5. El tipo Stream<T> en Java 8
5.1. Ejemplo-01 - La clase Stream
Las operaciones en flujos Observable tienen muchas similitudes con los flujos Stream. Una diferencia es que un elemento de un flujo Stream no se puede procesar hasta que se haya obtenido todo el flujo, mientras que un elemento de un flujo Observable se puede procesar (observar) tan pronto como se obtiene, sin esperar a que se obtenga todo el flujo Observable. Otra diferencia es que, una vez obtenido el Stream, sus valores se utilizan extrayéndolos uno a uno del Stream. En el caso del Observable, es diferente. Tan pronto como emite un valor, ese valor se envía a su suscriptor.
Varias clases implementan el concepto de Stream. A continuación presentamos la clase Stream<T>:
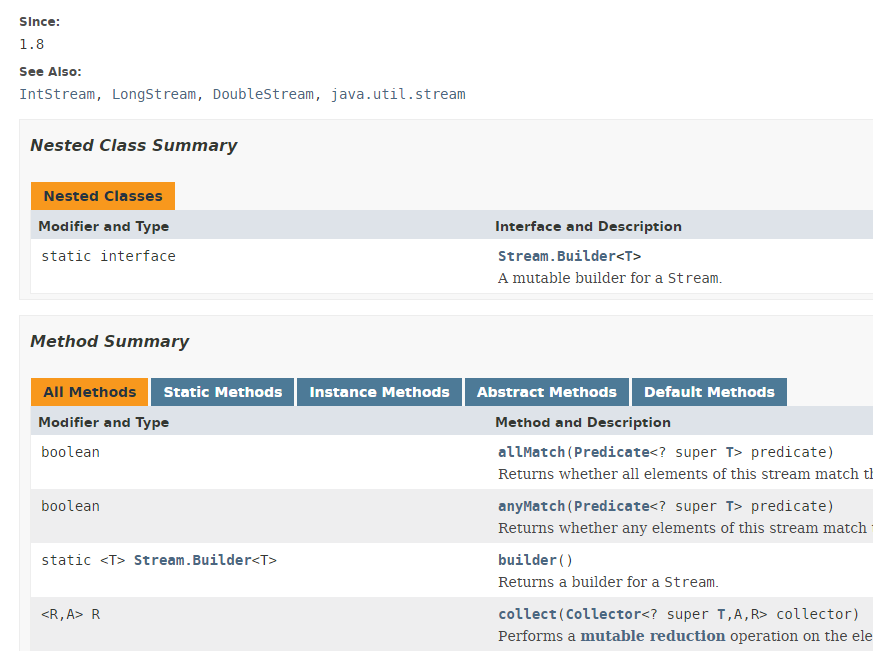
La clase Stream ofrece 39 métodos. Presentaremos algunos de ellos. Considera el siguiente código:
 |
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple01 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// display 1
personnes.stream().forEach(p -> {
System.out.println(p);
});
System.out.println("----------------");
// display 2
personnes.stream().forEach(System.out::println);
}
}
- línea 11: instanciamos una lista de personas;
- línea 13: a partir de esta lista, creamos un Stream. Todas las colecciones se pueden convertir en Streams de esta manera. Esto nos permite aprovechar todos los métodos de esta clase, lo que nos permite procesar los elementos de la colección de forma más concisa que con bucles. También nos permite beneficiarnos del procesamiento paralelo de elementos cuando sea posible;
- línea 13: el método [Stream.forEach] tiene la siguiente firma:
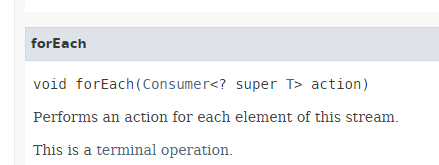 |
Vemos que el parámetro del método es la interfaz funcional [Consumer<T>] presentada en la sección 4.4, una interfaz cuyo único método opera sobre el tipo T y no devuelve nada.
- En el código:
personnes.stream().forEach(p -> {
System.out.println(p);
});
- [people.stream()] genera un flujo de elementos de tipo [Person] que alimenta el método [forEach]. El parámetro p es de tipo [Person], y la función lambda proporcionada imprime esta persona;
El código anterior se puede simplificar de la siguiente manera (línea 18):
personnes.stream().forEach(System.out::println);
En lugar de pasar el valor de una función lambda como parámetro, pasamos la referencia a un método existente, en este caso el método println de la clase System.out. Por supuesto, este método debe tener la firma correcta, en este caso la firma del método [Consumer.accept]: void accept(T t). Como se mencionó anteriormente, el parámetro del método [accept] será de tipo [Person];
Obtenemos los siguientes resultados:
Una vez que se ha procesado un Stream, ya no se puede volver a procesar. Si desea procesarlo de nuevo, deberá reconstruirlo. Esto se ilustra en el siguiente código [Ejemplo01b]:
package dvp.java8.streams;
import java.util.stream.Stream;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple01b {
public static void main(String[] args) {
// people flows
Stream<Personne> personnes = Personnes.get().stream();
// display 1
personnes.forEach(p -> {
System.out.println(p);
});
System.out.println("----------------");
// display 2
personnes.forEach(System.out::println);
}
}
- Línea 11: Para optimizar el código, decidimos construir el Stream solo una vez. Los resultados obtenidos son los siguientes:
{"nom":"jean","age":20,"poids":70.0,"sexe":"HOMME"}
{"nom":"marie","age":10,"poids":30.0,"sexe":"FEMME"}
{"nom":"camille","age":30,"poids":55.0,"sexe":"FEMME"}
----------------
Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.sourceStageSpliterator(Unknown Source)
at java.util.stream.ReferencePipeline$Head.forEach(Unknown Source)
at dvp.java8.streams.Exemple02b.main(Exemple02b.java:18)
Cada vez que quieras utilizar un Stream, debes crearlo, incluso si ya se ha creado anteriormente.
5.2. Ejemplo-02: procesamiento paralelo de elementos en un Stream
 |
Considera el siguiente código:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple02 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// display 1
personnes.stream().forEach(Exemple02::affiche);
System.out.println("-----------------");
// display 2
personnes.stream().parallel().forEach(Exemple02::affiche);
}
public static void affiche(Personne p) {
System.out.printf("Personne %s sur thread %s%n", p, Thread.currentThread().getName());
}
}
- líneas 19–21: el método [display] imprime en la consola la cadena JSON de una persona junto con el nombre del hilo de ejecución en el que se está realizando la visualización;
- línea 13: muestra una lista de personas. Tenga en cuenta que el parámetro del método [forEach] es la referencia al método estático anterior;
- línea 16: hacemos lo mismo, pero con el método [parallel], solicitamos que los elementos del flujo se procesen en paralelo en varios subprocesos. No todo el procesamiento se puede realizar en paralelo. Aquí, debemos asumir que el orden de visualización no importa porque, en el procesamiento en paralelo, el orden de ejecución de los subprocesos no está garantizado. Obsérvese también una sintaxis que se volverá omnipresente tanto para Streams como para Observables:
- (continuación)
- el flujo produce elementos e1 que alimentan el método m1;
- flux.m1 es, a su vez, un flujo de elementos e2 que alimentan el método m2;
- flux.m1.m2 es un flujo de elementos e3 que alimentan el método m3;
El tipo de los elementos e1, e2, e3 puede cambiar a medida que el flujo inicial se somete a procesamiento.
