out,xslErreurs,erreurs);
// è terminato
return;
}
// sono presenti tutti i parametri - li verifichiamo
// stato civile
if( ! optMarie.equals("oui") && ! optMarie.equals("non")){
// errore
erreurs.add("Etat marital incorrect");
}
// numero di figli
txtEnfants=txtEnfants.trim();
if(! Pattern.matches("^\\d+$",txtEnfants)){
// errore
erreurs.add("Nombre d'enfants incorrect");
}
// stipendio
txtSalaire=txtSalaire.trim();
if(! Pattern.matches("^\\d+$",txtSalaire)){
// errore
erreurs.add("Salaire incorrect");
}
if(erreurs.size()!=0){
// se ci sono errori, vengono segnalati
sendErreurs(out,xslErreurs,erreurs);
}else{
// nessun errore
try{
// è possibile calcolare l'imposta da versare
int nbEnfants=Integer.parseInt(txtEnfants);
int salaire=Integer.parseInt(txtSalaire);
String txtImpots=""+impots.calculer(optMarie.equals("oui"),nbEnfants,salaire);
// si aggiunge il risultato attuale alle simulazioni precedenti
String[] simulation={optMarie.equals("oui") ? "oui" : "non",txtEnfants, txtSalaire, txtImpots};
simulations.add(simulation);
// si invia la risposta con le simulazioni
sendSimulations(out,xslSimulations,simulations);
}catch(Exception ex){}
}//if-else
// si reinserisce l'elenco delle simulazioni nella sessione
session.setAttribute("simulations",simulations);
}//GET
//-------- POST
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException{
doGet(request,response);
}//POST
//-------- INIT
public void init(){
// si recuperano i parametri di inizializzazione
ServletConfig config=getServletConfig();
xslSimulations=config.getInitParameter("xslSimulations");
xslErreurs=config.getInitParameter("xslErreurs");
DSNimpots=config.getInitParameter("DSNimpots");
admimpots=config.getInitParameter("admimpots");
mdpimpots=config.getInitParameter("mdpimpots");
// parametri ok?
if(xslSimulations==null || DSNimpots==null || admimpots==null || mdpimpots==null){
msgErreur="Configuration incorrecte";
return;
}
// si crea un'istanza di impotsJDBC
try{
impots=new impotsJDBC(DSNimpots,admimpots,mdpimpots);
}catch(Exception ex){
msgErreur=ex.getMessage();
}
}//init
//-------- sendErreurs
private void sendErreurs(PrintWriter out,String xslErreurs,ArrayList erreurs){
String réponse="<?xml version=\"1.0\" encoding=\"windows-1252\"?>"
+ "<?xml-stylesheet type=\"text/xsl\" href=\""+xslErreurs+"\"?>\n"
+"<erreurs>\n";
for(int i=0;i<erreurs.size();i++){
réponse+="<erreur>"+(String)erreurs.get(i)+"</erreur>\n";
}//for
réponse+="</erreurs>\n";
// si invia la risposta
out.println(réponse);
}
//-------- sendSimulations
private void sendSimulations(PrintWriter out, String xslSimulations, ArrayList simulations){
String réponse="<?xml version=\"1.0\" encoding=\"windows-1252\"?>"
+ "<?xml-stylesheet type=\"text/xsl\" href=\""+xslSimulations+"\"?>\n"
+ "<simulations>\n";
String[] simulation=null;
for(int i=0;i<simulations.size();i++){
// simulazione n. i
simulation=(String[])simulations.get(i);
réponse+="<simulation "
+"marie=\""+(String)simulation[0]+"\" "
+"enfants=\""+(String)simulation[1]+"\" "
+"salaire=\""+(String)simulation[2]+"\" "
+"impot=\""+(String)simulation[3]+"\" />\n";
}//per
réponse+="</simulations>\n";
// si invia la risposta
out.println(réponse);
}
}
Analizziamo nel dettaglio le principali novità di questo codice rispetto a quanto già conoscevamo:
- la procedura init recupera nuovi parametri dal file di configurazione web.xml: i nomi dei due fogli di stile XSL che devono accompagnare la risposta vengono inseriti nelle variabili xslSimulations e xslErreurs. Questi due fogli di stile sono i file simulations.xsl e erreurs.xsl esaminati in precedenza. Questi sono collocati nella directory dell’applicazione impots:
dos>dir E:\data\serge\Servlets\impots\*.xsl
27/08/2002 08:15 1 030 simulations.xsl
27/08/2002 09:23 795 erreurs.xsl
- la procedura GET inizia verificando se si è verificato un errore durante l'inizializzazione. In caso affermativo, chiama la procedura sendErreurs che genera la risposta XML adatta a questo caso, quindi si interrompe. In questa risposta viene inserita l’istruzione XML che indica il foglio di stile da utilizzare.
