5. Clases .NET de uso habitual
A continuación presentamos algunas clases de la plataforma .NET que se utilizan con frecuencia. Antes de ello, mostramos cómo obtener información sobre los cientos de clases disponibles. Esta ayuda es indispensable incluso para los desarrolladores de C# con experiencia. El nivel de calidad de una guía (facilidad de acceso, organización clara, pertinencia de la información, etc.) puede determinar el éxito o el fracaso de un entorno de desarrollo.
5.1. Buscar ayuda sobre las clases .NET
A continuación ofrecemos algunas indicaciones para encontrar ayuda con Visual Studio.NET
5.1.1. Ayuda/Contenido
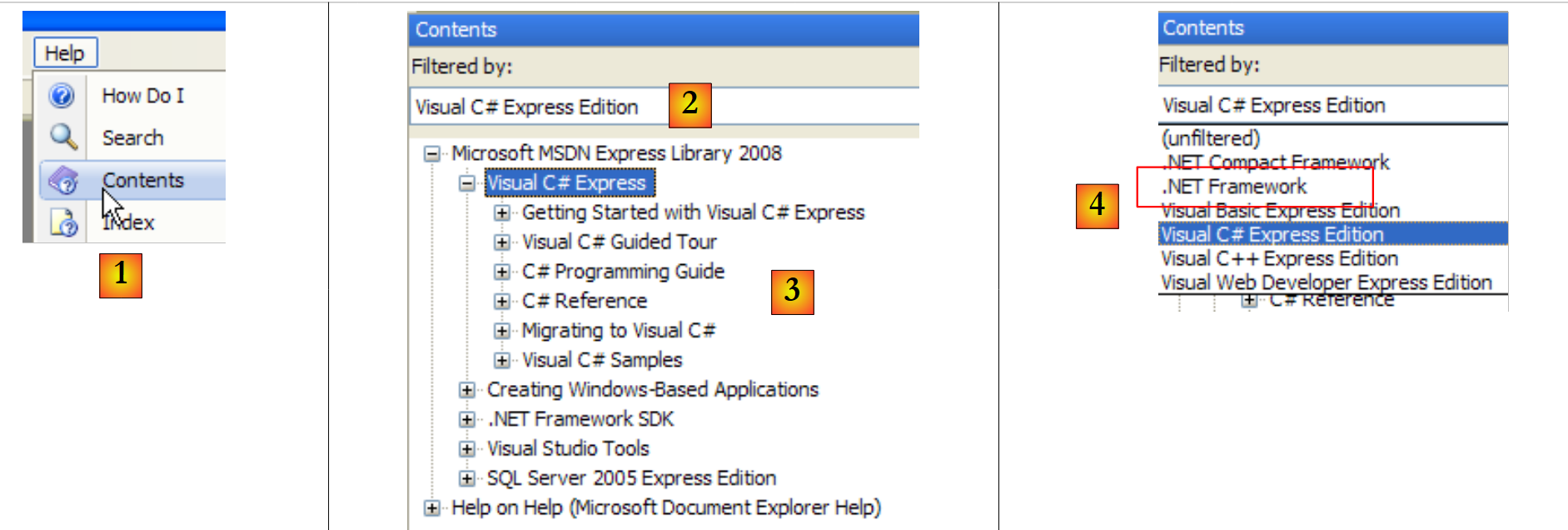 |
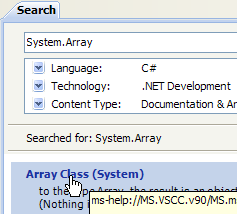
- en [1], selecciona la opción Help/Contents del menú.
- en [2], selecciona la opción Visual C# Express Edition
- en [3], el árbol de ayuda sobre C#
- en [4], otra opción útil es .NET Framework, que da acceso a todas las clases del framework .NET.
Echemos un vistazo a los títulos de los capítulos de la ayuda de C#:
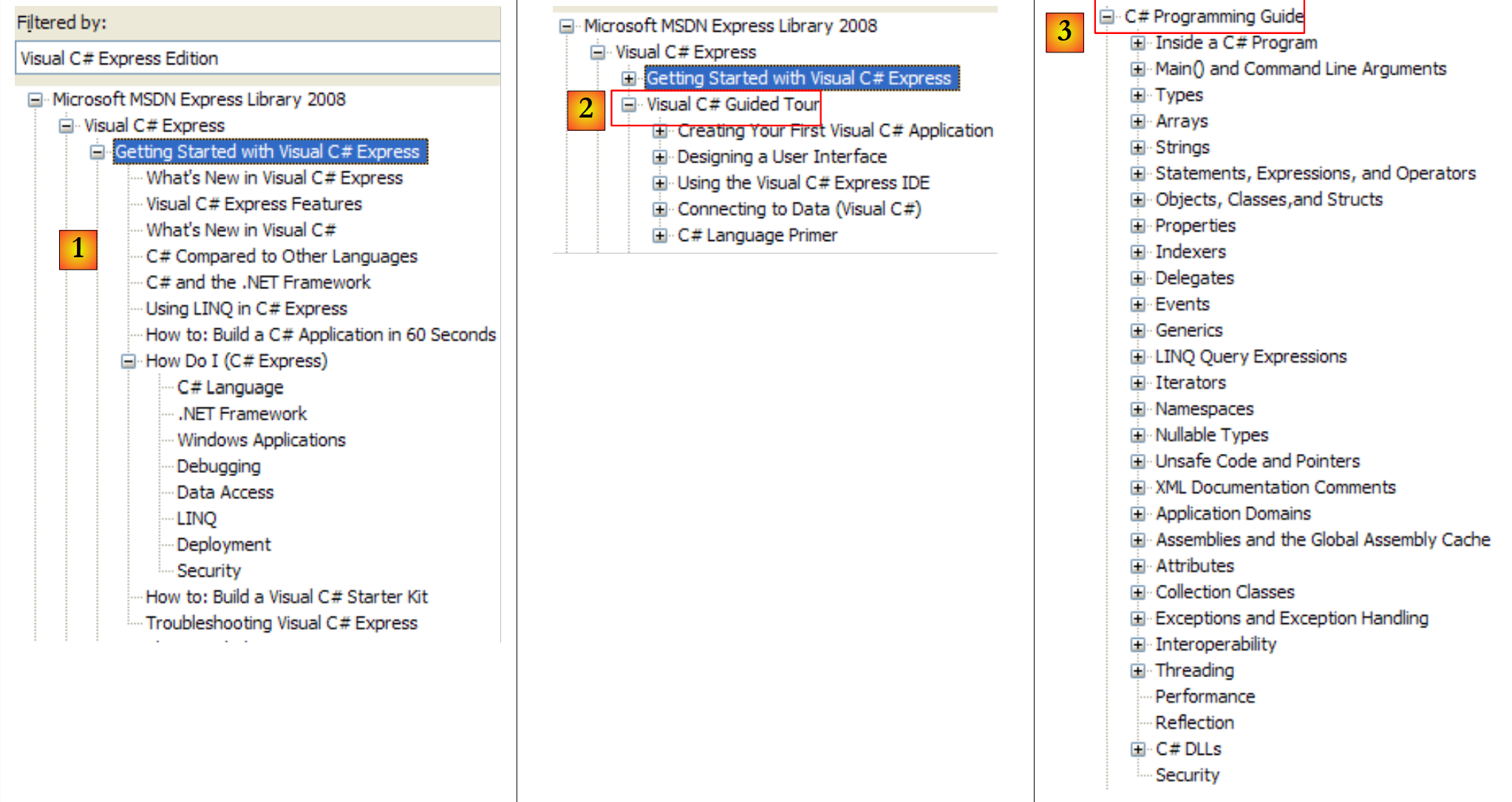 |
- [1]: una visión general de C#
- [2]: una serie de ejemplos sobre algunos aspectos de C#
- [3]: un curso de C#; podría sustituir ventajosamente al presente documento…
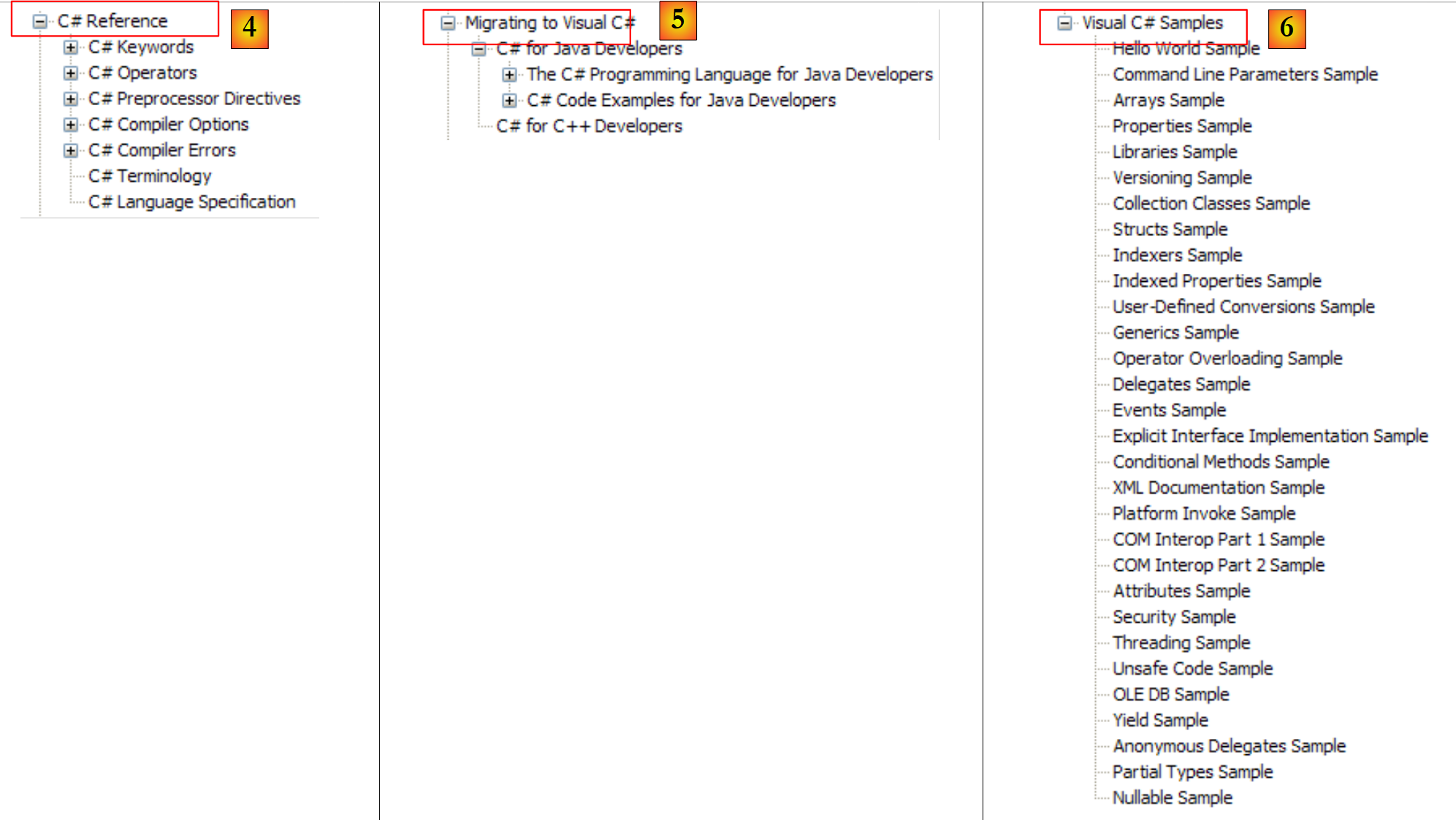 |
- [4]: para profundizar en los detalles de C#
- [5]: útil para desarrolladores de C++ o Java. Permite evitar algunos escollos.
- [6]: si buscas ejemplos, puedes empezar por aquí.
