6. XML y JAVA
En este capítulo, presentamos el uso de documentos XML con Java. Lo haremos en el contexto de la aplicación de impuestos estudiada en el capítulo anterior.
6.1. Archivos XML y hojas de estilo XSL
Consideremos el siguiente archivo XML simulations.xml, que podría representar el resultado de simulaciones de cálculos de impuestos:
<?xml version="1.0" encoding="ISO-8859-1"?>
<simulations>
<simulation marie="oui" enfants="2" salaire="200000" impot="22504"/>
<simulation marie="non" enfants="2" salaire="200000" impot="33388"/>
</simulations>
Si lo visualizamos con IE 6, obtenemos el siguiente resultado:
IE6 reconoce que se trata de un archivo XML (gracias a la extensión .xml del archivo) y lo maquetará a su manera. Con Netscape se obtiene una página en blanco. Sin embargo, si se mira el código fuente (Ver/Fuente), se ve claramente el archivo XML original:
¿Por qué Netscape no muestra nada? Porque necesita una hoja de estilo que le indique cómo transformar el archivo XML en el archivo HTML, que entonces podrá mostrar. Resulta que IE 6 tiene una hoja de estilo por defecto, mientras que el archivo XML no la tiene, como era el caso aquí.
Existe un lenguaje llamado XSL (eXtended StyleSheet Language) que permite describir las transformaciones que hay que realizar para convertir un archivo XML en cualquier archivo de texto. XSL permite el uso de numerosas instrucciones y se asemeja mucho a los lenguajes de programación. No lo detallaremos aquí, ya que se necesitarían varias decenas de páginas. Nos limitaremos a describir dos ejemplos de hojas de estilo XSL. La primera es la que transformará el archivo XML simulations.xml en código HTML. Modificamos este último para que indique la hoja de estilo que podrán utilizar los navegadores para transformarlo en el documento HTML, documento que podrán mostrar:
<?xml version="1.0" encoding="ISO-8859-1" ?>
<?xml-stylesheet type="text/xsl" href="simulations.xsl"?>
<simulations>
<simulation marie="oui" enfants="2" salaire="200000" impot="22504"/>
<simulation marie="non" enfants="2" salaire="200000" impot="33388"/>
</simulations>
El pedido XML
designa el archivo simulations.xsl como una hoja de estilo (xml-stylesheet) de tipo text/xsl c.a.d. un archivo de texto que contiene código XSL. Esta hoja de estilo será utilizada por los navegadores para transformar el texto XML en un documento HTML. Este es el resultado obtenido con Netscape 7 al cargar el archivo XML simulations.xml:

Cuando miramos el código fuente del documento (Ver/Fuente), encontramos el documento XML inicial y no el documento HTML que se muestra:
Netscape ha utilizado la hoja de estilo simulations.xsl para transformar el documento XML anterior en el documento HTML que se puede visualizar. Ahora es el momento de examinar el contenido de esta hoja de estilo:
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" indent="yes"/>
<xsl:template match="/">
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impôts</h3>
<hr/>
<table border="1">
<th>marié</th><th>enfants</th><th>salaire</th><th>impôt</th>
<xsl:apply-templates select="/simulations/simulation"/>
</table>
</center>
</body>
</html>
</xsl:template>
<xsl:template match="simulation">
<tr>
<td><xsl:value-of select="@marie"/></td>
<td><xsl:value-of select="@enfants"/></td>
<td><xsl:value-of select="@salaire"/></td>
<td><xsl:value-of select="@impot"/></td>
</tr>
</xsl:template>
</xsl:stylesheet>
- Una hoja de estilo XSL es un archivo XML y, por lo tanto, sigue sus reglas. Entre otras cosas, debe estar «bien formada», es decir, toda etiqueta abierta debe cerrarse.
- El archivo comienza con dos comandos XML que se pueden mantener en cualquier hoja de estilo XSL:
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
El atributo encoding="ISO-8859-1" permite utilizar caracteres acentuados en la hoja de estilo.
- La etiqueta <xsl:output method="html" indent="yes"/> indica al intérprete XSL que se desea generar HTML «sangrado».
- La etiqueta <xsl:template match="elemento"> sirve para definir el elemento del documento XML al que se aplicarán las instrucciones que se encuentran entre <xsl:template ...> y </xsl:template>.
En el ejemplo anterior, el elemento «/» designa la raíz del documento. Esto significa que, tan pronto como se encuentre el inicio del documento XML, se ejecutarán los comandos XSL situados entre ambas etiquetas.
- Todo lo que no sea una etiqueta XSL se incluye tal cual en el flujo de salida. Las etiquetas XSL se ejecutan. Algunas de ellas producen un resultado que se incluye en el flujo de salida. Veamos el siguiente ejemplo:
<xsl:template match="/">
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impôts</h3>
<hr/>
<table border="1">
<th>marié</th><th>enfants</th><th>salaire</th><th>impôt</th>
<xsl:apply-templates select="/simulations/simulation"/>
</table>
</center>
</body>
</html>
</xsl:template>
Recordemos que el documento XML analizado es el siguiente:
<?xml version="1.0" encoding="ISO-8859-1"?>
<simulations>
<simulation marie="oui" enfants="2" salaire="200000" impot="22504"/>
<simulation marie="non" enfants="2" salaire="200000" impot="33388"/>
</simulations>
Desde el inicio del documento XML analizado (match="/"), el intérprete XSL generará como salida el texto
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impôts</h3>
<hr>
<table border="1">
<th>marié</th><th>enfants</th><th>salaire</th><th>impôt</th>
