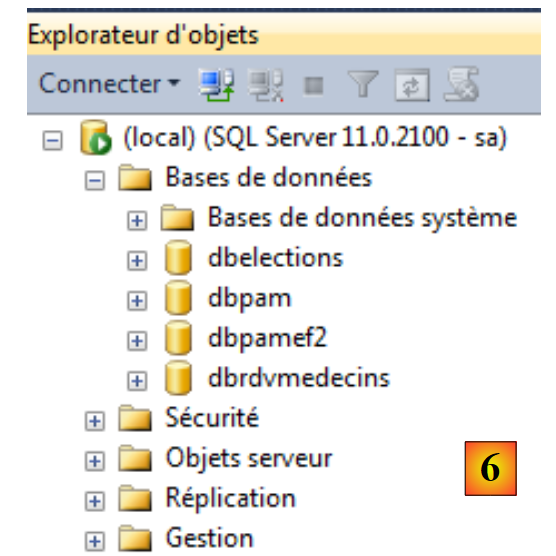
3. Caso di studio con SQL Server Express 2012
3.1. Introduction
Gli esempi che si trovano in rete per Entity Framework sono per la maggior parte relativi a SQL Server. È abbastanza normale. È probabile che SGBD sia il più diffuso al mondo tra le aziende che utilizzano .NET. Seguiremo questa tendenza. Gli esempi saranno poi estesi a tutti i database citati nel paragrafo 1.2.
3.2. Installazione degli strumenti
Non descriveremo l’installazione degli strumenti. Infatti, ciò richiederebbe un numero enorme di schermate che diventerebbero obsolete piuttosto rapidamente. Si tratta di un compito (non sempre facile, è vero) che lasciamo al lettore.
È necessario installare i seguenti strumenti:
- SGBD SQL Server Express 2012: [http://www.microsoft.com/fr-fr/download/details.aspx?id=29062]. Scaricare la versione “With Tools” che include, insieme a SGBD, uno strumento di amministrazione:
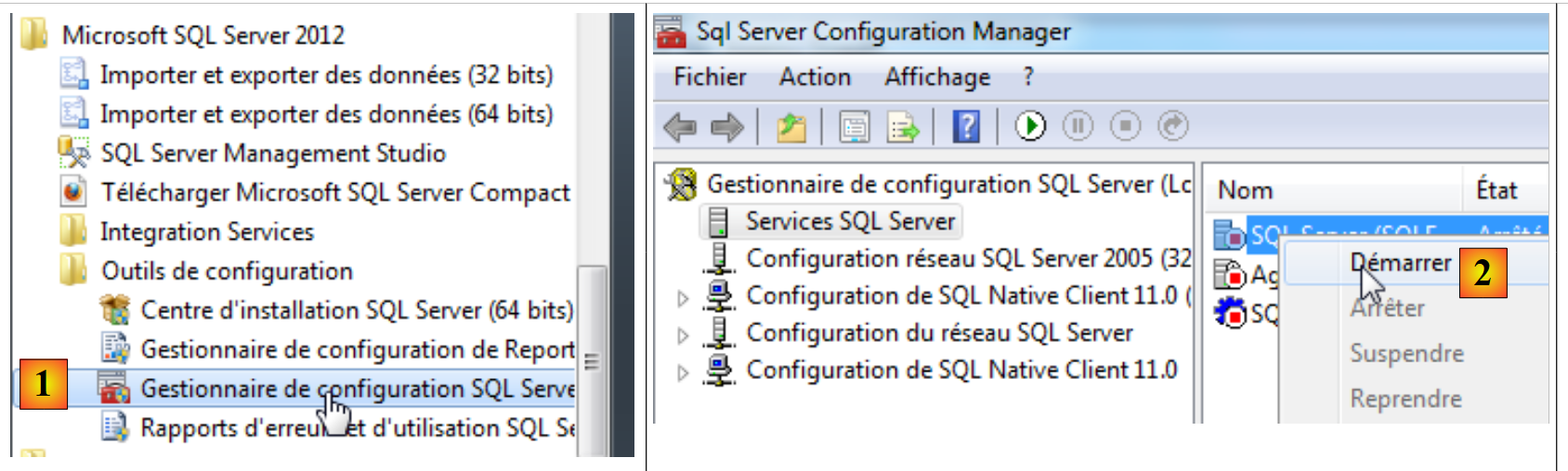
Una volta installato SGBD, lo avviamo:
 |
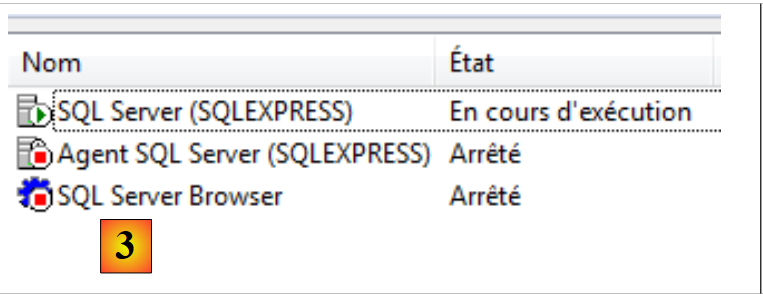 |
- [1]: dal menu Start, avviare il "Gestore di configurazione SQL Server";
- [2]: in questo gestore, avviare il server;
- [3]: il server è stato avviato.
Ora avviamo lo strumento di amministrazione di SQL Server:
 |
- [1]: dal menu Start, avviare "SQL Server Management Studio";
- [2]: lo strumento di amministrazione.
Ci collegheremo al server:
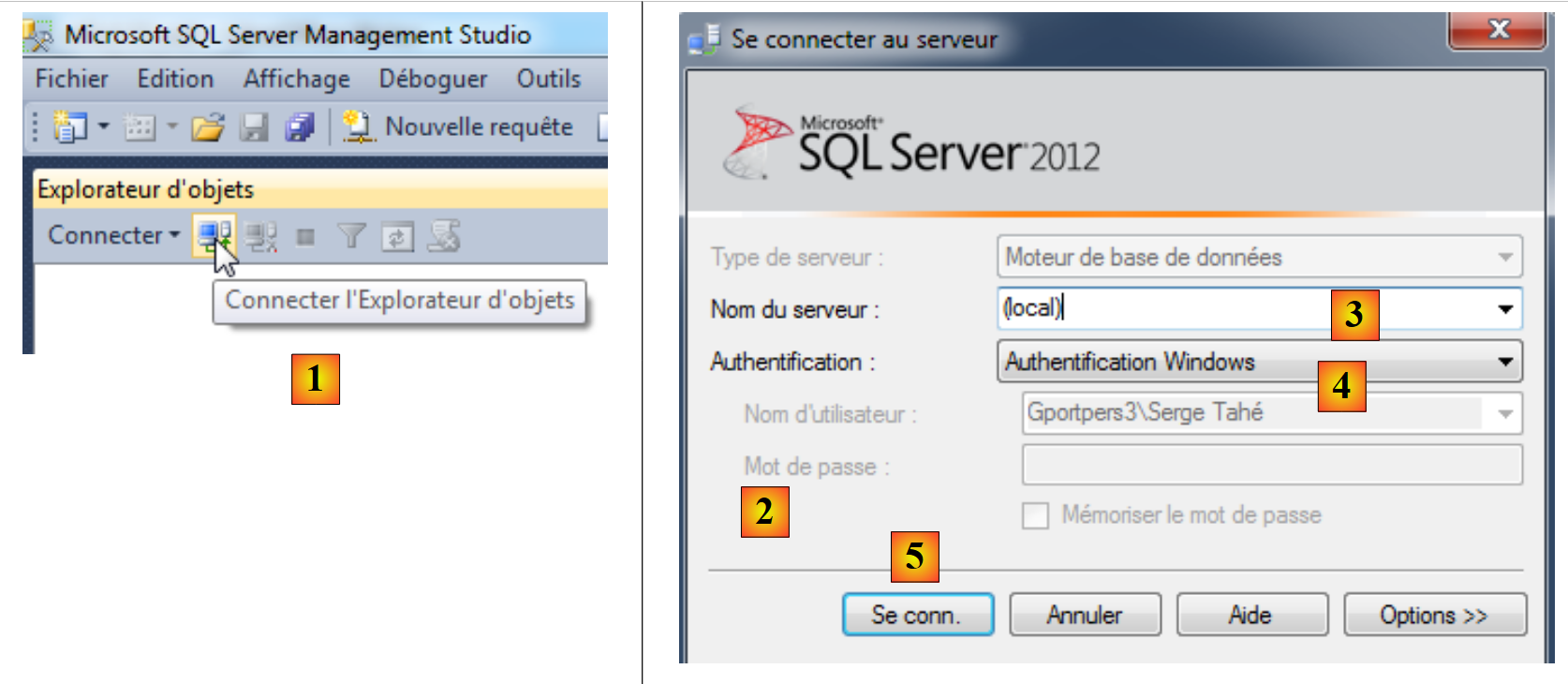 |
- in [1], si avvia l'Esplora oggetti;
- in [2], si specificano i parametri di connessione:
- [3]: il server (locale) (attenzione alle parentesi necessarie) indica il server installato sul computer,
- [4]: si sceglie l'autenticazione Windows. Per effettuare correttamente questa connessione è necessario essere amministratori del proprio computer,
- [5]: si effettua la connessione;
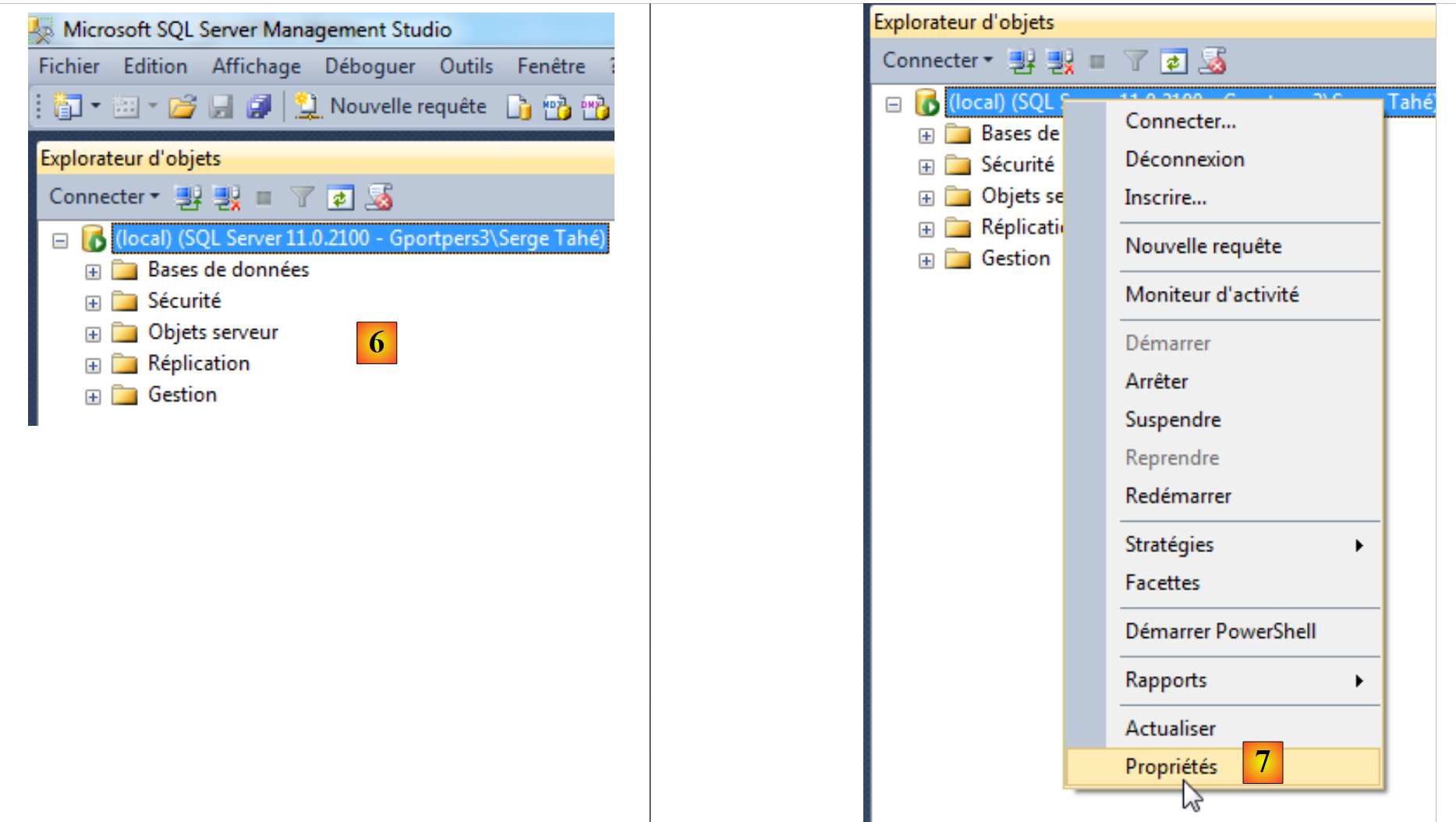 |
- [6]: la connessione è stata stabilita;
- [7]: si desidera modificare alcune proprietà del server;
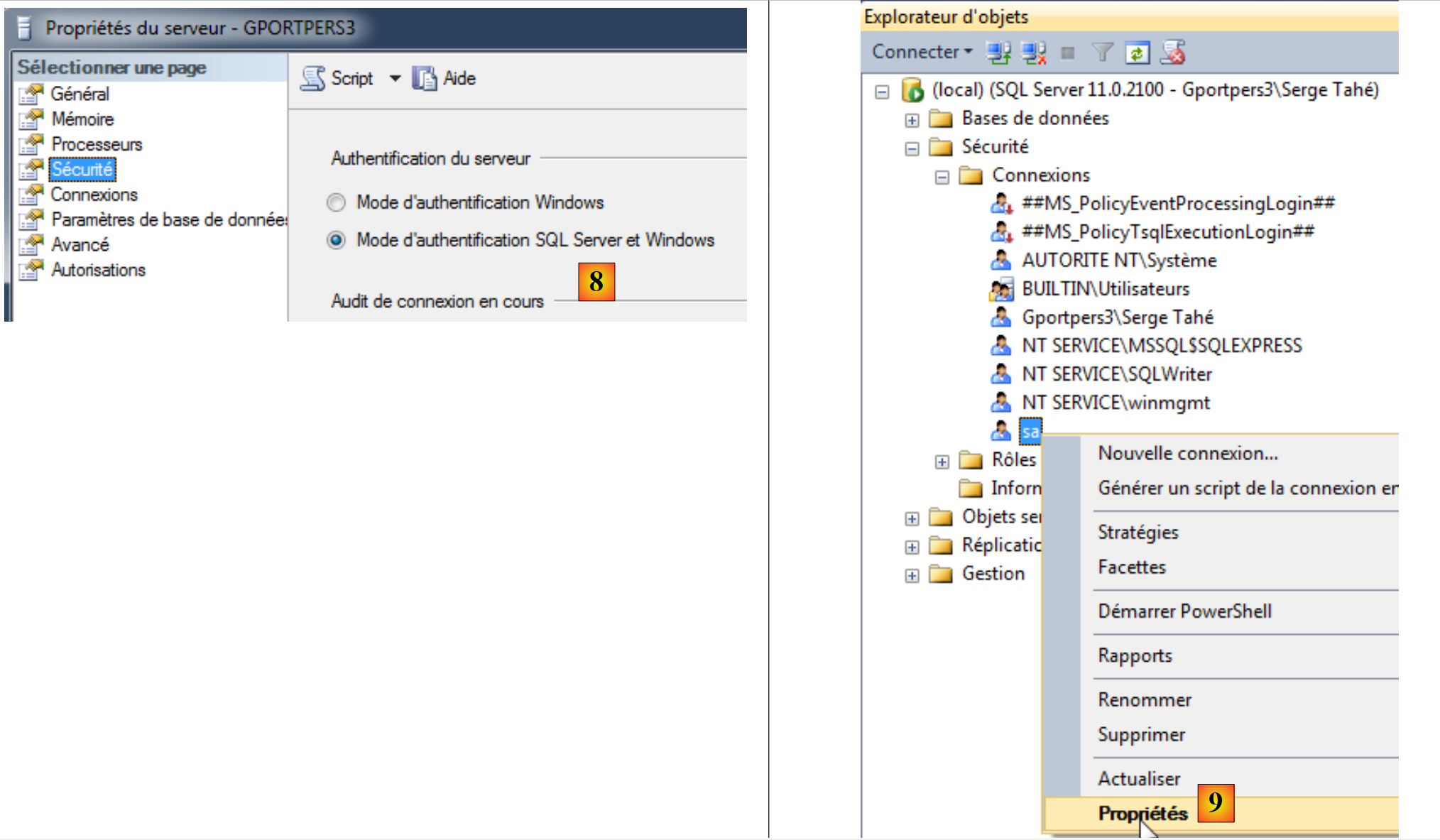 |
- [8]: si richiede che siano disponibili due modalità di autenticazione:
- autenticazione Windows, come appena utilizzata. Un utente Windows con i diritti appropriati può quindi connettersi,
- autenticazione SQL Server. L'utente deve far parte degli utenti registrati nel SGBD;
Fatto ciò, è possibile confermare le proprietà del server;
- [9]: si modificano le proprietà dell’utente «sa» (amministratore di sistema);
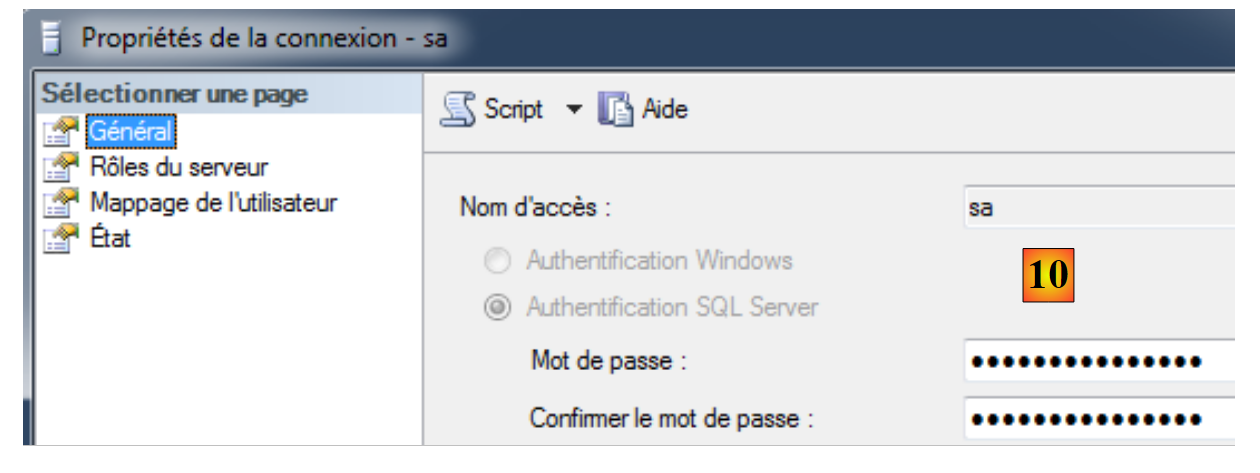 |
- in [10], si imposta una password. Nel prosieguo del documento, questa è sqlserver2012;
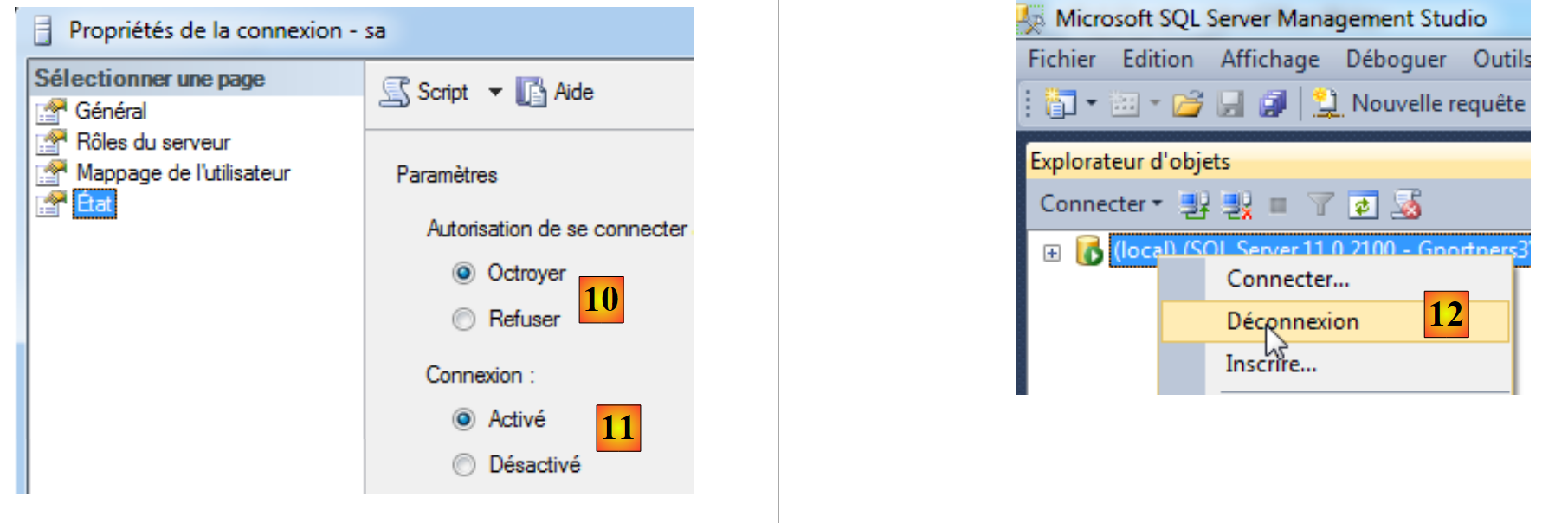 |
- in [10], gli si concede l'autorizzazione a connettersi;
- in [11], la connessione viene attivata. A questo punto è possibile confermare la procedura guidata;
- in [12], ci si disconnette dal server.
Ora ci ricolleghiamo con le credenziali sa/sqlserver2012:
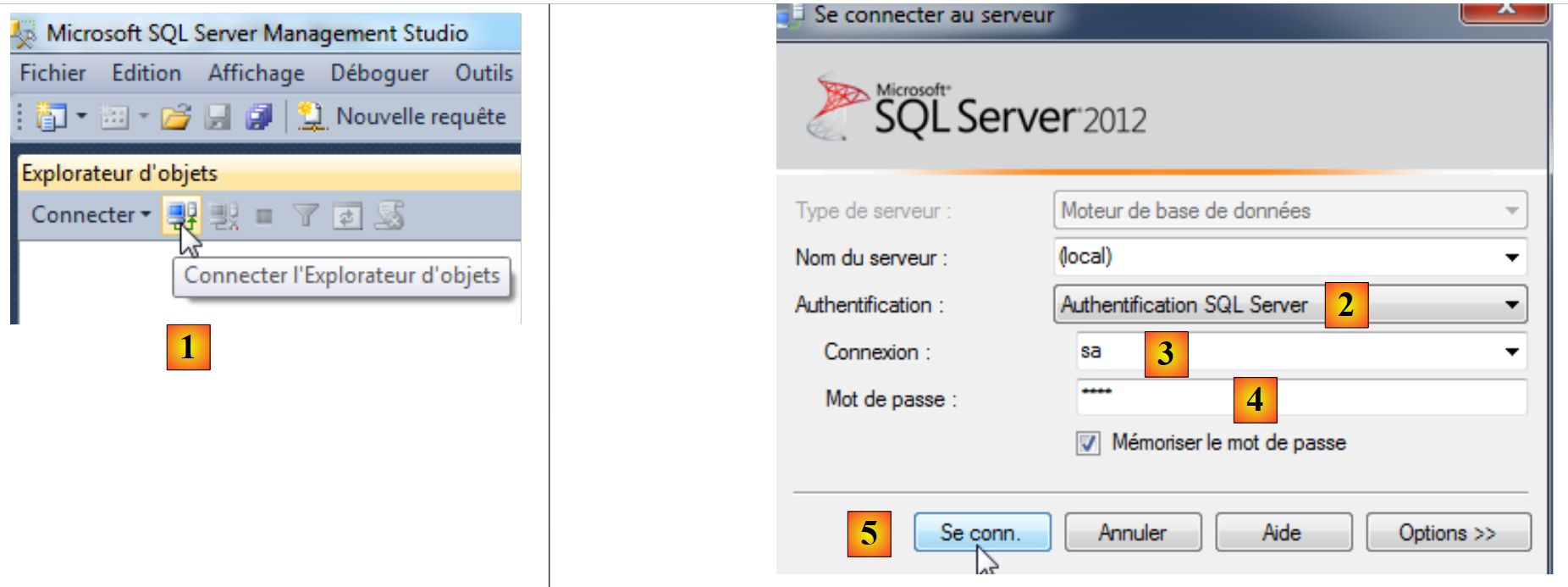 |
- in [1], ci riconnettiamo;
- in [2], l’autenticazione avviene tramite SQL Server;
- in [3], l'utente è sa;
- in [4], la sua password è sqlserver2012;
- in [5], si effettua l'accesso;
 |
- in [6], si è connessi.
Ora creeremo un database di dimostrazione:
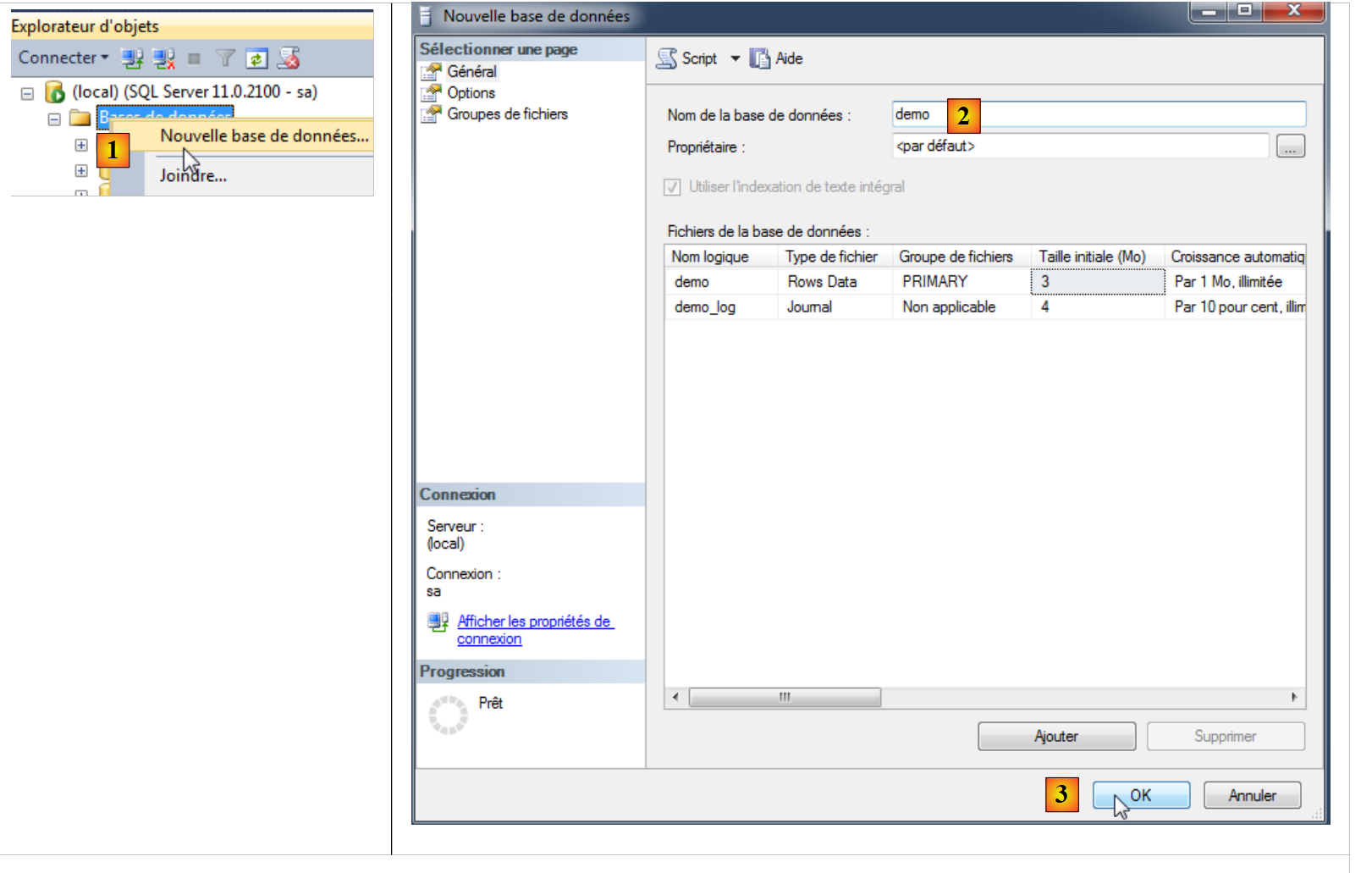 |
- in [1], si crea un nuovo BD;
- in [2], che si chiamerà demo;
- in [3], si conferma;
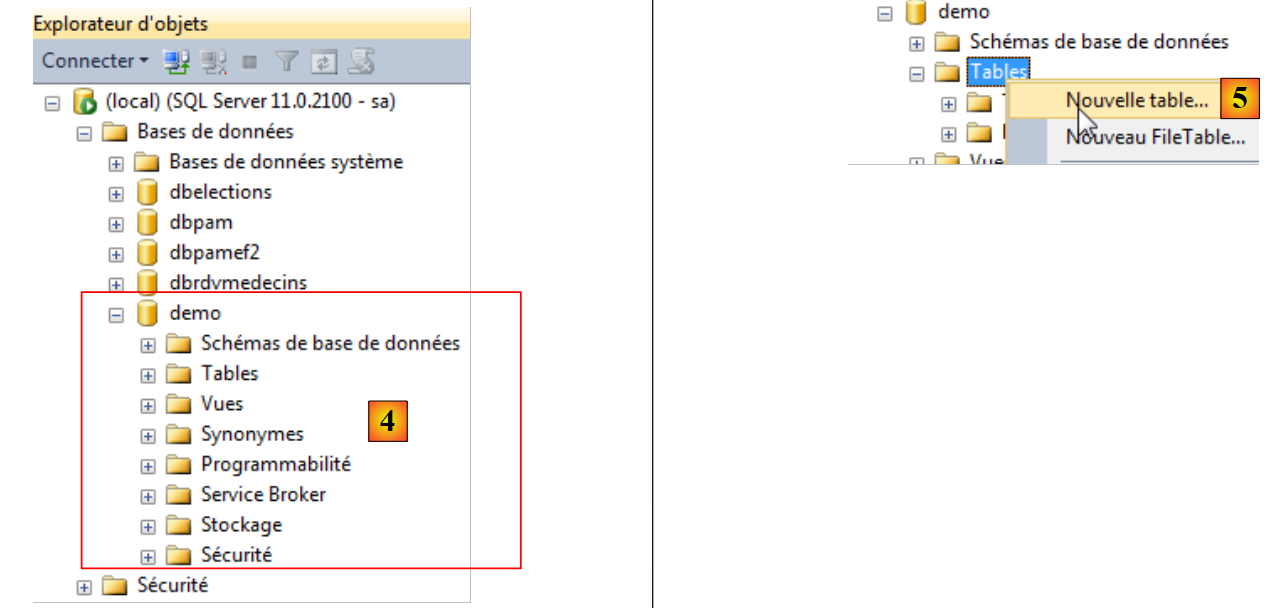 |
- in [4], il database è stato creato;
- in [5], si crea una nuova tabella nel database demo;
 |
 |
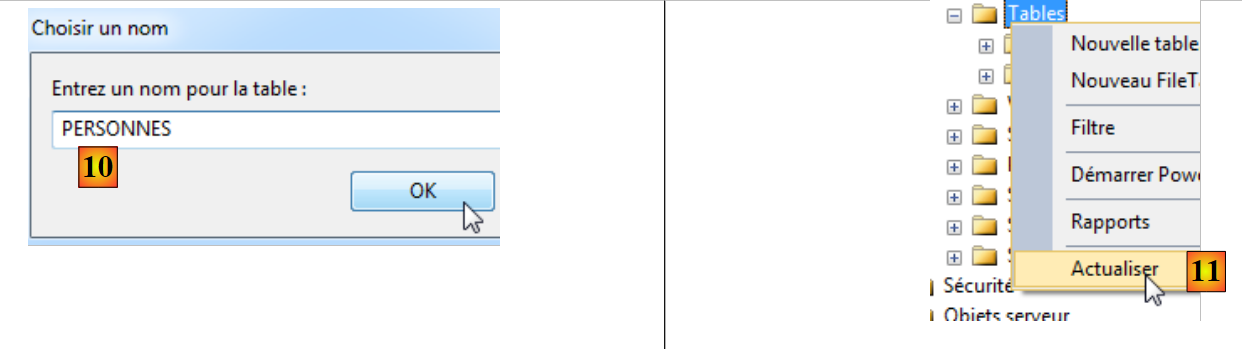 |
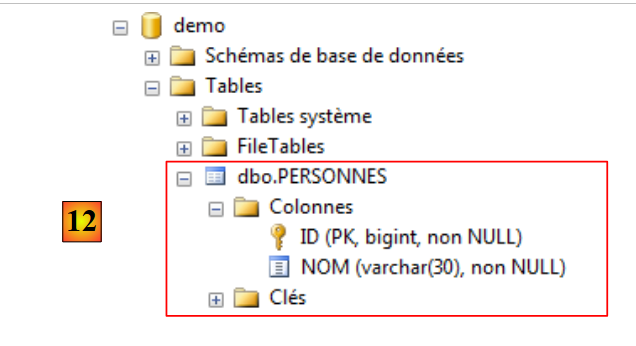 |
- in [6], si definisce una tabella a due colonne ID e NOM;
- in [7], la colonna [ID] viene impostata come chiave primaria;
- in [8], la chiave primaria è rappresentata da un simbolo a forma di chiave;
- in [9], si salva la tabella;
- in [10], le si assegna un nome;
- in [11], affinché la tabella compaia nel database [demo], è necessario aggiornare il database;
- in [12], la tabella [PERSONNES] è stata creata correttamente.
Per ora sappiamo abbastanza sull’utilizzo dello strumento di amministrazione di SQL Server.
3.3. Il server integrato (localdb)\v11.0
VS Express 2012 viene fornito con un server SQL integrato. Si presume che VS Express 2012 sia stato installato su [http://www.microsoft.com/visualstudio/fra/downloads]. Si avvia VS 2012 su [1]:
 |
Si avvia lo strumento di amministrazione di SQL Server 2012 [2] e si effettua l'accesso a [3].
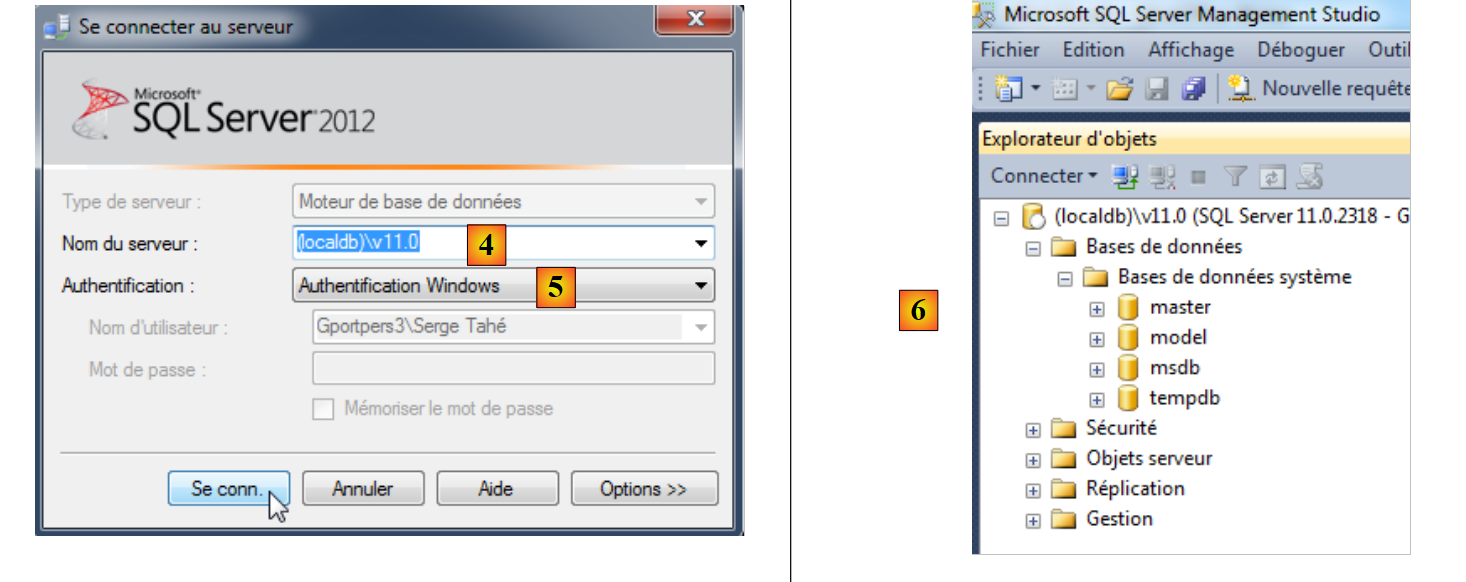 |
- in [4], ci si connette al server (localdb)\v11.0;
- in [5], con autenticazione Windows;
- in [6], una volta stabilita la connessione, vengono visualizzati i database del server. Come in precedenza, è possibile creare un nuovo database.