La ejecución de este código da como resultado lo siguiente:
Podemos ver que la ejecución en paralelo (líneas 5–7) tuvo lugar en tres subprocesos diferentes y no siguió el orden de los elementos tal y como se muestra en las líneas 1–3. En este documento, no nos centraremos mucho en el procesamiento en paralelo de elementos en un Stream, ya que eso requeriría discutir las condiciones que hacen posible dicho procesamiento. Descubrimos entonces que pocas operaciones pueden realizarse en paralelo. Una que se presta naturalmente al paralelismo es la suma de los elementos numéricos de un stream, que ahora vamos a presentar.
5.3. Ejemplo-03: Procesamiento paralelo de elementos de un Stream
 |
Consideremos el siguiente código (Ejemplo 03a):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class Exemple03a {
public static void main(String[] args) {
final long limite = 10_000_000L;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// sum of numbers - sequential method
début = new Date().getTime();
long somme = nombres.stream().reduce(0L, (s, i) -> s + i);
System.out.printf("somme séquentielle : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- En la línea 22, utilizamos el método [reduce], que tiene la siguiente firma:
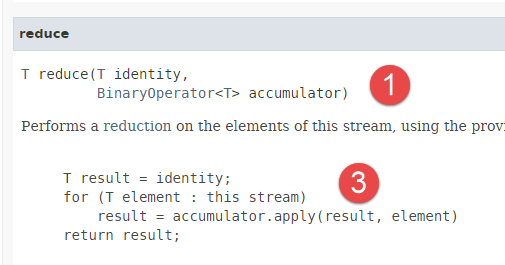 |  |
- El método [reduce] funciona con elementos de tipo T;
- el método [reduce] aplica el mismo procesamiento a todos los elementos de un flujo: el valor inicial de un acumulador se proporciona como primer parámetro. Como segundo parámetro se proporciona un método que implementa la interfaz funcional [BinaryOperator] [2]: basándose en cada elemento y en el acumulador, este método devuelve un nuevo valor para el acumulador. El valor final del acumulador es el valor devuelto por el método [reduce]. El código [3] ilustra este mecanismo. El método [apply] es el método de la interfaz funcional [BinaryOperator] [2];
Volvamos al código de ejemplo:
- línea 12: mostramos el número de núcleos detectados por la JVM;
- líneas 15-18: se crea una lista de 10 millones de números;
- línea 22: se calcula la suma de estos números de forma secuencial utilizando un único subproceso;
Obtenemos los siguientes resultados:
Ahora, sustituyamos la línea 22 del código por lo siguiente (Ejemplo03b):
long somme = nombres.stream().parallel().reduce(0L, (s, i) -> s + i);
Indicamos que los elementos del Stream se procesen en paralelo utilizando múltiples subprocesos. Esto es posible porque el orden en el que se suman los números no importa. Por lo tanto, podemos asignar n1 números al subproceso T1, n2 números al subproceso T2, ... y finalmente sumar los resultados proporcionados por estos diferentes subprocesos. A continuación, obtenemos los siguientes resultados:
Por lo tanto, prácticamente no hay ganancia de rendimiento. Esto suele ser el caso en los ejemplos que siguen. La gestión de subprocesos en sí misma requiere mucho tiempo. La operación realizada por cada núcleo debe ser lo suficientemente compleja como para que la ganancia de rendimiento sea apreciable. Esto queda demostrado en el siguiente ejemplo (Ejemplo03c):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.function.BinaryOperator;
public class Exemple03c {
public static void main(String[] args) {
final long limite = 10_000L;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// sum of numbers - sequential method
début = new Date().getTime();
BinaryOperator<Long> bo = (s, i) -> {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
}
return s + i;
};
long somme = nombres.stream().reduce(0L, bo);
System.out.printf("somme séquentielle : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- línea 30: volvemos a utilizar el método [reduce], pasándole como parámetro la referencia al método de las líneas 23–29;
- línea 28: el método [bo] devuelve la suma de sus dos parámetros;
- líneas 24–27: de forma artificial, hacemos que el subproceso espere 1 milisegundo para simular un trabajo intensivo;
A continuación, obtenemos los siguientes resultados:
Ahora, si sustituimos la línea 30 por lo siguiente:
long somme = nombres.stream().parallel().reduce(0L, bo);
obtenemos los siguientes resultados:
Podemos ver claramente la mejora de rendimiento conseguida al ejecutar el cálculo de la suma en paralelo. Para procesar 8 números:
- el hilo secuencial espera 8 veces 1 milisegundo, es decir, 8 ms;
- los 8 subprocesos paralelos esperan cada uno 1 milisegundo al mismo tiempo (por simplicidad), por lo que el total es de 1 milisegundo para los 8 números;
Por lo tanto, podemos esperar que la ejecución en paralelo sea 8 veces más rápida que la ejecución secuencial. Eso es más o menos lo que ocurre aquí.
5.4. Ejemplo-04: Filtrado de un flujo
 |
Considera el siguiente código:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple04 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// displays
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(p -> {
System.out.println(p);
});
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(p -> {
System.out.println(p);
});
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(System.out::println);
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(System.out::println);
}
}
- línea 14: el método [Stream.filter] tiene la siguiente firma:
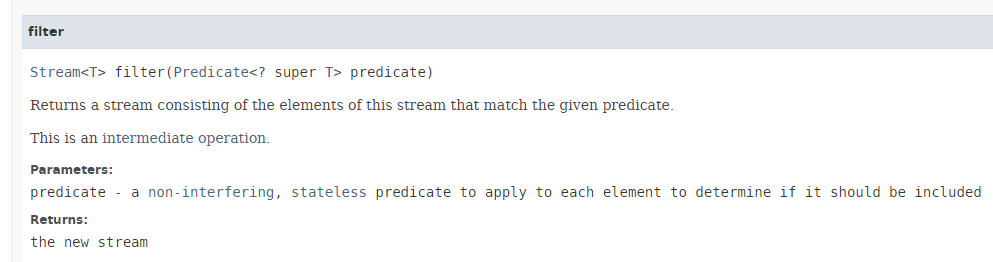 |
- El método [filter] espera como parámetro una instancia de la interfaz funcional [Predicate] presentada en la sección 4.2, cuyo único método que debe implementarse es el siguiente: boolean test(T t);
- El método [filter] devuelve los elementos del Stream que satisfacen el Predicate. Por lo tanto, se utiliza para filtrar el Stream;
Consideremos el siguiente código:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple04 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// displays
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(p -> {
System.out.println(p);
});
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(p -> {
System.out.println(p);
});
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(System.out::println);
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(System.out::println);
}
}
- líneas 14-16: muestra a las personas menores de 28 años;
- líneas 18-20: muestra a las personas con un peso <50;
- línea 22: hace lo mismo que las líneas 14-16, pero de forma más concisa;
- línea 24: hace lo mismo que las líneas 18-20, pero de forma más concisa;
Los resultados de la ejecución son los siguientes:
5.5. Ejemplo-05: Crear un Stream<T2> a partir de un Stream<T1>
 |
Fíjate en el siguiente código:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple05 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// displays
System.out.println("Personne --> String ----------------------");
personnes.stream().map(p -> p.getNom()).forEach(System.out::println);
System.out.println("Personne --> Integer ----------------------");
personnes.stream().map(p -> p.getAge()).forEach(System.out::println);
}
}
- Línea 13: El método [Stream.map] tiene la siguiente firma:
 |
El parámetro del método [Stream.map] es una instancia de la interfaz funcional [Function] presentada en la sección 4.3, cuyo único método que debe implementarse es: R apply(T t). Vemos que, dado un tipo T, la función [apply] produce un tipo R. Por lo tanto, el método [Stream.map] producirá un Stream de tipo R a partir de un stream de tipo T (un stream de tipo T significa aquí, en una imprecisión técnica que mantendremos, un stream de elementos de tipo T).
Examinemos ahora el código del ejemplo:
- línea 14: de una persona p, conservamos solo el nombre. Obtenemos así un stream de Strings;
- línea 14: de una persona p, solo conservamos el nombre. Por lo tanto, obtenemos un stream de Integer;
Los resultados obtenidos son los siguientes:
5.6. Ejemplo-06: Otros métodos de la clase Stream<T>
 |
A continuación, ilustramos algunos de los 39 métodos de la clase Stream con el siguiente código:
package dvp.java8.streams;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import dvp.data.Personne;
import dvp.data.Personnes;
import java.util.Comparator;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.DoubleStream;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class Exemple06 {
// mapper jSON
static private ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// list of persons
List<Personne> personnes = Personnes.get();
// all people
affiche("all", personnes);
// the 1st person
affiche("findFirst", personnes.stream().findFirst().get());
// any person
affiche("findAny", personnes.stream().findAny().get());
// people without the 1st
affiche("skip 1", personnes.stream().skip(1L).collect(Collectors.toList()));
// the first 2 people
affiche("limit 2", personnes.stream().limit(2L).collect(Collectors.toList()));
// the number of people
affiche("count", personnes.stream().count());
// the oldest person
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
// the lightest person
affiche("poids min", personnes.stream().min(Comparator.comparingDouble(Personne::getPoids)).get());
// last person in alphabetical order of name
affiche("nom max", personnes.stream().max((p1, p2) -> p1.getNom().compareToIgnoreCase(p2.getNom())).get());
// total age of all persons
affiche("âge total (reduce)", personnes.stream().map(p -> p.getAge()).reduce(0, (a1, a2) -> a1 + a2));
// people by ascending age
affiche("personnes par âge croissant",
personnes.stream().sorted(Comparator.comparingInt(Personne::getAge)).collect(Collectors.toList()));
// are there any people over 100?
affiche("des personnes de + de 100 ans (anyMatch)", personnes.stream().anyMatch(p -> p.getAge() > 100));
// are all people at most 100 years old?
affiche("des personnes de + de 100 ans (noneMatch)", personnes.stream().noneMatch(p -> p.getAge() > 100));
// are all people over 8 years old?
affiche("des personnes de + de 8 ans (allMatch)", personnes.stream().allMatch(p -> p.getAge() > 8));
// group people by gender
affiche("personnes regroupées par sexe", personnes.stream().collect(Collectors.groupingBy(p -> p.getSexe())));
// remove duplicate elements from a list
affiche("distinct", Stream.of(1, 2, 1).distinct().collect(Collectors.toList()));
// of a Stream<Stream<T>>, we make a Stream<T>
affiche("flatMap", Stream.of(1, 2, 3).flatMap(i -> Stream.of(i, i + 10)).collect(Collectors.toList()));
// of a Stream<Stream<Integer>>, we make a IntStream and calculate its sum
affiche("flatMapToInt", Stream.of(1, 2, 3).flatMapToInt(i -> IntStream.of(i, i + 10)).sum());
// of a Stream<Stream<Integer>>, we make a DoubleStream and then an array
affiche("flatMapToDouble", Stream.of(1, 2, 3).flatMapToDouble(i -> DoubleStream.of(i, i * 1.2)).toArray());
// max of a stream of integers
affiche("reduce Integer::max", Stream.of(1, 10, 8).reduce(Integer::max).get());
// min of a Double
affiche("reduce Integer::min", Stream.of(1.5, 10.4, 8.9).reduce(Double::min).get());
// average of a stream of integers
affiche("IntStream average", IntStream.of(1, 10, 8).average().getAsDouble());
// statistics for a stream of integers
affiche("IntStream summaryStatistics", IntStream.of(1, 10, 8).summaryStatistics());
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- líneas 72, 75: muestran la cadena JSON del segundo parámetro del método;
- línea 24: muestra la cadena JSON de todas las personas. El resultado es el siguiente:
5.6.1. [findFirst]
// la 1ère personne
affiche("findFirst", personnes.stream().findFirst().get());
El método [findFirst] devuelve el primer elemento de un flujo, si existe. Su firma es la siguiente:
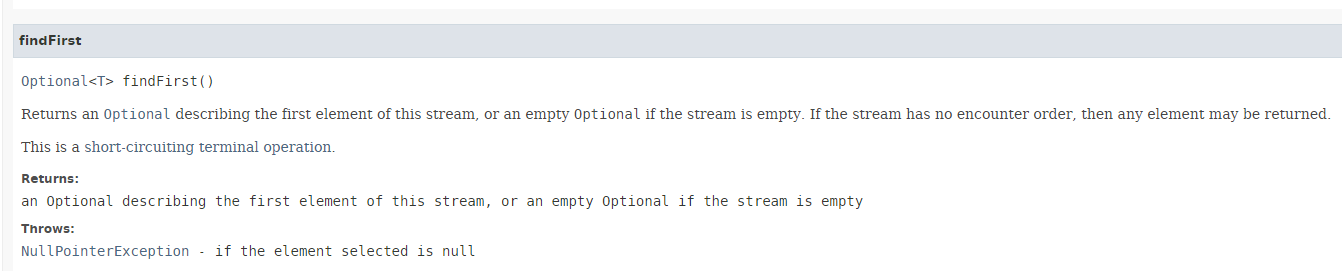 |
El resultado es de tipo Optional<T>, un tipo introducido en Java 8:
 |
La clase Optional<T> permite gestionar de forma diferente los punteros nulos. Un método que necesite devolver un tipo T que pueda tener el valor null puede optar por devolver un tipo Optional<T>. El método [Optional<T>.isPresent()] permite determinar si el método ha devuelto un valor o no. El siguiente código [Ejemplo06b] ilustra parte del funcionamiento de Optional<T>:
package dvp.java8.streams;
import java.util.Optional;
import com.fasterxml.jackson.core.JsonProcessingException;
public class Exemple06b {
public static void main(String[] args) throws JsonProcessingException {
// optional without value
Optional<Integer> o1 = m1();
System.out.println(o1.isPresent());
affiche(o1);
// optional with value
Optional<Integer> o2 = m2();
System.out.println(o2.isPresent());
affiche(o2);
}
private static void affiche(Optional<Integer> o1) {
try {
// retrieve the value of the Optional
// throws 1 exception if no value
System.out.println(o1.get());
} catch (Throwable th) {
System.out.printf("%s : %s%n", th.getClass().getName(), th.getMessage());
}
}
public static Optional<Integer> m1() {
// no value
return Optional.empty();
}
public static Optional<Integer> m2() {
// a value
return Optional.of(10);
}
}
Los resultados son los siguientes:
false
java.util.NoSuchElementException : No value present
true
10
Volvamos al código que ilustra el método [findFirst]:
// la 1ère personne
affiche("findFirst", personnes.stream().findFirst().get());
- línea 2: para simplificar el código, utilizamos el método [get] sobre el Optional<Person> generado por el método [findFirst]. Un código limpio requeriría llamar al método [Optional<Person>.isPresent()] antes de llamar al método [get];
El resultado es el siguiente:
5.6.2. [findAny]
// n'importe quelle personne
affiche("findAny", personnes.stream().findAny().get());
El método [findAny] tiene la siguiente firma:
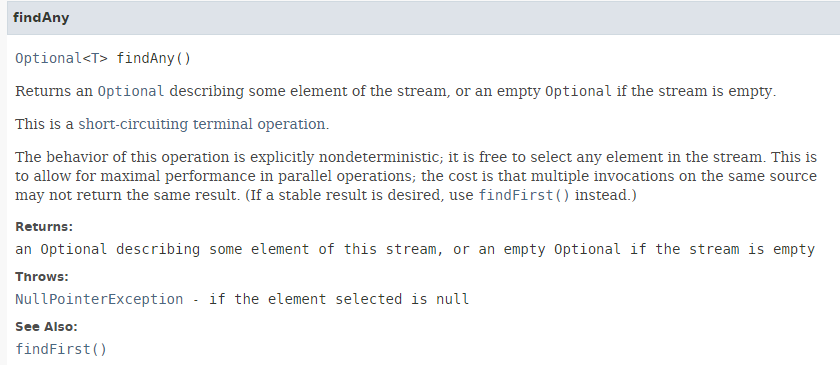 |
El método [findAny] puede devolver cualquier elemento del flujo. Durante las pruebas, observamos que una ejecución secuencial devuelve el primer elemento del flujo, mientras que una ejecución paralela puede, efectivamente, devolver cualquier elemento. Esto se demuestra con el siguiente código [Ejemplo06c]:
package dvp.java8.streams;
import java.util.List;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple06c {
// mapper jSON
static private ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// list of persons
List<Personne> personnes = Personnes.get();
// everyone
affiche("all", personnes);
// any person
affiche("findAny parallèle", personnes.stream().parallel().findAny().get());
// any person
affiche("findAny séquentiel", personnes.stream().findAny().get());
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- línea 22: findAny ejecutado en paralelo;
- línea 24: findAny ejecutado secuencialmente;
Los resultados obtenidos son los siguientes:
- línea 4: la ejecución paralela devolvió el segundo elemento de la lista de personas. Podría haber sido otro;
- línea 6: la ejecución secuencial devolvió el primer elemento de la lista de personas;
El uso del método [findAny] parece tener sentido solo en el procesamiento paralelo de un flujo.
5.6.3. [saltar]
// les personnes sans la 1ère
affiche("skip 1", personnes.stream().skip(1L).collect(Collectors.toList()));
El método [skip] tiene la siguiente firma:
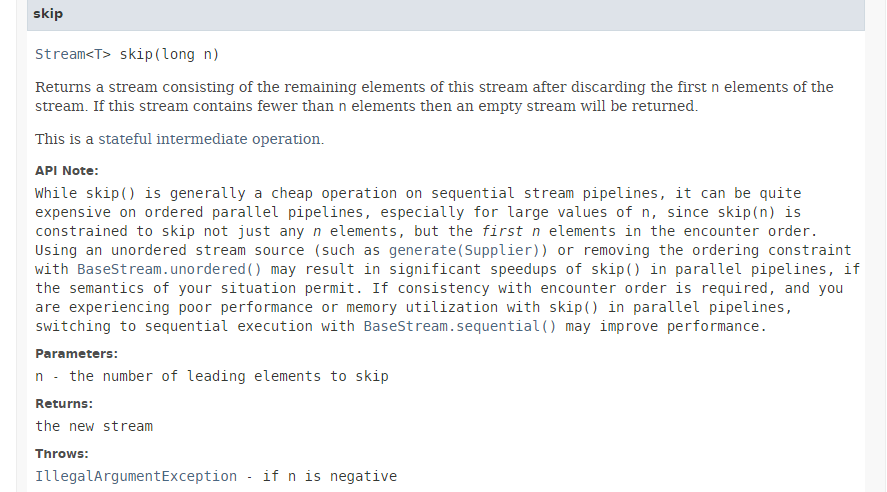 |
El método [skip] omite los primeros n elementos de un flujo. Como se indica en la documentación anterior, la ejecución de este método en paralelo aporta una ganancia de rendimiento mínima e incluso puede provocar una pérdida de rendimiento. De hecho, para omitir los primeros n elementos, los subprocesos se ven obligados a coordinarse, lo que anula las ganancias de rendimiento derivadas del paralelismo.
El método [skip] devuelve un Stream<Person> que se convierte en una List<Person> mediante el método [collect], que tiene la siguiente firma:
 |
El método [collect] toma como parámetro una instancia de tipo [Collector], que tiene una firma compleja. Existen implementaciones predefinidas del tipo [Collector] que suelen permitir evitar tener que implementarlo uno mismo. En este caso, la implementación utilizada es [Collectors.toList()]. [Collectors] es una clase con numerosos métodos estáticos que implementan el tipo [Collector<T,A,R>]. Este es el primer lugar donde hay que buscar cuando se desea convertir un Stream en una colección estándar de Java:
 |
Más adelante utilizaremos algunos de estos métodos.
La ejecución da el siguiente resultado:
Se ha omitido el primer elemento de la lista (jean).
5.6.4. [límite]
// les 2 premières personnes
affiche("limit 2", personnes.stream().limit(2L).collect(Collectors.toList()));
El método [limit] tiene la siguiente firma:
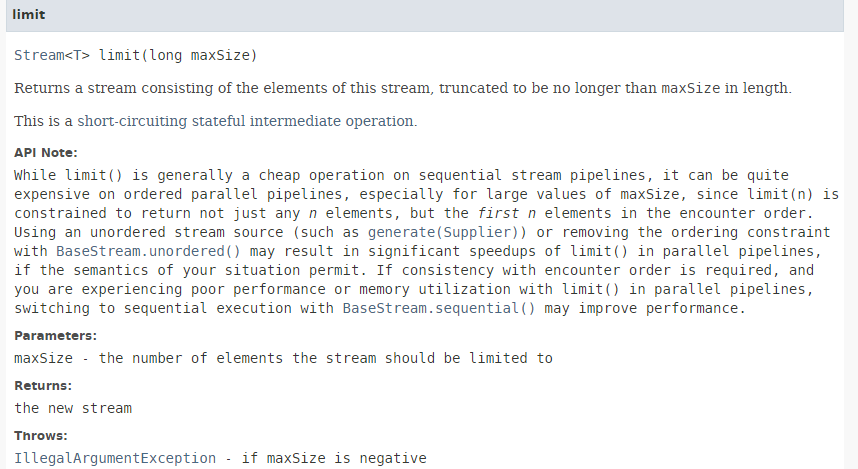 |
El método [limit] permite conservar solo los primeros n elementos de un flujo. No es adecuado para el procesamiento paralelo.
La ejecución arroja el siguiente resultado:
5.6.5. [count]
// le nombre de personnes
affiche("count", personnes.stream().count());
El método [count] tiene la siguiente firma:
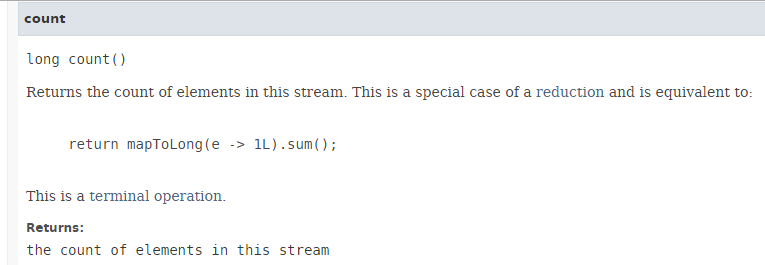 |
El método [count] devuelve el número de elementos de un Stream. La ejecución paralela del método no supone una mejora en el rendimiento, como se muestra en el siguiente código (Ejemplo06d1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.stream.Stream;
public class Exemple06d1 {
public static void main(String[] args) {
final long limite = 10_000_000L;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// counting numbers - sequential method
Stream<Long> sNombres = nombres.stream();
début = new Date().getTime();
long count = sNombres.count();
System.out.printf("comptage séquentiel : compteur=%s, durée (ms)=%s%n", count, new Date().getTime() - début);
}
}
- líneas 11–22: crear un Stream de 10 millones de números;
- líneas 22–24: contar el Stream;
La ejecución arroja el siguiente resultado:
Si sustituimos la línea 22 del código por lo siguiente (Ejemplo06d2):
Stream<Long> sNombres = nombres.stream().parallel();
obtenemos los siguientes resultados:
5.6.6. [máx, mín]
// la personne la + âgée
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
El método [max] tiene la siguiente firma:
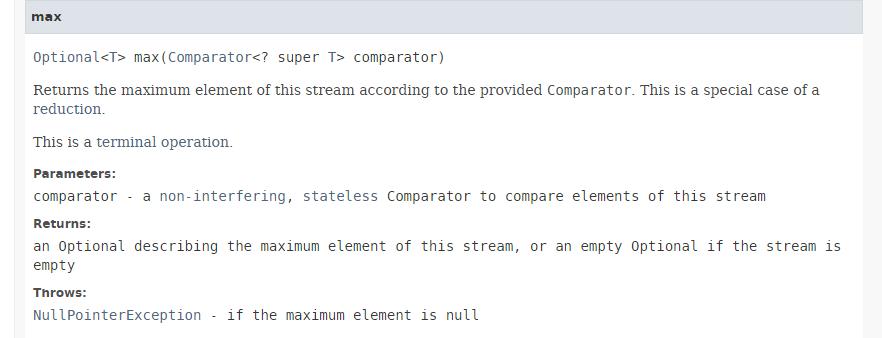 |
El método [max] devuelve el valor máximo de un flujo utilizando el comparador que se le pasa como parámetro. Comparator es una interfaz funcional cuyo único método que hay que implementar tiene la firma: int compare(T o1, T o2). Este método debe devolver -1 si o1 < o2, 0 si o1.equals(o2) y +1 si o1 > o2. La interfaz funcional Comparator tiene muchos métodos estáticos predeterminados que implementan la interfaz Comparator para los casos más comunes. Por lo tanto, en la instrucción:
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
utilizamos el método estático [Comparator.comparingInt], cuya firma es la siguiente:
 |
El tipo ToIntFunction es una interfaz funcional:
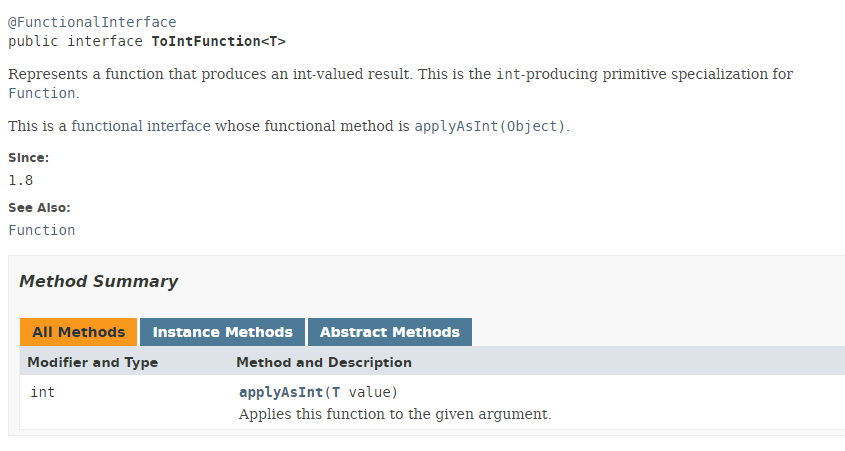 |
El método [applyAsInt] de la interfaz funcional ToIntFunction genera un tipo int a partir de un tipo T. Volvamos a nuestro código:
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
El parámetro real del método [Comparator.comparingInt] debe ser aquí una lambda de tipo Person --> int. Pasamos la referencia al método [Person.getAge], que tiene esta firma. Al final, obtendremos la persona de mayor edad. Obtenemos un tipo Optional<Person>, del que extraemos el valor utilizando el método [Optional.get]. Obtenemos el siguiente resultado:
Calcular el máximo en paralelo no supone ninguna mejora en el rendimiento, como se muestra en el siguiente ejemplo: (Ejemplo06e1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Date;
import java.util.List;
import java.util.Random;
import java.util.stream.Stream;
public class Exemple06e1 {
public static void main(String[] args) {
// data
// final long limit = 100L;
// final boolean verbose = true;
final long limite = 10_000_000L;
final boolean verbose = false;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextLong());
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// max numbers - sequential method
Stream<Long> sNombres = nombres.stream();
Comparator<Long> compLong = (l1, l2) -> {
if (verbose) {
// thread
System.out.printf("[%s]", Thread.currentThread().getName());
}
// comparison
long v1 = l1.longValue();
long v2 = l2.longValue();
if (v1 < v2) {
return -1;
} else {
if (v1 == v2) {
return 0;
} else {
return +1;
}
}
};
début = new Date().getTime();
// long max = sNombres.max(Comparator.naturalOrder()).get();
long max = sNombres.max(compLong).get();
System.out.printf("%nmax séquentiel : max=%s, durée (ms)=%s%n", max, new Date().getTime() - début);
}
}
- línea 29: tenemos un flujo de enteros aleatorios de tipo Long;
- líneas 30–47: la variable lambda compLong implementa la interfaz Comparator<Long>. Esta interfaz suele implementarse mediante el método [Comparator.naturalOrder()] de la línea 49. Pero aquí queremos mostrar el hilo de ejecución (líneas 31–33). Por lo tanto, implementamos la interfaz nosotros mismos;
- línea 50: búsqueda del máximo;
Obtenemos los siguientes resultados:
 |
Ahora bien, si sustituimos la línea 27 por lo siguiente (Ejemplo06e2):
Stream<Long> sNombres = nombres.stream().parallel();
obtenemos los siguientes resultados:
 |
Por lo tanto, la ejecución en paralelo fue más lenta. Si aumentamos el número de números a 10 millones con verbose=false, obtenemos los siguientes resultados:
Para la ejecución secuencial:
para la ejecución en paralelo, que sigue siendo más lenta.
