2. JPA-Entitäten
2.1. Beispiel 1 – Objektdarstellung einer einzelnen Tabelle
2.1.1. Die Tabelle [person]
Betrachten wir eine Datenbank mit einer einzigen Tabelle [person], deren Zweck darin besteht, Informationen über Personen zu speichern:
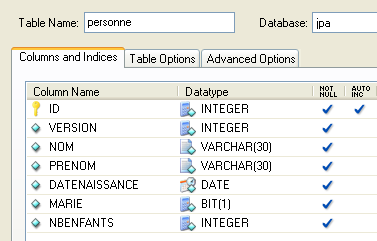 |
Primärschlüssel der Tabelle | |
Version der Zeile in der Tabelle. Jedes Mal, wenn die Person geändert wird, wird ihre Versionsnummer erhöht. | |
Nachname | |
Vorname | |
ihr Geburtsdatum | |
Ganzzahl 0 (ledig) oder 1 (verheiratet) | |
Anzahl der Kinder |
2.1.2. Die Entität [Person]
Wir befinden uns in der folgenden Laufzeitumgebung:
 |
Die JPA-Schicht [5] muss eine Brücke zwischen der relationalen Welt der Datenbank [7] und der Objektwelt [4] schlagen, die von Java-Programmen [3] bearbeitet wird. Diese Brücke wird durch Konfiguration hergestellt, und dafür gibt es zwei Möglichkeiten:
- die Verwendung von XML-Dateien. Bis zum Erscheinen von JDK 1.5 war dies praktisch die einzige Möglichkeit
- mit Java-Annotationen seit JDK 1.5
In diesem Dokument werden wir fast ausschließlich die zweite Methode verwenden.
Das [Person]-Objekt, das die zuvor vorgestellte [person]-Tabelle repräsentiert, könnte wie folgt aussehen:
...
@SuppressWarnings("unused")
@Entity
@Table(name="Personne")
public class Personne implements Serializable{
@Id
@Column(name = "ID", nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name = "VERSION", nullable = false)
@Version
private int version;
@Column(name = "NOM", length = 30, nullable = false, unique = true)
private String nom;
@Column(name = "PRENOM", length = 30, nullable = false)
private String prenom;
@Column(name = "DATENAISSANCE", nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(name = "MARIE", nullable = false)
private boolean marie;
@Column(name = "NBENFANTS", nullable = false)
private int nbenfants;
// manufacturers
public Personne() {
}
public Personne(String nom, String prenom, Date datenaissance, boolean marie,
int nbenfants) {
setNom(nom);
setPrenom(prenom);
setDatenaissance(datenaissance);
setMarie(marie);
setNbenfants(nbenfants);
}
// toString
public String toString() {
...
}
// getters and setters
...
}
Die Konfiguration erfolgt mithilfe von Java-Annotationen (@Annotation). Java-Annotationen werden entweder vom Compiler oder von speziellen Tools zur Laufzeit verarbeitet. Abgesehen von der Annotation in Zeile 3, die für den Compiler bestimmt ist, sind alle Annotationen hier für die verwendete JPA-Implementierung, also Hibernate oder Toplink, vorgesehen. Sie werden daher zur Laufzeit verarbeitet. Fehlen Tools, die sie interpretieren können, werden diese Annotationen ignoriert. Somit könnte die obige Klasse [Person] in einem Nicht-JPA-Kontext verwendet werden.
Es gibt zwei unterschiedliche Fälle für die Verwendung von JPA-Annotationen in einer Klasse C, die einer Tabelle T zugeordnet ist:
- Die Tabelle T existiert bereits: Die JPA-Annotationen müssen dann die vorhandene Struktur nachbilden (Spaltennamen und -definitionen, Integritätsbeschränkungen, Fremdschlüssel, Primärschlüssel usw.).
- Die Tabelle T existiert nicht und wird auf der Grundlage der in der Klasse C gefundenen Annotationen erstellt.
Fall 2 ist am einfachsten zu handhaben. Mithilfe von JPA-Annotationen legen wir die Struktur der gewünschten Tabelle T fest. Fall 1 ist oft komplexer. Die Tabelle T wurde möglicherweise vor langer Zeit außerhalb eines JPA-Kontexts erstellt. Ihre Struktur ist daher möglicherweise für die Relational-zu-Objekt-Brücke von JPA ungeeignet. Der Einfachheit halber konzentrieren wir uns auf Fall 2, in dem die mit der Klasse C verknüpfte Tabelle T auf der Grundlage der JPA-Annotationen in der Klasse C erstellt wird.
Betrachten wir die JPA-Annotationen der Klasse [Person]:
- Zeile 4: Die Annotation @Entity ist die erste wesentliche Annotation. Sie steht vor der Zeile, in der die Klasse deklariert wird, und gibt an, dass die betreffende Klasse von der JPA-Persistenzschicht verwaltet werden muss. Ohne diese Annotation würden alle anderen JPA-Annotationen ignoriert.
- Zeile 5: Die Annotation @Table bezeichnet die Datenbanktabelle, die die Klasse repräsentiert. Ihr Hauptargument ist name, das den Namen der Tabelle angibt. Ohne dieses Argument wird die Tabelle nach der Klasse benannt, in diesem Fall [Person]. In unserem Beispiel ist die Annotation @Table daher überflüssig.
- Zeile 8: Die Annotation @Id wird verwendet, um das Feld in der Klasse zu benennen, das den Primärschlüssel der Tabelle darstellt. Diese Annotation ist obligatorisch. Hier gibt sie an, dass das Feld „id“ in Zeile 11 den Primärschlüssel der Tabelle darstellt.
- Zeile 9: Die Annotation @Column wird verwendet, um ein Feld in der Klasse mit der Tabellenspalte zu verknüpfen, die das Feld repräsentiert. Das Attribut „name“ gibt den Namen der Spalte in der Tabelle an. Wird dieses Attribut weggelassen, erhält die Spalte denselben Namen wie das Feld. In unserem Beispiel war das Argument „name“ daher nicht erforderlich. Das Argument „nullable=false“ gibt an, dass die mit dem Feld verknüpfte Spalte nicht den Wert NULL annehmen darf und das Feld daher einen Wert haben muss.
- Zeile 10: Die Annotation @GeneratedValue legt fest, wie der Primärschlüssel generiert wird, wenn er automatisch vom DBMS generiert wird. Dies ist in allen unseren Beispielen der Fall. Sie ist nicht zwingend erforderlich. Somit könnte unsere Person eine Studenten-ID haben, die als Primärschlüssel dient und nicht vom DBMS generiert, sondern von der Anwendung gesetzt wird. In diesem Fall würde die Annotation @GeneratedValue weggelassen werden. Das Argument „strategy“ legt fest, wie der Primärschlüssel generiert wird, wenn er vom DBMS generiert wird. Nicht alle DBMS verwenden dieselbe Technik zur Generierung von Primärschlüsselwerten. Zum Beispiel:
verwendet einen Wertgenerator, der vor jedem Einfügen aufgerufen wird | |
ist das Primärschlüsselfeld als Typ „Identity“ definiert. Das Ergebnis ähnelt dem Wertgenerator von Firebird, mit dem Unterschied, dass der Schlüsselwert erst nach dem Einfügen der Zeile bekannt ist. | |
verwendet ein Objekt namens „SEQUENCE“, das ebenfalls als Wertgenerator fungiert |
Die JPA-Schicht muss je nach DBMS unterschiedliche SQL-Anweisungen generieren, um den Wertgenerator zu erstellen. Wir geben den zu verarbeitenden DBMS-Typ über die Konfiguration an. Dadurch kann sie die Standardstrategie zur Generierung von Primärschlüsselwerten für dieses DBMS ermitteln. Das Argument strategy = GenerationType.*****AUTO* weist die JPA-Schicht an, diese Standardstrategie zu verwenden. Diese Technik hat in allen Beispielen dieses Dokuments für die sieben verwendeten DBMS funktioniert.
- Zeile 14: Die Annotation @Version kennzeichnet das Feld, das zur Verwaltung des gleichzeitigen Zugriffs auf dieselbe Zeile in der Tabelle verwendet wird.
Um dieses Problem des gleichzeitigen Zugriffs auf dieselbe Zeile in der Tabelle [person] zu verstehen, nehmen wir an, dass eine Webanwendung die Aktualisierung von Personeninformationen ermöglicht, und betrachten wir das folgende Szenario:
Zum Zeitpunkt T1 beginnt Benutzer U1 mit der Bearbeitung einer Person P. In diesem Moment beträgt die Anzahl der Kinder 0. Er ändert diese Zahl auf 1, doch bevor er seine Änderungen übermittelt, beginnt Benutzer U2 mit der Bearbeitung derselben Person P. Da U1 seine Änderungen noch nicht übermittelt hat, sieht U2 die Anzahl der Kinder auf seinem Bildschirm als 0 an. U2 ändert den Namen der Person P in Großbuchstaben. Dann speichern U1 und U2 ihre Änderungen in dieser Reihenfolge. Die Änderung von U2 hat Vorrang: In der Datenbank wird der Name in Großbuchstaben stehen und die Anzahl der Kinder bleibt bei Null, obwohl U1 glaubt, sie auf 1 geändert zu haben.
Das Konzept der Versionsverwaltung hilft uns, dieses Problem zu lösen. Betrachten wir denselben Anwendungsfall noch einmal:
Zum Zeitpunkt T1 beginnt ein Benutzer U1 mit der Bearbeitung der Person P. Zu diesem Zeitpunkt beträgt die Anzahl der Kinder 0 und die Version ist V1. Er ändert die Anzahl der Kinder auf 1, doch bevor er seine Änderung festschreibt, beginnt ein Benutzer U2 mit der Bearbeitung derselben Person P. Da U1 seine Änderung noch nicht festgeschrieben hat, sieht U2 die Anzahl der Kinder als 0 und die Version als V1. U2 ändert den Namen der Person P in Großbuchstaben. Dann speichern U1 und U2 ihre Änderungen in dieser Reihenfolge. Vor dem Speichern einer Änderung überprüfen wir, ob der Benutzer, der die Person P ändert, dieselbe Version hat wie die aktuell gespeicherte Version der Person P im „ “. Dies ist bei Benutzer U1 der Fall. Seine Änderung wird daher akzeptiert, und wir ändern dann die Version der geänderten Person von V1 auf V2, um anzuzeigen, dass die Person eine Änderung erfahren hat. Bei der Validierung der Änderung von U2 stellen wir fest, dass U2 die Version V1 der Person P hat, während die aktuelle Version V2 ist. Wir können den Benutzer U2 dann darüber informieren, dass jemand anderes vor ihm gehandelt hat und dass er mit der neuen Version der Person P beginnen muss. Er wird dies tun, die Version V2 der Person P abrufen, die nun ein Kind hat, den Namen großschreiben und validieren. Seine Änderung wird akzeptiert, wenn die registrierte Person P noch Version V2 ist. Letztendlich werden die von U1 und U2 vorgenommenen Änderungen berücksichtigt, während im Anwendungsfall ohne Versionen eine der Änderungen verloren gegangen wäre.
Die [DAO]-Schicht der Client-Anwendung kann die Version der Klasse [Person] selbst verwalten. Jedes Mal, wenn ein Objekt P geändert wird, wird die Version dieses Objekts in der Tabelle um 1 erhöht. Die Annotation @Version ermöglicht es, diese Verwaltung auf die JPA-Schicht zu übertragen. Das betreffende Feld muss nicht wie im Beispiel „version“ heißen. Es kann einen beliebigen Namen haben.
Die Felder, die den Annotationen @Id und @Version entsprechen, dienen der Persistenz. Sie wären nicht erforderlich, wenn die Klasse [Person] nicht persistiert werden müsste. Wir sehen also, dass ein Objekt unterschiedlich dargestellt wird, je nachdem, ob es persistiert werden muss oder nicht.
- Zeile 17: Auch hier liefert die Annotation @Column Informationen über die Spalte in der Tabelle [person], die dem Feld „name“ der Klasse Person zugeordnet ist. Hier finden wir zwei neue Argumente:
- unique=true gibt an, dass der Name einer Person eindeutig sein muss. Dies führt zur Hinzufügung einer Eindeutigkeitsbeschränkung für die Spalte NAME der Tabelle [person] in der Datenbank.
- length=30 legt die Anzahl der Zeichen in der Spalte NAME auf 30 fest. Das bedeutet, dass der Typ dieser Spalte VARCHAR(30) ist.
- Zeile 24: Die Annotation @Temporal wird verwendet, um den SQL-Typ für eine Datums-/Uhrzeit-Spalte oder ein Datums-/Uhrzeit-Feld anzugeben. Der Typ TemporalType.DATE bezeichnet ein Datum ohne zugehörige Uhrzeit. Die anderen möglichen Typen sind TemporalType.TIME zur Kodierung einer Uhrzeit und TemporalType.TIMESTAMP zur Kodierung von Datum und Uhrzeit.
Lassen Sie uns nun den Rest des Codes in der Klasse [Person] kommentieren:
- Zeile 6: Die Klasse implementiert die Schnittstelle „Serializable“. Bei der Serialisierung eines Objekts wird dieses in eine Bitfolge umgewandelt. Die Deserialisierung ist der umgekehrte Vorgang. Serialisierung und Deserialisierung kommen insbesondere in Client-Server-Anwendungen zum Einsatz, bei denen Objekte über das Netzwerk ausgetauscht werden. Client- oder Server-Anwendungen nehmen diesen Vorgang nicht wahr, da er transparent von den JVMs durchgeführt wird. Damit dies jedoch möglich ist, müssen die Klassen der ausgetauschten Objekte mit dem Schlüsselwort „Serializable“ gekennzeichnet sein.
- Zeile 37: ein Konstruktor für die Klasse. Beachten Sie, dass die Felder „id“ und „version“ nicht zu den Parametern gehören. Dies liegt daran, dass diese beiden Felder von der JPA-Schicht und nicht von der Anwendung verwaltet werden.
- Zeile 51 ff.: Die get- und set-Methoden für jedes Feld der Klasse. Beachten Sie, dass JPA-Annotationen anstelle der Felder selbst auf den get-Methoden der Felder platziert werden können. Die Platzierung der Annotationen gibt den Modus an, den JPA für den Zugriff auf die Felder verwenden soll:
- Wenn die Annotationen auf Feldebene platziert sind, greift JPA direkt auf die Felder zu, um sie zu lesen oder zu schreiben
- Wenn die Annotationen auf der Get-Ebene platziert sind, greift JPA über die Get-/Set-Methoden auf die Felder zu, um sie zu lesen oder zu schreiben
Die Position der Annotation @Id bestimmt die Platzierung von JPA-Annotationen in einer Klasse. Bei Platzierung auf Feldebene bedeutet dies direkten Zugriff auf die Felder; bei Platzierung auf Get-Ebene bedeutet dies Zugriff auf die Felder über die Get- und Set-Methoden. Die anderen Annotationen müssen dann auf dieselbe Weise wie die Annotation @Id platziert werden.
2.1.3. Das Eclipse-Testprojekt
Wir werden unsere ersten Experimente mit der zuvor vorgestellten [Person]-Entität durchführen. Dazu verwenden wir die folgende Architektur:
 |
- in [7]: die Datenbank, die auf der Grundlage der Annotationen der Entität [Person] sowie zusätzlicher Konfigurationen, die in einer Datei namens [persistence.xml] festgelegt sind, generiert wird
- in [5, 6]: eine von Hibernate implementierte JPA-Schicht
- in [4]: die Entität [Person]
- in [3]: ein konsolenbasiertes Testprogramm
Wir werden verschiedene Experimente durchführen:
- Erstellen des Datenbankschemas mithilfe eines Ant-Skripts und der Hibernate-Tools
- die Datenbank generieren und mit einigen Daten initialisieren
- Interaktion mit der Datenbank und Durchführung der vier Grundoperationen an der Tabelle [person] (Einfügen, Aktualisieren, Löschen, Abfragen)
Die erforderlichen Tools sind wie folgt:
- Eclipse und die in Abschnitt 5.2 beschriebenen Plugins.
- das Projekt [hibernate-personnes-entites], das sich im Ordner <examples>/hibernate/direct/personnes-entites befindet
- die verschiedenen DBMS, die in den Anhängen (Abschnitt 5 und weiter) beschrieben sind.
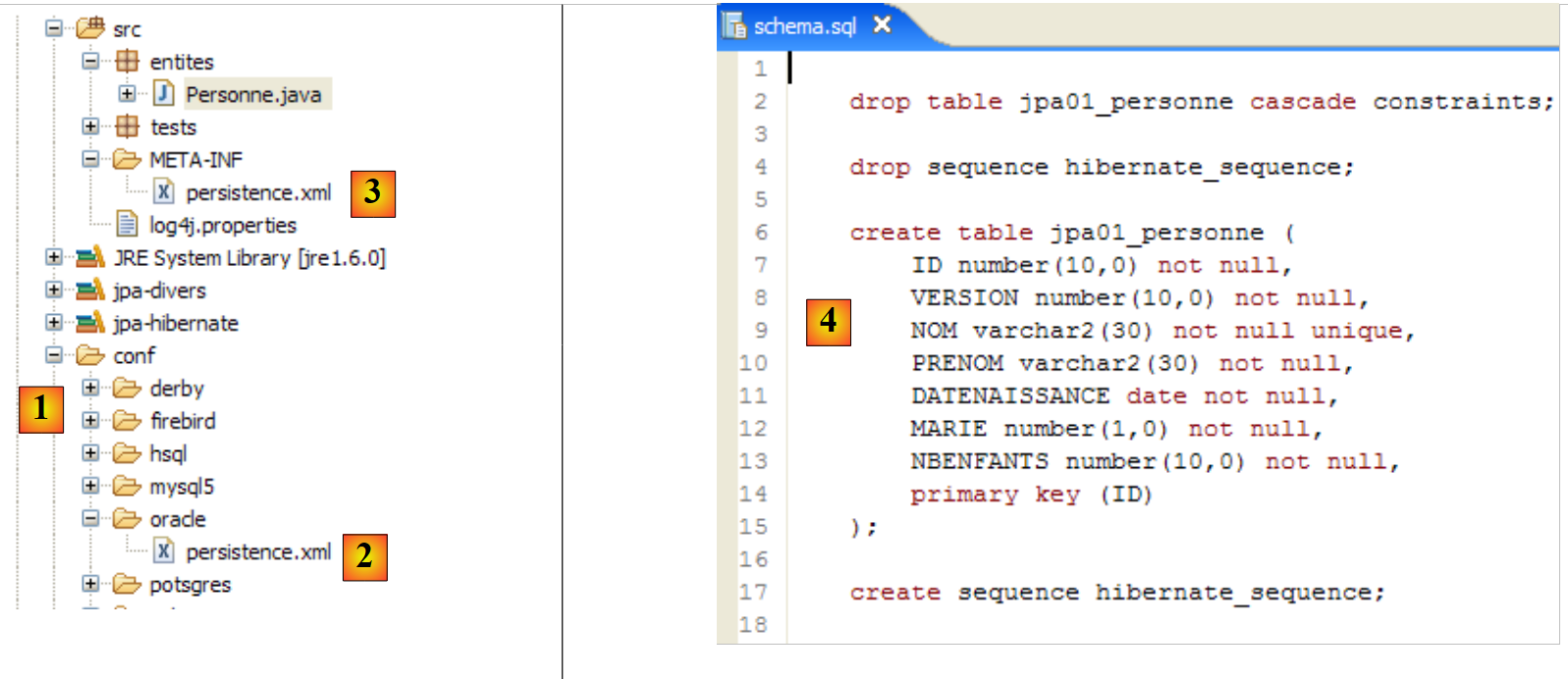
Das Eclipse-Projekt sieht wie folgt aus:
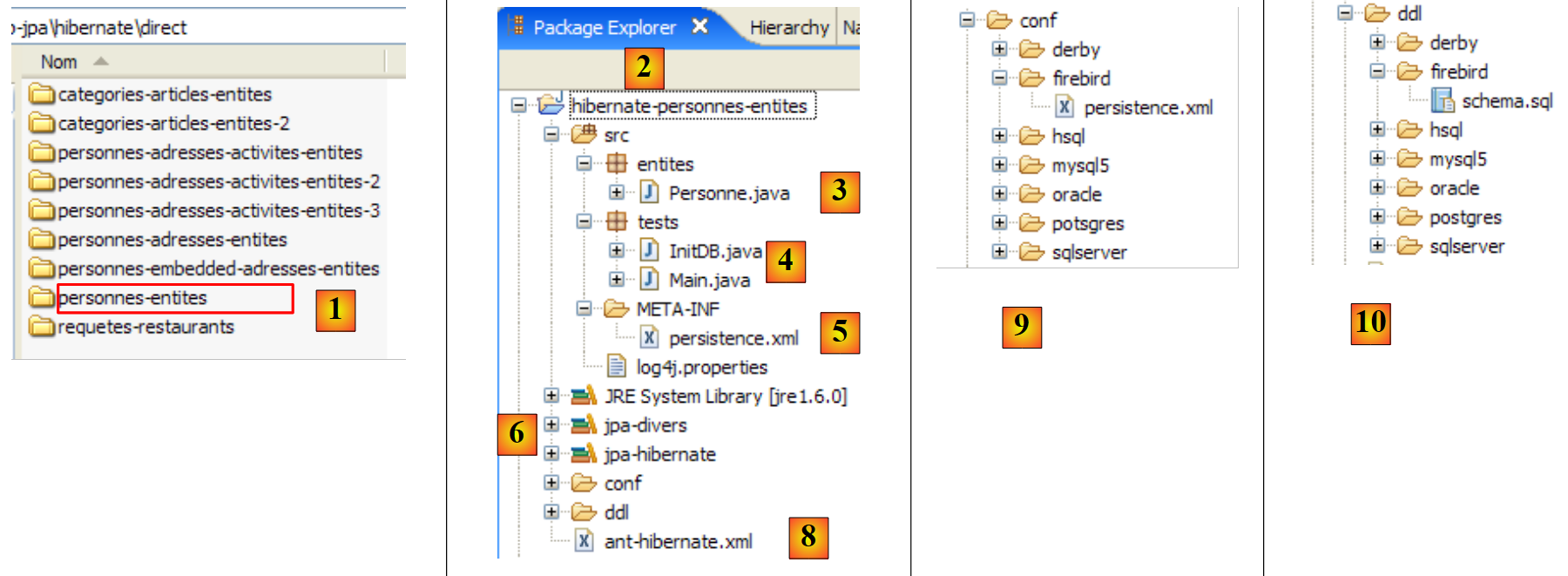 |
- in [1]: der Eclipse-Projektordner
- in [2]: das in Eclipse importierte Projekt (Datei / Importieren)
- in [3]: die zu testende Entität [Person]
- in [4]: die Testprogramme
- in [5]: [persistence.xml] ist die Konfigurationsdatei für die JPA-Schicht
- in [6]: die verwendeten Bibliotheken. Diese wurden in Abschnitt 1.5 beschrieben.
- in [8]: ein Ant-Skript, das zur Generierung der mit der Entität [Person] verbundenen Tabelle verwendet wird
- in [9]: die [persistence.xml]-Dateien für jedes der verwendeten DBMS
- in [10]: die Schemata der generierten Datenbank für jedes der verwendeten DBMS
Wir werden diese Elemente nacheinander beschreiben.
2.1.4. Die Entität [Person] (2)
Wir nehmen eine geringfügige Änderung an der vorherigen Beschreibung der Entität [Person] vor und fügen einige zusätzliche Informationen hinzu:
package entites;
...
@SuppressWarnings({ "unused", "serial" })
@Entity
@Table(name="jpa01_personne")
public class Personne implements Serializable{
@Id
@Column(name = "ID", nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name = "VERSION", nullable = false)
@Version
private int version;
@Column(name = "NOM", length = 30, nullable = false, unique = true)
private String nom;
@Column(name = "PRENOM", length = 30, nullable = false)
private String prenom;
@Column(name = "DATENAISSANCE", nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(name = "MARIE", nullable = false)
private boolean marie;
@Column(name = "NBENFANTS", nullable = false)
private int nbenfants;
// manufacturers
public Personne() {
}
public Personne(String nom, String prenom, Date datenaissance, boolean marie,
int nbenfants) {
....
}
// toString
public String toString() {
return String.format("[%d,%d,%s,%s,%s,%s,%d]", getId(), getVersion(),
getNom(), getPrenom(), new SimpleDateFormat("dd/MM/yyyy")
.format(getDatenaissance()), isMarie(), getNbenfants());
}
// getters and setters
...
}
- Zeile 7: Wir benennen die mit der Entität [Person] verbundene Tabelle [jpa01_personne]. In diesem Dokument werden verschiedene Tabellen in einem Schema erstellt, das immer den Namen jpa trägt. Am Ende dieses Tutorials wird das jpa-Schema viele Tabellen enthalten. Damit der Leser den Überblick behält, erhalten Tabellen, die miteinander in Beziehung stehen, das gleiche Präfix jpaxx_.
- Zeile 45: Eine [toString]-Methode, um ein [Person]-Objekt auf der Konsole anzuzeigen.
2.1.5. Konfigurieren der Datenzugriffsebene
Im obigen Eclipse-Projekt wird die JPA-Schicht über die Datei [META-INF/persistence.xml] konfiguriert:
 |
Zur Laufzeit wird im Klassenpfad der Anwendung nach der Datei [META-INF/persistence.xml] gesucht. In unserem Eclipse-Projekt wird der gesamte Inhalt des Ordners [/src] [1] in einen Ordner [/bin] [2] kopiert. Dieser Ordner ist Teil des Klassenpfads des Projekts. Aus diesem Grund wird [META-INF/persistence.xml] gefunden, wenn sich die JPA-Schicht konfiguriert.
Standardmäßig legt Eclipse den Quellcode nicht im Ordner [/src] des Projekts ab, sondern direkt unter dem Projektordner selbst. Alle unsere Eclipse-Projekte werden so konfiguriert, dass sich die Quellen in [/src] und die kompilierten Klassen in [/bin] befinden, wie in Abschnitt 5.2.1 gezeigt.
Sehen wir uns die Konfiguration der JPA-Schicht in der Datei [persistence.xml] unseres Projekts an:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Persistent classes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
<property name="hibernate.connection.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- automatic schematic creation -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!-- properties DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
Um diese Konfiguration zu verstehen, müssen wir uns noch einmal die Datenzugriffsarchitektur unserer Anwendung ansehen:
 |
- Die Datei [persistence.xml] konfiguriert die Schichten [4, 5, 6]
- [4]: Hibernate-Implementierung von JPA
- [5]: Hibernate greift über einen Verbindungspool auf die Datenbank zu. Ein Verbindungspool ist ein Pool offener Verbindungen zum DBMS. Auf ein DBMS greifen mehrere Benutzer zu, doch aus Leistungsgründen darf die Anzahl der gleichzeitig offenen Verbindungen ein Limit N nicht überschreiten. Gut geschriebener Code öffnet eine Verbindung zum DBMS für die kürzestmögliche Zeit: Er führt SQL-Befehle aus und schließt die Verbindung. Dies wiederholt er jedes Mal, wenn er mit der Datenbank arbeiten muss. Der Aufwand für das Öffnen und Schließen einer Verbindung ist nicht zu vernachlässigen, und hier kommt der Verbindungspool ins Spiel. Beim Start der Anwendung öffnet der Verbindungspool N1 Verbindungen zum DBMS. Die Anwendung fordert bei Bedarf eine offene Verbindung aus dem Pool an. Die Verbindung wird an den Pool zurückgegeben, sobald die Anwendung sie nicht mehr benötigt, vorzugsweise so schnell wie möglich. Die Verbindung wird nicht geschlossen und bleibt für den nächsten Benutzer verfügbar. Ein Verbindungspool ist daher ein System zur gemeinsamen Nutzung offener Verbindungen.
- [6]: der JDBC-Treiber für das verwendete DBMS
Sehen wir uns nun an, wie die Datei [persistence.xml] die oben genannten Schichten [4, 5, 6] konfiguriert:
- Zeile 2: Das Stamm-Tag der XML-Datei lautet <persistence>.
- Zeile 3: <persistence-unit> wird verwendet, um eine Persistenz-Einheit zu definieren. Es kann mehrere Persistenz-Einheiten geben. Jede hat einen Namen (name-Attribut) und einen Transaktionstyp (transaction-type-Attribut). Die Anwendung greift über ihren Namen auf die Persistenz-Einheit zu, in diesem Fall jpa. Der Transaktionstyp RESOURCE_LOCAL gibt an, dass die Anwendung Transaktionen mit dem DBMS selbst verwaltet. Dies ist hier der Fall. Wenn die Anwendung in einem EJB3-Container ausgeführt wird, kann sie den Transaktionsdienst des Containers nutzen. In diesem Fall würden wir transaction-type=JTA (Java Transaction API) festlegen. JTA ist der Standardwert, wenn das Attribut transaction-type weggelassen wird.
- Zeile 5: Das <provider>-Tag wird verwendet, um eine Klasse zu definieren, die die Schnittstelle [javax.persistence.spi.PersistenceProvider] implementiert, wodurch die Anwendung die Persistenzschicht „ “ initialisieren kann. Da wir eine JPA/Hibernate-Implementierung verwenden, handelt es sich bei der hier verwendeten Klasse um eine Hibernate-Klasse.
- Zeile 6: Das <properties>-Tag führt Eigenschaften ein, die für den gewählten Provider spezifisch sind. Je nachdem, ob Sie Hibernate, TopLink, Kodo usw. gewählt haben, stehen Ihnen also unterschiedliche Eigenschaften zur Verfügung. Die folgenden sind spezifisch für Hibernate.
- Zeile 8: Weist Hibernate an, den Klassenpfad des Projekts nach Klassen zu durchsuchen, die mit @Entity annotiert sind, damit es diese verwalten kann. @Entity-Klassen können auch mithilfe von <class>class_name</class>-Tags direkt unter dem <persistence-unit>-Tag deklariert werden. Dies werden wir beim JPA/TopLink-Anbieter tun.
- Die Zeilen 10–12, die hier auskommentiert sind, konfigurieren die Konsolenprotokolle von Hibernate:
- Zeile 10: Zum Aktivieren oder Deaktivieren der Anzeige von SQL-Anweisungen, die Hibernate an das DBMS sendet. Dies ist während der Lernphase sehr nützlich. Aufgrund der Relational-Objekt-Brücke arbeitet die Anwendung mit persistenten Objekten, auf die sie Operationen wie [persist, merge, remove] anwendet. Es ist sehr hilfreich zu wissen, welche SQL-Anweisungen für diese Operationen tatsächlich ausgegeben werden. Indem Sie diese studieren, lernen Sie nach und nach, die SQL-Anweisungen zu antizipieren, die Hibernate bei der Ausführung solcher Operationen auf persistente Objekte generiert, und die Relational-Objekt-Brücke nimmt in Ihrem Kopf Gestalt an.
- Zeile 11: Die auf der Konsole angezeigten SQL-Anweisungen können übersichtlich formatiert werden, um sie leichter lesbar zu machen
- Zeile 12: Die angezeigten SQL-Anweisungen werden zudem mit Anmerkungen versehen
- Die Zeilen 15–19 definieren die JDBC-Schicht (Schicht [6] in der Architektur):
- Zeile 15: die JDBC-Treiberklasse für das DBMS, hier MySQL5
- Zeile 16: die URL der verwendeten Datenbank
- Zeilen 17, 18: Benutzername und Passwort für die Verbindung
- Hier verwenden wir Elemente, die in den Anhängen in Abschnitt 5.5 erläutert werden. Dem Leser wird empfohlen, diesen Abschnitt über MySQL 5 zu lesen.
- Zeile 22: Hibernate muss wissen, mit welchem DBMS es arbeitet. Der Grund dafür ist, dass alle DBMS proprietäre SQL-Erweiterungen haben, wie beispielsweise ihre eigene Art der automatischen Generierung von Primärschlüsselwerten, ... was bedeutet, dass Hibernate das verwendete DBMS kennen muss, um SQL-Befehle zu senden, die das DBMS versteht. [MySQL5InnoDBDialect] bezieht sich auf das MySQL5-DBMS mit InnoDB-Tabellen, die Transaktionen unterstützen.
- Die Zeilen 24–28 konfigurieren den c3p0-Verbindungspool (Schicht [5] in der Architektur):
- Zeilen 24, 25: die minimale (Standard 3) und maximale Anzahl von Verbindungen (Standard 15) im Pool. Die standardmäßige anfängliche Anzahl von Verbindungen beträgt 3.
- Zeile 26: maximale Wartezeit in Millisekunden für eine Verbindungsanfrage vom Client. Nach Ablauf dieser Zeitüberschreitung löst c3p0 eine Ausnahme aus.
- Zeile 27: Für den Zugriff auf die Datenbank verwendet Hibernate vorbereitete SQL-Anweisungen (PreparedStatement), die c3p0 zwischenspeichern kann. Das bedeutet, dass, wenn die Anwendung eine vorbereitete SQL-Anweisung, die sich bereits im Cache befindet, ein zweites Mal anfordert, diese nicht erneut vorbereitet werden muss (die Vorbereitung einer SQL-Anweisung verursacht Kosten) und stattdessen die im Cache befindliche verwendet wird. Hier legen wir die maximale Anzahl an vorbereiteten SQL-Anweisungen fest, die der Cache über alle Verbindungen hinweg enthalten kann (eine vorbereitete SQL-Anweisung gehört zu einer einzelnen Verbindung).
- Zeile 28: Intervall für die Überprüfung der Verbindungsgültigkeit in Millisekunden. Eine Verbindung im Pool kann aus verschiedenen Gründen ungültig werden (der JDBC-Treiber erklärt die Verbindung für ungültig, weil sie zu lange inaktiv war, der JDBC-Treiber weist Fehler auf usw.).
- Zeile 20: Hier legen wir fest, dass bei der Initialisierung der Persistenzschicht das Datenbankschema für @Entity-Objekte generiert werden soll. Hibernate verfügt nun über alle Werkzeuge, um die SQL-Anweisungen zum Erstellen der Datenbanktabellen zu generieren:
- die Konfiguration der @Entity-Objekte ermöglicht es ihm zu erkennen, welche Tabellen generiert werden müssen
- Die Zeilen 15–18 und 24–28 ermöglichen es ihm, eine Verbindung zum DBMS herzustellen
- Zeile 22 gibt an, welcher SQL-Dialekt zur Generierung der Tabellen verwendet werden soll
Somit erstellt die hier verwendete Datei [persistence.xml] bei jeder neuen Ausführung der Anwendung eine neue Datenbank. Die Tabellen werden neu erstellt (create table), nachdem sie gelöscht wurden (drop table), sofern sie existierten. Beachten Sie, dass dies natürlich nicht in einer Produktionsdatenbank durchgeführt werden sollte...
Tests haben gezeigt, dass die Drop-/Create-Phase für Tabellen fehlschlagen kann. Dies war insbesondere dann der Fall, wenn wir für denselben Test von einer JPA/Hibernate-Schicht zu einer JPA/Toplink-Schicht oder umgekehrt wechselten. Ausgehend von denselben @Entity-Objekten generieren die beiden Implementierungen nicht genau dieselben Tabellen, Generatoren, Sequenzen usw., und es kam manchmal vor, dass die Drop-/Create-Phase fehlschlug, sodass die Tabellen manuell gelöscht werden mussten. Der Abschnitt „Anhänge“, beginnend mit Absatz 5, beschreibt die Tools, die zur manuellen Durchführung dieser Aufgabe zur Verfügung stehen. Es ist anzumerken, dass sich die JPA/Hibernate-Implementierung in dieser Anfangsphase der Erstellung von Datenbankinhalten als die effizienteste erwiesen hat: Abstürze waren selten.
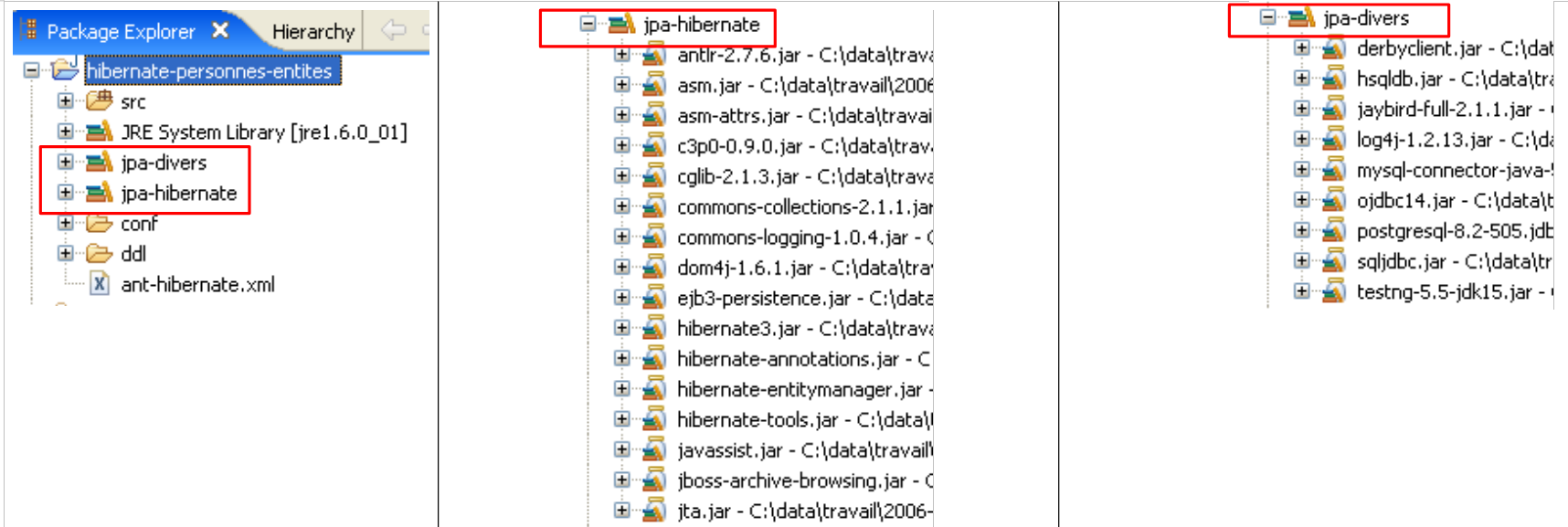
Die von der JPA/Hibernate-Schicht verwendeten Werkzeuge befinden sich in der Bibliothek [jpa-hibernate], die in Abschnitt 1.5 auf Seite 8 vorgestellt wird. Die für den Zugriff auf das DBMS erforderlichen JDBC-Treiber befinden sich in der Bibliothek [jpa-divers]. Diese beiden Bibliotheken wurden dem Klassenpfad des hier untersuchten Projekts hinzugefügt. Ihr Inhalt ist im Folgenden zusammengefasst:
 |
2.1.6. Erstellen der Datenbank mit einem Ant-Skript
Wie wir gerade gesehen haben, bietet Hibernate Werkzeuge zur Generierung des Datenbankschemas für die @Entity-Objekte der Anwendung. Hibernate kann:
- eine Textdatei generieren, die die SQL-Anweisungen enthält, mit denen die Datenbank erstellt wird. In diesem Fall wird nur der in [persistence.xml] angegebene Dialekt verwendet.
- die Tabellen erstellen, die die @Entity-Objekte in der in [persistence.xml] definierten Zieldatenbank repräsentieren. In diesem Fall wird die gesamte [persistence.xml]-Datei verwendet.
Wir werden ein Ant-Skript vorstellen, das das Datenbankschema für @Entity-Objekte generieren kann. Dieses Skript stammt nicht von mir: Es basiert auf einem ähnlichen Skript aus [ref1]. Ant (Another Neat Tool) ist ein Java-Batch-Task-Tool. Ant-Skripte sind für Anfänger nicht leicht zu verstehen. Wir werden nur eines verwenden, nämlich das, das wir gerade besprechen:
 |
- in [1]: die Verzeichnisstruktur der Beispiele in diesem Tutorial.
- in [2]: der Ordner [people-entities] des derzeit untersuchten Eclipse-Projekts
- in [3]: der Ordner <lib>, der die fünf in Abschnitt 1.5 definierten JAR-Bibliotheken enthält.
- in [4]: das Archiv [hibernate-tools.jar], das für eine der Aufgaben im Skript [ant-hibernate.xml] benötigt wird, das wir uns ansehen werden.
 |
- in [5]: das Eclipse-Projekt und das Skript [ant-hibernate.xml]
- in [6]: der Ordner [src] des Projekts
Das Skript [ant-hibernate.xml] [5] verwendet die JAR-Dateien im Ordner <lib> [3], insbesondere die Datei [hibernate-tools.jar] [4] im Ordner [lib/hibernate]. Wir haben die Verzeichnisstruktur nachgebildet, damit der Leser sehen kann, dass man, um den Ordner [lib] vom Ordner [people-entities] [2] im Skript [ant-hibernate.xml] zu finden, dem Pfad ../../../lib folgen muss.
Sehen wir uns das Skript [ant-hibernate.xml] einmal an:
<project name="jpa-hibernate" default="compile" basedir=".">
<!-- nom du projet et version -->
<property name="proj.name" value="jpa-hibernate" />
<property name="proj.shortname" value="jpa-hibernate" />
<property name="version" value="1.0" />
<!-- Propriété globales -->
<property name="src.java.dir" value="src" />
<property name="lib.dir" value="../../../lib" />
<property name="build.dir" value="bin" />
<!-- le Classpath du projet -->
<path id="project.classpath">
<fileset dir="${lib.dir}">
<include name="**/*.jar" />
</fileset>
</path>
<!-- les fichiers de configuration qui doivent être dans le classpath-->
<patternset id="conf">
<include name="**/*.xml" />
<include name="**/*.properties" />
</patternset>
<!-- Nettoyage projet -->
<target name="clean" description="Nettoyer le projet">
<delete dir="${build.dir}" />
<mkdir dir="${build.dir}" />
</target>
<!-- Compilation projet -->
<target name="compile" depends="clean">
<javac srcdir="${src.java.dir}" destdir="${build.dir}" classpathref="project.classpath" />
</target>
<!-- Copier les fichiers de configuration dans le classpath -->
<target name="copyconf">
<mkdir dir="${build.dir}" />
<copy todir="${build.dir}">
<fileset dir="${src.java.dir}">
<patternset refid="conf" />
</fileset>
</copy>
</target>
<!-- Hibernate Tools -->
<taskdef name="hibernatetool" classname="org.hibernate.tool.ant.HibernateToolTask" classpathref="project.classpath" />
<!-- Générer la DDL de la base -->
<target name="DDL" depends="compile, copyconf" description="Génération DDL base">
<hibernatetool destdir="${basedir}">
<classpath path="${build.dir}" />
<!-- Utiliser META-INF/persistence.xml -->
<jpaconfiguration />
<!-- export -->
<hbm2ddl drop="true" create="true" export="false" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
</hibernatetool>
</target>
<!-- Générer la base -->
<target name="BD" depends="compile, copyconf" description="Génération BD">
<hibernatetool destdir="${basedir}">
<classpath path="${build.dir}" />
<!-- Utiliser META-INF/persistence.xml -->
<jpaconfiguration />
<!-- export -->
<hbm2ddl drop="true" create="true" export="true" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
</hibernatetool>
</target>
</project>
- Zeile 1: Das [ant]-Projekt trägt den Namen „jpa-hibernate“. Es besteht aus einer Reihe von Aufgaben, von denen eine die Standardaufgabe ist: in diesem Fall die Aufgabe mit dem Namen „compile“. Ein Ant-Skript wird aufgerufen, um eine Aufgabe T auszuführen. Wenn keine Aufgabe angegeben ist, wird die Standardaufgabe ausgeführt. basedir="." gibt an, dass für alle im Skript gefundenen relativen Pfade der Ausgangspunkt der Ordner ist, der das Ant-Skript enthält, in diesem Fall der Ordner <examples>/hibernate/direct/people-entities.
- Zeilen 3–11: Definieren Skriptvariablen mithilfe des Tags <property name="variableName" value="variableValue"/>. Die Variable kann dann im Skript mit der Notation ${variableName} verwendet werden. Die Namen können beliebig gewählt werden. Schauen wir uns die in den Zeilen 9–11 definierten Variablen genauer an:
- Zeile 9: definiert eine Variable namens „src.java.dir“ (der Name ist beliebig), die später im Skript auf den Ordner verweist, der den Java-Quellcode enthält. Ihr Wert ist „src“, ein Pfad relativ zu dem Ordner, der durch das Attribut basedir (Zeile 1) angegeben wird. Dies ist also der Pfad „./src“, wobei „.“ hier auf den Ordner <examples>/hibernate/direct/people-entities verweist. Der Java-Quellcode befindet sich tatsächlich im Ordner <people-entities>/src (siehe [6] oben).
- Zeile 10: definiert eine Variable namens „lib.dir“, die später im Skript auf den Ordner verweist, der die von den Java-Aufgaben des Skripts benötigten JAR-Dateien enthält. Ihr Wert ../../../lib verweist auf den Ordner <examples>/lib (siehe [3] oben).
- Zeile 11: definiert eine Variable namens „build.dir“, die später im Skript auf den Ordner verweisen wird, in dem die durch die Kompilierung der .java-Quellen erzeugten .class-Dateien abgelegt werden müssen. Ihr Wert „bin“ verweist auf den Ordner <personnes-entites>/bin. Wir haben bereits erläutert, dass im untersuchten Eclipse-Projekt der Ordner <bin> der Ort war, an dem die .class-Dateien erzeugt wurden. Ant wird dasselbe tun.
- Zeilen 14–18: Das <path>-Tag wird verwendet, um Elemente des Klassenpfads zu definieren, die die Ant-Aufgaben verwenden werden. Hier umfasst der Pfad „project.classpath“ (der Name ist beliebig) alle .jar-Dateien im Verzeichnisbaum <examples>/lib.
- Zeilen 21–24: Das <patternset>-Tag wird verwendet, um eine Gruppe von Dateien anhand von Namensmustern zu bezeichnen. Hier bezieht sich das Patternset namens conf auf alle Dateien mit der Erweiterung .xml oder .properties. Dieses Patternset wird verwendet, um auf die .xml- und .properties-Dateien im Ordner <src> (persistence.xml, log4j.properties) (siehe [6]) zu verweisen, bei denen es sich um Anwendungskonfigurationsdateien handelt. Bei der Ausführung bestimmter Aufgaben müssen diese Dateien in den Ordner <bin> kopiert werden, damit sie sich im Klassenpfad des Projekts befinden. Wir werden dann das Patternset „conf“ verwenden, um auf sie zu verweisen.
- Zeilen 27–30: Das <target>-Tag bezeichnet eine Aufgabe im Skript. Dies ist die erste, auf die wir stoßen. Alles, was davor steht, bezieht sich auf die Konfiguration der Ausführungsumgebung des Ant-Skripts. Die Aufgabe heißt „clean“. Sie läuft in zwei Schritten ab: Der Ordner <bin> wird gelöscht (Zeile 28) und anschließend neu erstellt (Zeile 29).
- Zeilen 33–35: Die Aufgabe „compile“, die die Standardaufgabe des Skripts ist (Zeile 1). Sie hängt (Attribut „depends“) von der Aufgabe „clean“ ab. Das bedeutet, dass Ant vor der Ausführung der Aufgabe „compile“ die Aufgabe „clean“ ausführen muss, d. h. den Ordner <bin> bereinigen muss. Der Zweck der Aufgabe „compile“ besteht hier darin, die Java-Quelldateien im Ordner <src> zu kompilieren.
- Zeile 34: Aufruf des Java-Compilers mit drei Parametern:
- srcdir: der Ordner, der die Java-Quelldateien enthält, hier der Ordner <src>
- destdir: der Ordner, in dem die generierten .class-Dateien gespeichert werden sollen, hier der Ordner <bin>
- classpathref: der für die Kompilierung zu verwendende Klassenpfad, hier alle JAR-Dateien im Verzeichnisbaum <lib>
- (Fortsetzung)
- Zeilen 38–45: die Aufgabe „copyconf“, deren Zweck es ist, alle .xml- und .properties-Dateien aus dem Verzeichnis <src> in das Verzeichnis <bin> zu kopieren.
- Zeile 48: Definition einer Aufgabe mithilfe des <taskdef>-Tags. Eine solche Aufgabe ist für die Wiederverwendung an anderer Stelle im Skript vorgesehen. Dies dient der Programmierfreundlichkeit. Da die Aufgabe an verschiedenen Stellen im Skript verwendet wird, wird sie einmalig mit dem <taskdef>-Tag definiert und bei Bedarf über ihren Namen wiederverwendet.
- Die Aufgabe heißt hibernatetool (Attribut „name“).
- Die Klasse wird durch das Attribut „classname“ definiert. Die angegebene Klasse befindet sich in dem zuvor erwähnten Archiv [hibernate-tools.jar].
- Das Attribut „classpathref“ teilt Ant mit, wo nach der vorangehenden Klasse gesucht werden soll
- (Fortsetzung)
- Die Zeilen 51–60 beziehen sich auf die hier relevante Aufgabe: die Generierung des Datenbankschemas für die @Entity-Objekte in unserem Eclipse-Projekt.
- Zeile 51: Die Aufgabe heißt DDL (kurz für Data Definition Language, die SQL, die zum Erstellen von Datenbankobjekten verwendet wird). Sie hängt von den Aufgaben „compile“ und „copyconf“ ab, in dieser Reihenfolge. Die DDL-Aufgabe löst daher nacheinander die Ausführung der Aufgaben „clean“, „compile“ und „copyconf“ aus. Wenn die DDL-Aufgabe startet, enthält der Ordner <bin> die aus den .java-Quellen generierten .class-Dateien, insbesondere die @Entity-Objekte, sowie die Datei [META-INF/persistence.xml], die die JPA/Hibernate-Schicht konfiguriert.
- Zeilen 53–59: Die in Zeile 48 definierte [hibernatetool]-Aufgabe wird aufgerufen. Ihr werden zahlreiche Parameter übergeben, zusätzlich zu den bereits in Zeile 48 definierten:
- Zeile 53: Das Ausgabeverzeichnis für die von der Aufgabe erzeugten Ergebnisse ist das aktuelle Verzeichnis.
- Zeile 54: Der Klassenpfad der Aufgabe ist der Ordner <bin>.
- Zeile 56: Teilt der [hibernatetool]-Aufgabe mit, wie sie ihre Laufzeitumgebung ermitteln soll: Das <jpaconfiguration/>-Tag gibt an, dass sie sich in einer JPA-Umgebung befindet und daher die Datei [META-INF/persistence.xml] verwenden muss, die sie hier in ihrem Klassenpfad findet.
- Zeile 58 legt die Bedingungen für die Generierung der Datenbank fest: drop=true gibt an, dass SQL-Drop-Table-Anweisungen ausgeführt werden müssen, bevor die Tabellen erstellt werden; create=true gibt an, dass die Textdatei mit den SQL-Anweisungen zum Erstellen der Datenbank erstellt werden muss; outputfilename gibt den Namen dieser SQL-Datei an – hier schema.sql im Ordner <ddl> des Eclipse-Projekts; export=false gibt an, dass die generierten SQL-Anweisungen nicht in einer Verbindung zum DBMS ausgeführt werden dürfen. Dieser Punkt ist wichtig: Er bedeutet, dass das Ziel-DBMS nicht laufen muss, um die Aufgabe auszuführen. delimiter legt das Zeichen fest, das zwei SQL-Anweisungen im generierten Schema trennt, und format=true fordert an, dass eine grundlegende Formatierung auf den generierten Text angewendet wird.
- Die Zeilen 51–60 beziehen sich auf die hier relevante Aufgabe: die Generierung des Datenbankschemas für die @Entity-Objekte in unserem Eclipse-Projekt.
- (Fortsetzung)
- Die Zeilen 63–72 definieren die Aufgabe mit dem Namen BD. Sie ist identisch mit der vorherigen DDL-Aufgabe, außer dass sie diesmal die Datenbank generiert (export="true" in Zeile 70). Die Aufgabe öffnet eine Verbindung zum DBMS unter Verwendung der in [persistence.xml] enthaltenen Informationen, um das SQL-Schema auszuführen und die Datenbank zu generieren. Um die BD-Aufgabe auszuführen, muss das DBMS daher laufen.
2.1.7. Ausführen der Ant-DDL-Aufgabe „ “
Um das Skript [ant-hibernate.xml] auszuführen, müssen wir zunächst einige Konfigurationen in Eclipse vornehmen.
 |
- in [1]: Wählen Sie [Externe Werkzeuge]
- in [2]: Erstellen Sie eine neue Ant-Konfiguration
 |
- in [3]: Benennen Sie die Ant-Konfiguration
- In [5]: Geben Sie das Ant-Skript über die Schaltfläche [4] an
- Schritt [6]: Übernehmen Sie die Änderungen
- in [7]: Die DDL-Ant-Konfiguration wurde erstellt
 |
 |
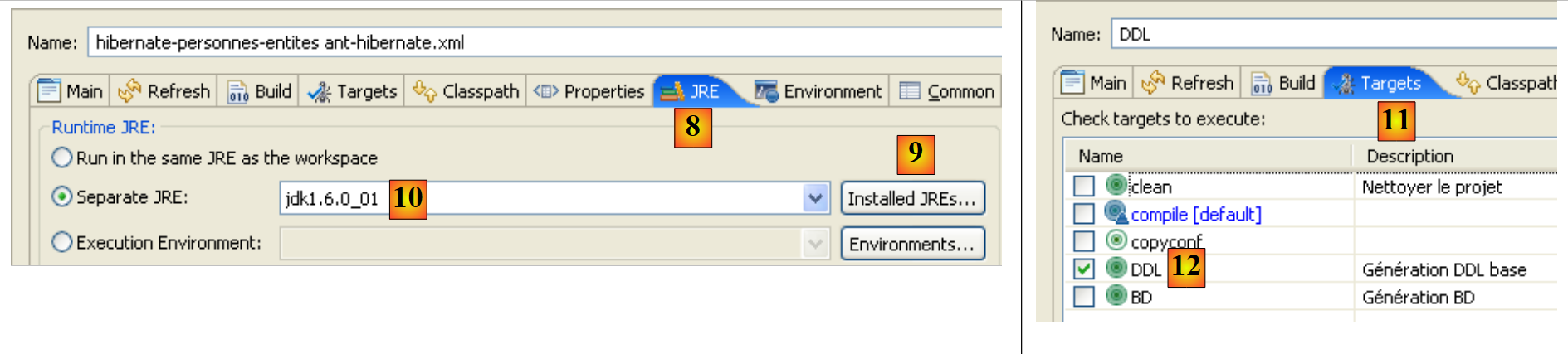
- in [8]: Definieren Sie auf der Registerkarte „JRE“ die zu verwendende JRE. Das Feld [10] ist normalerweise bereits mit der von Eclipse verwendeten JRE vorbelegt. Daher sind in diesem Bereich in der Regel keine weiteren Schritte erforderlich. Ich bin jedoch auf einen Fall gestoßen, in dem das Ant-Skript den <javac>-Compiler nicht finden konnte. Dieser Compiler befindet sich nicht in einer JRE (Java Runtime Environment), sondern in einem JDK (Java Development Kit). Das Ant-Tool von Eclipse findet diesen Compiler über die Umgebungsvariable JAVA_HOME (Start / Systemsteuerung / Leistung und Wartung / System / Registerkarte „Erweitert“ / Schaltfläche „Umgebungsvariablen“) [A]. Wenn diese Variable nicht definiert wurde, können Sie Ant ermöglichen, den <javac>-Compiler zu finden, indem Sie in [10] anstelle eines JRE ein JDK angeben. Das JDK befindet sich im selben Ordner wie das JRE [B]. Verwenden Sie die Schaltfläche [9], um das JDK unter den verfügbaren JREs [C] zu registrieren, damit Sie es anschließend in [10] auswählen können.
- In [12]: Wählen Sie auf der Registerkarte [Targets] die DDL-Aufgabe aus. Somit entspricht die Ant-Konfiguration, die wir DDL [7] genannt haben, der Ausführung der Aufgabe namens DDL [12], die, wie wir wissen, das DDL-Schema für die Datenbank generiert, das die @Entity-Objekte der Anwendung repräsentiert.
 |
- in [13]: Überprüfen Sie die Konfiguration
- In [14]: Ausführen
In der Ansicht [Konsole] sehen Sie Protokolle zur Ausführung der DDL-Ant-Aufgabe:
Buildfile: C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\ant-hibernate.xml
clean:
[delete] Deleting directory C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
[mkdir] Created dir: C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
compile:
[javac] Compiling 3 source files to C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
copyconf:
[copy] Copying 2 files to C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
DDL:
[hibernatetool] Executing Hibernate Tool with a JPA Configuration
[hibernatetool] 1. task: hbm2ddl (Generates database schema)
[hibernatetool] drop table if exists jpa01_personne;
[hibernatetool] create table jpa01_personne (
[hibernatetool] ID integer not null auto_increment,
[hibernatetool] VERSION integer not null,
[hibernatetool] NOM varchar(30) not null unique,
[hibernatetool] PRENOM varchar(30) not null,
[hibernatetool] DATENAISSANCE date not null,
[hibernatetool] MARIE bit not null,
[hibernatetool] NBENFANTS integer not null,
[hibernatetool] primary key (ID)
[hibernatetool] ) ENGINE=InnoDB;
BUILD SUCCESSFUL
Total time: 5 seconds
- Zur Erinnerung: Die DDL-Aufgabe heißt [hibernatetool] (Zeile 10) und hängt von den Aufgaben clean (Zeile 2), compile (Zeile 5) und copyconf (Zeile 7) ab.
- Zeile 10: Die Aufgabe [hibernatetool] verwendet die Datei [persistence.xml] aus einer JPA-Konfiguration
- Zeile 11: Die Aufgabe [hbm2ddl] generiert das DDL-Schema der Datenbank
- Zeilen 12–22: das Datenbank-DDL-Schema
Erinnern Sie sich daran, dass wir die Aufgabe [hbm2ddl] angewiesen haben, das DDL-Schema an einem bestimmten Speicherort zu generieren:
<hbm2ddl drop="true" create="true" export="true" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
- Zeile 74: Das Schema muss in der Datei ddl/schema.sql generiert werden. Schauen wir mal nach:
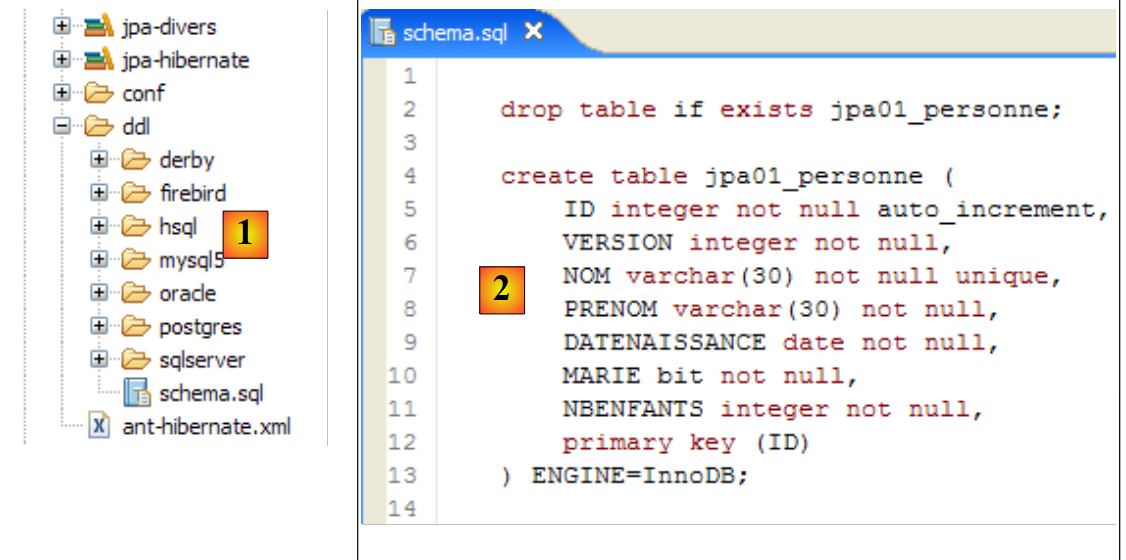 |
- in [1]: Die Datei ddl/schema.sql ist tatsächlich vorhanden (drücken Sie F5, um die Verzeichnisstruktur zu aktualisieren)
- in [2]: ihr Inhalt. Dies ist das Schema für eine MySQL5-Datenbank. Die Konfigurationsdatei [persistence.xml] für die JPA-Schicht hat tatsächlich ein MySQL5-DBMS angegeben (Zeile 8 unten):
<!-- connexion JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
...
<!-- création automatique du schéma -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialecte -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!-- propriétés DataSource c3p0 -->
...
Betrachten wir das hier implementierte objektrelationale Mapping anhand der Konfiguration des @Entity-Objekts „Person“ und des generierten DDL-Schemas:
 |
 |
Einige Punkte sind dabei besonders erwähnenswert:
- A1-B1: Der in A1 angegebene Tabellenname ist tatsächlich derjenige, der in B1 verwendet wird. Beachten Sie die `DROP`-Anweisung, die in B1 vor der `CREATE`-Anweisung steht.
- A2-B2: Zeigen, wie der Primärschlüssel generiert wird. Der in A2 angegebene AUTO-Modus führte zu dem für MySQL 5 spezifischen Autoincrement-Attribut. Der Modus zur Generierung des Primärschlüssels ist meist DBMS-spezifisch.
- A3-B3: Zeigen den für MySQL 5 spezifischen SQL-Bit-Typ, der zur Darstellung eines Java-Boolean-Typs verwendet wird.
Wiederholen wir diesen Test mit einem anderen DBMS:
 |
- Der Ordner [conf] [1] enthält [persistence.xml]-Dateien für verschiedene DBMS. Nehmen Sie beispielsweise die Oracle-Datei [2] und legen Sie sie im Ordner [META-INF] [3] anstelle der bisherigen Datei ab. Ihr Inhalt lautet wie folgt:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Persistent classes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="oracle.jdbc.OracleDriver" />
<property name="hibernate.connection.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- automatic schematic creation -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.OracleDialect" />
<!-- properties DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
Lesern wird empfohlen, den Anhang zu konsultieren, insbesondere den Abschnitt über Oracle (Abschnitt 5.7), vor allem um die JDBC-Konfiguration zu verstehen.
Nur Zeile 25 ist hier wirklich wichtig: Wir teilen Hibernate mit, dass das DBMS nun ein Oracle-DBMS ist. Die Ausführung der Ant-DDL-Aufgabe liefert das oben gezeigte Ergebnis [4]. Beachten Sie, dass sich das Oracle-Schema vom MySQL5-Schema unterscheidet. Dies ist eine wesentliche Stärke von JPA: Der Entwickler muss sich nicht um diese Details kümmern, was die Portabilität seiner Anwendungen erheblich erhöht.
2.1.8. Ausführen der Ant-Aufgabe „ “
Sie erinnern sich vielleicht, dass die Ant-Aufgabe namens BD dasselbe tut wie die *DDL*-Aufgabe, aber zusätzlich die Datenbank generiert. Das DBMS muss daher laufen. Wir verwenden das MySQL5-DBMS und bitten den Leser, die Datei [conf/mysql5/persistence.xml] in den Ordner [src/META-INF] zu kopieren. Um zu überprüfen, ob die Aufgabe funktioniert, verwenden wir das SQL Explorer-Plugin (siehe Abschnitt 5.2.6), um den Status der JPA-Datenbank vor und nach der Ausführung der Ant-Aufgabe „BD“ zu überprüfen.
Zunächst müssen wir eine neue Ant-Konfiguration erstellen, um die BD-Aufgabe auszuführen. Der Leser wird gebeten, die in Abschnitt 2.1.7 für die DDL-Ant-Konfiguration beschriebene Vorgehensweise zu befolgen. Die neue Ant-Konfiguration erhält den Namen BD:
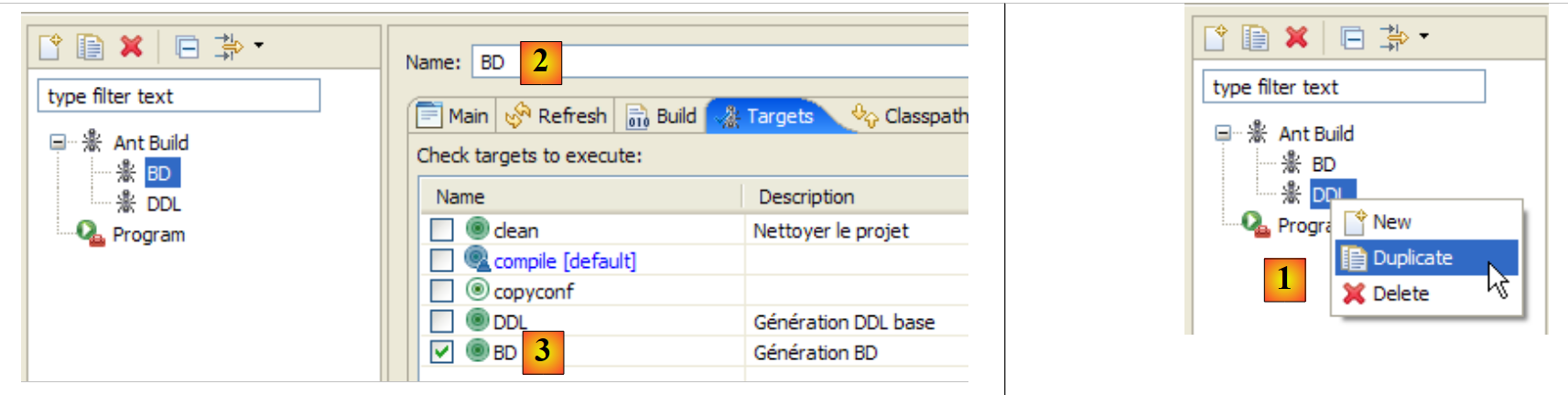 |
- in [1]: Wir duplizieren die vorherige Konfiguration namens DDL
- in [2]: Benennen Sie die neue Konfiguration „BD“. Sie führt die Ant-Aufgabe „BD“ aus [3], die die Datenbank physisch erstellt.
- Sobald dies erledigt ist, starten Sie das DBMS MySQL5 (Abschnitt 5.5).
Wir verwenden nun das SQL-Explorer-Plugin, um die vom DBMS verwalteten Datenbanken zu erkunden. Der Leser sollte sich bei Bedarf vorab mit diesem Plugin vertraut machen (siehe Abschnitt 5.2.6).
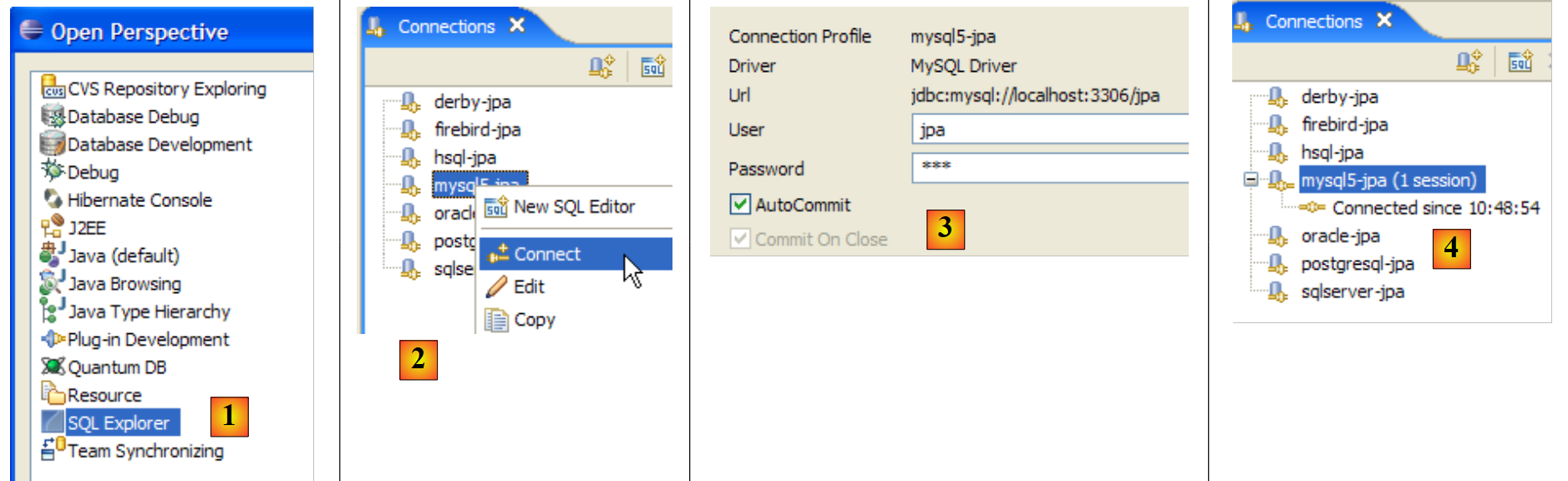 |
- [1]: Öffnen Sie die SQL-Explorer-Perspektive [Fenster / Perspektive öffnen / Sonstige]
- [2]: Erstellen Sie gegebenenfalls eine Verbindung [mysql5-jpa] (siehe Abschnitt 5.5.5, Seite 252) und öffnen Sie diese
- [3]: Melden Sie sich als jpa / jpa an
- [4]: Sie sind nun mit MySQL5 verbunden.
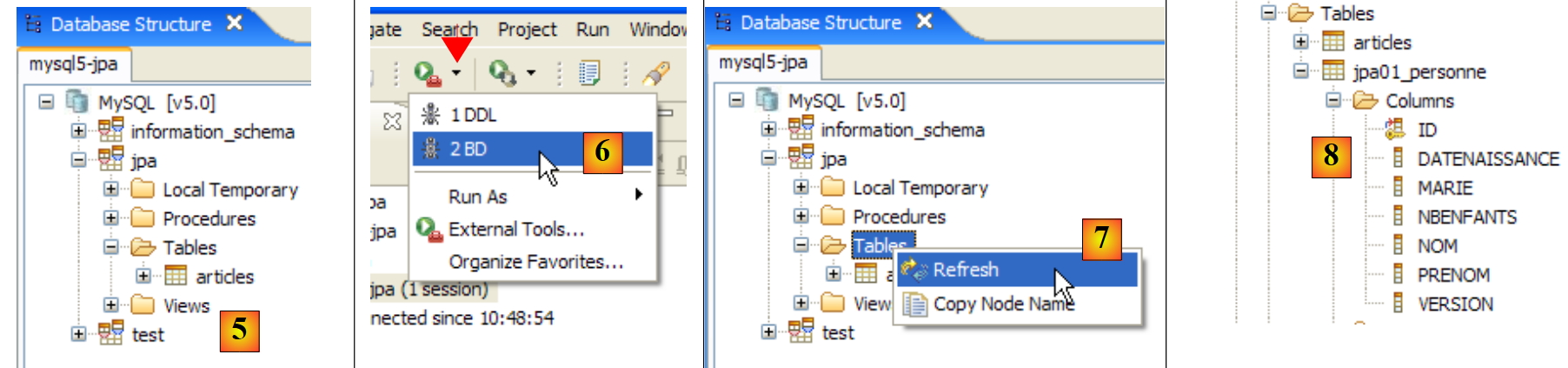 |
- In [5]: Die jpa-Datenbank enthält nur eine Tabelle: [articles]
- in [6]: Führen Sie die Ant-DB-Aufgabe aus. Da Sie sich in der [SQL Explorer]-Perspektive befinden, können Sie die Ansicht [Console] nicht sehen, in der die Aufgabenprotokolle angezeigt werden. Sie können diese Ansicht über [Fenster / Ansicht anzeigen / ...] aufrufen oder zur Java-Perspektive zurückkehren [Fenster / Perspektive öffnen / ...].
- in [7]: Sobald die DB-Aufgabe abgeschlossen ist, kehren Sie bei Bedarf zur [SQL Explorer]-Perspektive zurück und aktualisieren Sie den JPA-Datenbankbaum.
- In [8]: Sie sehen die Tabelle [jpa01_personne], die erstellt wurde.
Leser werden dazu ermutigt, diesen Prozess zur Datenbankgenerierung mit anderen DBMS zu wiederholen. Die Vorgehensweise ist wie folgt:
- Kopieren Sie die Datei [conf/<dbms>/persistence.xml] in den Ordner [src/META-INF], wobei <dbms> für das zu testende DBMS steht
- Starten Sie <dbms>, indem Sie die Anweisungen im Anhang für dieses DBMS befolgen
- Erstellen Sie in der Ansicht „SQL Explorer“ eine Verbindung zu <dbms>. Dies wird ebenfalls in den Anhängen für die einzelnen DBMS erläutert
- Wiederholen Sie die vorherigen Tests
An dieser Stelle haben wir eine Reihe von Erkenntnissen gewonnen:
- Wir haben ein besseres Verständnis des Konzepts der objektrelationalen Brücke. Hier wurde diese mit Hibernate implementiert. Später werden wir TopLink verwenden.
- Wir wissen, dass diese objektrelationale Brücke an zwei Stellen konfiguriert wird:
- in den @Entity-Objekten, wo wir die Beziehungen zwischen Objektfeldern und Datenbanktabellenspalten festlegen
- in [META-INF/persistence.xml], wo wir der JPA-Implementierung Informationen über die beiden Komponenten der objekt-relationalen Brücke bereitstellen: die @Entity-Objekte (Objekt) und die Datenbank (relational).
- Wir haben zwei Ant-Tasks namens DDL und DB erstellt, mit denen wir die Datenbank auf Basis der vorherigen Konfiguration erstellen können, noch bevor wir Java-Code schreiben.
Nachdem die JPA-Schicht unserer Anwendung nun ordnungsgemäß konfiguriert ist, können wir damit beginnen, die JPA-API mit Java-Code zu erkunden.
2.1.9. Der Persistenzkontext einer Anwendung
Schauen wir uns die Laufzeitumgebung eines JPA-Clients einmal genauer an:
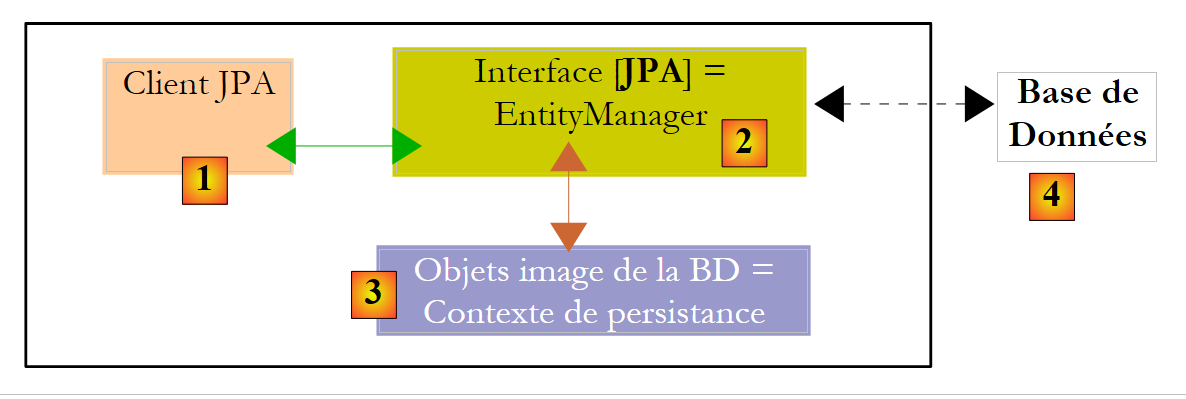 |
Wir wissen, dass die JPA-Schicht [2] eine Brücke zwischen Objekten [3] und relationalen Daten [4] bildet. Der „Persistenzkontext“ bezeichnet die Menge der Objekte, die von der JPA-Schicht innerhalb dieser objekt-relationalen Brücke verwaltet werden. Um auf Daten im Persistenzkontext zuzugreifen, muss ein JPA-Client [1] die JPA-Schicht [2] durchlaufen:
- Er kann ein Objekt erstellen und die JPA-Schicht auffordern, es persistent zu machen. Das Objekt wird dann Teil des Persistenzkontexts.
- Er kann von der [JPA]-Schicht eine Referenz auf ein vorhandenes persistentes Objekt anfordern.
- Er kann ein von der JPA-Schicht erhaltenes persistentes Objekt ändern.
- Er kann die JPA-Schicht auffordern, ein Objekt aus dem Persistenzkontext zu entfernen.
Die JPA-Schicht stellt dem Client eine Schnittstelle namens [EntityManager] zur Verfügung, die, wie der Name schon sagt, die Verwaltung von @Entity-Objekten im Persistenzkontext ermöglicht. Nachfolgend sind die wichtigsten Methoden dieser Schnittstelle aufgeführt:
Fügt die Entität zum Persistenzkontext hinzu | |
entfernt die Entität aus dem Persistenzkontext | |
führt eine Zusammenführung eines Entity-Objekts vom Client, das nicht vom Persistenzkontext verwaltet wird, mit dem Entitätsobjekt im Persistenzkontext zusammen, das denselben Primärschlüssel hat. Das zurückgegebene Ergebnis ist das Entitätsobjekt aus dem Persistenzkontext. | |
fügt ein aus der Datenbank abgerufenes Objekt über dessen Primärschlüssel. Der Typ T des Objekts ermöglicht es der JPA-Schicht, zu erkennen, welche Tabelle abgefragt werden muss. Das so erstellte persistente Objekt wird an den Client zurückgegeben. | |
erstellt ein Query-Objekt aus einer JPQL-Abfrage (Java Persistence Query Language). Eine JPQL-Abfrage entspricht einer SQL-Abfrage, mit dem Unterschied, dass sie Objekte statt Tabellen abfragt. | |
Eine Methode, die der vorherigen ähnelt, mit dem Unterschied, dass queryText eine SQL-Anweisung anstelle einer JPQL-Abfrage ist. | |
Eine Methode, die mit createQuery identisch ist, mit dem Unterschied, dass die JPQL-Abfrage queryText in eine Konfigurationsdatei ausgelagert und einem Namen zugeordnet wurde. Dieser Name ist der Parameter der Methode. |
Ein EntityManager-Objekt hat einen Lebenszyklus, der nicht unbedingt mit dem der Anwendung übereinstimmt. Es hat einen Anfang und ein Ende. Daher kann ein JPA-Client nacheinander mit verschiedenen EntityManager-Objekten arbeiten. Der mit einem EntityManager verbundene Persistenzkontext „ “ hat denselben Lebenszyklus wie der EntityManager selbst. Sie sind untrennbar miteinander verbunden. Wenn ein EntityManager-Objekt geschlossen wird, wird sein Persistenzkontext bei Bedarf mit der Datenbank synchronisiert und hört dann auf zu existieren. Um einen neuen Persistenzkontext zu erhalten, muss ein neuer EntityManager erstellt werden.
Der JPA-Client kann mit der folgenden Anweisung einen EntityManager und damit einen Persistenzkontext erstellen:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
- javax.persistence.Persistence ist eine statische Klasse, die dazu dient, eine Factory für EntityManager-Objekte zu erhalten. Diese Factory ist mit einer bestimmten Persistence Unit verknüpft. Zur Erinnerung: Die Konfigurationsdatei [META-INF/persistence.xml] dient zur Definition von Persistence Units, von denen jede einen Namen hat:
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
Im obigen Beispiel heißt die Persistenz-Einheit „jpa“. Sie verfügt über eine eigene spezifische Konfiguration, einschließlich des Datenbankmanagementsystems (DBMS), mit dem sie arbeitet. Die Anweisung [Persistence.createEntityManagerFactory("jpa")] erstellt eine EntityManagerFactory, die EntityManager-Objekte bereitstellen kann, die zur Verwaltung von Persistenzkontexten dienen, die mit der Persistence-Unit namens jpa verbunden sind. Ein EntityManager-Objekt – und damit ein Persistenzkontext – wird wie folgt vom EntityManagerFactory-Objekt abgerufen:
Mit den folgenden Methoden der [EntityManager]-Schnittstelle können Sie den Lebenszyklus des Persistenzkontexts verwalten:
Der Persistenzkontext wird geschlossen. Erzwingt die Synchronisierung des Persistenzkontexts mit der Datenbank:
| |
Der Persistenzkontext wird von allen Objekten bereinigt, aber nicht geschlossen. | |
Der Persistenzkontext wird mit der Datenbank synchronisiert, wie für close() beschrieben |
Der JPA-Client kann die Synchronisation des Persistenzkontexts mit der Datenbank mithilfe der Methode [EntityManager].flush erzwingen. Die Synchronisation kann explizit oder implizit erfolgen. Im ersten Fall ist es Sache des Clients, Flush-Operationen durchzuführen, wenn er synchronisieren möchte; andernfalls erfolgt die Synchronisation zu bestimmten Zeitpunkten, die wir festlegen. Der Synchronisationsmodus wird durch die folgenden Methoden der [EntityManager]-Schnittstelle verwaltet:
Für flushMode gibt es zwei mögliche Werte: FlushModeType.AUTO (Standard): Die Synchronisation erfolgt vor jeder SELECT-Abfrage, die an die Datenbank gestellt wird. FlushModeType.COMMIT: Die Synchronisation erfolgt nur am Ende von Datenbanktransaktionen. | |
gibt den aktuellen Synchronisationsmodus zurück |
Fassen wir zusammen. Im Modus FlushModeType.AUTO, der als Standard eingestellt ist, wird der Persistenzkontext zu folgenden Zeitpunkten mit der Datenbank synchronisiert:
- vor jeder SELECT-Operation in der Datenbank
- am Ende einer Transaktion in der Datenbank
- nach einer Flush- oder Close-Operation im Persistenzkontext
Im Modus FlushModeType.COMMIT gilt dasselbe, mit Ausnahme von Vorgang 1, der nicht stattfindet. Der normale Modus der Interaktion mit der JPA-Schicht ist der Transaktionsmodus. Der Client führt verschiedene Operationen am Persistenzkontext innerhalb einer Transaktion durch. In diesem Fall sind die Synchronisationspunkte zwischen dem Persistenzkontext und der Datenbank die oben genannten Fälle 1 und 2 im AUTO-Modus sowie nur Fall 2 im COMMIT-Modus.
Schließen wir mit der Query-Schnittstellen-API ab, die es Ihnen ermöglicht, JPQL-Befehle auf dem Persistenzkontext oder SQL-Befehle direkt auf der Datenbank auszuführen, um Daten abzurufen. Die Query-Schnittstelle sieht wie folgt aus:
 |
Wir werden die oben genannten Methoden 1 bis 4 verwenden:
- 1 – Die Methode `getResultList` führt eine SELECT-Abfrage aus, die mehrere Objekte zurückgibt. Diese werden in einem `List`-Objekt zurückgegeben. Dieses Objekt ist eine Schnittstelle. Es stellt ein `Iterator`-Objekt bereit, mit dem Sie wie folgt durch die Elemente der Liste `L` iterieren können:
Iterator iterator = L.iterator();
while (iterator.hasNext()) {
// exploiter l'objet iterator.next() qui représente l'élément courant de la liste
...
}
Die Liste L kann auch mit einer for-Schleife durchlaufen werden:
for (Object o : L) {
// exploiter objet o
}
- 2 – Die Methode `getSingleResult` führt eine JPQL-/SQL-SELECT-Anweisung aus, die ein einzelnes Objekt zurückgibt.
- 3 – Die Methode `executeUpdate` führt eine SQL-UPDATE- oder DELETE-Anweisung aus und gibt die Anzahl der von der Operation betroffenen Zeilen zurück.
- 4 – Mit der Methode `setParameter(String, Object)` können Sie einem benannten Parameter in einer parametrisierten JPQL-Abfrage einen Wert zuweisen.
- 5 - Die Methode `setParameter(int, Object)` setzt den Parameter, wobei dieser jedoch nicht anhand seines Namens, sondern anhand seiner Position in der JPQL-Abfrage identifiziert wird.
2.1.10. Ein erster JPA-Client
Kehren wir zur Java-Perspektive des Projekts zurück:
 |
Wir wissen nun fast alles über dieses Projekt, abgesehen vom Inhalt des Ordners [src/tests], den wir als Nächstes untersuchen werden. Der Ordner enthält zwei Testprogramme für die JPA-Schicht:
- [InitDB.java] ist ein Programm, das einige Zeilen in die Tabelle [jpa01_personne] in der Datenbank einfügt. Sein Code führt uns in die ersten Elemente der JPA-Schicht ein.
- [Main.java] ist ein Programm, das CRUD-Operationen an der Tabelle [jpa01_personne] durchführt. Durch die Untersuchung seines Codes können wir die grundlegenden Konzepte des Persistenzkontexts und den Lebenszyklus von Objekten innerhalb dieses Kontexts erkunden.
2.1.10.1. Der Code
Der Code für das Programm [InitDB.java] lautet wie folgt:
package tests;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
import javax.persistence.Persistence;
import entites.Personne;
public class InitDB {
// constant
private final static String TABLE_NAME = "jpa01_personne";
public static void main(String[] args) throws ParseException {
// Persistence unit
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
// retrieve a EntityManagerFactory from the persistence unit
EntityManager em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// delete items from the people table
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
// create two people
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// persistence of people
em.persist(p1);
em.persist(p2);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
// log
System.out.println("terminé ...");
}
}
Dieser Code sollte im Lichte der Erläuterungen in Abschnitt 2.1.9 gelesen werden.
- Zeile 19: Ein EntityManagerFactory-Objekt (emf) wird für die JPA-Persistenz-Einheit (definiert in persistence.xml) angefordert. Dieser Vorgang wird normalerweise nur einmal während der Laufzeit einer Anwendung durchgeführt.
- Zeile 21: Ein EntityManager (em)-Objekt wird angefordert, um einen Persistenzkontext zu verwalten.
- Zeile 23: Ein Transaction-Objekt wird angefordert, um eine Transaktion zu verwalten. Beachten Sie, dass Operationen am Persistenzkontext innerhalb einer Transaktion durchgeführt werden müssen. Wir werden sehen, dass dies nicht zwingend erforderlich ist, aber eine Nichtbeachtung kann zu Problemen führen. Wenn die Anwendung in einem EJB3-Container läuft, werden Operationen am Persistenzkontext immer innerhalb einer Transaktion durchgeführt.
- Zeile 24: Die Transaktion beginnt
- Zeile 26: Führt eine SQL-Löschanweisung für die Tabelle „jpa01_personne“ aus (nativeQuery). Dies geschieht, um die Tabelle vollständig zu leeren und so das Ergebnis der Anwendungsausführung besser erkennen zu können [InitDB]
- Zeilen 28–29: Es werden zwei „Person“-Objekte, p1 und p2, erstellt. Dabei handelt es sich um gewöhnliche Objekte, die vorerst nichts mit dem Persistenzkontext zu tun haben. Im Zusammenhang mit dem Persistenzkontext bezeichnet Hibernate diese Objekte als sich in einem vorübergehenden Zustand befindlich, im Gegensatz zu persistenten Objekten, die vom Persistenzkontext verwaltet werden. Wir werden stattdessen von nicht-persistenten Objekten (einem nicht standardmäßigen Begriff) sprechen, um anzugeben, dass sie noch nicht vom Persistenzkontext verwaltet werden, und von persistenten Objekten für diejenigen, die von ihm verwaltet werden. Wir werden auf eine dritte Kategorie von Objekten stoßen: detached Objekte, also Objekte, die zuvor persistent waren, deren Persistenzkontext jedoch geschlossen wurde. Der Client kann Referenzen auf solche Objekte halten, was erklärt, warum sie nicht unbedingt zerstört werden, wenn der Persistenzkontext geschlossen wird. Man sagt dann, sie befänden sich in einem detached Zustand. Die Operation [EntityManager].merge ermöglicht es, sie wieder an einen neu erstellten Persistenzkontext anzuhängen.
- Zeilen 31–32: Die Entitäten p1 und p2 werden über die Operation [EntityManager].persist zum Persistenzkontext hinzugefügt. Sie werden dann zu persistenten Objekten.
- Zeilen 35–37: Eine JPQL-Abfrage „select p from Person p order by p.name asc“ wird ausgeführt. Person ist nicht die Tabelle (die den Namen jpa01_person trägt), sondern das mit der Tabelle verknüpfte @Entity-Objekt. Hier handelt es sich um eine JPQL-Abfrage (Java Persistence Query Language) auf den Persistenzkontext, nicht um eine SQL-Abfrage auf die Datenbank. Abgesehen vom Person-Objekt, das die Tabelle jpa01_personne ersetzt hat, sind die Syntaxen jedoch identisch. Eine for-Schleife durchläuft die aus der Select-Anweisung resultierende Liste (der Personen), um jedes Element auf der Konsole anzuzeigen. Hier überprüfen wir, ob die in den Zeilen 31–32 in den Persistenzkontext aufgenommenen Elemente tatsächlich in der Tabelle vorhanden sind. Es findet eine transparente Synchronisation des Persistenzkontexts mit der Datenbank statt. Tatsächlich wird eine SELECT-Abfrage ausgeführt, und wir haben festgestellt, dass dies einer der Fälle ist, in denen eine Synchronisation stattfindet. Daher ist es genau in diesem Moment, in dem JPA/Hibernate im Hintergrund die beiden SQL-INSERT-Anweisungen ausgibt, die die beiden Personen in die Tabelle jpa01_personne einfügen. Die `persist`-Operation hat dies nicht bewirkt. Diese Operation fügt Objekte zum Persistenzkontext hinzu, ohne die Datenbank zu beeinflussen. Die eigentliche Arbeit findet während der Synchronisation statt, hier unmittelbar vor der `SELECT`-Abfrage an die Datenbank.
- Zeile 39: Wir beenden die in Zeile 24 gestartete Transaktion. Es findet erneut eine Synchronisation statt. Hier geschieht nichts, da sich der Persistenzkontext seit der letzten Synchronisation nicht verändert hat.
- Zeile 41: Wir schließen den Persistenzkontext.
- Zeile 43: Wir schließen die EntityManager-Factory.
2.1.10.2. Die „ “: Ausführung des Codes
- Starten Sie das MySQL5-DBMS
- Legen Sie conf/mysql5/persistence.xml bei Bedarf in META-INF/persistence.xml ab
- Führen Sie die Anwendung [InitDB] aus
Es werden folgende Ergebnisse erzielt:
 |
- in [1]: die Konsolenausgabe in der Java-Perspektive. Die erwarteten Ergebnisse werden erzielt.
- in [2]: Wir überprüfen den Inhalt der Tabelle [jpa01_personne] mithilfe der Ansicht „SQL Explorer“, wie in Abschnitt 2.1.8 erläutert. Zwei Punkte sind dabei besonders hervorzuheben:
- Die Primärschlüssel-ID wurde automatisch generiert
- das Gleiche gilt für die Versionsnummer. Wir sehen, dass die erste Version die Nummer 0 hat.
Hier haben wir die ersten Elemente des JPA-Frameworks. Wir haben erfolgreich Daten in eine Tabelle eingefügt. Auf dieser Grundlage werden wir den zweiten Test schreiben, aber lassen Sie uns zunächst die Protokolle besprechen.
2.1.11. Implementierung von Hibernate-Protokollen
Es ist möglich, die SQL-Anweisungen einzusehen, die von der JPA/Hibernate-Schicht an die Datenbank gesendet werden. Es ist sinnvoll, diese zu überprüfen, um festzustellen, ob die JPA-Schicht genauso effizient ist wie ein Entwickler, der die SQL-Anweisungen selbst geschrieben hätte.
Bei JPA/Hibernate kann die SQL-Protokollierung in der Datei [persistence.xml] konfiguriert werden:
<!-- Classes persistantes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connexion JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
- Zeilen 4–6: Zu diesem Zeitpunkt waren die SQL-Protokolle noch nicht aktiviert. Wir aktivieren sie nun, indem wir die Kommentarzeichen in den Zeilen 3 und 7 entfernen.
Wir führen die Anwendung [InitDB] erneut aus. Die Konsolenausgabe sieht dann wie folgt aus:
- Zeilen 2–4: Die SQL-DELETE-Anweisung, die sich aus dem Befehl ergibt:
// supprimer les éléments de la table des personnes
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
- Zeilen 5–18: die SQL-EINFÜGEN-Anweisungen aus der Anleitung:
// persistance des personnes
em.persist(p1);
em.persist(p2);
- Zeilen 21–32: Die SQL-SELECT-Anweisung, die sich aus der Anweisung ergibt:
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList())
Wenn wir Zwischenausgaben in der Konsole anzeigen, sehen wir, dass die SQL-Protokolle für die Anweisung I im Java-Code geschrieben werden, sobald die Anweisung I ausgeführt wird. Das bedeutet jedoch nicht, dass die angezeigte SQL-Anweisung in diesem Moment in der Datenbank ausgeführt wird. Sie wird vielmehr zwischengespeichert, um bei der nächsten Synchronisierung des Persistenzkontexts mit der Datenbank ausgeführt zu werden.
Zusätzliche Protokolle können über die Datei [src/log4j.properties] abgerufen werden:
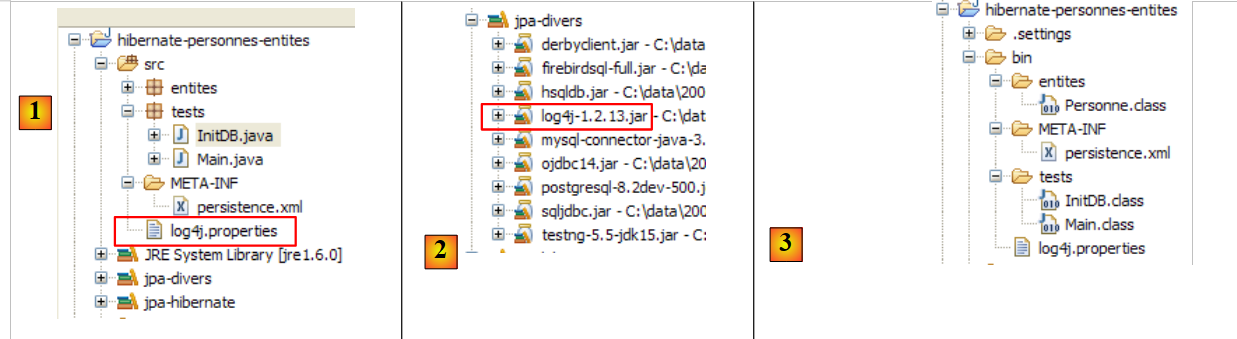 |
- In [1] wird die Datei [log4j.properties] vom Archiv [log4j-1.2.13.jar] [2] des Tools LOG4j (Logs for Java) verwendet, das unter der URL [http://logging.apache.org/log4j/docs/index.html] verfügbar ist. Da sie im Ordner [src] des Eclipse-Projekts abgelegt ist, wissen wir, dass [log4j.properties] automatisch in den Ordner [bin] des Projekts kopiert wird [3]. Sobald dies geschehen ist, befindet sie sich im Klassenpfad des Projekts, und genau dort wird das [2]-Archiv sie abrufen.
Die Datei [log4j.properties] ermöglicht es uns, bestimmte Hibernate-Protokolle zu steuern. In früheren Durchläufen lautete ihr Inhalt wie folgt:
# Direct log messages to stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
# Root logger option
log4j.rootLogger=ERROR, stdout
# Hibernate logging options (INFO only shows startup messages)
#log4j.logger.org.hibernate=INFO
# Log JDBC bind parameter runtime arguments
#log4j.logger.org.hibernate.type=DEBUG
Ich werde mich zu dieser Konfiguration nicht weiter äußern, da ich mir nie die Zeit genommen habe, mich ernsthaft mit LOG4j auseinanderzusetzen.
- Die Zeilen 1–8 finden sich in allen log4j.properties-Dateien, die mir begegnet sind
- Die Zeilen 10–14 sind in den log4j.properties-Dateien der Hibernate-Beispiele enthalten.
- Zeile 11: steuert die allgemeinen Protokolle von Hibernate. Da die Zeile auskommentiert ist, sind diese Protokolle hier deaktiviert. Es gibt mehrere Protokollstufen: INFO (allgemeine Informationen darüber, was Hibernate gerade tut), WARN (Hibernate warnt uns vor einem potenziellen Problem), DEBUG (detaillierte Protokolle). Die INFO-Stufe ist die knappste, während der DEBUG-Modus am ausführlichsten ist. Wenn Sie Zeile 11 aktivieren, können Sie sehen, was Hibernate gerade tut, insbesondere beim Start der Anwendung. Dies ist oft nützlich.
- Wenn Zeile 12 aktiviert ist, können Sie die tatsächlichen Argumente sehen, die bei der Ausführung parametrisierter SQL-Abfragen verwendet werden.
Beginnen wir damit, die Auskommentierung in Zeile 14 aufzuheben
# Log JDBC bind parameter runtime arguments
log4j.logger.org.hibernate.type=DEBUG
und führen Sie [InitDB] erneut aus. Die durch diese Änderung generierten neuen Protokolle lauten wie folgt (Auszug):
- Die Zeilen 8–10 sind neue Protokolleinträge, die durch die Aktivierung von Zeile 14 in [log4j.properties] generiert wurden. Sie zeigen die 5 Werte an, die den formalen Parametern ? der parametrisierten Abfrage in den Zeilen 2–7 zugewiesen wurden. Somit sehen wir, dass die Spalte VERSION den Wert 0 erhält (Zeile 8).
Aktivieren wir nun Zeile 11 in [log4j.properties]:
und führen Sie [InitDB] erneut aus:
Das Lesen dieser Protokolle liefert viele interessante Informationen:
- Zeile 7: Hibernate gibt den Namen einer gefundenen @Entity-Klasse an
- Zeile 8: gibt an, dass die Klasse [Person] der Tabelle [jpa01_person] zugeordnet wird
- Zeile 9: gibt den zu verwendenden C3P0-Verbindungspool, den Namen des JDBC-Treibers und die URL der zu verwaltenden Datenbank an
- Zeile 10: enthält weitere Details zur JDBC-Verbindung: Eigentümer, Commit-Typ usw.
- Zeile 14: Der Dialekt, der für die Kommunikation mit dem DBMS verwendet wird
- Zeile 15: Der verwendete Transaktionstyp. JDBCTransactionFactory gibt an, dass die Anwendung ihre eigenen Transaktionen verwaltet. Sie läuft nicht in einem EJB3-Container, der einen eigenen Transaktionsdienst bereitstellen würde.
- Die folgenden Zeilen beziehen sich auf Hibernate-Konfigurationsoptionen, auf die wir bisher noch nicht eingegangen sind. Interessierte Leser werden gebeten, die Hibernate-Dokumentation zu konsultieren.
- Zeile 37: SQL-Anweisungen werden auf der Konsole angezeigt. Dies wurde in [persistence.xml] angefordert:
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.format_sql" value="true" />
<property name="use_sql_comments" value="true" />
- Zeilen 43–45: Das Datenbankschema wird in das DBMS exportiert, d. h., die Datenbank wird geleert und anschließend neu erstellt. Dieser Mechanismus ergibt sich aus der Konfiguration in [persistence.xml] (Zeile 4 unten):
...
<property name="hibernate.connection.password" value="jpa" />
<!-- création automatique du schéma -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialecte -->
...
Wenn eine Anwendung mit einer Hibernate-Ausnahme „abstürzt“, die Sie nicht verstehen, aktivieren Sie zunächst die Hibernate-Protokolle im DEBUG-Modus in [log4j.properties], um sich ein klareres Bild zu verschaffen:
# Root logger option
log4j.rootLogger=ERROR, stdout
# Hibernate logging options (INFO only shows startup messages)
log4j.logger.org.hibernate=DEBUG
Im weiteren Verlauf dieses Dokuments ist die Protokollierung standardmäßig deaktiviert, um eine besser lesbare Konsolenausgabe zu gewährleisten.
2.1.12. Erkundung der Abfragesprache JPQL/HQL mit der Hibernate-Konsole
Hinweis: Für diesen Abschnitt ist das Hibernate Tools-Plugin erforderlich (Abschnitt 5.2.5).
Im Code der [InitDB]-Anwendung haben wir eine JPQL-Abfrage verwendet. JPQL (Java Persistence Query Language) ist eine Sprache zur Abfrage des Persistenzkontexts. Die verwendete Abfrage lautete wie folgt:
Sie wählte alle Datensätze aus der Tabelle aus, die mit der @Entity [Person] verknüpft ist, und gab sie in aufsteigender Reihenfolge nach dem Namen zurück. In der obigen Abfrage ist p.name das Feld „name“ einer Instanz p der Klasse [Person]. Eine JPQL-Abfrage wirkt sich daher auf die @Entity-Objekte im Persistenzkontext aus und nicht direkt auf die Datenbanktabellen. Die JPA-Schicht übersetzt diese JPQL-Abfrage in eine SQL-Abfrage, die für das verwendete DBMS geeignet ist. Im Fall einer JPA/Hibernate-Implementierung, die mit einem MySQL5-DBMS verbunden ist, wird die vorstehende JPQL-Abfrage daher in die folgende SQL-Abfrage übersetzt:
select
personne0_.ID as ID0_,
personne0_.VERSION as VERSION0_,
personne0_.NOM as NOM0_,
personne0_.PRENOM as PRENOM0_,
personne0_.DATENAISSANCE as DATENAIS5_0_,
personne0_.MARIE as MARIE0_,
personne0_.NBENFANTS as NBENFANTS0_
from
jpa01_personne personne0_
order by
personne0_.NOM asc
Die JPA-Schicht nutzte die Konfiguration des @Entity-Objekts [Person], um die richtige SQL-Abfrage zu generieren. Dies ist ein Beispiel für die hier implementierte objektrelationale Zuordnung.
Das Plugin [Hibernate Tools] (Abschnitt 5.2.5) bietet ein Tool namens „Hibernate Console“, mit dem
- Sie JPQL- oder HQL-Abfragen (Hibernate Query Language) im Persistenzkontext ausführen
- , um die Ergebnisse abzurufen
- und das SQL-Äquivalent anzuzeigen, das in der Datenbank ausgeführt wurde
Die Hibernate-Konsole ist ein unschätzbares Werkzeug, um die JPQL-Sprache zu erlernen und sich mit der JPQL/SQL-Brücke vertraut zu machen. Es ist allgemein bekannt, dass JPA stark auf ORM-Tools wie Hibernate oder TopLink zurückgriff. JPQL ist der HQL von Hibernate sehr ähnlich, umfasst jedoch nicht alle deren Funktionen. In der Hibernate-Konsole können Sie HQL-Befehle eingeben, die zwar in der Konsole normal ausgeführt werden, aber nicht Teil der JPQL-Sprache sind und daher in einem JPA-Client nicht verwendet werden können. In solchen Fällen werden wir darauf hinweisen.
Erstellen wir eine Hibernate-Konsole für unser aktuelles Eclipse-Projekt:
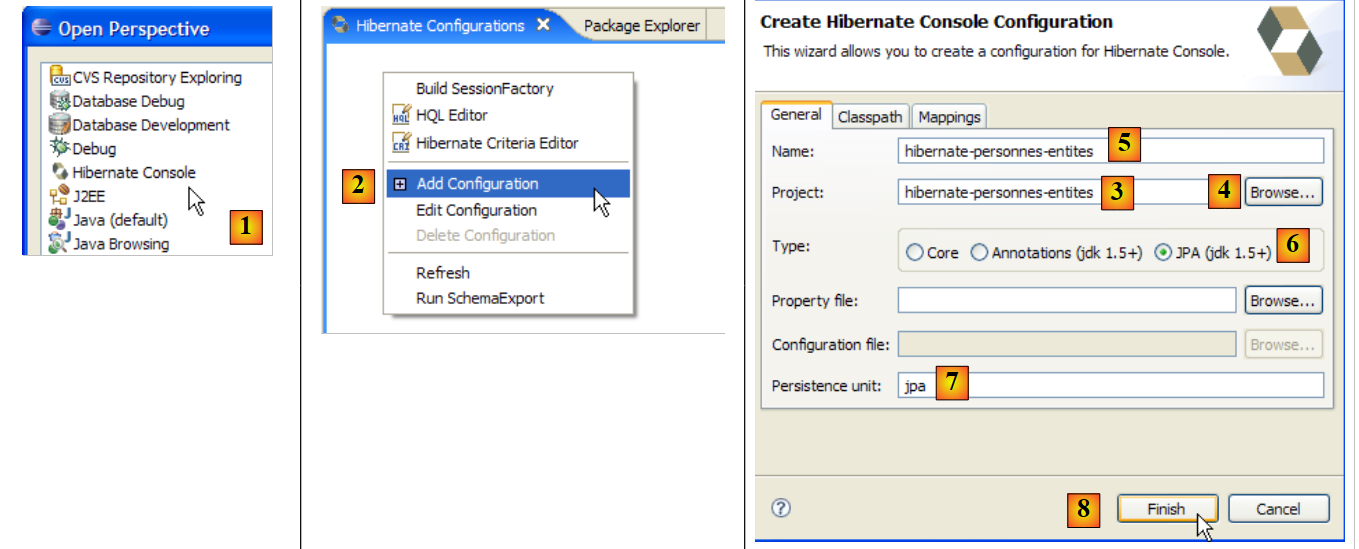 |
- [1]: Wechseln Sie zur Perspektive [Hibernate Console] (Fenster / Perspektive öffnen / Andere)
- [2]: Wir erstellen eine neue Konfiguration im Fenster [Hibernate-Konfiguration]
- Über die Schaltfläche [4] wählen wir das Java-Projekt aus, für das die Hibernate-Konfiguration erstellt wird. Sein Name erscheint in [3].
- In [5] geben wir den gewünschten Namen für diese Konfiguration ein. Hier haben wir [3] verwendet.
- In [6] geben wir an, dass wir eine JPA-Konfiguration verwenden, damit das Tool weiß, dass es die Datei [META-INF/persistence.xml] verwenden muss
- In [7] geben wir an, dass in dieser Datei [META-INF/persistence.xml] die Persistenz-Einheit namens jpa verwendet werden soll.
- In [8] validieren wir die Konfiguration.
Als Nächstes muss das DBMS gestartet werden. Hier verwenden wir MySQL 5.
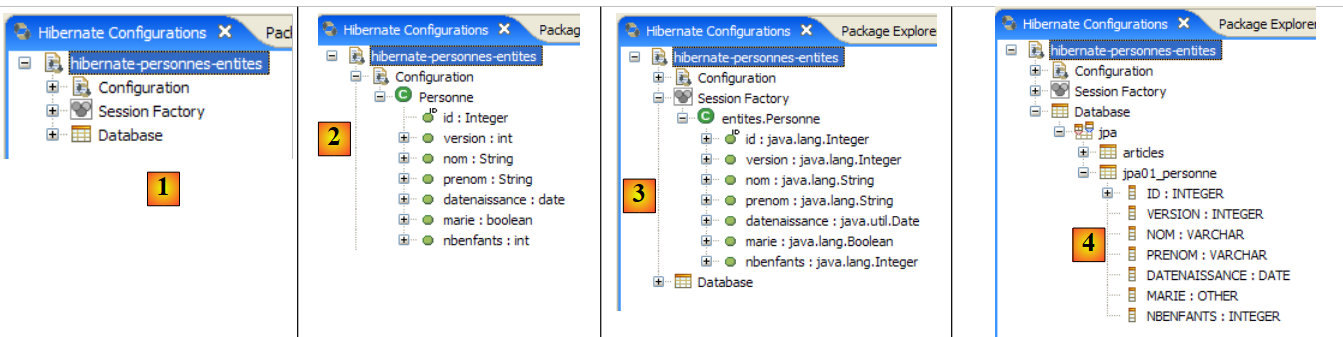 |
- In [1]: Die erstellte Konfiguration zeigt einen Baum mit drei Zweigen an
- In [2]: Der Zweig [Configuration] listet die Objekte auf, die die Konsole zur Selbstkonfiguration verwendet hat: hier das @Entity Person.
- In [3]: Die Session Factory ist ein Hibernate-Konzept, das dem EntityManager von JPA ähnelt. Sie überbrückt die objekt-relationale Kluft mithilfe der Objekte im Zweig [Configuration]. In [3] werden die Objekte des Persistenzkontexts angezeigt; hier wiederum die @Entity Person.
- in [4]: Die Datenbank, auf die über die in [persistence.xml] enthaltene Konfiguration zugegriffen wird. Dort befindet sich die Tabelle [jpa01_personne].
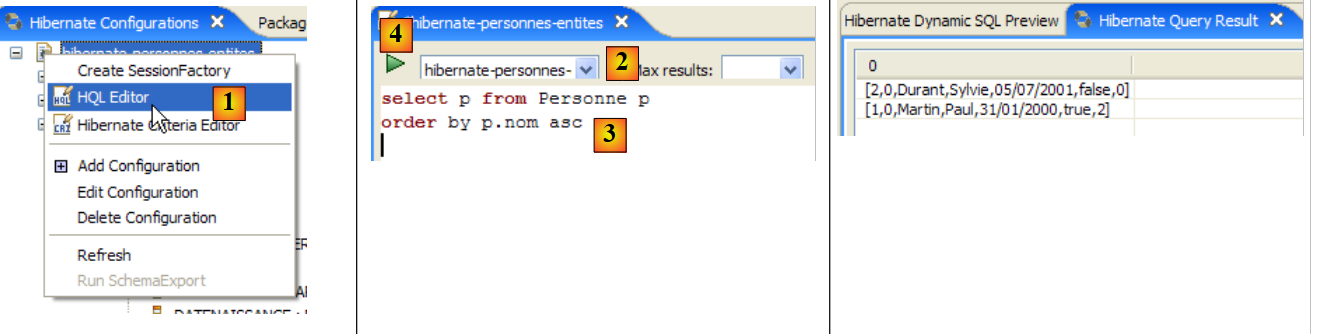 |
- In [1] erstellen wir einen HQL-Editor
- im HQL-Editor
- in [2] wählen wir die zu verwendende Hibernate-Konfiguration aus, falls mehrere vorhanden sind
- in [3] geben wir den JPQL-Befehl ein, den wir ausführen möchten
- in [4] führen wir ihn aus
- In [5] erhalten Sie die Abfrageergebnisse im Fenster [Hibernate Query Result]. Hier können zwei Probleme auftreten:
- Sie erhalten keine Ergebnisse (keine Zeilen). Die Hibernate-Konsole hat den Inhalt von [persistence.xml] verwendet, um eine Verbindung zum DBMS herzustellen. Diese Konfiguration enthält jedoch eine Eigenschaft, die anweist, die Datenbank zu leeren:
<property name="hibernate.hbm2ddl.auto" value="create" />
Sie müssen daher die Anwendung [InitDB] erneut ausführen, bevor Sie den obigen JPQL-Befehl erneut ausführen.
- (Fortsetzung)
- Das Fenster [Hibernate Query Result] wird nicht angezeigt. Sie können es über [Fenster / Ansicht anzeigen / ...] öffnen.
Das Fenster [Hibernate Dynamic SQL preview] ([1] unten) ermöglicht es Ihnen, die SQL-Abfrage zu sehen, die zur Ausführung des JPQL-Befehls, den Sie gerade schreiben, ausgeführt wird. Sobald die Syntax des JPQL-Befehls korrekt ist, erscheint der entsprechende SQL-Befehl in diesem Fenster:
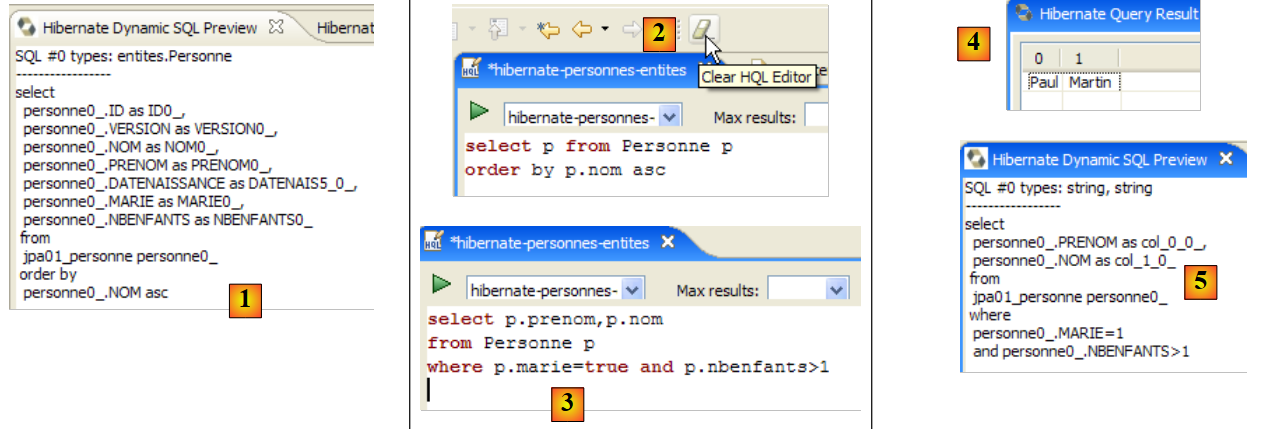 |
- Unter [2] können Sie den vorherigen HQL-Befehl löschen
- Unter [3] führen Sie einen neuen aus
- unter [4] das Ergebnis
- in [5] den SQL-Befehl, der in der Datenbank ausgeführt wurde
Der HQL-Editor bietet Unterstützung beim Schreiben von HQL-Befehlen:
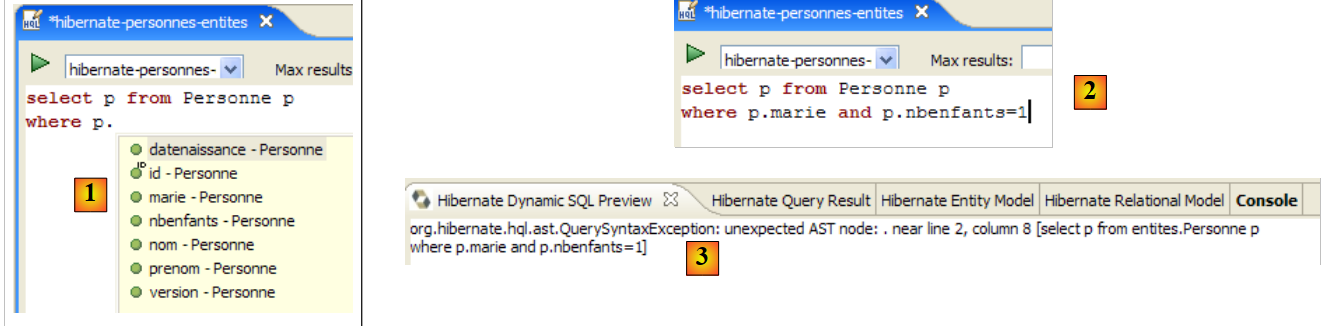 |
- in [1]: Sobald der Editor erkennt, dass p ein „Person“-Objekt ist, kann er während der Eingabe die Felder von p vorschlagen.
- in [2]: eine falsche HQL-Abfrage. Sie müssen where p.marie=true schreiben.
- in [3]: Der Fehler wird im Fenster [SQL-Vorschau] gemeldet
Wir laden den Leser ein, weitere HQL-/JPQL-Befehle in der Datenbank auszuführen.
2.1.13. Ein zweiter JPA-Client
Kehren wir zur Java-Perspektive des Projekts zurück:
|
- [InitDB.java] ist ein Programm, das einige Zeilen in die Tabelle [jpa01_personne] der Datenbank eingefügt hat. Durch die Untersuchung seines Codes konnten wir die Grundlagen der JPA-API verstehen.
- [Main.java] ist ein Programm, das CRUD-Operationen an der Tabelle [jpa01_personne] durchführt. Durch die Untersuchung seines Codes können wir die grundlegenden Konzepte des Persistenzkontexts und den Lebenszyklus von Objekten innerhalb dieses Kontexts noch einmal betrachten.
2.1.13.1. Die Struktur des Codes
[Main.java] führt eine Reihe von Tests durch, die jeweils darauf ausgelegt sind, einen bestimmten Aspekt von JPA zu veranschaulichen:
 |
Die [main]-Methode
- ruft nacheinander die Methoden test1 bis test11 auf. Wir werden den Code für jede dieser Methoden separat vorstellen.
- Außerdem werden private Hilfsmethoden verwendet: clean, dump, log, getEntityManager, getNewEntityManager.
Wir stellen die Hauptmethode und die sogenannten Hilfsmethoden vor:
package tests;
...
import entites.Personne;
@SuppressWarnings("unchecked")
public class Main {
// constant
private final static String TABLE_NAME = "jpa01_personne";
// Persistence context
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = null;
// shared objects
private static Personne p1, p2, newp1;
public static void main(String[] args) throws Exception {
// base cleaning
log("clean");clean();
// dump table
dump();
// test1
log("test1");test1();
...
// test11
log("test11");test11();
// fine persistence context
if (em.isOpen())
em.close();
// closure EntityManagerFactory
emf.close();
}
// retrieve the current EntityManager
private static EntityManager getEntityManager() {
if (em == null || !em.isOpen()) {
em = emf.createEntityManager();
}
return em;
}
// pick up a new EntityManager
private static EntityManager getNewEntityManager() {
if (em != null && em.isOpen()) {
em.close();
}
em = emf.createEntityManager();
return em;
}
// table content display
private static void dump() {
// current persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
}
// raz BD
private static void clean() {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// delete elements from the PERSONNES table
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
// end transaction
tx.commit();
}
// logs
private static void log(String message) {
System.out.println("main : ----------- " + message);
}
// object creation
public static void test1() throws ParseException {
...
}
// modify a context object
public static void test2() {
...
}
// request items
public static void test3() {
...
}
// delete an object belonging to the persistence context
public static void test4() {
....
}
// detach, reattach and modify
public static void test5() {
...
}
// delete an object not belonging to the persistence context
public static void test6() {
...
}
// modify an object not belonging to the persistence context
public static void test7() {
...
}
// reattach an object to the persistence context
public static void test8() {
...
}
// a select request causes synchronization
// with the persistence context
public static void test9() {
....
}
// version control (optimistic locking)
public static void test10() {
...
}
// transaction rollback
public static void test11() throws ParseException {
...
}
}
- Zeile 13: Das EntityManagerFactory-Objekt (emf) wird aus der in [persistence.xml] definierten JPA-Persistenz-Einheit erstellt. Damit können wir verschiedene Persistenzkontexte in der gesamten Anwendung erstellen.
- Zeile 14: Ein EntityManager-Persistenzkontext, der noch nicht initialisiert wurde
- Zeile 17: drei [Person]-Objekte, die von den Tests gemeinsam genutzt werden
- Zeile 21: Die Tabelle jpa01_personne wird geleert und dann in Zeile 24 angezeigt, um sicherzustellen, dass wir mit einer leeren Tabelle beginnen.
- Zeilen 27–31: Testsequenz
- Zeilen 34–35: Schließen des Persistenzkontexts, falls dieser geöffnet war.
- Zeile 38: Das EntityManagerFactory-Objekt emf wird geschlossen.
- Zeilen 42–47: Die Methode [getEntityManager] gibt den aktuellen EntityManager (oder Persistenzkontext) zurück oder erstellt einen neuen, falls dieser nicht existiert (Zeilen 43–44).
- Zeilen 50–56: Die Methode [getNewEntityManager] gibt einen neuen Persistenzkontext zurück. Falls zuvor bereits einer existierte, wird dieser geschlossen (Zeilen 51–52).
- Zeilen 59–72: Die Methode [dump] zeigt den Inhalt der Tabelle [jpa01_personne] an. Dieser Code ist bereits in [InitDB] aufgetreten.
- Zeilen 75–85: Die Methode [clean] leert die Tabelle [jpa01_personne]. Dieser Code wurde bereits in [InitDB] behandelt.
- Zeilen 88–90: Die Methode [log] gibt die als Parameter übergebene Nachricht auf der Konsole aus, damit sie wahrgenommen wird.
Wir können nun mit der Untersuchung der Tests fortfahren.
2.1.13.2. Test 1
Der Code für Test 1 lautet wie folgt:
// création d'objets
public static void test1() throws ParseException {
// contexte de persistance
EntityManager em = getEntityManager();
// création personnes
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistance des personnes
em.persist(p1);
em.persist(p2);
// fin transaction
tx.commit();
// on affiche la table
dump();
}
Dieser Code wurde bereits in [InitDB] behandelt: Er legt zwei Personen an und fügt sie dem Persistenzkontext hinzu.
- Zeile 4: Wir rufen den aktuellen Persistenzkontext ab
- Zeilen 6–7: Die beiden Personen werden angelegt
- Zeilen 9–15: Die beiden Personen werden innerhalb einer Transaktion in den Persistenzkontext aufgenommen
- Zeile 15: Da die Transaktion festgeschrieben wird, wird der Persistenzkontext mit der Datenbank synchronisiert. Die beiden Personen werden zur Tabelle [jpa01_personne] hinzugefügt.
- Zeile 17: Die Tabelle wird angezeigt
Die Konsolenausgabe für diesen ersten Test lautet wie folgt:
main : ----------- test1
[personnes]
[2,0,Durant,Sylvie,05/07/2001,false,0]
[1,0,Martin,Paul,31/01/2000,true,2]
2.1.13.3. Test 2
Der Code für Test 2 lautet wie folgt:
// modifier un objet du contexte
public static void test2() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on incrémente le nbre d'enfants de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// on modifie son état marital
p1.setMarie(false);
// l'objet p1 est automatiquement sauvegardé (dirty checking)
// lors de la prochaine synchronisation (commit ou select)
// fin transaction
tx.commit();
// on affiche la nouvelle table
dump();
}
- Test 2 zielt darauf ab, ein Objekt im Persistenzkontext zu ändern und anschließend den Tabelleninhalt anzuzeigen, um zu überprüfen, ob die Änderung stattgefunden hat
- Zeile 4: Abrufen des aktuellen Persistenzkontexts
- Zeilen 6–7: Die Operationen werden innerhalb einer Transaktion ausgeführt
- Zeilen 9, 11: Die Anzahl der Kinder der Person p1 wird geändert, ebenso wie deren Familienstand
- Zeile 15: Ende der Transaktion, daher wird der Persistenzkontext mit der Datenbank synchronisiert
- Zeile 17: Tabelle anzeigen
Die Konsolenausgabe für Test 2 lautet wie folgt:
- Zeile 4: Person p1 vor der Änderung
- Zeile 8: Person p1 nach der Änderung. Beachten Sie, dass sich die Versionsnummer auf 1 geändert hat. Diese Zahl wird bei jeder Aktualisierung der Zeile um 1 erhöht.
2.1.13.4. Test 3
Der Code für Test 3 lautet wie folgt:
// demander des objets
public static void test3() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on demande la personne p1
Personne p1b = em.find(Personne.class, p1.getId());
// parce que p1 est déjà dans le contexte de persistance, il n'y a pas eu d'accès à la base
// p1b et p1 sont les mêmes références
System.out.format("p1==p1b ? %s%n", p1 == p1b);
// demander un objet qui n'existe pas rend 1 pointeur null
Personne px = em.find(Personne.class, -4);
System.out.format("px==null ? %s%n", px == null);
// fin transaction
tx.commit();
}
- Test 3 konzentriert sich auf die Methode [EntityManager.find], die ein Objekt aus der Datenbank abruft und es in den Persistenzkontext einfügt. Wir werden die in allen Tests stattfindende Transaktion nicht mehr erläutern, es sei denn, sie wird auf ungewöhnliche Weise verwendet.
- Zeile 9: Wir fragen den Persistenzkontext nach der Person mit demselben Primärschlüssel wie Person p1. Es gibt zwei Fälle:
- p1 befindet sich bereits im Persistenzkontext. Dies ist hier der Fall. Daher wird kein Datenbankzugriff durchgeführt. Die find-Methode gibt einfach eine Referenz auf das persistierte Objekt zurück.
- p1 befindet sich nicht im Persistenzkontext. In diesem Fall wird eine Datenbankabfrage unter Verwendung des angegebenen Primärschlüssels durchgeführt. Der abgerufene Datensatz wird dem Persistenzkontext hinzugefügt, und find gibt eine Referenz auf dieses neue persistierte Objekt zurück.
- Zeile 12: Wir überprüfen, ob `find` die Referenz auf das bereits im Kontext vorhandene Objekt `p1` zurückgegeben hat
- Zeile 14: Wir fordern ein Objekt an, das weder im Persistenzkontext noch in der Datenbank vorhanden ist. Die find-Methode gibt dann einen Null-Zeiger zurück. Dies wird in Zeile 15 überprüft.
Die Konsolenausgabe für Test 3 lautet wie folgt:
2.1.13.5. Test 4
Der Code für Test 4 lautet wie folgt:
// supprimer un objet appartenant au contexte de persistance
public static void test4() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on supprime l'objet persisté p2
em.remove(p2);
// fin transaction
tx.commit();
// on affiche la nouvelle table
dump();
}
- Test 4 konzentriert sich auf die Methode [EntityManager.remove], mit der Sie ein Element aus dem Persistenzkontext und damit aus der Datenbank entfernen können.
- Zeile 9: person p2 wird aus dem Persistenzkontext entfernt
- Zeile 11: Synchronisieren des Kontexts mit der Datenbank
- Zeile 13: Anzeige der Tabelle. Normalerweise sollte Person p2 nicht mehr vorhanden sein.
Die Konsolenausgabe für Test 4 lautet wie folgt:
- Zeile 3: Person p2 in test1
- Zeilen 12–14: Sie existieren nach test4 nicht mehr.
2.1.13.6. Test 5
Der Code für Test 5 lautet wie folgt:
// détacher, réattacher et modifier
public static void test5() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// p1 détaché
Personne oldp1=p1;
// on réattache p1 au nouveau contexte
p1 = em.find(Personne.class, p1.getId());
// vérification
System.out.format("p1==oldp1 ? %s%n", p1 == oldp1);
// fin transaction
tx.commit();
// on incrémente le nbre d'enfants de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// on affiche la nouvelle table
dump();
}
- Test 5 untersucht den Lebenszyklus von persistierten Objekten über mehrere aufeinanderfolgende Persistenzkontexte hinweg. Bislang hatten wir in den verschiedenen Tests immer denselben Persistenzkontext verwendet.
- Zeile 4: Ein neuer Persistenzkontext wird angefordert. Die Methode [getNewEntityManager] schließt den vorherigen und öffnet einen neuen. Infolgedessen befinden sich die von der Anwendung verwalteten Objekte p1 und p2 nicht mehr in einem persistenten Zustand. Sie gehörten zu einem Kontext, der geschlossen wurde. Wir sagen, sie befinden sich in einem getrennten Zustand. Sie gehören nicht zum neuen Persistenzkontext.
- Zeilen 6–7: Start der Transaktion. Hier wird sie auf ungewöhnliche Weise verwendet.
- Zeile 9: Wir notieren die Adresse des nun getrennten Objekts p1.
- Zeile 11: Der Persistenzkontext wird nach der Person p1 abgefragt (unter Verwendung des Primärschlüssels von p1). Da der Kontext neu ist, ist die Person p1 darin nicht vorhanden. Daher wird eine Datenbankabfrage durchgeführt. Das abgerufene Objekt wird in den neuen Kontext gestellt.
- Zeile 13: Wir überprüfen, ob sich das persistente Objekt p1 im Kontext von dem Objekt oldp1 unterscheidet, das das alte, vom Kontext getrennte Objekt p1 war.
- Zeile 15: Die Transaktion wird abgeschlossen
- Zeile 17: Wir ändern das neue persistente Objekt p1 außerhalb der Transaktion. Was passiert in diesem Fall? Das wollen wir wissen.
- Zeile 19: Wir fordern die Anzeige der Tabelle an. Beachten Sie, dass aufgrund der von der `dump`-Methode ausgegebenen `SELECT`-Anweisung der Persistenzkontext automatisch mit der Datenbank synchronisiert wird.
Die Konsolenausgabe für Test 5 lautet wie folgt:
- Zeile 5: Die find-Methode hat tatsächlich auf die Datenbank zugegriffen; andernfalls wären die beiden Zeiger gleich
- Zeilen 7 und 3: Die Anzahl der Kinder von p1 hat sich tatsächlich um 1 erhöht. Die außerhalb einer Transaktion vorgenommene Änderung wurde daher berücksichtigt. Dies hängt tatsächlich vom verwendeten DBMS ab. In einem DBMS wird eine SQL-Anweisung immer innerhalb einer Transaktion ausgeführt. Wenn der JPA-Client nicht selbst eine explizite Transaktion startet, startet das DBMS eine implizite Transaktion. Es gibt zwei häufige Fälle:
- 1 – Jede einzelne SQL-Anweisung ist Teil einer Transaktion, die vor der Anweisung geöffnet und nach ihr geschlossen wird. Dies wird als Autocommit-Modus bezeichnet. Alles verhält sich daher so, als würde der JPA-Client für jede SQL-Anweisung Transaktionen durchführen.
- 2 – Das DBMS befindet sich nicht im Autocommit-Modus und startet eine implizite Transaktion bei der ersten SQL-Anweisung, die der JPA-Client außerhalb einer Transaktion ausgibt, wobei es dem Client überlassen bleibt, diese zu schließen. Alle vom JPA-Client ausgegebenen SQL-Anweisungen sind dann Teil der impliziten Transaktion. Diese Transaktion kann aufgrund verschiedener Ereignisse enden: Der Client schließt die Verbindung, startet eine neue Transaktion usw.
Diese Situation hängt von der DBMS-Konfiguration ab. Daher ist der Code nicht portabel. Wir werden später ein transaktionsfreies Codebeispiel zeigen und sehen, dass sich nicht alle DBMS bei diesem Code gleich verhalten. Wir betrachten das Arbeiten außerhalb von Transaktionen daher als Programmierfehler.
- Zeile 7: Beachten Sie, dass die Versionsnummer auf 2 aktualisiert wurde.
2.1.13.7. Test 6
Der Code für Test 6 lautet wie folgt:
// supprimer un objet n'appartenant pas au contexte de persistance
public static void test6() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on supprime p1 qui n'appartient pas au nouveau contexte
try {
em.remove(p1);
// fin transaction
tx.commit();
} catch (RuntimeException e1) {
System.out.format("Erreur à la suppression de p1 : [%s,%s]%n", e1.getClass().getName(), e1.getMessage());
// on fait un rollback de la transaction
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s,%s]%n", e2.getClass().getName(), e2.getMessage());
}
}
// on affiche la nouvelle table
dump();
}
- Test 6 versucht, ein Objekt zu löschen, das nicht zum Persistenzkontext gehört.
- Zeile 4: Ein neuer Persistenzkontext wird angefordert. Der alte wird daher geschlossen, und die darin enthaltenen Objekte werden getrennt. Dies ist der Fall für das Objekt p1 aus dem vorherigen Test 5.
- Zeilen 6–7: Start der Transaktion.
- Zeile 10: Das losgelöste Objekt p1 wird gelöscht. Da wir wissen, dass dies eine Ausnahme auslöst, haben wir die Operation in einen try/catch-Block eingeschlossen.
- Zeile 12: Der Commit findet nicht statt.
- Zeilen 16–21: Eine Transaktion muss mit einem Commit (alle Operationen in der Transaktion werden validiert) oder einem Rollback (alle Operationen in der Transaktion werden rückgängig gemacht) enden. Da eine Ausnahme aufgetreten ist, führen wir einen Rollback der Transaktion durch. Es gibt nichts rückgängig zu machen, da die einzige Operation in der Transaktion fehlgeschlagen ist, aber der Rollback beendet die Transaktion. Dies ist das erste Mal, dass wir die Operation [EntityTransaction].rollback verwenden. Wir hätten dies bereits in den allerersten Beispielen tun sollen. Wir haben es nicht getan, um den Code einfach zu halten. Der Leser sollte dennoch bedenken, dass der Fall eines Transaktions-Rollbacks im Code immer berücksichtigt werden muss.
- Zeile 24: Wir zeigen die Tabelle an. Normalerweise sollte sie sich nicht verändert haben.
Die Konsolenausgabe für Test 6 lautet wie folgt:
- Zeile 6: Das Löschen von p1 ist fehlgeschlagen. Die Ausnahmemeldung erklärt, dass versucht wurde, ein losgelöstes Objekt zu löschen, das nicht Teil des Kontexts ist. Dies ist nicht möglich.
- Zeile 8: Die Person p1 ist immer noch vorhanden.
2.1.13.8. Test 7
Der Code für Test 7 lautet wie folgt:
// modifier un objet n'appartenant pas au contexte de persistance
public static void test7() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on incrémente le nbre d'enfants de p1 qui n'appartient pas au nouveau contexte
p1.setNbenfants(p1.getNbenfants() + 1);
// fin transaction
tx.commit();
// on affiche la nouvelle table - elle n'a pas du changer
dump();
}
- Test 7 versucht, ein Objekt zu ändern, das nicht zum Persistenzkontext gehört, und beobachtet, welche Auswirkungen dies auf die Datenbank hat. Man könnte erwarten, dass es keine gibt. Genau das zeigen die Testergebnisse.
- Zeile 4: Ein neuer Persistenzkontext wird angefordert. Wir haben also einen neuen Kontext, der keine persistenten Objekte enthält.
- Zeilen 6–7: Start der Transaktion.
- Zeile 9: Das abgelöste Objekt p1 wird geändert. Dies ist eine Operation, an der der Persistenzkontext em nicht beteiligt ist. Daher sollten wir keine Ausnahme oder Ähnliches erwarten. Es handelt sich um eine grundlegende Operation an einem POJO.
- Zeile 11: Der Commit synchronisiert den Kontext mit der Datenbank. Dieser Kontext ist leer. Daher bleibt die Datenbank unverändert.
- Zeile 24: Die Tabelle wird angezeigt. Normalerweise sollte sie sich nicht verändert haben.
Die Konsolenausgabe für Test 7 lautet wie folgt:
- Zeile 7: Person p1 hat sich in der Datenbank nicht verändert. Für den nächsten Test werden wir jedoch berücksichtigen, dass die Anzahl der Kinder im Speicher nun 5 beträgt.
2.1.13.9. Test 8
Der Code für Test 8 lautet wie folgt:
// réattacher un objet au contexte de persistance
public static void test8() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on réattache l'objet détaché p1 au nouveau contexte
newp1 = em.merge(p1);
// c'est newp1 qui fait désormais partie du contexte, pas p1
// fin transaction
tx.commit();
// on affiche la nouvelle table - le nbre d'enfants de p1 a du changer
dump();
}
- Test 8 bindet ein abgelöstes Objekt wieder an den Persistenzkontext.
- Zeile 4: Ein neuer Persistenzkontext wird angefordert. Wir haben daher einen neuen Kontext, der keine persistenten Objekte enthält.
- Zeilen 6–7: Start der Transaktion.
- Zeile 9: Das abgelöste Objekt p1 wird wieder an den Persistenzkontext angehängt. Die Merge-Operation kann verschiedene Szenarien umfassen:
- Fall 1: Im Persistenzkontext befindet sich ein persistentes Objekt ps1 mit demselben Primärschlüssel wie das abgelöste Objekt p1. Der Inhalt von p1 wird in ps1 kopiert, und die Zusammenführung gibt eine Referenz auf ps1 zurück.
- Fall 2: Es gibt kein persistentes Objekt ps1 im Persistenzkontext mit demselben Primärschlüssel wie das abgelöste Objekt p1. Die Datenbank wird dann abgefragt, um festzustellen, ob das gesuchte Objekt in der Datenbank vorhanden ist. Wenn ja, wird dieses Objekt in den Persistenzkontext aufgenommen, wird zum persistenten Objekt ps1, und wir kehren zum vorherigen Fall 1 zurück.
- Fall 3: Es gibt weder im Persistenzkontext noch in der Datenbank ein Objekt mit demselben Primärschlüssel wie das abgelöste Objekt p1. Es wird dann ein neues [Person]-Objekt (new) erstellt und in den Persistenzkontext aufgenommen. Wir kehren dann zu Fall 1 zurück.
- Fazit: Das detached Objekt p1 bleibt detached. Die Merge-Operation gibt eine Referenz (hier newp1) auf das aus dem Merge resultierende persistente Objekt ps1 zurück. Die Client-Anwendung muss nun mit dem persistenten Objekt ps1 arbeiten und nicht mit dem detached Objekt p1.
- Beachten Sie den Unterschied zwischen den Fällen 1 und 3 hinsichtlich der für die Zusammenführung verwendeten SQL-Anweisung: In den Fällen 1 und 2 handelt es sich um eine UPDATE-Anweisung, während es in Fall 3 eine INSERT-Anweisung ist.
- Zeile 12: Der Commit synchronisiert den Kontext mit der Datenbank. Dieser Kontext ist nicht mehr leer. Er enthält das Objekt newp1. Dieses Objekt wird in der Datenbank persistent gespeichert.
- Zeile 24: Wir zeigen die Tabelle an, um sie zu überprüfen.
Die Konsolenausgabe für Test 8 lautet wie folgt:
- Die Anzahl der Kinder für p1 betrug in Test 6 (Zeile 4) 4, änderte sich dann in Test 7 auf 5, wurde jedoch nicht in der Datenbank gespeichert (Zeile 7). Nach dem Zusammenführen wurde newp1 in der Datenbank gespeichert: Zeile 10, wir haben nun 5 Kinder.
- Zeile 10: Die Versionsnummer von newp1 wurde auf 3 aktualisiert.
2.1.13.10. Test 9
Der Code für Test 9 lautet wie folgt:
// a select request causes synchronization
// with the persistence context
public static void test9() {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// increment the number of children of newp1
newp1.setNbenfants(newp1.getNbenfants() + 1);
// people display - the number of children in newp1 must have changed
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
}
- Test 9 veranschaulicht den Mechanismus der Kontextsynchronisation, der automatisch vor einer SELECT-Anweisung stattfindet.
- Zeile 5: Der Persistenzkontext wird nicht verändert. newp1 befindet sich daher innerhalb dieses Kontexts.
- Zeilen 7–8: Start der Transaktion.
- Zeile 10: Die Anzahl der untergeordneten Elemente des persistenten Objekts newp1 wird um 1 erhöht (5 -> 6).
- Zeilen 12–15: Die Tabelle wird mithilfe einer SELECT-Anweisung angezeigt. Der Kontext wird vor der Ausführung der SELECT-Anweisung mit der Datenbank synchronisiert.
- Zeile 17: Ende der Transaktion
Um die Synchronisation anzuzeigen, aktivieren Sie die Hibernate-Protokollausgabe im DEBUG-Modus (log4j.properties):
# Root logger option
log4j.rootLogger=ERROR, stdout
# Hibernate logging options (INFO only shows startup messages)
log4j.logger.org.hibernate=DEBUG
Die Konsolenausgabe für Test 9 lautet wie folgt:
- Zeile 1: Test 9 beginnt
- Zeilen 2–6: Die JDBC-Transaktion beginnt. Der Autocommit-Modus des DBMS ist deaktiviert (Zeile 5)
- Zeile 7: Anzeige, ausgelöst durch Zeile 12 des Java-Codes. Die folgenden Zeilen des Java-Codes lösen eine SELECT-Anweisung aus und synchronisieren so den Persistenzkontext mit der Datenbank.
- Zeile 8: Die JPQL-Abfrage, die wir ausführen wollen, wurde bereits ausgeführt. Hibernate findet sie in seinem Cache für „vorbereitete Abfragen“.
- Zeile 9: Hibernate kündigt an, dass es den Persistenzkontext leeren wird
- Zeilen 11–12: Hibernate (Hb) erkennt, dass die Entität „Person#1“ (mit Primärschlüssel 1) geändert wurde (dirty).
- Zeilen 12–13: Hb kündigt an, dass es dieses Element aktualisiert, und erhöht dessen Versionsnummer von 3 auf 4.
- Zeile 15: Die Kontextsynchronisation führt zu 0 Einfügungen, 1 Aktualisierung und 0 Löschungen
- Zeilen 17–34: Kontextsynchronisation (Flush). Hinweis: die Versionserhöhung (Zeile 19), die vorbereitete SQL-Update-Anweisung (Zeile 21) und die Parameterwerte für die Update-Anweisung (Zeilen 24–31).
- Zeile 35: Die SELECT-Anweisung beginnt
- Zeile 38: Die auszuführende SQL-Anweisung
- Zeile 40: Die SELECT-Anweisung gibt nur eine Zeile zurück
- Zeile 42: Hb stellt fest, dass es in seinem Persistenzkontext bereits die Entität „Person#1“ hat, die die SELECT-Anweisung aus der Datenbank zurückgegeben hat. Daher kopiert es die aus der Datenbank erhaltene Zeile nicht in den Kontext, ein Vorgang, den es als „Hydration“ bezeichnet.
- Zeile 43: Er prüft, ob die von der SELECT-Anweisung zurückgegebenen Objekte Abhängigkeiten (in der Regel Fremdschlüssel) haben, die ebenfalls geladen werden müssten (nicht-lazy-Sammlungen). Hier gibt es keine.
- Zeile 44: Anzeige durch den Java-Code ausgelöst
- Zeile 45: Ende der vom Java-Code angeforderten JDBC-Transaktion
- Zeile 46: Die automatische Kontextsynchronisation, die während Commits stattfindet, beginnt.
- Zeile 48: Hb stellt fest, dass sich der Kontext seit der letzten Synchronisation nicht geändert hat.
- Zeile 50: Ende des Commits.
Auch hier erweisen sich die Hibernate-Protokolle im DEBUG-Modus als sehr nützlich, um genau zu verstehen, was Hibernate tut.
2.1.13.11. Test 10
Der Code für Test10 lautet wie folgt:
// contrôle de version (optimistic locking)
public static void test10() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// incrémenter la version de newp1 directement dans la base (native query)
em.createNativeQuery(String.format("update %s set VERSION=VERSION+1 WHERE ID=%d", TABLE_NAME, newp1.getId())).executeUpdate();
// fin transaction
tx.commit();
// début nouvelle transaction
tx = em.getTransaction();
tx.begin();
// on incrémente le nbre d'enfants de newp1
newp1.setNbenfants(newp1.getNbenfants() + 1);
// fin transaction - elle doit échouer car newp1 n'a plus la bonne version
try {
tx.commit();
} catch (RuntimeException e1) {
System.out.format("Erreur lors de la mise à jour de newp1 [%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(), e1.getCause().getClass().getName(), e1.getCause().getMessage());
// on fait un rollback de la transaction
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s,%s]%n", e2.getClass().getName(), e2.getMessage());
}
}
// on ferme le contexte qui n'est plus à jour
em.close();
// dump de la table - la version de p1 a du changer
dump();
}
- Test 10 veranschaulicht den Mechanismus, der durch das Feld „version“ der @Entity Person eingeführt wird, die mit der JPA-Annotation @Version versehen ist. Wir haben erläutert, dass diese Annotation bewirkt, dass der Wert der Spalte, die mit der @Version-Annotation verknüpft ist, bei jeder Aktualisierung der Zeile, zu der sie gehört, in der Datenbank erhöht wird. Dieser Mechanismus, auch als optimistisches Sperren bekannt, erfordert, dass ein Client, der ein Objekt O in der Datenbank ändern möchte, über die neueste Version dieses Objekts verfügt. Ist dies nicht der Fall, bedeutet dies, dass das Objekt geändert wurde, seit der Client es abgerufen hat, und der Client muss benachrichtigt werden.
- Zeile 4: Wir ändern den Persistenzkontext nicht. newp1 befindet sich daher innerhalb dieses Kontexts.
- Zeilen 6–7: Beginn einer Transaktion.
- Zeile 9: Die Version des Objekts newp1 wird direkt in der Datenbank um 1 erhöht (4 -> 5). Abfragen vom Typ nativeQuery umgehen den Persistenzkontext und schreiben direkt in die Datenbank. Das Ergebnis ist, dass das persistente Objekt newp1 und seine Darstellung in der Datenbank nicht mehr dieselbe Version haben.
- Zeile 10: Ende der ersten Transaktion
- Zeilen 13–14: Beginn einer zweiten Transaktion
- Zeile 16: Die Anzahl der Kinder des persistenten Objekts newp1 wird um 1 erhöht (6 -> 7).
- Zeile 19: Ende der Transaktion. Es findet also eine Synchronisation statt. Dies löst eine Aktualisierung der Anzahl der Kinder von newp1 in der Datenbank aus. Dies schlägt fehl, da das persistente Objekt newp1 die Version 4 hat, während das zu aktualisierende Objekt in der Datenbank die Version 5 hat. Es wird eine Ausnahme ausgelöst, was den try/catch-Block im Code rechtfertigt.
- Zeile 21: Die Ausnahme und ihre Ursache werden angezeigt.
- Zeile 25: Rollback der Transaktion
- Zeile 33: Anzeige der Tabelle: Wir sollten sehen, dass die Version von newp1 in der Datenbank 5 ist.
Die Konsolenausgabe für Test 10 lautet wie folgt:
- Zeile 5: Das Commit löst tatsächlich eine Ausnahme aus. Es handelt sich um den Typ [javax.persistence.RollbackException]. Die zugehörige Meldung ist vage. Wenn wir uns die Ursache dieser Ausnahme ansehen (Exception.getCause), stellen wir fest, dass es sich um eine Hibernate-Ausnahme handelt, da wir versuchen, eine Zeile in der Datenbank zu ändern, ohne über die richtige Version zu verfügen.
- Zeile 7: Wir sehen, dass die Version von newp1 in der Datenbank durch die nativeQuery tatsächlich auf 5 gesetzt wurde.
2.1.13.12. Test 11
Der Code für Test11 lautet wie folgt:
// transaction rollback
public static void test11() throws ParseException {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = null;
try {
tx = em.getTransaction();
tx.begin();
// reattach p1 to the context by fetching it from the base
p1 = em.find(Personne.class, p1.getId());
// increment the number of children in p1
p1.setNbenfants(p1.getNbenfants() + 1);
// display people - the number of children in p1 must have changed
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// creation of 2 persons with identical names, which is forbidden by the DDL
Personne p3 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p4 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
// persistence of people
em.persist(p3);
em.persist(p4);
// end transaction
tx.commit();
} catch (RuntimeException e1) {
// we had a problem
System.out.format("Erreur dans transaction [%s,%s,%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage(), e1.getCause().getCause().getClass().getName(), e1.getCause().getCause()
.getMessage());
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s]%n", e2.getMessage());
}
// we abandon the current context
em.clear();
}
// dump - table must not have changed due to rollback
dump();
}
- Test 11 konzentriert sich auf den Rollback-Mechanismus von Transaktionen. Eine Transaktion funktioniert nach dem Alles-oder-Nichts-Prinzip: Die darin enthaltenen SQL-Operationen werden entweder alle erfolgreich ausgeführt (Commit) oder alle zurückgesetzt (Rollback), wenn eine davon fehlschlägt.
- Zeile 4: Wir fahren mit demselben Persistenzkontext fort. Der Leser erinnert sich vielleicht daran, dass der Kontext nach dem Absturz im vorherigen Test geschlossen wurde. In diesem Fall gibt [getEntityManager] einen brandneuen und daher leeren Kontext zurück.
- Zeilen 7–27: Ein einzelner try/catch-Block zur Behandlung eventuell auftretender Probleme
- Zeilen 8–9: Start einer Transaktion, die mehrere SQL-Operationen enthalten wird
- Zeile 11: p1 wird aus der Datenbank abgerufen und in den Kontext gestellt
- Zeile 13: Die Anzahl der Kinder von p1 wird erhöht (6 → 7)
- Zeilen 15–18: Wir zeigen den Datenbankinhalt an, was eine Kontextsynchronisation erzwingt. In der Datenbank ändert sich die Anzahl der Kinder von p1 auf 7, was die Konsolenausgabe bestätigen sollte.
- Zeilen 20–21: Erstellung von zwei Personen, p3 und p4, mit demselben Namen. Das Feld „name“ der @Entity Person verfügt jedoch über das Attribut unique=true, was zu einer Eindeutigkeitsbeschränkung für die Spalte NAME der Tabelle [jpa01_personne] führt.
- Zeilen 23–24: Die Personen p3 und p4 werden dem Persistenzkontext hinzugefügt.
- Zeile 26: Die Transaktion wird festgeschrieben. Darauf folgt eine zweite Synchronisierung des Kontexts, nachdem die erste bereits während der SELECT-Anweisung stattgefunden hat. JPA gibt zwei SQL-INSERT-Anweisungen für die Personen p3 und p4 aus. p3 wird eingefügt. Bei p4 löst das DBMS eine Ausnahme aus, da p4 denselben Namen wie p3 hat. p4 wird daher nicht eingefügt, und der JDBC-Treiber löst eine Ausnahme für den Client aus.
- Zeile 27: Wir behandeln die Ausnahme
- Zeilen 29–31: Wir zeigen die Ausnahme und ihre beiden vorangegangenen Ursachen in der Ausnahmekette an, die uns zu diesem Punkt geführt hat.
- Zeile 34: Wir rollen die aktuell aktive Transaktion zurück. Diese Transaktion begann in Zeile 9 des Java-Codes. Seitdem wurde eine Aktualisierungsoperation durchgeführt, um die Anzahl der Kinder für p1 zu ändern, gefolgt von einer Einfügeoperation für die Person p3. All dies wird durch das Rollback rückgängig gemacht.
- Zeile 39: Der Persistenzkontext wird gelöscht
- Zeile 42: Die Tabelle [jpa01_personne] wird angezeigt. Wir müssen überprüfen, ob p1 immer noch 6 Kinder hat und ob weder p3 noch p4 in der Tabelle enthalten sind.
Die Konsolenausgabe für Test 11 lautet wie folgt:
main : ----------- test11
[personnes]
[1,6,Martin,Paul,31/01/2000,false,7]
14:50:30,312 ERROR JDBCExceptionReporter:72 - Duplicate entry 'X' for key 2
Erreur dans transaction [javax.persistence.EntityExistsException,org.hibernate.exception.ConstraintViolationException: could not insert: [entites.Personne],org.hibernate.exception.ConstraintViolationException,could not insert: [entites.Personne],java.sql.SQLException,Duplicate entry 'X' for key 2]
[personnes]
[1,5,Martin,Paul,31/01/2000,false,6]
- Zeile 3: Die Anzahl der Kinder von p1 hat sich in der Datenbank von 6 auf 7 geändert; die Version von p1 wurde auf 6 aktualisiert.
- Zeile 4: Die während des Transaktions-Commits abgefangene Ausnahme. Bei genauer Betrachtung ist zu erkennen, dass die Ursache ein doppelter Schlüssel X (der Name) ist. Der Einfügevorgang von p4 verursacht diesen Fehler, da p3, das bereits eingefügt wurde, ebenfalls den Namen X trägt.
- Zeile 7: Die Tabelle nach dem Rollback. p1 ist auf Version 5 zurückgesetzt und hat wieder 6 Kinder; p3 und p4 wurden nicht eingefügt.
2.1.13.13. Test 12
Der Code für Test12 lautet wie folgt:
// we do the same thing again but without the transactions
// we obtain the same result as before with SGBD : FIREBIRD, ORACLE XE, POSTGRES, MYSQL5
// with SQLSERVER we have an empty table. The connection is left in a state that prevents reexecution
// of the program. The server must then be restarted.
// idem with SGBD Derby
// HSQL inserts 1st person - there is no rollback
public static void test12() throws ParseException {
// reconnect p1
p1 = em.find(Personne.class, p1.getId());
// increment the number of children in p1
p1.setNbenfants(p1.getNbenfants() + 1);
// display people - the number of children in p1 must have changed
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// creation of 2 persons with identical names, which is forbidden by the DDL
Personne p3 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p4 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
// persistence of people
em.persist(p3);
em.persist(p4);
// dump, which will sync the em context with the BD
try {
dump();
} catch (RuntimeException e3) {
System.out.format("Erreur dans dump [%s,%s,%s,%s]%n", e3.getClass().getName(), e3.getMessage(), e3.getCause().getClass().getName(), e3
.getCause().getMessage());
}
// we close the current context
em.close();
// dump
dump();
}
- Test 12 wiederholt denselben Vorgang wie Test 11, jedoch außerhalb einer Transaktion. Wir wollen sehen, was in diesem Fall passiert.
- Zeilen 1–6: zeigen die Testergebnisse mit verschiedenen DBMS:
- Bei einer Reihe von DBMS (Firebird, Oracle, MySQL5, Postgres) erhalten wir das gleiche Ergebnis wie bei Test 11. Dies deutet darauf hin, dass diese DBMS selbstständig eine Transaktion initiiert haben, die alle bis zu der fehlerverursachenden Anweisung empfangenen SQL-Anweisungen umfasste, und dass sie selbst einen Rollback initiiert haben.
- Bei anderen DBMS (SQL Server, Apache Derby) stürzt die Anwendung und/oder das DBMS ab.
- Beim HSQLDB-DBMS scheint die vom DBMS eröffnete Transaktion im Autocommit-Modus zu laufen: Die Änderung der Anzahl der Kinder von p1 und das Einfügen von p3 werden dauerhaft gespeichert. Nur das Einfügen von p4 schlägt fehl.
Wir erhalten daher ein vom DBMS abhängiges Ergebnis, was die Anwendung nicht portierbar macht. Beachten Sie, dass Operationen am Persistenzkontext immer innerhalb einer Transaktion durchgeführt werden müssen.
2.1.14. Wechsel des DBMS
Werfen wir noch einmal einen Blick auf die Testarchitektur unseres aktuellen Projekts:
 |
Die Client-Anwendung [3] sieht nur die JPA-Schnittstelle [5]. Sie sieht weder deren tatsächliche Implementierung noch das Ziel-DBMS. Wir müssen daher in der Lage sein, diese beiden Elemente der Kette zu ändern, ohne Änderungen am Client [3] vornehmen zu müssen. Dies werden wir nun zu demonstrieren versuchen, beginnend mit der Änderung des DBMS. Bislang haben wir MySQL5 verwendet. Wir stellen sechs weitere vor, die in den Anhängen (Abschnitt 5) beschrieben sind, in der Hoffnung, dass sich darunter das vom Leser bevorzugte DBMS befindet.
In jedem Fall ist die im Eclipse-Projekt vorzunehmende Änderung einfach (siehe unten): Ersetzen Sie die Konfigurationsdatei persistence.xml [1] für die JPA-Schicht durch eine der Dateien im Ordner conf [2] des Projekts. Die JDBC-Treiber für diese DBMS sind bereits in den Bibliotheken [jpa-divers] [3] und [4] vorhanden.
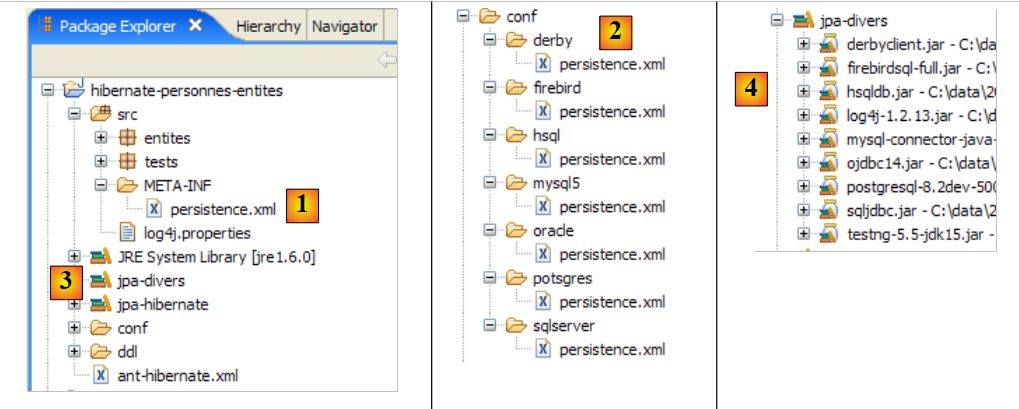 |
2.1.14.1. Oracle 10g Express
Oracle 10g Express wird im Anhang in Abschnitt 5.7 vorgestellt. Die Oracle-Datei „persistence.xml“ lautet wie folgt:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Persistent classes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="oracle.jdbc.OracleDriver" />
<property name="hibernate.connection.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- automatic schematic creation -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.OracleDialect" />
<!-- properties DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
Diese Konfiguration entspricht der für das DBMS MySQL5 verwendeten, mit folgenden geringfügigen Unterschieden:
- Zeilen 15–18, die die JDBC-Verbindung zur Datenbank konfigurieren
- Zeile 22: Hier wird der zu verwendende SQL-Dialekt festgelegt
In den folgenden Beispielen werden wir nur die Zeilen angeben, die sich ändern. Eine Erläuterung der Konfiguration finden Sie im Anhang zum jeweiligen DBMS. Dort wird jeweils ein Beispiel für die Verwendung der JDBC-Verbindung im Zusammenhang mit dem [SQL Explorer]-Plugin gegeben. Mit den Informationen aus dem Anhang kann der Leser den Vorgang zur Überprüfung des Ergebnisses der in Abschnitt 2.1.10.2 ausgeführten [InitDB]-Anwendung wiederholen.
Wir gehen wie im vorgenannten Abschnitt beschrieben vor:
- Starten Sie das Oracle-DBMS
- die Datei conf/oracle/persistence.xml in META-INF/persistence.xml ablegen
- die Anwendung [InitDB] ausführen
Die folgenden Ergebnisse werden auf der Konsole angezeigt:
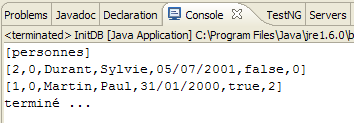 |
Von nun an werden wir diesen Screenshot nicht mehr zeigen, da er unverändert bleibt. Interessanter ist die Ansicht des SQL Explorers für die JDBC-Verbindung zum DBMS. Wir werden die in Abschnitt 2.1.8 beschriebene Vorgehensweise befolgen.
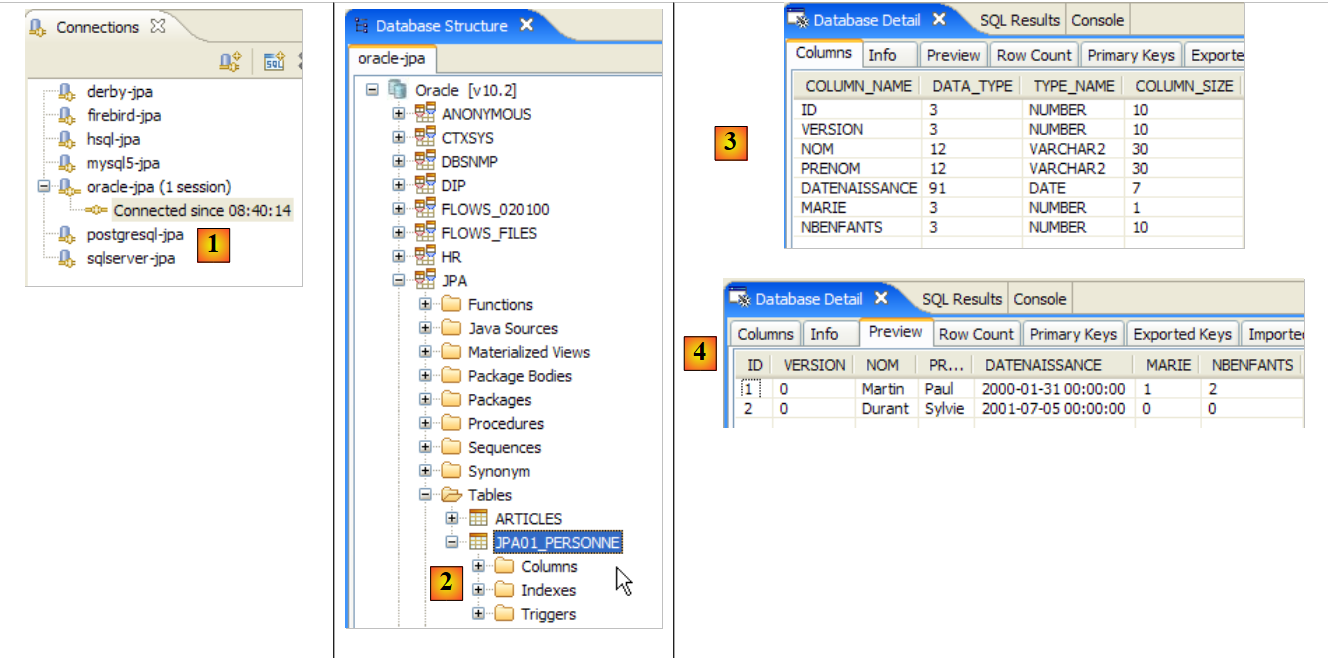 |
- in [1]: die Verbindung zu Oracle
- in [2]: der Verbindungsbaum nach Ausführung von [InitDB]
- in [3]: die Struktur der Tabelle [jpa01_personne]
- in [4]: deren Inhalt.
Sobald dies erledigt ist, wird der Leser gebeten, die Anwendung [Main] auszuführen und anschließend das DBMS herunterzufahren.
2.1.14.2. PostgreSQL 8.2
PostgreSQL 8.2 wird im Anhang in Abschnitt 5.6 vorgestellt. Die Datei persistence.xml sieht wie folgt aus:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="org.postgresql.Driver" />
<property name="hibernate.connection.url" value="jdbc:postgresql:jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.PostgreSQLDialect" />
...
</persistence-unit>
</persistence>
So führen Sie [InitDB] aus:
- Starten Sie das PostgreSQL-DBMS
- Legen Sie die Datei conf/postgres/persistence.xml in META-INF/persistence.xml ab
- Führen Sie die Anwendung [InitDB] aus
Die SQL-Explorer-Ansicht der JDBC-Verbindung zum DBMS sieht wie folgt aus:
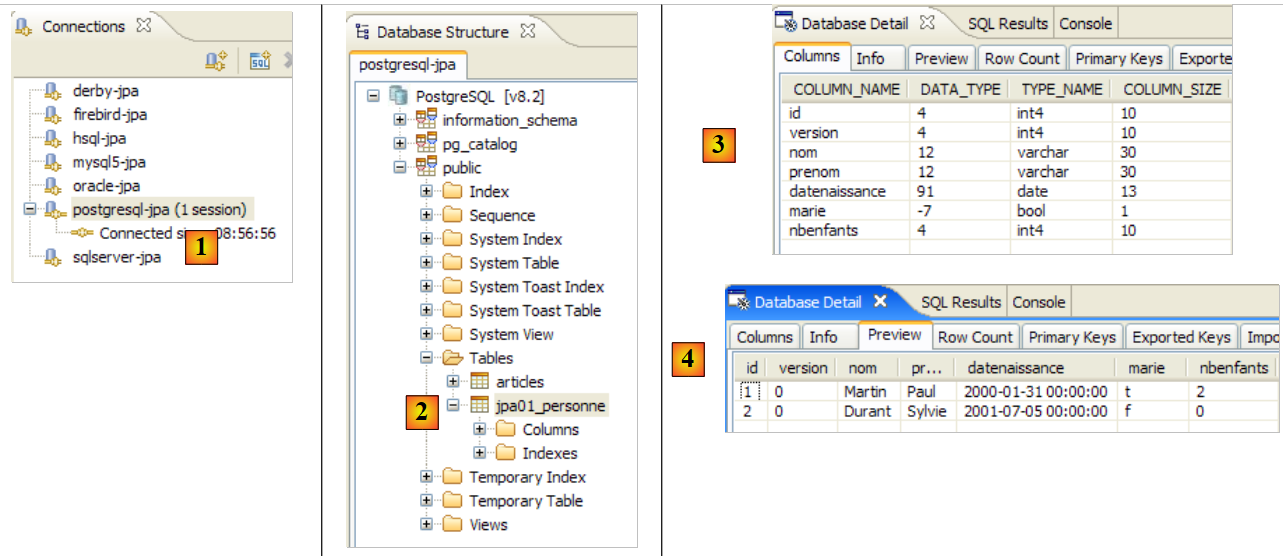 |
- in [1]: die Verbindung zu PostgreSQL
- unter [2]: der Verbindungsbaum nach Ausführung von [InitDB]
- unter [3]: die Struktur der Tabelle [jpa01_personne]
- unter [4]: deren Inhalt.
Sobald dies erledigt ist, wird der Leser gebeten, die Anwendung [Main] auszuführen und anschließend das DBMS herunterzufahren
2.1.14.3. SQL Server Express 2005
SQL Server Express 2005 wird im Anhang in Abschnitt 5.8, Seite 270, vorgestellt. Die Datei persistence.xml lautet wie folgt:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="com.microsoft.sqlserver.jdbc.SQLServerDriver" />
<property name="hibernate.connection.url" value="jdbc:sqlserver://localhost\\SQLEXPRESS:1433;databaseName=jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.SQLServerDialect" />
...
</persistence-unit>
</persistence>
So führen Sie [InitDB] aus:
- Starten Sie das SQL Server-DBMS
- Legen Sie die Datei conf/sqlserver/persistence.xml in META-INF/persistence.xml ab
- Führen Sie die Anwendung [InitDB] aus
Die SQL Explorer-Ansicht der JDBC-Verbindung zum DBMS sieht wie folgt aus:
 |
- in [1]: die Verbindung zu SQL Server
- unter [2]: der Verbindungsbaum nach Ausführung von [InitDB]
- unter [3]: die Struktur der Tabelle [jpa01_personne]
- unter [4]: deren Inhalt.
Sobald dies erledigt ist, wird der Leser gebeten, die Anwendung [Main] auszuführen und anschließend das DBMS herunterzufahren
2.1.14.4. Firebird 2.0
Firebird 2.0 wird im Anhang in Abschnitt 5.4 vorgestellt. Die Datei persistence.xml sieht wie folgt aus:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="org.firebirdsql.jdbc.FBDriver" />
<property name="hibernate.connection.url" value="jdbc:firebirdsql:localhost/3050:C:\data\2006-2007\eclipse\dvp-jpa\annexes\firebird\jpa.fdb" />
<property name="hibernate.connection.username" value="sysdba" />
<property name="hibernate.connection.password" value="masterkey" />
...
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.FirebirdDialect" />
...
</persistence-unit>
</persistence>
So führen Sie [InitDB] aus:
- Starten Sie das Firebird-DBMS
- Legen Sie die Datei conf/firebird/persistence.xml in META-INF/persistence.xml ab
- Führen Sie die Anwendung [InitDB] aus
Die SQL-Explorer-Ansicht der JDBC-Verbindung zum DBMS sieht wie folgt aus:
 |
- in [1]: die Verbindung zu Firebird
- unter [2]: der Verbindungsbaum nach Ausführung von [InitDB]
- unter [3]: die Struktur der Tabelle [jpa01_personne]
- unter [4]: deren Inhalt.
Sobald dies erledigt ist, wird der Leser gebeten, die Anwendung [Main] auszuführen und anschließend das DBMS herunterzufahren.
2.1.14.5. Apache Derby
Apache Derby wird im Anhang in Abschnitt 5.10 vorgestellt. Die Datei persistence.xml sieht wie folgt aus:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="org.apache.derby.jdbc.ClientDriver" />
<property name="hibernate.connection.url" value="jdbc:derby://localhost:1527//data/2006-2007/eclipse/dvp-jpa/annexes/derby/jpa;create=true" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialect -->
...
</persistence-unit>
</persistence>
So führen Sie [InitDB] aus:
- Starten Sie das Apache Derby-DBMS
- Legen Sie die Datei conf/derby/persistence.xml in META-INF/persistence.xml ab
- Führen Sie die Anwendung [InitDB] aus
Die SQL-Explorer-Ansicht der JDBC-Verbindung zum DBMS sieht wie folgt aus:
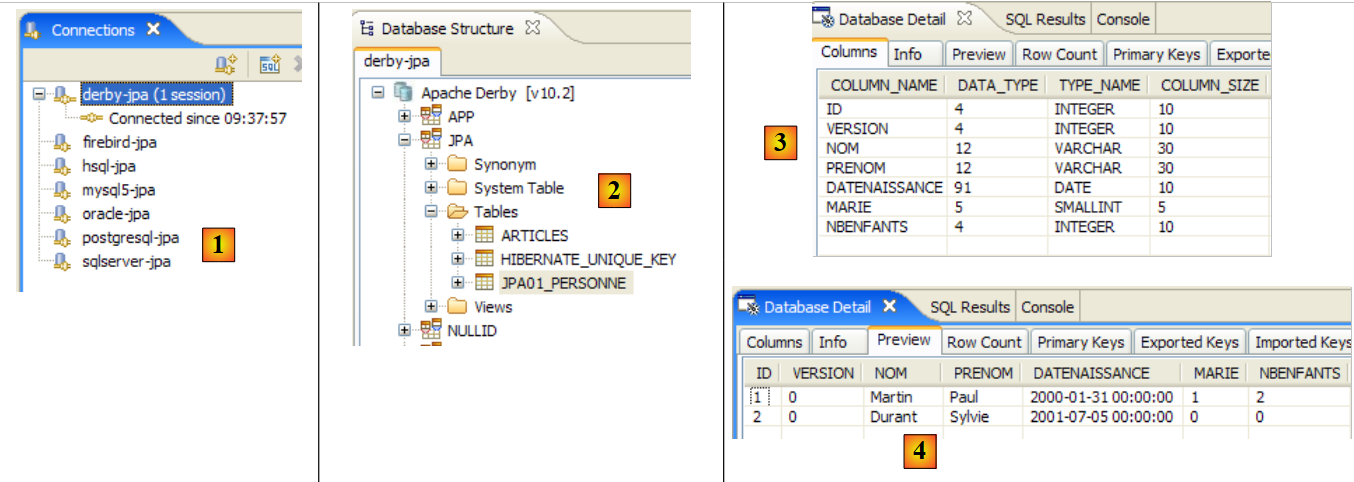 |
- in [1]: die Verbindung zu Apache Derby
- unter [2]: der Verbindungsbaum nach Ausführung von [InitDB]. Beachten Sie die von JPA/Hibernate erstellte Tabelle [HIBERNATE_UNIQUE_KEY], die automatisch fortlaufende Werte für die Primärschlüssel-ID generiert. Wir haben bereits angemerkt, dass dieser Mechanismus oft proprietär ist. Dies wird hier deutlich. Dank JPA muss sich der Entwickler nicht mit diesen DBMS-Details auseinandersetzen.
- in [3]: die Struktur der Tabelle [jpa01_personne]
- in [4]: ihr Inhalt.
Sobald dies erledigt ist, wird der Leser gebeten, die Anwendung [Main] auszuführen und anschließend das DBMS herunterzufahren.
2.1.14.6. HSQLDB
HSQLDB wird im Anhang in Abschnitt 5.9 vorgestellt. Die Datei persistence.xml sieht wie folgt aus:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="org.hsqldb.jdbcDriver" />
<property name="hibernate.connection.url" value="jdbc:hsqldb:hsql://localhost" />
<property name="hibernate.connection.username" value="sa" />
<!--
<property name="hibernate.connection.password" value="" />
-->
...
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.HSQLDialect" />
...
</properties>
</persistence-unit>
</persistence>
So führen Sie [InitDB] aus:
- Starten Sie das HSQL-DBMS
- Legen Sie die Datei conf/hsql/persistence.xml in META-INF/persistence.xml ab
- Führen Sie die Anwendung [InitDB] aus
Die SQL-Explorer-Ansicht der JDBC-Verbindung zum DBMS sieht wie folgt aus:
 |
- in [1]: die Verbindung zu HSQL
- bei [2]: der Verbindungsbaum nach Ausführung von [InitDB].
- unter [3]: die Struktur der Tabelle [jpa01_personne]
- unter [4]: deren Inhalt.
Sobald dies erledigt ist, wird der Leser gebeten, die Anwendung [Main] auszuführen und anschließend das DBMS anzuhalten.
2.1.15. Änderung der JPA-Implementierung
Werfen wir noch einmal einen Blick auf die Testarchitektur unseres aktuellen Projekts:
 |
Die vorherige Untersuchung hat gezeigt, dass wir das DBMS [7] ändern konnten, ohne etwas am Client-Code [3] zu ändern. Wir werden nun die JPA-Implementierung [6] ändern und erneut zeigen, dass dies für den Client-Code [3] transparent erfolgen kann. Wir werden eine TopLink-Implementierung [http://www.oracle.com/technology/products/ias/toplink/jpa/index.html] verwenden:
 |
2.1.15.1. Das Eclipse-Projekt
Im Zusammenhang mit der Änderung der JPA-Implementierung erstellen wir ein neues Eclipse-Projekt, um das bestehende Projekt nicht zu beeinträchtigen. Tatsächlich verwendet das neue Projekt Persistenz-Bibliotheken, die mit denen von Hibernate in Konflikt geraten könnten:
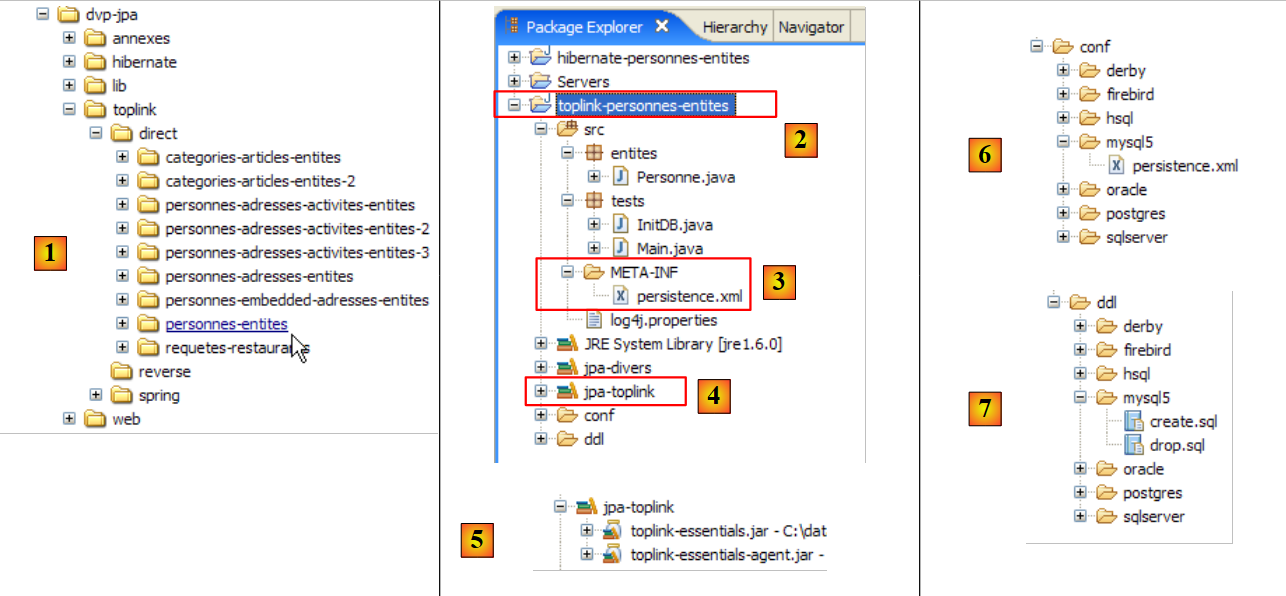 |
- in [1]: Der Ordner [<examples>/toplink/direct/people-entities] enthält das Eclipse-Projekt. Importieren Sie es.
- in [2]: das importierte Projekt [toplink-personnes-entites]. Es ist identisch (es wurde kopiert) mit dem Projekt [hibernate-personne-entites], mit Ausnahme von zwei Details:
- Die Datei [META-INF/persistence.xml] [3] konfiguriert nun eine JPA/Toplink-Schicht
- Die Bibliothek [jpa-hibernate] wurde durch die Bibliothek [jpa-toplink] ersetzt [4] und [5] (siehe Abschnitt 1.5).
- in [6]: Der Ordner [conf] enthält für jedes DBMS eine Version der Datei [persistence.xml].
- in [7]: der Ordner [ddl], der die SQL-Skripte zur Generierung des Datenbankschemas enthält.
2.1.15.2. Konfiguration der JPA-/Toplink-
Wir wissen, dass die JPA-Schicht über die Datei [META-INF/persistence.xml] konfiguriert wird. Diese Datei konfiguriert nun eine JPA-/Toplink-Implementierung. Ihr Inhalt für eine JPA-Schicht, die mit dem DBMS MySQL5 verbunden ist, lautet wie folgt:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- persistent classes -->
<class>entites.Personne</class>
<!-- persistence unit properties -->
<properties>
<!-- connection JDBC -->
<property name="toplink.jdbc.driver" value="com.mysql.jdbc.Driver" />
<property name="toplink.jdbc.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="toplink.jdbc.user" value="jpa" />
<property name="toplink.jdbc.password" value="jpa" />
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
<!-- SGBD -->
<property name="toplink.target-database" value="MySQL4" />
<!-- application server -->
<property name="toplink.target-server" value="None" />
<!-- generation diagram -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/mysql5" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
<!-- logs -->
<property name="toplink.logging.level" value="OFF" />
</properties>
</persistence-unit>
</persistence>
- Zeile 3: unverändert
- Zeile 5: Der Anbieter ist nun Toplink. Die hier genannte Klasse ist in der Bibliothek [jpa-toplink] zu finden ([1] unten):
 |
- Zeile 7: Das <class>-Tag wird verwendet, um alle @Entity-Klassen im Projekt aufzulisten; hier nur die Klasse „Person“. Hibernate verfügte über eine Konfigurationsoption, mit der wir die Auflistung dieser Klassen vermeiden konnten. Dabei wurde der Klassenpfad des Projekts nach @Entity-Klassen durchsucht.
- Zeile 9: Das <properties>-Tag führt Eigenschaften ein, die für die verwendete JPA-Implementierung spezifisch sind, in diesem Fall Toplink.
- Zeilen 11–14: Konfiguration der JDBC-Verbindung zum DBMS MySQL5
- Zeilen 15–18: Konfiguration des von Toplink nativ verwalteten JDBC-Verbindungspools:
- Zeilen 15, 16: Maximale und minimale Anzahl von Verbindungen im Lese-Verbindungspool. Standardwert (2,2)
- Zeilen 17, 18: Maximale und minimale Anzahl von Verbindungen im Schreib-Verbindungspool. Standard (10,2)
- Zeile 20: das Ziel-DBMS. Die Liste der unterstützten DBMS ist im Paket [oracle.toplink.essentials.platform.database] verfügbar (siehe [2] oben). Das DBMS MySQL5 ist in der Liste [2] nicht enthalten, daher haben wir MySQL4 gewählt. TopLink unterstützt etwas weniger DBMS als Hibernate. Von den sieben in unseren Beispielen verwendeten DBMS wird Firebird daher nicht unterstützt. Auch Oracle ist nicht in der Liste enthalten. Es befindet sich tatsächlich in einem anderen Paket (siehe [3] oben). Wenn in diesen beiden Paketen das Ziel-DBMS durch die Klasse <Sgbd>Platform.class bezeichnet wird, lautet das Tag wie folgt:
<property name="toplink.target-database" value="<Sgbd>" />
- Zeile 22: Legt den Anwendungsserver fest, falls die Anwendung auf einem solchen Server läuft. Derzeit mögliche Werte (None, OC4J_10_1_3, SunAS9). Standardwert (None).
- Zeilen 24–28: Bei der Initialisierung der JPA-Schicht wird diese angewiesen, die in den Zeilen 11–14 durch die JDBC-Verbindung definierte Datenbank zu löschen. Dadurch wird sichergestellt, dass wir mit einer leeren Datenbank beginnen.
- Zeile 24: TopLink wird angewiesen, die Tabellen im Datenbankschema zu löschen und anschließend neu anzulegen
- Zeile 25: Wir weisen TopLink an, die SQL-Skripte für die Lösch- und Erstellungsvorgänge zu generieren. application-location gibt das Verzeichnis an, in dem diese Skripte generiert werden. Standard: (aktuelles Verzeichnis).
- Zeile 26: Name des SQL-Skripts für die Erstellungsvorgänge. Standard: createDDL.jdbc.
- Zeile 27: Name des SQL-Skripts für die Löschvorgänge. Standard: dropDDL.jdbc.
- Zeile 28: Schema-Generierungsmodus (Standard: both):
- both: Skripte und Datenbank
- database: nur Datenbank
- sql-script: nur Skripte
- Zeile 30: Die TopLink-Protokollierung ist deaktiviert (OFF). Die verfügbaren Protokollierungsstufen sind: OFF, SEVERE, WARNING, INFO, CONFIG, FINE, FINER, FINEST. Standard: INFO.
Eine umfassende Definition der <property>-Tags, die mit TopLink verwendet werden können, finden Sie unter der URL [http://www.oracle.com/technology/products/ias/toplink/JPA/essentials/toplink-jpa-extensions.html].
2.1.15.3. Test [InitDB]
Es gibt nichts weiter zu tun. Wir sind bereit, den ersten [InitDB]-Test auszuführen:
- Starten Sie das DBMS, in diesem Fall MySQL5
- Führen Sie [InitDB] aus
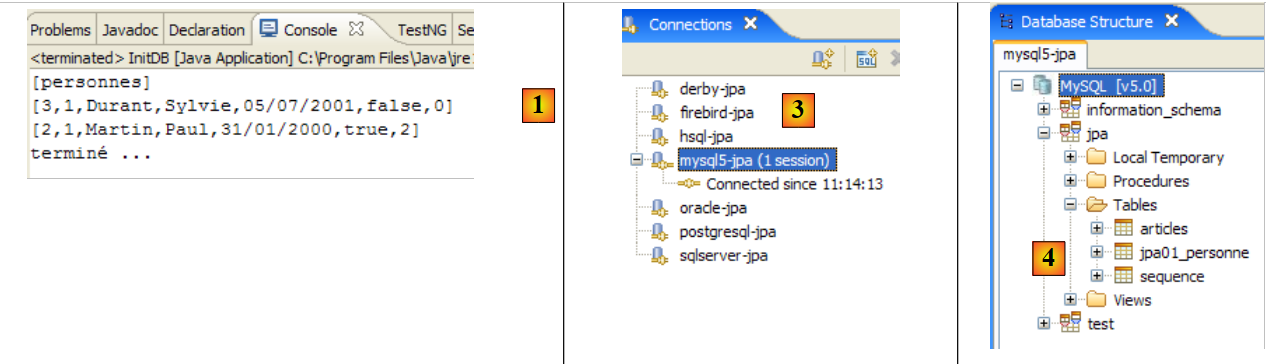 |
- in [1]: die Konsolenanzeige. Wir sehen die bereits mit JPA / Hibernate erzielten Ergebnisse.
- in [3]: Öffnen Sie die Perspektive [SQL Explorer] und anschließend die Verbindung [mysql5-jpa]
- in [4]: der JPA-Datenbankbaum. Wir sehen, dass durch die Ausführung von [InitDB] zwei Tabellen erstellt wurden: [jpa01_personne], was zu erwarten war, und die Tabelle [sequence], was weniger zu erwarten war.
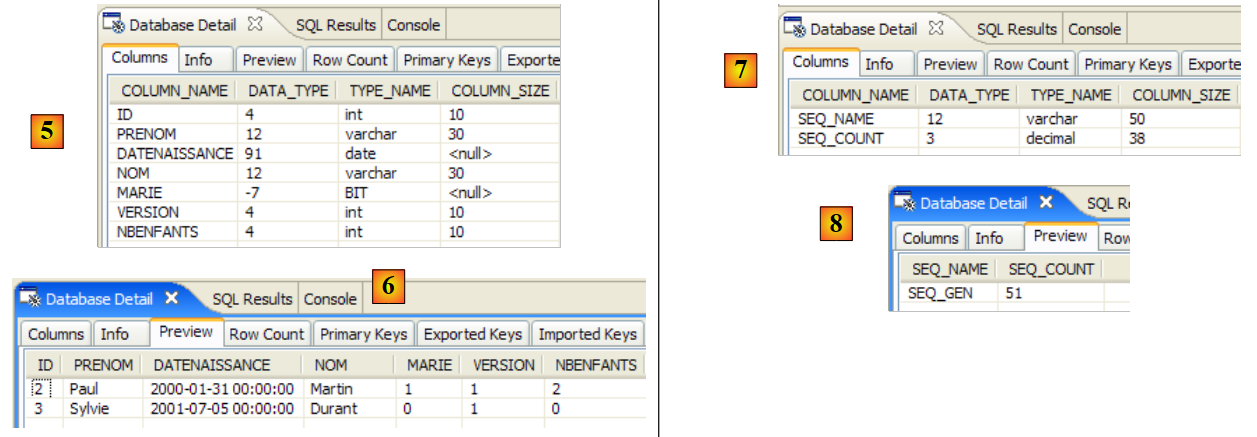 |
- in [5]: die Struktur der Tabelle [jpa01_personne] und in [6] deren Inhalt
- In [7]: die Struktur der Tabelle [sequence] und in [8] deren Inhalt.
Die Konfigurationsdatei [persistence.xml] forderte die Generierung von DDL-Skripten an:
<!-- génération schéma -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/mysql5" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
Werfen wir einen Blick darauf, was im Ordner [ddl/mysql5] generiert wurde:
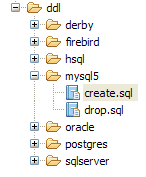 |
create.sql
CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
- Zeile 1: Die DDL für die Tabelle [jpa01_personne]. Beachten Sie, dass Toplink das Attribut „autoincrement“ für den Primärschlüssel „ID“ nicht verwendet hat. Daher wird die ID beim Einfügen von Zeilen nicht automatisch erhöht.
- Zeile 2: Die DDL für die Tabelle [sequence]. Der Name lässt vermuten, dass Toplink diese Tabelle verwendet, um Werte für den Primärschlüssel ID zu generieren.
- Zeile 3: Einfügen einer einzelnen Zeile in [SEQUENCE]
drop.sql
DROP TABLE jpa01_personne
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
- Zeile 1: Löschen der Tabelle [jpa01_personne]
- Zeile 2: Löscht eine bestimmte Zeile aus der Tabelle [SEQUENCE]. Die Tabelle selbst wird nicht gelöscht, ebenso wenig wie andere Zeilen, die sie möglicherweise enthält.
Um mehr über die Rolle der Tabelle [SEQUENCE] zu erfahren, aktivieren Sie die TopLink-Protokolle in der Datei [persistence.xml] auf der Stufe FINE. Auf dieser Stufe werden die von TopLink ausgegebenen SQL-Anweisungen protokolliert:
<!-- logs -->
<property name="toplink.logging.level" value="FINE" />
Führen Sie InitDB erneut aus. Nachfolgend finden Sie einen Ausschnitt aus der Konsolenausgabe:
...
[TopLink Config]: 2007.05.28 12:07:52.796--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--Connected: jdbc:mysql://localhost:3306/jpa
User: jpa@localhost
Database: MySQL Version: 5.0.37-community-nt
Driver: MySQL-AB JDBC Driver Version: mysql-connector-java-3.1.9 ( $Date: 2005/05/19 15:52:23 $, $Revision: 1.1.2.2 $ )
...
[TopLink Fine]: 2007.05.28 12:07:53.093--ServerSession(12910198)--Connection(19255406)--Thread(Thread[main,5,main])--DROP TABLE jpa01_personne
[TopLink Fine]: 2007.05.28 12:07:53.265--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
[TopLink Fine]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Connection(19255406)--Thread(Thread[main,5,main])--CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
[TopLink Warning]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Thread(Thread[main,5,main])--Exception [TOPLINK-4002] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (03/30/2007)): oracle.toplink.essentials.exceptions.DatabaseException
Internal Exception: java.sql.SQLException: Table 'sequence' already exists
Error Code: 1050
Call: CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
Query: DataModifyQuery()
[TopLink Fine]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
[TopLink Fine]: 2007.05.28 12:07:53.609--ServerSession(12910198)--Connection(19255406)--Thread(Thread[main,5,main])--SELECT * FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
[TopLink Fine]: 2007.05.28 12:07:53.609--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
[TopLink Fine]: 2007.05.28 12:07:53.734--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--delete from jpa01_personne
[TopLink Fine]: 2007.05.28 12:07:53.750--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--UPDATE SEQUENCE SET SEQ_COUNT = SEQ_COUNT + ? WHERE SEQ_NAME = ?
bind => [50, SEQ_GEN]
[TopLink Fine]: 2007.05.28 12:07:53.750--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--SELECT SEQ_COUNT FROM SEQUENCE WHERE SEQ_NAME = ?
bind => [SEQ_GEN]
[personnes]
[TopLink Fine]: 2007.05.28 12:07:53.906--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--INSERT INTO jpa01_personne (ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS) VALUES (?, ?, ?, ?, ?, ?, ?)
bind => [3, Sylvie, 2001-07-05, Durant, false, 1, 0]
[TopLink Fine]: 2007.05.28 12:07:53.921--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--INSERT INTO jpa01_personne (ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS) VALUES (?, ?, ?, ?, ?, ?, ?)
bind => [2, Paul, 2000-01-31, Martin, true, 1, 2]
[TopLink Fine]: 2007.05.28 12:07:53.937--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--SELECT ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS FROM jpa01_personne ORDER BY NOM ASC
[3,1,Durant,Sylvie,05/07/2001,false,0]
[2,1,Martin,Paul,31/01/2000,true,2]
[TopLink Config]: 2007.05.28 12:07:54.062--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--disconnect
[TopLink Info]: 2007.05.28 12:07:54.062--ServerSession(12910198)--Thread(Thread[main,5,main])--file:/C:/data/2006-2007/eclipse/dvp-jpa/toplink/direct/personnes-entites/bin/-jpa logout successful
...
terminé ...
- Zeilen 2–5: Eine Verbindung zum DBMS mit den entsprechenden Parametern. Aus den Protokollen geht hervor, dass Toplink tatsächlich drei Verbindungen zum DBMS herstellt. Wir müssen prüfen, ob diese Anzahl mit einem der Konfigurationswerte zusammenhängt, die für den JDBC-Verbindungspool verwendet werden:
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
- Zeile 7: Löschen der Tabelle [jpa01_personne]. Dies ist normal, da die Datei [persistence.xml] die Bereinigung der JPA-Datenbank anfordert.
- Zeile 8: Erstellung der Tabelle [jpa01_personne]. Beachten Sie, dass der Primärschlüssel-ID das Attribut „autoincrement“ fehlt.
- Zeile 9: Erstellung der Tabelle [SEQUENCE], die bereits existiert, da sie bei der vorherigen Ausführung erstellt wurde.
- Zeilen 10–13: TopLink meldet einen Fehler beim Anlegen der Tabelle [SEQUENCE].
- Zeilen 15–18: TopLink löscht die Tabelle [SEQUENCE]. Nach dieser Bereinigung enthält die Tabelle [SEQUENCE] eine Zeile (SEQ_NAME, SEQ_COUNT) mit den Werten ('SEQ_GEN', 1).
- Zeile 18: Die Tabelle [jpa01_personne] wird geleert.
- Zeilen 19–20: TopLink aktualisiert die einzige Zeile, in der SEQ_NAME = 'SEQ_GEN' in der Tabelle [SEQUENCE] ist, und ändert den Wert von ('SEQ_GEN', 1) auf ('SEQ_GEN', 51).
- Zeile 21: TopLink ruft den Wert 51 aus der Zeile ('SEQ_GEN', 51) in der Tabelle [SEQUENCE] ab.
- Zeilen 24–27: TopLink fügt die beiden Personen 'Martin' und 'Durant' in die Tabelle [jpa01_personne] ein. Hier gibt es ein Rätsel: Den Primärschlüsseln dieser beiden Zeilen werden die Werte 2 und 3 zugewiesen, ohne dass erklärt wird, wie diese Werte ermittelt wurden. Es ist unklar, ob der in Zeile 21 ermittelte SEQ_COUNT-Wert (51) irgendeinen Zweck erfüllte. Beachten Sie, dass der Versionswert der Zeilen 1 ist, während Hibernate bei 0 begann.
- Zeile 28: TopLink führt die SELECT-Anweisung aus, um alle Zeilen aus der Tabelle [jpa01_personne] abzurufen
- Zeilen 29–30: Vom Java-Client angezeigte Zeilen
- Zeilen 31–32: TopLink schließt eine Verbindung. Der Vorgang wird für jede der ursprünglich geöffneten Verbindungen wiederholt.
Letztendlich wissen wir nicht genau, wozu die Tabelle [SEQUENCE] dient, aber sie scheint dennoch eine Rolle bei der Generierung der Primärschlüssel-ID-Werte zu spielen. Indem wir die Protokollierungsstufe auf die feinste Stufe, FINEST, setzen, erfahren wir etwas mehr über die Rolle der Tabelle [SEQUENCE].
<!-- logs -->
<property name="toplink.logging.level" value="FINEST" />
Im Folgenden haben wir nur die Protokolle aufgeführt, die sich auf das Einfügen der beiden Personen in die Tabelle beziehen. Hier sehen wir den Mechanismus zur Generierung der Primärschlüsselwerte:
- Zeile 4: Wir sehen, dass die in Zeile 2 aus der Tabelle [SEQUENCE] abgerufene Zahl 51 verwendet wird, um einen Wertebereich für den Primärschlüssel abzugrenzen: [2,51]
- Zeile 5: Der ersten Person wird der Wert 2 als Primärschlüssel zugewiesen
- Zeile 8: Der zweiten Person wird der Wert 3 als Primärschlüssel zugewiesen
- Zeile 12: zeigt die Versionsverwaltung für die erste Person
- Zeile 17: dasselbe für die zweite Person
Die Protokollstufe [FINEST] zeigt auch die Grenzen der von Toplink ausgegebenen Transaktionen an. Die Analyse dieser Protokolle gibt Aufschluss darüber, was Toplink tut, und ist eine hervorragende Möglichkeit, die objektrelationale Brücke zu verstehen.
Wichtige Erkenntnisse aus dem Vorstehenden:
- Verschiedene JPA-Implementierungen erzeugen unterschiedliche Datenbankschemata. In diesem Beispiel haben Hibernate und Toplink nicht dieselben Schemata erzeugt.
- Die Protokollstufen „FINE“, „FINER“ und „FINEST“ von Toplink sollten immer dann verwendet werden, wenn Sie genau wissen möchten, was Toplink tut.
2.1.15.4. Test [Main]
Wir führen nun den [Main]-Test aus:
 |
- in [1]: Alle Tests sind bestanden, außer Test 11 [2]
- in [3]: Zeile 376, die Codezeile, in der die Ausnahme aufgetreten ist
Der Code, der die Ausnahme auslöst, lautet wie folgt:
} catch (RuntimeException e1) {
// on a eu un pb
System.out.format("Erreur dans transaction [%s,%s,%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage(), e1.getCause().getCause().getClass().getName(), e1.getCause().getCause()
.getMessage());
try {
...
- Zeile [3]: die Zeile der Ausnahme. Wir haben eine NullPointerException, was darauf hindeutet, dass eine der getCause-Methoden in den Zeilen 4 und 5 einen Null-Zeiger zurückgegeben hat. Ein Ausdruck wie [e1.getCause().getCause()] geht davon aus, dass die Ausnahmekette drei Elemente enthält [e1.getCause().getCause(), e1.getCause(), e1]. Wenn sie nur zwei Elemente enthält, löst der erste Ausdruck eine Ausnahme aus.
Wir ändern den vorherigen Code so, dass er nur die letzten beiden Ausnahmen in der Ausnahmekette anzeigt:
} catch (RuntimeException e1) {
// on a eu un pb
System.out.format("Erreur dans transaction [%s,%s,%s,%s,]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage());
try {
...
Bei der Ausführung erhalten wir das folgende Ergebnis:
...
[personnes]
[2,5,Martin,Paul,31/01/2000,false,6]
main : ----------- test11
[personnes]
Erreur dans transaction [javax.persistence.OptimisticLockException,Exception [TOPLINK-5006] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (03/30/2007))): oracle.toplink.essentials.exceptions.OptimisticLockException
Exception Description: The object [[2,6,Martin,Paul,31/01/2000,false,7]] cannot be updated because it has changed or been deleted since it was last read.
Class> entites.Personne Primary Key> [2],oracle.toplink.essentials.exceptions.OptimisticLockException,
Exception Description: The object [[2,6,Martin,Paul,31/01/2000,false,7]] cannot be updated because it has changed or been deleted since it was last read.
Class> entites.Personne Primary Key> [2],]
[personnes]
[2,5,Martin,Paul,31/01/2000,false,6]
Diesmal besteht Test 11. Die Ausnahmeprotokolle (Zeilen 6–10) wurden durch den Java-Code (Zeile 3 des obigen Codes) ausgelöst. Zur Erinnerung: Test 11 verkettete innerhalb einer einzigen Transaktion mehrere SQL-Operationen, von denen eine fehlschlug und erwartungsgemäß einen Rollback der Transaktion verursachte. Die Zustände der Tabelle [jpa01_personne] vor (Zeile 3) und nach dem Test (Zeile 12) sind identisch, was zeigt, dass der Rollback stattgefunden hat.
Es ist wichtig, an dieser Stelle zu beachten, dass die JPA/Hibernate- und JPA/Toplink-Implementierungen nicht zu 100 % austauschbar sind. In diesem Beispiel müssen wir den JPA-Client-Code ändern, um eine NullPointerException zu vermeiden. Wir werden später noch einmal auf dieses Problem stoßen, diesmal im Zusammenhang mit einer Ausnahme.
2.1.16. Änderung des DBMS in der JPA/Toplink-Implementierung
Werfen wir noch einmal einen Blick auf die Testarchitektur unseres aktuellen Projekts:
 |
Bisher wurde in [7] MySQL 5 als DBMS verwendet. Wir zeigen Ihnen, wie Sie das DBMS auf Oracle umstellen können. Die dafür erforderliche Änderung im Eclipse-Projekt ist in jedem Fall einfach (siehe unten): Ersetzen Sie die Konfigurationsdatei persistence.xml [1] für die JPA-Schicht durch eine der Dateien im Ordner „conf“ des Projekts ([2] und [3]).
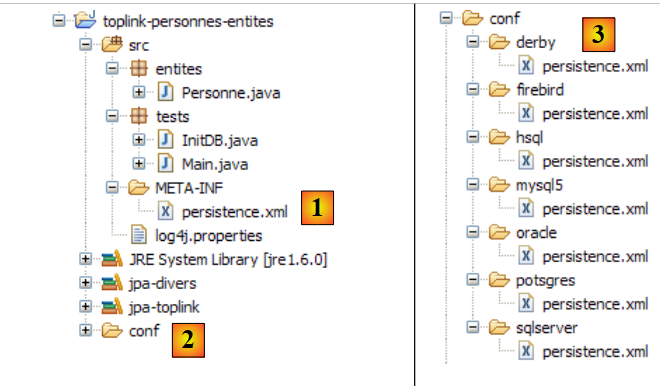 |
2.1.16.1. Oracle 10g Express
Oracle 10g Express wird im Anhang in Abschnitt 5.7 vorgestellt. Die Oracle-Datei persistence.xml für Toplink lautet wie folgt:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- persistent classes -->
<class>entites.Personne</class>
<!-- persistence unit properties -->
<properties>
<!-- connection JDBC -->
<property name="toplink.jdbc.driver" value="oracle.jdbc.OracleDriver" />
<property name="toplink.jdbc.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="toplink.jdbc.user" value="jpa" />
<property name="toplink.jdbc.password" value="jpa" />
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
<!-- SGBD -->
<property name="toplink.target-database" value="Oracle" />
<!-- application server -->
<property name="toplink.target-server" value="None" />
<!-- generation diagram -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/oracle" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
<!-- logs -->
<property name="toplink.logging.level" value="OFF" />
</properties>
</persistence-unit>
</persistence>
Diese Konfiguration entspricht der für das DBMS MySQL5 verwendeten, mit folgenden geringfügigen Unterschieden:
- Zeilen 11–14, die die JDBC-Verbindung zur Datenbank konfigurieren
- Zeile 20: Hier wird das Ziel-DBMS angegeben
- Zeile 25: gibt das Verzeichnis für die Generierung von DDL-SQL-Skripten an
So führen Sie den [InitDB]-Test aus:
- Starten Sie das Oracle-DBMS
- Legen Sie conf/oracle/persistence.xml in META-INF/persistence.xml ab
- Führen Sie die Anwendung [InitDB] aus
Die folgenden Ergebnisse werden auf der Konsole und in der Ansicht [SQL Explorer] angezeigt:
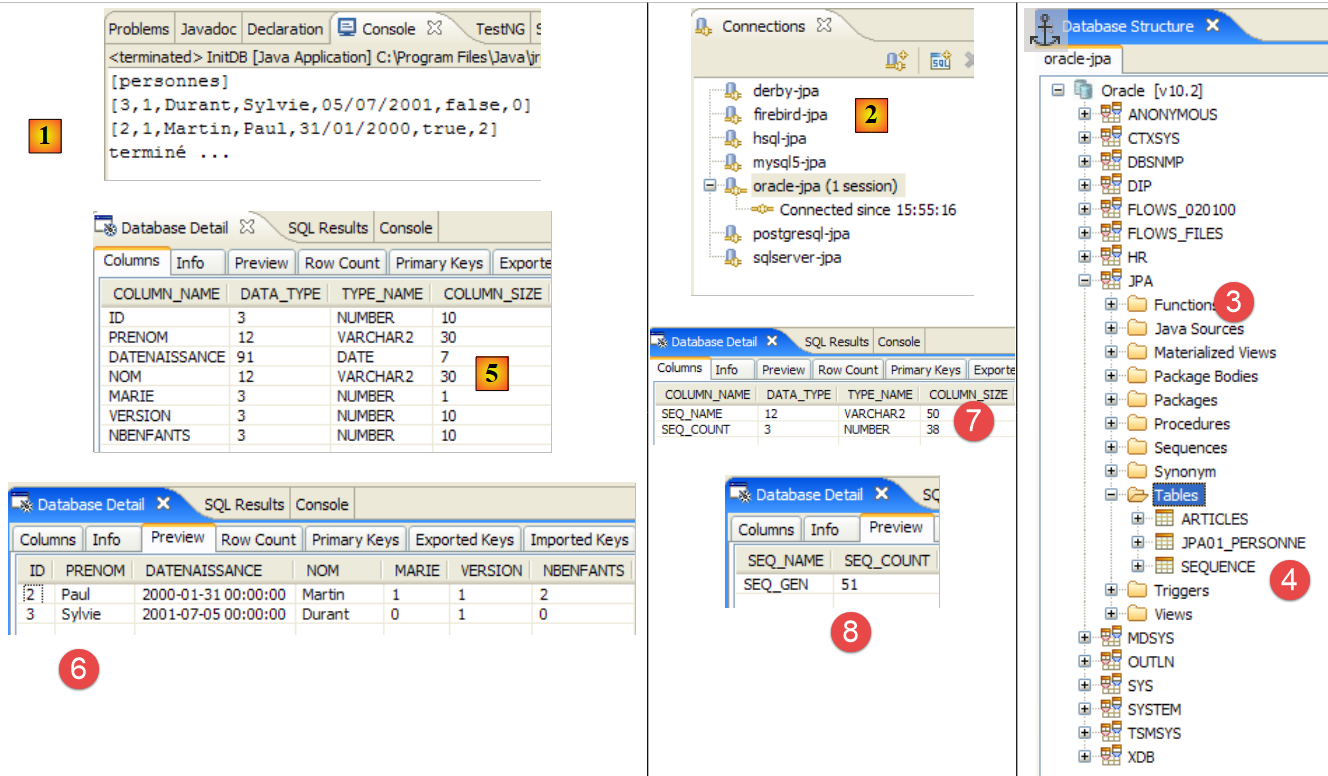 |
- [1]: die Konsolenanzeige
- [2]: die [oracle-jpa]-Verbindung im SQL Explorer
- [3]: die JPA-Datenbank
- [4]: InitDB hat zwei Tabellen erstellt: JPA01_PERSONNE und SEQUENCE, wie bei MySQL5. Manchmal erscheinen in [4] Tabellen mit dem Namen [BIN*]. Diese entsprechen gelöschten Tabellen. Um dieses Phänomen zu beobachten, führen Sie einfach [InitDB] erneut aus. Die Initialisierungsphase der JPA-Schicht umfasst eine Bereinigung der JPA-Datenbank, bei der die Tabelle [JPA01_PERSONNE] gelöscht wird:
 |
In [A] erscheint eine [BIN]-Tabelle. Oracle löscht eine gelöschte Tabelle nicht endgültig, sondern verschiebt sie in einen [Papierkorb]. Dieser Papierkorb ist [B] mit dem in Abschnitt 5.7.4 beschriebenen SQL Developer-Tool sichtbar. In [B] können wir die Tabelle [JPA01_PERSONNE] aus dem Papierkorb löschen. Dadurch wird der Papierkorb geleert [C]. Wenn wir die Tabellen im SQL Explorer aktualisieren (Rechtsklick / Aktualisieren), sehen wir, dass die BIN-Tabelle nicht mehr vorhanden ist [D].
- [5, 6]: Aufbau und Inhalt der Tabelle [JPA01_PERSONNE]
- [7, 8]: Struktur und Inhalt der Tabelle [SEQUENCE]
Das war's! Der Leser ist nun eingeladen, die Anwendung [Main] auf Oracle auszuführen.
2.1.16.2. Andere DBMS
Auf andere DBMS werden wir nicht im Detail eingehen. Sie müssen lediglich die gleiche Vorgehensweise wie bei Oracle befolgen. Beachten Sie dabei folgende Punkte:
- Unabhängig vom DBMS verwendet TopLink immer dieselbe Technik, um die Primärschlüssel-ID-Werte für die Tabelle [JPA01_PERSONNE] zu generieren: Es nutzt die oben beschriebene Tabelle [SEQUENCE].
- TopLink unterstützt das Firebird-DBMS nicht. Für solche Fälle gibt es eine generische Datenbankeinstellung:
Mit dieser generischen Datenbank namens [Auto] schlagen Tests mit Firebird aufgrund von SQL-Syntaxfehlern fehl. TopLink verwendet den SQL-Typ Number(10) für die Primärschlüssel-ID, den Firebird nicht erkennt. Sie müssen daher ein DBMS wählen, das (in diesem Beispiel) dieselben SQL-Typen wie Firebird verwendet. Dies ist bei Apache Derby der Fall:
<!-- connexion JDBC -->
<property name="toplink.jdbc.driver" value="org.firebirdsql.jdbc.FBDriver" />
...
<!-- SGBD -->
<!--
TopLink ne reconnaît pas Firebird pour l'instant (05/07). Derby convient pour remplacer.
-->
<property name="toplink.target-database" value="Derby" />
...
- TopLink kann das ursprüngliche Datenbankschema für das HSQLDB-DBMS nicht generieren. Das heißt, die Anweisung:
<!-- génération schéma -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
schlägt bei HSQLDB fehl. Die Ursache ist ein Syntaxfehler beim Anlegen der Tabelle [jpa01_personne]:
[TopLink Fine]: 2007.05.29 09:44:18.515--ServerSession(12910198)--Connection(29775659)--Thread(Thread[main,5,main])--DROP TABLE jpa01_personne
[TopLink Fine]: 2007.05.29 09:44:18.531--ServerSession(12910198)--Connection(29775659)--Thread(Thread[main,5,main])--CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
[TopLink Warning]: 2007.05.29 09:44:18.531--ServerSession(12910198)--Thread(Thread[main,5,main])--Exception [TOPLINK-4002] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (03/30/2007)): oracle.toplink.essentials.exceptions.DatabaseException
Internal Exception: java.sql.SQLException: Unexpected token: UNIQUE in statement [CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE]
Zeile 4: Die Syntax LAST_NAME VARCHAR(30) UNIQUE NOT NULL wird von HSQL nicht akzeptiert. Hibernate verwendete die Syntax: LAST_NAME VARCHAR(30) NOT NULL, UNIQUE(LAST_NAME).
Im Allgemeinen war Hibernate bei der Erkennung der in den in diesem Dokument beschriebenen Tests verwendeten DBMS effektiver als Toplink.
2.1.17. Fazit
Die Untersuchung der @Entity [Person] endet hier. Aus konzeptioneller Sicht wurde noch nicht viel erreicht: Wir haben die objektrelationale Brücke in ihrer einfachsten Form untersucht: ein @Entity-Objekt <--> eine Tabelle. Diese Untersuchung hat es uns jedoch ermöglicht, die Werkzeuge vorzustellen, die wir in diesem Dokument verwenden werden. Dadurch können wir von hier an etwas schneller vorankommen, während wir die anderen Fälle der objektrelationalen Brücke untersuchen:
- Zum bisherigen @Entity [Person] fügen wir ein Adressfeld hinzu, das durch eine [Address]-Klasse modelliert wird. Auf der Datenbankseite werden wir uns zwei mögliche Implementierungen ansehen. Die Objekte [Person] und [Address] führen zu
- eine einzige Tabelle [Person], die die Adresse enthält
- zwei Tabellen [Person] und [Adresse], die durch eine 1:1-Fremdschlüsselbeziehung verknüpft sind.
- Ein Beispiel für eine 1:n-Beziehung, bei der eine [Artikel]-Tabelle über einen Fremdschlüssel mit einer [Kategorie]-Tabelle verknüpft ist
- Ein Beispiel für eine Viele-zu-Viele-Beziehung, bei der zwei Tabellen [Person] und [Aktivität] durch eine Verknüpfungstabelle [Person_Aktivität] verbunden sind.
2.2. Beispiel 2: Eins-zu-Eins-Beziehung über eine Inklusion
2.2.1. Das Datenbankschema
1  | 2 |
- in [1]: die Datenbank (Azurri Clay-Plugin)
- in [2]: die von Hibernate für MySQL5 generierte DDL
Die Tabelle [jpa02_personne] ist die zuvor besprochene Tabelle [jpa01_personne], der ein Adressfeld hinzugefügt wurde (Zeilen 12–18 der DDL).
2.2.2. Die @Entity-Objekte, die die Datenbank repräsentieren
Die Adresse einer Person wird durch die folgende Klasse [Address] dargestellt:
package entites;
...
@SuppressWarnings("serial")
@Embeddable
public class Adresse implements Serializable {
// fields
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
// manufacturers
public Adresse() {
}
public Adresse(String adr1, String adr2, String adr3, String codePostal, String ville, String cedex, String pays) {
...
}
// getters and setters
...
// toString
public String toString() {
return String.format("A[%s,%s,%s,%s,%s,%s,%s]", getAdr1(), getAdr2(), getAdr3(), getCodePostal(), getVille(), getCedex(), getPays());
}
}
- Die wichtigste Neuerung liegt in der Annotation @Embeddable in Zeile 5. Die Klasse [Address] ist nicht dazu gedacht, eine Tabelle zu erstellen, daher verfügt sie nicht über die Annotation @Entity. Die Annotation @Embeddable gibt an, dass die Klasse dazu bestimmt ist, in ein @Entity-Objekt und damit in die damit verbundene Tabelle eingebettet zu werden. Aus diesem Grund erscheint die Klasse [Address] im Datenbankschema nicht als separate Tabelle, sondern als Teil der Tabelle, die mit der @Entity [Person] verknüpft ist.
Die @Entity [Person] hat sich gegenüber der vorherigen Version kaum verändert: Es wurde lediglich ein Adressfeld hinzugefügt:
package entites;
...
@Entity
@Table(name = "jpa02_hb_personne")
public class Personne implements Serializable{
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
@Embedded
private Adresse adresse;
// manufacturers
public Personne() {
}
...
}
- Die Änderung erfolgt in den Zeilen 33–34. Das Objekt [Person] verfügt nun über ein Adressfeld vom Typ Address. Dies gilt für das POJO. Die Annotation @Embedded ist für die objektrelationale Brücke vorgesehen. Sie gibt an, dass das Feld [Address address] in derselben Tabelle wie das Objekt [Person] gekapselt sein muss.
2.2.3. Die Testumgebung
Wir werden Tests durchführen, die den zuvor behandelten sehr ähnlich sind. Sie werden im folgenden Kontext durchgeführt:
 |
Die verwendete Implementierung ist JPA/Hibernate [6]. Das Eclipse-Testprojekt sieht wie folgt aus:
 |
Das Eclipse-Projekt [1] unterscheidet sich vom vorherigen lediglich durch seinen Java-Code [2]. Die Umgebung (Bibliotheken – persistence.xml – DBMS – conf- und DDL-Ordner – Ant-Skript) ist die bereits zuvor, insbesondere in Abschnitt 2.1.5, beschriebene. Dies wird auch für zukünftige Hibernate-Projekte gelten, und sofern keine Ausnahmen vorliegen, werden wir auf diese Umgebung nicht erneut eingehen. Insbesondere sind die persistence.xml-Dateien, die die JPA/Hibernate-Schicht für verschiedene DBMS konfigurieren, bereits untersucht worden und befinden sich im Ordner <conf>.
Sollte der Leser Zweifel hinsichtlich der zu befolgenden Vorgehensweisen haben, wird ihm empfohlen, die in der vorherigen Studie behandelten Inhalte noch einmal durchzugehen.
Das Eclipse-Projekt ist [3] im Ordner „examples“ [4] verfügbar. Wir werden es importieren.
2.2.4. Erstellen der Datenbank-DDL
Gemäß den Anweisungen in Abschnitt 2.1.7 lautet die für das DBMS MySQL 5 generierte DDL wie folgt:
drop table if exists jpa02_hb_personne;
create table jpa02_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
Hibernate hat korrekt erkannt, dass die Adresse der Person in die Tabelle aufgenommen werden muss, die mit der @Entity Person verknüpft ist (Zeilen 11–17).
2.2.5. InitDB
Der Code für [InitDB] lautet wie folgt:
package tests;
...
public class InitDB {
// constant
private final static String TABLE_NAME = "jpa02_hb_personne";
public static void main(String[] args) throws ParseException {
// Persistence context
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// a EntityManager is retrieved from the previous EntityManagerFactory
em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// request
Query sql1;
// delete elements from the PERSONNE table
sql1 = em.createNativeQuery("delete from " + TABLE_NAME);
sql1.executeUpdate();
// creating people
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// address creation
Adresse a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
Adresse a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
// associations person <--> address
p1.setAdresse(a1);
p2.setAdresse(a2);
// persistence of people
em.persist(p1);
em.persist(p2);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
// log
System.out.println("terminé...");
}
}
Dieser Code enthält nichts Neues. Alles wurde bereits zuvor behandelt. Die Ausführung von [InitDB] mit MySQL5 liefert folgende Ergebnisse:
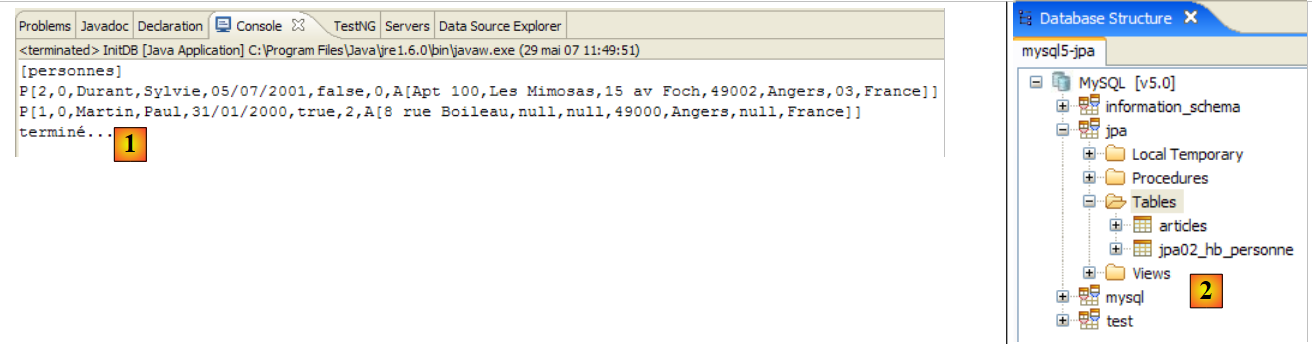 |
 |
- [1]: die Konsolenausgabe
- [2]: die Tabelle [jpa02_hb_personne] in der Ansicht „SQL Explorer“
- [3] und [4]: ihre Struktur und ihr Inhalt.
2.2.6. Main
Die Klasse [Main] sieht wie folgt aus:
package tests;
...
import entites.Adresse;
import entites.Personne;
@SuppressWarnings( { "unused", "unchecked" })
public class Main {
// constant
private final static String TABLE_NAME = "jpa02_hb_personne";
// Persistence context
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = null;
// shared objects
private static Personne p1, p2, newp1;
private static Adresse a1, a2, a3, a4, newa1, newa4;
public static void main(String[] args) throws Exception {
// we retrieve a EntityManager from the EntityManagerFactory
em = emf.createEntityManager();
// base cleaning
log("clean");clean();
// dump table
dumpPersonne();
// test1
log("test1"); test1();
// test2
log("test2"); test2();
// test3
log("test3"); test3();
// test4
log("test4"); test4();
// test5
log("test5");test5();
// fine persistence context
if (em != null && em.isOpen())
em.close();
// closure EntityManagerFactory
emf.close();
}
// retrieve the current EntityManager
private static EntityManager getEntityManager() {
...
}
// pick up a new EntityManager
private static EntityManager getNewEntityManager() {
...
}
// display table content Person
private static void dumpPersonne() {
...
}
// raz BD
private static void clean() {
...
}
// logs
private static void log(String message) {
...
}
// object creation
public static void test1() throws ParseException {
// persistence context
EntityManager em = getEntityManager();
// creating people
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// address creation
a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
// associations person <--> address
p1.setAdresse(a1);
p2.setAdresse(a2);
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistence of people
em.persist(p1);
em.persist(p2);
// end transaction
tx.commit();
// dump
dumpPersonne();
}
// modify a context object
public static void test2() {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// increment the number of children in p1
p1.setNbenfants(p1.getNbenfants() + 1);
// change your marital status
p1.setMarie(false);
// object p1 is automatically saved (dirty checking)
// at next synchronization (commit or select)
// end transaction
tx.commit();
// the new table is displayed
dumpPersonne();
}
// delete an object belonging to the persistence context
public static void test4() {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// delete attached object p2
em.remove(p2);
// end transaction
tx.commit();
// the new table is displayed
dumpPersonne();
}
// detach, reattach and modify
public static void test5() {
// new persistence context
EntityManager em = getNewEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// reattach p1 to the new context
p1 = em.find(Personne.class, p1.getId());
// end transaction
tx.commit();
// change p1's address
p1.getAdresse().setVille("Paris");
// the new table is displayed
dumpPersonne();
}
}
Auch hier wieder nichts, was wir nicht schon gesehen hätten. Die Konsolenausgabe sieht wie folgt aus:
Der Leser ist aufgefordert, den Zusammenhang zwischen den Ergebnissen und dem Code herzustellen.
2.2.7. JPA-/Toplink-Implementierung
Wir verwenden nun eine JPA-/Toplink-Implementierung:
 |
Das neue Eclipse-Testprojekt sieht wie folgt aus:
 |
Der Java-Code ist identisch mit dem des vorherigen Hibernate-Projekts. Die Umgebung (Bibliotheken – persistence.xml – DBMS – Ordner „conf“ und „ddl“ – Ant-Skript) ist diejenige, die bereits in Abschnitt 2.1.15.2 behandelt wurde. Dies wird auch für zukünftige Toplink-Projekte gelten, und sofern keine Ausnahmen vorliegen, werden wir auf diese Umgebung nicht erneut eingehen. Insbesondere sind die persistence.xml-Dateien, die die JPA/Toplink-Schicht für verschiedene DBMS konfigurieren, jene, die bereits besprochen wurden und sich im Ordner <conf> befinden.
Sollte der Leser Zweifel hinsichtlich der zu befolgenden Vorgehensweisen haben, wird ihm empfohlen, die in der vorherigen Studie behandelten Punkte noch einmal durchzugehen.
Das Eclipse-Projekt ist [3] im Ordner „examples“ [4] verfügbar. Wir werden es importieren.
Die Ausführung von [InitDB] mit dem DBMS MySQL5 liefert folgende Ergebnisse:
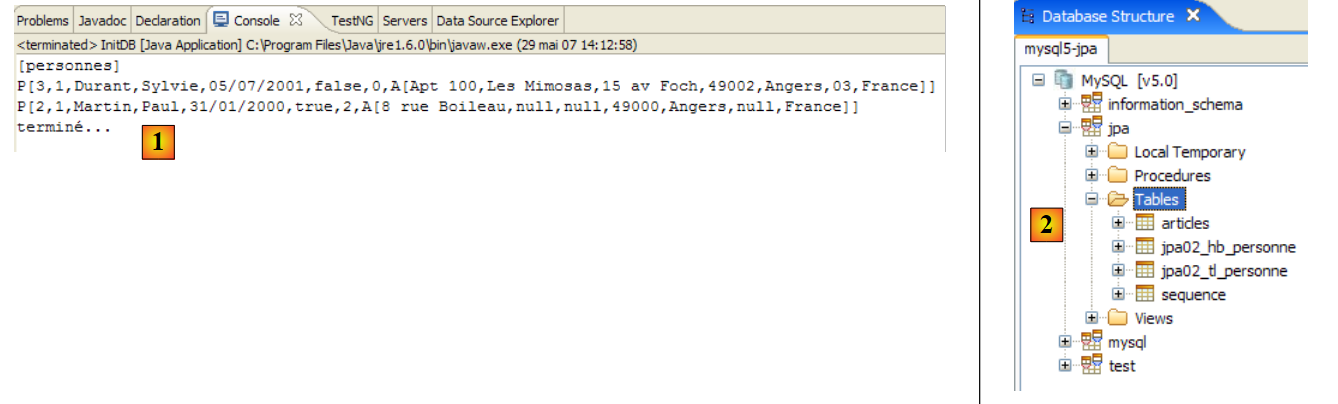 |
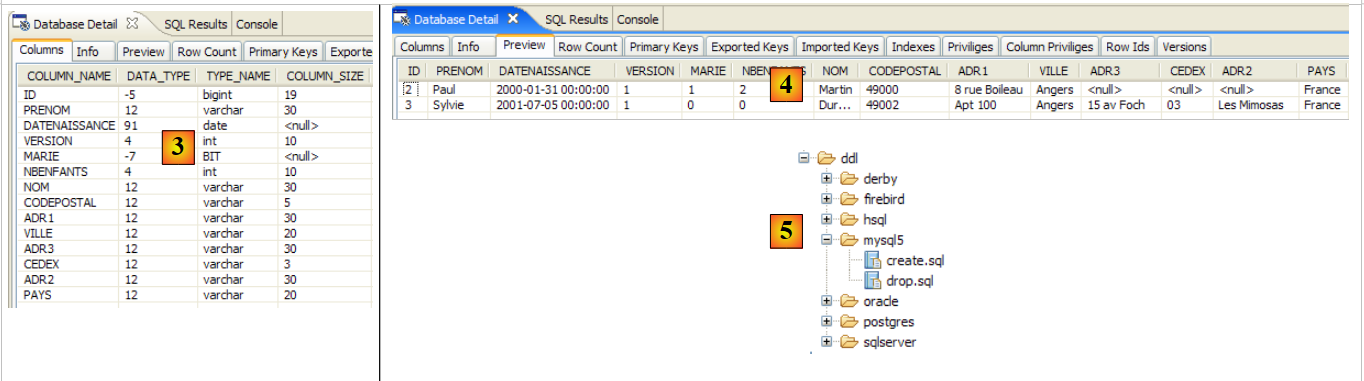 |
- [1]: die Konsolenausgabe
- [2]: die Tabellen [jpa02_tl_personne] und [SEQENCE] in der Ansicht „SQL Explorer“
- [3] und [4]: Struktur und Inhalt von [jpa02_tl_personne].
Die in ddl/mysql5 [5] generierten SQL-Skripte lauten wie folgt:
create.sql
CREATE TABLE jpa02_tl_personne (ID BIGINT NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, VERSION INTEGER NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NBENFANTS INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, CODEPOSTAL VARCHAR(5) NOT NULL, ADR1 VARCHAR(30) NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR3 VARCHAR(30), CEDEX VARCHAR(3), ADR2 VARCHAR(30), PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
DROP TABLE jpa02_tl_personne
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
2.3. Beispiel 3: Eins-zu-eins-Beziehung über einen Fremdschlüssel
2.3.1. : Datenbankschema
1 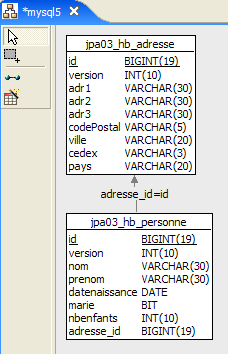 | 2 |
- in [1]: die Datenbank. Diesmal wird die Adresse der Person in einer separaten Tabelle [adresse] gespeichert. Die Tabelle [personne] ist über einen Fremdschlüssel mit dieser Tabelle verknüpft.
- in [2]: die von Hibernate für MySQL5 generierte DDL:
- Zeilen 9–20: die Tabelle [address], die mit der Klasse [Address] verknüpft wird, die zu einem @Entity-Objekt geworden ist.
- Zeile 10: der Primärschlüssel der Tabelle [address]
- Zeile 30: Anstelle einer vollständigen Adresse enthält die Tabelle [person] nun den Bezeichner [address_id] für diese Adresse.
- Zeilen 34–38: `person(address_id)` ist ein Fremdschlüssel auf `address(id)`.
2.3.2. Die @Entity-Objekte, die die Datenbank repräsentieren
Eine Person mit einer Adresse wird nun durch die folgende [Person]-Klasse dargestellt:
package entites;
...
@Entity
@Table(name = "jpa03_hb_personne")
public class Personne implements Serializable{
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
...
}
- Zeilen 32–34: die Adresse der Person
- Zeile 32: Die Annotation @OneToOne bezeichnet eine Eins-zu-Eins-Beziehung: Eine Person hat mindestens eine und höchstens eine Adresse. Das Attribut cascade = CascadeType.ALL bedeutet, dass jede Operation (persist, merge, remove) an der @Entity [Person] auf die @Entity [Address] kaskadiert werden muss. Aus der Perspektive des em-Persistenzkontexts bedeutet dies Folgendes: Wenn p eine Person ist und eine Adresse hat:
- löst eine explizite em.persist(p)-Operation eine implizite em.persist(a)-Operation aus
- löst eine explizite em.merge(p)-Operation eine implizite em.merge(a)-Operation aus
- löst eine explizite em.remove(p)-Operation eine implizite em.remove(a)-Operation aus
- Zeile 32: Die Annotation @OneToOne bezeichnet eine Eins-zu-Eins-Beziehung: Eine Person hat mindestens eine und höchstens eine Adresse. Das Attribut cascade = CascadeType.ALL bedeutet, dass jede Operation (persist, merge, remove) an der @Entity [Person] auf die @Entity [Address] kaskadiert werden muss. Aus der Perspektive des em-Persistenzkontexts bedeutet dies Folgendes: Wenn p eine Person ist und eine Adresse hat:
Die Erfahrung zeigt, dass diese impliziten Kaskaden kein Allheilmittel sind. Entwickler vergessen irgendwann, was sie bewirken. Explizite Operationen im Code sind daher möglicherweise vorzuziehen. Es gibt verschiedene Arten von Kaskaden. Die Annotation @OneToOne hätte wie folgt geschrieben werden können:
//@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@OneToOne(cascade = {CascadeType.MERGE, CascadeType.PERSIST, CascadeType.REFRESH, CascadeType.REMOVE}, fetch=FetchType.LAZY)
Das Attribut „cascade“ akzeptiert als Wert ein Array von Konstanten, die die gewünschten Kaskadierungstypen angeben.
Das Attribut fetch=FetchType.LAZY* weist Hibernate an, die Abhängigkeit zum spätestmöglichen Zeitpunkt zu laden. Wenn Sie eine Liste von Personen zum Persistenzkontext hinzufügen, möchten Sie deren Adressen möglicherweise nicht unbedingt mit einbeziehen. Beispielsweise möchten Sie die Adresse vielleicht nur für eine bestimmte Person, die von einem Benutzer über eine Weboberfläche ausgewählt wurde. Das Attribut fetch=FetchType.EAGER* hingegen fordert, dass Abhängigkeiten sofort geladen werden.
- (Fortsetzung)
- Zeile 33: Die Annotation @JoinColumn definiert den Fremdschlüssel, den die @Entity-Tabelle [Person] auf die @Entity-Tabelle [Address] hat. Das Attribut name definiert den Namen der Spalte, die als Fremdschlüssel dient. Das Attribut unique=true erzwingt eine Eins-zu-Eins-Beziehung: Der gleiche Wert darf in der Spalte [address_id] nicht zweimal vorkommen. Das Attribut nullable=false erzwingt, dass eine Person eine Adresse haben muss.
Die Adresse einer Person wird nun durch die folgende @Entity [Address] dargestellt:
package entites;
...
@Entity
@Table(name = "jpa03_hb_adresse")
public class Adresse implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
// manufacturers
public Adresse() {
}
...
}
- Zeile 4: Die Klasse [Address] wird zu einem @Entity-Objekt. Sie wird somit zum Gegenstand einer Tabelle in der Datenbank.
- Zeilen 9–12: Wie jedes @Entity-Objekt verfügt auch [Address] über einen Primärschlüssel. Dieser wurde „Id“ genannt und weist dieselben (Standard-)Annotationen auf wie der Primärschlüssel „Id“ des @Entity-Objekts [Person].
- Zeilen 39–40: die Eins-zu-Eins-Beziehung mit der @Entity [Person]. Hier gibt es einige Feinheiten:
- Zunächst einmal ist das Feld `person` nicht erforderlich. Es ermöglicht uns, anhand einer Adresse die einzelne Person zu identifizieren, die mit dieser Adresse verknüpft ist. Wenn wir diese Funktionalität nicht wollten, würde das Feld `person` nicht existieren, und alles würde trotzdem funktionieren.
- Die Eins-zu-Eins-Beziehung zwischen den beiden Entitäten [Person] und [Address] wurde bereits in der @Entity [Person] konfiguriert:
@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
Um zu verhindern, dass die beiden Eins-zu-Eins-Konfigurationen miteinander in Konflikt geraten, wird eine als primär und die andere als invers betrachtet. Es ist die primäre Beziehung, die von der objektrelationalen Brücke verwaltet wird. Die andere Beziehung, die als inverse Beziehung bezeichnet wird, wird nicht direkt verwaltet: Sie wird indirekt über die primäre Beziehung verwaltet. In @Entity [Adresse]:
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
Es ist das Attribut „mappedBy“, das die oben genannte Eins-zu-Eins-Beziehung zur umgekehrten Beziehung der primären Eins-zu-Eins-Beziehung macht, die durch das Feld „adresse“ von @Entity [Person] definiert ist.
2.3.3. Das Eclipse-/Hibernate-1-Projekt
Die hier verwendete JPA-Implementierung ist Hibernate. Das Eclipse-Testprojekt sieht wie folgt aus:
 |
Das Projekt befindet sich [3] im Ordner „examples“ [4]. Wir werden es importieren.
2.3.4. Erstellen der Datenbank-DDL
Gemäß den Anweisungen in Abschnitt 2.1.7 ist die für das DBMS MySQL 5 erhaltene DDL diejenige, die am Anfang dieses Abschnitts gezeigt wird.
2.3.5. InitDB
Der Code für [InitDB] lautet wie folgt:
package tests;
...
import entites.Adresse;
import entites.Personne;
public class InitDB {
// constant
private final static String TABLE_PERSONNE = "jpa03_hb_personne";
private final static String TABLE_ADRESSE = "jpa03_hb_adresse";
public static void main(String[] args) throws ParseException {
// Persistence context
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// a EntityManager is retrieved from the previous EntityManagerFactory
em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// request
Query sql1;
// delete elements from the PERSONNE table
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE);
sql1.executeUpdate();
// delete elements from the ADRESSE table
sql1 = em.createNativeQuery("delete from " + TABLE_ADRESSE);
sql1.executeUpdate();
// creating people
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// address creation
Adresse a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
Adresse a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
Adresse a3 = new Adresse("x", "x", "x", "x", "x", "x", "x");
Adresse a4 = new Adresse("y", "y", "y", "y", "y", "y", "y");
// associations person <--> address
p1.setAdresse(a1);
a1.setPersonne(p1);
p2.setAdresse(a2);
a2.setPersonne(p2);
// persistence of persons and cascading of their addresses
em.persist(p1);
em.persist(p2);
// and a3 and a4 addresses not linked to persons
em.persist(a3);
em.persist(a4);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// address display
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
// log
System.out.println("terminé...");
}
}
Wir werden nur auf die Neuerungen eingehen, die im Vergleich zu den bereits behandelten Themen hinzukommen:
- Zeilen 31–32: Wir erstellen zwei Personen
- Zeilen 34–37: Wir erstellen vier Adressen
- Zeilen 39–42: Wir verknüpfen die Personen (p1, p2) mit den Adressen (a1, a2). Die Adressen (a3, a4) sind verwaist. Keine Person verweist auf sie. Die DDL lässt dies zu. Während eine Person eine Adresse haben muss, gilt das Gegenteil nicht.
- Zeilen 44–45: Wir speichern die Personen (p1, p2). Da wir das Kaskadenattribut für die Eins-zu-Eins-Beziehung, die eine Person mit ihrer Adresse verknüpft, auf CascadeType.ALL gesetzt haben, sollten auch die Adressen (a1, a2) dieser beiden Personen gespeichert werden. Das wollen wir nun überprüfen. Für die verwaisten Adressen (a3, a4) müssen wir dies explizit tun (Zeilen 47–48).
- Zeilen 51–53: Anzeige der Personentabelle
- Zeilen 56–57: Anzeige der Adressentabelle
Die Ausführung von [InitDB] mit MySQL5 liefert folgende Ergebnisse:
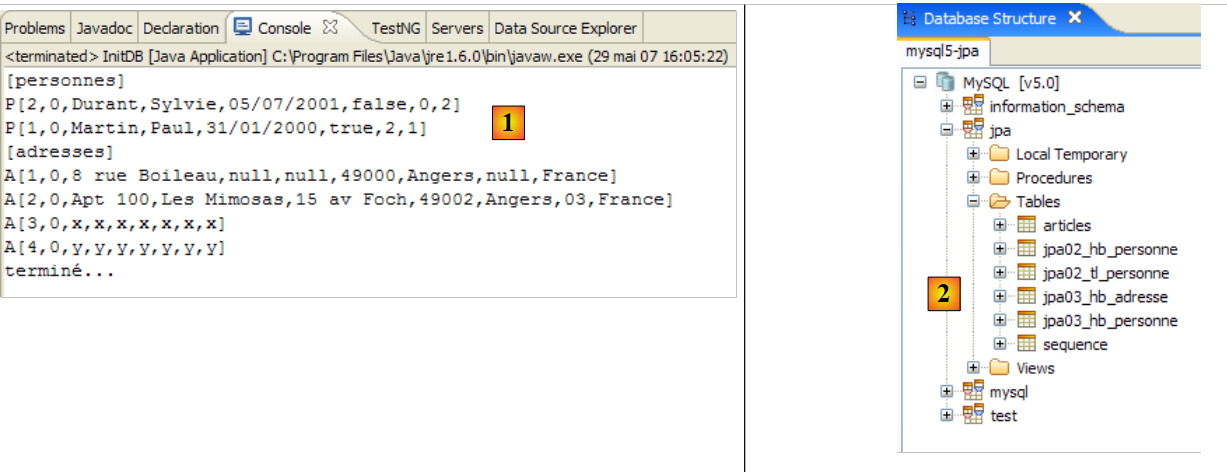 |
 |
- [1]: die Konsolenausgabe
- [2]: die [jpa03_hb_*]-Tabellen in der SQL-Explorer-Ansicht
- [3]: die Tabelle „people“
- [4]: die Tabelle „addresses“. Sie sind alle vorhanden. Beachten Sie auch die Beziehung zwischen der Spalte [adresse_id] in [3] und der Spalte [id] in [4] (Fremdschlüssel).
2.3.6. Main
Die Klasse [Main] führt sechs Tests aus, die wir uns nun ansehen werden.
2.3.6.1. Test1
Dieser Test sieht wie folgt aus:
// création d'objets
public static void test1() throws ParseException {
// contexte de persistance
EntityManager em = getEntityManager();
// création personnes
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// création adresses
a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
a3 = new Adresse("x", "x", "x", "x", "x", "x", "x");
a4 = new Adresse("y", "y", "y", "y", "y", "y", "y");
// associations personne <--> adresse
p1.setAdresse(a1);
a1.setPersonne(p1);
p2.setAdresse(a2);
a2.setPersonne(p2);
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistance des personnes
em.persist(p1);
em.persist(p2);
// et des adresses a3 et a4 non liées à des personnes
em.persist(a3);
em.persist(a4);
// fin transaction
tx.commit();
// on affiche les tables
dumpPersonne();
dumpAdresse();
}
Dieser Code stammt aus [InitDB]. Das Ergebnis lautet wie folgt:
Beide Tabellen wurden ausgefüllt.
2.3.6.2. Test2
Dieser Test läuft wie folgt ab:
// modifier un objet du contexte
public static void test2() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on incrémente le nbre d'enfants de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// on modifie son état marital
p1.setMarie(false);
// l'objet p1 est automatiquement sauvegardé (dirty checking)
// lors de la prochaine synchronisation (commit ou select)
// fin transaction
tx.commit();
// on affiche la nouvelle table
dumpPersonne();
}
Das Ergebnis sieht wie folgt aus:
- Zeile 4: Bei Person p1 hat sich die Anzahl der Kinder um 1 erhöht und die Versionsnummer von 0 auf 1 geändert
2.3.6.3. Test4
Dieser Test läuft wie folgt ab:
// supprimer un objet appartenant au contexte de persistance
public static void test4() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on supprime l'objet attaché p2
em.remove(p2);
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpAdresse();
}
- Zeile 9: Wir entfernen die Person p2. Diese Person steht in einer Kaskadenbeziehung zur Adresse a2. Daher sollte auch die Adresse a2 entfernt werden.
Das Ergebnis von Test 4 lautet wie folgt:
- Die Person p2, die in Zeile 3 von Test 1 erscheint, ist in Test 4 nicht mehr vorhanden
- Das Gleiche gilt für ihre Adresse a2, die in Zeile 7 von Test 1 vorkommt, in Test 4 jedoch fehlt.
2.3.6.4. Test 5
Dieser Test lautet wie folgt:
// détacher, réattacher et modifier
public static void test5() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on réattache p1 au nouveau contexte
p1 = em.find(Personne.class, p1.getId());
// on change l'adresse de p1
p1.getAdresse().setVille("Paris");
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpAdresse();
}
- Zeile 4: Wir haben einen neuen Persistenzkontext, daher ist er leer.
- Zeile 9: Wir fügen die Person p1 hinzu. p1 wird aus der Datenbank abgerufen, da sie nicht im Kontext vorhanden ist. Die von p1 abhängigen Elemente (ihre Adresse) werden nicht aus der Datenbank abgerufen, da wir geschrieben haben:
@OneToOne(..., fetch=FetchType.LAZY)
Dies ist das Konzept des „Lazy Loading“: Die Abhängigkeiten eines persistenten Objekts werden erst dann in den Speicher geladen, wenn sie benötigt werden.
- Zeile 11: Wir ändern das Feld „city“ der Adresse von p1. Aufgrund des Aufrufs von getAddress und falls die Adresse von p1 noch nicht im Persistenzkontext vorhanden war, wird sie aus der Datenbank abgerufen.
- Zeile 13: Wir führen den Commit der Transaktion durch, wodurch der Persistenzkontext mit der Datenbank synchronisiert wird. Die Datenbank erkennt, dass die Adresse der Person p1 geändert wurde, und speichert sie.
Die Ausführung von test5 liefert die folgenden Ergebnisse:
- Person p1 (Zeile 3 von test4, Zeile 10 von test5) hat den Wechsel ihres Wohnorts von Angers (Zeile 5 von test4) nach Paris (Zeile 12 von test5) korrekt beobachtet.
2.3.6.5. Test6
Dieser Test läuft wie folgt ab:
// delete an Address object
public static void test6() {
EntityTransaction tx = null;
// new persistence context
EntityManager em = getNewEntityManager();
// start of transaction
tx = em.getTransaction();
tx.begin();
// reattach address a3 to new context
a3 = em.find(Adresse.class, a3.getId());
System.out.println(a3);
// we delete it
em.remove(a3);
// end transaction
tx.commit();
// dump table Address
dumpAdresse();
}
- Zeile 5: Wir befinden uns in einem neuen Persistenzkontext, daher ist er leer.
- Zeile 10: Wir fügen die Adresse a3 in den Persistenzkontext ein
- Zeile 13: Wir löschen sie. Es handelte sich um eine verwaiste Adresse (die nicht mit einer Person verknüpft war). Eine Löschung ist daher möglich.
Das Ergebnis der Ausführung lautet wie folgt:
- Die Adresse a3 aus Test 5 (Zeile 6) ist aus den Adressen in Test 6 (Zeilen 11–12) verschwunden
2.3.6.6. Test 7
Dieser Test sieht wie folgt aus:
// rollback
public static void test7() {
EntityTransaction tx = null;
try {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
tx = em.getTransaction();
tx.begin();
// on réattache l'adresse a1 au nouveau contexte
newa1 = em.find(Adresse.class, a1.getId());
// on réattache l'adresse a4 au nouveau contexte
newa4 = em.find(Adresse.class, a4.getId());
// on essaie de les supprimer - devrait lancer une exception car on ne peut supprimer une adresse liée à une personne, ce qui est le cas de newa1
em.remove(newa4);
em.remove(newa1);
// fin transaction
tx.commit();
} catch (RuntimeException e1) {
// on a eu un pb
System.out.format("Erreur dans transaction [%s%n%s%n%s%n%s]%n", e1.getClass().getName(), e1.getMessage(), e1.getCause(), e1.getCause()
.getCause());
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s]%n", e2.getMessage());
}
// on abandonne le contexte courant
em.clear();
}
// dump - la table Adresse n'a pas du changer à cause du rollback
dumpAdresse();
}
- test7: Testen eines Transaktions-Rollbacks
- Zeile 6: Wir befinden uns in einem neuen Persistenzkontext, daher ist dieser leer.
- Zeile 11: Wir fügen die Adresse a1 unter der Referenz newa1 in den Persistenzkontext ein
- Zeile 13: Wir fügen die Adresse a4 in den Persistenzkontext ein, unter der Referenz newa4
- Zeilen 15–16: Wir löschen die beiden Adressen newa1 und newa4. newa1 ist die Adresse der Person p1 und wird daher von p1 in der Datenbank über einen Fremdschlüssel referenziert. Das Löschen von newa1 schlägt daher fehl und löst eine Ausnahme aus, wenn der Persistenzkontext beim Transaktions-Commit synchronisiert wird (Zeile 18). Die Transaktion wird zurückgesetzt (Zeile 25), wodurch beide Operationen in der Transaktion abgebrochen werden. Wir sollten daher feststellen, dass die Adresse newa4, die rechtmäßig hätte gelöscht werden können, nicht gelöscht wurde.
Die Ausführung liefert das folgende Ergebnis:
main : ----------- test6
A[3,0,x,x,x,x,x,x,x]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
main : ----------- test7
Erreur dans transaction [javax.persistence.RollbackException
Error while commiting the transaction
org.hibernate.ObjectDeletedException: deleted entity passed to persist: [entites.Adresse#<null>]
null]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
- Die Adressentabelle in Test 7 (Zeilen 12–13) ist identisch mit der in Test 6 (Zeilen 4–5). Der Rollback scheint erfolgt zu sein. Allerdings ist die Fehlermeldung in Zeile 9 rätselhaft und erfordert weitere Untersuchung. Es scheint, dass die aufgetretene Ausnahme nicht die erwartete ist. Wir müssen die Hibernate-Protokolle in log4j.properties auf den DEBUG-Modus setzen, um ein klareres Bild zu erhalten:
# Root logger option
log4j.rootLogger=ERROR, stdout
# Hibernate logging options (INFO only shows startup messages)
log4j.logger.org.hibernate=DEBUG
Wir können dann sehen, dass Hibernate, als die Adresse a1 in den Persistenzkontext aufgenommen wurde, dort auch die Person p1 abgelegt hat, wahrscheinlich aufgrund der Eins-zu-Eins-Beziehung von @Entity [Address]:
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
Obwohl hier „LazyLoading“ angefordert wurde, wird die Abhängigkeit [Person] dennoch sofort geladen. Dies bedeutet wahrscheinlich, dass das Attribut fetch=FetchType.LAZY hier keine Wirkung hat. Wir stellen dann fest, dass Hibernate beim Commit der Transaktion die Löschung der Adressen a1 und a4 sowie das Speichern der Person p1 vorbereitet hat. Und genau hier tritt die Ausnahme auf: Da die Person p1 eine Kaskade auf ihre Adresse hat, möchte Hibernate auch die Adresse a1 persistieren, obwohl sie gerade gelöscht wurde. Es ist Hibernate, das die Ausnahme auslöst, nicht der JDBC-Treiber. Daher die Meldung in Zeile 9 oben. Außerdem sehen wir, dass der Rollback in Zeile 25 nie ausgeführt wird, da die Transaktion inaktiv geworden ist. Der Test in Zeile 24 verhindert daher den Rollback.
Wir haben daher das angestrebte Ziel nicht erreicht: einen Rollback zu demonstrieren. Tatsächlich wurden zu keinem Zeitpunkt SQL-Anweisungen an die Datenbank gesendet. Fassen wir einige wichtige Punkte zusammen:
- den Wert der Aktivierung einer detaillierten Protokollierung, um zu verstehen, was das ORM tut
- ein ORM kann das Leben eines Entwicklers zwar erleichtern, es aber auch erschweren, indem es Verhaltensweisen verbirgt, die der Entwickler kennen muss. In diesem Fall die Art und Weise, wie Abhängigkeiten eines @Entity geladen werden.
2.3.7. Eclipse / Hibernate 2-Projekt
Wir kopieren das Eclipse/Hibernate-Projekt und fügen es ein, um einige kleinere Änderungen an der Konfiguration der @Entity-Objekte vorzunehmen:
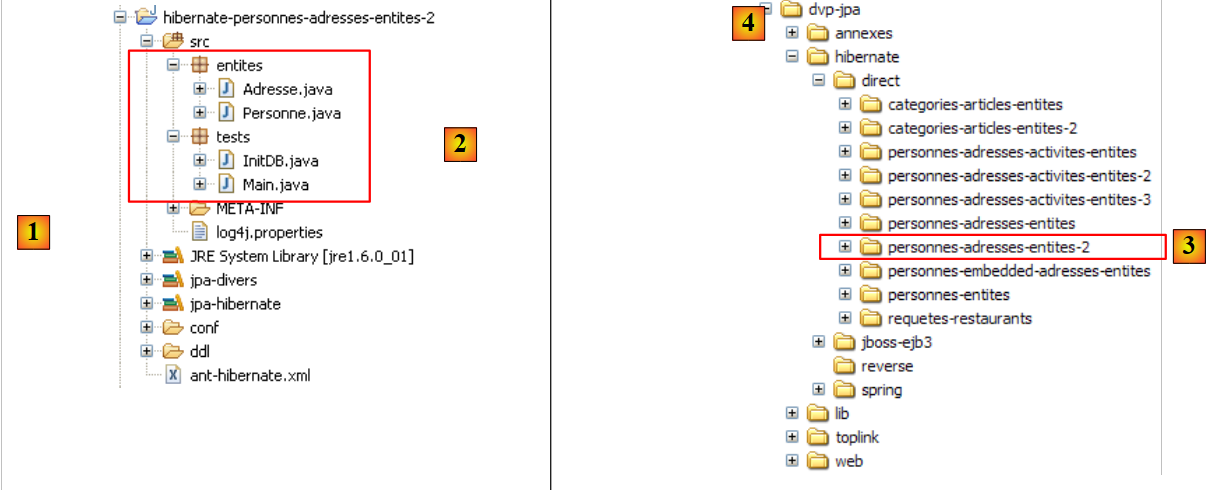 |
Das Projekt befindet sich [3] im Ordner „examples“ [4]. Wir werden es importieren.
Wir ändern lediglich die @Entity [Address], sodass sie keine 1:1-Umkehrbeziehung mehr zur @Entity [Person] aufweist:
package entites;
...
@Entity
@Table(name = "jpa04_hb_adresse")
public class Adresse implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
...
@Column(length = 20, nullable = false)
private String pays;
// @OneToOne(mappedBy = "address", fetch=FetchType.LAZY)
// private Person person;
// manufacturers
public Adresse() {
}
- Zeilen 25–26: Die inverse @OneToOne-Beziehung wird entfernt. Es ist wichtig zu verstehen, dass eine inverse Beziehung niemals unverzichtbar ist. Nur die primäre Beziehung ist es. Die inverse Beziehung kann aus Gründen der Benutzerfreundlichkeit verwendet werden. Hier bot sie eine einfache Möglichkeit, den Eigentümer einer Adresse abzurufen. Eine inverse Beziehung kann immer durch eine JPQL-Abfrage ersetzt werden. Dies werden wir im folgenden Beispiel demonstrieren.
Die Testprogramme sind identisch. Für uns ist nur Test 7 von Interesse, in dem wir die inverse Eins-zu-Eins-Beziehung in Aktion gesehen haben. Wir fügen außerdem Test 8 hinzu, um zu zeigen, wie wir auch ohne die inverse Beziehung „Adresse -> Person“ die Person mit einer bestimmten Adresse abrufen können.
Test 7 bleibt unverändert. Wenn man ihn jetzt ausführt, liefert er die folgenden Ergebnisse (Protokolle deaktiviert):
main : ----------- test6
A[3,0,x,x,x,x,x,x,x]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
main : ----------- test7
Erreur dans transaction [javax.persistence.RollbackException
Error while commiting the transaction
org.hibernate.exception.ConstraintViolationException: could not delete: [entites.Adresse#1]
java.sql.SQLException: Cannot delete or update a parent row: a foreign key constraint fails (`jpa/jpa04_hb_personne`, CONSTRAINT `FKEA3F04515FE379D0` FOREIGN KEY (`adresse_id`) REFERENCES `jpa04_hb_adresse` (`id`))]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
- Diesmal erhalten wir die erwartete Ausnahme: diejenige, die vom JDBC-Treiber ausgelöst wird, weil wir versucht haben, eine Zeile in der Tabelle [address] zu löschen, auf die ein Fremdschlüssel aus einer Zeile in der Tabelle [person] verweist. Zeile [10] erklärt eindeutig die Ursache des Fehlers.
- Der Rollback hat tatsächlich stattgefunden: Am Ende von Test 7 ist die Tabelle [address] (Zeilen 12–13) identisch mit dem Stand am Ende von Test 6 (Zeilen 4–5).
Was ist der Unterschied zu Test 7 im vorherigen Eclipse-Projekt? Warum erhalten wir hier eine JDBC-Ausnahme, die im vorherigen Test nicht aufgetreten ist? Weil die @Entity [Address] keine inverse Eins-zu-Eins-Beziehung mehr zur @Entity [Person] hat; sie wird von Hibernate unabhängig verwaltet. Als die Adresse newa1 in den Persistenzkontext aufgenommen wurde, hat Hibernate die Person p1 mit dieser Adresse nicht ebenfalls in diesen Kontext aufgenommen. Die Löschung der Adressen newa1 und newa4 erfolgte daher, ohne dass sich Person-Entitäten im Kontext befanden.
Wie könnten wir nun die Adresse newa1 nutzen, um die Person p1 mit dieser Adresse zu finden? Das ist eine berechtigte Frage. Der folgende Test 8 beantwortet sie:
// relation inverse un-à-un
// réalisée par une requête JPQL
public static void test8() {
EntityTransaction tx = null;
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
tx = em.getTransaction();
tx.begin();
// on réattache l'adresse a1 au nouveau contexte
newa1 = em.find(Adresse.class, a1.getId());
// on récupère la personne propriétaire de cette adresse
Personne p1 = (Personne) em.createQuery("select p from Personne p join p.adresse a where a.id=:adresseId").setParameter("adresseId", newa1.getId())
.getSingleResult();
// on les affiche
System.out.println("adresse=" + newa1);
System.out.println("personne=" + p1);
// fin transaction
tx.commit();
}
- Zeile 6: neuer leerer Persistenzkontext
- Zeilen 8–9: Transaktion starten
- Zeile 11: Die Adresse a1 wird in den Persistenzkontext aufgenommen und durch newa1 referenziert.
- Zeile 13: Die Person p1 mit der Adresse newa1 wird über eine JPQL-Abfrage abgerufen. Wir wissen, dass [Person] und [Address] durch eine Fremdschlüsselbeziehung verknüpft sind. In der Klasse [Person] ist es das Feld [address], das die Annotation @OneToOne trägt, welche diese Beziehung definiert. Die JPQL-Anweisung „select p from Person p join p.address a“ führt eine Verknüpfung zwischen den Tabellen [Person] und [Address] durch. Das entsprechende SQL, das in einer Hibernate-Konsole generiert wird (siehe Beispiele in Abschnitt 2.1.12), lautet wie folgt:
Die Verknüpfung zwischen den beiden Tabellen ist deutlich erkennbar. Jede Person ist nun mit ihrer Adresse verknüpft. Es muss noch festgelegt werden, dass wir nur an der Adresse „newa1“ interessiert sind. Die Abfrage lautet nun „select p from Person p join p.address a where a.id=:addressId“. Beachten Sie die Verwendung der Aliase p und a. JPQL-Abfragen nutzen Aliase in großem Umfang. Der Ausdruck „from Person p join p.address a“ bedeutet also, dass eine Person durch den Alias p und ihre Adresse (p.address) durch den Alias a dargestellt wird. Die Einschränkungsoperation „where a.id=:adresseId“ beschränkt die angeforderten Zeilen auf jene Personen p, deren Adresse a den Wert :adresseId als Kennung hat. :adresseId wird als Parameter bezeichnet, und die JPQL-Abfrage ist eine parametrisierte JPQL-Abfrage. Zur Laufzeit muss diesem Parameter ein Wert zugewiesen werden. Dies geschieht mithilfe der Methode
erfolgt, mit der Sie einem durch seinen Namen identifizierten Parameter einen Wert zuweisen können. Beachten Sie, dass setParameter genau wie die Methode createQuery ein Query-Objekt zurückgibt. Das bedeutet, dass Sie Methodenaufrufe verketten können [z. B. createQuery(...).setParameter(...).getSingleResult(...)], da die Methoden [setParameter, getSingleResult] Methoden der Query-Schnittstelle sind. Die Methode [getSingleResult] wird für Select-Abfragen verwendet, die nur ein einziges Ergebnis zurückgeben. Dies ist hier der Fall.
- Zeilen 16–17: Zur Überprüfung zeigen wir die Adresse newa1 und die mit dieser Adresse verknüpfte Person p1 an.
Das erhaltene Ergebnis lautet wie folgt:
Das ist korrekt. Aus diesem Beispiel lässt sich schließen, dass die 1:1-Inversbeziehung von der @entity [Adresse] zur @entity [Person] nicht unbedingt erforderlich war. Die Erfahrung hat hier gezeigt, dass das Entfernen dieser Beziehung zu einem besser vorhersehbaren Verhalten des Codes führte. Dies ist häufig der Fall.
2.3.8. Hibernate-Konsole
Im vorherigen Test 8 wurde ein JPQL-Befehl verwendet, um eine Verknüpfung zwischen den Entitäten „Person“ und „Address“ herzustellen. Obwohl sie SQL ähneln, erfordern JPQL von JPA und HQL von Hibernate eine gewisse Einarbeitungszeit, und die Hibernate-Konsole eignet sich hervorragend für diesen Zweck. Wir haben sie bereits in Abschnitt 2.1.12 verwendet, um eine einzelne Tabelle abzufragen. Wir werden dies hier erneut tun, um zwei Tabellen abzufragen, die durch eine Fremdschlüsselbeziehung verknüpft sind.
Erstellen wir eine Hibernate-Konsole für unser aktuelles Eclipse-Projekt:
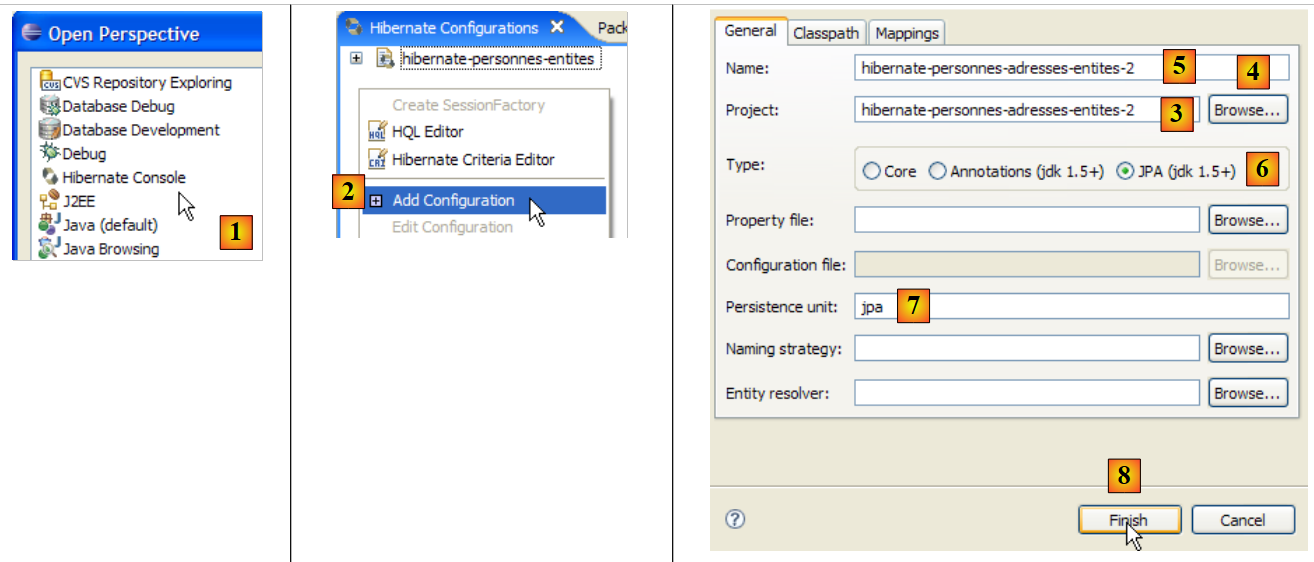 |
- [1]: Wechseln Sie zur Perspektive [Hibernate Console] (Fenster / Perspektive öffnen / Andere)
- [2]: Wir erstellen eine neue Konfiguration
- Über die Schaltfläche [4] wählen wir das Java-Projekt aus, für das die Hibernate-Konfiguration erstellt wird. Sein Name erscheint in [3].
- In [5] geben wir den gewünschten Namen für diese Konfiguration ein. Hier haben wir den Namen des Java-Projekts verwendet.
- In [6] geben wir an, dass wir eine JPA-Konfiguration verwenden, damit das Tool weiß, dass es die Datei [META-INF/persistence.xml] verwenden muss
- In [7] geben wir in der Datei [META-INF/persistence.xml] an, dass die Persistenz-Einheit mit dem Namen jpa verwendet werden soll.
- In [8] validieren wir die Konfiguration.
Als Nächstes muss das DBMS gestartet werden. In diesem Fall ist es MySQL 5.
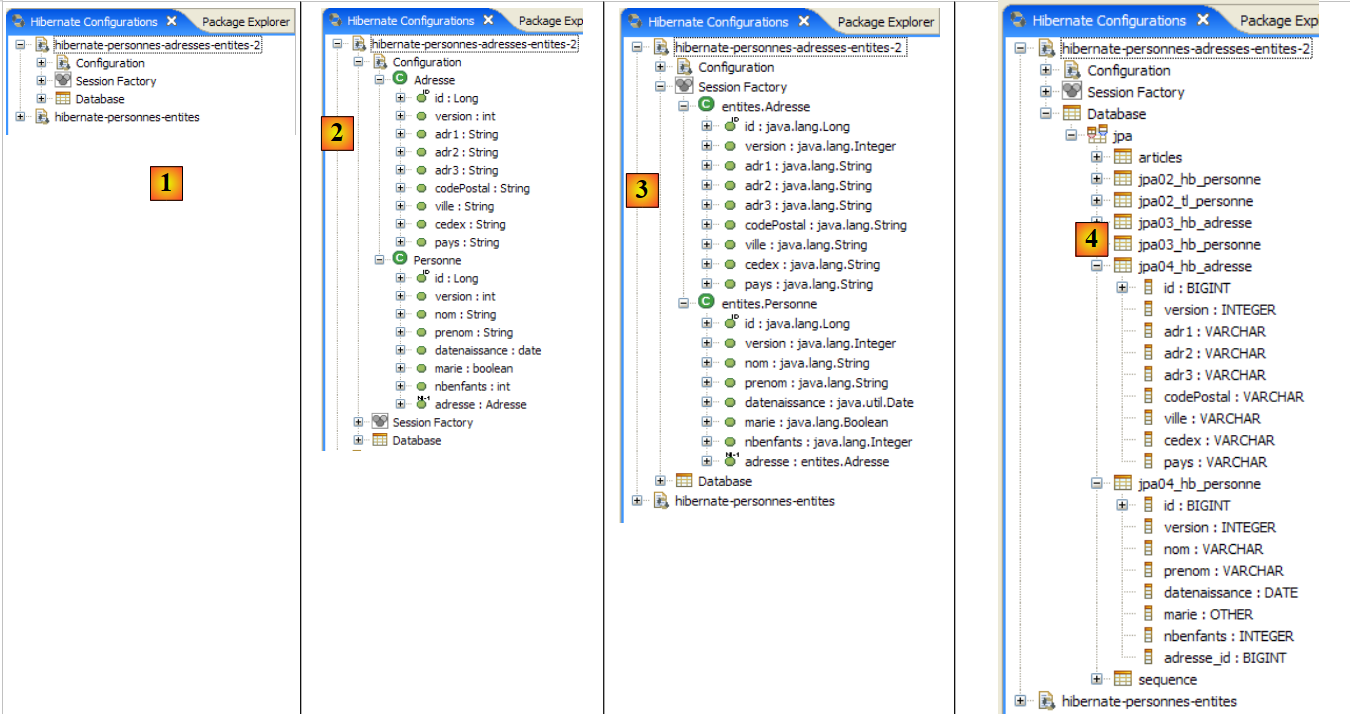 |
- In [1]: Die erstellte Konfiguration hat eine Baumstruktur mit drei Zweigen
- in [2]: Der Zweig [Configuration] listet die Objekte auf, die die Konsole zur Selbstkonfiguration verwendet hat: hier die @Entity-Objekte Person und Address.
- In [3]: Die Session Factory ist ein Hibernate-Konzept, das dem EntityManager von JPA ähnelt. Sie überbrückt die objektrelationale Lücke mithilfe von Objekten aus dem [Configuration]-Zweig. [3] stellt die Objekte des Persistenzkontexts dar, in diesem Fall die @Entity-Entitäten Person und Address.
- in [4]: Die Datenbank, auf die über die in [persistence.xml] enthaltene Konfiguration zugegriffen wird. Hier finden wir die [jpa04_hb_*]-Tabellen, die von unserem aktuellen Eclipse-Projekt generiert wurden.
 |
- In [1] erstellen wir einen HQL-Editor
- im HQL-Editor,
- wählen wir in [2] die zu verwendende Hibernate-Konfiguration aus, falls mehrere vorhanden sind (was hier der Fall ist)
- Geben Sie in [3] den JPQL-Befehl ein, den Sie ausführen möchten; hier den JPQL-Befehl aus Test 8
- In [4] führen wir ihn aus
- In [5] erhalten Sie die Abfrageergebnisse im Fenster [Hibernate Query Result].
- In [6] können Sie im Fenster [Hibernate Dynamic SQL preview] die ausgeführte SQL-Abfrage anzeigen.
Eine weitere Möglichkeit, das gleiche Ergebnis zu erzielen:
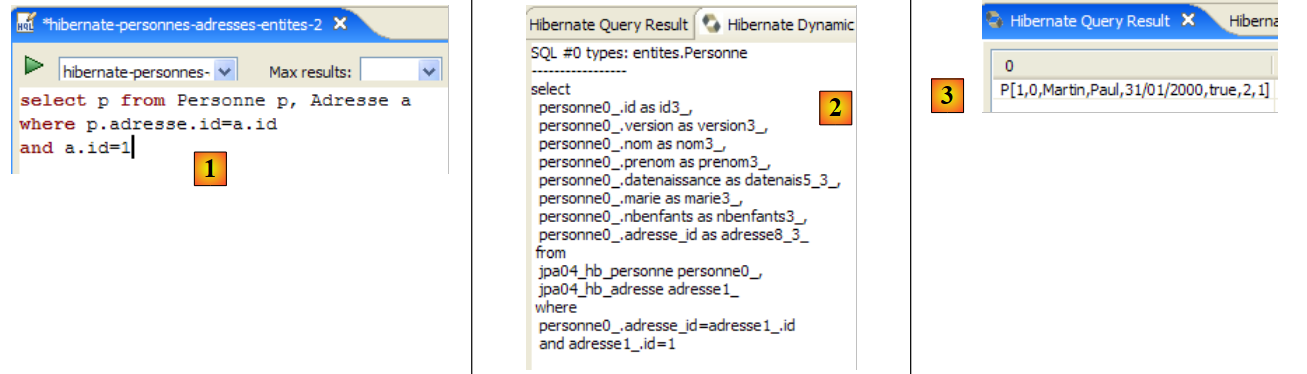 |
- In [1]: der JPQL-Befehl, der die Verknüpfung zwischen den Entitäten „Person“ und „Adresse“ durchführt. [ref1] bezeichnet diese Form als „Theta-Join“.
- in [2]: das SQL-Äquivalent
- In [3]: das Ergebnis
Eine dritte Form, die nur von Hibernate (HQL) akzeptiert wird:
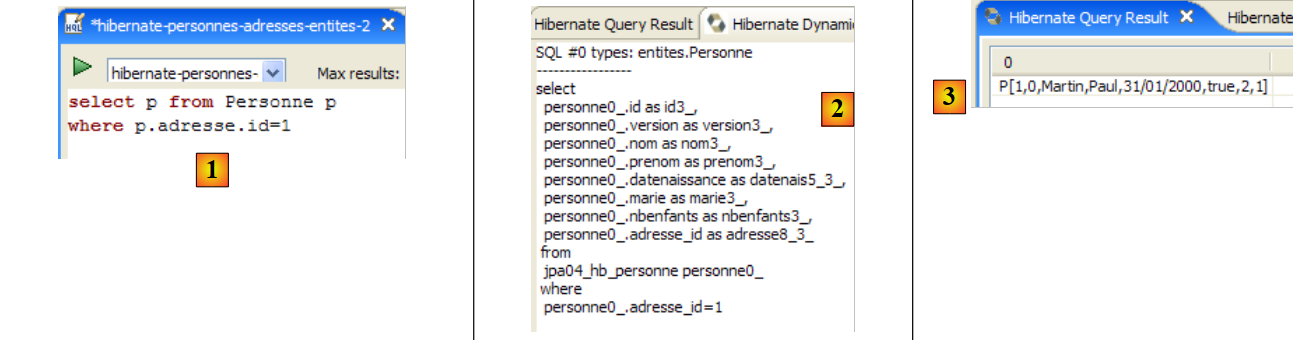 |
- in [1]: die HQL-Abfrage. JPQL akzeptiert die Notation p.address.id nicht. Es akzeptiert nur eine Indirektionsstufe.
- in [2]: das SQL-Äquivalent. Beachten Sie, dass hier die Tabellenverknüpfung vermieden wird.
- in [3]: das Ergebnis
Hier sind einige weitere Beispiele:
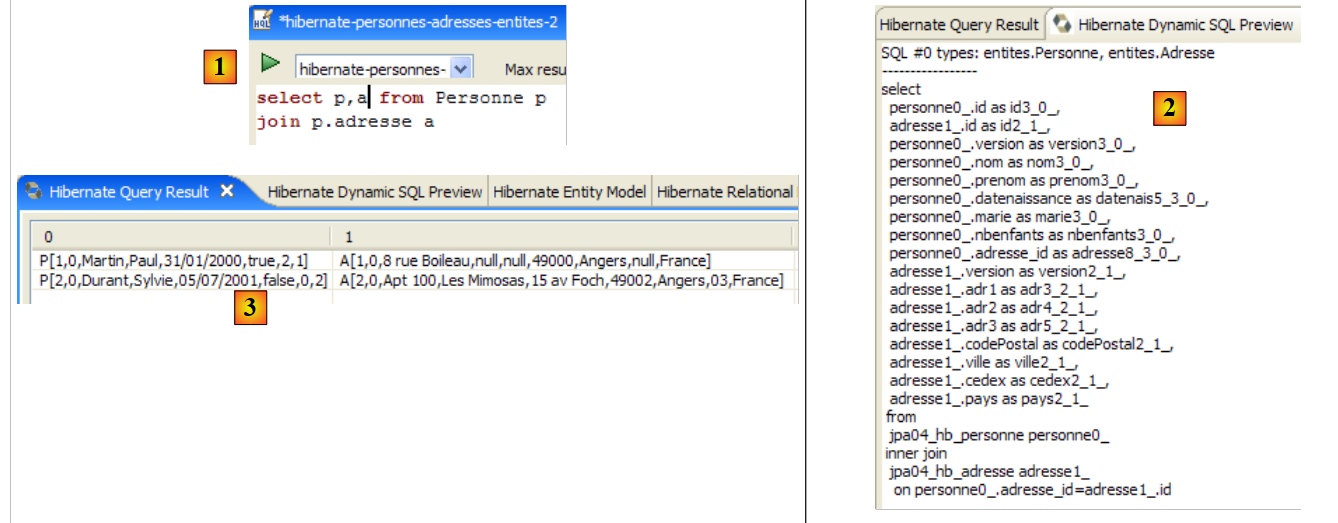 |
- in [1]: die Liste der Personen mit ihren Adressen
- in [2]: das SQL-Äquivalent.
- in [3]: das Ergebnis
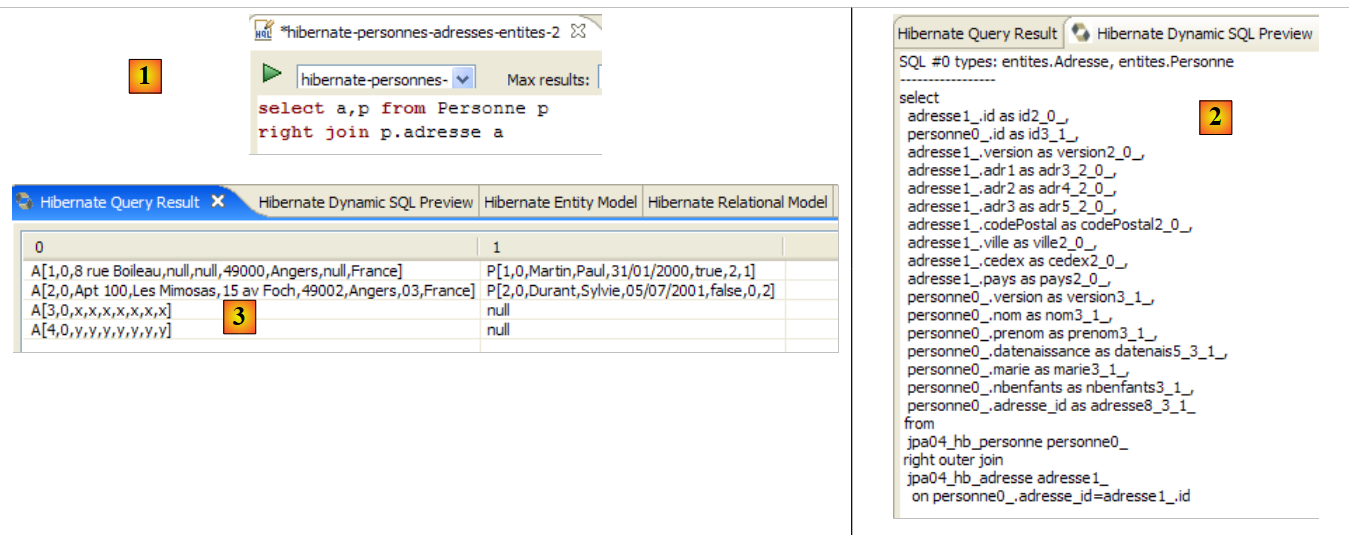 |
- in [1]: die Liste der Adressen mit ihrem Eigentümer, falls vorhanden, andernfalls keine (Right Outer Join: Die Entität „Address“, die die nicht mit „Person“ in Beziehung stehenden Zeilen liefert, steht rechts vom Join-Schlüsselwort).
- in [2]: das SQL-Äquivalent.
- in [3]: das Ergebnis
Beachten Sie, dass nur die Entität „Person“ eine Beziehung zur Entität „Adresse“ hat. Das Gegenteil trifft nicht mehr zu, da wir die als „Person“ bezeichnete 1:1-Umkehrbeziehung in der Entität „Adresse“ entfernt haben. Hätte diese Umkehrbeziehung bestanden, hätten wir schreiben können:
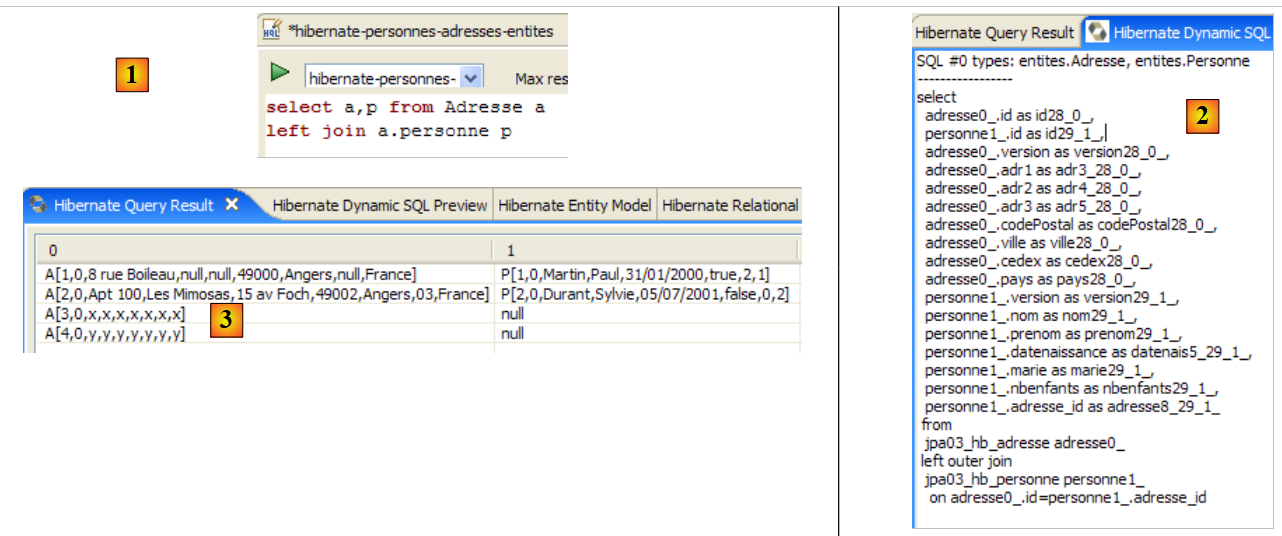 |
- in [1]: die Liste der Adressen mit ihrem Eigentümer, falls vorhanden, andernfalls keine (Left Outer Join: Die Entität „Address“, die Zeilen ohne Beziehung zu „Person“ zurückgibt, steht auf der linken Seite des Join-Schlüsselworts).
- in [2]: das SQL-Äquivalent.
- in [3]: das Ergebnis
Wir empfehlen dem Leser dringend, die JPQL-Sprache mithilfe der Hibernate-Konsole zu üben.
2.3.9. JPA-/Toplink-Implementierung
Wir verwenden nun eine JPA-/Toplink-Implementierung:
 |
Das neue Eclipse-Testprojekt sieht wie folgt aus:
 |
Der Java-Code ist identisch mit dem des vorherigen Hibernate-Projekts. Die Umgebung (Bibliotheken – persistence.xml – DBMS – Ordner „conf“ und „ddl“ – Ant-Skript) entspricht der in Abschnitt 2.1.15.2 beschriebenen. Das Eclipse-Projekt ist [3] im Ordner „examples“ [4] verfügbar. Wir werden es importieren.
Die Datei <persistence.xml> wurde an einer Stelle geändert, und zwar bei den deklarierten Entitäten:
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- classes persistantes -->
<class>entites.Personne</class>
<class>entites.Adresse</class>
<!-- propriétés de l'unité de persistance -->
...
- Zeilen 5 und 6: die beiden verwalteten Entitäten
Die Ausführung von [InitDB] mit dem DBMS MySQL5 liefert folgende Ergebnisse:
 |
In [1] die Konsolenausgabe; in [2] die beiden generierten [jpa04_tl]-Tabellen; in [3] die generierten SQL-Skripte. Ihr Inhalt lautet wie folgt:
create.sql
CREATE TABLE jpa04_tl_personne (ID BIGINT NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, VERSION INTEGER NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NBENFANTS INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa04_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, ADR1 VARCHAR(30) NOT NULL, VILLE VARCHAR(20) NOT NULL, VERSION INTEGER NOT NULL, CEDEX VARCHAR(3), ADR2 VARCHAR(30), PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa04_tl_personne ADD CONSTRAINT FK_jpa04_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa04_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
ALTER TABLE jpa04_tl_personne DROP FOREIGN KEY FK_jpa04_tl_personne_adresse_id
DROP TABLE jpa04_tl_personne
DROP TABLE jpa04_tl_adresse
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
2.4. Beispiel 4: Eins-zu-viele-Beziehung
2.4.1. Das Datenbankschema
1  | 2 |
- in [1] die Datenbank und in [2] deren DDL (MySQL5)
Ein Artikel A(id, version, name) gehört genau zu einer Kategorie C(id, version, name). Eine Kategorie C kann 0, 1 oder mehrere Artikel enthalten. Wir haben eine Eins-zu-Viele-Beziehung (Kategorie -> Artikel) und die umgekehrte Viele-zu-Eins-Beziehung (Artikel -> Kategorie). Diese Beziehung wird durch den Fremdschlüssel dargestellt, den die Tabelle [article] auf die Tabelle [category] hat (Zeilen 24–28 der DDL).
2.4.2. Die @Entity-Objekte, die die Datenbank repräsentieren
Ein Artikel wird durch das folgende @Entity [Article] dargestellt:
package entites;
...
@Entity
@Table(name="jpa05_hb_article")
public class Article implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// main relationship Article (many) -> Category (one)
// implemented by a foreign key (categorie_id) in Article
// 1 Article must have 1 Category (nullable=false)
@ManyToOne(fetch=FetchType.LAZY)
@JoinColumn(name = "categorie_id", nullable = false)
private Categorie categorie;
// manufacturers
public Article() {
}
// getters and setters
...
// toString
public String toString() {
return String.format("Article[%d,%d,%s,%d]", id, version, nom, categorie.getId());
}
}
- Zeilen 9–11: Primärschlüssel der @Entity
- Zeilen 13–15: deren Versionsnummer
- Zeilen 17–18: Name des Artikels
- Zeilen 20–25: Many-to-One-Beziehung, die die @Entity „Article“ mit der @Entity „Category“ verknüpft:
- Zeile 23: die ManyToOne-Annotation. „Many“ bezieht sich auf die @Entity „Article“, in der wir uns befinden, und „One“ bezieht sich auf die @Entity „Category“ (Zeile 25). Eine Kategorie (One) kann mehrere Artikel (Many) haben.
- Zeile 24: Die Annotation ManyToOne definiert die Fremdschlüsselspalte in der Tabelle [article]. Sie erhält den Namen (name) categorie_id, und jede Zeile muss einen Wert in dieser Spalte enthalten (nullable=false).
- Zeile 25: Die Kategorie, zu der der Artikel gehört. Wenn ein Artikel zum Persistenzkontext hinzugefügt wird, fordern wir an, dass seine Kategorie nicht sofort hinzugefügt wird (fetch=FetchType.LAZY, Zeile 23). Wir wissen nicht, ob diese Anforderung sinnvoll ist. Wir werden sehen.
Eine Kategorie wird durch die folgende @Entity [Category] dargestellt:
package entites;
...
@Entity
@Table(name="jpa05_hb_categorie")
public class Categorie implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// inverse relationship Category (one) -> Article (many) from relationship Article (many) -> Category (one)
// cascade insertion Category -> insertion Articles
// cascade maj Category -> maj Articles
// cascade delete Category -> delete Articles
@OneToMany(mappedBy = "categorie", cascade = { CascadeType.ALL })
private Set<Article> articles = new HashSet<Article>();
// manufacturers
public Categorie() {
}
// getters and setters
...
// toString
public String toString() {
return String.format("Categorie[%d,%d,%s]", id, version, nom);
}
// bidirectional association Category <--> Article
public void addArticle(Article article) {
// the item is added to the collection of items in the category
articles.add(article);
// article changes category
article.setCategorie(this);
}
}
- Zeilen 8–11: Der Primärschlüssel der @Entity
- Zeilen 12–14: deren Version
- Zeilen 16–17: der Name der Kategorie
- Zeilen 19–24: die Menge der Elemente in der Kategorie
- Zeile 23: Die Annotation @OneToMany bezeichnet eine Eins-zu-Viele-Beziehung. Das „One“ bezieht sich auf die @Entity [Category], in der wir uns gerade befinden, und das „Many“ bezieht sich auf den Typ [Article] in Zeile 24: Eine (One) Kategorie hat viele (Many) Artikel.
- Zeile 23: Die Annotation ist das Gegenteil (mappedBy) der ManyToOne-Annotation, die auf dem Feld „category“ der @Entity Article platziert ist: mappedBy=category. Die ManyToOne-Beziehung, die auf dem Feld „category“ der @Entity Article platziert ist, ist die primäre Beziehung. Sie ist unerlässlich. Sie implementiert die Fremdschlüsselbeziehung, die die @Entity Article mit der @Entity Category verknüpft. Die OneToMany-Beziehung, die auf das Feld „articles“ der @Entity Category gesetzt ist, ist die inverse Beziehung. Sie ist nicht unverzichtbar. Sie dient als Erleichterung beim Abrufen der Artikel einer Kategorie. Ohne diese Erleichterung müssten diese Artikel über eine JPQL-Abfrage abgerufen werden.
- Zeile 23: `cascadeType.ALL` legt fest, dass Operationen (persist, merge, remove), die an einer `@Entity Category` durchgeführt werden, auf deren Artikel kaskadieren sollen.
- Zeile 24: Die Artikel einer Kategorie werden in einem Objekt vom Typ `Set<Article>` abgelegt. Der Typ `Set` lässt keine Duplikate zu. Daher kann derselbe Artikel nicht zweimal zum Objekt `Set<Article>` hinzugefügt werden. Was bedeutet „derselbe Artikel“? Um anzugeben, dass Artikel `a` mit Artikel `b` identisch ist, verwendet Java den Ausdruck `a.equals(b)`. In der Klasse `Object`, der übergeordneten Klasse aller Klassen, ist `a.equals(b)` wahr, wenn `a == b` ist, d. h. wenn die Objekte `a` und `b` denselben Speicherort haben. Man könnte sagen, dass die Elemente `a` und `b` gleich sind, wenn sie denselben Namen haben. In diesem Fall muss der Entwickler zwei Methoden in der Klasse [Item] neu definieren:
- equals: Diese muss „true“ zurückgeben, wenn die beiden Elemente denselben Namen haben
- hashCode: muss für zwei [Article]-Objekte, die die equals-Methode als gleich betrachtet, einen identischen ganzzahligen Wert zurückgeben. Hier wird der Wert daher aus dem Namen des Artikels gebildet. Der von hashCode zurückgegebene Wert kann eine beliebige ganze Zahl sein. Er wird in verschiedenen Objektcontainern verwendet, insbesondere in Wörterbüchern (Hashtable).
Die OneToMany-Beziehung kann andere Typen als Set verwenden, um die Many-Seite zu speichern, beispielsweise List-Objekte. Diese Fälle werden in diesem Dokument nicht behandelt. Der Leser findet sie in [ref1].
- Zeile 38: Die Methode [addArticle] ermöglicht es uns, einen Artikel zu einer Kategorie hinzuzufügen. Die Methode stellt sicher, dass beide Enden der OneToMany-Beziehung, die [Category] mit [Article] verbindet, aktualisiert werden.
2.4.3. Das Eclipse/Hibernate-1-Projekt
Die hier verwendete JPA-Implementierung ist Hibernate. Das Eclipse-Testprojekt sieht wie folgt aus:
 |
Das Projekt befindet sich [3] im Ordner „examples“ [4]. Wir werden es importieren.
2.4.4. Erstellen der Datenbank-DDL
Gemäß den Anweisungen in Abschnitt 2.1.7 ist die für das DBMS MySQL 5 generierte DDL diejenige, die am Anfang dieses Beispiels in Abschnitt 2.4.1 gezeigt wird.
2.4.5. InitDB
Der Code für [InitDB] lautet wie folgt:
package tests;
...
public class InitDB {
// constant
private final static String TABLE_ARTICLE = "jpa05_hb_article";
private final static String TABLE_CATEGORIE = "jpa05_hb_categorie";
public static void main(String[] args) {
// Persistence context
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// a EntityManager is retrieved from the previous EntityManagerFactory
em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// request
Query sql1;
// delete elements from the ARTICLE table
sql1 = em.createNativeQuery("delete from " + TABLE_ARTICLE);
sql1.executeUpdate();
// delete elements from the CATEGORIE table
sql1 = em.createNativeQuery("delete from " + TABLE_CATEGORIE);
sql1.executeUpdate();
// create three categories
Categorie categorieA = new Categorie();
categorieA.setNom("A");
Categorie categorieB = new Categorie();
categorieB.setNom("B");
Categorie categorieC = new Categorie();
categorieC.setNom("C");
// create 3 items
Article articleA1 = new Article();
articleA1.setNom("A1");
Article articleA2 = new Article();
articleA2.setNom("A2");
Article articleB1 = new Article();
articleB1.setNom("B1");
// link them to their category
categorieA.addArticle(articleA1);
categorieA.addArticle(articleA2);
categorieB.addArticle(articleB1);
// persist categories and cascade (insert) articles
em.persist(categorieA);
em.persist(categorieB);
em.persist(categorieC);
// category display
System.out.println("[categories]");
for (Object p : em.createQuery("select c from Categorie c order by c.nom asc").getResultList()) {
System.out.println(p);
}
// item display
System.out.println("[articles]");
for (Object p : em.createQuery("select a from Article a order by a.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityMangerFactory
emf.close();
// log
System.out.println("terminé...");
}
}
- Zeilen 22–27: Die Tabellen [article] und [category] werden geleert. Beachten Sie, dass wir mit der Tabelle beginnen müssen, die den Fremdschlüssel enthält. Würden wir mit der Tabelle [category] beginnen, würden wir Kategorien löschen, auf die Zeilen in der Tabelle [article] verweisen, und das DBMS würde dies ablehnen.
- Zeilen 29–34: Wir erstellen drei Kategorien A, B, C
- Zeilen 36–41: Wir erstellen drei Artikel: A1, A2 und B1 (der Buchstabe gibt die Kategorie an)
- Zeilen 43–45: Die drei Artikel werden ihren jeweiligen Kategorien zugeordnet
- Zeilen 47–49: Die drei Kategorien werden in den Persistenzkontext aufgenommen. Aufgrund der Kaskade „Kategorie → Artikel“ werden auch die zugehörigen Artikel dort abgelegt. Somit befinden sich nun alle erstellten Objekte im Persistenzkontext.
- Zeilen 50–59: Der Persistenzkontext wird abgefragt, um die Liste der Kategorien und Artikel abzurufen. Wir wissen, dass dies eine Synchronisierung des Kontexts mit der Datenbank auslöst. An dieser Stelle werden die Kategorien und Artikel in ihren jeweiligen Tabellen gespeichert.
Die Ausführung von [InitDB] mit MySQL5 liefert folgende Ergebnisse:
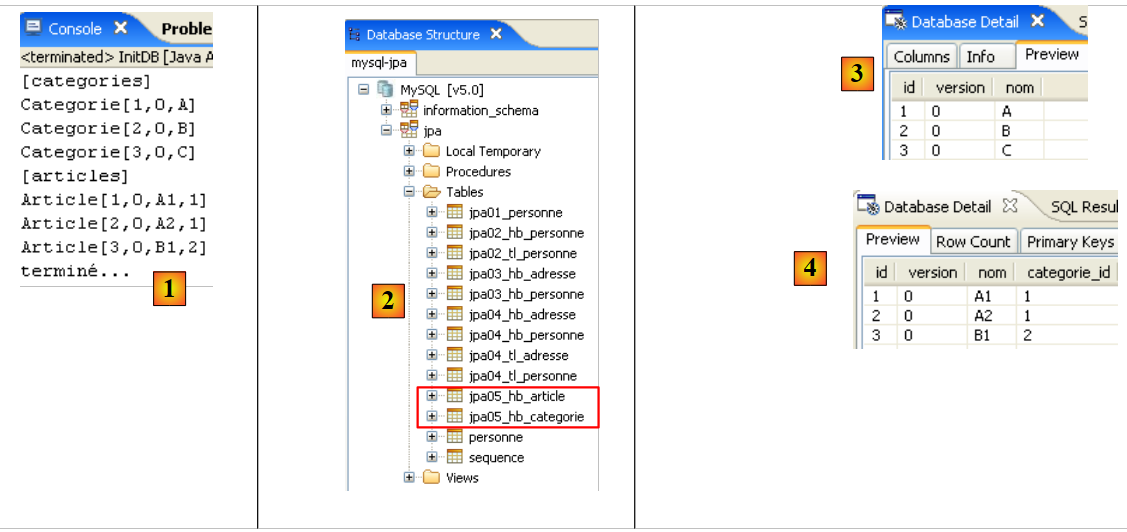 |
- [1]: die Konsolenausgabe
- [2]: die [jpa05_hb_*]-Tabellen in der SQL-Explorer-Ansicht
- [3]: die Tabelle „categories“
- [4]: die Tabelle „articles“. Beachten Sie die Beziehung zwischen [categorie_id] in [4] und [id] in [3] (Fremdschlüssel).
2.4.6. Main
Die Klasse [Main] führt eine Reihe von Tests aus, die wir überprüfen, mit Ausnahme der Tests 1 und 2, die den Code aus [InitDB] zur Initialisierung der Datenbank verwenden.
2.4.6.1. Test3
Dieser Test läuft wie folgt ab:
// search for a particular item
public static void test3() {
// new persistence context
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// loading category
Categorie categorie = em.find(Categorie.class, categorieA.getId());
// category display and related articles
System.out.format("Articles de la catégorie %s :%n", categorie);
for (Article a : categorie.getArticles()) {
System.out.println(a);
}
// end transaction
tx.commit();
}
- Zeile 4: Wir haben einen neuen Persistenzkontext, daher ist er leer
- Zeilen 6–7: Transaktion starten
- Zeile 9: Kategorie A wird aus der Datenbank in den Persistenzkontext geladen
- Zeile 11: Wir zeigen Kategorie A an
- Zeilen 12–14: Wir zeigen die Elemente in Kategorie A an. Dies verdeutlicht den Vorteil der umgekehrten OneToMany-Beziehung für die @Entity Category. Dank dieser Beziehung müssen wir keine JPQL-Abfrage erstellen, um die Elemente in Kategorie A abzurufen. Um sie zu erhalten, verwenden wir die get-Methode des Feldes items.
Die Ergebnisse lauten wie folgt:
- Zeile 20: Kategorie A
- Zeilen 21–22: die beiden Artikel in Kategorie A
2.4.6.2. Test4
Dieser Test läuft wie folgt ab:
// supprimer un article
@SuppressWarnings("unchecked")
public static void test4() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// chargement article A1
Article newarticle1 = em.find(Article.class, articleA1.getId());
// suppression article A1 (aucune catégorie n'est actuellement chargée)
em.remove(newarticle1);
// toplink : l'article doit être enlevé de sa catégorie sinon le test6 plante
// hibernate : ce n'est pas nécessaire
newarticle1.getCategorie().getArticles().remove(newarticle1);
// fin transaction
tx.commit();
// dump des articles
dumpArticles();
}
- Test 4 löscht Element A1
- Zeile 5: Wir beginnen mit einem neuen, leeren Kontext
- Zeile 10: Artikel A1 wird dem Persistenzkontext hinzugefügt. Dort wird er durch newarticle1 referenziert.
- Zeile 12: Er wird aus dem Kontext entfernt
- Zeile 15: Die Kategorien A, B und C sowie die Elemente A1, A2 und B1 befinden sich, auch wenn sie nicht mehr persistent sind, dennoch weiterhin im Speicher. Sie sind lediglich vom Persistenzkontext getrennt. Der Artikel A1, , der zu den Artikeln in Kategorie A gehört, wird aus dieser entfernt. Dies ermöglicht es später, Kategorie A wieder an den Persistenzkontext anzuhängen. Wenn dies nicht geschieht, wird Kategorie A mit einer Reihe von Artikeln wieder angehängt, von denen einer gelöscht wurde. Dies scheint Hibernate nicht zu stören, führt jedoch dazu, dass TopLink abstürzt.
- Zeile 19: Wir zeigen alle Elemente an, um zu überprüfen, ob A1 entfernt wurde.
Die Ergebnisse lauten wie folgt:
Der Artikel A1 ist tatsächlich verschwunden.
2.4.6.3. Test5
Dieser Test läuft wie folgt ab:
// modification d'1 article
public static void test5() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// modification articleA2
articleA2.setNom(articleA2.getNom() + "-");
// articleA2 est remis dans le contexte de persistance
em.merge(articleA2);
// fin transaction
tx.commit();
// dump des articles
dumpArticles();
}
- Test 5 ändert den Namen von Element A2
- Zeile 4: Wir beginnen mit einem neuen, leeren Kontext
- Zeile 9: Wir ändern den Namen des abgelösten Elements A2, das nun „A2-“ lautet.
- Zeile 11: Das vom Persistenzkontext getrennte Element A2 wird wieder mit dem Persistenzkontext verbunden. Beachten Sie, dass A2 weiterhin ein vom Persistenzkontext getrenntes Objekt bleibt. Es ist das Objekt em.merge(itemA2), das nun Teil des Persistenzkontexts ist. Dieses Objekt wurde hier nicht, wie üblich, in einer Variablen gespeichert. Es ist daher nicht zugänglich.
- Zeile 13: Synchronisierung des Persistenzkontexts mit der Datenbank. Der Artikel A2 wird in der Datenbank geändert, und seine Versionsnummer ändert sich von N auf N+1. Die abgelöste Speicherversion articleA2 ist nicht mehr gültig. Dasselbe gilt für das abgelöste Objekt, das die Kategorie A repräsentiert, da es den Artikel A2 unter seinen Artikeln enthält.
- Zeile 15: Wir zeigen alle Artikel an, um die Namensänderung von Artikel A2 zu überprüfen
Die Ergebnisse lauten wie folgt:
Der Name des Artikels A2 hat sich tatsächlich geändert.
2.4.6.4. Test6
Dieser Test läuft wie folgt ab:
// modification d'1 catégorie et de ses articles
public static void test6() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// chargement catégorie
categorieA = em.find(Categorie.class, categorieA.getId());
// liste des articles de la catégorie A
for (Article a : categorieA.getArticles()) {
a.setNom(a.getNom() + "-");
}
// modification nom catégorie
categorieA.setNom(categorieA.getNom() + "-");
// fin transaction
tx.commit();
// dump des catégories et des articles
dumpCategories();
dumpArticles();
}
- Test 6 ändert den Namen der Kategorie A und aller ihrer Artikel
- Zeile 4: Wir beginnen mit einem neuen, leeren Kontext
- Zeile 9: Wir rufen Kategorie A aus der Datenbank ab. Wir führen keine Zusammenführung des losgelösten categoryA-Objekts durch, da wir wissen, dass es eine Referenz auf Artikel A2 enthält, der inzwischen veraltet ist. Wir beginnen daher von vorne.
- Zeilen 11–12: Wir ändern den Namen aller Artikel in Kategorie A. Auch hier nutzen wir die inverse OneToMany-Beziehung über die Methode getArticles.
- Zeile 15: Der Name der Kategorie wird ebenfalls geändert
- Zeile 17: Ende der Transaktion. Der Kontext wird mit der Datenbank synchronisiert. Alle Objekte im Kontext, die geändert wurden, werden in der Datenbank aktualisiert.
- Zeilen 21–22: Die Artikel und Kategorien werden zur Überprüfung angezeigt
Die Ergebnisse lauten wie folgt:
Artikel A2 hat seinen Namen erneut geändert, ebenso wie Kategorie A.
2.4.6.5. Test7
Dieser Test läuft wie folgt ab:
// category deletion
public static void test7() {
// new persistence context
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistence catégorieB and cascade (merge) associated items
Categorie mergedcategorieB = em.merge(categorieB);
// category deletion and cascading (delete) of associated items
em.remove(mergedcategorieB);
// end transaction
tx.commit();
// dump categories and articles
dumpCategories();
dumpArticles();
}
- Test 7 löscht Kategorie B und damit auch deren Artikel
- Zeile 4: Wir beginnen mit einem neuen, leeren Kontext
- Zeile 9: Kategorie B existiert im Speicher als ein vom Persistenzkontext getrenntes Objekt. Wir führen sie wieder in den Persistenzkontext ein. Infolgedessen werden auch ihre Artikel (Artikel B1) eingefügt und somit wieder in den Persistenzkontext integriert.
- Zeile 11: Da sich Kategorie B nun im Kontext befindet, können wir sie entfernen. Durch die Kaskadierung werden auch ihre Elemente entfernt. Dieser Vorgang ist möglich, da die Zusammenführungsoperation in Zeile 9 sie wieder in den Persistenzkontext integriert hat.
- Zeile 13: Ende der Transaktion. Der Kontext wird synchronisiert. Objekte im Kontext, die entfernt wurden, werden aus der Datenbank gelöscht.
- Zeilen 15–16: Wir zeigen die Elemente und Kategorien zur Überprüfung an
Die Ergebnisse lauten wie folgt:
Kategorie B und Artikel B1 sind tatsächlich verschwunden.
2.4.6.6. Test8
Dieser Test läuft wie folgt ab:
// requêtes
@SuppressWarnings("unchecked")
public static void test8() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// liste des articles de la catégorie A
List articles = em
.createQuery(
"select a from Categorie c join c.articles a where c.nom like 'A%' order by a.nom asc")
.getResultList();
// affichages articles
System.out.println("Articles de la catégorie A");
for (Object a : articles) {
System.out.println(a);
}
// fin transaction
tx.commit();
}
- Test 7 zeigt, wie Elemente aus einer Kategorie abgerufen werden können, ohne die inverse Beziehung zu verwenden. Dies verdeutlicht, dass die inverse Beziehung nicht zwingend erforderlich ist.
- Zeile 4: Wir beginnen mit einem neuen, leeren Kontext
- Zeile 10: Eine JPQL-Abfrage, die alle Artikel einer Kategorie abruft, deren Name mit A beginnt
- Zeilen 15–17: Anzeige der Abfrageergebnisse.
Die Ergebnisse lauten wie folgt:
2.4.7. Eclipse / Hibernate-Projekt 2
Wir kopieren das Eclipse / Hibernate-Projekt, um einen Punkt bezüglich des Konzepts der primären Beziehung / inversen Beziehung zu verdeutlichen, das wir anhand der Annotation @ManyToOne (primär) der @Entity [Article] und der inversen Beziehung @OneToMany (invers) der @Entity [Category] erläutert haben. Wir möchten zeigen, dass, wenn diese letztere Beziehung nicht als die inverse der anderen deklariert wird, sich das für die Datenbank generierte Schema vollständig von dem zuvor generierten unterscheidet.
 |
Unter [1] befindet sich das neue Eclipse-Projekt. Unter [2] befindet sich der Java-Code und unter [3] das Ant-Skript, das das SQL-Schema der Datenbank generiert. Das Projekt befindet sich [4] im Ordner „examples“ [5]. Wir werden es importieren.
Wir ändern lediglich die @Entity [Category], sodass ihre @OneToMany-Beziehung zur @Entity [Article] nicht mehr als Umkehrung der @ManyToOne-Beziehung deklariert ist, die die @Entity [Article] zur @Entity [Category] hat:
...
@Entity
@Table(name="jpa05_hb_categorie")
public class Categorie implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// relationship OneToMany not inverse (no mappedby) Category (one) -> Article (many)
// implemented by a Categorie_Article join table, so that, starting from a category
// you can reach the items in this category
@OneToMany(cascade=CascadeType.ALL, fetch=FetchType.LAZY)
private Set<Article> articles = new HashSet<Article>();
// manufacturers
...
- Zeilen 18–22: Wir möchten weiterhin die Möglichkeit behalten, Artikel in einer bestimmten Kategorie mithilfe der @OneToMany-Beziehung in Zeile 21 zu finden. Wir möchten jedoch die Auswirkung des Attributs `mappedBy` verstehen, das eine Beziehung in die inverse einer primären Beziehung umwandelt, die an anderer Stelle in einer anderen @Entity definiert ist. Hier wurde das Attribut `mappedBy` entfernt.
Wir führen die ant-DLL-Aufgabe (siehe Abschnitt 2.1.7) mit dem DBMS MySQL5 aus. Das resultierende Schema sieht wie folgt aus:
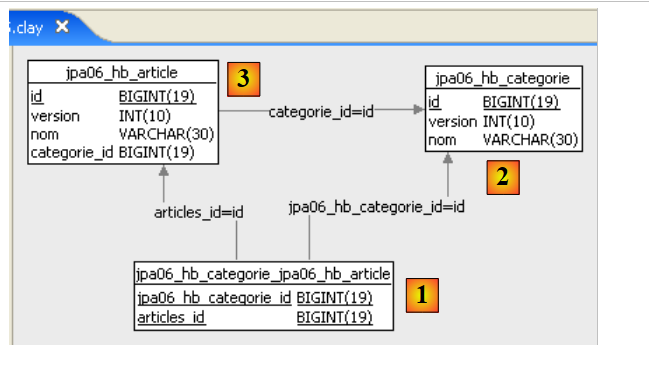 |
Beachten Sie folgende Punkte:
- Es wurde eine neue Tabelle [categorie_article] [1] erstellt. Diese existierte zuvor nicht.
- Dies ist eine Verknüpfungstabelle zwischen den Tabellen [categorie] [2] und [article] [3]. Wenn die Artikelobjekte a1 und a2 zur Kategorie c1 gehören, enthält die Verknüpfungstabelle die folgenden Zeilen:
wobei c1, a1 und a2 die Primärschlüssel der entsprechenden Objekte sind.
- Die Verknüpfungstabelle [category_article] [1] wurde von Hibernate erstellt, damit wir ausgehend von einem Category-Objekt c die zu c gehörenden Article-Objekte a abrufen können. Es ist die @OneToMany-Beziehung, die die Erstellung dieser Tabelle erzwungen hat. Da wir sie nicht als Umkehrung der primären @ManyToOne-Beziehung der @Entity Article deklariert haben, wusste Hibernate nicht, dass es diese primäre Beziehung nutzen konnte, um die Artikel einer Kategorie c abzurufen. Es hat daher einen anderen Weg gefunden.
- Dieses Beispiel hilft dabei, die Konzepte der primären und inversen Beziehungen zu verdeutlichen. Die eine (die inverse) nutzt die Eigenschaften der anderen (der primären).
Das SQL-Schema für diese Datenbank in MySQL 5 lautet wie folgt:
alter table jpa05_hb_categorie_jpa06_hb_article
drop
foreign key FK79D4BA1D26D17756;
alter table jpa05_hb_categorie_jpa06_hb_article
drop
foreign key FK79D4BA1D424C61C9;
alter table jpa06_hb_article
drop
foreign key FK4547168FECCE8750;
drop table if exists jpa05_hb_categorie;
drop table if exists jpa05_hb_categorie_jpa06_hb_article;
drop table if exists jpa06_hb_article;
create table jpa05_hb_categorie (
id bigint not null auto_increment,
version integer not null,
nom varchar(30),
primary key (id)
) ENGINE=InnoDB;
create table jpa05_hb_categorie_jpa06_hb_article (
jpa05_hb_categorie_id bigint not null,
articles_id bigint not null,
primary key (jpa05_hb_categorie_id, articles_id),
unique (articles_id)
) ENGINE=InnoDB;
create table jpa06_hb_article (
id bigint not null auto_increment,
version integer not null,
nom varchar(30),
categorie_id bigint not null,
primary key (id)
) ENGINE=InnoDB;
alter table jpa05_hb_categorie_jpa06_hb_article
add index FK79D4BA1D26D17756 (jpa05_hb_categorie_id),
add constraint FK79D4BA1D26D17756
foreign key (jpa05_hb_categorie_id)
references jpa05_hb_categorie (id);
alter table jpa05_hb_categorie_jpa06_hb_article
add index FK79D4BA1D424C61C9 (articles_id),
add constraint FK79D4BA1D424C61C9
foreign key (articles_id)
references jpa06_hb_article (id);
alter table jpa06_hb_article
add index FK4547168FECCE8750 (categorie_id),
add constraint FK4547168FECCE8750
foreign key (categorie_id)
references jpa05_hb_categorie (id);
- Zeilen 19–24: Erstellung der Tabelle [categorie] und Zeilen 33–39: Erstellung der Tabelle [article]. Beachten Sie, dass diese mit denen im vorherigen Beispiel identisch sind.
- Zeilen 26–31: Erstellung der Verknüpfungstabelle [categorie_article] aufgrund der nicht-inversen @OneToMany-Beziehung der @Entity Categorie. Die Zeilen in dieser Tabelle sind vom Typ [c,a], wobei c der Primärschlüssel einer Kategorie c und a der Primärschlüssel eines Artikels a ist, der zur Kategorie c gehört. Der Primärschlüssel dieser Verknüpfungstabelle besteht aus den beiden Primärschlüsseln [c,a], die miteinander verkettet sind (Zeile 29).
- Zeilen 41–45: Die Fremdschlüsselbeschränkung von der Tabelle [categorie_article] zur Tabelle [categorie]
- Zeilen 47–51: Die Fremdschlüsselbeschränkung von der Tabelle [categorie_article] zur Tabelle [article]
- Zeilen 53–57: Die Fremdschlüsselbeschränkung von der Tabelle [article] zur Tabelle [categorie]
Der Leser ist eingeladen, die Tests [InitDB] und [Main] auszuführen. Sie liefern dieselben Ergebnisse wie zuvor. Das Datenbankschema ist jedoch redundant, und die Leistung wird im Vergleich zur vorherigen Version beeinträchtigt sein. Wir sollten dieses Problem der inversen/primären Beziehungen wahrscheinlich weiter untersuchen, um zu prüfen, ob die neue Konfiguration auch Konflikte verursacht, da wir zwei unabhängige Beziehungen haben, die dasselbe darstellen: die Viele-zu-Eins-Beziehung zwischen der Tabelle [article] und der Tabelle [category].
2.4.8. JPA-/Toplink-Implementierung – 1
Wir verwenden nun eine JPA-/Toplink-Implementierung:
 |
Das Eclipse-Projekt mit Toplink ist eine Kopie des Eclipse-Projekts mit Hibernate, Version 1:
 |
Der Java-Code ist identisch mit dem des vorherigen Hibernate-Projekts – Version 1. Die Umgebung (Bibliotheken – persistence.xml – DBMS – Ordner „conf“ und „ddl“ – Ant-Skript) ist die in Abschnitt 2.1.15.2 beschriebene. Das Eclipse-Projekt ist [3] im Ordner „examples“ [4] verfügbar. Wir werden es importieren.
Die Datei <persistence.xml> [2] wurde in einem Punkt geändert, nämlich bei den deklarierten Entitäten:
...
<!-- classes persistantes -->
<class>entites.Categorie</class>
<class>entites.Article</class>
...
- Zeilen 3 und 4: die beiden verwalteten Entitäten
Die Ausführung von [InitDB] mit dem DBMS MySQL5 liefert folgende Ergebnisse:
 |
In [1] die Konsolenausgabe; in [2] die beiden generierten [jpa05_tl]-Tabellen; in [3] die generierten SQL-Skripte. Ihr Inhalt lautet wie folgt:
create.sql
CREATE TABLE jpa05_tl_article (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), categorie_id BIGINT NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa05_tl_categorie (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), PRIMARY KEY (ID))
ALTER TABLE jpa05_tl_article ADD CONSTRAINT FK_jpa05_tl_article_categorie_id FOREIGN KEY (categorie_id) REFERENCES jpa05_tl_categorie (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
ALTER TABLE jpa05_tl_article DROP FOREIGN KEY FK_jpa05_tl_article_categorie_id
DROP TABLE jpa05_tl_article
DROP TABLE jpa05_tl_categorie
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
Die Ausführung von [Main] wird ohne Fehler abgeschlossen.
2.4.9. JPA-/Toplink-Implementierung – 2
Dieses Eclipse-Projekt wurde durch Klonen des vorherigen Projekts erstellt. Da es mit Hibernate erstellt wurde, entfernen wir das Attribut mappedBy aus der @OneToMany-Beziehung der @Entity Category.
@Entity
@Table(name = "jpa06_tl_categorie")
public class Categorie implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
private int version;
@Column(length = 30)
private String nom;
// relation OneToMany not inverse (no mappedby) Category (one) ->
// Article (many)
// implemented by a Categorie_Article join table, so that from
// category
// several items can be reached
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private Set<Article> articles = new HashSet<Article>();
Das für MySQL5 generierte SQL-Schema lautet dann wie folgt:
create.sql
CREATE TABLE jpa06_tl_categorie (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), PRIMARY KEY (ID))
CREATE TABLE jpa06_tl_categorie_jpa06_tl_article (Categorie_ID BIGINT NOT NULL, articles_ID BIGINT NOT NULL, PRIMARY KEY (Categorie_ID, articles_ID))
CREATE TABLE jpa06_tl_article (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), categorie_id BIGINT NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa06_tl_categorie_jpa06_tl_article ADD CONSTRAINT FK_jpa06_tl_categorie_jpa06_tl_article_articles_ID FOREIGN KEY (articles_ID) REFERENCES jpa06_tl_article (ID)
ALTER TABLE jpa06_tl_categorie_jpa06_tl_article ADD CONSTRAINT jpa06_tl_categorie_jpa06_tl_article_Categorie_ID FOREIGN KEY (Categorie_ID) REFERENCES jpa06_tl_categorie (ID)
ALTER TABLE jpa06_tl_article ADD CONSTRAINT FK_jpa06_tl_article_categorie_id FOREIGN KEY (categorie_id) REFERENCES jpa06_tl_categorie (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
- Zeile 2: Die Verknüpfungstabelle, die die vorherige nicht-invertierte @OneToMany-Beziehung implementiert.
Die Ausführung von [InitDB] wird ohne Fehler abgeschlossen, aber die Ausführung von [Main] stürzt bei Test 7 mit den folgenden Protokollen (FINEST) ab:
- Zeile 3: die Verknüpfung nach Kategorie B
- Zeile 4: Der abhängige Artikel B1 wird in den Kontext eingefügt
- Zeile 5: dasselbe für Kategorie B selbst
- Zeile 6: Das Entfernen in Kategorie B
- Zeile 7: Entfernen des Elements B1 (kaskadierend)
- Zeile 8: Der Java-Code fordert einen Commit der Transaktion an
- Zeile 9: Eine Transaktion beginnt – sie hatte also offenbar noch nicht begonnen.
- Zeile 10: Element B1 soll durch eine DELETE-Operation in der Tabelle [item] gelöscht werden. Hier liegt das Problem. Die Verknüpfungstabelle [category_item] enthält einen Verweis auf Zeile B1 in der Tabelle [item]. Das Löschen von B1 aus [item] würde eine Fremdschlüsselbeschränkung verletzen.
- Zeile 13 und folgende: Die Ausnahme tritt auf
Was können wir daraus schließen?
- Wieder einmal haben wir ein Portabilitätsproblem zwischen Hibernate und TopLink: Hibernate hat diesen Test bestanden
- TopLink hat Schwierigkeiten mit Situationen, in denen zwei Beziehungen tatsächlich invers zueinander stehen, wobei eine nicht als primäre Beziehung und die andere als inverse Beziehung deklariert ist. Dies ist akzeptabel, da dieses Szenario tatsächlich einen Konfigurationsfehler darstellt. In unserem Beispiel hat die Tabelle [article] keine Beziehung zur Verknüpfungstabelle [categorie_article]. Es erscheint daher naheliegend, dass Toplink bei einer Operation an der Tabelle [article] nicht versucht, mit der Tabelle [categorie_article] zu arbeiten.
2.5. Beispiel 5: Viele-zu-viele-Beziehung mit einer expliziten Verknüpfungstabelle
2.5.1. Das Datenbankschema
|
- in [1], der MySQL5-Datenbank
Wir sind bereits mit den Tabellen [person] [2] und [address] [3] vertraut. Sie wurden in Abschnitt 2.3.1 behandelt. Wir verwenden die Version, bei der die Adresse der Person in einer separaten Tabelle [address] [3] gespeichert ist. In der Tabelle [person] wird die Beziehung zwischen einer Person und ihrer Adresse über eine Fremdschlüsselbeschränkung implementiert.
Eine Person übt Aktivitäten aus. Diese Aktivitäten werden in der Tabelle [activity] [4] gespeichert. Eine Person kann mehrere Aktivitäten ausüben, und eine Aktivität kann von mehreren Personen ausgeübt werden. Daher verbindet eine Viele-zu-Viele-Beziehung die Tabellen [person] und [activity]. Diese Beziehung wird durch die Verknüpfungstabelle [person_activity] [5] dargestellt.
2.5.2. Die @Entity-Objekte, die die Datenbank repräsentieren
Die oben genannten Tabellen werden durch die folgenden @Entities dargestellt:
- Die @Entity Person repräsentiert die Tabelle [person]
- Das @Entity-Objekt „Address“ repräsentiert die Tabelle [address]
- die @Entity Activity repräsentiert die Tabelle [activity]
- die @Entity PersonneActivite repräsentiert die Tabelle [personne_activite]
Die Beziehungen zwischen diesen Entitäten sind wie folgt:
- Eine Eins-zu-Eins-Beziehung verbindet die Entität „Person“ mit der Entität „Adresse“: Eine Person p hat eine Adresse a. Die Entität „Person“, die den Fremdschlüssel enthält, ist die primäre Entität, und die Entität „Adresse“ ist die inverse Entität.
- Eine Viele-zu-Viele-Beziehung verbindet die Entitäten „Person“ und „Activity“: Eine Person hat mehrere Aktivitäten, und eine Aktivität wird von mehreren Personen ausgeübt. Diese Beziehung könnte direkt mithilfe einer @ManyToMany-Annotation in jeder der beiden Entitäten implementiert werden, wobei eine als inverse der anderen deklariert wird. Diese Lösung wird später untersucht. Hier implementieren wir die Viele-zu-Viele-Beziehung mithilfe von zwei Eins-zu-Viele-Beziehungen:
- eine 1:n-Beziehung, die die Entität „Person“ mit der Entität „PersonActivity“ verknüpft: Eine einzelne Zeile (One) in der Tabelle [person] wird von mehreren (Many) Zeilen in der Tabelle [person_activity] referenziert. Die Tabelle [person_activity], die den Fremdschlüssel enthält, erhält die primäre @ManyToOne-Beziehung, und die Entität „Person“ erhält die inverse @OneToMany-Beziehung.
- eine 1:n-Beziehung, die die Entität „Activity“ mit der Entität „PersonActivity“ verknüpft: Eine (One) Zeile in der Tabelle [activity] wird von vielen (Many) Zeilen in der Tabelle [person_activity] referenziert. Die Tabelle [person_activity], die den Fremdschlüssel enthält, hat die primäre @ManyToOne-Beziehung, und die Entität „Activity“ hat die inverse @OneToMany-Beziehung.
Die @Entity Person sieht wie folgt aus:
@Entity
@Table(name = "jpa07_hb_personne")
public class Personne implements Serializable {
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
// main relationship Person (one) -> Address (one)
// implemented by the foreign key Person(adresse_id) -> Address
// cascade insert Person -> insert Address
// cascade shift Person -> shift Address
// cascade deletion Person -> deletion Address
// a Person must have 1 Address (nullable=false)
// 1 Address belongs to 1 person only (unique=true)
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
// relation Person (one) -> PersonneActivite (many)
// inverse of existing relationship PersonneActivite (many) -> Personne (one)
// cascade deletion Person -> supression PersonneActivite
@OneToMany(mappedBy = "personne", cascade = { CascadeType.REMOVE })
private Set<PersonneActivite> activites = new HashSet<PersonneActivite>();
// manufacturers
Diese @Entity ist bekannt. Wir werden nur auf die Beziehungen eingehen, die sie zu anderen Entitäten unterhält:
- Zeilen 30–39: eine 1:1-Beziehung (@OneToOne) mit der @Entity Address, implementiert über einen Fremdschlüssel [address_id] (Zeile 38), den die Tabelle [Person] auf die Tabelle [Address] verweist.
- Zeilen 41–45: eine 1:n-Beziehung (@OneToMany) mit der @Entity PersonneActivite. Eine Person (One) wird von mehreren (Many) Zeilen in der Verknüpfungstabelle [personne_activite] referenziert, die durch die @Entity PersonneActivite repräsentiert wird. Diese PersonneActivite-Objekte werden in einen Typ Set<PersonneActivite> eingefügt, wobei PersonneActivite ein Typ ist, den wir in Kürze definieren werden.
- Zeile 44: Die hier definierte Eins-zu-Viele-Beziehung ist die Umkehrung einer primären Beziehung, die für das Feld „person“ der @Entity PersonneActivite definiert ist (Schlüsselwort „mappedBy“). Wir haben eine Person -> Aktivität-Kaskade bei Löschungen: Das Löschen einer Person p führt zum Löschen der persistenten Elemente vom Typ PersonneActivite, die in der Sammlung p.activites gefunden werden.
Die @Entity Address lautet wie folgt:
@Entity
@Table(name = "jpa07_hb_adresse")
public class Adresse implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse")
private Personne personne;
- Zeilen 28–29: Die @OneToOne-Beziehung, die das Gegenstück zur @OneToOne-Beziehung „adresse“ der @Entity Person darstellt (Zeilen 37–38 von Person).
Die @Entity Activity sieht wie folgt aus
@Entity
@Table(name = "jpa07_hb_activite")
public class Activite implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
// relation Activite (one) -> PersonneActivite (many)
// inverse of existing relationship PersonneActivite (many) -> Activite (one)
// cascade suppression Activite -> supression PersonneActivite
@OneToMany(mappedBy = "activite", cascade = { CascadeType.REMOVE })
private Set<PersonneActivite> personnes = new HashSet<PersonneActivite>();
- Zeilen 6–9: Der Primärschlüssel der Aktivität
- Zeilen 11–13: die Versionsnummer der Aktivität
- Zeilen 15–16: der Name der Aktivität
- Zeilen 18–22: Die 1:n-Beziehung, die die @Entity Activity mit der @Entity PersonActivity verknüpft: Eine Aktivität (One) wird von mehreren (Many) Zeilen in der Verknüpfungstabelle [person_activity] referenziert, die durch die @Entity PersonActivity repräsentiert wird. Diese PersonneActivite-Objekte werden in einem Set<PersonneActivite>-Typ abgelegt.
- Zeile 22: Die hier definierte 1:n-Beziehung ist das Gegenteil einer primären Beziehung, die für das Feld `activity` in der `@Entity PersonneActivite` definiert wurde (unter Verwendung des Schlüsselworts `mappedBy`). Wir haben eine Kaskade von „Activity -> PersonActivity“ bei Löschungen: Das Löschen einer Aktivität aus der Tabelle [activity] löst das Löschen der persistenten PersonActivity-Entitäten aus, die in der Sammlung a.people der Verknüpfungstabelle [person_activity] gefunden werden.
Die @Entity PersonneActivite sieht wie folgt aus:
@Entity
// join table
@Table(name = "jpa07_hb_personne_activite")
public class PersonneActivite {
@Embeddable
public static class Id implements Serializable {
// composite key components
// points to a Person
@Column(name = "PERSONNE_ID")
private Long personneId;
// on an Activity
@Column(name = "ACTIVITE_ID")
private Long activiteId;
// manufacturers
...
// getters and setters
...
// toString
public String toString() {
return String.format("[%d,%d]", getPersonneId(), getActiviteId());
}
}
// fields of the Personne_Activite class
// composite key
@EmbeddedId
private Id id = new Id();
// main relationship PersonneActivite (many) -> Nobody (one)
// implemented by the foreign key: personneId (PersonneActivite (many) -> Personne (one)
// personneId is also part of the composite primary key
// JPA does not need to manage this foreign key (insertable = false, updatable = false), as this is done by the application itself in its constructor
@ManyToOne
@JoinColumn(name = "PERSONNE_ID", insertable = false, updatable = false)
private Personne personne;
// main relationship PersonneActivite -> Activity
// implemented by the foreign key: activiteId (PersonneActivite (many) -> Activite (one)
// activiteId is also part of the composite primary key
// JPA does not need to manage this foreign key (insertable = false, updatable = false), as this is done by the application itself in its constructor
@ManyToOne()
@JoinColumn(name = "ACTIVITE_ID", insertable = false, updatable = false)
private Activite activite;
// manufacturers
public PersonneActivite() {
}
public PersonneActivite(Personne p, Activite a) {
// foreign keys are set by the application
getId().setPersonneId(p.getId());
getId().setActiviteId(a.getId());
// two-way associations
this.setPersonne(p);
this.setActivite(a);
p.getActivites().add(this);
a.getPersonnes().add(this);
}
// getters and setters
...
// toString
public String toString() {
return String.format("[%s,%s,%s]", getId(), getPersonne().getNom(), getActivite().getNom());
}
}
Diese Klasse ist komplexer als die vorherigen.
- Die Tabelle [person_activity] enthält Zeilen der Form [p,a], wobei p der Primärschlüssel einer Person und a der Primärschlüssel einer Aktivität ist. Jede Tabelle muss einen Primärschlüssel haben, und [person_activity] bildet da keine Ausnahme. Bisher hatten wir Primärschlüssel definiert, die vom DBMS dynamisch generiert wurden. Wir könnten hier genauso vorgehen. Wir werden jedoch eine andere Technik verwenden, bei der die Anwendung selbst die Werte des Primärschlüssels einer Tabelle definiert. Hier bedeutet eine Zeile [p1,a1], dass die Person p1 an der Aktivität a1 teilnimmt. Dieselbe Zeile darf in der Tabelle nicht ein zweites Mal vorkommen. Somit ist das Paar (p,a) ein guter Kandidat für einen Primärschlüssel. Dies wird als zusammengesetzter Primärschlüssel bezeichnet.
- Zeilen 30–31: der zusammengesetzte Primärschlüssel. Die Annotation @EmbeddedId (früher @Id) entspricht der @Embedded-Notation, die auf das Feld „Address“ einer Person angewendet wurde. In jenem Fall bedeutete dies, dass das Feld „Address“ eine Instanz einer externen Klasse war, aber in dieselbe Tabelle wie die Person eingefügt werden musste. Hier ist die Bedeutung dieselbe, außer dass die Annotation zu @EmbeddedId wird, um anzuzeigen, dass es sich um den Primärschlüssel handelt.
- Zeile 31: Ein leeres Objekt, das den Primärschlüssel `id` darstellt, wird erstellt, wenn das `PersonneActivite`-Objekt instanziiert wird. Die Klasse, die den Primärschlüssel repräsentiert, wird in den Zeilen 7–26 als öffentliche statische Klasse innerhalb der Klasse `PersonneActivite` definiert. Dass sie öffentlich und statisch ist, wird von Hibernate verlangt. Wenn wir „public static“ durch „private“ ersetzen, tritt eine Ausnahme auf, und die zugehörige Fehlermeldung weist darauf hin, dass Hibernate versucht hat, die Anweisung „new PersonneActivite$Id“ auszuführen. Daher muss die Klasse „Id“ sowohl statisch als auch öffentlich sein.
- Zeile 6: Die Id-Klasse des Primärschlüssels wird als @Embeddable deklariert. Erinnern Sie sich daran, dass die Primärschlüssel-ID in Zeile 31 als @EmbeddedId deklariert wurde. Die entsprechende Klasse muss daher die Annotation @Embeddable aufweisen.
- Wir haben festgestellt, dass der Primärschlüssel der Tabelle [person_activity] aus dem Paar (p, a) besteht, wobei p der Primärschlüssel einer Person und a der Primärschlüssel einer Aktivität ist. Die beiden Elemente (p, a) des zusammengesetzten Schlüssels „ “ finden wir in Zeile 11 (personId) und Zeile 15 (activityId). Die mit diesen beiden Feldern verbundenen Spalten heißen: PERSON_ID für die Person, ACTIVITY_ID für die Aktivität.
- Zeile 31: Der Primärschlüssel wurde mit seinen beiden Spalten (PERSON_ID, ACTIVITY_ID) definiert. Es gibt keine weiteren Spalten in der Tabelle [person_activity]. Nun müssen nur noch die Beziehungen zwischen der @Entity PersonneActivite, die wir gerade beschreiben, und den anderen @Entities im relationalen Schema definiert werden. Diese Beziehungen spiegeln die Fremdschlüssel-Einschränkungen wider, die die Tabelle [personne_activite] gegenüber den anderen Tabellen aufweist.
- Zeilen 33–39: Definieren den Fremdschlüssel von der Tabelle [person_activity] zur Tabelle [person]
- Zeile 37: Die Beziehung ist vom Typ @ManyToOne: Eine (One) Zeile in der Tabelle [person] wird von vielen (Many) Zeilen in der Tabelle [person_activity] referenziert.
- Zeile 38: Wir benennen die Fremdschlüsselspalte. Wir verwenden denselben Namen wie für die Komponente „person“ des Fremdschlüssels (Zeile 10). Die Attribute insertable=false, updatable=false dienen dazu, Hibernate daran zu hindern, den Fremdschlüssel zu verwalten. Dieser Schlüssel ist nämlich eine Komponente eines von der Anwendung berechneten Primärschlüssels, und Hibernate darf nicht eingreifen.
- Zeilen 41–47: Definition des Fremdschlüssels von der Tabelle [person_activity] zur Tabelle [activity]. Die Erläuterungen entsprechen den zuvor gegebenen.
- Zeilen 54–63: Konstruktor für ein PersonActivity-Objekt basierend auf einer Person p und einer Aktivität a. Erinnern Sie sich daran, dass beim Erstellen eines PersonActivity-Objekts der Primärschlüssel id in Zeile 31 auf ein leeres Id-Objekt verwies. In den Zeilen 56–57 wird jedem der Felder (personId, activityId) des Id-Objekts ein Wert zugewiesen. Diese Werte sind jeweils die Primärschlüssel der Person p und der Aktivität a, die als Parameter an den Konstruktor übergeben wurden. Der Primärschlüssel id (Zeile 31) hat somit nun einen Wert.
- Zeile 59: Dem Feld „person“ in Zeile 39 wird der Wert „p“ zugewiesen
- Zeile 60: Dem Feld „activite“ in Zeile 47 wird der Wert „a“ zugewiesen
- Ein [PersonActivity]-Objekt wird nun erstellt und initialisiert. Wir aktualisieren die inversen Beziehungen zwischen der @Entity Person (Zeile 61) und der @Entity Activity (Zeile 62) mit der soeben erstellten @Entity PersonActivity.
Wir haben die Beschreibung der Datenbankentitäten abgeschlossen. Wir befinden uns in einer komplexen, aber leider häufigen Situation. Wir werden sehen, dass es eine weitere mögliche Konfiguration der JPA-Schicht gibt, die einen Teil dieser Komplexität verbirgt: Die Verknüpfungstabelle wird implizit, von der JPA-Schicht erstellt und verwaltet. Hier haben wir uns für die komplexeste Lösung entschieden, die jedoch eine Weiterentwicklung des relationalen Schemas ermöglicht. Dadurch können Spalten zur Verknüpfungstabelle hinzugefügt werden, was in der Konfiguration, bei der die Verknüpfungstabelle kein explizites @Entity ist, nicht möglich ist. [ref1] empfiehlt die Lösung, die wir derzeit untersuchen. Die Informationen, die die Entwicklung dieser Lösung ermöglichten, wurden in [ref1] gefunden.
2.5.3. Das Eclipse-/Hibernate-Projekt
Die hier verwendete JPA-Implementierung ist Hibernate. Das Eclipse-Projekt für die Tests sieht wie folgt aus:
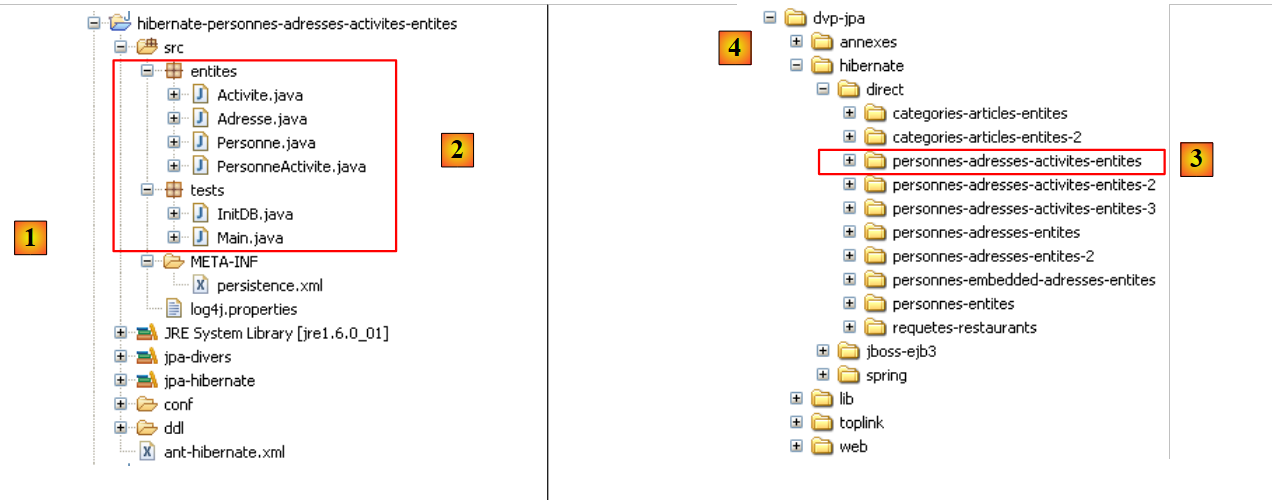
In [1] das Eclipse-Projekt, in [2] der Java-Code. Das Projekt befindet sich in [3] im Ordner „examples“ [4]. Wir werden es importieren.
2.5.4. Erstellen der Datenbank-DDL
Gemäß den Anweisungen in Abschnitt 2.1.7 lautet die für das DBMS MySQL 5 generierte DDL wie folgt:
alter table jpa07_hb_personne
drop
foreign key FKB5C817D45FE379D0;
alter table jpa07_hb_personne_activite
drop
foreign key FKD3E49B06CD852024;
alter table jpa07_hb_personne_activite
drop
foreign key FKD3E49B0668C7A284;
drop table if exists jpa07_hb_activite;
drop table if exists jpa07_hb_adresse;
drop table if exists jpa07_hb_personne;
drop table if exists jpa07_hb_personne_activite;
create table jpa07_hb_activite (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_adresse (
id bigint not null auto_increment,
version integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adresse_id bigint not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_personne_activite (
PERSONNE_ID bigint not null,
ACTIVITE_ID bigint not null,
primary key (PERSONNE_ID, ACTIVITE_ID)
) ENGINE=InnoDB;
alter table jpa07_hb_personne
add index FKB5C817D45FE379D0 (adresse_id),
add constraint FKB5C817D45FE379D0
foreign key (adresse_id)
references jpa07_hb_adresse (id);
alter table jpa07_hb_personne_activite
add index FKD3E49B06CD852024 (ACTIVITE_ID),
add constraint FKD3E49B06CD852024
foreign key (ACTIVITE_ID)
references jpa07_hb_activite (id);
alter table jpa07_hb_personne_activite
add index FKD3E49B0668C7A284 (PERSONNE_ID),
add constraint FKD3E49B0668C7A284
foreign key (PERSONNE_ID)
references jpa07_hb_personne (id);
- Zeilen 21–26: die Tabelle [activity]
- Zeilen 28–39: die Tabelle [address]
- Zeilen 41–51: die Tabelle [person]
- Zeilen 53–57: die Verknüpfungstabelle [person_activity]. Beachten Sie den zusammengesetzten Schlüssel (Zeile 56)
- Zeilen 59–63: der Fremdschlüssel von der Tabelle [person] zur Tabelle [address]
- Zeilen 65–69: der Fremdschlüssel von der Tabelle [person_activity] zur Tabelle [activity]
- Zeilen 71–75: der Fremdschlüssel von der Tabelle [person_activity] zur Tabelle [person]
2.5.5. InitDB
Der Code für [InitDB] lautet wie folgt:
package tests;
...
public class InitDB {
// constant
private final static String TABLE_PERSONNE_ACTIVITE = "jpa07_hb_personne_activite";
private final static String TABLE_PERSONNE = "jpa07_hb_personne";
private final static String TABLE_ACTIVITE = "jpa07_hb_activite";
private final static String TABLE_ADRESSE = "jpa07_hb_adresse";
public static void main(String[] args) throws ParseException {
// Persistence context
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// we retrieve a EntityManager from the EntityManagerFactory
// previous
em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// request
Query sql1;
// delete elements from the PERSONNE_ACTIVITE table
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE_ACTIVITE);
sql1.executeUpdate();
// delete elements from the PERSONNE table
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE);
sql1.executeUpdate();
// delete elements from the ACTIVITE table
sql1 = em.createNativeQuery("delete from " + TABLE_ACTIVITE);
sql1.executeUpdate();
// delete elements from the ADRESSE table
sql1 = em.createNativeQuery("delete from " + TABLE_ADRESSE);
sql1.executeUpdate();
// creation activities
Activite act1 = new Activite();
act1.setNom("act1");
Activite act2 = new Activite();
act2.setNom("act2");
Activite act3 = new Activite();
act3.setNom("act3");
// persistence activities
em.persist(act1);
em.persist(act2);
em.persist(act3);
// creating people
Personne p1 = new Personne("p1", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("p2", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
Personne p3 = new Personne("p3", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// address creation
Adresse adr1 = new Adresse("adr1", null, null, "49000", "Angers", null, "France");
Adresse adr2 = new Adresse("adr2", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
Adresse adr3 = new Adresse("adr3", "x", "x", "x", "x", "x", "x");
Adresse adr4 = new Adresse("adr4", "y", "y", "y", "y", "y", "y");
// associations person <--> address
p1.setAdresse(adr1);
adr1.setPersonne(p1);
p2.setAdresse(adr2);
adr2.setPersonne(p2);
p3.setAdresse(adr3);
adr3.setPersonne(p3);
// persistence of persons and therefore of associated addresses
em.persist(p1);
em.persist(p2);
em.persist(p3);
// persistence of a4 address not linked to a person
em.persist(adr4);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// address display
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
System.out.println("[activites]");
for (Object a : em.createQuery("select a from Activite a").getResultList()) {
System.out.println(a);
}
// associations person <-->activity
PersonneActivite p1act1 = new PersonneActivite(p1, act1);
PersonneActivite p1act2 = new PersonneActivite(p1, act2);
PersonneActivite p2act1 = new PersonneActivite(p2, act1);
PersonneActivite p2act3 = new PersonneActivite(p2, act3);
// persistence of person <--> activity associations
em.persist(p1act1);
em.persist(p1act2);
em.persist(p2act1);
em.persist(p2act3);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// address display
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
System.out.println("[activites]");
for (Object a : em.createQuery("select a from Activite a").getResultList()) {
System.out.println(a);
}
System.out.println("[personnes/activites]");
for (Object pa : em.createQuery("select pa from PersonneActivite pa").getResultList()) {
System.out.println(pa);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
// log
System.out.println("terminé...");
}
}
- Zeilen 27–38: Die Tabellen [person_activity], [person], [address] und [activity] werden geleert. Beachten Sie, dass wir mit den Tabellen beginnen müssen, die Fremdschlüssel enthalten.
- Zeilen 40–45: Wir erstellen drei Aktivitäten: act1, act2 und act3
- Zeilen 47–49: Sie werden in den Persistenzkontext aufgenommen.
- Zeilen 51–53: Es werden drei Personen, p1, p2 und p3, angelegt.
- Zeilen 55–58: Es werden vier Adressen (adr1 bis adr4) angelegt.
- Zeilen 60–65: Die Adressen adr1–adr4 werden den Personen p1–p3 zugeordnet. Da die Beziehung Person <-> Adresse bidirektional ist, müssen jedes Mal zwei Operationen durchgeführt werden.
- Zeilen 67–69: Die Personen p1 bis p3 werden in den Persistenzkontext aufgenommen. Aufgrund der Kaskade „Person -> Adresse“ gilt dies auch für die Adressen adr1 bis adr3.
- Zeile 71: Die vierte Adresse, adr4, die keiner Person zugeordnet ist, wird explizit in den Persistenzkontext aufgenommen.
- Zeilen 73–85: Der Persistenzkontext wird abgefragt, um die Listen der Entitäten vom Typ [Person], [Adresse] und [Aktivität] abzurufen. Wir wissen, dass diese Abfragen die Synchronisation des Kontexts mit der Datenbank auslösen: Die erstellten Entitäten werden in die Datenbank eingefügt und erhalten ihre Primärschlüssel. Es ist wichtig, dies für den weiteren Verlauf zu verstehen.
- Zeilen 87–90: Wir erstellen vier Assoziationen vom Typ Person <-> Activity. Ihre Namen geben an, welche Person mit welcher Aktivität verknüpft ist. Sie erinnern sich vielleicht, dass der Primärschlüssel einer PersonActivity-Entität ein zusammengesetzter Schlüssel ist, der sich aus den Primärschlüsseln einer Person und einer Activity zusammensetzt. Dieser Vorgang ist möglich, da die Entitäten Person und Activity ihre Primärschlüssel bei einer vorherigen Synchronisation erhalten haben.
- Zeilen 92–95: Diese 4 Assoziationen werden dem Persistenzkontext hinzugefügt.
- Zeilen 87–86: Der Persistenzkontext wird abgefragt, um die Listen der Entitäten vom Typ [Person], [Address], [Activity] und [PersonActivity] abzurufen. Wir wissen, dass diese Abfragen die Synchronisation des Kontexts mit der Datenbank auslösen: Die erstellten „PersonActivity“-Entitäten werden in die Datenbank eingefügt.
Die Ausführung von [InitDB] mit MySQL5 erzeugt die folgende Konsolenausgabe:
Es mag überraschen, dass in den Zeilen 15–16 die Versionsnummern für die Personen p1 und p2 1 lauten und dass dies in den Zeilen 24–26 für die drei Aktivitäten ebenfalls gilt. Versuchen wir, dies zu verstehen.
In den Zeilen 2–4 sind die Versionsnummern für Personen 0, und in den Zeilen 11–13 sind die Versionsnummern für Aktivitäten 0. Diese Anzeigen erscheinen, bevor die Beziehungen zwischen Person und Aktivität erstellt werden. Die Zeilen 87–90 des Java-Codes erstellen Beziehungen zwischen den Personen p1 und p2 und den Aktivitäten act1, act2 und act3. Diese werden mithilfe des Konstruktors @Entity PersonneActivite erstellt (siehe Abschnitt 2.5.2). Ein Blick auf den Code dieses Konstruktors zeigt, dass, wenn eine Person p mit einer Aktivität a verknüpft wird:
- die Aktivität a zur Menge p.activities hinzugefügt wird
- die Person p zur Menge a.personnes hinzugefügt
Wenn wir also *new PersonneActivite(p, a)* schreiben, werden die Person p und die Aktivität a im Speicher geändert. Bei der Ausführung der Zeilen 97–113 von [InitDB] wird der Persistenzkontext mit der Datenbank synchronisiert, und JPA/Hibernate erkennt, dass die persistenten Entitäten p1, p2, act1, act2 und act3 geändert wurden. Diese Änderungen müssen in der Datenbank vorgenommen werden. Sie werden tatsächlich in die Verknüpfungstabelle [person_activity] geschrieben, aber JPA/Hibernate erhöht dennoch die Versionsnummer jeder geänderten persistenten Entität.
In der Ansicht „SQL Explorer“ sehen die Ergebnisse wie folgt aus:
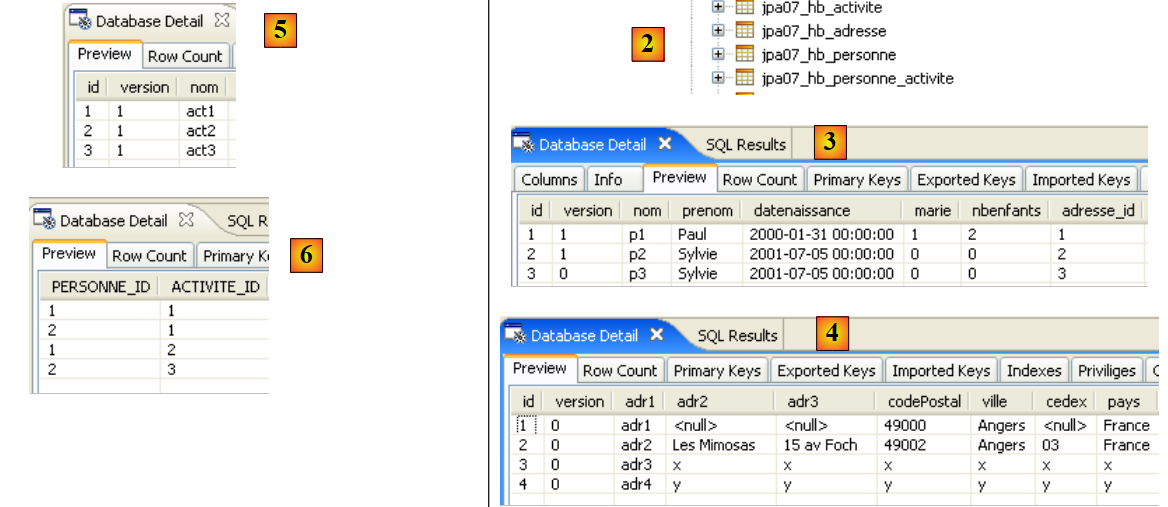 |
- [2]: die [jpa07_hb_*]
- [3]: die Tabelle „people“
- [4]: die Adressen-Tabelle.
- [5]: die Tabelle „activities“
- [6]: die Verknüpfungstabelle „Person <-> Aktivität“
2.5.6. Main
Die Klasse [Main] führt eine Reihe von Tests durch, die wir durchlaufen, mit Ausnahme von Test 1, der den Code aus [InitDB] verwendet, um die Datenbank zu initialisieren.
2.5.6.1. Test2
Dieser Test läuft wie folgt ab:
// suppression Personne p1
public static void test2() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// suppression dépendances sur p1 : pas nécessaire à hibernate mais
// indispensable à toplink
act1.getPersonnes().remove(p1act1);
act2.getPersonnes().remove(p1act2);
// suppression personne p1
em.remove(p1);
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- Zeile 4: Wir verwenden den Persistenzkontext von test1, wobei die Person p1 ein Objekt in diesem Kontext ist.
- Zeile 13: Löschen der Person p1. Aufgrund des Attributs:
- cascadeType.ALL bei Address wird die mit der Person p1 verknüpfte Adresse gelöscht
- cascadeType.REMOVE für PersonActivity werden die Aktivitäten der Person p1 gelöscht.
- Zeilen 10–11: Wir entfernen die Abhängigkeiten, die andere Entitäten von der Person p1 haben, die in Zeile 13 gelöscht wird. Die Aktivitäten act1 und act2 werden von der Person p1 ausgeführt. Die Verknüpfungen wurden vom Konstruktor der Entität PersonActivity erstellt, dessen Code wie folgt lautet:
public PersonneActivite(Personne p, Activite a) {
// les clés étrangères sont fixées par l'application
getId().setPersonneId(p.getId());
getId().setActiviteId(a.getId());
// associations bidirectionnelles
setPersonne(p);
setActivite(a);
p.getActivites().add(this);
a.getPersonnes().add(this);
}
In Zeile 9 erhält die Aktivität a ein zusätzliches Element vom Typ PersonActivity in ihrer Personen-Sammlung. Dieses Element ist vom Typ (p,a), um anzuzeigen, dass die Person p an der Aktivität a teilnimmt. In test1 innerhalb von [Main] wurden auf diese Weise zwei Verknüpfungen (p1,act1) und (p1,act2) erstellt. In den Zeilen 10 und 11 von test2 werden diese Abhängigkeiten entfernt. Beachten Sie, dass Hibernate auch ohne das Entfernen dieser Abhängigkeiten für Person p1 funktioniert, Toplink jedoch nicht.
- Zeilen 17–20: Alle Tabellen werden angezeigt
Die Ergebnisse lauten wie folgt:
- Person p1, die in test1 (Zeile 3) vorkommt, ist am Ende von test2 (Zeilen 22–23) nicht mehr vorhanden
- Die Adresse adr1 der Person p1, die in test1 (Zeile 11) vorhanden ist, ist nach test2 (Zeilen 29–31) nicht mehr vorhanden
- Die Aktivitäten (p1,act1) (Zeile 16) und (p1,act2) (Zeile 18) der Person p1, die in Test1 vorhanden ist, sind am Ende von Test2 (Zeilen 33–34) nicht mehr vorhanden
2.5.6.2. Test3
Dieser Test läuft wie folgt ab:
// suppression activite act1
public static void test3() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// suppression dépendances sur act1 : pas nécessaire à hibernate mais
// indispensable à toplink
p2.getActivites().remove(p2act1);
// suppression activité act1
em.remove(act1);
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- Zeile 4: Wir verwenden den Persistenzkontext von test2
- Zeile 12: Löschen der Aktivität act1. Aufgrund des Attributs:
- cascadeType.REMOVE bei PersonneActivite werden die Zeilen (p, act1) in der Tabelle [personne_activite] gelöscht.
- Zeile 10: Bevor wir act1 aus dem Persistenzkontext entfernen, beseitigen wir alle Abhängigkeiten, die andere Entitäten möglicherweise von diesem persistenten Objekt haben. Nach dem Löschen von Person p1 im vorherigen Test führt nur noch Person p2 die Aktivität act1 aus.
- Zeilen 13–16: Alle Tabellen werden angezeigt
Die Ergebnisse lauten wie folgt:
- In test2 existiert die Aktivität act1 (Zeile 6). In test3 existiert sie nicht mehr (Zeilen 21–22)
- In Test2 existiert die Verknüpfung (p2,act1) (Zeile 14). In Test3 existiert sie nicht mehr (Zeile 28)
2.5.6.3. Test4
Dieser Test läuft wie folgt ab:
// récupération activités d'une personne
public static void test4() {
// contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on récupère la personne p2
p2 = em.find(Personne.class, p2.getId());
System.out.format("1 - Activités de la personne p2 (JPQL) :%n");
// on scanne ses activités
for (Object pa : em.createQuery("select a.nom from Activite a join a.personnes pa where pa.personne.nom='p2'").getResultList()) {
System.out.println(pa);
}
// on passe par la relation inverse de p2
p2 = em.find(Personne.class, p2.getId());
System.out.format("2 - Activités de la personne p2 (relation inverse) :%n");
// on scanne ses activités
for (PersonneActivite pa : p2.getActivites()) {
System.out.println(pa.getActivite().getNom());
}
// fin transaction
tx.commit();
}
- Test 4 zeigt die Aktivitäten von Person p2 an.
- Zeile 4: Wir beginnen mit einem neuen, leeren Kontext
- Zeilen 12–14: Wir zeigen die Namen der von Person p2 durchgeführten Aktivitäten mithilfe einer JPQL-Abfrage an.
- Es wird eine Verknüpfung zwischen Activity (a) und PersonActivity (pa) durchgeführt (join a.people)
- In den Zeilen dieses Joins (a, pa) zeigen wir den Aktivitätsnamen (a.name) für Person p2 an (pa.person.name='p2').
- Zeilen 16–21: Wir verfahren wie zuvor, verwenden jedoch die OneToMany-Beziehung p2.activites der Person p2. Die JPQL-Abfrage wird von JPA generiert. Hier zeigt sich der Vorteil der inversen OneToMany-Beziehung: Sie vermeidet eine JPQL-Abfrage.
Die Ergebnisse lauten wie folgt:
2.5.6.4. Test5
Dieser Test läuft wie folgt ab:
// récupération personnes faisant une activité donnée
public static void test5() {
// contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
System.out.format("1 - Personnes pratiquant l'activité act3 (JPQL) :%n");
// on demande les activités de p2
for (Object pa : em.createQuery("select p.nom from Personne p join p.activites pa where pa.activite.nom='act3'").getResultList()) {
System.out.println(pa);
}
// on passe par la relation inverse de act3
System.out.format("2 - Personnes pratiquant l'activité act3 (relation inverse) :%n");
act3 = em.find(Activite.class, act3.getId());
for (PersonneActivite pa : act3.getPersonnes()) {
System.out.println(pa.getPersonne().getNom());
}
// fin transaction
tx.commit();
}
- Test 6 zeigt die Personen, die die Aktivität act3 ausführen. Der Ansatz ähnelt dem von Test 6. Wir überlassen es dem Leser, die Verbindung zwischen den beiden Codeausschnitten herzustellen.
Die Ergebnisse lauten wie folgt:
Die Tests 4 und 5 sollten erneut zeigen, dass eine inverse Beziehung niemals unverzichtbar ist und immer durch eine JPQL-Abfrage ersetzt werden kann.
2.5.7. JPA-/Toplink-Implementierung
Wir verwenden nun eine JPA-/Toplink-Implementierung:
 |
Das Eclipse-Projekt mit Toplink ist eine Kopie des Eclipse-Projekts mit Hibernate:
 |
Der Java-Code ist identisch mit dem des vorherigen Hibernate-Projekts, mit einigen geringfügigen Unterschieden, auf die wir noch eingehen werden. Die Umgebung (Bibliotheken – persistence.xml – DBMS – Ordner „conf“ und „ddl“ – Ant-Skript) entspricht der in Abschnitt 2.1.15.2 beschriebenen. Das Eclipse-Projekt ist [3] im Ordner „examples“ [4] verfügbar. Wir werden es importieren.
Die Datei <persistence.xml> [2] wurde in einem Punkt geändert: die deklarierten Entitäten:
<!-- classes persistantes -->
<class>entites.Activite</class>
<class>entites.Adresse</class>
<class>entites.Personne</class>
<class>entites.PersonneActivite</class>
- Zeilen 2–5: die vier verwalteten Entitäten
Die Ausführung von [InitDB] mit dem DBMS MySQL5 liefert folgende Ergebnisse:
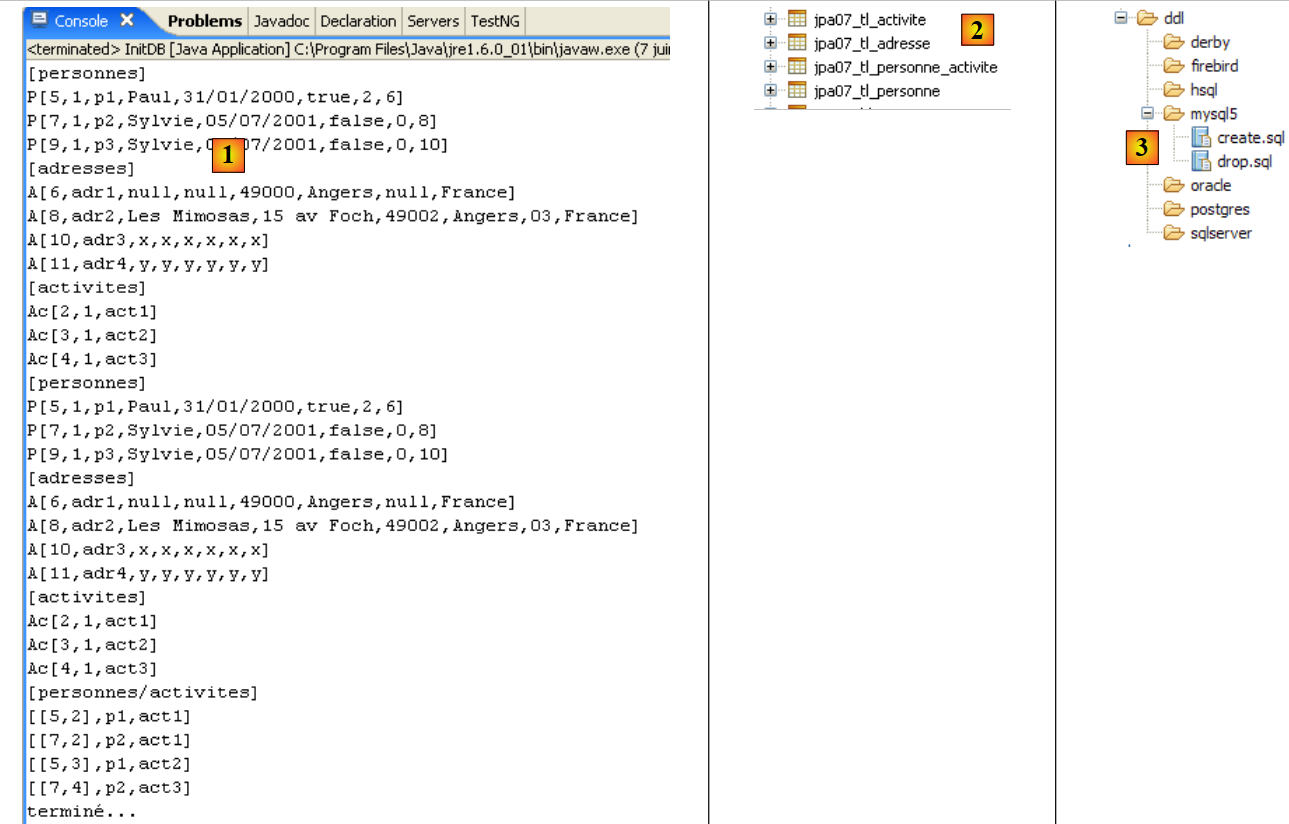 |
In [1] die Konsolenausgabe; in [2] die generierten [jpa07_tl]-Tabellen; in [3] die generierten SQL-Skripte. Ihr Inhalt lautet wie folgt:
create.sql
CREATE TABLE jpa07_tl_activite (ID BIGINT NOT NULL, VERSION INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa07_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, VERSION INTEGER NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR2 VARCHAR(30), CEDEX VARCHAR(3), ADR1 VARCHAR(30) NOT NULL, PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa07_tl_personne_activite (PERSONNE_ID BIGINT NOT NULL, ACTIVITE_ID BIGINT NOT NULL, PRIMARY KEY (PERSONNE_ID, ACTIVITE_ID))
CREATE TABLE jpa07_tl_personne (ID BIGINT NOT NULL, DATENAISSANCE DATE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, NBENFANTS INTEGER NOT NULL, VERSION INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa07_tl_personne_activite ADD CONSTRAINT FK_jpa07_tl_personne_activite_ACTIVITE_ID FOREIGN KEY (ACTIVITE_ID) REFERENCES jpa07_tl_activite (ID)
ALTER TABLE jpa07_tl_personne_activite ADD CONSTRAINT FK_jpa07_tl_personne_activite_PERSONNE_ID FOREIGN KEY (PERSONNE_ID) REFERENCES jpa07_tl_personne (ID)
ALTER TABLE jpa07_tl_personne ADD CONSTRAINT FK_jpa07_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa07_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
Die Ausführung von [InitDB] und [Main] wird ohne Fehler abgeschlossen.
2.6. Beispiel 6: Viele-zu-viele-Beziehung mit einer impliziten Verknüpfungstabelle
Wir kehren zu Beispiel 4 zurück, behandeln es nun jedoch mit einer impliziten Verknüpfungstabelle, die von der JPA-Schicht selbst generiert wird.
2.6.1. Das Datenbankschema
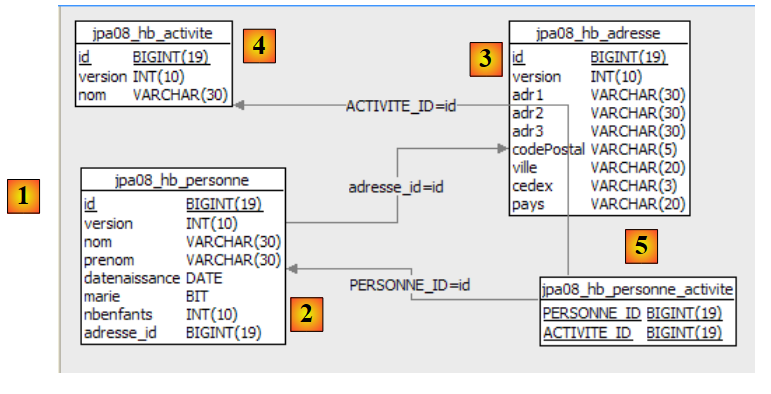 |
- in [1]: die MySQL5-Datenbank – in [2]: die Tabelle [person] – in [3]: die zugehörige Tabelle [address] – in [4]: die Tabelle [activity] für Aktivitäten – in [5]: die Verknüpfungstabelle [person_activity], die Personen und Aktivitäten miteinander verbindet.
2.6.2. Die @Entity-Objekte, die die Datenbank repräsentieren
Die oben genannten Tabellen werden durch die folgenden @Entity-Annotationen dargestellt:
- Das @Entity-Objekt „Person“ repräsentiert die Tabelle [person]
- die @Entity-Annotation „Address“ repräsentiert die Tabelle [address]
- das @Entity Activity repräsentiert die Tabelle [activity]
- Die Tabelle [person_activity] wird nicht mehr durch eine @Entity dargestellt
Die Beziehungen zwischen diesen Entitäten sind wie folgt:
- Eine Eins-zu-Eins-Beziehung verbindet die Entität „Person“ mit der Entität „Address“: Eine Person p hat eine Adresse a. Die Entität „Person“, die den Fremdschlüssel enthält, ist die primäre Entität, und die Entität „Address“ ist die inverse Entität.
- Eine Viele-zu-Viele-Beziehung verbindet die Entitäten „Person“ und „Activity“: Eine Person hat mehrere Aktivitäten, und eine Aktivität wird von mehreren Personen ausgeübt. Diese Beziehung wird mithilfe einer @ManyToMany-Annotation in jeder der beiden Entitäten implementiert, wobei eine als inverse der anderen deklariert wird.
Die @Entity Person sieht wie folgt aus:
@Entity
@Table(name = "jpa08_hb_personne")
public class Personne implements Serializable {
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
// toplink sqlserver :@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
// main relationship Person (one) -> Address (one)
// implemented by the foreign key Person(adresse_id) -> Address
// cascade insert Person -> insert Address
// cascade shift Person -> shift Address
// cascade deletion Person -> deletion Address
// a Person must have 1 Address (nullable=false)
// 1 Address belongs to 1 person only (unique=true)
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
// relationship Person (many) -> Activity (many) via a personne_activite join table
// personne_activite(PERSONNE_ID) is a foreign key on Person(id)
// personne_activite(ACTIVITE_ID) is a foreign key on Activite(id)
// cascade=CascadeType.PERSIST: persistence of 1 person leads to persistence of their activities
@ManyToMany(cascade={CascadeType.PERSIST})
@JoinTable(name="jpa08_hb_personne_activite",joinColumns = @JoinColumn(name = "PERSONNE_ID"), inverseJoinColumns = @JoinColumn(name = "ACTIVITE_ID"))
private Set<Activite> activites = new HashSet<Activite>();
// manufacturers
public Personne() {
}
Wir werden nur die @ManyToMany-Beziehung in den Zeilen 46–48 kommentieren, die die @Entity Person mit der @Entity Activity verknüpft:
- Zeile 48: Eine Person hat Aktivitäten. Das Feld „activities“ stellt diese dar. In der vorherigen Version war der Typ der Elemente im Set „activities“ PersonActivity. Hier ist es Activity. Wir greifen daher direkt auf die Aktivitäten einer Person zu, während wir in der vorherigen Version über die zwischengeschaltete Entität PersonActivity gehen mussten.
- Zeile 46: Die Beziehung, die die untersuchte @Entity Person mit der @Entity Activity im Aktivitäten-Set in Zeile 48 verbindet, ist vom Typ „Viele-zu-Viele“ (ManyToMany):
- Eine Person (One) hat mehrere Aktivitäten (Many)
- eine Aktivität (One) wird von mehreren Personen (Many) ausgeübt
- Letztendlich sind die @Entity Person und Activity durch eine ManyToMany-Beziehung verknüpft. Wie bei der OneToOne-Beziehung sind die Entitäten in dieser Beziehung symmetrisch. Wir können frei wählen, welche @Entity die primäre Beziehung und welche die inverse Beziehung einnimmt. Hier entscheiden wir, dass die @Entity Person die primäre Beziehung einnimmt.
- Wie wir im vorherigen Beispiel gesehen haben, erfordert die @ManyToMany-Beziehung eine Verknüpfungstabelle. Während wir diese zuvor mit einer @Entity definiert haben, wird die Verknüpfungstabelle hier mit der Annotation @JoinTable in Zeile 47 definiert.
- Das Attribut „name“ gibt der Tabelle einen Namen.
- Die Verknüpfungstabelle besteht aus den Fremdschlüsseln der Tabellen, die sie verknüpft. Hier gibt es zwei Fremdschlüssel: einen aus der Tabelle [person] und einen aus der Tabelle [activity]. Diese Fremdschlüsselspalten werden durch die Attribute joinColumns und inverseJoinColumns definiert.
- Die Annotation @JoinColumn im Attribut joinColumns definiert den Fremdschlüssel in der Tabelle der @Entity, die die primäre @ManyToMany-Beziehung enthält, in diesem Fall die Tabelle [person]. Diese Fremdschlüsselspalte erhält den Namen PERSON_ID.
- Die Annotation @JoinColumn des Attributs inverseJoinColumns definiert den Fremdschlüssel in der Tabelle der @Entity, die die inverse @ManyToMany-Beziehung enthält, in diesem Fall die Tabelle [activity]. Diese Fremdschlüsselspalte erhält den Namen ACTIVITY_ID.
Die @Entity Address lautet wie folgt:
@Entity
@Table(name = "jpa07_hb_adresse")
public class Adresse implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse")
private Personne personne;
- Zeilen 28–29: Die @OneToOne-Beziehung, die das Gegenstück zur @OneToOne-Beziehung „adresse“ der @Entity Person darstellt (Zeilen 37–38 von Person).
Die @Entity Activity sieht wie folgt aus
@Entity
@Table(name = "jpa08_hb_activite")
public class Activite implements Serializable {
// fields
@Id()
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
// toplink sqlserver : @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
// inverse relationship Activity -> Person
@ManyToMany(mappedBy = "activites")
private Set<Personne> personnes = new HashSet<Personne>();
...
- Zeilen 20–21: Die Many-to-Many-Beziehung, die die @Entity Activity mit der @Entity Person verknüpft. Diese Beziehung wurde bereits in der @Entity Person definiert. Hier legen wir lediglich fest, dass es sich um die inverse Beziehung (mappedBy) der bestehenden @ManyToMany-Beziehung im Feld activites (mappedBy="activites") der @Entity Person handelt.
- Beachten Sie, dass eine umgekehrte Beziehung immer optional ist. Hier verwenden wir sie, um die Personen abzurufen, die an der aktuellen Aktivität teilnehmen. Die Set<Person>-Sammlung people wird verwendet, um sie abzurufen. Der Lademodus für die Person-Abhängigkeiten der @Entity Activity ist nicht angegeben. Wir haben ihn auch im vorherigen Beispiel nicht angegeben. Standardmäßig ist dieser Modus fetch=FetchType.LAZY.
Wir haben die Beschreibung der Datenbankentitäten abgeschlossen. Dies war einfacher als in dem Fall, in dem die Verknüpfungstabelle [person_activity] eine explizite Tabelle ist. Diese einfachere Lösung kann im Laufe der Zeit Nachteile mit sich bringen: Sie erlaubt es nicht, Spalten zur Verknüpfungstabelle hinzuzufügen. Dies könnte sich jedoch als notwendig erweisen, um neuen Anforderungen gerecht zu werden, wie beispielsweise das Hinzufügen einer Spalte zur Tabelle [person_activity], die das Datum angibt, an dem sich die Person für die Aktivität angemeldet hat.
2.6.3. Das Eclipse-/Hibernate-Projekt
Die hier verwendete JPA-Implementierung ist Hibernate. Das Eclipse-Projekt für die Tests sieht wie folgt aus:
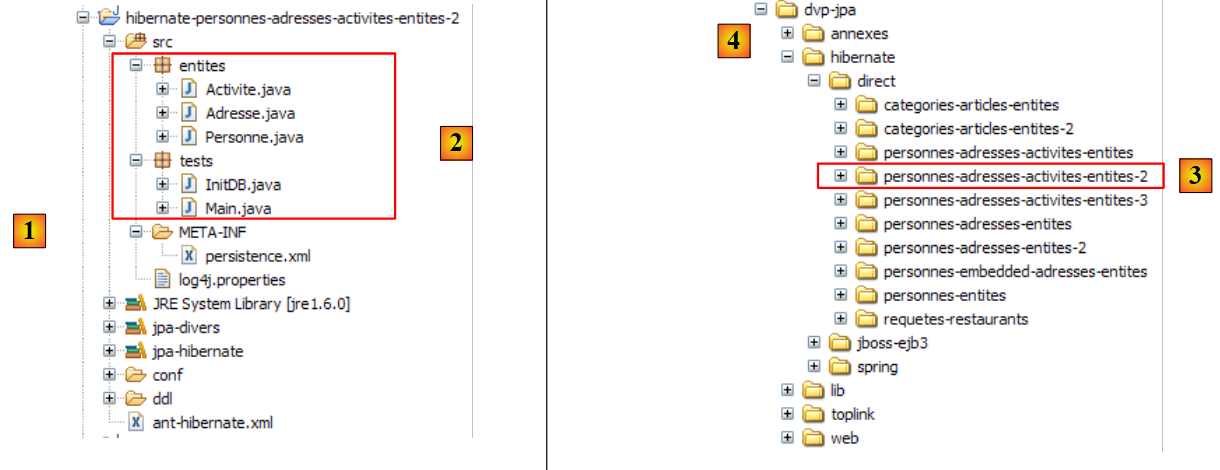 |
In [1] das Eclipse-Projekt, in [2] der Java-Code. Das Projekt befindet sich in [3] im Ordner „examples“ [4]. Wir werden es importieren.
2.6.4. Erstellen der Datenbank-DDL
Gemäß den Anweisungen in Abschnitt 2.1.7 lautet die für das DBMS MySQL 5 generierte DDL wie folgt:
alter table jpa08_hb_personne
drop
foreign key FKA44B1E555FE379D0;
alter table jpa08_hb_personne_activite
drop
foreign key FK5A6A55A5CD852024;
alter table jpa08_hb_personne_activite
drop
foreign key FK5A6A55A568C7A284;
drop table if exists jpa08_hb_activite;
drop table if exists jpa08_hb_adresse;
drop table if exists jpa08_hb_personne;
drop table if exists jpa08_hb_personne_activite;
create table jpa08_hb_activite (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_adresse (
id bigint not null auto_increment,
version integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adresse_id bigint not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_personne_activite (
PERSONNE_ID bigint not null,
ACTIVITE_ID bigint not null,
primary key (PERSONNE_ID, ACTIVITE_ID)
) ENGINE=InnoDB;
alter table jpa08_hb_personne
add index FKA44B1E555FE379D0 (adresse_id),
add constraint FKA44B1E555FE379D0
foreign key (adresse_id)
references jpa08_hb_adresse (id);
alter table jpa08_hb_personne_activite
add index FK5A6A55A5CD852024 (ACTIVITE_ID),
add constraint FK5A6A55A5CD852024
foreign key (ACTIVITE_ID)
references jpa08_hb_activite (id);
alter table jpa08_hb_personne_activite
add index FK5A6A55A568C7A284 (PERSONNE_ID),
add constraint FK5A6A55A568C7A284
foreign key (PERSONNE_ID)
references jpa08_hb_personne (id);
Diese DDL entspricht derjenigen, die mit der expliziten Join-Tabelle erhalten wurde, und entspricht dem bereits vorgestellten Schema:
 |
2.6.5. InitDB
Wir werden nicht viel zur Klasse [InitDB] sagen, da sie mit der vorherigen Version identisch ist und zu denselben Ergebnissen führt. Konzentrieren wir uns stattdessen auf den folgenden Code, der die Verknüpfung zwischen Person und Aktivität anzeigt:
// people/activities display
System.out.println("[personnes/activites]");
Iterator iterator = em.createQuery("select p.id,a.id from Personne p join p.activites a").getResultList().iterator();
while (iterator.hasNext()) {
Object[] row = (Object[]) iterator.next();
System.out.format("[%d,%d]%n", (Long) row[0], (Long) row[1]);
}
- Zeile 3: Die JPQL-Abfrage, die die Verknüpfung durchführt. Das Ergebnis der SELECT-Anweisung gibt die IDs der Entitäten „Person“ und „Activity“ zurück, die durch die Verknüpfungstabelle miteinander verbunden sind. Die von der SELECT-Anweisung zurückgegebene Liste besteht aus Zeilen, die zwei Long-Objekte enthalten. Um diese Liste zu durchlaufen, fordert Zeile 3 ein Iterator-Objekt für die Liste an.
- Zeilen 4–7: Mithilfe des Iterator-Objekts aus der vorherigen Zeile wird die Liste durchlaufen.
- Zeile 5: Jedes Element der Liste ist ein Array, das eine Zeile aus dem SELECT-Ergebnis enthält
- Zeile 6: Die Elemente der aktuellen Zeile, die aus der SELECT-Anweisung resultieren, werden durch entsprechende Typkonvertierungen abgerufen.
Das Ergebnis von [InitDB] lautet wie folgt:
2.6.6. Main
Die Klasse [Main] führt eine Reihe von Tests aus, von denen wir einige näher betrachten werden.
2.6.6.1. Test3
Dieser Test sieht wie folgt aus:
// suppression activite act1
public static void test3() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// suppression activité act1 de p2
p2.getActivites().remove(act1);
// on retire act1 du contexte de persistance
em.remove(act1);
// fin transactions
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- Zeile 11: Die Aktivität act1 wird aus dem Persistenzkontext entfernt
- Zeile 9: Die Aktivität act1 ist eine der Aktivitäten der einzigen im Kontext verbleibenden Person, Person p2. In Zeile 9 wird die Aktivität act1 aus den Aktivitäten von Person p2 entfernt. Dies geschieht, um die Konsistenz des Persistenzkontexts zu gewährleisten, da wir ihn später noch verwenden werden.
Die Ergebnisse lauten wie folgt:
- Die Aktivität act1 in Zeile 26 in test2 ist aus den Aktivitäten in test3 (Zeilen 40–41) verschwunden
- Person p2 hatte in test2 die Aktivität act1 (Zeile 33). Am Ende von test3 hat sie diese nicht mehr (Zeile 47)
2.6.6.2. Test6
Dieser Test sieht wie folgt aus:
// modification des activités d'une personne
public static void test6() {
// contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on récupère la personne p2
p2 = em.find(Personne.class, p2.getId());
// on récupère l'activité act2
act2 = em.find(Activite.class, act2.getId());
// p2 ne pratique plus que l'activité act2
p2.getActivites().clear();
p2.getActivites().add(act2);
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpActivite();
dumpPersonne_Activite();
}
- Zeile 4: Es wird ein neuer, leerer Persistenzkontext verwendet
- Zeile 9: Die Person p2 wird aus der Datenbank in den Persistenzkontext geladen
- Zeile 11: Die Aktivität act2 wird aus der Datenbank in den Persistenzkontext geladen
- Zeile 13: Die Aktivitäten (act3) der Person p2 werden aus der Datenbank in den Kontext geladen (fetchType.LAZY). Der Aufruf von [getActivities] löst dieses Laden aus. Wir entfernen die Aktivitäten von p2. Dies ist keine tatsächliche Entfernung der Aktivitäten (remove), sondern eine Änderung des Zustands der Person p2. Sie übt keine Aktivitäten mehr aus.
- Zeile 14: Die Aktivität act2 wird der Person p2 hinzugefügt. Letztendlich ist die Menge der neuen Aktivitäten für die Person p2 die Menge {act2}.
- Zeile 16: Ende der Transaktion. Die Synchronisation überprüft die Objekte im Kontext (p2, act2, act3) und stellt fest, dass sich der Zustand von p2 geändert hat. Die SQL-Anweisungen, die diese Änderung in der Datenbank widerspiegeln, werden ausgeführt.
- Zeilen 18–20: Alle Tabellen werden angezeigt
Die Ergebnisse lauten wie folgt:
- Am Ende von Test 4 führte Person p2 die Aktivität act3 aus (Zeile 3).
- Am Ende von Test 6 (Zeile 19) führt Person p2 die Aktivität act3 (Zeile 3) nicht mehr aus, sondern führt die Aktivität act2 aus.
2.6.7. JPA-/Toplink-Implementierung
Wir verwenden nun eine JPA-/Toplink-Implementierung:
 |
Das Eclipse-Projekt mit Toplink ist eine Kopie des Eclipse-Projekts mit Hibernate:
 |
Die Datei <persistence.xml> [2] wurde an einer Stelle geändert, und zwar in Bezug auf die deklarierten Entitäten:
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- classes persistantes -->
<class>entites.Activite</class>
<class>entites.Adresse</class>
<class>entites.Personne</class>
...
- Zeilen 4–6: die verwalteten Entitäten
Die Ausführung von [InitDB] mit dem DBMS MySQL5 liefert folgende Ergebnisse:
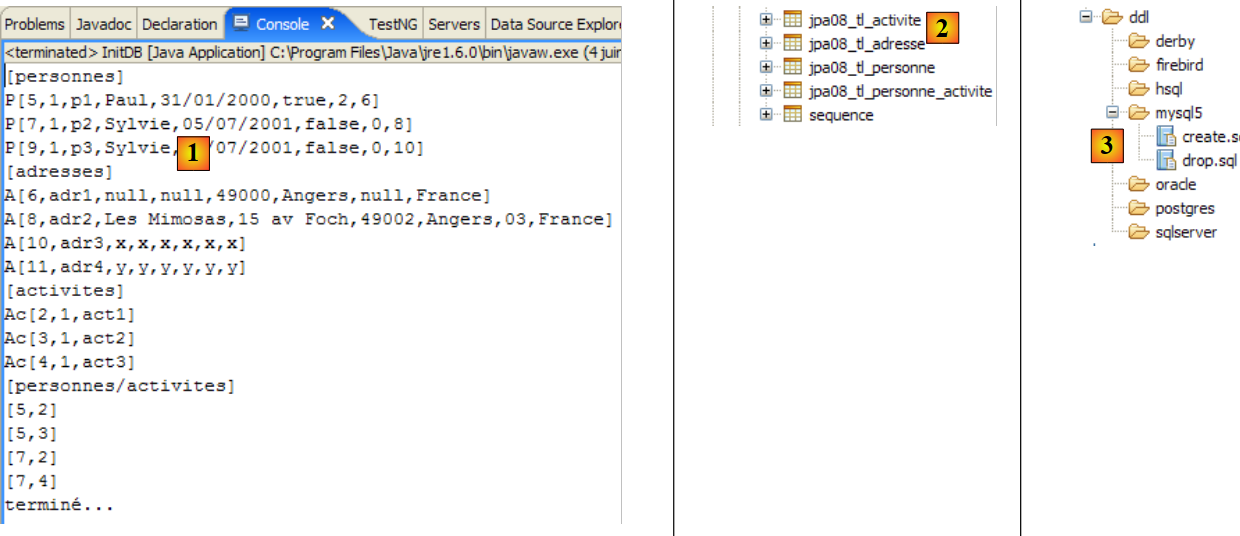 |
In [1] die Konsolenausgabe; in [2] die generierten [jpa07_tl]-Tabellen; in [3] die generierten SQL-Skripte. Ihr Inhalt lautet wie folgt:
create.sql
CREATE TABLE jpa08_tl_personne_activite (PERSONNE_ID BIGINT NOT NULL, ACTIVITE_ID BIGINT NOT NULL, PRIMARY KEY (PERSONNE_ID, ACTIVITE_ID))
CREATE TABLE jpa08_tl_activite (ID BIGINT NOT NULL, VERSION INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa08_tl_personne (ID BIGINT NOT NULL, DATENAISSANCE DATE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, NBENFANTS INTEGER NOT NULL, VERSION INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa08_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, VERSION INTEGER NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR2 VARCHAR(30), CEDEX VARCHAR(3), ADR1 VARCHAR(30) NOT NULL, PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa08_tl_personne_activite ADD CONSTRAINT FK_jpa08_tl_personne_activite_ACTIVITE_ID FOREIGN KEY (ACTIVITE_ID) REFERENCES jpa08_tl_activite (ID)
ALTER TABLE jpa08_tl_personne_activite ADD CONSTRAINT FK_jpa08_tl_personne_activite_PERSONNE_ID FOREIGN KEY (PERSONNE_ID) REFERENCES jpa08_tl_personne (ID)
ALTER TABLE jpa08_tl_personne ADD CONSTRAINT FK_jpa08_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa08_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
Die Ausführung von [InitDB] und [Main] wird ohne Fehler abgeschlossen.
2.6.8. Das Eclipse-/Hibernate-2-Projekt
Wir erstellen ein Eclipse-Projekt auf Basis des vorherigen, indem wir es kopieren:
 |
In [1] das Eclipse-Projekt; in [2] der Java-Code. Das Projekt befindet sich in [3] im Ordner „examples“ [4]. Wir werden es importieren.
Wir ändern die Beziehung zwischen „Person“ und „Activity“ wie folgt:
Person
// relation Personne (many) -> Activite (many) via une table de jointure personne_activite
// personne_activite(PERSONNE_ID) est clé étangère sur Personne(id)
// personne_activite(ACTIVITE_ID) est clé étangère sur Activite(id)
// plus de cascade sur les activités
// @ManyToMany(cascade={CascadeType.PERSIST})
@ManyToMany()
@JoinTable(name = "jpa09_hb_personne_activite", joinColumns = @JoinColumn(name = "PERSONNE_ID"), inverseJoinColumns = @JoinColumn(name = "ACTIVITE_ID"))
private Set<Activite> activites = new HashSet<Activite>();
- Zeile 6: Die primäre @ManyToMany-Beziehung weist keine Persistenzkaskade mehr von Person -> Aktivität auf (siehe vorherige Version, Zeile 5)
Aktivität
// plus de relation inverse avec Personne
// @ManyToMany(mappedBy = "activites")
// private Set<Personne> personnes = new HashSet<Personne>();
- Zeilen 2–3: Die inverse @ManyToMany-Beziehung „Aktivität -> Person“ wurde entfernt
Wir möchten zeigen, dass die entfernten Attribute (Kaskade und inverse Beziehung) nicht wesentlich sind. Die erste Änderung, die durch diese neue Konfiguration eingeführt wird, findet sich in [InitDB]:
// associations personnes <--> activites
p1.getActivites().add(act1);
p1.getActivites().add(act2);
p2.getActivites().add(act1);
p2.getActivites().add(act3);
// persistance des activites
em.persist(act1);
em.persist(act2);
em.persist(act3);
// persistance des personnes
em.persist(p1);
em.persist(p2);
em.persist(p3);
// et de l'adresse a4 non liée à une personne
em.persist(adr4);
- Zeilen 7–9: Wir müssen die Aktivitäten act1 bis act3 explizit in den Persistenzkontext aufnehmen. Als die Persistenzkaskade Person -> Aktivität noch existierte, wurden in den Zeilen 11–13 sowohl die Personen p1 bis p3 als auch deren Aktivitäten act1 bis act3 persistiert.
Eine zweite Änderung ist in [Main] zu sehen:
// récupération personnes faisant une activité donnée
public static void test5() {
// contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
System.out.format("1 - Personnes pratiquant l'activité act3 (JPQL) :%n");
// on demande les activités de p2
for (Object pa : em.createQuery("select p.nom from Personne p join p.activites a where a.nom='act3'").getResultList()) {
System.out.println(pa);
}
// fin transaction
tx.commit();
}
- Zeilen 9–12: Die JPQL-Abfrage, die die an der Aktivität act3 teilnehmenden Personen abruft
- In der vorherigen Version wurde das gleiche Ergebnis auch über die inverse Beziehung „Activity -> Person“ erzielt, die nun entfernt wurde:
// we use the inverse relationship of act3
System.out.format("2 - Personnes pratiquant l'activité act3 (relation inverse) :%n");
act3 = em.find(Activite.class, act3.getId());
for (Personne p : act3.getPersonnes()) {
System.out.println(p.getNom());
}
2.6.9. Das Eclipse-/Toplink-2-Projekt
Wir erstellen ein Eclipse-Projekt auf Basis des vorherigen Eclipse/Toplink-Projekts, indem wir es kopieren:
 |
In [1] das Eclipse-Projekt; in [2] den Java-Code. Das Projekt befindet sich in [3] im Ordner „examples“ [4]. Wir werden es importieren.
Der Java-Code ist identisch mit dem der Hibernate-Version.
2.7. Beispiel 7: Verwendung benannter Abfragen
Wir schließen diesen ausführlichen Überblick über JPA-Entitäten, der in Absatz 2 begann, mit einem abschließenden Beispiel ab, das die Verwendung von JPQL-Abfragen demonstriert, die in einer Konfigurationsdatei externalisiert sind. Dieses Beispiel stammt aus der folgenden Quelle:
[ref2]: „Getting Started With JPA in Spring 2.0“ von Mark Fisher unter der URL
[http://blog.springframework.com/markf/archives/2006/05/30/getting-started-with-jpa-in-spring-20/].
2.7.1. Die Beispieldatenbank
Die Datenbank sieht wie folgt aus:
 |
- in [1]: eine Liste von Restaurants mit ihren Namen und Adressen
- in [2]: die Tabelle mit den Restaurantadressen, beschränkt auf Hausnummer und Straßenname. Zwischen der Restaurant- und der Adresstabelle besteht eine Eins-zu-Eins-Beziehung: Ein Restaurant hat genau eine Adresse.
- in [3]: eine Tabelle mit Gerichten, deren Namen und einem True/False-Flag, das angibt, ob das Gericht vegetarisch ist oder nicht
- in [4]: die Verknüpfungstabelle für Restaurants und Gerichte: Ein Restaurant serviert mehrere Gerichte, und dasselbe Gericht kann von mehreren Restaurants serviert werden. Zwischen der Restaurant- und der Gerichtstabelle besteht eine viele-zu-viele-Beziehung.
2.7.2. Die @Entity-Objekte, die die Datenbank repräsentieren
Die oben genannten Tabellen werden durch die folgenden @Entities dargestellt:
- Die @Entity Restaurant repräsentiert die Tabelle [restaurant]
- die @Entity Address repräsentiert die Tabelle [address]
- das @Entity Dish repräsentiert die Tabelle [dish]
Die Beziehungen zwischen diesen Entitäten sind wie folgt:
- Eine Eins-zu-Eins-Beziehung verbindet die Entität „Restaurant“ mit der Entität „Address“: Ein Restaurant r hat eine Adresse a. Die Entität „Restaurant“, die den Fremdschlüssel enthält, ist die primäre Entität. Die Entität „Address“ hat keine umgekehrte Beziehung.
- Eine Viele-zu-Viele-Beziehung verbindet die Entitäten „Restaurant“ und „Gericht“: Ein Restaurant serviert mehrere Gerichte, und dasselbe Gericht kann von mehreren Restaurants serviert werden. Diese Beziehung wird mithilfe einer @ManyToMany-Annotation in der Entität „Restaurant“ implementiert. Die Entität „Gericht“ verfügt über keine umgekehrte Beziehung.
Die @Entity „Restaurant“ sieht wie folgt aus:
package entites;
...
@Entity
@Table(name = "jpa10_hb_restaurant")
public class Restaurant implements java.io.Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(unique = true, length = 30, nullable = false)
private String nom;
@OneToOne(cascade = CascadeType.ALL)
private Adresse adresse;
@ManyToMany(cascade = { CascadeType.PERSIST, CascadeType.MERGE })
@JoinTable(name = "jpa10_hb_restaurant_plat", inverseJoinColumns = @JoinColumn(name = "plat_id"))
private Set<Plat> plats = new HashSet<Plat>();
// manufacturers
public Restaurant() {
}
public Restaurant(String name, Adresse address, Set<Plat> entrees) {
...
}
// getters and setters
...
// toString
public String toString() {
String signature = "R[" + getNom() + "," + getAdresse();
for (Plat e : getPlats()) {
signature += "," + e;
}
return signature + "]";
}
}
- Zeile 17: Die Eins-zu-Eins-Beziehung zwischen der Entität „Restaurant“ und der Entität „Adresse“. Alle Persistenzoperationen an einem Restaurant werden auf dessen Adresse übertragen.
- Zeile 20: Die Beziehung, die die @Entity Restaurant mit der @Entity Dish in der Sammlung dishes in Zeile 22 verbindet, ist vom Typ „Viele-zu-Viele“ (ManyToMany):
- Ein Restaurant (One) hat mehrere Gerichte (Many)
- Ein Gericht (One) kann von mehreren Restaurants (Many) serviert werden
- Letztendlich sind die @Entity Restaurant und die @Entity Dish durch eine ManyToMany-Beziehung verknüpft. Wir legen fest, dass die @Entity Restaurant die primäre Beziehung ist und dass die @Entity Dish keine umgekehrte Beziehung hat.
- Die @ManyToMany-Beziehung erfordert eine Verknüpfungstabelle. Diese wird mit der Annotation @JoinTable in Zeile 47 definiert.
- Das Attribut „name“ gibt der Tabelle einen Namen.
- Die Verknüpfungstabelle besteht aus den Fremdschlüsseln der Tabellen, die sie verknüpft. Hier gibt es zwei Fremdschlüssel: einen aus der Tabelle [restaurant] und einen aus der Tabelle [dish]. Diese Fremdschlüsselspalten werden durch die Attribute joinColumns und inverseJoinColumns definiert.
- Das Attribut `joinColumns` definiert den Fremdschlüssel in der Tabelle der @Entity, die die primäre @ManyToMany-Beziehung enthält, in diesem Fall die Tabelle [restaurant]. Das Attribut `joinColumns` fehlt hier. JPA hat in diesem Fall einen Standardwert: [table]_[table_primary_key], hier [jpa10_hb_restaurant_id].
- Die Annotation @JoinColumn für das Attribut inverseJoinColumns definiert den Fremdschlüssel in der Tabelle der @Entity, die die inverse @ManyToMany-Beziehung enthält, in diesem Fall die Tabelle [dish]. Diese Fremdschlüsselspalte erhält den Namen dish_id.
Die @Entity Address lautet wie folgt:
package entites;
...
@Entity
@Table(name="jpa10_hb_adresse")
public class Adresse implements java.io.Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(name = "NUMERO_RUE")
private int numeroRue;
@Column(name = "NOM_RUE", length=30, nullable=false)
private String nomRue;
// getters and setters
...
// manufacturers
public Adresse(int streetNumber, String streetName){
...
}
public Adresse(){
}
// toString
public String toString(){
return "A["+getNumeroRue()+","+getNomRue()+"]";
}
}
- Die @Entity Address ist eine Entität ohne direkte Beziehung zu anderen Entitäten. Sie kann nur über eine Restaurant-Entität persistent gespeichert werden.
- Eine Adresse wird durch einen Straßennamen (Zeile 16) und eine Hausnummer (Zeile 13) definiert.
Die @Entity „Dish“ sieht wie folgt aus
package entites;
...
@Entity
@Table(name="jpa10_hb_plat")
public class Plat implements java.io.Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(unique=true, length=50, nullable=false)
private String nom;
private boolean vegetarien;
// manufacturers
public Plat() {
}
public Plat(String name, boolean vegetarian) {
...
}
// getters and setters
...
// toString
public String toString() {
return "E[" + getNom() + "," + isVegetarien() + "]";
}
}
- Die @Entity Dish ist eine Entität ohne direkte Beziehung zu anderen Entitäten. Sie kann nur über eine Restaurant-Entität persistent gespeichert werden.
- Ein Gericht wird durch einen Namen (Zeile 12) und die Angabe, ob es vegetarisch ist oder nicht (Zeile 14), definiert.
2.7.3. Das Eclipse-/Hibernate-Projekt
Die hier verwendete JPA-Implementierung ist Hibernate. Das Eclipse-Testprojekt sieht wie folgt aus:
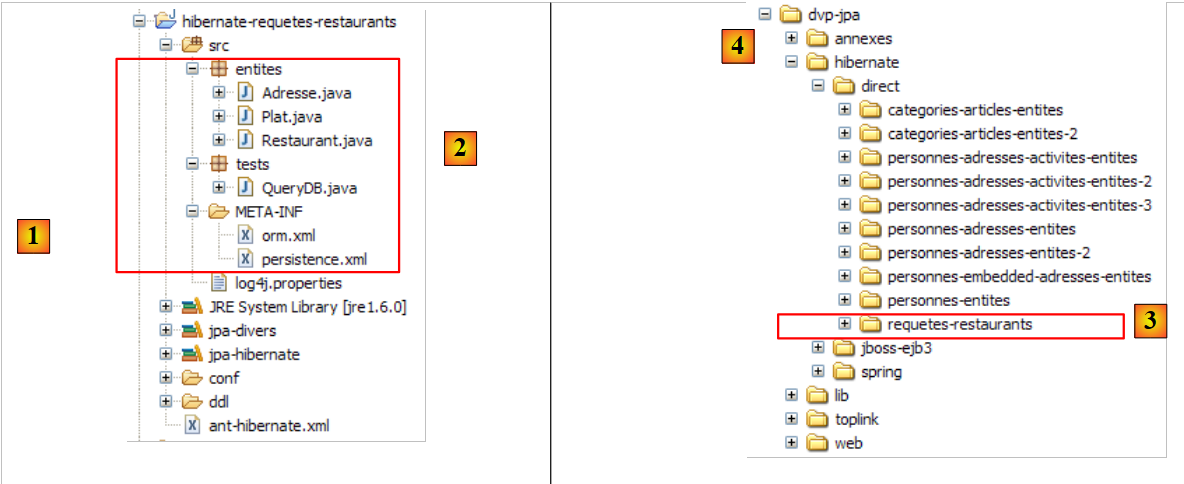 |
In [1] das Eclipse-Projekt; in [2] der Java-Code und die Konfiguration der JPA-Schicht. Beachten Sie das Vorhandensein einer [orm.xml]-Datei, die wir bisher noch nicht gesehen haben. Das Projekt befindet sich in [3] im Ordner „examples“ [4]. Wir werden es importieren.
2.7.4. Generieren der Datenbank-DDL
Gemäß den Anweisungen in Abschnitt 2.1.7 lautet die resultierende DDL für das DBMS MySQL5 wie folgt:
alter table jpa10_hb_restaurant
drop
foreign key FK3E8E4F5D5FE379D0;
alter table jpa10_hb_restaurant_plat
drop
foreign key FK1D2D06D11F0F78A4;
alter table jpa10_hb_restaurant_plat
drop
foreign key FK1D2D06D1AFAC3E44;
drop table if exists jpa10_hb_adresse;
drop table if exists jpa10_hb_plat;
drop table if exists jpa10_hb_restaurant;
drop table if exists jpa10_hb_restaurant_plat;
create table jpa10_hb_adresse (
id bigint not null auto_increment,
NUMERO_RUE integer,
NOM_RUE varchar(30) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_plat (
id bigint not null auto_increment,
nom varchar(50) not null unique,
vegetarien bit not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_restaurant (
id bigint not null auto_increment,
nom varchar(30) not null unique,
adresse_id bigint,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_restaurant_plat (
jpa10_hb_restaurant_id bigint not null,
plat_id bigint not null,
primary key (jpa10_hb_restaurant_id, plat_id)
) ENGINE=InnoDB;
alter table jpa10_hb_restaurant
add index FK3E8E4F5D5FE379D0 (adresse_id),
add constraint FK3E8E4F5D5FE379D0
foreign key (adresse_id)
references jpa10_hb_adresse (id);
alter table jpa10_hb_restaurant_plat
add index FK1D2D06D11F0F78A4 (plat_id),
add constraint FK1D2D06D11F0F78A4
foreign key (plat_id)
references jpa10_hb_plat (id);
alter table jpa10_hb_restaurant_plat
add index FK1D2D06D1AFAC3E44 (jpa10_hb_restaurant_id),
add constraint FK1D2D06D1AFAC3E44
foreign key (jpa10_hb_restaurant_id)
references jpa10_hb_restaurant (id);
- Zeilen 21–26: die Tabelle [address]
- Zeilen 28–33: die Tabelle [dish]
- Zeilen 35–40: die Tabelle [restaurant]
- Zeilen 42–46: die Verknüpfungstabelle [restaurant_dish]. Beachten Sie den zusammengesetzten Schlüssel (Zeile 45)
- Zeilen 48–52: der Fremdschlüssel von der Tabelle [restaurant] zur Tabelle [address]
- Zeilen 54–58: der Fremdschlüssel von der Tabelle [restaurant_dish] zur Tabelle [dish]
- Zeilen 60–64: der Fremdschlüssel von der Tabelle [restaurant_dish] zur Tabelle [restaurant]
Diese DDL entspricht dem bereits vorgestellten Schema:
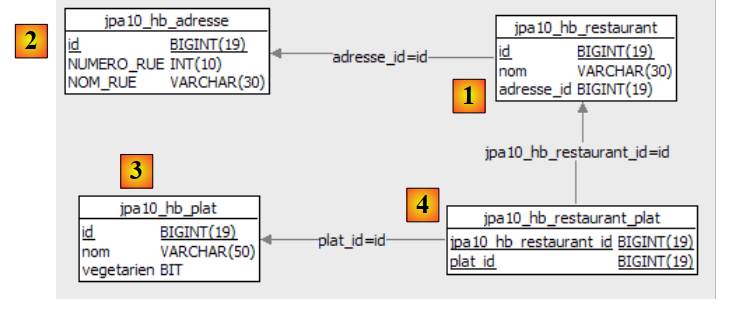 |
In der Ansicht „SQL Explorer“ wird die Datenbank wie folgt angezeigt:
 |
- in [1]: die 4 Tabellen der Datenbank
- unter [2]: die Adressen
- unter [3]: die Gerichte
- unter [4]: die Restaurants. [address_id] verweist auf die Adressen aus [2].
- in [5]: die Verknüpfungstabelle [restaurant,dish]. [jpa10_hb_restaurant_id] verweist auf die Restaurants in [4] und [dish_id] verweist auf die Gerichte in [3]. Somit bedeutet [1,1], dass das Restaurant „Burger Barn“ das Gericht „CheeseBurger“ serviert.
Um die oben genannten Daten abzurufen, wurde das Programm [QueryDB] aus dem Eclipse-Projekt ausgeführt.
2.7.5. JPQL-Abfragen mit einer Hibernate-Konsole
Wir erstellen eine Hibernate-Konsole, die mit dem vorherigen Eclipse-Projekt verknüpft ist. Wir folgen dabei der Vorgehensweise, die bereits zweimal beschrieben wurde, insbesondere in Abschnitt 2.1.12.
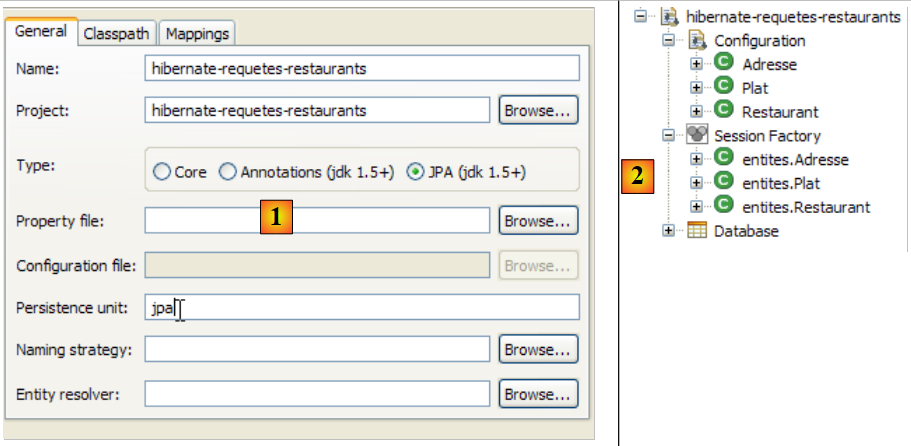 |
- In [1] und [2]: die Konfiguration der Hibernate-Konsole
 |
- in [3]: eine JPQL-Abfrage und in [4] das Ergebnis.
- in [5]: die entsprechende SQL-Anweisung
Wir werden nun eine Reihe von JPQL-Abfragen vorstellen. Der Leser ist eingeladen, diese auszuführen und die von Hibernate zur Ausführung generierte SQL-Anweisung zu entdecken.
Alle Restaurants mit ihren Gerichten abrufen:
 | 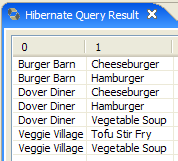 |
Restaurants abrufen, die mindestens ein vegetarisches Gericht anbieten:
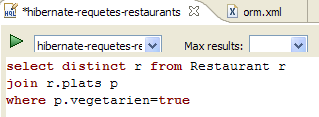 |  |
Finde die Namen von Restaurants, die ausschließlich vegetarische Gerichte servieren:
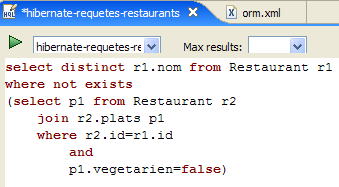 | 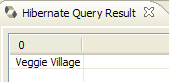 |
Hier findest du die Restaurants, die Burger servieren:
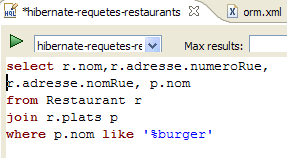 | 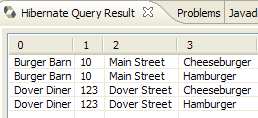 |
2.7.6. QueryDB
Wir werden uns nun das Programm [QueryDB] aus dem Eclipse-Projekt ansehen, das:
- die Datenbank füllt
- und eine Reihe von JPQL-Abfragen darauf ausführt. Diese sind in der Datei [META-INF/orm.xml] des Eclipse-Projekts gespeichert:
 |
Die Datei [orm.xml] kann anstelle von Java-Annotationen zur Konfiguration der JPA-Schicht verwendet werden. Dies bietet Flexibilität bei der Konfiguration der JPA-Schicht. Sie kann geändert werden, ohne den Java-Code oder die [ . Die JPA-Konfiguration wird zunächst mithilfe von Java-Annotationen und anschließend mithilfe der Datei [orm.xml] eingerichtet. Wenn Sie also eine durch eine Java-Annotation definierte Konfiguration ohne Neukompilierung ändern möchten, fügen Sie diese Konfiguration einfach in die [orm.xml] ein. Sie hat dann Vorrang.
In unserem Beispiel wird die Datei [orm.xml] zum Speichern von JPQL-Abfragetexten verwendet. Ihr Inhalt lautet wie folgt:
<?xml version="1.0" encoding="UTF-8" ?>
<entity-mappings xmlns="http://java.sun.com/xml/ns/persistence/orm" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence/orm http://java.sun.com/xml/ns/persistence/orm_1_0.xsd" version="1.0">
<description>Restaurants</description>
<named-query name="supprimer le contenu de la table restaurant">
<query>delete from Restaurant</query>
</named-query>
<named-query name="supprimer le contenu de la table plat">
<query>delete from Plat</query>
</named-query>
<named-query name="obtenir tous les restaurants">
<query>select r from Restaurant r order by r.nom asc</query>
</named-query>
<named-query name="obtenir toutes les adresses">
<query>select a from Adresse a order by a.nomRue asc</query>
</named-query>
<named-query name="obtenir tous les plats">
<query>select p from Plat p order by p.nom asc</query>
</named-query>
<named-query name="obtenir tous les restaurants avec leurs plats">
<query>select r.nom,p.nom from Restaurant r join r.plats p</query>
</named-query>
<named-query name="obtenir les restaurants ayant au moins un plat vegetarien">
<query>select distinct r from Restaurant r join r.plats p where p.vegetarien=true</query>
</named-query>
<named-query name="obtenir les restaurants avec uniquement des plats vegetariens">
<query>
select distinct r1.nom from Restaurant r1 where not exists (select p1 from Restaurant r2 join r2.plats p1 where r2.id=r1.id and
p1.vegetarien=false)
</query>
</named-query>
<named-query name="obtenir les restaurants d'une certaine rue">
<query>select r from Restaurant r where r.adresse.nomRue=:nomRue</query>
</named-query>
<named-query name="obtenir les restaurants qui servent des burgers">
<query>select r.nom,r.adresse.numeroRue, r.adresse.nomRue, p.nom from Restaurant r join r.plats p where p.nom like '%burger'</query>
</named-query>
<named-query name="obtenir les plats du restaurant untel">
<query>select p.nom from Restaurant r join r.plats p where r.nom=:nomRestaurant</query>
</named-query>
</entity-mappings>
- Die Wurzel der Datei [orm.xml] ist <entity-mappings> (Zeile 2).
- Zeilen 5–7: Benannte JPQL-Abfragen werden in <named-query name="...">text</named-query>-Tags eingeschlossen.
- Das name-Attribut des Tags ist der Name der Abfrage.
- Der Textinhalt des Tags ist der Abfragetext.
QueryDB führt die vorangehenden Abfragen aus. Der Code lautet wie folgt:
package tests;
...
public class QueryDB {
// Persistence context
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = emf.createEntityManager();
public static void main(String[] args) {
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// delete [restaurant] table items
em.createNamedQuery("supprimer le contenu de la table restaurant").executeUpdate();
// delete table items [flat]
em.createNamedQuery("supprimer le contenu de la table plat").executeUpdate();
// creation of Address objects
Adresse adr1 = new Adresse(10, "Main Street");
Adresse adr2 = new Adresse(20, "Main Street");
Adresse adr3 = new Adresse(123, "Dover Street");
// creation of Entree objects
Plat ent1 = new Plat("Hamburger", false);
Plat ent2 = new Plat("Cheeseburger", false);
Plat ent3 = new Plat("Tofu Stir Fry", true);
Plat ent4 = new Plat("Vegetable Soup", true);
// creation of Restaurant objects
Restaurant restaurant1 = new Restaurant();
restaurant1.setNom("Burger Barn");
restaurant1.setAdresse(adr1);
restaurant1.getPlats().add(ent1);
restaurant1.getPlats().add(ent2);
Restaurant restaurant2 = new Restaurant();
restaurant2.setNom("Veggie Village");
restaurant2.setAdresse(adr2);
restaurant2.getPlats().add(ent3);
restaurant2.getPlats().add(ent4);
Restaurant restaurant3 = new Restaurant();
restaurant3.setNom("Dover Diner");
restaurant3.setAdresse(adr3);
restaurant3.getPlats().add(ent1);
restaurant3.getPlats().add(ent2);
restaurant3.getPlats().add(ent4);
// persistence of Restaurant objects (and other objects through cascading)
em.persist(restaurant1);
em.persist(restaurant2);
em.persist(restaurant3);
// end transaction
tx.commit();
// dump base
dumpDataBase();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
}
// database content display
@SuppressWarnings("unchecked")
private static void dumpDataBase() {
// test2
log("données de la base");
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// restaurant displays
log("[restaurants]");
for (Object restaurant : em.createNamedQuery("obtenir tous les restaurants").getResultList()) {
System.out.println(restaurant);
}
// address display
log("[adresses]");
for (Object adresse : em.createNamedQuery("obtenir toutes les adresses").getResultList()) {
System.out.println(adresse);
}
// flat displays
log("[plats]");
for (Object plat : em.createNamedQuery("obtenir tous les plats").getResultList()) {
System.out.println(plat);
}
// displays links restaurants <--> dishes
log("[restaurants/plats]");
Iterator record = em.createNamedQuery("obtenir tous les restaurants avec leurs plats").getResultList().iterator();
while (record.hasNext()) {
Object[] currentRecord = (Object[]) record.next();
System.out.format("[%s,%s]%n", currentRecord[0], currentRecord[1]);
}
log("[Liste des restaurants avec au moins un plat végétarien]");
for (Object r : em.createNamedQuery("obtenir les restaurants ayant au moins un plat vegetarien").getResultList()) {
System.out.println(r);
}
// query
log("[Liste des restaurants avec seulement des plats végétariens]");
for (Object r : em.createNamedQuery("obtenir les restaurants avec uniquement des plats vegetariens").getResultList()) {
System.out.println(r);
}
// query
log("[Liste des restaurants dans Dover Street]");
for (Object r : em.createNamedQuery("obtenir les restaurants d'une certaine rue").setParameter("nomRue", "Dover Street").getResultList()) {
System.out.println(r);
}
// query
log("[Liste des restaurants ayant un plat de type burger]");
record = em.createNamedQuery("obtenir les restaurants qui servent des burgers").getResultList().iterator();
while (record.hasNext()) {
Object[] currentRecord = (Object[]) record.next();
System.out.format("[%s,%d,%s,%s]%n", currentRecord[0], currentRecord[1], currentRecord[2], currentRecord[3]);
}
// query
log("[Plats de Veggie Village]");
for (Object r : em.createNamedQuery("obtenir les plats du restaurant untel").setParameter("nomRestaurant", "Veggie Village").getResultList()) {
System.out.println(r);
}
// end transaction
tx.commit();
}
// logs
private static void log(String message) {
System.out.println(" -----------" + message);
}
}
Das Ergebnis der Ausführung von [QueryDB] lautet wie folgt:
Wir überlassen es dem Leser, den Zusammenhang zwischen dem Code und den Ergebnissen herzustellen. Dazu empfehlen wir, die JPQL-Abfragen in der Hibernate-Konsole auszuführen und den entsprechenden SQL-Code zu untersuchen.
2.7.7. Das Eclipse-/Toplink-Projekt
Interessierte Leser finden das zuvor mit Toplink implementierte Projekt in den Beispielen, die zusammen mit diesem Tutorial zum Download bereitstehen:
 |
Das Eclipse-Projekt mit Toplink ist eine Kopie des Eclipse-Projekts mit Hibernate:
 |
Die Datei <persistence.xml> [2] deklariert die verwalteten Entitäten:
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- classes persistantes -->
<class>entites.Restaurant</class>
<class>entites.Adresse</class>
<class>entites.Plat</class>
...
- Zeilen 4–6: verwaltete Entitäten
Die in [orm.xml] gespeicherten JPQL-Abfragen werden von TopLink korrekt ausgeführt. Um dies sicherzustellen, haben wir im vorherigen Projekt darauf geachtet, keine HQL-Abfragen (Hibernate Query Language) zu verwenden, die eigentlich eine Obermenge von JPQL darstellen und deren Syntax von JPQL nicht vollständig unterstützt wird.
2.8. Fazit
Damit ist unser Überblick über JPA-Entitäten abgeschlossen. Es war ein langwieriger Prozess, doch einige wichtige Themen (für den fortgeschrittenen Entwickler) wurden nicht behandelt. Wir empfehlen erneut, ein Nachschlagewerk zu lesen, wie das für dieses Tutorial verwendete:
[ref1]: Java Persistence with Hibernate, von Christian Bauer und Gavin King, erschienen bei Manning.