1. مقدمة
1.1. الأهداف
ملف PDF الخاص بالوثيقة متاح |HERE|.
أمثلة المستند متاحة |HERE|.
نقترح هنا اكتشاف المفاهيم الرئيسية لاستمرارية البيانات باستخدام API JPA (Java Persistence Api). بعد قراءة هذا المستند واختبار الأمثلة الواردة فيه، من المفترض أن يكون القارئ قد اكتسب الأساسيات اللازمة ليتمكن بعد ذلك من العمل بمفرده.
تعد API JPA حديثة. لم تتوفر إلا بدءًا من JDK 1.5. وتحتل طبقة JPA مكانها في بنية متعددة الطبقات. لنأخذ على سبيل المثال بنية شائعة إلى حد ما، وهي البنية ثلاثية الطبقات:
 |
- الطبقة [1]، المسماة هنا [ui] (واجهة المستخدم) هي الطبقة التي تتفاعل مع المستخدم، عبر واجهة رسومية Swing، أو واجهة وحدة التحكم، أو واجهة الويب. وتتمثل مهمتها في توفير البيانات الواردة من المستخدم إلى الطبقة [2] أو عرض البيانات المقدمة من الطبقة [2] على المستخدم.
- الطبقة [2]، والمشار إليها هنا بـ [metier]، هي الطبقة التي تطبق القواعد المعروفة باسم قواعد العمل، c.a.d. المنطق الخاص بالتطبيق، دون الاهتمام بمصدر البيانات التي يتم تزويده بها، أو وجهة النتائج التي ينتجها.
- الطبقة [3]، المسماة هنا [dao] (كائن الوصول إلى البيانات) هي الطبقة التي تزود الطبقة [2] ببيانات مسجلة مسبقًا (ملفات، قواعد بيانات، ...) وتسجل بعض النتائج التي توفرها الطبقة [2].
- الطبقة [JDBC] هي الطبقة القياسية المستخدمة في Java للوصول إلى قواعد البيانات. وهذا ما يُسمى عادةً برنامج تشغيل Jdbc لـ SGBD.
وقد بُذلت جهود متعددة لتسهيل كتابة هذه الطبقات المختلفة من قبل المطورين. ومن بين هذه الجهود، يهدف JPA إلى تسهيل كتابة الطبقة [dao]، وهي الطبقة التي تدير ما يُعرف بالبيانات الدائمة، ومن هنا جاء اسم API (Java Persistence Api). أحد الحلول التي حققت نجاحًا كبيرًا في هذا المجال خلال السنوات الأخيرة هو Hibernate:
 |
تقع الطبقة [Hibernate] بين الطبقة [dao] التي كتبها المطور والطبقة [Jdbc]. Hibernate هو أداة ORM (تعيين الكائنات العلائقية)، وهي أداة تربط بين عالم قواعد البيانات العلائقية وعالم الكائنات التي تعالجها Java. لم يعد مطور الطبقة [dao] يرى الطبقة [Jdbc] ولا جداول قاعدة البيانات التي يريد استغلال محتواها. إنه لا يرى سوى صورة الكائن لقاعدة البيانات، وهي صورة الكائن التي توفرها الطبقة [Hibernate]. يتم الربط بين جداول قاعدة البيانات والكائنات التي تعالجها الطبقة [dao] بشكل أساسي بطريقتين:
- من خلال ملفات التكوين من النوع XML
- عن طريق تعليقات Java في الكود، وهي تقنية متاحة فقط منذ الإصدار JDK 1.5
الطبقة [Hibernate] هي طبقة تجريدية تهدف إلى أن تكون شفافة قدر الإمكان. والهدف المثالي هو أن يتمكن مطور طبقة [dao] من تجاهل تمامًا أنه يعمل مع قاعدة بيانات. وهذا أمر ممكن إذا لم يكن هو من يكتب التكوين الذي يشكل الجسر بين عالم العلاقات وعالم الكائنات. وتكوين هذا الجسر أمر دقيق إلى حد ما ويتطلب قدرًا معينًا من الخبرة.
يُطلق على طبقة الكائنات [4]، وهي صورة لطبقة BD، اسم "سياق الاستمرارية". تقوم طبقة [dao] التي تعتمد على Hibernate بإجراء إجراءات الاستمرارية (CRUD، إنشاء - قراءة - تحديث - حذف) على كائنات سياق الاستمرارية، وهي إجراءات يترجمها Hibernate إلى أوامر SQL. بالنسبة لإجراءات الاستعلام عن قاعدة البيانات (SQL Select)، يوفر Hibernate للمطور لغة HQL (لغة استعلام Hibernate) لاستعلام سياق الاستمرارية [4] وليس BD نفسها.
