5. O tipo Stream<T> no Java 8
5.1. Exemplo-01 - A classe Stream
As operações em fluxos Observable têm muitas semelhanças com os Streams. Uma diferença é que um elemento de um Stream não pode ser processado até que todo o Stream tenha sido obtido, enquanto um elemento de um fluxo Observable pode ser processado (observado) assim que é obtido, sem esperar que todo o fluxo Observable seja obtido. Outra diferença é que, uma vez obtido o Stream, os seus valores são utilizados retirando-os um a um do Stream. No caso do Observable, é diferente. Assim que emite um valor, esse valor é enviado para o seu subscritor.
Várias classes implementam o conceito de um Stream. Aqui apresentamos a classe Stream<T>:
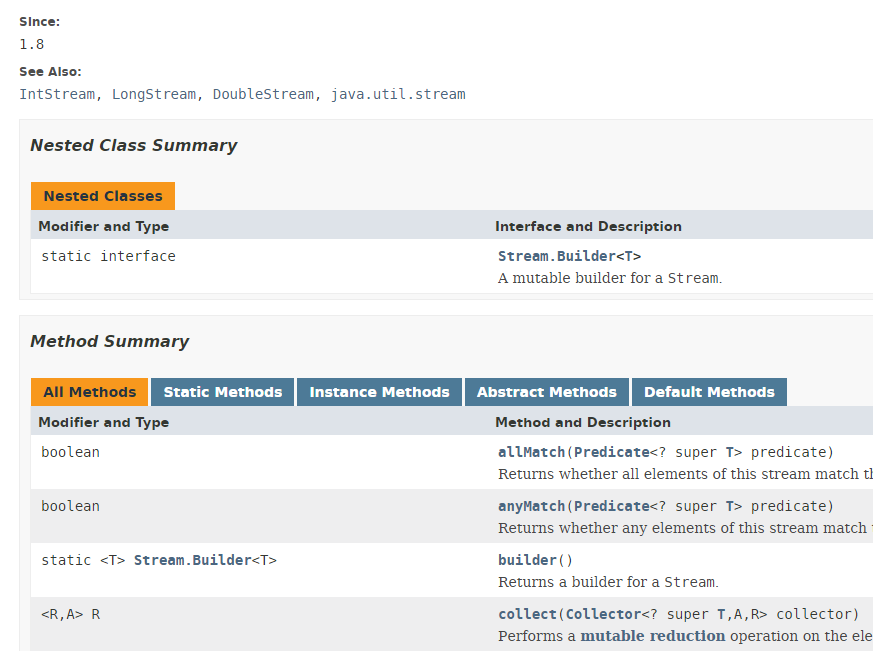
A classe Stream oferece 39 métodos. Apresentaremos alguns deles. Considere o seguinte código:
 |
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple01 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// display 1
personnes.stream().forEach(p -> {
System.out.println(p);
});
System.out.println("----------------");
// display 2
personnes.stream().forEach(System.out::println);
}
}
- linha 11: instanciamos uma lista de pessoas;
- linha 13: a partir desta lista, criamos um Stream. Todas as coleções podem ser convertidas em Streams desta forma. Isto permite-nos tirar partido de todos os métodos desta classe, o que nos permite processar os elementos da coleção de forma mais concisa do que com loops. Também nos permite beneficiar do processamento paralelo de elementos, quando possível;
- linha 13: o método [Stream.forEach] tem a seguinte assinatura:
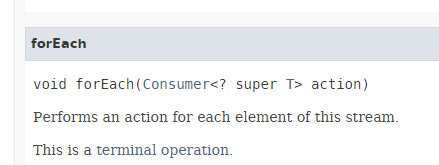 |
Vemos que o parâmetro do método é a interface funcional [Consumer<T>] apresentada na Secção 4.4 — uma interface cujo único método opera sobre o tipo T e não retorna nada.
- No código:
personnes.stream().forEach(p -> {
System.out.println(p);
});
- [people.stream()] produz um fluxo de elementos do tipo [Person] que alimenta o método [forEach]. O parâmetro p é do tipo [Person], e a função lambda fornecida imprime essa pessoa;
O código anterior pode ser simplificado da seguinte forma (linha 18):
personnes.stream().forEach(System.out::println);
Em vez de passar o valor de uma função lambda como parâmetro, passamos a referência a um método existente, neste caso o método println da classe System.out. É claro que este método deve ter a assinatura correta, neste caso a assinatura do método [Consumer.accept]: void accept(T t). Como mencionado anteriormente, o parâmetro do método [accept] será do tipo [Person];
Obtemos os seguintes resultados:
Depois de um Stream ter sido processado, já não pode ser processado novamente. Deve ser reconstruído se pretender processá-lo novamente. Isto é demonstrado pelo código seguinte [Exemplo01b]:
package dvp.java8.streams;
import java.util.stream.Stream;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple01b {
public static void main(String[] args) {
// people flows
Stream<Personne> personnes = Personnes.get().stream();
// display 1
personnes.forEach(p -> {
System.out.println(p);
});
System.out.println("----------------");
// display 2
personnes.forEach(System.out::println);
}
}
- Linha 11: Para otimizar o código, decidimos construir o Stream apenas uma vez. Os resultados obtidos são os seguintes:
{"nom":"jean","age":20,"poids":70.0,"sexe":"HOMME"}
{"nom":"marie","age":10,"poids":30.0,"sexe":"FEMME"}
{"nom":"camille","age":30,"poids":55.0,"sexe":"FEMME"}
----------------
Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.sourceStageSpliterator(Unknown Source)
at java.util.stream.ReferencePipeline$Head.forEach(Unknown Source)
at dvp.java8.streams.Exemple02b.main(Exemple02b.java:18)
Sempre que quiser utilizar um Stream, deve construí-lo, mesmo que já tenha sido construído anteriormente.
5.2. Exemplo-02 - Processamento paralelo de elementos num Stream
 |
Considere o seguinte código:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple02 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// display 1
personnes.stream().forEach(Exemple02::affiche);
System.out.println("-----------------");
// display 2
personnes.stream().parallel().forEach(Exemple02::affiche);
}
public static void affiche(Personne p) {
System.out.printf("Personne %s sur thread %s%n", p, Thread.currentThread().getName());
}
}
- linhas 19–21: o método [display] imprime na consola a cadeia JSON de uma pessoa, juntamente com o nome do segmento de execução em que a exibição está a ocorrer;
- linha 13: exibe uma lista de pessoas. Note-se que o parâmetro do método [forEach] é a referência ao método estático anterior;
- linha 16: fazemos o mesmo, mas com o método [parallel], solicitamos que os elementos do fluxo sejam processados em paralelo em várias threads. Nem todo o processamento pode ser feito em paralelo. Aqui, devemos assumir que a ordem de exibição não importa, pois, no processamento paralelo, a ordem de execução das threads não é garantida. Observe também uma sintaxe que se tornará onipresente tanto para Streams quanto para Observables:
- (continuação)
- o fluxo produz elementos e1 que alimentam o método m1;
- flux.m1 é, por sua vez, um fluxo de elementos e2 que alimentam o método m2;
- flux.m1.m2 é um fluxo de elementos e3 que alimentam o método m3;
O tipo dos elementos e1, e2, e3 pode mudar à medida que o fluxo inicial é processado.
A execução deste código produz o seguinte resultado:
Podemos ver que a execução paralela (linhas 5–7) ocorreu em três threads diferentes e não seguiu a ordem dos elementos, tal como mostrado nas linhas 1–3. Neste documento, não nos vamos concentrar muito no processamento paralelo de elementos num Stream, porque isso exigiria discutir as condições que tornam tal processamento possível. Descobrimos então que poucas operações podem ser realizadas em paralelo. Uma que se presta naturalmente ao paralelismo é a soma dos elementos numéricos de um stream, que iremos agora apresentar.
5.3. Exemplo-03 - Processamento Paralelo de Elementos de um Stream
 |
Considere o seguinte código (Exemplo 03a):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class Exemple03a {
public static void main(String[] args) {
final long limite = 10_000_000L;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// sum of numbers - sequential method
début = new Date().getTime();
long somme = nombres.stream().reduce(0L, (s, i) -> s + i);
System.out.printf("somme séquentielle : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- Na linha 22, utilizamos o método [reduce], que tem a seguinte assinatura:
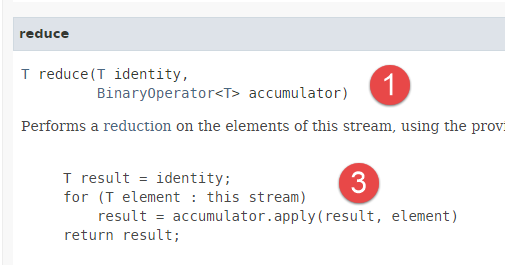 |  |
- O método [reduce] funciona com elementos do tipo T;
- o método [reduce] aplica o mesmo processamento a todos os elementos de um fluxo: o valor inicial de um acumulador é fornecido como primeiro parâmetro. Um método que implementa a interface funcional [BinaryOperator] [2] é fornecido como segundo parâmetro: com base em cada elemento e no acumulador, este método devolve um novo valor para o acumulador. O valor final do acumulador é o valor devolvido pelo método [reduce]. O código [3] ilustra este mecanismo. O método [apply] é o método da interface funcional [BinaryOperator] [2];
Voltemos ao código de exemplo:
- linha 12: exibimos o número de núcleos detetados pela JVM;
- linhas 15–18: é criada uma lista de 10 milhões de números;
- linha 22: a soma destes números é calculada sequencialmente utilizando um único thread;
Obtemos os seguintes resultados:
Agora, vamos substituir a linha 22 do código pelo seguinte (Exemplo03b):
long somme = nombres.stream().parallel().reduce(0L, (s, i) -> s + i);
Instruímos os elementos do Stream para serem processados em paralelo utilizando múltiplas threads. Isto é possível porque a ordem em que os números são somados não importa. Podemos, portanto, atribuir n1 números à thread T1, n2 números à thread T2, ... e, finalmente, somar os resultados fornecidos por estas diferentes threads. Obtemos então os seguintes resultados:
Não há, portanto, praticamente nenhum ganho de desempenho. Este será frequentemente o caso nos exemplos que se seguem. A própria gestão de threads é demorada. A operação realizada por cada núcleo deve ser suficientemente complexa para que o ganho de desempenho seja percetível. Isto é demonstrado pelo exemplo seguinte (Exemplo03c):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.function.BinaryOperator;
public class Exemple03c {
public static void main(String[] args) {
final long limite = 10_000L;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// sum of numbers - sequential method
début = new Date().getTime();
BinaryOperator<Long> bo = (s, i) -> {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
}
return s + i;
};
long somme = nombres.stream().reduce(0L, bo);
System.out.printf("somme séquentielle : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- linha 30: usamos novamente o método [reduce], passando-lhe a referência ao método das linhas 23–29 como parâmetro;
- linha 28: o método [bo] retorna a soma dos seus dois parâmetros;
- linhas 24–27: artificialmente, fazemos com que o thread espere 1 milissegundo para simular trabalho intensivo;
Obtenemos então os seguintes resultados:
Agora, se substituirmos a linha 30 pelo seguinte:
long somme = nombres.stream().parallel().reduce(0L, bo);
obtemos os seguintes resultados:
Podemos ver claramente o ganho de desempenho alcançado ao executar o cálculo da soma em paralelo. Para processar 8 números:
- o segmento sequencial espera 8 vezes 1 milésimo de segundo, ou seja, 8 ms;
- as 8 threads paralelas esperam, cada uma, 1 milissegundo ao mesmo tempo (por uma questão de simplicidade), perfazendo um total de 1 milissegundo para os 8 números;
Podemos, portanto, esperar que a execução paralela seja 8 vezes mais rápida do que a execução sequencial. É basicamente isso que acontece aqui.
5.4. Exemplo-04 - Filtragem de um fluxo
 |
Considere o seguinte código:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple04 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// displays
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(p -> {
System.out.println(p);
});
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(p -> {
System.out.println(p);
});
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(System.out::println);
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(System.out::println);
}
}
- linha 14: o método [Stream.filter] tem a seguinte assinatura:
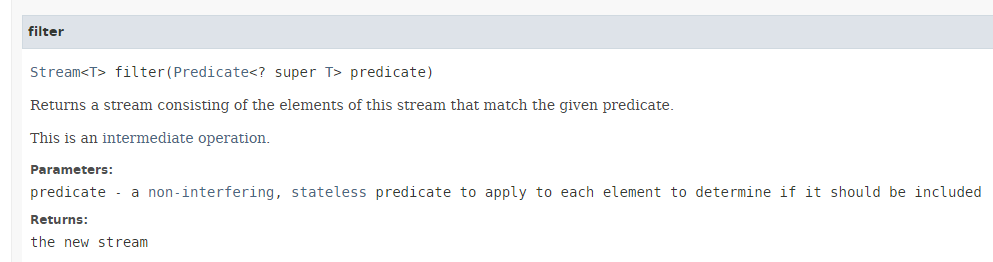 |
- O método [filter] espera como parâmetro uma instância da interface funcional [Predicate] apresentada na Secção 4.2, cujo único método a ser implementado é o seguinte: boolean test(T t);
- O método [filter] devolve os elementos do Stream que satisfazem o Predicate. É, portanto, utilizado para filtrar o Stream;
Considere o seguinte código:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple04 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// displays
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(p -> {
System.out.println(p);
});
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(p -> {
System.out.println(p);
});
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(System.out::println);
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(System.out::println);
}
}
- linhas 14-16: exibe pessoas com menos de 28 anos;
- linhas 18-20: exibe pessoas com peso <50;
- linha 22: faz o mesmo que as linhas 14–16, mas de forma mais concisa;
- linha 24: faz o mesmo que as linhas 18–20, mas de forma mais concisa;
Os resultados da execução são os seguintes:
5.5. Exemplo-05 - Criar um Stream<T2> a partir de um Stream<T1>
 |
Considere o seguinte código:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple05 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// displays
System.out.println("Personne --> String ----------------------");
personnes.stream().map(p -> p.getNom()).forEach(System.out::println);
System.out.println("Personne --> Integer ----------------------");
personnes.stream().map(p -> p.getAge()).forEach(System.out::println);
}
}
- Linha 13: O método [Stream.map] tem a seguinte assinatura:
 |
O parâmetro do método [Stream.map] é uma instância da interface funcional [Function] apresentada na Secção 4.3, cujo único método a ser implementado é: R apply(T t). Vemos que, dado um tipo T, a função [apply] produz um tipo R. O método [Stream.map] produzirá, portanto, um Stream do tipo R a partir de um stream do tipo T (um stream do tipo T significa aqui, numa imprecisão técnica que manteremos, um stream de elementos do tipo T).
Vamos agora examinar o código do exemplo:
- linha 14: de uma pessoa p, mantemos apenas o nome. Obtemos assim um fluxo de Strings;
- linha 14: de uma pessoa p, mantemos apenas o nome. Obtemos, portanto, um fluxo de Integer;
Os resultados obtidos são os seguintes:
5.6. Exemplo-06 - Outros métodos da classe Stream<T>
 |
Ilustramos alguns dos 39 métodos da classe Stream com o código seguinte:
package dvp.java8.streams;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import dvp.data.Personne;
import dvp.data.Personnes;
import java.util.Comparator;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.DoubleStream;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class Exemple06 {
// mapper jSON
static private ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// list of persons
List<Personne> personnes = Personnes.get();
// all people
affiche("all", personnes);
// the 1st person
affiche("findFirst", personnes.stream().findFirst().get());
// any person
affiche("findAny", personnes.stream().findAny().get());
// people without the 1st
affiche("skip 1", personnes.stream().skip(1L).collect(Collectors.toList()));
// the first 2 people
affiche("limit 2", personnes.stream().limit(2L).collect(Collectors.toList()));
// the number of people
affiche("count", personnes.stream().count());
// the oldest person
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
// the lightest person
affiche("poids min", personnes.stream().min(Comparator.comparingDouble(Personne::getPoids)).get());
// last person in alphabetical order of name
affiche("nom max", personnes.stream().max((p1, p2) -> p1.getNom().compareToIgnoreCase(p2.getNom())).get());
// total age of all persons
affiche("âge total (reduce)", personnes.stream().map(p -> p.getAge()).reduce(0, (a1, a2) -> a1 + a2));
// people by ascending age
affiche("personnes par âge croissant",
personnes.stream().sorted(Comparator.comparingInt(Personne::getAge)).collect(Collectors.toList()));
// are there any people over 100?
affiche("des personnes de + de 100 ans (anyMatch)", personnes.stream().anyMatch(p -> p.getAge() > 100));
// are all people at most 100 years old?
affiche("des personnes de + de 100 ans (noneMatch)", personnes.stream().noneMatch(p -> p.getAge() > 100));
// are all people over 8 years old?
affiche("des personnes de + de 8 ans (allMatch)", personnes.stream().allMatch(p -> p.getAge() > 8));
// group people by gender
affiche("personnes regroupées par sexe", personnes.stream().collect(Collectors.groupingBy(p -> p.getSexe())));
// remove duplicate elements from a list
affiche("distinct", Stream.of(1, 2, 1).distinct().collect(Collectors.toList()));
// of a Stream<Stream<T>>, we make a Stream<T>
affiche("flatMap", Stream.of(1, 2, 3).flatMap(i -> Stream.of(i, i + 10)).collect(Collectors.toList()));
// of a Stream<Stream<Integer>>, we make a IntStream and calculate its sum
affiche("flatMapToInt", Stream.of(1, 2, 3).flatMapToInt(i -> IntStream.of(i, i + 10)).sum());
// of a Stream<Stream<Integer>>, we make a DoubleStream and then an array
affiche("flatMapToDouble", Stream.of(1, 2, 3).flatMapToDouble(i -> DoubleStream.of(i, i * 1.2)).toArray());
// max of a stream of integers
affiche("reduce Integer::max", Stream.of(1, 10, 8).reduce(Integer::max).get());
// min of a Double
affiche("reduce Integer::min", Stream.of(1.5, 10.4, 8.9).reduce(Double::min).get());
// average of a stream of integers
affiche("IntStream average", IntStream.of(1, 10, 8).average().getAsDouble());
// statistics for a stream of integers
affiche("IntStream summaryStatistics", IntStream.of(1, 10, 8).summaryStatistics());
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- linhas 72, 75: exibem a cadeia JSON do segundo parâmetro do método;
- linha 24: exibe a cadeia JSON para todas as pessoas. O resultado é o seguinte:
5.6.1. [findFirst]
// la 1ère personne
affiche("findFirst", personnes.stream().findFirst().get());
O método [findFirst] devolve o primeiro elemento de um fluxo, se este existir. A sua assinatura é a seguinte:
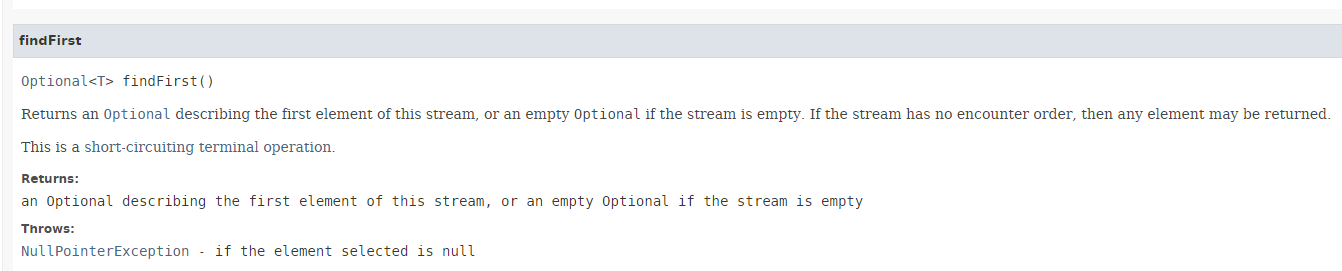 |
O resultado é do tipo Optional<T>, um tipo introduzido no Java 8:
 |
A classe Optional<T> permite um tratamento diferente dos ponteiros nulos. Um método que precise de devolver um tipo T que possa ter o valor nulo pode optar por devolver um tipo Optional<T>. O método [Optional<T>.isPresent()] permite determinar se o método devolveu um valor ou não. O código seguinte [Exemplo06b] ilustra parte do funcionamento do Optional<T>:
package dvp.java8.streams;
import java.util.Optional;
import com.fasterxml.jackson.core.JsonProcessingException;
public class Exemple06b {
public static void main(String[] args) throws JsonProcessingException {
// optional without value
Optional<Integer> o1 = m1();
System.out.println(o1.isPresent());
affiche(o1);
// optional with value
Optional<Integer> o2 = m2();
System.out.println(o2.isPresent());
affiche(o2);
}
private static void affiche(Optional<Integer> o1) {
try {
// retrieve the value of the Optional
// throws 1 exception if no value
System.out.println(o1.get());
} catch (Throwable th) {
System.out.printf("%s : %s%n", th.getClass().getName(), th.getMessage());
}
}
public static Optional<Integer> m1() {
// no value
return Optional.empty();
}
public static Optional<Integer> m2() {
// a value
return Optional.of(10);
}
}
Os resultados são os seguintes:
false
java.util.NoSuchElementException : No value present
true
10
Voltemos ao código que ilustra o método [findFirst]:
// la 1ère personne
affiche("findFirst", personnes.stream().findFirst().get());
- linha 2: para simplificar o código, usamos o método [get] no Optional<Person> produzido pelo método [findFirst]. Um código limpo exigiria chamar o método [Optional<Person>.isPresent()] antes de chamar o método [get];
O resultado é o seguinte:
5.6.2. [findAny]
// n'importe quelle personne
affiche("findAny", personnes.stream().findAny().get());
O método [findAny] tem a seguinte assinatura:
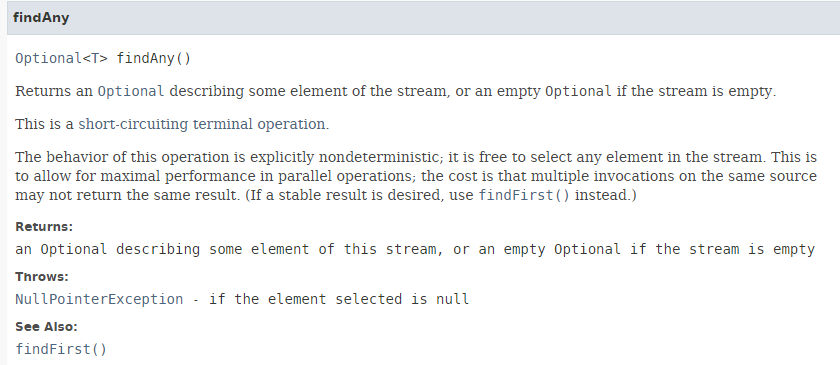 |
O método [findAny] pode devolver qualquer elemento do fluxo. Durante os testes, observamos que uma execução sequencial devolve o primeiro elemento do fluxo, enquanto uma execução paralela pode, de facto, devolver qualquer elemento. Isto é demonstrado pelo código seguinte [Exemplo06c]:
package dvp.java8.streams;
import java.util.List;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple06c {
// mapper jSON
static private ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// list of persons
List<Personne> personnes = Personnes.get();
// everyone
affiche("all", personnes);
// any person
affiche("findAny parallèle", personnes.stream().parallel().findAny().get());
// any person
affiche("findAny séquentiel", personnes.stream().findAny().get());
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- linha 22: findAny executado em paralelo;
- linha 24: findAny executado sequencialmente;
Os resultados obtidos são os seguintes:
- linha 4: a execução paralela devolveu o segundo elemento da lista de pessoas. Poderia ter sido outro;
- linha 6: a execução sequencial devolveu o primeiro elemento da lista de pessoas;
O uso do método [findAny] parece fazer sentido apenas no processamento paralelo de um fluxo.
5.6.3. [skip]
// les personnes sans la 1ère
affiche("skip 1", personnes.stream().skip(1L).collect(Collectors.toList()));
O método [skip] tem a seguinte assinatura:
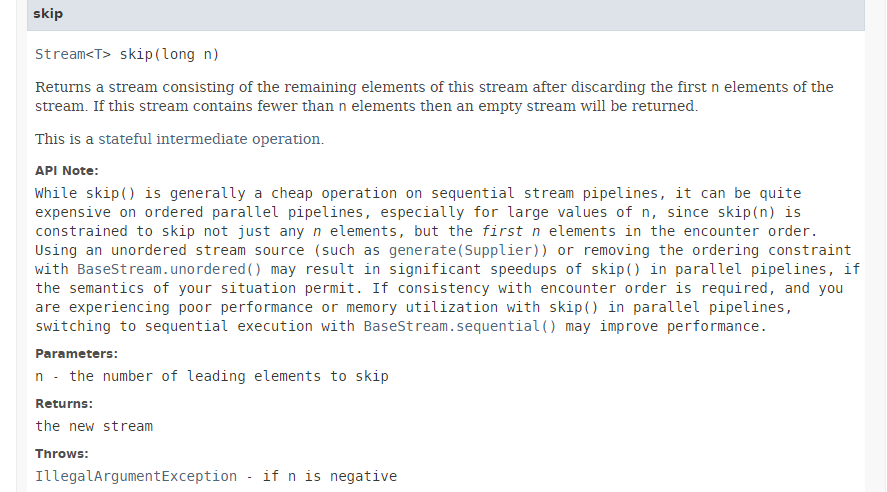 |
O método [skip] ignora os primeiros n elementos de um fluxo. Conforme indicado na documentação acima, a execução deste método em paralelo proporciona poucos ganhos de desempenho e pode até resultar numa perda de desempenho. De facto, para ignorar os primeiros n elementos, os threads são obrigados a coordenar-se, o que anula os ganhos de desempenho decorrentes do paralelismo.
O método [skip] devolve um Stream<Person> que é convertido numa List<Person> pelo método [collect], que tem a seguinte assinatura:
 |
O método [collect] recebe como parâmetro uma instância do tipo [Collector], que possui uma assinatura complexa. Existem implementações predefinidas do tipo [Collector] que, normalmente, permitem evitar a implementação por conta própria. Aqui, a implementação utilizada é [Collectors.toList()]. [Collectors] é uma classe com vários métodos estáticos que implementam o tipo [Collector<T,A,R>]. Este é o primeiro local a consultar quando se pretende converter um Stream numa coleção Java padrão:
 |
Iremos utilizar alguns destes métodos mais adiante.
A execução produz o seguinte resultado:
O primeiro elemento da lista (jean) foi omitido.
5.6.4. [limite]
// les 2 premières personnes
affiche("limit 2", personnes.stream().limit(2L).collect(Collectors.toList()));
O método [limit] tem a seguinte assinatura:
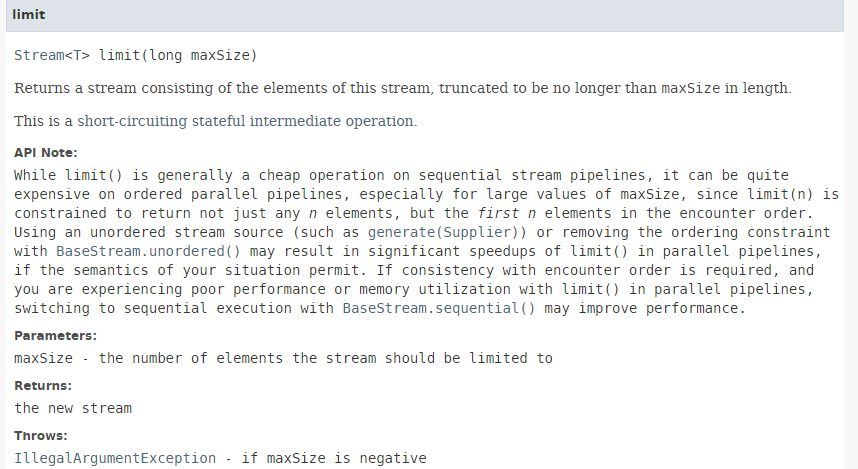 |
O método [limit] permite manter apenas os primeiros n elementos de um fluxo. Não é adequado para processamento paralelo.
A execução produz o seguinte resultado:
5.6.5. [count]
// le nombre de personnes
affiche("count", personnes.stream().count());
O método [count] tem a seguinte assinatura:
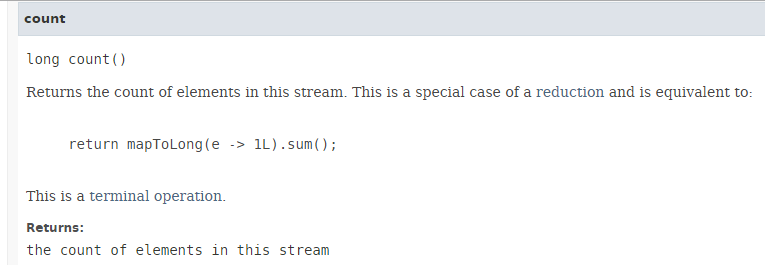 |
O método [count] devolve o número de elementos num Stream. A execução paralela do método não resulta num ganho de desempenho, como se pode ver no código seguinte (Exemplo06d1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.stream.Stream;
public class Exemple06d1 {
public static void main(String[] args) {
final long limite = 10_000_000L;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// counting numbers - sequential method
Stream<Long> sNombres = nombres.stream();
début = new Date().getTime();
long count = sNombres.count();
System.out.printf("comptage séquentiel : compteur=%s, durée (ms)=%s%n", count, new Date().getTime() - début);
}
}
- linhas 11–22: criar um Stream de 10 milhões de números;
- linhas 22–24: contagem do Stream;
A execução produz o seguinte resultado:
Se substituirmos a linha 22 do código pelo seguinte (Exemplo06d2):
Stream<Long> sNombres = nombres.stream().parallel();
obtemos os seguintes resultados:
5.6.6. [máx, mín]
// la personne la + âgée
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
O método [max] tem a seguinte assinatura:
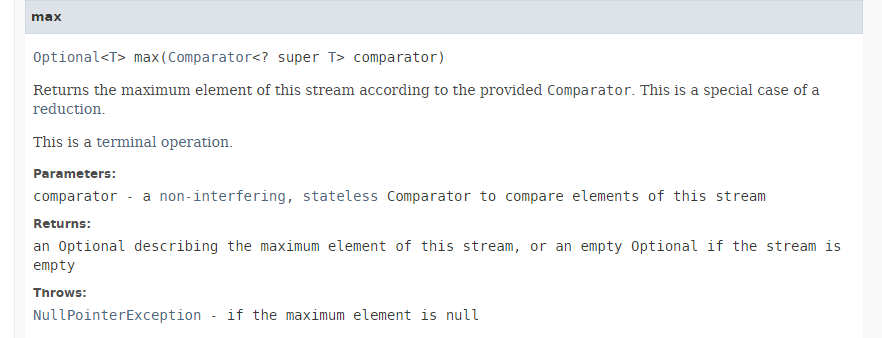 |
O método [max] devolve o valor máximo de um fluxo utilizando o comparador que lhe é passado como parâmetro. Comparator é uma interface funcional cujo único método a implementar tem a assinatura: int compare(T o1, T o2). Este método deve devolver -1 se o1 < o2, 0 se o1.equals(o2) e +1 se o1 > o2. A interface funcional Comparator possui muitos métodos estáticos predefinidos que implementam a interface Comparator para os casos mais comuns. Assim, na instrução:
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
Utilizamos o método estático [Comparator.comparingInt], cuja assinatura é a seguinte:
 |
O tipo ToIntFunction é uma interface funcional:
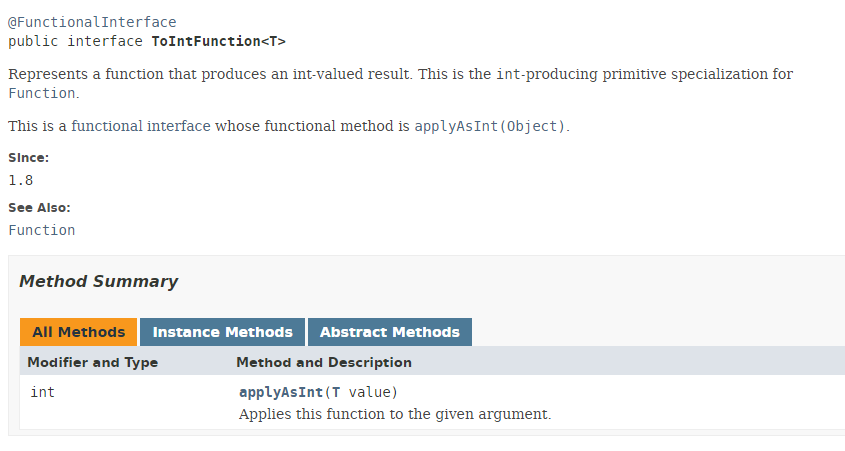 |
O método [applyAsInt] da interface funcional ToIntFunction produz um tipo int a partir de um tipo T. Voltemos ao nosso código:
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
O parâmetro real do método [Comparator.comparingInt] deve ser aqui uma lambda do tipo Person --> int. Passamos a referência ao método [Person.getAge], que tem esta assinatura. Por fim, obteremos a pessoa com a idade mais avançada. Obtemos um tipo Optional<Person>, do qual extraímos o valor utilizando o método [Optional.get]. Obtemos o seguinte resultado:
Calcular o máximo em paralelo não resulta em ganhos de desempenho, como mostrado no exemplo seguinte: (Exemplo06e1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Date;
import java.util.List;
import java.util.Random;
import java.util.stream.Stream;
public class Exemple06e1 {
public static void main(String[] args) {
// data
// final long limit = 100L;
// final boolean verbose = true;
final long limite = 10_000_000L;
final boolean verbose = false;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextLong());
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// max numbers - sequential method
Stream<Long> sNombres = nombres.stream();
Comparator<Long> compLong = (l1, l2) -> {
if (verbose) {
// thread
System.out.printf("[%s]", Thread.currentThread().getName());
}
// comparison
long v1 = l1.longValue();
long v2 = l2.longValue();
if (v1 < v2) {
return -1;
} else {
if (v1 == v2) {
return 0;
} else {
return +1;
}
}
};
début = new Date().getTime();
// long max = sNombres.max(Comparator.naturalOrder()).get();
long max = sNombres.max(compLong).get();
System.out.printf("%nmax séquentiel : max=%s, durée (ms)=%s%n", max, new Date().getTime() - début);
}
}
- linha 29: temos um fluxo de inteiros aleatórios do tipo Long;
- linhas 30–47: a variável lambda compLong implementa a interface Comparator<Long>. Esta interface é normalmente implementada pelo método [Comparator.naturalOrder()] na linha 49. Mas aqui, queremos exibir o segmento de execução (linhas 31–33). Por isso, implementamos a interface nós próprios;
- linha 50: encontrar o máximo;
Obtemos os seguintes resultados:
 |
Agora, se substituirmos a linha 27 pelo seguinte (Exemplo06e2):
Stream<Long> sNombres = nombres.stream().parallel();
obtemos os seguintes resultados:
 |
A execução paralela foi, portanto, mais lenta. Se aumentarmos o número de números para 10 milhões com verbose=false, obtemos os seguintes resultados:
Para execução sequencial:
para execução paralela, que continua a ser mais lenta.
Utilizamos o método [Stream.min] de forma semelhante:
// la personne la + légère
affiche("poids min", personnes.stream().min(Comparator.comparingDouble(Personne::getPoids)).get());
5.6.7. [reduce]
// l'âge total de toutes les personnes
affiche("âge total (reduce)", personnes.stream().map(p -> p.getAge()).reduce(0, (a1, a2) -> a1 + a2));
O método [reduce] foi apresentado na Secção 5.3. A linha 2 acima soma as idades de todas as pessoas. O resultado é o seguinte:
5.6.8. [ordenado]
// les personnes par âge croissant
affiche("personnes par âge croissant",
personnes.stream().sorted(Comparator.comparingInt(Personne::getAge)).collect(Collectors.toList()));
// les personnes par ordre alphabétique des noms
List<Personne> lPersonnes=personnes.stream().sorted((p1, p2) -> p1.getNom().compareTo(p2.getNom())).collect(Collectors.toList());
affiche("personnes par ordre alphabétique des noms", lPersonnes);
O método [sorted] (linhas 3 e 5) tem a seguinte assinatura:
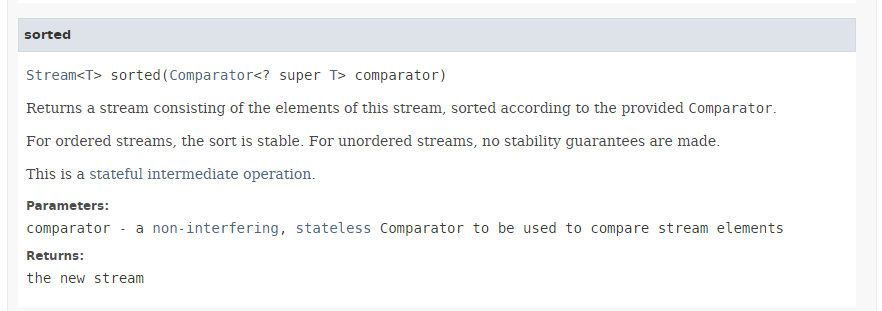 |
O método [sorted] recebe como parâmetro o tipo [Comparator] descrito na Secção 5.6.6 para os métodos min e max. Permite que um Stream seja ordenado de acordo com o comparador que lhe é passado como parâmetro. Vimos que a interface [Comparator] fornece vários métodos estáticos predefinidos que implementam comparadores comuns, nomeadamente para números e cadeias de caracteres. Aqui, utilizamos o método [Comparator.comparingInt], que recebe como parâmetro um tipo ToIntFunction, que é uma interface funcional para o método [applyAsInt] com a seguinte assinatura: int applyAsInt(T t). Aqui, o parâmetro real passado ao método [Comparator.comparingInt] na linha 3 é a referência ao método [Person.age], que devolve a idade da pessoa.
A interface [Comparator] não fornece métodos estáticos para comparar cadeias de caracteres. Na linha 5, construímos nós próprios uma lambda que implementa o único método desta interface: int compare(T t1, T t2)
(p1, p2) -> p1.getNom().compareTo(p2.getNom())
Esta lambda compara os nomes das pessoas. Os resultados obtidos são os seguintes:
A execução paralela da ordenação não parece ser possível, como se pode ver no código seguinte (Exemplo06f1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Date;
import java.util.List;
import java.util.Random;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class Exemple06f1 {
// mapper jSON
static ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// data
final long limite = 100L;
final boolean verbose = true;
// final long limit = 10_000_000L;
// final boolean verbose = false;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Integer> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextInt(1000));
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// number sorting - sequential method
Stream<Integer> sNombres = nombres.stream();
début = new Date().getTime();
Comparator<Integer> compInt = (i1, i2) -> {
if (verbose) {
// thread
System.out.printf("[%s]", Thread.currentThread().getName());
}
// comparison
int v1 = i1.intValue();
int v2 = i2.intValue();
if (v1 < v2) {
return +1;
} else {
if (v1 == v2) {
return 0;
} else {
return -1;
}
}
};
if (verbose) {
affiche("nombres", sNombres.sorted(compInt).collect(Collectors.toList()));
}
System.out.printf("tri séquentiel : durée (ms)=%s%n", new Date().getTime() - début);
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- linhas 30–36: construímos um fluxo de números aleatórios;
- linha 32: passamos a função lambda compInt (linhas 38-55) para o método [sorted]. Esta função lambda ordena os números por ordem decrescente e exibe o segmento de código que a está a executar.
Os resultados obtidos são os seguintes:
 |
Se, no código anterior, substituirmos a linha 36 pelo seguinte (Exemplo06f2):
Stream<Integer> sNombres = nombres.stream().parallel();
obtemos os seguintes resultados:
 |
Surpreendentemente, verificamos que o fluxo de números foi ordenado utilizando um único segmento. Não houve paralelismo. Ou será que me está a escapar alguma coisa?
5.6.9. [anyMatch, noneMatch, allMatch]
// y-a-t-il des personnes de + de 100 ans ?
affiche("des personnes de + de 100 ans (anyMatch)", personnes.stream().anyMatch(p -> p.getAge() > 100));
// est-ce que toutes les personnes ont au plus 100 ans ?
affiche("des personnes de + de 100 ans (noneMatch)", personnes.stream().noneMatch(p -> p.getAge() > 100));
// est-ce que toutes les personnes ont + de 8 ans
affiche("des personnes de + de 8 ans (allMatch)", personnes.stream().allMatch(p -> p.getAge() > 8));
Linhas 2, 4 e 6: os métodos [anyMatch, noneMatch, allMatch] recebem um tipo Predicate como parâmetro, conforme descrito na Secção 4.2. Por conseguinte, realizam uma filtragem. Todos os três devolvem um valor booleano:
- anyMatch retorna true se houver pelo menos um elemento no Stream que satisfaça o filtro;
- noneMatch retorna true se não houver elementos no Stream que satisfaçam o filtro;
- allMatch retorna true se todos os elementos do Stream satisfizerem o filtro;
Os resultados obtidos são os seguintes:
5.6.10. [collect(Collectors.groupingBy)]
// on regroupe les personnes par sexe
affiche("personnes regroupées par sexe", personnes.stream().collect(Collectors.groupingBy(p -> p.getSexe())));
O método [collect] foi apresentado na Secção 5.6.3. O seu parâmetro é uma implementação da interface [Collector]. A classe [Collectors] fornece vários métodos estáticos que implementam a interface [Collector]. Até agora, utilizámos o método [Collectors.toList()]. Aqui, utilizamos o método estático [Collectors.groupingBy], que cria um dicionário a partir do Stream. A sua assinatura é a seguinte:
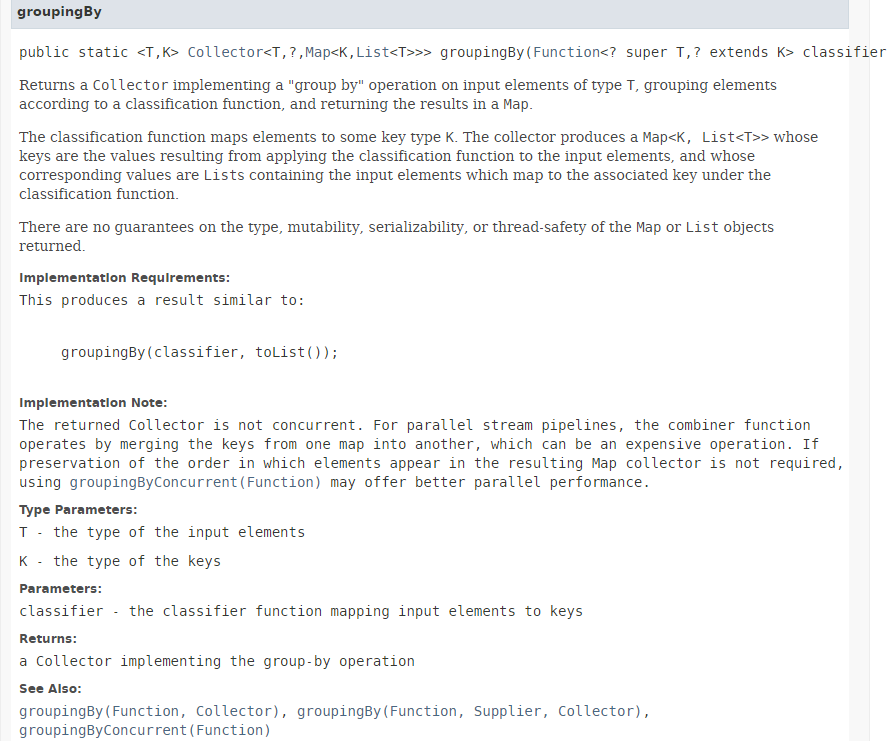 |
O método [groupingBy] cria um Map<K,List<T>> a partir de um Stream<T>. A chave K é fornecida pelo parâmetro do método [groupingBy] do tipo Function<T,K>, cujo único método tem a assinatura: K apply(T t). Se quisermos criar um mapa indexado pelo género de uma pessoa, temos de fornecer uma função que gere o género a partir de uma pessoa. Aqui, passamos a referência ao método [Person.getGender] como parâmetro real do método [groupingBy]. Os resultados obtidos são os seguintes:
A linha 2 contém a cadeia JSON de um dicionário indexado por duas chaves: HOMEM e MULHER.
O cálculo paralelo não resulta em ganhos de desempenho, como mostrado no exemplo seguinte (Exemplo06g1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class Exemple06g1 {
// mppeur jSON
static ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// data
final long limite = 100L;
final boolean verbose = true;
// final long limit = 10_000_000L;
// final boolean verbose = false;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Integer> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextInt(1000));
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// grouping numbers by hundred - sequential method
Stream<Integer> sNombres = nombres.stream();
Function<Integer, Integer> groupByCent = n -> {
if (verbose) {
System.out.printf("[%s]", Thread.currentThread().getName());
}
return n / 100;
};
début = new Date().getTime();
// Map<Integer, List<Integer>> lNombres = sNombres.collect(Collectors.groupingBy(number -> number / 100));
Map<Integer, List<Integer>> lNombres = sNombres.collect(Collectors.groupingBy(groupByCent));
System.out.printf("%nregroupement séquentiel : durée (ms)=%s%n", new Date().getTime() - début);
// results
if (verbose) {
affiche("nombres regroupés", lNombres);
}
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- linhas 23–38: construção de um fluxo de números;
- linha 47: os números são agrupados por centenas. A função lambda nas linhas 39–44 é utilizada para apresentar o fio de execução;
Os resultados da execução são os seguintes:
 |
Se, no código, substituirmos a linha 38 pela seguinte linha (Exemplo06g2):
Stream<Integer> sNombres = nombres.stream().parallel();
obtemos os seguintes resultados:
 |
Podemos ver que a execução paralela do agrupamento prejudicou o desempenho.
5.6.11. [distinct]
// supression des éléments en double d'une liste
affiche("distinct", Stream.of(1, 2, 1).distinct().collect(Collectors.toList()));
O método [distinct] tem a seguinte assinatura:
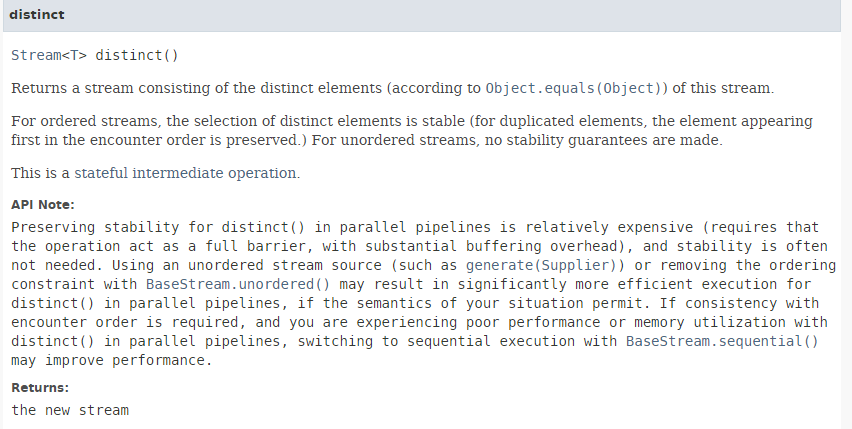 |
Remove duplicados de um fluxo. O método [Stream.of] (linha 2) tem a seguinte assinatura:
 |
Permite criar um Stream a partir de valores explicitamente fornecidos. Os resultados da execução são os seguintes:
5.6.12. [flatMap]
// d'un Stream<Stream<T>>, on fait un Stream<T>
affiche("flatMap", Stream.of(1, 2, 3).flatMap(i -> Stream.of(i, i + 10)).collect(Collectors.toList()));
O método [flatMap] tem a seguinte assinatura:
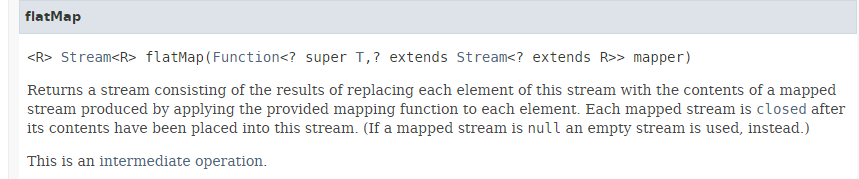  |
O método [flatMap] recebe como parâmetro uma função que:
- recebe um elemento do tipo T do Stream como parâmetro;
- retorna um Stream<R>;
Se, em vez do método [flatMap], tivéssemos utilizado o método [map] descrito na Secção 5.5, o resultado seria um tipo Stream<Stream<R>>, em que cada elemento de tipo T no fluxo inicial teria produzido um elemento Stream<R>. O método [flatMap], por outro lado, retorna um tipo Stream<R>. Ele achata os vários fluxos Stream<R> num único fluxo. É isso que mostram os resultados da execução do código anterior:
Existem variantes especializadas de [flatMap]:
// d'un Stream<IntStream>, on fait un IntStream dont on calcule la somme
affiche("flatMapToInt", Stream.of(1, 2, 3).flatMapToInt(i -> IntStream.of(i, i + 10)).sum());
O método [flatMapToInt] tem a seguinte assinatura:
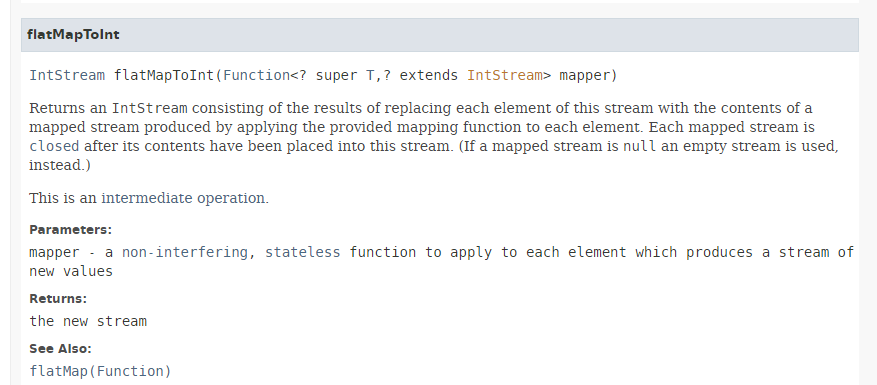 |
O método [flatMapToInt] recebe como parâmetro uma função que devolve um IntStream do seguinte tipo:
 |
IntStream é um fluxo de int. Este tipo é preferível ao tipo Stream<Integer> porque o seu processamento evita o boxing/unboxing entre os tipos Integer e int. Esta interface herda muitos métodos do tipo Stream<T> e adiciona outros, incluindo o método [sum] acima, que soma os elementos do IntStream.