Cabe señalar que en el texto inicial teníamos <hr/> y no <hr>. En el texto inicial no se podía escribir <hr>, ya que, si bien es una etiqueta HTML válida, es una etiqueta XML inválida. Ahora bien, aquí nos encontramos ante un texto XML que debe estar «bien formado», c.a.d es decir, que todas las etiquetas deben estar cerradas. Por lo tanto, se escribe <hr/> y, como se ha escrito <xsl:output text="html ...>, el intérprete XSL transformará el texto <hr/> en <hr>. Tras este texto, vendrá a continuación el texto producido por el comando XSL:
Más adelante veremos cuál es este texto. Por último, el intérprete añadirá el texto:
El comando <xsl:apply-templates select="/simulations/simulation"/> solicita que se ejecute la «plantilla» (modelo) del elemento /simulations/simulation. Se ejecutará cada vez que el intérprete XSL encuentre en el texto XML analizado una etiqueta <simulation>..</simulations> o <simulation/> dentro de una etiqueta <simulations>..</simulations>. Al encontrar la etiqueta <simulation>, el intérprete ejecutará las instrucciones del siguiente modelo:
<xsl:template match="simulation">
<tr>
<td><xsl:value-of select="@marie"/></td>
<td><xsl:value-of select="@enfants"/></td>
<td><xsl:value-of select="@salaire"/></td>
<td><xsl:value-of select="@impot"/></td>
</tr>
</xsl:template>
Consideremos las siguientes líneas XML:
La línea <simulation ..> corresponde a la plantilla de la instrucción XSL <xsl:apply-templates select="/simulations/simulation">. Por lo tanto, el intérprete XSL intentará aplicarle las instrucciones que corresponden a esta plantilla. Encontrará la plantilla <xsl:template match="simulation"> y la ejecutará. Recordemos que lo que no es un comando XSL es tomado tal cual por el intérprete XSL y que los comandos XSL son sustituidos por el resultado de su ejecución. La instrucción XSL <xsl:value-of select="@champ"/> se sustituye así por el valor del atributo «champ» del nodo analizado (en este caso, un nodo <simulation>). El análisis de la línea XML anterior producirá el siguiente resultado:
XSL | salida |
<tr><td> | <tr><td> |
<xsl:value-of select="@marie"/> | sí |
</td><td> | </td><td> |
<xsl:value-of select="@enfants"/> | 2 |
</td><td> | </td><td> |
<xsl:value-of select="@salaire"/> | 200000 |
</td><td> | </td><td> |
<xsl:value-of select="@impot"/> | 22504 |
</td></tr> | </td></tr> |
En total, la línea XML
se transformará en la línea HTML:
Todas estas explicaciones son un poco rudimentarias, pero ahora debería quedar claro para el lector que el siguiente texto XML:
<?xml version="1.0" encoding="ISO-8859-1"?>
<?xml-stylesheet type="text/xsl" href="simulations.xsl"?>
<simulations>
<simulation marie="oui" enfants="2" salaire="200000" impot="22504"/>
<simulation marie="non" enfants="2" salaire="200000" impot="33388"/>
</simulations>
acompañado de la hoja de estilo XSL simulations.xsl siguiente:
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" indent="yes"/>
<xsl:template match="/">
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impôts</h3>
<hr/>
<table border="1">
<th>marié</th><th>enfants</th><th>salaire</th><th>impôt</th>
<xsl:apply-templates select="/simulations/simulation"/>
</table>
</center>
</body>
</html>
</xsl:template>
<xsl:template match="simulation">
<tr>
<td><xsl:value-of select="@marie"/></td>
<td><xsl:value-of select="@enfants"/></td>
<td><xsl:value-of select="@salaire"/></td>
<td><xsl:value-of select="@impot"/></td>
</tr>
</xsl:template>
</xsl:stylesheet>
genera el siguiente texto HTML:
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impots</h3>
<hr>
<table border="1">
<th>marié</th><th>enfants</th><th>salaire</th><th>impôt</th>
<tr>
<td>oui</td><td>2</td><td>200000</td><td>22504</td>
</tr>
<tr>
<td>non</td><td>2</td><td>200000</td><td>33388</td>
</tr>
</table>
</center>
</body>
</html>
El archivo XML simulations.xml, acompañado de la hoja de estilo simulations.xsl, leído por un navegador reciente (en este caso, Netscape 7), se muestra entonces de la siguiente manera:
6.2. Aplicación de impuestos: version 6
6.2.1. Los archivos XML y las hojas de estilo XSL de la aplicación de impuestos
Volvamos a la aplicación web de impuestos y modifiquémosla para que la respuesta a clients sea una respuesta en formato XML en lugar de una respuesta HTML. Esta respuesta XML irá acompañada de una hoja de estilo XSL para que los navegadores puedan mostrarla. En el párrafo anterior, hemos presentado:
- el archivo simulations.xml, que es el prototipo de una respuesta XML que incluye simulaciones de cálculos de impuestos
- el archivo simulations.xsl, que será la hoja de estilo XSL que acompañará a esta respuesta XML
También debemos prever el caso de una respuesta con errores. El prototipo de la respuesta XML en este caso será el siguiente archivo errores.xml:
<?xml version="1.0" encoding="windows-1252"?>
<?xml-stylesheet type="text/xsl" href="erreurs.xsl"?>
<erreurs>
<erreur>erreur 1</erreur>
<erreur>erreur 2</erreur>
</erreurs>
La hoja de estilo erreurs.xsl que permite visualizar este documento XML en un navegador será la siguiente:
<?xml version="1.0" encoding="windows-1252"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="html" indent="yes"/>
<xsl:template match="/">
<html>
<head>
<title>Simulations de calculs d'impôts</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impôts</h3>
</center>
<hr/>
Les erreurs suivantes se sont produites :
<ul>
<xsl:apply-templates select="/erreurs/erreur"/>
</ul>
</body>
</html>
</xsl:template>
<xsl:template match="erreur">
<li><xsl:value-of select="."/></li>
</xsl:template>
</xsl:stylesheet>
Esta hoja de estilo introduce un comando XSL que aún no se ha encontrado: <xsl:value-of select="."/>. Este comando genera como salida el valor del nodo analizado, en este caso un nodo <erreur>texte</erreur>. El valor de este nodo es el texto comprendido entre las dos etiquetas de apertura y cierre, en este caso texte.
