4. [TD]: Architetture a livelli
Parole chiave: architettura a più livelli, Spring, iniezione di dipendenze.
4.1. Introduction
Ricordiamo cosa è stato fatto:
- nella parte 1 dell'esercizio ELECTIONS non è stata utilizzata alcuna classe. Abbiamo realizzato una soluzione come l'avremmo realizzata in linguaggio C.
- Nella parte 2 dell'esercizio sono state introdotte due classi:
- [ListeElectorale], che rappresenta gli attributi (id, nome, voti, seggi, eliminato) di una lista di candidati
- [ElectionsException], una classe di eccezioni non controllate. Questo tipo di eccezione viene utilizzato ogni volta che si verifica un errore fatale nell’applicazione elettorale. Si tratta di un’eccezione non controllata, c.a.d, che lo sviluppatore non è tenuto a gestire con un try-catch.
Il calcolo del risultato delle elezioni è stato finora affidato a un metodo [main] di una classe [MainElections]
La soluzione precedente comprende tre fasi classiche:
- l'acquisizione dei dati, righe 17-18
- il calcolo del risultato, righe 19-20
- la visualizzazione e/o la memorizzazione dei risultati, righe 21-22
Solo la fase 2 è realmente costante. La fase 1 può variare: i dati possono provenire dalla tastiera, come negli esempi esaminati, da un file di testo, da un'interfaccia grafica, da un database, dalla rete, ... Allo stesso modo, esistono molteplici modi per restituire i risultati nella fase 3: visualizzarli sullo schermo come è stato fatto negli esempi esaminati, salvarli in un file, in un database, inviarli in rete, ...
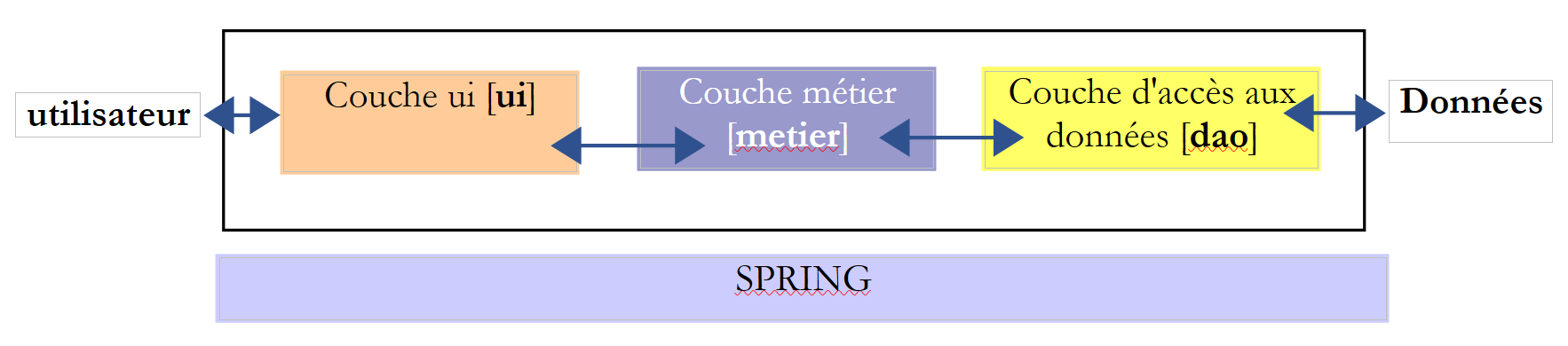
Più in generale, un’applicazione può spesso essere modellata in tre livelli, ciascuno con un ruolo ben definito:
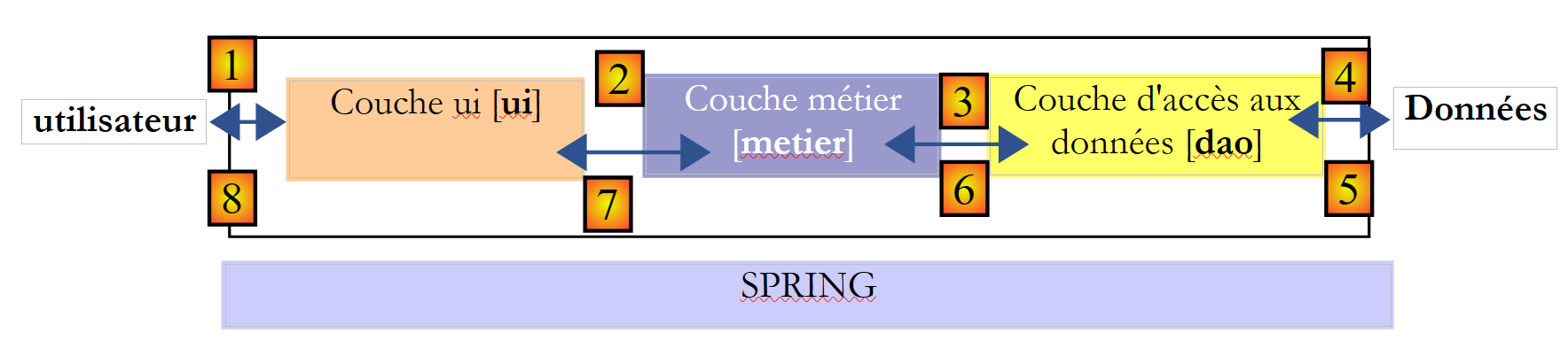 |
Questa architettura è anche denominata «architettura a tre livelli», traduzione dell’inglese «three-tier architecture». Il termine «tre livelli» indica normalmente un’architettura in cui ogni livello si trova su una macchina diversa. Quando i livelli si trovano sulla stessa macchina, l’architettura diventa un’architettura «a tre strati».