Hibernate شائع ولكنه معقد لإتقانه. منحنى التعلم الذي غالبًا ما يُصوَّر على أنه سهل هو في الواقع حاد إلى حد ما. بمجرد أن يكون لدينا قاعدة بيانات تحتوي على جداول ذات علاقات واحد إلى عدة أو عدة إلى عدة، فإن تكوين الجسر العلائقي/الكائنات لا يكون في متناول أي مبتدئ. وقد تؤدي أخطاء التكوين عندئذٍ إلى تطبيقات ذات أداء ضعيف.
في عالم التجارة، كان هناك منتج مكافئ لـ Hibernate يُدعى Toplink:
 |
ونظراً لنجاح منتجات ORM، قررت شركة Sun، مطورة لغة Java، توحيد طبقة ORM عبر مواصفة تسمى JPA ظهرت في نفس وقت ظهور Java 5. تم تنفيذ المواصفات JPA بواسطة منتجي Toplink و Hibernate. أصبح Toplink، الذي كان منتجًا تجاريًا، منتجًا مجانيًا منذ ذلك الحين. مع JPA، أصبحت البنية السابقة كما يلي:
 |
تتفاعل الطبقة [dao] الآن مع المواصفة JPA، وهي مجموعة من الواجهات. وقد استفاد المطور من ذلك من حيث التوحيد القياسي. ففي السابق، إذا قام بتغيير طبقة ORM، كان عليه أيضًا تغيير طبقة [dao] التي تمت كتابتها للتفاعل مع ORM محددة. أما الآن، فسيكتب طبقة [dao] التي ستتواصل مع طبقة JPA. بغض النظر عن المنتج الذي ينفذ هذه الطبقة، تظل واجهة الطبقة JPA المعروضة على الطبقة [dao] كما هي.
سيقدم هذا المستند أمثلة على JPA في مجالات مختلفة:
- أولاً، سنركز على الجسر العلائقي/الكائني الذي تنشئه الطبقة ORM. سيتم إنشاء هذا الجسر باستخدام تعليقات Java 5 لقواعد البيانات التي تحتوي على علاقات بين الجداول من النوع:
- واحد إلى واحد
- واحد إلى عدة
- عدة إلى عدة
لتوضيح هذا المجال، سننشئ بنى الاختبار التالية:
 |
ستكون برامج الاختبار الخاصة بنا عبارة عن تطبيقات وحدة التحكم التي ستستعلم مباشرة عن الطبقة JPA. سنكتشف في هذه المناسبة الطرق الرئيسية للطبقة JPA. سنكون في بيئة تسمى "Java SE" (الإصدار القياسي). يعمل JPA في كل من بيئة Java SE و Java EE5 (الإصدار المؤسسي).
- عندما نتقن تكوين الجسر العلائقي/الكائني واستخدام أساليب طبقة JPA، سنعود إلى بنية متعددة الطبقات أكثر تقليدية:
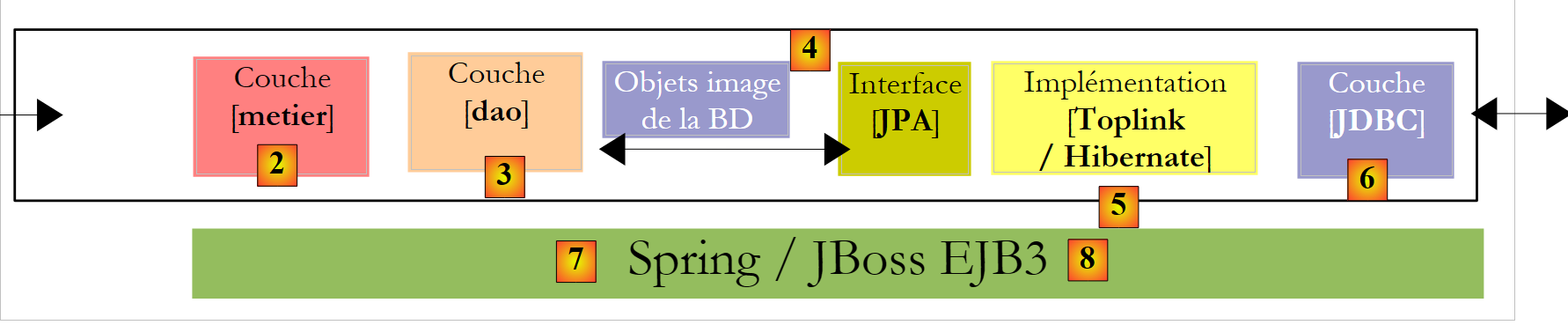 |
سيتم الوصول إلى الطبقة [JPA] عبر بنية ذات طبقتين [metier] و [dao]. سيتم استخدام إطار عمل Spring [7]، ثم الحاوية EJB3 من JBoss لربط هذه الطبقات ببعضها البعض.