El código errors.xml se transforma mediante la hoja de estilo erreurs.xsl en el siguiente documento HTML:
<html>
<head>
<title>Simulations de calculs d'impots</title>
</head>
<body>
<center>
<h3>Simulations de calculs d'impots</h3>
</center>
<hr>
Les erreurs suivantes se sont produites :
<ul>
<li>erreur 1</li>
<li>erreur 2</li>
</ul>
</body>
</html>
El archivo erreurs.xml, junto con su hoja de estilo, se muestra en un navegador de la siguiente manera:
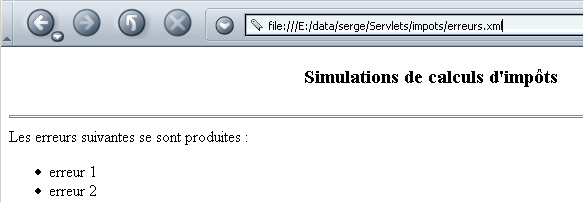
6.2.2. El servlet xmlsimulations
Creamos un archivo index.html que colocamos en el directorio de la aplicación impots. La página visualizada es la siguiente:
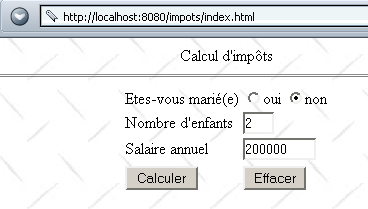
Este documento HTML es un documento estático. Su código es el siguiente:
<html>
<head>
<title>impots</title>
<script language="JavaScript" type="text/javascript">
function effacer(){
// borrar el formulario
with(document.frmImpots){
optMarie[0].checked=false;
optMarie[1].checked=true;
txtEnfants.value="";
txtSalaire.value="";
txtImpots.value="";
}//con
}//borrar
function calculer(){
// verificación de los parámetros antes de enviarlos al servidor
with(document.frmImpots){
//número de hijos
champs=/^\s*(\d+)\s*$/.exec(txtEnfants.value);
if(champs==null){
// el modelo no se ha verificado
alert("Le nombre d'enfants n'a pas été donné ou est incorrect");
nbEnfants.focus();
return;
}//si
//salario
champs=/^\s*(\d+)\s*$/.exec(txtSalaire.value);
if(champs==null){
// el modelo no se ha verificado
alert("Le salaire n'a pas été donné ou est incorrect");
salaire.focus();
return;
}//si
// Todo correcto - se envía
submit();
}//con
}//calcular
</script>
</head>
<body background="/impots/images/standard.jpg">
<center>
Calcul d'impôts
<hr>
<form name="frmImpots" action="/impots/xmlsimulations" method="POST">
<table>
<tr>
<td>Etes-vous marié(e)</td>
<td>
<input type="radio" name="optMarie" value="oui">oui
<input type="radio" name="optMarie" value="non" checked>non
</td>
</tr>
<tr>
<td>Nombre d'enfants</td>
<td><input type="text" size="3" name="txtEnfants" value=""></td>
</tr>
<tr>
<td>Salaire annuel</td>
<td><input type="text" size="10" name="txtSalaire" value=""></td>
</tr>
<tr></tr>
<tr>
<td><input type="button" value="Calculer" onclick="calculer()"></td>
<td><input type="button" value="Effacer" onclick="effacer()"></td>
</tr>
</table>
</form>
</center>
</body>
</html>
Cabe señalar que los datos del formulario se envían a URL /impots/xmlsimulations. Esta aplicación es un servlet Java configurado de la siguiente manera en el archivo web.xml de la aplicación impots:
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE web-app
PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
<web-app>
...........
<servlet>
<servlet-name>xmlsimulations</servlet-name>
<servlet-class>xmlsimulations</servlet-class>
<init-param>
<param-name>xslSimulations</param-name>
<param-value>simulations.xsl</param-value>
</init-param>
<init-param>
<param-name>xslErreurs</param-name>
<param-value>erreurs.xsl</param-value>
</init-param>
<init-param>
<param-name>DSNimpots</param-name>
<param-value>mysql-dbimpots</param-value>
</init-param>
<init-param>
<param-name>admimpots</param-name>
<param-value>admimpots</param-value>
</init-param>
<init-param>
<param-name>mdpimpots</param-name>
<param-value>mdpimpots</param-value>
</init-param>
</servlet>
........
<servlet-mapping>
<servlet-name>xmlsimulations</servlet-name>
<url-pattern>/xmlsimulations</url-pattern>
</servlet-mapping>
</web-app>
- El servlet se llama xmlsimulations y se basa en la clase xmlsimulations.class.
- Tiene como parámetros los parámetros DSNimpots, admimpots y mdpimpots, necesarios para acceder a la base de datos de impuestos. Además, admite otros dos parámetros:
- xslSimulations, que es el nombre del archivo de estilo que debe acompañar a la respuesta XML que contiene las simulaciones
- xslErreurs, que es el nombre del archivo de estilo que debe acompañar a la respuesta XML, que contiene los posibles errores
- tiene un alias xmlsimulations que la hace accesible a través de URL http://localhost:8080/impots/xmlsimulations.
El esqueleto del servlet xmlsimulations es similar al del servlet simulations ya estudiado. La principal diferencia radica en que debe generar XML en lugar de HTML. Esto supondrá la eliminación de los archivos JSP utilizados en las aplicaciones anteriores. Su función principal era mejorar la legibilidad del código HTML generado, evitando que este quedara oculto en el código Java del servlet. Esta función ya no tiene razón de ser. El servlet tiene dos tipos de código XML que generar:
- el de las simulaciones
- el de los errores
Anteriormente hemos presentado y estudiado los dos tipos de respuesta XML que deben proporcionarse en estos dos casos, así como las hojas de estilo que deben acompañarlas. El código del servlet es el siguiente:
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
import java.util.regex.*;
import java.util.*;
public class xmlsimulations extends HttpServlet{
// variables de instancia
String msgErreur=null;
String xslSimulations=null;
String xslErreurs=null;
String DSNimpots=null;
String admimpots=null;
String mdpimpots=null;
impotsJDBC impots=null;
//-------- GET
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException{
// se recupera el flujo de escritura hacia el cliente
PrintWriter out=response.getWriter();
// se especifica el tipo de respuesta
response.setContentType("text/xml");
// la lista de errores
ArrayList erreurs=new ArrayList();
// ¿Se ha realizado correctamente la inicialización?
if(msgErreur!=null){
// ya está, se envía la respuesta con errores al servidor
erreurs.add(msgErreur);
sendErreurs(out,xslErreurs,erreurs);
// se ha completado
return;
}
// se recuperan las simulaciones anteriores de la sesión
HttpSession session=request.getSession();
ArrayList simulations=(ArrayList)session.getAttribute("simulations");
if(simulations==null) simulations=new ArrayList();
// se recuperan los parámetros de la solicitud actual
String optMarie=request.getParameter("optMarie"); // estado civil
String txtEnfants=request.getParameter("txtEnfants"); // número de hijos
String txtSalaire=request.getParameter("txtSalaire"); // salario anual
// ¿Se tienen todos los parámetros esperados?
