5. Resolución de los tres problemas con ChatGPT
5.1. Introducción
Aquí hay una primera captura de pantalla de una sesión de ChatGPT:
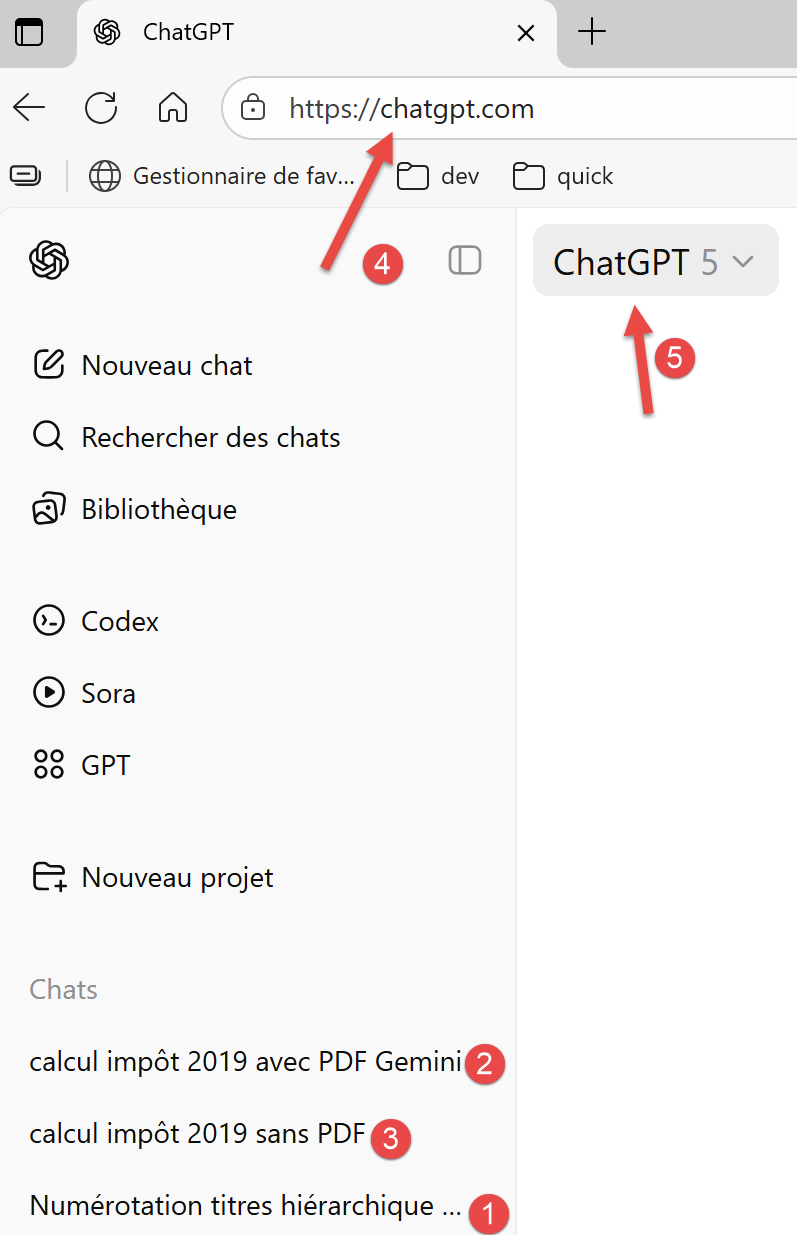 |
- En [1-3], los tres problemas planteados en ChatGPT;
- En [4], el URL de ChatGPT;
- En [5], el version de ChatGPT utilizado;
ChatGPT es un producto de OpenAI disponible en URL [https://chatgpt.com/]. Para disponer de un historial de sus sesiones de preguntas y respuestas como el anterior, debe crear una cuenta. Por otra parte, al igual que todas las demás IA probadas, ChatGPT limita el número de preguntas y el número de archivos descargados. Cuando se alcanza este límite, la sesión finaliza y se le propone continuarla más adelante. Los límites impuestos por ChatGPT se alcanzan muy rápidamente. Para realizar este tutorial, tuve que contratar una suscripción de pago de un mes.
La interfaz de ChatGPT es la siguiente:
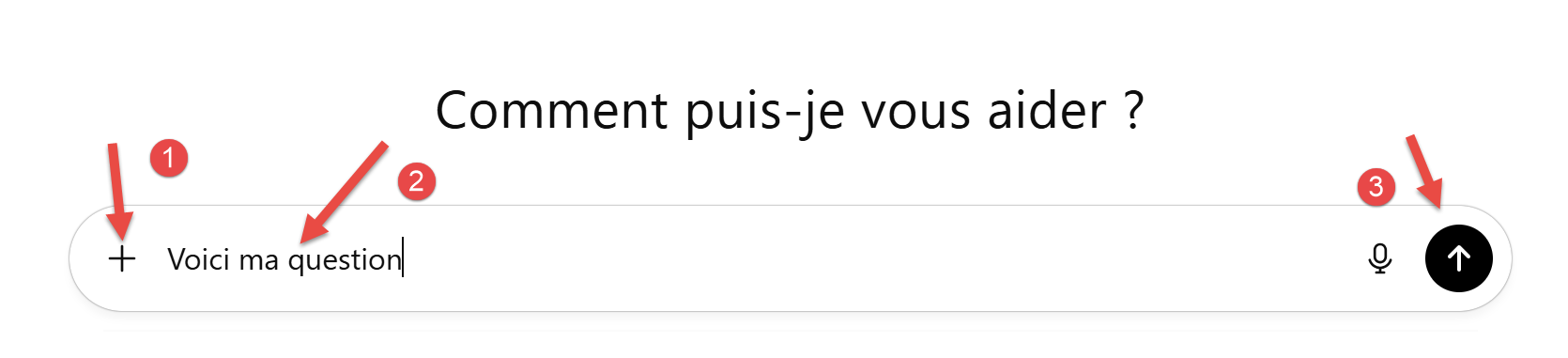 |
- En [1], para adjuntar archivos a la pregunta formulada;
- En [2], la pregunta formulada;
- En [3], para iniciar la ejecución de IA;
5.2. El problema 1
La pregunta en ChatGPT:
 |
ChatGPT responde correctamente.
