5. Il tipo Stream<T> in Java 8
5.1. Esempio-01 - La classe Stream
Le operazioni sugli stream Observable presentano molte somiglianze con gli Stream. Una differenza è che un elemento di uno Stream non può essere elaborato finché non è stato ottenuto l'intero Stream, mentre un elemento di uno stream Observable può essere elaborato (osservato) non appena viene ottenuto, senza attendere che venga ottenuto l'intero stream Observable. Un'altra differenza è che, una volta ottenuto lo Stream, i suoi valori vengono utilizzati estraendoli uno per uno dallo Stream. Per l'Observable è diverso. Non appena emette un valore, tale valore viene inviato al suo sottoscrittore.
Diverse classi implementano il concetto di Stream. Qui presentiamo la classe Stream<T>:
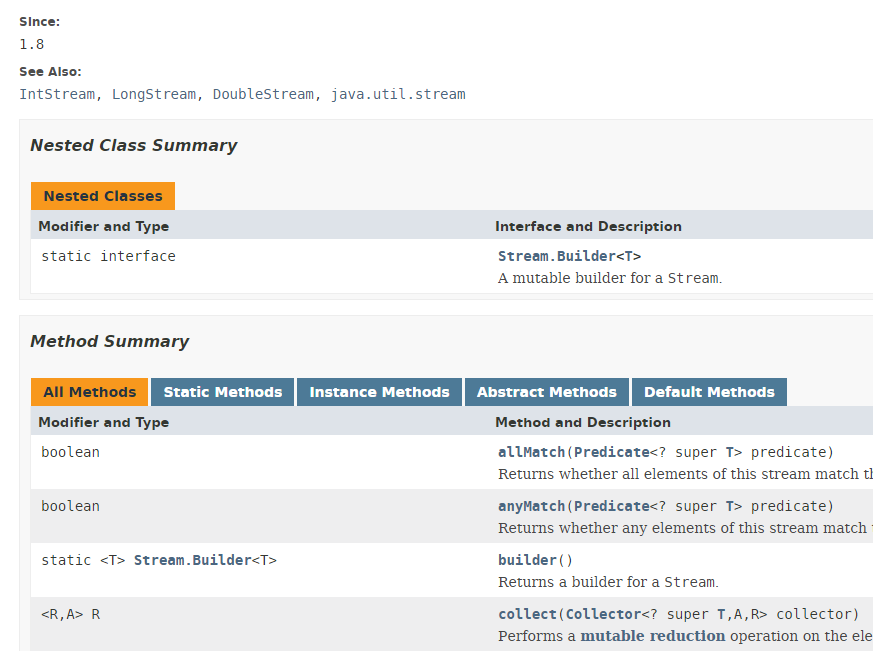
La classe Stream offre 39 metodi. Ne presenteremo alcuni. Consideriamo il codice seguente:
 |
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple01 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// display 1
personnes.stream().forEach(p -> {
System.out.println(p);
});
System.out.println("----------------");
// display 2
personnes.stream().forEach(System.out::println);
}
}
- riga 11: istanziamo un elenco di persone;
- riga 13: da questo elenco, creiamo uno Stream. Tutte le collezioni possono essere convertite in Stream in questo modo. Questo ci permette di sfruttare tutti i metodi di questa classe, che ci consentono di elaborare gli elementi della collezione in modo più conciso rispetto ai cicli. Ci permette inoltre di beneficiare dell'elaborazione parallela degli elementi quando possibile;
- riga 13: il metodo [Stream.forEach] ha la seguente firma:
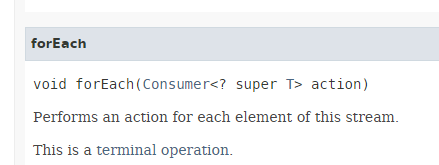 |
Notiamo che il parametro del metodo è l'interfaccia funzionale [Consumer<T>] presentata nella Sezione 4.4, un'interfaccia il cui unico metodo opera sul tipo T e non restituisce alcun valore.
- Nel codice:
personnes.stream().forEach(p -> {
System.out.println(p);
});
- [people.stream()] produce un flusso di elementi di tipo [Person] che alimenta il metodo [forEach]. Il parametro p è di tipo [Person] e la funzione lambda fornita stampa questa persona;
Il codice precedente può essere semplificato come segue (riga 18):
personnes.stream().forEach(System.out::println);
Anziché passare il valore di una funzione lambda come parametro, passiamo il riferimento a un metodo esistente, in questo caso il metodo println della classe System.out. Naturalmente, questo metodo deve avere la firma corretta, in questo caso la firma del metodo [Consumer.accept]: void accept(T t). Come accennato in precedenza, il parametro del metodo [accept] sarà di tipo [Person];
Otteniamo i seguenti risultati:
Una volta che uno Stream è stato elaborato, non può più essere elaborato. Se si desidera elaborarlo nuovamente, è necessario ricostruirlo. Ciò è dimostrato dal seguente codice [Esempio01b]:
package dvp.java8.streams;
import java.util.stream.Stream;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple01b {
public static void main(String[] args) {
// people flows
Stream<Personne> personnes = Personnes.get().stream();
// display 1
personnes.forEach(p -> {
System.out.println(p);
});
System.out.println("----------------");
// display 2
personnes.forEach(System.out::println);
}
}
- Riga 11: Per ottimizzare il codice, decidiamo di costruire lo Stream una sola volta. I risultati ottenuti sono i seguenti:
{"nom":"jean","age":20,"poids":70.0,"sexe":"HOMME"}
{"nom":"marie","age":10,"poids":30.0,"sexe":"FEMME"}
{"nom":"camille","age":30,"poids":55.0,"sexe":"FEMME"}
----------------
Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.sourceStageSpliterator(Unknown Source)
at java.util.stream.ReferencePipeline$Head.forEach(Unknown Source)
at dvp.java8.streams.Exemple02b.main(Exemple02b.java:18)
Ogni volta che si desidera utilizzare uno Stream, è necessario costruirlo, anche se è stato costruito in precedenza.
5.2. Esempio-02 - Elaborazione parallela degli elementi in uno Stream
 |
Si consideri il seguente codice:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple02 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// display 1
personnes.stream().forEach(Exemple02::affiche);
System.out.println("-----------------");
// display 2
personnes.stream().parallel().forEach(Exemple02::affiche);
}
public static void affiche(Personne p) {
System.out.printf("Personne %s sur thread %s%n", p, Thread.currentThread().getName());
}
}
- righe 19–21: il metodo [display] stampa sulla console la stringa JSON di una persona insieme al nome del thread di esecuzione in cui avviene la visualizzazione;
- riga 13: visualizza un elenco di persone. Si noti che il parametro del metodo [forEach] è il riferimento al precedente metodo statico;
- riga 16: facciamo la stessa cosa, ma con il metodo [parallel] richiediamo che gli elementi dello stream vengano elaborati in parallelo su più thread. Non tutte le elaborazioni possono essere eseguite in parallelo. Qui dobbiamo supporre che l'ordine di visualizzazione non abbia importanza perché, nell'elaborazione parallela, l'ordine di esecuzione dei thread non è garantito. Notate anche una sintassi che diventerà onnipresente sia per gli Stream che per gli Observable:
- (continua)
- stream produce elementi e1 che alimentano il metodo m1;
- flux.m1 è a sua volta un flusso di elementi e2 che alimentano il metodo m2;
- flux.m1.m2 è un flusso di elementi e3 che alimentano il metodo m3;
Il tipo degli elementi e1, e2, e3 può cambiare man mano che il flusso iniziale viene elaborato.
L'esecuzione di questo codice produce il seguente risultato:
Possiamo notare che l’esecuzione parallela (righe 5–7) ha avuto luogo su tre thread diversi e non ha seguito l’ordine degli elementi mostrato nelle righe 1–3. In questo documento non ci soffermeremo molto sull’elaborazione parallela degli elementi in uno Stream, poiché ciò richiederebbe di discutere le condizioni che rendono possibile tale elaborazione. Scopriamo quindi che poche operazioni possono essere eseguite in parallelo. Una che si presta naturalmente al parallelismo è la somma degli elementi numerici di uno stream, che presenteremo ora.
5.3. Esempio-03 - Elaborazione parallela degli elementi di uno Stream
 |
Si consideri il seguente codice (Esempio 03a):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class Exemple03a {
public static void main(String[] args) {
final long limite = 10_000_000L;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// sum of numbers - sequential method
début = new Date().getTime();
long somme = nombres.stream().reduce(0L, (s, i) -> s + i);
System.out.printf("somme séquentielle : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- Alla riga 22, utilizziamo il metodo [reduce], che ha la seguente firma:
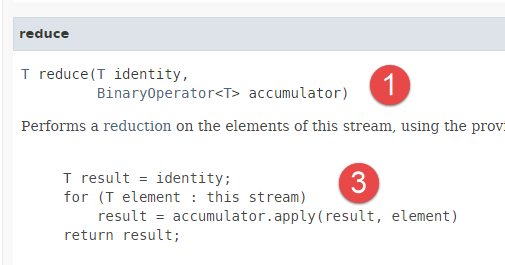 |  |
- Il metodo [reduce] funziona con elementi di tipo T;
- il metodo [reduce] applica la stessa elaborazione a tutti gli elementi di uno stream: il valore iniziale di un accumulatore viene fornito come primo parametro. Come secondo parametro viene fornito un metodo che implementa l'interfaccia funzionale [BinaryOperator] [2]: in base a ciascun elemento e all'accumulatore, questo metodo restituisce un nuovo valore per l'accumulatore. Il valore finale dell'accumulatore è il valore restituito dal metodo [reduce]. Il codice [3] illustra questo meccanismo. Il metodo [apply] è il metodo dell'interfaccia funzionale [BinaryOperator] [2];
Torniamo al codice di esempio:
- riga 12: visualizziamo il numero di core rilevati dalla JVM;
- righe 15–18: viene creato un elenco di 10 milioni di numeri;
- riga 22: la somma di questi numeri viene calcolata in modo sequenziale utilizzando un singolo thread;
Otteniamo i seguenti risultati:
Ora, sostituiamo la riga 22 del codice con quanto segue (Esempio03b):
long somme = nombres.stream().parallel().reduce(0L, (s, i) -> s + i);
Indichiamo agli elementi dello Stream di essere elaborati in parallelo utilizzando più thread. Ciò è possibile perché l'ordine in cui i numeri vengono sommati non ha importanza. Possiamo quindi assegnare n1 numeri al thread T1, n2 numeri al thread T2, ... e infine sommare i risultati forniti da questi diversi thread. Otteniamo quindi i seguenti risultati:
Non si riscontra quindi praticamente alcun guadagno in termini di prestazioni. Questo sarà spesso il caso negli esempi che seguono. La gestione dei thread richiede di per sé molto tempo. L'operazione eseguita da ciascun core deve essere sufficientemente complessa affinché il guadagno in termini di prestazioni sia percepibile. Ciò è dimostrato dal seguente esempio (Esempio03c):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.function.BinaryOperator;
public class Exemple03c {
public static void main(String[] args) {
final long limite = 10_000L;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// sum of numbers - sequential method
début = new Date().getTime();
BinaryOperator<Long> bo = (s, i) -> {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
}
return s + i;
};
long somme = nombres.stream().reduce(0L, bo);
System.out.printf("somme séquentielle : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- riga 30: utilizziamo nuovamente il metodo [reduce], passando come parametro il riferimento al metodo delle righe 23–29;
- riga 28: il metodo [bo] restituisce la somma dei suoi due parametri;
- righe 24–27: artificialmente, facciamo attendere il thread per 1 millisecondo per simulare un lavoro intensivo;
Otteniamo quindi i seguenti risultati:
Ora, se sostituiamo la riga 30 con quanto segue:
long somme = nombres.stream().parallel().reduce(0L, bo);
otteniamo i seguenti risultati:
Possiamo vedere chiaramente il guadagno in termini di prestazioni ottenuto eseguendo il calcolo della somma in parallelo. Per l'elaborazione di 8 numeri:
- il thread sequenziale attende 8 volte 1 millisecondo, ovvero 8 ms;
- gli 8 thread paralleli attendono ciascuno 1 millisecondo contemporaneamente (per semplicità), quindi un totale di 1 millisecondo per gli 8 numeri;
Possiamo quindi aspettarci che l'esecuzione parallela sia 8 volte più veloce di quella sequenziale. È più o meno quello che succede qui.
5.4. Esempio-04 - Filtraggio di uno stream
 |
Si consideri il seguente codice:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple04 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// displays
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(p -> {
System.out.println(p);
});
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(p -> {
System.out.println(p);
});
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(System.out::println);
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(System.out::println);
}
}
- riga 14: il metodo [Stream.filter] ha la seguente firma:
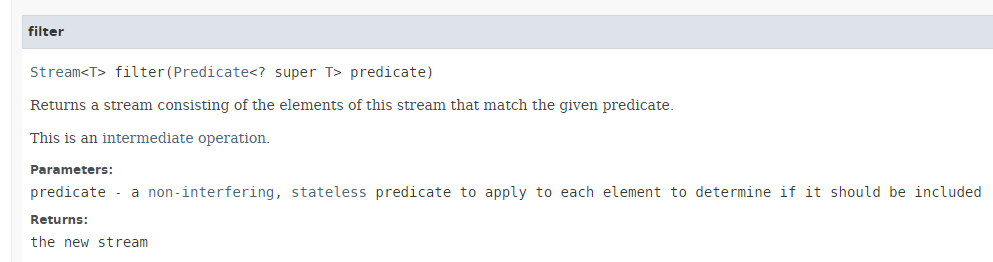 |
- Il metodo [filter] richiede come parametro un'istanza dell'interfaccia funzionale [Predicate] presentata nella Sezione 4.2, il cui unico metodo da implementare è il seguente: boolean test(T t);
- Il metodo [filter] restituisce gli elementi dello Stream che soddisfano il Predicate. Viene quindi utilizzato per filtrare lo Stream;
Si consideri il codice seguente:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple04 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// displays
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(p -> {
System.out.println(p);
});
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(p -> {
System.out.println(p);
});
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(System.out::println);
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(System.out::println);
}
}
- righe 14-16: visualizza le persone di età inferiore ai 28 anni;
- righe 18-20: visualizza le persone con un peso <50;
- riga 22: fa la stessa cosa delle righe 14–16 ma in modo più conciso;
- riga 24: fa la stessa cosa delle righe 18–20 ma in modo più conciso;
I risultati dell'esecuzione sono i seguenti:
5.5. Esempio-05 - Creare uno Stream<T2> da uno Stream<T1>
 |
Si consideri il seguente codice:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple05 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// displays
System.out.println("Personne --> String ----------------------");
personnes.stream().map(p -> p.getNom()).forEach(System.out::println);
System.out.println("Personne --> Integer ----------------------");
personnes.stream().map(p -> p.getAge()).forEach(System.out::println);
}
}
- Riga 13: Il metodo [Stream.map] ha la seguente firma:
 |
Il parametro del metodo [Stream.map] è un'istanza dell'interfaccia funzionale [Function] presentata nella Sezione 4.3, il cui unico metodo da implementare è: R apply(T t). Vediamo che, dato un tipo T, la funzione [apply] produce un tipo R. Il metodo [Stream.map] produrrà quindi uno Stream di tipo R da uno stream di tipo T (uno stream di tipo T significa qui, in un'imprecisione tecnica che manterremo, uno stream di elementi di tipo T).
Esaminiamo ora il codice dell'esempio:
- riga 14: da una persona p, conserviamo solo il nome. Otteniamo così uno stream di String;
- riga 14: da una persona p, conserviamo solo il nome. Otteniamo quindi uno stream di Integer;
I risultati ottenuti sono i seguenti:
5.6. Esempio-06 - Altri metodi della classe Stream<T>
 |
Illustriamo alcuni dei 39 metodi della classe Stream con il codice seguente:
package dvp.java8.streams;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import dvp.data.Personne;
import dvp.data.Personnes;
import java.util.Comparator;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.DoubleStream;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class Exemple06 {
// mapper jSON
static private ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// list of persons
List<Personne> personnes = Personnes.get();
// all people
affiche("all", personnes);
// the 1st person
affiche("findFirst", personnes.stream().findFirst().get());
// any person
affiche("findAny", personnes.stream().findAny().get());
// people without the 1st
affiche("skip 1", personnes.stream().skip(1L).collect(Collectors.toList()));
// the first 2 people
affiche("limit 2", personnes.stream().limit(2L).collect(Collectors.toList()));
// the number of people
affiche("count", personnes.stream().count());
// the oldest person
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
// the lightest person
affiche("poids min", personnes.stream().min(Comparator.comparingDouble(Personne::getPoids)).get());
// last person in alphabetical order of name
affiche("nom max", personnes.stream().max((p1, p2) -> p1.getNom().compareToIgnoreCase(p2.getNom())).get());
// total age of all persons
affiche("âge total (reduce)", personnes.stream().map(p -> p.getAge()).reduce(0, (a1, a2) -> a1 + a2));
// people by ascending age
affiche("personnes par âge croissant",
personnes.stream().sorted(Comparator.comparingInt(Personne::getAge)).collect(Collectors.toList()));
// are there any people over 100?
affiche("des personnes de + de 100 ans (anyMatch)", personnes.stream().anyMatch(p -> p.getAge() > 100));
// are all people at most 100 years old?
affiche("des personnes de + de 100 ans (noneMatch)", personnes.stream().noneMatch(p -> p.getAge() > 100));
// are all people over 8 years old?
affiche("des personnes de + de 8 ans (allMatch)", personnes.stream().allMatch(p -> p.getAge() > 8));
// group people by gender
affiche("personnes regroupées par sexe", personnes.stream().collect(Collectors.groupingBy(p -> p.getSexe())));
// remove duplicate elements from a list
affiche("distinct", Stream.of(1, 2, 1).distinct().collect(Collectors.toList()));
// of a Stream<Stream<T>>, we make a Stream<T>
affiche("flatMap", Stream.of(1, 2, 3).flatMap(i -> Stream.of(i, i + 10)).collect(Collectors.toList()));
// of a Stream<Stream<Integer>>, we make a IntStream and calculate its sum
affiche("flatMapToInt", Stream.of(1, 2, 3).flatMapToInt(i -> IntStream.of(i, i + 10)).sum());
// of a Stream<Stream<Integer>>, we make a DoubleStream and then an array
affiche("flatMapToDouble", Stream.of(1, 2, 3).flatMapToDouble(i -> DoubleStream.of(i, i * 1.2)).toArray());
// max of a stream of integers
affiche("reduce Integer::max", Stream.of(1, 10, 8).reduce(Integer::max).get());
// min of a Double
affiche("reduce Integer::min", Stream.of(1.5, 10.4, 8.9).reduce(Double::min).get());
// average of a stream of integers
affiche("IntStream average", IntStream.of(1, 10, 8).average().getAsDouble());
// statistics for a stream of integers
affiche("IntStream summaryStatistics", IntStream.of(1, 10, 8).summaryStatistics());
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- righe 72, 75: visualizzano la stringa JSON del secondo parametro del metodo;
- riga 24: visualizza la stringa JSON per tutte le persone. Il risultato è il seguente:
5.6.1. [findFirst]
// la 1ère personne
affiche("findFirst", personnes.stream().findFirst().get());
Il metodo [findFirst] restituisce il primo elemento di uno stream, se esiste. La sua firma è la seguente:
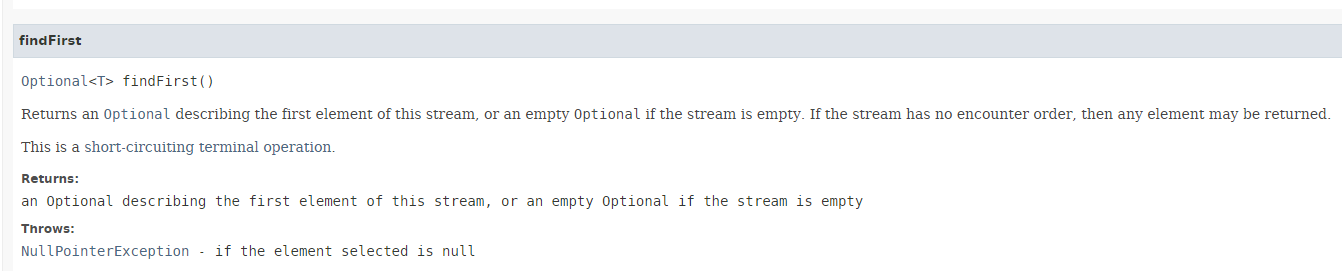 |
Il risultato è di tipo Optional<T>, un tipo introdotto in Java 8:
 |
La classe Optional<T> consente una gestione diversa dei puntatori null. Un metodo che deve restituire un tipo T che può avere il valore null può scegliere di restituire un tipo Optional<T>. Il metodo [Optional<T>.isPresent()] consente di determinare se il metodo ha restituito un valore o meno. Il codice seguente [Esempio06b] illustra in parte il funzionamento di Optional<T>:
package dvp.java8.streams;
import java.util.Optional;
import com.fasterxml.jackson.core.JsonProcessingException;
public class Exemple06b {
public static void main(String[] args) throws JsonProcessingException {
// optional without value
Optional<Integer> o1 = m1();
System.out.println(o1.isPresent());
affiche(o1);
// optional with value
Optional<Integer> o2 = m2();
System.out.println(o2.isPresent());
affiche(o2);
}
private static void affiche(Optional<Integer> o1) {
try {
// retrieve the value of the Optional
// throws 1 exception if no value
System.out.println(o1.get());
} catch (Throwable th) {
System.out.printf("%s : %s%n", th.getClass().getName(), th.getMessage());
}
}
public static Optional<Integer> m1() {
// no value
return Optional.empty();
}
public static Optional<Integer> m2() {
// a value
return Optional.of(10);
}
}
I risultati sono i seguenti:
false
java.util.NoSuchElementException : No value present
true
10
Torniamo al codice che illustra il metodo [findFirst]:
// la 1ère personne
affiche("findFirst", personnes.stream().findFirst().get());
- riga 2: per semplificare il codice, utilizziamo il metodo [get] sull'oggetto Optional<Person> generato dal metodo [findFirst]. Un codice pulito richiederebbe di chiamare il metodo [Optional<Person>.isPresent()] prima di chiamare il metodo [get];
Il risultato è il seguente:
5.6.2. [findAny]
// n'importe quelle personne
affiche("findAny", personnes.stream().findAny().get());
Il metodo [findAny] ha la seguente firma:
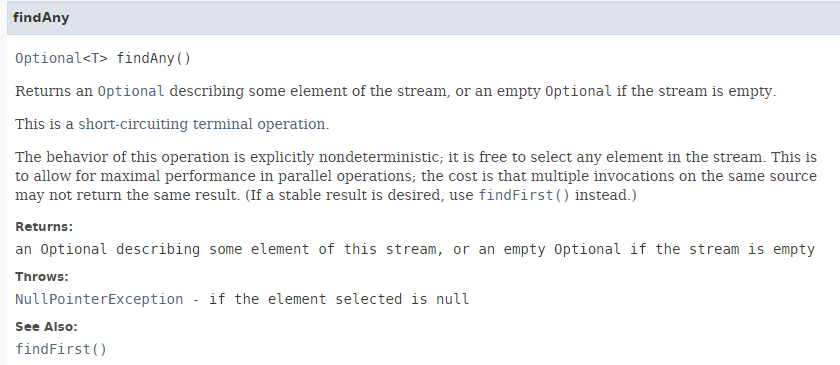 |
Il metodo [findAny] può restituire qualsiasi elemento dello stream. Durante i test, osserviamo che un'esecuzione sequenziale restituisce il primo elemento dello stream, mentre un'esecuzione parallela può effettivamente restituire qualsiasi elemento. Ciò è dimostrato dal seguente codice [Esempio06c]:
package dvp.java8.streams;
import java.util.List;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple06c {
// mapper jSON
static private ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// list of persons
List<Personne> personnes = Personnes.get();
// everyone
affiche("all", personnes);
// any person
affiche("findAny parallèle", personnes.stream().parallel().findAny().get());
// any person
affiche("findAny séquentiel", personnes.stream().findAny().get());
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- riga 22: findAny eseguito in parallelo;
- riga 24: findAny eseguito in sequenza;
I risultati ottenuti sono i seguenti:
- riga 4: l'esecuzione parallela ha restituito il secondo elemento dell'elenco delle persone. Avrebbe potuto essere un altro;
- riga 6: l'esecuzione sequenziale ha restituito il primo elemento dell'elenco delle persone;
L'uso del metodo [findAny] sembra avere senso solo nell'elaborazione parallela di uno stream.
5.6.3. [skip]
// les personnes sans la 1ère
affiche("skip 1", personnes.stream().skip(1L).collect(Collectors.toList()));
Il metodo [skip] ha la seguente firma:
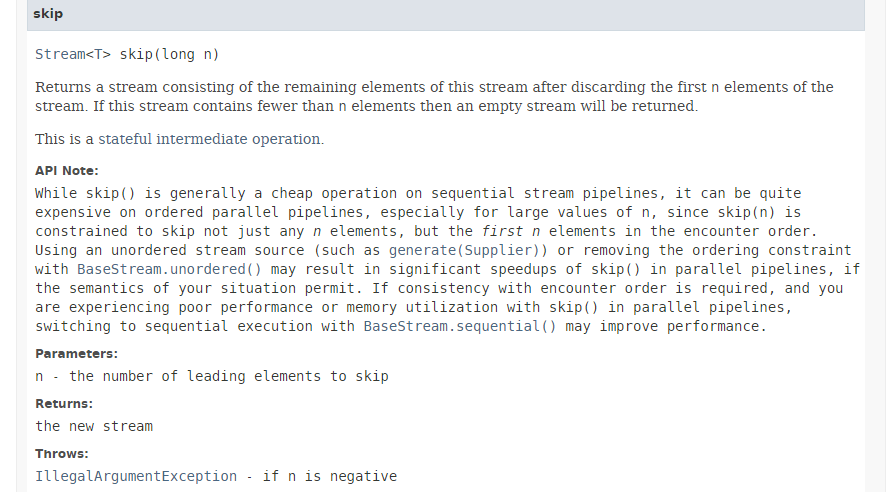 |
Il metodo [skip] salta i primi n elementi di uno stream. Come indicato nella documentazione sopra riportata, l'esecuzione di questo metodo in parallelo produce un guadagno di prestazioni minimo e può persino comportare una perdita di prestazioni. Infatti, per saltare i primi n elementi, i thread sono costretti a coordinarsi, il che annulla i guadagni di prestazioni derivanti dal parallelismo.
Il metodo [skip] restituisce uno Stream<Person> che viene convertito in una List<Person> dal metodo [collect], che ha la seguente firma:
 |
Il metodo [collect] accetta come parametro un'istanza di tipo [Collector], che presenta una firma complessa. Esistono implementazioni predefinite del tipo [Collector] che solitamente consentono di evitare di implementarlo autonomamente. In questo caso, l'implementazione utilizzata è [Collectors.toList()]. [Collectors] è una classe con numerosi metodi statici che implementano il tipo [Collector<T,A,R>]. Questo è il primo posto da consultare quando si desidera convertire uno Stream in una collezione Java standard:
 |
Utilizzeremo alcuni di questi metodi più avanti.
L'esecuzione produce il seguente risultato:
Il primo elemento della lista (jean) è stato omesso.
5.6.4. [limite]
// les 2 premières personnes
affiche("limit 2", personnes.stream().limit(2L).collect(Collectors.toList()));
Il metodo [limit] ha la seguente firma:
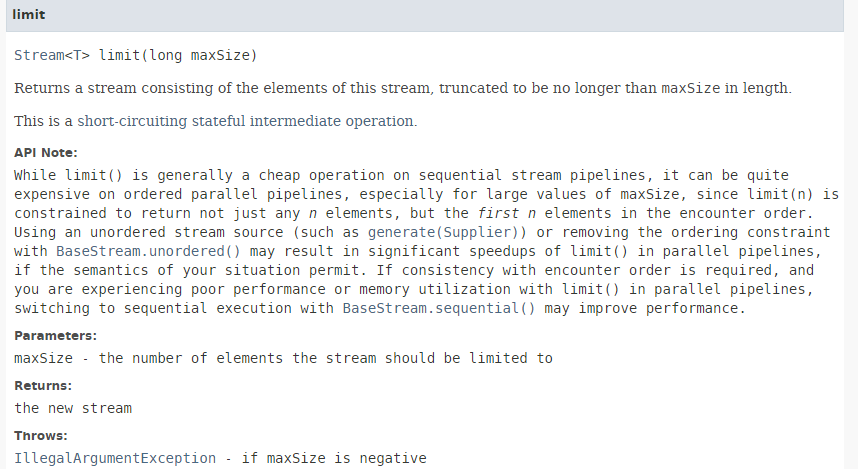 |
Il metodo [limit] consente di conservare solo i primi n elementi di uno stream. Non è adatto all'elaborazione parallela.
L'esecuzione produce il seguente risultato:
5.6.5. [count]
// le nombre de personnes
affiche("count", personnes.stream().count());
Il metodo [count] ha la seguente firma:
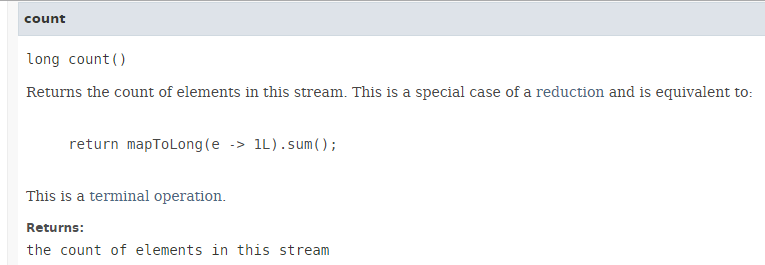 |
Il metodo [count] restituisce il numero di elementi presenti in uno Stream. L'esecuzione parallela del metodo non comporta un miglioramento delle prestazioni, come mostrato nel codice seguente (Esempio06d1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.stream.Stream;
public class Exemple06d1 {
public static void main(String[] args) {
final long limite = 10_000_000L;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// counting numbers - sequential method
Stream<Long> sNombres = nombres.stream();
début = new Date().getTime();
long count = sNombres.count();
System.out.printf("comptage séquentiel : compteur=%s, durée (ms)=%s%n", count, new Date().getTime() - début);
}
}
- righe 11–22: creazione di uno Stream di 10 milioni di numeri;
- righe 22–24: conteggio dello Stream;
L'esecuzione produce il seguente risultato:
Se sostituiamo la riga 22 del codice con quanto segue (Esempio06d2):
Stream<Long> sNombres = nombres.stream().parallel();
otteniamo i seguenti risultati:
5.6.6. [max, min]
// la personne la + âgée
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
Il metodo [max] ha la seguente firma:
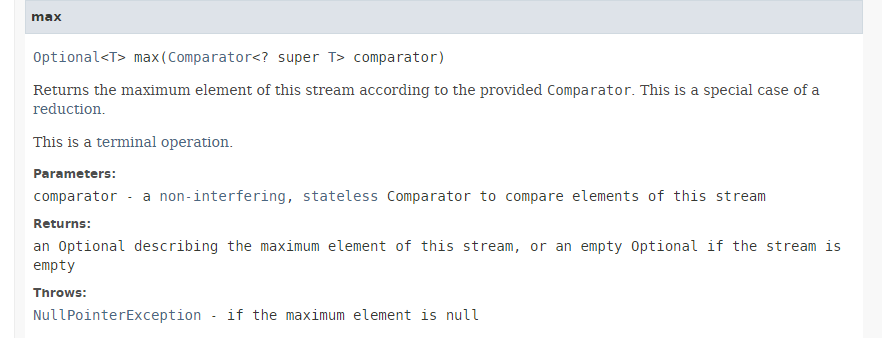 |
Il metodo [max] restituisce il valore massimo di uno stream utilizzando il comparatore passato come parametro. Comparator è un'interfaccia funzionale il cui unico metodo da implementare ha la firma: int compare(T o1, T o2). Questo metodo deve restituire -1 se o1 < o2, 0 se o1.equals(o2) e +1 se o1 > o2. L'interfaccia funzionale Comparator dispone di numerosi metodi statici predefiniti che implementano l'interfaccia Comparator per i casi più comuni. Pertanto, nell'istruzione:
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
utilizziamo il metodo statico [Comparator.comparingInt], la cui firma è la seguente:
 |
Il tipo ToIntFunction è un'interfaccia funzionale:
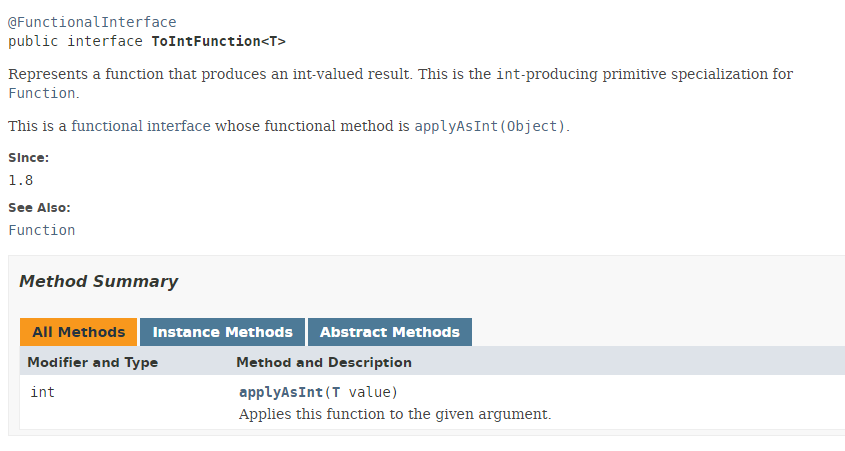 |
Il metodo [applyAsInt] dell'interfaccia funzionale ToIntFunction genera un tipo int a partire da un tipo T. Torniamo al nostro codice:
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
Il parametro effettivo del metodo [Comparator.comparingInt] deve essere qui una lambda Person --> int. Passiamo il riferimento al metodo [Person.getAge], che ha questa firma. Alla fine, otterremo la persona con l'età più avanzata. Otteniamo un tipo Optional<Person>, dal quale estraiamo il valore utilizzando il metodo [Optional.get]. Otteniamo il seguente risultato:
Il calcolo del massimo in parallelo non comporta alcun miglioramento delle prestazioni, come mostrato nell'esempio seguente: (Esempio06e1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Date;
import java.util.List;
import java.util.Random;
import java.util.stream.Stream;
public class Exemple06e1 {
public static void main(String[] args) {
// data
// final long limit = 100L;
// final boolean verbose = true;
final long limite = 10_000_000L;
final boolean verbose = false;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextLong());
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// max numbers - sequential method
Stream<Long> sNombres = nombres.stream();
Comparator<Long> compLong = (l1, l2) -> {
if (verbose) {
// thread
System.out.printf("[%s]", Thread.currentThread().getName());
}
// comparison
long v1 = l1.longValue();
long v2 = l2.longValue();
if (v1 < v2) {
return -1;
} else {
if (v1 == v2) {
return 0;
} else {
return +1;
}
}
};
début = new Date().getTime();
// long max = sNombres.max(Comparator.naturalOrder()).get();
long max = sNombres.max(compLong).get();
System.out.printf("%nmax séquentiel : max=%s, durée (ms)=%s%n", max, new Date().getTime() - début);
}
}
- riga 29: abbiamo un flusso di numeri interi casuali di tipo Long;
- righe 30–47: la variabile lambda compLong implementa l'interfaccia Comparator<Long>. Questa interfaccia è normalmente implementata dal metodo [Comparator.naturalOrder()] alla riga 49. Ma qui vogliamo visualizzare il thread di esecuzione (righe 31–33). Quindi implementiamo l'interfaccia noi stessi;
- riga 50: ricerca del massimo;
Otteniamo i seguenti risultati:
 |
Ora, se sostituiamo la riga 27 con quanto segue (Esempio06e2):
Stream<Long> sNombres = nombres.stream().parallel();
otteniamo i seguenti risultati:
 |
L'esecuzione parallela è stata quindi più lenta. Se aumentiamo il numero di numeri a 10 milioni con verbose=false, otteniamo i seguenti risultati:
Per l'esecuzione sequenziale:
per l'esecuzione parallela, che rimane più lenta.
Utilizziamo il metodo [Stream.min] in modo simile:
// la personne la + légère
affiche("poids min", personnes.stream().min(Comparator.comparingDouble(Personne::getPoids)).get());
5.6.7. [reduce]
// l'âge total de toutes les personnes
affiche("âge total (reduce)", personnes.stream().map(p -> p.getAge()).reduce(0, (a1, a2) -> a1 + a2));
Il metodo [reduce] è stato introdotto nella Sezione 5.3. La riga 2 sopra somma le età di tutte le persone. Il risultato è il seguente:
5.6.8. [ordinato]
// les personnes par âge croissant
affiche("personnes par âge croissant",
personnes.stream().sorted(Comparator.comparingInt(Personne::getAge)).collect(Collectors.toList()));
// les personnes par ordre alphabétique des noms
List<Personne> lPersonnes=personnes.stream().sorted((p1, p2) -> p1.getNom().compareTo(p2.getNom())).collect(Collectors.toList());
affiche("personnes par ordre alphabétique des noms", lPersonnes);
Il metodo [sorted] (righe 3 e 5) ha la seguente firma:
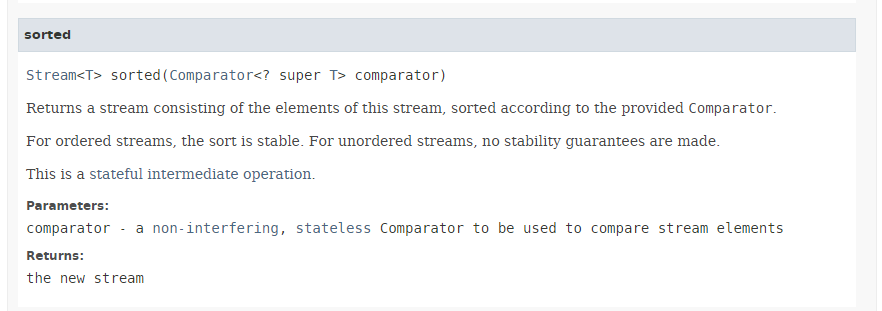 |
Il metodo [sorted] accetta come parametro il tipo [Comparator] descritto nella Sezione 5.6.6 per i metodi min e max. Consente di ordinare uno Stream secondo l'ordine del comparatore passato come parametro. Abbiamo visto che l'interfaccia [Comparator] fornisce diversi metodi statici predefiniti che implementano comparatori comuni, in particolare per numeri e stringhe. Qui utilizziamo il metodo [Comparator.comparingInt], che accetta come parametro un tipo ToIntFunction, che è un'interfaccia funzionale per il metodo [applyAsInt] con la seguente firma: int applyAsInt(T t). Qui, il parametro effettivo passato al metodo [Comparator.comparingInt] alla riga 3 è il riferimento al metodo [Person.age], che restituisce l'età della persona.
L'interfaccia [Comparator] non fornisce metodi statici per il confronto delle stringhe. Alla riga 5, costruiamo noi stessi una lambda che implementa l'unico metodo di questa interfaccia: int compare(T t1, T t2)
(p1, p2) -> p1.getNom().compareTo(p2.getNom())
Questo lambda confronta i nomi delle persone. I risultati ottenuti sono i seguenti:
L'esecuzione parallela dell'ordinamento non sembra possibile, come mostrato nel codice seguente (Esempio06f1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Date;
import java.util.List;
import java.util.Random;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class Exemple06f1 {
// mapper jSON
static ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// data
final long limite = 100L;
final boolean verbose = true;
// final long limit = 10_000_000L;
// final boolean verbose = false;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Integer> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextInt(1000));
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// number sorting - sequential method
Stream<Integer> sNombres = nombres.stream();
début = new Date().getTime();
Comparator<Integer> compInt = (i1, i2) -> {
if (verbose) {
// thread
System.out.printf("[%s]", Thread.currentThread().getName());
}
// comparison
int v1 = i1.intValue();
int v2 = i2.intValue();
if (v1 < v2) {
return +1;
} else {
if (v1 == v2) {
return 0;
} else {
return -1;
}
}
};
if (verbose) {
affiche("nombres", sNombres.sorted(compInt).collect(Collectors.toList()));
}
System.out.printf("tri séquentiel : durée (ms)=%s%n", new Date().getTime() - début);
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- righe 30–36: generiamo una sequenza di numeri casuali;
- riga 32: passiamo la funzione lambda compInt (righe 38-55) al metodo [sorted]. Questa funzione lambda ordina i numeri in ordine decrescente e visualizza il thread che la sta eseguendo.
I risultati ottenuti sono i seguenti:
 |
Se, nel codice precedente, sostituiamo la riga 36 con quanto segue (Esempio06f2):
Stream<Integer> sNombres = nombres.stream().parallel();
otteniamo i seguenti risultati:
 |
Sorprendentemente, scopriamo che la sequenza di numeri è stata ordinata utilizzando un unico thread. Non c'era alcun parallelismo. O mi sfugge qualcosa?
5.6.9. [anyMatch, noneMatch, allMatch]
// y-a-t-il des personnes de + de 100 ans ?
affiche("des personnes de + de 100 ans (anyMatch)", personnes.stream().anyMatch(p -> p.getAge() > 100));
// est-ce que toutes les personnes ont au plus 100 ans ?
affiche("des personnes de + de 100 ans (noneMatch)", personnes.stream().noneMatch(p -> p.getAge() > 100));
// est-ce que toutes les personnes ont + de 8 ans
affiche("des personnes de + de 8 ans (allMatch)", personnes.stream().allMatch(p -> p.getAge() > 8));
Righe 2, 4 e 6: i metodi [anyMatch, noneMatch, allMatch] accettano un tipo Predicate come parametro, come descritto nella Sezione 4.2. Eseguono quindi un'operazione di filtraggio. Tutti e tre restituiscono un valore booleano:
- anyMatch restituisce true se nello Stream è presente almeno un elemento che soddisfa il filtro;
- noneMatch restituisce true se non ci sono elementi nello Stream che soddisfano il filtro;
- allMatch restituisce true se tutti gli elementi dello Stream soddisfano il filtro;
I risultati ottenuti sono i seguenti:
5.6.10. [collect(Collectors.groupingBy)]
// on regroupe les personnes par sexe
affiche("personnes regroupées par sexe", personnes.stream().collect(Collectors.groupingBy(p -> p.getSexe())));
Il metodo [collect] è stato introdotto nella Sezione 5.6.3. Il suo parametro è un'implementazione dell'interfaccia [Collector]. La classe [Collectors] fornisce una serie di metodi statici che implementano l'interfaccia [Collector]. Finora abbiamo utilizzato il metodo [Collectors.toList()]. Qui utilizziamo il metodo statico [Collectors.groupingBy], che crea un dizionario dallo Stream. La sua firma è la seguente:
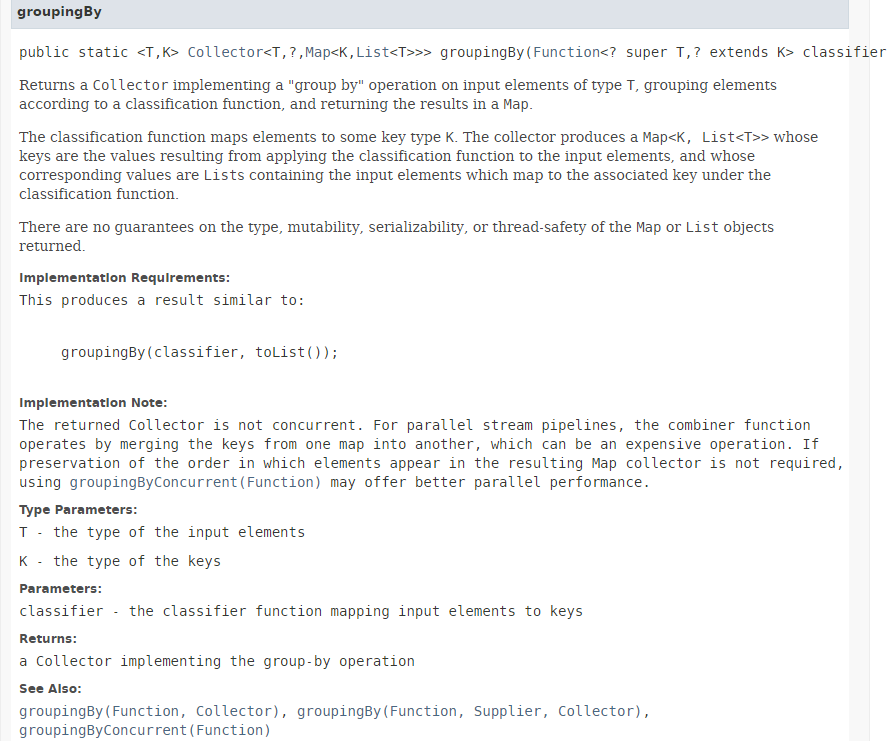 |
Il metodo [groupingBy] crea una Map<K,List<T>> da uno Stream<T>. La chiave K è fornita dal parametro del metodo [groupingBy] di tipo Function<T,K>, il cui unico metodo ha la firma: K apply(T t). Se vogliamo creare una mappa indicizzata in base al sesso di una persona, dobbiamo fornire una funzione che generi il sesso da una persona. Qui, passiamo il riferimento al metodo [Person.getGender] come parametro effettivo del metodo [groupingBy]. I risultati ottenuti sono i seguenti:
La riga 2 contiene la stringa JSON di un dizionario indicizzato da due chiavi: UOMO e DONNA.
Il calcolo parallelo non comporta miglioramenti delle prestazioni, come mostrato nell'esempio seguente (Esempio06g1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class Exemple06g1 {
// mppeur jSON
static ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// data
final long limite = 100L;
final boolean verbose = true;
// final long limit = 10_000_000L;
// final boolean verbose = false;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Integer> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextInt(1000));
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// grouping numbers by hundred - sequential method
Stream<Integer> sNombres = nombres.stream();
Function<Integer, Integer> groupByCent = n -> {
if (verbose) {
System.out.printf("[%s]", Thread.currentThread().getName());
}
return n / 100;
};
début = new Date().getTime();
// Map<Integer, List<Integer>> lNombres = sNombres.collect(Collectors.groupingBy(number -> number / 100));
Map<Integer, List<Integer>> lNombres = sNombres.collect(Collectors.groupingBy(groupByCent));
System.out.printf("%nregroupement séquentiel : durée (ms)=%s%n", new Date().getTime() - début);
// results
if (verbose) {
affiche("nombres regroupés", lNombres);
}
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- righe 23–38: costruzione di un flusso di numeri;
- riga 47: i numeri sono raggruppati per centinaia. La funzione lambda nelle righe 39–44 viene utilizzata per visualizzare il thread di esecuzione;
I risultati dell'esecuzione sono i seguenti:
 |
Se, nel codice, sostituiamo la riga 38 con la seguente riga (Esempio06g2):
Stream<Integer> sNombres = nombres.stream().parallel();
otteniamo i seguenti risultati:
 |
Si può notare che l'esecuzione parallela del raggruppamento ha compromesso le prestazioni.
5.6.11. [distinct]
// supression des éléments en double d'une liste
affiche("distinct", Stream.of(1, 2, 1).distinct().collect(Collectors.toList()));
Il metodo [distinct] ha la seguente firma:
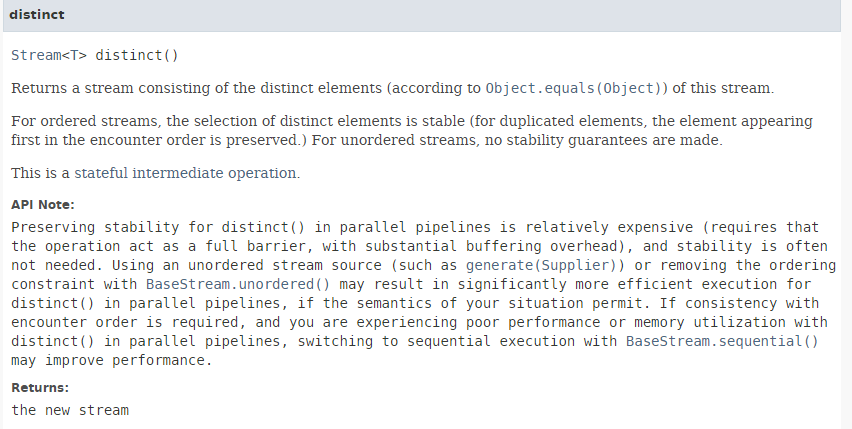 |
Rimuove i duplicati da uno stream. Il metodo [Stream.of] (riga 2) ha la seguente firma:
 |
Consente di creare uno Stream a partire da valori forniti esplicitamente. I risultati dell'esecuzione sono i seguenti:
5.6.12. [flatMap]
// d'un Stream<Stream<T>>, on fait un Stream<T>
affiche("flatMap", Stream.of(1, 2, 3).flatMap(i -> Stream.of(i, i + 10)).collect(Collectors.toList()));
Il metodo [flatMap] ha la seguente firma:
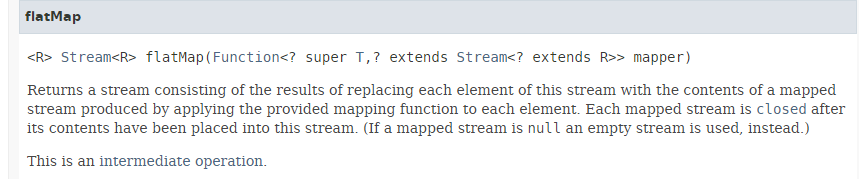  |
Il metodo [flatMap] accetta come parametro una funzione che:
- accetta come parametro un elemento di tipo T proveniente dallo Stream;
- restituisce uno Stream<R>;
Se, invece del metodo [flatMap], avessimo utilizzato il metodo [map] descritto nella Sezione 5.5, il risultato sarebbe stato un tipo Stream<Stream<R>>, dove ogni elemento di tipo T nello stream iniziale avrebbe prodotto un elemento Stream<R>. Il metodo [flatMap], invece, restituisce un tipo Stream<R>. Appiattisce i vari flussi Stream<R> in un unico flusso. Questo è ciò che mostrano i risultati dell'esecuzione del codice precedente:
Esistono varianti specializzate di [flatMap]:
// d'un Stream<IntStream>, on fait un IntStream dont on calcule la somme
affiche("flatMapToInt", Stream.of(1, 2, 3).flatMapToInt(i -> IntStream.of(i, i + 10)).sum());
Il metodo [flatMapToInt] ha la seguente firma:
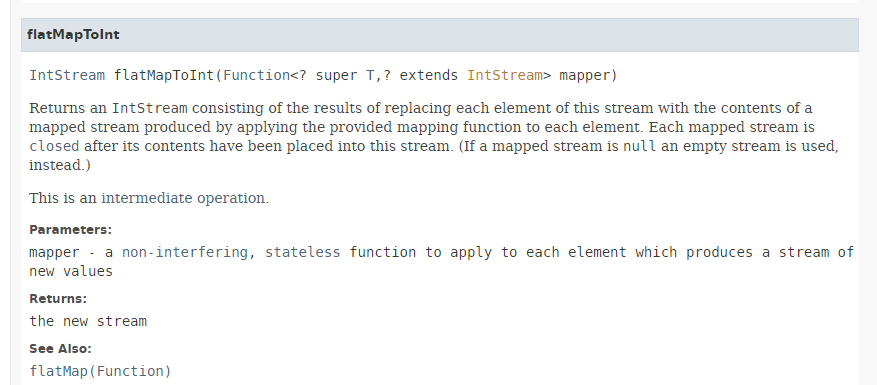 |
Il metodo [flatMapToInt] accetta come parametro una funzione che restituisce un IntStream del seguente tipo:
 |
IntStream è uno stream di int. Questo tipo è preferibile al tipo Stream<Integer> perché la sua elaborazione evita il boxing/unboxing tra i tipi Integer e int. Questa interfaccia eredita molti metodi dal tipo Stream<T> e ne aggiunge altri, incluso il metodo [sum] sopra riportato, che somma gli elementi dell'IntStream.
Il codice seguente illustra l'uso del metodo analogo [flatMapToDouble]:
// d'un Stream<DoubleStream>, on fait un DoubleStream puis un tableau
affiche("flatMapToDouble", Stream.of(1, 2, 3).flatMapToDouble(i -> DoubleStream.of(i, i * 1.2)).toArray());
Il metodo [DoubleStream.toArray] consente di convertire un tipo DoubleStream in un tipo double[].
I risultati di questi due esempi sono i seguenti:
L'esempio seguente illustra i miglioramenti in termini di prestazioni ottenuti passando dal tipo Stream<Long> al tipo LongStream (Esempio06i1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class Exemple06i1 {
public static void main(String[] args) {
final long limite = 10_000_000L;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// sum of numbers - sequential method
début = new Date().getTime();
long somme = nombres.stream().reduce(0L, (s, i) -> s + i);
System.out.printf("somme séquentielle du Stream<Integer> : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- riga 22: calcolo della somma di uno stream di numeri Long;
Si ottengono i seguenti risultati:
Ora, sostituiamo la riga 22 con quanto segue (Esempio06i2):
long somme = nombres.stream().mapToLong(n -> n.longValue()).sum();
Il metodo Stream<Integer>.mapToLong ci permette di ottenere un LongStream di elementi long primitivi, che poi sommiamo utilizzando la funzione sum. Otteniamo quindi i seguenti risultati:
Il guadagno in termini di prestazioni è evidente.
5.6.13. metodi primitivi per flussi di numeri
// max d'un flux de int
affiche("IntStream max", IntStream.of(1, 10, 8).max());
// min d'un flux de double
affiche("DoubleStream min", DoubleStream.of(1.5, 10.4, 8.9).min());
// moyenne d'un flux de int
affiche("IntStream average", IntStream.of(1, 10, 8).average().getAsDouble());
// statistiques d'un flux de int
affiche("IntStream summaryStatistics", IntStream.of(1, 10, 8).summaryStatistics());
Gli stream di valori primitivi (int, long, double) forniscono metodi specifici per questi tipi. Il risultato dell'esecuzione del codice precedente è il seguente:
- Il risultato della riga 2 del codice è un tipo OptionalInt analogo al tipo Optional<Integer>. Il valore memorizzato in questo oggetto può essere recuperato utilizzando il metodo [getAsInt()]. La presenza di un valore può essere verificata utilizzando il metodo [isPresent()]. La riga 2 dei risultati non significa che la classe [OptionalInt] abbia campi denominati [asInt] e [present]. Per impostazione predefinita, la libreria JSON utilizza tutti i metodi pubblici getX e isY dell'oggetto da serializzare in JSON. E qui, c'è effettivamente un metodo [getAsInt] e un altro metodo [isPresent], anche se i campi [asInt, present] stessi non esistono;
- il risultato della riga 4 del codice è un tipo OptionalDouble analogo al tipo Optional<Double>;
- il risultato della riga 6 del codice è un tipo OptionalDouble il cui valore può essere ottenuto utilizzando il metodo [getAsDouble()]. Il metodo [average] calcola la media del flusso di numeri;
- Il risultato della riga 8 del codice è un tipo IntSummaryStatistics definito come segue:
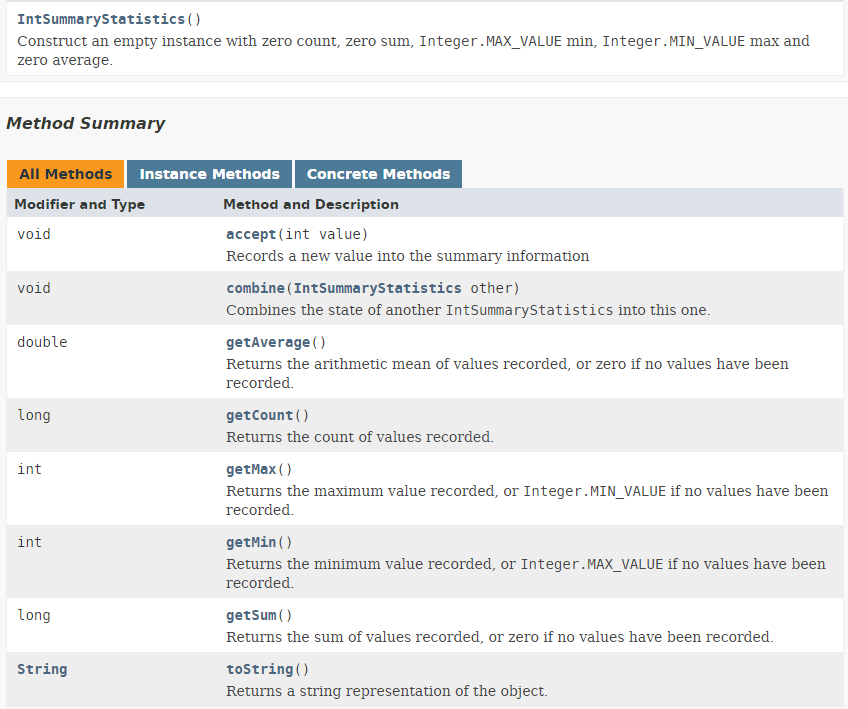 |
Possiamo notare che l'oggetto IntSummaryStatistics risultante fornisce varie statistiche relative al flusso di numeri, quali il numero di valori, la somma, il massimo, il minimo e la media.