2. Fundamentos de la programación web
El objetivo principal de este capítulo es dar a conocer los principios fundamentales de la programación web, que son independientes de la tecnología concreta utilizada para implementarlos. Presenta numerosos ejemplos que se recomienda probar para «empaparse» poco a poco de la filosofía del desarrollo web. El lector que ya posea estos conocimientos puede pasar directamente al capítulo 3.
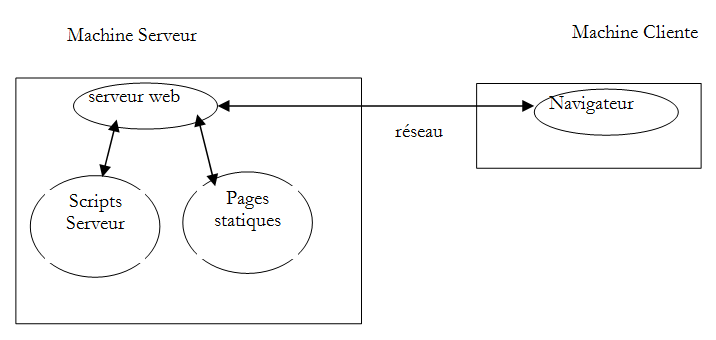
Los componentes de una aplicación web son los siguientes:
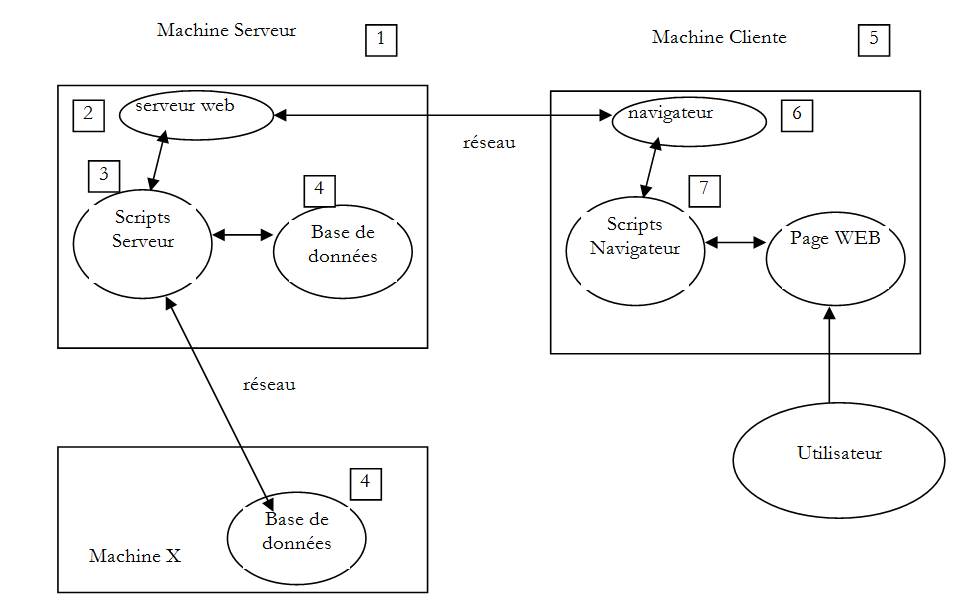
Número | Función | Ejemplos habituales |
1 | OS Servidor | Unix, Linux, Windows |
2 | Servidor web | Apache (Unix, Linux, Windows) IIS (Windows + plataforma .NET) Node.js (Unix, Linux, Windows) |
3 | Códigos ejecutados en el lado del servidor. Pueden ser ejecutados por módulos del servidor o por programas externos al servidor (CGI). | JAVASCRIPT (Node.js) PHP (Apache, IIS) JAVA (Tomcat, Websphere, JBoss, Weblogic, ...) C#, VB.NET (IIS) |
4 | Base de datos: puede estar en el mismo equipo que el programa que la utiliza o en otro a través de Internet. | Oracle (Linux, Windows) MySQL (Linux, Windows) Postgres (Linux, Windows) SQL Server (Windows) |
5 | OS Cliente | Unix, Linux, Windows |
6 | Navegador web | Chrome, Internet Explorer, Firefox, Opera, Safari, ... |
7 | Scripts ejecutados en el lado del cliente dentro del navegador. Estos scripts no tienen acceso a los discos del equipo del cliente. | Javascript (cualquier navegador) |
2.1. Intercambio de datos en una aplicación web con formulario
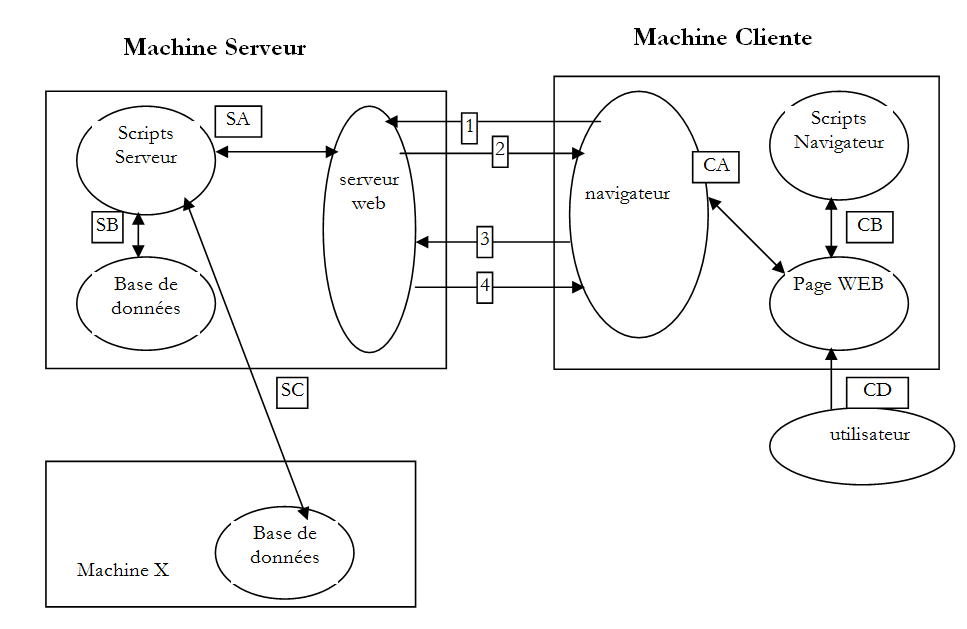
Número | Función |
1 | El navegador solicita un URL por primera vez (http://máquina/url). No se ha pasado ningún parámetro. |
2 | El servidor web le envía la página web de este URL. Esta puede ser estática o generada dinámicamente por un script de servidor (SA) que puede haber utilizado el contenido de bases de datos (SB, SC). En este caso, el script detectará que se ha solicitado URL sin pasar parámetros y generará la página web inicial. El navegador recibe la página y la muestra (CA). Los scripts del lado del navegador (CB) han podido modificar la página inicial enviada por el servidor. A continuación, mediante interacciones entre el usuario (CD) y los scripts (CB), la página web se modificará. En particular, se rellenarán los formularios. |
3 | El usuario valida los datos del formulario, que deben enviarse al servidor web. El navegador vuelve a solicitar la página URL inicial u otra, según el caso, y transmite al mismo tiempo al servidor los valores del formulario. Para ello, puede utilizar dos métodos denominados GET y POST. Al recibir la solicitud del cliente, el servidor activa el script (SA) asociado a la URL solicitada, script que detectará los parámetros y los procesará. |
4 | El servidor entrega la página web generada por el programa (SA, SB, SC). Este paso es idéntico al paso 2 anterior. A partir de ahora, los intercambios se realizan según los pasos 2 y 3. |
2.2. Páginas web estáticas, páginas web dinámicas
Una página estática está representada por un archivo HTML. Una página dinámica es una página HTML generada «sobre la marcha» por el servidor web.
2.2.1. Página estática HTML (lenguaje de marcado HyperText)
Creemos un primer proyecto Spring MVC [1-2]:
 |
- en [1-2], creamos un nuevo proyecto basado en Spring Boot [http://projects.spring.io/spring-boot/];
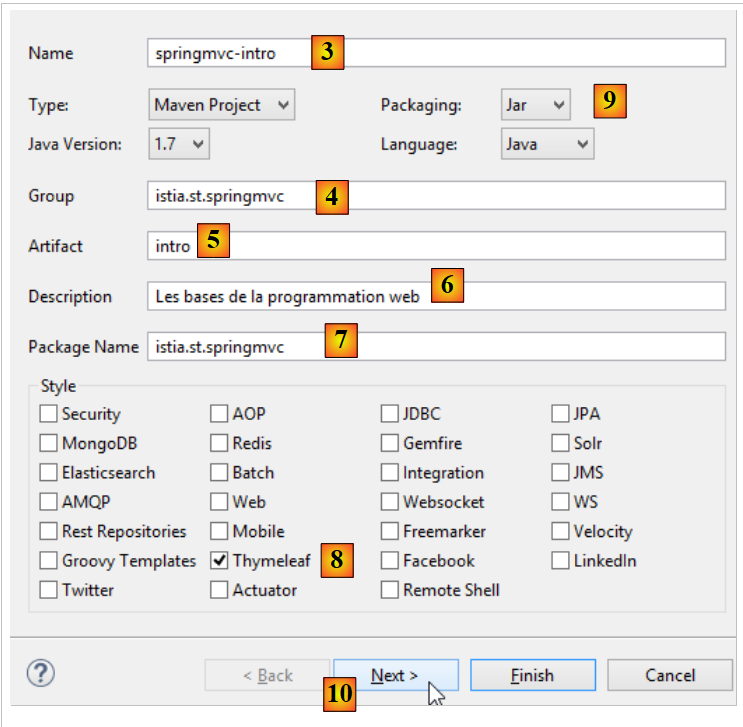 |
- la información [3-7] es para la configuración de Maven del proyecto;
- en [3], el nombre del proyecto Maven;
- en [4], el grupo Maven en el que se colocará el resultado de la compilación del proyecto;
- en [5], el nombre dado al producto de la compilación;
- en [6], una descripción del proyecto;
- en [7], el paquete en el que se colocará la clase ejecutable del proyecto;
- en [8], la naturaleza del proyecto. Se trata de un proyecto web con vistas Thymeleaf. Aquí vemos todas las dependencias de Maven listas para usar que ofrece el proyecto Spring Boot;
- en [9], se indica que el producto resultante de la compilación de Maven se empaquetará en un archivo jar y no en un archivo WAR. El proyecto utilizará entonces un servidor Tomcat integrado que se encontrará entre sus dependencias;
- en [10], continuamos con el asistente;
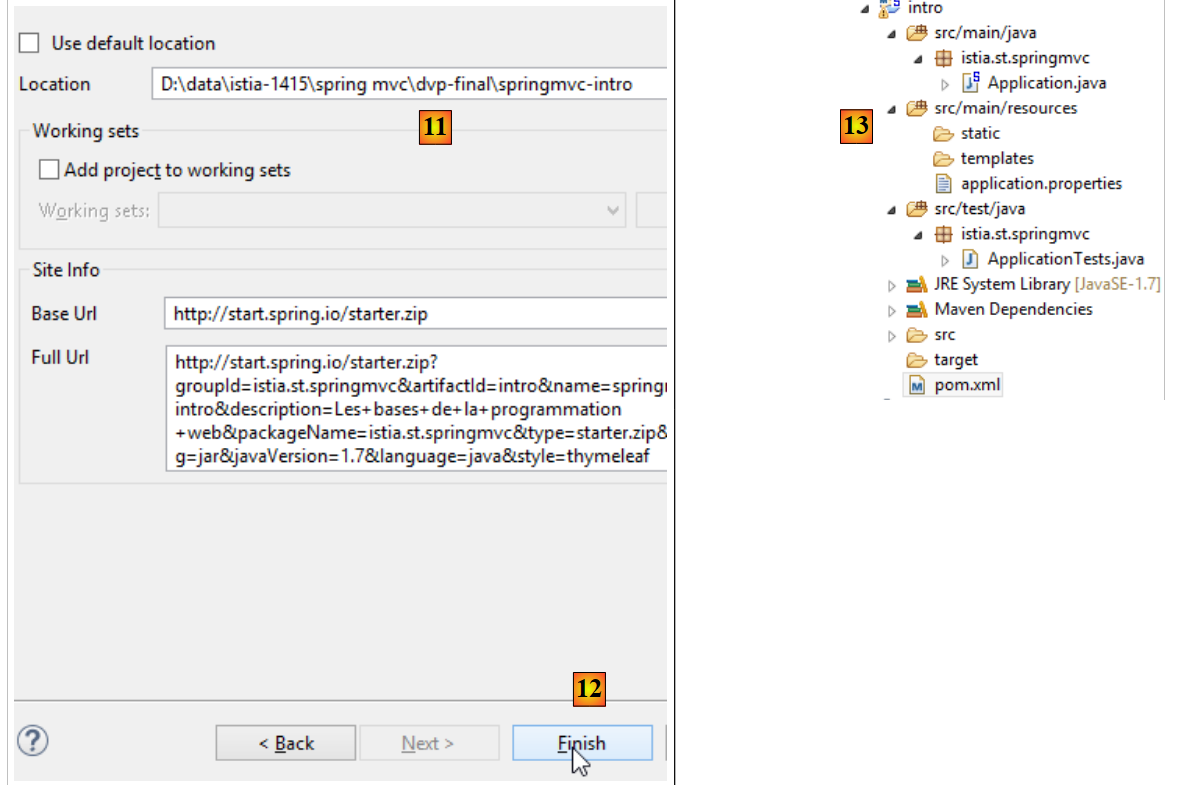 |
- en [11], se indica la carpeta del proyecto;
- en [12], se finaliza el asistente;
- en [13], el proyecto generado.