- Il livello [metier] è quello che contiene le regole di business dell’applicazione. Per la nostra applicazione elettorale, si tratta delle regole che consentono di calcolare i seggi ottenuti dalle diverse liste, una volta noti i voti ottenuti da ciascuna di esse. Questo livello necessita di dati per funzionare. Ad esempio, nell’applicazione elettorale:
- le liste, ciascuna con il proprio nome e il numero di voti
- il numero di seggi da assegnare
- la soglia elettorale al di sotto della quale una lista viene esclusa
Nello schema sopra riportato, i dati possono provenire da due fonti:
- il livello di accesso ai dati o [dao] (DAO = Data Access Object) per i dati già registrati in file o database. In questo caso potrebbero essere i nomi delle liste, il numero di seggi da assegnare e la soglia elettorale. Queste informazioni sono infatti note prima delle elezioni stesse.
- il livello di interfaccia con l’utente o [ui] (UI = User Interface) per i dati inseriti dall’utente o visualizzati all’utente. Questo potrebbe essere il caso, in questo contesto, dei voti delle liste, che si conoscono solo all’ultimo momento, nonché della visualizzazione dei risultati elettorali.
- In generale, il livello [dao] si occupa dell’accesso ai dati persistenti (file, database) o non persistenti (rete, sensori, ...).
- Il livello [ui], invece, si occupa delle interazioni con l’utente, se presente.
- I tre livelli sono resi indipendenti grazie all’utilizzo di interfacce Java.
- Per integrare questi livelli nell’applicazione, esistono diversi metodi. Utilizzeremo uno strumento chiamato “Spring”. Nello schema, esso è trasversale rispetto agli altri livelli.
Riprenderemo l’applicazione [Elections] sviluppata in precedenza per dotarla di un’architettura a tre livelli. A tal fine, esamineremo i livelli [ui, metier, dao] uno dopo l’altro, iniziando dal livello [dao], che si occupa dei dati persistenti.
Prima di tutto, dobbiamo definire le interfacce dei diversi livelli dell’applicazione [Elections].
4.2. Le interfacce dell’applicazione [Elections]
Ricordiamo che un'interfaccia definisce un insieme di firme di metodi. Le classi che implementano l'interfaccia danno un contenuto a questi metodi.
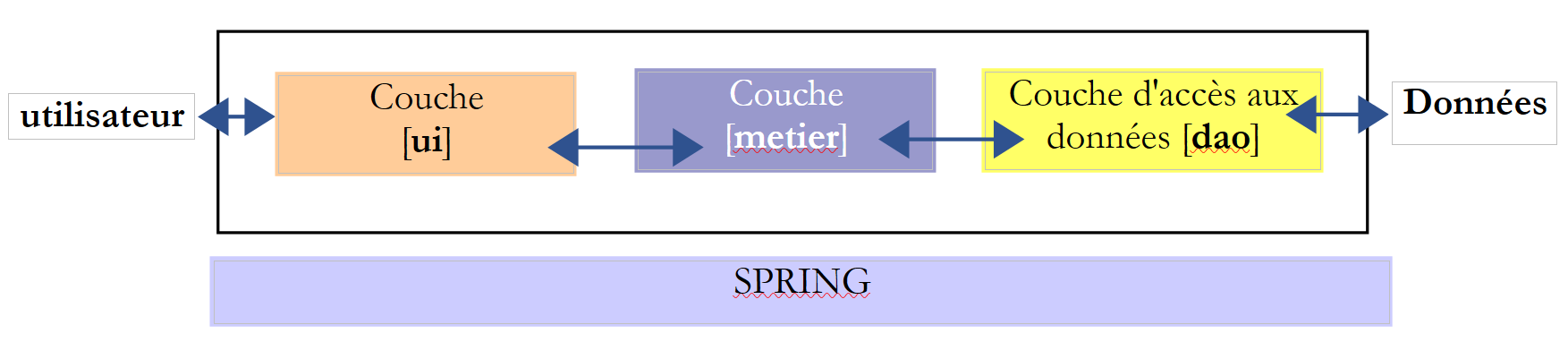
Torniamo all’architettura a 3 livelli della nostra applicazione:
|
In questo tipo di architettura, spesso è l’utente a prendere l’iniziativa. Effettua una richiesta in [1] e riceve una risposta in [8]. Questo processo è chiamato ciclo richiesta-risposta. Prendiamo l’esempio del calcolo dei seggi ottenuti la sera delle elezioni. Ciò richiederà diverse fasi:
- il livello [ui] dovrà chiedere all’utente il numero di voti ottenuti da ciascuna delle liste. A tal fine dovrà presentare all’utente i nomi delle liste in lizza. L’utente dovrà quindi semplicemente inserire il numero di voti accanto a ciascuna lista e poi richiedere il calcolo dei seggi.