- Se non si sono verificati errori, la procedura GET analizza i parametri della richiesta del cliente. Se rileva un errore qualsiasi, lo segnala utilizzando anche in questo caso la procedura sendErreurs. In caso contrario, calcola la nuova simulazione, la aggiunge a quelle precedenti memorizzate nella sessione corrente e conclude inviando la propria risposta XML tramite la procedura sendSimulations. Quest’ultima procede in modo analogo alla procedura sendErreurs.
- Si noti che il servlet annuncia la propria risposta come di tipo text/xml:
Ecco alcuni esempi di esecuzione. Il modulo iniziale viene compilato come segue:
Il database MySQL non è stato avviato, rendendo impossibile la creazione dell’oggetto impots nella procedura init del servlet. La risposta di quest’ultimo è quindi la seguente:
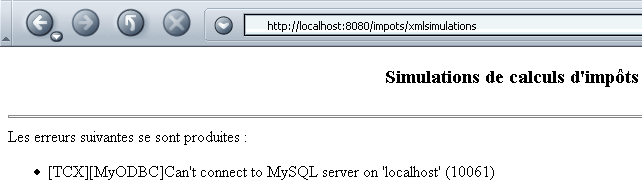
Il codice ricevuto dal browser (Visualizza/Sorgente) è il seguente:

Se ora si eseguono nuovamente due simulazioni dopo aver avviato il database MySQL, si ottiene il seguente risultato:
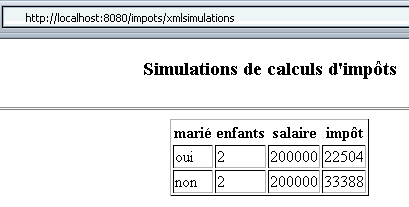
Questa volta il browser ha ricevuto il seguente codice:

Si noti che la nostra nuova applicazione è più semplice rispetto a prima grazie all’eliminazione dei file JSP. Parte del lavoro svolto da queste pagine è stato trasferito ai fogli di stile XSL. Il vantaggio della nostra nuova ripartizione dei compiti è che, una volta definito il formato XML delle risposte del servlet, lo sviluppo dei fogli di stile è indipendente da quello del servlet.
6.3. Analisi di un documento XML in Java
Le versioni 7 e 8 della nostra applicazione «impôts» saranno client programmati della precedente servlet «xmlsimulations». Questi riceveranno codice XML che dovranno analizzare per estrarne le informazioni di loro interesse. Facciamo qui una pausa nelle nostre diverse versioni per imparare come analizzare un documento XML in Java. Lo faremo partendo da un esempio fornito con JBuilder 7 chiamato MySaxParser. Il programma si chiama come segue:
L’applicazione MySaxParser accetta un parametro: l’URI (Uniform Resource Identifier) del documento XML da analizzare. Nel nostro esempio, questo URI sarà semplicemente il nome di un file XML presente nella directory dell'applicazione MySaxParser. Consideriamo due esempi di esecuzione. Nel primo esempio, il file XML analizzato è il file erreurs.xml:
<?xml version="1.0" encoding="ISO-8859-1"?>
<?xml-stylesheet type="text/xsl" href="erreurs.xsl"?>
<erreurs>
<erreur>erreur 1</erreur>
<erreur>erreur 2</erreur>
</erreurs>
L'analisi fornisce i seguenti risultati:
dos> java MySaxParser erreurs.xml
Début du document
Début élément <erreurs>
Début élément <erreur>
[erreur 1]
Fin élément <erreur>
Début élément <erreur>
[erreur 2]
Fin élément <erreur>
Fin élément <erreurs>
Fin du document
Non avevamo ancora spiegato a cosa servisse l'applicazione MySaxParser, ma qui si vede che visualizza la struttura del documento XML analizzato. Il secondo esempio analizza il file XML simulations.xml:
<?xml version="1.0" encoding="ISO-8859-1"?>
<?xml-stylesheet type="text/xsl" href="simulations.xsl"?>
<simulations>
<simulation marie="oui" enfants="2" salaire="200000" impot="22504"/>
<simulation marie="non" enfants="2" salaire="200000" impot="33388"/>
</simulations>
L'analisi fornisce i seguenti risultati:
dos>java MySaxParser simulations.xml
Début du document
Début élément <simulations>
Début élément <simulation>
marie = oui
enfants = 2
salaire = 200000
impot = 22504
