6. XML e JAVA
Neste capítulo, apresentamos a utilização de documentos XML com Java. Faremos isso no contexto da aplicação de impostos analisada no capítulo anterior.
6.1. Ficheiros XML e folhas de estilo XSL
Consideremos o seguinte ficheiro XML simulations.xml, que poderia representar o resultado de simulações de cálculos de impostos:
<?xml version="1.0" encoding="ISO-8859-1"?>
<simulations>
<simulation marie="oui" enfants="2" salaire="200000" impot="22504"/>
<simulation marie="non" enfants="2" salaire="200000" impot="33388"/>
</simulations>
Se o visualizarmos com o IE 6, obtemos o seguinte resultado:
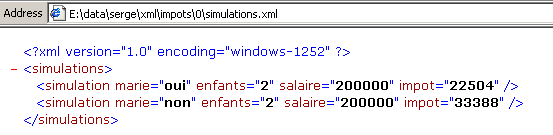
O
O IE6 reconhece que se trata de um ficheiro XML (graças à extensão .xml do ficheiro) e formata-o à sua maneira. Com o Netscape, obtém-se uma página em branco. No entanto, se se observar o código-fonte (View/Source), verifica-se que existe efetivamente o ficheiro XML original:
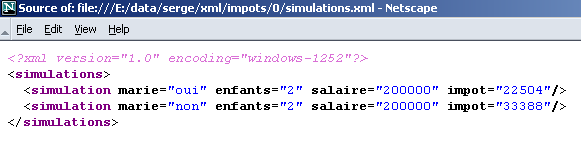
Por que razão o Netscape não exibe nada? Porque necessita de uma folha de estilo que lhe indique como transformar o ficheiro XML num ficheiro HTML, que poderá então exibir. Acontece que o IE 6 tem uma folha de estilo por predefinição, enquanto o ficheiro XML não a possui, o que era o caso aqui.
Existe uma linguagem chamada XSL (eXtended StyleSheet Language) que permite descrever as transformações a efetuar para converter um ficheiro XML num ficheiro de texto qualquer. O XSL permite a utilização de numerosas instruções e assemelha-se muito às linguagens de programação. Não o iremos detalhar aqui, pois seriam necessárias várias dezenas de páginas. Vamos simplesmente descrever dois exemplos de folhas de estilo XSL. A primeira é aquela que irá transformar o ficheiro XML simulations.xml em código HTML. Alteramos este último para que indique a folha de estilo que os navegadores poderão utilizar para o transformar no documento HTML, documento que poderão apresentar:
<?xml version="1.0" encoding="ISO-8859-1" ?>
<?xml-stylesheet type="text/xsl" href="simulations.xsl"?>
<simulations>
<simulation marie="oui" enfants="2" salaire="200000" impot="22504"/>
<simulation marie="non" enfants="2" salaire="200000" impot="33388"/>
</simulations>
A encomenda XML
designa o ficheiro simulations.xsl como uma folha de estilo (xml-stylesheet) do tipo text/xsl c.a.d. Um ficheiro de texto contendo código XSL. Esta folha de estilo será utilizada pelos navegadores para transformar o texto XML num documento HTML. Eis o resultado obtido com o Netscape 7 ao carregar o ficheiro XML simulations.xml:

Quando analisamos o código-fonte do documento (View/Source), encontramos o documento XML inicial e não o documento HTML apresentado:
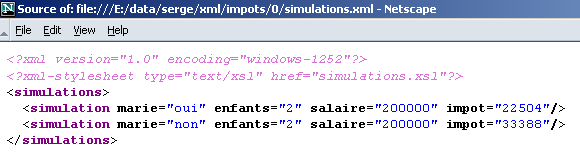
O Netscape utilizou a folha de estilo simulations.xsl para transformar o documento XML acima num documento HTML que pode ser visualizado. Chegou agora a altura de analisar o conteúdo desta folha de estilo:
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" indent="yes"/>
<xsl:template match="/">
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impôts</h3>
<hr/>
<table border="1">
<th>marié</th><th>enfants</th><th>salaire</th><th>impôt</th>
<xsl:apply-templates select="/simulations/simulation"/>
</table>
</center>
</body>
</html>
</xsl:template>
<xsl:template match="simulation">
<tr>
<td><xsl:value-of select="@marie"/></td>
<td><xsl:value-of select="@enfants"/></td>
<td><xsl:value-of select="@salaire"/></td>
<td><xsl:value-of select="@impot"/></td>
</tr>
</xsl:template>
</xsl:stylesheet>
- Uma folha de estilo XSL é um ficheiro XML e, como tal, segue as mesmas regras. Entre outras coisas, deve estar «bem formada», ou seja, todas as balizas abertas devem ser fechadas.
- O ficheiro começa com dois comandos XML que podem ser mantidos em qualquer folha de estilo XSL:
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
O atributo encoding="ISO-8859-1" permite utilizar caracteres acentuados na folha de estilo.
- A baliza <xsl:output method="html" indent="yes"/> indica ao interpretador XSL que se pretende produzir HTML «indentado».
- A baliza <xsl:template match="elemento"> serve para definir o elemento do documento XML ao qual serão aplicadas as instruções que se encontram entre <xsl:template ...> e </xsl:template>.
No exemplo acima, o elemento «/» designa a raiz do documento. Isto significa que, assim que for encontrado o início do documento XML, os comandos XSL situados entre as duas balizas serão executados.
- Tudo o que não for uma baliza XSL é inserido tal como está no fluxo de saída. As balizas XSL, por sua vez, são executadas. Algumas delas produzem um resultado que é inserido no fluxo de saída. Vejamos o seguinte exemplo:
<xsl:template match="/">
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impôts</h3>
<hr/>
<table border="1">
<th>marié</th><th>enfants</th><th>salaire</th><th>impôt</th>
<xsl:apply-templates select="/simulations/simulation"/>
</table>
</center>
</body>
</html>
</xsl:template>
Recorde-se que o documento XML analisado é o seguinte:
<?xml version="1.0" encoding="ISO-8859-1"?>
<simulations>
<simulation marie="oui" enfants="2" salaire="200000" impot="22504"/>
<simulation marie="non" enfants="2" salaire="200000" impot="33388"/>
</simulations>
Desde o início do documento XML analisado (match="/"), o interpretador XSL irá produzir como saída o texto
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impôts</h3>
<hr>
<table border="1">
<th>marié</th><th>enfants</th><th>salaire</th><th>impôt</th>
Note-se que no texto inicial tínhamos <hr/> e não <hr>. No texto inicial não era possível escrever <hr>, que, embora seja uma baliza HTML válida, é uma baliza XML inválida. No entanto, estamos aqui perante um texto XML que deve ser «bem formado», c.a.d, o que significa que todas as etiquetas devem ser fechadas. Escrevemos, portanto, <hr/> e, como escrevemos <xsl:output text="html ...">, o interpretador XSL transformará o texto <hr/> em <hr>. A seguir a este texto, virá o texto produzido pelo comando XSL:
Veremos mais tarde qual é esse texto. Por fim, o interpretador irá adicionar o texto:
O comando <xsl:apply-templates select="/simulations/simulation"/> solicita a execução do «template» (modelo) do elemento /simulations/simulation. Será executada sempre que o interpretador XSL encontrar, no texto XML analisado, uma baliza <simulation>..</simulations> ou <simulation/> dentro de uma baliza <simulations>..</simulations>. Ao encontrar a baliza <simulation>, o interpretador executará as instruções do modelo seguinte:
<xsl:template match="simulation">
<tr>
<td><xsl:value-of select="@marie"/></td>
<td><xsl:value-of select="@enfants"/></td>
<td><xsl:value-of select="@salaire"/></td>
<td><xsl:value-of select="@impot"/></td>
</tr>
</xsl:template>
Consideremos as seguintes linhas XML:
A linha <simulation ..> corresponde ao modelo da instrução XSL <xsl:apply-templates select="/simulations/simulation>". O interpretador XSL irá, portanto, procurar aplicar-lhe as instruções que correspondem a este modelo. Irá encontrar o modelo <xsl:template match="simulation"> e executá-lo. Recorde-se que o que não for um comando XSL é reproduzido tal como está pelo interpretador XSL e que os comandos XSL são, por sua vez, substituídos pelo resultado da sua execução. A instrução XSL <xsl:value-of select="@champ"/> é, assim, substituída pelo valor do atributo «champ» do nó analisado (neste caso, um nó <simulation>). A análise da linha XML anterior irá produzir o seguinte resultado:
XSL | saída |
<tr><td> | <tr><td> |
<xsl:value-of select="@marie"/> | sim |
</td><td> | </td><td> |
<xsl:value-of select="@enfants"/> | 2 |
</td><td> | </td><td> |
<xsl:value-of select="@salário"/> | 200000 |
</td><td> | </td><td> |
<xsl:value-of select="@impot"/> | 22504 |
</td></tr> | </td></tr> |
No total, a linha XML
será transformada na linha HTML:
Todas estas explicações são um pouco rudimentares, mas agora deve ficar claro para o leitor que o texto XML seguinte:
<?xml version="1.0" encoding="ISO-8859-1"?>
<?xml-stylesheet type="text/xsl" href="simulations.xsl"?>
<simulations>
<simulation marie="oui" enfants="2" salaire="200000" impot="22504"/>
<simulation marie="non" enfants="2" salaire="200000" impot="33388"/>
</simulations>
acompanhado da seguinte folha de estilo XSL simulations.xsl:
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" indent="yes"/>
<xsl:template match="/">
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impôts</h3>
<hr/>
<table border="1">
<th>marié</th><th>enfants</th><th>salaire</th><th>impôt</th>
<xsl:apply-templates select="/simulations/simulation"/>
</table>
</center>
</body>
</html>
</xsl:template>
<xsl:template match="simulation">
<tr>
<td><xsl:value-of select="@marie"/></td>
<td><xsl:value-of select="@enfants"/></td>
<td><xsl:value-of select="@salaire"/></td>
<td><xsl:value-of select="@impot"/></td>
</tr>
</xsl:template>
</xsl:stylesheet>
gera o seguinte texto: HTML:
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impots</h3>
<hr>
<table border="1">
<th>marié</th><th>enfants</th><th>salaire</th><th>impôt</th>
<tr>
<td>oui</td><td>2</td><td>200000</td><td>22504</td>
</tr>
<tr>
<td>non</td><td>2</td><td>200000</td><td>33388</td>
</tr>
</table>
</center>
</body>
</html>
O ficheiro XML simulations.xml, acompanhado da folha de estilo simulations.xsl, quando visualizado num navegador recente (neste caso, o Netscape 7), é apresentado da seguinte forma:
6.2. Aplicação de impostos: versão 6
6.2.1. Os ficheiros XML e as folhas de estilo XSL da aplicação de impostos
Voltemos à aplicação web de impostos e alteremo-la para que a resposta enviada aos clientes seja no formato XML, em vez de HTML. Esta resposta XML será acompanhada por uma folha de estilo XSL para que os navegadores a possam apresentar. No parágrafo anterior, apresentámos:
- o ficheiro simulations.xml, que é o protótipo de uma resposta XML contendo simulações de cálculos de impostos
- o ficheiro simulations.xsl, que constituirá a folha de estilo XSL que acompanhará esta resposta XML
Temos também de prever o caso de uma resposta com erros. O protótipo da resposta XML, neste caso, será o seguinte ficheiro erreurs.xml:
<?xml version="1.0" encoding="windows-1252"?>
<?xml-stylesheet type="text/xsl" href="erreurs.xsl"?>
<erreurs>
<erreur>erreur 1</erreur>
<erreur>erreur 2</erreur>
</erreurs>
A folha de estilo erreurs.xsl que permite visualizar este documento XML num navegador será a seguinte:
<?xml version="1.0" encoding="windows-1252"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" indent="yes"/>
<xsl:template match="/">
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impôts</h3>
</center>
<hr/>
Les erreurs suivantes se sont produites :
<ul>
<xsl:apply-templates select="/erreurs/erreur"/>
</ul>
</body>
</html>
</xsl:template>
<xsl:template match="erreur">
<li><xsl:value-of select="."/></li>
</xsl:template>
</xsl:stylesheet>
Esta folha de estilo introduz um comando XSL ainda não encontrado: <xsl:value-of select="."/>. Este comando produz como saída o valor do nó analisado, neste caso um nó <erreur>texte</erreur>. O valor deste nó é o texto contido entre as duas balizas de abertura e de fecho, neste caso texte.
O código erreurs.xml é transformado pela folha de estilo erreurs.xsl no seguinte documento HTML:
<html>
<head>
<title>Simulations de calculs d'impots</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impots</h3>
</center>
<hr>
Les erreurs suivantes se sont produites :
<ul>
<li>erreur 1</li>
<li>erreur 2</li>
</ul>
</body>
</html>
O ficheiro erreurs.xml, acompanhado da sua folha de estilo, é apresentado por um navegador da seguinte forma:
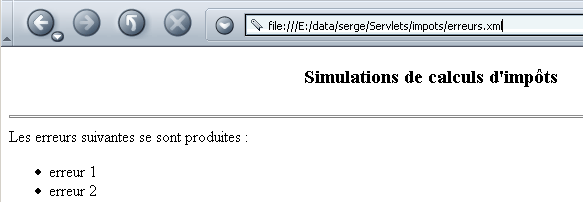
6.2.2. A servlet xmlsimulations
Criamos um ficheiro index.html que colocamos no diretório da aplicação impots. A página visualizada é a seguinte:
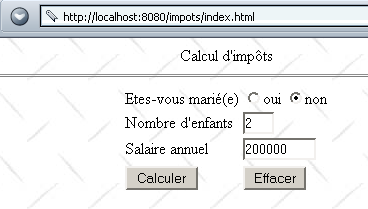
Este documento HTML é um documento estático. O seu código é o seguinte:
<html>
<head>
<title>impots</title>
<script language="JavaScript" type="text/javascript">
function effacer(){
// Limpar o formulário
with(document.frmImpots){
optMarie[0].checked=false;
optMarie[1].checked=true;
txtEnfants.value="";
txtSalaire.value="";
txtImpots.value="";
}//com
}//apagar
function calculer(){
// verificação dos parâmetros antes de os enviar para o servidor
with(document.frmImpots){
//número de filhos
champs=/^\s*(\d+)\s*$/.exec(txtEnfants.value);
if(champs==null){
// o modelo não foi verificado
alert("Le nombre d'enfants n'a pas été donné ou est incorrect");
nbEnfants.focus();
return;
}//se
//salário
champs=/^\s*(\d+)\s*$/.exec(txtSalaire.value);
if(champs==null){
// o modelo não foi verificado
alert("Le salaire n'a pas été donné ou est incorrect");
salaire.focus();
return;
}//se
//está tudo bem – vamos enviar
submit();
}//com
}//calcular
</script>
</head>
<body background="/impots/images/standard.jpg">
<center>
Calcul d'impôts
<hr>
<form name="frmImpots" action="/impots/xmlsimulations" method="POST">
<table>
<tr>
<td>Etes-vous marié(e)</td>
<td>
<input type="radio" name="optMarie" value="oui">oui
<input type="radio" name="optMarie" value="non" checked>non
</td>
</tr>
<tr>
<td>Nombre d'enfants</td>
<td><input type="text" size="3" name="txtEnfants" value=""></td>
</tr>
<tr>
<td>Salaire annuel</td>
<td><input type="text" size="10" name="txtSalaire" value=""></td>
</tr>
<tr></tr>
<tr>
<td><input type="button" value="Calculer" onclick="calculer()"></td>
<td><input type="button" value="Effacer" onclick="effacer()"></td>
</tr>
</table>
</form>
</center>
</body>
</html>
Note-se que os dados do formulário são enviados para o URL /impostos/xmlsimulações. Esta aplicação é um servlet Java configurado da seguinte forma no ficheiro web.xml da aplicação impots:
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
...........
<servlet>
<servlet-name>xmlsimulations</servlet-name>
<servlet-class>xmlsimulations</servlet-class>
<init-param>
<param-name>xslSimulations</param-name>
<param-value>simulations.xsl</param-value>
</init-param>
<init-param>
<param-name>xslErreurs</param-name>
<param-value>erreurs.xsl</param-value>
</init-param>
<init-param>
<param-name>DSNimpots</param-name>
<param-value>mysql-dbimpots</param-value>
</init-param>
<init-param>
<param-name>admimpots</param-name>
<param-value>admimpots</param-value>
</init-param>
<init-param>
<param-name>mdpimpots</param-name>
<param-value>mdpimpots</param-value>
</init-param>
</servlet>
........
<servlet-mapping>
<servlet-name>xmlsimulations</servlet-name>
<url-pattern>/xmlsimulations</url-pattern>
</servlet-mapping>
</web-app>
- A servlet chama-se xmlsimulations e baseia-se na classe xmlsimulations.class.
- Tem como parâmetros os parâmetros DSNimpots, admimpots e mdpimpots, necessários para aceder à base de dados dos impostos. Além disso, aceita dois outros parâmetros:
- xslSimulations, que é o nome do ficheiro de estilo que deve acompanhar a resposta XML contendo as simulações
- xslErreurs, que é o nome do ficheiro de estilo que deve acompanhar a resposta XML, contendo eventuais erros
- tem um alias «xmlsimulations» que a torna acessível através do URL http://localhost:8080/impots/xmlsimulations.
A estrutura da servlet xmlsimulations é semelhante à da servlet simulations já analisada. A principal diferença reside no facto de ela ter de gerar XML em vez de HTML. Isto implicará a eliminação dos ficheiros JSP utilizados nas aplicações anteriores. A sua principal função era melhorar a legibilidade do código HTML gerado, evitando que este ficasse perdido no código Java da servlet. Esta função já não se justifica. A servlet tem dois tipos de código XML a gerar:
- o código para as simulações
- o código para os erros
Anteriormente, apresentámos e analisámos os dois tipos de resposta XML a fornecer nestes dois casos, bem como as folhas de estilo que as devem acompanhar. O código da servlet é o seguinte:
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
import java.util.regex.*;
import java.util.*;
public class xmlsimulations extends HttpServlet{
// variáveis de instância
String msgErreur=null;
String xslSimulations=null;
String xslErreurs=null;
String DSNimpots=null;
String admimpots=null;
String mdpimpots=null;
impotsJDBC impots=null;
//-------- GET
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException{
// recuperamos o fluxo de gravação para o cliente
PrintWriter out=response.getWriter();
// especifica-se o tipo de resposta
response.setContentType("text/xml");
// a lista de erros
ArrayList erreurs=new ArrayList();
// A inicialização decorreu corretamente?
if(msgErreur!=null){
// Concluído — envia-se a resposta com erros para o servidor
erreurs.add(msgErreur);
sendErreurs(out,xslErreurs,erreurs);
// Concluído
return;
}
// recuperamos as simulações anteriores da sessão
HttpSession session=request.getSession();
ArrayList simulations=(ArrayList)session.getAttribute("simulations");
if(simulations==null) simulations=new ArrayList();
// estão a ser recuperados os parâmetros do pedido atual
String optMarie=request.getParameter("optMarie"); // estado civil
String txtEnfants=request.getParameter("txtEnfants"); // número de filhos
String txtSalaire=request.getParameter("txtSalaire"); // salário anual
// estão todos os parâmetros esperados?
if(optMarie==null || txtEnfants==null || txtSalaire==null){
// faltam parâmetros
// envia-se a resposta com erros
erreurs.add("Demande incomplète. Il manque des paramètres");
sendErreurs(out,xslErreurs,erreurs);
// concluído
return;
}
// temos todos os parâmetros — estamos a verificá-los
// estado civil
if( ! optMarie.equals("oui") && ! optMarie.equals("non")){
// erro
erreurs.add("Etat marital incorrect");
}
// número de filhos
txtEnfants=txtEnfants.trim();
if(! Pattern.matches("^\\d+$",txtEnfants)){
// erro
erreurs.add("Nombre d'enfants incorrect");
}
// salário
txtSalaire=txtSalaire.trim();
if(! Pattern.matches("^\\d+$",txtSalaire)){
// erro
erreurs.add("Salaire incorrect");
}
if(erreurs.size()!=0){
// se houver erros, estes são assinalados
sendErreurs(out,xslErreurs,erreurs);
}else{
// sem erros
try{
// é possível calcular o imposto a pagar
int nbEnfants=Integer.parseInt(txtEnfants);
int salaire=Integer.parseInt(txtSalaire);
String txtImpots=""+impots.calculer(optMarie.equals("oui"),nbEnfants,salaire);
// adiciona-se o resultado atual às simulações anteriores
String[] simulation={optMarie.equals("oui") ? "oui" : "non",txtEnfants, txtSalaire, txtImpots};
simulations.add(simulation);
// envia-se a resposta com as simulações
sendSimulations(out,xslSimulations,simulations);
}catch(Exception ex){}
}//if-else
// reinsere-se a lista de simulações na sessão
session.setAttribute("simulations",simulations);
}//GET
//-------- POST
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException{
doGet(request,response);
}//POST
//-------- INIT
public void init(){
// recuperam-se os parâmetros de inicialização
ServletConfig config=getServletConfig();
xslSimulations=config.getInitParameter("xslSimulations");
xslErreurs=config.getInitParameter("xslErreurs");
DSNimpots=config.getInitParameter("DSNimpots");
admimpots=config.getInitParameter("admimpots");
mdpimpots=config.getInitParameter("mdpimpots");
// parâmetros corretos?
if(xslSimulations==null || DSNimpots==null || admimpots==null || mdpimpots==null){
msgErreur="Configuration incorrecte";
return;
}
// criamos uma instância de impotsJDBC
try{
impots=new impotsJDBC(DSNimpots,admimpots,mdpimpots);
}catch(Exception ex){
msgErreur=ex.getMessage();
}
}//inicialização
//-------- sendErreurs
private void sendErreurs(PrintWriter out,String xslErreurs,ArrayList erreurs){
String réponse="<?xml version=\"1.0\" encoding=\"windows-1252\"?>"
+ "<?xml-stylesheet type=\"text/xsl\" href=\""+xslErreurs+"\"?>\n"
+"<erreurs>\n";
for(int i=0;i<erreurs.size();i++){
réponse+="<erreur>"+(String)erreurs.get(i)+"</erreur>\n";
}//for
réponse+="</erreurs>\n";
// envia-se a resposta
out.println(réponse);
}
//-------- sendSimulations
private void sendSimulations(PrintWriter out, String xslSimulations, ArrayList simulations){
String réponse="<?xml version=\"1.0\" encoding=\"windows-1252\"?>"
+ "<?xml-stylesheet type=\"text/xsl\" href=\""+xslSimulations+"\"?>\n"
+ "<simulations>\n";
String[] simulation=null;
for(int i=0;i<simulations.size();i++){
// simulação n.º i
simulation=(String[])simulations.get(i);
réponse+="<simulation "
+"marie=\""+(String)simulation[0]+"\" "
+"enfants=\""+(String)simulation[1]+"\" "
+"salaire=\""+(String)simulation[2]+"\" "
+"impot=\""+(String)simulation[3]+"\" />\n";
}//para
réponse+="</simulations>\n";
// envia-se a resposta
out.println(réponse);
}
}
Vamos detalhar as principais novidades deste código em relação ao que já conhecíamos:
- o procedimento init recupera novos parâmetros do ficheiro de configuração web.xml: os nomes das duas folhas de estilo XSL que devem acompanhar a resposta são colocados nas variáveis xslSimulations e xslErreurs. Estas duas folhas de estilo são os ficheiros simulations.xsl e erreurs.xsl analisados anteriormente. Estes são colocados no diretório da aplicação impots:
dos>dir E:\data\serge\Servlets\impots\*.xsl
27/08/2002 08:15 1 030 simulations.xsl
27/08/2002 09:23 795 erreurs.xsl
- O procedimento GET começa por verificar se ocorreu algum erro durante a inicialização. Se for o caso, chama o procedimento sendErreurs, que gera a resposta XML adequada a esta situação e, em seguida, termina. Nesta resposta XML é inserida a instrução que indica a folha de estilo a utilizar.
- Se não tiverem ocorrido erros, o procedimento GET analisa os parâmetros do pedido do cliente. Se detetar algum erro, sinaliza-o utilizando também o procedimento sendErreurs. Caso contrário, calcula a nova simulação, adiciona-a às anteriores armazenadas na sessão atual e conclui enviando a sua resposta XML através do procedimento sendSimulations. Este último procede de forma análoga ao procedimento sendErreurs.
- Note-se que o servlet anuncia a sua resposta como sendo do tipo text/xml:
Eis alguns exemplos de execução. O formulário inicial é preenchido da seguinte forma:
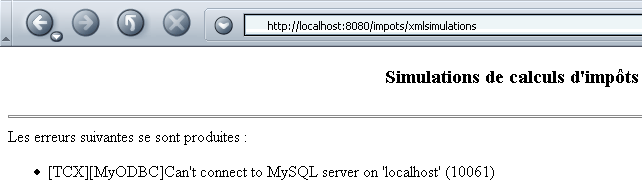
A base de dados MySQL não foi iniciada, tornando impossível a construção do objeto impots no procedimento init do servlet. A resposta deste é, então, a seguinte:
O código recebido pelo navegador (Ver/Fonte) é o seguinte:

Se agora repetirmos duas simulações após ter iniciado a base de dados MySQL, obtemos o seguinte resultado:
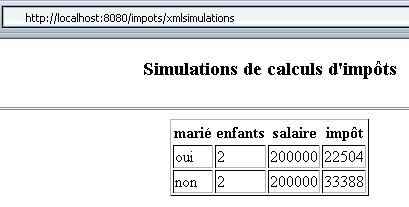
Desta vez, o navegador recebeu o seguinte código:

Note-se que a nossa nova aplicação é mais simples do que antes, devido à eliminação dos ficheiros JSP. Parte do trabalho realizado por estas páginas foi transferido para as folhas de estilo XSL. A vantagem da nossa nova repartição de tarefas é que, uma vez definido o formato XML das respostas do servlet, o desenvolvimento das folhas de estilo é independente do desenvolvimento do servlet.
6.3. Análise de um documento XML em Java
As versões 7 e 8 da nossa aplicação «impôts» serão clientes programados da servlet anterior «xmlsimulations». Estas irão receber código XML, que terão de analisar para extrair as informações que lhes interessam. Vamos fazer aqui uma pausa nas nossas diferentes versões e aprender como se pode analisar um documento XML em Java. Faremos isso a partir de um exemplo fornecido com o JBuilder 7, denominado MySaxParser. O programa tem o seguinte nome:
A aplicação MySaxParser aceita um parâmetro: o URI (Uniform Resource Identifier) do documento XML a analisar. No nosso exemplo, este URI será simplesmente o nome de um ficheiro XML localizado no diretório da aplicação MySaxParser. Consideremos dois exemplos de execução. No primeiro exemplo, o ficheiro XML analisado é o ficheiro erreurs.xml:
<?xml version="1.0" encoding="ISO-8859-1"?>
<?xml-stylesheet type="text/xsl" href="erreurs.xsl"?>
<erreurs>
<erreur>erreur 1</erreur>
<erreur>erreur 2</erreur>
</erreurs>
A análise apresenta os seguintes resultados:
dos> java MySaxParser erreurs.xml
Début du document
Début élément <erreurs>
Début élément <erreur>
[erreur 1]
Fin élément <erreur>
Début élément <erreur>
[erreur 2]
Fin élément <erreur>
Fin élément <erreurs>
Fin du document
Ainda não tínhamos indicado o que fazia a aplicação MySaxParser, mas vemos aqui que ela apresenta a estrutura do documento XML analisado. O segundo exemplo analisa o ficheiro XML simulations.xml:
<?xml version="1.0" encoding="ISO-8859-1"?>
<?xml-stylesheet type="text/xsl" href="simulations.xsl"?>
<simulations>
<simulation marie="oui" enfants="2" salaire="200000" impot="22504"/>
<simulation marie="non" enfants="2" salaire="200000" impot="33388"/>
</simulations>
A análise apresenta os seguintes resultados:
dos>java MySaxParser simulations.xml
Début du document
Début élément <simulations>
Début élément <simulation>
marie = oui
enfants = 2
salaire = 200000
impot = 22504
Fin élément <simulation>
Début élément <simulation>
marie = non
enfants = 2
salaire = 200000
impot = 33388
Fin élément <simulation>
Fin élément <simulations>
Fin du document
A classe MySaxParser contém tudo o que precisamos na nossa aplicação de impostos, uma vez que conseguiu detetar tanto os erros como as simulações que o servidor web poderia enviar. Vamos analisar o seu código:
import java.io.IOException;
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import org.apache.xerces.parsers.SAXParser;
import java.util.regex.*;
// a classe
public class MySaxParser extends DefaultHandler {
// valor de um elemento da árvore XML
private StringBuffer valeur=new StringBuffer();
// uma expressão regular do valor de um elemento quando se pretende ignorar
// os «espaços» que o precedem ou seguem
private static Pattern ptnValeur=null;
private static Matcher résultats=null;
// -------- principal
public static void main(String[] argv) {
// verificação do número de parâmetros
if (argv.length != 1) {
System.out.println("Usage: java MySaxParser [URI]");
System.exit(0);
}
// recupera-se o URI do ficheiro XML a analisar
String uri = argv[0];
try {
// criação de um analisador XML (parser)
XMLReader parser = XMLReaderFactory.createXMLReader("org.apache.xerces.parsers.SAXParser");
// indica-se ao analisador o objeto que irá implementar os métodos
// startDocument, endDocument, startElement, endElement, caracteres
MySaxParser MySaxParserInstance = new MySaxParser();
parser.setContentHandler(MySaxParserInstance);
// inicializa-se o modelo de valor de um elemento
ptnValeur=Pattern.compile("^\\s*(.*?)\\s*$");
// indica-se ao analisador o documento XML a analisar
parser.parse(uri);
}
catch(Exception ex) {
// erro
System.err.println("Erreur : " + ex);
// registo
ex.printStackTrace();
}
}//main
// -------- startDocument
public void startDocument() throws SAXException {
// procedimento chamado quando o analisador encontra o início do documento
System.out.println("Début du document");
}//startDocument
// -------- endDocument
public void endDocument() throws SAXException {
// procedimento chamado quando o analisador encontra o fim do documento
System.out.println("Fin du document");
}//endDocument
// -------- startElement
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
// procedimento chamado pelo analisador quando este encontra o início de uma baliza
// URI: URI do documento analisado?
// localName: nome do elemento que está a ser analisado
// qName: o mesmo, mas «qualificado» por um espaço de nomes, caso exista
// attributes: lista dos atributos do elemento
// acompanhamento
System.out.println("Début élément <"+localName+">");
// o elemento tem atributos?
for (int i = 0; i < attributes.getLength(); i++) {
System.out.println(attributes.getLocalName(i) + " = " + attributes.getValue(i));
}//para
}//startElement
// -------- caracteres
public void characters(char[] ch, int start, int length) throws SAXException {
// procedimento chamado repetidamente pelo analisador quando encontra texto
// entre duas balizas <baliza>texto</baliza>
// o texto está em ch a partir do caractere start e com length caracteres
// o texto é adicionado ao buffer «valor»
valeur.append(ch, start, length);
}//caracteres
// -------- endElement
public void endElement(String uri, String localName, String qName)
throws SAXException {
// procedimento chamado pelo analisador quando encontra o fim de uma baliza
// URI: URI do documento analisado?
// localName: nome do elemento que está a ser analisado
// qName: o mesmo, mas «qualificado» por um espaço de nomes, caso exista
// exibe-se o valor do elemento
String strValeur=valeur.toString();
if (ptnValeur==null) System.out.println("null");
résultats=ptnValeur.matcher(strValeur);
if (résultats.find() && ! résultats.group(1).equals("")){
System.out.println("["+résultats.group(1)+"]");
}//se
// define-se o valor do elemento como vazio
valeur.setLength(0);
// seguido de
System.out.println("Fin élément <"+localName+">");
}//endElement
}//classe
Comecemos por definir uma sigla que aparece frequentemente na análise de documentos XML: SAX, que significa «Simple API for XML». Trata-se de um conjunto de classes Java que facilitam o trabalho com documentos XML. Existem duas versões do API: SAX1 e SAX2. A aplicação acima utiliza o API SAX2.
A aplicação importa vários pacotes:
Os dois primeiros vêm incluídos no JDK 1.4, mas o terceiro não. O pacote xerces.jar está disponível no site do servidor Web Apache. Vem com o JBuilder 7, mas também com o Tomcat 4.x:
Portanto, se quisermos compilar a aplicação anterior fora do JBuilder 7 e tivermos o JDK 1.4 e o Tomcat 4.x, poderemos escrever:
Na execução, faremos o mesmo:
dos>java -classpath ".;E:\Program Files\Apache Tomcat 4.0\common\lib\xerces.jar" MySaxParser simulations.xml
A classe MySaxParser deriva da classe DefaultHandler. Voltaremos a este assunto. Analisemos o código da procedimento main:
// recupera-se o URI do ficheiro XML a analisar
String uri = argv[0];
try {
// criação de um analisador XML (parser)
XMLReader parser = XMLReaderFactory.createXMLReader("org.apache.xerces.parsers.SAXParser");
// indica-se ao analisador o objeto que irá implementar os métodos
// startDocument, endDocument, startElement, endElement, caracteres
MySaxParser MySaxParserInstance = new MySaxParser();
parser.setContentHandler(MySaxParserInstance);
// inicializa-se o modelo de valor de um elemento
ptnValeur=Pattern.compile("^\\s*(.*?)\\s*$");
// indica-se ao analisador o documento XML a analisar
parser.parse(uri);
}
catch(Exception ex) {
// erro
System.err.println("Erreur : " + ex);
// registo
ex.printStackTrace();
}
Para analisar um documento XML, a nossa aplicação necessita de um analisador de código XML denominado «parser».
O analisador XML utilizado é o fornecido pelo pacote xerces.jar. O objeto recuperado é do tipo XMLReader. XMLReader é uma interface da qual utilizamos aqui dois métodos:
indica ao analisador o objeto do tipo ContentHandler que irá tratar os eventos que este irá gerar durante a análise do documento XML | |
inicia a análise do documento XML passado como parâmetro |
Quando o analisador analisar o documento XML, irá emitir eventos tais como: «Encontrei o início do documento, o início de uma baliza, um atributo de baliza, o conteúdo de uma baliza, o fim de uma baliza, o fim do documento, ...». Transmite esses eventos ao objeto ContentHandler que lhe foi fornecido. ContentHandler é uma interface que define os métodos a implementar para processar todos os eventos que o analisador XML pode gerar. DefaultHandler é uma classe que fornece uma implementação por predefinição destes métodos. Os métodos implementados em DefaultHandler não realizam nenhuma ação, mas existem. Quando é necessário indicar ao analisador qual o objeto que irá tratar os eventos que ele irá gerar, através da instrução
, é então prático passar como parâmetro um objeto do tipo DefaultHandler. Se ficássemos por aí, nenhum evento do analisador seria tratado, mas o nosso programa seria sintaticamente correto. Na prática, passa-se como parâmetro ao analisador um objeto derivado da classe DefaultHandler, no qual são redefinidos os métodos que tratam apenas dos eventos que nos interessam. É isso que se faz aqui:
// indica-se ao analisador o objeto que irá implementar os métodos
// startDocument, endDocument, startElement, endElement, caracteres
MySaxParser MySaxParserInstance = new MySaxParser();
parser.setContentHandler(MySaxParserInstance);
// indica-se ao analisador o documento XML a analisar
parser.parse(uri);
Passamos ao analisador uma instância da classe mySaxParser, que é a nossa classe e que foi definida anteriormente pela declaração
e iniciamos a análise do documento, passando o URI como parâmetro. A partir daí, começa a análise do documento XML. O analisador emite eventos e, para cada um deles, chama um método específico do objeto responsável por tratar esses eventos, neste caso o nosso objeto MySaxParser. Este trata cinco eventos específicos, sendo os restantes ignorados:
evento emitido pelo analisador | método de processamento |
void startDocument() | |
void endDocument() | |
public void startElement(String uri, String localName, String qName, Attributes attributes) uri: ? localName: nome do elemento analisado. Se o elemento encontrado for <simulations>, teremos localName="simulações". qName: nome qualificado por um espaço de nomes do elemento analisado. Um documento XML pode definir um espaço de nomes, por exemplo, XX. O nome qualificado da baliza anterior seria, então, XX:simulations. attributes: lista de atributos da baliza | |
public void characters(char[] ch, int start, int length) ch: tabela de caracteres start: índice do primeiro carácter a utilizar na matriz ch length: número de caracteres a extrair da matriz ch O método characters pode ser chamado repetidamente. Para construir o valor de um elemento, utiliza-se então um buffer que:
| |
void endElement(String uri, String localName, String qName) os parâmetros são os do método startElement. |
O método startElement permite recuperar os atributos do elemento através do parâmetro attributes do tipo Attributes:
- o número de atributos está disponível em attributes.getLength()
- O nome do atributo i está disponível em attributes.getLocalName(i)
- o valor do atributo i está disponível em attributes.getValue(i)
- o valor do atributo de nome localName em attributes.getValue(localName)
Uma vez explicado isto, o programa anterior, acompanhado dos exemplos de execução, torna-se autoexplicativo. Foi utilizada uma expressão regular para recuperar os valores dos elementos, de modo a que um texto XML como:
resulte no valor associado à baliza <erreur>, ou seja, o texto «erro 1», sem os espaços e saltos de linha que possam precedê-lo e/ou segui-lo.
6.4. Aplicação de impostos: versão 7
Temos agora todos os elementos para escrever clientes programados para o nosso serviço fiscal que gera o XML. Retomamos a versão 4 da nossa aplicação para criar o cliente e mantemos a versão 6 no que diz respeito ao servidor. Nesta aplicação cliente-servidor:
- o serviço de simulações do cálculo de impostos é realizado pelo servlet xmlsimulations. A resposta do servidor está, portanto, no formato XML, tal como vimos na versão 6.
- o cliente já não é um navegador, mas sim um cliente Java autónomo. A sua interface gráfica é a da versão 4.
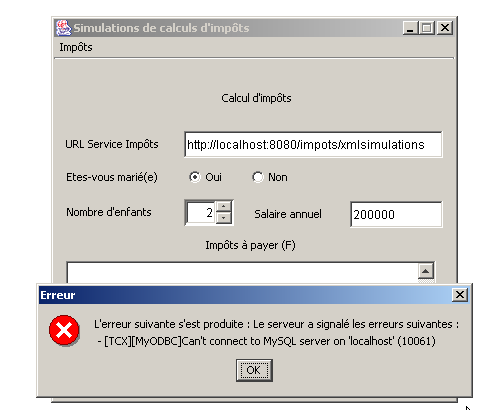
Eis alguns exemplos de execução. Em primeiro lugar, um caso de erro: o cliente consulta a servlet xmlsimulations, embora esta não tenha conseguido inicializar-se corretamente devido ao facto de o SGBD MySQL não ter sido iniciado:
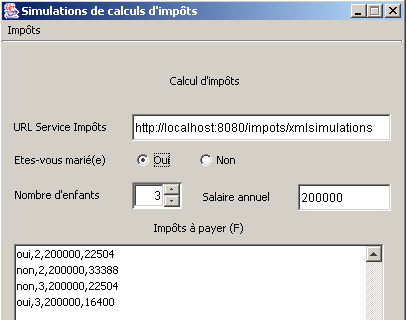
Iniciamos o MySQL e realizamos algumas simulações:
O cliente desta nova versão difere do cliente da versão 4 apenas na forma como processa a resposta do servidor. Nada mais muda. Na versão 4, o cliente recebia o código HTML, no qual procurava as informações que lhe interessavam utilizando expressões regulares. Aqui, o cliente recebe o código XML, no qual vai recuperar as informações que lhe interessam com a ajuda de um analisador XML.
Recorde-se as linhas gerais do procedimento relacionado com o menu «Calcular» da versão 4 do nosso cliente, uma vez que é principalmente aí que se verificam as alterações:
void mnuCalculer_actionPerformed(ActionEvent e) {
....
try{
// calcula-se o imposto
calculerImpots(urlImpots,rdOui.isSelected(),nbEnfants.intValue(),salaire);
}catch (Exception ex){
// exibe-se o erro
JOptionPane.showMessageDialog(this,"L'erreur suivante s'est produite : " + ex.getMessage(),"Erreur",JOptionPane.ERROR_MESSAGE);
}
....
}//mnuCalculer_actionPerformed
public void calculerImpots(URL urlImpots,boolean marié, int nbEnfants, int salaire)
throws Exception{
// cálculo do imposto
// urlImpots: URL da administração fiscal
// casado: true se for casado, false caso contrário
// nbEnfants: número de filhos
// salário: salário anual
// retiram-se de urlImpots as informações necessárias para a ligação ao servidor da administração fiscal
....
try{
// efetua-se a ligação ao servidor
....
// criam-se os fluxos de entrada e saída do cliente TCP
....
// solicita-se o URL - envio dos cabeçalhos HTTP
....
// lê-se a primeira linha da resposta
....
// lê-se a resposta até ao fim dos cabeçalhos, procurando um eventual cookie
while((réponse=IN.readLine())!=null){
.... }//enquanto
// as cabeçalhos terminam em HTTP — passa-se para o código HTML
// para recuperar as simulações
ArrayList listeSimulations=getSimulations(IN,OUT,simulations);
simulations.clear();
for (int i=0;i<listeSimulations.size();i++){
simulations.addElement(listeSimulations.get(i));
}
// acabou
....
}//calculerImpots
private ArrayList getSimulations(BufferedReader IN, PrintWriter OUT, DefaultListModel simulations) throws Exception{
....
}
Todo este código continua válido na nova versão. Apenas o processamento da resposta HTML do servidor (parte emoldurada acima) e a sua apresentação devem ser substituídos pelo processamento da resposta XML do servidor e pela sua apresentação:
// terminou para os cabeçalhos HTTP - passamos para o código XML
// para recuperar as simulações ou os erros
ImpotsSaxParser parseur=new ImpotsSaxParser(IN);
ArrayList listeErreurs=parseur.getErreurs();
ArrayList listeSimulations=parseur.getSimulations();
// encerramento da ligação ao servidor
client.close();
// limpeza da lista de visualização
simulations.clear();
// erros
if(listeErreurs.size()!=0){
// concatenamos todos os erros
String msgErreur="Le serveur a signalé les erreurs suivantes :\n";
for(int i=0;i<listeErreurs.size();i++){
msgErreur+=" - "+(String)listeErreurs.get(i);
}
// exibição de erros
throw new Exception(msgErreur);
}//if
// simulações
for (int i=0;i<listeSimulations.size();i++){
simulations.addElement(listeSimulations.get(i));
}
return;
O que faz o trecho de código acima?
- Cria um analisador XML e passa-lhe o fluxo IN, que contém o código XML enviado pelo servidor. Este fluxo também continha os cabeçalhos HTTP, mas estes já foram lidos e processados. Por isso, resta apenas a parte XML da resposta. O analisador produz duas listas de cadeias de caracteres: a lista de erros, caso existam, ou, caso contrário, a lista de simulações. Estas duas listas são mutuamente exclusivas.
- Se a lista de erros não estiver vazia, as mensagens contidas na lista são concatenadas numa única mensagem de erro e é lançada uma exceção com essa mensagem como parâmetro. Esta exceção é apresentada no procedimento mnuCalculer_actionPeformed que chamou o calculerImpots.
- Se a lista de simulações não estiver vazia, esta é apresentada no componente jList da interface gráfica.
Vamos agora explorar o analisador da resposta XML do servidor, analisador que decorre diretamente do estudo que realizámos anteriormente sobre como analisar um documento XML em Java:
import java.io.IOException;
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import org.apache.xerces.parsers.SAXParser;
import java.util.regex.*;
import java.io.*;
import java.util.*;
import javax.swing.*;
// a classe
public class ImpotsSaxParser extends DefaultHandler {
// valor de um elemento da árvore XML
private StringBuffer valeur=new StringBuffer();
// uma expressão regular do valor de um elemento quando se pretende ignorar
// os «espaços» que o precedem ou seguem
private Pattern ptnValeur=null;
private Matcher résultats=null;
// as listas de elementos XML
private ArrayList listeSimulations=new ArrayList();
private ArrayList listeErreurs=new ArrayList();
// elementos XML
private ArrayList éléments=new ArrayList();
String élément="";
// -------- fabricante
public ImpotsSaxParser(BufferedReader IN) throws Exception{
// criação de um analisador XML (parser)
XMLReader parser = XMLReaderFactory.createXMLReader("org.apache.xerces.parsers.SAXParser");
// indica-se ao analisador o objeto que irá implementar os métodos
// startDocument, endDocument, startElement, endElement, caracteres
parser.setContentHandler(this);
// inicializa-se o modelo de valor de um elemento
ptnValeur=Pattern.compile("^\\s*(.*?)\\s*$");
// inicialmente, não existe nenhum elemento XML ativo
éléments.add("");
// analisa-se o documento
parser.parse(new InputSource(IN));
}//construtor
// -------- startElement
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
// procedimento chamado pelo analisador quando encontra o início de uma baliza
// URI: URI do documento analisado?
// localName: nome do elemento que está a ser analisado
// qName: o mesmo, mas «qualificado» por um espaço de nomes, caso exista
// attributes: lista dos atributos do elemento
// regista-se o nome do elemento
élément=localName.toLowerCase();
éléments.add(élément);
// o elemento tem atributos?
if(élément.equals("simulation") && attributes.getLength()==4){
// trata-se de uma simulação — recuperam-se os atributos
String simulation=attributes.getValue("marie")+","+
attributes.getValue("enfants")+","+
attributes.getValue("salaire")+","+
attributes.getValue("impot");
// adiciona-se a simulação à lista de simulações
listeSimulations.add(simulation);
}//if
}//startElement
// -------- caracteres
public void characters(char[] ch, int start, int length) throws SAXException {
// procedimento chamado repetidamente pelo analisador quando encontra texto
// entre duas balizas <baliza>texto</baliza>
// o texto está em ch a partir do caractere start e tem length caracteres
// o texto é adicionado ao buffer «valor» se se tratar do elemento «erro»
if (élément.equals("erreur"))
valeur.append(ch, start, length);
}//caracteres
// -------- endElement
public void endElement(String uri, String localName, String qName)
throws SAXException {
// procedimento chamado pelo analisador quando encontra o fim de uma baliza
// URI: URI do documento analisado?
// localName: nome do elemento que está a ser analisado
// qName: o mesmo, mas «qualificado» por um espaço de nomes, caso exista
// caso de erro
if(élément.equals("erreur")){
// recuperamos o valor do elemento de erro
String strValeur=valeur.toString();
// retira-se os «espaços» desnecessários e regista-se na lista de
// erros, caso esta não esteja vazia
résultats=ptnValeur.matcher(strValeur);
if (résultats.find() && ! résultats.group(1).equals("")){
listeErreurs.add(résultats.group(1));
}//if
}
// define-se o valor do elemento como vazio
valeur.setLength(0);
// reinicializa-se o nome do elemento
éléments.remove(éléments.size()-1);
élément=(String)éléments.get(éléments.size()-1);
}//endElement
// --------- getErreurs
public ArrayList getErreurs(){
return listeErreurs;
}
// --------- getSimulations
public ArrayList getSimulations(){
return listeSimulations;
}
}//classe
- O construtor recebe o fluxo XML IN para análise e procede imediatamente a essa análise. Concluída a análise, o objeto foi criado e foram criadas as listas (ArrayList) de erros (listeErreurs) e de simulações (listeSimulations). Resta agora ao procedimento que criou o objeto recuperar as duas listas utilizando os métodos getErreurs e getSimulations.
- Apenas três eventos gerados pelo analisador XML nos interessam aqui:
- início de um elemento XML, evento que será tratado pela rotina startElement. Esta terá de processar as balizas <simulation marie=".." enfants=".." salaire=".." impot=".."> e <erreur>...</erreur>.
- valor de um elemento XML, evento que será tratado pela rotina characters.
- fim de um elemento XML, evento que será tratado pelo procedimento endElement.
- No procedimento startElement, se estivermos a lidar com o elemento <simulation marie=".." enfants=".." salaire=".." impot="..">, recuperamos os quatro atributos através de attributes.getValue("nome do atributo"). Em todos os casos, guarda-se o nome do elemento numa variável «elemento» e adiciona-se a uma lista (ArrayList) de elementos: elem1, elem2, ..., elemn. Esta lista é gerida como uma pilha cujo último elemento é o elemento XML que está a ser analisado. Quando ocorre o evento «fim de elemento», o último elemento da lista é removido e o novo elemento atual é alterado. Isto é feito no procedimento endElement.
- O procedimento «characters» é idêntico ao que tinha sido analisado num exemplo anterior. Basta ter o cuidado de verificar se o elemento atual é efetivamente o elemento <erreur>, precaução que, normalmente, não seria necessária neste caso. Este tipo de precaução também tinha sido tomado no procedimento startElement para verificar se se tratava de um elemento <simulation>.
6.5. Conclusão
Graças à sua resposta XML, a aplicação «impôts» tornou-se mais fácil de gerir, tanto para o seu criador como para os criadores das aplicações clientes.
- A conceção da aplicação de servidor pode agora ser confiada a dois tipos de pessoas: o programador Java do servlet e o designer gráfico que irá gerir a aparência da resposta do servidor nos navegadores. Basta que este último conheça a estrutura da resposta XML do servidor para criar as folhas de estilo que a irão acompanhar. Recorde-se que estas são objeto de ficheiros XSL separados e independentes do servlet Java. O designer gráfico pode, portanto, trabalhar independentemente do programador Java.
- Os criadores das aplicações cliente também precisam apenas de conhecer a estrutura da resposta XML do servidor. As alterações que o designer gráfico possa introduzir nas folhas de estilo não têm qualquer repercussão nesta resposta XML, que permanece sempre a mesma. Trata-se de uma enorme vantagem.
- Como é que o programador pode fazer evoluir o seu servlet Java sem estragar tudo? Em primeiro lugar, desde que a sua resposta XML não mude, pode organizar a sua servlet como quiser. Pode também atualizar a resposta XML, desde que mantenha os elementos <erro> e <simulação> esperados pelos seus clientes. Assim, pode adicionar novas balizas a esta resposta. O designer gráfico terá-as em conta nas suas folhas de estilo e os navegadores poderão receber as novas versões da resposta. Os clientes programados, por sua vez, continuarão a funcionar com o modelo antigo, sendo as novas balizas simplesmente ignoradas. Para que isso seja possível, é necessário que, na análise XML da resposta do servidor, as balizas procuradas sejam devidamente identificadas. Foi isso que se fez no nosso cliente XML da aplicação de impostos, onde, nos procedimentos, se especificava que se tratavam as balizas <erreur> e <simulation>. Assim, as outras balizas são ignoradas.