Non utilizzeremo questo server integrato in VS 2012.
3.4. Creazione del database a partire dalle entità
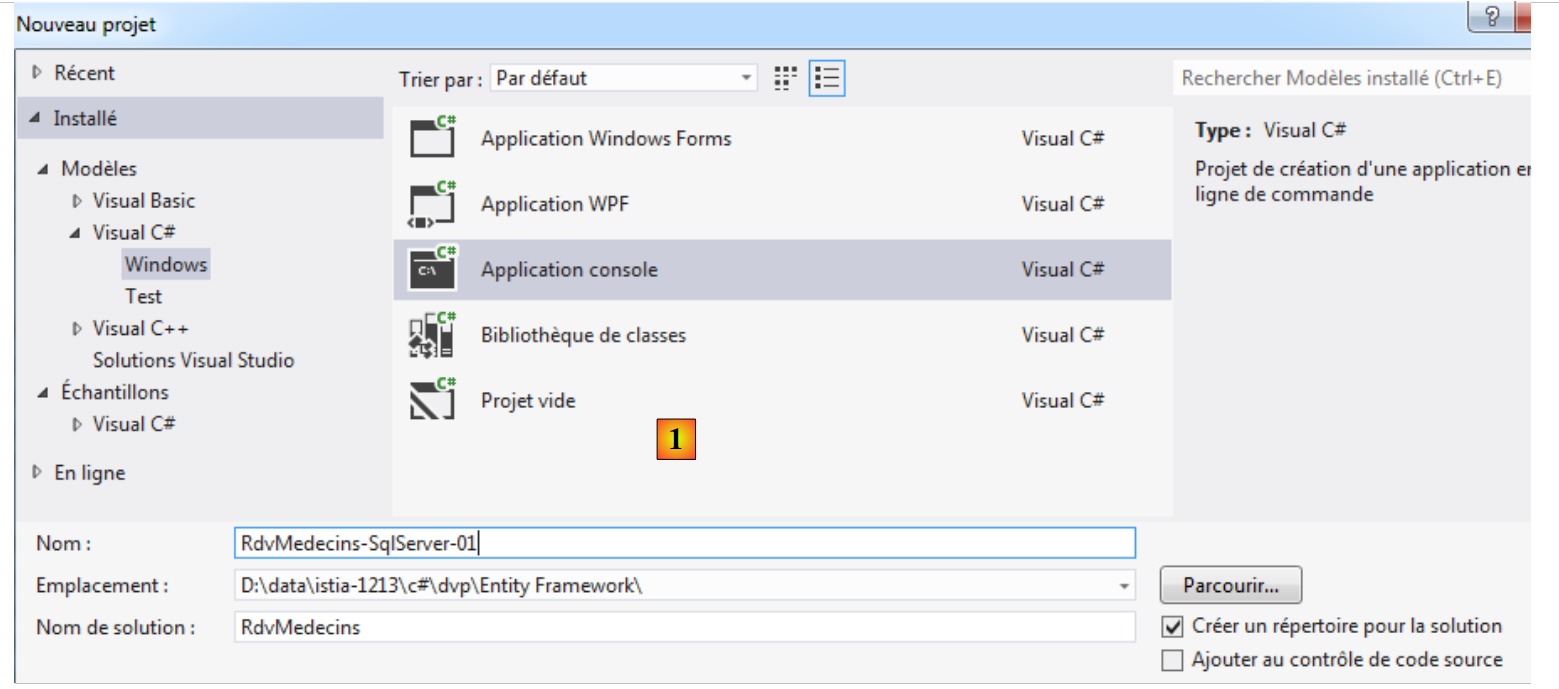
Entity Framework 5 Code First consente di creare un database a partire dalle entità. È proprio ciò che vedremo ora. Con VS Express 2012, creiamo un primo progetto console in C#:
 |
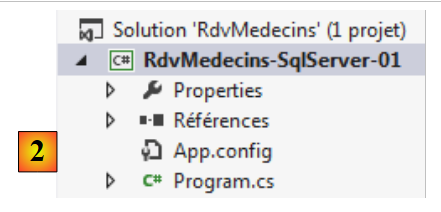 |
- in [1], la definizione del progetto;
- in [2], il progetto creato.
Tutti i nostri progetti avranno bisogno del e DLL di Entity Framework 5. Lo aggiungiamo:
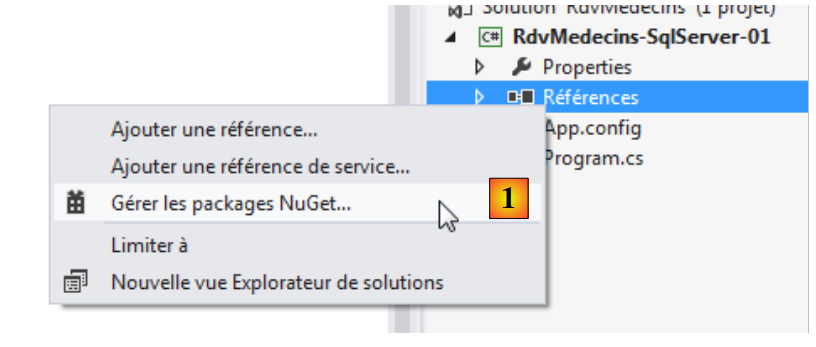 |
- in [1], lo strumento NuGet consente di scaricare le dipendenze;
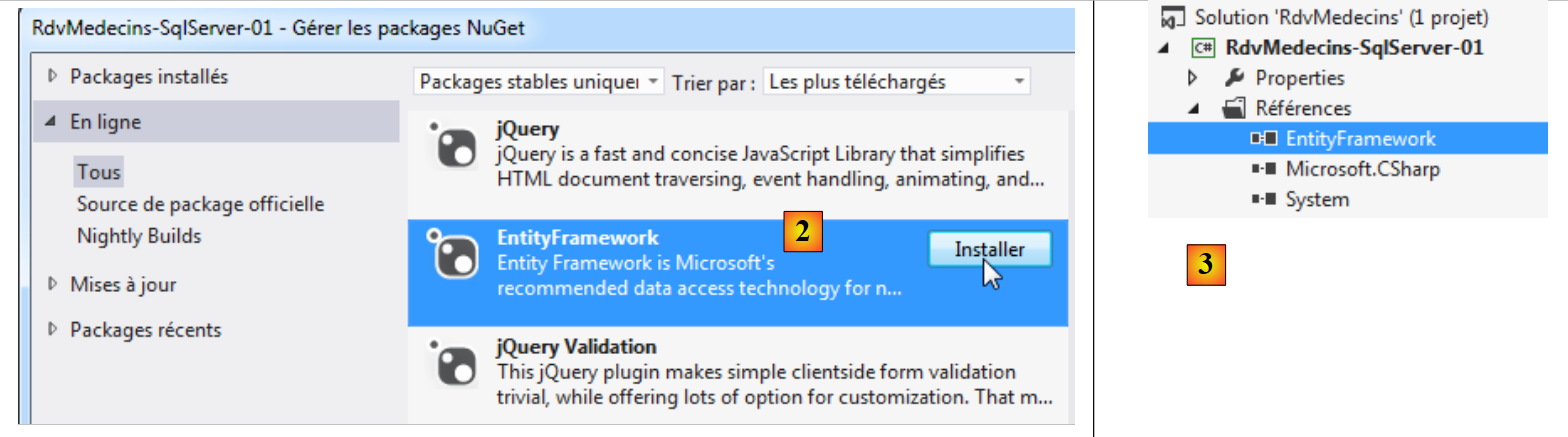 |
- in [2], si scarica la dipendenza Entity Framework;
- in [3], il riferimento è stato aggiunto al progetto.
Per ulteriori informazioni, è possibile visualizzare le proprietà del riferimento aggiunto:
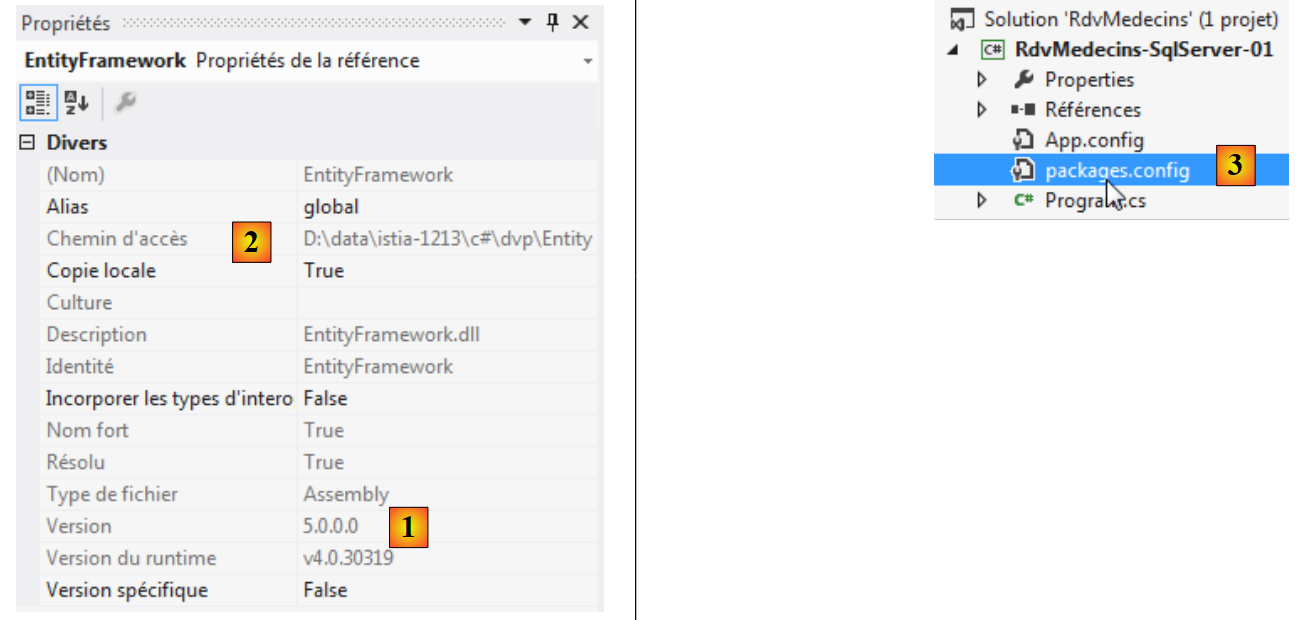 |
- in [1], la versione di DLL. È necessaria la versione 5;
- in [2], la sua posizione nel sistema di file: <soluzione>\packages\EntityFramework.5.0.0\lib\net45\EntityFramework.dll dove <soluzione> è la cartella della soluzione VS. Tutti i pacchetti aggiunti da NuGet verranno inseriti nella cartella <soluzione>/packages;
- in [3] è stato creato un file [packages.config]. Il suo contenuto è il seguente:
<?xml version="1.0" encoding="utf-8"?>
<packages>
<package id="EntityFramework" version="5.0.0" targetFramework="net45" />
</packages>
Elenca i pacchetti importati da NuGet.
Torniamo al progetto VS e creiamo una cartella [Models] all’interno del progetto:
 |
- in [1], aggiunta di una cartella al progetto;
- in [2], che si chiamerà [Models].
Manterremo questa abitudine anche in seguito, inserendo la definizione delle nostre entità nella cartella [Models].
Per creare le nostre entità, ci avvarremo della definizione del database MySQL 5 utilizzato nel progetto NHibernate. Ricordiamo il ruolo delle entità EF:
 |
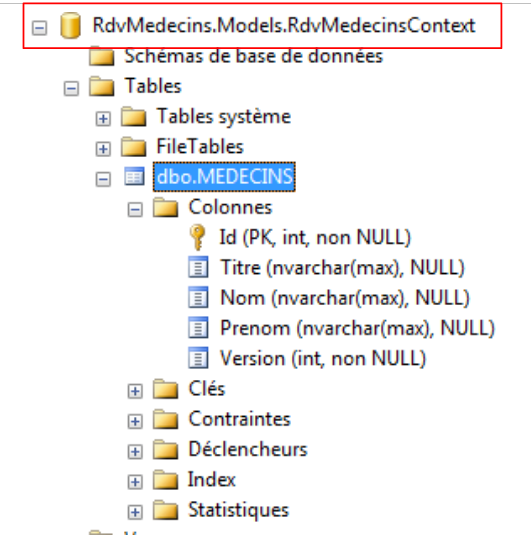
Le entità devono rispecchiare le tabelle del database. Il livello di accesso ai dati utilizza queste entità invece di operare direttamente con le tabelle. Iniziamo con la tabella [MEDECINS]:
3.4.1. L’entità [Medecin]
Contiene informazioni sui medici gestiti dall’applicazione [RdvMedecins].
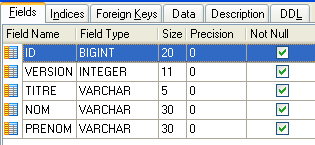 | 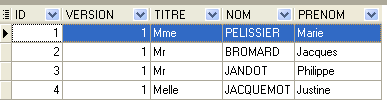 |
- ID: numero identificativo del medico - chiave primaria della tabella
- VERSION: numero che identifica la versione della riga nella tabella. Questo numero viene incrementato di 1 ogni volta che viene apportata una modifica alla riga.
- NOM: il cognome del medico
- PRENOM: il suo nome
- TITRE: il suo titolo (Sig.na, Sig.ra, Sig.)
Potremmo partire dalla seguente classe [Medecin]:
using System;
[Table("MEDECINS", Schema = "dbo")]
namespace RdvMedecins.Entites
{
public class Medecin
{
// dati
public int Id { get; set; }
public string Titre { get; set; }
public string Nom { get; set; }
public string Prenom { get; set; }
}
- riga 3: la classe [Medecin] è associata alla tabella [MEDECINS] del database. Quest’ultima si troverà in uno schema denominato "dbo".
Inseriamo questa classe in un file denominato [Entites.cs] [1]. È qui che inseriremo tutte le nostre entità.
 |
Sempre nella cartella [Models], creiamo il seguente file [Context.cs]:
using System.Data.Entity;
using RdvMedecins.Entites;
namespace RdvMedecins.Models
{
// il contesto
public class RdvMedecinsContext : DbContext
{
// i medici
public DbSet<Medecin> Medecins { get; set; }
}
// inizializzazione del database
public class RdvMedecinsInitializer : DropCreateDatabaseAlways<RdvMedecinsContext>
{
}
}
- riga 8: la classe [RdvMedecinsContext] rappresenterà il contesto di persistenza, c.-à-d. l'insieme delle entità gestite da ORM. Deve derivare dalla classe [System.Data.Entity.DbContext];
- riga 11: il campo [Medecins] rappresenterà le entità di tipo [Medecin] del contesto di persistenza. È di tipo DbSet<Medecin>. Generalmente si troveranno tanti [DbSet] quanti sono i tavoli nel database, uno per tavolo;
- riga 15: si definisce una classe [RdvMedecinsInitializer] per inizializzare il database creato. In questo caso deriva dalla classe [DropCreateDataBaseAlways] che, come indica il nome, elimina il database se già esiste e poi lo ricrea. Ciò risulta utile nella fase di sviluppo della classe BD. Il parametro della classe [DropCreateDataBaseAlways] è il tipo di contesto di persistenza associato al database. È possibile utilizzare classi madri diverse da [DropCreateDataBaseAlways] per la classe di inizializzazione:
- [DropCreateDatabaseIfModelChanges]: ricrea il database se le entità sono cambiate,
- [CreateDatabaseIfNotExists]: crea il database se non esiste;
Non resta che creare un programma principale. Sarà il seguente [CreateDB_01.cs]:
using System;
using System.Data.Entity;
using RdvMedecins.Models;
namespace RdvMedecins_01
{
class CreateDB_01
{
static void Main(string[] args)
{
// creazione del database
Database.SetInitializer(new RdvMedecinsInitializer());
using (var context = new RdvMedecinsContext())
{
context.Database.Initialize(false);
}
}
}
}
- riga 12: [System.Data.Entity.DataBase] è una classe che offre metodi statici per gestire il database associato a un contesto di persistenza. Il metodo statico [SetInitializer] consente di specificare la classe di inizializzazione del database. Ciò non avvia l'inizializzazione;
- riga 13: per lavorare con un contesto di persistenza, è necessario istanziarlo. È ciò che viene fatto qui. Si utilizza una clausola
usingaffinché il contesto venga chiuso automaticamente all'uscita dalla clausola. Pertanto, alla riga 17, il contesto viene chiuso; - riga 15: si avvia esplicitamente la generazione del database associato al contesto di persistenza [RdvMedecinsContext]. Il parametro false indica che questa operazione non deve essere eseguita se è già stata eseguita per quel contesto. In questo caso, si sarebbe potuto inserire anche true.
Quando si lavora con un database, i parametri di connessione sono generalmente registrati nel file [App.config]. Notiamo che, per il momento, non sono presenti:
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<configSections>
<!-- Per ulteriori informazioni sulla configurazione di Entity Framework, visitare il sito http://go.microsoft.com/fwlink/?LinkID=237468 -->
<section name="entityFramework" type="System.Data.Entity.Internal.ConfigFile.EntityFrameworkSection, EntityFramework, Version=5.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" requirePermission="false" />
</configSections>
<startup>
<supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.5" />
</startup>
<entityFramework>
<defaultConnectionFactory type="System.Data.Entity.Infrastructure.SqlConnectionFactory, EntityFramework" />
</entityFramework>
</configuration>
Gli elementi sopra indicati sono stati inseriti nel file [App.config] quando è stata aggiunta la dipendenza Entity Framework ai riferimenti del progetto.
Eseguiamo il progetto (Ctrl-F5) dopo aver avviato SQL Server Express (questo è importante):
 |  |
L’esecuzione dovrebbe concludersi senza errori. Apriamo ora lo strumento di amministrazione di SQL Server e aggiorniamo la visualizzazione:
 |
Si nota che è stato creato un database con il nome completo della classe [RdvMedecinsContext] e che contiene una tabella [dbo.MEDECINS] (questo è il nome che le era stato assegnato) con colonne che riprendono i nomi dei campi dell’entità [Medecin]. Se il codice è stato eseguito correttamente e il database sopra indicato non compare, è necessario controllare il server integrato (localdb)\v11.0 (cfr. pagina 19). Con VS 2012 Pro, questo server viene utilizzato se il server SQL non è attivo al momento dell’esecuzione del codice. Con VS 2012 Express, no.
Esaminiamo la struttura della tabella [MEDECINS]:
- riprende i nomi dei campi dell’entità [Medecin];
- la colonna [Id] è la chiave primaria. Si tratta di una convenzione di EF: se l’entità E ha un campo Id o Eid (MedecinId), allora questa colonna è la chiave primaria nella tabella associata;
- i tipi delle colonne della tabella corrispondono a quelli dei campi dell’entità;
- per le colonne Titolo, Cognome, Nome è stato utilizzato un tipo [nvarchar(max)]. Si potrebbe essere più precisi: 5 caratteri per il titolo, 30 per il cognome e il nome;
- le colonne Titolo, Cognome, Nome possono assumere il valore NULL. Modificheremo questo valore.
Esaminiamo le proprietà della chiave primaria [Id]:
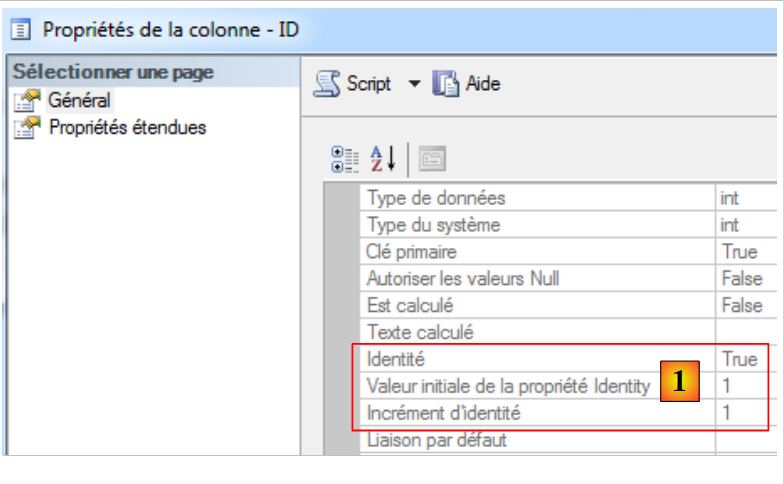 |
In [1], si vede che la chiave primaria è di tipo [Identité], il che significa che il suo valore viene generato automaticamente da SQL Server. Adotteremo questa strategia con tutti i SGBD.
Limiteremo l’uso delle convenzioni di EF ricorrendo alle annotazioni. Il codice dell’entità in [Entites.cs] diventa il seguente:
using System;
using System.ComponentModel.DataAnnotations;
using System.ComponentModel.DataAnnotations.Schema;
namespace RdvMedecins.Entites
{
[Table("MEDECINS", Schema = "dbo")]
public class Medecin
{
// dati
[Key]
[Column("ID")]
public int Id { get; set; }
[Required]
[MaxLength(5)]
[Column("TITRE")]
public string Titre { get; set; }
[Required]
[MaxLength(30)]
[Column("NOM")]
public string Nom { get; set; }
[Required]
[MaxLength(30)]
[Column("PRENOM")]
public string Prenom { get; set; }
[Required]
[Column("VERSION")]
public int Version { get; set; }
}
}
- righe 2 e 3: le annotazioni si trovano negli spazi dei nomi [System.ComponentModel.DataAnnotations] (Key, Required, MaxLength) e [System.ComponentModel.DataAnnotations.Schema] (Column). Altre annotazioni si trovano in URL e [http://msdn.microsoft.com/en-us/data/gg193958.aspx];
- riga 11: [Key] indica la chiave primaria;
- riga 12: [Column] definisce il nome della colonna corrispondente al campo;
- riga 14: [Required] indica che il campo è obbligatorio (SQL, NOT, NULL);
- riga 15: [MaxLength] definisce la lunghezza massima della stringa di caratteri, [MinLength] la lunghezza minima;
Eseguiamo il progetto con questa nuova definizione dell'entità [Medecin]. Il database creato è quindi il seguente:
 |
- le colonne hanno il nome che abbiamo loro assegnato;
- l’annotazione [Required] è stata tradotta in SQL NOT NULL;
- l'annotazione [MaxLength(N)] è stata convertita in un tipo SQL nvarchar(N).
Nell’applicazione NHibernate, la colonna [VERSION] serviva a impedire accessi concorrenti alla stessa riga di una tabella. Il principio è il seguente:
- un processo P1 legge una riga L della tabella [MEDECINS] al momento T1. La riga ha la versione V1;
- un processo P2 legge la stessa riga L della tabella [MEDECINS] al momento T2. La riga ha la versione V1 perché il processo P1 non ha ancora convalidato la propria modifica;
- il processo P1 convalida la propria modifica alla riga L. La versione della riga L passa quindi a V2=V1+1;
- il processo P2 convalida la modifica apportata alla riga L. Il processo ORM genera quindi un'eccezione poiché il processo P2 possiede una versione V1 della riga L diversa dalla versione V2 presente nel database.
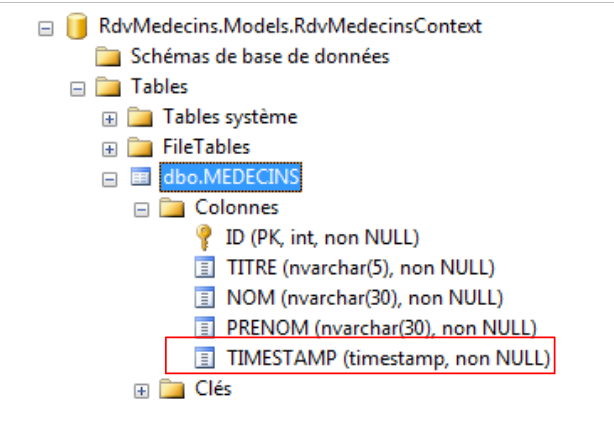
Questo fenomeno è noto come gestione ottimistica degli accessi concorrenti. Con EF 5, un campo che svolge questa funzione deve avere uno dei due attributi [Timestamp] o [ConcurrencyCheck]. SQL Server ha un tipo [timestamp]. Il valore di una colonna con questo tipo viene generato automaticamente da SQL Server ad ogni inserimento o modifica di una riga. Una colonna di questo tipo può quindi essere utilizzata per gestire la concorrenza di accesso. Riprendendo l’esempio precedente, il processo P2 troverà un timestamp diverso da quello che ha letto, poiché nel frattempo la modifica apportata dal processo P1 lo avrà modificato.
La nostra entità [Medecin] si evolve come segue:
using System;
using System.ComponentModel.DataAnnotations;
using System.ComponentModel.DataAnnotations.Schema;
namespace RdvMedecins.Entites
{
[Table("MEDECINS", Schema = "dbo")]
public class Medecin
{
// dati
[Key]
[Column("ID")]
public int Id { get; set; }
[Required]
[MaxLength(5)]
[Column("TITRE")]
public string Titre { get; set; }
[Required]
[MaxLength(30)]
[Column("NOM")]
public string Nom { get; set; }
[Required]
[MaxLength(30)]
[Column("PRENOM")]
public string Prenom { get; set; }
[Column("TIMESTAMP")]
[Timestamp]
public byte[] Timestamp { get; set; }
}
}
- righe 26-28: la nuova colonna con l’attributo [Timestamp] della riga 27. Il tipo del campo deve essere byte[] (riga 28). Il nome del campo può essere qualsiasi. Non gli si assegna l'attributo [Required] poiché non sarà l'applicazione a fornire questo valore, ma lo stesso SGBD.
Se si esegue il progetto con questa nuova entità, il database si evolve come segue:
 |
Resta da chiarire un ultimo punto. Il contesto di persistenza “sa” che un’entità deve essere inserita nel database perché in quel momento la sua chiave primaria è pari a null. È proprio l’inserimento nel database che assegnerà un valore alla chiave primaria. In questo caso, il tipo int assegnato alla chiave primaria [Id] non è adatto perché tale tipo non accetta il valore null. Gli viene quindi assegnato il tipo **int?, che accetta i valori *int e il puntatore *null. L’entità [Medecin] utilizzata sarà quindi la seguente:
public class Medecin
{
// dati
[Key]
[Column("ID")]
public int? Id { get; set; }
...
Resta da vedere come rappresentare in un’entità il concetto di chiave esterna tra tabelle.
3.4.2. L'entità [Creneau]
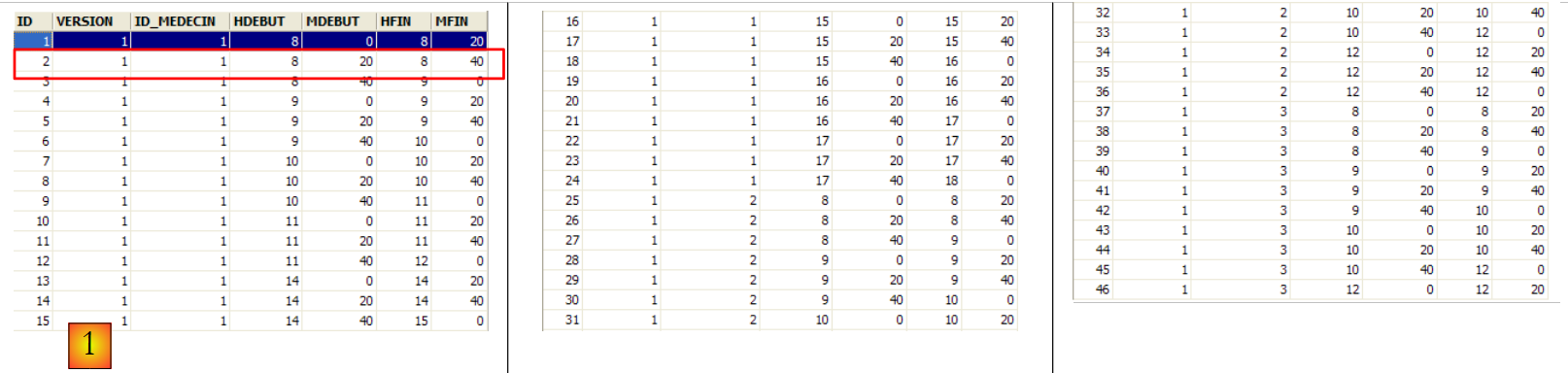
La tabella [CRENEAUX] elenca le fasce orarie in cui sono possibili i RV:
 |
 |
- ID: numero che identifica la fascia oraria - chiave primaria della tabella
- VERSION: numero che identifica la versione della riga nella tabella. Questo numero viene incrementato di 1 ogni volta che viene apportata una modifica alla riga.
- ID_MEDECIN: numero identificativo del medico a cui appartiene questa fascia oraria – chiave esterna sulla colonna MEDECINS(ID).
- HDEBUT: ora di inizio della fascia oraria
- MDEBUT: minuti di inizio della fascia oraria
- HFIN: ora di fine della fascia oraria
- MFIN: minuti di fine della fascia oraria
La seconda riga della tabella [CRENEAUX] (cfr. [1] sopra) indica, ad esempio, che la fascia n. 2 inizia alle 8:20 e termina alle 8:40 e appartiene al medico n. 1 (la signora Marie PELISSIER).
Con queste informazioni, possiamo definire l’entità [Creneau] come segue in [Entites.cs]:
[Table("CRENEAUX", Schema = "dbo")]
public class Creneau
{
// dati
[Key]
[Column("ID")]
public int? Id { get; set; }
[Required]
[Column("HDEBUT")]
public int Hdebut { get; set; }
[Required]
[Column("MDEBUT")]
public int Mdebut { get; set; }
[Required]
[Column("HFIN")]
public int Hfin { get; set; }
[Required]
[Column("MFIN")]
public int Mfin { get; set; }
[Required]
public virtual Medecin Medecin { get; set; }
[Column("TIMESTAMP")]
[Timestamp]
public byte[] Timestamp { get; set; }
}
L’unica novità riguarda le righe 20-21. Il fatto che la tabella [CRENEAUX] abbia una chiave esterna sulla tabella [MEDECINS] si riflette nell’entità [Creneau] attraverso la presenza di un riferimento all’entità [Medecin], riga 21. Il nome del campo non ha importanza, conta solo il tipo. La proprietà deve essere dichiarata virtuale con la parola chiave virtual. Infatti, EF è destinata a ridefinire tutte le cosiddette proprietà di navigazione, ovvero quelle che corrispondono a una chiave esterna e che consentono di passare da una tabella all’altra.
Per testare la nuova entità, dobbiamo apportare alcune modifiche in [Context.cs]:
using System.Data.Entity;
using RdvMedecins.Entites;
namespace RdvMedecins.Models
{
// il contesto
public class RdvMedecinsContext : DbContext
{
// le entità
public DbSet<Medecin> Medecins { get; set; }
public DbSet<Creneau> Creneaux { get; set; }
}
// inizializzazione del database
public class RdvMedecinsInitializer : DropCreateDatabaseIfModelChanges<RdvMedecinsContext>
{
}
}
La riga 12 riflette il fatto che il contesto ha un’entità in più da gestire. Quando eseguiamo il progetto, otteniamo il seguente nuovo database:
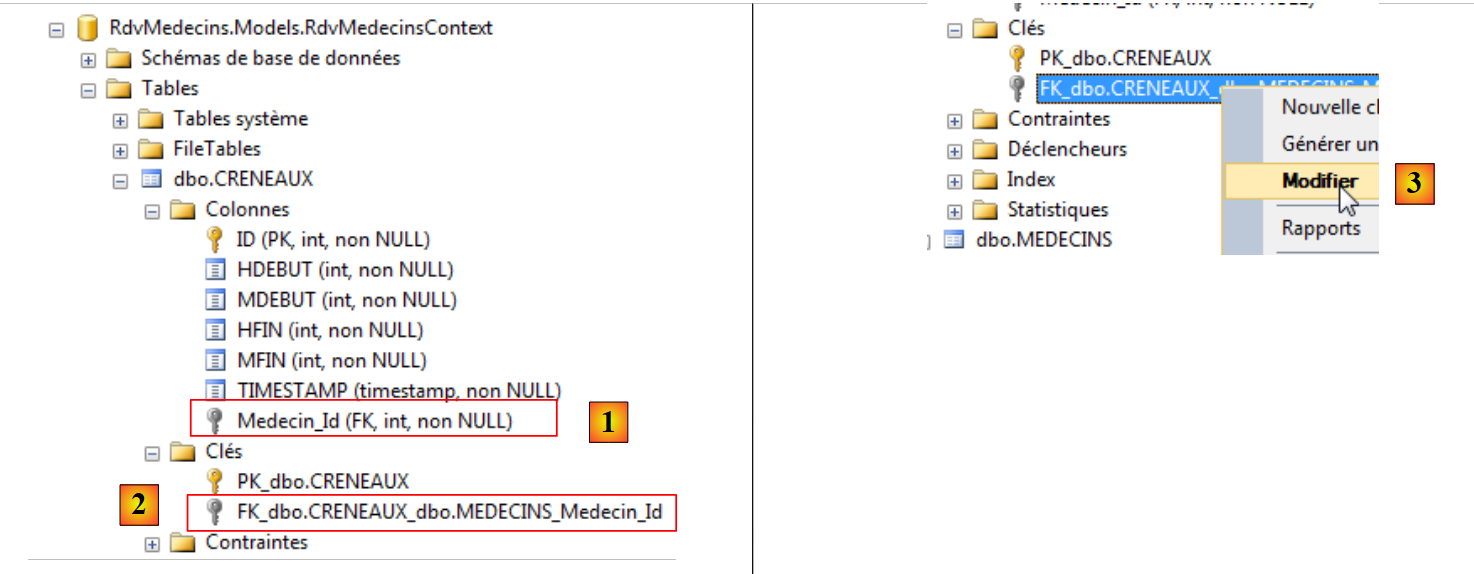 |
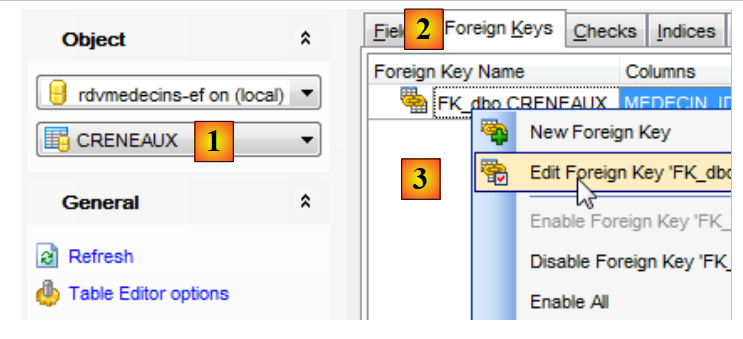
La tabella [CRENEAUX] è stata correttamente creata e la novità è rappresentata dalla presenza di una chiave esterna [1] e [2]. Il suo nome è stato generato a partire dal nome del campo corrispondente nell’entità (Medecin), con il suffisso “_Id”. Per conoscere le proprietà di questa chiave esterna, proviamo a modificarla in [3].
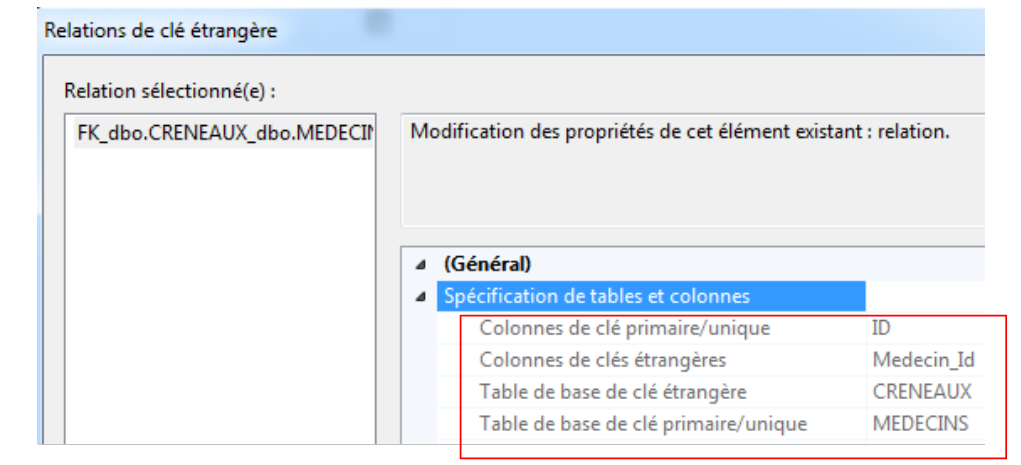 |
La schermata sopra riportata mostra che [Medecin_Id] è una chiave esterna della tabella [CRENEAUX] e che fa riferimento alla chiave primaria [ID] della tabella [MEDECINS].
Se si creano le entità per un database esistente, la colonna della chiave esterna non si chiamerà necessariamente [Medecin_Id]. Per le altre colonne, avevamo visto che l’annotazione [Column] risolveva questo problema. Stranamente, per una chiave esterna la questione è più complicata. È necessario procedere come segue:
public class Creneau
{
// dati
...
