2. Conceptos básicos
En este capítulo presentamos los fundamentos de la programación web. Su objetivo principal es dar a conocer los principios básicos de la programación web, que son independientes de la tecnología concreta que se utilice para ponerlos en práctica. Presenta numerosos ejemplos que se recomienda probar para «familiarizarse» poco a poco con la filosofía del desarrollo web. Las herramientas gratuitas necesarias para probarlos se presentan al final del documento, en el anexo titulado «Las herramientas de la web».
2.1. Los componentes de una aplicación web
Machine Serveur
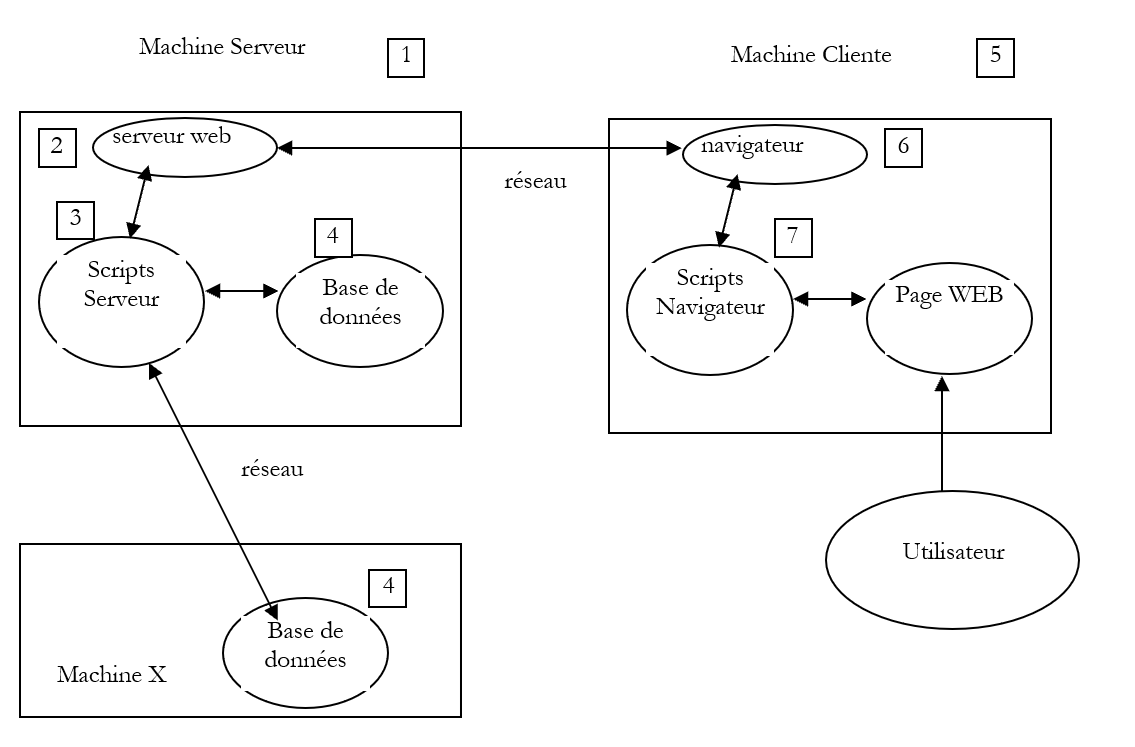
15Cliente
Número | Función | Ejemplos habituales |
OS Servidor | Linux, Windows | |
Servidor web | Apache (Linux, Windows) IIS (NT), PWS (Win9x), Cassini (Windows + plataforma .NET) | |
Scripts ejecutados en el lado del servidor. Pueden ser ejecutados por módulos del servidor o por programas externos al servidor (CGI). | PERL (Apache, IIS, PWS) VBSCRIPT (IIS, PWS) JAVASCRIPT (IIS, PWS) PHP (Apache, IIS, PWS) JAVA (Apache, IIS, PWS) C#, VB.NET (IIS) | |
Base de datos: puede estar en el mismo equipo que el programa que la utiliza o en otro a través de Internet. | Oracle (Linux, Windows) MySQL (Linux, Windows) Postgres (Linux, Windows) Access (Windows) SQL Server (Windows) | |
OS Cliente | Linux, Windows | |
Navegador web | Netscape, Internet Explorer, Mozilla, Opera | |
Scripts ejecutados en el lado del cliente dentro del navegador. Estos scripts no tienen acceso alguno a los discos del equipo del cliente. | VBscript (IE) JavaScript (IE, Netscape) PerlScript (IE) Applets JAVA |
2.2. El intercambio de datos en una aplicación web con formulario
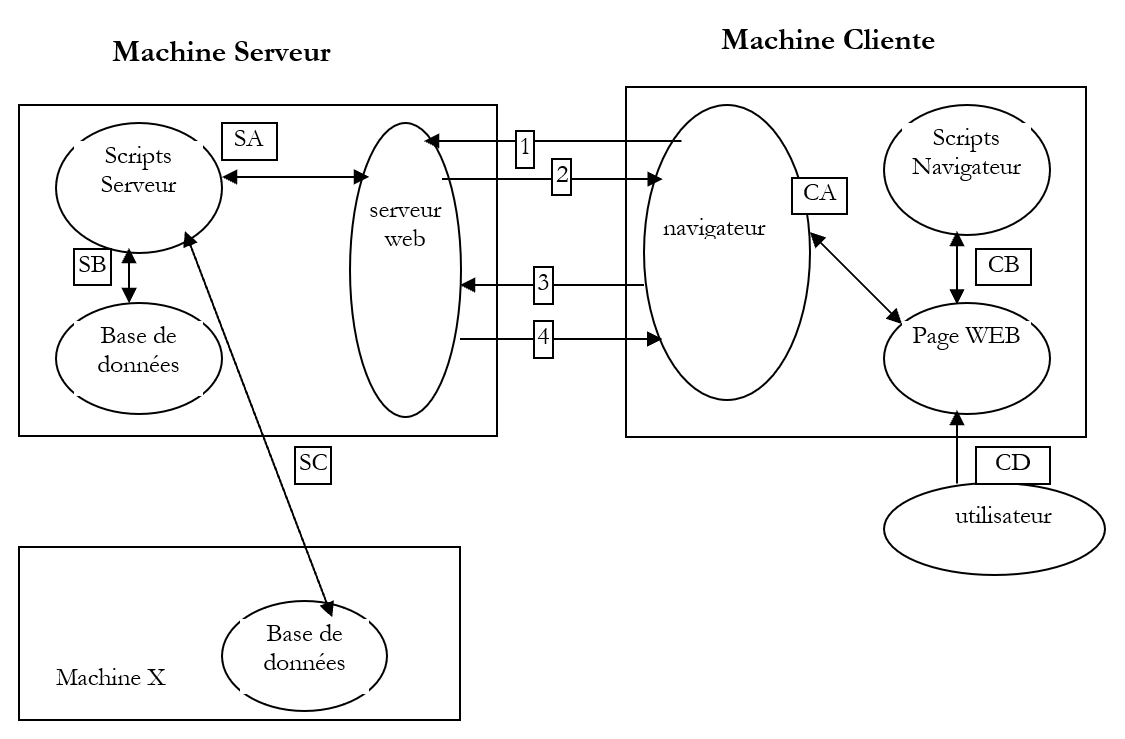
Equipo clienteEquipo servidor
Número | Función |
El navegador solicita un URL por primera vez (http://machine/url). No se ha pasado ningún parámetro. | |
El servidor web le envía la página web de este URL. Esta puede ser estática o generada dinámicamente por un script de servidor (SA) que puede haber utilizado el contenido de bases de datos (SB, SC). En este caso, el script detectará que se ha solicitado URL sin pasar parámetros y generará la página inicial WEB. El navegador recibe la página y la muestra (CA). Es posible que unos scripts del lado del navegador (CB) hayan modificado la página inicial enviada por el servidor. A continuación, mediante interacciones entre el usuario (CD) y los scripts (CB), la página web se modificará. En concreto, se rellenarán los formularios. | |
El usuario valida los datos del formulario, que a continuación deben enviarse al servidor web. El navegador vuelve a solicitar el URL inicial u otro, según el caso, y transmite al mismo tiempo al servidor los valores del formulario. Para ello, puede utilizar dos métodos denominados GET y POST. Al recibir la solicitud del cliente, el servidor activa el script (SA) asociado al URL solicitado, script que detectará los parámetros y los procesará. | |
El servidor envía la página WEB generada por el programa (SA, SB, SC). Este paso es idéntico al paso 2 anterior. A partir de ahora, los intercambios se realizan siguiendo los pasos 2 y 3. |
2.3. Notations
A partir de ahora, daremos por hecho que se han instalado una serie de herramientas y adoptaremos las siguientes notaciones:
notación | significado |
raíz del árbol de directorios del servidor Apache | |
raíz de las páginas web servidas por Apache. Las páginas web deben encontrarse en esta raíz. Así, la dirección http://localhost/page1.htm corresponde al archivo <apache-DocumentRoot>\page1.htm. | |
raíz del árbol de directorios vinculada al alias cgi-bin y donde se pueden colocar scripts CGI para Apache. Así, el URL http://localhost/cgi-bin/test1.pl corresponde al archivo <apache-cgi-bin>\test1.pl. | |
raíz de las páginas web generadas por IIS, PWS o Cassini. Las páginas web deben encontrarse en este directorio raíz. Así, URL http://localhost/page1.htm corresponde al archivo <IIS-DocumentRoot>\page1.htm. | |
raíz del árbol de directorios del lenguaje Perl. El ejecutable perl.exe suele encontrarse en <perl>\bin. | |
raíz del árbol del lenguaje PHP. El ejecutable php.exe suele encontrarse en <php>. | |
raíz del árbol de Java. Los ejecutables relacionados con Java se encuentran en <java>\bin. | |
raíz del servidor Tomcat. Se pueden encontrar ejemplos de servlets en <tomcat>\webapps\examples\servlets y ejemplos de páginas en JSP y <tomcat>\webbapps\examples\jsp |
Para cada una de estas herramientas, consulte el anexo, donde encontrará ayuda para su instalación.
2.4. Páginas web estáticas, páginas web dinámicas
Una página estática está representada por un archivo HTML. Una página dinámica, por su parte, es generada «sobre la marcha» por el servidor web. En este apartado le proponemos diversas pruebas con diferentes servidores web y diferentes lenguajes de programación para demostrar la universalidad del concepto web. Utilizaremos dos servidores web denominados Apache y IIS. Aunque IIS es un producto comercial, existe en dos versiones más limitadas pero gratuitas:
- PWS para equipos con Win9x
- Cassini para equipos con Windows 200 y XP
La carpeta <IIS-DocumentRoot> suele ser la carpeta [lecteur:\inetpub\wwwroot], donde [lecteur] es la unidad (C, D, ...) en la que se ha instalado IIS. Lo mismo ocurre con PWS. En el caso de Cassini, la carpeta <IIS-DocumentRoot> depende de cómo se haya iniciado el servidor. En el anexo se muestra que el servidor Cassini se puede iniciar en una ventana de DOS (o mediante un acceso directo) de la siguiente manera:
La aplicación [WebServer], también conocida como servidor web Cassini, admite tres parámetros:
- /port: número de puerto del servicio web. Puede ser cualquiera. Por defecto, el valor es 80
- /path: ruta física de una carpeta del disco
- /vpath: carpeta virtual asociada a la carpeta física anterior. Hay que tener en cuenta que la sintaxis no es /path=ruta, sino /vpath:ruta, al contrario de lo que indica el panel de ayuda anterior.
Si Cassini se ejecuta de la siguiente manera:
entonces la carpeta P es la raíz del árbol web del servidor Cassini. Por lo tanto, es esta carpeta la que se designa como <IIS-DocumentRoot>. Así, en el siguiente ejemplo:
el servidor Cassini funcionará en el puerto 80 y la raíz de su árbol de directorios <IIS-DocumentRoot> es la carpeta [d:\data\devel\webmatrix]. Las páginas web que se vayan a probar deberán encontrarse bajo esta raíz.
A partir de ahora, cada aplicación web estará representada por un único archivo que se podrá crear con cualquier archivo de texto. No se requiere ningún IDE.
2.4.1. Página estática HTML (lenguaje de marcado HyperText)
Consideremos el siguiente código HTML:
<html>
<head>
<title>essai 1 : une page statique</title>
</head>
<body>
<center>
<h1>Une page statique...</h1>
</body>
</html>
que genera la siguiente página web:
Las pruebas
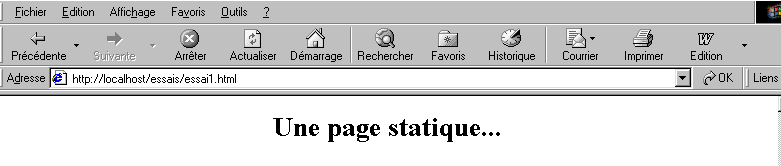
Prueba1
- Iniciar el servidor Apache
- colocar el script essai1.html en <apache-DocumentRoot>
- Visualizar el archivo URL http://localhost/essai1.html con un navegador
- Detener el servidor Apache
Prueba 2
- Iniciar el servidor IIS/PWS/Cassini
- colocar el script essai1.html en <IIS-DocumentRoot>
- Visualizar la página URL http://localhost/essai1.html con un navegador
2.4.2. Una página ASP (Active Server Pages)
El script essai2.asp:
<html>
<head>
<title>essai 1 : une page asp</title>
</head>
<body>
<center>
<h1>Une page asp générée dynamiquement par le serveur PWS</h1>
<h2>Il est <% =time %></h2>
<br>
A chaque fois que vous rafraîchissez la page, l'heure change.
</body>
</html>
genera la siguiente página web:

La prueba
- Iniciar el servidor IIS/PWS
- insertar el script essai2.asp en <IIS-DocumentRoot>
- Acceder a URL http://localhost/essai2.asp con un navegador
2.4.3. Un script PERL (Practical Extracting and Reporting Language)
El script essai3.pl:
#!d:\perl\bin\perl.exe
($secondes,$minutes,$heure)=localtime(time);
print <<HTML
Content-type: text/html
<html>
<head>
<title>essai 1 : un script Perl</title>
</head>
<body>
<center>
<h1>Une page générée dynamiquement par un script Perl</h1>
<h2>Il est $heure:$minutes:$secondes</h2>
<br>
A chaque fois que vous rafraîchissez la page, l'heure change.
</body>
</html>
HTML
;
La primera línea es la ruta del ejecutable perl.exe. Hay que adaptarla si es necesario. Una vez ejecutado por un servidor web, el script genera la siguiente página:
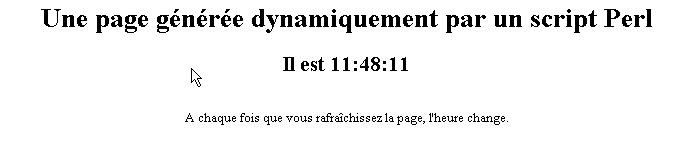
La prueba
- servidor web: Apache
- A título informativo, consulta el archivo de configuración srm.conf o httpd.conf, según la versión de Apache, en <apache>\confs y busque la línea que hace referencia a cgi-bin para conocer el directorio <apache-cgi-bin> en el que debe colocar essai3.pl.
- Coloca el script essai3.pl en <apache-cgi-bin>
- Accede a la URL http://localhost/cgi-bin/essai3.pl
Cabe señalar que se tarda más tiempo en cargar la página perl que la página asp. Esto se debe a que el script de Perl se ejecuta mediante un intérprete de Perl que hay que cargar antes de que pueda ejecutar el script. No permanece permanentemente en la memoria.
2.4.4. Un script PHP (procesador HyperText)
El script essai4.php
<html>
<head>
<title>essai 4 : une page php</title>
</head>
<body>
<center>
<h1>Une page PHP générée dynamiquement</h1>
<h2>
<?
$maintenant=time();
echo date("j/m/y, h:i:s",$maintenant);
?>
</h2>
<br>
A chaque fois que vous rafraîchissez la page, l'heure change.
</body>
</html>
El script anterior genera la siguiente página web:
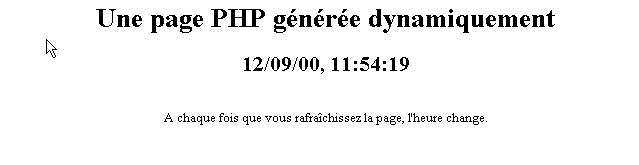
Las pruebas
Prueba 1
- Consulte el archivo de configuración srm.conf o httpd.conf de Apache en <Apache>\confs
- A título informativo, comprueba las líneas de configuración de php
- Iniciar el servidor Apache
- introducir essai4.php en <apache-DocumentRoot>
- solicitar el URL http://localhost/essai4.php
Prueba2
- Iniciar el servidor IIS/PWS
- A título informativo, comprueba la configuración de PWS en relación con PHP
- introducir essai4.php en <IIS-DocumentRoot>\php
- solicitar el URL http://localhost/essai4.php
2.4.5. Un script JSP (Java Server Pages)
El script heure.jsp
<% //: programa en Java que muestra la hora %>
<%@ page import="java.util.*" %>
<%
// código JAVA para calcular la hora
Calendar calendrier=Calendar.getInstance();
int heures=calendrier.get(Calendar.HOUR_OF_DAY);
int minutes=calendrier.get(Calendar.MINUTE);
int secondes=calendrier.get(Calendar.SECOND);
// las horas, los minutos y los segundos son variables globales
// que se podrán utilizar en el código HTML
%>
<% // código HTML %>
<html>
<head>
<title>Page JSP affichant l'heure</title>
</head>
<body>
<center>
<h1>Une page JSP générée dynamiquement</h1>
<h2>Il est <%=heures%>:<%=minutes%>:<%=secondes%></h2>
<br>
<h3>A chaque fois que vous rechargez la page, l'heure change</h3>
</body>
</html>
Una vez ejecutado por el servidor web, este script genera la siguiente página:
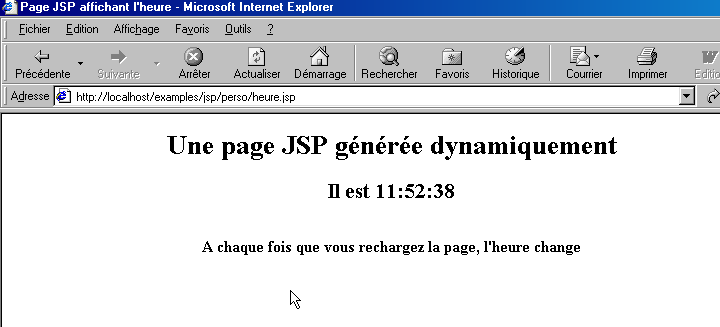
Las pruebas
- colocar el script heure.jsp en <tomcat>\jakarta-tomcat\webapps\examples\jsp (Tomcat 3.x) o en <tomcat>\webapps\examples\jsp (Tomcat 4.x)
- Inicie el servidor Tomcat
- Accede a la página URL http://localhost:8080/examples/jsp/heure.jsp
2.4.6. Una página ASP.NET
El script heure1.aspx:
<html>
<head>
<title>Démo asp.net </title>
</head>
<body>
Il est <% =Date.Now.ToString("hh:mm:ss") %>
</body>
</html>
Una vez ejecutado por el servidor web, este script genera la siguiente página:
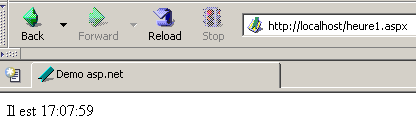
Para realizar esta prueba es necesario disponer de un equipo con Windows en el que se haya instalado la plataforma .NET (véase el anexo).
- Colocar el script heure1.aspx en <IIS-DocumentRoot>
- Iniciar el servidor IIS/CASSINI
- solicitar el URL http://localhost/heure1.aspx
2.4.7. Conclusión
Los ejemplos anteriores han demostrado que:
- una página HTML puede generarse dinámicamente mediante un programa. En eso consiste precisamente la programación web.
- que los lenguajes y los servidores web utilizados pueden ser muy diversos. Actualmente se observan las siguientes tendencias principales:
- las combinaciones Apache/PHP (Windows, Linux) y IIS/PHP (Windows)
- la tecnología ASP.NET en plataformas Windows, que combina el servidor IIS con un lenguaje .NET (C#, VB.NET, ...)
- la tecnología de servlets Java y páginas JSP que funcionan con diferentes servidores (Tomcat, Apache, IIS) y en diferentes plataformas (Windows, Linux).
2.5. Scripts del lado del navegador
Una página HTML puede contener scripts que serán ejecutados por el navegador. Existen numerosos lenguajes de script del lado del navegador. Estos son algunos de ellos:
Lenguaje | Navegadores compatibles |
VBScript | IE |
JavaScript | IE, Netscape |
PerlScript | IE |
Java | IE, Netscape |
Veamos algunos ejemplos.
2.5.1. Una página web con un script VBScript, en el navegador
La página vbs1.html
<html>
<head>
<title>essai : une page web avec un script vb</title>
<script language="vbscript">
function reagir
alert "Vous avez cliqué sur le bouton OK"
end function
</script>
</head>
<body>
<center>
<h1>Une page Web avec un script VB</h1>
<table>
<tr>
<td>Cliquez sur le bouton</td>
<td><input type="button" value="OK" name="cmdOK" onclick="reagir"></td>
</tr>
</table>
</body>
</html>
La página HTML anterior no solo contiene el código HTML, sino también un programa destinado a ser ejecutado por el navegador que haya cargado esta página. El código es el siguiente:
<script language="vbscript">
function reagir
alert "Vous avez cliqué sur le bouton OK"
end function
</script>
Las etiquetas <script></script> sirven para delimitar los scripts en la página HTML. Estos scripts pueden estar escritos en diferentes lenguajes y es la opción language de la etiqueta <script> la que indica el lenguaje utilizado. En este caso es VBScript. No vamos a entrar en detalles sobre este lenguaje. El script anterior define una función llamada réagir que muestra un mensaje. ¿Cuándo se llama a esta función? Nos lo indica la siguiente línea de código HTML:
El atributo onclick indica el nombre de la función que se debe llamar cuando el usuario haga clic en el botón OK. Cuando el navegador haya cargado esta página y el usuario haga clic en el botón OK, aparecerá la siguiente página:
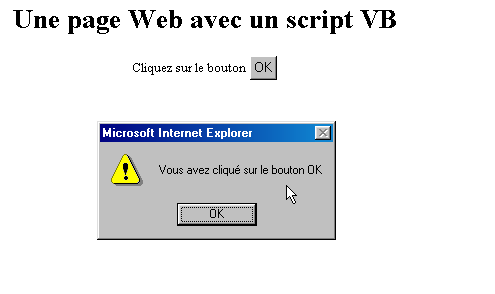
Las pruebas
Solo el navegador IE es capaz de ejecutar scripts VBScript. Netscape necesita complementos de software para hacerlo. Se pueden realizar las siguientes pruebas:
- servidor Apache
- script vbs1.html en <apache-DocumentRoot>
-
solicitar la URL http://localhost/vbs1.html con el navegador IE
-
servidor IIS/PWS
- script vbs1.html en <pws-DocumentRoot>
- solicitar la URL http://localhost/vbs1.html con el navegador IE
Una página web con un script de JavaScript, en el navegador
La page : js1.html
<html>
<head>
<title>essai 4 : une page web avec un script Javascript</title>
<script language="javascript">
function reagir(){
alert ("Vous avez cliqué sur le bouton OK");
}
</script>
</head>
<body>
<center>
<h1>Une page Web avec un script Javascript</h1>
<table>
<tr>
<td>Cliquez sur le bouton</td>
<td><input type="button" value="OK" name="cmdOK" onclick="reagir()"></td>
</tr>
</table>
</body>
</html>
Aquí tenemos algo idéntico a la página anterior, salvo que hemos sustituido el lenguaje VBScript por el lenguaje JavaScript. Este tiene la ventaja de que es compatible con los dos navegadores, IE y Netscape. Su ejecución ofrece los mismos resultados:
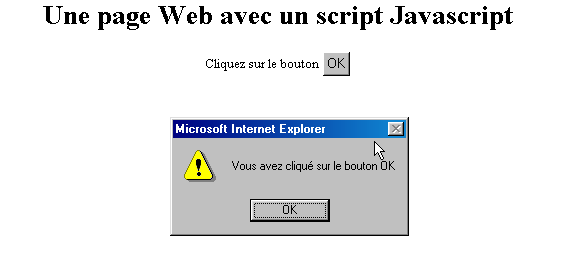
Las pruebas
- servidor Apache
- script js1.html en <apache-DocumentRoot>
-
Accede a la URL http://localhost/js1.html con el navegador IE o Netscape
-
servidor IIS/PWS
- script js1.html en <pws-DocumentRoot>
- solicitar la URL http://localhost/js1.html con el navegador IE o Netscape
2.6. Las interacciones entre el cliente y el servidor
Volvamos a nuestro esquema inicial, que ilustraba los componentes de una aplicación web:
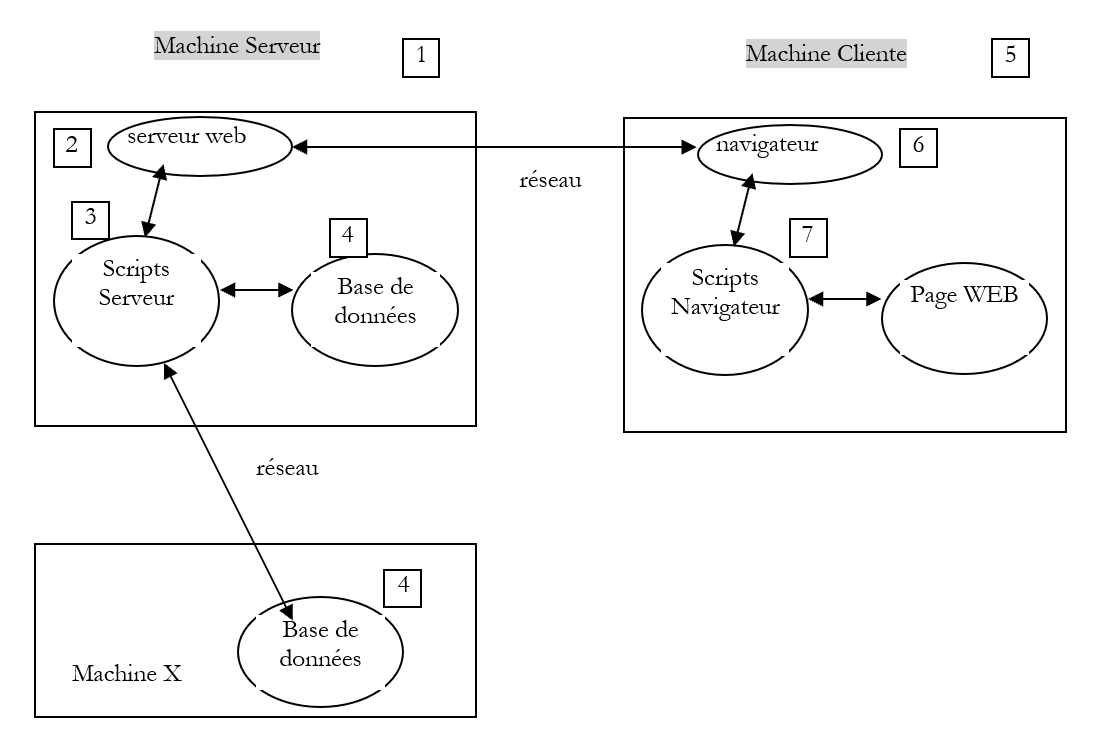
Servidor
Aquí nos centramos en las comunicaciones entre el equipo cliente y el servidor. Estas se producen a través de una red, por lo que conviene recordar la estructura general de las comunicaciones entre dos equipos remotos.
2.6.1. El modelo OSI
El modelo de red abierta denominado OSI (Open Systems Interconnection Reference Model), definido por la ISO (Organización Internacional de Normalización), describe una red ideal en la que la comunicación entre máquinas puede representarse mediante un modelo de siete capas:
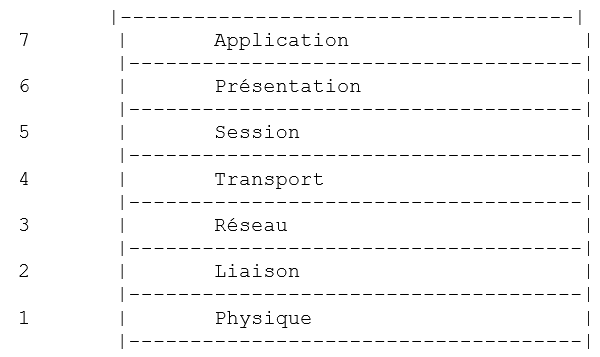
Cada capa recibe servicios de la capa inferior y ofrece los suyos a la capa superior. Supongamos que dos aplicaciones situadas en máquinas A y B diferentes quieren comunicarse: lo hacen a nivel de la capa Application. No necesitan conocer todos los detalles del funcionamiento de la red: cada aplicación entrega la información que desea transmitir a la capa inferior: la capa Présentation. Por lo tanto, la aplicación solo tiene que conocer las reglas de interfaz con la capa Présentation. Una vez que la información se encuentra en la capa Présentation, pasa, siguiendo otras reglas, a la capa Session y así sucesivamente, hasta que la información llega al soporte físico y se transmite físicamente al equipo de destino. Allí se someterá al proceso inverso al que se sometió en el equipo remitente.
En cada capa, el proceso emisor encargado de enviar la información la envía a un proceso receptor en la otra máquina que pertenece a la misma capa que él. Lo hace siguiendo ciertas reglas que se denominan «protocolo de la capa». Por lo tanto, el esquema de comunicación final es el siguiente:

La función de las diferentes capas es la siguiente:
Garantiza la transmisión de bits a través de un soporte físico. En esta capa se encuentran equipos terminales de procesamiento de datos (E.T.T.D), como terminales u ordenadores, así como equipos de terminación de circuitos de datos (E.T.C.D), como moduladores/demoduladores, multiplexores y concentradores. Los aspectos más destacados a este nivel son: . la elección de la codificación de la información (analógica o digital) . la elección del modo de transmisión (síncrono o asíncrono). | |
Oculta las características físicas de la capa física. Detecta y corrige los errores de transmisión. | |
Gestiona la ruta que debe seguir la información enviada por la red. A esto se le denomina routage: determinar la ruta que debe seguir la información para que llegue a su destinatario. | |
Permite la comunicación entre dos aplicaciones, mientras que las capas anteriores solo permitían la comunicación entre máquinas. Un servicio que ofrece esta capa puede ser la multiplexación: la capa de transporte podrá utilizar una misma conexión de red (de máquina a máquina) para transmitir información perteneciente a varias aplicaciones. | |
En esta capa se encuentran servicios que permiten a una aplicación abrir y mantener una sesión de trabajo en una máquina remota. | |
Su objetivo es uniformizar la representación de los datos en las diferentes máquinas. Así, los datos procedentes de una máquina A serán «formateados» por la capa Présentation de la máquina A, según un formato estándar, antes de ser enviados a la red. Una vez que llegan a la capa Présentation del equipo receptor B, que los reconocerá gracias a su formato estándar, se reformatearán de otra manera para que la aplicación del equipo B los reconozca. | |
En este nivel se encuentran las aplicaciones que suelen estar más cerca del usuario, como el correo electrónico o la transferencia de archivos. |
2.6.2. El modelo TCP/IP
El modelo OSI es un modelo ideal. El conjunto de protocolos TCP/IP se aproxima a él de la siguiente forma:
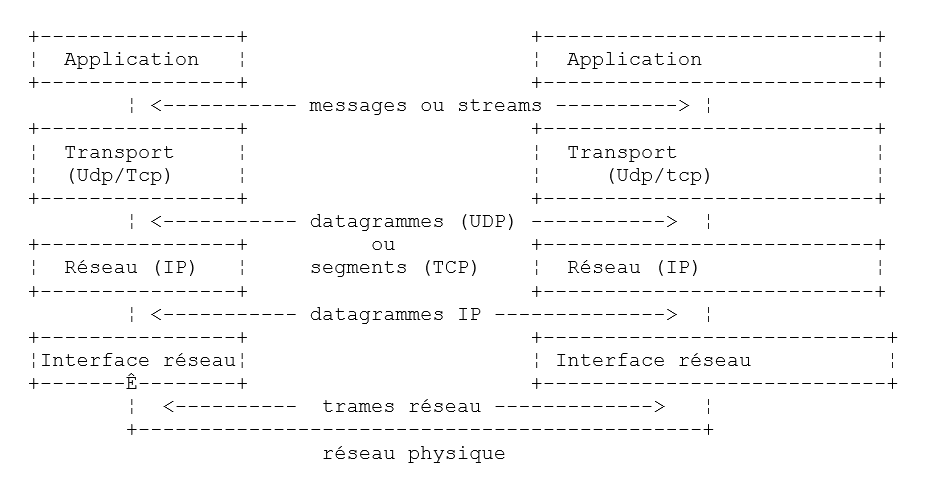
- la interfaz de red (la tarjeta de red del ordenador) se encarga de las funciones de las capas 1 y 2 del modelo OSI
- la capa IP (Protocolo de Internet) desempeña las funciones de la capa 3 (red)
- la capa TCP (Protocolo de control de transferencia) o UDP (Protocolo de datagramas de usuario) desempeña las funciones de la capa 4 (transporte). El protocolo TCP se encarga de que los paquetes de datos intercambiados entre los equipos lleguen correctamente a su destino. Si no es así, reenvía los paquetes que se han extraviado. El protocolo UDP no realiza esta tarea, por lo que corresponde al desarrollador de aplicaciones encargarse de ello. Por eso, en Internet, que no es una red 100 % fiable, el protocolo TCP es el más utilizado. En este caso, se habla de una red TCP-IP.
- La capa de aplicación abarca las funciones de los niveles 5 a 7 del modelo OSI.
