4. : resumen
Nos proponemos presentar JPA (Java Persistence API) con algunos ejemplos. JPA se desarrolla en el curso:
- Persistencia Java 5 en la práctica: [http://tahe.developpez.com/java/jpa] —proporciona las herramientas para construir la capa de acceso a los datos con JPA
4.1. El papel de JPA en una arquitectura por capas
Se invita al lector a volver a leer el inicio de este documento (apartado 2), donde se explica la función de la capa JPA en una arquitectura por capas. La capa JPA se integra en las capas de acceso a los datos:
 |
La capa [DAO] interactúa con la especificación JPA. Independientemente del producto que la implemente, la interfaz de la capa JPA que se presenta a la capa [DAO] sigue siendo la misma. A continuación presentamos algunos ejemplos extraídos de [ref1] que nos permitirán construir nuestra propia capa JPA.
4.2. JPA - ejemplos
4.2.1. Ejemplo 1: representación de objeto de una única tabla
4.2.1.1. La tabla [personne]
Consideremos una base de datos que contiene una única tabla, [personne], cuya función es almacenar cierta información sobre personas:
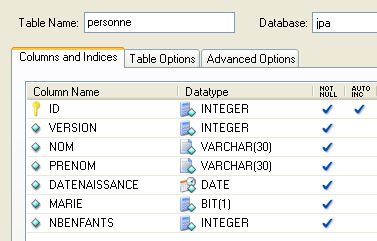 |
clave primaria de la tabla | |
versión de la fila en la tabla. Cada vez que se modifica la persona, se incrementa su número de versión. | |
nombre de la persona | |
su nombre | |
su fecha de nacimiento | |
número entero 0 (soltero) o 1 (casado) | |
Número de hijos de la persona |
4.2.1.2. La entidad [Personne]
Nos situamos en el siguiente entorno de ejecución:
 |
La capa JPA [5] debe servir de puente entre el mundo relacional de la base de datos [7] y el mundo de objetos [4] manipulado por los programas Java [3]. Este puente se establece mediante configuración y hay dos formas de hacerlo:
- mediante archivos XML. Esta era prácticamente la única forma de hacerlo hasta la llegada de JDK 1.5
- con anotaciones Java a partir de la versión 1.5 de JDK
En este documento utilizaremos exclusivamente el segundo método.
El objeto [Personne] que representa la tabla [personne] presentada anteriormente podría ser el siguiente:
...
@SuppressWarnings("unused")
@Entity
@Table(name="Personne")
public class Personne implements Serializable{
@Id
@Column(name = "ID", nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name = "VERSION", nullable = false)
@Version
private int version;
@Column(name = "NOM", length = 30, nullable = false, unique = true)
private String nom;
@Column(name = "PRENOM", length = 30, nullable = false)
private String prenom;
@Column(name = "DATENAISSANCE", nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(name = "MARIE", nullable = false)
private boolean marie;
@Column(name = "NBENFANTS", nullable = false)
private int nbenfants;
// fabricantes
public Personne() {
}
public Personne(String nom, String prenom, Date datenaissance, boolean marie,
int nbenfants) {
setNom(nom);
setPrenom(prenom);
setDatenaissance(datenaissance);
setMarie(marie);
setNbenfants(nbenfants);
}
// toString
public String toString() {
...
}
// getters y setters
...
}
La configuración se realiza mediante anotaciones Java @Annotation. Las anotaciones Java son interpretadas bien por el compilador, bien por herramientas especializadas en el momento de la ejecución. A excepción de la anotación de la línea 3, destinada al compilador, todas las demás anotaciones están destinadas a la implementación JPA utilizada, ya sea Hibernate o Toplink. Por lo tanto, se interpretarán en el momento de la ejecución. A falta de herramientas capaces de interpretarlas, estas anotaciones se ignoran. Así, la clase [Personne] anterior podría utilizarse en un contexto ajeno a JPA.
Hay que distinguir dos casos de uso de las anotaciones JPA en una clase C asociada a una tabla T:
- la tabla T ya existe: en ese caso, las anotaciones JPA deben reproducir lo existente (nombre y definición de las columnas, restricciones de integridad, claves externas, claves primarias, etc.)
- la tabla T no existe y se va a crear a partir de las anotaciones que se encuentren en la clase C.
El caso 2 es el más fácil de gestionar. Mediante las anotaciones JPA, indicamos la estructura de la tabla T que deseamos. El caso 1 suele ser más complejo. Es posible que la tabla T se haya creado hace mucho tiempo, al margen de cualquier contexto JPA. Por lo tanto, su estructura puede no estar bien adaptada al puente relacional/objeto de JPA. Para simplificar, nos centraremos en el caso 2, en el que la tabla T asociada a la clase C se creará según las anotaciones JPA de la clase C.
Comentemos las anotaciones JPA de la clase [Personne]:
- línea 4: la anotación @Entity es la primera anotación imprescindible. Se coloca antes de la línea que declara la clase e indica que la clase en cuestión debe ser gestionada por la capa de persistencia JPA. En ausencia de esta anotación, se ignorarían todas las demás anotaciones JPA.
- línea 5: la anotación @Table designa la tabla de la base de datos que representa la clase. Su argumento principal es «name», que indica el nombre de la tabla. Si no se incluye este argumento, la tabla llevará el nombre de la clase, en este caso [Personne]. Por lo tanto, en nuestro ejemplo, la anotación @Table es superflua.
- línea 8: la anotación @Id sirve para designar el campo de la clase que representa la clave primaria de la tabla. Esta anotación es obligatoria. En este caso, indica que el campo id de la línea 11 representa la clave primaria de la tabla.
- línea 9: la anotación @Column sirve para establecer el vínculo entre un campo de la clase y la columna de la tabla que dicho campo representa. El atributo name indica el nombre de la columna en la tabla. A falta de este atributo, la columna lleva el mismo nombre que el campo. En nuestro ejemplo, el argumento name no era, por tanto, obligatorio. El argumento nullable=false indica que la columna asociada al campo no puede tener el valor NULL y que, por lo tanto, el campo debe tener necesariamente un valor.
- línea 10: la anotación @GeneratedValue indica cómo se genera la clave primaria cuando la genera automáticamente el SGBD. Este será el caso en todos nuestros ejemplos. No es obligatorio. Así, nuestra persona podría tener un número de estudiante que sirviera como clave primaria y que no fuera generado por el SGBD, sino fijado por la aplicación. En ese caso, la anotación @GeneratedValue no aparecería. El argumento strategy indica cómo se genera la clave primaria cuando la genera el SGBD. No todos los SGBD utilizan la misma técnica para generar los valores de la clave primaria. Por ejemplo:
utiliza un generador de valores que se invoca antes de cada inserción | |
el campo de clave primaria se define con el tipo Identity. El resultado es similar al del generador de valores de Firebird, salvo que el valor de la clave solo se conoce tras la inserción de la fila. | |
utiliza un objeto denominado SEQUENCE que, una vez más, desempeña la función de generador de valores |
La capa JPA debe generar órdenes SQL diferentes en función de los SGBD para crear el generador de valores. Mediante la configuración, se le indica el tipo de SGBD que debe gestionar. De este modo, puede saber cuál es la estrategia habitual de generación de valores de clave primaria de ese SGBD. El argumento strategy = GenerationType.AUTO indica a la capa JPA que debe utilizar esta estrategia habitual. Esta técnica ha funcionado en todos los ejemplos de este documento para los siete SGBD utilizados.
- línea 14: la anotación @Version designa el campo que se utiliza para gestionar los accesos concurrentes a una misma línea de la tabla.
Para comprender este problema de accesos concurrentes a una misma línea de la tabla [personne], supongamos que una aplicación web permite actualizar los datos de una persona y analicemos el siguiente caso:
En el momento T1, un usuario U1 accede para modificar un registro de persona P. En ese momento, el número de hijos es 0. Cambia este número a 1, pero antes de que valide su modificación, un usuario U2 accede para modificar el mismo perfil P. Dado que U1 aún no ha validado su modificación, U2 ve en su pantalla que el número de hijos es 0. U2 cambia el nombre de la persona P a mayúsculas. A continuación, U1 y U2 validan sus modificaciones en ese orden. La modificación de U2 será la que prevalezca: en la base de datos, el nombre pasará a estar en mayúsculas y el número de hijos se mantendrá en cero, aunque U1 crea haberlo cambiado a 1.
El concepto de «versión de persona» nos ayuda a resolver este problema. Volvamos al mismo caso práctico:
En el momento T1, un usuario U1 accede para modificar una persona P. En ese momento, el número de hijos es 0 y la versión es V1. Cambia el número de hijos a 1, pero antes de que valide su modificación, un usuario U2 accede para modificar la misma persona P. Dado que U1 aún no ha validado su modificación, U2 ve que el número de hijos es 0 y que la versión es V1. U2 cambia el nombre de la persona P a mayúsculas. A continuación, U1 y U2 validan sus modificaciones en ese orden. Antes de validar una modificación, se comprueba que quien modifica a una persona P tenga la misma versión que la persona P registrada actualmente. Este será el caso del usuario U1. Por lo tanto, su modificación se acepta y se cambia la versión de la persona modificada de V1 a V2 para indicar que la persona ha sufrido un cambio. Al validar la modificación de U2, se observará que U2 tiene una versión V1 de la persona P, mientras que actualmente la versión de esta es V2. Entonces podremos indicar al usuario U2 que alguien le ha adelantado y que debe partir de la nueva versión de la persona P. Lo hará, recuperará una persona P de la versión V2 que ahora tiene un hijo, escribirá el nombre en mayúsculas y validará. Su modificación se aceptará si la persona P registrada sigue teniendo la versión V2. Al final, se tendrán en cuenta las modificaciones realizadas por U1 y U2, mientras que en el caso de uso sin versión, una de las modificaciones se perdía.