[Required]
[Column("MEDECIN_ID")]
public int MedecinId { get; set; }
[Required]
[ForeignKey("MedecinId")]
public virtual Medecin Medecin { get; set; }
...
}
- righe 5-7: si crea un campo del tipo della chiave esterna (int). Con l’attributo [Column], si specifica il nome della colonna che fungerà da chiave esterna nella tabella associata all’entità;
- riga 9: si aggiunge l’annotazione [ForeignKey] al campo di tipo [Medecin]. L’argomento di questa annotazione è il nome del campo (non della colonna) associato alla colonna chiave esterna della tabella.
L'esecuzione del progetto crea questa volta la seguente tabella:
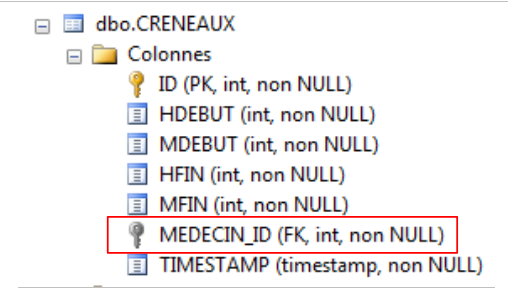 |
Come si può vedere, la colonna con la chiave esterna porta effettivamente il nome che le è stato assegnato. Si noti che i campi:
[Required]
[Column("MEDECIN_ID")]
public int MedecinId { get; set; }
[Required]
[ForeignKey("MedecinId")]
public virtual Medecin Medecin { get; set; }
hanno dato origine a una sola colonna, la colonna [MEDECIN_ID]. Tuttavia, la presenza del campo [MedecinId] è importante. Quando si legge una riga della tabella [CRENEAUX], essa riceverà il valore della colonna [MEDECIN_ID], ovvero il valore della chiave esterna nella tabella [MEDECINS]. Ciò risulta spesso utile.
Il campo [Medecin] sopra riportato riflette la relazione molti-a-uno che collega l’entità [Creneau] all’entità [Medecin]. Più oggetti [Creneau] sono collegati a un unico [Medecin]. La relazione inversa, in cui un oggetto [Medecin] è associato a più oggetti [Creneau], può essere modellata tramite un campo aggiuntivo nell’entità [Medecin]:
public class Medecin
{
// dati
[Key]
[Column("ID")]
public int? Id { get; set; }
...
public ICollection<Creneau> Creneaux { get; set; }
[Column("TIMESTAMP")]
[Timestamp]
public byte[] Timestamp { get; set; }
Alla riga 8 è stato aggiunto il campo [Creneaux], che è una raccolta di oggetti [Creneau]. Questo campo ci consentirà di accedere a tutte le fasce orarie del medico.
Quando si riesegue il progetto, si nota che la tabella [MEDECINS] non è cambiata:
 |
Non è stata aggiunta alcuna colonna. La relazione di chiave esterna esistente tra la tabella [CRENEAUX] e la tabella [MEDECINS] è sufficiente affinché EF sia in grado di generare i campi ad essa collegati:
public class Medecin
{
...
public ICollection<Creneau> Creneaux { get; set; }
...
}
public class Creneau
{
...
[Required]
[Column("MEDECIN_ID")]
public int MedecinId { get; set; }
[Required]
[ForeignKey("MedecinId")]
public virtual Medecin Medecin { get; set; }
...
}
Sappiamo l'essenziale. Possiamo concludere con la creazione delle altre due entità.
3.4.3. Le entità [Client] e [Rv]
Grazie a quanto abbiamo appreso, possiamo scrivere le entità [Client] e [Rv]. L’entità [Client] contiene informazioni sui clienti gestiti dall’applicazione [RdvMedecins].
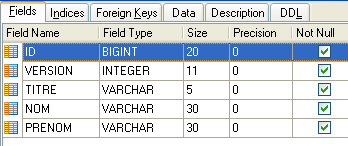 | 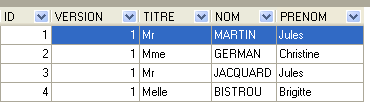 |
- ID: numero identificativo del cliente – chiave primaria della tabella
- VERSION: numero che identifica la versione della riga nella tabella. Questo numero viene incrementato di 1 ogni volta che viene apportata una modifica alla riga.
- NOM: il nome del cliente
- PRENOM: il suo nome
- TITRE: il suo titolo (Sig.na, Sig.ra, Sig.)
L’entità [Client] potrebbe essere la seguente:
[Table("CLIENTS", Schema = "dbo")]
public class Client
{
// dati
[Key]
[Column("ID")]
public int? Id { get; set; }
[Required]
[MaxLength(5)]
[Column("TITRE")]
public string Titre { get; set; }
[Required]
[MaxLength(30)]
[Column("NOM")]
public string Nom { get; set; }
[Required]
[MaxLength(30)]
[Column("PRENOM")]
public string Prenom { get; set; }
// gli Rvs del cliente
public ICollection<Rv> Rvs { get; set; }
[Column("TIMESTAMP")]
[Timestamp]
public byte[] Timestamp { get; set; }
}
La classe [Client] è quasi identica alla classe [Medecin]. Si potrebbero far derivare da una stessa classe padre. La novità è alla riga 21. Essa riflette il fatto che un cliente può avere più appuntamenti e deriva dalla presenza di una chiave esterna dalla tabella [RVS] alla tabella [CLIENTS].
L'entità [Rv] rappresenta un appuntamento:
 |
- ID: numero che identifica in modo univoco il RV – chiave primaria
- JOUR: giorno del RV
- ID_CRENEAU: fascia oraria del RV – chiave esterna sulla colonna [ID] della tabella [CRENEAUX] – determina sia la fascia oraria che il medico interessato.
- ID_CLIENT: numero del cliente per il quale è stata effettuata la prenotazione – chiave esterna sulla colonna [ID] della tabella [CLIENTS]
L'entità [Rv] potrebbe essere la seguente:
[Table("MEDECINS", Schema = "dbo")]
public class Rv
{
// dati
[Key]
[Column("ID")]
public int? Id { get; set; }
[Required]
[Column("JOUR")]
public DateTime Jour { get; set; }
[Column("CLIENT_ID")]
public int ClientId { get; set; }
[ForeignKey("ClientId")]
[Required]
public virtual Client Client { get; set; }
[Column("CRENEAU_ID")]
public int CreneauId { get; set; }
[ForeignKey("CreneauId")]
[Required]
public virtual Creneau Creneau { get; set; }
[Column("TIMESTAMP")]
[Timestamp]
public byte[] Timestamp { get; set; }
}
- righe 5-7: chiave primaria;
- righe 8-10: data dell’appuntamento;
- righe 11-12: chiave esterna dalla tabella [RVS] alla tabella [CLIENTS];
- righe 13-15: il cliente che ha l’appuntamento;
- righe 16-17: chiave esterna dalla tabella [RVS] alla tabella [CRENEAUX];
- righe 18-20: la fascia oraria dell'appuntamento;
- righe 21-23: il campo di gestione degli accessi concorrenti.
Alla riga 17 si osserva una relazione molti-a-uno: a una fascia oraria possono corrispondere più appuntamenti (non nello stesso giorno). La relazione inversa può essere rappresentata nell’entità [Creneau]:
public class Creneau
{
// gli Rvs della fascia oraria
public ICollection<Rv> Rvs { get; set; }
...
}
Riga 4: l'insieme degli appuntamenti fissati in quella fascia oraria.
Quando si esegue il progetto, il database generato è il seguente:
 |
Le tabelle [MEDECINS] e [CRENEAUX] non sono cambiate. Le tabelle [CLIENTS] e [RVS] sono le seguenti:
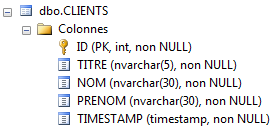 | 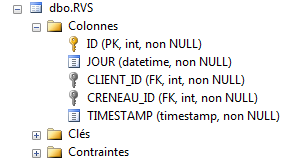 |
È proprio quello che ci aspettavamo. Ci restano ancora alcuni dettagli da sistemare:
- gestire il nome del database. In questo caso è stato generato da EF;
- inserire i dati nel database.
3.4.4. Impostare il nome del database
Per impostare il nome del database generato da EF, useremo una stringa di connessione definita in [App.config]. Questo file di configurazione viene modificato come segue:
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<configSections>
<!-- Per ulteriori informazioni sulla configurazione di Entity Framework, visitare http://go.microsoft.com/fwlink/?LinkID=237468 -->
<section name="entityFramework" type="System.Data.Entity.Internal.ConfigFile.EntityFrameworkSection, EntityFramework, Version=5.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" requirePermission="false" />
</configSections>
<startup>
<supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.5" />
</startup>
<entityFramework>
<defaultConnectionFactory type="System.Data.Entity.Infrastructure.SqlConnectionFactory, EntityFramework" />
</entityFramework>
<!-- Stringa di connessione al database -->
<connectionStrings>
<add name="RdvMedecinsContext"
connectionString="Data Source=localhost;Initial Catalog=rdvmedecins-ef;User Id=sa;Password=sqlserver2012;"
providerName="System.Data.SqlClient" />
</connectionStrings>
<!-- il provider di factory -->
<system.data>
<DbProviderFactories>
<add name="SqlClient Data Provider"
invariant="System.Data.SqlClient"
description=".Net Framework Data Provider for SqlServer"
type="System.Data.SqlClient.SqlClientFactory, System.Data,
Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089"
/>
</DbProviderFactories>
</system.data>
</configuration>
- righe 15-19: la stringa di connessione al database;
- riga 16: l'attributo [name] riprende il nome della classe [RdvMedecinsContext] utilizzata per il contesto di persistenza. È importante tenerlo presente. Questo vincolo può essere aggirato nel costruttore del contesto:
// costruttore
public RdvMedecinsContext()
: base("monContexte")
{
}
In questo caso, si potrà avere name= "monContexte". È ciò che avremo nel prosieguo del documento.
- riga 17: la stringa di connessione. [Data Source]: il nome del server su cui si trova il SGBD, [Initial Catalog]: il nome del database, quindi in questo caso [rdvmedecins-ef]; [User Id]: il proprietario della connessione; [Password]: la sua password. Il lettore dovrà adattare questa stringa al proprio ambiente;
- righe 21-29: definiscono un [DbProviderFactory]. Non so di cosa si tratti. A giudicare dal nome, potrebbe essere una classe che permette di generare il livello [ADO.NET] che separa EF da SGBD:
 |
In realtà, queste righe sono superflue per SQL Server, ma ho dovuto aggiungerle per gli altri SGBD. Le inserisco qui solo a titolo di promemoria. Non creano alcun problema. L’unico punto importante è la versione della riga 27. È quella del DLL e del [System.Data] presenti nei riferimenti del progetto:
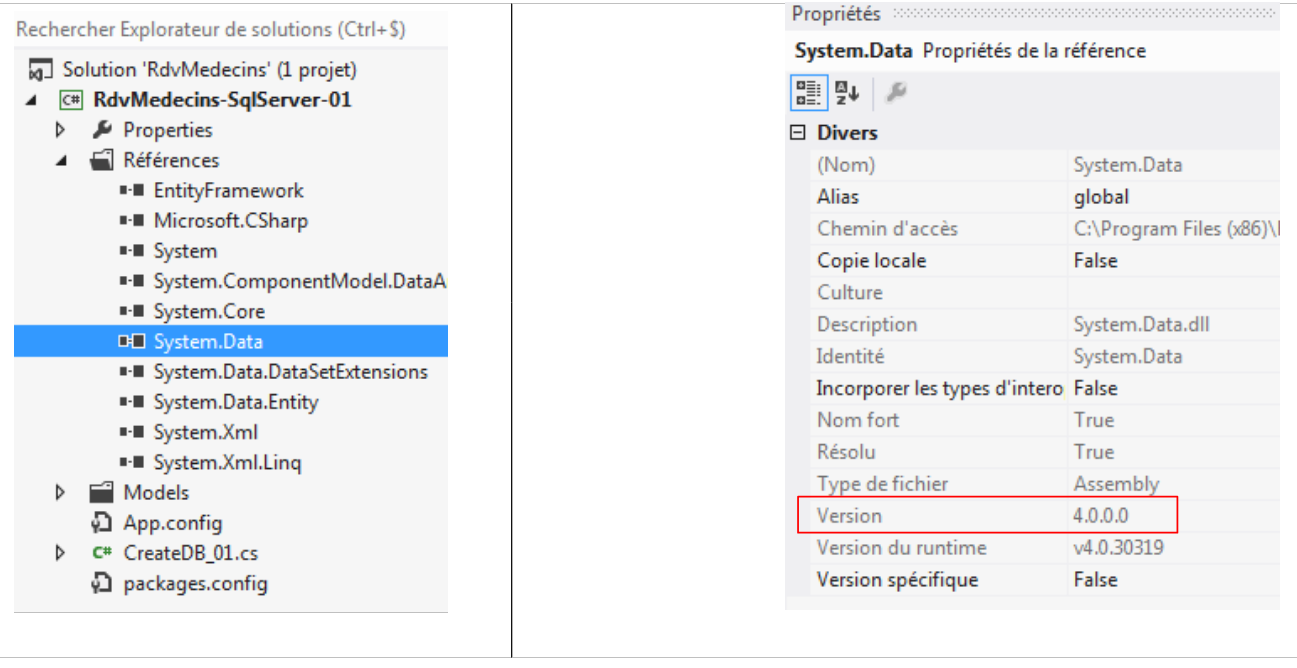 |
Ecco fatto. Siamo pronti. Eseguiamo il progetto e otteniamo la base [rdvmedecins-ef] seguente:
 |
Questo sarà il nostro database definitivo. Non ci resta che inserirvi i dati.
3.4.5. Compilazione del database
La classe di inizializzazione del database può essere utilizzata per inserirvi dei dati:
public class RdvMedecinsInitializer : DropCreateDatabaseIfModelChanges<RdvMedecinsContext>
{
// inizializzazione del database
public class RdvMedecinsInitializer : DropCreateDatabaseAlways<RdvMedecinsContext>
{
protected override void Seed(RdvMedecinsContext context)
{
base.Seed(context);
// si sta inizializzando il database
// i clienti
Client[] clients ={
new Client { Titre = "Mr", Nom = "Martin", Prenom = "Jules" },
new Client { Titre = "Mme", Nom = "German", Prenom = "Christine" },
new Client { Titre = "Mr", Nom = "Jacquard", Prenom = "Jules" },
new Client { Titre = "Melle", Nom = "Bistrou", Prenom = "Brigitte" }
};
foreach (Client client in clients)
{
context.Clients.Add(client);
}
// i medici
Medecin[] medecins ={
new Medecin { Titre = "Mme", Nom = "Pelissier", Prenom = "Marie" },
new Medecin { Titre = "Mr", Nom = "Bromard", Prenom = "Jacques" },
new Medecin { Titre = "Mr", Nom = "Jandot", Prenom = "Philippe" },
new Medecin { Titre = "Melle", Nom = "Jacquemot", Prenom = "Justine" }
};
foreach (Medecin medecin in medecins)
{
context.Medecins.Add(medecin);
}
// le fasce orarie
Creneau[] creneaux ={
new Creneau{ Hdebut=8,Mdebut=0,Hfin=8,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=8,Mdebut=20,Hfin=8,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=8,Mdebut=40,Hfin=9,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=9,Mdebut=0,Hfin=9,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=9,Mdebut=20,Hfin=9,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=9,Mdebut=40,Hfin=10,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=10,Mdebut=0,Hfin=10,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=10,Mdebut=20,Hfin=10,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=10,Mdebut=40,Hfin=11,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=11,Mdebut=0,Hfin=11,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=11,Mdebut=20,Hfin=11,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=11,Mdebut=40,Hfin=12,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=14,Mdebut=0,Hfin=14,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=14,Mdebut=20,Hfin=14,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=14,Mdebut=40,Hfin=15,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=15,Mdebut=0,Hfin=15,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=15,Mdebut=20,Hfin=15,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=15,Mdebut=40,Hfin=16,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=16,Mdebut=0,Hfin=16,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=16,Mdebut=20,Hfin=16,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=16,Mdebut=40,Hfin=17,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=17,Mdebut=0,Hfin=17,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=17,Mdebut=20,Hfin=17,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=17,Mdebut=40,Hfin=18,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=8,Mdebut=0,Hfin=8,Mfin=20,Medecin=medecins[1]},
new Creneau{ Hdebut=8,Mdebut=20,Hfin=8,Mfin=40,Medecin=medecins[1]},
new Creneau{ Hdebut=8,Mdebut=40,Hfin=9,Mfin=0,Medecin=medecins[1]},
new Creneau{ Hdebut=9,Mdebut=0,Hfin=9,Mfin=20,Medecin=medecins[1]},
new Creneau{ Hdebut=9,Mdebut=20,Hfin=9,Mfin=40,Medecin=medecins[1]},
new Creneau{ Hdebut=9,Mdebut=40,Hfin=10,Mfin=0,Medecin=medecins[1]},
new Creneau{ Hdebut=10,Mdebut=0,Hfin=10,Mfin=20,Medecin=medecins[1]},
new Creneau{ Hdebut=10,Mdebut=20,Hfin=10,Mfin=40,Medecin=medecins[1]},
new Creneau{ Hdebut=10,Mdebut=40,Hfin=11,Mfin=0,Medecin=medecins[1]},
new Creneau{ Hdebut=11,Mdebut=0,Hfin=11,Mfin=20,Medecin=medecins[1]},
new Creneau{ Hdebut=11,Mdebut=20,Hfin=11,Mfin=40,Medecin=medecins[1]},
new Creneau{ Hdebut=11,Mdebut=40,Hfin=12,Mfin=0,Medecin=medecins[1]},
};
foreach (Creneau creneau in creneaux)
{
context.Creneaux.Add(creneau);
}
// gli appuntamenti
context.Rvs.Add(new Rv { Jour = new System.DateTime(2012, 10, 8), Client = clients[0], Creneau = creneaux[0] });
}
}
}
- riga 6: l'inizializzazione avviene nel metodo [Seed]. Questo metodo è presente nella classe padre. Qui viene ridefinito. L'argomento è il contesto di persistenza [RdvMedecinsContext] dell'applicazione;
- riga 8: l'argomento viene passato alla classe padre; è probabile che quest'ultima apra il contesto di persistenza che le è stato passato, poiché tale apertura non è più necessaria in seguito;
- righe 11-16: creazione di 4 clienti;
- righe 17-20: questi vengono aggiunti al contesto di persistenza, più precisamente ai medici di quest’ultimo. Si noti il metodo [Add] che lo consente. È necessario ricordare qui la definizione del contesto:
public class RdvMedecinsContext : DbContext
{
// le entità
public DbSet<Medecin> Medecins { get; set; }
public DbSet<Creneau> Creneaux { get; set; }
public DbSet<Client> Clients { get; set; }
public DbSet<Rv> Rvs { get; set; }
...
Si dice anche che i clienti siano stati associati al contesto, ovvero che ora siano gestiti da EF. In precedenza non erano associati al contesto. Esistevano come oggetti ma non erano gestiti da EF;
- righe 21-27: creazione di 4 medici;
- righe 28-31: inserimento nel contesto di persistenza;
- righe 33-70: creazione di fasce orarie. Righe 34-57, per il medico medecins[0], righe 58-69, per il medico medecins[1]. Gli altri medici non hanno fasce orarie;
- righe 71-74: si inseriscono queste fasce orarie nel contesto di persistenza;
- riga 76: creazione di un appuntamento per il primo cliente con la prima fascia oraria e inserimento dello stesso nel contesto di persistenza.
Quando si esegue il progetto, si ottiene il database seguente:
 | 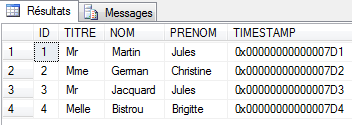 |
Sopra è riportata la tabella [CLIENTS] compilata.
3.4.6. Modifica delle entità
Attualmente, le classi [Medecin] e [Client] sono quasi identiche. Infatti, se si rimuovono i campi aggiunti per la gestione della persistenza con EF 5, risultano identiche. Le faremo derivare da una classe [Personne]. Queste due entità diventano quindi le seguenti:
// una persona
public abstract class Personne
{
// dati
[Key]
[Column("ID")]
public int? Id { get; set; }
[Required]
[MaxLength(5)]
[Column("TITRE")]
public string Titre { get; set; }
[Required]
[MaxLength(30)]
[Column("NOM")]
public string Nom { get; set; }
[Required]
[MaxLength(30)]
[Column("PRENOM")]
public string Prenom { get; set; }
[Column("TIMESTAMP")]
[Timestamp]
public byte[] Timestamp { get; set; }
// firma
public override string ToString()
{
return String.Format("[{0},{1},{2},{3},{4}]", Id, Titre, Prenom, Nom, dump(Timestamp));
}
// firma abbreviata
public string ShortIdentity()
{
...
}
// utilità
private string dump(byte[] timestamp)
{
...
}
}
[Table("MEDECINS", Schema = "dbo")]
public class Medecin : Personne
{
// gli orari di ricevimento del medico
public ICollection<Creneau> Creneaux { get; set; }
// firma
public override string ToString()
{
return String.Format("Medecin {0}", base.ToString());
}
}
[Table("CLIENTS", Schema = "dbo")]
public class Client : Personne
{
// gli appuntamenti del cliente
public ICollection<Rv> Rvs { get; set; }
// firma
public override string ToString()
{
return String.Format("Client {0}", base.ToString());
}
}
Quando si esegue il progetto, si ottiene lo stesso risultato di base. EF 5 ha mappato le classi più basse dell’ereditarietà, ciascuna in una tabella. Infatti, EF 5 utilizza diverse strategie di generazione delle tabelle per rappresentare l’ereditarietà delle entità. Non le presenteremo qui. Si può leggere, ad esempio, " Entity Framework Code First Inheritance: Table Per Hierarchy and Table Per Type", all'indirizzo URL [http://www.codeproject.com/Articles/393228/Entity-Framework-Code-First-Inheritance-Table-Per].
D'ora in poi utilizzeremo questa versione delle entità.
3.4.7. Aggiungere vincoli al database
Rimane un ultimo dettaglio da sistemare. La tabella [RVS] degli appuntamenti è la seguente:
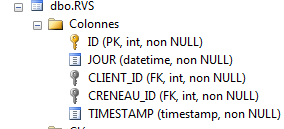 |
Questa tabella deve avere un vincolo di unicità: per un dato giorno, una fascia oraria di un medico può essere prenotata solo una volta per un appuntamento. In termini di tabella, ciò significa che la coppia (JOUR,CRENEAU_ID) deve essere unica. Non so se questo vincolo possa essere espresso direttamente nel codice, sia sulle entità che sul contesto. È probabile, ma non ho verificato. Adotteremo un altro approccio. Utilizzeremo un client di amministrazione di SQL Server per aggiungere questo vincolo.
Con «SQL Server Management Studio», non ho trovato un metodo semplice per aggiungere questo vincolo se non eseguire il comando SQL che lo crea:
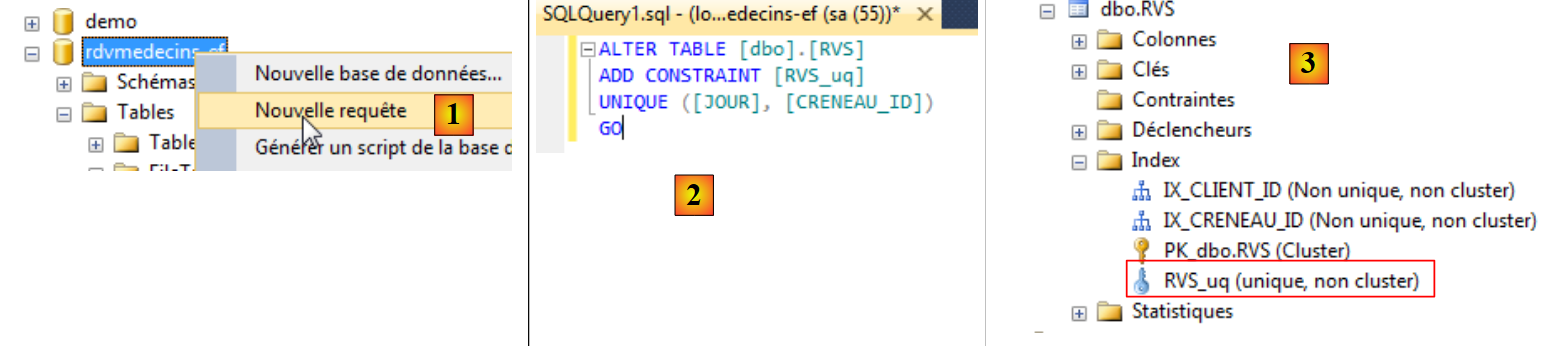 |
- in [1] si crea una query SQL per il database [rdvmedecins-ef];
- in [2], la query SQL che crea il vincolo di unicità;
- in [3], l'esecuzione di questa query ha creato un nuovo indice nella tabella [RVS].
Esistono altri strumenti di amministrazione di SQL Server. In questa sede utilizzeremo lo strumento EMS SQL Manager for SQL Server Freeware [http://www.sqlmanager.net/fr/products/mssql/manager/download]. Una volta installato, lo avviamo:
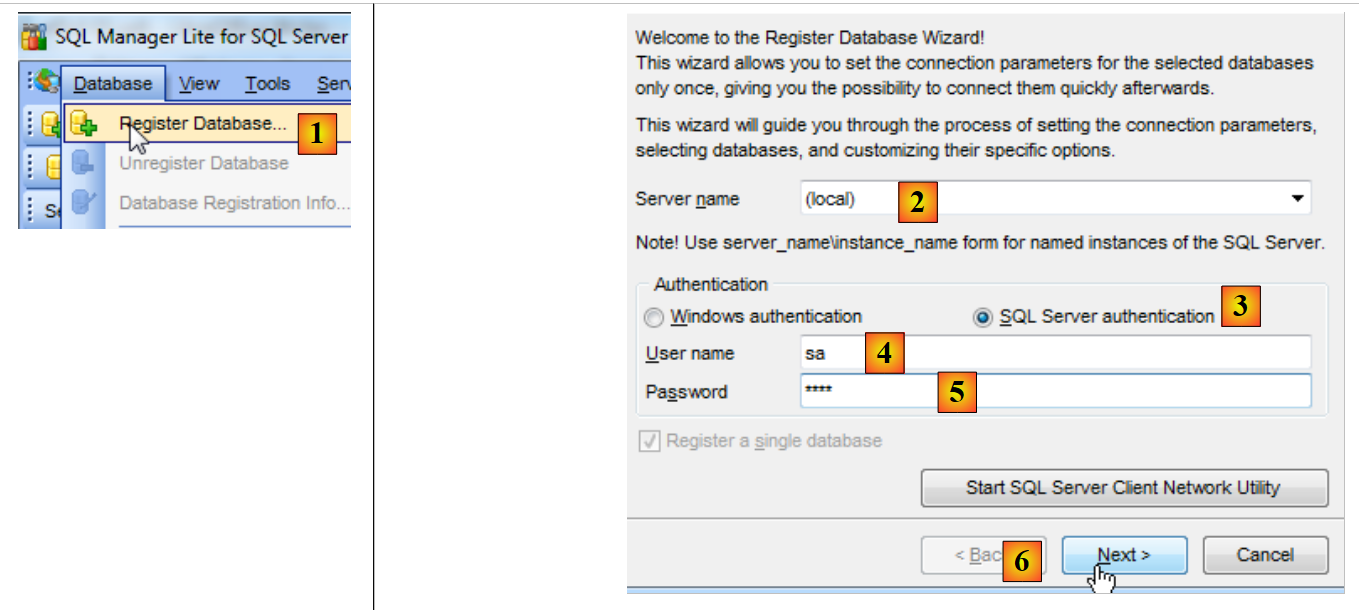 |
- in [1], si salva un database;
- in [2], ci si connette al server (locale);
- in [3], con autenticazione SQL Server;
- in [4], con l'identità sa;
- in [5], e la password sqlserver2012;
- in [6], si passa alla fase successiva;
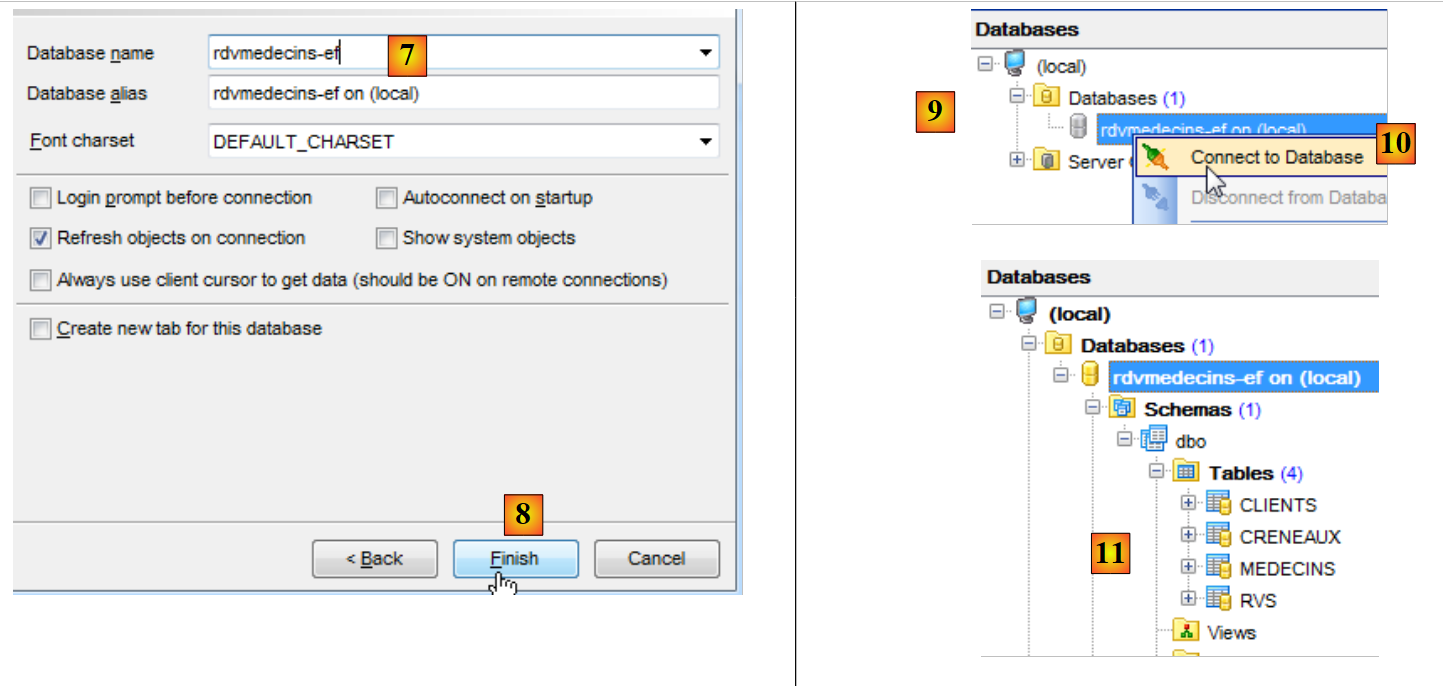 |
- in [7], si seleziona il database [rdvmedecins-ef];
- in [8], si completa la procedura guidata;
- in [9], il database compare nella struttura ad albero dei database. Ci si connette a [10];
- in [11], la connessione è stabilita.
"SQL Manager Lite for SQL Server" consente di creare il vincolo di unicità sulla tabella [RVS].
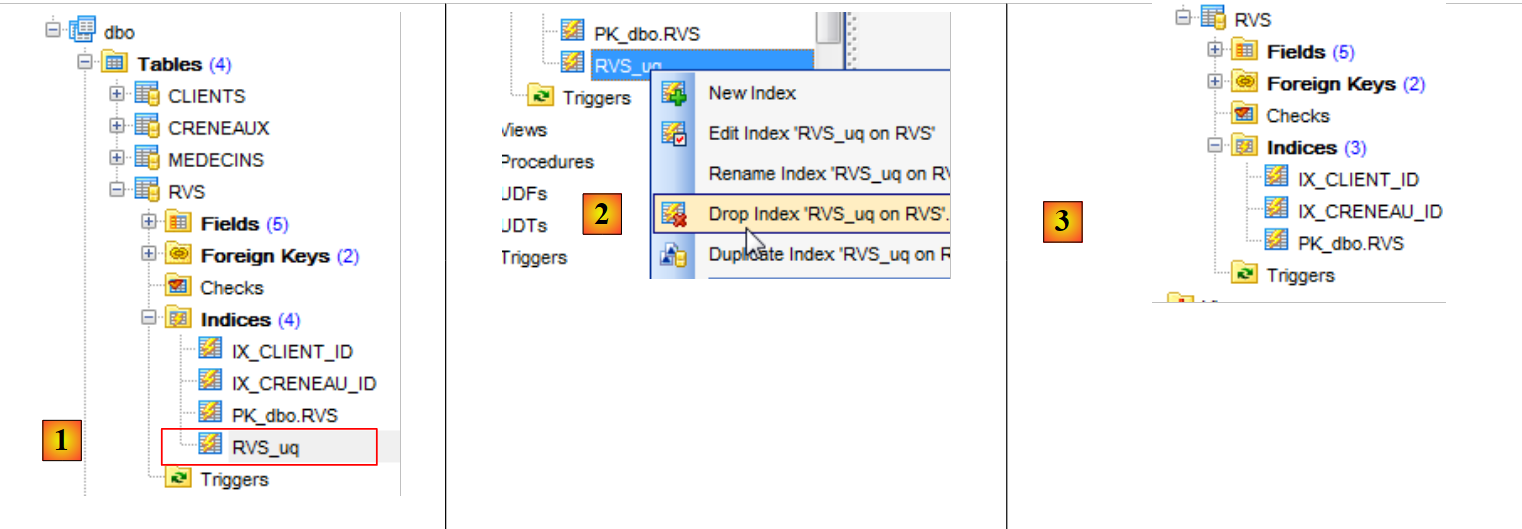 |
- in [1], si vede il vincolo di unicità che abbiamo creato in precedenza;
- in [2], la si elimina;
- in [3], l'indice corrispondente a questo vincolo di unicità è scomparso.