ذكرنا سابقًا أن بيئة JPA متوفرة في بيئتي SE و EE5. تقدم بيئة Java EE5 العديد من الخدمات في مجال الوصول إلى البيانات الدائمة، ولا سيما مجموعات الاتصال ومديري المعاملات، ... وقد يكون من المفيد للمطور الاستفادة من هذه الخدمات. بيئة Java EE5 ليست منتشرة بعد (مايو 2007). وهي موجودة حاليًا على خادم التطبيقات Sun Application Server 9.x (Glassfish). خادم التطبيقات هو في الأساس خادم لتطبيقات الويب. إذا قمنا بإنشاء تطبيق رسومي مستقل من نوع Swing، فلن نتمكن من الاستفادة من بيئة EE والخدمات التي توفرها. وهذا يمثل مشكلة. بدأنا نرى بيئات EE "مستقلة"، c.a.d. يمكن استخدامها خارج خادم التطبيقات. هذا هو الحال بالنسبة لـ JBos و EJB3 التي سنستخدمها في هذا المستند.
في بيئة EE5، يتم تنفيذ الطبقات بواسطة كائنات تسمى EJB (Enterprise Java Bean). في الإصدارات السابقة من EE، يُعرف عن EJB (EJB 2.x) صعوبة تنفيذها واختبارها، وأحيانًا ضعف أدائها. يتم التمييز بين "entity" EJB2.x و"session" EJB2.x. باختصار، "entity" EJB2.x هو صورة لسطر في جدول قاعدة بيانات و"session" EJB2.x هو كائن يُستخدم لتنفيذ طبقات [metier]، [dao] في بنية متعددة الطبقات. أحد الانتقادات الرئيسية الموجهة إلى الطبقات التي تم تنفيذها باستخدام EJB هو أنها لا يمكن استخدامها إلا داخل حاويات EJB، وهي خدمة تقدمها بيئة EE. وهذا يجعل الاختبارات الفردية مشكلة. وبالتالي، في المخطط أعلاه، ستتطلب الاختبارات الفردية للطبقات [metier] و [dao] التي تم إنشاؤها باستخدام EJB إنشاء خادم تطبيقات، وهي عملية مرهقة إلى حد ما ولا تشجع المطور حقًا على إجراء الاختبارات بشكل متكرر.
وقد نشأ إطار عمل Spring كرد فعل على تعقيد EJB2. يوفر Spring في بيئة SE عددًا كبيرًا من الخدمات التي توفرها عادةً بيئات EE. وهكذا، في الجزء "استمرارية البيانات" الذي يهمنا هنا، يوفر Spring مجموعات الاتصال ومديري المعاملات التي تحتاجها التطبيقات. وقد ساهم ظهور Spring في تعزيز ثقافة الاختبارات الفردية، التي أصبحت فجأة أسهل بكثير في التنفيذ. يسمح Spring بتنفيذ طبقات التطبيق باستخدام كائنات Java التقليدية (POJO، Plain Old/Ordinary Java Object)، مما يتيح إعادة استخدامها في سياق آخر. وأخيرًا، يدمج العديد من أدوات الجهات الخارجية بطريقة شفافة إلى حد كبير، لا سيما أدوات الاستمرارية مثل Hibernate وIbatis، ...
تم تصميم Java EE5 لتصحيح أوجه القصور في المواصفات السابقة EE. أصبحت EJB و 2.x هي EJB3. وهذه هي POJOs الموسومة بتعليقات توضيحية تجعلها كائنات خاصة عندما تكون داخل حاوية EJB3. في هذا الحاوية، سيتمكن EJB3 من الاستفادة من خدمات الحاوية (مجموعة الاتصالات، مدير المعاملات، ...). خارج الحاوية EJB3، يصبح EJB3 كائن Java عادي. يتم تجاهل تعليقاته التوضيحية EJB.
فيما سبق، قمنا بتمثيل Spring و JBoss EJB3 كبنية تحتية (إطار عمل) محتملة لهندستنا متعددة الطبقات. هذه البنية التحتية هي التي ستوفر الخدمات التي نحتاجها: تجمع اتصالات ومدير معاملات.
- مع Spring، سيتم تنفيذ الطبقات باستخدام POJOs. وستتمكن هذه من الوصول إلى خدمات Spring (مجموعة الاتصالات، مدير المعاملات) عن طريق حقن التبعيات في هذه POJOs: عند إنشاء هذه، يقوم Spring بحقنها بمراجع للخدمات التي ستحتاجها.
-
JBoss EJB3 هو حاوية EJB يمكنها العمل خارج خادم التطبيق. مبدأ عملها (بالنسبة للمطور) مشابه للمبدأ الموصوف لـ Spring. لن نجد سوى القليل من الاختلافات.
-
سنختتم هذا المستند بمثال لتطبيق ويب ثلاثي الطبقات، بسيط ولكنه مع ذلك تمثيلي:
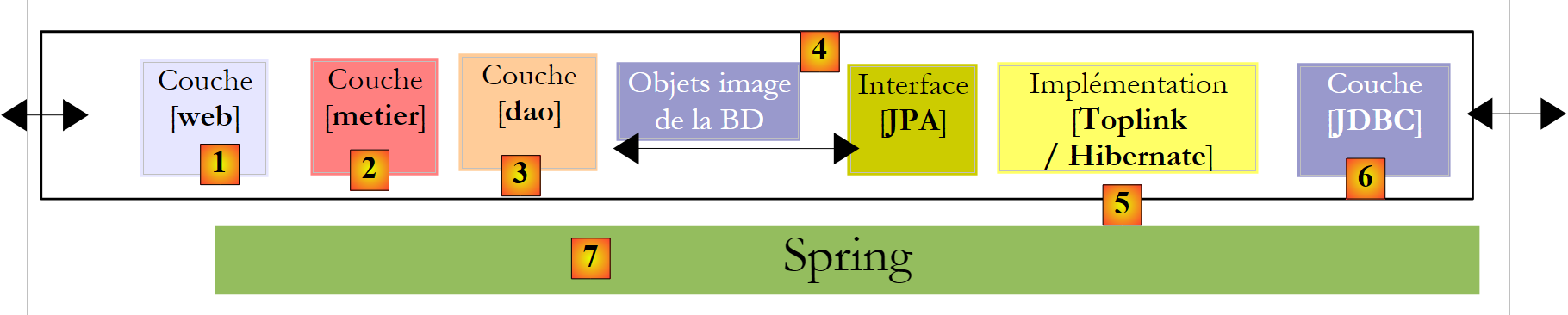 |
1.2. المراجع
[ref1]: Java Persistence with Hibernate، للكاتبين كريستيان باور وغافين كينغ، من دار مانينغ.
[ref1] هو الوثيقة التي شكلت أساسًا لما يلي. إنه كتاب شامل يزيد عن 800 صفحة حول استخدام Hibernate في سياقين مختلفين: مع أو بدون JPA. لا يزال استخدام Hibernate بدون JPA أمرًا ذا صلة بالمطورين الذين يستخدمون JDK 1.4 أو أقل، حيث لم يظهر JPA إلا مع JDK 1.5.
بعد قراءة أكثر من ثلاثة أرباع الكتاب، وتصفح الباقي، بدا لي أن كل شيء في هذا المستند مفيد. يجب أن يكون المستخدم المتمرس لـ Hibernate على دراية بجميع المعلومات الواردة في الـ 800 صفحة تقريبًا. كان كريستيان باور وغافين كينغ شاملين، لكن نادرًا ما وصفوا مواقف لن نواجهها أبدًا. كل شيء يستحق القراءة. الكتاب مكتوب بأسلوب تعليمي: هناك رغبة حقيقية في عدم ترك أي شيء غامض. حقيقة أنه كُتب لاستخدام Hibernate مع وبدون JPA في آن واحد تشكل صعوبة لأولئك الذين لا يهتمون إلا بإحدى هاتين التقنيتين. على سبيل المثال، يصف المؤلفان، من خلال العديد من الأمثلة، الجسر العلائقي/الكائني في كلا السياقين. المفاهيم المستخدمة متقاربة جدًا نظرًا لأن JPA مستوحى بشدة من Hibernate. لكن هناك بعض الاختلافات. لدرجة أن ما ينطبق على Hibernate قد لا ينطبق على JPA، مما يؤدي في النهاية إلى إرباك القارئ.
يعرض المؤلفون أمثلة لتطبيقات ثلاثية الطبقات في سياق حاوية EJB3. ولا يتطرقون إلى Spring. سنرى من خلال مثال أن Spring أسهل في الاستخدام وأكثر شمولية من الحاوية JBoss EJB3 المستخدمة في [ref1]. ومع ذلك، فإن "Java Persistence with Hibernate" هو كتاب ممتاز أنصح به لجميع الأساسيات التي نتعلمها فيه عن ORM.
يعد استخدام ORM أمرًا معقدًا للمبتدئين.
- هناك مفاهيم يجب فهمها لتكوين الجسر العلائقي/الكائني.
- هناك مفهوم سياق الاستمرارية مع مفاهيم الكائنات في حالة "مستمرة" و"منفصلة" و"جديدة"
- هناك آليات حول الاستمرارية (المعاملات، مجموعات الاتصالات)، وهي عادةً خدمات تقدمها حاوية
- هناك الإعدادات التي يجب إجراؤها لتحسين الأداء (ذاكرة التخزين المؤقت من المستوى الثاني)
- ...
سنقدم هذه المفاهيم من خلال أمثلة. ولن نخوض في الكثير من التفاصيل النظرية حولها. هدفنا ببساطة هو، في كل مرة، تمكين القارئ من فهم المثال واستيعابه حتى يصبح قادرًا على إجراء تعديلات عليه بنفسه أو إعادة تطبيقه في سياق آخر.
