5. Der Typ Stream<T> in Java 8
5.1. Beispiel-01 – Die Stream-Klasse
Operationen auf Observable-Streams weisen viele Ähnlichkeiten mit Streams auf. Ein Unterschied besteht darin, dass ein Element eines Streams erst verarbeitet werden kann, wenn der gesamte Stream abgerufen wurde, während ein Element eines Observable-Streams sofort nach dem Abruf verarbeitet (beobachtet) werden kann, ohne darauf zu warten, dass der gesamte Observable-Stream abgerufen wurde. Ein weiterer Unterschied besteht darin, dass die Werte eines Streams, sobald dieser abgerufen wurde, durch nacheinanderes Abrufen aus dem Stream genutzt werden. Bei Observables ist dies anders. Sobald ein Wert ausgegeben wird, wird dieser Wert an den Abonnenten weitergeleitet.
Mehrere Klassen implementieren das Konzept eines Streams. Hier stellen wir die Klasse Stream<T> vor:
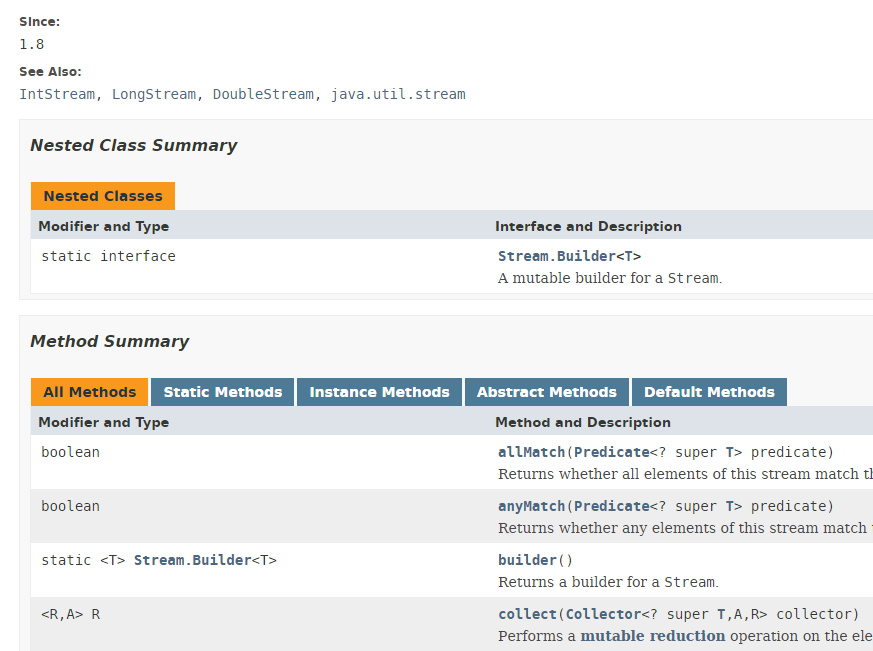
Die Stream-Klasse bietet 39 Methoden. Wir werden einige davon vorstellen. Betrachten Sie den folgenden Code:
 |
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple01 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// display 1
personnes.stream().forEach(p -> {
System.out.println(p);
});
System.out.println("----------------");
// display 2
personnes.stream().forEach(System.out::println);
}
}
- Zeile 11: Wir instanziieren eine Liste von Personen;
- Zeile 13: Aus dieser Liste erstellen wir einen Stream. Alle Sammlungen können auf diese Weise in Streams umgewandelt werden. Dadurch können wir alle Methoden dieser Klasse nutzen, die es uns ermöglichen, die Elemente der Sammlung prägnanter zu verarbeiten als mit Schleifen. Außerdem können wir so, sofern möglich, von der parallelen Verarbeitung der Elemente profitieren;
- Zeile 13: Die Methode [Stream.forEach] hat die folgende Signatur:
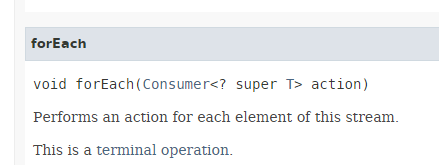 |
Wir sehen, dass der Parameter der Methode die in Abschnitt 4.4 vorgestellte funktionale Schnittstelle [Consumer<T>] ist – eine Schnittstelle, deren einzige Methode auf den Typ T angewendet wird und nichts zurückgibt.
- Im Code:
personnes.stream().forEach(p -> {
System.out.println(p);
});
- [people.stream()] erzeugt einen Stream von Elementen vom Typ [Person], der in die Methode [forEach] eingespeist wird. Der Parameter p ist vom Typ [Person], und die bereitgestellte Lambda-Funktion gibt diese Person aus;
Der vorherige Code lässt sich wie folgt vereinfachen (Zeile 18):
personnes.stream().forEach(System.out::println);
Anstatt den Wert einer Lambda-Funktion als Parameter zu übergeben, übergeben wir die Referenz auf eine vorhandene Methode, in diesem Fall die println-Methode der Klasse System.out. Natürlich muss diese Methode die richtige Signatur haben, in diesem Fall die Signatur der Methode [Consumer.accept]: void accept(T t). Wie bereits erwähnt, ist der Parameter der Methode [accept] vom Typ [Person];
Wir erhalten die folgenden Ergebnisse:
Sobald ein Stream verarbeitet wurde, kann er nicht mehr verarbeitet werden. Er muss neu erstellt werden, wenn Sie ihn erneut verarbeiten möchten. Dies wird durch den folgenden Code veranschaulicht [Beispiel01b]:
package dvp.java8.streams;
import java.util.stream.Stream;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple01b {
public static void main(String[] args) {
// people flows
Stream<Personne> personnes = Personnes.get().stream();
// display 1
personnes.forEach(p -> {
System.out.println(p);
});
System.out.println("----------------");
// display 2
personnes.forEach(System.out::println);
}
}
- Zeile 11: Um den Code zu optimieren, beschließen wir, den Stream nur einmal zu erstellen. Die erhaltenen Ergebnisse lauten wie folgt:
{"nom":"jean","age":20,"poids":70.0,"sexe":"HOMME"}
{"nom":"marie","age":10,"poids":30.0,"sexe":"FEMME"}
{"nom":"camille","age":30,"poids":55.0,"sexe":"FEMME"}
----------------
Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.sourceStageSpliterator(Unknown Source)
at java.util.stream.ReferencePipeline$Head.forEach(Unknown Source)
at dvp.java8.streams.Exemple02b.main(Exemple02b.java:18)
Jedes Mal, wenn Sie einen Stream verwenden möchten, müssen Sie ihn erstellen, auch wenn er bereits zuvor erstellt wurde.
5.2. Beispiel-02 – Parallele Verarbeitung von Elementen in einem Stream
 |
Betrachten Sie den folgenden Code:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple02 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// display 1
personnes.stream().forEach(Exemple02::affiche);
System.out.println("-----------------");
// display 2
personnes.stream().parallel().forEach(Exemple02::affiche);
}
public static void affiche(Personne p) {
System.out.printf("Personne %s sur thread %s%n", p, Thread.currentThread().getName());
}
}
- Zeilen 19–21: Die Methode [display] gibt die JSON-Zeichenkette einer Person zusammen mit dem Namen des Ausführungsthreads, in dem die Anzeige erfolgt, auf der Konsole aus;
- Zeile 13: Zeigt eine Liste von Personen an. Beachten Sie, dass der Parameter der [forEach]-Methode die Referenz auf die vorherige statische Methode ist;
- Zeile 16: Wir machen dasselbe, aber mit der [parallel]-Methode fordern wir an, dass die Stream-Elemente parallel über mehrere Threads hinweg verarbeitet werden. Nicht alle Verarbeitungsschritte können parallel ausgeführt werden. Hier müssen wir davon ausgehen, dass die Anzeigereihenfolge keine Rolle spielt, da bei der parallelen Verarbeitung die Ausführungsreihenfolge der Threads nicht garantiert ist. Beachten Sie auch eine Syntax, die sowohl für Streams als auch für Observables allgegenwärtig sein wird:
- (Fortsetzung)
- Der Stream erzeugt Elemente e1, die in die Methode m1 eingespeist werden;
- flux.m1 ist wiederum ein Strom von Elementen e2, die die Methode m2 speisen;
- flux.m1.m2 ist ein Stream von Elementen e3, die die Methode m3 versorgen;
Der Typ der Elemente e1, e2, e3 kann sich ändern, während der ursprüngliche Stream verarbeitet wird.
Die Ausführung dieses Codes liefert das folgende Ergebnis:
Wir sehen, dass die parallele Ausführung (Zeilen 5–7) auf drei verschiedenen Threads stattfand und nicht der Reihenfolge der Elemente folgte, wie sie in den Zeilen 1–3 dargestellt ist. In diesem Dokument werden wir uns nicht näher mit der parallelen Verarbeitung von Elementen in einem Stream befassen, da dies eine Erörterung der Bedingungen erfordern würde, die eine solche Verarbeitung ermöglichen. Wir stellen dann fest, dass nur wenige Operationen parallel ausgeführt werden können. Eine Operation, die sich auf natürliche Weise für Parallelität eignet, ist die Summe der numerischen Elemente eines Streams, die wir nun vorstellen werden.
5.3. Beispiel-03 – Parallele Verarbeitung von Stream-Elementen
 |
Betrachten Sie den folgenden Code (Beispiel 03a):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class Exemple03a {
public static void main(String[] args) {
final long limite = 10_000_000L;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// sum of numbers - sequential method
début = new Date().getTime();
long somme = nombres.stream().reduce(0L, (s, i) -> s + i);
System.out.printf("somme séquentielle : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- In Zeile 22 verwenden wir die Methode [reduce], die folgende Signatur hat:
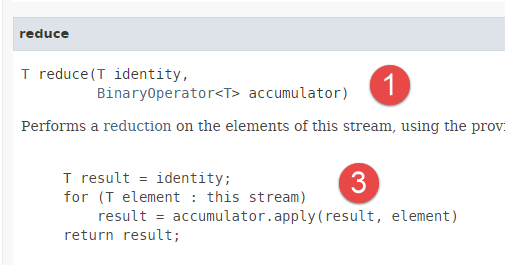 |  |
- Die Methode [reduce] arbeitet mit Elementen vom Typ T;
- die Methode [reduce] wendet dieselbe Verarbeitung auf alle Elemente in einem Stream an: Der Anfangswert eines Akkumulators wird als erster Parameter übergeben. Als zweiter Parameter wird eine Methode übergeben, die die funktionale Schnittstelle [BinaryOperator] [2] implementiert: Basierend auf jedem Element und dem Akkumulator gibt diese Methode einen neuen Wert für den Akkumulator zurück. Der Endwert des Akkumulators ist der von der Methode [reduce] zurückgegebene Wert. Der Code [3] veranschaulicht diesen Mechanismus. Die Methode [apply] ist die Methode der funktionalen Schnittstelle [BinaryOperator] [2];
Kehren wir zum Beispielcode zurück:
- Zeile 12: Wir zeigen die Anzahl der von der JVM erkannten Kerne an;
- Zeilen 15–18: Es wird eine Liste mit 10 Millionen Zahlen erstellt;
- Zeile 22: Die Summe dieser Zahlen wird sequenziell mit einem einzigen Thread berechnet;
Wir erhalten folgende Ergebnisse:
Ersetzen wir nun Zeile 22 des Codes durch Folgendes (Beispiel 03b):
long somme = nombres.stream().parallel().reduce(0L, (s, i) -> s + i);
Wir weisen die Stream-Elemente an, parallel unter Verwendung mehrerer Threads verarbeitet zu werden. Dies ist möglich, da die Reihenfolge, in der die Zahlen summiert werden, keine Rolle spielt. Wir können daher n1 Zahlen dem Thread T1, n2 Zahlen dem Thread T2 usw. zuweisen und schließlich die von diesen verschiedenen Threads gelieferten Ergebnisse summieren. Wir erhalten dann die folgenden Ergebnisse:
Es gibt also praktisch keinen Leistungsgewinn. Dies wird in den folgenden Beispielen häufig der Fall sein. Die Thread-Verwaltung selbst ist zeitaufwendig. Die von jedem Kern ausgeführte Operation muss ausreichend komplex sein, damit der Leistungsgewinn spürbar ist. Dies wird durch das folgende Beispiel (Beispiel03c) veranschaulicht:
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.function.BinaryOperator;
public class Exemple03c {
public static void main(String[] args) {
final long limite = 10_000L;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// sum of numbers - sequential method
début = new Date().getTime();
BinaryOperator<Long> bo = (s, i) -> {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
}
return s + i;
};
long somme = nombres.stream().reduce(0L, bo);
System.out.printf("somme séquentielle : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- Zeile 30: Wir verwenden erneut die Methode [reduce] und übergeben ihr die Referenz auf die Methode aus den Zeilen 23–29 als Parameter;
- Zeile 28: Die Methode [bo] gibt die Summe ihrer beiden Parameter zurück;
- Zeilen 24–27: Wir lassen den Thread künstlich 1 Millisekunde warten, um intensive Arbeit zu simulieren;
Wir erhalten dann die folgenden Ergebnisse:
Wenn wir nun Zeile 30 durch Folgendes ersetzen:
long somme = nombres.stream().parallel().reduce(0L, bo);
erhalten wir folgende Ergebnisse:
Wir können deutlich den Leistungsgewinn erkennen, der durch die parallele Ausführung der Summenberechnung erzielt wird. Bei der Verarbeitung von 8 Zahlen:
- wartet der sequenzielle Thread 8 Mal 1 Millisekunde, also 8 ms;
- die 8 parallelen Threads warten jeweils 1 Millisekunde gleichzeitig (der Einfachheit halber), also insgesamt 1 Millisekunde für die 8 Zahlen;
Wir können daher davon ausgehen, dass die parallele Ausführung 8-mal schneller ist als die sequenzielle Ausführung. Das trifft hier in etwa zu.
5.4. Beispiel-04 – Filtern eines Streams
 |
Betrachten Sie den folgenden Code:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple04 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// displays
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(p -> {
System.out.println(p);
});
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(p -> {
System.out.println(p);
});
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(System.out::println);
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(System.out::println);
}
}
- Zeile 14: Die Methode [Stream.filter] hat die folgende Signatur:
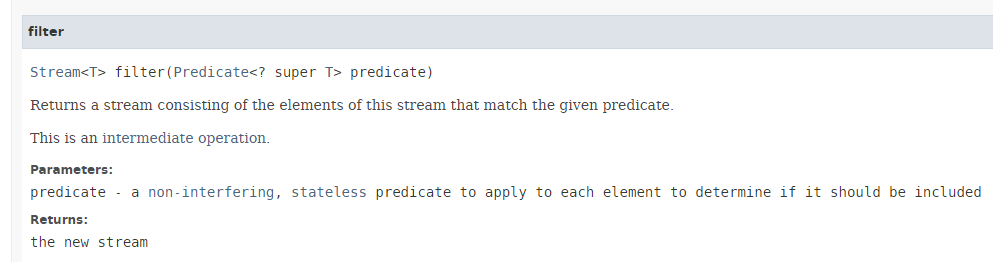 |
- Die Methode [filter] erwartet als Parameter eine Instanz der in Abschnitt 4.2 vorgestellten funktionalen Schnittstelle [Predicate], deren einzige zu implementierende Methode die folgende ist: boolean test(T t);
- Die Methode [filter] gibt die Elemente des Streams zurück, die das Predicate erfüllen. Sie wird daher zum Filtern des Streams verwendet;
Betrachten Sie den folgenden Code:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple04 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// displays
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(p -> {
System.out.println(p);
});
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(p -> {
System.out.println(p);
});
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(System.out::println);
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(System.out::println);
}
}
- Zeilen 14–16: Personen unter 28 Jahren anzeigen;
- Zeilen 18–20: Personen mit einem Gewicht <50 anzeigen;
- Zeile 22: macht dasselbe wie die Zeilen 14–16, aber prägnanter;
- Zeile 24: macht dasselbe wie die Zeilen 18–20, jedoch prägnanter;
Die Ergebnisse der Ausführung lauten wie folgt:
5.5. Beispiel-05 – Erstellen eines Stream<T2> aus einem Stream<T1>
 |
Betrachten Sie den folgenden Code:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple05 {
public static void main(String[] args) {
// list of persons
List<Personne> personnes = Personnes.get();
// displays
System.out.println("Personne --> String ----------------------");
personnes.stream().map(p -> p.getNom()).forEach(System.out::println);
System.out.println("Personne --> Integer ----------------------");
personnes.stream().map(p -> p.getAge()).forEach(System.out::println);
}
}
- Zeile 13: Die Methode [Stream.map] hat die folgende Signatur:
 |
Der Parameter der Methode [Stream.map] ist eine Instanz der in Abschnitt 4.3 vorgestellten funktionalen Schnittstelle [Function], deren einzige zu implementierende Methode lautet: R apply(T t). Wir sehen, dass die Funktion [apply] bei einem gegebenen Typ T einen Typ R erzeugt. Die Methode [Stream.map] erzeugt daher aus einem Stream vom Typ T einen Stream vom Typ R (ein Stream vom Typ T bedeutet hier – in einer technischen Ungenauigkeit, die wir beibehalten werden – einen Stream von Elementen vom Typ T).
Betrachten wir nun den Code im Beispiel:
- Zeile 14: Von einer Person p behalten wir nur den Namen. Wir erhalten somit einen Stream von Strings;
- Zeile 14: Von einer Person p behalten wir nur den Namen. Wir erhalten daher einen Stream vom Typ Integer;
Die erhaltenen Ergebnisse lauten wie folgt:
5.6. Beispiel-06 – Weitere Methoden der Klasse Stream<T>
 |
Anhand des folgenden Codes veranschaulichen wir einige der 39 Methoden der Klasse „Stream“:
package dvp.java8.streams;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import dvp.data.Personne;
import dvp.data.Personnes;
import java.util.Comparator;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.DoubleStream;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class Exemple06 {
// mapper jSON
static private ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// list of persons
List<Personne> personnes = Personnes.get();
// all people
affiche("all", personnes);
// the 1st person
affiche("findFirst", personnes.stream().findFirst().get());
// any person
affiche("findAny", personnes.stream().findAny().get());
// people without the 1st
affiche("skip 1", personnes.stream().skip(1L).collect(Collectors.toList()));
// the first 2 people
affiche("limit 2", personnes.stream().limit(2L).collect(Collectors.toList()));
// the number of people
affiche("count", personnes.stream().count());
// the oldest person
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
// the lightest person
affiche("poids min", personnes.stream().min(Comparator.comparingDouble(Personne::getPoids)).get());
// last person in alphabetical order of name
affiche("nom max", personnes.stream().max((p1, p2) -> p1.getNom().compareToIgnoreCase(p2.getNom())).get());
// total age of all persons
affiche("âge total (reduce)", personnes.stream().map(p -> p.getAge()).reduce(0, (a1, a2) -> a1 + a2));
// people by ascending age
affiche("personnes par âge croissant",
personnes.stream().sorted(Comparator.comparingInt(Personne::getAge)).collect(Collectors.toList()));
// are there any people over 100?
affiche("des personnes de + de 100 ans (anyMatch)", personnes.stream().anyMatch(p -> p.getAge() > 100));
// are all people at most 100 years old?
affiche("des personnes de + de 100 ans (noneMatch)", personnes.stream().noneMatch(p -> p.getAge() > 100));
// are all people over 8 years old?
affiche("des personnes de + de 8 ans (allMatch)", personnes.stream().allMatch(p -> p.getAge() > 8));
// group people by gender
affiche("personnes regroupées par sexe", personnes.stream().collect(Collectors.groupingBy(p -> p.getSexe())));
// remove duplicate elements from a list
affiche("distinct", Stream.of(1, 2, 1).distinct().collect(Collectors.toList()));
// of a Stream<Stream<T>>, we make a Stream<T>
affiche("flatMap", Stream.of(1, 2, 3).flatMap(i -> Stream.of(i, i + 10)).collect(Collectors.toList()));
// of a Stream<Stream<Integer>>, we make a IntStream and calculate its sum
affiche("flatMapToInt", Stream.of(1, 2, 3).flatMapToInt(i -> IntStream.of(i, i + 10)).sum());
// of a Stream<Stream<Integer>>, we make a DoubleStream and then an array
affiche("flatMapToDouble", Stream.of(1, 2, 3).flatMapToDouble(i -> DoubleStream.of(i, i * 1.2)).toArray());
// max of a stream of integers
affiche("reduce Integer::max", Stream.of(1, 10, 8).reduce(Integer::max).get());
// min of a Double
affiche("reduce Integer::min", Stream.of(1.5, 10.4, 8.9).reduce(Double::min).get());
// average of a stream of integers
affiche("IntStream average", IntStream.of(1, 10, 8).average().getAsDouble());
// statistics for a stream of integers
affiche("IntStream summaryStatistics", IntStream.of(1, 10, 8).summaryStatistics());
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- Zeilen 72, 75: Zeigen die JSON-Zeichenkette des zweiten Parameters der Methode an;
- Zeile 24: Zeigt die JSON-Zeichenkette für alle Personen an. Das Ergebnis lautet wie folgt:
5.6.1. [findFirst]
// la 1ère personne
affiche("findFirst", personnes.stream().findFirst().get());
Die Methode [findFirst] gibt das erste Element eines Streams zurück, sofern es vorhanden ist. Ihre Signatur lautet wie folgt:
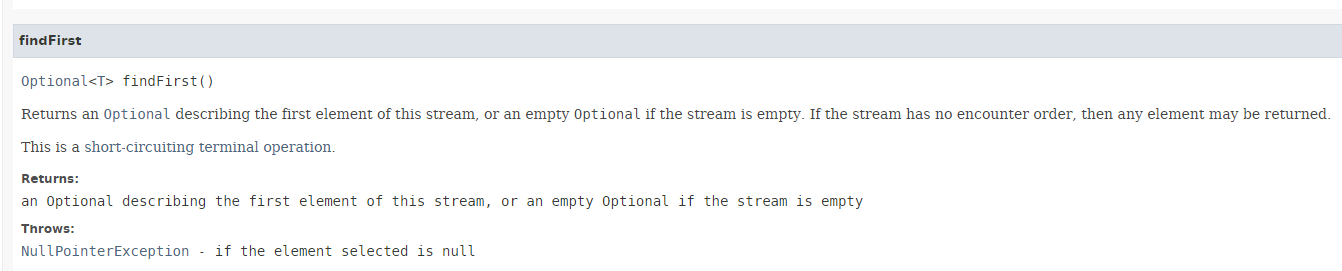 |
Das Ergebnis ist vom Typ Optional<T>, einem in Java 8 eingeführten Typ:
 |
Die Klasse Optional<T> ermöglicht eine unterschiedliche Behandlung von Null-Zeigern. Eine Methode, die einen Typ T zurückgeben muss, der den Wert null haben kann, kann stattdessen einen Typ Optional<T> zurückgeben. Mit der Methode [Optional<T>.isPresent()] lässt sich feststellen, ob die Methode einen Wert zurückgegeben hat oder nicht. Der folgende Code [Beispiel06b] veranschaulicht einen Teil der Funktionsweise von Optional<T>:
package dvp.java8.streams;
import java.util.Optional;
