5. نوع Stream<T> في Java 8
5.1. المثال-01 - فئة Stream
تشترك العمليات على تدفقات Observable في العديد من النقاط المشتركة مع تدفقات Stream. أحد الاختلافات هو أن عنصرًا من تدفق Stream لا يمكن معالجته قبل الحصول على تدفق Stream بالكامل، في حين أن عنصرًا من تدفق Observable يمكن معالجته (يتم ملاحظته) بمجرد استلامه دون انتظار استلام تدفق Observable بالكامل. وهناك اختلاف آخر، وهو أنه بمجرد الحصول على Stream، يتم استغلال قيمه عن طريق سحبها (pull) واحدة تلو الأخرى من Stream. أما بالنسبة للمراقب، فالأمر مختلف. فبمجرد أن يصدر المراقب قيمة، يتم دفعها (pushed) إلى المشترك.
تقوم عدة فئات بتنفيذ مفهوم Stream. نقدم هنا الفئة Stream<T>:
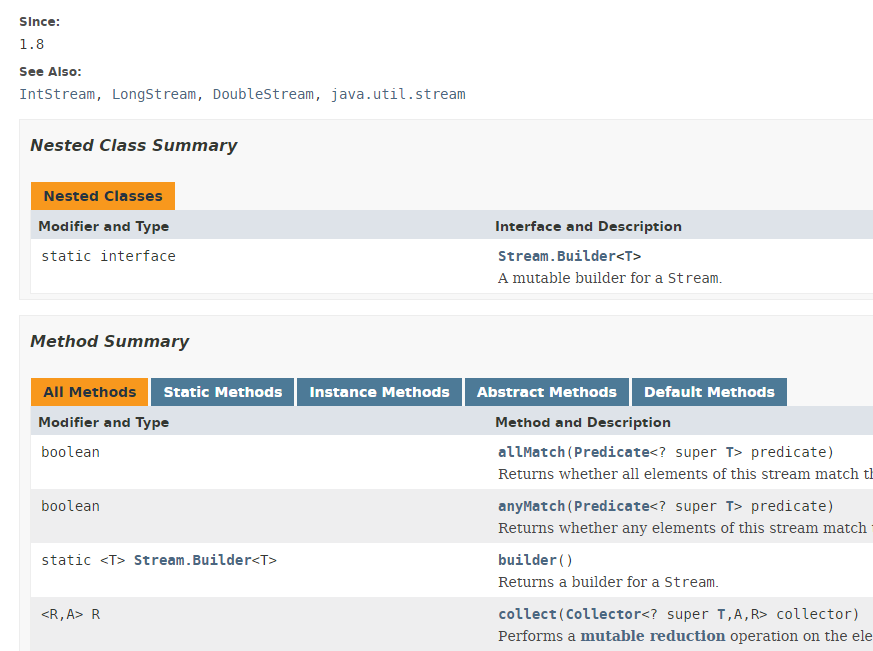
تحتوي الفئة Stream على 39 دالة. سنعرض بعضًا منها. لننظر إلى الكود التالي:
 |
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple01 {
public static void main(String[] args) {
// قائمة الأشخاص
List<Personne> personnes = Personnes.get();
// العرض 1
personnes.stream().forEach(p -> {
System.out.println(p);
});
System.out.println("----------------");
// العرض 2
personnes.stream().forEach(System.out::println);
}
}
- السطر 11: يتم إنشاء مثيل لقائمة بالأشخاص؛
- السطر 13: من هذه القائمة، يتم إنشاء Stream. وبالتالي، يمكن تحويل جميع المجموعات إلى تدفقات من نوع Stream. وهذا يتيح الاستفادة من جميع طرق هذه الفئة التي تسمح بمعالجة عناصر المجموعة بطريقة أكثر إيجازًا مقارنةً باستخدام الحلقات. كما يتيح أيضًا الاستفادة من التوازي في معالجة العناصر عندما يكون ذلك ممكنًا؛
- السطر 13: الطريقة [Stream.forEach] لها التوقيع التالي:
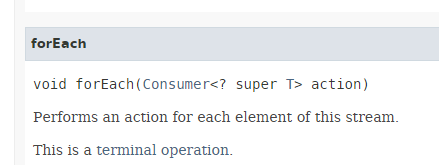 |
نلاحظ أن معلمة الأسلوب هي الواجهة الوظيفية [Consumer<T>] المذكورة في الفقرة 4.4، وهي واجهة تحتوي على أسلوب واحد يستخدم النوع T ولا تُرجع أي قيمة.
- في الكود:
personnes.stream().forEach(p -> {
System.out.println(p);
});
- تنتج [personnes.stream()] تدفقًا من العناصر من النوع [Personne] التي تغذي الطريقة [forEach]. المعلمة p من النوع [Personne]، وتقوم دالة لامدا المُقدمة بعرض هذه الشخصية؛
يمكن تبسيط الكود السابق على النحو التالي (السطر 18):
personnes.stream().forEach(System.out::println);
بدلاً من تمرير قيمة دالة لامدا كمعلمة، نقوم بتمرير مرجع طريقة موجودة، وهي هنا الطريقة println التابعة للفئة System.out. وبالطبع يجب أن يكون لهذه الطريقة التوقيع الصحيح، وهو في هذه الحالة توقيع الطريقة [Consumer.accept]: void accept(T t). وكما ذكرنا سابقًا، سيكون معلمة الطريقة [accept] من النوع [Personne]؛
ونحصل على النتائج التالية:
بمجرد استخدام دفق Stream، يصبح غير قابل للاستخدام مرة أخرى. يجب إعادة إنشاؤه إذا أردنا استخدامه مرة أخرى. يوضح ذلك الكود التالي [Exemple01b]:
package dvp.java8.streams;
import java.util.stream.Stream;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple01b {
public static void main(String[] args) {
// تدفق الأشخاص
Stream<Personne> personnes = Personnes.get().stream();
// عرض 1
personnes.forEach(p -> {
System.out.println(p);
});
System.out.println("----------------");
// العرض 2
personnes.forEach(System.out::println);
}
}
- السطر 11: لتحسين الكود، قررنا إنشاء Stream مرة واحدة فقط. وكانت النتائج التي تم الحصول عليها كما يلي:
{"nom":"jean","age":20,"poids":70.0,"sexe":"HOMME"}
{"nom":"marie","age":10,"poids":30.0,"sexe":"FEMME"}
{"nom":"camille","age":30,"poids":55.0,"sexe":"FEMME"}
----------------
Exception in thread "main" java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.sourceStageSpliterator(Unknown Source)
at java.util.stream.ReferencePipeline$Head.forEach(Unknown Source)
at dvp.java8.streams.Exemple02b.main(Exemple02b.java:18)
في كل مرة نريد فيها استخدام Stream، يجب إنشاؤه حتى لو كان قد تم إنشاؤه مسبقًا.
5.2. المثال-02 - المعالجة المتوازية لعناصر «ستريم»
 |
لننظر إلى الكود التالي:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple02 {
public static void main(String[] args) {
// قائمة الأشخاص
List<Personne> personnes = Personnes.get();
// العرض 1
personnes.stream().forEach(Exemple02::affiche);
System.out.println("-----------------");
// العرض 2
personnes.stream().parallel().forEach(Exemple02::affiche);
}
public static void affiche(Personne p) {
System.out.printf("Personne %s sur thread %s%n", p, Thread.currentThread().getName());
}
}
- الأسطر 19-21: تقوم الطريقة [affiche] بكتابة السلسلة jSON الخاصة بشخص ما على وحدة التحكم، بالإضافة إلى اسم مؤشر الترابط التنفيذي الذي يتم فيه العرض؛
- السطر 13: يعرض قائمة بالأشخاص. تجدر الإشارة إلى أن معلمة الطريقة [forEach] هي مرجع الطريقة الثابتة السابقة؛
- السطر 16: يتم إجراء الأمر نفسه، ولكن باستخدام الطريقة [parallel]، حيث يُطلب معالجة عناصر الدفق بشكل متوازٍ عبر عدة خيوط. لا يمكن إجراء كل المعالجات بشكل متوازٍ. هنا، يجب افتراض أن ترتيب العرض لا يهم؛ لأنه في المعالجة المتوازية، لا يمكن ضمان ترتيب تنفيذ الخيوط. كما نلاحظ صيغة ستصبح شائعة الاستخدام في كل من Stream وObservable:
- (تابع)
- تُنتج الدالة flux عناصر e1 التي تُغذي الدالة m1؛
- flux.m1 هو بدوره تدفق من العناصر e2 التي تغذي الأسلوب m2؛
- flux.m1.m2 عبارة عن تدفق لعناصر e3 التي تغذي الأسلوب m3؛
قد يتغير نوع العناصر e1 و e2 و e3 مع مرور التدفق الأولي عبر المعالجات المختلفة.
يؤدي تنفيذ هذا الكود إلى النتيجة التالية:
نلاحظ أن التنفيذ المتوازي (الأسطر 5-7) تم على ثلاثة خيوط مختلفة ولم يحترم ترتيب العناصر الموجود في الأسطر 1-3. في هذا المستند، لن نركز كثيرًا على المعالجة المتوازية لعناصر Stream، لأنه يتعين عندئذٍ التحدث عن الشروط التي تجعل هذه المعالجة ممكنة. ونكتشف عندئذٍ أن القليل من المعالجات يمكن تنفيذها بالتوازي. ومن بين المعالجات التي تصلح بشكل طبيعي للتوازي، نجد جمع العناصر الرقمية لتيار ما، وهو ما سنعرضه الآن.
5.3. المثال-03 - المعالجة المتوازية لعناصر دفق
 |
لننظر إلى الكود التالي (المثال 03أ):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class Exemple03a {
public static void main(String[] args) {
final long limite = 10_000_000L;
// عدد المعالجات
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// قائمة الأرقام
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// مجموع الأرقام - الطريقة التسلسلية
début = new Date().getTime();
long somme = nombres.stream().reduce(0L, (s, i) -> s + i);
System.out.printf("somme séquentielle : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- في السطر 22، نستخدم الطريقة [reduce] التي تكون صيغتها كما يلي:
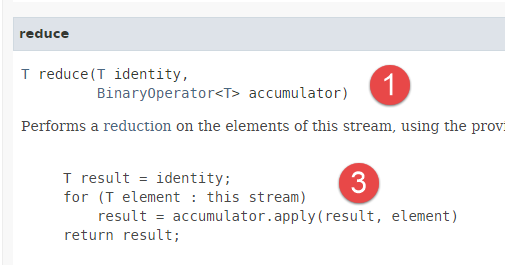 |  |
- تعمل الطريقة [reduce] مع عناصر من النوع T؛
- تطبق الطريقة [reduce] نفس المعالجة على جميع عناصر التدفق: يتم توفير القيمة الأولية للمُجمِّع كمعلمة أولى. يتم توفير دالة تُنشئ مثيلًا للواجهة الوظيفية [BinaryOperator] [2] كمعلمة ثانية: انطلاقًا من كل عنصر والمُجمِّع، توفر هذه الدالة قيمة جديدة للمُجمِّع. وتكون القيمة النهائية للمتراكم هي القيمة التي تُرجعها الطريقة [reduce]. يوضح الكود [3] هذه الآلية. الطريقة [apply] هي طريقة الواجهة الوظيفية [BinaryOperator] [2]؛
لنعد إلى كود المثال:
- السطر 12: يتم عرض عدد النوى التي تراها JVM؛
- الأسطر 15-18: يتم إنشاء قائمة تضم 10 ملايين عدد؛
- السطر 22: يتم حساب مجموع هذه الأعداد بالتسلسل باستخدام خيط واحد؛
ونحصل على النتائج التالية:
الآن، لنستبدل السطر 22 من الكود بالسطر التالي (مثال 03b):
long somme = nombres.stream().parallel().reduce(0L, (s, i) -> s + i);
نطلب معالجة عناصر الدفق بشكل متوازٍ باستخدام عدة خيوط. وهذا ممكن لأن ترتيب جمع الأرقام لا يهم. وبالتالي، يمكن تخصيص n1 عددًا من الأرقام لخيط T1، وn2 عددًا من الأرقام لخيط T2، ... وفي النهاية جمع المجاميع التي قدمتها هذه الخيوط المختلفة. وبذلك نحصل على النتائج التالية:
وبالتالي، لا توجد أي مكاسب في الأداء تقريبًا. وفي الأمثلة التالية، سيكون هذا هو الحال في أغلب الأحيان. فإدارة الخيوط نفسها تستغرق وقتًا طويلاً. ويجب أن تكون العملية التي يقوم بها كل نواة معقدة بما يكفي حتى تظهر المكاسب في الأداء. وهذا ما يوضحه المثال التالي (المثال 03c):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.function.BinaryOperator;
public class Exemple03c {
public static void main(String[] args) {
final long limite = 10_000L;
// عدد المعالجات
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// قائمة الأرقام
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// مجموع الأعداد - الطريقة التسلسلية
début = new Date().getTime();
BinaryOperator<Long> bo = (s, i) -> {
try {
Thread.sleep(1);
} catch (InterruptedException e) {
}
return s + i;
};
long somme = nombres.stream().reduce(0L, bo);
System.out.printf("somme séquentielle : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- السطر 30: نستخدم مرة أخرى الطريقة [reduce] التي نزودها كمعلمة بمرجع الطريقة الواردة في الأسطر 23-29؛
- السطر 28: توفر الطريقة [bo] مجموع معلمتيها؛
- الأسطر 24-27: بشكل مصطنع، نجعل الخيط ينتظر لمدة 1 مللي ثانية لمحاكاة عمل مكثف؛
ونحصل عندئذٍ على النتائج التالية:
الآن، إذا استبدلنا السطر 30 بالسطر التالي:
long somme = nombres.stream().parallel().reduce(0L, bo);
نحصل على النتائج التالية:
يمكننا أن نلاحظ بوضوح تحسن الأداء الناتج عن التنفيذ المتوازي لحساب المجموع. بالنسبة لمعالجة 8 أرقام:
- ينتظر الخيط التسلسلي 8 مرات 1 مللي ثانية، أي 8 مللي ثانية؛
- تنتظر الخيوط المتوازية الثمانية في نفس الوقت كل منها 1 مللي ثانية (توضيح تخيلي للتبسيط)، أي ما مجموعه 1 مللي ثانية للأرقام الثمانية؛
لذلك يمكننا توقع أن يكون التنفيذ المتوازي أسرع بـ 8 مرات من التنفيذ التسلسلي. وهذا هو الحال تقريبًا هنا.
5.4. المثال-04 - تصفية دفق
 |
لننظر إلى الكود التالي:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple04 {
public static void main(String[] args) {
// قائمة الأشخاص
List<Personne> personnes = Personnes.get();
// عدد مرات العرض
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(p -> {
System.out.println(p);
});
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(p -> {
System.out.println(p);
});
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(System.out::println);
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(System.out::println);
}
}
- السطر 14: الطريقة [Stream.filter] لها التوقيع التالي:
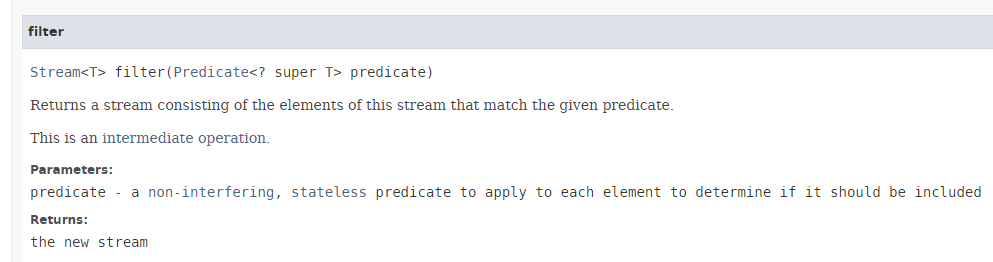 |
- تتوقع الطريقة [filter] كمعلمة مثيلًا للواجهة الوظيفية [Predicate] المذكورة في الفقرة 4.2، والتي تتمثل الطريقة الوحيدة المطلوب تنفيذها فيها فيما يلي: boolean test(T t)؛
- تُرجع الطريقة [filter] عناصر الدفق التي تتوافق مع Predicate. وبالتالي، فهي تُستخدم لتصفية Stream؛
لننظر إلى الكود التالي:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple04 {
public static void main(String[] args) {
// قائمة بالأشخاص
List<Personne> personnes = Personnes.get();
// عدد مرات العرض
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(p -> {
System.out.println(p);
});
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(p -> {
System.out.println(p);
});
System.out.println("age < 28 ----------------------");
personnes.stream().filter(p -> p.getAge() < 28).forEach(System.out::println);
System.out.println("poids < 50 ----------------------");
personnes.stream().filter(p -> p.getPoids() < 50).forEach(System.out::println);
}
}
- الأسطر 14-16: تعرض الأشخاص الذين تقل أعمارهم عن 28 عامًا؛
- السطور 18-20: تعرض الأشخاص الذين يقل وزنهم عن 50؛
- السطر 22: يقوم بنفس وظيفة الأسطر 14-16 ولكن بطريقة أكثر إيجازًا؛
- السطر 24: يقوم بنفس ما تقوم به الأسطر 18-20 ولكن بطريقة أكثر إيجازًا؛
نتائج التنفيذ هي كما يلي:
5.5. مثال-05 - إنشاء Stream<T2> من Stream<T1>
 |
لننظر إلى الكود التالي:
package dvp.java8.streams;
import java.util.List;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple05 {
public static void main(String[] args) {
// قائمة الأشخاص
List<Personne> personnes = Personnes.get();
// عدد مرات العرض
System.out.println("Personne --> String ----------------------");
personnes.stream().map(p -> p.getNom()).forEach(System.out::println);
System.out.println("Personne --> Integer ----------------------");
personnes.stream().map(p -> p.getAge()).forEach(System.out::println);
}
}
- في السطر 13، الطريقة [Stream.map] لها التوقيع التالي:
 |
المعلمة الخاصة بالطريقة [Stream.map] هي مثيل للواجهة الوظيفية [Function] المذكورة في الفقرة 4.3، والتي تتمثل الطريقة الوحيدة المطلوب تنفيذها فيها في: R apply(T t). ونلاحظ أن الدالة [apply] تنتج نوعًا R انطلاقًا من نوع T. وبالتالي، فإن الطريقة [Stream.map] ستنتج تدفقًا Stream من النوع R انطلاقًا من تدفق من النوع T (ويُقصد بـ«تدفق من النوع T» هنا، في استخدام لغوي غير دقيق سنحتفظ به، تدفق عناصر من النوع T).