- il livello [ui] non dispone dei nomi delle liste. Questi sono registrati nella fonte dati a destra dello schema. Utilizzerà il percorso [2, 3, 4, 5, 6, 7] per ottenerli. L’operazione [2] è la richiesta delle liste, l’operazione [7] la risposta a tale richiesta. Una volta fatto ciò, potrà presentarle all’utente tramite [8].
- L’utente trasmetterà al livello [ui] il numero di voti ottenuti da ciascuna delle liste. Si tratta dell’operazione [1] sopra indicata. Durante questa fase, l’utente interagisce esclusivamente con il livello [ui]. È proprio questo livello che verificherà, in particolare, la validità dei dati inseriti. Una volta fatto ciò, l’utente richiederà l’elenco dei seggi ottenuti da ciascuna delle liste.
- Il livello [ui] richiederà al livello di business di effettuare il calcolo dei seggi. A tal fine, gli trasmetterà i dati ricevuti dall’utente. Si tratta dell’operazione [2].
- Il livello [metier] necessita di alcune informazioni per portare a termine il proprio lavoro. Dispone già delle liste grazie all’operazione (b). Gli occorrono inoltre il numero di seggi da assegnare e il valore della soglia elettorale. Richiederà queste informazioni al livello [dao] tramite il percorso [3, 4, 5, 6]. [3] è la richiesta iniziale e [6] la risposta a tale richiesta.
- Avendo tutti i dati di cui aveva bisogno, il livello [metier] calcola i seggi ottenuti da ciascuna delle liste.
- Il livello [metier] può ora rispondere alla richiesta del livello [ui] effettuata al punto (d). Si tratta del percorso [7].
- Il livello [ui] formatterà questi risultati per presentarli all’utente in una forma adeguata e poi li visualizzerà. Si tratta del percorso [8].
- È ipotizzabile che tali risultati debbano essere memorizzati in un file o in un database. Ciò può avvenire in modo automatico. In tal caso, dopo l’operazione (f), il livello [metier] richiederà al livello [dao] di salvare i risultati. Si tratterà del percorso [3, 4, 5, 6]. Ciò può avvenire anche solo su richiesta dell’utente. In tal caso, sarà il percorso [1-8] a essere utilizzato dal ciclo richiesta-risposta.
Da questa descrizione si evince che un livello è portato a utilizzare le risorse del livello che si trova alla sua destra, mai di quello alla sua sinistra. Consideriamo due livelli contigui:
 |
Il livello [A] invia richieste al livello [B]. Nei casi più semplici, un livello è implementato da un’unica classe. Un’applicazione si evolve nel corso del tempo. Pertanto, il livello [B] può avere classi di implementazione diverse, come [B1, B2, ...]. Se il livello [B] è il livello [dao], quest’ultimo può avere una prima implementazione [B1] che recupera i dati da un file. Alcuni anni dopo, si potrebbe voler inserire i dati in un database. Si creerà quindi una seconda classe di implementazione [B2]. Se nell’applicazione iniziale il livello [A] interagiva direttamente con la classe [B1], si è costretti a riscrivere parzialmente il codice del livello [A]. Supponiamo, ad esempio, di aver scritto nel livello [A] qualcosa del genere:
- riga 1: viene creata un’istanza della classe [B1]
- riga 3: vengono richiesti dei dati a questa istanza
Se supponiamo che la nuova classe di implementazione [B2] utilizzi metodi con la stessa firma di quelli della classe [B1], sarà necessario sostituire tutti i [B1] con [B2]. Questo è il caso più favorevole e piuttosto improbabile se non si è prestata attenzione a queste firme dei metodi. In pratica, capita spesso che le classi [B1] e [B2] non abbiano le stesse firme dei metodi e che, di conseguenza, gran parte del livello [A] debba essere completamente riscritta.
