2. Articolo 1 - Spring IoC
Obiettivi del documento:
- scoprire le possibilità di configurazione e integrazione del framework Spring (http://www.springframework.org)
- definire e utilizzare il concetto di IoC (Inversion of Control), noto anche come iniezione di dipendenze (Dependency Injection)
2.1. Configurare un'applicazione a 3 livelli con Spring
Consideriamo un'applicazione a 3 livelli classica:
 |
Supponiamo che l’accesso ai livelli di business e DAO sia controllato da interfacce Java:
- l’interfaccia [IArticlesDao] per il livello di accesso ai dati
- l’interfaccia [IArticlesManager] per il livello business
Nel livello di accesso ai dati o livello DAO (Data Access Object), è frequente lavorare con un SGBD e quindi con un driver JDBC. Consideriamo lo scheletro di una classe che accede a una tabella di articoli in un SGBD:
Per eseguire un'operazione sul SGBD, ogni metodo necessita di un oggetto [Connection] che rappresenti la connessione al database, attraverso la quale transiteranno gli scambi tra quest'ultimo e il codice Java. Per creare questo oggetto, sono necessarie quattro informazioni:
il nome della classe del driver JDBC del SGBD | |
l’URL JDBC del database da utilizzare | |
l'identità con cui si crea la connessione | |
la password di tale identità |
Come può la nostra classe [ArticlesDaoPlainJdbc] ottenere queste informazioni? Esistono diverse possibilità:
soluzione 1 - le informazioni sono codificate in modo statico nella classe:
Lo svantaggio di questa soluzione è che occorre modificare il codice Java ogni volta che si verifica una modifica di tali informazioni, ad esempio la modifica della password.
Soluzione 2 - le informazioni vengono trasmesse all'oggetto al momento della sua creazione:
In questo caso, l’oggetto riceve al momento della sua creazione le informazioni di cui ha bisogno per funzionare. Il problema si sposta quindi sul codice che gli ha trasmesso le quattro informazioni. Come le ha ottenute? La seguente classe [ArticlesManagerWithDataBase] del livello business potrebbe creare un oggetto [ArticlesDaoPlainJdbc] del livello di accesso ai dati:
 |
Si nota che anche in questo caso le informazioni necessarie alla creazione dell’oggetto [ArticlesDaoPlainJdbc] vengono fornite al costruttore dell’oggetto [ArticlesManagerWithDataBase]. È possibile immaginare che gli vengano trasmesse da un livello superiore, come il livello di interfaccia con l’utente. Si arriva così, passo dopo passo, al livello più alto dell’applicazione. Data la sua posizione, quest’ultimo non viene chiamato da un livello che potrebbe trasmettergli le informazioni di configurazione di cui ha bisogno. È quindi necessario trovare una soluzione alternativa alla configurazione tramite costruttore. La soluzione più comune per configurare un’applicazione a livello del suo livello più alto consiste nell’utilizzare un file in cui sono contenute tutte le informazioni soggette a modifiche nel tempo. Possono esserci diversi file di questo tipo. All’avvio dell’applicazione, un livello di inizializzazione creerà quindi tutti o parte degli oggetti necessari ai diversi livelli dell’applicazione.
Esiste un’ampia varietà di file di configurazione. La tendenza attuale è quella di utilizzare file XML. È l’opzione scelta da Spring. Il file che configura un oggetto [ArticlesDaoPlainJdbc] potrebbe essere il seguente:
Un’applicazione è un insieme di oggetti che Spring chiama «bean», poiché seguono lo standard JavaBean per la denominazione dei metodi di accesso e inizializzazione (getter/setter) dei campi privati di un oggetto. Gli oggetti che, in un’applicazione, hanno il ruolo di fornire un servizio vengono spesso creati in un unico esemplare. Vengono chiamati singleton. Pertanto, nell’esempio di applicazione multi-tier qui esaminato, l’accesso al database degli articoli sarà gestito da un unico esemplare della classe [ArticlesDaoPlainJdbc]. In un’applicazione web, questi oggetti di servizio servono più clienti contemporaneamente. Non viene creato un oggetto di servizio per ogni cliente.
Il file di configurazione Spring sopra riportato consente di creare un unico oggetto di servizio di tipo [ArticlesDaoPlainJdbc] in un pacchetto denominato [istia.st.articles.dao]. Le quattro informazioni necessarie al costruttore di questo oggetto sono definite all’interno di un tag <bean>...</bean>. Si avranno tanti tag <bean> quanti sono i singleton da costruire.
