5. Einführung in Spring Data JPA
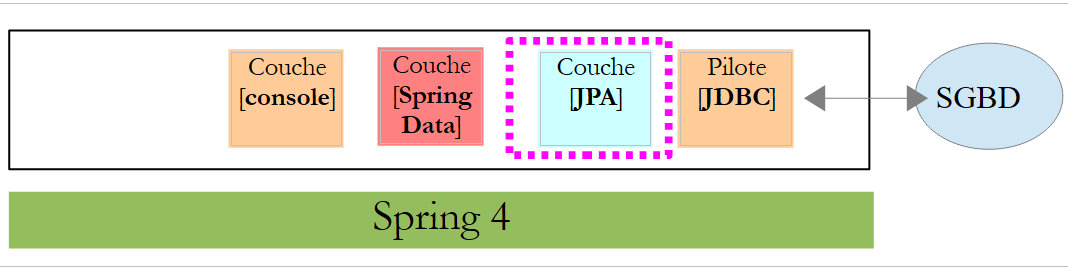
In diesem Kapitel werden wir die folgende Architektur untersuchen:
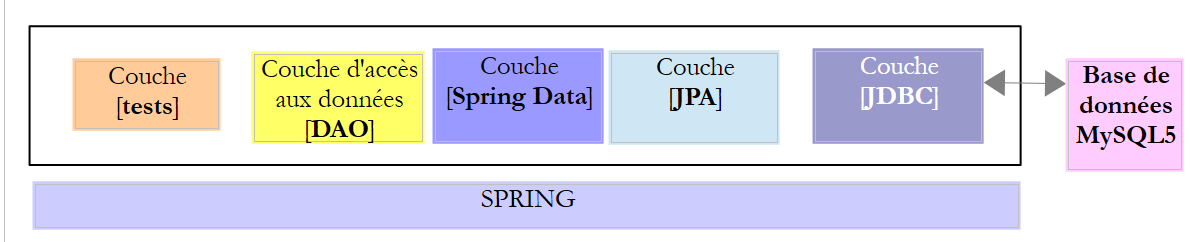 |
Zwischen der Schicht [DAO] und dem Treiber JDBC des SGBD wird eine Schicht [JPA] (Java Persistence API) eingefügt. Nun ist es die Schicht JPA, die die Befehle SQL an den SGBD sendet. Die Schicht [DAO] verarbeitet keine Befehle SQL mehr, sondern ausschließlich Objekte, die als Entitäten JPA bezeichnet werden und Abbilder der verschiedenen Tabellen der genutzten Datenbank darstellen. Die Felder dieser Entitäten sind mithilfe von Java-Annotationen eindeutig Spalten der Tabellen zugeordnet. Dadurch kann die Schicht JPA die Operationen der Schicht [DAO], die an den Entitäten JPA durchgeführt werden, in SQL übersetzen.
Spring Data ist ein Zweig von Spring, der sich mit dem Datenzugriff befasst, unabhängig davon, ob die Daten in einer relationalen Datenbank SGBDR, einer NOSQL-Datenbank oder anderen Arten von Speichern abgelegt sind. Wir befassen uns hier ausschließlich mit den SGBDR und deren Zugriff über JPA. Im weiteren Verlauf werden wir gelegentlich [Spring JPA] schreiben, um eigentlich [Spring Data JPA] zu bezeichnen. In der oben dargestellten Architektur stellt die Schicht [Spring Data] der Schicht [DAO] Funktionen zur Verwaltung der Entitäten JPA zur Verfügung.
JPA ist eigentlich eine Spezifikation. Wir werden drei ihrer Implementierungen testen:
- Hibernate (http://hibernate.org/);
- EclipseLink (http://www.eclipse.org/eclipselink/);
- OpenJpa (http://openjpa.apache.org/);
5.1. Beispiel-01
Auf der Spring-Website gibt es zahlreiche Tutorials für den Einstieg in Spring ([http://spring.io/guides]). Wir werden eines davon nutzen, um Spring Data vorzustellen. Dazu verwenden wir die Spring Tool Suite (STS).
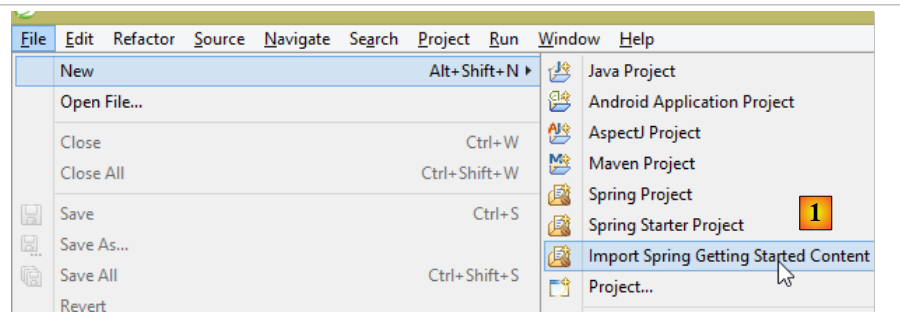 |
- In [1] importieren wir eines der Tutorials aus [spring.io/guides];
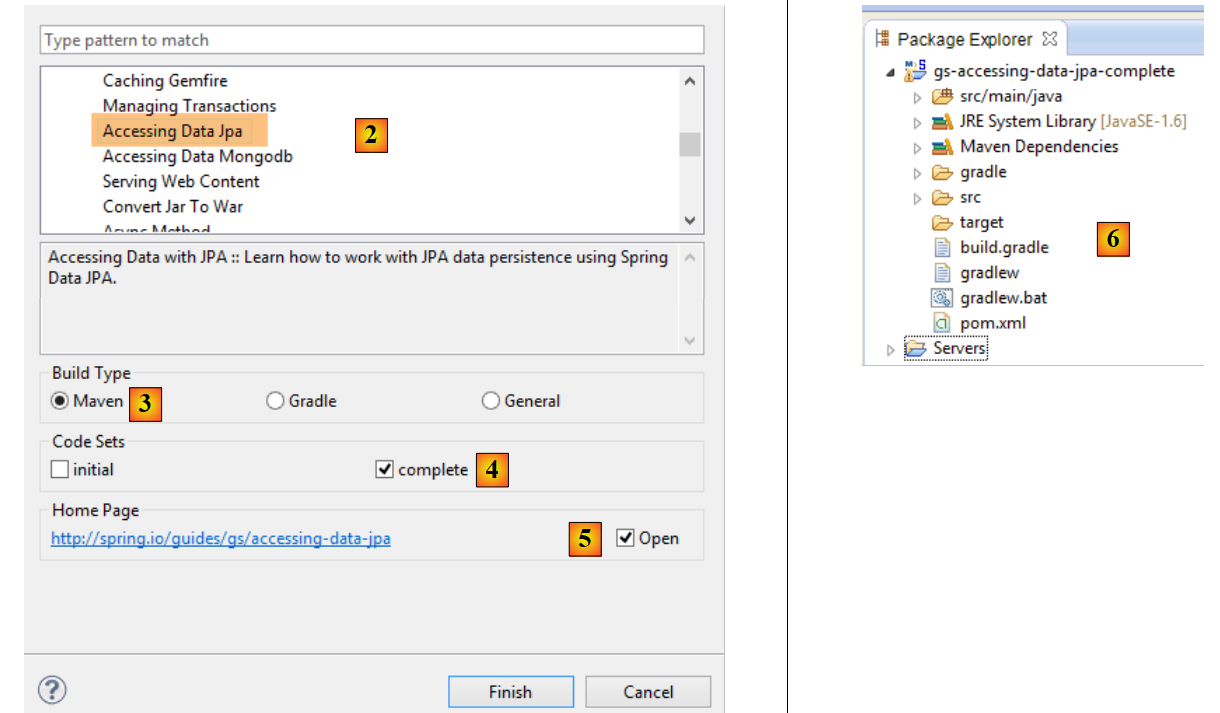 |
- in [2] wählen wir das Tutorial [Accessing Data Jpa] aus, das zeigt, wie man mit Spring Data auf eine Datenbank zugreift;
- in [3] wählen wir ein von Maven konfiguriertes Projekt aus;
- In [4] kann das Tutorial in zwei Formen bereitgestellt werden: [initial], eine leere Version, die man gemäß dem Tutorial ausfüllt, oder [complete], die endgültige Version des Tutorials. Wir wählen Letzteres;
- In [5] kann man das Tutorial in einem Browser anzeigen lassen;
- bei [6] das endgültige Projekt.
5.1.1. Die Maven-Konfiguration des Projekts
Die Maven-Abhängigkeiten des Projekts sind in der Datei [pom.xml] konfiguriert:
<groupId>org.springframework</groupId>
<artifactId>gs-accessing-data-jpa</artifactId>
<version>0.1.0</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
</dependencies>
<properties>
<!-- UTF-8 für alles verwenden -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<start-class>hello.Application</start-class>
</properties>
- Zeilen 5–9: Definieren ein übergeordnetes Maven-Projekt. Dieses legt den Großteil der Projektabhängigkeiten fest. Entweder sind diese bereits ausreichend – in diesem Fall werden keine weiteren hinzugefügt – oder es fehlen noch Abhängigkeiten, die dann ergänzt werden müssen;
- Zeilen 12–15: definieren eine Abhängigkeit von [spring-boot-starter-data-jpa]. Dieses Artefakt enthält die Spring-Data-Klassen;
- Zeilen 16–19: definieren eine Abhängigkeit von SGBD und H2, mit denen In-Memory-Datenbanken erstellt und verwaltet werden können.
Sehen wir uns die Klassen an, die durch diese Abhängigkeiten bereitgestellt werden:
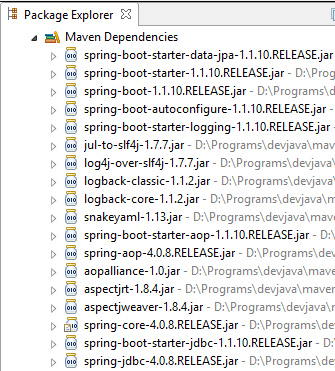 | 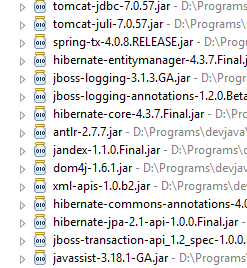 | 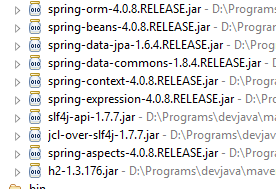 |
Es sind sehr viele:
- Einige gehören zum Spring-Ökosystem (diejenigen, die mit „spring“ beginnen);
- andere gehören zum Hibernate-Ökosystem (hibernate, jboss), von dem wir hier die Implementierung JPA verwenden;
- wieder andere sind Testbibliotheken (junit, hamcrest);
- wieder andere sind Protokollierungsbibliotheken (log4j, logback, slf4j);
Wir werden sie alle beibehalten. Für eine Anwendung im Produktivbetrieb sollten jedoch nur die notwendigen Bibliotheken beibehalten werden.
In Zeile 26 der Datei [pom.xml] findet sich die Zeile:
<start-class>hello.Application</start-class>
Diese Zeile steht in Zusammenhang mit den folgenden Zeilen:
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
In den Zeilen 6–9 ermöglicht das Plugin [spring-boot-maven-plugin] die Generierung der ausführbaren JAR-Datei der Anwendung. Zeile 26 der Datei [pom.xml] bezeichnet dann die ausführbare Klasse dieser JAR-Datei.
5.1.2. Die Schicht [JPA]
Der Zugriff auf die Datenbank erfolgt über eine Schicht [JPA], Java Persistence API:
 |
 |
Die Anwendung ist einfach aufgebaut und verwaltet Kunden [Customer]. Die Klasse [Customer] ist Teil der Schicht [JPA] und sieht wie folgt aus:
package hello;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
private String firstName;
private String lastName;
protected Customer() {
}
public Customer(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
@Override
public String toString() {
return String.format("Customer[id=%d, firstName='%s', lastName='%s']", id, firstName, lastName);
}
}
Ein Kunde hat eine ID [id], einen Vornamen [firstName] und einen Nachnamen [lastName]. Jede Instanz [Customer] repräsentiert eine Zeile einer Datenbanktabelle.
- Zeile 8: Annotation JPA, die bewirkt, dass die Persistenz der Instanzen [Customer] (Create, Read, Update, Delete) durch eine Implementierung JPA verwaltet wird. Den Maven-Abhängigkeiten zufolge wird die Implementierung JPA / Hibernate verwendet;
- Zeilen 11–12: Annotationen JPA, die das Feld [id] mit dem Primärschlüssel der Tabelle [Customer] verknüpfen. Zeile 12 gibt an, dass die Implementierung JPA die für das verwendete SGBD spezifische Methode zur Primärschlüsselgenerierung verwendet, in diesem Fall H2;
Es gibt keine weiteren Anmerkungen zu JPA. In diesem Fall werden Standardwerte verwendet:
- Die Tabelle [Customer] trägt den Namen der Klasse, d. h. [Customer];
- die Spalten dieser Tabelle tragen die Namen der Felder der Klasse: [id, firstName, lastName], wobei bei den Namen von Tabellenspalten die Groß-/Kleinschreibung nicht berücksichtigt wird;
Es ist zu beachten, dass die verwendete Implementierung JPA zu keinem Zeitpunkt namentlich genannt wird.
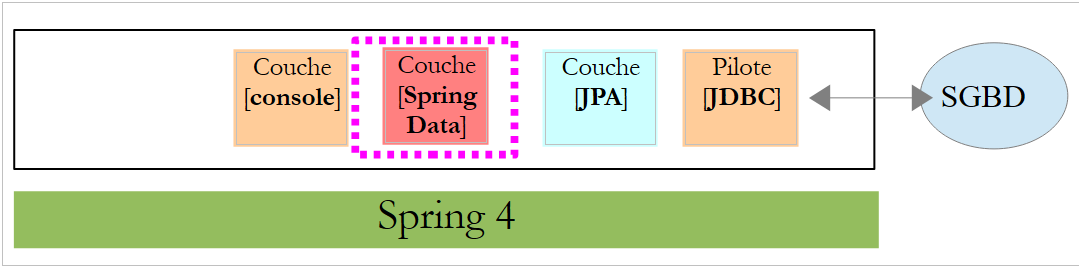
5.1.3. Die Schicht [Spring Data]
Die Klasse [CustomerRepository] implementiert die Zugriffsebene auf die Tabelle [Customer]. Ihr Code lautet wie folgt:
 |
 |
package hello;
import java.util.List;
import org.springframework.data.repository.CrudRepository;
public interface CustomerRepository extends CrudRepository<Customer, Long> {
List<Customer> findByLastName(String lastName);
}
Es handelt sich also um eine Schnittstelle und nicht um eine Klasse (Zeile 7). Sie erweitert die Schnittstelle [CrudRepository], eine Schnittstelle von Spring Data (Zeile 5). Diese Schnittstelle wird durch zwei Typen parametrisiert: Der erste ist der Typ der verwalteten Elemente, hier der Typ [Customer], der zweite ist der Typ des Primärschlüssels der verwalteten Elemente, hier ein Typ [Long]. Die Schnittstelle [CrudRepository] lautet wie folgt:
package org.springframework.data.repository;
import java.io.Serializable;
@NoRepositoryBean
public interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID> {
<S extends T> S save(S entity);
<S extends T> Iterable<S> save(Iterable<S> entities);
T findOne(ID id);
boolean exists(ID id);
Iterable<T> findAll();
Iterable<T> findAll(Iterable<ID> ids);
long count();
void delete(ID id);
void delete(T entity);
void delete(Iterable<? extends T> entities);
void deleteAll();
}
Diese Schnittstelle definiert die Operationen CRUD (Create – Read – Update – Delete), die an einem Typ JPA T durchgeführt werden können:
- Zeile 8: Die Methode „save“ ermöglicht es, eine Entität vom Typ T in der Datenbank zu speichern. Sie speichert die Entität unter dem Primärschlüssel, der ihr von SGBD zugewiesen wurde. Außerdem ermöglicht sie die Aktualisierung einer Entität vom Typ T, die durch ihren Primärschlüssel id identifiziert wird. Die Wahl der einen oder anderen Aktion richtet sich nach dem Wert des Primärschlüssels id: Ist dieser null, wird die Persistenzoperation durchgeführt, andernfalls die Aktualisierungsoperation;
- Zeile 10: dasselbe, jedoch für eine Liste von Entitäten;
- Zeile 12: Mit der Methode findOne kann eine Entität T abgerufen werden, die durch ihren Primärschlüssel id identifiziert wird;
- Zeile 22: Mit der Methode „delete“ kann eine Entität T gelöscht werden, die durch ihren Primärschlüssel id identifiziert wird;
- Zeilen 24–28: Varianten der Methode [delete];
- Zeile 16: Mit der Methode [findAll] lassen sich alle persistenten Entitäten T abrufen;
- Zeile 18: dasselbe, jedoch beschränkt auf Entitäten, für die eine Liste von Identifikatoren übergeben wurde;
Kehren wir zur Schnittstelle [CustomerRepository] zurück:
package hello;
import java.util.List;
import org.springframework.data.repository.CrudRepository;
public interface CustomerRepository extends CrudRepository<Customer, Long> {
List<Customer> findByLastName(String lastName);
}
- In Zeile 9 kann ein [Customer] anhand seines Namens [lastName] gefunden werden;
Und das war’s auch schon für die Schicht [DAO]. Es gibt keine Implementierungsklasse für die vorangegangene Schnittstelle. Diese wird zur Laufzeit von [Spring Data] generiert. Die Methoden der Schnittstelle [CrudRepository] werden automatisch implementiert. Bei den Methoden, die in der Schnittstelle [CustomerRepository] hinzugefügt wurden, kommt es darauf an. Kehren wir zur Definition von [Customer] zurück:
private long id;
private String firstName;
private String lastName;
Die Methode in Zeile 9 wird automatisch von [Spring Data] implementiert, da sie auf das Feld [lastName] (Zeile 3) von [Customer] verweist. Wenn Spring Data in der zu implementierenden Schnittstelle auf eine Methode [findBySomething] stößt, implementiert es diese mithilfe der folgenden JPQL-Abfrage (Java Persistence Query Language):
Der Typ T muss daher ein Feld mit dem Namen [something] besitzen. Somit lautet die Methode
wird durch einen Code implementiert, der in etwa wie folgt aussieht:
return [em].createQuery("select c from Customer c where c.lastName=:value").setParameter("value",lastName).getResultList()
wobei [em] den Persistenzkontext JPA bezeichnet. Dies ist nur möglich, wenn die Klasse [Customer] ein Feld namens [lastName] besitzt, was der Fall ist.
Zusammenfassend lässt sich sagen, dass Spring Data es uns in einfachen Fällen ermöglicht, die Schicht [DAO] mit einer einfachen Schnittstelle zu implementieren.
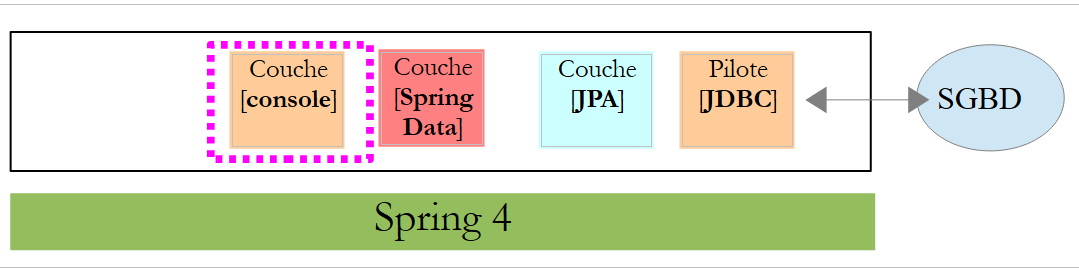
5.1.4. Die Schicht [console]
 |
 |
Die Klasse [Application] sieht wie folgt aus:
package hello;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Application implements CommandLineRunner {
@Autowired
CustomerRepository repository;
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
@Override
public void run(String... strings) throws Exception {
// einige Kunden speichern
repository.save(new Customer("Jack", "Bauer"));
repository.save(new Customer("Chloe", "O'Brian"));
repository.save(new Customer("Kim", "Bauer"));
repository.save(new Customer("David", "Palmer"));
repository.save(new Customer("Michelle", "Dessler"));
// alle Kunden abrufen
System.out.println("Customers found with findAll():");
System.out.println("-------------------------------");
for (Customer customer : repository.findAll()) {
System.out.println(customer);
}
System.out.println();
// einen einzelnen Kunden über ID abrufen
Customer customer = repository.findOne(1L);
System.out.println("Customer found with findOne(1L):");
System.out.println("--------------------------------");
System.out.println(customer);
System.out.println();
// Kunden nach Nachnamen abrufen
System.out.println("Customer found with findByLastName('Bauer'):");
System.out.println("--------------------------------------------");
for (Customer bauer : repository.findByLastName("Bauer")) {
System.out.println(bauer);
}
}
}
- Zeile 9: Die Klasse implementiert die Schnittstelle [CommandLineRunner], die eine Schnittstelle [Spring Boot] (Zeile 4) ist. Diese Schnittstelle hat nur eine Methode, nämlich die in Zeile 19;
- Zeile 8: @SpringBootApplication ist eine Annotation, die mehrere Annotationen [Spring Boot] zusammenfasst:
- @Configuration: gibt an, dass es sich bei der Klasse um eine Konfigurationsklasse handelt;
- @EnableAutoConfiguration: weist [Spring Boot] an, selbst eine bestimmte Anzahl von Beans basierend auf verschiedenen Eigenschaften zu erstellen, insbesondere dem Inhalt des Classpath des Projekts. Da sich die Hibernate-Bibliotheken im Classpath befinden, wird das Bean [entityManagerFactory] mit Hibernate implementiert. Da sich die Bibliothek von SGBD H2 im Classpath befindet, wird die Bean [dataSource] mit H2 implementiert. In der Bean [dataSource] müssen außerdem der Benutzer und sein Passwort definiert werden. Hier verwendet Spring Boot den Standardadministrator von H2, der kein Passwort hat. Da sich die Bibliothek [spring-tx] im Classpath befindet, wird der Transaktionsmanager von Spring verwendet;
- @EnableWebMvc: Wenn sich die Bibliothek [spring-mvc] im Classpath befindet. In diesem Fall erfolgt eine automatische Konfiguration für die Webanwendung;
- @ComponentScan: Teilt Spring mit, wo nach den anderen Beans, Konfigurationen und Diensten gesucht werden soll. Hier werden sie standardmäßig in dem Paket gesucht, das die mit dem Tag versehene Klasse enthält, d. h. im Paket [hello]. So werden die Klassen [Customer] und [CustomerRepository] gefunden. Da die erste die Annotation [@Entity] trägt, wird sie als von Hibernate zu verwaltende Entität katalogisiert. Da die zweite die Schnittstelle [CrudRepository] erweitert, wird sie als Spring-Bean registriert;
- Zeilen 11–12: Die Bean [CustomerRepository] wird in den Code der Hauptklasse injiziert;
- Zeile 15: Die statische Methode [run] der Klasse [SpringApplication] des Spring-Boot-Projekts wird ausgeführt. Ihr Parameter ist die Klasse, die eine Annotation [Configuration] oder [EnableAutoConfiguration] trägt. Anschließend läuft alles ab, was zuvor erläutert wurde. Das Ergebnis ist ein Spring-Anwendungskontext, d. h. eine Sammlung von Beans, die von Spring verwaltet werden;
- Zeilen 19–48: Die folgenden Operationen nutzen lediglich die Methoden des Beans, der die Schnittstelle [CustomerRepository] implementiert;
Die Konsolenausgaben lauten wie folgt:
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v1.2.2.RELEASE)
2015-03-10 15:35:43.661 INFO 5784 --- [ main] hello.Application : Starting Application on Gportpers3 with PID 5784 (started by ST in C:\Users\Serge Tahé\Documents\workspace-sts-3.6.3.RELEASE\gs-accessing-data-jpa-complete)
2015-03-10 15:35:43.708 INFO 5784 --- [ main] s.c.a.AnnotationConfigApplicationContext : Refreshing org.springframework.context.annotation.AnnotationConfigApplicationContext@5d11346a: startup date [Tue Mar 10 15:35:43 CET 2015]; root of context hierarchy
2015-03-10 15:35:45.230 INFO 5784 --- [ main] j.LocalContainerEntityManagerFactoryBean : Building JPA container EntityManagerFactory for persistence unit 'default'
2015-03-10 15:35:45.254 INFO 5784 --- [ main] o.hibernate.jpa.internal.util.LogHelper : HHH000204: Processing PersistenceUnitInfo [
name: default
...]
2015-03-10 15:35:45.331 INFO 5784 --- [ main] org.hibernate.Version : HHH000412: Hibernate Core {4.3.8.Final}
2015-03-10 15:35:45.332 INFO 5784 --- [ main] org.hibernate.cfg.Environment : HHH000206: hibernate.properties not found
2015-03-10 15:35:45.334 INFO 5784 --- [ main] org.hibernate.cfg.Environment : HHH000021: Bytecode provider name : javassist
2015-03-10 15:35:45.651 INFO 5784 --- [ main] o.hibernate.annotations.common.Version : HCANN000001: Hibernate Commons Annotations {4.0.5.Final}
2015-03-10 15:35:45.754 INFO 5784 --- [ main] org.hibernate.dialect.Dialect : HHH000400: Using dialect: org.hibernate.dialect.H2Dialect
2015-03-10 15:35:45.877 INFO 5784 --- [ main] o.h.h.i.ast.ASTQueryTranslatorFactory : HHH000397: Using ASTQueryTranslatorFactory
2015-03-10 15:35:46.154 INFO 5784 --- [ main] org.hibernate.tool.hbm2ddl.SchemaExport : HHH000227: Running hbm2ddl schema export
2015-03-10 15:35:46.169 INFO 5784 --- [ main] org.hibernate.tool.hbm2ddl.SchemaExport : HHH000230: Schema export complete
2015-03-10 15:35:46.779 INFO 5784 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Registering beans for JMX exposure on startup
Customers found with findAll():
-------------------------------
Customer[id=1, firstName='Jack', lastName='Bauer']
Customer[id=2, firstName='Chloe', lastName='O'Brian']
Customer[id=3, firstName='Kim', lastName='Bauer']
Customer[id=4, firstName='David', lastName='Palmer']
Customer[id=5, firstName='Michelle', lastName='Dessler']
Customer found with findOne(1L):
--------------------------------
Customer[id=1, firstName='Jack', lastName='Bauer']
Customer found with findByLastName('Bauer'):
--------------------------------------------
Customer[id=1, firstName='Jack', lastName='Bauer']
Customer[id=3, firstName='Kim', lastName='Bauer']
2015-03-10 15:35:47.040 INFO 5784 --- [ main] hello.Application : Started Application in 3.623 seconds (JVM running for 4.324)
2015-03-10 15:35:47.042 INFO 5784 --- [ Thread-1] s.c.a.AnnotationConfigApplicationContext : Closing org.springframework.context.annotation.AnnotationConfigApplicationContext@5d11346a: startup date [Tue Mar 10 15:35:43 CET 2015]; root of context hierarchy
2015-03-10 15:35:47.044 INFO 5784 --- [ Thread-1] o.s.j.e.a.AnnotationMBeanExporter : Unregistering JMX-exposed beans on shutdown
2015-03-10 15:35:47.046 INFO 5784 --- [ Thread-1] j.LocalContainerEntityManagerFactoryBean : Closing JPA EntityManagerFactory for persistence unit 'default'
2015-03-10 15:35:47.047 INFO 5784 --- [ Thread-1] org.hibernate.tool.hbm2ddl.SchemaExport : HHH000227: Running hbm2ddl schema export
2015-03-10 15:35:47.051 INFO 5784 --- [ Thread-1] org.hibernate.tool.hbm2ddl.SchemaExport : HHH000230: Schema export complete
- Zeilen 1–8: das Logo des Spring-Boot-Projekts;
- Zeile 9: Die Klasse „[hello.Application]“ wird ausgeführt;
- Zeile 10: [AnnotationConfigApplicationContext] ist eine Klasse, die die Spring-Schnittstelle [ApplicationContext] implementiert. Es handelt sich um einen Bean-Container;
- Zeile 11: Das Bean [entityManagerFactory] wird durch die Klasse [LocalContainerEntityManagerFactory] implementiert, eine Spring-Klasse. Es verwaltet die Schicht [JPA];
- Zeile 12: Hier taucht [Hibernate] auf. Diese Implementierung JPA wurde ausgewählt;
- Zeile 19: Als Hibernate-Dialekt wird die Variante SQL zur Verwendung mit SGBD angegeben. Hier zeigt der Dialekt [H2Dialect], dass Hibernate mit den Implementierungen SGBD und H2 arbeiten wird;
- Zeilen 21–22: Die Datenbank wird angelegt. Die Tabelle [CUSTOMER] wird angelegt. Das bedeutet, dass Hibernate so konfiguriert wurde, dass es die Tabellen anhand der Definitionen JPA generiert, in diesem Fall anhand der Definition JPA der Klasse [Customer];
- Zeilen 26–30: Ergebnis der Methode [findAll] der Schnittstelle;
- Zeile 34: Ergebnis der Methode [findOne] der Schnittstelle;
- Zeilen 38–39: Ergebnisse der Methode [findByLastName];
- Zeilen 41 ff.: Protokolle zum Schließen des Spring-Kontexts.
5.1.5. Manuelle Konfiguration des Spring-Data-Projekts
Wir duplizieren das vorherige Projekt im Projekt [gs-accessing-data-jpa-02]:
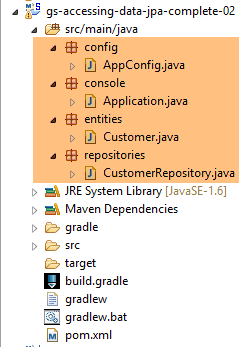 |
In diesem neuen Projekt verlassen wir uns nicht auf die automatische Konfiguration durch Spring Boot. Wir nehmen die Konfiguration manuell vor. Dies kann nützlich sein, wenn uns die Standardkonfigurationen nicht zusagen.
Zunächst legen wir die erforderlichen Abhängigkeiten in der Datei [pom.xml] fest:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<modelVersion>4.0.0</modelVersion>
<groupId>org.springframework</groupId>
<artifactId>gs-accessing-data-jpa-02</artifactId>
<version>0.1.0</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<!-- Spring Data -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
</dependency>
<!-- Hibernate -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
</dependency>
<!-- H2-Datenbank -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
<!-- Tomcat JDBC -->
<dependency>
<groupId>org.apache.tomcat</groupId>
<artifactId>tomcat-jdbc</artifactId>
</dependency>
</dependencies>
<properties>
<!-- Verwende UTF-8 für alles -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-releases</id>
<name>Spring Releases</name>
<url>https://repo.spring.io/libs-release</url>
</repository>
<repository>
<id>org.jboss.repository.releases</id>
<name>JBoss Maven Release Repository</name>
<url>https://repository.jboss.org/nexus/content/repositories/releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>spring-releases</id>
<name>Spring Releases</name>
<url>https://repo.spring.io/libs-release</url>
</pluginRepository>
</pluginRepositories>
</project>
- Zeilen 10–14: das übergeordnete Maven-Projekt, dessen definierte Bibliotheken wir verwenden werden;
- Zeilen 18–21: Spring Data, das für den Zugriff auf die Datenbank verwendet wird;
- Zeilen 23–26: die Hibernate-Implementierung der Spezifikation JPA;
- Zeilen 28–31: SGBD H2;
- Zeilen 33–36: Datenbanken werden häufig mit Pools offener Verbindungen verwendet, wodurch das wiederholte Öffnen und Schließen von Verbindungen vermieden wird. Hier kommt die Implementierung von [tomcat-jdbc] zum Einsatz;
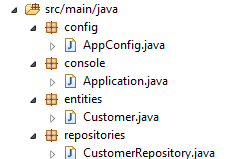
Im neuen Projekt bleiben die Entität [Customer] und die Schnittstelle [CustomerRepository] unverändert. Die Klasse [Application] wird geändert und in zwei Klassen aufgeteilt:
- [Config], das wird die Konfigurationsklasse sein:
- [Main], die als ausführbare Klasse dient;
 |
Die ausführbare Klasse [Application] lautet nun wie folgt:
package console;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import repositories.CustomerRepository;
import config.AppConfig;
import entities.Customer;
public class Application {
public static void main(String[] args) {
// Instanziierung des Spring-Kontexts
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
CustomerRepository repository = context.getBean(CustomerRepository.class);
// einige Kunden speichern
repository.save(new Customer("Jack", "Bauer"));
repository.save(new Customer("Chloe", "O'Brian"));
repository.save(new Customer("Kim", "Bauer"));
repository.save(new Customer("David", "Palmer"));
repository.save(new Customer("Michelle", "Dessler"));
...
// Kontext schließen
context.close();
}
}
- Zeile 9: Die Klasse [Application] enthält keine Konfigurationsanmerkungen mehr;
- Zeilen 3–7: Es ist zu beachten, dass keine Importe von [Spring Boot]-Paketen mehr vorhanden sind;
- Zeile 12: Die Spring-Beans werden instanziiert. Man erhält den Spring-Kontext, der die Referenz auf die so erstellten Beans enthält;
- Zeile 13: Es wird eine Referenz auf das Bean vom Typ [CustomerRepository] angefordert;
Die Klasse [Config] , die das Projekt konfiguriert, sieht wie folgt aus:
package config;
import javax.persistence.EntityManagerFactory;
import org.apache.tomcat.jdbc.pool.DataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.orm.jpa.JpaTransactionManager;
import org.springframework.orm.jpa.JpaVendorAdapter;
import org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean;
import org.springframework.orm.jpa.vendor.Database;
import org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@EnableTransactionManagement
@EnableJpaRepositories(basePackages = { "repositories" })
@Configuration
// @ComponentScan(basePackages={"package1","package2"})
public class AppConfig {
// die Datenbank H2
@Bean
public DataSource dataSource() {
// Datenquelle TomcatJdbc
DataSource dataSource = new DataSource();
// Zugriffskonfiguration JDBC
dataSource.setDriverClassName("org.h2.Driver");
dataSource.setUrl("jdbc:h2:./demo");
dataSource.setUsername("sa");
dataSource.setPassword("");
// eine ursprünglich geöffnete Verbindung
dataSource.setInitialSize(1);
// Ergebnis
return dataSource;
}
// der Provider JPA
@Bean
public JpaVendorAdapter jpaVendorAdapter() {
HibernateJpaVendorAdapter hibernateJpaVendorAdapter = new HibernateJpaVendorAdapter();
hibernateJpaVendorAdapter.setShowSql(false);
hibernateJpaVendorAdapter.setGenerateDdl(true);
hibernateJpaVendorAdapter.setDatabase(Database.H2);
return hibernateJpaVendorAdapter;
}
// EntityManagerFactory
@Bean
public EntityManagerFactory entityManagerFactory(JpaVendorAdapter jpaVendorAdapter, DataSource dataSource) {
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(jpaVendorAdapter);
factory.setPackagesToScan("entities");
factory.setDataSource(dataSource);
factory.afterPropertiesSet();
return factory.getObject();
}
// Transaktionsmanager
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {
JpaTransactionManager txManager = new JpaTransactionManager();
txManager.setEntityManagerFactory(entityManagerFactory);
return txManager;
}
}
- Zeile 17: Die Annotation [@EnableTransactionManagement] gibt an, dass die Annotationen [@Transactional] interpretiert werden müssen. Die Methoden der Schnittstellen [CrudRepository] tragen diese Annotationen. Sie werden somit innerhalb einer Transaktion ausgeführt;
- Zeile 18: Die Annotation [@EnableJpaRepositories] ermöglicht es, die Ordner anzugeben, in denen sich die Spring-Data-Schnittstellen [CrudRepository] befinden. Diese Schnittstellen werden zu Spring-Komponenten und stehen in dessen Kontext zur Verfügung;
- Zeile 19: Die Annotation [@Configuration] macht die Klasse [Config] zu einer Spring-Konfigurationsklasse;
- Zeile 20: Die Annotation [@ComponentScan] ermöglicht es, die Ordner aufzulisten, in denen nach Spring-Komponenten gesucht werden soll. Spring-Komponenten sind Klassen, die mit Spring-Annotationen wie @Service, @Component, @Controller usw. versehen sind. Hier gibt es keine anderen als die, die innerhalb der Klasse [AppConfig] definiert sind, daher wurde die Annotation auskommentiert;
- Zeilen 24–37: Definieren die Datenquelle, die Datenbank H2. Die Annotation @Bean in Zeile 25 sorgt dafür, dass das durch diese Methode erstellte Objekt zu einer von Spring verwalteten Komponente wird. Der Name der Methode kann hier beliebig gewählt werden. Sie muss jedoch [dataSource] heißen, wenn die Methode EntityManagerFactory aus Zeile 51 fehlt und per Autokonfiguration definiert wird;
- Zeile 30: Die Datenbank wird den Namen [demo] tragen und im Projektordner generiert;
- Zeilen 40–47: Definieren die verwendete Implementierung JPA, in diesem Fall eine Hibernate-Implementierung. Der Name der Methode kann hier beliebig gewählt werden;
- Zeile 43: keine Protokolle für SQL;
- Zeile 44: Die Datenbank wird angelegt, falls sie noch nicht existiert;
- Zeilen 50–58: Definieren die Methode EntityManagerFactory, die die Persistenz von JPA verwaltet. Die Methode muss zwingend [entityManagerFactory] heißen;
- Zeile 51: Die Methode erhält zwei Parameter vom Typ der beiden zuvor definierten Beans. Diese werden dann instanziiert und von Spring als Parameter der Methode injiziert;
- Zeile 53: Legt die verwendete Implementierung JPA fest;
- Zeile 54: Legt die Verzeichnisse fest, in denen die Entitäten JPA zu finden sind;
- Zeile 55: Legt die zu verwaltende Datenquelle fest;
- Zeilen 61–66: Der Transaktionsmanager. Die Methode muss zwingend den Namen [transactionManager] tragen. Sie erhält als Parameter die Bean aus den Zeilen 51–58;
- Zeile 64: Der Transaktionsmanager wird mit EntityManagerFactory verknüpft;
Die vorgenannten Methoden können in beliebiger Reihenfolge definiert werden.
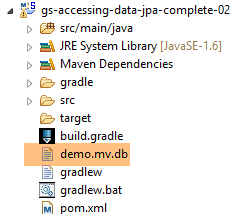
Die Ausführung des Projekts liefert die gleichen Ergebnisse. Im Projektordner erscheint eine neue Datei, nämlich die Datenbankdatei H2:
 |
5.1.6. Erstellung eines ausführbaren Archivs
Um ein ausführbares Archiv des Projekts zu erstellen, kann man wie folgt vorgehen:
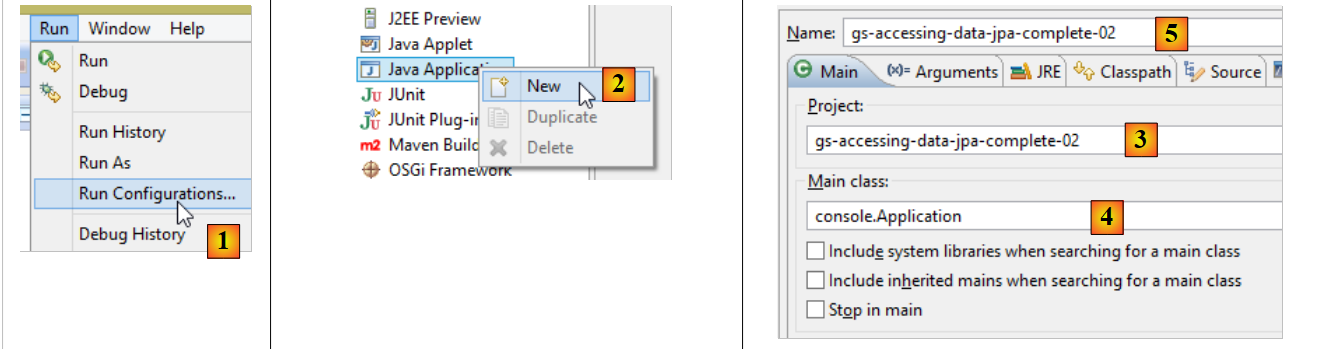 |
- in [1]: Man erstellt eine Ausführungskonfiguration;
- in [2]: vom Typ [Java Application]
- in [3]: gibt das auszuführende Projekt an (die Schaltfläche Browse verwenden);
- in [4]: gibt die auszuführende Klasse an;
- in [5]: der Name der Ausführungskonfiguration – kann beliebig sein;
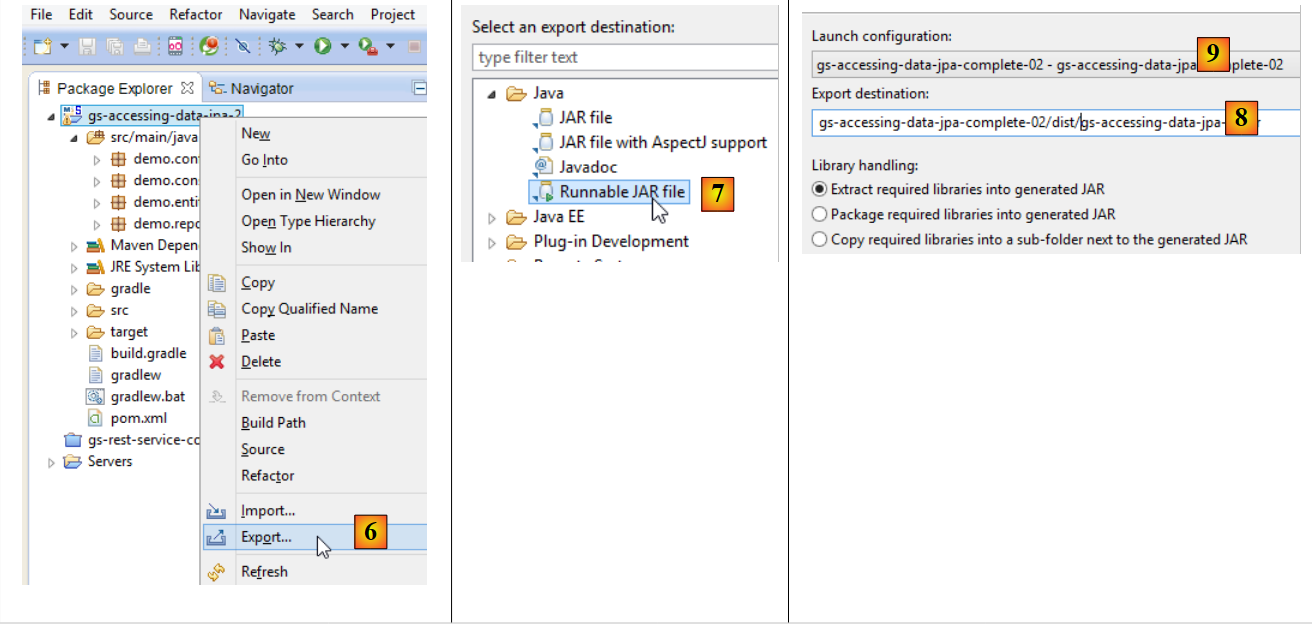 |
- in [6]: Das Projekt wird exportiert;
- in [7]: in Form eines ausführbaren JAR-Archivs;
- in [8]: gibt den Pfad und den Namen der zu erstellenden ausführbaren Datei an;
- in [9]: der Name der in [5] erstellten Ausführungskonfiguration;
10 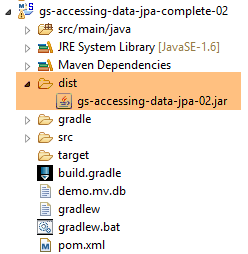 |
- in [10] das erstellte Archiv;
Anschließend öffnen wir eine Konsole in dem Ordner, der das ausführbare Archiv enthält:
Das Archiv wird wie folgt ausgeführt:
.....\dist>java -jar gs-accessing-data-jpa-02.jar
Die in der Konsole angezeigten Ergebnisse lauten wie folgt:
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder für weitere Details.
mars 10, 2015 5:27:20 PM org.hibernate.jpa.internal.util.LogHelper logPersistenceUnitInformation
INFO: HHH000204: Processing PersistenceUnitInfo [
name: default
...]
mars 10, 2015 5:27:20 PM org.hibernate.Version logVersion
INFO: HHH000412: Hibernate Core {4.3.8.Final}
mars 10, 2015 5:27:20 PM org.hibernate.cfg.Environment <clinit>
INFO: HHH000206: hibernate.properties not found
mars 10, 2015 5:27:20 PM org.hibernate.cfg.Environment buildBytecodeProvider
INFO: HHH000021: Bytecode provider name : javassist
mars 10, 2015 5:27:22 PM org.hibernate.annotations.common.reflection.java.JavaReflectionManager <clinit>
INFO: HCANN000001: Hibernate Commons Annotations {4.0.5.Final}
mars 10, 2015 5:27:22 PM org.hibernate.dialect.Dialect <init>
INFO: HHH000400: Using dialect: org.hibernate.dialect.H2Dialect
mars 10, 2015 5:27:22 PM org.hibernate.hql.internal.ast.ASTQueryTranslatorFactory <init>
INFO: HHH000397: Using ASTQueryTranslatorFactory
mars 10, 2015 5:27:22 PM org.hibernate.tool.hbm2ddl.SchemaUpdate execute
INFO: HHH000228: Running hbm2ddl schema update
mars 10, 2015 5:27:22 PM org.hibernate.tool.hbm2ddl.SchemaUpdate execute
INFO: HHH000102: Fetching database metadata
mars 10, 2015 5:27:22 PM org.hibernate.tool.hbm2ddl.SchemaUpdate execute
INFO: HHH000396: Updating schema
mars 10, 2015 5:27:22 PM org.hibernate.tool.hbm2ddl.DatabaseMetadata getTableMetadata
INFO: HHH000262: Table not found: Customer
mars 10, 2015 5:27:22 PM org.hibernate.tool.hbm2ddl.DatabaseMetadata getTableMetadata
INFO: HHH000262: Table not found: Customer
mars 10, 2015 5:27:22 PM org.hibernate.tool.hbm2ddl.DatabaseMetadata getTableMetadata
INFO: HHH000262: Table not found: Customer