È possibile migliorare la situazione inserendo un’interfaccia tra i livelli [A] e [B]. Ciò significa che si fissano in un'interfaccia le firme dei metodi presentati dal livello [B] al livello [A]. Lo schema precedente diventa quindi il seguente:
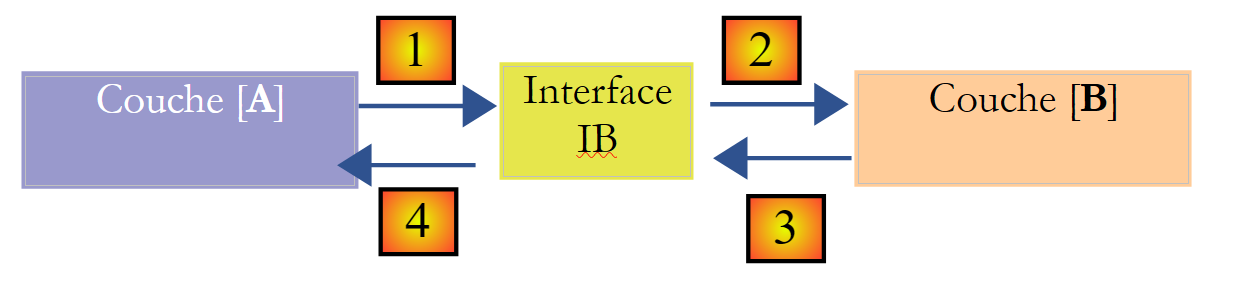 |
Il livello [A] non si rivolge più direttamente al livello [B], ma alla sua interfaccia [IB]. Pertanto, nel codice del livello [A], la classe di implementazione [Bi] del livello [B] compare una sola volta, al momento dell’implementazione dell’interfaccia [IB]. A questo punto, nel codice viene utilizzata l’interfaccia [IB] e non la sua classe di implementazione. Il codice precedente diventa il seguente:
- riga 1: viene creata un'istanza [ib] che implementa l'interfaccia [IB] tramite l'istanziazione della classe [B1]
- riga 3: vengono richiesti dei dati all’istanza [ib]
Ora, se si sostituisce l'implementazione [B1] del livello [B] con un'implementazione [B2], e se entrambe le implementazioni rispettano la stessa interfaccia [IB], allora solo la riga 1 del livello [A] deve essere modificata e nessun'altra. Si tratta di un grande vantaggio che, da solo, giustifica l'uso sistematico delle interfacce tra due livelli.
Si può andare ancora oltre e rendere il livello [A] totalmente indipendente dal livello [B]. Nel codice sopra riportato, la riga 1 pone un problema perché fa riferimento in modo rigido alla classe [B1]. L’ideale sarebbe che il livello [A] potesse disporre di un’implementazione dell’interfaccia [IB] senza dover specificare il nome di una classe. Ciò sarebbe coerente con lo schema sopra riportato. Si nota che il livello [A] si rivolge all’interfaccia [IB] e non si capisce perché dovrebbe conoscere il nome della classe che implementa tale interfaccia. Questo dettaglio non è utile al livello [A].
Il framework Spring (http://www.springframework.org) consente di ottenere questo risultato. L’architettura precedente si evolve come segue:
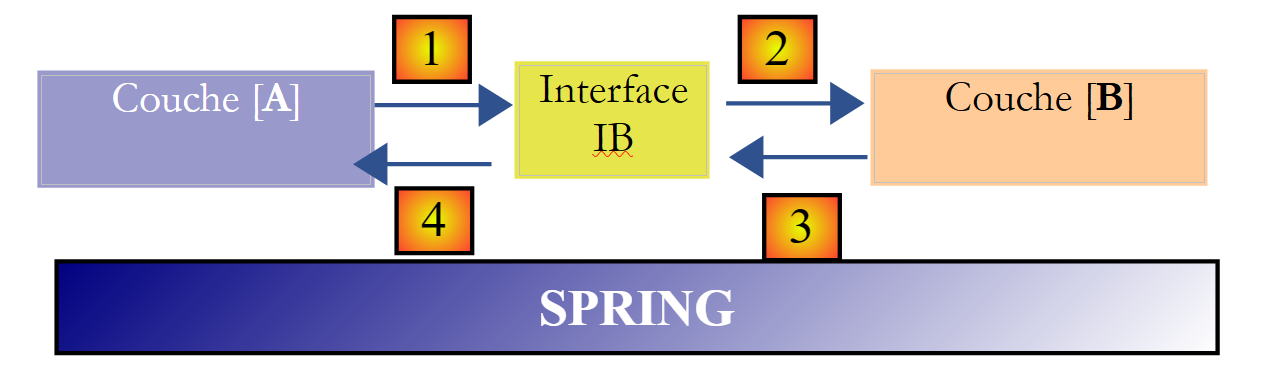 |
Il livello trasversale [Spring] consentirà a un livello di ottenere, tramite configurazione, un riferimento al livello situato alla sua destra senza dover conoscere il nome della classe di implementazione di tale livello. Tale nome sarà presente nei file di configurazione e non nel codice Java. Il codice Java dello strato [A] assume quindi la seguente forma:
- riga 1: un'istanza [ib] che implementa l'interfaccia [IB] del livello [B]. Questa istanza viene creata da Spring sulla base delle informazioni presenti in un file di configurazione. Spring si occuperà di creare:
- l'istanza [b] che implementa il livello [B]
- l'istanza [a] che implementa il livello [A]. Questa istanza verrà inizializzata. Il campo [ib] sopra riportato riceverà come valore il riferimento [b] dell’oggetto che implementa il livello [B]
- riga 3: vengono richiesti dati all'istanza [ib]
Si nota ora che la classe di implementazione [B1] del livello B non compare in nessuna parte nel codice del livello [A]. Quando l'implementazione [B1] verrà sostituita da una nuova implementazione [B2], non cambierà nulla nel codice della classe [A]. Basterà semplicemente modificare i file di configurazione di Spring per istanziare [B2] al posto di [B1].