La capa [DAO] de la aplicación cliente puede gestionar por sí misma la versión de la clase [Personne]. Cada vez que se produzca una modificación de un objeto P, la versión de dicho objeto se incrementará en 1 en la tabla. La anotación @Version permite transferir esta gestión a la capa JPA. El campo en cuestión no tiene por qué llamarse version, como en el ejemplo. Puede tener cualquier nombre.
Los campos correspondientes a las anotaciones @Id y @Version están presentes por motivos de persistencia. No serían necesarios si la clase [Personne] no tuviera que ser persistente. Por lo tanto, se observa que un objeto no tiene la misma representación dependiendo de si necesita o no ser persistente.
- Línea 17: de nuevo la anotación @Column para proporcionar información sobre la columna de la tabla [personne] asociada al campo nom de la clase Personne. Aquí encontramos dos nuevos argumentos:
- unique=true indica que el nombre de una persona debe ser único. Esto se traducirá en la base de datos en la adición de una restricción de unicidad en la columna NOM de la tabla [personne].
- length=30 establece en 30 el número de caracteres de la columna NOM. Esto significa que el tipo de esta columna será VARCHAR(30).
- línea 24: la anotación @Temporal sirve para indicar qué tipo SQL se debe asignar a una columna o campo de tipo fecha/hora. El tipo TemporalType.DATE designa una fecha sin hora asociada. Los demás tipos posibles son TemporalType.TIME para codificar una hora y TemporalType.TIMESTAMP para codificar una fecha con hora.
Comentemos ahora el resto del código de la clase [Personne]:
- línea 6: la clase implementa la interfaz Serializable. La sérialisation de un objeto consiste en transformarlo en una secuencia de bits. La désérialisation es la operación inversa. La serialización y deserialización se utilizan, en particular, en aplicaciones cliente-servidor en las que se intercambian objetos a través de la red. Las aplicaciones cliente o servidor desconocen esta operación, que se realiza de forma transparente mediante los JVM. Sin embargo, para que sea posible, es necesario que las clases de los objetos intercambiados estén «etiquetadas» con la palabra clave Serializable.
- Línea 37: un constructor de la clase. Cabe señalar que los campos id y version no forman parte de los parámetros. De hecho, estos dos campos son gestionados por la capa JPA y no por la aplicación.
- Líneas 51 y siguientes: los métodos get y set de cada uno de los campos de la clase. Cabe señalar que las anotaciones JPA pueden colocarse en los métodos get de los campos en lugar de en los propios campos. La ubicación de las anotaciones indica el modo que debe utilizar JPA para acceder a los campos:
- si las anotaciones se colocan a nivel de campo, JPA accederá directamente a los campos para leerlos o escribirlos
- si las anotaciones se colocan a nivel de get, JPA accederá a los campos a través de los métodos get/set para leerlos o escribirlos
Es la posición de la anotación @Id la que determina la posición de las anotaciones JPA de una clase. Si se coloca a nivel de campo, indica un acceso directo a los campos, y si se coloca a nivel de get, indica un acceso a los campos a través de los métodos get y set. Las demás anotaciones deben colocarse entonces de la misma forma que la anotación @Id.
4.2.2. Configuración de la capa JPA
Las pruebas de la capa JPA pueden realizarse con la siguiente arquitectura:
 |
- en [7]: la base de datos que se generará a partir de las anotaciones de la entidad [Personne], así como de configuraciones adicionales realizadas en un archivo denominado [persistence.xml]
- en [5, 6]: una capa JPA implementada por Hibernate
- en [4]: la entidad [Personne]
- en [3]: un programa de prueba de tipo consola
La configuración de la capa JPA se realiza mediante el archivo [META-INF/persistence.xml]:
 |
Al ejecutarse, se busca el archivo [META-INF/persistence.xml] en el archivo Classpath de la aplicación.
Veamos la configuración de la capa JPA definida en el archivo [persistence.xml] de nuestro proyecto:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- proveedor -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Clases persistentes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- registros SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- conexión JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
<property name="hibernate.connection.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- Creación automática del esquema -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialecto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!-- propiedades DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
Para comprender esta configuración, debemos repasar la arquitectura de acceso a los datos de nuestra aplicación:
 |
- El archivo [persistence.xml] configurará las capas [4, 5, 6]
- [4]: implementación de Hibernate de JPA
- [5]: Hibernate accede a la base de datos a través de un grupo de conexiones. Un grupo de conexiones es una reserva de conexiones abiertas con el SGBD. Un SGBD es utilizado por múltiples usuarios, aunque, por motivos de rendimiento, no puede superar un número límite N de conexiones abiertas simultáneamente. Un código bien escrito abre una conexión con el SGBD durante el menor tiempo posible: envía órdenes al SQL y cierra la conexión. Lo hará de forma repetida, cada vez que necesite trabajar con la base de datos. El coste de abrir y cerrar una conexión no es insignificante, y ahí es donde entra en juego el grupo de conexiones. Este, al iniciarse la aplicación, abrirá N1 conexiones con el SGBD. Es a este al que la aplicación solicitará una conexión abierta cuando la necesite. Dicha conexión se devolverá al grupo tan pronto como la aplicación ya no la necesite, preferiblemente lo antes posible. La conexión no se cierra y permanece disponible para el siguiente usuario. Por lo tanto, un grupo de conexiones es un sistema para compartir conexiones abiertas.
- [6]: el controlador JDBC del SGBD utilizado
Ahora veamos cómo el archivo [persistence.xml] configura las capas [4, 5, 6] anteriores:
- línea 2: la etiqueta raíz del archivo XML es <persistence>.
- línea 3: <persistence-unit> sirve para definir una unidad de persistencia. Puede haber varias unidades de persistencia. Cada una de ellas tiene un nombre (atributo name) y un tipo de transacción (atributo transaction-type). La aplicación tendrá acceso a la unidad de persistencia a través de su nombre, en este caso jpa. El tipo de transacción RESOURCE_LOCAL indica que la propia aplicación gestiona las transacciones con el SGBD. Este será el caso aquí. Cuando la aplicación se ejecuta en un contenedor EJB3, puede utilizar el servicio de transacciones de este. En este caso, se establecerá transaction-type=JTA (transacción Java API). JTA es el valor por defecto cuando no se especifica el atributo transaction-type.
- línea 5: la etiqueta <provider> sirve para definir una clase que implementa la interfaz [javax.persistence.spi.PersistenceProvider], interfaz que permite a la aplicación inicializar la capa de persistencia. Dado que se utiliza una implementación de JPA / Hibernate, la clase utilizada aquí es una clase de Hibernate.
- línea 6: la etiqueta <properties> introduce propiedades específicas del provider concreto elegido. Así, dependiendo de si se ha elegido Hibernate, Toplink, Kodo, etc., tendremos propiedades diferentes. Las que siguen son específicas de Hibernate.
- línea 8: solicita a Hibernate que explore el classpath del proyecto para encontrar las clases que tengan la anotación @Entity con el fin de gestionarlas. Las clases @Entity también pueden declararse mediante las etiquetas <class>nom_de_la_classe</class>, directamente bajo la etiqueta <persistence-unit>. Esto es lo que haremos con el provider JPA / Toplink.
- Las líneas 10-12, que aquí aparecen comentadas, configuran los registros de consola de Hibernate:
- línea 10: para mostrar o no los comandos SQL emitidos por Hibernate en el SGBD. Esto resulta muy útil durante la fase de aprendizaje. Debido al puente relacional/objeto, la aplicación trabaja con objetos persistentes a los que aplica operaciones de tipo [persist, merge, remove]. Resulta muy interesante saber cuáles son los comandos SQL que se emiten realmente en estas operaciones. Al estudiarlas, poco a poco se va adivinando cuáles son las órdenes SQL que Hibernate va a generar al realizar tal operación sobre los objetos persistentes, y el puente relacional/objeto empieza a cobrar sentido en la mente.
- línea 11: las órdenes SQL que se muestran en la consola se pueden formatear de forma clara para facilitar su lectura
- línea 12: además, los comandos SQL que se muestren irán acompañados de comentarios
- Las líneas 15-19 definen la capa JDBC (capa [6] en la arquitectura):
- línea 15: la clase del controlador JDBC del SGBD, en este caso MySQL5
- línea 16: la URL de la base de datos utilizada
- líneas 17 y 18: el usuario de la conexión y su contraseña
- línea 22: Hibernate necesita conocer el SGBD con el que está trabajando. De hecho, todos los SGBD tienen extensiones SQL propias, una forma específica de gestionar la generación automática de los valores de una clave primaria, ... lo que hace que Hibernate necesite conocer el SGBD con el que trabaja para enviarle las órdenes SQL que este entenderá. [MySQL5InnoDBDialect] designa el SGBD MySQL5 con tablas de tipo InnoDB que admiten transacciones.
- Las líneas 24-28 configuran el grupo de conexiones c3p0 (capa [5] en la arquitectura):
- líneas 24 y 25: el número mínimo (por defecto, 3) y máximo de conexiones (por defecto, 15) en el grupo. El número inicial de conexiones por defecto es 3.
- línea 26: tiempo máximo, en milisegundos, de espera de una solicitud de conexión por parte del cliente. Transcurrido este tiempo, c3p0 le devolverá una excepción.
- línea 27: para acceder a BD, Hibernate utiliza órdenes SQL preparadas (PreparedStatement) que c3p0 puede almacenar en caché. Esto significa que, si la aplicación solicita por segunda vez una orden SQL preparada que ya se encuentra en la caché, no será necesario volver a prepararla (la preparación de una orden SQL tiene un coste) y se utilizará la que está en la caché. Aquí se indica el número máximo de órdenes SQL preparadas que puede contener la caché, para todas las conexiones en conjunto (una orden SQL preparada pertenece a una conexión).
- línea 28: frecuencia de comprobación, en milisegundos, de la validez de las conexiones. Una conexión del grupo puede dejar de ser válida por diversas razones (el controlador JDBC invalida la conexión porque dura demasiado, el controlador JDBC presenta «errores», etc.).