Ricreiamo il vincolo eliminato:
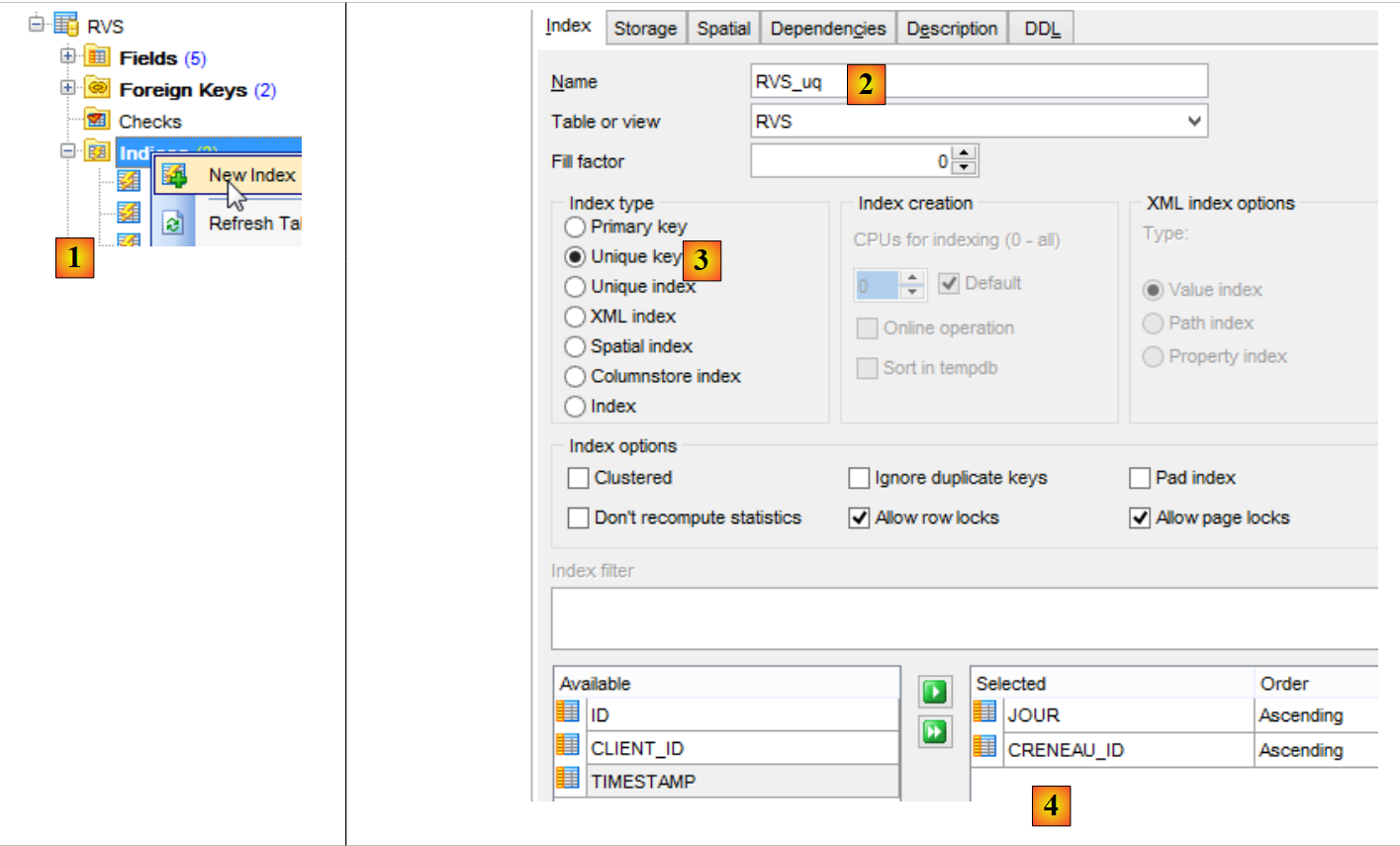 |
- in [1], si crea un nuovo indice per la tabella [RVS];
- in [2], gli si assegna un nome;
- in [3], si tratta di un vincolo di unicità;
- in [4], sulle colonne JOUR e CRENEAU_ID;
La scheda DDL ci fornisce il codice SQL che verrà eseguito:
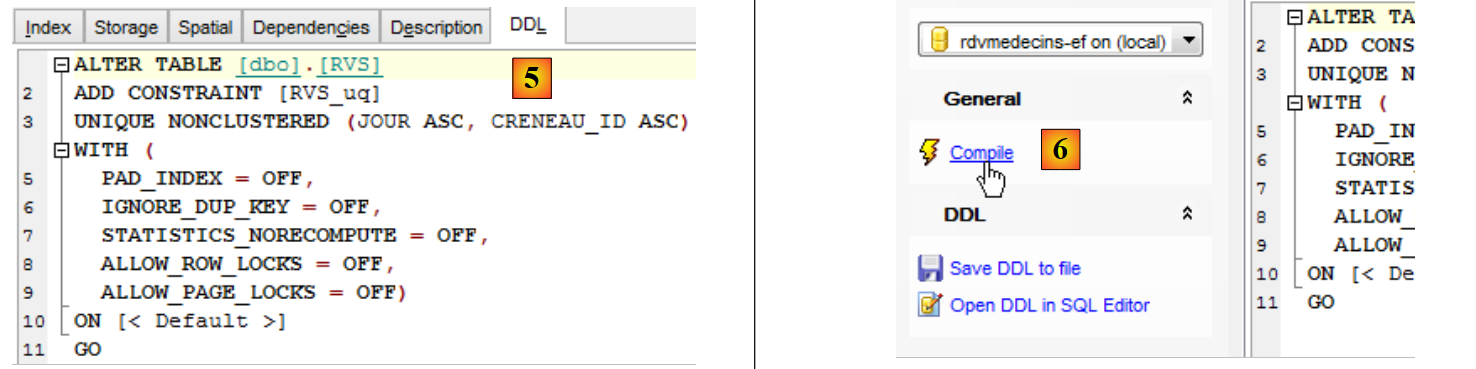 |
- in [6], si compila il comando SQL;
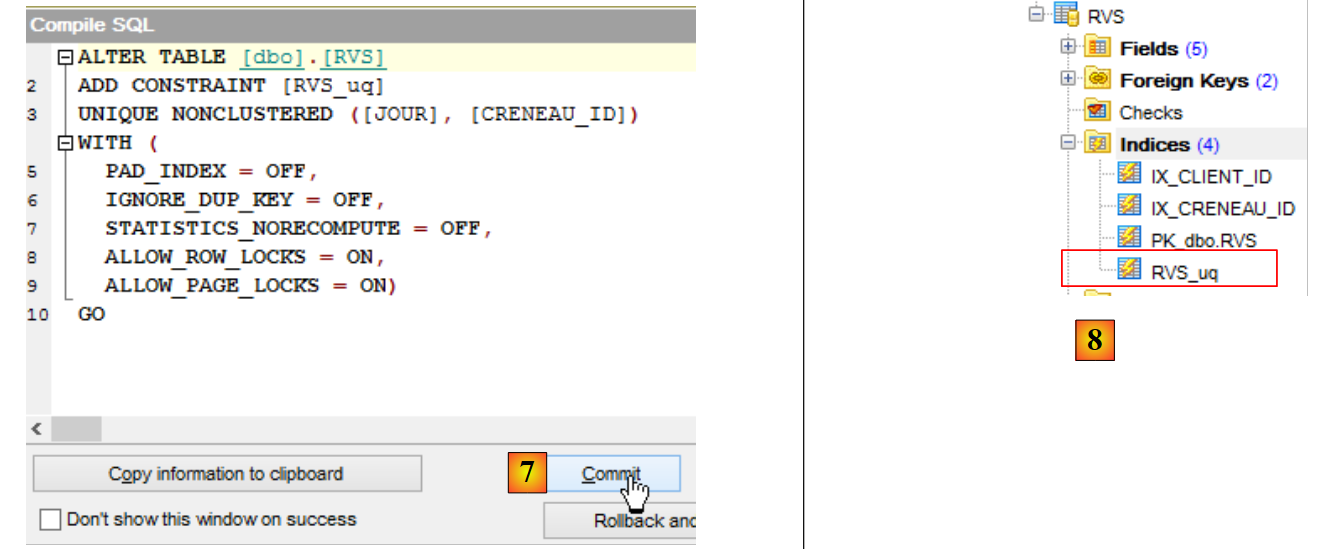 |
- in [7], si conferma;
- in [8], è apparso il nuovo indice.
L'interfaccia offerta da "SQL Manager Lite for SQL server" è analoga a quella offerta da "SQL Server Management Studio". Si possono trovare interfacce simili per SGBD Oracle, PostgreSQL, Firebird e MySQL. Proseguiremo quindi d’ora in poi con questa famiglia di strumenti di amministrazione di SGBD.
Per accedere alle informazioni contenute in una tabella, è sufficiente fare doppio clic su di essa:
 |
Le informazioni relative alla tabella selezionata sono disponibili nelle schede. Nell'immagine sopra è visibile la scheda [Fields] della tabella [CLIENTS]. La scheda [Data] mostra il contenuto della tabella:
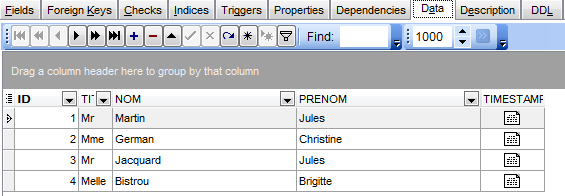
3.4.8. Il database definitivo
Abbiamo ottenuto la nostra base definitiva. Esportiamo il relativo script SQL per poterla rigenerare se necessario.
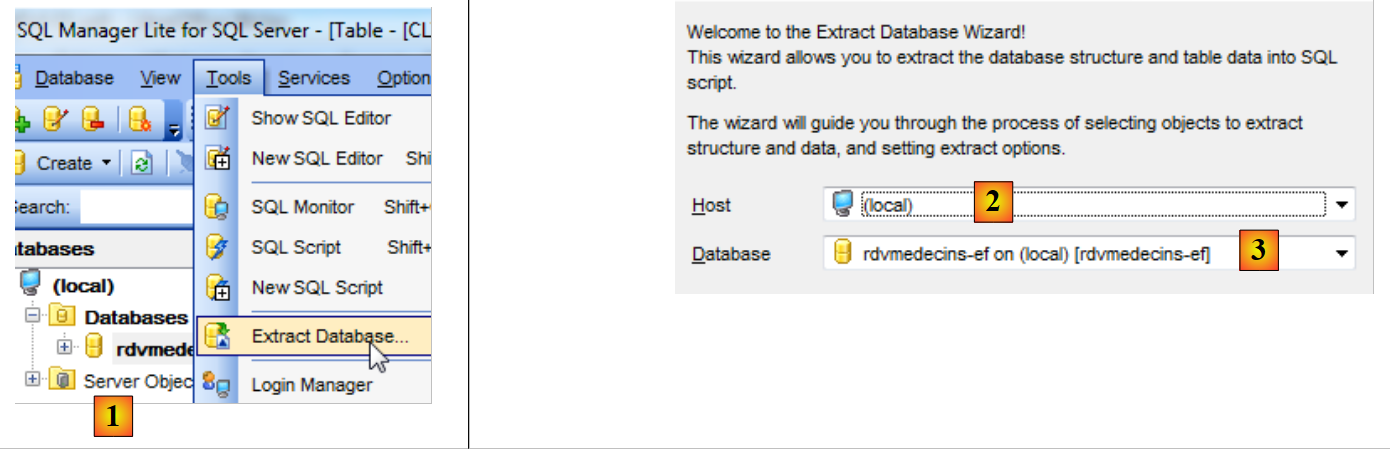 |
- in [1], inizio della procedura guidata;
- in [2], il server;
- in [3], il database che verrà esportato;
 |
- in [4], specificare il nome del file in cui verrà salvato lo script SQL;
- in [5], specificare la codifica;
- in [6], specificare cosa si desidera estrarre (tabelle, vincoli, dati);
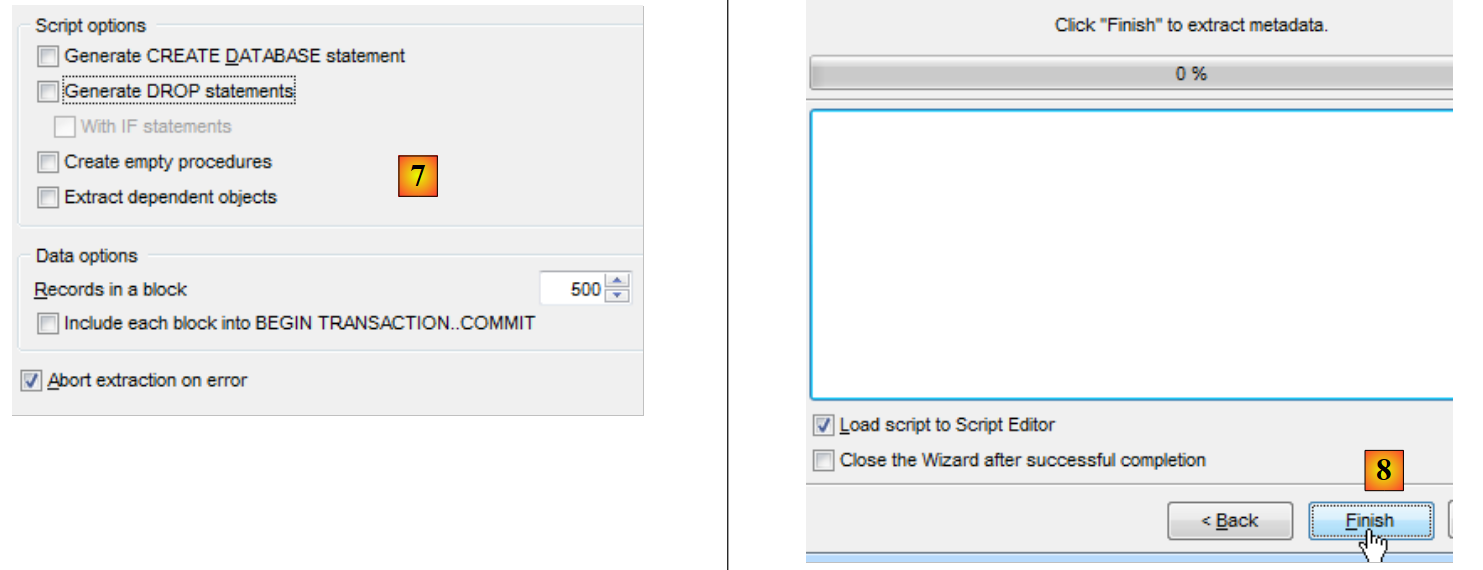 |
- in [7], è possibile perfezionare lo script che verrà generato;
- in [8], completate la procedura guidata.
Lo script è stato generato e caricato nell’editor di script. È possibile visualizzare il codice SQL generato. Ricostruiremo il database a partire da questo script.
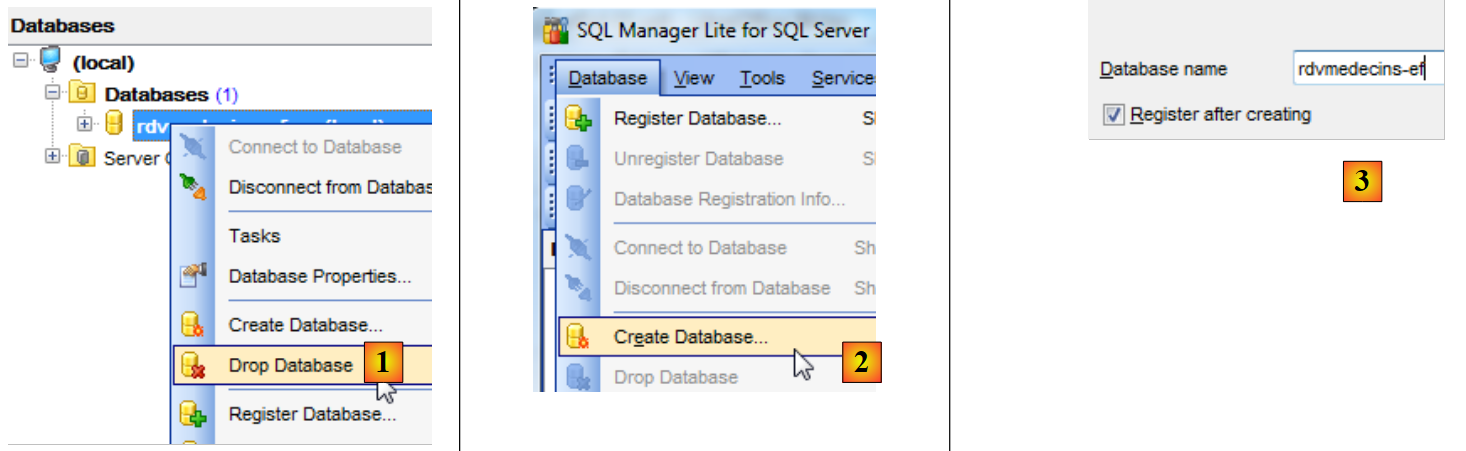 |
- in [1], si elimina il database;
- negli script [2] e [3], la ricreiamo;
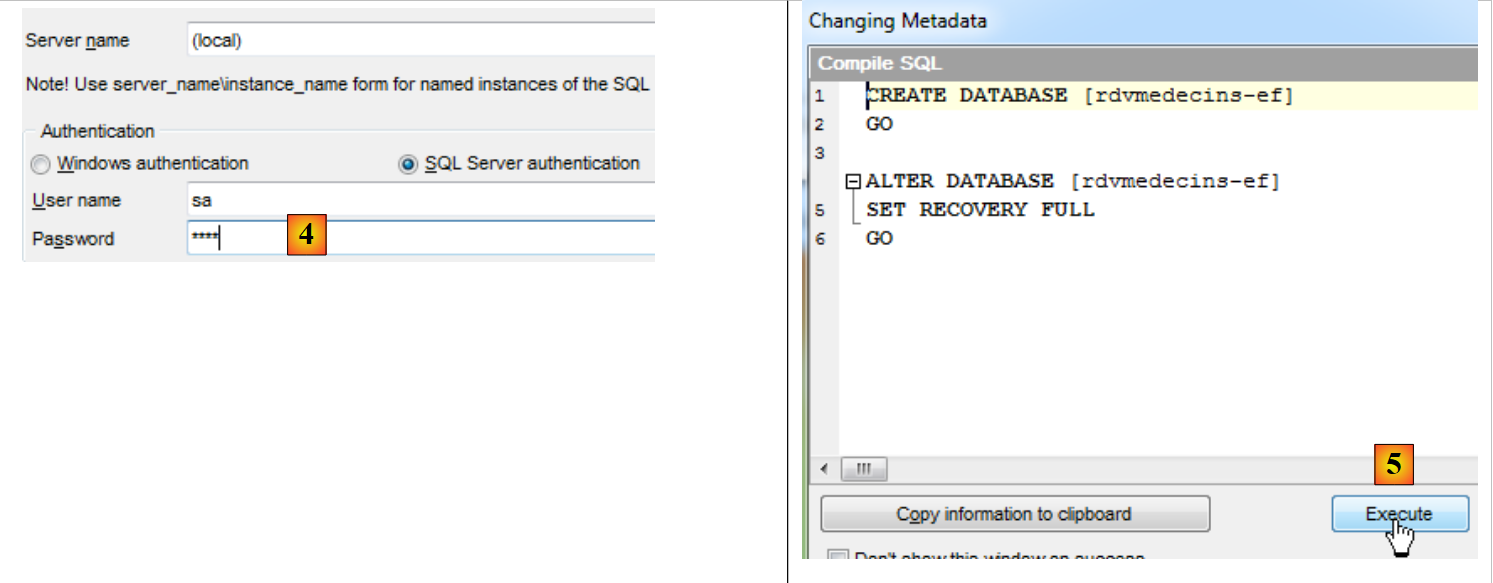 |
- in [4], si effettua l'autenticazione;
- in [5], si esegue lo script SQL per la creazione del database;
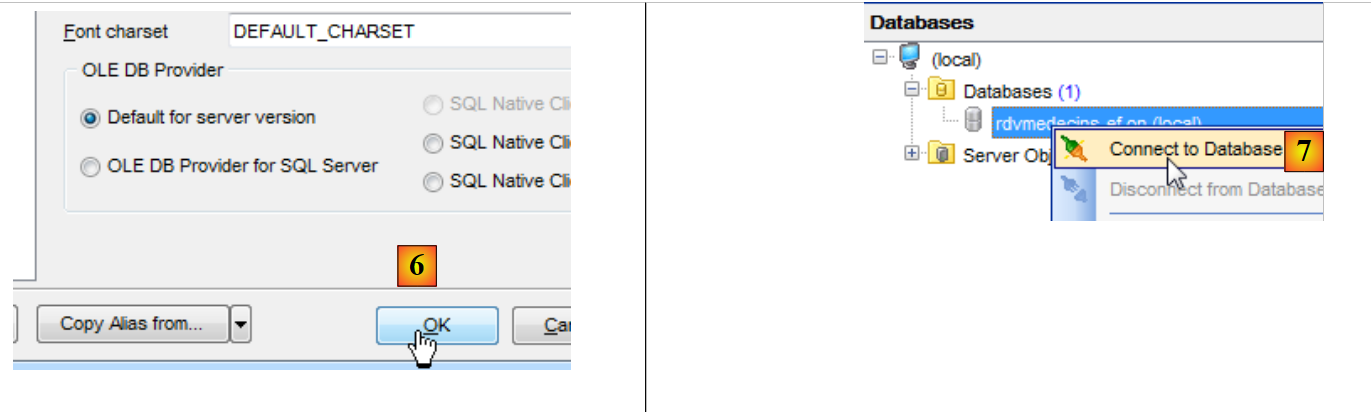 |
- in [6], la si registra in "SQL Manager";
- in [7], ci si connette al database appena creato;
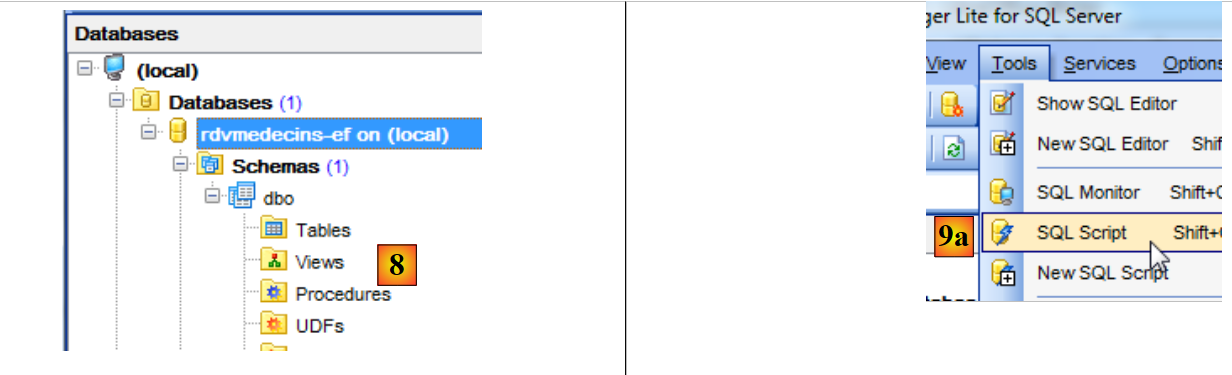 |
- in [8], il database al momento non contiene tabelle;
- in [9a], si apre un editor di script SQL;
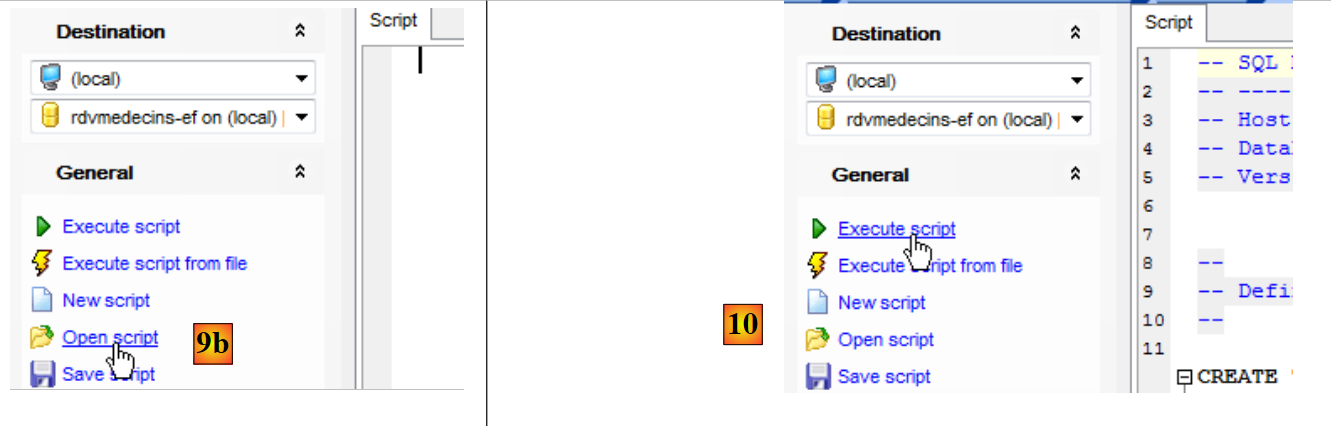 |
- in [9b], si apre lo script SQL creato in precedenza;
- in [10], lo si esegue;
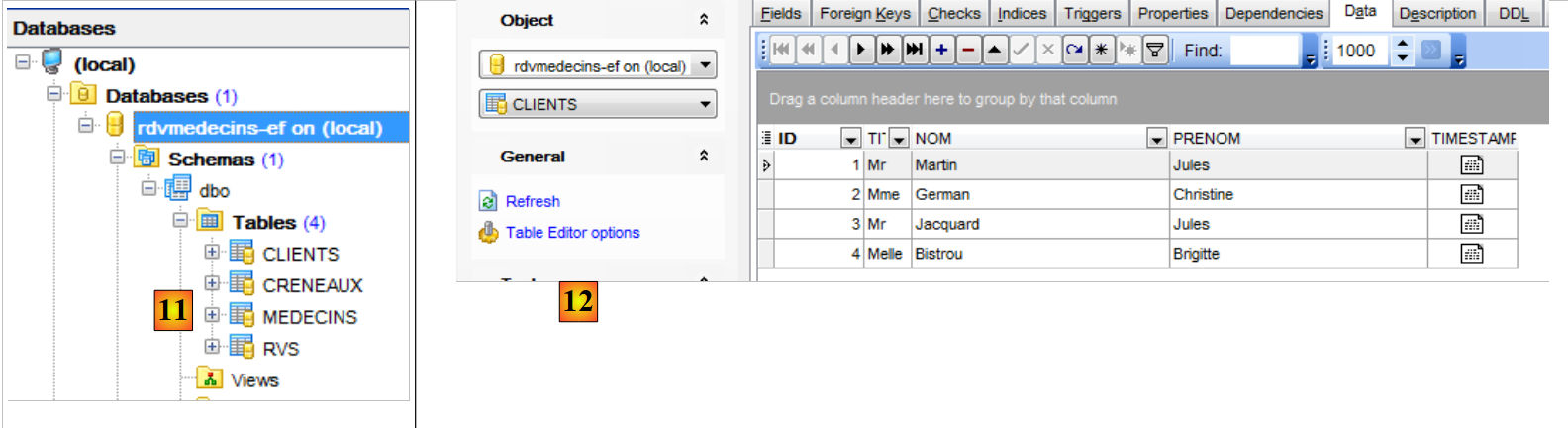 |
- in [11], le tabelle sono state create;
- in [12], vengono compilate;
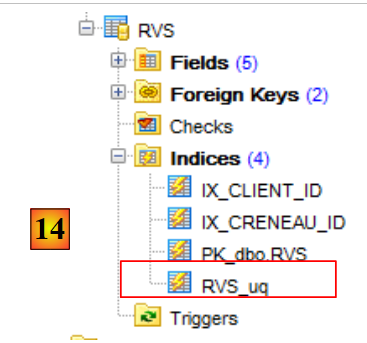 |
- in [14], ritroviamo il vincolo di unicità che avevamo creato per la tabella [RVS].
D'ora in poi lavoreremo con questo database esistente. Se dovesse essere distrutto o danneggiato, sappiamo come rigenerarlo.
3.5. Utilizzo del database con Entity Framework
Procederemo a:
- aggiungere, eliminare e modificare elementi del database;
- eseguire query sul database con LINQ to Entities;
- gestire gli accessi simultanei a uno stesso elemento del database;
- comprendere i concetti di Lazy Loading / Eager Loading;
- scoprire che l’aggiornamento del database tramite il contesto di persistenza avviene all’interno di una transazione.
3.5.1. Eliminazione di elementi dal contesto di persistenza
Abbiamo un database pieno. Lo svuoteremo. Creiamo una nuova classe [Erase.cs] nel progetto attuale [1]:
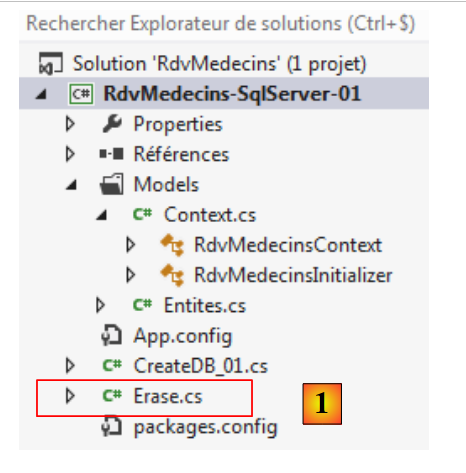 |
La classe [Erase] è la seguente:
using RdvMedecins.Models;
namespace RdvMedecins_01
{
class Erase
{
static void Main(string[] args)
{
using (var context = new RdvMedecinsContext())
{
// si svuota il database attuale
// i clienti
foreach (var client in context.Clients)
{
context.Clients.Remove(client);
}
// i medici
foreach (var medecin in context.Medecins)
{
context.Medecins.Remove(medecin);
}
// si salva il contesto di persistenza
context.SaveChanges();
}
}
}
}
- riga 9: le operazioni su un contesto di persistenza vengono sempre eseguite all’interno di una clausola [using]. Ciò garantisce che, all’uscita da [using], il contesto sia stato chiuso;
- riga 13: si esegue un ciclo sul contesto dei clienti [context.Clients]. Tutti i clienti del database verranno inseriti nel contesto di persistenza;
- riga 15: per ciascuno di essi si esegue l'operazione [Remove] che li rimuove dal contesto. In realtà, rimangono comunque nel contesto ma in uno stato "rimosso";
- righe 18-21: si esegue la stessa operazione per i medici;
- riga 23: si salva il contesto di persistenza nel database.
Durante il salvataggio del contesto nel database, le entità del contesto che:
- hanno una chiave primaria nulla sono oggetto di un’operazione SQL INSERT;
- si trovano in uno stato «eliminato» sono oggetto di un’operazione SQL DELETE;
- si trovano in stato «modificato» sono oggetto di un’operazione SQL UPDATE;
Come vedremo in seguito, queste operazioni SQL vengono eseguite all’interno di una transazione. Se una di esse fallisce, tutto ciò che è stato fatto in precedenza viene annullato.
Impostiamo il programma [Erase] come nuovo oggetto di avvio del progetto [1], quindi eseguiamo il progetto.
 |
Controlliamo il database. Noteremo che tutte le tabelle sono vuote ([2]). È sorprendente, poiché avevamo semplicemente richiesto l’eliminazione dei medici e dei clienti. È grazie al funzionamento delle chiavi esterne che le altre tabelle sono state svuotate a cascata.
La definizione della chiave esterna dalla tabella [CRENEAUX] alla tabella [MEDECINS] è stata definita come segue dal provider di EF 5:
 |
- in [1], selezionare la tabella [CRENEAUX];
- in [2], si seleziona la scheda delle chiavi esterne;
- in [3], si modifica l'unica chiave esterna;
 |
- in [4], nella scheda DDL, la definizione SQL del vincolo di chiave esterna;
- Nella tabella [5], la clausola ON DELETE CASCADE fa sì che l'eliminazione di un medico comporti l'eliminazione delle fasce orarie ad esso associate.
I vincoli delle chiavi esterne della tabella [RVS] sono definiti in modo analogo:
- righe 1-6: l’eliminazione di un cliente comporterà anche l’eliminazione degli appuntamenti ad esso associati;
- righe 1-6: l’eliminazione di una fascia oraria comporterà anche l’eliminazione di tutti gli appuntamenti ad essa associati.
3.5.2. Aggiunta di elementi al contesto di persistenza
Ora che abbiamo svuotato il database, lo riempiremo nuovamente. Aggiungiamo al progetto il programma [Fill.cs] [1].
 |
Il programma [Fill.cs] è il seguente:
using RdvMedecins.Entites;
using RdvMedecins.Models;
namespace RdvMedecins_01
{
class Fill
{
static void Main(string[] args)
{
using (var context = new RdvMedecinsContext())
{
// si svuota il database corrente
foreach (var client in context.Clients)
{
context.Clients.Remove(client);
}
foreach (var medecin in context.Medecins)
{
context.Medecins.Remove(medecin);
}
// la si reinizializza
// i clienti
Client[] clients ={
new Client { Titre = "Mr", Nom = "Martin", Prenom = "Jules" },
new Client { Titre = "Mme", Nom = "German", Prenom = "Christine" },
new Client { Titre = "Mr", Nom = "Jacquard", Prenom = "Jules" },
new Client { Titre = "Melle", Nom = "Bistrou", Prenom = "Brigitte" }
};
foreach (Client client in clients)
{
context.Clients.Add(client);
}
// i medici
Medecin[] medecins ={
new Medecin { Titre = "Mme", Nom = "Pelissier", Prenom = "Marie" },
new Medecin { Titre = "Mr", Nom = "Bromard", Prenom = "Jacques" },
new Medecin { Titre = "Mr", Nom = "Jandot", Prenom = "Philippe" },
new Medecin { Titre = "Melle", Nom = "Jacquemot", Prenom = "Justine" }
};
foreach (Medecin medecin in medecins)
{
context.Medecins.Add(medecin);
}
// le fasce orarie
Creneau[] creneaux ={
new Creneau{ Hdebut=8,Mdebut=0,Hfin=8,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=8,Mdebut=20,Hfin=8,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=8,Mdebut=40,Hfin=9,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=9,Mdebut=0,Hfin=9,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=9,Mdebut=20,Hfin=9,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=9,Mdebut=40,Hfin=10,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=10,Mdebut=0,Hfin=10,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=10,Mdebut=20,Hfin=10,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=10,Mdebut=40,Hfin=11,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=11,Mdebut=0,Hfin=11,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=11,Mdebut=20,Hfin=11,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=11,Mdebut=40,Hfin=12,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=14,Mdebut=0,Hfin=14,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=14,Mdebut=20,Hfin=14,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=14,Mdebut=40,Hfin=15,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=15,Mdebut=0,Hfin=15,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=15,Mdebut=20,Hfin=15,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=15,Mdebut=40,Hfin=16,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=16,Mdebut=0,Hfin=16,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=16,Mdebut=20,Hfin=16,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=16,Mdebut=40,Hfin=17,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=17,Mdebut=0,Hfin=17,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=17,Mdebut=20,Hfin=17,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=17,Mdebut=40,Hfin=18,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=8,Mdebut=0,Hfin=8,Mfin=20,Medecin=medecins[1]},
new Creneau{ Hdebut=8,Mdebut=20,Hfin=8,Mfin=40,Medecin=medecins[1]},
new Creneau{ Hdebut=8,Mdebut=40,Hfin=9,Mfin=0,Medecin=medecins[1]},
new Creneau{ Hdebut=9,Mdebut=0,Hfin=9,Mfin=20,Medecin=medecins[1]},
new Creneau{ Hdebut=9,Mdebut=20,Hfin=9,Mfin=40,Medecin=medecins[1]},
new Creneau{ Hdebut=9,Mdebut=40,Hfin=10,Mfin=0,Medecin=medecins[1]},
new Creneau{ Hdebut=10,Mdebut=0,Hfin=10,Mfin=20,Medecin=medecins[1]},
new Creneau{ Hdebut=10,Mdebut=20,Hfin=10,Mfin=40,Medecin=medecins[1]},
new Creneau{ Hdebut=10,Mdebut=40,Hfin=11,Mfin=0,Medecin=medecins[1]},
new Creneau{ Hdebut=11,Mdebut=0,Hfin=11,Mfin=20,Medecin=medecins[1]},
new Creneau{ Hdebut=11,Mdebut=20,Hfin=11,Mfin=40,Medecin=medecins[1]},
new Creneau{ Hdebut=11,Mdebut=40,Hfin=12,Mfin=0,Medecin=medecins[1]},
};
foreach (Creneau creneau in creneaux)
{
context.Creneaux.Add(creneau);
}
// gli appuntamenti
context.Rvs.Add(new Rv { Jour = new System.DateTime(2012, 10, 8), Client = clients[0], Creneau = creneaux[0] });
// si salva il contesto di persistenza
context.SaveChanges();
}
}
}
}
- riga 10: si apre il contesto di persistenza;
- righe 13-20: le righe delle tabelle [CLIENTS] e [MEDECINS] vengono inserite nel contesto e poi rimosse da esso. Abbiamo appena visto che ciò svuotava completamente il database;
- righe 22-88: vengono aggiunti elementi al contesto di persistenza. Tutti hanno la chiave primaria impostata a null. Verranno quindi inseriti nel database;
- riga 90: le modifiche apportate al contesto vengono sincronizzate con il database. Quest’ultima sarà oggetto di una serie di operazioni SQL DELETE seguite da una serie di operazioni SQL INSERT;
Si imposta il programma [Fill] come nuovo oggetto di avvio del progetto [1], quindi si esegue quest’ultimo.
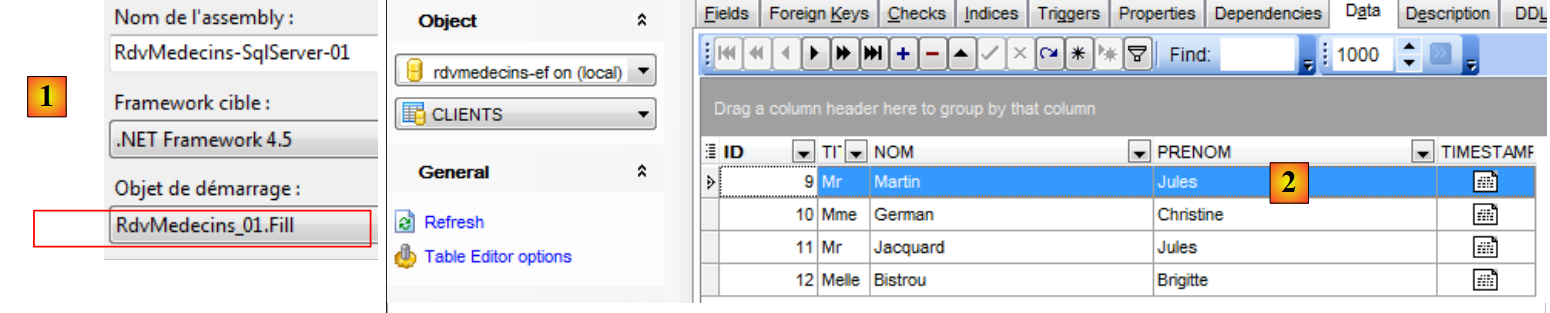 |
In [2] si constata che le tabelle sono state compilate.
3.5.3. Visualizzazione del contenuto del database
Ora visualizzeremo il contenuto del database utilizzando le query LINQ to Entity. LINQ (Language INtegrated Query) è stato introdotto con il framework .NET 3.5 nel 2007. Si presenta come un’estensione dei linguaggi .NET e c.a.d, nei quali è integrato, e la sua sintassi viene verificata dal compilatore. Consente di eseguire query su diverse collezioni con una sintassi che presenta somiglianze con il linguaggio SQL (Structured Query Language) per l'interrogazione dei database. Esistono diverse versioni di LINQ:
- LINQ to Object, per interrogare le collezioni in memoria;
- LINQ to XML, per eseguire query su XML;
- da LINQ a Entity, per eseguire query sui database;
Per funzionare, LINQ si basa su numerose estensioni apportate ai linguaggi .NET. Queste possono essere utilizzate al di fuori di LINQ. Non le presenteremo, ma ci limiteremo a fornire due riferimenti in cui il lettore potrà trovare una descrizione approfondita di LINQ:
- *LINQ in Action*, di Fabrice Marguerie, Steve Eichert e Jim Wooley, edito da Manning;
- "LINQ pocket reference", di Joseph e Ben Albahari, edito da O'Reilly.