La combinazione di Spring e delle interfacce Java apporta un miglioramento decisivo alla manutenzione delle applicazioni, rendendo i livelli di queste ultime a prova di interferenza tra loro. È questa la soluzione che useremo per l’applicazione [Elections].
Torniamo all’architettura a tre livelli della nostra applicazione:
 |
Nei casi più semplici, si può partire dal livello [metier] per individuare le interfacce dell’applicazione. Per funzionare, essa necessita di dati:
- già disponibili in file, database o tramite la rete. Questi dati sono forniti dal livello [dao].
- non ancora disponibili. In tal caso, vengono forniti dal livello [ui], che li ottiene dall’utente dell’applicazione.
Quale interfaccia deve offrire il livello [dao] al livello [metier]? Quali sono le possibili interazioni tra questi due livelli? Il livello [dao] deve fornire i seguenti dati al livello [metier]:
- il numero di seggi da assegnare
- il valore della soglia elettorale al di sotto della quale una lista viene esclusa
- i nomi delle liste
Queste informazioni sono infatti note prima delle elezioni e possono quindi essere memorizzate. Nella direzione [metier] -> [dao], il livello [metier] può richiedere al livello [dao] di registrare il risultato delle elezioni, in particolare i seggi ottenuti dalle diverse liste.
Con queste informazioni, si potrebbe tentare una prima definizione dell’interfaccia del livello [dao]:
public interface IElectionsDao {
public double getSeuilElectoral();
public int getNbSiegesAPourvoir();
public ListeElectorale[] getListesElectorales();
public void setListesElectorales(ListeElectorale[] listesElectorales);
}
- riga 1: l’interfaccia si chiama [IElectionsDao]. Definisce quattro metodi:
- tre metodi per leggere i dati provenienti dalla fonte dati: [getSeuilElectoral, getNbSiegesAPourvoir, getListesElectorales]. Questi tre metodi consentiranno al livello [metier] di ottenere i dati relativi alle elezioni in corso.
- un metodo per scrivere dati nella fonte dati: [setListesElectorales]. Questo metodo consentirà al livello [metier] di richiedere la registrazione dei risultati che avrà calcolato.
Torniamo all’architettura a tre livelli della nostra applicazione:
|
Quale interfaccia deve presentare il livello [metier] al livello [ui]? Esaminiamo le possibili interazioni tra questi due livelli.
- Il livello [ui] avrà il compito di chiedere all’utente i voti per le diverse liste in competizione. A tal fine, deve conoscere il numero di liste. Può richiedere questa informazione al livello [metier], che a sua volta può richiedere la tabella delle liste in competizione al livello [dao]. Se il livello [metier] dispone di tale tabella, è opportuno trasferirla al livello [ui]. Quest’ultimo disporrà così dei nomi delle liste e potrà perfezionare i messaggi all’utente chiedendo, ad esempio, «Numero di voti della lista A».
- Quando il livello [ui] avrà ottenuto i voti di tutte le liste, richiederà il calcolo dei seggi al livello [metier]. Quest’ultimo potrà effettuare tale calcolo e restituire il risultato al livello [ui].
- Il livello [ui] potrà quindi presentare tali risultati all’utente. Quest’ultimo potrà anche richiederne la registrazione.
- Il livello [ui] potrebbe inoltre voler presentare all’utente informazioni aggiuntive, quali la soglia elettorale o il numero di seggi da assegnare.
Con queste informazioni, si potrebbe tentare una prima definizione dell’interfaccia del livello [metier] :
public interface IElectionsMetier {
public ListeElectorale[] getListesElectorales();
public int getNbSiegesAPourvoir();
public double getSeuilElectoral();
public void recordResultats(ListeElectorale[] listesElectorales);
public ListeElectorale[] calculerSieges(ListeElectorale[] listesElectorales);
}
- riga 1: l’interfaccia si chiama [IElectionsMetier]. Definisce i seguenti metodi:
- riga 3: un metodo [getListesElectorales] che consentirà al livello [ui] di ottenere la tabella delle liste in competizione;
- riga 5: il metodo [getNbSiegesAPourvoir] consente di ottenere il numero di seggi da assegnare;
- riga 7: il metodo [getSeuilElectoral] consente di ottenere la soglia elettorale;
- riga 11: un metodo [calculerSieges] (riga 36) che consentirà al livello [ui] di richiedere il calcolo dei seggi una volta noti i numeri di voti delle diverse liste. Il parametro è l’array delle liste in competizione, senza i relativi seggi e senza il valore booleano «eliminato». Il risultato restituito è lo stesso array, ma questa volta con i campi [sièges, elimine] inizializzati;
- riga 9: un metodo [recordResultats] che consentirà al livello [ui] di richiedere la registrazione dei risultati.
Nota: data la sua posizione, il livello [métier] riprende alcuni dei metodi del livello [DAO] per renderli disponibili al livello [UI]. A causa di questa ridondanza, si potrebbe essere tentati di raggruppare tutto in un unico livello che riunisca sia la logica di business che l’accesso ai dati. Questo unico livello viene talvolta chiamato «modello», la M dell’acronimo MVC (Modello - Vista - Controller). MVC è un modello di progettazione (design pattern) diffuso nelle applicazioni web.
Esaminiamo la firma del metodo [calculerSieges]:
public ListeElectorale[] calculerSieges(ListeElectorale[] listesElectorales);
Come indicato in precedenza: «Il parametro è l’array delle liste in competizione, senza i relativi seggi e senza il valore booleano eliminato. Il risultato è lo stesso array, ma questa volta con i campi [sièges, elimine]». La firma del metodo potrebbe anche essere la seguente:
public void calculerSieges(ListeElectorale[] listesElectorales);
Il parametro [listesElectorales] è un riferimento a un oggetto, in questo caso un array. Ogni elemento è a sua volta un riferimento a un oggetto, in questo caso di tipo [ListeElectorale]. Il metodo [calculerSieges] modificherà i campi [sieges, elimine] di ciascuno di questi oggetti. Il metodo chiamante detiene un puntatore [listesElectorales] che:
- prima della chiamata, è il riferimento a un array di oggetti [ListeElectorale] i cui campi [sieges, elimine] non sono inizializzati;
- dopo la chiamata, è il riferimento (lo stesso) a un array di oggetti [ListeElectorale] i cui campi [sieges, elimine] sono inizializzati;
Allora perché utilizzare la firma:
public ListeElectorale[] calculerSieges(ListeElectorale[] listesElectorales);
Quando si scrive un'interfaccia, è bene ricordare che può essere utilizzata in due contesti diversi: local e distant. Nel contesto local, il metodo chiamante e il metodo chiamato vengono eseguiti nella stessa JVM (Java Virtual Machine):
|
Se il livello [ui] chiama il metodo calculerSieges del livello [DAO], dispone effettivamente di un riferimento al parametro [ListeElectorale[] listesElectorales] che passa al metodo.
