10. Creación de aplicaciones distribuidas CORBA
10.1. Introducción
En el capítulo anterior, vimos cómo crear aplicaciones distribuidas en Java con el paquete RMI. Aquí abordamos el mismo problema, pero en esta ocasión con la arquitectura CORBA. CORBA (Common Object Request Broker Architecture) es una especificación definida por el OMG (Object Management Group), que agrupa a numerosas empresas del sector informático. CORBA define un «bus de software» accesible para aplicaciones escritas en diferentes lenguajes:
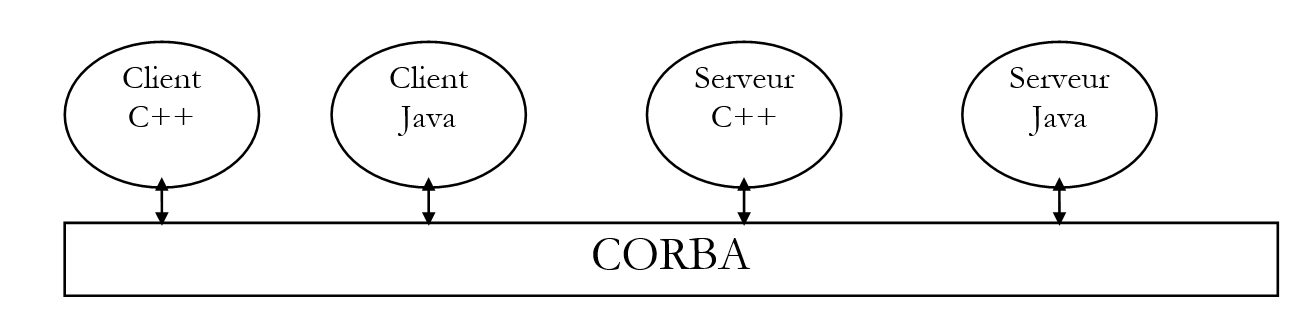
Veremos que la creación de una aplicación distribuida con CORBA es similar al método empleado con Java RMI: los conceptos son parecidos. CORBA presenta la ventaja de la interoperabilidad con aplicaciones escritas en otros lenguajes.
10.2. Proceso de desarrollo de una aplicación CORBA
10.2.1. Introducción
Para desarrollar una aplicación cliente-servidor CORBA, seguiremos los siguientes pasos:
- escritura de la interfaz del servidor con IDL (Interface Definition Language)
- generación de las clases «esqueleto» y «stub» del servidor
- escritura del servidor
- escritura del cliente
- compilación de todas las clases
- Inicio de un directorio de servicios CORBA
- Inicio del servidor
- inicio del cliente
Tomaremos como primer ejemplo el del servidor de eco ya utilizado en el contexto RMI. De este modo, el lector podrá ver las diferencias entre ambos métodos.
La aplicación se ha probado con el jdk1.2.
10.2.2. Escritura de la interfaz del servidor
Al igual que con Java RMI, desde el punto de vista del cliente, el servidor se define por su interfaz. Si bien las clases que implementan el servidor no son necesarias para el cliente, sí lo son las de su interfaz. Mientras que Java RMI utilizaba una interfaz Java que daba lugar a las clases «esqueleto» y «stub» del servidor, la arquitectura Java CORBA requiere que la interfaz se describa en un lenguaje distinto de Java. Esta interfaz dará lugar a varias clases, algunas de las cuales serán utilizadas por el cliente y otras por el servidor.
La descripción de la interfaz de eco será la siguiente:
La descripción de la interfaz se almacenará en un archivo echo.idl. Está escrita en el lenguaje IDL (Interface Definition Language) de OMG. Para que sea utilizable, debe ser analizada por un programa que creará archivos fuente en el lenguaje utilizado para desarrollar la aplicación CORBA. En este caso, utilizaremos el programa idltojava.exe, que, a partir de la interfaz anterior, creará los archivos fuente .java necesarios para la aplicación. El programa idltojava.exe no se incluye con el JDK. Se puede descargar de la página web de Sun: http://java.sun.com.
Analicemos las pocas líneas de la interfaz anterior de idl:
es equivalente al paquete «echo» de Java. La compilación de la interfaz dará lugar al paquete Java echo c.a.d, un directorio que contiene clases Java.
es equivalente a la interfaz iSrvEcho de Java. Dará lugar a una interfaz de Java.
es equivalente a la instrucción Java String echo(String msg). Los tipos del lenguaje IDL no se corresponden exactamente con los del lenguaje Java. Las correspondencias se pueden consultar más adelante en este capítulo. En el lenguaje IDL, los parámetros de una función pueden ser de entrada (in), de salida (out) o de entrada-salida (inout). En este caso, el método echo recibe un parámetro de entrada msg, que es una cadena de caracteres, y devuelve una cadena de caracteres como resultado.
La interfaz anterior es la de nuestro servidor de eco. Recordemos que una interfaz remota describe los métodos del objeto servidor a los que pueden acceder los clientes. En este caso, solo el método echo estará disponible para los clientes.
10.2.3. Compilación de la interfaz IDL del servidor
Una vez definida la interfaz del servidor, se generan los archivos Java correspondientes.
E:\data\java\corba\ECHO>dir *.idl
ECHO IDL 78 15/03/99 13:56 ECHO.IDL
E:\data\java\corba\ECHO>d:\javaidl\idltojava.exe -fno-cpp echo.idl
La opción -fno-cpp sirve para indicar que no hay que utilizar un preprocesador (se utiliza sobre todo con C/C++). La compilación del archivo echo.idl genera un subdirectorio echo que contiene los siguientes archivos:
E:\data\java\corba\ECHO>dir echo
_ISRVE~1 JAV 1 095 17/03/99 17:19 _iSrvEchoStub.java
ISRVEC~1 JAV 311 17/03/99 17:19 iSrvEcho.java
ISRVEC~2 JAV 825 17/03/99 17:19 iSrvEchoHolder.java
ISRVEC~3 JAV 1 827 17/03/99 17:19 iSrvEchoHelper.java
_ISRVE~2 JAV 1 803 17/03/99 17:19 _iSrvEchoImplBase.java
El archivo iSrvEcho.java es el archivo Java que describe la interfaz del servidor:
/* * Archivo: ./ECHO/ISRVECHO.JAVA * Procedencia: ECHO.IDL * Fecha: lunes, 15 de marzo, 13:56:08, 1999 * Por: D:\JAVAIDL\IDLTOJ~1.EXE Java IDL 1.2 18 de agosto de 1998 16:25:34 */
package echo;
public interface iSrvEcho
extends org.omg.CORBA.Object, org.omg.CORBA.portable.IDLEntity {
String echo(String msg)
;
}
Se puede observar que es prácticamente una traducción palabra por palabra de la interfaz IDL. Si tenemos curiosidad por echar un vistazo al contenido de los demás archivos .java, encontraremos cosas más complejas. Esto es lo que dice la documentación sobre la función de estos distintos archivos:
la interfaz del servidor
implementa la interfaz anterior iSrvEcho. Se trata de una clase abstracta, el «esqueleto» del servidor, que proporciona al servidor las funcionalidades CORBA necesarias para la aplicación distribuida.