Utilizamos el método [Stream.min] de manera similar:
// la personne la + légère
affiche("poids min", personnes.stream().min(Comparator.comparingDouble(Personne::getPoids)).get());
5.6.7. [reduce]
// l'âge total de toutes les personnes
affiche("âge total (reduce)", personnes.stream().map(p -> p.getAge()).reduce(0, (a1, a2) -> a1 + a2));
El método [reduce] se presentó en la sección 5.3. La línea 2 anterior suma las edades de todas las personas. El resultado es el siguiente:
5.6.8. [ordenadas]
// les personnes par âge croissant
affiche("personnes par âge croissant",
personnes.stream().sorted(Comparator.comparingInt(Personne::getAge)).collect(Collectors.toList()));
// les personnes par ordre alphabétique des noms
List<Personne> lPersonnes=personnes.stream().sorted((p1, p2) -> p1.getNom().compareTo(p2.getNom())).collect(Collectors.toList());
affiche("personnes par ordre alphabétique des noms", lPersonnes);
El método [sorted] (líneas 3 y 5) tiene la siguiente firma:
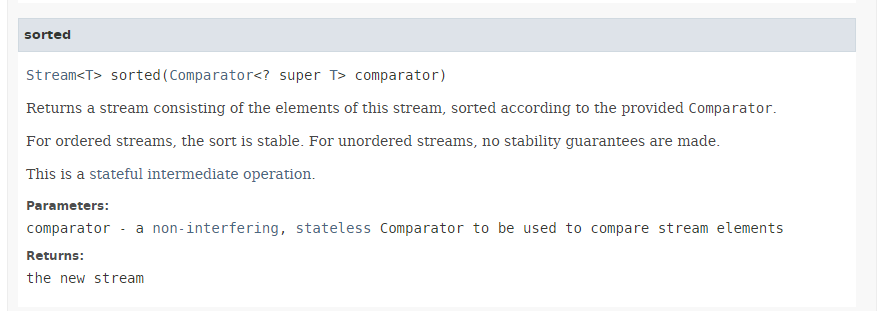 |
El método [sorted] toma como parámetro el tipo [Comparator] descrito en la sección 5.6.6 para los métodos min y max. Permite ordenar un Stream según el orden del comparador que se le pasa como parámetro. Hemos visto que la interfaz [Comparator] proporciona varios métodos estáticos predeterminados que implementan comparadores comunes, en particular para números y cadenas. Aquí utilizamos el método [Comparator.comparingInt], que toma como parámetro un tipo ToIntFunction, que es una interfaz funcional para el método [applyAsInt] con la siguiente firma: int applyAsInt(T t). Aquí, el parámetro real pasado al método [Comparator.comparingInt] en la línea 3 es la referencia al método [Person.age], que devuelve la edad de la persona.
La interfaz [Comparator] no proporciona métodos estáticos para comparar cadenas. En la línea 5, construimos nosotros mismos una lambda que implementa el único método de esta interfaz: int compare(T t1, T t2)
(p1, p2) -> p1.getNom().compareTo(p2.getNom())
Esta lambda compara los nombres de las personas. Los resultados obtenidos son los siguientes:
La ejecución en paralelo de la ordenación no parece posible, como se muestra en el siguiente código (Ejemplo06f1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Date;
import java.util.List;
import java.util.Random;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class Exemple06f1 {
// mapper jSON
static ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// data
final long limite = 100L;
final boolean verbose = true;
// final long limit = 10_000_000L;
// final boolean verbose = false;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Integer> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextInt(1000));
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// number sorting - sequential method
Stream<Integer> sNombres = nombres.stream();
début = new Date().getTime();
Comparator<Integer> compInt = (i1, i2) -> {
if (verbose) {
// thread
System.out.printf("[%s]", Thread.currentThread().getName());
}
// comparison
int v1 = i1.intValue();
int v2 = i2.intValue();
if (v1 < v2) {
return +1;
} else {
if (v1 == v2) {
return 0;
} else {
return -1;
}
}
};
if (verbose) {
affiche("nombres", sNombres.sorted(compInt).collect(Collectors.toList()));
}
System.out.printf("tri séquentiel : durée (ms)=%s%n", new Date().getTime() - début);
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- líneas 30–36: generamos una secuencia de números aleatorios;
- línea 32: pasamos la lambda compInt (líneas 38-55) al método [sorted]. Esta lambda ordena los números en orden descendente y muestra el hilo que la ejecuta.
Los resultados obtenidos son los siguientes:
 |
Si, en el código anterior, sustituimos la línea 36 por lo siguiente (Ejemplo06f2):
Stream<Integer> sNombres = nombres.stream().parallel();
obtenemos los siguientes resultados:
 |
Sorprendentemente, vemos que la secuencia de números se ha ordenado utilizando un único subproceso. No ha habido paralelismo. ¿O es que se me escapa algo?
5.6.9. [anyMatch, noneMatch, allMatch]
// y-a-t-il des personnes de + de 100 ans ?
affiche("des personnes de + de 100 ans (anyMatch)", personnes.stream().anyMatch(p -> p.getAge() > 100));
// est-ce que toutes les personnes ont au plus 100 ans ?
affiche("des personnes de + de 100 ans (noneMatch)", personnes.stream().noneMatch(p -> p.getAge() > 100));
// est-ce que toutes les personnes ont + de 8 ans
affiche("des personnes de + de 8 ans (allMatch)", personnes.stream().allMatch(p -> p.getAge() > 8));
Líneas 2, 4 y 6: los métodos [anyMatch, noneMatch, allMatch] toman un tipo Predicate como parámetro, tal y como se describe en la sección 4.2. Por lo tanto, realizan un filtrado. Los tres devuelven un valor booleano:
- anyMatch devuelve true si hay al menos un elemento en el Stream que satisface el filtro;
- noneMatch devuelve true si no hay ningún elemento en el Stream que satisfaga el filtro;
- allMatch devuelve true si todos los elementos del Stream satisfacen el filtro;
Los resultados obtenidos son los siguientes:
5.6.10. [collect(Collectors.groupingBy)]
// on regroupe les personnes par sexe
affiche("personnes regroupées par sexe", personnes.stream().collect(Collectors.groupingBy(p -> p.getSexe())));
El método [collect] se presentó en la sección 5.6.3. Su parámetro es una implementación de la interfaz [Collector]. La clase [Collectors] proporciona varios métodos estáticos que implementan la interfaz [Collector]. Hasta ahora, hemos utilizado el método [Collectors.toList()]. Aquí utilizamos el método estático [Collectors.groupingBy], que crea un diccionario a partir del Stream. Su firma es la siguiente:
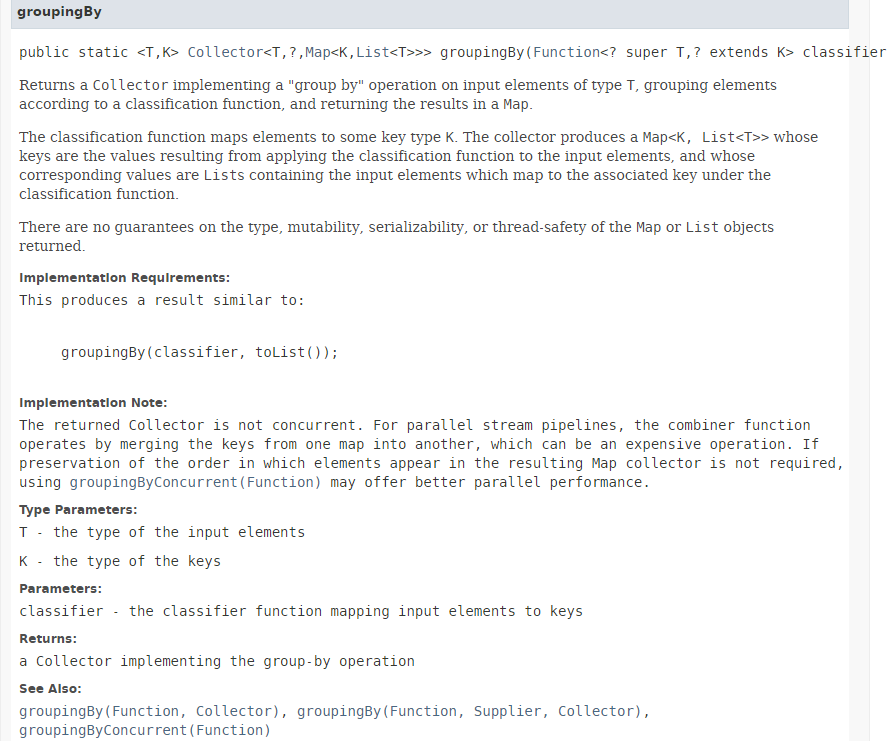 |
El método [groupingBy] crea un Map<K,List<T>> a partir de un Stream<T>. La clave K la proporciona el parámetro del método [groupingBy] de tipo Function<T,K>, cuyo único método tiene la firma: K apply(T t). Si queremos crear un mapa indexado por el género de una persona, debemos proporcionar una función que genere el género a partir de una persona. Aquí, pasamos la referencia al método [Person.getGender] como parámetro real del método [groupingBy]. Los resultados obtenidos son los siguientes:
La línea 2 contiene la cadena JSON de un diccionario indexado por dos claves: HOMBRE y MUJER.
El cálculo paralelo no supone una mejora en el rendimiento, como se muestra en el siguiente ejemplo (Ejemplo06g1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class Exemple06g1 {
// mppeur jSON
static ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// data
final long limite = 100L;
final boolean verbose = true;
// final long limit = 10_000_000L;
// final boolean verbose = false;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Integer> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextInt(1000));
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// grouping numbers by hundred - sequential method
Stream<Integer> sNombres = nombres.stream();
Function<Integer, Integer> groupByCent = n -> {
if (verbose) {
System.out.printf("[%s]", Thread.currentThread().getName());
}
return n / 100;
};
début = new Date().getTime();
// Map<Integer, List<Integer>> lNombres = sNombres.collect(Collectors.groupingBy(number -> number / 100));
Map<Integer, List<Integer>> lNombres = sNombres.collect(Collectors.groupingBy(groupByCent));
System.out.printf("%nregroupement séquentiel : durée (ms)=%s%n", new Date().getTime() - début);
// results
if (verbose) {
affiche("nombres regroupés", lNombres);
}
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- líneas 23–38: construcción de una secuencia de números;
- línea 47: los números se agrupan por centenas. La función lambda de las líneas 39–44 se utiliza para mostrar el hilo de ejecución;
Los resultados de la ejecución son los siguientes:
 |
Si, en el código, sustituimos la línea 38 por la siguiente línea (Ejemplo06g2):
Stream<Integer> sNombres = nombres.stream().parallel();
obtenemos los siguientes resultados:
 |
Podemos observar que la ejecución en paralelo de la agrupación ha reducido el rendimiento.
5.6.11. [distinct]
// supression des éléments en double d'une liste
affiche("distinct", Stream.of(1, 2, 1).distinct().collect(Collectors.toList()));
El método [distinct] tiene la siguiente firma:
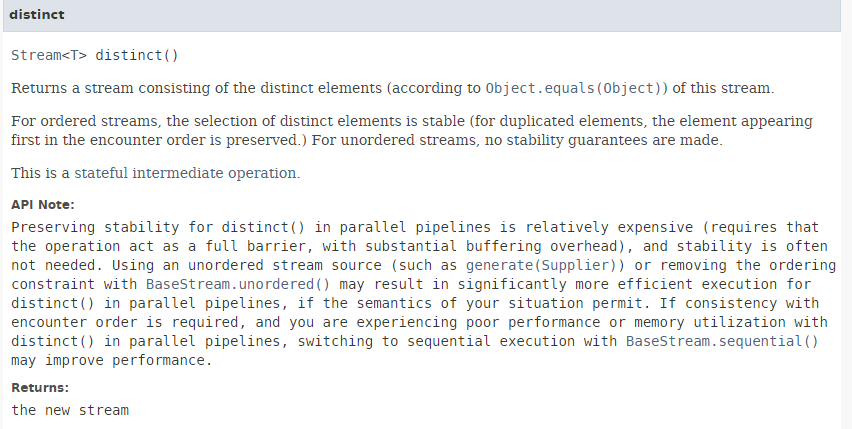 |
Elimina los duplicados de un flujo. El método [Stream.of] (línea 2) tiene la siguiente firma:
 |
Permite crear un Stream a partir de valores proporcionados explícitamente. Los resultados de la ejecución son los siguientes:
5.6.12. [flatMap]
// d'un Stream<Stream<T>>, on fait un Stream<T>
affiche("flatMap", Stream.of(1, 2, 3).flatMap(i -> Stream.of(i, i + 10)).collect(Collectors.toList()));
El método [flatMap] tiene la siguiente firma:
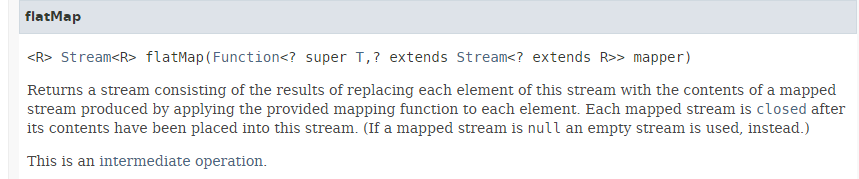  |
El método [flatMap] toma como parámetro una función que:
- toma como parámetro un elemento de tipo T del Stream;
- devuelve un Stream<R>;
Si, en lugar del método [flatMap], hubiéramos utilizado el método [map] descrito en la sección 5.5, el resultado sería un tipo Stream<Stream<R>>, donde cada elemento de tipo T del stream inicial habría producido un elemento Stream<R>. El método [flatMap], por otro lado, devuelve un tipo Stream<R>. Aplana los distintos flujos Stream<R> en un único flujo. Esto es lo que muestran los resultados de ejecutar el código anterior:
Existen variantes especializadas de [flatMap]:
// d'un Stream<IntStream>, on fait un IntStream dont on calcule la somme
affiche("flatMapToInt", Stream.of(1, 2, 3).flatMapToInt(i -> IntStream.of(i, i + 10)).sum());
El método [flatMapToInt] tiene la siguiente firma:
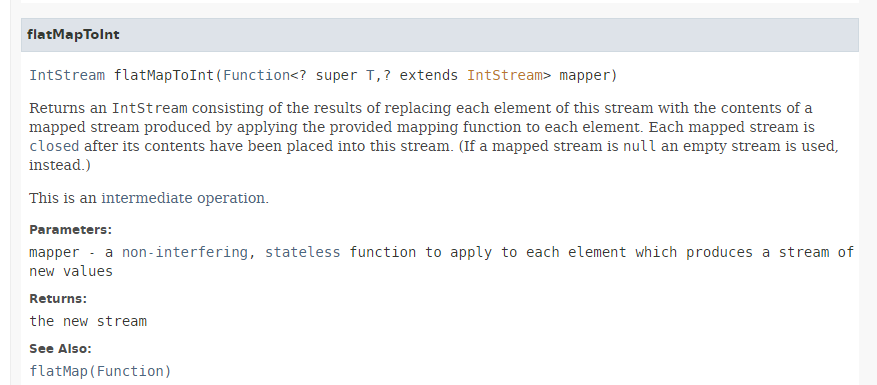 |
El método [flatMapToInt] toma como parámetro una función que devuelve un IntStream del siguiente tipo:
 |
IntStream es un flujo de int. Este tipo es preferible al tipo Stream<Integer> porque su procesamiento evita el boxing/unboxing entre los tipos Integer e int. Esta interfaz hereda muchos métodos del tipo Stream<T> y añade otros, incluido el método [sum] anterior, que suma los elementos del IntStream.
El siguiente código ilustra el uso del método análogo [flatMapToDouble]:
// d'un Stream<DoubleStream>, on fait un DoubleStream puis un tableau
affiche("flatMapToDouble", Stream.of(1, 2, 3).flatMapToDouble(i -> DoubleStream.of(i, i * 1.2)).toArray());
El método [DoubleStream.toArray] permite convertir un tipo DoubleStream a un tipo double[].
Los resultados de estos dos ejemplos son los siguientes:
El siguiente ejemplo muestra la mejora en el rendimiento que se consigue al cambiar del tipo Stream<Long> al tipo LongStream (Ejemplo06i1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class Exemple06i1 {
public static void main(String[] args) {
final long limite = 10_000_000L;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// sum of numbers - sequential method
début = new Date().getTime();
long somme = nombres.stream().reduce(0L, (s, i) -> s + i);
System.out.printf("somme séquentielle du Stream<Integer> : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- línea 22: cálculo de la suma de una secuencia de números Long;
Se obtienen los siguientes resultados:
Ahora, sustituyamos la línea 22 por lo siguiente (Ejemplo06i2):
long somme = nombres.stream().mapToLong(n -> n.longValue()).sum();
El método Stream<Integer>.mapToLong nos permite obtener un LongStream de elementos primitivos de tipo long, que luego sumamos utilizando la función sum. A continuación, obtenemos los siguientes resultados:
La mejora en el rendimiento es evidente.
5.6.13. Métodos primitivos de flujo numérico
// max d'un flux de int
affiche("IntStream max", IntStream.of(1, 10, 8).max());
// min d'un flux de double
affiche("DoubleStream min", DoubleStream.of(1.5, 10.4, 8.9).min());
// moyenne d'un flux de int
affiche("IntStream average", IntStream.of(1, 10, 8).average().getAsDouble());
// statistiques d'un flux de int
affiche("IntStream summaryStatistics", IntStream.of(1, 10, 8).summaryStatistics());
Los flujos de valores primitivos (int, long, double) proporcionan métodos adaptados a estos tipos. El resultado de ejecutar el código anterior es el siguiente:
- El resultado de la línea 2 del código es un tipo OptionalInt análogo al tipo Optional<Integer>. El valor almacenado en este objeto se puede recuperar utilizando el método [getAsInt()]. La presencia de un valor se puede comprobar utilizando el método [isPresent()]. La línea 2 de los resultados no significa que la clase [OptionalInt] tenga campos llamados [asInt] y [present]. Por defecto, la biblioteca JSON utiliza todos los métodos públicos getX e isY del objeto que se va a serializar a JSON. Y aquí, efectivamente, hay un método [getAsInt] y otro método [isPresent], aunque los campos [asInt, present] en sí mismos no existan;
- el resultado de la línea 4 del código es un tipo OptionalDouble análogo al tipo Optional<Double>;
- el resultado de la línea 6 del código es un tipo OptionalDouble cuyo valor se puede obtener utilizando el método [getAsDouble()]. El método [average] calcula la media de la secuencia de números;
- El resultado de la línea 8 del código es un tipo IntSummaryStatistics definido de la siguiente manera:
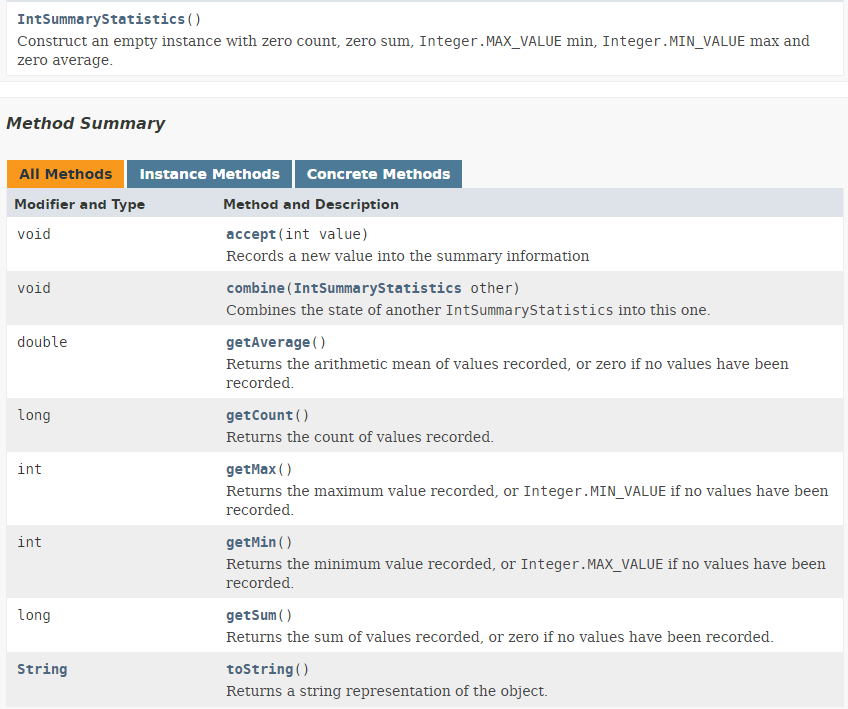 |
Podemos ver que el objeto IntSummaryStatistics resultante proporciona diversas estadísticas sobre la secuencia de números, como el número de valores, la suma, el máximo, el mínimo y la media.