4. [TD]: Schichtenarchitekturen
Stichworte: mehrschichtige Architektur, Spring, Abhängigkeitsinjektion.
4.1. Introduction
Zur Erinnerung:
- In Teil 1 der Übung ELECTIONS wurde keine Klasse verwendet. Wir haben eine Lösung erstellt, wie wir sie auch in der Programmiersprache C erstellt hätten.
- In Teil 2 der Übung wurden zwei Klassen eingeführt:
- [ListeElectorale], die die Attribute (ID, Name, Stimmen, Sitze, ausgeschieden) einer Kandidatenliste repräsentiert
- [ElectionsException], eine Klasse für unkontrollierte Ausnahmen. Dieser Ausnahmetyp wird immer dann verwendet, wenn in der Wahlanwendung ein schwerwiegender Fehler auftritt. Da es sich um eine unkontrollierte Ausnahme handelt (c.a.d), ist der Entwickler nicht verpflichtet, sie mit einem try-catch-Block zu behandeln.
Die Berechnung des Wahlergebnisses wurde bisher einer Methode [main] einer Klasse [MainElections] anvertraut
Die bisherige Lösung umfasst drei klassische Phasen:
- die Datenerfassung, Zeilen 17–18
- die Berechnung des Ergebnisses, Zeilen 19–20
- die Anzeige und/oder Speicherung der Ergebnisse, Zeilen 21–22
Nur Phase 2 ist wirklich konstant. Phase 1 kann variieren: Die Daten können wie in den untersuchten Beispielen von der Tastatur, aus einer Textdatei, über eine grafische Benutzeroberfläche, aus einer Datenbank, aus dem Netzwerk usw. stammen. Ebenso gibt es vielfältige Möglichkeiten, die Ergebnisse in Phase 3 auszugeben: sie auf dem Bildschirm anzuzeigen, wie es in den untersuchten Beispielen geschehen ist, sie in einer Datei oder einer Datenbank zu speichern, sie über das Netzwerk zu senden, …
Allgemeiner gesagt lässt sich eine Anwendung oft in drei Schichten modellieren, von denen jede eine klar definierte Rolle hat:
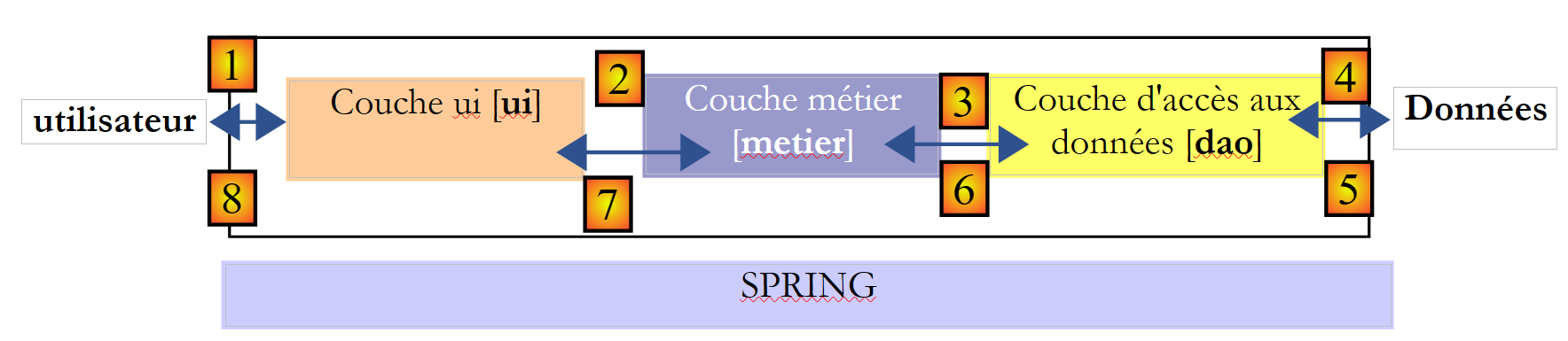 |
Diese Architektur wird auch als „Dreischichtenarchitektur“ bezeichnet, eine Übersetzung des englischen Begriffs „three-tier architecture“. Der Begriff „Dreischichtenarchitektur“ bezieht sich normalerweise auf eine Architektur, bei der sich jede Schicht auf einem anderen Rechner befindet. Befinden sich die Schichten auf demselben Rechner, wird die Architektur zu einer „Dreischichtenarchitektur“.
- Die Schicht [metier] enthält die Geschäftsregeln der Anwendung. Bei unserer Wahlanwendung sind dies die Regeln, mit denen die von den verschiedenen Listen erzielten Sitze berechnet werden, sobald die von jeder Liste erzielten Stimmen bekannt sind. Diese Schicht benötigt Daten, um zu funktionieren. Beispielsweise in der Wahlanwendung:
- die Listen mit jeweils ihrem Namen und ihrer Stimmenzahl
- die Anzahl der zu besetzenden Sitze
- die Wahlhürde, unterhalb derer eine Liste ausscheidet
In dem obigen Schema können die Daten aus zwei Quellen stammen:
- der Datenzugriffsebene oder [dao] (DAO = Data Access Object) für Daten, die bereits in Dateien oder Datenbanken gespeichert sind. Dies könnte hier der Fall sein bei den Namen der Listen, der Anzahl der zu besetzenden Sitze und der Wahlhürde. Diese Informationen liegen nämlich bereits vor der Wahl selbst vor.