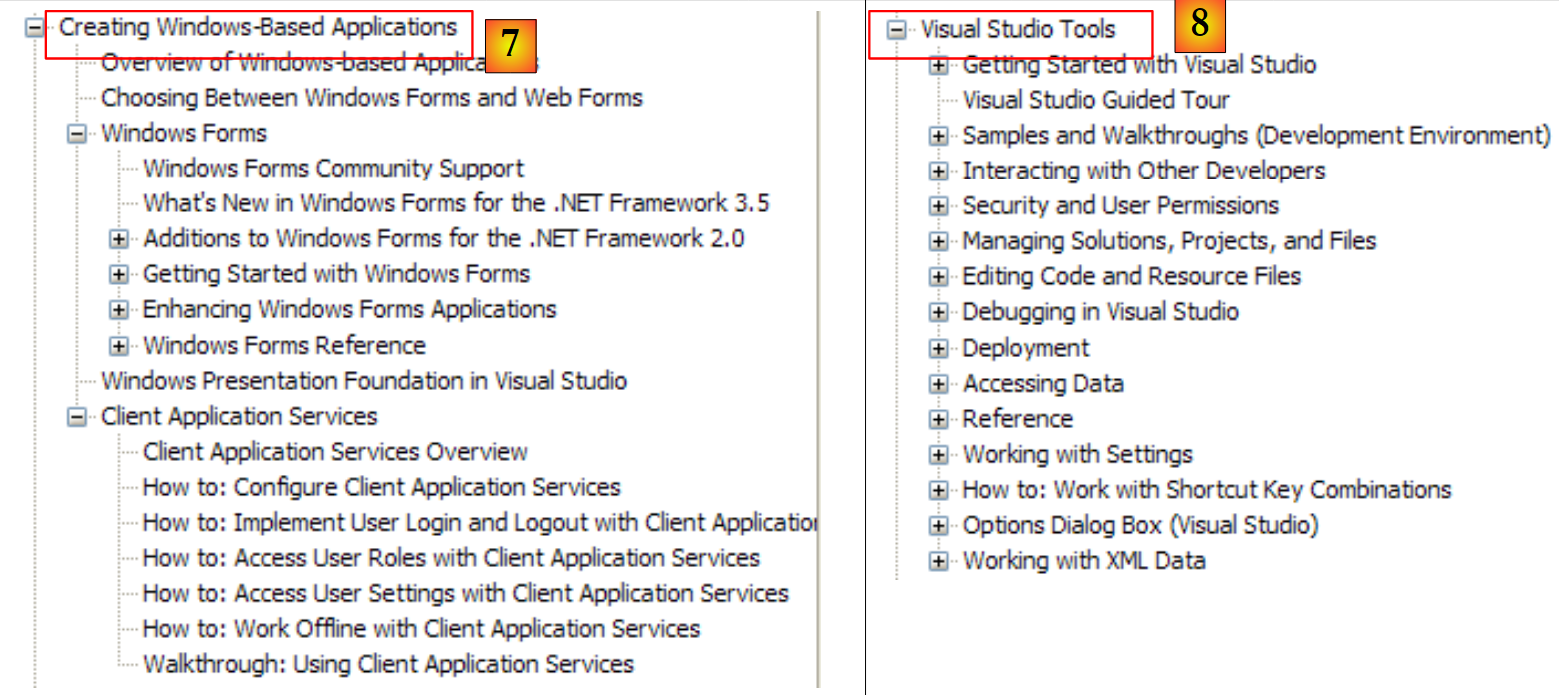 |
- [7]: lo que hay que saber para crear interfaces gráficas
- [8]: para sacar más partido a IDE Visual Studio Express
 |
- [9]: SQL Server Express 2005 es un SGBD de calidad que se distribuye de forma gratuita. Lo utilizaremos en este curso.
La ayuda de C# es solo una parte de lo que necesita el desarrollador. La otra parte es la ayuda sobre los cientos de clases del marco .NET que le facilitarán el trabajo.
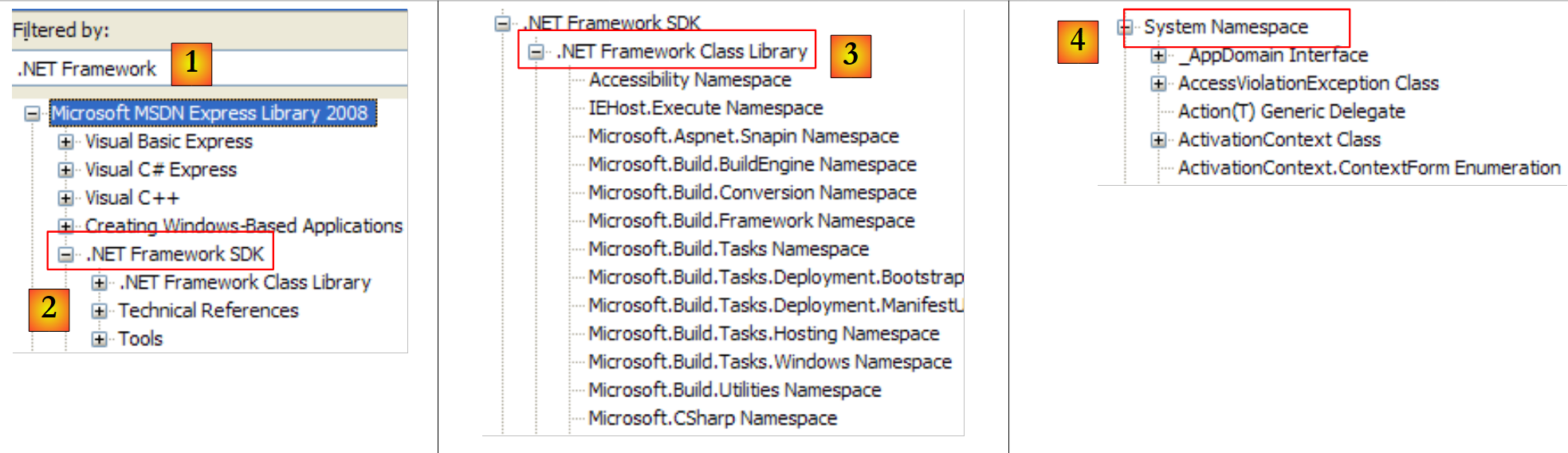 |
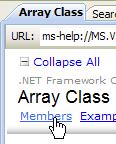
- [1]: seleccionamos la ayuda sobre el marco .NET
- [2]: la ayuda se encuentra en la rama .NET Framework SDK
- [3]: la rama «.NET Framework Class Library» presenta todas las clases «.NET» según el espacio de nombres al que pertenecen
- [4]: el espacio de nombres System, que ha sido el más utilizado en los ejemplos de los capítulos anteriores
 |
- [5]: en el espacio de nombres System, un ejemplo, en este caso la estructura DateTime
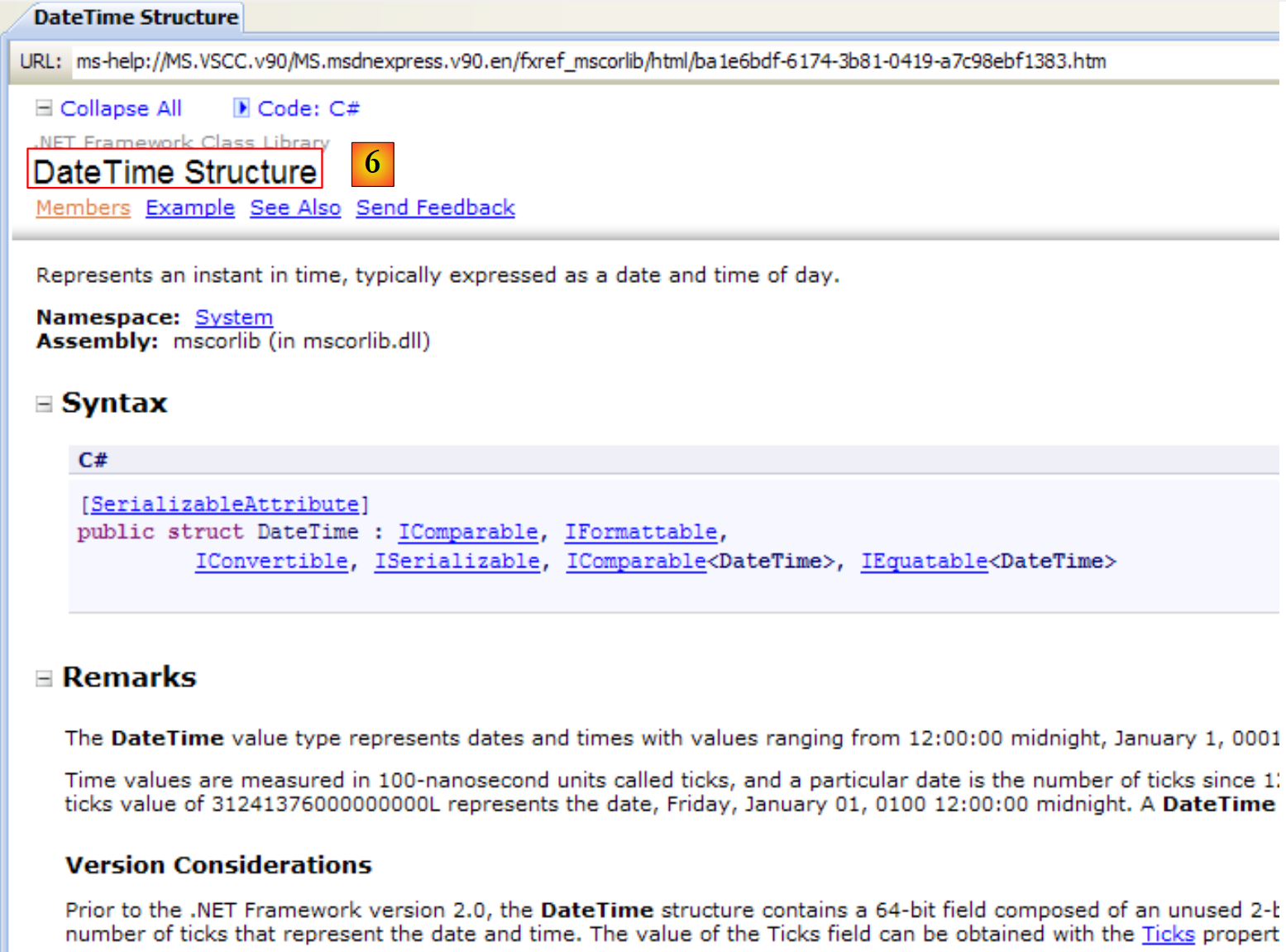 |
- [6]: la ayuda sobre la estructura DateTime
5.1.2. Ayuda/Índice/Buscar
La ayuda que ofrece MSDN es muy extensa y es posible que no se sepa dónde buscar. En ese caso, se puede utilizar el índice de la ayuda:
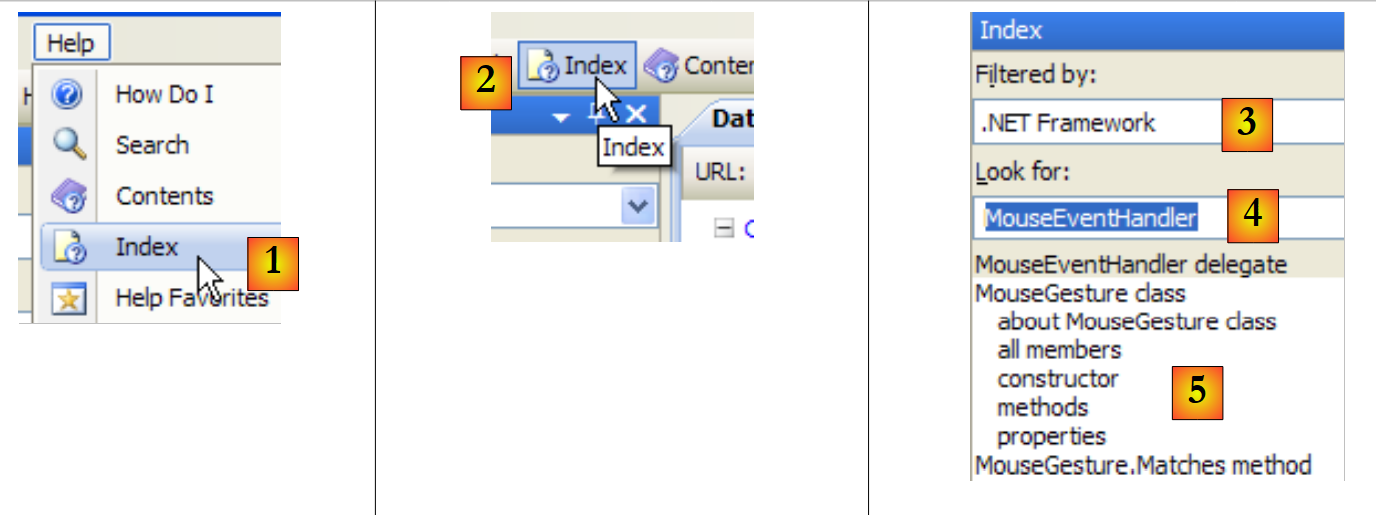 |
- en [1], utiliza la opción [Help/Index] si la ventana de ayuda aún no está abierta; de lo contrario, utiliza [2] en una ventana de ayuda ya abierta.