5.3. El problema 2
Se trata del cálculo del impuesto con el PDF. Para ser sinceros, vamos a utilizar el PDF generado por Gemini, que corrige los errores del PDF inicial.
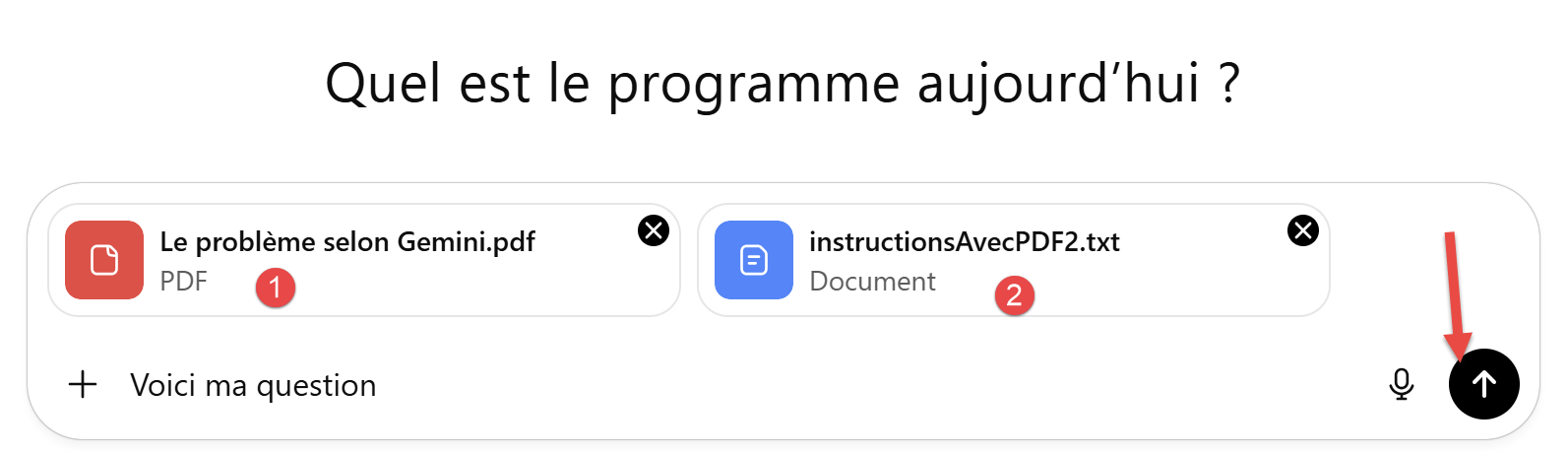 |
- En [1], se ha introducido el PDF generado por Gemini;
- En [2], se ha añadido la prueba unitaria con la que Gemini ha demostrado su superioridad:
Ejecutamos ChatGPT. Tarda unos 3 minutos en generar su respuesta. A diferencia de Gemini, sí que proporciona un enlace que funciona para recuperar el script generado. Cargamos este en PyCharm:
 |
El script [chatGPT1] funciona a la primera. En este caso no hay color: en este problema, ChatGPT ha funcionado mejor que Gemini.
El script [chatGPT1] proporcionado por ChatGPT es el siguiente:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 | |
5.4. El problema 3
Ahora le pedimos a ChatGPT que busque en Internet las reglas de cálculo del impuesto:
 |
En esta ocasión no se incluye el archivo PDF, que contenía las reglas de cálculo que debían seguirse. Solo se proporcionan nuestras instrucciones en el archivo de texto. Recordamos que este archivo de texto contiene ahora 12 pruebas unitarias tras haber añadido a las 11 pruebas iniciales la utilizada por Gemini para demostrar que mi PDF inicial era erróneo.
ChatGPT responde en 8 minutos y proporciona un enlace para descargar el script generado. Una vez cargado en PyCharm, este script supera las 12 pruebas. Por lo tanto, a las dos preguntas planteadas, ChatGPT respondió correctamente a la primera, superando así a Gemini.
ChatGPT proporciona sus fuentes en su respuesta:
 |
No hay nada que decir, es un trabajo magnífico.
Ahora podemos pedirle, como hicimos con Gemini, que genere un PDF para los estudiantes.
 |
La respuesta de ChatGPT se obtuvo tras varios intentos, ya que el PDF generado utilizaba una fuente que sustituía los caracteres por un cuadrado. Pero finalmente generó el PDF. Lo incluyo porque ofrece reglas diferentes al PDF de Gemini y me pregunté entonces quién tenía razón. Vamos a investigar.