1.3. الأدوات المستخدمة
تستخدم الأمثلة الواردة في هذا المستند الأدوات التالية. يتم وصف بعضها في الملاحق (التنزيل، التثبيت، التهيئة، الاستخدام). في هذه الحالة، نذكر رقم الفقرة والصفحة.
- JDK 1.6 (الفقرة 5.1)
- IDE لتطوير Java Eclipse 3.2.2 (الفقرة 5.2)
- المكون الإضافي Eclipse WTP (حزمة أدوات الويب) (الفقرة 5.2.3)
- المكون الإضافي Eclipse SQL explorer (الفقرة 5.2.6)
- مكون Eclipse الإضافي Hibernate Tools (الفقرة 5.2.5)
- المكون الإضافي Eclipse TestNG (الفقرة 5.2.4)
- حاوية سيرفلتات Tomcat 5.5.23 (الفقرة 5.3)
- SGBD Firebird 2.1 (الفقرة 5.4)
- SGBD MySQL5 (الفقرة 5.5)
- SGBD PosgreSQL (الفقرة 5.6)
- SGBD Oracle 10g Express (الفقرة 5.7)
- SGBD SQL Server 2005 Express (الفقرة 5.8)
- SGBD HSQLDB (الفقرة 5.9)
- SGBD Apache Derby (الفقرة 5.10)
- Spring 2.1 (الفقرة 5.11)
- حاوية EJB3 من JBoss (الفقرة 5.12)
1.4. تنزيل أمثلة
على موقع هذا المستند، يمكن تنزيل الأمثلة المدروسة في شكل ملف مضغوط، والذي ينتج عنه، بمجرد فك ضغطه، المجلد التالي:
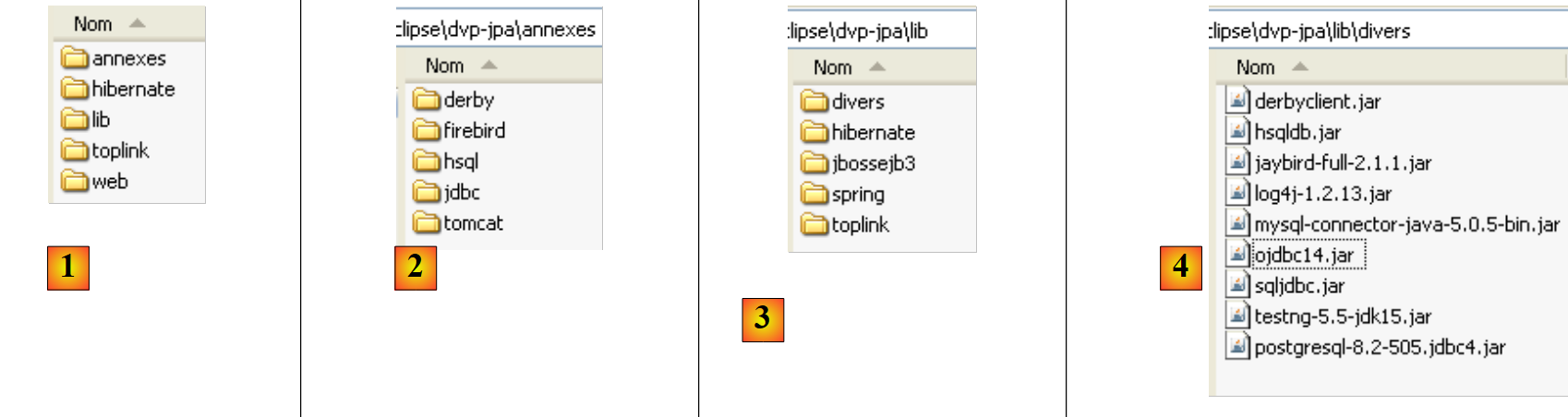 |
- في [1]: شجرة الأمثلة
- في [2]: يحتوي المجلد <annexes> على العناصر المعروضة في الجزء ANNEXES، الفقرة 5. وعلى وجه الخصوص، يحتوي المجلد <jdbc> على برامج تشغيل Jdbc الخاصة بـ SGBD المستخدمة في أمثلة البرنامج التعليمي.
- في [3]: يضم المجلد <lib> في 5 مجلدات الأرشيفات المختلفة .jar المستخدمة في البرنامج التعليمي
- في [4]: يضم المجلد <lib/divers> الملفات: - برامج تشغيل Jdbc لـ SGBD - أداة الاختبار الفردي [testNG] - أداة السجلات [log4j]
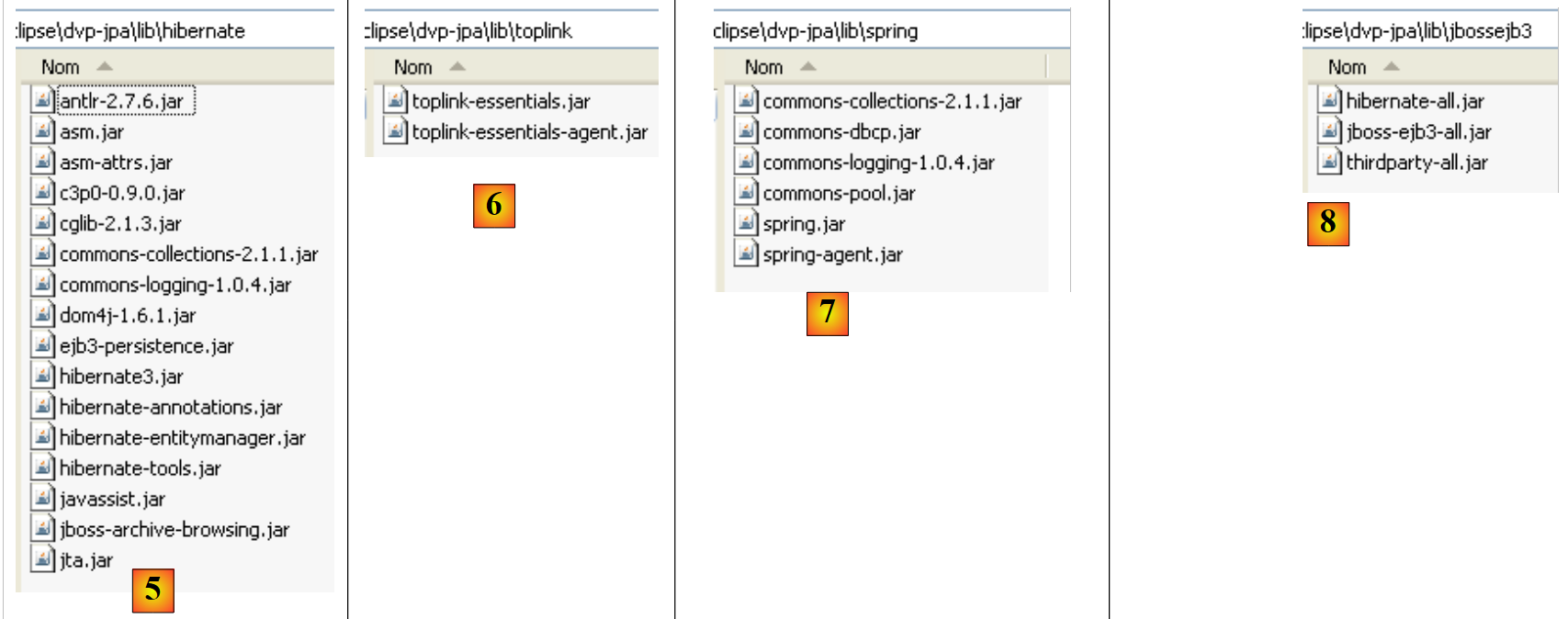 |
- في [5]: أرشيفات التنفيذ JPA/Hibernate والأدوات الخارجية اللازمة لـ Hibernate
- إلى [6]: أرشيفات التنفيذ JPA/Toplink
- في [7]: أرشيفات Spring 2.x والأدوات الخارجية اللازمة لـ Spring
- في [8]: أرشيفات الحاوية EJB3 من JBoss
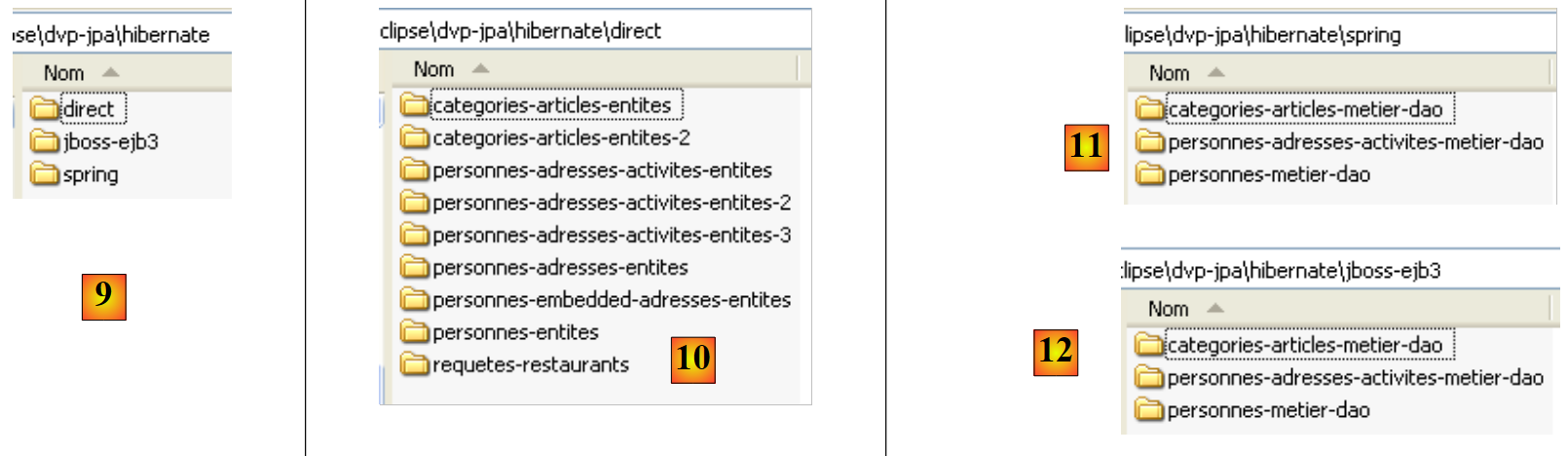 |
- في [9]: المجلد <hibernate> يضم الأمثلة التي تمت معالجتها باستخدام طبقة الاستمرارية JPA/Hibernate
- في [10]: المجلد <hibernate/direct> يضم الأمثلة التي يتم فيها استخدام الطبقة JPA مباشرة مع برنامج من النوع [Main].
