11. Überprüfung der generierten HTML-Website
Wir werden nun die HTML-Ausgabe dieses ODT-/DOCX-Dokuments überprüfen. Wir haben bereits gesehen, dass der Konverter das Inhaltsverzeichnis beibehält.
11.1. Die obere Leiste der Website
Sehen wir uns die obere Leiste der Website an:
 |
- In [1] der in [config.py] definierte Name der Website;
- Unter [2] das Symbol, mit dem man in den Dunkel- oder Hellmodus wechseln kann;
- Unter [3] das Symbol, das einen Link zum GitHub-Repository darstellt, in das die HTML-Website exportiert wird. Ebenfalls in [config.py] definiert;
- Unter [4] das Symbol, mit dem man das Inhaltsverzeichnis ein- oder ausblenden kann;
11.2. Die Fußzeile der Website
Sehen wir uns nun die Fußzeile an:
 |
Dies ist die Fußzeile, die in der Datei [config.py] definiert ist.
11.3. Die Startseite
Die Titelseite des ODT-/DOCX-Dokuments sah wie folgt aus:
 |
Diese Titelseite des ODT-/DOCX-Dokuments wird zur Startseite der HTML-Website:
 |
Der Konverter Gemini 3 / ChatGPT fügt auf der Startseite alles ein, was im ODT-/DOCX-Dokument als erster Titel der Ebene 1 im Stil „Titel 1“ vorliegt. Wenn Sie dort Bilder wie oben einfügen, werden diese angezeigt. Sie können sich also vorstellen, Ihrer Website ein Cover zu geben, wie bei einem echten Buch. In [1] ist dies der Haupttitel des Dokuments. Seine Darstellung wird durch die folgenden Zeilen in der Konfigurationsdatei [config.py] gesteuert:
# -------------------------------------------------------------------------
# Erkennung des Dokumenttitels
# -------------------------------------------------------------------------
"document_title": {
# ODT-Stile, die als Haupttitel des Dokuments (globaler H1) zu betrachten sind
"style_names": [
"P1"
],
# Auf diesen Titel im generierten Markdown angewendetes CSS
"css": "font-size: 28px; font-weight: bold; margin-bottom: 1em; line-height: 1.2; color: #2c3e50;"
},
- Zeilen [6–8]: Die Liste der möglichen Formatvorlagen für den Titel Ihres Dokuments. Wenn ich mir dieses Dokument ansehe, lautet die LibreOffice-Formatvorlage meines Titels „Haupttitel“. Der Gemini-Konverter konnte diesen jedoch nicht finden. Er hat die gefundenen Stile protokolliert, und dabei wurde [P1] angezeigt. Das ist ein großes Problem bei LibreOffice: Die angezeigten Namen der Stile stimmen nicht mit den internen Namen überein, die von der Software verwendet werden. Sie dienen lediglich dazu, sich an die Sprache des Benutzers anzupassen;
- Zeile 10: Sobald der Haupttitel erkannt wurde, können Sie dessen Darstellung festlegen. Ich wollte eine Schriftgröße von 28 (font-size: 28px;) und Fettdruck (font-weight: bold);
Mit den Bildern und dem Stil des Titels können Sie eine ansprechende Startseite gestalten.
Der Haupttitel Ihres Dokuments hat möglicherweise keinen der in den Zeilen [6–8] definierten Stile. Um den Stil Ihres Haupttitels zu ermitteln, verwenden Sie die folgende Zeile in der Datei [config.py]
Mit dem Wert [true] wird der Stil der Absätze, die dem ersten Titel der Ebene 1 vorausgehen, also die Absätze der Startseite, bei der Ausführung des Gemini/ChatGPT-Konverters angezeigt. So habe ich für ein anderes Dokument als dieses die folgenden Protokolle erhalten:
[DEBUG PRE-H1] Style='Standard (WW)' (Clean='standard (ww)') | Text='...'
[DEBUG PRE-H1] Style='P1' (Clean='p1') | Text='...'
[DEBUG PRE-H1] Style='P1' (Clean='p1') | Text='...'
[DEBUG PRE-H1] Style='P1' (Clean='p1') | Text='...'
[DEBUG PRE-H1] Style='P3' (Clean='p3') | Text='...'
[DEBUG PRE-H1] Style='P1' (Clean='p1') | Text='...'
[DEBUG PRE-H1] Style='P1' (Clean='p1') | Text='...'
[DEBUG PRE-H1] Style='P1' (Clean='p1') | Text='...'
[DEBUG PRE-H1] Style='P1' (Clean='p1') | Text='...'
[DEBUG PRE-H1] Style='P4' (Clean='p4') | Text='Einführung in die Sprache PHP7 anhand von Beispielen...'
>>> ERKANNTES DOKUMENTTITEL: Einführung in die Sprache PHP7 anhand eines Beispiels
[DEBUG PRE-H1] Style='Standard (WW)' (Clean='standard (ww)') | Text='...'
[DEBUG PRE-H1] Style='Standard (WW)' (Clean='standard (ww)') | Text='...'
[DEBUG PRE-H1] Style='Standard (WW)' (Clean='standard (ww)') | Text='...'
[DEBUG PRE-H1] Style='Standard (WW)' (Clean='standard (ww)') | Text='...'
[DEBUG PRE-H1] Style='Standard (WW)' (Clean='standard (ww)') | Text='...'
[DEBUG PRE-H1] Style='Standard (WW)' (Clean='standard (ww)') | Text='...'
[DEBUG PRE-H1] Style='P5' (Clean='p5') | Text='Serge Tahé, Juli 2019...'
[DEBUG PRE-H1] Style='P5' (Clean='p5') | Text='...'
[DEBUG PRE-H1] Style='P6' (Clean='p6') | Text='...'
[DEBUG PRE-H1] Style='Heading 1' (Clean='heading 1') | Text='Einführung in die Sprache PHP 7...'
- Zeile 10: Der Titel des Dokuments hat den Stil „P4“;
In der Datei [config.py] habe ich dann folgende Zeilen eingefügt:
"document_title": {
"style_names": [
"P4"
],
"css": "font-size: 28px; font-weight: bold; margin-bottom: 1em; line-height: 1.2; color: #2c3e50;"
},
- Zeile 3, der Stil, den ich gesucht habe;
Aus diesem Grund zeigt der Debugger folgende Zeilen an:
[DEBUG PRE-H1] Style='P4' (Clean='p4') | Text='Einführung in die Sprache PHP7 anhand von Beispielen...'
>>> DOKUMENTTITEL ERKANNT: Einführung in die Sprache PHP7 anhand eines Beispiels
Er ist auf den Stil „P4“ gestoßen und zeigt nun an, dass der Dokumenttitel gefunden wurde. Sobald dieser gefunden wurde, können Sie den Schlüssel [debug] in [config.py] auf [false] setzen:
Sehen wir uns nun die Konvertierung des Kapitels [Beispiele] an, das die Beispiele enthält, die der Gemini/ChatGPT-Konverter verarbeiten kann:
11.4. Aufzählungslisten
ODT-/DOCX-Dokument:
 |
Oben ist der Text [Aufzählungslisten] hervorgehoben, da es sich um einen Verweis handelt, der mit einer Fußnote verknüpft ist.
HTML-Dokument:
 |
Man beachte, dass das ODT-/DOCX-Dokument verschiedene Aufzählungszeichen verwendet, während das HTML-Dokument nur eine Art von Aufzählungszeichen verwendet.
11.5. Nummerierte Listen
ODT-/DOCX-Dokument:
 |
HTML-Dokument:
 |
11.5.1. Gemischte Listen 1
ODT-/DOCX-Dokument
 |
HTML-Dokument
 |
Auch hier gibt es manchmal Unterschiede zwischen den verwendeten Aufzählungszeichen.
11.5.2. Gemischte Listen 2
ODT-/DOCX-Dokument
 |
HTML-Dokument
 |
11.6. Rich-Text-Code-Blöcke
Rich-Code-Blöcke werden im HTML identisch dargestellt (abgesehen von der Hintergrundfarbe). Hier sind drei Beispiele:
11.6.1. Beispiel 1
ODT-/DOCX-Dokument
 |
HTML-Darstellung
 |
11.6.2. Beispiel 2
ODT-/DOCX-Dokument:
 |
HTML-Ausgabe
 |
11.6.3. Beispiel 3
ODT-/DOCX-Dokument
 |
HTML-Ausgabe
 |
11.7. Blöcke mit reinem Text (Plain Text)
Die im ODT-/DOCX-Dokument gefundenen Blöcke mit Rohcode werden von MkDocs entsprechend der im Code-Block gefundenen Sprache syntaktisch hervorgehoben. Um dem Konverter zu helfen, die richtige Sprache zu finden, wurden für jede Sprache „Schlüsselzeichenfolgen“ in die Datei [config.py] eingefügt. Der Konverter zählt die gefundenen „Schlüsselzeichenfolgen“. Er ordnet den Code-Block dann der Sprache zu, für die die meisten „Schlüsselzeichenfolgen“ gefunden wurden.
Sehen wir uns einige Beispiele an.
11.7.1. Beispiel 1
ODT-/DOCX-Dokument (Java)
 |
HTML-Ausgabe
 |
Im HTML-Dokument sieht man, dass der Java-Code syntaktisch eingefärbt wurde.
11.7.2. Beispiel 2
ODT-/DOCX-Dokument (XML)
 |
HTML-Ausgabe
 |
11.7.3. Beispiel 3
ODT-/DOCX-Dokument (HTML)
 |
HTML-Ausgabe
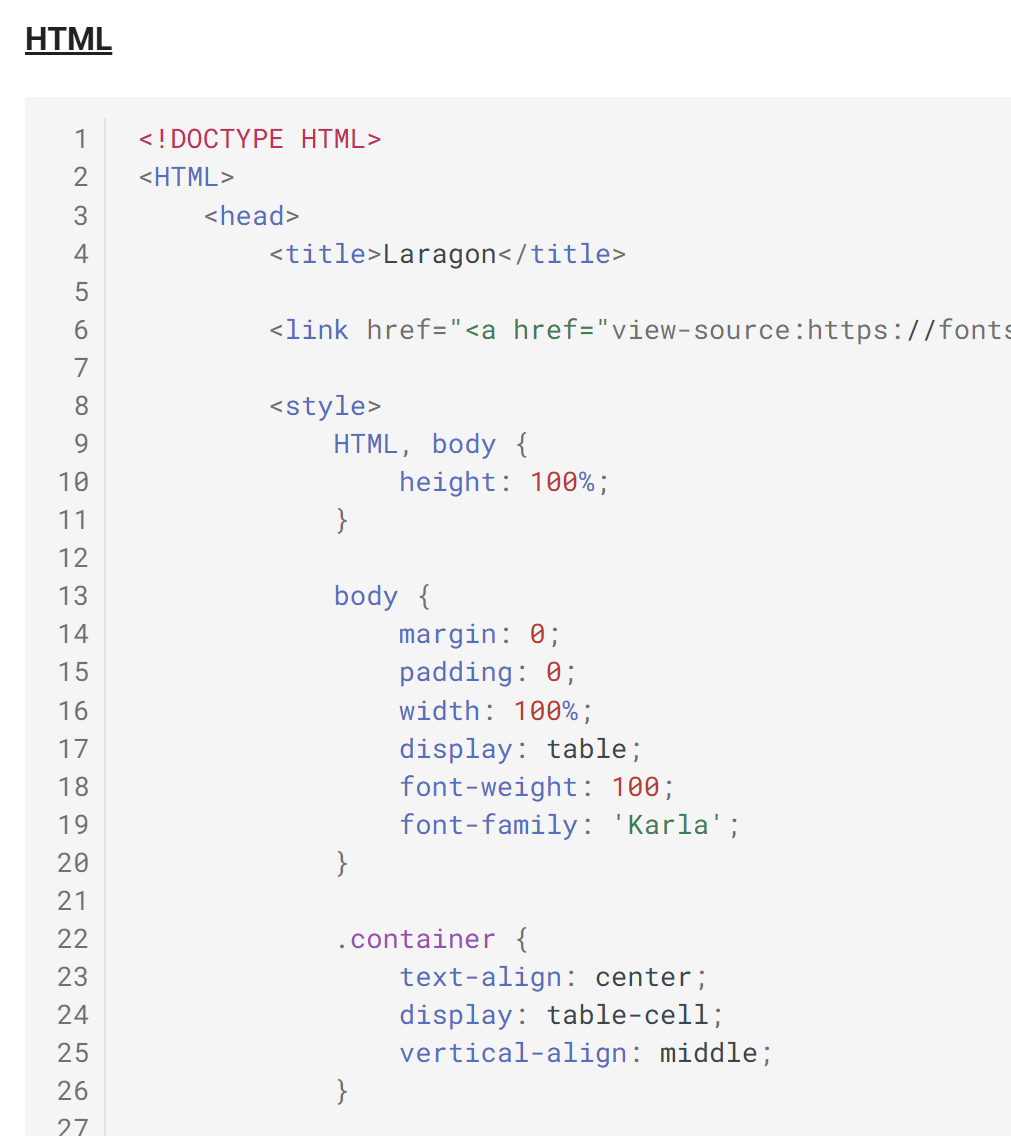 |
11.8. Weitere Code-Blöcke
ODT-/DOCX-Dokument
Ein Ausführungsergebnis mit einer ersten Zeile, die nicht bei 1 beginnt:
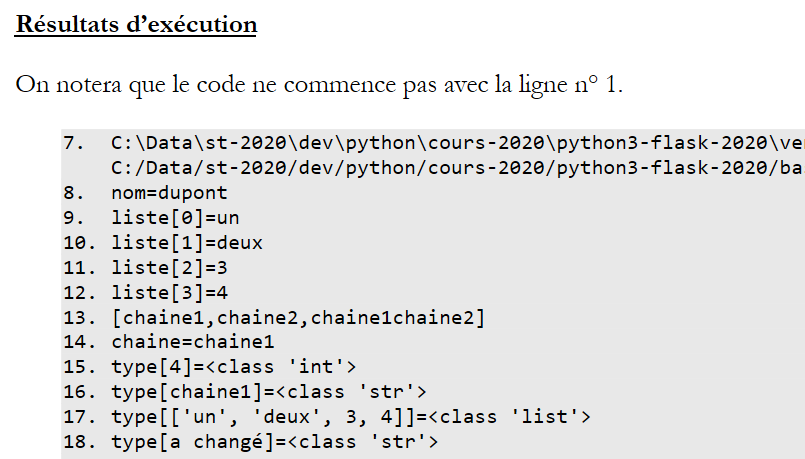 |
HTML-Ausgabe
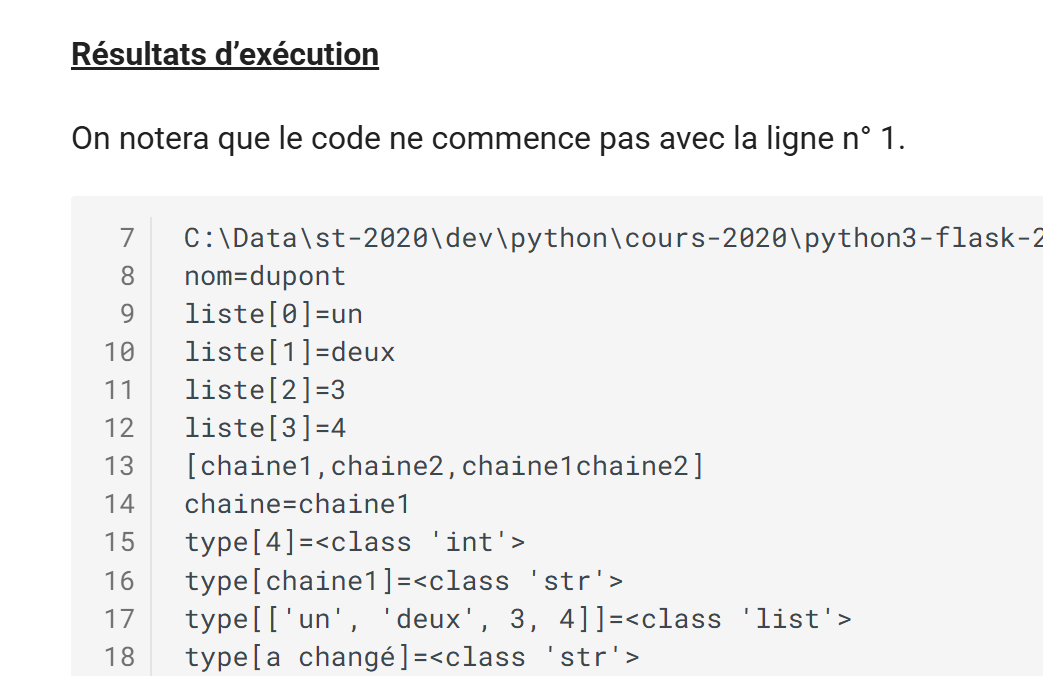 |
Ein nicht nummerierter Code-Block in ODT bleibt im HTML erhalten:
ODT-/DOCX-Dokument
 |
HTML-Ausgabe
 |
11.9. Die Links
ODT-/DOCX-Dokument
 |
HTML-Ausgabe
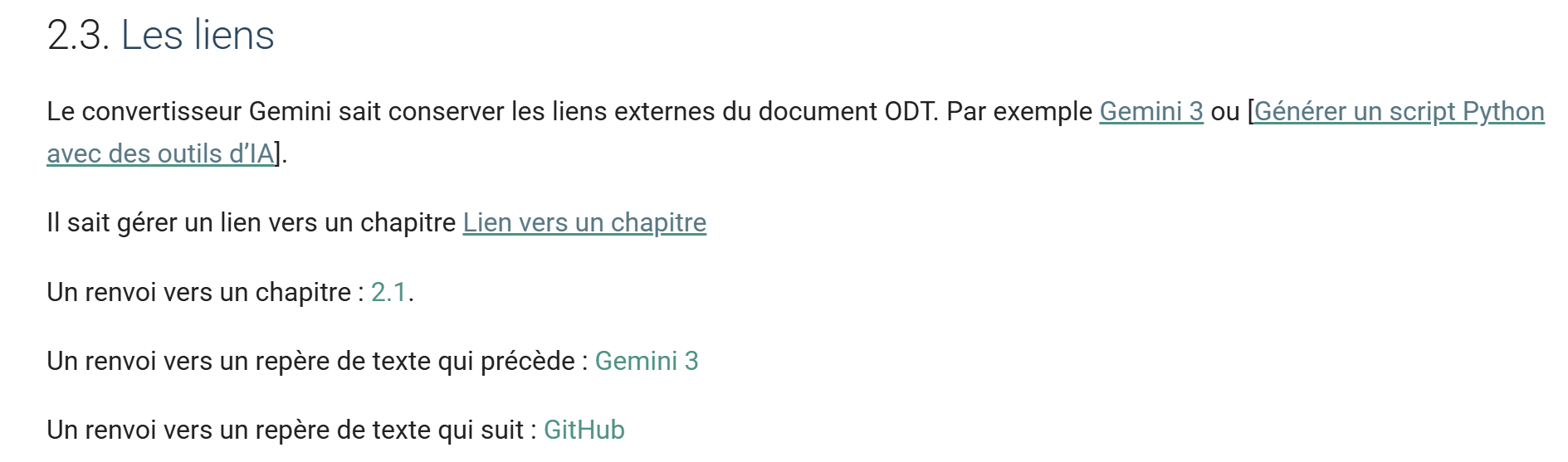 |
11.10. Textformatierung
ODT-/DOCX-Dokument
  |
HTML-Ausgabe
 |
11.11. Bilder
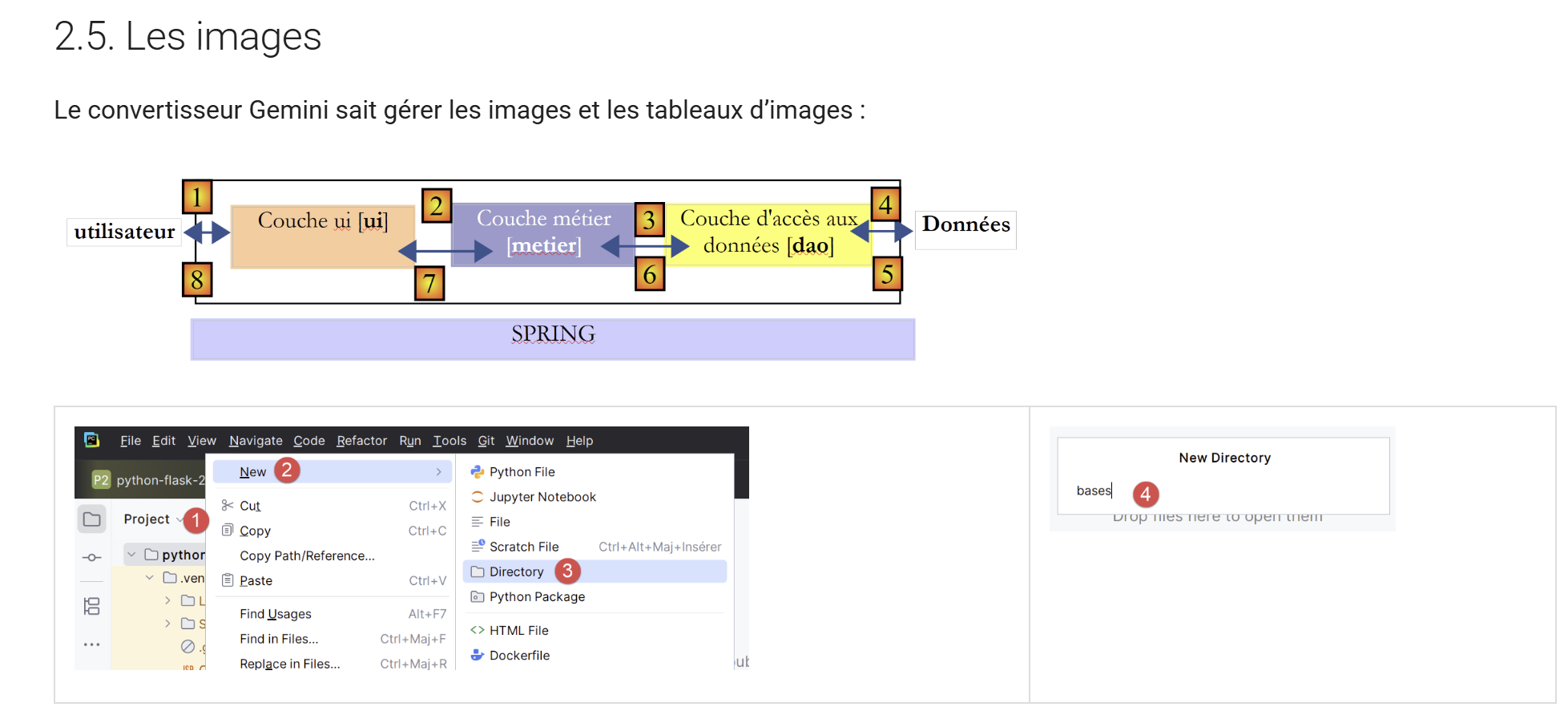 |
Es ist zu beachten, dass der Gemini/ChatGPT-Konverter die im ODT-/DOCX-Dokument vorgenommenen Bildgrößenanpassungen beibehält.
11.12. Geschützte Zeichen
ODT-/DOCX-Dokument
 |
HTML-Ausgabe
 |
ODT-/DOCX-Dokument (Markdown)
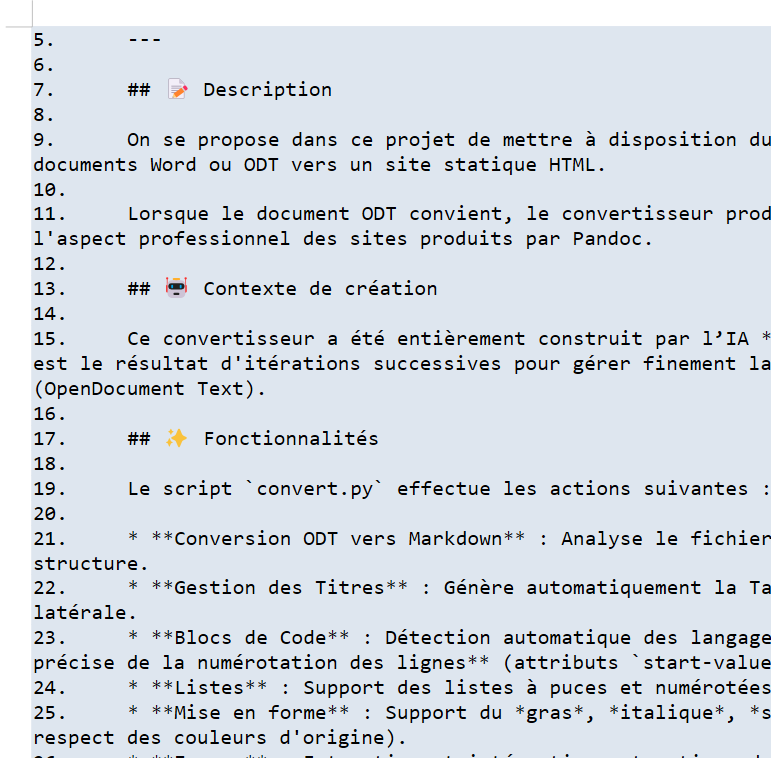 |
HTML-Ausgabe
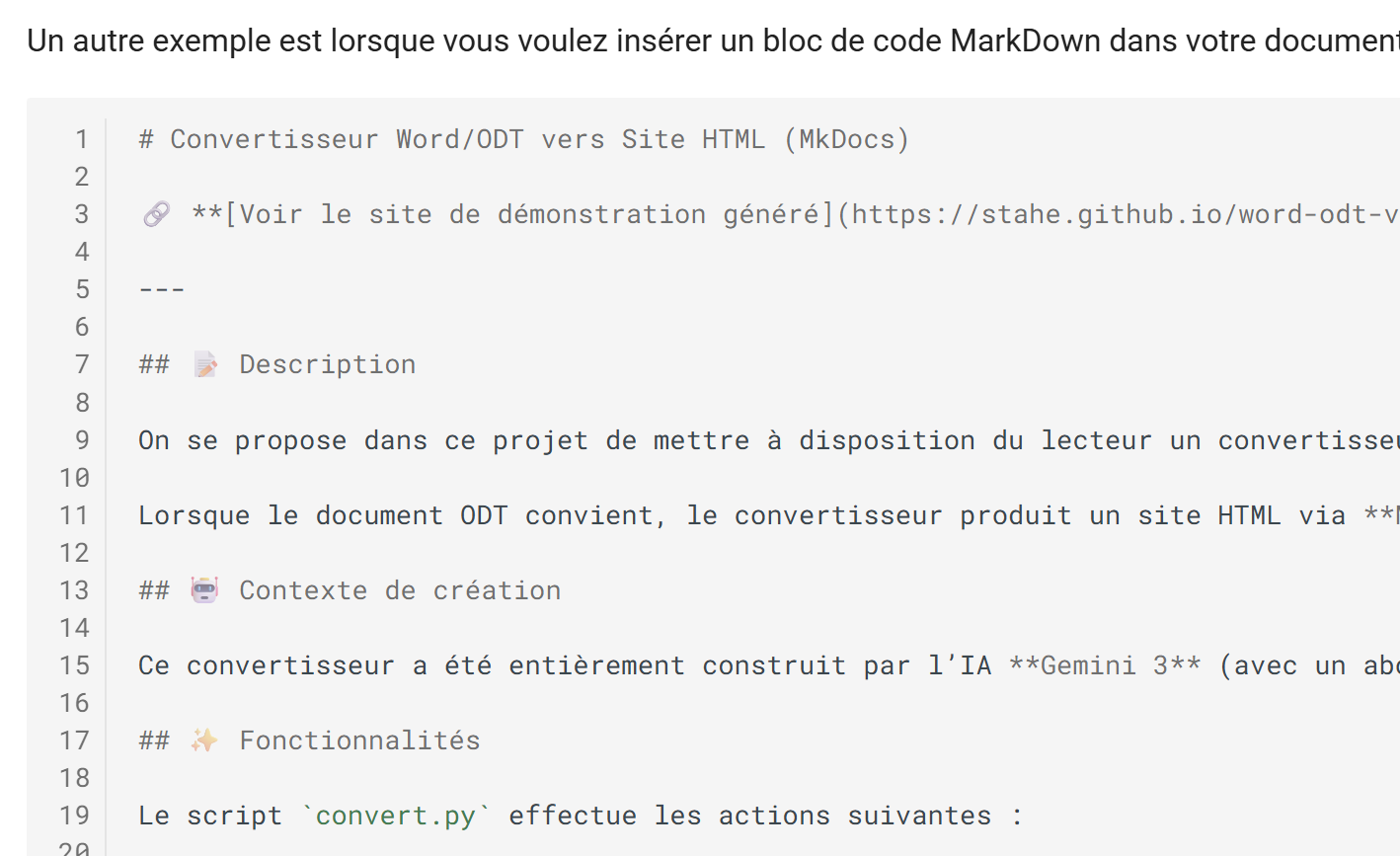 |
- Der Markdown-Code wurde beibehalten;
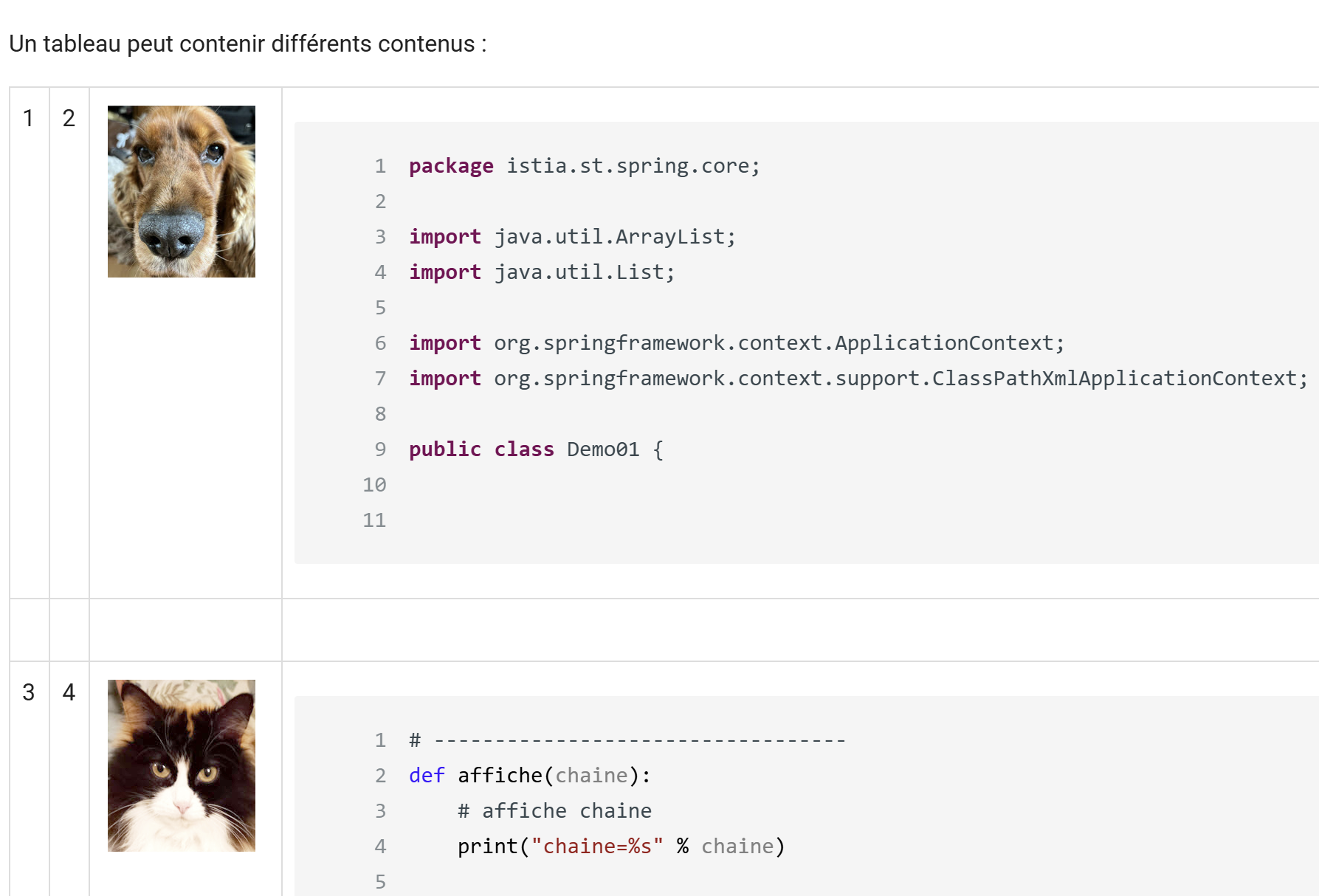
11.13. Tabellen
ODT-/DOCX-Dokument
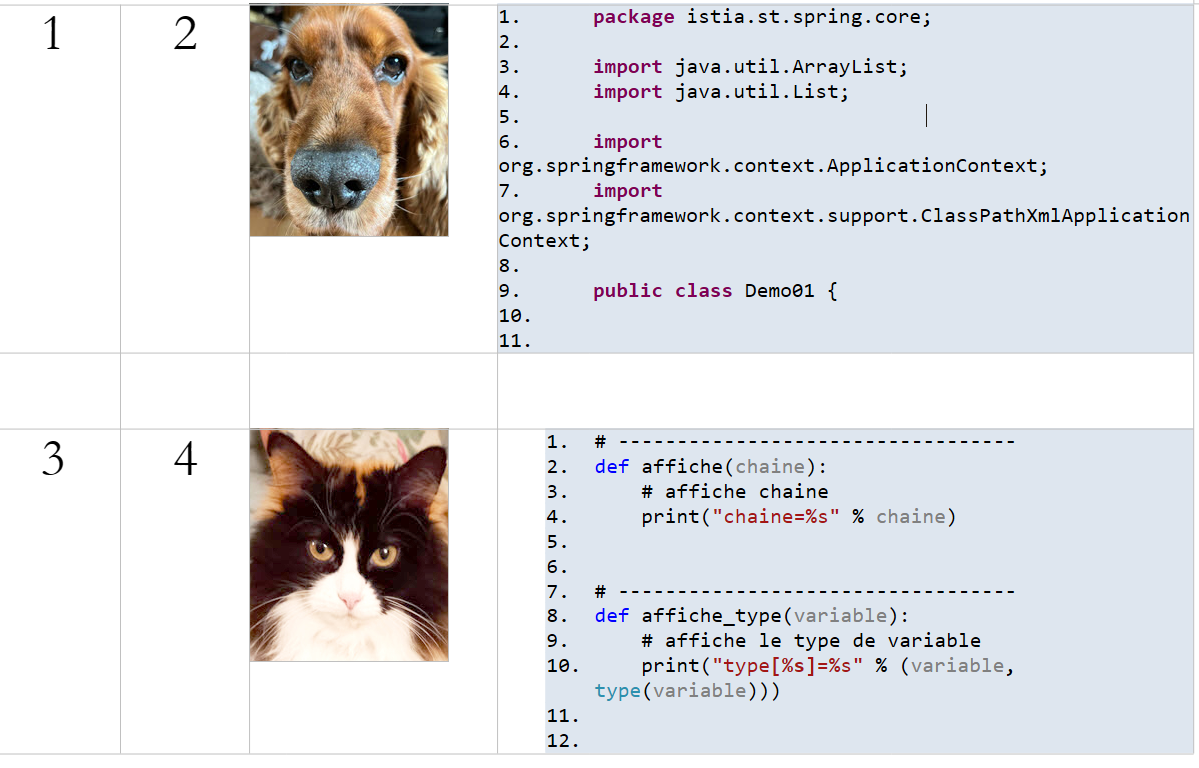 |
HTML-Ausgabe
 |
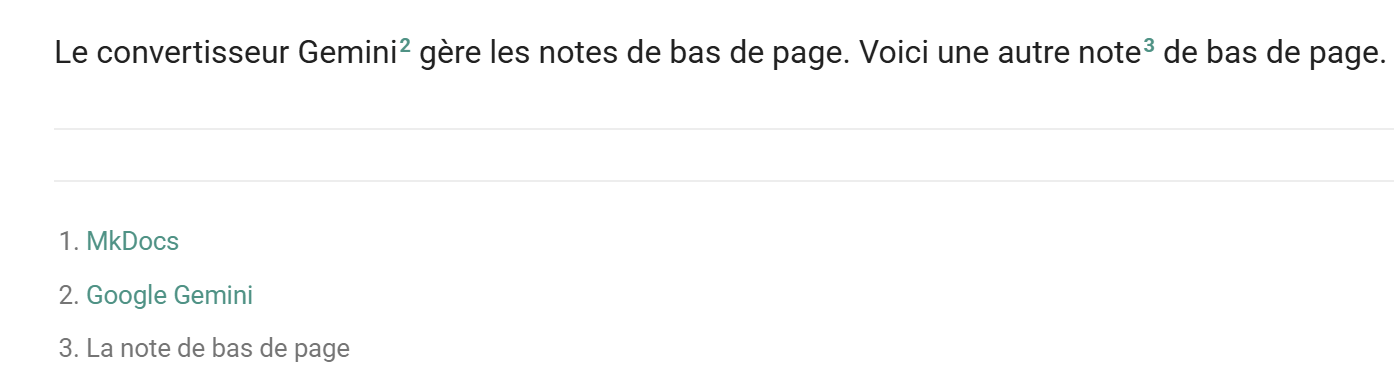
11.14. Fußnoten
 |
11.15. Bekannte Fehler
Es wurden einige Fehler festgestellt, die jedoch durch Bearbeiten der ODT-/DOCX-Datei behoben werden können:
- Auf Code-Blöcke muss eine Leerzeile folgen, da der Code-Block sonst möglicherweise nicht korrekt dargestellt wird. Der festgestellte Fall ist ein Code, auf den unmittelbar ein Titel folgt, ohne dass dieser durch eine Leerzeile davon getrennt ist;
- Aufzählungslisten dürfen keinen unteren Rand haben. Um diesen zu erhalten, muss hinter dem letzten Element der Liste eine Leerzeile eingefügt werden;
- Aufzählungslisten müssen hierarchisch gegliedert sein. So muss eine Liste der Ebene 2 immer in einer Liste der Ebene 1 enthalten sein, andernfalls wird die Liste der Ebene 2 als Code dargestellt;
Im Laufe der verschiedenen Versionen des Konverters werden einige dieser Anomalien verschwinden. Die drei oben genannten lassen sich durch Korrekturen am Quelldokument vermeiden.
11.16. Sonstige Fälle
Wenn Ihr Dokument andere Besonderheiten als die zuvor genannten aufweist, ist es sehr wahrscheinlich, dass diese vom Gemini/ChatGPT-Konverter nicht berücksichtigt werden. Was können Sie dann tun? Sie können Ihre neue Anfrage an eine der KI-Systeme richten, indem Sie ihr den aktuellen Konverter zur Verfügung stellen:
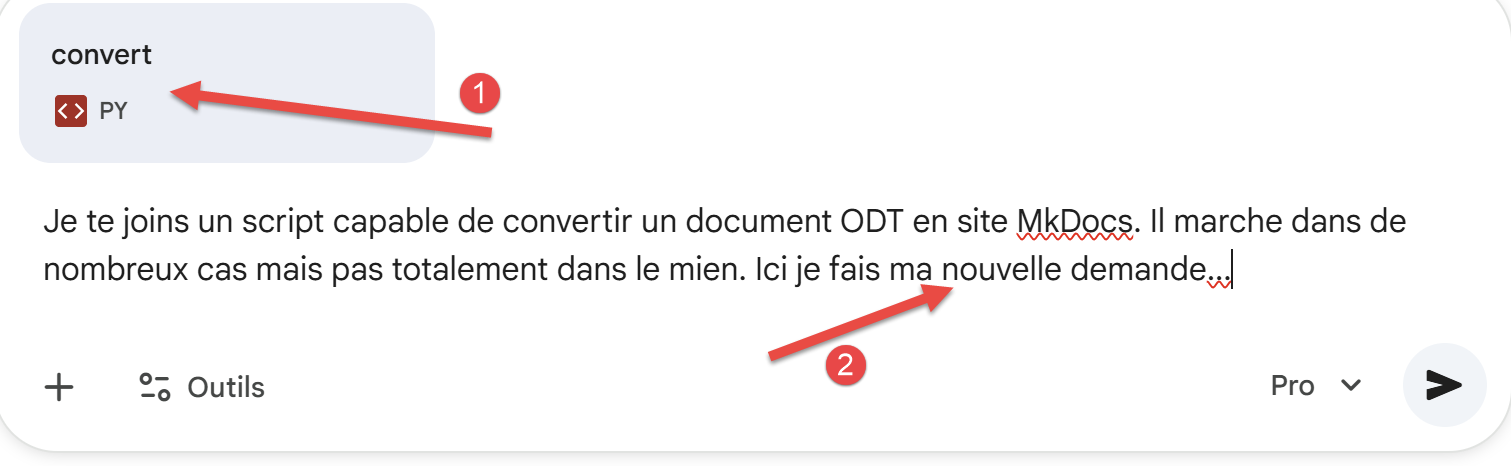 |
- In [1] füge ich den Konverter dieses Dokuments bei;
- In [2] stelle ich meine neue Anfrage;
Sie werden wahrscheinlich zahlreiche Iterationen durchlaufen. Wenn eine Version stabil ist, notieren Sie deren Nummer, um sie der KI im Falle eines Regressionsfehlers wieder mitteilen zu können. Es ist ebenfalls ratsam, von jeder stabilen Version eine Kopie anzulegen. Ein großer Nachteil beider KI-Systeme ist, dass sie relativ leicht Regressionen aufweisen. Es reicht schon, eine neue Funktion anzufordern, damit die KI den zuvor funktionierenden Code zerstört. Daher ist es wichtig, die Versionsnummern der stabilen Versionen zu notieren, um darauf zurückgreifen zu können. Im Januar 2026 schien mir ChatGPT 5.2 weniger anfällig für Regressionen zu sein als Gemini 3.