Es la imagen («stub») del servidor que utilizará el cliente. Proporciona al cliente las funcionalidades CORBA para conectarse al servidor.
Proporciona los métodos necesarios para la gestión de las referencias de objetos CORBA
Proporciona los métodos necesarios para gestionar los parámetros de entrada y salida de los métodos de la interfaz.
10.2.4. Compilación de las clases generadas a partir de la interfaz IDL
Es recomendable compilar las clases anteriores. En otro ejemplo veremos que aquí se pueden detectar errores debidos a un funcionamiento incorrecto del generador idltojava. En este caso todo va bien y, tras la compilación, en el directorio del paquete echo tenemos los siguientes archivos:
E:\data\java\corba\ECHO\echo>dir
_ISRVE~1 JAV 1 095 17/03/99 17:19 _iSrvEchoStub.java
ISRVEC~1 JAV 311 17/03/99 17:19 iSrvEcho.java
ISRVEC~2 JAV 825 17/03/99 17:19 iSrvEchoHolder.java
ISRVEC~3 JAV 1 827 17/03/99 17:19 iSrvEchoHelper.java
_ISRVE~2 JAV 1 803 17/03/99 17:19 _iSrvEchoImplBase.java
_ISRVE~1 CLA 2 275 18/03/99 11:25 _iSrvEchoImplBase.class
_ISRVE~2 CLA 1 383 18/03/99 11:25 _iSrvEchoStub.class
ISRVEC~1 CLA 251 18/03/99 11:25 iSrvEcho.class
ISRVEC~2 CLA 2 078 18/03/99 11:25 iSrvEchoHelper.class
ISRVEC~3 CLA 858 18/03/99 11:25 iSrvEchoHolder.class
10.2.5. Entrada del servidor
10.2.5.1. Implementación de la interfaz iSrvEcho
Anteriormente hemos definido la interfaz iSrvEcho. Ahora vamos a escribir la clase que implementa dicha interfaz. Derivará de la clase _iSrvEchoImplbase.java, que, como se ha indicado anteriormente, ya implementa la interfaz iSrvEcho.
// paquetes importados
import echo.*;
// clase que implementa el eco remoto
public class srvEcho extends _iSrvEchoImplBase{
// método que realiza el eco
public String echo(String msg){
return "[" + msg + "]";
}// fin del eco
}// fin de la clase
El código se entiende por sí solo. Esta clase se guarda en el archivo srvEcho.java, en el directorio principal del paquete de la interfaz iSrvEcho.
Se puede compilar para comprobarlo:
E:\data\java\corba\ECHO>j:\jdk12\bin\javac srvEcho.java
E:\data\java\corba\ECHO>dir
ECHO IDL 78 15/03/99 13:56 ECHO.IDL
SRVECH~1 CLA 488 18/03/99 11:30 srvEcho.class
SRVECH~1 JAV 252 15/03/99 14:02 srvEcho.java
ECHO <REP> 17/03/99 17:19 echo
10.2.5.2. Registro de la clase de creación del servidor
Al igual que en el caso de una aplicación cliente-servidor RMI, un servidor CORBA debe registrarse en un directorio para que los clientes puedan acceder a él. Es este procedimiento de registro el que, a nivel de desarrollo, difiere según se trate de una aplicación CORBA o RMI. A continuación se muestra el del servidor CORBA de eco registrado en el archivo serveurEcho.java:
// paquetes importados
import echo.*;
import org.omg.CosNaming.*;
import org.omg.CosNaming.NamingContextPackage.*;
import org.omg.CORBA.*;
//----------- clase serveurEcho
public class serveurEcho{
// ------- main: inicia el servidor de eco
// sintaxis pg machineAnnuaire portAnnuaire nomService
// máquina: máquina que aloja el directorio CORBA
// puerto: puerto del directorio CORBA
// nomService: nombre del servicio que se va a registrar
public static void main(String arg[]){
// ¿Están ahí los argumentos?
if(arg.length!=3){
System.err.println("Syntaxe : pg machineAnnuaire portAnnuaire nomService");
System.exit(1);
}
// se recuperan los argumentos
String machine=arg[0];
String port=arg[1];
String nomService=arg[2];
try{
// Necesitamos un objeto CORBA para trabajar
String[] initORB={"-ORBInitialHost",machine,"-ORBInitialPort",port};
ORB orb=ORB.init(initORB,null);
// se añade el servicio al directorio de servicios
// se llamará srvEcho
org.omg.CORBA.Object objRef=
orb.resolve_initial_references("NameService");
NamingContext ncRef=NamingContextHelper.narrow(objRef);
NameComponent nc= new NameComponent(nomService,"");
NameComponent path[]={nc};
// Creamos el servidor y lo asociamos al servicio srvEcho
srvEcho serveurEcho=new srvEcho();
ncRef.rebind(path,serveurEcho);
orb.connect(serveurEcho);
// seguimiento
System.out.println("Serveur d'écho prêt");
// espera de las solicitudes de los clientes
java.lang.Object sync=new java.lang.Object();
synchronized(sync){
sync.wait();
}
} catch(Exception e){
// se ha producido un error
System.err.println("Erreur " + e);
e.printStackTrace(System.err);
}
}// en espera
}// serveurEcho
A continuación explicamos las líneas generales de la puesta en marcha del servidor sin entrar en detalles que, a primera vista, pueden resultar complejos. Hay que recordar de ejemplo anterior sus líneas generales, que se repetirán en cualquier servidor CORBA.