Ho letto il primo e l’ho trovato eccellente. Non ho letto il secondo, ma ho letto, degli stessi autori, “C# 3.0 in a nutshell” all’uscita di LINQ. Ho trovato questo libro di gran lunga superiore alla media dei libri che sono solito leggere. Sembra che anche gli altri libri di questi due autori siano dello stesso livello. Utilizzeremo inoltre LINQPad, uno strumento di apprendimento di LINQ scritto da Joseph Albahari.
Visualizzeremo le entità presenti nel database. A tal fine, aggiungeremo alle loro classi due metodi di visualizzazione. Cominciamo con l’entità [Medecin]:
// un medico
public class Medecin
{
// dati
[Key]
[Column("ID")]
public int? Id { get; set; }
[Required]
[MaxLength(5)]
[Column("TITRE")]
public string Titre { get; set; }
[Required]
[MaxLength(30)]
[Column("NOM")]
public string Nom { get; set; }
[Required]
[MaxLength(30)]
[Column("PRENOM")]
public string Prenom { get; set; }
// le fasce orarie del medico
public ICollection<Creneau> Creneaux { get; set; }
[Column("TIMESTAMP")]
[Timestamp]
public byte[] Timestamp { get; set; }
// firma
public override string ToString()
{
return String.Format("Medecin[{0},{1},{2},{3},{4}]", Id, Titre, Prenom, Nom, dump(Timestamp));
}
// firma abbreviata
public string ShortIdentity()
{
return ToString();
}
// utilità
private string dump(byte[] timestamp){
string str = "";
foreach (byte b in timestamp)
{
str += b;
}
return str;
}
}
- righe 27-30: il metodo ToString della classe. Si noti che non visualizza la collezione della riga 21;
- righe 32-37: il metodo ShortIdentity che fa la stessa cosa.
A questo punto è necessario spiegare i concetti di Lazy e Eager Loading per valutare l’impatto dei due metodi precedenti. Abbiamo visto che un’entità può avere dipendenze da un’altra entità. Queste dipendenze sono di due tipi:
- da uno a più, come sopra, dove un medico è collegato a più fasce orarie;
- da più a uno, come nell’entità [Creneau] riportata di seguito, in cui più fasce orarie sono collegate allo stesso medico;
public class Creneau
{
// dati
...
[Required]
[Column("MEDECIN_ID")]
public int MedecinId { get; set; }
[Required]
[ForeignKey("MedecinId")]
public virtual Medecin Medecin { get; set; }
...
}
Quando le dipendenze vengono caricate contemporaneamente alle entità a cui sono associate, si parla di Eager Loading. Altrimenti, si parla di Lazy Loading: le dipendenze vengono caricate solo quando vengono referenziate per la prima volta. Per impostazione predefinita, EF 5 utilizza il Lazy Loading: le dipendenze non vengono caricate contemporaneamente all’entità.
Esaminiamo il nostro metodo [ToString] riportato sopra:
// gli orari di ricevimento del medico
public ICollection<Creneau> Creneaux { get; set; }
// firma
public override string ToString()
{
return String.Format("Medecin[{0},{1},{2},{3},{4}]", Id, Titre, Prenom, Nom, dump(Timestamp));
}
// firma abbreviata
public string ShortIdentity()
{
return ToString();
}
Il metodo [ToString] non visualizza la dipendenza [Creneaux] della riga 2. Se lo avesse fatto, avrebbe forzato il caricamento di tutte le fasce orarie del medico prima della sua esecuzione. È proprio per evitare questo caricamento dispendioso che la dipendenza non è stata inclusa nella firma dell’entità. In generale, includeremo due firme in ogni entità:
- un metodo ToString che visualizzerà l’entità e le sue eventuali dipendenze una per una. Come appena spiegato, ciò provocherà il caricamento della dipendenza;
- un metodo ShortIdentity che non farà riferimento ad alcuna dipendenza. Non vi sarà quindi alcun caricamento di dipendenze;
I metodi di visualizzazione delle altre entità saranno i seguenti:
L'entità [Client]:
public class Client
{
// dati
...
// gli appuntamenti del cliente
public ICollection<Rv> Rvs { get; set; }
// firma
public override string ToString()
{
return String.Format("Client[{0},{1},{2},{3},{4}]", Id, Titre, Prenom, Nom, dump(Timestamp));
}
// firma abbreviata
public string ShortIdentity()
{
return ToString();
}
}
- righe 9-12: il metodo [ToString] non visualizza la dipendenza della riga 6;
L'entità [Creneau]:
public class Creneau
{
...
[Required]
[Column("MEDECIN_ID")]
public int MedecinId { get; set; }
[Required]
[ForeignKey("MedecinId")]
public virtual Medecin Medecin { get; set; }
// gli appuntamenti della fascia oraria
public ICollection<Rv> Rvs { get; set; }
// firma
public override string ToString()
{
return String.Format("Creneau[{0},{1},{2},{3},{4}, {5}]", Id, Hdebut, Mdebut, Hfin, Mfin, Medecin, dump(Timestamp));
}
// firma breve
public string ShortIdentity()
{
return String.Format("Creneau[{0},{1},{2},{3},{4}, {5}, {6}]", Id, Hdebut, Mdebut, Hfin, Mfin, Timestamp, MedecinId, dump(Timestamp));
}
}
- riga 16: il metodo [ToString] fa riferimento alla dipendenza della riga 9. Ciò ne forzerà il caricamento;
- riga 11: la dipendenza [Rvs] non è referenziata. Non verrà caricata;
- righe 21-22: il metodo [ShortIdentity] non fa più riferimento al riferimento [Medecin] della riga 9. Quest'ultimo non verrà quindi caricato.
L'entità [Rv]:
public class Rv
{
// dati
...
[Column("CLIENT_ID")]
public int ClientId { get; set; }
[ForeignKey("ClientId")]
[Required]
public virtual Client Client { get; set; }
[Column("CRENEAU_ID")]
public int CreneauId { get; set; }
[ForeignKey("CreneauId")]
[Required]
public virtual Creneau Creneau { get; set; }
// firma
public override string ToString()
{
return String.Format("Rv[{0},{1},{2},{3},{4}]", Id, Jour, Client, Creneau, dump(Timestamp));
}
// firma breve
public string ShortIdentity()
{
return String.Format("Rv[{0},{1},{2},{3},{4}]", Id, Jour, ClientId, CreneauId, dump(Timestamp));
}
}
- righe 17-20: il metodo [ToString] fa riferimento alle dipendenze delle righe 9 e 14. Ciò ne forzerà il caricamento;
- righe 17-20: il metodo [ShortIdentity] evita ciò e quindi le dipendenze non verranno caricate.
In conclusione, occorre prestare attenzione ai metodi [ToString] delle entità. Se non si presta attenzione a questo aspetto, la visualizzazione di una tabella può comportare il caricamento di metà del database qualora la tabella presenti numerose dipendenze.
Detto questo, si scrive il seguente nuovo codice [Dump.cs]:
using RdvMedecins.Entites;
using RdvMedecins.Models;
using System;
using System.Linq;
namespace RdvMedecins_01
{
class Dump
{
static void Main(string[] args)
{
// dump del database
using (var context = new RdvMedecinsContext())
{
// i clienti
Console.WriteLine("Clients--------------------------------------");
var clients = from client in context.Clients select client;
foreach (Client client in clients)
{
Console.WriteLine(client);
}
// i medici
Console.WriteLine("Médecins--------------------------------------");
var medecins = from medecin in context.Medecins select medecin;
foreach (Medecin medecin in medecins)
{
Console.WriteLine(medecin);
}
// le fasce orarie
Console.WriteLine("Créneaux horaires--------------------------------------");
var creneaux = from creneau in context.Creneaux select creneau;
foreach (Creneau creneau in creneaux)
{
Console.WriteLine(creneau);
}
// gli appuntamenti
Console.WriteLine("Rendez-vous--------------------------------------");
var rvs = from rv in context.Rvs select rv;
foreach (Rv rv in rvs)
{
Console.WriteLine(rv);
}
}
}
}
}
Spiegheremo le righe 17-21 che visualizzano le entità [Client]. La spiegazione fornita vale anche per le altre entità.
// i clienti
Console.WriteLine("Clients--------------------------------------");
var clients = from client in context.Clients select client;
foreach (Client client in clients)
{
Console.WriteLine(client);
}
- riga 3: la parola chiave var è stata introdotta con C# 3.0. Consente di evitare di specificare il tipo esatto di una variabile. Il compilatore lo deduce quindi dal tipo dell’espressione assegnata alla variabile;
- riga 3: l’espressione assegnata alla variabile clients è una query LINQ to Entity. In essa si riconoscono parole chiave del linguaggio SQL riportate in LINQ. La sintassi utilizzata in questo caso è la seguente:
from variable in DbSet select variable
Una sintassi più generale di LINQ è
from variable in collection select variable
La collezione verrà iterata e, per ogni suo elemento, la variabile verrà valutata. Ciò avviene solo quando la variabile [clients] della riga 3 verrà enumerata dal ciclo for / each delle righe 4-7. Finché ciò non avviene, la variabile [clients] è solo una query non valutata;
- riga 4: la query [clients] viene iterata. Ciò forzerà la valutazione della query. Le righe della tabella [CLIENTS] verranno inserite una dopo l’altra nel contesto di persistenza;
- riga 6: il metodo [ToString] dell'entità [Client] viene utilizzato per la visualizzazione. Non viene caricata alcuna dipendenza;
Passiamo alle righe successive del codice:
- righe 24-28: le righe della tabella [MEDECINS] vengono inserite nel contesto di persistenza e visualizzate. Non vi è alcun caricamento di dipendenze;
- righe 31-35: le righe della tabella [CRENEAUX] vengono inserite nel contesto di persistenza e visualizzate. Abbiamo visto che il metodo [ToString] di questa entità visualizzava la dipendenza [Medecin]. Tuttavia, questa è già stata caricata. Non ci sarà quindi un nuovo caricamento;
- righe 38-42: le righe della tabella [RVS] vengono inserite nel contesto di persistenza e visualizzate. Abbiamo visto che il metodo [ToString] di questa entità visualizzava le dipendenze [Client] e [Creneau]. Tuttavia, queste sono già state caricate. Non ci saranno quindi nuovi caricamenti.
Si noti che l’ordine di visualizzazione non è casuale. Se si fosse voluto visualizzare per prime le entità [Rv], il metodo [ToString] di quest’ultima avrebbe provocato il caricamento delle entità [Client] e [Creneau] collegate a questi appuntamenti. Le altre non sarebbero state caricate, ma lo sarebbero state in un secondo momento in un’altra visualizzazione. Ciò incide sulle prestazioni. Il codice precedente richiede quattro comandi SQL per visualizzare tutte le entità. Supponiamo ora di interrogare prima la tabella [RVS] degli appuntamenti. È necessaria una prima query SQL per la tabella [RVS]. Successivamente, il metodo [ToString] dell’entità [Rv] provocherà l’eventuale caricamento delle entità associate [Client] e [Creneau]. È necessaria una richiesta SQL per ciascuna di esse. Supponendo che ci siano N2 clienti e N3 fasce orarie e che tutte queste entità siano referenziate nella tabella [RVS], la visualizzazione di quest’ultima richiederà 1+N2+N3 query SQL. Pertanto, le prestazioni sono inferiori rispetto alla versione esaminata. Per visualizzare la tabella [RVS] con le sue dipendenze, sarebbe necessario un join tra tabelle. È possibile realizzarlo con LINQ. Torneremo su questo argomento con un esempio. Per ora, ricordiamo che dobbiamo prestare attenzione alle query SQL sottostanti al nostro codice LINQ.
Configuriamo il progetto per eseguire questo nuovo codice [1] e [2], quindi lo eseguiamo:
 |
L'output della console è il seguente:
3.5.4. Apprendimento di LINQ con LINQPad
Abbiamo utilizzato in precedenza le query LINQ to Entity per visualizzare il contenuto delle tabelle del database. Joseph Albahari ha scritto un programma per l’apprendimento delle diverse forme di LINQ. Lo presentiamo ora.
LINQPad è disponibile al seguente URL [http://www.linqpad.net/]. Una volta installato, lo avviamo [1]:
 |
I principianti potranno familiarizzare con il programma grazie agli esempi presenti nelle schede [Samples] e [2], che ne illustrano numerosi. Selezioniamo l’esempio [3], che verrà quindi visualizzato in un’altra finestra [4]. Il codice completo dell’esempio è il seguente:
// Ora una semplice espressione di query LINQ-to-objects (notate l'assenza del punto e virgola):
from word in "The quick brown fox jumps over the lazy dog".Split()
orderby word.Length
select word
// Sentitevi liberi di modificarla... (non vi sta guardando nessuno!) Vi verrà chiesto di salvare eventuali
// modifiche in un file separato.
//
// Sugge rimento: è possibile eseguire una parte di una query evidenziandola e premendo poi F5.
Le righe 3-5 sono un esempio di query LINQ to Object. La query LINQ segue la sintassi:
from variable in collection orderby élément1 select élément2
- dove la variabile indica l’elemento corrente della collezione. Nel nostro esempio, questa collezione è l’elenco delle parole risultanti dalla stringa suddivisa;
- la collezione è ordinata in base al parametro élément1 di orderby. Nel nostro esempio, la collezione di parole sarà ordinata in base alla loro lunghezza;
- la parola chiave
selectindica ciò che si desidera estrarre dall’elemento corrente</span>*<span style="color: #000000">variable*della collezione. Nel nostro esempio, sarà la parola.
Eseguiamo questa query LINQ:
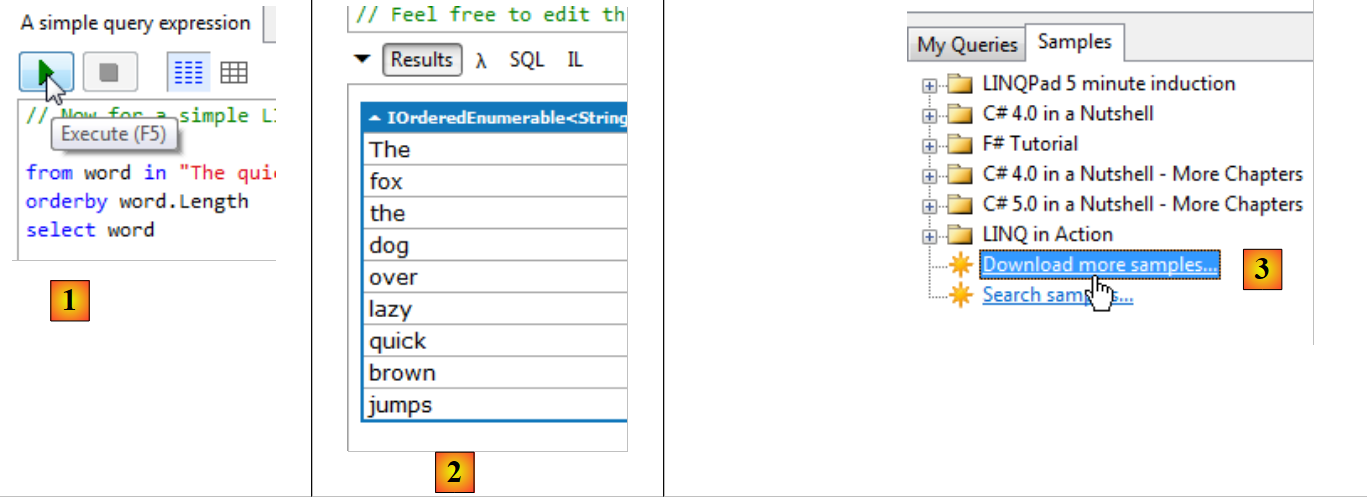 |
- in [1]: un'espressione LINQ viene eseguita da [F5] oppure tramite il pulsante di esecuzione;
- in [2]: la visualizzazione. Le parole vengono visualizzate in ordine di lunghezza. Questo semplice esempio mostra la potenza di LINQ;
- in [3] è possibile scaricare altri esempi, in particolare quelli tratti dal libro «LINQ in action» [4];
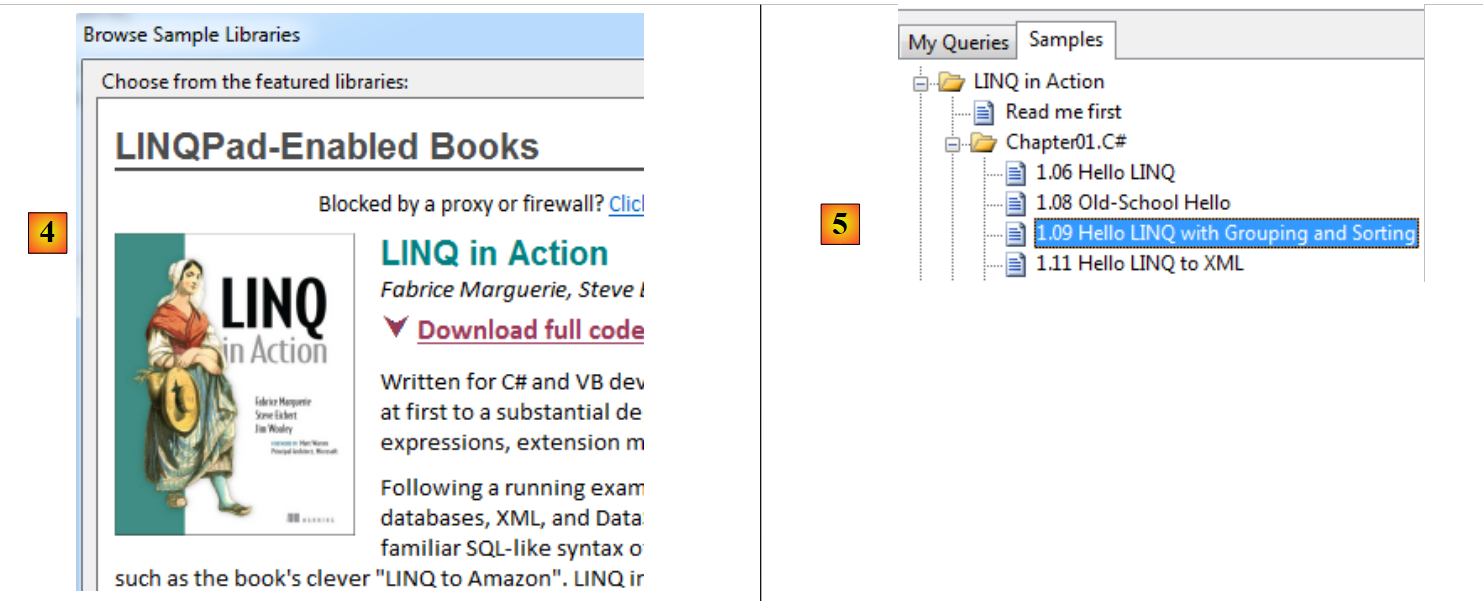 |
- in [5], scegliamo un esempio tratto dal libro;
string[] words = { "hello", "wonderful", "linq", "beautiful", "world" };
// Raggruppa le parole in base alla lunghezza
var groups =
from word in words
orderby word ascending
group word by word.Length into lengthGroups
orderby lengthGroups.Key descending
select new { Length = lengthGroups.Key, Words = lengthGroups };
// Stampa ogni gruppo
foreach (var group in groups)
{
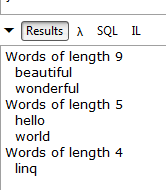
Console.WriteLine("Words of length " + group.Length);
foreach (string word in group.Words)
Console.WriteLine(" " + word);
}
- riga 4: una nuova richiesta LINQ con nuove parole chiave;
- riga 5: la raccolta richiesta è la tabella di parole della riga 1;
- riga 6: la collezione viene ordinata in ordine alfabetico delle parole;
- riga 7: la raccolta viene raggruppata (parola chiave into) in una nuova raccolta lengthGroups. lengthGroups.Key rappresenta il fattore di raggruppamento (parola chiave by), in questo caso la lunghezza delle parole. lengthGroups raggruppa le parole con lo stesso fattore di raggruppamento, quindi con la stessa lunghezza;
- riga 8: la collezione lengthGroups è ordinata in base alla chiave di raggruppamento in ordine decrescente, quindi in questo caso in base alla dimensione decrescente delle parole;
- riga 9: da questa collezione si generano nuovi oggetti (classi anonime) con due campi:
- Length: la lunghezza delle parole,
- Words: le parole con tale lunghezza;
Qui si nota in particolare l’utilità della parola chiave var della riga 4. Poiché nella riga 9 è stata utilizzata una classe anonima, non è possibile specificare il tipo della variabile groups. Il compilatore, dal canto suo, assegnerà un nome interno alla classe anonima e utilizzerà tale nome per tipizzare la variabile groups. Sarà quindi in grado di stabilire se la variabile groups viene utilizzata correttamente
- riga 12: elaborazione della query della riga 4. È solo in questo momento che viene valutata. Ricordiamo che la sua esecuzione produrrà una collezione di oggetti, specificati alla riga 9;
- riga 14: viene visualizzata la proprietà Length dell’elemento corrente, ovvero la lunghezza delle parole;
- righe 15-17: viene visualizzato ogni elemento della collezione della proprietà Words, ovvero l'insieme delle parole aventi la lunghezza visualizzata in precedenza.
Quando eseguiamo questa query, otteniamo il seguente risultato in LINQPad:
 |
Ora che abbiamo visto alcuni esempi di query [LINQ to Object], esaminiamo le query [LINQ to Entity] che ci consentiranno di interrogare i database. Per prima cosa ci collegheremo al database SQL Server che abbiamo creato e popolato:
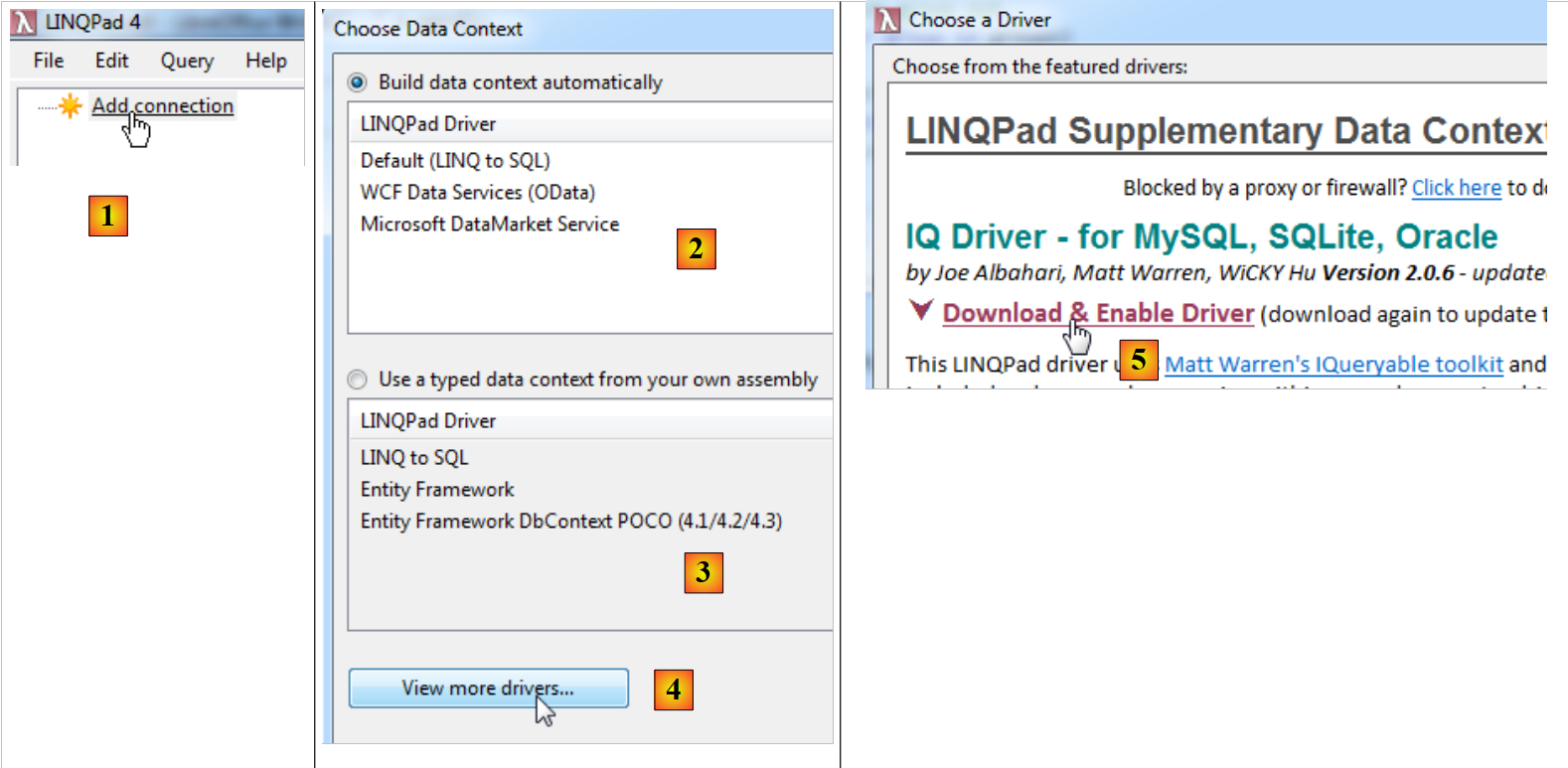 |
- in [1], aggiungiamo una connessione a un database;
- in [2], i metodi di accesso alla fonte dati. Per accedere al database SQL Server, utilizzeremo [LINQPad Driver];
- in [3], è anche possibile recuperare un contesto di persistenza [DbContext] definito in un file .exe o .dll assembly (opzione 3). Purtroppo, ad oggi (8 ottobre 2012), Entity Framework 5 non è supportato;
- in [4] è possibile scaricare driver per SGBD diversi da SQL Server;
- in [5], si scaricherà il driver per i SGBD, MySQL e Oracle;
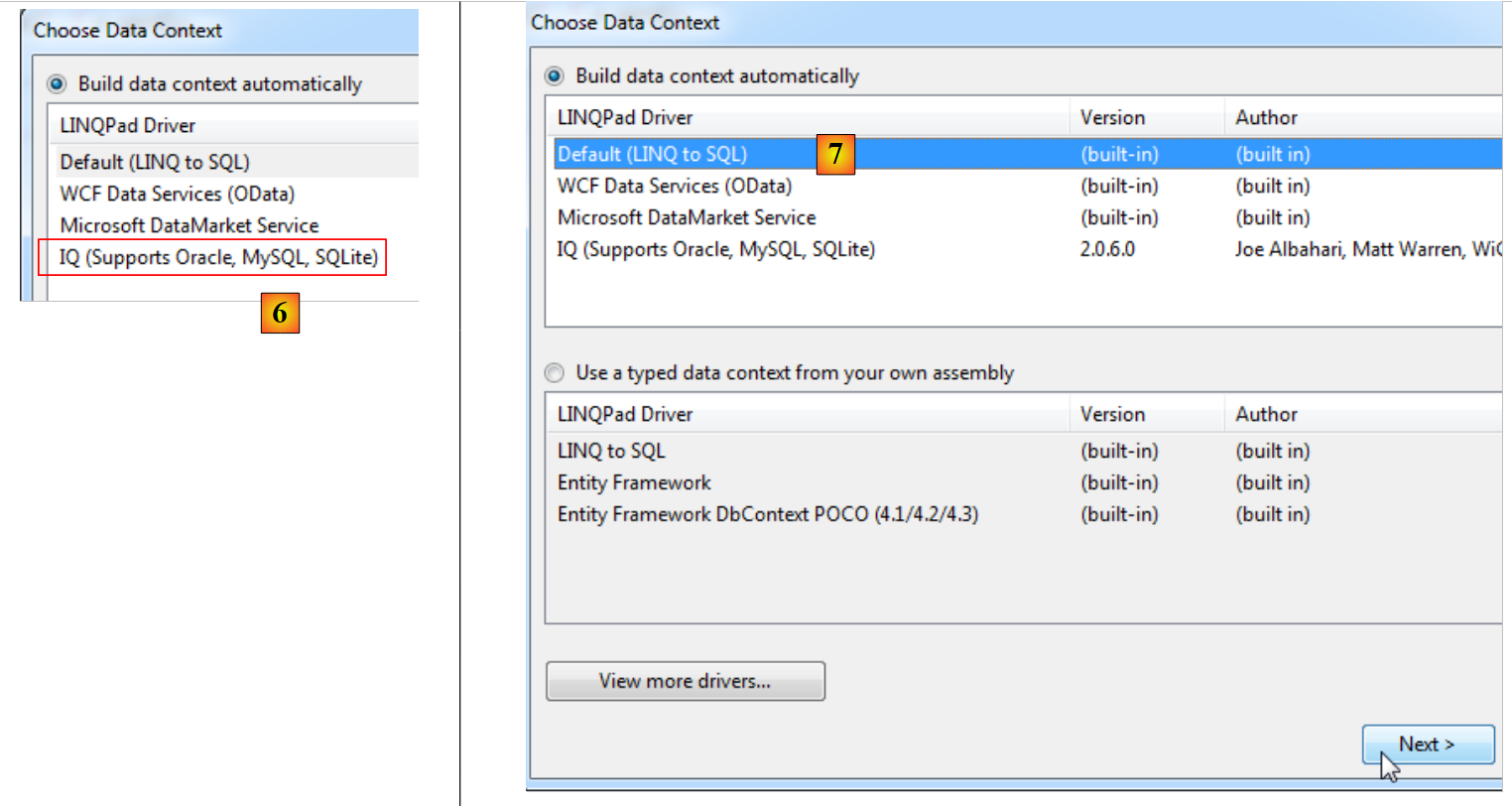 |
- in [6], il driver scaricato;
- in [7], ci si connette a un server SQL;
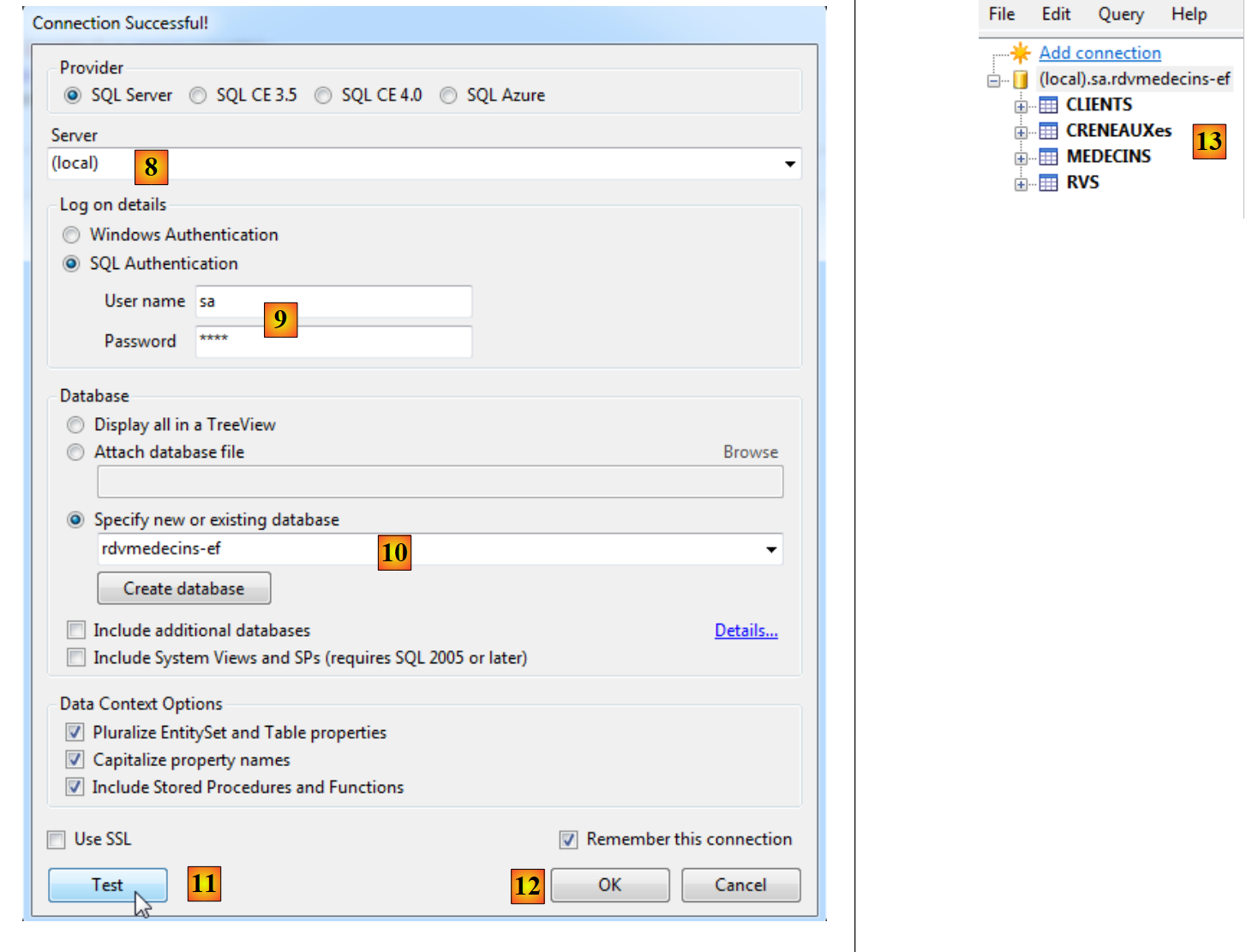 |
- in [8], il database si trova sul server dei nomi (locale);
- in [9], ci si connette con l'autenticazione sa / sqlserver2012;
- in [10], al database [rdvmedecins-ef] che abbiamo creato;
- in [11], è possibile verificare la connessione;
- in [12], si chiude la procedura guidata;
- in [13], la connessione compare in LINQPad.
Le entità sono state create a partire dalla tabella [rdvmedecins-ef]. Sono le seguenti:
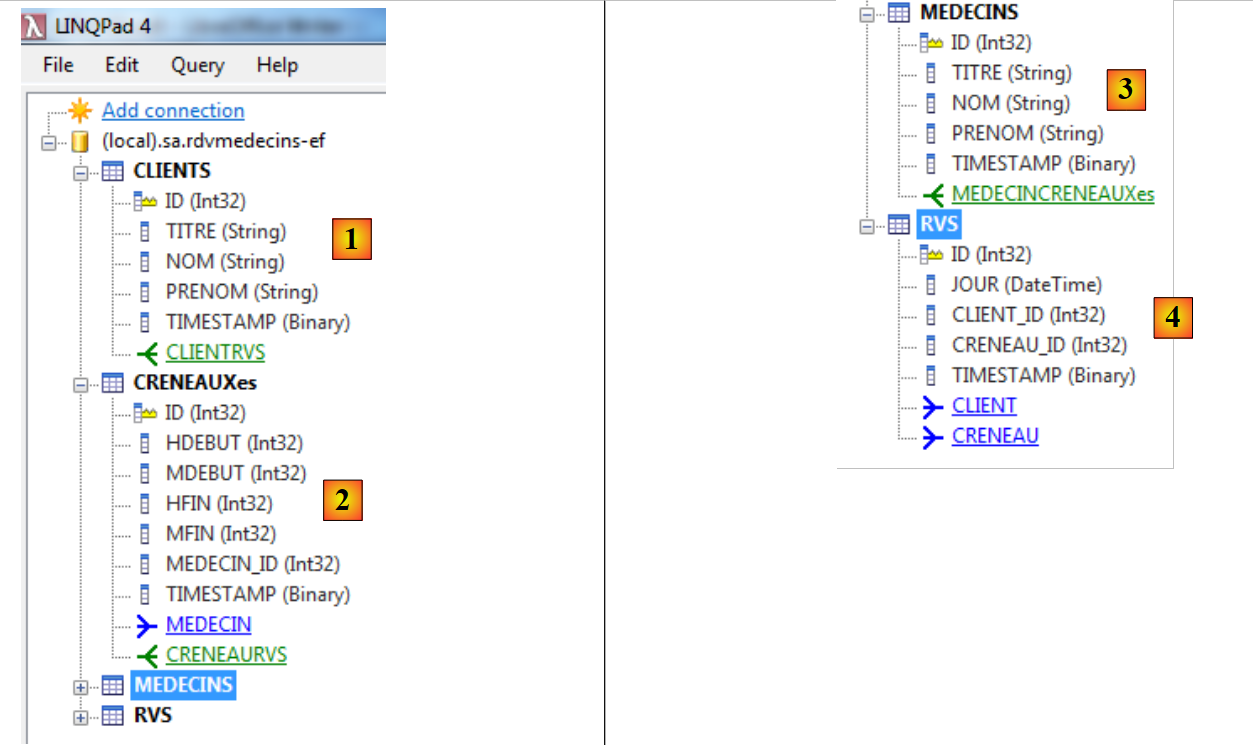 |
- in [1], [CLIENTS] rappresenta l’insieme delle entità [Client]. Ogni entità presenta:
- le proprietà (ID, TITRE, NOM, PRENOM, TIMESTAMP),
- una relazione 1 a più [CLIENTRVS];
- in cui [2] e [CRENEAUXes] rappresentano l’insieme delle entità [Creneau]. Ogni entità presenta:
- le proprietà (ID, HDEBUT, MDEBUT, HFIN, MFIN, MEDECIN_ID, TIMESTAMP),
- una relazione 1 a più [CRENEAURVS],
- una relazione da molti a uno [MEDECIN];
- in [3], l’entità [MEDECINS] rappresenta l’insieme delle entità [Medecin]. Ogni entità presenta:
- le proprietà (ID, TITRE, NOM, PRENOM, TIMESTAMP),
- una relazione 1 a più [MEDECINCRENEAUXes];
- in [4], l’entità [RVS] rappresenta l’insieme delle entità [Rv]. Ogni entità presenta:
- le proprietà (ID, JOUR, CLIET_ID, CRENEAU_ID, TIMESTAMP),
- una relazione "molti a uno" con [CLIENT],
- una relazione molti-a-uno [CRENEAU].