Fin élément <simulation>
Début élément <simulation>
marie = non
enfants = 2
salaire = 200000
impot = 33388
Fin élément <simulation>
Fin élément <simulations>
Fin du document
La classe MySaxParser contiene tutto ciò di cui abbiamo bisogno nella nostra applicazione impots, poiché è stata in grado di individuare sia gli errori che le simulazioni che il server web potrebbe inviare. Esaminiamo il suo codice:
import java.io.IOException;
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import org.apache.xerces.parsers.SAXParser;
import java.util.regex.*;
// la classe
public class MySaxParser extends DefaultHandler {
// valore di un elemento dell'albero XML
private StringBuffer valeur=new StringBuffer();
// un'espressione regolare del valore di un elemento quando si desidera ignorare
// gli "spazi" che lo precedono o lo seguono
private static Pattern ptnValeur=null;
private static Matcher résultats=null;
// -------- main
public static void main(String[] argv) {
// verifica del numero di parametri
if (argv.length != 1) {
System.out.println("Usage: java MySaxParser [URI]");
System.exit(0);
}
// si recupera il URI dal file XML da analizzare
String uri = argv[0];
try {
// creazione di un analizzatore XML (parser)
XMLReader parser = XMLReaderFactory.createXMLReader("org.apache.xerces.parsers.SAXParser");
// si indica al parser l'oggetto che implementerà i metodi
// startDocument, endDocument, startElement, endElement, caratteri
MySaxParser MySaxParserInstance = new MySaxParser();
parser.setContentHandler(MySaxParserInstance);
// si inizializza il modello di valore di un elemento
ptnValeur=Pattern.compile("^\\s*(.*?)\\s*$");
// si indica al parser il documento XML da analizzare
parser.parse(uri);
}
catch(Exception ex) {
// errore
System.err.println("Erreur : " + ex);
// traccia
ex.printStackTrace();
}
}//main
// -------- startDocument
public void startDocument() throws SAXException {
// procedura chiamata quando il parser incontra l'inizio del documento
System.out.println("Début du document");
}//startDocument
// -------- endDocument
public void endDocument() throws SAXException {
// procedura chiamata quando il parser raggiunge la fine del documento
System.out.println("Fin du document");
}//endDocument
// -------- startElement
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
// procedura chiamata dal parser quando incontra l'inizio di un tag
// URI: URI del documento analizzato?
// localName: nome dell'elemento attualmente in fase di analisi
// qName: idem, ma “qualificato” da uno spazio dei nomi, se presente
// attributes: elenco degli attributi dell'elemento
// monitoraggio
System.out.println("Début élément <"+localName+">");
// l'elemento ha degli attributi?
for (int i = 0; i < attributes.getLength(); i++) {
System.out.println(attributes.getLocalName(i) + " = " + attributes.getValue(i));
}//per
}//startElement
// -------- caratteri
public void characters(char[] ch, int start, int length) throws SAXException {
// procedura richiamata ripetutamente dal parser quando incontra del testo
// tra due tag <tag>testo</tag>
// il testo si trova in ch a partire dal carattere start per length caratteri
// il testo viene aggiunto al buffer valore
valeur.append(ch, start, length);
}//caratteri
// -------- endElement
public void endElement(String uri, String localName, String qName)
throws SAXException {
// procedura chiamata dal parser quando incontra la fine di un tag
// URI: URI del documento analizzato?