10.2.5.2.1. Los parámetros del servidor
Un servidor CORBA debe registrarse en un servicio de directorio que opere en una máquina y un puerto determinados. Nuestra aplicación recibirá estos dos datos como parámetros. El servicio así registrado debe tener un nombre, que será el tercer parámetro.
10.2.5.2.2. Crear el objeto de acceso al servicio de directorio CORBA
Para acceder al servicio de directorio y registrar nuestro servidor de eco, necesitamos un objeto denominado ORB (Object Request Broker), que se obtiene mediante el siguiente método de clase:
Args : tableau de paires de chaînes de caractères, chaque paire étant de la forme (paramètre,valeur)
Prop : propriétés de l’application
El ejemplo utiliza la siguiente secuencia para obtener el objeto ORB:
String[] initORB={"-ORBInitialHost",machine,"-ORBInitialPort",port};
ORB orb=ORB.init(initORB,null);
Los pares (parámetro, valor) utilizados son los siguientes:
("-ORBInitialHost",machine) : ce couple précise la machine ou opère l’annuaire des services CORBA, ici la machine passée en paramètre au serveur.
("-ORBInitialPort",port ) : ce couple précise le port ou opère l’annuaire des services CORBA, ici le port passé en paramètre au serveur.
El segundo parámetro del método init se deja en null. Si también se hubiera dejado el primer parámetro en null, el par (máquina, puerto) utilizado habría sido el predeterminado (localhost,900).
10.2.5.2.3. Registrar el servidor en el directorio de servicios CORBA
El registro del servidor en el directorio se realiza mediante las siguientes operaciones:
// se incluye el servicio en el directorio de servicios
// se llamará srvEcho
org.omg.CORBA.Object objRef=
orb.resolve_initial_references("NameService");
NamingContext ncRef=NamingContextHelper.narrow(objRef);
NameComponent nc= new NameComponent(nomService,"");
NameComponent path[]={nc};
// Se crea el servidor y se asocia al servicio srvEcho
srvEcho serveurEcho=new srvEcho();
ncRef.rebind(path,serveurEcho);
orb.connect(serveurEcho);
La primera parte del código consiste en preparar el nombre del servicio. Este nombre se representa en el código mediante la variable path. El nombre de un servicio consta de varios componentes:
- un componente inicial objRef, un objeto genérico que debe convertirse a un tipo NamingContext, en este caso ncRef.
- el nombre del servicio, en este caso nomService, que se ha pasado como parámetro al servidor
Estos componentes del nombre (NameComponent) se recogen en una matriz, en este caso path. Es esta matriz la que «nombra» de forma precisa el servicio creado. Una vez creado el nombre, queda
- asociarlo a una instancia del servidor (la clase srvEcho creada anteriormente)
srvEcho serveurEcho=new srvEcho();
- y registrarlo en el directorio
10.2.5.3. Compilación de la clase de inicio del servidor
Se compila la clase anterior:
E:\data\java\corba\ECHO>j:\jdk12\bin\javac serveurEcho.java
E:\data\java\corba\ECHO>dir
ECHO IDL 78 15/03/99 13:56 ECHO.IDL
SERVEU~1 CLA 1 793 18/03/99 13:18 serveurEcho.class
SERVEU~1 JAV 1 806 16/03/99 15:38 serveurEcho.java
SRVECH~1 CLA 488 18/03/99 11:30 srvEcho.class
SRVECH~1 JAV 252 15/03/99 14:02 srvEcho.java
ECHO <REP> 17/03/99 17:19 echo
10.2.6. Texto del cliente
10.2.6.1. El código
Escribimos un cliente para probar nuestro servicio de eco. Le pasaremos al cliente los mismos tres parámetros que al servidor:
Máquina: máquina en la que se encuentra el directorio de servicios CORBA
Puerto: puerto en el que opera este directorio
nomService: nombre del servicio de eco
El cliente se conecta al servicio de eco y, a continuación, solicita al usuario que escriba mensajes con el teclado. Estos se envían al servidor de eco, que los devuelve. El diálogo se muestra en pantalla.
El cliente CORBA del servicio de eco se parece mucho al cliente RMI ya escrito. Una vez más, el cliente debe conectarse a un servicio de directorio para obtener una referencia del objeto-servidor al que desea conectarse. La diferencia entre ambos clientes radica ahí y únicamente ahí. Este es el código del cliente de eco CORBA:
10.2.6.2. La conexión del cliente al servidor
El cliente CORBA anterior se conecta al servidor mediante la instrucción:
// se establece la conexión con el servidor de eco
iSrvEcho serveurEcho=getServeurEcho(machine,port,nomService);
Una vez finalizada esta operación, el cliente dispone de una referencia del servidor de eco. A partir de ahí, un cliente CORBA no difiere de un cliente RMI. El método privado que garantiza la conexión con el servidor es el siguiente:
// paquetes importados
import java.io.*;
import echo.*;
import org.omg.CosNaming.*;
import org.omg.CORBA.*;
// ---------- clase cltEcho
public class cltEcho {
public static void main(String arg[]){
// sintaxis: cltEcho machineAnnuaire portAnnuaire nombre del servicio
// máquina: máquina en la que opera el directorio de servicios CORBA
// puerto: puerto en el que opera el directorio de servicios
// nomService: nombre del servicio de eco
// verificación de los argumentos
if(arg.length!=3){
System.err.println("Syntaxe : pg machineAnnuaire portAnnuaire nomservice");
System.exit(1);
}
// se recuperan los parámetros
String machine=arg[0];
String port=arg[1];
String nomService=arg[2];
// se establece la conexión con el servidor de eco
iSrvEcho serveurEcho=getServeurEcho(machine,port,nomService);
// diálogo cliente-servidor
