4. Aplicación de ejemplo – 02: rdvmedecins-jsf2-spring
Ahora nos proponemos trasladar la aplicación anterior a un entorno Spring / Tomcat:
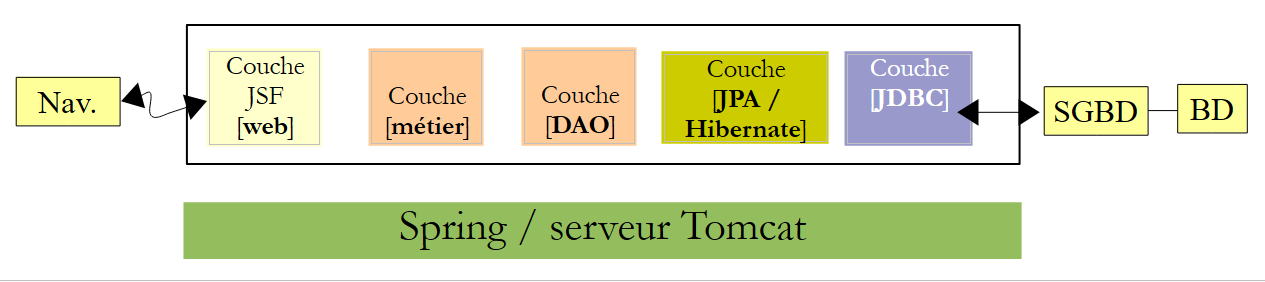 |
Se trata, en realidad, de una adaptación. Partiremos de la aplicación anterior y la adaptaremos al nuevo entorno. Solo comentaremos los cambios. Son de tres tipos:
- el servidor ya no es Glassfish, sino Tomcat, un servidor ligero que no dispone de contenedor EJB,
- para sustituir a EJB, utilizaremos Spring, el principal competidor de EJB y [http://www.springsource.com/],
- la implementación JPA que se utilizará será Hibernate en lugar de EclipseLink.
Dado que vamos a realizar muchas operaciones de copiar y pegar entre el proyecto antiguo y el nuevo, mantendremos abiertos los proyectos anteriores en NetBeans:
 |
El uso del framework Spring requiere ciertos conocimientos que se pueden encontrar en [ref7] (véase la página 166).
4.1. Las capas [DAO] y [JPA]
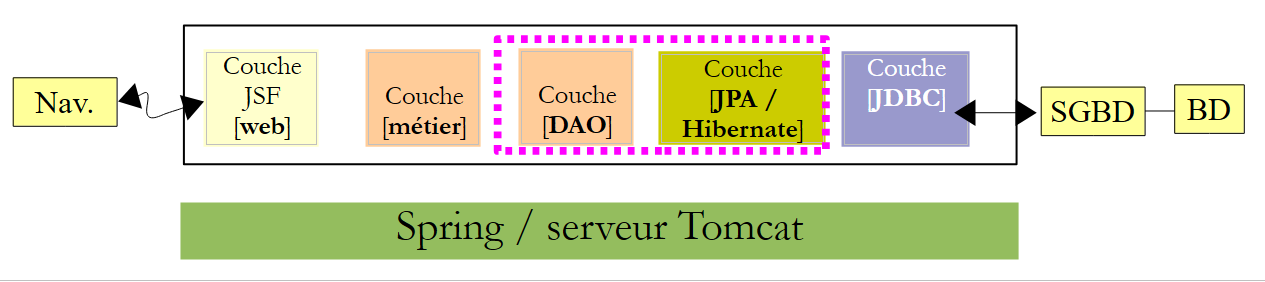 |
4.1.1. El proyecto NetBeans
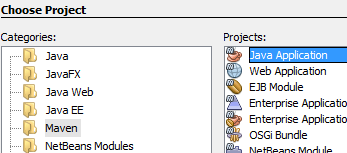
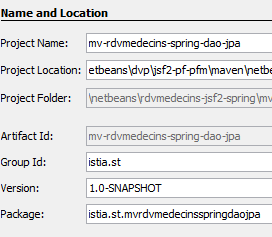
Creamos un proyecto Maven del tipo [Java Application]:
 |  |  |
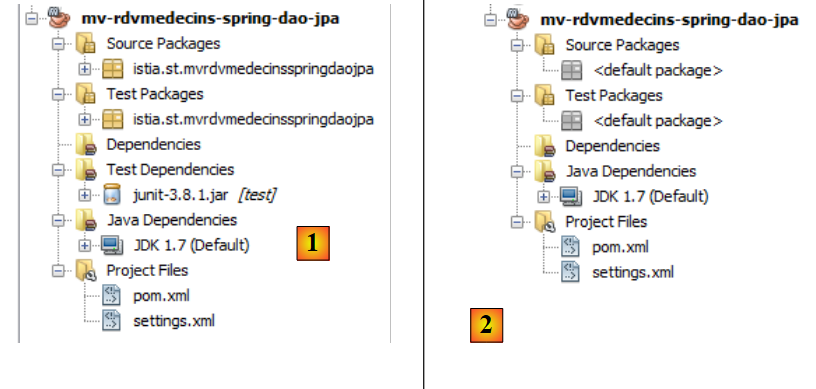 |
- en [1], el proyecto creado,
- en [2], el mismo sin los paquetes de [Source Packages] y [Test Packages], ni la dependencia [junit-3.8.1].
Lo más difícil en los proyectos de Maven es encontrar las dependencias adecuadas. Para este proyecto Spring / JPA / Hibernate, son las siguientes:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>istia.st</groupId>
<artifactId>mv-rdvmedecins-spring-dao-jpa</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>mv-rdvmedecins-spring-dao-jpa</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>4.1.2</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.hibernate.java-persistence</groupId>
<artifactId>jpa-api</artifactId>
<version>2.0.Beta-20090815</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
<type>jar</type>
</dependency>
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.2.2</version>
</dependency>
<dependency>
<groupId>commons-pool</groupId>
<artifactId>commons-pool</artifactId>
<version>1.6</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
</dependencies>
</project>
- líneas 18-29: para Hibernate,
- líneas 30-34: para el controlador JDBC de MySQL,
- líneas 35-41: para la prueba JUnit,
- líneas 42-51: para el grupo de conexiones de Apache Commons DBCP. Un grupo de conexiones es un conjunto de conexiones abiertas. Cuando la aplicación necesita una conexión, la solicita al grupo. Cuando ya no la necesita, la devuelve. Las conexiones se abren al iniciar la aplicación y permanecen abiertas durante toda la vida útil de la misma. Esto evita el coste que supone abrir y cerrar conexiones repetidamente. Este tipo de grupo ya existía en Glassfish, pero su uso nos resultaba transparente. Aquí también será así, pero tenemos que instalarlo y configurarlo,
- líneas 52-75: para Spring.
Añadamos estas dependencias y compilemos el proyecto:
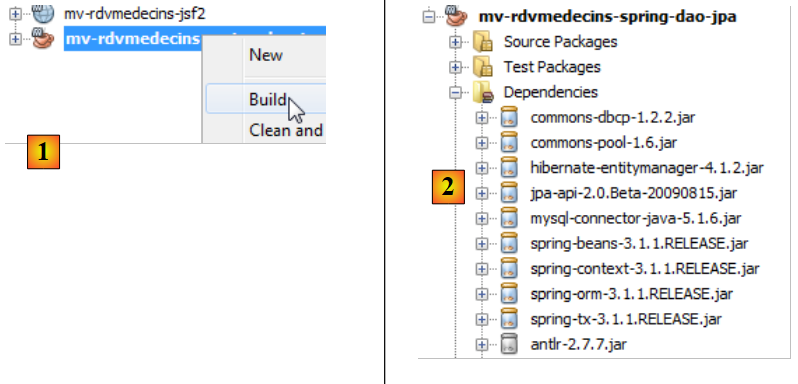 |
- en [1], al compilar el proyecto se obligará a Maven a descargar las dependencias,
- en [2], estas aparecen entonces en la rama [Dependencies]. Son muy numerosas, ya que los frameworks Hibernate y Spring tienen a su vez muchísimas dependencias. Una vez más, gracias a Maven, no tenemos que preocuparnos por ellas. Se descargan automáticamente.
Ahora que ya tenemos las dependencias, pegamos el código del proyecto EJB de la capa [dao] en el proyecto Spring de la capa [dao]:
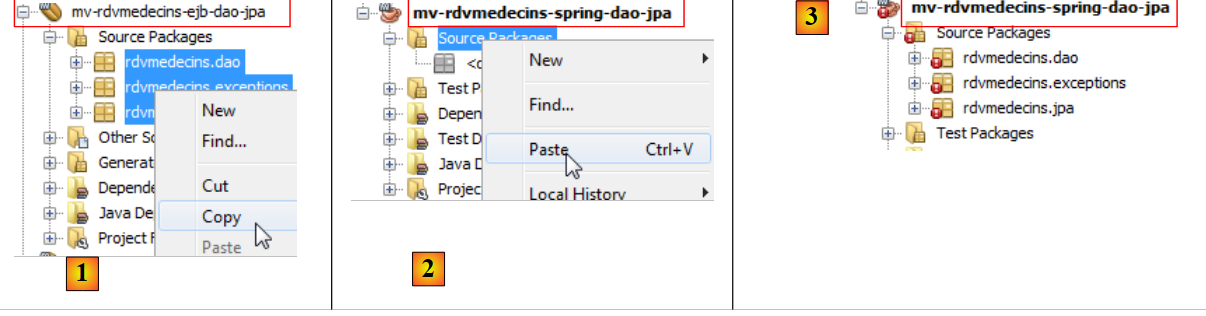 |
- en [1], lo copiamos en el proyecto de origen,
- en [2], se pega en el proyecto de destino,
- en [3], el resultado.
Una vez realizada la copia, hay que corregir los errores.
4.1.2. El paquete [exceptions]
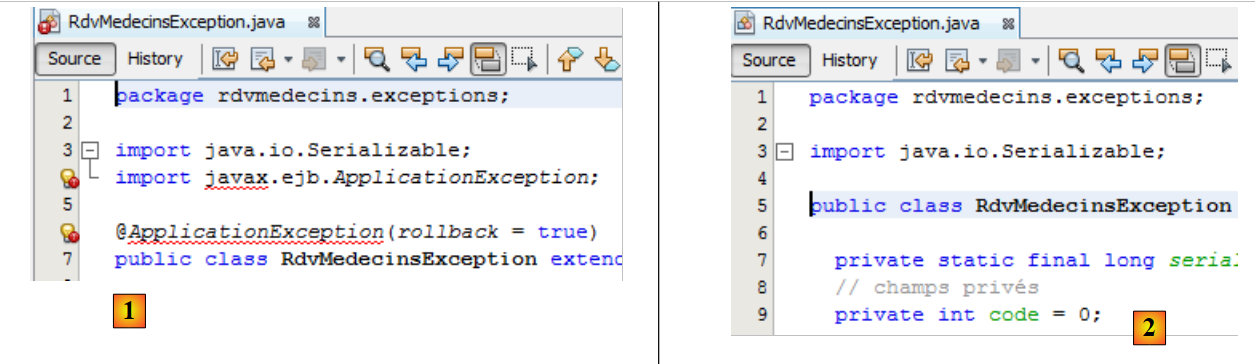 |
La clase [RdvMedecinsExceptions] [1] presenta errores debido al paquete [javax], línea 4, que ya no existe. Se trata de un paquete específico de EJB. El error de la línea 6 se deriva del de la línea 4. Se eliminan estas dos líneas. De este modo, se eliminan los errores [2].
4.1.3. El paquete [jpa]
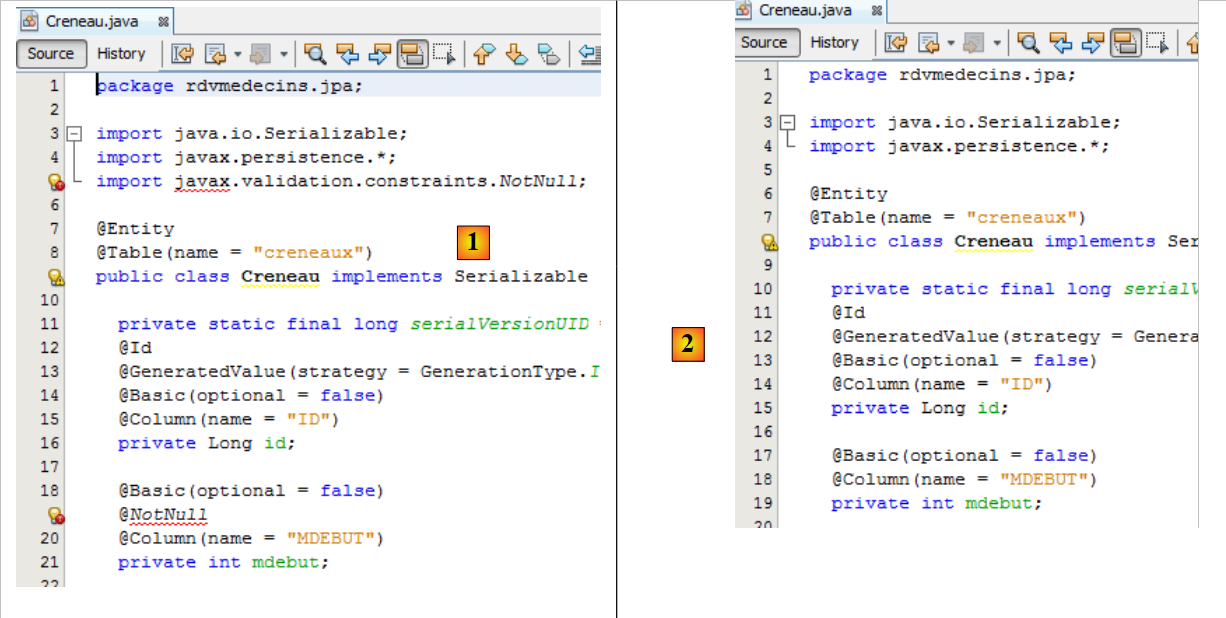 |
- en [1], la clase [Creneau] presenta un error debido a la ausencia del paquete de validación de la línea [5]. Se podría haber añadido este paquete a las dependencias del proyecto. Sin embargo, durante las pruebas, Hibernate lanza una excepción a causa de él. Como no es imprescindible para nuestra aplicación, lo hemos eliminado. Para corregir la clase, basta con eliminar todas las líneas erróneas [2]. Hacemos lo mismo con todas las clases erróneas.
