5. Classi .NET di uso comune
Presentiamo qui alcune classi della piattaforma .NET di uso frequente. In precedenza, mostriamo come ottenere informazioni sulle centinaia di classi disponibili. Questa guida è indispensabile per lo sviluppatore C#, anche esperto. Il livello di qualità di una guida (facilità di accesso, organizzazione chiara, pertinenza delle informazioni, ecc.) può determinare il successo o il fallimento di un ambiente di sviluppo.
5.1. Cercare la documentazione sulle classi .NET
Di seguito forniamo alcune indicazioni per trovare la guida con Visual Studio.NET
5.1.1. Aiuto/Indice
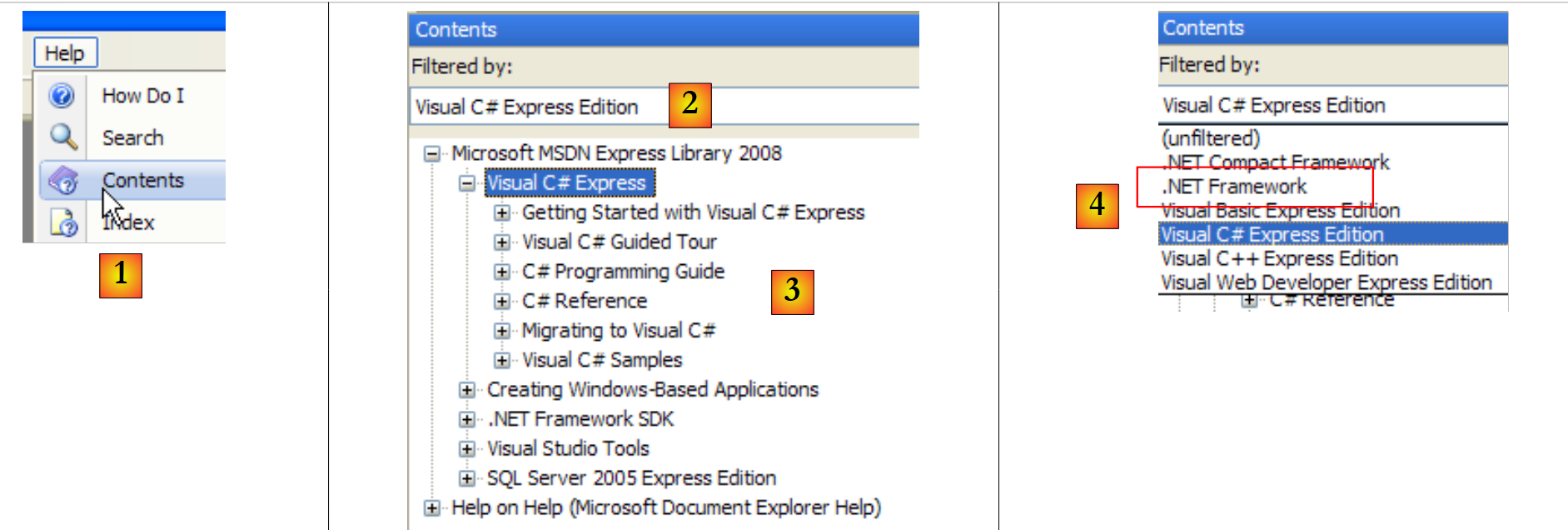 |
- in [1], selezionare l’opzione Help/Contents dal menu.
- in [2], selezionare l'opzione Visual C# Express Edition
- in [3], l'albero della guida su C#
- in [4], un'altra opzione utile è .NET Framework, che consente di accedere a tutte le classi del framework .NET.
Diamo un'occhiata ai titoli dei capitoli della guida di C#:
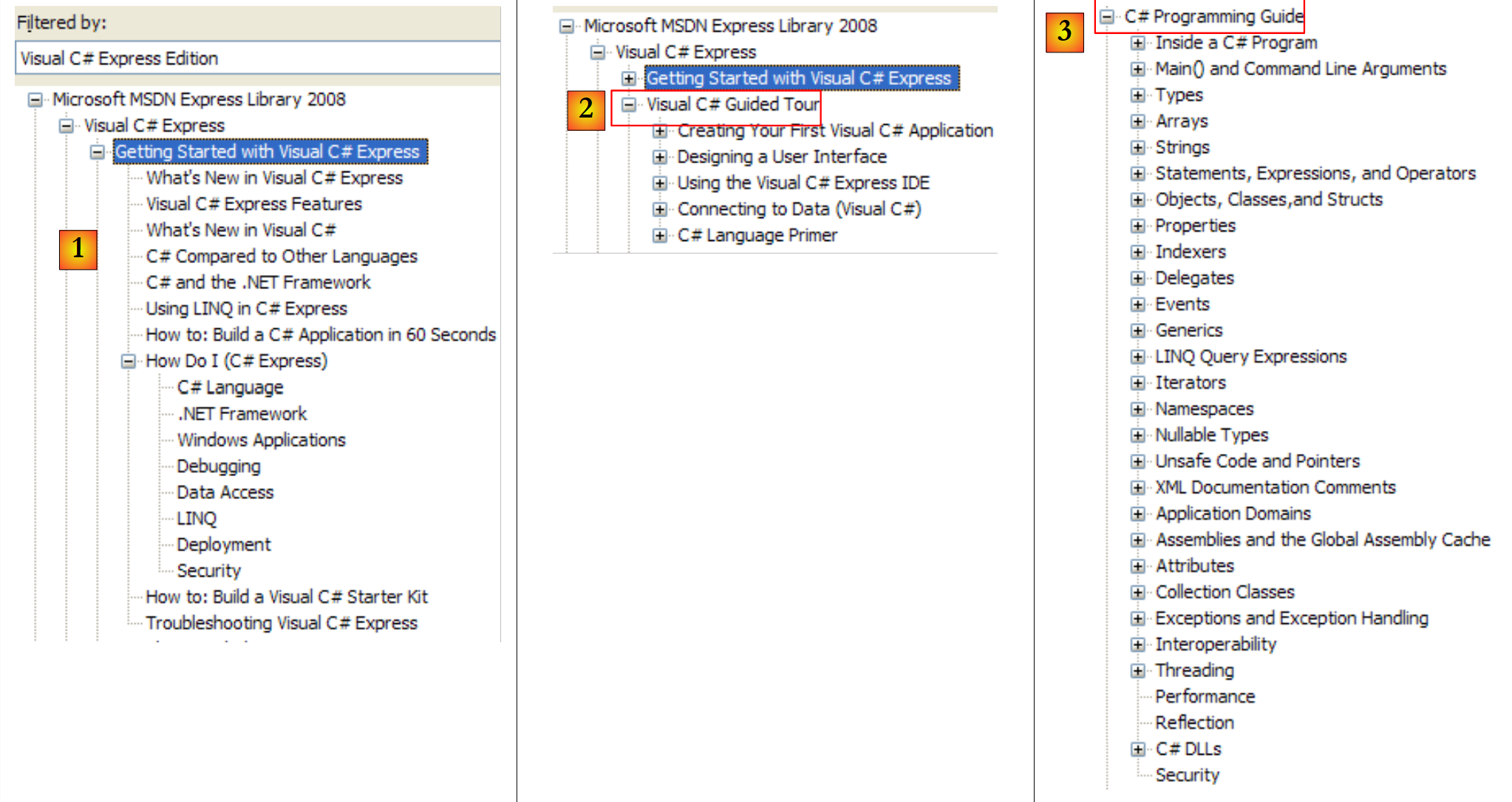 |
- [1]: una panoramica su C#
- [2]: una serie di esempi su alcuni aspetti di C#
- [3]: un corso su C# – potrebbe sostituire vantaggiosamente il presente documento…
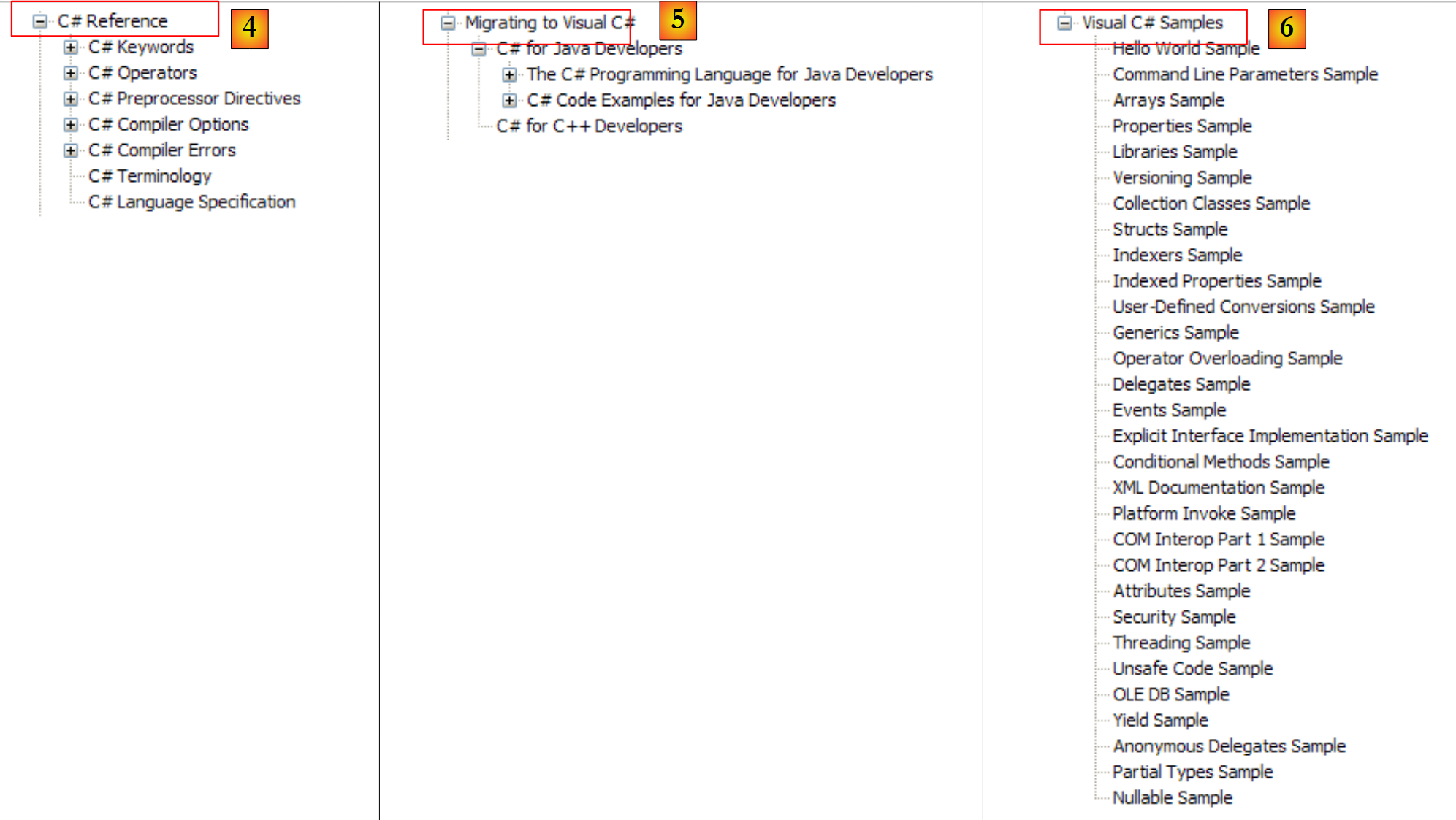 |
- [4]: per approfondire i dettagli di C#
- [5]: utile per gli sviluppatori C++ o Java. Permette di evitare alcune insidie.
- [6]: quando cercate degli esempi, potete iniziare da qui.
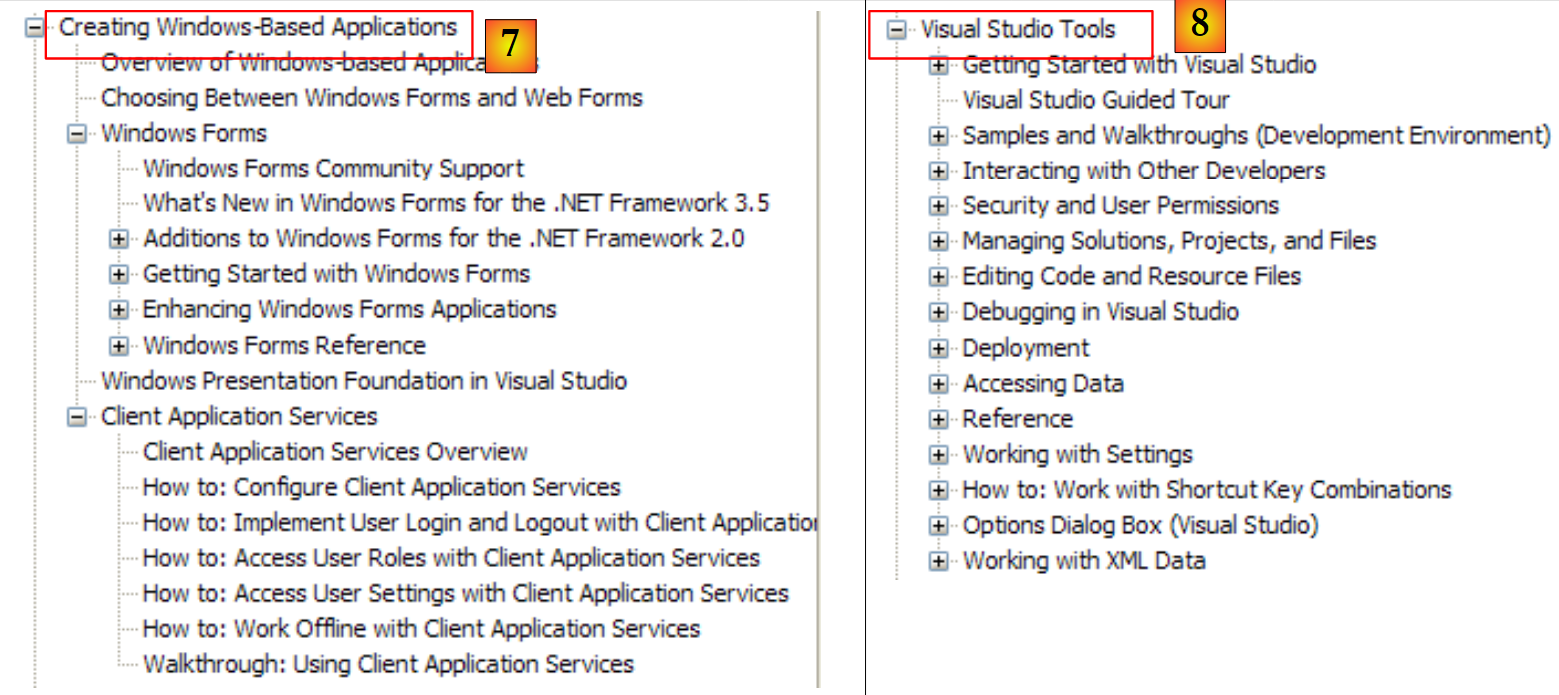 |
- [7]: cosa occorre sapere per creare interfacce grafiche
- [8]: per utilizzare al meglio IDE Visual Studio Express
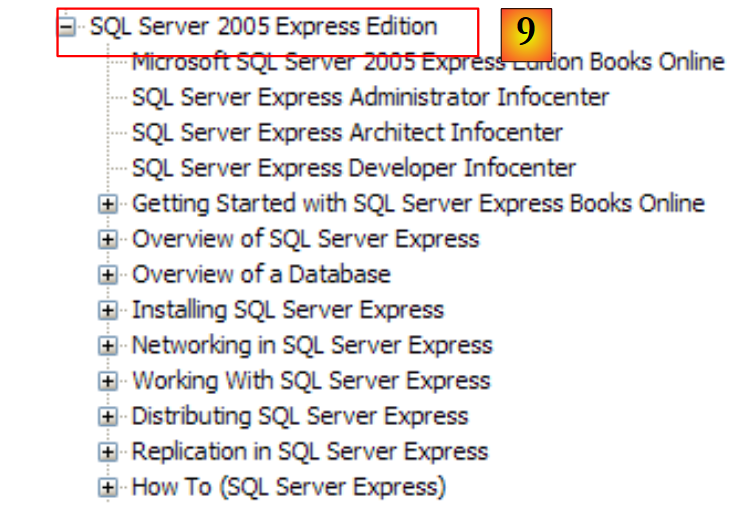 |
- [9]: SQL Server Express 2005 è un SGBD di qualità distribuito gratuitamente. Lo useremo in questo corso.
La guida di C# è solo una parte di ciò di cui ha bisogno lo sviluppatore. L’altra parte è la guida sulle centinaia di classi del framework .NET che gli faciliteranno il lavoro.
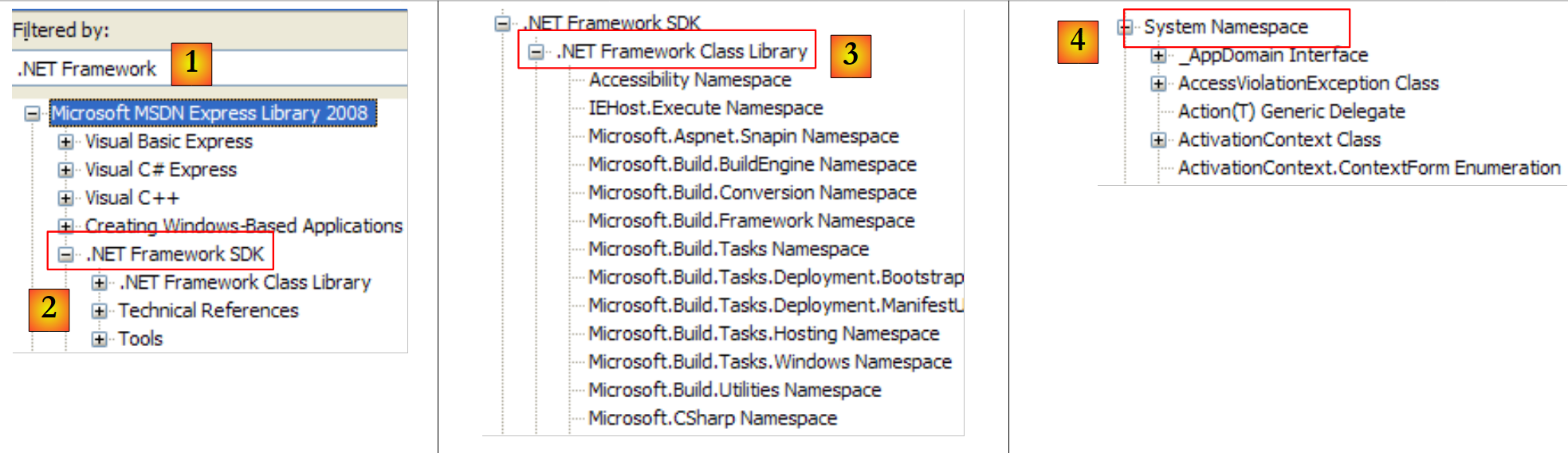 |
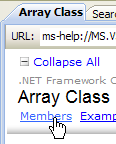
- [1]: selezioniamo la guida sul framework .NET
- [2]: la guida si trova nel ramo .NET Framework SDK
- [3]: il ramo .NET Framework Class Library presenta tutte le classi .NET in base allo spazio dei nomi a cui appartengono
- [4]: lo spazio dei nomi System che è stato utilizzato più spesso negli esempi dei capitoli precedenti
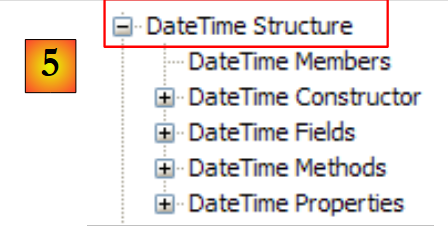 |
- [5]: nello spazio dei nomi System, un esempio, in questo caso la struttura DateTime
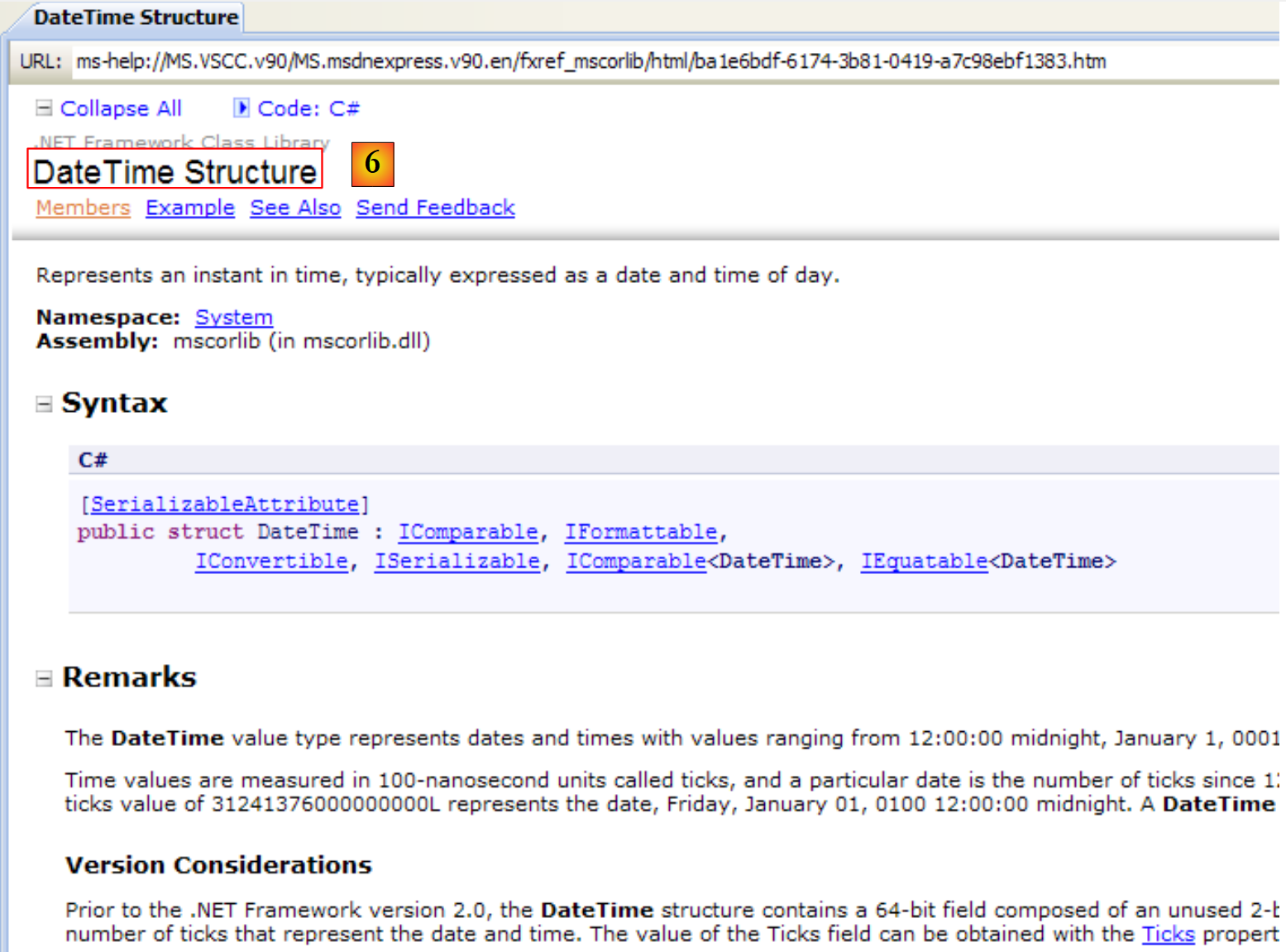 |
- [6]: la guida sulla struttura DateTime
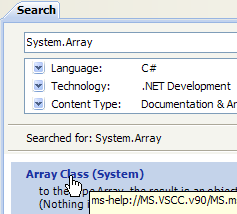
5.1.2. Help/Indice/Ricerca
La guida fornita da MSDN è molto ampia e potrebbe risultare difficile orientarsi. In tal caso, è possibile utilizzare l’indice della guida:
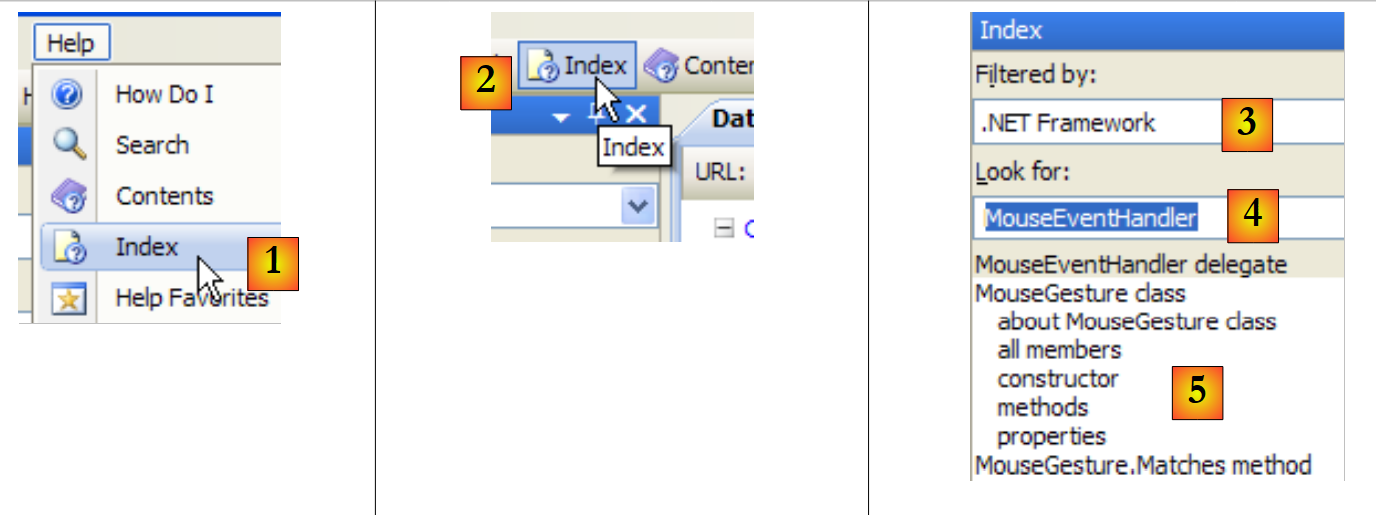 |
- in [1], utilizzare l'opzione [Help/Index] se la finestra della guida non è già aperta, altrimenti utilizzare [2] in una finestra della guida già aperta.
- in [3], specificare l'ambito in cui deve essere effettuata la ricerca
- in [4], specificare ciò che si sta cercando, in questo caso una classe
- in [5], la risposta
Un altro modo per cercare aiuto è utilizzare la funzione di ricerca della guida:
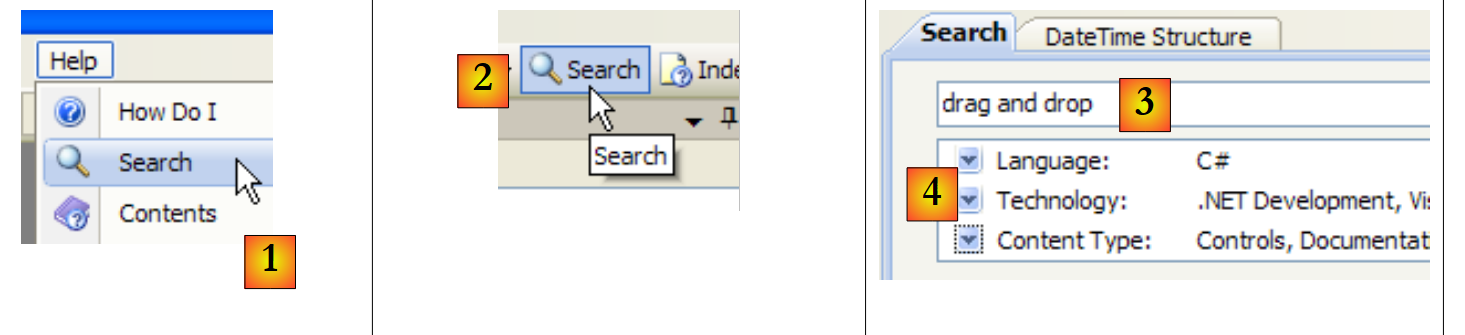 |
- in [1], utilizzare l'opzione [Help/Search] se la finestra della guida non è già aperta, altrimenti utilizzare [2] in una finestra della guida già aperta.
- in [3], specificare cosa si sta cercando
- in [4], filtrare i campi di ricerca
 |
- in [5], la risposta sotto forma di diversi argomenti in cui è stato trovato il testo cercato.
5.2. Le stringhe di caratteri
5.2.1. La classe System.String
 |  |  |
La classe System.String è identica al tipo stringa semplice. Presenta numerose proprietà e metodi. Eccone alcuni:
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
È importante notare che quando un metodo restituisce una stringa, questa è diversa dalla stringa a cui è stato applicato il metodo. Pertanto, S1.Trim() restituisce la stringa S2, mentre S1 e S2 sono due stringhe diverse.
Una stringa C può essere considerata come un array di caratteri. Pertanto
- C[i] è il carattere i di C
- C.Length è il numero di caratteri di C
Consideriamo il seguente esempio:
using System;
namespace Chap3 {
class Program {
static void Main(string[] args) {
string uneChaine = "l'oiseau vole au-dessus des nuages";
affiche("uneChaine=" + uneChaine);
affiche("uneChaine.Length=" + uneChaine.Length);
affiche("chaine[10]=" + uneChaine[10]);
affiche("uneChaine.IndexOf(\"vole\")=" + uneChaine.IndexOf("vole"));
affiche("uneChaine.IndexOf(\"x\")=" + uneChaine.IndexOf("x"));
affiche("uneChaine.LastIndexOf('a')=" + uneChaine.LastIndexOf('a'));
affiche("uneChaine.LastIndexOf('x')=" + uneChaine.LastIndexOf('x'));
affiche("uneChaine.Substring(4,7)=" + uneChaine.Substring(4, 7));
affiche("uneChaine.ToUpper()=" + uneChaine.ToUpper());
affiche("uneChaine.ToLower()=" + uneChaine.ToLower());
affiche("uneChaine.Replace('a','A')=" + uneChaine.Replace('a', 'A'));
string[] champs = uneChaine.Split(null);
for (int i = 0; i < champs.Length; i++) {
affiche("champs[" + i + "]=[" + champs[i] + "]");
}//for
affiche("Join(\":\",champs)=" + System.String.Join(":", champs));
affiche("(\" abc \").Trim()=[" + " abc ".Trim() + "]");
}//Main
public static void affiche(string msg) {
// visualizza messaggio
Console.WriteLine(msg);
}//visualizza
}//classe
}//spazio dei nomi
L'esecuzione fornisce i seguenti risultati:
Consideriamo un nuovo esempio:
using System;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// la riga da analizzare
string ligne = "un:deux::trois:";
// i separatori di campo
char[] séparateurs = new char[] { ':' };
// split
string[] champs = ligne.Split(séparateurs);
for (int i = 0; i < champs.Length; i++) {
Console.WriteLine("Champs[" + i + "]=" + champs[i]);
}
// join
Console.WriteLine("join=[" + System.String.Join(":", champs) + "]");
}
}
}
e i risultati dell'esecuzione:
Il metodo Split della classe String consente di inserire in un array gli elementi di una stringa di caratteri. La definizione del metodo Split qui utilizzato è la seguente:
public string[] Split(char[] separator);
tabella dei caratteri. Questi caratteri rappresentano quelli utilizzati per separare i campi della stringa. Pertanto, se la stringa è "champ1, champ2, champ3"", si potrà utilizzare separator=new char[] {','}. Se il separatore è una sequenza di spazi, si utilizzerà separator=null. | |
array di stringhe in cui ogni elemento dell'array è un campo della stringa. |
Il metodo Join è un metodo statico della classe String:
public static string Join(string separator, string[] value);
array di stringhe | |
una stringa che fungerà da separatore di campi | |
una stringa formata dalla concatenazione degli elementi dell'array value separati dalla stringa separator. |
5.2.2. La classe System.Text.StringBuilder
 |  |  |
In precedenza abbiamo detto che i metodi della classe String applicati a una stringa di caratteri S1 restituivano un’altra stringa S2. La classe System.Text.StringBuilder consente di manipolare S1 senza dover creare una stringa S2. Ciò migliora le prestazioni evitando la moltiplicazione di stringhe con una durata molto limitata.
La classe supporta diversi costruttori:
| |
|
Un oggetto StringBuilder utilizza blocchi di capacité caratteri per memorizzare la stringa sottostante. Per impostazione predefinita, capacité è pari a 16. Il terzo costruttore sopra indicato consente di specificare la capacità dei blocchi. Il numero di blocchi di caratteri capacité necessari per memorizzare una stringa S viene regolato automaticamente dalla classe StringBuilder. Esistono costruttori per impostare il numero massimo di caratteri in un oggetto StringBuilder. Per impostazione predefinita, questa capacità massima è 2 147 483 647.
Ecco un esempio che illustra questo concetto di capacité:
using System.Text;
using System;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// str
StringBuilder str = new StringBuilder("test");
Console.WriteLine("taille={0}, capacité={1}", str.Length, str.Capacity);
for (int i = 0; i < 10; i++) {
str.Append("test");
Console.WriteLine("taille={0}, capacité={1}", str.Length, str.Capacity);
}
// str2
StringBuilder str2 = new StringBuilder("test",10);
Console.WriteLine("taille={0}, capacité={1}", str2.Length, str2.Capacity);
for (int i = 0; i < 10; i++) {
str2.Append("test");
Console.WriteLine("taille={0}, capacité={1}", str2.Length, str2.Capacity);
}
}
}
}
- riga 7: creazione di un oggetto StringBuilder con una dimensione del blocco di 16 caratteri
- riga 8: str.Length è il numero attuale di caratteri della stringa str. str.Capacity è il numero di caratteri che la stringa str attuale può contenere prima della riassegnazione di un nuovo blocco.
- riga 10: str.Append(String S) consente di concatenare la stringa S di tipo String alla stringa str di tipo StringBuilder.
- riga 14: creazione di un oggetto StringBuilder con una capacità di blocco di 10 caratteri
Risultato dell'esecuzione:
Questi risultati dimostrano che la classe segue un proprio algoritmo per allocare nuovi blocchi quando la sua capacità è insufficiente:
- righe 4-5: aumento della capacità di 16 caratteri
- righe 8-9: aumento della capacità di 32 caratteri, mentre ne sarebbero bastati 16.
Ecco alcuni dei metodi della classe:
| |
| |
| |
| |
|
Ecco un esempio:
using System.Text;
using System;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// str3
StringBuilder str3 = new StringBuilder("test");
Console.WriteLine(str3.Append("abCD").Insert(2, "xyZT").Remove(0, 2).Replace("xy", "XY"));
}
}
}
e i relativi risultati:
5.3. Gli array
Le tabelle derivano dalla classe Array:
 |  | 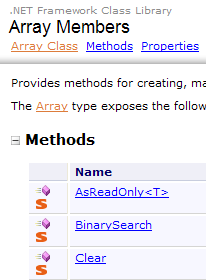 |
La classe Array dispone di vari metodi per ordinare un array, cercare un elemento in un array, ridimensionare un array, ... Presentiamo alcune proprietà e metodi di questa classe. Sono quasi tutti sovramodificati, c.a.d, in quanto esistono in diverse varianti. Ogni array ne eredita le proprietà.
Proprietà
Metodi
Il seguente programma illustra l'utilizzo di alcuni metodi della classe Array:
using System;
namespace Chap3 {
class Program {
// tipo di ricerca
enum TypeRecherche { linéaire, dichotomique };
// metodo principale
static void Main(string[] args) {
// lettura degli elementi di un array digitati dalla tastiera
double[] éléments;
Saisie(out éléments);
// visualizzazione dell'array non ordinato
Affiche("Tableau non trié", éléments);
// Ricerca lineare nell'array non ordinato
Recherche(éléments, TypeRecherche.linéaire);
// ordinamento dell'array
Array.Sort(éléments);
// Visualizzazione dell'array ordinato
Affiche("Tableau trié", éléments);
// Ricerca dicotomica nella tabella ordinata
Recherche(éléments, TypeRecherche.dichotomique);
}
// Inserimento dei valori dell'array «elementi»
// elementi: riferimento alla tabella creata dal metodo
static void Saisie(out double[] éléments) {
bool terminé = false;
string réponse;
bool erreur;
double élément = 0;
int i = 0;
// Inizialmente, la tabella non esiste
éléments = null;
// Ciclo di inserimento degli elementi dell'array
while (!terminé) {
// domanda
Console.Write("Elément (réel) " + i + " du tableau (rien pour terminer) : ");
// lettura della risposta
réponse = Console.ReadLine().Trim();
// fine dell'inserimento se la stringa è vuota
if (réponse.Equals(""))
break;
// verifica dell'inserimento
try {
élément = Double.Parse(réponse);
erreur = false;
} catch {
Console.Error.WriteLine("Saisie incorrecte, recommencez");
erreur = true;
}//try-catch
// se non ci sono errori
if (!erreur) {
// un elemento in più nell'array
i += 1;
// ridimensionamento dell'array per accogliere il nuovo elemento
Array.Resize(ref éléments, i);
// inserimento del nuovo elemento
éléments[i - 1] = élément;
}
}//while
}
// metodo generico per visualizzare gli elementi di un array
static void Affiche<T>(string texte, T[] éléments) {
Console.WriteLine(texte.PadRight(50, '-'));
foreach (T élément in éléments) {
Console.WriteLine(élément);
}
}
// ricerca di un elemento nell'array
// elementi: array di numeri reali
// TypeRecherche: dicotomico o lineare
static void Recherche(double[] éléments, TypeRecherche type) {
// Ricerca
bool terminé = false;
string réponse = null;
double élément = 0;
bool erreur = false;
int i = 0;
while (!terminé) {
// domanda
Console.WriteLine("Elément cherché (rien pour arrêter) : ");
// lettura-verifica della risposta
réponse = Console.ReadLine().Trim();
// finito?
if (réponse.Equals(""))
break;
// verifica
try {
élément = Double.Parse(réponse);
erreur = false;
} catch {
Console.WriteLine("Erreur, recommencez...");
erreur = true;
}//try-catch
// se non ci sono errori
if (!erreur) {
// si cerca l'elemento nell'array
if (type == TypeRecherche.dichotomique)
// ricerca dicotomica
i = Array.BinarySearch(éléments, élément);
else
// ricerca lineare
i = Array.IndexOf(éléments, élément);
// Visualizzazione della risposta
if (i >= 0)
Console.WriteLine("Trouvé en position " + i);
else
Console.WriteLine("Pas dans le tableau");
}//if
}//while
}
}
}
- righe 27-62: il metodo Saisie inserisce gli elementi di un array éléments digitati dalla tastiera. Poiché non è possibile dimensionare l'array a priori (non se ne conosce la dimensione finale), si è costretti a ridimensionarlo ad ogni nuovo elemento (riga 57). Un algoritmo più efficiente sarebbe stato quello di allocare spazio all'array per gruppi di N elementi. Tuttavia, un array non è progettato per essere ridimensionato. In questo caso è preferibile utilizzare una lista (ArrayList, List<T>).
- righe 75-113: il metodo Recherche consente di cercare nell’array éléments un elemento digitato dalla tastiera. La modalità di ricerca varia a seconda che l’array sia ordinato o meno. Per un array non ordinato, si esegue una ricerca lineare con il metodo IndexOf alla riga 106. Per un array ordinato, si esegue una ricerca dicotomica con il metodo BinarySearch alla riga 103.
- riga 18: si ordina la tabella éléments. Qui si utilizza una variante di Sort che ha un solo parametro: la tabella da ordinare. La relazione di ordinamento utilizzata per confrontare gli elementi dell’array è quindi quella implicita di tali elementi. In questo caso, gli elementi sono numerici. Viene utilizzato l’ordinamento naturale dei numeri.
I risultati visualizzati sullo schermo sono i seguenti:
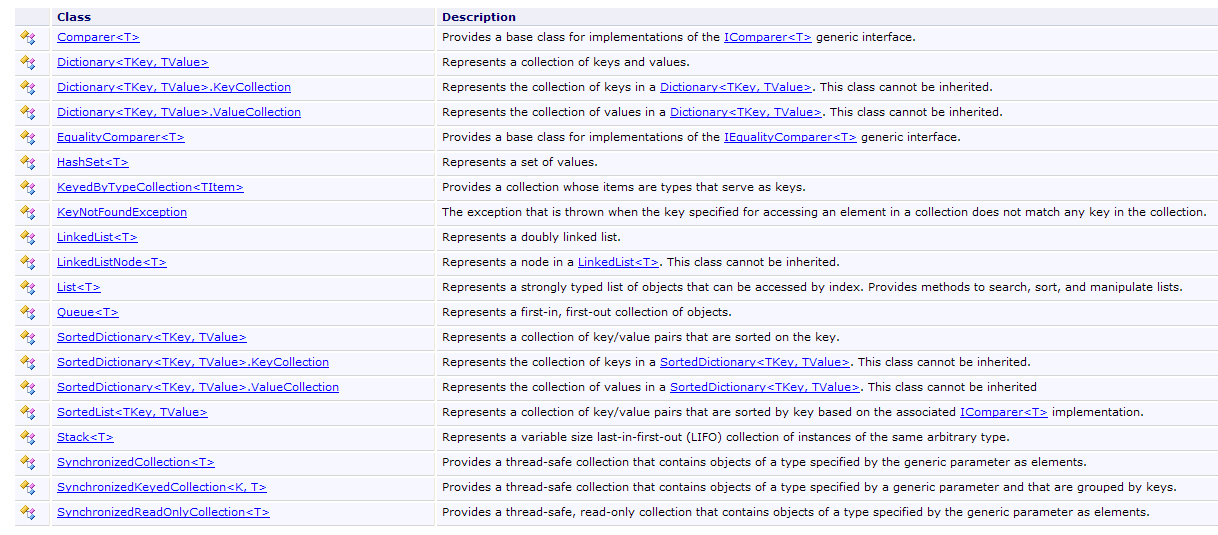
5.4. Le collezioni generiche
Oltre all'array, esistono diverse classi per memorizzare collezioni di elementi. Esistono versioni generiche nello spazio dei nomi System.Collections.Generic e versioni non generiche in System.Collections. Presenteremo due collezioni generiche di uso frequente: la lista e il dizionario.
L'elenco delle collezioni generiche è il seguente:
5.4.1. La classe generica List<T>
La classe System.Collections.Generic.List<T> consente di implementare collezioni di oggetti di tipo T la cui dimensione varia durante l’esecuzione del programma. Un oggetto di tipo List<T> si gestisce quasi come un array. Pertanto, l’elemento i di una lista l è indicato come l[i].
Esiste anche un tipo di lista non generico: ArrayList, in grado di memorizzare riferimenti a oggetti di qualsiasi tipo. ArrayList è funzionalmente equivalente a List<Object>.. Un oggetto ArrayList ha il seguente aspetto:
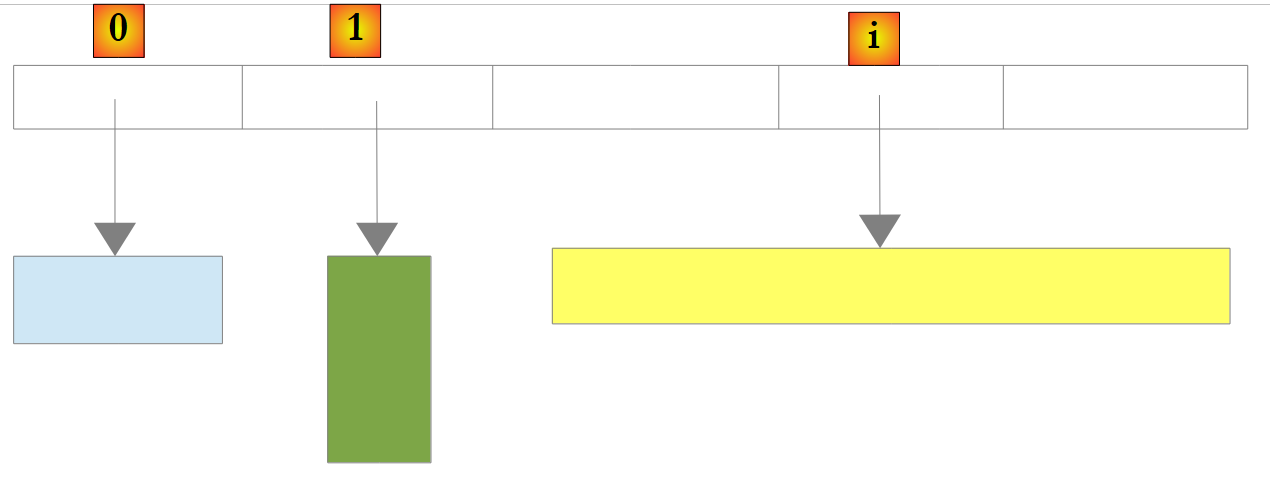 |
Nell’esempio sopra riportato, gli elementi 0, 1 e i dell’elenco puntano a oggetti di tipi diversi. È necessario che un oggetto venga prima creato prima di aggiungere il suo riferimento alla lista ArrayList. Sebbene un ArrayList memorizzi riferimenti a oggetti, è possibile memorizzarvi anche dei numeri. Ciò avviene tramite un meccanismo denominato Boxing: il numero viene incapsulato in un oggetto O di tipo Object ed è il riferimento a O che viene memorizzato nella lista. Si tratta di un meccanismo trasparente per lo sviluppatore. È quindi possibile scrivere:
Ciò produrrà il seguente risultato:
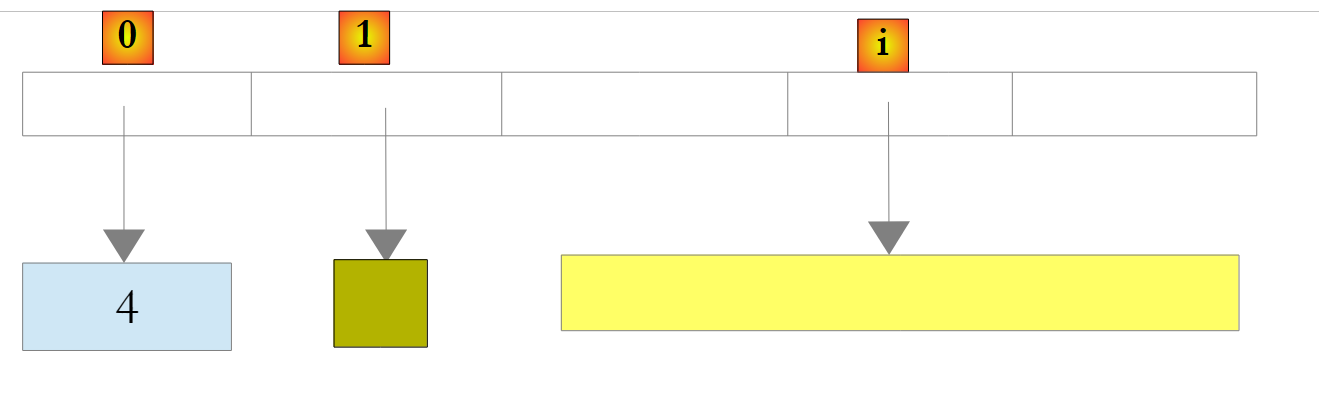 |
Nell’esempio sopra riportato, il numero 4 è stato incapsulato in un oggetto O e il riferimento O è memorizzato nella lista. Per recuperarlo, si potrà scrivere:
int i = (int)liste[0];
L'operazione Object -> int è denominata Unboxing. Se una lista è interamente composta da tipi int, dichiararla come List<int> migliora le prestazioni. Infatti, i numeri di tipo int vengono quindi memorizzati nella lista stessa e non in tipi Object esterni alla lista. Le operazioni di boxing/unboxing non vengono più eseguite.
Se un oggetto List<T> o T è una classe, l’elenco memorizza anche in questo caso i riferimenti agli oggetti di tipo T:
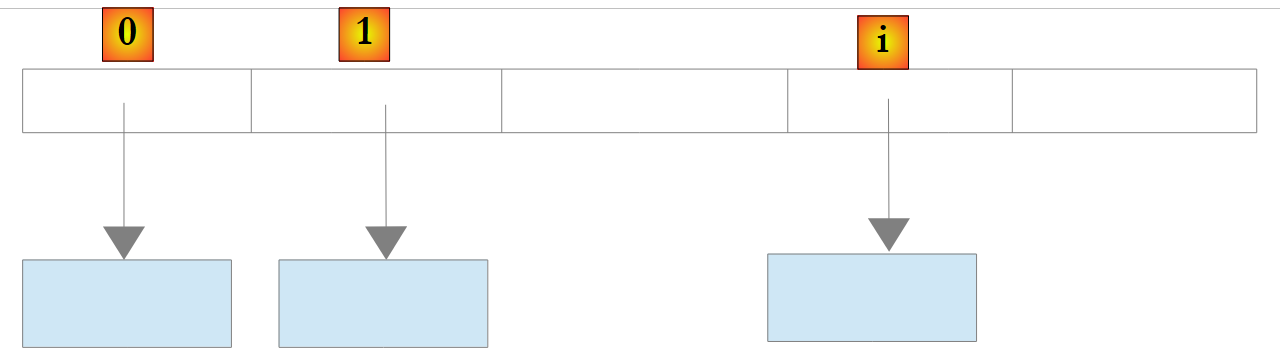 |
Ecco alcune delle proprietà e dei metodi delle liste generiche:
Proprietà
Metodi
Riprendiamo l'esempio trattato in precedenza con un oggetto di tipo Array e trattiamolo ora con un oggetto di tipo List<T>.. Poiché l'elenco è un oggetto simile a un array, il codice cambia di poco. Presentiamo solo le modifiche significative:
using System;
using System.Collections.Generic;
namespace Chap3 {
class Program {
// tipo di ricerca
enum TypeRecherche { linéaire, dichotomique };
// metodo principale
static void Main(string[] args) {
// lettura degli elementi di un elenco digitati dalla tastiera
List<double> éléments;
Saisie(out éléments);
// numero di elementi
Console.WriteLine("La liste a {0} éléments et une capacité de {1} éléments", éléments.Count, éléments.Capacity);
// visualizzazione dell'elenco non ordinato
Affiche("Liste non triée", éléments);
// Ricerca lineare nell'elenco non ordinato
Recherche(éléments, TypeRecherche.linéaire);
// ordinamento dell'elenco
éléments.Sort();
// visualizzazione dell'elenco ordinato
Affiche("Liste triée", éléments);
// Ricerca dicotomica nell'elenco ordinato
Recherche(éléments, TypeRecherche.dichotomique);
}
// Inserimento dei valori dell'elenco degli elementi
// elementi: riferimento all'elenco creato dal metodo
static void Saisie(out List<double> éléments) {
...
// Inizialmente, l'elenco è vuoto
éléments = new List<double>();
// Ciclo di inserimento degli elementi dell'elenco
while (!terminé) {
...
// se non ci sono errori
if (!erreur) {
// un elemento in più nell'elenco
éléments.Add(élément);
}
}//while
}
// metodo generico per visualizzare gli elementi di un oggetto enumerabile
static void Affiche<T>(string texte, IEnumerable<T> éléments) {
Console.WriteLine(texte.PadRight(50, '-'));
foreach (T élément in éléments) {
Console.WriteLine(élément);
}
}
// ricerca di un elemento nell'elenco
// elementi: elenco di numeri reali
// TypeRecherche: dicotomico o lineare
static void Recherche(List<double> éléments, TypeRecherche type) {
...
while (!terminé) {
...
// se non ci sono errori
if (!erreur) {
// si cerca l'elemento nell'elenco
if (type == TypeRecherche.dichotomique)
// ricerca dicotomica
i = éléments.BinarySearch(élément);
else
// ricerca lineare
i = éléments.IndexOf(élément);
// Visualizzazione della risposta
...
}//if
}//while
}
}
}
- righe 46-51: il metodo generico Affiche<T> accetta due parametri:
- il primo parametro è un testo da scrivere
- il secondo parametro è un oggetto che implementa l’interfaccia generica IEnumerable<T>:
La struttura foreach( T elemento in elementi) della riga 48 è valida per qualsiasi oggetto éléments che implementi l'interfaccia IEnumerable. Le tabelle (Array) e le liste (List<T>) implementano l'interfaccia IEnumerable<T>. Pertanto, il metodo Affiche è adatto sia per visualizzare tabelle che elenchi.
I risultati dell’esecuzione del programma sono gli stessi dell’esempio che utilizza la classe Array.
5.4.2. La classe Dictionary<TKey,TValue>
La classe System.Collections.Generic.Dictionary<TKey,TValue> consente di implementare un dizionario. È possibile considerare un dizionario come un array a due colonne:
chiave | valore |
chiave1 | valore1 |
chiave2 | valore2 |
.. | ... |
Nella classe Dictionary<TKey,TValue> le chiavi sono di tipo Tkey, i valori di tipo TValue. Le chiavi sono univoche, c.a.d, quindi non possono esserci due chiavi identiche. Un dizionario di questo tipo potrebbe apparire così se i tipi TKey e TValue indicassero delle classi:
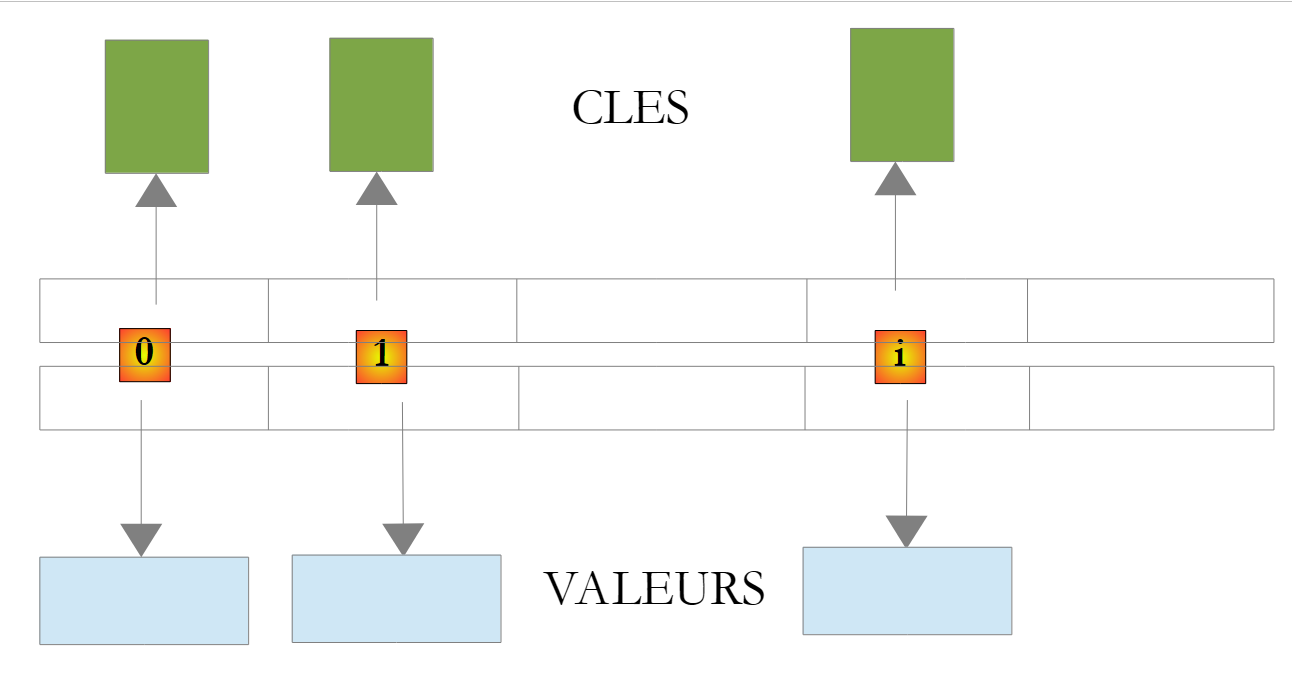 |
Il valore associato alla chiave C di un dizionario D si ottiene con la notazione D[C]. Questo valore è leggibile e scrivibile. Pertanto, è possibile scrivere:
Se la chiave c non esiste nel dizionario D, la notazione D[c] genera un'eccezione.
I metodi e le proprietà principali della classe Dictionary<TKey,TValue> sono i seguenti:
Costruttori
Proprietà
Metodi
Consideriamo il seguente programma di esempio:
using System;
using System.Collections.Generic;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// creazione di un dizionario <string,int>
string[] liste = { "jean:20", "paul:18", "mélanie:10", "violette:15" };
string[] champs = null;
char[] séparateurs = new char[] { ':' };
Dictionary<string,int> dico = new Dictionary<string,int>();
for (int i = 0; i <liste.Length; i++) {
champs = liste[i].Split(séparateurs);
dico[champs[0]]= int.Parse(champs[1]);
}//for
// numero di elementi nel dizionario
Console.WriteLine("Le dictionnaire a " + dico.Count + " éléments");
// elenco delle chiavi
Affiche("[Liste des clés]",dico.Keys);
// elenco dei valori
Affiche("[Liste des valeurs]", dico.Values);
// elenco delle chiavi e dei valori
Console.WriteLine("[Liste des clés & valeurs]");
foreach (string clé in dico.Keys) {
Console.WriteLine("clé=" + clé + " valeur=" + dico[clé]);
}
// si elimina la chiave "paul"
Console.WriteLine("[Suppression d'une clé]");
dico.Remove("paul");
// elenco delle chiavi e dei valori
Console.WriteLine("[Liste des clés & valeurs]");
foreach (string clé in dico.Keys) {
Console.WriteLine("clé=" + clé + " valeur=" + dico[clé]);
}
// ricerca nel dizionario
String nomCherché = null;
Console.Write("Nom recherché (rien pour arrêter) : ");
nomCherché = Console.ReadLine().Trim();
int value;
while (!nomCherché.Equals("")) {
dico.TryGetValue(nomCherché, out value);
if (value!=0) {
Console.WriteLine(nomCherché + "," + value);
} else {
Console.WriteLine("Nom " + nomCherché + " inconnu");
}
// ricerca successiva
Console.Out.Write("Nom recherché (rien pour arrêter) : ");
nomCherché = Console.ReadLine().Trim();
}//while
}
// metodo generico per visualizzare gli elementi di un tipo enumerabile
static void Affiche<T>(string texte, IEnumerable<T> éléments) {
Console.WriteLine(texte.PadRight(50, '-'));
foreach (T élément in éléments) {
Console.WriteLine(élément);
}
}
}
}
- riga 8: un array di string che servirà a inizializzare il dizionario <string,int>
- riga 11: il dizionario <string,int>
- righe 12-15: la sua inizializzazione a partire dall'array di string della riga 8
- riga 17: numero di voci del dizionario
- riga 19: le chiavi del dizionario
- riga 21: i valori del dizionario
- riga 29: eliminazione di una voce dal dizionario
- riga 41: ricerca di una chiave nel dizionario. Se non esiste, il metodo TryGetValue inserirà 0 in value, poiché value è di tipo numerico. Questa tecnica è utilizzabile in questo caso solo perché si sa che il valore 0 non è presente nel dizionario.
I risultati dell’esecuzione sono i seguenti:
5.5. I file di testo
5.5.1. La classe StreamReader
La classe System.IO.StreamReader consente di leggere il contenuto di un file di testo. È infatti in grado di gestire flussi che non sono file. Ecco alcune delle sue proprietà e dei suoi metodi:
Costruttori
Proprietà
Metodi
Ecco un esempio:
using System;
using System.IO;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// directory di esecuzione
Console.WriteLine("Répertoire d'exécution : "+Environment.CurrentDirectory);
string ligne = null;
StreamReader fluxInfos = null;
// lettura del contenuto del file infos.txt
try {
// lettura 1
Console.WriteLine("Lecture 1----------------");
using (fluxInfos = new StreamReader("infos.txt")) {
ligne = fluxInfos.ReadLine();
while (ligne != null) {
Console.WriteLine(ligne);
ligne = fluxInfos.ReadLine();
}
}
// lettura 2
Console.WriteLine("Lecture 2----------------");
using (fluxInfos = new StreamReader("infos.txt")) {
Console.WriteLine(fluxInfos.ReadToEnd());
}
} catch (Exception e) {
Console.WriteLine("L'erreur suivante s'est produite : " + e.Message);
}
}
}
}
- riga 8: visualizza il nome della directory di esecuzione
- righe 12, 27: un try/catch per gestire un'eventuale eccezione.
- riga 15: la struttura using flux=new StreamReader(...) è un espediente per evitare di dover chiudere esplicitamente il flusso dopo il suo utilizzo. Tale chiusura avviene automaticamente non appena si esce dall'ambito di using.
- riga 15: il file letto si chiama infos.txt. Trattandosi di un nome relativo, verrà cercato nella directory di esecuzione visualizzata dalla riga 8. Se non è presente, verrà generata un'eccezione che verrà gestita dal try/catch.
- righe 16-20: il file viene letto riga per riga
- riga 25: il file viene letto in un'unica volta
Il file infos.txt è il seguente:
ed è collocato nella seguente cartella del progetto C#:
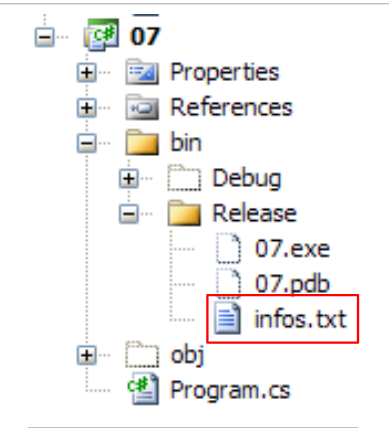 |
Si noterà che bin/Release è la cartella di esecuzione quando il progetto viene eseguito con Ctrl-F5.
L'esecuzione produce i seguenti risultati:
Se alla riga 15 si inserisce il nome del file xx.txt, si ottengono i seguenti risultati:
5.5.2. La classe StreamWriter
La classe System.IO.StreamReader consente di scrivere in un file di testo. Come la classe StreamReader, è infatti in grado di gestire flussi che non sono file. Ecco alcune delle sue proprietà e dei suoi metodi:
Costruttori
Proprietà
Metodi
Consideriamo il seguente esempio:
using System;
using System.IO;
namespace Chap3 {
class Program2 {
static void Main(string[] args) {
// directory di esecuzione
Console.WriteLine("Répertoire d'exécution : " + Environment.CurrentDirectory);
string ligne = null; // una riga di testo
StreamWriter fluxInfos = null; // il file di testo
try {
// creazione del file di testo
using (fluxInfos = new StreamWriter("infos2.txt")) {
Console.WriteLine("Mode AutoFlush : {0}", fluxInfos.AutoFlush);
// lettura della riga digitata dalla tastiera
Console.Write("ligne (rien pour arrêter) : ");
ligne = Console.ReadLine().Trim();
// ciclo finché la riga inserita non è vuota
while (ligne != "") {
// scrittura della riga nel file di testo
fluxInfos.WriteLine(ligne);
// lettura della nuova riga digitata dalla tastiera
Console.Write("ligne (rien pour arrêter) : ");
ligne = Console.ReadLine().Trim();
}//while
}
} catch (Exception e) {
Console.WriteLine("L'erreur suivante s'est produite : " + e.Message);
}
}
}
}
- riga 13: ancora una volta, utilizziamo la sintassi using(flux) per evitare di dover chiudere esplicitamente il flusso con un'operazione Close. Questa chiusura avviene automaticamente all'uscita da using.
- Perché un try/catch, righe 11 e 27? Alla riga 13, potremmo specificare un nome di file nel formato /rep1/rep2/ .../fichier con un percorso /rep1/rep2/... che non esiste, rendendo così impossibile la creazione di fichier. Verrebbe quindi generata un'eccezione. Esistono altri possibili casi di eccezione (disco pieno, diritti insufficienti, ...)
I risultati dell’esecuzione sono i seguenti:
Il file infos2.txt è stato creato nella cartella bin/Release del progetto:
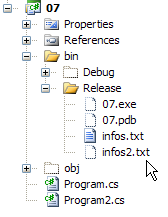 |  |
5.6. I file binari
Le classi System.IO.BinaryReader e System.IO.BinaryWriter servono a leggere e scrivere file binari.
Consideriamo la seguente applicazione:
// sintassi pg testo bin logs
// si legge un file di testo (text) e se ne memorizza il contenuto in un file binario (bin
// il file di testo contiene righe della forma nome : età che verranno memorizzate in una struttura string, int
// (logs) è un file di log di testo
Il file di testo ha il seguente contenuto:
Il programma è il seguente:
using System;
using System.IO;
// sintassi pg testo bin log
// si legge un file di testo (testo) e se ne memorizza il contenuto in un file binario (bin)
// il file di testo contiene righe della forma nome : età che verranno memorizzate in una struttura string, int
// (logs) è un file di log di testo
namespace Chap3 {
class Program {
static void Main(string[] arguments) {
// sono necessari 3 argomenti
if (arguments.Length != 3) {
Console.WriteLine("syntaxe : pg texte binaire log");
Environment.Exit(1);
}//if
// variabili
string ligne=null;
string nom=null;
int age=0;
int numLigne = 0;
char[] séparateurs = new char[] { ':' };
string[] champs=null;
StreamReader input = null;
BinaryWriter output = null;
StreamWriter logs = null;
bool erreur = false;
// lettura di un file di testo - scrittura di un file binario
try {
// apertura del file di testo in lettura
input = new StreamReader(arguments[0]);
// apertura del file binario in scrittura
output = new BinaryWriter(new FileStream(arguments[1], FileMode.Create, FileAccess.Write));
// apertura del file di log in scrittura
logs = new StreamWriter(arguments[2]);
// elaborazione del file di testo
while ((ligne = input.ReadLine()) != null) {
// un'altra riga
numLigne++;
// riga vuota?
if (ligne.Trim() == "") {
// ignora
continue;
}
// una riga nome: età
champs = ligne.Split(séparateurs);
// ci servono 2 campi
if (champs.Length != 2) {
// registriamo l'errore
logs.WriteLine("La ligne n° [{0}] du fichier [{1}] a un nombre de champs incorrect", numLigne, arguments[0]);
// riga successiva
continue;
}//if
// il primo campo deve essere non vuoto
erreur = false;
nom = champs[0].Trim();
if (nom == "") {
// si registra l'errore
logs.WriteLine("La ligne n° [{0}] du fichier [{1}] a un nom vide", numLigne, arguments[0]);
erreur = true;
}
// il secondo campo deve essere un numero intero >=0
if (!int.TryParse(champs[1],out age) || age<0) {
// si registra l'errore
logs.WriteLine("La ligne n° [{0}] du fichier [{1}] a un âge [{2}] incorrect", numLigne, arguments[0], champs[1].Trim());
erreur = true;
}//se
// se non ci sono errori, si scrivono i dati nel file binario
if (!erreur) {
output.Write(nom);
output.Write(age);
}
// riga successiva
}//while
}catch(Exception e){
Console.WriteLine("L'erreur suivante s'est produite : {0}", e.Message);
} finally {
// chiusura dei file
if(input!=null) input.Close();
if(output!=null) output.Close();
if(logs!=null) logs.Close();
}
}
}
}
Soffermiamoci sulle operazioni relative alla classe BinaryWriter:
- riga 34: l'oggetto BinaryWriter viene aperto dall'operazione
output=new BinaryWriter(new FileStream(arguments[1],FileMode.Create,FileAccess.Write));
L'argomento del costruttore deve essere uno stream (Stream). In questo caso si tratta di uno stream creato a partire da un file (FileStream) di cui si specificano:
- (continua)
- il nome
- l'operazione da eseguire, in questo caso FileMode.Create per creare il file
- il tipo di accesso, in questo caso FileAccess.Write per un accesso in scrittura al file
- righe 70-73: le operazioni di scrittura
La classe BinaryWriter dispone di diversi metodi Write sovrascritti per scrivere i diversi tipi di dati semplici
- riga 81: l'operazione di chiusura del flusso
I tre argomenti del metodo Main vengono specificati nel progetto (tramite le sue proprietà) [1] e il file di testo da elaborare viene inserito nella cartella bin/Release [2]:
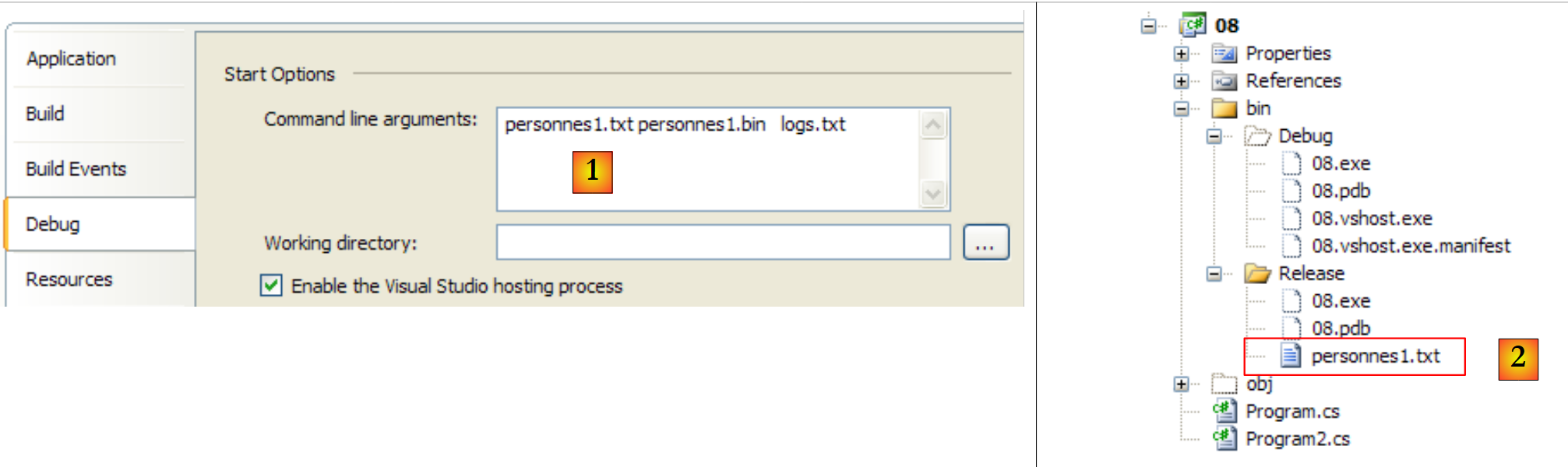 |
Con il seguente file [personnes1.txt]:
i risultati dell’esecuzione sono i seguenti:
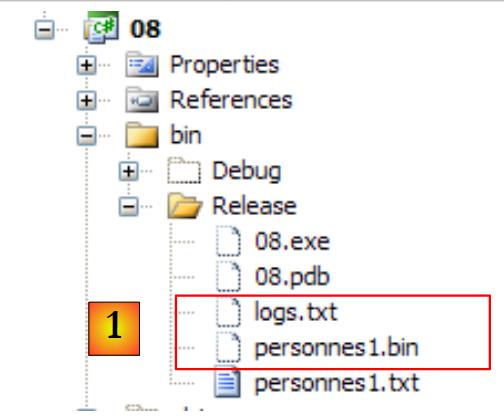 |
- in [1], il file binario [personnes1.bin] così creato e il file di log [logs.txt]. Quest'ultimo ha il seguente contenuto:
Il contenuto del file binario [personnes1.bin] ci verrà fornito dal programma riportato di seguito. Anche questo accetta tre argomenti:
// sintassi pg bin testo log
// si legge un file binario bin e se ne salva il contenuto in un file di testo (testo)
// il file binario ha una struttura string, int
// il file di testo contiene righe della forma nome : età
// logs è un file di testo contenente i log
Si esegue quindi l'operazione inversa. Si legge un file binario per creare un file di testo. Se il file di testo generato è identico al file originale, si avrà la certezza che la conversione testo --> binario --> testo è avvenuta correttamente. Il codice è il seguente:
using System;
using System.IO;
// sintassi pg bin testo logs
// si legge un file binario bin e se ne salva il contenuto in un file di testo (testo)
// il file binario ha una struttura string, int
// il file di testo contiene righe della forma nome : età
// logs è un file di testo contenente i log
namespace Chap3 {
class Program2 {
static void Main(string[] arguments) {
// sono necessari 3 argomenti
if (arguments.Length != 3) {
Console.WriteLine("syntaxe : pg binaire texte log");
Environment.Exit(1);
}//if
// variabili
string nom = null;
int age = 0;
int numPersonne = 1;
BinaryReader input = null;
StreamWriter output = null;
StreamWriter logs = null;
bool fini;
// lettura file binario - scrittura file di testo
try {
// apertura del file binario in lettura
input = new BinaryReader(new FileStream(arguments[0], FileMode.Open, FileAccess.Read));
// apertura del file di testo in scrittura
output = new StreamWriter(arguments[1]);
// apertura del file di log in scrittura
logs = new StreamWriter(arguments[2]);
// elaborazione del file binario
fini = false;
while (!fini) {
try {
// lettura del nome
nom = input.ReadString().Trim();
// lettura dell'età
age = input.ReadInt32();
// scrittura nel file di testo
output.WriteLine(nom + ":" + age);
// persona successiva
numPersonne++;
} catch (EndOfStreamException) {
fini = true;
} catch (Exception e) {
logs.WriteLine("L'erreur suivante s'est produite à la lecture de la personne n° {0} : {1}", numPersonne, e.Message);
}
}//while
} catch (Exception e) {
Console.WriteLine("L'erreur suivante s'est produite : {0}", e.Message);
} finally {
// chiusura dei file
if (input != null)
input.Close();
if (output != null)
output.Close();
if (logs != null)
logs.Close();
}
}
}
}
Soffermiamoci sulle operazioni relative alla classe BinaryReader:
- riga 30: l'oggetto BinaryReader viene aperto dall'operazione
input=new BinaryReader(new FileStream(arguments[0],FileMode.Open,FileAccess.Read));
L’argomento del costruttore deve essere uno stream. In questo caso si tratta di uno stream creato a partire da un file (FileStream) di cui si specificano:
- (continua)
- il nome
- l'operazione da eseguire, in questo caso FileMode.Open per aprire un file esistente
- il tipo di accesso, in questo caso FileAccess.Read per un accesso in lettura al file
- righe 40, 42: le operazioni di lettura
La classe BinaryReader dispone di diversi metodi ReadXX per leggere i diversi tipi di dati semplici
- riga 60: l'operazione di chiusura del flusso
Se si eseguono i due programmi in sequenza, trasformando personnes1.txt in personnes1.bin e poi personnes1.bin in personnes2.txt2, si ottengono i seguenti risultati:
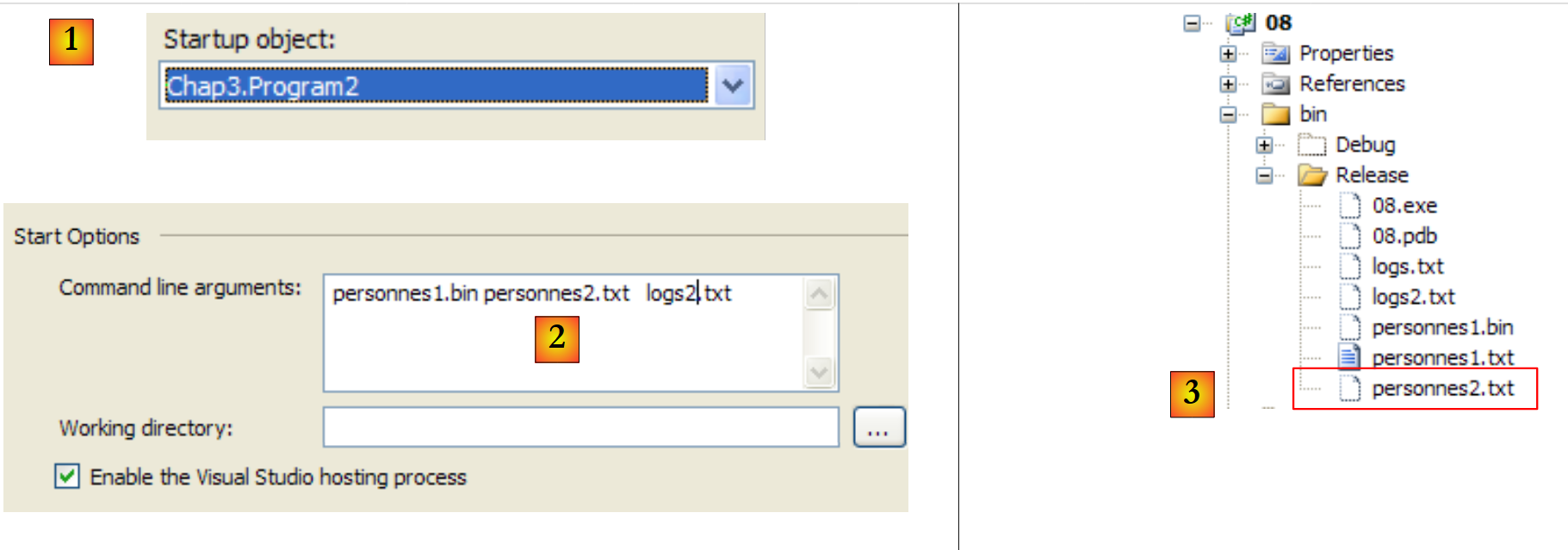 |
- in [1], il progetto è configurato per eseguire la seconda applicazione
- in [2], gli argomenti passati a Main
- in [3], i file generati dall'esecuzione dell'applicazione.
Il contenuto di [personnes2.txt] è il seguente:
5.7. Le espressioni regolari
La classe System.Text.RegularExpressions.Regex consente l'uso di espressioni regolari. Queste permettono di verificare il formato di una stringa di caratteri. In questo modo è possibile verificare che una stringa che rappresenta una data sia effettivamente nel formato gg/mm/aa. A tal fine si utilizza un modello e si confronta la stringa con tale modello. Pertanto, in questo esempio, j, m e a devono essere cifre. Il modello di un formato di data valido è quindi "\d\d/\d\d/\d\d", dove il simbolo \d indica una cifra. I simboli utilizzabili in un modello sono i seguenti:
Descrizione | |
Contrassegna il carattere seguente come carattere speciale o letterale. Ad esempio, "n" corrisponde al carattere "n". "\n" corrisponde a un carattere di nuova riga. La sequenza "\\" corrisponde a "\", mentre "\(" corrisponde a "(". | |
Corrisponde all'inizio dell'inserimento. | |
Corrisponde alla fine dell'inserimento. | |
Corrisponde al carattere precedente zero o più volte. Pertanto, "zo*" corrisponde a "z" o a "zoo". | |
Corrisponde al carattere precedente una o più volte. Pertanto, "zo+" corrisponde a "zoo", ma non a "z". | |
Corrisponde al carattere precedente zero o una volta. Ad esempio, "a?ve?" corrisponde a "ve" in "lever". | |
Corrisponde a qualsiasi carattere singolo, eccetto il carattere di nuova riga. | |
Cerca il modèle e memorizza la corrispondenza. La sottostringa corrispondente può essere estratta dalla collezione Matches ottenuta, utilizzando Item [0]...[n]. Per trovare corrispondenze con caratteri tra parentesi ( ), utilizzare "\(" o "\)". | |
Corrisponde sia a x sia a y. Ad esempio, "z|foot" corrisponde a "z" o a "foot". "(z|f)oo" corrisponde a "zoo" o a "foo". | |
n è un numero intero non negativo. Corrisponde esattamente a n moltiplicato per il carattere. Ad esempio, "o{2}" non corrisponde alla "o" in "Bob," ma alle prime due "o" in "fooooot". | |
n è un numero intero non negativo. Corrisponde ad almeno n volte il carattere. Ad esempio, "o{2,}" non corrisponde alla "o" in "Bob", ma a tutte le "o" in "fooooot". "o{1,}" equivale a "o+" e "o{0,}" equivale a "o*". | |
m e n sono numeri interi non negativi. Corrisponde ad almeno n e al massimo m volte il carattere. Ad esempio, "o{1,3}" corrisponde alle prime tre "o" in "foooooot" e "o{0,1}" equivale a "o?". | |
Set di caratteri. Corrisponde a uno dei caratteri indicati. Ad esempio, "[abc]" corrisponde alla "a" in "plat". | |
Set di caratteri negativo. Corrisponde a qualsiasi carattere non specificato. Ad esempio, "[^abc]" corrisponde alla "p" in "plat". | |
Intervallo di caratteri. Corrisponde a qualsiasi carattere compreso nella serie specificata. Ad esempio, "[a-z]" corrisponde a qualsiasi carattere alfabetico minuscolo compreso tra "a" e "z". | |
Intervallo di caratteri negativo. Corrisponde a qualsiasi carattere non presente nella serie specificata. Ad esempio, "[^m-z]" corrisponde a qualsiasi carattere non compreso tra "m" e "z". | |
Corrisponde a un limite che rappresenta una parola, in altre parole, alla posizione tra una parola e uno spazio. Ad esempio, "er\b" corrisponde a "er" in "lever", ma non a "er" in "verbe". | |
Corrisponde a un limite che non rappresenta una parola. «en*t\B» corrisponde a «ent» in «bien entendu». | |
Corrisponde a un carattere che rappresenta una cifra. Equivale a [0-9]. | |
Corrisponde a un carattere che non rappresenta una cifra. Equivale a [^0-9]. | |
Corrisponde a un carattere di fine pagina. | |
Corrisponde a un carattere di nuova riga. | |
Corrisponde a un carattere di ritorno a capo. | |
Corrisponde a qualsiasi spazio bianco, inclusi spazio, tabulazione, salto di pagina, ecc. Equivale a "[ \f\n\r\t\v]". | |
Corrisponde a qualsiasi carattere di spazio non bianco. Equivale a "[^ \f\n\r\t\v]". | |
Corrisponde a un carattere di tabulazione. | |
Corrisponde a un carattere di tabulazione verticale. | |
Corrisponde a qualsiasi carattere che rappresenti una parola e che includa un trattino basso. Equivale a "[A-Za-z0-9_]". | |
Corrisponde a qualsiasi carattere che non rappresenti una parola. Equivale a "[^A-Za-z0-9_]". | |
Corrisponde a num, dove num è un numero intero positivo. Fa riferimento alle corrispondenze memorizzate. Ad esempio, «(.)\1» corrisponde a due caratteri identici consecutivi. | |
Corrisponde a n, dove n è un valore di escape ottale. I valori di escape ottali devono essere composti da 1, 2 o 3 cifre. Ad esempio, sia "\11" che "\011" corrispondono a un carattere di tabulazione. "\0011" equivale a "\001" e "1". I valori di escape ottali non devono superare 256. In caso contrario, nell’espressione verrebbero prese in considerazione solo le prime due cifre. Consente di utilizzare i codici ASCII nelle espressioni regolari. | |
Corrisponde a n, dove n è un valore di escape esadecimale. I valori di escape esadecimali devono obbligatoriamente comprendere due cifre. Ad esempio, "\x41" corrisponde a "A". "\x041" equivale a "\x04" e "1". Consente di utilizzare i codici ASCII nelle espressioni regolari. |
Un elemento in un modello può essere presente una o più volte. Consideriamo alcuni esempi relativi al simbolo \d, che rappresenta una cifra:
modello | significato |
\d | una cifra |
\d? | 0 o 1 cifra |
\d* | 0 o più cifre |
\d+ | 1 o più cifre |
\d{2} | 2 cifre |
\d{3,} | almeno 3 cifre |
\d{5,7} | da 5 a 7 cifre |
Immaginiamo ora il modello in grado di descrivere il formato previsto per una stringa di caratteri:
stringa ricercata | modello |
una data nel formato gg/mm/aa | \d{2}/\d{2}/\d{2} |
un'ora nel formato hh:mm:ss | \d{2}:\d{2}:\d{2} |
un numero intero senza segno | \d+ |
una sequenza di spazi, eventualmente vuota | \s* |
un numero intero senza segno che può essere preceduto o seguito da spazi | \s*\d+\s* |
un numero intero che può essere con segno e preceduto o seguito da spazi | \s*[+|-]?\s*\d+\s* |
un numero reale senza segno che può essere preceduto o seguito da spazi | \s*\d+(.\d*)?\s* |
un numero reale che può essere con segno e preceduto o seguito da spazi | \s*[+|]?\s*\d+(.\d*)?\s* |
una stringa contenente la parola juste | \bjuste\b |
È possibile specificare dove cercare il modello nella stringa:
modello | significato |
^modello | il modello si trova all'inizio della stringa |
modello$ | il modello conclude la stringa |
^modello$ | il modello inizia e termina la stringa |
modello | il modello viene cercato in tutta la stringa a partire dall'inizio della stessa. |
stringa cercata | modello |
una stringa che termina con un punto esclamativo | !$ |
una stringa che termina con un punto | \.$ |
una stringa che inizia con la sequenza // | ^// |
una stringa composta da una sola parola, eventualmente preceduta o seguita da spazi | ^\s*\w+\s*$ |
una stringa contenente due parole, eventualmente precedute o seguite da spazi | ^\s*\w+\s*\w+\s*$ |
una stringa contenente la parola secret | \bsecret\b |
I sottoinsiemi di un modello possono essere "recuperati". In questo modo, non solo è possibile verificare che una stringa corrisponda a un modello specifico, ma è anche possibile recuperare all'interno di tale stringa gli elementi corrispondenti ai sottoinsiemi del modello che sono stati racchiusi tra parentesi. Pertanto, se si analizza una stringa contenente una data gg/mm/aa e si desidera inoltre estrarre gli elementi gg, mm, aa di tale data, si utilizzerà il modello (\d\d)/(\d\d)/(\d\d).
5.7.1. Verificare che una stringa corrisponda a un modello dato
Un oggetto di tipo Regex si costruisce nel modo seguente:
Una volta costruita l'espressione regolare modello, è possibile confrontarla con stringhe di caratteri utilizzando il metodo IsMatch:
Ecco un esempio:
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// un'espressione regolare modello
string modèle1 = @"^\s*\d+\s*$";
Regex regex1 = new Regex(modèle1);
// confronto di un'istanza con il modello
string exemplaire1 = " 123 ";
if (regex1.IsMatch(exemplaire1)) {
Console.WriteLine("[{0}] correspond au modèle [{1}]", exemplaire1, modèle1);
} else {
Console.WriteLine("[{0}] ne correspond pas au modèle [{1}]", exemplaire1, modèle1);
}//if
string exemplaire2 = " 123a ";
if (regex1.IsMatch(exemplaire2)) {
Console.WriteLine("[{0}] correspond au modèle [{1}]", exemplaire2, modèle1);
} else {
Console.WriteLine("[{0}] ne correspond pas au modèle [{1}]", exemplaire2, modèle1);
}//if
}
}
}
e i risultati dell'esecuzione:
5.7.2. Trovare tutte le occorrenze di un modello in una stringa
Il metodo Matches consente di recuperare gli elementi di una stringa che corrispondono a un modello:
La classe MatchCollection ha una proprietà Count che rappresenta il numero di elementi della collezione. Se résultats è un oggetto MatchCollection, risultati[i] è l'elemento i di questa collezione ed è di tipo Match. La classe Match ha diverse proprietà, tra cui le seguenti:
- Value: il valore dell’oggetto Match,, ovvero un elemento corrispondente al modello
- Index: la posizione in cui l'elemento è stato trovato nella stringa analizzata
Esaminiamo il seguente esempio:
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program2 {
static void Main(string[] args) {
// più occorrenze del modello nell'esempio
string modèle2 = @"\d+";
Regex regex2 = new Regex(modèle2);
string exemplaire3 = " 123 456 789 ";
MatchCollection résultats = regex2.Matches(exemplaire3);
Console.WriteLine("Modèle=[{0}],exemplaire=[{1}]", modèle2, exemplaire3);
Console.WriteLine("Il y a {0} occurrences du modèle dans l'exemplaire ", résultats.Count);
for (int i = 0; i < résultats.Count; i++) {
Console.WriteLine("[{0}] trouvé en position {1}", résultats[i].Value, résultats[i].Index);
}//for
}
}
}
- riga 8: il modello ricercato è una sequenza di cifre
- riga 10: la stringa in cui si cerca questo modello
- riga 11: vengono recuperati tutti gli elementi di exemplaire3 che soddisfano il modello modèle2
- righe 14-16: li visualizziamo
I risultati dell'esecuzione del programma sono i seguenti:
5.7.3. Recuperare parti di un modello
È possibile "recuperare" sottoinsiemi di un modello. In questo modo, non solo è possibile verificare che una stringa corrisponda a un modello specifico, ma è anche possibile recuperare all'interno di tale stringa gli elementi corrispondenti ai sottoinsiemi del modello racchiusi tra parentesi. Pertanto, se si analizza una stringa contenente una data gg/mm/aa e si desidera inoltre estrarre gli elementi gg, mm, aa di tale data, si utilizzerà il modello (\d\d)/(\d\d)/(\d\d).
Esaminiamo il seguente esempio:
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program3 {
static void Main(string[] args) {
// acquisizione di elementi nel modello
string modèle3 = @"(\d\d):(\d\d):(\d\d)";
Regex regex3 = new Regex(modèle3);
string exemplaire4 = "Il est 18:05:49";
// verifica del modello
Match résultat = regex3.Match(exemplaire4);
if (résultat.Success) {
// l'istanza corrisponde al modello
Console.WriteLine("L'exemplaire [{0}] correspond au modèle [{1}]",exemplaire4,modèle3);
// vengono visualizzati i gruppi di parentesi
for (int i = 0; i < résultat.Groups.Count; i++) {
Console.WriteLine("groupes[{0}]=[{1}] trouvé en position {2}",i, résultat.Groups[i].Value,résultat.Groups[i].Index);
}//for
} else {
// l'esemplare non corrisponde al modello
Console.WriteLine("L'exemplaire[{0}] ne correspond pas au modèle [{1}]", exemplaire4, modèle3);
}
}
}
}
L'esecuzione di questo programma produce i seguenti risultati:
La novità si trova nelle righe 12-19:
- riga 12: la stringa exemplaire4 viene confrontata con il modello regex3 tramite il metodo Match. Quest'ultimo restituisce un oggetto Match già presentato in precedenza. Qui utilizziamo due nuove proprietà di questa classe:
- Success (riga 13): indica se è stata trovata una corrispondenza
- Groups (righe 17, 18): collezione in cui
- Groups[0] corrisponde alla parte della stringa corrispondente al modello
- Groups[i] (i>=1) corrisponde al gruppo di parentesi n. i
Se résultat è di tipo Match, résultats.Groups è di tipo GroupCollection e résultats.Groups[i] è di tipo Group. La classe Group presenta due proprietà che utilizziamo in questo contesto:
- Value (riga 18): il valore dell’oggetto Group, che è l’elemento corrispondente al contenuto di una parentesi
- Index (riga 18): la posizione in cui l’elemento è stato trovato nella stringa analizzata
5.7.4. Un programma di esercitazione
Trovare l’espressione regolare che permette di verificare se una stringa corrisponde effettivamente a un determinato modello è talvolta una vera sfida. Il programma seguente permette di esercitarsi. Richiede un modello e una stringa e indica se la stringa corrisponde o meno al modello.
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program4 {
static void Main(string[] args) {
// dati
string modèle, chaine;
Regex regex = null;
MatchCollection résultats;
// all'utente vengono richiesti i modelli e gli esemplari da confrontare con questo
while (true) {
// viene richiesto il modello
Console.Write("Tapez le modèle à tester ou rien pour arrêter :");
modèle = Console.In.ReadLine();
// finito?
if (modèle.Trim() == "")
break;
// si crea l'espressione regolare
try {
regex = new Regex(modèle);
} catch (Exception ex) {
Console.WriteLine("Erreur : " + ex.Message);
continue;
}
// si chiede all'utente quali copie confrontare con il modello
while (true) {
Console.Write("Tapez la chaîne à comparer au modèle [{0}] ou rien pour arrêter :", modèle);
chaine = Console.ReadLine();
// finito?
if (chaine.Trim() == "")
break;
// si esegue il confronto
résultats = regex.Matches(chaine);
// Operazione riuscita?
if (résultats.Count == 0) {
Console.WriteLine("Je n'ai pas trouvé de correspondances");
continue;
}//if
// vengono visualizzati gli elementi corrispondenti al modello
for (int i = 0; i < résultats.Count; i++) {
Console.WriteLine("J'ai trouvé la correspondance [{0}] en position [{1}]", résultats[i].Value, résultats[i].Index);
// dei sottoelementi
if (résultats[i].Groups.Count != 1) {
for (int j = 1; j < résultats[i].Groups.Count; j++) {
Console.WriteLine("\tsous-élément [{0}] en position [{1}]", résultats[i].Groups[j].Value, résultats[i].Groups[j].Index);
}
}
}
}
}
}
}
}
Ecco un esempio di esecuzione:
5.7.5. Il metodo Split
Abbiamo già visto questo metodo nel corso String:
|
Il metodo Split della classe Regex ci permette di specificare il separatore in base a un modello:
|
Supponiamo, ad esempio, di avere in un file di testo delle righe della forma campo1, campo2, ..., campo n. I campi sono separati da una virgola, ma questa può essere preceduta o seguita da spazi. Il metodo Split della classe string non è quindi adatto. La soluzione è fornita dal metodo RegEx. Se ligne è la riga letta, i campi potranno essere ottenuti tramite
come mostra il seguente esempio:
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program5 {
static void Main(string[] args) {
// una riga
string ligne = "abc , def , ghi";
// un modello
Regex modèle = new Regex(@"\s*,\s*");
// scomposizione della riga in campi
string[] champs = modèle.Split(ligne);
// visualizzazione
for (int i = 0; i < champs.Length; i++) {
Console.WriteLine("champs[{0}]=[{1}]", i, champs[i]);
}
}
}
}
Risultati dell’esecuzione:
5.8. Applicazione di esempio - V3
Riprendiamo l'applicazione esaminata nei paragrafi 3.6 (versione 1) e 4.10 (versione 2).
Nell’ultima versione esaminata, il calcolo dell’imposta veniva effettuato nella classe astratta AbstractImpot:
namespace Chap2 {
abstract class AbstractImpot : IImpot {
// le fasce di imposta necessarie per il calcolo dell'imposta
// provengono da una fonte esterna
protected TrancheImpot[] tranchesImpot;
// calcolo dell'imposta
public int calculer(bool marié, int nbEnfants, int salaire) {
// calcolo del numero di quote
decimal nbParts;
if (marié) nbParts = (decimal)nbEnfants / 2 + 2;
else nbParts = (decimal)nbEnfants / 2 + 1;
if (nbEnfants >= 3) nbParts += 0.5M;
// calcolo del reddito imponibile e del quoziente familiare
decimal revenu = 0.72M * salaire;
decimal QF = revenu / nbParts;
// calcolo dell'imposta
tranchesImpot[tranchesImpot.Length - 1].Limite = QF + 1;
int i = 0;
while (QF > tranchesImpot[i].Limite) i++;
// restituzione del risultato
return (int)(revenu * tranchesImpot[i].CoeffR - nbParts * tranchesImpot[i].CoeffN);
}//calcolare
}//classe
}
Il metodo calculer alla riga 38 utilizza l'array tranchesImpot alla riga 35, array non inizializzato dalla classe AbstractImpot. Per questo motivo è astratta e deve essere derivata per essere utilizzabile. Tale inizializzazione veniva effettuata dalla classe derivata HardwiredImpot:
using System;
namespace Chap2 {
class HardwiredImpot : AbstractImpot {
// tabelle dei dati necessari per il calcolo dell'imposta
decimal[] limites = { 4962M, 8382M, 14753M, 23888M, 38868M, 47932M, 0M };
decimal[] coeffR = { 0M, 0.068M, 0.191M, 0.283M, 0.374M, 0.426M, 0.481M };
decimal[] coeffN = { 0M, 291.09M, 1322.92M, 2668.39M, 4846.98M, 6883.66M, 9505.54M };
public HardwiredImpot() {
// creazione della tabella delle fasce di imposta
tranchesImpot = new TrancheImpot[limites.Length];
// compilazione
for (int i = 0; i < tranchesImpot.Length; i++) {
tranchesImpot[i] = new TrancheImpot { Limite = limites[i], CoeffR = coeffR[i], CoeffN = coeffN[i] };
}
}
}// classe
}// namespace
In precedenza, i dati necessari al calcolo dell’imposta erano inseriti in modo «fisso» nel codice della classe. La nuova versione dell’esempio li inserisce in un file di testo:
4962:0:0
8382:0,068:291,09
14753:0,191:1322,92
23888:0,283:2668,39
38868:0,374:4846,98
47932:0,426:6883,66
0:0,481:9505,54
Poiché l'elaborazione di questo file potrebbe generare delle eccezioni, creiamo una classe speciale per gestirle:
using System;
namespace Chap3 {
class FileImpotException : Exception {
// codici di errore
[Flags]
public enum CodeErreurs { Acces = 1, Ligne = 2, Champ1 = 4, Champ2 = 8, Champ3 = 16 };
// codice di errore
public CodeErreurs Code { get; set; }
// costruttori
public FileImpotException() {
}
public FileImpotException(string message)
: base(message) {
}
public FileImpotException(string message, Exception e)
: base(message,e) {
}
}
}
- riga 4: la classe FileImpotException deriva dalla classe Exception. Servirà a memorizzare qualsiasi errore che si verifichi durante l'elaborazione del file di testo contenente i dati.
- riga 7: un'enumerazione che rappresenta i codici di errore:
- Acces: errore di accesso al file di testo contenente i dati
- Ligne: riga priva dei tre campi previsti
- Champ1: il campo n. 1 è errato
- Champ2: il campo n. 2 è errato
- Champ3: il campo n. 3 è errato
Alcuni di questi errori possono presentarsi in combinazione (Champ1, Champ2, Champ3). Pertanto, l’enumerazione CodeErreurs è stata annotata con l’attributo [Flags], il che implica che i diversi valori dell’enumerazione debbano essere potenze di 2. Un errore nei campi 1 e 2 comporterà quindi il codice di errore Champ1 | Champ2.
- riga 10: la proprietà automatica Code memorizzerà il codice dell'errore.
- riga 15: un costruttore che consente di creare un oggetto FileImpotException passando come parametro un messaggio di errore.
- riga 18: un costruttore che consente di creare un oggetto FileImpotException passando come parametri un messaggio di errore e l'eccezione all'origine dell'errore.
La classe che inizializza l'array tranchesImpot della classe AbstractImpot è ora la seguente:
using System;
using System.Collections.Generic;
using System.IO;
using System.Text.RegularExpressions;
namespace Chap3 {
class FileImpot : AbstractImpot {
public FileImpot(string fileName) {
// dati
List<TrancheImpot> listTranchesImpot = new List<TrancheImpot>();
int numLigne = 1;
// eccezione
FileImpotException fe = null;
// lettura del contenuto del file fileName, riga per riga
Regex pattern = new Regex(@"s*:\s*");
// inizialmente nessun errore
FileImpotException.CodeErreurs code = 0;
try {
using (StreamReader input = new StreamReader(fileName)) {
while (!input.EndOfStream && code == 0) {
// riga corrente
string ligne = input.ReadLine().Trim();
// le righe vuote vengono ignorate
if (ligne == "") continue;
// riga suddivisa in tre campi separati da:
string[] champsLigne = pattern.Split(ligne);
// ci sono 3 campi?
if (champsLigne.Length != 3) {
code = FileImpotException.CodeErreurs.Ligne;
}
// conversioni dei 3 campi
decimal limite = 0, coeffR = 0, coeffN = 0;
if (code == 0) {
if (!Decimal.TryParse(champsLigne[0], out limite)) code = FileImpotException.CodeErreurs.Champ1;
if (!Decimal.TryParse(champsLigne[1], out coeffR)) code |= FileImpotException.CodeErreurs.Champ2;
if (!Decimal.TryParse(champsLigne[2], out coeffN)) code |= FileImpotException.CodeErreurs.Champ3; ;
}
// errore?
if (code != 0) {
// si registra l'errore
fe = new FileImpotException(String.Format("Ligne n° {0} incorrecte", numLigne)) { Code = code };
} else {
// si memorizza la nuova fascia di imposta
listTranchesImpot.Add(new TrancheImpot() { Limite = limite, CoeffR = coeffR, CoeffN = coeffN });
// riga successiva
numLigne++;
}
}
}
// si trasferisce l'elenco listImpot nella tabella tranchesImpot
if (code == 0) {
// si trasferisce l'elenco listImpot nella tabella tranchesImpot
tranchesImpot = listTranchesImpot.ToArray();
}
} catch (Exception e) {
// si rileva l'errore
fe= new FileImpotException(String.Format("Erreur lors de la lecture du fichier {0}", fileName), e) { Code = FileImpotException.CodeErreurs.Acces };
}
// errore da segnalare?
if (fe != null) throw fe;
}
}
}
- riga 7: la classe FileImpot deriva dalla classe AbstractImpot, così come nella versione 2 derivava la classe HardwiredImpot.
- riga 9: il costruttore della classe FileImpot ha il compito di inizializzare il campo trancheImpot della sua classe base AbstractImpot. Accetta come parametro il nome del file di testo contenente i dati.
- riga 11: il campo tranchesImpot della classe base AbstractImpot è un array che deve essere popolato con i dati del file filename passato come parametro. La lettura di un file di testo è sequenziale. Il numero di righe è noto solo dopo aver letto l’intero file. Pertanto, non è possibile dimensionare l’array tranchesImpot. I dati verranno temporaneamente memorizzati nella lista generica listTranchesImpot.
Si ricorda che il tipo TrancheImpot è una struttura:
namespace Chap3 {
// una fascia di imposta
struct TrancheImpot {
public decimal Limite { get; set; }
public decimal CoeffR { get; set; }
public decimal CoeffN { get; set; }
}
}
- riga 14: fe, dello stesso tipo di FileImpotException, serve a incapsulare un eventuale errore di elaborazione del file di testo.
- riga 16: l'espressione regolare del separatore di campi in una riga champ1:champ2:champ3 del file di testo. I campi sono separati dal carattere : preceduto e seguito da un numero qualsiasi di spazi.
- riga 18: il codice di errore in caso di errore
- riga 20: elaborazione del file di testo con un StreamReader
- riga 21: si esegue un ciclo finché rimane una riga da leggere e non si è verificato alcun errore
- riga 27: la riga letta viene suddivisa in campi tramite l'espressione regolare della riga 16
- righe 29-31: si verifica che la riga contenga effettivamente tre campi; si registra un eventuale errore
- righe 33-38: conversione delle tre stringhe in tre numeri decimali; si registrano eventuali errori
- righe 40-43: se si è verificato un errore, viene generata un'eccezione di tipo FileImpotException.
- righe 44-47: se non si è verificato alcun errore, si passa alla lettura della riga successiva del file di testo dopo aver memorizzato i dati della riga corrente.
- righe 52-55: all'uscita dalla bocca while, i dati della lista generica listTranchesImpot vengono ricopiati nella tabella tranchesImpot della classe base AbstractImpot. Si ricorda che questo era l’obiettivo del costruttore.
- righe 56-59: gestione di un’eventuale eccezione. Questa viene incapsulata in un oggetto di tipo FileImpotException.
- riga 61: se l’eccezione fe della riga 18 è stata inizializzata, allora viene generata.
L'intero progetto C# è il seguente:
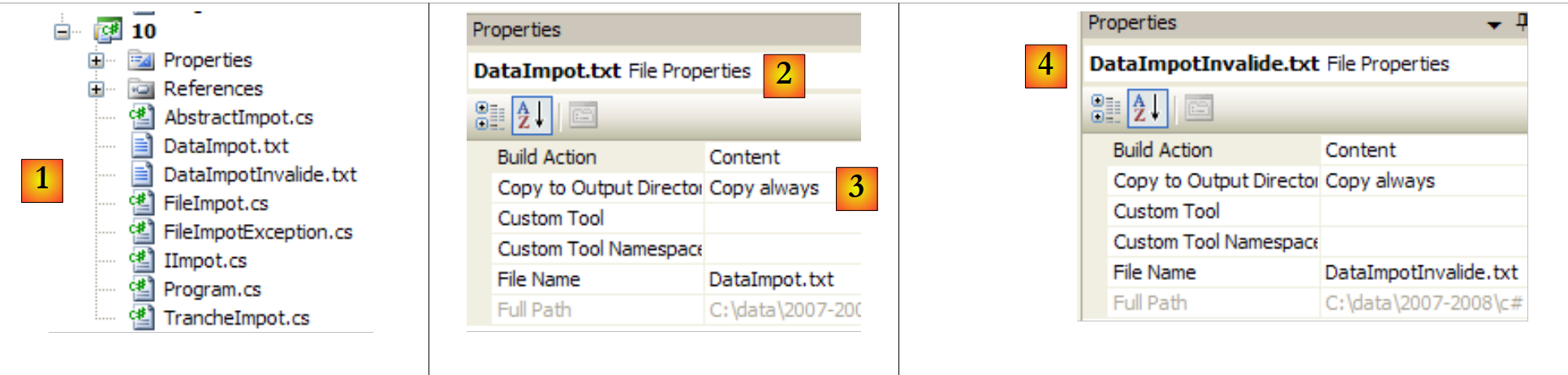 |
- in [1]: l'intero progetto
- in [2,3]: le proprietà del file [DataImpot.txt] [2]. La proprietà [Copy to Output Directory] [3] è impostata su "always". In questo modo, il file [DataImpot.txt] verrà copiato nella cartella bin/Release (modalità Release) o bin/Debug (modalità Debug) ad ogni esecuzione. È lì che viene cercato dall’eseguibile.
- In [4]: si procede allo stesso modo con il file [DataImpotInvalide.txt].
Il contenuto di [DataImpot.txt] è il seguente:
4962:0:0
8382:0,068:291,09
14753:0,191:1322,92
23888:0,283:2668,39
38868:0,374:4846,98
47932:0,426:6883,66
0:0,481:9505,54
Il contenuto di [DataImpotInvalide.txt] è il seguente:
Il programma di test [Program.cs] non è cambiato: è quello della versione 2, paragrafo 4.10, con la seguente differenza:
using System;
namespace Chap3 {
class Program {
static void Main() {
...
// creazione di un oggetto IImpot
IImpot impot = null;
try {
// creazione di un oggetto IImpot
impot = new FileImpot("DataImpot.txt");
} catch (FileImpotException e) {
// visualizzazione errore
string msg = e.InnerException == null ? null : String.Format(", Exception d'origine : {0}", e.InnerException.Message);
Console.WriteLine("L'erreur suivante s'est produite : [Code={0},Message={1}{2}]", e.Code, e.Message, msg == null ? "" : msg);
// arresto del programma
Environment.Exit(1);
}
// ciclo infinito
while (true) {
...
}//while
}
}
}
- riga 8: oggetto impot del tipo dell'interfaccia IImpot
- riga 11: istanziazione dell'oggetto impot con un oggetto di tipo FileImpot. Ciò può generare un'eccezione che viene gestita dal blocco try/catch alle righe 9, 12 e 18.
Ecco alcuni esempi di esecuzione:
Con il file [DataImpot.txt]
Con un file [xx] inesistente
Con il file [DataImpotInvalide.txt]