- die Benutzerschnittstellenebene oder [ui] (UI = User Interface) für die vom Benutzer eingegebenen oder dem Benutzer angezeigten Daten. Dies könnte hier bei den Stimmen der Listen der Fall sein, die erst im letzten Moment bekannt sind, sowie bei der Anzeige der Wahlergebnisse.
- Im Allgemeinen kümmert sich die Schicht [dao] um den Zugriff auf persistente (Dateien, Datenbanken) oder nicht-persistente (Netzwerk, Sensoren, …) Daten.
- Die Schicht [ui] hingegen kümmert sich um die Interaktionen mit dem Benutzer, sofern vorhanden.
- Die drei Schichten werden durch die Verwendung von Java-Schnittstellen voneinander unabhängig gemacht.
- Um diese Schichten in der Anwendung miteinander zu integrieren, gibt es verschiedene Methoden. Wir werden ein Tool namens „Spring“ verwenden. Im Schema verläuft es quer durch die anderen Schichten.
Wir werden die zuvor entwickelte Anwendung [Elections] wieder aufnehmen, um ihr eine 3-Schichten-Architektur zu verleihen. Dazu werden wir die Schichten von [ui, metier, dao] nacheinander untersuchen, beginnend mit der Schicht [dao], die sich um die persistenten Daten kümmert.
Zuvor müssen wir jedoch die Schnittstellen der verschiedenen Schichten der Anwendung [Elections] definieren.
4.2. Die Schnittstellen der Anwendung [Elections]
Zur Erinnerung: Eine Schnittstelle definiert eine Reihe von Methodensignaturen. Die Klassen, die die Schnittstelle implementieren, füllen diese Methoden mit Inhalt.
Kehren wir zur 3-Schichten-Architektur unserer Anwendung zurück:
|
Bei dieser Art von Architektur geht oft der Benutzer die Initiative ein. Er stellt eine Anfrage in [1] und erhält eine Antwort in [8]. Dies wird als Anfrage-Antwort-Zyklus bezeichnet. Nehmen wir das Beispiel der Berechnung der gewonnenen Sitze am Wahlabend. Dies erfordert mehrere Schritte:
- Die Ebene [ui] muss den Benutzer nach der Anzahl der Stimmen fragen, die jede der Listen erhalten hat. Dazu muss sie ihm die Namen der konkurrierenden Listen anzeigen. Der Benutzer muss dann nur noch die Anzahl der Stimmen neben jede Liste eintragen und anschließend die Berechnung der Sitze anfordern.
- Die Schicht [ui] verfügt nicht über die Namen der Listen. Diese sind in der Datenquelle rechts im Schema gespeichert. Sie wird den Pfad [2, 3, 4, 5, 6, 7] verwenden, um sie abzurufen. Die Operation [2] ist die Abfrage der Listen, die Operation [7] die Antwort auf diese Abfrage. Anschließend kann sie diese dem Benutzer über [8] anzeigen.
- Der Benutzer übermittelt der Schicht [ui] die Anzahl der Stimmen, die jede der Listen erhalten hat. Dies ist der oben genannte Vorgang [1]. In diesem Schritt interagiert der Benutzer ausschließlich mit der Schicht [ui]. Diese überprüft insbesondere die Gültigkeit der eingegebenen Daten. Anschließend fordert der Benutzer die Liste der Sitze an, die jede der Listen erhalten hat.
- Die Schicht [ui] fordert die Fachschicht auf, die Berechnung der Sitze durchzuführen. Dazu übermittelt sie ihr die Daten, die sie vom Benutzer erhalten hat. Dies ist der Vorgang [2].
- Die Schicht [metier] benötigt bestimmte Informationen, um ihre Aufgabe auszuführen. Die Listen liegen ihr bereits aus dem Vorgang (b) vor. Außerdem benötigt sie die Anzahl der zu vergebenden Sitze sowie den Wert der Wahlhürde. Sie fordert diese Informationen von der Schicht [dao] über den Pfad [3, 4, 5, 6] an. [3] ist die ursprüngliche Anfrage und [6] die Antwort auf diese Anfrage.
- Da nun alle benötigten Daten vorliegen, berechnet die Ebene [metier] die von jeder Liste erzielten Sitze.
- Die Schicht [metier] kann nun die in (d) gestellte Anfrage der Schicht [ui] beantworten. Dies ist der Pfad [7].
- Die Ebene [ui] wird diese Ergebnisse aufbereiten, um sie dem Benutzer in geeigneter Form darzustellen, und sie anschließend präsentieren. Dies ist der Pfad [8].
- Man kann sich vorstellen, dass diese Ergebnisse in einer Datei oder einer Datenbank gespeichert werden müssen. Dies kann automatisch erfolgen. In diesem Fall fordert die Ebene [metier] nach dem Vorgang (f) die Ebene [dao] auf, die Ergebnisse zu speichern. Dies erfolgt über den Pfad [3, 4, 5, 6]. Dies kann auch nur auf Anfrage des Benutzers erfolgen. In diesem Fall wird der Pfad [1-8] im Anfrage-Antwort-Zyklus verwendet.