4.1.4. El paquete [dao]
Nos encontramos en el siguiente punto:
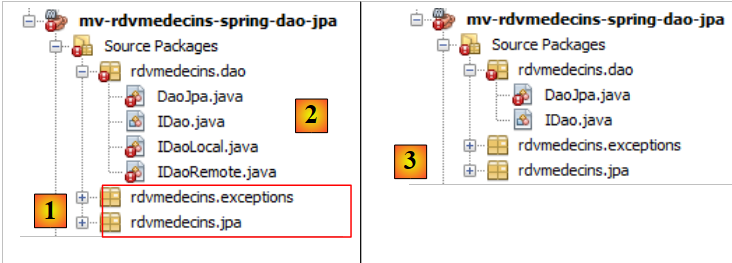 |
- en [1], los dos paquetes corregidos,
- en [2], el paquete [dao]. Como ya no existe EJB, tampoco existe ya el concepto de interfaz remota y local de EJB. Los eliminamos: [3].
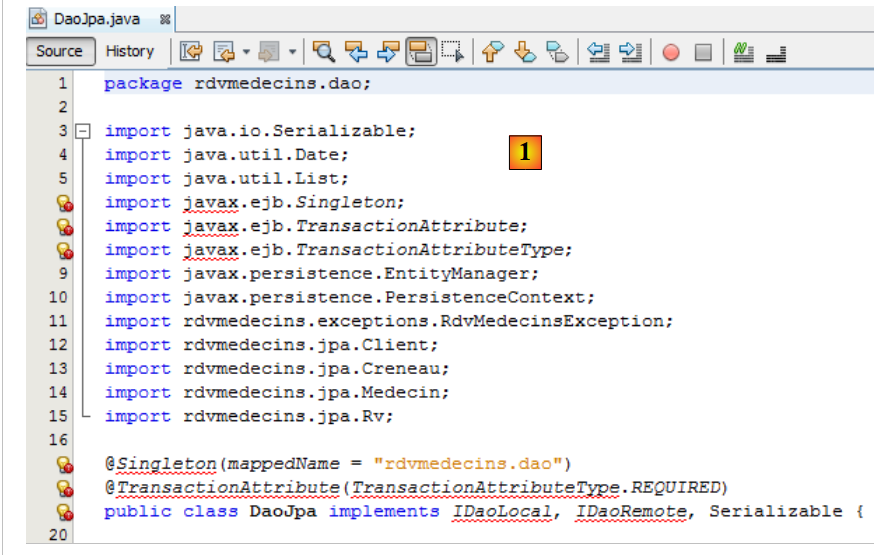 |
- En [1], los errores de la clase [DaoJpa] tienen dos orígenes:
- la importación de un paquete vinculado a EJB (líneas 6-8);
- el uso de las interfaces local y remota que acabamos de eliminar.
Eliminamos las líneas erróneas y utilizamos la interfaz [IDao] en lugar de las interfaces local y remota [2].
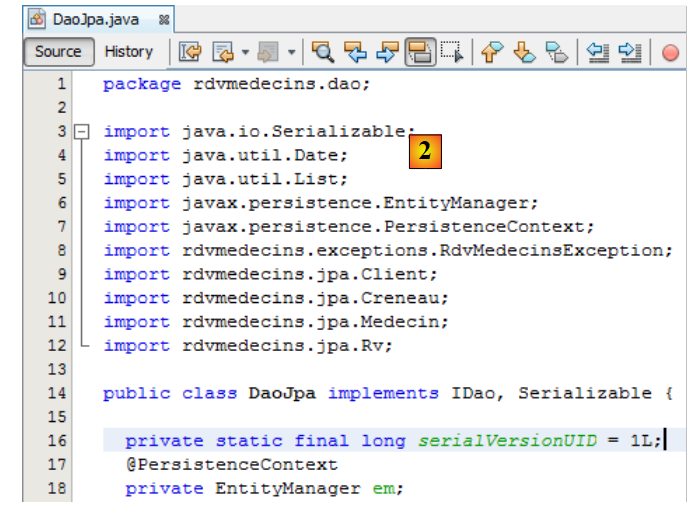 |
En el proyecto EJB, la clase [DaoJpa] era un singleton y sus métodos se ejecutaban dentro de una transacción. Veremos que la clase [DaoJpa] va a ser un bean gestionado por Spring. Por defecto, todo bean de Spring es un singleton. Esto en cuanto a la primera propiedad. La segunda se obtiene con la anotación @Transactional de Spring [3]:
 |
Una vez hecho esto, el proyecto ya no presenta errores [4].
4.1.5. Configuración de la capa [JPA]
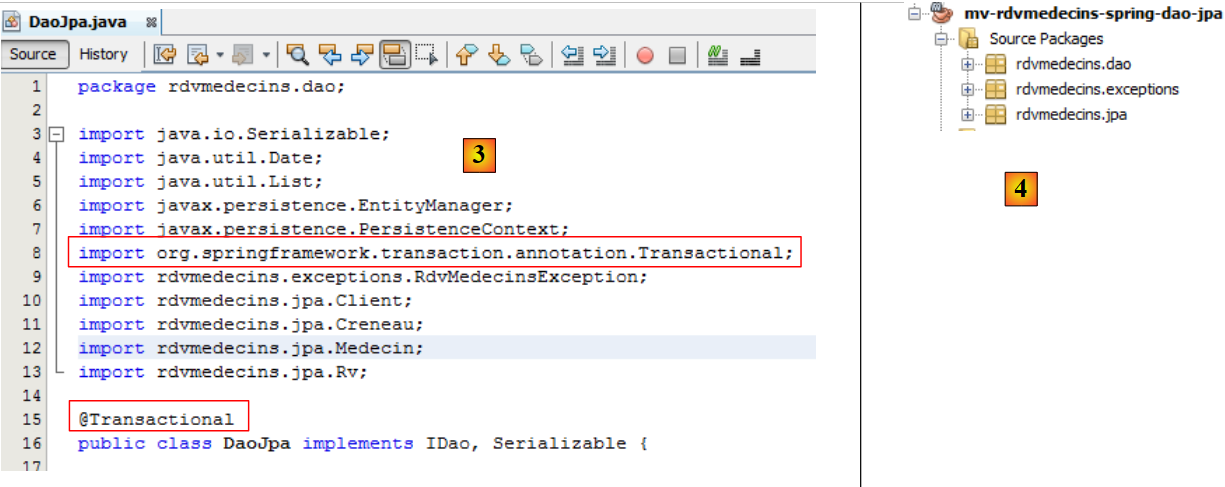
En el proyecto EJB, habíamos configurado la capa [JPA] con el archivo [persistence.xml]. Aquí tenemos una capa [JPA], por lo que debemos crear este archivo. En el proyecto EJB, lo habíamos generado con Glassfish. Aquí lo creamos manualmente. La razón principal es que parte de la configuración del archivo [persistence.xml] se traslada al propio archivo de configuración de Spring.
Creamos el archivo [persistence.xml]:
 |
con el siguiente contenido:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="spring-dao-jpa-hibernate-mysqlPU" transaction-type="RESOURCE_LOCAL">
<class>rdvmedecins.jpa.Client</class>
<class>rdvmedecins.jpa.Creneau</class>
<class>rdvmedecins.jpa.Medecin</class>
<class>rdvmedecins.jpa.Rv</class>
</persistence-unit>
</persistence>
- línea 3: se asigna un nombre a la unidad de persistencia,
- línea 3: el tipo de transacciones es RESOURCE_LOCAL. En el proyecto EJB, era JTA para indicar que las transacciones eran gestionadas por el contenedor EJB. El valor RESOURCE_LOCAL indica que la propia aplicación gestiona sus transacciones. En este caso, lo hará a través de Spring,
- líneas 4-7: los nombres completos de las cuatro entidades JPA. Esto es opcional, ya que Hibernate las busca automáticamente en el ClassPath del proyecto.
Eso es todo. El nombre del proveedor JPA, sus propiedades y las características JDBC de la fuente de datos ya se encuentran en el archivo de configuración de Spring.
4.1.6. El archivo de configuración de Spring
Hemos dicho que la clase [DaoJpa] es un bean gestionado por Spring. Esto se lleva a cabo mediante un archivo de configuración. Este archivo también incluirá la configuración del acceso a la base de datos, así como la gestión de las transacciones. Debe estar en el directorio ClassPath del proyecto. Lo colocamos en la rama [Other sources]:
 |
El archivo [spring-config-dao.xml] es el siguiente:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.0.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-2.0.xsd">
<!-- capas de aplicación -->
<bean id="dao" class=" " />
<!-- EntityManagerFactory -->
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter">
<property name="databasePlatform" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!--
<property name="showSql" value="true" />
<property name="generateDdl" value="true" />
-->
</bean>
</property>
</bean>
<!-- la fuente de datos DBCP -->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/dbrdvmedecins2" />
<property name="username" value="root" />
<property name="password" value="" />
</bean>
<!-- el gestor de transacciones -->
<tx:annotation-driven transaction-manager="txManager" />
<bean id="txManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactory" />
</bean>
<!-- traducción de excepciones -->
<bean class="org.springframework.dao.annotation.PersistenceExceptionTranslationPostProcessor" />
<!-- persistencia -->
<bean class="org.springframework.orm.jpa.support.PersistenceAnnotationBeanPostProcessor" />
</beans>
Es un archivo compatible con Spring 2.x. No hemos intentado utilizar las nuevas características de las versiones 3.x.
- líneas 2-4: la etiqueta raíz <beans> del archivo de configuración. No comentaremos los distintos atributos de esta etiqueta. Hay que tener cuidado al copiar y pegar, ya que un error en cualquiera de estos atributos provoca errores que a veces son difíciles de entender,
- línea 7: el bean «dao» es una referencia a una instancia de la clase [rdvmedecins.dao.DaoJpa]. Se creará una única instancia (singleton) que implementará la capa [dao] de la aplicación,
- líneas 24-29: se define una fuente de datos. Esta proporciona el servicio de «pool de conexiones» del que hemos hablado. Aquí se utiliza [DBCP] del proyecto Apache Commons DBCP [http://jakarta.apache.org/commons/dbcp/],
- líneas 25-28: para establecer conexiones con la base de datos de destino, la fuente de datos necesita conocer el controlador JDBC utilizado (línea 25), el URL de la base de datos (línea 26), el usuario de la conexión y su contraseña (líneas 27-28),
- líneas 10-21: configuran la capa JPA,
- línea 10: define un bean de tipo [EntityManagerFactory] capaz de crear objetos de tipo [EntityManager] para gestionar los contextos de persistencia. La clase instanciada [LocalContainerEntityManagerFactoryBean] la proporciona Spring. Necesita una serie de parámetros para instanciarse, definidos en las líneas 11-20,
- línea 11: la fuente de datos que se utilizará para obtener conexiones con SGBD. Se trata de la fuente [DBCP] definida en las líneas 24-29,
- líneas 12-20: la implementación JPA que se va a utilizar,
- línea 13: define Hibernate como la implementación JPA que se va a utilizar,
- línea 14: el dialecto SQL que Hibernate debe utilizar con el objetivo SGBD, en este caso MySQL5,
- línea 16 (comentada): solicita que las órdenes SQL ejecutadas por Hibernate se registren en la consola,
- línea 17 (comentada): indica que, al iniciar la aplicación, se genere la base de datos (drop y create),
- línea 32: indica que las transacciones se gestionan con anotaciones Java (también podrían haberse declarado en spring-config.xml). En concreto, se trata de la anotación @Transactional que aparece en la clase [DaoJpa],
- líneas 33-35: definen el gestor de transacciones que se va a utilizar,
- línea 33: el gestor de transacciones es una clase proporcionada por Spring,
- línea 34: el gestor de transacciones de Spring necesita conocer la clase EntityManagerFactory, que gestiona la capa JPA. Es la definida en las líneas 10-21,
- línea 41: define la clase que gestiona las anotaciones de persistencia de Spring,
- línea 38: definen la clase Spring que gestiona, entre otras cosas, la anotación @Repository, la cual hace que una clase así anotada sea apta para la conversión de las excepciones nativas del controlador JDBC de SGBD a excepciones genéricas de Spring de tipo [DataAccessException]. Esta conversión encapsula la excepción nativa JDBC en un tipo [DataAccessException] que tiene varias subclases:

Esta traducción permite al programa cliente gestionar las excepciones de forma genérica, independientemente del SGBD de destino. No hemos utilizado la anotación @Repository en nuestro código Java. Por lo tanto, la línea 38 es innecesaria. La hemos dejado ahí simplemente a título informativo.
Ya hemos terminado con el archivo de configuración de Spring. Se ha extraído de la documentación de Spring. Su adaptación a diversas situaciones suele reducirse a dos modificaciones:
- la de la base de datos de destino: líneas 24-29,
- la de la implementación JPA: líneas 12-20.
Al ejecutar el código, se instanciarán todos los beans del archivo de configuración. Veremos cómo.