// localName: nome dell'elemento attualmente in fase di analisi
// qName: idem, ma “qualificato” da uno spazio dei nomi, se presente
// viene visualizzato il valore dell'elemento
String strValeur=valeur.toString();
if (ptnValeur==null) System.out.println("null");
résultats=ptnValeur.matcher(strValeur);
if (résultats.find() && ! résultats.group(1).equals("")){
System.out.println("["+résultats.group(1)+"]");
}//if
// si imposta il valore dell'elemento su vuoto
valeur.setLength(0);
// seguito da
System.out.println("Fin élément <"+localName+">");
}//endElement
}//classe
Per prima cosa definiamo un acronimo che ricorre frequentemente nell'analisi dei documenti XML: SAX, che significa Simple API for XML. Si tratta di un insieme di classi Java che facilitano il lavoro con i documenti XML. Esistono due versioni di API: SAX1 e SAX2. L’applicazione sopra citata utilizza API e SAX2.
L'applicazione importa una serie di pacchetti:
I primi due sono inclusi nella versione 1.4 di JDK, mentre il terzo no. Il pacchetto xerces.jar è disponibile sul sito del server Web Apache. È fornito con JBuilder 7 ma anche con Tomcat 4.x:
Se quindi si desidera compilare l’applicazione precedente al di fuori di JBuilder 7 e si dispone di JDK 1.4 e di Tomcat 4.x, si potrà scrivere:
All’esecuzione, si procederà allo stesso modo:
dos>java -classpath ".;E:\Program Files\Apache Tomcat 4.0\common\lib\xerces.jar" MySaxParser simulations.xml
La classe MySaxParser deriva dalla classe DefaultHandler. Ci torneremo più avanti. Esaminiamo il codice della procedura main:
// si recupera il URI dal file XML da analizzare
String uri = argv[0];
try {
// creazione di un analizzatore XML (parser)
XMLReader parser = XMLReaderFactory.createXMLReader("org.apache.xerces.parsers.SAXParser");
// si indica al parser l'oggetto che implementerà i metodi
// startDocument, endDocument, startElement, endElement, caratteri
MySaxParser MySaxParserInstance = new MySaxParser();
parser.setContentHandler(MySaxParserInstance);
// si inizializza il modello di valore di un elemento
ptnValeur=Pattern.compile("^\\s*(.*?)\\s*$");
// si indica al parser il documento XML da analizzare
parser.parse(uri);
}
catch(Exception ex) {
// errore
System.err.println("Erreur : " + ex);
// traccia
ex.printStackTrace();
}
Per analizzare un documento XML, la nostra applicazione necessita di un analizzatore di codice XML denominato "parser".
Il parser XML utilizzato è quello fornito dal pacchetto xerces.jar. L’oggetto recuperato è di tipo XMLReader. XMLReader è un’interfaccia di cui qui utilizziamo due metodi:
indica al parser l’oggetto di tipo ContentHandler che gestirà gli eventi che genererà durante l’analisi del documento XML | |
avvia l’analisi del documento XML passato come parametro |
Quando il parser analizzerà il documento XML, emetterà eventi quali: «ho individuato l’inizio del documento, l’inizio di un tag, un attributo di tag, il contenuto di un tag, la fine di un tag, la fine del documento, ...». Trasmette questi eventi all’oggetto ContentHandler che gli è stato fornito. ContentHandler è un’interfaccia che definisce i metodi da implementare per gestire tutti gli eventi che il parser XML può generare. DefaultHandler è una classe che fornisce un’implementazione predefinita di questi metodi. I metodi implementati in DefaultHandler non eseguono alcuna operazione, ma esistono comunque. Quando è necessario indicare al parser quale oggetto gestirà gli eventi che genererà tramite l’istruzione
, è quindi pratico passare come parametro un oggetto di tipo DefaultHandler. Se ci fermassimo qui, nessun evento del parser verrebbe gestito, ma il nostro programma sarebbe sintatticamente corretto. In pratica, si passa come parametro al parser un oggetto derivato dalla classe DefaultHandler, in cui sono ridefiniti i metodi che gestiscono solo gli eventi che ci interessano. È ciò che viene fatto qui:
// si indica al parser l'oggetto che implementerà i metodi
// startDocument, endDocument, startElement, endElement, caratteri
MySaxParser MySaxParserInstance = new MySaxParser();
parser.setContentHandler(MySaxParserInstance);
// si indica al parser il documento XML da analizzare
parser.parse(uri);
Passiamo al parser un'istanza della classe mySaxParser, che è la nostra classe ed è stata definita in precedenza tramite la dichiarazione
e avviamo l'analisi del documento di cui abbiamo passato l'oggetto URI come parametro. A questo punto, ha inizio l'analisi del documento XML. Il parser genera degli eventi e, per ciascuno di essi, chiama un metodo specifico dell’oggetto incaricato di gestirli, in questo caso il nostro oggetto MySaxParser. Quest’ultimo gestisce cinque eventi specifici, mentre gli altri vengono ignorati:
evento generato dal parser | metodo di elaborazione |
void startDocument() | |
void endDocument() | |
public void startElement(String uri, String localName, String qName, Attributes attributes) uri: ? localName: nome dell'elemento analizzato. Se l'elemento individuato è <simulations>, si avrà localName="simulations". qName: nome qualificato da uno spazio dei nomi dell'elemento analizzato. Un documento XML può definire uno spazio dei nomi, ad esempio XX. Il nome qualificato del tag precedente sarebbe quindi XX:simulations. attributes: elenco degli attributi del tag | |
public void characters(char[] ch, int start, int length) ch: array di caratteri start: indice del primo carattere da utilizzare nell'array ch length: numero di caratteri da prelevare dall'array ch Il metodo characters può essere chiamato più volte. Per costruire il valore di un elemento, si utilizza quindi un buffer che:
| |
void endElement(String uri, String localName, String qName) i parametri sono quelli del metodo startElement. |
Il metodo startElement consente di recuperare gli attributi dell'elemento tramite il parametro attributes di tipo Attributes:
- il numero di attributi è disponibile in attributes.getLength()
- il nome dell'attributo i è disponibile in attributes.getLocalName(i)
- il valore dell'attributo i è disponibile in attributes.getValue(i)
- il valore dell'attributo denominato localName in attributes.getValue(localName)
Una volta chiarito questo, il programma precedente, corredato dagli esempi di esecuzione, risulta di per sé comprensibile. È stata utilizzata un'espressione regolare per recuperare i valori degli elementi in modo che un testo XML come:
fornisca come valore associato al tag <erreur> il testo «errore 1», privo di spazi e interruzioni di riga che potrebbero precederlo e/o seguirlo.
6.4. Applicazione fiscale: versione 7
Ora disponiamo di tutti gli elementi necessari per scrivere i client programmati per il nostro servizio fiscale che genera XML. Riprendiamo la versione 4 della nostra applicazione per realizzare il client e manteniamo la versione 6 per quanto riguarda il server. In questa applicazione client-server:
- il servizio di simulazione del calcolo delle imposte è gestito dal servlet xmlsimulations. La risposta del server è quindi nel formato XML, come abbiamo visto nella versione 6.
- il client non è più un browser, ma un client Java autonomo. La sua interfaccia grafica è quella della versione 4.
Ecco alcuni esempi di esecuzione. Innanzitutto un caso di errore: il client interroga la servlet xmlsimulations mentre questa non è riuscita a inizializzarsi correttamente poiché il processo SGBD MySQL non era stato avviato:
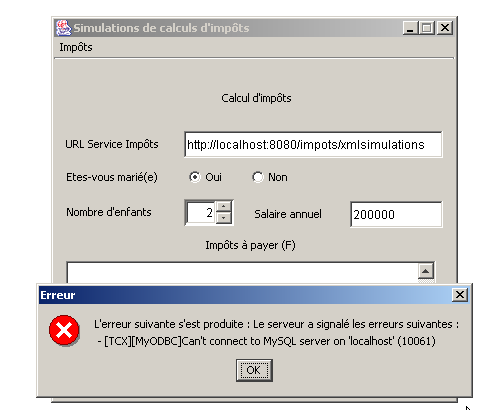
Si avvia MySQL e si eseguono alcune simulazioni:
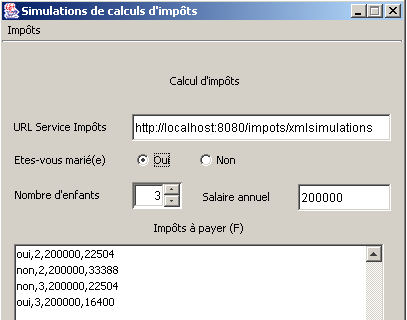
Il client di questa nuova versione differisce da quello della versione 4 solo per il modo in cui gestisce la risposta del server. Nient’altro cambia. Nella versione 4, il client riceveva il codice HTML, dal quale estraeva le informazioni di suo interesse utilizzando espressioni regolari. Qui il client riceve il codice XML, dal quale estrae le informazioni di suo interesse utilizzando un parser XML.
Ricordiamo le linee generali della procedura relativa al menu «Calcola» della versione 4 del nostro client, poiché è principalmente lì che vengono apportate le modifiche:
void mnuCalculer_actionPerformed(ActionEvent e) {
....
try{
// si calcola l'imposta
calculerImpots(urlImpots,rdOui.isSelected(),nbEnfants.intValue(),salaire);
}catch (Exception ex){
// viene visualizzato l'errore
JOptionPane.showMessageDialog(this,"L'erreur suivante s'est produite : " + ex.getMessage(),"Erreur",JOptionPane.ERROR_MESSAGE);
}
....
}//mnuCalculer_actionPerformed
public void calculerImpots(URL urlImpots,boolean marié, int nbEnfants, int salaire)
throws Exception{
// calcolo dell'imposta
// urlImpots: URL dell'ufficio delle imposte
// sposato: true se sposato, false altrimenti
// nbEnfants: numero di figli
// stipendio: stipendio annuale
// da urlImpots si estraggono le informazioni necessarie per la connessione al server dell'agenzia delle entrate
....
try{
// si effettua la connessione al server
....
// si creano i flussi di entrata e uscita del cliente TCP
....
// si richiede l'URL - invio delle intestazioni HTTP
....
// si legge la prima riga della risposta
....
// si legge la risposta fino alla fine delle intestazioni cercando l'eventuale cookie
while((réponse=IN.readLine())!=null){
.... }//while
// le intestazioni sono terminate HTTP - si passa al codice HTML
// per recuperare le simulazioni
ArrayList listeSimulations=getSimulations(IN,OUT,simulations);
simulations.clear();
for (int i=0;i<listeSimulations.size();i++){
simulations.addElement(listeSimulations.get(i));
}
// è tutto
....
}//calculerImpots
private ArrayList getSimulations(BufferedReader IN, PrintWriter OUT, DefaultListModel simulations) throws Exception{
....
}
Tutto questo codice rimane valido nella nuova versione. Solo l'elaborazione della risposta HTML del server (parte evidenziata sopra) e la sua visualizzazione devono essere sostituite dall'elaborazione della risposta XML del server e dalla sua visualizzazione:
// è tutto per le intestazioni HTTP - si passa al codice XML
// per recuperare le simulazioni o gli errori
ImpotsSaxParser parseur=new ImpotsSaxParser(IN);
ArrayList listeErreurs=parseur.getErreurs();
ArrayList listeSimulations=parseur.getSimulations();
// chiusura della connessione al server
client.close();
// pulizia dell'elenco di visualizzazione
simulations.clear();
// errori
if(listeErreurs.size()!=0){
// si concatenano tutti gli errori
String msgErreur="Le serveur a signalé les erreurs suivantes :\n";
for(int i=0;i<listeErreurs.size();i++){
msgErreur+=" - "+(String)listeErreurs.get(i);
}
// visualizzazione errori
throw new Exception(msgErreur);
}//if
// simulazioni
for (int i=0;i<listeSimulations.size();i++){
simulations.addElement(listeSimulations.get(i));
}
return;
Cosa fa il frammento di codice sopra riportato?
- Crea un parser XML e gli passa il flusso IN che contiene il codice XML inviato dal server. Questo flusso conteneva anche le intestazioni HTTP, ma queste sono già state lette ed elaborate. Rimane quindi solo la parte XML della risposta. Il parser genera due elenchi di stringhe: l’elenco degli errori, se presenti, oppure quello delle simulazioni. Questi due elenchi si escludono a vicenda.