- en [3], especifica el ámbito en el que debe realizarse la búsqueda
- En [4], especifica lo que estás buscando; en este caso, una clase
- en [5], la respuesta
Otra forma de buscar ayuda es utilizar la función de búsqueda de la ayuda:
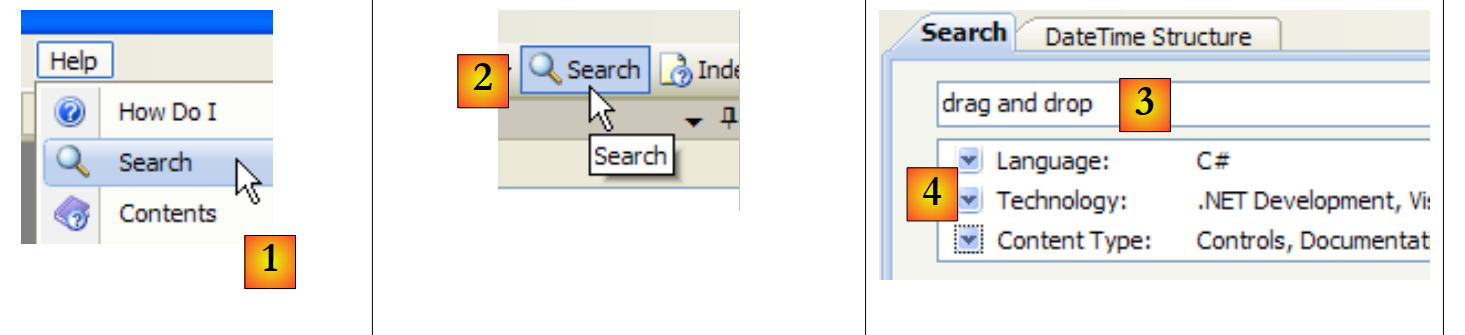 |
- en [1], utiliza la opción [Help/Search] si la ventana de ayuda aún no está abierta; de lo contrario, utiliza [2] en una ventana de ayuda ya abierta.
- en [3], especificar lo que se busca
- en [4], filtrar los ámbitos de búsqueda
 |
- en [5], la respuesta se presenta en forma de diferentes temas en los que se ha encontrado el texto buscado.
5.2. Las cadenas de caracteres
5.2.1. La clase System.String
 |  |  |
La clase System.String es idéntica al tipo «string» simple. Cuenta con numerosas propiedades y métodos. Estos son algunos de ellos:
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
Cabe destacar un punto importante: cuando un método devuelve una cadena de caracteres, esta es una cadena diferente de aquella a la que se ha aplicado el método. Así, S1.Trim() devuelve la cadena S2, y S1 y S2 son dos cadenas diferentes.
Una cadena C puede considerarse como una matriz de caracteres. Así,
- C[i] es el carácter i de C
- C.Length es el número de caracteres de C
Consideremos el siguiente ejemplo:
using System;
namespace Chap3 {
class Program {
static void Main(string[] args) {
string uneChaine = "l'oiseau vole au-dessus des nuages";
affiche("uneChaine=" + uneChaine);
affiche("uneChaine.Length=" + uneChaine.Length);
affiche("chaine[10]=" + uneChaine[10]);
affiche("uneChaine.IndexOf(\"vole\")=" + uneChaine.IndexOf("vole"));
affiche("uneChaine.IndexOf(\"x\")=" + uneChaine.IndexOf("x"));
affiche("uneChaine.LastIndexOf('a')=" + uneChaine.LastIndexOf('a'));
affiche("uneChaine.LastIndexOf('x')=" + uneChaine.LastIndexOf('x'));
affiche("uneChaine.Substring(4,7)=" + uneChaine.Substring(4, 7));
affiche("uneChaine.ToUpper()=" + uneChaine.ToUpper());
affiche("uneChaine.ToLower()=" + uneChaine.ToLower());
affiche("uneChaine.Replace('a','A')=" + uneChaine.Replace('a', 'A'));
string[] champs = uneChaine.Split(null);
for (int i = 0; i < champs.Length; i++) {
affiche("champs[" + i + "]=[" + champs[i] + "]");
}//for
affiche("Join(\":\",champs)=" + System.String.Join(":", champs));
affiche("(\" abc \").Trim()=[" + " abc ".Trim() + "]");
}//Principal
public static void affiche(string msg) {
// muestra mensaje
Console.WriteLine(msg);
}//muestra
}//clase
}//espacio de nombres
La ejecución da los siguientes resultados:
Veamos otro ejemplo:
using System;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// la línea que se va a analizar
string ligne = "un:deux::trois:";
// los separadores de campos
char[] séparateurs = new char[] { ':' };
// división
string[] champs = ligne.Split(séparateurs);
for (int i = 0; i < champs.Length; i++) {
Console.WriteLine("Champs[" + i + "]=" + champs[i]);
}
// unión
Console.WriteLine("join=[" + System.String.Join(":", champs) + "]");
}
}
}
y los resultados de la ejecución:
El método Split de la clase String permite colocar en un array los elementos de una cadena de caracteres. La definición del método Split que se utiliza aquí es la siguiente:
public string[] Split(char[] separator);
tabla de caracteres. Estos caracteres representan los que se utilizan para separar los campos de la cadena de caracteres. Así, si la cadena es «champ1, champ2, champ3"», se podrá utilizar separator=new char[] {','}. Si el separador es una secuencia de espacios, se utilizará separator=null. | |
matriz de cadenas de caracteres en la que cada elemento de la matriz es un campo de la cadena. |
El método Join es un método estático de la clase String:
public static string Join(string separator, string[] value);
matriz de cadenas de caracteres | |
una cadena de caracteres que servirá como separador de campos | |
una cadena de caracteres formada por la concatenación de los elementos de la tabla value, separados por la cadena separator. |
5.2.2. La clase System.Text.StringBuilder
 |  |  |
Anteriormente, dijimos que los métodos de la clase String que se aplicaban a una cadena de caracteres S1 devolvían otra cadena S2. La clase System.Text.StringBuilder permite manipular S1 sin tener que crear una cadena S2. Esto mejora el rendimiento al evitar la multiplicación de cadenas con una vida útil muy limitada.
La clase admite varios constructores:
| |
|
Un objeto StringBuilder trabaja con bloques de capacité caracteres para almacenar la cadena subyacente. Por defecto, capacité es igual a 16. El tercer constructor anterior permite especificar la capacidad de los bloques. El número de bloques de caracteres capacité necesarios para almacenar una cadena S se ajusta automáticamente mediante la clase StringBuilder. Existen constructores para establecer el número máximo de caracteres en un objeto StringBuilder. Por defecto, esta capacidad máxima es de 2 147 483 647.
A continuación se muestra un ejemplo que ilustra este concepto de capacité:
using System.Text;
using System;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// str
StringBuilder str = new StringBuilder("test");
Console.WriteLine("taille={0}, capacité={1}", str.Length, str.Capacity);
for (int i = 0; i < 10; i++) {
str.Append("test");
Console.WriteLine("taille={0}, capacité={1}", str.Length, str.Capacity);
}
// str2
StringBuilder str2 = new StringBuilder("test",10);
Console.WriteLine("taille={0}, capacité={1}", str2.Length, str2.Capacity);
for (int i = 0; i < 10; i++) {
str2.Append("test");
Console.WriteLine("taille={0}, capacité={1}", str2.Length, str2.Capacity);
}
}
}
}
- línea 7: creación de un objeto StringBuilder con un tamaño de bloque de 16 caracteres
- línea 8: str.Length es el número actual de caracteres de la cadena str. str.Capacity es el número de caracteres que puede almacenar la cadena str actual antes de reasignar un nuevo bloque.
- línea 10: str.Append(String S) permite concatenar la cadena S, de tipo String, con la cadena str, de tipo StringBuilder.
- línea 14: creación de un objeto StringBuilder con una capacidad de bloque de 10 caracteres
Resultado de la ejecución:
Estos resultados muestran que la clase sigue un algoritmo propio para asignar nuevos bloques cuando su capacidad es insuficiente:
- líneas 4-5: aumento de la capacidad en 16 caracteres
- líneas 8-9: aumento de la capacidad en 32 caracteres, cuando habrían bastado 16.
Estos son algunos de los métodos de la clase:
| |
| |
| |
| |
|
He aquí un ejemplo:
using System.Text;
using System;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// str3
StringBuilder str3 = new StringBuilder("test");
Console.WriteLine(str3.Append("abCD").Insert(2, "xyZT").Remove(0, 2).Replace("xy", "XY"));
}
}
}
y sus resultados:
5.3. Las matrices
Las matrices derivan de la clase Array:
 |  | 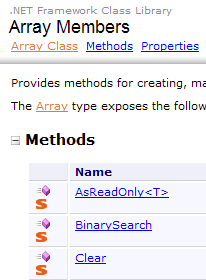 |
La clase Array dispone de diversos métodos para ordenar una matriz, buscar un elemento en una matriz, cambiar el tamaño de una matriz, etc. A continuación, presentamos algunas propiedades y métodos de esta clase. Casi todos están sobrecargados, c.a.d, por lo que existen en diferentes variantes. Todas las matrices heredan de ella.
Propiedades
Métodos
El siguiente programa ilustra el uso de algunos métodos de la clase Array:
using System;
namespace Chap3 {
class Program {
// tipo de búsqueda
enum TypeRecherche { linéaire, dichotomique };
// método principal
static void Main(string[] args) {
// lectura de los elementos de una tabla introducidos mediante el teclado
double[] éléments;
Saisie(out éléments);
// Visualización de la matriz sin ordenar
Affiche("Tableau non trié", éléments);
// Búsqueda lineal en la tabla sin ordenar
Recherche(éléments, TypeRecherche.linéaire);
// Ordenación de la tabla
Array.Sort(éléments);
// Visualización de una tabla ordenada
Affiche("Tableau trié", éléments);
// Búsqueda dicotómica en la tabla ordenada
Recherche(éléments, TypeRecherche.dichotomique);
}
// Introducción de los valores de la tabla de elementos
// elementos: referencia a la tabla creada por el método
static void Saisie(out double[] éléments) {
bool terminé = false;
string réponse;
bool erreur;
double élément = 0;
int i = 0;
// Al principio, la tabla no existe
éléments = null;
// bucle de introducción de los elementos de la tabla
while (!terminé) {
// pregunta
Console.Write("Elément (réel) " + i + " du tableau (rien pour terminer) : ");
// lectura de la respuesta
réponse = Console.ReadLine().Trim();
// fin de la introducción si la cadena está vacía
if (réponse.Equals(""))
break;
// verificación de la entrada
try {
élément = Double.Parse(réponse);
erreur = false;
} catch {
Console.Error.WriteLine("Saisie incorrecte, recommencez");
erreur = true;
}//try-catch
// si no hay error
if (!erreur) {
// un elemento más en la matriz
i += 1;
// redimensionar la matriz para dar cabida al nuevo elemento
Array.Resize(ref éléments, i);
// inserción del nuevo elemento
éléments[i - 1] = élément;
}
}//while
}
// método genérico para mostrar los elementos de una matriz
static void Affiche<T>(string texte, T[] éléments) {
Console.WriteLine(texte.PadRight(50, '-'));
foreach (T élément in éléments) {
Console.WriteLine(élément);
}
}
// búsqueda de un elemento en la matriz
// elementos: matriz de números reales
// TypeRecherche: dicotómico o lineal
static void Recherche(double[] éléments, TypeRecherche type) {
// Búsqueda
bool terminé = false;
string réponse = null;
double élément = 0;
bool erreur = false;
int i = 0;
while (!terminé) {
// pregunta
Console.WriteLine("Elément cherché (rien pour arrêter) : ");
// lectura y verificación de la respuesta
réponse = Console.ReadLine().Trim();
// ¿Terminado?
if (réponse.Equals(""))
break;
// verificación
try {
élément = Double.Parse(réponse);
erreur = false;
} catch {
Console.WriteLine("Erreur, recommencez...");
erreur = true;
}//try-catch
// si no hay error
if (!erreur) {
// se busca el elemento en el array
if (type == TypeRecherche.dichotomique)
// búsqueda dicotómica
i = Array.BinarySearch(éléments, élément);
else
// búsqueda lineal
i = Array.IndexOf(éléments, élément);
// Visualización de la respuesta
if (i >= 0)
Console.WriteLine("Trouvé en position " + i);
else
Console.WriteLine("Pas dans le tableau");
}//if
}//while
}
}
}
- líneas 27-62: el método Saisie introduce los elementos de un array éléments introducidos mediante el teclado. Como no se puede dimensionar el array a priori (no se conoce su tamaño final), nos vemos obligados a redimensionarlo con cada nuevo elemento (línea 57). Un algoritmo más eficaz habría consistido en asignar espacio a la matriz por grupos de N elementos. Sin embargo, una matriz no está diseñada para ser redimensionada. En este caso, es mejor utilizar una lista (ArrayList, List<T>).
- líneas 75-113: el método Recherche permite buscar en el array éléments un elemento introducido mediante el teclado. El modo de búsqueda varía en función de si el array está ordenado o no. Para un array no ordenado, se realiza una búsqueda lineal con el método IndexOf de la línea 106. Para un array ordenado, se realiza una búsqueda dicotómica con el método BinarySearch de la línea 103.
- línea 18: se ordena la tabla éléments. Aquí se utiliza una variante de Sort que solo tiene un parámetro: la tabla que se va a ordenar. La relación de orden utilizada para comparar los elementos de la tabla es, por tanto, la implícita de dichos elementos. En este caso, los elementos son numéricos. Se utiliza el orden natural de los números.
Los resultados en pantalla son los siguientes:
5.4. Las colecciones genéricas
Además de la tabla, existen diversas clases para almacenar colecciones de elementos. Hay versiones genéricas en el espacio de nombres System.Collections.Generic y versiones no genéricas en System.Collections. A continuación, presentaremos dos colecciones genéricas de uso frecuente: la lista y el diccionario.