import com.fasterxml.jackson.core.JsonProcessingException;
public class Exemple06b {
public static void main(String[] args) throws JsonProcessingException {
// optional without value
Optional<Integer> o1 = m1();
System.out.println(o1.isPresent());
affiche(o1);
// optional with value
Optional<Integer> o2 = m2();
System.out.println(o2.isPresent());
affiche(o2);
}
private static void affiche(Optional<Integer> o1) {
try {
// retrieve the value of the Optional
// throws 1 exception if no value
System.out.println(o1.get());
} catch (Throwable th) {
System.out.printf("%s : %s%n", th.getClass().getName(), th.getMessage());
}
}
public static Optional<Integer> m1() {
// no value
return Optional.empty();
}
public static Optional<Integer> m2() {
// a value
return Optional.of(10);
}
}
Die Ergebnisse lauten wie folgt:
false
java.util.NoSuchElementException : No value present
true
10
Kehren wir zu dem Code zurück, der die Methode [findFirst] veranschaulicht:
// la 1ère personne
affiche("findFirst", personnes.stream().findFirst().get());
- Zeile 2: Um den Code zu vereinfachen, verwenden wir die Methode [get] für das von der Methode [findFirst] erzeugte Optional<Person>. Für sauberen Code müsste vor dem Aufruf der Methode [get] die Methode [Optional<Person>.isPresent()] aufgerufen werden;
Das Ergebnis lautet wie folgt:
5.6.2. [findAny]
// n'importe quelle personne
affiche("findAny", personnes.stream().findAny().get());
Die Methode [findAny] hat die folgende Signatur:
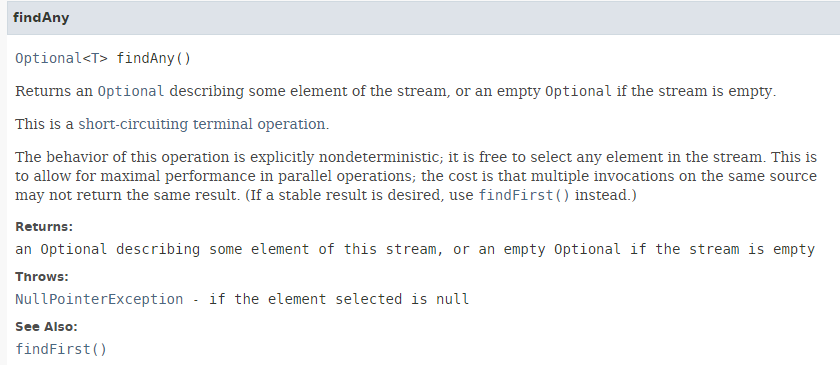 |
Die Methode [findAny] kann ein beliebiges Element aus dem Stream zurückgeben. Bei Tests stellen wir fest, dass eine sequenzielle Ausführung das erste Element des Streams zurückgibt, während eine parallele Ausführung tatsächlich ein beliebiges Element zurückgeben kann. Dies wird durch den folgenden Code [Beispiel06c] veranschaulicht:
package dvp.java8.streams;
import java.util.List;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple06c {
// mapper jSON
static private ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// list of persons
List<Personne> personnes = Personnes.get();
// everyone
affiche("all", personnes);
// any person
affiche("findAny parallèle", personnes.stream().parallel().findAny().get());
// any person
affiche("findAny séquentiel", personnes.stream().findAny().get());
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- Zeile 22: findAny wird parallel ausgeführt;
- Zeile 24: findAny wird sequenziell ausgeführt;
Die erhaltenen Ergebnisse lauten wie folgt:
- Zeile 4: Die parallele Ausführung gab das zweite Element der Personenliste zurück. Es hätte auch ein anderes sein können;
- Zeile 6: Die sequenzielle Ausführung gab das erste Element der Liste der Personen zurück;
Die Verwendung der Methode [findAny] scheint nur bei der parallelen Verarbeitung eines Streams sinnvoll zu sein.
5.6.3. [skip]
// les personnes sans la 1ère
affiche("skip 1", personnes.stream().skip(1L).collect(Collectors.toList()));
Die Methode [skip] hat die folgende Signatur:
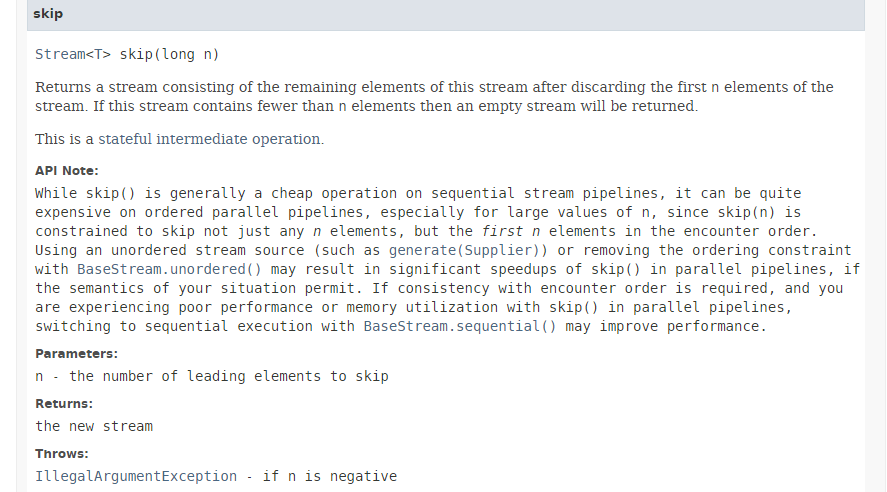 |
Die [skip]-Methode überspringt die ersten n Elemente eines Streams. Wie in der obigen Dokumentation angegeben, bringt die parallele Ausführung dieser Methode kaum Leistungsgewinne und kann sogar zu Leistungseinbußen führen. Tatsächlich sind die Threads gezwungen, sich zu koordinieren, um die ersten n Elemente zu überspringen, was die durch die Parallelität erzielten Leistungsgewinne zunichte macht.
Die [skip]-Methode gibt einen Stream<Person> zurück, der durch die [collect]-Methode in eine List<Person> umgewandelt wird. Diese Methode hat die folgende Signatur:
 |
Die Methode [collect] nimmt als Parameter eine Instanz vom Typ [Collector] entgegen, die eine komplexe Signatur aufweist. Es gibt vordefinierte Implementierungen des Typs [Collector], die es Ihnen in der Regel ermöglichen, eine eigene Implementierung zu vermeiden. Hier wird die Implementierung [Collectors.toList()] verwendet. [Collectors] ist eine Klasse mit zahlreichen statischen Methoden, die den Typ [Collector<T,A,R>] implementieren. Dies ist die erste Anlaufstelle, wenn Sie einen Stream in eine Standard-Java-Sammlung konvertieren möchten:
 |
Wir werden einige dieser Methoden später verwenden.
Die Ausführung liefert das folgende Ergebnis:
Das erste Element der Liste (jean) wurde weggelassen.
5.6.4. [limit]
// les 2 premières personnes
affiche("limit 2", personnes.stream().limit(2L).collect(Collectors.toList()));
Die Methode [limit] hat folgende Signatur:
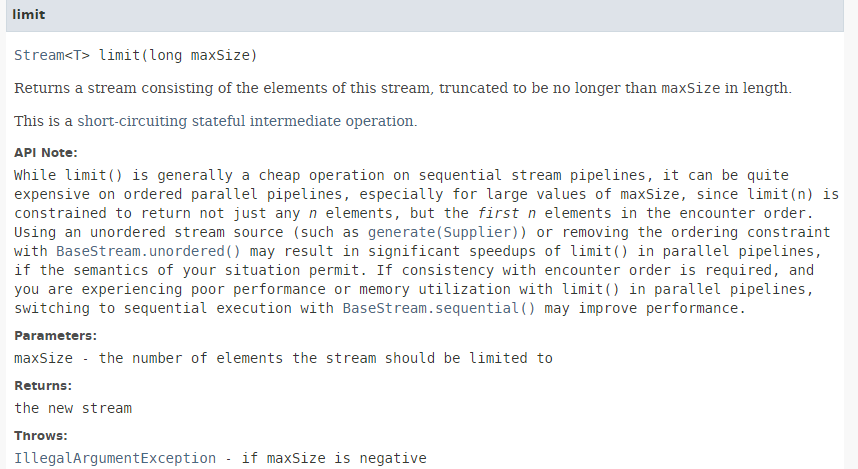 |
Mit der Methode [limit] können Sie nur die ersten n Elemente eines Streams beibehalten. Sie ist nicht für die parallele Verarbeitung geeignet.
Die Ausführung liefert das folgende Ergebnis:
5.6.5. [count]
// le nombre de personnes
affiche("count", personnes.stream().count());
Die Methode [count] hat folgende Signatur:
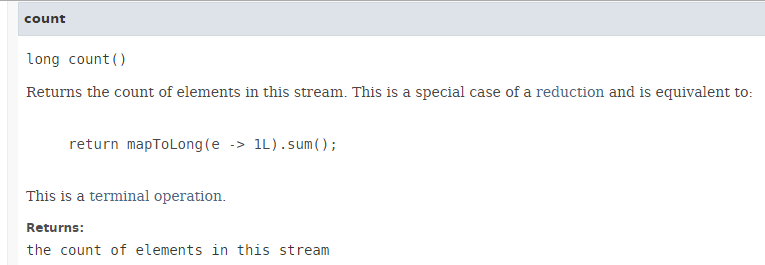 |
Die [count]-Methode gibt die Anzahl der Elemente in einem Stream zurück. Die parallele Ausführung der Methode führt zu keinem Leistungsgewinn, wie der folgende Code (Beispiel06d1) zeigt:
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.stream.Stream;
public class Exemple06d1 {
public static void main(String[] args) {
final long limite = 10_000_000L;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// counting numbers - sequential method
Stream<Long> sNombres = nombres.stream();
début = new Date().getTime();
long count = sNombres.count();
System.out.printf("comptage séquentiel : compteur=%s, durée (ms)=%s%n", count, new Date().getTime() - début);
}
}
- Zeilen 11–22: Erstellen eines Streams mit 10 Millionen Zahlen;
- Zeilen 22–24: Zählen des Streams;
Die Ausführung liefert das folgende Ergebnis:
Wenn wir Zeile 22 des Codes durch Folgendes ersetzen (Beispiel06d2):
Stream<Long> sNombres = nombres.stream().parallel();
erhalten wir folgende Ergebnisse:
5.6.6. [max, min]
// la personne la + âgée
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
Die Methode [max] hat folgende Signatur:
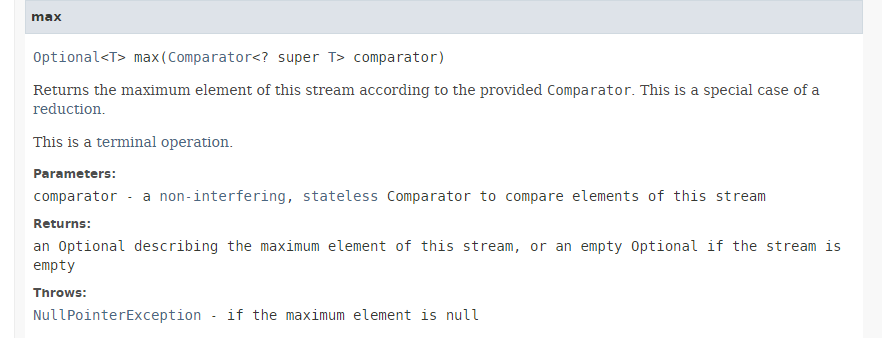 |
Die Methode [max] gibt den Maximalwert eines Streams unter Verwendung des als Parameter übergebenen Komparators zurück. Comparator ist eine funktionale Schnittstelle, deren einzige zu implementierende Methode die Signatur int compare(T o1, T o2) hat. Diese Methode muss -1 zurückgeben, wenn o1 < o2, 0, wenn o1.equals(o2), und +1, wenn o1 > o2. Die funktionale Schnittstelle Comparator verfügt über viele statische Standardmethoden, die die Comparator-Schnittstelle für die gängigsten Fälle implementieren. Daher gilt in der Anweisung:
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
verwenden wir die statische Methode [Comparator.comparingInt], deren Signatur wie folgt lautet:
 |
Der Typ *ToIntFunction* ist eine funktionale Schnittstelle:
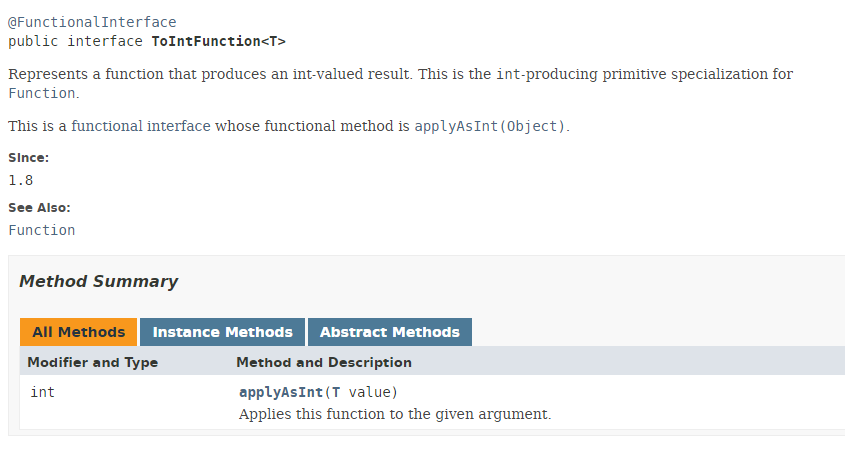 |
Die Methode [applyAsInt] der funktionalen Schnittstelle ToIntFunction erzeugt einen Typ int aus einem Typ T. Kehren wir zu unserem Code zurück:
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
Der tatsächliche Parameter der Methode [Comparator.comparingInt] muss hier ein Lambda vom Typ Person --> int sein. Wir übergeben die Referenz an die Methode [Person.getAge], die diese Signatur aufweist. Letztendlich erhalten wir die Person mit dem höchsten Alter. Wir erhalten einen Typ Optional<Person>, aus dem wir den Wert mithilfe der Methode [Optional.get] extrahieren. Wir erhalten das folgende Ergebnis:
Die parallele Berechnung des Maximums führt zu keinen Leistungssteigerungen, wie das folgende Beispiel zeigt: (Beispiel06e1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Date;
import java.util.List;
import java.util.Random;
import java.util.stream.Stream;
public class Exemple06e1 {
public static void main(String[] args) {
// data
// final long limit = 100L;
// final boolean verbose = true;
final long limite = 10_000_000L;
final boolean verbose = false;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextLong());
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// max numbers - sequential method
Stream<Long> sNombres = nombres.stream();
Comparator<Long> compLong = (l1, l2) -> {
if (verbose) {
// thread
System.out.printf("[%s]", Thread.currentThread().getName());
}
// comparison
long v1 = l1.longValue();
long v2 = l2.longValue();
if (v1 < v2) {
return -1;
} else {
if (v1 == v2) {
return 0;
} else {
return +1;
}
}
};
début = new Date().getTime();
// long max = sNombres.max(Comparator.naturalOrder()).get();
long max = sNombres.max(compLong).get();
System.out.printf("%nmax séquentiel : max=%s, durée (ms)=%s%n", max, new Date().getTime() - début);
}
}
- Zeile 29: Wir haben einen Strom von zufälligen Ganzzahlen vom Typ Long;
- Zeilen 30–47: Die Lambda-Variable compLong implementiert die Schnittstelle Comparator<Long>. Diese Schnittstelle wird normalerweise durch die Methode [Comparator.naturalOrder()] in Zeile 49 implementiert. Hier wollen wir jedoch den Ausführungs-Thread anzeigen (Zeilen 31–33). Deshalb implementieren wir die Schnittstelle selbst;
- Zeile 50: Ermittlung des Maximums;
Wir erhalten die folgenden Ergebnisse:
 |
Wenn wir nun Zeile 27 durch Folgendes ersetzen (Beispiel06e2):
Stream<Long> sNombres = nombres.stream().parallel();
erhalten wir folgende Ergebnisse:
 |
Die parallele Ausführung war daher langsamer. Wenn wir die Anzahl der Zahlen mit verbose=false auf 10 Millionen erhöhen, erhalten wir folgende Ergebnisse:
Für die sequenzielle Ausführung:
für die parallele Ausführung, die weiterhin langsamer ist.
Wir verwenden die Methode [Stream.min] auf ähnliche Weise:
// la personne la + légère
affiche("poids min", personnes.stream().min(Comparator.comparingDouble(Personne::getPoids)).get());
5.6.7. [reduce]
// l'âge total de toutes les personnes
affiche("âge total (reduce)", personnes.stream().map(p -> p.getAge()).reduce(0, (a1, a2) -> a1 + a2));
Die Methode [reduce] wurde in Abschnitt 5.3 vorgestellt. Zeile 2 oben summiert die Alterswerte aller Personen. Das Ergebnis lautet wie folgt:
5.6.8. [sortiert]
// les personnes par âge croissant
affiche("personnes par âge croissant",
personnes.stream().sorted(Comparator.comparingInt(Personne::getAge)).collect(Collectors.toList()));
// les personnes par ordre alphabétique des noms
List<Personne> lPersonnes=personnes.stream().sorted((p1, p2) -> p1.getNom().compareTo(p2.getNom())).collect(Collectors.toList());
affiche("personnes par ordre alphabétique des noms", lPersonnes);
Die Methode [sorted] (Zeilen 3 und 5) hat folgende Signatur:
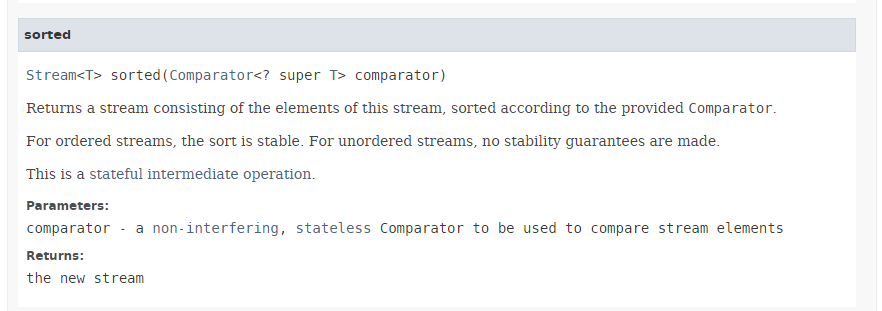 |
Die Methode [sorted] nimmt als Parameter den Typ [Comparator] entgegen, der in Abschnitt 5.6.6 für die Methoden min und max beschrieben wurde. Sie ermöglicht es, einen Stream in der Reihenfolge des als Parameter übergebenen Komparators zu sortieren. Wir haben gesehen, dass die Schnittstelle [Comparator] mehrere statische Standardmethoden bereitstellt, die gängige Komparatoren implementieren, insbesondere für Zahlen und Zeichenfolgen. Hier verwenden wir die Methode [Comparator.comparingInt], die als Parameter einen Typ ToIntFunction akzeptiert, bei dem es sich um eine funktionale Schnittstelle für die Methode [applyAsInt] mit der folgenden Signatur handelt: int applyAsInt(T t). Hier ist der tatsächliche Parameter, der in Zeile 3 an die Methode [Comparator.comparingInt] übergeben wird, die Referenz auf die Methode [Person.age], die das Alter der Person zurückgibt.
Die Schnittstelle [Comparator] bietet keine statischen Methoden zum Vergleichen von Zeichenfolgen. In Zeile 5 erstellen wir selbst ein Lambda, das die einzige Methode dieser Schnittstelle implementiert: int compare(T t1, T t2)
(p1, p2) -> p1.getNom().compareTo(p2.getNom())
Dieses Lambda vergleicht die Namen der Personen. Die erhaltenen Ergebnisse lauten wie folgt:
Eine parallele Ausführung der Sortierung scheint nicht möglich zu sein, wie der folgende Code zeigt (Beispiel06f1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Date;
import java.util.List;
import java.util.Random;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class Exemple06f1 {
// mapper jSON
static ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// data
final long limite = 100L;
final boolean verbose = true;
// final long limit = 10_000_000L;
// final boolean verbose = false;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Integer> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextInt(1000));
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// number sorting - sequential method
Stream<Integer> sNombres = nombres.stream();
début = new Date().getTime();
Comparator<Integer> compInt = (i1, i2) -> {
if (verbose) {
// thread
System.out.printf("[%s]", Thread.currentThread().getName());
}
// comparison
int v1 = i1.intValue();
int v2 = i2.intValue();
if (v1 < v2) {
return +1;
} else {
if (v1 == v2) {
return 0;
} else {
return -1;
}
}
};
if (verbose) {
affiche("nombres", sNombres.sorted(compInt).collect(Collectors.toList()));
}
System.out.printf("tri séquentiel : durée (ms)=%s%n", new Date().getTime() - début);
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- Zeilen 30–36: Wir erzeugen eine Folge von Zufallszahlen;
- Zeile 32: Wir übergeben das Lambda „compInt“ (Zeilen 38–55) an die Methode [sorted]. Dieses Lambda sortiert die Zahlen in absteigender Reihenfolge und zeigt den Thread an, der es ausführt.
Die erhaltenen Ergebnisse lauten wie folgt:
 |
Wenn wir im vorherigen Code Zeile 36 durch Folgendes ersetzen (Beispiel06f2):
Stream<Integer> sNombres = nombres.stream().parallel();
erhalten wir folgende Ergebnisse:
 |
Überraschenderweise stellen wir fest, dass der Zahlenstrom mit einem einzigen Thread sortiert wurde. Es gab keine Parallelität. Oder habe ich etwas übersehen?
5.6.9. [anyMatch, noneMatch, allMatch]
// y-a-t-il des personnes de + de 100 ans ?
affiche("des personnes de + de 100 ans (anyMatch)", personnes.stream().anyMatch(p -> p.getAge() > 100));
// est-ce que toutes les personnes ont au plus 100 ans ?
affiche("des personnes de + de 100 ans (noneMatch)", personnes.stream().noneMatch(p -> p.getAge() > 100));
// est-ce que toutes les personnes ont + de 8 ans
affiche("des personnes de + de 8 ans (allMatch)", personnes.stream().allMatch(p -> p.getAge() > 8));
Zeilen 2, 4 und 6: Die Methoden [anyMatch, noneMatch, allMatch] nehmen einen Predicate-Typ als Parameter entgegen, wie in Abschnitt 4.2 beschrieben. Sie führen daher eine Filterung durch. Alle drei geben einen booleschen Wert zurück:
- anyMatch gibt true zurück, wenn mindestens ein Element im Stream vorhanden ist, das den Filter erfüllt;
- noneMatch gibt „true“ zurück, wenn kein Element im Stream den Filter erfüllt;
- allMatch gibt „true“ zurück, wenn alle Elemente des Streams den Filter erfüllen;
Die erhaltenen Ergebnisse lauten wie folgt:
5.6.10. [collect(Collectors.groupingBy)]
// on regroupe les personnes par sexe
affiche("personnes regroupées par sexe", personnes.stream().collect(Collectors.groupingBy(p -> p.getSexe())));
Die Methode [collect] wurde in Abschnitt 5.6.3 vorgestellt. Ihr Parameter ist eine Implementierung der Schnittstelle [Collector]. Die Klasse [Collectors] stellt eine Reihe statischer Methoden bereit, die die Schnittstelle [Collector] implementieren. Bisher haben wir die Methode [Collectors.toList()] verwendet. Hier verwenden wir die statische Methode [Collectors.groupingBy], die aus dem Stream ein Dictionary erstellt. Ihre Signatur lautet wie folgt:
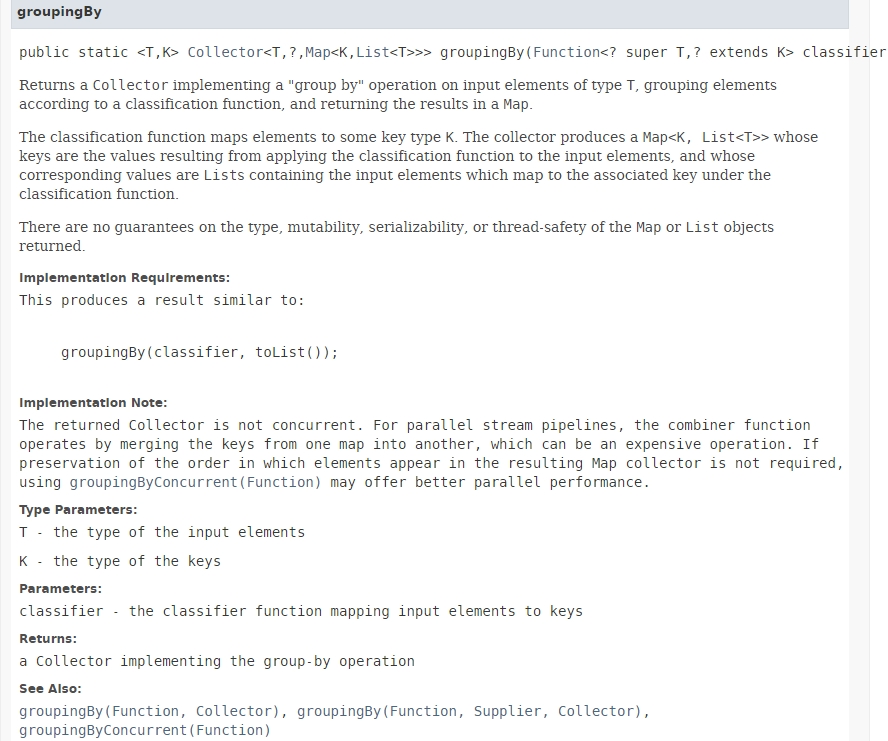 |
Die Methode [groupingBy] erstellt aus einem Stream<T> ein Map<K,List<T>>. Der Schlüssel K wird durch den Parameter der Methode [groupingBy] vom Typ Function<T,K> bereitgestellt, dessen einzige Methode die Signatur K apply(T t) hat. Wenn wir ein Map erstellen wollen, das nach dem Geschlecht einer Person indiziert ist, müssen wir eine Funktion bereitstellen, die das Geschlecht einer Person ermittelt. Hier übergeben wir die Referenz auf die Methode [Person.getGender] als tatsächlichen Parameter der Methode [groupingBy]. Die erhaltenen Ergebnisse lauten wie folgt:
Zeile 2 enthält die JSON-Zeichenkette eines Wörterbuchs, das durch zwei Schlüssel indiziert ist: MAN und WOMAN.
Parallele Berechnungen führen nicht zu Leistungssteigerungen, wie das folgende Beispiel (Beispiel06g1) zeigt:
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class Exemple06g1 {
// mppeur jSON
static ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// data
final long limite = 100L;
final boolean verbose = true;
// final long limit = 10_000_000L;
// final boolean verbose = false;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Integer> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextInt(1000));
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// grouping numbers by hundred - sequential method
Stream<Integer> sNombres = nombres.stream();
Function<Integer, Integer> groupByCent = n -> {
if (verbose) {
System.out.printf("[%s]", Thread.currentThread().getName());
}
return n / 100;
};
début = new Date().getTime();
// Map<Integer, List<Integer>> lNombres = sNombres.collect(Collectors.groupingBy(number -> number / 100));
Map<Integer, List<Integer>> lNombres = sNombres.collect(Collectors.groupingBy(groupByCent));
System.out.printf("%nregroupement séquentiel : durée (ms)=%s%n", new Date().getTime() - début);
// results
if (verbose) {
affiche("nombres regroupés", lNombres);
}
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- Zeilen 23–38: Erstellen eines Zahlenstroms;
- Zeile 47: Die Zahlen werden in Hundertergruppen zusammengefasst. Die Lambda-Funktion in den Zeilen 39–44 dient dazu, den Ausführungs-Thread anzuzeigen;
Die Ausführungsergebnisse lauten wie folgt:
 |
Wenn wir im Code Zeile 38 durch die folgende Zeile ersetzen (Beispiel06g2):
Stream<Integer> sNombres = nombres.stream().parallel();
erhalten wir folgende Ergebnisse:
 |
Wir können sehen, dass die parallele Ausführung der Gruppierung die Leistung beeinträchtigt hat.
5.6.11. [distinct]
// supression des éléments en double d'une liste
affiche("distinct", Stream.of(1, 2, 1).distinct().collect(Collectors.toList()));
Die Methode [distinct] hat die folgende Signatur:
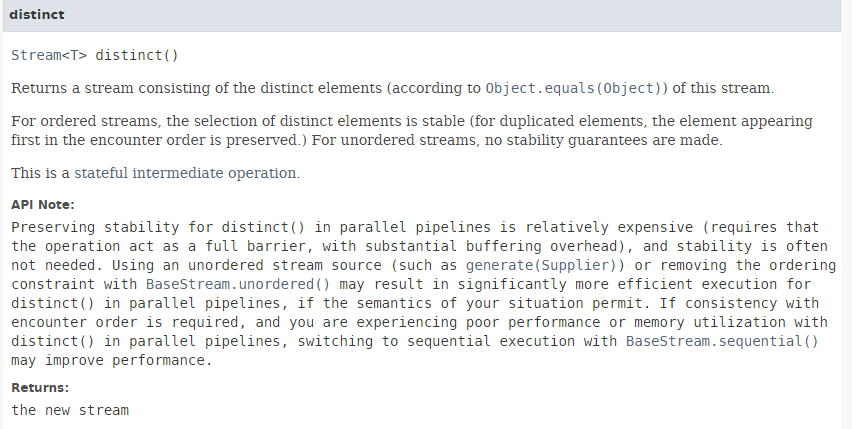 |
Sie entfernt Duplikate aus einem Stream. Die Methode [Stream.of] (Zeile 2) hat folgende Signatur:
 |
Damit können Sie einen Stream aus explizit angegebenen Werten erstellen. Die Ergebnisse der Ausführung lauten wie folgt:
5.6.12. [flatMap]
// d'un Stream<Stream<T>>, on fait un Stream<T>
affiche("flatMap", Stream.of(1, 2, 3).flatMap(i -> Stream.of(i, i + 10)).collect(Collectors.toList()));
Die Methode [flatMap] hat die folgende Signatur:
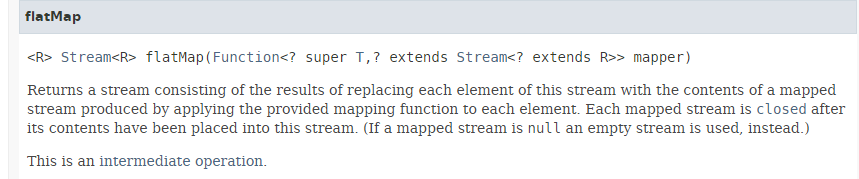  |
Die Methode [flatMap] nimmt als Parameter eine Funktion entgegen, die:
- ein Element vom Typ T aus dem Stream als Parameter entgegennimmt;
- einen Stream<R> zurückgibt;
Hätten wir anstelle der [flatMap]-Methode die in Abschnitt 5.5 beschriebene [map]-Methode verwendet, wäre das Ergebnis ein Typ Stream<Stream<R>>, wobei jedes Element vom Typ T im ursprünglichen Stream ein Stream<R>-Element erzeugt hätte. Die Methode [flatMap] hingegen gibt einen Typ Stream<R> zurück. Sie fasst die verschiedenen Stream<R>-Streams zu einem einzigen Stream zusammen. Dies zeigen die Ergebnisse der Ausführung des vorherigen Codes:
Es gibt spezielle Varianten von [flatMap]:
// d'un Stream<IntStream>, on fait un IntStream dont on calcule la somme
affiche("flatMapToInt", Stream.of(1, 2, 3).flatMapToInt(i -> IntStream.of(i, i + 10)).sum());
Die Methode [flatMapToInt] hat folgende Signatur:
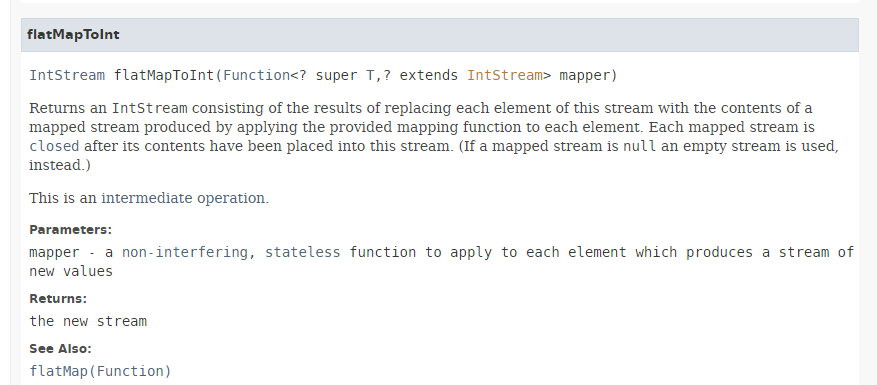 |
Die Methode [flatMapToInt] nimmt als Parameter eine Funktion entgegen, die einen IntStream des folgenden Typs zurückgibt:
 |
IntStream ist ein Stream vom Typ int. Dieser Typ ist dem Typ Stream<Integer> vorzuziehen, da bei seiner Verarbeitung das Boxing/Unboxing zwischen den Typen Integer und int vermieden wird. Diese Schnittstelle erbt viele Methoden vom Typ Stream<T> und fügt weitere hinzu, darunter die oben genannte Methode [sum], die die Elemente des IntStream summiert.
Der folgende Code veranschaulicht die Verwendung der entsprechenden Methode [flatMapToDouble]:
// d'un Stream<DoubleStream>, on fait un DoubleStream puis un tableau
affiche("flatMapToDouble", Stream.of(1, 2, 3).flatMapToDouble(i -> DoubleStream.of(i, i * 1.2)).toArray());
Mit der Methode [DoubleStream.toArray] können Sie von einem DoubleStream-Typ in einen double[]-Typ konvertieren.
Die Ergebnisse für diese beiden Beispiele lauten wie folgt:
Das folgende Beispiel veranschaulicht die Leistungssteigerungen, die durch den Wechsel vom Typ Stream<Long> zum Typ LongStream erzielt werden (Beispiel06i1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class Exemple06i1 {
public static void main(String[] args) {
final long limite = 10_000_000L;
// number of processors
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// list of numbers
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// sum of numbers - sequential method
début = new Date().getTime();
long somme = nombres.stream().reduce(0L, (s, i) -> s + i);
System.out.printf("somme séquentielle du Stream<Integer> : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- Zeile 22: Berechnung der Summe eines Streams von Long-Zahlen;
Es werden folgende Ergebnisse erhalten:
Ersetzen wir nun Zeile 22 durch Folgendes (Beispiel06i2):
long somme = nombres.stream().mapToLong(n -> n.longValue()).sum();
Die Methode Stream<Integer>.mapToLong ermöglicht es uns, einen LongStream mit primitiven long-Elementen zu erhalten, den wir dann mithilfe der sum-Funktion summieren. Wir erhalten daraufhin die folgenden Ergebnisse:
Der Leistungsgewinn ist deutlich.
5.6.13. Primitive Methoden für Zahlenströme
// max d'un flux de int
affiche("IntStream max", IntStream.of(1, 10, 8).max());
// min d'un flux de double
affiche("DoubleStream min", DoubleStream.of(1.5, 10.4, 8.9).min());
// moyenne d'un flux de int
affiche("IntStream average", IntStream.of(1, 10, 8).average().getAsDouble());
// statistiques d'un flux de int
affiche("IntStream summaryStatistics", IntStream.of(1, 10, 8).summaryStatistics());
Streams mit primitiven Werten (int, long, double) bieten auf diese Typen zugeschnittene Methoden. Das Ergebnis der Ausführung des vorherigen Codes lautet wie folgt:
- Das Ergebnis von Zeile 2 des Codes ist ein Typ „OptionalInt“, der dem Typ „Optional<Integer>“ entspricht. Der in diesem Objekt gespeicherte Wert kann mit der Methode [getAsInt()] abgerufen werden. Das Vorhandensein eines Werts kann mit der Methode [isPresent()] überprüft werden. Zeile 2 der Ergebnisse bedeutet nicht, dass die Klasse [OptionalInt] Felder namens [asInt] und [present] besitzt. Standardmäßig verwendet die JSON-Bibliothek alle öffentlichen getX- und isY-Methoden des Objekts, das in JSON serialisiert werden soll. Und hier gibt es tatsächlich eine [getAsInt]-Methode und eine weitere [isPresent]-Methode, auch wenn die Felder [asInt, present] selbst nicht existieren;
- Das Ergebnis von Zeile 4 des Codes ist ein Typ „OptionalDouble“, analog zum Typ „Optional<Double>“;
- Das Ergebnis von Zeile 6 des Codes ist ein Typ „OptionalDouble“, dessen Wert mit der Methode [getAsDouble()] abgerufen werden kann. Die Methode [average] berechnet den Durchschnitt des Zahlenstroms;
- Das Ergebnis von Zeile 8 des Codes ist ein Typ „IntSummaryStatistics“, der wie folgt definiert ist:
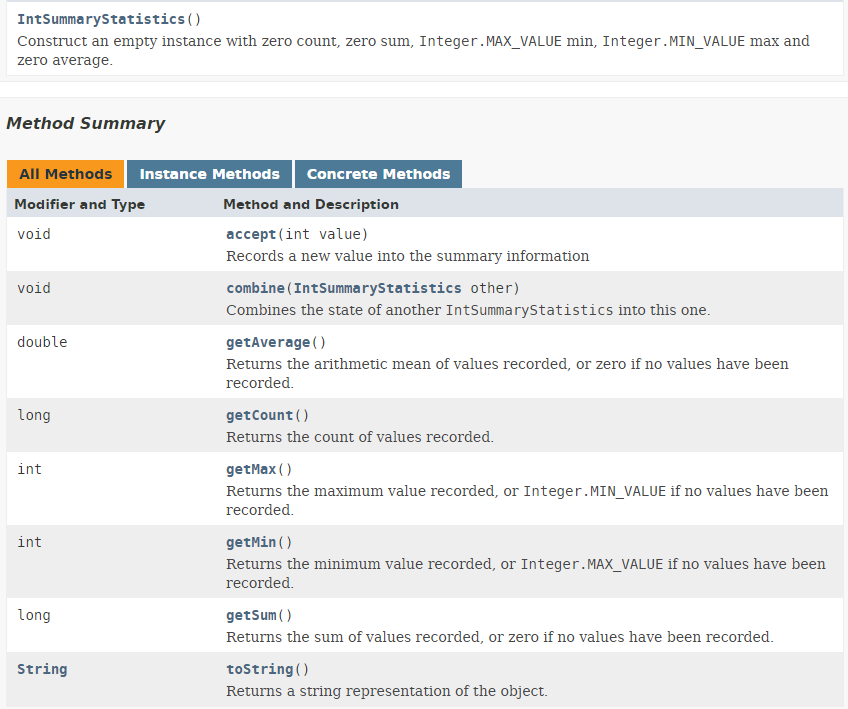 |
Wir sehen, dass das resultierende IntSummaryStatistics-Objekt verschiedene Statistiken über den Zahlen-Stream bereitstellt, wie beispielsweise die Anzahl der Werte, die Summe, den Maximalwert, den Minimalwert und den Durchschnitt.