BufferedReader in=null;
String msg=null;
String reponse=null;
iSrvEcho serveur=null;
try{
// apertura del flujo del teclado
in=new BufferedReader(new InputStreamReader(System.in));
// bucle de lectura de los mensajes que se van a enviar al servidor de eco
System.out.print("Message : ");
msg=in.readLine().toLowerCase().trim();
while(! msg.equals("fin")){
// envío del mensaje al servidor y recepción de la respuesta
reponse=serveurEcho.echo(msg);
// seguimiento
System.out.println("Réponse serveur : " + reponse);
// mensaje siguiente
System.out.print("Message : ");
msg=in.readLine().toLowerCase().trim();
}// while
// se ha terminado
System.exit(0);
// gestión de errores
} catch (Exception e){
System.err.println("Erreur : " + e);
System.exit(2);
}// try
}// main
// ---------------------- getServeurEcho
private static iSrvEcho getServeurEcho(String machine, String port,
String nomService){
// solicita una referencia del servidor de eco
// seguimiento
System.out.println("--> Connexion au serveur CORBA en cours...");
// la referencia del servidor de eco
iSrvEcho serveurEcho=null;
try{
// se solicita un objeto CORBA para trabajar
String[] initORB={"-ORBInitialHost",machine,"-ORBInitialPort",port};
ORB orb=ORB.init(initORB,null);
// se utiliza el servicio de directorio para localizar el servidor de eco
org.omg.CORBA.Object objRef=
orb.resolve_initial_references("NameService");
NamingContext ncRef=NamingContextHelper.narrow(objRef);
// el servicio buscado se llama srvEcho; se solicita
NameComponent nc= new NameComponent(nomService,"");
NameComponent path[]={nc};
serveurEcho=iSrvEchoHelper.narrow(ncRef.resolve(path));
} catch (Exception e){
System.err.println("Erreur lors de la localisation du serveur d'écho ("
+ e + ")");
System.exit(10);
}// try-catch
// se devuelve la referencia al servidor
return serveurEcho;
}// getServeurEcho
}// clase
Encontramos las mismas secuencias de código que en el servidor:
- creamos un objeto ORB que nos permitirá conectarnos al directorio de servicios CORBA
String[] initORB={"-ORBInitialHost",machine,"-ORBInitialPort",port};
ORB orb=ORB.init(initORB,null);
- se definen los distintos componentes del nombre del servicio de eco
org.omg.CORBA.Object objRef=orb.resolve_initial_references("NameService");
NamingContext ncRef=NamingContextHelper.narrow(objRef);
NameComponent nc= new NameComponent(nomService,"");
NameComponent path[]={nc};
- Se solicita al servicio de directorio una referencia del servicio de eco (aquí es donde nos diferenciamos del servidor)
10.2.6.3. Compilation
E:\data\java\corba\ECHO>j:\jdk12\bin\javac cltEcho.java
E:\data\java\corba\ECHO>dir
CLTECH~1 CLA 2 599 18/03/99 13:51 cltEcho.class
CLTECH~1 JAV 2 907 16/03/99 16:15 cltEcho.java
ECHO IDL 78 15/03/99 13:56 ECHO.IDL
SERVEU~1 CLA 1 793 18/03/99 13:18 serveurEcho.class
SERVEU~1 JAV 1 806 16/03/99 15:38 serveurEcho.java
SRVECH~1 CLA 488 18/03/99 11:30 srvEcho.class
SRVECH~1 JAV 252 15/03/99 14:02 srvEcho.java
ECHO <REP> 17/03/99 17:19 echo
10.2.7. Pruebas
10.2.7.1. Inicio del servicio de directorio
En un equipo con Windows, iniciamos el servicio de directorio de la siguiente manera:
lo que hace que se inicie el servicio de directorio en el puerto 1000 del equipo.
El servicio de directorio tnameserv muestra un mensaje en pantalla similar al siguiente:
Initial Naming Context:
IOR:000000000000002849444c3a6f6d672e6f72672f436f734e616d696e672f4e616d696e67436f
6e746578743a312e3000000000010000000000000030000100000000000a69737469612d30303900
044700000018afabcafe000000027620dd9a000000080000000000000000
TransientNameServer: setting port for initial object references to: 1000
No se lee muy bien, pero nos quedaremos con la última línea: el servicio está activo en el puerto 1000.
10.2.7.2. Puesta en marcha del servidor de eco
El servicio de eco se inicia con tres parámetros:
E:\data\java\corba\ECHO>start j:\jdk12\bin\java serveurEcho localhost 1000 srvEcho
El servidor muestra:
10.2.7.3. Inicio del cliente en el mismo equipo que el del servidor
E:\data\java\corba\ECHO>j:\jdk12\bin\java cltEcho localhost 1000 srvEcho
--> Connexion au serveur CORBA en cours...
Message : msg1
Réponse serveur : [msg1]
Message : msg2
Réponse serveur : [msg2]
Message : fin
10.2.7.4. Inicio del cliente en un equipo Windows distinto al del servidor
E:\data\java\corba\ECHO>j:\jdk12\bin\java cltEcho tahe.istia.univ-angers.fr 1000 srvEcho
--> Connexion au serveur CORBA en cours...
Message : abcd
Réponse serveur : [abcd]
Message : efgh
Réponse serveur : [efgh]
Message : fin
10.3. Ejemplo 2: un servidor SQL
10.3.1. Introducción
Retomamos aquí la descripción del servidor SQL, ya analizado en el contexto de Java RMI, con el objetivo de poner de relieve los puntos en común entre ambos métodos, así como sus diferencias. Recordemos la función de este servidor SQL: se encuentra en un equipo con Windows y permite a los clientes remotos acceder a las bases de datos públicas ODBC de ese equipo con Windows.
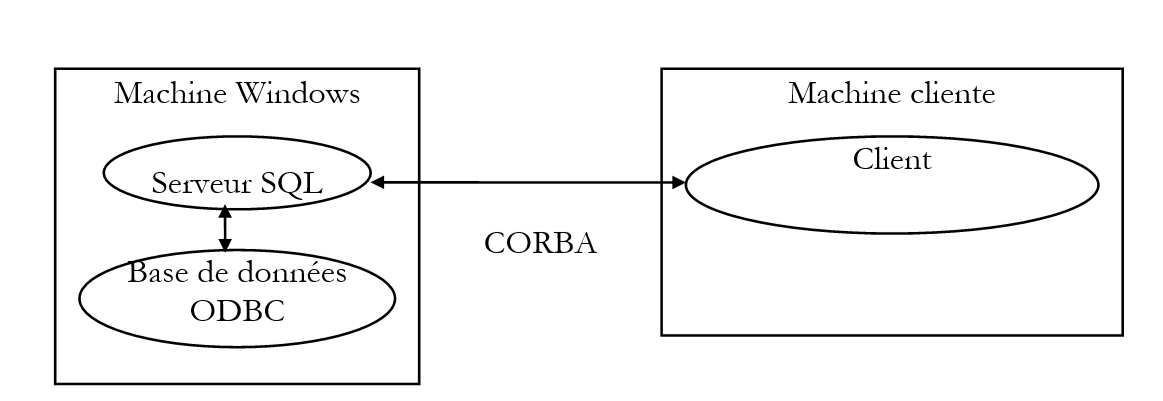
El cliente CORBA podría realizar tres operaciones:
- conectarse a la base de datos que elija
- enviar consultas SQL
- cerrar la conexión
El servidor ejecuta las consultas SQL del cliente y le envía los resultados. Esa es su función principal y por eso lo llamamos servidor SQL. Aplicamos los distintos pasos vistos anteriormente con el servidor de eco.
10.3.2. Escritura de la interfaz IDL del servidor
Recordemos, a modo de resumen, la interfaz RMI que habíamos utilizado para el servidor:
import java.rmi.*;
// la interfaz remota
public interface interSQL extends Remote{
public String connect(String pilote, String url, String id, String mdp)
throws java.rmi.RemoteException;
public String[] executeSQL(String requete, String separateur)
throws java.rmi.RemoteException;
public String close()
throws java.rmi.RemoteException;
}
La función de los distintos métodos era la siguiente:
Connect: el cliente se conecta a una base de datos remota, para lo cual proporciona el controlador, la URL JDBC, así como su identificador (id) y su contraseña (mdp) para acceder a dicha base. El servidor le devuelve una cadena de caracteres que indica el resultado de la conexión:
executeSQL: el cliente solicita la ejecución de una consulta SQL en la base de datos a la que está conectado. Indica el carácter que debe separar los campos en los resultados que se le devuelven. El servidor devuelve una matriz de cadenas:
para una consulta de actualización de la base de datos, siendo n el número de filas actualizadas
si la consulta ha generado un error
si la consulta no ha generado ningún resultado
si la consulta ha generado resultados. Las líneas devueltas por el servidor son los resultados de la consulta.
Close: el cliente cierra su conexión con la base de datos remota. El servidor devuelve una cadena que indica el resultado de este cierre:
La interfaz IDL del servidor será la siguiente:
module srvSQL{
typedef sequence<string> resultats;
interface interSQL{
string connect(in string pilote, in string urlBase, in string id, in string mdp);
resultats executeSQL(in string requete, in string separateur);
string close();
};// interfaz
};// módulo
La única novedad con respecto a lo que hemos visto con la interfaz IDL del servidor de eco es el uso de la palabra clave «sequence». Esta palabra clave permite definir una matriz unidimensional. La definición se realiza en dos pasos:
- definición de un tipo para designar la matriz, en este caso «resultados»:
La palabra clave typedef es bien conocida por los programadores de C/C++: permite definir un nuevo tipo. En este caso, el tipo resultats se define como equivalente al tipo sequence<string>, c.a.d, es decir, una matriz dinámica (sin tamaño fijo) de cadenas de caracteres.
- Uso del nuevo tipo donde sea necesario
Por lo tanto, el método executeSQL devuelve un array de cadenas de caracteres.
10.3.3. Compilación de la interfaz IDL del servidor
La interfaz IDL anterior se guarda en el archivo srvSQL.idl. Se compila este archivo:
E:\data\java\corba\sql>d:\javaidl\idltojava -fno-cpp srvSQL.idl
E:\data\java\corba\sql>dir
SRVSQL IDL 275 19/03/99 9:59 srvSQL.idl
SRVSQL <REP> 19/03/99 9:41 srvSQL
Se observa que la compilación ha dado lugar a un directorio con el nombre del módulo de la interfaz IDL (srvSQL). Veamos el contenido de este directorio:
E:\data\java\corba\sql>dir srvSQl
RESULT~1 JAV 833 19/03/99 10:00 resultatsHolder.java
RESULT~2 JAV 1 883 19/03/99 10:00 resultatsHelper.java
_INTER~1 JAV 2 474 19/03/99 10:00 _interSQLStub.java
INTERS~1 JAV 448 19/03/99 10:00 interSQL.java
INTERS~2 JAV 841 19/03/99 10:00 interSQLHolder.java
INTERS~3 JAV 1 855 19/03/99 10:00 interSQLHelper.java
_INTER~2 JAV 4 535 19/03/99 10:00 _interSQLImplBase.java
Cabe recordar que los archivos Helper y Holder son clases relacionadas con los parámetros de entrada-salida y los resultados de los métodos de la interfaz remota. El directorio srvSQL contiene todos los archivos .java relacionados con la interfaz interSQL definida en el archivo .idl. También contiene archivos relacionados con el tipo resultats creado en la interfaz IDL.
El archivo interSQL.java es el archivo Java de la interfaz de nuestro servidor. Es importante comprobar que lo que se ha generado automáticamente se ajusta a lo que esperábamos. El archivo interSQL.java generado es el siguiente:
/* * Archivo: ./SRVSQL/INTERSQL.JAVA * De: SRVSQL.IDL * Fecha: viernes, 19 de marzo de 1999, 09:59:48 * Por: D:\JAVAIDL\IDLTOJ~1.EXE Java IDL 1.2 18 de agosto de 1998 16:25:34 */
package srvSQL;
public interface interSQL
extends org.omg.CORBA.Object, org.omg.CORBA.portable.IDLEntity {
String connect(String pilote, String urlBase, String id, String mdp)
;
String[] executeSQL(String requete, String separateur)
;
String close()
;
}
Se observa que tenemos la misma interfaz que la utilizada para el cliente-servidor RMI. Por lo tanto, podemos continuar. Compilemos todos estos archivos .java:
E:\data\java\corba\sql\srvSQL>j:\jdk12\bin\javac *.java
Note: _interSQLImplBase.java uses or overrides a deprecated API. Recompile with
"-deprecation" for details.