if(optMarie==null || txtEnfants==null || txtSalaire==null){
// faltan parámetros
// se envía la respuesta con errores
erreurs.add("Demande incomplète. Il manque des paramètres");
sendErreurs(out,xslErreurs,erreurs);
// se ha completado
return;
}
// Tenemos todos los parámetros; los estamos comprobando
// estado civil
if( ! optMarie.equals("oui") && ! optMarie.equals("non")){
// error
erreurs.add("Etat marital incorrect");
}
// número de hijos
txtEnfants=txtEnfants.trim();
if(! Pattern.matches("^\\d+$",txtEnfants)){
// error
erreurs.add("Nombre d'enfants incorrect");
}
// salario
txtSalaire=txtSalaire.trim();
if(! Pattern.matches("^\\d+$",txtSalaire)){
// error
erreurs.add("Salaire incorrect");
}
if(erreurs.size()!=0){
// si hay errores, se señalan
sendErreurs(out,xslErreurs,erreurs);
}else{
// sin errores
try{
// se puede calcular el impuesto a pagar
int nbEnfants=Integer.parseInt(txtEnfants);
int salaire=Integer.parseInt(txtSalaire);
String txtImpots=""+impots.calculer(optMarie.equals("oui"),nbEnfants,salaire);
// se suma el resultado actual a las simulaciones anteriores
String[] simulation={optMarie.equals("oui") ? "oui" : "non",txtEnfants, txtSalaire, txtImpots};
simulations.add(simulation);
// se envía la respuesta con las simulaciones
sendSimulations(out,xslSimulations,simulations);
}catch(Exception ex){}
}//if-else
// se vuelve a introducir la lista de simulaciones en la sesión
session.setAttribute("simulations",simulations);
}//GET
//-------- POST
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException{
doGet(request,response);
}//POST
//-------- INIT
public void init(){
// se recuperan los parámetros de inicialización
ServletConfig config=getServletConfig();
xslSimulations=config.getInitParameter("xslSimulations");
xslErreurs=config.getInitParameter("xslErreurs");
DSNimpots=config.getInitParameter("DSNimpots");
admimpots=config.getInitParameter("admimpots");
mdpimpots=config.getInitParameter("mdpimpots");
// ¿parámetros ok?
if(xslSimulations==null || DSNimpots==null || admimpots==null || mdpimpots==null){
msgErreur="Configuration incorrecte";
return;
}
// se crea una instancia de impotsJDBC
try{
impots=new impotsJDBC(DSNimpots,admimpots,mdpimpots);
}catch(Exception ex){
msgErreur=ex.getMessage();
}
}//init
//-------- sendErreurs
private void sendErreurs(PrintWriter out,String xslErreurs,ArrayList erreurs){
String réponse="<?xml version=\"1.0\" encoding=\"windows-1252\"?>"
+ "<?xml-stylesheet type=\"text/xsl\" href=\""+xslErreurs+"\"?>\n"
+"<erreurs>\n";
for(int i=0;i<erreurs.size();i++){
réponse+="<erreur>"+(String)erreurs.get(i)+"</erreur>\n";
}//for
réponse+="</erreurs>\n";
// se envía la respuesta
out.println(réponse);
}
//-------- sendSimulations
private void sendSimulations(PrintWriter out, String xslSimulations, ArrayList simulations){
String réponse="<?xml version=\"1.0\" encoding=\"windows-1252\"?>"
+ "<?xml-stylesheet type=\"text/xsl\" href=\""+xslSimulations+"\"?>\n"
+ "<simulations>\n";
String[] simulation=null;
for(int i=0;i<simulations.size();i++){
// simulación n.º i
simulation=(String[])simulations.get(i);
réponse+="<simulation "
+"marie=\""+(String)simulation[0]+"\" "
+"enfants=\""+(String)simulation[1]+"\" "
+"salaire=\""+(String)simulation[2]+"\" "
+"impot=\""+(String)simulation[3]+"\" />\n";
}//para
réponse+="</simulations>\n";
// se envía la respuesta
out.println(réponse);
}
}
Detallamos las principales novedades de este código con respecto a lo que ya conocíamos:
- el procedimiento init recupera nuevos parámetros del archivo de configuración web.xml: los nombres de las dos hojas de estilo XSL que deben acompañar a la respuesta se colocan en las variables xslSimulations y xslErreurs. Estas dos hojas de estilo son los archivos simulations.xsl y erreurs.xsl analizados anteriormente. Estos se colocan en el directorio de la aplicación impots:
dos>dir E:\data\serge\Servlets\impots\*.xsl
27/08/2002 08:15 1 030 simulations.xsl
27/08/2002 09:23 795 erreurs.xsl
- El procedimiento GET comienza comprobando si se ha producido algún error durante la inicialización. En caso afirmativo, llama al procedimiento sendErreurs, que genera la respuesta XML adecuada para este caso y, a continuación, se detiene. En esta respuesta XML se inserta la instrucción que designa la hoja de estilo que se debe utilizar.
- Si no se han producido errores, el procedimiento GET analiza los parámetros de la solicitud del cliente. Si encuentra algún error, lo señala utilizando también el procedimiento sendErreurs. De lo contrario, calcula la nueva simulación, la añade a las anteriores almacenadas en la sesión actual y termina enviando su respuesta XML a través del procedimiento sendSimulations. Este último procede de forma análoga al procedimiento sendErreurs.
- Cabe destacar que el servlet anuncia su respuesta como de tipo text/xml:
A continuación se muestran algunos ejemplos de ejecución. El formulario inicial se rellena de la siguiente manera:
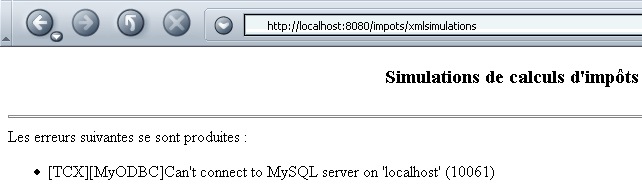
La base de datos MySQL no se ha iniciado, lo que imposibilita la construcción del objeto impots en el procedimiento init del servlet. La respuesta de este es entonces la siguiente:
El código recibido por el navegador (Ver/Fuente) es el siguiente:

Si ahora volvemos a realizar dos simulaciones tras haber iniciado la base de datos MySQL, obtenemos el siguiente resultado:
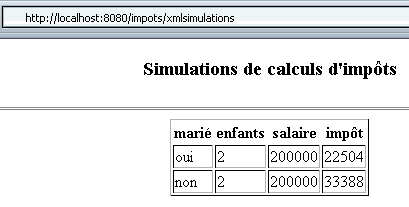
En esta ocasión, el navegador ha recibido el siguiente código:

Cabe destacar que nuestra nueva aplicación es más sencilla que antes debido a la eliminación de los archivos JSP. Parte del trabajo que realizaban estas páginas se ha transferido a las hojas de estilo XSL. La ventaja de nuestra nueva distribución de tareas es que, una vez fijado el formato XML de las respuestas del servlet, el desarrollo de las hojas de estilo es independiente del del servlet.