La lista de colecciones genéricas es la siguiente:
5.4.1. La clase genérica List<T>
La clase System.Collections.Generic.List<T> permite implementar colecciones de objetos de tipo T cuyo tamaño varía durante la ejecución del programa. Un objeto de tipo List<T> se maneja casi como un array. Así, el elemento i de una lista l se denota como l[i].
También existe un tipo de lista no genérica: ArrayList, capaz de almacenar referencias a cualquier objeto. ArrayList es funcionalmente equivalente a List<Object>.. Un objeto ArrayList tiene este aspecto:
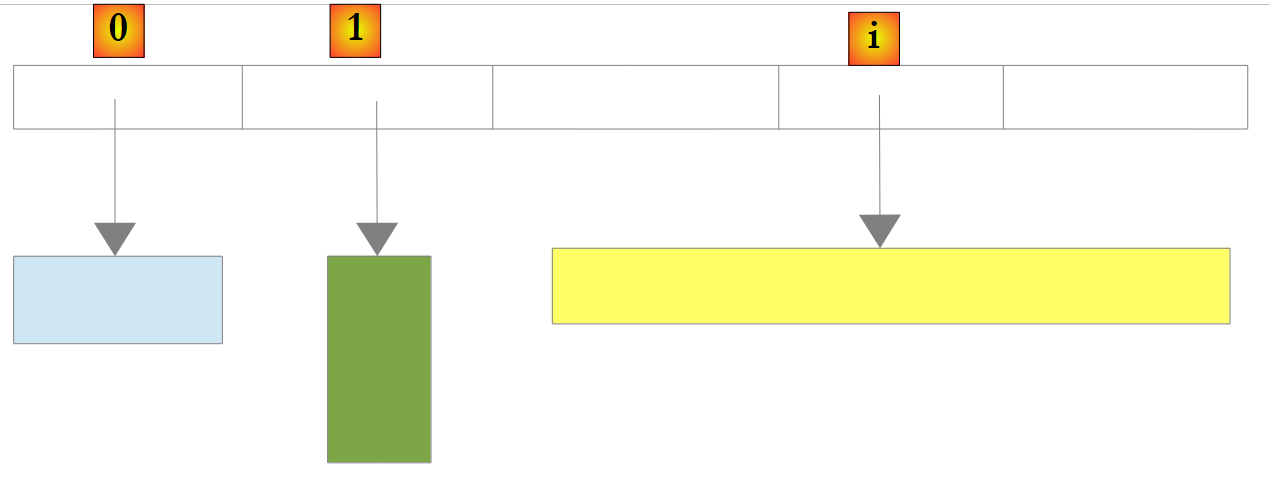 |
En el ejemplo anterior, los elementos 0, 1 e i de la lista apuntan a objetos de tipos diferentes. Es necesario crear primero un objeto antes de añadir su referencia a la lista ArrayList. Aunque un ArrayList almacena referencias a objetos, es posible almacenar números en él. Esto se lleva a cabo mediante un mecanismo denominado Boxing: el número se encapsula en un objeto O de tipo Object y es la referencia O la que se almacena en la lista. Se trata de un mecanismo transparente para el desarrollador. Así, se puede escribir:
Esto producirá el siguiente resultado:
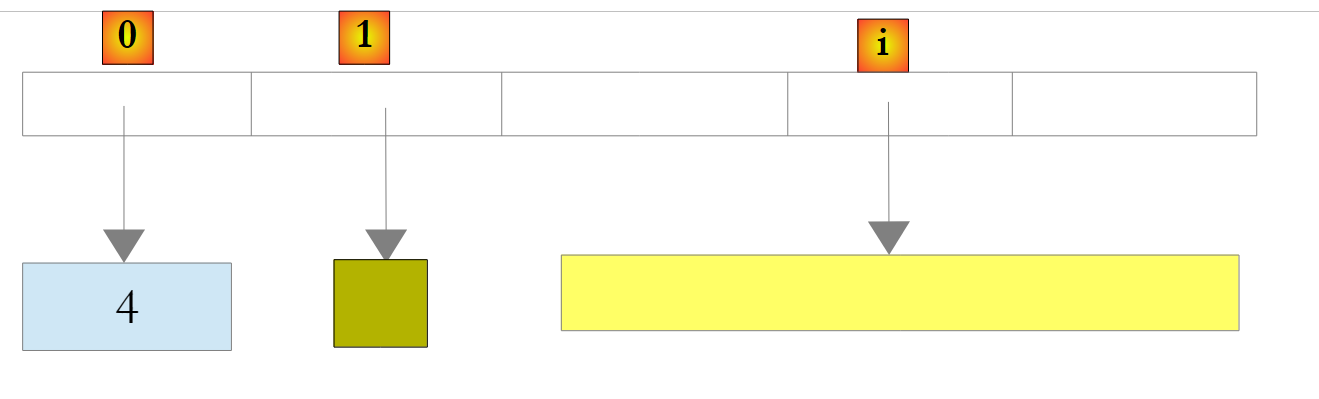 |
En el ejemplo anterior, el número 4 se ha encapsulado en un objeto O y la referencia O se almacena en la lista. Para recuperarlo, se puede escribir:
int i = (int)liste[0];
La operación Object -> int se denomina Unboxing. Si una lista está compuesta íntegramente por tipos int, declararla como List<int> mejora el rendimiento. De hecho, los números de tipo int se almacenan entonces en la propia lista y no en tipos Object externos a la lista. Las operaciones de boxing y unboxing ya no tienen lugar.
En el caso de que un objeto List<T> o T sea una clase, la lista almacena, una vez más, las referencias de los objetos de tipo T:
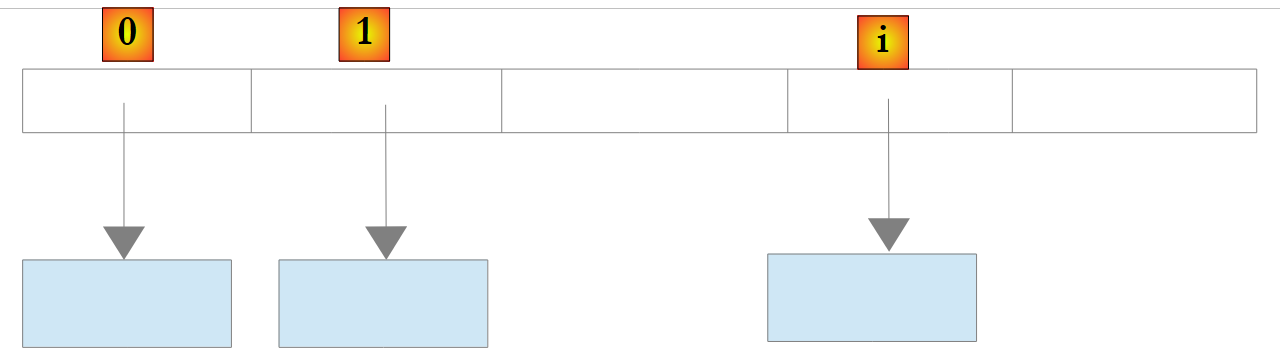 |
Estas son algunas de las propiedades y métodos de las listas genéricas:
Propiedades
Métodos
Retomemos el ejemplo tratado anteriormente con un objeto de tipo Array y procesémoslo ahora con un objeto de tipo List<T>.. Dado que la lista es un objeto similar a una matriz, el código apenas cambia. Solo presentamos las modificaciones más destacadas:
using System;
using System.Collections.Generic;
namespace Chap3 {
class Program {
// tipo de búsqueda
enum TypeRecherche { linéaire, dichotomique };
// método principal
static void Main(string[] args) {
// lectura de los elementos de una lista introducidos mediante el teclado
List<double> éléments;
Saisie(out éléments);
// número de elementos
Console.WriteLine("La liste a {0} éléments et une capacité de {1} éléments", éléments.Count, éléments.Capacity);
// Visualización de la lista sin ordenar
Affiche("Liste non triée", éléments);
// Búsqueda lineal en la lista sin ordenar
Recherche(éléments, TypeRecherche.linéaire);
// Ordenación de la lista
éléments.Sort();
// Visualización de la lista ordenada
Affiche("Liste triée", éléments);
// Búsqueda dicotómica en la lista ordenada
Recherche(éléments, TypeRecherche.dichotomique);
}
// Introducción de los valores de la lista de elementos
// elementos: referencia a la lista creada por el método
static void Saisie(out List<double> éléments) {
...
// Al principio, la lista está vacía
éléments = new List<double>();
// bucle de introducción de los elementos de la lista
while (!terminé) {
...
// si no hay error
if (!erreur) {
// un elemento más en la lista
éléments.Add(élément);
}
}//while
}
// método genérico para mostrar los elementos de un objeto enumerable
static void Affiche<T>(string texte, IEnumerable<T> éléments) {
Console.WriteLine(texte.PadRight(50, '-'));
foreach (T élément in éléments) {
Console.WriteLine(élément);
}
}
// búsqueda de un elemento en la lista
// elementos: lista de números reales
// TypeRecherche: dicotómico o lineal
static void Recherche(List<double> éléments, TypeRecherche type) {
...
while (!terminé) {
...
// si no hay error
if (!erreur) {
// se busca el elemento en la lista
if (type == TypeRecherche.dichotomique)
// búsqueda dicotómica
i = éléments.BinarySearch(élément);
else
// búsqueda lineal
i = éléments.IndexOf(élément);
// Visualización de la respuesta
...
}//if
}//while
}
}
}
- líneas 46-51: el método genérico Affiche<T> admite dos parámetros:
- el primer parámetro es un texto que se va a escribir
- el segundo parámetro es un objeto que implementa la interfaz genérica IEnumerable<T>:
La estructura foreach( T elemento in elementos), de la línea 48, es válida para cualquier objeto *éléments que implemente la interfaz *IEnumerable. Las tablas (Array) y las listas (List<T>) implementan la interfaz IEnumerable<T>. Por lo tanto, el método Affiche es adecuado tanto para mostrar tablas como listas.
Los resultados de la ejecución del programa son los mismos que en el ejemplo en el que se utiliza la clase Array.
5.4.2. La clase Dictionary<TKey,TValue>
La clase System.Collections.Generic.Dictionary<TKey,TValue> permite implementar un diccionario. Se puede considerar un diccionario como una tabla de dos columnas:
clave | valor |
clave1 | valor1 |
clave2 | valor2 |
.. | ... |
En la clase Dictionary<TKey,TValue>, las claves son de tipo Tkey y los valores, de tipo TValue. Las claves son únicas, c.a.d, por lo que no puede haber dos claves idénticas. Un diccionario de este tipo podría tener el siguiente aspecto si los tipos TKey y TValue designaran clases:
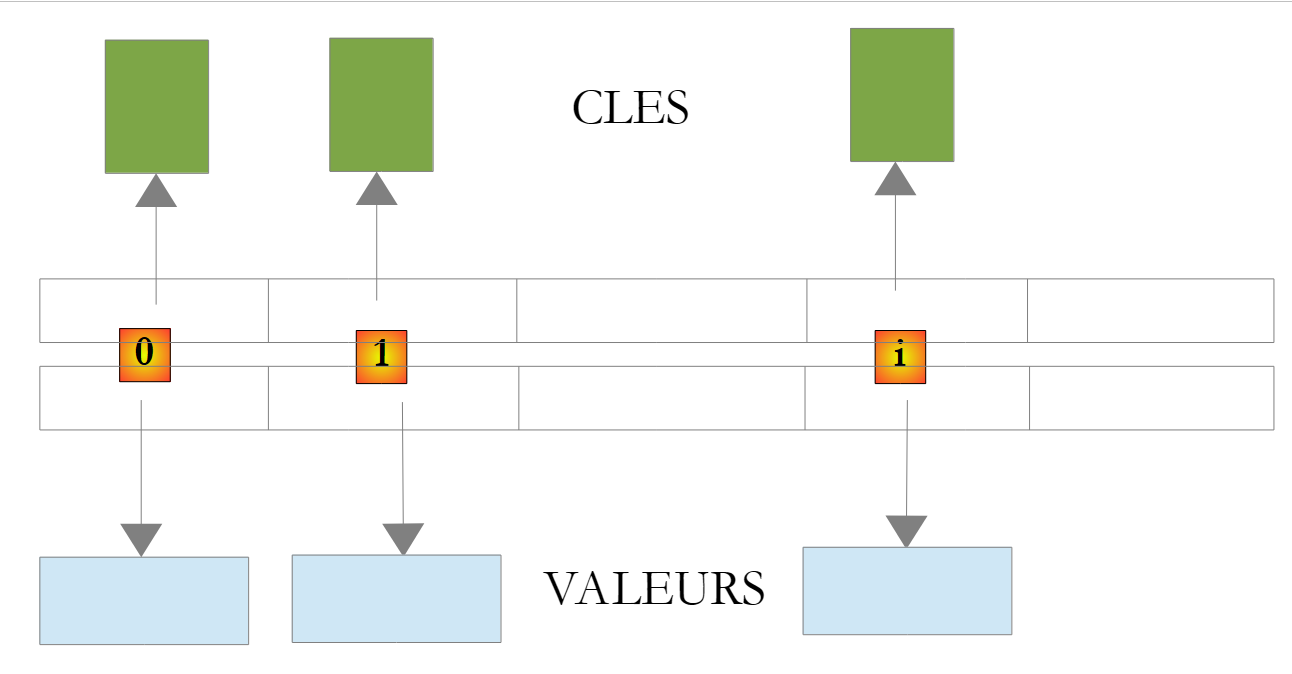 |
El valor asociado a la clave C de un diccionario D se obtiene mediante la notación D[C]. Este valor es de lectura y escritura. Así, se puede escribir:
Si la clave c no existe en el diccionario D, la notación D[c] lanza una excepción.