4.1.7. La clase de prueba JUnit
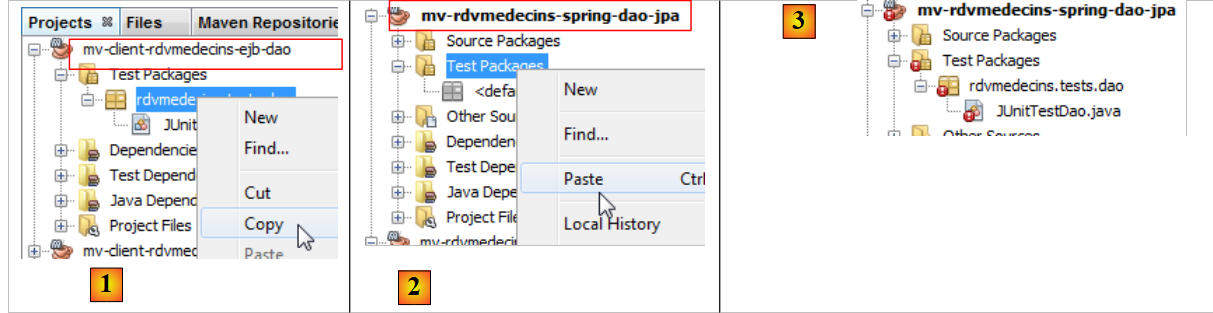 |
Habíamos probado la capa [DAO] del proyecto EJB con una prueba JUnit. Hacemos lo mismo con la capa [DAO] del proyecto Spring:
- en [1] y [2], al copiar y pegar la prueba JUnit entre ambos proyectos,
- en [3], la prueba importada presenta errores en su nuevo entorno.
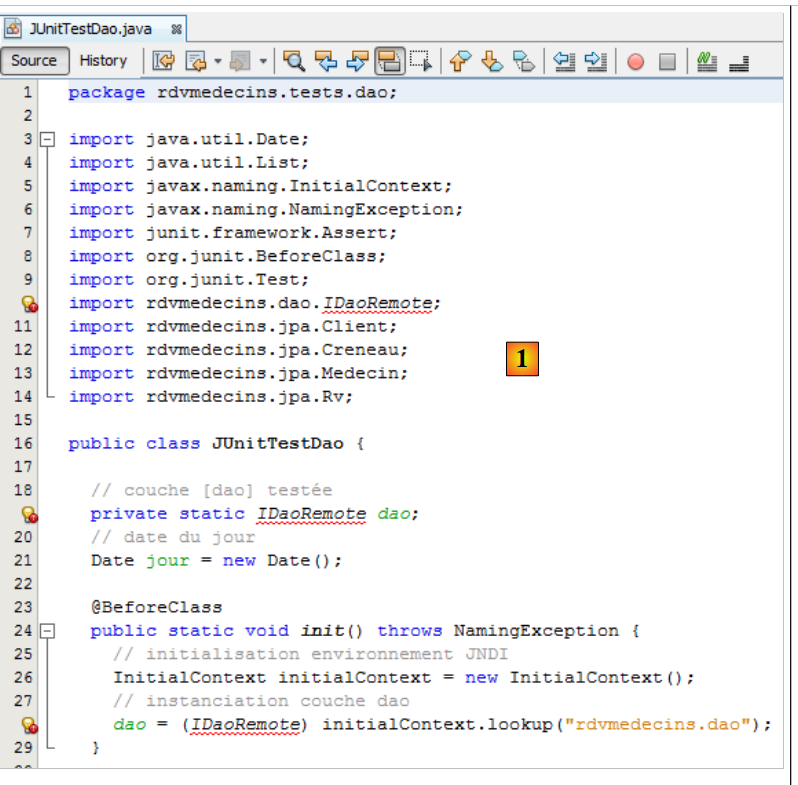 |
El error señalado [1] corresponde a la interfaz remota de EJB, que ya no existe. Por otra parte, el código de inicialización del campo [dao] de la línea 19 era una llamada a JNDI específica de EJB (líneas 25-28). Para instanciar el campo [dao] de la línea 19, debemos utilizar el archivo de configuración de Spring. Esto se hace de la siguiente manera:
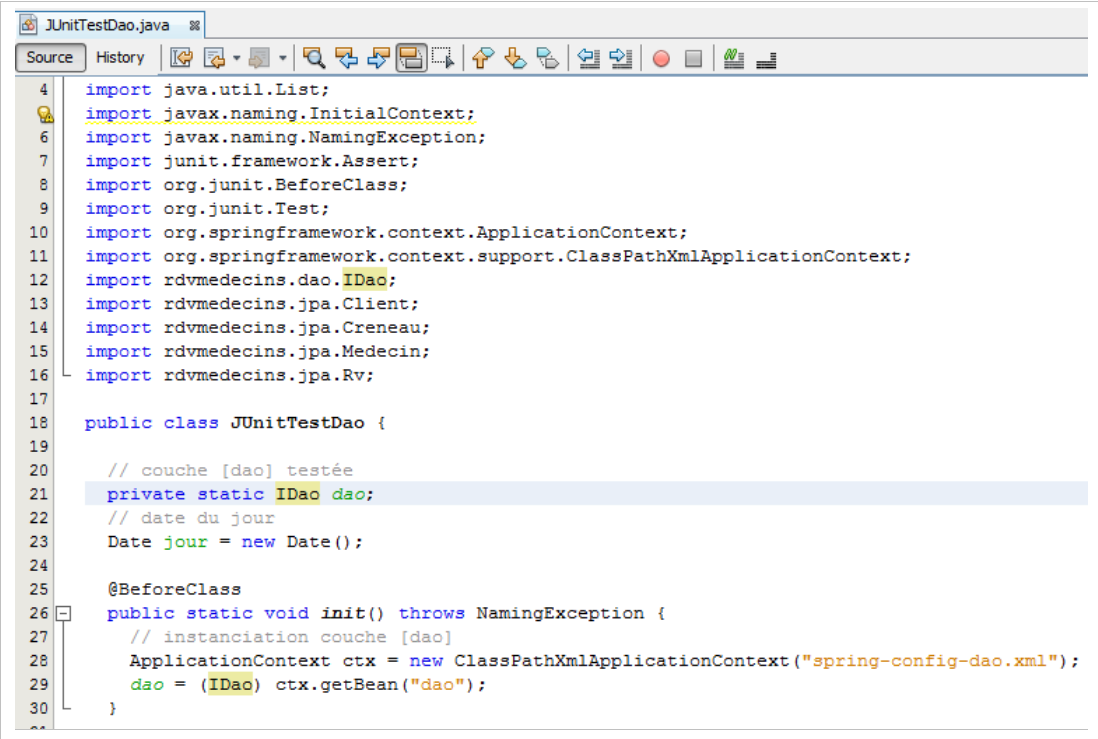 |
- línea 21: el tipo de la interfaz ha pasado a ser [IDao],
- línea 28: instancia todos los beans declarados en el archivo [spring-config-dao.xml], en particular este:
<bean id="dao" class="rdvmedecins.dao.DaoJpa" />
- la línea 29 solicita al contexto Spring de la línea 28 una referencia al bean que tiene id="dao". De este modo, se obtiene una referencia al singleton [DaoJpa] (class más arriba) que Spring ha instanciado.
Las líneas 28-29 construyen los siguientes bloques (puntos rosas):
 |
Cuando se ejecutan las pruebas del cliente JUnit, la capa [DAO] ya se ha instanciado. Por lo tanto, podemos probar sus métodos. Cabe señalar que no se necesita ningún servidor para realizar esta prueba, a diferencia de la prueba de EJB [DAO], que requirió el servidor Glassfish. En este caso, todo se ejecuta en el mismo JVM.
Ahora podemos ejecutar la prueba JUnit. Es necesario que el servidor MySQL esté en marcha. Los resultados son los siguientes:
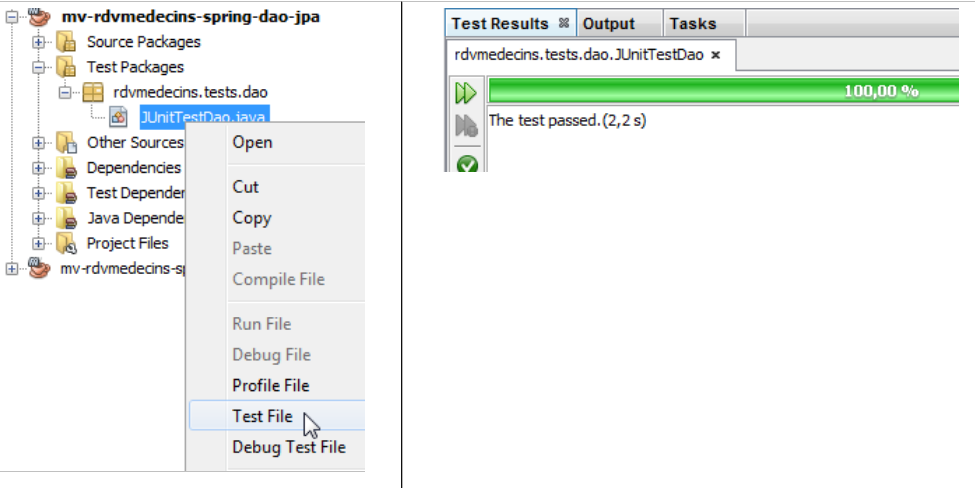 |
La prueba JUnit se ha superado. Analicemos los registros de la prueba tal y como se hizo en la prueba de EJB:
- líneas 1-4: registros de Spring,
- líneas 5-10: registros de Hibernate,
- línea 11: Spring muestra todos los beans que ha instanciado. En primer lugar aparece el bean [dao],
- líneas 12 y siguientes: los registros de la prueba JUnit,
- líneas 60-65: se ve claramente la excepción provocada por la adición de una cita que ya existe en la base de datos. Recordemos que con EJB no se produjo esta excepción debido a un problema de serialización.
La capa [dao] está operativa. Ahora vamos a desarrollar la capa [métier].
4.2. La capa [métier]
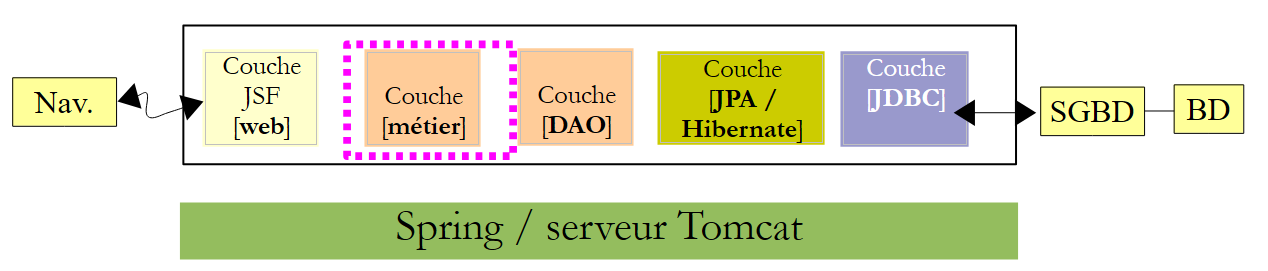 |
Procedemos de la misma manera que con la capa [DAO], copiando y pegando desde el proyecto EJB al proyecto Spring.
4.2.1. El proyecto NetBeans
Creamos un nuevo proyecto Maven de tipo [Java Application], depurado de todo lo que no queremos conservar de [1]:
 |
4.2.2. Las dependencias del proyecto
En la arquitectura:
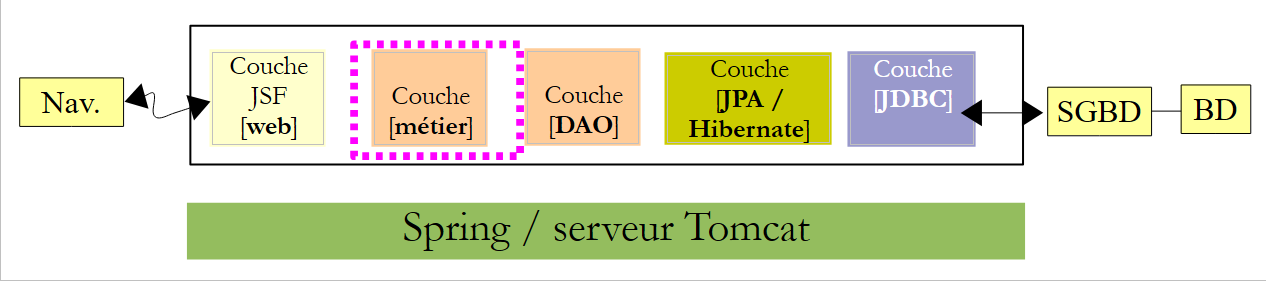 |
la capa [métier] se basa en la capa [dao]. Por lo tanto, añadimos una dependencia del proyecto anterior:
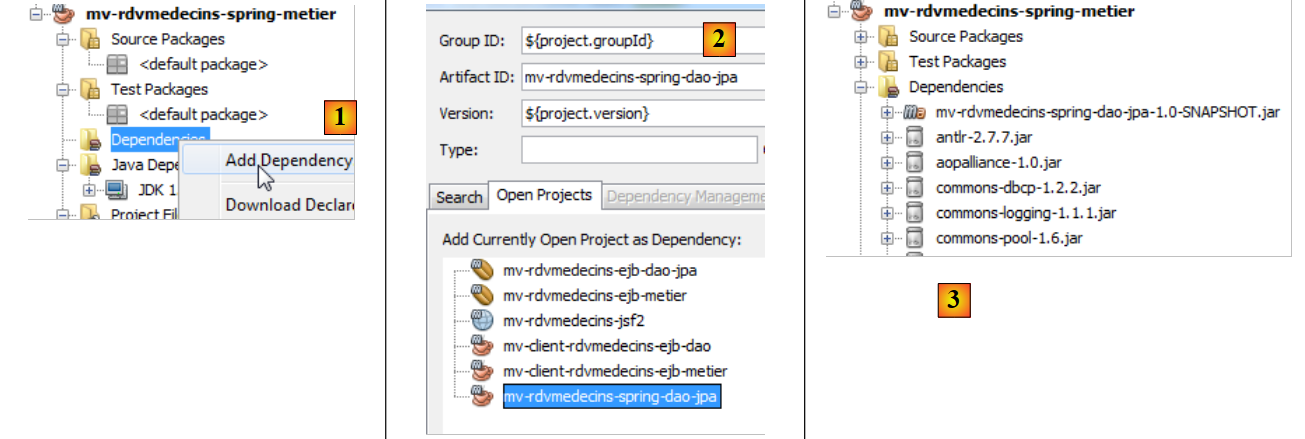 |
- en [1] y [2], añadimos una dependencia del proyecto de la capa [dao],
- en [3], esta dependencia ha dado lugar a otras dependencias, las del proyecto de la capa [dao].
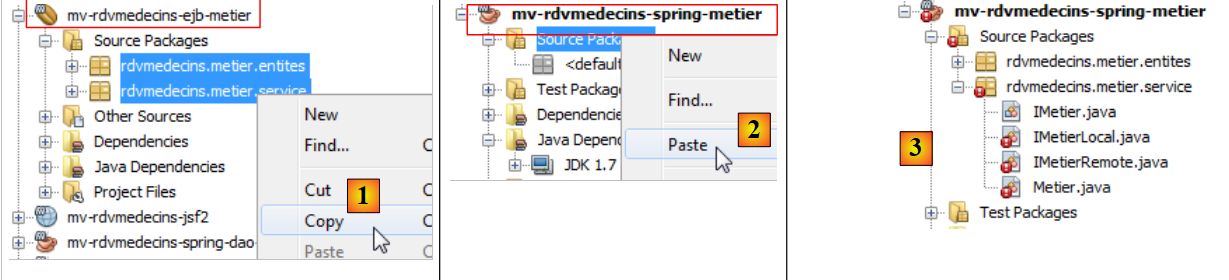 |
- en [1] y [2], se copian los archivos fuente Java del proyecto EJB al proyecto Spring,
- en [3], el código fuente importado presenta errores en su nuevo entorno.
Empezamos por eliminar las interfaces remota y local de la capa [métier], que ya no existen en [4]:
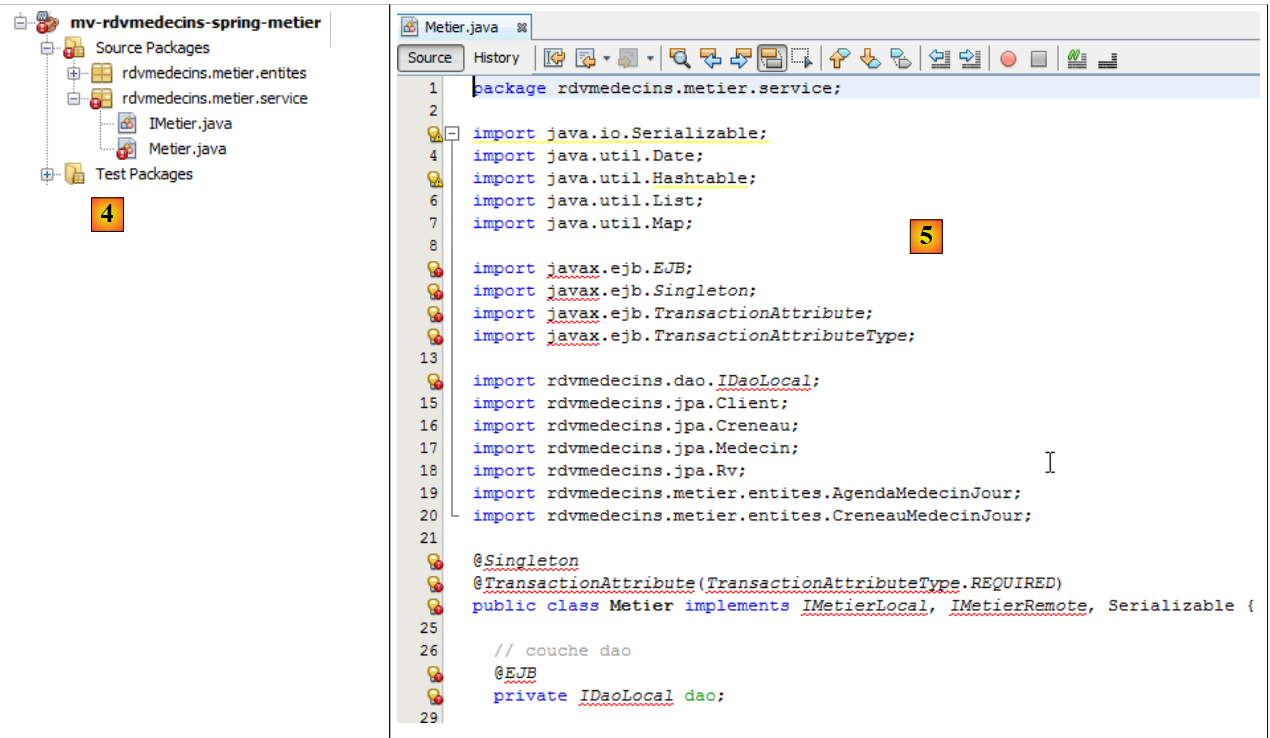 |
- en [5], los errores de la clase [Metier] tienen varias causas:
- el uso del paquete [javax.ejb], que ya no existe;
- el uso de la interfaz [IDaoLocal], que ya no existe;
- el uso de las interfaces [IMetierRemote] y [IMetierLocal], que ya no existen.
Vamos a
- eliminamos todas las líneas erróneas relacionadas con el paquete [javax.ejb],
- sustituimos la interfaz [IDaoLocal] por la interfaz [IDao],
- y sustituimos las interfaces [IMetierRemote] y [IMetierLocal] por la interfaz [IMetier].
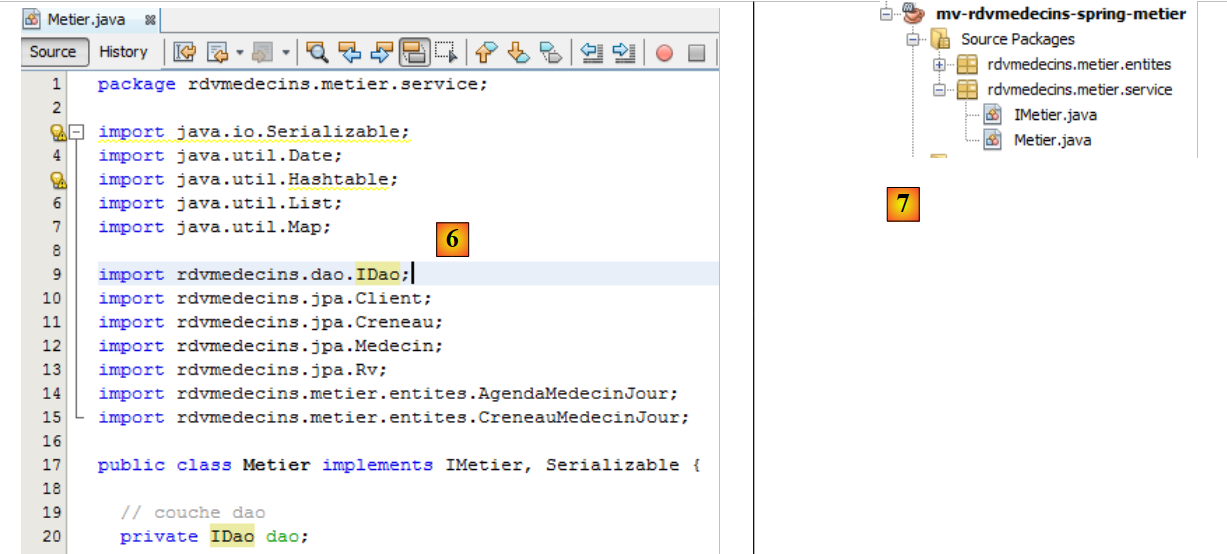 |
- por [6], la clase así corregida,
- En [7] ya no hay errores.
Hemos eliminado las referencias a EJB, pero ahora tenemos que recuperar sus propiedades:
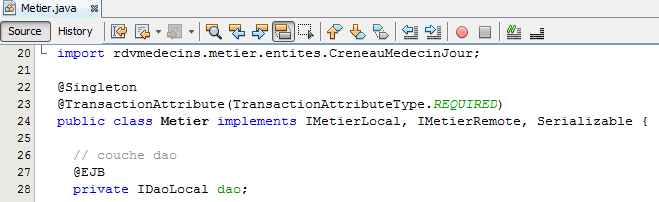 |
- línea 22: teníamos un singleton. Esta característica se conseguirá convirtiendo la clase en un bean gestionado por Spring,
- línea 23: cada método se ejecutaba en una transacción. Esto se conseguirá con la anotación de Spring @Transactional,
- líneas 27-28: la referencia a la capa [DAO] se obtenía mediante la inyección del contenedor EJB. Utilizaremos una inyección de Spring.
Por lo tanto, el código de la clase [Metier] del proyecto Spring queda así:
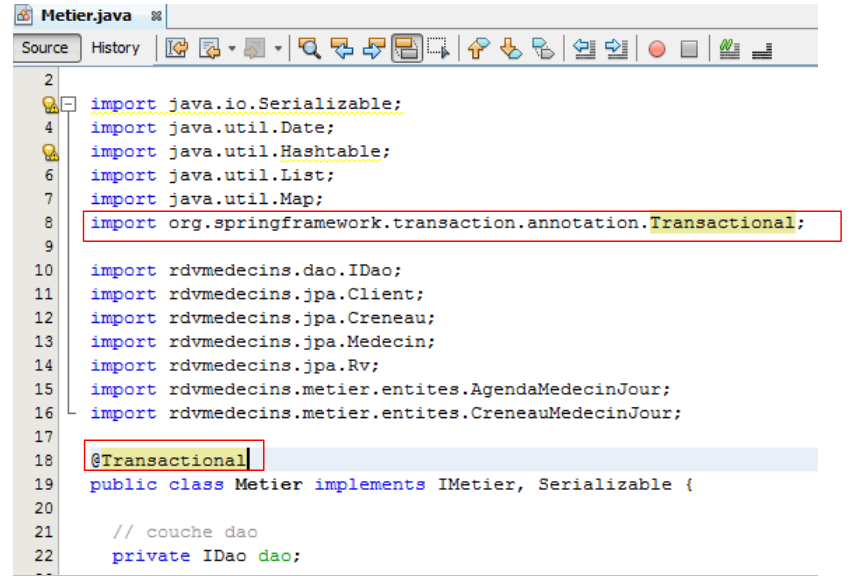 |
Esto es todo en cuanto al código Java. El resto se lleva a cabo en el archivo de configuración de Spring.
4.2.3. El archivo de configuración de Spring
Copiamos el archivo de configuración de Spring del proyecto de la capa [DAO] al proyecto de la capa [métier]. Empezamos creando la rama [Other Resources] en el proyecto de la capa [métier] si aún no existe:
 |
- En [1], en la pestaña [Files], creamos una subcarpeta dentro de la carpeta [main],
- en [2], debe llamarse [resources],
- en [3], en la pestaña [Projects], se ha creado la rama [Other Sources].
Ahora podemos pasar a copiar y pegar el archivo de configuración de Spring:
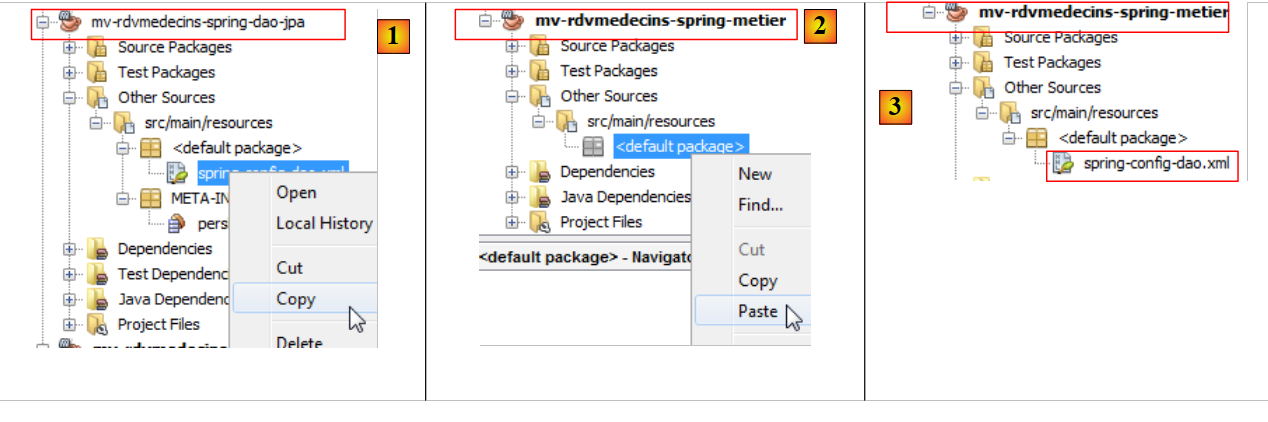 |
- en [1], copiamos el archivo del proyecto [DAO] al proyecto [métier] [2],
- en [3], el archivo copiado.
El archivo de configuración que se ha copiado configura la capa [DAO]. Le añadimos un bean para configurar la capa [métier]:
- línea 2: el bean de la capa [DAO],
- líneas 3-5: el bean de la capa [métier],
- línea 3: el bean se llama métier (atributo id) y es una instancia de la clase [rdvmedecins.metier.service.Metier] (atributo class). Este bean se instanciará como los demás al iniciar la aplicación.
Recordemos el código del bean [rdvmedecins.metier.service.Metier]:
package rdvmedecins.metier.service;
...
public class Metier implements IMetier, Serializable {
// capa DAO
private IDao dao;
public Metier() {
}
- línea 8: Spring instanciará el campo [dao] al mismo tiempo que el bean métier. Volvamos a la definición de este bean en el archivo de configuración de Spring:
- línea 4: la etiqueta <property> sirve para inicializar los campos del bean instanciado. El nombre del campo viene dado por el atributo name. Por lo tanto, se instanciará el campo dao de la clase [rdvmedecins.metier.service.Metier]. Esto se hará mediante un método setDao que debe existir. El valor que se le asignará es el del atributo ref. Este valor es, en este caso, la referencia del bean dao de la línea 2.
En términos más sencillos, en el código:
package rdvmedecins.metier.service;
...
public class Metier implements IMetier, Serializable {
// capa DAO
private IDao dao;
public Metier() {
}
El campo «dao» de la línea 19 será inicializado por Spring con una referencia a la capa [dao]. Eso es lo que queríamos. El campo «dao» será inicializado por Spring mediante un setter que debemos añadir:
// setter
public void setDao(IDao dao) {
this.dao = dao;
}
Renombramos el archivo de configuración de Spring para reflejar los cambios:
 |
Ya estamos listos para realizar una prueba. Volvemos a utilizar la prueba de consola empleada para probar el EJB [Metier].
4.2.4. Prueba de la capa [métier]
La prueba se llevará a cabo con la siguiente arquitectura:
 |
Copiamos la prueba de consola del proyecto EJB al proyecto Spring:
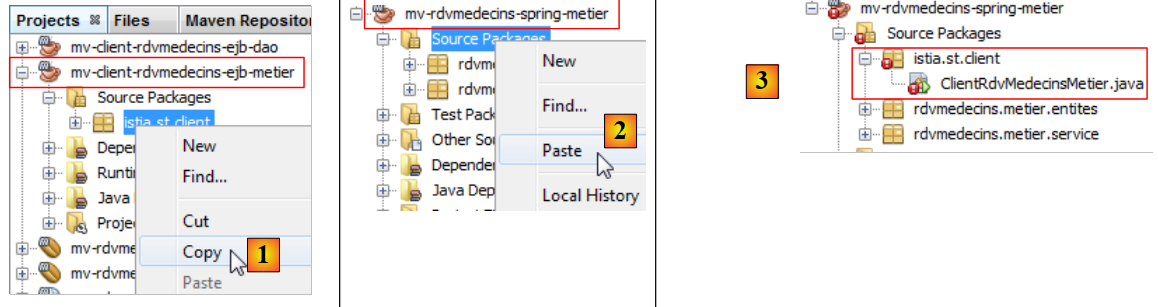 |
- en [1] y [2], al copiar y pegar entre ambos proyectos,
- en [3], el código importado presenta errores.
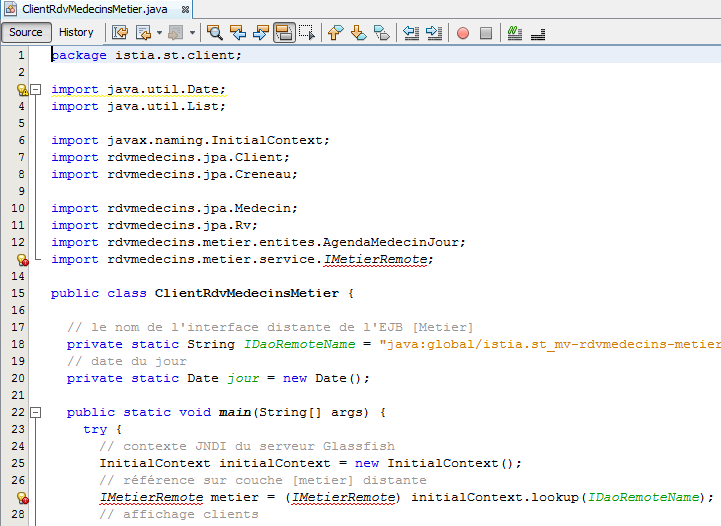 |
El código importado presenta dos tipos de error:
- línea 13: la interfaz [IMetierRemote] ha sido sustituida por la interfaz [IMetier],
- líneas 24-27: la instanciación de la capa [métier] ya no se realiza mediante una llamada a JNDI, sino mediante la instanciación de los beans del archivo de configuración de Spring.
Corregimos estos dos puntos:
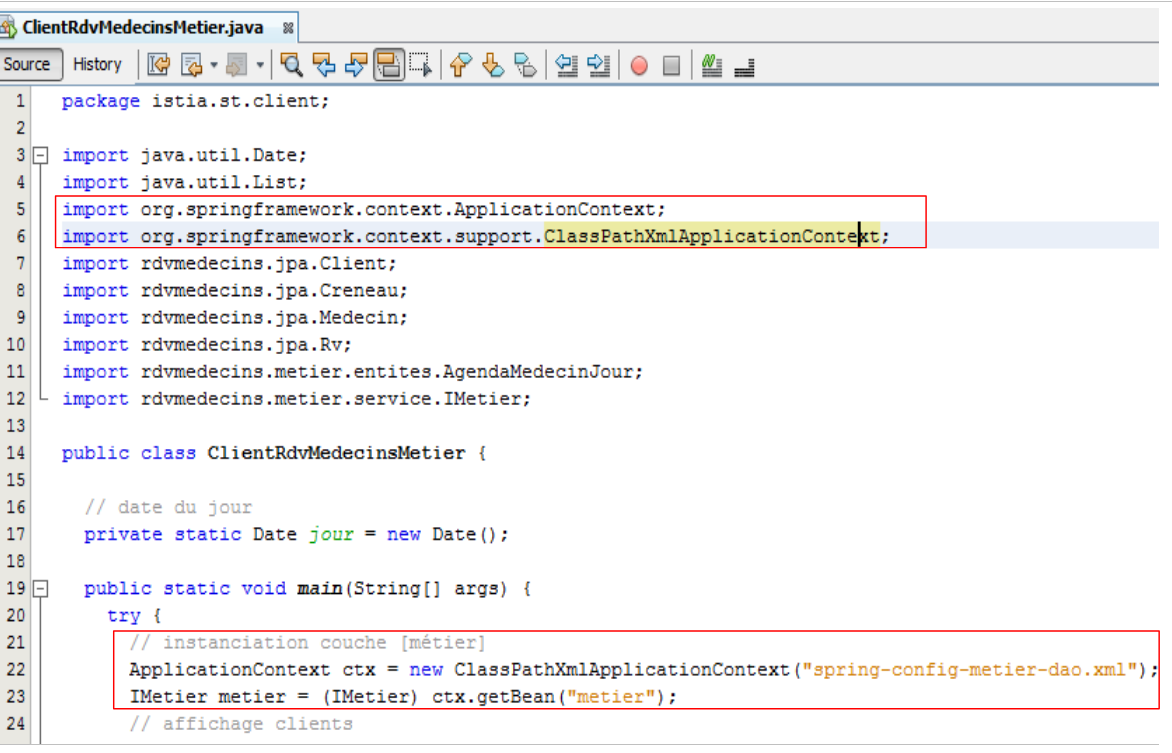 |
- línea 22: se utiliza el archivo [spring-config-metier-dao.xml]. A continuación, se instancian todos los beans de este archivo. Entre ellos se encuentran los siguientes:
<!-- capas de aplicación -->
<bean id="dao" class="rdvmedecins.dao.DaoJpa" />
<bean id="metier" class="rdvmedecins.metier.service.Metier">
<property name="dao" ref="dao"/>
</bean>
Estos dos beans representan las capas [DAO] y [métier] de la arquitectura de la prueba:
 |
Una vez hecho esto, la prueba puede ejecutarse:
 |
Los registros de la prueba son los siguientes:
- líneas 1-4: los registros de Spring y Hibernate,
- línea 5: los beans instanciados por Spring. Cabe destacar los beans DAO y de negocio,
- líneas 6-53: los registros de la prueba. Son conformes a lo obtenido con la prueba del proyecto EJB. Remitimos al lector a los comentarios de dicha prueba (apartado 3.5.3).
Hemos construido la capa [métier]. Pasamos a la última capa, la capa [web].
4.3. La capa [web]
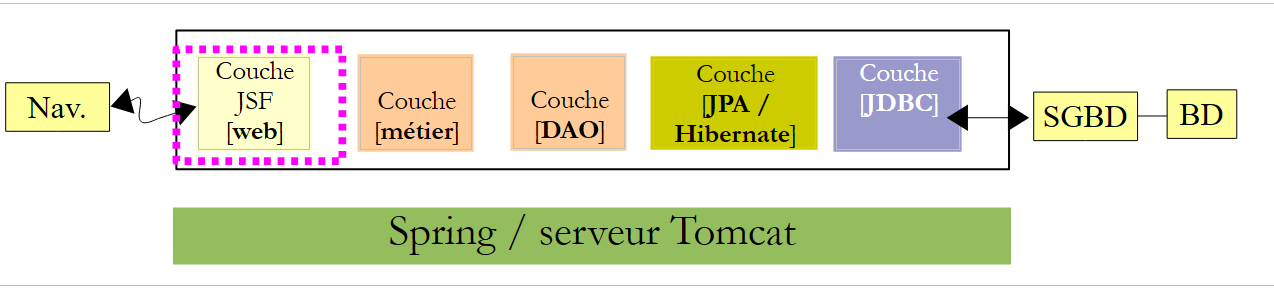 |
Para crear la capa [web], procederemos de la misma forma que con las otras dos capas, copiando y pegando desde la capa [web] del proyecto EJB.
4.3.1. El proyecto NetBeans
En primer lugar, creamos un proyecto web:
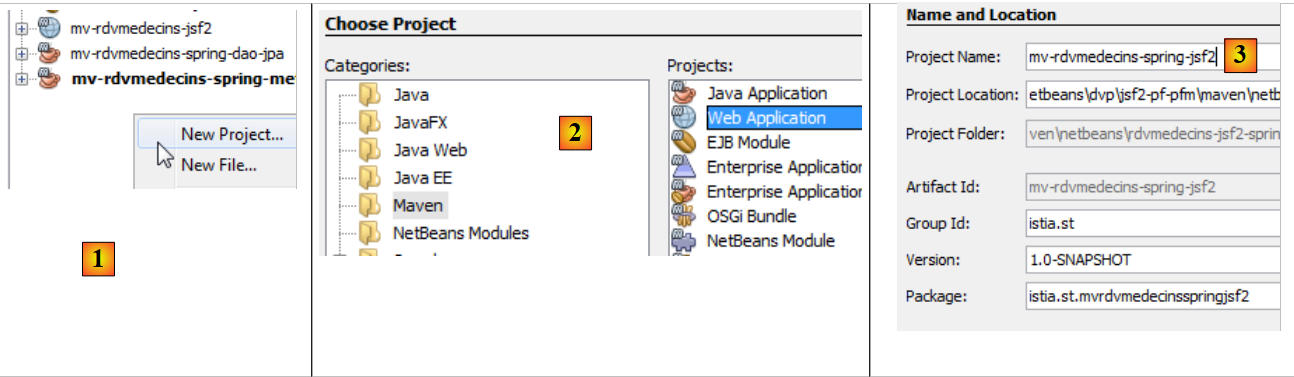 |
- En [1], creamos un nuevo proyecto,
- en [2], un proyecto Maven de tipo [Web Application],
- en [3], le damos un nombre,
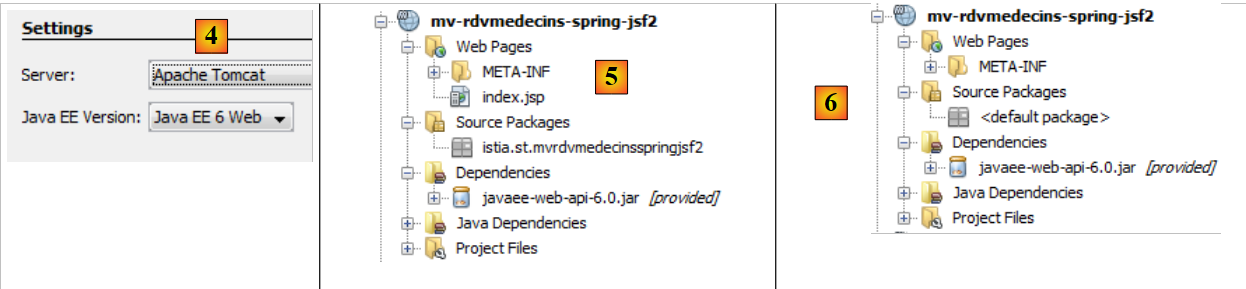 |
- en [4], esta vez se elige el servidor Tomcat y no Glassfish, que se utilizó en el proyecto EJB,
- en [5], el proyecto resultante,
- en [6], el proyecto tras eliminar [index.jsp] y el paquete de [Source Packages].
4.3.2. Las dependencias del proyecto
Veamos la arquitectura del proyecto:
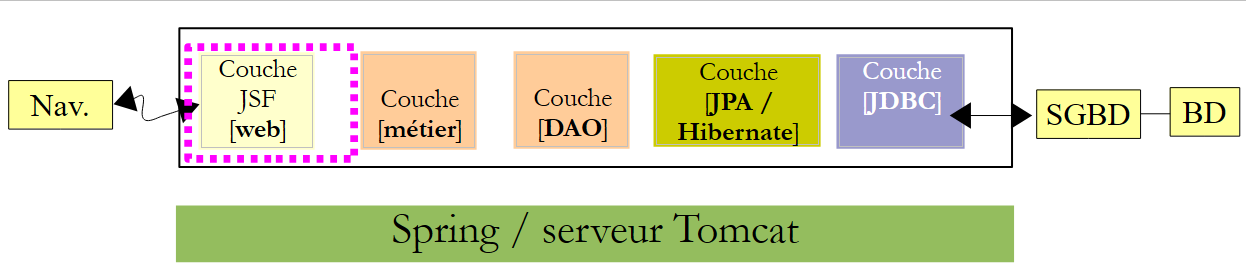 |
La capa [web] necesita las capas [métier], [DAO] y [JPA]. Estas forman parte de los dos proyectos que acabamos de compilar. De ahí que exista una dependencia respecto a cada uno de estos proyectos:
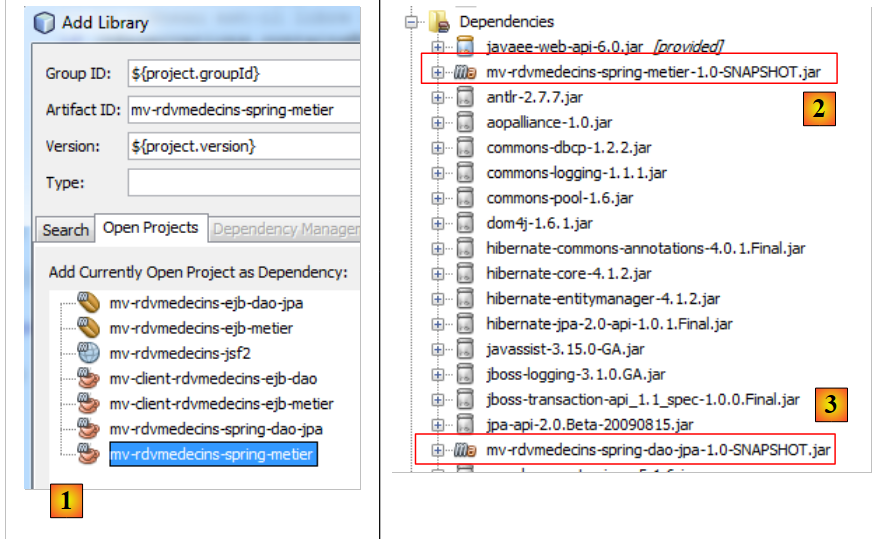 |
- en [1], añadimos la dependencia del proyecto Spring / negocio,
- en [2], se ha añadido el proyecto Spring / negocio. Como este, a su vez, tenía una dependencia del proyecto Spring / DAO / JPA, este se ha añadido automáticamente a las dependencias de [3].
Volvamos a la estructura de nuestra aplicación:
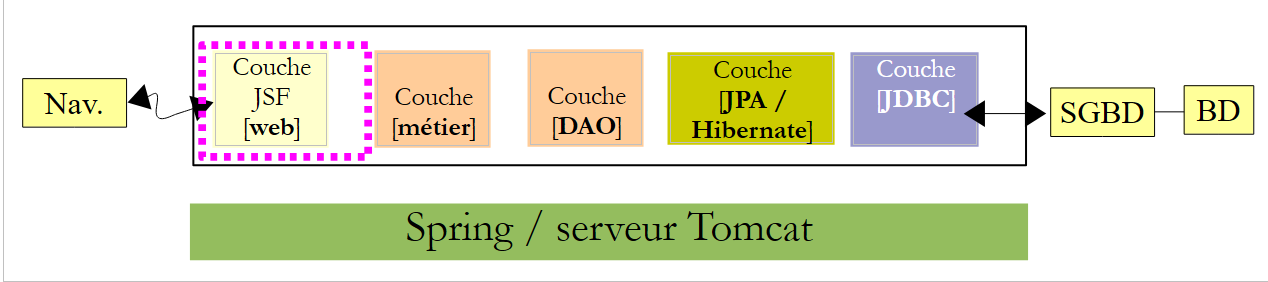 |
La capa web es una capa JSF. Por lo tanto, necesitamos las bibliotecas de Java Server Faces. El servidor Tomcat no las tiene. Por lo tanto, la dependencia no tendrá el ámbito (scope) [provided], como ocurría con el servidor Glassfish, sino el ámbito [compile], que es el ámbito por defecto cuando no se especifica ninguno.
Añadimos estas dependencias directamente en el código de [pom.xml]:
<dependencies>
<dependency>
<groupId>${project.groupId}</groupId>
<artifactId>mv-rdvmedecins-spring-metier</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>com.sun.faces</groupId>
<artifactId>jsf-api</artifactId>
<version>2.1.7</version>
</dependency>
<dependency>
<groupId>com.sun.faces</groupId>
<artifactId>jsf-impl</artifactId>
<version>2.1.7</version>
</dependency>
<dependency>
<groupId>javax</groupId>
<artifactId>javaee-web-api</artifactId>
<version>6.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
- Se han añadido las líneas 7-16 al archivo [pom.xml]. Son las dependencias respecto a JSF. Son las que se utilizan en el proyecto EJB / Glassfish. Cabe señalar que no tienen la etiqueta <scope>. Por lo tanto, tienen por defecto el ámbito [compile]. La biblioteca JSF se incluirá, por tanto, en el archivo [war] del proyecto web.
Tras añadir estas dependencias al archivo [pom.xml], compilamos el proyecto para que se descarguen.
4.3.3. Migración del proyecto JSF / Glassfish al proyecto JSF / Tomcat
Copiamos todo el código del proyecto JSF / Glassfish al proyecto JSF / Tomcat:
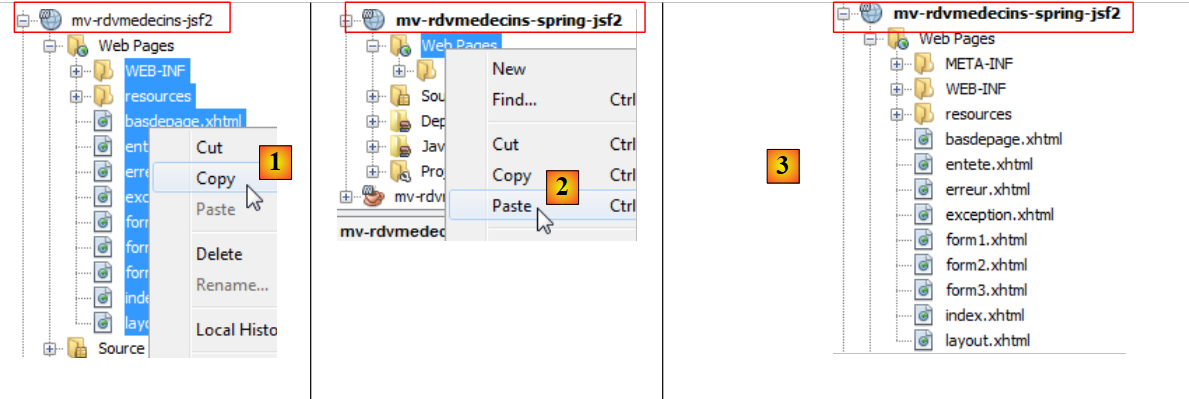 |
- [1, 2, 3]: copia de las páginas web del proyecto antiguo al nuevo,
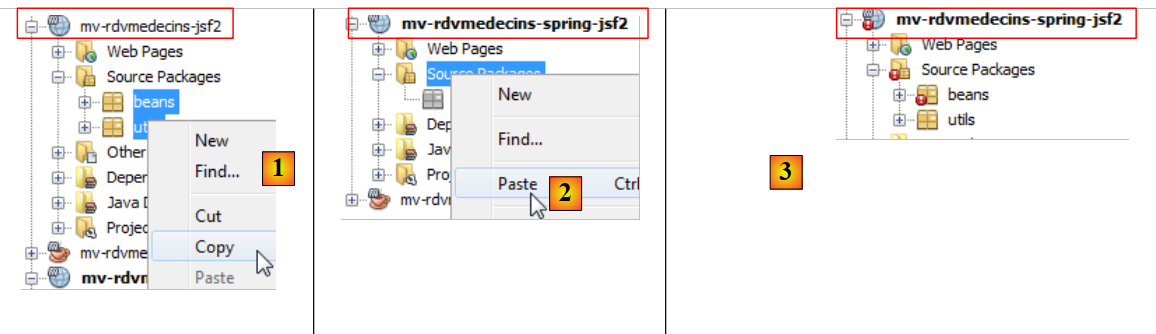 |
- [1, 2, 3]: copia del código Java del proyecto antiguo al nuevo. Hay errores. Es normal. Los corregiremos,
 |
- en [1], en la pestaña [Files] de NetBeans, se crea una subcarpeta [resources] dentro de la carpeta [main],
- lo que crea, en la pestaña [Projects], la rama [Other Sources] [3],
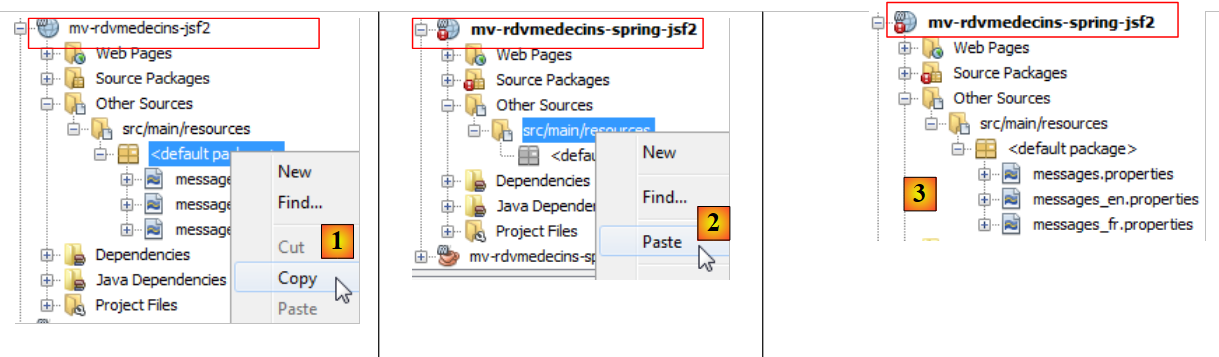 |
- [1, 2, 3]: se copian los archivos de mensajes del proyecto antiguo al nuevo.
4.3.4. Modificaciones en el proyecto importado
Hemos señalado que el código Java importado contenía errores. Analicémoslos:
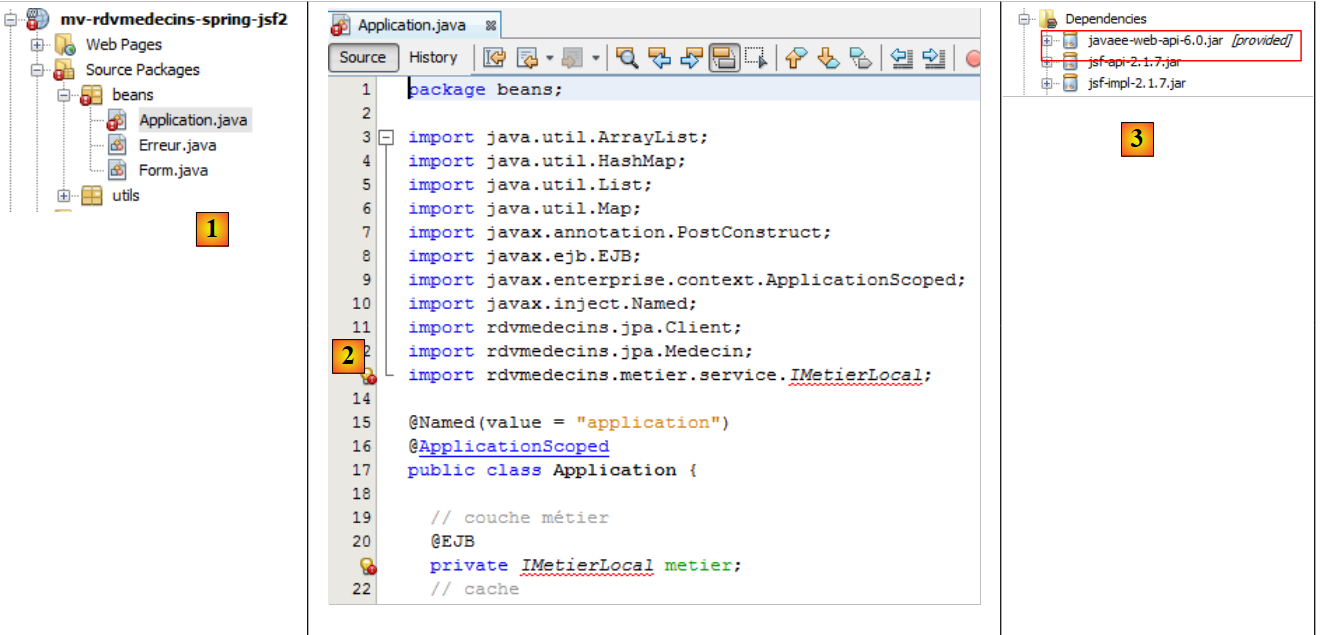 |
- en [1], solo el bean [Application] es erróneo,
- en [2], el error se debe únicamente a que la interfaz [IMetierLocal] ya no existe. En este caso, puede sorprender que la línea 20 no genere un error. La anotación @EJB hace referencia explícita a EJB y aquí se reconoce. Esto se debe a la presencia de la dependencia [javaee-web-api-6.0] [3]. Java EE 6 ha introducido una arquitectura que permite desplegar una aplicación web basada en EJB sin interfaz remota, en servidores que no dispongan de un contenedor EJB. Basta con que el servidor proporcione la dependencia [javaee-web-api-6.0]. De hecho, vemos que esta tiene el alcance [provided] [3].
En este caso no vamos a utilizar la dependencia [javaee-web-api-6.0]. La eliminamos: [1]:
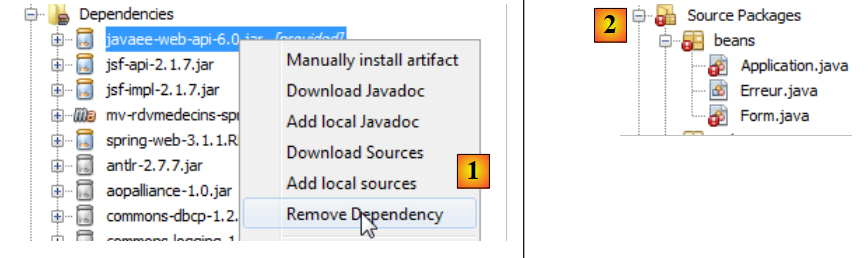 |
 |
Esto genera nuevos errores: [2]. Empezaremos por los del bean [Form]:
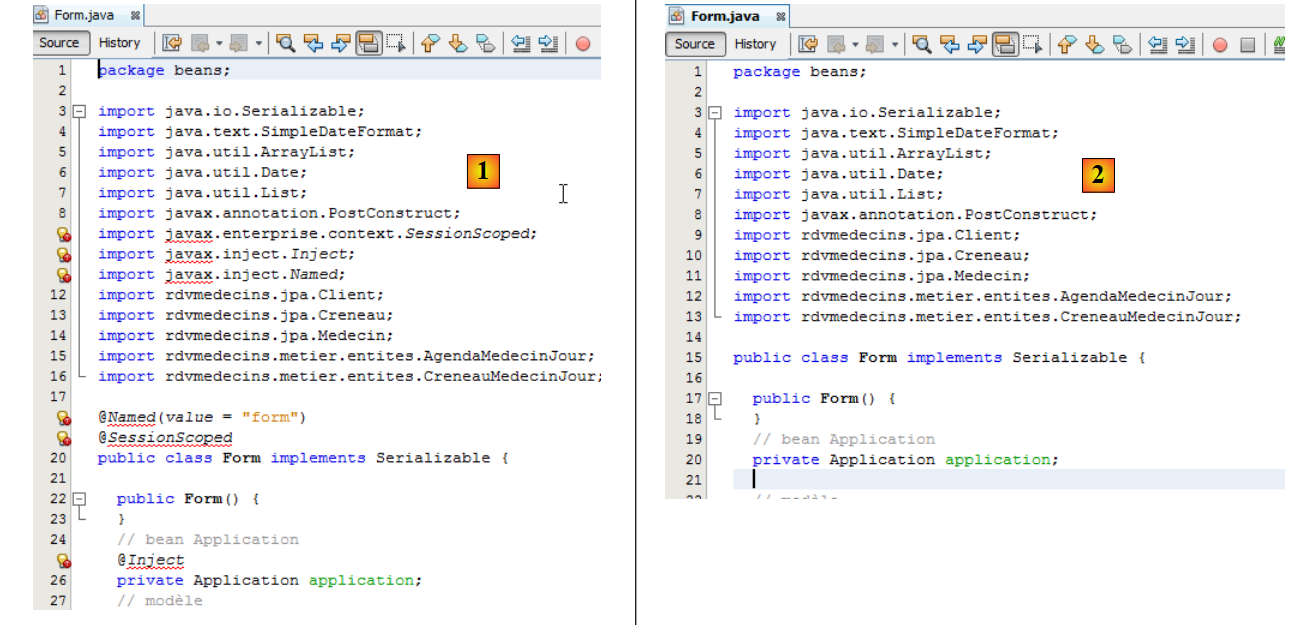 |
- En [1], las líneas erróneas están relacionadas con la pérdida del paquete [javax]. Las eliminamos todas de [2]. Las líneas erróneas convertían la clase [Form] en un bean de ámbito de sesión (líneas 18-20 de [1]). Por otra parte, el bean [Application] se inyectaba en la línea 25. Esta información se trasladará al archivo de configuración de JSF y [faces-config.xml].
Pasemos ahora al bean [Application]:
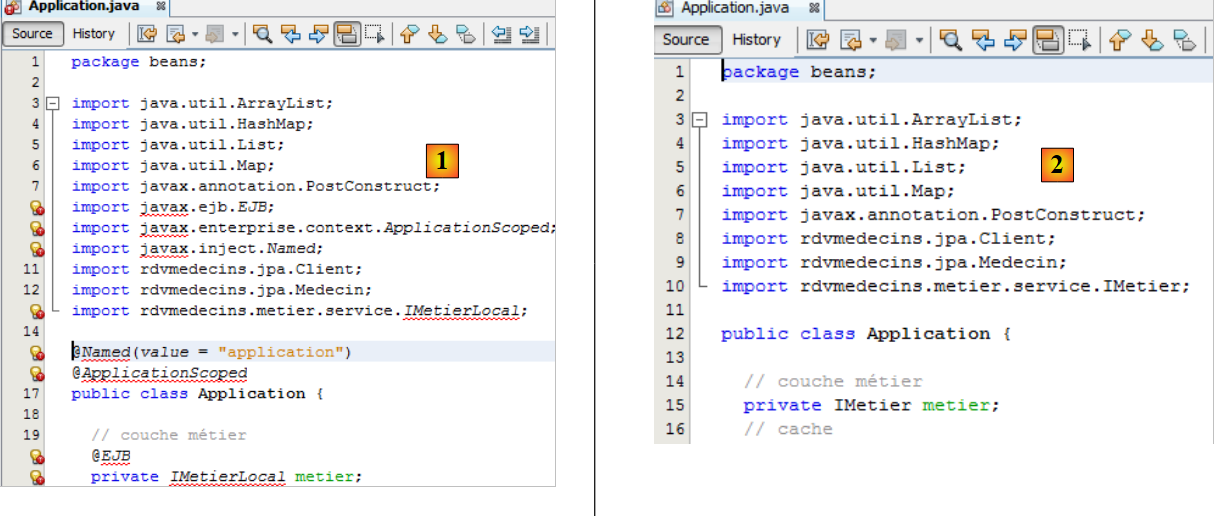 |
Se eliminan todas las líneas erróneas de [1] y se cambia la interfaz de las líneas 13 y 21 de [IMetierLocal] a [IMetier]. En [2] ya no hay errores. En [1], hemos eliminado las líneas 15 y 16 que convertían la clase [Application] en un bean de ámbito application.. Esta información se trasladará al archivo de configuración de JSF [faces-config.xml]. También hemos eliminado la línea 20, que inyectaba una referencia de la capa [métier] en el bean. Ahora, Spring se encargará de inicializarla. Ya disponemos del archivo de configuración necesario: es el del proyecto Spring / Métier. Lo copiamos:
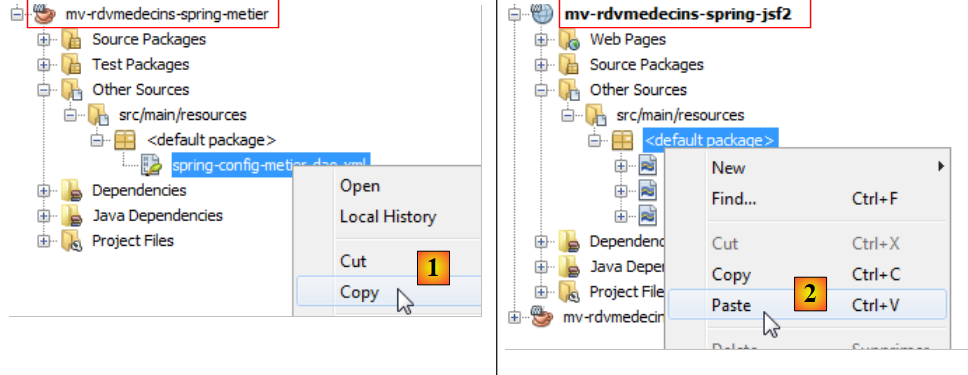 |
- en [1, 2]; copiamos el archivo de configuración de Spring del proyecto Spring / Métier al proyecto Spring / JSF,
 |
En [3], el resultado.
En el bean [Application], hay que utilizar este archivo de configuración para obtener una referencia en la capa [métier]. Esto se hace en su método [init]:
package beans;
...
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Application {
// capa de negocio
private IMetier metier;
...
public Application() {
}
@PostConstruct
public void init() {
try {
// instanciación de la capa [métier]
ApplicationContext ctx = new ClassPathXmlApplicationContext("spring-config-metier-dao.xml");
metier = (IMetier) ctx.getBean("metier");
// se almacenan en caché los médicos y los clientes
...
} catch (Throwable th) {
...
}
...
}
- línea 20: se instancian los beans del archivo de configuración de Spring,
- línea 21: se solicita una referencia al bean de negocio, es decir, a la capa [métier].
En general, la instanciación de los beans de Spring debe realizarse en el método init del bean de ámbito de aplicación. Existe otro método en el que la instanciación de los beans la realiza un servlet de Spring. Esto implica modificar el archivo [web.xml] y añadir una dependencia del artefacto [spring-web]. No lo hemos hecho aquí para mantener la coherencia con lo que se había utilizado en los códigos anteriores.
Hemos eliminado las anotaciones de las clases [Application] y [Form] que las convertían en beans JSF. Estas clases deben seguir siendo beans JSF. En lugar de las anotaciones, se utiliza el archivo de configuración de JSF y [WEB-INF / faces.config.xml] para declarar los beans.
 |
Este archivo queda ahora así:
<?xml version='1.0' encoding='UTF-8'?>
<!-- =========== FULL CONFIGURATION FILE ================================== -->
<faces-config version="2.0"
xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-facesconfig_2_0.xsd">
<application>
<!-- el archivo de mensajes -->
<resource-bundle>
<base-name>
messages
</base-name>
<var>msg</var>
</resource-bundle>
<message-bundle>messages</message-bundle>
</application>
<!-- el bean applicationBean -->
<managed-bean>
<managed-bean-name>applicationBean</managed-bean-name>
<managed-bean-class>beans.Application</managed-bean-class>
<managed-bean-scope>application</managed-bean-scope>
</managed-bean>
<!-- el bean de formulario -->
<managed-bean>
<managed-bean-name>form</managed-bean-name>
<managed-bean-class>beans.Form</managed-bean-class>
<managed-bean-scope>session</managed-bean-scope>
<managed-property>
<property-name>application</property-name>
<value>#{applicationBean}</value>
</managed-property>
</managed-bean>
</faces-config>
- las líneas 10-19 configuran el archivo de mensajes. Era la única configuración que teníamos en el proyecto JSF / EJB,
- las líneas 21-35 declaran los beans de la aplicación JSF. Este era el método estándar con JSF 1.x. JSF 2 introdujo las anotaciones, pero el método de JSF y 1.x sigue siendo compatible,
- líneas 21-25: declaran el bean applicationBean,
- línea 22: el nombre del bean. Podría resultarnos tentador utilizar el nombre «application». Hay que evitarlo, ya que es el nombre de un bean predefinido de JSF,
- línea 23: el nombre completo de la clase del bean,
- línea 24: su ámbito,
- líneas 27-35: definen el bean «form»,
- línea 28: el nombre del bean,
- línea 29: el nombre completo de la clase del bean,
- línea 30: su ámbito,
- líneas 31-34: definen una propiedad de la clase [beans.Form],
- línea 32: nombre de la propiedad. La clase [beans.Form] debe tener un campo con este nombre y el setter correspondiente,
- línea 33: el valor del campo. En este caso, es la referencia al bean applicationBean definido en la línea 21. Por lo tanto, lo que hacemos aquí es inyectar el bean de ámbito application en el bean de ámbito session para que este último tenga acceso a los datos del ámbito application.
Anteriormente hemos mencionado que el campo [application] del bean [beans.Form] se iba a inicializar mediante un setter. Por lo tanto, hay que añadirlo a la clase [beans.Form] si aún no existe:
public void setApplication(Application application) {
this.application = application;
}
4.3.5. Prueba de la aplicación
Nuestra aplicación ya no presenta errores y está lista para las pruebas:
 |
- en [1], el proyecto corregido,
- en [2], lo compilamos,
- en [3], se ejecuta. Es necesario que se inicien SGBD y MySQL. A continuación, se iniciará el servidor Tomcat ([4]) si aún no lo estaba, y luego se mostrará la página de inicio de la aplicación ([5]):
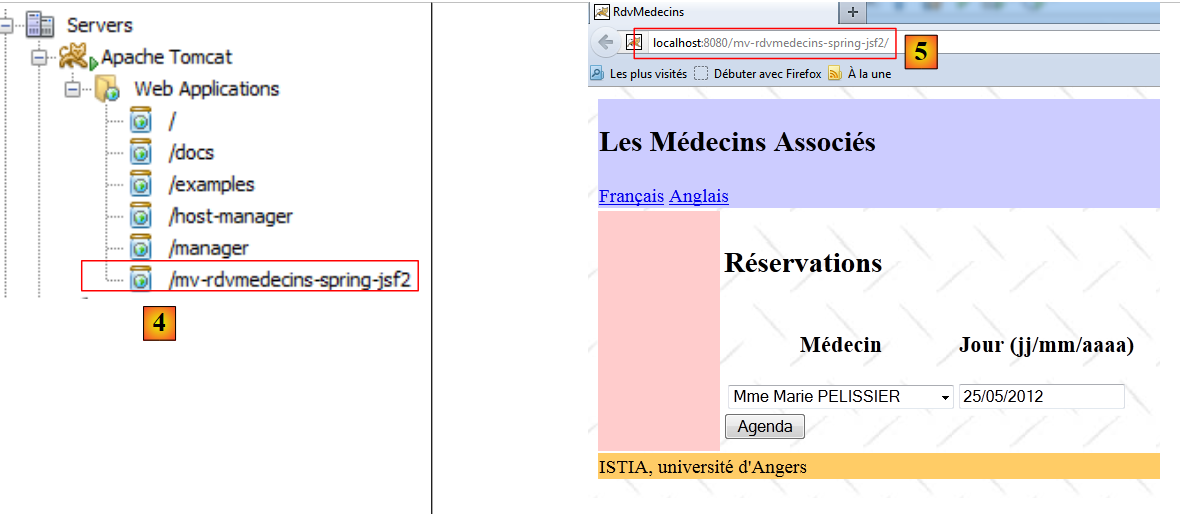 |
A partir de aquí, nos encontramos con la aplicación que estamos estudiando. Dejamos que el lector compruebe que funciona. Ahora detengamos la aplicación:
 |
- en [1], se descarga la aplicación,
- en [2], ya no está.
Veamos ahora los registros de de Tomcat:
Las líneas 2 y 4 indican un fallo al cerrar la aplicación. La línea 4 señala que existe un riesgo probable de fuga de memoria. Efectivamente, esto ocurre y, al cabo de un rato, NetBeans deja de funcionar. Este problema resulta especialmente molesto, ya que obliga a reiniciar NetBeans cada vez que se ejecuta el proyecto. Este problema ya se ha tratado en el documento «Introducción a Struts 2 con ejemplos» [http://tahe.developpez.com/java/struts2].
En Internet se encuentra mucha información sobre este error. Aparece cuando se carga y descarga una aplicación de Tomcat de forma repetida. Al cabo de un rato, se produce el error java.lang.OutOfMemoryError: PermGen space. Parece que no hay ninguna solución para evitar este error cuando se debe a archivos de terceros (jar), como ocurre en este caso. Por lo tanto, hay que reiniciar Tomcat para que desaparezca.
Sin embargo, es posible retrasar la aparición de este error. En primer lugar, se aumenta el espacio de la memoria que se ha desbordado.
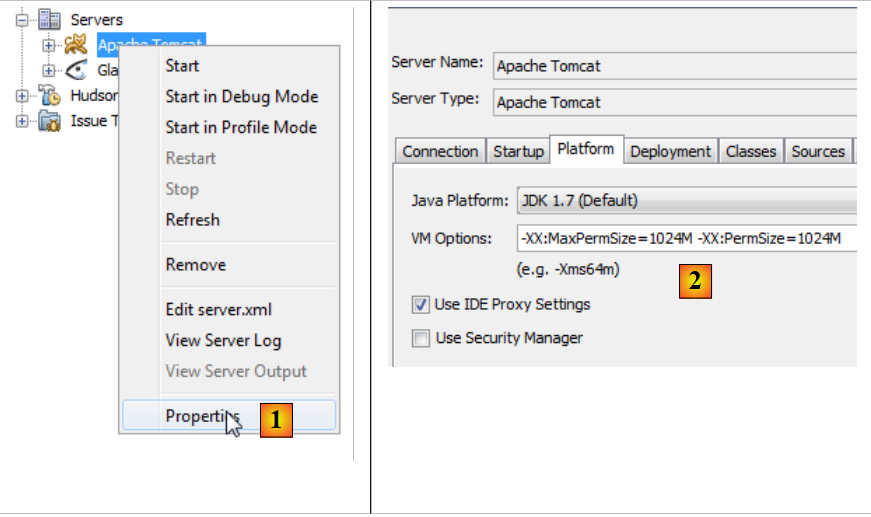 |
- en [1], accedemos a las propiedades del servidor Tomcat,
- en [2], en la pestaña [Platform], se establece el valor de la memoria que se desborda. En este caso, hemos puesto 1 GB porque teníamos una memoria total de 8 GB. Se podría poner 512M (512 megabytes) si la memoria fuera menor.
A continuación, se coloca el controlador JDBC de MySQL en <tomcat>/lib, donde <tomcat> es el directorio de instalación de Tomcat.
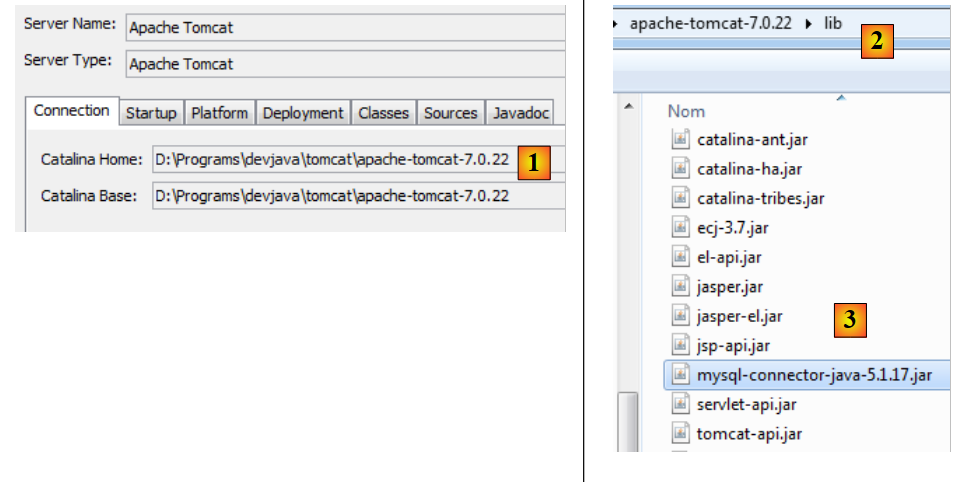 |
- en [1], en las propiedades de Tomcat, se anota su directorio de instalación <tomcat>,
- en <tomcat>/lib [2], se coloca un controlador JDBC reciente de MySQL [3].
A continuación, se elimina la dependencia que tenía el proyecto del controlador JDBC de MySQL y [4].
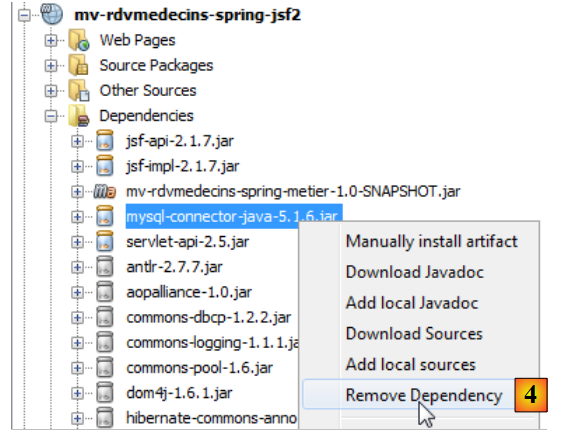 |
Una vez hecho esto, probamos la aplicación. Observamos que se pueden realizar cargas y descargas repetidas de la aplicación. Sin embargo, los problemas de fuga de memoria no se han resuelto. Simplemente aparecen más tarde.
4.4. Conclusion
Hemos migrado la aplicación JSF / EJB / Glassfish a un entorno JSF / Spring / Tomcat. Esto se ha realizado básicamente mediante copiar y pegar entre ambos proyectos. Esto ha sido posible porque las tecnologías Spring y EJB3 presentan grandes similitudes. De hecho, EJB3 se creó después de que Spring demostrara ser más eficaz que EJB2. EJB3 incorporó entonces las buenas ideas de Spring.
4.5. Pruebas con Eclipse
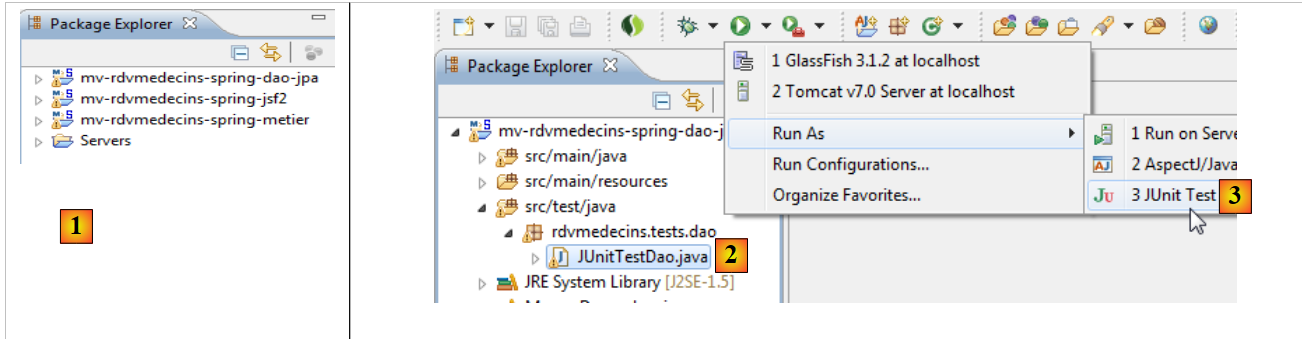 |
- en [1], se importan los tres proyectos de Spring,
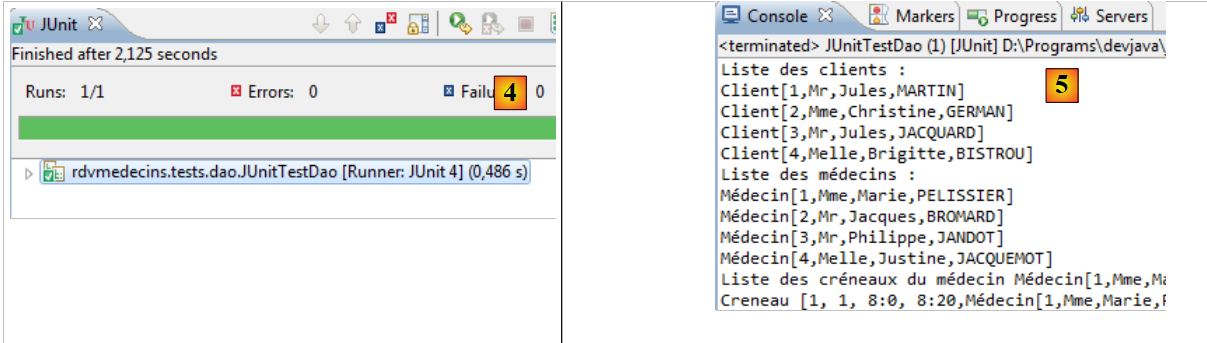
- en [2], se selecciona la prueba JUnit de la capa [DAO] y se ejecuta en [3],
 |
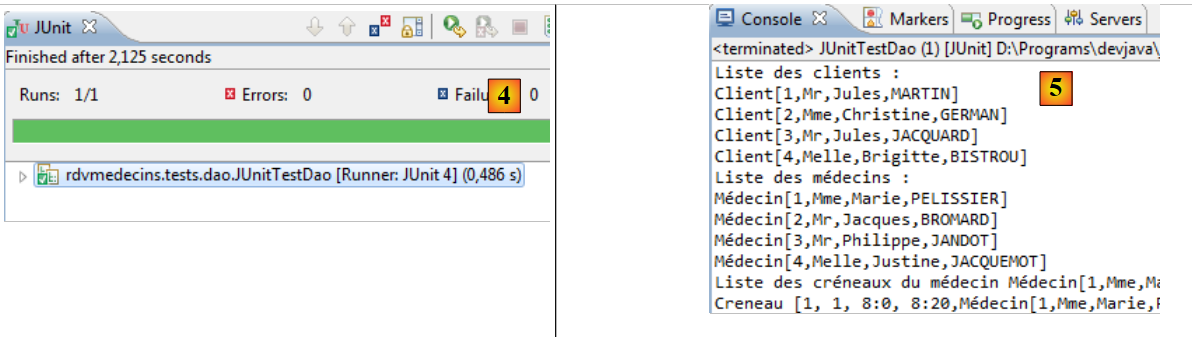 |
- en [4], la prueba se ha superado,
- en [5], los registros de la consola.
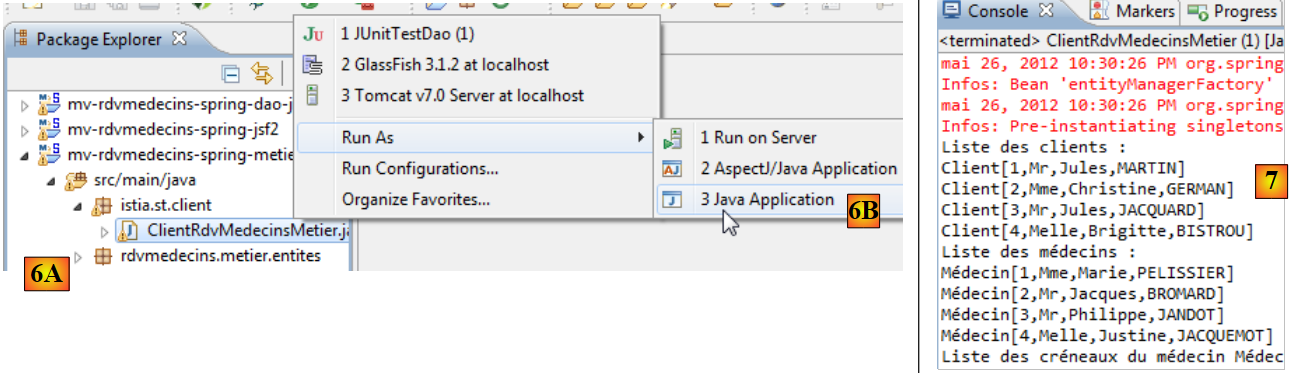 |
- en [6A] [6B], se ejecuta el cliente de consola de la capa [métier],
- en [7], la pantalla de la consola obtenida,
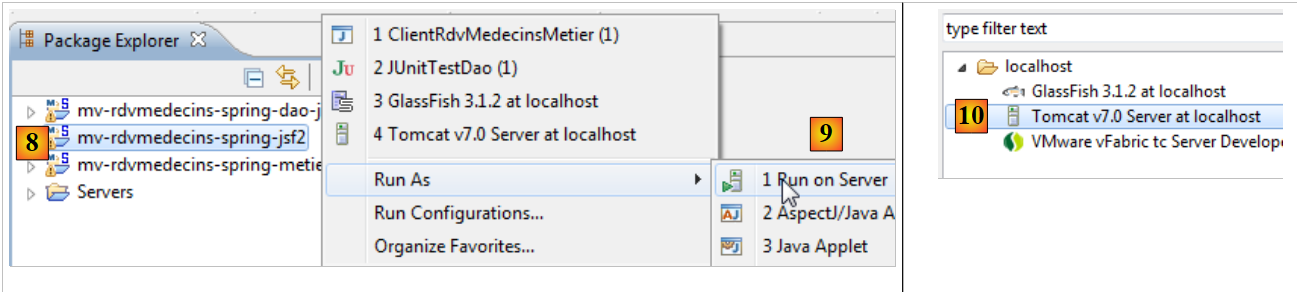 |
- en [8] [9], se ejecuta el proyecto web en un servidor Tomcat 7 [10],
 |
- en [11], la página de inicio de la aplicación se muestra en el navegador interno de Eclipse.