6.3. Análisis de un documento XML en Java
Las versiones 7 y 8 de nuestra aplicación de impuestos serán clients programadas a partir del servlet anterior xmlsimulations. Estas recibirán código XML que deberán analizar para extraer la información que les interesa. Haremos aquí una pausa en nuestras diferentes versiones y aprenderemos cómo se puede analizar un documento XML en Java. Lo haremos a partir de un ejemplo incluido en la versión 7 de JBuilder llamado MySaxParser. El programa se llama de la siguiente manera:
La aplicación MySaxParser admite un parámetro: el URI (Identificador Uniforme de Recursos) del documento XML que se va a analizar. En nuestro ejemplo, este URI será simplemente el nombre de un archivo XML ubicado en el directorio de la aplicación MySaxParser. Veamos dos ejemplos de ejecución. En el primer ejemplo, el archivo XML analizado es el archivo errores.xml:
<?xml version="1.0" encoding="ISO-8859-1"?>
<?xml-stylesheet type="text/xsl" href="erreurs.xsl"?>
<erreurs>
<erreur>erreur 1</erreur>
<erreur>erreur 2</erreur>
</erreurs>
El análisis arroja los siguientes resultados:
dos> java MySaxParser erreurs.xml
Début du document
Début élément <erreurs>
Début élément <erreur>
[erreur 1]
Fin élément <erreur>
Début élément <erreur>
[erreur 2]
Fin élément <erreur>
Fin élément <erreurs>
Fin du document
Aún no habíamos indicado qué hacía la aplicación MySaxParser, pero aquí vemos que muestra la estructura del documento XML analizado. El segundo ejemplo analiza el archivo XML simulaciones.xml:
<?xml version="1.0" encoding="ISO-8859-1"?>
<?xml-stylesheet type="text/xsl" href="simulations.xsl"?>
<simulations>
<simulation marie="oui" enfants="2" salaire="200000" impot="22504"/>
<simulation marie="non" enfants="2" salaire="200000" impot="33388"/>
</simulations>
El análisis arroja los siguientes resultados:
dos>java MySaxParser simulations.xml
Début du document
Début élément <simulations>
Début élément <simulation>
marie = oui
enfants = 2
salaire = 200000
impot = 22504
Fin élément <simulation>
Début élément <simulation>
marie = non
enfants = 2
salaire = 200000
impot = 33388
Fin élément <simulation>
Fin élément <simulations>
Fin du document
La clase MySaxParser contiene todo lo que necesitamos en nuestra aplicación de impuestos, ya que ha sido capaz de detectar tanto los errores como las simulaciones que podría enviar el servidor web. Examinemos su código:
import java.io.IOException;
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import org.apache.xerces.parsers.SAXParser;
import java.util.regex.*;
// la clase
public class MySaxParser extends DefaultHandler {
// valor de un elemento del árbol XML
private StringBuffer valeur=new StringBuffer();
// una expresión regular del valor de un elemento cuando se desea ignorar
// los «espacios en blanco» que lo preceden o lo siguen
private static Pattern ptnValeur=null;
private static Matcher résultats=null;
// -------- main
public static void main(String[] argv) {
// verificación del número de parámetros
if (argv.length != 1) {
System.out.println("Usage: java MySaxParser [URI]");
System.exit(0);
}
// se recupera el URI del archivo XML que se va a analizar
String uri = argv[0];
try {
// creación de un analizador XML (parser)
XMLReader parser = XMLReaderFactory.createXMLReader("org.apache.xerces.parsers.SAXParser");
// se indica al analizador el objeto que va a implementar los métodos
// startDocument, endDocument, startElement, endElement, caracteres
MySaxParser MySaxParserInstance = new MySaxParser();
parser.setContentHandler(MySaxParserInstance);
// se inicializa el modelo de valor de un elemento
ptnValeur=Pattern.compile("^\\s*(.*?)\\s*$");
// se indica al analizador el documento XML que debe analizar
parser.parse(uri);
}
catch(Exception ex) {
// error
System.err.println("Erreur : " + ex);
// registro
ex.printStackTrace();
}
}//main
// -------- startDocument
public void startDocument() throws SAXException {
// procedimiento que se invoca cuando el analizador encuentra el inicio del documento
System.out.println("Début du document");
}//startDocument
// -------- endDocument
public void endDocument() throws SAXException {
// procedimiento llamado cuando el analizador llega al final del documento
System.out.println("Fin du document");
}//endDocument
// -------- startElement
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
// procedimiento llamado por el analizador cuando encuentra el inicio de una etiqueta
// uri: ¿URI del documento analizado?
// localName: nombre del elemento que se está analizando
// qName: lo mismo, pero «calificado» por un espacio de nombres si lo hay
// attributes: lista de atributos del elemento
// seguimiento
System.out.println("Début élément <"+localName+">");
// ¿tiene el elemento atributos?
for (int i = 0; i < attributes.getLength(); i++) {
System.out.println(attributes.getLocalName(i) + " = " + attributes.getValue(i));
}//para
}//startElement
// -------- caracteres
public void characters(char[] ch, int start, int length) throws SAXException {
// procedimiento llamado repetidamente por el analizador cuando encuentra texto
// entre dos etiquetas <etiqueta>texto</etiqueta>
// el texto se encuentra en ch a partir del carácter start y tiene una longitud de length caracteres
// el texto se añade al búfer valor
valeur.append(ch, start, length);
}//caracteres
// -------- endElement
public void endElement(String uri, String localName, String qName)
throws SAXException {
// procedimiento llamado por el analizador cuando encuentra un fin de etiqueta
// uri: ¿URI del documento analizado?
// localName: nombre del elemento que se está analizando
// qName: lo mismo, pero «calificado» por un espacio de nombres si lo hay
// se muestra el valor del elemento
String strValeur=valeur.toString();
if (ptnValeur==null) System.out.println("null");
résultats=ptnValeur.matcher(strValeur);
if (résultats.find() && ! résultats.group(1).equals("")){
System.out.println("["+résultats.group(1)+"]");
}//if
// se deja el valor del elemento en blanco
valeur.setLength(0);
// seguido de
System.out.println("Fin élément <"+localName+">");
}//endElement
}//clase
En primer lugar, definamos un acrónimo que aparece con frecuencia en el análisis de documentos XML: SAX, que significa «Simple Api for Xml». Se trata de un conjunto de clases Java que facilitan el trabajo con los documentos XML. Hay dos versiones de API: SAX1 y SAX2. La aplicación anterior utiliza API y SAX2.