Nel contesto distant, il metodo chiamante e il metodo chiamato vengono eseguiti in JVM diversi:
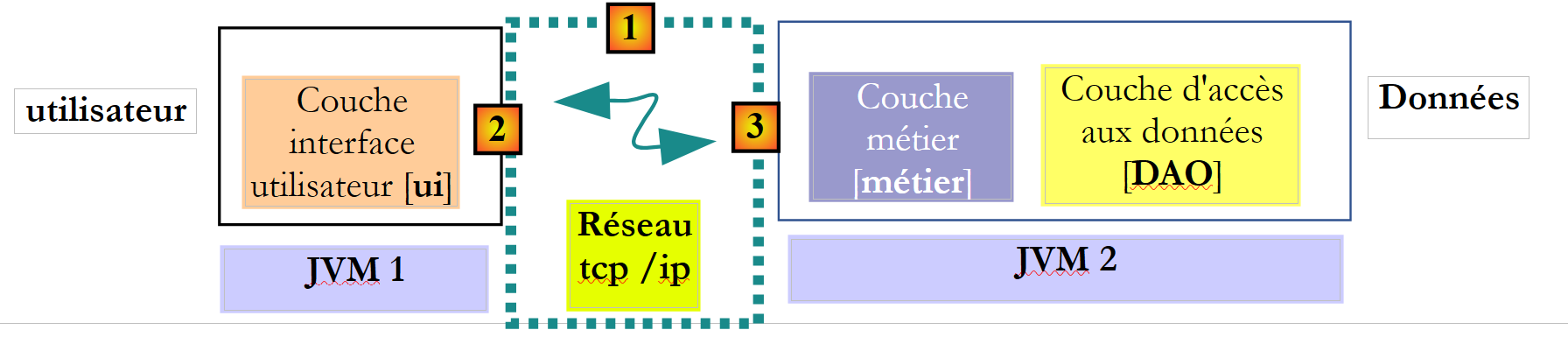 |
Nell’esempio sopra riportato, il livello [ui] viene eseguito nel livello JVM 1 e il livello [métier] nel livello JVM 2 su due macchine diverse. I due livelli non comunicano direttamente. Tra di essi si interpone un livello che chiameremo livello di comunicazione [1]. Questo è composto da un livello di trasmissione [2] e da un livello di ricezione [3]. In genere, lo sviluppatore non deve scrivere questi livelli di comunicazione. Essi vengono generati automaticamente da strumenti software. Il livello [metier] è scritto come se fosse eseguito nello stesso JVM del livello [DAO]. Non è quindi necessaria alcuna modifica al codice.
Il meccanismo di comunicazione tra il livello [ui] e il livello [métier] è il seguente:
- il livello [ui] chiama il metodo calculerSieges del livello [métier] passandole il parametro [ListeElectorale[] listesElectorales1];
- tale parametro viene infatti passato al livello di trasmissione [2]. Quest’ultimo trasmetterà sulla rete il valore del parametro listesElectorales1 e non il suo riferimento. La forma esatta di tale valore dipende dal protocollo di comunicazione utilizzato;
- il livello di ricezione [3] recupererà questo valore e ricostruirà da esso un oggetto [ListeElectorale[] listesElectorales2] che rispecchia il parametro iniziale inviato dal livello [metier]. Ora abbiamo due oggetti identici (in termini di contenuto) in due diversi JVM: listesElectorales1 e listesElectorales2.
- Il livello di ricezione passerà l’oggetto listesElectorales2 al metodo calculerSieges del livello [métier], che lo salverà nel database. Dopo questa operazione, il riferimento listesElectorales2 punta a un array di oggetti [ListeElectorale] i cui campi [sieges, elimine] sono stati inizializzati. . Questo non è il caso dell’oggetto listesElectorales1 a cui il livello [ui] fa riferimento. Se si desidera che il livello [ui] abbia un riferimento all’oggetto listesElectorales2, è necessario inviargli quest’ultimo. Pertanto, si è portati a utilizzare la seguente firma per il metodo [calculerSieges]:
public ListeElectorale[] calculerSieges(ListeElectorale[] listesElectorales);
- con questa firma, il metodo calculerSieges restituirà come risultato il riferimento listesElectorales2. Questo risultato viene restituito al livello di ricezione [3] che aveva chiamato il livello [métier]. Quest’ultimo restituirà il valore (e non il riferimento) di listesElectorales2 al livello di trasmissione [2];
- il livello di emissione [2] recupererà questo valore e ricostruirà da esso un oggetto [ListeElectorale[] listesElectorales3] che rappresenta il risultato restituito dal metodo calculerSieges del livello [métier].
- L'oggetto [ListeElectorale[] listesElectorales3] viene restituito al metodo del livello [ui], la cui chiamata al metodo calculerSieges del livello [DAO] aveva avviato l’intero meccanismo;
In questo processo, oggetti di tipo [ListeElectorale] transiteranno tra i livelli [2] e [3]:
- quando il livello [2] trasmette il valore di un oggetto [ListeElectorale] al livello [3], si dice che l’oggetto viene serializzato. La forma esatta di questa serializzazione dipende dal protocollo di comunicazione utilizzato;
- quando il livello [3] recupera il valore di un oggetto [ListeElectorale] per ricreare un oggetto [ListeElectorale], si dice che l’oggetto viene deserializzato;
Affinché un oggetto possa essere sottoposto a questa serializzazione/deserializzazione, alcuni protocolli richiedono che l’oggetto implementi l’interfaccia [Serializable]. Questa interfaccia è solo un indicatore. Non ci sono metodi da implementare. Pertanto, la classe [ListeElectorale] sarà d'ora in poi dichiarata come segue:
public abstract class ListeElectorale implements Serializable {
private static final long serialVersionUID = 1L;
- Il campo della riga 2 è predefinito. È possibile mantenerlo così com'è e utilizzarlo per qualsiasi classe di tipo [Serializable].