Examinemos el archivo [pom.xml] generado:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>istia.st.springmvc</groupId>
<artifactId>intro</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>springmvc-intro</name>
<description>Les bases de la programmation web</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.1.9.RELEASE</version>
<relativePath /> <!-- búsqueda de elemento principal en el repositorio -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<start-class>istia.st.springmvc.Application</start-class>
<java.version>1.7</java.version>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
Recoge toda la información proporcionada en el asistente. En las líneas 26-30, encontramos una dependencia que no conocíamos. Permite la integración de las pruebas unitarias JUnit con Spring.
Comencemos por crear una página estática HTML en este proyecto. Debe colocarse por defecto en la carpeta [src / main / resources / static]:
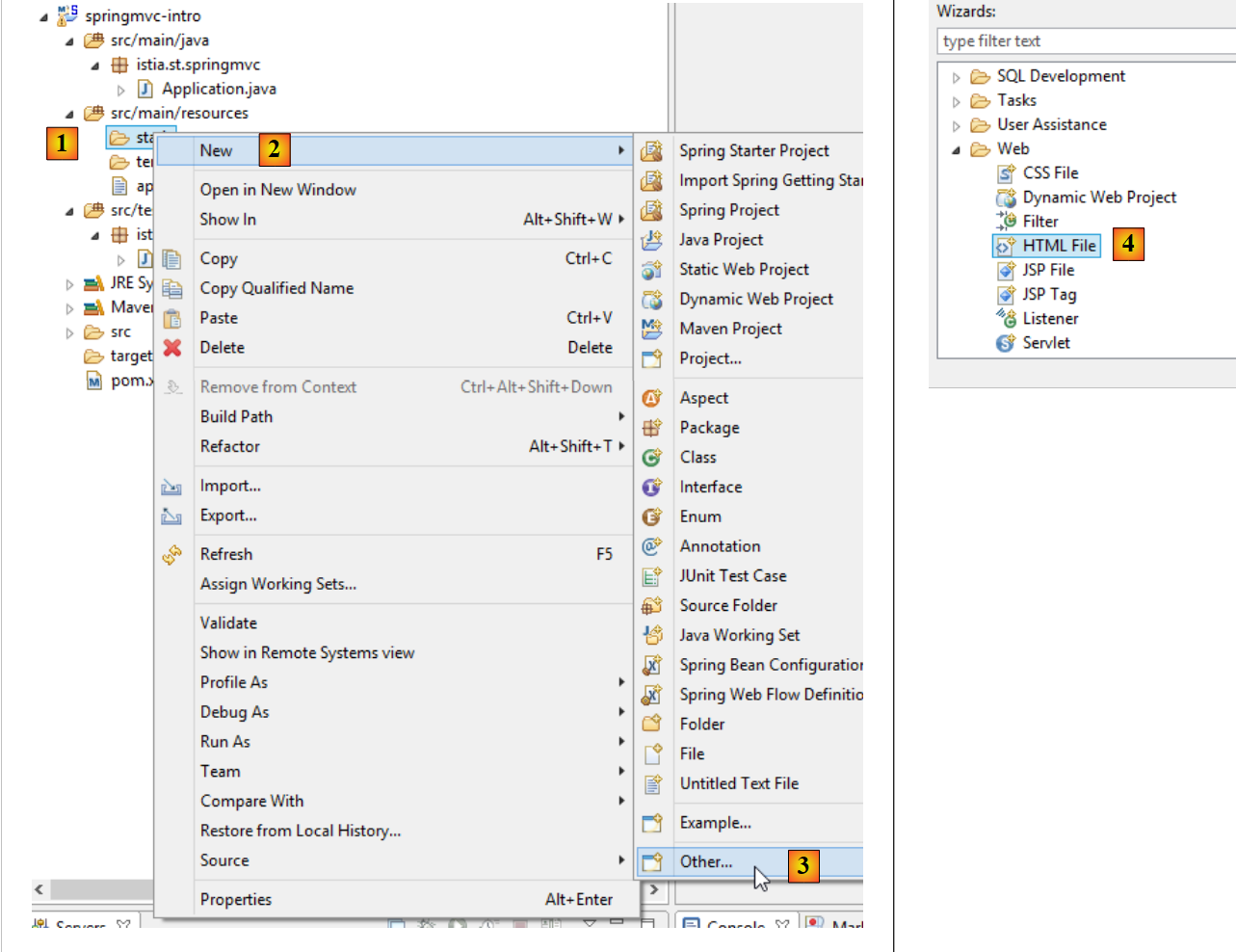 |
- en [1-4], creamos un archivo HTML en la carpeta [static];
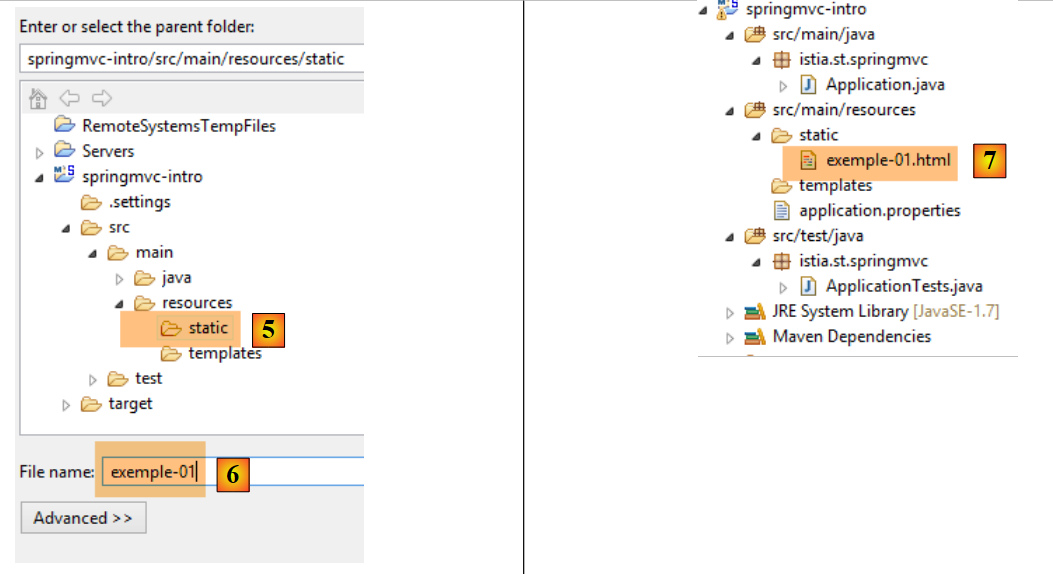 |
- en [6], asignar un nombre a la página;
- en [7], la página se ha añadido.
El contenido de la página creada es el siguiente:
<!DOCTYPE html>
<html>
<head>
<meta charset="ISO-8859-1">
<title>Insert title here</title>
</head>
<body>
</body>
</html>
- líneas 2-10: el código está delimitado por la etiqueta raíz <html>;
- líneas 3-6: la etiqueta <head> delimita lo que se denomina el encabezado de la página;
- líneas 7-9: la etiqueta <body> delimita lo que se denomina el cuerpo de la página.
Modifiquemos este código de la siguiente manera:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>essai 1 : une page statique</title>
</head>
<body>
<h1>Une page statique...</h1>
</body>
</html>
- línea 5: define el título de la página; se mostrará como título de la ventana del navegador que muestra la página;
- línea 8: un texto en letra grande (<h1>).
Ejecutemos la aplicación [1-3]:
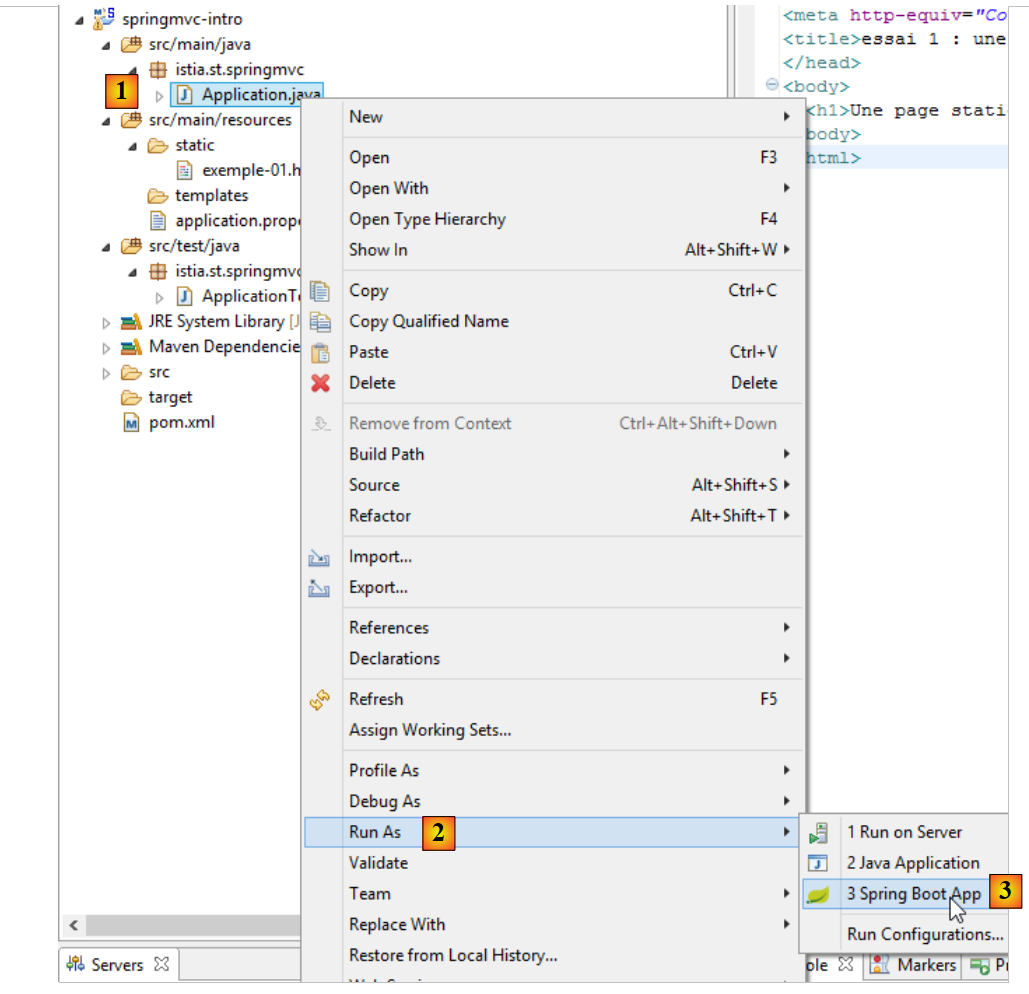 |
y, a continuación, con un navegador, solicitemos el URL [http://localhost:8080/exemple-01.html]:
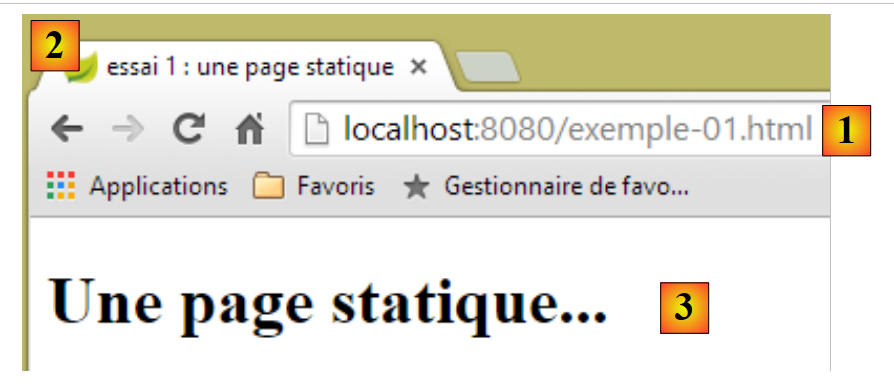 |
- en [1], el URL de la página visualizada;
- en [2], el título de la ventana —proporcionado por la etiqueta <title> de la página—;
- en [3], el cuerpo de la página —proporcionado por la etiqueta <h1>.