mars 10, 2015 5:27:22 PM org.hibernate.tool.hbm2ddl.SchemaUpdate execute
INFO: HHH000232: Schema update complete
Customers found with findAll():
-------------------------------
Customer[id=1, firstName='Jack', lastName='Bauer']
Customer[id=2, firstName='Chloe', lastName='O'Brian']
Customer[id=3, firstName='Kim', lastName='Bauer']
Customer[id=4, firstName='David', lastName='Palmer']
Customer[id=5, firstName='Michelle', lastName='Dessler']
Customer found with findOne(1L):
--------------------------------
Customer[id=1, firstName='Jack', lastName='Bauer']
Customer found with findByLastName('Bauer'):
--------------------------------------------
Customer[id=1, firstName='Jack', lastName='Bauer']
Customer[id=3, firstName='Kim', lastName='Bauer']
5.1.7. Erstellen eines Projekts [Spring Data]
Um ein Spring-Data-Projektgerüst zu erstellen, kann man wie folgt vorgehen:
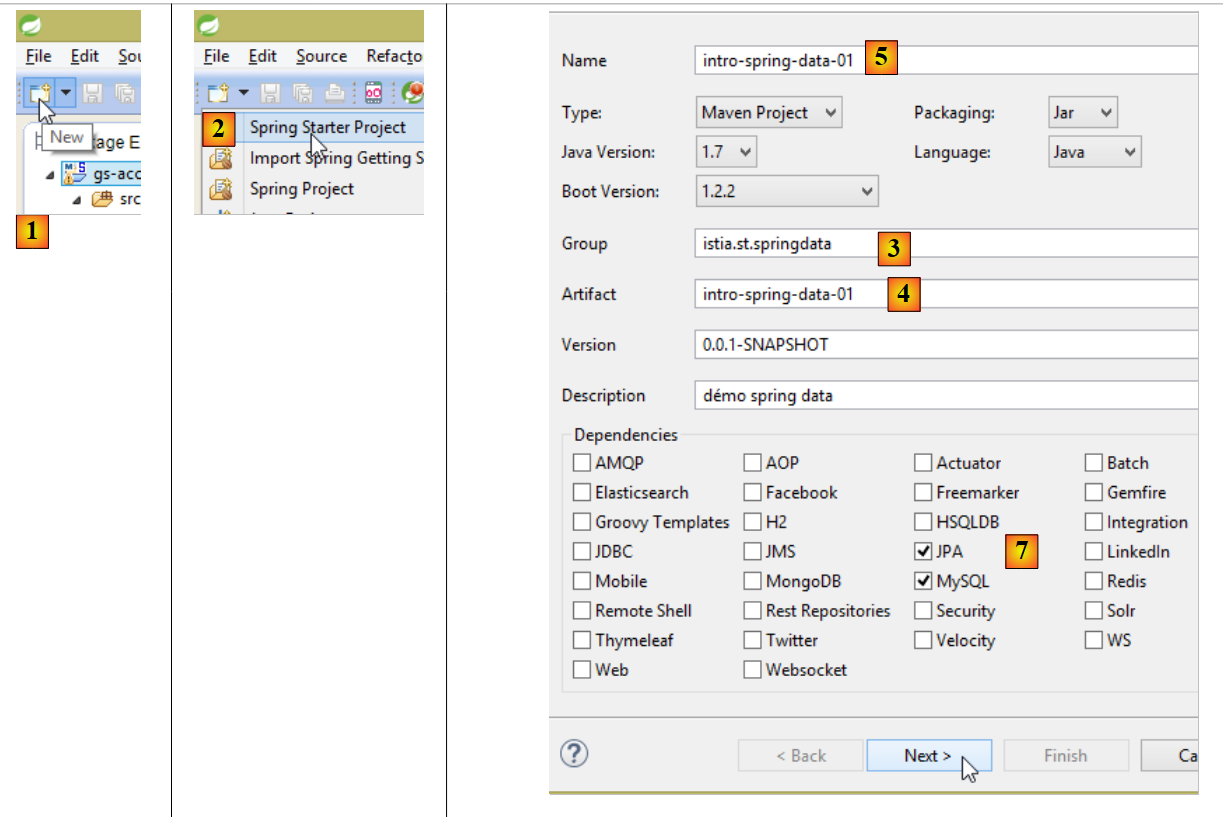 |
- In [1] wird ein neues Projekt angelegt;
- in [2]: vom Typ [Spring Starter Project];
- Das generierte Projekt ist ein Maven-Projekt. In [3] gibt man den Namen der Projektgruppe an;
- in [4]: Hier wird der Name des Artefakts (in diesem Fall eine JAR-Datei) angegeben, das beim Erstellen des Projekts generiert wird;
- in [5]: der Eclipse-Name des Projekts – kann beliebig sein (muss nicht mit [4] übereinstimmen);
- in [7]: Es wird angegeben, dass ein Projekt mit einer Ebene [JPA] und den Ebenen SGBD sowie MySQL erstellt werden soll. Die für ein solches Projekt erforderlichen Abhängigkeiten werden dann in die Datei [pom.xml] aufgenommen;
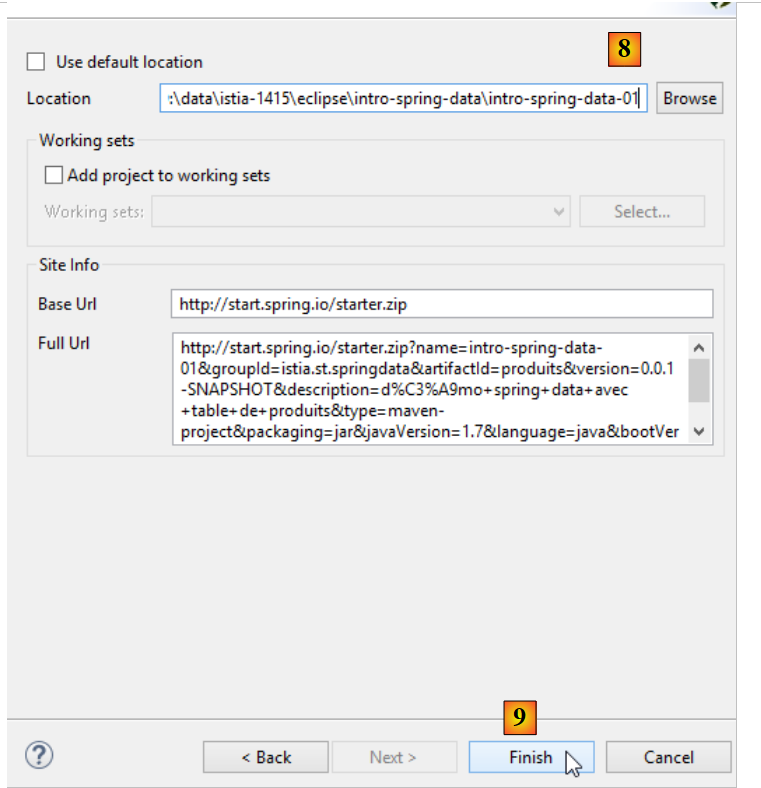 |
- in [8] den Namen des Projektordners angeben;
- in [9] den Assistenten abschließen;
 |
- in [10]: das erstellte Projekt;
Die Datei [pom.xml] enthält die erforderlichen Abhängigkeiten für ein Projekt JPA:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>istia.st.springdata</groupId>
<artifactId>intro-spring-data-01</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>intro-spring-data-01</name>
<description>démo spring data avec table de produits</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
<relativePath/> <!-- Übergeordnete Beziehung aus dem Repository abrufen -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<start-class>demo.IntroSpringData01Application</start-class>
<java.version>1.7</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
- Zeilen 14–19: das übergeordnete Maven-Projekt;
- Zeilen 28–31: die für JPA erforderliche Abhängigkeit – wird [Spring Data] einbinden;
- Zeilen 32–36: die Abhängigkeit von JDBC als Treiber für MySQL;
- Zeilen 37–41: Die erforderlichen Abhängigkeiten für die in Spring integrierten Tests JUnit;
Die ausführbare Klasse [Application] führt keine Aktion aus, ist jedoch vorkonfiguriert:
package demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class IntroSpringData01Application {
public static void main(String[] args) {
SpringApplication.run(IntroSpringData01Application.class, args);
}
}
- Die Annotation [@SpringBootApplication] macht die Klasse zu einer selbstkonfigurierenden Klasse des Projekts;
Die Testklasse [ApplicationTests] führt keine Aktion aus, ist jedoch vorkonfiguriert:
package demo;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.SpringApplicationConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringApplicationConfiguration(classes = IntroSpringData01Application.class)
public class IntroSpringData01ApplicationTests {
@Test
public void contextLoads() {
}
}
- Zeile 9: Die Annotation [@SpringApplicationConfiguration] ermöglicht die Nutzung der Konfigurationsdatei [IntroSpringData01Application]. Die Testklasse profitiert somit von allen in dieser Datei definierten Beans;
- Zeile 8: Die Annotation [@RunWith] ermöglicht die Integration von Spring mit JUnit: Die Klasse kann somit als JUnit-Test ausgeführt werden. [@RunWith] ist eine Annotation JUnit (Zeile 4), während die Klasse [SpringJUnit4ClassRunner] eine Spring-Klasse ist (Zeile 6);
Da wir nun ein Anwendungsgerüst JPA haben, können wir es vervollständigen.