9. Generieren von Datenbanken aus JPA-Entitäten
Es ist möglich, Datenbanktabellen aus JPA-Entitäten zu erstellen. Dies werden wir nun demonstrieren. Der Zweck besteht darin, zu überprüfen, ob die aus den JPA-Entitäten generierte Datenbank tatsächlich die gewünschte ist.
9.1. Einrichten der Arbeitsumgebung
Wir werden zunächst mit einer EclipseLink-JPA-Implementierung [1] arbeiten.
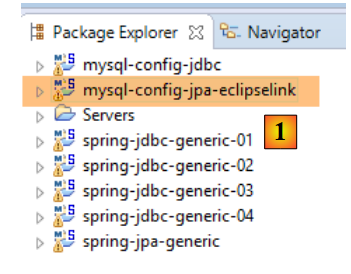 |
Anschließend löschen wir die Tabellen aus der MySQL-Datenbank [dbproduitscategories] mithilfe des Clients [MyManager] (siehe Abschnitt 23.5). Wir beginnen mit dem Löschen der Tabellen, die die Fremdschlüssel enthalten [1-3]:
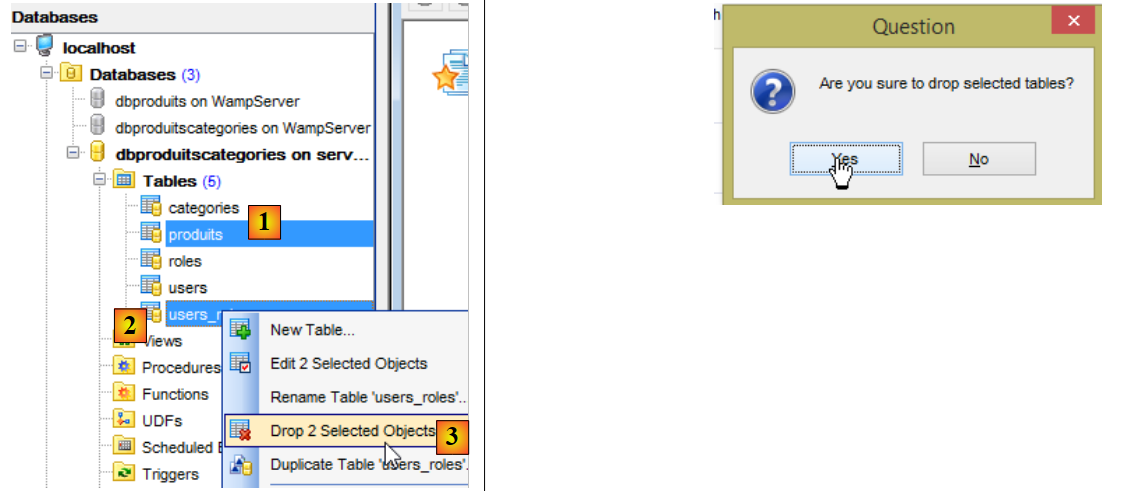 |
Anschließend wiederholen wir den Vorgang mit den drei verbleibenden Tabellen [4-6]:
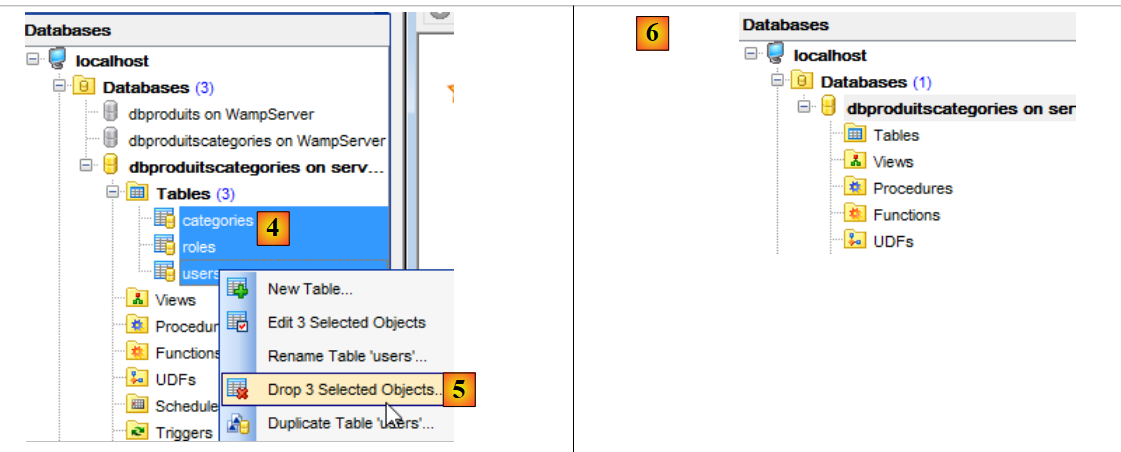 |
Das Gleiche tun wir mit der Tabelle [dbproduits], die von den Projekten [spring-jdbc-01 bis 03] verwendet wird:
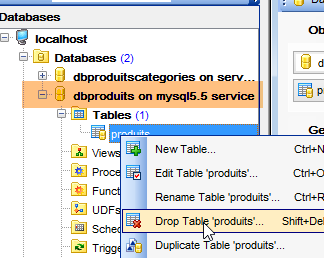 | 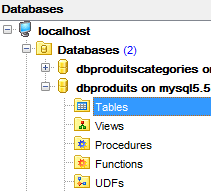 |
Außerdem müssen Sie die beiden Projekte zur Datenbankgenerierung importieren:
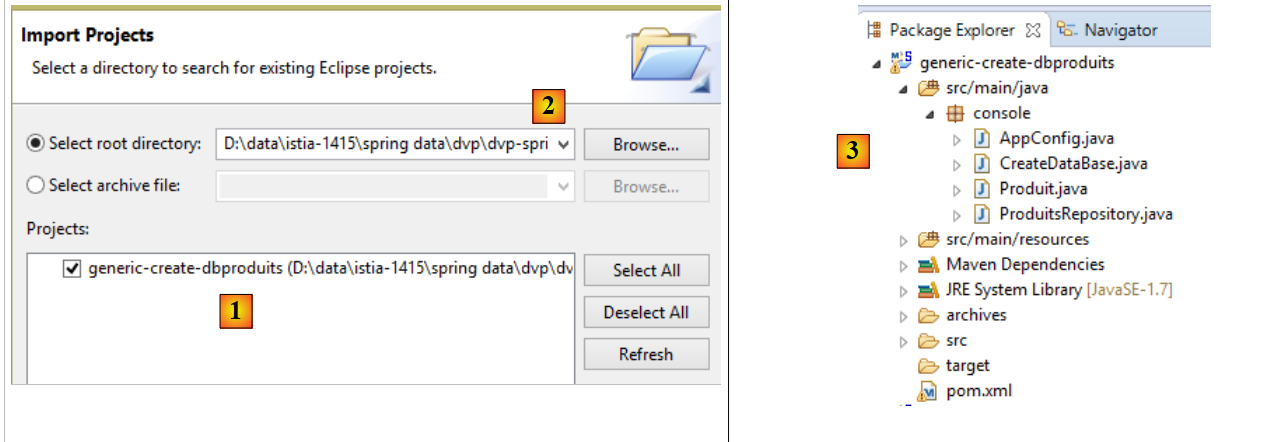 |
- Importieren Sie in [1] das Projekt [generic-create-dbproduits], das sich in [<examples>/spring-database-generic/spring-jpa] [2] befindet;
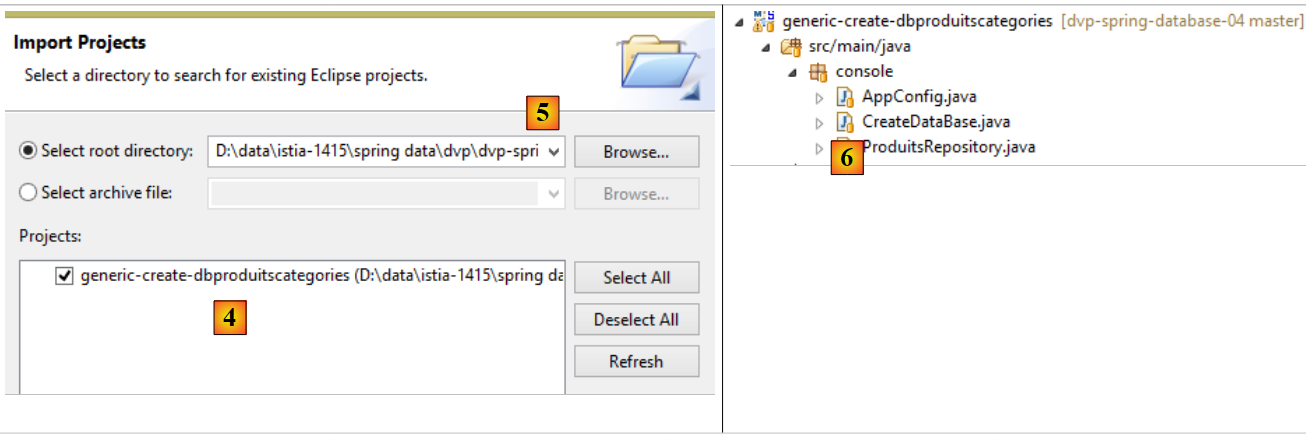 |
- Importieren Sie in [4] das Projekt [generic-create-dbproduitscategories], das sich in [<examples>/spring-database-generic/spring-jpa] [5] befindet;
Hinweis: Drücken Sie Alt-F5 und generieren Sie alle Maven-Projekte neu;
9.2. Erstellen der Datenbank [dbproduitscategories]
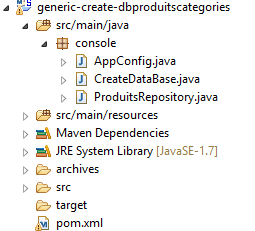 |
9.2.1. Maven-Konfiguration
Die [pom.xml]-Datei des Projekts sieht wie folgt aus:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-create-dbproduitscategories</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>generic-create-dbproduitscategories</name>
<description>création de la bases de données [dbproduitscategories] à l'aide des annotations JPA</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<!-- spring-jpa-generic -->
<dependency>
<groupId>dvp.spring.database</groupId>
<artifactId>spring-jpa-generic</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<!-- Weaver Spring -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-instrument</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<start-class>spring.data.console.Main</start-class>
<java.version>1.7</java.version>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
</plugin>
</plugins>
</build>
</project>
- Zeilen 22–26: die Abhängigkeit vom Projekt [spring-jpa-generic], das in Abschnitt 6.4 behandelt wurde;
- Zeilen 28–32: die Abhängigkeit von einem Weaver, der zur Anreicherung der JPA-Entitäten der EclipseLink- und OpenJpa-Implementierungen verwendet wird. Diese Abhängigkeit ist in der [pom.xml]-Datei nicht erforderlich, aber die zugehörige JAR-Datei wird als Java-Agent verwendet. Durch die Aufnahme der Abhängigkeit in die [pom.xml]-Datei wird sichergestellt, dass die JAR-Datei verfügbar ist;
Letztendlich lauten die Abhängigkeiten wie folgt:
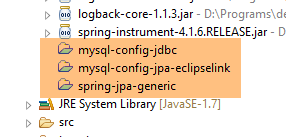 |
9.2.2. Spring-Konfiguration
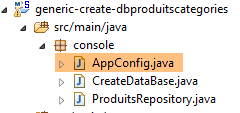 |
Die Klasse [AppConfig] konfiguriert das Spring-Projekt:
package console;
import generic.jpa.config.ConfigJpa;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
@Configuration
@Import({ ConfigJpa.class })
@EnableJpaRepositories(basePackages = { "console" })
public class AppConfig {
}
- Zeile 10: Die Klasse ruft die Beans aus der Klasse [ConfigJpa] ab. Beachten Sie, dass diese Klasse mit den JPA-Entitäten in der Datenbank [dbproduitscategories] arbeitet (siehe Abschnitt 6.3);
- Zeile 11: Wir legen fest, dass das [console]-Paket durchsucht werden muss, um [CrudRepository]-Instanzen zu finden;
In der Klasse [ConfigJpa] finden wir die folgende Bean (variiert je nach verwendeter JPA-Implementierung):
// the provider JPA
@Bean
public JpaVendorAdapter jpaVendorAdapter() {
// Note: JPA entities and Eclipselink configuration are in the META-INF/persistence.xml file
EclipseLinkJpaVendorAdapter eclipseLinkJpaVendorAdapter = new EclipseLinkJpaVendorAdapter();
eclipseLinkJpaVendorAdapter.setShowSql(false);
eclipseLinkJpaVendorAdapter.setDatabase(Database.MYSQL);
eclipseLinkJpaVendorAdapter.setGenerateDdl(true);
return eclipseLinkJpaVendorAdapter;
}
Zeile 8 ist hier entscheidend. Sie ist in allen verwendeten JPA-Implementierungen vorhanden. Sie legt fest, dass die mit den JPA-Entitäten verbundenen Tabellen erstellt werden müssen, falls sie nicht existieren. Wir werden diese Eigenschaft nutzen, um die Tabellen zu generieren.
9.2.3. Die Repositorys
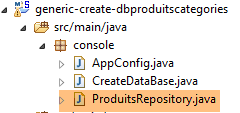 |
Die Schnittstelle [ProductsRepository] sieht wie folgt aus:
package console;
import generic.jpa.entities.dbproduitscategories.Produit;
import org.springframework.data.repository.CrudRepository;
public interface ProduitsRepository extends CrudRepository<Produit, Long> {
}
Die Instanziierung dieser Schnittstelle löst die Instanziierung der JPA-Schicht aus. Tatsächlich verweist die Schnittstelle in Zeile 7 auf die JPA-Entität [Product], was die Instanziierung der JPA-Schicht erzwingt. Wir hätten jede beliebige Schnittstelle [CrudRepository] verwenden können, die auf eine der JPA-Entitäten verweist. Wir sehen, dass zwar das [Repository] nur auf die JPA-Entität [Product] verweist, jedoch alle Tabellen für alle JPA-Entitäten generiert werden.
9.2.4. Die ausführbare Klasse
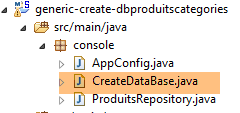 |
Die Klasse [CreateDatabase] sieht wie folgt aus:
package console;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class CreateDataBase {
public static void main(String[] args) {
// simply instantiate the Spring context to create the database tables [dbproduitscategories]
// you also need at least one Spring Data Repository, otherwise nothing happens
System.out.println("Travail en cours...");
new AnnotationConfigApplicationContext(AppConfig.class).close();
System.out.println("Travail terminé...");
}
}
- Zeile 11: Wir instanziieren den Spring-Kontext und schließen ihn sofort wieder. In diesem Kontext befindet sich die Bean [ProductsRepository], die auf die JPA-Entität [Product] verweist. Dies reicht aus, um die JPA-Schicht zu instanziieren und somit die Tabellen in der Datenbank [productcategories] zu generieren.
9.2.5. Tabellen mit EclipseLink generieren
Wir befinden uns in der folgenden Konfiguration:
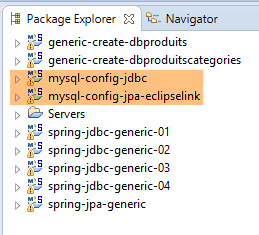 |
- Die [JDBC]-Schicht ist für die MySQL-Datenbank [dbproduitscategories] konfiguriert;
- die [JPA]-Schicht ist mit EclipseLink implementiert;
- die Datenbank [dbproduitscategories] enthält keine Tabellen;
Hinweis: Drücken Sie Alt-F5 und generieren Sie alle Maven-Projekte neu;
Wir verwenden die folgende Ausführungskonfiguration:
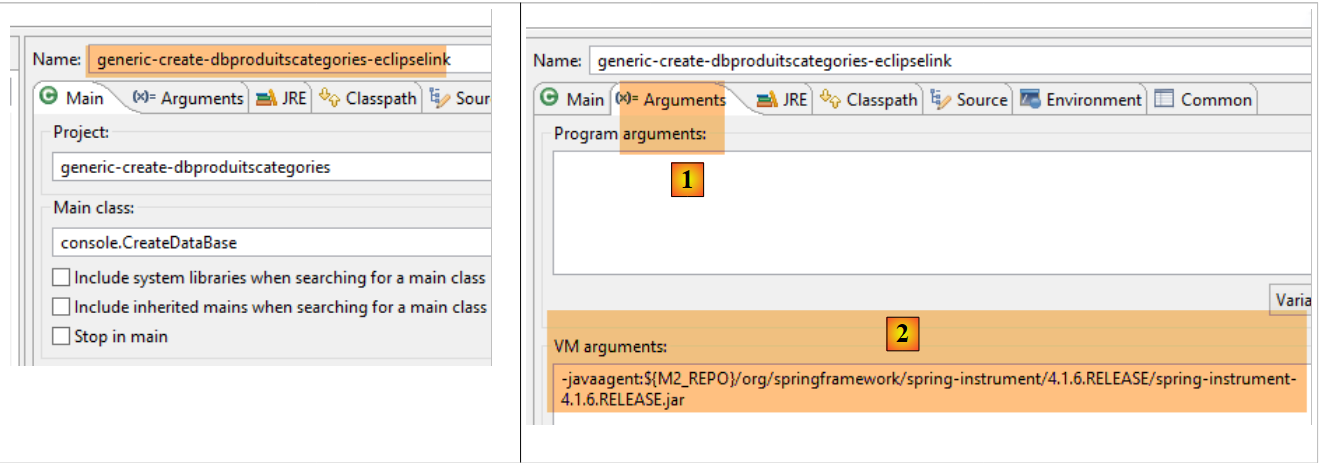 |
- In [1-2] erfordert diese Ausführungskonfiguration einen Java-Agenten, damit der Test erfolgreich ist. Je nach Situation benötigt EclipseLink diesen Agenten nicht immer, aber hier schlägt die Ausführung fehl, wenn er nicht vorhanden ist. Dieser Agent ist kein EclipseLink-Agent, sondern ein Spring-Agent. Er wird durch die Abhängigkeit bereitgestellt:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-instrument</artifactId>
<scope>runtime</scope>
</dependency>
in der [pom.xml]-Datei des Projekts enthalten. Der Agent befindet sich unter [<m2-repo>/org/springframework/spring-instrument/4.1.6.RELEASE/spring-instrument-4.1.6.RELEASE.jar], wobei <m2-repo> das lokale Maven-Repository ist;
Die Ausführung liefert das folgende Ergebnis:
 |
In [3] sehen wir, dass die Tabellen generiert wurden. Sehen wir uns nun die DDL (Domain Definition Language) der Datenbank an:
 | 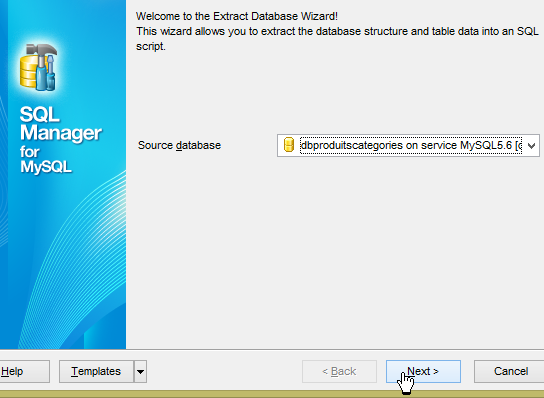 |
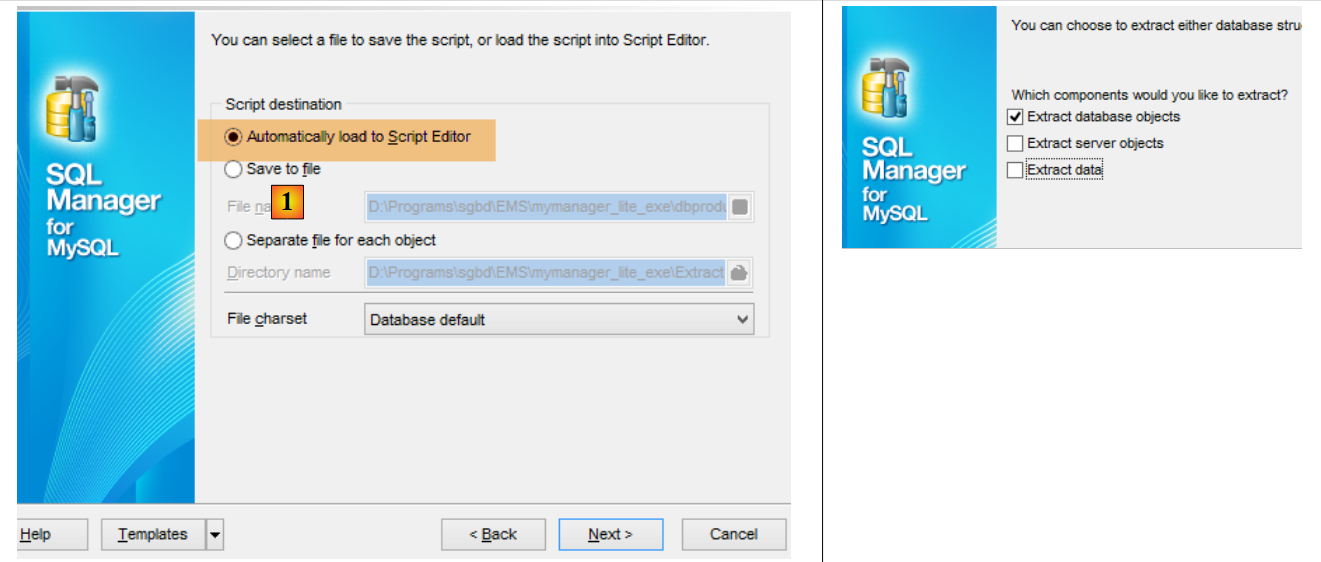 |
Das SQL-Skript zum Erstellen der Tabellen kann auch in einer Datei gespeichert werden [1].
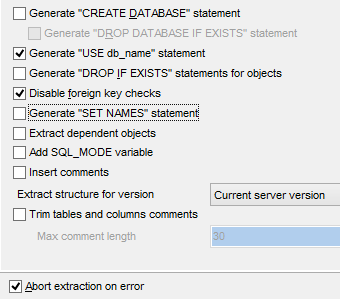 |   |
Das generierte SQL-Skript lautet wie folgt:
SET FOREIGN_KEY_CHECKS=0;
USE `dbproduitscategories`;
CREATE TABLE `categories` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `NOM` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci DEFAULT NULL,
`CATEGORIE_ID` BIGINT(20) NOT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
`CATEGORIE` INTEGER(11) NOT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `NOM` (`NOM`) USING BTREE,
KEY `FK_PRODUITS_CATEGORIE_ID` (`CATEGORIE_ID`) USING BTREE,
CONSTRAINT `FK_PRODUITS_CATEGORIE_ID` FOREIGN KEY (`CATEGORIE_ID`) REFERENCES `categories` (`ID`) ON DELETE CASCADE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `roles` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users_roles` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
Sehen wir uns zum Beispiel das SQL-Skript an, das die Tabelle [PRODUCTS] generiert (Zeilen 15–29):
- Zeile 16: [ID] ist der Primärschlüssel (Zeile 23) mit dem Attribut [AUTO_INCREMENT] (Zeile 5). Dies entspricht den Annotationen [@Id, @GeneratedValue(strategy = GenerationType.IDENTITY), @Column(name = ConfigJdbc.TAB_JPA_ID)] für das Feld [id] der JPA-Entität;
- Zeile 17: Die Definition der Spalte [DESCRIPTION] entspricht der Annotation [@Column(name = ConfigJdbc.TAB_PRODUITS_DESCRIPTION, length = 100)] für das Feld [description] der JPA-Entität;
- Zeile 18: Die Spalte [CATEGORIE_ID] ist ein Fremdschlüssel aus der Tabelle [PRODUITS] auf die Spalte [CATEGORIES.ID] (Zeile 26). Außerdem verfügt dieser Fremdschlüssel über das Attribut [ON DELETE CASCADE]. Dies entspricht den Annotationen [@ManyToOne(fetch = FetchType.LAZY), @JoinColumn(name = ConfigJdbc.TAB_PRODUITS_CATEGORIE_ID)] für das Feld [Produit.categorie] sowie der Annotation [@OneToMany(fetch = FetchType.LAZY, mappedBy = "categorie", cascade = { CascadeType.ALL }), @CascadeOnDelete] des Feldes [Categorie.produits];
- Zeile 19: Die Definition der Spalte [NAME] entspricht der Annotation [@Column(name = ConfigJdbc.TAB_PRODUITS_NAME, unique = true, length = 30, nullable = false)] des Feldes [Product.name];
- Zeile 20: Die Definition der Spalte [PRICE] entspricht der Annotation [@Column(name = ConfigJdbc.TAB_PRODUITS_PRIX, nullable = false)] des Feldes [Product.price];
- Zeilen 24–25: Das Skript erstellt drei Indizes für jede der eindeutigen Spalten der Tabelle;
Die generierten Tabellen haben keinen Standardwert für das Feld VERSIONING, während der Java-Code erwartet, dass einer vorhanden ist. Fehlt dieser Standardwert, schlagen bestimmte Tests fehl. Wir fügen dieses Attribut wie folgt hinzu:
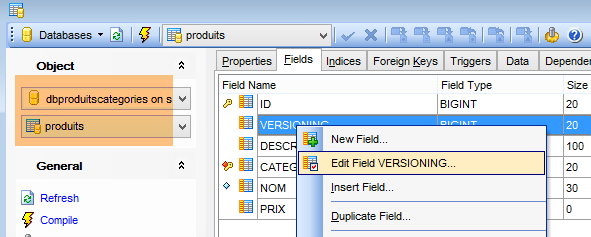 |
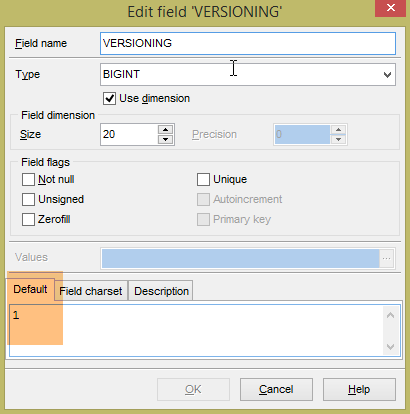 |
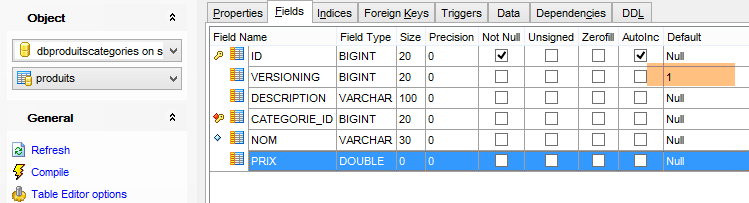 |
Dies geschieht für die fünf Tabellen, die die Spalte [VERSIONING] enthalten. Der Standardwert spielt keine Rolle; die Spalte muss lediglich vorhanden sein. Anschließend wird der Wert jedes Mal um 1 erhöht, wenn die Zeile, zu der er gehört, geändert wird.
Sobald dies erledigt ist, überprüfen Sie, ob die folgenden Testkonfigurationen erfolgreich sind:
- [spring-jdbc-generic-04.JUnitTestDao], der die JDBC-Implementierung testet;
- [spring-jpa-generic-JUnitTestDao-hibernate-eclipselink], der die Hibernate- oder EclipseLink-JPA-Implementierungen testet (in diesem Fall ist es EclipseLink)
Beide Tests müssen erfolgreich sein.
9.2.6. Tabellen mit Hibernate generieren
Wir erstellen die Hibernate-Tabellen unter Verwendung der folgenden Eclipse-Umgebung:
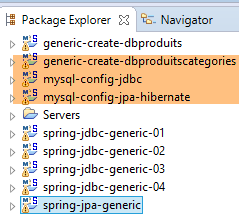 |
Die Tabellengenerierung erfolgt über die Laufkonfiguration mit dem Namen [generic-create-dbproduitscategories-hibernate] ohne Java-Agent;
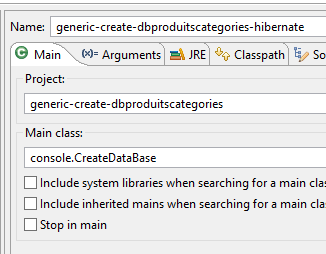 |  |
Das von Hibernate generierte SQL-Skript für die Datenbank lautet wie folgt:
SET FOREIGN_KEY_CHECKS=0;
USE `dbproduitscategories`;
CREATE TABLE `categories` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `UK_7ajcg7japnxw846ru01damg8s` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci DEFAULT NULL,
`CATEGORIE_ID` BIGINT(20) NOT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `UK_hfvjn9lp7qoo5x79uu0ump3rf` (`NOM`) USING BTREE,
KEY `FK_p3foj9yrqnmi7856n9s8mbpue` (`CATEGORIE_ID`) USING BTREE,
CONSTRAINT `FK_p3foj9yrqnmi7856n9s8mbpue` FOREIGN KEY (`CATEGORIE_ID`) REFERENCES `categories` (`ID`)
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `roles` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users_roles` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
Die generierten Tabellen sind identisch, da Hibernate ebenfalls JPA-Annotationen verwendet hat. Für Hibernate konnte ich kein Äquivalent zur EclipseLink-Annotation [@OnCascadeDelete] finden, die das SQL-Attribut [ON DELETE CASCADE] für den Fremdschlüssel [PRODUCTS.CATEGORY_ID] (Zeile 25) generiert hat. Dieses Attribut muss daher manuell generiert werden, da es für den Test erforderlich ist:
 |
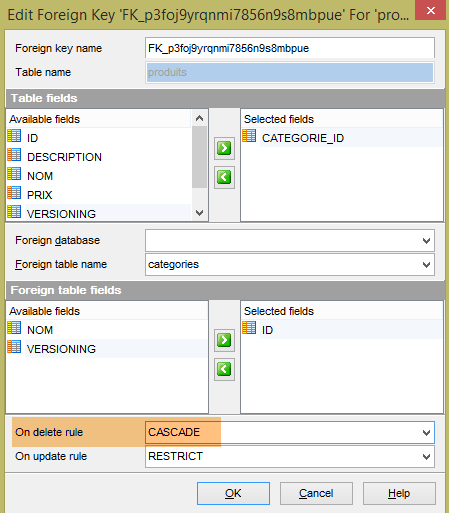 |
 |
Das Gleiche muss für die beiden Fremdschlüssel in der Tabelle [USERS_ROLES] getan werden:
 |
Schließlich müssen, wie bei der EclipseLink-Implementierung, die [VERSIONING]-Spalten in den fünf Tabellen einen Standardwert haben:
|
Sobald dies erledigt ist, überprüfen Sie, ob die folgenden Testkonfigurationen erfolgreich sind:
- [spring-jdbc-generic-04.JUnitTestDao], der die JDBC-Implementierung testet;
- [spring-jpa-generic-JUnitTestDao-hibernate-eclipselink], der die Hibernate- oder Eclipselink-JPA-Implementierungen testet (in diesem Fall ist es Hibernate)
Beide Tests müssen erfolgreich sein.
9.2.7. Tabellen mit OpenJpa generieren
Wir wiederholen den vorherigen Vorgang mit einer OpenJpa-JPA-Implementierung:
 |
Hinweis: Drücken Sie Alt-F5 und generieren Sie alle Maven-Projekte neu;
Wir ändern die Klasse [ConfigJpa], die das Projekt [mysql-config-jpa-openjpa] konfiguriert, wie folgt:
package generic.jpa.config;
import generic.jdbc.config.ConfigJdbc;
import java.util.Map;
import javax.persistence.EntityManagerFactory;
import org.apache.tomcat.jdbc.pool.DataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.orm.jpa.JpaTransactionManager;
import org.springframework.orm.jpa.JpaVendorAdapter;
import org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean;
import org.springframework.orm.jpa.vendor.Database;
import org.springframework.orm.jpa.vendor.OpenJpaVendorAdapter;
import org.springframework.transaction.PlatformTransactionManager;
@Configuration
@Import({ ConfigJdbc.class })
public class ConfigJpa {
// the provider JPA
@Bean
public JpaVendorAdapter jpaVendorAdapter() {
OpenJpaVendorAdapter openJpaVendorAdapter = new OpenJpaVendorAdapter();
openJpaVendorAdapter.setShowSql(false);
openJpaVendorAdapter.setDatabase(Database.MYSQL);
openJpaVendorAdapter.setGenerateDdl(true);
return openJpaVendorAdapter;
}
..
// EntityManagerFactory
@Bean
public EntityManagerFactory entityManagerFactory(JpaVendorAdapter jpaVendorAdapter, DataSource dataSource) {
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(jpaVendorAdapter);
factory.setPackagesToScan(ENTITIES_PACKAGES);
Map<String, Object> mapJpaProperties = factory.getJpaPropertyMap();
mapJpaProperties.put("openjpa.jdbc.MappingDefaults",
"ForeignKeyDeleteAction=cascade,JoinForeignKeyDeleteAction=restrict");
factory.setDataSource(dataSource);
factory.afterPropertiesSet();
return factory.getObject();
}
}
- Zeilen 40–41: Wir erstellen eine Eigenschaft für OpenJPA, die festlegt, wie Fremdschlüssel beim Generieren von Tabellen erzeugt werden sollen. Ohne diese Eigenschaft werden keine Fremdschlüssel generiert. Das Attribut [ForeignKeyDeleteAction=cascade] ermöglicht die Generierung der Klausel [ON DELETE CASCADE] für diese Fremdschlüssel;
Die Tabellengenerierung erfolgt durch die Laufzeitkonfiguration mit dem Namen [generic-create-dbproduitscategories-openjpa], die zwei Java-Agenten enthält;
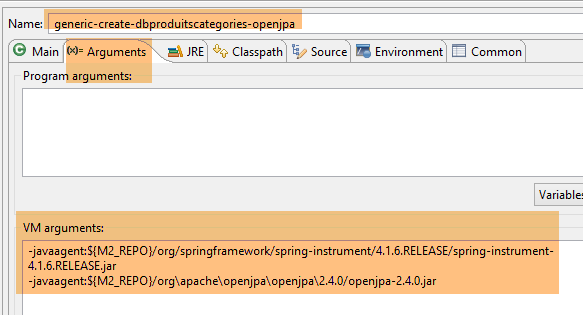
- Der erste Java-Agent ist der Spring-Agent, der bereits mit EclipseLink verwendet wird;
- Der zweite Java-Agent wird von OpenJpa bereitgestellt;
Das SQL-Skript für die generierte Datenbank lautet dann wie folgt:
SET FOREIGN_KEY_CHECKS=0;
USE `dbproduitscategories`;
CREATE TABLE `categories` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `U_CTGORIS_NOM` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci DEFAULT NULL,
`CATEGORIE_ID` BIGINT(20) DEFAULT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `U_PRODUTS_NOM` (`NOM`) USING BTREE,
KEY `CATEGORIE_ID` (`CATEGORIE_ID`) USING BTREE,
CONSTRAINT `produits_ibfk_1` FOREIGN KEY (`CATEGORIE_ID`) REFERENCES `categories` (`ID`) ON DELETE CASCADE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `roles` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`NAME` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `U_ROLES_NAME` (`NAME`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`LOGIN` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`NAME` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PASSWORD` VARCHAR(60) COLLATE utf8_general_ci NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `U_USERS_LOGIN` (`LOGIN`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users_roles` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`VERSIONING` BIGINT(20) DEFAULT NULL,
`ROLE_ID` BIGINT(20) NOT NULL,
`USER_ID` BIGINT(20) NOT NULL,
PRIMARY KEY (`ID`) USING BTREE,
KEY `ROLE_ID` (`ROLE_ID`) USING BTREE,
KEY `USER_ID` (`USER_ID`) USING BTREE,
CONSTRAINT `users_roles_ibfk_2` FOREIGN KEY (`USER_ID`) REFERENCES `users` (`ID`) ON DELETE CASCADE,
CONSTRAINT `users_roles_ibfk_1` FOREIGN KEY (`ROLE_ID`) REFERENCES `roles` (`ID`) ON DELETE CASCADE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
Dies entspricht der Vorgehensweise bei EclipseLink. Wir werden daher die gleichen Korrekturen an den Tabellen vornehmen. Sobald dies erledigt ist, überprüfen Sie, ob die folgenden Testfälle erfolgreich sind:
- [spring-jdbc-generic-04.JUnitTestDao], der die JDBC-Implementierung testet;
- [spring-jpa-generic-JUnitTestDao-openjpa], der eine OpenJPA-JPA-Implementierung testet;
Beide Durchläufe müssen erfolgreich sein.
9.3. Erstellen der Datenbank [dbproduits]
Die Datenbank [dbproduits] wird von den Projekten [spring-jdbc-01 bis 03] verwendet. Sie kann auch aus einer JPA-Entität generiert werden.
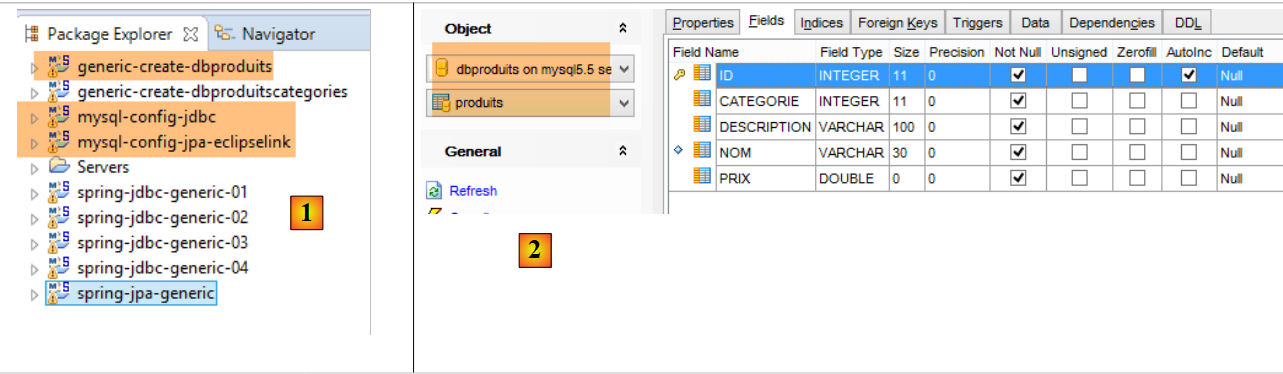 |
- In [1] die Eclipse-Projekte. Wir verwenden eine MySQL/EclipseLink-Konfiguration. Das Projekt zum Erstellen der Datenbank [dbproduits] ist [generic-create-dbproduits];
- in [2] die zu generierende Tabelle [PRODUITS];
Hinweis: Drücken Sie Alt-F5 und generieren Sie alle Maven-Projekte neu;
9.3.1. Maven-Konfiguration
Die Maven-Konfiguration für das Projekt [generic-create-dbproduits] lautet wie folgt:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-create-dbproduits</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>generic-create-dbproduits</name>
<description>création de la bases de données [dbproduits] à l'aide des annotations JPA</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<!-- configuration JPA of SGBD -->
<dependency>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-config-jpa</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
</dependencies>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<start-class>spring.data.console.Main</start-class>
<java.version>1.7</java.version>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
</plugin>
</plugins>
</build>
</project>
Es gibt nur eine Abhängigkeit in Zeilen 22–26 des Projekts, die die JPA-Schicht konfiguriert. Letztendlich lauten die Abhängigkeiten wie folgt:
 |
9.3.2. Die Spring-Konfiguration
 |
Die Spring-Konfigurationsklasse sieht wie folgt aus:
package console;
import generic.jdbc.config.ConfigJdbc;
import generic.jpa.config.ConfigJpa;
import javax.persistence.EntityManagerFactory;
import org.apache.tomcat.jdbc.pool.DataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.orm.jpa.JpaVendorAdapter;
import org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean;
@EnableJpaRepositories(basePackages = { "console" })
@Configuration
@Import({ ConfigJpa.class })
public class AppConfig {
// data source
@Bean
public DataSource dataSource() {
// data source TomcatJdbc
DataSource dataSource = new DataSource();
// configuration access JDBC
dataSource.setDriverClassName(ConfigJdbc.DRIVER_CLASSNAME);
dataSource.setUsername(ConfigJdbc.USER_DBPRODUITS);
dataSource.setPassword(ConfigJdbc.PASSWD_DBPRODUITS);
dataSource.setUrl(ConfigJdbc.URL_DBPRODUITS);
// initially open connections
dataSource.setInitialSize(5);
// result
return dataSource;
}
// EntityManagerFactory
@Bean
public EntityManagerFactory entityManagerFactory(JpaVendorAdapter jpaVendorAdapter, DataSource dataSource) {
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(jpaVendorAdapter);
factory.setPersistenceUnitName("generic-jpa-entities-dbproduits");
factory.setDataSource(dataSource);
factory.afterPropertiesSet();
return factory.getObject();
}
}
- Zeile 18: Wir importieren die Beans aus der Klasse [ConfigJpa] (Abschnitt 7.3);
- Zeilen 22–35: Wir definieren die Datenquelle [dataSource] neu. In [ConfigJpa] ist die Datenquelle die Datenbank [dbproduitscategories]. Hier ist es die Datenbank [dbproduits];
- Zeilen 38–46: Wir definieren die [entityManagerFactory]-Bean aus der Klasse [ConfigJpa] neu. In dieser Klasse waren die JPA-Entitäten [Product, Category]. Hier ist es nur [Product], und es hat nicht dieselbe Definition wie in dem Projekt, das die JPA-Schicht konfiguriert;
- Zeile 42: Um diese neue JPA-Entität zu definieren, verweisen wir auf die in der Datei [META-INF/persistence.xml] definierten JPA-Entitäten:
 |
Die Datei [persistence.xml] sieht wie folgt aus:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd">
<persistence-unit name="generic-jpa-entities-dbproduits" transaction-type="RESOURCE_LOCAL">
<!-- entities JPA -->
<class>generic.jpa.entities.dbproduits.Produit</class>
<exclude-unlisted-classes>true</exclude-unlisted-classes>
</persistence-unit>
</persistence>
- Zeile 6: die einzelne JPA-Entität;
- Zeile 4: der Name der Persistenz-Einheit [generic-jpa-entities-dbproduits], auf die in der [entityManagerFactory]-Bean verwiesen wird;
9.3.3. Die JPA-Entität [Product]
 |
Die JPA-Entität ist im Projekt [mysql-config-jpa-eclipselink] wie folgt definiert:
package generic.jpa.entities.dbproduits;
import generic.jdbc.config.ConfigJdbc;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity(name="Produit1")
@Table(name = ConfigJdbc.TAB_PRODUITS)
public class Produit {
// fields
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = ConfigJdbc.TAB_PRODUITS_ID)
private int id;
@Column(name = ConfigJdbc.TAB_PRODUITS_NOM, unique = true, length = 30, nullable = false)
private String nom;
@Column(name = ConfigJdbc.TAB_PRODUITS_CATEGORIE, nullable = false)
private int categorie;
@Column(name = ConfigJdbc.TAB_PRODUITS_PRIX, nullable = false)
private double prix;
@Column(name = ConfigJdbc.TAB_PRODUITS_DESCRIPTION, length = 100, nullable = false)
private String description;
// manufacturers
public Produit() {
}
public Produit(int id, String nom, int categorie, double prix, String description) {
this.id = id;
this.nom = nom;
this.categorie = categorie;
this.prix = prix;
this.description = description;
}
// getters and setters
...
}
Dies ist eine JPA-Definition, die mittlerweile zum Standard geworden ist. Beachten Sie folgende Punkte:
- Zeile 12: Wir haben der Entität einen Namen gegeben [Product1]. Standardmäßig entspricht der Name einer Entität dem Klassennamen, in diesem Fall [Product]. Da es jedoch im selben Projekt eine weitere JPA-Entität namens [Product] gibt, wurde bereits vor Beginn der Ausführung ein Fehler gemeldet. Wir haben das Problem folgendermaßen gelöst:
- Zeile 24: Die Kategorie ist hier lediglich eine Zahl;
- es gibt keine Beziehungen zwischen Entitäten. Wir haben es also mit einer sehr einfachen Situation zu tun;
9.3.4. Die ausführbare Klasse
 |
Die Klasse [CreateDatabase] sieht wie folgt aus:
package console;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class CreateDataBase {
public static void main(String[] args) {
// simply instantiate the Spring context to create the database tables [dbproduits]
// you also need at least one Spring Data Repository, otherwise nothing happens
System.out.println("Travail en cours...");
new AnnotationConfigApplicationContext(AppConfig.class).close();
System.out.println("Travail terminé...");
}
}
Das ist Code, den wir schon kennen.
9.3.5. EclipseLink-Generierung
Die Tabelle [PRODUCTS] wird mit der folgenden Laufzeitkonfiguration erstellt:
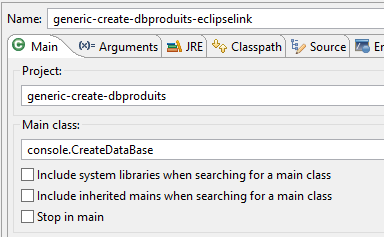 | 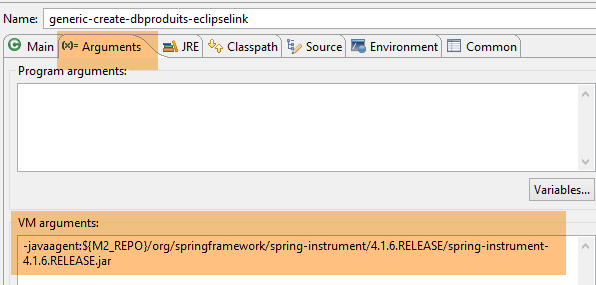 |
Die Konsolenprotokolle lauten wie folgt:
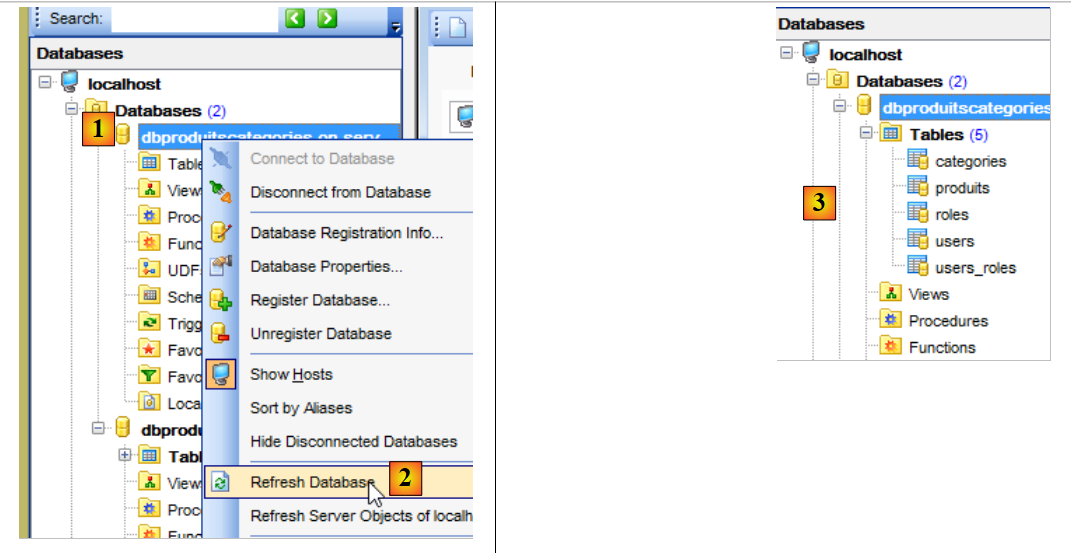
Kehren wir nun zum [MyManager]-Client zurück und aktualisieren die Anzeige [1-2]:
 |
In [3] sehen wir, dass eine Tabelle erstellt wurde. Sehen wir uns nun die DDL (Domain Definition Language) der Datenbank an:
SET FOREIGN_KEY_CHECKS=0;
USE `dbproduits`;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`CATEGORIE` INTEGER(11) NOT NULL,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci NOT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `NOM` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
Wir erhalten tatsächlich die erwartete Tabelle. Um dies zu überprüfen, führen wir die folgende Konfiguration aus:
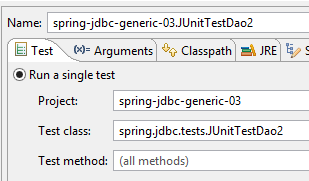 | 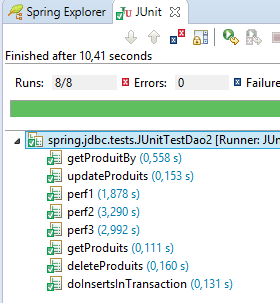 |
Das sollte funktionieren.
9.3.6. Hibernate-Generierung
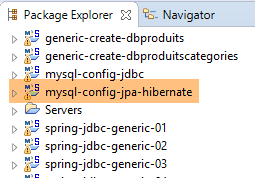 | 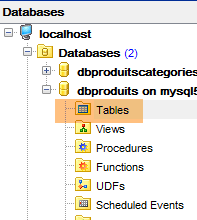 |
Hinweis: Drücken Sie Alt-F5 und generieren Sie alle Maven-Projekte neu;
Die Laufzeitkonfiguration lautet wie folgt:
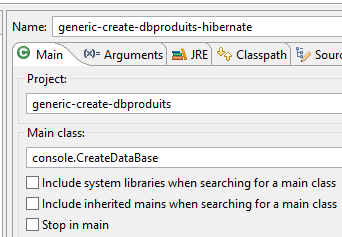 |  |
Das von Hibernate generierte SQL-Skript lautet wie folgt:
USE `dbproduits`;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`CATEGORIE` INTEGER(11) NOT NULL,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci NOT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `UK_hfvjn9lp7qoo5x79uu0ump3rf` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
9.3.7. OpenJpa-Generierung
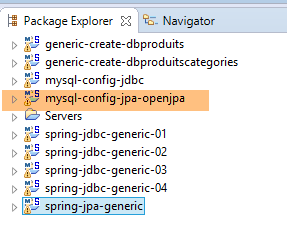 | |
Hinweis: Drücken Sie Alt-F5 und generieren Sie alle Maven-Projekte neu;
Die Laufzeitkonfiguration lautet wie folgt:
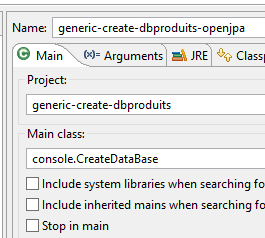 | 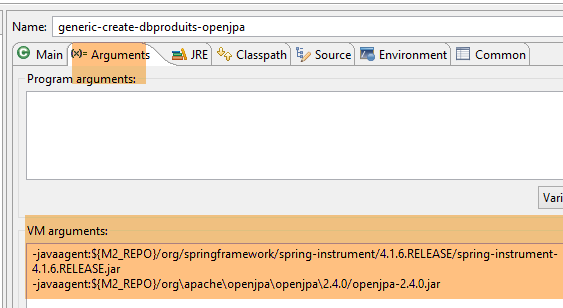 |
Das von OpenJpa generierte SQL-Skript lautet wie folgt:
USE `dbproduits`;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`CATEGORIE` INTEGER(11) NOT NULL,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci NOT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `U_PRODUTS_NOM` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;