Los principales métodos y propiedades de la clase Dictionary<TKey,TValue> son los siguientes:
Constructores
Propiedades
Métodos
Consideremos el siguiente programa de ejemplo:
using System;
using System.Collections.Generic;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// creación de un diccionario <string,int>
string[] liste = { "jean:20", "paul:18", "mélanie:10", "violette:15" };
string[] champs = null;
char[] séparateurs = new char[] { ':' };
Dictionary<string,int> dico = new Dictionary<string,int>();
for (int i = 0; i <liste.Length; i++) {
champs = liste[i].Split(séparateurs);
dico[champs[0]]= int.Parse(champs[1]);
}//«for»
// Número de elementos en el diccionario
Console.WriteLine("Le dictionnaire a " + dico.Count + " éléments");
// lista de claves
Affiche("[Liste des clés]",dico.Keys);
// lista de valores
Affiche("[Liste des valeurs]", dico.Values);
// lista de claves y valores
Console.WriteLine("[Liste des clés & valeurs]");
foreach (string clé in dico.Keys) {
Console.WriteLine("clé=" + clé + " valeur=" + dico[clé]);
}
// se elimina la clave «paul»
Console.WriteLine("[Suppression d'une clé]");
dico.Remove("paul");
// lista de claves y valores
Console.WriteLine("[Liste des clés & valeurs]");
foreach (string clé in dico.Keys) {
Console.WriteLine("clé=" + clé + " valeur=" + dico[clé]);
}
// búsqueda en el diccionario
String nomCherché = null;
Console.Write("Nom recherché (rien pour arrêter) : ");
nomCherché = Console.ReadLine().Trim();
int value;
while (!nomCherché.Equals("")) {
dico.TryGetValue(nomCherché, out value);
if (value!=0) {
Console.WriteLine(nomCherché + "," + value);
} else {
Console.WriteLine("Nom " + nomCherché + " inconnu");
}
// siguiente búsqueda
Console.Out.Write("Nom recherché (rien pour arrêter) : ");
nomCherché = Console.ReadLine().Trim();
}//while
}
// método genérico para mostrar los elementos de un tipo enumerable
static void Affiche<T>(string texte, IEnumerable<T> éléments) {
Console.WriteLine(texte.PadRight(50, '-'));
foreach (T élément in éléments) {
Console.WriteLine(élément);
}
}
}
}
- línea 8: un array de string que servirá para inicializar el diccionario <string,int>
- línea 11: el diccionario <string,int>
- líneas 12-15: su inicialización a partir del array de string de la línea 8
- línea 17: número de entradas del diccionario
- línea 19: las claves del diccionario
- línea 21: los valores del diccionario
- línea 29: eliminación de una entrada del diccionario
- línea 41: búsqueda de una clave en el diccionario. Si no existe, el método TryGetValue asignará el valor 0 a value, ya que value es de tipo numérico. Esta técnica solo se puede utilizar aquí porque sabemos que el valor 0 no está en el diccionario.
Los resultados de la ejecución son los siguientes:
5.5. Los archivos de texto
5.5.1. La clase StreamReader
La clase System.IO.StreamReader permite leer el contenido de un archivo de texto. De hecho, es capaz de procesar flujos que no son archivos. Estas son algunas de sus propiedades y métodos:
Constructores
Propiedades
Métodos
He aquí un ejemplo:
using System;
using System.IO;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// directorio de ejecución
Console.WriteLine("Répertoire d'exécution : "+Environment.CurrentDirectory);
string ligne = null;
StreamReader fluxInfos = null;
// lectura del contenido del archivo infos.txt
try {
// lectura 1
Console.WriteLine("Lecture 1----------------");
using (fluxInfos = new StreamReader("infos.txt")) {
ligne = fluxInfos.ReadLine();
while (ligne != null) {
Console.WriteLine(ligne);
ligne = fluxInfos.ReadLine();
}
}
// lectura 2
Console.WriteLine("Lecture 2----------------");
using (fluxInfos = new StreamReader("infos.txt")) {
Console.WriteLine(fluxInfos.ReadToEnd());
}
} catch (Exception e) {
Console.WriteLine("L'erreur suivante s'est produite : " + e.Message);
}
}
}
}
- línea 8: muestra el nombre del directorio de ejecución
- líneas 12 y 27: un try/catch para gestionar una posible excepción.
- línea 15: la estructura «using flux=new StreamReader(...)» es una facilidad para no tener que cerrar explícitamente el flujo tras su uso. Este cierre se realiza automáticamente en cuanto se sale del ámbito de using.
- línea 15: el archivo que se lee se llama infos.txt. Al tratarse de un nombre relativo, se buscará en el directorio de ejecución mostrado en la línea 8. Si no se encuentra allí, se lanzará una excepción que será gestionada por el «try / catch».
- Líneas 16-20: el archivo se lee línea por línea
- línea 25: el archivo se lee de una sola vez
El archivo infos.txt es el siguiente:
y se encuentra en la siguiente carpeta del proyecto C#:
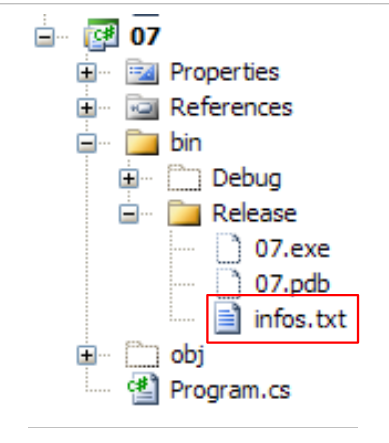 |
Veremos que bin/Release es la carpeta de ejecución cuando se ejecuta el proyecto con Ctrl+F5.
La ejecución da los siguientes resultados:
Si en la línea 15 se introduce el nombre de archivo xx.txt, se obtienen los siguientes resultados:
5.5.2. La clase StreamWriter
La clase System.IO.StreamReader permite escribir en un archivo de texto. Al igual que la clase StreamReader, es capaz de procesar flujos que no son archivos. Estas son algunas de sus propiedades y métodos:
Constructores
Propiedades
Métodos
Veamos el siguiente ejemplo:
using System;
using System.IO;
namespace Chap3 {
class Program2 {
static void Main(string[] args) {
// directorio de ejecución
Console.WriteLine("Répertoire d'exécution : " + Environment.CurrentDirectory);
string ligne = null; // una línea de texto
StreamWriter fluxInfos = null; // el archivo de texto
try {
// creación del archivo de texto
using (fluxInfos = new StreamWriter("infos2.txt")) {
Console.WriteLine("Mode AutoFlush : {0}", fluxInfos.AutoFlush);
// lectura de la línea introducida con el teclado
Console.Write("ligne (rien pour arrêter) : ");
ligne = Console.ReadLine().Trim();
// bucle mientras la línea introducida no esté vacía
while (ligne != "") {
// escritura de la línea en el archivo de texto
fluxInfos.WriteLine(ligne);
// lectura de una nueva línea introducida mediante el teclado
Console.Write("ligne (rien pour arrêter) : ");
ligne = Console.ReadLine().Trim();
}//while
}
} catch (Exception e) {
Console.WriteLine("L'erreur suivante s'est produite : " + e.Message);
}
}
}
}
- línea 13: de nuevo, utilizamos la sintaxis using(flux) para no tener que cerrar explícitamente el flujo mediante una operación Close. Este cierre se realiza automáticamente al salir de using.
- ¿Por qué se utiliza un «try / catch» en las líneas 11 y 27? En la línea 13, podríamos especificar un nombre de archivo con el formato /rep1/rep2/ .../fichier con una ruta /rep1/rep2/... que no existe, lo que imposibilitaría la creación de fichier. En ese caso, se lanzaría una excepción. Existen otros posibles casos de excepción (disco lleno, derechos insuficientes, etc.)
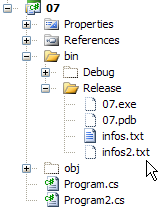
Los resultados de la ejecución son los siguientes:
El archivo infos2.txt se ha creado en la carpeta bin/Release del proyecto:
 |  |
5.6. Los archivos binarios
Las clases System.IO.BinaryReader y System.IO.BinaryWriter sirven para leer y escribir archivos binarios.
Consideremos la siguiente aplicación:
// sintaxis de pg: texto, binario, logs
// se lee un archivo de texto (texto) y se almacena su contenido en un archivo binario (bin
// el archivo de texto contiene líneas con el formato nombre: edad que se almacenarán en una estructura de tipo string, int
// (logs) es un archivo de texto de registros
El archivo de texto tiene el siguiente contenido:
El programa es el siguiente:
using System;
using System.IO;
// sintaxis pg texto bin logs
// se lee un archivo de texto (texto) y se almacena su contenido en un archivo binario (bin)
// el archivo de texto contiene líneas con el formato nombre: edad, que se almacenarán en una estructura string, int
// (logs) es un archivo de texto de registros
namespace Chap3 {
class Program {
static void Main(string[] arguments) {
// Se necesitan 3 argumentos
if (arguments.Length != 3) {
Console.WriteLine("syntaxe : pg texte binaire log");
Environment.Exit(1);
}//if
// variables
string ligne=null;
string nom=null;
int age=0;
int numLigne = 0;
char[] séparateurs = new char[] { ':' };
string[] champs=null;
StreamReader input = null;
BinaryWriter output = null;
StreamWriter logs = null;
bool erreur = false;
// lectura de un archivo de texto - escritura de un archivo binario
try {
// apertura del archivo de texto en modo lectura
input = new StreamReader(arguments[0]);
// apertura del archivo binario en modo de escritura
output = new BinaryWriter(new FileStream(arguments[1], FileMode.Create, FileAccess.Write));
// apertura del archivo de registros en modo de escritura
logs = new StreamWriter(arguments[2]);
// procesamiento del archivo de texto
while ((ligne = input.ReadLine()) != null) {
// una línea más
numLigne++;
// ¿Línea vacía?