1 warning
E:\data\java\corba\sql\srvSQL>dir *.class
_INTER~1 CLA 3 094 19/03/99 10:01 _interSQLImplBase.class
_INTER~2 CLA 1 953 19/03/99 10:01 _interSQLStub.class
INTERS~1 CLA 430 19/03/99 10:01 interSQL.class
INTERS~2 CLA 2 096 19/03/99 10:01 interSQLHelper.class
INTERS~3 CLA 870 19/03/99 10:01 interSQLHolder.class
RESULT~1 CLA 2 047 19/03/99 10:01 resultatsHelper.class
RESULT~2 CLA 881 19/03/99 10:01 resultatsHolder.class
10.3.4. Codificación del servidor SQL
Ahora escribimos el código del servidor SQL. Recordemos que esta clase debe derivarse de la clase abstracta _nomInterfaceImplBase generada al compilar el archivo IDL. Aparte de esta particularidad y salvo las secuencias de código relacionadas con el registro del servicio en un directorio, el código del servidor CORBA es idéntico al del servidor RMI:
// paquetes importados
import java.sql.*;
import java.util.*;
import srvSQL.*;
// clase SQLServant
public class SQLServant extends _interSQLImplBase{
// datos globales de la clase
private Connection DB;
// --------------- conexión
public String connect(String pilote, String url, String id,
String mdp){
// conexión a la base de datos url mediante el controlador
// identificación con el ID y la contraseña
String resultat=null; // resultado del método
try{
// carga del controlador
Class.forName(pilote);
// solicitud de conexión
DB=DriverManager.getConnection(url,id,mdp);
// ok
resultat="200 Connexion réussie";
} catch (Exception e){
// error
resultat="500 Echec de la connexion (" + e + ")";
}
// fin
return resultat;
}
// ------------- executeSQL
public String[] executeSQL(String requete, String separateur){
// ejecuta una consulta SQL en la base de datos DB
// y almacena los resultados en una matriz de cadenas
// datos necesarios para la ejecución de la consulta
Statement S=null;
ResultSet RS=null;
String[] lignes=null;
Vector resultats=new Vector();
String ligne=null;
try{
// creación del contenedor de la consulta
S=DB.createStatement();
// ejecución de la consulta
if (! S.execute(requete)){
// consulta de actualización
// se devuelve el número de líneas actualizadas
lignes=new String[1];
lignes[0]="100 "+S.getUpdateCount();
return lignes;
}
// era una consulta
// se recuperan los resultados
RS=S.getResultSet();
// número de campos del conjunto de resultados
int nbChamps=RS.getMetaData().getColumnCount();
// se procesan
while(RS.next()){
// creación de la línea de resultados
ligne="101 ";
for (int i=1;i<nbChamps;i++)
ligne+=RS.getString(i)+separateur;
ligne+=RS.getString(nbChamps);
// se añade al vector de resultados
resultats.addElement(ligne);
}// while
// fin del procesamiento de los resultados
// se liberan los recursos
RS.close();
S.close();
// se devuelven los resultados
int nbLignes=resultats.size();
if (nbLignes==0){
lignes=new String[1];
lignes[0]="501 Pas de résultats";
} else {
lignes=new String[resultats.size()];
for(int i=0;i<lignes.length;i++)
lignes[i]=(String) resultats.elementAt(i);
}//si
return lignes;
} catch (Exception e){
// error
lignes=new String[1];
lignes[0]="500 " + e;
return lignes;
}// try-catch
}// executeSQL
// --------------- cerrar
public String close(){
// cierra la conexión con la base de datos
String resultat=null;
try{
DB.close();
resultat="200 Base fermée";
} catch (Exception e){
resultat="500 Erreur à la fermeture de la base ("+e+")";
}
// devuelve el resultado
return resultat;
}
}// clase SQLServant
Esta clase se encuentra en el archivo SQLServant.java que estamos compilando:
E:\data\java\corba\sql>dir
SRVSQL IDL 275 19/03/99 9:59 srvSQL.idl
SRVSQL <REP> 19/03/99 9:41 srvSQL
SQLSER~1 JAV 2 941 15/03/99 9:09 SQLServant.java
E:\data\java\corba\sql>j:\jdk12\bin\javac SQLServant.java
E:\data\java\corba\sql>dir *.class
SQLSER~1 CLA 2 568 19/03/99 10:19 SQLServant.class
10.3.5. Codificación del programa de inicio del servidor SQL
La clase anterior representa el servidor SQL una vez iniciado. Previamente, debe registrarse en un directorio de servicios CORBA. Al igual que con el servicio de eco, lo haremos con una clase especial a la que pasaremos, en el momento de la ejecución, tres parámetros:
Máquina: máquina en la que se encuentra el directorio de servicios CORBA
Puerto: puerto en el que opera este directorio
nomService: nombre del servicio SQL
El código de esta clase es prácticamente idéntico al de la clase que realizaba la misma tarea para el servicio de eco. Hemos resaltado en negrita la línea que difiere entre ambas clases: no crea el mismo objeto de servidor. Así pues, vemos que seguimos teniendo el mismo mecanismo de inicio del servidor. Si aislamos este mecanismo en una clase, tal y como se ha hecho aquí, se vuelve prácticamente transparente para el desarrollador.
// paquetes importados
import srvSQL.*;
import org.omg.CosNaming.*;
import org.omg.CosNaming.NamingContextPackage.*;
import org.omg.CORBA.*;
//----------- clase serveurSQL
public class serveurSQL{
// ------- main: inicia el servidor SQL
public static void main(String arg[]){
// serveurSQL máquina, puerto, servicio
//¿Tenemos el número correcto de argumentos?