- Se l’elenco degli errori non è vuoto, i messaggi in esso contenuti vengono concatenati in un unico messaggio di errore e viene generata un’eccezione con tale messaggio come parametro. Questa eccezione viene visualizzata nella procedura mnuCalculer_actionPeformed che ha chiamato calculerImpots.
- Se l’elenco delle simulazioni non è vuoto, viene visualizzato nel componente jList dell’interfaccia grafica.
Esaminiamo ora il parser della risposta XML del server, parser che deriva direttamente dallo studio che abbiamo condotto in precedenza su come analizzare un documento XML in Java:
import java.io.IOException;
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import org.apache.xerces.parsers.SAXParser;
import java.util.regex.*;
import java.io.*;
import java.util.*;
import javax.swing.*;
// la classe
public class ImpotsSaxParser extends DefaultHandler {
// valore di un elemento dell'albero XML
private StringBuffer valeur=new StringBuffer();
// un'espressione regolare del valore di un elemento quando si desidera ignorare
// gli «spazi» che lo precedono o lo seguono
private Pattern ptnValeur=null;
private Matcher résultats=null;
// gli elenchi di elementi XML
private ArrayList listeSimulations=new ArrayList();
private ArrayList listeErreurs=new ArrayList();
// elementi XML
private ArrayList éléments=new ArrayList();
String élément="";
// -------- produttore
public ImpotsSaxParser(BufferedReader IN) throws Exception{
// creazione di un analizzatore XML (parser)
XMLReader parser = XMLReaderFactory.createXMLReader("org.apache.xerces.parsers.SAXParser");
// si indica al parser l'oggetto che implementerà i metodi
// startDocument, endDocument, startElement, endElement, caratteri
parser.setContentHandler(this);
// si inizializza il modello di valore di un elemento
ptnValeur=Pattern.compile("^\\s*(.*?)\\s*$");
// inizialmente non è presente alcun elemento XML corrente
éléments.add("");
// si analizza il documento
parser.parse(new InputSource(IN));
}//generatore
// -------- startElement
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
// procedura chiamata dal parser quando incontra l’inizio di un tag
// URI: URI del documento analizzato?
// localName: nome dell'elemento attualmente in fase di analisi
// qName: idem, ma “qualificato” da uno spazio dei nomi, se presente
// attributes: elenco degli attributi dell'elemento
// si indica il nome dell'elemento
élément=localName.toLowerCase();
éléments.add(élément);
// l'elemento ha degli attributi?
if(élément.equals("simulation") && attributes.getLength()==4){
// si tratta di una simulazione: si recuperano gli attributi
String simulation=attributes.getValue("marie")+","+
attributes.getValue("enfants")+","+
attributes.getValue("salaire")+","+
attributes.getValue("impot");
// si aggiunge la simulazione all'elenco delle simulazioni
listeSimulations.add(simulation);
}//if
}//startElement
// -------- caratteri
public void characters(char[] ch, int start, int length) throws SAXException {
// procedura richiamata ripetutamente dal parser quando incontra del testo
// tra due tag <tag>testo</tag>
// il testo si trova in ch a partire dal carattere start per length caratteri
// il testo viene aggiunto al buffer valore se si tratta dell'elemento errore
if (élément.equals("erreur"))
valeur.append(ch, start, length);
}//caratteri
// -------- endElement
public void endElement(String uri, String localName, String qName)
throws SAXException {
// procedura chiamata dal parser quando incontra la chiusura di un tag
// URI: URI del documento analizzato?