لندرس الآن كود المثال:
- السطر 14: من شخص p، لا نحتفظ إلا بالاسم. وبذلك نحصل على تدفق من نوع String؛
- السطر 14: من الشخص p، نحتفظ بالاسم فقط. وبذلك نحصل على تدفق من نوع Integer؛
النتائج التي تم الحصول عليها هي كما يلي:
5.6. المثال-06 - طرق أخرى لفئة Stream<T>
 |
نوضح بعضًا من الطرق الـ 39 للفئة Stream باستخدام الكود التالي:
package dvp.java8.streams;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import dvp.data.Personne;
import dvp.data.Personnes;
import java.util.Comparator;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.DoubleStream;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class Exemple06 {
// أداة التعيين jSON
static private ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// قائمة الأشخاص
List<Personne> personnes = Personnes.get();
// جميع الأشخاص
affiche("all", personnes);
// الشخص الأول
affiche("findFirst", personnes.stream().findFirst().get());
// أي شخص
affiche("findAny", personnes.stream().findAny().get());
// الأشخاص باستثناء الشخص الأول
affiche("skip 1", personnes.stream().skip(1L).collect(Collectors.toList()));
// أول شخصين
affiche("limit 2", personnes.stream().limit(2L).collect(Collectors.toList()));
// عدد الأشخاص
affiche("count", personnes.stream().count());
// الشخص الأكبر سنًا
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
// الشخص الأقل وزناً
affiche("poids min", personnes.stream().min(Comparator.comparingDouble(Personne::getPoids)).get());
// آخر شخص حسب الترتيب الأبجدي للأسماء
affiche("nom max", personnes.stream().max((p1, p2) -> p1.getNom().compareToIgnoreCase(p2.getNom())).get());
// العمر الإجمالي لجميع الأشخاص
affiche("âge total (reduce)", personnes.stream().map(p -> p.getAge()).reduce(0, (a1, a2) -> a1 + a2));
// الأشخاص مرتبة حسب العمر التصاعدي
affiche("personnes par âge croissant",
personnes.stream().sorted(Comparator.comparingInt(Personne::getAge)).collect(Collectors.toList()));
// هل يوجد أشخاص تزيد أعمارهم عن 100 عام؟
affiche("des personnes de + de 100 ans (anyMatch)", personnes.stream().anyMatch(p -> p.getAge() > 100));
// هل يبلغ عمر جميع الأشخاص 100 عامًا أو أقل؟
affiche("des personnes de + de 100 ans (noneMatch)", personnes.stream().noneMatch(p -> p.getAge() > 100));
// هل يبلغ عمر جميع الأشخاص أكثر من 8 سنوات؟
affiche("des personnes de + de 8 ans (allMatch)", personnes.stream().allMatch(p -> p.getAge() > 8));
// يتم تجميع الأشخاص حسب الجنس
affiche("personnes regroupées par sexe", personnes.stream().collect(Collectors.groupingBy(p -> p.getSexe())));
// حذف العناصر المكررة من قائمة
affiche("distinct", Stream.of(1, 2, 1).distinct().collect(Collectors.toList()));
// من Stream<Stream<T>>، نحولها إلى Stream<T>
affiche("flatMap", Stream.of(1, 2, 3).flatMap(i -> Stream.of(i, i + 10)).collect(Collectors.toList()));
// من Stream<Stream<Integer>>، نحولها إلى IntStream ونحسب مجموعها
affiche("flatMapToInt", Stream.of(1, 2, 3).flatMapToInt(i -> IntStream.of(i, i + 10)).sum());
// من Stream<Stream<Integer>>، نحولها إلى DoubleStream ثم إلى مصفوفة
affiche("flatMapToDouble", Stream.of(1, 2, 3).flatMapToDouble(i -> DoubleStream.of(i, i * 1.2)).toArray());
// القيمة القصوى لتيار من الأعداد الصحيحة
affiche("reduce Integer::max", Stream.of(1, 10, 8).reduce(Integer::max).get());
// الحد الأدنى لتيار من الأعداد المزدوجة
affiche("reduce Integer::min", Stream.of(1.5, 10.4, 8.9).reduce(Double::min).get());
// المتوسط لتيار من الأعداد الصحيحة
affiche("IntStream average", IntStream.of(1, 10, 8).average().getAsDouble());
// إحصائيات تدفق الأعداد الصحيحة
affiche("IntStream summaryStatistics", IntStream.of(1, 10, 8).summaryStatistics());
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- السطران 72 و75: يعرضان السلسلة jSON الخاصة بالمعلمة الثانية للطريقة؛
- السطر 24: يعرض السلسلة jSON لجميع الأشخاص. ونحصل على النتيجة التالية:
5.6.1. [findFirst]
// الشخص الأول
affiche("findFirst", personnes.stream().findFirst().get());
تُرجع الطريقة [findFirst] العنصر الأول من التدفق إن وجد. وتكون توقيعها كما يلي:
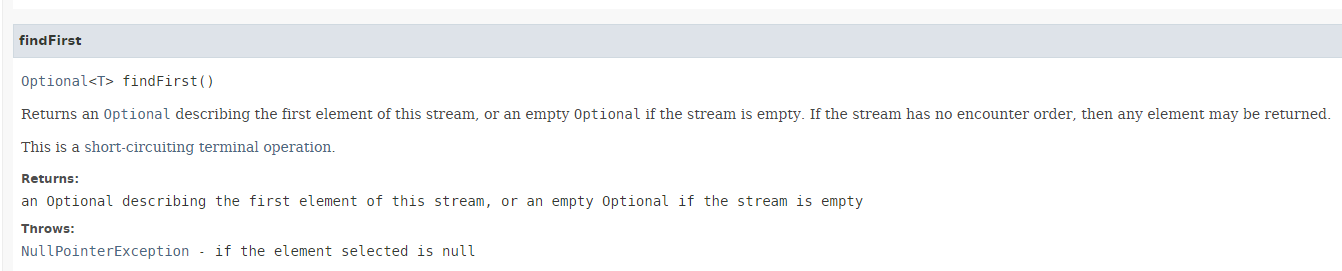 |
النتيجة من النوع Optional<T>، وهو نوع تم تقديمه في Java 8:
 |
تسمح فئة Optional<T> بإدارة المؤشرات null بطريقة مختلفة. يمكن لأي دالة من المفترض أن تُرجع نوعًا T قد يأخذ القيمة null أن تقرر إرجاع نوع Optional<T>. تسمح الطريقة [Optional<T>.isPresent()] بمعرفة ما إذا كانت الطريقة قد أعادت قيمة أم لا. يوضح الكود التالي [Exemple06b] جزءًا من طريقة عمل Optional<T>:
package dvp.java8.streams;
import java.util.Optional;
import com.fasterxml.jackson.core.JsonProcessingException;
public class Exemple06b {
public static void main(String[] args) throws JsonProcessingException {
// اختياري بدون قيمة
Optional<Integer> o1 = m1();
System.out.println(o1.isPresent());
affiche(o1);
// خيار اختياري مع قيمة
Optional<Integer> o2 = m2();
System.out.println(o2.isPresent());
affiche(o2);
}
private static void affiche(Optional<Integer> o1) {
try {
// يتم استرداد قيمة الخيار الاختياري
// يلقي استثناءً واحدًا في حالة عدم وجود قيمة
System.out.println(o1.get());
} catch (Throwable th) {
System.out.printf("%s : %s%n", th.getClass().getName(), th.getMessage());
}
}
public static Optional<Integer> m1() {
// لا توجد قيمة
return Optional.empty();
}
public static Optional<Integer> m2() {
// قيمة
return Optional.of(10);
}
}
النتائج التي تم الحصول عليها هي كما يلي:
false
java.util.NoSuchElementException : No value present
true
10
لنعد إلى الكود التوضيحي للطريقة [findFirst]:
// الشخص الأول
affiche("findFirst", personnes.stream().findFirst().get());
- السطر 2: لتبسيط الكود، نستخدم الطريقة [get] على Optional<Personne> الناتج عن الطريقة [findFirst]. والكود الصحيح يتطلب استدعاء الطريقة [Optional<Personne>.isPresent()] قبل استدعاء الطريقة [get]؛
والنتيجة التي تم الحصول عليها هي كما يلي:
5.6.2. [findAny]
// أي شخص
affiche("findAny", personnes.stream().findAny().get());
تتميز الطريقة [findAny] بالتوقيع التالي:
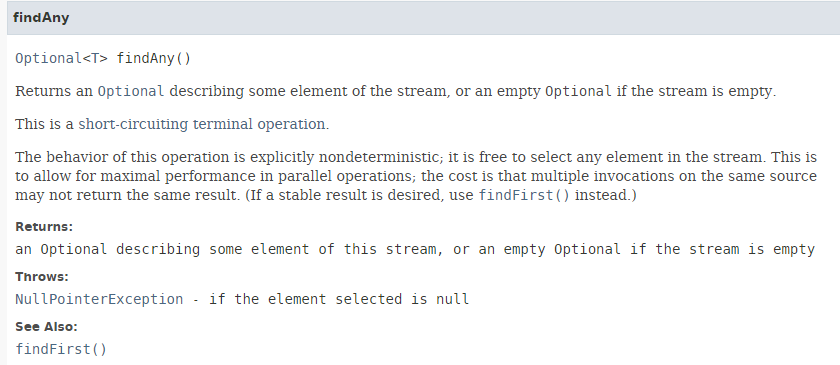 |
يمكن للطريقة [findAny] عرض أي عنصر من عناصر التدفق. أثناء الاختبارات، لوحظ أن التنفيذ التسلسلي يعرض العنصر الأول من التدفق، في حين أن التنفيذ المتوازي يمكنه فعليًا عرض أي عنصر. ويوضح ذلك الكود التالي [Exemple06c]:
package dvp.java8.streams;
import java.util.List;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import dvp.data.Personne;
import dvp.data.Personnes;
public class Exemple06c {
// أداة التعيين jSON
static private ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// قائمة بالأشخاص
List<Personne> personnes = Personnes.get();
// جميع الأشخاص
affiche("all", personnes);
// أي شخص
affiche("findAny parallèle", personnes.stream().parallel().findAny().get());
// أي شخص
affiche("findAny séquentiel", personnes.stream().findAny().get());
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- السطر 22: findAny يُنفَّذ بشكل متوازٍ؛
- السطر 24: findAny يُنفَّذ بشكل تسلسلي؛
النتائج التي تم الحصول عليها هي كما يلي:
- السطر 4: أدى التنفيذ المتوازي إلى إرجاع العنصر 2 من قائمة الأشخاص. كان من الممكن أن يكون عنصرًا آخر؛
- السطر 6: أدى التنفيذ التسلسلي إلى إرجاع العنصر الأول من قائمة الأشخاص؛
لا يبدو أن استخدام الطريقة [findAny] له معنى إلا في المعالجة المتوازية لتدفق البيانات.
5.6.3. [skip]
// الأشخاص باستثناء الأول
affiche("skip 1", personnes.stream().skip(1L).collect(Collectors.toList()));
الطريقة [skip] لها التوقيع التالي:
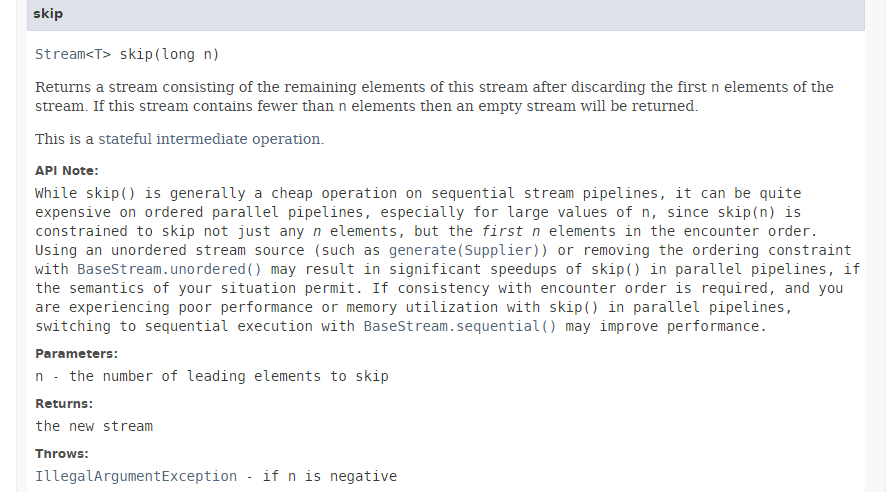 |
تتجاهل الطريقة [skip] العناصر n الأولى من التدفق. وكما هو موضح في الوثائق أعلاه، فإن تنفيذ هذه الطريقة بشكل متوازٍ لا يحقق سوى مكاسب ضئيلة في الأداء، بل وقد يؤدي إلى انخفاضه. ففي الواقع، لتجاهل العناصر n الأولى، تضطر الخيوط إلى التنسيق فيما بينها، مما يلغي المكاسب في الأداء الناتجة عن التوازي.
تُرجع الطريقة [skip] تدفقًا من النوع Stream<Personne>، والذي يتم تحويله إلى النوع List<Personne> بواسطة الطريقة [collect] التي تكون توقيعها كما يلي:
 |
تقبل الطريقة [collect] كمُعرِّف مثيلًا من النوع [Collector] الذي تتسم توقيعاته بالتعقيد. توجد تطبيقات مُحدَّدة مسبقًا للنوع [Collector]، والتي غالبًا ما تسمح بتجنب تنفيذها بنفسك. التنفيذ المستخدم هنا هو [Collectors.toList()]. [Collectors] هي فئة تحتوي على العديد من الطرق الثابتة التي تنفذ النوع [Collector<T,A,R>]. وهذا هو المكان الأول الذي يجب البحث فيه عندما نريد تحويل Stream إلى مجموعة قياسية في Java:
 |
وسنستخدم بعض هذه الطرق لاحقًا.
يؤدي تنفيذ البرنامج إلى النتيجة التالية:
تم حذف العنصر الأول من القائمة (jean).
5.6.4. [limit]
// أول شخصين
affiche("limit 2", personnes.stream().limit(2L).collect(Collectors.toList()));
تتميز الطريقة [limit] بالتوقيع التالي:
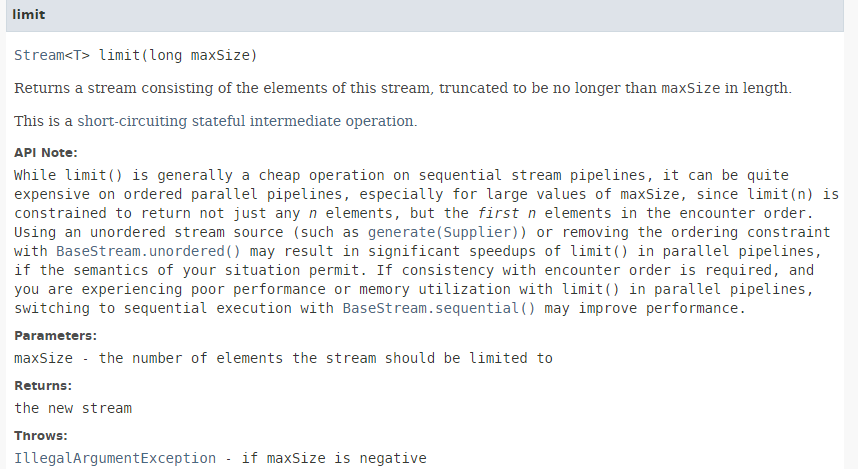 |
تسمح الطريقة [limit] بالاحتفاظ فقط بأول n عناصر من التدفق. وهي غير مناسبة للمعالجة المتوازية.
يؤدي تنفيذها إلى النتيجة التالية:
5.6.5. [count]
// عدد الأشخاص
affiche("count", personnes.stream().count());
تتميز الدالة [count] بالتوقيع التالي:
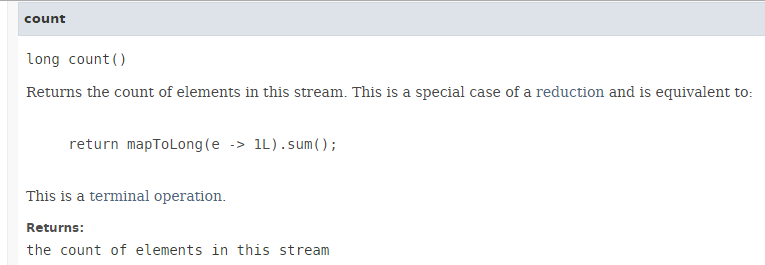 |
تُرجع الطريقة [count] عدد عناصر Stream. لا يؤدي التنفيذ المتوازي لهذه الطريقة إلى تحسن في الأداء كما يوضح الكود التالي (مثال 06d1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.stream.Stream;
public class Exemple06d1 {
public static void main(String[] args) {
final long limite = 10_000_000L;
// عدد المعالجات
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// قائمة الأرقام
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// عدد الأرقام - الطريقة التسلسلية
Stream<Long> sNombres = nombres.stream();
début = new Date().getTime();
long count = sNombres.count();
System.out.printf("comptage séquentiel : compteur=%s, durée (ms)=%s%n", count, new Date().getTime() - début);
}
}
- الأسطر 11-22: يتم إنشاء Stream مكون من 10 ملايين عدد؛
- الأسطر 22-24: يتم حساب عدد عناصر Stream؛
يُعطِي التنفيذ النتيجة التالية:
إذا استبدلنا السطر 22 من الكود بالسطر التالي (مثال 06d2):
Stream<Long> sNombres = nombres.stream().parallel();
نحصل على النتائج التالية:
5.6.6. [max, min]
// الشخص الأكبر سنًا
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
تتميز الطريقة [max] بالتوقيع التالي:
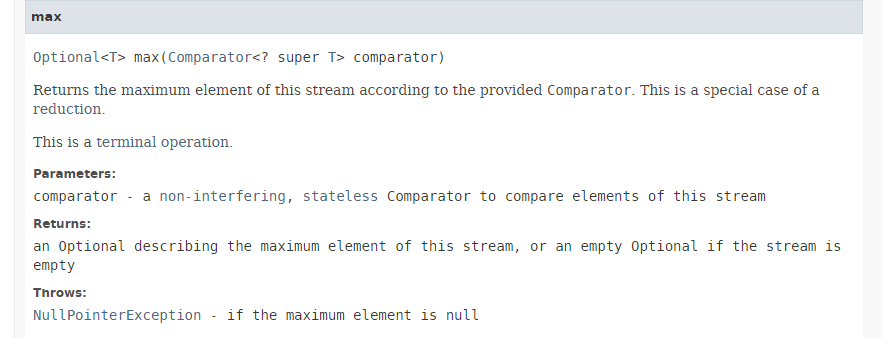 |
تُرجع الطريقة [max] القيمة القصوى لتدفق ما باستخدام المقارن الذي يتم تمريره إليها كمعلمة. Comparator هي واجهة وظيفية الطريقة الوحيدة التي يجب تنفيذها فيها لها التوقيع التالي: int compare (T o1, T o2). يجب أن تُرجع هذه الطريقة -1 إذا كان o1 < o2، و0 إذا كان o2 يساوي o1.equals، و+1 إذا كان o1 > o2. تحتوي الواجهة الوظيفية Comparator على العديد من الطرق الثابتة الافتراضية التي تنفذ الواجهة Comparator للحالات الأكثر شيوعًا. وهكذا في التعليمات التالية:
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
نستخدم الطريقة الثابتة [Comparator.comparingInt] التي تكون صيغتها كما يلي:
 |
النوع ToIntFunction هو واجهة وظيفية:
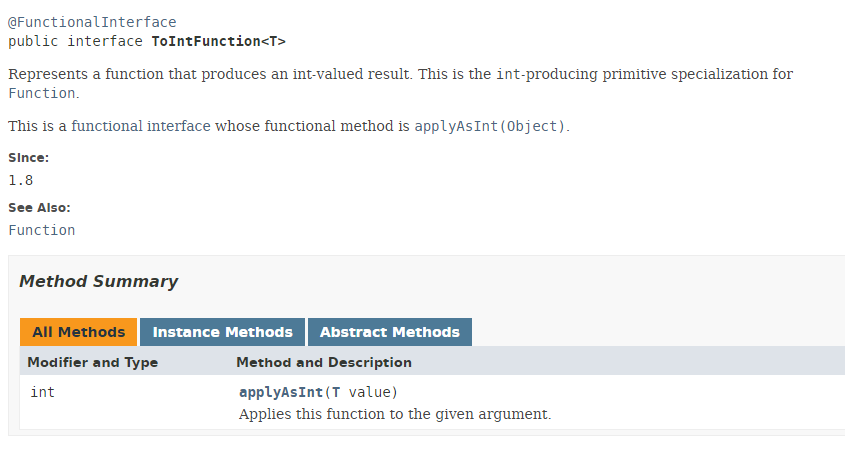 |
تُنتج الطريقة [applyAsInt] الخاصة بالواجهة الوظيفية ToIntFunction نوعًا int من نوع T. لنعد إلى الكود الخاص بنا:
affiche("age max", personnes.stream().max(Comparator.comparingInt(Personne::getAge)).get());
يجب أن يكون المعامل الفعلي للطريقة [Comparator.comparingInt] هنا عبارة عن لامدا Personne --> int. نمرر مرجع الطريقة [Personne.getAge] التي تحمل بالفعل هذا التوقيع. في النهاية، سنحصل على الشخص الذي يبلغ أكبر عمر. نحصل على نوع Optional<Personne> ونستخرج القيمة منه باستخدام الطريقة [Optional.get]. ونحصل على النتيجة التالية:
لا يؤدي حساب max بالتوازي إلى أي مكاسب في الأداء كما يوضح المثال التالي: (مثال06e1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Date;
import java.util.List;
import java.util.Random;
import java.util.stream.Stream;
public class Exemple06e1 {
public static void main(String[] args) {
// البيانات
// final long limit = 100L;
// final boolean verbose = true;
final long limite = 10_000_000L;
final boolean verbose = false;
// عدد المعالجات
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// قائمة الأرقام
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextLong());
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// الحد الأقصى للأرقام - الطريقة التسلسلية
Stream<Long> sNombres = nombres.stream();
Comparator<Long> compLong = (l1, l2) -> {
if (verbose) {
// خيط
System.out.printf("[%s]", Thread.currentThread().getName());
}
// المقارنة
long v1 = l1.longValue();
long v2 = l2.longValue();
if (v1 < v2) {
return -1;
} else {
if (v1 == v2) {
return 0;
} else {
return +1;
}
}
};
début = new Date().getTime();
// الحد الأقصى لطول = sNombres.max(Comparator.naturalOrder()).get();
long max = sNombres.max(compLong).get();
System.out.printf("%nmax séquentiel : max=%s, durée (ms)=%s%n", max, new Date().getTime() - début);
}
}
- السطر 29: لدينا تدفق من limite أرقام عشوائية من النوع Long؛
- الأسطر 30-47: المتغير لامدا compLong يُنفذ الواجهة Comparator<Long>. يتم عادةً تنفيذ هذه الواجهة بواسطة الطريقة [Comparator.naturalOrder()] في السطر 49. لكننا هنا نريد عرض مؤشر ترابط التنفيذ (السطور 31-33). ولذلك نقوم بتنفيذ الواجهة بأنفسنا؛
- السطر 50: البحث عن max؛
ونحصل على النتائج التالية:
 |
وإذا استبدلنا الآن السطر 27 بالسطر التالي (مثال 06e2):
Stream<Long> sNombres = nombres.stream().parallel();
نحصل على النتائج التالية:
 |
وبالتالي، كان التنفيذ المتوازي أبطأ. وإذا انتقلنا إلى 10 ملايين عدد باستخدام verbose=false، نحصل على النتائج التالية:
بالنسبة للتنفيذ التسلسلي:
بالنسبة للتنفيذ المتوازي الذي يظل أبطأ.
نستخدم الطريقة [Stream.min] بطريقة مماثلة:
// الشخص الأقل وزنًا
affiche("poids min", personnes.stream().min(Comparator.comparingDouble(Personne::getPoids)).get());
5.6.7. [reduce]
// العمر الإجمالي لجميع الأشخاص
affiche("âge total (reduce)", personnes.stream().map(p -> p.getAge()).reduce(0, (a1, a2) -> a1 + a2));
تم عرض الطريقة [reduce] في الفقرة 5.3. السطر 2 أعلاه يحسب مجموع أعمار جميع الأشخاص. والنتيجة هي كما يلي:
5.6.8. [sorted]
// الأشخاص مرتبة حسب العمر التصاعدي
affiche("personnes par âge croissant",
personnes.stream().sorted(Comparator.comparingInt(Personne::getAge)).collect(Collectors.toList()));
// الأشخاص مرتبة حسب الترتيب الأبجدي للأسماء
List<Personne> lPersonnes=personnes.stream().sorted((p1, p2) -> p1.getNom().compareTo(p2.getNom())).collect(Collectors.toList());
affiche("personnes par ordre alphabétique des noms", lPersonnes);
الطريقة [sorted] (السطران 3 و5) لها التوقيع التالي:
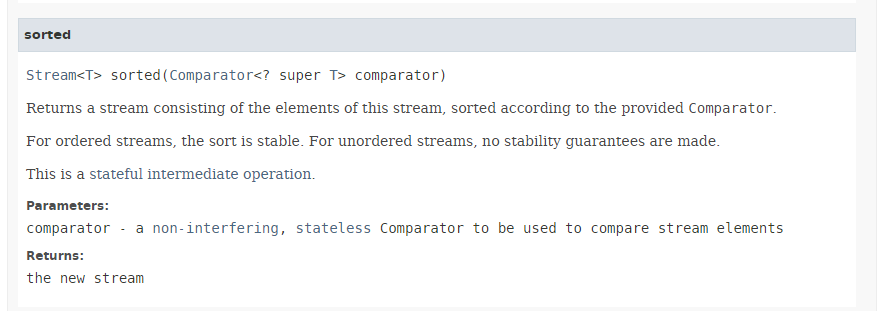 |
تقبل الطريقة [sorted] كمعلمة النوع [Comparator] الموصوف في الفقرة 5.6.6 بالنسبة للطريقتين min و max. وهي تسمح بفرز نوع Stream وفقًا لترتيب المقارن الذي يتم تمريره كمعلمة. وقد رأينا أن الواجهة [Comparator] توفر عدة طرق ثابتة افتراضية تُنفِّذ المقارنات الشائعة، لا سيما مقارنة الأعداد وسلاسل الأحرف. هنا، نستخدم الطريقة [Comparator.comparingInt] التي تقبل كمعلمة نوع ToIntFunction، وهو واجهة وظيفية للطريقة [applyAsInt] ذات التوقيع التالي: int applyAsInt(T t). هنا، المعلمة الفعلية التي تم تمريرها إلى الطريقة [Comparator.comparingInt] في السطر 3 هي مرجع الطريقة [Personne.age] التي تُرجع عمر الشخص.
لا توفر واجهة [Comparator] أي طرق ثابتة لمقارنة سلاسل الأحرف. في السطر 5، نقوم بأنفسنا بإنشاء دالة لامدا تُنفِّذ الطريقة الوحيدة في هذه الواجهة: int compare(T t1, T t2)
(p1, p2) -> p1.getNom().compareTo(p2.getNom())
يقوم هذا اللامدا بمقارنة أسماء الأشخاص. النتائج التي تم الحصول عليها هي كما يلي:
لا يبدو أن التنفيذ المتوازي لعملية الفرز ممكن، كما يوضح الكود التالي (مثال 06f1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.Date;
import java.util.List;
import java.util.Random;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class Exemple06f1 {
// أداة التعيين jSON
static ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// البيانات
final long limite = 100L;
final boolean verbose = true;
// الحد النهائي الطويل = 10_000_000L؛
// final boolean verbose = false;
// عدد المعالجات
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// قائمة الأرقام
long début = new Date().getTime();
List<Integer> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextInt(1000));
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// فرز الأرقام - الطريقة التسلسلية
Stream<Integer> sNombres = nombres.stream();
début = new Date().getTime();
Comparator<Integer> compInt = (i1, i2) -> {
if (verbose) {
// خيط
System.out.printf("[%s]", Thread.currentThread().getName());
}
// المقارنة
int v1 = i1.intValue();
int v2 = i2.intValue();
if (v1 < v2) {
return +1;
} else {
if (v1 == v2) {
return 0;
} else {
return -1;
}
}
};
if (verbose) {
affiche("nombres", sNombres.sorted(compInt).collect(Collectors.toList()));
}
System.out.printf("tri séquentiel : durée (ms)=%s%n", new Date().getTime() - début);
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- الأسطر 30-36: يتم إنشاء تدفق من الأرقام العشوائية limite؛
- السطر 32، يتم تمرير دالة لامدا compInt (الأسطر 38-55) إلى الطريقة [sorted]. تقوم دالة لامدا هذه بفرز الأرقام بترتيب تنازلي وعرض الخيط الذي يقوم بتنفيذها.
النتائج التي تم الحصول عليها هي كما يلي:
 |
إذا استبدلنا في الكود السابق السطر 36 بالسطر التالي (مثال 06f2):
Stream<Integer> sNombres = nombres.stream().parallel();
نحصل على النتائج التالية:
 |
نكتشف أنه، بشكل مثير للدهشة، تم فرز تدفق الأرقام باستخدام خيط واحد فقط. لم يكن هناك أي توازي. أم أن هناك شيئًا ما يفوتني؟
5.6.9. [anyMatch, noneMatch, allMatch]
// هل يوجد أشخاص تزيد أعمارهم عن 100 عام؟
affiche("des personnes de + de 100 ans (anyMatch)", personnes.stream().anyMatch(p -> p.getAge() > 100));
// هل يبلغ عمر جميع الأشخاص 100 عامًا أو أقل؟
affiche("des personnes de + de 100 ans (noneMatch)", personnes.stream().noneMatch(p -> p.getAge() > 100));
// هل عمر جميع الأشخاص أكثر من 8 سنوات؟
affiche("des personnes de + de 8 ans (allMatch)", personnes.stream().allMatch(p -> p.getAge() > 8));
في الأسطر 2 و4 و6، تأخذ الطرق [anyMatch, noneMatch, allMatch] كمعلمة نوعًا Predicate الموصوف في الفقرة 4.2. وبالتالي، فإنها تقوم بعملية تصفية. وتُرجع الطرق الثلاث جميعها قيمة منطقية:
- تُرجع الدالة anyMatch القيمة true إذا كان هناك عنصر واحد على الأقل من نوع Stream يستوفي شروط التصفية؛
- يُنتج noneMatch القيمة true إذا لم يكن هناك أي عنصر في Stream يستوفي شروط التصفية؛
- تُنتج allMatch القيمة true إذا كانت جميع عناصر Stream تستوفي شروط المرشح؛
النتائج التي تم الحصول عليها هي كما يلي:
5.6.10. [collect(Collectors.groupingBy)]
// يتم تجميع الأشخاص حسب الجنس
affiche("personnes regroupées par sexe", personnes.stream().collect(Collectors.groupingBy(p -> p.getSexe())));
تم عرض الطريقة [collect] في الفقرة 5.6.3. ومعلمتها عبارة عن تنفيذ للواجهة [Collector]. توفر الفئة [Collectors] عددًا من الطرق الثابتة التي تنفذ الواجهة [Collector]. لقد استخدمنا حتى الآن الطريقة [Collectors.toList()]. ونستخدم هنا الطريقة الثابتة [Collectors.groupingBy] التي تنشئ قاموسًا استنادًا إلى Stream. وتكون صيغتها كما يلي:
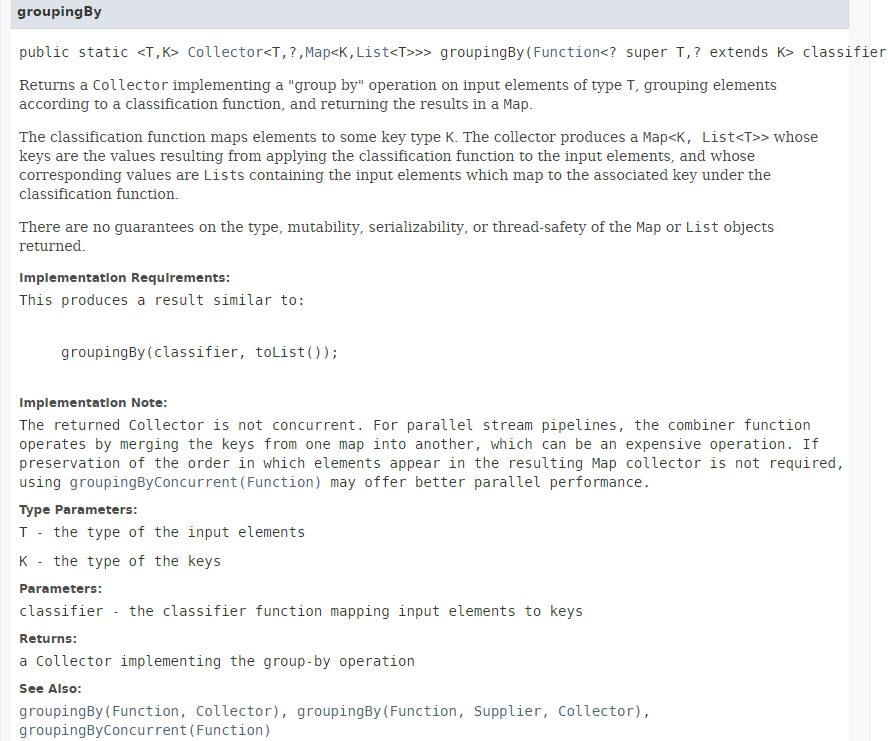 |
تُنشئ الطريقة [groupingBy] نوعًا Map<K,List<T>> انطلاقًا من نوع Stream<T>. يتم توفير المفتاح K بواسطة معلمة الطريقة [groupingBy] من النوع Function<T,K> التي تحتوي على طريقة واحدة بتوقيع: K apply(T t). إذا أردنا إنشاء قاموس مفهرس حسب جنس الأشخاص، فيجب توفير دالة تولد الجنس بناءً على شخص ما. هنا، نمرر كمعلمة فعلية للطريقة [groupingBy]، مرجع الطريقة [Personne.getSexe]. النتائج التي تم الحصول عليها هي التالية:
في السطر 2، لدينا السلسلة jSON من قاموس مفهرس بواسطة مفتاحين: HOMME و FEMME.
لا يؤدي الحساب المتوازي إلى تحسين في الأداء كما يوضح المثال التالي (مثال06g1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.function.Function;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class Exemple06g1 {
// أفضل jSON
static ObjectMapper jsonMapper = new ObjectMapper();
public static void main(String[] args) throws JsonProcessingException {
// البيانات
final long limite = 100L;
final boolean verbose = true;
// الحد الأقصى للطول النهائي = 10_000_000L؛
// final boolean verbose = false;
// عدد المعالجات
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// قائمة الأرقام
long début = new Date().getTime();
List<Integer> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(new Random().nextInt(1000));
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// تجميع الأرقام في مجموعات من مائة - الطريقة التسلسلية
Stream<Integer> sNombres = nombres.stream();
Function<Integer, Integer> groupByCent = n -> {
if (verbose) {
System.out.printf("[%s]", Thread.currentThread().getName());
}
return n / 100;
};
début = new Date().getTime();
// Map<Integer, List<Integer>> lNombres = sNombres.collect(Collectors.groupingBy(عدد -> عدد / 100));
Map<Integer, List<Integer>> lNombres = sNombres.collect(Collectors.groupingBy(groupByCent));
System.out.printf("%nregroupement séquentiel : durée (ms)=%s%n", new Date().getTime() - début);
// النتائج
if (verbose) {
affiche("nombres regroupés", lNombres);
}
}
public static <T> void affiche(String message, T value) throws JsonProcessingException {
System.out.println(String.format("%s ----", message));
System.out.println(jsonMapper.writeValueAsString(value));
}
}
- الأسطر 23-38: إنشاء تدفق من أرقام limite؛
- السطر 47، يتم تجميع الأرقام في مجموعات من مائة. تُستخدم دالة لامدا في الأسطر 39-44 لعرض مؤشر ترابط التنفيذ؛
نتائج التنفيذ هي كما يلي:
 |
إذا استبدلنا في الكود السطر 38 بالسطر التالي (مثال 06g2):
Stream<Integer> sNombres = nombres.stream().parallel();
نحصل على النتائج التالية:
 |
نلاحظ أن التنفيذ المتوازي لعملية التجميع أدى إلى انخفاض الأداء.
5.6.11. [distinct]
// إزالة العناصر المكررة من قائمة
affiche("distinct", Stream.of(1, 2, 1).distinct().collect(Collectors.toList()));
تتميز الدالة [distinct] بالتوقيع التالي:
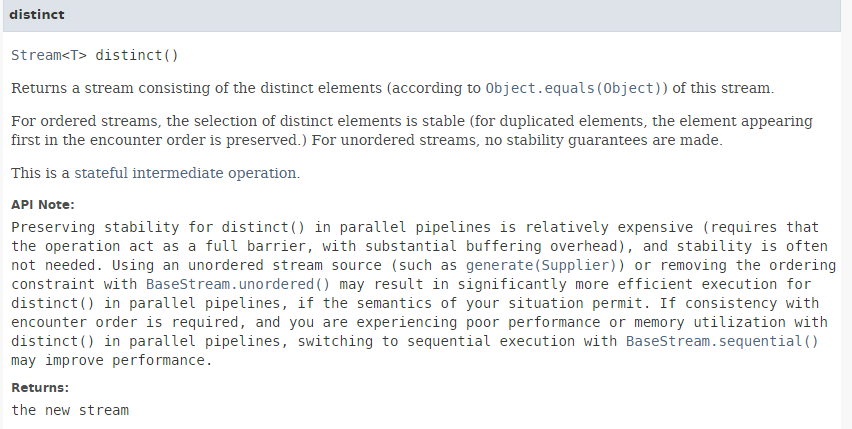 |
وهي تسمح بإزالة التكرارات من التدفق. الطريقة [Stream.of] (السطر 2) لها التوقيع التالي:
 |
وهي تسمح بإنشاء Stream استنادًا إلى القيم المُقدَّمة صراحةً. وفيما يلي نتائج التنفيذ:
5.6.12. [flatMap]
// من Stream<Stream<T>>، نحصل على Stream<T>
affiche("flatMap", Stream.of(1, 2, 3).flatMap(i -> Stream.of(i, i + 10)).collect(Collectors.toList()));
تتميز الطريقة [flatMap] بالتوقيع التالي:
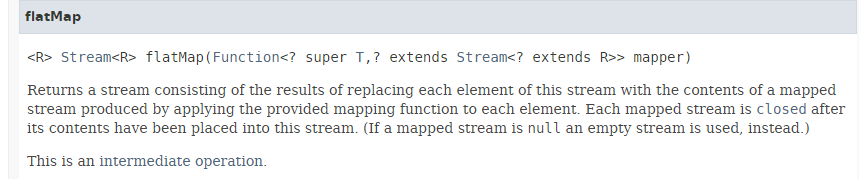  |
تقبل الطريقة [flatMap] كمعلمة دالة:
- تقبل كمعلمة عنصرًا من النوع T الخاص بـ Stream؛
- تُرجع تدفقًا من النوع Stream<R>؛
وإذا استُخدمت، بدلاً من الطريقة [flatMap]، استخدمنا الدالة [map] الموصوفة في الفقرة 5.5، لكانت النتيجة نوعًا من نوع Stream<Stream<R>> حيث كان كل عنصر من نوع T في التدفق الأولي سيؤدي إلى إنشاء عنصر من نوع Stream<R>. أما الطريقة [flatMap] فتنتج نوعًا Stream<R>. فهي تعمل على تسطيح (flatten) التدفقات المختلفة Stream<R> لتصبح تدفقًا واحدًا. وهذا ما تظهره نتائج تنفيذ الكود السابق:
توجد متغيرات متخصصة من [flatMap]:
// من Stream<IntStream>، نحولها إلى IntStream ونحسب مجموعها
affiche("flatMapToInt", Stream.of(1, 2, 3).flatMapToInt(i -> IntStream.of(i, i + 10)).sum());
تتميز الطريقة [flatMapToInt] بالتوقيع التالي:
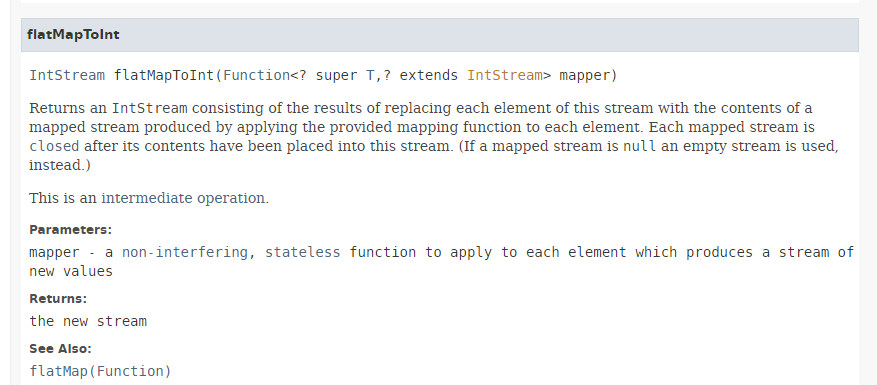 |
تقبل الطريقة [flatMapToInt] كمعلمة دالة تنتج النوع IntStream التالي:
 |
IntStream هو تدفق من int. ويُفضل هذا النوع على النوع Stream<Integer> لأن معالجته تتجنب عمليات التعبئة/التفريغ بين النوعين Integer و int. تتضمن هذه الواجهة العديد من الأساليب الخاصة بنوع Stream<T> وتضيف أساليب أخرى، منها الأسلوب [sum] المذكور أعلاه الذي يقوم بجمع عناصر IntStream.
يوضح الكود التالي استخدام الطريقة المماثلة [flatMapToDouble]:
// من Stream<DoubleStream>، نحولها إلى DoubleStream ثم إلى مصفوفة
affiche("flatMapToDouble", Stream.of(1, 2, 3).flatMapToDouble(i -> DoubleStream.of(i, i * 1.2)).toArray());
تسمح الطريقة [DoubleStream.toArray] بالانتقال من النوع DoubleStream إلى النوع double[].
وفيما يلي النتائج لهذين المثالين:
يوضح المثال التالي مكاسب الأداء التي تم تحقيقها بالانتقال من النوع Stream<Long> إلى النوع LongStream (مثال06i1):
package dvp.java8.streams;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class Exemple06i1 {
public static void main(String[] args) {
final long limite = 10_000_000L;
// عدد المعالجات
System.out.printf("La JVM a détecté [%s] coeurs sur votre machine%n", Runtime.getRuntime().availableProcessors());
// قائمة الأرقام
long début = new Date().getTime();
List<Long> nombres = new ArrayList<>();
for (long i = 0; i < limite; i++) {
nombres.add(i);
}
System.out.printf("création de la liste des %s nombres en %s ms%n", limite, new Date().getTime() - début);
// مجموع الأرقام - الطريقة التسلسلية
début = new Date().getTime();
long somme = nombres.stream().reduce(0L, (s, i) -> s + i);
System.out.printf("somme séquentielle du Stream<Integer> : somme=%s, durée (ms)=%s%n", somme, new Date().getTime() - début);
}
}
- السطر 22: حساب مجموع تدفق أرقام من النوع Long؛
ونحصل على النتائج التالية:
الآن، لنستبدل السطر 22 بالسطر التالي (مثال 06i2):
long somme = nombres.stream().mapToLong(n -> n.longValue()).sum();
تسمح لنا الطريقة Stream<Integer>.mapToLong بالحصول على دفق من النوع LongStream من العناصر ذات النوع البدائي long، والتي نجمعها بعد ذلك باستخدام الدالة sum. ونحصل عندئذٍ على النتائج التالية:
ويكون تحسن الأداء واضحًا.
5.6.13. طرق تدفق الأعداد الأولية
// القيمة القصوى لتدفق من نوع int
affiche("IntStream max", IntStream.of(1, 10, 8).max());
// الحد الأدنى لسلسلة من الأعداد من النوع double
affiche("DoubleStream min", DoubleStream.of(1.5, 10.4, 8.9).min());
// المتوسط لسلسلة من الأعداد الصحيحة
affiche("IntStream average", IntStream.of(1, 10, 8).average().getAsDouble());
// إحصائيات تدفق من نوع int
affiche("IntStream summaryStatistics", IntStream.of(1, 10, 8).summaryStatistics());
توفر تدفقات القيم الأولية (int، long، double) طرقًا ملائمة لهذه الأنواع. ونتيجة تنفيذ الكود السابق هي كما يلي:
- نتيجة السطر 2 من الكود هي نوع OptionalInt مشابه للنوع Optional<Integer>. يمكن الحصول على القيمة المخزنة في هذا الكائن باستخدام الطريقة [getAsInt()]. يمكن التحقق من وجود قيمة باستخدام الطريقة [isPresent()]. لا يعني السطر 2 من النتائج أن الفئة [OptionalInt] تحتوي على حقول تسمى [asInt, present]. بشكل افتراضي، تستخدم المكتبة jSON جميع الطرق العامة getX و isY للكائن المراد تسلسله إلى jSON. وهنا، توجد بالفعل طريقة [getAsInt] وطريقة أخرى [isPresent] دون أن توجد الحقول [asInt, present] نفسها؛
- ونتيجة السطر 4 من الكود هي نوع OptionalDouble مشابه لنوع Optional<Double>؛
- نتيجة السطر 6 من الكود هي نوع OptionalDouble يمكن الحصول على قيمته باستخدام الطريقة [getAsDouble()]. تحسب الطريقة [average] متوسط تدفق الأرقام؛
- نتيجة السطر 8 من الكود هي من النوع IntSummaryStatistics المُعرَّف على النحو التالي:
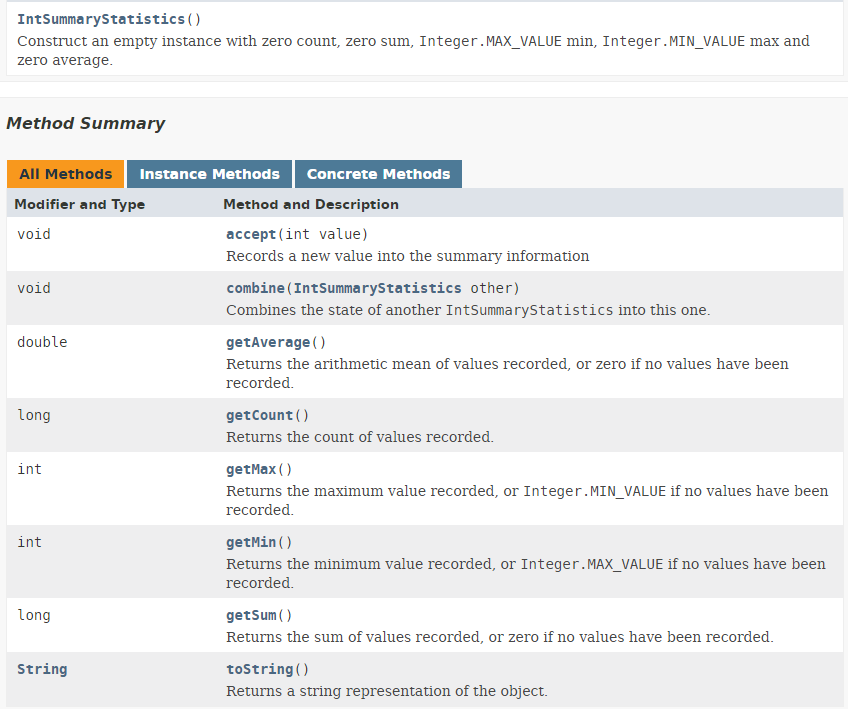 |
ونلاحظ أن الكائن IntSummaryStatistics الناتج يقدم معلومات مختلفة عن تدفق الأرقام، مثل عدد القيم، والمجموع، والقيمة القصوى، والقيمة الدنيا، والمتوسط.