Las aplicaciones web se encuentran en la capa Application y, por lo tanto, se basan en los protocolos TCP-IP. Las capas Application de los equipos cliente y servidor intercambian mensajes que se confían a las capas 1 a 4 del modelo para que sean encaminados a su destino. Para entenderse, las capas de aplicación de ambos equipos deben «hablar» un mismo lenguaje o protocolo. El de las aplicaciones web se denomina HTTP (HyperText Transfer Protocol). Se trata de un protocolo de tipo texto, c.a.d, mediante el cual los equipos intercambian líneas de texto a través de la red para comunicarse. Estos intercambios están estandarizados, c.a.d, de modo que el cliente dispone de una serie de mensajes para indicar exactamente lo que quiere al servidor y este último también dispone de una serie de mensajes para dar su respuesta al cliente. Este intercambio de mensajes tiene la siguiente forma:
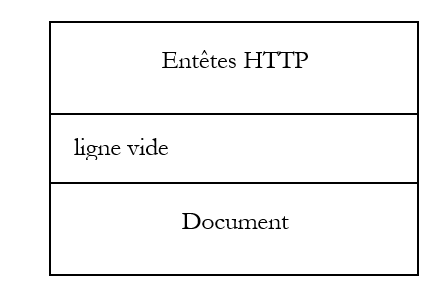
Cliente --> Servidor
Cuando el cliente realiza su solicitud al servidor web, envía
- líneas de texto en formato HTTP para indicar lo que quiere
- una línea en blanco
- opcionalmente, un documento
Servidor --> Cliente
Cuando el servidor responde al cliente, envía
- líneas de texto en formato HTTP para indicar lo que envía
- una línea en blanco
- opcionalmente, un documento
Por lo tanto, los intercambios tienen el mismo formato en ambos sentidos. En ambos casos, puede enviarse un documento, aunque es poco habitual que un cliente envíe un documento al servidor. Pero el protocolo HTTP lo prevé. Esto es lo que permite, por ejemplo, a los abonados de un proveedor de acceso descargar diversos documentos en su sitio web personal alojado en dicho proveedor. Los documentos intercambiados pueden ser de cualquier tipo. Tomemos como ejemplo un navegador que solicita una página web que contiene imágenes:
- el navegador se conecta al servidor web y solicita la página que desea. Los recursos solicitados se identifican de forma única mediante URL (Uniform Resource Locator). El navegador solo envía encabezados HTTP y ningún documento.
- El servidor le responde. En primer lugar, envía encabezados HTTP que indican qué tipo de respuesta envía. Puede tratarse de un error si la página solicitada no existe. Si la página existe, el servidor indicará en los encabezados HTTP de su respuesta que, tras estos, enviará un documento HTML (HyperText Markup Language). Este documento es una secuencia de líneas de texto en formato HTML. Un texto HTML contiene etiquetas (marcadores) que proporcionan al navegador instrucciones sobre cómo mostrar el texto.
- El cliente sabe, gracias a los encabezados HTTP del servidor, que va a recibir un documento HTML. Analizará dicho documento y quizá se dé cuenta de que contiene referencias a imágenes. Estas no se encuentran en el documento HTML. Por lo tanto, realiza una nueva solicitud al mismo servidor web para pedir la primera imagen que necesita. Esta solicitud es idéntica a la realizada en el paso 1, salvo que el recurso solicitado es diferente. El servidor procesará esta solicitud enviando al cliente la imagen solicitada. En esta ocasión, en su respuesta, los encabezados de HTTP especificarán que el documento enviado es una imagen y no un documento HTML.
- El cliente recupera la imagen enviada. Los pasos 3 y 4 se repetirán hasta que el cliente (por lo general, un navegador) disponga de todos los documentos que le permitan mostrar la página completa.
2.6.3. El protocolo HTTP
Veamos el protocolo HTTP con algunos ejemplos. ¿Qué se intercambian un navegador y un servidor web?
2.6.3.1. La respuesta de un servidor HTTP
Aquí veremos cómo responde un servidor web a las solicitudes de sus clientes. El servicio web o servicio HTTP es un servicio TCP-IP que suele funcionar en el puerto 80. Podría funcionar en otro puerto. En ese caso, el navegador del cliente tendría que especificar ese puerto en la solicitud que realiza. Una solicitud tiene la siguiente forma general:
con
protocolo | http para el servicio web. Un navegador también puede actuar como cliente de servicios ftp, news, telnet, etc. |
máquina | nombre del servidor en el que se ejecuta el servicio web |
puerto | puerto del servicio web. Si es el 80, se puede omitir el número de puerto. Este es el caso más habitual |
ruta | ruta que designa el recurso solicitado |
información | información adicional proporcionada al servidor para precisar la solicitud del cliente |
¿Qué hace un navegador cuando un usuario solicita la carga de un URL?
- Establece una comunicación TCP-IP con el equipo y el puerto indicados en la sección «machine[:port]» del URL. Establecer una comunicación TCP-IP significa crear un «canal» de comunicación entre dos máquinas. Una vez creado este canal, toda la información intercambiada entre ambas máquinas pasará por él. La creación de este canal TCP-IP aún no implica el protocolo web HTTP.
- Una vez creado el canal TCP-IP, el cliente realizará su solicitud al servidor web enviándole líneas de texto (comandos) en formato HTTP. Enviará al servidor la parte «ruta/información» del URL
- el servidor le responderá de la misma forma y a través del mismo canal
- uno de los dos interlocutores tomará la decisión de cerrar el canal. Esto depende del protocolo HTTP utilizado. Con el protocolo HTTP 1.0, el servidor cierra la conexión tras cada una de sus respuestas. Esto obliga a un cliente que deba realizar varias solicitudes para obtener los distintos documentos que componen una página web a abrir una nueva conexión con cada solicitud, lo cual conlleva un coste. Con el protocolo HTTP/1.1, el cliente puede indicar al servidor que mantenga la conexión abierta hasta que él le indique que la cierre. De este modo, puede recuperar todos los documentos de una página web con una sola conexión y cerrarla él mismo una vez obtenido el último documento. El servidor detectará este cierre y también cerrará la conexión.
Para conocer las interacciones entre un cliente y un servidor web, vamos a utilizar una herramienta llamada curl. Curl es una aplicación DOS que permite actuar como cliente de servicios de Internet compatibles con diferentes protocolos (HTTP, FTP, TELNET, GOPHER, ...). curl está disponible en http://curl.haxx.se/. Aquí descargaremos preferentemente la versión para Windows «win32-nossl», ya que la versión «win32-ssl» requiere DLL adicionales que no se incluyen en el paquete de curl. Este paquete contiene un conjunto de archivos que solo hay que descomprimir en una carpeta a la que a partir de ahora llamaremos <curl>. Esta carpeta contiene un ejecutable llamado [curl.exe]. Este será nuestro cliente para consultar servidores web. Abramos una ventana de DOS y accedamos a la carpeta <curl>:
dos>dir curl.exe
22/03/2004 13:29 299 008 curl.exe
E:\curl2>curl
curl: try 'curl --help' for more information
dos>curl --help | more
Usage: curl [options...] <url>
Options: (H) means HTTP/HTTPS only, (F) means FTP only
-a/--append Append to target file when uploading (F)
-A/--user-agent <string> User-Agent to send to server (H)
--anyauth Tell curl to choose authentication method (H)
-b/--cookie <name=string/file> Cookie string or file to read cookies from (H)
--basic Enable HTTP Basic Authentication (H)
-B/--use-ascii Use ASCII/text transfer
-c/--cookie-jar <file> Write cookies to this file after operation (H)
....
Utilicemos esta aplicación para consultar un servidor web y descubrir los intercambios entre el cliente y el servidor. Nos encontraremos en la siguiente situación:
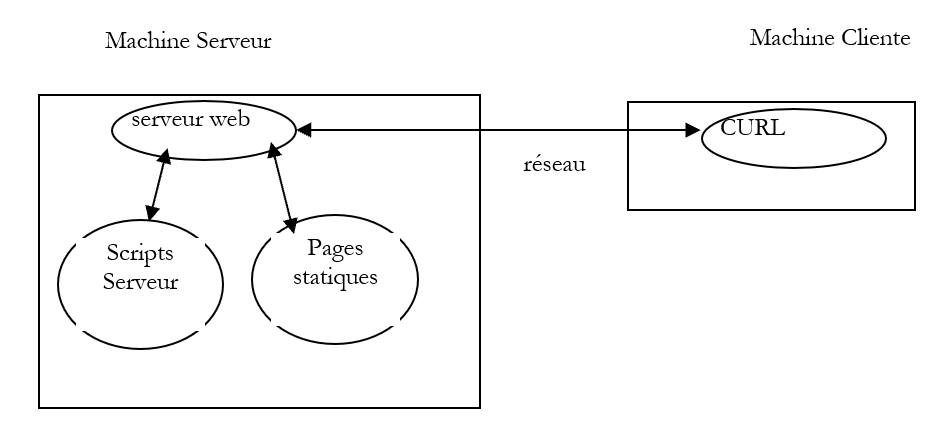
El servidor web puede ser cualquiera. Lo que buscamos aquí es descubrir las comunicaciones que se producirán entre el cliente web curl y el servidor web. Anteriormente, hemos creado la siguiente página estática HTML:
<html>
<head>
<title>essai 1 : une page statique</title>
</head>
<body>
<center>
<h1>Une page statique...</h1>
</body>
</html>
que visualizamos en un navegador:
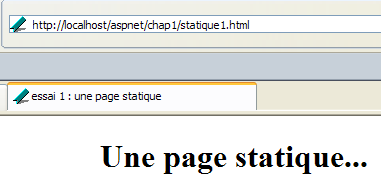
Vemos que el URL solicitado es: http://localhost/aspnet/chap1/statique1.html. Por lo tanto, el servidor del servicio web es localhost (=servidor local) y el puerto 80. Si solicitamos ver el texto HTML de esta página web (Ver/Fuente), encontramos el texto HTML creado inicialmente:
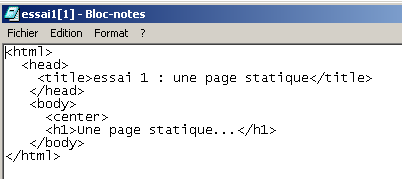
Ahora utilicemos nuestro cliente CURL para solicitar el mismo URL:
dos>curl http://localhost/aspnet/chap1/statique1.html
<html>
<head>
<title>essai 1 : une page statique</title>
</head>
<body>
<center>
<h1>Une page statique...</h1>
</body>
</html>
Vemos que el servidor web le ha enviado un conjunto de líneas de texto que representan el código HTML de la página solicitada. Anteriormente hemos dicho que la respuesta de un servidor web se presenta en el formato:
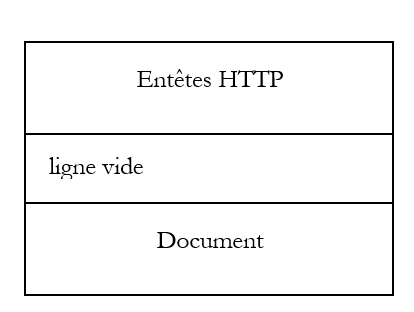
Sin embargo, aquí no hemos visto los encabezados HTTP. Esto se debe a que, por defecto, [curl] no los muestra. La opción --include permite mostrarlos:
E:\curl2>curl --include http://localhost/aspnet/cap1/statique1.html
HTTP/1.1 200 OK
Server: Microsoft ASP.NET Web Matrix Server/0.6.0.0
Date: Mon, 22 Mar 2004 16:51:00 GMT
X-AspNet-Version: 1.1.4322
Cache-Control: public
ETag: "1C4102CEE8C6400:1C4102CFBBE2250"
Content-Type: text/html
Content-Length: 161
Connection: Close
<html>
<head>
<title>essai 1 : une page statique</title>
</head>
<body>
<center>
<h1>Une page statique...</h1>
</body>
</html>
El servidor ha enviado correctamente una serie de encabezados HTTP seguidos de una línea en blanco:
HTTP/1.1 200 OK
Server: Microsoft ASP.NET Web Matrix Server/0.6.0.0
Date: Mon, 22 Mar 2004 16:51:00 GMT
X-AspNet-Version: 1.1.4322
Cache-Control: public
ETag: "1C4102CEE8C6400:1C4102CFBBE2250"
Content-Type: text/html
Content-Length: 161
Connection: Close
El servidor indica
| |
El servidor se identifica. En este caso, se trata de un servidor Cassini | |
la fecha y la hora de la respuesta | |
Encabezado específico del servidor Cassini | |
proporciona información al cliente sobre la posibilidad de almacenar en caché la respuesta que se le envía. El atributo [public] indica al cliente que puede almacenar la página en caché. Un atributo [no-cache] habría indicado al cliente que no debía almacenar la página en caché. | |
... | |
el servidor indica que va a enviar texto (text) en formato HTML (html). | |
Número de bytes del documento que se va a enviar tras los encabezados HTTP. Este número es, de hecho, el tamaño en bytes del archivo essai1.html: | |
El servidor indica que cerrará la conexión una vez enviado el documento |
El cliente recibe estas cabeceras HTTP y ahora sabe que va a recibir 161 bytes que representan un documento HTML. El servidor envía estos 161 bytes inmediatamente después de la línea en blanco que indicaba el final de las cabeceras HTTP:
<html>
<head>
<title>essai 1 : une page statique</title>
</head>
<body>
<center>
<h1>Une page statique...</h1>
</body>
</html>
Aquí reconocemos el archivo HTML creado inicialmente. Si nuestro cliente fuera un navegador, tras recibir estas líneas de texto, las interpretaría para mostrar al usuario, a través del teclado, la siguiente página:
Utilicemos de nuevo nuestro cliente [curl] para solicitar el mismo recurso, pero esta vez pidiendo únicamente los encabezados de la respuesta:
dos>curl --head http://localhost/aspnet/chap1/statique1.html
HTTP/1.1 200 OK
Server: Microsoft ASP.NET Web Matrix Server/0.6.0.0
Date: Tue, 23 Mar 2004 07:11:54 GMT
Cache-Control: public
ETag: "1C410A504D60680:1C410A58621AD3E"
Content-Type: text/html
Content-Length: 161
Connection: Close
Obtenemos el mismo resultado que antes sin el documento HTML. Ahora solicitemos una imagen tanto con un navegador como con el cliente genérico TCP. En primer lugar, con un navegador:
El archivo univ01.gif tiene 4052 bytes:
Ahora utilicemos el cliente [curl]:
dos>curl --head http://localhost/aspnet/chap1/univ01.gif
HTTP/1.1 200 OK
Server: Microsoft ASP.NET Web Matrix Server/0.6.0.0
Date: Tue, 23 Mar 2004 07:18:44 GMT
Cache-Control: public
ETag: "1C410A6795D7500:1C410A6868B1476"
Content-Type: image/gif
Content-Length: 4052
Connection: Close
Cabe destacar los siguientes puntos en el ciclo de solicitud-respuesta anterior:
| |
| |
|
2.6.3.2. La solicitud de un cliente HTTP
Ahora, planteémonos la siguiente pregunta: si queremos escribir un programa que «se comunique» con un servidor web, ¿qué comandos debe enviar al servidor web para obtener un recurso determinado? En los ejemplos anteriores hemos visto lo que recibía el cliente, pero no lo que enviaba. Vamos a utilizar la opción [--verbose] de curl para ver también lo que envía el cliente al servidor. Empecemos por solicitar la página estática:
dos>curl --verbose http://localhost/aspnet/chap1/statique1.html
* About to connect() to localhost:80
* Connected to portable1_tahe (127.0.0.1) port 80
> GET /aspnet/chap1/statique1.html HTTP/1.1
User-Agent: curl/7.10.8 (win32) libcurl/7.10.8 OpenSSL/0.9.7a zlib/1.1.4
Host: localhost
Pragma: no-cache
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*
< HTTP/1.1 200 OK
< Server: Microsoft ASP.NET Web Matrix Server/0.6.0.0
< Date: Tue, 23 Mar 2004 07:37:06 GMT
< Cache-Control: public
< ETag: "1C410A504D60680:1C410A58621AD3E"
< Content-Type: text/html
< Content-Length: 161
< Connection: Close
<html>
<head>
<title>essai 1 : une page statique</title>
</head>
<body>
<center>
<h1>Une page statique...</h1>
</body>
</html>
* Closing connection #0
En primer lugar, el cliente [curl] establece una conexión TCP/IP con el puerto 80 del equipo localhost (=127.0.0.1)
Una vez establecida la conexión, envía su solicitud HTTP. Se trata de una secuencia de líneas de texto que termina con una línea en blanco:
GET /aspnet/chap1/statique1.html HTTP/1.1
User-Agent: curl/7.10.8 (win32) libcurl/7.10.8 OpenSSL/0.9.7a zlib/1.1.4
Host: localhost
Pragma: no-cache
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*
La solicitud HTTP de un cliente web tiene dos funciones:
- indicar el recurso deseado. Esta es la función de la primera línea, GET
- proporcionar información sobre el cliente que realiza la solicitud para que el servidor pueda, en su caso, adaptar su respuesta a ese tipo de cliente concreto.
El significado de las líneas enviadas anteriormente por el cliente [curl] es el siguiente:
para solicitar un recurso determinado según una versión concreta del protocolo HTTP. El servidor envía una respuesta en formato HTTP, seguida de una línea en blanco y, a continuación, del recurso solicitado | |
para indicar quién es el cliente | |
para especificar (protocolo HTTP 1.1) el equipo y el puerto del servidor web consultado | |
aquí para especificar que el cliente no gestiona caché. | |
tipos MIME que especifican los tipos de archivos que el cliente sabe gestionar |
Repitamos la operación con la opción --head de [curl]:
dos>curl --verbose --head --output reponse.txt http://localhost/aspnet/chap1/statique1.html
* About to connect() to localhost:80
* Connected to portable1_tahe (127.0.0.1) port 80
> HEAD /aspnet/chap1/statique1.html HTTP/1.1
User-Agent: curl/7.10.8 (win32) libcurl/7.10.8 OpenSSL/0.9.7a zlib/1.1.4
Host: localhost
Pragma: no-cache
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*
< HTTP/1.1 200 OK
< Server: Microsoft ASP.NET Web Matrix Server/0.6.0.0
< Date: Tue, 23 Mar 2004 07:54:22 GMT
< Cache-Control: public
< ETag: "1C410A504D60680:1C410A58621AD3E"
< Content-Type: text/html
< Content-Length: 161
< Connection: Close
Nos centraremos únicamente en los encabezados HTTP enviados por el cliente:
HEAD /aspnet/chap1/statique1.html HTTP/1.1
User-Agent: curl/7.10.8 (win32) libcurl/7.10.8 OpenSSL/0.9.7a zlib/1.1.4
Host: localhost
Pragma: no-cache
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*
Solo ha cambiado el comando que solicita el recurso. En lugar de un comando GET, ahora tenemos un comando HEAD. Este comando solicita que la respuesta del servidor se limite a los encabezados HTTP y que no envíe el recurso solicitado. La captura de pantalla anterior no muestra los encabezados HTTP recibidos. Estos se han guardado en un archivo debido a la opción [--output reponse.txt] del comando [curl]:
dos>more reponse.txt
HTTP/1.1 200 OK
Server: Microsoft ASP.NET Web Matrix Server/0.6.0.0
Date: Tue, 23 Mar 2004 07:54:22 GMT
Cache-Control: public
ETag: "1C410A504D60680:1C410A58621AD3E"
Content-Type: text/html
Content-Length: 161
Connection: Close
2.6.4. Conclusión
Hemos analizado la estructura de la solicitud de un cliente web y la de la respuesta que le envía el servidor web a través de algunos ejemplos. La comunicación se realiza mediante el protocolo HTTP, un conjunto de comandos en formato de texto que intercambian ambas partes. Tanto la solicitud del cliente como la respuesta del servidor tienen la siguiente estructura:
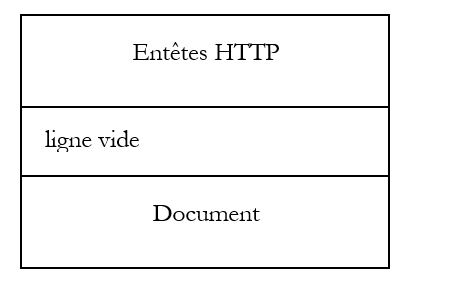
En el caso de una solicitud (a menudo denominada «petición») del cliente, la parte [Document] suele estar ausente. No obstante, es posible que un cliente envíe un documento al servidor. Lo hace mediante un comando denominado PUT. Los dos comandos habituales para solicitar un recurso son GET y POST. Este último se explicará más adelante. El comando HEAD permite solicitar únicamente los encabezados HTTP. Los comandos GET y POST son los más utilizados por los clientes web de tipo navegador.
A petición de un cliente, el servidor envía una respuesta que tiene la misma estructura. El recurso solicitado se transmite en la parte [Document], salvo si el comando del cliente era HEAD, en cuyo caso solo se envían los encabezados HTTP.
2.7. El lenguaje HTML
Un navegador web puede mostrar diversos documentos, siendo el más habitual el documento HTML (HyperText Markup Language). Se trata de un texto formateado con etiquetas del tipo <balise>texte</balise>. Así, el texto <B>important</B> mostrará el texto importante en negrita. Existen etiquetas independientes, como la etiqueta <hr>, que muestra una línea horizontal. No repasaremos las etiquetas que pueden encontrarse en un texto HTML. Existen numerosos programas WYSIWYG que permiten crear una página web sin escribir ni una sola línea de código HTML. Estas herramientas generan automáticamente el código HTML a partir de un diseño realizado con el ratón y controles predefinidos. De este modo, se puede insertar (con el ratón) una tabla en la página y, a continuación, consultar el código HTML generado por el programa para descubrir las etiquetas que hay que utilizar para definir una tabla en una página web. No es más complicado que eso. Por otra parte, el conocimiento del lenguaje HTML es imprescindible, ya que las aplicaciones web dinámicas deben generar por sí mismas el código HTML que se enviará a los clientes web. Este código se genera mediante un programa y, por supuesto, hay que saber qué hay que generar para que el cliente obtenga la página web que desea.
En resumen, no es necesario conocer todo el lenguaje HTML para iniciarse en la programación web. Sin embargo, este conocimiento es necesario y puede adquirirse mediante el uso de programas de creación de páginas web como Word, FrontPage, DreamWeaver y muchas otras. Otra forma de descubrir las sutilezas del lenguaje HTML es navegar por la web y visualizar el código fuente de las páginas que presenten características interesantes y que aún no conozcas.
2.7.1. Un ejemplo
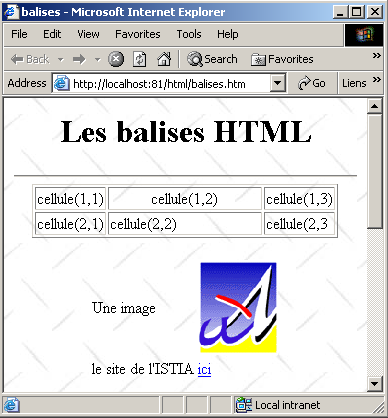
Consideremos el siguiente ejemplo, creado con FrontPage Express, una herramienta gratuita incluida en Internet Explorer. El código generado por FrontPage se ha simplificado aquí. Este ejemplo presenta algunos elementos que pueden encontrarse en un documento web, tales como:
- una tabla
- una imagen
- un enlace
Un documento HTML tiene la siguiente estructura general:
Todo el documento está enmarcado por las etiquetas <html>...</html>. Se compone de dos partes:
- <head>...</head>: es la parte no visible del documento. Proporciona información al navegador que va a mostrar el documento. A menudo contiene la etiqueta <title>...</title>, que establece el texto que se mostrará en la barra de título del navegador. También puede contener otras etiquetas, en particular aquellas que definen las palabras clave del documento, palabras clave que posteriormente utilizan los motores de búsqueda. En esta parte también pueden encontrarse scripts, escritos normalmente en JavaScript o VBScript, que serán ejecutados por el navegador.
- <body atributos>...</body>: es la parte que mostrará el navegador. Las etiquetas HTML contenidas en esta parte indican al navegador el aspecto visual «deseado» para el documento. Cada navegador interpretará estas etiquetas a su manera. Por lo tanto, dos navegadores pueden mostrar de forma diferente un mismo documento web. Esto suele ser uno de los quebraderos de cabeza de los diseñadores web.
El código HTML de nuestro documento de ejemplo es el siguiente:
<html>
<head>
<title>balises</title>
</head>
<body background="/images/standard.jpg">
<center>
<h1>Les balises HTML</h1>
<hr>
</center>
<table border="1">
<tr>
<td>cellule(1,1)</td>
<td valign="middle" align="center" width="150">cellule(1,2)</td>
<td>cellule(1,3)</td>
</tr>
<tr>
<td>cellule(2,1)</td>
<td>cellule(2,2)</td>
<td>cellule(2,3</td>
</tr>
</table>
<table border="0">
<tr>
<td>Une image</td>
<td><img border="0" src="/images/univ01.gif" width="80" height="95"></td>
</tr>
<tr>
<td>le site de l'ISTIA</td>
<td><a href="http://istia.univ-angers.fr">ici</a></td>
</tr>
</table>
</body>
</html>
En el código se han resaltado únicamente los puntos que nos interesan:
Elemento | etiquetas y ejemplos HTML |
<title>balises</title> balises aparecerá en la barra de título del navegador que muestre el documento | |
<hr>: muestra una línea horizontal | |
<atributos de tabla>....</table>: para definir la tabla <tr atributos>...</tr>: para definir una fila <td atributos>...</td>: para definir una celda Ejemplos: <table border="1">...</table>: el atributo border define el grosor del borde de la tabla <td valign="middle" align="center" width="150">celda(1,2)</td>: define una celda cuyo contenido será celda(1,2). Este contenido se centrará verticalmente (valign="middle") y horizontalmente (align="center"). La celda tendrá una anchura de 150 píxeles (width="150") | |
<img border="0" src="/images/univ01.gif" width="80" height="95">: define una imagen sin borde (border="0"), de 95 píxeles de altura (height="95"), de 80 píxeles de ancho (width="80") y cuyo archivo de origen se encuentra en /images/univ01.gif en el servidor web (src="/images/univ01.gif"). Este enlace se encuentra en un documento web que se ha obtenido con el URL http://localhost:81/html/balises.htm. Por lo tanto, el navegador solicitará el archivo URL http://localhost:81/images/univ01.gif para obtener la imagen a la que se hace referencia aquí. | |
<a href="http://istia.univ-angers.fr">aquí</a>: hace que el texto ici sirva de enlace a la página URL http://istia.univ-angers.fr. | |
<body background="/images/standard.jpg">: indica que la imagen que debe servir de fondo de página se encuentra en la ruta URL /images/standard.jpg del servidor web. En el contexto de nuestro ejemplo, el navegador solicitará la URL http://localhost:81/images/standard.jpg para obtener esta imagen de fondo. |
En este sencillo ejemplo se observa que, para construir el documento completo, el navegador debe realizar tres solicitudes al servidor:
- http://localhost:81/html/balises.htm para obtener el código fuente HTML del documento
- http://localhost:81/images/univ01.gif para obtener la imagen univ01.gif
- http://localhost:81/images/standard.jpg para obtener la imagen de fondo standard.jpg
El siguiente ejemplo muestra un formulario web creado también con FrontPage.
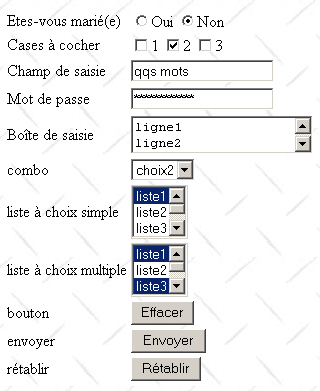
El código HTML generado por FrontPage y ligeramente simplificado es el siguiente:
<html>
<head>
<title>balises</title>
<script language="JavaScript">
function effacer(){
alert("Vous avez cliqué sur le bouton Effacer");
}//borrar
</script>
</head>
<body background="/images/standard.jpg">
<form method="POST" >
<table border="0">
<tr>
<td>Etes-vous marié(e)</td>
<td>
<input type="radio" value="Oui" name="R1">Oui
<input type="radio" name="R1" value="non" checked>Non
</td>
</tr>
<tr>
<td>Cases à cocher</td>
<td>
<input type="checkbox" name="C1" value="un">1
<input type="checkbox" name="C2" value="deux" checked>2
<input type="checkbox" name="C3" value="trois">3
</td>
</tr>
<tr>
<td>Champ de saisie</td>
<td>
<input type="text" name="txtSaisie" size="20" value="qqs mots">
</td>
</tr>
<tr>
<td>Mot de passe</td>
<td>
<input type="password" name="txtMdp" size="20" value="unMotDePasse">
</td>
</tr>
<tr>
<td>Boîte de saisie</td>
<td>
<textarea rows="2" name="areaSaisie" cols="20">
ligne1
ligne2
ligne3
</textarea>
</td>
</tr>
<tr>
<td>combo</td>
<td>
<select size="1" name="cmbValeurs">
<option>choix1</option>
<option selected>choix2</option>
<option>choix3</option>
</select>
</td>
</tr>
<tr>
<td>liste à choix simple</td>
<td>
<select size="3" name="lst1">
<option selected>liste1</option>
<option>liste2</option>
<option>liste3</option>
<option>liste4</option>
<option>liste5</option>
</select>
</td>
</tr>
<tr>
<td>liste à choix multiple</td>
<td>
<select size="3" name="lst2" multiple>
<option>liste1</option>
<option>liste2</option>
<option selected>liste3</option>
<option>liste4</option>
<option>liste5</option>
</select>
</td>
</tr>
<tr>
<td>bouton</td>
<td>
<input type="button" value="Effacer" name="cmdEffacer" onclick="effacer()">
</td>
</tr>
<tr>
<td>envoyer</td>
<td>
<input type="submit" value="Envoyer" name="cmdRenvoyer">
</td>
</tr>
<tr>
<td>rétablir</td>
<td>
<input type="reset" value="Rétablir" name="cmdRétablir">
</td>
</tr>
</table>
<input type="hidden" name="secret" value="uneValeur">
</form>
</body>
</html>
La correspondencia entre la comprobación visual y la etiqueta HTML es la siguiente:
Control | etiqueta HTML |
<form method="POST" > | |
<input type="text" name="txtSaisie" size="20" value="unas palabras"> | |
<input type="password" name="txtMdp" size="20" value="unMotDePasse"> | |
<textarea rows="2" name="areaSaisie" cols="20"> línea1 línea 2 línea 3 </textarea> | |
<input type="radio" value="Sí" name="R1">Sí <input type="radio" name="R1" value="no" checked>No | |
<input type="checkbox" name="C1" value="uno">1 <input type="checkbox" name="C2" value="dos" checked>2 <input type="checkbox" name="C3" value="tres">3 | |
<select size="1" name="cmbValeurs"> <option>opción1</option> <option selected>opción 2</option> <option>opción 3</option> </select> | |
<select size="3" name="lst1"> <option selected>lista1</option> <option>lista2</option> <option>lista3</option> <option>lista4</option> <option>lista5</option> </select> | |
<select size="3" name="lst2" multiple> <option>lista1</option> <option>lista2</option> <option selected>lista3</option> <option>lista4</option> <option>lista5</option> </select> | |
<input type="submit" value="Enviar" name="cmdRenvoyer"> | |
<input type="reset" value="Restablecer" name="cmdRétablir"> | |
<input type="button" value="Borrar" name="cmdEffacer" onclick="effacer()"> |
Repasemos estos diferentes controles.
2.7.1.1. El formulario
<form method="POST" > |
<form name="..." method="..." action="...">...</form> | |
name="frmexemple": nombre del formulario method="..." : método utilizado por el navegador para enviar al servidor web los valores recopilados en el formulario action="..." : URL a la que se enviarán los valores recopilados en el formulario. Un formulario web está delimitado por las etiquetas <form>...</form>. El formulario puede tener un nombre (name="xx"). Esto se aplica a todos los controles que pueden encontrarse en un formulario. Este nombre resulta útil si el documento web contiene scripts que deben hacer referencia a elementos del formulario. El objetivo de un formulario es recopilar la información introducida por el usuario mediante el teclado o el ratón y enviarla a una URL del servidor web. ¿Cuál? La que se indica en el atributo action="URL". Si este atributo no está presente, la información se enviará al servidor del documento en el que se encuentra el formulario. Este sería el caso del ejemplo anterior. Hasta ahora, siempre hemos visto al cliente web como quien «solicita» información a un servidor web, nunca como quien le «proporciona» información. ¿Cómo hace un cliente web para proporcionar información (la contenida en el formulario) a un servidor web? Volveremos sobre esto con más detalle un poco más adelante. Puede utilizar dos métodos diferentes denominados POST y GET. El atributo method="méthode", con el método igual a GET o POST, de la etiqueta <form> indica al navegador el método que debe utilizar para enviar la información recopilada en el formulario a la URL especificada por el atributo action="URL". Cuando no se especifica el atributo method, se utiliza por defecto el método GET. |
2.7.1.2. Campo de entrada
![]()
![]()
<input type="text" name="txtSaisie" size="20" value="unas palabras"> <input type="password" name="txtMdp" size="20" value="unMotDePasse"> |
<input type="..." name="..." size=".." value=".."> La etiqueta «input» existe para diversos controles. El atributo type es el que permite diferenciar estos controles entre sí. | |
type="text": especifica que se trata de un campo de entrada type="password": los caracteres que aparecen en el campo de entrada se sustituyen por asteriscos (*). Esta es la única diferencia con respecto al campo de entrada normal. Este tipo de control es adecuado para introducir contraseñas. size="20": número de caracteres visibles en el campo; no impide introducir más caracteres name="txtSaisie" : nombre del control value="unas palabras": texto que se mostrará en el campo de entrada. |
2.7.1.3. Campo de entrada de varias líneas
![]()
<textarea rows="2" name="areaSaisie" cols="20"> ligne1 ligne2 ligne3 </textarea> |
<textarea ...>texto</textarea> muestra un campo de entrada de varias líneas que inicialmente contiene texto | |
rows="2": número de líneas cols="'20": número de columnas name="areaSaisie": nombre del control |
2.7.1.4. Botones de opción
![]()
<input type="radio" value="Sí" name="R1">Sí <input type="radio" name="R1" value="no" checked>No |
<input type="radio" atributo2="valor2" ....>texto muestra un botón de opción con texto al lado. | |
name="radio": nombre del control. Los botones de opción que tienen el mismo nombre forman un grupo de botones que se excluyen entre sí: solo se puede marcar uno de ellos. value="valor": valor asignado al botón de opción. No hay que confundir este valor con el texto que aparece junto al botón de opción. Este último solo sirve para la visualización. checked: si está presente esta palabra clave, el botón de radio está marcado; de lo contrario, no lo está. |
2.7.1.5. Casillas de selección
<input type="checkbox" name="C1" value="uno">1 <input type="checkbox" name="C2" value="dos" checked>2 <input type="checkbox" name="C3" value="tres">3 |
![]()
<input type="checkbox" atributo2="valor2" ....>texto muestra una casilla de selección con texto al lado. | |
name="C1": nombre del control. Las casillas de selección pueden tener o no el mismo nombre. Las casillas que tienen el mismo nombre forman un grupo de casillas asociadas. value="valor": valor asignado a la casilla de selección. No hay que confundir este valor con el texto que aparece junto al botón de radio. Este último solo tiene fines de visualización. checked: si está presente esta palabra clave, el botón de radio está marcado; en caso contrario, no lo está. |
2.7.1.6. Lista desplegable (combo)
<select size="1" name="cmbValeurs"> <option>choix1</option> <option selected>opción2</option> <option>choix3</option> </select> |
![]()
<select size=".." name=".."> <option [selected]>...</option> ... </select> muestra en una lista los textos comprendidos entre las etiquetas <option>...</option> | |
name="cmbValeurs": nombre del control. size="1": número de elementos visibles de la lista. size="1" convierte la lista en el equivalente a un cuadro combinado. selected: si esta palabra clave está presente para un elemento de la lista, este aparece seleccionado en la lista. En nuestro ejemplo anterior, el elemento de la lista choix2 aparece como el elemento seleccionado del cuadro combinado cuando este se muestra por primera vez. |
2.7.1.7. Lista de selección única
<select size="3" name="lst1"> <option selected>lista1</option> <option>liste2</option> <option>liste3</option> <option>liste4</option> <option>liste5</option> </select> |
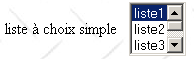
<select size=".." name=".."> <option [selected]>...</option> ... </select> muestra en una lista los textos comprendidos entre las etiquetas <option>...</option> | |
los mismos que para la lista desplegable que solo muestra un elemento. Este control solo se diferencia de la lista desplegable anterior en su atributo size>1. |
2.7.1.8. Lista de selección múltiple
<select size="3" name="lst2" multiple> <option selected>lista1</option> <option>liste2</option> <option selected>lista3</option> <option>liste4</option> <option>liste5</option> </select> |
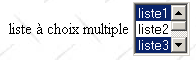
<select size=".." name=".." multiple> <option [selected]>...</option> ... </select> muestra en una lista los textos comprendidos entre las etiquetas <option>...</option> | |
múltiple: permite seleccionar varios elementos de la lista. En el ejemplo anterior, se seleccionan los elementos liste1 y liste3. |
2.7.1.9. Botón de tipo «button»
<input type="button" value="Borrar" name="cmdEffacer" onclick="effacer()"> |
![]()
<input type="button" value="..." name="..." onclick="effacer()" ....> | |
type="button": define un control de botón. Existen otros dos tipos de botón: los tipos submit y reset. value="Borrar": el texto que se muestra en el botón onclick="función()": permite definir una función que se ejecutará cuando el usuario haga clic en el botón. Esta función forma parte de los scripts definidos en el documento web mostrado. La sintaxis anterior es una sintaxis javascript. Si los scripts están escritos en VBScript, habría que escribir onclick="función" sin los paréntesis. La sintaxis es idéntica si hay que pasar parámetros a la función: onclick="función(val1, val2,...)" En nuestro ejemplo, al hacer clic en el botón Effacer se invoca la siguiente función JavaScript effacer: La función effacer muestra el siguiente mensaje: 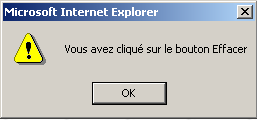 |
2.7.1.10. Botón de tipo «submit»
<input type="submit" value="Enviar" name="cmdRenvoyer"> |
![]()
<input type="submit" value="Enviar" name="cmdRenvoyer"> | |
type="submit": define el botón como un botón para enviar los datos del formulario al servidor web. Cuando el usuario haga clic en este botón, el navegador enviará los datos del formulario a la URL URL definida en el atributo action de la etiqueta <form>, según el método definido por el atributo method de dicha etiqueta. value="Enviar": el texto que se muestra en el botón |
2.7.1.11. Botón de tipo «reset»
<input type="reset" value="Restablecer" name="cmdRétablir"> |
![]()
<input type="reset" value="Restablecer" name="cmdRétablir"> | |
type="reset": define el botón como un botón de restablecimiento del formulario. Cuando el usuario haga clic en este botón, el navegador restablecerá el formulario al estado en el que lo recibió. value="Restablecer": el texto que se muestra en el botón |
2.7.1.12. Campo oculto
<input type="hidden" name="secret" value="uneValeur"> |
<input type="hidden" name="..." value="..."> | |
type="hidden": indica que se trata de un campo oculto. Un campo oculto forma parte del formulario, pero no se muestra al usuario. Sin embargo, si este solicitara a su navegador que mostrara el código fuente, vería la presencia de la etiqueta <input type="hidden" value="..."> y, por lo tanto, el valor del campo oculto. value="unValor": valor del campo oculto. ¿Para qué sirve el campo oculto? Permite al servidor web conservar información a lo largo de las solicitudes de un cliente. Pensemos en una aplicación de compras en línea. El cliente compra un primer artículo art1 en una cantidad de q1 en una primera página de un catálogo y, a continuación, pasa a otra página del catálogo. Para recordar que el cliente ha comprado q1 artículos art1, el servidor puede introducir estos dos datos en un campo oculto del formulario web de la nueva página. En esta nueva página, el cliente compra los artículos q2 y art2. Cuando los datos de este segundo formulario se envíen al servidor (submit), este no solo recibirá la información (q2, art2), sino también (q1, art1), que también forma parte del formulario como campo oculto no modificable por el usuario. A continuación, el servidor web colocará en un nuevo campo oculto la información (q1,art1) y (q2,art2) y enviará una nueva página del catálogo. Y así sucesivamente. |
2.7.2. Envío de los valores de un formulario a un servidor web por parte de un cliente web
En el estudio anterior mencionamos que el cliente web dispone de dos métodos para enviar a un servidor web los valores de un formulario que ha mostrado: los métodos GET y POST. Veamos con un ejemplo la diferencia entre ambos métodos. La página analizada anteriormente es una página estática. Para poder acceder a los encabezados HTTP enviados por el navegador que va a solicitar este documento, la transformamos en una página dinámica para un servidor web .NET (IIS o Cassini). No se trata aquí de centrarnos en la tecnología .NET, que se abordará en el siguiente capítulo, sino en las interacciones entre el cliente y el servidor. El código de la página ASP.NET es el siguiente:
<%@ Page Language="vb" CodeBehind="params.aspx.vb" AutoEventWireup="false" Inherits="ConsoleApplication1.params" %>
<script runat="server">
Private Sub Page_Init(Byval Sender as Object, Byval e as System.EventArgs)
' se guarda la consulta
saveRequest
end sub
Private Sub saveRequest
' guarda la solicitud actual en request.txt de la carpeta de la página
dim requestFileName as String=Me.MapPath(Me.TemplateSourceDirectory)+"\request.txt"
Me.Request.SaveAs(requestFileName,true)
end sub
</script>
<html>
<head>
<title>balises</title>
<script language="JavaScript">
function effacer(){
alert("Vous avez cliqué sur le bouton Effacer");
}//borrar
</script>
</head>
<body background="/images/standard.jpg">
....
</body>
</html>
Al contenido HTML de la página analizada, añadimos una parte de código en VB.NET. No comentaremos este código, salvo para señalar que, cada vez que se acceda al documento anterior, el servidor web guardará la solicitud del cliente web en el archivo [request.txt], ubicado en la carpeta del documento al que se accede.
2.7.2.1. Método GET
Hagamos una primera prueba, en la que, en el código HTML del documento, la etiqueta FORM se define de la siguiente manera:
<form method="get">
El documento anterior (HTML + código VB) se llama [params.aspx]. Se coloca en el árbol de directorios de un servidor web .NET (IIS/Cassini) y se accede a él mediante la URL http://localhost/aspnet/chap1/params.aspx:
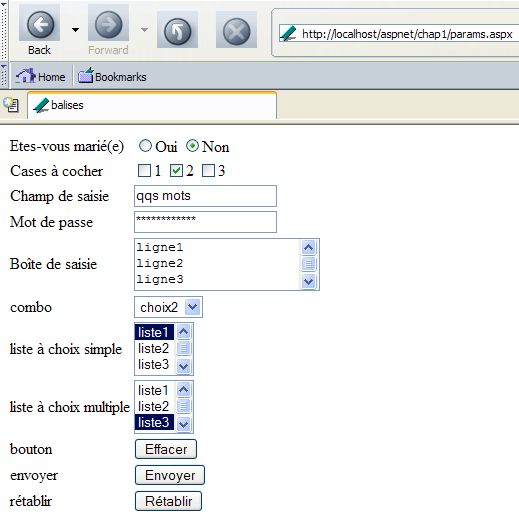
El navegador acaba de realizar una solicitud y sabemos que esta se ha guardado en el archivo [request.txt]. Veamos su contenido:
GET /aspnet/chap1/params.aspx HTTP/1.1
Connection: keep-alive
Keep-Alive: 300
Accept: application/x-shockwave-flash,text/xml,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,image/jpeg,image/gif;q=0.2,*/*;q=0,1
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Accept-Encoding: gzip,deflate
Accept-Language: en-us,en;q=0.5
Host: localhost
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.6) Gecko/20040113
Vemos elementos que ya hemos encontrado con el cliente [curl]. Otros aparecen por primera vez:
El cliente solicita al servidor que no cierre la conexión tras su respuesta. Esto le permitirá utilizar la misma conexión para una solicitud posterior. La conexión no permanece abierta indefinidamente. El servidor la cerrará tras un periodo de inactividad demasiado prolongado. | |
tiempo, en segundos, durante el cual permanecerá abierta la conexión [Keep-Alive] | |
Categoría de caracteres que el cliente sabe gestionar | |
Lista de idiomas preferidos por el cliente. |
Rellenamos el formulario de la siguiente manera:
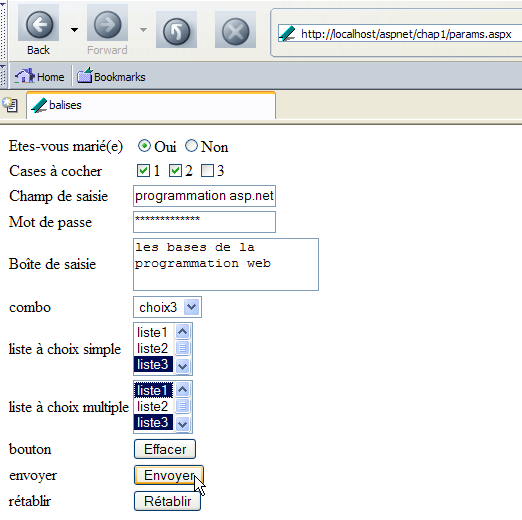
Utilizamos el botón [Envoyer] que aparece arriba. Su código HTML es el siguiente:
Al pulsar un botón del tipo [Submit], el navegador envía los parámetros del formulario (etiqueta <form>) al URL indicado en el atributo [action] de la etiqueta <form action="URL">, si existe. Si este atributo no existe, los parámetros del formulario se envían a la URL URL que ha generado el formulario. Este es el caso aquí. Por lo tanto, el botón [Envoyer] debería provocar una solicitud del navegador al URL [http://localhost/aspnet/chap1/params.aspx] con una transferencia de los parámetros del formulario. Dado que la página [params.aspx] almacena la solicitud recibida, deberíamos saber cómo ha enviado el cliente estos parámetros. Probemos. Hacemos clic en el botón [Envoyer]. Recibimos la siguiente respuesta del navegador:
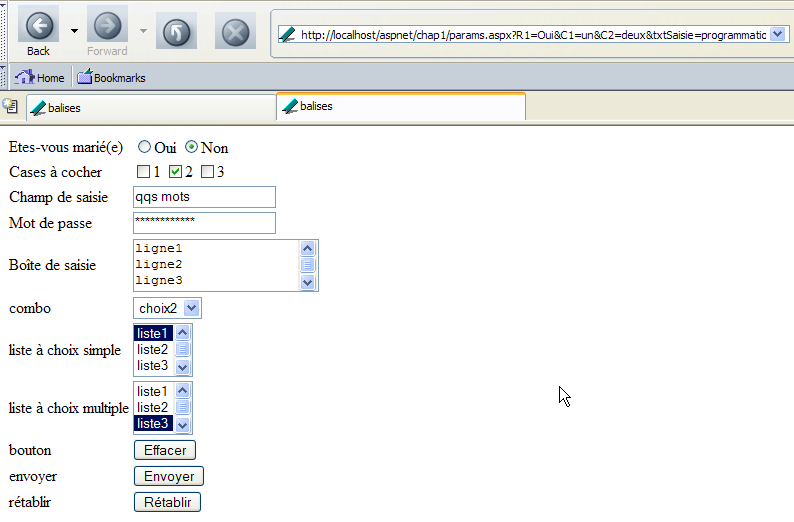
Es la página inicial, pero se puede observar que el valor «URL» ha cambiado en el campo «[Adresse]» del navegador. Ahora es el siguiente:
http://localhost/aspnet/chap1/params.aspx?R1=Sí&C1=uno&C2=dos&txtSaisie=programación+web&txtMdp=esto es secreto&areaSaisie=los+fundamentos+de+la%0D%0Aprogramación+web&cmbValeurs=opción3&lst1=lista3&lst2=lista1&lst2=lista3&cmdRenvoyer=Enviar&secret=uneValeur
Se observa que las opciones seleccionadas en el formulario aparecen en el campo «URL». Veamos el contenido del archivo «[request.txt]», que ha almacenado la solicitud del cliente:
GET /aspnet/chap1/params.aspx?R1=Oui&C1=un&C2=deux&txtSaisie=programmation+web&txtMdp=ceciestsecret&areaSaisie=les+bases+de+la%0D%0Aprogrammation+web&cmbValeurs=choix3&lst1=liste3&lst2=liste1&lst2=liste3&cmdRenvoyer=Envoyer&secret=uneValeur HTTP/1.1
Connection: keep-alive
Keep-Alive: 300
Accept: application/x-shockwave-flash,text/xml,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,image/jpeg,image/gif;q=0.2,*/*;q=0.1
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Accept-Encoding: gzip,deflate
Accept-Language: en-us,en;q=0.5
Host: localhost
Referer: http://localhost/aspnet/chap1/params.aspx
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.6) Gecko/20040113
Aparece una solicitud HTTP bastante similar a la que había realizado inicialmente el navegador al solicitar el documento sin enviar parámetros. Hay dos diferencias:
Los parámetros del formulario se han añadido al final de la URL del documento, en el formato ?param1=val1¶m2=val2&... | |
El cliente indica mediante este encabezado «HTTP» el «URL» del documento que estaba mostrando cuando realizó la solicitud |
Analicemos más detenidamente cómo se han pasado los parámetros en el comando GET URL?param1=valor1¶m2=valor2&... HTTP/1.1, donde parami son los nombres de los controles del formulario web y «valor» los valores que se les asocian. A continuación presentamos una tabla de tres columnas:
- columna 1: recoge la definición de un control HTML del ejemplo
- columna 2: muestra cómo se visualiza este control en un navegador
- columna 3: muestra el valor enviado al servidor por el navegador para el control de la columna 1, tal y como aparece en la solicitud GET del ejemplo
control HTML | Visualización | valor(es) devuelto(s) |
<input type="radio" value="Sí" name="R1">Sí <input type="radio" name="R1" value="no" checked>No | R1=Sí - el valor del atributo value del botón de opción marcado por el usuario. | |
<input type="checkbox" name="C1" value="uno">1 <input type="checkbox" name="C2" value="dos" checked>2 <input type="checkbox" name="C3" value="tres">3 | C1=uno C2=dos - valores de los atributos value de las casillas marcadas por el usuario | |
<input type="text" name="txtSaisie" size="20" value="unas palabras"> | txtSaisie = programación + web - texto introducido por el usuario en el campo de entrada. Los espacios se han sustituido por el signo + | |
<input type="password" name="txtMdp" size="20" value="unMotDePasse"> | txtMdp=estoesecreto - Texto introducido por el usuario en el campo de entrada | |
<textarea rows="2" name="areaSaisie" cols="20"> línea1 línea 2 línea 3 </textarea> | areaIntroducción=los+fundamentos+de+la%0D%0A programación+web - texto introducido por el usuario en el campo de entrada. %OD%OA es el marcador de fin de línea. Los espacios se han sustituido por el signo + | |
<select size="1" name="cmbValeurs"> <option>opción1</option> <option selected>opción2</option> <option>opción3</option> </select> | cmbValores=opción3 - valor elegido por el usuario en la lista de selección única | |
<select size="3" name="lst1"> <option selected>lista1</option> <option>lista2</option> <option>lista3</option> <option>lista4</option> <option>lista5</option> </select> | 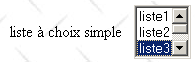 | lst1=lista3 - valor elegido por el usuario en la lista de selección única |
<select size="3" name="lst2" multiple> <option selected>lista1</option> <option>lista2</option> <option selected>lista3</option> <option>lista4</option> <option>lista5</option> </select> | 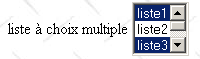 | lst2=lista1 lst2=lista3 - valores seleccionados por el usuario en la lista de selección múltiple |
<input type="submit" value="Enviar" name="cmdRenvoyer"> | cmdRenvoyer=Enviar - nombre y atributo value del botón que se ha utilizado para enviar los datos del formulario al servidor | |
<input type="hidden" name="secret" value="uneValeur"> | secret=unValor - atributo value del campo oculto |
Cabe preguntarse qué ha hecho el servidor con los parámetros que se le han pasado. En realidad, nada. Al recibir el comando
GET /aspnet/chap1/params.aspx?R1=Oui&C1=un&C2=deux&txtSaisie=programmation+web&txtMdp=ceciestsecret&areaSaisie=les+bases+de+la%0D%0Aprogrammation+web&cmbValeurs=choix3&lst1=liste3&lst2=liste1&lst2=liste3&cmdRenvoyer=Envoyer&secret=uneValeur HTTP/1.1
el servidor web ha transmitido los parámetros a URL en el documento http://localhost/aspnet/chap1/params.aspx, y a c.a.d en el documento que creamos inicialmente. No hemos escrito ningún código para recuperar y procesar los parámetros que nos envía el cliente. Por lo tanto, todo ocurre como si la solicitud del cliente fuera simplemente:
Por este motivo, al hacer clic en nuestro botón [Envoyer], hemos obtenido la misma página que la obtenida inicialmente al solicitar URL y [http://localhost/aspnet/chap1/params.aspx] sin parámetros.
2.7.2.2. Método POST
El documento HTML está ahora configurado para que el navegador utilice el método POST para enviar los valores del formulario al servidor web:
Solicitamos el nuevo documento mediante el URL [http://localhost/aspnet/chap1/params.aspx], rellenamos el formulario igual que para el método GET y enviamos los parámetros al servidor con el botón [Envoyer]. Recibimos del servidor la siguiente página de respuesta:
Por lo tanto, obtenemos el mismo resultado que con los métodos GET y c.a.d: la página inicial. Cabe destacar una diferencia: en el campo [Adresse] del navegador no aparecen los parámetros transmitidos. Ahora, veamos la solicitud enviada por el cliente y que se ha almacenado en el archivo [request.txt]:
POST /aspnet/chap1/params.aspx HTTP/1.1
Connection: keep-alive
Keep-Alive: 300
Content-Length: 210
Content-Type: application/x-www-form-urlencoded
Accept: application/x-shockwave-flash,text/xml,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,image/jpeg,image/gif;q=0.2,*/*;q=0,1
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Accept-Encoding: gzip,deflate
Accept-Language: en-us,en;q=0.5
Host: localhost
Referer: http://localhost/aspnet/chap1/params.aspx
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.6) Gecko/20040113
R1=Oui&C1=un&C2=deux&txtSaisie=programmation+web&txtMdp=ceciestsecrey&areaSaisie=les+bases+de+la%0D%0Aprogrammation+web&cmbValeurs=choix3&lst1=liste3&lst2=liste1&lst2=liste3&cmdRenvoyer=Envoyer&secret=uneValeur
Aparecen novedades en la consulta HTTP del cliente:
La consulta GET ha dado paso a la consulta POST. Los parámetros ya no aparecen en esta primera línea de la consulta. Se puede observar que ahora se sitúan después de la consulta HTTP, tras una línea en blanco. Su codificación es idéntica a la que tenían en la consulta GET. | |
número de caracteres «enviados», c.a.d. El número de caracteres que deberá leer el servidor web tras recibir los encabezados HTTP para recuperar el documento que le envía el cliente. El documento en cuestión es, en este caso, la lista de valores del formulario. | |
especifica el tipo de documento que el cliente enviará tras los encabezados HTTP. El tipo [application/x-www-form-urlencoded] indica que se trata de un documento que contiene valores de formulario. |
Existen dos métodos para transmitir datos a un servidor web: GET y POST. ¿Hay algún método mejor que el otro? Hemos visto que, si los valores de un formulario se enviaban desde el navegador mediante el método GET, el navegador mostraba en su campo Adresse la URL solicitada en el formato URL?param1=val1¶m2=val2&.... Esto puede considerarse una ventaja o un inconveniente:
- una ventaja si se quiere permitir al usuario añadir este URL configurado a sus favoritos
- un inconveniente si no queremos que el usuario tenga acceso a cierta información del formulario, como, por ejemplo, los campos ocultos
A partir de ahora, utilizaremos casi exclusivamente el método POST en nuestros formularios.
2.8. Conclusion
En este capítulo se han presentado diferentes conceptos básicos del desarrollo web:
- las diferentes herramientas y tecnologías disponibles (Java, ASP, asp.net, PHP, Perl, VBScript, JavaScript)
- las comunicaciones cliente-servidor a través del protocolo HTTP
- el diseño de un documento mediante el lenguaje HTML
- el diseño de formularios de introducción de datos
Hemos podido ver, a través de un ejemplo, cómo un cliente puede enviar información al servidor web. No hemos explicado cómo el servidor puede
- recuperar esa información
- procesarla
- enviar al cliente una respuesta dinámica en función del resultado del procesamiento
Este es el ámbito de la programación web, tema que abordaremos en el siguiente capítulo con la presentación de la tecnología ASP.NET.