- línea 20: aquí se solicita que, al inicializar la unidad de persistencia, se genere la base de datos de los objetos @Entity. Hibernate dispone ahora de todas las herramientas para emitir las órdenes SQL de generación de las tablas de la base de datos:
- la configuración de los objetos @Entity le permite saber qué tablas debe generar
- las líneas 15-18 y 24-28 le permiten establecer una conexión con el SGBD
- la línea 22 le permite saber qué dialecto SQL debe utilizar para generar las tablas
De este modo, el archivo [persistence.xml] utilizado aquí recrea una base de datos nueva cada vez que se ejecuta la aplicación. Las tablas se recrean (create table) tras haber sido eliminadas (drop table) si ya existían. Cabe señalar que, evidentemente, esto no debe hacerse con una base de datos en producción...
4.2.3. Ejemplo 2: relación uno a varios
4.2.3.1. El esquema de la base de datos « »
1 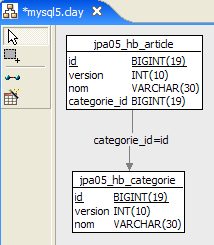 | 2 |
- en [1], la base de datos, y en [2], su DDL (MySQL5)
Un artículo A(id, versión, nombre) pertenece exactamente a una categoría C(id, versión, nombre). Una categoría C puede contener 0, 1 o varios artículos. Se trata de una relación uno a varios (Categoría → Artículo) y de la relación inversa varios a uno (Artículo → Categoría). Esta relación se materializa mediante la clave foránea que posee la tabla [article] sobre la tabla [categorie] (líneas 24-28 de la DDL).
4.2.3.2. Los objetos @Entity que representan la base de datos
Un artículo se representa mediante la siguiente @Entity [Article]:
package entites;
...
@Entity
@Table(name="jpa05_hb_article")
public class Article implements Serializable {
// campos
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// relación principal Artículo (muchos) -> Categoría (uno)
// implementada mediante una clave foránea (categorie_id) en Artículo
// 1 Artículo tiene necesariamente 1 Categoría (nullable=false)
@ManyToOne(fetch=FetchType.LAZY)
@JoinColumn(name = "categorie_id", nullable = false)
private Categorie categorie;
// constructores
public Article() {
}
// getter y setter
...
// toString
public String toString() {
return String.format("Article[%d,%d,%s,%d]", id, version, nom, categorie.getId());
}
}
- líneas 9-11: clave primaria de la @Entity
- líneas 13-15: su número de versión
- líneas 17-18: nombre del artículo
- líneas 20-25: relación «muchos a uno» que vincula la @Entity Article con la @Entity Categorie:
- línea 23: la anotación ManyToOne. El «Many» se refiere a la @Entity Article en la que nos encontramos y el «One» a la @Entity Categorie (línea 25). Una categoría (One) puede tener varios artículos (Many).
- Línea 24: la anotación ManyToOne define la columna de clave externa en la tabla [article]. Se llamará (name) categorie_id y cada fila deberá tener un valor en esta columna (nullable=false).
- línea 25: la categoría a la que pertenece el artículo. Cuando un artículo se introduzca en el contexto de persistencia, se solicita que su categoría no se incluya allí inmediatamente (fetch=FetchType.LAZY, línea 23). No sabemos si esta solicitud tiene sentido. Ya lo veremos.
Una categoría está representada por la siguiente @Entity [Categorie]:
package entites;
...
@Entity
@Table(name="jpa05_hb_categorie")
public class Categorie implements Serializable {
// campos
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// relación inversa Categoría (uno) -> Artículo (muchos) de la relación Artículo (muchos) -> Categoría (uno)
// inserción en cascada de Categoría -> inserción de Artículos
// cascada de actualización de Categoría -> actualización de Artículos
// eliminación en cascada de Categoría -> eliminación de Artículos
@OneToMany(mappedBy = "categorie", cascade = { CascadeType.ALL })
private Set<Article> articles = new HashSet<Article>();
// constructores
public Categorie() {
}
// getters y setters
...
// toString
public String toString() {
return String.format("Categorie[%d,%d,%s]", id, version, nom);
}
// asociación bidireccional Categoría <--> Artículo
public void addArticle(Article article) {
// el artículo se añade a la colección de artículos de la categoría
articles.add(article);
// El artículo cambia de categoría
article.setCategorie(this);
}
}
- líneas 8-11: la clave primaria de la @Entity
- líneas 12-14: su versión
- líneas 16-17: el nombre de la categoría
- líneas 19-24: el conjunto (set) de artículos de la categoría
- línea 23: la anotación @OneToMany indica una relación uno a varios. El «One» hace referencia a la @Entity [Categorie] en la que nos encontramos, y el «Many» al tipo [Article] de la línea 24: una (One) categoría tiene varios (Many) artículos.
- línea 23: la anotación es la inversa (mappedBy) de la anotación ManyToOne colocada en el campo categorie de la @Entity Article: mappedBy=categoría. La relación ManyToOne, definida en el campo categorie de la @Entity Article, es la relación principal. Es imprescindible. Esta relación materializa la relación de clave externa que vincula la @Entity Article con la @Entity Categorie. La relación OneToMany, definida sobre el campo articles de la @Entity Categorie, es la relación inversa. No es imprescindible. Es una facilidad para obtener los artículos de una categoría. Sin esta facilidad, dichos artículos se obtendrían mediante una consulta JPQL.
- Línea 23: cascadeType.ALL solicita que las operaciones (persist, merge, remove) realizadas sobre una @Entity Categorie se apliquen en cascada a sus artículos.
- línea 24: los artículos de una categoría se colocarán en un objeto de tipo Set<Article>. El tipo Set no admite duplicados. Por lo tanto, no se puede incluir dos veces el mismo artículo en el objeto Set<Article>. ¿Qué significa «el mismo artículo»? Para indicar que el artículo a es el mismo que el artículo b, Java utiliza la expresión a.equals(b). En la clase Object, clase padre de todas las clases, a.equals(b) es verdadera si a == b, c.a.d. si los objetos a y b tienen la misma ubicación en memoria. Podríamos querer decir que los artículos a y b son los mismos si tienen el mismo nombre. En ese caso, el desarrollador debe redefinir dos métodos en la clase [Article]:
- equals: debe devolver «verdadero» si ambos artículos tienen el mismo nombre
- hashCode: debe devolver un valor entero idéntico para dos objetos [Article] que el método equals considere iguales. En este caso, el valor se construirá a partir del nombre del artículo. El valor devuelto por hashCode puede ser cualquier entero. Se utiliza en diferentes contenedores de objetos, especialmente en los diccionarios (Hashtable).
La relación OneToMany puede utilizar otros tipos distintos de Set para almacenar el «Many», como, por ejemplo, objetos de tipo List. No abordaremos estos casos en este documento. El lector los encontrará en [ref1].
- Línea 38: el método [addArticle] nos permite añadir un artículo a una categoría. El método se encarga de actualizar ambos extremos de la relación OneToMany que vincula [Categorie] con [Article].
4.3. El API de la capa JPA
Explicaremos el entorno de ejecución de un cliente JPA:
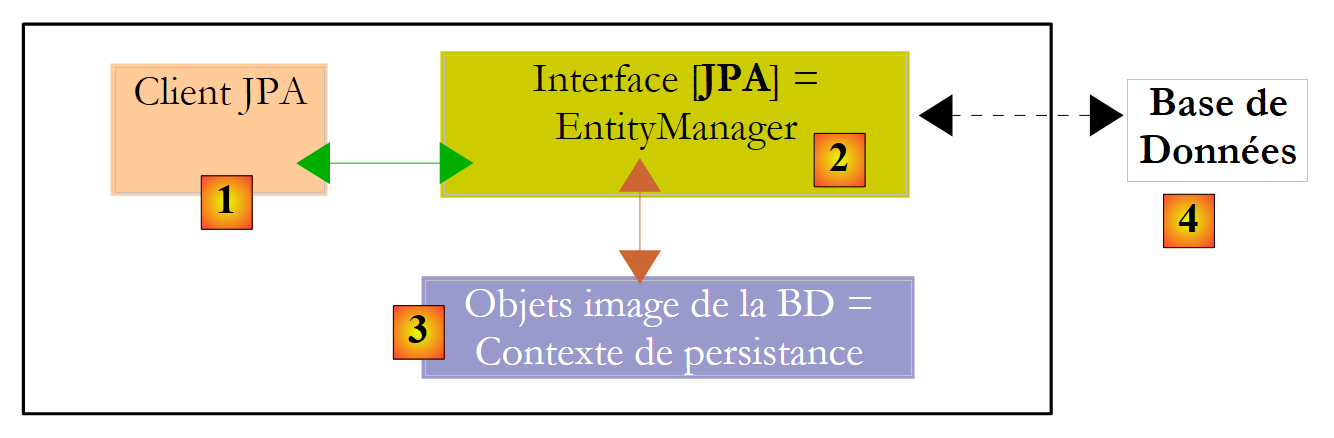 |
Sabemos que la capa JPA [2] crea un puente entre el modelo de objetos [3] y el modelo relacional [4]. Se denomina «contexto de persistencia» al conjunto de objetos gestionados por la capa JPA en el marco de este puente objeto/relacional. Para acceder a los datos del contexto de persistencia, un cliente JPA [1] debe pasar por la capa JPA [2]:
- puede crear un objeto y solicitar a la capa JPA que lo haga persistente. El objeto pasa entonces a formar parte del contexto de persistencia.
- puede solicitar a la capa [JPA] una referencia a un objeto persistente existente.
- Puede modificar un objeto persistente obtenido de la capa JPA.
- Puede solicitar a la capa JPA que elimine un objeto del contexto de persistencia.