if(arg.length!=3){
System.err.println("Syntaxe : pg machineAnnuaireCorba portAnnuaireCorba nomService");
System.exit(1);
}
// se recogen los argumentos
String machine=arg[0];
String port=arg[1];
String nomService=arg[2];
String[] initORB={"-ORBInitialHost",machine,"-ORBInitialPort",port};
try{
// se necesita un objeto CORBA para trabajar
ORB orb=ORB.init(initORB,null);
// se añade el servicio al directorio de servicios
org.omg.CORBA.Object objRef=
orb.resolve_initial_references("NameService");
NamingContext ncRef=NamingContextHelper.narrow(objRef);
NameComponent nc= new NameComponent(nomService,"");
NameComponent path[]={nc};
// creamos el servidor y lo asociamos al servicio srvSQL
SQLServant serveurSQL=new SQLServant();
ncRef.rebind(path,serveurSQL);
orb.connect(serveurSQL);
// seguimiento
System.out.println("Serveur SQL prêt");
// espera de las solicitudes de los clientes
java.lang.Object sync=new java.lang.Object();
synchronized(sync){
sync.wait();
}
} catch(Exception e){
// se ha producido un error
System.err.println("Erreur " + e);
e.printStackTrace(System.err);
}
}// en espera
}// srvSQL
Compilamos esta nueva clase:
E:\data\java\corba\sql>j:\jdk12\bin\javac serveurSQL.java
E:\data\java\corba\sql>dir *.class
SQLSER~1 CLA 2 568 19/03/99 10:19 SQLServant.class
SERVEU~1 CLA 1 800 19/03/99 10:33 serveurSQL.class
10.3.6. Escritura del cliente
El cliente del servidor CORBA se invoca con los siguientes parámetros:
máquina: máquina en la que se encuentra el directorio de servicios CORBA
puerto: puerto en el que opera este directorio
nomService: nombre del servicio SQL
controlador: controlador que debe utilizar el servidor SQL para gestionar la base de datos deseada
urlBase: URL JDBC de la base de datos que se va a gestionar
id: identidad del cliente o «null» si no hay identidad
mdp: contraseña del cliente o «null» si no hay contraseña
separador: carácter que debe utilizar el servidor SQL para separar los campos de las líneas de resultados de una consulta
A continuación se muestra un ejemplo de los parámetros posibles:
donde:
máquina: máquina en la que se encuentra el directorio de servicios CORBA
puerto: puerto en el que opera este directorio
srvSQL: srvSQL, nombre CORBA del servidor SQL
controlador: sun.jdbc.odbc.JdbcOdbcDriver, el controlador habitual para bases de datos con interfaz ODBC
urlBase: jdbc:odbc:articles, para utilizar una base de datos «articles» declarada en la lista de bases de datos públicas ODBC del equipo Windows
id: null, sin identidad
contraseña: null, sin contraseña
separador: , los campos de los resultados estarán separados por una coma
Una vez iniciado con los parámetros anteriores, el cliente sigue los siguientes pasos:
- se conecta al equipo «machine» en el puerto «port» para solicitar el servicio CORBA srvSQL
- solicita la conexión a la base de datos de artículos
- solicita al usuario que introduzca una consulta SQL mediante el teclado
- la envía al servidor SQL
- muestra en pantalla los resultados devueltos por el servidor
- vuelve a pedir al usuario que introduzca una consulta SQL con el teclado. Se detendrá cuando la consulta haya finalizado.
A continuación se muestra el código Java del cliente. Los comentarios deberían bastar para entenderlo. Se observará que:
- el código es idéntico al del cliente RMI que ya hemos estudiado. Se diferencia de este en el proceso de solicitud del servicio al directorio, proceso que se encuentra aislado en el método getServeurSQL.
- El método getServeurSQL es idéntico al escrito para el cliente de eco
Por lo tanto, vemos que:
- un cliente CORBA solo se diferencia de un cliente RMI en la forma de conectarse al servidor
- esta forma es idéntica para todos los clientes CORBA
import srvSQL.*;
import org.omg.CosNaming.*;
import org.omg.CORBA.*;
import java.io.*;
public class clientSQL {
// datos globales de la clase
private static String syntaxe =
"syntaxe : cltSQL machine port service pilote urlBase id mdp separateur";
private static BufferedReader in=null;
private static interSQL serveurSQL=null;
public static void main(String arg[]){
// sintaxis: cltSQL máquina puerto separador controlador URL ID contraseña
// máquina y puerto: máquina y puerto del directorio de servicios CORBA con el que hay que ponerse en contacto
// servicio: nombre del servicio
// controlador: controlador que se debe utilizar para la base de datos que se va a utilizar
// urlBase: URL JDBC de la base de datos que se va a utilizar
// id: identificador del usuario
// mdp: su contraseña
// separador: cadena que separa los campos en los resultados de una consulta
// verificación del número de argumentos
if(arg.length!=8)
erreur(syntaxe,1);
// inicialización de los parámetros de conexión a la base de datos
String machine=arg[0];
String port=arg[1];
String service=arg[2];
String pilote=arg[3];
String urlBase=arg[4];
String id, mdp, separateur;
if(arg[5].equals("null")) id=""; else id=arg[5];
if(arg[6].equals("null")) mdp=""; else mdp=arg[6];
if(arg[7].equals("null")) separateur=" "; else separateur=arg[7];
// parámetros del servicio de directorio CORBA
String[] initORB={"-ORBInitialHost",arg[0],"-ORBInitialPort",arg[1]};
// cliente CORBA: se solicita una referencia del servidor SQL
interSQL serveurSQL=getServeurSQL(machine,port,service);
// diálogo cliente-servidor
String requete=null;
String reponse=null;
String[] lignes=null;
String codeErreur=null;
try{
// apertura del flujo del teclado
in=new BufferedReader(new InputStreamReader(System.in));
// seguimiento
System.out.println("--> Connexion à la base de données en cours");
// solicitud de conexión inicial a la base de datos
reponse=serveurSQL.connect(pilote,urlBase,id,mdp);
// seguimiento
System.out.println("<-- "+reponse);
// análisis de la respuesta
codeErreur=reponse.substring(0,3);
if(codeErreur.equals("500"))
erreur("Abandon sur erreur de connexion à la base",3);
// bucle de lectura de las consultas que se van a enviar al servidor SQL
System.out.print("--> Requête : ");
requete=in.readLine().toLowerCase().trim();
while(! requete.equals("fin")){
// envío de la consulta al servidor y recepción de la respuesta
lignes=serveurSQL.executeSQL(requete,separateur);
// seguimiento
afficheLignes(lignes);
// siguiente solicitud
System.out.print("--> Requête : ");
requete=in.readLine().toLowerCase().trim();
}// while
// seguimiento
System.out.println("--> Fermeture de la connexion à la base de données distante");
// se cierra la conexión
reponse=serveurSQL.close();
// seguimiento
System.out.println("<-- " + reponse);
// fin
System.exit(0);
// gestión de errores
} catch (Exception e){
erreur("Abandon sur erreur : " + e,2);
}// intentar
}// main
// ----------- AfficheLignes
private static void afficheLignes(String[] lignes){
for (int i=0;i<lignes.length;i++)
System.out.println("<-- " + lignes[i]);
}// afficheLignes
// ------------ error
private static void erreur(String msg, int exitCode){
// visualización del mensaje de error
System.err.println(msg);
// posible liberación de recursos
try{
in.close();
serveurSQL.close();
} catch(Exception e){}
// salida
System.exit(exitCode);
}// error
// ---------------------- getServeurSQL
private static interSQL getServeurSQL(String machine, String port, String service){
// solicita una referencia del servidor SQL
// máquina: máquina del directorio de servicios CORBA
// puerto: puerto del directorio de servicios CORBA
// servicio: nombre del servicio CORBA que se va a solicitar
// seguimiento
System.out.println("--> Connexion au serveur CORBA en cours...");
// la referencia del servidor SQL
interSQL serveurSQL=null;
// parámetros del servicio de directorio CORBA
String[] initORB={"-ORBInitialHost",machine,"-ORBInitialPort",port};
try{
// se solicita un objeto CORBA para trabajar; para ello, se utiliza el puerto
// de escucha del directorio de servicios CORBA
ORB orb=ORB.init(initORB,null);
// se utiliza el servicio de directorio para localizar el servidor SQL
org.omg.CORBA.Object objRef=
orb.resolve_initial_references("NameService");
NamingContext ncRef=NamingContextHelper.narrow(objRef);
// el servicio buscado se llama srvSQL; lo solicitamos
NameComponent nc= new NameComponent(service,"");
NameComponent path[]={nc};
serveurSQL=interSQLHelper.narrow(ncRef.resolve(path));
} catch (Exception e){
System.err.println("Erreur lors de la localisation du serveur SQL ("
+ e + ")");
System.exit(10);
}// try-catch
// se devuelve la referencia al servidor
return serveurSQL;
}// getServeurSQL
}// clase
Compilemos la clase del cliente:
E:\data\java\corba\sql>j:\jdk12\bin\javac clientSQL.java
E:\data\java\corba\sql>dir *.class
SQLSER~1 CLA 2 568 19/03/99 10:19 SQLServant.class
SERVEU~1 CLA 1 800 19/03/99 10:33 serveurSQL.class
CLIENT~1 CLA 3 774 19/03/99 10:45 clientSQL.class
Estamos listos para las pruebas.