Quando avviene la creazione degli oggetti definiti nel file Spring? L’inizializzazione di un’applicazione può essere affidata al metodo main della stessa applicazione, se ne possiede uno. Per un’applicazione web, potrebbe trattarsi del metodo [init] del servlet principale. In ogni applicazione è presente un metodo che viene eseguito per primo. È generalmente in questo metodo che avviene la creazione dei singleton.
Facciamo un esempio. Supponiamo di voler testare la classe [ArticlesDaoPlainJdbc] precedente utilizzando un test JUnit. Una classe di test JUnit contiene un metodo [setUp] che viene eseguito prima di qualsiasi altro metodo. È lì che verrà creato il singleton [ArticlesDaoPlainJdbc].
Se si segue la soluzione che prevede il passaggio delle informazioni di configurazione tramite il costruttore, si otterrà la seguente classe di test:
La classe chiamante [TestArticlesPlainJdbc] deve conoscere le quattro informazioni necessarie per l’inizializzazione del singleton [ArticlesDaoPlainJdbc] da costruire.
Se si segue la soluzione che prevede il passaggio delle informazioni di configurazione tramite file di configurazione, si potrebbe ottenere la seguente classe di test utilizzando il file Spring descritto in precedenza.
In questo caso, la classe di chiamata [TestSpringArticlesPlainJdbc] non deve conoscere le informazioni necessarie per l’inizializzazione del singleton da creare. Deve semplicemente conoscere:
- [springArticlesPlainJdbc.xml]: il nome del file di configurazione Spring descritto in precedenza
- [articlesDao]: il nome del singleton da creare
Una modifica al file di configurazione, al di fuori di queste due entità, non ha alcun impatto sul codice Java. Questo metodo di configurazione degli oggetti di un’applicazione è molto flessibile. Per configurarsi, l’applicazione deve conoscere solo due cose:
- il nome del file Spring che contiene la definizione dei singleton da creare
- i nomi di questi singleton, che servono al codice Java per ottenere un riferimento agli oggetti a cui sono stati associati tramite il file di configurazione
2.2. Iniezione di dipendenze e inversione di controllo
Introduciamo ora il concetto di iniezione di dipendenze (Dependency Injection) utilizzato da Spring per configurare le applicazioni. Si utilizza anche il termine inversione di controllo (IoC, Inversion of Control). Consideriamo la creazione del singleton [ArticlesManagerWithDataBase] del livello business della nostra applicazione:
 |
Per accedere ai dati del SGBD, il livello business deve utilizzare i servizi di un oggetto che implementi l’interfaccia [IArticlesDao], ad esempio un oggetto di tipo [ArticlesDaoPlainJdbc]. Il codice della classe [ArticlesManagerWithDataBase] potrebbe essere simile al seguente:
public class ArticlesManagerWithDataBase implements IArticlesManager {
// un'istanza di accesso ai dati
private IArticlesDao articlesDao;
....
public ArticlesManagerWithDataBase (String driverClassName, String url, String user, String pwd, ...) {
...
// creazione del servizio di accesso ai dati
articlesDao =(IArticlesDao)new ArticlesDaoPlainJdbc(driverClassName,url,user,pwd);
...
}
public ... doSomething(...){
...
}
}
La classe [ArticlesDaoPlainJdbc] dovrebbe implementare qui un'interfaccia [IArticlesDao]:
Per creare il singleton di tipo [IArticlesDao] necessario al funzionamento della classe, il costruttore di quest'ultima utilizza esplicitamente il nome della classe di implementazione dell'interfaccia [IArticlesDao]:
Si ha quindi una dipendenza rigida nel codice dal nome della classe. Se la classe di implementazione dell’interfaccia [IArticlesDao] dovesse cambiare, il codice del costruttore precedente dovrebbe essere modificato. Si hanno le seguenti relazioni tra gli oggetti:
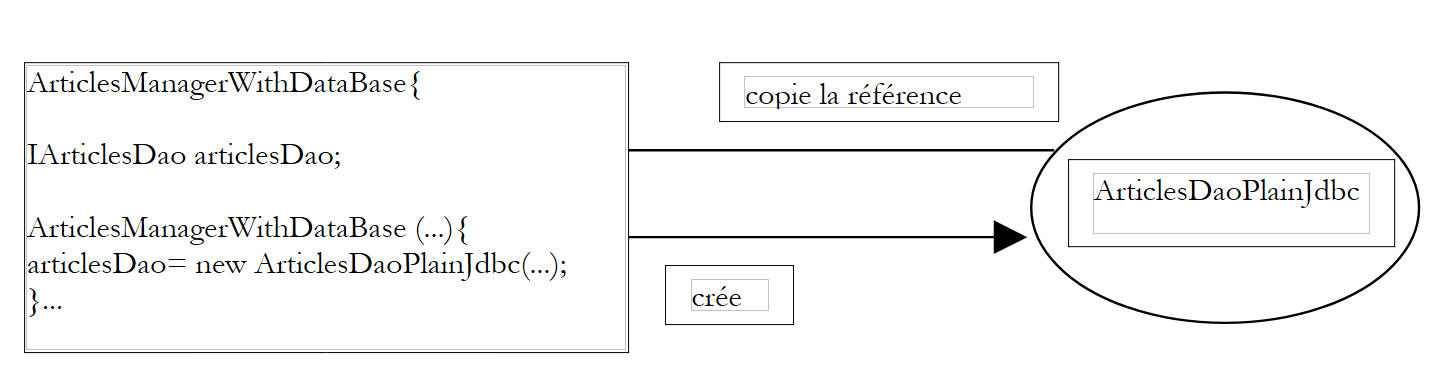 |
La classe [ArticlesManagerWithDataBase] prende autonomamente l'iniziativa di creare l'oggetto [ArticlesDaoPlainJdbc] di cui ha bisogno. Tornando al termine "inversione di controllo", si dirà che è lei ad avere il "controllo" per creare l'oggetto di cui ha bisogno.
Se dovessimo scrivere una classe di test JUnit per la classe [ArticlesManagerWithDataBase], potremmo ottenere qualcosa di simile a quanto segue:
La classe di test crea un’istanza della classe di business [ArticlesManagerWithDataBase] che, a sua volta, nel proprio costruttore, crea un’istanza della classe di accesso ai dati [ArticlesDaoPlainJdbc].
La soluzione con Spring eliminerà la necessità per la classe di business [ArticlesManagerWithDataBase] di conoscere il nome [ArticlesDaoPlainJdbc] della classe di accesso ai dati di cui ha bisogno. Ciò consentirà di modificarla senza intervenire sul codice Java della classe di business. Spring consentirà di creare contemporaneamente i due singleton, quello del livello di accesso ai dati e quello del livello business. Il file di configurazione di Spring definirà un nuovo bean:
La novità risiede nel bean che definisce il singleton della classe di business da creare:
<bean id="articlesManager" class="istia.st.articles.domain.ArticlesManagerWithDataBase">
<property name="articlesDao">
<ref bean="articlesDao"/>
</property>
</bean>
- è definita la classe che implementa il bean [articlesManager]: [ArticlesManagerWithDataBase]
- il campo [articlesDao] del bean riceve un valore tramite il tag <property name="articlesDao">. Si tratta del campo definito nella classe [ArticlesManagerWithDataBase]:
Affinché il campo [articlesDao] possa essere inizializzato da Spring tramite il tag <property>, è necessario che il campo rispetti lo standard JavaBean e che esista un metodo [setArticlesDao] per inizializzare il campo [articlesDao]. Si noti il nome del metodo, derivato in modo ben preciso dal nome del campo. Parallelmente, esiste spesso un metodo [get...] per ottenere il valore del campo. In questo caso, si tratta del metodo [getArticlesDao]. In questa nuova versione, la classe [ArticlesManagerWithDataBase] non ha più un costruttore. Non ne ha più bisogno.
- Il valore che verrà assegnato al campo [articlesDao] da Spring è quello del bean [articlesDao] definito nel suo file di configurazione:
<bean id="articlesManager" class="istia.st.articles.domain.ArticlesManagerWithDataBase">
<property name="articlesDao">
<ref bean="articlesDao"/>
</property>
</bean>
<bean id="articlesDao" class="istia.st.articles.dao.ArticlesDaoPlainJdbc">
<constructor-arg index="0">
.............
</bean>
- quando Spring creerà il singleton [ArticlesManagerWithDataBase], dovrà creare anche il singleton [ArticlesDaoPlainJdbc]:
- Spring creerà un grafico delle dipendenze dei bean e noterà che il bean [articlesManager] dipende dal bean [articlesDao]
- creerà il bean [articlesDao], ovvero un oggetto di tipo [ArticlesDaoPlainJdbc]
- quindi creerà il bean [articlesManager] di tipo [ArticlesManagerWithDataBase]
Immaginiamo ora un test JUnit per la classe [ArticlesManagerWithDataBase]. Potrebbe essere simile al seguente:
Seguiamo il processo di creazione dei due singleton definiti nel file Spring denominato [springArticlesManagerWithDataBase.xml].
- Il metodo [setUp] sopra riportato richiede un riferimento al bean denominato [articlesManager]
- Spring consulta il proprio file di configurazione e individua il bean [articlesManager]. Se è già stato creato, si limita a restituire un riferimento all’oggetto (singleton); in caso contrario, lo crea.
- Spring rileva la dipendenza del bean [articlesManager] dal bean [articlesDao]. Crea quindi il singleton [articlesDao] di tipo [ArticlesDaoPlainJdbc] se quest’ultimo non è già stato creato (singleton).
- Crea il singleton [articlesManager] di tipo [ArticlesManagerWithDataBase]
Questo meccanismo potrebbe essere schematizzato come segue:
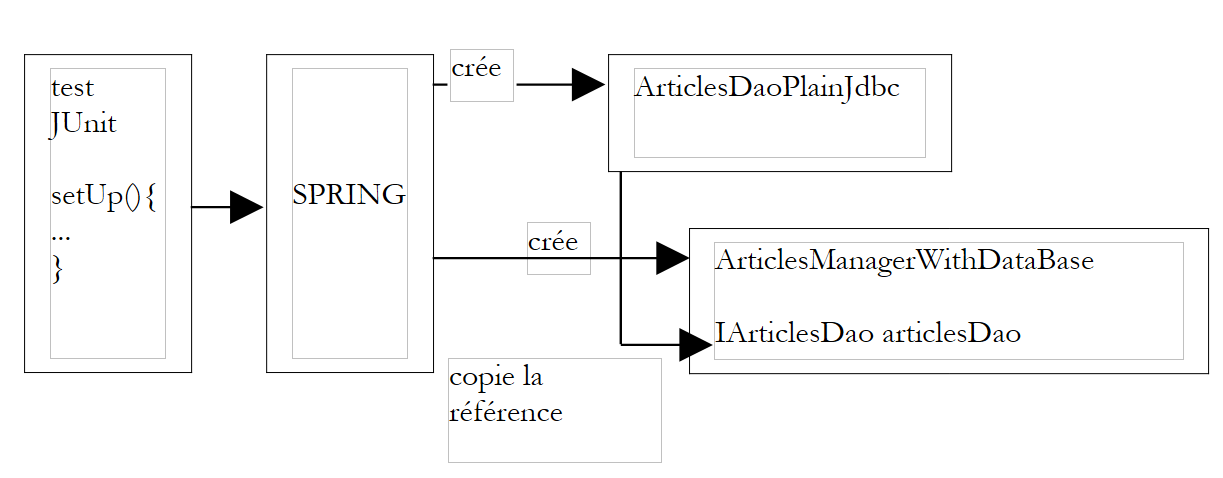 |
Ricordiamo la struttura della classe [ArticlesManagerWithDataBase]:
Al termine della creazione dei singleton da parte di Spring, si ottiene un oggetto di tipo [ArticlesManagerWithDataBase] il cui campo [articlesDao] è stato inizializzato senza che esso ne conosca il modo. Si dice che sia stata iniettata una dipendenza nell’oggetto [ArticlesManagerWithDataBase]. Si dice anche che si sia invertito il controllo: non è più l’oggetto [ArticlesManagerWithDataBase] a prendere l’iniziativa di creare autonomamente l’oggetto che implementa l’interfaccia [IArticlesDao] di cui ha bisogno, ma è l’applicazione al livello più alto (al momento dell’inizializzazione) che si occupa di creare tutti gli oggetti di cui ha bisogno, gestendo le dipendenze tra di essi.
Il vantaggio principale della configurazione del singleton [ArticlesManagerWithDataBase] tramite un file Spring è che ora è possibile modificare la classe di implementazione corrispondente al campo [articlesDao] della classe [ArticlesManagerWithDataBase] senza che il codice di quest’ultima venga modificato. È sufficiente modificare il nome della classe nella definizione del bean [articlesDao] nel file Spring:
diventerà, ad esempio:
Il bean [ArticlesManagerWithDataBase] funzionerà con questa nuova classe di accesso ai dati, senza nemmeno rendersene conto.
2.3. Spring IoC nella pratica
2.3.1. Esempio 1
Consideriamo la seguente classe:
La classe presenta:
- due campi privati nome ed età
- i metodi di lettura (get) e scrittura (set) di questi due campi
- un metodo toString per recuperare il valore dell’oggetto [Personne] sotto forma di stringa di caratteri
- un metodo init che verrà chiamato da Spring al momento della creazione dell'oggetto, un metodo close che verrà chiamato al momento della distruzione dell'oggetto
Per creare oggetti di tipo [Personne], utilizzeremo il seguente file Spring:
Questo file si chiamerà config.xml.
- Definisce due bean con chiavi rispettivamente "persona1" e "persona2" di tipo [Personne]
- Inizializza i campi [nom, age] di ciascuna persona
- definisce i metodi da chiamare durante la creazione iniziale dell’oggetto [init-method] e durante la distruzione dell’oggetto [destroy-method]
Per i nostri test, utilizzeremo un'unica classe di test JUnit alla quale aggiungeremo successivamente dei metodi. La prima versione di questa classe sarà la seguente:
Commenti:
- per ottenere i bean definiti nel file [config.xml], utilizziamo un oggetto di tipo [ListableBeanFactory]. Esistono altri tipi di oggetti che consentono di accedere ai bean. L’oggetto [ListableBeanFactory] viene ottenuto nel metodo [setUp] della classe di test e memorizzato in una variabile privata. Sarà così disponibile per tutti i metodi di test.
- Il file [config.xml] verrà inserito nel [ClassPath] dell’applicazione, c.a.d, in una delle directory esplorate dalla macchina virtuale Java quando cerca una classe a cui fa riferimento l’applicazione. L'oggetto [ClassPathResource] serve a cercare una risorsa nel [ClassPath] di un'applicazione, in questo caso il file [config.xml].
- Spring può utilizzare file di configurazione in vari formati. L’oggetto [XmlBeanFactory] consente di analizzare un file di configurazione in formato XML.
- L'elaborazione di un file Spring restituisce un oggetto di tipo [ListableBeanFactory], in questo caso l'oggetto bf. Con questo oggetto, un bean identificato dalla chiave C si ottiene tramite bf.getBean(C).
- Il metodo [test1] richiede e visualizza il valore dei bean con chiave "persona1" e "persona2".
La struttura del progetto Eclipse della nostra applicazione è la seguente:
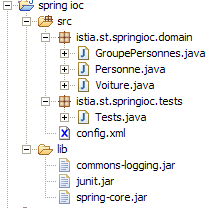
Commenti:
- la cartella [src] contiene i codici sorgente. I codici compilati andranno in una cartella [bin] non rappresentata qui.
- Il file [config.xml] si trova nella directory principale della cartella [src]. Durante la compilazione del progetto, il file viene automaticamente copiato nella cartella [bin], che fa parte della cartella [ClassPath] dell'applicazione. È lì che viene cercato dall'oggetto [ClassPathResource].
- La cartella [lib] contiene tre librerie Java necessarie all’applicazione:
- commons-logging.jar e spring-core.jar per le classi Spring
- junit.jar per le classi JUnit
- anche la cartella [lib] fa parte del [ClassPath] dell’applicazione
L'esecuzione del metodo [test1] del test JUnit fornisce i seguenti risultati:
Commenti:
- Spring registra una serie di eventi tramite la libreria [commons-logging.jar]. Questi log ci consentono di comprendere meglio il funzionamento di Spring.
- Il file [config.xml] è stato caricato e successivamente utilizzato
- L'operazione*
ha forzato la creazione del bean [personne1]. Si può vedere il log di Spring a questo proposito. Poiché nella definizione del bean [personne1] era stato scritto [init-method="init"], è stato eseguito il metodo [init] dell’oggetto [Personne] creato. Viene visualizzato il messaggio corrispondente.
- L'operazione
ha visualizzato il valore dell'oggetto [Personne] creato.
- Lo stesso fenomeno si ripete per il bean chiave [personne2].
- L'ultima operazione
personne2 = (Personne) bf.getBean("personne2");
System.out.println("personne2=" + personne2.toString());
non ha provocato la creazione di un nuovo oggetto di tipo [Personne]. Se così fosse stato, sarebbe stato visualizzato il metodo [init], cosa che qui non avviene. È il principio del singleton. Spring, per impostazione predefinita, crea una sola istanza dei bean presenti nel proprio file di configurazione. Si tratta di un servizio di riferimento agli oggetti. Se gli viene richiesto il riferimento a un oggetto non ancora creato, lo crea e ne restituisce un riferimento. Se l’oggetto è già stato creato, Spring si limita a fornirne un riferimento.
- Si può notare che non c’è traccia del metodo [close] dell’oggetto [Personne], mentre nella definizione dei bean era stato scritto [destroy-method=close]. È possibile che questo metodo venga eseguito solo quando la memoria occupata dall’oggetto viene recuperata dal garbage collector. Nel momento in cui ciò avviene, l’applicazione è già terminata e la scrittura sullo schermo non ha alcun effetto. Da verificare.
Avendo ormai acquisito le basi per una configurazione Spring, d’ora in poi saremo un po’ più rapidi nelle nostre spiegazioni.
2.3.2. Esempio 2
Consideriamo la seguente nuova classe [Voiture]:
La classe presenta:
- tre campi privati: tipo, marca e proprietario. Questi campi possono essere inizializzati e letti tramite i metodi pubblici get e set dei bean. Possono inoltre essere inizializzati utilizzando il costruttore Auto(String, String, Persona). La classe dispone anche di un costruttore senza argomenti per conformarsi allo standard JavaBean.
- un metodo toString per recuperare il valore dell’oggetto [Voiture] sotto forma di stringa
- un metodo `init` che verrà chiamato da Spring subito dopo la creazione dell’oggetto, un metodo `close` che verrà chiamato al momento della distruzione dell’oggetto
Per creare oggetti di tipo [Voiture], utilizzeremo il seguente file Spring [config.xml]:
Questo file aggiunge alle definizioni precedenti un bean con chiave "voiture1" di tipo [Voiture]. Per inizializzare questo bean, si sarebbe potuto scrivere:
Anziché optare per questo metodo già illustrato, in questo caso abbiamo scelto di utilizzare il costruttore Voiture(String, String, Personne) della classe. Inoltre, il bean [voiture1] definisce il metodo da chiamare durante la creazione iniziale dell’oggetto [init-method] e quello da chiamare durante la distruzione dell’oggetto [destroy-method].
Per i nostri test, utilizzeremo la classe di test JUnit già presentata, aggiungendovi il seguente metodo [test2]:
Il metodo [test2] recupera il bean [voiture1] e lo visualizza.
La struttura del progetto Eclipse rimane quella del test precedente. L'esecuzione del metodo [test2] del test JUnit fornisce i seguenti risultati:
Commenti:
- il metodo [test2] richiede un riferimento al bean [voiture1]
- riga 4: Spring avvia la creazione del bean [voiture1] poiché tale bean non è ancora stato creato (singleton)
- riga 6: poiché il bean [voiture1] fa riferimento al bean [personne2], quest'ultimo viene a sua volta creato
- riga 7: il bean [personne2] è stato creato. Viene quindi eseguito il suo metodo [init].
- riga 9: Spring indica che utilizzerà un costruttore per creare il bean [voiture1]
- riga 10: il bean [voiture1] è stato creato. Viene quindi eseguito il suo metodo [init].
- riga 11: il metodo [test2] visualizza il valore del bean [voiture1]
2.3.3. Esempio 3
Introduciamo la seguente nuova classe [GroupePersonnes]:
I suoi due membri privati sono:
membri: un array di persone appartenenti al gruppo
groupesDeTravail: un dizionario che associa una persona a un gruppo di lavoro
Si noti che la classe [GroupePersonnes] non definisce un costruttore senza argomenti per seguire lo standard JavaBean. Ricordiamo che, in assenza di qualsiasi costruttore, esiste un costruttore "predefinito" che è il costruttore senza argomenti e che non esegue alcuna operazione.
In questa sede si intende mostrare come Spring consenta di inizializzare oggetti complessi, quali quelli dotati di campi di tipo array o dizionario. Si aggiunge un nuovo bean al precedente file Spring [config.xml]:
- Il tag <list> consente di inizializzare un campo di tipo array o che implementa l’interfaccia List con valori diversi.
- Il tag <map> consente di fare la stessa cosa con un campo che implementa l’interfaccia Map
Per i nostri test, utilizzeremo la classe di test JUnit già presentata, aggiungendovi il seguente metodo [test3]:
Il metodo [test3] recupera il bean [groupe1] e lo visualizza.
La struttura del progetto Eclipse rimane quella del test precedente. L'esecuzione del metodo [test3] del test JUnit fornisce i seguenti risultati:
Commenti:
- il metodo [test3] richiede un riferimento al bean [groupe1]
- riga 4: Spring avvia la creazione di questo bean
- poiché il bean [groupe1] fa riferimento ai bean [personne1] e [personne2], questi due bean vengono creati (righe 6 e 9) e il loro metodo init viene eseguito (righe 7 e 10)
- riga 11: il bean [groupe1] è stato creato. Il suo metodo [init] viene ora eseguito.
- riga 12: visualizzazione richiesta dal metodo [test3].
2.4. Spring per configurare applicazioni web a tre livelli
2.4.1. Architettura generale dell’applicazione
Si desidera realizzare un’applicazione a tre livelli con la seguente struttura:
 |
- i tre livelli saranno resi indipendenti grazie all’utilizzo di interfacce Java
- l'integrazione dei tre livelli sarà realizzata da Spring
- Verranno creati pacchetti separati per ciascuno dei tre livelli, denominati Control, Domain e Dao. Un pacchetto aggiuntivo conterrà le applicazioni di test.
La struttura dell’applicazione in Eclipse potrebbe essere la seguente:
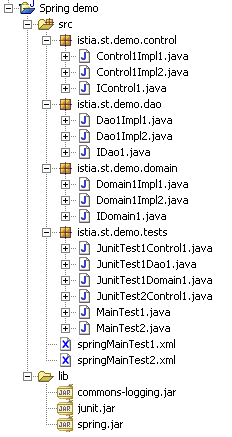
2.4.2. Il livello DAO di accesso ai dati
Il livello DAO implementerà la seguente interfaccia:
package istia.st.demo.dao;
public interface IDao1 {
public int doSometingInDaoLayer(int a, int b);
}
- Scrivere due classi Dao1Impl1 e Dao1Impl2 che implementino l'interfaccia IDao1. Il metodo Dao1Impl1. doSomethingInDaoLayer restituirà a+b, mentre il metodo Dao1Impl2. doSomethingInDaoLayer restituirà a-b.
- scrivere una classe di test JUnit che verifichi le due classi precedenti
2.4.3. Il livello business
Il livello business implementerà la seguente interfaccia:
package istia.st.demo.domain;
public interface IDomain1 {
public int doSomethingInDomainLayer(int a, int b);
}
- Scrivere due classi, Domain1Impl1 e Domain1Impl2, che implementino l'interfaccia IDomain1. Queste classi avranno un costruttore che accetta come parametro un oggetto di tipo IDao1. Il metodo Domain1Impl1.doSomethingInDomainLayer incrementerà a e b di un'unità, quindi passerà questi due parametri al metodo doSomethingInDaoLayer dell'oggetto di tipo IDao1 ricevuto. Il metodo Domain1Impl2.doSomethingInDomainLayer, invece, decrementerà a e b di un'unità prima di eseguire la stessa operazione.
- Scrivere una classe di test JUnit che verifichi le due classi precedenti
2.4.4. Il livello dell'interfaccia utente
Il livello dell'interfaccia utente implementerà la seguente interfaccia:
package istia.st.demo.control;
public interface IControl1 {
public int doSometingInControlLayer(int a, int b);
}
- Scrivere due classi, Control1Impl1 e Control1Impl2, che implementino l'interfaccia IControl1. Queste classi avranno un costruttore che accetta un parametro di tipo IDomain1. Il metodo Control1Impl1.doSomethingInControlLayer incrementerà a e b di un'unità, quindi passerà questi due parametri al metodo doSomethingInDomainLayer dell'oggetto di tipo IDomain1 ricevuto. Il metodo Control11Impl2.doSomethingInControlLayer, invece, decrementerà a e b di un'unità prima di eseguire la stessa operazione.
- Scrivere una classe di test JUnit che verifichi le due classi precedenti
2.4.5. Integrazione con Spring
- Scrivere un file di configurazione Spring che stabilisca quali classi dovrà utilizzare ciascuno dei tre livelli precedenti
- Scrivere una classe di test JUnit che utilizzi diverse configurazioni Spring, al fine di evidenziare la flessibilità dell'applicazione scritta
- Scrivere un'applicazione autonoma (metodo main) che passi due parametri all'interfaccia IControl1 e visualizzi il risultato restituito dall'interfaccia.
2.4.6. Una soluzione
2.4.6.1. Il progetto Eclipse
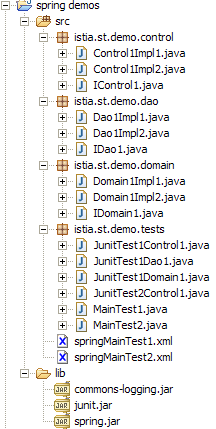
Gli archivi della cartella [lib] sono stati aggiunti al [ClassPath] del progetto.
2.4.6.2. Il pacchetto [istia.st.demo.dao]
L'interfaccia:
Una prima classe di implementazione:
Una seconda classe di implementazione:
2.4.6.3. Il pacchetto [istia.st.demo.domain]
L'interfaccia:
Una prima classe di implementazione:
Una seconda classe di implementazione:
2.4.6.4. Il pacchetto [istia.st.demo.control]
L'interfaccia
Una prima classe di implementazione:
Una seconda classe di implementazione:
2.4.6.5. I file di configurazione [Spring]
Un primo [springMainTest1.xml]:
Un secondo [springMainTest2.xml]:
2.4.6.6. Il pacchetto di test [istia.st.demo.tests]
Un test di tipo [main]:
I risultati ottenuti sulla console Eclipse:
Un altro test che utilizza il secondo file di configurazione [Spring]:
Risultati ottenuti sulla console di Eclipse:
Infine, un test Junit:
2.5. Conclusion
Il framework Spring offre una reale flessibilità sia nell'architettura delle applicazioni che nella loro configurazione. Abbiamo utilizzato il concetto IoC, uno dei due pilastri di Spring. L’altro pilastro è AOP (Aspect Oriented Programming), che non abbiamo presentato. Consente di aggiungere, tramite configurazione, un “comportamento” a un metodo di classe senza modificarne il codice. Schematicamente, AOP permette di filtrare le chiamate a determinati metodi:
 |
- il filtro può essere eseguito prima o dopo il metodo M di destinazione, oppure in entrambi i casi.
- Il metodo M ignora l’esistenza di questi filtri. Questi ultimi sono definiti nel file di configurazione di Spring.
- Il codice del metodo M non viene modificato. I filtri sono classi Java da implementare. Spring fornisce filtri predefiniti, in particolare per gestire le transazioni di SGBD.
- I filtri sono bean e, in quanto tali, sono definiti nel file di configurazione di Spring come bean.
Un filtro comune è il filtro transazionale. Prendiamo un metodo M del livello business che esegue due operazioni indissociabili sui dati (unità di lavoro). Esso richiama due metodi M1 e M2 del livello DAO per eseguire queste due operazioni.
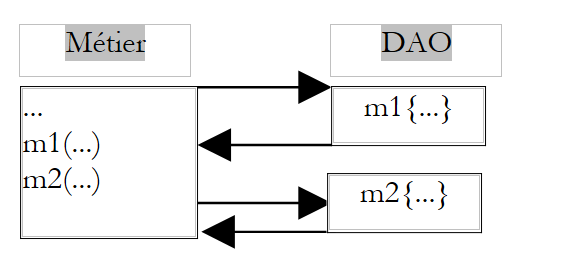 |
Poiché si trova nel livello business, il metodo M non tiene conto del supporto di questi dati. Ad esempio, non deve di ipotizzare che i dati si trovino in un SGBD e che sia necessario inserire le due chiamate ai metodi M1 e M2 all’interno di una transazione di SGBD. Spetta al livello DAO occuparsi di questi dettagli. Una soluzione al problema precedente consiste quindi nel creare un metodo nel livello DAO che a sua volta chiami i metodi M1 e M2, chiamate che includerebbe in una transazione di SGBD.
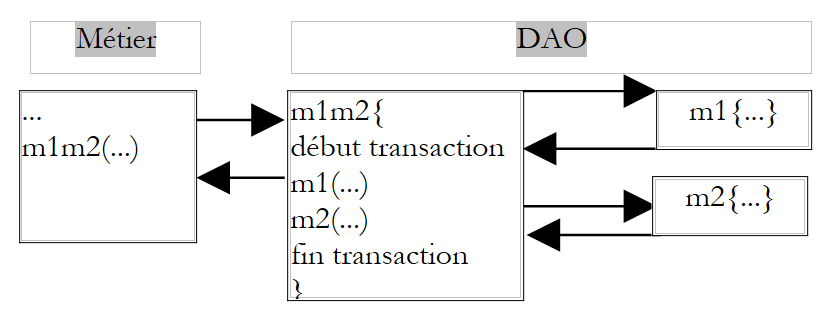 |
La soluzione di filtraggio AOP è più flessibile. Consentirà di definire un filtro che, prima della chiamata a M, avvierà una transazione e, dopo la chiamata, eseguirà un commit o un rollback a seconda dei casi.
 |
Questo approccio presenta diversi vantaggi:
- una volta definito il filtro, può essere applicato a più metodi, ad esempio a tutti quelli che richiedono una transazione
- i metodi così filtrati non devono essere riscritti
- poiché i filtri da utilizzare sono definiti tramite configurazione, è possibile modificarli
Oltre ai concetti IoC e AOP, Spring offre numerose classi di supporto per le applicazioni a tre livelli:
- per JDBC, SqlMap (iBatis), Hibernate, JDO (Java Data Object) nel livello DAO
- per il modello MVC nel livello Interfaccia utente
Per ulteriori informazioni: http://www.springframework.org.