Si noti che i nomi delle proprietà sopra riportati sono diversi da quelli che abbiamo utilizzato finora. Non ha importanza. Vogliamo solo imparare i principi di base delle query sui database.
Vediamo come possiamo eseguire una query su questa base di entità. Ad esempio, vogliamo l’elenco dei medici ordinato in base ai loro TITRE e NOM:
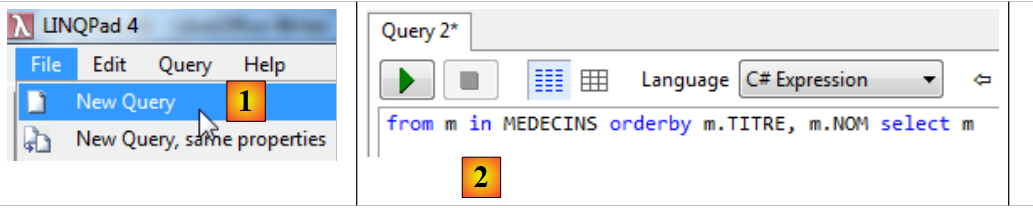 |
- in [1], creiamo una nuova query;
- in [2], il testo della query;
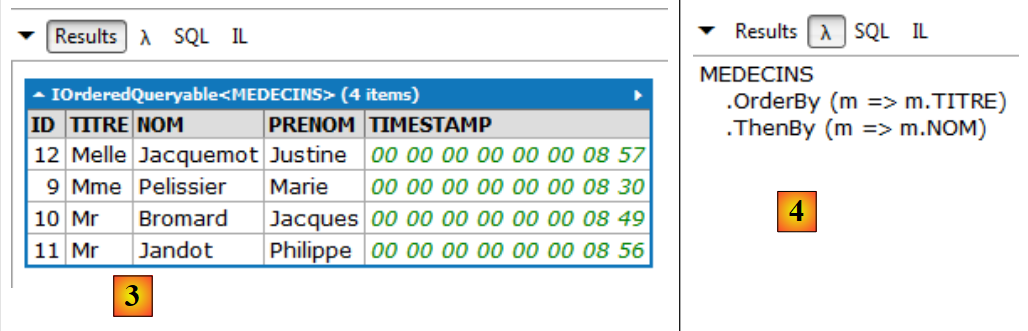 |
- in [3], il risultato della query;
- in [4], la stessa query con espressioni lambda. Una query con espressioni lambda è meno leggibile di una query testuale e si potrebbe preferire evitarla. Tuttavia, a volte sono indispensabili perché consentono alcune operazioni che le query testuali non permettono. Un'espressione lambda indica una funzione con un parametro di input a e un parametro di output b, nella forma a=>b. Il metodo OrderBy sopra riportato accetta una funzione lambda come unico parametro. Questa gli fornisce il parametro in base al quale deve essere ordinata una collezione. Pertanto, MEDECINS.OrderBy(m=>m.TITRE) è l’elenco dei medici ordinato in base ai titoli. L’istruzione va letta come una pipeline su una collezione. La collezione dei medici viene fornita in ingresso al metodo OrderBy. Quest’ultimo elaborerà le entità [Medecin] una per una. Nell’espressione lambda m=>m.TITRE, m rappresenta l’input della funzione lambda. È possibile denominarlo a proprio piacimento. In questo caso, l’input della funzione lambda sarà un’entità [Medecin]. La funzione m=>m.TITRE si legge come segue: se chiamo m il mio input (un'entità [Medecin]), allora il mio output è m.TITRE, ovvero il titolo del medico. MEDECINS.OrderBy(m=>m.TITRE) è a sua volta una collezione, ovvero la collezione dei medici ordinata in base ai titoli. Questa nuova collezione può alimentare un altro metodo, nell’esempio il metodo ThenBy. Quest’ultimo funziona secondo lo stesso principio. Serve a specificare parametri aggiuntivi per l’ordinamento della collezione.
Leggere il codice lambda equivalente al codice testuale che digitiamo abitualmente è un buon modo per impararlo;
 |
- in [5], l’ordine SQL emesso dal sistema. Anche in questo caso, leggeremo attentamente questo codice. Esso consente di valutare il costo effettivo di una query LINQ.
Di seguito presentiamo alcuni esempi di richiesta LINQ. In ogni caso, mostriamo i risultati visualizzati e i codici lambda e SQL equivalenti. Per comprendere queste richieste, è necessario ricordare le relazioni «molti a uno» che collegano le entità tra loro. È attraverso di esse che si naviga da un’entità all’altra. Si chiamano proprietà navigazionali.
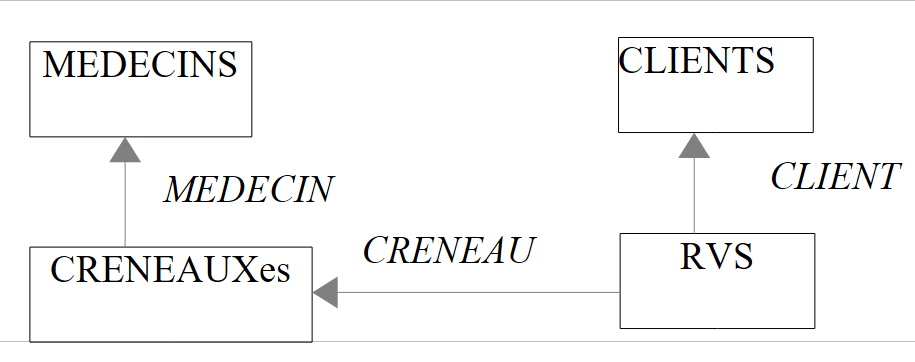 |
// i clienti il cui titolo è «Mr» ordinati in ordine decrescente per nome
Risultati:
 |
LINQ | |
Lambda | |
SQL | |
// tutte le fasce orarie con il medico associato
Risultati (parziali):
 |
LINQ | |
Lambda |  |
SQL | |
// tutti gli appuntamenti con il cliente e il medico associati
Risultati:
 |
LINQ | |
Lambda | 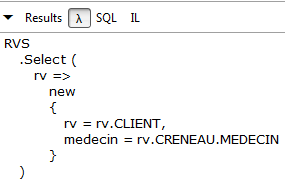 |
SQL | |
// medici senza appuntamenti
Risultati:
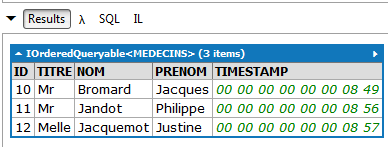 |
LINQ | |
Lambda | 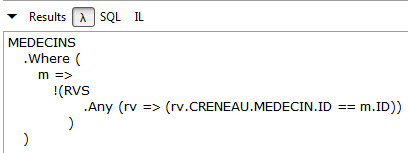 |
SQL | |
Non esiste una query LINQ per questa richiesta. È necessario utilizzare le espressioni lambda. Questa si legge come segue: prendo la raccolta dei medici (MEDECINS) e mantengo (Where) solo i medici (m) per i quali non riesco a trovare nella raccolta degli appuntamenti (RVS) un appuntamento (rv) con quel medico (m).
// fasce orarie della signora Pélissier
Risultati (parziali):
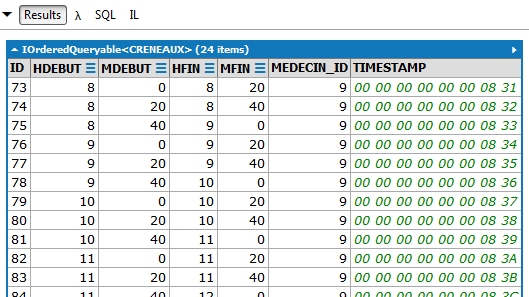 |
LINQ | |
Lambda |  |
SQL | |
// Numero di appuntamenti della signora Pélissier l'8/10/2012
Risultati:
 |
LINQ | |
Lambda | |
SQL | |
// elenco dei clienti che hanno fissato un appuntamento con la sig.ra Pélissier l'8/10/2012
Risultati:
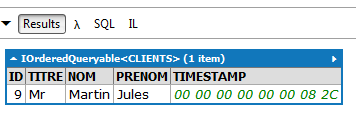 |
LINQ | |
Lambda | 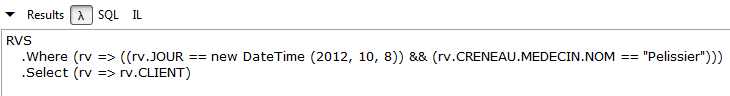 |
SQL | |
// numero di fasce orarie per medico
Risultati:
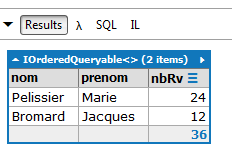 |
LINQ | |
Lambda | 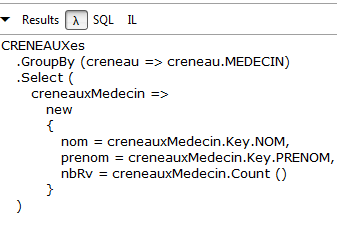 |
SQL | |
3.5.5. Modifica di un'entità associata al contesto di persistenza
Abbiamo visto le seguenti operazioni sul contesto di persistenza:
- aggiungere un elemento al contesto ([dbContext].[DbSet].Add);
- rimuovere un elemento dal contesto ([dbContext].[DbSet].Remove);
- eseguire una query sul contesto con le query LINQ.
Quando si desidera sincronizzare il contesto con il database, si scrive [dbContext].SaveChanges().
 |  |
Il codice [ModifyAttachedEntity] illustra la modifica di un’entità associata al contesto:
using System;
using System.Data;
using System.Linq;
using RdvMedecins.Entites;
using RdvMedecins.Models;
namespace RdvMedecins_01
{
class ModifyAttachedEntity
{
static void Main(string[] args)
{
Client client1, client2, client3;
// 1° contesto
using (var context = new RdvMedecinsContext())
{
// si svuota il database corrente
foreach (var client in context.Clients)
{
context.Clients.Remove(client);
}
foreach (var medecin in context.Medecins)
{
context.Medecins.Remove(medecin);
}
// si aggiunge un cliente
client1 = new Client { Nom = "xx", Prenom = "xx", Titre = "xx" };
context.Clients.Add(client1);
// monitoraggio
Console.WriteLine("client1--avant");
Console.WriteLine(client1);
// Salvataggio del contesto
context.SaveChanges();
// monitoraggio
Console.WriteLine("client1--après");
Console.WriteLine(client1);
}
// secondo contesto
using (var context = new RdvMedecinsContext())
{
// si recupera il cliente1 nel cliente2
client2 = context.Clients.Find(client1.Id);
// monitoraggio
Console.WriteLine("client2");
Console.WriteLine(client2);
// si modifica il cliente 2
client2.Nom = "yy";
// salvataggio del contesto
context.SaveChanges();
}
// terzo contesto
using (var context = new RdvMedecinsContext())
{
// si recupera il cliente2 nel cliente3
client3 = context.Clients.Find(client2.Id);
// monitoraggio
Console.WriteLine("client3");
Console.WriteLine(client3);
}
}
}
}
- riga 15: apertura del contesto dell’applicazione;
- righe 18-25: il contesto viene svuotato. Più precisamente, tutte le entità vengono trasferite nel contesto dal database e poi passano allo stato "eliminato". Si noti che a questo punto il database non ha subito alcuna modifica. Finché il contesto non viene sincronizzato con il database, quest'ultimo rimane invariato. Ricordiamo che l’eliminazione delle entità [Medecin] e [Client] è sufficiente a svuotare il database grazie al meccanismo delle eliminazioni a cascata;
- righe 27-28: viene aggiunto un nuovo cliente al database;
- righe 30-31: lo si visualizza prima di salvarlo nel database;
- riga 33: si sincronizza il contesto con il database. Le entità contrassegnate come «eliminate» saranno oggetto di un'operazione SQL DELETE, l'entità aggiunta sarà oggetto di un'operazione SQL INSERT;
- righe 35-36: viene visualizzato il cliente dopo la sincronizzazione con il database;
Il risultato ottenuto sulla console è il seguente:
Si notino i seguenti punti:
- prima della sincronizzazione con il database, il cliente non ha né chiave primaria né timestamp,
- dopo la sincronizzazione, li possiede. Si ricorda che la chiave primaria è stata configurata per essere generata da SQL Server. Allo stesso modo, SGBD genera automaticamente il timestamp;
- riga 37: il contesto di persistenza viene chiuso. Le entità in esso contenute diventano “distaccate”. Esse esistono come oggetti ma non come entità associate a un contesto di persistenza;
- riga 39: viene avviato un nuovo contesto vuoto;
- riga 42: si recupera il cliente direttamente dal database tramite la sua chiave primaria. Viene quindi inserito nel contesto. Se non viene trovato, il metodo Find restituisce il puntatore null;
- righe 48-49: lo si visualizza;
Si ottiene il seguente risultato:
- riga 47: lo si modifica;
- riga 49: si sincronizza il contesto con il database. EF rileverà che alcuni elementi del contesto sono stati modificati da quando vi sono stati inseriti. Per questi elementi, genererà i comandi SQL e UPDATE sul database. Quindi, in questo caso, la sincronizzazione consisterà in un unico comando UPDATE;
- riga 50: il secondo contesto viene chiuso. L’entità client2, che era associata al contesto, viene ora disassociata da esso;
- riga 52: si apre un terzo contesto vuoto;
- riga 55: vi si riporta l’unico cliente del database. Si vuole verificare se la modifica apportata su di esso nel contesto precedente sia stata riportata nel database;
- righe 57-58: si visualizza il cliente. Si ottiene il seguente risultato:
Il nome del cliente è stato effettivamente modificato nel database. È interessante notare che il suo codice timestamp è stato aggiornato.
- riga 59: si chiude il contesto. Si noti, tra l’altro, che a differenza delle due volte precedenti, non è stato necessario sincronizzare in precedenza il contesto con il database (SaveChanges) poiché il contesto non era stato modificato.
3.5.6. Gestione delle entità distaccate
Torniamo all’architettura a livelli di un’applicazione come quella del caso di studio:
 |
Il livello [DAO] utilizza ORM e EF5 per accedere ai dati. Abbiamo gli elementi fondamentali di questo livello. Ogni metodo aprirà un contesto di persistenza, eseguirà le operazioni necessarie (inserimento, modifica, cancellazione, interrogazione) e poi lo chiuderà. Le entità gestite dal livello [DAO] risaliranno fino al livello web ASP.NET. In questo livello, esse sono fuori dal contesto di persistenza e quindi distaccate. Nel livello web, un utente può modificare queste entità (aggiunta, modifica, eliminazione). Quando tornano al livello [DAO], sono ancora scollegate. Tuttavia, il livello [DAO] dovrà replicare nel database le modifiche apportate dall’utente. Dovrà quindi lavorare con entità scollegate. Esaminiamo i tre casi possibili:
Aggiungere un’entità scollegata
Questo è il caso normale per un’aggiunta. È sufficiente aggiungere (Add) l’entità distaccata al contesto assicurandosi che abbia una chiave primaria pari a null.
Modificare un'entità distaccata
È possibile utilizzare il seguente codice:
- il metodo [DbContext].Entry(entità-distaccata) inserirà l'entità nel contesto;
- lo stato di tale entità viene impostato su «modificato» affinché sia oggetto di un ordine SQL UPDATE.
Eliminare un'entità distaccata
È possibile utilizzare il seguente codice:
- riga 1: si inserisce nel contesto l’entità con la stessa chiave primaria dell’entità distaccata;
- riga 2: la si elimina:
Si noti che ciò richiede, come base, un SELECT seguito da un DELETE, mentre normalmente è sufficiente il solo DELETE. Si può anche seguire l'esempio della modifica di un'entità distaccata e scrivere:
Poiché non sono riuscito a implementare i log sulle operazioni SQL eseguite sul database, non so se sia consigliabile un metodo piuttosto che l’altro.
Ecco un esempio:
 | 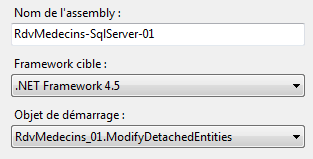 |
Il codice del programma [ModifyDetachedEntities] è il seguente:
using System;
using System.Data;
using RdvMedecins.Entites;
using RdvMedecins.Models;
namespace RdvMedecins_01
{
class ModifyDetachedEntities
{
static void Main(string[] args)
{
Client client1;
// si svuota il database attuale
Erase();
// si aggiunge un cliente
using (var context = new RdvMedecinsContext())
{
// creazione cliente
client1 = new Client { Titre = "x", Nom = "x", Prenom = "x" };
// aggiunta del cliente al contesto
context.Clients.Add(client1);
// salvataggio del contesto
context.SaveChanges();
}
// visualizzazione del database
Dump("1-----------------------------");
// il cliente1 non è presente nel contesto - lo si modifica
client1.Nom = "y";
// nuovo contesto
using (var context = new RdvMedecinsContext())
{
// qui si ha un contesto vuoto
// si inserisce client1 nel contesto in uno stato modificato
context.Entry(client1).State = EntityState.Modified;
// si salva il contesto
context.SaveChanges();
}
// visualizzazione di base
Dump("2-----------------------------");
// eliminazione entità fuori contesto
using (var context = new RdvMedecinsContext())
{
// qui si ha un nuovo contesto vuoto
// si inserisce client1 nel contesto in uno stato eliminato
context.Entry(client1).State = EntityState.Deleted;
// si salva il contesto
context.SaveChanges();
}
// visualizzazione del database
Dump("3-----------------------------");
}
static void Erase()
{
// svuota il database
using (var context = new RdvMedecinsContext())
{
foreach (var client in context.Clients)
{
context.Clients.Remove(client);
}
foreach (var medecin in context.Medecins)
{
context.Medecins.Remove(medecin);
}
// si salva il contesto
context.SaveChanges();
}
}
static void Dump(string str)
{
Console.WriteLine(str);
// visualizza la base
using (var context = new RdvMedecinsContext())
{
foreach (var rv in context.Rvs)
{
Console.WriteLine(rv);
}
foreach (var creneau in context.Creneaux)
{
Console.WriteLine(creneau);
}
foreach (var client in context.Clients)
{
Console.WriteLine(client);
}
foreach (var medecin in context.Medecins)
{
Console.WriteLine(medecin);
}
}
}
}
}
- riga 15: il database viene cancellato;
- righe 17-25: viene aggiunto un cliente al database;
- riga 27: visualizza il contenuto del database;
- dopo la riga 25, il contesto di persistenza non esiste più. Non ci sono quindi più entità associate. L'entità client1 è passata allo stato "non associata";
- riga 29: si modifica il nome dell’entità scollegata;
- riga 31: si apre un nuovo contesto vuoto;
- riga 35: l’entità scollegata client1 viene inserita nel contesto con lo stato “modificato”;
- riga 37: il contesto viene sincronizzato con il database;
- riga 38: viene chiuso;
- riga 40: viene visualizzato il database;
Il nome del cliente è stato correttamente modificato nel database. Si noti che il codice timestamp è stato aggiornato;
- riga 42: apertura di un nuovo contesto vuoto;
- riga 46: l'entità distaccata client1 viene inserita nel contesto con lo stato "eliminata";
- riga 48: il contesto viene sincronizzato con il database;
- riga 49: viene chiuso;
- riga 51: il database viene visualizzato;
L'entità è stata effettivamente eliminata dal database.
Ora vediamo le due modalità di caricamento delle dipendenze di un'entità: Lazy e Eager Loading.
3.5.7. Lazy e Eager Loading
Riprendiamo lo schema delle dipendenze «molti a uno» di una delle nostre quattro entità:
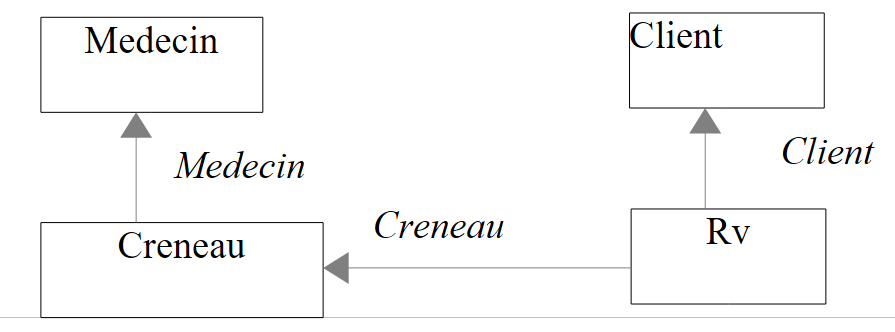 |
Nell’esempio sopra riportato, l’entità [Creneau] presenta una proprietà di navigazione [Creneau.Medecin] verso l’entità [Medecin]. Questo si chiama dipendenza. Abbiamo visto che esistono anche dipendenze "uno a molti". Il principio che verrà spiegato si applica anche a queste.
Per impostazione predefinita, EF 5 è in modalità Lazy Loading: quando importa un’entità nel contesto di persistenza dal database, non ne importa le dipendenze. Queste ultime verranno importate al momento del loro primo utilizzo. Si tratta di una misura dettata dal buon senso. Se così non fosse, importando gli appuntamenti nel contesto verrebbero importate, in base alle dipendenze sopra indicate:
- le entità [Creneau] collegate agli appuntamenti;
- le entità [Medecin] collegate a tali fasce orarie;
- le entità [Clients] collegate agli appuntamenti.
A volte, tuttavia, è necessario un’entità e le sue dipendenze. Illustreremo entrambe le modalità di caricamento.
 | 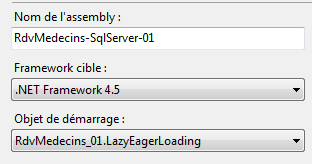 |
Il codice di [LazyEagerLoading] è il seguente:
using RdvMedecins.Entites;
using RdvMedecins.Models;
using System;
using System.Linq;
namespace RdvMedecins_01
{
class LazyEagerLoading
{
// le entità
static Medecin[] medecins;
static Client[] clients;
static Creneau[] creneaux;
static void Main(string[] args)
{
// inizializzazione del database
InitBase();
Console.WriteLine("Initialisation terminée");
// caricamento anticipato
Creneau creneau;
int idCreneau = (int)creneaux[0].Id;
using (var context = new RdvMedecinsContext())
{
// slot n. 0
creneau = context.Creneaux.Include("Medecin").Single<Creneau>(c => c.Id == idCreneau);
Console.WriteLine(creneau.ShortIdentity());
}
// visualizzazione delle dipendenze
try
{
Console.WriteLine("Médecin={0}", creneau.Medecin);
}
catch (Exception e)
{
Console.WriteLine("L'erreur 1 suivante s'est produite : {0}", e);
}
// caricamento differito - modalità predefinita
using (var context = new RdvMedecinsContext())
{
// slot n. 0
creneau = context.Creneaux.Single<Creneau>(c => c.Id == idCreneau);
Console.WriteLine(creneau.ShortIdentity());
}
// visualizzazione delle dipendenze
try
{
Console.WriteLine("Médecin={0}", creneau.Medecin);
}
catch (Exception e)
{
Console.WriteLine("L'erreur 2 suivante s'est produite : {0}", e);
}
}
static void InitBase()
{
// si inizializza il database
using (var context = new RdvMedecinsContext())
{
// si svuota il database attuale
...
// si inizializza il database
// i clienti
clients = new Client[] {
new Client { Titre = "Mr", Nom = "Martin", Prenom = "Jules" },
new Client { Titre = "Mme", Nom = "German", Prenom = "Christine" },
new Client { Titre = "Mr", Nom = "Jacquard", Prenom = "Jules" },
new Client { Titre = "Melle", Nom = "Bistrou", Prenom = "Brigitte" }
};
...
// gli appuntamenti
context.Rvs.Add(new Rv { Jour = new System.DateTime(2012, 10, 8), Client = clients[0], Creneau = creneaux[0] });
// si salva il contesto di persistenza
context.SaveChanges();
}
}
}
}
- riga 18: si parte da una base nota, quella utilizzata fino a questo momento. Dopo questa operazione, le tabelle delle righe 11-13 vengono riempite con entità separate;
- righe 21-22: ci si concentra sulla prima fascia oraria e sul medico associato;
- riga 23: nuovo contesto;
- riga 26: si inserisce la fascia oraria nel contesto con la sua dipendenza (eager loading). Poiché non si tratta della modalità predefinita, è necessario richiedere esplicitamente tale dipendenza. A ciò serve il metodo Include. Il suo parametro è il nome della dipendenza nell’entità inserita nel contesto. La query che inserisce l’entità nel contesto utilizza espressioni lambda. Il metodo Single consente di specificare una condizione per recuperare una singola entità. In questo caso, si cerca nel database l’entità [Creneau] che ha come chiave primaria lo slot n. 0;
- riga 27: si visualizza l’entità recuperata. Ricordiamo i due metodi di scrittura utilizzati nelle entità:
// firma
public override string ToString()
{
return String.Format("Creneau[{0},{1},{2},{3},{4}, {5},{6}]", Id, Hdebut, Mdebut, Hfin, Mfin, Medecin, dump(Timestamp));
}
// firma breve
public string ShortIdentity()
{
return String.Format("Creneau[{0},{1},{2},{3},{4}, {5}, {6}]", Id, Hdebut, Mdebut, Hfin, Mfin, MedecinId, dump(Timestamp));
}
- righe 2-5: il metodo [ToString] visualizza la dipendenza [Medecin]. Se questa non è già presente nel contesto, verrà cercata nel database per inserirla;
- righe 8-11: il metodo [ShortIdentity] non visualizza la dipendenza [Medecin]. Pertanto, se non è presente nel contesto, non verrà cercata nel database;
A questo punto, l’output della console è il seguente:
- riga 28: il contesto viene chiuso;
- righe 30-37: si tenta di scrivere la dipendenza [Medecin] dell’entità. Ricordiamo il funzionamento del Lazy Loading: una dipendenza viene caricata al momento del suo primo utilizzo se non è presente. In questo caso, normalmente è presente. L’output è il seguente:
- righe 39-44: in un nuovo contesto, lo slot n. 0 viene nuovamente ricercato nel database e inserito nel contesto. In questo caso, la dipendenza [Medecin] non viene richiesta esplicitamente. Non verrà quindi caricata (Lazy Loading);
- riga 43: la visualizzazione dell’identità breve dello slot è la seguente:
In questo caso, è importante utilizzare ShortIdentity anziché ToString per visualizzare l’entità. Se si utilizza ToString, verrà visualizzata la dipendenza [Medecin] e, di conseguenza, verrà ricercata nel database. Ma questo non è desiderabile.
- riga 44: il contesto viene chiuso;
- righe 46-53: si tenta di visualizzare la dipendenza dell’entità. È importante farlo fuori contesto, altrimenti verrà cercata nel database e trovata. Qui siamo fuori contesto. L’entità [Creneau] è scollegata e la sua dipendenza [Medecin] è assente (Lazy Loading). Cosa succederà? La visualizzazione sullo schermo è la seguente:
EF ha rilevato l’assenza della dipendenza [Medecin]. Ha tentato di caricarla, ma poiché il contesto era chiuso, tale operazione non era più possibile. Prenderemo nota di questa eccezione [System.ObjectDisposedException] poiché è tipica del caricamento di una dipendenza al di fuori di un contesto aperto.
Esaminiamo ora la concorrenza nell'accesso alle entità.
3.5.8. Concorrenza nell’accesso alle entità
Torniamo alla definizione dell’entità [Client]:
public class Client
{
// dati
[Key]
[Column("ID")]
public int? Id { get; set; }
[Required]
[MaxLength(5)]
[Column("TITRE")]
public string Titre { get; set; }
[Required]
[MaxLength(30)]
[Column("NOM")]
public string Nom { get; set; }
[Required]
[MaxLength(30)]
[Column("PRENOM")]
public string Prenom { get; set; }
// i Rvs del cliente
public ICollection<Rv> Rvs { get; set; }
[Column("TIMESTAMP")]
[Timestamp]
public byte[] Timestamp { get; set; }
// firma
...
}
Ci concentreremo sul campo [Timestamp] della riga 23. Sappiamo che il suo valore è generato da SGBD. Abbiamo anche detto che l’annotazione [Timestamp] della riga 22 faceva sì che EF 5 utilizzasse il campo annotato per gestire le conflittualità di accesso alle entità. Ricordiamo cos’è la gestione delle conflittualità di accesso:
- un processo P1 legge una riga L della tabella [MEDECINS] al tempo T1. La riga ha il timestamp TS1;
- un processo P2 legge la stessa riga L della tabella [MEDECINS] al momento T2. La riga presenta i valori timestamp e TS1 poiché il processo P1 non ha ancora convalidato la propria modifica;
- il processo P1 convalida la modifica della riga L. Il valore timestamp della riga L passa quindi a TS2;
- il processo P2 convalida la modifica della riga L. IlORM genera quindi un'eccezione poiché il processo P2 presenta un timestamp TS1 della riga L diverso dal timestamp TS2 trovato nel database.
Questo fenomeno è noto come gestione ottimistica degli accessi concorrenti. Con EF 5, un campo che svolge questo ruolo deve avere uno dei due attributi [Timestamp] o [ConcurrencyCheck]. Il server SQL ha un tipo [timestamp]. Il valore di una colonna con questo tipo viene generato automaticamente dal server SQL ad ogni inserimento o modifica di una riga. Una colonna di questo tipo può quindi essere utilizzata per gestire la concorrenza di accesso.
Illustreremo questa concorrenza di accesso con due thread che modificheranno contemporaneamente la stessa entità [Client] nel database. Il progetto si evolve come segue:
 |  |
Il codice del programma [AccèsConcurrents] è il seguente:
using System;
using System.Data;
using System.Linq;
using System.Threading;
using RdvMedecins.Entites;
using RdvMedecins.Models;
namespace RdvMedecins_01
{
// oggetto scambiato con i thread
class Data
{
public int Duree { get; set; }
public string Nom { get; set; }
public Client Client { get; set; }
}
// programma di test
class AccèsConcurrents
{
static void Main(string[] args)
{
Client client1;
using (var context = new RdvMedecinsContext())
{
// thread principale
Thread.CurrentThread.Name = "main";
// si svuota il database attuale
foreach (var client in context.Clients)
{
context.Clients.Remove(client);
}
foreach (var medecin in context.Medecins)
{
context.Medecins.Remove(medecin);
}
// si aggiunge un client
client1 = new Client { Nom = "xx", Prenom = "xx", Titre = "xx" };
context.Clients.Add(client1);
// monitoraggio
Console.WriteLine("{0} client1--avant sauvegarde du contexte", Thread.CurrentThread.Name);
Console.WriteLine(client1.ShortIdentity());
// salvataggio
context.SaveChanges();
// monitoraggio
Console.WriteLine("{0} client1--après sauvegarde du contexte", Thread.CurrentThread.Name);
Console.WriteLine(client1.ShortIdentity());
}
// modificheremo client1 con due thread
// thread t1
Thread t1 = new Thread(Modifie);
t1.Name = "t1";
t1.Start(new Data { Duree = 5000, Nom = "yy", Client = client1 });
// thread t2
Thread t2 = new Thread(Modifie);
t2.Name = "t2";
t2.Start(new Data { Duree = 5000, Nom = "zz", Client = client1 });
// si attende la fine dei 2 thread
Console.WriteLine("Thread {0} -- début attente fin des deux threads", Thread.CurrentThread.Name);
t1.Join();
t2.Join();
Console.WriteLine("Thread {0} -- fin attente fin des deux threads", Thread.CurrentThread.Name);
// visualizziamo la modifica: solo una deve essere andata a buon fine
using (var context = new RdvMedecinsContext())
{
// si recupera client1 in client2
Client client2 = context.Clients.Find(client1.Id);
Console.WriteLine("Thread {0} client2", Thread.CurrentThread.Name);
Console.WriteLine("Thread {0} {1}", Thread.CurrentThread.Name, client2.ShortIdentity());
}
}
// thread
static void Modifie(object infos)
{
...
}
- riga 26: si avvia un contesto vuoto;
- riga 29: si assegna un nome al thread corrente per distinguerlo dai due thread che verranno creati in seguito;
- righe 31-38: le entità [Medecin] e [Client] vengono impostate allo stato "eliminato";
- righe 40-41: si inserisce un cliente nel contesto;
- righe 43-44: lo si visualizza prima della sincronizzazione del contesto;
- riga 46: sincronizzazione del contesto con il database: le entità nello stato "eliminato" verranno eliminate dal database. L'entità [Client] inserita nel contesto verrà inserita nel database. Sarà l'unico elemento del database;
- righe 47-49: si visualizza il cliente dopo la sincronizzazione del contesto. A questo punto, le schermate sono le seguenti:
Si noti che, dopo la sincronizzazione del contesto, il cliente ha una chiave primaria e un timestamp;
- riga 50: il contesto viene chiuso;
- riga 53: un thread t1 è associato al metodo [Modifie] della riga 84. Ciò significa che, una volta avviato, eseguirà il metodo [Modifie];
- riga 54: si assegna un nome al thread t1;
- riga 55: il thread t1 viene avviato. Gli vengono passati dei parametri sotto forma di una struttura [Data] definita alle righe 12-17:
- Durata: il thread si arresterà Durée secondi prima di terminare la sua esecuzione,
- Cliente: un riferimento al cliente da aggiornare nel database,
- Nome: nome da assegnare a questo cliente;
- righe 57-59: lo stesso vale per un secondo thread. Alla fine, due thread tenteranno di modificare nel database il nome dello stesso cliente;
- righe 60-63: dopo aver avviato i due thread, il thread principale attende che terminino la loro esecuzione;
- riga 62: attesa del completamento del thread t1;
- riga 63: attesa della fine del thread t2;
- riga 64: non si sa in quale ordine i due thread termineranno. Quello che è certo è che alla riga 64 sono terminati;
- righe 66-72: in un nuovo contesto, si recupera il cliente dal database per verificarne lo stato.
Vediamo ora cosa fanno i due thread t1 e t2. Eseguono il seguente metodo [Modifie]:
static void Modifie(object infos)
{
// si recupera il parametro
Data data = (Data)infos;
try
{
using (var context = new RdvMedecinsContext())
{
Console.WriteLine("Début Thread {0}", Thread.CurrentThread.Name);
// si recupera client1 in client2
Client client2 = context.Clients.Find(data.Client.Id);
Console.WriteLine("Thread {0} client2", Thread.CurrentThread.Name);
Console.WriteLine("Thread {0} {1}", Thread.CurrentThread.Name, client2.ShortIdentity());
// si modifica client2
client2.Nom = data.Nom;
// si attende un po'
Thread.Sleep(data.Duree);
// si salvano le modifiche
context.SaveChanges();
}
}
catch (Exception e)
{
// eccezione
Console.WriteLine("Thread {0} {1}", Thread.CurrentThread.Name, e);
}
// fine del thread
Console.WriteLine("Fin Thread {0}", Thread.CurrentThread.Name);
}
- riga 4: si recuperano i parametri del thread (Durata, Nome, Cliente);
- riga 7: nuovo contesto;
- riga 11: il cliente viene inserito nel contesto;
- righe 12-13: controllo per verificare lo stato del cliente;
- riga 15: si cambia il suo nome;
- riga 17: il thread si ferma per Duree millisecondi. Ciò produce un effetto interessante. Il thread rilascia il processore che lo stava eseguendo, lasciando spazio a un altro thread. Nel nostro esempio, abbiamo tre thread: main, t1 e t2. Il thread main è in pausa in attesa che i thread t1 e t2 terminino. Supponendo che il thread t1 abbia il processore per primo, lo cede ora al thread t2. Ciò avrà come effetto che il thread t2 leggerà esattamente la stessa cosa del thread t1, lo stesso cliente con lo stesso timestamp;
- riga 19: il contesto è sincronizzato con il database. Supponiamo nuovamente che il thread t1 si riattivi per primo. Salverà il cliente con il nome "yy". Potrà farlo perché ha lo stesso timestamp presente nel database. A causa di questo aggiornamento, il SGBD modificherà il timestamp. Quando il thread t2 si riattiverà a sua volta, avrà un cliente con un timestamp diverso da quello attualmente presente nel database. Il suo aggiornamento verrà rifiutato.