- في [11] و [12]: أمثلة يتم فيها استخدام الطبقة JPA عبر الطبقات [metier] و [dao] في بنية متعددة الطبقات، وهو ما يمثل الحالة العادية للاستخدام. الخدمات (مجموعة الاتصالات، مدير المعاملات) التي تستخدمها الطبقات [metier] و [dao] يتم توفيرها إما بواسطة Spring [11] أو بواسطة JBoss EJB3 [12].
 |
- في [13]: يستند المجلد <toplink> إلى أمثلة المجلد <hibernate> [9] ولكن هذه المرة مع طبقة ثبات JPA/Toplink بدلاً من JPA/Hibernate. لايوجد في [13] مجلد <jbossejb3> لأنه لم يكن من الممكن تشغيل مثال حيث يتم توفير طبقة الاستمرارية بواسطة Toplink والخدمات بواسطة الحاوية EJB3 من JBoss.
- في [14]: يضم ملف <web> ثلاثة أمثلة لتطبيقات الويب مع طبقة استمرارية JPA:
- [15]: مثال باستخدام Spring / JPA / Hibernate
- [16]: نفس المثال مع Spring / JPA / Toplink
- [17]: نفس المثال مع JBoss EJB3 / JPA / Hibernate. هذا المثال لا يعمل، ربما بسبب مشكلة في التكوين لم يتم توضيحها. ومع ذلك، فقد تم تركه حتى يتمكن القارئ من دراسته وربما إيجاد حل لهذه المشكلة.