La capa JPA presenta al cliente una interfaz denominada [EntityManager] que, como su nombre indica, permite gestionar los objetos @Entity del contexto de persistencia. A continuación, presentamos los principales métodos de esta interfaz:
coloca entity en el contexto de persistencia | |
elimina entity del contexto de persistencia | |
fusiona un objeto entity del cliente no gestionado por el contexto de persistencia con el objeto entity del contexto de persistencia que tiene la misma clave primaria. El resultado obtenido es el objeto entity del contexto de persistencia. | |
introduce en el contexto de persistencia un objeto buscado en la base de datos mediante su clave primaria. El tipo T del objeto permite a la capa JPA saber qué tabla consultar. El objeto persistente así creado se devuelve al cliente. | |
crea un objeto Query a partir de una consulta JPQL (Java Persistence Query Language). Una consulta JPQL es análoga a una consulta SQL si salvo que consulta objetos en lugar de tablas. | |
método similar al anterior, salvo que queryText es un orden SQL y no JPQL. | |
Método idéntico al de createQuery, salvo que el orden JPQL queryText se ha se ha externalizado a un archivo de configuración y se le ha asignado un nombre. Este nombre es el parámetro del método. |
Un objeto EntityManager tiene un ciclo de vida que no es necesariamente el de la aplicación. Tiene un inicio y un final. Así, un cliente JPA puede trabajar sucesivamente con diferentes objetos EntityManager. El contexto de persistencia asociado a un EntityManager tiene el mismo ciclo de vida que él. Son inseparables el uno del otro. Cuando se cierra un objeto EntityManager, su contexto de persistencia se sincroniza, si es necesario, con la base de datos y, a continuación, deja de existir. Es necesario crear un nuevo EntityManager para disponer de nuevo de un contexto de persistencia.
El cliente JPA puede crear un EntityManager y, por lo tanto, un contexto de persistencia con la siguiente instrucción:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("nom d'une unité de persistance");
- javax.persistence.Persistence es una clase estática que permite obtener un generador (factory) de objetos EntityManager. Este generador está vinculado a una unidad de persistencia concreta. Recordemos que el archivo de configuración [META-INF/persistence.xml] permite definir unidades de persistencia y que estas tienen un nombre:
<persistence-unit name="elections-dao-jpa-mysql-01PU" transaction-type="RESOURCE_LOCAL">
En el ejemplo anterior, la unidad de persistencia se llama elections-dao-jpa-mysql-01PU. Con ella viene toda una configuración propia, en particular el SGBD con el que trabaja. La instrucción [Persistence.createEntityManagerFactory("elections-dao-jpa-mysql-01PU")] crea una fábrica de objetos de tipo EntityManagerFactory capaz de proporcionar objetos EntityManager destinados a gestionar contextos de persistencia vinculados a la unidad de persistencia denominada elections-dao-jpa-mysql-01PU. La obtención de un objeto EntityManager y, por lo tanto, de un contexto de persistencia, se realiza a partir del objeto EntityManagerFactory de la siguiente manera:
Los siguientes métodos de la interfaz [EntityManager] permiten gestionar el ciclo de vida del contexto de persistencia:
Se cierra el contexto de persistencia. Fuerza la sincronización del contexto de persistencia con la base de datos:
| |
El contexto de persistencia se vacía de todos sus objetos, pero no se cierra. | |
el contexto de persistencia se sincroniza con la base de datos tal y como se describe para close() |
El cliente JPA puede forzar la sincronización del contexto de persistencia con la base de datos mediante el método [EntityManager].flush anterior. La sincronización puede ser explícita o implícita. En el primer caso, es el cliente quien debe realizar las operaciones flush cuando desee llevar a cabo sincronizaciones; de lo contrario, estas se realizan en determinados momentos que especificaremos a continuación. El modo de sincronización se gestiona mediante los siguientes métodos de la interfaz [EntityManager]:
Hay dos valores posibles para flushmode: FlushModeType.AUTO (por defecto): la sincronización se lleva a cabo antes cada consulta SELECT realizada en la base de datos. FlushModeType.COMMIT: la sincronización solo se lleva a cabo al al finalizar las transacciones en la base de datos. | |
muestra el modo de sincronización actual |
Resumamos. En el modo FlushModeType.AUTO, que es el modo por defecto, el contexto de persistencia se sincronizará con la base de datos en los siguientes momentos:
- antes de cada operación SELECT en la base de datos
- al finalizar una transacción en la base de datos
- tras una operación flush o close en el contexto de persistencia
En el modo FlushModeType.COMMIT, ocurre lo mismo, salvo que la operación 1 no tiene lugar. El modo normal de interacción con la capa JPA es un modo transaccional. El cliente realiza diversas operaciones en el contexto de persistencia, dentro de una transacción. En este caso, los momentos de sincronización del contexto de persistencia con la base de datos son los casos 1 y 2 anteriores en el modo AUTO, y únicamente el caso 2 en el modo COMMIT.
Terminemos con el API de la interfaz Query, interfaz que permite emitir órdenes JPQL en el contexto de persistencia o bien órdenes SQL directamente en la base de datos para recuperar datos de ella. La interfaz Query es la siguiente:
 |
- 1 - El método getResultList ejecuta un SELECT que devuelve varios objetos. Estos se obtendrán en un objeto List. Este objeto es una interfaz. Dicha interfaz ofrece un objeto Iterator que permite recorrer los elementos de la lista L de la siguiente forma:
Iterator iterator = L.iterator();
while (iterator.hasNext()) {
// utilizar el objeto iterator.next() que representa el elemento actual de la lista
...
}
La lista L también se puede utilizar con un for:
for (Object o : L) {
// utilizar el objeto o
}
- 2 - El método getSingleResult ejecuta una orden JPQL / SQL SELECT que devuelve un único objeto.
- 3 - El método executeUpdate ejecuta una orden SQL de actualización o eliminación y devuelve el número de filas afectadas por la operación.
- 4 - El método setParameter(String, Object) permite asignar un valor a un parámetro con nombre de una orden JPQL configurada
- 5 - El método setParameter(int, Object) no designa el parámetro por su nombre, sino por su posición en la orden JPQL.
4.4. Las consultas JPQL
JPQL (Java Persistence Query Language) es el lenguaje de consultas de la capa JPA. El lenguaje JPQL está relacionado con el lenguaje SQL de las bases de datos. Mientras que SQL trabaja con tablas, JPQL trabaja con los objetos de imagen de dichas tablas. Vamos a estudiar un ejemplo dentro de la siguiente arquitectura:
 |
La base de datos, a la que llamaremos [dbrdvmedecins2] , es una base de datos MySQL5 con cuatro tablas:
 |
Recopila información que permite gestionar las citas de un grupo de médicos.
4.4.1. La tabla [MEDECINS]
Contiene información sobre los médicos.
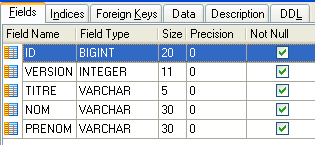 | 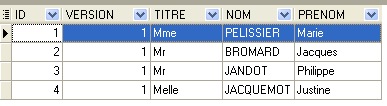 |
- ID: número que identifica al médico —clave primaria de la tabla
- VERSION: número que identifica la versión de la fila en la tabla. Este número se incrementa en 1 cada vez que se realiza una modificación en la fila.
- NOM: el apellido del médico
- PRENOM: su nombre
- TITRE: su tratamiento (Srta., Sra., Sr.)
4.4.2. La tabla [CLIENTS]
Los pacientes de los distintos médicos se registran en la tabla [CLIENTS]:
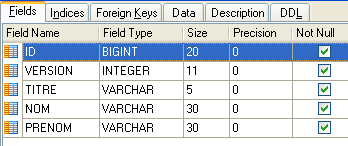 | 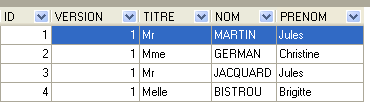 |
- ID: número de identificación del cliente —clave primaria de la tabla
- VERSION: número que identifica la versión de la línea en la tabla. Este número se incrementa en 1 cada vez que se realiza una modificación en la línea.
- NOM: el nombre del cliente
- PRENOM: su nombre
- TITRE: su tratamiento (Srta., Sra., Sr.)
4.4.3. La tabla [CRENEAUX]
En ella se enumeran las franjas horarias en las que son posibles los RV:
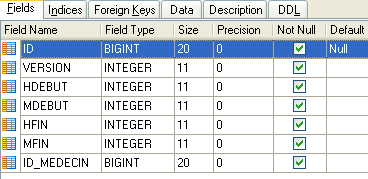 |
 |
- ID: número que identifica la franja horaria —clave primaria de la tabla (línea 8)
- VERSION: número que identifica la versión de la fila en la tabla. Este número se incrementa en 1 cada vez que se realiza una modificación en la fila.
- ID_MEDECIN: número que identifica al médico al que pertenece este horario – clave externa en la columna MEDECINS (ID).
- HDEBUT: hora de inicio de la franja horaria
- MDEBUT: minutos de inicio de la franja horaria
- HFIN: hora de finalización de la franja horaria
- MFIN: minutos de fin de franja
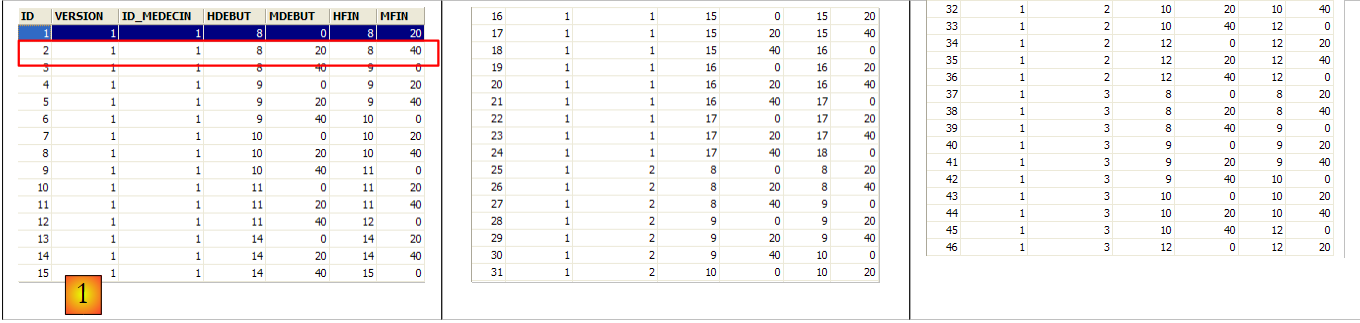
La segunda línea de la tabla [CRENEAUX] (véase [1] más arriba) indica, por ejemplo, que la franja n.º 2 comienza a las 8:20 y termina a las 8:40, y corresponde a la doctora n.º 1 (la Sra. Marie PELISSIER).