10.3.7. Pruebas
10.3.7.1. Pré-requis
Supongamos que una base de datos ACCESS llamada «Artículos» está disponible públicamente en el servidor Windows SQL:
Esta base de datos tiene la siguiente estructura:
nombre | tipo |
code | código del artículo de 4 caracteres |
nom | su nombre (cadena de caracteres) |
prix | su precio (real) |
stock_actu | su stock actual (número entero) |
stock_mini | el stock mínimo (en número entero) por debajo del cual hay que reponer el artículo |
10.3.7.2. Lanzamiento del servicio de directorio
E:\data\java\corba\sql>start j:\jdk12\bin\tnameserv -ORBInitialPort 1000
Le service d’annuaire est lancé sur le port 1000. Il affiche dans une fenêtre DOS quelque chose du genre :
Initial Naming Context:
IOR:000000000000002849444c3a6f6d672e6f72672f436f734e616d696e672f4e616d696e67436f
6e746578743a312e3000000000010000000000000030000100000000000a69737469612d30303900
052800000018afabcafe000000027693d3fd000000080000000000000000
TransientNameServer: setting port for initial object references to: 1000
10.3.7.3. Inicio del servidor SQL
Se inicia el servidor SQL:
Se muestra en una ventana DOS:
10.3.7.4. Inicio de un cliente en el mismo equipo que el servidor
Estos son los resultados obtenidos con un cliente en el mismo equipo que el servidor:
E:\data\java\corba\sql>j:\jdk12\bin\java clientSQL localhost 1000 srvSQL sun.jdbc.odbc.JdbcOdbcDriver jdbc:odbc:articles null null ,
--> Connexion au serveur CORBA en cours...
--> Connexion à la base de données en cours
<-- 200 Connexion réussie
--> Consulta: select nombre, stock_actu, stock_mini from artículos
<-- 101 vélo,31,8
<-- 101 arc,9,8
<-- 101 canoé,7,7
<-- 101 fusil,9,8
<-- 101 skis nautiques,13,8
<-- 101 essai3,13,9
<-- 101 cachalot,6,6
<-- 101 léopard,7,7
<-- 101 panthère,7,7
--> Consulta: delete from artículos where stock_mini<7
<-- 100 1
--> Consulta: SELECT nombre, stock_actu, stock_mini FROM artículos
<-- 101 vélo,31,8
<-- 101 arc,9,8
<-- 101 canoé,7,7
<-- 101 fusil,9,8
<-- 101 skis nautiques,13,8
<-- 101 essai3,13,9
<-- 101 léopard,7,7
<-- 101 panthère,7,7
--> Requête : fin
--> Fermeture de la connexion à la base de données distante
<-- 200 Base fermée
10.3.7.5. Inicio de un cliente en un equipo distinto al del servidor
Estos son los resultados obtenidos con un cliente en un equipo distinto al del servidor:
E:\data\java\corba\sql>j:\jdk12\bin\java clientSQL tahe.istia.univ-angers.fr 1000 srvSQL sun.jdbc.odbc.JdbcOdbcDriver jdbc:odbc:articles null null ,
--> Connexion au serveur CORBA en cours...
--> Connexion à la base de données en cours
<-- 200 Connexion réussie
--> Consulta: select * from artículos
<-- 101 a300,v_lo,1202,31,8
<-- 101 d600,arc,5000,9,8
<-- 101 d800,canoé,1502,7,7
<-- 101 x123,fusil,3000,9,8
<-- 101 s345,skis nautiques,1800,13,8
<-- 101 f450,essai3,3,13,9
<-- 101 z400,léopard,500000,7,7
<-- 101 g457,panthère,800000,7,7
--> Requête : fin
--> Fermeture de la connexion à la base de données distante
<-- 200 Base fermée
10.4. Correspondencias entre IDL y JAVA
A continuación se indican las correspondencias entre los tipos simples IDL y JAVA:
tipo IDL | tipo Java |
boolean | booleano |
char | char |
wchar | char |
byte | byte |
cadena | java.lang.String |
wstring | java.lang.String |
short | short |
short sin signo | short |
long | int |
long sin signo | int |
long long | long |
unsigned long long | long |
float | float |
double | double |
Recordemos que para definir una matriz de elementos de tipo T en la interfaz IDL, se utiliza la instrucción:
y que, a continuación, se utiliza nomType para hacer referencia al tipo del array. Así, en la interfaz del servidor SQL se ha utilizado la declaración:
para que resultats haga referencia a una matriz String[] en Java.