6. 3-Schicht-Architekturen
6.1. Einleitung
Werfen wir einen Blick auf die neueste Version der Steuerberechnungsanwendung:
using System;
namespace Chap3 {
class Program {
static void Main() {
// interactive tax calculator
// the user enters three data points on the keyboard: married nbEnfants salary
// the program then displays Tax payable
...
// creation of a IImpot object
IImpot impot = null;
try {
// creation of a IImpot object
impot = new FileImpot("DataImpotInvalide.txt");
} catch (FileImpotException e) {
// error display
...
// program stop
Environment.Exit(1);
}
// infinite loop
while (true) {
// tax calculation parameters are requested
Console.Write("Paramètres du calcul de l'Impot au format : Marié (o/n) NbEnfants Salaire ou rien pour arrêter :");
string paramètres = Console.ReadLine().Trim();
...
// parameters are correct - Impot is calculated
Console.WriteLine("Impot=" + impot.calculer(marié == "o", nbEnfants, salaire) + " euros");
// next taxpayer
}//while
}
}
}
Die vorherige Lösung enthält klassisches :
- Abrufen von Daten, die in Dateien, Datenbanken usw. gespeichert sind, Zeilen 12–21
- Dialog mit dem Benutzer, Zeilen 26 (Eingaben) und 29 (Anzeigen)
- die Verwendung eines Geschäftsalgorithmus, Zeile 29
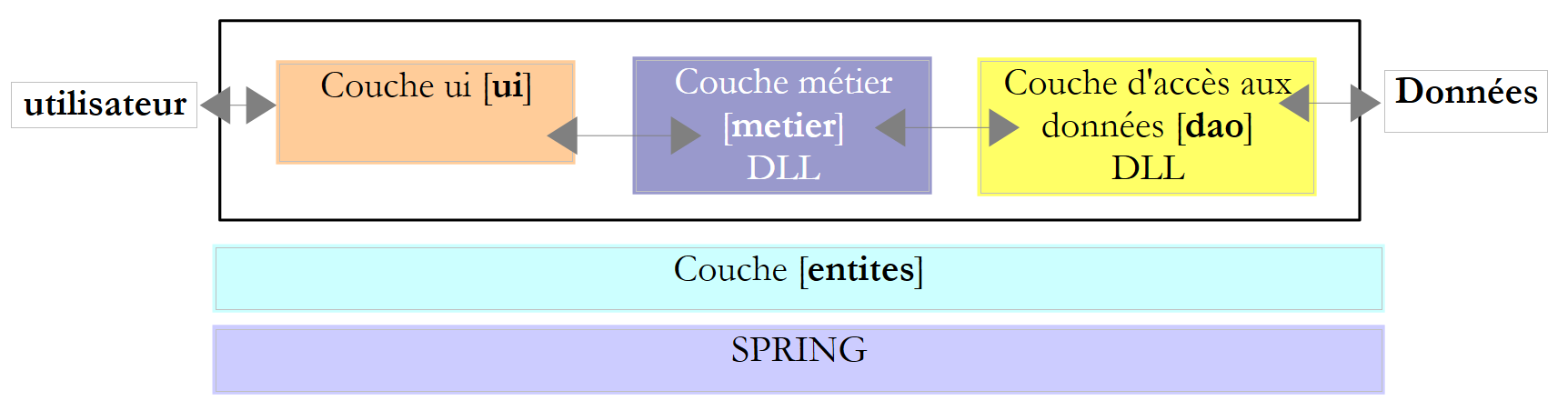
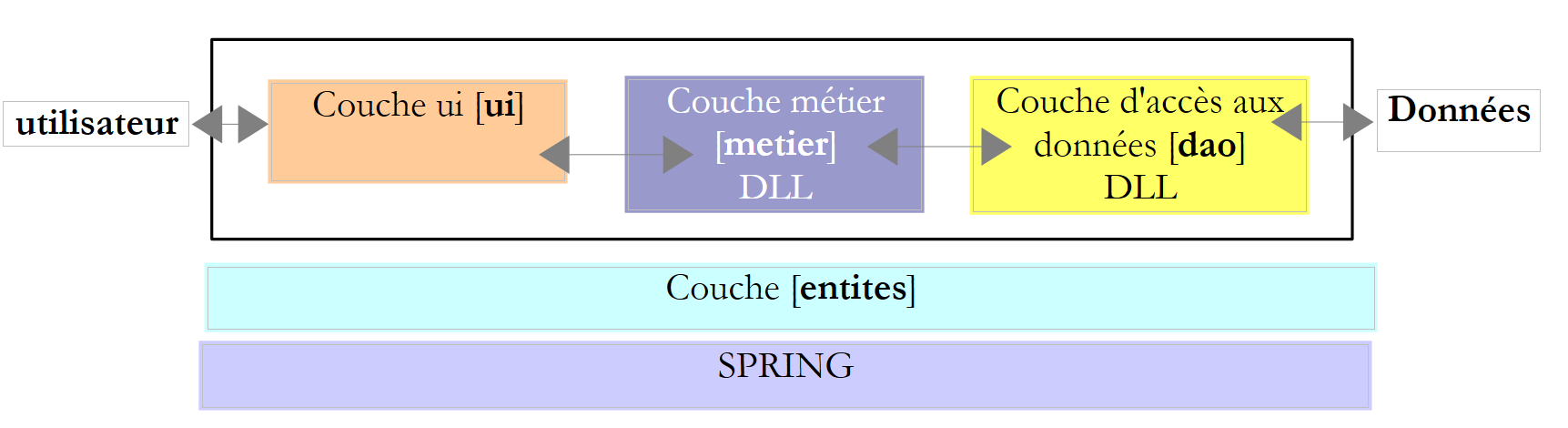
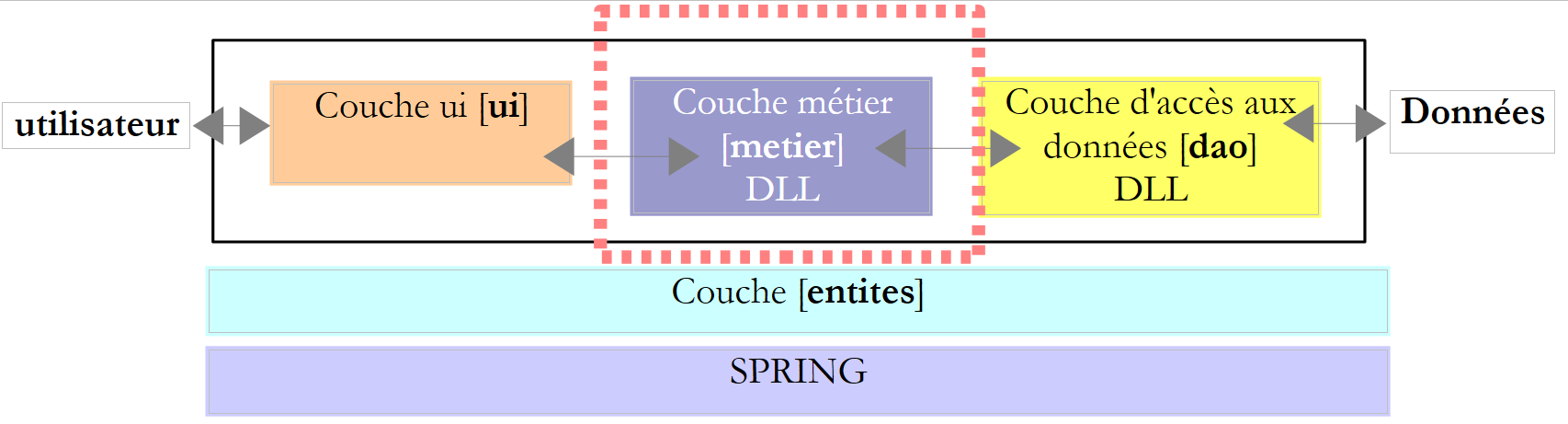
Die Praxis hat gezeigt, dass die Trennung dieser verschiedenen Prozesse in separate Klassen die Wartbarkeit von Anwendungen verbessert. Die Architektur einer auf diese Weise strukturierten Anwendung sieht wie folgt aus:
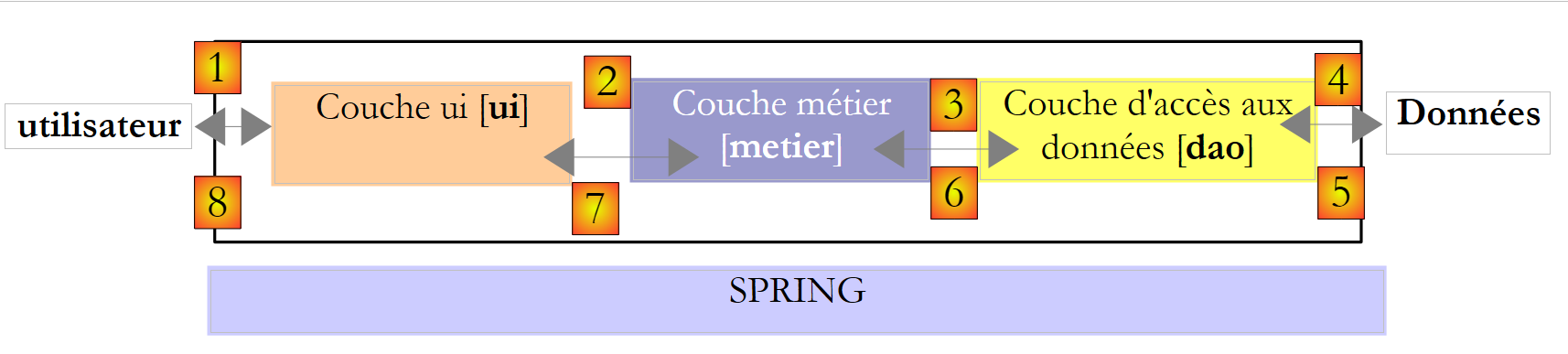 |
Diese Architektur wird als „dreischichtige Architektur“ bezeichnet. Der Begriff „dreischichtig“ bezieht sich normalerweise auf eine Architektur, bei der sich jede Schicht auf einem anderen Rechner befindet. Befinden sich die Schichten auf demselben Rechner, wird die Architektur zu einer „dreischichtigen Architektur“.
- Die [Business]-Schicht enthält die Geschäftsregeln der Anwendung. Bei unserer Steuerberechnungsanwendung sind dies die Regeln, die zur Berechnung der Steuer eines Steuerzahlers verwendet werden. Diese Schicht benötigt Daten, um zu funktionieren:
- Steuerklassen, die sich jedes Jahr ändern
- Anzahl der Kinder, Familienstand und Jahreseinkommen des Steuerpflichtigen
In der obigen Abbildung können die Daten aus zwei Quellen stammen:
- der Datenzugriffsebene oder [dao] (DAO = Data Access Object) für Daten, die bereits in Dateien oder Datenbanken gespeichert sind. Dies könnte hier bei den Steuerklassen der Fall sein, wie es in der vorherigen Version der Anwendung der Fall war.
- der Benutzeroberflächenschicht oder [ui] (UI = User Interface) für Daten, die vom Benutzer eingegeben oder ihm angezeigt werden. Dies könnte hier für die Anzahl der Kinder, den Familienstand und das Jahreseinkommen des Steuerpflichtigen gelten
- Im Allgemeinen verwaltet die [dao]-Schicht den Zugriff auf persistente Daten (Dateien, Datenbanken) oder nicht-persistente Daten (Netzwerk, Sensoren usw.).
- Die [ui]-Schicht verwaltet gegebenenfalls die Interaktionen mit dem Benutzer.
- Die drei Schichten werden durch die Verwendung von Schnittstellen voneinander unabhängig gemacht.
Wir werden die Anwendung [Impots], die wir bereits mehrfach behandelt haben, mit einer 3-Schichten-Architektur ausstatten. Dazu werden wir die Schichten [ui, metier, dao] nacheinander betrachten, beginnend mit der [dao]-Schicht, die persistente Daten verwaltet.
Zunächst müssen wir die Schnittstellen der verschiedenen Anwendungsschichten [Impots] definieren.
6.2. Anwendungsschnittstellen [Impots]
Denken Sie daran, dass eine Schnittstelle eine Reihe von Methodensignaturen definiert. Klassen, die die Schnittstelle implementieren, füllen diese Methoden mit Inhalt.
Kehren wir zur 3-Schichten-Architektur unserer Anwendung zurück:
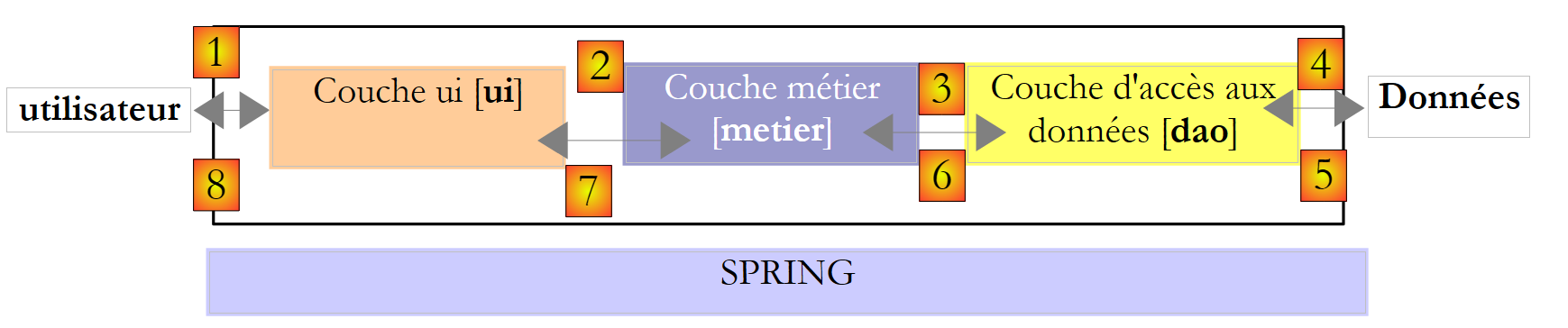 |
Bei dieser Art von Architektur ergreift oft der Benutzer die Initiative. Er stellt eine Anfrage in [1] und erhält eine Antwort in [8]. Dies wird als Anfrage-Antwort-Zyklus bezeichnet. Nehmen wir das Beispiel der Steuerberechnung eines Steuerzahlers. Dies erfordert mehrere Schritte:
- Die [ui]-Schicht muss den Nutzer nach der Anzahl seiner Kinder, seinem Familienstand und seinem Jahreseinkommen fragen. Dies ist der oben genannte Vorgang [1].
- Sobald dies geschehen ist, fordert die [ui]-Schicht die Geschäftsschicht auf, die Steuer zu berechnen. Dazu übermittelt sie die Daten, die sie vom Benutzer erhalten hat. Dies ist Vorgang [2].
- Die [metier]-Schicht benötigt bestimmte Informationen, um ihre Arbeit auszuführen: Steuerklassen. Sie fordert diese Informationen von der [dao]-Schicht über den Pfad [3, 4, 5, 6] an. [3] ist die ursprüngliche Anfrage und [6] die Antwort auf diese Anfrage.
- Mit allen benötigten Daten berechnet die [metier]-Schicht die Steuer.
- Die [metier]-Schicht kann nun auf die Anfrage der [ui]-Schicht aus (b) antworten. Dies ist der Pfad [7].
- Die [ui]-Schicht formatiert diese Ergebnisse und präsentiert sie dem Benutzer. Dies ist der Pfad [8].
- Man könnte sich vorstellen, dass der Benutzer Steuersimulationen durchführt und diese speichern möchte. Dazu würde er den Pfad [1-8] verwenden.
Diese Beschreibung zeigt, dass eine Schicht die Ressourcen der Schicht zu ihrer Rechten nutzt, niemals jedoch die der Schicht zu ihrer Linken. Betrachten wir zwei aneinandergrenzende Schichten:
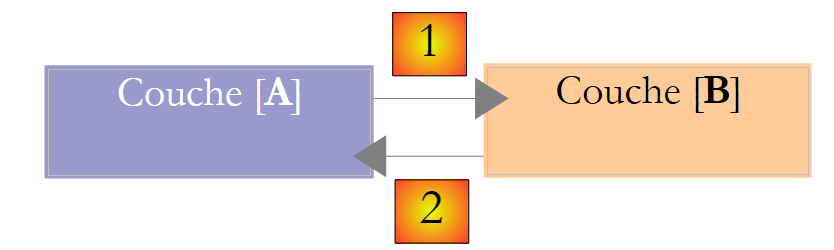 |
Schicht [A] sendet Anfragen an Schicht [B]. Im einfachsten Fall wird eine Schicht durch eine einzige Klasse implementiert. Eine Anwendung entwickelt sich im Laufe der Zeit weiter. Daher kann Schicht [B] verschiedene Implementierungsklassen [B1, B2, ...] haben. Wenn Schicht [B] die Schicht [dao] ist, kann sie eine erste Implementierung [B1] haben, die Daten aus einer Datei abruft. Einige Jahre später möchten Sie die Daten vielleicht in einer Datenbank speichern. Wir erstellen dann eine zweite Implementierungsklasse [B2]. Wenn in der ursprünglichen Anwendung die Schicht [A] direkt mit der Klasse [B1] zusammengearbeitet hat, müssen wir den Code der Schicht [A] teilweise umschreiben. Nehmen wir zum Beispiel an, dass die Schicht [A] wie folgt geschrieben wurde:
- Zeile 1: Eine Instanz der Klasse [B1] wird erstellt
- Zeile 3: Daten werden von dieser Instanz angefordert
Wenn wir davon ausgehen, dass die neue Implementierungsklasse [B2] Methoden mit derselben Signatur wie die der Klasse [B1] verwendet, müssen wir alle [B1] durch [B2] ersetzen. Dies ist ein sehr günstiger Fall und ziemlich unwahrscheinlich, wenn Sie diesen Methodensignaturen keine Beachtung geschenkt haben. In der Praxis haben die Klassen [B1] und [B2] oft nicht dieselben Methodensignaturen, sodass ein Großteil der Schicht [A] komplett neu geschrieben werden muss.
Dies lässt sich verbessern, indem eine Schnittstelle zwischen den Schichten [A] und [B] erstellt wird. Das bedeutet, dass die Signaturen der Methoden, die von der Schicht [B] an die Schicht [A] übergeben werden, in einer Schnittstelle festgehalten werden. Das vorherige Diagramm sieht dann wie folgt aus:
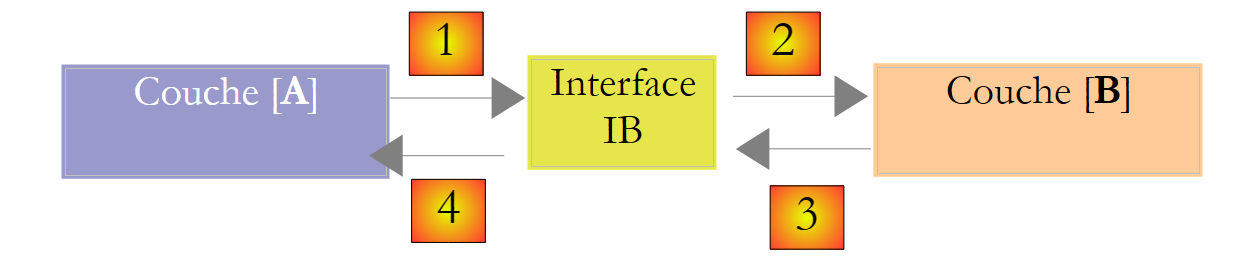 |
Schicht [A] greift nicht mehr direkt auf Schicht [B] zu, sondern auf deren Schnittstelle [IB]. Daher taucht die Implementierungsklasse [Bi] von Schicht [B] im Code von Schicht [A] nur einmal auf, nämlich bei der Implementierung der Schnittstelle [IB]. Sobald dies geschehen ist, wird im Code die Schnittstelle [IB] und nicht deren Implementierungsklasse verwendet. Der vorherige Code sieht nun wie folgt aus:
- Zeile 1: Eine Instanz [ib], die die Schnittstelle [IB] implementiert, wird durch Instanziierung der Klasse [B1] erstellt
- Zeile 3: Daten werden von der Instanz [ib] angefordert
Wenn wir nun die [B1]-Implementierung der Schicht [B] durch eine [B2]-Implementierung ersetzen und beide Implementierungen dieselbe Schnittstelle [IB] einhalten, muss nur Zeile 1 der Schicht [A] geändert werden, keine anderen. Dies ist ein großer Vorteil und rechtfertigt an sich schon die systematische Verwendung von Schnittstellen zwischen zwei Schichten.
Wir können sogar noch einen Schritt weiter gehen und die Schicht [A] vollständig von der Schicht [B] unabhängig machen. Im obigen Code ist Zeile 1 problematisch, da sie auf die Klasse [B1] verweist. Im Idealfall sollte die Schicht [A] über eine Implementierung der Schnittstelle [IB] verfügen, ohne eine Klasse benennen zu müssen. Dies würde mit unserem obigen Diagramm übereinstimmen. Wir sehen, dass die Schicht [A] die Schnittstelle [IB] adressiert, und wir sehen keinen Grund, warum sie den Namen der Klasse kennen müsste, die diese Schnittstelle implementiert. Dieses Detail ist für die Schicht [A] nutzlos.
Das Spring-Framework (http://www.springframework.org) erreicht dies. Die vorherige Architektur entwickelt sich wie folgt weiter:
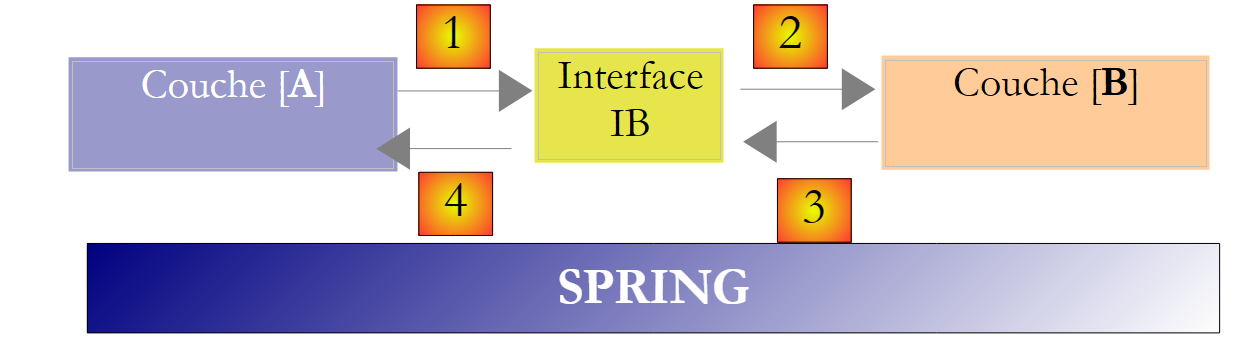 |
Die transversale Schicht [Spring] ermöglicht es einer Schicht, durch Konfiguration eine Referenz auf die Schicht rechts von ihr zu erhalten, ohne den Namen der Implementierungsklasse dieser Schicht kennen zu müssen. Dieser Name steht in den Konfigurationsdateien und nicht im C#-Code. Der C#-Code für die Schicht [A] sieht dann wie folgt aus:
- Zeile 1: eine Instanz [ib], die die Schnittstelle [IB] der Schicht [B] implementiert. Diese Instanz wird von Spring auf der Grundlage von Informationen aus einer Konfigurationsdatei erstellt. Spring erstellt:
- die Instanz [b], die die Schicht [B] implementiert
- die Instanz [a], die die Schicht [A] implementiert. Diese Instanz wird initialisiert. Das Feld [ib] oben wird auf die Referenz [b] des Objekts gesetzt, das die Schicht [B] implementiert
- Zeile 3: Daten werden von der Instanz [ib] angefordert
Wir sehen nun, dass die Implementierungsklasse [B1] der Schicht B nirgendwo im Code der Schicht [A] vorkommt. Wenn die Implementierung [B1] durch eine neue Implementierung [B2] ersetzt wird, ändert sich nichts am Code der Klasse [A]. Wir ändern lediglich die Spring-Konfigurationsdateien, um [B2] anstelle von [B1] zu instanziieren.
Die Kombination aus Spring und C#-Schnittstellen bringt eine entscheidende Verbesserung für die Anwendungswartung, indem sie die Schichten der Anwendung voneinander trennt. Dies ist die Lösung, die wir für eine neue Version der [Impots]-Anwendung verwenden werden.
Kehren wir zur dreischichtigen Architektur unserer Anwendung zurück:
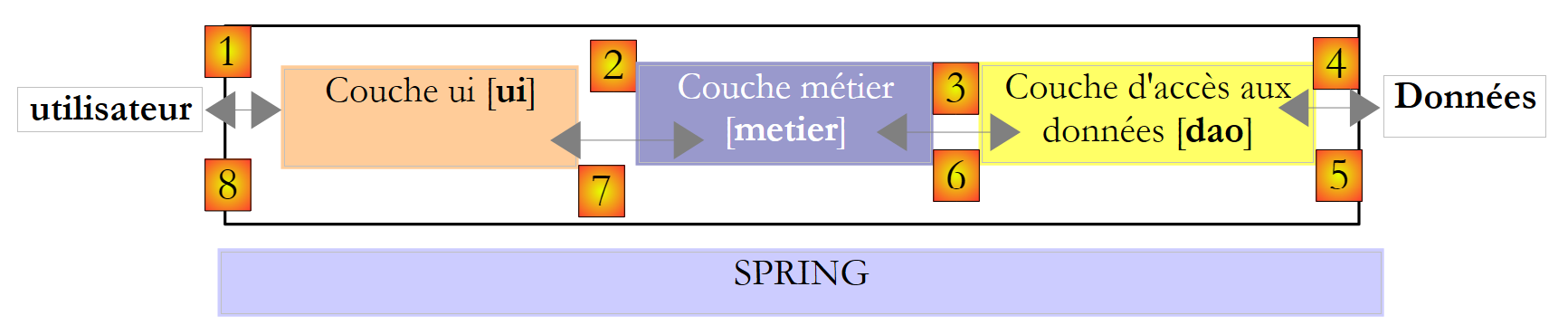 |
In einfachen Fällen können wir bei der [Business]-Schicht ansetzen, um die Schnittstellen der Anwendung zu ermitteln. Dazu benötigt sie:
- bereits in Dateien, Datenbanken oder über das Netzwerk verfügbar sein. Sie werden von der [dao]-Schicht bereitgestellt.
- noch nicht verfügbar. Sie werden von der [UI]-Schicht bereitgestellt, die sie vom Anwendungsbenutzer erhält.
Welche Schnittstelle sollte die [DAO]-Schicht der [Metier]-Schicht anbieten? Welche Interaktionen sind zwischen diesen beiden Schichten möglich? Die [DAO]-Schicht muss der [Metier]-Schicht die folgenden Daten bereitstellen:
- Steuerklassen
In unserer Anwendung nutzt die [dao]-Schicht vorhandene Daten, erstellt jedoch keine neuen Daten. Eine Schnittstellendefinition für die [dao]-Schicht könnte wie folgt aussehen:
using Entites;
namespace Dao {
public interface IImpotDao {
// tax brackets
TrancheImpot[] TranchesImpot{get;}
}
}
- Zeile 3: Die Ebene [dao] wird im Namensraum [Dao] platziert
- Zeile 6: Die Schnittstelle IImpotDao definiert die Eigenschaft TranchesImpot, die die Steuerklassen an die [business]-Schicht übergibt.
- Zeile 1: importiert den Namespace, in dem die Struktur TrancheImpot definiert ist:
namespace Entites {
// a tax bracket
public struct TrancheImpot {
public decimal Limite { get; set; }
public decimal CoeffR { get; set; }
public decimal CoeffN { get; set; }
}
}
Kehren wir zur dreischichtigen Architektur unserer Anwendung zurück:
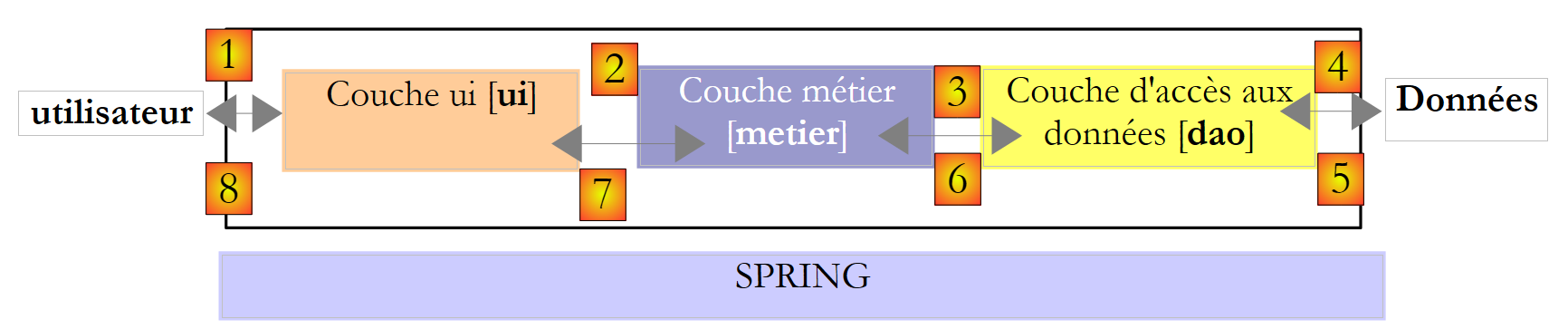 |
Welche Schnittstelle sollte die [Metier]-Schicht der [UI]-Schicht zur Verfügung stellen? Erinnern wir uns an die Interaktionen zwischen diesen beiden Schichten:
- Die [ui]-Schicht fragt den Benutzer nach der Anzahl seiner Kinder, seinem Familienstand und seinem Jahreseinkommen. Dies ist der oben genannte Vorgang [1].
- Sobald dies geschehen ist, fordert die [ui]-Schicht die Geschäftsschicht auf, die Sitzplätze zu berechnen. Dazu übermittelt sie die Daten, die sie vom Benutzer erhalten hat. Dies ist Vorgang [2].
Eine Schnittstellendefinition für die [metier]-Schicht könnte wie folgt lauten:
namespace Metier {
interface IImpotMetier {
int CalculerImpot(bool marié, int nbEnfants, int salaire);
}
}
- Zeile 1: Wir werden alles, was die [metier]-Schicht betrifft, in den [Metier]-Namensraum einfügen.
- Zeile 2: Die Schnittstelle IImpotMetier definiert nur eine Methode: die Berechnung der Steuerschuld eines Steuerpflichtigen auf der Grundlage des Familienstands, der Anzahl der Kinder und des Jahresgehalts.
Wir untersuchen eine erste Implementierung dieser Schichtenarchitektur.
6.3. Beispielanwendung – Version 4
6.3.1. Das Visual Studio-Projekt
Das Visual Studio-Projekt sieht wie folgt aus:
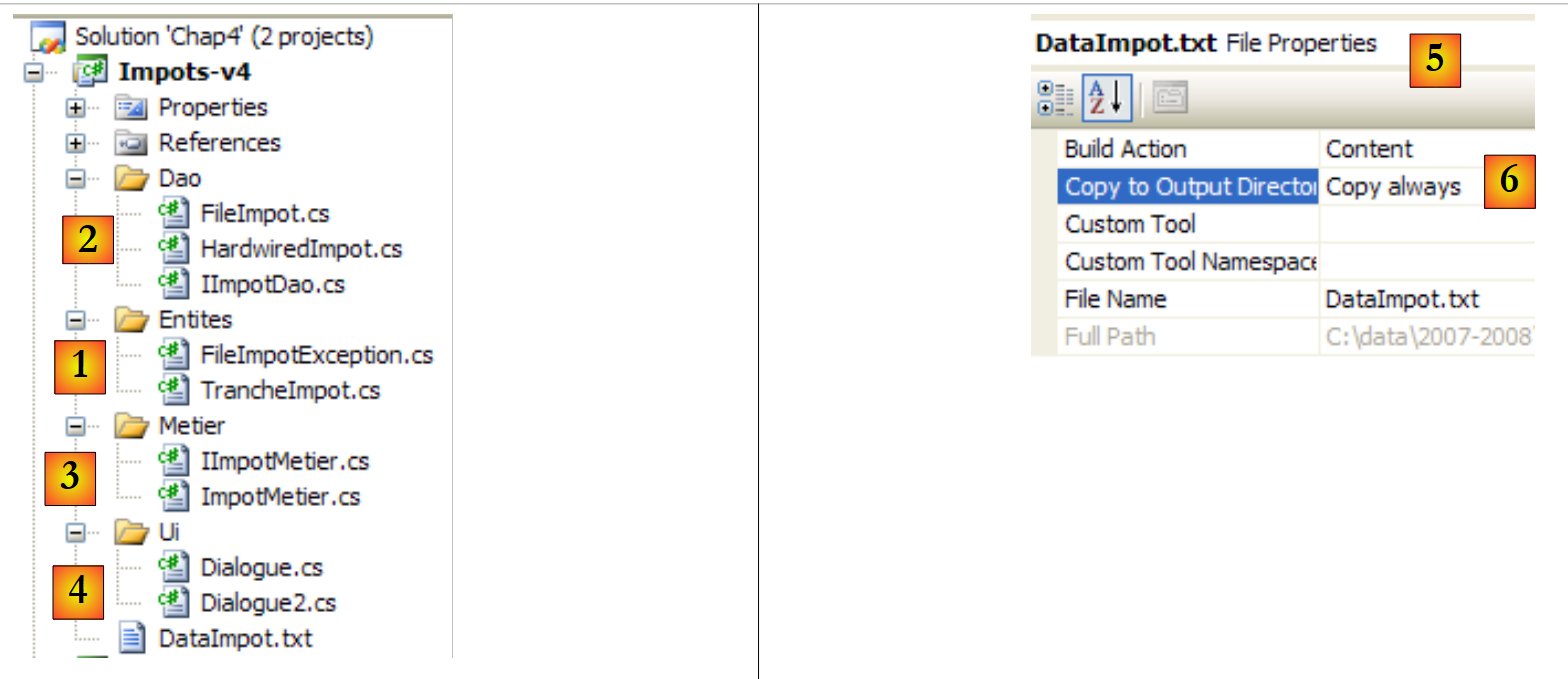 |
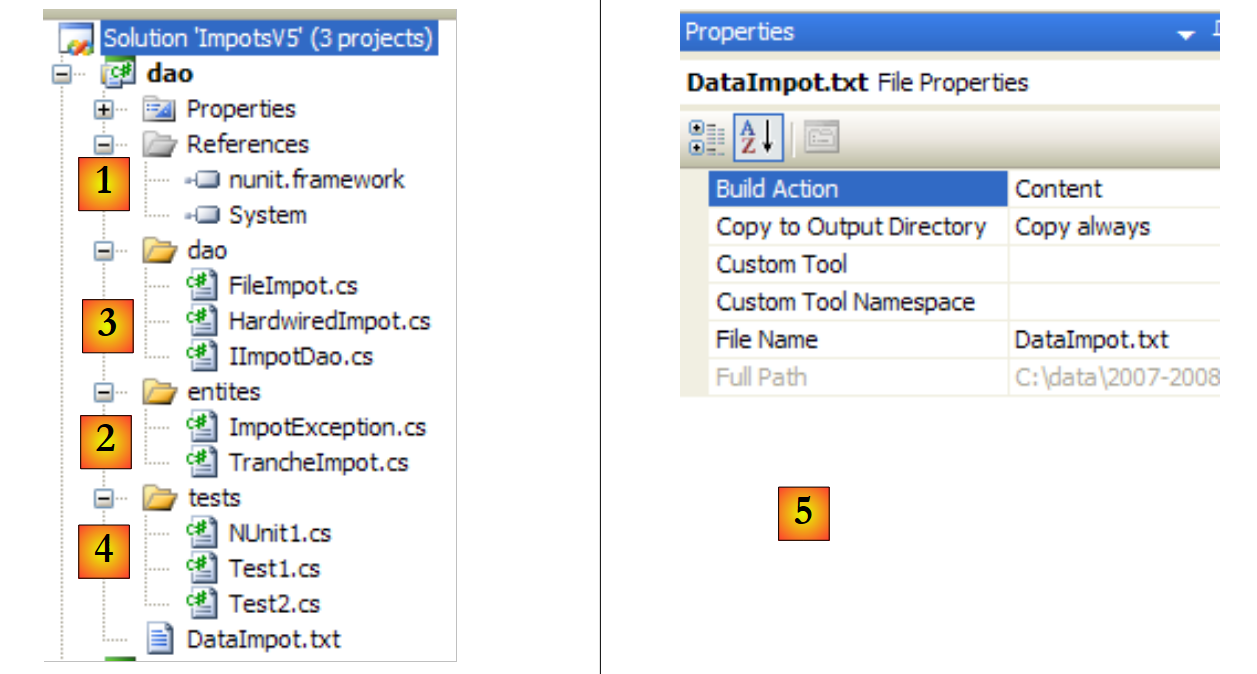
- [1]: Der Ordner [Entities] enthält Objekte, die die Schichten [ui, metier, dao] übergreifen: die Struktur TrancheImpot und die Ausnahme FileImpotException.
- [2]: Der Ordner [Dao] enthält die Klassen und Schnittstellen der [dao]-Schicht. Wir werden zwei Implementierungen von IImpotDao verwenden: die in Abschnitt 4.10 besprochene Klasse HardwiredImpot und die in Abschnitt 5.8 besprochene Klasse FileImpot.
- [3]: Der Ordner [Metier] enthält Klassen und Schnittstellen für die [metier]-Schicht
- [4]: Der Ordner [Ui] enthält die Klassen der [ui]-Schicht
- [5]: Die Datei [DataImpot.txt] enthält die Steuerklassen, die von der Implementierung FileImpot der Schicht [dao] verwendet werden. Sie ist so konfiguriert [6], dass sie automatisch in den Ausführungsordner des Projekts kopiert wird.
6.3.2. Anwendungsentitäten
Kehren wir zur 3-Schichten-Architektur unserer Anwendung zurück:
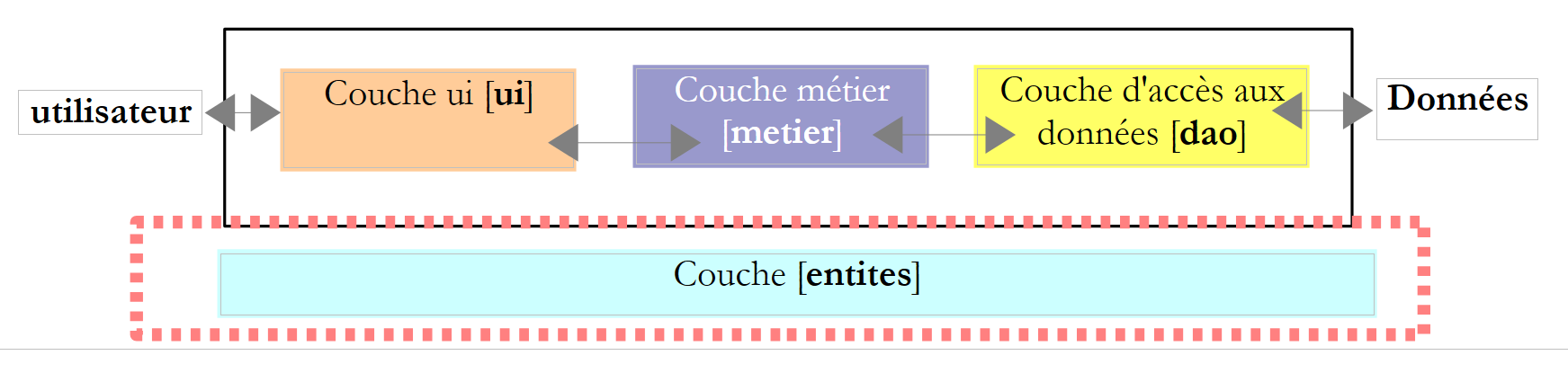 |
Wir bezeichnen sie als „Entity-Cross-Layer-Klassen“. Dies trifft im Allgemeinen auf Klassen und Strukturen zu, die Daten aus der [DAO]-Schicht kapseln. Diese Entitäten reichen in der Regel bis zur [UI]-Schicht zurück.
Die Entitäten der Anwendung sind wie folgt:
Die Struktur TrancheImpot
namespace Entites {
// a tax bracket
public struct TrancheImpot {
public decimal Limite { get; set; }
public decimal CoeffR { get; set; }
public decimal CoeffN { get; set; }
}
}
Die Ausnahme FileImportException
using System;
namespace Entites {
public class FileImpotException : Exception {
// error codes
[Flags]
public enum CodeErreurs { Acces = 1, Ligne = 2, Champ1 = 4, Champ2 = 8, Champ3 = 16 };
// error code
public CodeErreurs Code { get; set; }
// manufacturers
public FileImpotException() {
}
public FileImpotException(string message)
: base(message) {
}
public FileImpotException(string message, Exception e)
: base(message, e) {
}
}
}
Hinweis: Die FileImportException ist nur dann sinnvoll, wenn die [dao]-Schicht durch FileImport implementiert wird.
6.3.3. Die [dao]-Schicht
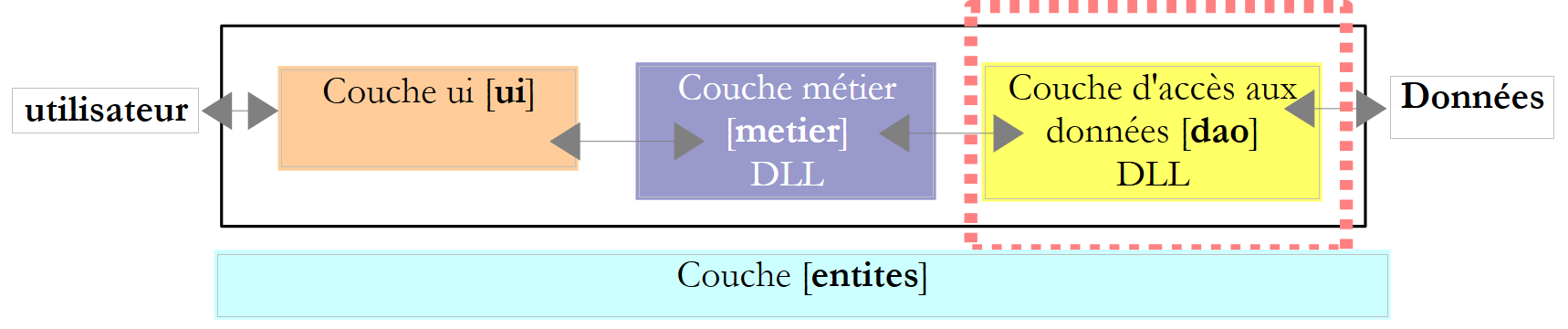 |
Erinnern Sie sich an die Schnittstelle der [dao]-Schicht:
using Entites;
namespace Dao {
public interface IImpotDao {
// tax brackets
TrancheImpot[] TranchesImpot{get;}
}
}
Wir werden diese Schnittstelle auf zwei verschiedene Arten implementieren.
Zunächst mit dem in Abschnitt 4.10 besprochenen HardwiredImpot:
using System;
using Entites;
namespace Dao {
public class HardwiredImpot : IImpotDao {
// data tables required to calculate the
decimal[] limites = { 4962M, 8382M, 14753M, 23888M, 38868M, 47932M, 0M };
decimal[] coeffR = { 0M, 0.068M, 0.191M, 0.283M, 0.374M, 0.426M, 0.481M };
decimal[] coeffN = { 0M, 291.09M, 1322.92M, 2668.39M, 4846.98M, 6883.66M, 9505.54M };
// ranges
public TrancheImpot[] TranchesImpot { get; private set; }
// manufacturer
public HardwiredImpot() {
// creation of a table of
TranchesImpot = new TrancheImpot[limites.Length];
// filling
for (int i = 0; i < TranchesImpot.Length; i++) {
TranchesImpot[i] = new TrancheImpot { Limite = limites[i], CoeffR = coeffR[i], CoeffN = coeffN[i] };
}
}
}// class
}// namespace
- Zeile 5: Die Klasse HardwiredImpot implementiert die Schnittstelle IImpotDao
- Zeile 12: Implementierung der Schnittstelle IImpotDao durch TranchesImpot. Diese Eigenschaft ist eine automatische Eigenschaft. Sie implementiert die Get-Eigenschaft der Schnittstelle IImpotDao von TranchesImpot. Wir haben außerdem eine Methode „set“ deklariert, die klassenintern ist, damit der Konstruktor in den Zeilen 15–22 die Tabelle der Steuerklassen initialisieren kann.
Die Schnittstelle IImpotDao wird auch von der in Abschnitt 5.8 behandelten Klasse FileImpot implementiert:
using System;
using System.Collections.Generic;
using System.IO;
using System.Text.RegularExpressions;
using Entites;
namespace Dao {
class FileImpot : IImpotDao {
// data file
public string FileName { get; set; }
// tax brackets
public TrancheImpot[] TranchesImpot { get; private set; }
// manufacturer
public FileImpot(string fileName) {
// save the file name
FileName = fileName;
// data
List<TrancheImpot> listTranchesImpot = new List<TrancheImpot>();
int numLigne = 1;
// exception
FileImpotException fe = null;
// read the contents of the fileName file, line by line
Regex pattern = new Regex(@"s*:\s*");
// initially no error
FileImpotException.CodeErreurs code = 0;
try {
using (StreamReader input = new StreamReader(FileName)) {
while (!input.EndOfStream && code == 0) {
// current line
string ligne = input.ReadLine().Trim();
// ignore empty lines
if (ligne == "")
continue;
// line broken down into three fields separated by :
string[] champsLigne = pattern.Split(ligne);
// do we have 3 fields?
if (champsLigne.Length != 3) {
code = FileImpotException.CodeErreurs.Ligne;
}
// 3-field conversions
decimal limite = 0, coeffR = 0, coeffN = 0;
if (code == 0) {
if (!Decimal.TryParse(champsLigne[0], out limite))
code = FileImpotException.CodeErreurs.Champ1;
if (!Decimal.TryParse(champsLigne[1], out coeffR))
code |= FileImpotException.CodeErreurs.Champ2;
if (!Decimal.TryParse(champsLigne[2], out coeffN))
code |= FileImpotException.CodeErreurs.Champ3;
;
}
// mistake?
if (code != 0) {
// on note l'erreur
fe = new FileImpotException(String.Format("Ligne n° {0} incorrecte", numLigne)) { Code = code };
} else {
// the new tax bracket is memorized
listTranchesImpot.Add(new TrancheImpot() { Limite = limite, CoeffR = coeffR, CoeffN = coeffN });
// next line
numLigne++;
}
}
}
} catch (Exception e) {
// on note l'erreur
fe = new FileImpotException(String.Format("Erreur lors de la lecture du fichier {0}", FileName), e) { Code = FileImpotException.CodeErreurs.Acces };
}
// error to report?
if (fe != null) {
// on lance l'exception
throw fe;
} else {
// return the listImpot list in the tranchesImpot array
TranchesImpot = listTranchesImpot.ToArray();
}
}
}
}
- Dieser Code wurde bereits in Abschnitt 5.8 behandelt.
- Zeile 14: die Methode TranchesImpot der Schnittstelle IImpotDao
- Zeile 76: Initialisierung der Steuerklassen im Klassenkonstruktor anhand der Datei, die dem Konstruktor in Zeile 17 übergeben wird.
6.3.4. Die Windel [Metier]
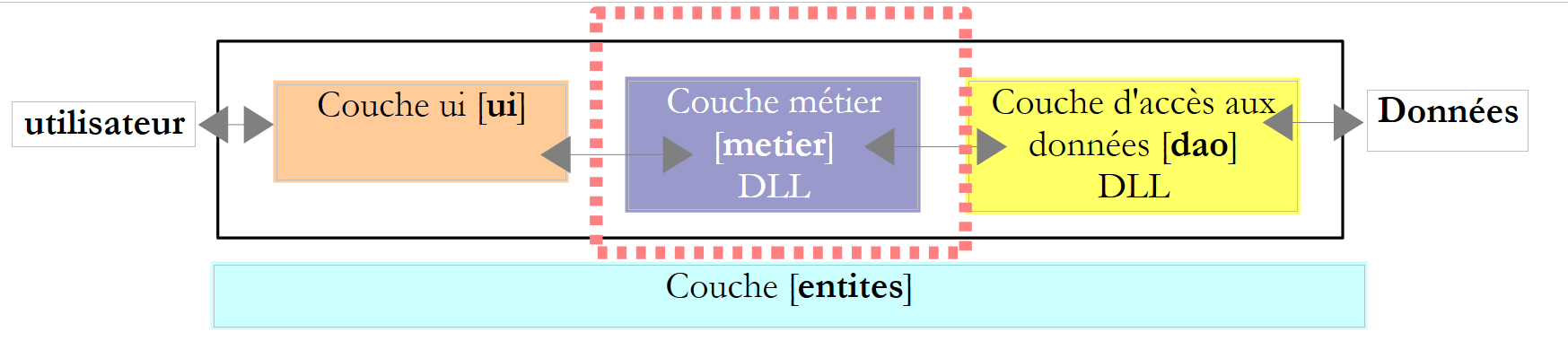 |
Erinnern wir uns an die Schnittstelle dieser Schicht:
namespace Metier {
public interface IImpotMetier {
int CalculerImpot(bool marié, int nbEnfants, int salaire);
}
}
Die Implementierung von ImpotMetier für diese Schnittstelle lautet wie folgt:
using Entites;
using Dao;
namespace Metier {
public class ImpotMetier : IImpotMetier {
// layer [dao]
private IImpotDao Dao { get; set; }
// tax brackets
private TrancheImpot[] tranchesImpot;
// manufacturer
public ImpotMetier(IImpotDao dao) {
// memorization
Dao = dao;
// tax brackets
tranchesImpot = dao.TranchesImpot;
}
// tAX CALCULATION
public int CalculerImpot(bool marié, int nbEnfants, int salaire) {
// calculating the number of shares
decimal nbParts;
if (marié)
nbParts = (decimal)nbEnfants / 2 + 2;
else
nbParts = (decimal)nbEnfants / 2 + 1;
if (nbEnfants >= 3)
nbParts += 0.5M;
// calculation of taxable income & family quota
decimal revenu = 0.72M * salaire;
decimal QF = revenu / nbParts;
// tAX CALCULATION
tranchesImpot[tranchesImpot.Length - 1].Limite = QF + 1;
int i = 0;
while (QF > tranchesImpot[i].Limite)
i++;
// return result
return (int)(revenu * tranchesImpot[i].CoeffR - nbParts * tranchesImpot[i].CoeffN);
}//calculate
}//class
}
- Zeile 5: Die Klasse [Metier] implementiert die Schnittstelle [IImpotMetier].
- Zeilen 14–19: Die [metier]-Schicht muss mit der [dao]-Schicht zusammenarbeiten. Sie muss daher über eine Referenz auf das Objekt verfügen, das die Schnittstelle IImpotDao implementiert. Aus diesem Grund wird diese Referenz als Parameter an den Konstruktor übergeben.
- Zeile 16: Die Schichtenreferenz [dao] wird im privaten Feld von Zeile 8 gespeichert
- Zeile 18: Anhand dieser Referenz fordert der Builder die Tabelle der Steuerklassen an und speichert eine Referenz in der privaten Eigenschaft in Zeile 8.
- Zeilen 22–41: Implementierung der Methode CalculerImpot der Schnittstelle IImpotMetier. Diese Implementierung verwendet die vom Konstruktor initialisierte Steuertabelle.
6.3.5. Die [ui]-Schicht
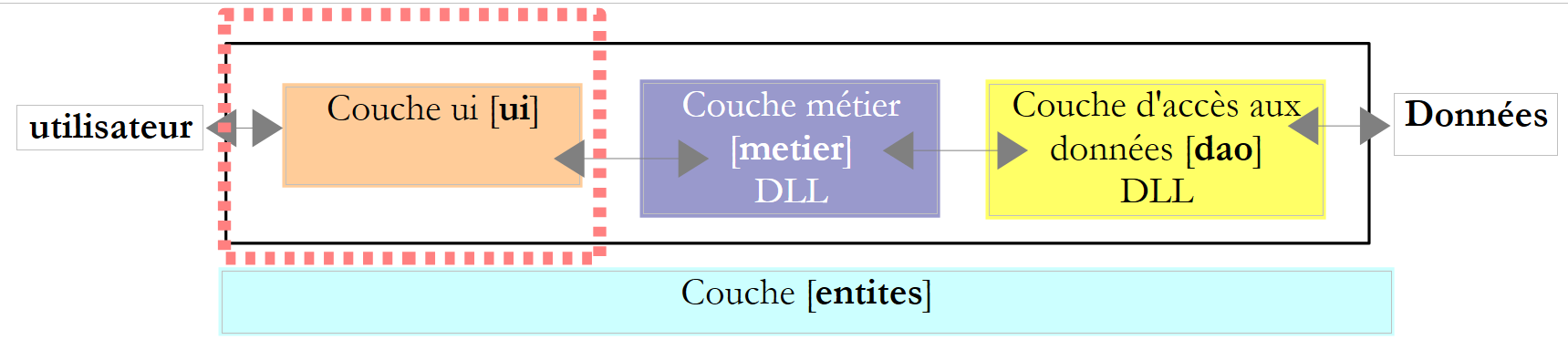 |
Die Benutzerdialogklassen in den Versionen 2 und 3 waren sehr ähnlich. Diejenige für Version 2 sah wie folgt aus:
using System;
namespace Chap2 {
public class Program {
static void Main() {
...
// creation of
IImpot impot = new HardwiredImpot();
// infinite loop
while (true) {
...
}//while
}
}
}
und Version 3:
using System;
namespace Chap3 {
public class Program {
static void Main() {
...
// creation of a IImpot object
IImpot impot = null;
try {
// creation of a IImpot object
impot = new FileImpot("DataImpotInvalide.txt");
} catch (FileImpotException e) {
// error display
string msg = e.InnerException == null ? null : String.Format(", Exception d'origine : {0}", e.InnerException.Message);
Console.WriteLine("L'erreur suivante s'est produite : [Code={0},Message={1}{2}]", e.Code, e.Message, msg == null ? "" : msg);
// program stop
Environment.Exit(1);
}
// infinite loop
while (true) {
...
}//while
}
}
}
Das Einzige, was sich ändert, ist die Art und Weise, wie Sie das IImpot-Objekt instanziieren, das zur Berechnung der Steuer verwendet wird. Dieses Objekt entspricht hier unserer [Business]-Schicht.
Für eine Implementierung [dao] mit der Klasse HardwiredImpot sieht die Dialogklasse wie folgt aus:
using System;
using Metier;
using Dao;
using Entites;
namespace Ui {
public class Dialogue2 {
static void Main() {
...
// we create the layers [metier and dao]
IImpotMetier metier = new ImpotMetier(new HardwiredImpot());
// infinite loop
while (true) {
...
// the parameters are correct - the
Console.WriteLine("Impot=" + metier.CalculerImpot(marié == "o", nbEnfants, salaire) + " euros");
// next taxpayer
}//while
}
}
}
- Zeile 12: Instanziierung der Schichten [dao] und [metier]. Beachten Sie, dass die Schicht [metier] die Schicht [dao] benötigt.
- Zeile 18: Verwendung der [metier]-Schicht zur Berechnung der Steuer
Für eine Implementierung von [dao] mit der Klasse FileImpot sieht die Dialogklasse wie folgt aus:
using System;
using Metier;
using Dao;
using Entites;
namespace Ui {
public class Dialogue {
static void Main() {
...
// we create the layers [metier and dao]
IImpotMetier metier = null;
try {
// layer creation [job]
metier = new ImpotMetier(new FileImpot("DataImpot.txt"));
} catch (FileImpotException e) {
// error display
string msg = e.InnerException == null ? null : String.Format(", Exception d'origine : {0}", e.InnerException.Message);
Console.WriteLine("L'erreur suivante s'est produite : [Code={0},Message={1}{2}]", e.Code, e.Message, msg == null ? "" : msg);
// program stop
Environment.Exit(1);
}
// infinite loop
while (true) {
...
// parameters are correct - Impot is calculated
Console.WriteLine("Impot=" + metier.CalculerImpot(marié == "o", nbEnfants, salaire) + " euros");
// next taxpayer
}//while
}
}
}
- Zeile 11–21: Instanziierung der Schichten [dao] und [metier]. Die Instanziierung der [dao]-Schicht kann eine Ausnahme auslösen, die von
- Zeile 26: Verwendung der [metier]-Schicht zur Berechnung der Steuer, wie in der vorherigen Version
6.3.6. Fazit
Die Schichtenarchitektur und die Verwendung von Schnittstellen haben unserer Anwendung eine gewisse Flexibilität verliehen. Dies zeigt sich insbesondere in der Art und Weise, wie die [ui]-Schicht die [dao]- und [business]-Schichten instanziiert:
// on crée les couches [metier et dao]
IImpotMetier metier = new ImpotMetier(new HardwiredImpot());
in einem Fall und:
// we create the layers [metier and dao]
IImpotMetier metier = null;
try {
// layer creation [job]
metier = new ImpotMetier(new FileImpot("DataImpot.txt"));
} catch (FileImpotException e) {
// error display
string msg = e.InnerException == null ? null : String.Format(", Exception d'origine : {0}", e.InnerException.Message);
Console.WriteLine("L'erreur suivante s'est produite : [Code={0},Message={1}{2}]", e.Code, e.Message, msg == null ? "" : msg);
// program stop
Environment.Exit(1);
}
im anderen. Mit Ausnahme der Ausnahmebehandlung in Fall 2 ist die Instanziierung der [dao]- und [metier]-Schichten in beiden Anwendungen ähnlich. Sobald die [dao]- und [metier]-Schichten instanziiert wurden, ist der Code für die [ui]-Schicht in beiden Fällen identisch. Dies liegt daran, dass die [metier]-Schicht über ihre Schnittstelle IImpotMetier und nicht über ihre Implementierungsklasse manipuliert wird. Eine Änderung der [metier]-Schicht oder der [dao]-Schicht der Anwendung ohne Änderung ihrer Schnittstellen bedeutet immer, dass nur die vorherigen Zeilen in der [ui]-Schicht geändert werden.
Ein weiteres Beispiel für die Flexibilität, die diese Architektur bietet, ist die Implementierung der [business]-Schicht:
using Entites;
using Dao;
namespace Metier {
public class ImpotMetier : IImpotMetier {
// layer [dao]
private IImpotDao Dao { get; set; }
// tax brackets
private TrancheImpot[] tranchesImpot;
// manufacturer
public ImpotMetier(IImpotDao dao) {
// memorization
Dao = dao;
// tax brackets
tranchesImpot = dao.TranchesImpot;
}
// tAX CALCULATION
public int CalculerImpot(bool marié, int nbEnfants, int salaire) {
...
}//calculate
}//class
}
Zeile 14 zeigt, dass die [business]-Schicht auf einer Referenz zur Schnittstelle der [dao]-Schicht aufbaut. Eine Änderung der Implementierung der [dao]-Schicht hat daher keinerlei Auswirkungen auf die [business]-Schicht. Aus diesem Grund konnte unsere einzige Implementierung der [business]-Schicht unverändert mit zwei verschiedenen Implementierungen der [dao]-Schicht funktionieren.
6.4. Anwendungsbeispiel – „ “ Version 5
 |
Diese neue Version basiert auf der Vorgängerversion und enthält folgende Änderungen:
- Die [Business]- und [DAO]-Schichten sind jeweils in einer DLL gekapselt und werden mit dem NUnit-Unit-Test-Framework getestet.
- Die Integration der Schichten wird durch das Spring-Framework bereitgestellt
In großen Projekten arbeiten mehrere Entwickler an demselben Projekt. Geschichtete Architekturen erleichtern diese Arbeitsweise: Da die Schichten über klar definierte Schnittstellen miteinander kommunizieren, muss sich ein Entwickler, der an einer Schicht arbeitet, keine Gedanken über die Arbeit anderer Entwickler an anderen Schichten machen. Es ist lediglich erforderlich, dass sich alle an die Schnittstellen halten.
Im obigen Beispiel benötigt der Entwickler der [business]-Schicht eine Implementierung der [dao]-Schicht, um seine Schicht zu testen. Bis diese fertiggestellt ist, kann er eine Dummy-Implementierung der [dao]-Schicht verwenden, solange diese der [dao]-Schnittstelle IImpotDao entspricht. Dies ist ein weiterer Vorteil der Schichtenarchitektur: Eine Verzögerung in der [dao]-Schicht verhindert nicht das Testen der [business]-Schicht. Die Dummy-Implementierung der [dao]-Schicht hat zudem den Vorteil, dass sie oft einfacher zu implementieren ist als die echte [dao]-Schicht, die möglicherweise den Start eines SGBD, Netzwerkverbindungen usw. erfordert.
Wenn die [dao]-Schicht fertiggestellt und getestet ist, wird sie den Entwicklern der [business]-Schicht in Form einer DLL statt als Quellcode bereitgestellt. Letztendlich wird die Anwendung oft in Form einer ausführbaren .exe-Datei (für die [ui]-Schicht) und .dll-Klassenbibliotheken (für die anderen Schichten) ausgeliefert.
6.4.1. NUnit
Bislang basierten die für unsere verschiedenen Anwendungen durchgeführten Tests auf einer visuellen Überprüfung. Wir haben überprüft, ob auf dem Bildschirm das erwartete Ergebnis angezeigt wurde. Diese Methode ist unbrauchbar, wenn viele Tests durchgeführt werden müssen. Menschen neigen zu Ermüdung, und ihre Fähigkeit, Tests zu überprüfen, lässt im Laufe des Tages nach. Tests müssen daher automatisiert werden und darauf abzielen, jeglichen menschlichen Eingriff zu vermeiden.
Eine Anwendung entwickelt sich im Laufe der Zeit weiter. Bei jeder Weiterentwicklung müssen wir überprüfen, ob die Anwendung keine „Regression“ aufweist, d. h. ob sie weiterhin die Funktionstests besteht, die bei ihrer Erstellung durchgeführt wurden. Diese Tests werden als „Non-Regressionstests“ bezeichnet. Eine große Anwendung kann Hunderte von Tests erfordern. Jede Methode jeder Klasse in der Anwendung wird getestet. Diese Tests werden als Unit-Tests bezeichnet. Wenn sie nicht automatisiert sind, kann dies einen hohen Aufwand für die Entwickler bedeuten.
Es wurden Tools entwickelt, um das Testen zu automatisieren. Eines davon heißt NUnit. Es ist auf [http://www.nunit.org] verfügbar:
 |  |
Für dieses Dokument wurde die oben genannte Version 2.4.6 verwendet (März 2008). Bei der Installation wird ein Symbol [1] auf dem Desktop abgelegt:
 |
Ein Doppelklick auf das Symbol [1] startet die NUnit-GUI [2]. Dies trägt jedoch nicht zur Testautomatisierung bei, da wir uns erneut auf eine visuelle Überprüfung beschränken müssen: Der Tester überprüft die in der GUI angezeigten Testergebnisse. Tests können jedoch auch über Batch-Tools ausgeführt und ihre Ergebnisse in XML-Dateien gespeichert werden. Diese Methode wird von Entwicklungsteams genutzt: Die Tests werden über Nacht ausgeführt, und die Entwickler verfügen am nächsten Morgen über die Ergebnisse.
Schauen wir uns ein Beispiel für NUnit-Tests an. Erstellen wir zunächst ein neues C#-Projekt vom Typ „Application Console“:
 |
In [1] sehen wir die Referenzen des Projekts. Diese Referenzen sind DLLs, die Klassen und Schnittstellen enthalten, die vom Projekt verwendet werden. Die in [1] aufgeführten Referenzen sind standardmäßig in jedem neuen C#-Projekt enthalten. Um die Klassen und Schnittstellen des NUnit-Frameworks nutzen zu können, müssen wir [2] eine neue Referenz zum Projekt hinzufügen.
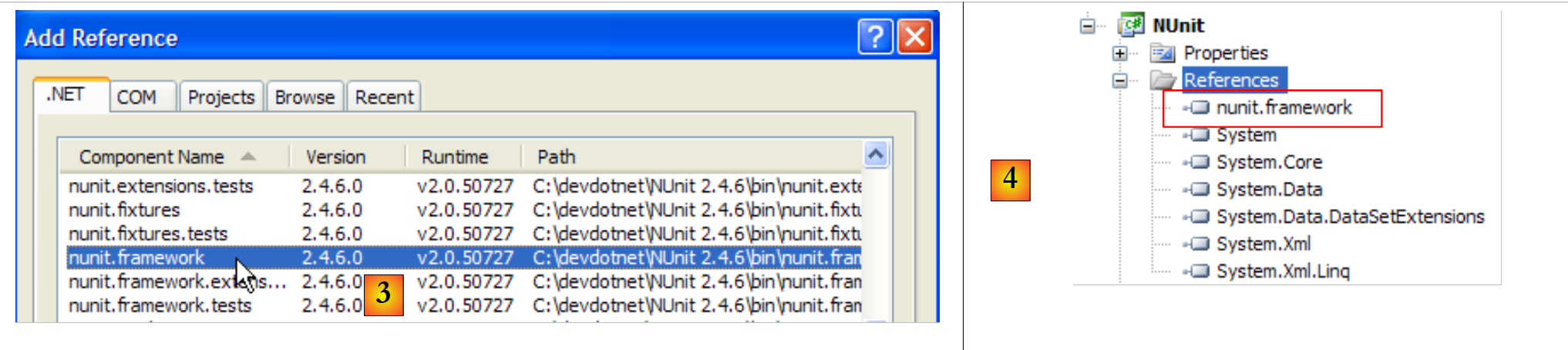 |
Auf der Registerkarte „.NET“ oben wählen wir die Komponente [nunit.framework] aus. Die oben aufgeführten Komponenten [nunit.*] sind keine Komponenten, die standardmäßig in der .NET-Umgebung vorhanden sind. Sie wurden durch die vorherige Installation des NUnit-Frameworks hinzugefügt. Sobald die Referenz hinzugefügt wurde, erscheint sie [4] in der Liste der Projektreferenzen.
Vor der Generierung der Anwendung ist der Ordner [bin/Release] des Projekts leer. Nach der Generierung (F6) ist der Ordner [bin/Release] nicht mehr leer:
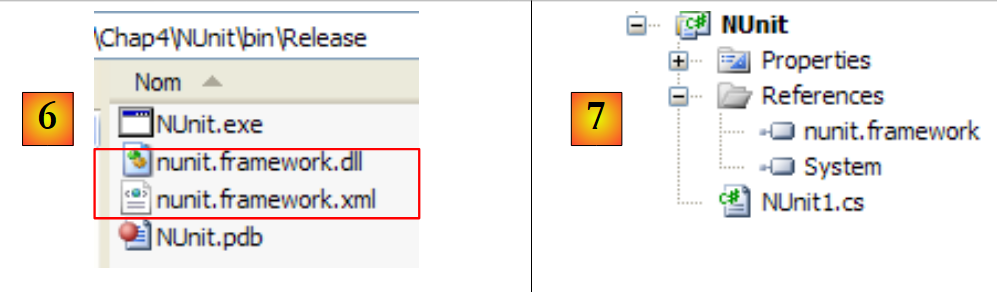 |
In [6] sehen wir das Vorhandensein der DLL [nunit.framework.dll]. Es war das Hinzufügen der Referenz [nunit.framework], das dazu führte, dass diese DLL in den Ausführungsordner kopiert wurde. Dies ist tatsächlich einer der Ordner, die von der CLR (Common Language Runtime) von .NET durchsucht werden, um die vom Projekt referenzierten Klassen und Schnittstellen zu finden.
Erstellen wir eine erste Testklasse NUnit. Dazu löschen wir die Standardklasse [Program.cs] und fügen dem Projekt eine neue Klasse [Nunit1.cs] hinzu. Außerdem löschen wir unnötige Referenzen [7].
Die Testklasse NUnit1 sieht wie folgt aus:
using System;
using NUnit.Framework;
namespace NUnit {
[TestFixture]
public class NUnit1 {
public NUnit1() {
Console.WriteLine("constructeur");
}
[SetUp]
public void avant() {
Console.WriteLine("Setup");
}
[TearDown]
public void après() {
Console.WriteLine("TearDown");
}
[Test]
public void t1() {
Console.WriteLine("test1");
Assert.AreEqual(1, 1);
}
[Test]
public void t2() {
Console.WriteLine("test2");
Assert.AreEqual(1, 2, "1 n'est pas égal à 2");
}
}
}
- Zeile 6: Die Klasse NUnit1 muss öffentlich sein. Das Schlüsselwort public wird von Visual Studio standardmäßig nicht generiert. Es muss hinzugefügt werden.
- Zeile 5: [TestFixture] ist ein Attribut von NUnit. Es gibt an, dass es sich bei der Klasse um eine Testklasse handelt.
- Zeilen 7–9: Der Konstruktor. Er wird hier nur verwendet, um eine Meldung auf den Bildschirm zu schreiben. Wir wollen sehen, wann er ausgeführt wird.
- Zeile 10: Das [SetUp] definiert eine Methode, die vor jedem Unit-Test ausgeführt wird.
- Zeile 14: Das [TearDown] definiert eine Methode, die nach jedem Unit-Test ausgeführt wird.
- Zeile 18: Das Attribut [Test] definiert eine Testmethode. Für jede mit [Test] gekennzeichnete Methode wird das mit [SetUp] gekennzeichnete Attribut vor dem Test und das mit [TearDown] gekennzeichnete Attribut nach dem Test ausgeführt.
- Zeile 21: Eine der [Assert.*-Methoden, die vom NUnit-Framework definiert werden. Die folgenden [Assert]-Methoden stehen zur Verfügung:
- [Assert.AreEqual(expression1, expression2)]: Prüft, ob die Werte der beiden Ausdrücke gleich sind. Viele Ausdruckstypen werden unterstützt (int, string, float, double, decimal, ...). Sind die beiden Ausdrücke nicht gleich, wird eine Ausnahme ausgelöst.
- [Assert.AreEqual(real1, real2, delta)]: überprüft, ob zwei reelle Zahlen bis auf delta nahe beieinander liegen, d. h. abs(real1-real2) <= delta. Beispielsweise können wir [Assert.AreEqual(real1, real2, 1E-6)] schreiben, um zu überprüfen, ob zwei Werte bis auf 10-6 nahe beieinander liegen.
- [Assert.AreEqual(expression1, expression2, message)] und [Assert.AreEqual(real1, real2, delta, message)] sind Varianten, mit denen die Fehlermeldung festgelegt wird, die der Ausnahme zugeordnet wird, die ausgelöst wird, wenn [Assert.AreEqual] fehlschlägt.
- [Assert.IsNotNull(object)] und [Assert.IsNotNull(object, message)] : überprüft, ob object nicht gleich null ist.
- [Assert.IsNull(object)] und [Assert.IsNull(object, message)] : Überprüft, ob object gleich null ist.
- [Assert.IsTrue(Ausdruck)] und [Assert.IsTrue(Ausdruck, Meldung)]: Prüft, ob der Ausdruck wahr ist.
- [Assert.IsFalse(Ausdruck)] und [Assert.IsFalse(Ausdruck, Meldung)]: Prüft, ob Ausdruck gleich false ist.
- [Assert.AreSame(Objekt1, Objekt2)] und [Assert.AreSame(Objekt1, Objekt2, Meldung)]: Prüft, ob die Referenzen Objekt1 und Objekt2 auf dasselbe Objekt verweisen.
- [Assert.AreNotSame(object1, object2)] und [Assert.AreNotSame(object1, object2, message)]: Prüft, ob die Referenzen object1 und object2 nicht auf dasselbe Objekt verweisen.
- Zeile 21: Die Assertion muss erfolgreich sein
- Zeile 26: Die Assertion muss fehlschlagen
Konfigurieren wir das Projekt so, dass bei der Generierung eine DLL statt einer ausführbaren .exe-Datei erstellt wird:
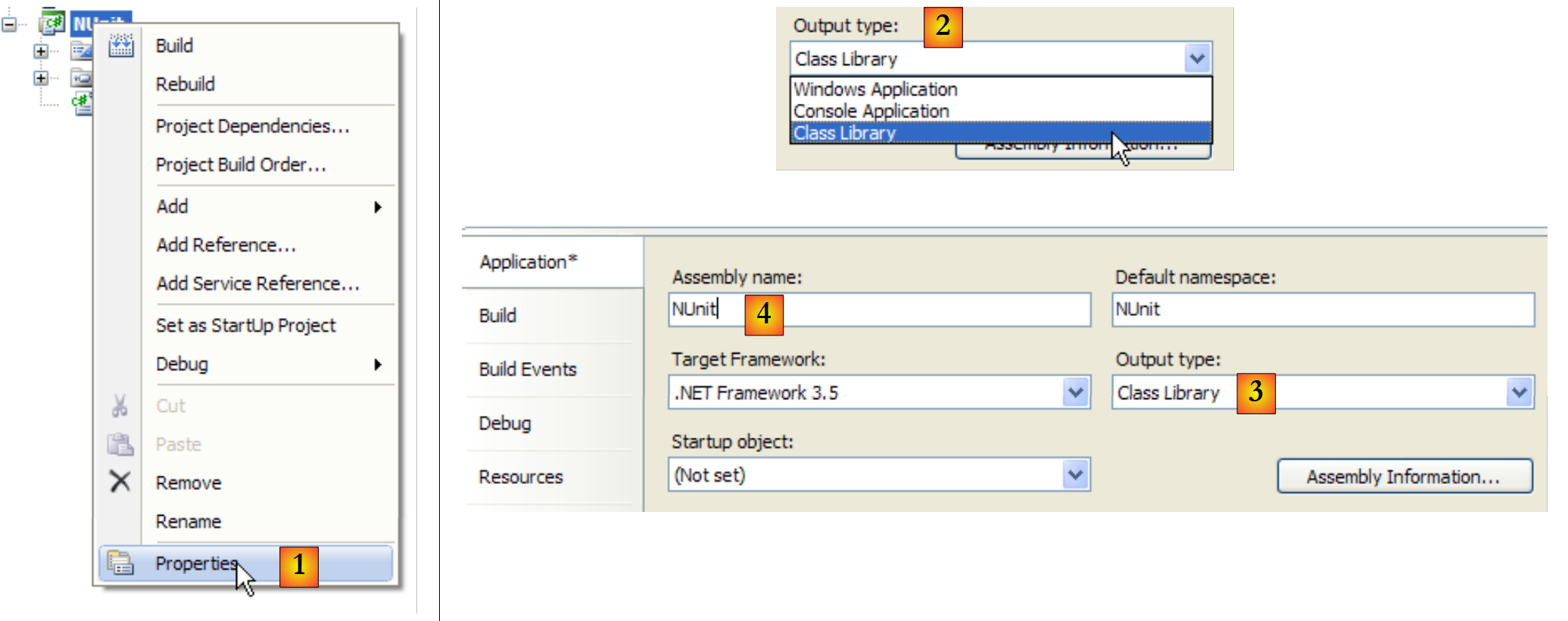 |
- in [1]: Projekteigenschaften
- in [2, 3]: Wählen Sie [Class Library] als Projekttyp
- in [4]: Die Projektgenerierung erzeugt eine DLL (Assembly) namens [Nunit.dll]
Nun führen wir die Testklasse mit NUnit aus:
 |
- in [1]: Öffnen Sie ein NUnit-Projekt
- in [2, 3]: Laden Sie die DLL „bin/Release/Nunit.dll“, die bei der C#-Projektgenerierung erstellt wurde
- in [4]: Die DLL wurde geladen
- in [5]: der Testbaum
- in [6]: Sie werden ausgeführt
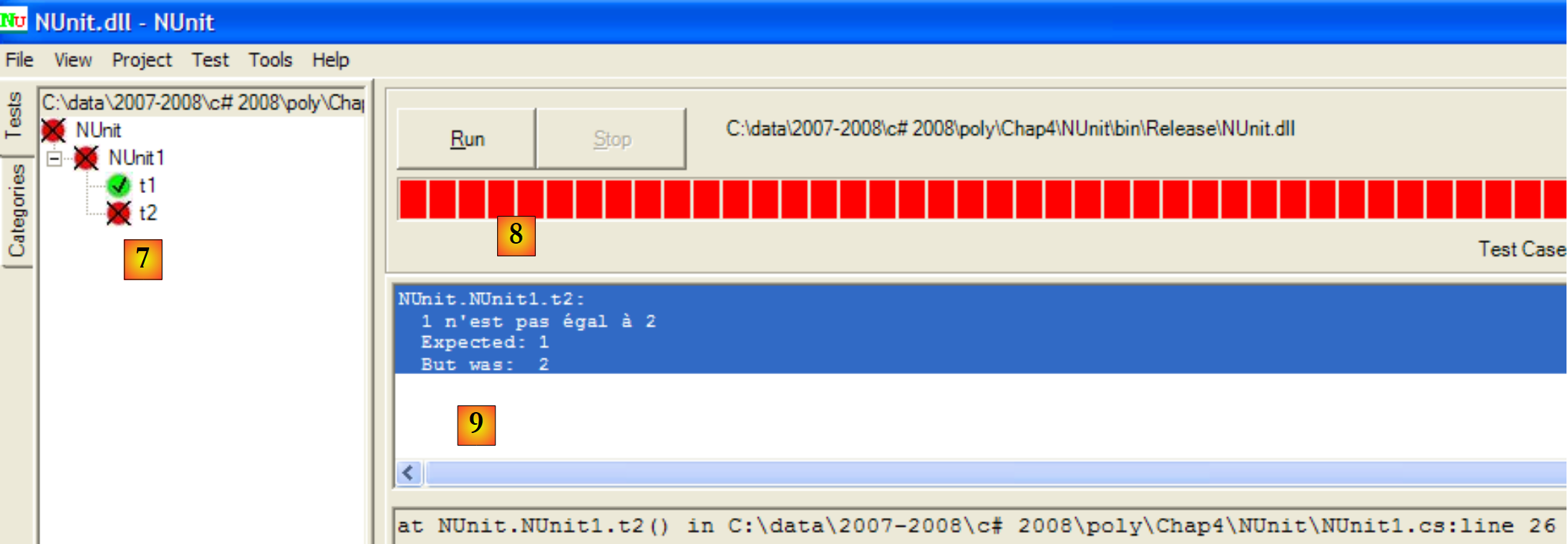 |
- in [7]: Ergebnisse: t1 erfolgreich, t2 fehlgeschlagen
- in [8]: Ein roter Balken zeigt an, dass die Testklasse insgesamt fehlgeschlagen ist
- in [9]: die Fehlermeldung des fehlgeschlagenen Tests
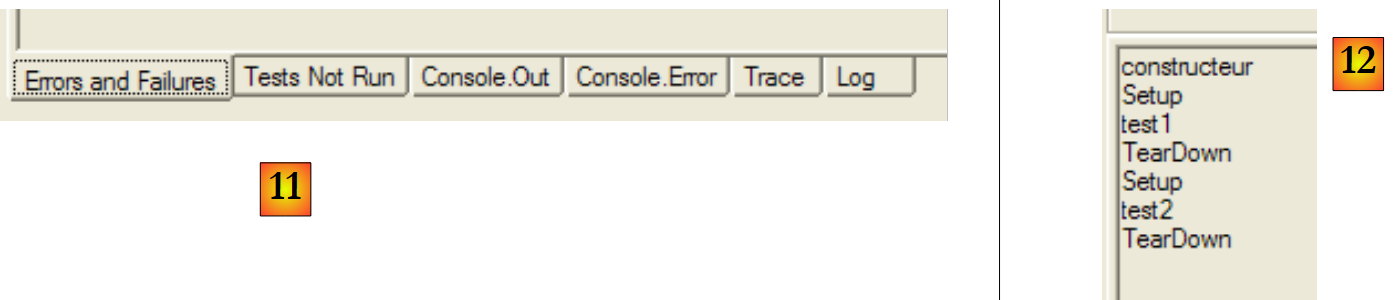 |
- in [11]: die verschiedenen Registerkarten im Ergebnisfenster
- in [12]: die Registerkarte [Console.Out]. Hier sehen wir, dass:
- der Builder nur einmal ausgeführt wurde
- die [SetUp]-Methode vor jedem der beiden Tests ausgeführt wurde
- die [TearDown]-Methode nach jedem der beiden Tests ausgeführt wurde
Sie können die zu testenden Methoden angeben:
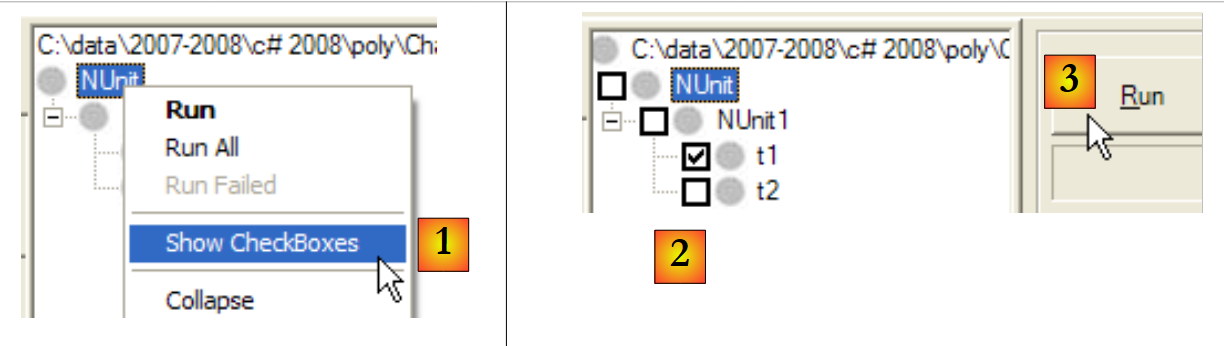 |
- in [1]: Neben jedem Test wird ein Kontrollkästchen angezeigt
- in [2]: Markieren Sie die auszuführenden Tests
- in [3]: Sie werden ausgeführt
Um Fehler zu beheben, korrigieren Sie einfach das C#-Projekt und generieren Sie es neu. NUnit erkennt, dass die getestete DLL geändert wurde, und lädt automatisch die neue Version. Sie müssen lediglich die Tests erneut ausführen.
Betrachten Sie die folgende neue Testklasse:
using System;
using NUnit.Framework;
namespace NUnit {
[TestFixture]
public class NUnit2 : AssertionHelper {
public NUnit2() {
Console.WriteLine("constructeur");
}
[SetUp]
public void avant() {
Console.WriteLine("Setup");
}
[TearDown]
public void après() {
Console.WriteLine("TearDown");
}
[Test]
public void t1() {
Console.WriteLine("test1");
Expect(1, EqualTo(1));
}
[Test]
public void t2() {
Console.WriteLine("test2");
Expect(1, EqualTo(2), "1 n'est pas égal à 2");
}
}
}
Ab Version 2.4 von NUnit steht eine neue Syntax zur Verfügung, wie in den Zeilen 21 und 26 zu sehen ist. Dazu muss die Testklasse von AssertionHelper abgeleitet sein (Zeile 6).
Die (nicht vollständige) Entsprechung zwischen alter und neuer Syntax lautet wie folgt:
Fügen wir den folgenden Test zur NUnit2-Klasse hinzu:
[Test]
public void t3() {
bool vrai = true, faux = false;
Expect(vrai, True);
Expect(faux, False);
Object obj1 = new Object(), obj2 = null, obj3=obj1;
Expect(obj1, Not.Null);
Expect(obj2, Null);
Expect(obj3, SameAs(obj1));
double d1 = 4.1, d2 = 6.4, d3 = d1;
Expect(d1, EqualTo(d3).Within(1e-6));
Expect(d1, Not.EqualTo(d2));
}
Wenn wir (F6) die neue DLL des C#-Projekts generieren, sieht das NUnit-Projekt wie folgt aus:
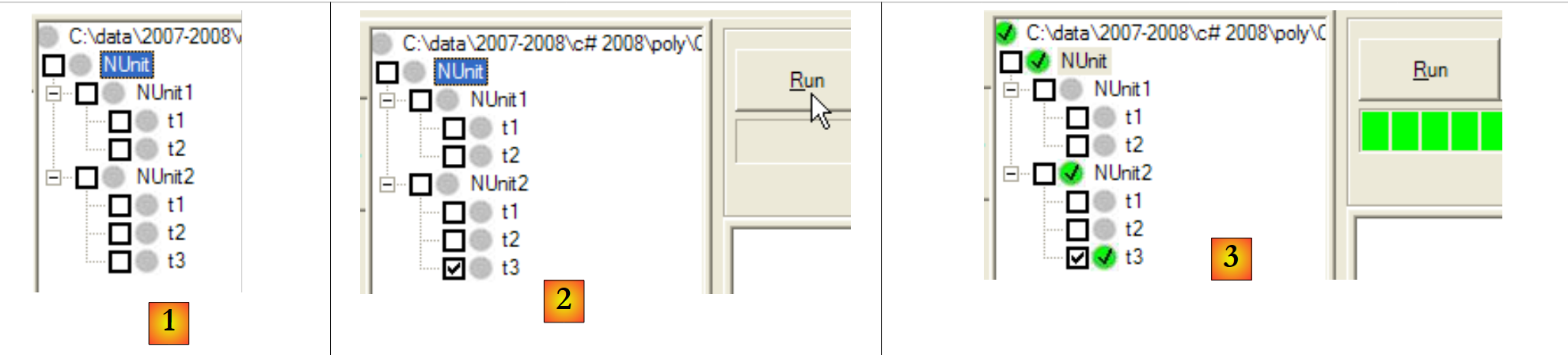 |
- in [1]: Die neue Testklasse [NUnit2] wurde automatisch erkannt
- in [2]: den t3-Test von NUnit2 ausführen
- in [3]: Der t3-Test wurde bestanden
Weitere Informationen zu NUnit finden Sie in der Hilfe zu NUnit:
 |  |
6.4.2. Die Visual Studio-Lösung
 |
Wir werden nach und nach die folgende Visual Studio-Lösung erstellen:
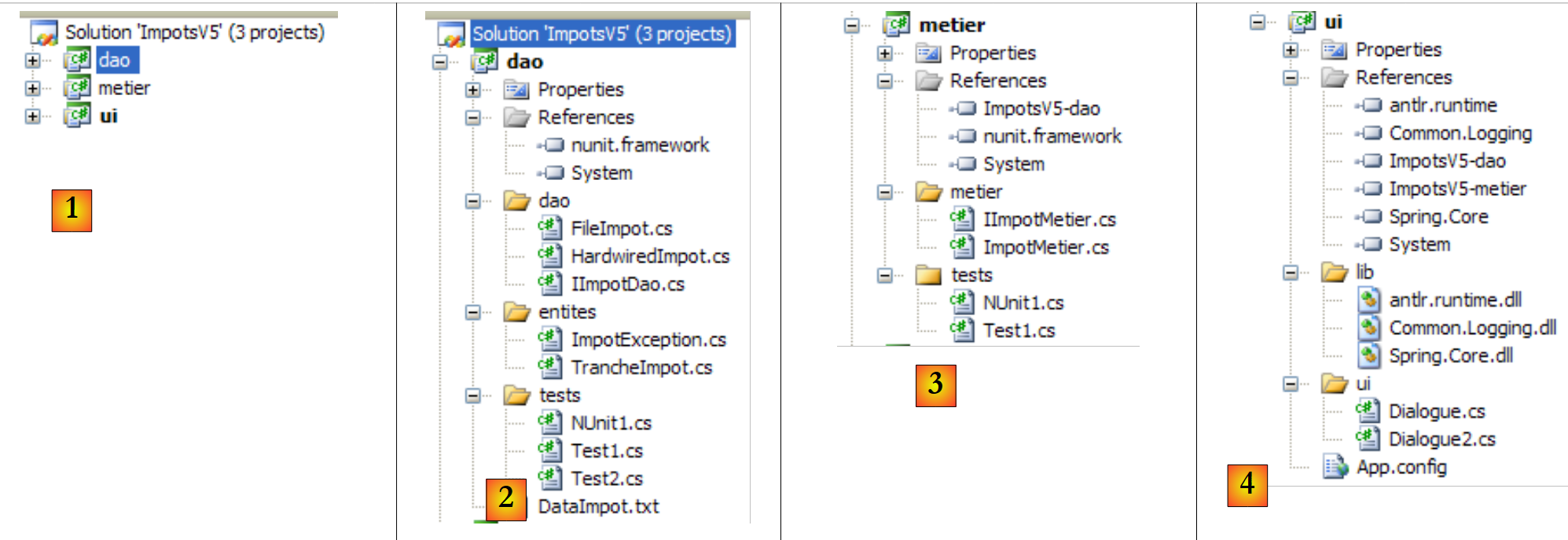 |
- in [1]: Die Lösung ImpotsV5 besteht aus drei Projekten, eines für jede der drei Schichten der Anwendung
- in [2]: das Projekt [dao] aus der Schicht [dao]
- in [3]: das Projekt [metier] für die [metier]-Schicht
- in [4]: Projekt [ui] aus der Schicht [ui]
Die Lösung ImpotsV5 lässt sich wie folgt aufbauen:
1  | 234 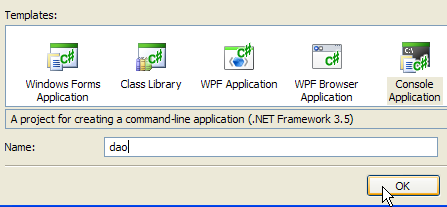 | 5 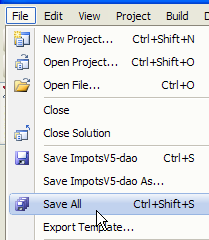 |
- de [1]: Neues Projekt erstellen
- de [2]: Wähle eine Konsolenanwendung aus
- in [3]: Projekt [dao] benennen
- in [4]: Erstellen Sie das Projekt
- in [5]: Sobald das Projekt erstellt wurde, speichern
 |
- in [6]: Behalte den Namen [dao] für das Projekt bei
- in [7]: Geben Sie einen Ordner an, in dem das Projekt und die Lösung gespeichert werden sollen
- in [8]: Benennen Sie die Lösung
- in [9]: Geben Sie an, dass die Lösung eine eigene Datei haben muss
- in [10]: Speichern Sie das Projekt und seine Lösung
- in [11]: das Projekt [dao] in seiner Lösung ImpotsV5
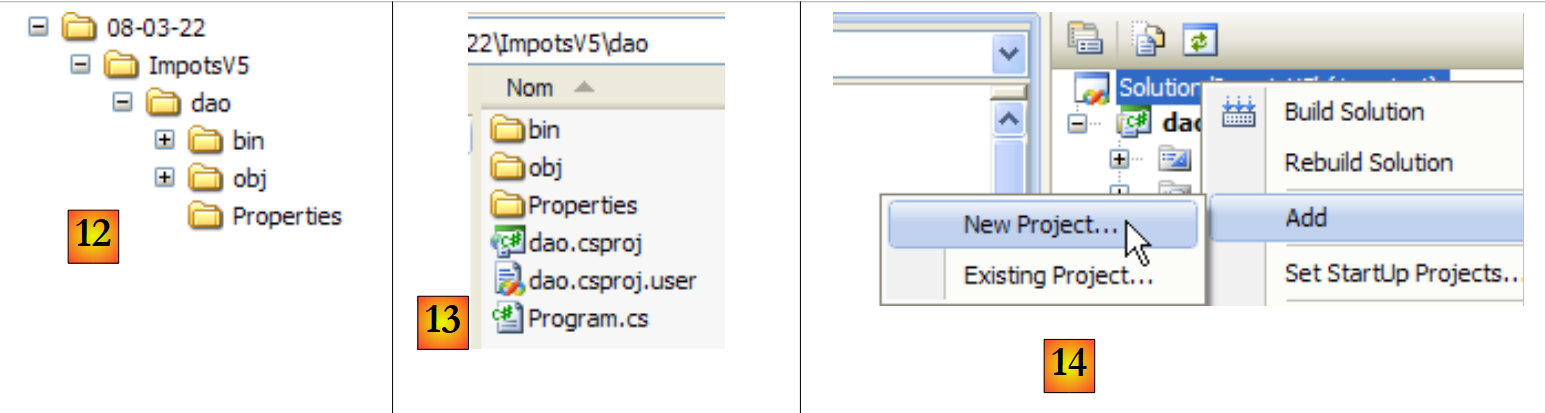 |
- in [12]: die Lösungsdatei ImpotsV5. Sie enthält den Ordner [dao] aus dem Ordner [dao].
- in [13]: den Inhalt des Ordners [dao]
- in [14]: Ein neues Projekt wird zur Lösung ImpotsV5 hinzugefügt
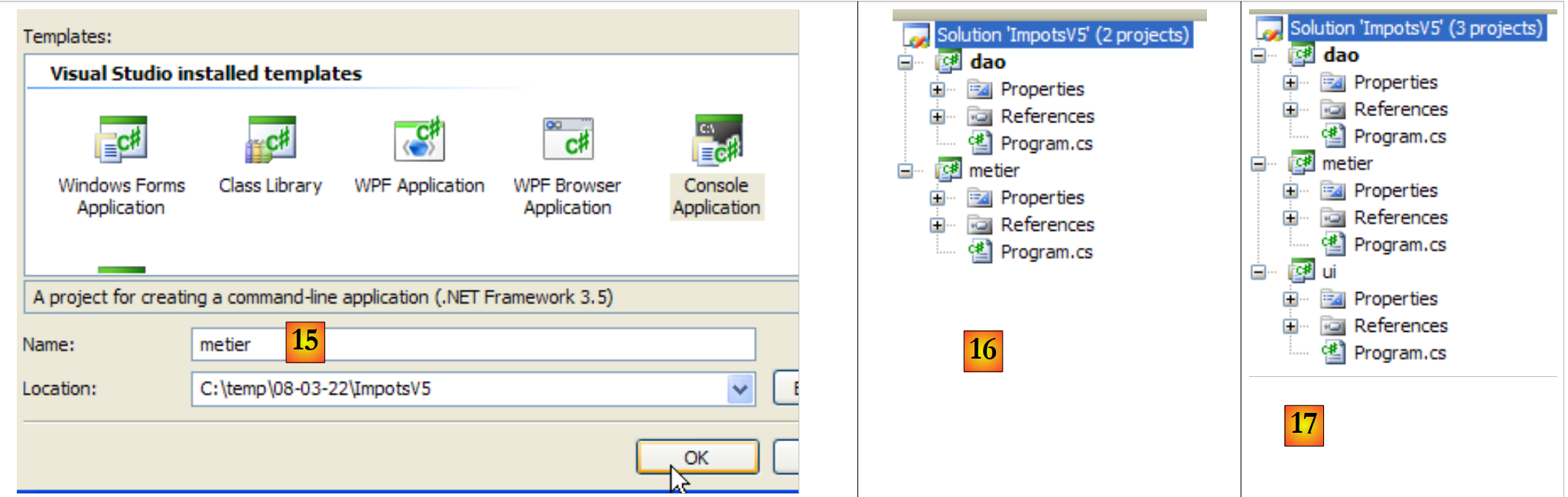 |
- in [15]: Das neue Projekt heißt [metier]
- in [16]: die Lösung mit ihren beiden Projekten
- in [17]: die Lösung, nachdem das dritte Projekt [ui] hinzugefügt wurde
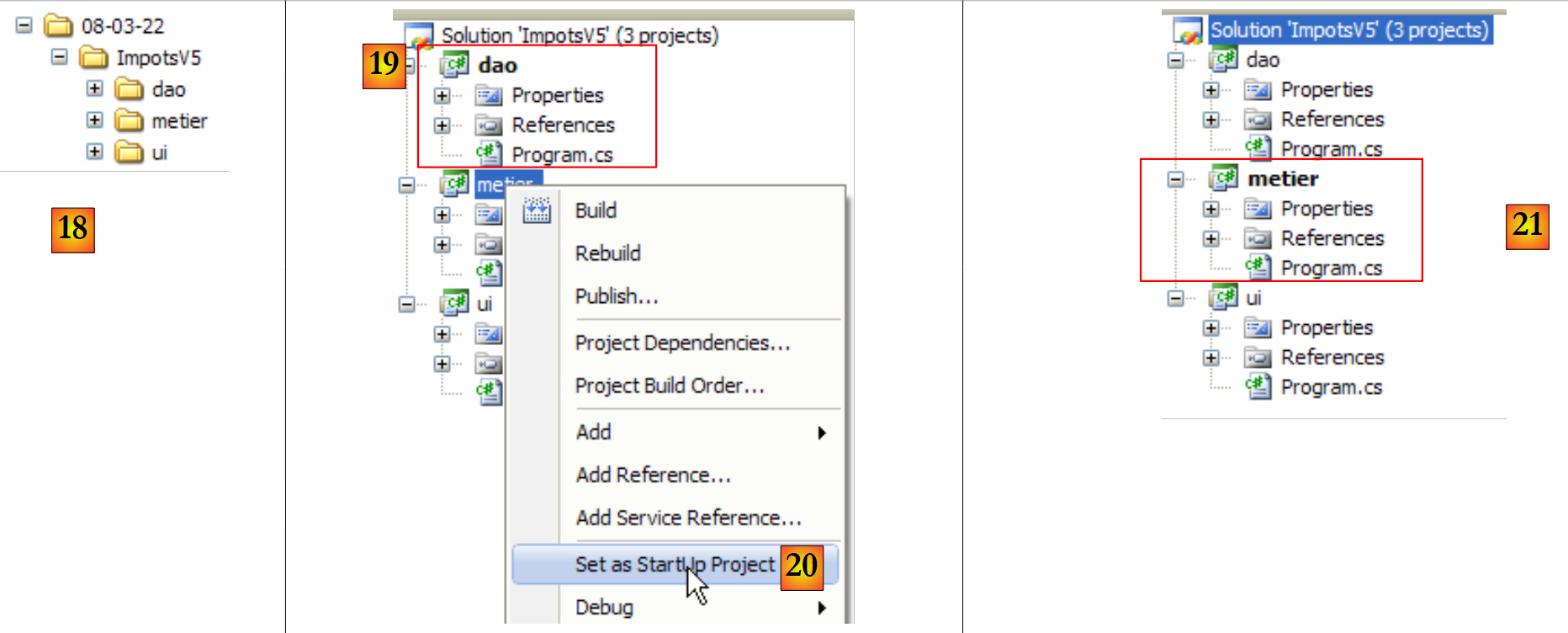 |
- in [18]: die Lösungsdatei und die Dateien für die drei Projekte
- Wenn eine Lösung mit (Strg+F5) ausgeführt wird, wird das aktive Projekt ausgeführt. Dasselbe gilt beim Generieren (F6) der Lösung. Der Name des aktiven Projekts ist in der Lösung fett gedruckt [19].
- in [20]: So ändern Sie das aktive Projekt der Lösung
- in [21]: Das Projekt [metier] ist nun das aktive Projekt in der Lösung
6.4.3. Die [Schicht DAO]
 |
 |
Projektreferenzen (siehe [1] im Projekt)
Wir fügen die für [NUnit]-Tests erforderliche [nunit.framework]-Referenz hinzu
Die Entitäten (siehe [2] im Projekt)
Die Klasse [TrancheImport] ist dieselbe wie in früheren Versionen. Die Klasse [FileImportException] aus der vorherigen Version wurde in [ImportException] umbenannt, um sie allgemeiner zu gestalten und nicht an eine bestimmte [DAO]-Schicht zu binden:
using System;
namespace Entites {
public class ImpotException : Exception {
// error code
public int Code { get; set; }
// manufacturers
public ImpotException() {
}
public ImpotException(string message)
: base(message) {
}
public ImpotException(string message, Exception e)
: base(message, e) {
}
}
}
Die [dao]-Schicht (siehe [3] im Projekt)
Die Schnittstelle [IImpotDao] ist dieselbe wie in der vorherigen Version. Gleiches gilt für die Klasse [HardwiredImpot]. Die Klasse [FileImpot] wurde angepasst, um der Umbenennung der Ausnahme [FileImpotException] in [ImpotException] Rechnung zu tragen:
...
namespace Dao {
public class FileImpot : IImpotDao {
// error codes
[Flags]
public enum CodeErreurs { Acces = 1, Ligne = 2, Champ1 = 4, Champ2 = 8, Champ3 = 16 };
...
// manufacturer
public FileImpot(string fileName) {
// save the file name
FileName = fileName;
...
// initially no error
CodeErreurs code = 0;
try {
using (StreamReader input = new StreamReader(FileName)) {
while (!input.EndOfStream && code == 0) {
...
// mistake?
if (code != 0) {
// on note l'erreur
fe = new ImpotException(String.Format("Ligne n° {0} incorrecte", numLigne)) { Code = (int)code };
} else {
...
}
}
}
} catch (Exception e) {
// on note l'erreur
fe = new ImpotException(String.Format("Erreur lors de la lecture du fichier {0}", FileName), e) { Code = (int)CodeErreurs.Acces };
}
// error to report?
...
}
}
}
- Zeile 8: Fehlercodes, die zuvor in der Klasse [FileImpotException] enthalten waren, wurden in die Klasse [FileImpot] verschoben. Es handelt sich hierbei um Fehlercodes, die spezifisch für diese Implementierung der Schnittstelle [IImpotDao] sind.
- Zeilen 26 und 34: Um einen Fehler zu kapseln, wird die Klasse [ImpotException] anstelle der Klasse [FileImpotException] verwendet.
Der Test [Test1] (siehe [4] im Projekt)
Die Klasse [Test1] zeigt lediglich die Steuerklassen auf dem Bildschirm an:
using System;
using Dao;
using Entites;
namespace Tests {
class Test1 {
static void Main() {
// create the [dao] layer
IImpotDao dao = null;
try {
// layer creation [dao]
dao = new FileImpot("DataImpot.txt");
} catch (ImpotException e) {
// error display
string msg = e.InnerException == null ? null : String.Format(", Exception d'origine : {0}", e.InnerException.Message);
Console.WriteLine("L'erreur suivante s'est produite : [Code={0},Message={1}{2}]", e.Code, e.Message, msg == null ? "" : msg);
// program stop
Environment.Exit(1);
}
// display tax brackets
TrancheImpot[] tranchesImpot = dao.TranchesImpot;
foreach (TrancheImpot t in tranchesImpot) {
Console.WriteLine("{0}:{1}:{2}", t.Limite, t.CoeffR, t.CoeffN);
}
}
}
}
- Zeile 13: Die Ebene [dao] wird durch die Klasse [FileImpot] implementiert
- Zeile 14: Behandelt die Ausnahme [ImpotException], die auftreten kann.
Die für den Test erforderliche Datei [DataImpot.txt] wird automatisch in den Projekt-Ausführungsordner kopiert (siehe [5] im Projekt). Das Projekt [dao] enthält mehrere Klassen mit einer [Main]-Methode. In diesem Fall müssen Sie die auszuführende Klasse explizit angeben, wenn der Benutzer die Projekt-Ausführung durch Drücken von Strg-F5 anfordert:
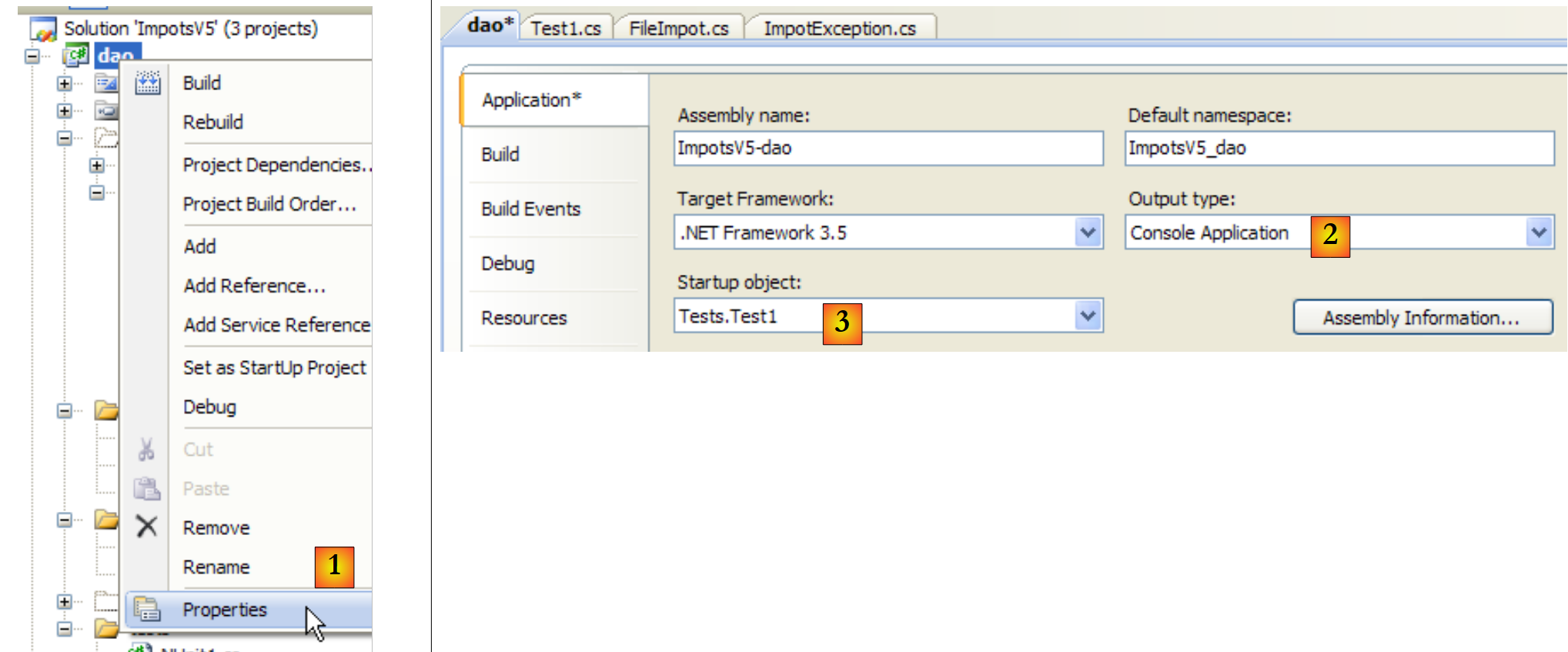 |
- en [1]: Projekt-Eigenschaften aufrufen
- en [2]: Geben Sie an, dass es sich um eine Konsolenanwendung handelt
- in [3]: die auszuführende Klasse angeben
Die Ausführung der vorherigen Klasse [Test1] liefert folgende Ergebnisse:
4962:0:0
8382:0,068:291,09
14753:0,191:1322,92
23888:0,283:2668,39
38868:0,374:4846,98
47932:0,426:6883,66
0:0,481:9505,54
Der [Test2]-Test (siehe [4] im Projekt)
Die Klasse [Test2] verhält sich genauso wie die Klasse [Test1] und implementiert die [dao]-Schicht mit der Klasse [HardwiredImpot]. Zeile 13 von [Test1] wird durch Folgendes ersetzt:
dao = new HardwiredImpot();
Das Projekt wird so geändert, dass die Klasse [Test2] ausgeführt wird:
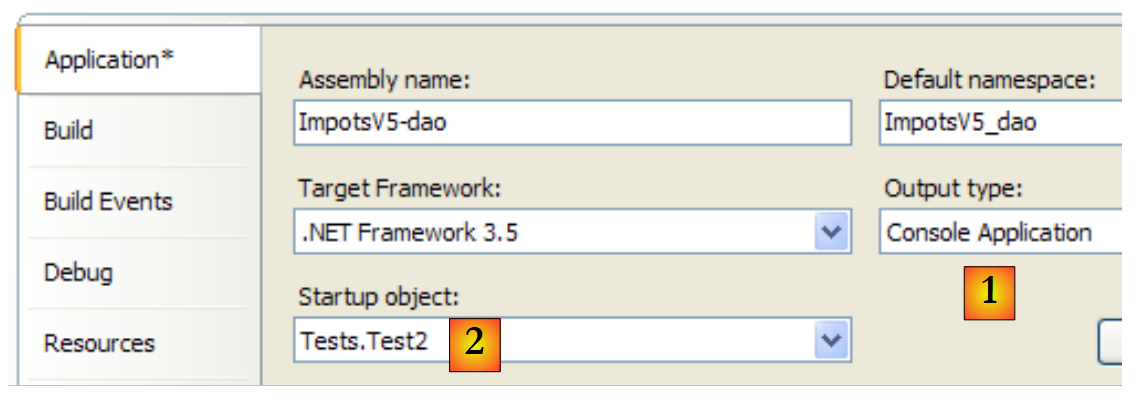 |
Die Ergebnisse auf dem Bildschirm sind dieselben wie zuvor.
Der NUnit-Test [NUnit1] (siehe [4] im Projekt)
Der Unit-Test [NUnit1] lautet wie folgt:
using System;
using Dao;
using Entites;
using NUnit.Framework;
namespace Tests {
[TestFixture]
public class NUnit1 : AssertionHelper{
// layer [dao] to be tested
private IImpotDao dao;
// manufacturer
public NUnit1() {
// dao] layer initialization
dao = new FileImpot("DataImpot.txt");
}
// test
[Test]
public void ShowTranchesImpot(){
// display tax brackets
TrancheImpot[] tranchesImpot = dao.TranchesImpot;
foreach (TrancheImpot t in tranchesImpot) {
Console.WriteLine("{0}:{1}:{2}", t.Limite, t.CoeffR, t.CoeffN);
}
// some tests
Expect(tranchesImpot.Length,EqualTo(7));
Expect(tranchesImpot[2].Limite,EqualTo(14753));
Expect(tranchesImpot[2].CoeffR, EqualTo(0.191));
Expect(tranchesImpot[2].CoeffN, EqualTo(1322.92));
}
}
}
- Die Testklasse leitet sich von der Klasse [AssertionHelper] ab, wodurch die Verwendung der statischen Methode Expect (Zeilen 27–30) ermöglicht wird.
- Zeile 10: ein Verweis auf die [dao]-Schicht
- Zeilen 13–16: Der Konstruktor instanziiert die Schicht [dao] mit der Klasse [FileImport]
- Zeilen 19–20: Die Testmethode
- Zeile 22: Ruft die Steuertabelle aus der [dao]-Schicht ab
- Zeilen 23–25: Anzeige wie zuvor. Diese Anzeige wäre in einem echten Unit-Test nicht erforderlich. Hier dient sie jedoch pädagogischen Zwecken.
- Zeile 27: Überprüfen Sie, ob 7 Steuerklassen vorhanden sind
- Zeilen 28–30: Überprüfen Sie die Werte für Steuerklasse Nr. 2
Um diesen Unit-Test auszuführen, muss das Projekt vom Typ [Class Library] sein:
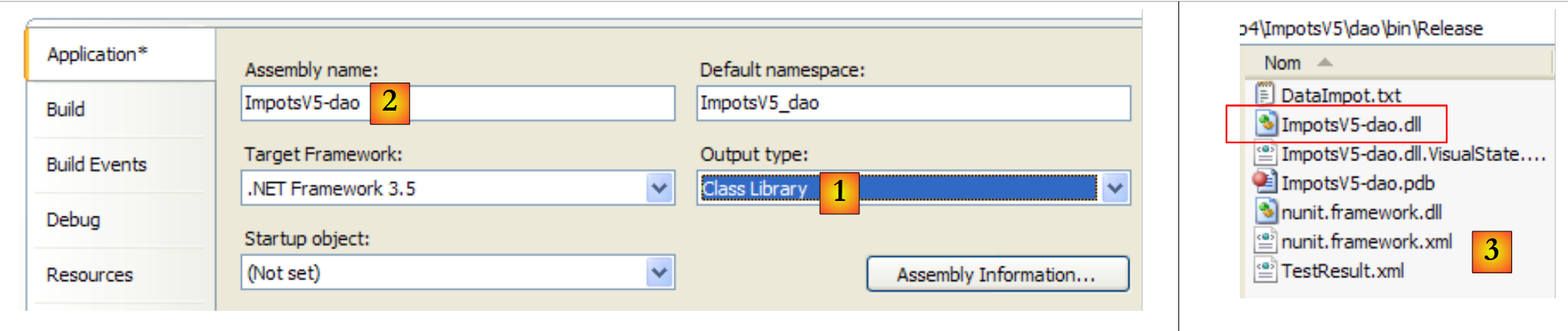 |
- in [1]: Die Art des Projekts wurde geändert
- in [2]: Die generierte DLL wird [ ImpotsV5-dao.dll] heißen
- in [3]: Nach der Generierung (F6) des Projekts enthält der Ordner [dao/bin/Release] die DLL [ImpotsV5-dao.dll]
Die DLL [ImpotsV5-dao.dll] wird dann in das NUnit-Framework geladen und ausgeführt:
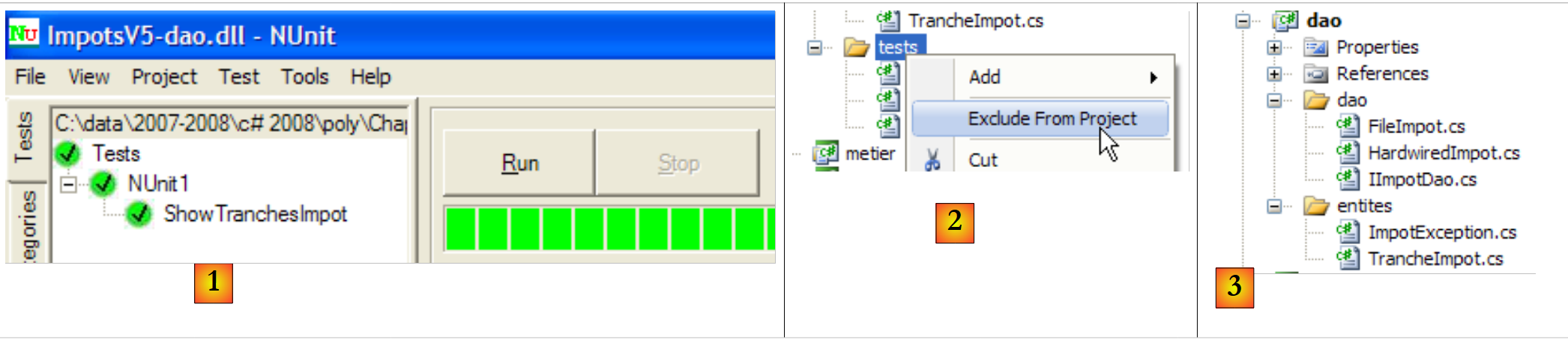 |
- in [1]: Tests bestanden. Wir betrachten die [dao]-Schicht nun als betriebsbereit. Ihre DLL enthält alle Klassen des Projekts, einschließlich der Testklassen. Diese werden nicht mehr benötigt. Wir erstellen die DLL neu, um die Testklassen auszuschließen.
- in [2]: Der Ordner [tests] wird aus dem Projekt ausgeschlossen
- in [3]: das neue Projekt. Dieses wird durch Drücken von F6 neu generiert, um eine neue DLL zu erstellen.
6.4.4. Der [Job „Layer “]
 |
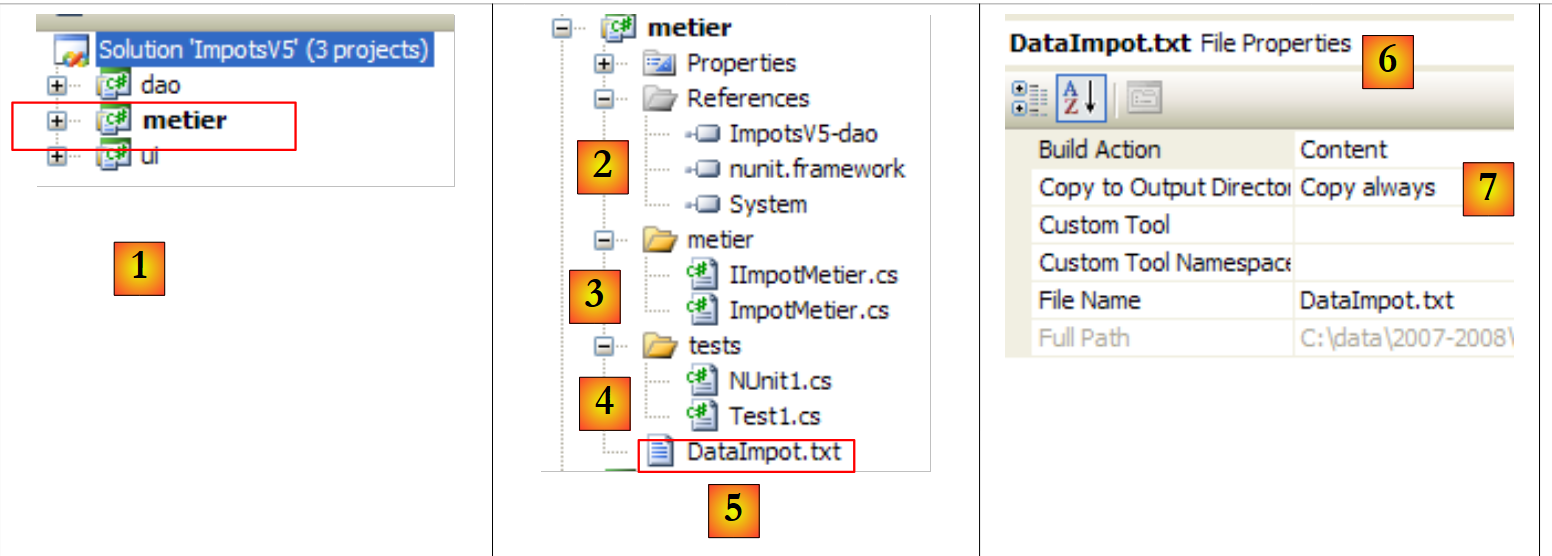 |
- in [1] wurde das [Metier]-Projekt zum aktiven Projekt der Lösung
- in [2]: Projektreferenzen
- en [3]: die [metier]-Schicht
- in [4]: Testklassen
- in [5]: die Steuerklasse-Datei [DataImpot.txt], die in [6] so konfiguriert wurde, dass sie automatisch in den Projekt-Ausführungsordner [7] kopiert wird
Projektreferenzen (siehe [2] im Projekt)
Wie beim [dao]-Projekt fügen wir die für [NUnit]-Tests erforderliche [nunit.framework]-Referenz hinzu. Die [metier]-Schicht benötigt die [dao]-Schicht. Sie benötigt daher eine Referenz auf die DLL dieser Schicht. Gehen Sie wie folgt vor:
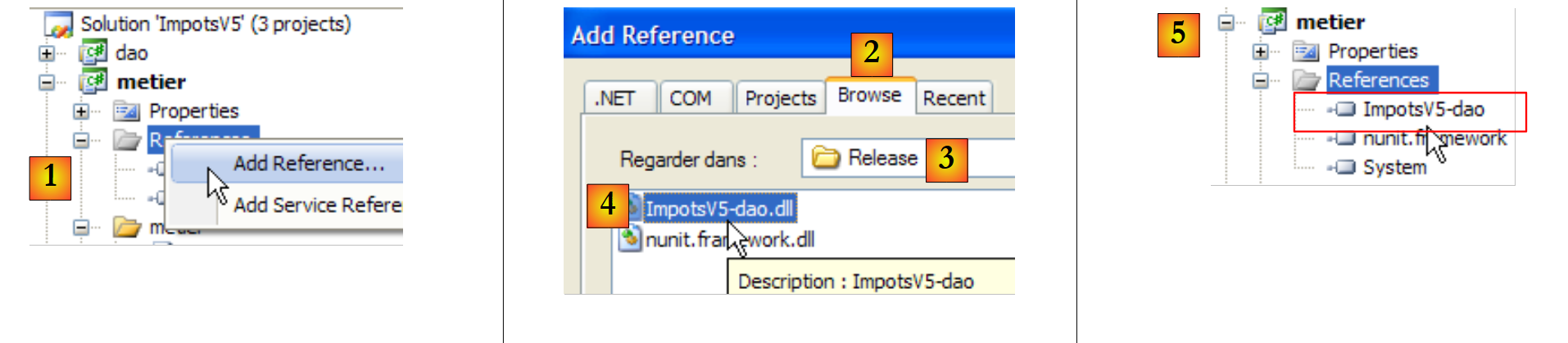 |
- in [1]: Eine neue Referenz wird zu den Projektreferenzen [metier]
- in [2]: Wählen Sie die Registerkarte [Durchsuchen]
- in [3]: Wählen Sie den Ordner [dao/bin/Release]
- in [4]: Wählen Sie die im Projekt [dao] generierte DLL [ImpotsV5-dao.dll] aus
- in [5]: die neue Referenz
Die Windel [metier] (siehe [3] im Projekt)
Die Schnittstelle [IImpotMetier] ist dieselbe wie in der vorherigen Version. Das Gleiche gilt für die Klasse [ImpotMetier].
Der Test [Test1] (siehe [4] im Projekt)
Die Klasse [Test1] führt lediglich einige Gehaltsberechnungen durch:
using System;
using Dao;
using Entites;
using Metier;
namespace Tests {
class Test1 {
static void Main() {
// we create the [metier] layer
IImpotMetier metier = null;
try {
// layer creation [job]
metier = new ImpotMetier(new FileImpot("DataImpot.txt"));
} catch (ImpotException e) {
// error display
string msg = e.InnerException == null ? null : String.Format(", Exception d'origine : {0}", e.InnerException.Message);
Console.WriteLine("L'erreur suivante s'est produite : [Code={0},Message={1}{2}]", e.Code, e.Message, msg == null ? "" : msg);
// program stop
Environment.Exit(1);
}
// on calcule qqs impots
Console.WriteLine(String.Format("Impot(true,2,60000)={0} euros", metier.CalculerImpot(true, 2, 60000)));
Console.WriteLine(String.Format("Impot(false,3,60000)={0} euros", metier.CalculerImpot(false, 3, 60000)));
Console.WriteLine(String.Format("Impot(false,3,60000)={0} euros", metier.CalculerImpot(false, 3, 6000)));
Console.WriteLine(String.Format("Impot(false,3,60000)={0} euros", metier.CalculerImpot(false, 3, 600000)));
}
}
}
- Zeile 14: Erstellung der Schichten [metier] und [dao]. Die Schicht [dao] wird mit der Klasse [FileImpot] implementiert
- Zeilen 12–21: Behandlung einer möglichen [ImpotException]-Ausnahme
- Zeilen 23–26: wiederholte Aufrufe der einzigen Methode der Schnittstelle [IImpotMetier] von CalculerImpot.
Das [metier]-Projekt ist wie folgt konfiguriert:
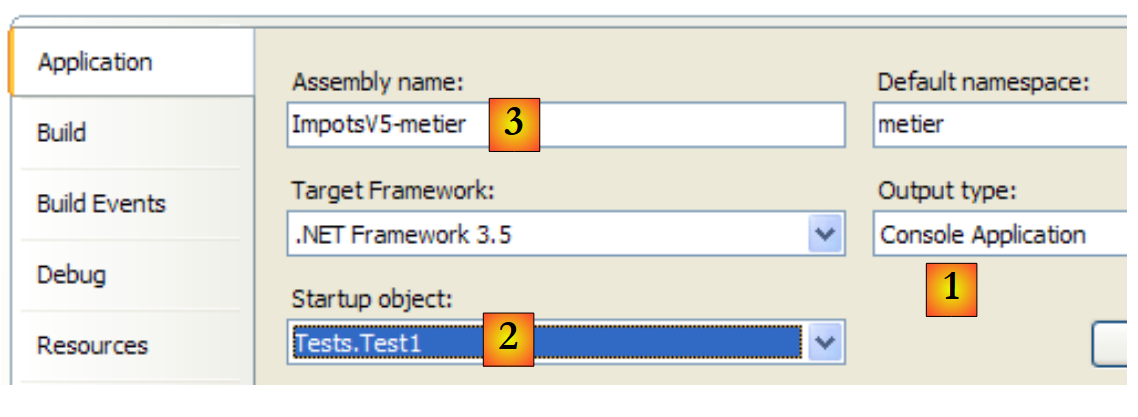 |
- [1]: Das Projekt ist eine Konsolenanwendung
- [2]: Die ausgeführte Klasse ist [Test1]
- [3]: Bei der Projektgenerierung wird die ausführbare Datei [ImpotsV5-metier.exe] erstellt
Das Projekt hat zu folgenden Ergebnissen geführt:
Der [NUnit1]-Test (siehe [4] im Projekt)
Die Unit-Test-Klasse [NUnit1] wiederholt die vier vorangegangenen Berechnungen und überprüft die Ergebnisse:
using Dao;
using Metier;
using NUnit.Framework;
namespace Tests {
[TestFixture]
public class NUnit1:AssertionHelper {
// layer [metier] to test
private IImpotMetier metier;
// manufacturer
public NUnit1() {
// initialization layer [metier]
metier = new ImpotMetier(new FileImpot("DataImpot.txt"));
}
// test
[Test]
public void CalculsImpot(){
// display tax brackets
Expect(metier.CalculerImpot(true, 2, 60000), EqualTo(4282));
Expect(metier.CalculerImpot(false, 3, 60000), EqualTo(4282));
Expect(metier.CalculerImpot(false, 3, 6000), EqualTo(0));
Expect(metier.CalculerImpot(false, 3, 600000), EqualTo(179275));
}
}
}
- Zeile 14: Erstellung der Schichten [metier] und [dao]. Die Schicht [dao] wird mit der Klasse [FileImpot] implementiert
- Zeilen 21–24: Wiederholte Aufrufe der einzigen Methode der Schnittstelle [IImpotMetier] mit Überprüfung der Ergebnisse.
Das [metier]-Projekt ist nun wie folgt konfiguriert:
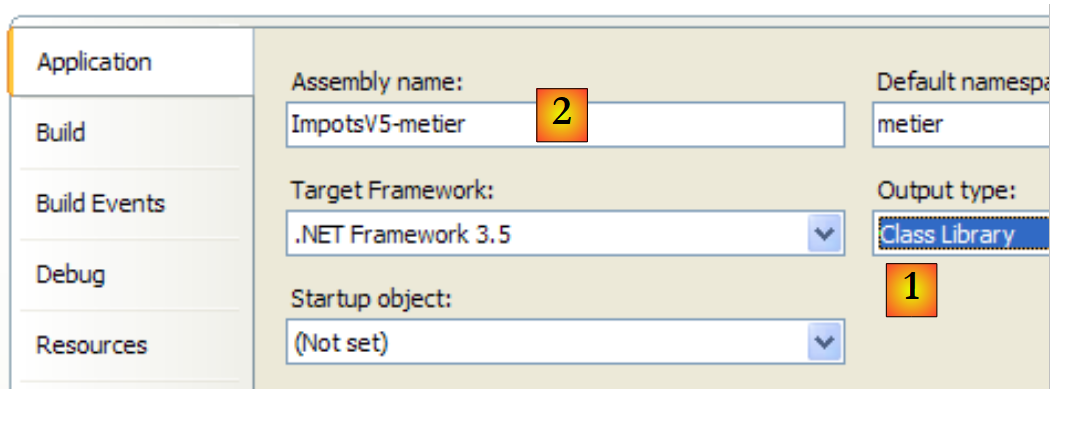 |
- [1]: Das Projekt ist vom Typ „Klassenbibliothek“
- [2]: Bei der Projektgenerierung wird die DLL [ImpotsV5-metier.dll] erstellt
Das Projekt wird generiert (F6). Anschließend wird die generierte DLL [ ImpotsV5-metier.dll] in NUnit geladen und getestet:
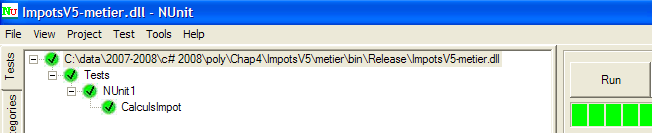 |
Die oben genannten Tests waren erfolgreich. Wir betrachten die [metier]-Schicht nun als betriebsbereit. Ihre DLL enthält alle Projektklassen, einschließlich der Testklassen. Diese werden nicht mehr benötigt. Wir erstellen die DLL neu, um die Testklassen auszuschließen.
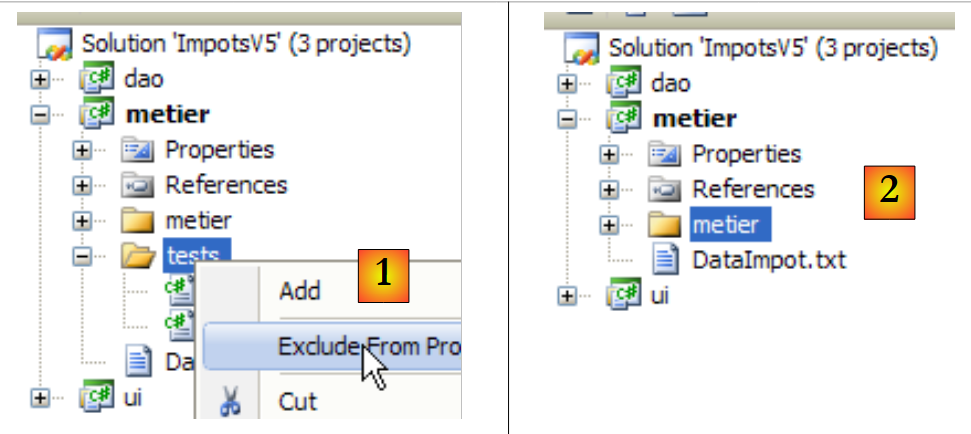 |
- in [1]: Der Ordner [tests] wird aus dem Projekt ausgeschlossen
- in [2]: das neue Projekt. Dieses wird durch Drücken von F6 neu generiert, um eine neue DLL zu erstellen.
6.4.5. Die [ui]-Ebene
 |
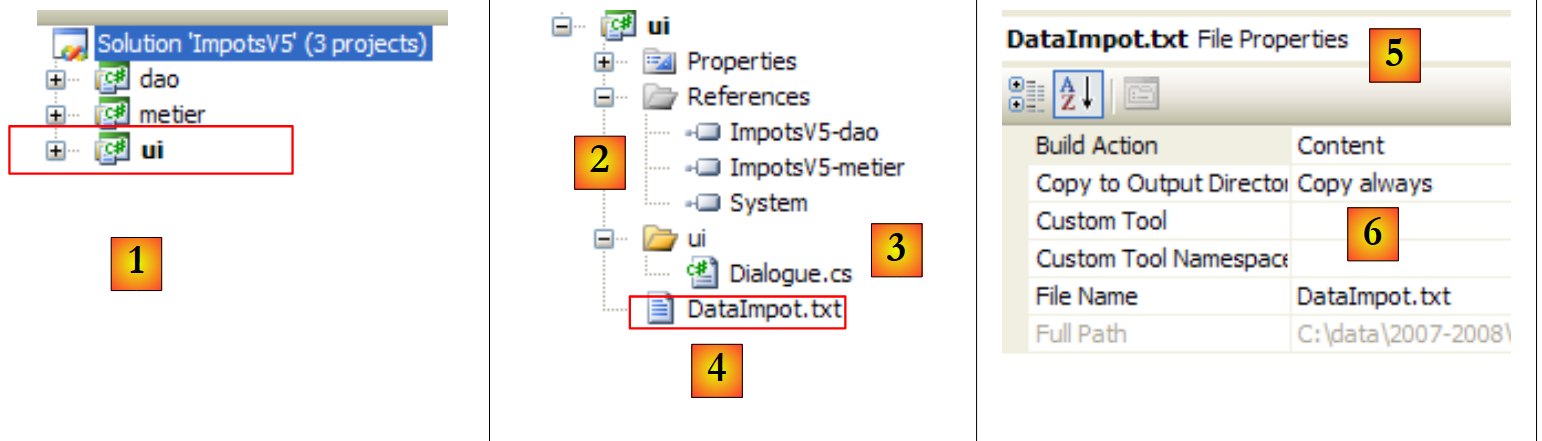 |
- In [1] wurde das [ui]-Projekt zum aktiven Projekt für die Lösung
- in [2]: Projektreferenzen
- in [3]: die [ui]-Ebene
- in [4]: die Steuerklassen-Datei [DataImport.txt], die so konfiguriert wurde [5], dass sie automatisch in den Projekt-Ausführungsordner [6] kopiert wird
Projektreferenzen (siehe [2] im Projekt)
Die [ui]-Schicht benötigt die [metier]- und [dao]-Schichten, um ihre Steuerberechnungen durchzuführen. Sie benötigt daher einen Verweis auf die DLL dieser beiden Schichten. Gehen Sie dabei wie für die [metier]-Schicht beschrieben vor
Die Hauptklasse [Dialogue.cs] (siehe [3] im Projekt)
Die Klasse [Dialogue.cs] ist dieselbe wie in der vorherigen Version.
Tests
Das [ui]-Projekt ist wie folgt konfiguriert:
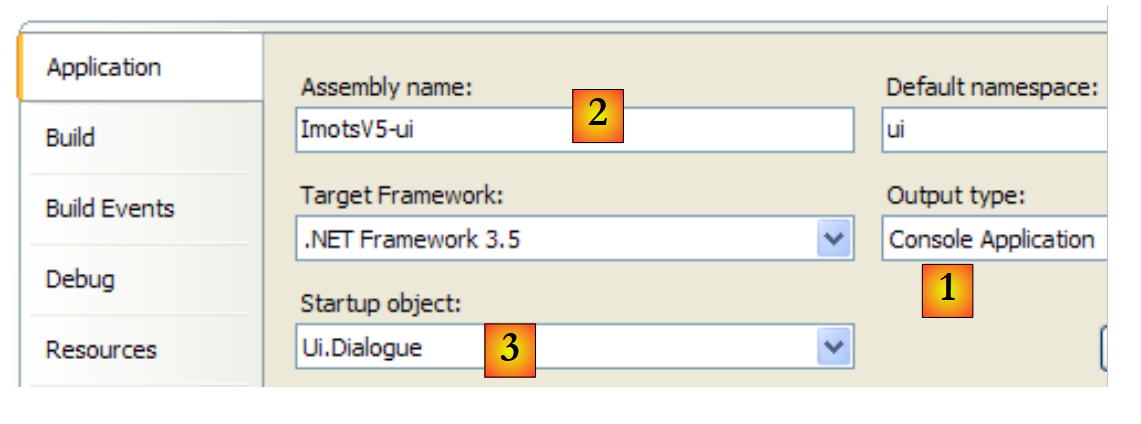 |
- [1]: Das Projekt ist vom Typ „Anwendungskonsole“
- [2]: Bei der Projektgenerierung wird die ausführbare Datei [ImpotsV5-ui.exe] erstellt
- [3]: die auszuführende Klasse
Ein Beispiel für die Ausführung (Strg+F5) ist unten dargestellt:
Paramètres du calcul de l'Impot au format : Marié (o/n) NbEnfants Salaire ou rien pour arrêter :o 2 60000
Impot=4282 euros
6.4.6. Die [Ebene -Frühling]
Kehren wir zum Code in [Dialogue.cs] zurück, der die Ebenen [dao] und [metier] erstellt:
// on crée les couches [metier et dao]
IImpotMetier metier = null;
try {
// création couche [metier]
metier = new ImpotMetier(new FileImpot("DataImpot.txt"));
} catch (ImpotException e) {
// affichage erreur
...
// arrêt programme
Environment.Exit(1);
}
In Zeile 5 werden die Schichten [dao] und [metier] erstellt, wobei die Implementierungsklassen für beide Schichten explizit benannt werden: FileImpot für die [dao]-Schicht, ImpotMetier für die [metier]-Schicht. Wenn eine der Schichten mit einer neuen Klasse implementiert wird, wird Zeile 5 geändert. Zum Beispiel:
metier = new ImpotMetier(new HardwiredImpot());
Abgesehen von dieser Änderung ändert sich nichts an der Anwendung, da jede Schicht über eine Schnittstelle mit der nächsten kommuniziert. Solange die Schnittstelle unverändert bleibt, bleibt auch die Kommunikation zwischen den Schichten unverändert. Das Spring-Framework ermöglicht es uns, die Unabhängigkeit der Schichten noch einen Schritt weiter zu treiben, indem wir die Namen der Klassen, die die verschiedenen Schichten implementieren ( ), in eine Konfigurationsdatei auslagern. Die Änderung der Implementierung einer Schicht entspricht der Änderung einer Konfigurationsdatei. Es gibt keine Auswirkungen auf den Anwendungscode.
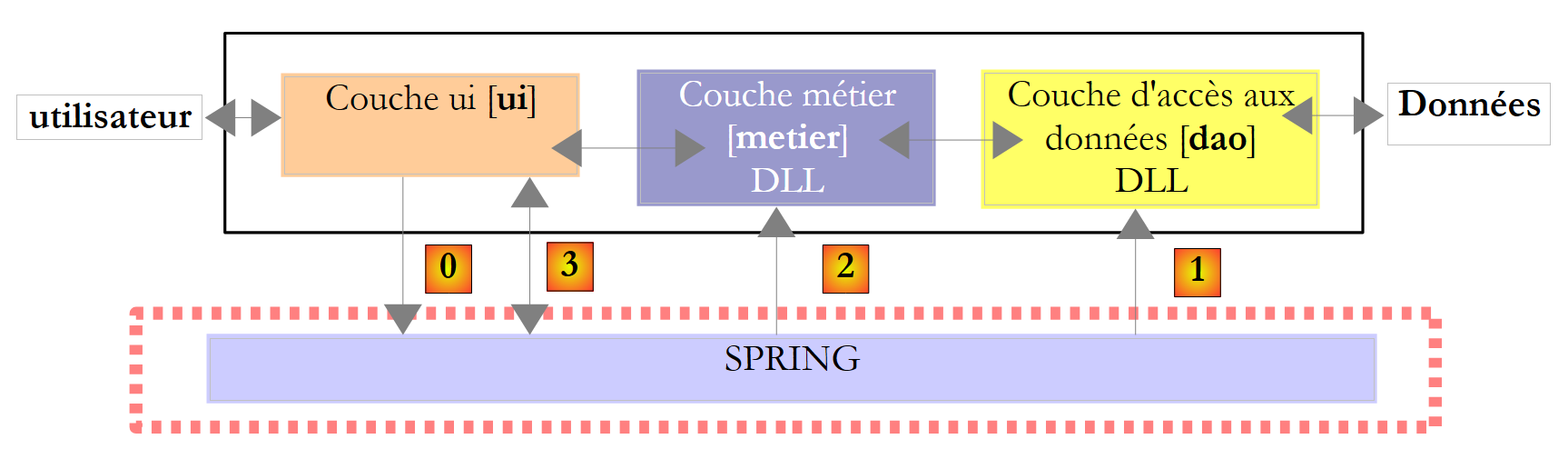 |
Oben fordert die [ui]-Schicht [0] Spring auf, die [dao]- [1] und [metier]- [2] Schichten gemäß den in einer Konfigurationsdatei enthaltenen Informationen zu instanziieren. Die [ui]-Schicht fordert dann Spring [3] um eine Referenz auf die [metier]-Schicht auf:
// we create the layers [metier and dao]
IImpotMetier metier = null;
try {
// spring context
IApplicationContext ctx = ContextRegistry.GetContext();
// a reference is requested on the [metier] layer
metier = (IImpotMetier)ctx.GetObject("metier");
} catch (Exception e1) {
...
}
- Zeile 5: Instanziierung der Schichten [dao] und [metier] durch Spring
- Zeile 7: Eine Referenz auf die [metier]-Schicht wird abgerufen. Beachten Sie, dass die [ui]-Schicht diese Referenz erhalten hat, ohne den Namen der Klasse anzugeben, die die [metier]-Schicht implementiert.
Das Spring-Framework gibt es in zwei Versionen: Java und .NET. Die .NET-Version ist unter folgender URL verfügbar (März 2008) [http://www.springframework.net/]:
 |
- in [1]: die [Spring.net]-Website
- in [2]: Download-Seite
 |
- in [3]: Spring 1.1 herunterladen (März 2008)
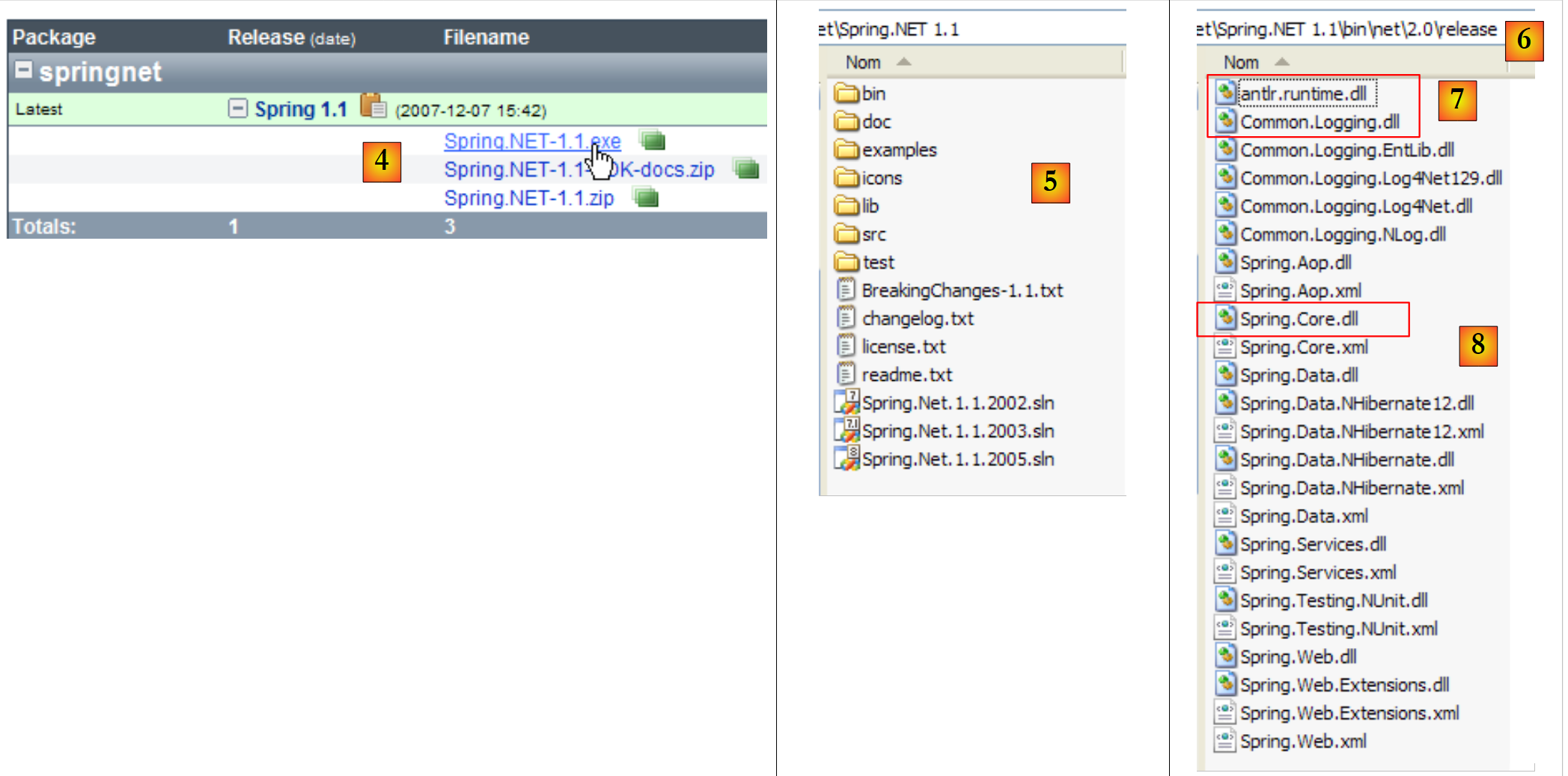 |
- en [4]: die .exe-Version herunterladen und installieren
- in [5]: der durch die Installation erstellte Ordner
- in [6]: Der Ordner [bin/net/2.0/release] enthält DLLs von Spring für Visual Studio .NET 2.0 oder höhere Projekte. Spring ist ein umfangreiches Framework. Der Aspekt von Spring, den wir hier zur Verwaltung der Integration von Schichten in einer Anwendung nutzen werden, heißt IoC: Inversion of Control oder DI: Dependence Injection. Spring bietet Bibliotheken für den Datenbankzugriff mit NHibernate, die Generierung und den Betrieb von Webdiensten, Webanwendungen usw.
- Die zur Verwaltung der Integration von Schichten in einer Anwendung benötigten DLLs sind die DLLs [7] und [8].
Wir speichern diese drei DLLs in einem [lib]-Ordner in unserem Projekt:
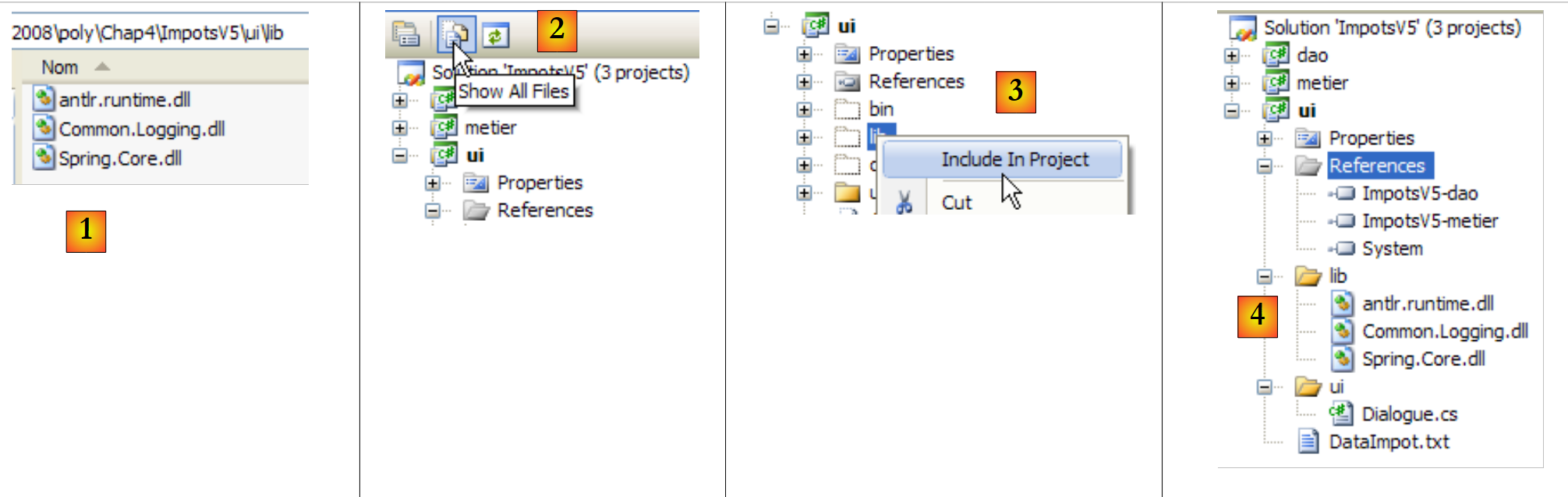 |
- [1]: Die drei DLL-Dateien werden mit dem Windows Explorer im Ordner [lib] abgelegt
- [2]: Im Projekt [ui] alle Dateien anzeigen
- [3]: Der Ordner [ui/lib] ist nun sichtbar. Wir fügen ihn in das
- [4]: Der Ordner [ui/lib] ist Teil des Projekts
Das Erstellen des Ordners [lib] ist keineswegs zwingend erforderlich. Die Verweise könnten direkt auf die drei DLLs im Ordner [bin/net/2.0/release] von [Spring.net] erstellt werden. Durch das Erstellen des Ordners [lib] kann die Anwendung jedoch auf einer Workstation ohne [Spring.net] entwickelt werden, wodurch sie weniger von der verfügbaren Entwicklungsumgebung abhängig ist.
Wir fügen dem [ui]-Projekt Verweise auf die drei neuen DLLs hinzu:
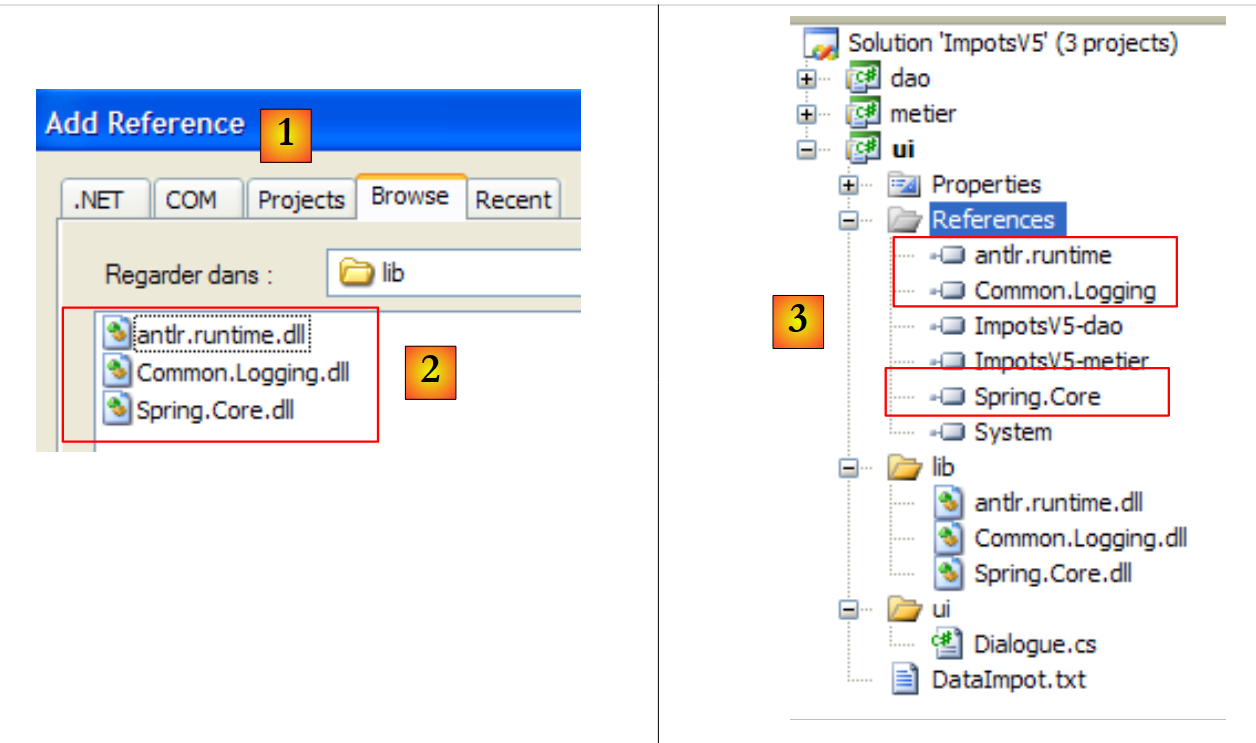 |
- [1]: Erstellen Sie Verweise auf die drei DLLs im Ordner [lib] [2]
- [3]: Die drei DLLs sind Teil der Projektreferenzen
Kehren wir zu einem Überblick über die Anwendungsarchitektur zurück:
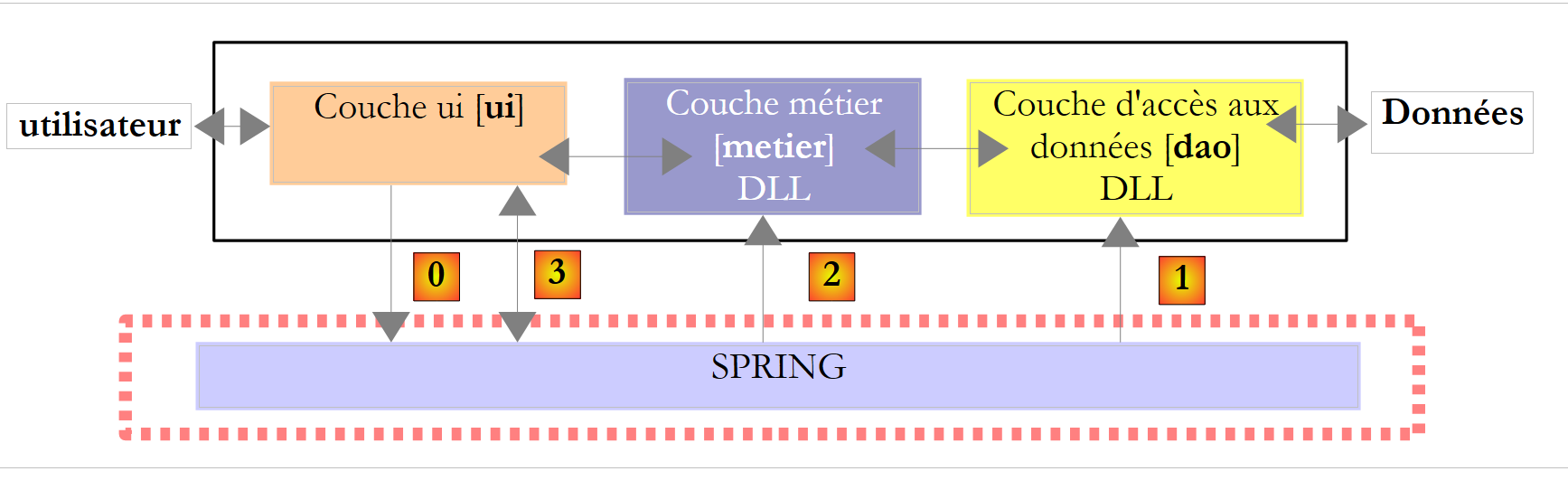 |
Oben fordert die [ui]-Schicht [0] Spring auf, die [dao]- [1] und [metier]- [2] Schichten gemäß den in einer Konfigurationsdatei enthaltenen Informationen zu instanziieren. Die [ui]-Schicht fordert dann Spring [3] um eine Referenz auf die [metier]-Schicht auf. Dies führt zu folgendem Code in der [ui]-Schicht:
// we create the layers [metier and dao]
IImpotMetier metier = null;
try {
// spring context
IApplicationContext ctx = ContextRegistry.GetContext();
// a reference is requested on the [metier] layer
metier = (IImpotMetier)ctx.GetObject("metier");
} catch (Exception e1) {
...
}
- Zeile 5: Instanziierung der Schichten [dao] und [metier] durch Spring
- Zeile 7: Ruft eine Referenz auf die [metier]-Schicht ab.
In Zeile [5] oben wird die Konfigurationsdatei [App.config] im Visual Studio-Projekt verwendet. In einem C#-Projekt dient diese Datei zur Konfiguration der Anwendung. [App.config] ist daher kein Spring-Konzept, sondern ein Visual Studio-Konzept, das Spring nutzt. Spring kann auch andere Konfigurationsdateien als [App.config] verwenden. Die hier vorgestellte Lösung ist daher nicht die einzige verfügbare.
Erstellen wir die Datei [App.config] mit dem Visual Studio-Assistenten:
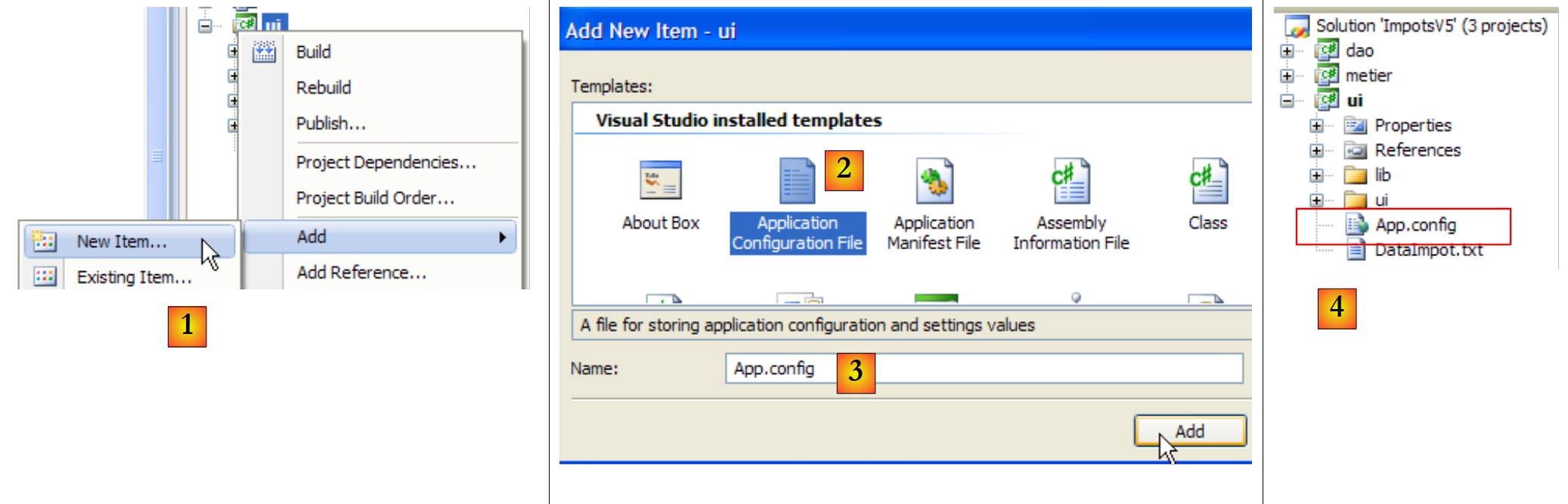 |
- in [1]: Fügen Sie dem Projekt ein neues Element hinzu
- in [2]: Wählen Sie „Anwendungskonfigurationsdatei“
- in [3]: [App.config] ist der Standardname dieser Konfigurationsdatei
- in [4]: Die Datei [App.config] wurde dem Projekt hinzugefügt
Der Inhalt der Datei [App.config] lautet wie folgt:
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
</configuration>
[ App.config] ist eine XML-Datei. Die Projektkonfiguration ist in <configuration>-Tags eingeschlossen. Die für Spring erforderliche Konfiguration lautet wie folgt:
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<configSections>
<sectionGroup name="spring">
<section name="context" type="Spring.Context.Support.ContextHandler, Spring.Core" />
<section name="objects" type="Spring.Context.Support.DefaultSectionHandler, Spring.Core" />
</sectionGroup>
</configSections>
<spring>
<context>
<resource uri="config://spring/objects" />
</context>
<objects xmlns="http://www.springframework.net">
<object name="dao" type="Dao.FileImpot, ImpotsV5-dao">
<constructor-arg index="0" value="DataImpot.txt"/>
</object>
<object name="metier" type="Metier.ImpotMetier, ImpotsV5-metier">
<constructor-arg index="0" ref="dao"/>
</object>
</objects>
</spring>
</configuration>
- Zeilen 11–23: Der durch das <spring>-Tag abgegrenzte Abschnitt wird als <spring>-Abschnittsgruppe bezeichnet. Sie können in [App.config] beliebig viele Abschnittsgruppen erstellen.
- Eine Abschnittgruppe enthält Abschnitte: Dies ist hier der Fall:
- Zeilen 12–14: der Abschnitt <spring/context>
- Zeilen 15–22: der Abschnitt <spring/objects>
- Zeilen 4–9: Der Bereich <configSections> definiert die Liste der in [App.config] vorhandenen Abschnittsgruppen-Handler.
- Zeilen 5–8: Definieren die Liste der Abschnittsmanager in der <spring>-Gruppe (name="spring").
- Zeile 6: der Manager des <context>-Abschnitts der <spring>-Gruppe:
- name: Name des verwalteten Abschnitts
- type: Name der Klasse, die den Abschnitt verwaltet, im Format NomClasse, NomDLL.
- Der Abschnitt <context> der Gruppe <spring> wird vom [Spring.Context.Support.ContextHandler] verwaltet, der sich in der DLL [Spring.Core.dll] befindet
- Zeile 7: Der Manager des <objects>-Abschnitts der <spring>-Gruppe
Die Zeilen 4–9 sind Standard in einer [App.config]-Datei mit Spring. Wir kopieren sie einfach von einem Projekt in ein anderes.
- Zeilen 12–14: Definieren den Abschnitt <spring/context>.
- Zeile 13: Das <resource>-Tag gibt den Speicherort der Datei an, in der die Klassen definiert sind, die Spring instanziieren soll. Diese können sich wie hier in [App.config] befinden, aber auch in einer anderen Konfigurationsdatei. Der Speicherort dieser Klassen wird im URI-Attribut des <resource>-Tags angegeben:
- <resource uri="config://spring/objects"> gibt an, dass sich die Liste der zu instanziierenden Klassen in der Datei [App.config] (Konfiguration:) im Verzeichnis //spring/objects befindet, d. h. im <objects>-Tag des <spring>-Tags.
- <resource uri="file://spring-config.xml"> würde bedeuten, dass die Liste der zu instanziierenden Klassen in der Datei [spring-config.xml] zu finden ist. Diese Datei sollte in den Laufzeitordnern des Projekts (bin/Release oder bin/Debug) abgelegt werden. Am einfachsten ist es, sie – wie bei der Datei [DataImport.txt] – im Stammverzeichnis des Projekts mit der Eigenschaft [Copy to output directory=always] abzulegen.
Die Zeilen 12–14 sind Standard in einer [App.config]-Datei mit Spring. Wir kopieren sie einfach von einem Projekt in ein anderes.
- Zeilen 15–22: Definition der zu instanziierenden Klassen. Hier erfolgt die spezifische Konfiguration einer Anwendung. Das <objects>-Element begrenzt den Definitionsabschnitt für die zu instanziierenden Klassen.
- Zeilen 16–18: Definieren der zu instanziierenden Klasse für die Ebene [dao]
- Zeile 16: Jedes von Spring instanziierte Objekt ist Gegenstand eines <object>-Tags. Dieses verfügt über ein Attribut „name“, das den Namen des instanziierten Objekts angibt. Auf diese Weise fordert die Anwendung von Spring eine Referenz an: „Gib mir eine Referenz auf das Objekt namens dao“. Das Attribut „type“ definiert die zu instanziierende Klasse als „NomClasse“ oder „NomDLL“. Zeile 16 definiert ein Objekt namens „dao“ als Instanz von „Dao.FileImport“, das in der DLL „ImportsV5-dao.dll“ zu finden ist. Beachten Sie, dass der vollständige Klassenname (einschließlich Namespace) angegeben wird und dass die Endung „.dll“ im DLL-Namen nicht angegeben ist.
Eine Klasse kann mit Spring auf zwei Arten instanziiert werden:
- über einen speziellen Konstruktor, an den Parameter übergeben werden: Dies geschieht in den Zeilen 16–18.
- über den Standardkonstruktor ohne Parameter. Das Objekt wird dann über seine öffentliche Eigenschaft initialisiert: Das <object>-Tag enthält dann <property>-Untertags, um diese Eigenschaften zu initialisieren. In diesem Fall haben wir kein Beispiel dafür.
- (Fortsetzung)
- Zeile 16: Die instanziierte Klasse ist FileImport. Sie verfügt über den folgenden Builder:
public FileImpot(string fileName);
Konstruktorparameter werden mit <constructor-arg> definiert.
- Zeile 17: Definiert den ersten und einzigen Konstruktorparameter. Der Attributindex ist die Nummer des Konstruktorparameters, der Attributwert sein Wert: <constructor-arg index="i" value="valuei"/>
- Zeilen 19–21: Definieren die Klasse, die für die [metier]-Ebene instanziiert werden soll: Klasse [Metier.ImpotMetier], die sich in der DLL [ImpotsV5-metier.dll] befindet.
- Zeile 19: Die instanziierte Klasse ist ImpotMetier. Sie verfügt über den folgenden Builder:
public ImpotMetier(IImpotDao dao);
- (Fortsetzung)
- Zeile 20: definiert den ersten und einzigen Konstruktorparameter. Oben ist der Parameter dao des Konstruktors eine Objektreferenz. In diesem Fall verwenden wir im <constructor-arg>-Tag das Attribut ref anstelle des Attributs value, das für die [dao]-Schicht verwendet wird: <constructor-arg index="i" ref="refi"/>. Im obigen Konstruktor repräsentiert der Parameter dao eine Instanz auf der [dao]-Schicht. Diese Instanz wurde in den Zeilen 16–18 der Konfigurationsdatei definiert. Somit gilt in Zeile 20:
<constructor-arg index="0" ref="dao"/>
steht ref="dao" für das Spring-Objekt „dao“, das in den Zeilen 16–18 definiert wurde.
Zusammenfassend lässt sich sagen, dass die Datei [App.config]:
- instanziiert die Schicht [dao] mit der Klasse FileImpot, die als Parameter DataImpot.txt erhält (Zeilen 16–18). Das resultierende Objekt wird „dao“ genannt
- instanziiert die [metier]-Schicht mit der Klasse ImpotMetier, die das vorherige „dao“-Objekt als Parameter erhält (Zeilen 19–21).
Nun muss diese Spring-Konfigurationsdatei nur noch in der [ui]-Schicht verwendet werden. Dazu duplizieren wir die Klasse [Dialogue.cs] in [Dialogue2.cs] und machen letztere zur Hauptklasse des [ui]-Projekts:
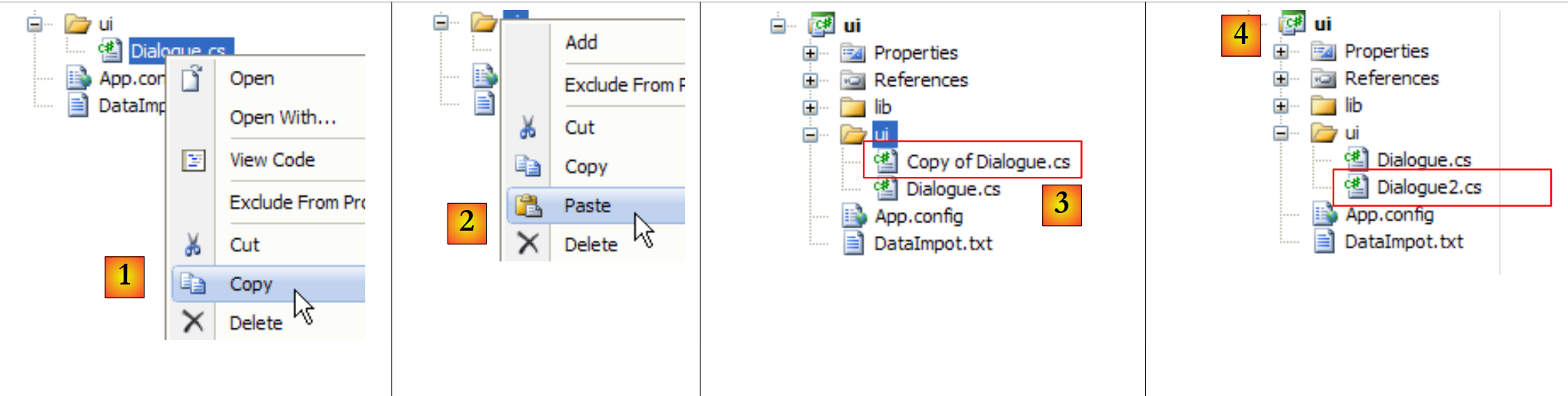 |
- in [1]: Kopie von [Dialogue.cs]
- en [2]: Einfügen
- in [3]: die Kopie von [Dialogue.cs]
- in [4]: umbenannt in [Dialogue2.cs]
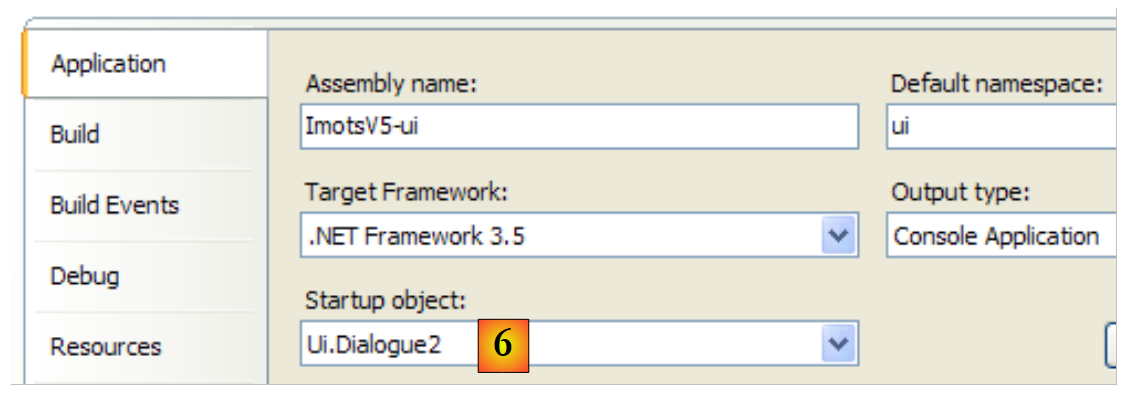 |
- in [6]: Wir machen [Dialogue2.cs] zur Hauptklasse des [ui]-Projekts.
Der folgende Code aus [Dialogue.cs]:
// we create the layers [metier and dao]
IImpotMetier metier = null;
try {
// layer creation [job]
metier = new ImpotMetier(new FileImpot("DataImpot.txt"));
} catch (ImpotException e) {
// error display
string msg = e.InnerException == null ? null : String.Format(", Exception d'origine : {0}", e.InnerException.Message);
Console.WriteLine("L'erreur suivante s'est produite : [Code={0},Message={1}{2}]", e.Code, e.Message, msg == null ? "" : msg);
// program stop
Environment.Exit(1);
}
// infinite loop
while (true) {
...
wird in [Dialogue2.cs] zu Folgendem:
// we create the layers [metier and dao]
IApplicationContext ctx = null;
try {
// spring context
ctx = ContextRegistry.GetContext();
} catch (Exception e1) {
// error display
Console.WriteLine("Chaîne des exceptions : \n{0}", "".PadLeft(40, '-'));
Exception e = e1;
while (e != null) {
Console.WriteLine("{0}: {1}", e.GetType().FullName, e.Message);
Console.WriteLine("".PadLeft(40, '-'));
e = e.InnerException;
}
// program stop
Environment.Exit(1);
}
// a reference is requested on the [metier] layer
IImpotMetier metier = (IImpotMetier)ctx.GetObject("metier");
// infinite loop
while (true) {
....................................
- Zeile 2: IApplicationContext gewährt Zugriff auf die von Spring instanziierten Objekte. Wir bezeichnen dieses Objekt als Spring-Kontext der Anwendung oder einfach als Anwendungskontext. Derzeit ist dieser Kontext noch nicht initialisiert. Dies geschieht durch den folgenden try/catch-Block.
- Zeile 5: Die Konfiguration von Spring in [App.config] wird gelesen und verwendet. Nach diesem Vorgang werden, sofern keine Ausnahme ausgelöst wurde, alle Objekte im Abschnitt <objects> gelesen und instanziiert:
- Das Spring-Objekt „dao“ ist eine Instanz auf der Ebene [dao]
- Das Spring-Objekt „metier“ ist eine Instanz auf der Ebene [metier]
- Zeile 19: Die Klasse [Dialogue2.cs] benötigt eine Referenz auf die [metier]-Schicht. Diese wird vom Anwendungskontext angefordert. Das Objekt IApplicationContext ermöglicht den Zugriff auf Spring-Objekte über deren Namen (Konfigurationsattribut <object> in Spring). Die gerenderte Referenz ist eine Referenz auf den generischen Typ Object. Wir müssen die gerenderte Referenz in den richtigen Typ umwandeln, hier den Typ der Schnittstelle der [metier]-Schicht: IImpotMetier.
Wenn alles gut gegangen ist, verfügt [Dialogue2.cs] nach Zeile 19 über eine Referenz auf die [metier]-Schicht. Der Code ab Zeile 21 entspricht dem der bereits behandelten Klasse [Dialogue.cs].
- Zeilen 6–17: Behandlung der Ausnahme, die auftritt, wenn die Spring-Konfigurationsdatei nicht verarbeitet werden kann. Dafür kann es verschiedene Gründe geben: falsche Syntax in der Konfigurationsdatei selbst oder die Unmöglichkeit, eines der konfigurierten Objekte zu instanziieren. In unserem Beispiel würde Letzteres auftreten, wenn die Datei DataImpot.txt aus Zeile 17 von [App.config] in der Projekt-Ausführungsdatei nicht gefunden würde.
Die Ausnahme in Zeile 6 ist eine Kette von Ausnahmen, wobei jede Ausnahme zwei Eigenschaften hat:
- Message: Fehlermeldung der Ausnahme
- InnerException: die vorherige Ausnahme in der Ausnahmekette
Die Schleife in den Zeilen 10–14 zeigt alle Ausnahmen in der Kette in folgender Form an: Ausnahmeklasse und zugehörige Meldung.
Wenn das [ui]-Projekt mit einer gültigen Konfigurationsdatei ausgeführt wird, erhält man die üblichen Ergebnisse:
Paramètres du calcul de l'Impot au format : Marié (o/n) NbEnfants Salaire ou rien pour arrêter :o 2 60000
Impot=4282 euros
Wenn das [ui]-Projekt mit einer nicht vorhandenen Datei [DataImpotInexistant.txt] ausgeführt wird,
<object name="dao" type="Dao.FileImpot, ImpotsV5-dao">
<constructor-arg index="0" value="DataImpotInexistant.txt"/>
</object>
Wir erhalten folgende Ergebnisse:
- Zeile 17: die ursprüngliche Ausnahme vom Typ [FileNotFoundException]
- Zeile 15: Die [dao]-Schicht kapselt diese Ausnahme in einen Typ [Entities.ImportException]
- Zeile 9: Die von Spring ausgelöste Ausnahme, da die Instanziierung des Objekts namens „dao“ fehlgeschlagen ist. Beim Erstellen dieses Objekts traten zuvor zwei weitere Ausnahmen auf: die in den Zeilen 11 und 13.
- Da das „dao“-Objekt nicht erstellt werden konnte, konnte der Anwendungskontext nicht erstellt werden. Dies ist die Bedeutung der Ausnahme in Zeile 5. Zuvor war eine weitere Ausnahme aufgetreten, nämlich die in Zeile 7.
- Zeile 3: Die oberste Ausnahme, die letzte in der Kette: Es wird ein Konfigurationsfehler gemeldet.
Aus all dem lernen wir, dass es oft die tiefstliegende Ausnahme ist, hier die in Zeile 17, die am bedeutendsten ist. Beachten Sie jedoch, dass Spring die Fehlermeldung aus Zeile 17 beibehalten und an die oberste Ausnahme in Zeile 3 weitergeleitet hat, um die ursprüngliche Fehlerursache auf der obersten Ebene zu haben.
Spring allein wäre ein ganzes Buch wert. Wir haben hier nur an der Oberfläche gekratzt. Vertiefende Informationen finden Sie in der Dokumentation [spring-net-reference.pdf] im Spring-Installationsordner:
 |
Siehe auch [http://tahe.developpez.com/dotnet/springioc], ein Spring-Tutorial im VB.NET-Kontext.