La aplicación importa varios paquetes:
Los dos primeros vienen con el JDK 1.4, el tercero no. El paquete xerces.jar está disponible en el sitio web del servidor Apache. Viene con JBuilder 7, pero también con Tomcat 4.x:
Por lo tanto, si queremos compilar la aplicación anterior fuera de JBuilder 7 y disponemos de JDK 1.4 y de Tomcat 4.x, podremos escribir:
Al ejecutarla, se hará lo mismo:
dos>java -classpath ".;E:\Program Files\Apache Tomcat 4.0\common\lib\xerces.jar" MySaxParser simulations.xml
La clase MySaxParser deriva de la clase DefaultHandler. Volveremos sobre ello más adelante. Analicemos el código del procedimiento main:
// se recupera el URI del archivo XML que se va a analizar
String uri = argv[0];
try {
// creación de un analizador XML (parser)
XMLReader parser = XMLReaderFactory.createXMLReader("org.apache.xerces.parsers.SAXParser");
// se indica al analizador el objeto que va a implementar los métodos
// startDocument, endDocument, startElement, endElement, caracteres
MySaxParser MySaxParserInstance = new MySaxParser();
parser.setContentHandler(MySaxParserInstance);
// se inicializa el modelo de valor de un elemento
ptnValeur=Pattern.compile("^\\s*(.*?)\\s*$");
// se indica al analizador el documento XML que debe analizar
parser.parse(uri);
}
catch(Exception ex) {
// error
System.err.println("Erreur : " + ex);
// registro
ex.printStackTrace();
}
Para analizar un documento XML, nuestra aplicación necesita un analizador de código XML denominado «parser».
El analizador XML utilizado es el que proporciona el paquete xerces.jar. El objeto recuperado es de tipo XMLReader. XMLReader es una interfaz de la que aquí utilizamos dos métodos:
indica al analizador el objeto de tipo ContentHandler que gestionará los eventos que generará durante el análisis del documento XML | |
inicia el análisis del documento XML pasado como parámetro |
Cuando el analizador analice el documento XML, emitirá eventos tales como: «he encontrado el inicio del documento, el inicio de una etiqueta, un atributo de etiqueta, el contenido de una etiqueta, el final de una etiqueta, el final del documento, ...». Transmite estos eventos al objeto ContentHandler que se le ha proporcionado. ContentHandler es una interfaz que define los métodos que deben implementarse para gestionar todos los eventos que el analizador XML puede generar. DefaultHandler es una clase que realiza una implementación por defecto de estos métodos. Los métodos implementados en DefaultHandler no hacen nada, pero existen. Cuando hay que indicar al analizador qué objeto va a gestionar los eventos que va a generar mediante la instrucción
, resulta práctico pasar como parámetro un objeto de tipo DefaultHandler. Si nos quedáramos ahí, no se procesaría ningún evento del analizador, pero nuestro programa sería sintácticamente correcto. En la práctica, se pasa como parámetro al analizador un objeto derivado de la clase DefaultHandler, en el que se redefinen los métodos que gestionan únicamente los eventos que nos interesan. Esto es lo que se hace aquí:
// se indica al analizador el objeto que va a implementar los métodos
// startDocument, endDocument, startElement, endElement, caracteres
MySaxParser MySaxParserInstance = new MySaxParser();
parser.setContentHandler(MySaxParserInstance);
// se indica al analizador el documento XML que debe analizar
parser.parse(uri);
Pasamos al analizador una instancia de la clase mySaxParser, que es nuestra clase y que se ha definido anteriormente mediante la declaración
y se inicia el análisis del documento, al que se ha pasado URI como parámetro. A partir de ahí, comienza el análisis del documento XML. El analizador emite eventos y, para cada uno de ellos, llama a un método específico del objeto encargado de procesar dichos eventos, en este caso nuestro objeto MySaxParser. Este procesa cinco eventos concretos, ignorando los demás:
evento emitido por el analizador | método de procesamiento |
void startDocument() | |
void endDocument() | |
public void startElement(String uri, String localName, String qName, Atributos attributes) uri: ? localName: nombre del elemento analizado. Si el elemento encontrado es <simulations>, tendremos localName="simulations". qName: nombre calificado por un espacio de nombres del elemento analizado. Un documento XML puede definir un espacio de nombres, por ejemplo, XX. El nombre calificado de la etiqueta anterior sería entonces XX:simulations. attributes: lista de atributos de la etiqueta | |
public void characters(char[] ch, int start, int length) ch: matriz de caracteres start: índice del primer carácter a utilizar en la matriz ch length: número de caracteres que se tomarán de la matriz ch El método characters puede invocarse repetidamente. Para construir el valor de un elemento, se utiliza entonces un búfer que:
| |
void endElement(String uri, String localName, String qName) los parámetros son los del método startElement. |
El método startElement permite recuperar los atributos del elemento mediante el parámetro attributes de tipo Attributes:
- el número de atributos está disponible en attributes.getLength()
- el nombre del atributo i está disponible en attributes.getLocalName(i)
- el valor del atributo i está disponible en attributes.getValue(i)
- el valor del atributo de nombre localName en attributes.getValue(localName)
Una vez explicado esto, el programa anterior, junto con los ejemplos de ejecución, se entiende por sí solo. Se ha utilizado una expresión regular para extraer los valores de los elementos, de modo que un texto como XML:
debe dar como valor asociado a la etiqueta <erreur> el texto «error 1», sin los espacios ni los saltos de línea que pudieran precederlo o seguirlo.
6.4. Aplicación de impuestos: version 7
Ahora disponemos de todos los elementos para escribir los clients programados para nuestro servicio de impuestos, que genera XML. Recuperamos el version 4 de nuestra aplicación para crear el cliente y conservamos el version 6 para el servidor. En esta aplicación cliente-servidor:
- el servicio de simulaciones del cálculo de impuestos lo realiza el servlet xmlsimulations. La respuesta del servidor está, por tanto, en formato XML, tal y como hemos visto en el version 6.
- el cliente ya no es un navegador, sino un cliente Java autónomo. Su interfaz gráfica es la de version 4.