if (ligne.Trim() == "") {
// se ignora
continue;
}
// una línea con nombre: edad
champs = ligne.Split(séparateurs);
// necesitamos 2 campos
if (champs.Length != 2) {
// se registra el error
logs.WriteLine("La ligne n° [{0}] du fichier [{1}] a un nombre de champs incorrect", numLigne, arguments[0]);
// línea siguiente
continue;
}//if
// el primer campo no debe estar vacío
erreur = false;
nom = champs[0].Trim();
if (nom == "") {
// se registra el error
logs.WriteLine("La ligne n° [{0}] du fichier [{1}] a un nom vide", numLigne, arguments[0]);
erreur = true;
}
// el segundo campo debe ser un número entero >=0
if (!int.TryParse(champs[1],out age) || age<0) {
// se registra el error
logs.WriteLine("La ligne n° [{0}] du fichier [{1}] a un âge [{2}] incorrect", numLigne, arguments[0], champs[1].Trim());
erreur = true;
}//si
// si no hay error, se escriben los datos en el archivo binario
if (!erreur) {
output.Write(nom);
output.Write(age);
}
// línea siguiente
}//mientras
}catch(Exception e){
Console.WriteLine("L'erreur suivante s'est produite : {0}", e.Message);
} finally {
// cierre de los archivos
if(input!=null) input.Close();
if(output!=null) output.Close();
if(logs!=null) logs.Close();
}
}
}
}
Analicemos las operaciones relacionadas con la clase BinaryWriter:
- línea 34: la operación abre el objeto BinaryWriter
output=new BinaryWriter(new FileStream(arguments[1],FileMode.Create,FileAccess.Write));
El argumento del constructor debe ser un flujo (Stream). En este caso, se trata de un flujo creado a partir de un archivo (FileStream) del que se proporciona:
- (continuación)
- el nombre
- la operación que se va a realizar, en este caso FileMode.Create para crear el archivo
- el tipo de acceso, en este caso FileAccess.Write para un acceso de escritura al archivo
- líneas 70-73: las operaciones de escritura
La clase BinaryWriter dispone de diferentes métodos Write sobrecargados para escribir los distintos tipos de datos simples
- línea 81: la operación de cierre del flujo
Los tres argumentos del método Main se proporcionan al proyecto (a través de sus propiedades) [1] y el archivo de texto que se va a procesar se coloca en la carpeta bin/Release [2]:
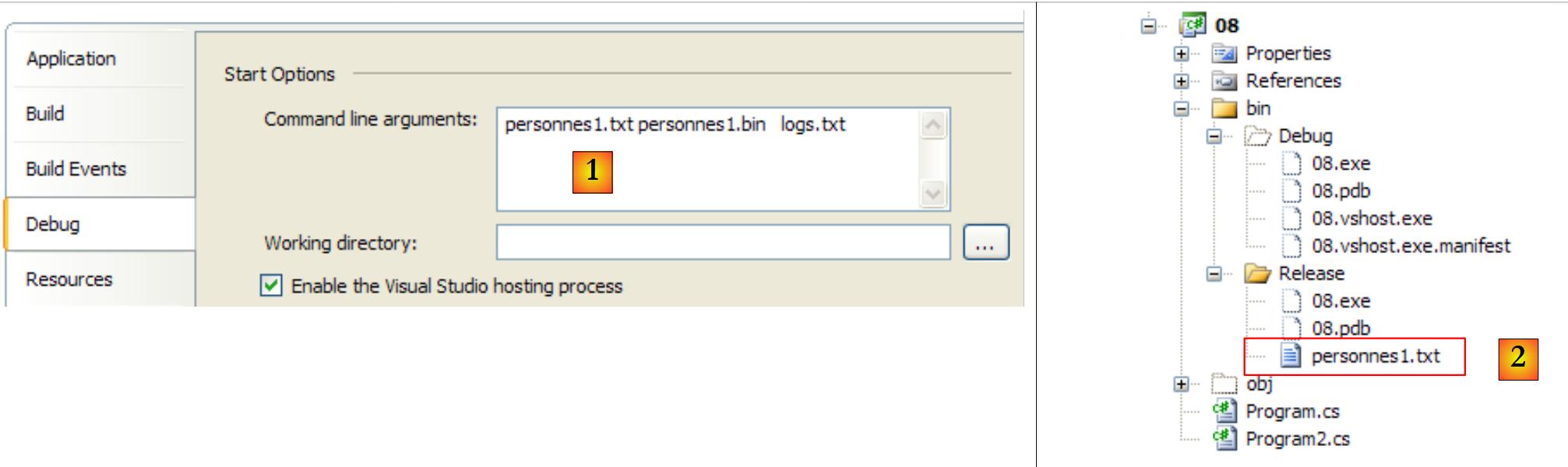 |
Con el siguiente archivo [personnes1.txt]:
los resultados de la ejecución son los siguientes:
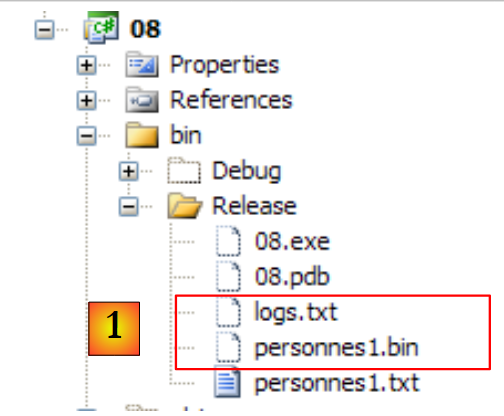 |
- en [1], el archivo binario [personnes1.bin] creado, así como el archivo de registros [logs.txt]. Este último tiene el siguiente contenido:
El contenido del archivo binario [personnes1.bin] nos lo proporcionará el siguiente programa. Este también admite tres argumentos:
// sintaxis pg bin texto logs
// se lee un archivo binario «bin» y se guarda su contenido en un archivo de texto («texto»)
// el archivo binario tiene una estructura de tipo string e int
// El archivo de texto contiene líneas con el formato «nombre: edad»
// logs es un archivo de texto con registros
Así pues, realizamos la operación inversa. Leemos un archivo binario para crear un archivo de texto. Si el archivo de texto resultante es idéntico al original, sabremos que la conversión de texto → binario → texto se ha realizado correctamente. El código es el siguiente:
using System;
using System.IO;
// sintaxis: pg, bin, texto, logs
// se lee un archivo binario «bin» y se guarda su contenido en un archivo de texto («texto»)
// El archivo binario tiene una estructura de tipo cadena e entero
// el archivo de texto contiene líneas con el formato nombre: edad
// logs es un archivo de texto con registros
namespace Chap3 {
class Program2 {
static void Main(string[] arguments) {
// Se necesitan 3 argumentos
if (arguments.Length != 3) {
Console.WriteLine("syntaxe : pg binaire texte log");
Environment.Exit(1);
}//if
// variables
string nom = null;
int age = 0;
int numPersonne = 1;
BinaryReader input = null;
StreamWriter output = null;
StreamWriter logs = null;
bool fini;
// lectura de un archivo binario - escritura de un archivo de texto
try {
// apertura del archivo binario en modo lectura
input = new BinaryReader(new FileStream(arguments[0], FileMode.Open, FileAccess.Read));
// apertura del archivo de texto en modo escritura
output = new StreamWriter(arguments[1]);
// apertura del archivo de registros en modo de escritura
logs = new StreamWriter(arguments[2]);
// procesamiento del archivo binario
fini = false;
while (!fini) {
try {
// lectura del nombre
nom = input.ReadString().Trim();
// lectura de la edad
age = input.ReadInt32();
// escritura en un archivo de texto
output.WriteLine(nom + ":" + age);
// persona siguiente
numPersonne++;
} catch (EndOfStreamException) {
fini = true;
} catch (Exception e) {
logs.WriteLine("L'erreur suivante s'est produite à la lecture de la personne n° {0} : {1}", numPersonne, e.Message);
}
}//while
} catch (Exception e) {
Console.WriteLine("L'erreur suivante s'est produite : {0}", e.Message);
} finally {
// cierre de archivos
if (input != null)
input.Close();
if (output != null)
output.Close();
if (logs != null)
logs.Close();
}
}
}
}
Analicemos las operaciones relacionadas con la clase BinaryReader:
- línea 30: el objeto BinaryReader se abre mediante la operación
input=new BinaryReader(new FileStream(arguments[0],FileMode.Open,FileAccess.Read));
El argumento del constructor debe ser un flujo (Stream). En este caso, se trata de un flujo creado a partir de un archivo (FileStream) del que se proporciona:
- (continuación)
- el nombre
- la operación que se va a realizar, en este caso FileMode.Open para abrir un archivo existente
- el tipo de acceso, en este caso FileAccess.Read para un acceso de lectura al archivo
- líneas 40 y 42: las operaciones de lectura
La clase BinaryReader dispone de diferentes métodos ReadXX para leer los distintos tipos de datos simples
- línea 60: la operación de cierre del flujo
Si se ejecutan los dos programas en cadena, transformando personnes1.txt en personnes1.bin y, a continuación, personnes1.bin en personnes2.txt2, se obtienen los siguientes resultados:
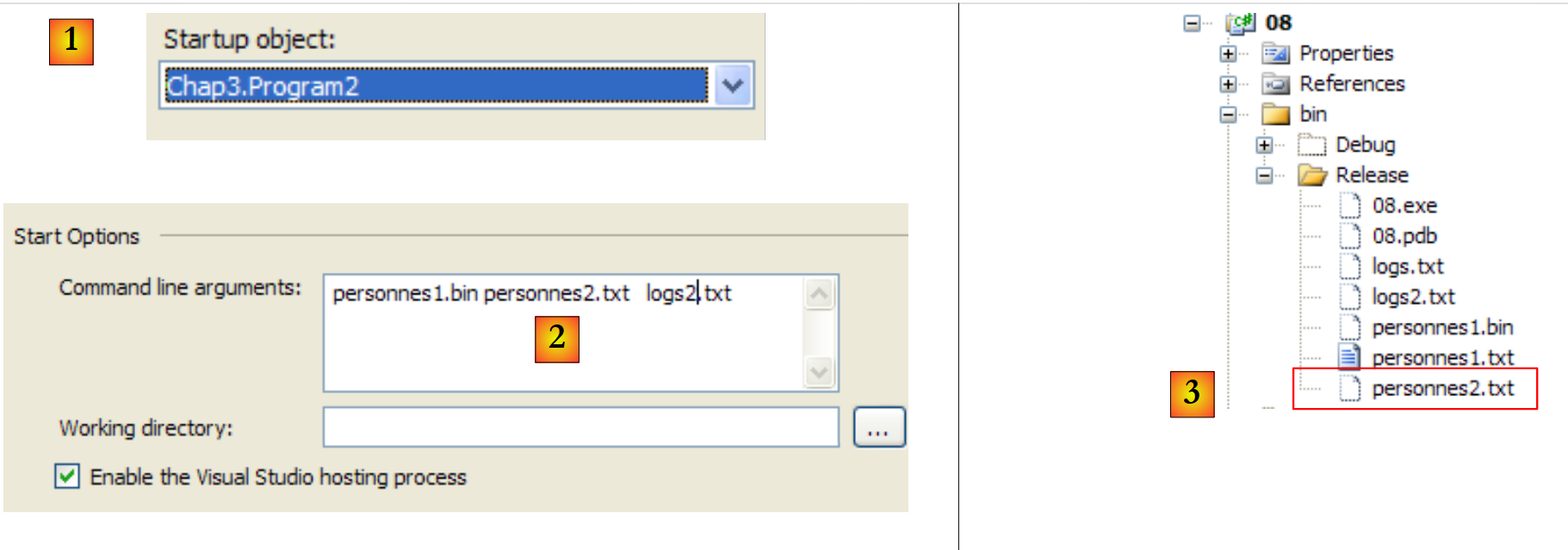 |
- en [1], el proyecto está configurado para ejecutar la segunda aplicación
- en [2], los argumentos pasados a Main
- en [3], los archivos generados por la ejecución de la aplicación.