Le schermate sono le seguenti:
- riga 4: il client presente nel database;
- riga 9: il cliente così come viene letto dal thread t2;
- riga 11: il cliente così come viene letto dal thread t1. I due thread hanno quindi letto la stessa cosa;
- riga 12: il thread t2 termina per primo. È quindi riuscito a effettuare l’aggiornamento. Il nome deve essere cambiato in "zz";
- riga 13: il thread t1 genera un'eccezione di tipo [System.Data.OptimisticConcurrencyException]. EF ha rilevato di non avere il timestamp corretto;
- riga 21: a sua volta, il thread t1 termina;
- riga 22: il thread principale ha terminato l'attesa;
- riga 24: il thread principale visualizza il cliente nel database. È proprio il thread t2 ad aver vinto. Il nome è "zz". Si noti che il timestamp è cambiato.
Ora esaminiamo un altro aspetto: la transazione che gestisce la sincronizzazione del contesto di persistenza con il database.
3.5.9. Sincronizzazione all’interno di una transazione
La tabella [CRENEAUX] presenta un vincolo di unicità che abbiamo aggiunto manualmente (cfr. paragrafo 2.2.4, pagina 12):
Procederemo nel modo seguente: aggiungeremo contemporaneamente due appuntamenti per lo stesso medico, lo stesso giorno e la stessa fascia oraria. Vedremo cosa succede.
Il progetto si evolve come segue:
 |  |
Il codice del programma [SynchronisationTransaction] è il seguente:
using System;
using System.Linq;
using RdvMedecins.Entites;
using RdvMedecins.Models;
namespace RdvMedecins_01
{
// programma di test
class SynchronisationTransaction
{
static void Main(string[] args)
{
using (var context = new RdvMedecinsContext())
{
// si svuota il database corrente
foreach (var client in context.Clients)
{
context.Clients.Remove(client);
}
foreach (var medecin in context.Medecins)
{
context.Medecins.Remove(medecin);
}
context.SaveChanges();
}
// si crea un cliente
Client client1 = new Client { Nom = "xx", Prenom = "xx", Titre = "xx" };
// si crea un medico
Medecin medecin1 = new Medecin { Nom = "xx", Prenom = "xx", Titre = "xx" };
// si crea una fascia oraria per questo medico
Creneau creneau1 = new Creneau { Hdebut = 8, Mdebut = 20, Hfin = 8, Mfin = 40, Medecin = medecin1 };
// si creano due appuntamenti per questo medico e questo cliente, stesso giorno, stessa fascia oraria
Rv rv1 = new Rv { Client = client1, Creneau = creneau1, Jour = new DateTime(2012, 10, 18) };
Rv rv2 = new Rv { Client = client1, Creneau = creneau1, Jour = new DateTime(2012, 10, 18) };
try
{
// si inserisce tutto questo gruppo nel contesto di persistenza
using (var context = new RdvMedecinsContext())
{
context.Clients.Add(client1);
context.Creneaux.Add(creneau1);
context.Medecins.Add(medecin1);
context.Rvs.Add(rv1);
context.Rvs.Add(rv2);
// si salva il contesto - dovrebbe verificarsi un'eccezione
// poiché il BD sottostante ha un vincolo di unicità che impedisce
// di avere due RDV nello stesso giorno e nella stessa fascia oraria
context.SaveChanges();
}
}
catch (Exception e)
{
Console.WriteLine("Erreur : {0}", e);
}
// se il salvataggio avviene all'interno di una transazione, allora non deve essere stato inserito nulla nel database
// a causa dell'eccezione precedente - si verifica
using (var context = new RdvMedecinsContext())
{
// i clienti
Console.WriteLine("Clients--------------------------------------");
var clients = from client in context.Clients select client;
foreach (Client client in clients)
{
Console.WriteLine(client);
}
// i medici
Console.WriteLine("Médecins--------------------------------------");
var medecins = from medecin in context.Medecins select medecin;
foreach (Medecin medecin in medecins)
{
Console.WriteLine(medecin);
}
// le fasce orarie
Console.WriteLine("Créneaux horaires--------------------------------------");
var creneaux = from creneau in context.Creneaux select creneau;
foreach (Creneau creneau in creneaux)
{
Console.WriteLine(creneau);
}
// gli appuntamenti
Console.WriteLine("Rendez-vous--------------------------------------");
var rvs = from rv in context.Rvs select rv;
foreach (Rv rv in rvs)
{
Console.WriteLine(rv);
}
}
}
}
}
- righe 15-27: si utilizza un contesto di persistenza per svuotare il database;
- riga 30: creazione di un oggetto [Client];
- riga 32: creazione di un oggetto [Medecin];
- riga 34: creazione di un oggetto [Creneau];
- riga 36: creazione di un oggetto [Rv];
- riga 37: creazione di un secondo oggetto [Rv] identico al precedente;
- riga 41: apertura di un nuovo contesto;
- righe 43-47: gli oggetti creati in precedenza vengono associati al nuovo contesto. Si noti che, tenendo conto delle dipendenze, avremmo potuto ridurre al minimo il numero di operazioni Add. Ma EF ottimizzerà gli ordini SQL e INSERT da inviare al database;
- riga 51: il contesto è sincronizzato con il database. Come indicato dal commento, l'inserimento di uno dei due appuntamenti deve fallire a causa del vincolo di unicità sulla tabella [RVS]. Ma oltre a ciò, se la sincronizzazione avviene all'interno di una transazione, tutto deve essere annullato. Pertanto, non deve avvenire alcun inserimento. Il database deve rimanere vuoto;
- riga 53: il contesto viene chiuso;
- righe 61-90: visualizzazione del contenuto del database. Deve essere vuoto.
La visualizzazione sullo schermo è la seguente:
- riga 1: eccezione dovuta alla violazione del vincolo di unicità sulla tabella [RVS];
- righe 9-12: il database è effettivamente vuoto. La sincronizzazione del contesto con il database è quindi avvenuta all'interno di una transazione.
Ci sarebbero senza dubbio altri aspetti da approfondire in EF 5. Ma sappiamo già abbastanza per tornare al nostro studio su un'architettura multistrato. All'inizio di questo documento il lettore troverà riferimenti ad articoli e libri che gli consentiranno di approfondire la propria conoscenza di EF 5.
3.6. Studio di un’architettura multilivello basata su EF 5
Torniamo al nostro caso di studio descritto al paragrafo 2. Si tratta di un’applicazione web ASP.NET strutturata come segue:
 |
Inizieremo con la realizzazione del livello [DAO] di accesso ai dati. Questo livello si baserà su EF5.
3.6.1. Il nuovo progetto
Creiamo un nuovo progetto console VS 2012 [RdvMedecins-SqlServer-02] nella soluzione corrente [1]:
 |
Aggiungiamo quattro cartelle [2] in cui distribuiremo i nostri codici. La cartella [Entites] è una copia della cartella [Entites] del progetto precedente. Dopo questa copia, compaiono degli errori dovuti al fatto che non disponiamo dei riferimenti corretti. Dobbiamo aggiungere un riferimento a Entity Framework 5. A tal fine, seguiremo il metodo spiegato al paragrafo 3.4, pagina 21. L’elenco dei riferimenti diventa il seguente: [3]:
 |
A questo punto, il progetto non dovrebbe più presentare errori di compilazione. Dal progetto precedente, copiamo anche il file [App.config] che configura la connessione al database:
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<configSections>
<!-- Per ulteriori informazioni sulla configurazione di Entity Framework, visitare http://go.microsoft.com/fwlink/?LinkID=237468 -->
<section name="entityFramework" type="System.Data.Entity.Internal.ConfigFile.EntityFrameworkSection, EntityFramework, Version=5.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" requirePermission="false" />
</configSections>
<startup>
<supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.5" />
</startup>
<entityFramework>
<defaultConnectionFactory type="System.Data.Entity.Infrastructure.SqlConnectionFactory, EntityFramework" />
</entityFramework>
<!-- stringa di connessione al database -->
<connectionStrings>
<add name="monContexte"
connectionString="Data Source=localhost;Initial Catalog=rdvmedecins-ef;User Id=sa;Password=sqlserver2012;"
providerName="System.Data.SqlClient" />
</connectionStrings>
<!-- il provider di factory -->
<system.data>
<DbProviderFactories>
<add name="SqlClient Data Provider"
invariant="System.Data.SqlClient"
description=".Net Framework Data Provider for SqlServer"
type="System.Data.SqlClient.SqlClientFactory, System.Data,
Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089"
/>
</DbProviderFactories>
</system.data>
</configuration>
3.6.2. La classe Exception
Utilizzeremo una classe di eccezione specifica del progetto. È quella che verrà generata dal livello [DAO]:
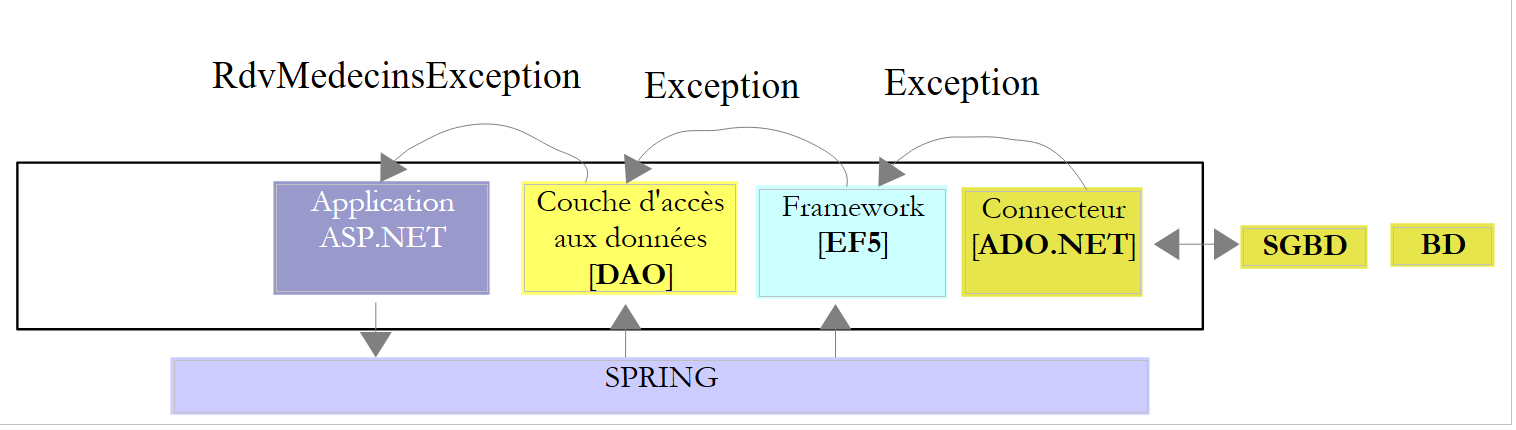 |
Il livello [DAO] interromperà tutte le eccezioni che gli verranno segnalate e le incapsulerà in un'eccezione di tipo [RdvMedecinsException]. Tale eccezione sarà la seguente:
using System;
namespace RdvMedecins.Exceptions
{
public class RdvMedecinsException : Exception
{
// proprietà
public int Code { get; set; }
// costruttori
public RdvMedecinsException()
: base()
{
}
public RdvMedecinsException(string message)
: base(message)
{
}
public RdvMedecinsException(int code, string message)
: base(message)
{
Code = code;
}
public RdvMedecinsException(int code, string message, Exception ex)
: base(message, ex)
{
Code = code;
}
// identità
public override string ToString()
{
if (InnerException == null)
{
return string.Format("RdvMedecinsException[{0},{1}]", Code, base.Message);
}
else
{
return string.Format("RdvMedecinsException[{0},{1},{2}]", Code, base.Message, base.InnerException.Message);
}
}
}
}
- riga 5: la classe deriva dalla classe [Exception];
- riga 9: aggiunge un codice di errore alla propria classe base;
- righe 12-32: i vari costruttori integrano la presenza del campo [Code].
Il progetto si evolve come segue:
 |
3.6.3. Il livello [DAO]
 |
Il livello [DAO] offre un'interfaccia al livello [ASP.NET]. Per identificarlo, occorre consultare le pagine web dell'applicazione:
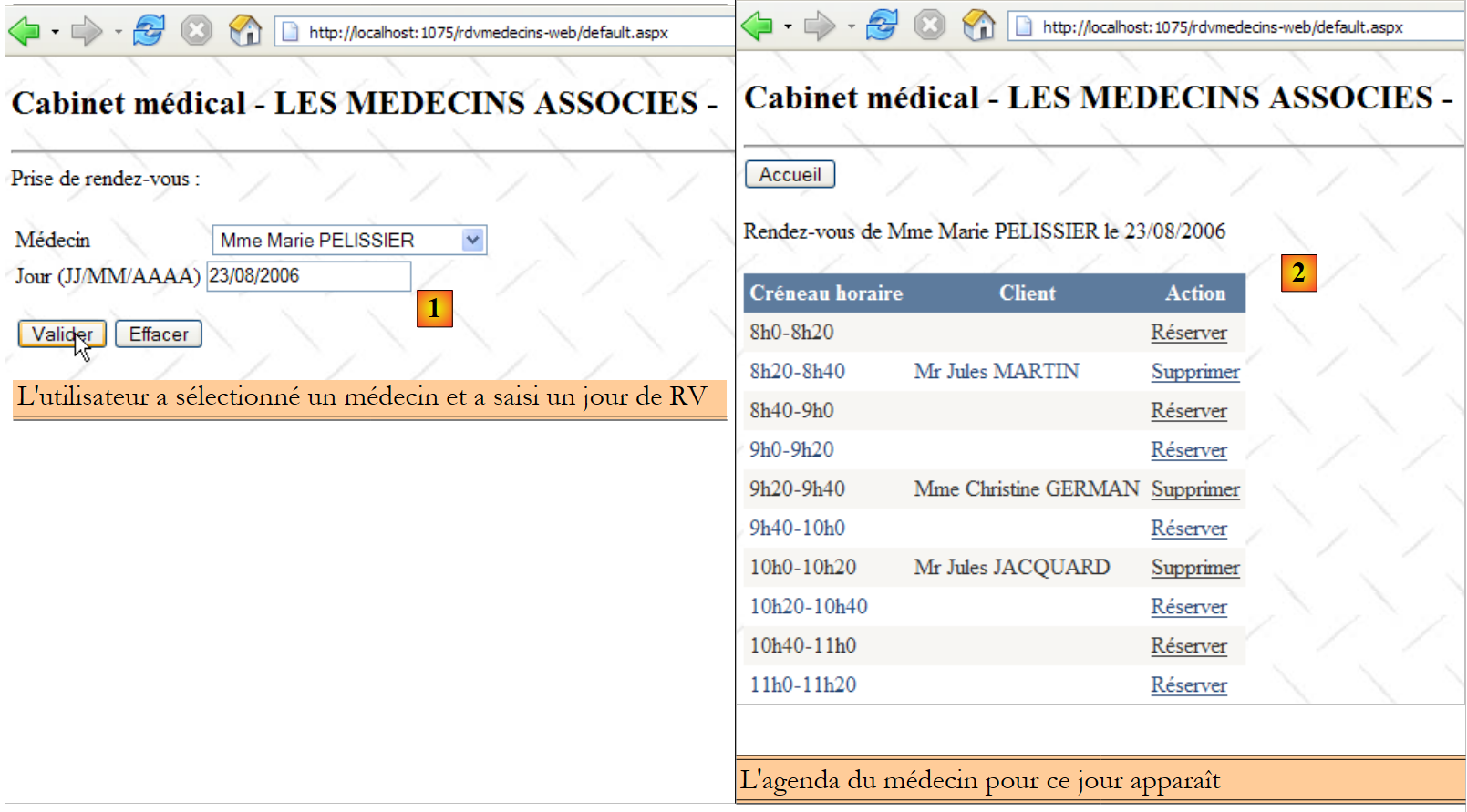 |
- nel [1] sopra riportato, l'elenco a discesa è stato popolato con l'elenco dei medici. Il livello [DAO] fornirà tale elenco;
- in [2], il livello [DAO] fornirà;
- l'elenco degli appuntamenti di un medico per quel giorno,
- l'elenco delle fasce orarie di un medico,
- informazioni aggiuntive sul medico selezionato;
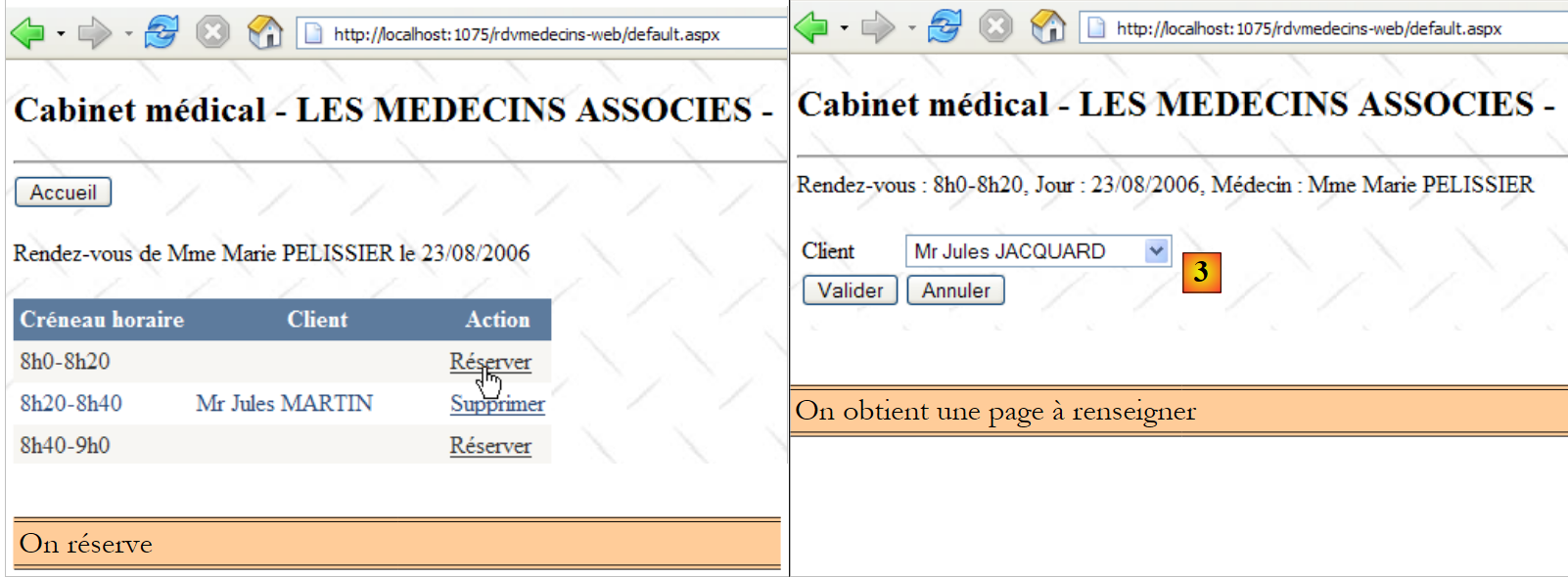 |
- in [3], l'elenco a discesa dei clienti sarà fornito dal livello [DAO];
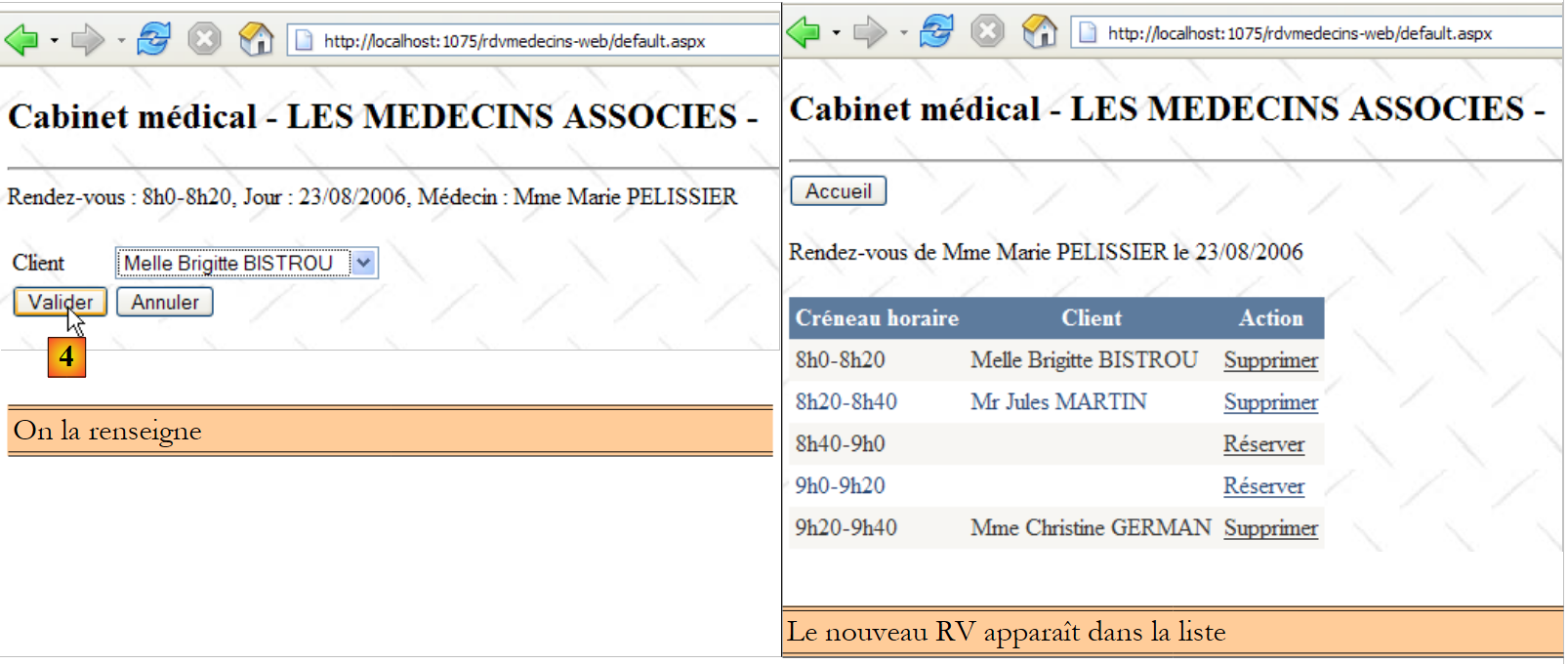 |
- in [4], l'utente conferma un appuntamento. Il livello [DAO] deve essere in grado di aggiungerlo al database. Deve inoltre essere in grado di fornire informazioni aggiuntive sul cliente selezionato;
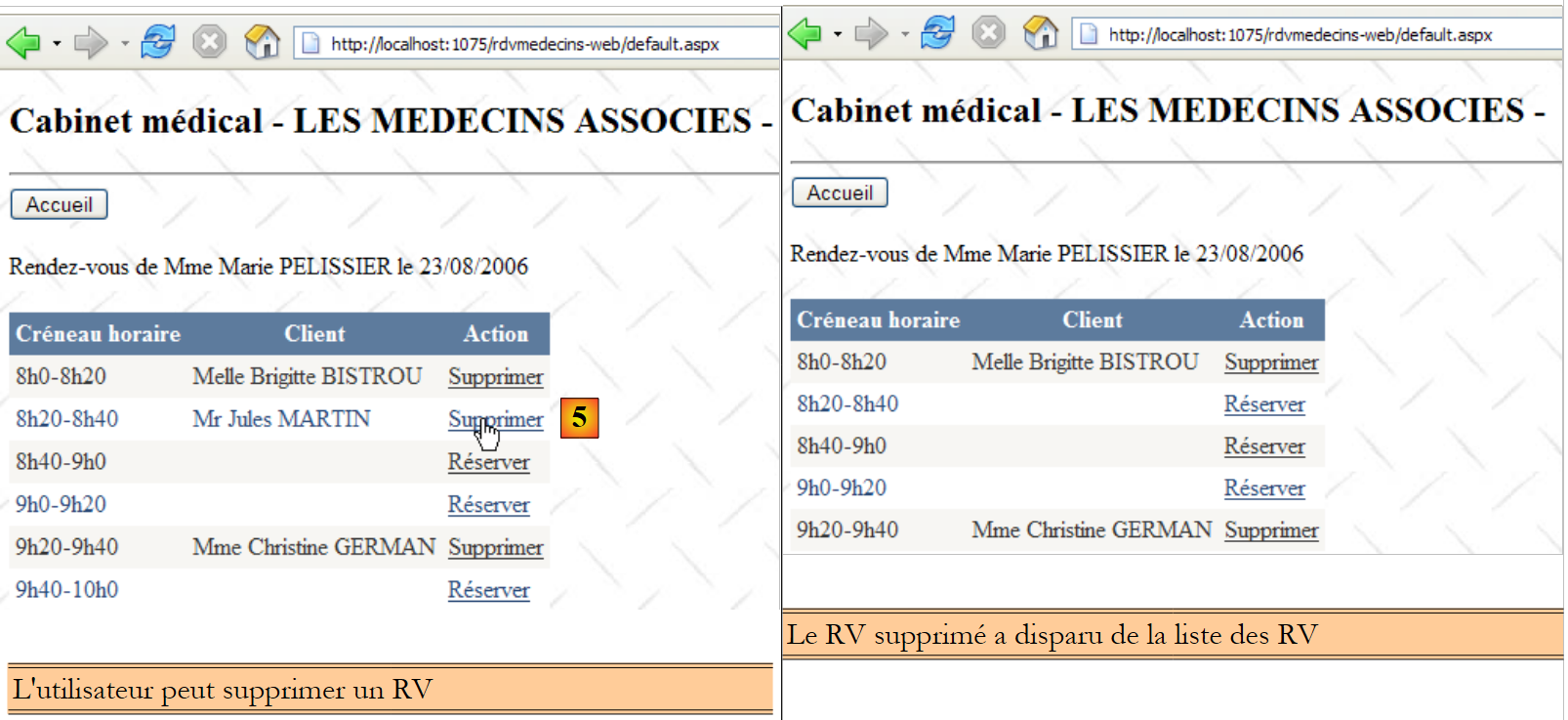 |
- in [5], l'utente elimina un appuntamento. Il livello [DAO] deve consentire questa operazione.
Con queste informazioni, l’interfaccia [IDao] del livello [DAO] potrebbe essere la seguente:
using System;
using System.Collections.Generic;
using RdvMedecins.Entites;
namespace RdvMedecins.Dao
{
public interface IDao
{
// elenco dei clienti
List<Client> GetAllClients();
// elenco dei medici
List<Medecin> GetAllMedecins();
// elenco delle fasce orarie di un medico
List<Creneau> GetCreneauxMedecin(int idMedecin);
// elenco dei RV di un determinato medico, in un determinato giorno
List<Rv> GetRvMedecinJour(int idMedecin, DateTime jour);
// aggiungere un RV
int AjouterRv(DateTime jour, int idCreneau, int idClient);
// eliminare un RV
void SupprimerRv(int idRv);
// ricerca di un'entità T tramite la sua chiave primaria
T Find<T>(int id) where T : class;
}
}
I metodi delle righe 10-20 derivano dall’analisi appena effettuata. Il metodo della riga 22 serve a ovviare al fatto che si lavora con il Lazy Loading. Se nel livello [ASP.NET] è necessaria una dipendenza da un’entità, la si recupererà dal database utilizzando questo metodo.
L'implementazione [Dao] di questa interfaccia sarà la seguente:
using System;
using System.Collections.Generic;
using System.Linq;
using RdvMedecins.Entites;
using RdvMedecins.Exceptions;
using RdvMedecins.Models;
namespace RdvMedecins.Dao
{
public class Dao : IDao
{
//elenco dei clienti
public List<Client> GetAllClients()
{
// elenco dei clienti
List<Client> clients = null;
try
{
// apertura del contesto di persistenza
using (var context = new RdvMedecinsContext())
{
// elenco dei clienti
clients = context.Clients.ToList();
}
}
catch (Exception ex)
{
throw new RdvMedecinsException(1, "GetAllClients", ex);
}
// restituzione del risultato
return clients;
}
// elenco dei medici
public List<Medecin> GetAllMedecins()
{
// elenco dei medici
List<Medecin> medecins = null;
try
{
// apertura contesto di persistenza
using (var context = new RdvMedecinsContext())
{
// elenco dei medici
medecins = context.Medecins.ToList();
}
}
catch (Exception ex)
{
throw new RdvMedecinsException(2, "GetAllMedecins", ex);
}
// si restituisce il risultato
return medecins;
}
// elenco delle fasce orarie di un determinato medico
public List<Creneau> GetCreneauxMedecin(int idMedecin)
{
...
}
// elenco dei RV di un medico per un determinato giorno
public List<Rv> GetRvMedecinJour(int idMedecin, DateTime jour)
{
...
}
// aggiungere un RV
public int AjouterRv(DateTime jour, int idCreneau, int idClient)
{
...
}
// eliminare un RV
public void SupprimerRv(int idRv)
{
...
}
// trovare un cliente
public Client FindClient(int id)
{
...
}
// trovare una fascia oraria
public Creneau FindCreneau(int id)
{
...
}
// trovare un medico
public Medecin FindMedecin(int id)
{
....
}
// trovare un appuntamento
public Rv FindRv(int id){
...
}
}
}
Spieghiamo il metodo [GetAllClients] che deve restituire l’elenco di tutti i clienti:
- righe 18-31: la ricerca dei clienti avviene all’interno di un try/catch. Lo stesso vale per tutti i metodi successivi;
- riga 21: apertura di un nuovo contesto;
- riga 24: le entità [Client] vengono caricate nel contesto e inserite in un elenco.
Il metodo [GetAllMedecins], che deve restituire l'elenco di tutti i medici, è analogo (righe 37-57).
Il metodo [GetCreneauxMedecin] è il seguente:
// elenco delle fasce orarie disponibili per un determinato medico
public List<Creneau> GetCreneauxMedecin(int idMedecin)
{
// elenco delle fasce orarie
try
{
// apertura del contesto di persistenza
using (var context = new RdvMedecinsContext())
{
// si recupera il medico con i relativi orari
Medecin medecin = context.Medecins.Include("Creneaux").Single(m => m.Id == idMedecin);
// elenco delle fasce orarie del medico
return medecin.Creneaux.ToList<Creneau>();
}
}
catch (Exception ex)
{
throw new RdvMedecinsException(3, "GetCreneauxMedecin", ex);
}
}
- riga 9: apertura di un nuovo contesto di persistenza;
- riga 11: si cerca il medico di cui si possiede la chiave primaria. Si richiede di includere la dipendenza [Creneaux], che è una raccolta delle fasce orarie del medico. Se il medico non esiste, il metodo Single genera un'eccezione;
- riga 13: si restituisce l'elenco delle fasce orarie.
Il metodo [GetRvMedecinJour] deve restituire l’elenco degli appuntamenti di un medico per un determinato giorno. Il suo codice potrebbe essere il seguente:
// elenco dei RV di un medico per un determinato giorno
public List<Rv> GetRvMedecinJour(int idMedecin, DateTime jour)
{
// elenco degli appuntamenti
List<Rv> rvs = null;
try
{
// apertura del contesto di persistenza
using (var context = new RdvMedecinsContext())
{
// si recupera il medico
Medecin medecin = context.Medecins.Find(idMedecin);
if (medecin == null)
{
throw new RdvMedecinsException(10, string.Format("Médecin [{0}] inexistant", idMedecin));
}
// elenco degli appuntamenti
rvs = context.Rvs.Where(r => r.Creneau.Medecin.Id == idMedecin && r.Jour == jour).ToList();
}
}
catch (Exception ex)
{
throw new RdvMedecinsException(4, "GetRvMedecinJour", ex);
}
// restituzione del risultato
return rvs;
}
- riga 13: si inserisce nel contesto il medico di cui si possiede la chiave primaria;
- righe 14-17: se non esiste, si genera un'eccezione;
- riga 19: si esegue la query LINQ per recuperare gli appuntamenti relativi a quel medico;
Il metodo [AjouterRv] deve aggiungere un appuntamento nel database e restituire la chiave primaria dell’elemento inserito. Il suo codice potrebbe essere il seguente:
// aggiungere un RV
public int AjouterRv(DateTime jour, int idCreneau, int idClient)
{
// numero dell'appuntamento aggiunto
int idRv;
try
{
// apertura del contesto di persistenza
using (var context = new RdvMedecinsContext())
{
// si recupera la fascia oraria
Creneau creneau = context.Creneaux.Find(idCreneau);
if (creneau == null)
{
throw new RdvMedecinsException(5, string.Format("Créneau [{0}] inexistant", idCreneau));
}
// si recupera il cliente
Client client = context.Clients.Find(idClient);
if (client == null)
{
throw new RdvMedecinsException(6, string.Format("Client [{0}] inexistant", idCreneau));
}
// creazione della fascia oraria
Rv rv = new Rv { Jour = jour, Client = client, Creneau = creneau };
// aggiunta nel contesto
context.Rvs.Add(rv);
// salvataggio del contesto
context.SaveChanges();
// si recupera la chiave primaria dell'appuntamento aggiunto
idRv = (int)rv.Id;
}
}
catch (Exception ex)
{
throw new RdvMedecinsException(7, "AjouterRv", ex);
}
// risultato
return idRv;
}
- riga 12: si cerca la fascia oraria dell'appuntamento nel database;
- righe 13-16: se non lo si trova, si genera un'eccezione;
- riga 18: si cerca il cliente dell'appuntamento nel database;
- righe 19-22: se non lo si trova, si genera un'eccezione;
- riga 24: si crea un oggetto [Rv] con le informazioni necessarie;
- riga 26: lo si aggiunge al contesto di persistenza;
- riga 28: si sincronizza il contesto di persistenza con il database. L'appuntamento verrà quindi inserito nel database;
- riga 30: sappiamo che, dopo la sincronizzazione del database, le chiavi primarie degli elementi inseriti sono disponibili. Recuperiamo quella dell'appuntamento aggiunto;
- riga 31: si chiude il contesto di persistenza.
Il metodo [SupprimerRv] deve eliminare un appuntamento di cui gli viene passata la chiave primaria.
// eliminazione di un RV
public void SupprimerRv(int idRv)
{
try
{
// apertura del contesto di persistenza
using (var context = new RdvMedecinsContext())
{
// si recupera l'Rv
Rv rv = context.Rvs.Find(idRv);
if (rv == null)
{
throw new RdvMedecinsException(5, string.Format("Rv [{0}] inexistant", idRv));
}
// eliminazione di Rv
context.Rvs.Remove(rv);
// salvataggio del contesto
context.SaveChanges();
}
}
catch (Exception ex)
{
throw new RdvMedecinsException(8, "SupprimerRv", ex);
}
}
- riga 7: nuovo contesto di persistenza;
- riga 10: si inserisce nel contesto l'appuntamento da eliminare;
- righe 11-15: se non esiste, viene generata un'eccezione;
- riga 16: lo si elimina dal contesto;
- riga 18: si sincronizza il contesto con il database;
- riga 19: si chiude il contesto.
Il metodo [Find<T>] consente di cercare nel database un'entità di tipo T tramite la sua chiave primaria. Il codice potrebbe essere il seguente:
public T Find<T>(int id) where T : class
{
try
{
// apertura del contesto di persistenza
using (var context = new RdvMedecinsContext())
{
return context.Set<T>().Find(id);
}
}
catch (Exception ex)
{
throw new RdvMedecinsException(20, "Find<T>", ex);
}
}
- riga 8: il metodo Set<T> consente di recuperare un DbSet<T> su cui è possibile applicare i metodi usuali.