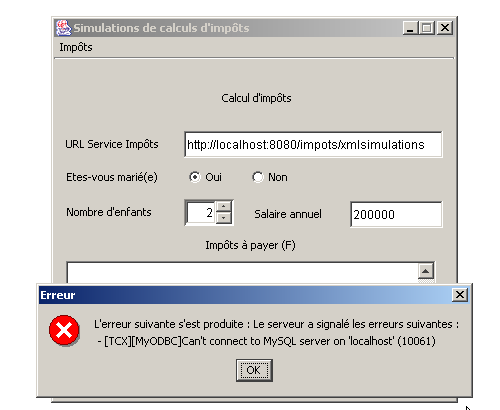
A continuación se muestran algunos ejemplos de ejecución. En primer lugar, un caso de error: el cliente consulta el servlet xmlsimulations cuando este no se ha podido inicializar correctamente debido a que el SGBD MySQL no se había iniciado:
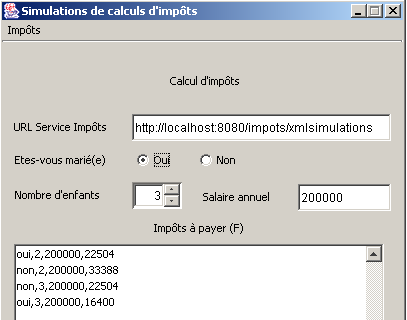
Se inicia MySQL y se realizan algunas simulaciones:
El cliente de este nuevo version solo se diferencia del cliente del version 4 en la forma en que procesa la respuesta del servidor. Nada más cambia. En el version 4, el cliente recibía código HTML en el que buscaba la información que le interesaba utilizando expresiones regulares. Aquí, el cliente recibe el código XML, del que extrae la información que le interesa mediante un analizador sintáctico XML.
Recordemos las líneas generales del procedimiento relacionado con el menú «Calcular» del version 4 de nuestro cliente, ya que es principalmente ahí donde se realizan los cambios:
void mnuCalculer_actionPerformed(ActionEvent e) {
....
try{
// se calcula el impuesto
calculerImpots(urlImpots,rdOui.isSelected(),nbEnfants.intValue(),salaire);
}catch (Exception ex){
// se muestra el error
JOptionPane.showMessageDialog(this,"L'erreur suivante s'est produite : " + ex.getMessage(),"Erreur",JOptionPane.ERROR_MESSAGE);
}
....
}//mnuCalculer_actionPerformed
public void calculerImpots(URL urlImpots,boolean marié, int nbEnfants, int salaire)
throws Exception{
// cálculo del impuesto
// urlImpots: URL de la Agencia Tributaria
// casado: true si está casado, false en caso contrario
// nbEnfants: número de hijos
// salario: salario anual
// se extrae de urlImpots la información necesaria para conectarse al servidor de Hacienda
....
try{
//: se conecta al servidor
....
// se crean los flujos de entrada y salida del cliente TCP
....
// se solicita el URL - envío de los encabezados HTTP
....
// se lee la primera línea de la respuesta
....
// se lee la respuesta hasta el final de los encabezados buscando la posible cookie
while((réponse=IN.readLine())!=null){
.... }//while
// se han terminado los encabezados HTTP - pasamos al código HTML
// para recuperar las simulaciones
ArrayList listeSimulations=getSimulations(IN,OUT,simulations);
simulations.clear();
for (int i=0;i<listeSimulations.size();i++){
simulations.addElement(listeSimulations.get(i));
}
// se acabó
....
}//calculerImpots
private ArrayList getSimulations(BufferedReader IN, PrintWriter OUT, DefaultListModel simulations) throws Exception{
....
}
Todo este código sigue siendo válido en el nuevo version. Solo el procesamiento de la respuesta HTML del servidor (parte enmarcada arriba) y su visualización deben sustituirse por el procesamiento de la respuesta XML del servidor y su visualización:
// se acabó para los encabezados HTTP - pasamos al código XML
// para recuperar las simulaciones o los errores
ImpotsSaxParser parseur=new ImpotsSaxParser(IN);
ArrayList listeErreurs=parseur.getErreurs();
ArrayList listeSimulations=parseur.getSimulations();
// cierre de la conexión al servidor
client.close();
// limpieza de la lista de visualización
simulations.clear();
// errores
if(listeErreurs.size()!=0){
// se concatenan todos los errores
String msgErreur="Le serveur a signalé les erreurs suivantes :\n";
for(int i=0;i<listeErreurs.size();i++){
msgErreur+=" - "+(String)listeErreurs.get(i);
}
// visualización de errores
throw new Exception(msgErreur);
}//if
// simulaciones
for (int i=0;i<listeSimulations.size();i++){
simulations.addElement(listeSimulations.get(i));
}
return;
¿Qué hace el fragmento de código anterior?
- Crea un analizador XML y le pasa el flujo IN, que contiene el código XML enviado por el servidor. Este flujo también contenía los encabezados HTTP, pero estos ya se han leído y procesado. Por lo tanto, solo queda la parte XML de la respuesta. El analizador genera dos listas de cadenas de caracteres: la lista de errores, si los ha habido, y, en caso contrario, la de simulaciones. Estas dos listas son mutuamente excluyentes.
- Si la lista de errores no está vacía, los mensajes contenidos en la lista se concatenan en un único mensaje de error y se lanza una excepción con este mensaje como parámetro. Esta excepción se muestra en el procedimiento mnuCalculer_actionPeformed que ha llamado a calculerImpots.
- Si la lista de simulaciones no está vacía, se muestra en el componente jList de la interfaz gráfica.
Veamos ahora el analizador de la respuesta XML del servidor, analizador que se deriva directamente del estudio que hemos realizado anteriormente sobre cómo analizar un documento XML en Java:
import java.io.IOException;
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import org.apache.xerces.parsers.SAXParser;
import java.util.regex.*;
import java.io.*;
import java.util.*;
import javax.swing.*;
// la clase
public class ImpotsSaxParser extends DefaultHandler {
// valor de un elemento del árbol XML
private StringBuffer valeur=new StringBuffer();
// una expresión regular del valor de un elemento cuando se desea ignorar
// los «espacios en blanco» que lo preceden o lo siguen
private Pattern ptnValeur=null;
private Matcher résultats=null;
// las listas de elementos XML
private ArrayList listeSimulations=new ArrayList();
private ArrayList listeErreurs=new ArrayList();
// elementos XML
private ArrayList éléments=new ArrayList();
String élément="";
// -------- generador
public ImpotsSaxParser(BufferedReader IN) throws Exception{
// creación de un analizador XML (parser)
XMLReader parser = XMLReaderFactory.createXMLReader("org.apache.xerces.parsers.SAXParser");
// se indica al analizador el objeto que va a implementar los métodos
// startDocument, endDocument, startElement, endElement, caracteres
parser.setContentHandler(this);
// se inicializa el modelo de valor de un elemento
ptnValeur=Pattern.compile("^\\s*(.*?)\\s*$");
// al principio no hay ningún elemento XML activo
éléments.add("");
// se analiza el documento
parser.parse(new InputSource(IN));
}//constructor
// -------- startElement
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
// procedimiento llamado por el analizador cuando encuentra el inicio de una etiqueta
// uri: ¿URI del documento analizado?
// localName: nombre del elemento que se está analizando
// qName: lo mismo, pero «calificado» por un espacio de nombres si lo hay
// attributes: lista de atributos del elemento
// se anota el nombre del elemento
élément=localName.toLowerCase();
éléments.add(élément);
// ¿tiene el elemento atributos?
if(élément.equals("simulation") && attributes.getLength()==4){
// es una simulación: se recuperan los atributos
String simulation=attributes.getValue("marie")+","+
attributes.getValue("enfants")+","+
attributes.getValue("salaire")+","+
attributes.getValue("impot");
// se añade la simulación a la lista de simulaciones
listeSimulations.add(simulation);
}//if
}//startElement
// -------- caracteres
public void characters(char[] ch, int start, int length) throws SAXException {
// procedimiento llamado repetidamente por el analizador cuando encuentra texto
// entre dos etiquetas <etiqueta>texto</etiqueta>
// el texto se encuentra en ch a partir del carácter start y tiene una longitud de length caracteres
// el texto se añade al búfer valor si se trata del elemento error
if (élément.equals("erreur"))
valeur.append(ch, start, length);
}//caracteres
// -------- endElement
public void endElement(String uri, String localName, String qName)
throws SAXException {
// procedimiento llamado por el analizador cuando encuentra un final de etiqueta
// uri: ¿URI del documento analizado?
// localName: nombre del elemento que se está analizando
// qName: lo mismo, pero «calificado» por un espacio de nombres si lo hay
// caso de error
if(élément.equals("erreur")){
//: se recupera el valor del elemento de error
String strValeur=valeur.toString();
// se eliminan los «espacios» innecesarios y se guarda en la lista de
// errores si no está vacía
résultats=ptnValeur.matcher(strValeur);
if (résultats.find() && ! résultats.group(1).equals("")){
listeErreurs.add(résultats.group(1));
}//if
}
// se pone el valor del elemento en vacío
valeur.setLength(0);
// se reinicia el nombre del elemento
éléments.remove(éléments.size()-1);
élément=(String)éléments.get(éléments.size()-1);
}//endElement
// --------- getErreurs
public ArrayList getErreurs(){
return listeErreurs;
}
// --------- getSimulations
public ArrayList getSimulations(){
return listeSimulations;
}
}//clase
- El generador recibe el flujo XML IN para analizarlo y realiza inmediatamente dicho análisis. Una vez finalizado este, se ha creado el objeto, así como las listas (ArrayList) de errores (listeErreurs) y de simulaciones (listeSimulations). Ahora solo le queda al procedimiento que ha construido el objeto recuperar las dos listas mediante los métodos getErreurs y getSimulations.
- Solo nos interesan aquí tres eventos generados por el analizador XML:
- inicio de un elemento XML, evento que será procesado por el procedimiento startElement. Este procedimiento deberá procesar las etiquetas <simulation marie=".." enfants=".." salaire=".." impot=".."> y <erreur>...</erreur>.
- valor de un elemento XML, evento que será procesado por el procedimiento characters.
- fin de un elemento XML, evento que será procesado por el procedimiento endElement.
- En el procedimiento startElement, si se trata del elemento <simulation marie=".." enfants=".." salaire=".." impot="..">, se recuperan los cuatro atributos mediante attributes.getValue("nombre del atributo"). En todos los casos, se almacena el nombre del elemento en una variable «elemento» y se añade a una lista (ArrayList) de elementos: elem1, elem2, ..., elemN. Esta lista se gestiona como una pila cuyo último elemento es el elemento XML que se está analizando. Cuando se produce el evento «fin de elemento», se retira el último elemento de la lista y se modifica el nuevo elemento actual. Esto se realiza en el procedimiento endElement.
- El procedimiento characters es idéntico al que se estudió en un ejemplo anterior. Simplemente nos aseguramos de que el elemento actual sea efectivamente el elemento <erreur>, precaución que normalmente no es necesaria aquí. Este tipo de precaución también se tomó en el procedimiento startElement para verificar que se trataba de un elemento <simulation>.
6.5. Conclusión
Gracias a su respuesta XML, la aplicación impots se ha vuelto más fácil de gestionar tanto para su diseñador como para los diseñadores de las aplicaciones cliente.
- El diseño de la aplicación de servidor puede ahora confiarse a dos tipos de personas: el desarrollador Java del servlet y el diseñador gráfico, que se encargará de la apariencia de la respuesta del servidor en los navegadores. A este último le basta con conocer la estructura de la respuesta XML del servidor para crear las hojas de estilo que la acompañarán. Recordemos que estas hojas de estilo son objeto de archivos XSL separados e independientes del servlet Java. Por lo tanto, el diseñador gráfico puede trabajar independientemente del desarrollador Java.
- Los diseñadores de las aplicaciones cliente también solo necesitan conocer la estructura de la respuesta XML del servidor. Las modificaciones que el diseñador gráfico pueda realizar en las hojas de estilo no tienen ninguna repercusión en esta respuesta XML, que sigue siendo siempre la misma. Esto supone una enorme ventaja.
- ¿Cómo puede el desarrollador hacer evolucionar su servlet Java sin estropearlo todo? En primer lugar, mientras su respuesta XML no cambie, puede organizar su servlet como quiera. También puede hacer evolucionar la respuesta XML siempre que mantenga los elementos <error> y <simulación> esperados por sus clients. De este modo, puede añadir nuevas etiquetas a esta respuesta. El diseñador gráfico las tendrá en cuenta en sus hojas de estilo y los navegadores podrán obtener las nuevas versiones de la respuesta. Los clients programados seguirán funcionando con el modelo antiguo, y las nuevas etiquetas simplemente se ignorarán. Para que esto sea posible, es necesario que en el análisis XML de la respuesta del servidor se identifiquen correctamente las etiquetas buscadas. Esto es lo que se ha hecho en nuestro cliente XML de la aplicación de impuestos, donde en los procedimientos se especificaba que se procesaban las etiquetas <erreur> y <simulation>. De este modo, se ignoran las demás etiquetas.