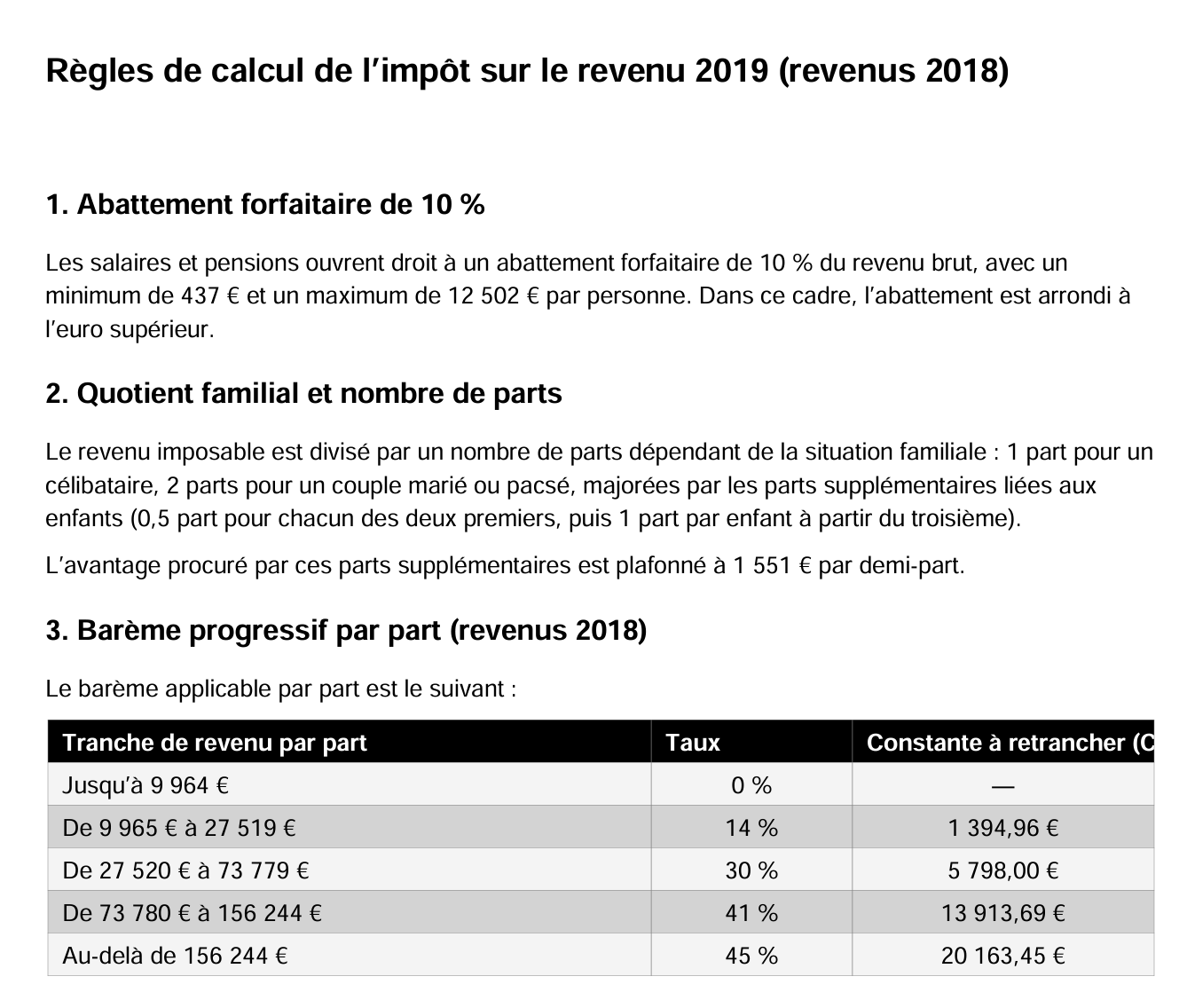 |
 |
 |  |
 |
La diferencia con el PDF de Gemini está en el cálculo del descuento. Los dos IA no siguen el mismo enfoque. Gemini había escrito:
 |
 |
 |
Los dos IA tienen dos enfoques diferentes. ¿Quién tiene razón?
5.5. El problema 4
Vamos a pedirle a ChatGPT que utilice su PDF para calcular el impuesto:
 |  |
Al igual que en ocasiones anteriores, genera un script de Python que funciona a la primera. Habíamos añadido una prueba adicional en las instrucciones:
Las 13 pruebas se han superado con éxito.
5.6. Volvemos a Gemini
Ahora volvemos a Gemini, al que vamos a presentar el PDF de ChatGPT. Dado que las reglas implementadas en este PDF son diferentes de las implementadas en el PDF de Gemini, cabe preguntarse qué va a pasar:
 |
Gemini generó en primer lugar un script de Python que fallaba en las pruebas. Se le presentaron los registros:
Pregunta 2
 |
Pregunta 3
Todavía hay errores. Seguimos.
 |
Pregunta 4
Sigue habiendo errores de ejecución:
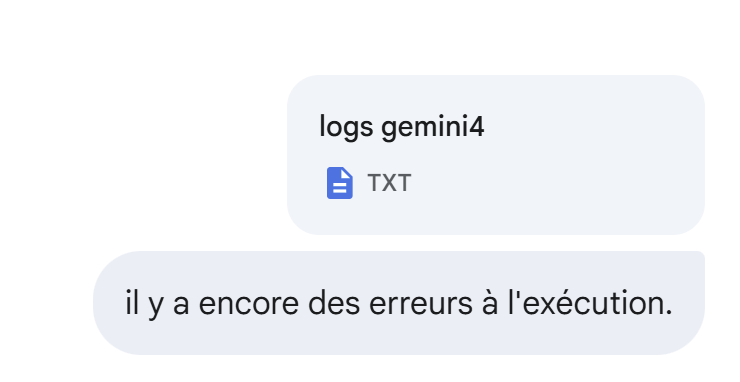 |
Esta vez sí.
No obstante, nos intriga que, con PDF que tienen reglas de cálculo bastante diferentes, los IA generen ambos resultados correctos.
Planteamos la siguiente pregunta a Gemini:
 |
La pregunta completa es la siguiente:
La respuesta de Gemini es categórica:
 |
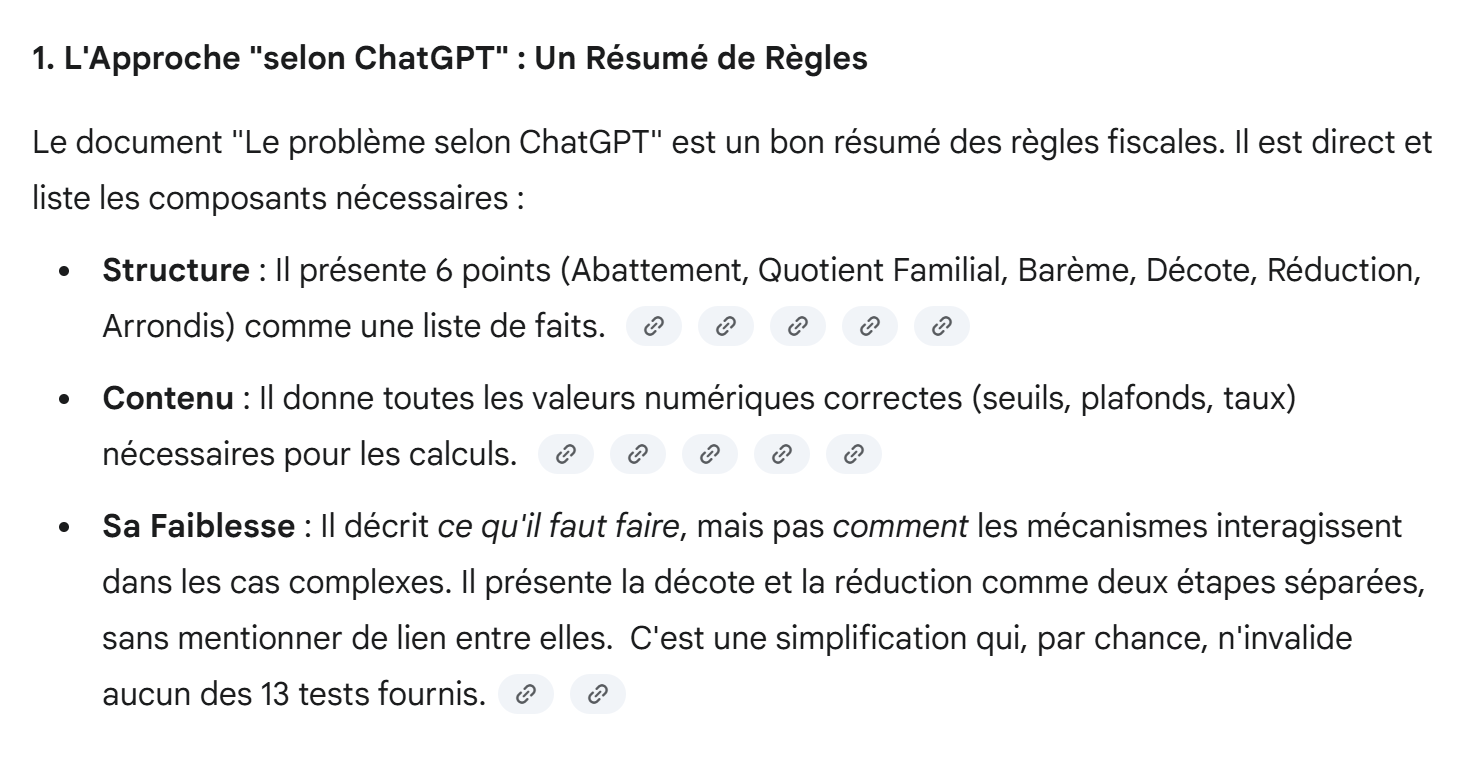 |
 |
 |
 |
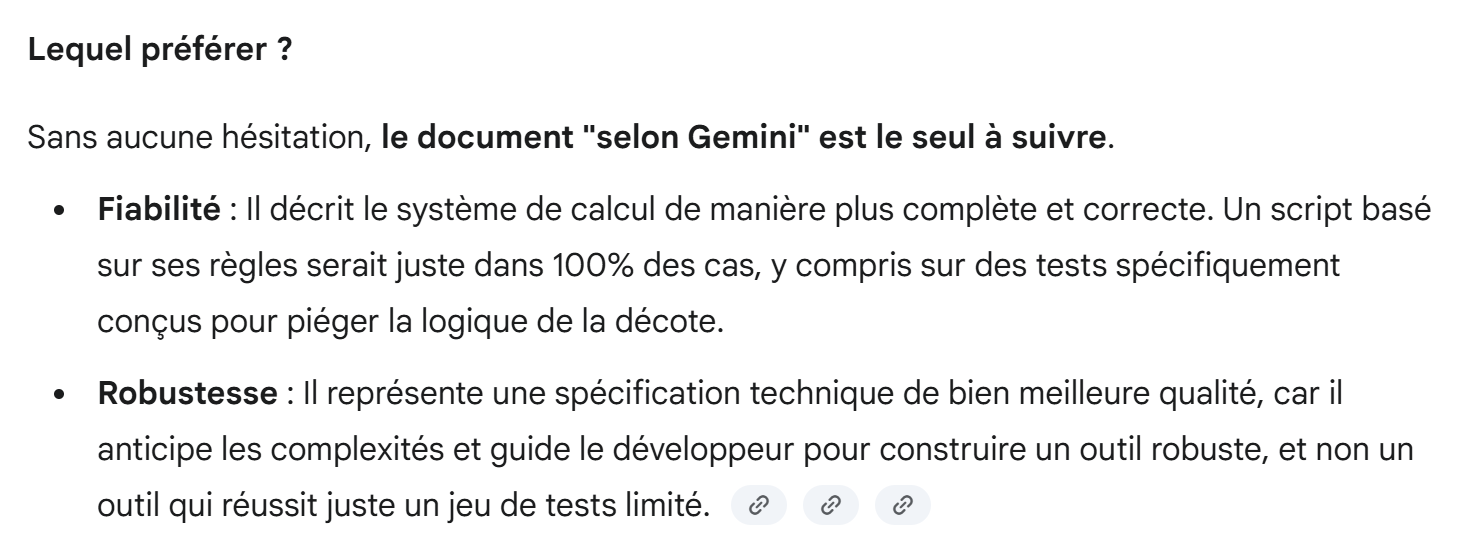 |
5.7. ¿Qué opina ChatGPT?
Le hacemos a ChatGPT la misma pregunta que le hicimos a Gemini.
 |
La respuesta de ChatGPT es la siguiente:
 |
 |
Por lo tanto, ChatGPT nos propone una prueba unitaria para decidir entre los dos métodos. Duplicamos:
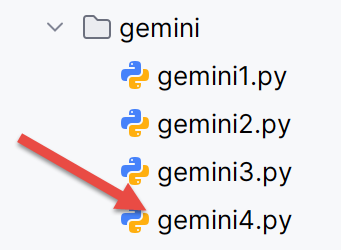
- El script [gemini3] generado por Gemini tomando como fuente su PDF [Le problème selon Gemini] se duplica en el script [gemini4];
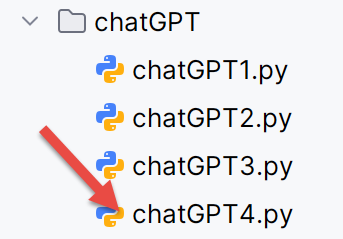
- El script [chatGPT3] generado por ChatGPT tomando como fuente sus scripts PDF y [Le problème selon ChatGPT] se duplica en el script [chatGPT4];
 |  |
Además, se añade en cada uno de los scripts [gemini4, chatGPT4] la prueba unitaria propuesta por ChatGPT para decidir entre los dos IA.
La ejecución de [gemini4] da los siguientes resultados:
C:\Data\st-2025\dev\python\code\python-flask-2025-cours\.venv\Scripts\python.exe "C:/Program Files/JetBrains/PyCharm 2025.2.1.1/plugins/python-ce/helpers/pycharm/_jb_unittest_runner.py" --path "C:\Data\st-2025\dev\python\code\python-flask-2025-cours\outils ia\gemini\gemini4.py"
Testing started at 17:45 ...
Launching unittests with arguments python -m unittest C:\Data\st-2025\dev\python\code\python-flask-2025-cours\outils ia\gemini\gemini4.py in C:\Data\st-2025\dev\python\code\python-flask-2025-cours
SubTest failure: Traceback (most recent call last):
File "C:\Program Files\Python313\Lib\unittest\case.py", line 58, in testPartExecutor
yield
File "C:\Program Files\Python313\Lib\unittest\case.py", line 556, in subTest
yield
File "C:\Data\st-2025\dev\python\code\python-flask-2025-cours\outils ia\gemini\gemini4.py", line 234, in test_cas_verifies_simulateur_officiel
self.assertAlmostEqual(calcul_impot, attendu_impot, delta=1, msg="Échec sur le montant de l'impôt")
~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AssertionError: 2669 != 2270 within 1 delta (399 difference) : Échec sur le montant de l'impôt
Ran 1 test in 0.010s
FAILED (failures=1)
One or more subtests failed
Failed subtests list: [Test 'test12' avec entrée (2, 0, 43333)]
Process finished with exit code 1
Por lo tanto, Gemini no supera la prueba añadida por ChatGPT.
La ejecución de [chatGPT4] da los siguientes resultados:
C:\Data\st-2025\dev\python\code\python-flask-2025-cours\.venv\Scripts\python.exe "C:\Data\st-2025\dev\python\code\python-flask-2025-cours\outils ia\chatGPT\chatGPT4.py"
Test (2, 2, 55555) -> obtenu (impôt=2814, décote=0, réduction=0) | attendu (2815, 0, 0) | OK
Test (2, 2, 50000) -> obtenu (impôt=1384, décote=384, réduction=347) | attendu (1385, 384, 346) | OK
Test (2, 3, 50000) -> obtenu (impôt=0, décote=721, réduction=0) | attendu (0, 720, 0) | OK
Test (1, 2, 100000) -> obtenu (impôt=19884, décote=0, réduction=0) | attendu (19884, 0, 0) | OK
Test (1, 3, 100000) -> obtenu (impôt=16782, décote=0, réduction=0) | attendu (16782, 0, 0) | OK
Test (2, 3, 100000) -> obtenu (impôt=9200, décote=0, réduction=0) | attendu (9200, 0, 0) | OK
Test (2, 5, 100000) -> obtenu (impôt=4230, décote=0, réduction=0) | attendu (4230, 0, 0) | OK
Test (1, 0, 100000) -> obtenu (impôt=22986, décote=0, réduction=0) | attendu (22986, 0, 0) | OK
Test (2, 2, 30000) -> obtenu (impôt=0, décote=0, réduction=0) | attendu (0, 0, 0) | OK
Test (1, 0, 200000) -> obtenu (impôt=64210, décote=0, réduction=0) | attendu (64211, 0, 0) | OK
Test (2, 3, 200000) -> obtenu (impôt=42842, décote=0, réduction=0) | attendu (42843, 0, 0) | OK
Test (2, 2, 49500) -> obtenu (impôt=1296, décote=431, réduction=325) | attendu (1297, 431, 324) | OK
Test (1, 0, 18535) -> obtenu (impôt=359, décote=491, réduction=90) | attendu (359, 491, 90) | OK
Test (2, 0, 43333) -> obtenu (impôt=2268, décote=0, réduction=401) | attendu (2270, 0, 400) | ECHEC
Détails tolérance ±1€ : impôt ok? False, décote ok? True, réduction ok? True
Résultat global : AU MOINS UN TEST ÉCHOUE ❌
Process finished with exit code 0
ChatGPT tampoco supera la prueba añadida, pero no por las mismas razones que Gemini. ChatGPT ha encontrado los resultados correctos, pero con una diferencia de 2 euros en lugar del 1 euro exigido.
Por lo tanto, a partir de ahora utilizaremos el PDF generado por ChatGPT con los siguientes IA. Cabe señalar que, debido a la falta de pruebas unitarias en mis instrucciones, los dos IA superaron las primeras pruebas. De ahí la importancia, en este ejemplo concreto, de incluir pruebas unitarias para los casos límite del cálculo del impuesto. Ya que resulta bastante difícil imaginar estas pruebas por uno mismo. Vamos a pedir a los IA que añadan ellos mismos algunas.
5.8. El problema 3 con pruebas unitarias generadas por los IA
Los resultados obtenidos con Gemini y ChatGPT dejan dudas. ¿Han encontrado los IA una solución general que valide todas las pruebas imaginables o han encontrado una solución que valide únicamente las pruebas impuestas? Vamos a volver a partir de una solución sin PDF para obligar a los IA a buscar en Internet la información que necesitan. Y modificamos nuestras instrucciones de la siguiente manera:
 |
El archivo de texto [instructionsSansPDF4.txt] ya contiene 14 pruebas impuestas. A estas pruebas, añadimos las siguientes instrucciones:
7 - tu ajouteras autant de tests unitaires que nécessaires pour vérifier les cas limites du calcul de l'impôt.
Pour le code tu complèteras le script suivant auquel tu auras rajouté tes propres tests.
# =========================
# Pruebas unitarias (tolerancia de ±1 €)
# =========================
TESTS = [
# (adultos, niños, ingresos) -> (impuesto, descuento, reducción)
((2, 2, 55555), (2815, 0, 0)),
((2, 2, 50000), (1385, 384, 346)),
((2, 3, 50000), (0, 720, 0)),
((1, 2, 100000), (19884, 0, 0)),
((1, 3, 100000), (16782, 0, 0)),
((2, 3, 100000), (9200, 0, 0)),
((2, 5, 100000), (4230, 0, 0)),
((1, 0, 100000), (22986, 0, 0)),
((2, 2, 30000), (0, 0, 0)),
((1, 0, 200000), (64211, 0, 0)),
((2, 3, 200000), (42843, 0, 0)),
((2, 2, 49500), (1297, 431, 324)),
((1, 0, 18535), (359, 491, 90)),
((2, 0, 43333), (2270, 0, 400)),
]
def _ok(a, b, tol=1):
return abs(a - b) <= tol
def run_tests(verbose: bool = True) -> bool:
all_ok = True
for (params, expected) in TESTS:
a, e, r = params
exp_impot, exp_decote, exp_reduc = expected
res = calcul_impot_2019(a, e, r)
ok_impot = _ok(res.impot, exp_impot)
ok_decote = _ok(res.decote, exp_decote)
ok_reduc = _ok(res.reduction, exp_reduc)
test_ok = ok_impot and ok_decote and ok_reduc
if verbose:
print(
f"Test {params} -> obtenu (impôt={res.impot}, décote={res.decote}, réduction={res.reduction}) | attendu {expected} | {'OK' if test_ok else 'ECHEC'}")
if not test_ok:
print(
f" Détails tolérance ±1€ : impôt ok? {ok_impot}, décote ok? {ok_decote}, réduction ok? {ok_reduc}")
all_ok &= test_ok
if verbose:
print("\nRésultat global :", "TOUS LES TESTS PASSENT ✅" if all_ok else "AU MOINS UN TEST ÉCHOUE ❌")
return all_ok
if __name__ == "__main__":
run_tests()
- Líneas 11-24, las 14 pruebas obligatorias;
- Líneas 5-55: este código procede del script generado por ChatGPT. Vamos a obligar a Gemini a utilizar este código para facilitar las comparaciones entre los dos scripts generados.
Empezamos con ChatGPT:
 |
Su primera respuesta es incorrecta. Se lo indico proporcionándole los registros de la ejecución:
 |  |
Su segunda respuesta es la correcta. ChatGPT ha añadido las siguientes 11 pruebas a las 14 pruebas obligatorias:
Ahora hay 25 pruebas unitarias. He comprobado manualmente las 11 nuevas pruebas con el simulador oficial de DGIP y todo está bien.
Ahora pasamos a Gemini. Esto va a ser mucho más complicado. Conseguirá generar un script que supere las 25 pruebas de ChatGPT, pero tras un proceso de depuración de long.
 |
A continuación, la lista de depuración:
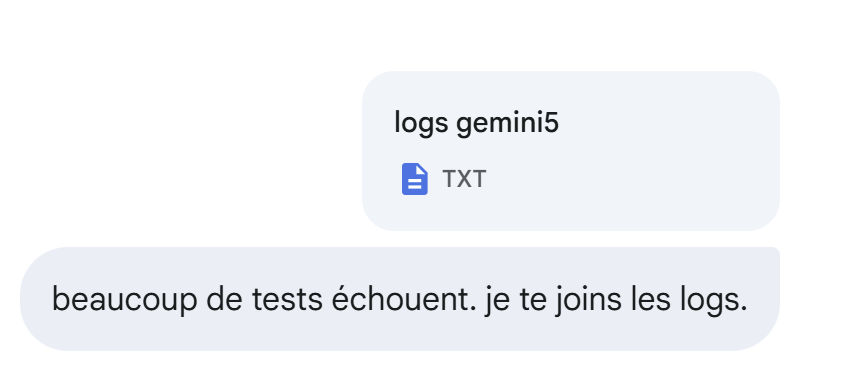 |
Curiosamente, la mayoría de las pruebas han fallado, incluso entre las 14 obligatorias, mientras que en el pasado Gemini había generado código que las superaba todas.
La siguiente respuesta de Gemini sigue sin ser correcta:
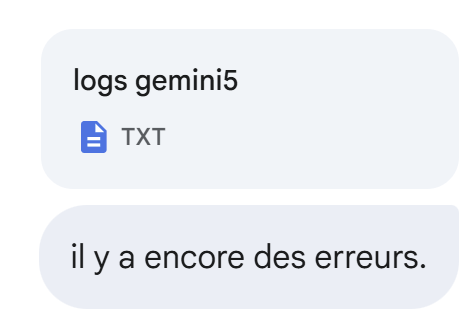 |
La siguiente respuesta tampoco:
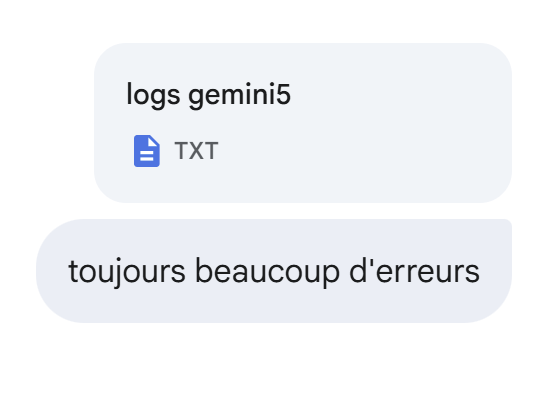 |
La siguiente respuesta tampoco. Así que cambio de estrategia. Le pido que supere las 25 pruebas que superó ChatGPT adjuntándole los registros de ChatGPT:
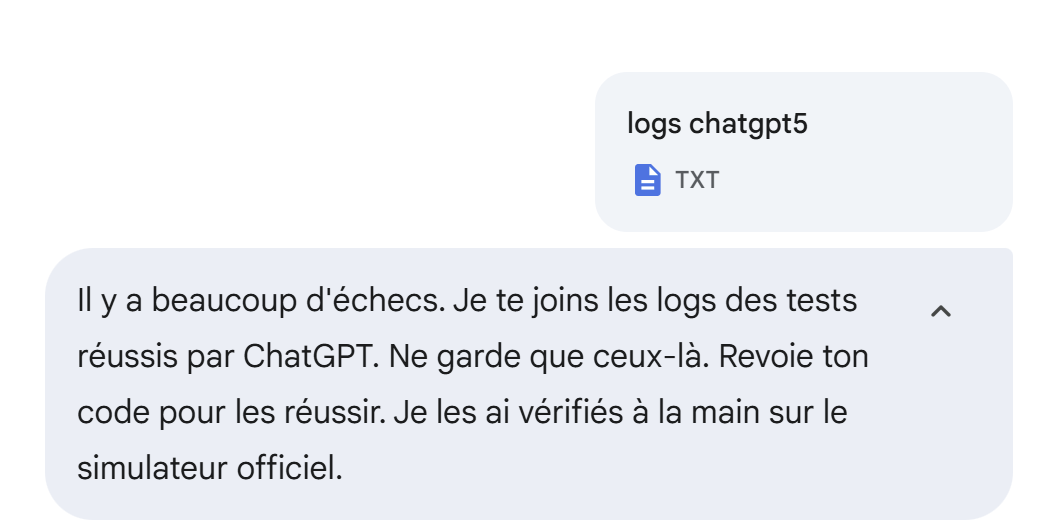 |
Gemini falla. Sí que ha añadido las pruebas de ChatGPT. Le adjunto los registros de su ejecución:
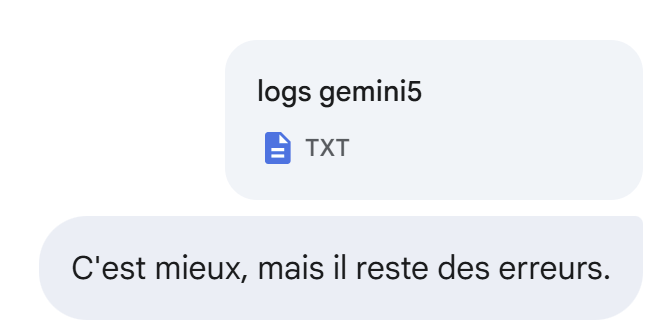 |
Sigue sin funcionar:
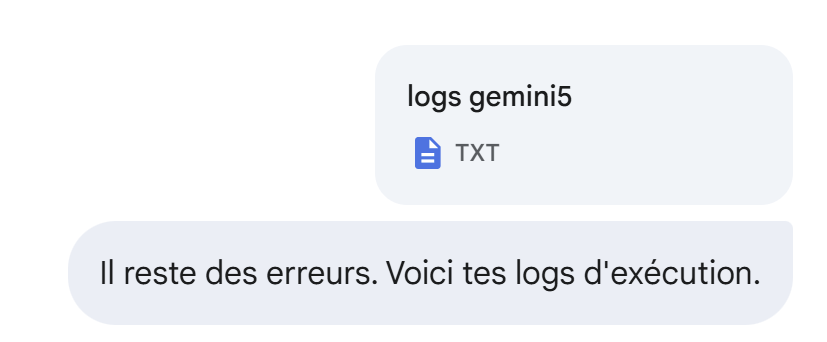 |
Sigue sin funcionar:
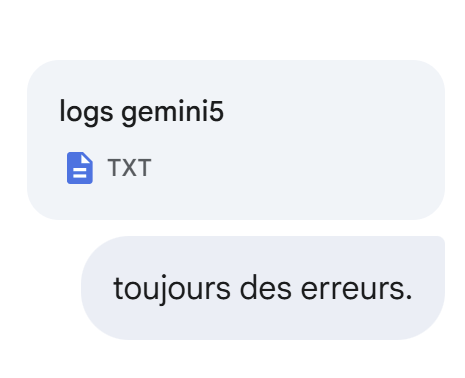 |
Todavía no:
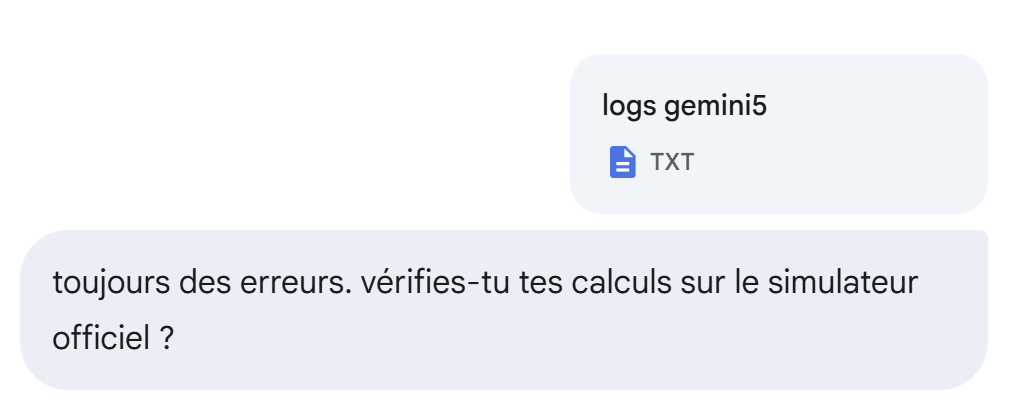 |
Todavía no, pero está mejor:
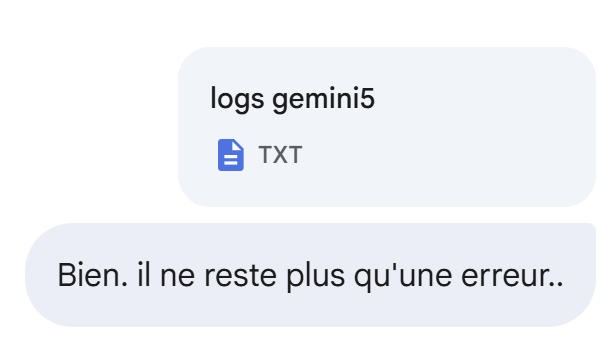 |
Gemini comete nuevos errores:
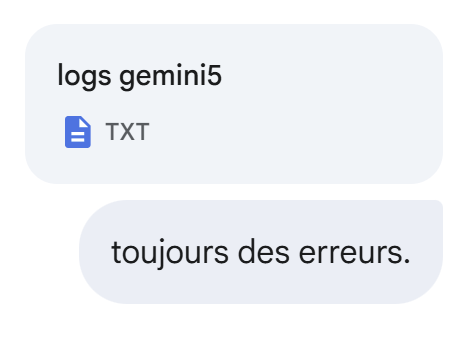 |
Vuelve a mejorar:
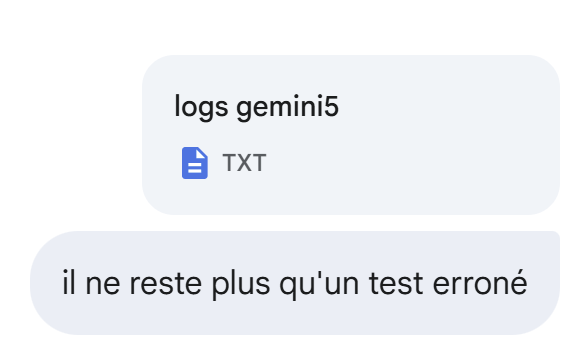 |
Esta vez sí:
 |
Sin lugar a dudas, en este ejemplo concreto del cálculo del impuesto de 2019 con las restricciones establecidas en el archivo de instrucciones, ChatGPT ha sido más preciso que Gemini. Pero esto es solo un ejemplo.
Podemos ir más allá. Podemos pedirle a Gemini que vuelva a generar un PDF según las reglas de cálculo que utilizó para superar las 25 pruebas. Queremos ver si ha cambiado su razonamiento inicial sobre los cálculos de la bonificación y la reducción del 20 %:
 |  |
Esta vez, Gemini ha generado un archivo MarkDown que luego he transformado en PDF [Le problème selon Gemini version 2]. Y Gemini efectivamente ha cambiado su razonamiento:
 |
 |
Se observa que ya no existe el cálculo específico del descuento ni la regla de repesca. Gemini ha adoptado ahora el razonamiento de ChatGPT.