9. Verwendung des DOCX-zu-HTML-Konverters
Der Befehl zur Konvertierung eines Word-DOCX-Dokuments ist dem zur Konvertierung eines LibreOffice-ODT-Dokuments sehr ähnlich. Wir werden den Stil des Dokumenttitels in [config.py] ändern:
STYLES = {
"style_names": [
"Titel"
]
}
- Zeile 3: Geben Sie „Titel“ ein. Dies ist der Stil des DOCX-Dokuments, das Sie konvertieren möchten. Wir werden dies in den Debugging-Zeilen des Konverters sehen.
Geben Sie im PyCharm-Terminal den folgenden Befehl ein:
PS C:\Data\st-2025\GitHub Pages\word-odt-vers-html\v2> python .\convert_docx_v18.py .\word-odt-vers-html-janv-2026.docx .\config.py
C:\Data\st-2025\GitHub Pages\word-odt-vers-html\v2\convert_docx_v18.py:976: SyntaxWarning: ungültige Escape-Sequenz '\h'
- REF Lesezeichen \h
--- DOCX to MkDocs Converter V16 ---
Kopiert: google5179c0eaff293e02.html
Kopiert: robots.txt
Kopiert: word-odt-zu-html-Jan-2026.pdf
Kopiert: word-odt-zu-html-Jan-2026.zip
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Titel heading=Keine rebase=0 numId=Keine ilvl=Keine list=Keine:0/Keine txt='<span>Ein Word- oder ODT-Dokument in eine statische, Mk-kompatible HTML-Website konvertieren...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='<b>Serge Tahé</b><span>, Januar 2026</span>...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='<b>Diese Website wurde mit dem Konverter [Word oder ODT - > HTML] erstellt...'
[DEBUG PRE-H1] style=Titel1 heading=1 rebase=0 numId=1 ilvl=0 list=numPr:1/ordered txt='<span>Einleitung</span>...'
Fertig. (audit.json, audit.txt, report.txt generiert)
- Zeile 1: Der Befehl lautet wie folgt: [python .\convert_docx_v18.py .\word-odt-vers-html-janv-2026.docx .\config.py] (Passen Sie die Versionsnummer (hier 18) an die von Ihnen heruntergeladene Version an.):
- Der erste Parameter [.\convert_docx_v18.py] ist der DOCX-zu-HTML-Konverter
- Der zweite Parameter [.\word-odt-vers-html-janv-2026.docx] ist der Name des zu konvertierenden DOCX-Dokuments;
- der dritte Parameter [.\config.py] ist die Konfigurationsdatei;
- Zeile 33: Der Konverter meldet, dass drei Dateien erstellt wurden:
 |
Die Datei [audit.txt] lautet wie folgt:
Version: V16
Absätze: 2029
Tabellen: 97
Bilder (Blips): 2
Erkannte Überschriften (Rohdaten): 53
Erkannte minimale Überschriftenebene (Rohdaten): 1
Angewandter Rebase-Offset: 0
Top-Absatzstile:
- SourceCodenumrot: 1054
- StandardWW: 594
- Standard: 146
- Paragraphedeliste: 113
- SourceCodenumrotrsultats: 33
- neuerCode: 28
- Titel 2: 25
- Überschrift 1: 14
- Titel 3: 14
- StandardWWWW: 6
- Klartext: 1
- Überschrift: 1
Absätze auflisten:
- mit Nummerierung: 1329
- nach Stil-Fallback: 49
- nicht erkannt: 0
- Zeile 2: die Anzahl der Absätze im Word-Dokument;
- Zeile 3: die Anzahl der Tabellen;
- Zeilen 9–21: die im Dokument gefundenen Stile;
- Zeilen 10, 14, 15: der Stil der Codeblöcke. Ein einziger Stil hätte wahrscheinlich ausgereicht;
- Zeilen 11–12, 19: der Stil der Standardabsätze. Ein einziger Stil hätte wahrscheinlich ausgereicht;
- Zeilen 16–18, 21: die Stile der Überschriften im Dokument. In Zeile 21 sieht man, dass nur ein Absatz den Stil „Überschrift“ hat. Es handelt sich um die Überschrift des Dokuments, die dem ersten „Überschrift 1“ vorangeht;
Diese Überprüfung des Word-Dokuments ist eine gute Möglichkeit, die Qualität des Dokuments zu beurteilen. Hier sehe ich, dass ich in meinem Word-Dokument zu viele verschiedene Formatvorlagen für ein und dasselbe verwendet habe.
Die Datei [audit.json] ist identisch mit der Datei [audit.txt], jedoch im JSON-Format:
{
"version": "V16",
"file": "word-odt-vers-html-janv-2026.docx",
"counts": {
"paragraphs": 2029,
"tables": 97,
"Bild-Blips": 2,
"headings_raw": 53
},
"Listen": {
"with_numpr": 1329,
"by_style": 49,
"unrecognized": 0
},
"heading": {
"min_level_raw": 1,
"rebase_offset": 0
},
"top_styles": [
[
"SourceCodenumrot",
1054
],
[
"StandardWW",
594
],
[
"Standard",
146
],
[
„Absatzliste“,
113
],
[
"Quellcode-Nummer-Ergebnisse",
33
],
[
"codenouveau",
28
],
[
"Titel2",
25
],
[
"Titel1",
14
],
[
"Titel3",
14
],
[
"StandardWWWW",
6
],
[
"Klartext",
1
],
[
"Titel",
1
]
]
}
Die Datei [report.txt] sieht wie folgt aus:
[SUMMARY] Über Fallback „nach Stil“ erkannte Listen (aggregiert)
- Paragraphedeliste -> level=1 type=unordered: 49
[SUMMARY] Ignorierte Word-Blöcke (aggregiert)
- <w:sectPr>: 1
Ich habe das nicht verstanden…
Mit dem Parameter [--audit] kann man nur das Audit des Word-Dokuments anfordern, um dessen Qualität zu beurteilen:
python .\convert_docx_v18.py .\word-odt-vers-html-janv-2026.docx .\config.py --audit
In diesem Fall wird nur das Dokument geprüft. Die MkDocs-Website wird nicht generiert.