El contenido de [personnes2.txt] es el siguiente:
5.7. Las expresiones regulares
La clase System.Text.RegularExpressions.Regex permite el uso de expresiones regulares. Estas permiten comprobar el formato de una cadena de caracteres. De este modo, se puede verificar que una cadena que representa una fecha tenga efectivamente el formato dd/mm/aa. Para ello, se utiliza un patrón y se compara la cadena con dicho patrón. Así, en este ejemplo, j, m y a deben ser números. El patrón de un formato de fecha válido es, por tanto, «\d\d/\d\d/\d\d», donde el símbolo \d representa un dígito. Los símbolos que se pueden utilizar en un patrón son los siguientes:
Descripción | |
Marca el carácter siguiente como carácter especial o literal. Por ejemplo, «n» corresponde al carácter «n». «\n» corresponde a un carácter de nueva línea. La secuencia «\\» corresponde a «\», mientras que «\»(» corresponde a «(». | |
Corresponde al inicio de la entrada. | |
Corresponde al final de la entrada. | |
Corresponde al carácter anterior cero o más veces. Así, «zo*» corresponde a «z» o a «zoo». | |
Corresponde al carácter anterior una o varias veces. Así, «zo+» corresponde a «zoo», pero no a «z». | |
Coincide con el carácter anterior cero o una vez. Por ejemplo, «a?ve?» coincide con «ve» en «lever». | |
Coincide con cualquier carácter único, excepto el carácter de nueva línea. | |
Busca el modèle y almacena la coincidencia. La subcadena correspondiente se puede extraer de la colección Matches obtenida, utilizando el elemento [0]...[n]. Para encontrar coincidencias con caracteres entre paréntesis ( ), utiliza «\(» o «\)». | |
Corresponde a x o a y. Por ejemplo, «z|foot» corresponde a «z» o a «foot». «(z|f)oo» corresponde a «zoo» o a «foo». | |
n es un número entero no negativo. Se corresponde exactamente con n multiplicado por el carácter. Por ejemplo, «o{2}» no se corresponde con la «o» de «Bob», sino con las dos primeras «o» de «fooooot». | |
n es un número entero no negativo. Corresponde al menos a n veces el carácter. Por ejemplo, «o{2,}» no coincide con la «o» de «Bob», sino con todas las «o» de «fooooot». «o{1,}» equivale a «o+» y «o{0,}» equivale a «o*». | |
m y n son números enteros no negativos. Corresponde al carácter al menos n y como máximo m veces. Por ejemplo, «o{1,3}» corresponde a las tres primeras «o» de «foooooot» y «o{0,1}» equivale a «o?». | |
Conjunto de caracteres. Corresponde a uno de los caracteres indicados. Por ejemplo, «[abc]» corresponde a la «a» de «plat». | |
Conjunto de caracteres negativo. Corresponde a cualquier carácter no indicado. Por ejemplo, «[^abc]» corresponde a «p» en «plat». | |
Rango de caracteres. Corresponde a cualquier carácter de la serie especificada. Por ejemplo, «[a-z]» corresponde a cualquier letra minúscula comprendida entre «a» y «z». | |
Rango de caracteres negativo. Corresponde a cualquier carácter que no se encuentre en la serie especificada. Por ejemplo, «[^m-z]» corresponde a cualquier carácter que no se encuentre entre «m» y «z». | |
Corresponde a un límite que representa una palabra; es decir, a la posición entre una palabra y un espacio. Por ejemplo, «er\b» corresponde a «er» en «lever», pero no a «er» en «verbe». | |
Corresponde a un límite que no representa una palabra. «en*t\B» corresponde a «ent» en «bien entendu». | |
Corresponde a un carácter que representa un número. Equivale a [0-9]. | |
Corresponde a un carácter que no representa un número. Equivale a [^0-9]. | |
Corresponde a un carácter de salto de página. | |
Corresponde a un carácter de nueva línea. | |
Corresponde a un carácter de retorno de carro. | |
Corresponde a cualquier espacio en blanco, incluidos el espacio, la tabulación, el salto de página, etc. Equivale a «[ \f\n\r\t\v]». | |
Corresponde a cualquier carácter de espacio no en blanco. Equivale a «[^ \f\n\r\t\v]». | |
Corresponde a un carácter de tabulación. | |
Corresponde a un carácter de tabulación vertical. | |
Corresponde a cualquier carácter que represente una palabra e incluya un guión bajo. Equivale a «[A-Za-z0-9_]». | |
Corresponde a cualquier carácter que no represente una palabra. Equivale a «[^A-Za-z0-9_]». | |
Corresponde a num, donde num es un número entero positivo. Hace referencia a las correspondencias memorizadas. Por ejemplo, «(.)\1» corresponde a dos caracteres idénticos consecutivos. | |
Equivale a n, donde n es un valor de escape octal. Los valores de escape octales deben tener 1, 2 o 3 dígitos. Por ejemplo, tanto «\11» como «\011» corresponden a un carácter de tabulación. «\0011» equivale a «\001» y «1». Los valores de escape octales no deben superar 256. Si lo hicieran, solo se tendrían en cuenta los dos primeros dígitos en la expresión. Permite utilizar los códigos ASCII en expresiones regulares. | |
Equivale a n, donde n es un valor de escape hexadecimal. Los valores de escape hexadecimales deben constar obligatoriamente de dos dígitos. Por ejemplo, «\x41» corresponde a «A». «\x041» equivale a «\x04» y «1». Permite utilizar los códigos ASCII en expresiones regulares. |
Un elemento de una plantilla puede aparecer una o varias veces. Veamos algunos ejemplos relacionados con el símbolo \d, que representa un dígito:
plantilla | significado |
\d | un dígito |
\d? | 0 o 1 dígito |
\d* | 0 o más dígitos |
\d+ | 1 o más dígitos |
\d{2} | 2 dígitos |
\d{3,} | al menos 3 dígitos |
\d{5,7} | entre 5 y 7 dígitos |
Imaginemos ahora el modelo capaz de describir el formato esperado para una cadena de caracteres:
cadena buscada | modelo |
una fecha en formato dd/mm/aa | \d{2}/\d{2}/\d{2} |
una hora en formato hh:mm:ss | \d{2}:\d{2}:\d{2} |
un número entero sin signo | \d+ |
una secuencia de espacios, que puede estar vacía | \s* |
un número entero sin signo que puede ir precedido o seguido de espacios | \s*\d+\s* |
un número entero que puede ser con signo y estar precedido o seguido de espacios | \s*[+|-]?\s*\d+\s* |
un número real sin signo que puede ir precedido o seguido de espacios | \s*\d+(.\d*)?\s* |
un número real que puede ser con signo y estar precedido o seguido de espacios | \s*[+|]?\s*\d+(.\d*)?\s* |
una cadena que contenga la palabra juste | \bjuste\b |
Se puede especificar dónde se busca el patrón en la cadena:
patrón | significado |
^patrón | el patrón comienza la cadena |
patrón$ | el patrón termina la cadena |
^patrón$ | el patrón comienza y termina la cadena |
patrón | el patrón se busca en toda la cadena, empezando por el principio de la misma. |
cadena buscada | patrón |
una cadena que termina con un signo de exclamación | !$ |
una cadena que termina en un punto | \.$ |
una cadena que comienza con la secuencia // | ^// |
una cadena que contiene solo una palabra, seguida o precedida opcionalmente de espacios | ^\s*\w+\s*$ |
una cadena que contenga dos palabras, que pueden ir precedidas o seguidas de espacios | ^\s*\w+\s*\w+\s*$ |
una cadena que contenga la palabra secret | \bsecret\b |
Los subconjuntos de un patrón pueden «extraerse». De este modo, no solo se puede comprobar si una cadena se ajusta a un patrón concreto, sino que también se pueden extraer de dicha cadena los elementos correspondientes a los subconjuntos del patrón que se han encerrado entre paréntesis. Así, si se analiza una cadena que contiene una fecha dd/mm/aa y, además, se desea extraer los elementos dd, mm y aa de dicha fecha, se utilizará el patrón (\d\d)/(\d\d)/(\d\d).
5.7.1. Comprobar que una cadena se ajusta a un patrón determinado
Un objeto de tipo Regex se construye de la siguiente manera:
Una vez creada la expresión regular de referencia, se puede comparar con cadenas de caracteres mediante el método IsMatch:
He aquí un ejemplo:
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// una expresión regular de patrón
string modèle1 = @"^\s*\d+\s*$";
Regex regex1 = new Regex(modèle1);
// comparar un ejemplo con el patrón
string exemplaire1 = " 123 ";
if (regex1.IsMatch(exemplaire1)) {
Console.WriteLine("[{0}] correspond au modèle [{1}]", exemplaire1, modèle1);
} else {
Console.WriteLine("[{0}] ne correspond pas au modèle [{1}]", exemplaire1, modèle1);
}//if
string exemplaire2 = " 123a ";
if (regex1.IsMatch(exemplaire2)) {
Console.WriteLine("[{0}] correspond au modèle [{1}]", exemplaire2, modèle1);
} else {
Console.WriteLine("[{0}] ne correspond pas au modèle [{1}]", exemplaire2, modèle1);
}//if
}
}
}
y los resultados de la ejecución:
5.7.2. Buscar todas las apariciones de un patrón en una cadena
El método Matches permite recuperar los elementos de una cadena que coincidan con un patrón:
La clase MatchCollection tiene una propiedad Count que indica el número de elementos de la colección. Si résultats es un objeto MatchCollection, entonces [i] es el elemento i de esta colección y es de tipo Match. La clase Match tiene varias propiedades, entre las que se incluyen las siguientes:
- Value: el valor del objeto Match,, es decir, un elemento que se ajusta al modelo
- Índice: la posición en la que se ha encontrado el elemento en la cadena explorada
Veamos el siguiente ejemplo:
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program2 {
static void Main(string[] args) {
// varias ocurrencias del patrón en el ejemplo
string modèle2 = @"\d+";
Regex regex2 = new Regex(modèle2);
string exemplaire3 = " 123 456 789 ";
MatchCollection résultats = regex2.Matches(exemplaire3);
Console.WriteLine("Modèle=[{0}],exemplaire=[{1}]", modèle2, exemplaire3);
Console.WriteLine("Il y a {0} occurrences du modèle dans l'exemplaire ", résultats.Count);
for (int i = 0; i < résultats.Count; i++) {
Console.WriteLine("[{0}] trouvé en position {1}", résultats[i].Value, résultats[i].Index);
}//«for»
}
}
}
- línea 8: el patrón buscado es una secuencia de números
- línea 10: la cadena en la que se busca este patrón
- línea 11: se recuperan todos los elementos de exemplaire3 que cumplen el patrón modèle2
- líneas 14-16: se muestran
Los resultados de la ejecución del programa son los siguientes:
5.7.3. Recuperar partes de un patrón
Se pueden «extraer» subconjuntos de un patrón. De este modo, no solo se puede comprobar que una cadena se ajusta a un patrón concreto, sino que también se pueden extraer de dicha cadena los elementos correspondientes a los subconjuntos del patrón que se han encerrado entre paréntesis. Así, si analizamos una cadena que contiene una fecha dd/mm/aa y, además, queremos extraer los elementos dd, mm y aa de dicha fecha, utilizaremos el patrón (\d\d)/(\d\d)/(\d\d).
Veamos el siguiente ejemplo:
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program3 {
static void Main(string[] args) {
// captura de elementos en la plantilla
string modèle3 = @"(\d\d):(\d\d):(\d\d)";
Regex regex3 = new Regex(modèle3);
string exemplaire4 = "Il est 18:05:49";
// verificación de la plantilla
Match résultat = regex3.Match(exemplaire4);
if (résultat.Success) {
// el ejemplar se corresponde con la plantilla
Console.WriteLine("L'exemplaire [{0}] correspond au modèle [{1}]",exemplaire4,modèle3);
// se muestran los grupos de paréntesis
for (int i = 0; i < résultat.Groups.Count; i++) {
Console.WriteLine("groupes[{0}]=[{1}] trouvé en position {2}",i, résultat.Groups[i].Value,résultat.Groups[i].Index);
}//for
} else {
// el ejemplar no se ajusta a la plantilla
Console.WriteLine("L'exemplaire[{0}] ne correspond pas au modèle [{1}]", exemplaire4, modèle3);
}
}
}
}
La ejecución de este programa produce los siguientes resultados:
La novedad se encuentra en las líneas 12-19:
- línea 12: la cadena exemplaire4 se compara con el patrón regex3 mediante el método Match. Este método devuelve un objeto Match que ya se ha presentado anteriormente. Aquí utilizamos dos nuevas propiedades de esta clase:
- Success (línea 13): indica si ha habido coincidencia
- Groups (líneas 17 y 18): colección en la que
- Groups[0] corresponde a la parte de la cadena que se ajusta al patrón
- Groups[i] (i>=1) corresponde al grupo de paréntesis n.º i
Si résultat es de tipo Match, résultats.Groups es de tipo GroupCollection y résultats.Groups[i] es de tipo Group. La clase Group tiene dos propiedades que utilizamos aquí:
- Value (línea 18): el valor del objeto Group, que es el elemento correspondiente al contenido de un paréntesis
- Index (línea 18): la posición en la que se ha encontrado el elemento en la cadena explorada
5.7.4. Un programa de aprendizaje
Encontrar la expresión regular que permita verificar que una cadena se ajusta a un determinado patrón puede suponer, en ocasiones, todo un reto. El siguiente programa permite practicar. Solicita un patrón y una cadena, e indica si la cadena se ajusta o no al patrón.
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program4 {
static void Main(string[] args) {
// datos
string modèle, chaine;
Regex regex = null;
MatchCollection résultats;
// se solicita al usuario las plantillas y los ejemplares que desea comparar con este
while (true) {
// se solicita la plantilla
Console.Write("Tapez le modèle à tester ou rien pour arrêter :");
modèle = Console.In.ReadLine();
//ya está listo?
if (modèle.Trim() == "")
break;
// se crea la expresión regular
try {
regex = new Regex(modèle);
} catch (Exception ex) {
Console.WriteLine("Erreur : " + ex.Message);
continue;
}
// se le pide al usuario los ejemplares que se van a comparar con el modelo
while (true) {
Console.Write("Tapez la chaîne à comparer au modèle [{0}] ou rien pour arrêter :", modèle);
chaine = Console.ReadLine();
// ¿Terminado?
if (chaine.Trim() == "")
break;
// se realiza la comparación
résultats = regex.Matches(chaine);
// ¿Éxito?
if (résultats.Count == 0) {
Console.WriteLine("Je n'ai pas trouvé de correspondances");
continue;
}//si
// se muestran los elementos que coinciden con el modelo
for (int i = 0; i < résultats.Count; i++) {
Console.WriteLine("J'ai trouvé la correspondance [{0}] en position [{1}]", résultats[i].Value, résultats[i].Index);
// de los subelementos
if (résultats[i].Groups.Count != 1) {
for (int j = 1; j < résultats[i].Groups.Count; j++) {
Console.WriteLine("\tsous-élément [{0}] en position [{1}]", résultats[i].Groups[j].Value, résultats[i].Groups[j].Index);
}
}
}
}
}
}
}
}
He aquí un ejemplo de ejecución:
5.7.5. El método Split
Ya hemos visto este método en la clase String:
|
El método Split de la clase Regex nos permite definir el separador según un patrón:
|
Supongamos, por ejemplo, que en un archivo de texto tenemos líneas con el formato campo1, campo2, …, campo n. Los campos están separados por una coma, pero esta puede ir precedida o seguida de espacios. En ese caso, el método Split de la clase string no es adecuado. El método RegEx ofrece la solución. Si ligne es la línea leída, los campos se pueden obtener mediante
tal y como se muestra en el siguiente ejemplo:
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program5 {
static void Main(string[] args) {
// una línea
string ligne = "abc , def , ghi";
// una plantilla
Regex modèle = new Regex(@"\s*,\s*");
// desglose de la línea en campos
string[] champs = modèle.Split(ligne);
// visualización
for (int i = 0; i < champs.Length; i++) {
Console.WriteLine("champs[{0}]=[{1}]", i, champs[i]);
}
}
}
}
Resultados de la ejecución:
5.8. Aplicación de ejemplo - V3
Retomamos la aplicación analizada en los apartados 3.6 (versión 1) y 4.10 (versión 2).
En la última versión analizada, el cálculo del impuesto se realizaba en la clase abstracta AbstractImpot:
namespace Chap2 {
abstract class AbstractImpot : IImpot {
// los tramos impositivos necesarios para el cálculo del impuesto
// proceden de una fuente externa
protected TrancheImpot[] tranchesImpot;
// cálculo del impuesto
public int calculer(bool marié, int nbEnfants, int salaire) {
// cálculo del número de participaciones
decimal nbParts;
if (marié) nbParts = (decimal)nbEnfants / 2 + 2;
else nbParts = (decimal)nbEnfants / 2 + 1;
if (nbEnfants >= 3) nbParts += 0.5M;
// cálculo de la base imponible y del coeficiente familiar
decimal revenu = 0.72M * salaire;
decimal QF = revenu / nbParts;
// cálculo del impuesto
tranchesImpot[tranchesImpot.Length - 1].Limite = QF + 1;
int i = 0;
while (QF > tranchesImpot[i].Limite) i++;
// resultado
return (int)(revenu * tranchesImpot[i].CoeffR - nbParts * tranchesImpot[i].CoeffN);
}//calcular
}//Clase
}
El método calculer de la línea 38 utiliza la tabla tranchesImpot de la línea 35, tabla que no ha sido inicializada por la clase AbstractImpot. Por eso es abstracta y debe derivarse para que sea útil. Esta inicialización la realizaba la clase derivada HardwiredImpot:
using System;
namespace Chap2 {
class HardwiredImpot : AbstractImpot {
// tablas de datos necesarias para el cálculo del impuesto
decimal[] limites = { 4962M, 8382M, 14753M, 23888M, 38868M, 47932M, 0M };
decimal[] coeffR = { 0M, 0.068M, 0.191M, 0.283M, 0.374M, 0.426M, 0.481M };
decimal[] coeffN = { 0M, 291.09M, 1322.92M, 2668.39M, 4846.98M, 6883.66M, 9505.54M };
public HardwiredImpot() {
// creación de la tabla de tramos impositivos
tranchesImpot = new TrancheImpot[limites.Length];
// cumplimentación
for (int i = 0; i < tranchesImpot.Length; i++) {
tranchesImpot[i] = new TrancheImpot { Limite = limites[i], CoeffR = coeffR[i], CoeffN = coeffN[i] };
}
}
}// clase
}// espacio de nombres
En el ejemplo anterior, los datos necesarios para el cálculo del impuesto se incluían de forma «fija» en el código de la clase. La nueva versión del ejemplo los coloca en un archivo de texto:
4962:0:0
8382:0,068:291,09
14753:0,191:1322,92
23888:0,283:2668,39
38868:0,374:4846,98
47932:0,426:6883,66
0:0,481:9505,54
Dado que la ejecución de este archivo puede generar excepciones, creamos una clase especial para gestionarlas:
using System;
namespace Chap3 {
class FileImpotException : Exception {
// Códigos de error
[Flags]
public enum CodeErreurs { Acces = 1, Ligne = 2, Champ1 = 4, Champ2 = 8, Champ3 = 16 };
// código de error
public CodeErreurs Code { get; set; }
// constructores
public FileImpotException() {
}
public FileImpotException(string message)
: base(message) {
}
public FileImpotException(string message, Exception e)
: base(message,e) {
}
}
}
- línea 4: la clase FileImpotException deriva de la clase Exception. Servirá para almacenar cualquier error que se produzca durante el procesamiento del archivo de texto de datos.
- línea 7: una enumeración que representa los códigos de error:
- Acces: error de acceso al archivo de texto de datos
- Ligne: la línea no contiene los tres campos esperados
- Champ1: el campo n.º 1 es erróneo
- Champ2: el campo n.º 2 es incorrecto
- Champ3: el campo n.º 3 es incorrecto
Algunos de estos errores pueden combinarse (Champ1, Champ2, Champ3). Por ello, la enumeración CodeErreurs se ha anotado con el atributo [Flags], lo que implica que los distintos valores de la enumeración deben ser potencias de 2. Un error en los campos 1 y 2 se traducirá entonces en el código de error Champ1 | Champ2.
- Línea 10: la propiedad automática Code almacenará el código del error.
- Línea 15: un constructor que permite crear un objeto FileImpotException pasándole como parámetro un mensaje de error.
- Línea 18: un constructor que permite crear un objeto FileImpotException pasándole como parámetros un mensaje de error y la excepción que ha provocado el error.
La clase que inicializa el array tranchesImpot de la clase AbstractImpot queda ahora así:
using System;
using System.Collections.Generic;
using System.IO;
using System.Text.RegularExpressions;
namespace Chap3 {
class FileImpot : AbstractImpot {
public FileImpot(string fileName) {
// datos
List<TrancheImpot> listTranchesImpot = new List<TrancheImpot>();
int numLigne = 1;
// excepción
FileImpotException fe = null;
// lectura del contenido del archivo fileName, línea por línea
Regex pattern = new Regex(@"s*:\s*");
// al principio no hay errores
FileImpotException.CodeErreurs code = 0;
try {
using (StreamReader input = new StreamReader(fileName)) {
while (!input.EndOfStream && code == 0) {
// línea actual
string ligne = input.ReadLine().Trim();
// se ignoran las líneas vacías
if (ligne == "") continue;
// línea descompuesta en tres campos separados por:
string[] champsLigne = pattern.Split(ligne);
// ¿Hay tres campos?
if (champsLigne.Length != 3) {
code = FileImpotException.CodeErreurs.Ligne;
}
// conversiones de los tres campos
decimal limite = 0, coeffR = 0, coeffN = 0;
if (code == 0) {
if (!Decimal.TryParse(champsLigne[0], out limite)) code = FileImpotException.CodeErreurs.Champ1;
if (!Decimal.TryParse(champsLigne[1], out coeffR)) code |= FileImpotException.CodeErreurs.Champ2;
if (!Decimal.TryParse(champsLigne[2], out coeffN)) code |= FileImpotException.CodeErreurs.Champ3; ;
}
// ¿Error?
if (code != 0) {
// se anota el error
fe = new FileImpotException(String.Format("Ligne n° {0} incorrecte", numLigne)) { Code = code };
} else {
// se memoriza el nuevo tramo impositivo
listTranchesImpot.Add(new TrancheImpot() { Limite = limite, CoeffR = coeffR, CoeffN = coeffN });
// línea siguiente
numLigne++;
}
}
}
// se transfiere la lista listImpot a la tabla tranchesImpot
if (code == 0) {
// se transfiere la lista listImpot a la tabla tranchesImpot
tranchesImpot = listTranchesImpot.ToArray();
}
} catch (Exception e) {
// se anota el error
fe= new FileImpotException(String.Format("Erreur lors de la lecture du fichier {0}", fileName), e) { Code = FileImpotException.CodeErreurs.Acces };
}
// ¿Hay que notificar el error?
if (fe != null) throw fe;
}
}
}
- línea 7: la clase FileImpot deriva de la clase AbstractImpot, al igual que lo hacía en la versión 2 la clase HardwiredImpot.
- línea 9: el constructor de la clase FileImpot tiene como función inicializar el campo trancheImpot de su clase base AbstractImpot. Admite como parámetro el nombre del archivo de texto que contiene los datos.
- Línea 11: el campo tranchesImpot de la clase base AbstractImpot es una matriz que debe rellenarse con los datos del archivo filename pasado como parámetro. La lectura de un archivo de texto es secuencial. El número de líneas solo se conoce una vez que se ha leído todo el archivo. Por lo tanto, no es posible dimensionar el array tranchesImpot. Los datos se almacenarán temporalmente en la lista genérica listTranchesImpot.
Recordemos que el tipo TrancheImpot es una estructura:
namespace Chap3 {
// un tramo impositivo
struct TrancheImpot {
public decimal Limite { get; set; }
public decimal CoeffR { get; set; }
public decimal CoeffN { get; set; }
}
}
- línea 14: fe, del tipo FileImpotException, sirve para encapsular un posible error de procesamiento del archivo de texto.
- línea 16: la expresión regular del separador de campos en una línea champ1:champ2:champ3 del archivo de texto. Los campos están separados por el carácter :, precedido y seguido de cualquier número de espacios.
- línea 18: el código de error en caso de producirse un error
- línea 20: procesamiento del archivo de texto con un StreamReader
- línea 21: se repite el bucle mientras quede una línea por leer y no se haya producido ningún error
- línea 27: la línea leída se divide en campos mediante la expresión regular de la línea 16
- líneas 29-31: se comprueba que la línea tenga efectivamente tres campos; se registra cualquier error que pueda haber
- líneas 33-38: conversión de las tres cadenas en tres números decimales; se registran los posibles errores
- líneas 40-43: si se ha producido un error, se genera una excepción de tipo FileImpotException.
- líneas 44-47: si no ha habido ningún error, se pasa a la lectura de la siguiente línea del archivo de texto tras haber almacenado los datos de la línea actual.
- líneas 52-55: al salir de la boca while, los datos de la lista genérica listTranchesImpot se copian en la tabla tranchesImpot de la clase base AbstractImpot. Cabe recordar que ese era el objetivo del constructor.
- Líneas 56-59: gestión de una posible excepción. Esta se encapsula en un objeto de tipo FileImpotException.
- línea 61: si se ha inicializado la excepción fe de la línea 18, entonces se lanza.
El proyecto completo en C# es el siguiente:
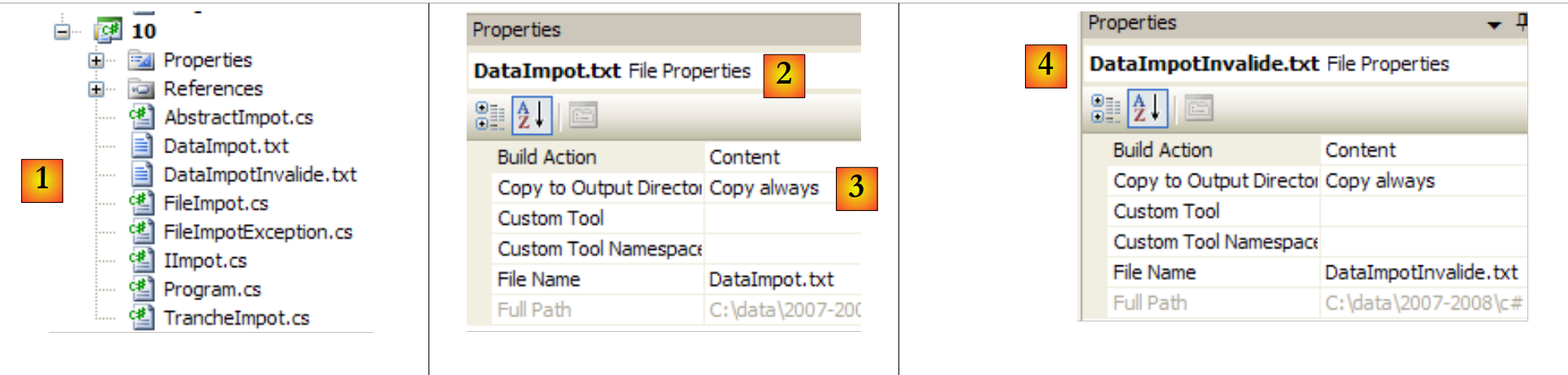 |
- en [1]: el proyecto completo
- en [2,3]: las propiedades del archivo [DataImpot.txt] [2]. La propiedad [Copy to Output Directory] [3] se establece en «always». Esto hace que el archivo [DataImpot.txt] se copie en la carpeta bin/Release (modo Release) o bin/Debug (modo Debug) en cada ejecución. Es ahí donde lo busca el ejecutable.
- En [4]: se hace lo mismo con el archivo [DataImpotInvalide.txt].
El contenido de [DataImpot.txt] es el siguiente:
4962:0:0
8382:0,068:291,09
14753:0,191:1322,92
23888:0,283:2668,39
38868:0,374:4846,98
47932:0,426:6883,66
0:0,481:9505,54
El contenido de [DataImpotInvalide.txt] es el siguiente:
El programa de prueba [Program.cs] no ha cambiado: es el de la versión 2, apartado 4.10, con la siguiente diferencia:
using System;
namespace Chap3 {
class Program {
static void Main() {
...
// creación de un objeto IImpot
IImpot impot = null;
try {
// creación de un objeto IImpot
impot = new FileImpot("DataImpot.txt");
} catch (FileImpotException e) {
// visualización de error
string msg = e.InnerException == null ? null : String.Format(", Exception d'origine : {0}", e.InnerException.Message);
Console.WriteLine("L'erreur suivante s'est produite : [Code={0},Message={1}{2}]", e.Code, e.Message, msg == null ? "" : msg);
// parada del programa
Environment.Exit(1);
}
// bucle infinito
while (true) {
...
}//while
}
}
}
- línea 8: objeto impot del tipo de la interfaz IImpot
- línea 11: instanciación del objeto impot con un objeto de tipo FileImpot. Esto puede generar una excepción que se gestiona mediante el bloque try/catch de las líneas 9, 12 y 18.
A continuación se muestran algunos ejemplos de ejecución:
Con el archivo [DataImpot.txt]
Con un archivo [xx] inexistente
Con el archivo [DataImpotInvalide.txt]