O código seguinte ilustra a utilização do método análogo [flatMapToDouble]:
// d'un Stream<DoubleStream>, on fait un DoubleStream puis un tableau
affiche("flatMapToDouble", Stream.of(1, 2, 3).flatMapToDouble(i -> DoubleStream.of(i, i * 1.2)).toArray());
O método [DoubleStream.toArray] permite converter um tipo DoubleStream para um tipo double[].
Os resultados destes dois exemplos são os seguintes:
O exemplo seguinte demonstra os ganhos de desempenho obtidos ao mudar do tipo Stream<Long> para o tipo LongStream (Exemplo06i1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class Exemple06i1 {
public static void main(String[] args) {
final long limite = 10_000_000L;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// sum of numbers - sequential method
début = new Date().getTime();
long somme = nombres.stream().reduce(0L, (s, i) -> s + i);
System.out.printf("somme séquentielle du Stream<Integer> : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- linha 22: cálculo da soma de um fluxo de números Long;
Obteve-se os seguintes resultados:
Agora, vamos substituir a linha 22 pelo seguinte (Exemplo06i2):
long somme = nombres.stream().mapToLong(n -> n.longValue()).sum();
O método Stream<Integer>.mapToLong permite-nos obter um LongStream de elementos long primitivos, que depois somamos utilizando a função sum. Obtemos então os seguintes resultados:
O ganho de desempenho é evidente.
5.6.13. métodos de fluxo de números primitivos
// max d'un flux de int
affiche("IntStream max", IntStream.of(1, 10, 8).max());
// min d'un flux de double
affiche("DoubleStream min", DoubleStream.of(1.5, 10.4, 8.9).min());
// moyenne d'un flux de int
affiche("IntStream average", IntStream.of(1, 10, 8).average().getAsDouble());
// statistiques d'un flux de int
affiche("IntStream summaryStatistics", IntStream.of(1, 10, 8).summaryStatistics());
Os fluxos de valores primitivos (int, long, double) fornecem métodos adaptados a estes tipos. O resultado da execução do código anterior é o seguinte:
- O resultado da linha 2 do código é um tipo OptionalInt análogo ao tipo Optional<Integer>. O valor armazenado neste objeto pode ser recuperado utilizando o método [getAsInt()]. A presença de um valor pode ser verificada utilizando o método [isPresent()]. A linha 2 dos resultados não significa que a classe [OptionalInt] tenha campos denominados [asInt] e [present]. Por predefinição, a biblioteca JSON utiliza todos os métodos públicos getX e isY do objeto a ser serializado para JSON. E aqui, existe de facto um método [getAsInt] e outro método [isPresent], mesmo que os próprios campos [asInt, present] não existam;
- o resultado da linha 4 do código é um tipo OptionalDouble análogo ao tipo Optional<Double>;
- o resultado da linha 6 do código é um tipo OptionalDouble cujo valor pode ser obtido utilizando o método [getAsDouble()]. O método [average] calcula a média do fluxo de números;
- O resultado da linha 8 do código é um tipo IntSummaryStatistics definido da seguinte forma:
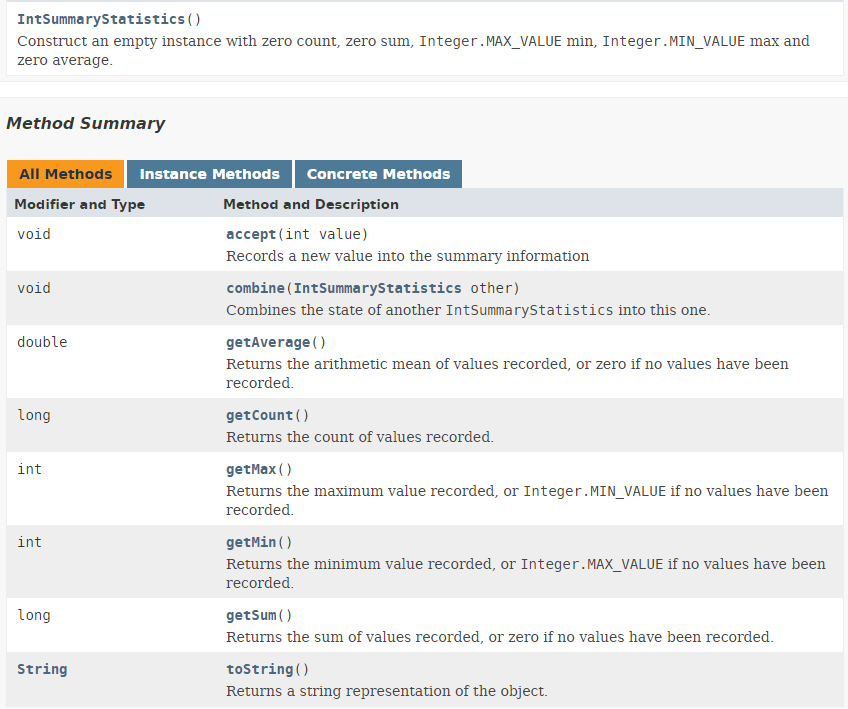 |
Podemos ver que o objeto IntSummaryStatistics resultante fornece várias estatísticas sobre o fluxo de números, tais como o número de valores, a soma, o máximo, o mínimo e a média.