2. Schichtarchitektur einer Java-Anwendung
Eine Java-Anwendung ist oft in Schichten unterteilt, von denen jede eine klar definierte Rolle hat. Betrachten wir eine gängige Architektur, die dreischichtige Architektur:
 |
- Schicht [1], hier als [ui] (User Interface) bezeichnet, ist die Schicht, die über eine Swing-GUI, eine Konsolenoberfläche oder eine Weboberfläche mit dem Benutzer interagiert. Ihre Aufgabe besteht darin, Daten vom Benutzer an Schicht [2] weiterzuleiten oder vom Benutzer bereitgestellte Daten dem Benutzer zu präsentieren.
- Schicht [2], hier als [business] bezeichnet, ist die Schicht, die die sogenannten Geschäftsregeln – d. h. die anwendungsspezifische Logik – anwendet, ohne sich darum zu kümmern, woher die empfangenen Daten stammen oder wohin die erzeugten Ergebnisse gelangen.
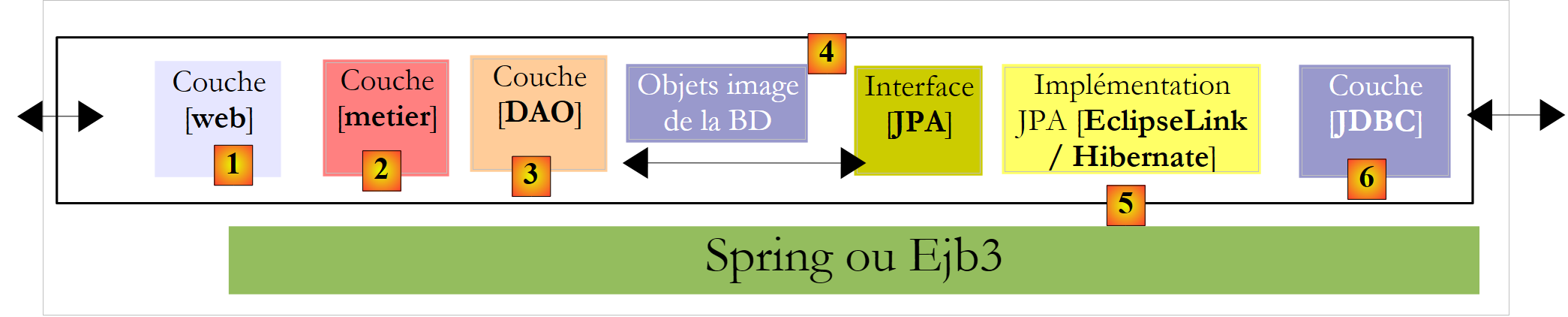
- Schicht [3], hier als [DAO] (Data Access Object) bezeichnet, ist die Schicht, die Schicht [2] mit vorab gespeicherten Daten (Dateien, Datenbanken usw.) versorgt und einen Teil der von Schicht [2] bereitgestellten Ergebnisse speichert.
Es gibt verschiedene Möglichkeiten, die [DAO]-Schicht zu implementieren. Betrachten wir einige davon:
 |
Die oben genannte [JDBC]-Schicht ist die in Java standardmäßig verwendete Schicht für den Zugriff auf Datenbanken. Sie trennt die [DAO]-Schicht vom DBMS, das die Datenbank verwaltet. Theoretisch kann man das DBMS wechseln, ohne den Code der [DAO]-Schicht zu ändern. Trotz dieses Vorteils weist die JDBC-API gewisse Nachteile auf:
- Alle Operationen auf dem DBMS lösen wahrscheinlich die geprüfte SQLException aus. Dies zwingt den aufrufenden Code (in diesem Fall die [DAO]-Schicht), sie in try/catch-Blöcke zu verpacken, wodurch der Code recht ausführlich wird.
- Die [DAO]-Schicht ist nicht vollständig unabhängig vom DBMS. Beispielsweise verfügen DBMS über proprietäre Methoden zur automatischen Generierung von Primärschlüsselwerten, die die [DAO]-Schicht nicht ignorieren kann. Beim Einfügen eines Datensatzes gilt daher:
- Bei Oracle muss die [DAO]-Schicht zunächst einen Wert für den Primärschlüssel des Datensatzes abrufen und dann den Datensatz einfügen.
- Bei SQL Server fügt die [DAO]-Schicht den Datensatz ein, dem vom DBMS automatisch ein Primärschlüsselwert zugewiesen wird, der an die [DAO]-Schicht zurückgegeben wird.
Diese Unterschiede lassen sich durch die Verwendung von gespeicherten Prozeduren beseitigen. Im vorigen Beispiel ruft die [DAO]-Schicht in Oracle oder SQL Server eine gespeicherte Prozedur auf, die die spezifischen Funktionen des DBMS berücksichtigt. Diese bleiben für die [DAO]-Schicht verborgen. Zwar erfordert ein Wechsel des DBMS zwar keine Neuprogrammierung der [DAO]-Schicht, doch müssen die gespeicherten Prozeduren neu geschrieben werden. Dies ist jedoch kein Ausschlusskriterium.
Es wurden zahlreiche Anstrengungen unternommen, um die [DAO]-Schicht von den proprietären Aspekten der DBMS zu isolieren. Eine Lösung, die in diesem Bereich in den letzten Jahren sehr erfolgreich war, ist Hibernate:
 |
Die [Hibernate]-Schicht befindet sich zwischen der vom Entwickler geschriebenen [DAO]-Schicht und der [JDBC]-Schicht. Hibernate ist ein ORM (Object-Relational Mapper), ein Werkzeug, das die relationale Welt der Datenbanken mit der Welt der von Java manipulierten Objekte verbindet. Der Entwickler der [DAO]-Schicht sieht weder die [JDBC]-Schicht noch die Datenbanktabellen, deren Inhalt er nutzen möchte. Er sieht nur die Objektdarstellung der Datenbank, die von der [Hibernate]-Schicht bereitgestellt wird. Die Brücke zwischen den Datenbanktabellen und den von der [DAO]-Schicht manipulierten Objekten wird hauptsächlich auf zwei Arten hergestellt:
- über Konfigurationsdateien im XML-Stil
- durch Java-Annotationen im Code, eine Technik, die erst seit JDK 1.5 verfügbar ist
Die [Hibernate]-Schicht ist eine Abstraktionsschicht, die so transparent wie möglich gestaltet ist. Im Idealfall ist dem Entwickler der [DAO]-Schicht überhaupt nicht bewusst, dass er mit einer Datenbank arbeitet. Dies ist möglich, wenn er nicht selbst die Konfiguration schreibt, die die relationale und die objektorientierte Welt miteinander verbindet. Die Konfiguration dieser Brücke ist recht heikel und erfordert etwas Erfahrung.
Die [4]-Objektschicht, die die Datenbank widerspiegelt, wird als „Persistenzkontext“ bezeichnet. Eine auf Hibernate basierende [DAO]-Schicht führt Persistenzoperationen (CRUD: Create, Read, Update, Delete) an den Objekten im Persistenzkontext durch; diese Operationen werden von Hibernate in SQL-Anweisungen übersetzt, die von der JDBC-Schicht ausgeführt werden. Für Datenbankabfragen (SQL SELECT) stellt Hibernate den Entwicklern eine HQL (Hibernate Query Language) zur Verfügung, um den Persistenzkontext [4] statt der Datenbank selbst abzufragen.
Hibernate ist beliebt, aber komplex zu beherrschen. Die Lernkurve, die oft als einfach dargestellt wird, ist in Wirklichkeit ziemlich steil. Sobald man eine Datenbank mit Tabellen hat, die Eins-zu-Viele- oder Viele-zu-Viele-Beziehungen aufweisen, übersteigt die Konfiguration der Relational-Objekt-Brücke die Fähigkeiten eines durchschnittlichen Anfängers. Konfigurationsfehler können zu Anwendungen mit schlechter Performance führen.
Angesichts des Erfolgs von ORM-Produkten beschloss Sun, der Entwickler von Java, eine ORM-Schicht über eine Spezifikation namens JPA (Java Persistence API) zu standardisieren, die zusammen mit Java 5 veröffentlicht wurde. Die JPA-Spezifikation wurde von verschiedenen Produkten implementiert: Hibernate, TopLink, EclipseLink, OpenJPA usw. Mit JPA sieht die bisherige Architektur wie folgt aus:
 |
Die [DAO]-Schicht interagiert nun mit der JPA-Spezifikation, einer Reihe von Schnittstellen. Entwickler profitieren von der Standardisierung. Früher mussten Entwickler, wenn sie ihre ORM-Schicht änderten, auch ihre [DAO]-Schicht ändern, die für die Interaktion mit einem bestimmten ORM geschrieben worden war. Jetzt schreiben sie eine [DAO]-Schicht, die mit einer JPA-Schicht interagiert. Unabhängig davon, welches Produkt die JPA-Schicht implementiert, bleibt die Schnittstelle zur [DAO]-Schicht dieselbe.
In diesem Dokument verwenden wir eine [DAO]-Schicht, die auf einer JPA/Hibernate- oder JPA/EclipseLink-Schicht aufbaut. Außerdem nutzen wir das Spring 2.8-Framework, um diese Schichten miteinander zu verknüpfen.
 |
Der Hauptvorteil von Spring besteht darin, dass es Ihnen ermöglicht, Schichten über die Konfiguration statt im Code zu verknüpfen. Wenn also die JPA/Hibernate-Implementierung durch eine Hibernate-Implementierung ohne JPA ersetzt werden muss – beispielsweise weil die Anwendung in einer JDK 1.4-Umgebung läuft, die JPA nicht unterstützt –, hat diese Änderung in der Implementierung der [DAO]-Schicht keine Auswirkungen auf den Code der [Business]-Schicht. Es muss lediglich die Spring-Konfigurationsdatei geändert werden, die die Schichten miteinander verknüpft.
Mit Java EE 5 gibt es eine weitere Lösung: die Implementierung der [Business]- und [DAO]-Schichten unter Verwendung von EJB3 (Enterprise JavaBeans Version 3):
 |
Wir werden sehen, dass sich diese Lösung nicht wesentlich von der mit Spring unterscheidet. Die Java EE 5-Umgebung ist in sogenannten Anwendungsservern wie Sun Application Server 9.x (Glassfish), JBoss Application Server, Oracle Container for Java (OC4J) usw. verfügbar. Ein Anwendungsserver ist im Wesentlichen ein Webanwendungsserver. Es gibt auch sogenannte „Stand-alone“-EE-5-Umgebungen, d. h. solche, die außerhalb eines Anwendungsservers genutzt werden können. Dies ist bei JBoss EJB3 oder OpenEJB der Fall.
In einer EE5-Umgebung werden die Schichten durch Objekte implementiert, die als EJBs (Enterprise Java Beans) bezeichnet werden. In früheren Versionen von EE galten EJBs (EJB 2.x) als schwer zu implementieren und zu testen und zeigten manchmal eine unzureichende Leistung. Es wird zwischen EJB 2.x-„Entity“-Beans und EJB 2.x-„Session“-Beans unterschieden. Kurz gesagt entspricht ein EJB 2.x-„Entity“-Bean einer Zeile in einer Datenbanktabelle, während ein EJB 2.x-„Session“-Bean ein Objekt ist, das zur Implementierung der [Geschäftslogik]- und [DAO]-Schichten einer mehrschichtigen Architektur verwendet wird. Einer der Hauptkritikpunkte an mit EJBs implementierten Schichten ist, dass sie nur innerhalb von EJB-Containern verwendet werden können, einem Dienst, der von der EE-Umgebung (Enterprise Edition) bereitgestellt wird. Diese Umgebung, deren Einrichtung komplexer ist als die einer SE-Umgebung (Standard Edition), kann Entwickler davon abhalten, häufig Tests durchzuführen. Dennoch gibt es Java-Entwicklungsumgebungen, die die Nutzung eines Anwendungsservers erleichtern, indem sie die Bereitstellung von EJBs auf dem Server automatisieren: Eclipse, NetBeans, JDeveloper, IntelliJ IDEA. Hier verwenden wir NetBeans 6.8 und den Anwendungsserver GlassFish v3.
Das Spring-Framework wurde als Antwort auf die Komplexität von EJB2 entwickelt. In einer SE-Umgebung stellt Spring eine beträchtliche Anzahl der Dienste bereit, die typischerweise von EE-Umgebungen angeboten werden. Im Abschnitt „Datenpersistenz“ bietet Spring beispielsweise die von Anwendungen benötigten Verbindungspools und Transaktionsmanager. Das Aufkommen von Spring hat eine Kultur des Unit-Testings gefördert, das im SE-Kontext einfacher zu implementieren ist als im EE-Kontext. Spring ermöglicht die Implementierung von Anwendungsschichten unter Verwendung von Standard-Java-Objekten (POJO, Plain Old/Ordinary Java Object), wodurch deren Wiederverwendung in anderen Kontexten möglich wird. Schließlich integriert es zahlreiche Tools von Drittanbietern relativ transparent, insbesondere Persistenz-Tools wie Hibernate, EclipseLink, iBatis, ...
Java EE 5 wurde entwickelt, um die Mängel der EJB 2-Spezifikation zu beheben. EJB 2.x hat sich zu EJB 3 weiterentwickelt. Dabei handelt es sich um POJOs, die mit Tags versehen sind, die sie zu speziellen Objekten machen, wenn sie sich in einem EJB 3-Container befinden. Innerhalb des Containers kann das EJB 3 die Dienste des Containers (Verbindungspool, Transaktionsmanager usw.) nutzen. Außerhalb des EJB3-Containers wird das EJB3 zu einem Standard-Java-Objekt. Seine EJB-Annotationen werden ignoriert.
Oben haben wir Spring und einen EJB3-Container als mögliche Infrastruktur (Framework) für unsere mehrschichtige Architektur dargestellt. Diese Infrastruktur stellt die Dienste bereit, die wir benötigen: einen Verbindungspool und einen Transaktionsmanager.
- Mit Spring werden die Schichten mithilfe von POJOs implementiert. Diese haben über die Abhängigkeitsinjektion in diese POJOs Zugriff auf die Dienste von Spring (Verbindungspool, Transaktionsmanager): Beim Erstellen injiziert Spring Referenzen auf die Dienste, die sie benötigen.
- Mit dem EJB3-Container werden die Schichten mithilfe von EJBs implementiert. Eine mit EJB3s implementierte Schichtenarchitektur unterscheidet sich nicht wesentlich von einer mit von Spring instanziierten POJOs. Wir werden viele Gemeinsamkeiten feststellen.
- Abschließend stellen wir ein Beispiel für eine mehrschichtige Webanwendung vor:
 |