4.4.4. La tabla [RV]
Enumera los RV asignados a cada médico:
 |
- ID: número que identifica de forma única el RV – clave primaria
- JOUR: día del RV
- ID_CRENEAU: franja horaria del RV —clave externa en el campo [ID] de la tabla [CRENEAUX]—; determina tanto la franja horaria como el médico correspondiente.
- ID_CLIENT: n.º del cliente para el que se realiza la reserva – clave externa en el campo [ID] de la tabla [CLIENTS]
Esta tabla tiene una restricción de unicidad de « » sobre los valores de las columnas unidas (JOUR, ID_CRENEAU):
Si una fila de la tabla [RV] tiene el valor (JOUR1, ID_CRENEAU1) en las columnas (JOUR, ID_CRENEAU), dicho valor no puede aparecer en ningún otro lugar. De lo contrario, significaría que se han registrado dos RV al mismo tiempo para el mismo médico. Desde el punto de vista de la programación en Java, el controlador JDBC de la base de datos lanza un SQLException cuando se produce este caso.
La línea de id igual a 3 (véase [1] más arriba) significa que se ha reservado un RV para la franja horaria n.º 20 y el cliente n.º 4 el 23/08/2006. La tabla [CRENEAUX] nos indica que la franja n.º 20 corresponde al horario de 16:20 a 16:40 y pertenece a la médica n.º 1 (la Sra. Marie PELISSIER). La tabla [CLIENTS] nos indica que el cliente n.º 4 es la Srta. Brigitte BISTROU.
4.4.5. Creación de la base de datos
Para crear las tablas y rellenarlas, se puede utilizar el script [dbrdvmedecins2.sql]. Con [WampServer], se puede proceder de la siguiente manera:
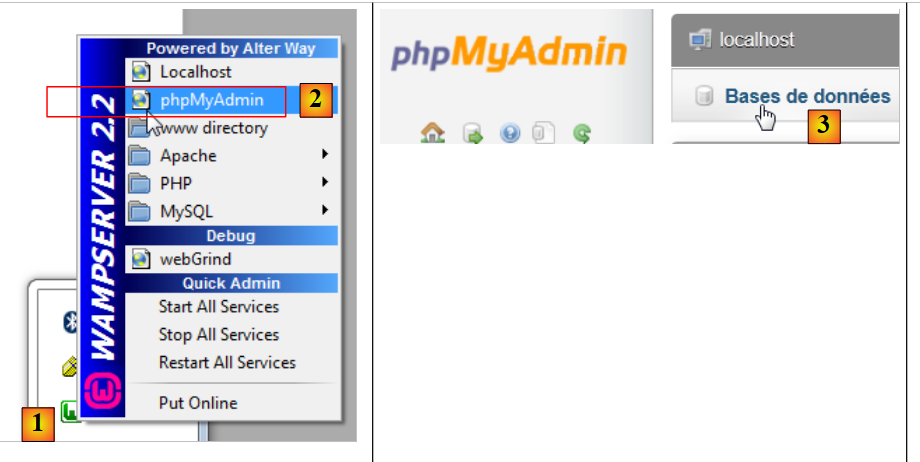 |
- En [1], haz clic en el icono de [WampServer] y selecciona la opción [PhpMyAdmin] [2],
- en [3], en la ventana que se ha abierto, selecciona el enlace [Bases de données],
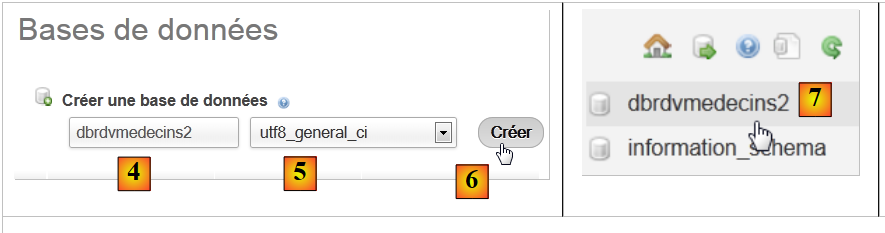 |
- en [2], se crea una base de datos a la que se le ha asignado el nombre [4] y la codificación [5],
- en [7], la base de datos ya se ha creado. Hacemos clic en su enlace,
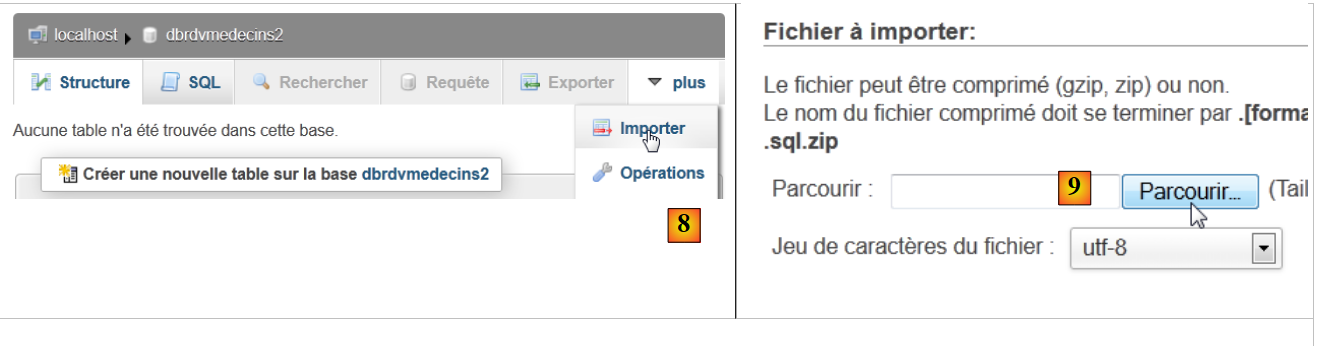 |
- en [8], se importa un archivo SQL,
- que se selecciona en el sistema de archivos con el botón [9],
 |
- en [11], se selecciona el script SQL y en [12] se ejecuta,
- en [13], se han creado las cuatro tablas de la base de datos. Seguimos uno de los enlaces,
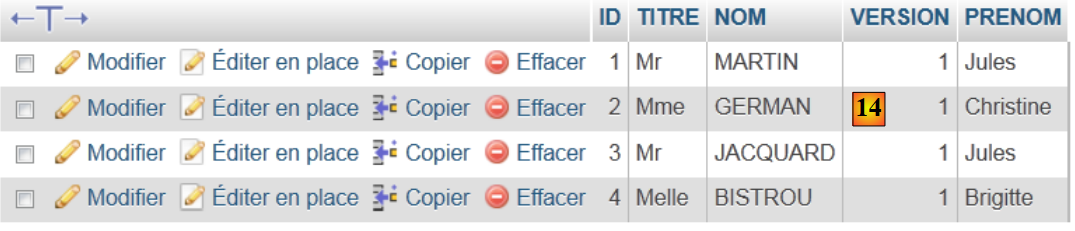 |
- en [14], el contenido de la tabla.
A partir de ahora, no volveremos a referirnos a esta base de datos. No obstante, invitamos al lector a seguir su evolución a lo largo de los programas, sobre todo cuando no funcione.
4.4.6. La capa [JPA]
Volvamos a la arquitectura del ejemplo:
 |
Ahora vamos a crear el proyecto Maven de la capa [JPA].
4.4.7. El proyecto NetBeans
Es el siguiente:
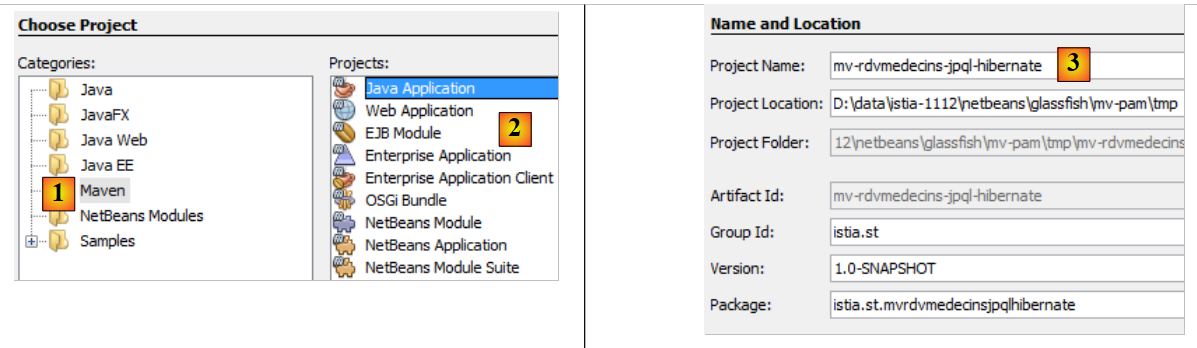 |
- En [1], se crea un proyecto Maven de tipo [Java Application] [2],
- en [3], se le da un nombre al proyecto,
 |
- en [4], el proyecto generado.
4.4.8. Generación de la capa [JPA]
Volvamos a la arquitectura que debemos construir:
 |
Con NetBeans, es posible generar automáticamente la capa [JPA]. Resulta interesante conocer estos métodos de generación automática, ya que el código generado ofrece valiosas indicaciones sobre cómo escribir entidades JPA.
4.4.9. Creación de una conexión de NetBeans a la base de datos
- ejecutar el SGBD MySQL 5 para que el BD esté disponible,
- crear una conexión de NetBeans a la base de datos [dbrdvmedecins2],
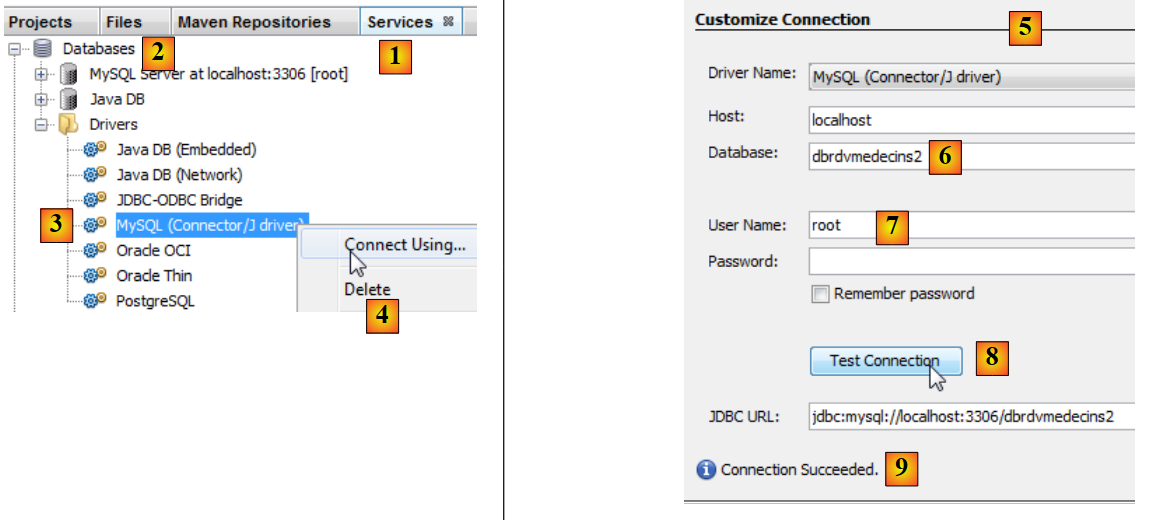 |
- en la pestaña [Services] [1], en la rama [Databases] [2], seleccionar el controlador JDBC MySQL [3],
- y, a continuación, seleccionar la opción [4] «Connect Using», que permite establecer una conexión con una base de datos MySQL,
- en [5], introduce la información que se te solicita. En [6], el nombre de la base de datos; en [7], el usuario de la base de datos y su contraseña;
- en [8], se puede comprobar la información introducida,
- en [9], el mensaje que se espera recibir cuando los datos son correctos,
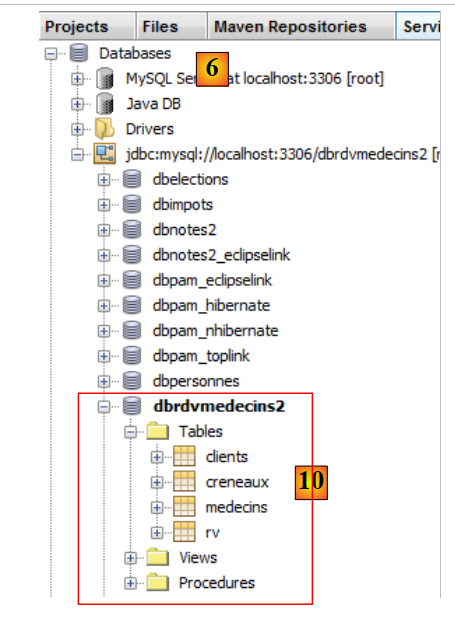 |
- en [10], se establece la conexión. Aquí se pueden ver las cuatro tablas de la base de datos conectada.
4.4.10. Creación de una unidad de persistencia
Volvamos a la arquitectura que estamos construyendo:
 |
Estamos construyendo la capa [JPA]. Su configuración se realiza en un archivo [persistence.xml] en el que se definen las unidades de persistencia. Cada una de ellas necesita la siguiente información:
- las características JDBC de acceso a la base de datos (URL, usuario, contraseña),
- las clases que servirán de representaciones de las tablas de la base de datos,
- la implementación JPA utilizada. De hecho, JPA es una especificación implementada por diversos productos. En este caso, utilizaremos Hibernate.
NetBeans puede generar este archivo de persistencia mediante un asistente.
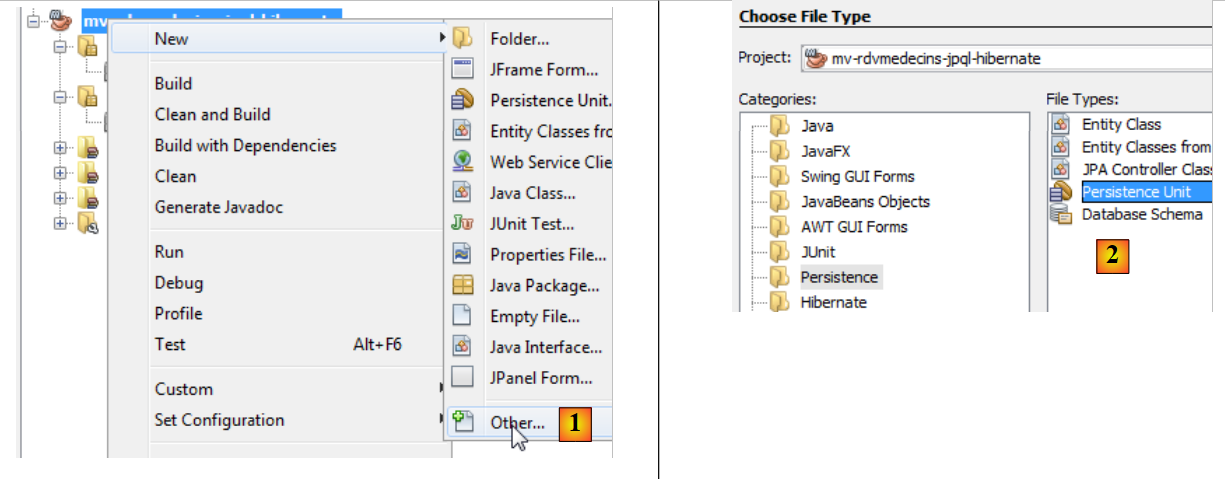 |
- haz clic con el botón derecho del ratón sobre el proyecto y selecciona la creación de una unidad de persistencia [1],
- en [2], crear una unidad de persistencia,
|
- en [3], asignar un nombre a la unidad de persistencia que se está creando,
- en [4], seleccionar la implementación JPA de Hibernate (JPA 2.0),
- en [5], indicar que las tablas de BD ya están creadas y que, por lo tanto, no se van a crear. Se valida el asistente,
- en [6], el nuevo proyecto,
- en [7], se ha generado el archivo [persistence.xml] en la carpeta [META-INF],
- en [8], se han añadido nuevas dependencias al proyecto Maven.
El archivo [META-INF/persistence.xml] generado es el siguiente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-rdvmedecins-jpql-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbrdvmedecins2"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
</properties>
</persistence-unit>
</persistence>
Recoge la información introducida en el asistente:
- línea 3: el nombre de la unidad de persistencia,
- línea 3: el tipo de transacciones con la base de datos. En este caso, RESOURCE_LOCAL indica que la aplicación gestionará sus propias transacciones,
- líneas 6-9: las propiedades JDBC de la fuente de datos.
En la pestaña [Design], se puede obtener una visión general del archivo [persistence.xml]:
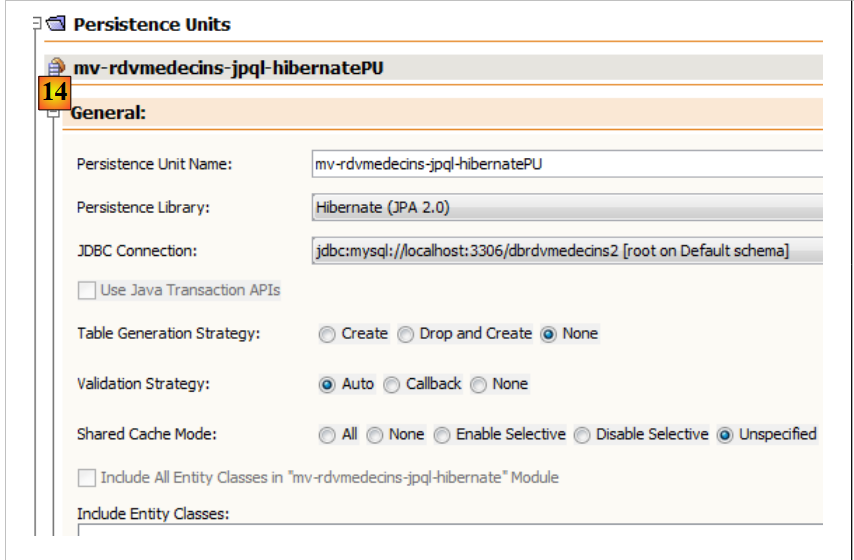 |
Para obtener los registros de Hibernate, completamos el archivo [persistence.xml] de la siguiente manera:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-rdvmedecins-jpql-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbrdvmedecins2"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>
- línea 11: se solicita ver las órdenes SQL emitidas por Hibernate,
- línea 12: esta propiedad permite obtener una visualización formateada de las mismas.
Se han añadido dependencias al proyecto. El archivo [pom.xml] es el siguiente:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>istia.st</groupId>
<artifactId>mv-rdvmedecins-jpql-hibernate</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>mv-rdvmedecins-jpql-hibernate</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>org.jboss.logging</groupId>
<artifactId>jboss-logging</artifactId>
<version>3.1.0.GA</version>
</dependency>
<dependency>
<groupId>org.jboss.spec.javax.transaction</groupId>
<artifactId>jboss-transaction-api_1.1_spec</artifactId>
<version>1.0.0.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>antlr</groupId>
<artifactId>antlr</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.hibernate.javax.persistence</groupId>
<artifactId>hibernate-jpa-2.0-api</artifactId>
<version>1.0.1.Final</version>
</dependency>
<dependency>
<groupId>org.javassist</groupId>
<artifactId>javassist</artifactId>
<version>3.15.0-GA</version>
</dependency>
<dependency>
<groupId>org.hibernate.common</groupId>
<artifactId>hibernate-commons-annotations</artifactId>
<version>4.0.1.Final</version>
</dependency>
</dependencies>
</project>
Todas las dependencias añadidas se refieren a Hibernate (ORM). Añadiremos la dependencia del controlador JDBC de MySQL:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
4.4.11. Generación de entidades JPA
Las entidades JPA se pueden generar mediante un asistente de NetBeans:
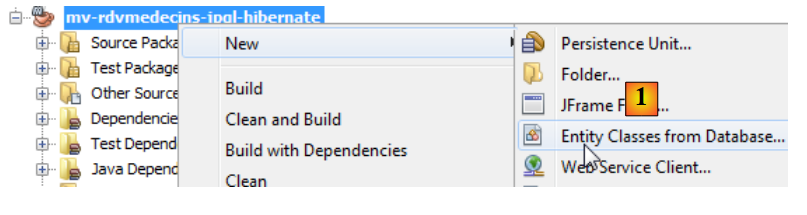 |
- en [1], se crean entidades JPA a partir de una base de datos,
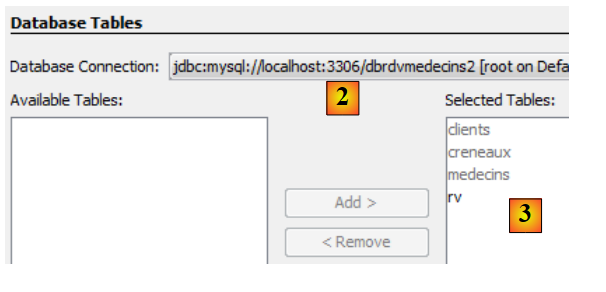 |
- en [2], se selecciona la conexión [dbrdvmedecins2] creada anteriormente,
- en [3], se seleccionan todas las tablas de la base de datos asociada,
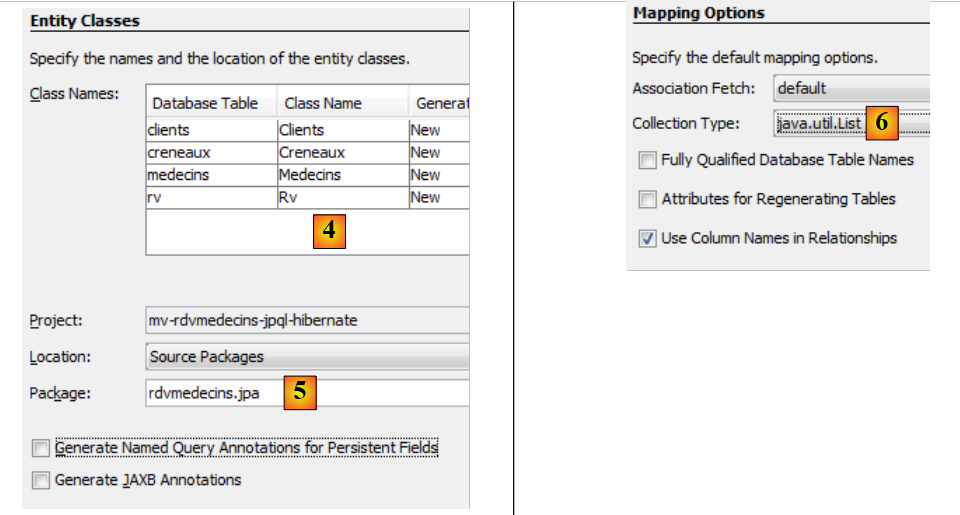 |
- en [4], se asigna un nombre a las clases Java asociadas a las cuatro tablas,
- así como un nombre de paquete [5],
- en [6], JPA agrupa las filas de las tablas de BD en colecciones. Elegimos la lista como colección,
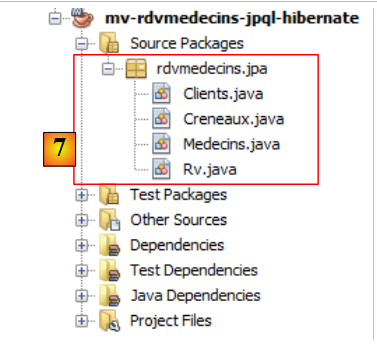 |
- en [7], las clases Java creadas por el asistente.
4.4.12. Las entidades JPA generadas
La entidad [Medecin] es la imagen de la tabla [medecins]. La clase Java está repleta de anotaciones que hacen que el código resulte poco legible a primera vista. Si nos quedamos solo con lo esencial para comprender la función de la entidad, obtenemos el siguiente código:
package rdvmedecins.jpa;
...
@Entity
@Table(name = "medecins")
public class Medecin implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "TITRE")
private String titre;
@Column(name = "NOM")
private String nom;
@Column(name = "VERSION")
private int version;
@Column(name = "PRENOM")
private String prenom;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idMedecin")
private List<Creneau> creneauList;
// constructores
....
// getters y setters
....
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
- En la línea 4, la anotación @Entity convierte la clase [Medecin] en una entidad JPA, c.a.d. una clase vinculada a una tabla de BD a través de API y JPA,
- línea 5, el nombre de la tabla BD asociada a la entidad JPA. Cada campo de la tabla se corresponde con un campo de la clase Java,
- línea 6, la clase implementa la interfaz Serializable. Esto es necesario en aplicaciones cliente/servidor, donde las entidades se serializan entre el cliente y el servidor.
- líneas 10-11: el campo id de la clase [Medecin] se corresponde con el campo [ID] (línea 10) de la tabla [medecins],
- líneas 13-14: el campo «título» de la clase [Medecin] se corresponde con el campo [TITRE] (línea 13) de la tabla [medecins],
- líneas 16-17: el campo «nombre» de la clase [Medecin] se corresponde con el campo [NOM] (línea 16) de la tabla [medecins],
- líneas 19-20: el campo «versión» de la clase [Medecin] se corresponde con el campo [VERSION] (línea 19) de la tabla [medecins]. En este caso, el asistente no reconoce que la columna es, en realidad, una columna de versión que debe incrementarse cada vez que se modifica la línea a la que pertenece. Para asignarle esta función, hay que añadir la anotación @Version. Lo haremos en un paso posterior,
- líneas 22-23: el campo «prenom» de la clase [Medecin] se corresponde con el campo [PRENOM] de la tabla [medecins],
- líneas 10-11: el campo «id» se corresponde con la clave primaria [ID] de la tabla. Las anotaciones de las líneas 8-9 precisan este punto,
- línea 8: la anotación @Id indica que el campo anotado está asociado a la clave primaria de la tabla,
- línea 9: la capa [JPA] generará la clave primaria de las líneas que insertará en la tabla [Medecins]. Existen varias estrategias posibles. En este caso, la estrategia GenerationType.IDENTITY indica que la capa JPA utilizará el modo auto_increment de la tabla MySQL,
- líneas 25-26: la tabla [creneaux] tiene una clave foránea sobre la tabla [medecins]. Una franja horaria pertenece a un médico. A la inversa, un médico tiene varias franjas horarias asociadas a él. Por lo tanto, tenemos una relación de uno (médico) a varios (franjas horarias), una relación calificada por la anotación @OneToMany por JPA (línea 25). El campo de la línea 26 contendrá todas las franjas horarias del médico. Esto sin necesidad de programación. Para comprender plenamente la línea 25, debemos presentar la clase [Creneau].
Esta es la siguiente:
package rdvmedecins.jpa;
import java.io.Serializable;
import java.util.List;
import javax.persistence.*;
import javax.validation.constraints.NotNull;
@Entity
@Table(name = "creneaux")
public class Creneau implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "MDEBUT")
private int mdebut;
@Column(name = "HFIN")
private int hfin;
@Column(name = "HDEBUT")
private int hdebut;
@Column(name = "MFIN")
private int mfin;
@Column(name = "VERSION")
private int version;
@JoinColumn(name = "ID_MEDECIN", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Medecin idMedecin;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idCreneau")
private List<Rv> rvList;
// constructores
...
// getters y setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
Solo comentaremos las nuevas anotaciones:
- ya hemos dicho que la tabla [creneaux] tiene una clave foránea hacia la tabla [medecins]: cada franja horaria está asociada a un médico. Se pueden asociar varias franjas horarias al mismo médico. Tenemos una relación de la tabla [creneaux] a la tabla [medecins] que se califica como de varios (franjas horarias) a uno (médico). La anotación @ManyToOne de la línea 32 sirve para definir la clave foránea,
- La línea 31, con la anotación @JoinColumn, especifica la relación de clave externa: la columna [ID_MEDECIN] de la tabla [creneaux] es una clave externa sobre la columna [ID] de la tabla [medecins],
- línea 33: una referencia al médico titular de la franja horaria. De nuevo, se obtiene sin necesidad de programación.
La relación de clave externa entre la entidad [Creneau] y la entidad [Medecin] se materializa, por tanto, mediante dos anotaciones:
- en la entidad [Creneau]:
@JoinColumn(name = "ID_MEDECIN", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Medecin idMedecin;
- en la entidad [Medecin]:
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idMedecin")
private List<Creneau> creneauList;
Ambas anotaciones reflejan la misma relación: la de la clave foránea de la tabla [creneaux] hacia la tabla [medecins]. Se dice que son inversas entre sí. Solo la relación @ManyToOne es imprescindible. Esta califica sin ambigüedad la relación de clave externa. La relación @OneToMany es opcional. Si está presente, se limita a hacer referencia a la relación @ManyToOne a la que está asociada. Este es el significado del atributo mappedBy de la línea 1 de la entidad [Medecin]. El valor de este atributo es el nombre del campo de la entidad [Creneau] que tiene la anotación @ManyToOne, la cual especifica la clave foránea. También en esta misma línea 1 de la entidad [Medecin], el atributo cascade=CascadeType.ALL establece el comportamiento de la entidad [Medecin] con respecto a la entidad [Creneau]:
- si se inserta una nueva entidad [Medecin] en la base de datos, entonces también deben insertarse las entidades [Creneau] del campo de la línea 2;
- si se modifica una entidad [Medecin] en la base de datos, entonces las entidades [Creneau] del campo de la línea 2 también deben modificarse,
- si se elimina una entidad [Medecin] de la base de datos, entonces también deben eliminarse las entidades [Creneau] del campo de la línea 2.
Proporcionamos el código de las otras dos entidades sin comentarios específicos, ya que no introducen nuevas notaciones.
La entidad [Client]
package rdvmedecins.jpa;
...
@Entity
@Table(name = "clients")
public class Client implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "TITRE")
private String titre;
@Column(name = "NOM")
private String nom;
@Column(name = "VERSION")
private int version;
@Column(name = "PRENOM")
private String prenom;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idClient")
private List<Rv> rvList;
// constructores
...
// getters y setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
- Las líneas 24-25 reflejan la relación de clave externa entre la tabla [rv] y la tabla [clients].
La entidad [Rv]:
package rdvmedecins.jpa;
...
@Entity
@Table(name = "rv")
public class Rv implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "JOUR")
@Temporal(TemporalType.DATE)
private Date jour;
@JoinColumn(name = "ID_CRENEAU", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Creneau idCreneau;
@JoinColumn(name = "ID_CLIENT", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Client idClient;
// constructores
...
// getters y setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
- la línea 13 describe el campo «día» de tipo Java Date. Se indica que, en la tabla [rv], la columna [JOUR] (línea 12) es de tipo fecha (sin hora),
- líneas 16-18: definen la relación de clave externa que tiene la tabla [rv] con la tabla [creneaux],
- líneas 20-22: definen la relación de clave externa que tiene la tabla [rv] con la tabla [clients].
La generación automática de las entidades JPA nos permite obtener una base de trabajo. A veces es suficiente, otras veces no. Este es el caso aquí:
- hay que añadir la anotación @Version a los distintos campos de versión de las entidades,
- hay que escribir métodos toString más explícitos que los generados,
- las entidades [Medecin] y [Client] son análogas. Las derivaremos de una clase [Personne],
- vamos a eliminar las relaciones @OneToMany inversas a las relaciones @ManyToOne. No son imprescindibles y complican la programación,
- eliminamos la validación @NotNull sobre las claves primarias. Cuando se persiste una entidad JPA con MySQL, la entidad inicial tiene una clave primaria null. Solo tras la persistencia en la base de datos, la clave primaria del elemento persistido tiene un valor.
Con estas especificaciones, las diferentes clases quedan así:
La clase «Persona» se utiliza para representar a los médicos y a los clientes:
package rdvmedecins.jpa;
import java.io.Serializable;
import javax.persistence.*;
@MappedSuperclass
public class Personne implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Basic(optional = false)
@Column(name = "TITRE")
private String titre;
@Basic(optional = false)
@Column(name = "NOM")
private String nom;
@Basic(optional = false)
@Column(name = "VERSION")
@Version
private int version;
@Basic(optional = false)
@Column(name = "PRENOM")
private String prenom;
// constructores
...
// getters y setters
...
@Override
public String toString() {
return String.format("[%s,%s,%s,%s,%s]", id, version, titre, prenom, nom);
}
}
- línea 6: cabe señalar que la clase [Personne] no es en sí misma una entidad (@Entity). Será la clase padre de las entidades. La anotación @MappedSuperClass indica esta situación.
La entidad [Client] encapsula las filas de la tabla [clients]. Deriva de la clase anterior [Personne]:
package rdvmedecins.jpa;
import java.io.Serializable;
import javax.persistence.*;
@Entity
@Table(name = "clients")
public class Client extends Personne implements Serializable {
private static final long serialVersionUID = 1L;
// constructores
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
return String.format("Client[%s,%s,%s,%s]", getId(), getTitre(), getPrenom(), getNom());
}
}
- línea 6: la clase [Client] es una entidad JPA,
- línea 7: está asociada a la tabla [clients],
- línea 8: deriva de la clase [Personne].
La entidad [Medecin], que encapsula las filas de la tabla [medecins], sigue el mismo patrón:
package rdvmedecins.jpa;
import java.io.Serializable;
import javax.persistence.*;
@Entity
@Table(name = "medecins")
public class Medecin extends Personne implements Serializable {
private static final long serialVersionUID = 1L;
// constructores
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
return String.format("Médecin[%s,%s,%s,%s]", getId(), getTitre(), getPrenom(), getNom());
}
}
La entidad [Creneau] encapsula las líneas de la tabla [creneaux]:
package rdvmedecins.jpa;
import java.io.Serializable;
import java.util.List;
import javax.persistence.*;
@Entity
@Table(name = "creneaux")
public class Creneau implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Basic(optional = false)
@Column(name = "ID")
private Long id;
@Basic(optional = false)
@Column(name = "MDEBUT")
private int mdebut;
@Basic(optional = false)
@Column(name = "HFIN")
private int hfin;
@Basic(optional = false)
@NotNull
@Column(name = "HDEBUT")
private int hdebut;
@Basic(optional = false)
@Column(name = "MFIN")
private int mfin;
@Basic(optional = false)
@Column(name = "VERSION")
@Version
private int version;
@JoinColumn(name = "ID_MEDECIN", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Medecin medecin;
// constructores
...
// métodos getter y setter
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
// TODO: Advertencia: este método no funcionará si los campos de ID no están definidos
...
}
@Override
public String toString() {
return String.format("Creneau [%s, %s, %s:%s, %s:%s,%s]", id, version, hdebut, mdebut, hfin, mfin, medecin);
}
}
- Las líneas 40-42 modelan la relación «muchos a uno» que existe entre la tabla [creneaux] y la tabla [medecins] de la base de datos: un médico tiene varias franjas horarias, y una franja horaria pertenece a un solo médico.
La entidad [Rv] encapsula las líneas de la tabla [rv]:
package rdvmedecins.jpa;
import java.io.Serializable;
import java.util.Date;
import javax.persistence.*;
@Entity
@Table(name = "rv")
public class Rv implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Basic(optional = false)
@Column(name = "ID")
private Long id;
@Basic(optional = false)
@Column(name = "JOUR")
@Temporal(TemporalType.DATE)
private Date jour;
@JoinColumn(name = "ID_CRENEAU", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Creneau creneau;
@JoinColumn(name = "ID_CLIENT", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Client client;
// constructores
...
// métodos getter y setter
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
return String.format("Rv[%s, %s, %s]", id, creneau, client);
}
}
- las líneas 27-29 modelan la relación «muchos a uno» que existe entre la tabla [rv] y la tabla [clients] (un cliente puede aparecer en varias citas) de la base de datos, y las líneas 23-25, la relación «muchos a uno» que existe entre la tabla [rv] y la tabla [creneaux] (una franja horaria puede aparecer en varias citas).
4.4.13. El código de acceso a los datos
Ahora vamos a añadir al proyecto el código de acceso a los datos a través de la capa JPA:
 |
 |
La clase [MainJpql] es la siguiente:
package rdvmedecins.console;
import java.util.Scanner;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public class MainJpql {
public static void main(String[] args) {
// EntityManagerFactory
EntityManagerFactory emf = Persistence.createEntityManagerFactory("mv-rdvmedecins-jpql-hibernatePU");
// entityManager
EntityManager em = emf.createEntityManager();
// escáner de teclado
Scanner clavier = new Scanner(System.in);
// bucle de introducción de consultas JPQL
System.out.println("Requete JPQL sur la base dbrdvmedecins2 (* pour arrêter) :");
String requete = clavier.nextLine();
while (!requete.trim().equals("*")) {
try {
// visualización del resultado de la consulta
for (Object o : em.createQuery(requete).getResultList()) {
System.out.println(o);
}
} catch (Exception e) {
System.out.println("L'exception suivante s'est produite : " + e);
}
// se vacía el contexto de persistencia
em.clear();
// nueva consulta
System.out.println("---------------------------------------------");
System.out.println("Requete JPQL sur la base dbrdvmedecins2 (* pour arrêter) :");
requete = clavier.nextLine();
}
// cierre de recursos
em.close();
emf.close();
}
}
- línea 12: creación de EntityManagerFactory asociado a la unidad de persistencia que hemos creado anteriormente. El parámetro del método createEntityManagerFactory es el nombre de esta unidad de persistencia:
<persistence-unit name="mv-rdvmedecins-jpql-hibernatePU" transaction-type="RESOURCE_LOCAL">
...
</persistence-unit>
- línea 14: creación del EntityManager que gestiona la capa de persistencia,
- línea 19: introducción de una consulta JPQL select,
- líneas 23-28: visualización del resultado de la consulta,
- línea 20: la introducción de datos se detiene cuando el usuario escribe *.
Pregunta: indique las consultas JPQL que permiten obtener la siguiente información:
- lista de médicos en orden descendente por sus apellidos
- lista de médicos cuyo título sea «Sr.»
- lista de franjas horarias de la Sra. Pelissier
- lista de citas concertadas en orden ascendente por días
- lista de clientes (nombre) que concertaron una cita con la Sra. PELISSIER el 24/08/2006
- Número de clientes de la Sra. PELISSIER el 24/08/2006
- Clientes que no han concertado cita
- los médicos que no tienen cita
Nos basaremos en el ejemplo del apartado 2.7 de [ref1]. A continuación se muestra un ejemplo de ejecución:
- línea 2: la consulta JPQL,
- líneas 3-11: la consulta SQL correspondiente,
- líneas 12-15: el resultado de la consulta JPQL.
4.5. Relaciones entre el contexto de persistencia y SGBD
4.5.1. La clase Persona
4.5.2. El programa de prueba
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 | |
4.5.3. La configuración de Hibernate
4.5.4. La configuración de log4j.properties
4.5.5. Los resultados
Pregunta: establece la relación entre el código Java y los resultados mostrados.