Veamos [4-5], el código HTML recibido por el navegador:
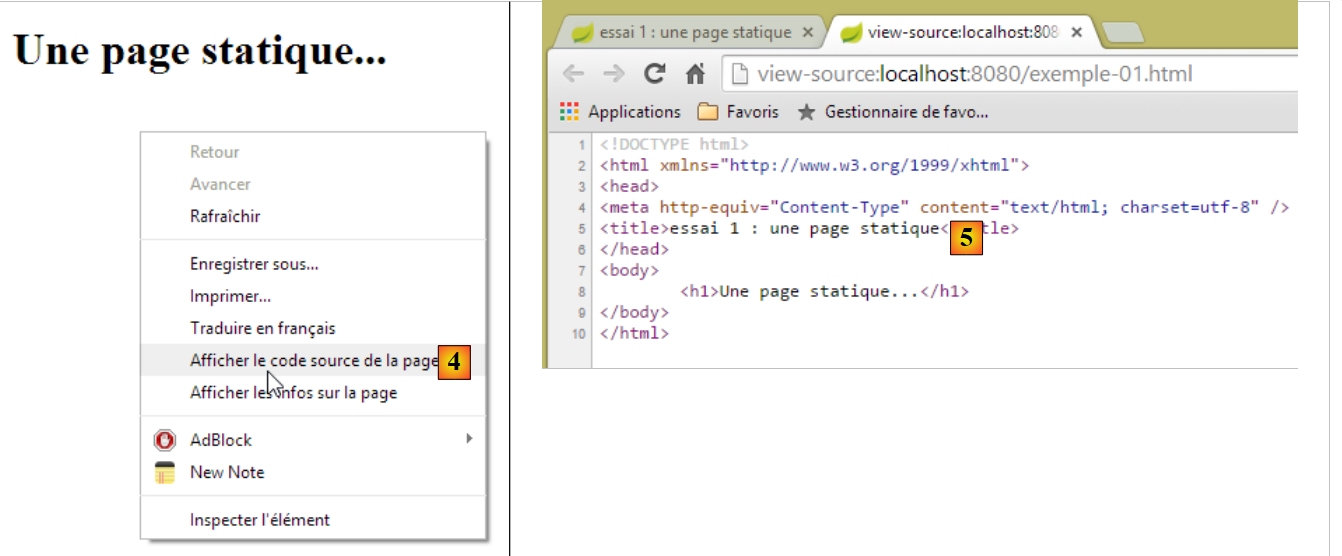 |
- en [5], el navegador recibió la página HTML que habíamos creado. La interpretó y la convirtió en una visualización gráfica.
2.2.2. Una página Thymeleaf dinámica
Ahora vamos a crear una página Thymeleaf. Se trata de una página HTML clásica con etiquetas enriquecidas con atributos [Thymeleaf] [http://www.thymeleaf.org/]. Seguimos un procedimiento similar al de la creación de la página HTML, pero esta vez hay que colocar la nueva página HTML en la carpeta [templates]:
 |
La página [exemple-02.html] será la siguiente:
<!DOCTYPE HTML>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>spring mvc intro</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
</head>
<body>
<p th:text="'Il est ' + ${heure}">Voici l'heure</p>
</body>
</html>
- línea 8: la etiqueta <p> es una etiqueta HTML que introduce un párrafo en la página mostrada. [th:text] es un atributo [Thymeleaf] que tiene dos destinos diferentes dependiendo de si [Thymeleaf] está activo o no:
- si [Thymeleaf] no interpreta la página HTML, el atributo [th:text] se ignorará porque es desconocido en HTML. El texto que se mostrará será entonces [Voici l'heure],
- si [Thymeleaf] interpreta la página HTML, se evaluará el atributo [th:text] y su valor sustituirá al texto [Voici l'heure]. Su valor será del tipo [Il est 17:11:06];
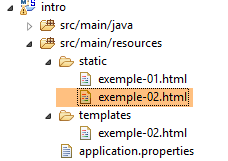
Veamos cómo funciona esto. Duplicamos la página [templates / exemple-02.html] en la carpeta [static]. Las páginas HTML colocadas en esta carpeta no son interpretadas por [Thymeleaf]:
 |  |  |
Ejecutamos la aplicación como ya lo hemos hecho varias veces y, a continuación, solicitamos con un navegador el URL [http://localhost:8080/exemple-02.html]:
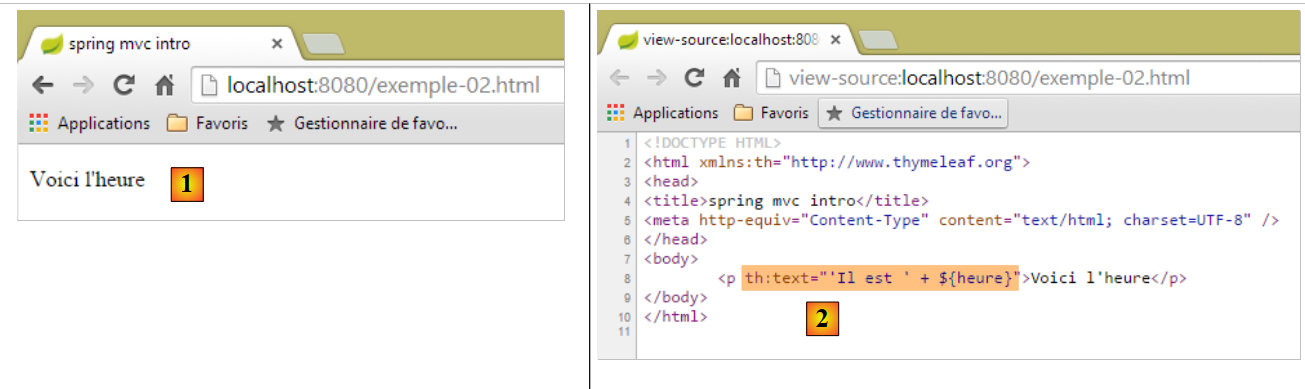 |
Vemos en [1] que el atributo [th:text] no se ha interpretado y tampoco ha provocado ningún error. El código fuente de la página recibida en [2] muestra que el navegador ha recibido correctamente la página completa.
Volvamos a la página [exemple-02.html] del archivo [templates]:
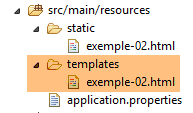 |
Las páginas HTML ubicadas en la carpeta [templates] son interpretadas por [Thymeleaf]. Volvamos al código de la página:
<!DOCTYPE HTML>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>spring mvc intro</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
</head>
<body>
<p th:text="'Il est ' + ${heure}">Voici l'heure</p>
</body>
</html>
- línea 7: [Thymeleaf] interpretará el atributo [th:text] y sustituirá [Voici l'heure] por el valor de la expresión:
Esta expresión utiliza la variable [${heure}], donde [heure] pertenece al modelo de la vista [exemple-02.html]. Por lo tanto, debemos crear este modelo. Para ello, seguiremos el ejemplo estudiado en el apartado 1.6. Modificamos el proyecto de la siguiente manera:
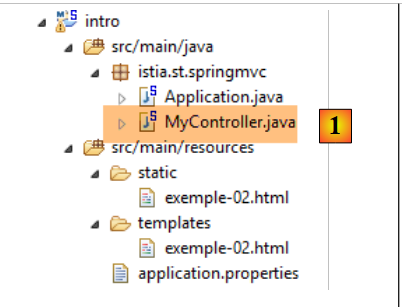 |
En [1], añadimos el siguiente controlador:
package istia.st.springmvc;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.RequestMapping;
@Controller
public class MyController {
@RequestMapping("/")
public String heure(Model model) {
// formato de la hora
SimpleDateFormat formater = new SimpleDateFormat("HH:MM:ss");
// la hora actual
String heure = formater.format(new Date());
// se introduce la hora en la plantilla de la vista
model.addAttribute("heure", heure);
// se muestra la vista [exemple-02.html]
return "exemple-02";
}
}
- líneas 13-14: el método [heure] procesa el URL [/];
- línea 14: [Model model] es una plantilla vacía. La acción [heure] debe introducir en ella los atributos que desea que aparezcan en la plantilla. Sabemos que la vista [exemple-02.html] espera un atributo llamado [heure];
- líneas 19-22: realizan lo que acabamos de explicar. La vista [exemple-02.html] se mostrará (línea 22) con un atributo llamado [heure] en su modelo (línea 20);
- línea 16: se crea un formador de fecha. El formato [HH:MM:ss] utilizado es un formato [heures:minutes:secondes] en el que las horas se encuentran en el intervalo [0-24];
- línea 18: con este formador, se formatea la fecha del día;
- línea 20: la hora obtenida se asocia a un atributo denominado [heure];
Iniciamos la aplicación y solicitamos el URL [/]:
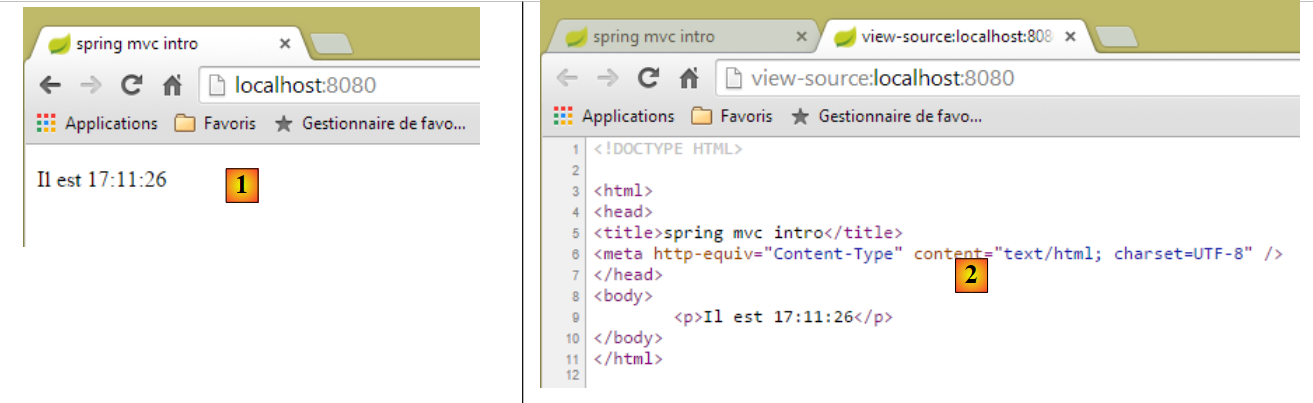 |
- en [1] la página obtenida y en [2] su contenido HTML. Se puede observar que el texto inicial [Voici l'heure] ha desaparecido por completo;
Si ahora actualizamos la página [1] (F5), obtenemos otra visualización (nueva hora), mientras que URL no cambia. Este es el aspecto dinámico de la página: su contenido puede cambiar con el tiempo.
De lo anterior, cabe destacar la naturaleza fundamentalmente diferente de las páginas dinámicas y estáticas.
2.2.3. Configuración de la aplicación Spring Boot
Volvamos a la arquitectura del proyecto Eclipse:
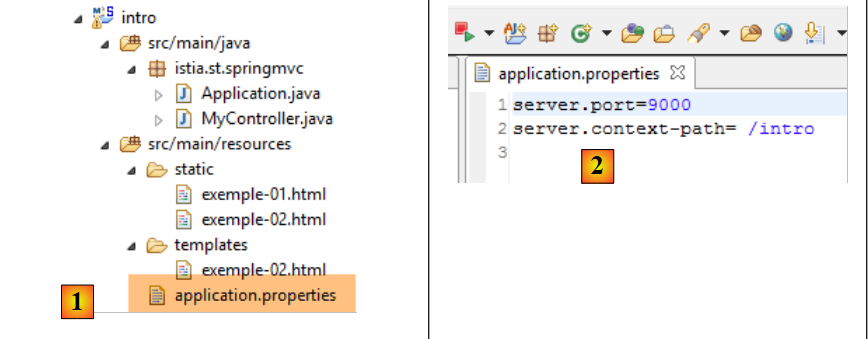 |
El archivo [application.properties] permite configurar la aplicación Spring Boot. Por el momento, este archivo está vacío. Se puede utilizar para configurar la aplicación de múltiples formas, tal y como se describe en URL y [http://docs.spring.io/spring-boot/docs/current/reference/html/common-application-properties.html]. Vamos a utilizar el archivo [application.properties] de la siguiente manera:
- línea 1: establece el puerto de servicio de la aplicación web;
- línea 2: establece el contexto de la aplicación web;
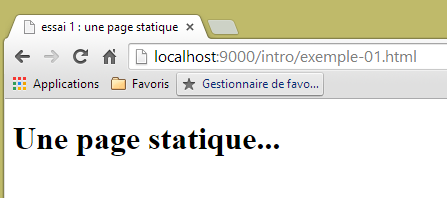
Con esta configuración, se obtendrá la página estática [exemple-01.html] con URL [http://localhost:9000/intro/exemple-01.html]:
 |
2.3. Scripts del lado del navegador
Una página HTML puede contener scripts que serán ejecutados por el navegador. El principal lenguaje de script del lado del navegador es actualmente (enero de 2015) Javascript. Se han creado cientos de bibliotecas con este lenguaje para facilitar el trabajo del desarrollador.