// localName: nome dell'elemento attualmente in fase di analisi
// qName: idem, ma “qualificato” da uno spazio dei nomi, se presente
// caso di errore
if(élément.equals("erreur")){
// si recupera il valore dell'elemento di errore
String strValeur=valeur.toString();
// si eliminano gli "spazi" superflui e lo si registra nell'elenco degli
// errori, se non è vuota
résultats=ptnValeur.matcher(strValeur);
if (résultats.find() && ! résultats.group(1).equals("")){
listeErreurs.add(résultats.group(1));
}//if
}
// si imposta il valore dell'elemento su vuoto
valeur.setLength(0);
// si reimposta il nome dell'elemento
éléments.remove(éléments.size()-1);
élément=(String)éléments.get(éléments.size()-1);
}//endElement
// --------- getErreurs
public ArrayList getErreurs(){
return listeErreurs;
}
// --------- getSimulations
public ArrayList getSimulations(){
return listeSimulations;
}
}//classe
- il produttore riceve il flusso XML IN da analizzare e procede immediatamente all'analisi. Una volta completata l’analisi, l’oggetto è stato creato e sono stati generati gli elenchi (ArrayList) degli errori (listeErreurs) e delle simulazioni (listeSimulations). Alla procedura che ha creato l’oggetto non resta che recuperare i due elenchi utilizzando i metodi getErreurs e getSimulations.
- In questo contesto ci interessano solo tre eventi generati dal parser XML:
- l’inizio di un elemento XML, evento che verrà gestito dalla procedura startElement. Quest’ultima dovrà gestire i tag <simulation marie=".." enfants=".." salaire=".." impot=".."> e <erreur>...</erreur>.
- valore di un elemento XML, evento che verrà gestito dalla procedura characters.
- fine di un elemento XML, evento che verrà gestito dalla procedura endElement.
- nella procedura startElement, se si ha a che fare con l'elemento <simulation marie=".." enfants=".." salaire=".." impot="..">, si recuperano i quattro attributi tramite attributes.getValue("nome dell'attributo"). In ogni caso, si memorizza il nome dell’elemento in una variabile «elemento» e lo si aggiunge a un elenco (ArrayList) di elementi: elem1, elem2, …, elemn. Questo elenco viene gestito come uno stack il cui ultimo elemento è l’elemento XML attualmente in fase di analisi. Quando si verifica l’evento “fine elemento”, l’ultimo elemento dell’elenco viene rimosso e il nuovo elemento corrente viene aggiornato. Ciò avviene nella procedura endElement.
- La procedura `characters` è identica a quella esaminata in un esempio precedente. Ci si limita semplicemente a verificare che l'elemento corrente sia effettivamente l'elemento <erreur>, precauzione che normalmente qui non sarebbe necessaria. Questo tipo di precauzione era stata adottata anche nella procedura startElement per verificare che si trattasse di un elemento <simulation>.
6.5. Conclusione
Grazie alla sua risposta XML, l’applicazione impots è diventata più facile da gestire sia per il suo progettista che per i progettisti delle applicazioni client.
- La progettazione dell’applicazione server può ora essere affidata a due figure professionali: lo sviluppatore Java del servlet e il grafico che gestirà l’aspetto della risposta del server nei browser. A quest’ultimo basta conoscere la struttura della risposta XML del server per creare i fogli di stile che la accompagneranno. Ricordiamo che questi ultimi sono oggetto di file XSL separati e indipendenti dal servlet Java. Il grafico può quindi lavorare indipendentemente dallo sviluppatore Java.
- Anche i progettisti delle applicazioni client devono semplicemente conoscere la struttura della risposta XML del server. Le modifiche che il grafico potrebbe apportare ai fogli di stile non hanno alcuna ripercussione su questa risposta XML, che rimane sempre la stessa. Si tratta di un enorme vantaggio.
- Come può lo sviluppatore far evolvere il proprio servlet Java senza compromettere il funzionamento del sistema? Innanzitutto, fintanto che la sua risposta XML non cambia, può organizzare il proprio servlet come preferisce. Può anche aggiornare la risposta XML purché mantenga gli elementi <errore> e <simulazione> previsti dai propri clienti. Può quindi aggiungere nuovi tag a questa risposta. Il grafico ne terrà conto nei propri fogli di stile e i browser potranno visualizzare le nuove versioni della risposta. I client programmati, invece, continueranno a funzionare con il vecchio modello, ignorando semplicemente i nuovi tag. Affinché ciò sia possibile, è necessario che nell’analisi XML della risposta del server i tag ricercati siano correttamente identificati. È quanto è stato fatto nel nostro client XML dell’applicazione fiscale, dove nelle procedure si specificava espressamente che venivano trattati i tag <erreur> e <simulation>. Di conseguenza, gli altri tag vengono ignorati.