Il progetto si evolve come segue:
 |
3.6.4. Test del livello [DAO]
Creeremo un programma di test del livello [DAO]. L’architettura del test sarà la seguente:
 |
Un programma da console richiede a [Spring.net] di istanziare il livello [DAO]. Una volta fatto ciò, verifica le diverse funzionalità dell'interfaccia del livello [DAO]. Anziché un programma da console, sarebbe stato preferibile scrivere un programma di test del tipo NUnit. Un programma di test del livello [DAO] potrebbe essere il seguente:
using System;
using System.Collections.Generic;
using RdvMedecins.Dao;
using RdvMedecins.Entites;
using RdvMedecins.Exceptions;
using Spring.Context.Support;
namespace RdvMedecins.Tests
{
class Program
{
public static void Main()
{
IDao dao = null;
try
{
// istanziazione del livello [DAO] tramite Spring
dao = ContextRegistry.GetContext().GetObject("rdvmedecinsDao") as IDao;
// visualizzazione clienti
List<Client> clients = dao.GetAllClients();
DisplayClients("Liste des clients :", clients);
// visualizzazione dei medici
List<Medecin> medecins = dao.GetAllMedecins();
DisplayMedecins("Liste des médecins :", medecins);
// elenco delle fasce orarie del medico n. 0
List<Creneau> creneaux = dao.GetCreneauxMedecin((int)medecins[0].Id);
DisplayCreneaux(string.Format("Liste des créneaux horaires du médecin {0}", medecins[0]), creneaux);
// elenco degli appuntamenti di un medico per un determinato giorno
DisplayRvs(string.Format("Liste des RV du médecin {0}, le 23/11/2013 :", medecins[0]), dao.GetRvMedecinJour((int)medecins[0].Id, new DateTime(2013, 11, 23)));
// aggiungere un RV al medico n. 1 nella fascia oraria n. 0
Console.WriteLine(string.Format("Ajout d'un RV au médecin {0} avec client {1} le 23/11/2013", medecins[0], clients[0]));
int idRv1 = dao.AjouterRv(new DateTime(2013, 11, 23), (int)creneaux[0].Id, (int)clients[0].Id);
Console.WriteLine("Rdv ajouté");
DisplayRvs(string.Format("Liste des RV du médecin {0}, le 23/11/2013 :", medecins[0]), dao.GetRvMedecinJour((int)medecins[0].Id, new DateTime(2013, 11, 23)));
// aggiungere un appuntamento in una fascia oraria già occupata - deve generare un'eccezione
int idRv2;
Console.WriteLine("Ajout d'un RV dans un créneau déjà occupé");
try
{
idRv2 = dao.AjouterRv(new DateTime(2013, 11, 23), (int)creneaux[0].Id, (int)clients[0].Id);
Console.WriteLine("Rdv ajouté");
DisplayRvs(string.Format("Liste des RV du médecin {0}, le 23/11/2013 :", medecins[0]), dao.GetRvMedecinJour((int)medecins[0].Id, new DateTime(2013, 11, 23)));
}
catch (RdvMedecinsException ex)
{
Console.WriteLine(string.Format("L'erreur suivante s'est produite : {0}", ex));
}
// eliminare un appuntamento
Console.WriteLine(string.Format("Suppression du RV n° {0}", idRv1));
dao.SupprimerRv(idRv1);
DisplayRvs(string.Format("Liste des RV du médecin {0}, le 23/11/2013 :", medecins[0]), dao.GetRvMedecinJour((int)medecins[0].Id, new DateTime(2013, 11, 23)));
}
catch (Exception ex)
{
Console.WriteLine(string.Format("L'erreur suivante s'est produite : {0}", ex));
}
//pausa
Console.ReadLine();
}
// metodi di utilità - visualizza elenchi
public static void DisplayClients(string Message, List<Client> clients)
{
Console.WriteLine(Message);
foreach (Client c in clients)
{
Console.WriteLine(c.ShortIdentity());
}
}
public static void DisplayMedecins(string Message, List<Medecin> medecins)
{
...
}
public static void DisplayCreneaux(string Message, List<Creneau> creneaux)
{
...
}
public static void DisplayRvs(string Message, List<Rv> rvs)
{
...
}
}
}
- riga 14: il riferimento al livello [DAO]. Per rendere il test indipendente dall’effettiva implementazione di quest’ultimo, tale riferimento è del tipo dell’interfaccia [IDao] e non del tipo della classe [Dao];
- riga 18: il livello [DAO] viene istanziato da Spring. Torneremo sulla configurazione necessaria affinché ciò sia possibile. Effettuiamo il cast del riferimento all’oggetto restituito da Spring in un riferimento del tipo dell’interfaccia [IDao];
- righe 21-22: visualizzano i clienti;
- righe 25-26: visualizzano i medici;
- righe 29-30: visualizzano l'elenco delle fasce orarie del medico n. 0;
- riga 33: visualizza gli appuntamenti del medico n. 0 alla data del 23/11/2013. Non dovrebbero essercene;
- riga 37: aggiunge un appuntamento al medico n. 0 per il 23/11/2013;
- riga 39: visualizza gli appuntamenti del medico n. 0 alla data del 23/11/2013. Dovrebbe essercene uno;
- riga 46: si aggiunge una seconda volta lo stesso appuntamento. Deve verificarsi un'eccezione;
- riga 57: si elimina l'unico appuntamento aggiunto;
- riga 58: visualizza gli appuntamenti del medico n. 0 alla data del 23/11/2013. Non deve essercene nessuno.
3.6.5. Configurazione di Spring.net
Nel programma di test sopra riportato, abbiamo tralasciato rapidamente l’istruzione che istanzia il livello [DAO]:
dao = ContextRegistry.GetContext().GetObject("rdvmedecinsDao") as IDao;
La classe [ContextRegistry] è una classe di Spring nello spazio dei nomi [Spring.Context.Support]. Per poter utilizzare Spring, dobbiamo aggiungere il suo DLL nei riferimenti del progetto. Procediamo come segue:
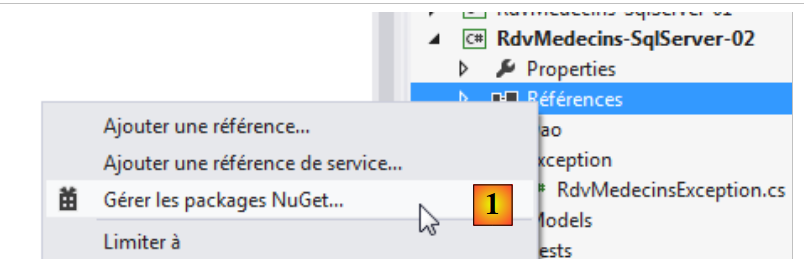 |
- in [1], si cercano i pacchetti con lo strumento [NuGet];
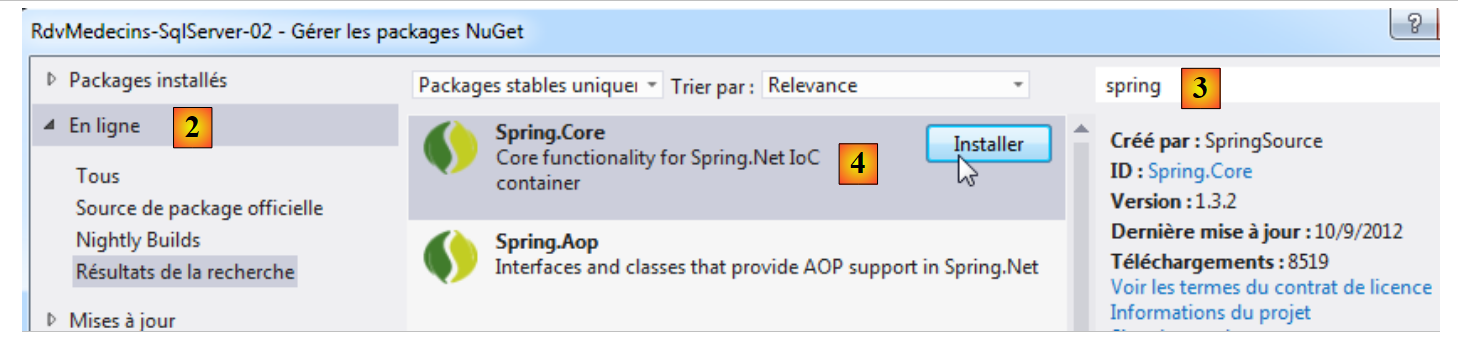 |
- in [2], si cercano i pacchetti online;
- in [3], si inserisce la parola chiave spring nella casella di ricerca;
- in [4], vengono visualizzati i pacchetti la cui descrizione contiene questa parola chiave. In questo caso, quello che fa al caso nostro è [Spring.Core]. Lo installiamo.
I riferimenti del progetto si modificano come segue:
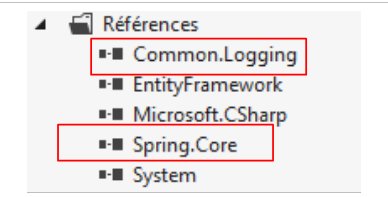 |
Il pacchetto [Spring.Core] dipendeva dal pacchetto [Common.Logging]. Anche quest'ultimo è stato caricato. A questo punto, il progetto non dovrebbe più presentare errori.
Ciò non significa però che funzionerà. Dobbiamo prima configurare Spring nel file [App.config]. Questa è la parte più delicata del progetto. Il nuovo file [App.config] è il seguente:
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<configSections>
<!-- Per ulteriori informazioni sulla configurazione di Entity Framework, visitare http://go.microsoft.com/fwlink/?LinkID=237468 -->
<section name="entityFramework" type="System.Data.Entity.Internal.ConfigFile.EntityFrameworkSection, EntityFramework, Version=5.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" requirePermission="false" />
<!-- spring -->
<sectionGroup name="spring">
<section name="context" type="Spring.Context.Support.ContextHandler, Spring.Core" />
<section name="objects" type="Spring.Context.Support.DefaultSectionHandler, Spring.Core" />
</sectionGroup>
<!-- registrazione comune-->
<section name="logging" type="Common.Logging.ConfigurationSectionHandler, Common.Logging" />
</configSections>
<startup>
<supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.5" />
</startup>
<!-- Entity Framework -->
<entityFramework>
<defaultConnectionFactory type="System.Data.Entity.Infrastructure.LocalDbConnectionFactory, EntityFramework">
<parameters>
<parameter value="v11.0" />
</parameters>
</defaultConnectionFactory>
</entityFramework>
<!-- Stringhe di connessione -->
<connectionStrings>
<add name="monContexte" connectionString="Data Source=localhost;Initial Catalog=rdvmedecins-ef;User Id=sa;Password=sqlserver2012;" providerName="System.Data.SqlClient" />
</connectionStrings>
<system.data>
<DbProviderFactories>
<add name="SqlClient Data Provider" invariant="System.Data.SqlClient" description=".Net Framework Data Provider for SqlServer" type="System.Data.SqlClient.SqlClientFactory, System.Data, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" />
</DbProviderFactories>
</system.data>
<!-- configurazione Spring -->
<spring>
<context>
<resource uri="config://spring/objects" />
</context>
<objects xmlns="http://www.springframework.net">
<object id="rdvmedecinsDao" type="RdvMedecins.Dao.Dao,RdvMedecins-SqlServer-02" />
</objects>
</spring>
<!-- configurazione common.logging -->
<logging>
<factoryAdapter type="Common.Logging.Simple.ConsoleOutLoggerFactoryAdapter, Common.Logging">
<arg key="showLogName" value="true" />
<arg key="showDataTime" value="true" />
<arg key="level" value="DEBUG" />
<arg key="dateTimeFormat" value="yyyy/MM/dd HH:mm:ss:fff" />
</factoryAdapter>
</logging>
</configuration>
Cominciamo rimuovendo tutto ciò che è già noto: Entity Framework, stringhe di connessione, ProviderFactory. Il file si evolve come segue:
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<configSections>
<!-- Per ulteriori informazioni sulla configurazione di Entity Framework, visitare http://go.microsoft.com/fwlink/?LinkID=237468 -->
<section name="entityFramework" ... />
<!-- spring -->
<sectionGroup name="spring">
<section name="context" type="Spring.Context.Support.ContextHandler, Spring.Core" />
<section name="objects" type="Spring.Context.Support.DefaultSectionHandler, Spring.Core" />
</sectionGroup>
<!-- registrazione comune-->
<sectionGroup name="common">
<section name="logging" type="Common.Logging.ConfigurationSectionHandler, Common.Logging" />
</sectionGroup>
</configSections>
...
<!-- configurazione Spring -->
<spring>
<context>
<resource uri="config://spring/objects" />
</context>
<objects xmlns="http://www.springframework.net">
<object id="rdvmedecinsDao" type="RdvMedecins.Dao.Dao,RdvMedecins-SqlServer-02" />
</objects>
</spring>
<!-- configurazione common.logging -->
<common>
<logging>
<factoryAdapter type="Common.Logging.Simple.ConsoleOutLoggerFactoryAdapter, Common.Logging">
<arg key="showLogName" value="true" />
<arg key="showDataTime" value="true" />
<arg key="level" value="DEBUG" />
<arg key="dateTimeFormat" value="yyyy/MM/dd HH:mm:ss:fff" />
</factoryAdapter>
</logging>
</common>
</configuration>
- righe 3-15: definiscono le sezioni di configurazione;
- riga 8: definisce la classe che gestirà la sezione <spring><context> del file XML (righe 19-21);
- riga 9: definisce la classe che gestirà la sezione <spring><objects> del file XML (righe 22-24);
- riga 13: definisce la classe che gestirà la sezione <common><logging> del file XML (righe 27-36);
- righe 7-14: sono fisse. Non devono essere modificate in un altro progetto;
- righe 18-25: configurazione Spring. È stabile tranne che per le righe 22-24 che definiscono gli oggetti che Spring dovrà istanziare;
- riga 23: definizione di un oggetto. L’attributo id è libero. È l’identificatore dell’oggetto. L’attributo type indica la classe da istanziare nella forma «nome completo della classe, Assembly che contiene la classe». La classe in questo caso è quella che implementa il livello [DAO]: [RdvMedecins.Dao.Dao]. Per conoscere il relativo assembly, occorre consultare le proprietà del progetto:
 |
In [1], il nome dell’assembly da specificare;
- righe 27-36: la configurazione di "Common Logging" è stabile. Potrebbe essere necessario modificare il livello di log, riga 32. Dopo la fase di debug, è possibile impostare il livello su INFO.
In definitiva, sebbene a prima vista possa sembrare complesso, il file di configurazione di Spring risulta semplice. È necessario modificare solo:
- le righe 22-24 che definiscono gli oggetti da istanziare;
- la riga 32: il livello di log.
Nel programma di test, l’istruzione che istanzia il livello [DAO] è la seguente:
dao = ContextRegistry.GetContext().GetObject("rdvmedecinsDao") as IDao;
[ContextRegistry] è una classe di Spring che utilizza la configurazione di Spring definita in un file [Web.config] o [App.config]. In questo caso, utilizzerà la seguente sezione del file [App.config]:
<spring>
<context>
<resource uri="config://spring/objects" />
</context>
<objects xmlns="http://www.springframework.net">
<object id="rdvmedecinsDao" type="RdvMedecins.Dao.Dao,RdvMedecins-SqlServer-02" />
</objects>
</spring>
- ContextRegistry.GetContext() utilizza il contesto delle righe 2-4. La riga 3 indica che gli oggetti Spring sono definiti nella sezione [spring/objects] del file di configurazione. Tale sezione corrisponde alle righe 5-7;
- ContextRegistry.GetContext().GetObject("rdvmedecinsDao") utilizza la sezione delle righe 5-7. Restituisce un riferimento all’oggetto che ha l’attributo id= "rdvmedecinsDao". Si tratta dell’oggetto definito alla riga 6. Spring istanzierà quindi la classe definita dall’attributo type utilizzando il suo costruttore senza parametri. Quest’ultimo deve quindi esistere. Una volta fatto ciò, il riferimento all’oggetto creato viene restituito al codice chiamante. Se l’oggetto viene richiesto una seconda volta nel codice, Spring si limita a restituire un riferimento al primo oggetto creato. Si tratta del modello di progettazione (Design Pattern) denominato singleton.
La creazione dell’oggetto può essere più complessa. È possibile utilizzare un costruttore con parametri o specificare l’inizializzazione di alcuni campi dell’oggetto una volta creato. Per ulteriori informazioni su questo argomento, si può consultare l’articolo “Tutorial Spring IOC per .NET”, all’indirizzo URL [http://tahe.developpez.com/dotnet/springioc/].
Fatto ciò, possiamo eseguire l’applicazione. I risultati visualizzati sullo schermo sono i seguenti:
I risultati sono conformi a quanto previsto. Considereremo quindi valido il nostro livello [DAO]. Il tutorial potrebbe terminare qui. Finora abbiamo illustrato:
- le basi di ORM Entity Framework 5;
- un livello [DAO] che utilizza questo ORM.
Ricordiamo il nostro caso di studio descritto all’inizio di questo documento. Partiamo da un’applicazione esistente con la seguente architettura:
 |
che vogliamo trasformare in questa:
 |
dove EF5 ha sostituito NHibernate. Abbiamo appena realizzato il livello [DAO2]. In realtà, esso non presenta la stessa interfaccia del livello [DAO1], la cui interfaccia era più ridotta:
public interface IDao
{
// elenco dei clienti
List<Client> GetAllClients();
// elenco dei medici
List<Medecin> GetAllMedecins();
// elenco delle fasce orarie di un medico
List<Creneau> GetCreneauxMedecin(int idMedecin);
// elenco dei RV di un determinato medico, in un determinato giorno
List<Rv> GetRvMedecinJour(int idMedecin, DateTime jour);
// aggiungere un RV
int AjouterRv(DateTime jour, int idCreneau, int idClient);
// eliminare un RV
void SupprimerRv(int idRv);
}
Il livello [DAO2] ha aggiunto a questa interfaccia il metodo:
// trovare un'entità T tramite la sua chiave primaria
T Find<T>(int id) where T : class;
L’aggiunta di questo metodo deriva dal fatto che il livello ORM EF 5 funziona per impostazione predefinita in modalità Lazy Loading. Le entità arrivano nel livello [ASP.NET] senza le loro dipendenze. Il metodo sopra indicato ci permette di recuperarle se necessario, e in alcuni casi ne abbiamo effettivamente bisogno. Anche NHibernate funziona di default in modalità Lazy Loading, ma io lo avevo utilizzato in modalità Eager Loading. Le entità arrivavano nel livello [ASP.NET] con le loro dipendenze.
Concluderemo il porting dell’applicazione ASP.NET / NHibernate verso l’applicazione ASP.NET / EF 5. Tuttavia, poiché ciò non riguarda più EF5, non commenteremo il codice web. Spiegheremo semplicemente come configurare l’applicazione web e testarla. Quest’ultima è disponibile sul sito di questo tutorial.
3.6.6. Generazione di DLL dal livello [DAO]
Nella seguente architettura:
 |
il livello [ASP.NET] avrà a disposizione i livelli alla sua destra sotto forma di DLL. Costruiamo quindi il DLL del livello [DAO].
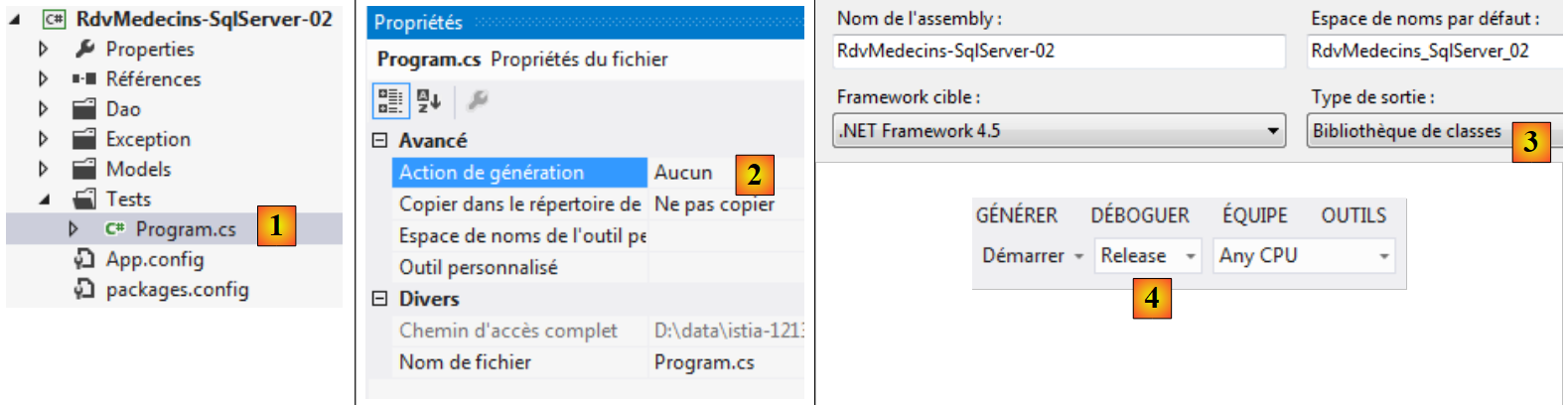 |
- in [1], si seleziona il programma di test, mentre in [2] non lo si include nel DLL che verrà generato;
- in [3], nelle proprietà del progetto, si indica che l’assembly da creare è un DLL;
- in [4], nel menu di VS, si specifica che verrà generato un assembly di tipo [Release] che contiene meno informazioni rispetto a un assembly di tipo [Debug];
 |
- in [5], si rigenera l'assembly del progetto. Verrà generato il file DLL;
- in [6], si visualizzano tutti i file del progetto;
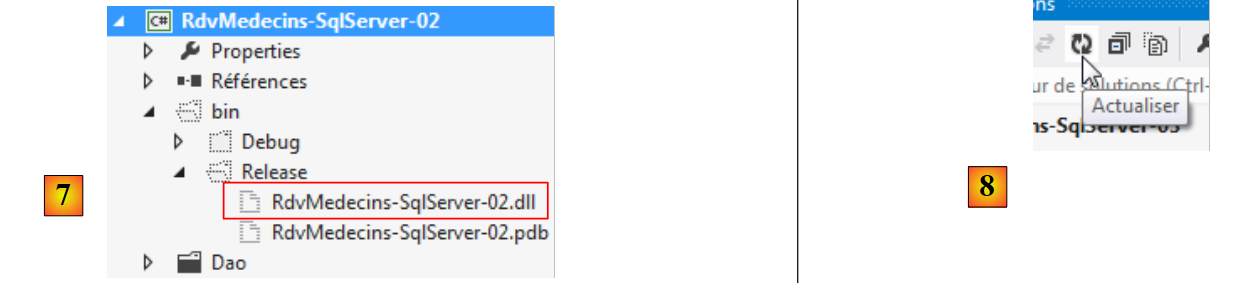 |
- in [7], il file DLL del progetto del livello [DAO]. È proprio questo che verrà utilizzato dal progetto web ASP.NET;
- in [8], aggiorniamo la visualizzazione del progetto;
 |
- in [9], i file DLL della cartella [Release] vengono raggruppati in una cartella esterna [lib] denominata [10]. È da lì che il progetto web preleverà i propri riferimenti.
3.6.7. Il livello [ASP.NET]
Qui spiegheremo il porting dell’applicazione [ASP.NET / NHibernate] verso l’applicazione [ASP.NET / EF 5]. Lavoreremo con Visual Studio Express 2012 per il web, disponibile gratuitamente all'indirizzo URL [http://www.microsoft.com/visualstudio/fra/downloads].
Lavoreremo partendo dal progetto web esistente creato con VS 2010.
 |
- in [1], apriamo il progetto esistente:
- in [2], il progetto caricato presenta i seguenti riferimenti [3]:
- [NHibernate] è il DLL del framework NHibernate,
- [Spring.Core] è il DLL del framework Spring.net,
- [log4net] è il DLL del framework di log log4net. Questo framework è utilizzato da Spring.net,
- [MySql.Data] è il driver ADO.NET del SGBD MySQL,
- [rdvmedecins] è il DLL del livello [DAO] costruito con NHibernate;
- in [4], modifichiamo il nome del progetto e in [5], eliminiamo i riferimenti precedenti;
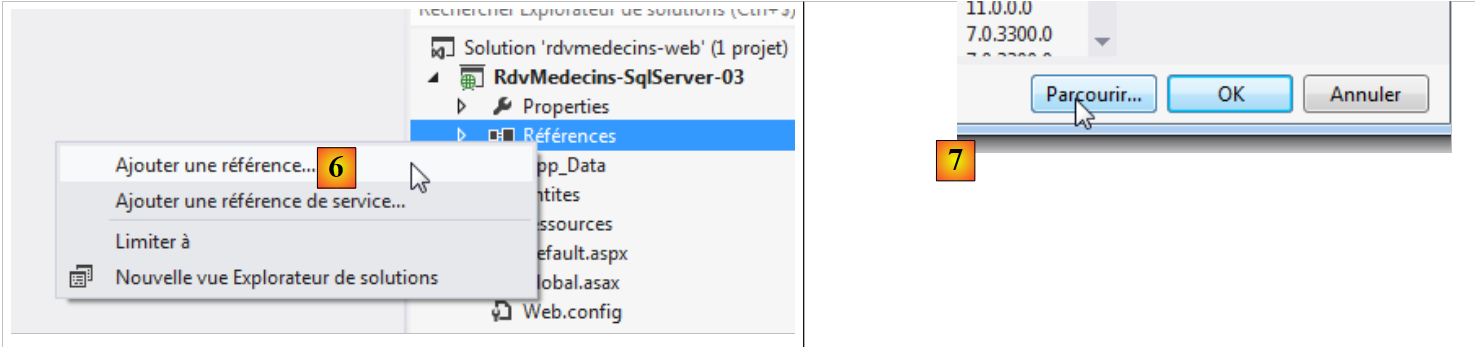 |
- in [6], aggiungiamo dei riferimenti al progetto;
- in [7], nell'assistente utilizziamo l'opzione [Parcourir];
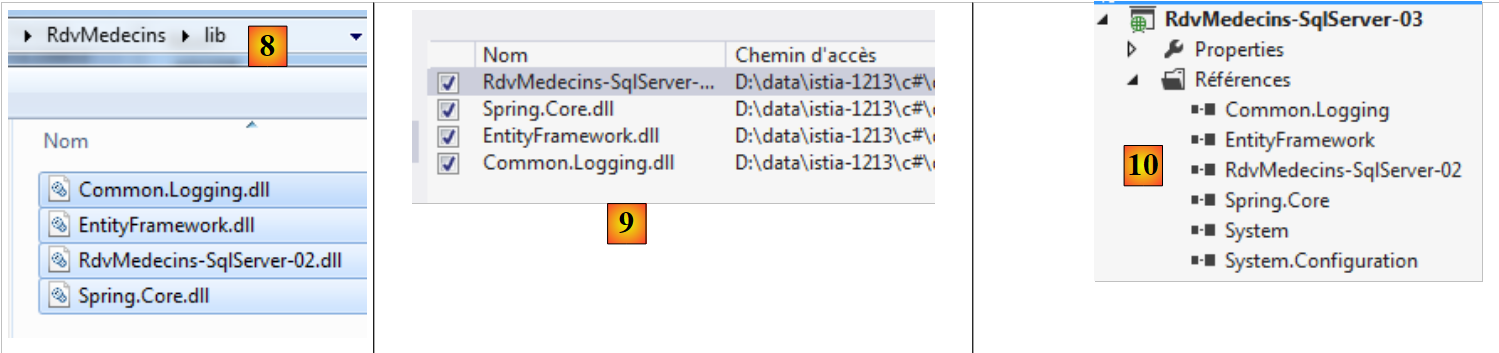 |
- in [8], selezioniamo tutti i file DLL del progetto n. 2 precedentemente inseriti nella cartella [lib];
- in [9], un riepilogo che convalidiamo;
- in [10], il progetto web con i suoi nuovi riferimenti.
Una volta fatto ciò, il progetto si presenta come segue:
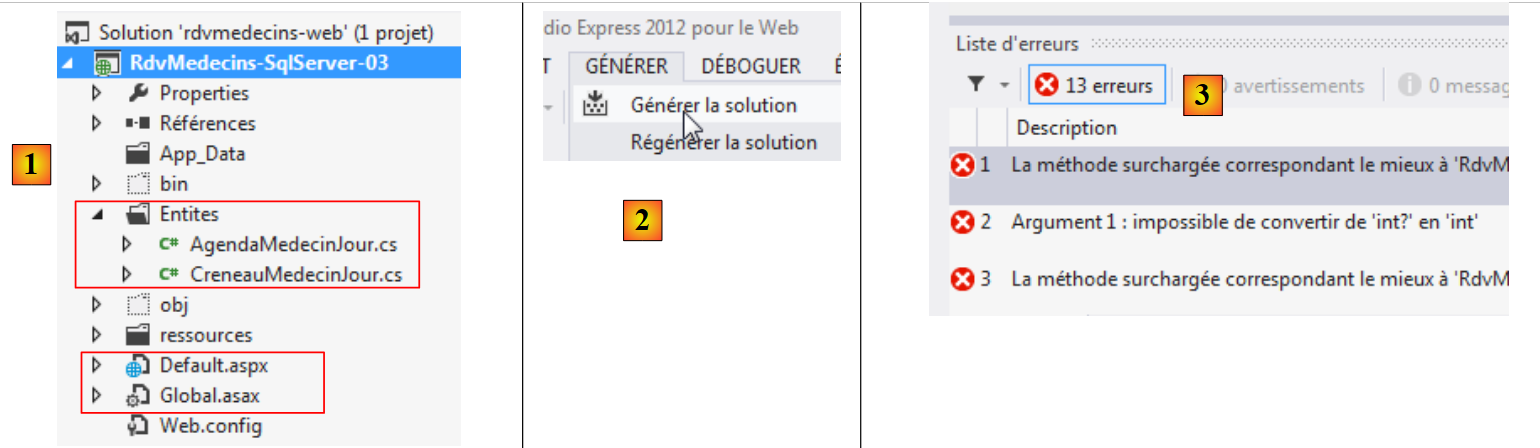 |
- in [1], il codice di gestione delle pagine web è suddiviso tra i due file [Global.asax] e [Default.aspx]. Il codice di utilità è stato inserito nella cartella [Entites]. Infine, l'applicazione è configurata dal file [Web.config];
- nel file [2] generiamo l’assembly del progetto;
- nel file [3] compaiono degli errori.
Esaminiamo gli errori, ad esempio il seguente:
![]()
e la relativa spiegazione:
![]()
Il tipo di [medecin.Id] è int?, mentre il metodo [GetCreneauxMedecin] è di tipo int. È quindi necessario un cast. Questo errore si ripete in tutto il codice poiché le entità del progetto ASP.NET / NHibernate avevano chiavi primarie di tipo int, mentre quelle del progetto ASP.NET / EF 5 sono di tipo int?. Si correggono tutti gli errori di questo tipo e si rigenera il progetto. A questo punto non ce ne sono più.
Rimane un ultimo dettaglio da sistemare prima di eseguire il progetto: l’istanziazione del livello [DAO] da parte del framework Spring. Questa operazione viene effettuata in [Global.asax]:
protected void Application_Start(object sender, EventArgs e)
{
// si memorizzano nella cache alcuni dati del database
try
{
// istanziazione del livello [dao]
Dao = ContextRegistry.GetContext().GetObject("rdvmedecinsDao") as IDao;
...
}
catch (Exception ex)
{...
}
}
Nel programma di test del livello [DAO], quest’ultimo istanziava il livello [DAO] nel modo seguente:
dao = ContextRegistry.GetContext().GetObject("rdvmedecinsDao") as IDao;
I due metodi sono identici. Ricordiamo che questa istanziazione del livello [DAO] si basava su una configurazione effettuata in [App.config]. Si sostituisce quindi il contenuto attuale [Web.config] del progetto web con quello di [App.config] del progetto del livello [DAO], in modo da ottenere la stessa configurazione.
Siamo pronti per una prima esecuzione. Viene visualizzata la pagina iniziale [1]:
 |
- in [2], si inserisce una data per l’appuntamento e si conferma;
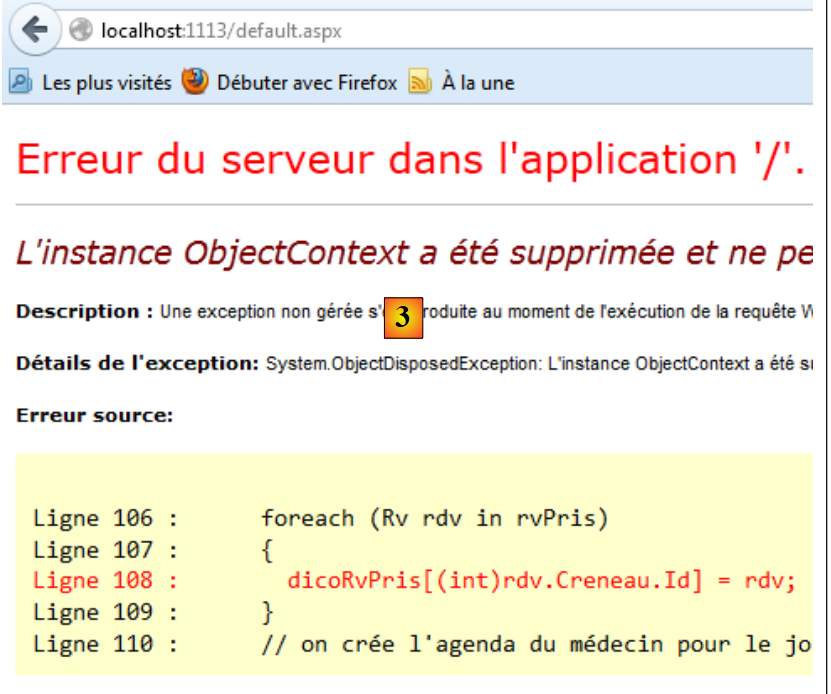 |
- in [3], si verifica un errore.
Esaminando il testo dell'errore visualizzato dalla pagina, si nota che l'eccezione segnalata è quella del Lazy Loading: si è tentato di caricare una dipendenza di un oggetto mentre il contesto di persistenza che lo gestisce era stato chiuso. L'oggetto si trova ora in uno stato "distaccato". Questo errore è dovuto al fatto che NHibernate era stato utilizzato in modalità Eager Loading, mentre EF funziona di default in modalità Lazy Loading. Nella riga in rosso sopra riportata:
- rdv rappresenta un oggetto [Rv] che è stato caricato senza le sue dipendenze;
- per valutare rdv.Creneau.Id, l’applicazione tenta di caricare la dipendenza rdv.Creneau. Tuttavia, poiché non ci si trova più nel contesto, ciò non è possibile, da cui l’eccezione.
In questo caso, la soluzione è semplice. Alla riga 108, si crea una voce in un dizionario con come chiave la chiave primaria della fascia oraria di un appuntamento. Ora, l’entità [Rv] incapsula la chiave primaria della fascia oraria associata. Si scrive quindi:
dicoRvPris[(int)rdv.CreneauId] = rdv;
Riproviamo l’esecuzione. Questa volta l’errore è il seguente:
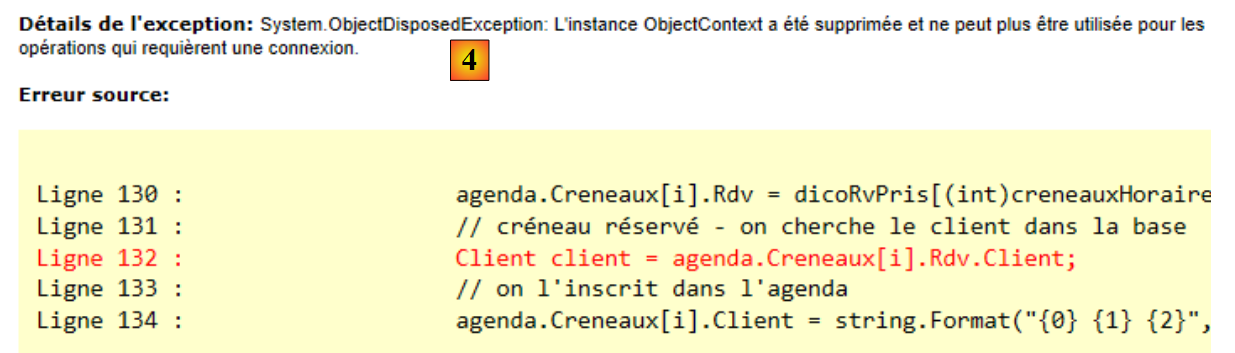 |
L’errore è analogo. Alla riga 132, si sta tentando di caricare la dipendenza [Client] di un oggetto [Rv] nel livello ASP.NET, quindi fuori contesto. È necessario recuperare l’oggetto [Client] dal database. Per risolvere questo problema, l’interfaccia [IDao] è stata arricchita con il seguente metodo:
// trovare un'entità T tramite la sua chiave primaria
T Find<T>(int id) where T : class;
Questo permetterà di recuperare le dipendenze. Pertanto, la riga errata sopra riportata verrà riscritta nel modo seguente:
Client client = Global.Dao.Find<Client>(agenda.Creneaux[i].Rdv.ClientId);
Ancora una volta si nota l’importanza che le entità includano le proprie chiavi esterne. In questo caso, l’entità [Rv] ci consente di accedere alla chiave esterna della dipendenza associata [Creneau]. Una volta apportate queste due correzioni, l’applicazione funziona. Il lettore è invitato a provare l’applicazione [RdvMedecins-SqlServer-03] disponibile nella sezione «Download degli esempi» del sito web di questo articolo.
3.7. Conclusion
Abbiamo completato con successo il porting di un'applicazione ASP.NET / NHibernate:
 |
verso un'applicazione ASP.NET / EF 5:
 |
Sebbene questa architettura avrebbe dovuto consentirci di mantenere intatto il livello [ASP.NET], abbiamo dovuto modificarlo per due motivi:
- le entità non erano esattamente le stesse. Il tipo delle chiavi primarie delle entità NHibernate era int, mentre quello di EF 5 era int?. Ciò ci ha portato a introdurre cast nel codice web;
- la modalità di caricamento delle entità non era la stessa per le due entità ORM: Eager Loading per NHibernate, Lazy Loading per EF 5. Ciò ci ha portato ad arricchire l’interfaccia del livello [DAO] con un metodo generico che consente di recuperare un’entità tramite la sua chiave primaria.
Tuttavia, il porting si è rivelato piuttosto semplice, giustificando ancora una volta, se ce ne fosse stato bisogno, l’architettura a livelli e l’iniezione di dipendenze con Spring o un altro framework di iniezione di dipendenze.
Ora valuteremo l’impatto di una modifica al SGBD sull’architettura precedente. Trasferiremo tutti i progetti precedenti su altri quattro SGBD:
- Oracle Database Express Edition 11g Release 2;
- MySQL 5.5.28;
- PostgreSQL 9.2.1;
- Firebird 2.1.
I codici non cambieranno più. Cambieranno solo i seguenti elementi:
- la definizione, nelle entità, del campo utilizzato per controllare la concorrenza di accesso a un'entità;
- i file di configurazione [App.config] o [Web.config];
Commenteremo solo gli elementi che cambiano.