4.3. La classe di eccezione
Torniamo all’interfaccia del livello [DAO]:
 |
public interface IElectionsDao {
public double getSeuilElectoral();
public int getNbSiegesAPourvoir();
public ListeElectorale[] getListesElectorales();
public void setListesElectorales(ListeElectorale[] listesElectorales);
}
Questi metodi operano con un database e possono incontrare diversi errori, ad esempio un SGBD non disponibile. Quando si scrive un metodo, è necessario prevedere sempre i casi di errore. Questi vengono segnalati tradizionalmente tramite un’eccezione. Abbiamo già incontrato la classe [ElectionsException] nel paragrafo 3.3. Continueremo a utilizzarla, ma arricchendola nel modo seguente:
package ...;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
// classe di eccezione per l'applicazione Elezioni
// l'eccezione è non controllata
public class ElectionsException extends RuntimeException implements Serializable {
// serial ID
private static final long serialVersionUID = 1L;
// campi locali
private int code;
private List<String> erreurs;
// costruttori
public ElectionsException() {
super();
}
public ElectionsException(int code, Throwable e) {
// genitore
super(e);
// locale
this.code = code;
this.erreurs = getErreursForException(e);
}
public ElectionsException(int code, String message, Throwable e) {
// genitore
super(message,e);
// locale
this.code = code;
this.erreurs = getErreursForException(e);
}
public ElectionsException(int code, String message) {
// genitore
super(message);
// locale
this.code = code;
List<String> erreurs = new ArrayList<>();
erreurs.add(message);
this.erreurs = erreurs;
}
public ElectionsException(int code, List<String> erreurs) {
// genitore
super();
// locale
this.code = code;
this.erreurs = erreurs;
}
// elenco dei messaggi di errore di un'eccezione
private List<String> getErreursForException(Throwable th) {
// si recupera l'elenco dei messaggi di errore dell'eccezione
Throwable cause = th;
List<String> erreurs = new ArrayList<>();
while (cause != null) {
// si recupera il messaggio solo se !=null e non è vuoto
String message = cause.getMessage();
if (message != null) {
message = message.trim();
if (message.length() != 0) {
erreurs.add(message);
}
}
// causa successiva
cause = cause.getCause();
}
return erreurs;
}
// getter e setter
...
}
- righe 16-17: il tipo [ElectionsException] incapsula:
- un codice di errore, riga 16;
- un elenco di messaggi di errore, riga 17;
La classe supporta cinque costruttori:
- riga 20: ElectionsException()
- riga 24: ElectionsException(int code, Throwable e): il secondo parametro è un tipo [Throwable], che è la classe padre della classe [Exception]. Questo costruttore consente di incapsulare l'eccezione e con un codice di errore. Il tipo [Throwable] (e quindi il tipo Exception) consente di incapsulare una o più eccezioni. L'idea è:
- intercettare (catch) un'eccezione che si verifica;
- arricchirla con un messaggio incapsulandola in una nuova eccezione;
- rilanciare la nuova eccezione;
L'incapsulamento avviene alla riga 34 tramite l'istruzione [super(message,e)]. Questo processo di incapsulamento può essere ripetuto e l'eccezione iniziale arricchita con diversi messaggi. Si parla quindi di una pila di eccezioni. Il metodo [private List<String> getErreursForException(Throwable th)] consente di ottenere i diversi messaggi associati alle eccezioni incapsulate:
- (continua)
- (continua)
- l’eccezione incapsulata si ottiene tramite il metodo Throwable [Throwable].getCause();
- il messaggio associato a un'eccezione è il metodo String [Throwable].getMessage();
- (continua)
- righe 28-29: si costruiscono i campi [code, erreurs];
- riga 32: public ElectionsException(int code, String message, Throwable e): questo costruttore è analogo al precedente, tranne per il fatto che arricchisce l'eccezione che incapsulerà con un codice e un messaggio;
- riga 40: public ElectionsException(int code, String message): costruttore senza incapsulamento dell'eccezione;
- riga 50: public ElectionsException(int code, List<String> errori): costruttore senza incapsulamento di eccezioni né messaggi;
La classe [ElectionsException] potrà essere utilizzata nel modo seguente:
dove il messaggio potrà essere presente o meno. Una volta creata, l'eccezione [ElectionsException] non è destinata a incapsulare nuove eccezioni. Nell’esempio sopra riportato, essa incapsula l’eccezione e1 e le eccezioni incapsulate da e1. Non vi sono quindi ulteriori incapsulamenti.
La classe [ElectionsException] potrà essere utilizzata anche nel modo seguente: