5. Java 8 中的 Stream<T> 类型
5.1. 示例-01 - Stream 类
对流 Observable 的操作与流 Stream 有许多共同点。 一个区别在于:在获取整个 Stream 流之前,无法处理 Stream 流中的任何元素;而 Observable 流中的元素 (被观察到)即可进行处理,无需等待整个 Observable 流的获取。 另一个区别在于,一旦获取了 Stream,我们会通过逐个从 Stream 中提取(pull)其值来利用这些值。对于可观察对象,情况则不同。一旦它发出一个值,该值就会被推送(pushed)给其订阅者。
有多个类实现了 Stream 的概念。这里我们介绍 Stream<T> 类:
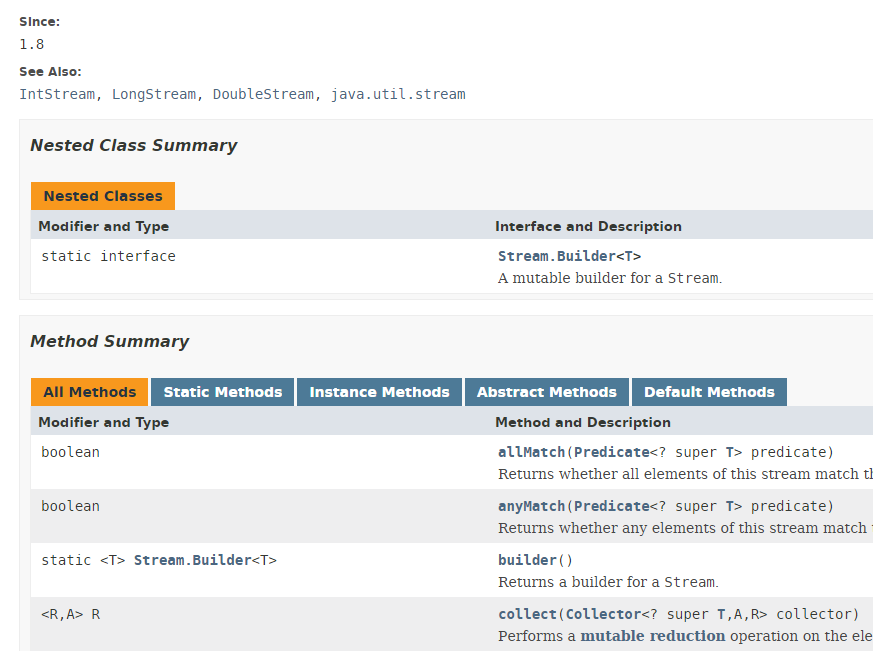
Stream类包含39个方法。我们将介绍其中几个。请看以下代码:
 |
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple01 {
public static void main(String[] args) {
// 人员列表
List<Personne> personnes = Personnes.get();
// 显示 1
personnes.stream().forEach(p -> {
System.out.println(p);
});
System.out.println("----------------");
// 显示 2
personnes.stream().forEach(System.out::println);
}
}
- 第 11 行:实例化一个人员列表;
- 第13行:基于该列表,创建一个Stream。 所有集合均可按此方式转换为 Stream 流。这使得我们可以利用该类的所有方法,从而比使用循环更简洁地处理集合中的元素。此外,在条件允许的情况下,这还能利用元素处理的并行性;
- 第 13 行:[Stream.forEach] 方法的签名如下:
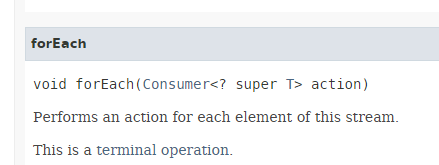 |
可以看出,该方法的参数是第 4.4 节中介绍的功能接口 [Consumer<T>],该接口的唯一方法使用类型 T 且不返回任何值。
- 在代码中:
personnes.stream().forEach(p -> {
System.out.println(p);
});
- [personnes.stream()] 生成类型为 [Personne] 的元素流,该流作为 [forEach] 方法的输入。参数 p 的类型为 [Personne],提供的 lambda 函数用于显示该人员;
上述代码可简化如下(第 18 行):
personnes.stream().forEach(System.out::println);
与其将 lambda 表达式的值作为参数传递,我们直接传递现有方法的引用,此处即 System.out 类中的 println 方法。 当然,该方法必须具有正确的签名,此处即方法 [Consumer.accept] 的签名:void accept(T t)。如前所述,方法 [accept] 的参数类型为 [Personne];
我们得到以下结果:
一旦流(Stream)被使用过,就无法再次使用。若需再次使用,必须重新构建该流。以下代码 [Exemple01b] 展示了这一点:
package dvp.java8.streams;
import java.util.stream.Stream;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple01b {
public static void main(String[] args) {
// 人员流动
Stream<Personne> personnes = Personnes.get().stream();
// 显示 1
personnes.forEach(p -> {
System.out.println(p);
});
System.out.println("----------------");
// 显示 2
personnes.forEach(System.out::println);
}
}
- 第 11 行:为优化代码,我们决定仅构建一次 Stream。此时得到的结果如下:
{"nom":"jean","age":20,"poids":70.0,"sexe":"HOMME"}
{"nom":"marie","age":10,"poids":30.0,"sexe":"FEMME"}
{"nom":"camille","age":30,"poids":55.0,"sexe":"FEMME"}
----------------
Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.sourceStageSpliterator(Unknown Source)
at java.util.stream.ReferencePipeline$Head.forEach(Unknown Source)
at dvp.java8.streams.Exemple02b.main(Exemple02b.java:18)
每次需要使用 Stream 时,即使它之前已被构建过,也必须重新构建。
5.2. 示例-02 - 流中元素的并行处理
 |
考虑以下代码:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple02 {
public static void main(String[] args) {
// 人员名单
List<Personne> personnes = Personnes.get();
// 显示 1
personnes.stream().forEach(Exemple02::affiche);
System.out.println("-----------------");
// 显示 2
personnes.stream().parallel().forEach(Exemple02::affiche);
}
public static void affiche(Personne p) {
System.out.printf("Personne %s sur thread %s%n", p, Thread.currentThread().getName());
}
}
- 第19-21行:方法[affiche]将某人的字符串jSON以及执行显示的线程名称写入控制台;
- 第 13 行:显示人员列表。请注意,方法 [forEach] 的参数是前一个静态方法的引用;
- 第 16 行:操作相同,但通过 [parallel] 方法要求对流中的元素进行并行处理,由多个线程并行执行。并非所有处理操作都能并行进行。 在此,需假设显示顺序无关紧要,因为在并行处理中,无法保证线程的执行顺序。此外,请注意以下语法,该语法在 Stream 和 Observable 中均将频繁出现:
- (待续)
- flux 生成 e1 元素,这些元素作为 m1 方法的输入;
- flux.m1 则是一组 e2 元素流,为方法 m2 提供数据;
- flux.m1.m2 是一个 e3 元素流,为方法 m3 提供数据;
随着初始数据流经过处理,e1、e2、e3 元素的类型可能会发生变化。
执行此代码将得到以下结果:
可以看出,并行执行(第5-7行)是在三个不同的线程上进行的,且未遵循第1-3行中元素的顺序。在本文中,我们将较少讨论 Stream 元素的并行处理,因为这需要探讨使这种处理成为可能的条件。 我们发现,实际上很少有处理操作能够并行执行。其中一种天然适合并行处理的操作是流中数值元素的求和,我们现在就来介绍这一操作。
5.3. 示例-03 - 流中元素的并行处理
 |
请看以下代码(示例03a):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class Exemple03a {
public static void main(String[] args) {
final long limite = 10_000_000L;
// 处理器数量
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// 数字列表
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// 数字之和 - 顺序法
début = new Date().getTime();
long somme = nombres.stream().reduce(0L, (s, i) -> s + i);
System.out.printf("somme séquentielle : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- 第22行,我们使用了方法 [reduce],其签名如下:
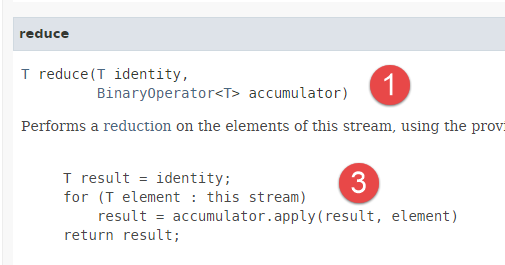 |  |
- 方法 [reduce] 处理 T 类型的元素;
- 方法 [reduce] 对流中的所有元素应用相同的处理:累加器的初始值作为第一个参数提供。 作为第二个参数,提供了一个实现功能接口 [BinaryOperator] [2] 的方法:该方法基于每个元素和累加器,返回累加器的新值。 累加器的最终值即为方法 [reduce] 返回的值。 代码 [3] 阐释了这一机制。方法 [apply] 是功能接口 [BinaryOperator] [2] 的方法;
让我们回到示例代码:
- 第 12 行:显示 JVM 所检测到的核心数量;
- 第 15-18 行:创建一个包含 1000 万个数字的列表;
- 第22行:使用单线程顺序计算这些数字的和;
得到以下结果:
现在,将代码第22行替换为以下内容(示例03b):
long somme = nombres.stream().parallel().reduce(0L, (s, i) -> s + i);
要求使用多个线程并行处理流中的元素。之所以可行,是因为数字求和的顺序并不重要。 因此,我们可以将 n1 个数字分配给线程 T1,将 n2 个数字分配给线程 T2,……最后将这些不同线程提供的和相加。这样就得到了以下结果:
因此,性能提升几乎可以忽略不计。在接下来的示例中,这种情况将经常出现。线程管理本身就消耗大量时间。只有当每个内核执行的操作足够复杂时,性能提升才会显现。下例(示例03c)就说明了这一点:
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.function.BinaryOperator;
public class Exemple03c {
public static void main(String[] args) {
final long limite = 10_000L;
// 处理器数量
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// 数字列表
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// 数字之和 - 顺序法
début = new Date().getTime();
BinaryOperator<Long> bo = (s, i) -> {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
}
return s + i;
};
long somme = nombres.stream().reduce(0L, bo);
System.out.printf("somme séquentielle : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- 第30行:再次调用方法[reduce],并将其作为参数传入第23-29行方法的引用;
- 第28行:方法[bo]返回其两个参数的和;
- 第24-27行:人为地让线程等待1毫秒,以模拟高强度工作;
由此得到以下结果:
现在,如果将第 30 行替换为以下内容:
long somme = nombres.stream().parallel().reduce(0L, bo);
则得到以下结果:
可以清楚地看到,通过并行执行求和计算带来的性能提升。对于处理8个数字的情况:
- 顺序线程等待8次,每次1毫秒,即总共8毫秒;
- 8个并行线程则同时各自等待1毫秒(为简化起见,此处仅作概念性描述),因此处理8个数字总共耗时1毫秒;
因此,我们可以预期并行执行的速度将比顺序执行快8倍。本例中结果大致如此。
5.4. 示例-04 - 过滤流
 |
考虑以下代码:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple04 {
public static void main(String[] args) {
// 人员列表
List<Personne> personnes = Personnes.get();
// 显示次数
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(p -> {
System.out.println(p);
});
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(p -> {
System.out.println(p);
});
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(System.out::println);
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(System.out::println);
}
}
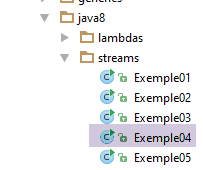
- 第14行:方法 [Stream.filter] 的签名如下:
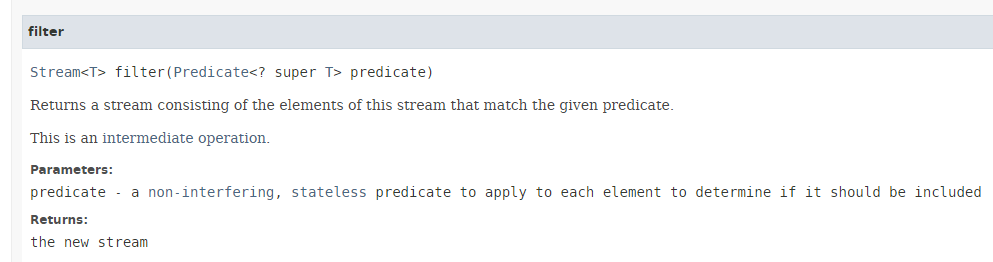 |
- 方法 [filter] 期望作为参数接收第 4.2 节中介绍的功能接口 [Predicate] 的一个实例,该接口需要实现的唯一方法如下:boolean test(T t);
- 方法 [filter] 返回满足 Predicate 条件的流元素。因此,它用于过滤 Stream;
考虑以下代码:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple04 {
public static void main(String[] args) {
// 人员列表
List<Personne> personnes = Personnes.get();
// 显示
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(p -> {
System.out.println(p);
});
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(p -> {
System.out.println(p);
});
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(System.out::println);
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(System.out::println);
}
}
- 第14-16行:显示年龄<28岁的人员;
- 第18-20行:显示体重<50的人;
- 第22行:与第14-16行功能相同,但表达更为简洁;
- 第24行:与第18至20行功能相同,但表达更为简洁;
执行结果如下:
5.5. 示例-05 - 基于 Stream<T1> 创建 Stream<T2>
 |
请看以下代码:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple05 {
public static void main(String[] args) {
// 人员列表
List<Personne> personnes = Personnes.get();
// 显示
System.out.println("Personne --> String ----------------------");
personnes.stream().map(p -> p.getNom()).forEach(System.out::println);
System.out.println("Personne --> Integer ----------------------");
personnes.stream().map(p -> p.getAge()).forEach(System.out::println);
}
}
- 第 13 行,方法 [Stream.map] 的签名如下:
 |
方法 [Stream.map] 的参数是第 4.3 节中介绍的功能接口 [Function] 的一个实例,该接口需要实现的唯一方法是:R apply(T t)。 可见,基于类型 T,函数 [apply] 生成类型 R。 因此,方法 [Stream.map] 将基于类型 T 的流(此处“类型 T 的流”一词虽属语义上的不准确,但我们将沿用此表述,指代类型 T 的元素流)生成类型 R 的流 Stream。
现在让我们研究一下示例代码:
- 第 14 行:对于某人 p,仅保留其姓名。因此得到一个 String 数据流;
- 第14行:对于人员p,仅保留其姓名。因此得到一个Integer数据流;
所得结果如下:
5.6. 示例-06 - Stream<T> 类的其他方法
 |
我们通过以下代码演示 Stream 类中的部分方法:
package dvp.java8.streams;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import dvp.data.Personne;
import dvp.data.Personnes;
import java.util.Comparator;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.DoubleStream;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class Exemple06 {
// 映射器 jSON
static private ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// 人员列表
List<Personne> personnes = Personnes.get();
// 所有人员
affiche("all", personnes);
// 第1个人
affiche("findFirst", personnes.stream().findFirst().get());
// 任意人员
affiche("findAny", personnes.stream().findAny().get());
// 除第1位以外的人员
affiche("skip 1", personnes.stream().skip(1L).collect(Collectors.toList()));
// 前2人
affiche("limit 2", personnes.stream().limit(2L).collect(Collectors.toList()));
// 人数
affiche("count", personnes.stream().count());
// 最年长的人
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
// 体重最轻的人
affiche("poids min", personnes.stream().min(Comparator.comparingDouble(Personne::getPoids)).get());
// 按姓名字母顺序排列的最后一人
affiche("nom max", personnes.stream().max((p1, p2) -> p1.getNom().compareToIgnoreCase(p2.getNom())).get());
// 所有人的总年龄
affiche("âge total (reduce)", personnes.stream().map(p -> p.getAge()).reduce(0, (a1, a2) -> a1 + a2));
// 按年龄从小到大排序的人员
affiche("personnes par âge croissant",
personnes.stream().sorted(Comparator.comparingInt(Personne::getAge)).collect(Collectors.toList()));
// 是否有年龄超过100岁的人?
affiche("des personnes de + de 100 ans (anyMatch)", personnes.stream().anyMatch(p -> p.getAge() > 100));
// 所有人的年龄是否均不超过100岁?
affiche("des personnes de + de 100 ans (noneMatch)", personnes.stream().noneMatch(p -> p.getAge() > 100));
// 所有人的年龄是否都大于8岁
affiche("des personnes de + de 8 ans (allMatch)", personnes.stream().allMatch(p -> p.getAge() > 8));
// 按性别对人员进行分组
affiche("personnes regroupées par sexe", personnes.stream().collect(Collectors.groupingBy(p -> p.getSexe())));
// 从列表中删除重复项
affiche("distinct", Stream.of(1, 2, 1).distinct().collect(Collectors.toList()));
// 将一个 Stream<Stream<T>> 转换为 Stream<T>
affiche("flatMap", Stream.of(1, 2, 3).flatMap(i -> Stream.of(i, i + 10)).collect(Collectors.toList()));
// 将一个 Stream<Stream<Integer>> 转换为 IntStream,并计算其总和
affiche("flatMapToInt", Stream.of(1, 2, 3).flatMapToInt(i -> IntStream.of(i, i + 10)).sum());
// 从一个 Stream<Stream<Integer>> 中,生成一个 DoubleStream,然后生成一个数组
affiche("flatMapToDouble", Stream.of(1, 2, 3).flatMapToDouble(i -> DoubleStream.of(i, i * 1.2)).toArray());
// 从整数流中获取最大值
affiche("reduce Integer::max", Stream.of(1, 10, 8).reduce(Integer::max).get());
// 双精度数流的最小值
affiche("reduce Integer::min", Stream.of(1.5, 10.4, 8.9).reduce(Double::min).get());
// 整数流的平均值
affiche("IntStream average", IntStream.of(1, 10, 8).average().getAsDouble());
// 整数流的统计信息
affiche("IntStream summaryStatistics", IntStream.of(1, 10, 8).summaryStatistics());
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- 第 72、75 行:显示方法第二个参数的字符串 jSON;
- 第24行:显示所有人员的字符串 jSON。结果如下:
5.6.1. [findFirst]
// 第一人称
affiche("findFirst", personnes.stream().findFirst().get());
方法 [findFirst] 返回流中的第一个元素(如果存在)。其签名如下:
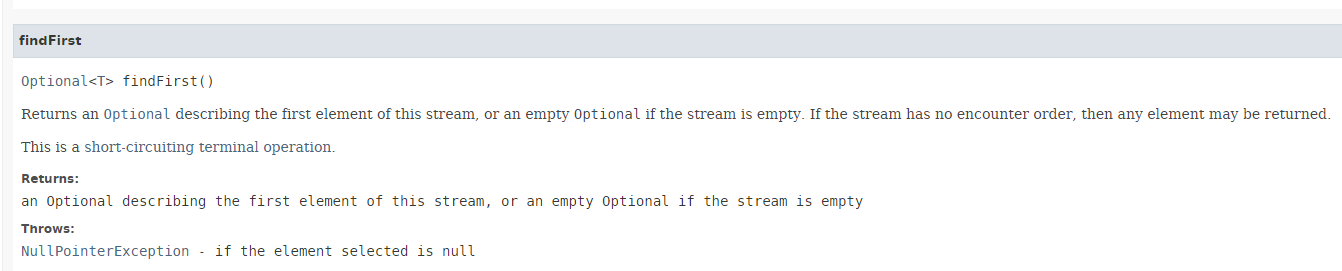 |
返回值类型为 Optional<T>,这是 Java 8 引入的一种类型:
 |
Optional<T> 类允许以不同方式处理 null 指针。一个本应返回可能取值为 null 的 T 类型的方法,可以决定返回 Optional<T> 类型。 [Optional<T>.isPresent()] 方法可用于判断该方法是否返回了值。以下代码 [Exemple06b] 演示了 Optional<T> 部分的工作原理:
package dvp.java8.streams;
import java.util.Optional;
import com.fasterxml.jackson.core.JsonProcessingException;
public class Exemple06b {
public static void main(String[] args) throws JsonProcessingException {
// 无值的选项
Optional<Integer> o1 = m1();
System.out.println(o1.isPresent());
affiche(o1);
// 带值的可选参数
Optional<Integer> o2 = m2();
System.out.println(o2.isPresent());
affiche(o2);
}
private static void affiche(Optional<Integer> o1) {
try {
// 获取可选参数的值
// 若无值则抛出1个异常
System.out.println(o1.get());
} catch (Throwable th) {
System.out.printf("%s : %s%n", th.getClass().getName(), th.getMessage());
}
}
public static Optional<Integer> m1() {
// 无值
return Optional.empty();
}
public static Optional<Integer> m2() {
// 有值
return Optional.of(10);
}
}
所得结果如下:
false
java.util.NoSuchElementException : No value present
true
10
让我们回到演示 [findFirst] 方法的代码:
// 第一人称
affiche("findFirst", personnes.stream().findFirst().get());
- 第 2 行:为简化代码,我们对由方法 [findFirst] 生成的 Optional<Personne> 调用方法 [get]。 规范的代码应先调用方法 [Optional<Personne>.isPresent()],再调用方法 [get];
所得结果如下:
5.6.2. [findAny]
// 任意人
affiche("findAny", personnes.stream().findAny().get());
方法 [findAny] 的签名如下:
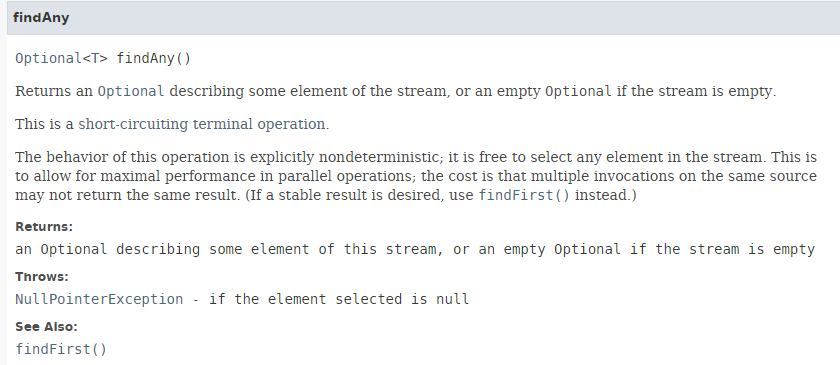 |
方法 [findAny] 可以返回流中的任意元素。在测试中,我们注意到顺序执行会返回流中的第一个元素,而并行执行确实可以返回任意元素。以下代码 [Exemple06c] 展示了这一点:
package dvp.java8.streams;
import java.util.List;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple06c {
// 映射器 jSON
static private ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// 人员列表
List<Personne> personnes = Personnes.get();
// 所有人员
affiche("all", personnes);
// 任何人
affiche("findAny parallèle", personnes.stream().parallel().findAny().get());
// 任意人员
affiche("findAny séquentiel", personnes.stream().findAny().get());
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- 第 22 行:并行执行的 findAny;
- 第 24 行:findAny 按顺序执行;
所得结果如下:
- 第4行:并行执行返回了人员列表中的第2项。这本可能是另一项;
- 第6行:顺序执行返回了人员列表中的第一个元素;
[findAny]方法的使用似乎仅在流的并行处理中才有意义。
5.6.3. [skip]
// 除第1位以外的人员
affiche("skip 1", personnes.stream().skip(1L).collect(Collectors.toList()));
方法 [skip] 的签名如下:
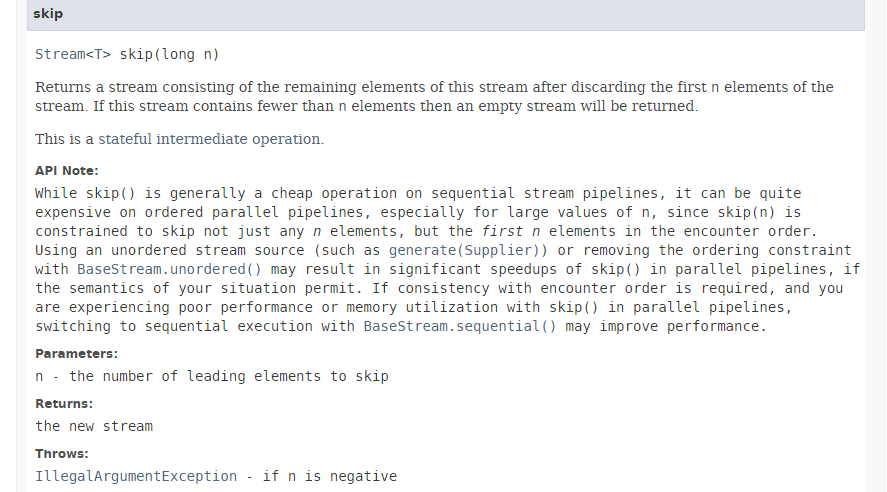 |
方法 [skip] 会忽略流中的前 n 个元素。如上文文档所述,并行执行此方法带来的性能提升微乎其微,甚至可能导致性能下降。事实上,为了忽略前 n 个元素,线程必须进行协调,这抵消了并行处理带来的性能优势。
方法 [skip] 返回一个流 Stream<Personne>,该流通过方法 [collect] 转换为类型 List<Personne>,其签名如下:
 |
方法 [collect] 接受一个 [Collector] 类型的实例作为参数,其签名较为复杂。[Collector] 类型存在预定义的实现,通常可以避免自行实现。 此处使用的实现是 [Collectors.toList()]。[Collectors] 是一个拥有众多静态方法的类,这些方法实现了 [Collector<T,A,R>] 类型。 当需要将 Stream 转换为标准的 Java 集合时,首先应在此处查找:
 |
我们稍后将使用其中的一些方法。
执行后得到以下结果:
列表中的第一个元素(jean)已被省略。
5.6.4. [limit]
// 前两名人员
affiche("limit 2", personnes.stream().limit(2L).collect(Collectors.toList()));
方法 [limit] 的签名如下:
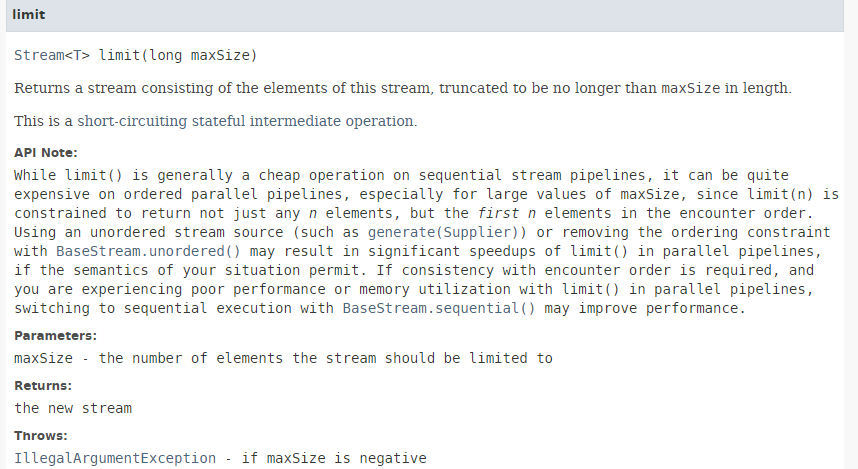 |
方法 [limit] 允许仅保留数据流中的前 n 个元素。该方法不适用于并行处理。
执行结果如下:
5.6.5. [count]
// 人数
affiche("count", personnes.stream().count());
方法 [count] 的签名如下:
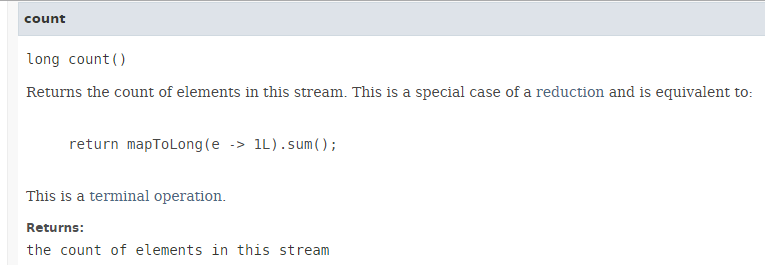 |
方法 [count] 返回 Stream 的元素数量。如下面的代码(示例06d1)所示,并行执行该方法并不会带来性能提升:
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.stream.Stream;
public class Exemple06d1 {
public static void main(String[] args) {
final long limite = 10_000_000L;
// 处理器数量
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// 数字列表
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// 数字计数 - 顺序法
Stream<Long> sNombres = nombres.stream();
début = new Date().getTime();
long count = sNombres.count();
System.out.printf("comptage séquentiel : compteur=%s, durée (ms)=%s%n", count, new Date().getTime() - début);
}
}
- 第 11-22 行:创建一个包含 1000 万个数字的 Stream;
- 第22-24行:对Stream进行计数;
执行结果如下:
如果将代码第22行替换为以下内容(示例06d2):
Stream<Long> sNombres = nombres.stream().parallel();
将得到以下结果:
5.6.6. [max, min]
// 最年长的人
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
方法 [max] 的签名如下:
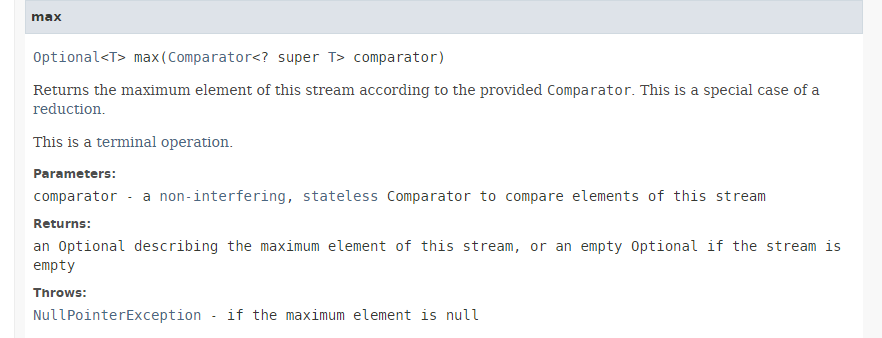 |
方法 [max] 使用作为参数传递的比较器,返回流的最大值。Comparator 是一个功能接口,其中唯一需要实现的方法具有以下签名:int compare (T o1, T o2)。 该方法在 o1 < o2 时应返回 -1,在 o1 < o1.equals(o2) 时应返回 0,在 o1 > o2 时应返回 +1。 功能接口 Comparator 提供了许多默认的静态方法,这些方法针对最常见的情况实现了接口 Comparator。因此,在以下语句中:
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
中,我们使用了静态方法 [Comparator.comparingInt],其签名如下:
 |
类型 ToIntFunction 是一个功能接口:
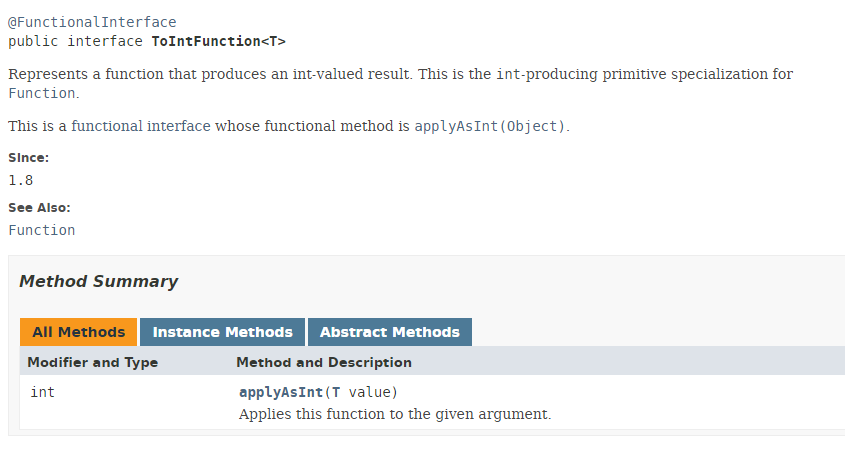 |
功能接口 ToIntFunction 中的方法 [applyAsInt] 会根据类型 T 生成类型 int。让我们回到我们的代码:
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
此处方法 [Comparator.comparingInt] 的实际参数应为 Personne --> int 类型的 lambda 表达式。我们将具有此签名的方法 [Personne.getAge] 的引用作为参数传递。最终,我们将得到年龄最大的人。 我们得到类型 Optional<Personne>,并通过方法 [Optional.get] 从中提取值。结果如下:
如下例所示,并行计算 max 并不会带来性能提升:(示例06e1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Date;
import java.util.List;
import java.util.Random;
import java.util.stream.Stream;
public class Exemple06e1 {
public static void main(String[] args) {
// 数据
// final long 限值 = 100L;
// final boolean verbose = true;
final long limite = 10_000_000L;
final boolean verbose = false;
// 处理器数量
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// 数字列表
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextLong());
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// 数字最大值 - 顺序方法
Stream<Long> sNombres = nombres.stream();
Comparator<Long> compLong = (l1, l2) -> {
if (verbose) {
// 线程
System.out.printf("[%s]", Thread.currentThread().getName());
}
// 比较
long v1 = l1.longValue();
long v2 = l2.longValue();
if (v1 < v2) {
return -1;
} else {
if (v1 == v2) {
return 0;
} else {
return +1;
}
}
};
début = new Date().getTime();
// 最大长度 = sNombres.max(Comparator.naturalOrder()).get();
long max = sNombres.max(compLong).get();
System.out.printf("%nmax séquentiel : max=%s, durée (ms)=%s%n", max, new Date().getTime() - début);
}
}
- 第 29 行:有一个 limite 数据流,其中包含 Long 类型的随机数;
- 第30-47行:lambda变量compLong实现了接口Comparator<Long>。 该接口通常由第49行的方法[Comparator.naturalOrder()]实现。但在此,我们希望显示执行线程(第31-33行)。因此,我们自行实现了该接口;
- 第 50 行:搜索 max;
得到以下结果:
 |
现在,如果将第27行替换为以下内容(示例06e2):
Stream<Long> sNombres = nombres.stream().parallel();
将得到以下结果:
 |
因此,并行执行的速度较慢。如果使用 verbose=false 处理 1000 万个数字,将得到以下结果:
对于顺序执行:
并行执行速度依然较慢。
我们以类似的方式使用方法 [Stream.min]:
// 最轻的人
affiche("poids min", personnes.stream().min(Comparator.comparingDouble(Personne::getPoids)).get());
5.6.7. [reduce]
// 所有人的总年龄
affiche("âge total (reduce)", personnes.stream().map(p -> p.getAge()).reduce(0, (a1, a2) -> a1 + a2));
方法 [reduce] 已在第 5.3 节中介绍。上文第 2 行计算了所有人员的年龄总和。结果如下:
5.6.8. [sorted]
// 按年龄从小到大排序的人员
affiche("personnes par âge croissant",
personnes.stream().sorted(Comparator.comparingInt(Personne::getAge)).collect(Collectors.toList()));
// 按姓名字母顺序排列的人员
List<Personne> lPersonnes=personnes.stream().sorted((p1, p2) -> p1.getNom().compareTo(p2.getNom())).collect(Collectors.toList());
affiche("personnes par ordre alphabétique des noms", lPersonnes);
方法 [sorted](第 3 行和第 5 行)的签名如下:
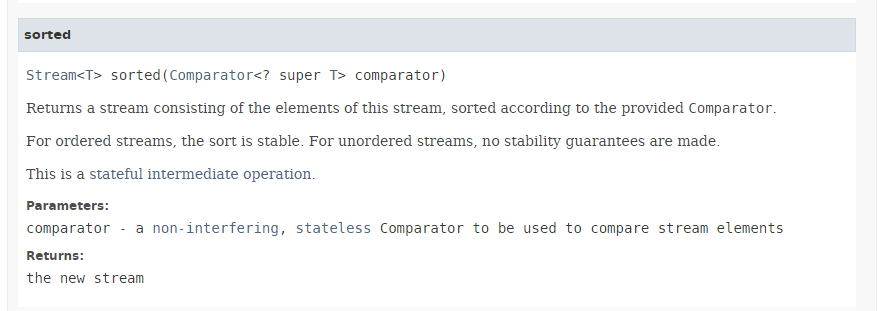 |
方法 [sorted] 接受第 5.6.6 节中针对方法 min 和 max 所描述的类型 [Comparator] 作为参数。 该方法允许根据作为参数传递的比较器,对 Stream 进行排序。我们已经看到,[Comparator] 接口默认提供了多个静态方法,实现了常见的比较器,特别是针对数字和字符串的比较器。 在此,我们使用 [Comparator.comparingInt] 方法,该方法接受 ToIntFunction 类型的参数,后者是 [applyAsInt] 方法的功能接口,其签名如下: int applyAsInt(T t)。 在此,传递给第 3 行方法 [Comparator.comparingInt] 的实际参数是方法 [Personne.age] 的引用,该方法返回该人的年龄。
接口 [Comparator] 未提供用于比较字符串的静态方法。在第 5 行,我们自行构建了一个 lambda 表达式,用于实现该接口的唯一方法:int compare(T t1, T t2)
(p1, p2) -> p1.getNom().compareTo(p2.getNom())
该 lambda 表达式用于比较人员的姓名。所得结果如下:
如下面的代码(示例06f1)所示,排序似乎无法并行执行:
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Date;
import java.util.List;
import java.util.Random;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class Exemple06f1 {
// 映射器 jSON
static ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// 数据
final long limite = 100L;
final boolean verbose = true;
// 最终长限制 = 10_000_000L;
// final boolean verbose = false;
// 处理器数量
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// 数字列表
long début = new Date().getTime();
List<Integer> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextInt(1000));
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// 数字排序 - 顺序方法
Stream<Integer> sNombres = nombres.stream();
début = new Date().getTime();
Comparator<Integer> compInt = (i1, i2) -> {
if (verbose) {
// 线程
System.out.printf("[%s]", Thread.currentThread().getName());
}
// 比较
int v1 = i1.intValue();
int v2 = i2.intValue();
if (v1 < v2) {
return +1;
} else {
if (v1 == v2) {
return 0;
} else {
return -1;
}
}
};
if (verbose) {
affiche("nombres", sNombres.sorted(compInt).collect(Collectors.toList()));
}
System.out.printf("tri séquentiel : durée (ms)=%s%n", new Date().getTime() - début);
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- 第30-36行:构建一个由随机数组成的流;
- 第32行,将lambda表达式(第38-55行)传递给方法。该lambda表达式按降序对数字进行排序,并显示执行它的线程。
所得结果如下:
 |
如果将上述代码中的第 36 行替换为以下内容(示例 06f2):
Stream<Integer> sNombres = nombres.stream().parallel();
则会得到以下结果:
 |
令人惊讶的是,我们发现数字流的排序仅由单个线程完成。完全没有并行处理。难道是我漏掉了什么吗?
5.6.9. [anyMatch, noneMatch, allMatch]
// 是否有年龄超过100岁的人?
affiche("des personnes de + de 100 ans (anyMatch)", personnes.stream().anyMatch(p -> p.getAge() > 100));
// 所有人的年龄是否都不超过100岁?
affiche("des personnes de + de 100 ans (noneMatch)", personnes.stream().noneMatch(p -> p.getAge() > 100));
// 所有人的年龄都超过8岁吗
affiche("des personnes de + de 8 ans (allMatch)", personnes.stream().allMatch(p -> p.getAge() > 8));
第2、4和6行中的[anyMatch, noneMatch, allMatch]方法,其参数类型为第4.2节中描述的Predicate。因此,它们执行的是过滤操作。这三个方法都返回一个布尔值:
- 若 Stream 中至少有一个元素符合过滤条件,则 anyMatch 返回 true;
- 如果 Stream 中不存在任何符合过滤条件的元素,则 noneMatch 将生成 true;
- 如果 Stream 中的所有元素都符合过滤条件,则 allMatch 返回 true;
所得结果如下:
5.6.10. [collect(Collectors.groupingBy)]
// 按性别分组
affiche("personnes regroupées par sexe", personnes.stream().collect(Collectors.groupingBy(p -> p.getSexe())));
方法 [collect] 已在第 5.6.3 节中介绍。其参数是对接口 [Collector] 的实现。 类 [Collectors] 提供了一系列实现接口 [Collector] 的静态方法。到目前为止,我们一直使用的是方法 [Collectors.toList()]。 在此我们使用静态方法 [Collectors.groupingBy],该方法基于 Stream 创建一个字典。其签名如下:
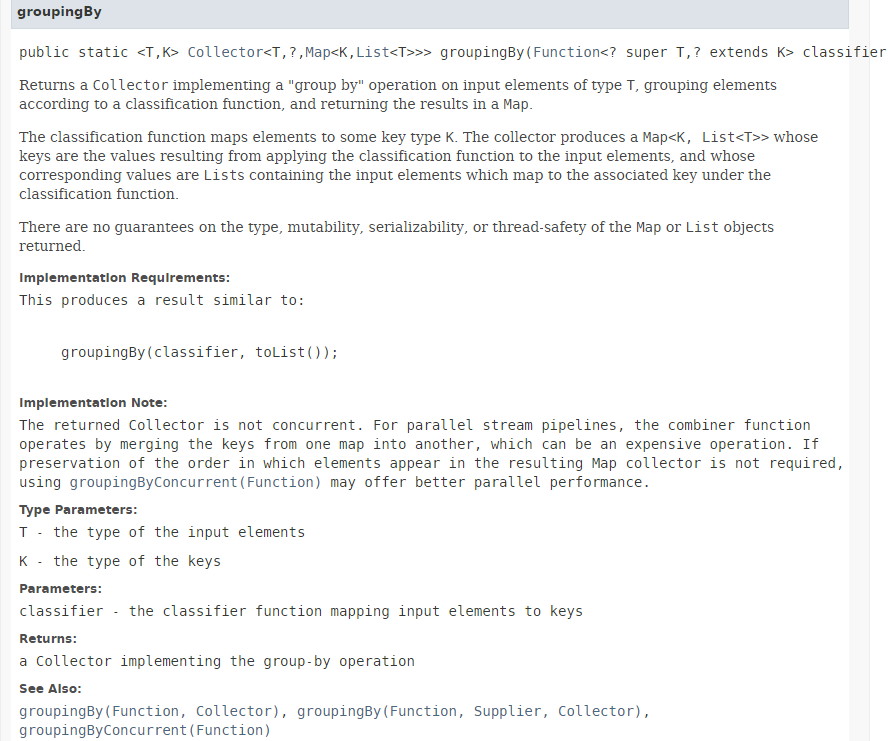 |
方法 [groupingBy] 基于类型 Stream<T> 生成类型 Map<K,List<T>>。 键 K 由方法 [groupingBy] 的参数提供,该参数类型为 Function<T,K>,其唯一方法的签名如下:K apply(T t)。若要创建一个按人员性别索引的字典,则需提供一个能根据人员生成性别的函数。 在此,我们将方法 [Personne.getSexe] 的引用作为方法 [groupingBy] 的实际参数传入。所得结果如下:
第 2 行中,字符串 jSON 来自一个由两个键(HOMME 和 FEMME)索引的字典。
如下例(示例06g1)所示,并行计算并未带来性能提升:
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class Exemple06g1 {
// mppeur jSON
static ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// 数据
final long limite = 100L;
final boolean verbose = true;
// 最终长限 = 10_000_000L;
// final boolean verbose = false;
// 处理器数量
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// 数字列表
long début = new Date().getTime();
List<Integer> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextInt(1000));
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// 按百位分组数字 - 顺序方法
Stream<Integer> sNombres = nombres.stream();
Function<Integer, Integer> groupByCent = n -> {
if (verbose) {
System.out.printf("[%s]", Thread.currentThread().getName());
}
return n / 100;
};
début = new Date().getTime();
// Map<Integer, List<Integer>> lNombres = sNombres.collect(Collectors.groupingBy(数字 -> 数字 / 100));
Map<Integer, List<Integer>> lNombres = sNombres.collect(Collectors.groupingBy(groupByCent));
System.out.printf("%nregroupement séquentiel : durée (ms)=%s%n", new Date().getTime() - début);
// 结果
if (verbose) {
affiche("nombres regroupés", lNombres);
}
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- 第23-38行:构建一个包含limite个数字的流;
- 第 47 行,将数字按百位分组。使用第 39-44 行的 lambda 函数以便显示执行线程;
执行结果如下:
 |
如果将代码中的第38行替换为以下内容(示例06g2):
Stream<Integer> sNombres = nombres.stream().parallel();
则会得到以下结果:
 |
可以看出,并行执行分组操作导致了性能下降。
5.6.11. [distinct]
// 从列表中删除重复项
affiche("distinct", Stream.of(1, 2, 1).distinct().collect(Collectors.toList()));
方法 [distinct] 的签名如下:
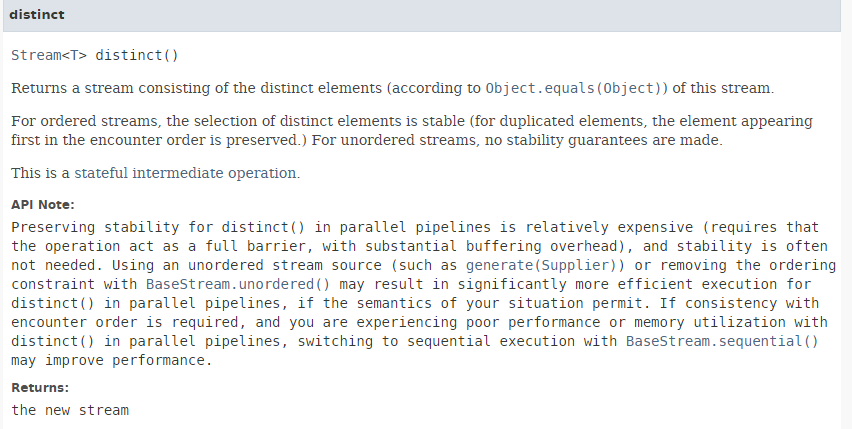 |
该方法用于从数据流中删除重复项。方法 [Stream.of](第 2 行)的签名如下:
 |
该方法允许根据显式提供的值创建 Stream。执行结果如下:
5.6.12. [flatMap]
// 从 Stream<Stream<T>> 中生成 Stream<T>
affiche("flatMap", Stream.of(1, 2, 3).flatMap(i -> Stream.of(i, i + 10)).collect(Collectors.toList()));
方法 [flatMap] 的签名如下:
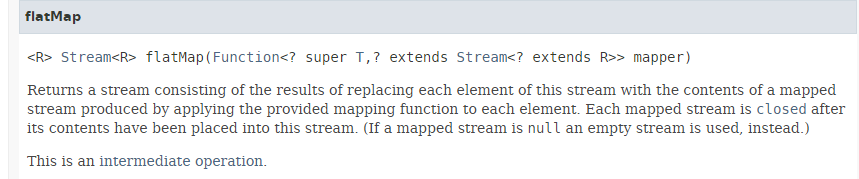  |
方法 [flatMap] 接受一个函数作为参数,该函数:
- 该函数接受一个类型为 T 的 Stream 元素作为参数;
- 返回一个 Stream<R> 流;
如果不用方法 [flatMap], 而是使用了第 5.5 节中描述的 [map] 方法,则结果将是一个 Stream<Stream<R>> 类型,其中初始流中每个类型为 T 的元素都会生成一个 Stream<R> 元素。 而方法 [flatMap] 则生成类型 Stream<R>。它将各个 Stream<R> 数据流扁平化(flatten)为单一数据流。这正是前文代码执行结果所展示的:
[flatMap] 还有一些专门的变体:
// 将一个 Stream<IntStream> 转换为 IntStream,并计算其和
affiche("flatMapToInt", Stream.of(1, 2, 3).flatMapToInt(i -> IntStream.of(i, i + 10)).sum());
方法 [flatMapToInt] 的签名如下:
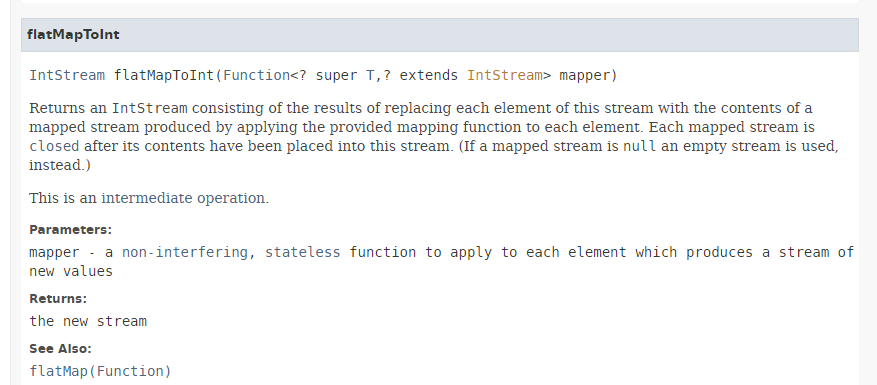 |
方法 [flatMapToInt] 接受一个函数作为参数,该函数返回以下类型的 IntStream:
 |
IntStream 是 int 的派生类型。 该类型优于 Stream<Integer> 类型,因为其处理过程避免了 Integer 与 int 类型之间的装箱/拆箱操作。 该接口继承了 Stream<T> 类型的许多方法,并新增了其他方法,包括上述的 [sum] 方法,该方法对 IntStream 的元素进行求和。
以下代码演示了类似方法 [flatMapToDouble] 的用法:
// 从一个 Stream<DoubleStream> 中,生成一个 DoubleStream,然后将其转换为数组
affiche("flatMapToDouble", Stream.of(1, 2, 3).flatMapToDouble(i -> DoubleStream.of(i, i * 1.2)).toArray());
方法 [DoubleStream.toArray] 允许从类型 DoubleStream 转换为类型 double[]。
这两个示例的结果如下:
以下示例展示了从类型 Stream<Long> 转换为类型 LongStream 所获得的性能提升(示例06i1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class Exemple06i1 {
public static void main(String[] args) {
final long limite = 10_000_000L;
// 处理器数量
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// 数字列表
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// 数字之和 - 顺序方法
début = new Date().getTime();
long somme = nombres.stream().reduce(0L, (s, i) -> s + i);
System.out.printf("somme séquentielle du Stream<Integer> : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- 第 22 行:计算类型为 Long 的数字流之和;
得到以下结果:
现在,将第 22 行替换为以下内容(示例06i2):
long somme = nombres.stream().mapToLong(n -> n.longValue()).sum();
Stream<Integer>.mapToLong 方法允许我们获取一个类型为 LongStream 的流,其中包含类型为 long 的基本类型元素,随后使用 sum 函数对其求和。 由此得到以下结果:
性能提升非常明显。
5.6.13. 原始数流方法
// 整数流的最大值
affiche("IntStream max", IntStream.of(1, 10, 8).max());
// 双精度数流的最小值
affiche("DoubleStream min", DoubleStream.of(1.5, 10.4, 8.9).min());
// 整数流的平均值
affiche("IntStream average", IntStream.of(1, 10, 8).average().getAsDouble());
// 整型数据流的统计信息
affiche("IntStream summaryStatistics", IntStream.of(1, 10, 8).summaryStatistics());
基本值流(int、long、double)提供了适用于这些类型的专用方法。执行上述代码的结果如下:
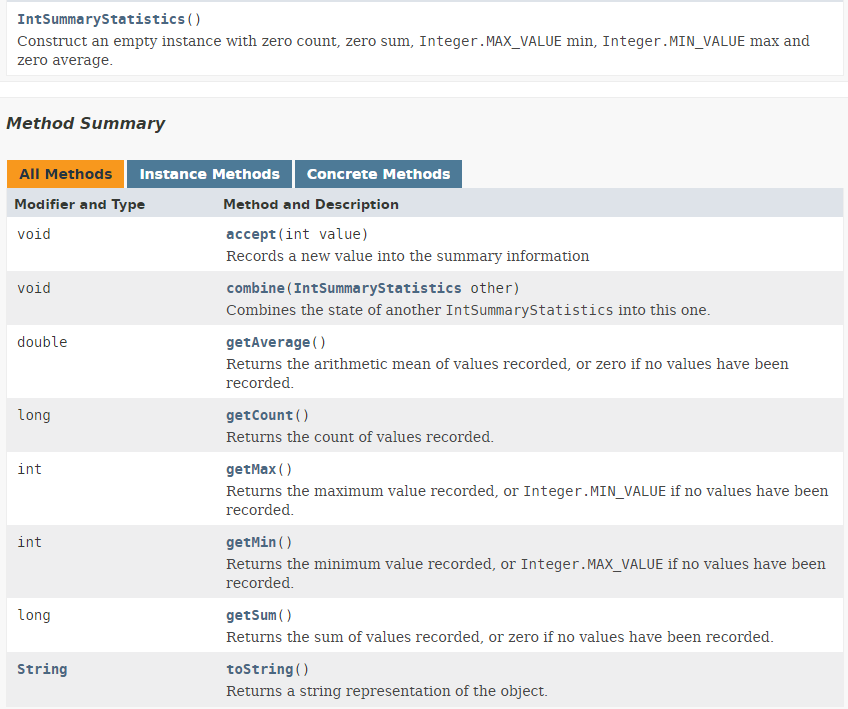
- 代码第 2 行的结果是一个与类型 Optional<Integer> 类似的类型 OptionalInt。可以通过方法 [getAsInt()] 获取存储在此对象中的值。 可通过方法 [isPresent()] 检测是否存在该值。结果中的第 2 行并不意味着类 [OptionalInt] 具有名为 [asInt, present] 的字段。 默认情况下,库 jSON 会使用待序列化对象中所有名为 getX 和 isY 的公共方法,并将它们转换为 jSON。 而这里确实存在一个 [getAsInt] 方法和另一个 [isPresent] 方法,但 [asInt, present] 字段本身并不存在;
- 代码第4行的结果是一个与类型Optional<Double>类似的类型OptionalDouble;
- 代码第6行的结果是一个类型为OptionalDouble的值,可通过方法[getAsDouble()]获取其值。方法[average]计算数流的平均值;
- 代码第8行的结果是一个类型为IntSummaryStatistics的值,其定义如下:
 |
可以看出,生成的 IntSummaryStatistics 对象提供了关于数字流的各种信息,例如值个数、总和、最大值、最小值和平均值。