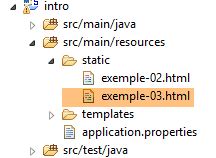
Creemos una nueva página [exemple-03.html] en la carpeta [static] del proyecto existente:
 |
Editaremos el archivo [exemple-03.html] con el siguiente contenido:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>exemple Javascript</title>
<script type="text/javascript">
function réagir() {
alert("Vous avez cliqué sur le bouton !");
}
</script>
</head>
<body>
<input type="button" value="Cliquez-moi" onclick="réagir()" />
</body>
</html>
- línea 13: define un botón (atributo type) con el texto «Haga clic aquí» (atributo value). Al hacer clic en él, se ejecuta la función Javascript [réagir] (atributo onclick);
- líneas 6-10: un script Javascript;
- líneas 7-9: la función [réagir];
- línea 8: muestra un cuadro de diálogo con el mensaje [Vous avez cliqué sur le bouton].
Visualicemos la página en un navegador:
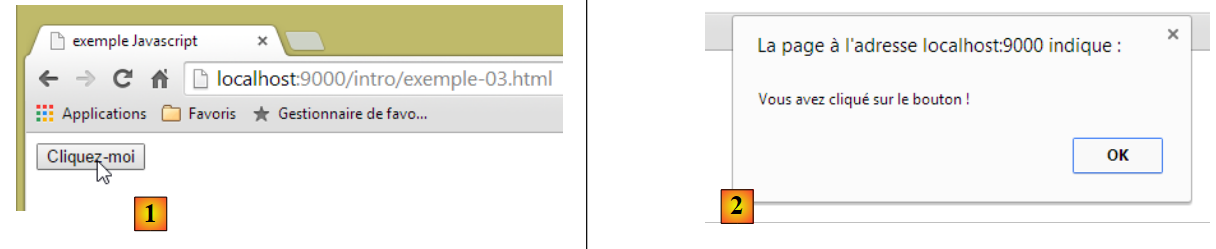 |
- en [1], la página mostrada;
- en [2], el cuadro de diálogo que aparece al hacer clic en el botón.
Al hacer clic en el botón, no hay intercambio de datos con el servidor. El código Javascript es ejecutado por el navegador.
Gracias a la gran cantidad de bibliotecas Javascript disponibles, ahora es posible integrar aplicaciones completas en el navegador. Por lo tanto, la tendencia se inclina hacia las siguientes arquitecturas:
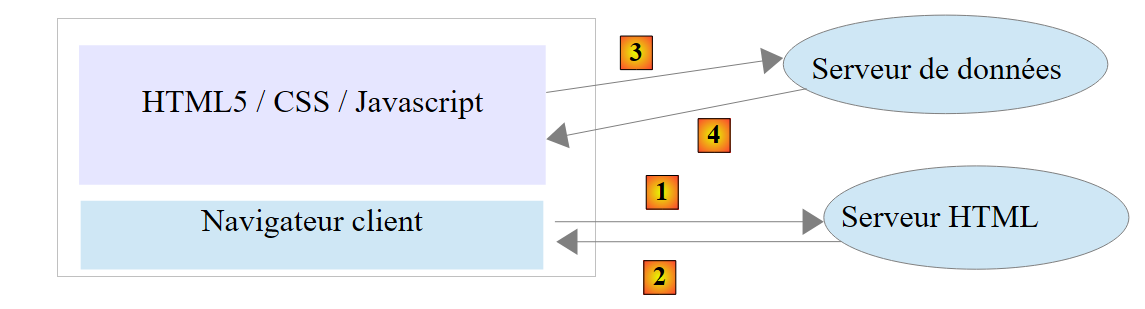 |
- 1-2: el servidor HTML es un servidor de páginas estáticas HTML5 / CSS / Javascript;
- 3-4: las páginas HTML5 / CSS / Javascript generadas interactúan directamente con el servidor de datos. Este solo proporciona datos sin diseño HTML. Es el Javascript el que las inserta en las páginas HTML ya presentes en el navegador.
En esta arquitectura, el código Javascript puede resultar pesado. Por lo tanto, se busca estructurarlo en capas, tal y como se hace con el código del lado del servidor:
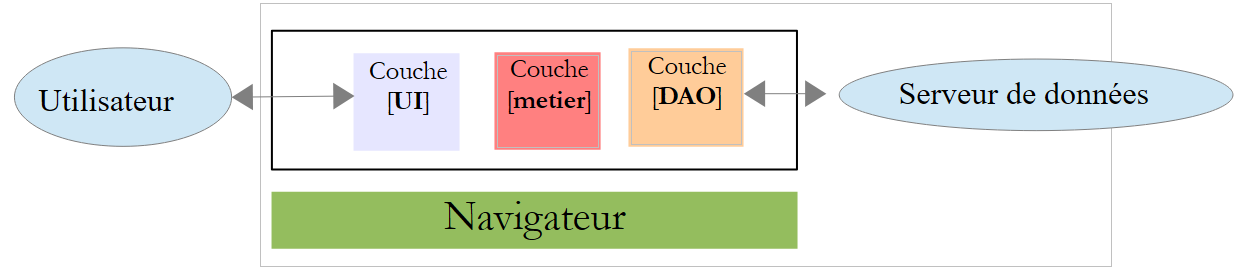 |
- la capa [UI] es la que interactúa con el usuario;
- la capa [DAO] interactúa con el servidor de datos;
- la capa [métier] agrupa los procedimientos de negocio que no interactúan ni con el usuario ni con el servidor de datos. Esta capa puede no existir.
2.4. Los intercambios cliente-servidor
Volvamos a nuestro esquema inicial, que ilustraba los actores de una aplicación web:
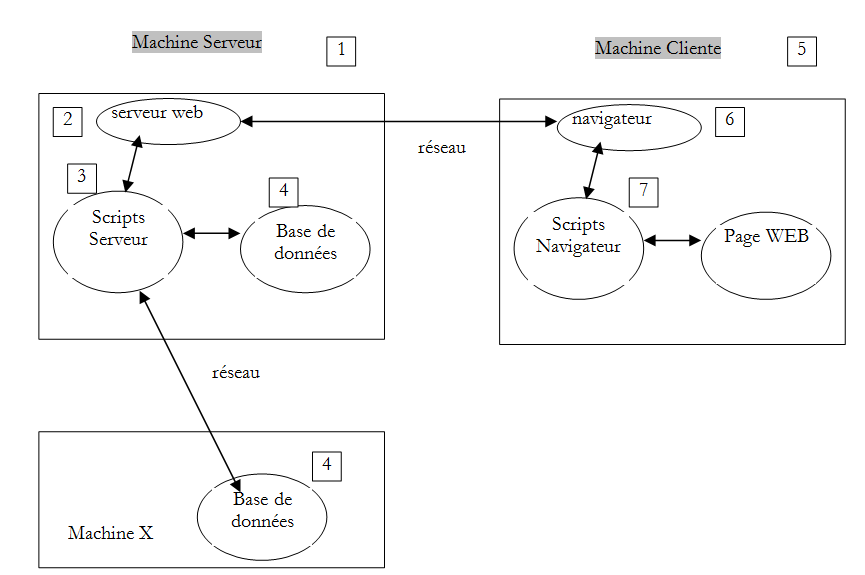
Aquí nos centramos en los intercambios entre el equipo cliente y el equipo servidor. Estos se realizan a través de una red y conviene recordar la estructura general de los intercambios entre dos equipos remotos.
2.4.1. El modelo OSI
El modelo de red abierta denominado OSI (Open Systems Interconnection Reference Model), definido por la ISO (Organización Internacional de Normalización), describe una red ideal en la que la comunicación entre máquinas puede representarse mediante un modelo de siete capas:
 |
Cada capa recibe servicios de la capa inferior y ofrece los suyos a la capa superior. Supongamos que dos aplicaciones situadas en máquinas A y B diferentes quieren comunicarse: lo hacen a nivel de la capa de aplicación. No necesitan conocer todos los detalles del funcionamiento de la red: cada aplicación entrega la información que desea transmitir a la capa inferior: la capa de presentación. Por lo tanto, la aplicación solo tiene que conocer las reglas de interfaz con la capa de presentación. Una vez que la información se encuentra en la capa de presentación, se pasa, según otras reglas, a la capa de sesión y así sucesivamente, hasta que la información llega al soporte físico y se transmite físicamente a la máquina de destino. Allí, se someterá al proceso inverso al que se sometió en la máquina remitente.
En cada capa, el proceso emisor encargado de enviar la información la envía a un proceso receptor en la otra máquina que pertenece a la misma capa que él. Lo hace siguiendo ciertas reglas que se denominan protocolo de la capa. Por lo tanto, tenemos el siguiente esquema de comunicación final:
 |
La función de las diferentes capas es la siguiente:
Física | Garantiza la transmisión de bits a través de un soporte físico. En esta capa se encuentran equipos terminales de procesamiento de datos (E.T.T.D), como terminales u ordenadores, así como equipos de terminación de circuitos de datos (E.T.C.D), como moduladores/demoduladores, multiplexores y concentradores. Los puntos de interés a este nivel son:
|
Enlace de datos | Oculta las particularidades físicas de la capa física. Detecta y corrige los errores de transmisión. |
Red | Gestiona la ruta que debe seguir la información enviada a la red. A esto se le llama enrutamiento: determinar la ruta que debe seguir la información para llegar a su destinatario. |
Transporte | Permite la comunicación entre dos aplicaciones, mientras que las capas anteriores solo permitían la comunicación entre máquinas. Un servicio que ofrece esta capa puede ser la multiplexación: la capa de transporte puede utilizar una misma conexión de red (de máquina a máquina) para transmitir información perteneciente a varias aplicaciones. |
Sesión | En esta capa se encuentran los servicios que permiten a una aplicación abrir y mantener una sesión de trabajo en una máquina remota. |
Presentación | Su objetivo es uniformizar la representación de los datos en las diferentes máquinas. Así, los datos procedentes de una máquina A serán «maquillados» por la capa de presentación de la máquina A, según un formato estándar, antes de ser enviados a la red. Una vez llegados a la capa de Presentación de la máquina destinataria B, que los reconocerá gracias a su formato estándar, se adaptarán de otra forma para que la aplicación de la máquina B los reconozca. |
Aplicación | En este nivel se encuentran las aplicaciones que suelen estar más cerca del usuario, como el correo electrónico o la transferencia de archivos. |
2.4.2. El modelo TCP/IP
El modelo OSI es un modelo ideal. El conjunto de protocolos TCP/IP se aproxima a él de la siguiente forma:
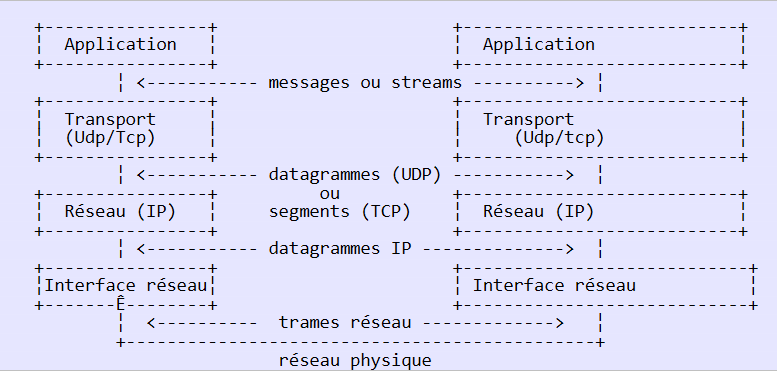 |
- la interfaz de red (la tarjeta de red del ordenador) se encarga de las funciones de las capas 1 y 2 del modelo OSI
- La capa IP (Protocolo de Internet) desempeña las funciones de la capa 3 (red)
- la capa TCP (Protocolo de control de transferencia) o UDP (Protocolo de datagramas de usuario) desempeña las funciones de la capa 4 (transporte). El protocolo TCP se asegura de que los paquetes de datos intercambiados por los equipos lleguen correctamente a su destino. Si no es así, devuelve los paquetes que se han extraviado. El protocolo UDP no realiza esta tarea, por lo que corresponde al desarrollador de aplicaciones llevarla a cabo. Por eso, en Internet, que no es una red 100 % fiable, el protocolo TCP es el más utilizado. Se habla entonces de red TCP-IP.
- La capa de aplicación abarca las funciones de los niveles 5 a 7 del modelo OSI.
Las aplicaciones web se encuentran en la capa de aplicación y, por lo tanto, se basan en los protocolos TCP-IP. Las capas de aplicación de los equipos cliente y servidor intercambian mensajes que se confían a las capas 1 a 4 del modelo para ser encaminados a su destino. Para entenderse, las capas de aplicación de ambas máquinas deben «hablar» un mismo lenguaje o protocolo. El de las aplicaciones web se llama HTTP (HyperText Transfer Protocol). Se trata de un protocolo de tipo texto, c.a.d, por el que las máquinas intercambian líneas de texto a través de la red para entenderse. Estos intercambios están estandarizados, es decir, el cliente dispone de una serie de mensajes para indicar exactamente lo que quiere al servidor y este último también dispone de una serie de mensajes para dar su respuesta al cliente. Este intercambio de mensajes tiene la siguiente forma:
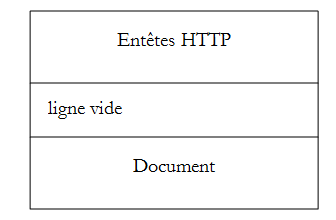
Cliente --> Servidor
Cuando el cliente realiza su solicitud al servidor web, envía
- líneas de texto en formato HTTP para indicar lo que quiere;
- una línea en blanco;
- opcionalmente, un documento.
Servidor --> Cliente
Cuando el servidor responde al cliente, envía
- líneas de texto en formato HTTP para indicar lo que envía;
- una línea en blanco;
- opcionalmente, un documento.
Por lo tanto, los intercambios tienen la misma forma en ambos sentidos. En ambos casos, puede enviarse un documento, aunque es poco habitual que un cliente envíe un documento al servidor. Pero el protocolo HTTP lo prevé. Esto es lo que permite, por ejemplo, a los abonados de un proveedor de acceso descargar diversos documentos en su sitio web personal alojado en dicho proveedor. Los documentos intercambiados pueden ser de cualquier tipo. Tomemos como ejemplo un navegador que solicita una página web que contiene imágenes:
- el navegador se conecta al servidor web y solicita la página que desea. Los recursos solicitados se designan de forma única mediante URL (Uniform Resource Locator). El navegador solo envía encabezados HTTP y ningún documento.
- El servidor le responde. En primer lugar, envía encabezados HTTP que indican qué tipo de respuesta envía. Puede tratarse de un error si la página solicitada no existe. Si la página existe, el servidor indicará en los encabezados HTTP de su respuesta que, tras estos, enviará un documento HTML (HyperText Markup Language). Este documento es una secuencia de líneas de texto en formato HTML. Un texto HTML contiene etiquetas (marcadores) que dan al navegador indicaciones sobre cómo mostrar el texto.
- El cliente sabe, a partir de los encabezados HTTP del servidor, que va a recibir un documento HTML. Lo analizará y quizá se dé cuenta de que contiene referencias a imágenes. Estas no se encuentran en el documento HTML. Por lo tanto, realiza una nueva solicitud al mismo servidor web para pedir la primera imagen que necesita. Esta solicitud es idéntica a la realizada en el paso 1, salvo que el recurso solicitado es diferente. El servidor procesará esta solicitud enviando al cliente la imagen solicitada. En esta ocasión, en su respuesta, los encabezados HTTP especificarán que el documento enviado es una imagen y no un documento HTML.
- El cliente recupera la imagen enviada. Los pasos 3 y 4 se repetirán hasta que el cliente (un navegador, por lo general) tenga todos los documentos que le permitan mostrar la página completa.
2.4.3. El protocolo HTTP
Descubramos el protocolo HTTP con algunos ejemplos. ¿Qué se intercambian un navegador y un servidor web?
El servicio web o servicio HTTP es un servicio TCP-IP que suele funcionar en el puerto 80. Podría funcionar en otro puerto. En ese caso, el navegador cliente tendría que especificar ese puerto en la solicitud URL que realiza. Una solicitud URL tiene la siguiente forma general:
protocolo://máquina[:port]/ruta/información
con
protocolo | http para el servicio web. Un navegador también puede actuar como cliente de servicios ftp, news, telnet, etc. |
máquina | nombre de la máquina en la que se aloja el servicio web |
puerto | puerto del servicio web. Si es el 80, se puede omitir el número de puerto. Este es el caso más frecuente |
ruta | ruta que designa el recurso solicitado |
información | información adicional proporcionada al servidor para precisar la solicitud del cliente |
¿Qué hace un navegador cuando un usuario solicita la carga de un URL?
- abre una comunicación TCP-IP con la máquina y el puerto indicados en la parte machine[:port] del URL. Abrir una comunicación TCP-IP significa crear un «canal» de comunicación entre dos máquinas. Una vez creado este canal, toda la información intercambiada entre las dos máquinas pasará por él. La creación de este canal TCP-IP aún no implica el protocolo web HTTP.
- Una vez creado el canal TCP-IP, el cliente realizará su solicitud al servidor web enviándole líneas de texto (comandos) en formato HTTP. Enviará al servidor la parte de ruta/información del URL
- el servidor le responderá de la misma manera y por el mismo canal
- uno de los dos interlocutores tomará la decisión de cerrar el canal. Esto depende del protocolo HTTP utilizado. Con el protocolo HTTP 1.0, el servidor cierra la conexión tras cada una de sus respuestas. Esto obliga a un cliente que debe realizar varias solicitudes para obtener los distintos documentos que componen una página web a abrir una nueva conexión con cada solicitud, lo cual tiene un coste. Con el protocolo HTTP/1.1, el cliente puede indicar al servidor que mantenga la conexión abierta hasta que le indique que la cierre. De este modo, puede recuperar todos los documentos de una página web con una sola conexión y cerrarla él mismo una vez obtenido el último documento. El servidor detectará este cierre y también cerrará la conexión.
Para conocer los intercambios entre un cliente y un servidor web, utilizaremos la extensión [Advanced Rest Client] del navegador Chrome que instalamos en el apartado 9.6. Nos encontraremos en la siguiente situación:
El servidor web puede ser cualquiera. Lo que buscamos aquí es descubrir los intercambios que se producirán entre el navegador y el servidor web. Anteriormente, creamos la siguiente página estática HTML:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>essai 1 : une page statique</title>
</head>
<body>
<h1>Une page statique...</h1>
</body>
</html>
que visualizamos en un navegador:
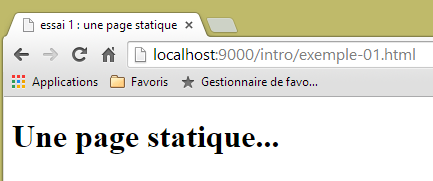 |
Vemos que la URL solicitada es: [http://localhost:9000/intro/exemple-01.html]. Por lo tanto, la máquina del servicio web es localhost (=máquina local) y el puerto 9000. Utilicemos la aplicación [Advanced Rest Client] para solicitar el mismo URL:
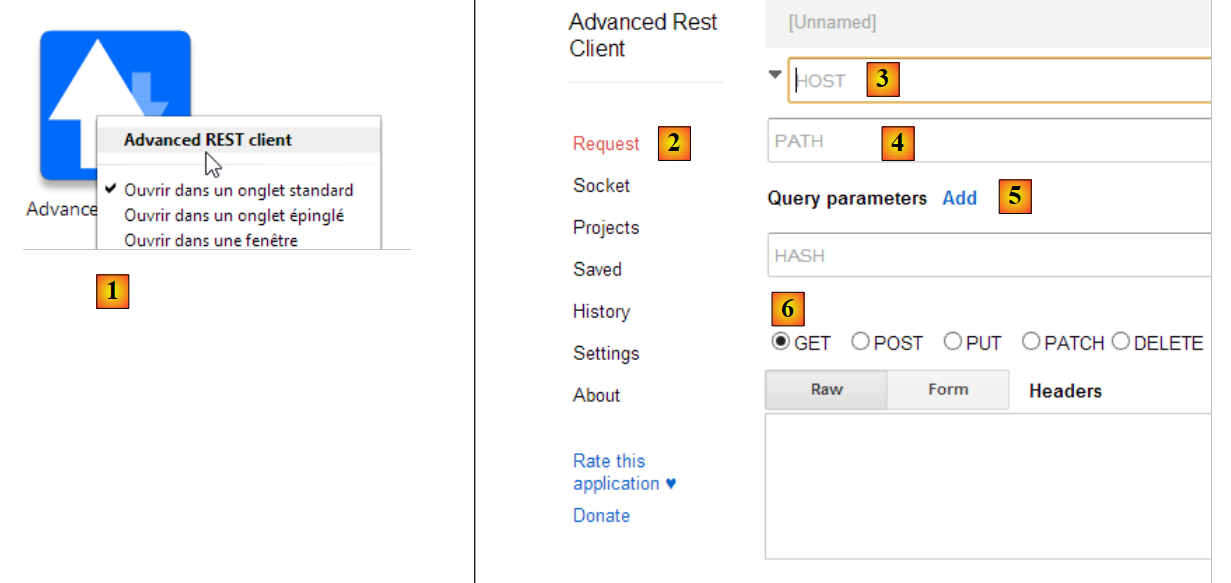 |
- en [1], iniciamos la aplicación (en la pestaña [Applications] de una nueva pestaña de Chrome);
- en [2], se selecciona el option [Request];
- en [3], se especifica el servidor al que se consulta: http://localhost:9000;
- en [4], se especifica la URL solicitada: /intro/ejemplo-01.html;
- en [5], se añaden los posibles parámetros a URL. Aquí no hay ninguno;
- en [6], se especifica el comando HTTP utilizado para la consulta, aquí GET.
Esto da como resultado la siguiente consulta:
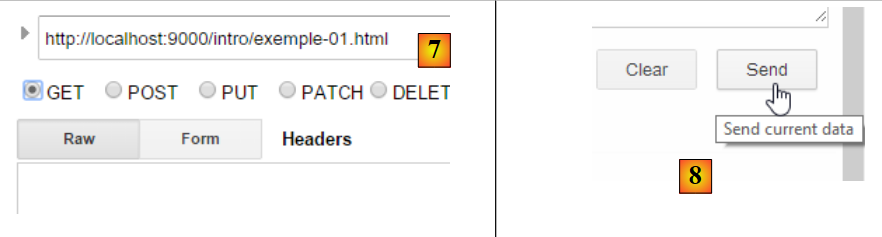 |
La consulta así preparada, [7], se envía al servidor mediante [8]. La respuesta obtenida es entonces la siguiente:
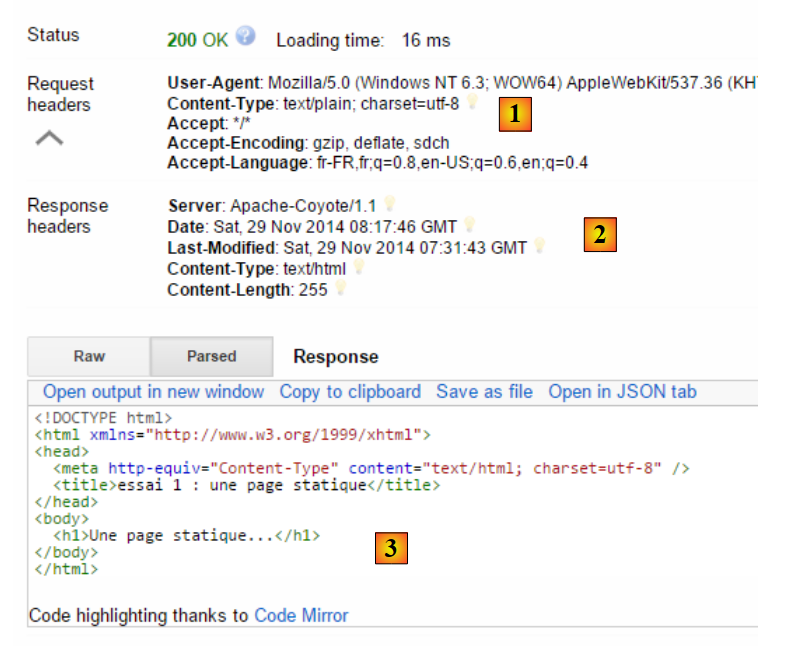 |
Hemos dicho anteriormente que los intercambios cliente-servidor tenían la siguiente forma:
- en [1], vemos los encabezados HTTP enviados por el navegador en su solicitud. No tenía ningún documento que enviar;
- en [2], vemos los encabezados HTTP enviados por el servidor en respuesta. En [3], vemos el documento que envió.
En [3], reconocemos la página estática HTML que hemos colocado en el servidor web.
Examinemos la solicitud HTTP del navegador:
- la línea 1 no ha sido mostrada por la aplicación;
- línea 6: el navegador se identifica con el encabezado [User-Agent];
- línea 7: el navegador indica que envía al servidor un documento de texto (text/plain) en formato UTF-8. De hecho, en este caso, el navegador no ha enviado ningún documento;
- línea 8: el navegador indica que acepta cualquier tipo de documento como respuesta;
- línea 9: el navegador especifica los formatos de documento aceptados;
- línea 10: el navegador especifica los idiomas que desea por orden de preferencia.
El servidor le respondió enviando los siguientes encabezados HTTP:
- línea 1: no ha sido mostrada por la aplicación;
- línea 2: el servidor se identifica, en este caso un servidor Apache-Coyote;
- línea 3: la fecha de la última modificación del documento enviado;
- línea 4: el tipo de documento enviado por el servidor. En este caso, un documento HTML;
- línea 5: el tamaño en bytes del documento HTML enviado.
- línea 6: fecha y hora de la respuesta;
2.4.4. Conclusión
Hemos descubierto la estructura de la solicitud de un cliente web y la de la respuesta que le da el servidor web a través de algunos ejemplos. El diálogo se realiza mediante el protocolo HTTP, un conjunto de comandos en formato de texto intercambiados por ambas partes. La solicitud del cliente y la respuesta del servidor tienen la misma estructura:
Los dos comandos habituales para solicitar un recurso son GET y POST. El comando GET no va acompañado de un documento. El comando POST, por su parte, va acompañado de un documento que suele ser una cadena de caracteres que reúne el conjunto de valores introducidos en un formulario. El comando HEAD permite solicitar únicamente los encabezados HTTP y no va acompañado de ningún documento.
A petición de un cliente, el servidor envía una respuesta que tiene la misma estructura. El recurso solicitado se transmite en la parte [Document], salvo si el comando del cliente era HEAD, en cuyo caso solo se envían los encabezados HTTP.
2.5. Fundamentos del lenguaje HTML
Un navegador web puede mostrar diversos documentos, siendo el más habitual el documento HTML (HyperText Markup Language). Se trata de un texto formateado con etiquetas de la forma <etiqueta>texto</etiqueta>. Así, el texto <B>importante</B> mostrará el texto «importante» en negrita. Existen etiquetas independientes, como la etiqueta <hr/>, que muestra una línea horizontal. No repasaremos las etiquetas que se pueden encontrar en un texto HTML. Existen numerosos programas WYSIWYG que permiten crear una página web sin escribir una sola línea de código HTML. Estas herramientas generan automáticamente el código HTML de un diseño realizado con el ratón y controles predefinidos. Así, se puede insertar (con el ratón) una tabla en la página y, a continuación, consultar el código HTML generado por el programa para descubrir las etiquetas que hay que utilizar para definir una tabla en una página web. No es más complicado que eso. Por otra parte, el conocimiento del lenguaje HTML es indispensable, ya que las aplicaciones web dinámicas deben generar ellas mismas el código HTML que se enviará a los servidores web. Este código se genera mediante un programa y, por supuesto, hay que saber qué hay que generar para que el cliente obtenga la página web que desea.
En resumen, no es necesario conocer todo el lenguaje HTML para iniciarse en la programación web. Sin embargo, este conocimiento es necesario y se puede adquirir mediante el uso de programas de creación de páginas web como WYSIWYG, DreamWeaver y muchos otros. Otra forma de descubrir las sutilezas del lenguaje HTML es navegar por la web y visualizar el código fuente de las páginas que presentan características interesantes y aún desconocidas para ti.
2.5.1. Un ejemplo
Consideremos el siguiente ejemplo, que presenta algunos elementos que se pueden encontrar en un documento web, tales como:
- una tabla;
- una imagen;
- un enlace.
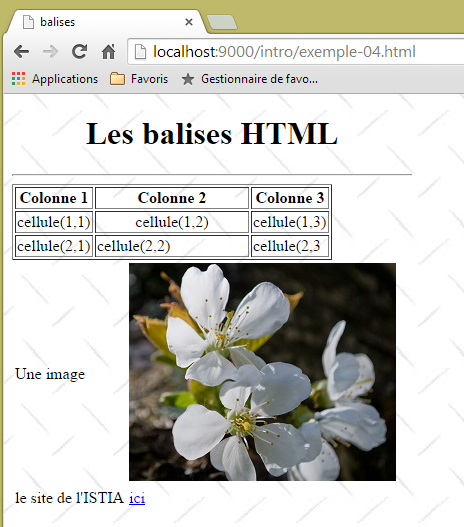 |  |
Un documento HTML tiene la siguiente estructura general:
Todo el documento está enmarcado por las etiquetas <html>...</html>. Se compone de dos partes:
- <head>...</head>: es la parte no visible del documento. Proporciona información al navegador que va a mostrar el documento. A menudo se encuentra aquí la etiqueta <title>...</title>, que establece el texto que se mostrará en la barra de título del navegador. En ella pueden encontrarse otras etiquetas, en particular las que definen las palabras clave del documento, palabras clave que posteriormente utilizan los motores de búsqueda. En esta parte también pueden encontrarse scripts, escritos con mayor frecuencia en javascript o vbscript, que serán ejecutados por el navegador.
- <body atributos>...</body>: es la parte que mostrará el navegador. Las etiquetas HTML contenidas en esta parte indican al navegador la forma visual «deseada» para el documento. Cada navegador interpretará estas etiquetas a su manera. Por lo tanto, dos navegadores pueden mostrar de forma diferente un mismo documento web. Esto suele ser uno de los quebraderos de cabeza de los diseñadores web.
El código HTML de nuestro documento de ejemplo es el siguiente:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>balises</title>
</head>
<body style="height: 400px; width: 400px; background-image: url(images/standard.jpg)">
<h1 style="text-align: center">Les balises HTML</h1>
<hr />
<table border="1">
<thead>
<tr>
<th>Colonne 1</th>
<th>Colonne 2</th>
<th>Colonne 3</th>
</tr>
</thead>
<tbody>
<tr>
<td>cellule(1,1)</td>
<td style="width: 150px; text-align: center;">cellule(1,2)</td>
<td>cellule(1,3)</td>
</tr>
<tr>
<td>cellule(2,1)</td>
<td>cellule(2,2)</td>
<td>cellule(2,3</td>
</tr>
</tbody>
</table>
<table>
<tr>
<td>Une image</td>
<td><img border="0" src="images/cerisier.jpg" /></td>
</tr>
<tr>
<td>le site de l'ISTIA</td>
<td><a href="http://istia.univ-angers.fr">ici</a></td>
</tr>
</table>
</body>
</html>
Elemento | etiquetas y ejemplos HTML |
título del documento | <title>etiquetas</title> (línea 5) El texto «Etiquetas» aparecerá en la barra de título del navegador que muestre el documento |
barra horizontal | <hr/>: muestra una línea horizontal (línea 10) |
tabla | <table atributos>....</table>: para definir la tabla (líneas 11, 31) <thead>...</thead>: para definir los encabezados de las columnas (líneas 12, 18) <tbody>...</tbody>: para definir el contenido de la tabla (líneas 19, 30) <tr atributos>...</tr>: para definir una fila (líneas 20, 24) <td atributos>...</td>: para definir una celda (línea 21) ejemplos: <table border="1">...</table>: el atributo border define el grosor del borde de la tabla <td style="width: 150px; text-align: center;">celda(1,2)</td>: define una celda cuyo contenido será celda(1,2). Este contenido se centrará horizontalmente (text-align: center). La celda tendrá una anchura de 150 píxeles (width: 150px) |
imagen | <img border="0" src="/images/cerisier.jpg"/> (línea 36): define una imagen sin borde (border=0") cuyo archivo de origen es /images/cerisier.jpg en el servidor web (src="images/cerisier.jpg"). Este enlace se encuentra en un documento web obtenido con el URL http://localhost:puerto/intro/ejemplo-04.html. Por lo tanto, el navegador solicitará el URL http://localhost:port/intro/images/cerisier.jpg para obtener la imagen a la que se hace referencia aquí. |
enlace | <a href="http://istia.univ-angers.fr">aquí</a> (línea 40): hace que el texto aquí sirva de enlace hacia URL http://istia.univ-angers.fr. |
pie de página | <body style="height:400px;width:400px;background-image:url(images/standard.jpg)"> (línea 8): indica que la imagen que se utilizará como fondo de página se encuentra en la ruta URL [images/standard.jpg] del servidor web. En el contexto de nuestro ejemplo, el navegador solicitará la ruta URL http://localhost:puerto/intro/images/standard.jpg para obtener esta imagen de fondo. Por otra parte, el cuerpo del documento se mostrará en un rectángulo de 400 píxeles de alto y 400 píxeles de ancho. |
En este sencillo ejemplo se observa que, para construir la totalidad del documento, el navegador debe realizar tres solicitudes al servidor:
- http://localhost:port/intro/exemple-04.html para obtener el código fuente HTML del documento
- http://localhost:puerto/intro/images/cerisier.jpg para obtener la imagen cerisier.jpg
- http://localhost:puerto/intro/images/standard.jpg para obtener la imagen de fondo standard.jpg
2.5.2. Un formulario HTML
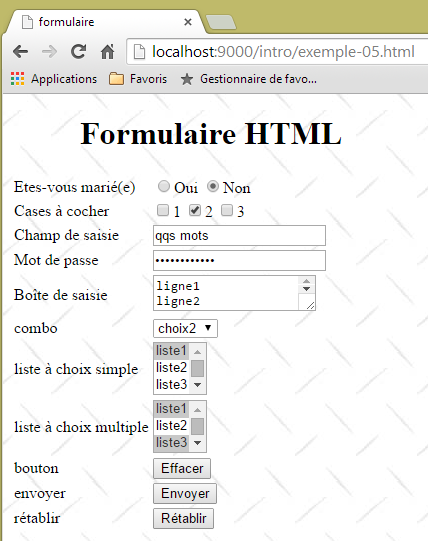
El siguiente ejemplo muestra un formulario:
 |  |
El código HTML que genera esta visualización es el siguiente:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>formulaire</title>
<script type="text/javascript">
function effacer() {
alert("Vous avez cliqué sur le bouton Effacer");
}
</script>
</head>
<body style="height: 400px; width: 400px; background-image: url(images/standard.jpg)">
<h1 style="text-align: center">Formulaire HTML</h1>
<form method="post" action="postFormulaire">
<table>
<tr>
<td>Etes-vous marié(e)</td>
<td>
<input type="radio" value="Oui" name="R1" />Oui
<input type="radio" name="R1" value="non" checked="checked" />Non
</td>
</tr>
<tr>
<td>Cases à cocher</td>
<td>
<input type="checkbox" name="C1" value="un" />1
<input type="checkbox" name="C2" value="deux" checked="checked" />2
<input type="checkbox" name="C3" value="trois" />3
</td>
</tr>
<tr>
<td>Champ de saisie</td>
<td>
<input type="text" name="txtSaisie" size="20" value="qqs mots" />
</td>
</tr>
<tr>
<td>Mot de passe</td>
<td>
<input type="password" name="txtMdp" size="20" value="unMotDePasse" />
</td>
</tr>
<tr>
<td>Boîte de saisie</td>
<td>
<textarea rows="2" name="areaSaisie" cols="20">
ligne1
ligne2
ligne3
</textarea>
</td>
</tr>
<tr>
<td>combo</td>
<td>
<select size="1" name="cmbValeurs">
<option value="1">choix1</option>
<option selected="selected" value="2">choix2</option>
<option value="3">choix3</option>
</select>
</td>
</tr>
<tr>
<td>liste à choix simple</td>
<td>
<select size="3" name="lst1">
<option selected="selected" value="1">liste1</option>
<option value="2">liste2</option>
<option value="3">liste3</option>
<option value="4">liste4</option>
<option value="5">liste5</option>
</select>
</td>
</tr>
<tr>
<td>liste à choix multiple</td>
<td>
<select size="3" name="lst2" multiple="multiple">
<option value="1" selected="selected">liste1</option>
<option value="2">liste2</option>
<option selected="selected" value="3">liste3</option>
<option value="4">liste4</option>
<option value="5">liste5</option>
</select>
</td>
</tr>
<tr>
<td>bouton</td>
<td>
<input type="button" value="Effacer" name="cmdEffacer" onclick="effacer()" />
</td>
</tr>
<tr>
<td>envoyer</td>
<td>
<input type="submit" value="Envoyer" name="cmdRenvoyer" />
</td>
</tr>
<tr>
<td>rétablir</td>
<td>
<input type="reset" value="Rétablir" name="cmdRétablir" />
</td>
</tr>
</table>
<input type="hidden" name="secret" value="uneValeur" />
</form>
</body>
</html>
La asociación entre el control visual y la etiqueta HTML es la siguiente:
Control | etiqueta HTML |
formulario | <form method="post" action="..."> |
campo de entrada | <input type="text" name="txtSaisie" size="20" value="unas palabras" /> |
campo de entrada oculto | <input type="password" name="txtMdp" size="20" value="unMotDePasse" /> |
campo de entrada multilínea | <textarea rows="2" name="areaSaisie" cols="20"> línea1 línea 2 línea 3 </textarea> |
botones de radio | <input type="radio" value="Sí" name="R1" />Sí <input type="radio" name="R1" value="no" checked="checked" />No |
casillas de selección | <input type="checkbox" name="C1" value="uno" />1 <input type="checkbox" name="C2" value="dos" checked="checked" />2 <input type="checkbox" name="C3" value="tres" />3 |
Combo | <select size="1" name="cmbValeurs"> <option value="1">opción1</option> <option selected="selected" value="2">opción2</option> <option value="3">opción3</option> </select> |
lista de selección única | <select size="3" name="lst1"> <option selected="selected" value="1">lista1</option> <option value="2">lista2</option> <option value="3">lista3</option> <option value="4">lista4</option> <option value="5">lista5</option> </select> |
lista de selección múltiple | <select size="3" name="lst2" multiple="multiple"> <option value="1">lista1</option> <option value="2">lista2</option> <option selected="selected" value="3">lista3</option> <option value="4">lista4</option> <option value="5">lista5</option> </select> |
botón de tipo submit | <input type="submit" value="Enviar" name="cmdRenvoyer" /> |
botón de tipo reset | <input type="reset" value="Restablecer" name="cmdRétablir" /> |
botón de tipo button | <input type="button" value="Borrar" name="cmdEffacer" onclick="effacer()" /> |
Repasemos estas diferentes etiquetas:
2.5.2.1. El formulario « »
formulario | |
etiqueta HTML | <form name="..." method="..." action="...">...</form> |
atributos | name="frmexemple": nombre del formulario method="..." : método utilizado por el navegador para enviar al servidor web los valores recopilados en el formulario action="..." : URL a la que se enviarán los valores recopilados en el formulario. Un formulario web está delimitado por las etiquetas <form>...</form>. El formulario puede tener un nombre (name="xx"). Este es el caso de todos los controles que pueden encontrarse en un formulario. El objetivo de un formulario es recopilar la información introducida por el usuario mediante el teclado o el ratón y enviarla a una URL del servidor web. ¿Cuál? La indicada en el atributo action="URL". Si este atributo no está presente, la información se enviará al servidor del documento en el que se encuentra el formulario. Un cliente web puede utilizar dos métodos diferentes, denominados «POST» y «GET», para enviar datos a un servidor web. El atributo method="método", con method igual a GET o POST, de la etiqueta <form> indica al navegador el método que debe utilizar para enviar la información recopilada en el formulario al URL especificado por el atributo action="URL". Cuando no se especifica el atributo method, se utiliza el método GET por defecto. |
2.5.2.2. Los campos de entrada de texto
campo de entrada | <input type="text" name="txtSaisie" size="20" value="unas palabras" /> <input type="password" name="txtMdp" size="20" value="unMotDePasse" /> |
 |
etiqueta HTML | <input type="..." name="..." size=".." value=".."/> La etiqueta input existe para diversos controles. Es el atributo type el que permite diferenciar estos controles entre sí. |
atributos | type="text": especifica que se trata de un campo de entrada type="password": los caracteres presentes en el campo de entrada se sustituyen por asteriscos (*). Esta es la única diferencia con respecto al campo de entrada normal. Este tipo de control es adecuado para la introducción de contraseñas. size="20": número de caracteres visibles en el campo; no impide introducir más caracteres name="txtSaisie": nombre del control value="algunas palabras": texto que se mostrará en el campo de entrada. |
2.5.2.3. Los campos de entrada de varias líneas
campo de entrada de varias líneas | <textarea rows="2" name="areaSaisie" cols="20"> línea1 línea2 línea 3 </textarea> |
 |
etiqueta HTML | <textarea ...>texto</textarea> muestra un campo de entrada de varias líneas con texto inicial en su interior |
atributos | rows="2": número de líneas cols="'20" : número de columnas name="areaSaisie": nombre del control |
2.5.2.4. Los botones de radio
botones de radio | <input type="radio" value="Sí" name="R1" />Sí <input type="radio" name="R1" value="no" checked="checked" />No |
etiqueta HTML | <input type="radio" atributo2="valor2" ..../>texto muestra un botón de radio con texto al lado. |
atributos | name="radio": nombre del control. Los botones de radio con el mismo nombre forman un grupo de botones que se excluyen entre sí: solo se puede marcar uno de ellos. value="valor": valor asignado al botón de radio. No hay que confundir este valor con el texto que se muestra junto al botón de radio. Este último solo tiene fines de visualización. checked= "checked": si esta palabra clave está presente, el botón de radio está marcado; de lo contrario, no lo está. |
2.5.2.5. Las casillas de selección
casillas de selección | <input type="checkbox" name="C1" value="uno" />1 <input type="checkbox" name="C2" value="dos" checked="checked" />2 <input type="checkbox" name="C3" value="tres" />3 |
etiqueta HTML | <input type="checkbox" atributo2="valor2" ....>texto muestra una casilla de verificación con texto al lado. |
atributos | name="C1": nombre del control. Las casillas de verificación pueden tener o no el mismo nombre. Las casillas con el mismo nombre forman un grupo de casillas asociadas. value="valor": valor asignado a la casilla de verificación. No hay que confundir este valor con el texto que se muestra junto al botón de radio. Este último solo tiene fines de visualización. checked= "checked": si esta palabra clave está presente, la casilla de verificación está marcada; de lo contrario, no lo está. |
2.5.2.6. El menú desplegable (combo)
Combo | <select size="1" name="cmbValeurs"> <option value="1">opción1</option> <option selected="selected" value="2">opción2</option> <option value="3">opción3</option> </select> |
etiqueta HTML | <select size=".." name=".."> <option [selected="selected"] value=”v”>...</option> ... </select> muestra en una lista los textos comprendidos entre las etiquetas <option>...</option> |
atributos | name="cmbValeurs": nombre del control. size="1": número de elementos de la lista visibles. size="1" convierte la lista en el equivalente a un cuadro combinado. selected="selected": si esta palabra clave está presente para un elemento de la lista, este aparece seleccionado en la lista. En nuestro ejemplo anterior, el elemento de la lista «choix2» aparece como el elemento seleccionado del cuadro combinado cuando este se muestra por primera vez. value=”v”: si el usuario selecciona el elemento, es este valor [v] el que se envía al servidor. Si no existe este atributo, es el texto mostrado y seleccionado el que se envía al servidor. |
2.5.2.7. Lista de selección única
lista de selección única | <select size="3" name="lst1"> <option selected="selected" value="1">lista1</option> <option value="2">lista2</option> <option value="3">lista3</option> <option value="4">lista4</option> <option value="5">lista5</option> </select> |
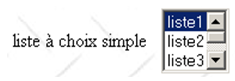 |
etiqueta HTML | <select size=".." name=".."> <option [selected="selected"]>...</option> ... </select> muestra en una lista los textos comprendidos entre las etiquetas <option>...</option> |
atributos | los mismos que para la lista desplegable que muestra un solo elemento. Este control solo se diferencia de la lista desplegable anterior en su atributo size>1. |
2.5.2.8. Lista de selección múltiple
lista de selección única | <select size="3" name="lst2" multiple="multiple"> <option value="1" selected="selected">lista1</option> <option value="2">lista2</option> <option selected="selected" value="3">lista3</option> <option value="4">lista4</option> <option value="5">lista5</option> </select> |
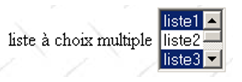 |
etiqueta HTML | <select size=".." name=".." multiple="multiple"> <option [selected="selected"]>...</option> ... </select> muestra en una lista los textos comprendidos entre las etiquetas <option>...</option> |
atributos | múltiple: permite seleccionar varios elementos de la lista. En el ejemplo anterior, se seleccionan los elementos lista1 y lista3. |
2.5.2.9. Botón de tipo button
botón de tipo button | <input type="button" value="Borrar" name="cmdEffacer" onclick="effacer()" /> |
etiqueta HTML | <input type="button" value="..." name="..." onclick="effacer()" ..../> |
atributos | type="button": define un control de botón. Existen otros dos tipos de botón: los tipos submit y reset. value="Borrar": el texto que se muestra en el botón onclick="función()": permite definir una función que se ejecutará cuando el usuario haga clic en el botón. Esta función forma parte de los scripts definidos en el documento web mostrado. La sintaxis anterior es una sintaxis javascript. Si los scripts están escritos en vbscript, habría que escribir onclick="función" sin los paréntesis. La sintaxis es idéntica si hay que pasar parámetros a la función: onclick="función(val1, val2,...)" En nuestro ejemplo, al hacer clic en el botón Borrar se llama a la siguiente función javascript borrar: <script type="text/javascript"> function borrar() { alert("Ha hecho clic en el botón Borrar"); } </script> La función borrar muestra un mensaje: 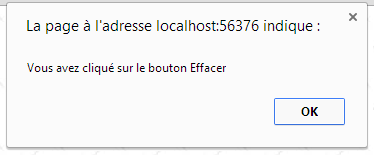 |
2.5.2.10. Botón de tipo submit
Botón de tipo submit | <input type="submit" value="Enviar" name="cmdRenvoyer" /> |
etiqueta HTML | <input type="submit" value="Enviar" name="cmdRenvoyer" /> |
atributos | type="submit": define el botón como un botón para enviar los datos del formulario al servidor web. Cuando el cliente haga clic en este botón, el navegador enviará los datos del formulario a la URL definida en el atributo action de la etiqueta <form>, según el método definido por el atributo method de dicha etiqueta. value="Enviar": el texto que se muestra en el botón |
2.5.2.11. Botón de tipo reset
Botón de tipo reset | <input type="reset" value="Restablecer" name="cmdRétablir" /> |
etiqueta HTML | <input type="reset" value="Restablecer" name="cmdRétablir"/> |
atributos | type="reset": define el botón como un botón de restablecimiento del formulario. Cuando el usuario haga clic en este botón, el navegador restablecerá el formulario al estado en el que lo recibió. value="Restablecer": el texto que se muestra en el botón |
2.5.2.12. Campo oculto
campo oculto | <input type="hidden" name="secret" value="uneValeur" /> |
etiqueta HTML | <input type="hidden" name="..." value="..."/> |
atributos | type="hidden": indica que se trata de un campo oculto. Un campo oculto forma parte del formulario, pero no se muestra al usuario. Sin embargo, si este solicitara a su navegador que mostrara el código fuente, vería la presencia de la etiqueta <input type="hidden" value="..."> y, por lo tanto, el valor del campo oculto. value="unValor": valor del campo oculto. ¿Cuál es la utilidad del campo oculto? Permite al servidor web conservar información a lo largo de las solicitudes de un cliente. Consideremos una aplicación de compras en la web. El cliente compra un primer artículo art1 en cantidad q1 en una primera página de un catálogo y luego pasa a una nueva página del catálogo. Para recordar que el cliente ha comprado q1 artículos art1, el servidor puede colocar esta información en un campo oculto del formulario web de la nueva página. En esta nueva página, el cliente compra q2 artículos art2. Cuando los datos de este segundo formulario se envíen al servidor (submit), este no solo recibirá la información (q2,art2), sino también (q1,art1), que también forma parte del formulario como campo oculto. A continuación, el servidor web colocará en un nuevo campo oculto la información (q1,art1) y (q2,art2) y enviará una nueva página del catálogo. Y así sucesivamente. |
2.5.3. Envío de los valores de un formulario a un servidor web por parte de un cliente web
En el estudio anterior dijimos que el cliente web disponía de dos métodos para enviar a un servidor web los valores de un formulario que había mostrado: los métodos GET y POST. Veamos con un ejemplo la diferencia entre ambos métodos.
2.5.3.1. Método GET
Hagamos una primera prueba, en la que, en el código HTML del documento, la etiqueta <form> se define de la siguiente manera:
<form method="get" action="doNothing">
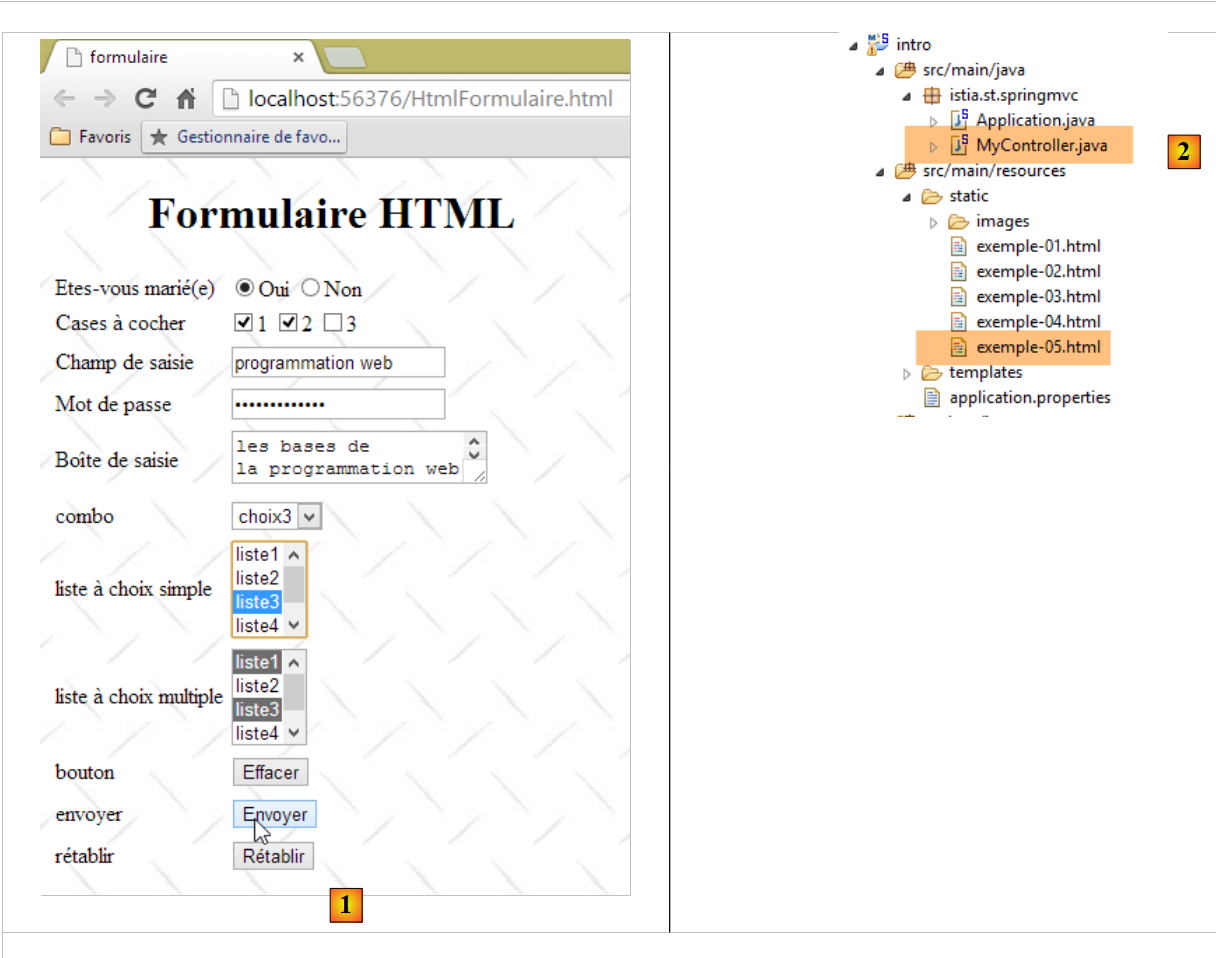 |
Cuando el usuario haga clic en el botón [1], los valores introducidos en el formulario se enviarán al controlador Spring [2]. Hemos visto que los valores del formulario se enviarán a URL [doNothing]:
<form method="get" action="doNothing">
La acción [doNothing] se define en el controlador [MyController] [2] de la siguiente manera:
// ----------------------- vaciar un flujo [Content-Length=0]
@RequestMapping(value = "/doNothing")
@ResponseBody
public void doNothing() {
}
- línea 1: la acción procesa URL [/doNothing], por lo que en realidad es [/context/doNothing], donde [context] es el contexto o nombre de la aplicación web, en este caso, [/intro];
- línea 3: la anotación [@ResponseBody] indica que el resultado del método anotado debe enviarse directamente al cliente;
- línea 4: el método no devuelve nada. Por lo tanto, el cliente recibirá una respuesta vacía del servidor.
Solo queremos saber cómo transmite el navegador los valores introducidos al servidor web. Para ello, utilizaremos una herramienta de depuración disponible en Chrome. Se activa pulsando CTRL-Mayús-I (mayúscula) [3]:
 |
Como nos interesan los intercambios de red entre el navegador y el servidor web, activamos arriba la pestaña [Network] y luego hacemos clic en el botón [Envoyer] del formulario. Este es un botón de tipo [submit] dentro de una etiqueta [form]. El navegador responde al clic solicitando el URL [/intro/doNothing] indicado en el atributo [action] de la etiqueta [form], con el método GET indicado en el atributo [method]. A continuación, obtenemos la siguiente información:
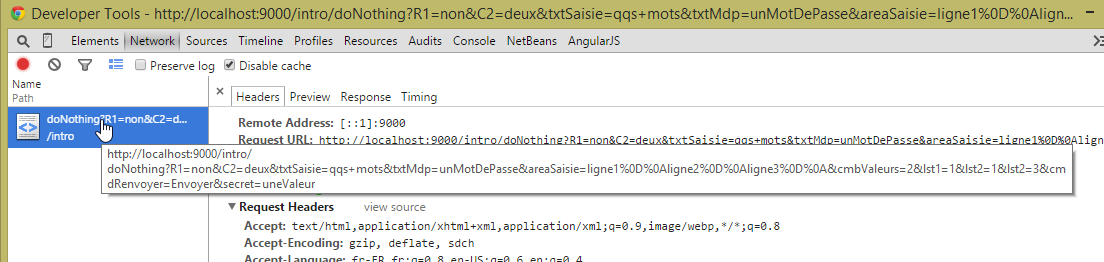 |
La captura de pantalla anterior nos muestra el URL solicitado por el navegador tras hacer clic en el botón [envoyer]. Efectivamente, solicita el URL previsto [/intro/doNothing], pero al final añade información que son los valores introducidos en el formulario. Para obtener más información, hacemos clic en el enlace anterior:
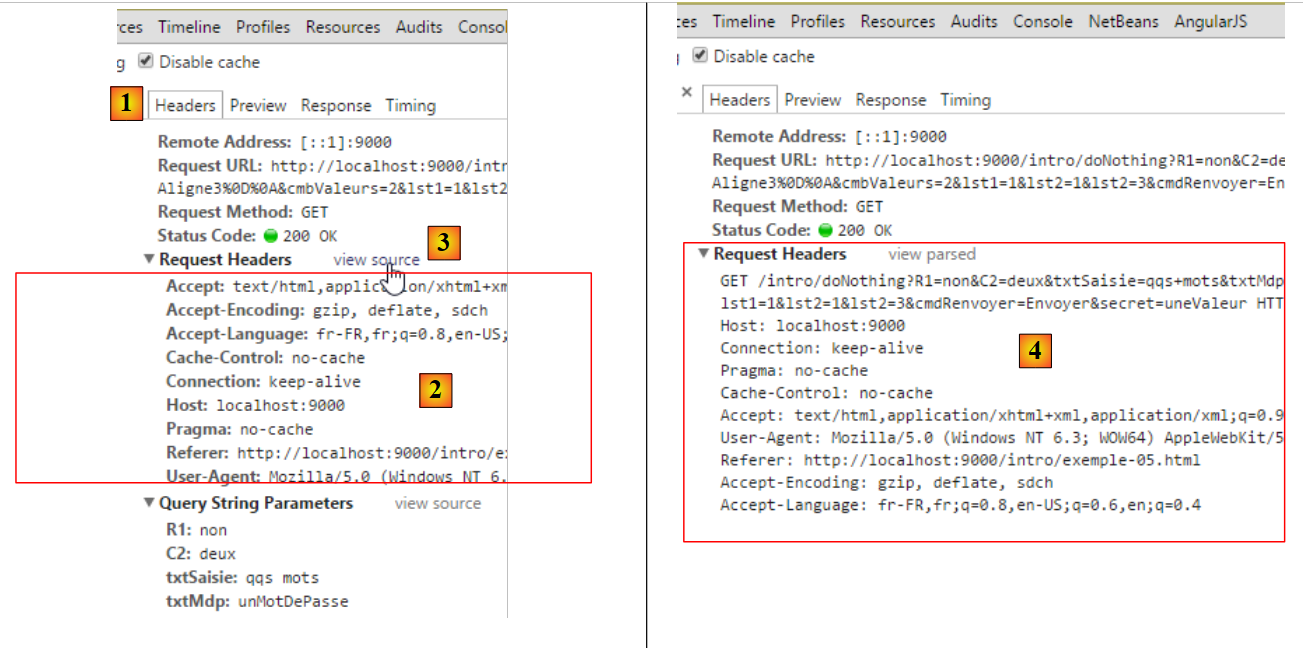 |
Arriba, en [1, 2], vemos los encabezados HTTP enviados por el navegador. Aquí se han formateado. Para ver el texto sin formato de estos encabezados, seguimos el enlace [view source] [3, 4]. El texto completo es el siguiente:
Encontramos elementos que ya hemos visto anteriormente. Otros aparecen por primera vez:
Connection: keep-alive | el cliente solicita al servidor que no cierre la conexión tras su respuesta. Esto le permitirá utilizar la misma conexión para una solicitud posterior. La conexión no permanece abierta indefinidamente. El servidor la cerrará tras un tiempo de inactividad excesivo. |
Referer | la URL que se mostraba en el navegador cuando se realizó la nueva solicitud. |
La novedad es la línea 1 en la información que sigue a la URL. Se observa que las opciones seleccionadas en el formulario se reflejan en el URL. Los valores introducidos por el usuario en el formulario se han pasado a la orden GET URL?param1=valor1¶m2=valor2&... HTTP/1.1, donde los parami son los nombres (atributo name) de los controles del formulario web y los valores son los valores que se les asocian. A continuación, presentamos una tabla de tres columnas:
- columna 1: recoge la definición de un control HTML del ejemplo;
- columna 2: muestra cómo se visualiza este control en un navegador;
- columna 3: muestra el valor enviado al servidor por el navegador para el control de la columna 1, tal y como aparece en la solicitud GET del ejemplo.
control HTML | visual | valor(es) devuelto(s) |
<input type="radio" value="Sí" name="R1"/>Sí <input type="radio" name="R1" value="no" checked="checked"/>No | R1=Sí - el valor del atributo value del botón de radio seleccionado por el usuario. | |
<input type="checkbox" name="C1" value="uno"/>1 <input type="checkbox" name="C2" value="dos" checked="checked"/>2 <input type="checkbox" name="C3" value="tres"/>3 | C1=uno C2=dos - valores de los atributos «value» de las casillas marcadas por el usuario | |
<input type="text" name="txtSaisie" size="20" value="unas palabras"/> | txtSaisie=programación+Web - texto escrito por el usuario en el campo de entrada. Los espacios se han sustituido por el signo + | |
<input type="password" name="txtMdp" size="20" value="unMotDePasse"/> | txtMdp=estoesecreto - texto introducido por el usuario en el campo de entrada | |
<textarea rows="2" name="areaSaisie" cols="20"> línea1 línea2 línea3 </textarea> | areaSaisie=los+fundamentos+de+la%0D%0A programación+web - texto escrito por el usuario en el campo de entrada. %OD%OA es el marcador de fin de línea. Los espacios se han sustituido por el signo + | |
<select size="1" name="cmbValeurs"> <option value='1'>opción1</option> <option selected="selected" value='2'>opción2</option> <option value='3'>opción3</option> </select> | cmbValores=3 - atributo [value] del elemento seleccionado por el usuario | |
<select size="3" name="lst1"> <option selected="selected" value='1'>lista1</option> <option value='2'>lista2</option> <option value='3'>lista3</option> <option value='4'>lista4</option> <option value='5'>lista5</option> </select> | 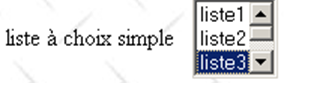 | lst1=3 - atributo [value] del elemento seleccionado por el usuario |
<select size="3" name="lst2" multiple="multiple"> <option selected="selected" value='1'>lista1</option> <option value='2'>lista2</option> <option selected="selected" value='3'>lista3</option> <option value='4'>lista4</option> <option value='5'>lista5</option> </select> | lst2=1 lst2=3 - atributos [value] de los elementos seleccionados por el usuario | |
<input type="submit" value="Enviar" name="cmdRenvoyer"/> | cmdRenvoyer=Enviar - nombre y atributo value del botón que se ha utilizado para enviar los datos del formulario al servidor | |
<input type="hidden" name="secret" value="uneValeur"/> | secret=unValor - atributo value del campo oculto |
2.5.3.2. Método POST
Modificamos el documento HTML para que el navegador utilice ahora el método POST para enviar los valores del formulario al servidor web:
<form method="post" action="doNothing">
Rellenamos el formulario igual que para el método GET y enviamos los parámetros al servidor con el botón [Envoyer]. Al igual que en el párrafo anterior de la página 63, en Chrome tenemos acceso a los encabezados HTTP de la solicitud enviada por el navegador:
Aparecen novedades en la solicitud HTTP del cliente:
POST URL HTTP/1.1 | La consulta GET ha dado paso a una consulta POST. Los parámetros ya no aparecen en esta primera línea de la solicitud. Se puede observar que ahora se encuentran (línea 15) detrás de la solicitud HTTP, tras una línea en blanco. Su codificación es idéntica a la que tenían en la solicitud GET. |
Content-Length | número de caracteres «enviados», c.a.d. El número de caracteres que deberá leer el servidor web tras recibir los encabezados HTTP para recuperar el documento que le envía el cliente. El documento en cuestión es, en este caso, la lista de valores del formulario. |
Content-type | especifica el tipo de documento que el cliente enviará tras los encabezados HTTP. El tipo [application/x-www-form-urlencoded] indica que se trata de un documento que contiene valores de formulario. |
Hay dos métodos para enviar datos a un servidor web: GET y POST. ¿Hay algún método que sea mejor que el otro? Hemos visto que si los valores de un formulario se enviaban desde el navegador con el método GET, el navegador mostraba en su campo Dirección la URL solicitada en forma de URL?param1=val1¶m2=val2&.... Esto puede considerarse una ventaja o un inconveniente:
- una ventaja si se quiere permitir al usuario añadir este URL configurado a sus favoritos;
- una desventaja si no se desea que el usuario tenga acceso a cierta información del formulario, como, por ejemplo, los campos ocultos.
A partir de ahora, utilizaremos casi exclusivamente el método POST en nuestros formularios.
2.6. Conclusión
En este capítulo se han presentado diferentes conceptos básicos del desarrollo web:
- los intercambios cliente-servidor a través del protocolo HTTP;
- el diseño de un documento mediante el lenguaje HTML;
- el diseño de formularios de entrada de datos.
Hemos visto en un ejemplo cómo un cliente puede enviar información al servidor web. No hemos explicado cómo el servidor puede
- recuperar esa información;
- procesarla;
- enviar al cliente una respuesta dinámica en función del resultado del procesamiento.
Este es el ámbito de la programación web, tema que abordaremos en el siguiente capítulo con la presentación de la tecnología Spring MVC.