3. SQL 语言简介
在本节中,我们将介绍用于创建和操作单个表的最初命令。通常我们提供的是简化版本。完整的语法可在 Firebird 参考指南中查阅(参见第 2.2 节)。
数据库的使用者具备不同的技能:
- 数据库管理员通常精通SQL语言和数据库。表的创建工作通常只需进行一次,因此由管理员负责。随着时间的推移,他可能需要修改表的结构。 数据库是由通过关系相互关联的表组成的集合。数据库管理员负责定义这些关系,并为不同用户分配权限。例如,他可以设定某用户仅具有查看某张表内容的权限,但无权对其进行修改。
- 数据库用户是数据运作的核心。根据数据库管理员授予的权限,用户可在数据库的不同表中添加、修改或删除数据。用户还会利用这些数据,从中提取对企业、行政机构等正常运作有用的信息。
在第2.6节中,我们介绍了工具[IB-Expert]中的编辑器SQL。我们将使用该工具。请回顾以下几点:
- 可通过菜单选项 [Tools/SQL Editor] 或按键 [F12] 调用编辑器 SQL

随后将弹出一个 [SQL Editor] 窗口,我们可以在其中输入命令 SQL:
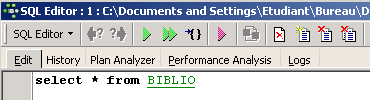
上方的屏幕截图通常会用以下文字表示:
3.1. Firebird的数据类型
在创建表时,我们需要指定表中各列可包含的数据类型。本文将介绍 Firebird 中最常用的数据类型。需要注意的是,这些数据类型在不同系统之间可能存在差异。
[-32768, 32767] 域中的整数:4 | |
[–2 147 483 648, 2 147 483 647] 域中的整数:-100 | |
n 位实数,其中小数点后有 m 位 NUMERIC(5,2):-100.23, +027.30 | |
有效数字为7位的近似实数:10.4 | |
有效数字为15位的近似实数:-100.89 | |
精确为 N 个字符的字符串。如果存储的字符串少于 N 个字符,则用空格补足。 CHAR(10):'ANGERS '(末尾有4个空格) | |
长度不超过 N 个字符的字符串 VARCHAR(10):'ANGERS' | |
一个日期:'2006-01-09'(格式 YYYY-MM-DD) | |
一个时间:'16:43:00'(格式为 HH:MM:SS) | |
日期和时间:'2006-01-09 16:43:00'(格式 YYYY-MM-DD HH:MM:SS) |
函数 CAST() 允许在必要时在两种类型之间进行转换。 要将声明为 T1 类型的值 V 转换为 T2 类型,应编写:CAST(V,T2)。可以进行以下类型转换:
- 数字转字符串。这种类型转换是隐式的,无需使用函数 CAST。因此,运算 1 + '3' 无需对字符 '3' 进行转换。其结果是数字 4。
- DATE、TIME、TIMESTAMP 与字符串之间的转换,反之亦然。因此
- TIMESTAMP 转换为 TIME 或 DATE,反之亦然
在表中,某行可能包含无值的列。此时该列的值被定义为常量 NULL。可通过以下运算符检测该值是否存在
IS NULL / IS NOT NULL
3.2. 创建表
要了解如何创建表,我们首先使用 [Design] 模式配合 IBExpert 创建一个表。为此,我们将遵循第 2.3 节中描述的方法。这样,我们就创建了以下表:
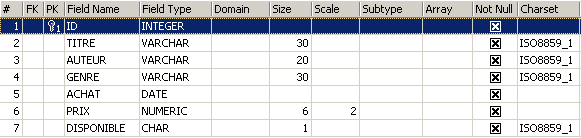
该表用于记录图书馆购买的书籍。各字段的含义如下:
Name | 类型 | 约束 | 含义 |
该表虽使用工具 IBEXPERT 作为向导创建,但本可直接通过 SQL 命令创建。要了解这些命令,只需查看该表的 [DDL] 选项卡:
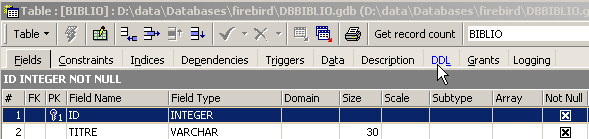
用于创建表 [BIBLIO] 的代码 SQL 如下:
- 第 1 行:Firebird 所有者 - 指示所使用的 SQL 方言级别
- 第 2 行:Firebird 所有者 - 指定所使用的字符集
- 第 6 至 14 行:SQL 标准:通过定义各列的名称和类型来创建表 BIBLIO。
- 第 16 行:SQL 标准:创建约束,规定 TITRE 列不允许重复
- 第 17 行:标准 SQL:指定列 [ID] 为表的主键。这意味着表中两行不能具有相同的 ID。 这与 [TITRE] 列的 [UNIQUE NOT NULL] 约束非常相似,实际上 TITRE 列本可以作为主键。 当前的趋势是使用没有具体含义、由SGBD生成的主键。
命令 [CREATE TABLE] 的语法如下:
CREATE TABLE 表 (nom_colonne1 type_colonne1 contrainte_colonne1, nom_colonne2 type_colonne2 contrainte_colonne2, ..., nom_colonnen type_colonnen contrainte_colonnen,其他约束条件) | |||||||||
创建表 table 并包含指定的列
|
表 [BIBLIO] 也可以按照以下 SQL 顺序构建:
让我们演示一下。在编辑器中使用该顺序 SQL (F12) 创建一个名为 [BIBLIO2] 的表:
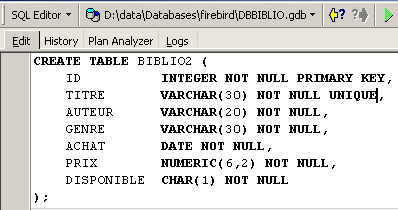
执行后,需提交事务才能在数据库中查看结果:
完成上述操作后,该表将出现在数据库中:
双击表名即可查看其结构:
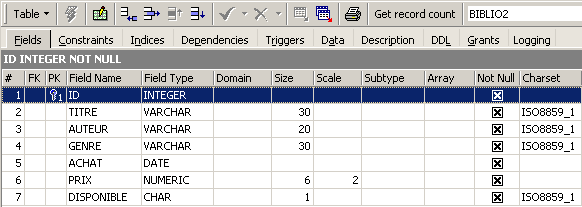
这里确实显示了我们之前定义的[BIBLIO2]表
3.3. 删除表
用于删除表的命令 SQL 如下:
DROP TABLE 表 | |
删除 [table] |
要删除我们刚刚创建的表 [BIBLIO2],现在执行以下命令 SQL:
并通过 [Commit] 进行确认。表 [BIBLIO2] 已被删除:
3.4. 填充表
在刚刚创建的表 [BIBLIO] 中插入一行:
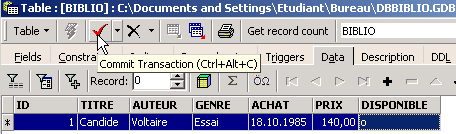
通过 [Commit] 确认添加该行,然后右键单击已添加的行:
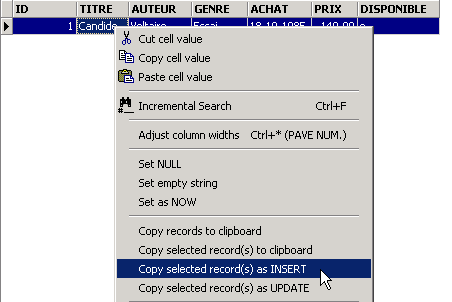
并如上图所示,要求将插入的行以 SQL INSERT 命令的形式复制到剪贴板中。 接着打开任意文本编辑器,粘贴(粘贴 / Paste)刚才复制的内容。我们将得到以下 SQL 代码:
INSERT INTO BIBLIO (ID,TITRE,AUTEUR,GENRE,ACHAT,PRIX,DISPONIBLE) VALUES (1,'Candide','Voltaire','Essai','18-OCT-1985',140,'o');
SQL insert 命令的语法如下:
insert into table [(colonne1, colonne2, ..)] values (值1, 值2, ....) | |
向 table 表中添加一行 (值1, 值2, ..)。这些值将分配给 colonne1、colonne2 等表(如果存在),否则按定义顺序分配给该表的列。 |
要在表 [BIBLIO] 中插入新行,需在编辑器 SQL 中输入以下 INSERT 命令。 将逐一执行并确认这些命令。使用按钮切换到下一个命令。
在确认了 [Commit] 以及其他 SQL 命令后,我们得到以下表格:
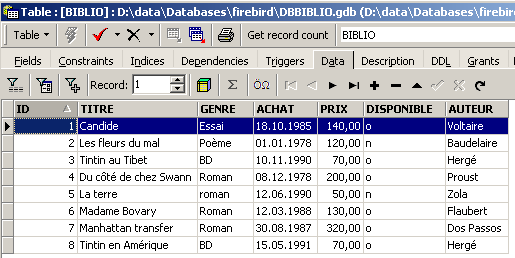 |
3.5. 查询表
3.5.1. 简介
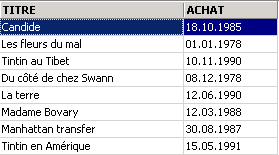
在编辑器 SQL 中,输入以下命令:
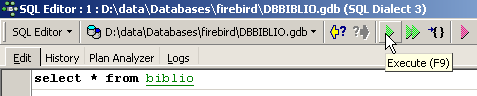
并执行该命令。我们将得到以下结果:
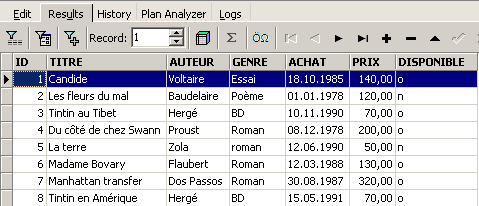
命令 SELECT 用于查询数据库表中的内容。该命令的语法非常丰富。 此处仅介绍查询单个表的语法。关于同时查询多个表的内容,我们将在后续章节中讨论。命令 SQL [SELECT] 的语法如下:
SELECT [ALL|DISTINCT] [*|expression1 alias1, expression2 alias2, ...] FROM table | |
显示所有表行中 expressioni 的值。expressioni 可以是一列或更复杂的表达式。 符号 * 表示所有列。默认情况下,将显示所有表行(ALL)。如果存在 DISTINCT,则选定的相同行仅显示一次。 expressioni 的值将显示在标题为 expressioni 或 aliasi 的列中(如果使用了后者)。 |
示例:
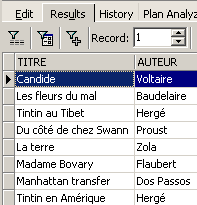
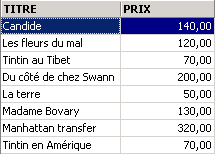
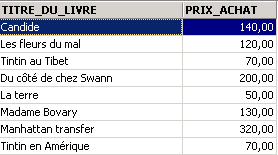
在上文中,我们已为所需的列分配了别名(TITRE_DU_LIVRE、PRIX_ACHAT)。
3.5.2. 显示满足条件的行
SELECT .... WHEREcondition | |
仅显示满足 condition 条件的行 |
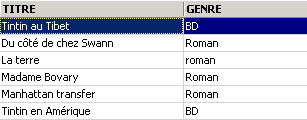
示例
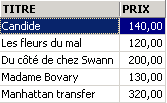

其中一本书的类型是“小说”,而不是“小说”。我们使用函数 upper,该函数将字符串转换为大写,从而获取所有小说。
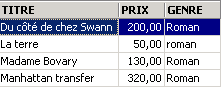
我们可以使用逻辑运算符组合条件
ET 逻辑 | |
OU 逻辑 | |
逻辑否定 |
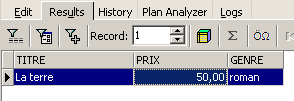

![]()
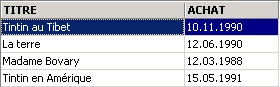 |
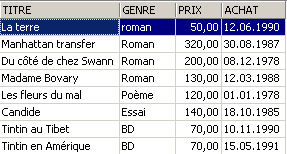
3.5.3. 按指定顺序显示行
在上述语法中,可以添加一个 ORDER BY 子句,指定所需的显示顺序:
SELECT .... ORDER BY expression1 [asc|desc], expression2 [asc|dec], ... | |
筛选结果行按以下顺序显示: 1:按 expression1 的升序(asc / ascending,即默认值)或降序(desc / descending)排序 2:当 expression1 值相同时,按 expression2 的值排序 等等…… |
示例:
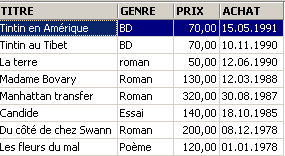
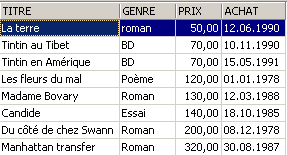
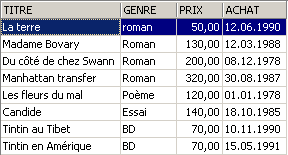
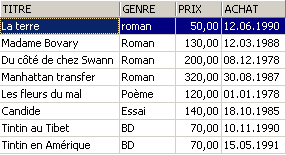
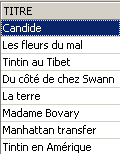
3.6. 删除表格中的行
DELETE FROM table [WHERE condition] | |
删除 table 行,并检查 condition。如果后者不存在,则删除所有行。 |
示例:
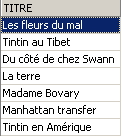
以下两个命令依次执行:
3.7. 修改表中的内容
update table set 列1 = 表达式1, 列2 = 表达式2, ... [where condition] | |
对于验证 condition 的 table 行(如果没有条件,则为所有行),colonnei 将接收 expressioni 的值。 |
示例:
所有类型均大写:
验证:
![]()
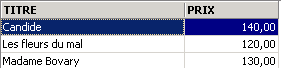
显示价格:

小说价格上涨5%:
进行验证:

3.8. 表的最终更新
当对表进行修改时,Firebird 实际上是在表的副本上进行操作。随后可通过命令 COMMIT 和 ROLLBACK 将这些修改最终确定或撤销。
COMMIT | |
将自上次运行 COMMIT 以来对表所做的更新永久保存。 |
ROLLBACK | |
撤销自上次运行 COMMIT 以来对表所做的所有修改。 |
在以下情况下会隐式执行 COMMIT: a) 退出 Firebird 时 b) 每次执行影响表结构的命令后:CREATE、ALTER、DROP。 |
示例
在编辑器 SQL 中,通过验证自上次 COMMIT 或 ROLLBACK 以来执行的所有操作,将数据库置于已知状态:
查询标题列表:
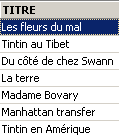
删除一个标题:
验证:
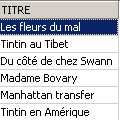
标题已成功删除。现在,我们将撤销自上次 COMMIT / ROLLBACK 以来所做的所有修改:
验证:
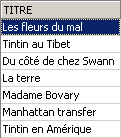
被删除的标题已恢复。现在查询价格列表:
![]()
假设所有价格都被设为零。
检查价格:
![]()
撤销对数据库所做的修改:
然后再次检查价格:
![]()
我们已恢复原始价格。
3.9. 将一行数据从一个表添加到另一个表
当两个表的结构兼容时,可以将一个表的行添加到另一个表中。为了演示这一点,我们先创建一个与 [BIBLIO] 结构相同的表 [BIBLIO2]。
在 IBExpert 的数据库资源管理器中,双击表 [BIBLIO] 以访问其属性页:
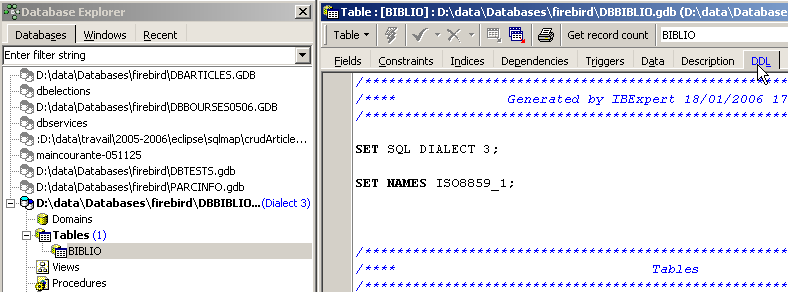
在此选项卡中,列出了用于生成表 [BIBLIO] 的命令列表 SQL。 将该代码全部复制到剪贴板中(CTRL-A、CTRL-C)。 然后调用名为 [Script Executive] 的工具,该工具可执行 SQL 命令列表:
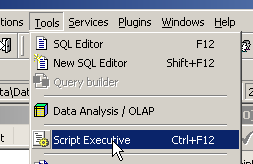
此时会弹出一个文本编辑器,我们可以在其中粘贴(CTRL-V)之前复制到剪贴板中的文本:
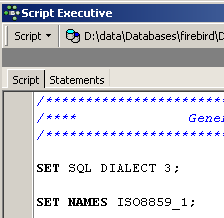
通常将一组命令称为脚本。 [Script Executive]将允许我们执行此类脚本,而编辑器SQL则仅允许一次执行单个命令。 当前的脚本 SQL 可以创建表 [BIBLIO]。 让我们使其创建一个名为 [BIBLIO2] 的表。只需将 [BIBLIO] 改为 [BIBLIO2] 即可:
现在点击下方的 [Run Script] 按钮运行该脚本:

脚本已执行:
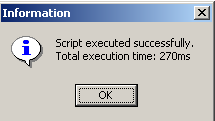
现在可以在数据库管理器中看到新表:
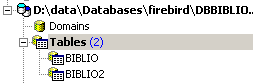
如果双击 [BIBLIO2] 来查看其内容,会发现它是空的,这是正常的:
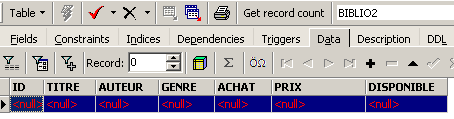
使用 SQL INSERT 这种变体命令,可以将来自另一张表的行插入到当前表中:
INSERT INTO table1 [(colonne1, colonne2, ...)] SELECT 列a、列b、... FROM table2 WHERE condition | |
验证 condition 的 table2 行已添加到 table1 中。 table2 中的列 colonnea、colonneb、……按顺序分配给 table1 中的列 colonne1、colonne2、……,因此必须是兼容的类型。 |
让我们回到编辑器 SQL:
并发出以下命令 SQL:
该命令将 [BIBLIO] 中所有对应于一部小说的行插入到 [BIBLIO2] 中。执行完 SQL 命令后,通过 [Commit] 进行确认:
完成上述操作后,查询表 [BIBLIO2] 中的数据:

3.10. 删除表
DROPTABLEtable | |
删除 table |
示例:删除表 BIBLIO2
确认更改:
在数据库浏览器中刷新表的显示:
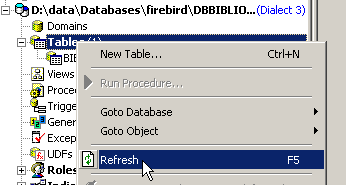
发现表 [BIBLIO2] 已被删除:
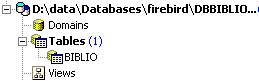
3.11. 修改表结构
ALTER TABLE table [ ADD nom_colonne1 type_colonne1 contrainte_colonne1] [ALTER nom_colonne2 TYPE type_colonne2] [DROP nom_colonne3] [ADD contrainte] [DROP CONSTRAINT nom_contrainte] | |
可用于添加(ADD)、修改(ALTER)和删除(DROP)表列。 nom_colonnei type_colonnei contrainte_colonnei 的语法与 CREATE TABLE 相同。还可以添加/删除表约束。 |
示例:在编辑器 SQL 中依次执行以下两个命令 SQL
在数据库浏览器中,检查表 [BIBLIO] 的结构:
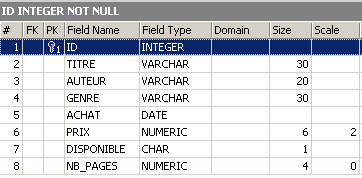
更改已生效。让我们看看表的内容发生了哪些变化:
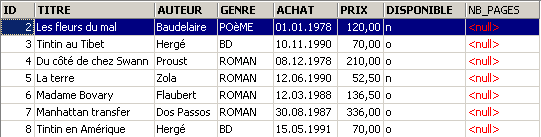
新列 [NB_PAGES] 已创建,但没有值。让我们删除该列:
检查表 [BIBLIO] 的新结构:
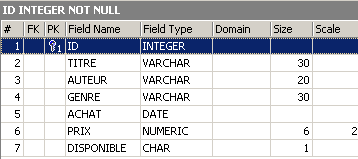
[NB_PAGES] 列已成功删除。
3.12. 视图
可以对一个或多个表创建部分视图。视图的行为类似于表,但不包含数据。其数据是从其他表或视图中提取的。视图具有以下优点:
- 用户可能仅对特定表中的某些列和行感兴趣。视图允许用户仅查看这些列和行。
- 表的所有者可能希望仅向其他用户授予有限的访问权限。视图使其能够实现这一点。经其授权的用户只能访问其定义的视图。
3.12.1. 创建视图
CREATE VIEW nom_vue AS SELECT 列1, 列2, ... FROM table WHERE condition [ WITH CHECK OPTION ] | |
创建视图 nom_vue。 该视图是一个表,其结构为 table 的列 1、列 2、...,行来自 table,并满足 condition 的条件(如果没有条件,则包含所有行) | |
此可选子句指定,对视图的插入和更新操作不得创建视图无法选中的行。 |
注 CREATE VIEW 的语法实际上比上文介绍的更为复杂,特别是它允许基于多个表创建视图。为此,只需让查询 SELECT 涉及多个表即可(参见下一章)。
示例
基于 biblio 表,创建一个仅包含小说(行选择)且仅包含标题、作者、价格(列选择)列的视图:
在数据库资源管理器中,刷新视图(F5)。此时将显示一个视图:
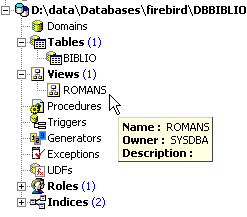
我们可以查看到与该视图关联的 SQL 序列号。为此,请双击视图 [ROMANS]:
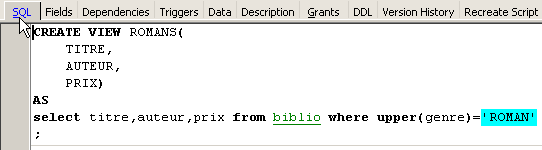
视图就像一张表。它具有以下结构:
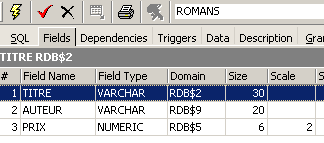
以及内容:
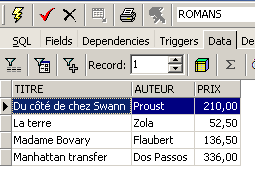
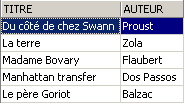
视图的使用方式与表格类似。我们可以对其执行查询 SQL。以下是在编辑器 SQL 中可以尝试的一些示例:
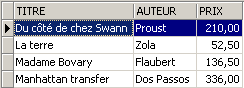
新小说在 [ROMANS] 视图中可见吗?
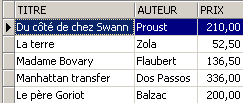
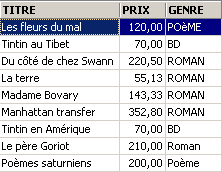
让我们在表 [BIBLIO] 中添加除小说以外的其他内容:
SQL> insert into biblio(id,titre,auteur,genre,achat,prix,disponible) values (11,'Poèmes saturniens','Verlaine','Poème','02-sep-92',200,'o');
检查表 [BIBLIO]:
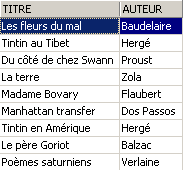
检查视图 [ROMANS]:
添加的书籍未出现在视图 [ROMANS] 中,因为它没有 upper(genre)='ROMAN'。
3.12.2. 视图更新
更新视图的方式与更新表类似。视图数据所提取的所有表都会受到此更新的影响。以下是一些示例:
SQL> insert into biblio(id,titre,auteur,genre,achat,prix,disponible) values (13,'Le Rouge et le Noir','Stendhal','Roman','03-oct-92',110,'o')
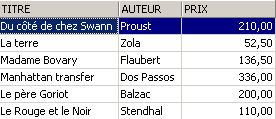
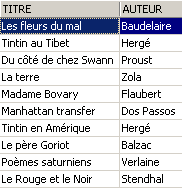
从视图 [ROMANS] 中删除一行:
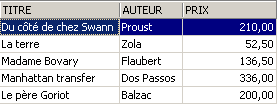
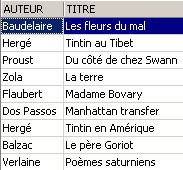
视图 [ROMANS] 中删除的行在表 [BIBLIO] 中也被删除了。现在,我们将提高视图 [ROMANS] 中书籍的价格:
在 [ROMANS] 中进行验证:
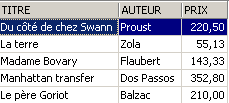
这对表 [BIBLIO] 产生了什么影响?
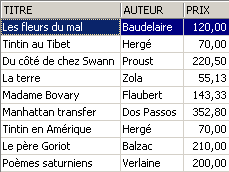
小说在 [BIBLIO] 表中也确实增加了 5%。
3.12.3. 删除视图
DROP VIEW nom_vue | |
删除名为 |
示例
在数据库浏览器中,可以刷新视图(F5),以确认视图 [ROMANS] 已消失:
3.13. 使用分组函数
有些函数并非针对表中的每一行进行操作,而是针对行组进行操作。这些主要是统计函数,可让我们获取某列数据的平均值、标准差等。
SELECT f1, f2, .., fn FROM table [ WHERE condition ] | |
计算统计函数 fi,并检查所有表行是否存在 condition。 |
SELECT f1, f2, .., fn FROM table [ WHERE condition ] [ GROUP BY expr1, expr2, ..] | |
关键字 GROUP BY 的作用是将表行划分为若干组。每组包含那些表达式 expr1、expr2、... 具有相同值的行。 示例:GROUP BY genre 将同一类型的书籍归入同一组。 子句 GROUP BY 作者,类型 会将作者和类型相同的书籍归入同一组。子句 WHERE 条件 首先会从表中剔除不符合条件的行。 随后,通过子句 GROUP BY 形成各组。接着,针对每组行计算函数 fi。 |
SELECT f1, f2, .., fn FROM table [ WHERE condition ] [ GROUP BY expression] [ HAVING condition_de_groupe] | |
子句 HAVING 筛选由子句 GROUP BY 形成的组。 因此,它始终与该子句 GROUP BY 的存在相关。 示例:GROUP BY 类型 HAVING 类型!='ROMAN' |
可用的统计函数 fi 如下:
表达式平均值 | |
表达式取值的行数 | |
表中的总行数 | |
表达式的最大值 | |
表达式最小值 | |
表达式之和 |
示例
![]()
平均价格? 最高价格? 最低价格?
![]()
小说的平均价格?最高价格?
![]()
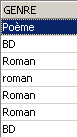
有多少 BD?
![]()
价格低于100法郎的小说有多少本?
![]()

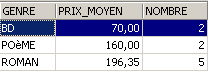
同一类别的书籍数量及平均单价是多少?
SQL> select upper(genre) GENRE,avg(prix) PRIX_MOYEN,count(*) NOMBRE from biblio group by upper(genre)
同样的问题,但仅限于非小说类书籍:
SQL>
select upper(genre) GENRE,avg(prix) PRIX_MOYEN,count(*) NOMBRE
from biblio
group by upper(genre)
having upper(GENRE)!='ROMAN'
![]()
同样的问题,但仅限150法郎以下的书籍:
SQL>
select upper(genre) GENRE,avg(prix) PRIX_MOYEN,count(*) NOMBRE
from biblio
where prix<150
group by upper(genre)
having upper(GENRE)!='ROMAN'
![]()
同样的问题,但只保留平均单价>100法郎的书组
SQL>
select upper(genre) GENRE, avg(prix) PRIX_MOYEN,count(*) NOMBRE
from biblio
group by upper(genre)
having avg(prix)>100
![]()
3.14. 创建表的 脚本SQL
SQL 是一种标准语言,可与许多 SGBD 配合使用。为了能够从一个 SGBD 切换到另一个, 将整个数据库或其中某些元素导出为 SQL 脚本会非常有用,该脚本在另一个 SGBD 中重新运行时,将能够重建脚本中导出的元素。
这里我们将导出表 [BIBLIO]。以选项 [Extract Metadata] 为例:
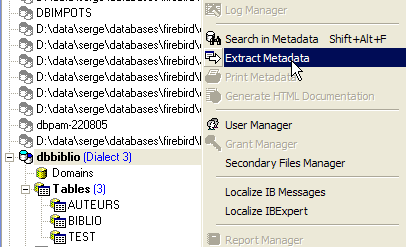
请注意,必须先定位到要导出元素的数据库。该选项将启动一个向导:
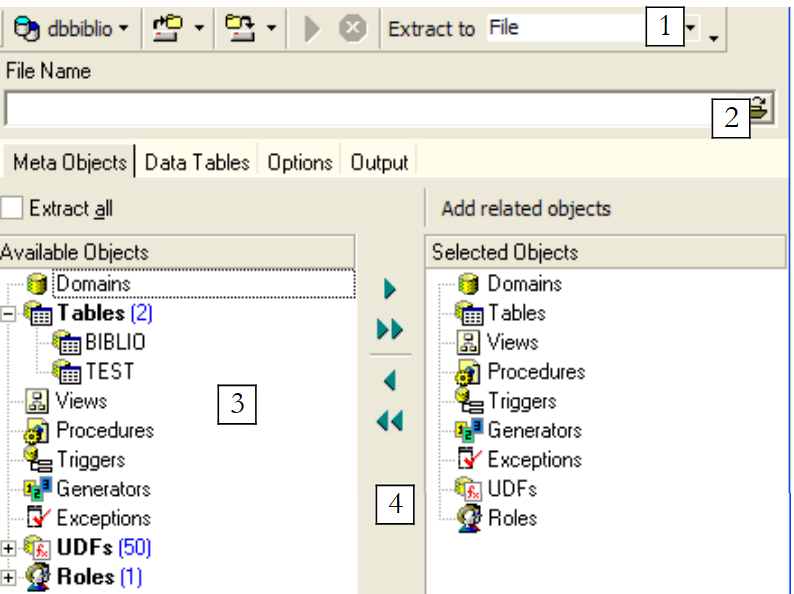 |
生成脚本的位置 SQL:
| |
若选择 [File] 选项,则为文件名 | |
导出内容 | |
用于选择(->)或取消选择(<-)要导出对象的按钮 |
如果我们要导出整个数据库,则勾选上方的 [Extract All] 选项。 我们只想导出表 BIBLIO。为此,使用 [4] 选中表 [BIBLIO],并使用 [2] 指定一个文件:
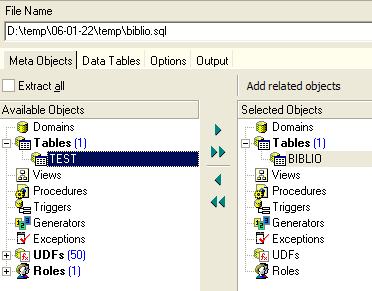
如果仅进行上述操作,将仅导出表 [BIBLIO] 的结构。若要导出其内容,需使用选项卡 [Data Tables]:
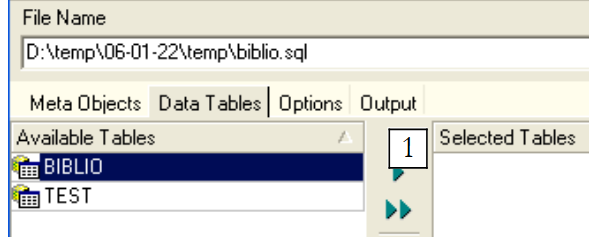 |
使用 [1] 选择表 [BIBLIO]:
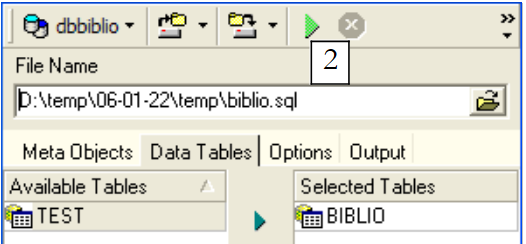 |
使用 [2] 生成脚本 SQL:
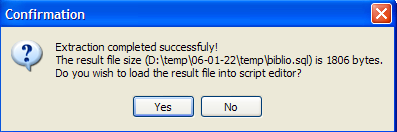
接受该提议。这样我们就能在文件 [biblio.sql] 中查看生成的脚本:
- 第 1 至 3 行是注释
- 第 5 至 12 行是 Firebird 专有的 SQL 代码
- 其余行属于标准 SQL 格式,应可在 SGBD 中重新执行,该脚本将采用 BIBLIO 表中声明的数据类型。
让我们在 Firebird 中重新运行此脚本,以创建一个名为 BIBLIO2 的表,该表将是 BIBLIO 表的克隆。为此,请使用 [Script Executive](Ctrl-F12):
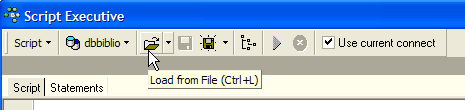
加载我们刚刚生成的脚本 [biblio.sql]:
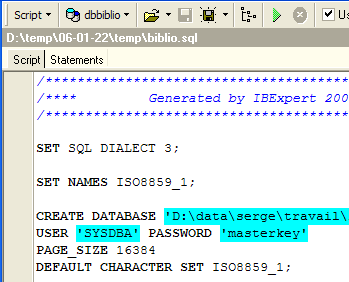
对其进行修改,仅保留创建表和插入行部分。该脚本重命名为 [BIBLIO2]:
CREATE TABLE BIBLIO2 (
ID INTEGER NOT NULL,
TITRE VARCHAR(30) NOT NULL,
AUTEUR VARCHAR(20) NOT NULL,
GENRE VARCHAR(30) NOT NULL,
ACHAT DATE NOT NULL,
PRIX NUMERIC(6,2) DEFAULT 10 NOT NULL,
DISPONIBLE CHAR(1) NOT NULL
);
INSERT INTO BIBLIO2 (ID, TITRE, AUTEUR, GENRE, ACHAT, PRIX, DISPONIBLE) VALUES (2, 'Les fleurs du mal', 'Baudelaire', 'POèME', '1978-01-01', 120, 'n');
...
COMMIT WORK;
运行此脚本:
 |  |
我们可以在数据库浏览器中验证,表 [BIBLIO2] 是否已成功创建,并且其结构和内容是否符合预期:
 | 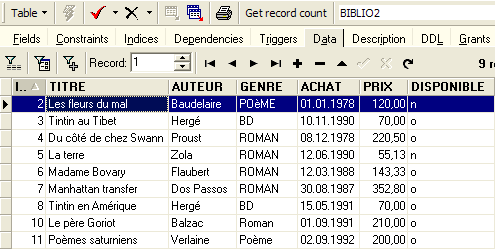 |