Aus dieser Beschreibung geht hervor, dass eine Schicht die Ressourcen der rechts von ihr liegenden Schicht nutzt, niemals jedoch die der links von ihr liegenden. Betrachten wir zwei benachbarte Schichten:
 |
Die Schicht [A] sendet Anfragen an die Schicht [B]. In den einfachsten Fällen wird eine Schicht durch eine einzige Klasse implementiert. Eine Anwendung entwickelt sich im Laufe der Zeit weiter. So kann die Schicht [B] verschiedene Implementierungsklassen wie [B1, B2, ...] haben. Wenn die Schicht [B] die Schicht [dao] ist, kann diese eine erste Implementierung [B1] haben, die Daten aus einer Datei abruft. Einige Jahre später möchte man die Daten möglicherweise in eine Datenbank speichern. Dann wird eine zweite Implementierungsklasse [B2] erstellt. Wenn in der ursprünglichen Anwendung die Schicht [A] direkt mit der Klasse [B1] zusammengearbeitet hat, muss der Code der Schicht [A] teilweise neu geschrieben werden. Nehmen wir zum Beispiel an, wir hätten in der Schicht [A] etwa Folgendes geschrieben:
- Zeile 1: Eine Instanz der Klasse [B1] wird erstellt
- Zeile 3: Von dieser Instanz werden Daten angefordert
Angenommen, die neue Implementierungsklasse [B2] verwendet Methoden mit derselben Signatur wie die Klasse [B1], dann müssen alle [B1] in [B2] geändert werden. Das ist der sehr günstige Fall, der jedoch eher unwahrscheinlich ist, wenn man diesen Methodensignaturen keine Beachtung geschenkt hat. In der Praxis kommt es häufig vor, dass die Klassen [B1] und [B2] nicht dieselben Methodensignaturen haben und daher ein Großteil der Schicht [A] komplett neu geschrieben werden muss.
Man kann die Situation verbessern, indem man eine Schnittstelle zwischen den Schichten [A] und [B] einfügt. Das bedeutet, dass die Methodensignaturen, die die Schicht [B] der Schicht [A] bereitstellt, in einer Schnittstelle festgelegt werden. Das vorherige Schema sieht dann wie folgt aus:
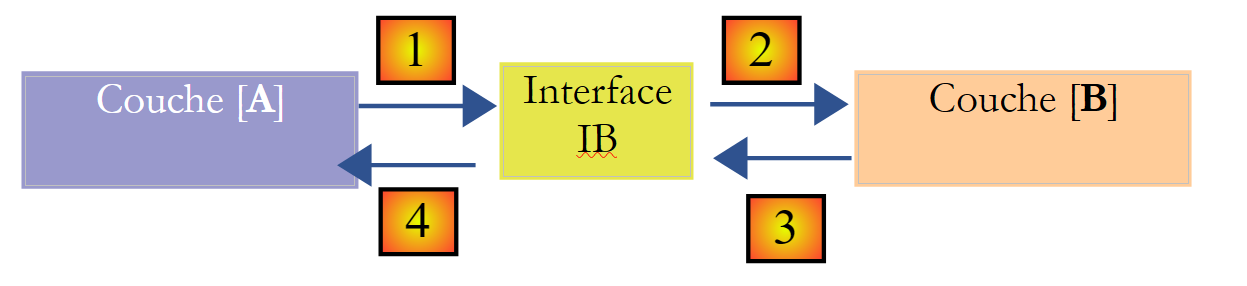 |
Die Schicht [A] kommuniziert nun nicht mehr direkt mit der Schicht [B], sondern mit deren Schnittstelle [IB]. Somit erscheint im Code der Schicht [A] die Implementierungsklasse [Bi] der Schicht [B] nur einmal auf, und zwar bei der Implementierung der Schnittstelle [IB]. Danach wird im Code die Schnittstelle [IB] und nicht deren Implementierungsklasse verwendet. Der vorherige Code sieht nun wie folgt aus:
- Zeile 1: Eine Instanz [ib], die die Schnittstelle [IB] implementiert, wird durch Instanziierung der Klasse [B1] erstellt
- Zeile 3: Von der Instanz [ib] werden Daten angefordert
Wenn nun die Implementierung [B1] der Schicht [B] durch eine Implementierung [B2] ersetzt wird und beide Implementierungen dieselbe Schnittstelle [IB] einhalten, dann muss nur Zeile 1 der Schicht [A] geändert werden und keine andere. Dies ist ein großer Vorteil, der allein schon die systematische Verwendung von Schnittstellen zwischen zwei Schichten rechtfertigt.
Man kann noch einen Schritt weiter gehen und die Schicht [A] vollständig unabhängig von der Schicht [B] machen. Im obigen Code stellt Zeile 1 ein Problem dar, da sie eine harte Referenz auf die Klasse [B1] enthält. Ideal wäre es, wenn die Schicht [A] über eine Implementierung der Schnittstelle [IB] verfügen könnte, ohne eine Klasse benennen zu müssen. Dies würde mit unserem obigen Schema übereinstimmen. Dort ist zu sehen, dass die Schicht [A] auf die Schnittstelle [IB] zugreift, und es ist nicht ersichtlich, warum sie den Namen der Klasse kennen müsste, die diese Schnittstelle implementiert. Dieses Detail ist für die Schicht [A] nicht relevant.
Das Spring-Framework (http://www.springframework.org) ermöglicht es, dieses Ergebnis zu erzielen. Die bisherige Architektur entwickelt sich wie folgt weiter:
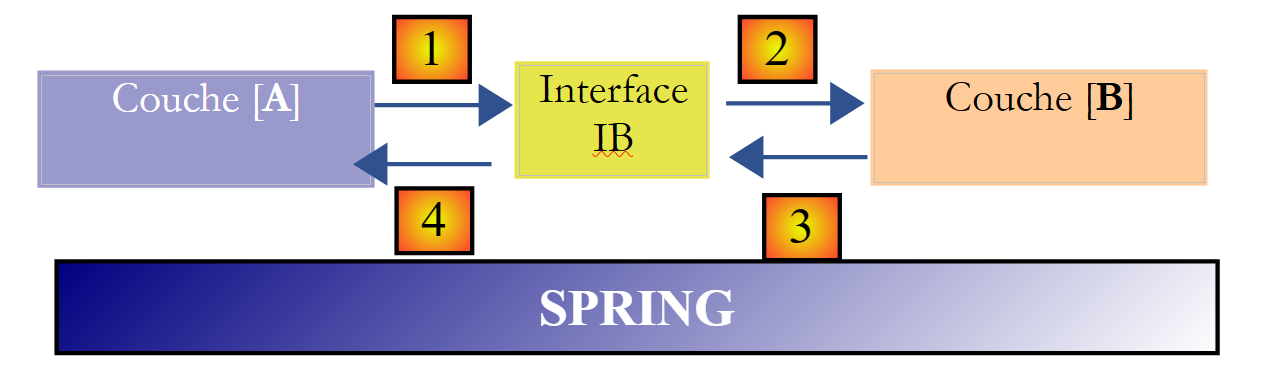 |
Die Querschnittschicht [Spring] ermöglicht es einer Schicht, über die Konfiguration einen Verweis auf die rechts davon liegende Schicht zu erhalten, ohne den Namen der Implementierungsklasse dieser Schicht kennen zu müssen. Dieser Name befindet sich in den Konfigurationsdateien und nicht im Java-Code. Der Java-Code der Schicht [A] sieht dann wie folgt aus:
- Zeile 1: Eine Instanz [ib], die die Schnittstelle [IB] der Schicht [B] implementiert. Diese Instanz wird von Spring auf der Grundlage von Informationen aus einer Konfigurationsdatei erstellt. Spring übernimmt die Erstellung:
- die Instanz [b], die die Schicht [B] implementiert
- die Instanz [a], die die Schicht [A] implementiert. Diese Instanz wird initialisiert. Das oben genannte Feld [ib] erhält als Wert die Referenz [b] des Objekts, das die Schicht [B] implementiert
- Zeile 3: Daten werden von der Instanz [ib] angefordert
Nun ist ersichtlich, dass die Implementierungsklasse [B1] der Schicht B nirgendwo im Code der Schicht [A] vorkommt. Wenn die Implementierung [B1] durch eine neue Implementierung [B2] ersetzt wird, ändert sich im Code der Klasse [A] nichts. Es werden lediglich die Spring-Konfigurationsdateien geändert, um [B2] anstelle von [B1] zu instanziieren.
Die Kombination aus Spring und Java-Schnittstellen sorgt für eine entscheidende Verbesserung bei der Wartung von Anwendungen, indem sie die Schichten voneinander isoliert. Genau diese Lösung werden wir für die Anwendung [Elections] verwenden.
Kehren wir zur dreischichtigen Architektur unserer Anwendung zurück:
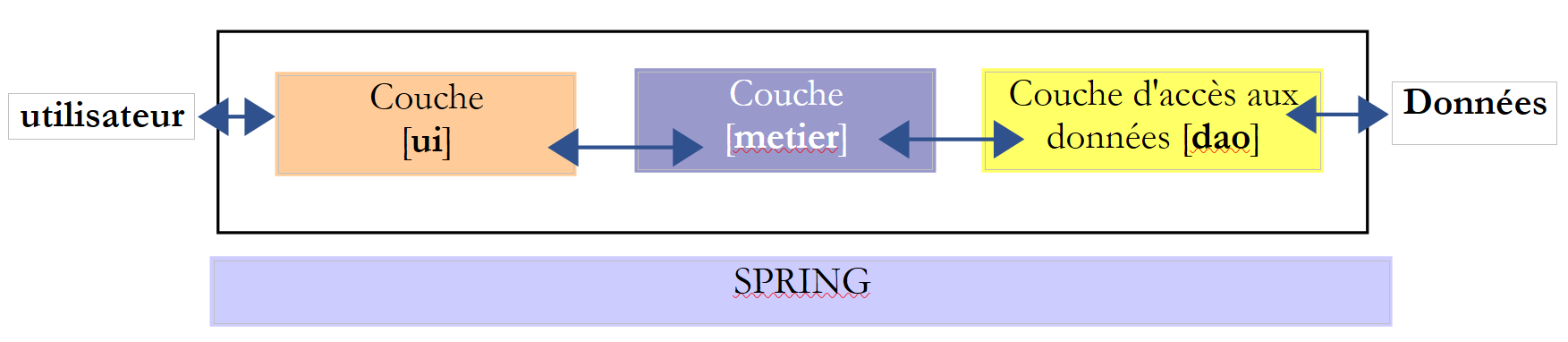 |
In einfachen Fällen kann man von der Schicht [metier] ausgehen, um die Schnittstellen der Anwendung zu ermitteln. Für ihre Arbeit benötigt sie Daten:
- die bereits in Dateien, Datenbanken oder über das Netzwerk verfügbar sind. Diese werden von der Schicht [dao] bereitgestellt.
- noch nicht verfügbar sind. Sie werden dann von der Schicht [ui] bereitgestellt, die sie vom Benutzer der Anwendung erhält.
Welche Schnittstelle muss die Schicht [dao] der Schicht [metier] bereitstellen? Welche Interaktionen sind zwischen diesen beiden Schichten möglich? Die Schicht [dao] muss der Schicht [metier] folgende Daten bereitstellen:
- die Anzahl der zu besetzenden Sitze
- den Wert der Wahlhürde, unterhalb derer eine Liste ausscheidet
- die Namen der Listen
Diese Informationen sind bereits vor der Wahl bekannt und können daher gespeichert werden. In der Richtung [metier] -> [dao] kann die Schicht [metier] die Schicht [dao] auffordern, das Wahlergebnis zu speichern, insbesondere die von den verschiedenen Listen errungenen Sitze.
Anhand dieser Informationen könnte man versuchen, eine erste Definition der Schnittstelle der Schicht [dao] zu erstellen:
public interface IElectionsDao {
public double getSeuilElectoral();
public int getNbSiegesAPourvoir();
public ListeElectorale[] getListesElectorales();
public void setListesElectorales(ListeElectorale[] listesElectorales);
}
- Zeile 1: Die Schnittstelle heißt [IElectionsDao]. Sie definiert vier Methoden:
- drei Methoden zum Lesen von Daten aus der Datenquelle: [getSeuilElectoral, getNbSiegesAPourvoir, getListesElectorales]. Diese drei Methoden ermöglichen es der Schicht [metier], die Daten zu erhalten, die die aktuelle Wahl charakterisieren.
- eine Methode zum Schreiben von Daten in die Datenquelle: [setListesElectorales]. Diese Methode ermöglicht es der Schicht [metier], die Speicherung der von ihr berechneten Ergebnisse anzufordern.
Kehren wir zur dreischichtigen Architektur unserer Anwendung zurück:
|
Welche Schnittstelle muss die Schicht [metier] gegenüber der Schicht [ui] bereitstellen? Betrachten wir die möglichen Interaktionen zwischen diesen beiden Schichten.
- Die Schicht [ui] hat die Aufgabe, den Benutzer nach den Stimmen für die verschiedenen konkurrierenden Listen zu befragen. Dazu muss sie die Anzahl der Listen kennen. Sie kann diese Information bei der Schicht [metier] abfragen, die ihrerseits die Tabelle der konkurrierenden Listen bei der Schicht [dao] anfordern kann. Wenn die Schicht [metier] über diese Tabelle verfügt, kann sie diese ebenso gut an die Schicht [ui] weiterleiten. Diese verfügt dann über die Namen der Listen und kann ihre Meldungen an den Benutzer präzisieren, indem sie beispielsweise nach der „Stimmenzahl der Liste A“ fragt.
- Sobald die Ebene [ui] die Stimmen aller Listen erhalten hat, wird sie die Berechnung der Sitze bei der Ebene [metier] anfordern. Diese kann die Berechnung durchführen und das Ergebnis an die Ebene [ui] zurückgeben.
- Die Ebene [ui] kann diese Ergebnisse dann dem Nutzer anzeigen. Dieser kann zudem deren Speicherung anfordern.
- Die Ebene [ui] möchte dem Benutzer möglicherweise darüber hinaus zusätzliche Informationen anzeigen, wie beispielsweise die Wahlhürde oder die Anzahl der zu vergebenden Sitze.
Anhand dieser Informationen könnte man eine erste Definition der Schnittstelle der Schicht [metier] „ “ versuchen:
public interface IElectionsMetier {
public ListeElectorale[] getListesElectorales();
public int getNbSiegesAPourvoir();
public double getSeuilElectoral();
public void recordResultats(ListeElectorale[] listesElectorales);
public ListeElectorale[] calculerSieges(ListeElectorale[] listesElectorales);
}
- Zeile 1: Die Schnittstelle heißt [IElectionsMetier]. Sie definiert die folgenden Methoden:
- Zeile 3: Eine Methode [getListesElectorales], die es der Schicht [ui] ermöglicht, das Array der konkurrierenden Listen abzurufen;
- Zeile 5: Die Methode [getNbSiegesAPourvoir] ermöglicht es, die Anzahl der zu besetzenden Sitze abzurufen;
- Zeile 7: Die Methode [getSeuilElectoral] ermöglicht es, die Wahlhürde abzurufen;
- Zeile 11: Eine Methode [calculerSieges] (Zeile 36), die es der Ebene [ui] ermöglicht, die Berechnung der Sitze anzufordern, sobald die Stimmenzahlen der verschiedenen Listen bekannt sind. Als Parameter dient das Array der konkurrierenden Listen, ohne deren Sitze und ohne den Booleschen Wert „eliminiert“. Als Ergebnis wird dasselbe Array zurückgegeben, diesmal jedoch mit den initialisierten Feldern [sièges, elimine];
- Zeile 9: Eine Methode [recordResultats], die es der Ebene [ui] ermöglicht, die Speicherung der Ergebnisse anzufordern.
Hinweis: Aufgrund ihrer Position übernimmt die Schicht [métier] einige der Methoden der Schicht [DAO], um sie der Schicht [UI] zur Verfügung zu stellen. Aufgrund dieser Redundanz könnte man versucht sein, alles in einer einzigen Schicht zusammenzufassen, die sowohl die Geschäftslogik als auch den Datenzugriff umfasst. Diese einzige Schicht wird manchmal als „Modell“ bezeichnet, das M im Akronym MVC (Modell – Ansicht – Controller). MVC ist ein in Webanwendungen weit verbreitetes Entwurfsmuster (Design Pattern).
Betrachten wir die Signatur der Methode [calculerSieges]:
public ListeElectorale[] calculerSieges(ListeElectorale[] listesElectorales);
Weiter oben hieß es: „Der Parameter ist das Array der konkurrierenden Listen, ohne deren Plätze und ohne den eliminierten Booleschen Wert. Das Ergebnis ist dasselbe Array, diesmal jedoch mit den Feldern [sièges, elimine].“ Die Signatur der Methode könnte auch wie folgt lauten:
public void calculerSieges(ListeElectorale[] listesElectorales);
Der Parameter [listesElectorales] ist eine Objektreferenz, in diesem Fall ein Array. Jedes Element ist wiederum eine Objektreferenz, in diesem Fall vom Typ [ListeElectorale]. Die Methode [calculerSieges] ändert die Felder [sieges, elimine] jedes dieser Objekte. Die aufrufende Methode verfügt über einen Zeiger [listesElectorales], der:
- vor dem Aufruf ist die Referenz auf ein Objektarray [ListeElectorale], dessen Felder [sieges, elimine] nicht initialisiert sind;
- nach dem Aufruf ist es die Referenz (dieselbe) auf ein Objektarray [ListeElectorale], dessen Felder [sieges, elimine] initialisiert sind;
Warum also die Signatur verwenden:
public ListeElectorale[] calculerSieges(ListeElectorale[] listesElectorales);
Beim Schreiben einer Schnittstelle sollte man bedenken, dass sie in zwei verschiedenen Kontexten verwendet werden kann: local und distant. Im Kontext local werden die aufrufende und die aufgerufene Methode in derselben JVM (Java Virtual Machine) ausgeführt:
|
Wenn die Schicht [ui] die Methode calculerSieges der Schicht [DAO] aufruft, verfügt sie tatsächlich über eine Referenz auf den Parameter [ListeElectorale[] listesElectorales], die sie an die Methode übergibt.
Im Kontext distant werden die aufrufende und die aufgerufene Methode in unterschiedlichen JVM ausgeführt:
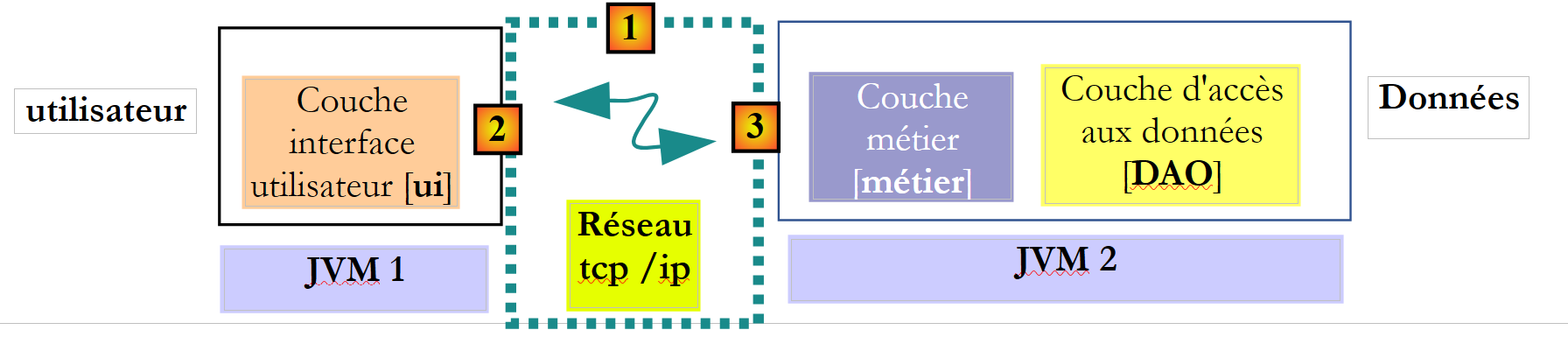 |
Im obigen Beispiel wird die Schicht [ui] in der JVM 1 und die Schicht [métier] in der JVM 2 auf zwei verschiedenen Rechnern ausgeführt. Die beiden Schichten kommunizieren nicht direkt miteinander. Zwischen ihnen befindet sich eine Schicht, die wir als Kommunikationsschicht [1] bezeichnen. Diese besteht aus einer Sendeschicht [2] und einer Empfangsschicht [3]. Der Entwickler muss diese Kommunikationsschichten in der Regel nicht selbst schreiben. Sie werden automatisch von Software-Tools generiert. Die Schicht [metier] wird so geschrieben, als würde sie in derselben JVM ausgeführt wie die Schicht [DAO]. Es sind daher keine Codeänderungen erforderlich.
Der Kommunikationsmechanismus zwischen der Schicht [ui] und der Schicht [métier] ist wie folgt:
- Die Schicht [ui] ruft die Methode calculerSieges der Schicht [métier] auf und übergibt ihr dabei den Parameter [ListeElectorale[] listesElectorales1] übergibt;
- dieser Parameter wird tatsächlich an die Sendeschicht [2] übergeben. Diese überträgt den Wert des Parameters listesElectorales1 und nicht dessen Referenz über das Netzwerk. Die genaue Form dieses Werts hängt vom verwendeten Kommunikationsprotokoll ab;
- die Empfangsschicht [3] ruft diesen Wert ab und rekonstruiert daraus ein Objekt [ListeElectorale[] listesElectorales2], das dem ursprünglichen, von der Schicht [metier] gesendeten Parameter entspricht. Nun liegen zwei (inhaltlich) identische Objekte in zwei verschiedenen JVM vor: listesElectorales1 und listesElectorales2.
- Die empfangende Schicht übergibt das Objekt listesElectorales2 an die Methode calculerSieges der Schicht [métier], die es in der Datenbank speichert. Nach diesem Vorgang verweist die Referenz listesElectorales2 auf ein Array von Objekten [ListeElectorale], deren Felder [sieges, elimine] initialisiert sind. . Dies ist beim Objekt listesElectorales1 nicht der Fall, auf das die Schicht [ui] verweist. Wenn die Schicht [ui] eine Referenz auf das Objekt listesElectorales2 haben soll, muss man ihr dieses Objekt übermitteln. Daher muss man für die Methode [calculerSieges] die folgende Signatur verwenden:
public ListeElectorale[] calculerSieges(ListeElectorale[] listesElectorales);
- Mit dieser Signatur gibt die Methode calculerSieges als Ergebnis die Referenz listesElectorales2 zurück. Dieses Ergebnis wird an die empfangende Schicht [3] zurückgegeben, die die Schicht [métier] aufgerufen hatte. Diese gibt den Wert (und nicht die Referenz) von listesElectorales2 an die Sendeschicht [2] zurück;
- die Sendeschicht [2] wird diesen Wert abrufen und daraus ein Objekt [ListeElectorale[] listesElectorales3] des von der Methode calculerSieges der Ebene [métier] gerenderten Ergebnisses.
- Das Objekt [ListeElectorale[] listesElectorales3] wird an die Methode der Schicht [ui] übergeben, deren Aufruf der Methode calculerSieges der Schicht [DAO] diesen gesamten Mechanismus ausgelöst hatte;
In diesem Prozess werden Objekte vom Typ [ListeElectorale] zwischen den Schichten [2] und [3] übertragen:
- Wenn die Schicht [2] den Wert eines Objekts vom Typ [ListeElectorale] an die Schicht [3] überträgt, spricht man davon, dass das Objekt serialisiert wird. Die genaue Form dieser Serialisierung hängt vom verwendeten Kommunikationsprotokoll ab;
- wenn die Schicht [3] den Wert eines Objekts [ListeElectorale] abruft, um erneut ein Objekt [ListeElectorale] zu erstellen, spricht man davon, dass das Objekt deserialisiert wird;
Damit ein Objekt dieser Serialisierung/Deserialisierung unterzogen werden kann, verlangen bestimmte Protokolle, dass das Objekt die Schnittstelle [Serializable] implementiert. Diese Schnittstelle dient lediglich als Marker. Es müssen keine Methoden implementiert werden. Daher wird die Klasse [ListeElectorale] nun wie folgt deklariert:
public abstract class ListeElectorale implements Serializable {
private static final long serialVersionUID = 1L;
- Das Feld in Zeile 2 ist vorgegeben. Es kann unverändert beibehalten und für alle Klassen vom Typ [Serializable] verwendet werden.
4.3. Die Ausnahmeklasse
Kehren wir zur Schnittstelle der Schicht [DAO] zurück:
 |
public interface IElectionsDao {
public double getSeuilElectoral();
public int getNbSiegesAPourvoir();
public ListeElectorale[] getListesElectorales();
public void setListesElectorales(ListeElectorale[] listesElectorales);
}
Diese Methoden arbeiten mit einer Datenbank und können auf verschiedene Fehler stoßen, beispielsweise ein nicht verfügbares SGBD. Beim Schreiben einer Methode muss man stets Fehlerfälle einkalkulieren. Diese werden üblicherweise durch eine Ausnahme gemeldet. Die Klasse [ElectionsException] haben wir bereits in Abschnitt 3.3 kennengelernt. Wir werden sie weiterhin verwenden, sie jedoch wie folgt erweitern:
package ...;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
// Ausnahmeklasse für die Anwendung „Wahlen“
// Die Ausnahme ist unkontrolliert
public class ElectionsException extends RuntimeException implements Serializable {
// serial ID
private static final long serialVersionUID = 1L;
// lokale Felder
private int code;
private List<String> erreurs;
// Konstruktoren
public ElectionsException() {
super();
}
public ElectionsException(int code, Throwable e) {
// übergeordnet
super(e);
// lokal
this.code = code;
this.erreurs = getErreursForException(e);
}
public ElectionsException(int code, String message, Throwable e) {
// übergeordnet
super(message,e);
// lokal
this.code = code;
this.erreurs = getErreursForException(e);
}
public ElectionsException(int code, String message) {
// übergeordnet
super(message);
// lokal
this.code = code;
List<String> erreurs = new ArrayList<>();
erreurs.add(message);
this.erreurs = erreurs;
}
public ElectionsException(int code, List<String> erreurs) {
// übergeordnet
super();
// lokal
this.code = code;
this.erreurs = erreurs;
}
// Liste der Fehlermeldungen einer Ausnahme
private List<String> getErreursForException(Throwable th) {
// Die Liste der Fehlermeldungen der Ausnahme wird abgerufen
Throwable cause = th;
List<String> erreurs = new ArrayList<>();
while (cause != null) {
// Die Meldung wird nur abgerufen, wenn sie != null und nicht leer ist
String message = cause.getMessage();
if (message != null) {
message = message.trim();
if (message.length() != 0) {
erreurs.add(message);
}
}
// nächste Ursache
cause = cause.getCause();
}
return erreurs;
}
// Getter und Setter
...
}
- Zeilen 16–17: Der Typ [ElectionsException] kapselt:
- einen Fehlercode, Zeile 16;
- eine Liste von Fehlermeldungen, Zeile 17;
Die Klasse unterstützt fünf Konstruktoren:
- Zeile 20: ElectionsException()
- Zeile 24: ElectionsException(int code, Throwable e): Der zweite Parameter ist vom Typ [Throwable], der die übergeordnete Klasse der Klasse [Exception] darstellt. Dieser Konstruktor ermöglicht es, die Ausnahme e mit einem Fehlercode zu kapseln. Der Typ [Throwable] (und damit der Typ Exception) ermöglicht es, eine oder mehrere Ausnahmen zu kapseln. Die Idee dahinter ist:
- eine auftretende Ausnahme abzufangen (catch);
- sie durch Kapselung in eine neue Ausnahme mit einer Meldung zu ergänzen;
- die neue Ausnahme erneut auszulösen;
Die Kapselung erfolgt in Zeile 34 durch die Anweisung [super(message,e)]. Dieser Kapselungsprozess kann wiederholt werden, und die ursprüngliche Ausnahme kann um verschiedene Meldungen erweitert werden. Man spricht dann von einem Ausnahmestapel. Mit der Methode [private List<String> getErreursForException(Throwable th)] lassen sich die verschiedenen Meldungen abrufen, die mit den gekapselten Ausnahmen verbunden sind:
- (Fortsetzung)
- (Fortsetzung)
- Die gekapselte Ausnahme wird über die Methode `Throwable [Throwable].getCause()` abgerufen;
- Die einer Ausnahme zugeordnete Meldung wird über die String-Methode [Throwable].getMessage() abgerufen;
- (Fortsetzung)
- Zeilen 28–29: Die Felder [code, erreurs] werden angelegt;
- Zeile 32: public ElectionsException(int code, String message, Throwable e): Dieser Konstruktor entspricht dem vorherigen, mit dem Unterschied, dass er die Ausnahme, die er kapseln wird, um einen Code und eine Meldung ergänzt;
- Zeile 40: public ElectionsException(int code, String message): Konstruktor ohne Ausnahmekapselung;
- Zeile 50: public ElectionsException(int code, List<String> errors): Konstruktor ohne Ausnahmekapselung und ohne Meldung;
Die Klasse [ElectionsException] kann wie folgt verwendet werden:
wo die Meldung vorhanden ist oder nicht. Nach ihrer Erstellung ist die Ausnahme [ElectionsException] nicht dazu vorgesehen, neue Ausnahmen zu kapseln. Im obigen Beispiel kapselt sie die Ausnahme e1 sowie die Ausnahmen, die von e1 gekapselt werden. Es folgen keine weiteren Kapselungen mehr.
Die Klasse [ElectionsException] kann ebenfalls wie folgt verwendet werden: