2. JPA 实体
2.1. 示例 1 - 单张表的对象表示
2.1.1. [person] 表
假设有一个数据库,其中包含一个名为 [person] 的表,其目的是存储有关个人的某些信息:
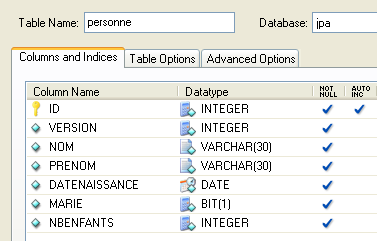 |
该表的主键 | |
表中该行的版本号。每次 修改该人时,其版本号都会递增。 | |
姓氏 | |
名字 | |
她的出生日期 | |
整数 0(未婚)或 1(已婚) | |
子女数 |
2.1.2. [Person] 实体
我们处于以下运行时环境中:
 |
JPA 层 [5] 必须在数据库 [7] 的关系型世界与 Java 程序 [3] 操作的对象世界 [4] 之间架起桥梁。这种连接是通过配置建立的,主要有两种实现方式:
- 使用 XML 文件。在 JDK 1.5 问世之前,这几乎是唯一的方法
- 自 JDK 1.5 起,使用 Java 注解
在本文档中,我们将几乎完全采用第二种方法。
代表前面介绍的 [person] 表的 [Person] 对象可以如下所示:
...
@SuppressWarnings("unused")
@Entity
@Table(name="Personne")
public class Personne implements Serializable{
@Id
@Column(name = "ID", nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name = "VERSION", nullable = false)
@Version
private int version;
@Column(name = "NOM", length = 30, nullable = false, unique = true)
private String nom;
@Column(name = "PRENOM", length = 30, nullable = false)
private String prenom;
@Column(name = "DATENAISSANCE", nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(name = "MARIE", nullable = false)
private boolean marie;
@Column(name = "NBENFANTS", nullable = false)
private int nbenfants;
// manufacturers
public Personne() {
}
public Personne(String nom, String prenom, Date datenaissance, boolean marie,
int nbenfants) {
setNom(nom);
setPrenom(prenom);
setDatenaissance(datenaissance);
setMarie(marie);
setNbenfants(nbenfants);
}
// toString
public String toString() {
...
}
// getters and setters
...
}
配置通过 Java 注解(@Annotation)实现。Java 注解要么由编译器处理,要么由运行时的专用工具处理。除了第 3 行用于编译器的注解外,此处的所有注解都是针对所使用的 JPA 实现(Hibernate 或 Toplink)而设计的。因此,它们将在运行时被处理。 如果没有能够解释这些注解的工具,这些注解将被忽略。因此,上面的 [Person] 类可以在非 JPA 环境中使用。
在与表 T 关联的类 C 中使用 JPA 注解有两种截然不同的情况:
- 表 T 已存在:此时 JPA 注解必须复制现有结构(列名和定义、完整性约束、外键、主键等)
- 表 T 不存在,并将根据类 C 中发现的注解进行创建。
情况 2 最容易处理。通过使用 JPA 注解,我们可以指定所需表 T 的结构。 情况 1 通常更为复杂。表 T 可能早在很久以前就在任何 JPA 上下文之外被创建,因此其结构可能与 JPA 的关系-对象桥接机制不匹配。为简化讨论,我们将重点关注情况 2,即与类 C 关联的表 T 将基于类 C 中的 JPA 注解进行创建。
让我们来查看 [Person] 类的 JPA 注解:
- 第 4 行:@Entity 注解是第一个必不可少的注解。它位于声明该类的行之前,表明该类必须由 JPA 持久化层进行管理。如果没有此注解,所有其他 JPA 注解都将被忽略。
- 第 5 行:@Table 注解用于指定该类所代表的数据库表。其主要参数是 name,用于指定表名。若省略该参数,表名将默认采用类名,本例中即为 [Person]。因此,在本例中 @Table 注解是多余的。
- 第 8 行:@Id 注解用于指定类中代表表主键的字段。该注解是必需的。此处表明第 11 行的 id 字段代表表的主键。
- 第 9 行:@Column 注解用于将类中的字段与该字段所代表的表列建立关联。name 属性指定表中列的名称。如果省略该属性,则列名与字段名相同。因此,在本例中,name 参数并非必需。nullable=false 参数表示与该字段关联的列不能为 NULL,因此该字段必须有值。
- 第 10 行:@GeneratedValue 注解用于指定当主键由数据库管理系统 (DBMS) 自动生成时,其生成方式。在我们的所有示例中均采用此方式。该注解并非强制要求。因此,Person 类中的学生 ID 可以作为主键,且不由 DBMS 生成,而是由应用程序设置。在这种情况下,应省略 @GeneratedValue 注解。 strategy 参数指定了由 DBMS 生成主键时的生成方式。并非所有 DBMS 都采用相同的技术来生成主键值。例如:
在每次插入前调用一个值生成器 | |
主键字段被定义为 Identity 类型。其结果与 Firebird 的值生成器类似,不同之处在于,在行插入完成之前无法得知键值。 | |
使用名为 SEQUENCE 的对象,该对象同样充当值生成器 |
JPA 层必须根据所用的 DBMS 生成不同的 SQL 语句,以创建该值生成器。我们通过配置指定它需要处理的 DBMS 类型。因此,它可以确定针对该 DBMS 生成主键值的标准策略。参数 strategy = GenerationType.*****AUTO* 指示 JPA 层使用此标准策略。在本文档中针对所使用的七种 DBMS 的所有示例中,该技术均已成功运行。
- 第 14 行:@Version 注解指定了用于管理对表中同一行并发访问的字段。
为理解 [person] 表中同一行数据的并发访问问题,假设某个 Web 应用程序允许更新人员信息,并考虑以下场景:
在时间点 T1,用户 U1 开始编辑某人 P。此时,子女数为 0。他将该数值改为 1,但在提交更改之前,用户 U2 开始编辑同一人 P。由于 U1 尚未提交更改,U2 在屏幕上看到的子女数仍是 0。U2 将人 P 的名字改为大写。 随后,U1和U2按此顺序保存了各自的修改。U2的修改将具有优先权:在数据库中,姓名将显示为大写,且子女数量仍保持为零,尽管U1认为自己已将其修改为1。
“人员版本”的概念有助于我们解决这个问题。让我们重新审视这个用例:
在时间点 T1,用户 U1 开始编辑人员 P。此时,子女数量为 0,版本号为 V1。他将子女数量改为 1,但在提交更改之前,用户 U2 开始编辑同一个人 P。由于 U1 尚未提交更改,U2 看到的子女数量为 0,版本号为 V1。 U2将人物P的姓名改为大写。随后U1和U2按此顺序提交了各自的修改。在提交修改前,我们会验证修改人物P的用户所持有的版本是否与 当前保存的人物P版本一致。对于用户U1而言,情况确实如此。因此其修改被接受,随后我们将该人物的版本号从V1更新为V2,以表明该人物已发生变更。 在验证用户 U2 的修改时,我们会发现用户 U2 持有的 P 人物版本为 V1,而当前版本为 V2。此时我们可以告知用户 U2,有人已先于其进行操作,因此必须基于 P 人物的新版本开始修改。用户 U2 将照此操作,检索到版本 V2 的 P 人物(此时该人物已有一个子女),将名字首字母大写,并提交验证。如果注册的 P 人物仍为版本 V2,则其修改将被接受。 最终,U1和U2所做的修改都将被采纳;而在没有版本控制的用例中,其中一项修改本会丢失。
客户端应用程序的 [DAO] 层可以自行管理 [Person] 类的版本。每次对象 P 被修改时,该对象在表中的版本号将增加 1。@Version 注解允许将此管理职责转移至 JPA 层。相关字段无需像示例中那样命名为 version,可以使用任意名称。
对应 @Id 和 @Version 注解的字段是为了持久化目的而存在的。如果 [Person] 类不需要被持久化,这些字段就不再需要。因此,我们可以看到,一个对象的表示方式会因其是否需要被持久化而有所不同。
- 第 17 行:同样,@Column 注解提供了关于 [person] 表中与 Person 类的 name 字段关联的列的信息。这里出现了两个新参数:
- unique=true 表示人员的姓名必须唯一。这将在数据库的 [person] 表中 NAME 列上添加一个唯一性约束。
- length=30 将 NAME 列的字符数设置为 30。这意味着该列的类型将为 VARCHAR(30)。
- 第 24 行:@Temporal 注解用于指定日期/时间列或字段的 SQL 类型。TemporalType.DATE 类型表示不包含时间的日期。其他可能的类型包括用于编码时间的 TemporalType.TIME,以及用于编码日期和时间的 TemporalType.TIMESTAMP。
现在让我们对 [Person] 类中的其余代码进行说明:
- 第 6 行:该类实现了 Serializable 接口。序列化对象是指将其转换为一串二进制数据。反序列化则是其逆操作。序列化/反序列化特别适用于客户端/服务器应用程序,在这些应用程序中,对象是通过网络进行交换的。 客户端或服务器应用程序无需知晓此操作,该操作由 JVM 透明地执行。但要实现这一点,交换对象的类必须使用 Serializable 关键字进行“标记”。
- 第 37 行:该类的构造函数。请注意,id 和 version 字段未包含在参数中。这是因为这两个字段由 JPA 层管理,而非由应用程序管理。
- 第 51 行及之后:该类各字段的 get 和 set 方法。请注意,JPA 注解可以放置在字段的 get 方法上,而非字段本身。注解的位置决定了 JPA 访问字段时应采用的模式:
- 如果注解位于字段级别,JPA 将直接访问字段进行读写
- 如果注解位于 get 方法级别,JPA 将通过 get/set 方法访问字段以进行读写
@Id 注解的位置决定了类中其他 JPA 注解的放置方式。当置于字段级别时,表示直接访问字段;当置于 get 方法级别时,表示通过 get 和 set 方法访问字段。其他注解必须与 @Id 注解采用相同的方式放置。
2.1.3. Eclipse 测试项目
我们将使用前面的 [Person] 实体进行首次实验。我们将采用以下架构来实施这些实验:
 |
- 在 [7] 中:该数据库将基于 [Person] 实体的注解生成,同时结合名为 [persistence.xml] 的文件中指定的额外配置
- 在 [5, 6] 中:由 Hibernate 实现的 JPA 层
- 在 [4] 中:[Person] 实体
- 在 [3] 中:一个基于控制台的测试程序
我们将进行以下实验:
- 使用 Ant 脚本和 Hibernate Tools 生成数据库模式
- 生成数据库并用部分数据进行初始化
- 与数据库交互,并对 [person] 表执行四种基本操作(插入、更新、删除、查询)
所需工具如下:
- Eclipse及其在第5.2节中描述的插件。
- [hibernate-personnes-entites] 项目,位于 <examples>/hibernate/direct/personnes-entites 文件夹中
- 附录(第5节及后续章节)中描述的各种数据库管理系统(DBMS)。
Eclipse 项目如下:
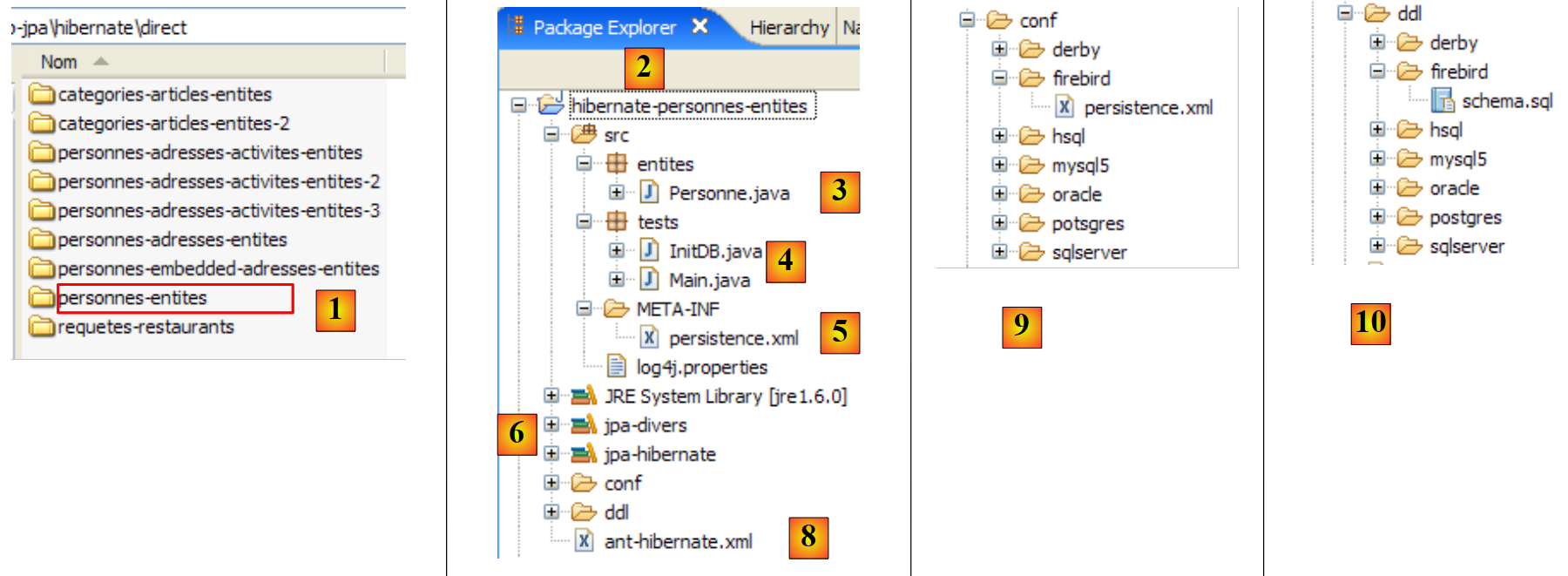 |
- 在 [1] 中:Eclipse 项目文件夹
- 在 [2] 中:导入到 Eclipse 中的项目(文件 / 导入)
- 在 [3] 中:正在测试的 [Person] 实体
- [4] 中的:测试程序
- [5]:[persistence.xml] 是 JPA 层的配置文件
- 在 [6] 中:所使用的库。这些库已在第 1.5 节中进行了说明。
- 在 [8] 中:一个 Ant 脚本,将用于生成与 [Person] 实体关联的表
- 在 [9] 中:用于各数据库管理系统(DBMS)的 [persistence.xml] 文件
- 在 [10] 中:针对所用各数据库管理系统生成的数据库模式
我们将逐一描述这些内容。
2.1.4. [Person] 实体 (2)
我们对之前对 [Person] 实体的描述进行了一些微调,并补充了一些信息:
package entites;
...
@SuppressWarnings({ "unused", "serial" })
@Entity
@Table(name="jpa01_personne")
public class Personne implements Serializable{
@Id
@Column(name = "ID", nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name = "VERSION", nullable = false)
@Version
private int version;
@Column(name = "NOM", length = 30, nullable = false, unique = true)
private String nom;
@Column(name = "PRENOM", length = 30, nullable = false)
private String prenom;
@Column(name = "DATENAISSANCE", nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(name = "MARIE", nullable = false)
private boolean marie;
@Column(name = "NBENFANTS", nullable = false)
private int nbenfants;
// manufacturers
public Personne() {
}
public Personne(String nom, String prenom, Date datenaissance, boolean marie,
int nbenfants) {
....
}
// toString
public String toString() {
return String.format("[%d,%d,%s,%s,%s,%s,%d]", getId(), getVersion(),
getNom(), getPrenom(), new SimpleDateFormat("dd/MM/yyyy")
.format(getDatenaissance()), isMarie(), getNbenfants());
}
// getters and setters
...
}
- 第 7 行:我们将与 [Person] 实体关联的表命名为 [jpa01_personne]。在本文档中,各个表都将创建在始终命名为 jpa 的模式中。到本教程结束时,jpa 模式将包含许多表。为了方便读者区分,相互关联的表将使用相同的前缀 jpaxx_。
- 第 45 行:一个 [toString] 方法,用于在控制台上显示 [Person] 对象。
2.1.5. 配置数据访问层
在上述 Eclipse 项目中,JPA 层通过 [META-INF/persistence.xml] 文件进行配置:
 |
运行时,系统会在应用程序的类路径中搜索 [META-INF/persistence.xml] 文件。 在我们的 Eclipse 项目中,[/src] 文件夹 [1] 中的所有内容都会被复制到 [/bin] 文件夹 [2] 中。该文件夹是项目类路径的一部分。这就是为什么当 JPA 层进行自我配置时,能够找到 [META-INF/persistence.xml] 文件。
默认情况下,Eclipse 不会将源代码放置在项目的 [/src] 文件夹中,而是直接放在项目文件夹的根目录下。我们将配置所有 Eclipse 项目,使源代码位于 [/src] 文件夹中,编译后的类文件位于 [/bin] 文件夹中,如第 5.2.1 节所示。
让我们来查看项目中 [persistence.xml] 文件中的 JPA 层配置:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Persistent classes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
<property name="hibernate.connection.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- automatic schematic creation -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!-- properties DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
要理解此配置,我们需要重新审视应用程序的数据访问架构:
 |
- [persistence.xml] 文件配置了第 [4、5、6] 层
- [4]:Hibernate 对 JPA 的实现
- [5]:Hibernate 通过连接池访问数据库。连接池是一组已打开的数据库管理系统(DBMS)连接。虽然多个用户可以访问同一个 DBMS,但出于性能考虑,同时打开的连接数量不能超过上限 N。 良好的代码会将与 DBMS 的连接保持在最短时间内:执行 SQL 命令后立即关闭连接。每次需要操作数据库时,都会重复这一过程。打开和关闭连接的开销不容忽视,这正是连接池发挥作用的地方。应用程序启动时,连接池会向 DBMS 建立 N1 个连接。应用程序每次需要连接时,都会从池中请求一个已打开的连接。 一旦应用程序不再需要该连接,应尽快将其归还给连接池。该连接不会被关闭,而是保持可用状态以供下一个用户使用。因此,连接池是一种共享已建立连接的系统。
- [6]:所用数据库管理系统(DBMS)的 JDBC 驱动程序
现在让我们看看 [persistence.xml] 文件是如何配置上述 [4、5、6] 层的:
- 第 2 行:XML 文件的根标签是 <persistence>。
- 第 3 行:<persistence-unit> 用于定义持久化单元。可以存在多个持久化单元。每个单元都有一个名称(name 属性)和一个事务类型(transaction-type 属性)。应用程序将通过其名称访问持久化单元,在本例中为 jpa。事务类型 RESOURCE_LOCAL 表示应用程序自行管理与 DBMS 之间的事务。本例中即采用此方式。 当应用程序在 EJB3 容器中运行时,可以使用容器的事务服务。在这种情况下,我们会将 transaction-type 设置为 JTA(Java 事务 API)。如果省略 transaction-type 属性,JTA 将是默认值。
- 第 5 行:<provider> 标签用于定义一个实现 [javax.persistence.spi.PersistenceProvider] 接口的类,该接口允许应用程序初始化 持久层。由于我们使用的是 JPA/Hibernate 实现,因此此处使用的类是 Hibernate 类。
- 第 6 行:<properties> 标签用于声明所选提供程序特有的属性。因此,根据您选择的是 Hibernate、TopLink、Kodo 等,属性会有所不同。以下内容专用于 Hibernate。
- 第 8 行:指示 Hibernate 扫描项目的类路径,查找带有 @Entity 注解的类以便进行管理。@Entity 类也可以使用 <class>class_name</class> 标签在 <persistence-unit> 标签的直接下方进行声明。这就是我们使用 JPA/TopLink 提供程序时将要做的事情。
- 第 10–12 行(此处已注释掉)用于配置 Hibernate 的控制台日志:
- 第 10 行:用于启用或禁用显示 Hibernate 向 DBMS 发出的 SQL 语句。这在学习阶段非常有用。由于关系型/对象桥梁的存在,应用程序对持久化对象进行操作(如 [persist、merge、remove])。了解这些操作实际生成的 SQL 语句非常有帮助。 通过研究这些语句,您将逐渐学会预判 Hibernate 在对持久化对象执行此类操作时会生成哪些 SQL 语句,从而在脑海中逐渐形成对关系/对象桥接机制的清晰认知。
- 第 11 行:控制台上显示的 SQL 语句可以进行格式化,使其更易于阅读
- 第 12 行:显示的 SQL 语句还将添加注释
- 第 15–19 行定义了 JDBC 层(架构中的第 [6] 层):
- 第 15 行:DBMS 的 JDBC 驱动程序类,此处为 MySQL5
- 第 16 行:所用数据库的 URL
- 第 17、18 行:连接用户名和密码
- 此处我们使用了附录第5.5节中介绍的内容。建议读者阅读该节关于MySQL5的内容。
- 第22行:Hibernate需要知道它正在与哪个数据库管理系统(DBMS)进行交互。这是因为所有DBMS都有专有的SQL扩展,例如它们处理主键值自动生成的独特方式……这意味着Hibernate需要知道它正在与哪个DBMS交互,以便向其发送该DBMS能够理解的SQL命令。 [MySQL5InnoDBDialect] 指使用支持事务的 InnoDB 表的 MySQL5 数据库管理系统。
- 第 24–28 行配置 c3p0 连接池(架构中的第 [5] 层):
- 第 24、25 行:连接池中的最小(默认 3)和最大连接数(默认 15)。初始连接数默认为 3。
- 第 26 行:客户端连接请求的最大等待时间(单位为毫秒)。超时后,c3p0 将抛出异常。
- 第 27 行:访问数据库时,Hibernate 使用预编译 SQL 语句(PreparedStatement),而 c3p0 可以对这些语句进行缓存。这意味着,如果应用程序第二次请求缓存中已存在的预编译 SQL 语句,则无需再次预编译(预编译 SQL 语句会产生开销),而是直接使用缓存中的语句。 此处,我们指定了缓存中可容纳的预编译 SQL 语句的最大数量,该数量适用于所有连接(一个预编译 SQL 语句属于单个连接)。
- 第 28 行:连接有效性检查间隔(单位为毫秒)。连接池中的连接可能因各种原因失效(例如 JDBC 驱动程序因连接闲置过久而将其标记为无效,或 JDBC 驱动程序存在缺陷等)。
- 第 20 行:此处指定在初始化持久层时,应生成 @Entity 对象的数据库模式。Hibernate 现已具备生成用于创建数据库表的 SQL 语句的所有工具:
- 通过 @Entity 对象的配置,它能够确定需要生成哪些表
- 第 15–18 行和第 24–28 行使其能够与 DBMS 建立连接
- 第 22 行指定了生成表时应使用的 SQL 方言
因此,此处使用的 [persistence.xml] 文件会在每次应用程序执行时重建一个新的数据库。如果表已存在,则会在删除(drop table)后重新创建(create table)。请注意,这显然不适用于生产数据库……
测试表明,表的删除/创建阶段可能会失败。特别是在同一测试中,当我们将实现从 JPA/Hibernate 层切换到 JPA/Toplink 层,或反之亦然时,这种情况尤为明显。虽然基于相同的 @Entity 对象,但这两种实现生成的表、生成器、序列等并不完全一致,因此有时会导致删除/创建阶段失败,需要手动删除这些表。 “附录”部分从第5段开始,介绍了可用于手动执行此任务的工具。需要注意的是,在数据库内容创建的这一初始阶段,JPA/Hibernate实现被证明是最高效的:崩溃情况很少发生。
JPA/Hibernate 层使用的工具位于 [jpa-hibernate] 库中,该库在第 1.5 节(第 8 页)中进行了介绍。访问 DBMS 所需的 JDBC 驱动程序位于 [jpa-drivers] 库中。这两个库已添加到本文研究项目的类路径中。其内容总结如下:
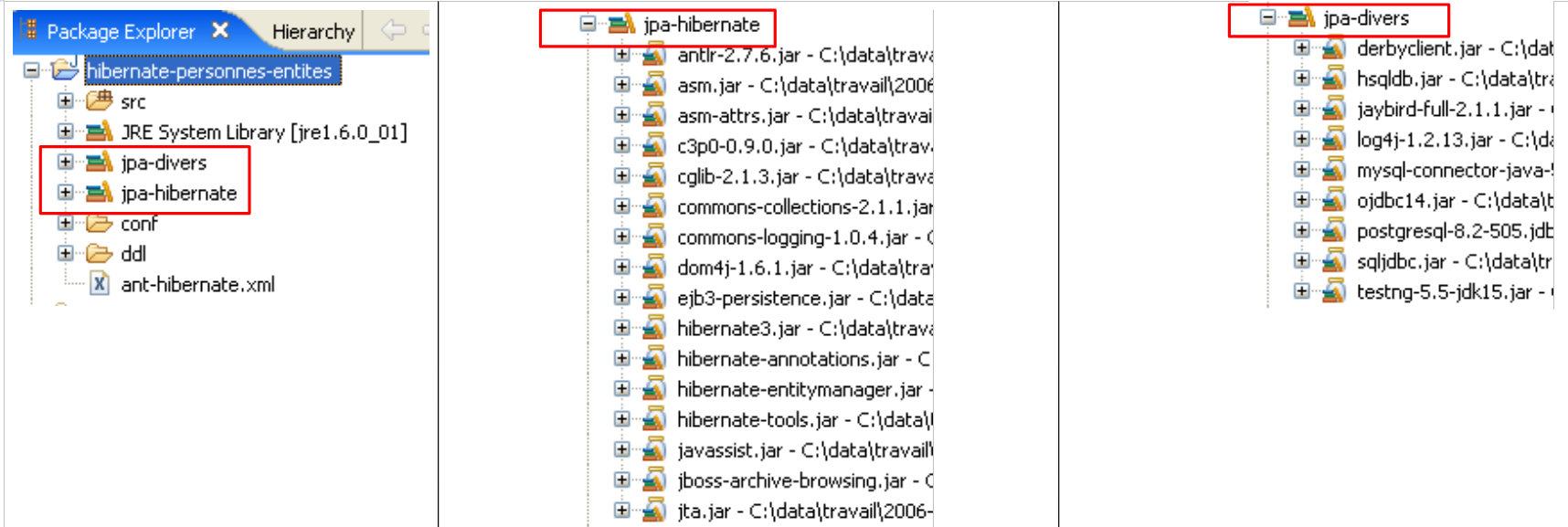 |
2.1.6. 使用 Ant 脚本生成数据库
正如我们刚才所见,Hibernate 提供了用于生成应用程序中 @Entity 对象数据库模式的工具。Hibernate 可以:
- 生成包含创建数据库 SQL 语句的文本文件。此时仅使用 [persistence.xml] 中指定的方言。
- 在 [persistence.xml] 中定义的目标数据库中创建代表 @Entity 对象的表。此时将使用完整的 [persistence.xml] 文件。
我们将介绍一个能够为 @Entity 对象生成数据库模式的 Ant 脚本。该脚本并非本人原创:它基于 [ref1] 中一个类似的脚本。Ant(Another Neat Tool)是一个 Java 批处理任务工具。Ant 脚本对于初学者来说并不容易理解。我们将仅使用其中一个,即我们正在讨论的这个:
 |
- 在 [1] 中:本教程示例的目录结构。
- 在 [2] 中:当前正在研究的 Eclipse 项目的 [people-entities] 文件夹
- 在 [3] 中:包含第 1.5 节中定义的五个 JAR 库的 <lib> 文件夹。
- 在 [4] 中:[ant-hibernate.xml] 脚本中某项任务所需的 [hibernate-tools.jar] 归档文件,我们将对此进行分析。
 |
- 在 [5] 中:Eclipse 项目和 [ant-hibernate.xml] 脚本
- 在 [6] 中:项目的 [src] 文件夹
[ant-hibernate.xml] 脚本 [5] 将使用 <lib> 文件夹 [3] 中的 JAR 文件,具体来说是 [lib/hibernate] 文件夹中的 [hibernate-tools.jar] 文件 [4]。 我们重现了该目录树,以便读者能够看到:要在 [ant-hibernate.xml] 脚本中从 [people-entities] 文件夹 [2] 找到 [lib] 文件夹,必须遵循路径:../../../lib。
让我们来分析一下 [ant-hibernate.xml] 脚本:
<project name="jpa-hibernate" default="compile" basedir=".">
<!-- nom du projet et version -->
<property name="proj.name" value="jpa-hibernate" />
<property name="proj.shortname" value="jpa-hibernate" />
<property name="version" value="1.0" />
<!-- Propriété globales -->
<property name="src.java.dir" value="src" />
<property name="lib.dir" value="../../../lib" />
<property name="build.dir" value="bin" />
<!-- le Classpath du projet -->
<path id="project.classpath">
<fileset dir="${lib.dir}">
<include name="**/*.jar" />
</fileset>
</path>
<!-- les fichiers de configuration qui doivent être dans le classpath-->
<patternset id="conf">
<include name="**/*.xml" />
<include name="**/*.properties" />
</patternset>
<!-- Nettoyage projet -->
<target name="clean" description="Nettoyer le projet">
<delete dir="${build.dir}" />
<mkdir dir="${build.dir}" />
</target>
<!-- Compilation projet -->
<target name="compile" depends="clean">
<javac srcdir="${src.java.dir}" destdir="${build.dir}" classpathref="project.classpath" />
</target>
<!-- Copier les fichiers de configuration dans le classpath -->
<target name="copyconf">
<mkdir dir="${build.dir}" />
<copy todir="${build.dir}">
<fileset dir="${src.java.dir}">
<patternset refid="conf" />
</fileset>
</copy>
</target>
<!-- Hibernate Tools -->
<taskdef name="hibernatetool" classname="org.hibernate.tool.ant.HibernateToolTask" classpathref="project.classpath" />
<!-- Générer la DDL de la base -->
<target name="DDL" depends="compile, copyconf" description="Génération DDL base">
<hibernatetool destdir="${basedir}">
<classpath path="${build.dir}" />
<!-- Utiliser META-INF/persistence.xml -->
<jpaconfiguration />
<!-- export -->
<hbm2ddl drop="true" create="true" export="false" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
</hibernatetool>
</target>
<!-- Générer la base -->
<target name="BD" depends="compile, copyconf" description="Génération BD">
<hibernatetool destdir="${basedir}">
<classpath path="${build.dir}" />
<!-- Utiliser META-INF/persistence.xml -->
<jpaconfiguration />
<!-- export -->
<hbm2ddl drop="true" create="true" export="true" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
</hibernatetool>
</target>
</project>
- 第 1 行:该 [ant] 项目名为“jpa-hibernate”。它由一组任务组成,其中之一是默认任务:在此情况下,即名为“compile”的任务。 调用 Ant 脚本时,会执行任务 T。如果未指定任务,则执行默认任务。basedir="." 表示脚本中所有相对路径的起点均为包含 Ant 脚本的文件夹,在此示例中即 <examples>/hibernate/direct/people-entities 文件夹。
- 第 3–11 行:使用 <property name="variableName" value="variableValue"/> 标签定义脚本变量。随后可在脚本中使用 ${variableName} 语法调用该变量。变量名可以是任意名称。让我们仔细看看第 9–11 行定义的变量:
- 第 9 行:定义了一个名为 "src.java.dir" 的变量(名称可任意设定),该变量在脚本后续部分将指向包含 Java 源代码的文件夹。其值为 "src",这是一个相对于由 basedir 属性(第 1 行)指定的文件夹的路径。 因此,该路径即为 "./src",其中这里的 . 指代 <examples>/hibernate/direct/people-entities 文件夹。Java 源代码确实位于 <people-entities>/src 文件夹中(参见上文 [6])。
- 第 10 行:定义了一个名为 "lib.dir" 的变量,在脚本后续部分中,它将指向包含脚本 Java 任务所需 JAR 文件的文件夹。其值 ../../../lib 指向 <examples>/lib 文件夹(参见上文 [3])。
- 第 11 行:定义了一个名为 "build.dir" 的变量,在脚本后续部分中,该变量将指向存放编译 .java 源代码生成的 .class 文件的文件夹。其值 "bin" 指向 <personnes-entites>/bin 文件夹(参见上文 [3])。我们之前已经解释过,在我们研究的 Eclipse 项目中,<bin> 文件夹就是生成 .class 文件的位置。Ant 也会这样做。
- 第 14–18 行:<path> 标签用于定义 Ant 任务将使用的类路径元素。此处,路径 "project.classpath"(名称可任意设定)包含 <examples>/lib 目录树中的所有 .jar 文件。
- 第 21–24 行:<patternset> 标签用于通过命名模式指定一组文件。此处,名为 conf 的模式集指代所有扩展名为 .xml 或 .properties 的文件。 该模式集将用于引用 <src> 文件夹中的 .xml 和 .properties 文件(persistence.xml、log4j.properties)(参见 [6]),这些是应用程序配置文件。当执行某些任务时,必须将这些文件复制到 <bin> 文件夹中,以便将其纳入项目的类路径。随后我们将使用 conf 模式集来引用它们。
- 第 27–30 行:<target> 标签表示脚本中的一个任务。这是我们遇到的第一个任务。此前的所有内容均涉及 Ant 脚本执行环境的配置。该任务名为 clean。它分两步运行:先删除 <bin> 文件夹(第 28 行),然后重新创建(第 29 行)。
- 第 33–35 行:compile 任务,即脚本的默认任务(第 1 行)。它依赖于(depends 属性)clean 任务。这意味着在执行 compile 任务之前,Ant 必须先执行 clean 任务,即清理 <bin> 文件夹。此处的 compile 任务旨在编译 <src> 文件夹中的 Java 源文件。
- 第 34 行:调用 Java 编译器,并传入三个参数:
- srcdir:包含 Java 源文件的文件夹,此处为 <src> 文件夹
- destdir:生成的 .class 文件应存储的文件夹,此处为 <bin> 文件夹
- classpathref:编译时使用的类路径,此处为 <lib> 目录树中的所有 JAR 文件
- (待续)
- 第 38–45 行:copyconf 任务,其目的是将 <src> 目录中的所有 .xml 和 .properties 文件复制到 <bin> 目录中。
- 第 48 行:使用 <taskdef> 标签定义一个任务。此类任务旨在在脚本的其他地方被重复使用。这是为了方便编码。由于该任务在脚本的多个位置被使用,因此使用 <taskdef> 标签定义一次,然后在需要时通过其名称进行重复使用。
- 该任务名为 hibernatetool(name 属性)。
- 其类由 classname 属性定义。在此,指定的类将位于我们之前提到的 [hibernate-tools.jar] 压缩包中。
- classpathref 属性告诉 Ant 在何处查找上述类
- (待续)
- 第 51–60 行涉及本文关注的任务:为 Eclipse 项目中的 @Entity 对象生成数据库模式。
- 第 51 行:该任务名为 DDL(Data Definition Language 的缩写,即用于创建数据库对象的 SQL)。它依賴于 compile 和 copyconf 任务,顺序依次为 compile 和 copyconf。 因此,DDL 任务将依次触发 clean、compile 和 copyconf 任务的执行。当 DDL 任务启动时,<bin> 文件夹中已包含由 .java 源文件生成的 .class 文件(特别是 @Entity 对象),以及用于配置 JPA/Hibernate 层的 [META-INF/persistence.xml] 文件。
- 第 53–59 行:调用第 48 行定义的 [hibernatetool] 任务。除第 48 行已定义的参数外,还向其传递了大量参数:
- 第 53 行:该任务生成的结果将输出到当前目录。
- 第 54 行:任务的类路径为 <bin> 文件夹。
- 第 56 行:告知 [hibernatetool] 任务如何确定其运行时环境:<jpaconfiguration/> 标签表示当前处于 JPA 环境中,因此必须使用 [META-INF/persistence.xml] 文件,该文件位于其类路径中。
- 第 58 行设置了生成数据库的条件:drop=true 表示在创建表之前必须执行 SQL DROP TABLE 语句;create=true 表示必须创建包含数据库创建 SQL 语句的文本文件;outputfilename 指定了该 SQL 文件的名称——此处为 Eclipse 项目中 <ddl> 文件夹内的 schema.sql;export=false 表示生成的 SQL 语句不得在连接到 DBMS 的情况下执行。 这一点很重要:这意味着执行该任务时,目标 DBMS 无需处于运行状态。delimiter 设置了生成的架构中分隔两个 SQL 语句的字符,而 format=true 要求对生成的文本应用基本格式化。
- 第 51–60 行涉及本文关注的任务:为 Eclipse 项目中的 @Entity 对象生成数据库模式。
- (待续)
- 第 63–72 行定义了名为 BD 的任务。它与之前的 DDL 任务完全相同,只是这次会生成数据库(第 70 行中的 export="true")。该任务使用 [persistence.xml] 中的信息打开与 DBMS 的连接,以执行 SQL 模式并生成数据库。因此,要运行 BD 任务,DBMS 必须处于运行状态。
2.1.7. 运行 ant DDL 任务
要运行 [ant-hibernate.xml] 脚本,我们需要先在 Eclipse 中进行一些配置。
 |
- 在 [1] 中:选择 [外部工具]
- 在 [2] 中:创建一个新的 Ant 配置
 |
- 在 [3] 中:为 Ant 配置命名
- 在 [5] 中:使用 [4] 按钮指定 Ant 脚本
- 步骤 [6]:应用更改
- 在 [7] 中:DDL Ant 配置已创建
 |
 |
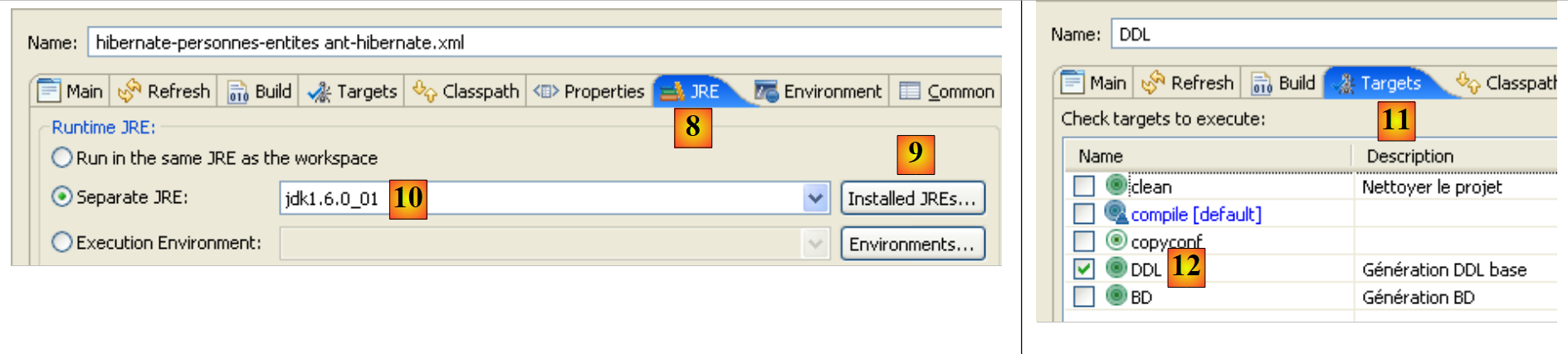
- 在 [8] 中:在“JRE”选项卡中,定义要使用的 JRE。字段 [10] 通常会预先填入 Eclipse 使用的 JRE。因此,此面板中通常无需进行任何操作。 然而,我曾遇到过 Ant 脚本无法找到 <javac> 编译器的情况。该编译器并不位于 JRE(Java 运行时环境)中,而是位于 JDK(Java 开发工具包)中。Eclipse 的 Ant 工具通过 JAVA_HOME 环境变量(开始 / 控制面板 / 性能和维护 / 系统 / 高级选项卡 / 环境变量按钮)[A] 来定位此编译器。 如果该变量尚未定义,您可以在 [10] 中指定 JDK 而不是 JRE,从而让 Ant 找到 <javac> 编译器。JDK 位于与 JRE 相同的文件夹中 [B]。使用按钮 [9] 将 JDK 注册到可用 JRE 列表中 [C],这样您就可以在 [10] 中选择它。
- 在 [12] 中:在 [目标] 选项卡中,选择 DDL 任务。因此,我们命名为 DDL [7] 的 Ant 配置将对应于名为 DDL [12] 的任务的执行,而如我们所知,该任务会为表示应用程序 @Entity 对象的数据库生成 DDL 模式。
 |
- 在 [13] 中:验证配置
- 在 [14] 中:运行它
在 [Console] 视图中,您将看到 DDL Ant 任务执行时的日志:
Buildfile: C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\ant-hibernate.xml
clean:
[delete] Deleting directory C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
[mkdir] Created dir: C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
compile:
[javac] Compiling 3 source files to C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
copyconf:
[copy] Copying 2 files to C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
DDL:
[hibernatetool] Executing Hibernate Tool with a JPA Configuration
[hibernatetool] 1. task: hbm2ddl (Generates database schema)
[hibernatetool] drop table if exists jpa01_personne;
[hibernatetool] create table jpa01_personne (
[hibernatetool] ID integer not null auto_increment,
[hibernatetool] VERSION integer not null,
[hibernatetool] NOM varchar(30) not null unique,
[hibernatetool] PRENOM varchar(30) not null,
[hibernatetool] DATENAISSANCE date not null,
[hibernatetool] MARIE bit not null,
[hibernatetool] NBENFANTS integer not null,
[hibernatetool] primary key (ID)
[hibernatetool] ) ENGINE=InnoDB;
BUILD SUCCESSFUL
Total time: 5 seconds
- 请注意,DDL 任务名为 [hibernatetool](第 10 行),并依赖于 clean(第 2 行)、compile(第 5 行)和 copyconf(第 7 行)任务。
- 第 10 行:[hibernatetool] 任务使用来自 JPA 配置的 [persistence.xml] 文件
- 第 11 行:[hbm2ddl] 任务将生成数据库 DDL 模式
- 第 12–22 行:数据库 DDL 模式
请注意,我们已指示 [hbm2ddl] 任务将 DDL 架构生成到特定位置:
<hbm2ddl drop="true" create="true" export="true" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
- 第 74 行:模式必须生成在 ddl/schema.sql 文件中。让我们检查一下:
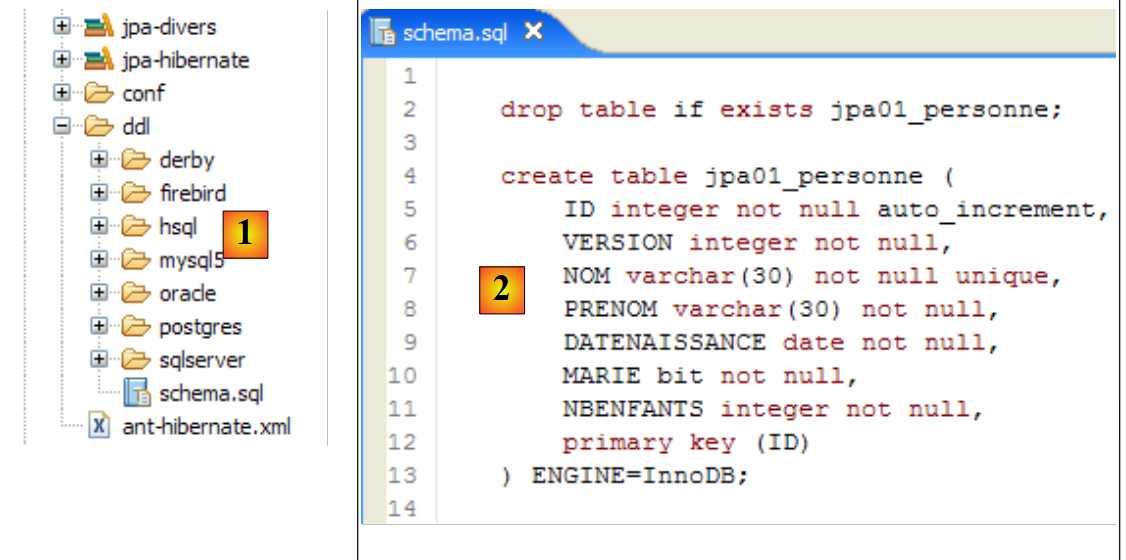 |
- 在 [1] 中:ddl/schema.sql 文件确实存在(按 F5 刷新目录树)
- 在 [2] 中:其内容。这是 MySQL5 数据库的模式。JPA 层的 [persistence.xml] 配置文件确实指定了 MySQL5 数据库管理系统(见下文第 8 行):
<!-- connexion JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
...
<!-- création automatique du schéma -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialecte -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!-- propriétés DataSource c3p0 -->
...
让我们通过查看 @Entity Person 对象的配置以及生成的 DDL 模式,来分析此处实现的对象-关系映射:
 |
 |
有几点值得注意:
- A1-B1:A1中指定的表名确实是B1中使用的表名。请注意B1中`CREATE`语句前面的`DROP`语句。
- A2-B2:展示主键的生成方式。A2中指定的AUTO模式导致了MySQL5特有的自动递增属性。主键生成模式通常取决于具体的DBMS。
- A3-B3:展示了用于表示 Java 布尔类型的、MySQL 5 特有的 SQL 位类型。
让我们用另一个数据库管理系统重复此测试:
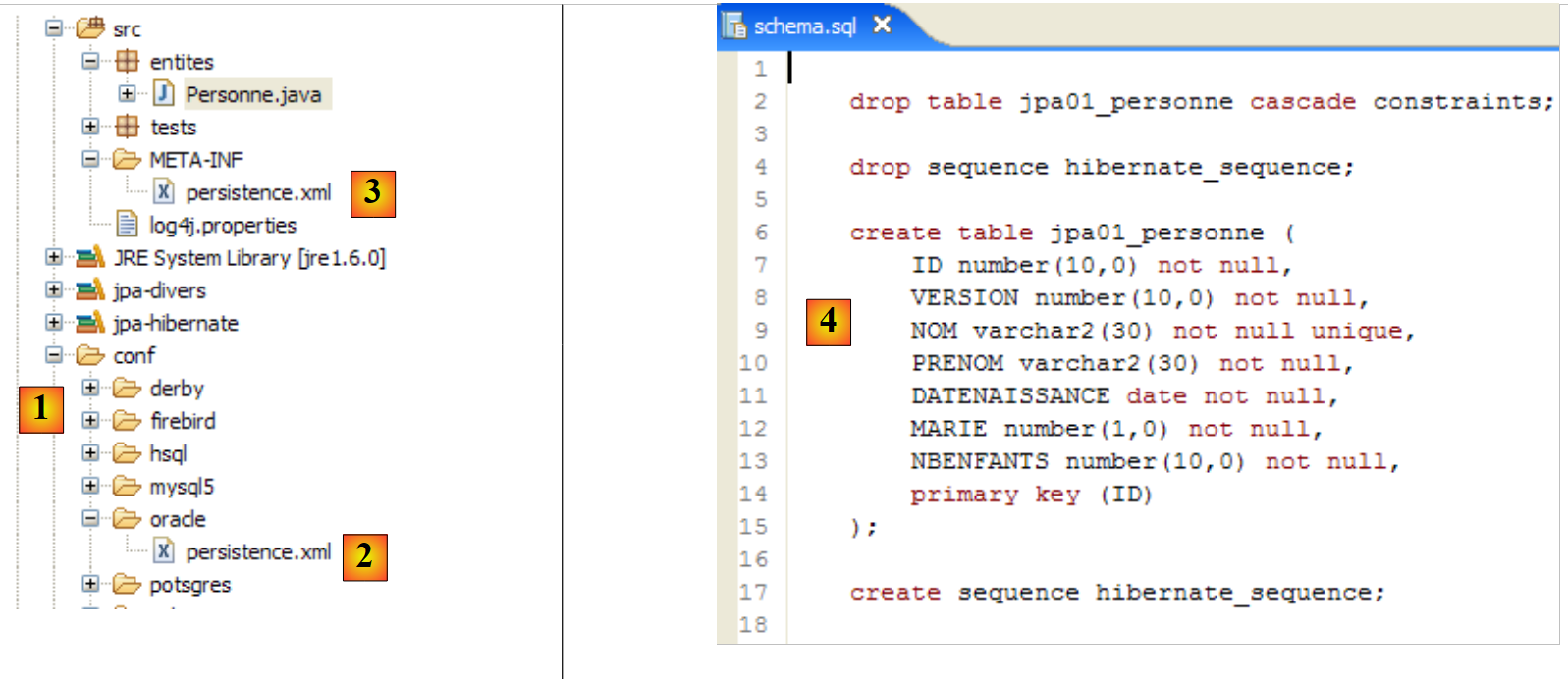 |
- [conf] 文件夹 [1] 中包含适用于各种数据库管理系统 (DBMS) 的 [persistence.xml] 文件。以 Oracle 的文件 [2] 为例,将其放置在 [META-INF] 文件夹 [3] 中,替换掉原有的文件。其内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Persistent classes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="oracle.jdbc.OracleDriver" />
<property name="hibernate.connection.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- automatic schematic creation -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.OracleDialect" />
<!-- properties DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
建议读者查阅附录,特别是关于 Oracle 的章节(第 5.7 节),以便更好地理解 JDBC 配置。
这里真正重要的是第25行:我们正在告知Hibernate,数据库管理系统(DBMS)现已切换为Oracle。执行ant的DDL任务将产生如上所示的结果[4]。请注意,Oracle模式与MySQL5模式有所不同。这是JPA的一大优势:开发人员无需担心这些细节,从而显著提高了应用程序的可移植性。
2.1.8. 执行“ ”Ant任务
您可能还记得,名为 BD 的 Ant 任务与 *DDL* 任务功能相同,但还会自动创建数据库。因此,数据库管理系统必须处于运行状态。 我们将使用 MySQL5 数据库管理系统,并请读者将文件 [conf/mysql5/persistence.xml] 复制到 [src/META-INF] 文件夹中。为了验证该任务是否正常工作,我们将使用 SQL Explorer 插件(参见第 5.2.6 节)来检查在运行 Ant BD 任务之前和之后 JPA 数据库的状态。
首先,我们需要创建一个新的 Ant 配置来运行 BD 任务。建议读者参考第 2.1.7 节中关于 DDL Ant 配置的步骤。该新 Ant 配置将命名为 BD:
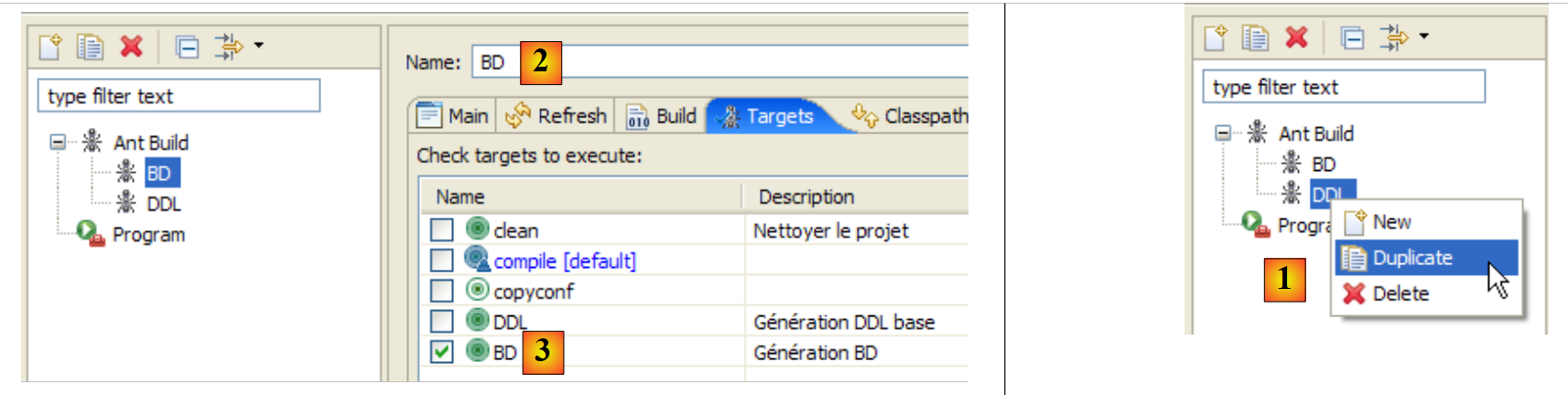 |
- 在 [1] 中:复制名为 DDL 的先前配置
- 在 [2] 中:将新配置命名为 BD。它将执行 ant BD 任务 [3],该任务会实际生成数据库。
- 完成此操作后,启动 MySQL5 数据库管理系统(第 5.5 节)。
现在,我们将使用 SQL Explorer 插件来浏览由该 DBMS 管理的数据库。如有必要,读者应事先熟悉该插件(参见第 5.2.6 节)。
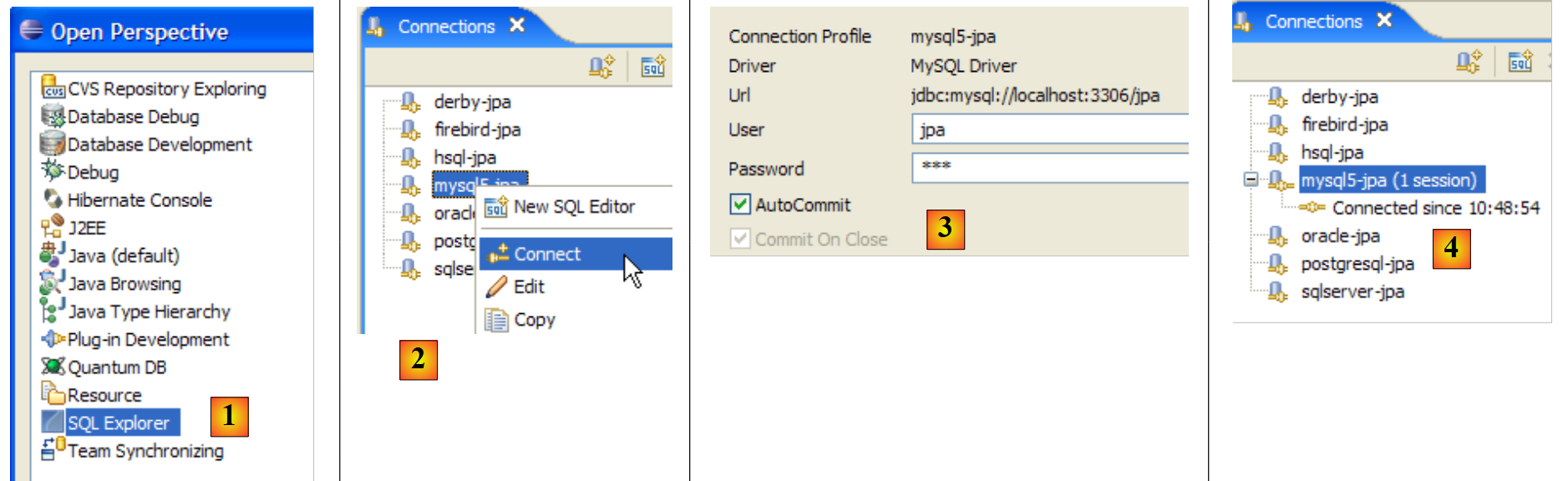 |
- [1]:打开 SQL Explorer 视图 [窗口 / 打开视图 / 其他]
- [2]: 如有必要,创建一个连接 [mysql5-jpa](参见第 5.5.5 节,第 252 页)并打开它
- [3]: 以 jpa / jpa 身份登录
- [4]: 您现已连接到 MySQL5。
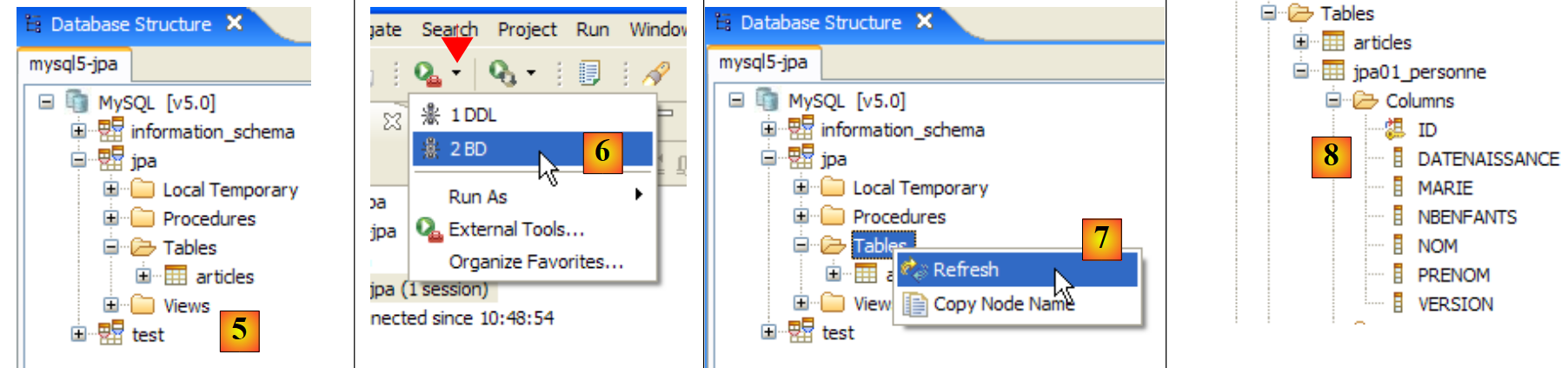 |
- 在 [5] 中:jpa 数据库仅包含一个表:[articles]
- 在 [6] 中:运行 Ant DB 任务。由于您当前处于 [SQL Explorer] 视图中,因此无法看到显示任务日志的 [Console] 视图。您可以通过 [Window / Show View / ...] 显示该视图,或返回 Java 视图 [Window / Open Perspective / ...]。
- 在 [7] 中:一旦 DB 任务完成,如有必要请返回 [SQL Explorer] 视图,并刷新 JPA 数据库树。
- 在 [8] 中:您可以看到已创建的 [jpa01_personne] 表。
建议读者尝试使用其他数据库管理系统(DBMS)重复此数据库生成过程。具体步骤如下:
- 将文件 [conf/<dbms>/persistence.xml] 复制到 [src/META-INF] 文件夹中,其中 <dbms> 代表待测试的数据库管理系统
- 按照附录中针对该 DBMS 的说明启动 <dbms>
- 在 SQL 资源管理器视图中,建立与 <dbms> 的连接。具体操作方法在各数据库管理系统(DBMS)的附录中亦有说明
- 重复之前的测试
至此,我们已获得以下几点认识:
- 我们对对象-关系桥接的概念有了更深入的理解。在此,我们使用 Hibernate 实现了该功能。后续我们将使用 TopLink。
- 我们了解到,该对象-关系桥的配置主要在两个地方进行:
- 在 @Entity 对象中,我们在此处指定对象字段与数据库表列之间的关系
- 在 [META-INF/persistence.xml] 中,我们向 JPA 实现提供关于对象-关系桥两个组成部分的信息:@Entity 对象(对象)和数据库(关系)。
- 我们创建了两个名为 DDL 和 DB 的 Ant 任务,它们允许我们在编写任何 Java 代码之前,根据之前的配置创建数据库。
现在,应用程序的 JPA 层已配置妥当,我们可以开始通过 Java 代码探索 JPA API 了。
2.1.9. 作为应用程序的持久化上下文
让我们来仔细看看 JPA 客户端的运行时环境:
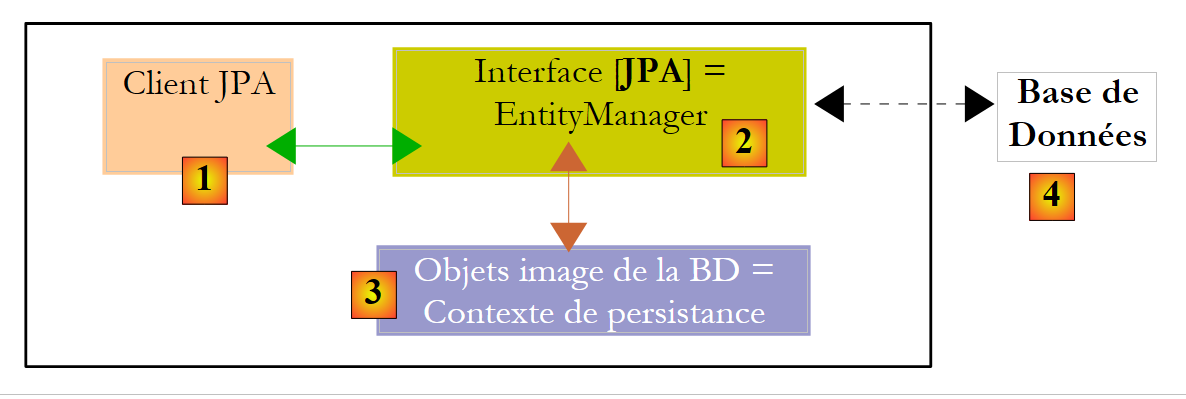 |
我们知道,JPA 层 [2] 在对象 [3] 与关系型数据 [4] 之间架起了一座桥梁。“持久化上下文”指的是在这个对象-关系桥梁中由 JPA 层管理的对象集合。要访问持久化上下文中的数据,JPA 客户端 [1] 必须通过 JPA 层 [2]:
- 它可以创建一个对象,并请求 JPA 层使其持久化。该对象随后便成为持久化上下文的一部分。
- 它可向 [JPA] 层请求现有持久化对象的引用。
- 它可以修改从 JPA 层获取的持久化对象。
- 它可请求 JPA 层将对象从持久化上下文中移除。
JPA 层为客户端提供了一个名为 [EntityManager] 的接口,顾名思义,该接口用于管理持久化上下文中的 @Entity 对象。以下是该接口的主要方法:
将实体添加到持久化上下文中 | |
从持久化上下文中移除实体 | |
将客户端提供的、未被持久化上下文管理的实体对象 与持久化上下文中具有相同主键的实体对象进行合并。 返回的结果是持久化上下文中的实体对象。 | |
将从数据库中检索到的对象 。该对象的类型 T 可让 JPA 层确定应查询哪张表。 由此创建的持久化对象将返回给客户端。 | |
根据 JPQL 查询 (Java 持久化查询语言)。JPQL 查询类似 SQL 查询,不同之处在于它查询的是对象而非表。 | |
该方法与前一个类似,区别在于 queryText 是 SQL语句而非JPQL查询。 | |
该方法与 createQuery 完全相同,区别在于 JPQL 查询 queryText 已被 已外部化到配置文件中,并关联了一个名称。 该名称即为该方法的参数。 |
EntityManager 对象的生命周期不一定与应用程序的生命周期相同。它有开始和结束。因此,JPA 客户端可以依次与不同的 EntityManager 对象进行交互。 与 EntityManager 关联的持久化上下文( )与 EntityManager 本身具有相同的生命周期。它们彼此密不可分。当 EntityManager 对象被关闭时,其持久化上下文会在必要时与数据库进行同步,然后停止存在。若要获取新的持久化上下文,必须创建一个新的 EntityManager。
JPA 客户端可通过以下语句创建 EntityManager 并由此建立持久化上下文:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
- javax.persistence.Persistence 是一个静态类,用于获取 EntityManager 对象的工厂。该工厂与特定的持久化单元相关联。请注意,配置文件 [META-INF/persistence.xml] 用于定义持久化单元,每个单元都有一个名称:
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
在上例中,持久化单元名为 jpa。它带有自己的特定配置,包括其所使用的数据库管理系统(DBMS)。 语句 [Persistence.createEntityManagerFactory("jpa")] 创建了一个 EntityManagerFactory,该工厂能够提供 EntityManager 对象,用于管理与名为 jpa 的持久化单元相关的持久化上下文。可以如下所示从 EntityManagerFactory 对象中获取 EntityManager 对象(即持久化上下文):
[EntityManager] 接口的以下方法可用于管理持久化上下文的生命周期:
关闭持久化上下文。强制持久化上下文与数据库进行同步:
| |
持久化上下文中的所有对象将被清除,但不会关闭。 | |
持久化上下文将与数据库进行同步,具体操作如 close() 所述 |
JPA 客户端可以通过 [EntityManager].flush 方法强制将持久化上下文与数据库进行同步。同步可以是显式的,也可以是隐式的。在第一种情况下,由客户端决定何时执行刷新操作以进行同步;否则,同步将在我们指定的特定时间发生。同步模式由 [EntityManager] 接口的以下方法管理:
flushMode 可能有两个取值: FlushModeType.AUTO(默认):在每次对数据库执行 SELECT 查询之前进行同步。 FlushModeType.COMMIT:仅在数据库事务结束时进行同步。 | |
返回当前的同步模式 |
让我们总结一下。在 FlushModeType.AUTO 模式下(这是默认模式),持久化上下文将在以下时间点与数据库进行同步:
- 每次对数据库执行 SELECT 操作之前
- 数据库事务结束时
- 在持久化上下文执行 flush 或 close 操作之后
在 FlushModeType.COMMIT 模式下,情况与上述相同,但第 1 项操作不会发生。与 JPA 层交互的常规模式是事务模式。客户端会在事务内对持久化上下文执行各种操作。在此情况下,持久化上下文与数据库之间的同步点在 AUTO 模式下为上述第 1 和第 2 项,而在 COMMIT 模式下仅为第 2 项。
最后,让我们来探讨 Query 接口 API,它允许您在持久化上下文中执行 JPQL 命令,或直接在数据库上执行 SQL 命令以检索数据。Query 接口如下所示:
 |
我们将使用上述第 1 至 4 种方法:
- 1 - getResultList 方法执行一个 SELECT 查询,该查询返回多个对象。这些对象被封装在一个 List 对象中。该对象是一个接口。它提供了一个 Iterator 对象,允许您按以下方式遍历列表 L 中的元素:
Iterator iterator = L.iterator();
while (iterator.hasNext()) {
// exploiter l'objet iterator.next() qui représente l'élément courant de la liste
...
}
列表 L 也可以使用 for 循环进行遍历:
for (Object o : L) {
// exploiter objet o
}
- 2 - getSingleResult 方法执行一个返回单个对象的 JPQL/SQL SELECT 语句。
- 3 - `executeUpdate` 方法执行一个 SQL UPDATE 或 DELETE 语句,并返回受该操作影响的行数。
- 4 - setParameter(String, Object) 方法允许您为参数化 JPQL 查询中的命名参数赋值。
- 5 - setParameter(int, Object) 方法用于设置参数,但该参数并非通过名称来识别,而是通过其在 JPQL 查询中的位置来识别。
2.1.10. 首个 JPA 客户端
让我们回到项目的 Java 视图:
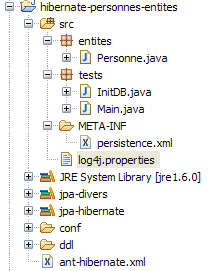 |
现在我们已经了解了该项目的几乎所有内容,唯独[src/tests]文件夹的内容除外,我们接下来将对其进行查看。该文件夹包含两个针对JPA层的测试程序:
- [InitDB.java] 是一个向数据库中的 [jpa01_personne] 表插入几行数据的程序。其代码将向我们介绍 JPA 层的基础概念。
- [Main.java] 是一个对 [jpa01_personne] 表执行 CRUD 操作的程序。通过研究其代码,我们将能够探索持久化上下文的基本概念以及该上下文中对象的生命周期。
2.1.10.1. 代码
[InitDB.java] 程序的代码如下:
package tests;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
import javax.persistence.Persistence;
import entites.Personne;
public class InitDB {
// constant
private final static String TABLE_NAME = "jpa01_personne";
public static void main(String[] args) throws ParseException {
// Persistence unit
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
// retrieve a EntityManagerFactory from the persistence unit
EntityManager em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// delete items from the people table
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
// create two people
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// persistence of people
em.persist(p1);
em.persist(p2);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
// log
System.out.println("terminé ...");
}
}
应结合第2.1.9节的说明来理解这段代码。
- 第 19 行:为 JPA 持久化单元(在 persistence.xml 中定义)请求一个 EntityManagerFactory (emf) 对象。此操作通常在应用程序的生命周期内仅执行一次。
- 第 21 行:请求一个 EntityManager (em) 对象来管理持久化上下文。
- 第 23 行:请求一个 Transaction 对象来管理事务。请注意,对持久化上下文的操作必须在事务内进行。我们将看到这并非严格必要,但若不这样做可能会导致问题。如果应用程序在 EJB3 容器中运行,对持久化上下文的操作总是会在事务内进行。
- 第 24 行:事务开始
- 第 26 行:在“jpa01_personne”表上执行一条删除 SQL 语句(nativeQuery)。这样做是为了清空表中的所有内容,从而更清晰地观察应用程序执行的结果 [InitDB]
- 第 28–29 行:创建了两个 Person 对象 p1 和 p2。这些是普通对象,目前与持久化上下文无关。就持久化上下文而言,Hibernate 将这些对象称为处于“暂存状态”,而“持久对象”则由持久化上下文管理。 我们将使用“非持久化对象”(非标准术语)来表示尚未由持久化上下文管理的对象,并将由持久化上下文管理的对象称为“持久化对象”。 我们还将遇到第三类对象:脱离对象。这类对象此前曾是持久对象,但其持久化上下文已被关闭。客户端可能持有对这类对象的引用,这解释了为何在持久化上下文关闭时,它们未必会被销毁。此时,它们被视为处于脱离状态。[EntityManager].merge 操作允许将它们重新附加到新创建的持久化上下文中。
- 第 31–32 行:通过 [EntityManager].persist 操作将实体 p1 和 p2 添加到持久化上下文中。它们随后成为持久化对象。
- 第 35–37 行:执行 JPQL 查询“select p from Person p order by p.name asc”。Person 并非表(表名为 jpa01_person),而是与该表关联的 @Entity 对象。此处是对持久化上下文执行的 JPQL(Java 持久化查询语言)查询,而非针对数据库的 SQL 查询。 话虽如此,除了 Person 对象已取代 jpa01_personne 表这一区别外,两者的语法是完全相同的。一个 for 循环遍历 select 语句返回的(人员)列表,将每个元素显示在控制台上。此处,我们正在验证第 31–32 行放入持久化上下文中的元素是否确实存在于表中。 此时将发生持久化上下文与数据库的透明同步。实际上,系统会发出一个 SELECT 查询,而我们注意到这正是发生同步的场景之一。因此,就在这一刻,JPA/Hibernate 会在后台发出两条 SQL INSERT 语句,将这两个人插入到 jpa01_personne 表中。 `persist` 操作并未执行此操作。该操作仅将对象添加到持久化上下文中,而不影响数据库。实际操作发生在同步过程中,即在此处对数据库执行 `SELECT` 查询之前。
- 第 39 行:我们结束了在第 24 行开始的事务。此时将再次进行同步。由于自上次同步以来持久化上下文未发生变化,此处不会有任何操作。
- 第 41 行:我们关闭持久化上下文。
- 第 43 行:关闭 EntityManager 工厂。
2.1.10.2. :执行代码
- 启动 MySQL5 数据库管理系统
- 如有必要,将 conf/mysql5/persistence.xml 放置到 META-INF/persistence.xml 中
- 运行 [InitDB] 应用程序
将得到以下结果:
 |
- 在 [1] 中:Java 视图中的控制台输出。得到了预期的结果。
- 在 [2] 中:我们按照第 2.1.8 节的说明,使用 SQL Explorer 视图验证了 [jpa01_personne] 表的内容。有两点值得注意:
- 主键ID是自动生成的
- 版本号也是如此。我们可以看到,第一个版本的编号为 0..
至此,我们已掌握了 JPA 框架的基础要素。我们已成功将数据插入表中。我们将以此为基础编写第二个测试,但首先让我们讨论一下日志。
2.1.11. 实现 Hibernate 日志
我们可以查看 JPA/Hibernate 层发送给数据库的 SQL 语句。检查这些语句有助于判断 JPA 层的效率是否与亲自编写 SQL 语句的开发人员相当。
在 JPA/Hibernate 中,SQL 日志记录可在 [persistence.xml] 文件中进行配置:
<!-- Classes persistantes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connexion JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
- 第 4–6 行:此时尚未启用 SQL 日志。现在,我们通过移除第 3 行和第 7 行的注释标签来启用它们。
我们重新运行 [InitDB] 应用程序。此时控制台输出如下:
- 第2-4行:由该命令生成的SQL DELETE语句:
// supprimer les éléments de la table des personnes
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
- 第 5-18 行:来自说明中的 SQL 插入语句:
// persistance des personnes
em.persist(p1);
em.persist(p2);
- 第 21-32 行:该指令生成的 SQL SELECT 语句:
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList())
如果我们在执行过程中输出中间控制台日志,会发现当语句 I 被执行时,Java 代码中语句 I 的 SQL 日志会被写入。但这并不意味着此时显示的 SQL 语句已在数据库上执行。实际上,该语句会被缓存起来,待持久化上下文与数据库下次同步时再执行。
可以通过 [src/log4j.properties] 文件获取更多日志:
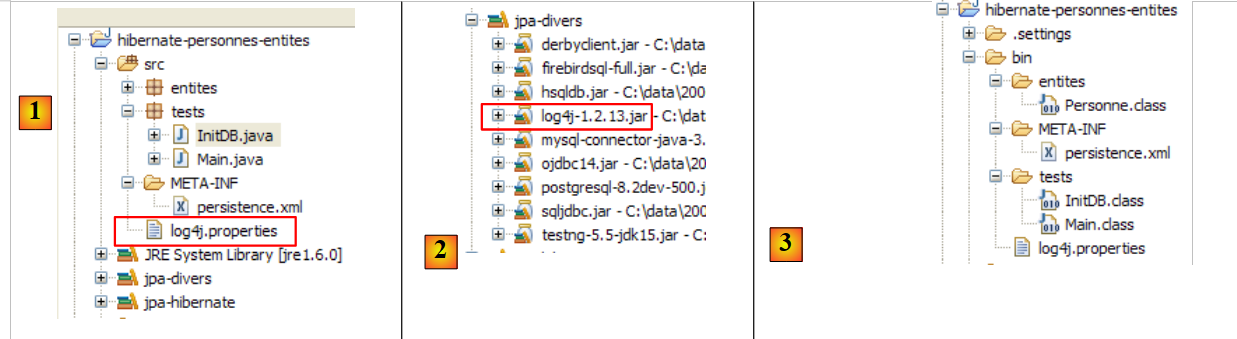 |
- 在 [1] 中,[log4j-1.2.13.jar] [2] 归档文件使用了名为 LOG4j(Java 日志)的工具中的 [log4j.properties] 文件,该工具可在 URL [http://logging.apache.org/log4j/docs/index.html] 获取。 将该文件放置在 Eclipse 项目的 [src] 文件夹中,我们知道 [log4j.properties] 会自动复制到项目的 [bin] 文件夹 [3]。完成此操作后,该文件便位于项目的类路径中,而 [2] 归档包将从该位置加载它。
通过 [log4j.properties] 文件,我们可以控制某些 Hibernate 日志。在之前的运行中,其内容如下:
# Direct log messages to stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
# Root logger option
log4j.rootLogger=ERROR, stdout
# Hibernate logging options (INFO only shows startup messages)
#log4j.logger.org.hibernate=INFO
# Log JDBC bind parameter runtime arguments
#log4j.logger.org.hibernate.type=DEBUG
对于这个配置,我不会多做评论,因为我从未花时间认真学习过 LOG4j。
- 第1至8行出现在我遇到过的所有log4j.properties文件中
- 第 10–14 行出现在 Hibernate 示例的 log4j.properties 文件中。
- 第 11 行:控制 Hibernate 的一般日志。由于该行已被注释掉,因此此处的日志功能已被禁用。 日志级别有几种:INFO(关于 Hibernate 当前操作的一般信息)、WARN(Hibernate 向我们发出潜在问题的警告)、DEBUG(详细日志)。INFO 级别最简洁,而 DEBUG 模式最详细。启用第 11 行可让您查看 Hibernate 的运行情况,特别是在应用程序启动时。这通常很有用。
- 第 12 行若启用,可让您查看执行参数化 SQL 查询时实际使用的参数。
让我们先取消第 14 行的注释
# Log JDBC bind parameter runtime arguments
log4j.logger.org.hibernate.type=DEBUG
并重新运行 [InitDB]。此更改生成的新的日志如下(部分视图):
- 第 8–10 行是启用 [log4j.properties] 文件第 14 行后生成的新的日志。它们显示了第 2–7 行中参数化查询的正式参数 ? 被赋予的 5 个值。因此,我们可以看到 VERSION 列将接收值 0(第 8 行)。
现在,让我们启用 [log4j.properties] 文件的第 11 行:
然后重新运行 [InitDB]:
阅读这些日志可以获得许多有用的信息:
- 第 7 行:Hibernate 指出了它找到的 @Entity 类的名称
- 第 8 行:表示 [Person] 类将映射到 [jpa01_person] 表
- 第 9 行:指明了将使用的 C3P0 连接池、JDBC 驱动程序的名称以及待管理的数据库 URL
- 第 10 行:提供了有关 JDBC 连接的更多详细信息:所有者、提交类型等
- 第 14 行:用于与 DBMS 通信的方言
- 第 15 行:所使用的事务类型。JDBCTransactionFactory 表示应用程序自行管理事务。它不在会提供自身事务服务的 EJB3 容器中运行。
- 以下几行涉及我们尚未接触过的 Hibernate 配置选项。感兴趣的读者建议查阅 Hibernate 文档。
- 第 37 行:SQL 语句将显示在控制台上。此设置是在 [persistence.xml] 中要求的:
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.format_sql" value="true" />
<property name="use_sql_comments" value="true" />
- 第 43–45 行:将数据库模式导出到 DBMS,即清空数据库并重新创建。此机制源于 [persistence.xml] 中的配置(下文第 4 行):
...
<property name="hibernate.connection.password" value="jpa" />
<!-- création automatique du schéma -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialecte -->
...
当应用程序因您无法理解的 Hibernate 异常而“崩溃”时,请先在 [log4j.properties] 中将 Hibernate 日志设置为 DEBUG 模式,以便更清楚地了解情况:
# Root logger option
log4j.rootLogger=ERROR, stdout
# Hibernate logging options (INFO only shows startup messages)
log4j.logger.org.hibernate=DEBUG
在本文档的其余部分中,默认情况下已禁用日志记录,以确保控制台输出更易于阅读。
2.1.12. 使用 Hibernate 控制台探索 JPQL/HQL 语言
注意:本节需要安装 Hibernate Tools 插件(参见第 5.2.5 节)。
在 [InitDB] 应用程序的代码中,我们使用了一个 JPQL 查询。JPQL(Java 持久化查询语言)是一种用于查询持久化上下文的语言。所使用的查询如下:
该查询选取了与 @Entity [Person] 关联的表中的所有记录,并按姓名升序返回。在上方的查询中,p.name 是 [Person] 类实例 p 的姓名字段。 因此,JPQL 查询操作的是持久化上下文中的 @Entity 对象,而非直接操作数据库表。JPA 层会将此 JPQL 查询转换为适用于其所连接的 DBMS 的 SQL 查询。因此,对于连接到 MySQL5 DBMS 的 JPA/Hibernate 实现,上述 JPQL 查询会被转换为以下 SQL 查询:
select
personne0_.ID as ID0_,
personne0_.VERSION as VERSION0_,
personne0_.NOM as NOM0_,
personne0_.PRENOM as PRENOM0_,
personne0_.DATENAISSANCE as DATENAIS5_0_,
personne0_.MARIE as MARIE0_,
personne0_.NBENFANTS as NBENFANTS0_
from
jpa01_personne personne0_
order by
personne0_.NOM asc
JPA 层利用 @Entity 标注的 [Person] 对象的配置,生成了正确的 SQL 查询。这正是此处实现对象关系映射的一个示例。
[Hibernate Tools] 插件(第 5.2.5 节)提供了一个名为“Hibernate Console”的工具,允许
- 在持久化上下文中执行 JPQL 或 HQL(Hibernate 查询语言)查询
- 以检索结果
- 查看在数据库上执行的等效 SQL 语句
Hibernate 控制台是学习 JPQL 语言并熟悉 JPQL/SQL 桥接机制的宝贵工具。众所周知,JPA 在很大程度上借鉴了 Hibernate 或 TopLink 等 ORM 工具。JPQL 与 Hibernate 的 HQL 非常相似,但并未包含其所有功能。 在 Hibernate 控制台中,您可以发出 HQL 命令,这些命令将在控制台中正常执行,但它们不属于 JPQL 语言的一部分,因此无法在 JPA 客户端中使用。遇到这种情况时,我们会特别指出。
让我们为当前的 Eclipse 项目创建一个 Hibernate 控制台:
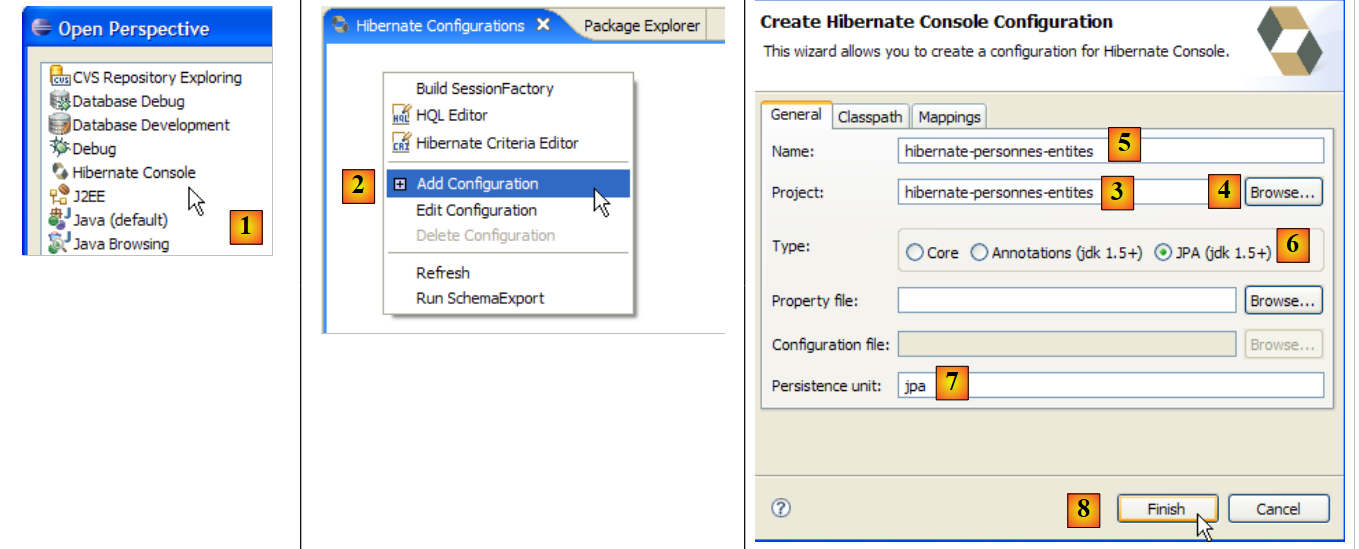 |
- [1]:切换到 [Hibernate Console] 视图(窗口 / 打开视图 / 其他)
- [2]: 在 [Hibernate 配置] 窗口中创建一个新配置
- 通过 [4] 按钮,选择需要为其创建 Hibernate 配置的 Java 项目。其名称将显示在 [3] 中。
- 在 [5] 中,输入此配置的名称。此处我们使用了 [3]。
- 在 [6] 中,我们指定使用 JPA 配置,以便工具知道必须使用 [META-INF/persistence.xml] 文件
- 在 [7] 中,我们指定在该 [META-INF/persistence.xml] 文件中应使用名为 jpa 的持久化单元。
- 在 [8] 中,我们验证该配置。
接下来,必须启动数据库管理系统(DBMS)。此处我们使用的是 MySQL 5。
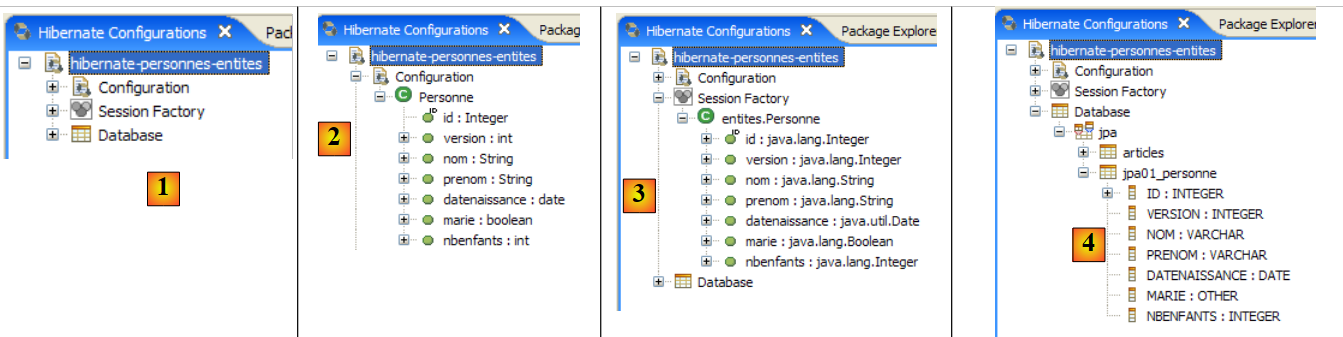 |
- 在 [1] 中:生成的配置显示了一个三叉树
- 在 [2] 中:[Configuration] 分支列出了控制台用于配置自身的对象:此处为 @Entity Person。
- 在 [3] 中:会话工厂(Session Factory)是 Hibernate 中的一个概念,类似于 JPA 的 EntityManager。它利用 [Configuration] 分支中的对象来弥合对象与关系数据库之间的鸿沟。在 [3] 中,显示了持久化上下文中的对象;这里再次出现了 @Entity Person。
- 在 [4] 中:通过 [persistence.xml] 中的配置访问数据库。该文件中包含 [jpa01_personne] 表。
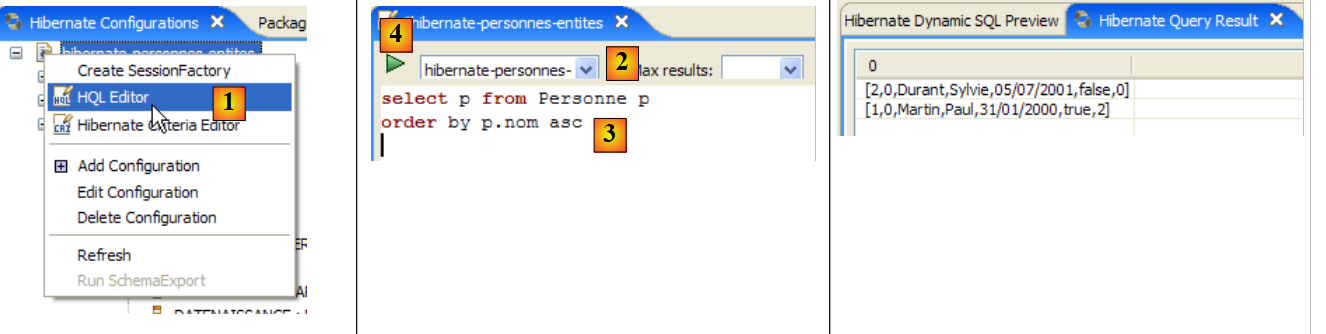 |
- 在 [1] 中,我们创建一个 HQL 编辑器
- 在 HQL 编辑器中,
- 在[2]中,若存在多个配置,我们将选择要使用的Hibernate配置
- 在[3]中,我们输入要执行的JPQL命令
- 在 [4] 中,执行该命令
- 在 [5] 中,您将在 [Hibernate 查询结果] 窗口中看到查询结果。此处可能会遇到两个问题:
- 没有返回任何结果(无行)。Hibernate 控制台使用 [persistence.xml] 中的内容与 DBMS 建立了连接。然而,该配置中包含一个属性,该属性指示将数据库清空:
<property name="hibernate.hbm2ddl.auto" value="create" />
因此,在重新执行上述 JPQL 命令之前,您必须先重新运行 [InitDB] 应用程序。
- (待续)
- [Hibernate 查询结果] 窗口未显示。您可以通过 [窗口 / 显示视图 / ...] 打开它
[Hibernate 动态 SQL 预览] 窗口(下文 [1])可让您查看为执行当前正在编写的 JPQL 命令而将要执行的 SQL 查询。只要 JPQL 命令的语法正确,相应的 SQL 命令就会出现在此窗口中:
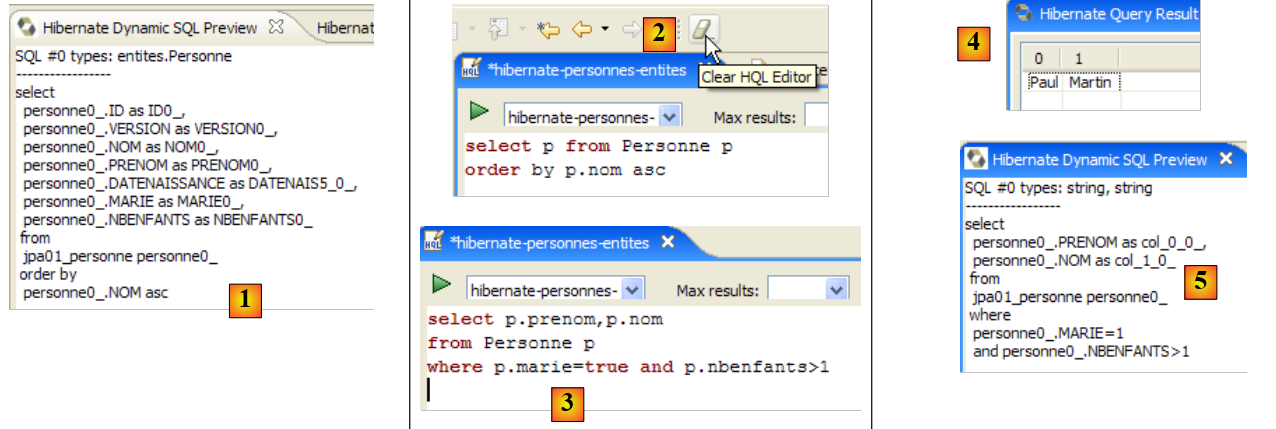 |
- 在 [2] 处,您可以清除之前的 HQL 命令
- 在 [3] 处,执行一个新的命令
- 在 [4] 处,显示结果
- 在 [5] 中,显示在数据库上执行的 SQL 命令
HQL 编辑器为编写 HQL 命令提供辅助功能:
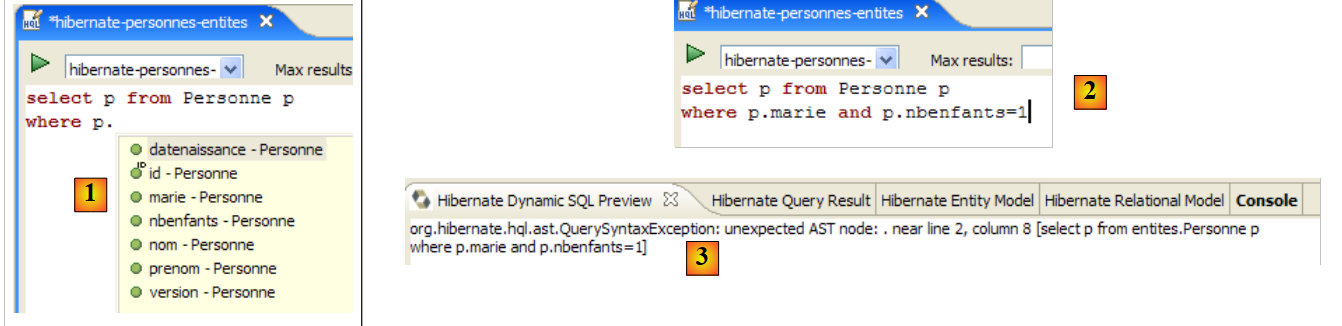 |
- 在 [1] 中:一旦编辑器识别出 p 是 Person 对象,它就能在您输入时为 p 的字段提供建议。
- 在 [2] 中:这是一个错误的 HQL 查询。你必须写成 where p.marie=true。
- 在 [3] 中:错误已在 [SQL 预览] 窗口中报告
我们邀请读者在数据库上执行其他 HQL/JPQL 命令。
2.1.13. 第二个 JPA 客户端
让我们回到项目的 Java 视图:
|
- [InitDB.java] 是一个向数据库中的 [jpa01_personne] 表插入几行数据的程序。通过研究其代码,我们掌握了 JPA API 的基础知识。
- [Main.java] 是一个对 [jpa01_personne] 表执行 CRUD 操作的程序。通过分析其代码,我们将重新回顾持久化上下文的基本概念以及该上下文中对象的生命周期。
2.1.13.1. 代码结构
[Main.java] 将运行一系列测试,每个测试都旨在演示 JPA 的某个特定方面:
 |
[main] 方法
- 依次调用 test1 到 test11 这些方法。我们将分别展示这些方法的代码。
- 它还使用了私有辅助方法:clean、dump、log、getEntityManager、getNewEntityManager。
下面我们展示 main 方法以及所谓的辅助方法:
package tests;
...
import entites.Personne;
@SuppressWarnings("unchecked")
public class Main {
// constant
private final static String TABLE_NAME = "jpa01_personne";
// Persistence context
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = null;
// shared objects
private static Personne p1, p2, newp1;
public static void main(String[] args) throws Exception {
// base cleaning
log("clean");clean();
// dump table
dump();
// test1
log("test1");test1();
...
// test11
log("test11");test11();
// fine persistence context
if (em.isOpen())
em.close();
// closure EntityManagerFactory
emf.close();
}
// retrieve the current EntityManager
private static EntityManager getEntityManager() {
if (em == null || !em.isOpen()) {
em = emf.createEntityManager();
}
return em;
}
// pick up a new EntityManager
private static EntityManager getNewEntityManager() {
if (em != null && em.isOpen()) {
em.close();
}
em = emf.createEntityManager();
return em;
}
// table content display
private static void dump() {
// current persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
}
// raz BD
private static void clean() {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// delete elements from the PERSONNES table
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
// end transaction
tx.commit();
}
// logs
private static void log(String message) {
System.out.println("main : ----------- " + message);
}
// object creation
public static void test1() throws ParseException {
...
}
// modify a context object
public static void test2() {
...
}
// request items
public static void test3() {
...
}
// delete an object belonging to the persistence context
public static void test4() {
....
}
// detach, reattach and modify
public static void test5() {
...
}
// delete an object not belonging to the persistence context
public static void test6() {
...
}
// modify an object not belonging to the persistence context
public static void test7() {
...
}
// reattach an object to the persistence context
public static void test8() {
...
}
// a select request causes synchronization
// with the persistence context
public static void test9() {
....
}
// version control (optimistic locking)
public static void test10() {
...
}
// transaction rollback
public static void test11() throws ParseException {
...
}
}
- 第 13 行:EntityManagerFactory 对象 (emf) 是根据 [persistence.xml] 中定义的 JPA 持久化单元构建的。它将允许我们在应用程序中创建各种持久化上下文。
- 第 14 行:一个尚未初始化的 EntityManager 持久化上下文
- 第 17 行:三个由测试共享的 [Person] 对象
- 第 21 行:清空 jpa01_personne 表,并在第 24 行显示其内容,以确保我们是从空表开始的。
- 第 27–31 行:测试序列
- 第 34–35 行:若持久化上下文处于打开状态,则将其关闭。
- 第 38 行:关闭 EntityManagerFactory 对象 emf。
- 第 42–47 行:[getEntityManager] 方法返回当前的 EntityManager(或持久化上下文),如果不存在则创建一个新的(第 43–44 行)。
- 第 50–56 行:[getNewEntityManager] 方法返回一个新的持久化上下文。如果之前存在一个,则将其关闭(第 51–52 行)
- 第 59–72 行:[dump] 方法显示 [jpa01_personne] 表的内容。该代码已在 [InitDB] 中出现过。
- 第 75–85 行:[clean] 方法清空 [jpa01_personne] 表。该代码已在 [InitDB] 中出现过。
- 第 88–90 行:[log] 方法将作为参数传递给它的消息显示在控制台上,以便用户注意到。
现在我们可以继续研究测试了。
2.1.13.2. 测试 1
测试1的代码如下:
// création d'objets
public static void test1() throws ParseException {
// contexte de persistance
EntityManager em = getEntityManager();
// création personnes
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistance des personnes
em.persist(p1);
em.persist(p2);
// fin transaction
tx.commit();
// on affiche la table
dump();
}
这段代码已在 [InitDB] 中出现过:它创建了两个人,并将他们放入持久化上下文中。
- 第 4 行:我们获取当前的持久化上下文
- 第 6-7 行:创建两个人员
- 第 9–15 行:在事务内将这两个人放入持久化上下文
- 第 15 行:由于事务已提交,持久化上下文与数据库同步。这两个人将被添加到 [jpa01_personne] 表中。
- 第 17 行:显示该表
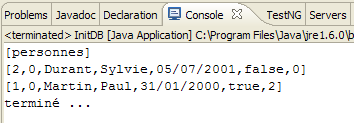
此首次测试的控制台输出如下:
main : ----------- test1
[personnes]
[2,0,Durant,Sylvie,05/07/2001,false,0]
[1,0,Martin,Paul,31/01/2000,true,2]
2.1.13.3. 测试 2
测试2的代码如下:
// modifier un objet du contexte
public static void test2() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on incrémente le nbre d'enfants de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// on modifie son état marital
p1.setMarie(false);
// l'objet p1 est automatiquement sauvegardé (dirty checking)
// lors de la prochaine synchronisation (commit ou select)
// fin transaction
tx.commit();
// on affiche la nouvelle table
dump();
}
- 测试 2 旨在修改持久化上下文中的对象,然后显示表内容以查看修改是否生效
- 第 4 行:获取当前持久化上下文
- 第 6–7 行:操作将在事务内执行
- 第 9、11 行:修改了 person p1 的子女数量及其婚姻状况
- 第 15 行:事务结束,因此持久化上下文与数据库同步
- 第 17 行:显示表格
测试 2 的控制台输出如下:
- 第4行:修改前的p1
- 第 8 行:修改后的人物 p1。请注意,其版本号已更改为 1。每次更新该行时,此数字都会增加 1。
2.1.13.4. 测试 3
测试 3 的代码如下:
// demander des objets
public static void test3() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on demande la personne p1
Personne p1b = em.find(Personne.class, p1.getId());
// parce que p1 est déjà dans le contexte de persistance, il n'y a pas eu d'accès à la base
// p1b et p1 sont les mêmes références
System.out.format("p1==p1b ? %s%n", p1 == p1b);
// demander un objet qui n'existe pas rend 1 pointeur null
Personne px = em.find(Personne.class, -4);
System.out.format("px==null ? %s%n", px == null);
// fin transaction
tx.commit();
}
- 测试 3 重点关注 [EntityManager.find] 方法,该方法从数据库中检索一个对象并将其放入持久化上下文中。除非以非常规方式使用,否则我们将不再解释所有测试中发生的事务。
- 第 9 行:我们向持久化上下文查询与 person p1 主键相同的 person 对象。有两种情况:
- p1 已存在于持久化上下文中。此处即为这种情况。因此,不会执行任何数据库访问。find 方法仅返回对该持久化对象的引用。
- p1 不在持久化上下文中。此时,系统会使用提供的主键执行数据库查询。检索到的记录会被添加到持久化上下文中,而 find 方法则返回对这个新持久化对象的引用。
- 第 12 行:我们验证 `find` 是否返回了已存在于上下文中的 `p1` 对象的引用
- 第 14 行:我们请求一个既不在持久化上下文中也不在数据库中的对象。此时 find 方法将返回一个空指针。这一点在第 15 行得到了验证。
测试 3 的控制台输出如下:
2.1.13.5. 测试 4
测试4的代码如下:
// supprimer un objet appartenant au contexte de persistance
public static void test4() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on supprime l'objet persisté p2
em.remove(p2);
// fin transaction
tx.commit();
// on affiche la nouvelle table
dump();
}
- 测试 4 重点关注 [EntityManager.remove] 方法,该方法允许您从持久化上下文中移除一个元素,从而将其从数据库中删除。
- 第 9 行:person p2 被从持久化上下文中移除
- 第 11 行:将上下文与数据库同步
- 第 13 行:显示表格。通常情况下,person p2 应该已经不在其中了。
测试 4 的控制台输出如下:
- 第3行:test1中的第2个人
- 第12-14行:在test4之后已不存在。
2.1.13.6. 测试5
test5的代码如下:
// détacher, réattacher et modifier
public static void test5() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// p1 détaché
Personne oldp1=p1;
// on réattache p1 au nouveau contexte
p1 = em.find(Personne.class, p1.getId());
// vérification
System.out.format("p1==oldp1 ? %s%n", p1 == oldp1);
// fin transaction
tx.commit();
// on incrémente le nbre d'enfants de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// on affiche la nouvelle table
dump();
}
- 测试 5 考察了持久化对象在多个连续持久化上下文中的生命周期。此前,我们在各项测试中始终使用同一个持久化上下文。
- 第 4 行:请求一个新的持久化上下文。[getNewEntityManager] 方法会关闭之前的上下文并打开一个新的。因此,应用程序持有的对象 p1 和 p2 不再处于持久化状态。它们属于一个已被关闭的上下文。我们说它们处于脱离状态。它们不属于新的持久化上下文。
- 第 6–7 行:事务开始。此处将以一种非典型的方式使用事务。
- 第 9 行:我们记录下现已脱离上下文的对象 p1 的地址。
- 第 11 行:向持久化上下文查询 person p1(使用 p1 的主键)。由于上下文是新的,person p1 并不存在于其中。因此将执行数据库查询。检索到的对象将被放入新的上下文中。
- 第 13 行:我们验证上下文中的持久化对象 p1 与 oldp1(即原先脱离上下文的对象 p1)不同。
- 第 15 行:事务完成
- 第 17 行:我们在事务外部修改新的持久化对象 p1。这种情况下会发生什么?我们想知道。
- 第 19 行:我们请求显示该表。请注意,由于 `dump` 方法发出的 `SELECT` 语句,持久化上下文会自动与数据库同步。
测试 5 的控制台输出如下:
- 第5行:find方法确实访问了数据库;否则,这两个指针的值将相等
- 第 7 行和第 3 行:p1 的子节点数量确实增加了 1。因此,在事务外部进行的修改已被纳入考量。这实际上取决于所使用的 DBMS。在 DBMS 中,SQL 语句总是执行于事务之内。如果 JPA 客户端未自行启动显式事务,DBMS 将启动隐式事务。常见情况有两种:
- 1 - 每个单独的 SQL 语句都属于一个事务,该事务在语句执行前打开,执行后关闭。这被称为自动提交模式。因此,一切行为都仿佛 JPA 客户端为每个 SQL 语句都在执行事务。
- 2 - DBMS 未处于自动提交模式,并在 JPA 客户端在事务外部发出的第一个 SQL 语句时启动隐式事务,由客户端负责关闭该事务。随后 JPA 客户端发出的所有 SQL 语句都属于该隐式事务。该事务可能因各种事件而结束:客户端关闭连接、启动新事务等。
这种情况取决于 DBMS 的配置。因此,该代码不具备可移植性。我们稍后将展示一个无事务的代码示例,并看到并非所有 DBMS 在处理此代码时都表现一致。因此,我们将不在事务中进行操作视为编程错误。
- 第 7 行:请注意,版本号已更新为 2。
2.1.13.7. 测试 6
测试 6 的代码如下:
// supprimer un objet n'appartenant pas au contexte de persistance
public static void test6() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on supprime p1 qui n'appartient pas au nouveau contexte
try {
em.remove(p1);
// fin transaction
tx.commit();
} catch (RuntimeException e1) {
System.out.format("Erreur à la suppression de p1 : [%s,%s]%n", e1.getClass().getName(), e1.getMessage());
// on fait un rollback de la transaction
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s,%s]%n", e2.getClass().getName(), e2.getMessage());
}
}
// on affiche la nouvelle table
dump();
}
- 测试 6 尝试删除一个不属于持久化上下文的对象。
- 第 4 行:请求创建新的持久化上下文。因此旧的持久化上下文被关闭,其中包含的对象变为脱离状态。这正是前一个测试 5 中 p1 对象的情况。
- 第 6–7 行:开始事务。
- 第 10 行:删除脱离的对象 p1。我们知道这会引发异常,因此将该操作包裹在 try/catch 块中。
- 第 12 行:提交操作不会执行。
- 第 16–21 行:事务必须以提交(事务中的所有操作均被确认)或回滚(事务中的所有操作均被撤销)结束。由于发生了异常,因此我们回滚事务。由于事务中的唯一操作已失败,因此无需撤销任何内容,但回滚操作会终止事务。这是我们首次使用 [EntityTransaction].rollback 操作。 我们本应从最初的示例开始就这样做。之所以没有这样做,是为了保持代码的简洁。但读者仍应牢记,代码中必须始终考虑事务回滚的情况。
- 第 24 行:我们显示该表格。通常情况下,它不应该有任何变化。
测试 6 的控制台输出如下:
- 第 6 行:删除 p1 失败。异常信息说明尝试删除了一个脱离上下文的对象,而该对象不属于当前上下文。这是不可行的。
- 第 8 行:人员 p1 仍然存在。
2.1.13.8. 测试 7
测试 7 的代码如下:
// modifier un objet n'appartenant pas au contexte de persistance
public static void test7() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on incrémente le nbre d'enfants de p1 qui n'appartient pas au nouveau contexte
p1.setNbenfants(p1.getNbenfants() + 1);
// fin transaction
tx.commit();
// on affiche la nouvelle table - elle n'a pas du changer
dump();
}
- 测试 7 试图修改一个不属于持久化上下文的对象,并观察这对数据库产生的影响。人们可能会认为没有任何影响。测试结果也确实如此。
- 第 4 行:请求创建新的持久化上下文。因此,我们获得了一个不包含任何持久化对象的新上下文。
- 第 6–7 行:事务开始。
- 第 9 行:修改脱离上下文的对象 p1。此操作不涉及持久化上下文 em。因此,我们不应预期会抛出异常或出现类似情况。这只是对 POJO 进行的基本操作。
- 第 11 行:提交操作将上下文与数据库同步。该上下文为空,因此数据库保持不变。
- 第 24 行:显示该表。通常情况下,该表不应发生变化。
测试 7 的控制台输出如下:
- 第7行:数据库中人员p1未发生变化。但在接下来的测试中,我们将注意,内存中子女的数量现在是5。
2.1.13.9. 测试 8
测试8的代码如下:
// réattacher un objet au contexte de persistance
public static void test8() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on réattache l'objet détaché p1 au nouveau contexte
newp1 = em.merge(p1);
// c'est newp1 qui fait désormais partie du contexte, pas p1
// fin transaction
tx.commit();
// on affiche la nouvelle table - le nbre d'enfants de p1 a du changer
dump();
}
- 测试 8 将一个已脱离的对象重新附加到持久化上下文中。
- 第 4 行:请求创建一个新的持久化上下文。因此,我们获得了一个不包含任何持久化对象的新上下文。
- 第 6-7 行:事务开始。
- 第 9 行:将脱离的对象 p1 重新附加到持久化上下文中。合并操作可能涉及以下几种情况:
- 情况 1:持久化上下文中存在一个主键与脱离对象 p1 相同的主对象 ps1。此时 p1 的内容会被复制到 ps1 中,merge 方法返回对 ps1 的引用。
- 情况 2:持久化上下文中不存在与脱离对象 p1 主键相同的持久化对象 ps1。此时将查询数据库以确定所寻对象是否存在。若存在,则将该对象引入持久化上下文,使其成为持久化对象 ps1,并返回至前述情况 1。
- 情况 3:持久化上下文和数据库中均不存在与脱离对象 p1 主键相同的对象。此时将创建一个新的 [Person] 对象(new),并将其放入持久化上下文中。随后返回情况 1。
- 最终结果:脱离对象 p1 仍保持脱离状态。合并操作返回一个指向合并后持久对象 ps1 的引用(此处为 newp1)。客户端应用程序现在必须操作持久对象 ps1,而非脱离对象 p1。
- 请注意案例 1 和 3 在合并所用 SQL 语句上的区别:在案例 1 和 2 中,使用的是 UPDATE 语句,而在案例 3 中,使用的是 INSERT 语句。
- 第 12 行:提交操作将上下文与数据库同步。该上下文不再为空,其中包含对象 newp1。该对象将被持久化到数据库中。
- 第 24 行:我们显示该表以进行验证。
测试 8 的控制台输出如下:
- 在测试6中(第4行),p1的子节点数量为4,随后在测试7中变为5,但未被写入数据库(第7行)。合并后,newp1被写入数据库(第10行),现在共有5个子节点。
- 第 10 行:newp1 的版本号已更新为 3。
2.1.13.10. 测试 9
测试 9 的代码如下:
// a select request causes synchronization
// with the persistence context
public static void test9() {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// increment the number of children of newp1
newp1.setNbenfants(newp1.getNbenfants() + 1);
// people display - the number of children in newp1 must have changed
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
}
- 测试 9 演示了在 SELECT 语句执行前自动发生的上下文同步机制。
- 第 5 行:持久化上下文未发生改变。因此 newp1 仍处于该上下文中。
- 第 7–8 行:事务开始。
- 第 10 行:持久化对象 newp1 的子对象数量增加 1(5 → 6)。
- 第 12–15 行:使用 SELECT 语句显示表。在执行 SELECT 语句之前,上下文将与数据库同步。
- 第 17 行:事务结束
要查看同步过程,请在 DEBUG 模式下启用 Hibernate 日志输出(log4j.properties):
# Root logger option
log4j.rootLogger=ERROR, stdout
# Hibernate logging options (INFO only shows startup messages)
log4j.logger.org.hibernate=DEBUG
测试 9 的控制台输出如下:
- 第 1 行:测试 9 开始
- 第 2–6 行:JDBC 事务开始。DBMS 的自动提交模式已被禁用(第 5 行)
- 第 7 行:由 Java 代码第 12 行触发的显示操作。接下来的几行 Java 代码将触发 SELECT 语句,从而将持久化上下文与数据库同步。
- 第 8 行:我们要执行的 JPQL 查询已经执行过。Hibernate 在其“预编译查询”缓存中找到了它。
- 第 9 行:Hibernate 宣布将刷新持久化上下文
- 第 11–12 行:Hibernate (Hb) 检测到 Person#1 实体(主键为 1)已被修改(处于脏状态)。
- 第 12–13 行:Hb 宣布正在更新该元素,并将版本号从 3 递增至 4。
- 第 15 行:上下文同步将导致 0 次插入、1 次更新和 0 次删除
- 第 17–34 行:上下文同步(刷新)。注意:版本号递增(第 19 行)、预编译的 SQL 更新语句(第 21 行)以及更新语句的参数值(第 24–31 行)。
- 第 35 行:SELECT 语句开始
- 第 38 行:待执行的 SQL 语句
- 第 40 行:SELECT 仅返回一行
- 第 42 行:Hb 发现其持久化上下文中已存在 SELECT 语句从数据库返回的 Person#1 实体。因此,它不会将从数据库获取的行复制到上下文中,这一操作被称为“水化”。
- 第 43 行:他检查 SELECT 返回的对象是否存在依赖关系(通常是外键),这些依赖关系也需要被加载(非延迟加载的集合)。此处不存在此类依赖。
- 第 44 行:由 Java 代码触发的显示操作
- 第 45 行:Java 代码请求的 JDBC 事务结束
- 第 46 行:自动上下文同步开始,该操作发生在提交期间。
- 第 48 行:Hb 检测到自上次同步以来上下文未发生变化。
- 第 50 行:提交结束。
再次证明,Hibernate 在 DEBUG 模式下的日志对于准确理解 Hibernate 的具体行为非常有用。
2.1.13.11. 测试 10
测试10的代码如下:
// contrôle de version (optimistic locking)
public static void test10() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// incrémenter la version de newp1 directement dans la base (native query)
em.createNativeQuery(String.format("update %s set VERSION=VERSION+1 WHERE ID=%d", TABLE_NAME, newp1.getId())).executeUpdate();
// fin transaction
tx.commit();
// début nouvelle transaction
tx = em.getTransaction();
tx.begin();
// on incrémente le nbre d'enfants de newp1
newp1.setNbenfants(newp1.getNbenfants() + 1);
// fin transaction - elle doit échouer car newp1 n'a plus la bonne version
try {
tx.commit();
} catch (RuntimeException e1) {
System.out.format("Erreur lors de la mise à jour de newp1 [%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(), e1.getCause().getClass().getName(), e1.getCause().getMessage());
// on fait un rollback de la transaction
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s,%s]%n", e2.getClass().getName(), e2.getMessage());
}
}
// on ferme le contexte qui n'est plus à jour
em.close();
// dump de la table - la version de p1 a du changer
dump();
}
- 测试 10 演示了 @Entity Person 中的 version 字段所引入的机制,该字段被标注了 JPA 的 @Version 注解。 我们曾解释过,该注解会导致与 @Version 注解关联的列值在数据库中随所属行每次更新而递增。这种机制也被称为乐观锁,它要求希望修改数据库中对象 O 的客户端必须拥有该对象的最新版本。如果客户端没有最新版本,则意味着该对象在客户端获取后已被修改,此时必须通知客户端。
- 第 4 行:我们不更改持久化上下文。因此 newp1 位于该上下文内部。
- 第 6–7 行:事务开始。
- 第 9 行:newp1 对象的版本号直接在数据库中增加 1(4 -> 5)。nativeQuery 类型的查询会绕过持久化上下文,直接写入数据库。结果是,持久化对象 newp1 及其在数据库中的表示不再具有相同的版本号。
- 第 10 行:第一个事务结束
- 第 13–14 行:开始第二个事务
- 第 16 行:持久化对象 newp1 的子节点数量增加 1(6 -> 7)。
- 第 19 行:事务结束。因此会进行同步。这将触发对数据库中 newp1 子节点数量的更新。由于持久化对象 newp1 的版本为 4,而数据库中待更新的对象版本为 5,因此更新将失败。系统将抛出异常,这也正是代码中 try/catch 代码块存在的理由。
- 第 21 行:显示异常及其原因。
- 第 25 行:回滚事务
- 第 33 行:显示表:我们应看到数据库中 newp1 的版本为 5。
测试 10 的控制台输出如下:
- 第 5 行:提交操作确实抛出了异常。异常类型为 [javax.persistence.RollbackException]。相关消息较为模糊。如果查看该异常的根本原因(Exception.getCause),我们会发现这是一个 Hibernate 异常,原因是我们在没有正确版本的情况下试图修改数据库中的行。
- 第 7 行:我们可以看到,数据库中 newp1 的版本确实已被 nativeQuery 设置为 5。
2.1.13.12. 测试 11
test11 的代码如下:
// transaction rollback
public static void test11() throws ParseException {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = null;
try {
tx = em.getTransaction();
tx.begin();
// reattach p1 to the context by fetching it from the base
p1 = em.find(Personne.class, p1.getId());
// increment the number of children in p1
p1.setNbenfants(p1.getNbenfants() + 1);
// display people - the number of children in p1 must have changed
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// creation of 2 persons with identical names, which is forbidden by the DDL
Personne p3 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p4 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
// persistence of people
em.persist(p3);
em.persist(p4);
// end transaction
tx.commit();
} catch (RuntimeException e1) {
// we had a problem
System.out.format("Erreur dans transaction [%s,%s,%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage(), e1.getCause().getCause().getClass().getName(), e1.getCause().getCause()
.getMessage());
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s]%n", e2.getMessage());
}
// we abandon the current context
em.clear();
}
// dump - table must not have changed due to rollback
dump();
}
- 测试 11 侧重于事务回滚机制。事务遵循“全有或全无”的原则:其中包含的 SQL 操作要么全部成功执行(提交),要么在任何一个操作失败时全部回滚(回滚)。
- 第 4 行:我们继续使用相同的持久化上下文。读者可能还记得,在上一个测试中,该上下文在崩溃后已被关闭。在此情况下,[getEntityManager] 返回了一个全新的(因此为空的)上下文。
- 第 7–27 行:一个 try/catch 代码块用于处理可能出现的任何问题
- 第 8–9 行:开始一个将包含多个 SQL 操作的事务
- 第 11 行:从数据库中检索 p1 并将其放入上下文中
- 第 13 行:将 p1 的子节点数量增加(6 → 7)
- 第 15–18 行:我们显示数据库内容,这将强制执行上下文同步。在数据库中,p1 的子节点数量将变为 7,控制台输出应能证实这一点。
- 第 20–21 行:创建两个同名人员 p3 和 p4。然而,@Entity Person 的 name 字段具有 unique=true 属性,这会在 [jpa01_personne] 表的 NAME 列上产生唯一性约束。
- 第 23–24 行:将人员 p3 和 p4 添加到持久化上下文中。
- 第 26 行:提交事务。随后对上下文进行第二次同步(第一次同步发生在 SELECT 语句执行期间)。JPA 将针对人员 p3 和 p4 分别发出两条 SQL INSERT 语句。p3 将被插入。对于 p4,由于其姓名与 p3 相同,数据库管理系统(DBMS)将抛出异常。因此 p4 未被插入,且 JDBC 驱动程序向客户端抛出异常。
- 第 27 行:我们处理该异常
- 第 29–31 行:我们显示该异常及其在导致当前情况的异常链中之前的两个原因。
- 第 34 行:回滚当前活动的事务。该事务始于 Java 代码的第 9 行。此后,执行了一次更新操作以更改 p1 的子女数量,随后又执行了一次针对人员 p3 的插入操作。回滚将撤销所有这些操作。
- 第 39 行:清除持久化上下文
- 第 42 行:显示 [jpa01_personne] 表。我们必须验证 p1 仍有 6 个子女,且 p3 和 p4 均不在表中。
测试 11 的控制台输出如下:
main : ----------- test11
[personnes]
[1,6,Martin,Paul,31/01/2000,false,7]
14:50:30,312 ERROR JDBCExceptionReporter:72 - Duplicate entry 'X' for key 2
Erreur dans transaction [javax.persistence.EntityExistsException,org.hibernate.exception.ConstraintViolationException: could not insert: [entites.Personne],org.hibernate.exception.ConstraintViolationException,could not insert: [entites.Personne],java.sql.SQLException,Duplicate entry 'X' for key 2]
[personnes]
[1,5,Martin,Paul,31/01/2000,false,6]
- 第3行:数据库中p1的子节点数量已从6变为7;p1的版本已更新为6。
- 第4行:事务提交期间捕获的异常。仔细阅读可知,原因在于重复键X(名称)。这是由于插入p4导致的错误,因为已插入的p3也具有名称X。
- 第 7 行:回滚后的表。p1 已恢复到版本 5,且再次拥有 6 个子节点;p3 和 p4 未被插入。
2.1.13.13. 测试 12
test12 的代码如下:
// we do the same thing again but without the transactions
// we obtain the same result as before with SGBD : FIREBIRD, ORACLE XE, POSTGRES, MYSQL5
// with SQLSERVER we have an empty table. The connection is left in a state that prevents reexecution
// of the program. The server must then be restarted.
// idem with SGBD Derby
// HSQL inserts 1st person - there is no rollback
public static void test12() throws ParseException {
// reconnect p1
p1 = em.find(Personne.class, p1.getId());
// increment the number of children in p1
p1.setNbenfants(p1.getNbenfants() + 1);
// display people - the number of children in p1 must have changed
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// creation of 2 persons with identical names, which is forbidden by the DDL
Personne p3 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p4 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
// persistence of people
em.persist(p3);
em.persist(p4);
// dump, which will sync the em context with the BD
try {
dump();
} catch (RuntimeException e3) {
System.out.format("Erreur dans dump [%s,%s,%s,%s]%n", e3.getClass().getName(), e3.getMessage(), e3.getCause().getClass().getName(), e3
.getCause().getMessage());
}
// we close the current context
em.close();
// dump
dump();
}
- 测试 12 重复了测试 11 的相同过程,但不在事务中进行。我们想看看这种情况下会发生什么。
- 第 1–6 行:展示在多种数据库管理系统(DBMS)上的测试结果:
- 在多种数据库管理系统(Firebird、Oracle、MySQL5、Postgres)中,我们得到的结果与测试 11 相同。这表明这些数据库管理系统自行启动了一个事务,涵盖了截至引发错误的语句之前收到的所有 SQL 语句,并且它们自行执行了回滚。
- 在其他数据库管理系统(SQL Server、Apache Derby)中,应用程序和/或数据库管理系统会崩溃。
- 在 HSQLDB 数据库管理系统中,该系统开启的事务似乎处于自动提交模式:p1 的子节点数量修改以及 p3 的插入操作均被永久保存。仅 p4 的插入操作失败。
因此,我们得到的结果取决于所使用的 DBMS,这导致应用程序无法移植。请注意,对持久化上下文的操作必须始终在事务内进行。
2.1.14. 更换数据库管理系统
让我们重新审视当前项目的测试架构:
 |
客户端应用程序 [3] 仅能看到 JPA 接口 [5]。 它既看不到其实际实现,也看不到目标数据库管理系统(DBMS)。因此,我们必须能够在不修改客户端[3]的情况下,更改链条中的这两个元素。这就是我们接下来将尝试演示的内容,首先从更换数据库管理系统开始。迄今为止,我们一直使用MySQL5。我们将在附录(第5节)中介绍另外六种数据库管理系统,希望其中有读者偏好的数据库管理系统。
无论如何,在 Eclipse 项目中进行的修改都很简单(见下文):将 JPA 层的 persistence.xml [1] 配置文件替换为项目 conf [2] 文件夹中的其中一个。这些 DBMS 的 JDBC 驱动程序已包含在 [jpa-drivers] [3] 和 [4] 库中。
 |
2.1.14.1. Oracle 10g Express
Oracle 10g Express 介绍见附录第 5.7 节。Oracle 的 persistence.xml 文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Persistent classes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="oracle.jdbc.OracleDriver" />
<property name="hibernate.connection.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- automatic schematic creation -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.OracleDialect" />
<!-- properties DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
此配置与用于 MySQL5 数据库管理系统(DBMS)的配置完全相同,仅有以下细微差异:
- 第 15–18 行,用于配置与数据库的 JDBC 连接
- 第22行:设置要使用的SQL方言
在接下来的示例中,我们将仅列出发生变更的行。 有关配置的详细说明,请参阅针对所用数据库管理系统(DBMS)的附录。该附录中每次都会提供一个使用 JDBC 连接的示例,并结合 [SQL Explorer] 插件进行说明。借助附录中的信息,读者可以重现第 2.1.10.2 节中执行 [InitDB] 应用程序并验证其结果的过程。
我们按照前述章节的说明进行操作:
- 启动 Oracle DBMS
- 将 conf/oracle/persistence.xml 放置于 META-INF/persistence.xml 目录下
- 运行 [InitDB] 应用程序
控制台将显示以下结果:
 |
从现在起,我们将不再显示此屏幕截图,因为它保持不变。更有趣的是通过 SQL Explorer 查看与 DBMS 的 JDBC 连接。我们将按照第 2.1.8 节中所述的步骤进行操作。
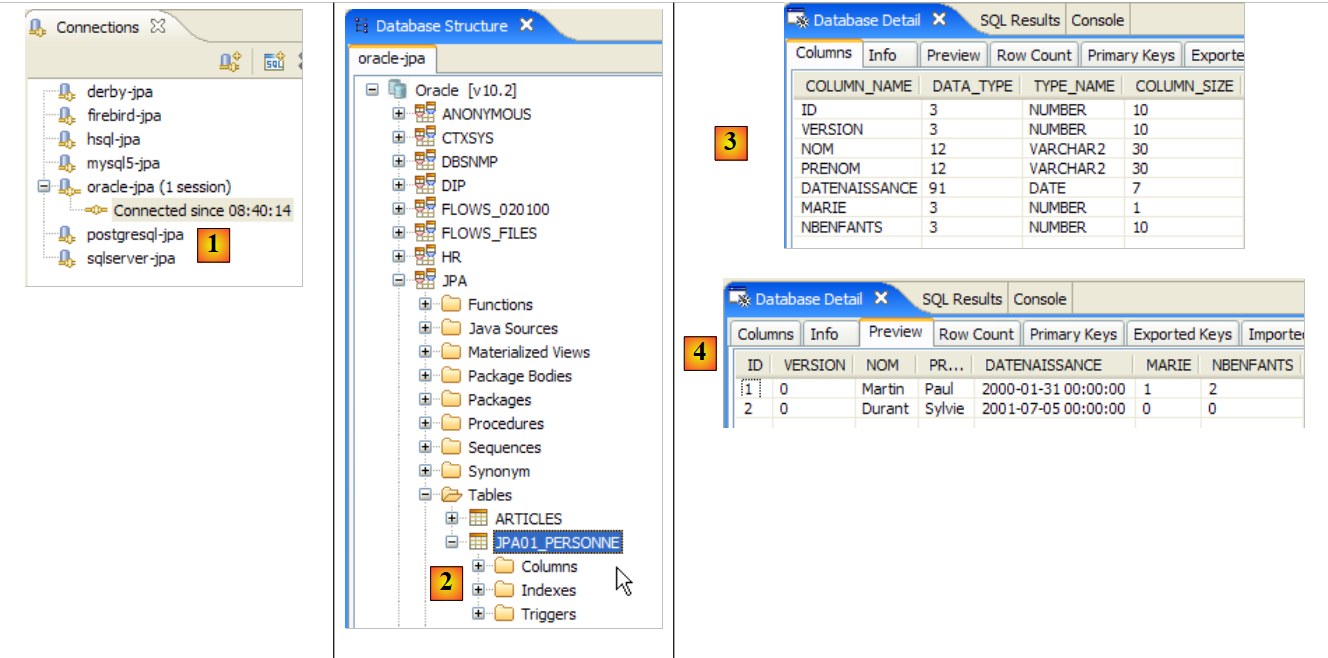 |
- 在 [1] 中:与 Oracle 的连接
- 在 [2] 中:运行 [InitDB] 后的连接树
- 在 [3] 中:[jpa01_personne] 表的结构
- 在 [4] 中:其内容。
完成上述步骤后,请运行 [Main] 应用程序,然后关闭数据库管理系统。
2.1.14.2. PostgreSQL 8.2
PostgreSQL 8.2 的内容在附录第 5.6 节中介绍。其 persistence.xml 文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="org.postgresql.Driver" />
<property name="hibernate.connection.url" value="jdbc:postgresql:jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.PostgreSQLDialect" />
...
</persistence-unit>
</persistence>
要运行 [InitDB]:
- 启动 PostgreSQL 数据库管理系统
- 将 conf/postgres/persistence.xml 放置到 META-INF/persistence.xml 中
- 运行 [InitDB] 应用程序
JDBC 连接到 DBMS 的 SQL Explorer 视图如下:
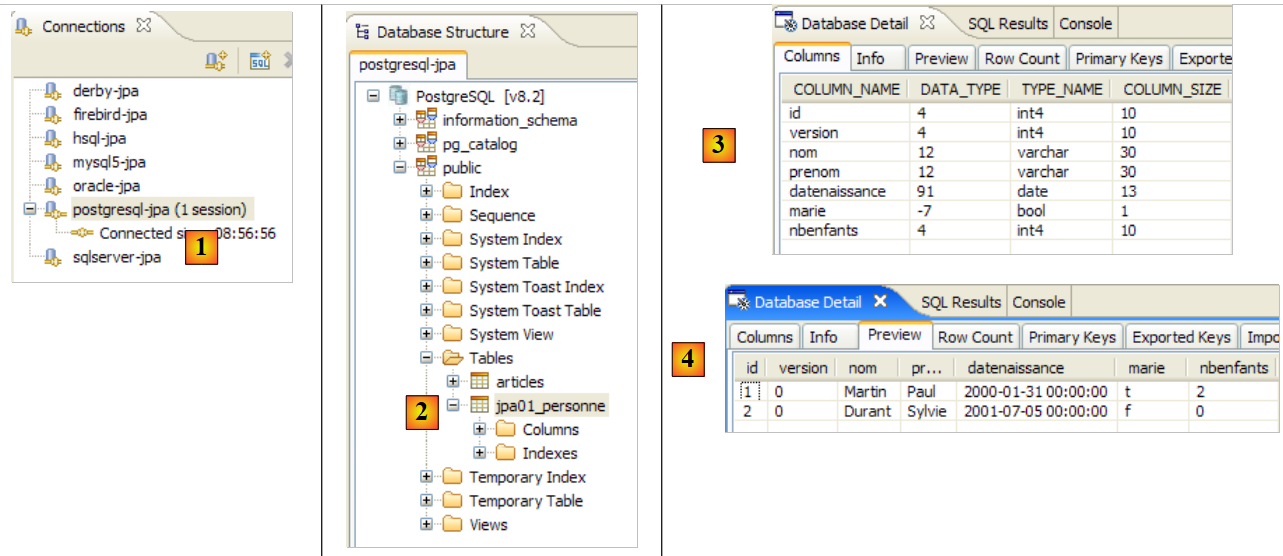 |
- 在 [1] 中:与 PostgreSQL 的连接
- 在 [2]:运行 [InitDB] 后的连接树
- 在 [3]:[jpa01_personne] 表的结构
- 在 [4]:其内容。
完成上述步骤后,请读者运行 [Main] 应用程序,然后关闭数据库管理系统
2.1.14.3. SQL Server Express 2005
SQL Server Express 2005 的介绍见附录第 5.8 节,第 270 页。其 persistence.xml 文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="com.microsoft.sqlserver.jdbc.SQLServerDriver" />
<property name="hibernate.connection.url" value="jdbc:sqlserver://localhost\\SQLEXPRESS:1433;databaseName=jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.SQLServerDialect" />
...
</persistence-unit>
</persistence>
要运行 [InitDB]:
- 启动 SQL Server 数据库管理系统
- 将 conf/sqlserver/persistence.xml 放置到 META-INF/persistence.xml
- 运行 [InitDB] 应用程序
通过 JDBC 连接到数据库管理系统(DBMS)的 SQL Explorer 视图如下:
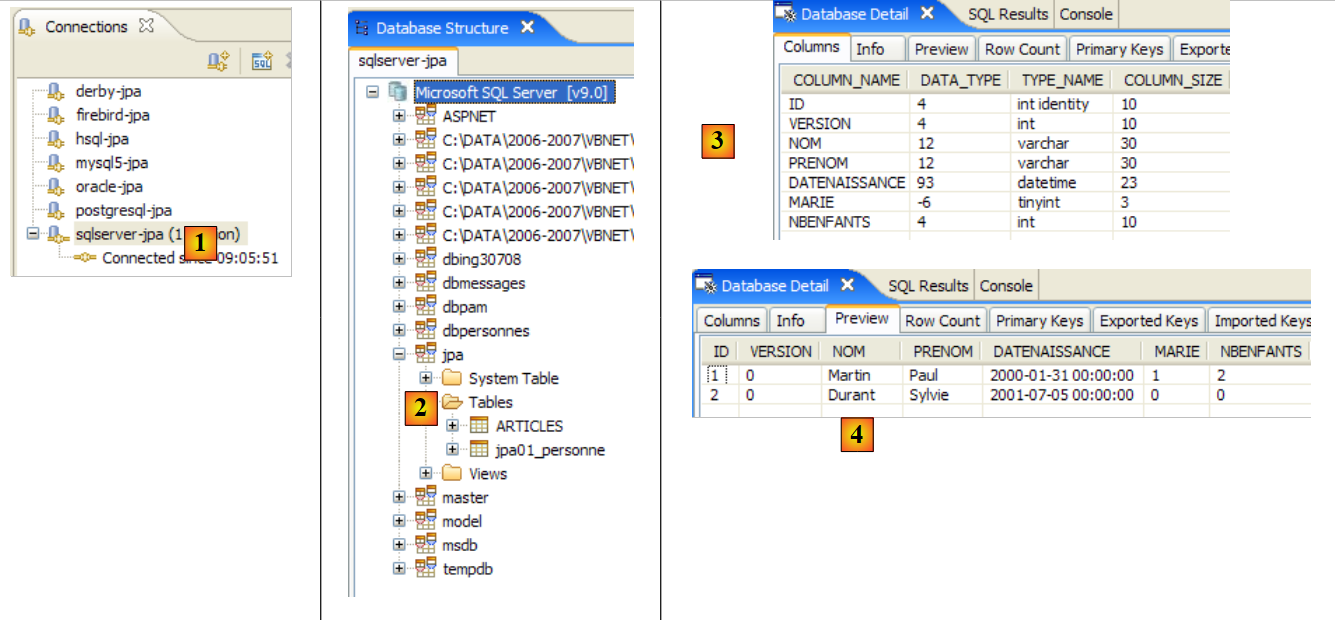 |
- 在 [1] 中:与 SQL Server 的连接
- 在 [2]:运行 [InitDB] 后的连接树
- 在 [3]:[jpa01_personne] 表的结构
- 在 [4]:其内容。
完成上述操作后,请运行 [Main] 应用程序,然后关闭数据库管理系统
2.1.14.4. Firebird 2.0
Firebird 2.0 的介绍见附录第 5.4 节。其 persistence.xml 文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="org.firebirdsql.jdbc.FBDriver" />
<property name="hibernate.connection.url" value="jdbc:firebirdsql:localhost/3050:C:\data\2006-2007\eclipse\dvp-jpa\annexes\firebird\jpa.fdb" />
<property name="hibernate.connection.username" value="sysdba" />
<property name="hibernate.connection.password" value="masterkey" />
...
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.FirebirdDialect" />
...
</persistence-unit>
</persistence>
要运行 [InitDB]:
- 启动 Firebird 数据库管理系统
- 将 conf/firebird/persistence.xml 放置到 META-INF/persistence.xml 目录下
- 运行 [InitDB] 应用程序
JDBC 连接至 DBMS 的 SQL Explorer 视图如下:
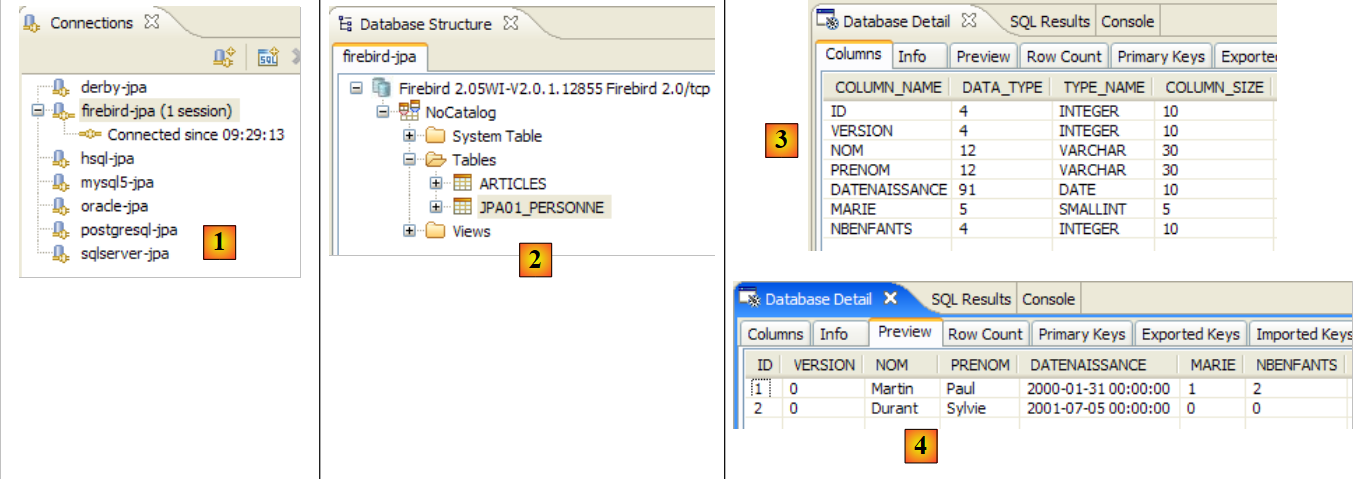 |
- 在 [1] 中:与 Firebird 的连接
- 在 [2]:运行 [InitDB] 后的连接树
- 在 [3]:[jpa01_personne] 表的结构
- 在 [4]:其内容。
完成上述步骤后,请运行 [Main] 应用程序,然后关闭数据库管理系统。
2.1.14.5. Apache Derby
Apache Derby 的介绍见附录第 5.10 节。其 persistence.xml 文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="org.apache.derby.jdbc.ClientDriver" />
<property name="hibernate.connection.url" value="jdbc:derby://localhost:1527//data/2006-2007/eclipse/dvp-jpa/annexes/derby/jpa;create=true" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialect -->
...
</persistence-unit>
</persistence>
要运行 [InitDB]:
- 启动 Apache Derby 数据库管理系统
- 将 conf/derby/persistence.xml 放置到 META-INF/persistence.xml 目录下
- 运行 [InitDB] 应用程序
JDBC 连接到 DBMS 的 SQL Explorer 视图如下:
 |
- [1]:与 Apache Derby 的连接
- 在 [2] 中:运行 [InitDB] 后的连接树。请注意由 JPA/Hibernate 创建的 [HIBERNATE_UNIQUE_KEY] 表,用于为主键 ID 自动生成连续值。我们此前已指出,这种机制通常具有专有性。这一点在此处显而易见。得益于 JPA,开发人员无需深入研究这些数据库管理系统(DBMS)的细节。
- 在 [3] 中:[jpa01_personne] 表的结构
- 在 [4] 中:其内容。
完成上述操作后,请运行 [Main] 应用程序,然后关闭数据库管理系统。
2.1.14.6. HSQLDB
HSQLDB 的介绍见附录第 5.9 节。其 persistence.xml 文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="org.hsqldb.jdbcDriver" />
<property name="hibernate.connection.url" value="jdbc:hsqldb:hsql://localhost" />
<property name="hibernate.connection.username" value="sa" />
<!--
<property name="hibernate.connection.password" value="" />
-->
...
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.HSQLDialect" />
...
</properties>
</persistence-unit>
</persistence>
要运行 [InitDB]:
- 启动 HSQL 数据库管理系统
- 将 conf/hsql/persistence.xml 放置到 META-INF/persistence.xml 目录下
- 运行 [InitDB] 应用程序
JDBC 连接到 DBMS 的 SQL Explorer 视图如下:
 |
- 在 [1] 中:与 HSQL 的连接
- 在 [2]:运行 [InitDB] 后的连接树。
- 在 [3]:[jpa01_personne] 表的结构
- 在 [4]:其内容。
完成上述操作后,请运行 [Main] 应用程序,然后停止 DBMS。
2.1.15. 更改 JPA 实现
让我们重新审视当前项目的测试架构:
 |
前文研究表明,我们可以在不修改客户端代码[3]的情况下更换数据库管理系统[7]。现在我们将更换 JPA 实现[6],并再次证明这一操作对客户端代码[3]而言是透明的。我们将使用 TopLink 实现[http://www.oracle.com/technology/products/ias/toplink/jpa/index.html]:
 |
2.1.15.1. Eclipse 项目
鉴于 JPA 实现方式的变更,我们正在创建一个新的 Eclipse 项目,以免影响现有项目。事实上,新项目使用的持久化库可能会与 Hibernate 的持久化库发生冲突:
 |
- 在 [1] 中:文件夹 [<examples>/toplink/direct/people-entities] 包含该 Eclipse 项目。请将其导入。
- 在 [2] 中:导入的 [toplink-personnes-entites] 项目。该项目与 [hibernate-personne-entites] 项目完全相同(因为是复制的),但有两个细节不同:
- [META-INF/persistence.xml] 文件 [3] 现已配置为 JPA/Toplink 层
- [jpa-hibernate] 库已被 [jpa-toplink] 库 [4] 和 [5] 取代(参见第 1.5 段)。
- 在 [6] 中:[conf] 文件夹包含针对每个数据库管理系统(DBMS)的 [persistence.xml] 文件版本。
- 在 [7] 中:[ddl] 文件夹将包含用于生成数据库模式的 SQL 脚本。
2.1.15.2. 配置 JPA / Toplink
我们知道,JPA 层由 [META-INF/persistence.xml] 文件进行配置。该文件目前配置的是 JPA / Toplink 实现。其用于 JPA 层与 MySQL5 DBMS 对接的内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- persistent classes -->
<class>entites.Personne</class>
<!-- persistence unit properties -->
<properties>
<!-- connection JDBC -->
<property name="toplink.jdbc.driver" value="com.mysql.jdbc.Driver" />
<property name="toplink.jdbc.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="toplink.jdbc.user" value="jpa" />
<property name="toplink.jdbc.password" value="jpa" />
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
<!-- SGBD -->
<property name="toplink.target-database" value="MySQL4" />
<!-- application server -->
<property name="toplink.target-server" value="None" />
<!-- generation diagram -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/mysql5" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
<!-- logs -->
<property name="toplink.logging.level" value="OFF" />
</properties>
</persistence-unit>
</persistence>
- 第 3 行:未更改
- 第 5 行:提供者现为 Toplink。此处命名的类可在 [jpa-toplink] 库中找到(见下文 [1]):
 |
- 第 7 行:<class> 标签用于列出项目中的所有 @Entity 类;此处仅列出了 Person 类。Hibernate 曾提供过一个配置选项,允许我们无需手动列出这些类。该选项会扫描项目的类路径以查找 @Entity 类。
- 第 9 行:<properties> 标签用于声明所用 JPA 实现(此处为 Toplink)的特定属性。
- 第 11–14 行:配置与 MySQL5 数据库管理系统 (DBMS) 的 JDBC 连接
- 第 15–18 行:配置由 Toplink 原生管理的 JDBC 连接池:
- 第 15、16 行:读取连接池中的最大和最小连接数。默认值为 (2,2)
- 第 17、18 行:写入连接池中的最大和最小连接数。默认值为 (10,2)
- 第 20 行:目标数据库管理系统(DBMS)。支持的数据库管理系统列表可在 [oracle.toplink.essentials.platform.database] 包中找到(参见上文 [2])。由于列表 [2] 中未包含 MySQL5 数据库管理系统,因此我们选择了 MySQL4。TopLink 支持的数据库管理系统种类比 Hibernate 略少。 因此,在我们示例中使用的七种 DBMS 中,Firebird 不受支持。Oracle 也不在该列表中。它实际上位于另一个包中(见上文 [3])。如果在这两个包中,目标 DBMS 由 <Sgbd>Platform.class 类指定,则该标签将写为:
<property name="toplink.target-database" value="<Sgbd>" />
- 第 22 行:如果应用程序在应用服务器上运行,则设置应用服务器。当前可能的值包括 (None、OC4J_10_1_3、SunAS9)。默认值为 (None)。
- 第 24–28 行:当 JPA 层初始化时,会指令其清空第 11–14 行中通过 JDBC 连接定义的数据库。这确保我们从空数据库开始。
- 第 24 行:指示 TopLink 先删除再创建数据库模式中的表
- 第 25 行:我们指示 TopLink 生成用于删除和创建操作的 SQL 脚本。application-location 指定了生成这些脚本的目录。默认值:(当前目录)。
- 第 26 行:用于创建操作的 SQL 脚本名称。默认值:createDDL.jdbc。
- 第 27 行:用于删除操作的 SQL 脚本名称。默认值:dropDDL.jdbc。
- 第 28 行:模式生成模式(默认:both):
- both:脚本和数据库
- database:仅数据库
- sql-script:仅生成脚本
- 第 30 行:TopLink 日志记录已禁用(OFF)。可用的日志级别包括:OFF、SEVERE、WARNING、INFO、CONFIG、FINE、FINER、FINEST。默认值:INFO。
有关可与 TopLink 配合使用的 <property> 标签的完整定义,请参阅 URL [http://www.oracle.com/technology/products/ias/toplink/JPA/essentials/toplink-jpa-extensions.html]。
2.1.15.3. 测试 [InitDB]
无需进行其他操作。我们已准备好运行第一个 [InitDB] 测试:
- 启动数据库管理系统(DBMS),本例中为 MySQL5
- 运行 [InitDB]
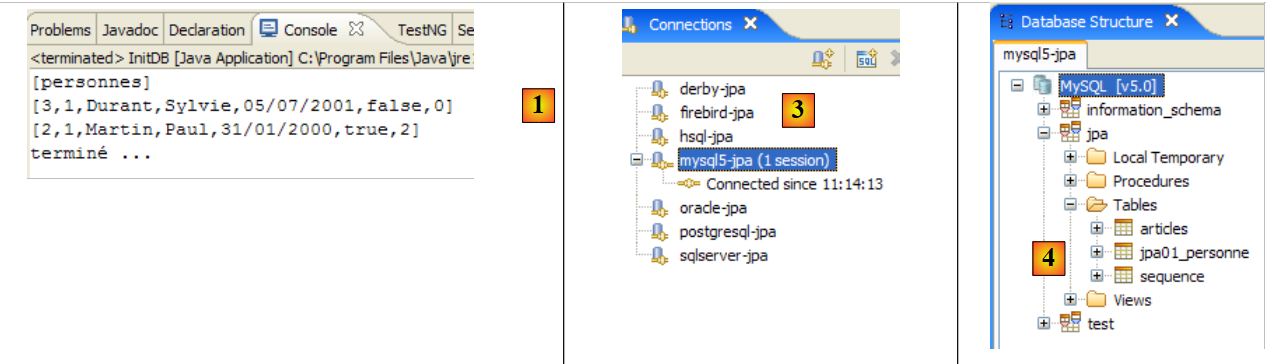 |
- 在 [1] 中:控制台显示。我们可以看到已通过 JPA / Hibernate 获得的结果。
- 在 [3] 中:打开 [SQL Explorer] 视图,然后打开 [mysql5-jpa] 连接
- 在 [4] 中:JPA 数据库树。我们可以看到,运行 [InitDB] 创建了两个表:预期的 [jpa01_personne] 表,以及不太预期的 [sequence] 表。
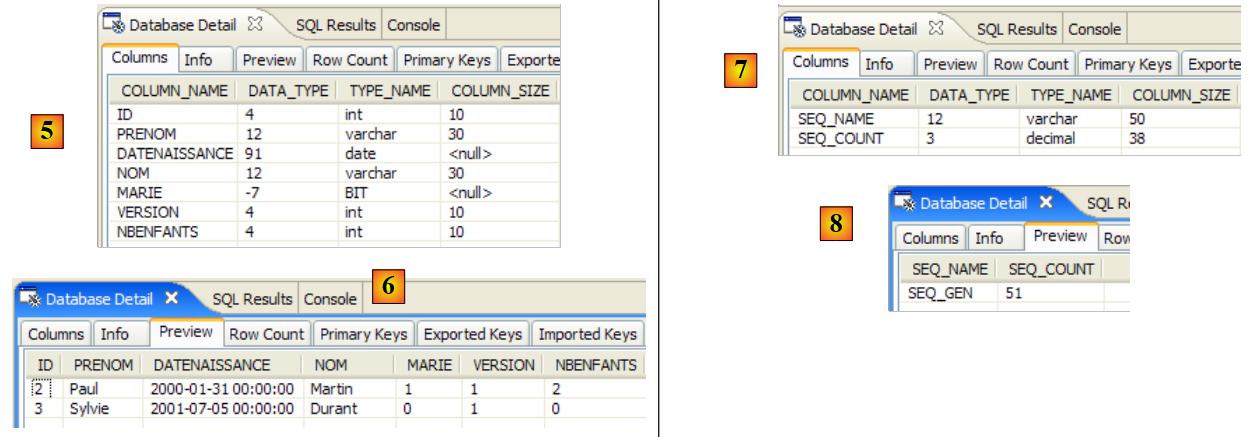 |
- 在 [5] 中:[jpa01_personne] 表的结构,以及在 [6] 中其内容
- 在 [7] 中:[sequence] 表的结构,以及在 [8] 中其内容。
配置文件 [persistence.xml] 请求生成 DDL 脚本:
<!-- génération schéma -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/mysql5" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
让我们来看看 [ddl/mysql5] 文件夹中生成了什么:
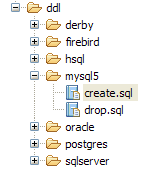 |
create.sql
CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
- 第 1 行:[jpa01_personne] 表的 DDL。请注意,Toplink 并未为 ID 主键使用 autoincrement 属性。因此,插入行时 ID 不会自动递增。
- 第 2 行:[sequence] 表的 DDL。其名称表明 Toplink 使用该表为 ID 主键生成值。
- 第 3 行:向 [SEQUENCE] 表插入一行数据
drop.sql
DROP TABLE jpa01_personne
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
- 第 1 行:删除 [jpa01_personne] 表
- 第 2 行:从 [SEQUENCE] 表中删除特定行。该表本身不会被删除,其中可能包含的其他行也不会被删除。
若要进一步了解 [SEQUENCE] 表的作用,请在 [persistence.xml] 中将 TopLink 日志级别设置为 FINE 级别,该级别会记录 TopLink 发出的 SQL 语句:
<!-- logs -->
<property name="toplink.logging.level" value="FINE" />
再次运行 InitDB。以下是控制台输出的部分内容:
...
[TopLink Config]: 2007.05.28 12:07:52.796--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--Connected: jdbc:mysql://localhost:3306/jpa
User: jpa@localhost
Database: MySQL Version: 5.0.37-community-nt
Driver: MySQL-AB JDBC Driver Version: mysql-connector-java-3.1.9 ( $Date: 2005/05/19 15:52:23 $, $Revision: 1.1.2.2 $ )
...
[TopLink Fine]: 2007.05.28 12:07:53.093--ServerSession(12910198)--Connection(19255406)--Thread(Thread[main,5,main])--DROP TABLE jpa01_personne
[TopLink Fine]: 2007.05.28 12:07:53.265--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
[TopLink Fine]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Connection(19255406)--Thread(Thread[main,5,main])--CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
[TopLink Warning]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Thread(Thread[main,5,main])--Exception [TOPLINK-4002] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (03/30/2007)): oracle.toplink.essentials.exceptions.DatabaseException
Internal Exception: java.sql.SQLException: Table 'sequence' already exists
Error Code: 1050
Call: CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
Query: DataModifyQuery()
[TopLink Fine]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
[TopLink Fine]: 2007.05.28 12:07:53.609--ServerSession(12910198)--Connection(19255406)--Thread(Thread[main,5,main])--SELECT * FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
[TopLink Fine]: 2007.05.28 12:07:53.609--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
[TopLink Fine]: 2007.05.28 12:07:53.734--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--delete from jpa01_personne
[TopLink Fine]: 2007.05.28 12:07:53.750--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--UPDATE SEQUENCE SET SEQ_COUNT = SEQ_COUNT + ? WHERE SEQ_NAME = ?
bind => [50, SEQ_GEN]
[TopLink Fine]: 2007.05.28 12:07:53.750--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--SELECT SEQ_COUNT FROM SEQUENCE WHERE SEQ_NAME = ?
bind => [SEQ_GEN]
[personnes]
[TopLink Fine]: 2007.05.28 12:07:53.906--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--INSERT INTO jpa01_personne (ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS) VALUES (?, ?, ?, ?, ?, ?, ?)
bind => [3, Sylvie, 2001-07-05, Durant, false, 1, 0]
[TopLink Fine]: 2007.05.28 12:07:53.921--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--INSERT INTO jpa01_personne (ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS) VALUES (?, ?, ?, ?, ?, ?, ?)
bind => [2, Paul, 2000-01-31, Martin, true, 1, 2]
[TopLink Fine]: 2007.05.28 12:07:53.937--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--SELECT ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS FROM jpa01_personne ORDER BY NOM ASC
[3,1,Durant,Sylvie,05/07/2001,false,0]
[2,1,Martin,Paul,31/01/2000,true,2]
[TopLink Config]: 2007.05.28 12:07:54.062--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--disconnect
[TopLink Info]: 2007.05.28 12:07:54.062--ServerSession(12910198)--Thread(Thread[main,5,main])--file:/C:/data/2006-2007/eclipse/dvp-jpa/toplink/direct/personnes-entites/bin/-jpa logout successful
...
terminé ...
- 第 2-5 行:使用相关参数连接到数据库管理系统(DBMS)。实际上,日志显示 Toplink 实际上创建了 3 个连接到 DBMS 的连接。我们需要检查这个数字是否与 JDBC 连接池所使用的某个配置值有关:
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
- 第 7 行:删除 [jpa01_personne] 表。这是正常的,因为 [persistence.xml] 文件要求清理 JPA 数据库。
- 第 8 行:创建 [jpa01_personne] 表。请注意,主键 ID 没有 autoincrement 属性。
- 第 9 行:创建 [SEQUENCE] 表,该表已存在,是在上次执行时创建的。
- 第 10–13 行:TopLink 报告创建 [SEQUENCE] 表时发生错误。
- 第 15–18 行:TopLink 清空 [SEQUENCE] 表。清理后,[SEQUENCE] 表包含一行(SEQ_NAME, SEQ_COUNT),其值为 ('SEQ_GEN', 1)。
- 第 18 行:清空 [jpa01_personne] 表。
- 第 19–20 行:TopLink 更新 [SEQUENCE] 表中 SEQ_NAME = 'SEQ_GEN' 的单行,将值从 ('SEQ_GEN', 1) 更改为 ('SEQ_GEN', 51)。
- 第 21 行:TopLink 从 [SEQUENCE] 表中的行 ('SEQ_GEN', 51) 中检索值 51。
- 第 24–27 行:TopLink 将两名人员 'Martin' 和 'Durant' 插入到 [jpa01_personne] 表中。 这里存在一个谜团:这两行数据的主键被分配了值 2 和 3,却没有任何关于这些值如何获得的解释。第 21 行获取的 SEQ_COUNT 值(51)是否起到了任何作用,这一点尚不明确。请注意,这些行的版本值为 1,而 Hibernate 通常从 0 开始。
- 第 28 行:TopLink 执行 SELECT 语句,从 [jpa01_personne] 表中检索所有行
- 第 29–30 行:Java 客户端显示的行
- 第 31–32 行:TopLink 关闭连接。它将针对最初打开的每个连接重复此操作。
最终,我们虽不清楚 [SEQUENCE] 表的具体用途,但它似乎在生成主键 ID 值的过程中起着一定作用。通过将日志级别设置为最高级别 FINEST,我们可以进一步了解 [SEQUENCE] 表的作用。
<!-- logs -->
<property name="toplink.logging.level" value="FINEST" />
下面,我们仅列出了与将这两个人插入表相关的日志。在这里,我们可以看到生成主键值的机制:
- 第4行:我们可以看到,第2行从[SEQUENCE]表中检索到的数字51被用于限定主键的取值范围:[2,51]
- 第 5 行:将值 2 作为主键分配给第一个人
- 第 8 行:第二个人被分配了值 3 作为主键
- 第 12 行:显示了第一人的版本管理
- 第 17 行:第二位人员的情况相同
[FINEST] 日志级别还会显示 Toplink 发起的交易边界。分析这些日志可以揭示 Toplink 的工作原理,是理解对象-关系桥接机制的绝佳途径。
上述内容的要点:
- 不同的 JPA 实现会生成不同的数据库模式。在此示例中,Hibernate 和 Toplink 生成的模式并不相同。
- 当您需要明确了解 Toplink 的具体操作时,应使用 Toplink 的 FINE、FINER 和 FINEST 日志级别。
2.1.15.4. 测试 [Main]
现在我们运行 [Main] 测试:
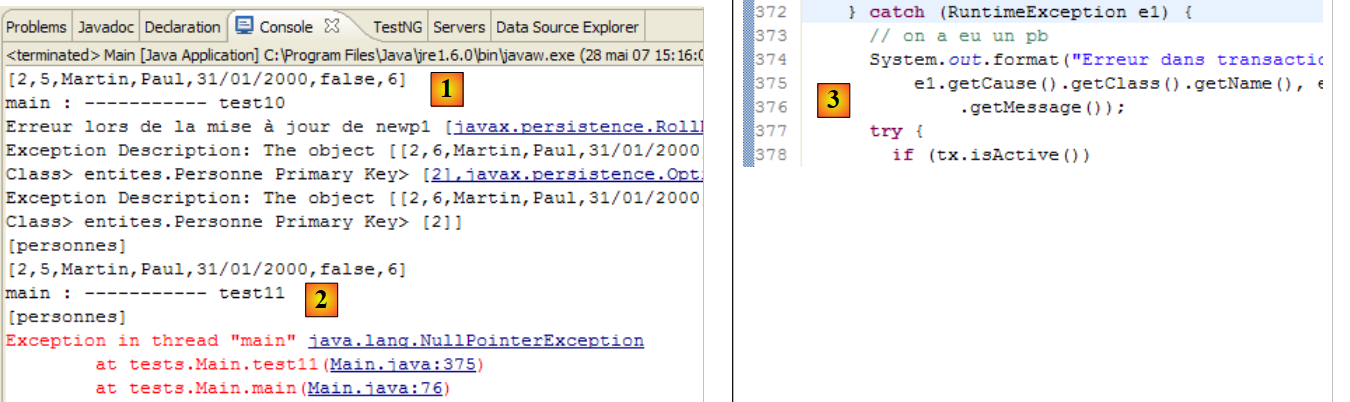 |
- 在 [1]:除测试 11 外,所有测试均通过 [2]
- 在 [3] 中:第 376 行,即发生异常的代码行
抛出异常的代码如下:
} catch (RuntimeException e1) {
// on a eu un pb
System.out.format("Erreur dans transaction [%s,%s,%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage(), e1.getCause().getCause().getClass().getName(), e1.getCause().getCause()
.getMessage());
try {
...
- 第 [3] 行:抛出异常的行。 这里出现了一个 NullPointerException,这表明第 4 行和第 5 行中的某个 getCause 方法返回了空指针。诸如 [e1.getCause().getCause()] 之类的表达式假设异常链包含 3 个元素 [e1.getCause().getCause(), e1.getCause(), e1]。如果只有两个元素,第一个表达式将引发异常。
我们将之前的代码进行修改,使其仅显示异常链中的最后两个异常:
} catch (RuntimeException e1) {
// on a eu un pb
System.out.format("Erreur dans transaction [%s,%s,%s,%s,]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage());
try {
...
执行后,我们得到以下结果:
...
[personnes]
[2,5,Martin,Paul,31/01/2000,false,6]
main : ----------- test11
[personnes]
Erreur dans transaction [javax.persistence.OptimisticLockException,Exception [TOPLINK-5006] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (03/30/2007))): oracle.toplink.essentials.exceptions.OptimisticLockException
Exception Description: The object [[2,6,Martin,Paul,31/01/2000,false,7]] cannot be updated because it has changed or been deleted since it was last read.
Class> entites.Personne Primary Key> [2],oracle.toplink.essentials.exceptions.OptimisticLockException,
Exception Description: The object [[2,6,Martin,Paul,31/01/2000,false,7]] cannot be updated because it has changed or been deleted since it was last read.
Class> entites.Personne Primary Key> [2],]
[personnes]
[2,5,Martin,Paul,31/01/2000,false,6]
这次,测试 11 通过了。异常日志(第 6–10 行)是由 Java 代码(上述代码的第 3 行)触发的。 回顾一下,测试 11 在单个事务内串联了多个 SQL 操作,其中一个操作失败,预计会导致事务回滚。测试前(第 3 行)和测试后(第 12 行)[jpa01_personne] 表的状态完全一致,表明回滚已发生。
这里需要特别注意的是,JPA/Hibernate 和 JPA/Toplink 的实现并非完全互换。在此示例中,我们必须修改 JPA 客户端代码以避免 NullPointerException。稍后我们将在异常处理的背景下再次遇到此问题。
2.1.16. 在 JPA/Toplink 实现中更换 DBMS
让我们重新审视当前项目的测试架构:
 |
此前,[7]中使用的数据库管理系统(DBMS)是MySQL 5。我们将演示如何切换至Oracle作为DBMS。无论如何,Eclipse项目所需的修改都很简单(见下文):将JPA层的persistence.xml配置文件[1]替换为项目conf文件夹中的其中一个([2]和[3])。
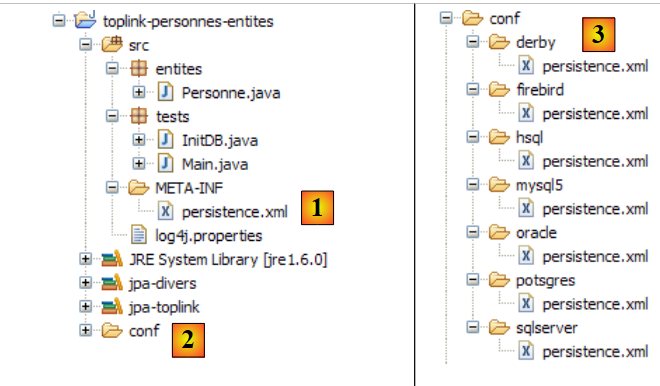 |
2.1.16.1. Oracle 10g Express
Oracle 10g Express 介绍详见附录第 5.7 节。TopLink 的 Oracle persistence.xml 文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- persistent classes -->
<class>entites.Personne</class>
<!-- persistence unit properties -->
<properties>
<!-- connection JDBC -->
<property name="toplink.jdbc.driver" value="oracle.jdbc.OracleDriver" />
<property name="toplink.jdbc.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="toplink.jdbc.user" value="jpa" />
<property name="toplink.jdbc.password" value="jpa" />
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
<!-- SGBD -->
<property name="toplink.target-database" value="Oracle" />
<!-- application server -->
<property name="toplink.target-server" value="None" />
<!-- generation diagram -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/oracle" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
<!-- logs -->
<property name="toplink.logging.level" value="OFF" />
</properties>
</persistence-unit>
</persistence>
此配置与用于 MySQL5 数据库管理系统(DBMS)的配置完全相同,仅有以下细微差异:
- 第 11–14 行,用于配置与数据库的 JDBC 连接
- 第 20 行:指定目标数据库管理系统
- 第 25 行:指定生成 DDL SQL 脚本的目录
要运行 [InitDB] 测试:
- 启动 Oracle DBMS
- 将 conf/oracle/persistence.xml 放置于 META-INF/persistence.xml 目录下
- 运行 [InitDB] 应用程序
控制台和 [SQL Explorer] 视图中将显示以下结果:
 |
- [1]: 控制台显示
- [2]: SQL Explorer 中的 [oracle-jpa] 连接
- [3]:JPA 数据库
- [4]:InitDB 已创建两个表:JPA01_PERSONNE 和 SEQUENCE,与 MySQL5 相同。有时在 [4] 中会出现 [BIN*] 表,这些对应于已被删除的表。 要观察这一现象,只需重新运行 [InitDB]。JPA 层的初始化阶段包含对 JPA 数据库的清理,在此过程中会删除 [JPA01_PERSONNE] 表:
 |
在 [A] 中,会出现一个 [BIN] 表。Oracle 不会永久删除已被删除的表,而是将其放入 [回收站]。如第 5.7.4 节所述,使用 SQL Developer 工具可查看此回收站 [B]。 在[B]中,我们可以将[JPA01_PERSONNE]表从回收站中彻底清除。这将清空回收站[C]。如果我们在SQL Explorer中刷新表(右键单击 / 刷新),会发现该BIN表已不复存在[D]。
- [5, 6]:[JPA01_PERSONNE] 表的结构和内容
- [7, 8]:[SEQUENCE] 表的结构和内容
好了!现在请读者在 Oracle 上运行 [Main] 应用程序。
2.1.16.2. 其他数据库管理系统
本文不会详细介绍其他数据库管理系统。您只需按照针对 Oracle 的相同步骤操作即可。请注意以下几点:
- 无论使用何种DBMS,TopLink始终采用相同的技术为[JPA01_PERSONNE]表生成主键ID值:即使用上文所述的[SEQUENCE]表。
- TopLink 不支持 Firebird 数据库管理系统。针对此类情况,有一个通用的数据库设置:
使用名为 [Auto] 的通用数据库时,Firebird 测试会因 SQL 语法错误而失败。TopLink 为主键 ID 使用了 SQL 类型 Number(10),而 Firebird 不识别该类型。因此,您必须选择一种与 Firebird 具有相同 SQL 类型的数据库管理系统(以本例为例)。Apache Derby 即符合此要求:
<!-- connexion JDBC -->
<property name="toplink.jdbc.driver" value="org.firebirdsql.jdbc.FBDriver" />
...
<!-- SGBD -->
<!--
TopLink ne reconnaît pas Firebird pour l'instant (05/07). Derby convient pour remplacer.
-->
<property name="toplink.target-database" value="Derby" />
...
- TopLink 无法为 HSQLDB 数据库管理系统生成原始数据库模式。也就是说,该指令:
<!-- génération schéma -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
在 HSQLDB 上失败。原因是创建表 [jpa01_personne] 时出现语法错误:
[TopLink Fine]: 2007.05.29 09:44:18.515--ServerSession(12910198)--Connection(29775659)--Thread(Thread[main,5,main])--DROP TABLE jpa01_personne
[TopLink Fine]: 2007.05.29 09:44:18.531--ServerSession(12910198)--Connection(29775659)--Thread(Thread[main,5,main])--CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
[TopLink Warning]: 2007.05.29 09:44:18.531--ServerSession(12910198)--Thread(Thread[main,5,main])--Exception [TOPLINK-4002] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (03/30/2007)): oracle.toplink.essentials.exceptions.DatabaseException
Internal Exception: java.sql.SQLException: Unexpected token: UNIQUE in statement [CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE]
第 4 行:HSQL 不接受语法 LAST_NAME VARCHAR(30) UNIQUE NOT NULL。Hibernate 使用的语法是:LAST_NAME VARCHAR(30) NOT NULL, UNIQUE(LAST_NAME)。
总体而言,在识别本文所述测试中使用的数据库管理系统方面,Hibernate 比 Toplink 更有效。
2.1.17. 结论
对 @Entity [Person] 的研究到此结束。从概念角度来看,我们尚未深入探讨:我们仅考察了对象-关系映射的最简单形式:一个 @Entity 对象 <--> 一张表。然而,这一考察使我们得以介绍本文将贯穿始终使用的工具。这将使我们能够在此之后更快速地推进,进而探讨对象-关系映射的其他情况:
- 在之前的 @Entity [Person] 基础上,我们将添加一个由 [Address] 类建模的地址字段。在数据库方面,我们将探讨两种可能的实现方案。[Person] 和 [Address] 对象将产生
- 一个包含地址信息的[Person]表
- 两个表[person]和[address],通过一对一的外键关系关联。
- 一个一对多关系的示例,其中 [item] 表通过外键与 [category] 表相关联
- 一个多对多关系的示例,其中两个表 [Person] 和 [Activity] 通过关联表 [Person_Activity] 关联。
2.2. 示例 2:通过包含关系建立的一对一关系
2.2.1. 数据库模式
1  | 2 |
- 在 [1] 中:数据库(Azurri Clay 插件)
- 在 [2] 中:Hibernate 为 MySQL5 生成的 DDL
表 [jpa02_personne] 即前文所述的 [jpa01_personne] 表,其中新增了地址字段(DDL 的第 12–18 行)。
2.2.2. 表示数据库的 @Entity 对象
一个人的地址将由以下 [Address] 类表示:
package entites;
...
@SuppressWarnings("serial")
@Embeddable
public class Adresse implements Serializable {
// fields
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
// manufacturers
public Adresse() {
}
public Adresse(String adr1, String adr2, String adr3, String codePostal, String ville, String cedex, String pays) {
...
}
// getters and setters
...
// toString
public String toString() {
return String.format("A[%s,%s,%s,%s,%s,%s,%s]", getAdr1(), getAdr2(), getAdr3(), getCodePostal(), getVille(), getCedex(), getPays());
}
}
- 主要创新点在于第 5 行中的 @Embeddable 注解。[Address] 类并非用于创建表,因此它没有 @Entity 注解。 @Embeddable 注解表明该类旨在嵌入到 @Entity 对象中,从而嵌入与其关联的表中。这就是为什么在数据库模式中,[Address] 类不会作为独立的表出现,而是作为与 @Entity [Person] 关联的表的一部分。
@Entity [Person] 与之前的版本相比变化不大:仅仅是添加了一个 address 字段:
package entites;
...
@Entity
@Table(name = "jpa02_hb_personne")
public class Personne implements Serializable{
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
@Embedded
private Adresse adresse;
// manufacturers
public Personne() {
}
...
}
- 更改发生在第 33–34 行。现在,[Person] 对象拥有一个类型为 Address 的 address 字段。这是针对 POJO 的。@Embedded 注解旨在用于对象关系映射。它表明 [Address address] 字段必须与 [Person] 对象封装在同一张表中。
2.2.3. 测试环境
我们将进行与之前所学非常相似的测试。这些测试将在以下环境中进行:
 |
所使用的实现是 JPA/Hibernate [6]。Eclipse 测试项目如下:
 |
该 Eclipse 项目 [1] 与前一个项目仅在 Java 代码 [2] 上有所不同。环境(库 – persistence.xml – 数据库管理系统 – conf 和 DDL 文件夹 – Ant 脚本)与之前讨论的相同,特别是第 2.1.5 节中所述的。未来的 Hibernate 项目也将沿用此环境,除非有特殊情况,否则我们将不再重新讨论该环境。 值得注意的是,用于为不同数据库管理系统配置 JPA/Hibernate 层的 persistence.xml 文件正是我们之前已经分析过的那些,它们位于 <conf> 文件夹中。
若读者对具体操作流程存有疑问,建议查阅前文的相关内容。
Eclipse 项目位于示例文件夹 [4] 中 [3]。我们将导入该项目。
2.2.4. 生成数据库 DDL
按照第 2.1.7 节中的说明,为 MySQL5 数据库管理系统生成的 DDL 如下:
drop table if exists jpa02_hb_personne;
create table jpa02_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
Hibernate 正确识别出需要将该人员的地址包含在与 @Entity Person 关联的表中(第 11–17 行)。
2.2.5. InitDB
[InitDB] 的代码如下:
package tests;
...
public class InitDB {
// constant
private final static String TABLE_NAME = "jpa02_hb_personne";
public static void main(String[] args) throws ParseException {
// Persistence context
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// a EntityManager is retrieved from the previous EntityManagerFactory
em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// request
Query sql1;
// delete elements from the PERSONNE table
sql1 = em.createNativeQuery("delete from " + TABLE_NAME);
sql1.executeUpdate();
// creating people
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// address creation
Adresse a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
Adresse a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
// associations person <--> address
p1.setAdresse(a1);
p2.setAdresse(a2);
// persistence of people
em.persist(p1);
em.persist(p2);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
// log
System.out.println("terminé...");
}
}
这段代码没有什么新内容。所有内容之前都已介绍过。在 MySQL5 上运行 [InitDB] 会得到以下结果:
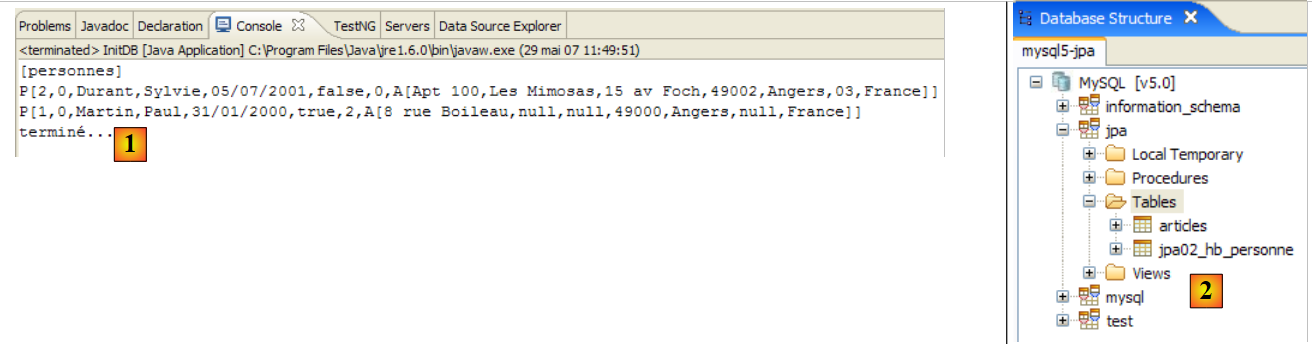 |
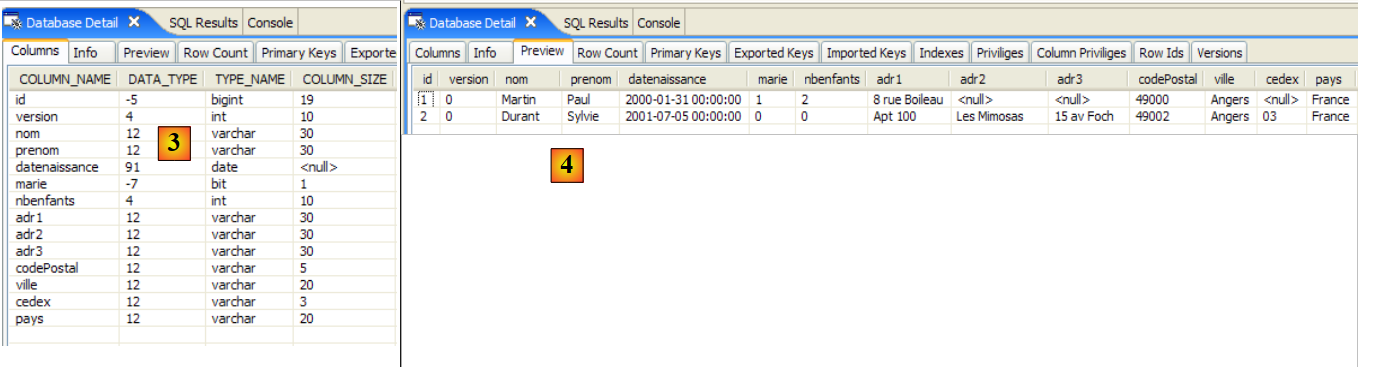 |
- [1]: 控制台输出
- [2]:SQL Explorer 视图中的 [jpa02_hb_personne] 表
- [3] 和 [4]:其结构和内容。
2.2.6. Main
[Main] 类如下所示:
package tests;
...
import entites.Adresse;
import entites.Personne;
@SuppressWarnings( { "unused", "unchecked" })
public class Main {
// constant
private final static String TABLE_NAME = "jpa02_hb_personne";
// Persistence context
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = null;
// shared objects
private static Personne p1, p2, newp1;
private static Adresse a1, a2, a3, a4, newa1, newa4;
public static void main(String[] args) throws Exception {
// we retrieve a EntityManager from the EntityManagerFactory
em = emf.createEntityManager();
// base cleaning
log("clean");clean();
// dump table
dumpPersonne();
// test1
log("test1"); test1();
// test2
log("test2"); test2();
// test3
log("test3"); test3();
// test4
log("test4"); test4();
// test5
log("test5");test5();
// fine persistence context
if (em != null && em.isOpen())
em.close();
// closure EntityManagerFactory
emf.close();
}
// retrieve the current EntityManager
private static EntityManager getEntityManager() {
...
}
// pick up a new EntityManager
private static EntityManager getNewEntityManager() {
...
}
// display table content Person
private static void dumpPersonne() {
...
}
// raz BD
private static void clean() {
...
}
// logs
private static void log(String message) {
...
}
// object creation
public static void test1() throws ParseException {
// persistence context
EntityManager em = getEntityManager();
// creating people
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// address creation
a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
// associations person <--> address
p1.setAdresse(a1);
p2.setAdresse(a2);
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistence of people
em.persist(p1);
em.persist(p2);
// end transaction
tx.commit();
// dump
dumpPersonne();
}
// modify a context object
public static void test2() {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// increment the number of children in p1
p1.setNbenfants(p1.getNbenfants() + 1);
// change your marital status
p1.setMarie(false);
// object p1 is automatically saved (dirty checking)
// at next synchronization (commit or select)
// end transaction
tx.commit();
// the new table is displayed
dumpPersonne();
}
// delete an object belonging to the persistence context
public static void test4() {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// delete attached object p2
em.remove(p2);
// end transaction
tx.commit();
// the new table is displayed
dumpPersonne();
}
// detach, reattach and modify
public static void test5() {
// new persistence context
EntityManager em = getNewEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// reattach p1 to the new context
p1 = em.find(Personne.class, p1.getId());
// end transaction
tx.commit();
// change p1's address
p1.getAdresse().setVille("Paris");
// the new table is displayed
dumpPersonne();
}
}
再次强调,这没什么新鲜的。控制台输出如下:
请读者自行将结果与代码建立联系。
2.2.7. JPA / Toplink 实现
我们目前正在使用一个 JPA / Toplink 实现:
 |
新的 Eclipse 测试项目如下:
 |
Java 代码与之前的 Hibernate 项目完全相同。环境(库文件 – persistence.xml – 数据库管理系统 – conf 和 ddl 文件夹 – Ant 脚本)即第 2.1.15.2 节中已讨论过的配置。未来的 Toplink 项目也将沿用此环境,除非有特殊情况,否则我们将不再重新讨论该环境。 特别是,用于为不同数据库管理系统配置 JPA/Toplink 层的 persistence.xml 文件,正是前文已讨论过的、位于 <conf> 文件夹中的那些文件。
若读者对具体操作流程存有疑问,建议查阅前文所述内容。
Eclipse 项目可在 [3] 的 examples 文件夹 [4] 中找到。我们将导入该项目。
在 MySQL5 数据库管理系统上运行 [InitDB] 将得到以下结果:
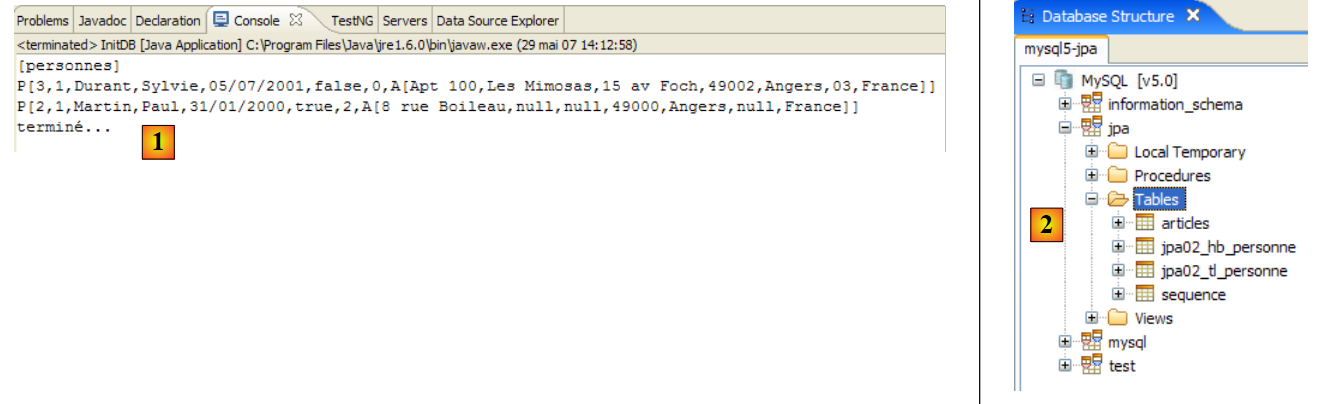 |
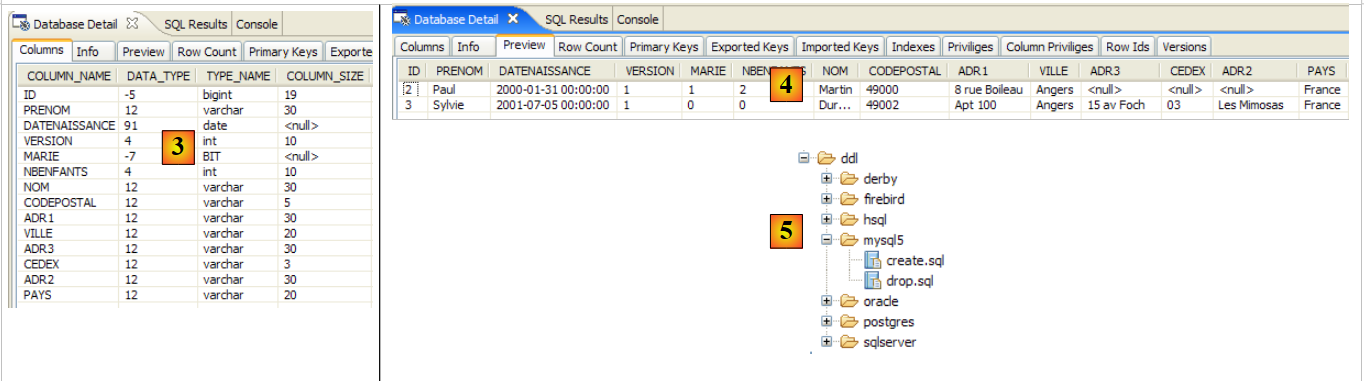 |
- [1]: 控制台输出
- [2]: SQL Explorer 视图中的 [jpa02_tl_personne] 和 [SEQENCE] 表
- [3] 和 [4]:[jpa02_tl_personne] 的结构和内容。
在 ddl/mysql5 [5] 中生成的 SQL 脚本如下:
create.sql
CREATE TABLE jpa02_tl_personne (ID BIGINT NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, VERSION INTEGER NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NBENFANTS INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, CODEPOSTAL VARCHAR(5) NOT NULL, ADR1 VARCHAR(30) NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR3 VARCHAR(30), CEDEX VARCHAR(3), ADR2 VARCHAR(30), PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
DROP TABLE jpa02_tl_personne
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
2.3. 示例 3:通过外键建立的一对一关系
2.3.1. :数据库模式
1 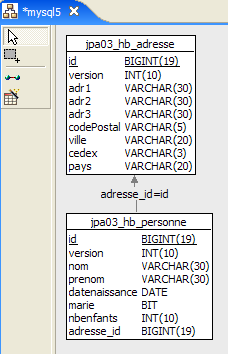 | 2 |
- 在[1]中:数据库。这次,该人员的地址存储在单独的[adresse]表中。[personne]表通过外键与该表相关联。
- 在 [2] 中:Hibernate 为 MySQL5 生成的 DDL:
- 第 9–20 行:将与 [Address] 类关联的 [address] 表,该类已作为 @Entity 对象定义。
- 第 10 行:[address] 表的主键
- 第 30 行:[person] 表不再存储完整地址,而是包含该地址的 [address_id] 标识符。
- 第 34–38 行:`person(address_id)` 是指向 `address(id)` 的外键。
2.3.2. 代表数据库的 @Entity 对象
现在,拥有地址的人员由以下 [Person] 类表示:
package entites;
...
@Entity
@Table(name = "jpa03_hb_personne")
public class Personne implements Serializable{
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
...
}
- 第 32–34 行:人员的地址
- 第 32 行:@OneToOne 注解表示一对一关系:一个人至少有一个且至多有一个地址。cascade = CascadeType.ALL 属性意味着对 @Entity [Person] 执行的任何操作(persist、merge、remove)都必须级联到 @Entity [Address]。 从 em 持久化上下文的角度来看,这意味着:如果 p 是一个人且拥有一个地址:
- 显式的 em.persist(p) 操作将触发隐式的 em.persist(a) 操作
- 显式的 em.merge(p) 操作将触发隐式的 em.merge(a) 操作
- 显式的 em.remove(p) 操作将触发隐式的 em.remove(a) 操作
- 第 32 行:@OneToOne 注解表示一对一关系:一个人至少有一个且至多有一个地址。cascade = CascadeType.ALL 属性意味着对 @Entity [Person] 执行的任何操作(persist、merge、remove)都必须级联到 @Entity [Address]。 从 em 持久化上下文的角度来看,这意味着:如果 p 是一个人且拥有一个地址:
实践表明,这些隐式级联并非万能良方。开发人员最终会忘记它们的作用。因此,在代码中使用显式操作可能更可取。级联有不同类型。@OneToOne 注解本可以写成如下形式:
//@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@OneToOne(cascade = {CascadeType.MERGE, CascadeType.PERSIST, CascadeType.REFRESH, CascadeType.REMOVE}, fetch=FetchType.LAZY)
cascade 属性接受一个常量数组作为其值,该数组指定所需的级联类型。
fetch=FetchType.LAZY 属性指示 Hibernate 在可能的最后时刻加载依赖关系。当将人员列表添加到持久化上下文时,您未必希望包含他们的地址。例如,您可能只希望获取用户通过 Web 界面选定的一位特定人员的地址。另一方面,fetch=FetchType.EAGER 属性则要求立即加载依赖关系。
- (待续)
- 第 33 行:@JoinColumn 注解定义了 @Entity [Person] 表与 @Entity [Address] 表之间的外键关系。name 属性定义了作为外键的列名。unique=true 属性强制执行一对一关系:[address_id] 列中不能出现相同的值。nullable=false 属性强制要求每个人必须拥有一个地址。
现在,一个人的地址由以下 @Entity [Address] 表示:
package entites;
...
@Entity
@Table(name = "jpa03_hb_adresse")
public class Adresse implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
// manufacturers
public Adresse() {
}
...
}
- 第 4 行:[Address] 类变成了 @Entity 对象。因此,它将成为数据库中某张表的实体。
- 第 9–12 行:与任何 @Entity 对象一样,[Address] 拥有一个主键。该主键被命名为 Id,并具有与 @Entity [Person] 的主键 Id 相同的(标准)注解。
- 第 39–40 行:与 @Entity [Person] 建立的一对一关系。这里有几个细节需要注意:
- 首先,`person` 字段并非必需。它允许我们通过地址来识别与该地址关联的特定个人。如果不需要此功能,`person` 字段可以不存在,系统仍能正常运行。
- 连接 [Person] 和 [Address] 这两个实体的一对一关系已在 @Entity [Person] 中配置:
@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
为避免两个一对一配置相互冲突,其中一个被视为主关系,另一个被视为逆向关系。由对象-关系桥管理的是主关系。另一个关系,即逆向关系,不会被直接管理:它是通过主关系间接管理的。在 @Entity [Address] 中:
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
正是 mappedBy 属性使得上述一对一关系成为由 @Entity [Person] 的 address 字段定义的主一对一关系的逆关系。
2.3.3. Eclipse / Hibernate 1 项目
此处使用的 JPA 实现是 Hibernate。Eclipse 测试项目如下:
 |
该项目位于 [3] 的 examples 文件夹 [4] 中。我们将导入它。
2.3.4. 生成数据库 DDL
按照第2.1.7节中的说明,为MySQL5数据库管理系统生成的DDL即为本节开头所示的内容。
2.3.5. InitDB
[InitDB] 的代码如下:
package tests;
...
import entites.Adresse;
import entites.Personne;
public class InitDB {
// constant
private final static String TABLE_PERSONNE = "jpa03_hb_personne";
private final static String TABLE_ADRESSE = "jpa03_hb_adresse";
public static void main(String[] args) throws ParseException {
// Persistence context
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// a EntityManager is retrieved from the previous EntityManagerFactory
em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// request
Query sql1;
// delete elements from the PERSONNE table
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE);
sql1.executeUpdate();
// delete elements from the ADRESSE table
sql1 = em.createNativeQuery("delete from " + TABLE_ADRESSE);
sql1.executeUpdate();
// creating people
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// address creation
Adresse a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
Adresse a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
Adresse a3 = new Adresse("x", "x", "x", "x", "x", "x", "x");
Adresse a4 = new Adresse("y", "y", "y", "y", "y", "y", "y");
// associations person <--> address
p1.setAdresse(a1);
a1.setPersonne(p1);
p2.setAdresse(a2);
a2.setPersonne(p2);
// persistence of persons and cascading of their addresses
em.persist(p1);
em.persist(p2);
// and a3 and a4 addresses not linked to persons
em.persist(a3);
em.persist(a4);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// address display
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
// log
System.out.println("terminé...");
}
}
我们将仅针对与已涵盖内容相比的新内容进行说明:
- 第31–32行:我们创建两个人物
- 第34–37行:我们创建了四个地址
- 第 39–42 行:我们将人员 (p1, p2) 与地址 (a1, a2) 建立关联。地址 (a3, a4) 成为孤立对象,没有人员引用它们。DDL 允许这种情况。虽然人员必须拥有地址,但反之则不成立。
- 第 44–45 行:我们将人员 (p1, p2) 持久化。由于我们在连接人员与其地址的一对一关系上将 cascade 属性设置为 CascadeType.ALL,因此这两名人员的地址 (a1, a2) 也应被持久化。这就是我们要验证的内容。 对于孤立的地址 (a3, a4),我们需要显式地进行持久化(第 47–48 行)。
- 第 51–53 行:显示人员表
- 第 56–57 行:显示地址表
在 MySQL5 上运行 [InitDB] 会得到以下结果:
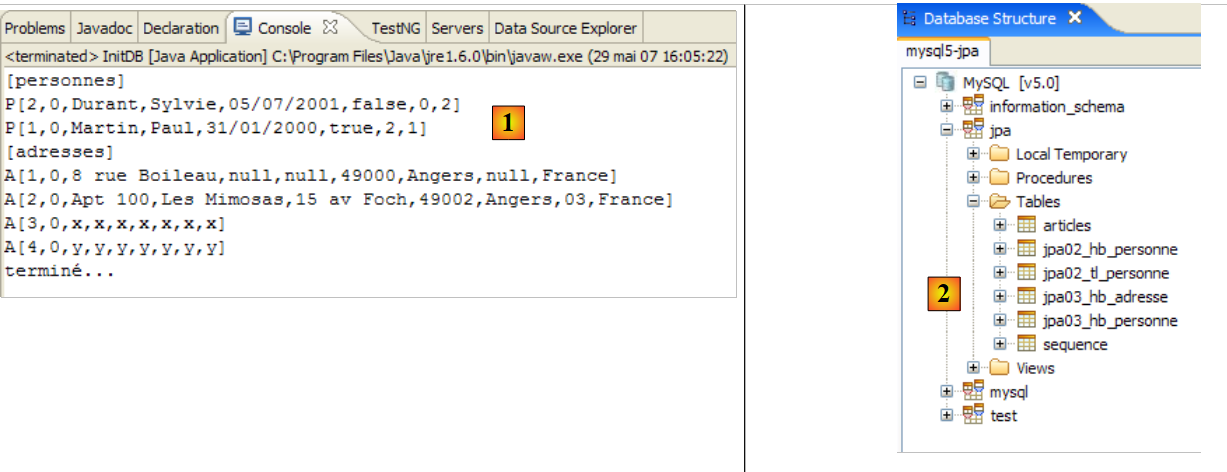 |
 |
- [1]: 控制台输出
- [2]: SQL Explorer 视图中的 [jpa03_hb_*] 表
- [3]:people 表
- [4]: addresses 表。这些表均已存在。请注意 [3] 中 [adresse_id] 列与 [4] 中 [id] 列之间的关系(外键)。
2.3.6. Main
[Main] 类运行了六个测试,我们将逐一审查。
2.3.6.1. Test1
该测试内容如下:
// création d'objets
public static void test1() throws ParseException {
// contexte de persistance
EntityManager em = getEntityManager();
// création personnes
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// création adresses
a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
a3 = new Adresse("x", "x", "x", "x", "x", "x", "x");
a4 = new Adresse("y", "y", "y", "y", "y", "y", "y");
// associations personne <--> adresse
p1.setAdresse(a1);
a1.setPersonne(p1);
p2.setAdresse(a2);
a2.setPersonne(p2);
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistance des personnes
em.persist(p1);
em.persist(p2);
// et des adresses a3 et a4 non liées à des personnes
em.persist(a3);
em.persist(a4);
// fin transaction
tx.commit();
// on affiche les tables
dumpPersonne();
dumpAdresse();
}
此代码摘自 [InitDB]。结果如下:
两张表均已填满。
2.3.6.2. 测试2
此测试如下:
// modifier un objet du contexte
public static void test2() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on incrémente le nbre d'enfants de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// on modifie son état marital
p1.setMarie(false);
// l'objet p1 est automatiquement sauvegardé (dirty checking)
// lors de la prochaine synchronisation (commit ou select)
// fin transaction
tx.commit();
// on affiche la nouvelle table
dumpPersonne();
}
结果如下:
- 第4行:人物 p1 的子女数量增加了1,版本号从0变为1
2.3.6.3. 测试4
本次测试内容如下:
// supprimer un objet appartenant au contexte de persistance
public static void test4() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on supprime l'objet attaché p2
em.remove(p2);
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpAdresse();
}
- 第 9 行:我们移除了人员 p2。该人员与地址 a2 存在级联关系。因此,地址 a2 也应被移除。
测试 4 的结果如下:
- 出现在测试 1 第 3 行的人员 p2 在测试 4 中已不存在
- 其地址 a2 也是如此,该地址出现在测试 1 的第 7 行,但在测试 4 中已不存在。
2.3.6.4. 测试5
该测试如下:
// détacher, réattacher et modifier
public static void test5() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on réattache p1 au nouveau contexte
p1 = em.find(Personne.class, p1.getId());
// on change l'adresse de p1
p1.getAdresse().setVille("Paris");
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpAdresse();
}
- 第 4 行:我们有一个新的持久化上下文,因此它是空的。
- 第 9 行:我们将人员 p1 添加到其中。由于 p1 不在上下文中,因此会从数据库中检索它。依赖于 p1 的元素(即其地址)不会从数据库中检索,因为我们写道:
@OneToOne(..., fetch=FetchType.LAZY)
这就是“延迟加载”的概念:持久化对象的依赖项仅在需要时才会加载到内存中。
- 第 11 行:我们修改了 p1 地址的 city 字段。由于调用了 getAddress 方法,且如果 p1 的地址尚未存在于持久化上下文中,系统将从数据库中检索该地址。
- 第 13 行:我们提交事务,这将使持久化上下文与数据库保持同步。数据库会检测到人员 p1 的地址已被修改,并将其保存。
运行 test5 会产生以下结果:
- 用户 p1(test4 的第 3 行,test5 的第 10 行)正确观察到其所在城市从昂热(test4 的第 5 行)变为巴黎(test5 的第 12 行)。
2.3.6.5. Test6
该测试内容如下:
// delete an Address object
public static void test6() {
EntityTransaction tx = null;
// new persistence context
EntityManager em = getNewEntityManager();
// start of transaction
tx = em.getTransaction();
tx.begin();
// reattach address a3 to new context
a3 = em.find(Adresse.class, a3.getId());
System.out.println(a3);
// we delete it
em.remove(a3);
// end transaction
tx.commit();
// dump table Address
dumpAdresse();
}
- 第 5 行:我们处于一个新的持久化上下文中,因此它是空的。
- 第 10 行:我们将地址 a3 放入持久化上下文
- 第 13 行:我们将其删除。这是一个孤立的地址(未与任何人关联)。因此可以进行删除。
执行结果如下:
- 测试 5(第 6 行)中的地址 a3 在测试 6(第 11-12 行)的地址列表中消失了
2.3.6.6. 测试7
该测试内容如下:
// rollback
public static void test7() {
EntityTransaction tx = null;
try {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
tx = em.getTransaction();
tx.begin();
// on réattache l'adresse a1 au nouveau contexte
newa1 = em.find(Adresse.class, a1.getId());
// on réattache l'adresse a4 au nouveau contexte
newa4 = em.find(Adresse.class, a4.getId());
// on essaie de les supprimer - devrait lancer une exception car on ne peut supprimer une adresse liée à une personne, ce qui est le cas de newa1
em.remove(newa4);
em.remove(newa1);
// fin transaction
tx.commit();
} catch (RuntimeException e1) {
// on a eu un pb
System.out.format("Erreur dans transaction [%s%n%s%n%s%n%s]%n", e1.getClass().getName(), e1.getMessage(), e1.getCause(), e1.getCause()
.getCause());
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s]%n", e2.getMessage());
}
// on abandonne le contexte courant
em.clear();
}
// dump - la table Adresse n'a pas du changer à cause du rollback
dumpAdresse();
}
- test7:测试事务回滚
- 第 6 行:我们处于一个新的持久化上下文中,因此它是空的。
- 第 11 行:我们将地址 a1 放入持久化上下文中,位于引用 newa1 之下
- 第 13 行:我们将地址 a4 放入持久化上下文中,作为引用 newa4
- 第 15-16 行:我们删除了两个地址 newa1 和 newa4。newa1 是人员 p1 的地址,因此通过外键在数据库中被 p1 引用。 因此,当事务提交时(第 18 行)同步持久化上下文,删除 newa1 将失败并抛出异常。事务将被回滚(第 25 行),从而该事务中的两项操作均被取消。因此,我们应观察到本可合法删除的地址 newa4 并未被删除。
执行结果如下:
main : ----------- test6
A[3,0,x,x,x,x,x,x,x]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
main : ----------- test7
Erreur dans transaction [javax.persistence.RollbackException
Error while commiting the transaction
org.hibernate.ObjectDeletedException: deleted entity passed to persist: [entites.Adresse#<null>]
null]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
- 测试 7(第 12–13 行)中的地址表与测试 6(第 4–5 行)中的完全一致。回滚似乎已经发生。话虽如此,第 9 行出现的错误信息仍是个谜,值得进一步调查。似乎发生的异常并非预期的那个。我们需要在 log4j.properties 中将 Hibernate 日志设置为 DEBUG 模式,以获得更清晰的状况:
# Root logger option
log4j.rootLogger=ERROR, stdout
# Hibernate logging options (INFO only shows startup messages)
log4j.logger.org.hibernate=DEBUG
随后我们可以看到,当地址 a1 被放入持久化上下文时,Hibernate 也将人 p1 放入其中,这很可能是由于 @Entity [Address] 的一对一关系所致:
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
尽管此处请求了“延迟加载”,但 [Person] 依赖项仍被立即加载。这很可能意味着 fetch=FetchType.LAZY 属性在此处无效。 随后我们观察到,在提交事务时,Hibernate 已准备好删除地址 a1 和 a4 以及保存人员 p1。而异常正是在此处发生:由于人员 p1 的地址具有级联删除,Hibernate 试图持久化地址 a1,尽管该地址刚刚被删除。抛出异常的是 Hibernate,而非 JDBC 驱动程序。因此才会有上文第 9 行中的那条消息。 此外,我们可以看到第 25 行的回滚从未执行,因为事务已变为非活动状态。因此,第 24 行的测试阻止了回滚。
因此,我们未能实现预期目标:演示回滚操作。事实上,数据库从未收到任何 SQL 语句。让我们总结几个关键点:
- 启用详细日志记录以了解 ORM 行为的重要性
- 虽然 ORM 能让开发者的工作更轻松,但也可能因隐藏开发者需要了解的行为而增加复杂性。在此案例中,具体表现为 @Entity 的依赖项加载方式。
2.3.7. Eclipse / Hibernate 2 项目
我们将 Eclipse/Hibernate 项目复制粘贴过来,并对 @Entity 对象的配置进行一些微调:
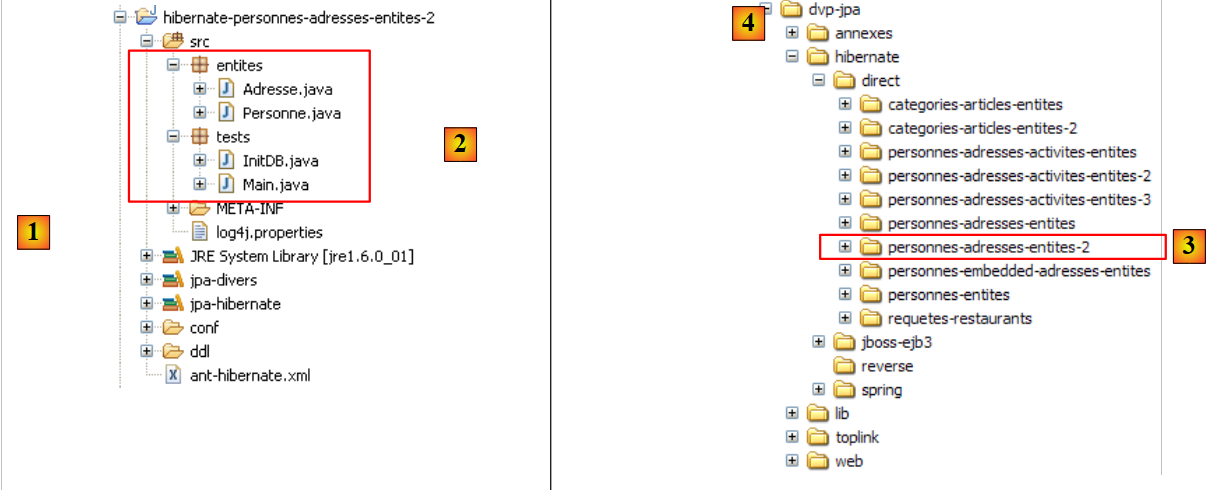 |
该项目位于 [3] 的 examples 文件夹 [4] 中。我们将导入该项目。
我们仅修改 @Entity [Address],使其不再与 @Entity [Person] 保持一对一的反向关系:
package entites;
...
@Entity
@Table(name = "jpa04_hb_adresse")
public class Adresse implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
...
@Column(length = 20, nullable = false)
private String pays;
// @OneToOne(mappedBy = "address", fetch=FetchType.LAZY)
// private Person person;
// manufacturers
public Adresse() {
}
- 第 25-26 行:移除了 @OneToOne 的反向关系。需要明确的是,反向关系绝非必需,只有主关系才是必需的。反向关系仅用于提供便利。在此,它提供了一种简便的方式来获取地址的所有者。反向关系始终可以被 JPQL 查询所替代。这正是我们在接下来的示例中将要演示的内容。
测试程序完全相同。我们需要关注的是测试 7,即我们之前看到一对一反向关系实际应用的那个测试。我们还添加了测试 8,以展示在没有 Address -> Person 反向关系的情况下,我们如何仍能根据给定的地址检索到对应的人员。
测试 7 保持不变。现在运行它将产生以下结果(日志已禁用):
main : ----------- test6
A[3,0,x,x,x,x,x,x,x]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
main : ----------- test7
Erreur dans transaction [javax.persistence.RollbackException
Error while commiting the transaction
org.hibernate.exception.ConstraintViolationException: could not delete: [entites.Adresse#1]
java.sql.SQLException: Cannot delete or update a parent row: a foreign key constraint fails (`jpa/jpa04_hb_personne`, CONSTRAINT `FKEA3F04515FE379D0` FOREIGN KEY (`adresse_id`) REFERENCES `jpa04_hb_adresse` (`id`))]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
- 这次,我们得到了预期的异常:这是由 JDBC 驱动程序抛出的,因为我们试图删除 [address] 表中的一行,而该行被 [person] 表中的一行通过外键引用。第 [10] 行清楚地解释了错误的原因。
- 回滚确实发生了:在测试 7 结束时,[address] 表(第 12–13 行)与测试 6 结束时(第 4–5 行)的状态完全一致。
这与之前 Eclipse 项目中的测试 7 有什么区别?为什么这里会出现一个在之前测试中未遇到的 Jdbc 异常?因为 @Entity [Address] 不再与 @Entity [Person] 保持一对一的反向关系;它由 Hibernate 独立管理。 当地址 newa1 被引入持久化上下文时,Hibernate 并未将拥有该地址的人员 p1 也放入该上下文中。因此,在删除地址 newa1 和 newa4 时,上下文中没有任何 Person 实体。
那么,我们该如何利用地址 newa1 来查找拥有该地址的人员 p1 呢?这是一个合理的问题。下面的测试 8 给出了答案:
// relation inverse un-à-un
// réalisée par une requête JPQL
public static void test8() {
EntityTransaction tx = null;
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
tx = em.getTransaction();
tx.begin();
// on réattache l'adresse a1 au nouveau contexte
newa1 = em.find(Adresse.class, a1.getId());
// on récupère la personne propriétaire de cette adresse
Personne p1 = (Personne) em.createQuery("select p from Personne p join p.adresse a where a.id=:adresseId").setParameter("adresseId", newa1.getId())
.getSingleResult();
// on les affiche
System.out.println("adresse=" + newa1);
System.out.println("personne=" + p1);
// fin transaction
tx.commit();
}
- 第 6 行:新建空的持久化上下文
- 第 8-9 行:开始事务
- 第 11 行:将地址 a1 引入持久化上下文,并通过 newa1 引用它。
- 第 13 行:通过 JPQL 查询检索具有地址 newa1 的 person p1。我们知道 [Person] 和 [Address] 通过外键关系关联。在 [Person] 类中,带有 @OneToOne 注解的 [address] 字段定义了这种关系。 JPQL语句“select p from Person p join p.address a”执行了[Person]和[Address]表之间的连接。在Hibernate控制台中生成的等效SQL(参见第2.1.12节中的示例)如下:
两张表之间的连接关系清晰可见。现在,每位人员都与其地址相关联。接下来需要明确的是,我们仅关注地址 newa1。查询语句变为“select p from Person p join p.address a where a.id=:addressId”。 请注意别名 p 和 a 的使用。JPQL 查询广泛使用别名。因此,表达式“from Person p join p.address a”意味着:Person 通过别名 p 表示,其地址(p.address)通过别名 a 表示。限制操作“where a.id=:adresseId”将查询结果限定为仅包含那些地址 a 的标识符值为 :adresseId 的 Person p。 :adresseId 被称为参数,而该 JPQL 查询即为参数化 JPQL 查询。在运行时,必须为该参数赋值。这通过以下方法实现:
来实现,该方法允许您为通过名称标识的参数赋值。请注意,setParameter 方法会返回一个 Query 对象,这与 createQuery 方法类似。这意味着您可以链式调用方法 [例如,createQuery(...).setParameter(...).getSingleResult(...)],因为 [setParameter, getSingleResult] 方法是 Query 接口的方法。 [getSingleResult] 方法用于仅返回单个结果的 Select 查询。本例即属于这种情况。
- 第 16–17 行:我们显示地址 newa1 及其关联的人员 p1,以便进行验证。
获得的结果如下:
这是正确的。从这个例子中我们可以得出结论:@entity [Address] 到 @entity [Person] 的单向反向关系并非必需。经验表明,在此处移除该关系使得代码行为更加可预测。这种情况经常发生。
2.3.8. Hibernate 控制台
前面的测试 8 使用了一个 JPQL 命令来对 Person 和 Address 实体进行连接。尽管与 SQL 类似,但 JPA 的 JPQL 和 Hibernate 的 HQL 仍需学习,而 Hibernate 控制台正是为此而设计的绝佳工具。我们在第 2.1.12 节中已经使用它查询过单张表。现在我们将再次使用它来查询两张通过外键关系关联的表。
让我们为当前的 Eclipse 项目创建一个 Hibernate 控制台:
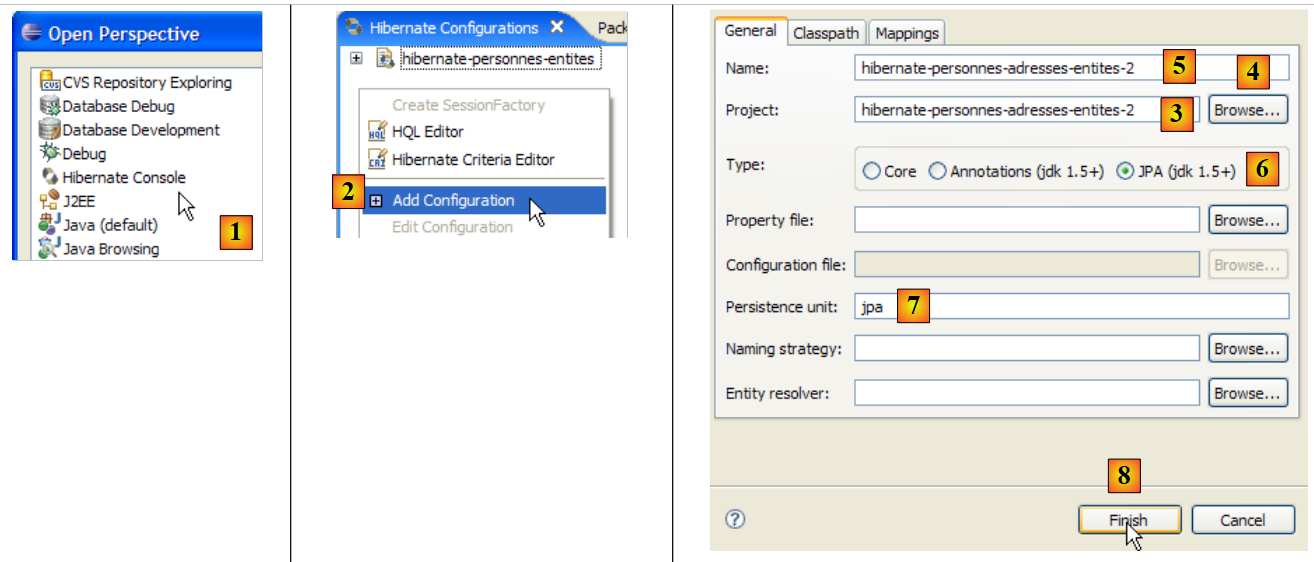 |
- [1]:切换到 [Hibernate Console] 视图(窗口 / 打开视图 / 其他)
- [2]: 创建新配置
- 通过 [4] 按钮,选择需要创建 Hibernate 配置的 Java 项目。其名称将显示在 [3] 中。
- 在 [5] 中,输入此配置的名称。此处我们使用了 Java 项目的名称。
- 在 [6] 中,我们指定使用 JPA 配置,以便工具知道必须使用 [META-INF/persistence.xml] 文件
- 在 [7] 中,我们在 [META-INF/persistence.xml] 文件中指定应使用名为 jpa 的持久化单元。
- 在 [8] 中,我们验证了配置。
接下来,必须启动数据库管理系统(DBMS)。在此情况下,使用的是 MySQL 5。
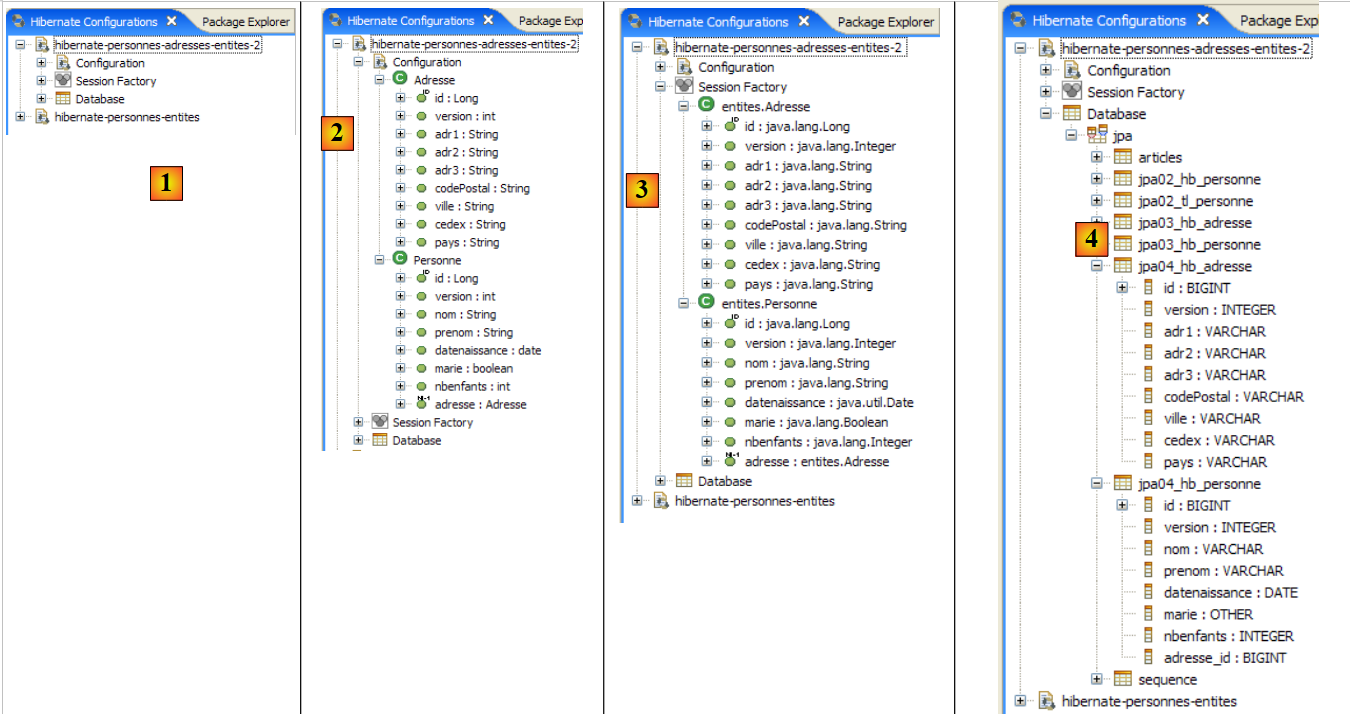 |
- 在 [1] 中:创建的配置具有三叉树结构
- 在 [2] 中:[Configuration] 分支列出了控制台用于配置自身的对象:此处为 @Entity 注解的 Person 和 Address。
- 在 [3] 中:Session Factory 是 Hibernate 中的一个概念,类似于 JPA 的 EntityManager。它利用 [Configuration] 分支中的对象来弥合对象与关系数据库之间的鸿沟。[3] 展示了持久化上下文中的对象,在此示例中即 @Entity 注解下的 Person 和 Address 实体。
- 在 [4] 中:通过 [persistence.xml] 中的配置访问的数据库。在此处,我们可以看到当前 Eclipse 项目生成的 [jpa04_hb_*] 表。
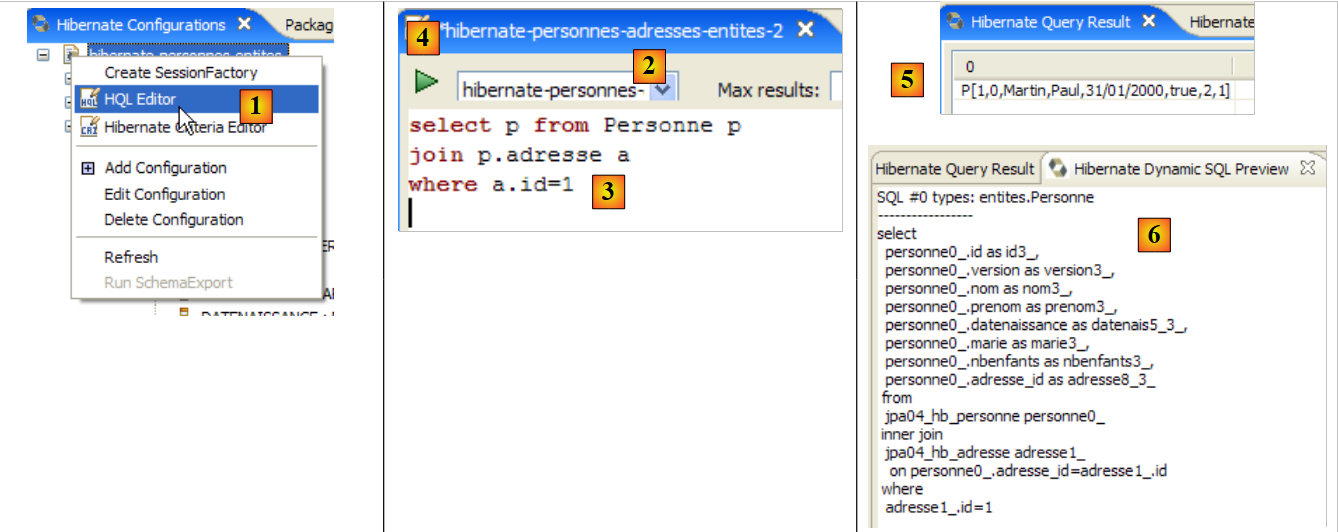 |
- 在 [1] 中,我们创建一个 HQL 编辑器
- 在 HQL 编辑器中,
- 在 [2] 中,如果存在多个 Hibernate 配置(本例中即为这种情况),则选择要使用的配置
- 在[3]中,输入要执行的JPQL命令;此处为测试8中的JPQL命令
- 在 [4] 中,我们执行该命令
- 在 [5] 中,您可以在 [Hibernate 查询结果] 窗口中查看查询结果。
- 在 [6] 中,[Hibernate 动态 SQL 预览] 窗口允许您查看已执行的 SQL 查询。
另一种获得相同结果的方法:
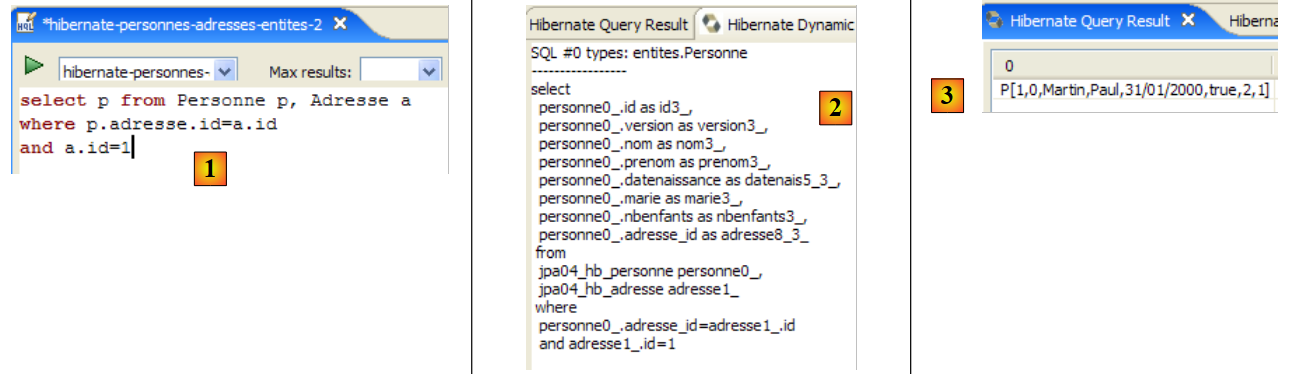 |
- 在 [1] 中:执行 Person 和 Address 实体之间连接的 JPQL 命令。[ref1] 将此形式称为“theta 连接”。
- 在 [2] 中:等效的 SQL 语句
- 在 [3] 中:结果
仅 Hibernate(HQL)支持的第三种形式:
 |
- 在 [1] 中:HQL 查询。JPQL 不支持 p.address.id 这种写法,它只允许一层间接引用。
- 在 [2] 中:等效的 SQL 语句。请注意,它避免了表连接。
- 在 [3] 中:结果
以下是其他一些示例:
 |
- 在 [1] 中:人员及其地址的列表
- 在 [2] 中:对应的 SQL 语句。
- 在 [3] 中:查询结果
 |
- 在 [1] 中:地址列表及其所有者(如有),否则为空(右外连接:地址实体位于连接关键字右侧,该实体将提供与人员无关的行)。
- 在 [2] 中:等效的 SQL 语句。
- 在 [3] 中:结果
请注意,只有 Person 实体与 Address 实体存在关联。反之则不再成立,因为我们已从 Address 实体中删除了名为 Person 的“一对一”反向关联。如果该反向关联存在,我们可以这样写:
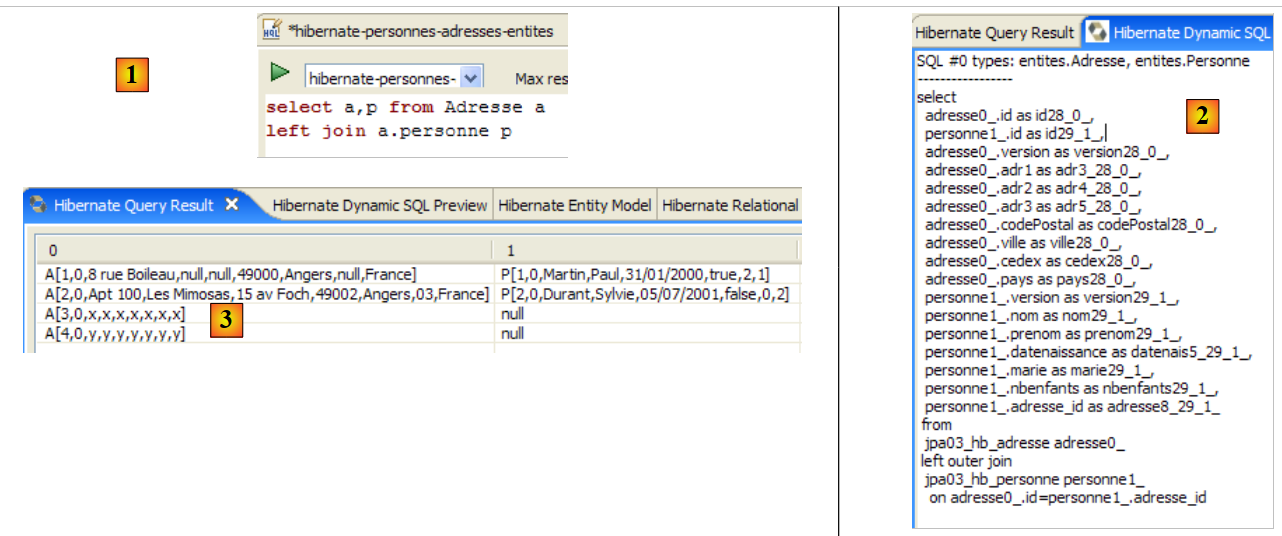 |
- 在 [1] 中:地址列表及其所有者(如有),否则为空(左外连接:地址实体位于连接关键字的左侧,该连接将返回与人员实体无关联的行)。
- 在 [2] 中:等效的 SQL 语句。
- 在 [3] 中:结果
我们强烈建议读者使用 Hibernate 控制台练习 JPQL 语言。
2.3.9. JPA / Toplink 实现
我们现在使用的是 JPA / Toplink 实现:
 |
新的 Eclipse 测试项目如下:
 |
Java 代码与之前的 Hibernate 项目完全相同。环境(库文件 – persistence.xml – 数据库管理系统 – conf 和 ddl 文件夹 – Ant 脚本)与第 2.1.15.2 节中讨论的一致。该 Eclipse 项目位于 [3] 的 examples 文件夹 [4] 中。我们将导入该项目。
<persistence.xml> 文件仅在一点上进行了修改,具体是声明的实体:
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- classes persistantes -->
<class>entites.Personne</class>
<class>entites.Adresse</class>
<!-- propriétés de l'unité de persistance -->
...
- 第 5 行和第 6 行:两个受管实体
在 MySQL5 数据库管理系统上运行 [InitDB] 会得到以下结果:
 |
[1] 为控制台输出;[2] 为生成的两个 [jpa04_tl] 表;[3] 为生成的 SQL 脚本。其内容如下:
create.sql
CREATE TABLE jpa04_tl_personne (ID BIGINT NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, VERSION INTEGER NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NBENFANTS INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa04_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, ADR1 VARCHAR(30) NOT NULL, VILLE VARCHAR(20) NOT NULL, VERSION INTEGER NOT NULL, CEDEX VARCHAR(3), ADR2 VARCHAR(30), PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa04_tl_personne ADD CONSTRAINT FK_jpa04_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa04_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
ALTER TABLE jpa04_tl_personne DROP FOREIGN KEY FK_jpa04_tl_personne_adresse_id
DROP TABLE jpa04_tl_personne
DROP TABLE jpa04_tl_adresse
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
2.4. 示例 4:一对多关系
2.4.1. 数据库模式
1  | 2 |
- 在 [1] 中,数据库;在 [2] 中,其 DDL(MySQL5)
一篇文章 A(id, version, name) 仅属于一个类别 C(id, version, name)。 一个类别 C 可以包含 0、1 或多个文章。我们有一个一对多关系(Category -> Article)和一个反向的多对一关系(Article -> Category)。这种关系由 [article] 表对 [category] 表的外键表示(DDL 的第 24–28 行)。
2.4.2. 表示数据库的 @Entity 对象
一篇文章由以下 @Entity [Article] 表示:
package entites;
...
@Entity
@Table(name="jpa05_hb_article")
public class Article implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// main relationship Article (many) -> Category (one)
// implemented by a foreign key (categorie_id) in Article
// 1 Article must have 1 Category (nullable=false)
@ManyToOne(fetch=FetchType.LAZY)
@JoinColumn(name = "categorie_id", nullable = false)
private Categorie categorie;
// manufacturers
public Article() {
}
// getters and setters
...
// toString
public String toString() {
return String.format("Article[%d,%d,%s,%d]", id, version, nom, categorie.getId());
}
}
- 第 9-11 行:@Entity 的主键
- 第 13-15 行:其版本号
- 第 17-18 行:文章的名称
- 第 20-25 行:将 @Entity Article 与 @Entity Category 关联的多对一关系:
- 第 23 行:ManyToOne 注解。Many 指代当前所在的 @Entity Article,One 指代 @Entity Category(第 25 行)。一个类别(One)可以关联多个文章(Many)。
- 第 24 行:ManyToOne 注解定义了 [article] 表中的外键列。该列将被命名为 (name) categorie_id,且每行必须在此列中具有一个值(nullable=false)。
- 第 25 行:文章所属的类别。当文章被添加到持久化上下文中时,我们要求其类别不要立即加载(fetch=FetchType.LAZY,第 23 行)。我们尚不确定此请求是否合理。稍后再看。
类别由以下 @Entity [Category] 表示:
package entites;
...
@Entity
@Table(name="jpa05_hb_categorie")
public class Categorie implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// inverse relationship Category (one) -> Article (many) from relationship Article (many) -> Category (one)
// cascade insertion Category -> insertion Articles
// cascade maj Category -> maj Articles
// cascade delete Category -> delete Articles
@OneToMany(mappedBy = "categorie", cascade = { CascadeType.ALL })
private Set<Article> articles = new HashSet<Article>();
// manufacturers
public Categorie() {
}
// getters and setters
...
// toString
public String toString() {
return String.format("Categorie[%d,%d,%s]", id, version, nom);
}
// bidirectional association Category <--> Article
public void addArticle(Article article) {
// the item is added to the collection of items in the category
articles.add(article);
// article changes category
article.setCategorie(this);
}
}
- 第 8-11 行:@Entity 的主键
- 第 12-14 行:其版本号
- 第 16-17 行:类别名称
- 第 19-24 行:该类别下的项目集合
- 第 23 行:@OneToMany 注解表示一对多关系。其中的“One”指代当前所在的 @Entity [Category],而“Many”指代第 24 行中的 [Article] 类型:一个(One)类别包含多个(Many)文章。
- 第 23 行:该注解是 @Entity Article 的 category 字段上所置 ManyToOne 注解的反向(mappedBy)关系:mappedBy=category。@Entity Article 的 category 字段上所置的 ManyToOne 关系是主关系。它是必不可少的。它实现了将 @Entity Article 与 @Entity Category 关联的外键关系。 置于 @Entity Category 的 articles 字段上的 OneToMany 关系是反向关系。它并非必需的。它是为了方便检索某个类别的文章。如果没有这种便利,这些文章将需要通过 JPQL 查询来检索。
- 第 23 行:`cascadeType.ALL` 指定对 `@Entity Category` 执行的操作(persist、merge、remove)应级联到其所属的文章。
- 第 24 行:类别中的文章将被放入一个类型为 `Set<Article>` 的对象中。`Set` 类型不允许重复项。因此,同一篇文章不能被两次添加到 `Set<Article>` 对象中。“同一篇文章”是什么意思?为了表示文章 `a` 与文章 `b` 相同,Java 使用表达式 `a.equals(b)`。 在所有类的父类 Object 类中,如果 a==b,即对象 a 和 b 具有相同的内存位置,则 a.equals(b) 为 true。有人可能希望定义:如果项目 a 和 b 具有相同的名称,则它们是相同的。在这种情况下,开发者必须在 [Item] 类中重新定义两个方法:
- equals:当两个项名称相同时,该方法必须返回 true
- hashCode:对于 equals 方法认为相等的两个 [Article] 对象,必须返回相同的整数值。因此,该值将根据文章的名称生成。hashCode 返回的值可以是任意整数。它被用于各种对象容器中,尤其是字典(Hashtable)。
OneToMany 关系可以使用 Set 以外的类型来存储“多”方,例如 List 对象。本文档中将不涉及这些情况。读者可在 [ref1] 中查阅相关内容。
- 第 38 行:[addArticle] 方法允许我们将一篇文章添加到某个类别中。该方法确保连接 [Category] 与 [Article] 的 OneToMany 关系两端均被更新。
2.4.3. Eclipse / Hibernate 1 项目
此处使用的 JPA 实现是 Hibernate。Eclipse 测试项目如下:
 |
该项目位于 [3] 的 examples 文件夹 [4] 中。我们将导入该项目。
2.4.4. 生成数据库 DDL
按照第2.1.7节中的说明,为MySQL5数据库管理系统生成的DDL即为本示例开头第2.4.1节中所示的内容。
2.4.5. InitDB
[InitDB] 的代码如下:
package tests;
...
public class InitDB {
// constant
private final static String TABLE_ARTICLE = "jpa05_hb_article";
private final static String TABLE_CATEGORIE = "jpa05_hb_categorie";
public static void main(String[] args) {
// Persistence context
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// a EntityManager is retrieved from the previous EntityManagerFactory
em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// request
Query sql1;
// delete elements from the ARTICLE table
sql1 = em.createNativeQuery("delete from " + TABLE_ARTICLE);
sql1.executeUpdate();
// delete elements from the CATEGORIE table
sql1 = em.createNativeQuery("delete from " + TABLE_CATEGORIE);
sql1.executeUpdate();
// create three categories
Categorie categorieA = new Categorie();
categorieA.setNom("A");
Categorie categorieB = new Categorie();
categorieB.setNom("B");
Categorie categorieC = new Categorie();
categorieC.setNom("C");
// create 3 items
Article articleA1 = new Article();
articleA1.setNom("A1");
Article articleA2 = new Article();
articleA2.setNom("A2");
Article articleB1 = new Article();
articleB1.setNom("B1");
// link them to their category
categorieA.addArticle(articleA1);
categorieA.addArticle(articleA2);
categorieB.addArticle(articleB1);
// persist categories and cascade (insert) articles
em.persist(categorieA);
em.persist(categorieB);
em.persist(categorieC);
// category display
System.out.println("[categories]");
for (Object p : em.createQuery("select c from Categorie c order by c.nom asc").getResultList()) {
System.out.println(p);
}
// item display
System.out.println("[articles]");
for (Object p : em.createQuery("select a from Article a order by a.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityMangerFactory
emf.close();
// log
System.out.println("terminé...");
}
}
- 第 22-27 行:清空 [article] 和 [category] 表。请注意,我们必须从包含外键的表开始。如果从 [category] 表开始,我们将删除 [article] 表中行所引用的分类,而数据库管理系统会拒绝此操作。
- 第 29-34 行:我们创建三个分类 A、B、C
- 第 36–41 行:创建三篇文章:A1、A2 和 B1(字母表示所属分类)
- 第 43–45 行:将这三篇文章放入各自的类别中
- 第 47–49 行:将三个类别放入持久化上下文中。由于存在 Category → Article 的级联关系,其关联的文章也会被放入其中。因此,所有创建的对象现在都在持久化上下文中。
- 第 50–59 行:查询持久化上下文以获取类别和项目的列表。我们知道这将触发上下文与数据库的同步。此时,类别和项目将被保存到各自的表中。
在 MySQL5 上运行 [InitDB] 会得到以下结果:
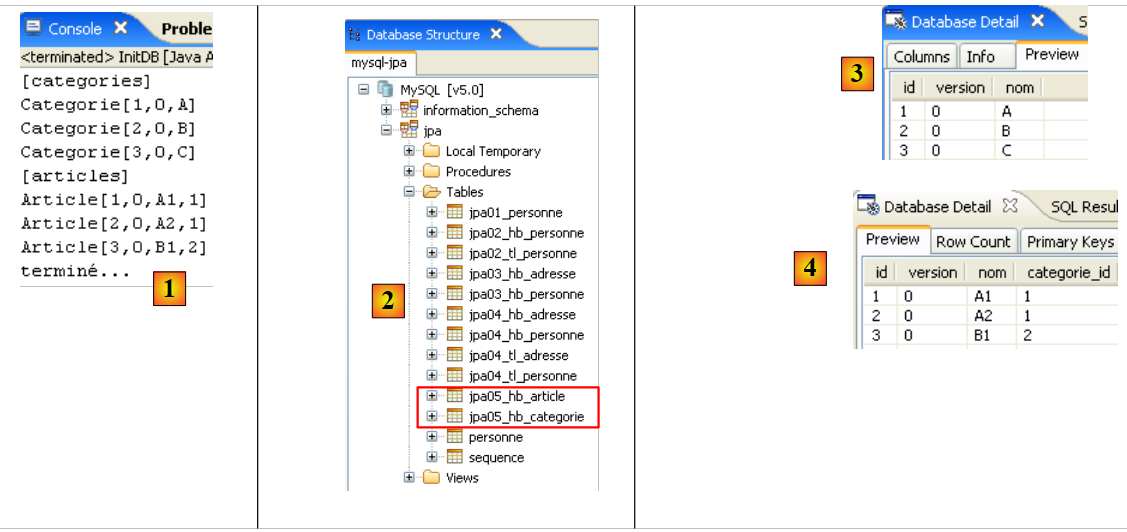 |
- [1]: 控制台输出
- [2]: SQL Explorer 视图中的 [jpa05_hb_*] 表
- [3]: categories 表
- [4]: articles 表。请注意 [4] 中的 [categorie_id] 与 [3] 中的 [id] 之间的关系(外键)。
2.4.6. Main
[Main] 类运行了一系列我们将要审查的测试,但测试 1 和 2 除外,它们使用 [InitDB] 中的代码来初始化数据库。
2.4.6.1. 测试3
该测试内容如下:
// search for a particular item
public static void test3() {
// new persistence context
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// loading category
Categorie categorie = em.find(Categorie.class, categorieA.getId());
// category display and related articles
System.out.format("Articles de la catégorie %s :%n", categorie);
for (Article a : categorie.getArticles()) {
System.out.println(a);
}
// end transaction
tx.commit();
}
- 第 4 行:我们有一个新的持久化上下文,因此它是空的
- 第 6-7 行:开始事务
- 第 9 行:从数据库中检索类别 A 并将其放入持久化上下文
- 第 11 行:我们显示类别 A
- 第 12–14 行:显示类别 A 中的项目。这展示了 @Entity Category 上的 OneToMany 反向关系带来的优势。该关系的存在使我们无需编写 JPQL 查询来检索类别 A 中的项目。要获取这些项目,我们使用 items 字段的 get 方法。
结果如下:
- 第20行:类别A
- 第21-22行:类别A中的两项
2.4.6.2. 测试4
该测试内容如下:
// supprimer un article
@SuppressWarnings("unchecked")
public static void test4() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// chargement article A1
Article newarticle1 = em.find(Article.class, articleA1.getId());
// suppression article A1 (aucune catégorie n'est actuellement chargée)
em.remove(newarticle1);
// toplink : l'article doit être enlevé de sa catégorie sinon le test6 plante
// hibernate : ce n'est pas nécessaire
newarticle1.getCategorie().getArticles().remove(newarticle1);
// fin transaction
tx.commit();
// dump des articles
dumpArticles();
}
- 测试 4 删除项目 A1
- 第 5 行:我们从一个新的、空的上下文开始
- 第 10 行:将文章 A1 添加到持久化上下文中。它将在那里通过 newarticle1 进行引用。
- 第 12 行:将其从上下文中移除
- 第 15 行:类别 A、B 和 C,以及项目 A1、A2 和 B1,即使它们不再持久化,仍保留在内存中。它们只是从持久化上下文中脱离了。 文章 A1( )属于类别 A 中的文章,现已被移出该类别。此操作将使后续能够将类别 A 重新附加到持久化上下文中。如果不执行此操作,类别 A 将被重新附加,且其中包含一组文章,其中一篇已被删除。这似乎不会影响 Hibernate,但会导致 TopLink 崩溃。
- 第 19 行:我们显示所有项目以验证 A1 是否已消失。
结果如下:
项目 A1 确实不见了。
2.4.6.3. 测试5
该测试如下:
// modification d'1 article
public static void test5() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// modification articleA2
articleA2.setNom(articleA2.getNom() + "-");
// articleA2 est remis dans le contexte de persistance
em.merge(articleA2);
// fin transaction
tx.commit();
// dump des articles
dumpArticles();
}
- 测试 5 更改了项目 A2 的名称
- 第 4 行:我们从一个新的、空的上下文开始
- 第 9 行:我们将分离项 A2 的名称更改为“A2-”。
- 第 11 行:脱离的项 A2 被重新附加到持久化上下文中。请注意,A2 仍然是一个脱离的对象。现在成为持久化上下文一部分的是对象 em.merge(itemA2)。此处并未像通常那样将该对象存储在变量中,因此无法访问它。
- 第 13 行:持久化上下文与数据库同步。数据库中的文章 A2 将被修改,其版本号将从 N 变为 N+1。内存中脱离上下文的版本 articleA2 不再有效。代表类别 A 的脱离上下文对象同样如此,因为其文章列表中包含 articleA2。
- 第 15 行:我们显示所有商品以验证商品 A2 的名称变更
结果如下:
项目A2的名称确实发生了变化。
2.4.6.4. 测试6
该测试如下:
// modification d'1 catégorie et de ses articles
public static void test6() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// chargement catégorie
categorieA = em.find(Categorie.class, categorieA.getId());
// liste des articles de la catégorie A
for (Article a : categorieA.getArticles()) {
a.setNom(a.getNom() + "-");
}
// modification nom catégorie
categorieA.setNom(categorieA.getNom() + "-");
// fin transaction
tx.commit();
// dump des catégories et des articles
dumpCategories();
dumpArticles();
}
- 测试 6 更改了类别 A 及其所有文章的名称
- 第 4 行:我们从一个新的、空的上下文开始
- 第 9 行:从数据库中检索类别 A。我们不合并已脱离的 categoryA 对象,因为我们知道它引用了文章 A2,而该文章已不再有效。因此,我们从头开始。
- 第 11–12 行:我们将类别 A 中所有文章的名称更改为新名称。同样,我们通过 getArticles 方法使用反向 OneToMany 关系。
- 第 15 行:分类名称也随之更改
- 第 17 行:事务结束。上下文与数据库同步。上下文中所有已修改的对象都将在数据库中更新。
- 第 21–22 行:显示商品和分类以便验证
结果如下:
文章 A2 再次更名,类别 A 亦是如此。
2.4.6.5. 测试7
此测试内容如下:
// category deletion
public static void test7() {
// new persistence context
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistence catégorieB and cascade (merge) associated items
Categorie mergedcategorieB = em.merge(categorieB);
// category deletion and cascading (delete) of associated items
em.remove(mergedcategorieB);
// end transaction
tx.commit();
// dump categories and articles
dumpCategories();
dumpArticles();
}
- 测试 7 删除类别 B 及其所属文章
- 第 4 行:我们从一个新的、空的上下文开始
- 第 9 行:类别 B 作为与持久化上下文分离的对象存在于内存中。我们将它合并回持久化上下文。因此,其文章(文章 B1)也将被合并,从而重新整合到持久化上下文中。
- 第 11 行:现在类别 B 已处于上下文中,我们可以将其移除。通过级联机制,其条目也将被移除。此操作之所以可行,是因为第 9 行的合并操作已将其重新整合回持久化上下文中。
- 第 13 行:事务结束。上下文将被同步。上下文中已被移除的对象将从数据库中删除。
- 第 15–16 行:我们显示项目和类别以供验证
结果如下:
类别 B 和文章 B1 确实已经消失了。
2.4.6.6. 测试8
该测试如下:
// requêtes
@SuppressWarnings("unchecked")
public static void test8() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// liste des articles de la catégorie A
List articles = em
.createQuery(
"select a from Categorie c join c.articles a where c.nom like 'A%' order by a.nom asc")
.getResultList();
// affichages articles
System.out.println("Articles de la catégorie A");
for (Object a : articles) {
System.out.println(a);
}
// fin transaction
tx.commit();
}
- 测试 7 展示了如何在不使用反向关联的情况下从类别中检索项目。这说明反向关联并非必不可少。
- 第 4 行:我们从一个新的、空的上下文开始
- 第 10 行:一个 JPQL 查询,用于检索名称以 A 开头的类别中的所有文章
- 第 15–17 行:显示查询结果。
结果如下:
2.4.7. Eclipse / Hibernate 项目 2
我们复制并粘贴 Eclipse / Hibernate 项目,以阐明关于主关系/逆关系概念的一个要点。此前我们围绕 @Entity [Article] 的 @ManyToOne(主)注解,以及 @Entity [Category] 的 @OneToMany(逆)关系进行了说明。 我们希望说明,如果后者未被声明为前者的反向关系,那么生成的数据库模式将与之前生成的完全不同。
 |
[1] 处是新的 Eclipse 项目。[2] 处是 Java 代码,[3] 处是用于生成数据库 SQL 模式的 Ant 脚本。该项目位于 [4] 的 examples 文件夹 [5] 中。我们将导入该项目。
我们仅修改 @Entity [Category],使其与 @Entity [Article] 之间的 @OneToMany 关系不再被声明为 @Entity [Article] 与 @Entity [Category] 之间 @ManyToOne 关系的逆向关系:
...
@Entity
@Table(name="jpa05_hb_categorie")
public class Categorie implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// relationship OneToMany not inverse (no mappedby) Category (one) -> Article (many)
// implemented by a Categorie_Article join table, so that, starting from a category
// you can reach the items in this category
@OneToMany(cascade=CascadeType.ALL, fetch=FetchType.LAZY)
private Set<Article> articles = new HashSet<Article>();
// manufacturers
...
- 第 18–22 行:我们仍希望保留通过第 21 行中的 @OneToMany 关系在给定类别中查找文章的能力。然而,我们希望了解 mappedBy 属性的作用,该属性会将一种关系转换为在另一个 @Entity 中定义的主关系的反向关系。在此处,mappedBy 已被移除。
我们使用 MySQL5 数据库管理系统运行 ant-DLL 任务(参见第 2.1.7 节)。生成的模式如下:
 |
请注意以下几点:
- 已创建了一个新表 [categorie_article] [1]。该表此前并不存在。
- 这是一个连接表,用于连接表 [categorie] [2] 和 [article] [3]。如果文章对象 a1 和 a2 属于类别 c1,则该连接表将包含以下行:
其中 c1、a1 和 a2 是相应对象的主键。
- 关联表 [category_article] [1] 是由 Hibernate 生成的,以便我们能够从 Category 对象 c 开始,检索属于 c 的 Article 对象 a。正是 @OneToMany 关系迫使生成了该表。由于我们未将其声明为 @Entity Article 的 @ManyToOne 主关系的反向关系,Hibernate 无法得知可以利用该主关系来检索类别 c 下的文章。因此,它另寻他法。
- 此示例有助于阐明主关系与逆向关系的概念。其中一方(逆向关系)利用另一方(主关系)的属性。
该数据库在 MySQL 5 中的 SQL 模式如下:
alter table jpa05_hb_categorie_jpa06_hb_article
drop
foreign key FK79D4BA1D26D17756;
alter table jpa05_hb_categorie_jpa06_hb_article
drop
foreign key FK79D4BA1D424C61C9;
alter table jpa06_hb_article
drop
foreign key FK4547168FECCE8750;
drop table if exists jpa05_hb_categorie;
drop table if exists jpa05_hb_categorie_jpa06_hb_article;
drop table if exists jpa06_hb_article;
create table jpa05_hb_categorie (
id bigint not null auto_increment,
version integer not null,
nom varchar(30),
primary key (id)
) ENGINE=InnoDB;
create table jpa05_hb_categorie_jpa06_hb_article (
jpa05_hb_categorie_id bigint not null,
articles_id bigint not null,
primary key (jpa05_hb_categorie_id, articles_id),
unique (articles_id)
) ENGINE=InnoDB;
create table jpa06_hb_article (
id bigint not null auto_increment,
version integer not null,
nom varchar(30),
categorie_id bigint not null,
primary key (id)
) ENGINE=InnoDB;
alter table jpa05_hb_categorie_jpa06_hb_article
add index FK79D4BA1D26D17756 (jpa05_hb_categorie_id),
add constraint FK79D4BA1D26D17756
foreign key (jpa05_hb_categorie_id)
references jpa05_hb_categorie (id);
alter table jpa05_hb_categorie_jpa06_hb_article
add index FK79D4BA1D424C61C9 (articles_id),
add constraint FK79D4BA1D424C61C9
foreign key (articles_id)
references jpa06_hb_article (id);
alter table jpa06_hb_article
add index FK4547168FECCE8750 (categorie_id),
add constraint FK4547168FECCE8750
foreign key (categorie_id)
references jpa05_hb_categorie (id);
- 第 19–24 行:创建 [categorie] 表,第 33–39 行:创建 [article] 表。请注意,这些与前一个示例中的内容完全相同。
- 第 26–31 行:由于 @Entity Categorie 存在非反向的 @OneToMany 关系,因此创建了关联表 [categorie_article]。 该表中的行数据类型为 [c,a],其中 c 是类别 c 的主键,a 是属于类别 c 的项目 a 的主键。该关联表的主键由两个主键 [c,a] 拼接而成(第 29 行)。
- 第 41-45 行:从 [categorie_article] 表到 [categorie] 表的外键约束
- 第 47–51 行:从 [categorie_article] 表到 [article] 表的外键约束
- 第 53–57 行:从 [article] 表到 [categorie] 表的外键约束
欢迎读者运行 [InitDB] 和 [Main] 测试。它们将产生与之前相同的结果。然而,数据库模式存在冗余,与之前的版本相比,性能将会下降。 我们或许应该进一步探讨这种反向/主关系的问题,以确认新配置是否也会因存在两条独立关系(它们代表同一事物:即 [article] 表与 [category] 表之间的多对一关系)而引发冲突。
2.4.8. JPA / Toplink 实现 - 1
我们现在正在使用 JPA / Toplink 实现:
 |
包含 Toplink 的 Eclipse 项目是包含 Hibernate 的 Eclipse 项目(版本 1)的副本:
 |
Java 代码与之前的 Hibernate 项目(版本 1)完全相同。环境(库文件 – persistence.xml – 数据库管理系统 – conf 和 ddl 文件夹 – Ant 脚本)即第 2.1.15.2 节中讨论的内容。该 Eclipse 项目位于 [3] 的 examples 文件夹 [4] 中。我们将导入该项目。
<persistence.xml>文件[2]在一点上进行了修改,即声明的实体:
...
<!-- classes persistantes -->
<class>entites.Categorie</class>
<class>entites.Article</class>
...
- 第 3 行和第 4 行:两个受管实体
在 MySQL5 数据库管理系统上运行 [InitDB] 会得到以下结果:
 |
[1] 为控制台输出;[2] 为生成的两个 [jpa05_tl] 表;[3] 为生成的 SQL 脚本。其内容如下:
create.sql
CREATE TABLE jpa05_tl_article (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), categorie_id BIGINT NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa05_tl_categorie (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), PRIMARY KEY (ID))
ALTER TABLE jpa05_tl_article ADD CONSTRAINT FK_jpa05_tl_article_categorie_id FOREIGN KEY (categorie_id) REFERENCES jpa05_tl_categorie (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
ALTER TABLE jpa05_tl_article DROP FOREIGN KEY FK_jpa05_tl_article_categorie_id
DROP TABLE jpa05_tl_article
DROP TABLE jpa05_tl_categorie
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
[Main] 的执行已无错误完成。
2.4.9. JPA / Toplink 实现 - 2
此 Eclipse 项目是通过克隆前一个项目创建的。由于该项目是基于 Hibernate 构建的,因此我们从 @Entity Category 的 @OneToMany 关系中移除了 mappedBy 属性。
@Entity
@Table(name = "jpa06_tl_categorie")
public class Categorie implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
private int version;
@Column(length = 30)
private String nom;
// relation OneToMany not inverse (no mappedby) Category (one) ->
// Article (many)
// implemented by a Categorie_Article join table, so that from
// category
// several items can be reached
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private Set<Article> articles = new HashSet<Article>();
随后生成的适用于 MySQL5 的 SQL 模式如下:
create.sql
CREATE TABLE jpa06_tl_categorie (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), PRIMARY KEY (ID))
CREATE TABLE jpa06_tl_categorie_jpa06_tl_article (Categorie_ID BIGINT NOT NULL, articles_ID BIGINT NOT NULL, PRIMARY KEY (Categorie_ID, articles_ID))
CREATE TABLE jpa06_tl_article (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), categorie_id BIGINT NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa06_tl_categorie_jpa06_tl_article ADD CONSTRAINT FK_jpa06_tl_categorie_jpa06_tl_article_articles_ID FOREIGN KEY (articles_ID) REFERENCES jpa06_tl_article (ID)
ALTER TABLE jpa06_tl_categorie_jpa06_tl_article ADD CONSTRAINT jpa06_tl_categorie_jpa06_tl_article_Categorie_ID FOREIGN KEY (Categorie_ID) REFERENCES jpa06_tl_categorie (ID)
ALTER TABLE jpa06_tl_article ADD CONSTRAINT FK_jpa06_tl_article_categorie_id FOREIGN KEY (categorie_id) REFERENCES jpa06_tl_categorie (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
- 第 2 行:实现前一个非反向 @OneToMany 关系的关联表。
[InitDB] 的执行未出现错误,但 [Main] 的执行在第 7 个测试用例处崩溃,并输出以下日志(FINEST):
- 第 3 行:对类别 B 的合并
- 第 4 行:将依赖文章 B1 放入上下文
- 第 5 行:对类别 B 本身执行相同操作
- 第6行:对类别B执行移除操作
- 第 7 行:对项目 B1 执行删除(级联)
- 第 8 行:Java 代码请求提交事务
- 第 9 行:事务开始——因此显然此前尚未开始。
- 第 10 行:项目 B1 即将被 [item] 表上的 DELETE 操作删除。问题就出在这里。连接表 [category_item] 引用了 [item] 表中的行 B1。从 [item] 表中删除 B1 将违反外键约束。
- 第 13 行及之后:发生异常
我们可以得出什么结论?
- 这再次暴露出 Hibernate 与 TopLink 之间的兼容性问题:Hibernate 通过了此测试
- TopLink 在处理两条关系实际上互为反向(其中一条未声明为主关系,另一条未声明为反向关系)的情况时存在困难。这可以接受,因为这种情况实际上代表了配置错误。 在我们的示例中,[article] 表与关联表 [categorie_article] 之间不存在关系。因此,在对 [article] 表进行操作时,TopLink 不会尝试操作 [categorie_article] 表,这似乎是理所当然的。
2.5. 示例 5:带有显式关联表的多对多关系
2.5.1. 数据库模式
|
- 在[1]中,MySQL5数据库
我们已经熟悉了表 [person] [2] 和 [address] [3]。第 2.3.1 节中已对此进行了讨论。我们采用的是将人员的地址存储在单独的表 [address] [3] 中的版本。在 [person] 表中,通过外键约束实现了将人员与其地址关联的关系。
一个人会参与各种活动。这些活动存储在 [activity] 表 [4] 中。一个人可以参与多项活动,而一项活动也可以由多人参与。因此,[person] 和 [activity] 表之间存在多对多关系。这种关系由关联表 [person_activity] [5] 表示。
2.5.2. 表示数据库的 @Entity 对象
上述表将由以下 @Entity 表示:
- @Entity Person 将表示 [person] 表
- @Entity Address 将表示 [address] 表
- @Entity Activity 将表示 [activity] 表
- @Entity PersonneActivite 将表示 [personne_activite] 表
这些实体之间的关系如下:
- Person 实体与 Address 实体之间建立了一对一关系:一个人 p 有一个地址 a。持有外键的 Person 实体将作为主实体,而 Address 实体将作为从实体。
- Person 和 Activity 实体之间存在多对多关系:一个人有多个活动,一个活动由多人参与。这种关系可以通过在两个实体中分别使用 @ManyToMany 注解来直接实现,其中一个实体被声明为另一个的逆实体。该方案将在后面探讨。在此,我们通过两个一对多关系来实现多对多关系:
- 一个将 Person 实体与 PersonActivity 实体关联的一对多关系:[person] 表中的一行(One)由 [person_activity] 表中的多行(Many)引用。持有外键的 [person_activity] 表将具有主 @ManyToOne 关系,而 Person 实体将具有反向的 @OneToMany 关系。
- 将 Activity 实体与 PersonActivity 实体关联的一对多关系:[activity] 表中的一行(One)被 [person_activity] 表中的多行(Many)引用。持有外键的 [person_activity] 表将具有主 @ManyToOne 关系,而 Activity 实体将具有反向的 @OneToMany 关系。
@Entity Person 定义如下:
@Entity
@Table(name = "jpa07_hb_personne")
public class Personne implements Serializable {
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
// main relationship Person (one) -> Address (one)
// implemented by the foreign key Person(adresse_id) -> Address
// cascade insert Person -> insert Address
// cascade shift Person -> shift Address
// cascade deletion Person -> deletion Address
// a Person must have 1 Address (nullable=false)
// 1 Address belongs to 1 person only (unique=true)
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
// relation Person (one) -> PersonneActivite (many)
// inverse of existing relationship PersonneActivite (many) -> Personne (one)
// cascade deletion Person -> supression PersonneActivite
@OneToMany(mappedBy = "personne", cascade = { CascadeType.REMOVE })
private Set<PersonneActivite> activites = new HashSet<PersonneActivite>();
// manufacturers
这个 @Entity 类是众所周知的。我们仅对其与其他实体之间的关系进行说明:
- 第 30–39 行:与 @Entity Address 建立一对一 (@OneToOne) 关系,通过 [Person] 表中指向 [Address] 表的外键 [address_id](第 38 行)实现。
- 第 41–45 行:与 @Entity PersonneActivite 建立一对多 (@OneToMany) 关系。 一个人员(One)由连接表 [personne_activite](由 @Entity PersonneActivite 表示)中的多行(Many)引用。这些 PersonneActivite 对象将被放入 Set<PersonneActivite> 类型中,其中 PersonneActivite 是我们将稍后定义的类型。
- 第 44 行:此处定义的一对多关系是 @Entity PersonneActivite 的 person 字段上定义的主关系(mappedBy 关键字)的逆向关系。我们设置了 Person -> Activity 的删除级联:删除一个 person p 将导致 p.activites 集合中所有 PersonneActivite 类型的持久化元素被删除。
@Entity Address 如下所示:
@Entity
@Table(name = "jpa07_hb_adresse")
public class Adresse implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse")
private Personne personne;
- 第 28-29 行:该 @OneToOne 关系是 @Entity Person 类中 @OneToOne address 关系的逆向关系(见 Person 类第 37-38 行)。
@Entity Activity 如下所示
@Entity
@Table(name = "jpa07_hb_activite")
public class Activite implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
// relation Activite (one) -> PersonneActivite (many)
// inverse of existing relationship PersonneActivite (many) -> Activite (one)
// cascade suppression Activite -> supression PersonneActivite
@OneToMany(mappedBy = "activite", cascade = { CascadeType.REMOVE })
private Set<PersonneActivite> personnes = new HashSet<PersonneActivite>();
- 第 6-9 行:活动的primary key
- 第 11-13 行:活动的版本号
- 第 15-16 行:活动名称
- 第 18-22 行:将 @Entity Activity 与 @Entity PersonActivity 关联的一对多关系:一个活动(One)由 @Entity PersonActivity 表示的关联表 [person_activity] 中的多行(Many)引用。这些 PersonneActivite 对象将被放入 Set<PersonneActivite> 类型中。
- 第 22 行:此处定义的一对多关系是 `@Entity PersonneActivite` 中 `activity` 字段上定义的主关系(使用 `mappedBy` 关键字)的逆向关系。 我们设置了从 Activity 到 PersonActivity 的删除级联:从 [activity] 表中删除一个活动时,将触发删除 [person_activity] 关联表中 a.people 集合内找到的持久化 PersonActivity 实体。
@Entity PersonneActivite 定义如下:
@Entity
// join table
@Table(name = "jpa07_hb_personne_activite")
public class PersonneActivite {
@Embeddable
public static class Id implements Serializable {
// composite key components
// points to a Person
@Column(name = "PERSONNE_ID")
private Long personneId;
// on an Activity
@Column(name = "ACTIVITE_ID")
private Long activiteId;
// manufacturers
...
// getters and setters
...
// toString
public String toString() {
return String.format("[%d,%d]", getPersonneId(), getActiviteId());
}
}
// fields of the Personne_Activite class
// composite key
@EmbeddedId
private Id id = new Id();
// main relationship PersonneActivite (many) -> Nobody (one)
// implemented by the foreign key: personneId (PersonneActivite (many) -> Personne (one)
// personneId is also part of the composite primary key
// JPA does not need to manage this foreign key (insertable = false, updatable = false), as this is done by the application itself in its constructor
@ManyToOne
@JoinColumn(name = "PERSONNE_ID", insertable = false, updatable = false)
private Personne personne;
// main relationship PersonneActivite -> Activity
// implemented by the foreign key: activiteId (PersonneActivite (many) -> Activite (one)
// activiteId is also part of the composite primary key
// JPA does not need to manage this foreign key (insertable = false, updatable = false), as this is done by the application itself in its constructor
@ManyToOne()
@JoinColumn(name = "ACTIVITE_ID", insertable = false, updatable = false)
private Activite activite;
// manufacturers
public PersonneActivite() {
}
public PersonneActivite(Personne p, Activite a) {
// foreign keys are set by the application
getId().setPersonneId(p.getId());
getId().setActiviteId(a.getId());
// two-way associations
this.setPersonne(p);
this.setActivite(a);
p.getActivites().add(this);
a.getPersonnes().add(this);
}
// getters and setters
...
// toString
public String toString() {
return String.format("[%s,%s,%s]", getId(), getPersonne().getNom(), getActivite().getNom());
}
}
这个类比之前的要复杂一些。
- [person_activity] 表的行形式为 [p,a],其中 p 是某人的主键,a 是某项活动的主键。每个表都必须有一个主键,[person_activity] 表也不例外。到目前为止,我们定义的主键都是由数据库管理系统(DBMS)动态生成的。在这里,我们也可以采用同样的做法。 我们将采用另一种技术,即由应用程序本身定义表的主键值。在此,行 [p1,a1] 表示人员 p1 参与活动 a1。该行在表中不能重复出现。因此,(p,a) 这一对是主键的理想候选。这被称为复合主键。
- 第 30–31 行:复合主键。 @EmbeddedId 注解(此前为 @Id)与应用于人员 Address 字段的 @Embedded 语法类似。在那种情况下,它表示 Address 字段是外部类的实例,但必须插入到与人员相同的表中。此处的含义相同,只是为了表明我们正在处理主键,注解变成了 @EmbeddedId。
- 第 31 行:在实例化 `PersonneActivite` 对象时,会创建一个表示主键 `id` 的空对象。 第 7–26 行定义了代表主键的类,该类作为 `PersonneActivite` 类内部的 public static 类。其 public 和 static 属性是 Hibernate 的要求。如果将 public static 替换为 private,将会引发异常,且相关的错误信息表明 Hibernate 试图执行语句 new PersonneActivite$Id。因此,Id 类必须同时是 static 和 public 的。
- 第 6 行:主键的 Id 类被声明为 @Embeddable。回顾第 31 行,主键 id 被声明为 @EmbeddedId。因此,对应的类必须带有 @Embeddable 注解。
- 我们曾指出,[person_activity] 表的主键由 (p, a) 这对组成,其中 p 是人员的primary key,a 是活动的primary key。 我们在第 11 行(personId)和第 15 行(activityId)中找到了 复合键的两个元素 (p, a)。与这两个字段关联的列分别命名为:personId 对应 person,activityId 对应 activity。
- 第 31 行:已通过两个列(PERSON_ID、ACTIVITY_ID)定义了主键。 [person_activity] 表中没有其他列。剩下的就是定义我们当前正在描述的 @Entity PersonneActivite 与关系模式中其他 @Entity 之间的关系。这些关系反映了 [personne_activite] 表与其他表之间的外键约束。
- 第 33–39 行:定义从 [person_activity] 表到 [person] 表的外键
- 第 37 行:该关系类型为 @ManyToOne:[person] 表中的一行(One)被 [person_activity] 表中的多行(Many)引用。
- 第 38 行:我们为外键列命名。该名称与外键中“person”组件的名称(第 10 行)保持一致。属性 insertable=false、updatable=false 的设置旨在防止 Hibernate 管理该外键。实际上,该键是应用程序计算的主键的组成部分,Hibernate 不得干预。
- 第 41–47 行:定义从 [person_activity] 表到 [activity] 表的外键。相关说明与前文所述相同。
- 第 54–63 行:基于 person p 和 activity a 构造 PersonActivity 对象的构造函数。请注意,在构造 PersonActivity 对象时,第 31 行中的主键 id 指向了一个空的 Id 对象。 第 56–57 行分别向 Id 对象的各个字段(personId、activityId)赋值。这些值分别是作为构造函数参数传递的 person p 和 activity a 的主键。因此,主键 id(第 31 行)现在有了具体值。
- 第 59 行:将值 p 赋给第 39 行中的 person 字段
- 第 60 行:第 47 行中的 activite 字段被赋值为 a
- 现在已创建并初始化了一个 [PersonActivity] 对象。我们将 @Entity Person(第 61 行)与 @Entity Activity(第 62 行)之间的反向关联更新为刚刚创建的 @Entity PersonActivity。
至此,我们已完成数据库实体的描述。当前我们面临一种复杂但不幸的是很常见的情况。我们将看到,JPA 层还有另一种可能的配置,可以隐藏部分复杂性:连接表将变为隐式,由 JPA 层自动构建和管理。 在此,我们选择了最复杂的解决方案,但它允许关系模式随时间演进。这使得可以在连接表中添加列,而在连接表不是显式 @Entity 的配置中,这是无法实现的。[ref1] 推荐了我们目前正在探讨的解决方案。支持开发此解决方案的信息源自 [ref1]。
2.5.3. Eclipse / Hibernate 项目
此处使用的 JPA 实现是 Hibernate。用于测试的 Eclipse 项目如下:
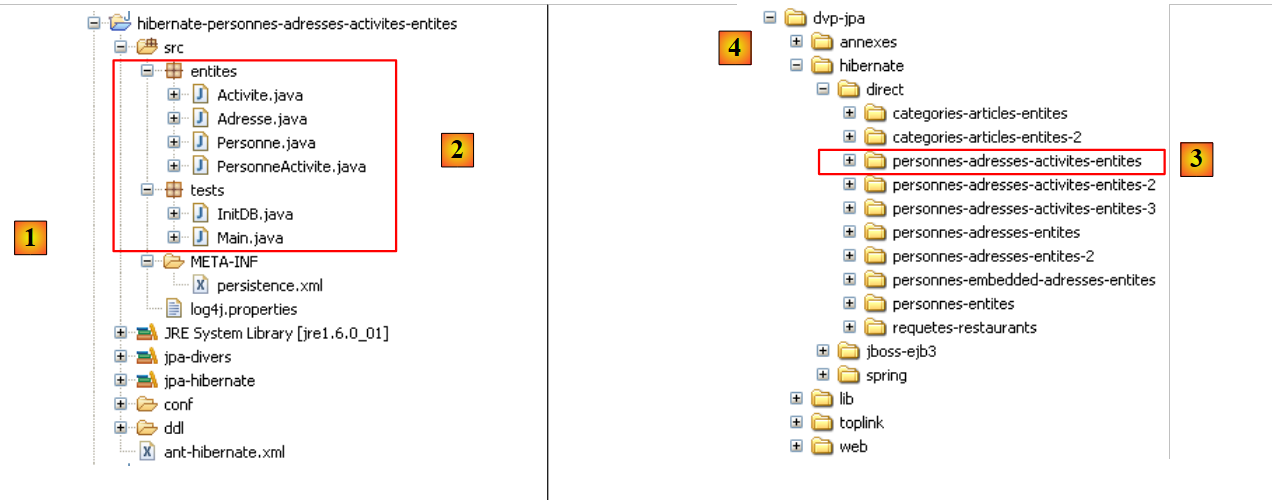
[1] 处为 Eclipse 项目;[2] 处为 Java 代码。该项目位于 [3] 中的 examples 文件夹 [4] 内。我们将导入该项目。
2.5.4. 生成数据库 DDL
按照第2.1.7节中的说明,为MySQL5数据库管理系统生成的DDL如下:
alter table jpa07_hb_personne
drop
foreign key FKB5C817D45FE379D0;
alter table jpa07_hb_personne_activite
drop
foreign key FKD3E49B06CD852024;
alter table jpa07_hb_personne_activite
drop
foreign key FKD3E49B0668C7A284;
drop table if exists jpa07_hb_activite;
drop table if exists jpa07_hb_adresse;
drop table if exists jpa07_hb_personne;
drop table if exists jpa07_hb_personne_activite;
create table jpa07_hb_activite (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_adresse (
id bigint not null auto_increment,
version integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adresse_id bigint not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_personne_activite (
PERSONNE_ID bigint not null,
ACTIVITE_ID bigint not null,
primary key (PERSONNE_ID, ACTIVITE_ID)
) ENGINE=InnoDB;
alter table jpa07_hb_personne
add index FKB5C817D45FE379D0 (adresse_id),
add constraint FKB5C817D45FE379D0
foreign key (adresse_id)
references jpa07_hb_adresse (id);
alter table jpa07_hb_personne_activite
add index FKD3E49B06CD852024 (ACTIVITE_ID),
add constraint FKD3E49B06CD852024
foreign key (ACTIVITE_ID)
references jpa07_hb_activite (id);
alter table jpa07_hb_personne_activite
add index FKD3E49B0668C7A284 (PERSONNE_ID),
add constraint FKD3E49B0668C7A284
foreign key (PERSONNE_ID)
references jpa07_hb_personne (id);
- 第 21-26 行:[activity] 表
- 第 28-39 行:[address] 表
- 第 41-51 行:[person] 表
- 第 53-57 行:关联表 [person_activity]。请注意复合主键(第 56 行)
- 第 59-63 行:从 [person] 表到 [address] 表的外键
- 第 65-69 行:从 [person_activity] 表到 [activity] 表的外键
- 第 71-75 行:从 [person_activity] 表到 [person] 表的外键
2.5.5. InitDB
[InitDB] 的代码如下:
package tests;
...
public class InitDB {
// constant
private final static String TABLE_PERSONNE_ACTIVITE = "jpa07_hb_personne_activite";
private final static String TABLE_PERSONNE = "jpa07_hb_personne";
private final static String TABLE_ACTIVITE = "jpa07_hb_activite";
private final static String TABLE_ADRESSE = "jpa07_hb_adresse";
public static void main(String[] args) throws ParseException {
// Persistence context
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// we retrieve a EntityManager from the EntityManagerFactory
// previous
em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// request
Query sql1;
// delete elements from the PERSONNE_ACTIVITE table
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE_ACTIVITE);
sql1.executeUpdate();
// delete elements from the PERSONNE table
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE);
sql1.executeUpdate();
// delete elements from the ACTIVITE table
sql1 = em.createNativeQuery("delete from " + TABLE_ACTIVITE);
sql1.executeUpdate();
// delete elements from the ADRESSE table
sql1 = em.createNativeQuery("delete from " + TABLE_ADRESSE);
sql1.executeUpdate();
// creation activities
Activite act1 = new Activite();
act1.setNom("act1");
Activite act2 = new Activite();
act2.setNom("act2");
Activite act3 = new Activite();
act3.setNom("act3");
// persistence activities
em.persist(act1);
em.persist(act2);
em.persist(act3);
// creating people
Personne p1 = new Personne("p1", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("p2", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
Personne p3 = new Personne("p3", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// address creation
Adresse adr1 = new Adresse("adr1", null, null, "49000", "Angers", null, "France");
Adresse adr2 = new Adresse("adr2", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
Adresse adr3 = new Adresse("adr3", "x", "x", "x", "x", "x", "x");
Adresse adr4 = new Adresse("adr4", "y", "y", "y", "y", "y", "y");
// associations person <--> address
p1.setAdresse(adr1);
adr1.setPersonne(p1);
p2.setAdresse(adr2);
adr2.setPersonne(p2);
p3.setAdresse(adr3);
adr3.setPersonne(p3);
// persistence of persons and therefore of associated addresses
em.persist(p1);
em.persist(p2);
em.persist(p3);
// persistence of a4 address not linked to a person
em.persist(adr4);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// address display
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
System.out.println("[activites]");
for (Object a : em.createQuery("select a from Activite a").getResultList()) {
System.out.println(a);
}
// associations person <-->activity
PersonneActivite p1act1 = new PersonneActivite(p1, act1);
PersonneActivite p1act2 = new PersonneActivite(p1, act2);
PersonneActivite p2act1 = new PersonneActivite(p2, act1);
PersonneActivite p2act3 = new PersonneActivite(p2, act3);
// persistence of person <--> activity associations
em.persist(p1act1);
em.persist(p1act2);
em.persist(p2act1);
em.persist(p2act3);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// address display
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
System.out.println("[activites]");
for (Object a : em.createQuery("select a from Activite a").getResultList()) {
System.out.println(a);
}
System.out.println("[personnes/activites]");
for (Object pa : em.createQuery("select pa from PersonneActivite pa").getResultList()) {
System.out.println(pa);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
// log
System.out.println("terminé...");
}
}
- 第 27-38 行:清空 [person_activity]、[person]、[address] 和 [activity] 表。请注意,我们必须从包含外键的表开始。
- 第 40-45 行:创建三个活动:act1、act2 和 act3
- 第 47–49 行:将它们放入持久化上下文中。
- 第 51-53 行:创建了三个人:p1、p2 和 p3。
- 第 55–58 行:创建四个地址(adr1 至 adr4)。
- 第 60–65 行:将地址 adr1–adr4 与人员 p1–p3 建立关联。由于 Person <-> Address 关系是双向的,因此每次需要执行两项操作。
- 第 67–69 行:将人员 p1 至 p3 放入持久化上下文。由于 Person -> Address 的级联关系,地址 adr1 至 adr3 也将被放入持久化上下文。
- 第 71 行:第四个地址 adr4 未与任何人相关联,因此被显式放入持久化上下文中。
- 第 73–85 行:查询持久化上下文以检索 [Person]、[Address] 和 [Activity] 类型的实体列表。我们知道这些查询将触发上下文与数据库的同步:已创建的实体将被插入数据库并分配主键。理解这一点对于后续内容至关重要。
- 第 87–90 行:我们创建了四个 Person <-> Activity 关联。这些关联的名称表明了哪个人与哪项活动相关联。您可能还记得,PersonActivity 实体的主键是由 Person 和 Activity 实体的主键组成的复合键。之所以能进行此操作,是因为 Person 和 Activity 实体在之前的同步过程中已获得了各自的主键。
- 第 92–95 行:这 4 个关联被添加到持久化上下文中。
- 第 87–86 行:查询持久化上下文以检索 [Person]、[Address]、[Activity] 和 [PersonActivity] 类型的实体列表。我们知道这些查询将触发上下文与数据库的同步:创建的 PersonActivity 实体将被插入数据库。
在 MySQL5 环境下运行 [InitDB] 会产生以下控制台输出:
看到第15–16行中人物p1和p2的版本号为1,以及第24–26行中三个活动的版本号也是1,这可能会让人感到惊讶。让我们试着理解一下。
在第 2–4 行中,人员的版本号为 0;而在第 11–13 行中,活动的版本号也是 0。这些显示发生在 Person <-> Activity 关系建立之前。 Java 代码的第 87–90 行在人员 p1 和 p2 与活动 act1、act2 及 act3 之间建立了关系。这些关系是通过 @Entity PersonneActivite 构造函数创建的(参见第 2.5.2 节)。阅读该构造函数的代码可知,当人员 p 与活动 a 建立关联时:
- 活动 a 会被添加到集合 p.activities 中
- 人员 p 会被添加到集合 a.personnes 中
因此,当我们编写 new PersonneActivite(p, a)* 时,人员 p 和活动 a 在内存中会发生变更。当执行 [InitDB] 的第 97–113 行时,持久化上下文会与数据库同步,JPA/Hibernate 会检测到持久化实体 p1、p2、act1、act2 和 act3* 已被修改。 这些更改必须在数据库中进行。它们实际上被写入关联表 [person_activity],但 JPA/Hibernate 仍会递增每个被修改的持久化实体的版本号。
在 SQL Explorer 视图中,结果如下:
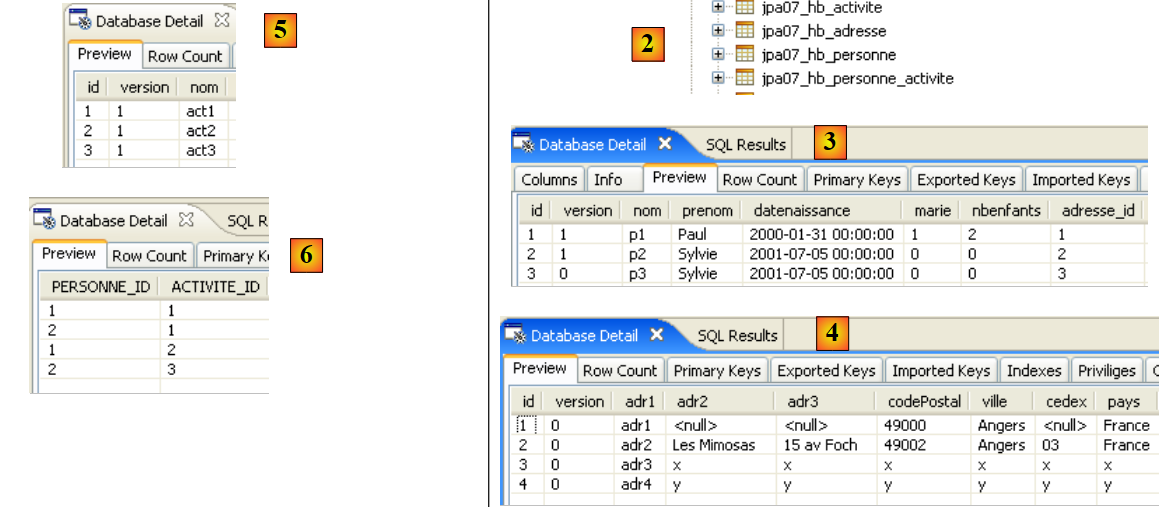 |
- [2]: [jpa07_hb_*]
- [3]: people 表
- [4]: 地址表。
- [5]: 活动表
- [6]: 人员 <-> 活动 关联表
2.5.6. Main
[Main] 类运行了一系列测试,我们逐一执行这些测试,但测试 1 除外,该测试使用 [InitDB] 中的代码来初始化数据库。
2.5.6.1. 测试2
该测试内容如下:
// suppression Personne p1
public static void test2() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// suppression dépendances sur p1 : pas nécessaire à hibernate mais
// indispensable à toplink
act1.getPersonnes().remove(p1act1);
act2.getPersonnes().remove(p1act2);
// suppression personne p1
em.remove(p1);
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- 第 4 行:我们使用 test1 的持久化上下文,其中 person p1 是该上下文中的一个对象。
- 第 13 行:删除人员 p1。由于属性:
- Address 上的 cascadeType.ALL,与 person p1 关联的地址将被删除
- PersonActivity 的 cascadeType.REMOVE 属性,person p1 的活动记录将被删除。
- 第 10–11 行:我们移除了其他实体对 person p1 的依赖关系,person p1 将在第 13 行被删除。活动 act1 和 act2 由 person p1 执行。这些关联是由 PersonActivity 实体构造函数创建的,其代码如下:
public PersonneActivite(Personne p, Activite a) {
// les clés étrangères sont fixées par l'application
getId().setPersonneId(p.getId());
getId().setActiviteId(a.getId());
// associations bidirectionnelles
setPersonne(p);
setActivite(a);
p.getActivites().add(this);
a.getPersonnes().add(this);
}
在第 9 行,活动 a 的 persons 集合中接收了一个额外的 PersonActivity 类型的元素。该元素的类型为 (p,a),表示人员 p 参与了活动 a。在 [Main] 中的 test1 中,通过这种方式创建了两个链接:(p1,act1) 和 (p1,act2)。 test2 的第 10 行和第 11 行删除了这些依赖关系。请注意,Hibernate 在不删除对人员 p1 的这些依赖关系的情况下仍能正常工作,但 Toplink 则不能。
- 第 17–20 行:显示所有表
结果如下:
- 人物 p1 出现在 test1(第 3 行),但在 test2 结束时(第 22–23 行)已不复存在
- 人物 p1 的地址 adr1 出现在 test1(第 11 行),但在 test2 之后(第 29–31 行)已不复存在
- 人物 p1 在 test1 中存在的活动 (p1,act1)(第 16 行)和 (p1,act2)(第 18 行),在 test2 结束时(第 33–34 行)已不复存在
2.5.6.2. Test3
该测试如下:
// suppression activite act1
public static void test3() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// suppression dépendances sur act1 : pas nécessaire à hibernate mais
// indispensable à toplink
p2.getActivites().remove(p2act1);
// suppression activité act1
em.remove(act1);
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- 第 4 行:我们使用 test2 的持久化上下文
- 第 12 行:删除活动 act1。由于 PersonneActivite 上的属性:
- PersonneActivite 上的 cascadeType.REMOVE,[personne_activite] 表中的 (p, act1) 行将被删除。
- 第 10 行:在将 act1 从持久化上下文中移除之前,我们会先移除其他实体对该持久化对象可能存在的依赖。在前一个测试中删除 person p1 之后,只有 person p2 执行活动 act1。
- 第 13–16 行:显示所有表
结果如下:
- 在 test2 中,活动 act1 存在(第 6 行)。在 test3 中,它已不存在(第 21-22 行)
- 在 test2 中,链接 (p2,act1) 存在(第 14 行)。在 test3 中,它已不存在(第 28 行)
2.5.6.3. Test4
该测试如下:
// récupération activités d'une personne
public static void test4() {
// contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on récupère la personne p2
p2 = em.find(Personne.class, p2.getId());
System.out.format("1 - Activités de la personne p2 (JPQL) :%n");
// on scanne ses activités
for (Object pa : em.createQuery("select a.nom from Activite a join a.personnes pa where pa.personne.nom='p2'").getResultList()) {
System.out.println(pa);
}
// on passe par la relation inverse de p2
p2 = em.find(Personne.class, p2.getId());
System.out.format("2 - Activités de la personne p2 (relation inverse) :%n");
// on scanne ses activités
for (PersonneActivite pa : p2.getActivites()) {
System.out.println(pa.getActivite().getNom());
}
// fin transaction
tx.commit();
}
- 测试 4 展示了用户 p2 的活动。
- 第 4 行:我们从一个新的、空的上下文开始
- 第 12–14 行:我们使用 JPQL 查询显示人物 p2 执行的活动名称。
- 执行了 Activity(a)与 PersonActivity(pa)之间的连接(join a.people)
- 在该连接 (a, pa) 的行中,我们显示人员 p2 的活动名称 (a.name)(pa.person.name='p2')。
- 第 16–21 行:我们采用与之前相同的方法,但使用人员 p2 的 OneToMany 关系 p2.activities。JPQL 查询将由 JPA 自动生成。在此我们看到了反向 OneToMany 关系的优势:它避免了手动编写 JPQL 查询。
结果如下:
2.5.6.4. 测试5
本次测试内容如下:
// récupération personnes faisant une activité donnée
public static void test5() {
// contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
System.out.format("1 - Personnes pratiquant l'activité act3 (JPQL) :%n");
// on demande les activités de p2
for (Object pa : em.createQuery("select p.nom from Personne p join p.activites pa where pa.activite.nom='act3'").getResultList()) {
System.out.println(pa);
}
// on passe par la relation inverse de act3
System.out.format("2 - Personnes pratiquant l'activité act3 (relation inverse) :%n");
act3 = em.find(Activite.class, act3.getId());
for (PersonneActivite pa : act3.getPersonnes()) {
System.out.println(pa.getPersonne().getNom());
}
// fin transaction
tx.commit();
}
- 测试 6 展示了执行活动 act3 的人员。其方法与测试 6 类似。关于这两个代码片段之间的联系,我们留给读者自行推敲。
结果如下:
测试 4 和 5 旨在再次证明,反向关系绝非必需,且始终可以由 JPQL 查询替代。
2.5.7. JPA / Toplink 实现
我们现在使用的是 JPA / Toplink 实现:
 |
包含 Toplink 的 Eclipse 项目是包含 Hibernate 的 Eclipse 项目的副本:
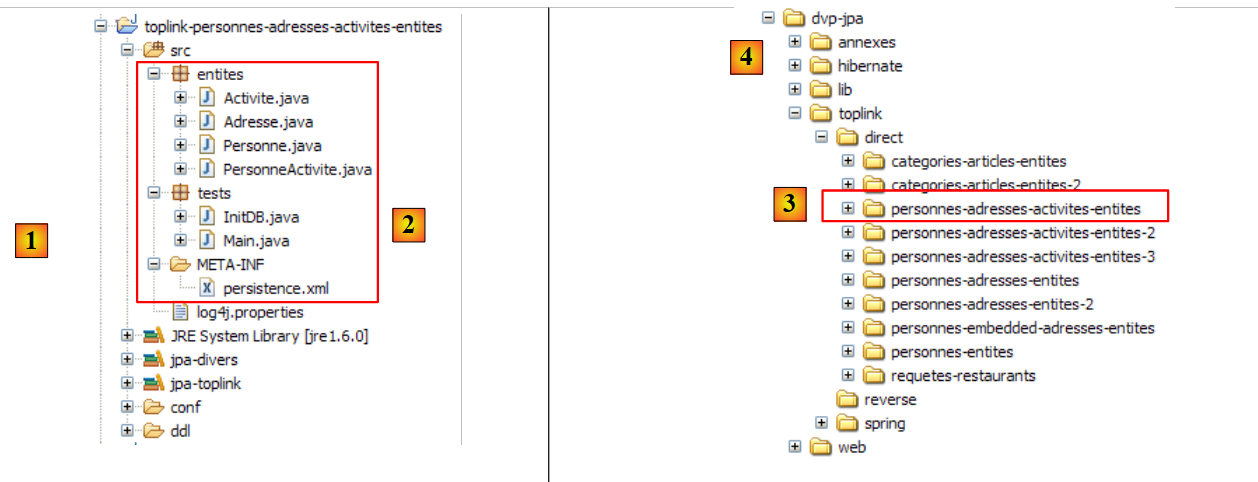 |
Java 代码与之前的 Hibernate 项目完全相同,仅有少数细微差异,我们将在下文讨论。环境(库文件 – persistence.xml – 数据库管理系统 – conf 和 ddl 文件夹 – Ant 脚本)与第 2.1.15.2 节中描述的一致。该 Eclipse 项目位于 [3] 的 examples 文件夹 [4] 中。我们将导入该项目。
<persistence.xml>文件[2]在一点上进行了修改:声明的实体:
<!-- classes persistantes -->
<class>entites.Activite</class>
<class>entites.Adresse</class>
<class>entites.Personne</class>
<class>entites.PersonneActivite</class>
- 第 2–5 行:四个受管实体
在 MySQL5 数据库管理系统上运行 [InitDB] 会得到以下结果:
 |
[1] 为控制台输出;[2] 为生成的 [jpa07_tl] 表;[3] 为生成的 SQL 脚本。其内容如下:
create.sql
CREATE TABLE jpa07_tl_activite (ID BIGINT NOT NULL, VERSION INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa07_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, VERSION INTEGER NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR2 VARCHAR(30), CEDEX VARCHAR(3), ADR1 VARCHAR(30) NOT NULL, PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa07_tl_personne_activite (PERSONNE_ID BIGINT NOT NULL, ACTIVITE_ID BIGINT NOT NULL, PRIMARY KEY (PERSONNE_ID, ACTIVITE_ID))
CREATE TABLE jpa07_tl_personne (ID BIGINT NOT NULL, DATENAISSANCE DATE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, NBENFANTS INTEGER NOT NULL, VERSION INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa07_tl_personne_activite ADD CONSTRAINT FK_jpa07_tl_personne_activite_ACTIVITE_ID FOREIGN KEY (ACTIVITE_ID) REFERENCES jpa07_tl_activite (ID)
ALTER TABLE jpa07_tl_personne_activite ADD CONSTRAINT FK_jpa07_tl_personne_activite_PERSONNE_ID FOREIGN KEY (PERSONNE_ID) REFERENCES jpa07_tl_personne (ID)
ALTER TABLE jpa07_tl_personne ADD CONSTRAINT FK_jpa07_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa07_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
[InitDB] 和 [Main] 的执行均已成功完成。
2.6. 示例 6:使用隐式连接表的多对多关系
我们回到示例 4,但现在使用由 JPA 层自身生成的隐式连接表来处理它。
2.6.1. 数据库模式
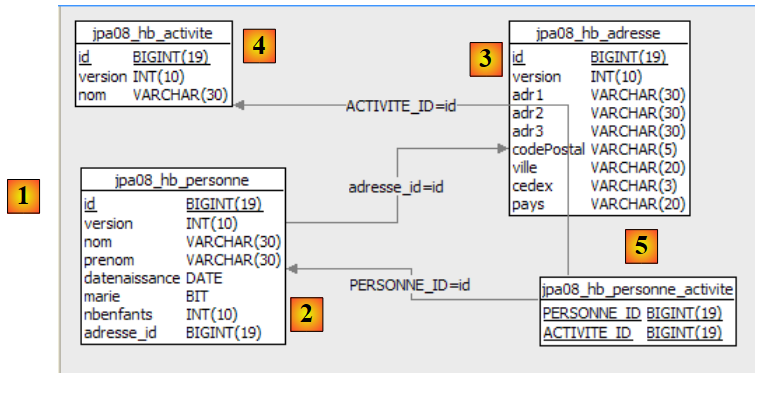 |
- 在 [1] 中:MySQL5 数据库 – 在 [2] 中:[person] 表 – 在 [3] 中:相关的 [address] 表 – 在 [4] 中:用于记录活动的 [activity] 表 – 在 [5] 中:连接人员与活动的关联表 [person_activity]。
2.6.2. 表示数据库的 @Entity 对象
上述表将通过以下 @Entity 注解进行表示:
- @Entity Person 将表示 [person] 表
- @Entity Address 将表示 [address] 表
- @Entity Activity 将表示 [activity] 表
- [person_activity] 表不再由 @Entity 注解表示
这些实体之间的关系如下:
- Person 实体与 Address 实体之间建立了一对一关系:一个人 p 有一个地址 a。持有外键的 Person 实体将作为主实体,而 Address 实体将作为从属实体。
- Person 实体与 Activity 实体之间存在多对多关系:一个人有多个活动,一个活动由多人参与。该关系将通过在两个实体中分别使用 @ManyToMany 注解来实现,其中一个实体被声明为另一个实体的逆实体。
@Entity Person 定义如下:
@Entity
@Table(name = "jpa08_hb_personne")
public class Personne implements Serializable {
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
// toplink sqlserver :@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
// main relationship Person (one) -> Address (one)
// implemented by the foreign key Person(adresse_id) -> Address
// cascade insert Person -> insert Address
// cascade shift Person -> shift Address
// cascade deletion Person -> deletion Address
// a Person must have 1 Address (nullable=false)
// 1 Address belongs to 1 person only (unique=true)
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
// relationship Person (many) -> Activity (many) via a personne_activite join table
// personne_activite(PERSONNE_ID) is a foreign key on Person(id)
// personne_activite(ACTIVITE_ID) is a foreign key on Activite(id)
// cascade=CascadeType.PERSIST: persistence of 1 person leads to persistence of their activities
@ManyToMany(cascade={CascadeType.PERSIST})
@JoinTable(name="jpa08_hb_personne_activite",joinColumns = @JoinColumn(name = "PERSONNE_ID"), inverseJoinColumns = @JoinColumn(name = "ACTIVITE_ID"))
private Set<Activite> activites = new HashSet<Activite>();
// manufacturers
public Personne() {
}
我们仅对第 46–48 行中的 @ManyToMany 关系进行说明,该关系将 @Entity Person 与 @Entity Activity 关联起来:
- 第 48 行:一个人拥有若干活动。activities 字段将表示这些活动。在之前的版本中,activities 集合中元素的类型是 PersonActivity。而在这里,类型是 Activity。因此,我们可以直接访问一个人的活动,而在之前的版本中,我们必须通过中间实体 PersonActivity 进行访问。
- 第 46 行:将我们正在考察的 @Entity Person 与第 48 行 activities 集合中的 @Entity Activity 关联的关系属于多对多(ManyToMany)类型:
- 一个人员(One)拥有多个活动(Many)
- 一项活动(One)由多人(Many)参与
- 最终,@Entity Person 和 @Entity Activity 通过多对多 (ManyToMany) 关系相连。与一对一 (OneToOne) 关系类似,该关系中的实体是互为对称的。我们可以自由选择哪个 @Entity 作为主实体,哪个作为从实体。在此,我们决定由 @Entity Person 作为主实体。
- 正如我们在前一个示例中所见,@ManyToMany 关系需要一个关联表。虽然之前我们使用 @Entity 来定义它,但这里的关联表是通过第 47 行上的 @JoinTable 注解定义的。
- name 属性用于为该表命名。
- 关联表由其所连接的各表的外键组成。此处包含两个外键:一个来自 [person] 表,另一个来自 [activity] 表。这些外键列由 joinColumns 和 inverseJoinColumns 属性定义。
- joinColumns 属性上的 @JoinColumn 注解定义了持有主 @ManyToMany 关系的 @Entity 表(此处为 [person] 表)上的外键。该外键列将被命名为 PERSON_ID。
- inverseJoinColumns 属性的 @JoinColumn 注解定义了持有反向 @ManyToMany 关系的 @Entity 表(此处为 [activity] 表)上的外键。该外键列将命名为 ACTIVITY_ID。
@Entity Address 如下所示:
@Entity
@Table(name = "jpa07_hb_adresse")
public class Adresse implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse")
private Personne personne;
- 第 28-29 行:该 @OneToOne 关系是 @Entity Person 类中 @OneToOne address 关系的逆向关系(见 Person 类第 37-38 行)。
@Entity Activity 如下所示
@Entity
@Table(name = "jpa08_hb_activite")
public class Activite implements Serializable {
// fields
@Id()
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
// toplink sqlserver : @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
// inverse relationship Activity -> Person
@ManyToMany(mappedBy = "activites")
private Set<Personne> personnes = new HashSet<Personne>();
...
- 第 20–21 行:将 @Entity Activity 与 @Entity Person 关联的多对多关系。该关系已在 @Entity Person 中定义。此处我们仅指定该关系是 @Entity Person 中 activites 字段(mappedBy="activites")上现有 @ManyToMany 关系的逆向关系(mappedBy)。
- 请注意,反向关系始终是可选的。在此,我们使用它来检索参与当前活动的参与者。将使用 Set<Person> people 集合来检索这些参与者。@Entity Activity 的 Person 依赖项的加载模式未指定。我们在前面的示例中也没有指定它。默认情况下,该模式为 fetch=FetchType.LAZY。
至此,我们已完成数据库实体的描述。这比将关联表 [person_activity] 显式定义的情况更为简单。但这种简化的方案随着时间推移可能会显现出缺点:它不允许向关联表添加列。然而,为满足新需求(例如在 [person_activity] 表中添加一列以记录人员报名活动的时间),这可能变得必要。
2.6.3. Eclipse / Hibernate 项目
此处使用的 JPA 实现是 Hibernate。用于测试的 Eclipse 项目如下:
 |
[1] 处为 Eclipse 项目;[2] 处为 Java 代码。该项目位于 [3] 中的 examples 文件夹 [4] 内。我们将导入该项目。
2.6.4. 生成数据库 DDL
按照第2.1.7节中的说明,为MySQL5数据库管理系统生成的DDL如下:
alter table jpa08_hb_personne
drop
foreign key FKA44B1E555FE379D0;
alter table jpa08_hb_personne_activite
drop
foreign key FK5A6A55A5CD852024;
alter table jpa08_hb_personne_activite
drop
foreign key FK5A6A55A568C7A284;
drop table if exists jpa08_hb_activite;
drop table if exists jpa08_hb_adresse;
drop table if exists jpa08_hb_personne;
drop table if exists jpa08_hb_personne_activite;
create table jpa08_hb_activite (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_adresse (
id bigint not null auto_increment,
version integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adresse_id bigint not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_personne_activite (
PERSONNE_ID bigint not null,
ACTIVITE_ID bigint not null,
primary key (PERSONNE_ID, ACTIVITE_ID)
) ENGINE=InnoDB;
alter table jpa08_hb_personne
add index FKA44B1E555FE379D0 (adresse_id),
add constraint FKA44B1E555FE379D0
foreign key (adresse_id)
references jpa08_hb_adresse (id);
alter table jpa08_hb_personne_activite
add index FK5A6A55A5CD852024 (ACTIVITE_ID),
add constraint FK5A6A55A5CD852024
foreign key (ACTIVITE_ID)
references jpa08_hb_activite (id);
alter table jpa08_hb_personne_activite
add index FK5A6A55A568C7A284 (PERSONNE_ID),
add constraint FK5A6A55A568C7A284
foreign key (PERSONNE_ID)
references jpa08_hb_personne (id);
此 DDL 与显式连接表生成的 DDL 类似,且与之前展示的模式相对应:
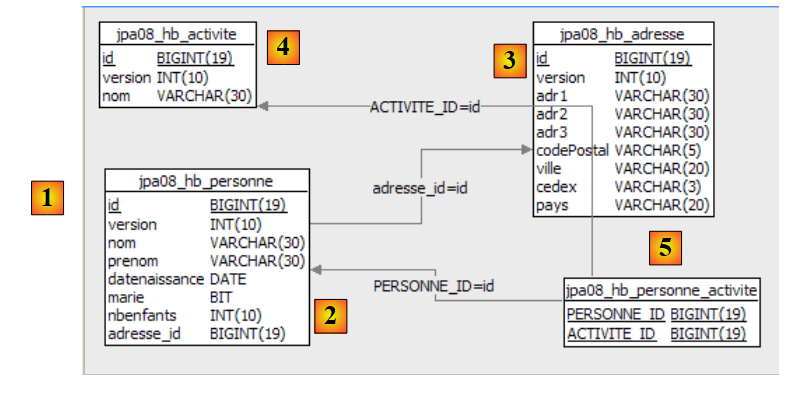 |
2.6.5. InitDB
关于 [InitDB] 类,我们不再赘述,因为它与之前的版本完全相同,且产生相同的结果。相反,让我们关注以下展示 Person <-> Activity 关联的代码:
// people/activities display
System.out.println("[personnes/activites]");
Iterator iterator = em.createQuery("select p.id,a.id from Personne p join p.activites a").getResultList().iterator();
while (iterator.hasNext()) {
Object[] row = (Object[]) iterator.next();
System.out.format("[%d,%d]%n", (Long) row[0], (Long) row[1]);
}
- 第 3 行:执行连接操作的 JPQL 查询。SELECT 语句的结果返回通过连接表关联的 Person 和 Activity 实体的 ID。SELECT 语句返回的列表由包含两个 Long 对象的行组成。为了遍历此列表,第 3 行请求了该列表的 Iterator 对象。
- 第 4–7 行:利用上一行获取的 Iterator 对象,遍历该列表。
- 第 5 行:列表的每个元素都是一个数组,其中包含 SELECT 结果中的一行
- 第 6 行:通过进行适当的类型转换,获取 SELECT 语句生成的当前行中的元素。
[InitDB] 的结果如下:
2.6.6. Main
[Main] 类运行一系列测试,其中部分测试我们将进行回顾。
2.6.6.1. Test3
该测试如下:
// suppression activite act1
public static void test3() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// suppression activité act1 de p2
p2.getActivites().remove(act1);
// on retire act1 du contexte de persistance
em.remove(act1);
// fin transactions
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- 第 11 行:将活动 act1 从持久化上下文中移除
- 第 9 行:活动 act1 是上下文中唯一剩余的人员 person p2 的活动之一。第 9 行将活动 act1 从 person p2 的活动列表中移除。我们这样做是为了保持持久化上下文的一致性,因为我们稍后会使用它。
结果如下:
- test2第26行的活动act1已从test3的活动列表中消失(第40-41行)
- 人员 p2 在 test2 中曾有活动 act1(第 33 行)。在 test3 结束时,他们已不再拥有该活动(第 47 行)
2.6.6.2. Test6
该测试内容如下:
// modification des activités d'une personne
public static void test6() {
// contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on récupère la personne p2
p2 = em.find(Personne.class, p2.getId());
// on récupère l'activité act2
act2 = em.find(Activite.class, act2.getId());
// p2 ne pratique plus que l'activité act2
p2.getActivites().clear();
p2.getActivites().add(act2);
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpActivite();
dumpPersonne_Activite();
}
- 第 4 行:使用了一个新的、空的持久化上下文
- 第 9 行:从数据库中检索人员 p2 并将其放入持久化上下文
- 第 11 行:将活动 act2 从数据库加载到持久化上下文中
- 第 13 行:将人员 p2 的活动 (act3) 从数据库加载到上下文中(fetchType.LAZY)。[getActivities] 调用触发了此加载操作。我们移除了 p2 的活动。这并非实际移除活动(remove),而是修改了人员 p2 的状态。他们不再参与任何活动。
- 第 14 行:将活动 act2 添加到人员 p2。最终,人员 p2 的新活动集合为 {act2}。
- 第 16 行:事务结束。同步机制将检查上下文中的对象(p2、act2、act3),并检测到 p2 的状态已发生变化。反映此变化的 SQL 语句将在数据库中执行。
- 第18–20行:显示所有表
结果如下:
- 在测试4结束时,人员p2正在执行活动act3(第3行)。
- 在第6次测试结束时(第19行),人物p2不再执行活动act3(第3行),而是正在执行活动act2。
2.6.7. JPA / Toplink 实现
我们现在正在使用一个 JPA / Toplink 实现:
 |
包含 Toplink 的 Eclipse 项目是包含 Hibernate 的 Eclipse 项目的副本:
 |
<persistence.xml> 文件 [2] 仅在一点上进行了修改,具体涉及声明的实体:
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- classes persistantes -->
<class>entites.Activite</class>
<class>entites.Adresse</class>
<class>entites.Personne</class>
...
- 第 4-6 行:受管实体
在 MySQL5 数据库管理系统上运行 [InitDB] 会得到以下结果:
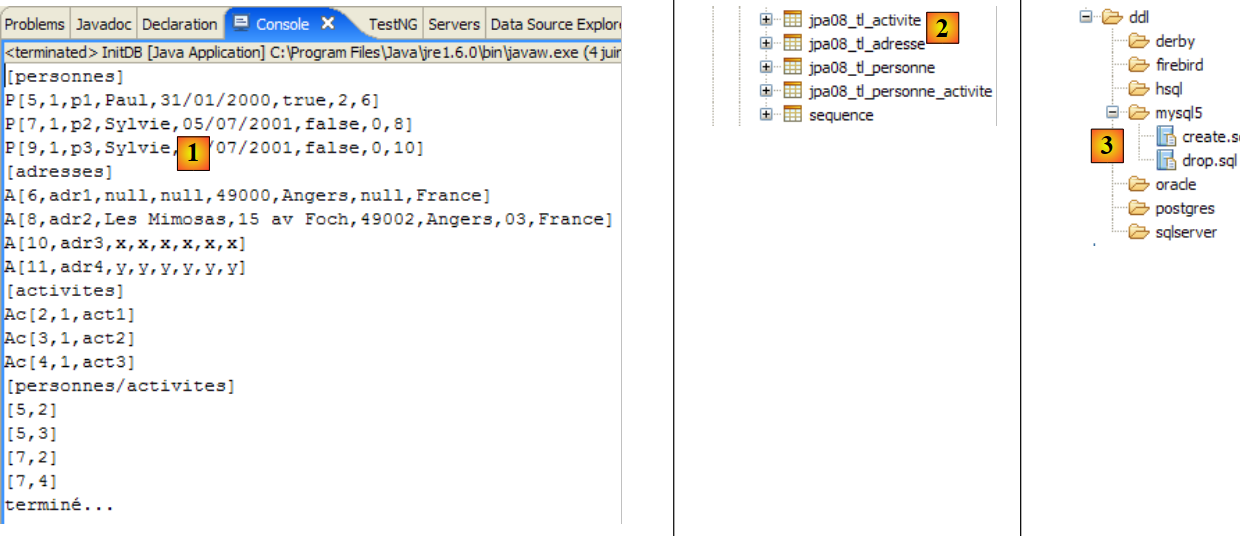 |
[1] 为控制台输出;[2] 为生成的 [jpa07_tl] 表;[3] 为生成的 SQL 脚本。其内容如下:
create.sql
CREATE TABLE jpa08_tl_personne_activite (PERSONNE_ID BIGINT NOT NULL, ACTIVITE_ID BIGINT NOT NULL, PRIMARY KEY (PERSONNE_ID, ACTIVITE_ID))
CREATE TABLE jpa08_tl_activite (ID BIGINT NOT NULL, VERSION INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa08_tl_personne (ID BIGINT NOT NULL, DATENAISSANCE DATE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, NBENFANTS INTEGER NOT NULL, VERSION INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa08_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, VERSION INTEGER NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR2 VARCHAR(30), CEDEX VARCHAR(3), ADR1 VARCHAR(30) NOT NULL, PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa08_tl_personne_activite ADD CONSTRAINT FK_jpa08_tl_personne_activite_ACTIVITE_ID FOREIGN KEY (ACTIVITE_ID) REFERENCES jpa08_tl_activite (ID)
ALTER TABLE jpa08_tl_personne_activite ADD CONSTRAINT FK_jpa08_tl_personne_activite_PERSONNE_ID FOREIGN KEY (PERSONNE_ID) REFERENCES jpa08_tl_personne (ID)
ALTER TABLE jpa08_tl_personne ADD CONSTRAINT FK_jpa08_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa08_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
[InitDB] 和 [Main] 的执行已无错误完成。
2.6.8. Eclipse / Hibernate 2 项目
我们通过复制前一个项目来创建一个基于该项目的 Eclipse 项目:
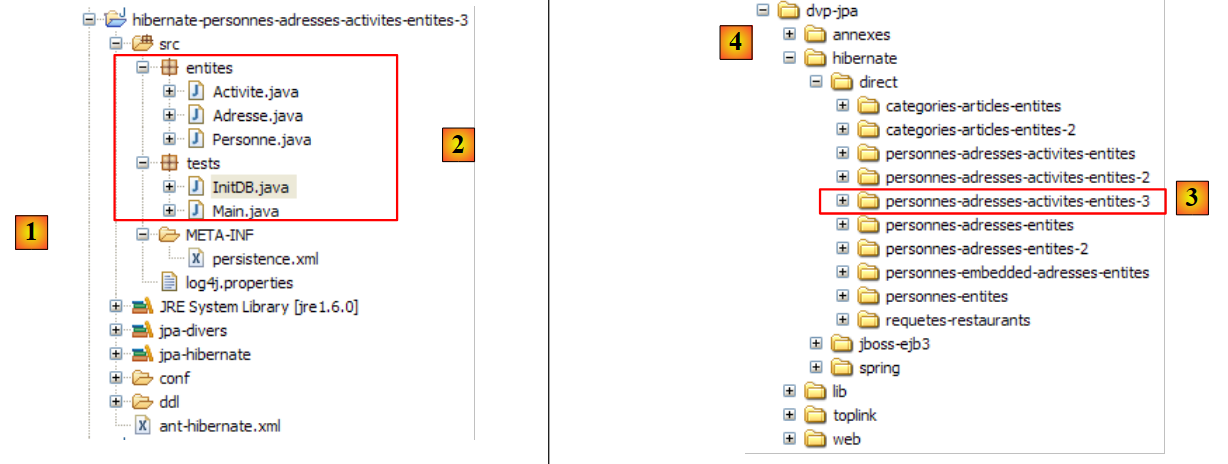 |
[1] 处为 Eclipse 项目;[2] 处为 Java 代码。该项目位于 [3] 处的 examples 文件夹 [4] 内。我们将导入该项目。
我们将 Person 与 Activity 之间的关联修改如下:
Person
// relation Personne (many) -> Activite (many) via une table de jointure personne_activite
// personne_activite(PERSONNE_ID) est clé étangère sur Personne(id)
// personne_activite(ACTIVITE_ID) est clé étangère sur Activite(id)
// plus de cascade sur les activités
// @ManyToMany(cascade={CascadeType.PERSIST})
@ManyToMany()
@JoinTable(name = "jpa09_hb_personne_activite", joinColumns = @JoinColumn(name = "PERSONNE_ID"), inverseJoinColumns = @JoinColumn(name = "ACTIVITE_ID"))
private Set<Activite> activites = new HashSet<Activite>();
- 第 6 行:主 @ManyToMany 关系不再具有 Person -> Activity 的持久化级联(参见前一版本的第 5 行)
Activity
// plus de relation inverse avec Personne
// @ManyToMany(mappedBy = "activites")
// private Set<Personne> personnes = new HashSet<Personne>();
- 第 2-3 行:已移除 Activity -> Person 的 @ManyToMany 反向关系
我们的目的是证明被移除的属性(级联和反向关系)并非必需。此新配置带来的第一个变化体现在 [InitDB] 中:
// associations personnes <--> activites
p1.getActivites().add(act1);
p1.getActivites().add(act2);
p2.getActivites().add(act1);
p2.getActivites().add(act3);
// persistance des activites
em.persist(act1);
em.persist(act2);
em.persist(act3);
// persistance des personnes
em.persist(p1);
em.persist(p2);
em.persist(p3);
// et de l'adresse a4 non liée à une personne
em.persist(adr4);
- 第 7–9 行:我们需要显式地将活动 act1 到 act3 放入持久化上下文中。当存在 Person -> Activity 的持久化级联时,第 11–13 行会同时持久化人员 p1 到 p3 以及这些人员的活动 act1 到 act3。
第二个改动可见于 [Main]:
// récupération personnes faisant une activité donnée
public static void test5() {
// contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
System.out.format("1 - Personnes pratiquant l'activité act3 (JPQL) :%n");
// on demande les activités de p2
for (Object pa : em.createQuery("select p.nom from Personne p join p.activites a where a.nom='act3'").getResultList()) {
System.out.println(pa);
}
// fin transaction
tx.commit();
}
- 第 9-12 行:检索参与活动 act3 的人员的 JPQL 查询
- 在之前的版本中,通过反向关系 Activity -> Person 也能得到相同的结果,该关系现已移除:
// we use the inverse relationship of act3
System.out.format("2 - Personnes pratiquant l'activité act3 (relation inverse) :%n");
act3 = em.find(Activite.class, act3.getId());
for (Personne p : act3.getPersonnes()) {
System.out.println(p.getNom());
}
2.6.9. Eclipse / Toplink 2 项目
我们将通过复制之前的 Eclipse / Toplink 项目来创建一个新的 Eclipse 项目:
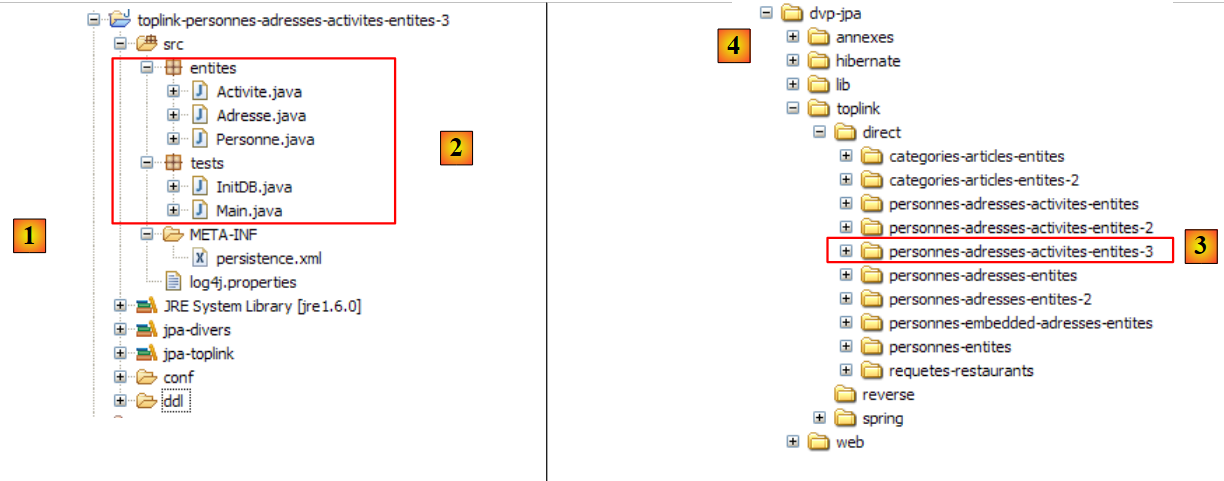 |
[1] 处是 Eclipse 项目;[2] 处是 Java 代码。该项目位于 [3] 的 examples 文件夹 [4] 中。我们将导入该项目。
该 Java 代码与 Hibernate 版本完全相同。
2.7. 示例 7:使用命名查询
我们以一个最后的示例来结束这篇从第2段开始的关于JPA实体的长篇概述,该示例演示了如何在配置文件中外部化JPQL查询。此示例摘自以下来源:
[ref2]:Mark Fisher 撰写的《Spring 2.0 中 JPA 入门指南》,网址为
[http://blog.springframework.com/markf/archives/2006/05/30/getting-started-with-jpa-in-spring-20/]。
2.7.1. 示例数据库
数据库内容如下:
 |
- [1]:包含餐厅名称和地址的列表
- 在 [2] 中:餐厅地址表,仅包含门牌号和街道名称。餐厅表与地址表之间存在一对一关系:每家餐厅仅有一个地址。
- 在 [3] 中:一道菜的表格,包含菜名以及一个布尔标志,用于指示该菜是否为素食
- 在 [4] 中:餐厅/菜品关联表:一家餐厅提供多种菜品,而同一道菜品可能由多家餐厅提供。餐厅表与菜品表之间存在多对多关系。
2.7.2. 表示数据库的 @Entity 对象
上述表将由以下 @Entity 表示:
- @Entity Restaurant 将表示 [restaurant] 表
- @Entity Address 将表示 [address] 表
- @Entity Dish 将表示 [dish] 表
这些实体之间的关系如下:
- Restaurant 实体与 Address 实体之间存在一对一关系:一家餐厅 r 有一个地址 a。持有外键的 Restaurant 实体将作为主实体。Address 实体不具备反向关系。
- “餐厅”和“菜品”实体之间存在多对多关系:一家餐厅提供多道菜品,而同一道菜品可能由多家餐厅提供。该关系将通过在“餐厅”实体中使用 @ManyToMany 注解来实现。“菜品”实体将不建立反向关系。
@Entity Restaurant 定义如下:
package entites;
...
@Entity
@Table(name = "jpa10_hb_restaurant")
public class Restaurant implements java.io.Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(unique = true, length = 30, nullable = false)
private String nom;
@OneToOne(cascade = CascadeType.ALL)
private Adresse adresse;
@ManyToMany(cascade = { CascadeType.PERSIST, CascadeType.MERGE })
@JoinTable(name = "jpa10_hb_restaurant_plat", inverseJoinColumns = @JoinColumn(name = "plat_id"))
private Set<Plat> plats = new HashSet<Plat>();
// manufacturers
public Restaurant() {
}
public Restaurant(String name, Adresse address, Set<Plat> entrees) {
...
}
// getters and setters
...
// toString
public String toString() {
String signature = "R[" + getNom() + "," + getAdresse();
for (Plat e : getPlats()) {
signature += "," + e;
}
return signature + "]";
}
}
- 第 17 行:Restaurant 实体与 Address 实体之间的一对一关系。对餐厅执行的所有持久化操作都会级联到其地址。
- 第 20 行:将 @Entity Restaurant 与第 22 行中 dishes 集合中的 @Entity Dish 关联的关系属于多对多(ManyToMany)类型:
- 一家餐厅(One)拥有多道菜品(Many)
- 一道菜(One)可由多家餐厅(Many)提供
- 最终,@Entity Restaurant 与 @Entity Dish 通过多对多 (ManyToMany) 关系建立关联。我们决定由 @Entity Restaurant 作为主关系,而 @Entity Dish 不建立反向关系。
- @ManyToMany 关系需要一个关联表。这通过第 47 行上的 @JoinTable 注解进行定义。
- name 属性用于为该表命名。
- 关联表由其所连接的表的外键组成。此处有两个外键:一个来自 [restaurant] 表,另一个来自 [dish] 表。这些外键列由 joinColumns 和 inverseJoinColumns 属性定义。
- joinColumns 属性定义了持有主 @ManyToMany 关系的 @Entity 表(此处为 [restaurant] 表)上的外键。此处缺少 joinColumns 属性。在这种情况下,JPA 有一个默认值:[table]_[table_primary_key],即 [jpa10_hb_restaurant_id]。
- 用于 inverseJoinColumns 属性的 @JoinColumn 注解定义了持有反向 @ManyToMany 关系的 @Entity 表(本例中为 [dish] 表)上的外键。该外键列将被命名为 dish_id。
@Entity Address 的定义如下:
package entites;
...
@Entity
@Table(name="jpa10_hb_adresse")
public class Adresse implements java.io.Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(name = "NUMERO_RUE")
private int numeroRue;
@Column(name = "NOM_RUE", length=30, nullable=false)
private String nomRue;
// getters and setters
...
// manufacturers
public Adresse(int streetNumber, String streetName){
...
}
public Adresse(){
}
// toString
public String toString(){
return "A["+getNumeroRue()+","+getNomRue()+"]";
}
}
- @Entity Address 是一个与其他实体没有直接关系的实体。它只能通过 Restaurant 实体进行持久化。
- 一个地址由街道名称(第 16 行)和门牌号(第 13 行)定义。
@Entity Dish 的定义如下
package entites;
...
@Entity
@Table(name="jpa10_hb_plat")
public class Plat implements java.io.Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(unique=true, length=50, nullable=false)
private String nom;
private boolean vegetarien;
// manufacturers
public Plat() {
}
public Plat(String name, boolean vegetarian) {
...
}
// getters and setters
...
// toString
public String toString() {
return "E[" + getNom() + "," + isVegetarien() + "]";
}
}
- @Entity 注解下的 Dish 是一个与其他实体没有直接关系的实体。它只能通过 Restaurant 实体进行持久化。
- 一道菜由名称(第 12 行)及其是否为素食(第 14 行)来定义。
2.7.3. Eclipse / Hibernate 项目
此处使用的 JPA 实现是 Hibernate。Eclipse 测试项目如下:
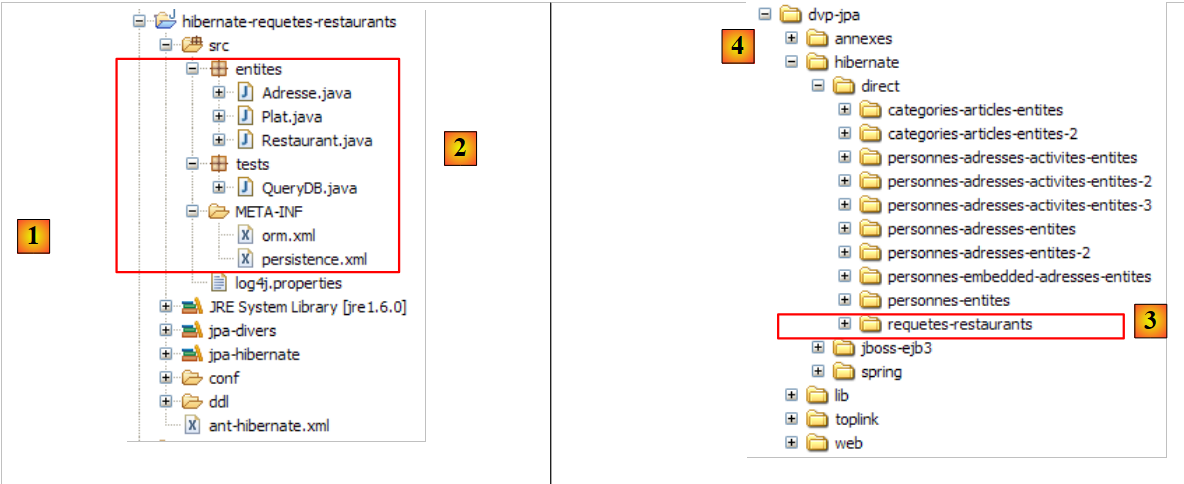 |
[1] 处是 Eclipse 项目;[2] 处是 Java 代码和 JPA 层的配置。请注意 [orm.xml] 文件的存在,这是我们之前未曾见过的。该项目位于 [3] 中的 examples 文件夹 [4] 内。我们将导入该项目。
2.7.4. 生成数据库 DDL
按照第2.1.7节中的说明,生成的MySQL5数据库管理系统(DBMS)的DDL如下:
alter table jpa10_hb_restaurant
drop
foreign key FK3E8E4F5D5FE379D0;
alter table jpa10_hb_restaurant_plat
drop
foreign key FK1D2D06D11F0F78A4;
alter table jpa10_hb_restaurant_plat
drop
foreign key FK1D2D06D1AFAC3E44;
drop table if exists jpa10_hb_adresse;
drop table if exists jpa10_hb_plat;
drop table if exists jpa10_hb_restaurant;
drop table if exists jpa10_hb_restaurant_plat;
create table jpa10_hb_adresse (
id bigint not null auto_increment,
NUMERO_RUE integer,
NOM_RUE varchar(30) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_plat (
id bigint not null auto_increment,
nom varchar(50) not null unique,
vegetarien bit not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_restaurant (
id bigint not null auto_increment,
nom varchar(30) not null unique,
adresse_id bigint,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_restaurant_plat (
jpa10_hb_restaurant_id bigint not null,
plat_id bigint not null,
primary key (jpa10_hb_restaurant_id, plat_id)
) ENGINE=InnoDB;
alter table jpa10_hb_restaurant
add index FK3E8E4F5D5FE379D0 (adresse_id),
add constraint FK3E8E4F5D5FE379D0
foreign key (adresse_id)
references jpa10_hb_adresse (id);
alter table jpa10_hb_restaurant_plat
add index FK1D2D06D11F0F78A4 (plat_id),
add constraint FK1D2D06D11F0F78A4
foreign key (plat_id)
references jpa10_hb_plat (id);
alter table jpa10_hb_restaurant_plat
add index FK1D2D06D1AFAC3E44 (jpa10_hb_restaurant_id),
add constraint FK1D2D06D1AFAC3E44
foreign key (jpa10_hb_restaurant_id)
references jpa10_hb_restaurant (id);
- 第 21-26 行:[address] 表
- 第 28-33 行:[dish] 表
- 第 35-40 行:[restaurant] 表
- 第 42-46 行:关联表 [restaurant_dish]。请注意复合主键(第 45 行)
- 第 48-52 行:[restaurant] 表指向 [address] 表的外键
- 第 54–58 行:从 [restaurant_dish] 表到 [dish] 表的外键
- 第 60–64 行:从 [restaurant_dish] 表到 [restaurant] 表的外键
此 DDL 对应于已介绍的模式:
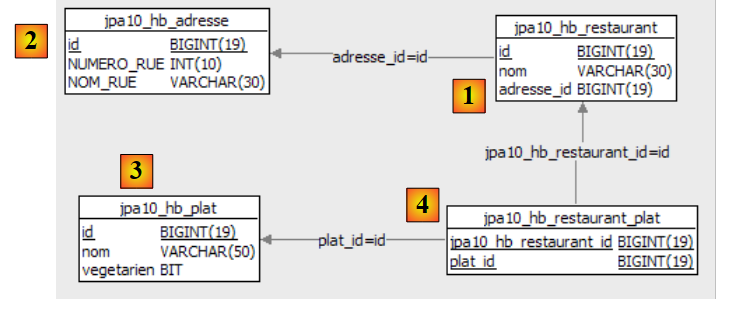 |
在 SQL 资源管理器视图中,数据库显示如下:
 |
- 在 [1] 中:数据库的 4 张表
- 在 [2]:地址
- 在 [3]:菜品
- 在 [4]:餐厅。[address_id] 引用来自 [2] 的地址。
- 在 [5] 中:关联表 [restaurant,dish]。[jpa10_hb_restaurant_id] 引用 [4] 中的餐厅,[dish_id] 引用 [3] 中的菜品。因此,[1,1] 表示餐厅“Burger Barn”供应菜品“CheeseBurger”。
为检索上述数据,执行了Eclipse项目中的[QueryDB]程序。
2.7.5. 使用 Hibernate 控制台进行 JPQL 查询
我们创建一个与前述 Eclipse 项目关联的 Hibernate 控制台。我们将遵循已两次概述的步骤,特别是第 2.1.12 节中的步骤。
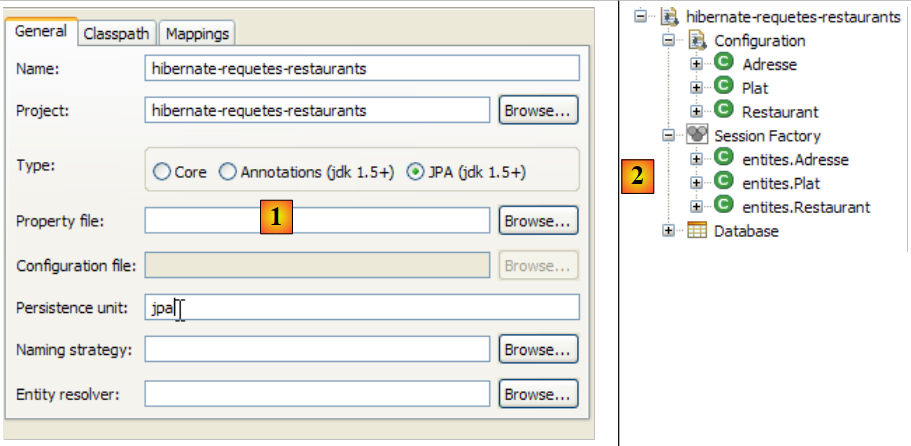 |
- 在 [1] 和 [2] 中:Hibernate 控制台的配置
 |
- 在 [3] 中:一个 JPQL 查询,而在 [4] 中是查询结果。
- 在 [5] 中:等效的 SQL 语句
接下来我们将展示一系列 JPQL 查询。欢迎读者亲自运行这些查询,并探索 Hibernate 为执行它们所生成的 SQL 语句。
获取所有餐厅及其菜品:
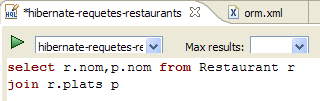 | 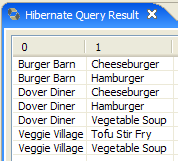 |
获取至少提供一道素食菜品的餐厅:
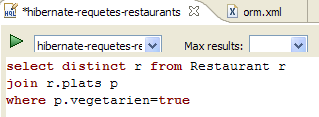 |  |
获取仅提供素食菜肴的餐厅名称:
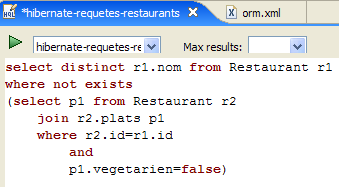 | 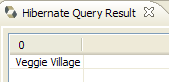 |
查看供应汉堡的餐厅:
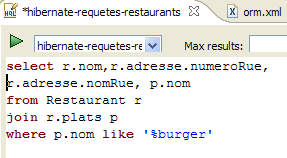 | 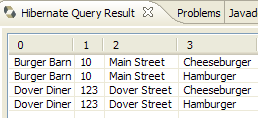 |
2.7.6. QueryDB
接下来我们将了解Eclipse项目中的[QueryDB]程序,该程序:
- 向数据库中插入数据
- 并在其上执行若干 JPQL 查询。这些查询存储在 Eclipse 项目的 [META-INF/orm.xml] 文件中:
 |
[orm.xml] 文件可用于配置 JPA 层,以替代 Java 注解。这为配置 JPA 层提供了灵活性。无需重新编译 Java 代码或 [orm.xml] 文件即可对其进行修改。JPA 配置首先通过 Java 注解进行设置,随后通过 [orm.xml] 文件进行配置。 因此,若需在不重新编译的情况下修改由 Java 注解定义的配置,只需将该配置移至 [orm.xml] 文件中,新配置将具有更高优先级。
在本示例中,[orm.xml] 文件用于存储 JPQL 查询语句。其内容如下:
<?xml version="1.0" encoding="UTF-8" ?>
<entity-mappings xmlns="http://java.sun.com/xml/ns/persistence/orm" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence/orm http://java.sun.com/xml/ns/persistence/orm_1_0.xsd" version="1.0">
<description>Restaurants</description>
<named-query name="supprimer le contenu de la table restaurant">
<query>delete from Restaurant</query>
</named-query>
<named-query name="supprimer le contenu de la table plat">
<query>delete from Plat</query>
</named-query>
<named-query name="obtenir tous les restaurants">
<query>select r from Restaurant r order by r.nom asc</query>
</named-query>
<named-query name="obtenir toutes les adresses">
<query>select a from Adresse a order by a.nomRue asc</query>
</named-query>
<named-query name="obtenir tous les plats">
<query>select p from Plat p order by p.nom asc</query>
</named-query>
<named-query name="obtenir tous les restaurants avec leurs plats">
<query>select r.nom,p.nom from Restaurant r join r.plats p</query>
</named-query>
<named-query name="obtenir les restaurants ayant au moins un plat vegetarien">
<query>select distinct r from Restaurant r join r.plats p where p.vegetarien=true</query>
</named-query>
<named-query name="obtenir les restaurants avec uniquement des plats vegetariens">
<query>
select distinct r1.nom from Restaurant r1 where not exists (select p1 from Restaurant r2 join r2.plats p1 where r2.id=r1.id and
p1.vegetarien=false)
</query>
</named-query>
<named-query name="obtenir les restaurants d'une certaine rue">
<query>select r from Restaurant r where r.adresse.nomRue=:nomRue</query>
</named-query>
<named-query name="obtenir les restaurants qui servent des burgers">
<query>select r.nom,r.adresse.numeroRue, r.adresse.nomRue, p.nom from Restaurant r join r.plats p where p.nom like '%burger'</query>
</named-query>
<named-query name="obtenir les plats du restaurant untel">
<query>select p.nom from Restaurant r join r.plats p where r.nom=:nomRestaurant</query>
</named-query>
</entity-mappings>
- [orm.xml] 文件的根元素是 <entity-mappings>(第 2 行)。
- 第 5–7 行:命名 JPQL 查询被包含在 <named-query name="...">text</named-query> 标签中。
- 该标签的 name 属性即为查询的名称。
- 该标签的文本内容即为查询文本。
QueryDB 将执行上述查询。其代码如下:
package tests;
...
public class QueryDB {
// Persistence context
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = emf.createEntityManager();
public static void main(String[] args) {
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// delete [restaurant] table items
em.createNamedQuery("supprimer le contenu de la table restaurant").executeUpdate();
// delete table items [flat]
em.createNamedQuery("supprimer le contenu de la table plat").executeUpdate();
// creation of Address objects
Adresse adr1 = new Adresse(10, "Main Street");
Adresse adr2 = new Adresse(20, "Main Street");
Adresse adr3 = new Adresse(123, "Dover Street");
// creation of Entree objects
Plat ent1 = new Plat("Hamburger", false);
Plat ent2 = new Plat("Cheeseburger", false);
Plat ent3 = new Plat("Tofu Stir Fry", true);
Plat ent4 = new Plat("Vegetable Soup", true);
// creation of Restaurant objects
Restaurant restaurant1 = new Restaurant();
restaurant1.setNom("Burger Barn");
restaurant1.setAdresse(adr1);
restaurant1.getPlats().add(ent1);
restaurant1.getPlats().add(ent2);
Restaurant restaurant2 = new Restaurant();
restaurant2.setNom("Veggie Village");
restaurant2.setAdresse(adr2);
restaurant2.getPlats().add(ent3);
restaurant2.getPlats().add(ent4);
Restaurant restaurant3 = new Restaurant();
restaurant3.setNom("Dover Diner");
restaurant3.setAdresse(adr3);
restaurant3.getPlats().add(ent1);
restaurant3.getPlats().add(ent2);
restaurant3.getPlats().add(ent4);
// persistence of Restaurant objects (and other objects through cascading)
em.persist(restaurant1);
em.persist(restaurant2);
em.persist(restaurant3);
// end transaction
tx.commit();
// dump base
dumpDataBase();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
}
// database content display
@SuppressWarnings("unchecked")
private static void dumpDataBase() {
// test2
log("données de la base");
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// restaurant displays
log("[restaurants]");
for (Object restaurant : em.createNamedQuery("obtenir tous les restaurants").getResultList()) {
System.out.println(restaurant);
}
// address display
log("[adresses]");
for (Object adresse : em.createNamedQuery("obtenir toutes les adresses").getResultList()) {
System.out.println(adresse);
}
// flat displays
log("[plats]");
for (Object plat : em.createNamedQuery("obtenir tous les plats").getResultList()) {
System.out.println(plat);
}
// displays links restaurants <--> dishes
log("[restaurants/plats]");
Iterator record = em.createNamedQuery("obtenir tous les restaurants avec leurs plats").getResultList().iterator();
while (record.hasNext()) {
Object[] currentRecord = (Object[]) record.next();
System.out.format("[%s,%s]%n", currentRecord[0], currentRecord[1]);
}
log("[Liste des restaurants avec au moins un plat végétarien]");
for (Object r : em.createNamedQuery("obtenir les restaurants ayant au moins un plat vegetarien").getResultList()) {
System.out.println(r);
}
// query
log("[Liste des restaurants avec seulement des plats végétariens]");
for (Object r : em.createNamedQuery("obtenir les restaurants avec uniquement des plats vegetariens").getResultList()) {
System.out.println(r);
}
// query
log("[Liste des restaurants dans Dover Street]");
for (Object r : em.createNamedQuery("obtenir les restaurants d'une certaine rue").setParameter("nomRue", "Dover Street").getResultList()) {
System.out.println(r);
}
// query
log("[Liste des restaurants ayant un plat de type burger]");
record = em.createNamedQuery("obtenir les restaurants qui servent des burgers").getResultList().iterator();
while (record.hasNext()) {
Object[] currentRecord = (Object[]) record.next();
System.out.format("[%s,%d,%s,%s]%n", currentRecord[0], currentRecord[1], currentRecord[2], currentRecord[3]);
}
// query
log("[Plats de Veggie Village]");
for (Object r : em.createNamedQuery("obtenir les plats du restaurant untel").setParameter("nomRestaurant", "Veggie Village").getResultList()) {
System.out.println(r);
}
// end transaction
tx.commit();
}
// logs
private static void log(String message) {
System.out.println(" -----------" + message);
}
}
执行 [QueryDB] 的结果如下:
关于代码与结果之间的关联,我们留给读者自行探索。为此,我们建议在 Hibernate 控制台中运行这些 JPQL 查询,并查看相应的 SQL 代码。
2.7.7. Eclipse / Toplink 项目
感兴趣的读者可以在本教程提供的可下载示例中找到使用 Toplink 实现的先前项目:
 |
使用 Toplink 的 Eclipse 项目是使用 Hibernate 的 Eclipse 项目的副本:
 |
<persistence.xml> 文件 [2] 声明了受管理的实体:
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- classes persistantes -->
<class>entites.Restaurant</class>
<class>entites.Adresse</class>
<class>entites.Plat</class>
...
- 第 4-6 行:托管实体
存储在 [orm.xml] 中的 JPQL 查询会被 TopLink 正确执行。为了确保这一点,在之前的项目中,我们特意避免使用 HQL(Hibernate 查询语言)查询,因为 HQL 实际上是 JPQL 的超集,而其语法并未被 JPQL 完全支持。
2.8. 结论
至此,我们对 JPA 实体的概述已告一段落。虽然这一过程较为冗长,但仍有部分重要内容(针对高级开发者)尚未涉及。我们再次建议阅读参考书籍,例如本教程所使用的:
[ref1]: 《Java Persistence with Hibernate》,作者:Christian Bauer 和 Gavin King,Manning 出版社。