غالبًا ما يشير البرنامج التعليمي إلى هذه الشجرة، لا سيما أثناء اختبار الأمثلة المدروسة. يُدعى القارئ إلى تنزيل هذه الأمثلة وتثبيتها. بعد ذلك، سنطلق على الشجرة المذكورة أعلاه اسم <exemples>.
1.5. تكوين مشاريع Eclipse الخاصة بـ
تستخدم الأمثلة مكتبات "مستخدم". وهي عبارة عن أرشيفات .jar مجمعة تحت اسم واحد. عند تضمين مكتبة من هذا النوع في مسار فئة مشروع Java، يتم تضمين جميع الأرشيفات التي تحتوي عليها في مسار الفئة هذا. لنرى كيفية القيام بذلك في Eclipse:
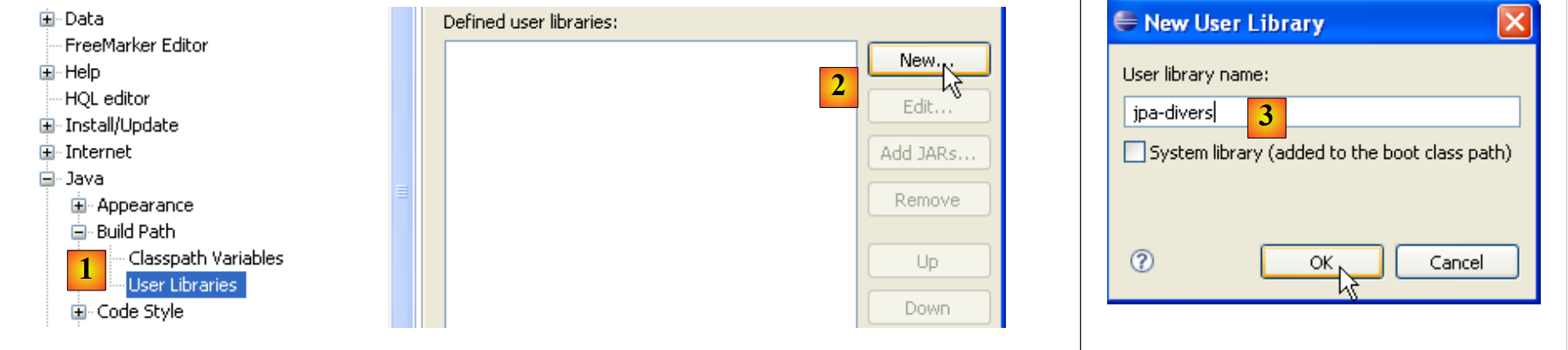 |
- في [1]: [Window / Preferences / Java / Buld Path / User Libraries]
- في [2]: نقوم بإنشاء مكتبة جديدة
- في [3]: نسميها ونؤكد
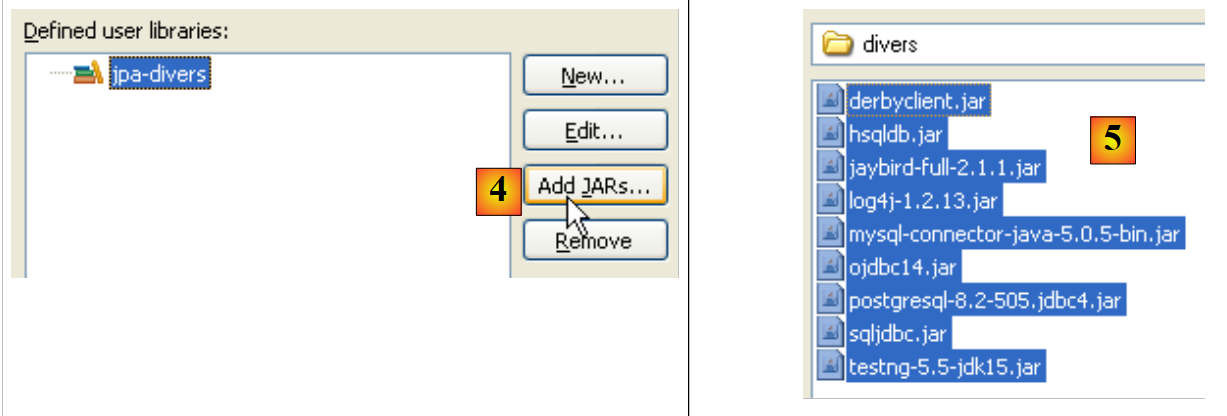 |
- في [4]: سنقوم باختيار ملفات jar التي ستشكل جزءًا من المكتبة [jpa-divers]
- في [5]: نختار جميع ملفات jar الموجودة في المجلد <exemples>/lib/divers
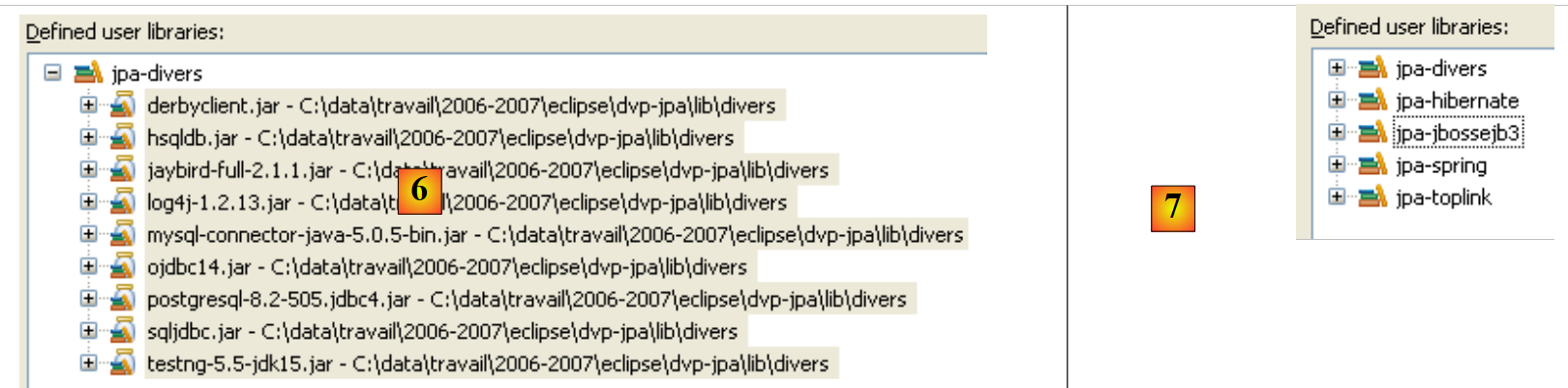 |
- في [6]: تم تعريف مكتبة المستخدم [jpa-divers]
- في [7]: نكرر نفس الخطوات لإنشاء 4 مكتبات أخرى:
مكتبة | ملف المجلدات في المكتبة |
<أمثلة>/lib/hibernate | |
<أمثلة>/lib/toplink | |
<أمثلة>/lib/spring | |
<أمثلة>/lib/jbossejb3 |