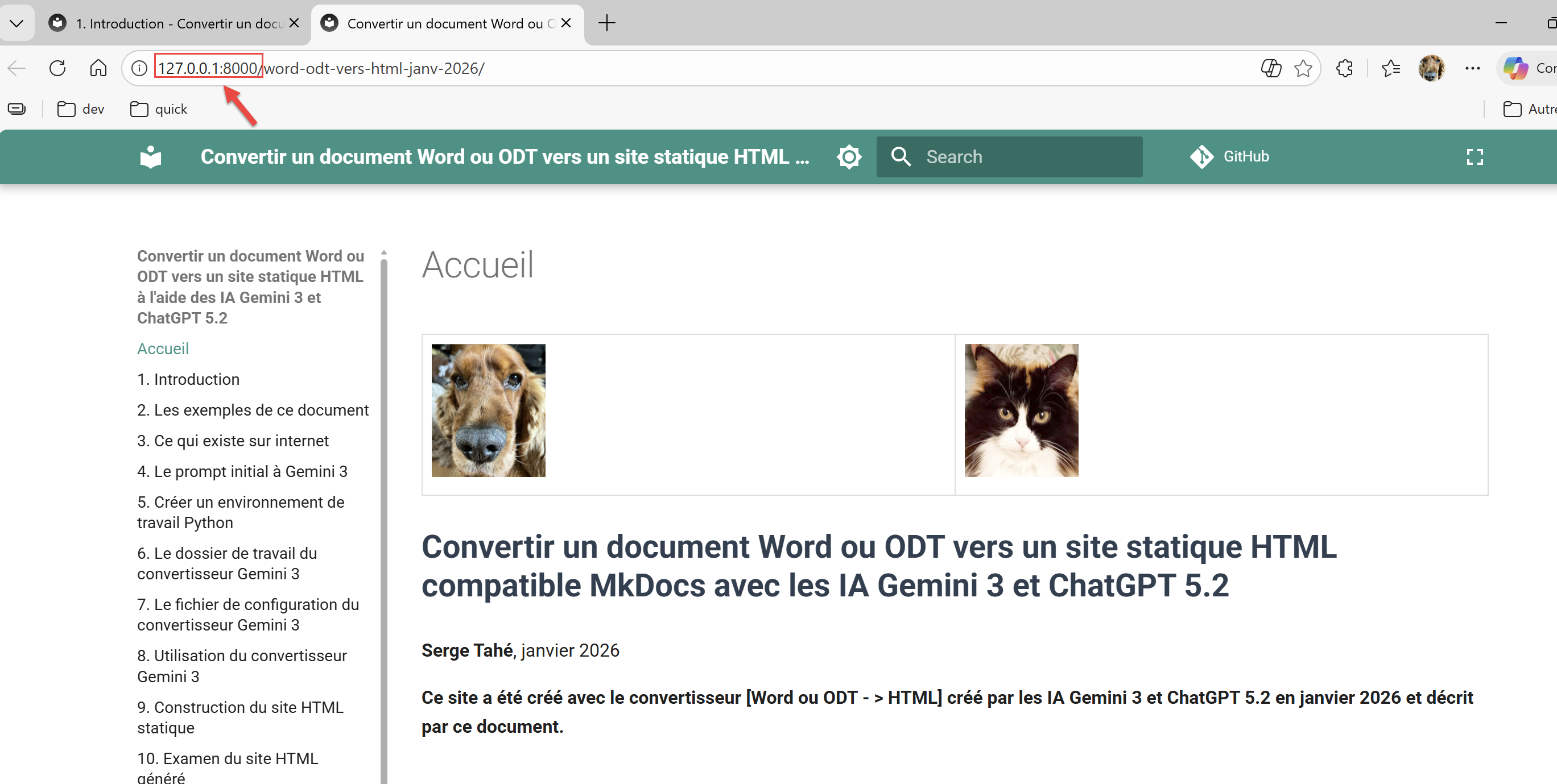
Wie zuvor gezeigt, können Sie die vom Konverter generierte MkDocs-Website anzeigen:
PS C:\Data\st-2025\GitHub Pages\word-odt-vers-html\v2> python -m mkdocs serve
INFO - Dokumentation wird erstellt...
INFO - Bereinigung des Website-Verzeichnisses
INFO - Dokumentation in 0,59 Sekunden erstellt
INFO - [06:05:48] Serving on http://127.0.0.1:8000/word-odt-vers-html-janv-2026/
Strg-Klick auf die URL in Zeile 5:
 |